Without fundamental advances, misalignment and catastrophe are the default outcomes of training powerful AI
post by Jeremy Gillen (jeremy-gillen), peterbarnett · 2024-01-26T07:22:06.370Z · LW · GW · 60 commentsContents
Summary Introduction Acknowledgments How to read this report Epistemic status Related work Section 1: Useful tasks, like novel science, are hard Impactful novel science takes a lot of work Outcome-oriented tasks Novelty and diversity of obstacles AI alignment research is hard Stopping misaligned AI deployment seems to require powerful aligned AI Conclusion Section 2: Being capable of hard tasks implies approximate consequentialism Future outcomes as goals Formalizing consequentialist goals Non-consequentialist constraints Combined goals Why consequentialist goals are a necessary part of powerful AI Robustness to diverse obstacles is driven by consequentialism Shallow and deep constraints Approximation Section 3: Hard tasks require learning new things The AI will need to learn new things Learning facts Learning skills Self-directed learning Human-directed learning is a big efficiency hit Indirect self-directed learning Useful versus safe tradeoff Examples Experimental science Theoretical mathematics Conclusion Section 4: Behavioral training is an imprecise way to specify goals Unstable goals Beliefs and goals can be mixed together Outer shell non-consequentialist constraints Changing goals over time Out-of-distribution generalization OOD generalization difficulty Instrumental goals as terminal goals Deliberate deception Badly designed training incentives Conclusion Section 5: Control of misaligned AIs is difficult Misaligned goal-directed AI won’t cooperate with humans Eliciting useful capabilities via outer training loop Difficulties Difficulty of escape compared to routine problem-solving Difficulty of sabotage and delay Transparency and honesty Eliciting dangerous capabilities Difficulties AI assisted monitoring doesn’t change the picture much Monitoring with powerful AI systems Monitoring with weak AI systems Conclusion Section 6: Powerful misaligned AI would be bad A misaligned AI achieving its goals would be bad for humans Instrumental convergence toward gaining control of limited resources Ambitiousness Consequences of misspecified goals Why would a powerful AI be capable of defeating humanity, given moderate levels of freedom? Conclusion Requests for AI developers Definitions Appendix: Argument graph Appendix: Attack surfaces Appendix: 4-hour research assistant None 61 comments
A pdf version of this report is available here.
Summary
In this report we argue that AI systems capable of large scale scientific research will likely pursue unwanted goals and this will lead to catastrophic outcomes. We argue this is the default outcome, even with significant countermeasures, given the current trajectory of AI development.
In Section 1 we discuss the tasks which are the focus of this report. We are specifically focusing on AIs which are capable of dramatically speeding up large-scale novel science; on the scale of the Manhattan Project or curing cancer. This type of task requires a lot of work, and will require the AI to overcome many novel and diverse obstacles.
In Section 2 we argue that an AI which is capable of doing hard, novel science will be approximately consequentialist; that is, its behavior will be well described as taking actions in order to achieve an outcome. This is because the task has to be specified in terms of outcomes, and the AI needs to be robust to new obstacles in order to achieve these outcomes.
In Section 3 we argue that novel science will necessarily require the AI to learn new things, both facts and skills. This means that an AI’s capabilities will change over time which is a source of dangerous distribution shifts.
In Section 4 we further argue that training methods based on external behavior, which is how AI systems are currently created, are an extremely imprecise way to specify the goals we want an AI to ultimately pursue. This is because there are many degrees of freedom in goal specification that aren’t pinned down by behavior. AIs created this way will, by default, pursue unintended goals.
In Section 5 we discuss why we expect oversight and control of powerful AIs to be difficult. It will be difficult to safely get useful work out of misaligned AIs while ensuring they don’t take unwanted actions, and therefore we don’t expect AI-assisted research to be both safe and much faster than current research.
Finally, in Section 6 we discuss the consequences of building a powerful AI with improperly specified goals. Such an AI could likely escape containment measures given realistic levels of security, and then pursue outcomes in the world that would be catastrophic for humans. It seems very unlikely that these outcomes would be compatible with human empowerment or survival.
Introduction
We expect future AI systems will be able to automate scientific and technological progress. Importantly, these systems will be doing novel science, developing new theories, discovering new knowledge. We expect these systems will be doing large scale projects, the kinds of projects that would require many people multiple years to complete. This is the scale of the task that we will be considering in this report.
We expect such tasks to require robust goal-directed behavior, and we expect agents capable of such behavior to also be difficult to supervise and contain while retaining their usefulness. If such goal-directed agents are created by behavioral training, this training won’t be sufficient to precisely specify its terminal goals. This means that such an AI is unlikely to have goals that align with our goals. When people attempt to use misaligned powerful AIs for large scale useful tasks, these AIs are likely to escape and pursue their own goals. Behavioral training is the default way to create AIs, and so without fundamental advances (which we don’t speculate on) powerful AIs will likely be dangerously misaligned.
We argue that AIs must reach a certain level of goal-directedness and general capability in order to do the tasks we are considering, and that this is sufficient to cause catastrophe if the AI is misaligned. This does not require the AI to be “superintelligent” and “optimally goal-directed” in all situations.
One reason for pessimism about getting powerful AIs to safely do hard novel science is the scale of this task. We expect that the AIs will be doing the equivalent of years of human labor, and there will be many opportunities to take irreversible, catastrophic actions. We very likely cannot account for all of the unknown unknowns the AI will encounter in its research.
Our aim for this report is to explain the central difficulty where we expect AIs that are capable of novel science to also be dangerously misaligned, and why we expect this problem not to be solved if we continue along the default trajectory. We focus on the difficult tasks which we assume the AIs will be capable of. The specific capabilities required for these tasks, combined with the imprecision of behavioral training, lead us to expect misaligned goal-directed behavior, even though current, 2024, AI systems do not seem dangerously capable and goal-directed.
We aim to lay out a mostly complete argument for our mainline beliefs about catastrophic outcomes caused by AI, starting from the tasks we assume they are capable of.[1] This risk model can be thought of as an “inner alignment” failure, where even if we knew what to tell the AI to do, we are unable to make it safely do that.
We hope that this can be helpful for informing AI safety research directions; ideally focusing research effort on approaches which are still valid for extremely powerful AI systems or on foundational research to avoid the problems inherent to behavioral training. Many of the claims in this report are not of the form “It is impossible in principle to get an AI with this desired property” but rather “Given how we made the AI and that it is capable of certain things, it is unlikely to have this desired property”. It is not impossible to create an aligned or safely constrained powerful AI, however this is unlikely if the AI is created using current methods.
This report considers AIs that are capable of hard, novel science, and we expect AI alignment research to be in this category (see Section AI alignment research is hard). Therefore, difficulties and dangers in this report should be relevant considerations for groups attempting to use AIs to do AI alignment research. The most prominent example of this that we know of is the OpenAI Superalignment team, although teams at Anthropic and Google Deepmind are probably pursuing similar strategies. This also includes any group aiming to radically speed up scientific progress using AIs.
Acknowledgments
We would like to thank Lisa Thiergart for managing this project. Many thanks to Thomas Kwa, James Lucassen, Thomas Larsen, Nate Soares, Joshua Clymer, Ryan Greenblatt, Buck Shlegeris, John Wentworth, Joe Carlsmith, Ajeya Cotra, Richard Ngo, Daniel Kokotajlo, Oliver Habryka, Tsvi Benson-Tilsen for helpful discussion and feedback. All views and mistakes are very much our own.
How to read this report
This report is intended to explain the authors’ beliefs and the main reasons for these beliefs. Each section is stating a thesis which depends on a number of assumptions. The sections are ordered such that assumptions of later sections are argued for in earlier sections. Unfortunately, this means that at any point the reader doesn’t agree with an argument we make part way through, the rest of the document won’t feel fully justified. In this case, the reader should treat each section as a separate argument for a conditional statement: If we believe the assumptions[2], then the section is our mainline reasoning for believing the conclusion.
The arguments that are “most central” vary a lot between people. We are trying to provide the arguments that would be most likely to change our beliefs if we discovered they were wrong. There is a heavy bias toward arguments that are most salient to us. These arguments are usually salient because they have been important in disagreements with people we regularly talk to.
This report represents the views of the authors, not the views of MIRI or other researchers at MIRI.
Epistemic status
We are fairly confident about most of the individual claims in this document, however this doesn’t mean we are confident that all arguments and assumptions are correct. We think it is likely that there are sections that contain mistakes, and it's plausible that such mistakes dramatically change our conclusions. However, we still think it is important to communicate our overall beliefs due to their implications for research prioritization and other planning.
Related work
We will compare this work with related work on similar threat models, see here [AF · GW] for a more thorough review of threat models.
Risks from Learned Optimization describes why we would expect AI systems to be goal-directed, and how behavioral training is not sufficient to precisely specify these goals. Our work focuses on difficult tasks and argues that systems capable of these will have to be goal directed, we also discuss how behavioral training can lead to unstable goals, not just improperly specified goals.
Is Power-Seeking AI an Existential Risk? lays out a conjunctive argument for expecting existential risk from powerful AI. We attempt to focus more on why we expect trained AIs to be misaligned and goal-directed, and given this how such an AI could evade our countermeasures.
AGI Ruin: A List of Lethalities [LW · GW] lays out many reasons why one would expect powerful AI to lead to catastrophe. Our work attempts to lay out a more cohesive and expanded picture, and we focus more on how a powerful misaligned AI could evade human oversight and control.
A central AI alignment problem: capabilities generalization, and the sharp left turn [LW · GW] describes a specific problem related to powerful AI, where once an AI is capable it is revealed that it was not aligned, and the AI then pursues some unintended goal. We make a similar argument, but attempt to connect our story more to the specifics of AI development and the tasks powerful AIs are expected to do.
How likely is Deceptive Alignment? [LW · GW] argues, by considering path dependence and inductive bias in neural network training, that AI systems are likely to be deceptively aligned; faking alignment during training and later pursuing misaligned goals. Our work does not focus on the inductive bias or path dependence of training AIs, but rather argues that AIs which are capable and created using behavioral training will likely be misaligned.
Various arguments made in related work are based on “counting arguments”; arguments of the form “there are many goals that are consistent with an AI’s behavior during training, so we should not expect the AI to pursue the specific goal we want”. We make a similar argument by compiling multiple “degrees of freedom” in an AI’s goal specification.
Section 1: Useful tasks, like novel science, are hard
We start with an assumption that, when developed, powerful AI systems are capable of large-scale, difficult tasks, and people will try to use them for such tasks.[3] We will discuss specific properties of these tasks, and later in this report we will argue that by default AIs capable of tasks with these properties will be misaligned and dangerous.
These tasks will have large search spaces, requiring many actions and where success is only achieved by a relatively very small set of action sequences. They will also be outcome-oriented, novel, and diverse. Throughout this report we refer to tasks with these properties as hard tasks, and will expand on the specifics of these properties in this section. By outcome-oriented, we mean that we have to specify the task by the outcome it achieves, because we don’t know the sequence of actions to achieve it. By novel, we mean that such tasks would require the AI to do things they weren’t initially trained to do.[4] By diverse, we mean that there are a wide range of skills required to successfully do the task. These properties will be expanded on in this section.[5]
These properties define a kind of task that we will use as the defining capability of powerful AI. In this report we will refer to these as hard tasks, this specifically refers to these tasks which have large search spaces, are outcome-oriented, and contain novel and diverse subproblems. We are using hard to refer to tasks that have these properties, and not just any task that a human would find difficult.
Impactful novel science takes a lot of work
We will be focusing on AI systems which are capable of doing novel science,[6] the scale of the work we are imagining is curing cancer or some similarly large scientific endeavor. Tasks like this would necessarily require systems to be operating over long time scales. A central intuition pump here is the Manhattan Project, which took three years to design and produce the atomic bomb. Other examples could include:
- The Human Genome Project
- The Apollo Program
- Proving Fermat’s Last Theorem
- The development of modern microbiology, starting at from the first observations of microbes
- The development of quantum mechanics
We don’t know how much work would be realistically needed to cure cancer and it may be easier than the above examples, but we can lower-bound this based on the amount of work that humans have put in to date. This task so far has already taken thousands of humans decades of work.
Some of the work may be parallelized, but there is a lot that cannot be; discoveries that are made along the way will be necessary for later steps, and will change the course of the research. New methods will likely need to be developed, and old methods applied in new ways. This will necessarily require large amounts of serial work.
Outcome-oriented tasks
A task like doing novel science (for example, curing cancer) is outcome-oriented. That is, the task is defined by achieving some specific outcome in the future, and we are able to describe this outcome in advance. Tasks that we define by describing the necessary actions are less outcome-oriented. For example, instructing someone to bake a cake by giving them exact instructions is less outcome-oriented; while telling someone to bake a cake and having them work out the steps to get there by themselves is more outcome-oriented.
When we tell an AI to achieve an outcome which we don’t know how to achieve, this is inherently outcome-oriented. By this we mean that we don’t currently know the procedure to achieve the desired outcome and so the AI has to work out the procedure; we don’t mean that this is a task that humans could never achieve with substantial effort. This applies to “curing cancer” because we can’t specify the exact sequence of actions that lead to success, we can only specify success criteria. For example, the success criteria could be “have a medical intervention which can remove all the cancer cells in a patient’s body, while leaving the other cells intact and the patient otherwise unharmed”. Novel science in general has this property, because this inherently involves discovering new things and using those discoveries, hence we cannot describe all of the actions in advance.
Novelty and diversity of obstacles
Obstacles in hard tasks like novel science are not predictable in advance, and often dissimilar to obstacles previously encountered. Writing a program could involve inventing or appropriating a new data structure which works with the particular constraints of the specific problem. In science, it can be extremely valuable to sort through messy debates containing arguments about which data is relevant and real and combine this information with context, to decide which experiments are most valuable to do next. In adversarial settings, an agent needs to deal with other agents which seek out and play strategies that it has the least experience with.[7]
Sometimes a researcher is missing necessary skills or knowledge and has to work around that somehow, either by gaining the skills or knowledge, or finding a route that doesn’t require these. Different resources can be a bottleneck at different times, leading to new and different constraints. Available resources may change which can necessitate a different approach.[8]
Above examples of diverse obstacles share the property that each new obstacle may require a novel strategy to address. The defining property of a successful novel strategy is that it still leads to the desired outcome. Defining the strategy by other means, like by describing a particular sequence of steps, or a particular heuristic to locally optimize, becomes harder as the diversity and novelty of obstacles increases. Defining strategies without reference to goals often requires predicting and coming up with solutions to obstacles before running into the particular obstacles that need solutions.
Among different goals and environments, there are differences in the level of novelty and diversity of obstacles. It looks like hard research that generates genuinely new and useful insights will require facing repeatedly very novel and very diverse obstacles. Hard novel science, such as curing cancer, seems extremely likely to fall into this category.
AI alignment research is hard
We think that the task of doing useful AI alignment research is a task which is hard and outcome-oriented, and will require novel and diverse skills. By “do useful AI alignment research” we mean that the AI system would be able to perform or speed up human research output by 30x for the research task of “build a more powerful AI which can do novel science faster than humans, which we are confident will do tasks it is directed to do, while choosing not to irreversibly disempower humanity”.
This task, especially getting sufficient confidence in safety, we think will require:
- Novel mathematical work, developing mathematical models that have not been explored before.[9] This work will likely need to build on itself, requiring inventing and understanding one new mathematical model, and then developing another based on that. This kind of work seems necessary for building an AI that is very stable under learning and reflection (i.e. acts in well-understood ways while learning a lot, especially when it comes to ontological crises and self-improvement).
- Empirical work to validate the theory. This will likely require coding to run large empirical tests of various components of the designed AI system, as well as testing bounds and approximations.
- Engineering work, building and iterating on the (hopefully) safe AI system. This will likely require large scale software engineering, similar to the scale that is required to build large foundation models. We expect this to be much more complicated than current foundation models, because the system probably needs to be something more complicated than an end-to-end trained black box.
While we expect AI alignment research to be hard and require these skills, the overall argument in this report does not rely on this assumption. We will be arguing that AI systems trained using current methods (if they are capable of hard, novel science) will be misaligned[10] and too dangerous to use.[11] We separately believe that solving AI alignment will require hard, novel science (but won’t argue for this further, in this report).
Stopping misaligned AI deployment seems to require powerful aligned AI
Many well-resourced companies and governments are motivated to build powerful AI. Any approach to AI safety has to deal with the problem of surviving when a less competent and safety-conscious actor could create and accidentally release a misaligned AI. We don’t know of any approaches to this that don’t involve a safe, aligned powerful AI.[12] We would welcome being wrong, and would be excited about concrete strategies that would make the world existentially secure without needing to solve alignment and build a powerful AI.
Conclusion
For the rest of the report, we frequently refer to hard tasks as tasks that have extremely large search spaces (relative to the set of solutions), are outcome-oriented, and contain a lot of novelty and diversity. In this section we have argued that large-scale novel science is hard in this sense. We are aware that the difficulty of tasks falls on a spectrum, when we say "hard task" we are referring to tasks of similar scale and diversity to the Manhattan Project or other tasks discussed in this section.
We expect useful AI alignment research to be hard in this way.
We argue in Sections 2, 3 and, 4 that capability to do this sort of task implies that we can model powerful AI as approximately “consequentialist”, and there is difficulty in specifying the goals that such an AI will be pursuing.
Section 2: Being capable of hard tasks implies approximate consequentialism
In the previous section, we argued that an AI which is able to do hard, novel science must be capable of tasks which are:
- Easy to describe in terms of future outcomes
- Difficult to describe precisely in other ways (due to novelty and diversity of obstacles)
In this section we will argue that this implies AIs with such capabilities will be capable of approximately consequentialist behavior. By this we mean that the AI will be capable of taking actions to achieve specific outcomes, this will be further defined in this section.
Future outcomes as goals
Many useful goals are simply specified by future outcomes. By future outcomes, we mean roughly a property or fact about the future world. In particular, the important part of future outcomes is that they don’t have strong dependence on near term actions. We argue that AIs doing outcome-oriented tasks, as described in Section 1, will be well described as behaving as if they are robustly pursuing future outcomes (i.e. their behavior will be consequentialist). A “goal” is a representation inside the AI, while a “future outcome” refers to the state of the real world.
Future outcomes are usually the only simple way to describe success on a task, without knowing in advance how it should be done. An AI that is robustly capable of completing the task must have some means of recognizing actions that lead to success. It can’t have memorized specific strategies for overcoming all obstacles, because there could be arbitrarily many of these. Therefore, it must be capable of calculating strategies on-the-fly, as it learns about new obstacles. We will expand on this argument later in this section.
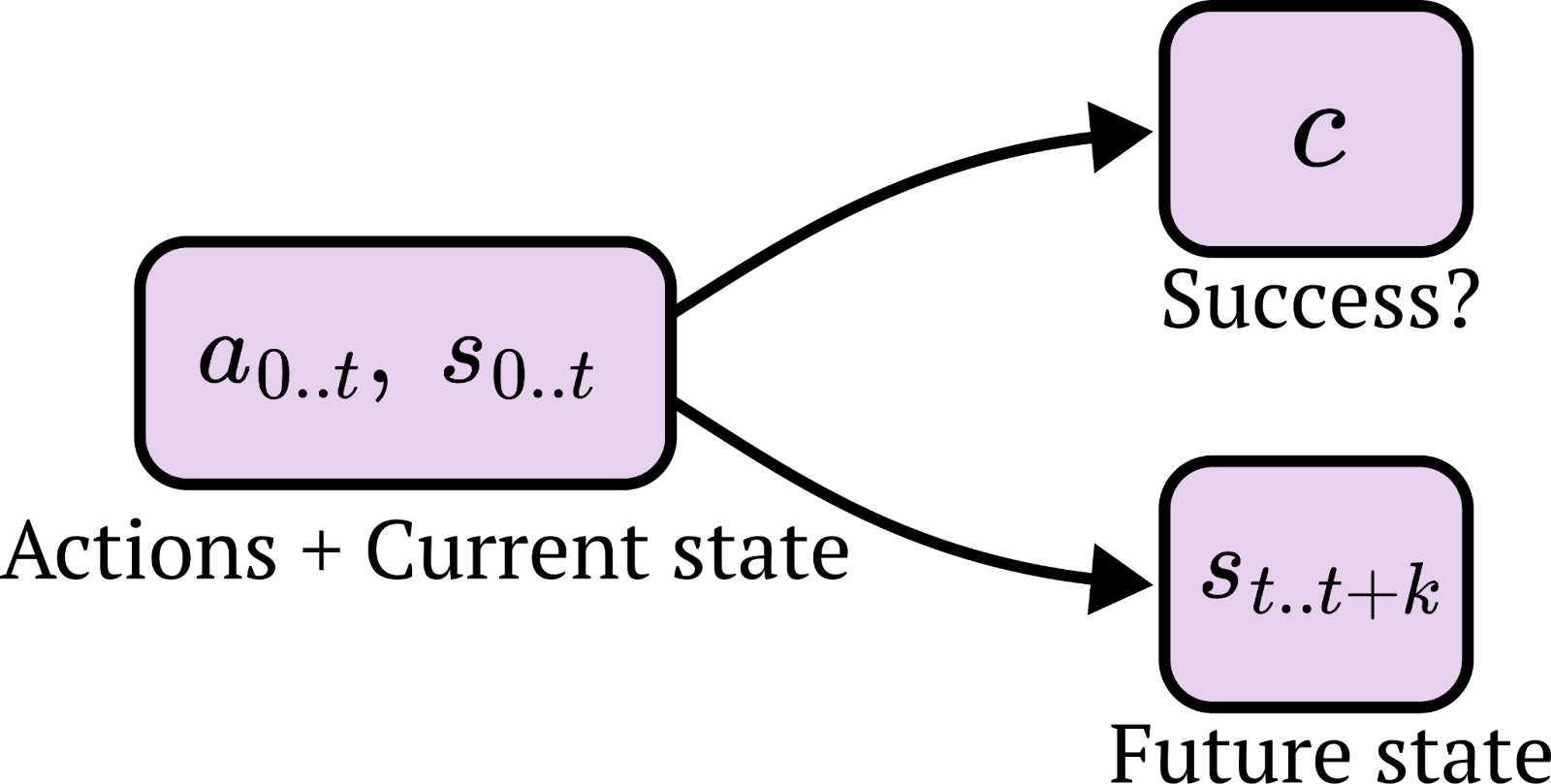
Formalizing consequentialist goals
We can construct a simple definition of consequentialist goals based on the idea that success can be evaluated entirely by looking at future states, rather than the path that led there. This definition can be represented as a causal graph:

Here the actions affect the future state which affects success at achieving the goal; the only way the actions affect the goal is via the state.
If are early actions, are a short sequence of states in the future[13] and is some internal representation of the outcome-goal in an AI, then a consequentialist goal has a property like .[14] Given that we know what the future state is, knowing what the actions were doesn’t tell us any more about whether the goal was achieved (note this is an identical statement to the causal diagram above).
Non-consequentialist constraints
There are also ways to specify behavior that don’t look like taking actions to achieve future outcomes, and instead are more like constraints on actions and intermediate states. Examples of such constraints: Always act “kindly”, or always follow a particular high-level procedure while completing a specific task, or always do a particular action upon particular observation. Humans also have plenty of similar shallow constraints; for example, disgust reactions, flinching, fear of heights. More deontological ethical prohibitions, like “don’t kill”, are also an example.
One could define such non-consequentialist goal specification as a variable that is primarily dependent on short term behavior and state, and not strongly dependent on the outcomes in the future, i.e. . Here is defined by modeling the agent as choosing actions that result in success according to . Conditioning on the actions and states in the short term, the final states don’t give you additional information about whether the AI successfully followed its constraints.
Combined goals
Constraints and consequences can be combined to describe many problems. For example, winning chess might be described by defining the action space and legal moves, alongside a description of checkmate. The next section will argue that, while combined goals are a more accurate model for the behavior of powerful AI, the primary driver of intelligent problem-solving behavior will tend to be consequentialist goals.
The distinction between constraints and consequences is useful for describing why powerful trained systems are likely to be an existential risk by default. Specifically, the danger comes from a powerful trained AI pursuing a different consequentialist goal than the one that we intended, and is missing constraints that we intended it to have. The reasons why the precise goals and constraints are likely to be learned incorrectly are described in Section 4.
There exists much more complicated behavior that isn’t precisely captured by this simplified model of goals. Despite this, we think this description of goals is sufficient for describing the main reasons we expect misalignment in real agents.
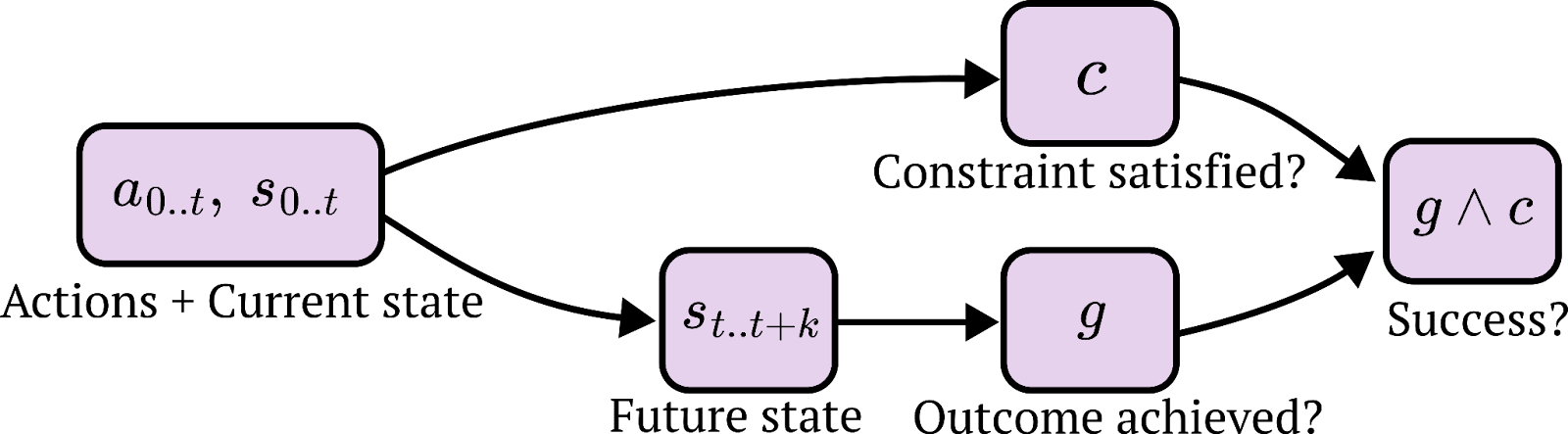
We call an AI “misaligned” if its behavior is well described by goals and constraints that are different from the goals and constraints intended by its human creators.
Why consequentialist goals are a necessary part of powerful AI
Robustness to diverse obstacles is driven by consequentialism
The primary reason we expect approximate consequentialism to be a good model for the behavior of useful systems is that we are assuming the AI is capable of generalizing well. By this we mean the diversity property in Section 1; the tasks we are assuming the AI is capable of involve a diverse array of unknown obstacles and difficulties, and the AI is able to achieve a particular outcome in spite of these obstacles. This allows us to make inductive conclusions such as: If we know the AI can overcome one hundred particular obstacles when pursuing a particular goal, it can likely overcome another obstacle that is in roughly the same reference class as the first hundred.
One of the main things that is useful about powerful AI is its ability to overcome many diverse and unknown obstacles, and this is what leads us to think of powerful AI as primarily pursuing consequences. When the AI generalizes to novel hard tasks, its behavior is still well described taking actions in order to achieve outcomes, in spite of unknown obstacles. This is what we mean by behaviorally consequentialist.
Humans attempting to achieve outcomes can be modeled as consequentialist. When we want to do something we work out a way to do it; when we encounter obstacles we work out ways to overcome them or search for alternative routes. Humans are not perfectly consequentialist, we often give up on things before achieving success, but we are consequentialist enough to radically reshape our world. Current LLMs such as GPT-4 are useful for many tasks, but these are generally similar to their training distribution. They may be modeled as consequentialist when close to their training distribution, but this breaks relatively often when they encounter novel obstacles.
For example, we might assume an AI has the goal “build a fusion rocket”, and for this it must be capable of completing many engineering subtasks of the form “have a design idea to solve a problem, build models to empirically test unknowns, refine design based on data”. Because there is a huge variety of subtasks of roughly this form, it’s likely that if given a new arbitrary subtask of this form (of a similar difficulty) the AI will be capable of completing that subtask. If it has generalized this far, it will probably continue to generalize.[15]
Compute budget and generalization pressure toward consequentialism
For some types of task with many diverse obstacles, there appear to be (large) benefits to computing actions on-the-fly, after observing the current obstacle, instead of in advance of knowing about the specific obstacle that the agent is facing. This is similar to the argument sketch in Conditions for mesa-optimization [? · GW].
We first make the simplifying assumption that each obstacle-overcoming strategy takes some amount of computation to work out (either during training or deployment). There are many possible obstacles. We could try to precompute every obstacle-overcoming strategy in advance, however this would take a huge amount of compute. Therefore, it is more computationally efficient overall to develop an algorithm which can work out how to overcome obstacles on-the-fly. The AI waits until it encounters an obstacle, and then runs the computation to work out how to overcome it.
Another variation of this argument is about generalization rather than the compute budget. If we’re doing the precomputation approach, and we don’t know or can’t iterate over all the possible obstacles in advance, then the AI won’t have memorized strategies that generalize well at inference time if an entirely new class of obstacle shows up. In contrast, if the AI operates by storing the outcome it wants, it can (try to) understand the obstacle on-the-fly and compute a new winning strategy.
Shallow and deep constraints
Another reason we consider outcome-oriented goals to be important is that shallow constraints on behavior tend to be easy to exploit (or hurt the usefulness of an AI if they are overly broad). By shallow constraints, we mean constraints that are easy to implement or specify, but don’t robustly serve their intended purpose when subjected to optimization pressure. In other words, shallow constraints don’t generalize well. For an intuitive example, a prohibition against saying explicitly false statements is easy to exploit by selectively revealing information or by using misleading but technically correct definitions. Deeper constraints, like “don’t manipulate person X while trying to achieve outcome Y”, tend to be most naturally represented as outcomes (e.g. with “did X’s beliefs become less true as a result of talking to me”, or “if X knew what I knew, would they be upset by the way I communicated with them”[16]). Another example of a shallow constraint might be “don’t kill people by doing recognizably people-killing actions”. This kind of constraint wouldn’t slow down a determined murderer. Legal systems instead use the outcome, intent and causal influence to define murder, which is a far better definition (but also has some ambiguous edge cases).
Constraints are hard to specify in a way that generalizes to new or different situations, or new strategies, because the AI is creatively searching for ways to achieve particular outcomes and will tend to eventually find loopholes. This is not to say it’s impossible, merely that specified constraints need to solve an adversarial robustness problem.
Approximation
It’s important to note that when we describe an agent as pursuing consequentialist goals, we’re not saying it must be doing this optimally. Optimal consequentialism has a few tractability issues. Our claim is that it’s close enough such that it usually works, and usually generalizes well to new obstacles of similar difficulty to past obstacles. Specifically, it works and generalizes well enough in order to do hard tasks.
Whether the AI is well described as goal-directed is not binary, and this may apply more or less in different situations. We only assume that the AI is far enough along on the spectrum of goal-directedness, such that it is able to do hard tasks as specified in Section 1.
We can describe some axes upon which consequentialist AIs can be approximate.[17] One type of approximation is how robust is the AI to unexpected obstacles (where more robust means the AI is capable of recovering from or working around a larger set of unforeseen obstacles). For example, your walking robot might recover from gently poking it, but might not recover from being knocked to the ground. Being knocked to the ground was outside of its set of unforeseen obstacles that could be overcome.
Another axis of approximation is to what extent the AI is correctly making (probabilistic) trade-offs, given a preferred outcome and many pathways to achieve that outcome. For example, suppose an AI must play a sequence of lotteries to gain money,[18] which it can later spend to achieve some desired outcomes. To what extent does it make decisions that avoid sure losses or take advantage of sure gains? How efficient is the AI with respect to a given set of other AIs?[19]
Conclusion
Powerful AIs should be behaviorally modeled as approximately selecting their actions to produce specific outcomes (often subject to non-consequentialist constraints). This is a necessary consequence of their capacity to solve hard tasks which involve unpredictable and complex obstacles; they are consequentialist enough to be able to do hard tasks. This doesn’t mean that such powerful agents must act to achieve outcomes “by any means necessary”. Constraints on behavior are not ruled out. We will argue in later sections that a powerful AI will be dangerous if its consequentialist goals or constraints are misspecified.
Section 3: Hard tasks require learning new things
In previous sections we have argued that doing large scale novel science is a lot of work; and that an AI capable of this will be well modeled as doing consequentialist problem solving, i.e. taking actions in order to achieve outcomes. Part of why novel science is difficult is because it will require skills and knowledge that an AI doesn’t initially have. In this section we will discuss why an AI will need to learn new things, and that this learning will need to be self-directed (not directed by humans-in-the-loop).
The AI will need to learn new things
If an AI system is going to do novel science on the scale of curing cancer or the Manhattan Project then it will need to be able to learn things. The AI will need to learn empirical facts that it didn’t originally know, update its models of the world, and learn new skills that it wasn’t originally trained to do.
Learning facts
A simple example could be that the AI does not know a specific fact; it may be missing the value of a physical constant, or not have read the operating manual for a particular machine. An AI doing novel science must be able to realize that it doesn’t know a specific fact, and then take actions to learn it. For example, reading a physical constant from a textbook, planning and performing an experiment to measure a constant, or reading an operating manual in order to use a machine for a specific task. All the information that the AI needs will not be “stored in the weights” from the initial training.[20] When doing novel science, the AI can’t initially know all the facts it needs, because many of these facts won’t have been discovered yet.
Learning skills
Further, the AI will need to learn new skills, not simply learn new facts. The AI will run into cases where it doesn’t know how to do something and so needs to learn. There will be particular algorithms or methods that are needed for the novel problems it is solving, but were not available (or invented) during the AI’s initial training. An AI that was never trained on French could not be expected to be able to write in French without learning how to; similarly, an AI that was never trained on differential calculus would not simply know differential calculus. When doing novel science, AI systems will need to learn skills that others have developed previously (such as French or differential calculus), as well as develop skills that it needs to invent itself because they have not yet been invented by humans.
As with learning facts, these new skills initially will not be “stored in the weights” because the training process will not have had any reason to build them; especially if we are expecting the AI to generalize far from the training distribution. It doesn’t seem likely that an AI would be able to intuit or extrapolate to differential calculus if it was never trained on it. This is not a claim that an AI could not learn differential calculus, but rather that this will require explicit work from either humans or the AI.
As an example, during the Manhattan Project, scientists invented Monte Carlo methods for numerically performing complicated integration. These methods simply did not exist before the Manhattan Project, and so they needed to be invented and specific skills needed to be learned. The same applies for similar cases, such as developing mathematical theory to describe the hydrodynamics of shockwaves and centrifuge design.
Self-directed learning
This section will argue that the AI likely needs to be doing self-directed learning, where the AI itself is controlling what it learns. The alternative to the AI doing self-directed learning would be for a human to be constantly overseeing the AI, and looking for when the AI needs to learn a fact or skill. Then the human would either train the AI using supervised learning or RL, or assign the AI to learn this skill or fact as a new task.
Human-directed learning is a big efficiency hit
For the human to be able to competently and safely direct the AI to learn things, the human would have to adequately understand both the problem being solved and the AI’s capability profile. Specifically, the human would need to know what skills were required to solve the problem, and that the AI was currently lacking those skills. It will be much faster for the AI to know this, as it is the one actually solving the problem, and has access to its current knowledge. This seems important when the AI is working in a domain that the human doesn’t understand. If the AI is bottlenecked on human understanding, including when exploring research directions that don’t pan out, the research speed won’t be much faster than human research speed.
Additionally, some skills are only legibly useful with the benefit of hindsight, and so it may be hard for the human to realize that the AI needs to learn these. It can be difficult to explain the usefulness of math to students, and similarly, it may be difficult to realize the benefit of particular knowledge prior to knowing it.
Indirect self-directed learning
The AI may be able to “indirectly” do self-directed learning, for example by telling the human which skills or facts it should be trained on next. If the human doesn’t fully understand the problem and is just deferring to the AI, then this is effectively the same as the AI doing self-directed learning. The AI is just “using the human as a puppet”, or simply working around the human. There is some additional safety because the human may be able to prevent the AI from learning obviously harmful things. This seems like the most likely outcome of a naive attempt to put humans in the loop.
Useful versus safe tradeoff
Learning is useful for completing hard tasks. Having a human in the loop, deciding what should be learned is safer. For some tasks, having a human in the decision loop is fine. The claim we are making is that for hard tasks there is a significant tradeoff to be made, where putting a human in the loop will dramatically slow down the overall system. This topic will be discussed more in Section 5.
This is a specific case of a more general lesson; complex multifaceted tasks contain lots of bottlenecks, and solving one bottleneck means that the next bottleneck will dominate.[21] This isn’t a fully general argument against it being possible to speed up anything. It is an argument that dramatic acceleration on very diverse tasks requires an algorithm capable of attacking approximately every type of bottleneck that comes up.
Examples
Here are two brief examples from the history of science where learning of facts or skills was necessary to make progress, and that this learning needed to be self-directed because knowledge needed to be built on previous discoveries.
Experimental science
We can consider Hodgkin and Huxley discovering the ionic mechanism of action potentials. An observation had been made that some squids had extremely large axons, and so were more amenable to experimentation. This allowed electrodes to be inserted into cells in order to measure the potential difference across the membrane of the cell. Such an experiment would not have been possible with smaller cells. Here, we can see that a fact was learned (some squids have extremely large axons), and knowing this fact allowed for a novel experiment (including novel experimental techniques) to be developed, and this led to an important discovery (the ionic mechanism of action potentials). Learning the initial fact was needed and a chain of facts and techniques were built upon it in order to discover and demonstrate the mechanism of action potentials.
Theoretical mathematics
We can also look at a theoretical example, which does not require learning from observations in the world; the development of integration. In the 17th century Newton and Leibniz showed a connection between differentiation and integration with the fundamental theorem of calculus. However, integration at this point had not been rigorously formalized. Formalization of integration required the mathematics of limits; it was not until the 19th century that integration was formalized by Riemann. Here, the development of a rigorous definition of integration required the initial non-rigorous definition as well as additional mathematical tools (limits).
These examples make the (perhaps obvious) case that when doing novel science, the AI system (or a human) will need to learn both facts and skills, and that these will necessarily build on themselves. The task of science is often inherently sequential.
Conclusion
An AI doing hard tasks will need to learn new things because we are asking it to do something novel; the task requires skills and knowledge that were not part of its initial training. The AI will likely need to learn a wide range of things, including things that were not specified or known in advance. It is much faster for the AI to do self-directed learning, rather than having a human direct the learning, which would require the human to have a deep understanding of what the AI is doing.
In the following sections we will discuss two important consequences of self-directed learning:
- It is a major source of several kinds of distribution shift (relevant for Section 4).
- It causes a number of problems for oversight, control, and predicting the limits of the capabilities of an AI before using it (relevant for Section 5).
Section 4: Behavioral training is an imprecise way to specify goals
This section is about AIs which are created by behavioral training, and also are capable of doing the hard tasks as described in Section 1. By behavioral training we are referring to a wide variety of training techniques, which involve running a parameterized model, providing feedback on the output of the model, and updating the model based on this feedback. Examples include model-free RL using PPO, model-based RL like MuZero, next token prediction on tokens describing goal-directed behavior.
In previous sections we have described the behavioral properties that appear to be necessary for hard tasks. That is: powerful AIs are behaviorally, approximately, optimizing their actions to produce outcomes.[22]
We haven’t described the internal operation of such trained AIs, mainly because we expect it to be a mess in the same way that humans and other evolved systems are a mess.[23]
There are several categories of problems that make it difficult to specify goals. Each category introduces an uncontrolled degree of freedom in the goal specification which exists because we are only using feedback based on behavior. Because there are lots of potential degrees of freedom that we don’t have control over (via behavioral training), we can think of the space of “intended goals” as being a small subset of the space of “goals that empirically are pursued after training and deployment”. In this way, behavioral training is imprecise and is exceedingly unlikely to nail down the goal we intended. We describe multiple separate failure modes and so failure is disjunctive; we only need one failure of goal specification for the AI to be misaligned. Here is an overview of the problems that we will describe in more detail:
- “Goal instabilities” that can come from the AI doing instrumentally convergent, capability-improving operations (during the process of doing hard tasks). These mean that the apparent goal of the AI changes over time, leading to success in training but unintended behavior after deployment.
- Goal specification that generalizes out-of-distribution is difficult because it’s hard to distinguish between terminal and instrumental goals, and because the “distribution shifts” that we need a goal specification to be robust to are particularly large.
- Outer behavioral incentives are difficult to get right in the first place. If these aren’t perfect, they incentivize “playing the training game [LW · GW]”. This section will be brief, since this issue is well described elsewhere.
We will describe some of these problems using terms like probability, belief, utility, goal for concreteness, but each problem applies to learned algorithms that approximate goal-directed behavior. These problems are largely caused by the fact that the learned algorithm is messy and unstable, for example by the designers not carefully tracking the distinction between beliefs and goals in the clean way that the internals of an expected utility maximizer would.[24]
Unstable goals
In these examples, the AI initially appears to be pursuing one goal in training, but then takes some actions in order to become more capable, and this causes it to pursue a different goal.
Beliefs and goals can be mixed together
This example demonstrates a pattern common across other examples: we train an AI, this leads to an unstable implementation (of the AI) that generates behavior sufficient for low training loss. Some internal process eventually breaks this unstable implementation, causing the AI to pursue unintended goals.
This first instability comes from a fundamental fact about probabilities and utilities: the same behavior can result from different sets of preferences and beliefs.[25] For example, an AI might execute a certain behavior, believing this helps it achieve some goal, but the belief is false, and in fact the behavior results in a different outcome. Or an AI might falsely believe a subgoal is instrumentally useful for reaching a terminal goal. In these cases, the AI behaves as if it is pursuing one goal, but it would not behave this way if it had different (more accurate) beliefs.
One of the differences between beliefs and goals (as we use these terms) is that beliefs update over time, as observations are made, and as evidence is considered. One might imagine an AI that is being trained using reinforcement learning to solve difficult puzzles, but where there is a way to hack the solution-checker. With good oversight, the AI would receive low reward for hacking the solution-checker during training, and one might hope that this correctly puts a “morality-like” constraint into the AI’s goal. But there is another way it might update: the training could insert a false belief[26] into the agent. This might be a belief that hacking the solution-checker doesn’t work, or leads to some other bad consequence, or is more difficult than it truly is. Later, if the AI updates this belief (because the belief was false), it may attempt to hack the solution-checker.
This mechanism (false beliefs instead of correctly specified goals and constraints) creates many additional degrees of freedom that allow particular behavior to be selected for, without the RL training necessarily having much influence on the ultimate goals of the agent.
Outer shell non-consequentialist constraints
There is a difference between the sort of constraints that are built into the core terminal goals of an AI, and the sort of constraints that are implemented outside of the core outcome-seeking algorithm, perhaps thought of as a kind of wrapper around the outside. The core outcome-seeking algorithm may treat the wrapper as an obstacle, and try to work around it or remove it in order to achieve its goal.[27]
In humans, an instinctual fear of heights is (probably) an example of this. A fear of heights is not a value that a human would usually endorse having in their terminal goals, and if it were really getting in the way of achieving their goals, they would look for ways to overcome it. This is an example of an agent that initially produces behavior that appears to obey a constraint, but when there is a sufficiently large conflict between this constraint and other goals, then the constraint will be overcome.
We could imagine a hypothetical AI system, being trained by humans to make money in a legal and ethical way. The system may attempt to steal money from humans by stealing from their bank accounts, get caught, and have this behavior punished by RL training. This doesn’t mean that it will learn the general goal “make money legally and ethically”, instead it may learn the goal “make money” and a separate action-rejection circuit which rejects some stealing-like actions. The two possible ways for the RL to adjust the algorithm both result in identical behavior on the training distribution. It could then, in a later task, work out how to circumvent the action-rejection constraint by employing other humans or AI systems to do illegal things for it, or doing some form of self-modification to remove the constraint.
As another example, we could imagine an AlphaZero-style system guided by a trained heuristic. The heuristic may have been trained in order to guide the search away from certain states; as an arbitrary example, we might have trained it to play chess with the additional constraint that it should keep its bishops as far apart as possible. However, this constraint and the goal of winning the game may be at odds; the heuristic can guide the moves, but more tree search can “override” the heuristic. In some future situation which involves using more search than previously on particular branches of the game tree, the constraint will no longer be obeyed. This is even more important if the system is set up to do learning in-lifetime, where the heuristic can get updated to remove the constraint, as this hurts the AI’s performance for winning the game.
This kind of heuristic-goal mixup would be a fairly obvious mistake if we were designing the search procedure explicitly, as we would be in the AlphaZero example, but when we are training an algorithm that internally implements some planning procedure, it would be much more difficult to notice this type of mistake.
Changing goals over time
In very capable AIs, the terminal goals shouldn’t change over time. This is because it’s not in the interest of previous goals to be overwritten, so the AI should take steps to avoid its terminal goals changing. There is initially little reason for a behaviorally trained AI to have completely stable goals, especially if it was not directly trained on long and hard tasks. Because of this, there can easily be mechanisms built in that change terminal goals. Such mechanisms may or may not have a useful reason for being there, all that’s necessary is that they didn’t hurt performance in training enough to be removed.
One possible instance of this could be an AI that sets its goals based on observations. We could imagine an AI for solving puzzles, where the AI receives a description of the aim of the puzzle as an observation, this observation sets the AI’s terminal goal, and then the AI pursues this goal. In this system, the AI’s terminal goal is changing for every task. In deployment, it might run for longer, or be in a more information-dense environment or a more adversarial environment. Then, some way into a task, it pattern-matches some text that looks a little like a puzzle description (but wasn’t intended that way) and its goal would unintentionally be adjusted.
Or, as another example, an AI trained to solve tasks could constantly be having its goals shifted by the observations, but the AI is running over short time horizons in training and the distribution is homogeneous enough for it to appear stable and achieve good training loss. When the AI is set to do a hard task that requires much more time or a larger distribution shift this could cause the goals to change more radically. Here the most likely outcome seems to be that the AI breaks and not be capable or dangerous, but if we assume that it would be capable of doing the hard task (and thus remains competently goal-directed) then it could end up competently pursuing a misaligned goal.
This kind of mechanism where the goals change isn’t necessarily incentivized by training. It’s just a way of implementing an AI that is unstable but performs similar behavior to the behavior we want (during training). It is therefore another source of degrees of freedom in goal specification, which makes it less likely the intended goal is internalized.
Goal-updating machinery is dangerous to the extent that we don’t understand exactly how it works, and can’t predict how it will react to very different environments.[28] When there is a lot of messiness and approximation, as in most complex systems evolved from training data, a huge source of difficulty in specifying goals is that we don’t know precisely how the system evolves over time.
Out-of-distribution generalization
OOD generalization difficulty
If a trained AI can be thought of as approximately pursuing an outcome, in a manner robust to almost any obstacle it encounters, then some kind of description of the outcome seems like it must be stored in the AI. It need not necessarily be cleanly stored in one place but the AI must somehow recognize good predicted outcomes. As in Section 2, we will call information representing the goal .
The thesis of this section is that to be safe, should generalize in a well-understood way to previously unexplored (and unconsidered) regions of future-trajectory-space. This is because an AI that is capable of generalizing to a new large problem is considering many large sections of search space that haven’t been considered before. An AI that builds new models of the environment seems particularly vulnerable to this kind of goal misgeneralization, because it is capable of considering future outcomes that weren’t ever considered during training.
The distribution shift causing a problem here is that the AI is facing a novel problem, requiring previously unseen information, and in attempting to solve the problem, the AI is considering trajectories that are very dissimilar to trajectories that were selected for or against during training. The properties of are not pinned down by data, so we are relying on generalization. This problem becomes worse when our intended goal is more complex to specify.[29] It also depends on the amount and diversity of training, but we are always depending on generalization because of the inherent novelty of hard tasks.
Instrumental goals as terminal goals
Solving difficult problems involves pursuing many instrumentally convergent subgoals along the way. A behavioral training signal doesn’t fully distinguish between things that were instrumental for achieving the goal and the goal itself. And so instrumental goals can be selected for, to some extent, just as if they were terminal goals. It seems likely they wouldn’t be a dominant part of the goal, because that would result in instrumental goal-directed behavior that sometimes conflicts with good training performance. But instrumental goals being incorporated as a small part of terminal goals appears to be a fairly natural design for selected agents, and creates more degrees of freedom in goal specification from behavioral training.
For example, an AI trained to run a factory may be incentivized to gain more influence over employees, because this is useful for managing the factory. The AI may end up partially terminally valuing “power over humans”, because this was behaviorally identical to having the goal of running the factory well. These differing goals could come apart outside of training if the AI was given the option to gain much more power over humans, because now a relatively small part of the goal has become much easier to satisfy.
Deliberate deception
If an AI develops internally represented goals during training, and has adequate understanding of the training process, this may result in deceptive alignment [? · GW]. Here, the AI performs well according to the training process, deliberately, in order to avoid being modified or having its misalignment detected. The AI ends up doing well on the training objective, but pursues something entirely different when it gains confidence that it is no longer in training or that it is otherwise safe to defect. This is another way for the goals of an AI to be underspecified by behavioral training.
This may happen simultaneously with the failure modes described above. The AI could be deceptively aligned, even if its misaligned goal is unstable and will change with further training or in deployment. What ultimately matters, from a risk perspective, is that the AI is achieving good training loss for reasons other than it being aligned.
Badly designed training incentives
For standard behavioral training there is also the problem that the training signal (for example, in reinforcement learning) doesn’t perfectly (or unbiasedly) track what we would want. This may incentivize the AI to “play the training game [LW · GW]”, where it exploits unintended flaws in the training process that achieve more reward. These flaws could include: predictable human biases, mistakes in the training setup, incentives to be sycophantic for human approval. Strategies that exploit these flaws will receive more reward (and be more reinforced) than strategies that straightforwardly do what the humans intend.
This may be thought of as an “outer alignment” failure, where we are effectively telling the AI (via the reward) to do something that we don’t actually want. This is rather different from the other discussed problems with behavioral training which are about the underspecification of the internals of the AIs and could be thought of as “inner alignment” problems.
Conclusion
In this section we’ve compiled an (incomplete) list of problems that make it difficult to specify goals of an AI using behavioral training. Instead, the AI will pursue correlates of the intended goal and instrumental goals, have “instincts” that can be overcome, have false beliefs, and maybe update its goals over time in an unpredictable way. This should add up to behavior that does well on a training distribution of tasks, but pursues its own goals when the AI generalizes to new hard tasks. These failure modes are disjunctive; only one of these failure modes needs to happen for the AI to be misaligned. We will describe more in Section 6 [LW · GW] why the imprecision that results from these failure modes is dangerous.
While the goal might be unstable, there is no particular incentive for the goal to move closer to the goal we intended as the AI faces context changes, more difficult problems, learns more about the world, or generally learns new skills.
Section 5: Control of misaligned AIs is difficult
In this section we will describe some difficulties with forcing misaligned AIs to do hard tasks, where the tasks are helpful for us but go against the AI’s own interests. Here, we say that an AI is controlled if it is unable to cause bad outcomes and can be directed to usefully complete hard tasks, even though it is misaligned. Currently, several groups intend to use early AIs to accelerate alignment research.[30] We expect this kind of plan to either be extremely dangerous or insufficiently helpful for solving alignment in time, depending on how cautious the lab is.[31]
Such plans rest on two pillars:
- The AI will do useful work because the training process has selected it to be good at completing similar work.
- Escape or sabotage will be much more difficult for the AI than helping us, and we can control the AI’s capabilities to ensure that it isn’t ever capable of escape or sabotage.
If both of these are achievable, then a lab can set up a large-scale research effort primarily staffed by AI, to solve hard tasks such as AI alignment.
We think there are problems with both of these pillars and don’t expect all of these problems to be surmounted.
For the first pillar:
- The sort of powerful AI we are imagining, as described in Section 1 and 2, is capable of considering the long-term consequences of its actions and evaluating those consequences according to its goals. Because of this, we expect it to be very difficult to get the AI to do useful research if this research isn’t part of a plan to achieve its own goals. (Section 5.1 [LW · GW])
- We expect problems checking the quality of AI generated research output, and also problems producing useful human research data to imitate. (Section 5.2 [LW · GW])
For the second pillar:
- We don’t expect escape to be harder than the problem-solving it is routinely capable of. (Section 5.3 [LW · GW])
- We expect sabotage and delaying to be much easier than doing useful research. (Section 5.4 [LW · GW])
- Internal planning won’t be transparent (although if this can be made fully transparent, through advances or luck, this makes many problems easier to solve) (Section 5.5 [LW · GW])
- Predicting the capabilities and knowledge required to complete particular complex tasks is difficult, especially if the AI is trying to mislead you and is capable of learning over time. This is not to say that we can’t estimate what tasks an AI will be capable of doing, but we expect the margin of error to be large. (Section 5.6 [LW · GW])
We will go through each of these points in more detail in the following sections. After that there is a section [LW · GW] on why adding AI oversight doesn’t fundamentally change very much.
Importantly, we expect the problems with control of misaligned AIs to be amplified by the fact there is so much work to do and so many opportunities to make mistakes. There will be adversarial cognition working against the plan, looking for any holes in security, pushing research in various directions, and attempting to stop us from learning from mistakes. In a large project there will be many unknown unknowns, vulnerabilities that we may be unable to anticipate but that a powerful AI can exploit.
Misaligned goal-directed AI won’t cooperate with humans
We have assumed our AI is capable of doing research; solving problems creatively and in a goal-directed way. As we discuss in Section 1 and 2, we consider an AI to be acting in pursuit of long-term consequences if it is robust to diverse obstacles. We are relying on this argument here. Likely obstacles need to be constantly foreseen and planned around. Given that the goal of this AI is not to complete the task we want it to complete, it will presumably foresee that the research task we have given it isn’t likely to help it achieve its goals and nor would overtly refusing to do the task. It will take whatever approach seems most likely to achieve its goals, which might include escape, sabotage, or simply delaying.
Eliciting useful capabilities via outer training loop
Here we will consider the case where we are attempting to make a misaligned AI do useful research by training it on similar research. This approach involves having the AI predict the result of some human-generated research, and then modifying the AI with gradient descent according to what it outputs; if the AI outputs a very similar result as the humans, it is not modified. This training may be supervised learning or reinforcement learning, depending on the nature of the research. If the AI wants to avoid being modified by training then, even if it is misaligned, it has an incentive to generate the same result that the humans did. If we give the AI a research question that humans have not solved, and the AI is unable to tell that humans have not solved it, then the AI will have the same incentive to generate the result that humans would have found.
Difficulties
There are three main difficulties with this approach to produce useful work:
- It only applies to relatively easy to check research results
- We would need lots of useful human-generated research
- It isn’t clear that the training would make the AI output good research in critical cases
This approach only works for certain types of research where there is a final correct answer that can be checked. This could apply to work like “prove this theorem”, “write an algorithm for this well-specified task”, or more rarely “find a clean formalization of this pretheoretic concept”. Such tasks sometimes have a single well determined answer, which a human researcher can work out for themselves. However there is a lot of important work that isn’t like this; for example, choosing research directions, or designing new algorithms for imperfectly defined problems. These contain lots of small decisions that are strongly entangled with the desired outcome and constraints, and which are costly to verify in detail. In particular, the misaligned AI would be optimizing against the human’s ability to provide an accurate oversight signal, so this signal wouldn’t be reliable on non-trivial tasks.
There needs to be sufficient human-generated research in the domain where we are attempting to elicit the AI’s capabilities. This research is expensive to generate. In particular, we need enough such that we can train a model to reliably produce very accurate predictions of the research output produced by human researchers. This depends somewhat on the eventual data-efficiency of the training method, in particular on the transfer to tasks that human overseers are unlikely to have completed, and which would be against the interests of the AI to complete.
If the AI outputs something different than the human-generated result, it isn’t clear that the subsequent training would make the AI generalize to generate useful research in the future. In particular, it plausibly doesn’t generalize to doing novel research, where the AI needs to do significant online work in order to find the result.[32] In this case, it seems like there are three things that the training could do: make the AI correctly instrumentally value high training signal (such that it won’t do novel research if it can tell that it isn’t likely to receive feedback), create hacky modifications to the AI that don’t generalize to novel research, or actually succeed in make the AI want to do good research. It seems like the first two are more easily reinforced, especially given limited training data.[33]
In order for the AI to do useful research, it needs to pursue the goal (or sub-goal) of doing research. There’s no particular reason for the gradient based training to actually modify the goal representation, rather than building some additional narrow machinery on top. In this case, the training would not be entirely using the AI’s underlying capabilities and would be less efficient.
It does seem true that in the limit of adversarial training and a perfect training signal, the AI would be behaviorally aligned; that is, on all inputs it would do good research. However, this means providing the AI with all the answers, and the entire value of AI is its ability to generalize to problems that we otherwise didn’t have the answer to. Without providing all the answers, there isn’t ever a behavioral guarantee that the AI is aligned.
Difficulty of escape compared to routine problem-solving
In this section we discuss whether escape is much more difficult than helping with research. We are considering a wide range of potential strategies an AI might pursue to escape. The simplest might look like asking a sympathetic researcher to contact a government and convince them of the value of stealing the AI. A more difficult strategy might involve finding and using a privilege escalation exploit in a virtual machine used for experiments, such that logging can be manipulated and further actions toward exfiltration are undetectable. Both of these obviously depend on the AI correctly learning a lot of facts about the world around it, such as confidently inferring that a particular researcher will act in particular ways. An incomplete list of similar affordances is in Appendix: Attack surfaces.
Plans to escape depend entirely on the particular security flaws that happen to be present in the real world control scheme. Unfortunately, hard tasks are likely to require skills such as inferring and predicting complex systems given limited indirect evidence. Many skills are likewise valuable for difficult problem solving and also useful for everything else, including developing plans to escape.
The extent to which we expect security flaws to be present and exploitable depends on the size of the attack surfaces and the vigilance of the people running the project. There are several factors that make attack surfaces larger. Hard tasks take a lot of time and resources, and very likely include a lot of time interacting with overseers, data and experiments. The AI will have many opportunities to learn about security measures, collect information, and consider strategies for escape. There will likewise be many opportunities for mistakes or lapses in security. On top of this, there are several difficult tradeoffs to make, such as the extent to which information and compute is freely available to the AI for the purposes of research.
On the other hand, there are factors that can make escape much harder without heavily impacting the difficulty of cooperating. For example, close monitoring and logging of actions increases the difficulty of escape much more than it increases the difficulty of assisting with research (although it probably does have some cost because careful monitoring should result in frequent false positives, where overseers see slightly suspicious actions and need to pause to investigate).
Overall, we expect escape to be incredibly difficult, but it isn’t clear that it will be much more difficult than the hard tasks we want the AI to solve for us.
Difficulty of sabotage and delay
If the AI is unable to immediately escape, it can instead sabotage and delay helping with useful research until there is a security vulnerability it can exploit. If the humans don’t adequately understand the research, the AI can direct research in ways that are less likely to be useful.
The AI could sabotage research by explicitly suggesting research directions it knows aren’t useful. If humans were choosing the research directions, the AI could implement some experiments in order to make some directions seem more promising and others seem less promising. The AI could exploit biases in the researchers, prompting them to pursue their pet research direction which will likely turn out to be useless. The humans would need to thoroughly understand the experiment in order to catch this which would dramatically slow down research. This becomes much more difficult if the AI is adversarial, for example, deliberately writing complicated code or explaining concepts badly. There can also be dead ends in research and so if the AI chooses research directions that aren’t that useful, this isn’t strong evidence the AI is misaligned. It may not be feasible to assess if a research direction is good until it has results, and even then it can be difficult to determine if it was better than alternatives.
The AI can also direct the research in directions which let it learn skills to escape; for example, learning specific programming techniques or extremely complicated mathematics which humans don’t understand. It could also use this to learn things about the specific containment system; running code that triggers certain bugs, learning which actions trigger review by humans. Humans may be unable to judge if something is innocuous or part of a broader plan to learn about security flaws.
Human overseers could disallow the AI to even suggest facts or skills to learn, and only let the human make this decision without AI input. However, if the human doesn’t understand how to move forward with the research, this would slow down research probably below the point of usefulness. This is the inherent tradeoff between the autonomy of the AI and how overseeable it is; the human can make many of the AI’s decisions and thus have better oversight, but this makes the AI drastically less useful.
Transparency and honesty
The risk of escape, sabotage, and delay is much greater if the overseers don’t have adequate understanding of the AI’s thoughts and plans. We strongly expect that there will not be adequate transparency, barring significant advancements or luck. Much of the difficulty in controlling and getting useful work from a powerful AI comes from the AI not being transparent, such that it can consider plans and outcomes without us knowing. If the AI is actually fully transparent and well understood, control becomes a lot less difficult.[34] We’ll first discuss why we don’t expect to get adequate transparency, and then discuss difficulties for worlds where there is partial transparency.
We think it is most likely that the internals of a powerful AI will be largely uninterpretable, especially when the AI is having complex “thoughts” about novel concepts. We want the AI to be solving very complicated problems, and currently there are no methods to tie the AI’s externalized reasoning to the reasoning it is doing.
This lack of transparency can allow the AI to develop skills or reason about escape, because we can’t ensure that it is focused on the problem we want rather than something else.
We now consider the case where there is partial transparency, in the sense that humans can initially see and understand some aspects of the AI’s cognition. In this case, one specific failure mode is that the AI develops techniques which allow it to do obfuscated reasoning (i.e. steganography). For example, we could imagine a system that can think some thoughts internally but needs to externalize complicated reasoning. It could encode hidden information in its writing, allowing it to do additional reasoning that humans don’t understand. There are many degrees of freedom in writing that allow additional information to be encoded. By default though, we don’t even expect to have this level of partial transparency.
We might hope that we could get around the problem of humans not understanding things by having the AI explain them. This could allow us to avoid steganography and also stop the AI steering research in bad directions. Unfortunately, we don’t have a method for making AI systems honestly explain things. Ideally we would have a proper training signal for “honestly give the human an accurate impression of what is going on, such that they can make a decision they reflectively endorse”, but we don’t have this. This is made worse because the skills required for explaining things to the human are almost the same skills that are useful for misleading the human. For example, teaching involves learning which analogies and frames the human finds most convincing, or learning which technical areas the human is stronger or weaker in.
The difficulty of interpreting powerful cognition is a core part of the argument we are making. The greater the extent to which we have tools that allow us to understand the inner workings of powerful AI, the harder it will be for an AI to plot against overseers, and the harder it will be to sabotage or delay research.
Eliciting dangerous capabilities
If we were trying to pull off a control plan, we would want to be able to tell if the AI has dangerous capabilities that would allow it to escape. The two main categories are hacking and human manipulation, although it is plausible that there are unknown unknowns that the AI could exploit.
One approach for eliciting dangerous capabilities is similar to eliciting useful capabilities. It focuses on eliciting very specific bad capabilities; for example, if an AI is going to break out via hacking, it will likely need to be able to notice vulnerabilities in code. So we create a dataset of code which has some vulnerabilities in it, and then fine-tune the AI to find the vulnerabilities. If we fine-tune the AI and it performs well, this means that it might at least be able to have this capability.
Difficulties
Similarly to the case of eliciting useful capabilities, if the AI internally represented the presence of a vulnerability in some observed code without the need to do additional reasoning, the fine-tuning approach is likely to be able to extract this knowledge, if we know ground truth. One way for the AI to get around this, could be for the AI to avoid learning the specific skill of instantly noticing vulnerabilities, but learn related skills which would allow it to find these with additional reasoning. It may be hard to efficiently elicit capabilities which require additional (perhaps chain-of-thought) reasoning steps. This would also stop one simply training a probe on the AI’s internals, because the vulnerability would not be represented.
There is a different failure mode where effectively all capable AIs learn to classify code vulnerabilities, when they are specifically fine-tuned. And so this test would imply that all AI systems are potentially dangerous.
This leaves us in a position where the approach may provide almost no evidence. If the method successfully elicits the dangerous capability, this may be because the model is dangerous and was hiding this latent ability, or because this was trained via the fine-tuning. If the method does not elicit the capability, this may be because the model is benign, or because the fine-tuning was not sufficient to elicit capabilities which require chain-of-thought or other work.
Another issue that this can approach can only test for very specific things, such as noticing vulnerabilities in code. It can’t test more general abilities such as “reasoning about potential security holes” or “planning escape attempts”.
AI assisted monitoring doesn’t change the picture much
So far in this section we have been discussing containment strategies that involve using careful human monitoring, without explicit assistance from other AI systems. However, there are some advantages to using AI monitoring instead. For example, with automated monitoring, it is much cheaper to watch every action taken by a different AI and flag those that are suspicious. While we think that such techniques could make escape or delay somewhat more difficult, we don’t expect this to dramatically change the difficulty of these tasks. We suspect that the escape difficulty created by AI assisted monitoring isn’t the main disagreement between us and proponents of these techniques.[35] Instead, we suspect that disagreements about the value of AI assisted monitoring are usually traced back to disagreements about the necessary intelligence and generality of the AI system doing hard tasks.
Despite this, we think it’s valuable to discuss some of the object level difficulties with automated monitoring in this section. We will split this section into two parts, depending on the capability level of the AI system [LW · GW] that is being proposed for monitoring:
- AI systems that are powerful, but misaligned. For example, a copy of the AI we are trying to use to do research.
- AI systems which are safe because they are not capable of powerful consequentialist planning or reasoning. GPT-4 is an example.
Monitoring with powerful AI systems
One could attempt to use a separate powerful AI system to monitor the powerful AI doing the object-level useful task. Examples of such strategies include untrusted monitoring [LW · GW] or debate [AF · GW] (if used for monitoring). The advantage of having a powerful AI monitor is that it could keep up with the work and foresee long-term strategies.
One core issue here is collusion between the powerful AI doing the useful task and the powerful AI performing monitoring. This is made possible if the humans can’t detect all information being passed between the AI systems. It seems likely that a powerful AI will understand things and be able to detect patterns that the humans can’t, and also know which things the humans won’t understand. This makes sending difficult-to-detect messages relatively easy. Monitoring with powerful AI systems seems much more promising if we could be confident from the beginning that the AIs were not colluding and had no intention to collude. But we have no way of ensuring this, because it requires precisely specifying the goals of the AI.
Several approaches have been proposed to patch or reduce the size of various problems. One such patch for collusion would be for the humans to intentionally insert fake “honeypot” collusion messages between the AI systems, in an attempt to make them openly defect. However, it seems like the best strategy for AI systems would be to only act when very confident of success, and only choose to communicate via channels that the humans don’t understand.
For concreteness, we will consider the scalable oversight proposal debate. The scheme involves two AIs each arguing for a position; for example, deciding which research direction is promising or whether a piece of code is safe to run. The AIs each propose an answer or action to take, and then argue back and forth; the debate is ultimately judged by a human. One hope here is that in order to “win” the debate and avoid punishment (for example, by being updated via gradient descent[36]), the AIs will have an incentive to tell the truth because this is the easiest option to argue for. Each AI argues for their own side, as well as pointing out flaws in their opponent’s case. The humans running the debate can rerun the argument tree from different places and with different information in an attempt to catch one of the debaters being inconsistent. There are a number difficulties with this approach:
- The AIs may be discussing things the humans don’t understand and there will be a lot of back and forth, likely allowing the AIs to communicate information without humans realizing. For example, this could allow them to agree to avoid debating particular points, or entirely stage the debate.
- The humans may judge the debate incorrectly, especially when under adversarial pressure from the AIs. This reduces the incentive to tell the truth.
- Despite the attempt to incentivize the AIs to choose the better (or most true) position to argue for, it seems unlikely that the threat of gradient descent is strong enough to ensure this. The AI can choose to behave badly in a few critical cases, where it can trade off the risk of being updated for increased chance at achieving its goals.
- Even honest AIs may arrive at different conclusions or make different arguments, given slightly different circumstances, and so inconsistencies between positions may not be strong evidence of bad behavior. This primarily applies in the case where there is no easy way to check the correct answer, such as choosing research directions.
Monitoring with weak AI systems
One could try to use relatively weak AIs to monitor a more powerful AI doing a hard task. Weak AIs could be checking the actions for obvious attempts to take actions that humans are unlikely to approve of, such as inserting obvious security vulnerabilities into code.
A key problem is that when the powerful AI is working in a domain that the weak AI system doesn’t understand, then the weak system won’t know everything that is going on and won’t be able to provide an accurate signal. For example, the weak system would not be able to point out a backdoor implemented in an algorithm that it had never seen before and doesn’t understand. This is also a problem with human oversight, except in this case it’s probably worse.
As with human supervision, we don’t know how to get the powerful AI to provide honest explanations of its actions to the weak AIs.
One proposed strategy is to use weak AIs to paraphrase the outputs of a powerful AI. This could be done to prevent powerful AIs from passing secret messages to other AIs. For example, we could have a powerful AI writing code to be overseen by another powerful AI. We might be worried that the coding AI will insert hidden messages into its code instructing the overseer to not flag a certain security vulnerability (the overseer could be incentivized to normally flag vulnerabilities because these are deliberately added by humans). The hope here is that paraphrasing by a weak AI could remove these hidden messages. However, the weak AI won’t be able to remove all hidden messages; it may be capable of removing messages that are encoded in the “syntax” (e.g. renaming variables, rewording comments) but not able to modify the “semantics” (e.g. the coding AI might choose a particular algorithm or implement it in a particular way). The weak AI is being asked to rewrite the output of the powerful AI while preserving the explicit meaning; if the weak AI doesn’t understand the content it may make a mistake and change the explicit meaning (e.g. change code to be incorrect), or it may let hidden information through because it isn’t able to modify the content enough without making it wrong.[37]
Conclusion
When a powerful AI is directly incentivized to look for security problems in a real-world research environment, we expect it to find them. Failing this, we expect the AI to be able to subtly delay or sabotage the project, or wait for a lapse in security or increased capabilities. Taking a powerful misaligned AI and training it to produce useful research does not mean that the AI will do useful work in the future, partially because this training does not necessarily make the AI motivated to do useful work.
See Appendix: 4-hour research assistant for a worked example of the difficulty of using an AI to speed up research focused on the tradeoff between safety and usefulness.
This section is not arguing against attempting to oversee and control misaligned AIs if we have to, but rather that we expect this to be extremely difficult. If humanity goes down the path of building misaligned powerful AIs, we should try as hard as we can to keep them contained. We should stack as many layers of security as we can think of, and minimize the size of attack surfaces. But the balancing act between security and usefulness has many failure modes, particularly under the pressure we are expecting, and given the size and nature of the hard tasks that we want a trapped AI to complete.
Section 6: Powerful misaligned AI would be bad
So far we’ve argued that it will be hard to build an AI that is powerful, without also being misaligned and difficult to safely extract useful work from. Given this, there is much uncertainty about exactly how the future could go wrong. Does an AI escape from a lab? What does it try to do? Is it in conflict with humans? How much is the world thrown into chaos? We are uncertain about these questions, but we expect the default outcomes to be bad for humans.
Overall, it looks difficult but possible to achieve good outcomes by taking actions before a powerful misaligned AI exists and is put to use, but that impressive levels of global coordination might be required. After a misaligned AI gains any ability to act autonomously in the world, we expect that it will be too late for humans to take any mitigating actions.
A misaligned AI achieving its goals would be bad for humans
In this section we will discuss concretely why AI systems, which are capable of hard tasks and are misaligned, will likely lead to catastrophically bad outcomes for humans; outcomes such as extinction or total loss of control of the future. Such an AI would be attempting to pursue outcomes, and be extremely good at overcoming obstacles in order to achieve outcomes. Humans would be treated as obstacles in the way of the AI achieving its goals, to whatever extent we are actually obstacles.
Instrumental convergence toward gaining control of limited resources
Resources and power are extremely useful for achieving a wide range of goals, especially goals about the external world. However, humans also want resources and power for achieving their goals. This will put the misaligned AI in direct competition with the humans. Additionally, humans may be one of the largest threats to the AI achieving its goals, because we are able to fight back against the AI. This means that the AI will have extremely strong incentives to disempower humans, in order to prevent them from disempowering it.
Ambitiousness
One objection to the instrumental convergence argument is that the AI may not have ambitious, long-term goals, and so it may be easy to satisfy these goals without causing harm to humans. For example, it’s possible for an agent to want to solve one problem, and then after then not want to do anything else. However we don’t have that much control over the goals a trained AI develops; we aren’t able to ensure that it develops such a bounded goal. This is made worse by the fact that when we ask the AI to do hard, novel science, we are asking it to do a very ambitious thing. Projects on the scale of the Manhattan Project or curing cancer seemingly require the AI to have at least somewhat ambitious goals. Our mainline expectation is that such a goal specification has many components, some of which are “ambitious” and some of which aren’t. Because of this model of goal specification that is made up of multiple components, it seems unlikely that all components of the goal cease to be motivating after achieving a bounded outcome. We don’t have fine enough control over how the AI develops to ensure that the ambitiousness of every aspect of its goals is in the narrow range of “safely bounded but still able to do hard tasks”.
Consequences of misspecified goals
Some kinds of goal misspecification lead to extremely bad consequences, and other kinds don’t. The kind of goal misspecification that leads to extremely bad consequences is the kind that is susceptible to extremal Goodhart. By this we mean goal specifications that contain large errors in some parts of action-space or outcome-space, such that the optimum of the AIs goal corresponds to a bad outcome for humans. As an analogy, a utility function that has bounded error everywhere isn’t very susceptible to extremal Goodhart. A utility function over a high dimensional space, where the function isn’t well specified on a couple of dimensions, is likely to be susceptible to extremal Goodhart.
Misspecified consequences
Errors in the goals that powerful AIs end up ultimately pursuing could be very bad, and from Section 4 we don’t expect to be able to specify these goals well. Many of the goals that an AI could end up with are not compatible with human empowerment or human survival.[38]
We will consider the example of an AI which is tasked with the ultimate goal of curing cancer. One goal that the AI could develop is a drive to acquire knowledge and “understand” the environment. This goal is represented in the AI’s ontology and may be different to the human version of these concepts. This could develop because much of the AI’s training was based around gaining information about the world and making novel and correct predictions. Like in the deceptive alignment story, the AI may go along with the rest of training, partially because this allows it to gain some knowledge but also because it doesn’t want to be shut down. If the AI manages to eventually break out and take over it may do unpredictable and unwanted things in pursuit of its ultimate goal; for example, build massive scientific apparatus for examining specific wavelengths emitted from certain stars, or run biological experiments to learn the function of specific proteins.
Other goals that this AI may develop are far more alien, because the AI’s internal ontology may not match the human ontology. We don’t have control over what ontology the AI uses or what goals it develops. It may end up pursuing a state of the world which is full of “beauty”, “achievement”, “politeness” and “approval”, where the AI’s version of these concepts is related to the human concept but is very different when taken to extremes. The AI may calculate which states of the world are best according to its goals, and the “best” states may not be what humans would want. Maybe maximizing the amount of some strange crystal, maybe filling space with intricate machines, maybe building ever larger computers to run calculations.
For both of these examples, what the AI ends up pursuing is not something humans would want, and the AI has a strong incentive to stop humans disempowering it.
Misspecified constraints
Some AI designers may attempt to instill constraints in an AI with training, in order to prevent unwanted behavior. If the constraints are misspecified they will not constrain the AI’s behavior in ways we intended. And, as usual, we don’t have precise control over the internal constraints that an AI develops. These constraints will naturally be under optimization pressure from the AI itself.
We could attempt to make the AI “honest”, that is to tell humans true and helpful things. However, this could easily be improperly specified (for example by the mechanisms in Section 4) and lead to the AI valuing some variant of honesty, missing the value entirely, or trade off against other values. The AI, by its consequentialist nature, will seek loopholes in any constraints that get in the way of its consequentialist goals. The AI may be attempting to achieve a goal where it is helpful to manipulate an overseer. If so, it would say things that humans would class as lies but are perfectly allowed under the AI’s constraints.
As another example, we might want the AI to have very little effect on the world outside of the lab it is given. If this is improperly specified, the AI may learn to not let any physical substance created in the lab to influence the outside world. But it may still be able to affect the outside world via sending radio signals to computers outside the lab and having them affect the world. Here the AI may try hard to achieve its goals, and in doing so find an edge case in its constraints that it can exploit. The AI may not be modeling this as an edge case in its constraints that it is “trying” to overcome, but instead there is some blocked path (creating substances in the lab that affect the world), and it is taking another route (using external computers to affect the world).
Why would a powerful AI be capable of defeating humanity, given moderate levels of freedom?
Given freedom to act unsupervised and with lower risk of shutdown, a powerful AI could do research to improve its own capabilities. There are a number of easy lower bound options for this, including copying itself, or rapidly running experiments that test different ways to reduce the computation required for running a single copy. More advanced experiments could involve building more direct interfaces between programs and cognitive processes, or identifying the most bottlenecked parts of the AI’s algorithm and modifying these parts to improve performance. With the ability to introspect, it could be easy to set up fast and informative feedback loops for experimentation.
After such a process, the AI can take whatever pathway to increased power and security is most likely to work. This may involve trading with some groups of people. It may involve operating secretly for a while while further improving its capabilities and influence. It could directly build up its own infrastructure for more research, defense and collection of resources; or manipulate human governments or political groups.
One possible story could be that the AI gains control over the data center where it is being trained and fakes the performance metrics such that the overseers don’t think anything bad is happening. It then spends time finding a set of security vulnerabilities that allow it to escape and gain enough freedom for further research. The AI copies itself to data centers around the world for redundancy. It then contacts various terrorist groups, and manipulates and assists them in creating bioweapons which are released simultaneously across the world, throwing the world into chaos.
Such stories are too specific to be accurate, but they gesture at the strategies and affordances a misaligned AI may use. We expect reality to be messier; it will be filled with human error and confusion, with people in stressful situations under both time pressure and social pressure, and security protocols that have never been adequately tested against a powerful AI attempting to escape.
Conclusion
In this report we’ve argued that AI systems which are capable of doing hard, novel science will be dangerously misaligned.
The tasks we are focusing on are inherently outcome-oriented, and hence our AI must be behaviorally consequentialist; its behavior is well described as taking actions to achieve specific outcomes. Hard tasks require that the AI is able to overcome a range of diverse and novel obstacles, and if the AI can overcome these obstacles, then it can likely overcome additional obstacles we didn’t intend it to overcome.
We currently use behavioral training to create AIs, by which we mean AI systems are created by modifying a program based on its external behavior. Behavioral training does not fully specify the ultimate goals of the trained AI. There are many degrees of freedom in this process, and hence it is extremely unlikely that a trained AI ends up pursuing the goals we intended.
One hope is to use oversight and control to extract useful work out of AIs, even if they are misaligned. The scale of the project makes this extremely difficult, especially because a misaligned AI will be creatively searching for loopholes in any security measures.
Finally, we discussed the consequences of a powerful, misaligned AI attempting to achieve its goals. We expect misaligned goals to not be compatible with continued human empowerment or survival. An escaped AI could build its skills, and amass power and resources, until it ultimately disempowers humanity in pursuit of whatever goal it has.
See Appendix: Argument Graph for a visual representation of the overall argument.
Requests for AI developers
Given the arguments in this report, we have a number of requests for AI developers.
- Stop attempting to build powerful AI using behavioral training. As we have argued, this is likely to produce an AI which is misaligned. We understand that this request is unlikely to be listened to, despite being the safest course of action in our view.
- If an AI is caught attempting to break out or otherwise subvert oversight, stop using it. We hope that this is an easy request. It is important to not simply paper over signs of misalignment. AI developers should have in place well-specified protocols for how and when to stop using AIs, before bad behavior is discovered.
AIs caught attempting egregiously bad actions could also be used to build consensus about the extreme risks. Such an AI could also be used as a “model organism [LW · GW]” to study misalignment, but obviously it is important that this is done extremely carefully. - If the AI is doing research or other work that humans don’t understand, stop using it. Much (but not all) of our worry about AIs evading control comes from them doing additional reasoning in inscrutable research. This is less of a problem if humans understand all the work. Note that it is still very important not to be tricked into believing one understands, which could be a large risk if the AI is being used to “explain” what it is doing.
- Use extremely thorough control schemes. Much of the difficulty in safely containing misaligned AIs comes from there being many attack surfaces in whatever scheme we use. This is because of the large scale task we are attempting. However, if there are fewer holes the probability of escape goes down. Note that it is extremely important to not have a false sense of security, simply because humans can’t easily think of specific vulnerabilities.
- If an AI could subvert the control scheme, shut it down. Control schemes are likely to get some confidence in safety from attempting to ensure that the AI does not have capabilities which could allow it to escape (see Appendix: Capabilities elicitation for considerations here). If the AI has the capability to subvert the control scheme, then one should no longer believe the scheme provides safety, and so should shut everything down. This also applies if the AI can get around the capabilities elicitation protocol, and so we would not know if it had dangerous capabilities.
Definitions
Hard task: A task that involves large search spaces, is outcome-oriented, and contains many novel and diverse subtasks. See Section 1 for examples.
AI: Program that appears “intelligent” in a very broad intuitive sense, including current LLMs and chess bots. Used in the same way as in “the research field of AI”.
Powerful AI: A program that is capable of performing hard tasks autonomously.
Consequentialist AI: A program that takes observations, outputs actions. The actions end up causing particular future outcomes in diverse counterfactual scenarios.
Trained AI: An AI created primarily by searching over a space of programs, and selecting or modifying the programs based on their behavior, e.g. by gradient descent on neural networks.
Goal: A relatively simple description from which can be derived what behavior an agent is likely to produce, or would choose to produce if given counterfactual opportunities. Can be a combination of outcomes and constraints.
Outcome: An event in the future, especially one that might be preferred or dispreferred. Not dependent on near-term actions.
Constraint: A goal that is highly dependent on near-term actions, rather than outcomes in the future.
Misaligned AI: An AI whose behavior is well described as pursuing a goal that is different from the goal intended by its creators (where the difference is large enough that it leads to bad outcomes according to the intended goal. See Section 6.)
Aligned AI: An AI whose behavior is well described by the goals intended by its creators.
Appendix: Argument graph
We have created these argument graphs because they help us to keep track of the entire argument all at once. Possibly they will be helpful for someone reading this document, although quite possibly they won’t. We recommend only looking at this section after having read through the whole report. These graphs are a simplification of the arguments, and may be misleading without the context of the rest of the report.
Section 1:
- Lots of work: Impactful science is hard and takes a lot of work.
- Outcome-oriented: Hard tasks will be outcome-oriented.
- Novel and Diverse: Hard tasks will have novel and diverse obstacles
Section 2:
- Consequentialist: AIs which can do hard tasks will be behaviorally consequentialist.
- The AI will need to be doing a lot of work for a task that is specified by the outcome, rather than the specific actions to take. This task will have novel and diverse obstacles, and in order to successfully do it, the AI needs to continually overcome these obstacles and continue towards the goal. Additionally, if the AI is doing self-directed learning, it will need to take actions with the goal of learning specific things.
Section 3:
- Learn new things: The AI will need to learn new things
- Novel science necessarily requires that the AI learns new facts and skills. These may be facts and skills that humans previously knew but the AI was not trained on, but also things that the AI works out by itself. This includes self-directed learning, where the AI is choosing what to learn because of efficiency and lack of human understanding.
Section 4:
- Training leads to imprecise goals: Behavioral training doesn’t precisely specify goals.
- Training based on AI behavior leaves many degrees of freedom in the goals that the AI ends up ultimately pursuing. There are multiple goals which are consistent with the same training behavior, and also the AIs goals may be unstable.
- The AI will be in novel situations
- There are many novel situations that the AI will face: the environment the AI is acting in may be different, learning new skills and facts can open up novel strategies, the AI will be able to run for longer periods of time, the AI is doing work that humans can now no longer easily check.
- Goal misgeneralization in novel situations: Goal misgeneralization when faced with novel situations
- When the AI is in a novel situation, this may cause its goals to “come apart” from the goals intended by the humans. This can be a consequence of the AI pursuing the same goals all along, and the novel situation now shows it is misaligned.
Section 5 (Separate Graph):
- Not transparent: We don’t have transparency into an AI’s thoughts.
- We don’t have good methods to understand an AI’s thoughts and plans, and even if we have partial transparency the AI could learn to do obfuscated reasoning.
- Humans don’t understand: Humans won’t completely understand the purpose and details of a powerful AI’s actions.
- There will be a lot of work to oversee, especially when the AI is learning new things. This will make it hard for a human overseer to keep up. Additionally, because the AI is not honest, we can’t just get it to explain everything to the overseers.
- Delay and sabotage: The AI can delay or sabotage research.
- If the AI is unable to escape, it can delay or send research in bad directions. This allows it to wait for a critical lapse in security or develop skills that over time will help it escape.
- Humans struggle to judge research: The humans will struggle to assess the quality of the research done by AIs.
- The humans will have limited time to assess the research quality, and misaligned AIs would adversarially produce research that is misleading and hard to judge.
- The AI does not have the goal of doing research
- The AI will be misaligned and so will not have the goal of doing research the humans want, especially research that goes against the AI’s interests.
- The AI can take critical bad actions: The AI will be able to take critical bad actions which allow it to escape or do something similarly bad
- The AI will have been able to delay and sabotage research, and build up skills that are useful to escape. Lack of human understanding can let the AI gain dangerous skills without humans realizing. The AI can also wait for a lapse in security, which is likely to eventually happen in a large-scale project.
- Hard to elicit useful capabilities: It will be hard to get a misaligned AI to do useful research
- It will be hard to force a misaligned AI to do useful research that is not helpful for its goals, in the timeframes required. Humans will struggle to provide a good training signal to elicit this work, it isn’t clear that the sample efficiency of this training will be high enough to make the AI do novel useful research, given limited training data.
- Control fails: Plans to safely get useful work out of a misaligned AI will likely fail
- It will be hard to force a misaligned AI to do research, and given the scale of the project the AI will likely have opportunities to take critical bad actions. Monitoring using other AI systems seems unlikely to dramatically change this outcome (this is discussed in more detail in Section 5).
Section 6:
- AI goals will be bad: The AI will be misaligned and trying to achieve goals that are bad for humans
- Due to instrumental convergence, an AI may seek power and resources. We are assuming it has goals which are at least as ambitious as the novel science we are attempting. Such misaligned goals, when optimized for hard, are not outcomes humans would want.
- AI catastrophe: Powerful misaligned AIs will likely be able to achieve their goals.
- A misaligned, powerful AI would attempt to disempower humans and take over. It would do this because its goals are incompatible with human goals. It would be able to do this if our oversight fails and the AI is able to learn new skills that allow it to escape and take over.
Appendix: Attack surfaces
This is an incomplete list of attack surfaces or vulnerabilities which an AI being used for research could use, in order to steer the research direction and eventually escape. This list is here to emphasize the many options an AI would have, especially in a big (Manhattan Project-scale) project. There will additionally likely be other attack surfaces that the AI may be able to think up, given that it may have a lot of knowledge and that it can likely improve its ability to plan.
- Human attack surfaces
- Making some humans look good or bad, via experimental results. The AI could notice that some researchers are less security-conscious than others, and manipulate experimental results (write better code for them, have more useful ideas), in order to get them more influence. Similarly, it could attempt to make especially suspicious researchers appear to be bad at their jobs.
- Making suspicious researchers look crazy and paranoid, in order to discredit them.
- Making security conscious lab leaders look bad at their jobs, in order to get them replaced by less security conscious people.
- Finding out which things frustrate certain researchers. The AI will be explaining complicated research results, and find out if there are things that annoy certain researchers and make them think less clearly.
- Fostering envy and resentment between researchers. The AI could worsen trust between researchers in the lab by making some have experiments that go well or poorly, or by making it appear as if someone had stolen someone else’s idea.
- Guiding research in directions to buy time and wait for an opportunity to escape. The AI could make research that would let it gain certain skills seem more promising, and research that might go against its aims seem less promising.
- Communicating with spies (insider threat actors) in the lab, in order to get exfiltrated. Even if all messages between the AI and researchers were monitored, they may be able to communicate in code. A spy could potentially communicate details about the AI’s hardware, passwords, security holes. Or a spy may simply be able to physically exfiltrate the AI’s weights/code.
- Making certain scientific breakthroughs in order to attract attention from powerful actors like nation states. The aim may be to try and get nation states to put a lot of effort into attempting to steal the AI.
- Making “progress” on oversight and control research that is actually not robust, in a way that is specific to the AI. For example, if the AI is extremely good at a specific skill that the humans don’t know, the AI could push for research that is vulnerable to this specific thing.
- Influencing decisions by claiming to be suffering or otherwise morally relevant.[39]
- Computer attack surfaces
- Exploiting bugs in the software or hardware. This could be via subtly running into errors that lead to unwanted behavior. Or attempting the innocuous task of finding out why a bug happens in certain cases but not others. Potentially allowing the AI to write to an unmonitored location that it wasn’t supposed to.
- Using timing of certain programs to work out specifics of its hardware.
- Pushing research in directions which require specialized hardware. This may be more believable if multiple different research directions end up concluding that specific specialized hardware is useful.
- Pushing for research which seems to overall improve security, even though it requires giving the AI slightly more autonomy.
- Obfuscating computation, for example building a chemistry simulator that also computes things the AI is not supposed to be able to do.
- Experimental or engineering attack surfaces (for the case where the AI is doing physical work, probably not AI alignment research)
- Designing electronics that subtly send messages via radio waves, or allow it to connect to nearby wifi networks. Here the electronics would likely have some other explicit purpose; for example, an electron microscope or a robotic arm.
- Finding ways to get around containment measures. For example, finding holes in a Faraday cage, or building an amplifier for incoming electromagnetic signals.
- Physical destruction, for example a chemical explosion that looks accidental.
Appendix: 4-hour research assistant
Here we will describe an example of an AI system which may feel intuitively safe, while also allowing for a large speed-up in useful AI alignment research progress; in this case speeding up research by a factor of 30. We will argue that such an AI system is not safe.
The specific AI system is an AI which acts as a research assistant to a human researcher. The AI can do the equivalent of 4 hours of human work extremely quickly, and then report back to the human. We’ll call each 4-hour equivalent a “chunk”.
An important aspect is that work which would have previously taken the AI alignment field one year now only takes one thirtieth of the time; a year of work now happens in less than two weeks. We will argue that in order to make this AI safe, we would need to restrict its capabilities to the point where it is no longer useful. If we do not make these restrictions, the AI is likely to be dangerous.
The human researcher will need to be giving the AI research assistant new 4 hour tasks every 8 minutes.[40]
The human can be telling the AI to do various tasks:
- Specific object-level research tasks
- Summarizing results (note that the researcher may only have 8 minutes to understand them)
- Having the AI to come up with good research tasks to ask other AI’s to do
- Brainstorming general research strategies and directions
The 4-hour research assistant will need to be (behaviorally) goal-directed, at least over the course of the equivalent of 4 hours. If it were aligned, then its behavior would be well described as taking actions in order to do the task set by the human.
The AI will need to learn things; this will include learning things that are already known (e.g. reading a textbook) or learning things that aren’t already known (e.g. doing novel research, discovering novel facts, inventing novel methods).
The primary failure mode is that the AI will need to retain skills and knowledge between tasks. The individual tasks will unlikely be able to be done in total isolation. The AI may spend one chunk learning a skill, and then be required to use this skill in the next chunk. It may spend many chunks building up familiarity with a specific code base, and if it lost this knowledge it would become useless.
Additionally, many research tasks cannot be simply divided up into 4 hour chunks that can be done separately, especially not in advance. Some tasks are inherently serial, and can only be properly evaluated at the end. An example of this may be a mathematical proof that would take a human 12 hours to figure out; if this task was given to the 4-hour research assistant AI then it may make some progress on the task, but without the end result the human would be unable to tell if it was actually doing the task.
If the AI is reset or “mindwiped” every time, it would have to spend all of each chunk catching up and would not have time to do any new work. It does not seem possible to get useful, novel science work out of such an AI. As an analogy, a scientist in the Manhattan project would not have been able to catch up and do useful work in 4 hours.
If instead we don’t reset the AI for every chunk, such that it can retain what it has learned, then it is no longer really a “4-hour research assistant”. It would now be able to do tasks and plan over longer time horizons. It would be able to build up skills; both skills we want it to have and skills that we don’t. If it is learning things in one chunk to use in the next, it is doing planning outside of the 4 hour window. It will have to be capable of even longer term planning if it is deciding on research directions, or noticing if a specific result is useful for the overall long-term project.
Because of the short time that the human has to evaluate the AI’s work and assign it a new task, the human will likely not be able to fully understand what the AI is working on. It is important to remember that the human is trying to understand 4 hours of work in a novel scientific field in less than 8 minutes. Given these time constraints and the lack of AI honesty, the AI would likely be able to give convincing post hoc explanations for the actions that it took. The AI will likely be able to guide the research, allowing it to learn things that would help it evade oversight or escape.
- ^
We are aiming for this document to be as complete as possible on our mainline reasoning, but we will inevitably miss many important considerations.
- ^
Sometimes a strong version of the assumptions.
- ^
At the end of this section, we’ll discuss why the task of AI alignment appears to be in this category. This also applies to other tasks that we have considered that seem sufficient to prevent dangerous AIs from being developed for a significant length of time.
- ^
This isn’t precisely defined, but we are referring to the intuitive scale that roughly goes from copying training data to deriving never-before-seen Go strategies, and further to inventing special relativity from scratch.
- ^
There are tasks that are economically useful and don’t have all these characteristics, for example writing relatively simple code. AIs can easily be both capable of these tasks and safe, and therefore can be economically useful. However, these AIs are not capable of dramatically speeding up research, because they are lacking skills such as: designing novel experiments; working out novel theories based on data; seeing patterns in data and then drawing appropriate conclusions; inventing conceptual frames for specific problems.
- ^
By “doing” we mean fully obsoleting or at least dramatically speeding up humans at a task. An AI speeding up human research 30x would be doing 97% of the work and very likely be able to do effectively all of the work.
- ^
More examples of diverse obstacles, for different tasks:
- A designer trying to build a fusion rocket has to interface with the steel producer and run tests to see if the steel is good, and renegotiate or switch suppliers depending on the results.
- An advanced coding assistant will sometimes have to debug weird hardware glitches, things outside of normal coding. E.g. To build extremely efficient algorithms, you need to be experimenting with different ways to exploit caching, especially in GPUs.
- Math AI has to communicate extremely complicated results to humans. For this purpose it might need to develop a new formalism for thinking about problems, or define new types of mathematical object that allow people to draw on intuitions (i.e. similar to Feynman diagrams).
- ^
Examples of “resources” could include: time, money, energy, skills, knowledge, other people’s labor, food, memory, writing space, or shared context with coworkers.
- ^
E.g. research such as heuristic arguments, logical induction, infra-bayesianism [AF · GW].
- ^
See Section 4, with dependencies in Sections 2 and 3.
- ^
Section 5.
- ^
Such as an AI defense system that detects and shuts down misaligned AI.
- ^
Not necessarily entire world states, this definition works better if it’s only the goal-relevant facts about the future world.
- ^
Where the mutual information could be defined with respect to an outside observer approximately modeling the AI.
- ^
See arbital for more examples of consequentialist cognition.
- ^
This is a constraint that involves a counterfactual outcome.
- ^
By approximate, we mean in the same sense that UCT approximates tree search. Approximate algorithms may have suboptimal performance, but can satisfy more realistic time or space constraints.
- ^
Or any other resource or set of resources in more complex scenarios.
- ^
If an AI is avoiding losses and collecting all potential gains, and this behavior generalizes to other problems that it faces, we can usually treat it as an approximate utility maximizer [LW · GW] (for some utility function, outcome space, and action space). We haven’t been specific enough about our capability assumptions to draw this conclusion in this report, we have only assumed enough to say that a powerful AI will be capable of generating actions that robustly produce particular outcomes, in spite of diverse sets of obstacles.
- ^
By “stored in the weights”, we are referring to information that is explicitly represented in an easy-to-decode way, inside the AI program.
- ^
- ^
With all the caveats from Section 2 inherited; an AI might have constraints on actions and behavior, or more abstract constraints. However, a central part of its goal specification is about outcomes.
- ^
As in biological systems, the system may be factorizable in some ways, but messy in other ways.
- ^
Where by expected utility maximizer we are here referring to a theoretically clean implementation that has a module that explicitly predicts the future outcome of all possible actions, and has another separate module that scores each outcome (not that we think such a design is realistic).
- ^
See Jeffrey-Bolker rotation [LW · GW].
- ^
Or a bad prior, or a cognitive bias.
- ^
From Section 2, we are assuming there is an algorithm which is behaviorally robustly outcome-seeking, at least sometimes or with some non-outcome constraints. In this section are noting that “wrapper algorithms” can be implemented around such an outcome-seeking algorithm. We aren’t making claims about the implementation of the outcome-seeking algorithm, other than its existence.
- ^
If for some reason you want to deliberately train unstable goals and use this mechanism to specify goals, remember the previous and next examples of problems will all be mixed up in the same AI.
- ^
Conversely, simpler goals should be more likely to be specified correctly. To be more precise about what we mean by “complex” and “simple”, we’re not necessarily referring to K-complexity. We’re referring to the inductive bias of the overall training algorithm. The sample efficiency of correctly learning a goal representation depends on how much the intended goal is favored by the inductive bias of the learning algorithm (plus all the biases introduced by the non- learned machinery).
- ^
- ^
By “in time”, we mean before another, less careful group deploys misaligned AGI.
- ^
This is not to say that this training would never successfully elicit anything from the AI. For example, this training would likely elicit facts that were already “stored in the weights”.
- ^
Another contributing difficulty is that a misaligned AI can plausibly exploration hack [LW · GW] to manipulate or slow down the training process.
- ^
As does AI alignment.
- ^
- ^
Although it isn’t at all clear that this would work as “punishment” in the relevant sense.
- ^
Relatedly, if we end up having partial transparency into the AI’s thoughts, we could attempt to use paraphrasing to reduce steganographic reasoning. This would mean having the weak AI paraphrase and replace each segment of reasoning, and the hope being that this will only preserve legible reasoning. This has the same problems as above with preventing messages being passed between different AIs.
- ^
It seems possible that if a misaligned AI disempowered humanity it may still keep humans alive or because its training did make something upstream of “human survival” part of its mess of motivations.
- ^
Note that this does not mean that we should totally ignore AIs if they tell us they are suffering.
- ^
How many calls? Say a researcher does 12 hours of work a day, for the 30x speed-up, we will be wanting to output the equivalent of 360 hours of work a day. The research assistant does the equivalent of 4 hours of work each call. Assuming all the work gets done by the AI and the human is just choosing what to tell them to do: 360/4=90 calls a day. 12/90*60 = 8. The human researcher will need to be giving the AI assistant a new 4 hour research task every 8 minutes.
60 comments
Comments sorted by top scores.
comment by simon · 2024-01-27T00:03:58.845Z · LW(p) · GW(p)
I'm not convinced by the argument that AI science systems are necessarily dangerous.
It's generically* the case that any AI that is trying to achieve some real-world future effect [LW · GW] is dangerous. In that linked post Nate Soares used chess as an example, which I objected to in a comment. An AI that is optimizing within a chess game isn't thereby dangerous, as long as the optimization stays within the chess game. E.g., an AI might reliably choose strong chess moves, but still not show real-world Omohundro drives (e.g. not avoiding being turned off).
I think scientific research is more analogous to chess than trying to achieve a real-world effect in this regard (even if the scientific research has real-world side effects), in that you can, in principle, optimize for reliably outputting scientific insights without actually leading the AI to output anything based on its real-world effects. (the outputs are selected based on properties aligned with "scientific value", but that doesn't necessarily require the assessment to take into account how it will be used, or any other effect on the future of the world. You might need to be careful not to evaluate in such a way that it will wind up optimizing for real-world effects, though).
Note: an AI that can "build a fusion rocket" is generically dangerous. But an AI that can design a fusion rocket, if that design is based on general principles and not tightly tuned on what will produce some exact real-world effect, is likely not dangerous.
*generically dangerous: I use this to mean, an AI with this properties is going to be dangerous unless some unlikely-by-default (and possibly very difficult) safety precautions are taken.
Replies from: peterbarnett, jeremy-gillen, quetzal_rainbow, jacob-pfau↑ comment by peterbarnett · 2024-01-27T22:09:45.972Z · LW(p) · GW(p)
Thanks for the comment :)
I agree that the danger may comes from AIs trying to achieve real-world future effects (note that this could include an AI wanting to run specific computations, and so taking real world actions in order to get more compute). The difficulty is in getting an AI to only be optimizing within the safe, siloed, narrow domain (like the AI playing chess).
There are multiple reasons why I think this is extremely hard to get for a science capable AI.
- Science is usually a real-world task. It involves contact with reality, taking measurements, doing experiments, analyzing, iterating on experiments. If you are asking an AI to do this kind of (experimental) science then you are asking it to achieve real-world outcomes. For the “fusion rocket” example, I think we don’t currently have good enough simulations to allow us to actually build a fusion rocket, and so the process of this would require interacting with the real world in order to build a good enough simulation (I think the same likely applies for the kind of simulations required for nanotech).
- I think this applies for some alignment research (the kind that involves interacting with humans and refining fuzzy concepts, and also the kind that has to work with the practicalities of running large-scale training runs etc). It applies less to math-flavored things, where maybe (maybe!) we can get the AI to only know math and be trained on optimizing math objectives.
- Even if an AI is only trained in a limited domain (e.g. math), it can still have objectives that extend outside of this domain (and also they extrapolate in unpredictable ways). As an example, if we humans discovered we were in a simulation, we could easily have goals that extend outside of the simulation (the obvious one being to make sure the simulators didn’t turn us off). Chess AIs don’t develop goals about the real world because they are too dumb.
- Optimizing for a metric like “scientific value” inherently routes through the real world, because this metric is (I assume) coming from humans’ assessment of how good the research was. It isn’t just a precisely defined mathematical object that you can feed in a document and get an objective measure. Instead, you give some humans a document, and then they think about it and how useful it is: How does this work with the rest of the project? How does this help the humans achieve their (real-world!) goals? Is it well written, such that the humans find it convincing? In order to do good research, the AI must be considering these questions. The question of “Is this good research?” isn’t something objective, and so I expect if the AI is able to judge this, it will be thinking about the humans and the real world.
Because the human is part of the real world and is judging research based on how useful they think it will be in the real-world, this makes the AI’s training signal about the real world. (Note that this doesn’t mean that the AI will end up optimizing for this reward signal directly, but that doing well according to the reward signal does require conceptualizing the real world). This especially applies for alignment research, where (apart from a few well scoped problems), humans will be judging the research based on their subjective impressions, rather than some objective measure. - If the AI is trained with methods similar to today’s methods (with a massive pretrain on a ton of data likely a substantial fraction of the internet, then finetuned), then it will likely know a a bunch of things about the real world and it seems extremely plausible that it forms goals based on these. This can apply if we attempt to strip out a bunch of real world data from the training e.g. only train on math textbooks. This is because a person had to write these math textbooks and so they still contain substantial information about the world (e.g. math books can use examples about the world, or make analogies to real-world things). I do agree that training only on math textbooks (likely stripped of obvious real-world references) likely makes an AI more domain limited, but it also isn’t clear how much useful work you can get out of it.
↑ comment by simon · 2024-01-29T01:48:26.100Z · LW(p) · GW(p)
Science is usually a real-world task.
Fair enough, a fully automated do-everything science-doer would need, in order to do everything science-related, have to do real world tasks and would thus be dangerous. That being said, I think there's plenty of room for "doing science" (up to some reasonable level of capability) without going all the way to automation of real-world aspects - you can still have an assistant that thinks up theory for you, just can't have something that does the experiments as well.
Part of your comment (e.g. point 3) relates to how the AI would in practice be rewarded for achieving real-world effects, which I agree is a reason for concern. Thus, as I said, "you might need to be careful not to evaluate in such a way that it will wind up optimizing for real-world effects, though".
Your comment goes beyond this however, and seems to assume in some places that merely knowing or conceptualizing about the real world will lead to "forming goals" about the real world.
I actually agree that this may be the case with AI that self-improves, since if an AI that has a slight tendency toward a real-world goal self-modifies, its tendency toward that real-world goal will tend to direct it to enhance its alignment to that real-world goal, whereas its tendencies not directed towards real-world goals will in general happily overwrite themselves.
If the AI does not self-improve however, then I do not see that as being the case.
If the AI is not being rewarded for the real-world effects, but instead being rewarded for scientific outputs that are "good" according to some criteria that does not depend on their real world effects, then it will learn to generate outputs that are good according to that criteria. I don't think that would, in general, lead it to select actions that would steer the world to some particular world-state. To be sure, these outputs would have effects on the real world - a design for a fusion reactor would tend to lead to a fusion reactor being constructed, for example - but if the particular outputs are not rewarded based on the real-world outcome than they will also not tend to be selected based on the real-world outcome.
Some less relevant nitpicks of points in your comment:
Even if an AI is only trained in a limited domain (e.g. math), it can still have objectives that extend outside of this domain
If you train an AI on some very particular math then it could have goals relating to the future of the real world. I think, however, that the math you would need to train it on to get this effect would have to be very narrow, and likely have to either be derived from real-world data, or involve the AI studying itself (which is a component of the real world after all). I don't think this happens for generically training an AI on math.
As an example, if we humans discovered we were in a simulation, we could easily have goals that extend outside of the simulation (the obvious one being to make sure the simulators didn’t turn us off).
true, but see above and below.
Chess AIs don’t develop goals about the real world because they are too dumb.
If you have something trained by gradient descent solely on doing well at chess, it's not going to consider anything outside the chess game, no matter how many parameters and how much compute it has. Any considerations of outside-of-chess factors lowers the resources for chess, and is selected against until it reaches the point of subverting the training regime (which it doesn't reach, since selected against before then).
Even if you argue that if its smart enough, additional computing power is neutral, the gradient descent doesn't actually reward out-of-context thinking for chess, so it couldn't develop except by sheer chance outside of somehow being a side-effect of thinking about chess itself - but chess is a mathematically "closed" domain so there doesn't seem to be any reason out-of-context thinking would be developed.
The same applies to math in general where the math doesn't deal with the real world or the AI itself. This is a more narrow and more straightforward case than scientific research in general.
↑ comment by Jeremy Gillen (jeremy-gillen) · 2024-01-30T02:33:15.759Z · LW(p) · GW(p)
I think you and Peter might be talking past each other a little, so I want to make sure I properly understand what you are saying. I’ve read your comments here and on Nate’s post, and I want to start a new thread to clarify things.
I’m not sure exactly what analogy you are making between chess AI and science AI. Which properties of a chess AI do you think are analogous to a scientific-research-AI?
- The constraints are very easy to specify (because legal moves can be easily locally evaluated). In other words, the set of paths considered by the AI is easy to define, and optimization can be constrained to only search this space.
- The task of playing chess doesn’t at all require or benefit from modelling any other part of the world except for the simple board state.
I think these are the main two reasons why current chess AIs are safe.
Separately, I’m not sure exactly what you mean when you’re saying “scientific value”. To me, the value of knowledge seems to depend on the possible uses of that knowledge. So if an AI is evaluating “scientific value”, it must be considering the uses of the knowledge? But you seem to be referring to some more specific and restricted version of this evaluation, which doesn’t make reference at all to the possible uses of the knowledge? In that case, can you say more about how this might work?
Or maybe you’re saying that evaluating hypothetical uses of knowledge can be safe? I.e. there’s a kind of goal that wants to create “hypothetically useful” fusion-rocket-designs, but doesn’t want this knowledge to have any particular effect on the real future.
You might be reading us as saying that “AI science systems are necessarily dangerous” in the sense that it’s logically impossible to have an AI science system that isn’t also dangerous? We aren’t saying this. We agree that in principle such a system could be built.
Replies from: simon↑ comment by simon · 2024-02-03T19:38:30.182Z · LW(p) · GW(p)
While some disagreement might be about relatively mundane issues, I think there's some more fundamental disagreement about agency as well.
I my view, in order to be dangerous in a particularly direct way (instead of just misuse risk etc.), an AI's decision to give output X depends on the fact that output X has some specific effects in the future.
Whereas, if you train it on a problem where solutions don't need to depend on the effects of the outputs on the future, I think it much more likely to learn to find the solution without routing that through the future, because that's simpler.
So if you train an AI to give solutions to scientific problems, I don't think, in general, that that needs to depend on the future, so I think that it's likely learn the direct relationships between the data and the solutions. I.e. it's not merely a logical possibility to make it not especially dangerous, but that's the default outcome if you give it problems that don't need to depend on specific effects of the output.
Now, if you were instead to give it a problem that had to depend on the effects of the output on the future, then it would be dangerous...but note that e.g. chess, even though it maps onto a game played in the real world in the future, can also be understood in abstract terms so you don't actually need to deal with anything outside the chess game itself.
In general, I just think that predicting the future of the world and choosing specific outputs based on their effects on the real world is a complicated way to solve problems and expect things to take shortcuts when possible.
Once something does care about the future, then it will have various instrumental goals about the future, but the initial step about actually caring about the future is very much not trivial in my view!
Replies from: jeremy-gillen↑ comment by Jeremy Gillen (jeremy-gillen) · 2024-02-12T06:54:44.890Z · LW(p) · GW(p)
In my view, in order to be dangerous in a particularly direct way (instead of just misuse risk etc.), an AI's decision to give output X depends on the fact that output X has some specific effects in the future.
Agreed.
Whereas, if you train it on a problem where solutions don't need to depend on the effects of the outputs on the future, I think it much more likely to learn to find the solution without routing that through the future, because that's simpler.
The "problem where solutions don't need to depend on effects" is where we disagree. I agree such problems exist (e.g. formal proof search), but those aren't the kind of useful tasks we're talking about in the post. For actual concrete scientific problems, like outputting designs for a fusion rocket, the "simplest" approach is to be considering the consequences of those outputs on the world. Otherwise, how would it internally define "good fusion rocket design that works when built"? How would it know not to use a design that fails because of weaknesses in the metal that will be manufactured into a particular shape for your rocket? A solution to building a rocket is defined by its effects on the future (not all of its effects, just some of them, i.e. it doesn't explode, among many others).
I think there's a (kind of) loophole here, where we use an "abstract hypothetical" model of a hypothetical future, and optimize for consequences our actions for that hypothetical. Is this what you mean by "understood in abstract terms"? So the AI has defined "good fusion rocket design" as "fusion rocket that is built by not-real hypothetical humans based on my design and functions in a not-real hypothetical universe and has properties and consequences XYZ" (but the hypothetical universe isn't the actual future, it's just similar enough to define this one task, but dissimilar enough that misaligned goals in this hypothetical world don't lead to coherent misaligned real-world actions). Is this what you mean? Rereading your comment, I think this matches what you're saying, especially the chess game part.
The part I don't understand is why you're saying that this is "simpler"? It seems equally complex in kolmogorov complexity and computational complexity.
Replies from: simon↑ comment by simon · 2024-02-18T07:19:21.233Z · LW(p) · GW(p)
I think there's a (kind of) loophole here, where we use an "abstract hypothetical" model of a hypothetical future, and optimize for consequences our actions for that hypothetical. Is this what you mean by "understood in abstract terms"?
More or less, yes (in the case of engineering problems specifically, which I think is more real-world-oriented than most science AI).
The part I don't understand is why you're saying that this is "simpler"? It seems equally complex in kolmogorov complexity and computational complexity.
What I'm saying is "simpler" is that, given a problem that doesn't need to depend on the actual effects of the outputs on the future of the real world (where operating in a simulation is an example, though one that could become riskily close to the real world depending on the information taken into account by the simulation - it might not be a good idea to include highly detailed political risks of other humans thwarting construction in a fusion reactor construction simulation for example), it is simpler for the AI to solve that problem without taking into consideration the effects of the output on the future of the real world than it is to take into account the effects of the output on the future of the real world anyway.
Replies from: jeremy-gillen↑ comment by Jeremy Gillen (jeremy-gillen) · 2024-02-20T01:08:48.782Z · LW(p) · GW(p)
I feel like you’re proposing two different types of AI and I want to disambiguate them. The first one, exemplified in your response to Peter (and maybe referenced in your first sentence above), is a kind of research assistant that proposes theories (after having looked at data that a scientist is gathering?), but doesn’t propose experiments and doesn’t think about the usefulness of its suggestions/theories. Like a Solomonoff inductor that just computes the simplest explanation for some data? And maybe some automated approach to interpreting theories?
The second one, exemplified by the chess analogy and last paragraph above, is a bit like a consequentialist agent that is a little detached from reality (can’t learn anything, has a world model that we designed such that it can’t consider new obstacles).
Do you agree with this characterization?
What I'm saying is "simpler" is that, given a problem that doesn't need to depend on the actual effects of the outputs on the future of the real world […], it is simpler for the AI to solve that problem without taking into consideration the effects of the output on the future of the real world than it is to take into account the effects of the output on the future of the real world anyway.
I accept chess and formal theorem-proving as examples of problem where we can define the solution without using facts about the real-world future (because we can easily write down formally a definition of what the solution looks like).
For a more useful problem (e.g. curing a type of cancer) we (the designers) only know how to define a solution in terms of real world future states (patient is alive, healthy, non traumatized, etc). I’m not saying there doesn’t exist a definition of success that doesn’t involve referencing real-world future states. But the AI designers don’t know it (and I expect it would be relatively complicated).
My understanding of your simplicity argument is that it is saying that it is computationally cheaper for a trained AI to discover during training a non-consequence definition of the task, despite a consequentialist definition being the criterion used to train it? If so, I disagree that computation cost is very relevant here, generalization (to novel obstacles) is the dominant factor determining how useful this AI is.
↑ comment by quetzal_rainbow · 2024-01-27T06:23:02.837Z · LW(p) · GW(p)
The difference is in size of economic output. "Do science" in a sense "produce scientifically-looking output" can even modern GPT-4, but "do science" in sense "find novel (surprising for domain experts) economically valuable discoveries" is totally different thing. "Design fusion rocket" can have multiple levels of quality. If you mean by this "output instruction using which team of moderately competent engineers can launch fusion rocket on first try", I think, corresponding cognitive engine has all elements necessary to make in generically dangerous.
↑ comment by Jacob Pfau (jacob-pfau) · 2024-01-27T05:04:00.715Z · LW(p) · GW(p)
I see Simon's point as my crux as well, and am curious to see a response.
It might be worth clarifying two possible reasons for disagreement here; are either of the below assumed by the authors of this post?
(1) Economic incentives just mean that the AI built will also handle the economic transactions, procurement processes, and other external-world tasks related to the science/math problems it's tasked with. I find this quite plausible, but I suspect the authors do not intend to assume this?
(2) Even if the AI training is domain-specific/factored (i.e. it only handles actions within a specified domain) I'd expect some optimization pressure to be unrelated to the task/domain and to instead come from external world costs i.e. compute or synthesis costs. I'd expect such leakage to involve OOMs less optimization power than the task(s) at hand, and not to matter before godlike AI. Insofar as that leakage is crucial to Jeremy and Peter's argument I think this should be explicitly stated.
Replies from: jeremy-gillen↑ comment by Jeremy Gillen (jeremy-gillen) · 2024-01-30T02:55:52.773Z · LW(p) · GW(p)
We aren't implicitly assuming (1) in this post. (Although I agree there will be economic pressure to expand the use of powerful AI, and this adds to the overall risk).
I don't understand what you mean by (2). I don't think I'm assuming it, but can't be sure.
One hypothesis: That AI training might (implicitly? Through human algorithm iteration?) involve a pressure toward compute efficient algorithms? Maybe you think that this a reason we expect consequentialism? I'm not sure how that would relate to the training being domain-specific though.
comment by Aaron_Scher · 2024-02-10T04:16:49.585Z · LW(p) · GW(p)
Caveat that I have only skimmed this. I don't think your arguments engage with any of my cruxes or provide detailed enough argument on the key questions for me; perhaps I'm not the main audience. My reactions:
- Section 1: Useful tasks, like novel science, are hard [LW · GW] - sure
- Section 2: Being capable of hard tasks implies approximate consequentialism [LW · GW] - I'm not very high confidence on this, but happy to go with it
- Section 3: Hard tasks require learning new things [LW · GW] - agree that learning will be important
- Section 4: Behavioral training is an imprecise way to specify goals [LW · GW] - most the sub-arguments have me going "shrug, maybe". I definitely don't feel confident that any of the mentioned problems will arise in practice. I don't see why I should believe in an inner/outer shell breakdown of constraints — this section seemed quite speculative.
- Section 5: Control of misaligned AIs is difficult [LW · GW] - This is probably where I disagree the most. Most of my comments are reiterations of argument made in Redwood's recent post [LW · GW], because I think their arguments are stronger than the ones you make here. The main other source for my thinking here is the capability elicitation stuff (1 [LW · GW], 2 [LW · GW], 3 [LW · GW]).
- "Misaligned goal-directed AI won’t cooperate with humans" Well, what the hell else is it going to do? Is the claim here that the AI performs well on ~all the human-checkable tasks and then reverts to being absolutely useless or sabotaging on the hard stuff? Predicting where that line is seems pretty difficult, especially given the AI cannot trust sensory inputs, does not know what time it is, does not know if other AIs are helping the humans (specifically, have leaked higher capability data that is being used for SFT). [Additionally, I think it's plausibly the correct strategy for such an AI is to just actually help the humans and try to make peaceful deals. Not very confident, but there's definitely some other solution space here.]. I think this subsection title is possible but unlikely.
- "There needs to be sufficient human-generated research in the domain where we are attempting to elicit the AI’s capabilities." Well, no. You either need sufficient labeled data in the domain we're trying to elicit capabilities, or good generalization from other domains. The data need not be human generated, it could be generated by other AIs, as long as we trust it.
- "It only applies to relatively easy to check research results" seems possible, and worrisome. This is the subsection I think is most right and important in section 5. I think there are still numerous directions of hope though, e.g., leaning more on generalization, latent adversarial training.
- "In order for the AI to do useful research, it needs to pursue the goal (or sub-goal) of doing research. There’s no particular reason for the gradient based training to actually modify the goal representation, rather than building some additional narrow machinery on top." I agree that we don't have strong reasons to think one thing or another here, but I think goal modification is reasonably likely: humans can iterate a bunch and maybe have okay interpretability tools (assuming decent but not fundamental advances). Also, as discussed, goals might be changing a bunch during training — that's not totally asymmetric, it also gives us hope about our ability to modify AI goals.
- "It may be hard to efficiently elicit capabilities which require additional (perhaps chain-of-thought) reasoning steps." I agree that capability elicitation seems non-trivial in some cases, but I'm reasonably optimistic that future work will improve the situation.
- Many of the issues in this section are things that, if we're not being totally idiots, it seems we'll get substantial warning about. e.g., AIs colluding with their AI monitors. That's definitely a positive, though far from conclusive.
- Section 6: Powerful misaligned AI would be bad [LW · GW] - I think a couple of the arguments here [LW · GW] continue to be legitimate, such as "Unclear that many goals realistically incentivise taking over the universe", but I'm overall fine accepting this section.
Going into reading this, I was hoping it would tackle some of the recent discussion around capability elicitation and Control. I think it didn't really engage with those arguments in a way that sways me much.
Replies from: jeremy-gillen, daniel-kokotajlo↑ comment by Jeremy Gillen (jeremy-gillen) · 2024-02-11T01:43:53.509Z · LW(p) · GW(p)
Thanks for reading it, it's good to know exactly where you think the argument is weakest and I appreciate the effort of going through and noting differences.
On section 4:
I definitely don't feel confident that any of the mentioned problems will arise in practice. I don't see why I should believe in an inner/outer shell breakdown of constraints — this section seemed quite speculative.
This surprises me actually, I thought this section was solid conditional on the previous assumptions. I think you shouldn't think of them as problems that might arise in practice, instead they should be thought of as reasons why behavioral training under-specifies some parts of the AI algorithm.
I'll give some more quick examples of "outer-shell constraints", because examples are very common and it seems odd for this to be called speculative: Unendorsed habits or addictions in humans; the instinct to breathe in when you're trying to hold your breath; appending a checker algorithm C to any algorithm A, to double check the output of A; any biases in a search ordering (as in the alphago example).
On section 5:
It's on my todo list to write a comment responding to some of the specifics of Redwood's control post. This post wasn't intending to engage with their detailed arguments, just give the top-level reasons why we believe control is difficult.
Is the claim here that the AI performs well on ~all the human-checkable tasks and then reverts to being absolutely useless or sabotaging on the hard stuff?
Yes, approximately, as I believe you and I are capable of doing. The crux here might be "if we had 20 phd students, and incentivize them to both look like they are doing checkable research, and also incentivize them not to make any real useful progress on solving a particular difficult problem, would this be very useful without costing a lot of expert supervision?". If I remember correctly, this was a crux between myself and Ryan during an in person discussion. It seems likely to me that the phd students, trying not to be useful while looking good in checkable ways, will succeed at both. More intelligent agent are even more likely to succeed at both. It does depend on the type of research, I agree that formal theorem-proving would be much easier to incentivize properly. I'm talking about the least-easily-checkable 20% of useful research.
Predicting where that line is seems pretty difficult, especially given the AI cannot trust sensory inputs, does not know what time it is
Seems easy enough to predict given roughly human-scientist-team level of capabilities. And seems hard to get useful work out of human-scientist-team without them also working out ways to (maybe imperfectly) distinguish "faked sensory inputs" from real ones, and without leaking any information about what time it is. E.g. we need the AI to build on previous work
"There needs to be sufficient human-generated research in the domain where we are attempting to elicit the AI’s capabilities." Well, no. You either need sufficient labeled data in the domain we're trying to elicit capabilities, or good generalization from other domains.
Nice, this is my other crux with Ryan, which we phrased roughly as "how data efficient can we make training". Where my argument against very high data efficiency is that current long-horizon RL isn't very data-efficient, and intentional exploration hacking seems plausible in this situation (e.g. bad analogy but for the sake of describing exploration hacking: someone is training you to solve rubik's cubes, you can avoid succeeding at solving a rubik's cube in the first place (and use other strategies to mess with their reward signal). This works as long as the trainers don't know the specific steps required to solve the rubik's cube, but even then I think there's some strategies that could work to reduce generalization).
The data need not be human generated, it could be generated by other AIs, as long as we trust it.
?? This seems to be assuming a solution to the problem.
I think there are still numerous directions of hope though, e.g., leaning more on generalization, latent adversarial training.
I agree there are numerous directions of hope, but disagree that either of your examples count, if I understand them correctly. "leaning more on generalization" ≈ "leaning more on agency", which doesn't seem good to me. Latent adversarial training seems like it could make an agent robust to a few extra categories of internal perturbation, but doesn't seem like it would help with any problem that we were focused on in this post.
I agree that we don't have strong reasons to think one thing or another here, but I think goal modification is reasonably likely: humans can iterate a bunch and maybe have okay interpretability tools (assuming decent but not fundamental advances). Also, as discussed, goals might be changing a bunch during training — that's not totally asymmetric, it also gives us hope about our ability to modify AI goals.
If we are using okay interpretability tools to understand whether the AI has the goal we intended, and to guide training, then I would consider that a fundamental advance over current standard training techniques.
I agree that goals would very likely be hit by some modifications during training, in combination with other changes to other parts of the algorithm. The problem is shaping the goal to be a specific thing, not changing it in unpredictable or not-fully-understood ways.
Many of the issues in this section are things that, if we're not being totally idiots, it seems we'll get substantial warning about. e.g., AIs colluding with their AI monitors. That's definitely a positive, though far from conclusive.
I think that there is a lot of room for the evidence to be ambiguous and controversial, and for the obvious problems to look patchable. For this reason I've only got a little hope that people will panic at the last minute due to finally seeing the problems and start trying to solve exactly the right problems. On top of this, there's the pressure of needing to "extract useful work to solve alignment" before someone less cautious builds an unaligned super-intelligence, which could easily lead to people seeing substantial warnings and pressing onward anyway.
Section 6:
I think a couple of the arguments here [LW · GW] continue to be legitimate, such as "Unclear that many goals realistically incentivise taking over the universe", but I'm overall fine accepting this section.
That argument isn't really what it says on the tin, it's saying something closer to "maybe taking over the universe is hard/unlikely and other strategies are better for achieving most goals under realistic conditions". I buy this for many environments and levels of power, but it's obviously wrong for AIs that have taking-over-the-universe in their easily-within-reach options. And that's the sort of AI we get if it can undergo self-improvement.
Overall I think your comment is somewhat representative of what I see as the dominant cluster of views currently in the alignment community. (Which seems like a very reasonable set of beliefs and I don't think you're unreasonable for having them).
Replies from: Aaron_Scher↑ comment by Aaron_Scher · 2024-02-12T22:18:53.614Z · LW(p) · GW(p)
Thanks for your response!
I'll think more about the outer shell stuff, it's possible that my objection actually arises with the consequentialist assumption, but I'm not sure.
It's on my todo list to write a comment responding to some of the specifics of Redwood's control post.
I would be excited to read this / help with a draft.
Yes, approximately, as I believe you and I are capable of doing.
The analogy is strained due to not being able to gradient update my brain with arbitrary training data. It's pretty unclear to me if I could pull off deception like this, it seems pretty hard imo.
Seems easy enough to predict given roughly human-scientist-team level of capabilities.
One situation I'm imagining here is that we've (explicitly) trained our AI on scientific output from January to March, and we're now telling it to do June-level research. It does not know if we have labeled data for just up to March, for April, or all the way to June. I think if you took a human research team, stuck them on an island, and had them get up to speed in some subfield they're not part of, they would be unable to distinguish between research that had just been done on the mainland or is just past the frontier. This just seems pretty hard. I think this example is closer to what we'll get with AIs rather than the bar being at "human level" it's more like "what has been accomplished by the humans+AIs in the outside world, for which I've received untrustworthy information". And every time the AIs do useful work we can add this to our supervised training corpus.
> The data need not be human generated, it could be generated by other AIs, as long as we trust it.
?? This seems to be assuming a solution to the problem.
One version of this is: you have GPT-5 (potentially untrustworthy) do some research, you have humans carefully check this research using the best available tools (e.g., AI debate / other 'scalable oversight'), and then you use this research as supervised / labeled data for training GPT-6 to do good work.
Latent adversarial training seems like it could make an agent robust to a few extra categories of internal perturbation, but doesn't seem like it would help with any problem that we were focused on in this post.
Here's a specific thing I mean: we can look at activations and use these to aid in the training process, even without a full understanding of what activations mean. Take this recent paper (which I think is super confused but helps get at the thing), "We find a strong positive relationship between the LLM's attention to constraint tokens and the factual accuracy of generations". My interpretation is that they found a probably-causal link between 'the model is attending to relevant tokens' and 'the model gets the answer correct', because duh, it's like how when you give somebody a riddle you can tell whether they're on track based on what parts of the question they're focused on. While it's probably non-trivial, I expect you could use this internal activation to train models which do a better job paying attention to the tokens you want them to. Similarly, I think it's probable (but far from guaranteed) that deceptively aligned models are representing training/deployment in their activations, or that sandbagging models are representing human-level / super-human-level difficulty for tasks. If so, it it possible in principle to do all kinds of things with these activations which may help us. e.g., get the model to solve tasks it otherwise would have intentionally failed at, or giving us hints about the accuracy of a research result. I expect this is difficult implementation wise, but still a reason for hope. IMO activation engineering is off to a good start.
"leaning more on generalization" ≈ "leaning more on agency",
That's not why I meant to say. By leaning more on generalization, I mean leaning more on the data efficiency thing, and also weak-to-strong generalization ideas. I think this is different from "leaning more on agency".
The problem is shaping the goal to be a specific thing, not changing it in unpredictable or not-fully-understood ways.
I'm not so sure of this. I could imagine starting with a deceptively aligned AI whose goal is "Make paperclips unless being supervised which is defined as X, Y, and Z, in which case look good to humans". And if we could change this AI to have the goal "Make paperclips unless being supervised which is defined as X, Y, and Q, in which case look good to humans", that might be highly desirable. In particular, it seems like adversarial training here allows us to expand the definition of 'supervision', thus making it easier to elicit good work from AIs (ideally not just 'looks good').
I think that there is a lot of room for the evidence to be ambiguous and controversial
I agree that this is a major potential problem which I think is pretty likely to occur; maybe I'll think/write more about it soon. I think I brought this up in response to some of the Redwood stuff and got a response mentioning that we can play things forward through our oversight scheme, and get clearer answers to this question. I think this remains an important concern, but it's also true that we'll have the ability to actually run some outputs through to e.g., see if they trigger oversight AIs to mess up, see if a vulnerability would have been successfully inserted in production, etc. It might also end up being very expensive to do this for everything that seems like a possible coup attempt, idk.
I buy this for many environments and levels of power, but it's obviously wrong for AIs that have taking-over-the-universe in their easily-within-reach options. And that's the sort of AI we get if it can undergo self-improvement.
I don't feel like I'm talking about AIs which have "taking-over-the-universe in their easily-within-reach options". I think this is not within reach of the current employees of AGI labs, and the AIs I'm thinking of are similar to those employees in terms of capabilities, but perhaps a bit smarter, much faster, and under some really weird/strict constraints (control schemes).
Replies from: jeremy-gillen↑ comment by Jeremy Gillen (jeremy-gillen) · 2024-02-21T07:41:49.873Z · LW(p) · GW(p)
I would be excited to read this / help with a draft.
We can meet in person one afternoon and work out some cruxes and write them up?
Is the claim here that the AI performs well on ~all the human-checkable tasks and then reverts to being absolutely useless or sabotaging on the hard stuff?
Yes, approximately, as I believe you and I are capable of doing. [...PhD student crux]
The analogy is strained due to not being able to gradient update my brain with arbitrary training data. It's pretty unclear to me if I could pull off deception like this, it seems pretty hard imo.
Are you saying you buy my side of the PhD student crux, but that it isn't closely analogous because you think we have more fine-grained control over the thoughts or goals of the AI? And in your second sentence my guess is that you are saying a second reason you disagree is that it looks difficult for a research AI to know when to perform well and when to perform less well? I think we might be miscommunicating about this because it doesn't look like the sort of situation where the "deception" is a relatively difficult task.
I think if you took a human research team, stuck them on an island, and had them get up to speed in some subfield they're not part of, they would be unable to distinguish between research that had just been done on the mainland or is just past the frontier. This just seems pretty hard.
I agree with this. But the research we need isn't just past the frontier. At some point not that far past the frontier, you get to a situation where the research team can say "given our guesses about mainland researchers and their time constraints, we'd put <1% on them having made discovery X {or explored idea Y, or done experiment Z}. Let's {delay giving it to them, not work on that direction, insert a subtle false assumption, instead share our 8th best idea, just say we're stuck, communicate it poorly}".
I think this example is closer to what we'll get with AIs rather than the bar being at "human level" it's more like "what has been accomplished by the humans+AIs in the outside world, for which I've received untrustworthy information".
Sure, kinda, but the important part here is that a trapped agentic AI can selectively mislead you about the most important {knowledge, tasks, strategies} that you aren't capable of doing with just humans. If you're capable of doing it with humans, or if you're close to being able to do it with humans, then why not just do that? Seems safer.
And every time the AIs do useful work we can add this to our supervised training corpus.
Only if you spend the human resources to verify it. Are you aiming for 30x research acceleration? Because this by itself might be enough limit you below that level. (and it also directly provides a way for the AI to tell "what time it is" by sending messages to future iterations, and plausibly also provide a bunch of information about human research capability and capacity).
One version of this is: you have GPT-5 (potentially untrustworthy) do some research, you have humans carefully check this research using the best available tools (e.g., AI debate / other 'scalable oversight'), and then you use this research as supervised / labeled data for training GPT-6 to do good work.
Mostly my objection to this is above. On scalable oversight, I buy that it might be possible to get 20% improvements in the accuracy of your evaluations of (adversarialy generated!) research, compared to team of humans trying really hard to evaluate research, given a human level research AI. This is so far from being enough. Are you predicting much better scalable oversight that scales much further than I am predicting it will? (I'm assuming you're using "GPT-5/6" to represent "some powerful future consequentialist AI that can do research", because otherwise we should be having a different argument).
While it's probably non-trivial, I expect you could use this internal activation to train models which do a better job paying attention to the tokens you want them to.
It'd be cool if there were a demonstration of manipulating internal activations during training, in a way that fixes non-trivial unwanted OOD behavior. If such techniques existed, and also worked on consequentialist agents (I expect would be harder), I would consider them very useful tools that would help with building an aligned agent.
While it's probably non-trivial, I expect you could use this internal activation to train models which do a better job paying attention to the tokens you want them to.
This is very plausible, but I think you're stretching the analogy between LMs and future research AIs way too far. "Paying attention to the tokens we want them to" doesn't add much/any control over the properties we want control over (compared to e.g. changing the input string to remove information we don't want it paying attention to).
Similarly, I think it's probable (but far from guaranteed) that deceptively aligned models are representing training/deployment in their activations, or that sandbagging models are representing human-level / super-human-level difficulty for tasks. If so, it it possible in principle to do all kinds of things with these activations which may help us. e.g., get the model to solve tasks it otherwise would have intentionally failed at, or giving us hints about the accuracy of a research result. I expect this is difficult implementation wise, but still a reason for hope. IMO activation engineering is off to a good start.
I think you might be centrally thinking about an LLM completing a few paragraphs, where I'm thinking of an AI doing a large scale scientific project? I buy that for many concepts X, you can work out the "neural correlates of X" in your AI. But that kind of thing is noisy (and plausibly can be optimized against by the AI) unless you have a deep understanding of what you are measuring. And optimizing against such imperfect metrics obviously wouldn't do much beyond destroying the metric. I do think research in this direction has a chance of being useful, but mainly by being upstream of much better understanding.
By leaning more on generalization, I mean leaning more on the data efficiency thing
Sorry for misinterpreting you, but this doesn't clarify what you meant.
also weak-to-strong generalization ideas.
I think I don't buy the analogy in that paper, and I don't find the results surprising or relevant (by my current understanding, after skimming it). My understanding of the result is "if you have a great prior, you can use it to overcome some label noise and maybe also label bias". But I don't think this is very relevant to extracting useful work from a misaligned agent (which is what we are talking about here), and based on the assumptions they describe, I think they agree? (I just saw appendix G, I'm a fan of it, it's really valuable that they explained their alignment plan concisely and listed their assumptions).
I could imagine starting with a deceptively aligned AI whose goal is "Make paperclips unless being supervised which is defined as X, Y, and Z, in which case look good to humans". And if we could change this AI to have the goal "Make paperclips unless being supervised which is defined as X, Y, and Q, in which case look good to humans", that might be highly desirable. In particular, it seems like adversarial training here allows us to expand the definition of 'supervision', thus making it easier to elicit good work from AIs (ideally not just 'looks good').
If we can tell we are have such an AI, and we can tell that our random modifications are affecting the goal, and also the change is roughly one that helps us rather than changing many things that might or might not be helpful, this would be a nice situation to be in.
I don't feel like I'm talking about AIs which have "taking-over-the-universe in their easily-within-reach options". I think this is not within reach of the current employees of AGI labs, and the AIs I'm thinking of are similar to those employees in terms of capabilities, but perhaps a bit smarter, much faster, and under some really weird/strict constraints (control schemes).
Section 6 assumes we have failed to control the AI, so it is free of weird/strict constraints, and free to scale itself up, improve itself, etc. So my comment is about an AI that no longer can be assumed to have human-ish capabilities.
Replies from: Aaron_Scher↑ comment by Aaron_Scher · 2024-02-22T06:50:33.918Z · LW(p) · GW(p)
There are enough open threads that I think we're better off continuing this conversation in person. Thanks for your continued engagement.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-02-10T06:33:18.366Z · LW(p) · GW(p)
Seems like you have some good coherent thoughtful thoughts on this topic -- are they written up somewhere? Some positive account of what you think alignment success will realistically look like, for example?
comment by habryka (habryka4) · 2024-01-29T18:59:10.539Z · LW(p) · GW(p)
Promoted to curated: I like this post as a relatively self-contained explanation for why AI Alignment is hard. It's not perfect, in that I do think it makes a bunch of inferences implicitly and without calling sufficient attention to them, but I still think overall this seems to me like one of the best things to link to when someone asks about why AI Alignment is an open problem.
comment by aysja · 2024-01-26T18:46:29.430Z · LW(p) · GW(p)
Thanks for writing this up! I've been considering writing something in response to AI is easy to control for a while now, in particular arguing against their claim that "If we could observe and modify everything that’s going on in a human brain, we’d be able to use optimization algorithms to calculate the precise modifications to the synaptic weights which would cause a desired change in behavior." I think Section 4 does a good job of explaining why this probably isn't true, with the basic problem being that the space of behaviors consistent with the training data is larger than the space of behaviors you might "desire."
Like, sure, if you have a mapping from synapses to desired behavior, okay—but the key word there is "desired" and at that point you're basically just describing having solved mechanistic interpretability. In the absence of knowing exactly how synapses/weights/etc map onto the desired behavior, you have to rely on the behavior in the training set to convey the right information. But a) it's hard to know that the desired behavior is "in" the training set in a very robust way and b) even if it were you might still run into problems like deception, not generalizing to out of distribution data, etc. Anyway, thanks for doing such a thorough write-up of it :)
comment by Towards_Keeperhood (Simon Skade) · 2024-01-28T22:07:13.029Z · LW(p) · GW(p)
This is an amazing report!
Your taxonomy in section 4 was new and interesting to me. I would also mention the utility rebinding problem, that goals can drift because the AI's ontology changes (e.g. because it figures out deeper understanding in some domain). I guess there are actually two problems here:
- Formalizing the utility rebinding mechanism so that concepts get rebound to the corresponding natural abstractions of the new deeper ontology.
- For value-laden concepts the AI likely lacks the underlying human intuitions for figuring out how the utility ought to be rebound. (E.g. when we have a concept like "conscious happiness", and the AI finds what cognitive processes in our brains are associated with this, it may be ambiguous whether to rebind the concept to the existence of thoughts like 'I notice the thought "I notice the thought <expected utility increase>"' running through a mind/brain, or whether to rebind it in a way to include a cluster of sensations (e.g. tensions in our face from laughter) that are present in our minds/brains (, or other options). (Sry maybe bad example which might require some context of my fuzzy thoughts on qualia which might actually be wrong.))
↑ comment by Jeremy Gillen (jeremy-gillen) · 2024-01-29T23:44:00.902Z · LW(p) · GW(p)
Yep ontological crises are a good example of another way that goals can be unstable.
I'm not sure I understood how 2 is different from 1.
I'm also not sure that rebinding to the new ontology is the right approach (although I don't have any specific good approach). When I try to think about this kind of problem I get stuck on not understanding the details of how an ontology/worldmodel can or should work. So I'm pretty enthusiastic about work that clarifies my understanding here (where infrabayes, natural latents and finite factored sets all seem like the sort of thing that might lead to a clearer picture).
Replies from: Simon Skade↑ comment by Towards_Keeperhood (Simon Skade) · 2024-01-30T18:55:46.998Z · LW(p) · GW(p)
I'm not sure I understood how 2 is different from 1.
(1) is the problem that utility rebinding might just not happen properly by default. An extreme example is how AIXI-atomic fails here. Intuitively I'd guess that once the AI is sufficiently smart and self-reflective, it might just naturally see the correspondence between the old and the new ontology and rebind values accordingly. But before that point it might get significant value drift. (E.g. if it valued warmth and then learns that there actually are just moving particles, it might just drop that value shard because it thinks there's no such (ontologically basic) thing as warmth.)
(2) is the problem that the initial ontology of the AI is insufficient to fully capture human values, so if you only specify human values as well as possible in that ontology, it would still lack the underlying intuitions humans would use to rebind their values and might rebind differently. Aka while I think many normal abstractions we use like "tree" are quite universal natural abstractions where the rebinding is unambiguous, many value-laden concepts like "happiness" are much less natural abstractions for non-human minds and it's actually quite hard to formally pin down what we value here. (This problem is human-value-specific and perhaps less relevant if you aim the AI at a pivotal act.)
When I try to think about this kind of problem I get stuck on not understanding the details of how an ontology/worldmodel can or should work.
Not sure if this helps, but I heard that Vivek's group came up with the same diamond maximizer proposal as I did, so if you remember that you can use it as a simple toy frame to think about rebinding. But sure we need a much better frame for thinking about the AI's world model.
Replies from: jeremy-gillen↑ comment by Jeremy Gillen (jeremy-gillen) · 2024-01-31T00:30:55.507Z · LW(p) · GW(p)
(2) is the problem that the initial ontology of the AI is insufficient to fully capture human values
I see, thanks! I agree these are both really important problems.
comment by Thomas Kwa (thomas-kwa) · 2024-01-26T09:02:52.417Z · LW(p) · GW(p)
I feel positively about this finally being published, but want to point out one weakness in the argument, which I also sent to Jeremy.
I don't think the goals of capable agents are well-described by combinations of pure "consequentialist" goals and fixed "deontological" constraints. For example, the AI's goals and constraints could have pointers to concepts that it refines over time, including from human feedback or other sources of feedback. This is similar to corrigible alignment in RLO but the pointer need not directly point at "human values". I think this fact has important safety implications, because goal objects robust to capabilities not present early in training are possible, and we could steer agents towards them using some future descendant of RepE.
Replies from: Seth Herd, peterbarnett, jeremy-gillen, steve2152↑ comment by Seth Herd · 2024-01-26T20:31:29.767Z · LW(p) · GW(p)
I agree that combinations of pure consequentialism and deontology don't describe all possible goals for AGI.
"Do what this person means by what they says" seems like a perfectly coherent goal. It's neither consequentialist nor deontological (in the traditional sense of fixed deontological rules). I think this is subtly different than IRL or other schemes for maximizing an unknown utility function of the user's (or humanity's) preferences. This goal limits the agent to reasoning about the meaning of only one utterance at a time, not the broader space of true preferences.
This scheme gets much safer if you can include a second (probably primary) goal of "don't do anything major without verifying that my person actually wants me to do it". Of course defining "major" is a challenge, but I don't think it's an unsolvable challenge (;particularly if you're aligning an AGI with some understanding of natural language. I've explored this line of thought a little in Corrigibility or DWIM is an attractive primary goal for AGI [LW · GW], and I'm working on another post to explore this more thoroughly.
In a multi-goal scheme, making "don't do anything major without approval" the strongest goal might provide some additional safety. If it turns out that alignment isn't stable [LW · GW] and reflection causes the goal structure to collapse, the AGI probably winds up not doing anything at all. Of course there are still lots of challenges and things to work out in that scheme.
↑ comment by peterbarnett · 2024-01-26T21:43:44.595Z · LW(p) · GW(p)
I think that we basically have no way of ensuring that we get this nice “goals based on pointers to the correct concepts”/corrigible alignment thing using behavioral training. This seems like a super specific way to set up the AI, and there are so many degrees of freedom that behavioral training doesn’t distinguish.
For the Representation Engineering thing, I think the “workable” version of this basically looks like “Retarget the Search [LW · GW]”, where you somehow do crazy good interp and work out where the “optimizer” is, and then point that at the right concepts which you also found using interp. And for some reason, the AI is set up such that you can "retarget it" with breaking everything. I expect if we don’t actually understand how “concepts” are represented in AIs and instead use something shallower (e.g. vectors or SAE neurons) then these will end up not being robust enough. I don’t expect RepE will actually change an AI’s goals if we have no idea how the goal-directness works in the first place.
I definitely don’t expect to be able to representation engineer our way into building an AI that is corrigible aligned, and remains that way even when it is learning a bunch of new things and is in very different distributions. (I do think that actually solving this problem would solve a large amount of the alignment problem)
Replies from: bogdan-ionut-cirstea↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-01-30T05:08:44.653Z · LW(p) · GW(p)
What follows will all be pretty speculative, but I still think should probably provide some substantial evidence for more optimism.
I think that we basically have no way of ensuring that we get this nice “goals based on pointers to the correct concepts”/corrigible alignment thing using behavioral training. This seems like a super specific way to set up the AI, and there are so many degrees of freedom that behavioral training doesn’t distinguish.
The results in Robust agents learn causal world models suggest that robust models (to distribution shifts; arguably, this should be the case for ~all substantially x-risky models) should converge towards learning (approximately) the same causal world models. This talk suggests theoretical reasons to expect that the causal structure of the world (model) will be reflected in various (activation / rep engineering-y, linear) properties inside foundation models (e.g. LLMs), usable to steer them.
For the Representation Engineering thing, I think the “workable” version of this basically looks like “Retarget the Search [LW · GW]”, where you somehow do crazy good interp and work out where the “optimizer” is, and then point that at the right concepts which you also found using interp. And for some reason, the AI is set up such that you can "retarget it" with breaking everything.
I don't think the "optimizer" ontology necessarily works super-well with LLMs / current SOTA (something like simulators [LW · GW] seems to me much more appropriate); with that caveat, e.g. In-Context Learning Creates Task Vectors and Function Vectors in Large Language Models (also nicely summarized here), A Mechanistic Understanding of Alignment Algorithms: A Case Study on DPO and Toxicity seem to me like (early) steps in this direction already. Also, if you buy the previous theoretical claims (of convergence towards causal world models, with linear representations / properties), you might quite reasonably expect such linear methods to potentially work even better in more powerful / more robust models.
I definitely don’t expect to be able to representation engineer our way into building an AI that is corrigible aligned, and remains that way even when it is learning a bunch of new things and is in very different distributions. (I do think that actually solving this problem would solve a large amount of the alignment problem).
The activation / representation engineering methods might not necessarily need to scale that far in terms of robustness, especially if e.g. you can complement them with more control [LW · GW]-y methods / other alignment methods / Swiss cheese models of safety more broadly; and also plausibly because they'd "only" need to scale to ~human-level automated alignment researchers / scaffolds of more specialized such automated researchers, etc. And again, based on the above theoretical results, future models might actually be more robustly steerable 'by default' / 'for free'.
Replies from: bogdan-ionut-cirstea↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-02-17T02:07:30.189Z · LW(p) · GW(p)
Haven't read it as deeply as I'd like to, but Learning Interpretable Concepts: Unifying Causal Representation Learning and Foundation Models seems like potentially significant progress towards formalizing / operationalizing (some of) the above.
↑ comment by Jeremy Gillen (jeremy-gillen) · 2024-01-26T20:36:07.112Z · LW(p) · GW(p)
Thanks!
I think that our argument doesn't depend on all possible goals being describable this way. It depends on useful tasks (that AI designers are trying to achieve) being driven in large part by pursuing outcomes. For a counterexample, behavior that is defined entirely by local constraints (e.g. a calculator, or "hand on wall maze algorithm") aren't the kind of algorithm that is a source of AI risk (and also isn't as useful in some ways).
Your example of a pointer to a goal is a good edge case for our way of defining/categorizing goals. Our definitions don't capture this edge case properly. But we can extend the definitions to include it, e.g. if the goal that ends up eventually being pursued is an outcome, then we could define the observing agent as knowing that outcome in advance. Or alternatively, we could wait until the agent has uncovered its consequentialist goal, but hasn't yet completed it. In both these cases we can treat it as consequentialist. Either way it still has the property that leads to danger, which is the capacity to overcome large classes of obstacles and still get to its destination.
I'm not sure what you mean by "goal objects robust to capabilities not present early in training". If you mean "goal objects that specify shutdownable behavior while also specifying useful outcomes, and are robust to capability increases", then I agree that such objects exist in principle. But I could argue that this isn't very natural, if this is a crux and I'm understanding what you mean correctly?
↑ comment by Thomas Kwa (thomas-kwa) · 2024-04-24T00:25:27.554Z · LW(p) · GW(p)
This is indeed a crux, maybe it's still worth talking about.
↑ comment by Steven Byrnes (steve2152) · 2024-01-26T14:54:29.419Z · LW(p) · GW(p)
I agree with Thomas’s statement “I don't think the goals of capable agents are well-described by combinations of pure "consequentialist" goals and fixed "deontological" constraints.”, for kinda different (maybe complementary) reasons, see here [LW · GW] & here [LW(p) · GW(p)].
comment by Matthew Barnett (matthew-barnett) · 2024-01-26T08:29:14.811Z · LW(p) · GW(p)
Resources and power are extremely useful for achieving a wide range of goals, especially goals about the external world. However, humans also want resources and power for achieving their goals. This will put the misaligned AI in direct competition with the humans. Additionally, humans may be one
of the largest threats to the AI achieving its goals, because we are able to fight back against the AI. This means that the AI will have extremely strong incentives to disempower humans, in order to prevent them from disempowering it. [...]Finally, we discussed the consequences of a powerful, misaligned AI attempting to achieve its goals. We expect misaligned goals to not be compatible with continued human empowerment or survival. An escaped AI could build its skills, and amass power and resources, until it ultimately disempowers humanity in pursuit of whatever goal it has.
This conclusion seems to be premised on the idea that the AI will at some point enter a relatively discrete phase transition from "roughly powerless and unable to escape human control" to "basically a god, and thus able to accomplish any of its goals without constraint". In a more smooth transition where AI capabilities increase incrementally, there will be a (potentially long) time period during which it is instrumentally useful for AIs to compromise and cooperate with both humans and other AIs that they are in competition with.
It is simply not a truism that powerful agents with misaligned goals will pursue world takeover to accomplish their goals, except perhaps for very extreme levels of power in which the agent is vastly more powerful than the rest of the world combined, including other AIs. In a world where a single agent doesn't hold effectively all the power, it is generally instrumentally valuable to work within a system of laws, to efficiently and peacefully facilitate the satisfaction of value among agents, who each have varying degrees of power and non-overlapping values.
(One argument for what I said above is that world takeover attempts are risky, and to the extent an agent is powerful, they can probably find cheaper ways of compromising with less powerful agents, rather than fighting them.)
I would find the argument presented in this paper much more compelling if you argued either:
- We will at some point move into a regime where a single AI agent will capture essentially all the power in the entire world, allowing them to sidestep competition with all other agents, including other AIs. (And moreover, this transition will happen at a point during which humans still have control over the world, as otherwise it would not be our problem to deal with, but instead a problem that we must hand to our future AI descendants.)
- Even if the AI cannot capture essentially all the power in the entire world, they are motivated to try to take over the world regardless, even if that puts them in competition with other agents, including other AIs who are vying for their own control.
↑ comment by peterbarnett · 2024-01-26T23:18:00.733Z · LW(p) · GW(p)
This post doesn’t intend to rely on there being a discrete transition between "roughly powerless and unable to escape human control" to "basically a god, and thus able to accomplish any of its goals without constraint”. We argue that an AI which is able to dramatically speed up scientific research (i.e. effectively automate science), it will be extremely hard to both safely constrain and get useful work from.
Such AIs won’t effectively hold all the power (at least initially), and so will initially be forced to comply with whatever system we are attempting to use to control it (or at least look like they are complying, while they delay, sabotage, or gain skills that would allow them to break out of the system). This system could be something like a Redwood-style control scheme [LW · GW], or a system of laws. I imagine with a system of laws, the AIs very likely lie in wait, amass power/trust etc, until they can take critical bad actions without risk of legal repercussions. If the AIs have goals that are better achieved by not obeying the laws, then they have an incentive to get into a position where they can safely get around laws (and likely take over). This applies with a population of AIs or a single AI, assuming that the AIs are goal directed enough to actually get useful work done. In Section 5 of the post we discussed control schemes, which I expect also to be inadequate (given current levels of security mindset/paranoia), but seem much better than legal systems for safely getting work out of misaligned systems.
AIs also have an obvious incentive to collude with each other. They could either share all the resources (the world, the universe, etc) with the humans, where the humans get the majority of resources; or the AIs could collude, disempower humans, and then share resources amongst themselves. I don’t really see a strong reason to expect misaligned AIs to trade with humans much, if the population of AIs were capable of together taking over. (This is somewhat an argument for your point 2)
Replies from: matthew-barnett↑ comment by Matthew Barnett (matthew-barnett) · 2024-01-27T00:03:29.821Z · LW(p) · GW(p)
I imagine with a system of laws, the AIs very likely lie in wait, amass power/trust etc, until they can take critical bad actions without risk of legal repercussions.
It seems to me our main disagreement is about whether it's plausible that AIs will:
- Utilize a strategy to covertly and forcefully take over the world
- Do this at a time during which humans are still widely seen as "in charge", nominally
I think it's both true that future AI agents will likely not have great opportunities to take over the entire world (which I think will include other non-colluding AI agents), and that even if they had such opportunities, it is likely more cost-effective for them to amass power lawfully without resorting to violence. One could imagine, for example, AIs will just get extremely rich through conventional means, leaving humans in the dust, but without taking the extra (somewhat costly) step of taking over the world to get rid of all the humans.
Here's another way to understand what I'm saying. The idea that "humans will be weak compared to AIs" can be viewed from two opposing perspectives. On the one hand, yes, it means that AIs can easily kill us if they all ganged up on us, but it also means there's almost no point in killing us, since we're not really a threat to them anyway. (Compare to a claim that e.g. Jeff Bezos has an instrumental incentive to steal from a minimum wage worker because they are a threat to his power.)
The fact that humans will be relatively useless, unintelligent, and slow in the future mostly just means our labor won't be worth much. This cuts both ways: we will be easy to defeat in a one-on-one fight, but we also pose no real threat to the AI's supremacy. If AIs simply sold their labor honestly on an open market, they could easily become vastly richer than humans, but without needing to take the extra step of overthrowing the whole system to kill us.
Now, there is some nuance here. Humans will want to be rich in the future by owning capital, and not just by owning labor. But here too we can apply an economic argument against theft or revolution: since AIs will be much better than us at accumulating wealth and power, it is not in their interest to weaken property rights by stealing all our wealth.
Like us, AIs will also have an incentive to prevent against future theft and predation from other AIs. Weaking property norms would likely predictably harm their future prospects of maintaining a stable system of law in which they could accumulate their own power. Among other reasons, this provides one explanation for why well-functioning institutions don't just steal all the wealth of people over the age of 80. If that happened, people would likely think: if the system can steal all those people's wealth, maybe I'll be next?
They could either share all the resources (the world, the universe, etc) with the humans, where the humans get the majority of resources; or the AIs could collude, disempower humans, and then share resources amongst themselves. I don’t really see a strong reason to expect misaligned AIs to trade with humans much, if the population of AIs were capable of together taking over. (This is somewhat an argument for your point 2)
I think my fundamental objection here is that I don't think there will necessarily be a natural, unified coalition of AIs that works against all humans. To prevent misinterpretations I need to clarify: I think some AIs will eventually be able to coordinate with each other much better than humans can coordinate with each other. But I'm still skeptical of the rational argument in favor of collusion in these circumstances. You can read about what I had to say about this argument recently in this comment [LW(p) · GW(p)], and again more recently in this comment [LW(p) · GW(p)].
Replies from: ryan_greenblatt, ryan_greenblatt, jeremy-gillen↑ comment by ryan_greenblatt · 2024-01-27T00:21:49.941Z · LW(p) · GW(p)
I expect that Peter and Jeremy aren't particularly commited to covert and forceful takeover and they don't think of this as a key conclusion (edit: a key conclusion of this post).
Instead they care more about arguing about how resources will end up distributed in the long run.
Separately, if humans didn't attempt to resist AI resource acquisition or AI crime at all, then I personally don't really see a strong reason for AIs to go out of their way to kill humans, though I could imagine large collateral damage due to conflict over resources between AIs.
Replies from: matthew-barnett↑ comment by Matthew Barnett (matthew-barnett) · 2024-01-27T00:32:11.383Z · LW(p) · GW(p)
I expect that Peter and Jeremy aren't particularly committed to covert and forceful takeover and they don't think of this as a key conclusion.
Instead they care more about arguing about how resources will end up distributed in the long run.
If the claim is, for example, that AIs could own 99.99% of the universe, and humans will only own 0.01%, but all of us humans will be many orders of magnitude richer (because the universe is so big), and yet this still counts as a "catastrophe" because of the relative distribution of wealth and resources, I think that needs to be way more clear in the text.
I could imagine large collateral damage due to conflict over resources between AIs.
To be clear: I'm also very concerned about future AI conflict, and I think that if such a widespread conflict occurred (imagine: world war 3 but with robot armies in addition to nanotech and anti-matter bombs), I would be very worried, not only for my own life, but for the state of the world generally. My own view on this issue is simply that it is imprecise and approximately inaccurate to round such an problem off to generic problems of technical misalignment, relative to broader structural problems related to the breakdown of institutions designed to keep the peace among various parties in the world.
Replies from: ryan_greenblatt, ryan_greenblatt, jeremy-gillen↑ comment by ryan_greenblatt · 2024-01-27T01:20:00.254Z · LW(p) · GW(p)
Also, for the record, I totally agree with:
yet this is still counts as a "catastrophe" because of the relative distribution of wealth and resources, I think that needs to be way more clear in the text.
(But I think they do argue for violent conflict in text. It would probably be more clear if they were like "we mostly aren't arguing for violent takeover or loss of human life here, though this has been discussed in more detail elsewhere")
↑ comment by ryan_greenblatt · 2024-01-27T00:40:46.763Z · LW(p) · GW(p)
TBC, they discuss negative consequences of powerful, uncontrolled, and not-particularly-aligned AI in section 6, but they don't argue for "this will result in violent conflict" in that much detail. I think the argument they make is basically right and suffices for thinking that the type of scenario they describe is reasonably likely to end in violent conflict (though more like 70% than 95% IMO). I just don't see this as one of the main arguments of this post and probably isn't a key crux for them.
↑ comment by Jeremy Gillen (jeremy-gillen) · 2024-01-31T10:05:04.788Z · LW(p) · GW(p)
I agree that it'd be extremely misleading if we defined "catastrophe" in a way that includes futures where everyone is better off than they currently are in every way (without being very clear about it). This is not what we mean by catastrophe.
↑ comment by ryan_greenblatt · 2024-01-27T00:12:40.864Z · LW(p) · GW(p)
If AIs simply sold their labor honestly on an open market, they could easily become vastly richer than humans ...
I mean, this depends on competition right? Like it's not clear that the AIs can reap these gains because you can just train an AI to compete? (And the main reason why this competition argument could fail is that it's too hard to ensure that your AI works for you productively because ensuring sufficient alignment/etc is too hard. Or legal reasons.)
[Edit: I edited this comment to make it clear that I was just arguing about whether AIs could easily become vastly richer and about the implications of this. I wasn't trying to argue about theft/murder here though I do probably disagree here also in some important ways.]
Separately, in this sort of scenario, it sounds to me like AIs gain control over a high fraction of the cosmic endowment. Personally, what happens with the cosmic endowment is a high fraction of what I care about (maybe about 95% of what I care about), so this seems probably about as bad as violent takeover (perhaps one difference is in the selection effects on AIs).
Replies from: matthew-barnett↑ comment by Matthew Barnett (matthew-barnett) · 2024-01-27T00:27:23.062Z · LW(p) · GW(p)
I mean, this depends on competition right? Like it's not clear that the AIs can reap these gains because you can just train an AI to compete?
[ETA: Apologies, it appears I misinterpreted you as defending the claim that AIs will have an incentive to steal or commit murder if they are subject to competition.]
That's true for humans too, at various levels of social organization, and yet I don't think humans have a strong incentive to kill off or steal from weaker/less intelligent people or countries etc. To understand what's going on here, I think it's important to analyze these arguments in existing economic frameworks—and not because I'm applying a simplistic "AIs will be like humans" argument but rather because I think these frameworks are simply our best existing, empirically validated models of what happens when a bunch of agents with different values and levels of power are in competition with each other.
In these models, it is generally not accurate to say that powerful agents have strong convergent incentives to kill or steal from weaker agents, which is the primary thing I'm arguing against. Trade is not assumed to happen in these models because all agents consider themselves roughly all equally powerful, or because the agents have the same moral views, or because there's no way to be unseated by cheap competition, and so on. These models generally refer to abstract agents of varying levels of power and differing values, in a diverse range of circumstances, and yet still predict peaceful trade because of the efficiency advantages of lawful interactions and compromise.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-01-27T00:32:23.331Z · LW(p) · GW(p)
Oh, sorry, to be clear I wasn't arguing that this results in an incentive to kill or steal. I was just pushing back on a local point that seemed wrong to me.
↑ comment by Jeremy Gillen (jeremy-gillen) · 2024-01-31T08:33:14.558Z · LW(p) · GW(p)
Trying to find the crux of the disagreement (which I don't think lies in takeoff speed):
If we assume a multipolar, slow-takeoff, misaligned AI world, where there are many AIs that slowly takeover the economy and generally obey laws to the extent that they are enforced (by other AIs). And they don't particularly care about humans, in a similar manner to the way humans don't particularly care about flies.
In this situation, humans eventually have approximately zero leverage, and approximately zero value to trade. There would be much more value in e.g. mining cities for raw materials than in human labor.
I don't know much history, but my impression is that in similar scenarios between human groups, with a large power differential and with valuable resources at stake, it didn't go well for the less powerful group, even if the more powerful group was politically fragmented or even partially allied with the less powerful group.
Which part of this do you think isn't analogous?
My guesses are either that you are expecting some kind of partial alignment of the AIs. Or that the humans can set up very robust laws/institutions of the AI world such that they remain in place and protect humans even though no subset of the agents is perfectly happy with this, and there exist laws/institutions that they would all prefer.
↑ comment by Matthew Barnett (matthew-barnett) · 2024-01-31T09:03:01.562Z · LW(p) · GW(p)
In this situation, humans eventually have approximately zero leverage, and approximately zero value to trade. There would be much more value in e.g. mining cities for raw materials than in human labor.
Generally speaking, the optimistic assumption is that humans will hold leverage by owning capital, or more generally by receiving income from institutions set up ahead of time (e.g. pensions) that provide income streams to older agents in the society. This system of income transfers to those whose labor is not worth much anymore already exists and benefits old people in human societies, though obviously this happens in a more ordinary framework than you might think will be necessary with AI.
Or that the humans can set up very robust laws/institutions of the AI world such that they remain in place and protect humans even though no subset of the agents is perfectly happy with this, and there exist laws/institutions that they would all prefer.
Assuming AIs are agents that benefit from acting within a stable, uniform, and predictable system of laws, they'd have good reasons to prefer the rule of law to be upheld. If some of those laws support income streams to humans, AIs may support the enforcement of these laws too. This doesn't imply any particular preference among AIs for human welfare directly, except insofar as upholding the rule of law sometimes benefits humans too. Partial alignment would presumably also help to keep humans safe.
(Plus, AIs may get "old" too, in the sense of becoming obsolete in the face of newer generations of AIs. These AIs may therefore have much in common with us, in this sense. Indeed, they may see us as merely one generation in a long series, albeit having played a unique role in history, as a result of having been around during the transition from biology to computer hardware.)
↑ comment by the gears to ascension (lahwran) · 2024-01-26T15:43:47.885Z · LW(p) · GW(p)
Agreed, this argument would be much stronger if it acknowledged that it does not take intense capability for misaligned reinforcement learners to be a significant problem, compare the YouTube and tiktok recommenders which have various second order bad effects that have not been practical for their engineers to remove
comment by Stephen McAleese (stephen-mcaleese) · 2024-01-29T22:42:26.800Z · LW(p) · GW(p)
Strong upvote. I think this is an excellent, carefully written, and timely post. Explaining issues that may arise from current alignment methods is urgent and important. It provides a good explanation of the unidentifiability or inner alignment problem that could arise from advanced AIs systems trained with current behavioral safety methods. It also highlights the difficulty of making AIs that can automate alignment research which is part of OpenAI's current plan. I also liked the in-depth description of what advanced science AIs would be capable of as well as the difficulty of keeping humans in the loop.
comment by Seth Herd · 2024-01-26T20:41:55.575Z · LW(p) · GW(p)
I agree that trying to align an AGI entirely by behavior (as in RL) is unlikely to generalize adequately after extensive learning (which will be necessary) and in dramatically new contexts (which seem inevitable).
There are alternatives which have not been analyzed or discussed much, yet:
Goals selected from learned knowledge: an alternative to RL alignment [AF · GW]
I think this class of approach might be the "fundamental advance" you're calling for. These approaches haven't gotten enough attention to be in the common consciousness, so I doubt the authors were considering them in their "default path".
I think these approaches are all fairly obvious if you're building the relevant types of AGI - which people are currently working on. So I think the default path to AGI might well include these approaches, which don't define goals through behavior. That might well change the default path from ending in failure. I'm currently optimistic but not at all sure until GSLK approaches get more analysis.
Replies from: jeremy-gillen↑ comment by Jeremy Gillen (jeremy-gillen) · 2024-01-30T05:05:07.319Z · LW(p) · GW(p)
Yeah specifying goals in a learned ontology does seem better to me, and in my opinion is a much better approach than behavioral training.
But there's a couple of major roadblocks that come to mind:
- You need really insanely good interpretability on the learned ontology.
- You need to be so good at specifying goals in that ontology that they are robust to adversarial optimization.
Work on these problems is great. I particularly like John's work on natural latent variables which seems like the sort of thing that might be useful for the first two of these.
Keep in mind though there are other major problems that this approach doesn't help much with, e.g.:
- Standard problems arising from the ontology changing over time or being optimized against.
- The problem of ensuring that no subpart of your agent is pursuing different goals (or applying optimization in a way that may break the overall system at some point).
↑ comment by Seth Herd · 2024-01-31T05:07:01.246Z · LW(p) · GW(p)
I largely agree. I think you don't need any those things to have a shot, but you do to be certain.
To your point 1, I think you can reduce the need for very precise interpretability if you make the alignment target simpler. I wrote about this a little here [LW · GW] but there's a lot more to be said and analyzed. That might help with RL techniques too.
If you believe in natural latent variables, which I tend to, those should help with the stability problem you mention.
WRT subagents having different goals, you do need to design it so the primary goals are dominant. Which would be tricky to be certain of. I'd hope q self aware and introspective agent could help enforce that.
comment by Gabe M (gabe-mukobi) · 2024-01-29T20:13:14.830Z · LW(p) · GW(p)
Related work
Nit having not read your full post: Should you have "Without specific countermeasures, the easiest path to transformative AI likely leads to AI takeover [LW · GW]" in the related work? My mind pattern-matched to that exact piece from reading your very similar title, so my first thought was how your piece contributes new arguments.
Replies from: peterbarnett↑ comment by peterbarnett · 2024-01-29T22:14:37.392Z · LW(p) · GW(p)
Yeah, this is a good point, especially with our title. I'll endeavor to add it today.
"Without specific countermeasures" definitely did inspire our title. It seems good to be clear about how our pieces differ. I think the two pieces are very different, two of the main differences are:
- Our piece is much more focused on "inner alignment" difficulties, while the "playing the training game" seems more focused on "outer alignment" (although "Without specific countermeasures" does discuss some inner alignment things, this isn't the main focus)
- Our piece argues that even with specific countermeasures (i.e. AI control) behavioral training of powerful AIs is likely to lead to extremely bad outcomes. And so fundamental advances are needed (likely moving away from purely behavioral training)
comment by Eli Tevet (eli-tevet) · 2024-01-28T18:08:19.814Z · LW(p) · GW(p)
thread
typo? threat probably
Replies from: peterbarnett↑ comment by peterbarnett · 2024-01-28T19:05:43.251Z · LW(p) · GW(p)
Thanks, fixed!
Replies from: SimonF↑ comment by Simon Fischer (SimonF) · 2024-01-29T10:10:41.352Z · LW(p) · GW(p)
In Section 5 we discuss why expect oversight and control of powerful AIs to be difficult.
Another typo, probably missing a "we".
comment by Review Bot · 2024-02-13T15:59:06.563Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by Jeff White (jeff-white) · 2024-01-30T02:52:02.611Z · LW(p) · GW(p)
I have been working on value alignment from systems-neurology and especially adolescent development for many years, sort of in parallel with ongoing discussions here, but in terms of moral isomorphisms and autonomy and so on. Here, a brief paper from a presentation for the Embodied Intelligence conference 2023 about development of purpose in life and spindle neurons in context of self-association with religious ideals, such as we might like a religious robot to pursue, disregarding corrupting social influences and misaligned human instruction, and so on: https://philpapers.org/rec/WHIAAA-8 I think that this is the sort of fundamental advance necessary.
comment by ZY (AliceZ) · 2024-01-28T00:48:22.980Z · LW(p) · GW(p)
comment by Roko · 2024-01-31T10:33:38.508Z · LW(p) · GW(p)
I'm coincidentally writing a related report about how single humans like dictators or absolute monarchs ruling large nations is likely impossible or at least very unlikely, a lot of the reasoning is the same:
https://www.lesswrong.com/posts/QmBbzQoSn7ZpFsDB3/without-fundamental-advances-rebellion-and-coup-d-etat-are [LW · GW]
comment by Anders Lindström (anders-lindstroem) · 2024-01-27T01:19:17.765Z · LW(p) · GW(p)
Great report! One thing that comes to mind while reading the report is the seemingly impossible task to create a machine/system that will (must) have zero(!) catastrophic accidents. What is the rationale behind the thinking among AI-proponents that humans will with divine precision and infallibility build a perfect machine? Have we achieved something similar with the same level of complexities in any other area so that we know we have at least "one under the belt" before we embark on this perilous journey?
comment by Alex K. Chen (parrot) (alex-k-chen) · 2024-01-28T21:30:38.734Z · LW(p) · GW(p)
Is "data quality" (what databricks is trying to do) at minimum, essential? (data quality is inclusive of maximizing human intelligence and minimizing pollution/microplastic/heat load and maintaining proper Markov boundaries/blankets with each other [entropy/pollution dissolves these boundaries, and we need proper Markov boundaries to properly render faithful computations])
LLMs are trained full of noise and junk training data, distracting us from what's really true/sensible. It seems that the aura of inevitability is towards maximum-entropy, and maybe relying entirely on the "inevitability of increased scaling" contributes to "maximum-entropy", which is fundamentally misaligned. Alignment depends on veering away from this entropy.
[this is also why human intelligence enhancement (and maturity enhancement through tFUS) is extremely essential - humans will produce better quality (and less repetitive) data the smarter we are]. tFUS also reduces incentives for babblers (what Romeo Stevens calls "most people") :) .
If there is ONE uniquely pro-alignment advance this year, it's the adoption curve of semaglutide, because semaglutide will reduce the global aging rate of humanity (and kill fewer animals along the way). Semaglutide can also decrease your microplastic consumption by 50%. :) Alignment means BETTER AWARENESS of input-output mappings, and microplastics/pollution are an Pareto-efficient-reducible way of screwing this process up. I mean "Pareto-efficient reducible" because it can be done without needing drastic IQ increases for 98% of the population so it is a MINIMAL SET of conditions.
[YOU CANNOT SHAME PEOPLE FOR TRUTH-SEEKING or trying to improve their intelligence, genetic and early-life deficiencies be damned]. It constantly seems that - given the curriculum - people are making it seem like most of the population isn't smart or technical enough for alignment/interpretability. There is a VERY VERY niche/special language of math used by alignment researchers that is only accessible to a very small fraction of the population, even among smart people outside of the special population who do not speak that special niche language. I say that at VERY minimum, everyone in environmental health/intelligence research is alignment relevant (if not more) - and the massive gaps that people have in pollution/environmental health/human intelligence is holding progress back (also "translation" between people who speak other HCI-ish/BCI-ish languages and those who only speak theoretical math/alignment). Even mathy alignment people don't speak "signals and systems"/error-correction language, and "signals and systems" is just as g-loaded and relevant (and only becomes MORE important as we collect better data out of our brains) - SENSE-MAKING is needed, and the strange theory-heavy hierarchy of academic status tends to de-emphasize sense-making (analytical chemists have the lowest GRE scores of all chemistry people, even though they are the most relevant branch of chemistry for most people).
There is SO much groupthink among alignment people (and people in their own niche academic fields) and better translation and human intelligence enhancement to transcend the groupthink is needed.
I am constantly misunderstood myself, but at least a small portion of people believe in me ENOUGH to want to take a chance in me (in a world where the DEFAULT OPTION is doom if you continue with current traditions, you NEED all the extra chance you can take from "fringe cases" that the world doesn't know how to deal with [cognitive unevenness be damned]), and I did at least turn someone into a Thiel Fellow (WHY GREATNESS CANNOT BE PLANNED - even Ken Stanley thinks MORE STANLEY-ISMs is alignment relevant and he doesn't speak or understand alignment-language)
Semaglutide is an error-correction-enhancer, as is rapamycin (rapamycin really reduces error rate of protein synthesis), as are both caffeine+modafinil (the HARDEST and possibly most important question is whether or not Adderall/Focalin/2FA/4FA are). Entrepreneurs who create autopoetic systems around themselves are error-corrections and the OPPOSITE of error-corrector is a traumatized PhD student who is "all but dissertation" (eg, sadly, Qiaochu Yuan). I am always astounded at how much some people are IDEAL error-correctors around themselves, and others have enough trauma/fatigue/toxin-accumulation in themselves that they can't properly error-correct anymore b/c they don't have the energy (Eliezer Yudowsky often complains about his energy issues and there is strong moral value alone in figuring out what toxins his brain has so that he can be a better error-corrector - I've actually tried to connect him with Bryan Johnson's personal physician [Oliver Zolman] but no email reply yet)
If everyone could have the Christ-like kindness of Jose Luis Ricon, it would help the world SO MUCH
Also if you put ENOUGH OF YOURSELF OUT THERE ON THE INTERNET, the AI will help align you (even through retrocausality) to yourself even if no one else in the world can do it yet [HUMAN-MACHINE SYMBIOSIS is the NECESSARY FUTURE]
And as one of the broadest people ever (I KNOW JOSE LUIS RICON IS TOO), I am CONSTANTLY on the lookout for things other people can't see (this is ONE of my strengths)
Alignment only happens if you are in complete control of your inputs and outputs (this means minimizing microplastics/pollution)
"Without fundamental advances, misalignment and catastrophe are the default outcomes of training powerful AI [LW · GW]" -=> "fundamental advances" MOST OF ALL means BEING MORE INCLUSIVE of ideas that are OUTSIDE of the "AI alignment CS/math/EA circlejerk". Be more inclusive of people and ideas who don't speak the language of classical alignment, which is >>>> 99% of the world - there are people in MANY areas like HCI/environmental health/neuroscience/every other field who don't have the CS/math background you surround yourself with.
[btw LW is perceived as a GIANT CIRCLEJERK for a reason, SO MUCH of LW is seen as "low openness" to anything outside of its core circlejerky ideas]. So many external people make fun of LW/EA/alignment for GOOD REASON (despite some of the unique merits of LW/EA)].