Posts
Comments
Say more about "ray-tracing"? What does that look like? And do you have a bullshit-but-useful PCA-flavored breakdown of those few dimensions of variation?
What are "latential" string diagrams?
Just the word I use to describe "thing that has something to do with (natural) latents". More specifically for this case: a string diagram over a Markov category equipped with the extra stuff, structure, and properties that a Markov category needs to have in order to faithfully depict everything we care about when we want to write down statements or proofs about Bayes nets which might transform in some known restricted ways.
What does it it mean that you can't derive them all from a "fixed" set? Do you imagine some strong claim e.g. that the set of rewriting rules being undecidable, or something else?
Something else. I'm saying that:
- You would need to pick your set of identities once and for all at the start, as part of specifying what extra properties the category has; you could totally use those as (or to derive) some of the rules (and indeed I show how you can do just that for Breakout Joint Independence)
- Binary operations like Frankenstein or Stitching probably don't fall out of an approach like that (they look a lot more like colimits
- Rules which a categorical approach trivializes like Factorization Transfer don't particularly fall out of an approach like that
- You could probably get some kind of "ruleset completeness" result if you had a strong sense of what would constitute a complete ruleset - the paper I linked above looks to be trying to do this
...so maybe some approach where you start by listing off all the identities you want to have hold and then derive the full ruleset from those would work at least partially? I guess I'm not totally clear what you mean by "categorical axioms" here - there's a fair amount that goes into a category; you're setting down all the rules for a tiny toy mathematical universe and are relatively unconstrained in how you do so, apart from your desired semantics. I'm also not totally confident that I've answered your question.
Okay, so this is not what you care about? Maybe you are saying the following: Given two diagrams X,Y, we want to ask whether any distribution compatible with X is compatible with Y. We don't ask whether the converse also holds. This is a certain asymmetric relation, rather than an equivalence.
Yes. Well... almost. Classically you'd care a lot more about the MEC, but I've gathered that that's not actually true for latential Bayes nets. For those, we have some starting joint distribution J, which we care about a lot, and some diagram D_J which it factors over; alternatively, we have some starting set of conditionality requirements J, and some diagram D_J from among those that realize J. (The two cases are the same apart from the map that gives you actual numerical valuations for the states and transitions.)
We do indeed care about the asymmetric relation of "is every distribution compatible with X also compatible with Y", but we care about it because we started with some X_J and transformed it such that at every stage, the resulting diagram was still compatible with J.
that's not a thing that really happens?
What is the thing that doesn't happen? Reading the rest of the paragraph only left me more confused.
Somehow being able to derive all relevant string diagram rewriting rules for latential string diagrams, starting with some fixed set of equivalences? Maybe this is just a framing thing, or not answering your question, but I would expect to need to explicitly assume/include things like the Frankenstein rule - more generally, picking which additional rewriting rules you want to use/include/allow is something you do in order to get equivalence/reachability in the category to line up correctly with what you want that equvialence to mean - you could just as soon make those choices poorly and (e.g.) allow arbitrary deletions of states, or addition of sampling flow that can't possibly respect causality; we don't do that here because it wouldn't result in string diagram behavior that matches what we want it to match.
I think I may have misunderstood, though, because that does sounds almost exactly like what I found to happen for the Joint Independence rule - you have some stated equivalence, and then you use string diagram rewriting rules common to all Markov category string diagrams in order to write the full form of the rule.
Simple form of the JI Rule - note the equivalences in the antecedent, which we can use to prove the consequent, not just enforce the equivalence!
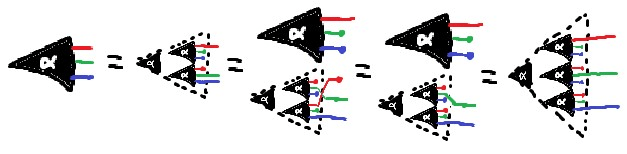
we don't quite care about Markov equivalence class
What do you mean by "Markov equivalence class"?
Two Bayes nets are of the same Markov equivalence class when they have precisely the same set of conditionality relations holding on them (and by extension, precisely the same undirected skeleton). You may recognize this as something that holds true when applicable for most of these rules, notably (sometimes) including the binary operations and notably excluding direct arrow-addition; additionally, this is something that applies for abstract Bayes nets just as well as concrete ones.
Hi! I spent some time working on exactly this approach last summer at MATS, and since then have kept trying to work out the details. It's been going slowly but parts of it have been going at all.
My take regarding your and @Alexander Gietelink Oldenziel's comments below is - that's not a thing that really happens? You pick the rules and your desired semantics first, and then you write down your manipulation rules to reflect those. Maybe it turns out that you got it wrong and there's more (or fewer!) rules of derivation to write down, but as long as the rules you wrote down follow some very easy constraints, you can just... write down anything. Or decline to. (Also, from a quick read I'm fairly sure you need a little bit more than just "free cartesian category" to hold of your domain category if you want nice structures to hang state/kernel-labels on. You want to be able to distinguish a concrete Bayes net (like, with numbers and everything) from an abstract "Bayes net", which is just a directed acyclic graph representing local conditionality structures - though we should note that usually people working with Bayes nets assume that we actually have trees, and not just DAGs!)
Maybe there's arguments from things like mathematical elegance or desired semantics or problematizing cases to choose to include or exclude some rule, or formulate a rule in one or another way, but ultimately you get to add structure to a category as suits you.
- Can we derive a full classification of such rules?
Probably there's no full classification, but I think that a major important point (which I should have just written up quickly way way long ago) is that we don't quite care about Markov equivalence class - only about whether any given move takes us to a diagram still compatible with the joint distribution/factorization that we started with.
- Is there a category-theoretic story behind the rules? Meaning, is there a type of category for which Bayes nets are something akin to string diagrams and the rules follow from the categorical axioms?
In my understanding there's a pretty clear categorical story - some of which are even just straight trivial! - to most of the rules. They make good sense in the categorical frame; some of them make so much sense that they're the kind of thing string diagrams don't even bother to track. I'm thinking of Factorization Transfer here, though the one major thing I've managed to get done is that the Joint Independence rule actually follows as a quick technical lemma from its assumptions/setup, rather than having to be assumed.
There's noncanonical choices getting made in the two "binary operation" rules, but even then it seems to me like the fact that we only ever apply that operation to two diagrams of the same "flavor" means we should likely only ever get back another diagram of the same "flavor"; apart from that, there's a strong smell of colimitness to both of those rules, which has kept me mulling over whether there's a useful "limitish" sort of rule that John and David both missed. Underlying this is my suspicion that we might get a natural preorder structure on latent Bayes nets/string diagrams as the pullback of the natural lattice on Markov equivalence classes, where one MEC is above another if it has strictly more conditionality relationships in it - i.e. the unique minimal element of the lattice is "everything is independent", and there's lots of maximal elements, and all our rules need to keep us inside the preimage of the upset of our starting MEC.
Which is to say: yes, yes there totally is such a type of category, but existing work mostly stopped at "Bayes nets akin to string diagrams", although I've seen some non-me work lately that looks to be attacking similar problems.
Did you ever get back to reading this? I think I got some very different things out of it when I read through! (And @whatstruekittycat will talk your ear off about it, among other topics.)
I think you maybe miss an entire branch of the tech-tree here I consider important - the bit about the Lindy case of divination with a coin-flip and checking your gut. It doesn't stop at a single bit in my experience; it's something you can use more generally to get your own read on some situation much less filtered by masking-type self-delusion. At the absolute least, you can get a "yes/no/it's complicated" out of it pretty easily with a bit more focusing!
I claim that divination[1] is specifically a good way for routing around the worried self-deception and yeah-sure-whatever daily frames and getting at how you really feel about something you're clearly uncertain-and-high-arousal enough about to Do A Divination about.
As a maybe-tangent, a friend of mine has a self-designed divination method I like a lot but haven't managed to fully learn how to do; what I like about it is its compositionality/modularity, where you pull a handful (3-5 IIRC) of symbolic rune-type things from a bag and toss them onto a surface, such that both the divination-tiles you pulled out and their relative-location/absolute-location/orientation/pointing-with-respect-to-each-other all matter. I don't think I have a maximally good sense of why I like it so much past the obvious factors of "fun system/novelty/a friend made this" and "fine-grained expressive power" and "combinatorial explosion power", though.
For my own part I like to use coins that I've made for other reasons for this purpose. They're not fair coins; that's the fun part.
- ^
In the explicit epistemic frame of "we are getting the bits of interest from some internal mental process to use for planning/self-check purposes", mind you!
Got it, thanks. I'll see if I can figure out who that was or where to find that claim. Cheers.
Maybe this is the right place to ask/discuss this, and maybe not - if it's not; say so and I'll stop.
IIRC you (or maybe someone once mentioned hearing about people who try to [experience the first jhana][1] and then feeling pain as a result, and that you didn't really understand why that happened. There was maybe also a comment about "don't do that, that sounds like you were doing it wrong".
After some time spent prodding at myself and pulling threads and seeing where they lead... I am not convinced that they were doing it wrong at all. There's a kind of way you can end up where the application of that kind of comfort/pleasure/positive-valence is, of itself, painful/aversive/immiserating, if not necessarily enduringly so. Reframing it
I don't have a full explicit model for it, so here's some metaphors that hopefully collectively shed light:
- Hunger beyond reason, hunger for weeks, hunger to the point of starvation. A rich and lavish meal set before you, of all your favorite foods and drinks, prepared expertly. A first bite - overwhelming; so perfect and so intense. You toy with the idea of eating nothing more and find you can neither eat nor decline - at least not comfortably. You gorge yourself and die of refeeding syndrome.
- Dreams of your childhood home, of the forests around it, of the sparkling beauty of the night sky. The building was knocked down years ago, the forest cut, the sky bleached with light pollution, all long after you moved away anyway.
- Like the itch/pain of a healing wound, or of a limb fallen asleep, or an amputated limb. Like internal screaming or weeping, suddenly given voice.
- Like staring at something dazzlingly bright and incomparably precious, even coveted; especially one that you can't touch or even reach - a sapphire the size of your fist, say, or the sun. What would you even do with those, really, if you could grab them?
- ^
Not sure if my terminology is correct here - I'm talking about doing the meditation/mental-action process itself. You know, the one which causes you tons of positive valence in a way you like but don't want.
Here's a game-theory game I don't think I've ever seen explicitly described before: Vicious Stag Hunt, a two-player non-zero-sum game elaborating on both Stag Hunt and Prisoner's Dilemma. (Or maybe Chicken? It depends on the obvious dials to turn. This is frankly probably a whole family of possible games.)
The two players can pick from among 3 moves: Stag, Hare, and Attack.
Hunting stag is great, if you can coordinate on it. Playing Stag costs you 5 coins, but if the other player also played Stag, you make your 5 coins back plus another 10.
Hunting hare is fine, as a fallback. Playing Hare costs you 1 coin, and assuming no interference, makes you that 1 coin back plus another 1.
But to a certain point of view, the richest targets are your fellow hunters. Preparing to Attack costs you 2 coins. If the other player played Hare, they escape you, barely recouping their investment (0 payoff), and you get nothing for your boldness. If they played Stag, though, you can backstab them right after securing their aid, taking their 10 coins of surplus destructively, costing them 10 coins on net. Finally, if you both played Attack, you both starve for a while waiting for the attack, you heartless fools. Your payoffs are symmetric, though this is one of the most important dials to turn: if you stand to lose less in such a standoff than you would by getting suckered, then Attack dominates Stag. My scratchpad notes have payoffs at (-5, -5), for instance.
To resummarize the payoffs:
- (H, H) = (1, 1)
- (H, S) = (1, -5)
- (S, S) = (10, 10)
- (H, A) = (0, -2)
- (S, A) = (-10(*), 20)
- (A, A) = (-n, -n); n <(=) 10(*) -> A >(=) S
So what happens? Disaster! Stag is dominated, so no one plays it, and everyone converges to Hare forever.
And what of the case where n > 10? While initially I'd expected a mixed equilibrium, I should have expected the actual outcome: the sole Nash equilibrium is still the pure all-Hare strategy - after all, we've made Attacking strictly worse than in the previous case! (As given by https://cgi.csc.liv.ac.uk/~rahul/bimatrix_solver/ ; I tested n = 12.)
A snowclone summarizing a handful of baseline important questions-to-self: "What is the state of your X, and why is that what your X's state is?" Obviously also versions that are less generally and more naturally phrased, that's just the most obviously parametrized form of the snowclone.
Classic(?) examples:
"What do you (think you) know, and why do you (think you) know it?" (X = knowledge/belief)
"What are you doing, and why are you doing it?" (X = action(-direction?)/motivation?)
Less classic examples that I recognized or just made up:
"How do you feel, and why do you feel that way?" (X = feelings/emotions)
"What do you want, and why do you want it?" (X = goal/desire)
"Who do you know here, and how do you know them?" (X = social graph?)
"What's the plan here, and what are you hoping to achieve by that plan?" (X = plan)
I think this post is pretty cool, and represents good groundwork on sticky questions of bioethics and the principles that should underpin them that most people don't think about very hard. Thanks for writing it.
The phrasing I got from the mentor/research partner I'm working with is pretty close to the former but closer in attitude and effective result to the latter. Really, the major issue is that string diagrams for a flavor of category and commutative diagrams for the same flavor of category are straight-up equivalent, but explicitly showing this is very very messy, and even explicitly describing Markov categories - the flavor of category I picked as likely the right one to use, between good modelling of Markov kernels and their role doing just that for causal theories (themselves the categorification of "Bayes nets up to actually specifying the kernels and states numerically") - is probably too much to put anywhere in a post but an appendix or the like.
...if there is no available action like snapping a photo that takes less time than writing the reply I'm replying to did...
There is not, but that's on me. I'm juggling too much and having trouble packaging my research in a digestible form. Precarious/lacking funding and consequent binding demands on my time really don't help here either. I'll add you to the long long list of people who want to see a paper/post when I finally complete one.
I guess a major blocker for me is - I keep coming back to the idea that I should write the post as a partially-ordered series of posts instead. That certainly stands out to me as the most natural form for the information, because there's three near-totally separate branches of context - Bayes nets, the natural latent/abstraction agenda, and (monoidal category theory/)string diagrams - of which you need to somewhat understand some pair in order to understand major necessary background (causal theories, motivation for Bayes net algebra rules, and motivation for string diagram use), and all three to appreciate the research direction properly. But I'm kinda worried that if I start this partially-ordered lattice of posts, I'll get stuck somewhere. Or run up against the limits of what I've already worked out yet. Or run out of steam with all the writing and just never finish. Or just plain "no one will want to read through it all".
I guess? I mean, there's three separate degrees of "should really be kept contained"-ness here:
- Category theory -> string diagrams, which pretty much everyone keeps contained, including people who know the actual category theory
- String diagrams -> Bayes nets, which is pretty straightforward if you sit and think for a bit about the semantics you accept/are given for string diagrams generally and maybe also look at a picture of generators and rules - not something anyone needs to wrap up nicely but it's also a pretty thin
- [Causal theory/Bayes net] string diagrams -> actual statements about (natural) latents, which is something I am still working on; it's turning out to be pretty effortful to grind through all the same transcriptions again with an actually-proof-usable string diagram language this time. I have draft writeups of all the "rules for an algebra of Bayes nets" - a couple of which have turned out to have subtleties that need working out - and will ideally be able to write down and walk through proofs entirely in string diagrams while/after finishing specifications of the rules.
So that's the state of things. Frankly I'm worried and generally unhappy about the fact that I have a post draft that needs restructuring, a paper draft that needs completing, and a research direction to finish detailing, all at once. If you want some partial pictures of things anyway all the same, let me know.
Not much to add apart from "this is clean and really good, thanks!".
I promise I am still working on working out all the consequences of the string diagram notation for latential Bayes nets, since the guts of the category theory are all fixed (and can, as a mentor advises me, be kept out of the public eye as they should be). Things can be kept (basically) purely in terms of string diagrams. In whatever post I write, they certainly will be.
I want to be able to show that isomorphism of natural latents is the categorical property I'm ~97% sure it is (and likewise for minimal and maximal latents). I need to sit myself down and at least fully transcribe the Fundamental Theorem of Latents in preparation for supplying the proof to that.
Mostly I'm spending a lot of time on a data science bootcamp and an AISC track and taking care of family and looking for work/funding and and and.
Because RLHF works, we shouldn't be surprised when AI models output wrong answers which are specifically hard for humans to distinguish from a right answer.
This observably (seems like it) generalizes to all humans, instead of (say) it being totally trivial somehow to train an AI on feedback only from some strict and distinguished subset of humanity such that any wrong answers it produced could be easily spotted by the excluded humans.
Such wrong answers which look right (on first glance) also observably exist, and we should thus expect that if there's anything like a projection-onto-subspace going on here, our "viewpoint" for the projection, given any adjudicating human mind, is likely all clustered in some low-dimensional subspace of all possible viewpoints and maybe even just around a single point.
This is why I'd agree that RLHF was so specifically a bad tradeoff in capabilities improvement vs safety/desirability outcomes but still remain agnostic as to the absolute size of that tradeoff.
Sent you an admonymous.
(Random thought I had and figured this was the right place to set it down:) Given how centally important token-based word embeddings as to the current LLM paradigm, how plausible is it that (put loosely) "doing it all in Chinese" (instead of English) is actually just plain a more powerful/less error-prone/generally better background assumption?
Associated helpful intuition pump: LLM word tokenization is like a logographic writing system, where each word corresponds to a character of the logography. There need be no particular correspondence between the form of the token and the pronunciation/"alphabetical spelling"/other things about the word, though it might have some connection to the meaning of the word - and it often makes just as little sense to be worried about the number of grass radicals in "草莓" as it does to worry about the number of r's in a "strawberry" token.
(And yes, I am aware that in Mandarin Chinese, there's lots of multi-character words and expressions!)
As someone who does both data analysis and algebraic topology, my take is that TDA showed promise but ultimately there's something missing such that it's not at full capacity. Either the formalism isn't developed enough or it's being consistently used on the wrong kinds of datasets. Which is kind of a shame, because it's the kind of thing that should work beautifully and in some cases even does!
I imagine it's something like "look for things that are notably absent, when you would expect them to have been found if there"?
Do you know when you started experiencing having an internal music player? I recall that that started for me when I was about 6. Also, do you know whether you can deliberately pick a piece of music, or other nonmusical sonic experiences, to playback internally? Can you make them start up from internal silence? Under what conditions can you make them stop? Do you ever experience long stretches where you have no internal music at all?
Sure - I can believe that that's one way a person's internal quorum can be set up. In other cases, or for other reasons, they might be instead set up to demand results, and evaluate primarily based on results. And that's not great or necessarily psychologically healthy, but then the question becomes "why do some people end up one way and other people the other way?" Also, there's the question of just how big/significant the effort was, and thus how big of an effective risk the one predictor took. Be it internal to one person or relevant to a group of humans, a sufficiently grand-scale noble failure will not generally be seen as all that noble (IME).
This makes some interesting predictions re: some types of trauma: namely, that they can happen when someone was (probably even correctly!) pushing very hard towards some important goal, and then either they ran out of fuel just before finishing and collapsed, or they achieved that goal and then - because of circumstances, just plain bad luck, or something else - that goal failed to pay off in the way that it usually does, societally speaking. In either case, the predictor/pusher that burned down lots of savings in investment doesn't get paid off. This is maybe part of why "if trauma, and help, you get stronger; if trauma, and no help, you get weaker".
I didn't enjoy this one as much, but that's likely down to not having had the time/energy to spend on thinking this through deeply. That said... I did not in fact enjoy it as much and I mostly feel like garbage for having done literally worse than chance, and I feel like it probably would have been better if I hadn't participated at all.
Let me see if I've understood point 3 correctly here. (I am not convinced I have actually found a flaw, I'm just trying to reconcile two things in my head here that look to conflict, so I can write down a clean definition elsewhere of something that matters to me.)
factors over . In , were conditionally independent of each other, given . Because factors over and because in , were conditionally independent of each other, given , we can very straightforwardly show that factors over , too. This is the stuff you said above, right?
But if we go the other direction, assuming that some arbitrary factors over , I don't think that we can then still derive that factors over in full generality, which was what worried me. But that break of symmetry (and thus lack of equivalence) is... genuinely probably fine, actually - there's no rule for arbitrarily deleting arrows, after all.
That's cleared up my confusion/worries, thanks!
We’ll refer to these as “Bookkeeping Rules”, since they feel pretty minor if you’re already comfortable working with Bayes nets. Some examples:
- We can always add an arrow to a diagram (assuming it doesn’t introduce a loop), and the approximation will get no worse.
Here's something that's kept bothering me on and off for the last few months: This graphical rule immediately breaks Markov equivalence. Specifically, two DAGs are Markov-equivalent only if they share an (undirected) skeleton. (Lemma 6.1 at the link.)
If the major/only thing we care about here regarding latential Bayes nets is that our Grand Joint Distribution factorize over (that is, satisfy) our DAG (and all of the DAGs we can get from it by applying the rules here), then by Thm 6.2 in the link above, is also globally/locally Markov wrt . This holds even when is not guaranteed for some of the possible joint states in , unlike Hammersley-Clifford would require.
That in turn means that (Def 6.5) there's some distributions can be such that factors over , but not (where trivially has the same vertices as does); specifically, because don't (quite) share a skeleton, they can't be Markov-equivalent, and because they aren't Markov-equivalent, no longer needs to be (locally/globally) Markov wrt (and in fact there must exist some which explicitly break this), and because of that, such need not factor over . Which I claim we should not want here, because (as always) we care primarily about preserving which joint probability distributions factorize over/satisfy which DAGs, and of course we probably don't get to pick whether our is one of the ones where that break in the chain of logic matters.
I'm going to start by attacking this a little on my own before I even look much at what other people have done.
Some initial observations from the SQL+Python practice this gave me a good excuse to do:
- Adelon looks to have rough matchups against Elf Monks. Which we don't have. They are however soft to even level 3-4 challengers sometimes. Maybe Monks and/or Fencers have an edge on Warriors?
- Bauchard seems to have particularly strong matchups against other Knights, so we don't send Velaya there. They seem a little soft to Monks and to Dwarf Ninjas and especially to Knights, so maybe Zelaya? Boots should help here.
- Cadagal has precious few defeats, but one of them might be to a level 2(!) Human Warrior with fancy +3 Gauntlets. Though it seems like there's a lot of combats where some Cadagal-like fighter has +4 Boots instead? Not sure if that's the same guy.
- And on that note, the max level is 7, and the max bonus for Boots and Gauntlets both is +4.
- Max Boots (+4) is always on a level 7 Elf Ninja with +3 Gauntlets (but disappears altogether most of the way through the dataset).
- Max Gauntlets (+4) is on either a level 7 Dwarf Monk who upgraded from +1 Boots to +3 Boots halfway through, or else there's two of them. Thankfully we're not facing them.
- Deepwrack poses problems. They have just as few defeats, and one of them even contradicts the ordering I derived below! Ninjas are meant to lose to Monks. Maybe the speed matters a lot in that case?
- It looks like a strict advantage in level or gear - holding all else constant - means you win every time. If everything is totally identical, you win about half the time. (Which seems obvious but worth checking.)
- Looking through upsets - bouts where the classes are different, the losing fighter had at least 2 levels on the winner, and the loser's gear was no better than the winner's - we generally see that:
- Fencers beat Monks and Rangers and lose to Knights, Ninjas, and Warriors
- Knights beat Fencers and Ninjas, tie(???) with Monks and Warriors, and lose (weakly) to Rangers
- Monks beat Ninjas, Rangers, and maybe Warriors, tie (?) with Knights, and lose to Fencers
- Ninjas beat Fencers and (weakly) Rangers, and lose to Knights, Monks, and Warriors
- Rangers beat Knights (weakly), Ninjas, and Warriors, tie with Fencers, and lose to Monks
- Warriors beat Fencers, Ninjas, tie(?) with Knights, and lose to Rangers and maybe Monks
So my current best guess (pending understanding which gear is best for which class/race) is:
Willow v Adelon, Varina v Bauchard, Xerxes v Cadagal, Yalathinel v Deepwrack.
If I had to guess what gear to give to who: Warrior v Knight is a rough matchup, so Varina's going to need the help; the rest of my assignments are based thus far on ~vibes~ for whether speed or power will matter more for the class. Thus:
Willow gets +2 Boots and +1 Gauntlets, Varina gets +4 Boots and +3 Gauntlets, Xerxes gets +1 Boots and +2 Gauntlets, and Yalathinel gets +3 Boots.
Some theories I need to test:
- Race affects how good you are at a class. Elves might be best at rangering, say.
- Race and/or class affect how much benefit you get out of boots and/or gauntlets. Being a warrior might mean you get full benefit from gauntlets but none from boots.
- Color might affect how well classes do. Ninjas wearing red might win way less often.
- The color does not actually seem to affect ninjas all that much if at all - 6963 vs 6762 wins. Could still be a tiebreaker?
- Color doesn't affect things much overall either: 40136 vs 39961 wins.
- There's some rank-ordering of class+race+level matchups, maybe an additive one.
- Alternatively there could be some nontransitive thing going on with tiebreaks sometimes from levels, races, and gear?
- On further reflection that totally seems to be what's going on here.
- Maybe there's something about the matchup ordering being sorted over (race, class)? D's loss (as a L6 Dwarf Monk) to a L4 Dwarf Ninja is... unexpected to say the least!
Wild speculation:
- If you [use the +4 Boots in combat and beat Cadagal then they'll know you were] responsible [for] ????? ?????? [Boots from his/her/the] House. [You will gain its] lasting enmity, [and] [people? will?] ???????? ???? ??? ???? ?? ??? ???? ??????? ?? ?? ????? ?? ????????? ?? ??? [upon] your honor [if] ????????? ???? ?? ???? ??? ???? ??? ??? friendship ???? ?? ??? ???? ?? ??? ?????? ??????? ?? ?? ?????.
- So maybe we're OK to use the +4 Boots as long as it's not against Cadagal?
- No idea how to even guess at what's going on in that second sentence apart from "bad things will happen and everyone will hate you, you dirty thief".
I'm gonna leave my thoughts on the ramifications for academia, where a major career step is to repeatedly join and leave different large bureaucratic organizations for a decade, as an exercise to the reader.
Like, in a world where the median person is John Wentworth (“Wentworld”), I’m pretty sure there just aren’t large organizations of the sort our world has.
I have numerous thoughts on how Lorxusverse Polity handles this problem but none of it is well-worked out enough to share. In sum though: Probably cybernetics (in the Beer sense) got discovered way earlier and actually ever used as stated and that was that, no particular need for dominance-status as glue or desire for it as social-good. (We'd be way less social overall, though, too, and less likely to make complex enduring social arrangements. There would be careful Polity-wide projects for improving social-contact and social-nutrition. They would be costly and weird. Whether that's good or bad on net, I can't say.)
Sure, but you obviously don't (and can't even in principle) turn that up all the way! The key is to make sure that that mode still exists and that you don't simply amputate and cauterize it.
[2.] maybe one could go faster by trying to more directly cleave to the core philosophical problems.
...
An underemphasized point that I should maybe elaborate more on: a main claim is that there's untapped guidance to be gotten from our partial understanding--at the philosophical level and for the philosophical level. In other words, our preliminary concepts and intuitions and propositions are, I think, already enough that there's a lot of progress to be made by having them talk to each other, so to speak.
OK but what would this even look like?\gen
Toss away anything amenable to testing and direct empirical analysis; it's all too concrete and model-dependent.
Toss away mathsy proofsy approaches; they're all too formalized and over-rigid and can only prove things from starting assumptions we haven't got yet and maybe won't think of in time.
Toss away basically all settled philosophy, too; if there were answers to be had there rather than a few passages which ask correct questions, the Vienna Circle would have solved alignment for us.
What's left? And what causes it to hang together? And what causes it not to vanish up its own ungrounded self-reference?
Clearly academia has some blind spots, but how big? Do I just have a knack for finding ideas that academia hates, or are the blind spots actually enormous?
From someone who left a corner of it: the blindspots could be arbitrarily large as far as I know, because there seemed to me to be no real explicit culture of Hamming questions/metalooking for anything neglected. You worked on something vaguely similar/related to your advisor's work, because otherwise you can't get connections to people who know how to attack the problem.
As my reacts hopefully implied, this is exactly the kind of clarification I needed - thanks!
Like, bro, I'm saying it can't think. That's the tweet. What thinking is, isn't clear, but That thinking is should be presumed, pending a forceful philosophical conceptual replacement!
Sure, but you're not preaching to the choir at that point. So surely the next step in that particular dance is to stick a knife in the crack and twist?
That is -
"OK, buddy:
Here's property P (and if you're good, Q and R and...) that [would have to]/[is/are obviously natural and desirable to]/[is/are pretty clearly a critical part if you want to] characterize 'thought' or 'reasoning' as distinct from whatever it is LLMs do when they read their own notes as part of a new prompt and keep chewing them up and spitting the result back as part of the new prompt for itself to read.
Here's thing T (and if you're good, U and V and...) that an LLM cannot actually do, even in principle, which would be trivially easy for (say) an uploaded (and sane, functional, reasonably intelligent) human H could do, even if H is denied (almost?) all of their previously consolidated memories and just working from some basic procedural memory and whatever Magical thing this 'thinking'/'reasoning' thing is."
And if neither you nor anyone else can do either of those things... maybe it's time to give up and say that this 'thinking'/'reasoning' thing is just philosophically confused? I don't think that that's where we're headed, but I find it important to explicitly acknowledge the possibility; I don't deal in more than one epiphenomenon at a time and I'm partial to Platonism already. So if this 'reasoning' thing isn't meaningfully distinguishable in some observable way from what LLMs do, why shouldn't I simply give in?
> https://www.lesswrong.com/posts/r7nBaKy5Ry3JWhnJT/announcing-iliad-theoretical-ai-alignment-conference#whqf4oJoYbz5szxWc
you didn't invite me so you don't get to have all the nice things, but I did leave several good artifacts and books I recommend lying around. I invite you to make good use of them!
(Minor quibble: I’d be careful about using “should” here, as in “the heart should pump blood”, because “should” is often used in a moral sense. For instance, the COVID-19 spike protein presumably has some function involving sneaking into cells, it “should” do that in the teleological sense, but in the moral sense COVID-19 “should” just die out. I think that ambiguity makes a sentence like “but it might be another thing to say, that the heart should pump blood” sound deeper/more substantive than it is, in this context.
This puts me in mind of what I've been calling "the engineer's 'should'" vs "the strategist's 'should'" vs "the preacher's 'should'". Teleological/mechanistic, systems-predictive, is-ought. Really, these ought to all be different words, but I don't really have a good way to cleanly/concisely express the difference between the first two.
To paraphrase:
Want and have. See and take. Run and chase. Thirst and slake. And if you're thwarted in pursuit of your desire… so what? That's just the way of things, not always getting what you hunger for. The desire itself is still yours, still pure, still real, so long as you don't deny it or seek to snuff it out.
@habryka Forgot to comment on the changes you implemented for soundscape at LH during the mixer - possibly you may want to put a speaker in the Bayes window overlooking the courtyard firepit. People started congregating/pooling there (and notably not at the other firepit next to it!) because it was the locally-quietest location, and then the usual failure modes of an attempted 12-person conversation ensued.
any finite-entropy function
Uh...
- .
- By "oh, no, the s have to be non-repeating", Thus by the nth term test, .
- By properties of logarithms, has no upper bound over . In particular, has no upper bound over .
- I'm not quite clear on how @johnswentworth defines a "finite-entropy function", but whichever reasonable way he does that, I'm pretty sure that the above means that the set of all such functions over our as equipped with distribution of finite entropy is in fact the empty set. Which seems problematic. I do actually want to know how John defines that. Literature searches are mostly turning up nothing for me. Notably, many kinds of reasonable-looking always-positive distributions over merely countably-large sample spaces have infinite Shannon entropy.
(h/t to @WhatsTrueKittycat for spotlighting this for me!)
most of them are small and probably don’t have the mental complexity required to really grasp three dimensions
Foxes and ferrets strike me as two obvious exceptions here, and indeed, we see both being incredibly good at getting into, out of, and around spaces, sometimes in ways that humans might find unexpected.
, and here]
This overleaf link appears to be restricted-access-only?
As someone who's spent meaningful amounts of time at LH during parties, absolutely yes. You successfully made it architecturally awkward to have large conversations, but that's often cashed out as "there's a giant conversation group in and totally blocking [the Entry Hallway Room of Aumann]/[the lawn between A&B]/[one or another firepit and its surrounding walkways]; that conversation group is suffering from the obvious described failure modes, but no one in it is sufficiently confident or agentic or charismatic to successfully break out into a subgroup/subconversation.
I'd recommend quiet music during parties? Or maybe even just a soundtrack of natural noises - birdsong and wind? rain and thunder? - to serve the purpose instead.
I liked this post so much that I made my own better Lesser Scribing Artifact and I'm preparing a post meant to highlight the differences between my standard and yours. Cheers!
Why do you need to be certain? Say there's a screen showing a nice "high-level" interface that provides substantial functionality (without directly revealing the inner workings, e.g. there's no shell). Something like that should be practically convincing.
Then whatever that's doing is a constraint in itself, and I can start off by going looking for patterns of activation that correspond to e.g. simple-but-specific mathematical operations that I can actuate in the computer.
I'm unsure about that, but the more pertinent questions are along the lines of "is doing so the first (in understanding-time) available, or fastest, way to make the first few steps along the way that leads to these mathematically precise definitions? The conjecture here is "yes".
Maybe? But I'm definitely not convinced. Maybe for idealized humanesque minds, yes, but for actual humans, if your hypothesis were correct, Euler would not have had to invent topology in the 1700s, for instance.
I don't have much to say except that this seems broadly correct and very important in my professional opinion. Generating definitions is hard, and often depends subtly/finely on the kinds of theorems you want to be able to prove (while still having definitions that describe the kind of object you set out to describe, and not have them be totally determined by the theorem you want - that would make the objects meaningless!). Generating frameworks out of whole cloth is harder yet; understanding them is sometimes easiest of all.
Thinking about it more, I want to poke at the foundations of the koan. Why are we so sure that this is a computer at all? What permits us this certainty, that this is a computer, and that it is also running actual computation rather than glitching out?
B: Are you basically saying that it's a really hard science problem?
From a different and more conceit-cooperative angle: it's not just that this is a really hard science problem, it might be a maximally hard science problem. Maybe too hard for existing science to science at! After all, hash functions are meant to be maximally difficult, computationally speaking, to invert (and in fact impossible in the general case but merely very hard to generate hash collisions).
Another prompt: Suppose you leave Green alone for six months, and when you come back, it turns out ze's figured out what hash tables are. What do you suppose might have happened that led to zer figuring out hash tables?
That Green has figured out how to probe the RAM properly, and how to assign meaning to the computations, and that zer Alien Computer is doing the same-ish thing that mine is?
Although you never do figure out what algorithm is running on the alien computer, it happens to be the case that in the year 3000, the algorithm will be called "J-trees".
It would follow, to me, that I should be looking for treelike patterns of activation, and in particular that maybe this is some application of the principles inherent to hash sort or radix sort to binary self-balancing trees, likely in memory address assignment, as might be necessary/worthwhile in a computer of a colossal scale such as we won't even get until Y3k?
B: It sounds nice, but it kind of just sounds like you're recommending mindfulness or something.
I'd disagree with Blue here! To clean and oil a machine and then run a quick test of function than setting it running to carefully watch it do its thing!
...However, we can put the metaphysicist's ramblings in special quotes:
Doing so still never gets you to the idea of a homology sphere, and it isn't enough to point towards the mathematically precise definition of an infinite 3-manifold without boundary.
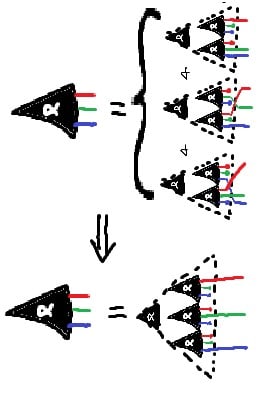
EDIT: I and the person who first tried to render this SHAPE for me misunderstood its nature.
You maybe got stuck in some of the many local optima that Nurmela 1995 runs into. Genuinely, the best sphere code for 9 points in 4 dimensions is known to have a minimum angular separation of ~1.408 radians, for a worst-case cosine similarity of about 0.162.
You got a lot further than I did with my own initial attempts at random search, but you didn't quite find it, either.
On @TsviBT's recommendation, I'm writing this up quickly here.
re: the famous graph from https://transformer-circuits.pub/2022/toy_model/index.html#geometry with all the colored bands, plotting "dimensions per feature in a model with superposition", there look to be 3 obvious clusters outside of any colored band and between 2/5 and 1/2, the third of which is directly below the third inset image from the right. All three of these clusters are at 1/(1-S) ~ 4.
A picture of the plot, plus a summary of my thought processes for about the first 30 seconds of looking at it from the right perspective:
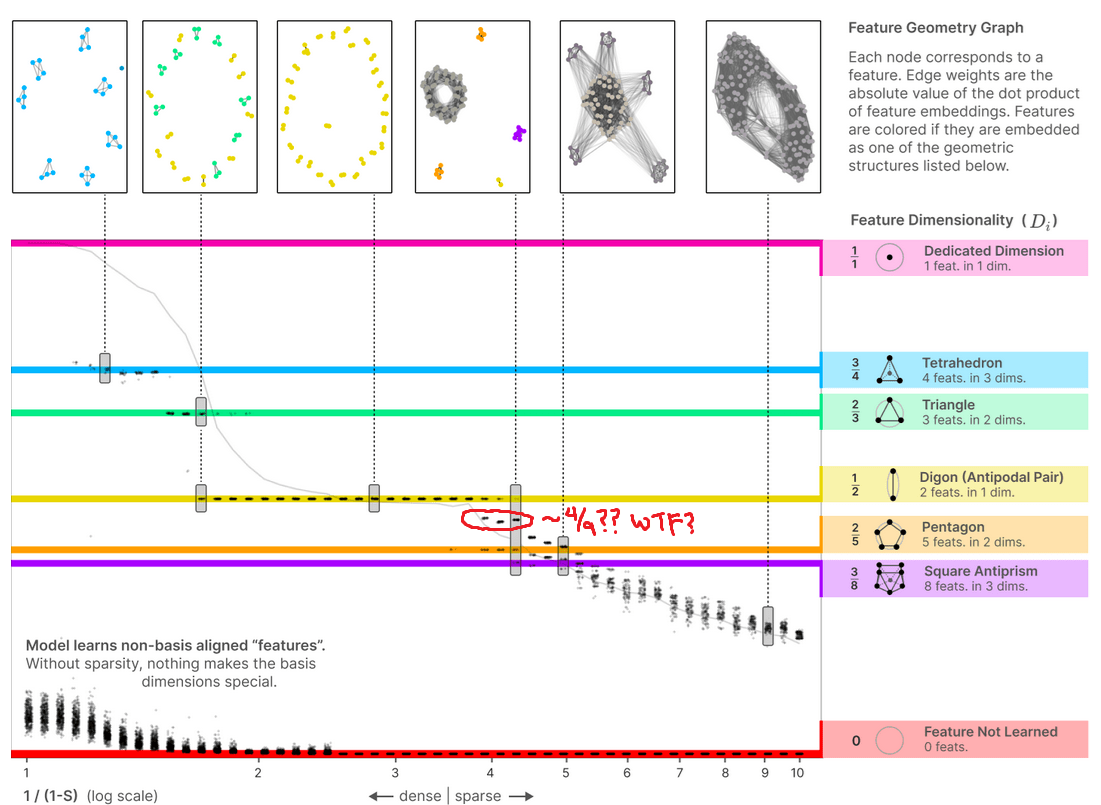
In particular, the clusters appear to correspond to dimensions-per-feature of about 0.44~0.45, that is, 4/9. Given the Thomson problem-ish nature of all the other geometric structures displayed, and being professionally dubious that there should be only such structures of subspace dimension 3 or lower, my immediate suspicion since last week when I first thought about this is that the uncolored clusters should be packing 9 vectors as far apart from each other as possible on the surface of a 3-sphere in some 4D subspace.
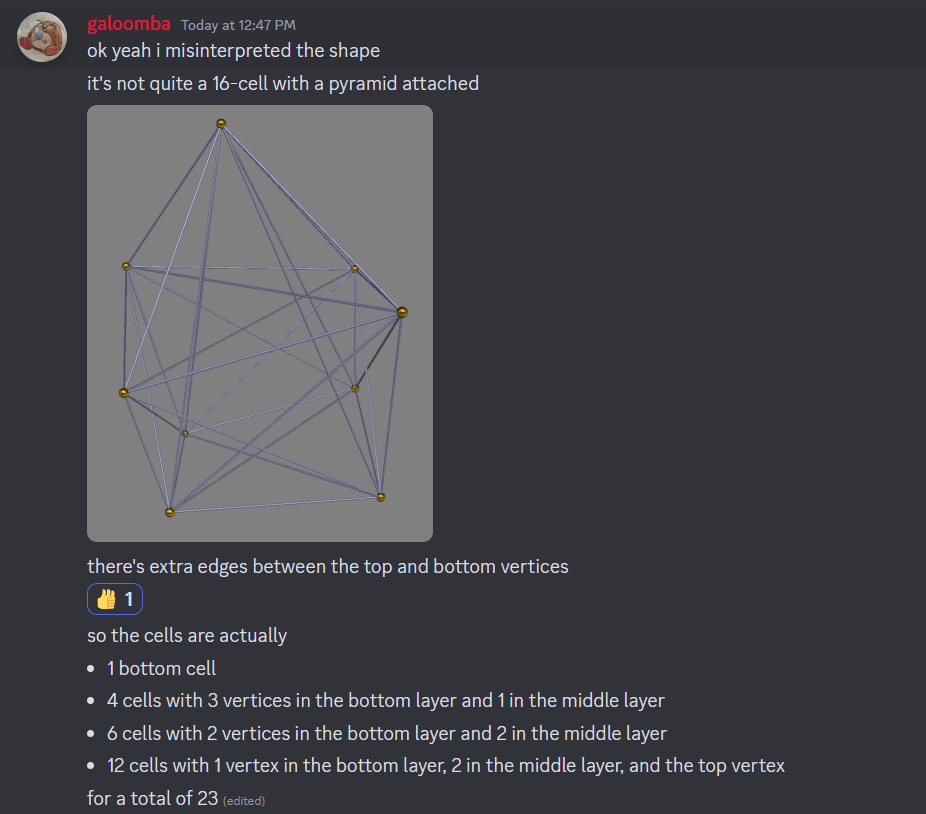
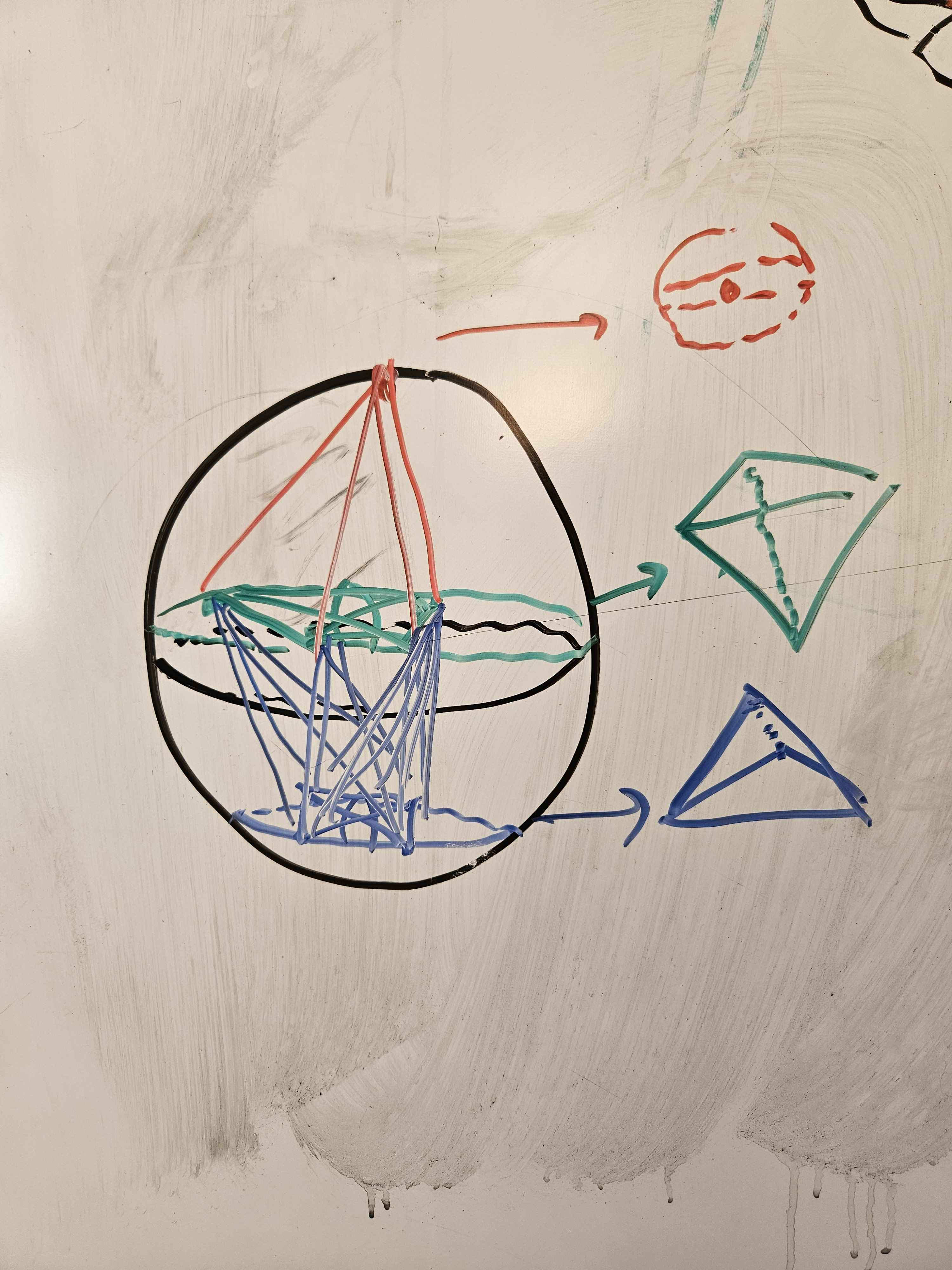
In particular, mathematicians have already found a 23-celled 4-tope with 9 vertices (which I have made some sketches of) where the angular separation between vertices is ~80.7° : http://neilsloane.com/packings/index.html#I . Roughly, the vertices are: the north pole of S^3; on a slice just (~9°) north of the equator, the vertices of a tetrahedron "pointing" in some direction; on a slice somewhat (~19°) north of the south pole, the vertices of a tetrahedron "pointing" dually to the previous tetrahedron. The edges are given by connecting vertices in each layer to the vertices in the adjacent layer or layers. Cross sections along the axis I described look like growing tetrahedra, briefly become various octahedra as we cross the first tetrahedon, and then resolve to the final tetrahedron before vanishing.
I therefore predict that we should see these clusters of 9 embedding vectors lying roughly in 4D subspaces taking on pretty much exactly the 23-cell shape mathematicians know about, to the same general precision as we'd find (say) pentagons or square antiprisms, within the model's embedding vectors, when S ~ 3/4.
Potentially also there's other 3/f, 4/f, and maybe 5/f; given professional experience I would not expect to see 6+/f sorts of features, because 6+ dimensions is high-dimensional and the clusters would (approximately) factor as products of lower-dimensional clusters already listed. There's a few more clusters that I suspect might correspond to 3/7 (a pentagonal bipyramid?) or 5/12 (some terrifying 5-tope with 12 vertices, I guess), but I'm way less confident in those.
A hand-drawn rendition of the 23-cell in whiteboard marker:
As I also said in person, very much so!
Probabilities of zero are extremely load-bearing for natural latents in the exact case...
Dumb question: Can you sketch out an argument for why this is the case and/or why this has to be the case? I agree that ideally/morally this should be true, but if we're already accepting a bounded degree of error elsewhere, what explodes if we accept it here?
Yeah. I agree that it's a huge problem that I can't immediately point to what the output might be, or why it might cause something helpful downstream.