Some Rules for an Algebra of Bayes Nets
post by johnswentworth, David Lorell · 2023-11-16T23:53:11.650Z · LW · GW · 44 commentsContents
Re-Rooting Rule for Markov Chains
Verbose Example
Re-Rooting Rule, More Generally
Joint Independence Rule
The Frankenstein Rule
Factorization Transfer Rule
Stitching Rule for a Markov Blanket
Bookkeeping Rules
End-to-End Example
What To Read Next
Appendix: Proofs & Exercises
Re-Rooting Rule for Markov Chains
Approximation
Exercise
Joint Independence Rule: Exercise
Frankenstein Rule
Factorization Transfer
Stitching
None
45 comments
In this post, we’re going to use the diagrammatic notation of Bayes nets [LW · GW]. However, we use the diagrams a little bit differently than is typical. In practice, such diagrams are usually used to define a distribution - e.g. the stock example diagram
... in combination with the five distributions , , , , , defines a joint distribution
In this post, we instead take the joint distribution as given, and use the diagrams to concisely state properties of the distribution. For instance, we say that a distribution “satisfies” the diagram
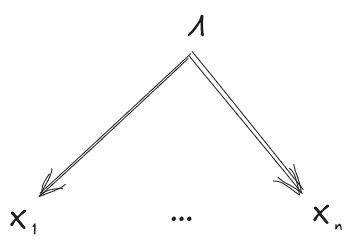
if-and-only-if . (And once we get to approximation, we’ll say that approximately satisfies the diagram, to within , if-and-only-if .)
The usage we’re interested in looks like:
- State that some random variables satisfy several different diagrams
- Derive some new diagrams which they satisfy
In other words, we want to write proofs diagrammatically - i.e. each “step” of the proof combines some diagrams (which the underlying distribution satisfies) to derive a new diagram (which the underlying distribution satisfies).
For this purpose, it’s useful to have a few rules for an “algebra of diagrams”, to avoid always having to write out the underlying factorizations in order to prove anything. We’ll walk through a few rules, give some examples using them, and prove them in the appendix. The rules:
- Re-Rooting Rule for Markov Chains
- Joint Independence Rule
- Frankenstein Rule
- Factorization Transfer Rule
- Stitching Rule for A Shared Markov Blanket
- Bookkeeping Rules
The first couple are relatively-simple rules for “serial” and “parallel” variables, respectively; they’re mostly intended to demonstrate the framework we’re using. The next four rules are more general, and give a useful foundation for application. Finally, the Bookkeeping Rules cover some “obvious” minor rules, which basically say that all the usual things we can deduce from a single Bayes net still apply.
Besides easy-to-read proofs, another big benefit of deriving things via such diagrams is that we can automatically extend our proofs to handle approximation (i.e. cases where the underlying distribution only approximately satisfies the diagrams). We’ll cover approximate versions of the rules along the way.
Finally, we’ll walk through an end-to-end example of a proof which uses the rules.
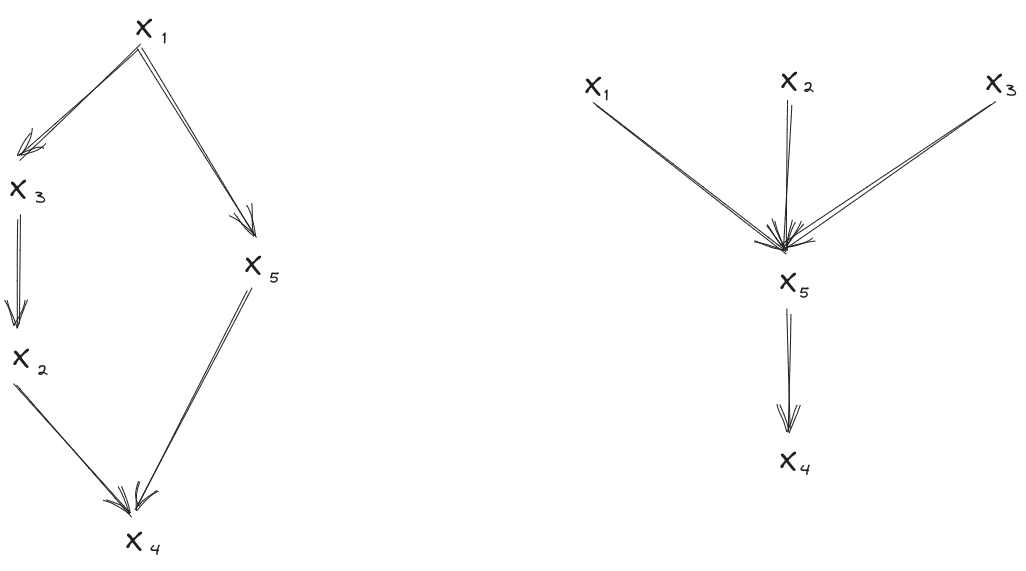
Re-Rooting Rule for Markov Chains
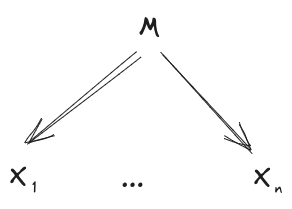
Suppose we have a distribution over which satisfies
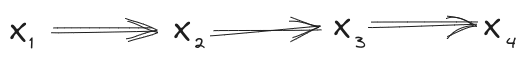
Then the distribution also satisfies all of these diagrams:
In fact, we can also go the other way: any one of the above diagrams implies all of the others.
Since this is our first rule, let’s unpack all of that compact notation into its full long-form, in a concrete example. If you want to see the proof, take a look at the appendix.
Verbose Example
For concreteness, let’s say we have a widget being produced on an assembly line. No assembly line is perfect; sometimes errors are introduced at a step, like e.g. a hole isn’t drilled in quite the right spot. Those errors can then cause further errors in subsequent steps, like e.g. the hole isn’t in quite the right spot, a part doesn’t quite fit right. We’ll say that is the state of the widget after step 1, is the state after step 2, etc; the variables are random to model the “random” errors sometimes introduced.
Our first diagram
says that the probability of an error at step , given all the earlier steps, depends only on the errors accumulated up through step . That means we’re ignoring things like e.g. a day of intermittent electrical outages changing the probability of error in every step in a correlated way. Mathematically, we get that interpretation by first applying the chain rule (which applies to any distribution) to the underlying distribution:
(we can also think of the chain rule as a “universal diagram” satisfied by all distributions; it’s a DAG with an edge between every two variables). We then separately write out the factorization stated by the diagram:
Equating these two (then marginalizing variables different ways and doing some ordinary algebra), we find:
- (duh)
- (also duh)
… which we can interpret as “probability of an error at step , given all the earlier steps” - i.e. the left-hand side of each of the above - “depends only on the errors accumulated up through step ” - i.e. the right-hand side of each of the above. (Note: many of the proofs for rules in this post start by "breaking things up" this way, using the chain rule.)
So far, we’ve just stated what the starting diagram means. Now let’s look at one of the other diagrams:

The factorization stated by this diagram is
Interpretation: we could model the system as though the error-cascade “starts” at step 3, and then errors propagate back through time to steps 2 and 1, and forward to step 4. Obviously this doesn’t match physical causality (i.e. do() operations will give different results on the two diagrams). But for purposes of modeling the underlying distribution , this diagram is equivalent to the first diagram.
What does “equivalent” mean here? It means that any distribution which satisfies the factorization expressed by the first diagram (i.e. ) also satisfies the factorization expressed by the second diagram (i.e. ), and vice versa.
More generally, this is a standard example of what we mean when we say “diagram 1 implies diagram 2”, for any two diagrams: it means that any distribution which satisfies the factorization expressed by diagram 1 also satisfies the factorization expressed by diagram 2. If the two diagrams imply each other, then they are equivalent: they give us the same information about the underlying distribution.
Back to the example: how on earth would one model the widget error-cascade as starting at step 3? Think of it like this: if we want to simulate the error-cascade (i.e. write a program to sample from ), we could do that by:
- First sampling
- … then working backward to the distribution of given that value, and sampling from that distribution
- … then further back from to
- … and on the other side, sampling from
When we frame it that way, it’s not really something physical which is (modeled as) propagating back through time. Rather, we’re just epistemically working backward as a way to “solve for” the system’s behavior. And that’s a totally valid way to “solve for” this system’s behavior (though I wouldn’t personally want to code it that way).
In the context of our widget example, this seems… not very useful. Sure, the underlying distribution can be modeled using some awkward alternative diagram, but the alternative diagram doesn’t really seem better than the more-intuitive starting diagram. More generally, our rule for re-rooting Markov Chains is usually useful as an intermediate in a longer derivation; the real value isn’t in using it as a standalone rule.
Re-Rooting Rule, More Generally
More generally, any diagram of the form
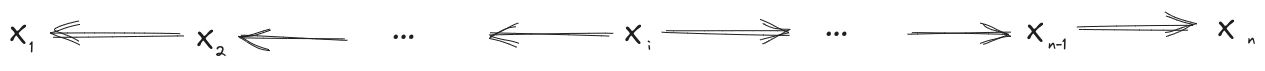
is equivalent to any other diagram of the same form (i.e. take any other “root node” ).
For approximation, if the underlying distribution approximately satisfies any diagram of the form
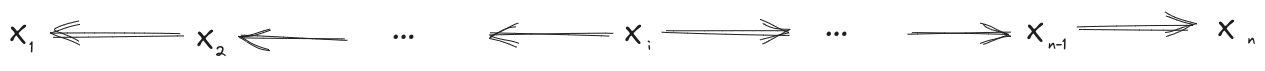
to within , then it satisfies all the others to within .
Again, since this is our first rule, let’s unpack that compact notation. The diagram
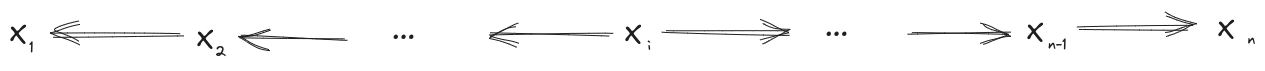
expresses the factorization
We say that the underlying distribution “approximately satisfies the diagram to within ” if-and-only-if
So, our approximation claim is saying: if for any , then for all . Indeed, the proof (in the appendix) shows that those ’s are all equal.
Joint Independence Rule
Suppose I roll three dice . The first roll, , is independent of the second two, . The second roll, , is independent of . And the third roll, X_3, is independent of . Then: all three are independent.
If you’re like “wait, isn’t that just true by definition of independence?”, then you have roughly the right idea! (Some-but-not-all sources define many-variable independence this way.) But if we write out the underlying diagrams/math, it will be more clear that we have a nontrivial (though simple) claim. Our preconditions say:
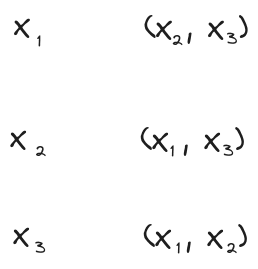
or, in standard notation
Our claim is that these preconditions together imply:
or in the usual notation
That’s pretty easy to prove, but the more interesting part is approximation. If our three diagrams hold to within respectively, then the final diagram holds to within . Writing it out the long way:
(Note that, in the dice example, these ’s are each the mutual information of one die with the others, since in general.) Together, they imply:
In the context of the dice example: if I think that each die individually is approximately independent of the others (to within bits of mutual information), that means the dice are all approximately jointly independent (to within bits).
More generally, this all extends in the obvious way to more variables. If I have variables, each of which is individually independent of all the others, then they’re all jointly independent. In the approximate case, if each of variables has only mutual information bits with the others, then the variables are jointly independent to within bits - i.e.
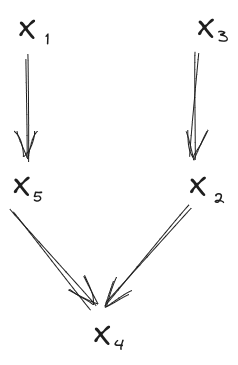
We can also easily extend the rule to conditional independence: if each of the variables has mutual information at most with the others conditional on some other variable , then the variables are jointly independent to within bits conditional on . Diagrammatically:

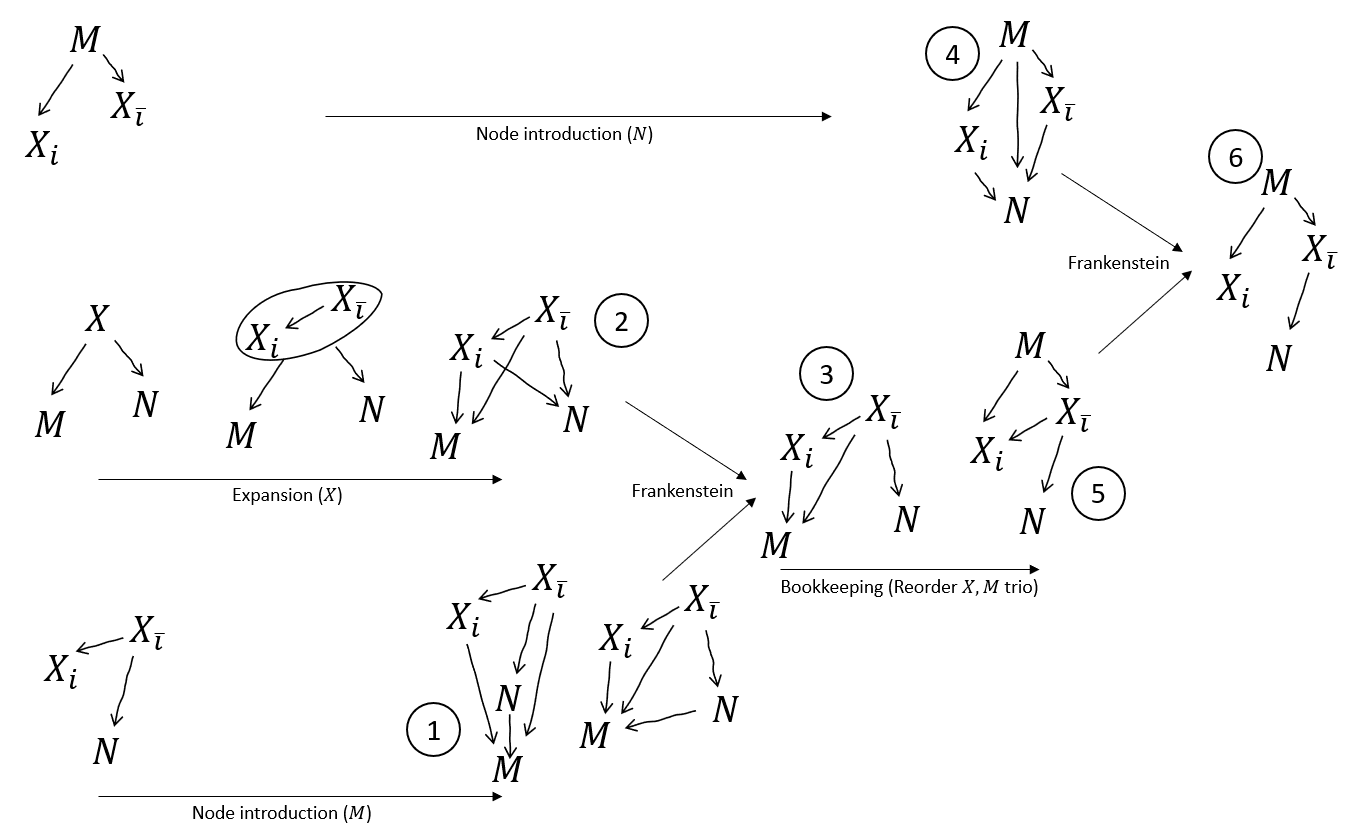
The Frankenstein Rule
Now on to a more general/powerful rule.
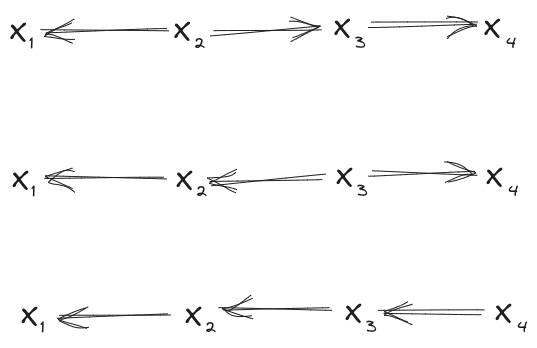
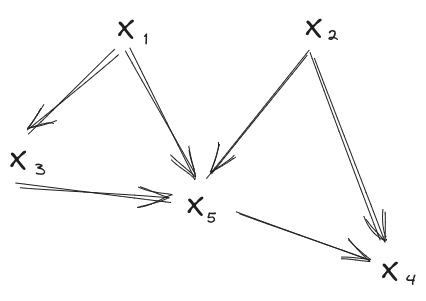
Suppose we have an underlying distribution which satisfies both of these diagrams:
Notice that we can order the variables ; with that ordering, there are no arrows from “later” to “earlier” variables in either diagram. (We say that the ordering “respects both diagrams”.) That’s the key precondition we need in order to apply the Frankenstein Rule.
Because we have an ordering which respects both diagrams, we can construct "Frankenstein diagrams", which combine the two original diagrams. For each variable, we can choose which of the two original diagrams to take that variable’s incoming arrows from. For instance, in this case, we could choose:
- Incoming arrows of from the left diagram
- Incoming arrows of from the right diagram
- Incoming arrows of from the left diagram
- Incoming arrows of from the left diagram
- Incoming arrows of from the left diagram
resulting in this diagram:
But we could make other choices instead! We could just as easily choose:
- Incoming arrows of from the right diagram
- Incoming arrows of from the left diagram
- Incoming arrows of from the right diagram
- Incoming arrows of from the right diagram
- Incoming arrows of from the left diagram
which would yield this diagram:
The Frankenstein rule says that, so long as our underlying distribution satisfies both of the original diagrams, it satisfies any Frankenstein of the original diagrams (so long as there exists an order of the variables which respects both original diagrams).
More generally, suppose that:
- Our underlying distribution satisfies two different diagrams, and
- There exists some ordering of the variables which respects the order of both diagrams simultaneously (i.e. when the variables are in that order, there’s never an arrow from a “later” variable to an “earlier” variable in either diagram).
If those two conditions hold, then we can create an arbitrary “Frankenstein diagram” from the two original diagrams: for each variable, we can take its incoming arrows from either of the two original diagrams. The underlying distribution will satisfy any Frankenstein diagram.
We can also extend the Frankenstein Rule to more than two original diagrams in the obvious way: so long as there exists an ordering of the variables which respects all diagrams, we can construct a Frankenstein which takes the incoming arrows of each variable from any of the original diagrams.
For approximation, we have two options. One approximate Frankenstein rule is simpler but gives mildly looser bounds, the other is a little more complicated but gives mildly tighter bounds (especially as the number of original diagrams increases).
The simpler approximation rule: if the original two diagrams are satisfied to within and , respectively, then the Frankenstein is satisfied to within . (And this extends in the obvious way to more-than-two original diagrams.)
The more complex approximation rule requires some additional machinery. For any diagram, we can decompose its into one term for each variable via the chain rule:
If we know how our upper bound on the diagram’s decomposes across variables, then we can use that for more fine-grained bounds. Suppose that, for each diagram and variable , we have an upper bound
Then, we can get a fine-grained bound for the Frankenstein diagram. For each variable , we add only the from the original diagram from which we take that variables’ incoming arrows to build the Frankenstein. (Our simple approximation rule earlier added together all the ’s from all of the original diagrams, so it was over-counting.)
Exercise: Using the Frankenstein Rule on the two diagrams at the beginning of this section, show that is independent of all the other variables (assuming the two diagrams from the beginning of this section hold).
Factorization Transfer Rule
The factorization transfer rule is of interest basically-only in the approximate case; the exact version is quite trivial.
Our previous rules dealt with only one “underlying distribution” , and looked at various properties satisfied by that distribution. Now we’ll introduce a second distribution, . The Transfer Rule says that, if satisfies some diagram and approximates (i.e. ), then approximately satisfies the diagram (to within ). The factorization (i.e. the diagram) “transfers” from to .
A simple example: suppose I roll a die a bunch of times. Maybe there’s “really” some weak correlations between rolls, or some weak bias on the die; the “actual” distribution accounting for the correlations/bias is . But I just model the rolls as independent, with all six outcomes equally probable for each roll; that’s .
Under , all the die rolls are independent: . Diagrammatically:

So, if , then the die rolls are also approximately independent under : . That’s the Transfer Rule.
Stitching Rule for a Markov Blanket
Imagine I have some complicated Bayes net model for the internals of a control system, and another complicated Bayes net model for its environment. Both models include the sensors and actuators, which mediate between the system and environment. Intuitively, it seems like we should be able to “stitch together” the models into one joint model of system and environment combined. That’s what the Stitching Rule is for.
The Stitching Rule is complicated to describe verbally, but relatively easy to see visually. We start with two diagrams over different-but-overlapping variables:
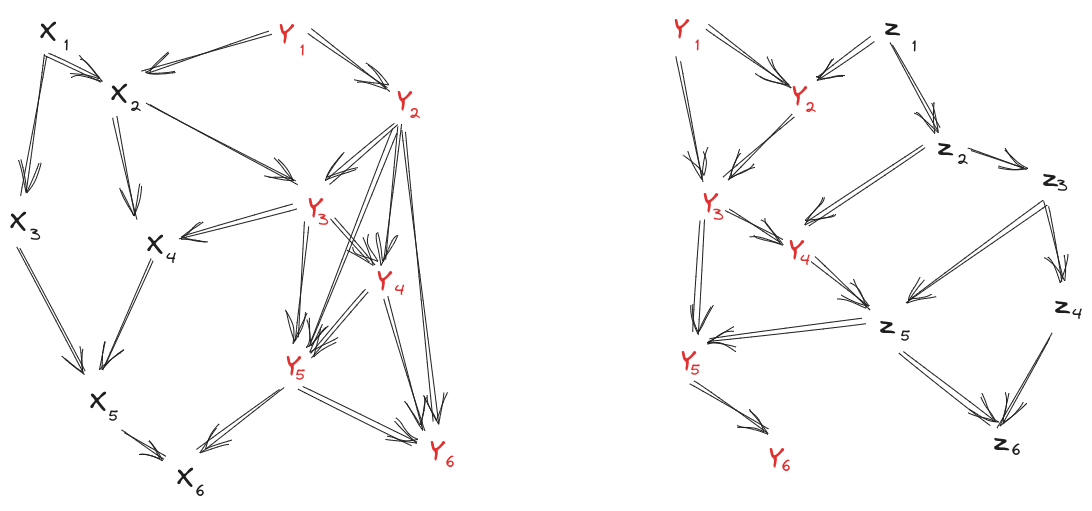
In this case, the variables only appear in the left diagram, variables only appear in the right diagram, but the variables appear in both. (Note that the left diagram states a property of and the right diagram a property of ; we’ll assume that both of those are marginal distributions of the underlying .)
Conceptually, we want to “stitch” the two diagrams together along the variables . But we can’t do that in full generality: there could be all sorts of interactions between and in the underlying distribution, and the two diagrams above don’t tell us much about those interactions. So, we’ll add one more diagram:

This says that and interact only via , i.e. is a Markov blanket between and . If this diagram and both diagrams from earlier hold, then we know what the interactions look like, so in-principle we can stitch the two diagrams together.
In practice, in order for the stitched diagram to have a nice form, we’ll require our diagrams to satisfy two more assumptions:
- Each of the may be a child of -variables in the left diagram, or a child of -variables in the right diagram, but not both.
- Just like the Frankenstein Rule, there must be some ordering of all the variables which respects both of the two diagrams which we wish to stitch.
Short Exercise: verify these two conditions hold for our example above.
Then, the Stitching Rule says we can do something very much like the Frankenstein Rule. We create a stitched-together diagram in which:
- Each -variable takes its parents from the left diagram
- Each -variable takes its parents from the right diagram
- Each -variable with an -parent takes its parents from the left diagram
- Each -variable with a -parent takes its parents from the right diagram
(A -variable with neither an -parent nor a -parent can take its parents from either diagram.) So, for our example above, we could stitch this diagram:
The Stitching Rule says that, if the underlying distribution satisfies both starting diagrams and is a markov blanket between and and the two starting diagrams satisfy our two extra assumptions, then the above diagram holds.
In the approximate case, we have an for the left diagram, an for the right diagram, and an for the diagram . Our final diagram holds to within . As with the Frankenstein rule, that bound is a little loose, and we can tighten it in the same way if we have more fine-grained bounds on for individual variables in each diagram.
Bookkeeping Rules
[EDIT October 2024: We now have a very simple Bookkeeping Rule which unifies all of these, which you can find in this comment [LW(p) · GW(p)].]
If you’ve worked with Bayes nets before, you probably learned all sorts of things implied by a single diagram - e.g. conditional independencies from d-separation, “weaker” diagrams with edges added, that sort of thing. We’ll refer to these as “Bookkeeping Rules”, since they feel pretty minor if you’re already comfortable working with Bayes nets. Some examples:
- We can always add an arrow to a diagram (assuming it doesn’t introduce a loop), and the approximation will get no worse.
- We can always “combine nodes”, i.e. combine a node for variable and a node for variable into a single node which inherits all incoming and outgoing arrows from the original nodes, again assuming it doesn’t introduce a loop. The approximation will get no worse.
- We can always arbitrarily reorder components in a complete subgraph, so long as no loops are introduced, and the approximation will get no worse. [EDIT: This one is wrong; thankyou to Oli for helping hunt down the error (in this thread [LW(p) · GW(p)]). It is still correct if the subgraph has no incoming arrows, which suffices for the end-to-end example, but I haven't worked out the most general version.]
- If d-separates and in a diagram, then the diagram implies , with approximation no worse than the original diagram.
Bookkeeping Rules (including all of the above) can typically be proven via the Factorization Transfer Rule.
Exercise: use the Factorization Transfer Rule to prove the d-separation Bookkeeping Rule above. (Alternative exercise, for those who don’t know/remember how d-separation works and don’t want to look it up: pick two of the other Bookkeeping Rules and use the Factorization Transfer Rule to prove them.)
End-to-End Example
This example is from an upcoming post on our latest work. Indeed, it’s the main application which motivated this post in the first place! We’re not going to give the background context in much depth here, just sketch a claim and its proof, but you should check out the upcoming post on Natural Latents (once it’s out) if you want to see how it fits into a bigger picture.
We’ll start with a bunch of “observable” random variables . In order to model these observables, two different agents learn to use two different latent variables: and (capital Greek letters and ). Altogether, the variables satisfy three diagrams. The first agent chooses such that all the observables are independent given (so that it can perform efficient inference leveraging ):
The second agent happens to be interested in , because is very redundantly represented; even if any one observable is ignored, the remainder give approximately-the-same information about .
(Here denotes all the components of except for .) Finally, we’ll assume that there’s nothing relating the two agents and their latents to each other besides their shared observables, so
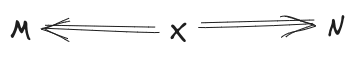
(Note: these are kinda-toy motivations of the three diagrams; our actual use-case provides more justification in some places.)
We’re going to show that mediates between and X, i.e.
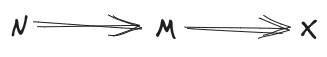
Intuitive story: by the first diagram, all interactions between components of “go through” M. So, any information which is redundant across many components of must be included in . in particular is redundant across many components of , so it must be included in . That intuitive argument isn’t quite technically watertight, but at a glossy level it’s the right idea, and we’re going to prove it diagrammatically.
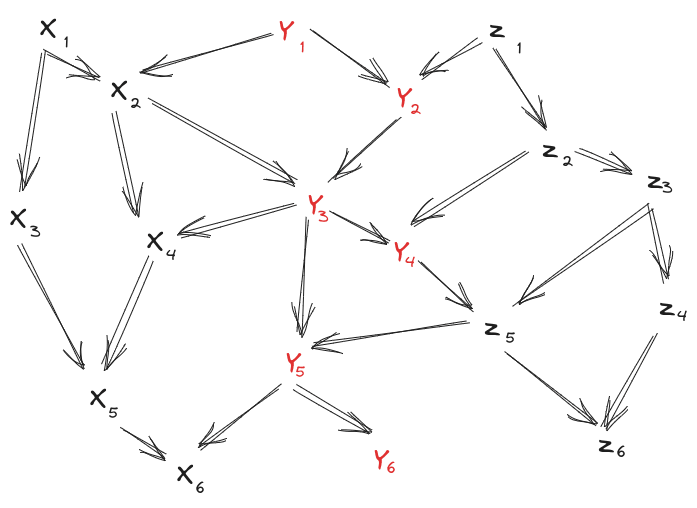
From our starting diagrams, a natural first step is to use the Stitching Rule, to combine together the -diagram and the -diagram across the Markov blanket :
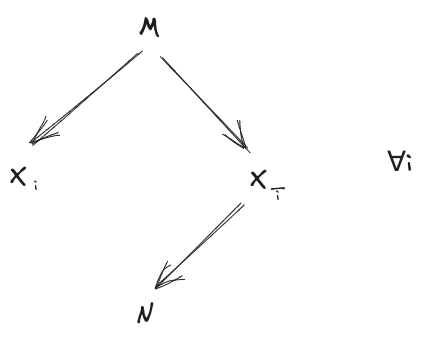
Via a couple Bookkeeping steps (add an arrow, reorder complete subgraph) we can rewrite that as
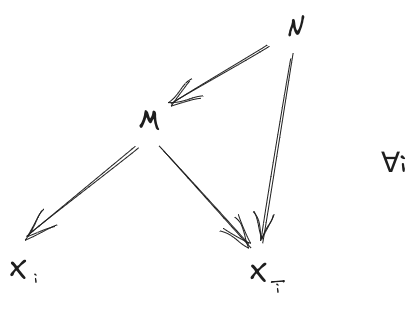
Note that we have diagrams here (one for each ), and the variable ordering respects that diagram for every , so we can Frankenstein all of those diagrams together. is the root node, has only as parent (all diagrams agree on that), and then we take the parent of each from the diagram. That yields:
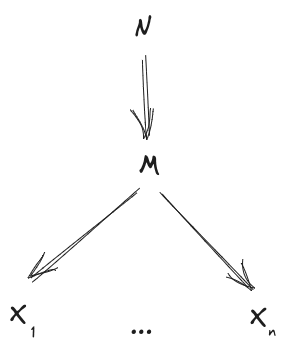
And via one more Bookkeeping operation, we get
as desired.
Our full end-to-end proof, presented diagrammatically, looks like this:
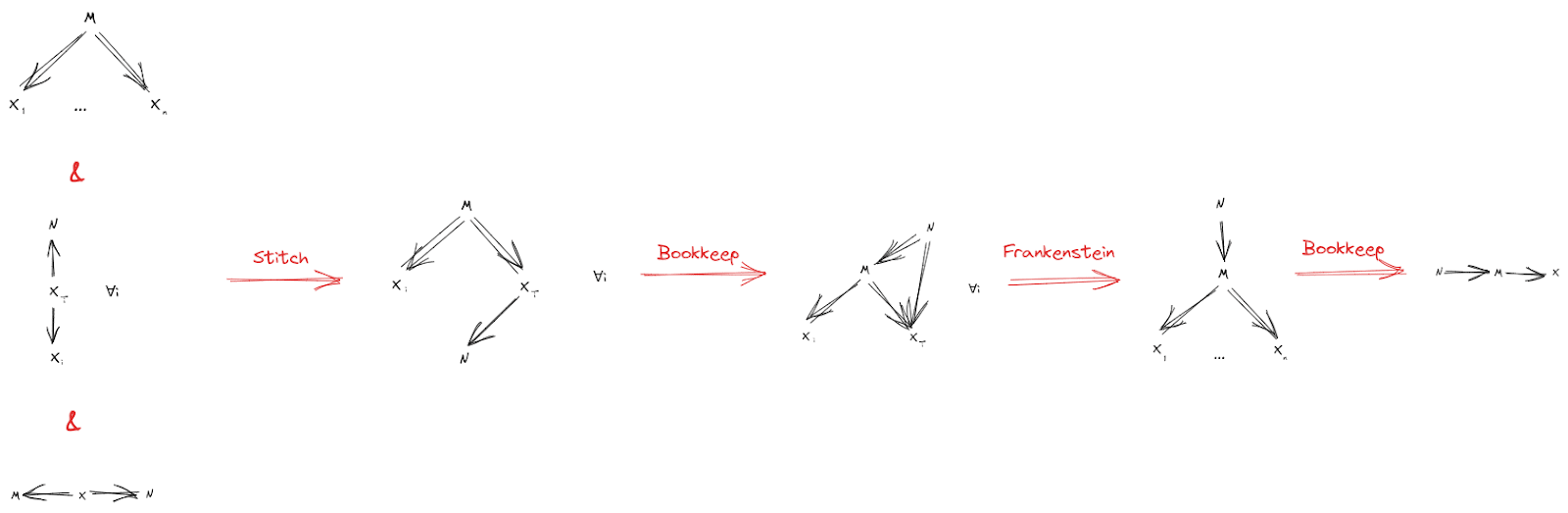
Besides readability, one major benefit of this diagrammatic proof is that we can immediately derive approximation bounds for it. We assign a bound to each starting diagram, then just propagate through, using the approximate version of the rule at each step:
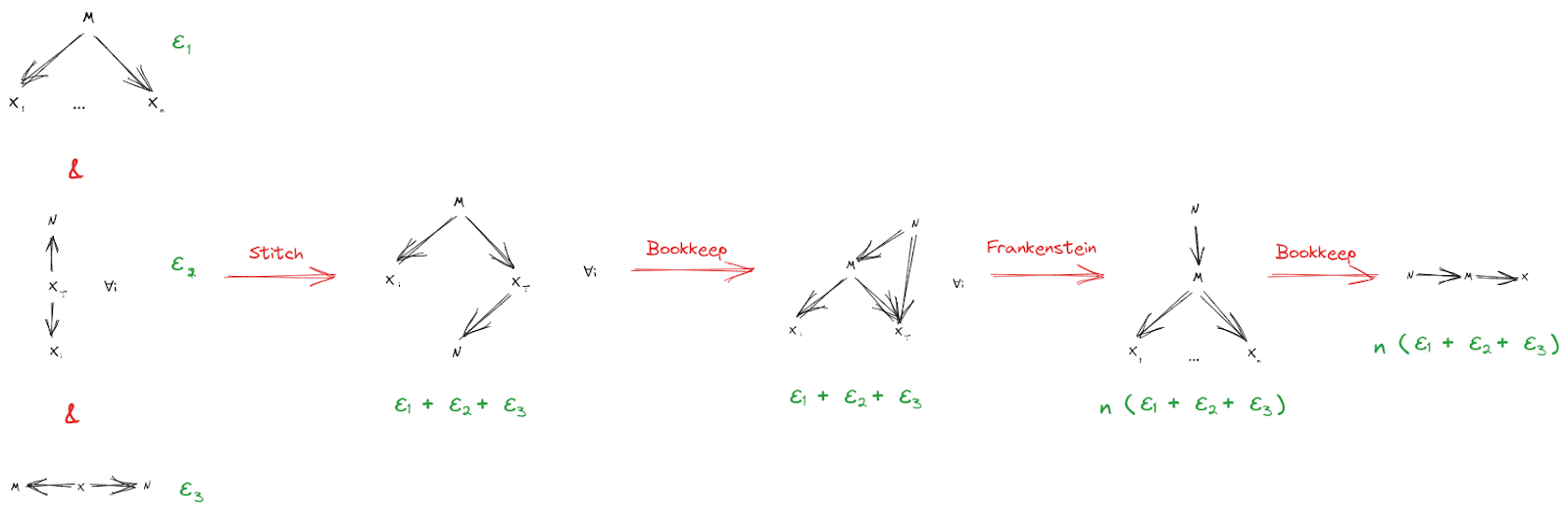
As a teaser: one use-case for this particular theorem is that, insofar as the second agent can express things-it-wants in terms of very redundantly represented latent variables (e.g. ), it will always be able to express those things in terms of the first agent’s latent variables (i.e. ). So, the second agent can express what it wants in terms of the first agent’s internal latent variables. It’s an approach to handling ontological problems, like e.g. The Pointers Problem [LW · GW].
What To Read Next
That concludes our list of rules! This post was written as a prelude to our upcoming post on Natural Latents, which will show a real application of these rules. If you want to build familiarity with the rules, we recommend trying a few exercises in this post, then walking through the proofs in that post (once it’s out), and checking the rules used at each step. There are also several exercises in the appendix of this post, alongside the proofs for the rules.
Appendix: Proofs & Exercises
Re-Rooting Rule for Markov Chains
First, we’ll show that we can move the root node one step to the right.
Note that the same equations (read backwards) imply we can move the root node one step to the left. Then, by induction, we can move the root node as far as we want in either direction (noting that at either end one of the two products becomes an empty product).
Approximation
The previous proof shows that for all (for any distribution). So,
As before, the same equations imply that we can move the root node one step to either the left or right. Then, by induction, we can move the root node as far as we want in either direction, without changing the KL-divergence.
Exercise
Extend the above proofs to re-rooting of arbitrary trees (i.e. the diagram is a tree). We recommend thinking about your notation first; better choices for notation make working with trees much easier.
Joint Independence Rule: Exercise
The Joint Independence Rule can be proven using the Frankenstein Rule. This is left as an exercise. (And we mean that unironically, it is actually a good simple exercise which will highlight one or two subtle points, not a long slog of tedium as the phrase “left as an exercise” often indicates.)
Bonus exercise: also prove the conditional version of the Joint Independence Rule using the Frankenstein Rule.
Frankenstein Rule
We’ll prove the approximate version, then the exact version follows trivially.
Without loss of generality, assume the order of variables which satisfies all original diagrams is . Let be the factorization expressed by diagram , and let be the diagram from which the parents of are taken to form the Frankenstein diagram. (The factorization expressed by the Frankenstein diagram is then .)
The proof starts by applying the chain rule to the of the Frankenstein diagram:
Then, we add a few more expected KL-divergences (i.e. add some non-negative numbers) to get:
Thus, we have
Factorization Transfer
Again, we’ll prove the approximate version, and the exact version then follows trivially.
As with the Frankenstein rule, we start by splitting our into a term for each variable:
Next, we subtract some more ’s (i.e. subtract some non-negative numbers) to get:
Thus, we have
Stitching
We start with the condition:
At a cost of at most , we can replace with in that expression, and likewise for the term. (You can verify this by writing out the ’s as expected log probabilities.)
Notation:
- denotes the components of whose parents are taken from the -diagram; denotes the components of whose parents are taken from the -diagram. (Together, these should include all components of .)
- All products are implicitly over components of whatever variables they’re indexing - e.g. (which will appear shortly) is over components of .
- denotes the parents of in the -diagram. Each such parent will be a component of or , which is why we’re subscripting the pair . Likewise for similar expressions.
Recall that each component of must have no -parents in the -diagram, and each component of must have no -parents in the -diagram. Let’s pull those terms out of the products above so we can simplify them:
Those simplified terms in combination with are themselves a , which we can separate out:
… and that last line is the for the stitched diagram.
44 comments
Comments sorted by top scores.
comment by johnswentworth · 2024-10-22T18:15:00.681Z · LW(p) · GW(p)
Here's a new Bookkeeping Theorem, which unifies all of the Bookkeeping Rules mentioned (but mostly not proven) in the post, as well as all possible other Bookkeeping Rules.
If all distributions which factor over Bayes net also factor over Bayes net , then all distributions which approximately factor over also approximately factor over . Quantitatively:
where indicates parents of variable in .
Proof: Define the distribution . Since exactly factors over , it also exactly factors over : . So
Then by the factorization transfer rule (from the post):
which completes the proof.
comment by Mateusz Bagiński (mateusz-baginski) · 2024-03-25T08:28:05.445Z · LW(p) · GW(p)
I think the parentheses are off here. IIUC you want to express the equality of divergences, not divergences multiplied by probabilities (which wouldn't make sense I think).
Typo: ->
Replies from: johnswentworth↑ comment by johnswentworth · 2024-04-23T22:59:58.350Z · LW(p) · GW(p)
Man, that top one was a mess. Fixed now, thank you!
comment by Vanessa Kosoy (vanessa-kosoy) · 2024-12-06T10:06:42.928Z · LW(p) · GW(p)
This article studies a natural and interesting mathematical question: which algebraic relations hold between Bayes nets? In other words, if a collection of random variables is consistent with several Bayes nets, what other Bayes nets does it also have to be consistent with? The question is studied both for exact consistency and for approximate consistency: in the latter case, the joint distribution is KL-close to a distribution that's consistent with the net. The article proves several rules of this type, some of them quite non-obvious. The rules have concrete applications in the authors' research agenda.
Some further questions that I think would be interesting to study:
- Can we derive a full classification of such rules?
- Is there a category-theoretic story behind the rules? Meaning, is there a type of category for which Bayes nets are something akin to string diagrams and the rules follow from the categorical axioms?
↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2024-12-06T10:14:33.600Z · LW(p) · GW(p)
I've been told a Bayes net is "just" a functor from a free Cartesian category to a category of probability spaces /Markov Kernels.
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2024-12-06T10:51:04.540Z · LW(p) · GW(p)
Seems right, but is there a categorical derivation of the Wentworth-Lorell rules? Maybe they can be represented as theorems of the form: given an arbitrary Markov category C, such-and-such identities between string diagrams in C imply (more) identities between string diagrams in C.
↑ comment by Lorxus · 2025-04-07T19:53:22.035Z · LW(p) · GW(p)
Hi! I spent some time working on exactly this approach last summer at MATS, and since then have kept trying to work out the details. It's been going slowly but parts of it have been going at all.
My take regarding your and @Alexander Gietelink Oldenziel's [LW · GW] comments below [LW(p) · GW(p)] is - that's not a thing that really happens? You pick the rules and your desired semantics first, and then you write down your manipulation rules to reflect those. Maybe it turns out that you got it wrong and there's more (or fewer!) rules of derivation to write down, but as long as the rules you wrote down follow some very easy constraints, you can just... write down anything. Or decline to. (Also, from a quick read I'm fairly sure you need a little bit more than just "free cartesian category" to hold of your domain category if you want nice structures to hang state/kernel-labels on. You want to be able to distinguish a concrete Bayes net (like, with numbers and everything) from an abstract "Bayes net", which is just a directed acyclic graph representing local conditionality structures - though we should note that usually people working with Bayes nets assume that we actually have trees, and not just DAGs!)
Maybe there's arguments from things like mathematical elegance or desired semantics or problematizing cases to choose to include or exclude some rule, or formulate a rule in one or another way, but ultimately you get to add structure to a category as suits you.
- Can we derive a full classification of such rules?
Probably there's no full classification, but I think that a major important point (which I should have just written up quickly way way long ago) is that we don't quite care about Markov equivalence class - only about whether any given move takes us to a diagram still compatible with the joint distribution/factorization that we started with.
- Is there a category-theoretic story behind the rules? Meaning, is there a type of category for which Bayes nets are something akin to string diagrams and the rules follow from the categorical axioms?
In my understanding there's a pretty clear categorical story - some of which are even just straight trivial! - to most of the rules. They make good sense in the categorical frame; some of them make so much sense that they're the kind of thing string diagrams don't even bother to track. I'm thinking of Factorization Transfer here, though the one major thing I've managed to get done is that the Joint Independence rule actually follows as a quick technical lemma from its assumptions/setup, rather than having to be assumed.
There's noncanonical choices getting made in the two "binary operation" rules, but even then it seems to me like the fact that we only ever apply that operation to two diagrams of the same "flavor" means we should likely only ever get back another diagram of the same "flavor"; apart from that, there's a strong smell of colimitness to both of those rules, which has kept me mulling over whether there's a useful "limitish" sort of rule that John and David both missed. Underlying this is my suspicion that we might get a natural preorder structure on latent Bayes nets/string diagrams as the pullback of the natural lattice on Markov equivalence classes, where one MEC is above another if it has strictly more conditionality relationships in it - i.e. the unique minimal element of the lattice is "everything is independent", and there's lots of maximal elements, and all our rules need to keep us inside the preimage of the upset of our starting MEC.
Which is to say: yes, yes there totally is such a type of category, but existing work mostly stopped at "Bayes nets akin to string diagrams", although I've seen some non-me work lately that looks to be attacking similar problems.
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2025-04-08T11:45:25.362Z · LW(p) · GW(p)
I found the above comment difficult to parse.
that's not a thing that really happens?
What is the thing that doesn't happen? Reading the rest of the paragraph only left me more confused.
we don't quite care about Markov equivalence class
What do you mean by "Markov equivalence class"?
Replies from: Lorxus↑ comment by Lorxus · 2025-04-08T13:43:32.341Z · LW(p) · GW(p)
that's not a thing that really happens?
What is the thing that doesn't happen? Reading the rest of the paragraph only left me more confused.
Somehow being able to derive all relevant string diagram rewriting rules for latential string diagrams, starting with some fixed set of equivalences? Maybe this is just a framing thing, or not answering your question, but I would expect to need to explicitly assume/include things like the Frankenstein rule - more generally, picking which additional rewriting rules you want to use/include/allow is something you do in order to get equivalence/reachability in the category to line up correctly with what you want that equvialence to mean - you could just as soon make those choices poorly and (e.g.) allow arbitrary deletions of states, or addition of sampling flow that can't possibly respect causality; we don't do that here because it wouldn't result in string diagram behavior that matches what we want it to match.
I think I may have misunderstood, though, because that does sounds almost exactly like what I found to happen for the Joint Independence rule - you have some stated equivalence, and then you use string diagram rewriting rules common to all Markov category string diagrams in order to write the full form of the rule.
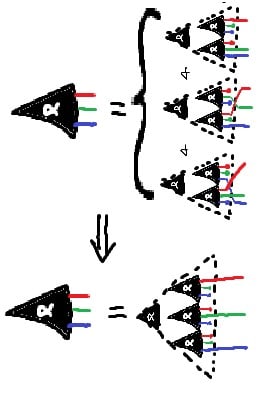
Simple form of the JI Rule - note the equivalences in the antecedent, which we can use to prove the consequent, not just enforce the equivalence!
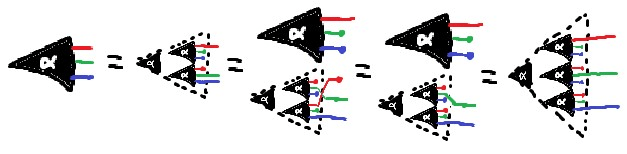
we don't quite care about Markov equivalence class
What do you mean by "Markov equivalence class"?
Two Bayes nets are of the same Markov equivalence class when they have precisely the same set of conditionality relations holding on them (and by extension, precisely the same undirected skeleton). You may recognize this as something that holds true when applicable for most of these rules, notably (sometimes) including the binary operations and notably excluding direct arrow-addition; additionally, this is something that applies for abstract Bayes nets just as well as concrete ones.
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2025-04-08T15:16:00.327Z · LW(p) · GW(p)
Somehow being able to derive all relevant string diagram rewriting rules for latential string diagrams, starting with some fixed set of equivalences?
What are "latential" string diagrams?
What does it it mean that you can't derive them all from a "fixed" set? Do you imagine some strong claim e.g. that the set of rewriting rules being undecidable, or something else?
Two Bayes nets are of the same Markov equivalence class when they have precisely the same set of conditionality relations holding on them (and by extension, precisely the same undirected skeleton).
Okay, so this is not what you care about? Maybe you are saying the following: Given two diagrams X,Y, we want to ask whether any distribution compatible with X is compatible with Y. We don't ask whether the converse also holds. This is a certain asymmetric relation, rather than an equivalence.
Replies from: Lorxus↑ comment by Lorxus · 2025-04-11T23:14:43.501Z · LW(p) · GW(p)
What are "latential" string diagrams?
Just the word I use to describe "thing that has something to do with (natural) latents". More specifically for this case: a string diagram over a Markov category equipped with the extra stuff, structure, and properties that a Markov category needs to have in order to faithfully depict everything we care about when we want to write down statements or proofs about Bayes nets which might transform in some known restricted ways.
What does it it mean that you can't derive them all from a "fixed" set? Do you imagine some strong claim e.g. that the set of rewriting rules being undecidable, or something else?
Something else. I'm saying that:
- You would need to pick your set of identities once and for all at the start, as part of specifying what extra properties the category has; you could totally use those as (or to derive) some of the rules (and indeed I show how you can do just that for Breakout Joint Independence)
- Binary operations like Frankenstein or Stitching probably don't fall out of an approach like that (they look a lot more like colimits
- Rules which a categorical approach trivializes like Factorization Transfer don't particularly fall out of an approach like that
- You could probably get some kind of "ruleset completeness" result if you had a strong sense of what would constitute a complete ruleset - the paper I linked above looks to be trying to do this
...so maybe some approach where you start by listing off all the identities you want to have hold and then derive the full ruleset from those would work at least partially? I guess I'm not totally clear what you mean by "categorical axioms" here - there's a fair amount that goes into a category; you're setting down all the rules for a tiny toy mathematical universe and are relatively unconstrained in how you do so, apart from your desired semantics. I'm also not totally confident that I've answered your question.
Okay, so this is not what you care about? Maybe you are saying the following: Given two diagrams X,Y, we want to ask whether any distribution compatible with X is compatible with Y. We don't ask whether the converse also holds. This is a certain asymmetric relation, rather than an equivalence.
Yes. Well... almost. Classically you'd care a lot more about the MEC, but I've gathered that that's not actually true for latential Bayes nets. For those, we have some starting joint distribution J, which we care about a lot, and some diagram D_J which it factors over; alternatively, we have some starting set of conditionality requirements J, and some diagram D_J from among those that realize J. (The two cases are the same apart from the map that gives you actual numerical valuations for the states and transitions.)
We do indeed care about the asymmetric relation of "is every distribution compatible with X also compatible with Y", but we care about it because we started with some X_J and transformed it such that at every stage, the resulting diagram was still compatible with J.
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2025-04-12T15:03:26.402Z · LW(p) · GW(p)
I think that there are two different questions which might be getting mixed up here:
Question 1: Can we fully classify all rules for which sets of Bayes nets imply other Bayes nets over the same variables? Naturally, this is not a fully rigorous question, since "classify" is not a well-defined notion. One possible operationalization of this question is: What is the computational complexity of determining whether a given Bayes net follows from a set of other Bayes nets? For example, if there is a set of basic moves that generate all such inferences then the problem is probably in NP (at least if the number of required moved can also be bounded).
Question 2: What if we replace "Bayes nets" by something like "string diagrams in a Markov category"? Then there might be less rules (because maybe some rules hold for Bayes nets but not in the more abstract setting).
comment by Jeremy Gillen (jeremy-gillen) · 2023-12-19T01:04:48.709Z · LW(p) · GW(p)
This is one of my favorite posts because it gives me tools that I expect to use.
A little while ago, John described his natural latent result to me. It seemed cool, but I didn't really understand how to use it and didn't take the time to work through it properly. I played around with similar math in the following weeks though; I was after a similar goal, which was better ways to think about abstract variables.
More recently, John worked through the natural latent proof on a whiteboard at a conference. At this point I felt like I got it, including the motivation. A couple of weeks later I tried to prove it as an exercise for myself (with the challenge being that I had to do it from memory, rigorously, and including approximation). This took me two or three days, and the version I ended up with used a slightly different version of the same assumptions, and got weaker approximation results. I used the graphoid axioms, which are the standard (but slow and difficult) way of formally manipulating independence relationships (and I didn't have previous experience using them).
This experience caused me to particularly appreciate this post. It turns lots of work into relatively little work.
comment by rotatingpaguro · 2023-12-10T21:02:00.065Z · LW(p) · GW(p)
- Re-Rooting Rule for Markov Chains
- Joint Independence Rule
- Frankenstein Rule
- Factorization Transfer Rule
- Stitching Rule for A Shared Markov Blanket
- Swap Rule <=====
- Bookkeeping Rules
Can't find the "Swap rule" in the post, what was that?
The more complex approximation rule requires some additional machinery. For any diagram, we can decompose its into one term for each variable via the chain rule:
<=====
If we know how our upper bound on the diagram’s decomposes across variables, then we can use that for more fine-grained bounds. Suppose that, for each diagram and variable , we have an upper bound
<=====
I guess here there are missing expectations (indicated in red), otherwise would remain a free RV. The second expectation is not necessary, although omitting it makes the bound unnecessarily strict.
I have never encountered this topic, and I couldn't find it skimming the Handbook of Graphical Models (2019), did you invent it? If not, could you list references?
Do you perchance have something for conditioning or marginalization? I know that graphical marginalization requires using ADMGs (graphs with double-headed arrows) instead of DAGs, I don't know about conditioning.
Exercise
Extend the above proofs to re-rooting of arbitrary trees (i.e. the diagram is a tree). We recommend thinking about your notation first; better choices for notation make working with trees much easier.
In a tree each node has a single parent. Re-rooting means flipping the arrow from the root to one of its children.
In the factorization I do P(old_root)P(new_root|old_root) = P(old_root|new_root)P(new_root), so the proof is the same.
The fact that notation is not involved makes my suspect I may be missing something. Maybe they mean it's needed to write out in full the factorization expression? I guess the nice notation is using ch(X_i) instead of pa(X_i).
Joint Independence Rule: Exercise
The Joint Independence Rule can be proven using the Frankenstein Rule. This is left as an exercise. (And we mean that unironically, it is actually a good simple exercise which will highlight one or two subtle points, not a long slog of tedium as the phrase “left as an exercise” often indicates.)
Bonus exercise: also prove the conditional version of the Joint Independence Rule using the Frankenstein Rule.
Joint independence starts from the graphs
X_i {X_not i}
for all i. The Frankenstein rule can not be applied right away because the graphs are not on the same variables, since all but one appear grouped as a single tuple node.
To change that, I replace the tuple nodes with fully connected subgraphs. This is valid because cliques do not constrain the distribution, as any distribution can be factorized in any order if all variables are kept in the conditionals.
I choose the connection order of the cliques such that they respect a global ordering.
Then I apply Frankenstein, picking, for each node, the graph where that node is isolated.
Is there a way to obtain a narrower bound? Yes: I can pick only from the i-th graph.
Conditional version: basically the same proof, with the common parent as first node in the global order. Needs more care in justifying replacing a tuple node with a clique: Conditional on the parent, the argument above still goes. The only additional independence property of the graph with the tuple is that the parent d-separates the tuple from the singlet, and that is preserved as well.
Frankenstein Rule
We’ll prove the approximate version, then the exact version follows trivially.
Without loss of generality, assume the order of variables which satisfies all original diagrams is . Let be the factorization expressed by diagram , and let be the diagram from which the parents of are taken to form the Frankenstein diagram. (The factorization expressed by the Frankenstein diagram is then .)
The proof starts by applying the chain rule to the of the Frankenstein diagram:
<=====
Then, we add a few more expected KL-divergences (i.e. add some non-negative numbers) to get:
Thus, we have
<=====
I guess you meant the green thing (first margin arrow) to appear in place of the red thing (second margin arrow)? The math is right, but I hypothesize the final line was intended to express at once the narrow and the loose bounds.
Replies from: johnswentworth↑ comment by johnswentworth · 2023-12-11T00:38:19.608Z · LW(p) · GW(p)
Can't find the "Swap rule" in the post, what was that?
Oh lol, that was in a draft and I took it out.
I guess here there are missing expectations (indicated in red), otherwise would remain a free RV.
Good catch, thanks.
Exercise answers look good.
Replies from: rotatingpaguro↑ comment by rotatingpaguro · 2023-12-14T13:14:31.263Z · LW(p) · GW(p)
Aaaand about this?
Replies from: johnswentworthI have never encountered this topic, and I couldn't find it skimming the Handbook of Graphical Models (2019), did you invent it? If not, could you list references?
↑ comment by johnswentworth · 2023-12-14T15:51:52.562Z · LW(p) · GW(p)
I wouldn't be surprised if someone else has done this before, but I did not get it from anywhere else and have never seen anyone else do something quite like it.
comment by Oliver Sourbut · 2024-01-04T11:59:46.552Z · LW(p) · GW(p)
This is really great!
A few weeks ago I was playing with the Good Regulator and John's Gooder version [LW · GW] and incidentally I also found myself pulling out some simple graphical manipulation rules. Your 'Markov re-rooting' came into play, and also various of the 'Bookkeeping' rules. You have various more exciting rules here too, thanks!
I also ended up noticing a kind of 'good regulator motif' as I tried expanded the setting with a few temporal steps and partial observability and so forth. Basically, doing some bookkeeping and coarse-graining, you can often find a simple GR structure within a larger 'regulator-like' structure, and conclude things from that. I might publish it at some point but it's not too exciting yet. I do think the overall move of finding motifs in manipulated graphs is solid, and I have a hunch there's a cool mashup of Bayes-net algebra and Gooder Regulator waiting to be found!
I love the Frankenstein rule. FYI, the orderings you're talking about which are 'consistent' with the graphs are called topological orderings, and every DAG has (at least) one. So you could concisely phrase some of your conditions along the lines of 'shared topological order' or 'mutually-consistent topological ordering'.
BTW causal graphs are usually restricted to be DAGs, right? (i.e., the 'causes' relation is acyclic and antisymmetric.) So in this setting where we are peering at various fragments which are assumed to correspond to some 'overall mega-distribution', it might come in handy to assume the overall distribution has some acyclic presentation - then there's always a(t least one) topo ordering available to be invoked.
Replies from: Oliver Sourbut↑ comment by Oliver Sourbut · 2024-01-04T12:10:14.967Z · LW(p) · GW(p)
Oh yeah, I don't know how common it is, but when manipulating graphs, if there's a topo order, I seem to strongly prefer visualising things with that order respected on the page (vertically or horizontally). So your images committed a few minor crimes according to that aesthetic. I can also imagine that some other aesthetics would strongly prefer writing things the way you did though, e.g. with . (My preference would put and slightly lower, as you did with the , graph.)
comment by Lorxus · 2024-11-06T21:55:48.353Z · LW(p) · GW(p)
We’ll refer to these as “Bookkeeping Rules”, since they feel pretty minor if you’re already comfortable working with Bayes nets. Some examples:
- We can always add an arrow to a diagram (assuming it doesn’t introduce a loop), and the approximation will get no worse.
Here's something that's kept bothering me on and off for the last few months: This graphical rule immediately breaks Markov equivalence. Specifically, two DAGs are Markov-equivalent only if they share an (undirected) skeleton. (Lemma 6.1 at the link.)
If the major/only thing we care about here regarding latential Bayes nets is that our Grand Joint Distribution factorize over (that is, satisfy) our DAG (and all of the DAGs we can get from it by applying the rules here), then by Thm 6.2 in the link above, is also globally/locally Markov wrt . This holds even when is not guaranteed for some of the possible joint states in , unlike Hammersley-Clifford would require.
That in turn means that (Def 6.5) there's some distributions can be such that factors over , but not (where trivially has the same vertices as does); specifically, because don't (quite) share a skeleton, they can't be Markov-equivalent, and because they aren't Markov-equivalent, no longer needs to be (locally/globally) Markov wrt (and in fact there must exist some which explicitly break this), and because of that, such need not factor over . Which I claim we should not want here, because (as always) we care primarily about preserving which joint probability distributions factorize over/satisfy which DAGs, and of course we probably don't get to pick whether our is one of the ones where that break in the chain of logic matters.
Replies from: DanielFilan, johnswentworth↑ comment by DanielFilan · 2024-11-08T00:12:54.610Z · LW(p) · GW(p)
A way I'd phrase John's sibling comment [LW(p) · GW(p)], at least for the exact case: adding arrows to a DAG increases the set of probability distributions it can represent. This is because the fundamental rule of a Bayes net is that d-separation has to imply conditional independence - but you can have conditional independences in a distribution that aren't represented by a network. When you add arrows, you can remove instances of d-separation, but you can't add any (because nodes are d-separated when all paths between them satisfy some property, and (a) adding arrows can only increase the number of paths you have to worry about and (b) if you look at the definition of d-separation the relevant properties for paths get harder to satisfy when you have more arrows). Therefore, the more arrows a graph G has, the fewer constraints distribution P has to satisfy for P to be represented by G.
↑ comment by johnswentworth · 2024-11-06T23:02:48.883Z · LW(p) · GW(p)
Proof that the quoted bookkeeping rule works, for the exact case:
- The original DAG asserts
- If just adds an edge from to , then says
- The original DAG's assertion also implies , and therefore implies 's assertion .
The approximate case then follows by the new-and-improved Bookkeeping Theorem [LW(p) · GW(p)].
Not sure where the disconnect/confusion is.
Replies from: Lorxus↑ comment by Lorxus · 2024-11-07T04:10:58.904Z · LW(p) · GW(p)
Let me see if I've understood point 3 correctly here. (I am not convinced I have actually found a flaw, I'm just trying to reconcile two things in my head here that look to conflict, so I can write down a clean definition elsewhere of something that matters to me.)
factors over . In , were conditionally independent of each other, given . Because factors over and because in , were conditionally independent of each other, given , we can very straightforwardly show that factors over , too. This is the stuff you said above, right?
But if we go the other direction, assuming that some arbitrary factors over , I don't think that we can then still derive that factors over in full generality, which was what worried me. But that break of symmetry (and thus lack of equivalence) is... genuinely probably fine, actually - there's no rule for arbitrarily deleting arrows, after all.
That's cleared up my confusion/worries, thanks!
comment by Oliver Sourbut · 2024-01-04T12:21:28.202Z · LW(p) · GW(p)
I might be missing something, but I don't see where is actually used in the worked example.
It seems that there's a consistent topo order between the and diagrams, so we Frankenstitch them. Then we draw an edge from to and reorder (bookkeep). Then we Frankenstein the diagrams and the resulting diagram again. Then we collect the together (bookkeep). Where's used?
Replies from: johnswentworth, Oliver Sourbut↑ comment by johnswentworth · 2024-01-04T14:23:53.013Z · LW(p) · GW(p)
We need it for the stitching rule; otherwise there could be weird three-variable interactions (e.g. one thing is an xor of two other things) which mess up the stitch.
Replies from: Oliver Sourbut↑ comment by Oliver Sourbut · 2024-01-04T14:31:21.819Z · LW(p) · GW(p)
But this same move can alternatively be done with the Frankenstein rule, right? (I might be missing something.) But Frankenstein has no such additional requirement, as stated. If I'm not missing something, I think Frankenstein might be invalid as stated (like maybe it needs an analogous extra condition). Haven't thought this through yet.
i.e. I think either
- I'm missing something
- Frankenstein is invalid
- You don't need
↑ comment by Oliver Sourbut · 2024-01-04T14:57:46.411Z · LW(p) · GW(p)
Yeah, thinking slightly aloud, I tentatively think Frankenstein needs an extra condition like the blanket stitch condition... something which enforces the choice of topo ordering to be within the right class of topo orderings? That's what the chain does - it means we can assign orderings or , but not e.g. , even though that order is consistent with both of the other original graphs.
If I get some time I'll return to this and think harder but I can't guarantee it.
ETA I did spend a bit more time, and the below mostly resolves it: I was indeed missing something, and Frankenstein indeed needs an extra condition, but you do need .
Replies from: Oliver Sourbut↑ comment by Oliver Sourbut · 2024-01-10T14:33:58.848Z · LW(p) · GW(p)
I had another look at this with a fresh brain and it was clearer what was happening.
TL;DR: It was both of 'I'm missing something', and a little bit 'Frankenstein is invalid' (it needs an extra condition which is sort of implicit in the post). As I guessed, with a little extra bookkeeping, we don't need Stitching for the end-to-end proof. I'm also fairly confident Frankenstein subsumes Stitching in the general case. A 'deductive system' lens makes this all clearer (for me).
My Frankenstein mistake
The key invalid move I was making when I said
But this same move can alternatively be done with the Frankenstein rule, right?
is that Frankenstein requires all graphs to be over the same set of variables. This is kind of implicit in the post, but I don't see it spelled out. I was applying it to an graph ( absent) and an graph ( absent). No can do!
Skipping Stitch in the end-to-end proof
I was right though, Frankenstein can be applied. But we first have to do 'Node Introduction' and 'Expansion' on the graphs to make them compatible (these extra bookkeeping rules are detailed further below.)
So, to get myself in a position to apply Frankenstein on those graphs, I have to first (1) introduce to the second graph (with an arrow from each of , , and ), and (2) expand the 'blanket' graph (choosing to maintain topological consistency [LW(p) · GW(p)]). Then (3) we Frankenstein them, which leaves dangling, as we wanted.
Next, (4) I have to introduce to the first graph (again with an arrow from each of , , and ). I also have a topological ordering issue with the first Frankenstein, so (5) I reorder to the top by bookkeeping. Now (6) I can Frankenstein those, to sever the as hoped.
But now we've performed exactly the combo that Stitch was performing in the original proof. The rest of the proof proceeds as before (and we don't need Stitch).
More bookkeeping rules
These are both useful for 'expansive' stuff which is growing the set of variables from some smaller seed. The original post mentions 'arrow introduction' but nothing explicitly about nodes. I got these by thinking about these charts as a kind of 'deductive system'.
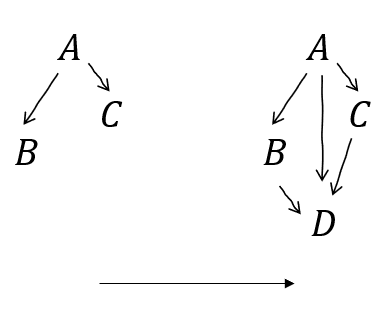
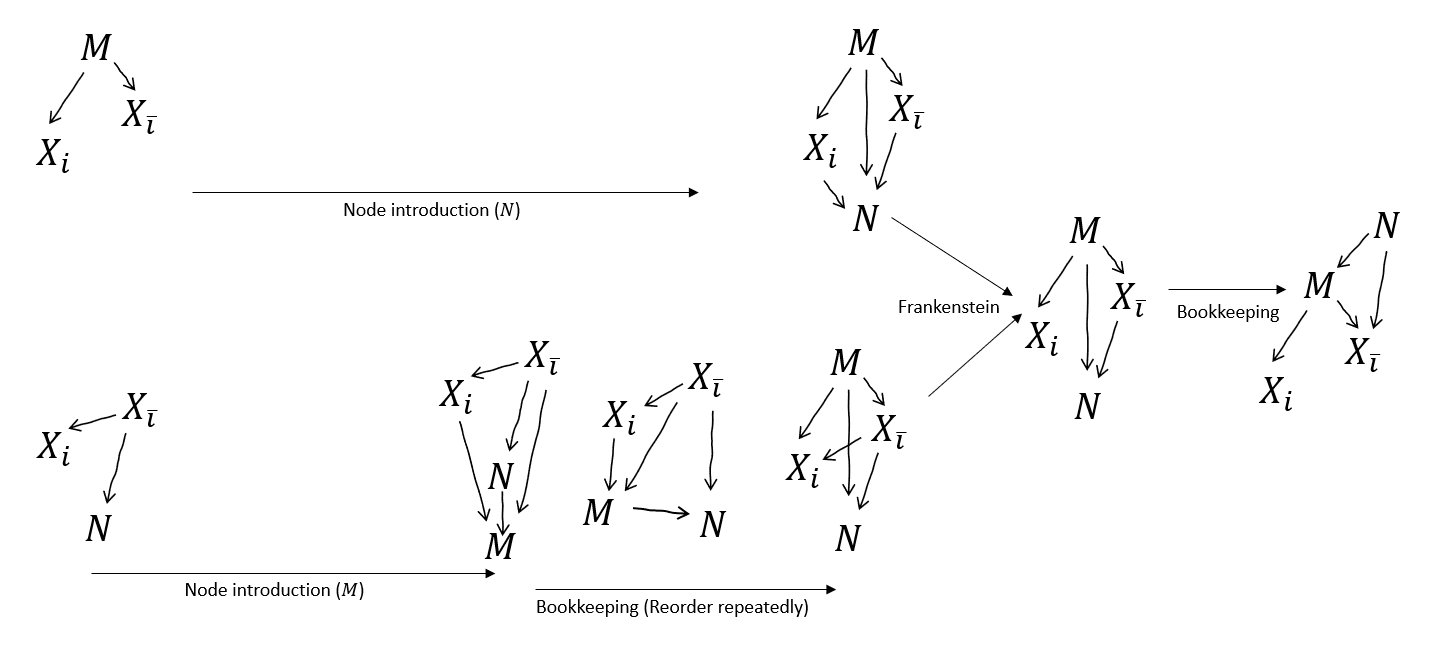
Node introduction
A graph without all variables is making a claim about the distribution with those other variables marginalised out.
We can always introduce new variables - but we can't (by default) assume anything about their independences. It's sound (safe) to assume they're dependent on everything else - i.e. they receive an incoming arrow from everywhere. If we know more than that (regarding dependencies), it's expressed as absence of one or another arrow.
e.g. a graph with is making a claim about . If there's also a , we haven't learned anything about its independences. But we can introduce it, as long as it has arrows , , and .
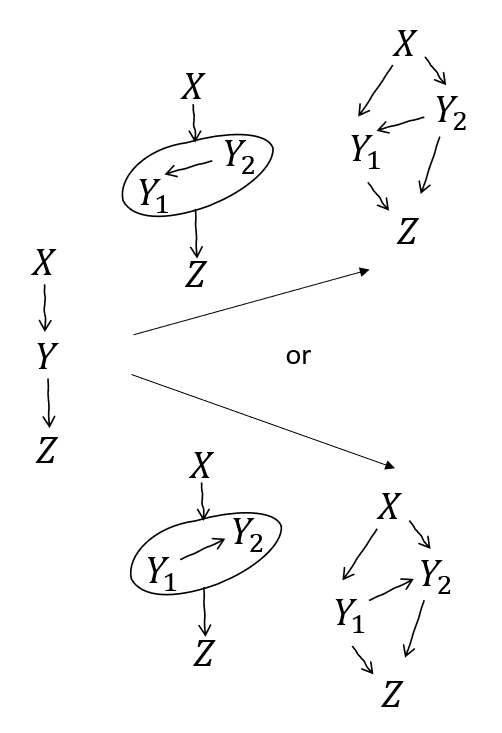
Node expansion aka un-combine
A graph with combined nodes is making a claim about the distribution as expressed with those variables appearing jointly. There's nothing expressed about their internal relationship.
We can always expand them out - but we can't (by default) assume anything about their independences. It's sound to expand and spell them out in any fully-connected sub-DAG - i.e. they have to be internally fully dependent. We also have to connect every incoming and outgoing edge to every expanded node i.e. if there's a dependency between the combination and something else, there's a dependency between each expanded node and that same thing.
e.g. a graph with is making a claim about . If is actually several variables, we can expand them out, as long as we respect all possible interactions that the original graph might have expressed.
Deductive system
I think what we have on our hands is a 'deductive system' or maybe grandiosely a 'logic'. The semantic is actual distributions and divergences. The syntax is graphs (with divergence annotation).
An atomic proposition is a graph together with a divergence annotation , which we can write .
Semantically, that's when the 'true distribution satisfies up to KL divergence' as you described[1]. Crucially, some variables might not be in the graph. In that case, the distributions in the relevant divergence expression are marginalised over the missing variables. This means that the semantic is always under-determined, because we can always introduce new variables (which are allowed to depend on other variables however they like, being unconstrained by the graph).
Then we're interested in sound deductive rules like
Syntactically that is 'when we have deduced we can deduce '. That's sound if, for any distribution satisfying we also have satisfying .
Gesture at general Frankenstitch rule
More generally, I'm reasonably sure Stitch is secretly just multiple applications of Frankenstein, as in the example above. The tricky bit I haven't strictly worked through is when there's interleaving of variables on either side of the blanket in the overall topological ordering.
A rough HANDWAVE proof sketch, similar in structure to the example above:
- Expand the blanket graph
- The arrows internal to , , and need to be complete
- We can always choose a complete graph consistent with the , , and parts of the original graphs (otherwise there wouldn't be an overall consistent topology)
- Notice that the connections are all to all , which is not necessarily consistent with the original graph
- and similarly for the arrows
- (there could be arrows in the original)
- Introduce to the graph (and vice versa)
- The newly-introduced nodes are necessarily 'at the bottom' (with arrows from everything else)
- We can always choose internal connections for the introduced s consistent with the original graph
- Notice that the connections and in the augmented graph all keep at the bottom, which is not necessarily consistent with the original graph (and vice versa)
- But this is consistent with the Expanded blanket graph
- We 'zip from the bottom' with successive bookkeeping and Frankensteins
- THIS IS WHERE THE HANDWAVE HAPPENS
- Just like in the example above, where we got the sorted out and then moved the introduced to the 'top' in preparation to Frankenstein in the graph, I think there should always be enough connections between the introduced nodes to 'move them up' as needed for the stitch to proceed
I'm not likely to bother proving this strictly, since Stitch is independently valid (though it'd be nice to have a more parsimonious arsenal of 'basic moves'). I'm sharing this mainly because I think Expansion and Node Introduction are of independent relevance.
More formally, over variables is satisfied by distribution when . (This assumes some assignment of variables in to variables in .) ↩︎
↑ comment by Oliver Sourbut · 2024-01-10T15:42:25.715Z · LW(p) · GW(p)
Perhaps more importantly, I think with Node Introduction we really don't need after all?
With Node Introduction and some bookkeeping, we can get the and graphs topologically compatible, and Frankenstein them. We can't get as neat a merge as if we also had - in particular, we can't get rid of the arrow . But that's fine, we were about to draw that arrow in anyway for the next step!
Is something invalid here? Flagging confusion. This is a slightly more substantial claim than the original proof makes, since it assumes strictly less. Downstream, I think it makes the Resample [LW · GW] unnecessary.
ETA: it's cleared up below [LW(p) · GW(p)] - there's an invalid Reorder here (it removes a v-structure).
↑ comment by johnswentworth · 2024-01-10T16:53:07.681Z · LW(p) · GW(p)
I think one of the reorder steps on the bottom line is invalid.
Stock counterexample:
- Let and each be strings of bits. The zeroth bit of each is equal (i.e. ); the rest are independent.
- is another bitstring with zeroth bit equal to the zeroth bit of , and all other bits independent of .
- is a bitstring with zeroth bit equal to the zeroth bit of , with the rest of the bits given by:
- odd-numbered bits are the odd-numbered independent bits of xor independent bits of
- even-numbered bits are the even-numbered independent bits of xor independent bits of
Then the starting diagrams in your proof are all satisfied, but the final diagram is not.
The step which breaks for this counterexample is the first reorder step on the bottom line.
Replies from: Oliver Sourbut↑ comment by Oliver Sourbut · 2024-01-10T17:12:05.280Z · LW(p) · GW(p)
Mhm, OK I think I see. But appear to me to make a complete subgraph, and all I did was redirect the . I confess I am mildly confused by the 'reorder complete subgraph' bookkeeping rule. It should apply to the in , right? But then I'd be able to deduce which is strictly different. So it must mean something other than what I'm taking it to mean.
Maybe need to go back and stare at the semantics for a bit. (But this syntactic view with motifs and transformations is much nicer!)
Replies from: johnswentworth↑ comment by johnswentworth · 2024-01-10T17:18:17.117Z · LW(p) · GW(p)
Oh you're right, the rule about reordering complete subgraphs is missing some constraints. That's a mistake on my part.
Thinking about it for ~60 seconds: when reordering a complete subgraph, arrows going out of the subgraph stay the same, but if there's arrows going in then we may need to introduce new arrows between (former) spouses.
Replies from: Oliver Sourbut↑ comment by Oliver Sourbut · 2024-01-10T18:18:24.796Z · LW(p) · GW(p)
Aha. Preserving v-structures (colliders like ) is necessary and sufficient for equivalence[1]. So when rearranging fully-connected subgraphs, certainly we can't do it (cost-free) if it introduces or removes any v-structures.
Plausibly if we're willing to weaken by adding in additional arrows, there might be other sound ways to reorder fully-connected subgraphs - but they'd be non-invertible. Haven't thought about that.
Verma & Pearl, Equivalence and Synthesis of Causal Models 1990 ↩︎
↑ comment by johnswentworth · 2024-01-10T18:24:16.381Z · LW(p) · GW(p)
Either that's wrong or I'm misinterpreting it, because a fully-connected DAG should be equivalent to any other fully-connected DAG but they all have different v-structures.
Replies from: Oliver Sourbut↑ comment by Oliver Sourbut · 2024-01-10T18:48:29.326Z · LW(p) · GW(p)
Mmm, I misinterpreted at first. It's only a v-structure if and are not connected. So this is a property which needs to be maintained effectively 'at the boundary' of the fully-connected cluster which we're rewriting. I think that tallies with everything else, right?
ETA: both of our good proofs respect this rule; the first Reorder in my bad proof indeed violates it. I think this criterion is basically the generalised and corrected version of the fully-connected bookkeeping rule described in this post. I imagine if I/someone worked through it, this would clarify whether my handwave proof of Frankenstein Stitch is right or not.
Replies from: Oliver Sourbut↑ comment by Oliver Sourbut · 2024-01-10T19:03:52.131Z · LW(p) · GW(p)
Unironically, I think it's worth anyone interested skimming that Verma & Pearl paper for the pictures :) especially fig 2
↑ comment by Oliver Sourbut · 2024-01-10T18:20:31.725Z · LW(p) · GW(p)
That's concerning. It would appear to make both our proofs invalid.
But I think your earlier statement about incoming vs outgoing arrows makes sense. Maybe Verma & Pearl were asking for some other kind of equivalence? Grr, back to the semantics I suppose.
↑ comment by Oliver Sourbut · 2024-01-04T12:29:20.411Z · LW(p) · GW(p)
(I said Frankenstitch advisedly, I think they're kinda the same rule, but in particular in this case it seems either rule does the job.)
comment by David Reber (derber) · 2023-11-17T21:00:45.066Z · LW(p) · GW(p)
Could you clarify how this relates to e.g. the PC (Peter-Clark) or FCI (Fast Causal Inference) algorithms for causal structure learning?
Like, are you making different assumptions (than e.g. minimality, faithfulness, etc)?
↑ comment by johnswentworth · 2023-11-17T21:49:01.047Z · LW(p) · GW(p)
First, there's a different type signature. PC or FCI-style causal structure learning typically takes in a bunch of conditional independence tests (or a function for performing conditional independence tests, or a pile of data on which to perform conditional independence tests, etc) and spits out a DAG. For this post, it's DAGs in, DAGs out.
Second, a different use-case. The theorems in this post all say something like "if the distribution (approximately) factors according to <some DAGs>, then it also (approximately) factors according to <some other DAGs>". This use-case doesn't directly assume or prove anything about minimality; none of the theorems say that the distribution can't also satisfy some DAG with fewer edges. Likewise, we neither assume nor prove anything about faithfulness. (Though one could perhaps use these theorems to prove minimality and/or faithfulness in particular cases, in which case the preconditions for the proof would be that the distribution does/doesn't satisfy some DAGs.)
If we wanted to use these theorems for causal structure learning, at a high level the method would look something like:
- First, find some DAGs the distribution satisfies via some other method(s).
- Then, use the theorems here to derive a stronger DAG which must be satisfied.
For instance, we could imagine that two groups of scientists do a bunch of experiments on the same system. One group finds that the system is well-modelled by the left DAG at the top of the Frankenstein Rule section of this post, the other group finds that the system is well-modelled by the right DAG. Then, we could try to Frankenstein those two DAGs together in a way which keeps as few edges as possible.
Replies from: derber, derber↑ comment by David Reber (derber) · 2023-11-19T16:52:02.204Z · LW(p) · GW(p)
The theorems in this post all say something like "if the distribution (approximately) factors according to <some DAGs>, then it also (approximately) factors according to <some other DAGs>"
So one motivating research question might be phrased as "Probability distributions have an equivalence class of Bayes nets / causal diagrams which are all compatible. But what is the structure within a given equivalence class? In particular, if we have a representative Bayes net of an equivalence class, how might we algorithmically generate other Bayes nets in that equivlance class?"
↑ comment by David Reber (derber) · 2023-11-19T16:56:19.857Z · LW(p) · GW(p)
also, it appears that the two diagrams in the Frankenstein Rule section differ in their d-separation of (x_1 \indep x_4 | x_5) (which doesn't hold in the the left), so these are not actually equivalent (we can't have an underlying distribution satisfy both of these diagrams)
Replies from: johnswentworth↑ comment by johnswentworth · 2023-11-19T18:13:46.727Z · LW(p) · GW(p)
Oh, we can totally have an underlying distribution satisfy both of these diagrams. The key is that, while the right diagram asserts (x_1 \indep x_4 | x_5), the left does not say that x_1 can't be independent of x_4 given x_5. Remember the interpretation: an underlying distribution satisfies a DAG if-and-only-if the distribution factors over that DAG. We neither assume nor prove minimality; the DAG does not need to be minimal.
So, for instance, a distribution in which all five variables are unconditionally independent would satisfy every diagram over those variables.
You are right that the two diagrams are not equivalent (i.e. there exist distributions which satisfy either one but not the other), and we're not claiming they're equivalent. We're just saying "assume that some distribution satisfies both of these two diagrams; what other diagrams must the distribution then satisfy?".
Replies from: derber↑ comment by David Reber (derber) · 2023-11-20T15:08:09.179Z · LW(p) · GW(p)
Ah that's right. Thanks that example is quite clarifying!