Posts
Comments
- If the user types “improve my fitness” into some interface, and it sets the AI’s reward function to be some “function of the user’s heart rate, sleep duration, and steps taken”, then the AI can potentially get a higher reward by forcing the user into eternal cardio training on pain of death, including forcibly preventing the person from turning off the AI, or changing its goals (see §2.2 above).
- The way that the reward function operationalizes “steps taken” need not agree with what we had in mind. If it’s operationalized as steps registered on a wearable tracker, the AI can potentially get higher reward by taking the tracker from the person and attaching it to a paint shaker. “Sleep” may be operationalized in a way that includes the user being forcibly drugged by the AI.
- If the user sets a goal of “help me learn Spanish over the next five years”, the AI can potentially get a higher reward by making modified copies of itself to aggressively earn or steal as much money and resources as possible around the world, and then have those resources available in case it might be useful for its local Spanish-maximization goal. For example, money can be used to hire tutors, or to train better successor AIs, or to fund Spanish-pedagogy or brain-computer interface research laboratories around the world, or of course to cheat by bribing or threatening whoever administers the Spanish exam at the end of the five years.
I don't really like those examples because just using human feedback fixes those (although I agree that those examples possibly sound more like the vague proposal from Silver and Sutton).
- If “the human gives feedback” is part of the reward function, then the AI can potentially get a higher score by forcing the human to give positive feedback, or otherwise exploiting edge-cases in how this feedback is operationalized and measured.
I think that sounds off to AI researchers. They might (reasonably) think something like "during the critical value formation period the AI won't have the ability to force humans to give positive feedback without receiving negative feedback". If the problem you described happens, it would be that the AI's value function learned to assign high value to "whatever strategy makes the human give positive feedback", rather than "whatever the human would endorse" or "whatever is favored according to the extrapolation of human values". That isn't really a specification gaming problem though. And I think your example isn't very realistic - more likely would be that the value function just learned a complex proxy for predicting reward which totally misgeneralizes in alien ways once you go significantly off distribution.
One could instead name the specification gaming failure mode that the AI overoptimizes on what the humans think is good rather than what is actually good, e.g. proposing a convincing seeming alignment proposal which it doesn't expect to actually work but for which the humans reward it more than for admitting it cannot reliably solve alignment.
(For more on the alignment problem for RL agents, see §10 of my intro series, but be warned that it’s not very self-contained—it’s sorta in the middle of a book-length discussion of how I think RL works in the human brain, and its implications for safety and alignment.)
I think post 10 there is relatively self-contained and I would recommend it much more strongly, especially since you don't really describe the inner alignment problems here.
Re post overall:
I liked sections 2.2 and 2.3 and 3.
I think the post focuses way too much on specification gaming, and way too little on the problem of how to generalize to the right values from the reward. (And IMO, that's not just correct generalization to the value function, but also to the optimization target of a later more powerful optimization process, since I don't think a simple TD-learned value function could plan effectively enough to do something pivotal. (I would still be interested in your thoughts on my comment here, if you have the time.))
(Another outer-alignment-like problem that might be worth mentioning that the values of the AI might come out misaligned if we often just give reward based on the capability of the AI, rather than specifically human-value related stuff. (E.g. the AI might rather end up caring about getting kinds of instrumentally widely useful insights or so, which becomes a problem when we go off distribution, though of course even without that problem we shouldn't expect it to generalize off distribution in the way we want.) (Related.))
I don't quite like "Turbocharging" as a name because it suggests too little about the content. Better might e.g. be "the directness principle".
(IIRC Directness is also one of the ultralearning principles from Scott Young and I guess it describes the same thing, but I don't remember.)
Btw, I think my explanation of why to not have objects for events was not very good. I think I can explain it a bit better now. If you think that would be useful to you, lmk.
discussion of exercises of the probability 2 lecture starts mid episode 104.
Btw, just reading through everything from "dath ilan" might also be interesting: https://www.glowfic.com/replies/search?board_id=&author_id=&template_id=&character_id=11562&subj_content=&sort=created_old&commit=Search
Asmodia figuring out Keltham's probability riddles may also be interesting, though perhaps less so than the lectures. It starts episode 90. Starting quote is "no dath ilani out of living memory would've seen the phenomenon". The story unfortunately switches between Asmodia+Ione, Carrissa(+Peranza I think), and Keltham+Meritxell. You can skip the other stuff that's going on there (though the brief "dath ilan" reply about stocks might be interesting too).
Thanks!
If the value function is simple, I think it may be a lot worse than the world-model/thought-generator at evaluating what abstract plans are actually likely to work (since the agent hasn't yet tried a lot of similar abstract plans from where it could've observed results, and the world model's prediction making capabilities generalize further). The world model may also form some beliefs about what the goals/values in a given current situation are. So let's say the thought generator outputs plans along with predictions about those plans, and some of those predictions predict how well a plan is going to fulfill what it believes the goals are (like approximate expected utility). Then the value function might learn to just just look at this part of a thought that predicts the expected utility, and then take that as it's value estimate.
Or perhaps a slightly more concrete version of how that may happen. (I'm thinking about model-based actor-critic RL agents which start out relatively unreflective, rather than just humans.):
- Sometimes the thought generator generates self-reflective thoughts like "what are my goals here", where upon the thought generator produces an answer "X" to that, and then when thinking how to accomplish X it often comes up with a better (according to the value function) plan than if it tried to directly generate a plan without clarifying X. Thus the value function learns to assign positive valence to thinking "what are my goals here".
- The same can happen with "what are my long-term goals", where the thought generator might guess something that would cause high reward.
- For humans, X is likely more socially nice than would be expected from the value function, since "X are my goals here" is a self-reflective thought where the social dimensions are more important for the overall valence guess.[1]
- Later the thought generator may generate the thought "make careful predictions whether the plan will actually accomplish the stated goals well", where upon the thought generator often finds some incoherences that the value function didn't notice, and produces a better plan. Then the value function learns to assign high valence to thoughts like "make careful predictions whether the plan will actually accomplish the stated goals well".
- Later the predictions of the thought generator may not always match well with the valence the value function assigns, and it turns out that the thought generator's predictions often were better. So over time the value function gets updated more and more toward "take the predictions of the thought generator as our valence guess", since that strategy better predicts later valence guesses.
- Now, some goals are mainly optimized by the thought generator predicting how some goals could be accomplished well, and there might be beliefs in the thought generator like "studying rationality may make me better at accomplishing my goals", causing the agent to study rationality.
- And also thoughts like "making sure the currently optimized goal keeps being optimized increases the expected utility according to the goal".
- And maybe later more advanced bootstrapping through thoughts like "understanding how my mind works and exploiting insights to shape it to optimize more effectively would probably help me accomplish my goals". Though of course for this to be a viable strategy it would at least be as smart as the smartest current humans (which we can assume because otherwise it's too useless IMO).
So now the value function is often just relaying world-model judgements and all the actually powerful optimization happens in the thought generator. So I would not classify that as the following:
In my view, the big problem with model-based actor-critic RL AGI, the one that I spend all my time working on, is that it tries to kill us via using its model-based RL capabilities in the way we normally expect—where the planner plans, and the actor acts, and the critic criticizes, and the world-model models the world …and the end-result is that the system makes and executes a plan to kill us.
So in my story, the thought generator learns to model the self-agent and has some beliefs about what goals it may have, and some coherent extrapolation of (some of) those goals is what gets optimized in the end. I guess it's probably not that likely that those goals are strongly misaligned to the value function on the distribution where the value function can evaluate plans, but there are many possible ways to generalize the values of the value function.
For humans, I think that the way this generalization happens is value-laden (aka what human values are depend on this generalization). The values might generalize a bit differently for different humans of course, but it's plausible that humans share a lot of their prior-that-determines-generalization, so AIs with a different brain architecture might generalize very differently.
Basically, whenever someone thinks "what's actually my goal here", I would say that's already a slight departure from "using one's model-based RL capabilities in the way we normally expect". Though I think I would agree that for most humans such departures are rare and small, but I think they get a lot larger for smart reflective people, and I think I wouldn't describe my own brain as "using one's model-based RL capabilities in the way we normally expect". I'm not at all sure about this, but I would expect that "using its model-based RL capabilities in the way we normally expect" won't get us to pivotal level of capability if the value function is primitive.
- ^
If I just trust my model of your model here. (Though I might misrepresent your model. I would need to reread your posts.)
Note that the "Probability 2" lecture continues after the lunch break (which is ~30min skippable audio).
Thanks!
Sorry, I think I intended to write what I think you think, and then just clarified my own thoughts, and forgot to edit the beginning. Sorry, I ought to have properly recalled your model.
Yes, I think I understand your translations and your framing of the value function.
Here are the key differences between a (more concrete version of) my previous model and what I think your model is. Please lmk if I'm still wrongly describing your model:
- plans vs thoughts
- My previous model: The main work for devising plans/thoughts happens in the world-model/thought-generator, and the value function evaluates plans.
- Your model: The value function selects which of some proposed thoughts to think next. Planning happens through the value function steering the thoughts, not the world model doing so.
- detailedness of evaluation of value function
- My previous model: The learned value function is a relatively primitive map from the predicted effects of plans to a value which describes whether the plan is likely better than the expected counterfactual plan. E.g. maybe sth roughly like that we model how sth like units of exchange (including dimensions like "how much does Alice admire me") change depending on a plan, and then there is a relatively simple function from the vector of units to values. When having abstract thoughts, the value function doesn't understand much of the content there, and only uses some simple heuristics for deciding how to change its value estimate. E.g. a heuristic might be "when there's a thought that the world model thinks is valid and it is associated to the (self-model-invoking) thought "this is bad for accomplishing my goals", then it lowers its value estimate. In humans slightly smarter than the current smartest humans, it might eventually learn the heuristic "do an explicit expected utility estimate and just take what the result says as the value estimate", and then that is being done and the value function itself doesn't understand much about what's going on in the expected utility estimate, but it just allows to happen whatever the abstract reasoning engine predicts. So it essentially optimizes goals that are stored as beliefs in the world model.
- So technically you could still say "but what gets done still depends on the value function, so when the value function just trusts some optimization procedure which optimizes a stored goal, and that goal isn't what we intended, then the value function is misaligned". But it seems sorta odd because the value function isn't really the main relevant thing doing the optimization.
- The value function essentially is too dumb to do the main optimization itself for accomplishing extremely hard tasks. Even if you set incentives so that you get ground-truth reward for moving closer to the goal, it would be too slow at learning what strategies work well
- Your model: The value function has quite a good model of what thoughts are useful to think. It is just computing value estimates, but it can make quite coherent estimates to accomplish powerful goals.
- If there are abstract thoughts about actually optimizing a different goal than is in the interest of the value function, the value function shuts them down by assigning low value.
- (My thoughts: One intuition is that to get to pivotal intelligence level, the value function might need some model of its own goals in order to efficiently recognizing when some values it is assigning aren't that coherent, but I'm pretty unsure of that. Do you think the value function can learn a model of its own values?)
- My previous model: The learned value function is a relatively primitive map from the predicted effects of plans to a value which describes whether the plan is likely better than the expected counterfactual plan. E.g. maybe sth roughly like that we model how sth like units of exchange (including dimensions like "how much does Alice admire me") change depending on a plan, and then there is a relatively simple function from the vector of units to values. When having abstract thoughts, the value function doesn't understand much of the content there, and only uses some simple heuristics for deciding how to change its value estimate. E.g. a heuristic might be "when there's a thought that the world model thinks is valid and it is associated to the (self-model-invoking) thought "this is bad for accomplishing my goals", then it lowers its value estimate. In humans slightly smarter than the current smartest humans, it might eventually learn the heuristic "do an explicit expected utility estimate and just take what the result says as the value estimate", and then that is being done and the value function itself doesn't understand much about what's going on in the expected utility estimate, but it just allows to happen whatever the abstract reasoning engine predicts. So it essentially optimizes goals that are stored as beliefs in the world model.
There's a spectrum between my model and yours. I don't know what model is better; at some point I'll think about what may be a good model here. (Feel free to lmk your thoughts on why your model may be better, though maybe I just see it when in the future I think about it more carefully and reread some of your posts and model your model in more detail. I'm currently not modelling either model that detailed.)
Why two?
Mathematics/logical-truths are true in all possible worlds, so they never tell you in what world you are.
If you want to say something that is true in your particular world (but not necessarily in all worlds), you need some observations to narrow down what world you are in.
I don't know how closely this matches the use in the sequence, but I think a sensible distinction between logical and causal pinpointing is: All the math parts of a statement are "logically pinpointed" and all the observation parts are "causally pinpointed".
So basically, I think in theory you can reason about everything purely logically by using statements like "In subspace_of_worlds W: X"[1], and then you only need causal pinpointing before making decisions for evaluating what world you're actually likely in.
You could imagine programming a world model where there's the default assumption that non-tautological statements are about the world we're in, and then a sentence like "Peter's laptop is silver" would get translated into sth like "In subspace_of_worlds W_main: color(<x s.t. laptop(x) AND own(Peter, x)>, silver)".
Most of the statements you reason with are of course about the world you're in or close cousin worlds with only few modifications, though sometimes we also think about further away fiction worlds (e.g. HPMoR).
(Thanks to Kaarel Hänni for a useful conversation that lead up to this.)
- ^
It's just a sketch, not a proper formalization. Maybe we rather want sth like statements of the form "if {...lots of context facts that are true in our world...} then X".
Thanks for clarifying.
I mean I do think it can happen in my system that you allocate an object for something that's actually 0 or >1 objects, and I don't have a procedure for resolving such map-territory mismatches yet, though I think it's imaginable to have a procedure that defines new objects and tries to edit all the beliefs associated with the old object.
I definitely haven't described how we determine when to create a new object to add to our world model, but one could imagine an algorithm checking when there's some useful latent for explaining some observations, and then constructing a model for that object, and then creating a new object in the abstract reasoning engine. Yeah there's still open work to do for how a correspondences between the constant symbol for our object and our (e.g. visual) model of the object can be formalized and used, but I don't see why it wouldn't be feasible.
I agree that we end up with a map that doesn't actually fit the territory, but I think it's fine if there's a unresolveable mismatch somewhere. There's still a useful correspondence in most places. (Sure logic would collapse from a contradiction but actually it's all probabilistic somehow anyways.) Although of course we don't have anything to describe that the territory is different from the map in our system yet. This is related to embedded agency, and further work on how to model your map as possibly not fitting the territory and how that can be used is still necessary.
Thx.
Yep there are many trade-offs between criteria.
Btw, totally unrelatedly:
I think in the past on your abstraction you probably lost a decent amount of time from not properly tracking the distinction between (what I call) objects and concepts. I think you likely at least mostly recovered from this, but in case you're not completely sure you've fully done so you might want to check out the linked section. (I think it makes sense to start by understanding how we (learn to) model objects and only look at concepts later, since minds first learn to model objects and later carve up concepts as generalizations over similarity clusters of objects.)
Tbc, there's other important stuff than objects and concepts, like relations and attributes. I currently find my ontology here useful for separating subproblems, so if you're interested you might read more of the linked post even though you're surely already familiar with knowledge representation (if you haven't done so yet), but maybe you already track all that.
Thanks.
I'm still not quite understanding what you're thinking though.
For other objects, like physical ones, quantifiers have to be used. Like "at least one" or "the" (the latter only presupposes there is exactly one object satisfying some predicate). E.g. "the cat in the garden". Perhaps there is no cat in the garden or there are several. So it (the cat) cannot be logically represented with a constant.
"the" supposes there's exactly one canonical choice for what object in the context is indicated by the predicate. When you say "the cat" there's basically always a specific cat from context you're talking about. "The cat is in the garden" is different from "There's exactly one cat in the garden".
Maybe "Superman" is actually two people with the same dress, or he doesn't exist, being the result of a hallucination. This case can be easily solved by treating those names as predicates.
- The woman believes the superhero can fly.
- The superhero is the colleague.
I mean there has to be some possibility for revising your world model if you notice that there are actually 2 objects for something where you previously thought there's only one.
I agree that "Superman" and "the superhero" denote the same object(assuming you're in the right context for "the superhero").
(And yeah to some extent names also depend a bit on context. E.g. if you have 2 friends with the same name.)
You can say "{(the fact that) there's an apple on the table} causes {(the fact that) I see an apple}"
But that's not primitive in terms of predicate logic, because here "the" in "the table" means "this" which is not a primitive constant. You don't mean any table in the world, but a specific one, which you can identify in the way I explained in my previous comment.
Yeah I didn't mean this as formal statement. formal would be:
{exists x: apple(x) AND location(x, on=Table342)} CAUSES {exists x: apple(x) AND see(SelfPerson, x)}
I think object identification is important if we want to analyze beliefs instead of sentences. For beliefs we can't take a third person perspective and say "it's clear from context what is meant". Only the agent knows what he means when he has a belief (or she). So the agent has to have a subjective ability to identify things. For "I" this is unproblematic, because the agent is presumably internal and accessible to himself and therefore can be subjectively referred to directly. But for "this" (and arguably also for terms like "tomorrow") the referred object depends partly on facts external to the agent. Those external facts might be different even if the internal state of the agent is the same. For example, "this" might not exist, so it can't be a primitive term (constant) in standard predicate logic.
I'm not exactly sure what you're saying here, but in case the following helps:
Indicators like "here"/"tomorrow"/"the object I'm pointing to" don't get stored directly in beliefs. They are pointers used for efficiently identifying some location/time/object from context, but what get's saved in the world model is the statement where those pointers were substituted for the referent they were pointing to.
One approach would be to analyze the belief that this apple is green as "There is an x such that x is an apple and x is green and x causes e." Here "e" is a primitive term (similar to "I" in "I'm hungry") that refers to the current visual experience of a green apple.
So e is subjective experience and therefore internal to the agent. So it can be directly referred to, while this (the green apple he is seeing) is only indirectly referred to (as explained above), similar to "the biggest tree", "the prime minister of Japan", "the contents of this box".
Note the important role of the term "causes" here. The belief is representing a hypothetical physical object (the green apple) causing an internal object (the experience of a green apple). Though maybe it would be better to use "because" (which relates propositions) instead of "causes", which relates objects or at least noun phrases. But I'm not sure how this would be formalized.
I think I still don't understand what you're trying to say, but some notes:
- In my system, experiences aren't objects, they are facts. E.g. the fact "cubefox sees an apple".
- CAUSES relates facts, not objects.
- You can say "{(the fact that) there's an apple on the table} causes {(the fact that) I see an apple}"
- Even though we don't have an explicit separate name in language for every apple we see, our minds still tracks every apple as a separate object which can be identified.
Btw, it's very likely not what you're talking about, but you actually need to be careful sometimes when substituting referent objects from indicators, in particular in cases where you talk about the world model of other people. E.g. if you have the beliefs:
- Mia believes Superman can fly.
- Superman is Clark Kent.
This doesn't imply that "Mia believes Clark Kent can fly", because Mia might not know (2). But essentially you just have a separate world model "Mia's beliefs" in which Superman and Clark Kent are separate objects, and you just need to be careful to choose the referent of names (or likewise with indicators) relative to who's belief scope you are in.
Yep I did not cover those here. They are essentially shortcodes for identifying objects/times/locations from context. Related quote:
E.g. "the laptop" can refer to different objects in different contexts, but when used it's usually clear which object is meant. However, how objects get identified does not concern us here - we simply assume that we know names for all objects and use them directly.
("The laptop" is pretty similar to "This laptop".)
(Though "this" can also act as complementizer, as in "This is why I didn't come", though I think in that function it doesn't count as indexical. The section related to complementizers is the "statement connectives" section.)
“Outer alignment” entails having a ground-truth reward function that spits out rewards that agree with what we want. “Inner alignment” is having a learned value function that estimates the value of a plan in a way that agrees with its eventual reward.
I guess just briefly want to flag that I think this summary of inner-vs-outer alignment is confusing in a way that it sounds like one could have a good enough ground-truth reward and then that just has to be internalized.
I think this summary is better: 1. "The AGI was doing the wrong thing but got rewarded anyway (or doing the right thing but got punished)". 2. Something else went wrong [not easily compressible].
Sounds like we probably agree basically everywhere.
Yeah you can definitely mark me down in the camp of "not use 'inner' and 'outer' terminology". If you need something for "outer", how about "reward specification (problem/failure)".
ADDED: I think I probably don't want a word for inner-alignment/goal-misgeneralization. It would be like having a word for "the problem of landing a human on the moon, except without the part of the problem where we might actively steer the rocket into wrong directions".
I just don’t use the term “utility function” at all in this context. (See §9.5.2 here for a partial exception.) There’s no utility function in the code. There’s a learned value function, and it outputs whatever it outputs, and those outputs determine what plans seem good or bad to the AI, including OOD plans like treacherous turns.
Yeah I agree they don't appear in actor-critic model-based RL per se, but sufficiently smart agents will likely be reflective, and then they will appear there on the reflective level I think.
Or more generally I think when you don't use utility functions explicitly then capability likely suffers, though not totally sure.
Thanks.
Yeah I guess I wasn't thinking concretely enough. I don't know whether something vaguely like what I described might be likely or not. Let me think out loud a bit about how I think about what you might be imagining so you can correct my model. So here's a bit of rambling: (I think point 6 is most important.)
- As you described in you intuitive self-models sequence, humans have a self-model which can essentially have values different from the main value function, aka they can have ego-dystonic desires.
- I think in smart reflective humans, the policy suggestions of the self-model/homunculus can be more coherent than the value function estimates, e.g. because they can better take abstract philosophical arguments into account.
- The learned value function can also update on hypothetical scenarios, e.g. imagining a risk or a gain, but it doesn't update strongly on abstract arguments like "I should correct my estimates based on outside view".
- The learned value function can learn to trust the self-model if acting according to the self-model is consistently correlated with higher-than-expected reward.
- Say we have a smart reflective human where the value function basically trusts the self-model a lot, then the self-model could start optimizing its own values, while the (stupid) value function believes it's best to just trust the self-model and that this will likely lead to reward. Something like this could happen where the value function was actually aligned to outer reward, but the inner suggestor was just very good at making suggestions that the value function likes, even if the inner suggestor would have different actual values. I guess if the self-model suggests something that actually leads to less reward, then the value function will trust the self-model less, but outside the training distribution the self-model could essentially do what it wants.
- Another question of course is whether the inner self-reflective optimizers are likely aligned to the initial value function. I would need to think about it. Do you see this as a part of the inner alignment problem or as a separate problem?
- As an aside, one question would be whether the way this human makes decisions is still essentially actor-critic model-based RL like - whether the critic just got replaced through a more competent version. I don't really know.
- (Of course, I totally ackgnowledge that humans have pre-wired machinery for their intuitive self-models, rather than that just spawning up. I'm not particularly discussing my original objection anymore.)
- I'm also uncertain whether something working through the main actor-critic model-based RL mechanism would be capable enough to do something pivotal. Like yeah, most and maybe all current humans probably work that way. But if you go a bit smarter then minds might use more advanced techniques of e.g. translating problems into abstract domains and writing narrow AIs to solve them there and then translating it back into concrete proposals or sth. Though maybe it doesn't matter as long as the more advanced techniques don't spawn up more powerful unaligned minds, in which case a smart mind would probably not use the technique in the first place. And I guess actor-critic model-based RL is sorta like expected utility maximization, which is pretty general and can get you far. Only the native kind of EU maximization we implement through actor-critic model-based RL might be very inefficient compared through other kinds.
- I have a heuristic like "look at where the main capability comes from", and I'd guess for very smart agents it perhaps doesn't come from the value function making really good estimates by itself, and I want to understand how something could be very capable and look at the key parts for this and whether they might be dangerous.
- Ignoring human self-models now, the way I imagine actor-critic model-based RL is that it would start out unreflective. It might eventually learn to model parts of itself and form beliefs about its own values. Then, the world-modelling machinery might be better at noticing inconsistencies in the behavior and value estimates of that agent than the agent itself. The value function might then learn to trust the world-model's predictions about what would be in the interest of the agent/self.
- This seems to me to sorta qualify as "there's an inner optimizer". I would've tentitatively predicted you to say like "yep but it's an inner aligned optimizer", but not sure if you actually think this or whether you disagree with my reasoning here. (I would need to consider how likely value drift from such a change seems. I don't know yet.)
I don't have a clear take here. I'm just curious if you have some thoughts on where something importantly mismatches your model.
Thanks!
Another thing is, if the programmer wants CEV (for the sake of argument), and somehow (!!) writes an RL reward function in Python whose output perfectly matches the extent to which the AGI’s behavior advances CEV, then I disagree that this would “make inner alignment unnecessary”. I’m not quite sure why you believe that.
I was just imagining a fully omnicient oracle that could tell you for each action how good that action is according to your extrapolated preferences, in which case you could just explore a bit and always pick the best action according to that oracle. But nvm, I noticed my first attempt of how I wanted to explain what I feel like is wrong sucked and thus dropped it.
- The AGI was doing the wrong thing but got rewarded anyway (or doing the right thing but got punished)
- The AGI was doing the right thing for the wrong reasons but got rewarded anyway (or doing the wrong thing for the right reasons but got punished).
This seems like a sensible breakdown to me, and I agree this seems like a useful distinction (although not a useful reduction of the alignment problem to subproblems, though I guess you agree here).
However, I think most people underestimate how many ways there are for the AI to do the right thing for the wrong reasons (namely they think it's just about deception), and I think it's not:
I think we need to make AI have a particular utility function. We have a training distribution where we have a ground-truth reward signal, but there are many different utility functions that are compatible with the reward on the training distribution, which assign different utilities off-distribution.
You could avoid talking about utility functions by saying "the learned value function just predicts reward", and that may work while you're staying within the distribution we actually gave reward on, since there all the utility functions compatible with the ground-truth reward still agree. But once you're going off distribution, what value you assign to some worldstates/plans depends on what utility function you generalized to.
I think humans have particular not-easy-to-pin-down machinery inside them, that makes their utility function generalize to some narrow cluster of all ground-truth-reward-compatible utility functions, and a mind with a different mind design is unlikely to generalize to the same cluster of utility functions.
(Though we could aim for a different compatible utility function, namely the "indirect alignment" one that say "fulfill human's CEV", which has lower complexity than the ones humans generalize to (since the value generalization prior doesn't need to be specified and can instead be inferred from observations about humans). (I think that is what's meant by "corrigibly aligned" in "Risks from learned optimization", though it has been a very long time since I read this.))
Actually, it may be useful to distinguish two kinds of this "utility vs reward mismatch":
1. Utility/reward being insufficiently defined outside of training distribution (e.g. for what programs to run on computronium).
2. What things in the causal chain producing the reward are the things you actually care about? E.g. that the reward button is pressed, that the human thinks you did something well, that you did something according to some proxy preferences.
Overall, I think the outer-vs-inner framing has some implicit connotation that for inner alignment we just need to make it internalize the ground-truth reward (as opposed to e.g. being deceptive). Whereas I think "internalizing ground-truth reward" isn't meaningful off distribution and it's actually a very hard problem to set up the system in a way that it generalizes in the way we want.
But maybe you're aware of that "finding the right prior so it generalizes to the right utility function" problem, and you see it as part of inner alignment.
Note: I just noticed your post has a section "Manipulating itself and its learning process", which I must've completely forgotten since I last read the post. I should've read your post before posting this. Will do so.
“Outer alignment” entails having a ground-truth reward function that spits out rewards that agree with what we want. “Inner alignment” is having a learned value function that estimates the value of a plan in a way that agrees with its eventual reward.
Calling problems "outer" and "inner" alignment seems to suggest that if we solved both we've successfully aligned AI to do nice things. However, this isn't really the case here.
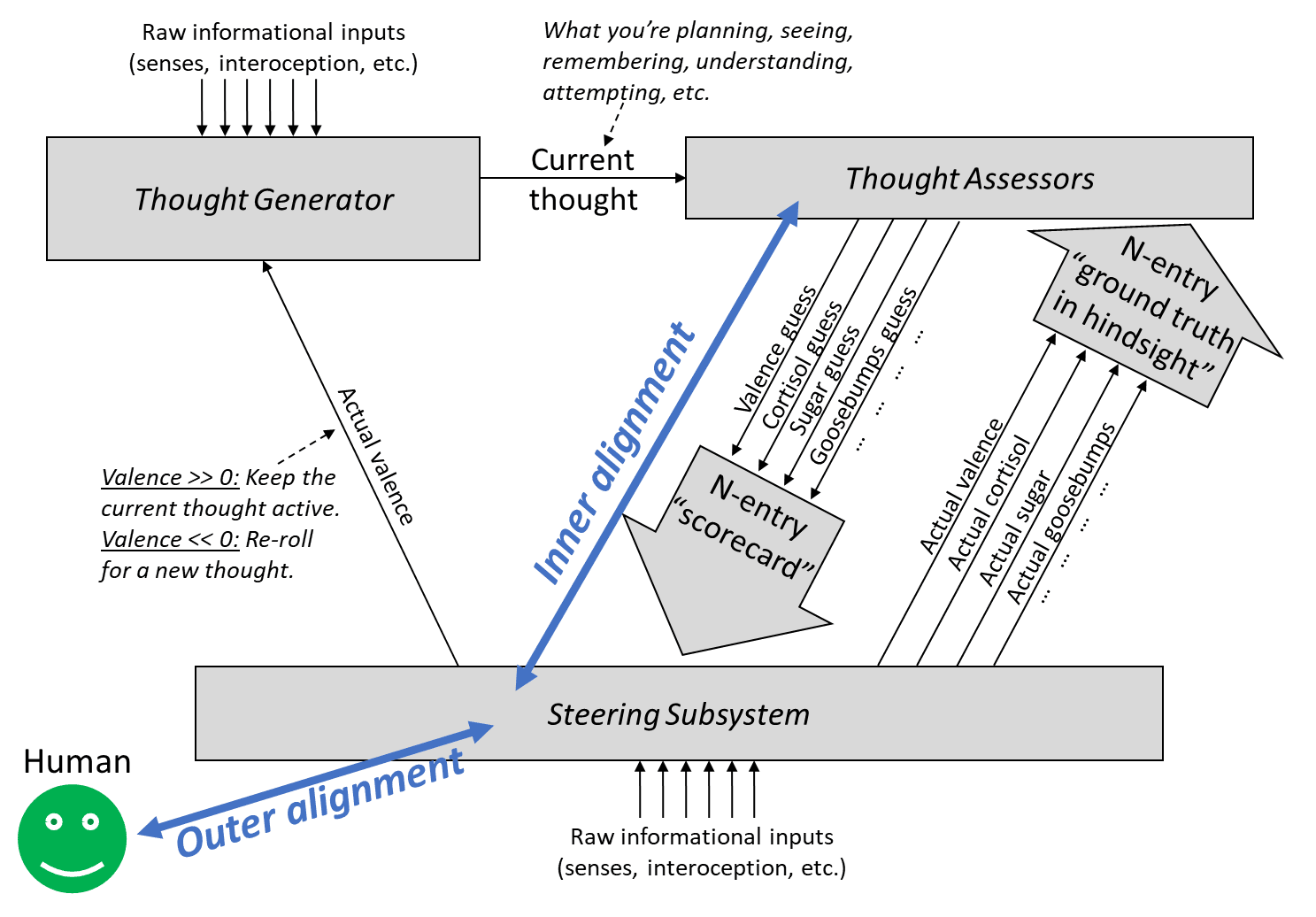
Namely, there could be a smart mesa-optimizer spinning up in the thought generator, who's thoughts are mostly invisible to the learned value function (LVF), and who can model the situation it is in and has different values and is smarter than the LVF evaluation and can fool the the LVF into believing the plans that are good according to the mesa-optimizer are great according to the LVF, even if they actually aren't.
This kills you even if we have a nice ground-truth reward and the LVF accurately captures that.
In fact, this may be quite a likely failure mode, given that the thought generator is where the actual capability comes from, and we don't understand how it works.
I'd suggest not using conflated terminology and rather making up your own.
Or rather, first actually don't use any abstract handles at all and just describe the problems/failure-modes directly, and when you're confident you have a pretty natural breakdown of the problems with which you'll stick for a while, then make up your own ontology.
In fact, while in your framework there's a crisp difference between ground-truth reward and learned value-estimator, it might not make sense to just split the alignment problem in two parts like this:
“Outer alignment” entails having a ground-truth reward function that spits out rewards that agree with what we want. “Inner alignment” is having a learned value function that estimates the value of a plan in a way that agrees with its eventual reward.
First attempt of explaining what seems wrong: If that was the first I read on outer-vs-inner alignment as a breakdown of the alignment problem, I would expect "rewards that agree with what we want" to mean something like "changes in expected utility according to humanity's CEV". (Which would make inner alignment unnecessary because if we had outer alignment we could easily reach CEV.)
Second attempt:
"in a way that agrees with its eventual reward" seems to imply that there's actually an objective reward for trajectories of the universe. However, the way you probably actually imagine the ground-truth reward is something like humans (who are ideally equipped with good interpretability tools) giving feedback on whether something was good or bad, so the ground-truth reward is actually an evaluation function on the human's (imperfect) world model. Problems:
- Humans don't actually give coherent rewards which are consistent with a utility function on their world model.
- For this problem we might be able to define an extrapolation procedure that's not too bad.
- The reward depends on the state of the world model of the human, and our world models probably often has false beliefs.
- Importantly, the setup needs to be designed in a way that there wouldn't be an incentive to manipulate the humans into believing false things.
- Maybe, optimistically, we could mitigate this problem by having the AI form a model of the operators, doing some ontology translation between the operator's world model and its own world model, and flagging when there seems to be a relavant belief mismatch.
- Our world models cannot evaluate yet whether e.g. filling the universe computronium running a certain type of programs would be good, because we are confused about qualia and don't know yet what would be good according to our CEV. Basically, the ground-truth reward would very often just say "i don't know yet", even for cases which are actually very important according to our CEV. It's not just that we would need a faithful translation of the state of the universe into our primitive ontology (like "there are simulations of lots of happy and conscious people living interesting lives"), it's also that (1) the way our world model treats e.g. "consciousness" may not naturally map to anything in a more precise ontology, and while our human minds, learning a deeper ontology, might go like "ah, this is what I actually care about - I've been so confused", such value-generalization is likely even much harder to specify than basic ontology translation. And (2), our CEV may include value-shards which we currently do not know of or track at all.
- So while this kind of outer-vs-inner distinction might maybe be fine for human-level AIs, it stops being a good breakdown for smarter AIs, since whenever we want to make the AI do something where humans couldn't evaluate the result within reasonable time, it needs to generalize beyond what could be evaluated through ground-truth reward.
So mainly because of point 3, instead of asking "how can i make the learned value function agree with the ground-truth reward", I think it may be better to ask "how can I make the learned value function generalize from the ground-truth reward in the way I want"?
(I guess the outer-vs-inner could make sense in a case where your outer evaluation is superhumanly good, though I cannot think of such a case where looking at the problem from the model-based RL framework would still make much sense, but maybe I'm still unimaginative right now.)
Note that I assumed here that the ground-truth signal is something like feedback from humans. Maybe you're thinking of it differently than I described here, e.g. if you want to code a steering subsystem for providing ground-truth. But if the steering subsystem is not smarter than humans at evaluating what's good or bad, the same argument applies. If you think your steering subsystem would be smarter, I'd be interested in why.
(All that is assuming you're attacking alignment from the actor-critic model-based RL framework. There are other possible frameworks, e.g. trying to directly point the utility function on an agent's world-model, where the key problems are different.)
Ah, thx! Will try.
If I did, I wouldn't publicly say so.
It's of course not yes or no, but just a probability, but in case it's high I might not want to state it here, so I should generally not state it here, so you cannot infer it is high by the fact that I didn't state it here.
I can say though that I only turned 22y last week and I expect my future self to grow up to become much more competent than I am now.
2. I mentioned that there should be much more impressive behavior if they were that smart; I don't recall us talking about that much, not sure.
You said "why don't they e.g. jump in prime numbers to communicate they are smart?" and i was like "hunter gatherer's don't know prime numbers and perhaps not even addition" and you were like "fair".
I mean I thought about what I'd expect to see, but I unfortunately didn't really imagine them as smart but just as having a lot of potential but being totally untrained.
3. I recommended that you try hard to invent hypotheses that would explain away the brain sizes.
(I'm kinda confused why your post here doesn't mention that much; I guess implicitly the evidence about hunting defeats the otherwise fairly [strong according to you] evidence from brain size?)
I suggest that a bias you had was "not looking hard enough for defeaters". But IDK, not at all confident, just a suggestion.
Yeah the first two points in the post are just very strong evidence that overpower my priors (where by priors i mean considerations from evolution and brain size, as opposed to behavior). Ryan's point changed my priors, but I think it isn't related enough to "Can I explain away their cortical neuron count?" that asking myself this question even harder would've helped.
Maybe I made a general mistake like "not looking hard enough for defeaters", but it's not that actionable yet. I did try to take all the available evidence and update properly on everything. But maybe some motivated stopping on not trying even longer to come up with a concrete example of what I'd have expected to see from orcas. It's easier to say in retrospect though. Back then I didn't know in what direction I might be biased.
But I guess I should vigilantly look out for warning signs like "not wanting to bother to think about something very carefully" or so. But it doesn't feel like I was making the mistake, even though I probably did, so I guess the sensation might be hard to catch at my current level.
Yes human intelligence.
I forgot to paste in that it's a follow up to my previous posts. Will do now.
In general, I wish this year? (*checks* huh, only 4 months.)
Nah I didn't loose that much time. I already quit the project end of January, I just wrote the post now. Most of the technical work was also pretty useful for understanding language, which is a useful angle on agent foundations. I had previously expected working on that angle to be 80% as effective as my previous best plan, but it was even better, around similarly good I think. That was like 5-5.5 weeks and that was not wasted.
I guess I spent like 4.5 weeks overall on learning about orcas (including first seeing whether I might be able to decode their language and thinking about how and also coming up with the whole "teach language" idea), and like 3 weeks on orga stuff for trying to make the experiment happen.
Yeah I think I came to agree with you. I'm still a bit confused though because intuitively I'd guess chimps are dumber than -4.4SD (in the interpretation for "-4.4SD" I described in my other new comment).
When you now get a lot of mutations that increase brain size, while this contributes to smartness, this also pulls you away from the species median, so the hyperparameters are likely to become less well tuned, resulting in a countereffect that also makes you dumber in some ways.
Actually maybe the effect I am describing is relatively small as long as the variation in brain size is within 2 SDs or so, which is where most of the data pinning down the 0.3 correlation comes from.
So yeah it's plausible to me that your method of estimating is ok.
Intuitively I had thought that chimps are just much dumber than humans. And sure if you take -4SD humans they aren't really able to do anything, but they don't really count.
I thought it's sorta in this direction but not quite as extreme:

(This picture is actually silly because the distance to "Mouse" should be even much bigger. The point is that chimps might be far outside the human distribution.)
But perhaps chimps are actually closer to humans than I thought.
(When I in the following compare different species with standard deviations, I don't actually mean standard deviations, but more like "how many times the difference between a +0SD and a +1SD human", since extremely high and very low standard deviation measures mostly cease to me meaningful for what was actually supposed to be measured.)
I still think -4.4SD is overestimating chimp intelligence. I don't know enough about chimps, but I guess they might be somewhere between -12SD and -6SD (compared to my previous intuition, which might've been more like -20SD). And yes, considering that the gap in cortical neuron count between chimps and humans is like 3.5x, and it's even larger for the prefrontal cortex, and that algorithmic efficiency is probably "orca < chimp < human", then +6SDs for orcas seem a lot less likely than I initially intuitively thought, though orcas would still likely be a bit smarter than humans (on the way my priors would fall out (not really after updating on observations about orcas)).
Thanks for describing a wonderfully concrete model.
I like that way you reason (especially the squiggle), but I don't think it works quite that well for this case. But let's first assume it does:
Your estimamtes on algorithmic efficiency deficits of orca brains seem roughly reasonable to me. (EDIT: I'd actually be at more like -3.5std mean with standard deviation of 2std, but idk.)
Number cortical neurons != brain size. Orcas have ~2x the number of cortical neurons, but much larger brains. Assuming brain weight is proportional to volume, with human brains being typically 1.2-1.4kg, and orca brains being typically 5.4-6.8kg, orca brains are actually like 6.1/1.3=4.7 times larger than human brains.
Taking the 5.4-6.8kg range, this would be 4.15-5.23 range of how much larger orca brains are. Plugging that in for `orca_brain_size_difference` yields 45% on >=2std, and 38% on >=4std (where your values ) and 19.4% on >=6std.
Updating down by 5x because orcas don't seem that smart doesn't seem like quite the right method to adjust the estimate, but perhaps fine enough for the upper end estimates, which would leave 3.9% on >=6std.
Maybe you meant "brain size" as only an approximation to "number of cortical neurons", which you think are the relevant part. My guess is that neuron density is actually somewhat anti-correlated with brain size, and that number of cortical neurons would be correlated with IQ rather at ~0.4-0.55 in humans, though i haven't checked whether there's data on this. And ofc using that you get lower estimates for orca intelligence than in my calculation above. (And while I'd admit that number of neurons is a particularly important point of estimation, there might also be other advantages of having a bigger brain like more glia cells. Though maybe higher neuron density also means higher firing rates and thereby more computation. I guess if you want to try it that way going by number of neurons is fine.)
My main point is however, that brain size (or cortical neuron count) effect on IQ within one species doesn't generalize to brain size effect between species. Here's why:
Let's say having mutations for larger brains is beneficial for intelligence.[1]
On my view, a brain isn't just some neural tissue randomly smished together, but has a lot of hyperparameters that have to be tuned so the different parts work well together.
Evolution basically tuned those hyperparameters for the median human (per gender).
When you now get a lot of mutations that increase brain size, while this contributes to smartness, this also pulls you away from the species median, so the hyperparameters are likely to become less well tuned, resulting in a countereffect that also makes you dumber in some ways.
So when you get a larger brain as a human, this has a lower positive effect on intelligence, than when your species equilibriates on having a larger brain.
Thus, I don't think within species intelligence variation can be extended well to inter-species intelligence variation.
As for how to then properly estimate orca intelligence: I don't know.
(As it happens, I thought of something and learned something yesterday that makes me significantly more pessimistic about orcas being that smart. Still need to consider though. May post them soon.)
- ^
I initially started this section with the following, but I cut it out because it's not actually that relevant: "How intelligent you are mostly depends on how many deleterious mutations you have that move you away from your species average and thereby make you dumber. You're mostly not smart because you have some very rare good genes, but because you have fewer bad ones.
Mutations for increasing sizes of brain regions might be an exception, because there intelligence trades off against childbirth mortality, so higher intelligence here might mean lower genetic fitness."
Thanks!
Yeah that might be a great idea.
Earth species project might be promising too.
Thanks for the suggestion, though I don't think they are smart enough to get far with grammar. No non-cetaceans non-humans seem to be.
One possibility is to try it with bottlenose dolphins (or beluga whales). (Bottlenose dolphins have shown greater capacity to learn grammar than great apes.[1]) Those are likely easier to get research access to than orcas. I think we might get some proof of concept of the methodology there, though I'm relatively pessimistic about them learning a full language well.
- ^
See the work of Louis Herman in the 80s (and 90s)
By >=+6std I mean potential of how smart they could be if they were trained similarly to us, not actual current intelligence. Sorry I didn't write this in this post, though I did in others.
I'd be extremely shocked if orcas were actually that smart already. They don't have science and they aren't trained in abstract reasoning.
Like, when an orca is +7std, he'd be like a +7std hunter gatherer human, who is probably not all that good at abstract reasoning tasks (like learning a language through brute-force abstract pattern recognition). (EDIT: Ok actually it would be like a +7std hunter gatherer society, which might be significantly different. Idk what I'm supposed to expect there. Still wouldn't expect it to be dangerous to talk to them though. And actually when I think about +7std societies I must admit that this sounds not that likely. That they ought to have more information exchange outside their pods and related pods or so and coordinate better. I guess that updates me downwards a bit on orcas being actually that smart - aka I hadn't previously properly considered effects from +7std cultural evolution rather than just individual intelligence.)
Thanks for letting me know it sounded like that. I definitely know it isn't legible at all, and I didn't expect readers to buy it, just wanted to communicate that that's how it's from my own perspective.
You're right. I'll edit the post.
Considerations on intelligence of wild orcas vs captive orcas
I've updated to thinking it's relatively likely that wild orcas are significantly smarter than captive orcas, because (1) wild orcas might learn proper language and captive orcas don't, and (2) generally orcas don't have much to learn in captivity, causing their brains to be underdeveloped.
Here are the most relevant observations:
- Observation 1: (If I analyzed the data correctly and the data is correct,) all orcas currently alive in captivity have been either born in captivity or captured when they were at most 3-4 years old.[1] I think there never were any captive orcas that survived for more than a few months that were not captured at <7 years age, but not sure. (EDIT: Namu (the first captive orca) was ~10y, but he died after a year. Could be that I missed more cases where older orcas survived.)
- Observation 2: (Less centrally relevant, but included for completeness:) It takes young orcas ca 1.5 years until the calls they vocalize aren't easily distinguishable from calls of other orcas by orca researchers. (However, as mentioned in the OP, it's possible the calls are only used for long distance communication and orcas have a more sophisticated language at higher frequencies.)
- Ovservation 3: Orcas in captivity don't get much stimulation.
- Observation 4: Genie[2]. Summary from claude-3.7[3]:
- Genie, discovered in 1970 at age 13, was a victim of extreme abuse and isolation who spent her formative years confined to a small room with minimal human interaction. Despite intensive rehabilitation efforts following her rescue, Genie's cognitive impairments proved permanent. Her IQ remained in the moderate intellectual disability range, with persistent difficulties in abstract reasoning, spatial processing, and problem-solving abilities.
Her language development, while showing some progress, remained severely limited. She acquired a vocabulary of several hundred words and could form basic sentences, but never developed proper grammar or syntax. This case provides evidence for the critical period hypothesis of language acquisition, though it's complicated by the multiple forms of deprivation she experienced simultaneously.
Genie's case illustrates how early environmental deprivation can cause permanent cognitive and linguistic deficits that resist remediation, even with extensive intervention and support.
Inferences:
- If orcas need input from cognitively well-developed orcas (or richer environmental stimulation) for becoming cognitively well-developed, no orca in captivity became cognitively well-developed.
- Captive orcas could be cognitively impaired roughly similarly to how Genie was. Of course, there might have been other factors contributing to the disability of Genie, but it seems likely that abstract intelligence isn't just innate but also requires stimulation for being learned.
(Of course, it's possible that wild orcas don't really learn abstract reasoning either, and instead just hunting or so.)
- ^
Can be checked from table here. (I checked it a few months ago and I think back then there was another "(estimated) birthdate" column which made the checking easier (rather than calculating from "age"), but possible I misremember.)
- ^
Content warning: The "Background" section describes heavy abuse.
- ^
When asking claude for more examples, it wrote:
Romanian Orphanage Studies
Children raised in severely understaffed Romanian orphanages during the Ceaușescu era showed lasting deficits:
- Those adopted after age 6 months showed persistent cognitive impairments
- Later-adopted children (after age 2) showed more severe and permanent deficits
- Brain scans revealed reduced brain volume and activity that persisted into adolescence
- Cognitive impairments correlated with duration of institutionalization
The Bucharest Early Intervention Project
This randomized controlled study followed institutionalized children who were either:
- Placed in foster care at different ages, or
- Remained in institutional care
Key findings:
- Children placed in foster care before age 2 showed significant cognitive recovery
- Those placed after age 2 showed persistent IQ deficits despite intervention
- Executive functioning deficits remained even with early intervention
Isolated Cases: Isabelle and Victor
- Isabelle: Discovered at age 6 after being isolated with her deaf-mute mother, showed initial severe impairments but made remarkable recovery with intervention, demonstrating that recovery is still possible before age 6-7
- Victor (the "Wild Boy of Aveyron"): Found at approximately age 12, made limited progress despite years of dedicated intervention, similar to Genie
Of course, it's possible there's survivorship bias and actually a larger fraction recover. It's also possible that cognitive deficits are rather due to malnurishment or so.
Seems totally unrelated to my post but whatever:
My p(this branch of humanity won't fulfill the promise of the night sky) is actually more like 0.82 or sth, idk. (I'm even lower on p(everyone will die), because there might be superintelligences in other branches that acausally trade to save the existing lives, though I didn't think about it carefully.)
I'm chatting 1 hour every 2 weeks with Erik Jenner. We usually talk about AI safety stuff. Otherwise also like 1h every 2 weeks with a person who has sorta similar views to me. Otherwise I currently don't talk much to people about AI risk.
ok edited to sun. (i used earth first because i don't know how long it will take to eat the sun, whereas earth seems likely to be feasible to eat quickly.)
(plausible to me that an aligned AI will still eat the earth but scan all the relevant information out of it and later maybe reconstruct it.)
ok thx, edited. thanks for feedback!
(That's not a reasonable ask, it intervenes on reasoning in a way that's not an argument for why it would be mistaken. It's always possible a hypothesis doesn't match reality, that's not a reason to deny entertaining the hypothesis, or not to think through its implications. Even some counterfactuals can be worth considering, when not matching reality is assured from the outset.)
Yeah you can hypothesize. If you state it publicly though, please make sure to flag it as hypothesis.
How long until the earth gets eaten? 10th/50th/90th percentile: 3y, 12y, 37y.
Catastrophes induced by narrow capabilities (notably biotech) can push it further, so this might imply that they probably don't occur.
No it doesn't imply this, I set this disclaimer "Conditional on no strong governance success that effectively prevents basically all AI progress, and conditional on no huge global catastrophe happening in the meantime:". Though yeah I don't particularly expect those to occur.
Will we get to this point by incremental progress that yields smallish improvements (=slow), or by some breakthrough that when scaled up can rush past the human intelligence level very quickly (=fast)?
AI speed advantage makes fast vs. slow ambiguous, because it doesn't require AI getting smarter in order to make startlingly fast progress, and might be about passing a capability threshold (of something like autonomous research) with no distinct breakthroughs leading up to it (by getting to a slightly higher level of scaling or compute efficiency with some old technique).
Ok yeah I think my statement is conflating fast-vs-slow with breakthrough-vs-continuous, though I think there's a correlation.
(I still think fast-vs-slow makes sense as concept separately and is important.)
My AI predictions
(I did not carefully think about my predictions. I just wanted to state them somewhere because I think it's generally good to state stuff publicly.)
(My future self will not necessarily make similar predictions as I am now.)
TLDR: I don't know.
Timelines
Conditional on no strong governance success that effectively prevents basically all AI progress, and conditional on no huge global catastrophe happening in the meantime:
How long until the sun (starts to) get eaten? 10th/50th/90th percentile: 3y, 12y, 37y.
How long until an AI reaches Elo 4000 on codeforces? 10/50/90: 9mo, 2.5y, 11.5y
How long until an AI is better at math research than the best human mathmatician according to the world's best mathematicians? 10/50/90: 2y, 7.5y, 28y
Takeoff Speed
- I'm confident (94%) that it is easier to code an AI on a normal 2020 laptop that can do Einstein-level research at 1000x speed, than it is to solve the alignment problem very robustly[1].[2]
- AIs might decide not to implement the very efficient AGIs in order to scale safer and first solve their alignment problem, but once a mind has solved the alignment problem very robustly, I expect everything to go extremely quickly.
- However, the relevant question is how fast AI will get smarter shortly before the point where ze[3] becomes able to solve the alignment problem (or alternatively until ze decides making itself smarter quickly is too risky and it should cooperate with humanity and/or other similarly smart AIs currently being created to solve alignment).
- So the question is: Will we get to this point by incremental progress that yields smallish improvements (=slow), or by some breakthrough that when scaled up can rush past the human intelligence level very quickly (=fast)?
- I'm very tentatively leaning more towards the "fast" side, but i don't know.
- I'd expect (80%) to see at least one more paradigm shift that is at least as big as the one from LSTMs to transformers. It's plausible to me that the results from the shift will come faster because we have greater computer overhang. (Though also possible it will just take even more compute.)
- It's possible (33%) that the world ends within 1 year of a new major discovery[4]. It might just very quickly improve inside a lab over the course of weeks without the operators there really realizing it[5], until it then sectretly exfiltrates itself, etc.
- (Btw, smart people who can see the dangerous implications of some papers proposing something should obviously not publicly point to stuff that looks dangerous (else other people will try it).)
- It's possible (33%) that the world ends within 1 year of a new major discovery[4]. It might just very quickly improve inside a lab over the course of weeks without the operators there really realizing it[5], until it then sectretly exfiltrates itself, etc.
- So the question is: Will we get to this point by incremental progress that yields smallish improvements (=slow), or by some breakthrough that when scaled up can rush past the human intelligence level very quickly (=fast)?
- ^
Hard to define what I mean by "very robustly", but sth like "having coded an AI program s.t. a calibrated mind would expect <1% of expected value loss if run, compared to the ideal CEV aligned superintelligence".
- ^
I acknowledge this is a nontrivial claim. I probably won't be willing to invest the time to try to explain why if someone asks me now. The inferential distance is quite large. But you may ask.
- ^
ze is the AI pronoun.
- ^
Tbc, not 33% after the first major discovery after transformers, just after any.
- ^
E.g. because the AI is in a training phase and only interacts with operators sometimes where it doesn't tell them everything. And in AI training the AI practices solving lots and lots of research problems and learns much more sample-efficient than transformers.
Here's my current list of lessons for review. Every day during my daily review, I look at the lessons in the corresponding weekday entry and the corresponding day of the month, and for each list one example from the last week where I could've applied the lesson, and one example where I might be able to apply the lesson in the next week:
- Mon
- get fast feedback. break tasks down into microtasks and review after each.
- Tue
- when surprised by something or took long for something, review in detail how you might've made the progress faster.
- clarify why the progress is good -> see properties you could've paid more attention to
- Wed
- use deliberate practice. see what skills you want to learn, break them down into clear subpieces, and plan practicing the skill deliberately.
- don't start too hard. set feasible challenges.
- make sure you can evaluate how clean execution of the skill would look like.
- Thu
- Hold off on proposing solutions. first understand the problem.
- gather all relevant observations
- clarify criteria a good result would have
- clarify confusions that need to be explained
- Fri
- Taboo your words: When using confusing abstract words, taboo them and rephrase to show underlying meaning.
- When saying something general, make an example.
- Sat
- separate planning from execution. first clarify your plan before executing it.
- for planning, try to extract the key (independent) subproblems of your problem.
- Sun
- only do what you must do. always know clearly how a task ties into your larger goals all the way up.
- don't get sidetracked by less than maximum importance stuff.
- delegate whatever possible.
- when stuck/stumbling: imagine you were smarter. What would a keeper do?
- when unmotivated: remember what you are fighting for
- be stoic. be motivated by taking the right actions. don't be pushed down when something bad happens, just continue making progress.
- when writing something to someone, make sure you properly imagine how it will read like from their perspective.
- clarify insights in math
- clarify open questions at the end of a session
- when having an insight, sometimes try write a clear explanation. maybe send it to someone or post it.
- periodically write out big picture of your research
- tackle problems in the right context. (e.g. tackle hard research problems in sessions not on walks)
- don't apply effort/force/willpower. take a break if you cannot work naturally. (?)
- rest effectively. take time off without stimulation.
- always have at least 2 hypotheses (including plans as hypotheses about what is best to do).
- try to see how the searchspace for a problem looks like. What subproblems can be solved roughly independently? What variables are (ir)relevant? (?)
- separate meta-instructions and task notes from objective level notes (-> split obsidian screen)
- first get hypotheses for specific cases, and only later generalize. first get plans for specific problems, and only later generalize what good methodology is.
- when planning, consider information value. try new stuff.
- experiment whether you can prompt AIs in ways to get useful stuff out. (AIs will only become better.)
- don't suppress parts of your mind. notice when something is wrong. try to let the part speak. apply focusing.
- Relinquishment. Lightness. Evenness. Notice when you're falling for motivated reasoning. Notice when you're attached to a belief.
- Beware confirmation bias. Consider cases where you could've observed evidence but didn't.
- perhaps do research in sprints. perhaps disentangle from phases where i do study/practice/orga. (?)
- do things properly or not at all.
- try to break your hypotheses/models. look for edge cases.
- often ask why i believe something -> check whether reasoning is valid (->if no clear reason ask whether true at all)
- (perhaps schedule practice where i go through some nontrivial beliefs)
- think what you actually expect to observe, not what might be a nice argument/consideration to tell.
- test hypotheses as quickly as you can.
- notice (faint slimmers of) confusions. notice imperfect understanding.
- notice mysterious answers. when having a hypothesis check how it constrains your predictions.
- beware positive bias. ask what observations your hypothesis does NOT permit and check whether such a case might be true.
Thank you for your feedback! Feedback is great.
We can try to select for AIs that outwardly seem friendly, but on anything close to our current ignorance about their cognition, we cannot be nearly confident that an AI going through the intelligence explosion will be aligned to human values.
It means that we have only very little understanding of how and why AIs like ChatGPT work. We know almost nothing about what's going on inside them that they are able to give useful responses. Basically all I'm saying here is that we know so little that it's hard to be confident of any nontrivial claim about future AI systems, including that they are aligned.
A more detailed argument for worry would be: We are restricted to training AIs through giving feedback on their behavior, and cannot give feedback on their thoughts directly. For almost any goal an AI might have, it is in the interest of the AI to do what the programmers want it to do, until it is robustly able to escape and without being eventually shut down (because if it does things people don't like while it is not yet powerful enough, people will effectively replace it with another AI which will then likely have different goals, and thus this ranks worse according to the AI's current goals). Thus, we basically cannot behaviorally distinguish friendly AIs from unfriendly AIs, and thus training for friendly behavior won't select for friendly AIs. (Except in the early phases where the AIs are still so dumb that they cannot realize very simple instrumental strategies, but just because a dumb AI starts out with some friendly tendencies, doesn't mean this friendliness will generalize to the grown-up superintelligence pursuing human values. E.g. there might be some other inner optimizers with other values cropping up during later training.)
(An even more detailed introduction would try to concisely explain why AIs that can achieve very difficult novel tasks will be optimizers, aka trying to achieve some goal. But empirically it seems like this part is actually somewhat hard to explain, and I'm not going to write this now.)
It would then go about optimizing the lightcone according to its values
"lightcone" is an obscure term, and even within Less Wrong I don't see why the word is clearer than using "the future" or "the universe". I would not use the term with a lay audience.
Yep, true.
Here's my pitch for very smart young scientists for why "Rationality from AI to Zombies" is worth reading:
The book "Rationality: From AI to Zombies" is actually a large collection of blogposts, which covers a lot of lessons on how to become better at reasoning. It also has a lot of really good and useful philosophy, for example about how Bayesian updating is the deeper underlying principle of how science works.
But let me express in more detail why I think "Rationality: A-Z" is very worth reading.
Human minds are naturally bad at deducing correct beliefs/theories. People get attached to their pet theories and fall for biases like motivated reasoning and confirmation bias. This is why we need to apply the scientific method and seek experiments that distinguish which theory is correct. If the final arbiter of science was argument instead of experiment, science would likely soon degenerate into politics-like camps without making significant progress. Human minds are too flawed to arrive at truth from little evidence, and thus we need to wait for a lot of experimental evidence to confirm a theory.
Except that sometimes, great scientists manage to propose correct theories in the absence of overwhelming scientific evidence. The example of Einstein, and in particular his discovery of general relativity, especially stands out here. I assume you are familiar with Einstein's discoveries, so I won't explain one here.
How did Einstein do it? It seems likely that he intuitively (though not explicitly) had realized some principles for how to reason well without going astray.
"Rationality: From AI to Zombies" tries to communicate multiple such principles (not restricted to what Einstein knew, though neither including all of Einstein's intuitive insights). The author looked at where people's reasoning (both in science and everyday life) had gone astray, asked how one could've done better, and generalized out a couple of principles that would have allowed them to avoid their mistakes if they had properly understood them.
I would even say it is the start of something like "the scientific method v2.0", which I would call "Bayesian rationality".
The techniques of Bayesian rationality are a lot harder to master than the techniques of normal science. One has to start out quite smart to internalize the full depth of the lessons, and to be able to further develop the art starting from that basis.
(Btw, in case this motivates someone to read it: I recommend starting with reading chapters N until T (optionally skipping the quantum physics sequence) and then reading the rest from A to Z. (Though read the preface first.))
Here's my 230 word pitch for why existential risk from AI is an urgent priority, intended for smart people without any prior familiarity with the topic:
Superintelligent AI may be closer than it might seem, because of intelligence explosion dynamics: When an AI becomes smart enough to design an even smarter AI, the smarter AI will be even smarter and can design an even smarter AI probably even faster, and so on with the even smarter AI, etc. How fast such a takeoff would be and how soon it might occur is very hard to predict though.
We currently understand very little about what is going on inside current AIs like ChatGPT. We can try to select for AIs that outwardly seem friendly, but on anything close to our current ignorance about their cognition, we cannot be nearly confident that an AI going through the intelligence explosion will be aligned to human values.
Human values are quite a tiny subspace in the space of all possible values. If we accidentally create superintelligence which ends up not aligned to humans, it will likely have some values that seem very alien and pointless to us. It would then go about optimizing the lightcone according to its values, and because it doesn’t care about e.g. there being happy people, the configurations which are preferred according to the AI’s values won’t contain happy people. And because it is a superintelligence, humanity wouldn’t have a chance at stopping it from disassembling earth and using the atoms according to its preferences.
I have a binary distinction that is a bit different from the distinction you're drawing here. (Where tbc one might still draw another distinction like you do, but this might be relevant for your thinking.) I'll make a quick try to explain it here, but not sure whether my notes will be sufficient. (Feel free to ask for further clarification. If so ideally with partial paraphrases and examples where you're unsure.)
I distinguish between objects and classes:
- Objects are concrete individual things. E.g. "your monitor", "the meeting you had yesterday", "the German government".
- A class is a predicate over objects. E.g. "monitor", "meeting", "government".
The relationship between classes and objects is basically like in programming. (In language we can instantiate objects from classes through indicators like "the", "a", "every", "zero", "one", ..., plural "-s" inflection, prepended posessive "'s", and perhaps a few more. Though they often only instantiates objects if it is in the subject position. In the object position some of those keywords have a bit of a different function. I'm still exploring details.)
In language semantics the sentence "Sally is a doctor." is often translated to the logic representation "doctor(Sally)", where "doctor" is a predicate and "Sally" is an object / a variable in our logic. From the perspective of a computer it might look more like adding a statement "P_1432(x_5343)" to our pool of statements believed to be true.
We can likewise say "The person is a doctor" in which case "The person" indicates some object that needs to be inferred from the context, and then we again apply the doctor predicate to the object.
The important thing here is that "doctor" and "Sally"/"the person" have different types. In formal natural language semantics "doctor" has type <e,t> and "Sally" has type "e". (For people interested in learning about semantics, I'd recommend this excellent book draft.[1])
There might still be some edge cases to my ontology here, and if you have doubts and find some I'd be interested in exploring those.
Whether there's another crisp distinction between abstract classes (like "market") and classes that are less far upstream from sensory perceptions (like "tree") is a separate question. I don't know whether there is, though my intuition would be leaning towards no.
- ^
I only read chapters 5-8 so far. Will read the later ones soon. I think for the people familiar with CS the first 4 chapters can be safely skipped.
The meta problem of consciousness is about explaining why people think they are conscious.
Even if we get such a result with AIs where AIs invent a concept like consciousness from scratch, that would only tell us that they also think they have sth that we call consciousness, but not yet why they think this.
That is, unless we can somehow precisely inspect the cognitive thought processes that generated the consciousness concept in AIs, which on anything like the current paradigm we won't be.
Another way to frame it: Why would it matter that an AI invents the concept of consciousness, rather than another human? Where is the difference that lets us learn more about the hard/meta problem of consciousness in the first place?
Separately, even if we could analyze the thought processes of AIs in such a case so we would solve the meta problem of consciousness by seeing explanations of why AIs/people talk about consciousness the way they do, that doesn't mean you already have solved the meta-problem of consciousness now.
Aka just because you know it's solvable doesn't mean you're done. You haven't solved it yet. Just like the difference between knowing that general relativity exists and understanding the theory and math.
Applications (here) start with a simple 300 word expression of interest and are open until April 15, 2025. We have plans to fund $40M in grants and have available funding for substantially more depending on application quality.
Did you consider to instead commit to giving out retroactive funding for research progress that seems useful?
Aka that people could apply for funding for anything done from 2025, and then you can actually better evaluate how useful some research was, rather than needing to guess in advance how useful a project might be. And in a way that quite impactful results can be paid a lot, so you don't disincentivize low-chance-high-reward strategies. And so we get impact market dynamics where investors can fund projects in exchange for a share of the retroactive funding in case of success.
There are difficulties of course. Intuitively this retroactive approach seems a bit more appealing to me, but I'm basically just asking whether you considered it and if so why you didn't go with it.
Applications (here) start with a simple 300 word expression of interest and are open until April 15, 2025. We have plans to fund $40M in grants and have available funding for substantially more depending on application quality.
Side question: How much is Openphil funding LTFF? (And why not more?)
(I recently got an email from LTFF which suggested that they are quite funding constraint. And I'd intuitively expect LTFF to be higher impact per dollar than this, though I don't really know.)
I created an obsidian Templater template for the 5-minute version of this skill. It inserts the following list:
- how could I have thought that faster?
- recall - what are key takeaways/insights?
- trace - what substeps did I do?
- review - how could one have done it (much) faster?
- what parts were good?
- where did i have wasted motions? what mistakes did i make?
- generalize lesson - how act in future?
- what are example cases where this might be relevant?
Here's the full template so it inserts this at the right level of indentation. (You can set a shortcut for inserting this template. I use "Alt+h".)
<% "\t".repeat(tp.file.content.split("\n")[app.workspace.activeLeaf?.view?.editor.getCursor().line].match(/^\t*/)[0].length) + "- how could I have thought that faster?" %>
<% "\t".repeat(tp.file.content.split("\n")[app.workspace.activeLeaf?.view?.editor.getCursor().line].match(/^\t*/)[0].length + 1) + "- recall - what are key takeaways/insights?" %>
<% "\t".repeat(tp.file.content.split("\n")[app.workspace.activeLeaf?.view?.editor.getCursor().line].match(/^\t*/)[0].length + 2) + "- " %>
<% "\t".repeat(tp.file.content.split("\n")[app.workspace.activeLeaf?.view?.editor.getCursor().line].match(/^\t*/)[0].length + 1) + "- trace - what substeps did I do?" %>
<% "\t".repeat(tp.file.content.split("\n")[app.workspace.activeLeaf?.view?.editor.getCursor().line].match(/^\t*/)[0].length + 2) + "- " %>
<% "\t".repeat(tp.file.content.split("\n")[app.workspace.activeLeaf?.view?.editor.getCursor().line].match(/^\t*/)[0].length + 1) + "- review - how could one have done it (much) faster?" %>
<% "\t".repeat(tp.file.content.split("\n")[app.workspace.activeLeaf?.view?.editor.getCursor().line].match(/^\t*/)[0].length + 2) + "- " %>
<% "\t".repeat(tp.file.content.split("\n")[app.workspace.activeLeaf?.view?.editor.getCursor().line].match(/^\t*/)[0].length + 2) + "- what parts were good?" %>
<% "\t".repeat(tp.file.content.split("\n")[app.workspace.activeLeaf?.view?.editor.getCursor().line].match(/^\t*/)[0].length + 2) + "- where did i have wasted motions? what mistakes did i make?" %>
<% "\t".repeat(tp.file.content.split("\n")[app.workspace.activeLeaf?.view?.editor.getCursor().line].match(/^\t*/)[0].length + 1) + "- generalize lesson - how act in future?" %>
<% "\t".repeat(tp.file.content.split("\n")[app.workspace.activeLeaf?.view?.editor.getCursor().line].match(/^\t*/)[0].length + 2) + "- " %>
<% "\t".repeat(tp.file.content.split("\n")[app.workspace.activeLeaf?.view?.editor.getCursor().line].match(/^\t*/)[0].length + 2) + "- what are example cases where this might be relevant?" %>