The Core of the Alignment Problem is...
post by Thomas Larsen (thomas-larsen), Jeremy Gillen (jeremy-gillen), JamesH (AtlasOfCharts) · 2022-08-17T20:07:35.157Z · LW · GW · 10 commentsContents
Introduction The Technical Alignment Problem Layout Frames on outer alignment The Pointers Problem Distribution Shift Corrigibility Goodharting General Cruxes for Outer Alignment Frames on inner alignment Mesa-Optimizers Ontology Identification Wireheading Deception Cruxes for Inner Alignment Other Frames Non-agentic AI/Oracle AI The Sharp Left Turn Conclusion None 11 comments
Produced As Part Of The SERI ML Alignment Theory Scholars Program 2022 Under John Wentworth [LW · GW]
Introduction
When trying to tackle a hard problem, a generally effective opening tactic is to Hold Off On Proposing Solutions [LW · GW]: to fully discuss a problem and the different facets and aspects of it. This is intended to prevent you from anchoring to a particular pet solution and (if you're lucky) to gather enough evidence that you can see what a Real Solution would look like. We wanted to directly tackle the hardest part of the alignment problem, and make progress towards a Real Solution, so when we had to choose a project for SERI MATS, we began by arguing in a Google doc about what the core problem is. This post is a cleaned-up version of that doc.
The Technical Alignment Problem
The overall problem of alignment is the problem of, for an Artificial General Intelligence with potentially superhuman capabilities, making sure that the AGI does not use these capabilities to do things that humanity would not want. There are many reasons that this may happen such as instrumental convergent goals [? · GW] or orthogonality [? · GW].
Layout
In each section below we make a different case for what the "core of the alignment problem" is. It's possible we misused some terminology when naming each section.
The document is laid out as follows: We have two supra-framings on alignment: Outer Alignment and Inner Alignment. Each of these is then broken down further into subproblems. Some of these specific problems are quite broad, and cut through both Outer and Inner alignment, we've tried to put problems in the sections we think fits best (and when neither fits best, collected them in an Other category) though reasonable people may disagree with our classifications. In each section, we've laid out some cruxes, which are statements that support that frame on the core of the alignment problem. These cruxes are not necessary or sufficient conditions for a problem to be central.
Frames on outer alignment
The core of the alignment problem is being able to precisely specify what we value, so that we can train an AGI on this, deploy it, and have it do things we actually want it to do. The hardest part of this is being mathematically precise about 'what we value', so that it is robust to optimization pressure.
The Pointers Problem [LW · GW]
The hardest part of this problem is being able to point robustly at anything in the world at all (c.f. Diamond Maximizer). We currently have no way to robustly specify even simple, crisply defined tasks, and if we want an AI to be able to do something like 'maximize human values in the Universe,' the first hurdle we need to overcome is having a way to point at something that doesn't break in calamitous ways off-distribution and under optimization pressure. Once we can actually point at something, the hope is that this will enable us to point the AGI at some goal that we are actually okay with applying superhuman levels of optimization power on.
There are different levels at which people try to tackle the pointers problem: some tackle it on the level of trying to write down a utility function that is provably resilient to large optimization pressure, and some tackle it on the level of trying to prove things about how systems must represent data in general (e.g. selection theorems).
Cruxes (around whether this is the highest priority problem to work on)
- This problem being tractable relies on some form of the Natural Abstractions Hypothesis.
- There is, ultimately, going to end up being a thing like "Human Values," that can be pointed to and holds up under strong optimization pressure.
- We are sufficiently confused about 'pointing to things in the real world' that we could not reliably train a diamond maximizer right now, if that were our goal.
Distribution Shift
The hardest part of alignment is getting the AGI to generalize the values we give it to new and different environments. We can only ever test the AGI's behavior on a limited number of samples, and these samples cannot cover every situation the AGI will encounter once deployed. This means we need to find a way to obtain guarantees that the AGI will generalize these concepts when out-of-distribution in the way that we'd want, and well enough to be robust to intense optimization pressure (from the vast capabilities of the AGI).
If we are learning a value function then this problem falls under outer alignment, because the distribution shift breaks the value function. On the other hand, if you are training an RL agent, this becomes more of an inner alignment problem.
Cruxes:
- Creating an AGI necessarily induces distribution shift because:
- The real world changes from train to test time.
- The agent becomes more intelligent at test time, which is itself a distribution shift.
- Understanding inductive biases well enough to get guarantees on generalization is tractable.
- We will be able to obtain bounds even for deep and fundamental distribution shifts.
Corrigibility
The best way to solve this problem is to specify a utility function that, for the most part, avoids instrumentally convergent [? · GW] goals (power seeking, preventing being turned off). This will allow us to make an AGI that is deferential to humans, so that we can safely perform a pivotal act, and hopefully buy us enough time to solve the alignment problem more robustly.
Cruxes:
- Corrigibility is further along the easier/safer Pareto-frontier than Coherent Extrapolated Volition [? · GW] of Humanity.
- Corrigibility is a concept that is more "natural" than human values.
Goodharting [? · GW]
Encoding what we actually want in a loss function is, in fact, too hard and will not be solved, so we will ultimately end up training the AGI on a proxy. But proxies for what we value are generally correlated with what we actually value, until you start optimizing on the proxy somewhat unreasonably. An AGI will apply this unreasonable optimization pressure, since it has no reason to 'understand what we mean, rather than what we said.'
Cruxes:
- The inner values of an AGI will be a proxy for our values. In other words, it will not be a True Name for what we care about, when we apply optimization pressure, it will perform worse and not better as measured by our true preferences.
- We can get a soft-optimization proposal that works to solve this problem (instead of having the AGI hard-optimize something safe).
- It is either impossible, or too hard, to specify the correct loss function and so we will end up using a proxy.
General Cruxes for Outer Alignment
- Getting the AGI to do what we want it to do (when we learn how to specify that) is at least one of:
- Not as hard.
- Going to be solved anyway by making sufficient progress on these problems.
- Solvable through architectural restrictions.
- The best way to make progress on alignment is to write down a utility function for an AI that:
- Generalizes
- Is robust to large optimization pressure
- Specifies precisely what we want
Frames on inner alignment
The core of the alignment problem is figuring out how to induce inner values into an AGI from an outer training loop. If we cannot do this, then an AGI might end up optimizing for something that corresponded to the outer objective on the training set but generalizes poorly.
Mesa-Optimizers
The hardest part of this problem is avoiding the instantiation of malign learned optimizers [LW · GW] within the AGI. These arise when training on the base reward function does not in fact cause the AGI to learn to optimize for that reward function, but instead to optimize for some mesa-objective that obtains good performance in the training environment.
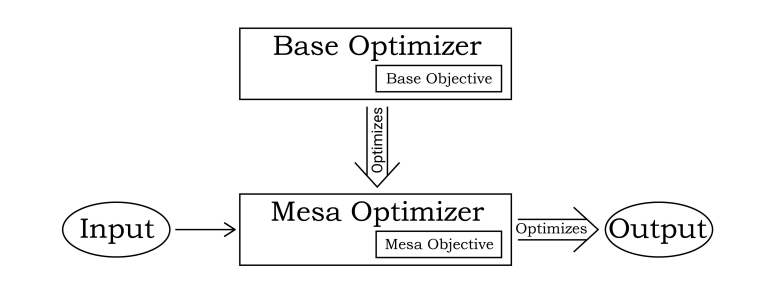
One key insight for why this is the core of the alignment problem is human intelligence being a mesa-optimizer induced by evolution. Evolution found intelligence as a good method for performing well on the 'training set' of the ancestral environment, but now that human intelligence has moved to a new environment where we have things like contraception, the mesa objective of having sex has decoupled from the base objective of maximizing inclusive genetic fitness, and we pursue the former, and do not much care about the latter.
Some ways that mesa-optimization can happen:
- There is a learned inner optimizer, e.g. in a language model, that values things in the outside world, and so outputs things to hijack the output of the LM.
- You train an RL agent to accomplish a task, e.g. pick strawberries, but there is a distribution shift from training to test time, and though the goal aligned on the training distribution, the actual inner goal, e.g. take red things and put them in a shiny metal basket extrapolates off-distribution to pulling off someone's nose and throwing it at a lamppost
- You prompt an LLM to accomplish a task, e.g. be a twitter bot that spreads memes. You've now instantiated something that is optimizing the real world. The LLM's outer objective was just text prediction, but via prompting, we've induced a totally different mesa-objective.
- Some people think that this doesn't count because the optimizer is still optimizing the outer objective of text autocompletion.
Cruxes:
- We will not be able to prevent the instantiation of learned optimizers through architectural adaptations.
- Gradient descent selects for compressed and generalizable strategies, and optimization/search capabilities meet both of these requirements. See also: Conditions for Mesa-Optimization. [? · GW]
Ontology Identification
The hardest part of this problem is being able to translate from a human ontology to an AGI's ontology. An AGI is likely to use a different ontology from us, potentially radically different, and also to learn new ontologies once deployed. Translating from a human ontology to an AGI's ontology is going to be hard enough, but we also need translation mechanisms that are robust to (potentially very large) ontology shifts.
We think that a lot of the paths to impact for interpretability research are as solutions to this problem. Whether it is: using interpretability to obtain guarantees that an AGI has learned precisely the concepts that we want, using interpretability tools in training to incentivize the AGI to learn the concepts we want, using interpretability to improve the efficiency/effectiveness of human feedback on AGI models during training, or other more detailed interpretability agendas; most of interpretability's impact comes down to its use in ontology identification.
Cruxes:
- Natural Abstraction Hypothesis will make this problem tractable, or even if NAH ends up holding only very weakly, then with enough work, we can overcome that.
- If working on circuits-style ontology identification, then at least one of:
- AGI will look a lot like modern systems.
- We will get good information about how to interpret future systems (although they may look very different) by working on modern systems.
Wireheading [? · GW]
We will end up using reward-circuitry mechanisms to train an AGI to optimize for what we want, however when we do this, it may instead learn to optimize only for maximizing its reward-circuitry. The hardest part of inner alignment is preventing these 'reward-optimizers' from developing, since as these get more capable, they will start pretending to be aligned to the outer-objective in the training process, and then once deployed and given access to their reward-circuitry, they will wirehead. This entails the AGI maximizing its reward circuitry, and then taking actions to maintain that high reward value, including eliminating threats that may try to turn it off, or modify it in any way (i.e. us).
Cruxes:
- Reward is not not the optimization target [LW · GW].
Deception
When an agent interacts with the world, there are two possible ways the agent makes mistakes:
- Its values were not aligned with the outer objective, and so it does something intentionally wrong,
- Its world model was incorrect, so it makes an accidental mistake.
Thus, the training process of an AGI will improve its values or its world model, and since it eventually gets diminishing marginal returns from both of these, both the world model and the values must improve together. Therefore, it is very likely that the agent will have a sufficiently good world model to understand that it is in a training loop before it has fully aligned inner values.
This means we are likely to see deception: the agent will act aligned to the outer objective while it's in the training phase, in order to get humans to deploy it in the real world where it can pursue its true objectives. If we can see this misalignment then hitting it with gradient descent should be able to fix it, but deception gets around this, so the core problem in alignment is avoiding deceptive alignment during training.
Cruxes:
- Deception becomes a natural thing for an AGI to learn at high-enough capabilities levels.
- Detecting deception will be very hard at high-enough capabilities levels.
Cruxes for Inner Alignment
- What matters is not so much the explicit outer utility function that we train the AGI on, but instead the values that the training process instantiates in the AGI.
- These values actually exist, and we're not just anthropomorphizing.
- The agent will learn to model the training process as a whole before it learns to value the utility function we are training it on.
Other Frames
Non-agentic AI/Oracle AI
The core problem in alignment is to figure out how to make an AI that does not act like an agent (and avoids malign subagents), and get this AI to solve the alignment problem (or perform a pivotal act). This tries to avoid the problem of corrigibility, by developing AIs that aren't (generally capable) optimizers (and hence won't stop you from turning them off).
Cruxes:
- A non-agentic AI can be intelligent enough to do something pivotal, e.g. writing the alignment textbook from the future.
- Training an LLM using methods like SSL is accurately described as learning a distribution over text completions, and then conditioning on the prompt.
- You can simulate an optimizer without being an optimizer yourself.
The Sharp Left Turn
The core of alignment is the specific distribution shift that happens at general intelligence: the sharp left turn [LW · GW] — the AI goes from being able to only do narrow tasks similar to what it is trained on, to having general capabilities that allow it to succeed on different tasks.
Capabilities generalize by default: in a broad range of environments, there are feedback loops that incentivize the agent to be capable. When operating in the real world, you can keep on getting information about how well you are doing, according to your current utility function.
However, you can't keep on getting information about how "good" your utility function is. But there is nothing like this for alignment, nothing pushing the agent towards “what we meant” in situations far from the training distribution. In a separate utility function model, this problem appears when the utility function doesn’t generalize well, and in a direct policy selection model, this problem appears in the policy selector.
Cruxes:
- There will be a large, sudden distribution shift from below human level to far superhuman level.
- There will be no way to keep the AGI on-distribution for its training data.
- Capabilities generalize faster than alignment. [AF · GW]
- For a given RL training environment, “strategies” are more overdetermined than “goals”.
Conclusion
The frame we think gets at the core problem best is (drumroll please) distribution shift: robustly pointing to the right goal/concepts when OOD or under extreme optimization pressure. This frame gives us a good sense of why mesa-optimizers are bad, fits well with the sharp left turn framing, and explains why ontology identification is important. Even though this is what we landed on, it should not be the main takeaway -- the real post was the framings we made along the way.
10 comments
Comments sorted by top scores.
comment by johnswentworth · 2022-08-18T00:05:10.758Z · LW(p) · GW(p)
I would love to see more people write this sort of thing, seems very high-value for newcomers to orient, and for existing researchers to see how people understand/misunderstand their arguments, and for the writers to accelerate the process of orienting, and generally for people to understand the generators behind each others' work and communicate better.
Some notes...
The best way to solve this problem is to specify a utility function that, for the most part, avoids instrumentally convergent [? · GW] goals (power seeking, preventing being turned off).
I'm not sure that a good formulation of corrigibility would look like a utility function at all.
Same with the "crux" later on:
- The best way to make progress on alignment is to write down a utility function for an AI that:
- Generalizes
- Is robust to large optimization pressure
- Specifies precisely what we want
Outer alignment need not necessarily look like a utility function. (There are good arguments that it will behave like a utility function, but that should probably be a derived fact rather than an assumed fact, at the very least.) And even if it is, there's a classic failure mode in which someone says "well, it should maximize utility, so we want a function of the form u(X)..." and they don't notice that most of the interesting work is in figuring out what the utility function is over (i.e. what "X" is), not the actual utility function.
Also, while we're talking about a "crux"...
In each section, we've laid out some cruxes, which are statements that support that frame on the core of the alignment problem. These cruxes are not necessary or sufficient conditions for a problem to be central.
Terminological nitpick: the term "crux [? · GW]" was introduced to mean something such that, if you changed your mind about that thing, it would also probably change your mind about whatever thing we're talking about (in this case, centrality of a problem). A crux is not just a statement which supports a frame.
We can get a soft-optimization proposal that works to solve this problem (instead of having the AGI hard-optimize something safe).
Not sure if this is already something you know, but "soft-optimization" is a thing we know how to do [? · GW]. The catch, of course, is that mild optimization can only do things which are "not very hard" in the sense that they don't require very much optimization pressure.
- This problem being tractable relies on some form of the Natural Abstractions Hypothesis.
- There is, ultimately, going to end up being a thing like "Human Values," that can be pointed to and holds up under strong optimization pressure.
Note that whether human values or corrigibility or "what I mean" or some other direct alignment target is a natural abstraction is not strictly part of the pointers problem. Pointers problem is about pointing to latent concepts in general; whether a given system has an internal latent variable corresponding to "human values" specifically is a separate question.
Also, while tractability of the pointers problem does depend heavily on NAH, note that it's still a problem (and probably an even more core and urgent one!) even if NAH turns out to be relatively weak.
Overall, the problem-summaries were quite good IMO.
Replies from: jeremy-gillen, tailcalled↑ comment by Jeremy Gillen (jeremy-gillen) · 2022-08-22T20:00:47.644Z · LW(p) · GW(p)
Yeah I agree in retrospect about utility functions not being a good formulation of corrigibility, we phrased it like that because we spent some time thinking about the MIRI corrigibility paper, which uses a framing like this to make it concrete.
On outer alignment: I think if we have utility function over universe histories/destinies, then this is a sufficiently general framing that any outer alignment solution should be capable of being framed this way. Although it might not end up being the most natural framing.
On cruxes: Good point, we started off using it pretty much correctly but ended up abusing those sections. Oops.
On soft optimization: We talked a lot about quantilizers, the quantilizers paper is among my favorite papers. I'm not really convinced yet that the problems we would want an AGI to solve (in the near term) are in the "requires super high optimization pressure" category. But we did discuss how to improve the capabilities of quantilizers, by adjusting the level of quantilization based on some upper bound on the uncertainty about the goal on the local task.
On pointers problem: Yeah we kind of mushed together extra stuff into the pointers problem section, because this was how our discussion went. Someone did also argue that it would be more of a problem if NAH was weak, but overall I thought it would probably be a bad way to frame the problem if the NAH was weak.
↑ comment by tailcalled · 2022-08-18T07:41:24.857Z · LW(p) · GW(p)
I would be curious if you have any good illustrations of alternatives to utility functions.
comment by Stephen McAleese (stephen-mcaleese) · 2023-01-05T23:04:46.937Z · LW(p) · GW(p)
I like how this post lists several arguments impartially instead of picking one and arguing that it's the best option.
comment by deepthoughtlife · 2022-08-18T13:47:39.374Z · LW(p) · GW(p)
I had a thought while reading the section on Goodharting. You could fix a lot of the potential issues with an agentic AI by training it to want its impact on the world to be within small bounds. Give it a strong and ongoing bias toward 'leave the world the way I found it.' This could only be overcome by a very clear and large benefit toward its other goals per small amount of change. It should not be just part of the decision making process though, but part of the goal state. This wouldn't solve every possible issue, but it would solve a lot of them. In other words, make it unambitious and conservative, and then its interventions will be limited and precise if it has a good model of the world.
Replies from: thomas-larsen↑ comment by Thomas Larsen (thomas-larsen) · 2022-08-18T19:51:10.258Z · LW(p) · GW(p)
I think this is part of the idea behind Eliezer-corrigibility, and I agree that if executed correctly, this would be helpful.
The difficulty with this approach that I see is:
1) how do you precisely specifying what you mean by "impact on the world to be within small bounds" -- this seems to require a measure of impact. This would be amazing (and is related to value extrapolation [LW · GW]).
2) how do you induce the inner value of "being low impact" into the agent, and make sure that this generalizes in the intended way off of the training distribution.
(these roughly correspond to the inner and outer alignment problem)
3) being low impact is strongly counter to the "core of consequentialism": convergent instrumental goals for pretty much any agent cause it to seek power.
Replies from: Vladimir_Nesov, deepthoughtlife↑ comment by Vladimir_Nesov · 2022-08-18T21:06:17.707Z · LW(p) · GW(p)
how do you induce the inner value of
As with alternatives to utility functions [LW(p) · GW(p)], the practical solution seems to be to avoid explicit optimization (which is known to do the wrong things), and instead work on model-generated behaviors in other ways, without getting them explicitly reshaped into optimization. If there is no good theory of optimization (that doesn't predictably only do the wrong things), it needs to be kept out of the architecture, so that it's up to the system to come up with optimization it decides on later, when it grows up. What an architecture needs to ensure is clarity of aligned cognition sufficient to eventually make decisions like that, not optimization (of the world) directly.
↑ comment by deepthoughtlife · 2022-08-19T01:18:26.394Z · LW(p) · GW(p)
The easy first step, is a simple bias toward inaction, which you can provide with a large punishment per output of any kind. For instance, a language model with this bias would write out something extremely likely, and then stop quickly thereafter. This is only a partial measure, of course, but it is a significant first step.
Second through n-th step, harder, I really don't even know, how do you figure out what values to try to train it with to reduce impact. The immediate things I can think of might also train deceit, so it would take some thought.
Also, across the time period of training, ask a panel (many separate panels) of judges to determine whether actions it is promoting for use in hypothetical situations or games was the minimal action it could have taken for the level of positive impact. Obviously, if the impact is negative, it wasn't the minimal action. Perhaps also train a network explicitly on the decisions of similar panels on such actions humans have taken, and use those same criteria.
Somewhere in there, best place unknown, penalize heavy use of computation in coming up with plans (though perhaps not with evaluating them.).
Final step (and perhaps at other stages too), penalize any actions taken that humans don't like. This can be done in a variety of ways. For instance, have 3 random humans vote on each action it takes, and for each person that dislikes the action, give it a penalty.
comment by Vladimir_Nesov · 2022-08-18T00:34:31.390Z · LW(p) · GW(p)
distribution shift: robustly pointing to the right goal/concepts when OOD or under extreme optimization pressure
Robustly going some distance off-distribution takes some work. It's never possible to quickly jump arbitrarily far (maintaining robustness), concepts are always broken sufficiently far off-distribution, either by their natural definition, or until something is built there that takes the load.
So I think this is misleading to frame as something that can succeed at some point, rather than as something that needs to keep happening. That's why instead of allowing the unclear extreme optimization pressure, optimization needs to respect the distribution where alignment has been achieved (as in base distribution of quantilizers), to deliberately avoid stepping off of it and plunging into uncharted waters.
And that requires maintaining knowledge of the scope of situations where model's behavior is currently expected/assured to be aligned. I think this is not emphasized enough, that current scope of alignment needs to be a basic piece of data. Take this discussion of quantilizers [LW · GW], where formulating a base distribution is framed as a puzzle specific to quantilizers, rather than a core problem of alignment.
comment by Michel (MichelJusten) · 2022-12-16T21:03:27.872Z · LW(p) · GW(p)
As a beginner to alignment, I found it very helpful to see these different frames written out