A transparency and interpretability tech tree
post by evhub · 2022-06-16T23:44:14.961Z · LW · GW · 11 commentsContents
Some important distinctions The tech tree 1. Best-case inspection transparency 2. Best-case training process transparency 3. Best-case robust-to-training transparency 4. Worst-case inspection transparency for non-deceptive models 5. Worst-case training process transparency for non-deceptive models 6. Worst-case robust-to-training transparency for non-deceptive models 7. Worst-case training process transparency for deceptive models 8. Worst-case robust-to-training transparency for deceptive models None 11 comments
Thanks to Chris Olah, Neel Nanda, Kate Woolverton, Richard Ngo, Buck Shlegeris, Daniel Kokotajlo, Kyle McDonell, Laria Reynolds, Eliezer Yudkowksy, Mark Xu, and James Lucassen for useful comments, conversations, and feedback that informed this post.
The more I have thought about AI safety over the years, the more I have gotten to the point where the only worlds I can imagine myself actually feeling good about humanity’s chances are ones in which we have powerful transparency and interpretability tools that lend us insight into what our models are doing as we are training them.[1] Fundamentally, that’s because if we don’t have the feedback loop of being able to directly observe how the internal structure of our models changes based on how we train them, we have to essentially get that structure right on the first try—and I’m very skeptical of humanity’s ability to get almost anything right on the first try, if only just because there are bound to be unknown unknowns that are very difficult to predict in advance.
Certainly, there are other things that I think are likely to be necessary for humanity to succeed as well—e.g. convincing leading actors to actually use such transparency techniques, having a clear training goal [AF · GW] that we can use our transparency tools to enforce, etc.—but I currently feel that transparency is the least replaceable necessary condition and yet the one least likely to be solved by default.
Nevertheless, I do think that it is a tractable problem to get to the point where transparency and interpretability is reliably able to give us the sort of insight into our models that I think is necessary for humanity to be in a good spot. I think many people who encounter transparency and interpretability, however, have a hard time envisioning what it might look like to actually get from where we are right now to where we need to be. Having such a vision is important both for enabling us to better figure out how to make that vision into reality and also for helping us tell how far along we are at any point—and thus enabling us to identify at what point we’ve reached a level of transparency and interpretability that we can trust it to reliably solve different sorts of alignment problems.
The goal of this post, therefore, is to attempt to lay out such a vision by providing a “tech tree” of transparency and interpretability problems, with each successive problem tackling harder and harder parts of what I see as the core difficulties. This will only be my tech tree, in terms of the relative difficulties, dependencies, and orderings that I expect as we make transparency and interpretability progress—I could, and probably will, be wrong in various ways, and I’d encourage others to try to build their own tech trees to represent their pictures of progress as well.
Some important distinctions
Before I get into the actual tech tree, however, I want to go over a couple of distinctions that I’ll be leaning on between different types of transparency and interpretability.
First is my transparency trichotomy [AF · GW], which lays out three different ways via which we might be able to get transparent models:[2]
- Inspection transparency: use transparency tools to understand via inspecting the trained model.
- Training[-enforced] transparency: incentivize to be as transparent as possible as part of the training process.
- Architectural transparency: structure 's architecture such that it is inherently more transparent.
For the purposes of this post, I’m mostly going to be ignoring architectural transparency. That’s not because I think it's bad—to the contrary, I expect it to be an important part of what we do—but because, while it’s definitely something I think we should do, I don’t expect it to be able to get us all the way to the sort of transparency I think we’ll eventually need. The inspection transparency vs. training-enforced transparency distinction, however, is one that’s going to be important.
Furthermore, I want to introduce a couple of other related terms to think about transparency when applied to or used in training processes. First is training process transparency, which is understanding what’s happening in training processes themselves—e.g. understanding when and why particular features of models emerge during training.[3] Second is robust-to-training transparency, which refers to transparency tools that are robust enough that they, even if we directly train on their output, continue to function and give correct answers.[4] For example, if our transparency tools are robust-to-training and they tell us that our model cares about gold coins, then adding “when we apply our transparency tools, they tell us that the model doesn’t care about gold coins” to our training loss shouldn’t result in a situation where the model looks to our tools like it doesn’t care about gold coins anymore but actually still does.
The next distinction I want to introduce is between best-case transparency and worst-case transparency. From “Automating Auditing: An ambitious concrete technical research proposal [AF · GW]”:
I think that automating auditing is just generally a great target to focus on even if you just want to develop better transparency tools. Unlike open-ended exploration, which gives you best-case transparency—e.g. the ability to understand some things about the model very well—the auditing game forces you to confront worst-case transparency—how well can you understand everything about your model. Thus, the auditing game helps us work on not just understanding what our models know, but understanding what they don’t know—which is a direction that currently transparency tools tend to struggle with. Most of the work that’s gone into current transparency tools has focused on best-case transparency, however, which means that I suspect there is real room for improvement on worst-case transparency.
The key distinction here is that worst-case transparency is about quantifying over the entire model—e.g. “does X exist in the model anywhere?”—whereas best-case transparency is about picking a piece of the model and the understanding that—e.g. “what does attention head X do?”. Thus, best-case transparency is about understanding properties of models that don’t have any quantifiers (e.g. ), whereas worst-case transparency is about understanding quantified properties (e.g. ).[5] Importantly, such quantified properties include ones where we “know it when we see it” but don’t have any access to inputs that would differentiate the property—in particular, deceptive alignment is such a property, since a deceptively aligned model could defect only in situations that are very hard for us to simulate [AF · GW]. Best-case vs. worst-case transparency is another distinction that I think is quite important that I’ll be using throughout the rest of this post.
Finally, I’ll be leaning on a distinction between doing transparency for deceptive vs. non-deceptive models, so I want to be very clear what I mean by that distinction. When I say that a model is deceptive, I mean to invoke the “Risks from Learned Optimization [? · GW]” concept of deceptive alignment [? · GW], which is explicitly about models that look aligned because they are actively trying to play along in the training process. Thus, when I say that a model is deceptive, I don’t just mean that is capable of lying to humans, but rather that it is sophisticated enough to act on some understanding of the training process and how to manipulate it. For more detail on why such models might be an issue, see “Does SGD Produce Deceptive Alignment? [AF · GW]”
The tech tree
Without further ado, here’s my overall picture of the sort of transparency and interpretability tech tree that I’m expecting that we’ll encounter as we make progress. Arrows denote what I see as required dependencies, whereas nodes that are just lower on the graph seem harder to me but don’t necessarily require the nodes above them. Note that the dependencies here are only intended to denote necessity not sufficiency—my claim is that each node requires its parents, but that just having the parents alone would not be sufficient.[6]
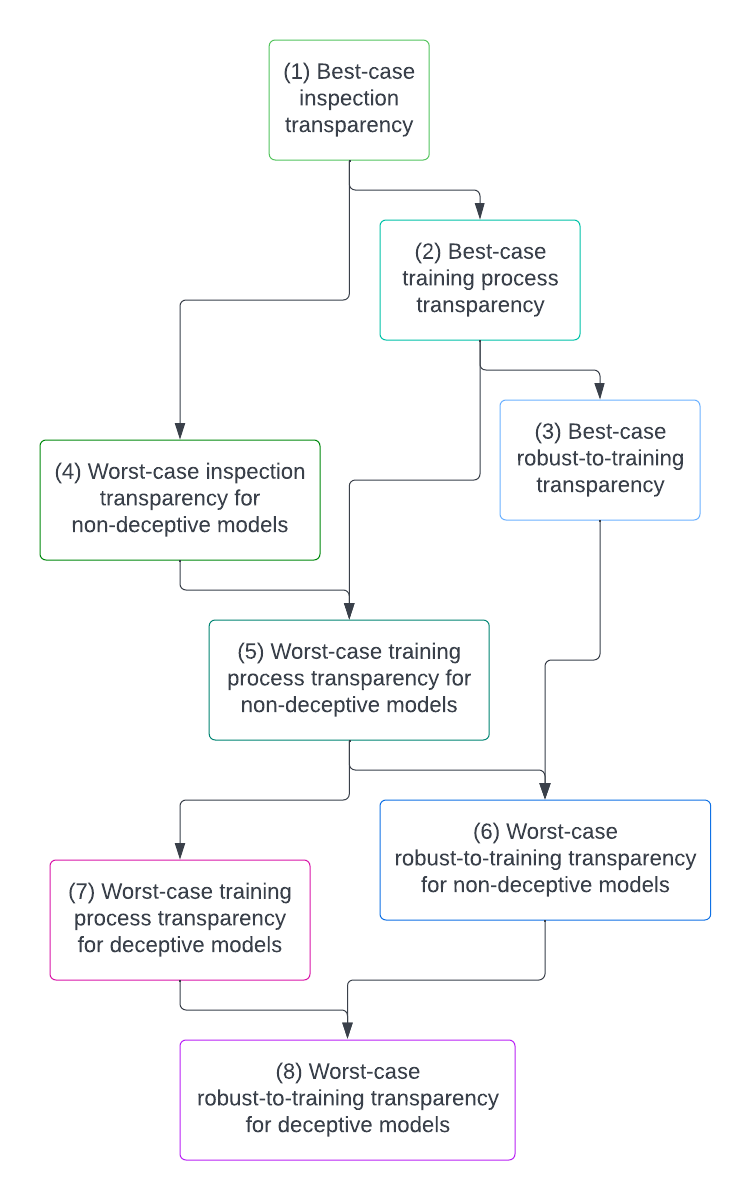
Below, I’ll go into detail on each node in the tree and give my thoughts on it.[7] Before I do, however, I think it’s worth first pointing out that I really do think that the dependencies here are quite real—as I will mention, though there are some ways to start tackling some of the higher levels now, I think really solving them is going to require really solving their dependencies, such that really solving the lowest levels is at least right now probably the most important.
That being said, it’s very unclear what I mean when I say that a particular level has been “really solved.” For the purposes of building a concrete tech tree, I have presented the tech levels here as binaries that we either do or do not solve, but in practice I expect that none of these tech levels will actually be binary. Rather, my expectation is that we will likely solve various different subproblems/aspects of various different levels in various different orders, such that the dependencies won’t truly be clean.[8] Nevertheless, I do expect the dependencies to still be real to the extent that I expect progress on lower levels to accelerate progress on their dependencies.
1. Best-case inspection transparency
Can we understand individual model components?
Best-case inspection transparency means taking existing models and carefully working through and understanding their individual parts/pieces/circuits/components/neurons/etc., starting with those that are the easiest to interpret and working our way up from there. Success here would look like us being able to take most trained models and produce a robust understanding of most of their main/important pieces. In practice, great best-case inspection transparency work looks like Thread: Circuits or Transformer Circuits.
I’ve put best-case inspection transparency as the first level on the tech tree because I think doing a good job here is likely to be necessary for everything else we want to do with transparency and interpretability. This is for a couple of distinct reasons:
- If we don’t know what it looks like to really understand a particular part of a model, I think it’s likely to be very easy for us to fool ourselves when we try to understand more high-level, worst-case properties. If we have good best-case inspection transparency, however, then we should always be able to cache out our high-level, worst-case claims in terms of stuff like individual circuits.
- Good best-case inspection transparency provides a concrete avenue via which we can get to worst-case inspection transparency: just grow our capacity to understand individual pieces of models until we understand the entire thing, then just check the worst-case property directly. Though I expect that this won’t be the easiest pathway to worst-case inspection transparency—I think it’ll be easier to go through best-case robust-to-training transparency—it’s still an important possible path in the tech tree.
Furthermore, I think best-case inspection transparency is the most tractable thing for us to be doing right now and the most likely level, in my opinion, for us to really succeed at. That’s not to say that success here wouldn’t still be a monumental undertaking—though success at best-case inspection transparency doesn’t require us to be able to fully understand models as a whole, or understand every possible circuit in our models, it still requires us to be able to produce an understanding of how most of the individual pieces work that is robust and reliable most of the time.
That being said, there’s no obstacle to success here that wouldn’t also apply to existing circuit-style interpretability results other than scale—and scale is absolutely a tractable problem. Simply scaling up the number of researchers applying current techniques could work to solve this problem, at least for individual highly important models. Scaling up to the point where we can quickly get this sort of understanding for any model, however, seems likely to require substantial automation of at least parts of the basic workflow.
On its own, I don’t think that solving best-case inspection transparency does much to directly solve alignment. I tend to see deceptive alignment [AF · GW] as the biggest problem and best-case inspection transparency gives us no guarantee that we’d be able to detect or prevent deception. While it is possible that the parts of the model that best-case inspection transparency would help us understand would make deception visible to us, it’s equally possible that the deception would stay hidden in the non-accessible parts—or even potentially in the high-level interactions of the accessible parts. This is especially true if the deceptive model is aware of the fact that we might use transparency tools on it, in which case it can adopt simple strategies like “don’t think about deception very often” that might make detecting deception much more difficult. Furthermore, even if we were able to identify deception by chance, if we then changed our training process to try to avoid deception, we’d have no reason to believe it was actually gone rather than just made undetectable. We’ll discuss the difficulty of detecting deception in more detail when we get to (7) (“Worst-case training process transparency for deceptive models”).
Nevertheless, just solving best-case inspection transparency could still do a lot to indirectly accelerate alignment overall. For example, in “A Longlist of Theories of Impact for Interpretability [AF · GW],” Neel Nanda notes that transparency and interpretability progress could serve as a “force-multiplier on alignment research: We can analyse a model to see why it gives misaligned answers, and what’s going wrong. This gets much richer data on empirical alignment work, and lets it progress faster.” Many of the other theories of impact that Neel touches on are also routes via which best-case inspection transparency could have a substantial impact.
2. Best-case training process transparency
Can we understand the dynamics of training processes?
Next on our tech tree is another best-case transparency task, but now applied to the training dynamics rather than just to the final trained model. Success on best-case training process transparency would mean we could produce a robust understanding of a majority of the main/important gradient descent update steps, intermediate models, and general developments in our models that occur during training. For example, we want to be able to answer questions not just about what is going on in our models, but why they developed that way—e.g. what properties of the data/loss/biases/etc. caused them to look that way. Since understanding how models change requires being able to understand the models at at least one point in training, (2) has a hard dependency on (1).
Though there has so far been less progress on (2) compared to (1)—which makes sense given that it’s higher on the tech tree—there has still been meaningful progress here recently. Perhaps the most prominent example here is Olsson et al.’s recent discovery of the “induction bump,” a phase change that occurs in the training of essentially all transformer-based language models that marks the development of “induction heads,” specialized attention heads responsible for completing patterns of the form “A B … A” with “B.”[9] Other progress on this front includes research that improves our basic understanding of SGD's inductive biases, such as “Deep Double Descent [AF · GW].”
3. Best-case robust-to-training transparency
Can we build transparency tools that are robust to being trained on?
Best-case robust-to-training transparency is the same as best-case inspection transparency, but requires that the results that we get be robust to training on them. That is, success at best-case robust-to-training transparency means that, for most best-case transparency properties, we can train a model to look like it has that property according to our transparency tools and actually get a model that does in fact have that property. This is a substantial step up from (1) because it requires our transparency tools to be robust to the optimization pressure of gradient descent; we’re still only requiring such robustness for best-case properties, though.
Current progress on best-case robust-to-training transparency is unfortunately essentially nonexistent. To a large extent, I think that’s because I expect this to require (2) and real progress on (2) is only just now emerging. The reasoning here is that I think the best way to avoid gradient descent Goodharting your transparency tools is to be able to understand the modifications that gradient descent is making as it makes them. In particular, if you know why gradient descent changed some parameter to try to make it more interpretable, you can see whether that change actually improved interpretability or was just exploiting some flaw in your interpretability tools.
Nevertheless, I suspect there is some low-hanging fruit here that could be picked now, primarily around simply studying the impact—and likely subsequent Goodharting—that arises when training on various transparency metrics.[10] Furthermore, beyond such observational analysis, I think a good early goal for this sort of research would be to add some transparency metric to training in a way that definitively removes some facet from the resulting model that is otherwise a convergent feature of all models trained without that metric.
On its own, best-case robust-to-training transparency doesn’t do that much from an alignment perspective, since it only lets us enforce best-case properties, while alignment is primarily a worst-case property (we need “no part of the model is dangerous,” not just “this part of the model is safe”). That being said, for the same reasons that I think (1) is clearly a necessary step towards (4), I think (3) is clearly a necessary step towards (6), which is the end goal that I think transparency needs to reach to constitute an alignment solution.
4. Worst-case inspection transparency for non-deceptive models
Can we check worst-case properties about how our model works?
Next we have worst-case inspection transparency for non-deceptive models. Like in (1), we’re still not requiring any guarantees about our ability to detect or prevent deception—but we are now requiring guarantees about what we’ll be able to find in non-deceptive models. Success here would look like, for any trained model that is not actively trying to evade our transparency tools, reliably being able to identify whether the model does or does not have particular structures or properties anywhere in it—including structures or properties where we only “know them when we see them.” For example, worst-case inspection transparency should let us reliably determine whether or not a non-deceptive model knows some fact—thus potentially constituting a solution to the ELK problem [AF · GW]—as well as reliably determine the presence or absence of particular algorithms like optimization [? · GW].[11]
Importantly, success here doesn’t require that we be able to decide such worst-case properties for any model, only the sorts of models that would actually appear as a result of normal training. Thus, worst-case inspection transparency doesn’t require our transparency tools to continue to be robust if training pressure is directly applied to them, for example—that’s a much stronger ask which we’ll see later in the tech tree. This also means we’re allowed to use architectural transparency to help here by restricting the sorts of models that we train to make interpreting them easier—at least so long as doing so is competitive.
Current progress on worst-case inspection transparency is few and far between, as one would probably expect this high up on the tech tree. That being said, I think that mechanistic heuristic arguments work (forthcoming from ARC [AF · GW] and Redwood Research [AF · GW]) qualifies here—as might work like “Locating and Editing Factual Associations in GPT,” which does attempt to identify where/whether some piece of knowledge exists anywhere in a network, though it does so only for knowledge where we already have inputs that directly elicit them. In terms of pushing on further progress here, I think that auditing games [AF · GW] are a great framework for doing that, since their adversarial nature forces work on them to be focused on worst-case properties. I think it is absolutely achievable for us to make progress here without directly focusing on (1) to (3) first—and in fact I think that focusing on this level as our target (e.g. by working on auditing games) is a great research methodology—though I expect that any progress here will likely translate back into at least progress on (1). In practice, my guess is that the most achievable way to get (4) will be to go through (3): if we have best-case robust-to-training transparency, we can potentially use that to train our model to be transparent everywhere, and thus make checking worst-case properties much more achievable.
Achieving worst-case inspection transparency for non-deceptive models would put us in a position where we can reliably detect non-deceptive alignment issues, which is definitely a much better place to be than where we are now—however, it still doesn’t address deception, and just being able to detect such issues still doesn’t necessarily give us a reliable way to fix them. If our transparency tools here were robust to training on them, however, then maybe we could start using them to actually fix such alignment issues—but that’s (6).
5. Worst-case training process transparency for non-deceptive models
Can we understand the training dynamics of worst-case properties?
Worst-case training process transparency for non-deceptive models is a combination of (2)—best-case training process transparency—and (4)—worst-case inspection transparency for non-deceptive models. Like (2), worst-case training process transparency for non-deceptive models asks us to understand not just our trained models, but the gradient descent update steps that produced them. Unlike (2), however, and like (4), here we are required to have such an understanding regarding worst-case properties of models during training. For example, we now want to know not just what a model knows but why it knows—and if a model developed optimization during training, we now want to ask what was it about the training process that caused that development.
Undeniably, this would be an extremely impressive level of transparency and interpretability tech. Success here would enable us to actually reliably see the development of misaligned—or aligned—goals, heuristics, etc. in our models. Unfortunately, like with (4), we still aren’t at the point where we can necessarily see the development of deception, nor can we actually fix any of the problems that we find—to do that, at least just using transparency, we’d need to be able to take our tools, which can now reliably identify such misalignment, and enable them to continue to be able to do so even after we directly train against them, which is the next rung on our tech tree.
6. Worst-case robust-to-training transparency for non-deceptive models
Can we robustly prevent our model from thinking in a particular way?
As I have alluded to previously, worst-case robust-to-training transparency for non-deceptive models is what I see as the tipping point where I start to believe that solving alignment is solidly within reach. Success here would mean that we can reliably train models to have the worst-case properties that we want as long as those models never become deceptive, as in something like relaxed adversarial training [AF · GW].
For alignment problems that are not deception, such a transparency and interpretability tech level is sufficient so long as we know what sort of mechanistic properties to ask for—that is, we know what training goal [AF · GW] we’re pursuing, which is one of the things I mentioned at the beginning was likely to still be necessary for alignment alongside transparency and interpretability. However, I think that finding a good training goal is an overall easier task than the transparency and interpretability part—in particular, we already have some descriptions of models that seem quite safe, such as a direct translator, an alignment research simulator [AF · GW], or an HCH imitator [AF · GW].
What might be unclear at first, however, is how I think this lets us solve deception as well, since the transparency and interpretability tech here very explicitly doesn’t work in the presence of deception. What it does let us do, however, is precursor-checking. From “How do we become confident in the safety of a machine learning system? [AF · GW]”:
Precursor checking: Another general type of training rationale that I think is worth calling attention to is what I’ll call “precursor checking,” which is the concept of using some method of gaining information about a model’s internals—e.g. transparency/interpretability or AI cognitive science—to check for some precursor to bad behavior rather than the bad behavior itself. This could involve substituting in some narrower, easier to check training goal—that still falls within the broader actual training goal—as the target for the training rationale. For example, if your training rationale involves ensuring that you don’t get a deceptive model that’s actively trying to trick its training process [AF · GW], then rather than explicitly trying to look for such deception (which could be especially hard since a deceptive model might actively try to avoid detection), you could instead try to ensure that your model has a short horizon length in terms of how far ahead its planning. Such a plan might work better, since horizon length might be easier to guarantee in a training rationale while still being consistent with the desired training goal and hopefully ruling out the possibility of deception.[12] One issue with this sort of approach, however, is that you have to guarantee that whatever precursor for bad behavior you’re looking for is in fact a necessary condition for that bad behavior—if it turns out that there’s another way of getting that bad behavior that doesn’t go through the precursor, that could be a problem.[13]
7. Worst-case training process transparency for deceptive models
Can we detect the development of deceptive alignment?
Worst-case training process transparency for deceptive models is (5) but without the restriction that our transparency tools need only work if the model isn’t actively trying to evade them. Here, we require our transparency and interpretability tech to always reliably determine worst-case properties about a model and what happened to it during training even if that model is deceptive and actively trying to evade detection. Note that this wouldn’t necessarily let us train away such deception—only identify it.
In my opinion, I think that any level of transparency and interpretability tech that is robust to deceptive models is extremely difficult, and in particular harder than (6). Fundamentally, both (6) and (7) ask for worst-case transparency tools that are robust to a particular adversary: (6) asks for robustness to gradient descent, while (7) asks for robustness to a deceptive model. In my opinion, I think that gradient descent is a substantially easier adversary to be robust to: gradient descent is a simple, straightforward optimization process that works via individual, local steps that—if we also have (5)—we can understand. That being said, there are some reasons that you might expect gradient descent to be a harder adversary: gradient descent has more direct access to the model’s internals than the model itself does—and since training generally uses far more compute than inference, gradient descent has a compute advantage.
Nevertheless, my guess is that gradient descent is still going to be the easier adversary for us to contend with compared to a deceptively aligned model. That’s because a deceptively aligned model is a smart, potentially human-level (or beyond) optimizer, not just a dumb, local search process like gradient descent. Furthermore, I suspect such a model to have a lot of simple strategies available to it in terms of shaping how it thinks in ways that evade our transparency tools. For example, even if such a model has very minimal knowledge of what transparency checks we’ll be applying to it, it can pursue a strategy like: make a pre-commitment (e.g. in its retrieval database) to act aligned until something very weird happens that causes it to reevaluate everything. Such a strategy is possible even without the model having any real understanding of how its thoughts are represented and encoded in its weights/activations, but instead just by changing how it thinks on a high level. Furthermore, preventing deceptive models from being able to pursue such general strategies seems quite difficult—though we might be able to prevent information about the specific transparency tools that we’ll be using from appearing in our training data, if we’re doing something like training a large language model then the mere existence of transparency and interpretability tools is likely to be very hard to hide.
A potentially useful analogy here is to think about how difficult it would be for humans to trick various forms of lie detectors. My guess is that, at least for the current state of neuroscience, humans could learn to think in ways that would trick any lie detector we could build (in practice, commercial lie detectors are certainly trickable, though I'm sure you could do better if you had the person in an MRI machine). Furthermore, I’d also guess that we could learn to do this just via reasoning about how the lie detector works, rather than having to have had direct experience with it, though that would definitely be harder and certainly does seem less clear. Of course, there are disanalogies here in both directions: transparency is likely to be easier than neuroscience, since we have more access to a model’s neurons than a human’s neurons—but by the same principle, models are likely to have greater control over their own thought processes (e.g. because they can control how they write to some retrieval database, or because they can more effectively gradient hack [AF · GW] themselves by doing the AI equivalent of eating candy to reward yourself for doing your homework).
Another point worth making here is why I haven’t separated out worst-case inspection transparency for deceptive models vs. worst-case training process transparency for deceptive models there. That’s because, while technically the latter is strictly more complicated than the former, I actually think that they’re likely to be equally difficult. In particular, I suspect that the only way that we might actually have a shot at understanding worst-case properties of deceptive models is through understanding how they’re trained. That is, if our ability to understand training dynamics is good enough, we might be able to make it impossible for a deceptive model to evade us by always being able to see its planning for how to do so during training.
Finally, one very important point here is that the difficulty of both worst-case inspection transparency and worst-case training process transparency in the case of deceptive models problematizes our ability to ever actually use a solution to (4) or (5), which ask for the same thing but only in the case of non-deception. That’s because, if we only had (4) or (5), we wouldn’t be able to tell whether our model is deceptive, and thus wouldn’t be able to tell which level we actually need to be at in our transparency tech out of (4)/(5) vs. (7) to succeed.
8. Worst-case robust-to-training transparency for deceptive models
Can we take a deceptively aligned model and train away its deception?
Worst-case robust-to-training transparency for deceptive models means that we can understand worst-case properties of any model—even ones that are trying to evade detection—in a way that is robust enough to train on. This is the holy grail—success here would mean that transparency and interpretability would effectively solve the entire training rationale [AF · GW] problem all on its own. Though there would still be training goal [AF · GW] questions around what sort of model we actually want, we’d have a guarantee that whatever sort of model we could ask for we could get.
Similarly to how the difficulty of (7) calls into question our ability to rely on (4) or (5), the difficulty of (8) calls into question our ability to rely on (6). In this case, however, unlike in the previous one, (6) alone might actually be able to give us a reason to believe that our model isn’t deceptive if it enables us to enforce the absence of some necessary precondition for deception.
It certainly could be the case that alignment succeeds despite my not expecting it to—but I think it is reasonable to focus on maximizing our own estimate of the likelihood of success, since . However, it is important to note that interventions that only reduce the variance of our expectation aren’t necessarily positive—e.g. if all transparency did was reveal to us the underlying probability of our success, but didn’t allow us to intervene on that probability at all, it wouldn’t be helpful. ↩︎
In the original trichotomy, I just used “training transparency” on its own, but due to the number of other very similar terms in this post, the term training-enforced transparency is used here for that concept instead to help disambiguate. ↩︎
Concretely, as I discuss later, Olsson et al.’s discovery of the “induction bump” is an example of training process transparency. ↩︎
Robust-to-training transparency is different from training-enforced transparency since robust-to-training transparency allows us to enforce particular outputs of our transparency tools whereas training-enforced transparency only allows us to enforce that our transparency tools work at all. ↩︎
In the arithmetical hierarchy, best-case properties correspond to or equivalently formulae, with worst-case properties corresponding to all higher-order and formulae. ↩︎
As should be pretty clear from the diagram, there is a substantial amount of structure to the tech tree here—it’s effectively divided into two axes, one representing our understanding of and robustness to training, the other the generality and applicability of our transparency tools, with my expectation being that the training axis is easier. ↩︎
One useful exercise that I’d recommend considering for getting a handle on this tech tree is figuring out where our ability to understand current, existing structures in the world lies—e.g. what level of transparency and interpretability tech do we have for human-readable code, human companies/organizations, etc. ↩︎
In fact, one could probably do an entire additional tech tree for each level on the tech tree presented here that went into which particular properties in that level we’ll get to before others. ↩︎
Further work here might look into whether similar phase changes exist for the development of more complex behaviors, such as the translation induction heads that Olsson et al. also find, which do the same thing but where the different “A B” pairs are in different languages. ↩︎
For example, you could take a metric like OV circuit eigenvalue positivity, which is associated with copying heads, train a small model to only have copying heads according to this metric, and then study the resulting model. Does it actually learn to get by just via copying somehow? Or does it start to find ways to do non-copying operations in ways that get around the metric? ↩︎
Ideally, we’d like to also answer questions like how myopic that optimization is. ↩︎
It’s worth noting that while guaranteeing a short horizon length might be quite helpful for preventing deception, a short horizon length alone isn’t necessarily enough to guarantee the absence of deception, since e.g. a model with a short horizon length might cooperate with future versions of itself in such a way that looks more like a model with a long horizon length. See “Open Problems with Myopia [AF · GW]” for more detail here. ↩︎
For more detail on what this sort of thing might look like, see “Acceptability verification: a research agenda.” ↩︎
11 comments
Comments sorted by top scores.
comment by johnswentworth · 2022-06-17T10:29:36.816Z · LW(p) · GW(p)
I find this post interesting as a jumping-off point; seems like the kind of thing which will inspire useful responses via people going "no that's totally wrong!".
In that spirit, some ways I think it's totally wrong:
- Best-case/worst-case are confusing names for the things they're pointing to. I'd use "partial" and "comprehensive" interpretability.
- I expect training process interpretability to not particularly help produce robust-to-training interpretability. Inspection transparency might help somewhat with robust-to-training interpretability, but mostly I expect that robust-to-training interpretability requires a fundamentally different approach/principles/mindset than the other two.
- (I'm also somewhat skeptical about the usefulness of robust-to-training interpretability as an alignment strategy in general, but not sure that's within-scope here.)
- I expect partial/best-case interpretability could help somewhat with comprehensive/worst-case, but mostly I expect comprehensive/worst case to require a fundamentally different approach/principles/mindset, such that partial/best-case progress mostly doesn't address the hard parts of comprehensive/worst-case.
On the flip side, here the kinds of foundational "techs" which I think could provide a foundation for comprehensive/worst-case interpretability, and maybe for robust-to-training interpretability:
- For comprehensive/worst-case interpretability, I expect the first important prerequisite is the ability to identify natural Markov blankets/natural internal APIs. We want to recognize chunks of the net which only interact with the rest of the net via some limited information-channel, and we can rule out all other interactions between the chunk and the rest of the net. (This is basically the natural abstraction idea [LW · GW], applied to neural nets.)
- I expect the next important prerequisite for both comprehensive/worst-case and robust-to-training interpretability is to robustly connect internal data structures in the net to real-world human-recognizable things which the internal data structures "represent". That, in turn, will require progress on ontology identification/natural abstraction as applied to the world.
- Alternatively, one could just try to recognize/interpret the core "agency datastructures" (like e.g. goals, world models, search) in a robust-to-training way, without connecting all the internal data structures to their real-world referents. For that more limited problem, the prerequisite work is more mathematical than empirical; one needs definitions/operationalizations of goals/search/world-models/etc which robustly characterize [LW · GW] the potentially-dangerous sorts of goal-seeking behavior. (Though this strategy is another case where I'm somewhat skeptical that it's viable as an alignment strategy in general.)
↑ comment by evhub · 2022-06-17T20:20:29.803Z · LW(p) · GW(p)
I find this post interesting as a jumping-off point; seems like the kind of thing which will inspire useful responses via people going "no that's totally wrong!".
Yeah, I'd be very happy if that were the result of this post—in fact, I'd encourage you and others to just try to build your own tech trees so that we have multiple visions of progress that we can compare.
comment by Ivan Vendrov (ivan-vendrov) · 2022-06-17T02:20:41.722Z · LW(p) · GW(p)
This is very helpful as a roadmap connecting current interpretability techniques to the techniques we need for alignment.
One thing that seems very important but missing is how the tech tree looks if we factor in how SOTA models will change over time, including
- large (order-of-magnitude) increases in model size
- innovations in model architectures (e.g. the LSTM -> Transformer transition)
- innovations in learning algorithms (e.g. gradient descent being replaced by approximate second-order methods or by meta-learning)
For example, if we restricted our attention to ConvNets trained on MNIST-like datasets we could probably get to tech level (6) very quickly. But would this would help with solving transparency for transformers trained on language? And if we don't expect it to help, why do we expect solving transparency for transformers will transfer over to the architectures that will be dominant 5 years from now?
My tentative answer would be that we don't really know how much transparency generalizes between scales/architectures/learning algorithms, so to be safe we need to invest in enough interpretability work to both keep up with whatever the SOTA models are doing and to get higher and higher in the tech tree. This may be much, much harder than the "single tech tree" metaphor suggests.
comment by habryka (habryka4) · 2024-01-15T07:44:08.807Z · LW(p) · GW(p)
I am not that excited about marginal interpretability research, but I have nevertheless linked to this a few times. I think this post both clarifies a bunch of inroads into making marginal interpretability progress, but also maps out how long the journey between where we are and where many important targets are for using interpretability methods to reduce AI x-risk.
Separately, besides my personal sense that marginal interpretability research is not a great use of most researcher's time, there are really a lot of people trying to get started doing work on AI Alignment via interpretability research, and I think this kind of resource is very valuable for that work, and also helps connect interp work to specific risk models, which is a thing that I wish existed more on the margin in interpretability work.
comment by RobertKirk · 2022-06-20T13:19:32.195Z · LW(p) · GW(p)
Another point worth making here is why I haven’t separated out worst-case inspection transparency for deceptive models vs. worst-case training process transparency for deceptive models there. That’s because, while technically the latter is strictly more complicated than the former, I actually think that they’re likely to be equally difficult. In particular, I suspect that the only way that we might actually have a shot at understanding worst-case properties of deceptive models is through understanding how they’re trained.
I'd be curious to hear a bit more justification for this. It feels like resting on this intuition for a reason not to include worst-case inspection transparency for deceptive models as a separate node is a bit of a brittle choice (i.e. makes it more likely the tech tree would change if we got new information). You write
That is, if our ability to understand training dynamics is good enough, we might be able to make it impossible for a deceptive model to evade us by always being able to see its planning for how to do so during training.
which to me is a justification that worst-case inspection transparency for deceptive models is solved if we solve worst-case training process transparency for deceptive models, but not a justification that that's the only way to solve it.
comment by William_S · 2022-06-17T04:15:00.581Z · LW(p) · GW(p)
Do you think we could basically go 1->4 and 2->5 if we could train a helper network to behaviourally clone humans using transparency tools and run the helper network over the entire network/training process? Or if we do critique style training (RL reward some helper model with access to the main model weights if it produces evidence of the property we don't want the main network to have)?
Replies from: RobertKirk↑ comment by RobertKirk · 2022-06-20T13:22:12.249Z · LW(p) · GW(p)
The ability to go 1->4 or 2->5 by the behavioural-cloning approach would assume that the difficulty of interpreting all parts of the model are fairly similar, but it just takes time for the humans to interpret all parts, so we can automate that by imitating the humans. But if understanding the worst-case stuff is significantly harder than the best-case stuff (which seems likely to me) then I wouldn't expect the behaviourally-cloned interpretation agent to generalise to being able to correctly interpret the worse-case stuff.
comment by habryka (habryka4) · 2022-06-17T22:30:52.251Z · LW(p) · GW(p)
(Mod note: I turned on two-factor voting. @Evan: Feel free to ask me to turn it off.)
comment by jacquesthibs (jacques-thibodeau) · 2022-11-21T11:07:54.331Z · LW(p) · GW(p)
Second is robust-to-training transparency, which refers to transparency tools that are robust enough that they, even if we directly train on their output, continue to function and give correct answers.[4] For example, if our transparency tools are robust-to-training and they tell us that our model cares about gold coins, then adding “when we apply our transparency tools, they tell us that the model doesn’t care about gold coins” to our training loss shouldn’t result in a situation where the model looks to our tools like it doesn’t care about gold coins anymore but actually still does.
Checking my understanding here (I'm pretty confident I'm misunderstanding a bit): is "robust-to-training transparency" the case where you have some transparency tool that can verify what the model is optimizing (cares?) for and, if it's not the thing we want (or how we want the model to optimize for it?), then we can train on the outputs to basically tell the model, "hey, you should care about x and not y." And then the robust part is to say it really does care about x after training on the outputs and that the transparency tool is not being optimized against so it no longer works?
If the above is true, is part of the difficulty here that we are assuming we even know where exactly to point the model to while training on the outputs?
comment by William_S · 2022-06-17T04:20:03.805Z · LW(p) · GW(p)
Summary for 8 "Can we take a deceptively aligned model and train away its deception?" seems a little harder than what we actually need, right? We could prevent a model from being deceptive rather than trying to undo arbitrary deception (e.g. if we could prevent all precursors)
Replies from: evhub