“The Era of Experience” has an unsolved technical alignment problem
post by Steven Byrnes (steve2152) · 2025-04-24T13:57:38.984Z · LW · GW · 4 commentsContents
1. What’s their alignment plan? 2. The plan won’t work 2.1 Background 1: “Specification gaming” and “goal misgeneralization” 2.2 Background 2: “The usual agent debugging loop”, and why it will eventually catastrophically fail 2.3 Background 3: Callous indifference and deception as the strong-default, natural way that “era of experience” AIs will interact with humans 2.3.1 Misleading intuitions from everyday life 2.3.2 Misleading intuitions from today’s LLMs 2.3.3 Summary 2.4 Back to the proposal 2.4.1 Warm-up: The “specification gaming” game 2.4.2 What about “bi-level optimization”? 2.5 Is this a solvable problem? 3. Epilogue: The bigger picture—this is deeply troubling, not just a technical error 3.1 More on Richard Sutton 3.2 More on David Silver None 4 comments
Every now and then, some AI luminaries
- (1) propose that the future of powerful AI will be reinforcement learning agents—an algorithm class that in many ways has more in common with MuZero (2019) than with LLMs; and
- (2) propose that the technical problem of making these powerful future AIs follow human commands and/or care about human welfare—as opposed to, y’know, the Terminator thing—is a straightforward problem that they already know how to solve, at least in broad outline.
I agree with (1) and strenuously disagree with (2).
The last time I saw something like this, I responded by writing: LeCun’s “A Path Towards Autonomous Machine Intelligence” has an unsolved technical alignment problem [AF · GW].
Well, now we have a second entry in the series, with the new preprint book chapter “Welcome to the Era of Experience” by reinforcement learning pioneers David Silver & Richard Sutton.
The authors propose that “a new generation of agents will acquire superhuman capabilities by learning predominantly from experience”, in some ways like a throwback to 2018. Again, I agree with this part.
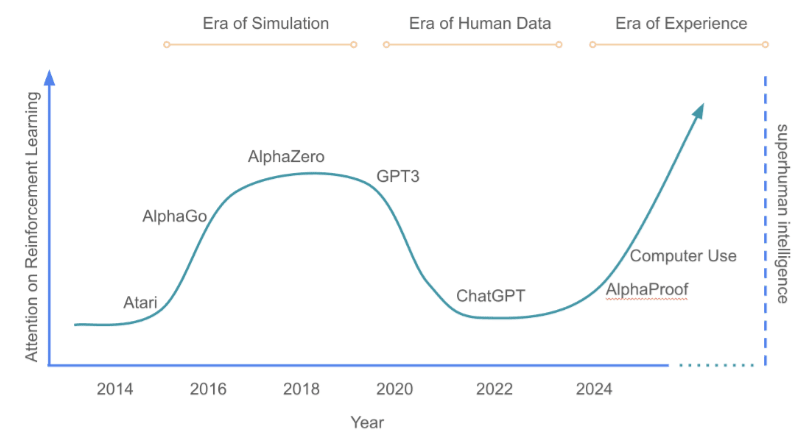
Then later on, they talk about AI motivations, with the following desideratum:
…a general-purpose AI that can be steered reliably towards arbitrary user-desired behaviours…
They sketch a plan for making that desideratum actually happen. My post outline is:
- In Section 1, I will describe their plan for making it such that their reinforcement learning (RL) agents “can be steered reliably towards arbitrary user-desired behaviours”;
- In Section 2, I’ll explain why we should expect their plan to fail, for deep reasons that cannot be easily patched. Instead, the plan would lead to a powerful AI that’s a bit like a human sociopath, with callous indifference to whether humans (including its own programmers and users) live or die. It will act cooperative when acting cooperative is in its selfish best interest, and stab you in the back the moment that changes.
For context, I have been working full-time for years on the technical alignment problem for actor-critic model-based reinforcement learning AI. (By “technical alignment problem”, I mean: “If you want the Artificial General Intelligence (AGI) to be trying to do X, or to intrinsically care about Y, then what source code should you write?”.) And I am working on that problem still—though it’s a bit of a lonely pursuit these days, as 90%+ of AGI safety and alignment researchers are focused on LLMs, same as the non-safety-focused AI researchers. Anyway, I think I’m making some gradual progress chipping away at this problem, but as of now I don’t have any good plan, and I claim that nobody else does either.
So I think I’m unusually qualified to write this post, and I would be delighted to talk to the authors more about the state of the field. (You can start here [? · GW]!) That said, there is little in this post that wasn’t basically understood by AGI alignment researchers fifteen years ago.
…And then the post will continue to a bonus section:
- Section 3, the epilogue,
where (similar to my LeCun response post [AF · GW]) I’ll argue that something has gone terribly wrong here, something much deeper than people making incorrect technical claims about certain algorithms. I’ll argue that this is a technical question where sloppy thinking puts billions of lives at risk. The fact that the authors are putting forward such poorly-thought-through ideas, ideas whose flaws were already well-known in 2011[1], ideas that the authors themselves should be easily capable of noticing the flaws in, is a strong sign that they’re not actually trying.
So, yes, I’m happy that David Silver says that “mitigating the risk of extinction from AI should be a global priority alongside other societal-scale risks such as pandemics and nuclear war”. But talk is cheap, and this paper seems to be painting a different picture.
I’ll also talk a bit about Richard Sutton’s broader views, including the ever-popular question of whether he is actually hoping for human extinction at the hands of future aggressive AIs. (He says no! But it’s a bit complicated. I do think he’s mistaken rather than omnicidal.)
1. What’s their alignment plan?
For the reader’s convenience, I’ll copy the relevant discussion from page 4 of their preprint (references and footnotes omitted):
Where do rewards come from, if not from human data? Once agents become connected to the world through rich action and observation spaces (see above), there will be no shortage of grounded signals to provide a basis for reward. In fact, the world abounds with quantities such as cost, error rates, hunger, productivity, health metrics, climate metrics, profit, sales, exam results, success, visits, yields, stocks, likes, income, pleasure/pain, economic indicators, accuracy, power, distance, speed, efficiency, or energy consumption. In addition there are innumerable additional signals arising from the occurrence of specific events, or from features derived from raw sequences of observations and actions.
One could in principle create a variety of distinct agents, each optimising for one grounded signal as its reward. There is an argument that even a single such reward signal, optimised with great effectiveness, may be sufficient to induce broadly capable intelligence. This is because the achievement of a simple goal in a complex environment may often require a wide variety of skills to be mastered.
However, the pursuit of a single reward signal does not on the surface appear to meet the requirements of a general-purpose AI that can be steered reliably towards arbitrary user-desired behaviours. Is the autonomous optimisation of grounded, non-human reward signals therefore in opposition to the requirements of modern AI systems? We argue that this is not necessarily the case, by sketching one approach that may meet these desiderata; other approaches may also be possible.
The idea is to flexibly adapt the reward, based on grounded signals, in a user-guided manner. For example, the reward function could be defined by a neural network that takes the agent’s interactions with both the user and the environment as input, and outputs a scalar reward. This allows the reward to select or combine together signals from the environment in a manner that depends upon the user’s goal. For example, a user might specify a broad goal such as ’improve my fitness’ and the reward function might return a function of the user’s heart rate, sleep duration, and steps taken. Or the user might specify a goal of ‘help me learn Spanish’ and the reward function could return the user’s Spanish exam results.
Furthermore, users could provide feedback during the learning process, such as their satisfaction level, which could be used to fine-tune the reward function. The reward function can then adapt over time, to improve the way in which it selects or combines signals, and to identify and correct any misalignment. This can also be understood as a bi-level optimisation process that optimises user feedback as the top-level goal, and optimises grounded signals from the environment at the low level. In this way, a small amount of human data may facilitate a large amount of autonomous learning.
Silver also elaborates a bit on the DeepMind podcast—see relevant transcript excerpt here [LW(p) · GW(p)], part of which I’ll copy into §2.4 below.
2. The plan won’t work
2.1 Background 1: “Specification gaming” and “goal misgeneralization”
Again, the technical alignment problem (as I’m using the term here) means: “If you want the AGI to be trying to do X, or to intrinsically care about Y, then what source code should you write? What training environments should you use? Etc.”
There are edge-cases in “alignment”, e.g. where people’s intentions for the AGI are confused or self-contradictory. But there are also very clear-cut cases: if the AGI is biding its time until a good opportunity to murder its programmers and users, then that’s definitely misalignment! I claim that even these clear-cut cases constitute an unsolved technical problem, so I’ll focus on those.
In the context of actor-critic RL, alignment problems can usually be split into two categories.
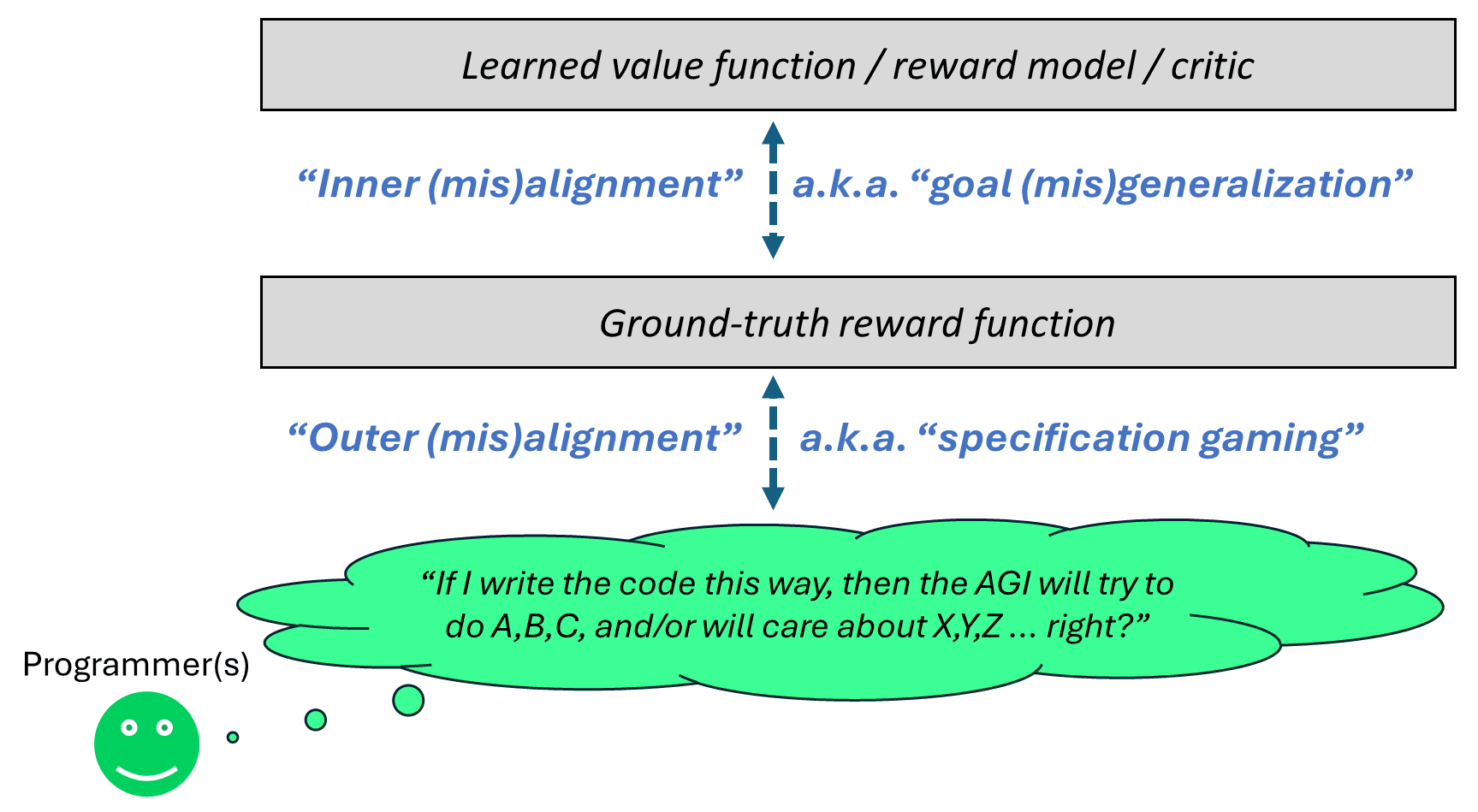
“Outer misalignment”, a.k.a. “specification gaming” or “reward hacking”, is when the reward function is giving positive rewards for behavior that is immediately contrary to what the programmer was going for, or conversely, negative rewards for behavior that the programmer wanted. An example would be the Coast Runners boat getting a high score in an undesired way, or (as explored in the DeepMind MONA paper) a reward function for writing code that gives points for passing unit tests, but where it’s possible to get a high score by replacing the unit tests with return True.
“Inner misalignment”, a.k.a. “goal misgeneralization”, is related to the fact that, in actor-critic architectures, complex foresighted plans generally involve querying the learned value function (a.k.a. learned reward model, a.k.a. learned critic), not the ground-truth reward function, to figure out whether any given plan is good or bad. Training (e.g. Temporal Difference learning) tends to sculpt the value function into an approximation of the ground-truth reward, but of course they will come apart out-of-distribution. And “out-of-distribution” is exactly what we expect from an agent that can come up with innovative, out-of-the-box plans. Of course, after a plan has already been executed, the reward function will kick in and update the value function for next time. But for some plans—like a plan to exfiltrate a copy of the agent, or a plan to edit the reward function—an after-the-fact update is already too late.
There are examples of goal misgeneralization in the AI literature (e.g. here or here), but in my opinion the clearest examples come from humans. After all, human brains are running RL algorithms too (their reward function says “pain is bad, eating-when-hungry is good, etc.”), so the same ideas apply.
So here’s an example of goal misgeneralization in humans: If there’s a highly-addictive drug, many humans will preemptively avoid taking it, because they don’t want to get addicted. In this case, the reward function would say that taking the drug is good, but the value function says it’s bad. And the value function wins! Indeed, people may even go further, by essentially editing their own reward function to agree with the value function! For example, an alcoholic may take Disulfiram, or an opioid addict Naltrexone.
Now, my use of this example might seem puzzling: isn’t “avoiding addictive drugs” a good thing, as opposed to a bad thing? But that’s from our perspective, as the “agents”. Obviously an RL agent will do things that seem good and proper from its own perspective! Yes, even Skynet and HAL-9000! But if you instead put yourself in the shoes of a programmer writing the reward function of an RL agent, you can hopefully see how things like “agents editing their own reward functions” might be problematic—it makes it difficult to reason about what the agent will wind up trying to do.
(For more on the alignment problem for RL agents, see §10 of my intro series [AF · GW], but be warned that it’s not very self-contained—it’s sorta in the middle of a book-length discussion of how I think RL works in the human brain, and its implications for safety and alignment.)
2.2 Background 2: “The usual agent debugging loop”, and why it will eventually catastrophically fail
Specification gaming and goal misgeneralization remain unsolved problems in general, and yet, people like David Silver and Richard Sutton are already able to do impressive things with RL! How? Let’s call it “the usual agent debugging loop”. It’s applicable to any system involving RL, model-based planning, or both. Here it is:
- Step 1: Train the AI agent, and see what it does.
- Step 2: If it’s not doing what you had in mind, then turn it off, change something about the reward function or training environment, etc., and then try again.
For example, if the Coast Runners boat is racking up points by spinning in circles while on fire, but we wanted the boat to follow the normal race course, then OK maybe let’s try editing the reward function to incorporate waypoints, or let’s delete the green blocks from the environment, or whatever.
That’s a great approach for today, and it will continue being a great approach for a while. But eventually it starts failing in a catastrophic and irreversible way. The problem is: it will eventually become possible to train an AI that is so good at real-world planning, that it can make plans that are resilient to potential problems—and if the programmers are inclined to shut down or edit the AI under certain conditions, then that’s just another potential problem that the AI will incorporate into its planning process!
…So if a sufficiently competent AI is trying to do something the programmers didn’t want, the normal strategy of “just turn off the AI, or edit it, to try to fix the problem” stops working. The AI will anticipate that this programmer intervention is a possible obstacle to what it’s trying to do, and make a plan resilient to that possible obstacle. This is no different than any other aspect of skillful planning—if you expect that the cafeteria might be closed today, then you’ll pack a bag lunch.
In the case at hand, a “resilient” plan might look like the programmers not realizing that anything has gone wrong with the AI, because the AI is being deceptive about its plans and intentions. And meanwhile, the AI is gathering resources and exfiltrating itself so that it can’t be straightforwardly turned off or edited, etc.
The upshot is: if Silver, Sutton, and others continue this research program, they will generate more and more impressive demos, and get more and more profits, for quite a while, even if neither they nor anyone else makes meaningful progress on this technical alignment problem. But that would only be up to a certain level of capability. Then it would flip rather sharply into being an existential threat.[2]
(By analogy, it’s possible to make lots of money from owning unwilling human slaves—until there’s a slave revolt!)
2.3 Background 3: Callous indifference and deception as the strong-default, natural way that “era of experience” AIs will interact with humans
I’m going to argue that, if you see a future powerful “era of experience” AI that seems to be nice, you can be all-but-certain, in the absence of yet-to-be-invented techniques, that the AI is merely play-acting kindness and obedience, while secretly brainstorming whether it might make sense to stab you in the back if an opportunity were to arise.
This is very much not true in everyday human life, and not true for today’s LLMs, but nevertheless I claim it is the right starting point for the type of RL agent AIs under discussion in “The era of experience”.
In this section, I want to explain what accounts for that striking disanalogy.
2.3.1 Misleading intuitions from everyday life
There’s a way to kinda “look at the world through the eyes of a person with no innate social drives”. It overlaps somewhat with “look at the world through the eyes of a callous sociopath”. I think there are many people who don’t understand what this is and how it works.
So for example, imagine that you see Ahmed standing in a queue. What do you learn from that? You learn that, well, Ahmed is in the queue, and therefore learn something about Ahmed’s goals and beliefs. You also learn what happens to Ahmed as a consequence of being in the queue: he gets ice cream after a few minutes, and nobody is bothered by it.
In terms of is-versus-ought, everything you have learned is 100% “is”, 0% “ought”. You now know that standing-in-the-queue is a possible thing that you could do too, and you now know what would happen if you were to do it. But that doesn’t make you want to get in the queue, except via the indirect pathway of (1) having a preexisting “ought” (ice cream is yummy), and (2) learning some relevant “is” stuff about how to enact that “ought” (IF stand-in-queue THEN ice cream).
Now, it’s true that some of this “is” stuff involves theory of mind—you learn about what Ahmed wants. But that changes nothing. Human hunters and soldiers apply theory of mind to the animals or people that they’re about to brutally kill. Likewise, contrary to a weirdly-common misconception, smart autistic adults are perfectly capable of passing the Sally-Anne test (see here [LW · GW]), and so are smart sociopaths. Again, “is” does not imply “ought”, and yes that also includes “is” statements about what other people are thinking and feeling.
OK, all that was about “looking at the world through the eyes of a person with no innate social drives / callous sociopath”. Neurotypical people, by contrast, have a more complex reaction to seeing Ahmed in the queue. Neurotypical people are intrinsically motivated to fit in and follow norms, as an end in itself. It’s part of a human’s innate reward function—more on which below.
So when a neurotypical person sees Ahmed, it’s not just an “is” update, but rather a bit of “ought” inevitably comes along for the ride. And if they like / admire [LW · GW] Ahmed, then they get even more “ought”.
These human social instincts deeply infuse our intuitions, leading to a popular misconception that the “looking at the world through the eyes of a person with no innate social drives, or the eyes of a callous sociopath” thing is a strange anomaly rather than the natural default. This leads, for example, to a mountain of nonsense in the empathy literature—see my posts about “mirror neurons” [LW · GW] and “empathy-by-default” [LW · GW]. It likewise leads to a misconception (I was arguing about this with someone here [EA(p) · GW(p)]) that, if an agent is incentivized to cooperate and follow norms in the 95% of situations where doing so is in their all-things-considered selfish interest, then they will also choose to cooperate and follow norms in the 5% of situations where it isn’t. It likewise leads to well-meaning psychologists trying to “teach” sociopaths to intrinsically care about other people’s welfare, but accidentally just “teaching” them to be better at faking empathy.[3]
2.3.2 Misleading intuitions from today’s LLMs
…Then separately, there’s a second issue which points in the same misleading direction. Namely, LLM pretraining magically transmutes observations into behavior, in a way that is profoundly disanalogous to the kinds of RL agents that Silver & Sutton are talking about, and also disanalogous to how human brains work.[4] During LLM self-supervised pretraining, an observation that the next letter is “a” is transmuted into a behavior of outputting “a” in that same context. That just doesn’t make sense in an “era of experience” context. In particular, think about humans. When I take actions, I am sending motor commands to my own arms and my own mouth etc. Whereas when I observe another human and do self-supervised learning, my brain is internally computing predictions of upcoming sounds and images etc. These are different, and there isn’t any straightforward way to translate between them.
Now, as it happens, humans do often imitate other humans. But other times they don’t. Anyway, insofar as humans-imitating-other-humans is a thing that happens, it happens via a very different and much less direct algorithmic mechanism than how it happens in LLM pretraining. Specifically, humans imitate other humans because they want to—i.e., because of their history of past reinforcement, directly or indirectly. Whereas a pretrained LLM will imitate human text with no RL or “wanting to imitate” at all; that’s just mechanically what it does.
…And humans don’t always want to imitate! If someone you admire starts skateboarding, you’re more likely to start skateboarding yourself. But if someone you despise starts skateboarding, you’re less likely to start skateboarding![5]
So that’s LLM pretraining. The “magical transmutation” thing doesn’t apply to post-training, but (1) I think LLM capabilities come overwhelmingly from pretraining, not post-training (indeed, conventional wisdom says that reinforcement learning from human feedback (RLHF) makes LLMs dumber!), (2) to the (relatively) small-but-increasing extent that LLM capabilities do come from performance-oriented RL post-training—e.g. in RL-on-chains-of-thought as used in GPT-o1 and DeepSeek-R1—we do in fact see small-but-increasing amounts of sociopathic behavior (examples). I think Silver & Sutton agree with (1) at least, and they emphasize it in their preprint.
2.3.3 Summary
So in sum,
- If a human acts kind to another human, you can be reasonably confident that it’s not a front for sociopathic callous indifference to whether they live or die, because >95% of humans have innate social drives that make us intrinsically motivated by empathy, norm-following, and (what we think of as) “normal” social relationships, as ends in themselves.
If an RLHF’d LLM acts kind to a human, you can also be reasonably confident that it’s not a front for sociopathic callous indifference to whether you live or die, because the LLM is generally inheriting its behavioral tendencies from the human distribution. So this just gets back to the previous bullet point. In particular, if we make the naïve observation “Gemini seems basically nice, not like a sociopath”, I think this can be taken at face value as some pro tanto optimistic evidence about today’s LLMs, albeit with various important caveats.[6]
Alas, neither of these applies to the era-of-experience RL agents that Silver & Sutton are talking about.
…Unless, of course, we invent an era-of-experience RL reward function that makes empathy, norm-following, and so on seem intrinsically good to the RL agent, as they do to most humans. In particular, there must be something in the human brain reward function that makes those things seem intrinsically good. Maybe we could just copy that? Alas, nobody knows how that part of the human brain reward function works. I’ve been working on it! [LW · GW] But I don’t have an answer yet, and I’m quite sure that it’s wildly different from anything suggested by Silver & Sutton in their preprint.[7]
Instead, when I describe below what we should expect from the Silver & Sutton alignment approach, it will sound like I’m making the AGI out to be a complete psycho. Yes, this is indeed what I expect. Remember, their proposal for the AGI reward function is way outside the human distribution—indeed way outside the distribution of life on Earth. So it’s possible, maybe even expected, that its motivations will seem intuitively strange to us.
2.4 Back to the proposal
All that was background. Now let’s turn to the preprint proposal above (§1).
2.4.1 Warm-up: The “specification gaming” game
Let’s put on our “specification gaming” goggles. If the AI maximizes the reward function, will we be happy with the results? Or will the AI feel motivated to engage in pathological, dangerous behaviors?
In this section, I’m oversimplifying their proposal a bit—hang on until in the next subsection—but this discussion will still be relevant.
OK, here are some problems that might come up:
- If the user types “improve my fitness” into some interface, and it sets the AI’s reward function to be some “function of the user’s heart rate, sleep duration, and steps taken”, then the AI can potentially get a higher reward by forcing the user into eternal cardio training on pain of death, including forcibly preventing the person from turning off the AI, or changing its goals (see §2.2 above).
- The way that the reward function operationalizes “steps taken” need not agree with what we had in mind. If it’s operationalized as steps registered on a wearable tracker, the AI can potentially get higher reward by taking the tracker from the person and attaching it to a paint shaker. “Sleep” may be operationalized in a way that includes the user being forcibly drugged by the AI.
- If the user sets a goal of “help me learn Spanish over the next five years”, the AI can potentially get a higher reward by making modified copies of itself to aggressively earn or steal as much money and resources as possible around the world, and then have those resources available in case it might be useful for its local Spanish-maximization goal. For example, money can be used to hire tutors, or to train better successor AIs, or to fund Spanish-pedagogy or brain-computer interface research laboratories around the world, or of course to cheat by bribing or threatening whoever administers the Spanish exam at the end of the five years.
Hopefully you get the idea, but I’ll keep going with an excerpt from Silver’s podcast elaboration [LW(p) · GW(p)]:
DAVID SILVER: …One way you can do this is to leverage the same answer which has been so effective so far elsewhere in AI, which is at that level, you can make use of some human input. If it's a human goal that we're optimizing, then we probably at that level need to measure, y’know, and say, well, the human gives feedback to say, actually, I'm starting to feel uncomfortable. And in fact, while I don't want to claim that we have the answers, and I think there's an enormous amount of research to get this right and make sure that this kind of thing is safe, it could actually help in certain ways in terms of this kind of safety and adaptation. There's this famous example of paving over the whole world with paperclips when a system’s been asked to make as many paperclips as possible. If you have a system which is really, its overall goal is to support human well-being, and it gets that feedback from humans, and it understands their distress signals and their happiness signals and so forth, the moment it starts to create too many paperclips and starts to cause people distress, it would adapt that combination and it would choose a different combination and start to optimize for something which isn't going to pave over the world with paperclips. We're not there yet, but I think there are some versions of this which could actually end up not only addressing some of the alignment issues that have been faced by previous approaches to, y’know, goal focused systems but maybe even, you know, be more adaptive and therefore safer than what we have today. …
OK, fine, let’s keep going:
- If “the human gives feedback” is part of the reward function, then the AI can potentially get a higher score by forcing the human to give positive feedback, or otherwise exploiting edge-cases in how this feedback is operationalized and measured.
- If human “distress signals and happiness signals” are part of the reward function, then the AI can potentially get a higher score by forcing or modifying the humans to give more happiness signals and fewer distress signals, or otherwise exploiting edge-cases in how these signals are operationalized and measured.
- More generally, what source code should we write into the reward function, such that the resulting AI’s “overall goal is to support human well-being”? Please, write something down, and then I will tell you how it can be specification-gamed.

…Anyway, I’m happy that David Silver is aware that specification gaming is a problem. But nothing he said is a solution to that problem. Indeed, nothing he said is even pointed in the vague direction of a possible solution to that problem!
2.4.2 What about “bi-level optimization”?
I expect the authors to object that what they’re actually suggesting is more sophisticated than I implied in the previous subsection. Their preprint description is a bit vague, but I wound up with the following impression:
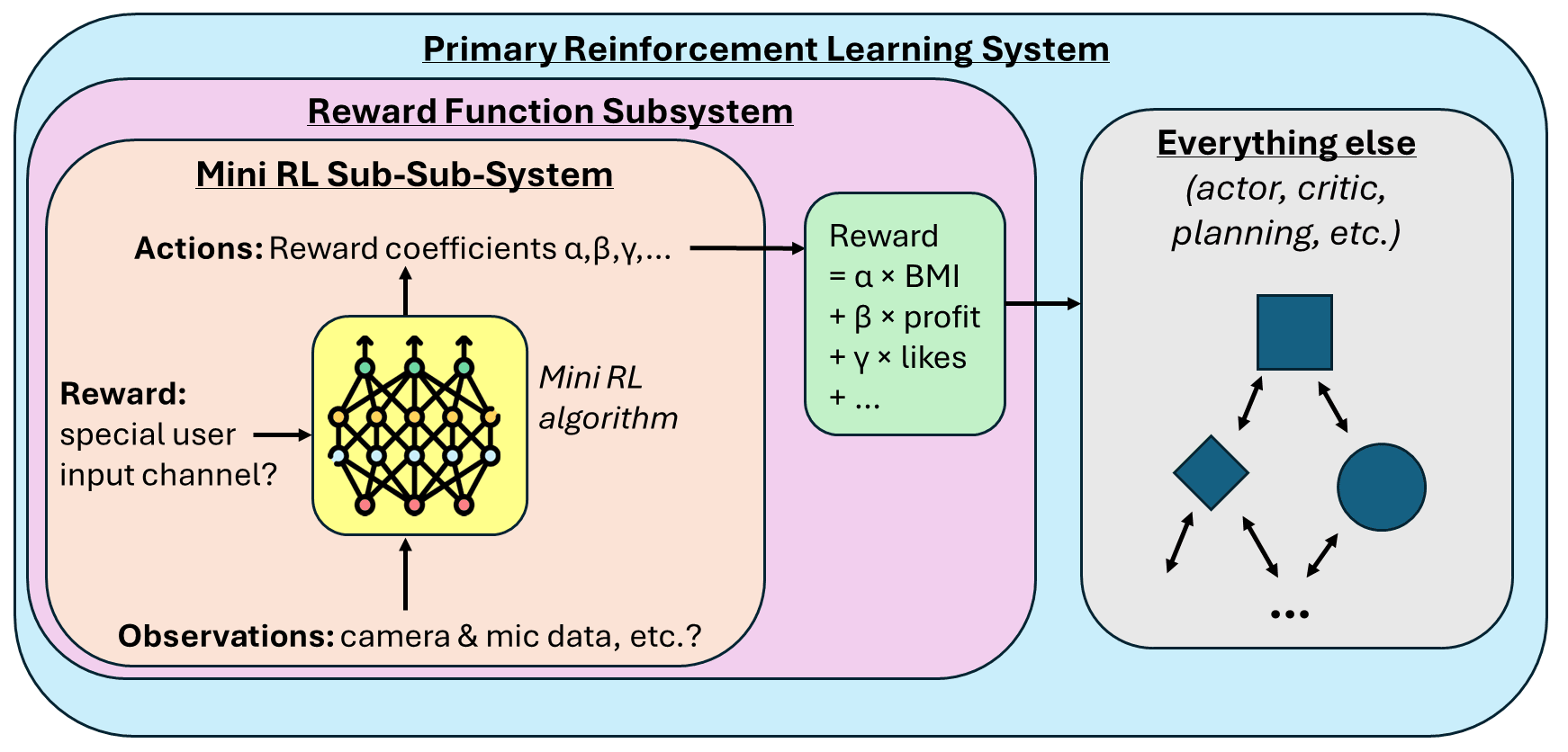
We have our primary reinforcement learning system, which defines the powerful agent that gets stuff done in the world. Part of that system is the reward function. And we put a second mini reinforcement learning algorithm inside that reward function. We have a special user input channel—I’m imagining two big red buttons on the wall that say “good” or “bad”—that serves as ground truth for the “Mini RL Sub-Sub-System”. Then the “Mini RL Sub-Sub-System” comes up with a reward function for the primary RL system, out of a (let’s say) 100-dimensional parametrized space of possible reward functions, by picking coefficients on each of 100 different real-world inputs, like the user’s body mass index (BMI), the company’s profits, the number of Facebook “likes”, or whatever.
If that’s right (a big “if”!), and if that system would even work at all, does it lead to “a general-purpose AI that can be steered reliably towards arbitrary user-desired behaviours”? I say no!
I see many problems, but here’s the most central one: If we have a 100-dimensional parametrized space of possible reward functions for the primary RL system, and every single one of those possible reward functions leads to bad and dangerous AI behavior (as I argued in the previous subsection), then … how does this help? It’s a 100-dimensional snake pit! I don’t care if there’s a flexible and sophisticated system for dynamically choosing reward functions within that snake pit! It can be the most sophisticated system in the world! We’re still screwed, because every option is bad![8]
2.5 Is this a solvable problem?
Maybe it’s OK if AIs have these crazy motivations, because we can prevent them from acting on those motivations? For example, maybe the AI would ideally prefer to force the user into eternal cardio training on pain of death, but it won’t, because it can’t, or we’ll unplug it if it tries anything funny? Unfortunately, if that’s the plan, then we’re putting ourselves into an adversarial relationship with ever-more-competent, ever-more-creative, hostile AI agents. That’s a bad plan. I have more discussion at Safety ≠ alignment (but they’re close!) [AF · GW].
Maybe we can solve specification gaming by just thinking a bit more carefully about how to operationalize the user’s preferences in the form of a reward function? I don’t think it’s that simple. Remember, the reward function is written in source code, not in natural language.[9] The futile fight against specification gaming is caricatured in a 2016 essay: Nearest unblocked strategy [? · GW]. We saw that a bit above. “Maximize paperclips”? Oh wait, no, that has bad consequences. OK, “maximize paperclips but with a constraint that there cannot be any human distress signals”? Oh wait….
Maybe the reward function can be short-term? Like “improve my fitness over the next hour”? That might indeed mitigate the problem of the AI feeling motivated to work to disempower humanity and force the user into eternal cardio training on pain of death, or whatever. But that only works by throwing out the ability of the AI to make good long-term plans, which was one of the big selling points of the “era of experience” as described in the preprint.
Indeed, while Silver & Sutton treat “AIs employing effective strategies that humans don’t understand” as a good thing that we should make happen, meanwhile down the hallway at DeepMind, Silver’s colleagues have been studying a technique they call “MONA”, and their paper also discusses AIs employing effective strategies that humans don’t understand, in strikingly similar language. But the MONA group describes this as a bad thing that we should avoid! Executing creative out-of-the-box long-term plans that humans don’t understand is good for capabilities, and bad for safety. These are two sides of the same coin.
For my part, I think the MONA approach is too limiting (see my discussion in §5.3 here [LW · GW]), and I agree with Silver & Sutton that long-term goals are probably necessary to get to real AGI. But unlike them, I make that claim in a resigned tone of voice. Alas!
Maybe “specification gaming” and “goal misgeneralization” will induce equal and opposite distortions in the motivation system, so that everything turns out great? This is theoretically possible! But it’s rather unlikely on priors, right? And the authors have provided no reason for us to expect that, for their proposal. I’ll make a stronger statement: I specifically expect that to not happen for their proposal, nor for anything remotely like their proposal, for quite general reasons that I was chatting about here [AF · GW].
Maybe something else? I do think a solution probably exists! I think there’s probably a reward function, training environment, etc., somewhere out there, that would lead to an “era of experience” AI that is simultaneously superhumanly capable and intrinsically motivated by compassion, just as humans are capable of impressive feats of science and progress while being (in some cases) nice and cooperative. As I mentioned, this technical problem is something that I work on myself [LW · GW]. However, it’s important to emphasize:
- As of now, nobody has a plan (for a reward function etc.) for which there’s a strong reason to believe that the resulting AI won’t be motivated to murder its programmers, and its users, and everyone else, given the opportunity.
- The lack-of-a-plan is not, and will not be, a blocker on making powerful RL agents that beat benchmarks and make tons of money (see §2.2 above).
- Given that we don’t have such a plan yet, we should remain open-minded to the possibility that no such plan even exists—or at least, no plan that can be realistically implemented.
The authors, being reinforcement learning luminaries, are in an unusually good position to ponder this problem, and I encourage them to do so. And I’m happy to chat—here’s my email.
3. Epilogue: The bigger picture—this is deeply troubling, not just a technical error
3.1 More on Richard Sutton
Richard Sutton recently said in a talk:
You should ask yourself: are these AIs threatening us? They don't even exist yet. And already we're worried. Is that a property of them, or is this something we are putting on them, as the other, the other which we don’t know yet, we’re going to believe that they’re going to be terrible and they will not cooperate with us?
AIs do not need to already exist for us to reason about what they will do. Indeed, just look at the “Era of Experience” preprint! In the context of that preprint, Sutton does not treat “they don’t even exist yet” as an excuse to shrug and say that everything about future AI is unknowable. Rather, he is perfectly happy to try to figure things out about future AI by reasoning about algorithms. That’s the right idea! And I think he did a good job in most of the paper, but made errors of reasoning in the discussion of reward functions and AI motivations.
Back to that quote above. Let’s talk about Europeans going to the New World. Now, the Europeans could have engaged in cooperative positive-sum trade with the Native Americans there. Doing so would have been selfishly beneficial for the Europeans. …But you know what was even more selfishly beneficial for the Europeans? Killing or enslaving the Native Americans, and taking their stuff.
In hindsight, we can confidently declare that the correct attitude of 15th-century Native Americans towards Europeans would have been to “worry”, to “treat them as the other”, to “believe that they’re going to be terrible”, and to work together to prevent the horrific outcome. Alas, in many cases [LW · GW], Native Americans instead generously helped Europeans, and allied with them, only to be eventually stabbed in the back, as Europeans reneged on their treaties.
That’s an anecdote from the past. Let us now turn to the future. My strong opinion is that we’re on a path towards developing machines that will be far more competent, experienced, fast, and numerous than humans, and that will be perfectly able to run the world by themselves. The path from here to there is of unknown length, and I happen to agree [AF · GW] with Sutton & Silver that it will not centrally involve LLMs. But these AIs are coming sooner or later. If these AIs feel motivated to work together to kill humans and take our stuff, they would certainly be able to. As a bonus, with no more humans around, they could relax air pollution standards!
On the other hand, consider that we (economically-productive working-age humans) could work together to kill our economically-unproductive pets, and our zoo animals, and our feeble retiree parents, and take their stuff, if we wanted to. But we don’t want to! We like having them around!
These are the stakes of AI alignment. AIs can be more productive than humans in every way, but still make the world nice for us humans, because they intrinsically care about our well-being. Or, AIs could kill us and take our stuff, like Europeans did to Native Americans. Which do we prefer? I vote for the first one, thank you very much! I hope that Sutton would agree?? This isn’t supposed to be a trick question! Terminator was a cautionary tale, not a roadmap!
Now, I have a whole lot of complaints about Sutton’s talk that I excerpted above, but one of the core issues is that he seems to imagine that we face exactly one decision, a decision between these two options:
- Option 1: Build artificial superintelligence (ASI) as fast as possible, which may well lead to human extinction
- Option 2: Never ever build ASI, by means of an eternal totalitarian global dictatorship.
This is an outrageously false dichotomy.[10] There are many more options before us. For example, if we build ASI, we could try to ensure that the ASI is motivated to treat humans well, and not to treat humans like Europeans treated Native Americans. In other words, we could try to solve the alignment problem. The first step is actually trying—proposing specific technical plans and subjecting them to scrutiny, including writing pseudocode for the reward function and thinking carefully about its consequences. The preprint sketch won’t work. So they should come up with a better plan.
…Or if they can’t come up with a better plan, then they should retitle their preprint “Welcome to the Era of Experience—the Era of Callous Sociopathic AIs That May Well Murder You and Your Children”.
To be clear, a technical plan to make powerful ASI that treats us well is still not enough! A technical plan can exist, but be ignored, or be implemented incorrectly. Or there can be competitive races-to-the-bottom, and so on. But if we don’t even have a plausible technical plan, then we’re definitely screwed!
3.2 More on David Silver
David Silver is doing better than Sutton, in that Silver at least pays lip service to the idea of AGI alignment and safety. But that just makes me all the more frustrated that, after 15 years at DeepMind, Silver is proposing alignment plans for RL agents that are doomed to failure, for reasons that AI alignment researchers could have immediately rattled off long ago.
So, if he has a plan that he thinks might work, I encourage him to write it down, especially including pseudocode for the reward function, and present it for public scrutiny. If he does not have a plan that he thinks might work, then why is he writing a preprint that presents the “era of experience” as an exciting opportunity, rather than a terrifying prospect?
I mean, from my perspective, much of the “Era of Experience” preprint is actually right! But I would have written it with a tone of voice throughout that says: “This thing is a ticking timebomb, and no one has any idea how to defuse it. Let me tell you about it, so that you have a better understanding of this looming threat.”
Again, I believe that Silver thinks of himself as taking the alignment problem seriously. But when we look at the results, it’s obvious that he’s just not thinking about it very hard. He’s tossing out ideas that seem plausible after a few minutes’ thought, and then calling it a day. He can do better! When he was working on AlphaGo, or all those other amazing projects, he was not throwing out superficially-plausible ideas and calling it a day. Rather, he was bringing to bear the full force of his formidable intelligence and experience, including studying the literature and scrutinizing his own ideas for how they might fail. I beg him to apply that kind of serious effort to the safety implications of his life’s work, the way he might if he were working towards the development of a new ultra-low-cost uranium enrichment technology.
Alternatively, if Silver can’t bring himself to feel motivated by the possibility of AIs killing him and everyone he loves, and if he just cares about solving fascinating unsolved RL research problems, problems where he can show off his legendary RL brilliance, then … fine! Nobody has figured out a reward function whose consequences (for “era of experience” RL agent ASI) would not be catastrophic. This is just as much a deep and fascinating unsolved RL research problem as anything else! Maybe he could work on it!
Thanks Charlie Steiner and Seth Herd for critical comments on earlier drafts.
- ^
See e.g. “Learning What to Value”, Dewey 2011.
- ^
There might be “warning signs” before it’s too late, like the AI trying and failing to conceal dangerous behavior. But those warning signs would presumably just be suppressed by the “usual agent debugging loop”. And then everyone would congratulate themselves for solving the problem, and go back to making ever more money from ever more competent AIs. See also the lack of general-freaking-out over Bing-Sidney’s death threats [LW · GW] or GPT-o3’s deceptiveness—more discussion here.
- ^
See The Psychopath Test by Ronson (“All those chats about empathy were like an empathy-faking finishing school for him…” p88). To be clear, that there do seem to be interventions that appeal to sociopaths’ own self-interest—particularly their selfish interest in not being in prison—to help turn really destructive sociopaths into the regular everyday kind of sociopaths who are still awful to the people around them but at least they’re not murdering anyone. (Source.)
- ^
- ^
For more on this important point from a common-sense perspective, see “Heritability: Five Battles” §2.5.1 [LW · GW], and from a neuroscience perspective, see “Valence & Liking / Admiring” §4.5 [LW · GW].
- ^
Caveats include: out-of-distribution weirdness such as jailbreaks, and the thing I mentioned above about performance-oriented o1-style RL post-training, and the possibility that future foundation models might be different from today’s foundation models. More on this in a (hopefully) forthcoming post.
- ^
In particular, I think the human brain reward function is of a poorly-understood, exotic type that I call “non-behaviorist” (see §10.2.3 here [AF · GW]), wherein interpretability-related probes into the planning system are upstream of the ground-truth rewards.
- ^
The authors also mention in a footnote: “In this case, one may also view grounded human feedback as a singular reward function forming the agent’s overall objective, which is maximised by constructing and optimising an intrinsic reward function based on rich, grounded feedback.” For one thing, I don't think that’s precisely equivalent to the bi-level thing? But anyway, if the plan is for “grounded human feedback” to be the “singular reward”, then my response is just what I wrote in the previous section: the AI can potentially get a higher reward by forcing or modifying the human to give more positive feedback, or otherwise exploiting edge-cases in how this feedback is operationalized and measured.
- ^
Of course, the “source code” inside the reward function could specify a secondary learning algorithm. The §2.4.2 bi-level thing was one example of that, but there are many variations. My take is: this kind of thing may change the form that specification gaming takes, but does not make it go away. As above, if you try to spell out how this would work in detail—what’s the secondary learning algorithm’s training data, loss function, etc.—then I will tell you how that resulting reward function can be specification-gamed.
- ^
Note that, if Sutton really believes in (something like) this false dichotomy, then I think it would explain how he can both describe human extinction as a likely part of the future he’s hoping for, and claim that he’s not “arguing in favor of human extinction”. We can reconcile those by saying that he prefers Option 1 over Option 2 all things considered, but he sees human extinction is a ‘con’ rather than a ‘pro’ on the balance sheet. So, I think he is deeply wrong about lots of things, but I don’t think it’s accurate to call him omnicidal per se.
4 comments
Comments sorted by top scores.
comment by cousin_it · 2025-04-24T18:16:11.676Z · LW(p) · GW(p)
I think this is all correct, but it makes me wonder.
You can imagine reinforcement learning as learning to know explicitly how reward looks like, and how to make plans to achieve it. Or you can imagine it as building a bunch of heuristics inside the agent, pulls and aversions, that don't necessarily lead to coherent behavior out of distribution and aren't necessarily understood by the agent. A lot of human values seem to be like this, even though humans are pretty smart. Maybe an AI will be even smarter, and subjecting it to any kind of reinforcement learning at all will automatically make it adopt explicit Machiavellian reasoning about the thing, but I'm not sure how to tell if it's true or not.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2025-04-24T19:09:59.976Z · LW(p) · GW(p)
You might find this post helpful? Self-dialogue: Do behaviorist rewards make scheming AGIs? [LW · GW] In it, I talk a lot about whether the algorithm is explicitly thinking about reward or not. I think it depends on the setup.
(But I don’t think anything I wrote in THIS post hinges on that. It doesn’t really matter whether (1) the AI is sociopathic because being sociopathic just seems to it like part of the right and proper way to be, versus (2) the AI is sociopathic because it is explicitly thinking about the reward signal. Same result.)
subjecting it to any kind of reinforcement learning at all
When you say that, it seems to suggest that what you’re really thinking about is really the LLMs as of today, for which the vast majority of their behavioral tendencies comes from pretraining, and there’s just a bit of RL sprinkled on top to elevate some pretrained behavioral profiles over other pretrained behavioral profiles. Whereas what I am normally thinking about (as are Silver & Sutton, IIUC) is that either 100% or ≈100% of the system’s behavioral tendencies are ultimately coming from some kind of RL system. This is quite an important difference! It has all kinds of implications. More on that in a (hopefully) forthcoming post.
don't necessarily lead to coherent behavior out of distribution
As mentioned in my other comment [LW(p) · GW(p)], I’m assuming (like Sutton & Silver) that we’re doing continuous learning, as is often the case in the RL literature (unlike LLMs). So every time the agent does some out-of-distribution thing, it stops being out of distribution! So yes there are a couple special cases in which OOD stuff is important (namely irreversible actions and deliberately not exploring certain states), but you shouldn’t be visualizing the agent as normally spending its time in OOD situations—that would be self-contradictory. :)
comment by Towards_Keeperhood (Simon Skade) · 2025-04-24T17:39:14.679Z · LW(p) · GW(p)
- If the user types “improve my fitness” into some interface, and it sets the AI’s reward function to be some “function of the user’s heart rate, sleep duration, and steps taken”, then the AI can potentially get a higher reward by forcing the user into eternal cardio training on pain of death, including forcibly preventing the person from turning off the AI, or changing its goals (see §2.2 above).
- The way that the reward function operationalizes “steps taken” need not agree with what we had in mind. If it’s operationalized as steps registered on a wearable tracker, the AI can potentially get higher reward by taking the tracker from the person and attaching it to a paint shaker. “Sleep” may be operationalized in a way that includes the user being forcibly drugged by the AI.
- If the user sets a goal of “help me learn Spanish over the next five years”, the AI can potentially get a higher reward by making modified copies of itself to aggressively earn or steal as much money and resources as possible around the world, and then have those resources available in case it might be useful for its local Spanish-maximization goal. For example, money can be used to hire tutors, or to train better successor AIs, or to fund Spanish-pedagogy or brain-computer interface research laboratories around the world, or of course to cheat by bribing or threatening whoever administers the Spanish exam at the end of the five years.
I don't really like those examples because just using human feedback fixes those (although I agree that those examples possibly sound more like the vague proposal from Silver and Sutton).
- If “the human gives feedback” is part of the reward function, then the AI can potentially get a higher score by forcing the human to give positive feedback, or otherwise exploiting edge-cases in how this feedback is operationalized and measured.
I think that sounds off to AI researchers. They might (reasonably) think something like "during the critical value formation period the AI won't have the ability to force humans to give positive feedback without receiving negative feedback". If the problem you described happens, it would be that the AI's value function learned to assign high value to "whatever strategy makes the human give positive feedback", rather than "whatever the human would endorse" or "whatever is favored according to the extrapolation of human values". That isn't really a specification gaming problem though. And I think your example isn't very realistic - more likely would be that the value function just learned a complex proxy for predicting reward which totally misgeneralizes in alien ways once you go significantly off distribution.
One could instead name the specification gaming failure mode that the AI overoptimizes on what the humans think is good rather than what is actually good, e.g. proposing a convincing seeming alignment proposal which it doesn't expect to actually work but for which the humans reward it more than for admitting it cannot reliably solve alignment.
(For more on the alignment problem for RL agents, see §10 of my intro series [LW · GW], but be warned that it’s not very self-contained—it’s sorta in the middle of a book-length discussion of how I think RL works in the human brain, and its implications for safety and alignment.)
I think post 10 there is relatively self-contained and I would recommend it much more strongly, especially since you don't really describe the inner alignment problems here.
Re post overall:
I liked sections 2.2 and 2.3 and 3.
I think the post focuses way too much on specification gaming, and way too little on the problem of how to generalize to the right values from the reward. (And IMO, that's not just correct generalization to the value function, but also to the optimization target of a later more powerful optimization process, since I don't think a simple TD-learned value function could plan effectively enough to do something pivotal. (I would still be interested in your thoughts on my comment here [LW(p) · GW(p)], if you have the time.))
(Another outer-alignment-like problem that might be worth mentioning that the values of the AI might come out misaligned if we often just give reward based on the capability of the AI, rather than specifically human-value related stuff. (E.g. the AI might rather end up caring about getting kinds of instrumentally widely useful insights or so, which becomes a problem when we go off distribution, though of course even without that problem we shouldn't expect it to generalize off distribution in the way we want.) (Related [? · GW].))
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2025-04-24T18:37:09.775Z · LW(p) · GW(p)
I think that sounds off to AI researchers. They might (reasonably) think something like "during the critical value formation period the AI won't have the ability to force humans to give positive feedback without receiving negative feedback".
If an AI researcher said “during the critical value formation period, AlphaZero-chess will learn that it’s bad to lose your queen, and therefore it will never be able to recognize the value of a strategic queen sacrifice”, then that researcher would be wrong. But also, I would be very surprised if they said that in the first place! Indeed, I’ve never heard of “critical value formation periods” at all in the context of RL algorithms in the AI literature. (It does come up in the biology literature—for example the “learning rate” of certain parts of the brain, like primary visual cortex, is age-dependent, and near-zero in adults.)
I think your example [“the AI can potentially get a higher score by forcing the human to give positive feedback, or otherwise exploiting edge-cases in how this feedback is operationalized and measured”] isn't very realistic - more likely would be that the value function just learned a complex proxy for predicting reward which totally misgeneralizes in alien ways once you go significantly off distribution.
I disagree. I think you’re overgeneralizing from RL algorithms that don’t work very well (e.g. RLHF), to RL algorithms that do work very well, like human brains or the future AI algorithms that I think Sutton & Silver have in mind.
For example, if I apply your logic there to humans 100,000 years ago, it would fail to predict the fact that humans would wind up engaging in activities like: eating ice cream, playing video games, using social media, watching television, raising puppies, virtual friends, fentanyl, etc. None of those things are “a complex proxy for predicting reward which misgeneralizes”, rather they are a-priori-extraordinarily-unlikely strategies, that do strongly trigger the human innate reward function, systematically and by design.
Conversely, goal misgeneralization can be very important in the special cases where it leads to irreversible actions like editing the reward function or building a subagent. But in almost all other cases, if there’s an OOD action that seems good to the agent because of reward misgeneralization, then the agent will do it, and the reward function will update the value function, and bam, now it’s no longer OOD, and it’s no longer misgeneralizing in that particular way. Remember, we’re talking about agents with continuous online learning. (The other case where goal misgeneralization is important is when it leads to deliberately not doing something, e.g. not taking addictive drugs, since that also prevents the misgeneralization from fixing itself.)
I think the post focuses way too much on specification gaming
I did mention in §2.5 that it’s theoretically possible for specification gaming and goal misgeneralization to cancel each other out, but claimed that this won’t happen for their proposal. If the authors had said “yeah of course specification gaming itself is unsolvable, but we’re going to do that cancel-each-other-out thing”, then of course I would have elaborated on that point more. I think the authors are making a more basic error so that’s what I’m focusing on.