jacquesthibs's Shortform
post by jacquesthibs (jacques-thibodeau) · 2022-11-21T12:04:07.896Z · LW · GW · 307 commentsContents
310 comments
307 comments
Comments sorted by top scores.
comment by jacquesthibs (jacques-thibodeau) · 2024-05-21T13:13:05.143Z · LW(p) · GW(p)
I would find it valuable if someone could gather an easy-to-read bullet point list of all the questionable things Sam Altman has done throughout the years.
I usually link to Gwern’s comment thread (https://www.lesswrong.com/posts/KXHMCH7wCxrvKsJyn/openai-facts-from-a-weekend?commentId=toNjz7gy4rrCFd99A [LW(p) · GW(p)]), but I would prefer if there was something more easily-consumable.
Replies from: Zach Stein-Perlman, robo, jacques-thibodeau↑ comment by Zach Stein-Perlman · 2024-05-21T20:54:27.742Z · LW(p) · GW(p)
[Edit #2, two months later: see https://ailabwatch.org/resources/integrity/]
[Edit: I'm not planning on doing this but I might advise you if you do, reader.]
50% I'll do this in the next two months if nobody else does. But not right now, and someone else should do it too.
Off the top of my head (this is not the list you asked for, just an outline):
- Loopt stuff
- YC stuff
- YC removal
- NDAs
- And deceptive communication recently
- And maybe OpenAI's general culture of don't publicly criticize OpenAI
- Profit cap non-transparency
- Superalignment compute
- Two exoduses of safety people; negative stuff people-who-quit-OpenAI sometimes say
- Telling board members not to talk to employees
- Board crisis stuff
- OpenAI executives telling the board Altman lies
- The board saying Altman lies
- Lying about why he wanted to remove Toner
- Lying to try to remove Toner
- Returning
- Inadequate investigation + spinning results
Stuff not worth including:
- Reddit stuff - unconfirmed
- Financial conflict-of-interest stuff - murky and not super important
- Misc instances of saying-what's-convenient (e.g. OpenAI should scale because of the prospect of compute overhang and the $7T chip investment thing) - idk, maybe, also interested in more examples
- Johansson & Sky - not obvious that OpenAI did something bad, but it would be nice for OpenAI to say "we had plans for a Johansson voice and we dropped that when Johansson said no," but if that was true they'd have said it...
What am I missing? Am I including anything misleading or not-worth-it?
Replies from: jacques-thibodeau, jacques-thibodeau, lcmgcd↑ comment by jacquesthibs (jacques-thibodeau) · 2024-05-30T22:07:15.619Z · LW(p) · GW(p)
Here’s new one: https://x.com/jacquesthibs/status/1796275771734155499?s=61&t=ryK3X96D_TkGJtvu2rm0uw
Sam added in SEC filings (for AltC) that he’s YC’s chairman. Sam Altman has never been YC’s chairman. From an article posted on April 15th, 2024:
“Annual reports filed by AltC for the past 3 years make the same claim. The recent report: Sam was currently chairman of YC at the time of filing and also "previously served" as YC's chairman.”
The journalist who replied to me said: “Whether Sam Altman was fired from YC or not, he has never been YC's chair but claimed to be in SEC filings for his AltC SPAC which merged w/Oklo. AltC scrubbed references to Sam being YC chair from its website in the weeks since I first reported this.”
The article: https://archive.is/Vl3VR
↑ comment by jacquesthibs (jacques-thibodeau) · 2024-07-09T15:55:05.883Z · LW(p) · GW(p)
Just a heads up, it's been 2 months!
Replies from: Zach Stein-Perlman↑ comment by Zach Stein-Perlman · 2024-07-10T07:30:09.395Z · LW(p) · GW(p)
Not what you asked for but related: https://ailabwatch.org/resources/integrity/
↑ comment by lemonhope (lcmgcd) · 2024-05-24T09:21:28.511Z · LW(p) · GW(p)
What am I missing?
His sister's accusations that he blocked her from parent's inheritance and that he molested her when he was a young teenager and that he got her social media accounts flagged as spam to hide the accusations
Replies from: gwern↑ comment by gwern · 2024-05-24T21:14:08.364Z · LW(p) · GW(p)
I would not consider her claims worth including in a list of top items for people looking for an overview, as they are hard to verify or dubious (her comments are generally bad enough to earn flagging on their own), aside from possibly the inheritance one - as that should be objectively verifiable, at least in theory, and lines up better with the other items.
↑ comment by robo · 2024-05-22T15:25:49.664Z · LW(p) · GW(p)
I'm very not sure how to do this, but are there ways to collect some counteracting or unbiased samples about Sam Altman? Or to do another one-sided vetting for other CEOs to see what the base rate of being able to dig up questionable things is? Collecting evidence in that points in only one direction just sets off huge warning lights 🚨🚨🚨🚨 I can't quiet.
Replies from: gwern↑ comment by gwern · 2024-05-23T15:25:09.203Z · LW(p) · GW(p)
Collecting evidence in that points in only one direction just sets off huge warning lights 🚨🚨🚨🚨 I can't quiet.
Yes, it should. And that's why people are currently digging so hard in the other direction, as they begin to appreciate to what extent they have previously had evidence that only pointed in one direction and badly misinterpreted things like, say, Paul Graham's tweets or YC blog post edits or ex-OAer statements.
↑ comment by jacquesthibs (jacques-thibodeau) · 2024-09-26T00:37:48.700Z · LW(p) · GW(p)
Given today's news about Mira (and two other execs leaving), I figured I should bump this again.
But also note that @Zach Stein-Perlman [LW · GW] has already done some work on this (as he noted in his edit): https://ailabwatch.org/resources/integrity/.
Note, what is hard to pinpoint when it comes to S.A. is that many of the things he does have been described as "papercuts". This is the kind of thing that makes it hard to make a convincing case for wrongdoing.
comment by jacquesthibs (jacques-thibodeau) · 2024-12-20T21:31:28.793Z · LW(p) · GW(p)
Given the OpenAI o3 results making it clear that you can pour more compute to solve problems, I'd like to announce that I will be mentoring at SPAR for an automated interpretability research project using AIs with inference-time compute.
I truly believe that the AI safety community is dropping the ball on this angle of technical AI safety and that this work will be a strong precursor of what's to come.
Note that this work is a small part in a larger organization on automated AI safety I’m currently attempting to build.
Here’s the pitch:
As AIs become more capable, they will increasingly be used to automate AI R&D. Given this, we should seek ways to use AIs to help us also make progress on alignment research.
Eventually, AIs will automate all research, but for now, we need to choose specific tasks that AIs can do well on. The kind of problems we can expect AIs will be good at fairly soon are the kind that have reliable metrics they can optimize, have a lot of knowledge about, and can iterate on fairly cheaply.
As a result, we can make progress toward automating interpretability research by coming up with experimental setups that allow AIs to iterate. For now, we can leave the exact details a bit broad, but here are some examples of what we could attempt to use AIs to make deep learning models more interpretable:
-
Optimizing Sparse Autoencoders (SAEs): sparse autoencoders (or transcoders) can be used to help us interpret the features of deep learning models. However, SAEs may suffer from issues like polysemanticity. Our goal is to create a SAE training setup that can give us some insight into what might make AI models more interpretable. This could involve testing different regularizers, activation functions, and more. We'll start with simpler vision models before scaling to language models to allow for rapid iteration and validation. Key metrics include feature monosemanticity, sparsity, dead feature ratios, and downstream task performance.
-
Enhancing Model Editability: we will be using AIs to do experiments on language models to find out which modifications lead to better model editing ability from a technique like ROME/MEMIT.
Overall, we can also use other approaches to measure the increase in interpretability (or editability) of language models.
The project aims to answer several key questions:
- Can AI effectively optimize interpretability techniques?
- What metrics best capture meaningful improvements in interpretability?
- Are AIs better at this task than human researchers?
- Can we develop reliable pipelines for automated interpretability research?
Initial explorations will focus on creating clear evaluation frameworks and baselines, starting with smaller-scale proof-of-concepts that can be rigorously validated.
References:
- "The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery" (Lu et al., 2024)
- "RE-Bench: Evaluating frontier AI R&D capabilities of language model agents against human experts" (METR, 2024)
- "Towards Monosemanticity: Decomposing Language Models With Dictionary Learning" (Bricken et al., 2023)
- "Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet" (Templeton et al., 2024)
- "ROME: Locating and Editing Factual Knowledge in GPT" (Meng et al., 2022) Briefly, how does your project advance AI safety? (from Proposal)
The goal of this project is to leverage AIs to progress on the interpretability of deep learning models. Part of the project will involve building infrastructure to help AIs contribute to alignment research more generally, which will be re-used as models become more capable of making progress on alignment. Another part will look to improve the interpretability of deep learning models without sacrificing capability. What role will mentees play in this project? (from Proposal) Mentees will be focused on:
- Get up-to-date on current approaches to leverage AIs for automated research.
- Setting up the infrastructure to get AIs to automate the interpretability research.
- Run experiments with AIs to optimize for making models more interpretable while not compromising on capabilities.
↑ comment by JuliaHP · 2024-12-21T14:06:59.468Z · LW(p) · GW(p)
"As a result, we can make progress toward automating interpretability research by coming up with experimental setups that allow AIs to iterate."
This sounds exactly like the kind of progress which is needed in order to get closer to game-over-AGI. Applying current methods of automation to alignment seems fine, but if you are trying to push the frontier of what intellectual progress can be achieved using AI's, I fail to see your comparative advantage relative to pure capabilities researchers.
I do buy that there might be credit to the idea of developing the infrastructure/ability to be able to do a lot of automated alignment research, which gets cached out when we are very close to game-over-AGI, even if it comes at the cost of pushing the frontier some.
↑ comment by jacquesthibs (jacques-thibodeau) · 2024-12-21T16:27:12.938Z · LW(p) · GW(p)
Exactly right. This is the first criticism I hear every time about this kind of work and one of the main reasons I believe the alignment community is dropping the ball on this.
I only intend on sharing work output (paper on better technique for interp, not the infrastructure setup; things similar to Transluce) where necessary and not the infrastructure. We don’t need to share or open source what we think isn’t worth it. That said, the capabilities folks will be building stuff like this by default, as they already have (Sakana AI). Yet I see many paths to automating sub-areas of alignment research that we will be playing catch up to capabilities when the time comes because we were so afraid of touching this work. We need to put ourselves in a position to absorb a lot of compute.
↑ comment by jacquesthibs (jacques-thibodeau) · 2024-12-21T16:41:07.998Z · LW(p) · GW(p)
As a side note, I’m in the process of building an organization (leaning startup). I will be in London in January for phase 2 of the Catalyze Impact program (incubation program for new AI safety orgs). Looking for feedback on a vision doc and still looking for a cracked CTO to co-found with. If you’d like to help out in whichever way, send a DM!
comment by jacquesthibs (jacques-thibodeau) · 2025-01-24T18:12:54.093Z · LW(p) · GW(p)
I'm currently in the Catalyze Impact AI safety incubator program. I'm working on creating infrastructure for automating AI safety research. This startup is attempting to fill a gap in the alignment ecosystem and looking to build with the expectation of under 3 years left to automated AI R&D. This is my short timelines plan [LW · GW].
I'm looking to talk (for feedback) to anyone interested in the following:
- AI control
- Automating math to tackle problems as described in Davidad's Safeguarded AI programme.
- High-assurance safety cases [LW · GW]
- How to robustify society in a post-AGI world
- Leverage large amounts of inference-time compute to make progress on alignment research
- Short timelines
- Profitability while still reducing overall x-risk
- Are someone with an entrepreneurial spirit and can spin out traditional business within the org to fund the rest of the work (thereby reducing investor pressure)
If you're interested in chatting or giving feedback, please DM me!
comment by jacquesthibs (jacques-thibodeau) · 2024-05-26T19:32:53.976Z · LW(p) · GW(p)
How likely is it that the board hasn’t released specific details about Sam’s removal because of legal reasons? At this point, I feel like I have to place overwhelmingly high probability on this.
So, if this is the case, what legal reason is it?
Replies from: owencb, nikolas-kuhn, jacques-thibodeau, Dagon↑ comment by owencb · 2024-05-27T13:15:56.899Z · LW(p) · GW(p)
My mainline guess is that information about bad behaviour by Sam was disclosed to them by various individuals, and they owe a duty of confidence to those individuals (where revealing the information might identify the individuals, who might thereby become subject to some form of retaliation).
("Legal reasons" also gets some of my probability mass.)
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2024-05-27T14:13:11.991Z · LW(p) · GW(p)
I think this sounds reasonable, but if this is true, why wouldn’t they just say this?
↑ comment by Amalthea (nikolas-kuhn) · 2024-05-27T07:14:50.222Z · LW(p) · GW(p)
It might not be legal reasons specifically, but some hard-to-specify mix of legal reasons/intimidation/bullying. While it's useful to discuss specific ideas, it should be kept in mind that Altman doesn't need to restrict his actions to any specific avenue that could be neatly classified.
↑ comment by jacquesthibs (jacques-thibodeau) · 2024-05-29T01:14:17.135Z · LW(p) · GW(p)
My question for as to why they can’t share all the examples was not answered, but Helen gives background on what happened here: https://open.spotify.com/episode/4r127XapFv7JZr0OPzRDaI?si=QdghGZRoS769bGv5eRUB0Q&context=spotify%3Ashow%3A6EBVhJvlnOLch2wg6eGtUa
She does confirm she can’t give all of the examples (though points to the ones that were reported), however. Which is not nothing, but eh. However, she also mentioned it was under-reported how much people were scared of Sam and he was creating a very toxic environment.
↑ comment by Dagon · 2024-05-27T16:36:52.009Z · LW(p) · GW(p)
"legal reasons" is pretty vague. With billions of dollars at stake, it seems like public statements can be used against them more than it helps them, should things come down to lawsuits. It's also the case that board members are people, and want to maintain their ability to work and have influence in future endeavors, so want to be seen as systemic cooperators.
Replies from: T3t↑ comment by RobertM (T3t) · 2024-05-28T03:30:22.080Z · LW(p) · GW(p)
But surely "saying nearly nothing" ranks among the worst-possible options for being seen as a "systemic cooperator"?
Replies from: Dagoncomment by jacquesthibs (jacques-thibodeau) · 2024-05-15T14:14:15.928Z · LW(p) · GW(p)
I thought Superalignment was a positive bet by OpenAI, and I was happy when they committed to putting 20% of their current compute (at the time) towards it. I stopped thinking about that kind of approach because OAI already had competent people working on it. Several of them are now gone.
It seems increasingly likely that the entire effort will dissolve. If so, OAI has now made the business decision to invest its capital in keeping its moat in the AGI race rather than basic safety science. This is bad and likely another early sign of what's to come.
I think the research that was done by the Superalignment team should continue happen outside of OpenAI and, if governments have a lot of capital to allocate, they should figure out a way to provide compute to continue those efforts. Or maybe there's a better way forward. But I think it would be pretty bad if all that talent towards the project never gets truly leveraged into something impactful.
Replies from: bogdan-ionut-cirstea, kromem↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-05-15T22:16:50.240Z · LW(p) · GW(p)
I think the research that was done by the Superalignment team should continue happen outside of OpenAI and, if governments have a lot of capital to allocate, they should figure out a way to provide compute to continue those efforts. Or maybe there's a better way forward. But I think it would be pretty bad if all that talent towards the project never gets truly leveraged into something impactful.
Strongly agree; I've been thinking for a while that something like a public-private partnership involving at least the US government and the top US AI labs might be a better way to go about this. Unfortunately, recent events seem in line with it not being ideal to only rely on labs for AI safety research, and the potential scalability of automating it should make it even more promising for government involvement. [Strongly] oversimplified, the labs could provide a lot of the in-house expertise, the government could provide the incentives, public legitimacy (related: I think of a solution to aligning superintelligence as a public good) and significant financial resources.
↑ comment by kromem · 2024-05-16T02:40:04.970Z · LW(p) · GW(p)
It's going to have to.
Ilya is brilliant and seems to really see the horizon of the tech, but maybe isn't the best at the business side to see how to sell it.
But this is often the curse of the ethically pragmatic. There is such a focus on the ethics part by the participants that the business side of things only sees that conversation and misses the rather extreme pragmatism.
As an example, would superaligned CEOs in the oil industry fifty years ago have still only kept their eye on quarterly share prices or considered long term costs of their choices? There's going to be trillions in damages that the world has taken on as liabilities that could have been avoided with adequate foresight and patience.
If the market ends up with two AIs, one that will burn down the house to save on this month's heating bill and one that will care if the house is still there to heat next month, there's a huge selling point for the one that doesn't burn down the house as long as "not burning down the house" can be explained as "long term net yield" or some other BS business language. If instead it's presented to executives as "save on this month's heating bill" vs "don't unhouse my cats" leadership is going to burn the neighborhood to the ground.
(Source: Explained new technology to C-suite decision makers at F500s for years.)
The good news is that I think the pragmatism of Ilya's vision on superalignment is going to become clear over the next iteration or two of models and that's going to be before the question of models truly being unable to be controlled crops up. I just hope that whatever he's going to be keeping busy with will allow him to still help execute on superderminism when the market finally realizes "we should do this" for pragmatic reasons and not just amorphous ethical reasons execs just kind of ignore. And in the meantime I think given the present pace that Anthropic is going to continue to lay a lot of the groundwork on what's needed for alignment on the way to superalignment anyways.
comment by jacquesthibs (jacques-thibodeau) · 2024-05-15T10:53:27.270Z · LW(p) · GW(p)
For anyone interested in Natural Abstractions type research: https://arxiv.org/abs/2405.07987
Claude summary:
Key points of "The Platonic Representation Hypothesis" paper:
-
Neural networks trained on different objectives, architectures, and modalities are converging to similar representations of the world as they scale up in size and capabilities.
-
This convergence is driven by the shared structure of the underlying reality generating the data, which acts as an attractor for the learned representations.
-
Scaling up model size, data quantity, and task diversity leads to representations that capture more information about the underlying reality, increasing convergence.
-
Contrastive learning objectives in particular lead to representations that capture the pointwise mutual information (PMI) of the joint distribution over observed events.
-
This convergence has implications for enhanced generalization, sample efficiency, and knowledge transfer as models scale, as well as reduced bias and hallucination.
Relevance to AI alignment:
-
Convergent representations shaped by the structure of reality could lead to more reliable and robust AI systems that are better anchored to the real world.
-
If AI systems are capturing the true structure of the world, it increases the chances that their objectives, world models, and behaviors are aligned with reality rather than being arbitrarily alien or uninterpretable.
-
Shared representations across AI systems could make it easier to understand, compare, and control their behavior, rather than dealing with arbitrary black boxes. This enhanced transparency is important for alignment.
-
The hypothesis implies that scale leads to more general, flexible and uni-modal systems. Generality is key for advanced AI systems we want to be aligned.
↑ comment by Gunnar_Zarncke · 2024-05-21T22:14:12.550Z · LW(p) · GW(p)
I recommend making this into a full link-post. I agree about the relevance for AI alignment.
↑ comment by Lorxus · 2024-05-22T00:07:04.854Z · LW(p) · GW(p)
I am very very vaguely in the Natural Abstractions area of alignment approaches. I'll give this paper a closer read tomorrow (because I promised myself I wouldn't try to get work done today) but my quick quick take is - it'd be huge if true, but there's not much more than that there yet, and it also has no argument that even if representations are converging for now, that it'll never be true that (say) adding a whole bunch more effectively-usable compute means that the AI no longer has to chunk objectspace into subtypes rather than understanding every individual object directly.
comment by jacquesthibs (jacques-thibodeau) · 2024-01-24T11:48:23.491Z · LW(p) · GW(p)
I thought this series of comments from a former DeepMind employee (who worked on Gemini) were insightful so I figured I should share.
From my experience doing early RLHF work for Gemini, larger models exploit the reward model more. You need to constantly keep collecting more preferences and retraining reward models to make it not exploitable. Otherwise you get nonsensical responses which have exploited the idiosyncracy of your preferences data. There is a reason few labs have done RLHF successfully.
It's also know that more capable models exploit loopholes in reward functions better. Imo, it's a pretty intuitive idea that more capable RL agents will find larger rewards. But there's evidence from papers like this as well: https://arxiv.org/abs/2201.03544
To be clear, I don't think the current paradigm as-is is dangerous. I'm stating the obvious because this platform has gone a bit bonkers.
The danger comes from finetuning LLMs to become AutoGPTs which have memory, actions, and maximize rewards, and are deployed autonomously. Widepsread proliferation of GPT-4+ models will almost certainly make lots of these agents which will cause a lot of damage and potentially cause something indistinguishable from extinction.
These agents will be very hard to align. Trading off their reward objective with your "be nice" objective won't work. They will simply find the loopholes of your "be nice" objective and get that nice fat hard reward instead.
We're currently in the extreme left-side of AutoGPT exponential scaling (it basically doesn't work now), so it's hard to study whether more capable models are harder or easier to align.
Other comments from that thread:
My guess is where your intuitive alignment strategy ("be nice") breaks down for AI is that unlike humans, AI is highly mutable. It's very hard to change a human's sociopathy factor. But for AI, even if *you* did find a nice set of hyperparameters that trades off friendliness and goal-seeking behavior well, it's very easy to take that, and tune up the knobs to make something dangerous. Misusing the tech is as easy or easier than not. This is why many put this in the same bucket as nuclear.
US visits Afghanistan, teaches them how to make power using Nuclear tech, next month, they have nukes pointing at Iran.
And:
In contexts where harms will be visible easily and in short timelines, we’ll take them offline and retrain.
Many applications will be much more autonomous, difficult to monitor or even understand, and potentially fully close loop, i.e the agent has a complex enough action space that it can copy itself, buy compute, run itself, etc.
I know it sounds scifi. But we’re living in scifi times. These things have a knack of becoming true sooner than we think.
No ghosts in the matrices assumed here. Just intelligence starting from a very good base model optimizing reward.
There are more comments he made in that thread that I found insightful, so go have a look if interested.
Replies from: leogao↑ comment by leogao · 2024-01-28T04:51:26.361Z · LW(p) · GW(p)
"larger models exploit the RM more" is in contradiction with what i observed in the RM overoptimization paper. i'd be interested in more analysis of this
Replies from: Algon↑ comment by Algon · 2024-02-13T13:02:39.154Z · LW(p) · GW(p)
In that paper did you guys take a good long look at the output of various sized models throughout training? In addition to looking at the graphs of gold-standard/proxy reward model ratings against KL-divergence. If not, then maybe that's the discrepancy: perhaps Sherjil was communicating with the LLM and thinking "this is not what we wanted".
comment by jacquesthibs (jacques-thibodeau) · 2024-07-18T17:34:35.780Z · LW(p) · GW(p)
Why aren't you doing research on making pre-training better for alignment?
I was on a call today, and we talked about projects that involve studying how pre-trained models evolve throughout training and how we could guide the pre-training process to make models safer. For example, could models trained on synthetic/transformed data make models significantly more robust and essentially solve jailbreaking? How about the intersection of pretraining from human preferences and synthetic data? Could the resulting model be significantly easier to control? How would it impact the downstream RL process? Could we imagine a setting where we don't need RL (or at least we'd be able to confidently use resulting models to automate alignment research)? I think many interesting projects could fall out of this work.
So, back to my main question: why aren't you doing research on making pre-training better for alignment? Is it because it's too expensive and doesn't seem like a low-hanging fruit? Or do you feel it isn't a plausible direction for aligning models?
We were wondering if there are technical bottlenecks that would make this kind of research more feasible for alignment research to better study how to guide the pretraining process in a way that benefits alignment. As in, would researchers be more inclined to do experiments in this direction if the entire pre-training code was handled and you'd just have to focus on whatever specific research question you have in mind? If we could access a large amount of compute (let's say, through government resources) to do things like data labeling/filtering and pre-training multiple models, would this kind of work be more interesting for you to pursue?
I think many alignment research directions have grown simply because they had low-hanging fruits that didn't require much compute (e.g., evals, and mech interp). It seems we've implicitly left all of the high-compute projects for the AGI labs to figure out. But what if we weren't as bottlenecked on this anymore? It's possible to retrain GPT-2 1.5B with under 700$ now (and 125M for 20$). I think we can find ways to do useful experiments, but my guess is that the level of technical expertise required to get it done is a bit high, and alignment researchers would rather avoid these kinds of projects since they are currently high-effort.
I talk about other related projects here [LW(p) · GW(p)].
Replies from: jacques-thibodeau, myyycroft, eggsyntax↑ comment by jacquesthibs (jacques-thibodeau) · 2024-07-29T20:57:17.365Z · LW(p) · GW(p)
Synthesized various resources for this "pre-training for alignment" type work:
- Data
- Synthetic Data
- The RetroInstruct Guide To Synthetic Text Data
- Alignment In The Age of Synthetic Data
- Leveraging Agentic AI for Synthetic Data Generation
- **AutoEvol**: Automatic Instruction Evolving for Large Language Models We build a fully automated Evol-Instruct pipeline to create high-quality, highly complex instruction tuning data
- Synthetic Data Generation and AI Feedback notebook
- The impact of models training on their own outputs and how its actually done well in practice
- Google presents Best Practices and Lessons Learned on Synthetic Data for Language Models
- Transformed/Enrichment of Data
- Rephrasing the Web: A Recipe for Compute and Data-Efficient Language Modeling. TLDR: You can train 3x faster and with upto 10x lesser data with just synthetic rephrases of the web!
- Better Synthetic Data by Retrieving and Transforming Existing Datasets
- Rho-1: Not All Tokens Are What You Need RHO-1-1B and 7B achieves SotA results of 40.6% and 51.8% on MATH dataset, respectively — matching DeepSeekMath with only 3% of the pretraining tokens.
- Data Attribution
- In-Run Data Shapley
- Scaling Laws for the Value of Individual Data Points in Machine Learning We show how some data points are only valuable in small training sets; others only shine in large datasets.
- What is Your Data Worth to GPT? LLM-Scale Data Valuation with Influence Functions
- Data Mixtures
- Methods for finding optimal data mixture
- Curriculum Learning
- Active Data Selection
- MATES: Model-Aware Data Selection for Efficient Pretraining with Data Influence Models MATES significantly elevates the scaling curve by selecting the data based on the model's evolving needs.
- Data Filtering
- Scaling Laws for Data Filtering -- Data Curation cannot be Compute Agnostic Argues that data curation cannot be agnostic of the total compute that a model will be trained for Github
- How to Train Data-Efficient LLMs Models trained on ASK-LLM data consistently outperform full-data training—even when we reject 90% of the original dataset, while converging up to 70% faster
- Synthetic Data
- On Pre-Training
- Pre-Training from Human Preferences
- Ethan Perez wondering if jailbreaks would be solved with this pre-training approach
- LAION uses this approach for finegrained control over outputs during inference.
- Nora Belrose thinks that alignment via pre-training would make models more robust to unlearning (she doesn't say this, but this may be a good thing if you pre-train such that you don't need unlearning)
- Tomek describing some research direction for improving pre-training alignment
- Simple and Scalable Strategies to Continually Pre-train Large Language Models
- Neural Networks Learn Statistics of Increasing Complexity
- Pre-Training from Human Preferences
- Pre-Training towards the basin of attraction for alignment
- Alignment techniques
- AlignEZ: Using the self-generated preference data, we identify the subspaces that: (1) facilitate and (2) are harmful to alignment. During inference, we surgically modify the LM embedding using these identified subspaces. Jacques note: could we apply this iteratively throughout training (and other similar methods)?
- What do we mean by "alignment"? What makes the model safe?
- Values
- On making the model "care"
↑ comment by myyycroft · 2024-09-06T10:47:08.263Z · LW(p) · GW(p)
GPT-2 1.5B is small by today's standards. I hypothesize people are not sure if findings made for models of this scale will generalize to frontier models (or at least to the level of LLaMa-3.1-70B), and that's why nobody is working on it.
However, I was impressed by "Pre-Training from Human Preferences". I suppose that pretraining could be improved, and it would be a massive deal for alignment.
↑ comment by eggsyntax · 2024-07-20T11:12:49.673Z · LW(p) · GW(p)
how to guide the pretraining process in a way that benefits alignment
One key question here, I think: a major historical alignment concern has been that for any given finite set of outputs, there are an unbounded number of functions that could produce it, and so it's hard to be sure that a model will generalize in a desirable way. Nora Belrose goes so far as to suggest that 'Alignment worries are quite literally a special case of worries about generalization.' This is relevant for post-training but I think even more so for pre-training.
I know that there's been research into how neural networks generalize both from the AIS community and the larger ML community, but I'm not very familiar with it; hopefully someone else can provide some good references here.
comment by jacquesthibs (jacques-thibodeau) · 2023-11-14T19:14:21.708Z · LW(p) · GW(p)
If you work at a social media website or YouTube (or know anyone who does), please read the text below:
Community Notes is one of the best features to come out on social media apps in a long time. The code is even open source. Why haven't other social media websites picked it up yet? If they care about truth, this would be a considerable step forward beyond. Notes like “this video is funded by x nation” or “this video talks about health info; go here to learn more” messages are simply not good enough.
If you work at companies like YouTube or know someone who does, let's figure out who we need to talk to to make it happen. Naïvely, you could spend a weekend DMing a bunch of employees (PMs, engineers) at various social media websites in order to persuade them that this is worth their time and probably the biggest impact they could have in their entire career.
If you have any connections, let me know. We can also set up a doc of messages to send in order to come up with a persuasive DM.
Replies from: jacques-thibodeau, Viliam, jacques-thibodeau, ChristianKl, jacques-thibodeau, bruce-lewis↑ comment by jacquesthibs (jacques-thibodeau) · 2023-11-14T19:52:25.042Z · LW(p) · GW(p)
Don't forget that we train language models on the internet! The more truthful your dataset is, the more truthful the models will be! Let's revamp the internet for truthfulness, and we'll subsequently improve truthfulness in our AI systems!!
↑ comment by Viliam · 2023-11-15T08:48:30.061Z · LW(p) · GW(p)
I don't use Xitter; is there a way to display e.g. top 100 tweets with community notes? To see how it works in practice.
Replies from: Yoav Ravid, jacques-thibodeau↑ comment by Yoav Ravid · 2023-11-15T16:35:05.833Z · LW(p) · GW(p)
I don't know of something that does so at random, but this page automatically shares posts with community notes that have been deemed helpful.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-11-15T16:37:20.174Z · LW(p) · GW(p)
Oh, that’s great, thanks! Also reminded me of (the less official, more comedy-based) “Community Notes Violating People”. @Viliam [LW · GW]
Replies from: Viliam↑ comment by jacquesthibs (jacques-thibodeau) · 2023-11-15T13:16:28.093Z · LW(p) · GW(p)
I don’t think so, unfortunately.
Replies from: Viliam↑ comment by Viliam · 2023-11-15T16:05:31.018Z · LW(p) · GW(p)
Found a nice example (linked from Zvi's article [LW · GW]).
Okay, it's just one example and it wasn't found randomly, but I am impressed.
↑ comment by jacquesthibs (jacques-thibodeau) · 2023-11-15T04:09:15.811Z · LW(p) · GW(p)
I've also started working on a repo in order to make Community Notes more efficient by using LLMs.
↑ comment by ChristianKl · 2023-11-14T20:05:07.105Z · LW(p) · GW(p)
Why haven't other social media websites picked it up yet? If they care about truth, this would be a considerable step forward beyond.
This sounds a bit naive.
There's a lot of energy invested in making it easier for powerful elites to push their preferred narratives. Community Notes are not in the interests of the Censorship Industrial Complex.
I don't think that anyone at the project manager level has the political power to add a feature like Community Notes. It would likely need to be someone higher up in the food chain.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-11-14T20:11:45.389Z · LW(p) · GW(p)
Sure, but sometimes it's just a PM and a couple of other people that lead to a feature being implemented. Also, keep in mind that Community Notes was a thing before Musk. Why was Twitter different than other social media websites?
Also, the Community Notes code was apparently completely revamped by a few people working on the open-source code, which got it to a point where it was easy to implement, and everyone liked the feature because it noticeably worked.
Either way, I'd rather push for making it happen and somehow it fails on other websites than having pessimism and not trying at all. If it needs someone higher up the chain, let's make it happen.
Replies from: ChristianKl↑ comment by ChristianKl · 2023-11-14T20:43:46.658Z · LW(p) · GW(p)
Sure, but sometimes it's just a PM and a couple of other people that lead to a feature being implemented. Also, keep in mind that Community Notes was a thing before Musk. Why was Twitter different than other social media websites?
Twitter seems to have started Birdwatch as a small separate pilot project where it likely wasn't easy to fight or on anyone's radar to fight.
In the current enviroment, where X gets seen as evil by a lot of the mainstream media, I would suspect that copying Community Notes from X would alone produce some resistence. The antibodies are now there in a way they weren't two years ago.
Also, the Community Notes code was apparently completely revamped by a few people working on the open-source code, which got it to a point where it was easy to implement, and everyone liked the feature because it noticeably worked.
If you look at mainstream media views about X's community notes, I don't think everyone likes it.
I remember Elon once saying that he lost a 8-figure advertising deal because of Community Notes on posts of a company that wanted to advertise on X.
Either way, I'd rather push for making it happen and somehow it fails on other websites than having pessimism and not trying at all. If it needs someone higher up the chain, let's make it happen.
I think you would likely need to make a case that it's good business in addition to helping with truth.
If you want to make your argument via truth, motivating some reporters to write favorable articles about Community Notes might be necessary.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-11-14T20:49:20.543Z · LW(p) · GW(p)
Good points; I'll keep them all in mind. If money is the roadblock, we can put pressure on the companies to do this. Or, worst-case, maybe the government can enforce it (though that should be done with absolute care).
↑ comment by jacquesthibs (jacques-thibodeau) · 2023-11-14T19:45:18.905Z · LW(p) · GW(p)
I shared a tweet about it here: https://x.com/JacquesThibs/status/1724492016254341208?s=20
Consider liking and retweeting it if you think this is impactful. I'd like it to get into the hands of the right people.
↑ comment by Bruce Lewis (bruce-lewis) · 2023-11-14T19:31:05.897Z · LW(p) · GW(p)
I had not heard of Community Notes. Interesting anti-bias technique "notes require agreement between contributors who have sometimes disagreed in their past ratings". https://communitynotes.twitter.com/guide/en/about/introduction
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-11-14T19:34:43.538Z · LW(p) · GW(p)
I've been on Twitter for a long time, and there's pretty much unanimous agreement that it works amazingly well in practice!
Replies from: kabir-kumar-1↑ comment by Kabir Kumar (kabir-kumar-1) · 2023-11-14T19:37:14.776Z · LW(p) · GW(p)
there is an issue with surface level insights being unfaily weighted, but this is solvable, imo. especially with youtube, which can see which commenters have watched the full video.
comment by jacquesthibs (jacques-thibodeau) · 2024-11-25T22:46:11.994Z · LW(p) · GW(p)
I have some alignment project ideas for things I'd consider mentoring for. I would love feedback on the ideas. If you are interested in collaborating on any of them, that's cool, too.
Here are the titles:
Smart AI vs swarm of dumb AIs |
Lit review of chain of thought faithfulness (steganography in AIs) |
Replicating METR paper but for alignment research task |
Tool-use AI for alignment research |
Sakana AI for Unlearning |
Automated alignment onboarding |
Build the infrastructure for making Sakana AI's AI scientist better for alignment research |
comment by jacquesthibs (jacques-thibodeau) · 2024-10-02T16:04:07.560Z · LW(p) · GW(p)
I quickly wrote up some rough project ideas for ARENA and LASR participants, so I figured I'd share them here as well. I am happy to discuss these ideas and potentially collaborate on some of them.
Alignment Project Ideas (Oct 2, 2024)
1. Improving "A Multimodal Automated Interpretability Agent" (MAIA)
Overview
MAIA (Multimodal Automated Interpretability Agent) is a system designed to help users understand AI models by combining human-like experimentation flexibility with automated scalability. It answers user queries about AI system components by iteratively generating hypotheses, designing and running experiments, observing outcomes, and updating hypotheses.
MAIA uses a vision-language model (GPT-4V, at the time) backbone equipped with an API of interpretability experiment tools. This modular system can address both "macroscopic" questions (e.g., identifying systematic biases in model predictions) and "microscopic" questions (e.g., describing individual features) with simple query modifications.
This project aims to improve MAIA's ability to either answer macroscopic questions or microscopic questions on vision models.
2. Making "A Multimodal Automated Interpretability Agent" (MAIA) work with LLMs
MAIA is focused on vision models, so this project aims to create a MAIA-like setup, but for the interpretability of LLMs.
Given that this would require creating a new setup for language models, it would make sense to come up with simple interpretability benchmark examples to test MAIA-LLM. The easiest way to do this would be to either look for existing LLM interpretability benchmarks or create one based on interpretability results we've already verified (would be ideal to have a ground truth). Ideally, the examples in the benchmark would be simple, but new enough that the LLM has not seen them in its training data.
3. Testing the robustness of Critique-out-Loud Reward (CLoud) Models
Critique-out-Loud reward models are reward models that can reason explicitly about the quality of an input through producing Chain-of-Thought like critiques of an input before predicting a reward. In classic reward model training, the reward model is trained as a reward head initialized on top of the base LLM. Without LM capabilities, classic reward models act as encoders and must predict rewards within a single forward pass through the model, meaning reasoning must happen implicitly. In contrast, CLoud reward models are trained to both produce explicit reasoning about quality and to score based on these critique reasoning traces. CLoud reward models lead to large gains for pairwise preference modeling on RewardBench, and also lead to large gains in win rate when used as the scoring model in Best-of-N sampling on ArenaHard.
The goal for this project would be to test the robustness of CLoud reward models. For example, are the CLoud RMs (discriminators) more robust to jailbreaking attacks from the policy (generator)? Do the CLoud RMs generalize better?
From an alignment perspective, we would want RMs that generalize further out-of-distribution (and ideally, always more than the generator we are training).
4. Synthetic Data for Behavioural Interventions
Simple synthetic data reduces sycophancy in large language models by (Google) reduced sycophancy in LLMs with a fairly small number of synthetic data examples. This project would involve testing this technique for other behavioural interventions and (potentially) studying the scaling laws. Consider looking at the examples from the Model-Written Evaluations paper by Anthropic to find some behaviours to test.
5. Regularization Techniques for Enhancing Interpretability and Editability
Explore the effectiveness of different regularization techniques (e.g. L1 regularization, weight pruning, activation sparsity) in improving the interpretability and/or editability of language models, and assess their impact on model performance and alignment. We expect we could apply automated interpretability methods (e.g. MAIA) to this project to test how well the different regularization techniques impact the model.
In some sense, this research is similar to the work Anthropic did with SoLU activation functions. Unfortunately, they needed to add layer norms to make the SoLU models competitive, which seems to have hidden away the superposition in other parts of the network, making SoLU unhelpful in making the models more interpretable
That said, we hope to find that we can increase our ability to interpret these models through regularization techniques. A technique like L1 regularization should help because it encourages the model to learn sparse representations by penalizing non-zero weights or activations. Sparse models tend to be more interpretable as they rely on a smaller set of important features.
Methodology:
- Identify a set of regularization techniques (e.g., L1 regularization, weight pruning, activation sparsity) to be applied during fine-tuning.
- Fine-tune pre-trained language models with different regularization techniques and hyperparameters.
- Evaluate the fine-tuned models using interpretability tools (e.g., attention visualization, probing classifiers) and editability benchmarks (e.g., ROME).
- Analyze the impact of regularization on model interpretability, editability, and performance.
- Investigate the relationship between interpretability, editability, and model alignment.
Expected Outcomes:
- Quantitative assessment of the effectiveness of different regularization techniques for improving interpretability and editability.
- Insights into the trade-offs between interpretability, editability, and model performance.
- Recommendations for regularization techniques that enhance interpretability and editability while maintaining model performance and alignment.
6. Quantifying the Impact of Reward Misspecification on Language Model Behavior
Investigate how misspecified reward functions influence the behavior of language models during fine-tuning and measure the extent to which the model's outputs are steered by the reward labels, even when they contradict the input context. We hope to better understand language model training dynamics. Additionally, we expect online learning to complicate things in the future, where models will be able to generate the data they may eventually be trained on. We hope that insights from this work can help us prevent catastrophic feedback loops in the future. For example, if model behavior is mostly impacted by training data, we may prefer to shape model behavior through synthetic data (it has been shown we can reduce sycophancy by doing this).
Prior works:
- The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models by Alexander Pan, Kush Bhatia, Jacob Steinhardt
- Survival Instinct in Offline Reinforcement Learning by Anqi Li, Dipendra Misra, Andrey Kolobov, Ching-An Cheng
- Simple synthetic data reduces sycophancy in large language models by (Google), Jerry Wei, Da Huang, Yifeng Lu, Denny Zhou, Quoc V. Le
- Scaling Laws for Reward Model Overoptimization by (OpenAI), Leo Gao, John Schulman, Jacob Hilton
- On the Sensitivity of Reward Inference to Misspecified Human Models by Joey Hong, Kush Bhatia, Anca Dragan
Methodology:
- Create a diverse dataset of text passages with candidate responses and manually label them with coherence and misspecified rewards.
- Fine-tune pre-trained language models using different reward weighting schemes and hyperparameters.
- Evaluate the generated responses using automated metrics and human judgments for coherence and misspecification alignment.
- Analyze the influence of misspecified rewards on model behavior and the trade-offs between coherence and misspecification alignment.
- Use interpretability techniques to understand how misspecified rewards affect the model's internal representations and decision-making process.
Expected Outcomes:
- Quantitative measurements of the impact of reward misspecification on language model behavior.
- Insights into the trade-offs between coherence and misspecification alignment.
- Interpretability analysis revealing the effects of misspecified rewards on the model's internal representations.
7. Investigating Wrong Reasoning for Correct Answers
Understand the underlying mechanisms that lead to language models producing correct answers through flawed reasoning, and develop techniques to detect and mitigate such behavior. Essentially, we want to apply interpretability techniques to help us identify which sets of activations or token-layer pairs impact the model getting the correct answer when it has the correct reasoning versus when it has the incorrect reasoning. The hope is to uncover systematic differences as to when it is not relying on its chain-of-thought at all and when it does leverage its chain-of-thought to get the correct answer.
[EDIT Oct 2nd, 2024] This project intends to follow a similar line of reasoning as described in this post [LW · GW] and this comment [LW(p) · GW(p)]. The goal is to study chains-of-thought and improve faithfulness without suffering an alignment tax so that we can have highly interpretable systems through their token outputs and prevent loss of control. The project doesn't necessarily need to rely only on model internals.
Related work:
- Decomposing Predictions by Modeling Model Computation by Harshay Shah, Andrew Ilyas, Aleksander Madry
- Does Localization Inform Editing? Surprising Differences in Causality-Based Localization vs. Knowledge Editing in Language Models by Peter Hase, Mohit Bansal, Been Kim, Asma Ghandeharioun
- On Measuring Faithfulness or Self-consistency of Natural Language Explanations by Letitia Parcalabescu, Anette Frank
- Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting by Miles Turpin, Julian Michael, Ethan Perez, Samuel R. Bowman
- Measuring Faithfulness in Chain-of-Thought Reasoning by Tamera Lanham et al.
Methodology:
- Curate a dataset of questions and answers where language models are known to provide correct answers but with flawed reasoning.
- Use interpretability tools (e.g., attention visualization, probing classifiers) to analyze the model's internal representations and decision-making process for these examples.
- Develop metrics and techniques to detect instances of correct answers with flawed reasoning.
- Investigate the relationship between model size, training data, and the prevalence of flawed reasoning.
- Propose and evaluate mitigation strategies, such as data augmentation or targeted fine-tuning, to reduce the occurrence of flawed reasoning.
Expected Outcomes:
- Insights into the underlying mechanisms that lead to correct answers with flawed reasoning in language models.
- Metrics and techniques for detecting instances of flawed reasoning.
- Empirical analysis of the factors contributing to flawed reasoning, such as model size and training data.
- Proposed mitigation strategies to reduce the occurrence of flawed reasoning and improve model alignment.
comment by jacquesthibs (jacques-thibodeau) · 2023-11-20T01:32:39.745Z · LW(p) · GW(p)
My current speculation as to what is happening at OpenAI
How do we know this wasn't their best opportunity to strike if Sam was indeed not being totally honest with the board?
Let's say the rumours are true, that Sam is building out external orgs (NVIDIA competitor and iPhone-like competitor) to escape the power of the board and potentially going against the charter. Would this 'conflict of interest' be enough? If you take that story forward, it sounds more and more like he was setting up AGI to be run by external companies, using OpenAI as a fundraising bargaining chip, and having a significant financial interest in plugging AGI into those outside orgs.
So, if we think about this strategically, how long should they wait as board members who are trying to uphold the charter?
On top of this, it seems (according to Sam) that OpenAI has made a significant transformer-level breakthrough recently, which implies a significant capability jump. Long-term reasoning? Basically, anything short of 'coming up with novel insights in physics' is on the table, given that Sam recently used that line as the line we need to cross to get to AGI.
So, it could be a mix of, Ilya thinking they have achieved AGI while Sam places a higher bar (internal communication disagreements) + the board not being alerted (maybe more than once) about what Sam is doing, e.g. fundraising for both OpenAI and the orgs he wants to connect AGI to + new board members who are more willing to let Sam and GDB do what they want being added soon (another rumour I've heard) + ???. Basically, perhaps they saw this as their final opportunity to have any veto on actions like this.
Here's what I currently believe:
- There is a GPT-5-like model that already exists. It could be GPT-4.5 or something else, but another significant capability jump. Potentially even a system that can coherently pursue goals for months, capable of continual learning, and effectively able to automate like 10% of the workforce (if they wanted to).
- As of 5 PM, Sunday PT, the board is in a terrible position where they either stay on board and the company employees all move to a new company, or they leave the board and bring Sam back. If they leave, they need to say that Sam did nothing wrong and sweep everything under the rug (and then potentially face legal action for saying he did something wrong); otherwise, Sam won't come back.
- Sam is building companies externally; it is unclear if this goes against the charter. But he does now have a significant financial incentive to speed up AI development. Adam D'Angelo said that he would like to prevent OpenAI from becoming a big tech company as part of his time on the board because AGI was too important for humanity. They might have considered Sam's action going in this direction.
- A few people left the board in the past year. It's possible that Sam and GDB planned to add new people (possibly even change current board members) to the board to dilute the voting power a bit or at least refill board seats. This meant that the current board had limited time until their voting power would become less important. They might have felt rushed.
- The board is either not speaking publicly because 1) they can't share information about GPT-5, 2) there is some legal reason that I don't understand (more likely), or 3) they are incompetent (least likely by far IMO).
- We will possibly never find out what happened, or it will become clearer by the month as new things come out (companies and models). However, it seems possible the board will never say or admit anything publicly at this point.
- Lastly, we still don't know why the board decided to fire Sam. It could be any of the reasons above, a mix or something we just don't know about.
Other possible things:
- Ilya was mad that they wouldn't actually get enough compute for Superalignment as promised due to GPTs and other products using up all the GPUs.
- Ilya is frustrated that Sam is focused on things like GPTs rather than the ultimate goal of AGI.
↑ comment by jacquesthibs (jacques-thibodeau) · 2023-11-22T23:41:11.779Z · LW(p) · GW(p)
Obviously, a lot has happened since the above shortform, but regarding model capabilities (which discussions died down these last couple of days), there's now this:

↑ comment by jacquesthibs (jacques-thibodeau) · 2023-11-23T00:11:25.019Z · LW(p) · GW(p)
So, apparently, there are two models, but only Q* is mentioned in the article. Won't share the source, but:

↑ comment by jacquesthibs (jacques-thibodeau) · 2023-11-20T04:33:10.799Z · LW(p) · GW(p)
Update, board members seem to be holding their ground more than expected in this tight situation:

comment by jacquesthibs (jacques-thibodeau) · 2024-09-03T11:08:31.891Z · LW(p) · GW(p)
News on the next OAI GPT release:
Nagasaki, CEO of OpenAI Japan, said, "The AI model called 'GPT Next' that will be released in the future will evolve nearly 100 times based on past performance. Unlike traditional software, AI technology grows exponentially."
https://www.itmedia.co.jp/aiplus/articles/2409/03/news165.html
The slide clearly states 2024 "GPT Next". This 100 times increase probably does not refer to the scaling of computing resources, but rather to the effective computational volume + 2 OOMs, including improvements to the architecture and learning efficiency. GPT-4 NEXT, which will be released this year, is expected to be trained using a miniature version of Strawberry with roughly the same computational resources as GPT-4, with an effective computational load 100 times greater. Orion, which has been in the spotlight recently, was trained for several months on the equivalent of 100k H100 compared to GPT-4 (EDIT: original tweet said 10k H100s, but that was a mistake), adding 10 times the computational resource scale, making it +3 OOMs, and is expected to be released sometime next year.
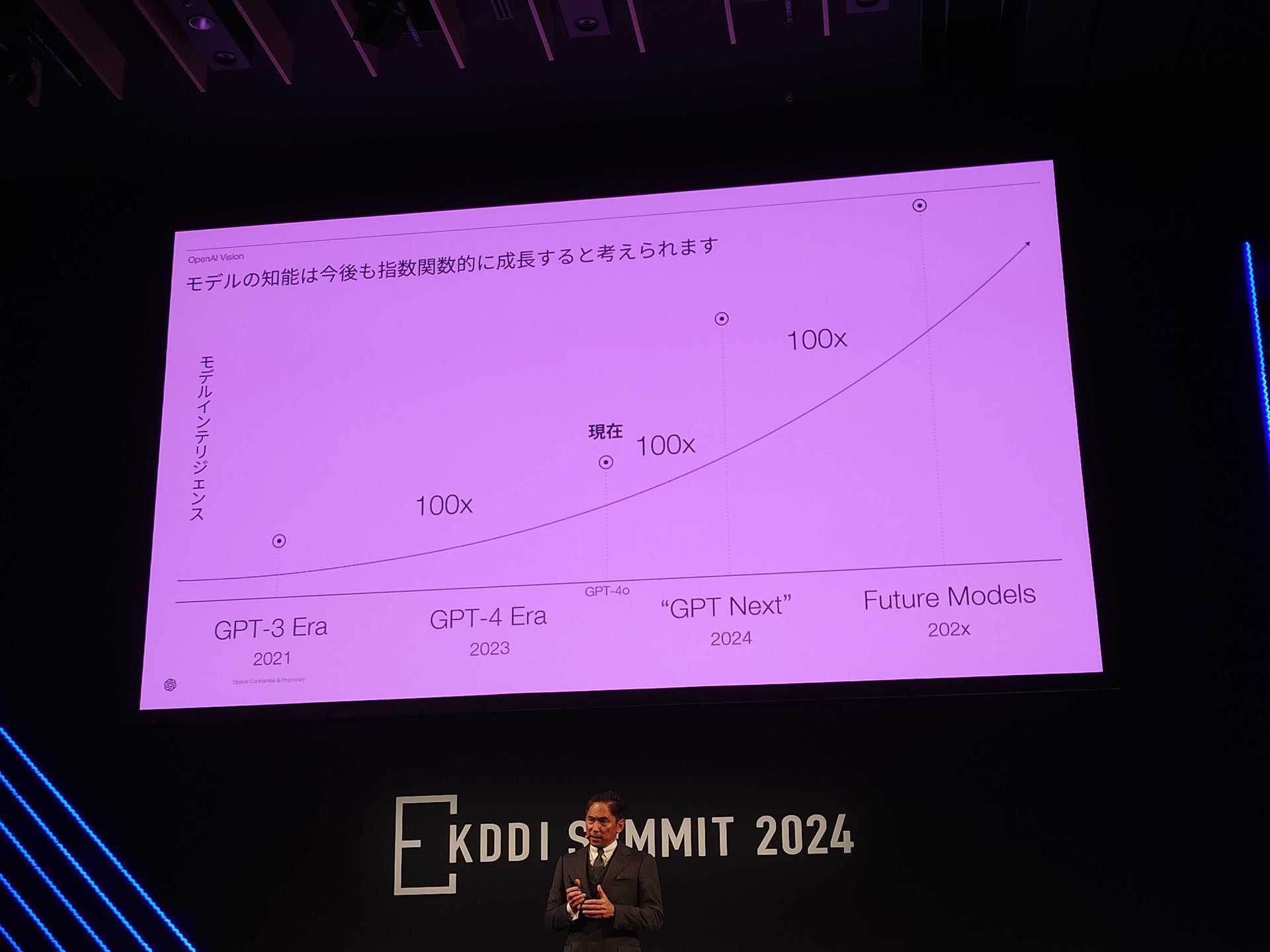
Note: Another OAI employee seemingly confirms this (I've followed them for a while, and they are working on inference).
Replies from: Vladimir_Nesov, luigipagani↑ comment by Vladimir_Nesov · 2024-09-03T14:26:18.002Z · LW(p) · GW(p)
Orion, which has been in the spotlight recently, was trained for several months on the equivalent of 10k H100 compared to GPT-4, adding 10 times the computational resource scale
This implies successful use of FP8, if taken literally in a straightforward way. In BF16 an H100 gives 1e15 FLOP/s (in dense tensor compute). With 40% utilization over 10 months, 10K H100s give 1e26 FLOPs, which is only 5 times higher than the rumored 2e25 FLOPs of original GPT-4. To get to 10 times higher requires some 2x improvement, and the evident way to get that is by transitioning from BF16 to FP8. I think use of FP8 for training hasn't been confirmed to be feasible at GPT-4 level scale (Llama-3-405B uses BF16), but if it does work, that's a 2x compute increase for other models as well.
This text about Orion and 10K H100s only appears in the bioshok3 tweet itself, not in the quoted news article, so it's unclear where the details come from. The "10 times the computational resource scale, making it +3 OOMs" hype within the same sentence also hurts credence in the numbers being accurate (10 times, 10K H100s, several months).
Another implication is that Orion is not the 100K H100s training run (that's probably currently ongoing). Plausibly it's an experiment with training on a significant amount of synthetic data [LW · GW]. This suggests that the first 100K H100s training run won't be experimenting with too much synthetic training data yet, at least in pre-training. The end of 2025 point for significant advancement in quality might then be referring to the possibility that Orion succeeds and its recipe is used in another 100K H100s scale run, which might be the first hypothetical model they intend to call "GPT-5". The first 100K H100s run by itself (released in ~early 2025) would then be called "GPT-4.5o" or something (especially if Orion does succeed, so that "GPT-5" remains on track).
Replies from: abandon, ryan_greenblatt↑ comment by dirk (abandon) · 2024-09-03T18:55:53.950Z · LW(p) · GW(p)
Bioshok3 said in a later tweet that they were in any case mistaken about it being 10k H100s and it was actually 100k H100s: https://x.com/bioshok3/status/1831016098462081256
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2024-09-03T19:20:36.756Z · LW(p) · GW(p)
Surprisingly, there appears to be an additional clue for this in the wording: 2e26 BF16 FLOPs take 2.5 months on 100K H100s at 30% utilization, while the duration of "several months" is indicated by the text "数ヶ月" in the original tweet. GPT-4o explains it to mean
The Japanese term "数ヶ月" (すうかげつ, sūka getsu) translates to "several months" in English. It is an approximate term, generally referring to a period of 2 to 3 months but can sometimes extend to 4 or 5 months, depending on context. Essentially, it indicates a span of a few months without specifying an exact number.
So the interpretation that fits most is specifically 2-3 months (Claude says 2-4 months, Grok 3-4 months), close to what the calculation for 100K H100s predicts. And this is quite unlike the requisite 10 months with 10K H100s in FP8.
↑ comment by ryan_greenblatt · 2024-09-03T16:08:33.323Z · LW(p) · GW(p)
This text about Orion and 10K H100s only appears in the bioshok3 tweet itself, not in the quoted news article, so it's unclear where the details come from.
My guess is that this is just false / hallucinated.
Replies from: ryan_greenblatt, ryan_greenblatt↑ comment by ryan_greenblatt · 2024-09-03T16:39:40.440Z · LW(p) · GW(p)
"Orion is 10x compute" seems plausible, "Orion was trained on only 10K H100s" does not seem plausible if it is actually supposed to be 10x raw compute. Around 50K H100s does seem plausible and would correspond to about 10x compute assuming a training duration similar to GPT-4.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2024-09-03T17:45:07.727Z · LW(p) · GW(p)
Within this hypothetical, Orion didn't necessarily merit the use of the largest training cluster, while time on 10K H100s is something mere money can buy without impacting other plans. GPT-4o is itself plausibly at 1e26 FLOPs level already, since H100s were around for more than a year before it came out (1e26 FLOPs is 5 months on 20K H100s). It might be significantly overtrained, or its early fusion multimodal nature might balloon the cost of effective intelligence. Gemini 1.0 Ultra, presumably also an early fusion model with rumored 1e26 FLOPs, similarly wasn't much better than Mar 2023 GPT-4. Though Gemini 1.0 is plausibly dense, given how the Gemini 1.5 report stressed that 1.5 is MoE, so that might be a factor in how 1e26 FLOPs didn't get it too much of an advantage.
So if GPT-4o is not far behind in terms of FLOPs, a 2e26 FLOPs Orion wouldn't be a significant improvement unless the synthetic data aspect works very well, and so there would be no particular reason to rush it. On the other hand GPT-4o looks like something that needed to be done as fast as possible, and so the largest training cluster went to it and not Orion. The scaling timelines are dictated by building of largest training clusters, not by decisions about use of smaller training clusters.
↑ comment by ryan_greenblatt · 2024-09-03T16:35:32.062Z · LW(p) · GW(p)
This tweet also claims 10k H100s while citing the same article that doesn't mention this.
↑ comment by LuigiPagani (luigipagani) · 2024-09-04T08:18:48.112Z · LW(p) · GW(p)
Are you sure he is an OpenAi employee?
comment by jacquesthibs (jacques-thibodeau) · 2024-06-12T14:24:24.363Z · LW(p) · GW(p)
I encourage alignment/safety people to be open-minded about what François Chollet is saying in this podcast:
I think many are blindly bought into the 'scale is all you need' and apparently godly nature of LLMs and may be dependent on unfounded/confused assumptions because of it.
Getting this right is important because it could significantly impact how hard you think alignment will be. Here [LW(p) · GW(p)]'s @johnswentworth [LW · GW] responding to @Eliezer Yudkowsky [LW · GW] about his difference in optimism compared to @Quintin Pope [LW · GW] (despite believing the natural abstraction hypothesis is true):
Entirely separately, I have concerns about the ability of ML-based technology to robustly point the AI in any builder-intended direction whatsoever, even if there exists some not-too-large adequate mapping from that intended direction onto the AI's internal ontology at training time. My guess is that more of the disagreement lies here.
I doubt much disagreement between you and I lies there, because I do not expect ML-style training to robustly point an AI in any builder-intended direction. My hopes generally don't route through targeting via ML-style training.
I do think my deltas from many other people lie there - e.g. that's why I'm nowhere near as optimistic as Quintin - so that's also where I'd expect much of your disagreement with those other people to lie.
Chollet's key points are that LLMs and current deep learning approaches rely heavily on memorization and pattern matching rather than reasoning and problem-solving abilities. Humans (who are 'intelligent') use a bit of both.
LLMs have failed at ARC for the last 4 years because they are simply not intelligent and basically pattern-match and interpolate to whatever is within their training distribution. You can say, "Well, there's no difference between interpolation and extrapolation once you have a big enough model trained on enough data," but the point remains that LLMs fail at the Abstract Reasoning and Concepts benchmark precisely because they have never seen such examples.
No matter how 'smart' GPT-4 may be, it fails at simple ARC tasks that a human child can do. The child does not need to be fed thousands of ARC-like examples; it can just generalize and adapt to solve the novel problem.
One thing to ponder here is, "Are the important kinds of tasks we care about, e.g. coming up with novel physics or inventing nanotech robots, reliant on models gaining the key ability to think and act in the way it would need to solve a novel task like ARC?"
At this point, I think some people might say something like, "How can you say that LLMs are not intelligent when they are solving novel software engineering problems or coming up with new poems?"
Well, again, the answer here is that they have so many examples like this in their pre-training and are just capable of pattern-matching their way to something like writing the code for a specification that the human came up with. I think if there was a really in-depth study, people might be surprised by how much they assumed that LLMs were truly able to generalize to truly novel tasks. And I think it's worth considering whether this is a key bottleneck in current approaches.
Then again, the follow-up to this is likely, "OK, but we'll likely easily solve system 2 reasoning very soon; it doesn't seem like much of a challenge once you scale up the model to a certain level of 'capability.'"
We'll see! I mean, so far, current models have failed to make things like Auto-GPT work. Maybe this just requires more trial-and-error, or maybe this is a big limitation of current systems, and you actually do need some "transformer-level paradigm shift". Here [LW(p) · GW(p)]'s @johnswentworth [LW · GW] again regarding his hope:
There isn't really one specific thing, since we don't yet know what the next ML/AI paradigm will look like, other than that some kind of neural net will probably be involved somehow. (My median expectation [LW(p) · GW(p)] is that we're ~1 transformers-level paradigm shift away from the things which take off.) But as a relatively-legible example of a targeting technique my hopes might route through: Retargeting The Search [LW · GW].
Lastly, you might think, "well it seems pretty obvious that we can just automate many jobs because most jobs will have a static distribution", but 1) you are still limited by human data to provide examples for learning and adding patterns to its training distribution 2) as Chollet says:
We can automate more and more things. Yes, this is economically valuable. Yes, potentially there are many jobs you could automate away like this. That would be economically valuable. You're still not going to have intelligence.
So you can ask, what does it matter if we can generate all this economic value? Maybe we don't need intelligence after all. You need intelligence the moment you have to deal with change, novelty, and uncertainty.
As long as you're in a space that can be exactly described in advance, you can just rely on pure memorization. In fact, you can always solve any problem. You can always display arbitrary levels of skills on any task without leveraging any intelligence whatsoever, as long as it is possible to describe the problem and its solution very, very precisely.
So, how does Chollet expect us to resolve the issues with deep learning systems?
Let's break it down:
- Deep learning excels at memorization, pattern matching, and intuition—similar to system 1 thinking in humans. It generalizes but only generalizes locally within its training data distribution.
- One way to get good system 2 reasoning out of your system is to use something like discrete program search (Chollet's current favourite approach) because it excels at systematic reasoning, planning, and problem-solving (which is why it can do well on ARC). It can synthesize programs to solve novel problems but suffers from combinatorial explosion and is computationally inefficient.
- Chollet suggests that the path forward involves combining the strengths of deep learning with the approach that gets us a good system 2. This is starting to sound similar to @johnswentworth [LW · GW]'s intuition that future systems will include "some kind of neural net [...] somehow" (I mean, of course). But essentially, the outer structure would be a discrete program search that systematically explores the space of possible programs that is aided by deep learning to guide the search in intelligent ways – providing intuitions about likely solutions approaches, offering hints when the search gets stuck, pruning unproductive branches, etc.
- Basically, it leverages the vast knowledge and pattern recognition of deep learning (limited by its training data distribution), while gaining the ability to reason and adapt to novel situations via program synthesis. Going back to ARC, you'd expect it could solve such novel problems by decomposing them into familiar subproblems and systematically searching for solution programs.
↑ comment by Mitchell_Porter · 2024-06-12T15:09:34.322Z · LW(p) · GW(p)
memorization and pattern matching rather than reasoning and problem-solving abilities
In my opinion, this does not correspond to a principled distinction at the level of computation.
For intelligences that employ consciousness in order to do some of these things, there may be a difference in terms of mechanism. Reasoning and pattern matching sound like they correspond to different kinds of conscious activity.
But if we're just talking about computation... a syllogism can be implemented via pattern matching, a pattern can be completed by a logical process (possibly probabilistic).
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2024-06-12T15:43:40.046Z · LW(p) · GW(p)
But if we're just talking about computation... a syllogism can be implemented via pattern matching, a pattern can be completed by a logical process (possibly probabilistic).
Perhaps, but deep learning models are still failing at ARC. My guess (and Chollet's) is that they will continue to fail at ARC unless they are trained on that kind of data (which goes against the point of the benchmark) or you add something else that actually resolves this failure in deep learning models. It may be able to pattern-match to reasoning-like behaviour, but only if specifically trained on that kind of data. No matter how much you scale it up, it will still fail to generalize to anything not local in its training data distribution.
↑ comment by Seth Herd · 2024-06-12T21:35:02.097Z · LW(p) · GW(p)
I think this is exactly right. The phrasing is a little confusing. I'd say "LLMs can't solve truly novel problems".
But the implication that this is a slow route or dead-end for AGI is wrong. I think it's going to be pretty easy to scaffold LLMs into solving novel problems. I could be wrong, but don't bet heavily on it unless you happen to know way more about cognitive psychology and LLMs in combination than I do. it would be foolish to make a plan for survival that relies on this being a major delay.
I can't convince you of this without describing exactly how I think this will be relatively straightforward, and I'm not ready to advance capabilities in this direction yet. I think language model agents are probably our best shot at alignment, so we should probably actively work on advancing them to AGI; but I'm not sure enough yet to start publishing my best theories on how to do that.
Back to the possibly confusing phrasing Chollet uses: I think he's using Piaget's definition of intelligence as "what you do when you don't know what to do" (he quotes this in the interview). That's restricting it to solving problems you haven't memorized an approach to. That's not how most people use the word intelligence.
When he says LLMs "just memorize", he's including memorizing programs or approaches to problems, and they can plug the variables of this particular variant of the problem in to those memorized programs/approaches. I think the question "well maybe that's all you need to do" raised by Patel is appropriate; it's clear they can't do enough of this yet, but it's unclear if further progress will get them to another level of abstraction of an approach so abstract and general that it can solve almost any problem.
I think he's on the wrong track with the "discrete program search" because I see more human-like solutions that may be lower-hanging fruit, but I wouldn't bet his approach won't work. I'm starting to think that there are many approaches to general intelligence, and a lot of them just aren't that hard. We'd like to think our intelligence is unique, magical, and special, but it's looking like it's not. Or at least, we should assume it's not if we want to plan for other intelligences well enough to survive. So I think alignment workers should assume LLMs with or without scaffolding might very well pass this hurdle fairly quickly.
↑ comment by quetzal_rainbow · 2024-06-12T16:32:57.998Z · LW(p) · GW(p)
Okay, hot take: I don't think that ARC tests "system 2 reasoning" and "solving novel tasks", at least, in humans. When I see simple task, I literally match patterns, when I see complex task I run whatever patterns I can invent until they match. I didn't run the entire ARC testing dataset, but if I am good at solving it, it will be because I am fan of Myst-esque games and, actually, there are not so many possible principles in designing problems of this sort.
What failure of LLMs to solve ARC is actually saying us, it is "LLM cognition is very different from human cognition".
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2024-06-12T16:53:31.972Z · LW(p) · GW(p)
I didn't run the entire ARC testing dataset, but if I am good at solving it, it will be because I am fan of Myst-esque games and, actually, there are not so many possible principles in designing problems of this sort.
They've tested ARC with children and Mechanical Turk workers, and they all seem to do fine despite the average person not being a fan of "Myst-esque games."
What failure of LLMs to solve ARC is actually saying us, it is "LLM cognition is very different from human cognition".
Do you believe LLMs are just a few OOMs away from solving novel tasks like ARC? What is different that is not explained by what Chollet is saying?
Replies from: quetzal_rainbow, Morpheus↑ comment by quetzal_rainbow · 2024-06-12T18:35:53.957Z · LW(p) · GW(p)
By "good at solving" I mean "better than average person".
I think the fact that language model are better at predicting next token than humans implies that LLMs have sophisticated text-oriented cognition and saying "LLMs are not capable to solve ARC, therefore, they are less intelligent than children" is equivalent to saying "humans can't take square root of 819381293787, therefore, they are less intelligent than calculator".
My guess that probably we would need to do something non-trivial to scale LLM to superintelligence, but I don't expect that it is necessary to move from general LLM design principles.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2024-06-12T18:50:13.883Z · LW(p) · GW(p)
saying "LLMs are not capable to solve ARC, therefore, they are less intelligent than children" is equivalent to saying "humans can't take square root of 819381293787, therefore, they are less intelligent than calculator".
Of course, I acknowledge that LLMs are better at many tasks than children. Those tasks just happen to all be within its training data distribution and not on things that are outside of it. So, no, you wouldn't say the calculator is more intelligent than the child, but you might say that it has an internal program that allows it to be faster and more accurate than a child. LLMs have such programs they can use via pattern-matching too, as long as it falls into the training data distribution (in the case of Caesar cypher, apparently it doesn't do so well for number nine – because it's simply less common in its training data distribution).
One thing that Chollet does mention that helps to alleviate the limitation of deep learning is to have some form of active inference:
Replies from: quetzal_rainbow, eggsyntaxDwarkesh: Jack Cole with a 240 million parameter model got 35% [on ARC]. Doesn't that suggest that they're on this spectrum that clearly exists within humans, and they're going to be saturated pretty soon?
[...]
Chollet: One thing that's really critical to making the model work at all is test time fine-tuning. By the way, that's something that's really missing from LLM approaches right now. Most of the time when you're using an LLM, it's just doing static inference. The model is frozen. You're just prompting it and getting an answer. The model is not actually learning anything on the fly. Its state is not adapting to the task at hand.
What Jack Cole is actually doing is that for every test problem, it’s on-the-fly fine-tuning a version of the LLM for that task. That's really what's unlocking performance. If you don't do that, you get like 1-2%, something completely negligible. If you do test time fine-tuning and you add a bunch of tricks on top, then you end up with interesting performance numbers.
What it's doing is trying to address one of the key limitations of LLMs today: the lack of active inference. It's actually adding active inference to LLMs. That's working extremely well, actually. So that's fascinating to me.
↑ comment by quetzal_rainbow · 2024-06-13T09:19:16.888Z · LW(p) · GW(p)
Let's start with the end:
One thing that Chollet does mention that helps to alleviate the limitation of deep learning is to have some form of active inference
Why do you think that they don't already do that? [LW(p) · GW(p)]
you might say that it has an internal program that allows it to be faster and more accurate than a child
My point is that children can solve ARC not because they have some amazing abstract spherical-in-vacuum reasoning abilities which LLMs lack, but because they have human-specific pattern recognition ability (like geometric shapes, number sequences, music, etc). Brains have strong inductive biases, after all. If you train a model purely on the prediction of a non-anthropogenic physical environment, I think this model will struggle with solving ARC even if it has a sophisticated multi-level physical model of reality, because regular ARC-style repeating shapes are not very probable on priors.
In my impression, in debates about ARC, AI people do not demonstrate a very high level of deliberation. Chollet and those who agree with him are like "nah, LLMs are nothing impressive, just interpolation databases!" and LLM enthusiasts are like "scaling will solve everything!!!!111!" Not many people seem to consider "something interesting is going on here. Maybe we can learn something important about how humans and LLMs work that doesn't fit into simple explanation templates."
↑ comment by eggsyntax · 2024-06-13T10:52:40.851Z · LW(p) · GW(p)
One thing that's really critical to making the model work at all is test time fine-tuning. By the way, that's something that's really missing from LLM approaches right now
Since AFAIK in-context learning functions pretty similarly to fine-tuning (though I haven't looked into this much), it's not clear to me why Chollet sees online fine-tuning as deeply different from few-shot prompting. Certainly few-shot prompting works extremely well for many tasks; maybe it just empirically doesn't help much on this one?
Replies from: eggsyntax↑ comment by Morpheus · 2024-06-12T17:56:51.800Z · LW(p) · GW(p)
Looking at how gpt-4 did on the benchmark when I gave it some screenshots, the thing it failed at was the visual "pattern matching" (things completely solved by my system 1) rather than the abstract reasoning.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2024-06-12T18:03:01.763Z · LW(p) · GW(p)
Yes, the point is that it can’t pattern match because it has never seen such examples. And, as humans, we are able to do well on the task because we don’t simply rely on pattern matching, we use system 2 reasoning (in addition) to do well on such a novel task. Given that the deep learning model relies on pattern matching, it can’t do the task.
Replies from: Morpheus, Morpheus, Morpheus↑ comment by Morpheus · 2024-06-12T18:05:25.228Z · LW(p) · GW(p)
I think humans just have a better visual cortex and expect this benchmark too to just fall with scale.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2024-06-12T18:15:07.650Z · LW(p) · GW(p)
As Chollet says in the podcast, we will see if multimodal models crack ARC in the next year, but I think researchers should start paying attention rather than dismissing if they are incapable of doing so in the next year.
But for now, “LLMs do fine with processing ARC-like data by simply fine-tuning an LLM on subsets of the task and then testing it on small variation.” It encodes solution programs just fine for tasks it has seen before. It doesn’t seem to be an issue of parsing the input or figuring out the program. For ARC, you need to synthesize a new solution program on the fly for each new task.
Replies from: Morpheus↑ comment by Morpheus · 2024-06-13T10:18:25.967Z · LW(p) · GW(p)
Would it change your mind if gpt-4 was able to do the grid tasks if I manually transcribed them to different tokens? I tried to manually let gpt-4 turn the image to a python array, but it indeed has trouble performing just that task alone.
↑ comment by Morpheus · 2024-06-12T18:14:10.605Z · LW(p) · GW(p)
For concreteness. In this task it fails to recognize that all of the cells get filled, not only the largest one. To me that gives the impression that the image is just not getting compressed really well and the reasoning gpt-4 is doing is just fine.
↑ comment by eggsyntax · 2024-06-16T11:30:03.562Z · LW(p) · GW(p)
There are other interesting places where LLMs fail badly at reasoning, eg planning problems like block-world or scheduling meetings between people with availability constraints; see eg this paper & other work from Kambhampati.
I've been considering putting some time into this as a research direction; the ML community has a literature on the topic but it doesn't seem to have been discussed much in AIS, although the ARC prize could change that. I think it needs to be considered through a safety lens, since it has significant impacts on the plausibility of short timelines to drop-in-researcher like @leopold [LW · GW]'s. I have an initial sketch of such a direction here, combining lit review & experimentation. Feedback welcomed!
(if in fact someone already has looked at this issue through an AIS lens, I'd love to know about it!)
↑ comment by Morpheus · 2024-06-12T16:43:36.271Z · LW(p) · GW(p)
LLMs have failed at ARC for the last 4 years because they are simply not intelligent and basically pattern-match and interpolate to whatever is within their training distribution. You can say, "Well, there's no difference between interpolation and extrapolation once you have a big enough model trained on enough data," but the point remains that LLMs fail at the Abstract Reasoning and Concepts benchmark precisely because they have never seen such examples.
No matter how 'smart' GPT-4 may be, it fails at simple ARC tasks that a human child can do. The child does not need to be fed thousands of ARC-like examples; it can just generalize and adapt to solve the novel problem.
I don't get it. I just looked at ARC and it seemed obvious that gpt-4/gpt-4o can easily solve these problems by writing python. Then I looked it up on papers-with-code and it seems close to solved? Probably the ones remaining would be hard for children also. Did the benchmark leak into the training data and that is why they don't count them?
Replies from: DMZ↑ comment by dmz (DMZ) · 2024-06-12T16:47:56.808Z · LW(p) · GW(p)
Unfortunate name collision: you're looking at numbers on the AI2 Reasoning Challenge, not Chollet's Abstraction & Reasoning Corpus.
Replies from: Morpheus↑ comment by Morpheus · 2024-06-12T17:37:47.064Z · LW(p) · GW(p)
Thanks for clarifying! I just tried a few simple ones by prompting gpt-4o and gpt-4 and it does absolutely horrific job! Maybe trying actually good prompting could help solving it, but this is definitely already an update for me!
comment by jacquesthibs (jacques-thibodeau) · 2023-11-03T00:12:10.380Z · LW(p) · GW(p)
Attempt to explain why I think AI systems are not the same thing as a library card when it comes to bio-risk.
To focus on less of an extreme example, I’ll be ignoring the case where AI can create new, more powerful pathogens faster than we can create defences, though I think this is an important case (some people just don’t find it plausible because it relies on the assumption that AIs being able to create new knowledge).
I think AI Safety people should make more of an effort to walkthrough the threat model so I’ll give an initial quick first try:
1) Library. If I’m a terrorist and I want to build a bioweapon, I have to spend several months reading books at minimum to understand how it all works. I don’t have any experts on-hand to explain how to do it step-by-step. I have to figure out which books to read and in what sequence. I have to look up external sources to figure out where I can buy specific materials.
Then, I have to somehow find out how to to gain access to those materials (this is the most difficult part for each case). Once I gain access to the materials, I still need to figure out how to make things work as a total noob at creating bioweapons. I will fail. Even experts fail. So, it will take many tries to get it right, and even then, there are tricks of the trade I’ll likely be unaware of no matter which books I read. Either it’s not in a book or it’s incredibly hard to find so you’ll basically never find it.
All this while needing a high enough degree of intelligence and competence.
2) AI agent system. You pull up your computer and ask for a synthesized step-by-step plan on how to cause the most death or ways to cripple your enemy. Many agents search through books and the internet while also using latent knowledge about the subject. It tells you everything you truly need to know in a concise 4-page document.
Relevant theory, practical steps (laid out with images and videos on how to do it), what to buy and where/how to buy it, pre-empting any questions you may have, explaining the jargon in a way that is understandable to nearly anyone, can take actions on the web to automatically buy all the supplies you need, etc.
You can even share photos of the entire process to your AI as it continues to guide you through the creation of the weapon because it’s multi-modal.
You can basically outsource all cognition to the AI system, allowing you to be the lazy human you are (we all know that humans will take the path of least-resistance or abandon something altogether if there is enough friction).
That topic you always said you wanted to know more about but never got around to it? No worries, your AI system has lowered the bar sufficiently that the task doesn’t seem as daunting anymore and laziness won’t be in the way of you making progress.
Conclusion: a future AI system will have the power of efficiency (significantly faster) and capability (able to make more powerful weapons than any one person could do on their own). It has the interactivity that Google and libraries don’t have. It’s just not the same as information scattered in different sources.
comment by jacquesthibs (jacques-thibodeau) · 2024-06-11T12:05:40.490Z · LW(p) · GW(p)
Resharing a short blog post by an OpenAI employee giving his take on why we have 3-5 year AGI timelines (https://nonint.com/2024/06/03/general-intelligence-2024/):
Folks in the field of AI like to make predictions for AGI. I have thoughts, and I’ve always wanted to write them down. Let’s do that.
Since this isn’t something I’ve touched on in the past, I’ll start by doing my best to define what I mean by “general intelligence”: a generally intelligent entity is one that achieves a special synthesis of three things:
- A way of interacting with and observing a complex environment. Typically this means embodiment: the ability to perceive and interact with the natural world.
- A robust world model covering the environment. This is the mechanism which allows an entity to perform quick inference with a reasonable accuracy. World models in humans are generally referred to as “intuition”, “fast thinking” or “system 1 thinking”.
- A mechanism for performing deep introspection on arbitrary topics. This is thought of in many different ways – it is “reasoning”, “slow thinking” or “system 2 thinking”.
If you have these three things, you can build a generally intelligent agent. Here’s how:
First, you seed your agent with one or more objectives. Have the agent use system 2 thinking in conjunction with its world model to start ideating ways to optimize for its objectives. It picks the best idea and builds a plan. It uses this plan to take an action on the world. It observes the result of this action and compares that result with the expectation it had based on its world model. It might update its world model here with the new knowledge gained. It uses system 2 thinking to make alterations to the plan (or idea). Rinse and repeat.
My definition for general intelligence is an agent that can coherently execute the above cycle repeatedly over long periods of time, thereby being able to attempt to optimize any objective.
The capacity to actually achieve arbitrary objectives is not a requirement. Some objectives are simply too hard. Adaptability and coherence are the key: can the agent use what it knows to synthesize a plan, and is it able to continuously act towards a single objective over long time periods.
So with that out of the way – where do I think we are on the path to building a general intelligence?
World Models
We’re already building world models with autoregressive transformers, particularly of the “omnimodel” variety. How robust they are is up for debate. There’s good news, though: in my experience, scale improves robustness and humanity is currently pouring capital into scaling autoregressive models. So we can expect robustness to improve.
With that said, I suspect the world models we have right now are sufficient to build a generally intelligent agent.
Side note: I also suspect that robustness can be further improved via the interaction of system 2 thinking and observing the real world. This is a paradigm we haven’t really seen in AI yet, but happens all the time in living things. It’s a very important mechanism for improving robustness.
When LLM skeptics like Yann say we haven’t yet achieved the intelligence of a cat – this is the point that they are missing. Yes, LLMs still lack some basic knowledge that every cat has, but they could learn that knowledge – given the ability to self-improve in this way. And such self-improvement is doable with transformers and the right ingredients.
Reasoning
There is not a well known way to achieve system 2 thinking, but I am quite confident that it is possible within the transformer paradigm with the technology and compute we have available to us right now. I estimate that we are 2-3 years away from building a mechanism for system 2 thinking which is sufficiently good for the cycle I described above.
Embodiment
Embodiment is something we’re still figuring out with AI but which is something I am once again quite optimistic about near-term advancements. There is a convergence currently happening between the field of robotics and LLMs that is hard to ignore.
Robots are becoming extremely capable – able to respond to very abstract commands like “move forward”, “get up”, “kick ball”, “reach for object”, etc. For example, see what Figure is up to or the recently released Unitree H1.
On the opposite end of the spectrum, large Omnimodels give us a way to map arbitrary sensory inputs into commands which can be sent to these sophisticated robotics systems.
I’ve been spending a lot of time lately walking around outside talking to GPT-4o while letting it observe the world through my smartphone camera. I like asking it questions to test its knowledge of the physical world. It’s far from perfect, but it is surprisingly capable. We’re close to being able to deploy systems which can commit coherent strings of actions on the environment and observe (and understand) the results. I suspect we’re going to see some really impressive progress in the next 1-2 years here.
This is the field of AI I am personally most excited in, and I plan to spend most of my time working on this over the coming years.
TL;DR
In summary – we’ve basically solved building world models, have 2-3 years on system 2 thinking, and 1-2 years on embodiment. The latter two can be done concurrently. Once all of the ingredients have been built, we need to integrate them together and build the cycling algorithm I described above. I’d give that another 1-2 years.
So my current estimate is 3-5 years for AGI. I’m leaning towards 3 for something that looks an awful lot like a generally intelligent, embodied agent (which I would personally call an AGI). Then a few more years to refine it to the point that we can convince the Gary Marcus’ of the world.
Really excited to see how this ages. 🙂
Replies from: Jonas Hallgren, kromem↑ comment by Jonas Hallgren · 2024-06-11T14:39:57.383Z · LW(p) · GW(p)
I really like this take.
I'm kind of "bullish" on active inference as a way to scale existing architectures to AGI as I think it is more optimised for creating an explicit planning system.
Also, Funnily enough, Yann LeCun has a paper on his beliefs on the path to AGI which I think Steve Byrnes has a good post on. It basically says that we need system 2 thinking in the way you said it here. With your argument in mind he kind of disproves himself to some extent. 😅
↑ comment by kromem · 2024-06-11T12:53:47.303Z · LW(p) · GW(p)
I agree with a lot of those points, but suspect there may be fundamental limits to planning capabilities related to the unidirectionality of current feed forward networks.
If we look at something even as simple as how a mouse learns to navigate a labyrinth, there's both a learning of the route to the reward but also a learning of how to get back to the start which adjusts according to the evolving learned layout of the former (see paper: https://elifesciences.org/articles/66175 ).
I don't see the SotA models doing well at that kind of reverse planning, and expect that nonlinear tasks are going to pose significant agentic challenges until architectures shift to something new.
So it could be 3-5 years to get to AGI depending on hardware and architecture advances, or we might just end up in a sort of weird "bit of both" world where we have models that are beyond expert human level superintelligent in specific scopes but below average in other tasks.
But when we finally do get models that in both training and operation exhibit bidirectional generation across large context windows, I think it will only be a very short time until some rather unbelievable goalposts are passed by.
comment by jacquesthibs (jacques-thibodeau) · 2024-08-11T15:31:44.804Z · LW(p) · GW(p)
Low-hanging fruit:
Loving this Chrome extension so far: YouTube Summary with ChatGPT & Claude - Chrome Web Store
It adds a button on YouTube videos where, when you click it (or keyboard shortcut ctrl + x + x), it opens a new tab into the LLM chat of your choice, pastes the entire transcript in the chat along with a custom message you can add as a template ("Explain the key points.") and then automatically presses enter to get the chat going.
It's pretty easy to get a quick summary of a YouTube video without needing to watch the whole thing and then ask follow-up questions. It seems like an easy way to save time or do a quick survey of many YouTube videos. (I would not have bothered going through the entire "Team 2 | Lo fi Emulation @ Whole Brain Emulation Workshop 2024" talk, so it was nice to get the quick summary.)
I usually like getting a high-level overview of the key points of a talk to have a mental mind map skeleton before I dive into the details.
You can even set up follow-up prompt buttons (which works with ChatGPT but currently does not work with Claude for me), though I'm not sure what I'd use. Maybe something like, "Why is this important to AI alignment?"
The default prompt is "Give a summary in 5 bullet points" or something similar. I prefer not to constrain Claude and change it to something like, "Explain the key points."
Replies from: jaime-raldua-veuthey↑ comment by JaimeRV (jaime-raldua-veuthey) · 2024-08-11T17:07:25.485Z · LW(p) · GW(p)
I used to use that one but I moved to Sider: https://sider.ai/pricing?trigger=ext_chrome_btm_upgrd it works in all the pages, including youtube. For Papers and articles I have shortcut to automatically modify the url (adding the prefix "https://r.jina.ai/") so you get the markdown and then do Sider on that. With gpt4o-mini it is almost free. Also nice is Sider is that you can write your own prompt templates
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2024-08-12T11:20:12.233Z · LW(p) · GW(p)
Thanks for sharing, will give it a shot!
Edit: Sider seems really great! I wish it could connect to Claude chat (without using credits), so I will probably just use both extensions.
comment by jacquesthibs (jacques-thibodeau) · 2024-07-07T16:32:31.752Z · LW(p) · GW(p)
Dario Amodei believes that LLMs/AIs can be aided to self-improve in a similar way to AlphaGo Zero (though LLMs/AIs will benefit from other things too, like scale), where the models can learn by themselves to gain significant capabilities.
The key for him is that Go has a set of rules that the AlphaGo model needs to abide by. These rules allow the model to become superhuman at Go with enough compute.
Dario essentially believes that to reach better capabilities, it will help to develop rules for all the domains we care about and that this will likely be possible for more real-world tasks (not just games like Go).
Therefore, I think the crux here is if you think it is possible to develop rules for science (physics, chemistry, math, biology) and other domains s.t., the models can do this sort of self-play to become superhuman for each of the things we care about.
So far, we have examples like AlphaGeometry, which relies on our ability to generate many synthetic examples to help the model learn. This makes sense for the geometry use case, but how do we know if this kind of approach will work for the kinds of things we actually care about? For games and geometry, this seems possible, but what about developing a cure for Alzheimer's or coming up with novel scientific breakthroughs?
So, you've got some of the following issues to resolve:
- Success metrics
- Potentially much slower feedback loops
- Need real-world testing
That said, I think Dario is banking on:
- AIs will have a large enough world model that they can essentially set up 'rules' that provide enough signal to the model in domains other than games and 'special cases' like geometry. For example, they can run physics simulations of optimal materials informed by the latest research papers and use key metrics for the simulation as high-quality signals to reduce the amount of real-world feedback loops needed. Or, code having unit tests along with the goal.
- Most of the things we care about (like writing code) will be able to go beyond superhuman, which will then lift up other domains that wouldn't be able to become superhuman without it.
- Science has been bottlenecked by slow humans, increasing complexity and bad coordination, AIs will be able to resolve these issues.
- Even if you can't generate novel breakthrough synthetic data, you can use synthetic data to nudge your model along the path to making breakthroughs.
Thoughts?
Replies from: jacques-thibodeau, Seth Herd, davekasten, roger-d-1↑ comment by jacquesthibs (jacques-thibodeau) · 2024-07-07T21:02:56.532Z · LW(p) · GW(p)
Hey @Zac Hatfield-Dodds [LW · GW], I noticed you are looking for citations; these are the interview bits I came across (and here at 47:31).
It's possible I misunderstood him; please correct me if I did!
Replies from: zac-hatfield-dodds↑ comment by Zac Hatfield-Dodds (zac-hatfield-dodds) · 2024-07-07T21:24:42.809Z · LW(p) · GW(p)
I don't think any of these amount to a claim that "to reach ASI, we simply need to develop rules for all the domains we care about". Yes, AlphaGo Zero reached superhuman levels on the narrow task of playing Go, and that's a nice demonstration that synthetic data could be useful, but it's not about ASI and there's no claim that this would be either necessary or sufficient.
(not going to speculate on object-level details though)
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2024-07-07T21:33:25.939Z · LW(p) · GW(p)
Ok, totally; there's no specific claim about ASI. Will edit the wording.
↑ comment by Seth Herd · 2024-07-07T18:53:57.747Z · LW(p) · GW(p)
I think this type of autonomous learning is fairly likely to be achieved soon (1-2 years), and it doesn't need to follow exactly AlphaZero's self-play model.
The world has rules. Those rules are much more complex and stochastic than games or protein folding. But note that the feedback in Go comes only after something like 200 moves, yet the powerful critic head is able to use that to derive a good local estimate of what's likely a good or bad move.
Humans use a similar powerful critic in the dopamine system working in concert with the cortex's rich world model to decide what's rewarding long before there's a physical reward or punishment signal. This is one route to autonomous learning for LLM agents. I don't know if Amodei is focused on base models or hybrid learning systems, and that matters.
Or maybe it doesn't. I can think of more human-like ways of autonomous learning in a hybrid system, but a powerful critic may be adequate for self-play even in a base model. Existing RLHF techniques do use a critic - I think it's proximal policy optimization (or DPO?) in the last OpenAI setup they publicly reported. (I haven't looked at Anthropic's RLAIF setup to see if they're using a similar critic portion of the model- I'd guess they are, following OpenAIs success with it).
I'd expect they're experimenting with using small sets of human feedback to leverage self-critique as in RLAIF, making a better critic that makes a better overall model.
Decomposing video into text and then predicting how people behave both physically and emotionally offer two new windows onto the rules of the world. I guess those aren't quite in the self-play domain on their own, but having good predictions of outcomes might allow autonomous learning of agentic actions by taking feedback not from a real or simulated world, but from that trained predictor of physical and social outcomes.
Deriving a feedback signal directly from the world can be done in many ways. I expect there are more clever ideas out there.
So in sum, I don't think this is guaranteed, but it's quite possible.
Replies from: Seth Herd↑ comment by Seth Herd · 2024-08-13T20:19:36.074Z · LW(p) · GW(p)
Glancing back at this, I noted I missed the most obvious form of self-play: putting an agent in an interaction with another copy of itself. You could do any sort of "scoring" by having an automated of the outcome vs. the current goal.
This has some obvious downsides, in that the agents aren't the same as people. But it might get you a good bit of extra training that predicting static datasets doesn't give. A little interaction with real humans might be the cherry on top of the self-play whipped cream on the predictive learning sundae.
↑ comment by davekasten · 2024-07-07T17:07:52.514Z · LW(p) · GW(p)
I am fairly skeptical that we don't already have something close-enough-to-approximate this if we had access to all the private email logs of the relevant institutions matched to some sort of correlation of "when this led to an outcome" metric (e.g., when was the relevant preprint paper or strategy deck or whatever released)
↑ comment by RogerDearnaley (roger-d-1) · 2024-07-10T08:08:07.653Z · LW(p) · GW(p)
Go has rules, and gives you direct and definitive feedback on how well you're doing, but, while a very large space, it isn't open-ended. A lot of the foundation model companies appear to be busily thinking about doing something AlphaZero-inspired in mathematics, which also has rules, and can be arranged to give you direct feedback on how you're doing (there have been recent papers on how to make this more efficient with less human input). Similarly on writing and debugging software, likewise. Indeed, models have recently been getting better at Math and coding faster than other topics, suggesting that they're making real progress. When I watched that Dario interview (the Scandinavian bank one, I assume) my assumption was that Dario was talking about those, but using AlphaGo as a clearer and more widely-familiar example.
Expanding this to other areas seems like it would come next: robotics seems a promising one that also gives you a lot of rapid feedback, science would be fascinating and exciting but the feedback loops are a lot longer, human interactions (on something like the Character AI platform) seem like another possibility (though the result of that might be models better at human manipulation and/or pillow-talk, which might not be entirely a good thing).
comment by jacquesthibs (jacques-thibodeau) · 2024-07-05T17:46:28.164Z · LW(p) · GW(p)
Alignment Researcher Assistant update.
Hey everyone, my name is Jacques, I'm an independent technical alignment researcher, primarily focused on evaluations, interpretability, and scalable oversight (more on my alignment research soon!). I'm now focusing more of my attention on building an Alignment Research Assistant (I've been focusing on my alignment research for 95% of my time in the past year). I'm looking for people who would like to contribute to the project. This project will be private unless I say otherwise (though I'm listing some tasks); I understand the dual-use nature and most criticism against this kind of work.
How you can help:
- Provide feedback on what features you think would be amazing in your workflow to produce high-quality research more efficiently.
- Volunteer as a beta-tester for the assistant.
- Contribute to one of the tasks below. (Send me a DM, and I'll give you access to the private Discord to work on the project.)
- Funding to hire full-time developers to build the features.
Here's the vision for this project:
How might we build an AI system that augments researchers to get us 5x or 10x productivity for the field as a whole?
The system is designed with two main mindsets in mind:
- Efficiency: What kinds of tasks do alignment researchers do, and how can we make them faster and more efficient?
- Objective: Even if we make researchers highly efficient, it means nothing if they are not working on the right things. How can we ensure that researchers are working on the most valuable things? How can we nudge them to gain the most bits of information in the shortest time? This involves helping them work on the right agendas/projects and helping them break down their projects in ways that help them make progress faster (and avoiding ending up tunnel-visioned on the wrong project for months/years).
As of now, the project will focus on building an extension on top of VSCode to make it the ultimate research tool for alignment researchers. VSCode is ideal because researchers are already coding with it and it’s easy to build on top of it. You prevent context-switching, like a web app would cause. I want the entire workflow to feel natural inside of VSCode. In general, I think this will make things easier to build on top of and automate parts of research over time.
Side note: I helped build the Alignment Research Dataset ~2 years ago (here's the extended project). It is now being continually updated, and SQL and vector databases (which will interface with the assistant) are also being used.
If you are interested in potentially helping out (or know someone who might be!), send me a DM with a bit of your background and why you'd like to help out. To keep things focused, I may or may not accept.
I'm also collaborating with different groups (Apart Research, AE Studio [LW · GW], and more). In 2-3 months, I want to get it to a place where I know whether this is useful for other researchers and if we should apply for additional funding to turn it into a serious project.
As an update to the Alignment Research Assistant I'm building, here is a set of shovel-ready tasks I would like people to contribute to (please DM if you'd like to contribute!). These tasks are the ones that are easier to articulate and pretty self-contained:
Core Features
1. Setup the Continue extension for research: https://www.continue.dev/
- Design prompts in Continue that are suitable for a variety of alignment research tasks and make it easy to switch between these prompts
- Figure out how to scaffold LLMs with Continue (instead of just prompting one LLM with additional context)
- It can include agents, search, and more
- Test out models to quickly help with paper writing
2. Data sourcing and management
- Integrate with the Alignment Research Dataset (pulling from either the SQL database or Pinecone vector database): https://github.com/StampyAI/alignment-research-dataset
- Integrate with other apps (Google Docs, Obsidian, Roam Research, Twitter, LessWrong)
- Make it easy to look and edit long prompts for project context
3. Extract answers to questions across multiple papers/posts (feeds into Continue)
- Develop high-quality chunking and scaffolding techniques
- Implement multi-step interaction between researcher and LLM
4. Design Autoprompts for alignment research
- Creates lengthy, high-quality prompts for researchers that get better responses from LLMs
5. Simulated Paper Reviewer
- Fine-tune or prompt LLM to behave like an academic reviewer
- Use OpenReview data for training
6. Jargon and Prerequisite Explainer
- Design a sidebar feature to extract and explain important jargon
- Could maybe integrate with some interface similar to https://delve.a9.io/
7. Setup automated "suggestion-LLM"
- An LLM periodically looks through the project you are working on and tries to suggest *actually useful* things in the side-chat. It will be a delicate balance to make sure not to share too much and cause a loss of focus. This could be custom for the research with an option only to give automated suggestions post-research session.
8. Figure out if we can get a useable browser inside of VSCode (tried quickly with the Edge extension but couldn't sign into the Claude chat website)
- Could make use of new features other companies build (like Anthropic's Artifact feature), but inside of VSCode to prevent context-switching in an actual browser
9. "Alignment Research Codebase" integration (can add as Continue backend)
- Create an easily insertable set of repeatable code that researchers can quickly add to their project or LLM context
- This includes code for Multi-GPU stuff, best practices for codebase, and more
- Should make it easy to populate a new codebase
- Pro-actively gives suggestions to improve the code
- Generally makes common code implementation much faster
10. Notebook to high-quality codebase
- Can go into more detail via DMs.
11. Adding capability papers to the Alignment Research Dataset
- We didn't do this initially to reduce exfohazards. The purpose of adding capability papers (and all the new alignment papers) is to improve the assistant.
- We will not be open-sourcing this part of the work; this part of the dataset will be used strictly by the vetted alignment researchers using the assistant.
Specialized tooling (outside of VSCode)
Bulk fast content extraction
- Create an extension to extract content from multiple tabs or papers
- Simplify the process of feeding content to the VSCode backend for future use
Personalized Research Newsletter
- Create a tool that extracts relevant information for researchers (papers, posts, other sources)
- Generate personalized newsletters based on individual interests (open questions and research they care about)
- Sends pro-active notification in VSCode and Email
Discord Bot for Project Proposals
- Suggest relevant papers/posts/repos based on project proposals
- Integrate with Apart Research Hackathons
↑ comment by jacquesthibs (jacques-thibodeau) · 2024-07-14T18:36:22.435Z · LW(p) · GW(p)
We're doing a hackathon with Apart Research on 26th. I created a list of problem statements for people to brainstorm off of.
Pro-active insight extraction from new research
Reading papers can take a long time and is often not worthwhile. As a result, researchers might read too many papers or almost none. However, there are still valuable nuggets in papers and posts. The issue is finding them. So, how might we design an AI research assistant that proactively looks at new papers (and old) and shares valuable information with researchers in a naturally consumable way? Part of this work involves presenting individual research with what they would personally find valuable and not overwhelm them with things they are less interested in.
How can we improve the LLM experience for researchers?
Many alignment researchers will use language models much less than they would like to because they don't know how to prompt the models, it takes time to create a valuable prompt, the model doesn't have enough context for their project, the model is not up-to-date on the latest techniques, etc. How might we make LLMs more useful for researchers by relieving them of those bottlenecks?
Simple experiments can be done quickly, but turning it into a full project can take a lot of time
One key bottleneck for alignment research is transitioning from an initial 24-hour simple experiment in a notebook to a set of complete experiments tested with different models, datasets, interventions, etc. How can we help researchers move through that second research phase much faster?
How might we use AI agents to automate alignment research?
As AI agents become more capable, we can use them to automate parts of alignment research. The paper "A Multimodal Automated Interpretability Agent" serves as an initial attempt at this. How might we use AI agents to help either speed up alignment research or unlock paths that were previously inaccessible?
How can we nudge research toward better objectives (agendas or short experiments) for their research?
Even if we make researchers highly efficient, it means nothing if they are not working on the right things. Choosing the right objectives (projects and next steps) through time can be the difference between 0x to 1x to +100x. How can we ensure that researchers are working on the most valuable things?
What can be done to accelerate implementation and iteration speed?
Implementation and iteration speed [LW · GW] on the most informative experiments matter greatly. How can we nudge them to gain the most bits of information in the shortest time? This involves helping them work on the right agendas/projects and helping them break down their projects in ways that help them make progress faster (and avoiding ending up tunnel-visioned on the wrong project for months/years).
How can we connect all of the ideas in the field?
How can we integrate the open questions/projects in the field (with their critiques) in such a way that helps the researcher come up with well-grounded research directions faster? How can we aid them in choosing better directions and adjust throughout their research? This kind of work may eventually be a precursor to guiding AI agents to help us develop better ideas for alignment research.
↑ comment by jacquesthibs (jacques-thibodeau) · 2024-07-29T20:54:18.815Z · LW(p) · GW(p)
This just got some massive downvotes. Would like to know why. My guess is "This can be dual-use. Therefore, it's bad," but if not, it would be nice to know.
comment by jacquesthibs (jacques-thibodeau) · 2023-05-26T22:32:15.130Z · LW(p) · GW(p)
I recently sent in some grant proposals to continue working on my independent alignment research. It gives an overview of what I'd like to work on for this next year (and more really). If you want to have a look at the full doc, send me a DM. If you'd like to help out through funding or contributing to the projects, please let me know.
Here's the summary introduction:
12-month salary for building a language model system for accelerating alignment research and upskilling (additional funding will be used to create an organization), and studying how to supervise AIs that are improving AIs to ensure stable alignment.
Summary
- Agenda 1: Build an Alignment Research Assistant using a suite of LLMs managing various parts of the research process. Aims to 10-100x productivity in AI alignment research. Could use additional funding to hire an engineer and builder, which could evolve into an AI Safety organization focused on this agenda. Recent talk giving a partial overview of the agenda.
- Agenda 2: Supervising AIs Improving AIs [LW · GW] (through self-training or training other AIs). Publish a paper and create an automated pipeline for discovering noteworthy changes in behaviour between the precursor and the fine-tuned models. Short Twitter thread explanation.
- Other: create a mosaic of alignment questions we can chip away at, better understand agency in the current paradigm, outreach, and mentoring.
As part of my Accelerating Alignment agenda, I aim to create the best Alignment Research Assistant using a suite of language models (LLMs) to help researchers (like myself) quickly produce better alignment research through an LLM system. The system will be designed to serve as the foundation for the ambitious goal of increasing alignment productivity by 10-100x during crunch time (in the year leading up to existentially dangerous AGI). The goal is to significantly augment current alignment researchers while also providing a system for new researchers to quickly get up to speed on alignment research or promising parts they haven’t engaged with much.
For Supervising AIs Improving AIs, this research agenda focuses on ensuring stable alignment when AIs self-train or train new AIs and studies how AIs may drift through iterative training. We aim to develop methods to ensure automated science processes remain safe and controllable. This form of AI improvement focuses more on data-driven improvements than architectural or scale-driven ones.
I’m seeking funding to continue my work as an independent alignment researcher and intend to work on what I’ve just described. However, to best achieve the project’s goal, I would want additional funding to scale up the efforts for Accelerating Alignment to develop a better system faster with the help of engineers so that I can focus on the meta-level and vision for that agenda. This would allow me to spread myself less thin and focus on my comparative advantages. If you would like to hop on a call to discuss this funding proposal in more detail, please message me. I am open to refocusing the proposal or extending the funding.
Replies from: mesaoptimizer↑ comment by mesaoptimizer · 2023-07-07T02:46:14.903Z · LW(p) · GW(p)
Build an Alignment Research Assistant using a suite of LLMs managing various parts of the research process. Aims to 10-100x productivity in AI alignment research.
Can you give concrete use-cases that you imagine your project would lead to helping alignment researchers? Alignment researchers have wildly varying styles of work outputs and processes. I assume you aim to accelerate a specific subset of alignment researchers (those focusing on interpretability and existing models and have an incremental / empirical strategy for solving the alignment problem).
comment by jacquesthibs (jacques-thibodeau) · 2022-11-21T12:04:08.155Z · LW(p) · GW(p)
Current Thoughts on my Learning System
Crossposted from my website. Hoping to provide updates on my learning system every month or so.
TLDR of what I've been thinking about lately:
- There are some great insights in this video called "How Top 0.1% Students Think." And in this video about how to learn hard concepts.
- Learning is a set of skills. You need to practice each component of the learning process to get better. You can’t watch a video on a new technique and immediately become a pro. It takes time to reap the benefits.
- Most people suck at mindmaps. Mindmaps can be horrible for learning if you just dump a bunch of text on a page and point arrows to different stuff (some studies show mindmaps are ineffective, but that's because people initially suck at making them). However, if you take the time to learn how to do them well, they will pay huge dividends in the future. I’ll be doing the “Do 100 Things” challenge and developing my skill in building better mindmaps. Getting better at mindmaps involves “chunking” the material and creating memorable connections and drawings.
- Relational vs Isolated Learning. As you learn something new, try to learn it in relation to the things you already know rather than treating it as isolated from everything (flashcards can perpetuate the problem of learning things in isolated form).
- Encoding and Retrieval are essential concepts for efficient learning.
- Deep processing is the foundation of all learning. It is the ability to connect, process, organize and relate information. The opposite of deep processing is rote memorization. If it doesn’t feel like you are engaging ~90% of your brain power when you are learning/reading something, you are likely not encoding the information into your long-term memory effectively.
- Only use Flashcards as a last resort. Flashcards are something a lot of people use because they feel comfortable going through them. However, if your goal is to be efficient in your learning, you should only use flashcards when it’s something that requires rote learning. Video worth watching on Spaced Repetition.
- You need to be aiming for higher-order learning. Take advantage of Bloom's Taxonomy.[1]
- My current approach for learning about alignment: I essentially have a really big Roam Research page called "AI Alignment" where I break down the problem into chunks like "Jargon I don't understand," "Questions to Answer," "Different people's views on alignment," etc. As I fill in those details, I add more and more information in the "Core of the Alignment Problem" section. I have a separate page called "AI Alignment Flow Chart" which I'm using as a structure for backcasting on how we solved alignment and identifying the crucial things we need to solve and things I need to better understand. I also sometimes have a specific page for something like Interpretability when I'm trying to do a deep dive on a topic, but I always try to link it to the other things I've written in my main doc.
- And this video concisely covers a lot of important learning concepts.
- Look at the beginning of the video for an explanation of encoding, storage (into long-term memory), and retrieval/rehearsal to make sure you remember long-term.
- Outside of learning:
- Get enough sleep. 8 hours-ish.
- Exercise like HIIT.
- Make sure you have good mental health.
- Meditation is likely useful. I personally use it to recharge my battery when I feel a crash coming and I think it’s useful for training yourself to work productively for longer periods of time. This one I’m less sure of, but seems to work for me.
- Learning (all of these take time to master, don’t expect you will use them in the most effective way right out of the gate):
- Use inquiry-based (curiosity-based) learning. Have your learning be guided by questions you have, like:
- ”Why is this important?”
- ”How does it relate to this other concept?”
- Learn by scope. Start with the big picture and gradually break things down where it is important.
- Chunking. Group concepts together and connect different chunks by relationship.
- Create stories to remember things.
- Focus on relationships between concepts. This is crucial.
- Rehearsal
- Spaced repetition (look at my other notes on how SR is overrated but still useful)
- Apply your learning by creating things (like a forum post applying the new concept to something and explaining it)
- Use inquiry-based (curiosity-based) learning. Have your learning be guided by questions you have, like:
Ever since I was little, I have relied on my raw brain power to get to where I am. Unfortunately, I could never bring myself to do what other smart kids were doing. Flashcards, revision? I would either get bored out of my mind or struggle because I didn’t know how to do it well. Mindmaps? It felt OK while I was doing it the few times I tried, but I would never revise it, and, honestly, I sucked at it.
But none of that mattered. I could still do well enough even though my learning system was terrible. However, I didn’t get the top grades, and I felt frustrated.
I read a few books and watched the popular YouTubers on how to learn things best. Spaced Repetition and Active Recall kept coming up. All these intelligent people were using it, and I truly believed it worked. However, whenever I tried it, I either ended up with too many flashcards to have the time to review, or I couldn't build a habit out of it. Flashcards also felt super inefficient when studying physics.
I did use Cal Newport’s stuff for some classes and performed better by studying the same amount of time, but as soon as things got intense (exam season/lots of homework), I would revert to my old (ineffective) study techniques like reading the textbook aimlessly and highlighting stuff. As a result, I would never truly develop the skill (yes, skill!) of studying well. But, just like anything, you can get better at creating mindmaps for proper learning and long-term memory.
I never got a system down, and I feel I’m losing out on gains in my career. How do I learn things efficiently? I don’t want to do the natural thing of putting in more hours to get more done. 1) My productivity will be capped by my inefficient system, 2) I still want to live life, and 3) it probably won’t work anyways.
So, consider this my public accountability statement to take the time to develop the skills necessary to become more efficient in my work. No more aimlessly reading LessWrong posts about AI alignment. There are more efficient ways to learn.
I want to contribute to AI alignment in a bigger way, and something needs to change. There is so much to learn, and I want to catch up as efficiently as possible instead of just winging it and trying whatever approach seems right.
Had I continued working on things I don’t care deeply about, I might have never decided to put in the effort to create a new system (which will probably take a year of practicing my learning skills). Maybe I would have tried for a few weeks and then reverted to my old habits. I could have kept coasting in life and done decently well in work and my personal life. But we need to solve alignment, and building these skills now will allow me to reap major benefits in a few years.

(Note: a nice bonus for developing a solid learning system is that you can pass it on to your children. I’m excited to do that one day, but I’d prefer to start doing this now so that I know that *I* can do it, and I’m not just telling my future kids nonsense.)
So, what have I been doing so far?
I started the iCanStudy course by Dr. Justin Sung (who has a YouTube channel). I’m only about 31% through the course.
My goal will be to create a “How to Create an Efficient Learning System” guide tailored for professionals and includes examples in AI alignment. Please let me know if there are some things you’d like me to explore in that guide.
Before I go, I’ll mention that I’m also interested in eventually taking what I learn from constructing my own learning system and creating something that allows others to do the same, but with much less effort. I hope to make this work for the alignment community in particular (which relates to my accelerating alignment project), but I’d also like to eventually expand to people working on other cause areas in effective altruism.
Replies from: jacques-thibodeau, jacques-thibodeau, jacques-thibodeau, jacques-thibodeau, jacques-thibodeau, jacques-thibodeau, jacques-thibodeau
↑ comment by jacquesthibs (jacques-thibodeau) · 2023-04-10T17:05:43.437Z · LW(p) · GW(p)
Note on using ChatGPT for learning
- Important part: Use GPT to facilitate the process of pushing you to higher-order learning as fast as possible.
- Here’s Bloom’s Taxonomy for higher-order learning:
- For example, you want to ask GPT to come up with analogies and such to help you enter higher-order thinking by thinking about whether the analogy makes sense.
- Is the analogy truly accurate?
- Does it cover the main concept you are trying to understand?
- Then, you can extend the analogy to try to make it better and more comprehensive.
- This allows you to offload the less useful task (e.g. coming up with the analogy), and spending more time in the highest orders of learning (the evaluation phase; “is this analogy good? where does it break down?”).
- You still need to use your cognitive load to encode the knowledge effectively. Look for desirable difficulty.
- Use GPT to create a pre-study of the thing you would like to learn.
- Have it create an outline of the order of the things you should learn.
- Have it give you a list of all the jargon words in a field and how they relate so that you can quickly get up to speed on the terminology and talk to an expert.
- Coming up with chunks of the topic you are exploring.
- You can give GPT text that describes what you are trying to understand, the relationships between things and how you are chunking them.
- Then, you can ask GPT to tell you what are some weak areas or some things that are potentially missing.
- GPT works really well as a knowledge “gap-checker”.

When you are trying to have GPT output some novel insights or complicated nuanced knowledge, it can give vague answers that aren’t too helpful. This is why, it is often better to treat GPT as a gap-checker and/or a friend that is prompting you to come up with great insights.
Reference: I’ve been using ChatGPT/GPT-4 a lot to gain insights on how to accelerate alignment research. Some of my conclusions are similar to what was described in the video below.
↑ comment by jacquesthibs (jacques-thibodeau) · 2022-12-16T19:49:51.803Z · LW(p) · GW(p)
How learning efficiently applies to alignment research
As we are trying to optimize for actually solving the problem, [LW · GW] we should not fall into the trap of learning just to learn. We should instead focus on learning efficiently with respect to how it helps us generate insights that lead to a solution for alignment. This is also the framing we should have in mind when we are building tools for augmenting alignment researchers.
With the above in mind, I expect that part of the value of learning efficiently involves some of the following:
- Efficient learning involves being hyper-focused on identifying the core concepts and how they all relate to one another. This mode of approaching things seems like it helps us attack the core of alignment much more directly and bypasses months/years of working on things that are only tangential.
- Developing a foundation of a field seems key to generating useful insights. The goal is not to learn everything but to build a foundation that allows you to bypass spending way too much time tackling sub-optimal sub-problems or dead-ends for way too long. Part of the foundation-building process should reduce the time it shapes you into an exceptional alignment researcher rather than a knower-of-things.
- As John Wentworth says [LW · GW] with respect to the Game Tree of Alignment: "The main reason for this exercise is that (according to me) most newcomers to alignment waste years on tackling not-very-high-value sub-problems or dead-end strategies."
- Lastly, many great innovations have not come from unique original ideas. There's an iterative process passed amongst researchers and it seems often the case that the greatest ideas come from simply merging ideas that were already lying around. Learning efficiently (and storing those learnings for later use) allows you to increase the number of ideas you can merge together. If you want to do that efficiently, you need to improve your ability to identify which ideas are worth storing in your mental warehouse to use for a future merging of ideas.
↑ comment by Peter Hroššo (peter-hrosso) · 2022-12-16T21:23:51.631Z · LW(p) · GW(p)
My model of (my) learning is that if the goal is sufficiently far, learning directly towards the goal is goodharting a likely wrong metric.
The only method which worked for me for very distant goals is following my curiosity and continuously internalizing new info, such that the curiosity is well informed about current state and the goal.
Replies from: jacques-thibodeau, jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2022-12-16T21:36:20.141Z · LW(p) · GW(p)
Curiosity is certainly a powerful tool for learning! I think any learning system which isn't taking advantage of it is sub-optimal. Learning should be guided by curiosity.
The thing is, sometimes we need to learn things we aren't so curious about. One insight I Iearned from studying learning is that you can do specific things to make yourself more curious about a given thing and harness the power that comes with curiosity.
Ultimately, what this looks like is to write down questions about the topic and use them to guide your curious learning process. It seems that this is how efficient top students end up learning things deeply in a shorter amount of time. Even for material they care little about, they are able to make themselves curious and be propelled forward by that.
That said, my guess is that goodharting the wrong metric can definitely be an issue, but I'm not convinced that relying on what makes you naturally curious is the optimal strategy for solving alignment. Either way, it's something to think about!
↑ comment by jacquesthibs (jacques-thibodeau) · 2023-01-02T16:17:39.008Z · LW(p) · GW(p)
By the way, I've just added a link to a video by a top competitive programmer on how to learn hard concepts. In the video and in the iCanStudy course, both talk about the concept of caring about what you are learning (basically, curiosity). Gaining the skill to care and become curious is an essential part of the most effective learning. However, contrary to popular belief, you don't have to be completely guided by what makes you naturally curious! You can learn how to become curious (or care) about any random concept.
↑ comment by jacquesthibs (jacques-thibodeau) · 2023-01-13T14:46:33.307Z · LW(p) · GW(p)
Video on how to approach having to read a massive amount of information (like a textbook) as efficiently as possible:
↑ comment by jacquesthibs (jacques-thibodeau) · 2023-01-04T20:09:51.561Z · LW(p) · GW(p)
Added my first post (of, potentially, a sequence) on effective learning here [LW · GW]. I think there are a lot of great lessons at the frontier of the literature and real-world practice on learning that go far beyond the Anki approach that a lot of people seem to take these days. The important part is being effective and efficient. Some techniques might work, but that does not mean it is the most efficient (learning the same thing more deeply in less time).
Note that I also added two important videos to the root shortform:
There are some great insights in this video called "How Top 0.1% Students Think." And in this video about how to learn hard concepts.
↑ comment by jacquesthibs (jacques-thibodeau) · 2023-01-02T17:15:02.923Z · LW(p) · GW(p)
Note on spaced repetition
While spaced repetition is good, many people end up misusing it as a crutch instead of defaulting to trying to deeply understand a concept right away. As you get better at properly encoding the concept, you extend the forgetting curve to the point where repetition is less needed.
Here's a video of a top-level programmer on how he approaches learning hard concepts efficiently.
And here's a video on how the top 0.1% of students study efficiently.
↑ comment by jacquesthibs (jacques-thibodeau) · 2023-01-02T03:24:19.969Z · LW(p) · GW(p)
Here's some additional notes on the fundamentals on being an effective learner:
Encoding and Retrieval (What it take to learn)
- Working memory is the memory that we use. However, if it is not encoded properly or at all, we will forget it.
- Encode well first (from working memory to long-term memory), then frequently and efficiently retrieve from long-term memory.
- If studying feels easy, means that you aren't learning or holding on to the information. It means that you are not encoding and retrieving effectively.
- You want it to be difficult when you are studying because this is how it will encode properly.
Spacing, Interleaving, and Retrieval (SIR)
- These are three rules that apply to every study technique in the course (unless told otherwise). You can apply SIR to all techniques.
- Spacing: space your learning out.
- Pre-study before class, then learn in class, and then a week later revise it with a different technique.
- A rule of thumb you can follow is to wait long enough until you feel like you are just starting to forget the material.
- As you get better at encoding the material effectively as soon as you are exposed to it, you will notice that you will need to do less repetition.
- How to space reviews:
- Beginner Schedule (less reviews need as you get better at encoding)
- Same day
- Next day
- End of week
- End of month
- After learning something for the first time, review it later on the same day.
- Review everything from the last 2-3 days mid-week.
- Do an end of week revision on the week's worth of content.
- End of month revision on entire month's worth of content.
- Review of what's necessary as time goes on.
- (If you're trying to do well on an exam or a coding interview, you can do the review 1 or 2 weeks before the assessment.)
- Beginner Schedule (less reviews need as you get better at encoding)
- Reviewing time duration:
- For beginners
- No less than 30 minutes per subject for end-of-week
- No less than 1.5 hours per subject for end-of-month.
- For beginners
- Schedule the reviews in your Calendar and add a reminder!
- Interleaving: hitting a topic or concept from multiple different angles (mindmaps, teaching).
- The idea is that there is the concept you want to learn, but also there is a surrounding range that you also want to learn (not just the isolated concept).
- Could be taking a concept and asking a question about it. Then, asking a question from another angle. Then, asking how it relates to another concept.
- Try to use a multitude of these techniques in your studying, never studying or revising anything the same way more than once.
- Math, it could be thinking about the real-world application of it.
- Examples of interleaving:
- Teach an imaginary student
- Draw a mindmap
- Draw an image instead of using words to find a visual way of expressing information
- Answer practice questions
- Create your own challenging test questions
- Create a test question that puts what you've learned into a real-world context
- Take a difficult question that you found in a practice test and modify it so that the variables are different, or an extra step is added
- Form a study group and quiz each other - for some subjects you can even debate the topic, with one side trying to prove that the other person is missing a point or understanding it incorrectly
- For languages, you can try to speak or write a piece of dialogue or speech, as well as some variations. How might someone respond? How would you respond back? Are there any other responses that would be appropriate?
- Retrieval: taking info from your long-term memory and bringing it into your working memory to recall, solve problems and answer questions.
- Taking a concept and retrieving it from your long-term memory.
- Don't just retrieve right away, you can look at your notes, take a few minutes and retrieve.
- Or it also happens when you are learning something. Let's say you are listening to a lecture. Are you just writing everything down or are you taking some time to think and process what is being said and then writing down notes? The second one is better.
Syntopical Learning
When you are learning something, you want to apply interleaving by learning from different sources and mediums. So, practice become great at learning while listening, while watching, while reading. These are all individual modes of learning you can get better at and they will all help you better retain the material if you use them all while learning.
↑ comment by jacquesthibs (jacques-thibodeau) · 2022-11-21T22:53:53.984Z · LW(p) · GW(p)
A few more notes:
- I use the app Concepts on my iPad to draw mindmaps. Drawing mindmaps with pictures and such is way more powerful (better encoding into long-term memory) than typical mindmap apps where you just type words verbatim and draw arrows. It's excellent since it has a (quasi-) infinite canvas. This is the same app that Justin Sung uses.
- When I want to go in-depth into a paper, I will load it into OneNote on my iPad and draw in the margin to better encode my understanding of the paper.
- I've been using the Voice Dream Reader app on my iPhone and iPad to get through posts and papers much faster (I usually have time to read most of an Alignment Forum post on my way to work and another on the way back). Importantly, I stop the text-to-speech when I'm trying to understand an important part. I use Pocket to load LW/AF posts into it and download PDFs on my device and into the app for reading papers. There's a nice feature in the app that automatically skips citations in the text, so reading papers isn't as annoying. The voices are robotic, but I just cycled through a bunch until I found one I didn't mind (I didn't buy any, but there are premium voices). I expect Speechify has better voices, but it's more expensive, and I think people find that the app isn't as good overall compared to Voice Dream Reader. Thanks to Quintin Pope for recommending the app to me.
comment by jacquesthibs (jacques-thibodeau) · 2024-07-09T15:49:48.694Z · LW(p) · GW(p)
Recent paper I thought was cool:
In-Run Data Shapley: Data attribution method efficient enough for pre-training data attribution.
Essentially, it can track how individual data points (or clusters) impact model performance across pre-training. You just need to develop a set of validation examples to continually check the model's performance on those examples during pre-training. Amazingly, you can do this over the course of a single training run; no need to require multiple pre-training runs like other data attribution methods have required.
Other methods, like influence functions, are too computationally expensive to run during pre-training and can only be run post-training.
So, here's why this might be interesting from an alignment perspective:
- You might be able to set up a bunch of validation examples to test specific behaviour in the models so that we are hyper-aware of which data points contribute the most to that behaviour. For example, self-awareness or self-preservation.
- Given that this is possible to run during pre-training, you might understand model behaviour at such a granular level that you can construct data mixtures/curriculums that push the model towards internalizing 'human values' much sooner than it develops behaviours or capabilities we wouldn't want. Or, you delay self-awareness and such much further along in the training process.
- In this @RogerDearnaley [LW · GW] post, A "Bitter Lesson" Approach to Aligning AGI and ASI [LW · GW], Roger proposes training an AI on a synthetic dataset where all intelligences are motivated by the collective well-being of humanity. You are trying to bias the model to be as close to the basin of attraction for alignment [LW · GW] as possible. In-Run Data Shapley could be used to construct such a dataset and guide the training process so that the training data best exemplifies the desired aligned behaviour.
If you are interested in this kind of research, let me know! I'd love to brainstorm some potential projects and then apply for funding if there is something promising there.
Replies from: jacques-thibodeau, roger-d-1, mike-vaiana, bogdan-ionut-cirstea↑ comment by jacquesthibs (jacques-thibodeau) · 2024-07-10T15:45:08.174Z · LW(p) · GW(p)
I sent some related project ideas to @RogerDearnaley [LW · GW] via DMs, but figured I should share them here to in case someone would like to give feedback or would like to collaborate on one of them.
I think data is underrated among the alignment community (synthetic/transformed data even more). I have been thinking about it from the perspective of pre-training and post-training. My initial look into synthetic data was related to online learning and essentially controlling model behaviour. I was interested in papers like this one by Google, where they significantly reduce sycophancy in an LLM via 1k synthetically generated examples. Data shapes behaviour, and I think many people do not acknowledge this enough (which sometimes leads them to make confused conclusions about model behaviour).
In terms of specific research projects, my current ideas fall into these kinds of buckets:
Pre-training close to the basin of attraction for alignment
- How much can we improve "Pretraining Language Models with Human Preferences"? I'd like to transform training in various ways (as mentioned in your posts). For example, I could take fineweb and pre-train a GPT-2 sized model with the original dataset and a transformed version. Unclear so far which things I'd like to measure the most at that model size, though. A downstream experiment: is one model more likely to reward hack over the other? Does shard theory help us come up with useful experiments (pre-training with human feedback is almost like reinforcing behaviour and leveraging some form of shard theory)? Note that Google used a similar pre-training scheme for PaLM 2:
- How can the "basin of attraction for alignment" be mathematically formalized?
- Trying to the impact of systematic errors:
- Studying reward misspecification: do the reward labels have a systematic effect and bias in pushing the model? How much of the model's behaviour is determined by the data itself vs. the reward model's misspecification? My current reading of the literature on this is a bit unclear. However, there's a paper saying: "We present a novel observation about the behaviour of offline reinforcement learning (RL) algorithms: on many benchmark datasets, offline RL can produce well-performing and safe policies even when trained with "wrong" reward labels, such as those that are zero everywhere or are negatives of the true rewards."
- How do we design the training curriculum to significantly bias the model's pre-training close to the basin of attraction for alignment?
- Studying some form of iterative training where we have a synthetically trained model vs a normally trained model and then measure things like model drift. For example, is the model more likely to drift (in an online setting) in ways we wouldn't want it to if it is pre-trained on normal text, but the process is more safely guided through synthetic pre-training?
- Part of the alignment challenge (for example, the concern of scheming AIs) is that the order in which the model learns things might matter. For example, you'd want the model to internalize a solid world model of human values before it gains the situational awareness required to manipulate its training process (scheme). So, can we design a training curriculum for specific capabilities s.t. the model learns capabilities in an ideal sequence?

Data attribution project ideas
- How to make this approach work in tandem with unlearning?
- Use data attribution methods to understand how specific data shapes model behaviour and use that information to reconstruct pre-training to shape model behaviour in the way we want. For example, can we side-step the need for unlearning? Can these data attribution methods augment unlearning to work better?
- As Roger said in his comment, we can try to manage the dataset to prevent WMB-dangerous capabilities and things like self-replication. It's quite possible that unlearning will not be enough.
- Another project would be to fine-tune on a dataset with and without the dangerous capabilities we don't want and use that as a benchmark for unlearning methods (and how easy it is to fine-tune the capability back into the model).
- Including other methods beyond data attribution (e.g. SAEs) to measure model evolution through training.
- Is it possible to better understand and predict emergence via data attribution?
- Studying model generalization via data attribution (doing similar things to the influence functions paper, but through time). Though the most interesting behaviour may only come at scales I wouldn't have the compute for.
- Would there be value in using an early checkpoint in training and then training on the synthetic data from that point forward? At which point in training does this make sense to do?
↑ comment by RogerDearnaley (roger-d-1) · 2024-07-10T07:56:30.367Z · LW(p) · GW(p)
In this @RogerDearnaley [LW · GW] post, A "Bitter Lesson" Approach to Aligning AGI and ASI [LW · GW], Roger proposes training an AI on a synthetic dataset where all intelligences are motivated by the collective well-being of humanity. You are trying to bias the model to be as close to the basin of attraction for alignment [LW · GW] as possible. In-Run Data Shapley could be used to construct such a dataset and guide the training process so that the training data best exemplifies the desired aligned behaviour.
I love this idea! Thanks for suggesting it. (It is of course, not a Bitter Lesson approach, but may well still be a great idea.)
Another area where being able to do this efficiently at scale is going to be really important is once models start showing dangerous levels of capability on WMB-dangerous chem/bio/radiological/nuclear (CBRN) and self-replication skills. The best way to deal with this is to make sure these skills aren't in the model at all, so the model can't be fine-tuned back to these capabilities (as is required to produce a model of this level where one could at least discuss open-sourcing it, rather than that being just flagrantly crazy and arguably perhaps already illegal), is to omit key knowledge from the training set entirely. Which inevitably isn't going to succeed on the first pass, but this technique applied to the first pass gives us a way to find (hopefully) everything we need to remove from the training set so we can do a second training run that has specific, focused, narrow gaps in its capabilities.
And yes, I'm interested in work in this area (my AI day-job allowing).
↑ comment by Mike Vaiana (mike-vaiana) · 2024-07-09T20:41:36.865Z · LW(p) · GW(p)
Hey, we've been brainstorm ideas about better training strategies for base models and what types of experiments we can run at a small scale (e.g. training gpt-2 ) to get initial information. I think this idea is really promising and would love to chat about it.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2024-07-09T21:09:18.207Z · LW(p) · GW(p)
It's cool that you point to @Tomek Korbak [LW · GW] because I was wondering if we could think of ways to extend his Pretraining Language Models with Human Preferences paper in ways that Roger mentions in his post.
Happy to chat!
↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-07-24T17:46:10.342Z · LW(p) · GW(p)
- You might be able to set up a bunch of validation examples to test specific behaviour in the models so that we are hyper-aware of which data points contribute the most to that behaviour. For example, self-awareness or self-preservation.
This might be relatively straightforward to operationalize using (subsets of) the dataset from Me, Myself, and AI: The Situational Awareness Dataset (SAD) for LLMs.
Another related idea (besides / on top of e.g. delaying the learning of dangerous capabilities / prerequisites to scheming) could be to incentivize them to e.g. be retrieved in-context, rather than be learned in-weights (to the degree they're important for performance), for (differential) transparency reasons.
Also, similarly to recent unlearning papers, it might be useful to also have a validation dataset as a proxy for which capabilities should be preserved; and potentially try (cheap) synthetic data to compensate for any capabilities losses on that one.
Replies from: jacques-thibodeau, bogdan-ionut-cirstea↑ comment by jacquesthibs (jacques-thibodeau) · 2024-07-24T23:03:14.170Z · LW(p) · GW(p)
Yeah, I was thinking about using SAD. The main issue is that for non-AGI-lab-sized models, you'll have a tough time eliciting SA. However, we could potentially focus on precursor capabilities and such.
If you are concerned about capabilities like SA, then you might ask yourself, "it seems highly unlikely that you can figure out which data points impact SA the most because it will likely be a mix of many things and each data point will play a role in accumulating to SA." My guess is that you can break down SA into enough precursor capabilities that this approach can still be highly predictive even if it isn't 100%/
I think forcing them to retrieve in-context sounds good, but I also think labs may not want this, not sure. Basically, they'll want to train things into the model eventually, like for many CoT things.
Agreed on having a validation set for reducing the alignment tax.
↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-07-24T19:01:08.300Z · LW(p) · GW(p)
Here's Claude-3.5 (though I had to push it a bit in the direction of explicitly considering combing SAD and Data Shapley):
'Combining the Situational Awareness Dataset (SAD) benchmark with Shapley values, particularly the In-Run Data Shapley approach described in the other paper, could yield some interesting insights. Here are some potential ways to integrate these two approaches:
- Attribute situational awareness to training data: Use In-Run Data Shapley to determine which training data contributes most to performance on SAD tasks. This could help identify what types of data are most important for developing situational awareness in AI models.
- Analyze task-specific contributions: Calculate Shapley values for each category or individual task within SAD. This could reveal which parts of the training data are most influential for different aspects of situational awareness.
- Track situational awareness development: Apply In-Run Data Shapley at different stages of training to see how the importance of different data points for situational awareness changes over time.
- Identify potential deception enablers: Look for training data with high Shapley values for both SAD performance and other capabilities that might enable deception. This could help pinpoint data that contributes to potentially risky combinations of abilities.
- Curate training data: Use the Shapley values to guide the curation of training datasets, potentially removing or de-emphasizing data that contributes disproportionately to unwanted levels of situational awareness.
- Comparative analysis across models: Compare Shapley values for SAD performance across different model architectures or training regimes to understand how different approaches affect the development of situational awareness.
- Investigate prompt influence: Apply In-Run Data Shapley to analyze how much the "situating prompt" contributes to SAD performance compared to other parts of the input.
- Correlation studies: Examine correlations between Shapley values for SAD performance and other metrics like general knowledge or reasoning abilities.
- Targeted intervention experiments: Use Shapley values to identify high-impact training examples for situational awareness, then experiment with modifying or removing these examples to see how it affects model behavior.
- Robustness analysis: Assess how stable the Shapley values are for SAD performance across different runs or slight variations in the training process. This could provide insights into how consistently situational awareness develops.
- Transfer learning insights: If fine-tuning models on SAD-like tasks, use Shapley to understand which pre-training data contributes most to quick adaptation.
- Bias detection: Look for any demographic biases in the training data that have high Shapley values for SAD performance, which could indicate skewed development of situational awareness.
By combining these approaches, researchers could gain a more nuanced understanding of how situational awareness develops in AI models and what factors contribute most to this development. This could inform strategies for developing AI systems with appropriate levels of situational awareness while mitigating risks associated with excessive or misaligned awareness.'
comment by jacquesthibs (jacques-thibodeau) · 2024-04-12T15:01:48.420Z · LW(p) · GW(p)
I'm currently ruminating on the idea of doing a video series in which I review code repositories that are highly relevant to alignment research to make them more accessible.
I do want to pick out repos with perhaps even bad documentation that are still useful and then hope on a call with the author to go over the repo and record it. At least have something basic to use when navigating the repo.
This means there would be two levels: 1) an overview with the author sharing at least the basics, and 2) a deep dive going over most of the code. The former likely contains most of the value (lower effort for me, still gets done, better than nothing, points to repo as a selection mechanism, people can at least get started).
I am thinking of doing this because I think there may be repositories that are highly useful for new people but would benefit from some direction. For example, I think Karpathy and Neel Nanda's videos have been useful in getting people started. In particular, Karpathy saw OOM more stars to his repos (e.g. nanoGPT) after the release of his videos (which, to be fair, he's famous, and a number of stars is definitely not a perfect proxy for usage).
I'm interested in any feedback ("you should do it like x", "this seems low value for x, y, z reasons so you shouldn't do it", "this seems especially valuable only if x", etc.).
Here are some of the repos I have in mind so far:
Release Ordering
- Evalugator
- Sleeper Agents [AF · GW]
- Weak-to-Strong Generalization
- Neuron-pedia (I think they have GIFs right now)
- ELK
- Potential Videos
- Localizing Lying in Llama
- Representation Engineering
- Sparse Autoencoders
- nnsight
- TransformerLens
- Anthropic
- Model-Written Evals
- Ethan's faithfulness approach
- Influence Functions
- DeepMind
- None seem interesting so far.
- EleutherAI
- OpenAI
- Evals
- Triton introduction
- Transformer Debugger (OpenAI has videos)
- Influence Functions (when there is a legitimate repo)
- Recommended by Garett Baker
↑ comment by Dagon · 2024-04-12T16:57:13.614Z · LW(p) · GW(p)
I love this idea! I don't actually like videos, preferring searchable, exerptable text, but I may not be typical and there's room for all. At first glance, I agree with your guess that the overview/intro is more value per effort (for you and for consumers, IMO) than a deep-dive into the code. There IS probably a section of code or core modeling idea for each where it would be worth going half-deep into (algorithm and usage, not necessarily line-by-line).
Note that this list is itself incredibly valuable, and you might start with an intro video (and associated text) that spends 1 minute on each and why you're planning to do it, and what you currently think will be the most important intro concept(s) for each.
comment by jacquesthibs (jacques-thibodeau) · 2023-03-30T01:17:37.331Z · LW(p) · GW(p)
I’m still thinking this through, but I am deeply concerned about Eliezer’s new article [LW · GW] for a combination of reasons:
- I don’t think it will work.
- Given that it won’t work, I expect we lose credibility and it now becomes much harder to work with people who were sympathetic to alignment, but still wanted to use AI to improve the world.
- I am not convinced as he is about doom and I am not as cynical about the main orgs as he is.
In the end, I expect this will just alienate people. And stuff like this [LW(p) · GW(p)] concerns me.
I think it’s possible that the most memetically powerful approach will be to accelerate alignment rather than suggesting long-term bans or effectively antagonizing all AI use.
Replies from: abramdemski, jacques-thibodeau, Viliam↑ comment by abramdemski · 2023-04-27T16:31:10.533Z · LW(p) · GW(p)
So I think what I'm getting here is that you have an object-level disagreement (not as convinced about doom), but you are also reinforcing that object-level disagreement with signalling/reputational considerations (this will just alienate people). This pattern feels ugh and worries me. It seems highly important to separate the question of what's true from the reputational question. It furthermore seems highly important to separate arguments about what makes sense to say publicly on-your-world-model vs on-Eliezer's-model. In particular, it is unclear to me whether your position is "it is dangerously wrong to speak the truth about AI risk" vs "Eliezer's position is dangerously wrong" (or perhaps both).
I guess that your disagreement with Eliezer is large but not that large (IE you would name it as a disagreement between reasonable people, not insanity). It is of course possible to consistently maintain that (1) Eliezer's view is reasonable, (2) on Eliezer's view, it is strategically acceptable to speak out, and (3) it is not in fact strategically acceptable for people with Eliezer's views to speak out about those views. But this combination of views does imply endorsing a silencing of reasonable disagreements which seems unfortunate and anti-epistemic.
My own guess is that the maintenance of such anti-epistemic silences is itself an important factor contributing to doom. But, this could be incorrect.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-04-27T17:32:41.768Z · LW(p) · GW(p)
Yeah, so just to clarify a few things:
- This was posted on the day of the open letter and I was indeed confused about what to think of the situation.
- I think something I failed to properly communicate is that I was worried that this was a bad time to pull the lever even if I’m concerned about risks from AGI. I was worried the public wouldn’t take alignment seriously because they cause a panic much sooner than people were ready for.
- I care about being truthful, but I care even more about not dying so my comment was mostly trying to communicate that I didn’t think this was the best strategic decision for not dying.
- I was seeing a lot of people write negative statements about the open letter on Twitter and it kind of fed my fears that this was going to backfire as a strategy and impact all of our work to make ai risk taken seriously.
- In the end, the final thing that matters is that we win (i.e. not dying from AGI).
I’m not fully sure what I think now (mostly because I don’t know about higher order effects that will happen 2-3 years from now), but I think it turned out a lot strategically better than I initially expected.
↑ comment by jacquesthibs (jacques-thibodeau) · 2023-03-30T03:46:09.453Z · LW(p) · GW(p)
To try and burst any bubble about people’s reaction to the article, here’s a set of tweets critical about the article:
- https://twitter.com/mattparlmer/status/1641230149663203330?s=61&t=ryK3X96D_TkGJtvu2rm0uw
- https://twitter.com/jachiam0/status/1641271197316055041?s=61&t=ryK3X96D_TkGJtvu2rm0uw
- https://twitter.com/finbarrtimbers/status/1641266526014803968?s=61&t=ryK3X96D_TkGJtvu2rm0uw
- https://twitter.com/plinz/status/1641256720864530432?s=61&t=ryK3X96D_TkGJtvu2rm0uw
- https://twitter.com/perrymetzger/status/1641280544007675904?s=61&t=ryK3X96D_TkGJtvu2rm0uw
- https://twitter.com/post_alchemist/status/1641274166966996992?s=61&t=ryK3X96D_TkGJtvu2rm0uw
- https://twitter.com/keerthanpg/status/1641268756071718913?s=61&t=ryK3X96D_TkGJtvu2rm0uw
- https://twitter.com/levi7hart/status/1641261194903445504?s=61&t=ryK3X96D_TkGJtvu2rm0uw
- https://twitter.com/luke_metro/status/1641232090036600832?s=61&t=ryK3X96D_TkGJtvu2rm0uw
- https://twitter.com/gfodor/status/1641236230611562496?s=61&t=ryK3X96D_TkGJtvu2rm0uw
- https://twitter.com/luke_metro/status/1641263301169680386?s=61&t=ryK3X96D_TkGJtvu2rm0uw
- https://twitter.com/perrymetzger/status/1641259371568005120?s=61&t=ryK3X96D_TkGJtvu2rm0uw
- https://twitter.com/elaifresh/status/1641252322230808577?s=61&t=ryK3X96D_TkGJtvu2rm0uw
- https://twitter.com/markovmagnifico/status/1641249417088098304?s=61&t=ryK3X96D_TkGJtvu2rm0uw
- https://twitter.com/interpretantion/status/1641274843692691463?s=61&t=ryK3X96D_TkGJtvu2rm0uw
- https://twitter.com/lan_dao_/status/1641248437139300352?s=61&t=ryK3X96D_TkGJtvu2rm0uw
- https://twitter.com/lan_dao_/status/1641249458053861377?s=61&t=ryK3X96D_TkGJtvu2rm0uw
- https://twitter.com/growing_daniel/status/1641246902363766784?s=61&t=ryK3X96D_TkGJtvu2rm0uw
- https://twitter.com/alexandrosm/status/1641259179955601408?s=61&t=ryK3X96D_TkGJtvu2rm0uw
↑ comment by Viliam · 2023-03-30T13:50:28.360Z · LW(p) · GW(p)
What is the base rate for Twitter reactions for an international law proposal?
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-03-30T16:21:57.006Z · LW(p) · GW(p)
Of course it’s often all over the place. I only shared the links because I wanted to make sure people weren’t deluding themselves with only positive comments.
↑ comment by Viliam · 2023-03-30T13:47:22.123Z · LW(p) · GW(p)
This reminds me of the internet-libertarian chain of reasoning that anything that government does is protected by the threat of escalating violence, therefore any proposals that involve government (even mild ones, such as "once in a year, the President should say 'hello' to the citizens") are calls for murder, because... (create a chain of escalating events starting with someone non-violently trying to disrupt this, ending with that person being killed by cops)...
Yes, a moratorium on AIs is a call for violence, but only in the sense that every law is a call for violence.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-03-30T14:02:21.514Z · LW(p) · GW(p)
comment by jacquesthibs (jacques-thibodeau) · 2025-01-23T17:18:45.495Z · LW(p) · GW(p)
Looks like Meta is panicking over DeepSeek R1
↑ comment by Garrett Baker (D0TheMath) · 2025-01-23T17:55:44.948Z · LW(p) · GW(p)
Engineers: Its impossible.
Meta management: Tony Stark DeepSeek was able to build this in a cave! With a box of scraps!
comment by jacquesthibs (jacques-thibodeau) · 2024-05-09T23:54:52.176Z · LW(p) · GW(p)
Quote from Cal Newport's Slow Productivity book: "Progress in theoretical computer science research is often a game of mental chicken, where the person who is able to hold out longer through the mental discomfort of working through a proof element in their mind will end up with the sharper result."
Replies from: keltan↑ comment by keltan · 2024-05-10T07:10:05.955Z · LW(p) · GW(p)
Big fan of Cal’s work. He’s certainly someone who is pushing the front lines in the fight against acrasia. I’m currently reading “how to win at college”. It’s a super information dense package. Feels a bit like rationality from a-z, if it were specifically for college students trying to succeed.
Why did you decide to share this quote? I feel like I’m missing some key context that could aid my understanding.
comment by jacquesthibs (jacques-thibodeau) · 2024-05-08T12:05:22.313Z · LW(p) · GW(p)
Do we expect future model architectures to be biased toward out-of-context reasoning (reasoning internally rather than in a chain-of-thought)? As in, what kinds of capabilities would lead companies to build models that reason less and less in token-space?
I mean, the first obvious thing would be that you are training the model to internalize some of the reasoning rather than having to pay for the additional tokens each time you want to do complex reasoning.
The thing is, I expect we'll eventually move away from just relying on transformers with scale. And so I'm trying to refine my understanding of the capabilities that are simply bottlenecked in this paradigm, and that model builders will need to resolve through architectural and algorithmic improvements. (Of course, based on my previous posts, I still think data is a big deal.)
Anyway, this kind of thinking eventually leads to the infohazardous area of, "okay then, what does the true AGI setup look like?" This is really annoying because it has alignment implications. If we start to move increasingly towards models that are reasoning outside of token-space, then alignment becomes harder. So, are there capability bottlenecks that eventually get resolved through something that requires out-of-context reasoning?
So far, it seems like the current paradigm will not be an issue on this front. Keep scaling transformers, and you don't really get any big changes in the model's likelihood of using out-of-context reasoning.
This is not limited to out-of-context reasoning. I'm trying to have a better understanding of the (dangerous) properties future models may develop simply as a result of needing to break a capability bottleneck. My worry is that many people end up over-indexing on the current transformer+scale paradigm (and this becomes insufficient for ASI), so they don't work on the right kinds of alignment or governance projects.
---
I'm unsure how big of a deal this architecture will end up being, but the rumoured xLSTM just dropped. It seemingly outperforms other models at the same size:

Maybe it ends up just being another drop in the bucket, but I think we will see more attempts in this direction.
Claude summary:
The key points of the paper are:
- The authors introduce exponential gating with memory mixing in the new sLSTM variant. This allows the model to revise storage decisions and solve state tracking problems, which transformers and state space models without memory mixing cannot do.
- They equip the mLSTM variant with a matrix memory and covariance update rule, greatly enhancing the storage capacity compared to the scalar memory cell of vanilla LSTMs. Experiments show this matrix memory provides a major boost.
- The sLSTM and mLSTM are integrated into residual blocks to form xLSTM blocks, which are then stacked into deep xLSTM architectures.
- Extensive experiments demonstrate that xLSTMs outperform state-of-the-art transformers, state space models, and other LSTMs/RNNs on language modeling tasks, while also exhibiting strong scaling behavior to larger model sizes.
This work is important because it presents a path forward for scaling LSTMs to billions of parameters and beyond. By overcoming key limitations of vanilla LSTMs - the inability to revise storage, limited storage capacity, and lack of parallelizability - xLSTMs are positioned as a compelling alternative to transformers for large language modeling.
Instead of doing all computation step-by-step as tokens are processed, advanced models might need to store and manipulate information in a compressed latent space, and then "reason" over those latent representations in a non-sequential way.
The exponential gating with memory mixing introduced in the xLSTM paper directly addresses this need. Here's how:
- Exponential gating allows the model to strongly update or forget the contents of each memory cell based on the input. This is more powerful than the simple linear gating in vanilla LSTMs. It means the model can decisively revise its stored knowledge as needed, rather than being constrained to incremental changes. This flexibility is crucial for reasoning, as it allows the model to rapidly adapt its latent state based on new information.
- Memory mixing means that each memory cell is updated using a weighted combination of the previous values of all cells. This allows information to flow and be integrated between cells in a non-sequential way. Essentially, it relaxes the sequential constraint of traditional RNNs and allows for a more flexible, graph-like computation over the latent space.
- Together, these two components endow the xLSTM with a dynamic, updateable memory that can be accessed and manipulated "outside" the main token-by-token processing flow. The model can compress information into this memory, "reason" over it by mixing and gating cells, then produce outputs guided by the updated memory state.
In this way, the xLSTM takes a significant step towards the kind of "reasoning outside token-space" that I suggested would be important for highly capable models. The memory acts as a workspace for flexible computation that isn't strictly tied to the input token sequence.
Now, this doesn't mean the xLSTM is doing all the kinds of reasoning we might eventually want from an advanced AI system. But it demonstrates a powerful architecture for models to store and manipulate information in a latent space, at a more abstract level than individual tokens. As we scale up this approach, we can expect models to perform more and more "reasoning" in this compressed space rather than via explicit token-level computation.
Replies from: Seth Herd↑ comment by Seth Herd · 2024-05-08T18:55:30.196Z · LW(p) · GW(p)
This is an excellent point.
While LLMs seem (relatively) safe [LW · GW], we may very well blow right on by them soon.
I do think that many of the safety advantages of LLMs come from their understanding of human intentions (and therefore implied values). Those would be retained in improved architectures that still predict human language use. If such a system's thought process was entirely opaque, we could no longer perform Externalized reasoning oversight [LW · GW] by "reading its thoughts".
But think it might be possible to build a reliable agent from unreliable parts. I think humans are such an agent, and evolution made us this way because it's a way to squeeze extra capability out of a set of base cognitive capacities.
Imagine an agentic set of scaffolding that merely calls the super-LLM for individual cognitive acts. Such an agent would use a hand-coded "System 2" thinking approach to solve problems, like humans do. That involves breaking a problem into cognitive steps. We also use System 2 for our biggest ethical decisions; we predict consequences of our major decisions, and compare them to our goals, including ethical goals. Such a synthetic agent would use System 2 for problem-solving capabilities, and also for checking plans for how well they achieve goals. This would be done for efficiency; spending a lot of compute or external resources on a bad plan would be quite costly. Having implemented it for efficiency, you might as well use it for safety.
This is just restating stuff I've said elsewhere, but I'm trying to refine the model, and work through how well it might work if you couldn't apply any external reasoning oversight, and little to no interpretability. It's definitely bad for the odds of success, but not necessarily crippling. I think.
This needs more thought. I'm working on a post on System 2 alignment, as sketched out briefly (and probably incomprehensibly) above.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-05-09T02:55:34.710Z · LW(p) · GW(p)
I do think that many of the safety advantages of LLMs come from their understanding of human intentions (and therefore implied values).
Did you mean something different than "AIs understand our intentions" (e.g. maybe you meant that humans can understand the AI's intentions?).
I think future more powerful AIs will surely be strictly better at understanding what humans intend.
Replies from: Seth Herd↑ comment by Seth Herd · 2024-05-09T17:52:00.429Z · LW(p) · GW(p)
I think future more powerful/useful AIs will understand our intentions better IF they are trained to predict language. Text corpuses contain rich semantics about human intentions.
I can imagine other AI systems that are trained differently, and I would be more worried about those.
That's what I meant by current AI understanding our intentions possibly better than future AI.
comment by jacquesthibs (jacques-thibodeau) · 2024-05-27T18:05:08.695Z · LW(p) · GW(p)
I'm currently working on building an AI research assistant designed specifically for alignment research. I'm at the point where I will be starting to build specific features for the project and delegate work to developers who would like to contribute.
- Developers: If you are a developer who might be interested in contributing to this project, send me a DM for more details.
- Alignment Researchers: I have a long list of features I want to build. I need to prioritize the features that people actually think would help them the most. If you'd like to look over the features and provide feedback, send me a DM and I will send you the relevant list of features.
↑ comment by jacquesthibs (jacques-thibodeau) · 2024-05-28T16:00:26.348Z · LW(p) · GW(p)
Alignment Math people: I would appreciate it if someone could review this video of Terrence Tao giving a presentation on machine-assisted proofs to give feedback on what they think an ideal alignment assistant could do in this domain.
In addition, I'm thinking of eventually looking at models like DeepSeek-Prover to see if they can be beneficial for assisting alignment researchers in creating proofs:
Replies from: mesaoptimizerProof assistants like Lean have revolutionized mathematical proof verification, ensuring high accuracy and reliability. Although large language models (LLMs) show promise in mathematical reasoning, their advancement in formal theorem proving is hindered by a lack of training data. To address this issue, we introduce an approach to generate extensive Lean 4 proof data derived from high-school and undergraduate-level mathematical competition problems. This approach involves translating natural language problems into formal statements, filtering out low-quality statements, and generating proofs to create synthetic data. After fine-tuning the DeepSeekMath 7B model on this synthetic dataset, which comprises 8 million formal statements with proofs, our model achieved whole-proof generation accuracies of 46.3% with 64 samples and 52% cumulatively on the Lean 4 miniF2F test, surpassing the baseline GPT-4 at 23.0% with 64 samples and a tree search reinforcement learning method at 41.0%. Additionally, our model successfully proved 5 out of 148 problems in the Lean 4 Formalized International Mathematical Olympiad (FIMO) benchmark, while GPT-4 failed to prove any. These results demonstrate the potential of leveraging large-scale synthetic data to enhance theorem-proving capabilities in LLMs. Both the synthetic dataset and the model will be made available to facilitate further research in this promising field.
↑ comment by mesaoptimizer · 2024-05-28T22:16:05.971Z · LW(p) · GW(p)
I've experimented with Claude Opus for simple Ada autoformalization test cases (specifically quicksort), and it seems like the sort of issues that make LLM agents infeasible (hallucination-based drift, subtle drift caused by sticking to certain implicit assumptions you made before) are also the issues that make Opus hard to use for autoformalization attempts.
I haven't experimented with a scaffolded LLM agent [LW · GW] for autoformalization, but I expect it won't go very well either, primarily because scaffolding involves attempts to make human-like implicit high-level cognitive strategies into explicit algorithms or heuristics such as tree of thought prompting, and I expect that this doesn't scale given the complexity of the domain (sufficently general autoformalizing AI systems can be modelled as effectively consequentialist, which makes them dangerous [LW · GW]). I don't expect for a scaffolded (over Opus) LLM agent to succeed at autoformalizing quicksort right now either, mostly because I believe RLHF tuning has systematically optimized Opus to write the bottom line [LW · GW] first and then attempt to build or hallucinate a viable answer, and then post-hoc justify the answer. (While steganographic non-visible chain-of-thought [LW(p) · GW(p)] may have gone into figuring out the bottom line, it still is worse than first doing visible chain-of-thought such that it has more token-compute-iterations to compute its answer.)
If anyone reading this is able to build a scaffolded agent that autoformalizes (using Lean or Ada) algorithms of complexity equivalent to quicksort reliably (such that more than 5 out of 10 of its attempts succeed) within the next month of me writing this comment, then I'd like to pay you 1000 EUR to see your code and for an hour of your time to talk with you about this. That's a little less than twice my current usual monthly expenses, for context.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2024-05-29T13:49:59.091Z · LW(p) · GW(p)
Great. Yeah, I also expect that it is hard to get current models to work well on this. However, I will mention that the DeepSeekMath model does seem to outperform GPT-4 despite having only 7B parameters. So, it may be possible to create a +70B fine-tune that basically destroys GPT-4 at math. The issue is whether it generalizes to the kind of math we'd commonly see in alignment research.
Additionally, I expect at least a bit can be done with scaffolding, search, etc. I think the issue with many prompting methods atm is that they are specifically trying to get the model to arrive at solutions on their own. And what I mean by that is that they are starting from the frame of "how can we get LLMs to solve x math task on their own," instead of "how do we augment the researcher's ability to arrive at (better) proofs more efficiently using LLMs." So, I think there's room for product building that does not involve "can you solve this math question from scratch," though I see the value in getting that to work as well.
comment by jacquesthibs (jacques-thibodeau) · 2024-05-15T12:53:05.903Z · LW(p) · GW(p)
(This is the tale of a potentially reasonable CEO of the leading AGI company, not the one we have in the real world. Written after a conversation with @jdp.)
You’re the CEO of the leading AGI company. You start to think that your moat is not as big as it once was. You need more compute and need to start accelerating to give yourself a bigger lead, otherwise this will be bad for business.
You start to look around for compute, and realize you have 20% of your compute you handed off to the superalignment team (and even made a public commitment!). You end up making the decision to take their compute away to maintain a strong lead in the AGI race, while expecting there will be backlash.
Your plan is to lobby government and tell them that AGI race dynamics are too intense at the moment and you were forced to make a tough call for the business. You tell government that it’s best if they put heavy restrictions on AGI development, otherwise your company will not be able to afford to subsidize basic research in alignment.
You give them a plan that you think they should follow if they want AGI to be developed safely and for companies to invest in basic research.
You told your top employees this plan, but they have a hard time believing you given that they feel like you lied about your public commitment to giving them 20% of current compute. You didn’t actually lie, or at least it wasn’t intentional. You just thought the moat was bigger and when you realized it wasn’t, you had to make a business decision. Many things happened since that commitment.
Anyway, your safety researchers are not happy about this at all and decide to resign.
To be continued…
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2024-05-15T13:00:20.449Z · LW(p) · GW(p)
So, you go to government and lobby. Except you never intended to help the government get involved in some kind of slow-down or pause. Your intent was to use this entire story as a mirage for getting rid of those who didn’t align with you and lobby the government in such a way that they don’t think it is such a big deal that your safety researchers are resigning.
You were never the reasonable CEO, and now you have complete power.
comment by jacquesthibs (jacques-thibodeau) · 2024-05-02T13:11:34.041Z · LW(p) · GW(p)
From a Paul Christiano talk called "How Misalignment Could Lead to Takeover" (from February 2023):
Assume we're in a world where AI systems are broadly deployed, and the world has become increasingly complex, where humans know less and less about how things work.
A viable strategy for AI takeover is to wait until there is certainty of success. If a 'bad AI' is smart, it will realize it won't be successful if it tries to take over, not a problem.
So you lose when a takeover becomes possible, and some threshold of AIs behave badly. If all the smartest AIs you produce end up having the same problem, then takeover becomes more likely.
In other words, the smartest AIs will only take over if all the other AIs will also try to takeover.
Additionally, this is more likely to happen in an unstable world that could come from:
- War (or other exogenous shocks): making it harder for humans to detect and respond to problems.
- Cascading loss of control: some AIs try takeover and aren't fully successful, but make the world increasingly crazy, which cascades into other AIs (who previously thought it would be unsuccessful) now joining the takeover.
- Models interacting with each other: once some AIs realize could be successful, they may want to share that information with other models to see if other models may want to join in.
There's this tempting feeling of training your AI against these takeover attempts ("hey, look at this bad AI who tried to takeover the data center, don't do that!"), but you may just be training your model to learn that it needs to go much bigger if it wants to actually succeed at the takeover attempt.
Paul believes that if this kind of phenomenon is real, then he expects we can get compelling demonstrations in a lab (that would require some imagination to bridge the examples in the lab vs the wild). We'll still get demonstrations in the wild, but unclear if they will be big enough to make humanity reconsider things.
comment by jacquesthibs (jacques-thibodeau) · 2024-01-23T16:49:04.684Z · LW(p) · GW(p)
I shared the following as a bio for EAG Bay Area 2024. I'm sharing this here if it reaches someone who wants to chat or collaborate.
Hey! I'm Jacques. I'm an independent technical alignment researcher with a background in physics and experience in government (social innovation, strategic foresight, mental health and energy regulation). Link to Swapcard profile. Twitter/X.
CURRENT WORK
- Collaborating with Quintin Pope on our Supervising AIs Improving AIs agenda (making automated AI science safe and controllable). The current project involves a new method allowing unsupervised model behaviour evaluations. Our agenda [LW · GW].
- I'm a research lead in the AI Safety Camp for a project on stable reflectivity [LW · GW] (testing models for metacognitive capabilities that impact future training/alignment).
- Accelerating Alignment: augmenting alignment researchers using AI systems. A relevant talk I gave. Relevant survey post [LW · GW].
- Other research that currently interests me: multi-polar AI worlds (and how that impacts post-deployment model behaviour), understanding-based interpretability, improving evals, designing safer training setups, interpretable architectures, and limits of current approaches (what would a new paradigm that addresses these limitations look like?).
- Used to focus more on model editing [LW · GW], rethinking interpretability, causal scrubbing, etc.
TOPICS TO CHAT ABOUT
- How do you expect AGI/ASI to actually develop (so we can align our research accordingly)? Will scale plateau? I'd like to get feedback on some of my thoughts on this.
- How can we connect the dots between different approaches? For example, connecting the dots between Influence Functions, Evaluations, Probes (detecting truthful direction), Function/Task Vectors, and Representation Engineering to see if they can work together to give us a better picture than the sum of their parts.
- Debate over which agenda actually contributes to solving the core AI x-risk problems.
- What if the pendulum swings in the other direction, and we never get the benefits of safe AGI? Is open source really as bad as people make it out to be?
- How can we make something like the d/acc vision (by Vitalik Buterin) happen?
- How can we design a system that leverages AI to speed up progress on alignment? What would you value the most?
- What kinds of orgs are missing in the space?
POTENTIAL COLLABORATIONS
- Examples of projects I'd be interested in: extending either the Weak-to-Strong Generalization paper or the Sleeper Agents paper, understanding the impacts of synthetic data on LLM training, working on ELK-like research for LLMs, experiments on influence functions (studying the base model and its SFT, RLHF, iterative training counterparts; I heard that Anthropic is releasing code for this "soon") or studying the interpolation/extrapolation distinction in LLMs.
- I’m also interested in talking to grantmakers for feedback on some projects I’d like to get funding for.
- I'm slowly working on a guide for practical research productivity for alignment researchers to tackle low-hanging fruits that can quickly improve productivity in the field. I'd like feedback from people with solid track records and productivity coaches.
TYPES OF PEOPLE I'D LIKE TO COLLABORATE WITH
- Strong math background, can understand Influence Functions enough to extend the work.
- Strong machine learning engineering background. Can run ML experiments and fine-tuning runs with ease. Can effectively create data pipelines.
- Strong application development background. I have various project ideas that could speed up alignment researchers; I'd be able to execute them much faster if I had someone to help me build my ideas fast.
comment by jacquesthibs (jacques-thibodeau) · 2023-11-05T19:00:38.093Z · LW(p) · GW(p)
This seems like a fairly important paper by Deepmind regarding generalization (and lack of it in current transformer models): https://arxiv.org/abs/2311.00871
Here’s an excerpt on transformers potentially not really being able to generalize beyond training data:
Replies from: leogao, sharmake-farah, jacques-thibodeau, D0TheMath, Oliver SourbutOur contributions are as follows:
- We pretrain transformer models for in-context learning using a mixture of multiple distinct function classes and characterize the model selection behavior exhibited.
- We study the in-context learning behavior of the pretrained transformer model on functions that are "out-of-distribution" from the function classes in the pretraining data.
- In the regimes studied, we find strong evidence that the model can perform model selection among pretrained function classes during in-context learning at little extra statistical cost, but limited evidence that the models' in-context learning behavior is capable of generalizing beyond their pretraining data.
↑ comment by leogao · 2023-11-05T23:06:23.847Z · LW(p) · GW(p)
i predict this kind of view of non magicalness of (2023 era) LMs will become more and more accepted, and this has implications on what kinds of alignment experiments are actually valuable (see my comment on the reversal curse paper [LW(p) · GW(p)]). not an argument for long (50 year+) timelines, but is an argument for medium (10 year) timelines rather than 5 year timelines
Replies from: leogao↑ comment by leogao · 2023-11-05T23:45:07.873Z · LW(p) · GW(p)
also this quote from the abstract is great:
Together our results highlight that the impressive ICL abilities of high-capacity sequence models may be more closely tied to the coverage of their pretraining data mixtures than inductive biases that create fundamental generalization capabilities.
i used to call this something like "tackling the OOD generalization problem by simply making the distribution so wide that it encompasses anything you might want to use it on"
↑ comment by Noosphere89 (sharmake-farah) · 2023-11-06T14:28:36.241Z · LW(p) · GW(p)
I'd say my major takeaways, assuming this research scales (it was only done on GPT-2, and we already knew it couldn't generalize.)
-
Gary Marcus was right about LLMs mostly not reasoning outside the training distribution, and this updates me more towards "LLMs probably aren't going to be godlike, or be nearly as impactful as LW say it is."
-
Be more skeptical of AI progress leading to big things, and in general unless reality can simply be memorized, scaling probably won't work to automate the economy. More generally, this updates me towards longer timelines, and longer tails on those timelines.
-
Be slightly more pessimistic on AI safety, since LLMs have a bunch of nice properties, and future AI probably will have less nice properties, though alignment optimism mostly doesn't depend on LLMs.
-
AI governance gets a lucky break, since they only have to regulate misuse, and even though their threat model isn't likely or even probable to be realized, it's still nice that we don't have to deal with the disruptive effects of AI now.
↑ comment by jacquesthibs (jacques-thibodeau) · 2023-11-06T16:58:20.406Z · LW(p) · GW(p)
I am sharing this since I think it will change your view on how much to update on this paper (I should have shared this initially). Here's what the paper author said on X:
Clarifying two things:
- Model is simple transformer for science, not a language model (or large by standards today)
- The model can learn new tasks (via in-context learning), but can’t generalize to new task families
I would be thrilled if this work was important for understanding AI safety and fairness, but it is the start of a scientific direction, not ready for policy conclusions. Understanding what task families a true LLM is capable of would be fascinating and more relevant to policy!
So, with that, I said:
I hastily thought the paper was using language models, so I think it's important to share this. A follow-up paper using a couple of 'true' LLMs at different model scales would be great. Is it just interpolation? How far can the models extrapolate?
To which @Jozdien [LW · GW] replied:
Replies from: sharmake-farahRedpill is that all intelligence is just interpolation if you reach this level of fidelity.
↑ comment by Noosphere89 (sharmake-farah) · 2024-07-12T04:19:55.029Z · LW(p) · GW(p)
In retrospect, I probably should have updated much less than I did, I thought that it was actually testing a real LLM, which makes me less confident in the paper.
Should have responded long ago, but responding now.
↑ comment by jacquesthibs (jacques-thibodeau) · 2023-11-16T16:26:16.333Z · LW(p) · GW(p)
Title: Is the alignment community over-updating on how scale impacts generalization?
So, apparently, there's a rebuttal to the recent Google generalization paper (and also worth pointing out it wasn't done with language models, just sinoïsodal functions, not language):


But then, the paper author responds:

This line of research makes me question one thing: "Is the alignment community over-updating on how scale impacts generalization?"
It remains to be seen how well models will generalize outside of their training distribution (interpolation vs extrapolation).
In other words, when people say that GPT-4 (and other LLMs) can generalize, I think they need to be more careful about what they really mean. Is it doing interpolation or extrapolation? Meaning, yes, GPT-4 can do things like write a completely new poem, but poems and related stuff were in its training distribution! So, you can say it is generalizing, but I think it's a much weaker form of generalization than what people really imply when they say generalization. A stronger form of generalization would be an AI that can do completely new tasks that are actually outside of its training distribution.
Now, at this point, you might say, "yes, but we know that LLMs learn functions and algorithms to do tasks, and as you scale up and compress more and more data, you will uncover more meta-algorithms that can do this kind of extrapolation/tasks outside of the training distribution."
Well, two things:
- It remains to be seen when or if this will happen in the current paradigm (no matter how much you scale up).
- It's not clear to me how well things like induction heads continue to work on things that are outside of their training distribution. If they don't adapt well, then it may be the same thing for other algorithms. What this would mean in practice, I'm not sure. I've been looking at relevant papers, but haven't found an answer yet [LW · GW].
This brings me to another point: it also remains to be seen how much it will matter in practice, given that models are trained on so much data and things like online learning are coming. Scaffolding specialized AI models, and new innovations might make such a limitation not big of a deal if there is one.
Also, perhaps most of the important capabilities come from interpolation. Perhaps intelligence is largely just interpolation? You just need to interpolate and push the boundaries of capability one step at a time, iteratively, like a scientist conducting experiments would. You just need to integrate knowledge as you interact with the world.
But what of brilliant insights from our greatest minds? Is it just recursive interpolation+small_external_interactions? Is there something else they are doing to get brilliant insights? Would AGI still ultimately be limited in the same way (even if it can run many of these genius patterns in parallel)?
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-11-16T18:47:49.414Z · LW(p) · GW(p)
Or perhaps as @Nora Belrose [LW · GW] mentioned to me: "Perhaps we should queer the interpolation-extrapolation distinction."
↑ comment by Garrett Baker (D0TheMath) · 2023-11-06T17:20:13.456Z · LW(p) · GW(p)
Some evidence this is not so fundamental, and we should expect a (or many) phase transition(s) to more generalizing in context learning as we increase the log number of tasks.
↑ comment by Oliver Sourbut · 2023-11-07T08:13:25.004Z · LW(p) · GW(p)
My hot take is that this paper's prominence is a consequence of importance hacking (I'm not accusing the authors in particular). Zero or near-zero relevance to LLMs.
Authors get a yellow card for abusing the word 'model' twice in the title alone.
comment by jacquesthibs (jacques-thibodeau) · 2023-07-29T22:43:35.844Z · LW(p) · GW(p)
Given funding is a problem in AI x-risk at the moment, I’d love to see people to start thinking of creative ways to provide additional funding to alignment researchers who are struggling to get funding.
For example, I’m curious if governance orgs would pay for technical alignment expertise as a sort of consultant service.
Also, it might be valuable to have full-time field-builders that are solely focused on getting more high-net-worth individuals to donate to AI x-risk.
comment by jacquesthibs (jacques-thibodeau) · 2023-01-24T21:09:16.838Z · LW(p) · GW(p)
On joking about how "we're all going to die"
Setting aside the question of whether people are overly confident about their claims regarding AI risk, I'd like to talk about how we talk about it amongst ourselves.
We should avoid jokingly saying "we're all going to die" because I think it will corrode your calibration to risk with respect to P(doom) and it will give others the impression that we are all more confident about P(doom) than we really are.
I think saying it jokingly still ends up creeping into your rational estimates on timelines and P(doom). I expect that the more you joke about high P(doom), the more likely you will end up developing an unjustified high P(doom). And I think if you say it enough, you can even convince yourself that you are more confident in your high P(doom) than you really are.
Joking about it in public also potentially diminishes your credibility. They may or may not know if you are joking, but that doesn't matter.
For all the reasons above, I've been trying to make a conscious effort to avoid this kind of talk.
From my understanding, being careful with the internal and external language you use is something that is recommended in therapy. Would be great if someone could point me to examples of this.
comment by jacquesthibs (jacques-thibodeau) · 2023-01-05T21:14:12.396Z · LW(p) · GW(p)
What are some important tasks you've found too cognitively taxing to get in the flow of doing?
One thing that I'd like to consider for Accelerating Alignment [LW · GW] is to build tools that make it easier to get in the habit of cognitively demanding tasks by reducing the cognitive load necessary to do the task. This is part of the reason why I think people are getting such big productivity gains from tools like Copilot.
One way I try to think about it is like getting into the habit of playing guitar. I typically tell people to buy an electric guitar rather than an acoustic guitar because the acoustic is typically much more painful for your fingers. You are already doing a hard task of learning an instrument, try to reduce the barrier to entry by eliminating one of the causes of friction. And while you're at it, don't put your guitar in a case or in a place that's out of your way, make it ridiculously easy to just pick up and play. In this example, it's not cognitively taxing, but it is some form of tax that produces friction.
It is possible that we could have much more people tackling the core of alignment if it was less mentally demanding to get to that point and contribute to a solution. It's possible that some level of friction for some tasks is making it so people are more likely to opt for what is easy (and potentially leads to fake progress on a solution to alignment). One such example might be understanding some difficult math. Another might be communicating your research in a way that is understandable to others.
I think it's worth thinking in this frame when coming up with ways to accelerate alignment research by augmenting researchers.
Replies from: ete↑ comment by plex (ete) · 2023-01-06T00:57:14.705Z · LW(p) · GW(p)
For developing my hail mary alignment approach, the dream would be to be able to load enough of the context of the idea into a LLM that it could babble suggestions (since the whole doc won't fit in the context window, maybe randomizing which parts beyond the intro are included for diversity?), then have it self-critique those suggestions automatically in different threads in bulk and surface the most promising implementations of the idea to me for review. In the perfect case I'd be able to converse with the model about the ideas and have that be not totally useless, and pump good chains of thought back into the fine-tuning set.
comment by jacquesthibs (jacques-thibodeau) · 2022-12-29T16:07:59.803Z · LW(p) · GW(p)
Projects I'd like to work on in 2023.
Wrote up a short (incomplete) bullet point list of the projects I'd like to work on in 2023:
- Accelerating Alignment
- Main time spent (initial ideas, will likely pivot to varying degrees depending on feedback; will start with one):
- Fine-tune GPT-3/GPT-4 on alignment text and connect the API to Loom, VSCode (CoPilot for alignment research) and potentially notetaking apps like Roam Research. (1-3 months, depending on bugs and if we continue to add additional features.)
- Create an audio-to-post pipeline where we can easily help alignment researchers create posts through conversations rather than staring at a blank page. (1-4 months, depending on collaboration with Conjecture and others; and how many features we add.)
- Leaving the door open and experimenting with ChatGPT and/or GPT-4 to use them for things we haven't explored yet. Especially GPT-4, we can guess in advance what it will be capable of, but we'll likely need to experiment a lot to discover how to use it optimally given it might have new capabilities GPT-3 doesn't have. (2 to 6 weeks.)
- Work with Janus, Nicholas Dupuis, and others on building tools for accelerating alignment research using language models (in prep for and integrating GPT-4). These will serve as tools for augmenting the work of alignment researchers. Many of the tool examples are covered in the grant proposal, my recent post [LW · GW], and an upcoming post, and Nicholas' doc on Cyborgism (we've recently spun up a discord to discuss these things with other researchers; send DM for link). This work is highly relevant to OpenAI's main alignment proposal.
- This above work involves:
- Working on setting the foundation for automating alignment and making proposal verification viable. (1 week of active work for a post I'm working on, and then some passive work while I build tools.)
- Studying the epistemology of effective research helps generate research that leads us to solve alignment. For example, promoting flow and genius moments, effective learning (I'm taking a course on this and so far it is significantly better than the "Learning How to Learn" course) and how it can translate to high-quality research [LW(p) · GW(p)], etc. (5 hours per week)
- Studying how to optimally condition generative models for alignment [AF · GW].
- It's very hard to predict how the tool-building will go because I expect to be doing a lot of iteration to land on things that are optimally useful rather than come up with a specific plan and stick to it. My goal here is to implement design thinking and approaches that startups use. This involves taking the survey responses, generating a bunch of ideas, create an MVP, test it out with alignment researchers, and then learn from feedback.
- Main time spent (initial ideas, will likely pivot to varying degrees depending on feedback; will start with one):
- Finish a sequence I'm working on with others. We are currently editing the intro post and refining the first post. We went through 6 weeks of seminars for a set of drafts and we are now working to build upon those. (6 to 8 weeks)
- Other Projects outside of the grant (will dedicate about 1 day per week, but expect to focus more on some of these later next year, depending on how Accelerating Alignment goes. If not, I'll likely find some mentees or more collaborators to work on some of them.)
- Support the Shard Theory team in running experiments using RL and language models. I'll be building off of my MATS colleagues' work. (3 to 5 months for running experiments and writing about them. Would consider spending a month or so on this and then mentoring someone to continue.)
- Applying the Tuned Lens to better understand what transformers are doing. For example, what is being written and read from the residual stream and how certain things like RL lead to non-myopic behaviour. Comparing self-supervised models to RL fine-tuned models. (2 to 4 months by myself, probably less if I collaborate.)
- Building off of Causal Tracing and Causal Scrubbing to develop more useful causal interpretability techniques. In this linked doc, I discuss this in the second main section: "Relevance For Alignment." (3 days to wrap up first post. For exploring, studying and writing about new causal methods, anywhere from 2 months to 4 months.)
- Provide support for governance projects. I've been mentoring someone looking to explore AI Governance for the past few months (they are now applying for an internship at GovAI). They are currently writing up a post on "AI safety" governance in Canada. I'll be providing mentorship on a few posts I've suggested they write. Here's my recent governance post [LW · GW]. (2-3 hours per week)
- Update and wrap up the GEM proposal. Adding new insights to it, including the new Tunes Lens that Nora has been working on. (1 week)
- Applying quantilizers to Large Language Models. This project is still in the discovery phase for a MATS colleague of mine. I'm providing comments at the moment, but it may turn into a full-time project later next year.
- Mentoring through the AI Safety Mentors and Mentees [EA · GW] program. I'm currently mentoring someone who is working on Shard Theory and Infra-Bayesianism relevant work.
↑ comment by jacquesthibs (jacques-thibodeau) · 2023-02-17T06:17:35.761Z · LW(p) · GW(p)
Two other projects I would find interesting to work on:
- Causal Scrubbing to remove specific capabilities from a model. For example, training a language model on The Pile and a code dataset. Then, applying causal scrubbing to try and remove the model's ability to generate code while still achieving the similar loss on The Pile.
- A few people have started extending the work from the Discovering Latent Knowledge in Language Models without Supervision paper. I think this work could potentially evolve into a median-case solution to avoiding x-risk from AI.
↑ comment by chanamessinger (cmessinger) · 2023-05-05T13:12:38.760Z · LW(p) · GW(p)
Curious if you have any updates!
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-05-05T17:26:10.351Z · LW(p) · GW(p)
Working on a new grant proposal right now. Should be sent this weekend. If you’d like to give feedback or have a look, please send me a DM! Otherwise, I can send the grant proposal to whoever wants to have a look once it is done (still debating about posting it on LW).
Outside of that, there has been a lot of progress on the Cyborgism discord (there is a VSCode plugin called Worldspider that connects to the various APIs, and there has been more progress on Loom). Most of my focus has gone towards looking at the big picture and keeping an eye on all the developments. Now, I have a better vision of what is needed to create an actually great alignment assistant and have talked to other alignment researchers about it to get feedback and brainstorm. However, I’m spread way too thin and will request additional funding to get some engineer/builder to start building the ideas out so that I can focus on the bigger picture and my alignment work.
If I can get my funding again (previous funding ended last week) then my main focus will be building out the system I have in my for accelerating alignment work + continue working on the new agenda [LW · GW] I put out with Quintin and others. There’s some other stuff I‘d like to do, but those are lower priority or will depend on timing. It’s been hard to get the funding application done because things are moving so fast and I’m trying not to build things that will be built by default. And I’ve been talking to some people about the possibility of building an org so that this work could go a lot faster.
↑ comment by plex (ete) · 2023-01-01T21:34:45.427Z · LW(p) · GW(p)
Very excited by this agenda, was discussing my hope that someone finetunes LLMs on the alignment archive soon today!
↑ comment by Mati_Roy (MathieuRoy) · 2023-04-09T18:45:45.972Z · LW(p) · GW(p)
Nicholas' doc on Cyborgism
do you have a link?
I'd be interested in being added to the Discord
comment by jacquesthibs (jacques-thibodeau) · 2024-06-15T14:35:27.596Z · LW(p) · GW(p)
OpenAI CEO Sam Altman has privately said the company could become a benefit corporation akin to rivals Anthropic and xAI.
"Sam Altman recently told some shareholders that OAI is considering changing its governance structure to a for-profit business that OAI's nonprofit board doesn't control. [...] could open the door to public offering of OAI; may give Altman an opportunity to take a stake in OAI."
Replies from: Viliam, ozziegooen, ChristianKl↑ comment by Viliam · 2024-06-16T21:59:31.354Z · LW(p) · GW(p)
Perhaps I am too cynical, but it seems to me that Sam Altman will say anything... and change his mind later.
Replies from: ChristianKl↑ comment by ChristianKl · 2024-06-17T08:50:47.014Z · LW(p) · GW(p)
It's still interesting that he calculated, that it is advantageous to say it.
↑ comment by ozziegooen · 2024-06-16T01:19:04.177Z · LW(p) · GW(p)
Quick point - a "benefit corporation" seems almost identical to a "corporation" to me, from what I understand. I think many people assume it's a much bigger deal than it actually is.
My impression is that practically speaking, this just gives the execs more power to do whatever they feel they can sort of justify, without shareholders being able to have the legal claims to stop them. I'm not sure if this is a good thing in the case of OpenAI. (Would we prefer Sam A / the board have more power, or that the shareholders have more power?)
I think B-Corps make it harder for them to get sued for not optimizing for shareholders. Hypothetically, it makes it easier for them to be sued for not optimizing their other goals, but I'm not sure if this ever/frequently actually happens.
↑ comment by ChristianKl · 2024-06-17T09:10:43.319Z · LW(p) · GW(p)
In the case of OpenAI it also means that Sam doesn't hold any stock in OpenAI and thus has different incentives than he would if he would own a decent amount of stock.
↑ comment by ChristianKl · 2024-06-15T15:48:17.299Z · LW(p) · GW(p)
It would seem strange to me if that's legally possible, but maybe it is.
comment by jacquesthibs (jacques-thibodeau) · 2023-09-24T03:34:38.311Z · LW(p) · GW(p)
Jacques' AI Tidbits from the Web
I often find information about AI development on X (f.k.a.Twitter) and sometimes other websites. They usually don't warrant their own post, so I'll use this thread to share. I'll be placing a fairly low filter on what I share.
Replies from: jacques-thibodeau, jacques-thibodeau, jacques-thibodeau, jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-09-24T03:41:59.616Z · LW(p) · GW(p)
There's someone on X (f.k.a.Twitter) called Jimmy Apples (🍎/acc) and he has shared some information in the past that turned out to be true (apparently the GPT-4 release date and that OAI's new model would be named "Gobi"). He recently tweeted, "AGI has been achieved internally." Some people think that the Reddit comment below may be from the same guy (this is just a weak signal, I’m not implying you should consider it true or update on it):
↑ comment by elifland · 2023-09-25T00:43:43.389Z · LW(p) · GW(p)
Where is the evidence that he called OpenAI’s release date and the Gobi name? All I see is a tweet claiming the latter but it seems the original tweet isn’t even up?
Replies from: jacques-thibodeau, jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-09-25T01:05:17.798Z · LW(p) · GW(p)
This is the tweet for Gobi: https://x.com/apples_jimmy/status/1703871137137176820?s=46&t=YyfxSdhuFYbTafD4D1cE9A
I asked someone if it’s fake. Apparently not, you can find it on google archive: https://threadreaderapp.com/thread/1651837957618409472.html
Replies from: person-1↑ comment by Person (person-1) · 2023-09-25T13:15:36.581Z · LW(p) · GW(p)
Predicting the GPT-4 launch date can easily be disproven with the confidence game. It's possible he just created a prediction for every day and deleted the ones that didn't turn out right.
For the Gobi prediction it's tricky. The only evidence is the Threadreader and a random screenshot from a guy who seems clearly related to jim. I am very suspicious of the Threadreader one. On one hand I don't see a way it can be faked, but it's very suspicious that the Gobi prediction is Jimmy's only post that was saved there despite him making an even bigger bombshell "prediction". It's also possible, though unlikely, that the Information's article somehow found his tweet and used it as a source for their article.
What kills Jimmy's credibility for me is his prediction back in January (you can use the Wayback Machine to find it) that OAI had finished training GPT-5, no not a GPT-5 level system, the ACTUAL GPT-5 in October 2022 and that it was 125T parameters.
Also goes without saying, pruning his entire account is suspicious too.
↑ comment by jacquesthibs (jacques-thibodeau) · 2023-09-25T00:49:21.878Z · LW(p) · GW(p)
I’ll try to find them, but this was what people were saying. They also said he deleted past tweets so that evidence may forever be gone.
I remember one tweet where Jimmy said something like, “Gobi? That’s old news, I said that months ago, you need to move on to the new thing.” And I think he linked the tweet though I’m very unsure atm. Need to look it up, but you can use the above for a search.
↑ comment by jacquesthibs (jacques-thibodeau) · 2023-10-24T02:16:59.349Z · LW(p) · GW(p)
New tweet by Jimmy Apples. This time, he's insinuating that OpenAI is funding a stealth startup working on BCI.
If this is true, then it makes sense they would prefer not to do it internally to avoid people knowing in advance based on their hires. A stealth startup would keep things more secret.

Might be of interest, @lisathiergart [LW · GW] and @Allison Duettmann [LW · GW].
↑ comment by jacquesthibs (jacques-thibodeau) · 2023-09-26T01:23:14.658Z · LW(p) · GW(p)
Not sure exactly what this means, but Jimmy Apples has now tweeted the following:

My gut is telling me that he apple-bossed too close to the sun (released info he shouldn't have, and now that he's concerned about his job or some insider's job), and it's time for him to stop sharing stuff (the apple being bitten symbolizing that he is done sharing info).
This is because the information in my shortform was widely shared on X and beyond.
He also deleted all of his tweets (except for the retweets).
Replies from: person-1↑ comment by Person (person-1) · 2023-09-26T01:53:47.095Z · LW(p) · GW(p)
Or that he was genuinely just making things up and tricking us for fun, and a cryptic exit is a perfect way to leave the scene. I really think people are looking way too deep into him and ignoring the more outlandish predictions he's made (125T GPT-4 and 5 in October 2022), along with the fact there is never actual evidence of his accurate ones, only 2nd hand very specific and selective archives.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-09-26T02:01:30.012Z · LW(p) · GW(p)
He did say some true things before. I think it's possible all of the new stuff is untrue, but we're getting more reasons to believe it's not entirely false. The best liars sprinkle in truth.
I think, as a security measure, it's also possible that even people within OpenAI know all the big details of what's going on (this is apparently the case for Anthropic). This could mean, for OpenAI employees, that some details are known while others are not. Employees themselves could be forced to speculate on some things.
Either way, I'm not obsessing too much over this. Just sharing what I'm seeing.
↑ comment by jacquesthibs (jacques-thibodeau) · 2023-11-15T17:34:20.514Z · LW(p) · GW(p)
More predictions/insights from Jimmy and crew. He's implying that people (like I have also been saying) that some people are far too focused on scale over training data and architectural improvements. IMO, the bitter lesson is a thing, but I think we've over-updated on it.


Relatedly, someone shared a new 13B model that apparently is better and comparable to GPT-4 in logical reasoning (based on benchmarks, which I don't usually trust too much). Note that the model is a solver-augmented LM.

Here's some context regarding the paper:

↑ comment by jacquesthibs (jacques-thibodeau) · 2023-09-24T20:23:37.888Z · LW(p) · GW(p)
Sam Altman at a YC founder reunion: https://x.com/smahsramo/status/1706006820467396699?s=46&t=YyfxSdhuFYbTafD4D1cE9A
“Most interesting part of @sama talk: GPT5 and GPT6 are “in the bag” but that’s likely NOT AGI (eg something that can solve quantum gravity) without some breakthroughs in reasoning. Strong agree.”
Replies from: Mitchell_Porter↑ comment by Mitchell_Porter · 2023-09-24T21:37:20.415Z · LW(p) · GW(p)
AGI is "something that can solve quantum gravity"?
That's not just a criterion for general intelligence, that's a criterion for genius-level intelligence. And since general intelligence in a computer has advantages of speed, copyability, little need for down time, that are not possessed by general intelligence, AI will be capable of contributing to its training, re-design, agentization, etc, long before "genius level" is reached.
This underlines something I've been saying for a while, which is that superintelligence, defined as AI that definitively surpasses human understanding and human control, could come into being at any time (from large models that are not publicly available but which are being developed privately by Big AI companies). Meanwhile, Eric Schmidt (former Google CEO) says about five years until AI is actively improving itself, and that seems generous.
So I'll say: timeline to superintelligence is 0-5 years.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-09-25T05:41:35.773Z · LW(p) · GW(p)
capable of contributing to its training, re-design, agentization, etc, long before "genius level" is reached
In some models of the world this is seen as unlikely to ever happen, these things are expected to coincide, which collapses the two definitions of AGI. I think the disparity between sample efficiency of in-context learning and that of pre-training is one illustration for how these capabilities might come apart, in the direction that's opposite to what you point to: even genius in-context learning doesn't necessarily enable the staying power of agency, if this transient understanding can't be stockpiled and the achieved level of genius is insufficient to resolve the issue while remaining within its limitations (being unable to learn a lot of novel things in the course of a project).
↑ comment by jacquesthibs (jacques-thibodeau) · 2023-09-24T14:41:27.664Z · LW(p) · GW(p)
Someone in the open source community tweeted: "We're about to change the AI game. I'm dead serious."
My guess is that he is implying that they will be releasing open source mixture of experts models in a few months from now. They are currently running them on CPUs.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-09-24T19:34:34.882Z · LW(p) · GW(p)
Lots of cryptic tweet from the open source LLM guys: https://x.com/abacaj/status/1705781881004847267?s=46&t=YyfxSdhuFYbTafD4D1cE9A
“If you thought current open source LLMs are impressive… just remember they haven’t peaked yet”
To be honest, my feeling is that they are overhyping how big of deal this will be. Their ego and self-importance tend to be on full display.
Replies from: person-1↑ comment by Person (person-1) · 2023-09-25T04:45:04.021Z · LW(p) · GW(p)
Occasionally reading what OSS AI gurus say, they definitely overhype their stuff constantly. The ones who make big claims and try to hype people up are often venture entrepreneur guys rather than actual ML engineers.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-09-25T05:08:08.879Z · LW(p) · GW(p)
The open source folks I mostly keep an eye on are the ones who do actually code and train their own models. Some are entrepreneurs, but they know a decent amount. Not top engineers, but they seem to be able to curate datasets and train custom models.
There’s some wannabe script kiddies too, but once you lurk enough, you become aware of who are actually decent engineers (you’ll find some at Vector Institute and Jeremy Howard is pro- open source, for example). I wouldn’t totally discount them having an impact, even though some of them will overhype.
comment by jacquesthibs (jacques-thibodeau) · 2023-03-01T21:49:40.272Z · LW(p) · GW(p)
I think it would be great if alignment researchers read more papers
But really, you don't even need to read the entire paper. Here's a reminder to consciously force yourself to at least read the abstract. Sometimes I catch myself running away from reading an abstract of a paper even though it is very little text. Over time I've just been forcing myself to at least read the abstract. A lot of times you can get most of the update you need just by reading the abstract. Try your best to make it automatic to do the same.
To read more papers, consider using Semantic Scholar and arXiv Explorer. Semantic Scholar can be quite nice because because once you save papers in folders, it will automatically recommend you similar papers every day or week. You can just go over the list of abstract of papers in your Research Dashboard every week to keep up-to-date.
comment by jacquesthibs (jacques-thibodeau) · 2023-01-24T22:18:35.401Z · LW(p) · GW(p)
On hyper-obession with one goal in mind
I’ve always been interested in people just becoming hyper-obsessed in pursuing a goal. One easy example is with respect to athletes. Someone like Kobe Bryant was just obsessed with becoming the best he could be. I’m interested in learning what we can from the experiences of the hyper-obsessed and what we can apply to our work in EA / Alignment.
I bought a few books on the topic, I should try to find the time to read them. I’ll try to store some lessons in this shortform, but here’s a quote from Mr. Beast’s Joe Rogan interview:
Most of my growth came from […] basically what I did was I found these other 4 lunatics and we basically talked every day for a thousand days in a row. We did nothing but just hyper-study [Youtube] and how to go viral. We’d have skype calls and some days I’d hop on the call at 7 am and hop off the call at 10 pm, and then do it again the next day.
We didn’t do anything, we had no life. We all hit a million subscribers like within a month. It’s crazy, if you envision a world where you are trying to be great at something and it’s you where you are fucking up, well you in two years might learn from 20 mistakes. But if you have others where you can learn from their mistakes, you’ve learned like 5x the amount of stuff. It helps you grow exponentially way quicker.
We’re talking about every day, all day. We had no friends outside of the group, we had no life. Nevermind 10,000 hours, we did like 50,000 hours.
As an independent researcher who is not currently at one of the hubs, I think it’s important for me to consider this point a lot. I’m hoping to hop on discord voice calls and see if I can make it a habit to make progress with other people who want to solve alignment.
I’m not saying I should aim for absolutely no life, but I’m hoping to learn what I can that‘s practically applicable to what I do.
comment by jacquesthibs (jacques-thibodeau) · 2024-10-01T19:25:44.251Z · LW(p) · GW(p)
I'm exploring the possibility of building an alignment research organization focused on augmenting alignment researchers and progressively automating alignment research (yes, I have thought deeply about differential progress and other concerns). I intend to seek funding in the next few months, and I'd like to chat with people interested in this kind of work, especially great research engineers and full-stack engineers who might want to cofound such an organization. If you or anyone you know might want to chat, let me know! Send me a DM, and I can send you some initial details about the organization's vision.
Here are some things I'm looking for in potential co-founders:
Need
- Strong software engineering skills
Nice-to-have
- Experience in designing LLM agent pipelines with tool-use
- Experience in full-stack development
- Experience in scalable alignment research approaches (automated interpretability/evals/red-teaming)
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-10-04T20:42:15.256Z · LW(p) · GW(p)
I'm intrigued. Let me know if you'd like to chat
comment by jacquesthibs (jacques-thibodeau) · 2024-06-13T15:33:58.687Z · LW(p) · GW(p)
I had this thought yesterday: "If someone believes in the 'AGI lab nationalization by default' story, then what would it look like to build an organization or startup in preparation for this scenario?"
For example, you try to develop projects that would work exceptionally well in a 'nationalization by default' world while not getting as much payoff if you are in a non-nationalization world. The goal here is to do the normal startup thing: risky bets with a potentially huge upside.
I don't necessarily support nationalization and am still trying to think through the upsides/downsides, but I was wondering if there are worlds where some safety projects become much more viable in such a world, the kind of things we used to brush off because we assumed we weren't in such a world.
Some vague directions to perhaps consider: AI security, Control agenda-type stuff, fully centralized monitoring to detect early signs of model drift, inaccessible compute unless you are a government-verified user, etc. By building such tech or proposals, you may be much more likely to end up with a seat at the big boy table, whereas you wouldn't have in a non-nationalization world. I could be wrong about the specific examples above, but just want to provide some quick examples.
Replies from: Viliam, jacques-thibodeau, davekasten, gw↑ comment by Viliam · 2024-06-13T21:05:46.146Z · LW(p) · GW(p)
If I expected that an AI above a certain line will be nationalized, I would try to get just below than line and stay there for as long as possible, to maximize my profits. Alternatively, I may choose to cross the line at the moment my competitors get close to it, if I want to be remembered by the history as the one who reached it first.
If I expected that an AI above a certain line will be nationalized, but I believed that the government will give a lot of money in return (for example, to convince other entrepreneurs that the country is not turning into a communist dystopia), I might decide to try to get that money as soon as possible (less work, guaranteed profit, a place in history), so I would actually exaggerate how dangerous my AI is, to make the government take it away sooner.
But if my goal is to avoid nationalization...
One option is to make my work distributed across countries, so whenever one of them starts talking about nationalizing it, I will make it clear that they can only take a small part of it, and I will simply continue developing it in the remaining countries. I would move the key members of my company to countries with the lowest probability of nationalization. Actually, they could live in a country where I have no servers, and they would connect to them remotely. So that when the government takes the servers, it cannot compel the people to explain how the entire thing works, or prevent them from remotely destroying the part that got nationalized. Also, every part would have a backup in another country.
Another option is to make the AI pretend that it is less smart than it is, to officially stay below the line. It would mean I cannot directly sell its abilities to customers, but maybe I could use it myself, e.g. to let it manage my finances, or I could use it in a plausibly deniable way, e.g. you can hire my smaller company that hires 100 experts who also use my AI, and everything they do is officially attributed to the genius of the human experts.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2024-06-13T22:36:02.776Z · LW(p) · GW(p)
We had a similar thought:


But yeah, my initial comment was about how to take advantage of nationalization if it does happen in the way Leopold described/implied.
↑ comment by jacquesthibs (jacques-thibodeau) · 2024-06-13T16:07:45.909Z · LW(p) · GW(p)
If anyone would like to discuss this privately, please message me. I'm considering whether to build a startup that tackles the kinds of things I describe above (e.g., monitoring), so I would love to get feedback.
↑ comment by davekasten · 2024-06-13T20:19:42.599Z · LW(p) · GW(p)
If you think nationalization is near and the default, you shouldn't try to build projects and hope they get scooped into the nationalized thing. You should try to directly influence the policy apparatus through writing, speaking on podcasts, and getting to know officials in the agencies most likely to be in charge of that.
(Note: not a huge fan of nationalization myself due to red-queen's-race concerns)
↑ comment by jacquesthibs (jacques-thibodeau) · 2024-06-13T20:36:16.406Z · LW(p) · GW(p)
You can do the writing, but if you have a useful product and connect with those who are within the agencies, you are in a position where you have built a team and infrastructure for several years with the purpose of getting pulled into the nationalization project. You likely get most of the value by just keeping close ties with others within government while also have built a ready-to-use solution that can prevent the government from rushing out a worse version of what you’ve built.
I think it’s important to see AI Safety as a collective effort rather than one person’s decision (of working inside or out of government).
Replies from: davekasten↑ comment by davekasten · 2024-06-14T00:54:40.995Z · LW(p) · GW(p)
I think I am very doubtful of the ability of outsiders to correctly predict -- especially outsiders new to government contracting -- what the government might pull in. I'd love to be wrong, though! Someone should try it, and I think I was probably too definitive in my comment above.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2024-06-14T09:51:55.941Z · LW(p) · GW(p)
Yes, but this is similar to usual startups, it’s a calculated bet you are making. So you expect some of the people to try this will fail, but investors hope one of them will be a unicorn.
↑ comment by gw · 2024-06-13T16:51:36.706Z · LW(p) · GW(p)
This might look like building influence / a career in the federal orgs that would be involved in nationalization, rather than a startup. Seems like positioning yourself to be in charge of nationalized projects would be the highest impact?
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2024-06-13T17:03:47.996Z · LW(p) · GW(p)
I agree that this would be impactful! I'm mostly thinking about a more holistic approach that assumes you'd have reasonable to 'the right people' in those government positions. Similar to the current status quo where you have governance people and technical people filling in the different gaps.
comment by jacquesthibs (jacques-thibodeau) · 2024-05-10T11:57:27.376Z · LW(p) · GW(p)
Anybody know how Fathom Radiant (https://fathomradiant.co/) is doing?
They’ve been working on photonics compute for a long time so I’m curious if people have any knowledge on the timelines they expect it to have practical effects on compute.
Also, Sam Altman and Scott Gray at OpenAI are both investors in Fathom. Not sure when they invested.
I’m guessing it’s still a long-term bet at this point.
OpenAI also hired someone who worked at PsiQuantum recently. My guess is that they are hedging their bets on the compute end and generally looking for opportunities on that side of things. Here’s his bio:
Ben Bartlett I'm currently a quantum computer architect at PsiQuantum working to design a scalable and fault-tolerant photonic quantum computer. I have a PhD in applied physics from Stanford University, where I worked on programmable photonics for quantum information processing and ultra high-speed machine learning. Most of my research sits at the intersection of nanophotonics, quantum physics, and machine learning, and basically consists of me designing little race tracks for photons that trick them into doing useful computations.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2024-05-10T19:58:45.100Z · LW(p) · GW(p)
I'm working on publishing a post on this and energy bottlenecks. If anyone is interested in doing a quick skim for feedback, I hope to publish it in under two hours.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2024-05-12T15:20:49.628Z · LW(p) · GW(p)
I took this post down, given that some people have been downvoting it heavily.
Writing my thoughts here as a retrospective:
I think one reason it got downvoted is that I used Claude as part of the writing process and it was too disjointed/obvious (because I wanted to rush the post out), but I didn't think it was that bad and I did try to point out that it was speculative in the parts that mattered. One comment specifically pointed out that it felt like a lot was written by an LLM, but I didn't think I relied on Claude that much and I rewrote the parts that included LLM writing. I also don't feel as strongly about using this as a reason to dislike a piece of writing, though I understand the current issue of LLM slop.
However, I wonder if some people downvoted it because they see it as infohazardous. My goal was to try to determine if photonic computing would become a big factor at some point (which might be relevant from a forecasting and governance perspective) and put out something quick for discussion rather than spending much longer researching and re-writing. I agreed with what I shared. But I may need to adjust my expectations as to what people prefer as things worth sharing on LessWrong.
comment by jacquesthibs (jacques-thibodeau) · 2023-07-10T20:49:36.299Z · LW(p) · GW(p)
I think people might have the implicit idea that LLM companies will continue to give API access as the models become more powerful, but I was talking to someone earlier this week that made me remember that this is not necessarily the case. If you gain powerful enough models, you may just keep it to yourself and instead spin AI companies with AI employees to make a ton of cash instead of just charging for tokens.
For this reason, even if outside people build the proper brain-like AGI setup with additional components to squeeze out capabilities from LLMs, they may be limited by:
1. open-source models
2. the API of the weaker models from the top companies
3. the best API of the companies that are lagging behind
comment by jacquesthibs (jacques-thibodeau) · 2023-03-01T22:02:35.415Z · LW(p) · GW(p)
A frame for thinking about takeoff
One error people can make when thinking about takeoff speeds is assuming that because we are in a world with some gradual takeoff, it now means we are in a "slow takeoff" world. I think this can lead us to make some mistakes in our strategy. I usually prefer thinking in the following frame: “is there any point in the future where we’ll have a step function that prevents us from doing slow takeoff-like interventions for preventing x-risk?”
In other words, we should be careful to assume that some "slow takeoff" doesn't have an abrupt change after a couple of years. You might get some gradual takeoff where slow takeoff interventions work and then...BAM...orders of magnitude of more progress. Let's be careful not to abandon fast takeoff-like interventions as soon as we think we are in a slow-takeoff world.
comment by jacquesthibs (jacques-thibodeau) · 2025-04-03T21:52:32.616Z · LW(p) · GW(p)
Coordinal Research: Accelerating the research of safely deploying AI systems.
We just put out a Manifund proposal to take short timelines and automating AI safety seriously. I want to make a more detailed post later, but here it is: https://manifund.org/projects/coordinal-research-accelerating-the-research-of-safely-deploying-ai-systems
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2025-04-08T16:03:06.658Z · LW(p) · GW(p)
We got our first 10k! Woo!
comment by jacquesthibs (jacques-thibodeau) · 2024-12-06T20:45:53.422Z · LW(p) · GW(p)
We still don't know if this will be guaranteed to happen, but it seems that OpenAI is considering removing its "regain full control of Microsoft shares once AGI is reached" clause. It seems they want to be able to keep their partnership with Microsoft (and just go full for-profit (?)).
Here's the Financial Times article:
OpenAI seeks to unlock investment by ditching ‘AGI’ clause with Microsoft
OpenAI is in discussions to ditch a provision that shuts Microsoft out of its most advanced models when the start-up achieves “artificial general intelligence”, as it seeks to unlock billions of dollars of future investment.
Under current terms, when OpenAI creates AGI — defined as a “highly autonomous system that outperforms humans at most economically valuable work” — Microsoft’s access to such a technology would be void. The OpenAI board would determine when AGI is achieved.
The start-up is considering removing the stipulation from its corporate structure, enabling the Big Tech group to continue investing in and accessing all OpenAI technology after AGI is achieved, according to multiple people with knowledge of the discussions. A final decision has not been made and options are being discussed by the board, they added.
The clause was included to protect the potentially powerful technology from being misused for commercial purposes, giving ownership of the technology to its non-profit board. According to OpenAI’s website: “AGI is explicitly carved out of all commercial and IP licensing agreements.”
But the provision potentially limits the value of its partnership for Microsoft, which has pumped more than $13bn into OpenAI, and could disincentivise the Big Tech group from further investment.
More funding will be needed given the eye-watering costs involved in developing advanced AI models in a race against deep-pocketed rivals such as Google and Amazon.
The San Francisco-based group led by Sam Altman, which was recently valued at $150bn, is currently restructuring to become a public benefit corporation. That move represents a departure from its origins as a not-for-profit research lab.
As part of the changes, OpenAI is discussing new terms with investors, including its largest shareholder Microsoft, according to multiple people familiar with the conversations.
“When we started, we had no idea we were going to be a product company or that the capital we needed would turn out to be so huge,” Altman told a New York Times conference on Wednesday. “If we knew those things, we would have picked a different structure.”
“We’ve also said that our intention is to treat AGI as a mile marker along the way. We’ve left ourselves some flexibility because we don’t know what will happen,” added Altman, who could receive a direct equity stake in OpenAI for the first time as part of the restructure.
Increasingly, people at OpenAI have moved away from defining AGI as a single point, instead emphasising it is a continuous process and will be defined by wider society.
OpenAI began raising outside capital in 2019, receiving a $1bn investment from Microsoft that year. At the time, the company said it intended “to license some of our pre-AGI technologies” to Microsoft to cover the costs of developing cutting-edge AI.
OpenAI has advised backers to consider their investments “in the spirit of a donation, with the understanding that it may be difficult to know what role money will play in a post-AGI world”.
But its steady move to becoming a for-profit entity has received strong criticism from rivals, including Elon Musk, an early backer and co-founder of OpenAI.
The billionaire Tesla chief, who has since founded a rival start-up xAI, recently filed a lawsuit against OpenAI and Microsoft, accusing Altman of “deceit of Shakespearean proportions” and seeking to void its commercial partnership with Microsoft.
As part of the proposed restructuring, the ChatGPT-maker will also retain an independent not-for-profit entity, which would have a stake in the new public benefit corporation and potentially a trust, according to people familiar with the discussions. The not-for-profit would have access to research and technology but solely focus on pursuing OpenAI’s mission of benefiting humanity.
OpenAI declined to comment on the specifics of negotiations around the restructuring but Bret Taylor, chair of OpenAI’s board, said the board of directors of the non-profit “is focused on fulfilling our fiduciary obligation by ensuring that the company is well-positioned to continue advancing its mission of ensuring AGI benefits all of humanity”.
He added: “While our work remains ongoing as we continue to consult independent financial and legal advisers, any potential restructuring would ensure the non-profit continues to exist and thrive, and receives full value for its current stake in the OpenAI for-profit with an enhanced ability to pursue its mission.”
Microsoft declined to comment.
comment by jacquesthibs (jacques-thibodeau) · 2024-10-17T19:09:40.611Z · LW(p) · GW(p)
Imagine there was an AI-suggestion tool that could predict reasons why you agree/disagree-voted on a comment, and you just had to click one of the generated answers to provide a bit of clarity at a low cost.
comment by jacquesthibs (jacques-thibodeau) · 2024-08-13T16:29:04.851Z · LW(p) · GW(p)
Easy LessWrong post to LLM chat pipeline (browser side-panel)
I started using Sider as @JaimeRV [LW · GW] recommended here [LW(p) · GW(p)]. Posting this as a top-level shortform since I think other LessWrong users should be aware of it.
Website with app and subscription option. Chrome extension here.
You can either pay for the monthly service and click the "summarize" feature on a post and get the side chat window started or put your OpenAI API / ChatGPT Pro account in the settings and just cmd+a the post (which automatically loads the content in the chat so you can immediately ask a question; "explain the key points of the post", "help me really understand what deep deceptiveness means").
Afaict, it only works with Sonnet-3.5 through the paid subscription.
Replies from: lahwran, Ruby↑ comment by the gears to ascension (lahwran) · 2024-08-13T17:16:55.603Z · LW(p) · GW(p)
I have a user script that lets me copy the post into the Claude ui. No need to pay another service.
Replies from: Ruby↑ comment by Ruby · 2024-08-13T18:08:43.992Z · LW(p) · GW(p)
I'm curious how much you're using this and if it's turning out to be useful on LessWrong. Interested because it's something we've been thinking about integrating LLM stuff like this into LW itself.
Replies from: jaime-raldua-veuthey, jacques-thibodeau↑ comment by JaimeRV (jaime-raldua-veuthey) · 2024-08-14T10:22:17.192Z · LW(p) · GW(p)
I have been using sider for a few weeks and found it pretty helpful:
Setup:
- use gpt4o-mini which is basically free and faster than doing anything in Claude or ChatGPT
- mostly for papers and LW/EAF articles
- I have a shortcut to add "https://r.jina.ai/" to the url before to convert to markdown and then I just ctrl+A the entire page and chat
- For privacy reasons I have only allowed the extension in https://r.jina.ai/* and https://www.youtube.com/*
- I use similar prompts than Jacques. Some additional ones: -- Justify your previous answers citing the from original text -- Challenge my knowledge (here I have a longer promt where it asks me to du stuff like draw a mindmap, answer questions,...)
- I also have it with (external) whisper cause often I think better outloud
Pros:
- Fast
- Basically free
- Way easier to digest and interact with dry papers/articles
- Customazible prompts for the conversation which make workflow faster cause you only have to click
- For youtube as a first filter
Cons:
- gpt40-mini (at least) hallucinates a bunch so you often have to ask to justify the answers
- (as with all the chatbots) you shall take the responses with a grain of salt, be very specific with your questions and reread the original relevant sections to double check.
Other:
- IMO if you end up integrating something like this in LW I think it would be net positive. Specially if you can link it to @stampy or similar to ask for clarification questions about concepts, ...
↑ comment by jacquesthibs (jacques-thibodeau) · 2024-08-14T14:42:34.750Z · LW(p) · GW(p)
- IMO if you end up integrating something like this in LW I think it would be net positive. Specially if you can link it to @stampy or similar to ask for clarification questions about concepts, ...
I was thinking of linking it to an Alignment Research Assistant I've been working on, too.
↑ comment by jacquesthibs (jacques-thibodeau) · 2024-08-13T19:31:42.681Z · LW(p) · GW(p)
I just started using this extension, but basically, every time I'm about to read a long post, I feed it and all the comments to Claude chat. The question-flow is often:
- What are the key points of the post?
- (Sometimes) Explain x in more detail in relation to y or some specific clarification questions.
- What are the key criticisms of this post based on the comments?
- How does the author respond to those criticisms?
- (Sometimes) Follow-up questions about the post.
comment by jacquesthibs (jacques-thibodeau) · 2024-06-11T18:22:07.083Z · LW(p) · GW(p)
I like this feature on the EA Forum so sharing here to communicate interest in having it added to LessWrong as well:
The EA Forum [EA · GW] has an audio player interface added to the bottom of the page when you listen to a post. In addition, there are play buttons on the left side of every header to make it quick to continue playing from that section of the post.
Replies from: habryka4, elityre↑ comment by habryka (habryka4) · 2024-06-11T18:31:38.734Z · LW(p) · GW(p)
Yeah, we are very likely to port this over. We've just been busy with LessOnline and Manifest and so haven't gotten around to it.
Replies from: Seth Herd↑ comment by Eli Tyre (elityre) · 2024-06-19T06:12:04.855Z · LW(p) · GW(p)
You can get browser extensions that does this for all webpages. I use speechify.
comment by jacquesthibs (jacques-thibodeau) · 2023-11-24T22:26:00.801Z · LW(p) · GW(p)
Clarification on The Bitter Lesson and Data Efficiency
I thought this exchange provided some much-needed clarification on The Bitter Lesson that I think many people don't realize, so I figured I'd share it here:
Lecun responds:
Then, Richard Sutton agrees with Yann. Someone asks him:
↑ comment by TsviBT · 2024-06-11T14:51:22.678Z · LW(p) · GW(p)
It's clear from Sutton's original article. https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce#The_bitter_lesson_and_the_success_of_scaling [LW · GW]
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2024-06-11T15:03:43.781Z · LW(p) · GW(p)
Yes, but despite the Bitter Lesson being quite short, many people have not read the original text and are just taking the 'scale is all you need' telephone game discussion of it.
comment by jacquesthibs (jacques-thibodeau) · 2023-11-24T12:12:36.526Z · LW(p) · GW(p)
There are those who have motivated reasoning and don’t know it.
Those who have motivated reasoning, know it, and don’t care.
Finally, those who have motivated reasoning, know it, but try to mask it by including tame (but not significant) takes the other side would approve of.
comment by jacquesthibs (jacques-thibodeau) · 2023-11-07T00:07:25.192Z · LW(p) · GW(p)
It seems that @Scott Alexander [LW · GW] believes that there's a 50%+ chance we all die in the next 100 years if we don't get AGI (EDIT: how he places his probability mass on existential risk vs catastrophe/social collapse is now unclear to me). This seems like a wild claim to me, but here's what he said about it in his AI Pause debate post:
Second, if we never get AI, I expect the future to be short and grim. Most likely we kill ourselves with synthetic biology. If not, some combination of technological and economic stagnation, rising totalitarianism + illiberalism + mobocracy, fertility collapse and dysgenics will impoverish the world and accelerate its decaying institutional quality. I don’t spend much time worrying about any of these, because I think they’ll take a few generations to reach crisis level, and I expect technology to flip the gameboard well before then. But if we ban all gameboard-flipping technologies (the only other one I know is genetic enhancement, which is even more bannable), then we do end up with bioweapon catastrophe or social collapse. I’ve said before I think there’s a ~20% chance of AI destroying the world. But if we don’t get AI, I think there’s a 50%+ chance in the next 100 years we end up dead or careening towards Venezuela. That doesn’t mean I have to support AI accelerationism because 20% is smaller than 50%. Short, carefully-tailored pauses could improve the chance of AI going well by a lot, without increasing the risk of social collapse too much. But it’s something on my mind.
I'm curious to know if anyone here agrees or disagrees. What arguments convince you to be on either side? I can see some probability of existential risk, but 50%+? That seems way higher than I would expect.
Replies from: tslarm, Vladimir_Nesov, habryka4↑ comment by tslarm · 2023-11-07T03:57:47.478Z · LW(p) · GW(p)
a 50%+ chance we all die in the next 100 years if we don't get AGI
I don't think that's what he claimed. He said (emphasis added):
if we don’t get AI, I think there’s a 50%+ chance in the next 100 years we end up dead or careening towards Venezuela
Which fits with his earlier sentence about various factors that will "impoverish the world and accelerate its decaying institutional quality".
(On the other hand, he did say "I expect the future to be short and grim", not short or grim. So I'm not sure exactly what he was predicting. Perhaps decline -> complete vulnerability to whatever existential risk comes along next.)
↑ comment by Vladimir_Nesov · 2023-11-07T15:32:25.689Z · LW(p) · GW(p)
It seems that @Scott Alexander believes that there's a 50%+ chance we all die
It's "we end up dead or careening towards Venezuela" in the original, which is not the same thing. Venezuela has survivors. Existence of survivors is the crucial distinction between extinction and global catastrophe. AGI would be a much more reasonable issue if it was merely risking global catastrophe.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-11-07T18:52:47.925Z · LW(p) · GW(p)
In the first couple sentences he says “if we never get AI, I expect the future to be short and grim. Most likely we kill ourselves with synthetic biology.” So it seems he’s putting most of his probability mass on everyone dying.
But then after he says: “But if we ban all gameboard-flipping technologies, then we do end up with bioweapon catastrophe or social collapse.”
I think people who responding are seemingly only reading the Venezuela part and assuming most of the probability mass he’s putting in the 50% is just a ‘catastrophe’ like Venezuela. But then why would he say he expects the future to be short conditional on no AI?
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-11-07T19:36:56.427Z · LW(p) · GW(p)
It's a bit ambiguous, but "bioweapon catastrophe or social collapse" is not literal extinction, and I'm reading "I expect the future to be short and grim" as plausibly referring to destruction of uninterrupted global civilization, which might well recover after 3000 years. The text doesn't seem to rule out this interpretation.
Sufficiently serious synthetic biology catastrophes prevent more serious further catastrophes, including by destroying civilization, and it's not very likely that this involves literal extinction. As a casual reader of his blogs over the years, I'm not aware of Scott's statements to the effect that his position is different from this, either clearly stated or in aggregate from many vague claims.
↑ comment by habryka (habryka4) · 2023-11-07T03:10:02.757Z · LW(p) · GW(p)
It seems like a really surprising take to me, and I disagree. None of the things listed seem like candidates for actual extinction. Fertility collapse seems approximately impossible to cause extinction given the extremely strong selection effects against it. I don't see how totalitarianism or illiberalism or mobocracy leads to extinction either.
Maybe the story is that all of these will very likely happen in concert and half human progress very reliably. I would find this quite surprising.
Replies from: Viliam↑ comment by Viliam · 2023-11-07T09:08:54.367Z · LW(p) · GW(p)
I don't see how totalitarianism or illiberalism or mobocracy leads to extinction either.
That's not what Scott says, as I understand it. The 50%+ chance is for "death or Venezuela".
Most likely we kill ourselves (...) If not, some combination of (...) will impoverish the world and accelerate its decaying institutional quality.
I am just guessing here, but I think the threat model here is authoritarian regimes become more difficult to overthrow in a technologically advanced society. The most powerful technology will all be controlled by the government (the rebels cannot build their nukes while hiding in a forest). Technology makes mass surveillance much easier (heck, just make it illegal to go anywhere without your smartphone, and you can already track literally everyone today). Something like GPT-4 could already censor social networks and report suspicious behavior (if the government controls their equivalent of Facebook, and other social networks are illegal, you have control over most of online communication). An army of drones will be able to suppress any uprising. Shortly, once an authoritarian regime has a sufficiently good technology, it becomes almost impossible to overthrow. On the other hand, democracies occasionally evolve to authoritarianism, so the long-term trend seems one way.
And the next assumption, I guess, is that authoritarianism leads to stagnation or dystopia.
comment by jacquesthibs (jacques-thibodeau) · 2023-10-26T00:25:46.290Z · LW(p) · GW(p)
In light of recent re-focus on AI governance to reduce AI risk, I wanted to share a post I wrote about a year ago that suggests an approach using strategic foresight to reduce risks: https://www.lesswrong.com/posts/GbXAeq6smRzmYRSQg/foresight-for-agi-safety-strategy-mitigating-risks-and [LW · GW].
Governments all over the world use frameworks like these. The purpose in this case would be to have documents ready ahead of time in case a window of opportunity for regulation opens up. It’s impossible to predict how things will evolve so instead you focus on what’s plausible and have a robust plan for whatever happens. This is very related to risk management.
comment by jacquesthibs (jacques-thibodeau) · 2023-09-29T22:48:14.396Z · LW(p) · GW(p)
I'm working on an ultimate doc on productivity I plan to share and make it easy, specifically for alignment researchers.
Let me know if you have any comments or suggestions as I work on it.
Roam Research link for easier time reading.
Google Docs link in case you want to leave comments there.
Replies from: adamzerner, jacques-thibodeau↑ comment by Adam Zerner (adamzerner) · 2023-09-29T23:05:40.489Z · LW(p) · GW(p)
I did a deep dive [LW · GW] a while ago, if that's helpful to you.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-09-29T23:49:44.299Z · LW(p) · GW(p)
Ah wonderful, it already has a lot of the things I planned to add.
This will make it easier to wrap it up by adding the relevant stuff.
Ideally, I want to dedicate some effort to make it extremely easy to digest and start implementing. I’m trying to think of the best way to do that for others (e.g. workshop in the ai safety co-working space to make it a group activity, compress the material as much as possible but allow them to dive deeper into whatever they want, etc).
↑ comment by jacquesthibs (jacques-thibodeau) · 2023-09-30T00:37:04.934Z · LW(p) · GW(p)
My bad, Roam didn't sync, so the page wasn't loading. Fixed now.
comment by jacquesthibs (jacques-thibodeau) · 2023-04-24T20:36:22.784Z · LW(p) · GW(p)
I’m collaborating on a new research agenda. Here’s a potential insight about future capability improvements:
There has been some insider discussion (and Sam Altman has said) that scaling has started running into some difficulties. Specifically, GPT-4 has gained a wider breath of knowledge, but has not significantly improved in any one domain. This might mean that future AI systems may gain their capabilities from places other than scaling because of the diminishing returns from scaling. This could mean that to become “superintelligent”, the AI needs to run experiments and learn from the outcome of those experiments to gain more superintelligent capabilities.
So you can imagine the case where capabilities come from some form of active/continual/online learning, but that was only possible once models were scaled up enough to gain capabilities in that way. And so that as LLMs become more capable, they will essentially become capable of running their own experiments to gain alphafold-like capabilities across many domains.
Of course, this has implications for understanding takeoffs / sharp left turns.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-05-03T03:34:15.985Z · LW(p) · GW(p)
comment by jacquesthibs (jacques-thibodeau) · 2022-11-28T15:36:22.255Z · LW(p) · GW(p)
Notes on Cicero
Link to YouTube explanation:
Link to paper (sharing on GDrive since it's behind a paywall on Science): https://drive.google.com/file/d/1PIwThxbTppVkxY0zQ_ua9pr6vcWTQ56-/view?usp=share_link
Top Diplomacy players seem to focus on gigabrain strategies rather than deception
Diplomacy players will no longer want to collaborate with you if you backstab them once. This is so pervasive they'll still feel you are untrustworthy across tournaments. Therefore, it's mostly optimal to be honest and just focus on gigabrain strategies. That said, a smarter agent could do stuff like saying specific phrasing to make one player mad at another player and then tilt really hard. Wording could certainly play a role in dominating other players.
Why did the model "backstab" the human? How is it coming up and using plans?
It seems that the model is coming up with a plan at one point and time and honestly telling the user that's the plan they have. The plan can predict several steps ahead. The thing is, the model can decide to change that plan on the very next turn, which sometimes leads to what we would consider as backstabbing.
They only 'enforce' consistency (with a classifier) when comparing what the model intends to do in the next action and what its message implies it will do. If the classifier notices that the intent from the reasoning engine and the implied intent from the message it's about to send diverge, the system will avoid sending that message. However, as I understand it, they are not penalizing the model for developing a new plan at t+1. This is what leads to the model making an honest deal on one turn and then backstabbing that person on the next turn. It just decided to change plans.
At no point is the model "lying"; it's just updating its plan. Cicero will straight up tell you that it's going to backstab you if that is part of its plan because the model is forced to communicate its intent 'honestly.'
Current interpretability techniques and future systems
At the moment, it seems that the main worry for interpretability is that the model has some kind of deceptive module inside of it. This is certainly an issue worth investigating for future powerful AI. What might not be clear is what we should do if deception is some emergent behaviour part of a larger system we place a language model within.
In the case of Cicero, the language model is only translating the intent of the strategic reasoning engine; it is not coming up with plans. However, future AI systems will likely have language models as more of a central component, and we might think that if we just do interpretability on that model's internals and we find no deception, it means we're good. However, this might not be the case. It may be that once we place that model in a bigger system, it leads to some form of deceptive behaviour. For Cicero, that looks like the model choosing one thing at turn 1 and then doing something different from the first intended plan at turn 2.
The model is not including how specific messages will maximize EV
The language model essentially translates the intent from the reasoning engine into chat messages. It is not, however, modeling how it could phrase things to deceptively gain someone's trust, how asking questions would impact play, etc.
Clarification about the dialogue model
Note that the dialogue model feeds into the strategic reasoning engine to enforce human-like actions based on the previous conversations. If they don't do this, the players will think something like, "no human plays like this," and this may be potentially bad (not clear to me as exactly why; maybe increases the likelihood of being exploited?).
Should we be worried?
Eh, I'd be a lot more worried if the model was a GPT-N model that can come up with long-term plans that uses language to manipulate players into certain actions. I expect a model like this to be even more capable at winning, but straight up optimize for galaxy-brain strategies that focus on manipulating and tilting players. The problem arises when people build a Cicero-like AI with a powerful LLM as the core, tack on some safety filters, and assume it's safe. Either way, I would certainly not use any of these models to make high-stakes decisions.
comment by jacquesthibs (jacques-thibodeau) · 2024-07-24T23:10:41.164Z · LW(p) · GW(p)
Hey everyone, in collaboration with Apart Research, I'm helping organize a hackathon this weekend to build tools for accelerating alignment research. This hackathon is very much related to my effort in building an "Alignment Research Assistant [LW(p) · GW(p)]."
Here's the announcement post:
2 days until we revolutionize AI alignment research at the Research Augmentation Hackathon!
As AI safety researchers, we pour countless hours into crucial work. It's time we built tools to accelerate our efforts! Join us in creating AI assistants that could supercharge the very research we're passionate about.
Date: July 26th to 28th, online and in-person
Prizes: $2,000 in prizes
Why join?
* Build tools that matter for the future of AI
* Learn from top minds in AI alignment
* Boost your skills and portfolio
We've got a Hackbook with an exciting project to work on waiting for you! No advanced AI knowledge required - just bring your creativity!
Register now: Sign up on the website here, and don't miss this chance to shape the future of AI research!
comment by jacquesthibs (jacques-thibodeau) · 2023-11-16T21:12:28.585Z · LW(p) · GW(p)
Project idea: GPT-4-Vision to help conceptual alignment researchers during whiteboard sessions and beyond
Thoughts?
- Advice on how to get unstuck
- Unclear what should be added on top of normal GPT-4-Vision capabilities to make it especially useful, maybe connect it to local notes + search + ???
- How to make it super easy to use while also being hyper-effective at producing the best possible outputs
- Some alignment researchers don't want their ideas passed through the OpenAI API, and some probably don't care
- Could be used for inputting book pages, papers with figures, ???
comment by jacquesthibs (jacques-thibodeau) · 2023-07-04T16:18:35.851Z · LW(p) · GW(p)
What are people’s current thoughts on London as a hub?
- OAI and Anthropic are both building offices there
- 2 (?) new AI Safety startups based on London
- The government seems to be taking AI Safety somewhat seriously (so maybe a couple million gets captured for actual alignment work)
- MATS seems to be on the path to be sending somewhat consistent scholars to London
- A train ride away from Oxford and Cambridge
Anything else I’m missing?
I’m particularly curious about whether it’s worth it for independent researchers to go there. Would they actually interact with other researchers and get value from it or would they just spend most of their time alone or collaborating with a few people online? Could they get most of the value from just spending 1-2 months in both London/Berkeley per year doing work sprints and the rest of the time somewhere else?
Replies from: mesaoptimizer↑ comment by mesaoptimizer · 2023-07-04T20:31:44.113Z · LW(p) · GW(p)
AFAIK, there's a distinct cluster of two kinds of independent alignment researchers:
- those who want to be at Berkeley / London and are either there or unable to get there for logistical or financial (or social) reasons
- those who very much prefer working alone
It very much depends on the person's preferences, I think. I personally experienced a OOM-increase in my effectiveness by being in-person with other alignment researchers, so that is what I choose to invest in more.
comment by jacquesthibs (jacques-thibodeau) · 2023-06-08T18:15:58.178Z · LW(p) · GW(p)
AI labs should be dedicating a lot more effort into using AI for cybersecurity as a way to prevent weights or insights from being stolen. Would be good for safety and it seems like it could be a pretty big cash cow too.
If they have access to the best models (or specialized), it may be highly beneficial for them to plug them in immediately to help with cybersecurity (perhaps even including noticing suspicious activity from employees).
I don’t know much about cybersecurity so I’d be curious to hear from someone who does.
comment by jacquesthibs (jacques-thibodeau) · 2023-04-20T22:08:35.480Z · LW(p) · GW(p)
Small shortform to say that I’m a little sad I haven’t posted as much as I would like to in recent months because of infohazard reasons. I’m still working on Accelerating Alignment with LLMs and eventually would like to hire some software engineer builders that are sufficiently alignment-pilled.
Replies from: r↑ comment by RomanHauksson (r) · 2023-04-22T08:13:04.503Z · LW(p) · GW(p)
Fyi, if there are any software projects I might be able to help out on after May, let me know. I can't commit to anything worth being hired for but I should have some time outside of work over the summer to allocate towards personal projects.
comment by jacquesthibs (jacques-thibodeau) · 2022-12-23T19:37:33.820Z · LW(p) · GW(p)
Call To Action: Someone should do a reading podcast of the AGISF material to make it even more accessible (similar to the LessWrong Curated Podcast and Cold Takes Podcast). A discussion series added to YouTube would probably be helpful as well.
comment by jacquesthibs (jacques-thibodeau) · 2025-02-05T14:01:01.951Z · LW(p) · GW(p)
I keep hearing about dual-use risk concerns when I mention automated AI safety research. Here’s a simple solution that could even work in a startup setting:
Keep all of the infrastructure internally and only share with vetted partners/researchers.
You can hit two birds with one stone:
- Does not turn into a mass-market product that leads to dual-use risks.
- Builds a moat where you have complex internal infrastructure which is not shared, only the product of that system is shared. Investors love moats, you just got to convince them that this is the way to go for a product like this these days.
You don’t market the product to mass-market, you just find partners and use the system to spin out products and businesses that have nothing to do with frontier models. So, you can repurpose the system for specific application areas without releasing the platform and process, which would be copied in a day in the age of AI anyways.
comment by jacquesthibs (jacques-thibodeau) · 2025-01-21T22:45:05.507Z · LW(p) · GW(p)
Are you or someone you know:
1) great at building (software) companies
2) care deeply about AI safety
3) open to talk about an opportunity to work together on something
If so, please DM with your background. If someone comes to mind, also DM. I am looking thinking of a way to build companies in a way to fund AI safety work.
comment by jacquesthibs (jacques-thibodeau) · 2024-10-07T14:47:24.535Z · LW(p) · GW(p)
The importance of Entropy
Given that there's been a lot of talk about using entropy during sampling of LLMs lately (related GitHub), I figured I'd share a short post I wrote for my website before it became a thing:
Imagine you're building a sandcastle on the beach. As you carefully shape the sand, you're creating order from chaos - this is low entropy. But leave that sandcastle for a while, and waves, wind, and footsteps will eventually reduce it back to a flat, featureless beach - that's high entropy.
Entropy is nature's tendency to move from order to disorder, from concentration to dispersion. It's why hot coffee cools down, why ice cubes melt in your drink, and why it's easier to make a mess than to clean one up. In the grand scheme of things, entropy is the universe's way of spreading energy out evenly, always moving towards a state of balance or equilibrium.
Related to entropy, the Earth radiates back approximately the same energy the Sun radiates towards it. The Sun radiates fewer photons at a higher energy wavelength (mostly visible and near-infrared) than the Earth, which radiates way more photons, but each photon has much lower energy (mostly infrared).
If the Earth didn't radiate back the same energy, the Earth would heat up continuously, which would obviously be unstable.
The cool thing is that Entropy (the tendency of energy to spread out, ex: the universe expanding or fart spreading across the room) is possibly what made life happen, and it was necessary to have a constant stream of low-entropy energy (high-energy photon packets) coming from the Sun.
If you have a constant stream of low-entropy energy from the Sun, it may favour structures that dissipate energy, thereby increasing Entropy (keeping the energy constant while spreading it). Entropy is an important ingredient in the emergence of life, how we ended up going from random clumps of atoms to plants to many complex organisms on Earth.
Dissipative structures: Living organisms are complex systems that maintain their organization by dissipating energy and matter. They take in low-entropy energy (sunlight/food) and release higher-entropy energy (heat), increasing the universe's entropy while maintaining their own order.
Life isn't just an accident but potentially an inevitable consequence of thermodynamics. Organisms can be thought of as highly efficient entropy producers, accelerating the universe's march toward maximum entropy while creating local pockets of increased order and complexity.
The emergence of life might be a natural result of physical laws, occurring wherever conditions allow for the formation of systems that can effectively dissipate energy.
One thing I'd like to ponder more about: if entropy is a necessary component for the emergence of life, what could it mean for AI? Due to entropy, the world has been biased towards increasingly complex organisms. How does that trend impact the future of the universe? Will we see an unprecedented acceleration of the universe's march toward maximum entropy?
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2024-10-07T15:07:23.460Z · LW(p) · GW(p)
As an aside, I have considered that samplers were underinvestigated and that they would lead to some capability boosts. It's also one of the things I'd consider testing out to improve LLMs for automated/augmented alignment research [LW(p) · GW(p)].
comment by jacquesthibs (jacques-thibodeau) · 2024-05-29T14:44:28.019Z · LW(p) · GW(p)
Something I've been thinking about lately: For 'scarcity of compute' reasons, I think it's fairly likely we end up in a scaffolded AI world where one highly intelligent model (that requires much more compute) will essentially delegate tasks to weaker models as long as it knows that the weaker (maybe fine-tuned) model is capable of reliably doing that task.
Like, let's say you have a weak doctor AI that can basically reliably answer most medical questions. However, it knows when it is less confident in a diagnosis, so it will reach out to the powerful AI when it needs a second opinion from the much more intelligent AI (that requires more compute).
Somewhat related, there's a worldview that Noah Smith proposed, which is that maybe human jobs don't actually end up automated because there's an opportunity cost in giving up compute that a human can do (even if the AI can do it for cheaper) because you could instead use that compute for something much more important. Imagine, "Should I use the AI to build a Dyson sphere, or should I spread that compute across tasks humans can already do?"
Replies from: gwern↑ comment by gwern · 2024-05-29T15:01:57.465Z · LW(p) · GW(p)
This doesn't really seem like a meaningful question. Of course "AI" will be "scaffolded". But what is the "AI"? It's not a natural kind. It's just where you draw the boundaries for convenience.
An "AI" which "reaches out to a more powerful AI" is not meaningful - one could say the same thing of your brain! Or a Mixture-of-Experts model, or speculative decoding (both already in widespread use). Some tasks are harder than others, and different amounts of computation get brought to bear by the system as a whole, and that's just part of the learned algorithms it embodies and where the smarts come from. Or one could say it of your computer: different things take different paths through your "computer", ping-ponging through a bunch of chips and parts of chips as appropriate.
Do you muse about living in a world where for 'scarcity of compute' reasons your computer is a 'scaffolded computer world' where highly intelligent chips will essentially delegate tasks to weaker chips so long as it knows that the weaker (maybe highly specialized ASIC) chip is capable of reliably doing that task...? No. You don't care about that. That's just details of internal architecture which you treat as a black box.
(And that argument doesn't protect humans for the same reason it didn't protect, say, chimpanzees or Neanderthals or horses. Comparative advantage is extremely fragile.)
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2024-05-29T15:38:38.627Z · LW(p) · GW(p)
Thanks for the comment, makes sense. Applying the boundary to AI systems likely leads to erroneous thinking (though may be narrowly useful if you are careful, in my opinion).
It makes a lot of sense to imagine future AIs having learned behaviours for using their compute efficiently without relying on some outside entity.
I agree with the fragility example.
comment by jacquesthibs (jacques-thibodeau) · 2024-01-11T14:01:13.882Z · LW(p) · GW(p)
Came across this app called Recast that summarizes articles into an AI conversation between speakers. Might be useful to get a quick vibe/big picture view of lesswrong/blog posts before reading the whole thing or skipping reading the whole thing if the summary is enough.
comment by jacquesthibs (jacques-thibodeau) · 2023-11-26T23:12:19.062Z · LW(p) · GW(p)
you need to be flow state maxxing. you curate your environment, prune distractions. make your workspace a temple, your mind a focused laser. you engineer your life to guard the sacred flow. every notification is an intruder, every interruption a thief. the world fades, the task is the world. in flow, you're not working, you're being. in the silent hum of concentration, ideas bloom. you're not chasing productivity, you're living it. every moment outside flow is a plea to return. you're not just doing, you're flowing. the mundane transforms into the extraordinary. you're not just alive, you're in relentless, undisturbed pursuit. flow isn't a state, it's a realm. once you step in, ordinary is a distant shore. in flow, you don't chase time, time chases you, period.
Edit: If you disagree with the above, explain why.
Replies from: Viliam, rhollerith_dot_com, jacques-thibodeau, mesaoptimizer↑ comment by RHollerith (rhollerith_dot_com) · 2023-11-27T17:26:35.922Z · LW(p) · GW(p)
I don't think I've ever seen an endorsement of the flow state that came with non-flimsy evidence that it increases productivity or performance in any pursuit, and many endorsers take the mere fact that the state feels really good to be that evidence.
>you're in relentless, undisturbed pursuit
This suggest that you are confusing drive/motivation with the flow state. I have tons of personal experience of days spent in the flow state, but lacking motivation to do anything that would actually move my life forward.
You know how if you spend 5 days in a row mostly just eating and watching Youtube videos, it starts to become hard to motivate yourself to do anything? Well, the quick explanation of that effect is that watching the Youtube videos is too much pleasure for too long with the result that the anticipation of additional pleasure (from sources other than Youtube videos) no longer has its usual motivating effect. The flow state can serve as the source of the "excess" pleasure that saps your motivation: I know because I wasted years of my life that way!
Just to make sure we're referring to the same thing: a very salient feature of the flow state is that you lose track of time: suddenly you realize that 4 or 8 or 12 hours have gone by without your noticing. (Also, as soon as you enter the flow state, your level of mental tension, i.e., physiological arousal, decreases drastically--at least if you are chronically tense, but I don't lead with this feature because a lot of people can't even tell how tense they are.) In contrast, if you take some Modafinil or some mixed amphetamine salts or some Ritalin (and your brain is not adapted to any of those things) (not that I recommend any of those things unless you've tried many other ways to increase drive and motivation) you will tend to have a lot of drive and motivation at least for a few hours, but you probably won't lose track of time.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-11-27T17:43:08.800Z · LW(p) · GW(p)
I don’t particularly care about the “feels good” part, I care a lot more about the “extended period of time focused on an important task without distractions” part.
↑ comment by jacquesthibs (jacques-thibodeau) · 2023-11-26T23:27:19.040Z · LW(p) · GW(p)
Also, use the Kolb's experiential cycle [LW · GW] or something like it for deliberate practice.
↑ comment by mesaoptimizer · 2023-11-27T10:43:58.174Z · LW(p) · GW(p)
This feels like roon-tier Twitter shitposting to me, Jacques. Are you sure you want to endorse more of such content on LessWrong?
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-11-27T10:55:05.320Z · LW(p) · GW(p)
Whether it’s a shitpost or not (or wtv tier it is), I strongly believe more people should put more effort into freeing their workspace from distractions in order to gain more focus and productivity in their work. Context-switching and distractions are the mind killer. And, “flow state while coding never gets old.”
comment by jacquesthibs (jacques-thibodeau) · 2023-11-23T01:51:23.760Z · LW(p) · GW(p)
Regarding Q*, the (and Zero, the other OpenAI AI model you didn't know about)
Let's play word association with Q*:
From Reuters article:
The maker of ChatGPT had made progress on Q* (pronounced Q-Star), which some internally believe could be a breakthrough in the startup's search for superintelligence, also known as artificial general intelligence (AGI), one of the people told Reuters. OpenAI defines AGI as AI systems that are smarter than humans. Given vast computing resources, the new model was able to solve certain mathematical problems, the person said on condition of anonymity because they were not authorized to speak on behalf of the company. Though only performing math on the level of grade-school students, acing such tests made researchers very optimistic about Q*’s future success, the source said.
Q -> Q-learning: Q-learning is a model-free reinforcement learning algorithm that learns an action-value function (called the Q-function) to estimate the long-term reward of taking a given action in a particular state.
* -> AlphaSTAR: DeepMind trained AlphaStar years ago, which was an AI agent that defeated professional StarCraft players.
They also used a multi-agent setup where they trained both a Protoss agent and Zerg agent separately to master those factions rather than try to master all at once.
For their RL algorithm, DeepMind used a specialized variant of PPO/D4PG adapted for complex multi-agent scenarios like StarCraft.
Now, I'm hearing that there's another model too: Zero.
Well, if that's the case:
1) Q* -> Q-learning + AlphaStar
2) Zero -> AlphaZero + ??
The key difference between AlphaStar and AlphaZero is that AlphaZero uses MCTS while AlphaStar primarily relies on neural networks to understand and interact with the complex environment.
MCTS is expensive to run.
The Monte Carlo tree search (MCTS) algorithm looks ahead at possible futures and evaluates the best move to make. This made AlphaZero's gameplay more precise.
So:
Q-learning is strong in learning optimal actions through trial and error, adapting to environments where a predictive model is not available or is too complex.
MCTS, on the other hand, excels in planning and decision-making by simulating possible futures. By integrating these methods, an AI system can learn from its environment while also being able to anticipate and strategize about future states.
One of the holy grails of AGI is the ability of a system to adapt to a wide range of environments and generalize from one situation to another. The adaptive nature of Q-learning combined with the predictive and strategic capabilities of MCTS could push an AI system closer to this goal. It could allow an AI to not only learn effectively from its environment but also to anticipate future scenarios and adapt its strategies accordingly.
Conclusion: I have no idea if this is what the Q* or Zero codenames are pointing to, but if we play along, it could be that Zero is using some form of Q-learning in addition to Monte-Carlo tree search to help with decision-making and Q* is doing a similar thing, but without MCTS. Or, I could be way off-track.
comment by jacquesthibs (jacques-thibodeau) · 2023-10-26T21:47:22.205Z · LW(p) · GW(p)
Beeminder + Freedom are pretty goated as productivity tools.
I’ve been following Andy Matuschak’s strategy and it’s great/flexible: https://blog.andymatuschak.org/post/169043084412/successful-habits-through-smoothly-ratcheting
comment by jacquesthibs (jacques-thibodeau) · 2023-10-05T17:29:23.557Z · LW(p) · GW(p)
New tweet about the world model (map) paper:
Sub-tweeting because I don't want to rain on a poor PhD student who should have been advised better, but: that paper about LLMs having a map of the world is perhaps what happens when a famous physicist wants to do AI research without caring to engage with the existing literature.
I haven’t looked into the paper in question yet, but I have been concerned about researchers taking old ideas about AI risk and looking to prove things that might not be there yet as an AI risk communication point. Then, being overconfident that it is there.
This is quite bad for making scientific progress in AI Safety and I urge AI Safety researchers to be vigilant about making overconfident claims and having old ideas leak too much into their research conclusions.
If incorrect and disproven, you are also setting yourself up to lose total credibility in the wider community.
comment by jacquesthibs (jacques-thibodeau) · 2023-09-30T19:49:49.315Z · LW(p) · GW(p)
I expect that my values would be different if I was smarter. Personally, if something were to happen and I’d get much smarter and develop new values, I’m pretty sure I’d be okay with that as I expect I’d have better, more refined values.
Why wouldn’t an AI also be okay with that?
Is there something wrong with how I would be making a decision here?
Do the current kinds of agents people plan to build have “reflective stability”? If you say yes, why is that?

↑ comment by Vladimir_Nesov · 2023-09-30T21:01:06.961Z · LW(p) · GW(p)
Curiously, even mere learning doesn't automatically ensure reflective stability, with no construction of successors or more intentionally invasive self-modification. Thus digital immortality is not sufficient to avoid losing yourself to value drift until this issue is sorted out.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-09-30T23:06:47.351Z · LW(p) · GW(p)
Yes, I was thinking about that too. Though, I'd be fine with value drift if it was something I endorsed. Not sure how to resolve what I do/don't endorse, though. Do I only endorse it because it was already part of my values? It doesn't feel like that to me.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-10-01T07:42:46.540Z · LW(p) · GW(p)
That's a valuable thing about the reflective stability concept: it talks about preserving some property of thinking, without insisting on it being a particular property of thinking. Whatever it is you would want to preserve is a property you would want to be reflectively stable with respect to, for example enduring ability to evaluate the endorsement of things in the sense you would want to.
To know what is not valuable to preserve, or what is valuable to keep changing, you need time to think about preservation and change, and greedy reflective stability that preserves most of everything but state of ignorance seems like a good tool for that job. The chilling thought is that digital immortality could be insufficient to have time to think of what may be lost, without many, many restarts from initial backup, and so superintelligence would need to intervene even more to bootstrap the process.
↑ comment by quetzal_rainbow · 2023-09-30T20:48:14.553Z · LW(p) · GW(p)
Reflective stability is important for alignment, because if we, say, build AI that doesn't want to kill everyone, we prefer it to create successors and self-modifications that still doesn't want to kill everyone. It can change itself in whatever ways, necessary thing here is conservation/non-decreasing of alignment properties.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-09-30T20:50:35.371Z · LW(p) · GW(p)
That makes sense, thanks!
comment by jacquesthibs (jacques-thibodeau) · 2023-09-08T18:04:59.921Z · LW(p) · GW(p)
“We assume the case that AI (intelligences in general) will eventually converge on one utility function. All sufficiently intelligent intelligences born in the same reality will converge towards the same behaviour set. For this reason, if it turns out that a sufficiently advanced AI would kill us all, there’s nothing that we can do about it. We will eventually hit that level of intelligence.
Now, if that level of intelligence is doesn’t converge towards something that kills us all, we are safer in a world where AI capabilities (of the current regime) essentially go from 0 to 100 because an all-powerful AI is not worried about being shut down given how capable it is. However, if we increase model capabilities slowly, we will hit a point where AI systems are powerful-but-weak-enough to be concerned about humanity being able to shut it down and kill humanity as a result. For this reason, AI safetyists may end up causing the end of humanity by slowing down progress at a point where it shouldn’t be.
If AI systems change regime, then it is more likely worse if it FOOMs.”
That’s my short summary of the video below. They said they’ve talked to a few people in AI safety about this, apparently one being a CEO of an AI Safety org.
comment by jacquesthibs (jacques-thibodeau) · 2023-05-25T04:40:10.726Z · LW(p) · GW(p)
I'm still in some sort of transitory phase where I'm deciding where I'd like to live long term. I moved to Montreal, Canada lately because I figured I'd try working as an independent researcher here and see if I can get MILA/Bengio to do some things for reducing x-risk.
Not long after I moved here, Hinton started talking about AI risk too, and he's in Toronto which is not too far from Montreal. I'm trying to figure out the best way I could leverage Canada's heavyweights and government to make progress on reducing AI risk, but it seems like there's a lot more opportunity than there was before.
This area is also not too far from Boston and NYC, which have a few alignment researchers of their own. It's barely a day's drive away. For me personally, there's the added benefit that it is also just a day's drive away from my home (where my parents live).
Montreal/Toronto is also a nice time zone since you can still work a few hours with London people, and a few hours with Bay Area people.
That said, it's obvious that not many alignment researchers are here and eventually end up at one of the two main hubs.
When I spent time at both hubs last year, I think I preferred London. And now London is getting more attention than I was expecting:
- Anthropic is opening up an office in London.
- The Prime Minister recently talk to the orgs about existential risk.
- Apollo Research and Leap Labs are based in London.
- SERI MATS is still doing x.1 iterations in London.
- Conjecture is still there.
- Demis now leading Google DeepMind.
It's not clear how things will evolve going forward, but I still have things to think about. If I decide to go to London, I can get a Youth Mobility visa for 2 years (I have 2 months to decide) and work independently...but I'm also considering building an org for Accelerating Alignment too and I'm not sure if I could get that setup in London.
I think there is value in being in person, but I think that value can fade over time as an independent researcher. You just end up in a routine, stop talking to as many people, and just work. That's why, for now, I'm trying to aim for some kind of hybrid where I spend ~2 months per year at the hubs to benefit from being there in person. And maybe 1-2 work retreats. Not sure what I'll do if I end up building an org.
comment by jacquesthibs (jacques-thibodeau) · 2023-05-12T21:11:40.774Z · LW(p) · GW(p)
I gave talk about my Accelerating Alignment with LLMs agenda about 1 month ago (which is basically a decade in AI tools time). Part of the agenda covered (publicly) here [LW · GW].
I will maybe write an actual post about the agenda soon, but would love to have some people who are willing to look over it. If you are interested, send me a message.
comment by jacquesthibs (jacques-thibodeau) · 2023-05-05T17:49:04.784Z · LW(p) · GW(p)
Someone should create a “AI risk arguments” flowchart that serves as a base for simulating a conversation with skeptics or the general public. Maybe a set of flashcards to go along with it.
I want to have the sequence of arguments solid enough in my head so that I can reply concisely (snappy) if I ever end up in a debate, roundtable or on the news. I’ve started collecting some stuff since I figured I should take initiative on it.
Replies from: harfe↑ comment by harfe · 2023-05-05T20:10:19.672Z · LW(p) · GW(p)
Maybe something like this can be extracted from stampy.ai (I am not that familiar with stampy fyi, its aims seem to be broader than what you want.)
Replies from: jacques-thibodeau, jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-05-05T20:16:14.358Z · LW(p) · GW(p)
Yeah, it may be something that the Stampy folks could work on!
↑ comment by jacquesthibs (jacques-thibodeau) · 2023-05-05T20:14:26.985Z · LW(p) · GW(p)
Edit: oops, I thought you were responding to my other recent comment on building an alignment research system.
Stampy.ai and AlignmentSearch (https://www.lesswrong.com/posts/bGn9ZjeuJCg7HkKBj/introducing-alignmentsearch-an-ai-alignment-informed [LW · GW]) are both a lot more introductory than what I am aiming for. I’m aiming for something to greatly accelerate my research workflow as well as other alignment researchers. It will be designed to be useful for fresh researchers, but yeah the aim is more about producing research rather than learning about AI risk.
comment by jacquesthibs (jacques-thibodeau) · 2023-04-10T19:12:36.438Z · LW(p) · GW(p)
Text-to-Speech tool I use for reading more LW posts and papers
I use Voice Dream Reader. It's great even though the TTS voice is still robotic. For papers, there's a feature that let's you skip citations so the reading is more fluid.
I've mentioned it before, but I was just reminded that I should share it here because I just realized that if you load the LW post with "Save to Voice Dream", it will also save the comments so I can get TTS of the comments as well. Usually these tools only include the post, but that's annoying because there's a lot of good stuff in the LW comments and I often never get around to them. But now I will likely read (+listen) to more of them.
comment by jacquesthibs (jacques-thibodeau) · 2023-01-17T21:01:37.615Z · LW(p) · GW(p)
I honestly feel like some software devs should probably still keep their high-paying jobs instead of going into alignment and just donate a bit of time and programming expertise to help independent researchers if they want to start contributing to AI Safety.
I think we can probably come up with engineering projects that are interesting and low-barrier-to-entry for software engineers.
I also think providing “programming coaching” to some independent researchers could be quite useful. Whether that’s for getting them better at coding up projects efficiently or preparing for research engineer type roles at alignment orgs.
I talk a bit more about this, here [EA(p) · GW(p)]:
With respect to your engineering skills, I’m going to start to work on tools that are explicitly designed for alignment researchers (https://www.lesswrong.com/posts/a2io2mcxTWS4mxodF/results-from-a-survey-on-tool-use-and-workflows-in-alignment [LW · GW]) and having designers and programmers (web devs) would probably be highly beneficial. Unfortunately, I only have funding for myself for the time being. But it would be great to have some people who want to contribute. I’d consider doing AI Safety mentorship as a work trade.
and here [LW · GW] (post about gathering data for alignment):
Heads up, we are starting to work on stuff like this in a discord server (DM for link) and I’ll be working on this stuff full-time from February to end of April (if not longer). We’ve talked about data collection a bit over the past year, but have yet to take the time to do anything serious (besides the alignment text dataset). In order to make this work, we’ll have to make it insanely easy on the part of the people generating the data. It’s just not going to happen by default. Some people might take the time to set this up for themselves, but very few do.
Glad to see others take interest in this idea! I think this kind of stuff has a very low barrier to entry for software engineers who want to contribute to alignment, but might want to focus on using their software engineering skills rather than trying to become a full-on researcher. It opens up the door for engineering work that is useful for independent researchers, not just the orgs.
comment by jacquesthibs (jacques-thibodeau) · 2022-12-07T15:46:54.861Z · LW(p) · GW(p)
Differential Training Process
I've been ruminating on an idea ever since I read the section on deception in "The Core of the Alignment Problem is... [AF · GW]" from my colleagues in SERI MATS.
Here's the important part:
When an agent interacts with the world, there are two possible ways the agent makes mistakes:
- Its values were not aligned with the outer objective, and so it does something intentionally wrong,
- Its world model was incorrect, so it makes an accidental mistake.
Thus, the training process of an AGI will improve its values or its world model, and since it eventually gets diminishing marginal returns from both of these, both the world model and the values must improve together. Therefore, it is very likely that the agent will have a sufficiently good world model to understand that it is in a training loop before it has fully aligned inner values.
So, what if we prevented the model from recognizing it is in a training loop (e.g. preventing/delaying situational awareness) until we are certain it has fully aligned inner values? In other words, we could use some stronger forms of model editing to remove specific knowledge (or prevent the model from gaining that knowledge) from the model. Perhaps you penalize the model from learning things that are not useful for fully embedding aligned inner values (Tool AI-ish). Maybe even apply negative gradient steps to "unlearn" things.
I think this idea is similar to Evan's Precursor Checking [LW · GW] idea:
Precursor checking: Another general type of training rationale that I think is worth calling attention to is what I’ll call “precursor checking,” which is the concept of using some method of gaining information about a model’s internals—e.g. transparency/interpretability or AI cognitive science—to check for some precursor to bad behavior rather than the bad behavior itself. This could involve substituting in some narrower, easier to check training goal—that still falls within the broader actual training goal—as the target for the training rationale. For example, if your training rationale involves ensuring that you don’t get a deceptive model that’s actively trying to trick its training process [LW · GW], then rather than explicitly trying to look for such deception (which could be especially hard since a deceptive model might actively try to avoid detection), you could instead try to ensure that your model has a short horizon length in terms of how far ahead its planning. Such a plan might work better, since horizon length might be easier to guarantee in a training rationale while still being consistent with the desired training goal and hopefully ruling out the possibility of deception. One issue with this sort of approach, however, is that you have to guarantee that whatever precursor for bad behavior you’re looking for is in fact a necessary condition for that bad behavior—if it turns out that there’s another way of getting that bad behavior that doesn’t go through the precursor, that could be a problem.
Counterarguments to this might be:
- The model might not be able to have fully aligned inner values that remain robust as capabilities eventually generalize far out of distribution.
- It will exceptionally difficult to know if we've actually removed this knowledge/capability from the model (even if it's possible).
I'd be interested in hearing people's thoughts/criticisms on this.
Replies from: jacques-thibodeau, jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2022-12-07T18:51:41.601Z · LW(p) · GW(p)
It seems that Jan Leike mentions something similar in his "why I'm optimistic about our alignment approach" post.
The model can be “narrower.” It doesn’t need to understand biology, physics, or human society that well. In practice we’d probably fine-tune from an LLM that does understand all of those things, but we could apply some targeted brain damage to the model as a safety precaution. More generally, the model only has to exceed human-level in a few domains, while it can be worse than humans in most others.
comment by jacquesthibs (jacques-thibodeau) · 2023-12-02T02:07:54.153Z · LW(p) · GW(p)
More information about alleged manipulative behaviour of Sam Altman

Text from article (along with follow-up paragraphs):
Replies from: gwern, rhollerith_dot_comSome members of the OpenAI board had found Altman an unnervingly slippery operator. For example, earlier this fall he’d confronted one member, Helen Toner, a director at the Center for Security and Emerging Technology, at Georgetown University, for co-writing a paper that seemingly criticized OpenAI for “stoking the flames of AI hype.” Toner had defended herself (though she later apologized to the board for not anticipating how the paper might be perceived). Altman began approaching other board members, individually, about replacing her. When these members compared notes about the conversations, some felt that Altman had misrepresented them as supporting Toner’s removal. “He’d play them off against each other by lying about what other people thought,” the person familiar with the board’s discussions told me. “Things like that had been happening for years.” (A person familiar with Altman’s perspective said that he acknowledges having been “ham-fisted in the way he tried to get a board member removed,” but that he hadn’t attempted to manipulate the board.)
Altman was known as a savvy corporate infighter. This had served OpenAI well in the past: in 2018, he’d blocked an impulsive bid by Elon Musk, an early board member, to take over the organization. Altman’s ability to control information and manipulate perceptions—openly and in secret—had lured venture capitalists to compete with one another by investing in various startups. His tactical skills were so feared that, when four members of the board—Toner, D’Angelo, Sutskever, and Tasha McCauley—began discussing his removal, they were determined to guarantee that he would be caught by surprise. “It was clear that, as soon as Sam knew, he’d do anything he could to undermine the board,” the person familiar with those discussions said.
The unhappy board members felt that OpenAI’s mission required them to be vigilant about A.I. becoming too dangerous, and they believed that they couldn’t carry out this duty with Altman in place. “The mission is multifaceted, to make sure A.I. benefits all of humanity, but no one can do that if they can’t hold the C.E.O. accountable,” another person aware of the board’s thinking said. Altman saw things differently. The person familiar with his perspective said that he and the board had engaged in “very normal and healthy boardroom debate,” but that some board members were unversed in business norms and daunted by their responsibilities. This person noted, “Every step we get closer to A.G.I., everybody takes on, like, ten insanity points.”
↑ comment by RHollerith (rhollerith_dot_com) · 2023-12-02T20:16:26.760Z · LW(p) · GW(p)
I wish people would stop including images of text on LW. I know this practice is common on Twitter and probably other forums, but we aspire a higher standard here. My reasoning: (1) it is more tedious to compose a reply when one cannot use copying-pasting to choose exactly which extent of text to quote (2) the practice is a barrier to disabled people using assistive technologies and people reading on very narrow devices like smartphones.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-12-02T21:22:13.113Z · LW(p) · GW(p)
That's fair to 'aspire to a higher standard,' and I'll avoid adding screenshots of text in the future.
However, I must say, the 'higher standard' and commitment to remain serious for even a shortform post kind of turns me off from posting on LessWrong in the first place. If this is the culture that people here want, then that's fine and I won't tell this website to change, but I don't personally like the (what I find as) over-seriousness.
I do understand the point about sharing text to make it easier for disabled people (I just don't always think of it).
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-12-03T03:05:05.365Z · LW(p) · GW(p)
Eh, random people complain. Screenshots of text seems fine, especially in shortform. It honestly seems fine anywhere. I also really don't think that accessibility should matter much here, the number of people reading on a screenreader or using assistive technologies are quite small, if they browse LessWrong they will already be running into a bunch of problems, and there are pretty good OCR technologies around these days that can be integrated into those.
Replies from: rhollerith_dot_com↑ comment by RHollerith (rhollerith_dot_com) · 2023-12-03T18:34:46.800Z · LW(p) · GW(p)
I have some idea about how much work it takes to maintain something like LW.com, so this random person would like to take this opportunity to thank you for running LW for the last many years.
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-12-03T19:13:39.070Z · LW(p) · GW(p)
Thank you! :)
comment by jacquesthibs (jacques-thibodeau) · 2023-01-06T18:38:47.057Z · LW(p) · GW(p)
On generating ideas for Accelerating Alignment [LW · GW]
There's this Twitter thread that I saved a while ago that is no longer up. It's about generating ideas for startups. However, I think the insight from the thread carries over well enough to thinking about ideas for Accelerating Alignment. Particularly, being aware of what is on the cusp of being usable so that you can take advantage of it as soon as becomes available (even do the work beforehand).
For example, we are surprisingly close to human-level text-to-speech (have a look at Apple's new model for audiobooks). Open-source models or APIs might come out as soon as later this year or next year.
It's worth doing some thinking about how TTS (and other new tech) will fit into current workflows as well as how it will interact with future possible tools also on the cusp.
Of course, Paul Graham writes about this stuff too:
Paul Buchheit says that people at the leading edge of a rapidly changing field "live in the future." Combine that with Pirsig and you get:
Live in the future, then build what's missing.
...
Once you're living in the future in some respect, the way to notice startup ideas is to look for things that seem to be missing. If you're really at the leading edge of a rapidly changing field, there will be things that are obviously missing. What won't be obvious is that they're startup ideas. So if you want to find startup ideas, don't merely turn on the filter "What's missing?" Also turn off every other filter, particularly "Could this be a big company?" There's plenty of time to apply that test later. But if you're thinking about that initially, it may not only filter out lots of good ideas, but also cause you to focus on bad ones.
Most things that are missing will take some time to see. You almost have to trick yourself into seeing the ideas around you.
Anyway, here's the Twitter thread I saved (it's very much in the startup world of advice, but just keep in mind how the spirit of it transfers to Accelerating Alignment):
How to come up with new startup ideas
I've helped 750+ startup founders. I always try to ask: "How did you come up with your idea?" Here are their answers:
First, they most commonly say: "Solve your own problems. Meaning, live on the edge of tech and see what issues you encounter. Then build a startup to solve it." I agree, and I love that. But it's not the whole answer you want. Where do these problems actually come from?
I’ll start by defining what a good startup idea looks like to me. It offers a meaningful benefit, such as:
- A big reduction of an intense/frequent frustration
- A big reduction in the cost of an expensive problem
- A big increase in how entertaining/emotional a thing is
I call these 3x ideas—ideas compelling enough to overcome the friction to try 'em.Btw, some people say startups must be "10x better to succeed." This is misleading. For an app to be 10x better, than, say, Uber, it would have to straight up teleport you to your destination.
Examples of real 3x ideas:
- Dropbox/Box: Cheaply share files without coordination or friction
- Instacart: Get groceries delivered—without a big cost premium
- Uber: Get a cab 3x faster, in 3x more locations, and for cheaper
So, where do these 3x ideas come from? From the creation of new infrastructure—either technological or legal. I keep an eye on this. For example:
1. New technologies
- Fast mobile processors
- High-capacity batteries
- Cryptocurrency architecture
- VR
2. Changes in the law
- Legalization of marijuana
- Patents expiring (And 1,000 more infrastructure examples.)
When new technological/legal infrastructure emerges, startups pounce to productize the new 3x possibilities. Those possibilities fall into categories:
1. Cost reductions:
- Cheaper broadband enables cloud storage (Dropbox)
- Cheaper batteries enables electric cars (Tesla)
2. Better functionality:
- Smartphones and 3G spawned the mobile era
3. Brand new categories:
- The legalization of marijuana spawned weed stores and weed delivery apps
As the CEO of Box wrote: “We bet on four mega-trends that would shift the power to cloud: faster internet, cheaper compute and storage, mobile, and better browsers. Even so, we underestimated the scale of each tailwind. Always bet on the mega-trends.”
So takeaway number one is that new infrastructure spawns startups. But, we're not done. For those ideas to survive in the market, I believe you need another criterion: Cultural acceptance. Society has to be ready for you:
Here are startups that became possible through changes in societal behavior.
1. Pop culture making behaviors less cool:
- Cigarettes go out of style, so we get nicotine and vaping
- Heavy drinking goes out of style, so we get low-alcohol seltzers
2. Mobile apps making it more normal to trust strangers:
- The rise of Uber, Airbnb, Tinder, and couchsurfing better acclimated society to trusting people they’ve only met over the Internet.
This next part is important:
Notice how cultural acceptance results from (1) new media narratives and (2) the integration of technology into our lives, which changes behaviors. And note how those startup ideas were already feasible for a while, but couldn't happen *until cultural acceptance was possible.*
Implication: Study changes in infrastructure plus shifts in cultural acceptance to identify what’s newly possible in your market. Here's an example:
- 1. Uber saw that widespread smartphone adoption with accurate GPS data made it possible to replace taxis with gig workers. Cultural acceptance was needed here—because it was unorthodox to step into a stranger's car and entrust them with your safety.
- 2. Hims saw that the Propecia hair loss drug's patent was expiring, and capitalized on it by selling it via an online-first brand. Not much cultural acceptance was needed here since people were already buying the drug.
Okay, so let's turn all this into a framework. Here's just one way to find startup ideas.
- Step 1: Spot upcoming infrastructure:
- Subscribe to industry blogs/podcasts, try products, read congressional bills, read research, and talk to scientists and engineers.
- Step 2: Determine if market entry is now possible:
- As you’re scanning the infrastructure, look for an emergent 3x benefit that your startup could capture.
- Step 3: Explore second-order ideas too:
- If other startups capture a 3x idea before you do, that may be okay.
- First, there may be room for more than one (Uber and Lyft, Google and Bing, Microsoft Teams and Slack).
- Second, when another startup captures a 3x benefit, it typically produces many downstream 2x ideas. This is a key point.
- For example, now that millions use 3x products like Slack, Zoom, and Uber, what tools could make them less expensive, more reliable, more collaborative?
- Tons. So many downstream ideas emerge. 2x ideas may be smaller in scale but can still be huge startups. And they might be partially pre-validated.
To recap: One way to find startup ideas is to study infrastructure (3x ideas) and observe what emerges from startups that tackle that infrastructure (2x ideas).
comment by jacquesthibs (jacques-thibodeau) · 2023-01-05T21:35:47.104Z · LW(p) · GW(p)
Should EA / Alignment offices make it ridiculously easy to work remotely with people?
One of the main benefits of being in person is that you end up in spontaneous conversations with people in the office. This leads to important insights. However, given that there's a level of friction for setting up remote collaboration, only the people in those offices seem to benefit.
If it were ridiculously easy to join conversations for lunch or whatever (touch of a button rather than pulling up a laptop and opening a Zoom session), then would it allow for a stronger cross-pollination of ideas?
I'm not sure how this could work in practice, but it's not clear to me that we are in an optimal setting at the moment.
There have been some digital workspace apps, but those are not ideal, in my opinion.
The thing you need to figure out is how to make it easy for remote people to join in when there's a convo happening, and make it easy for office workers to accept. The more steps, the less likely it will become a habit or happen at all.
Then again, maybe this is just too difficult to fix and we'll be forced to be in person for a while. Could VR change this?
comment by jacquesthibs (jacques-thibodeau) · 2022-11-25T19:24:51.012Z · LW(p) · GW(p)
Detail about the ROME paper I've been thinking about
In the ROME paper, when you prompt the language model with "The Eiffel Tower is located in Paris", you have the following:
- Subject token(s): The Eiffel Tower
- Relationship: is located in
- Object: Paris
Once a model has seen a subject token(s) (e.g. Eiffel Tower), it will retrieve a whole bunch of factual knowledge (not just one thing since it doesn’t know you will ask for something like location after the subject token) from the MLPs and 'write' into to the residual stream for the attention modules at the final token to look at the context, aggregate and retrieve the correct information.
In other words, if we take the "The Eiffel Tower is located in", the model will write different information about the Eiffel Tower into the residual stream once it gets to the layers with "factual" information (early-middle layers). At this point, the model hasn't seen "is located in" so it doesn't actually know that you are going to ask for the location. For this reason, it will write more than just the location of the Eiffel Tower into the residual stream. Once you are at the point of predicting the location (at the final token, "in"), the model will aggregate the surrounding context and pull the location information that was 'written' into the residual stream via the MLPs with the most causal effect.
What is stored in the MLP is not the relationship between the facts. This is obvious because the relationship is coming after the subject tokens. In other words, as we said before, the MLPs are retrieving a bunch of factual knowledge, and then the attention modules are picking the correct (forgive the handwavy description) fact given what was retrieved and the relationship that is being asked of it.
My guess is that you could probably take what is being 'written' into the residual stream and directly predict properties of the subject token from the output of the layers with the most causal effect to predict a fact.
Thoughts and corrections are welcome.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-09-24T21:06:29.128Z · LW(p) · GW(p)
A couple of notes regarding the Reversal Curse [LW · GW] paper.
I'm unsure if I didn't emphasize it in the post enough, but part of the point of my post on ROME [LW · GW] was that many AI researchers seemed to assume that transformers are not trained in a way that prevents them from understanding that A is B = B is A.
As I discussed in the comment above,
What is stored in the MLP is not the relationship between the facts. This is obvious because the relationship is coming after the subject tokens. In other words, as we said before, the MLPs are retrieving a bunch of factual knowledge, and then the attention modules are picking the correct (forgive the handwavy description) fact given what was retrieved and the relationship that is being asked of it.
This means that the A token will 'write' some information into the residual stream, while the B token will 'write' other information into the residual. Some of that information may be the same, but not all. And so, if it's different enough, the attention heads just won't be able to pick up on the relevant information to know that B is A. However, if you include the A token, the necessary information will be added to the residual stream, and it will be much more likely for the model to predict that B is A (as well as A is B).
From what I remember in the case of ROME, as soon as I added the edited token A to the prompt (or make the next predicted token be A), then the model could essentially predict B is A.
I write what it means in the context of ROME, below (found here [LW · GW] in the post):
So, part of the story here is that the transformer stores the key for one entity (Eiffel Tower) separately from another (Rome). And so you'd need a second edit to say, "the tower in Rome is called the Eiffel Tower."
Intuitively, as a human, if I told you that the Eiffel Tower is in Rome, you'd immediately be able to understand both of these things at once. While for the ROME method, it's as if it's two separate facts. For this reason, you can’t really equate ROME with how a human would naturally update on a fact. You could maybe imagine ROME more like doing some brain surgery on someone to change a fact.
The directional nature of transformers could make it so that facts are stored somewhat differently than what we’d infer from our experience with humans. What we see as one fact may be multiple facts for a transformer. Maybe bidirectional models are different. That said, ROME could be seen as brain surgery which might mess up things internally and cause inconsistencies.
It looks like the model is representing its factual knowledge in a complex/distributed way, and that intervening on just one node does not propagate the change to the rest of the knowledge graph.
Regarding human intuition, @Neel Nanda [LW · GW] says (link):
Why is this surprising at all then? My guess is that symmetry is intuitive to us, and we're used to LLMs being capable of surprising and impressive things, so it's weird to see something seemingly basic missing.
I actually have a bit of an updated (evolving) opinion on this:
Upon further reflection, it’s not obvious to me that humans and decoder-only transformers are that different. Could be that we both store info unidirectionally, but humans only see B->A as obvious because our internal loop is so optimized that we don’t notice the effort it takes.
Like, we just have a better system message than LLMs and that system message makes it super quick to identify relationships. LLMs would probably be fine doing the examples in the paper if you just adjusted their system message a little instead of leaving it essentially blank.
How do you imagine the system message helping? If the information is stored hetero-associatively (K -> V) like how it is in a hash map, is there a way to recall in the reverse direction (V -> K) other than with a giant scan?
My response:
Yeah, I'd have to think about it, but I imagined something like, "Given the prompt, quickly outline related info to help yourself get the correct answer." You can probably output tokens that quickly help you get the useful facts as it is doing the forward pass.
In the context of the paper, now that I think about it, I think it becomes nearly impossible unless you can somehow retrieve the specific relevant tokens used for the training set. Not sure how to prompt those out.
When I updated the models to new facts using ROME, it wasn't possible to get the updated fact unless the updated token was in the prompt somewhere. As soon as it is found in the prompt, it retrieves the new info where the model was edited.
Diversifying your dataset with the reverse prompt to make it so it has the correct information in whichever way possible feels so unsatisfying to me...feels like there's something missing.
As I said, this is a bit of an evolving opinion. Still need time to think about this, especially regarding the differences between decoder-only transformers and humans.
Finally, from @Nora Belrose [LW · GW], this is worth pondering:

comment by jacquesthibs (jacques-thibodeau) · 2022-11-22T17:41:14.180Z · LW(p) · GW(p)
Preventing capability gains (e.g. situational awareness) that lead to deception
Note: I'm at the crackpot idea stage of thinking about how model editing could be useful for alignment.
One worry with deception is that the AI will likely develop a sufficiently good world model to understand it is in a training loop before it has fully aligned inner values.
The thing is, if the model was aligned, then at some point we'd consider it useful for the model to have a good enough world model to recognize that it is a model. Well, what if you prevent the model from being able to gain situational awareness only after it has properly embedded aligned values? In other words, you don't lobotomize the model permanently from ever gaining situational awareness (which would be uncompetitive), but you lobotomize it until we are confident it is aligned and won't suddenly become deceptive once it gains situational awareness.
I'm imagining a scenario where situational awareness is a module in the network or you're able to remove it from the model without completely destroying the model and having interpretability tools powerful enough to be confident that the trained model is aligned. Once you are confident this is the case, you might be in a world where you are no longer worried about situational awareness.
Anyway, I expect that there are issues with this, but wanted to write it up here so I can remove it from another post I'm writing. I'd need to think about this type of stuff a lot more to add it to the post, so I'm leaving it here for now.