Heritability: Five Battles
post by Steven Byrnes (steve2152) · 2025-01-14T18:21:17.756Z · LW · GW · 21 commentsContents
0.1 tl;dr 0.2 Introduction 0.3 What is heritability? 1. Maybe you care about heritability because: you’re trying to guess someone’s likely adult traits based on their family history, and childhood environment 1.1 The ACE model, and the classic twin study 1.2 What do these studies find? 1.3 What does C (shared environment) ≈ 0% mean? 1.4 What is E, really? 1.5 Twin study assumptions 1.5.1 The simplest twin study analysis assumes that mitochondrial DNA isn’t important 1.5.2 The simplest twin study analysis assumes that assortative mating isn’t important 1.5.3 The simplest twin study analysis assumes no interaction between genes and shared environment 1.5.4 The simplest twin study analysis involves the “Equal Environment Assumption” (EEA) 1.5.5 The simplest twin study analysis assumes there’s no non-additive genetic effects 1.5.6 Summary: what do we make of these assumptions? 1.6 Side-note on comparing parents to children 2. Maybe you care about heritability because: you’re trying to figure out whether some parenting or societal intervention will have a desired effect 2.1 Caveat 1: The rule-of-thumb only applies within the distribution of reasonably common middle-class child-rearing practices 2.2 Caveat 2: There are in fact some outcomes for which shared environment (C) explains a large part of the population variation. 2.2.1 “Setting defaults” 2.2.2 “Seeding ideas” and “creating possibilities” 2.2.3 Special case: birth order effects 2.2.4 Stuff that happens during childhood 2.3 Caveat 3: Adult decisions have lots of effect on kids, not all of which will show up in surveys of adult intelligence, personality, health, etc. 2.4 Caveat 4: Good effects are good, and bad effects are bad, even if they amount to a small fraction of the population variation 2.5 Implications 2.5.1 Children are active agents, not passive recipients of acculturation 2.5.2 Anecdotes and studies about childhood that don’t control for genetics are garbage 3. Maybe you care about heritability because: you’re trying to figure out whether you can change something about yourself through “free will” 4. Maybe you care about heritability because: you want to create or use polygenic scores (PGSs) 4.1 Single-Nucleotide Polymorphisms (SNPs) 4.2 Genome-Wide Association Studies (GWASs), Polygenic scores (PGSs), and the Missing Heritability Problem 4.3 Missing Heritability Problem: Three main categories of explanation 4.3.1 Possibility 1: Twin and adoption studies are methodologically flawed, indeed so wildly flawed that their results can be off by a factor of ≳10, or even entirely spurious 4.3.2 Possibility 2: GWAS technical limitations—rare variants, copy number variation, insufficient sample size, etc. 4.3.3 Possibility 3: Non-additive genetics (a.k.a. “a nonlinear map from genomes to outcomes”) (a.k.a. “epistasis”) 4.4 Missing Heritability Problem: My take 4.4.1 Analysis plan 4.4.2 Applying that analysis plan to different traits and outcomes 4.4.3 My rebuttal to some papers arguing against non-additive genetics being a big factor in human outcomes 4.5 Implications for using polygenic scores (PGSs) to get certain outcomes 5. Maybe you care about heritability because: you hope to learn something about how schizophrenia, extroversion, and other human traits work, from the genes that “cause” them 6. Other things 7. Conclusion Changelog None 21 comments
(See changelog at the bottom for minor updates since publication.)
0.1 tl;dr
This is an opinionated but hopefully beginner-friendly discussion of heritability: what is it, what do we know about it, and how we should think about it? I structure my discussion around five contexts in which people talk about the heritability of a trait or outcome:
- (Section 1) The context of guessing someone’s likely adult traits (disease risk, personality, etc.) based on their family history and childhood environment.
- …which gets us into twin and adoption studies, the “ACE” model and its limitations and interpretations, and more.
- (Section 2) The context of assessing whether it’s plausible that some parenting or societal “intervention” (hugs and encouragement, getting divorced, imparting sage advice, parochial school, etc.) will systematically change what kind of adult the kid will grow into.
- …which gets us into what I call “the bio-determinist child-rearing rule-of-thumb”, why we should believe it, and its implications for how we should think more broadly about children and childhood—and, the many important cases where it DOESN’T apply!
- (Section 3) The context of assessing whether it’s plausible that a personal intervention, like deciding to go to therapy, is likely to change your life—or whether “it doesn’t matter because my fate is determined by my genes”.
- (…spoiler: the latter sentiment is deeply confused!)
- (Section 4) The context of “polygenic scores”.
- …which gets us into “The Missing Heritability Problem”. I favor explaining the Missing Heritability Problem as follows:
- For things like adult height, blood pressure, and (I think) IQ, the Missing Heritability is mostly due to limitations of present gene-based studies—sample size, rare variants, copy number variation, etc.
- For things like adult personality, mental health, and marital status, the (much larger) Missing Heritability is mostly due to non-additive genetic effects (a.k.a. epistasis), i.e. a nonlinear relationship between genome and outcomes.
- In particular, I argue that non-additive genetic effects are important, widely-misunderstood, and easy to estimate from existing literature.
- …which gets us into “The Missing Heritability Problem”. I favor explaining the Missing Heritability Problem as follows:
- (Section 5) The context of trying to understand some outcome (schizophrenia, extroversion, intelligence, or whatever) by studying the genes that correlate with it.
- I agree with skeptics that we shouldn’t expect behavior genetics studies to be magic bullets that lead directly to clear mechanistic explanations of how these outcomes come about. But the studies do seem helpful on the margin.
0.2 Introduction
I just finished reading Eric Turkheimer’s new book Understanding The Nature-Nurture Debate. It’s an easy read, pedagogical, and mercifully short—almost pocket-sized. Good for novices like me.[1]

Turkheimer is very opinionated about all kinds of things, and I don’t always agree with him. But that’s healthy, and his book seems pretty clear about the lay of the land, and where consensus ends and his own takes begin.
From the book, I got a vague impression that there’s a war going on between “hereditarian” versus “anti-hereditarian”, and that Turkheimer is proudly on the “anti-hereditarian” side. Don’t get the wrong idea: Turkheimer is a leading researcher in behavior genetics, past President of the Behavior Genetics Association, etc. But my impression is that, while Turkheimer is perfectly willing to criticize people he sees as too far on the side of ignoring genes (example from his blog), those people don’t seem to get his goat nearly as much as the people he sees as too far on the opposite side.
Anyway, I’m giving some cultural context, but pro- versus anti- is (as always) a terrible framing for a complex field of inquiry.
Here’s a better framing: You can’t answer a question about how to correctly think about heritability until you answer a more basic question about why you’re thinking about heritability in the first place. (“Hug the query” [LW · GW]!) Different questions bring different issues to the foreground, are informed by different data, and require different caveats. For example, I’ll explain below how there are two methods to estimate heritability, and one gives numbers around 50%, the other as low as 5% or less. Which one is “right” and which one is “wrong”? Is heritability irrelevant or central? Depends on the question you’re asking!
So here’s where I’m at. This post has an (incomplete) list of five reasons that someone might care about heritability. Each is accordingly the site of a battle over whether heritability is important, and what its implications are. For each of these five issues, I’ll talk about where I stand, where Turkheimer stands, key concepts, and common confusions and pitfalls.
So let’s dive in! …But first,
0.3 What is heritability?
Heritability is “the degree of variation in a phenotypic trait in a population that is due to genetic variation between individuals in that population” (per wikipedia). It ranges from 0% to 100%.
If everyone in the world had the same DNA (i.e., if everyone were identical twins with everyone else), there would be much less global variation in eye color, somewhat less global variation in height, and just as much global variation in native language. Therefore, the heritability of those three things in the global population is high, medium, and zero, respectively.
Note some subtle consequences of this definition:
- “Organic” things like “how many arms you have”, while obviously caused by genes, can have low heritability in the global population, because there’s not much global variation in “number of arms”, and what variation there is is pretty random—mostly from accidents, I assume. If everyone in the world had the same DNA, the standard deviation of “number of arms” would be only a little bit smaller than it is today. Thus, “number of arms” is extremely related to genes, but variation among people in “number of arms” is only sometimes related to genes. And remember that heritability is always by definition about variation among people.
- Conversely, non-“organic” things, like divorce, are heritable too. You could think of those as being partly downstream from “organic” things like personality, looks, etc., which are more intuitively related to genes.
- …Thus, “X is Y% heritable” is not directly informative about whether we should think of X as a kinda “organic” thing like how many arms you have, or whether we should think of X as a kinda non-“organic” outcome like whether you’re divorced, which is very sensitive to cultural norms around marriage.
- The heritability of a trait in a population depends a lot on the population (in a particular time and place). As a simple example, if aliens zapped half of the USA population at random with a death ray, then bam, the heritability of lifespan among the USA population would get dramatically lower, because now there’s a giant new source of variation uncorrelated with genes, so the fraction of total variation associated with genes is now lower. A real-life example of this: I believe heritability of height is lower in countries where many people are malnourished.
- From Turkheimer’s book, p95:
A classic example of the problem of identifying causes based on genetic correlations was developed many years ago by the sociologist Christopher Jencks. Imagine a society in which children with red hair are despised. Their mothers fail to feed them, their families ignore them, their peers bully them, and schools discriminate against them. We would not be surprised to learn that such children would grow up with all sorts of problems, perhaps including low IQ scores. In that world, genes related to having red hair would be correlated with IQ; they would look like “IQ genes.” (If that example seems trivial, try substituting skin color for hair color.)
1. Maybe you care about heritability because: you’re trying to guess someone’s likely adult traits based on their family history, and childhood environment
For example, if my parents were alcoholic, am I at elevated risk of alcoholism? (Spoiler: yes.) What if I were adopted as a young child—to assess my risk of future alcoholism, should I be asking whether my adoptive parents are alcoholic, or whether my biological parents are alcoholic? (Spoiler: the latter).
To answer these kinds of questions, “classic” behavior genetics methodologies like twin studies and adoption studies provide a treasure trove of data. A handy summary of this whole literature is summed up by Turkheimer’s famous “Three Laws of Behavioral Genetics” (2000):
- First Law. All human behavioral traits are heritable.
- Second Law. The effect of being raised in the same family is smaller than the effect of genes.
- Third Law. A substantial portion of the variation in complex human behavioral traits is not accounted for by the effects of genes or families.
1.1 The ACE model, and the classic twin study
Heritability is easiest to think about when things are “linear” (in math lingo), a.k.a. “additive” (in genetics lingo). (Whether things are in fact additive / linear is another question; much more on that later.) For example, if we’re talking about heritability of height, imagine that having a Single-Nucleotide Polymorphism (SNP) type 838723 increases your height by 34 μm compared to the counterfactual where you don’t have it (an additive genetic effect); and having parents who bought Wheaties breakfast cereal when you were in kindergarten increases your height by 2.7 μm on average compared to the counterfactual where they bought Frosted Flakes breakfast cereal instead (an additive environmental effect); and so on for every other aspect of your genome and life. Non-additive effects, by contrast, would be if SNP 838723 or Wheaties breakfast cereal increased in heights by systematically different amounts (perhaps even with different signs) depending on other genes, or depending on socioeconomic situation, etc. Again, much more on non-additivity later.
Quoting Turkheimer (p53) [formatting and emphasis added]:
[There’s] a framework called the ACE model that distilled quantitative genetics into three bitesize pieces that could be consumed by social scientists conducting twin and adoption research.
- The A in ACE, the genetic portion of the model, stands for “additive” … a sum of many small genetic effects. The A term is the simplest estimate of heritability. The C and E in the model are the environmental portions.
- C stands for “common” and represents the environmental effect of families. It is usually referred to as the “shared environment,” the part of the environment that is shared by siblings raised together, or the portion of the environment that tends to make siblings in the same family more alike.
- E stands for … environment, I think, and represents the flip side of C: it is the part of the environment that is not shared by siblings, all nongenetic events (including measurement error in tests) that make siblings raised together different.
Here’s an illustration of how the ACE model works, in the context of a twin study. Twin studies, by the way, are one of the most common types of study in behavior genetics, and are methodologically very simple: you measure some property for many pairs of twins, and you almost always find that identical twins (a.k.a. “MZ” twins, for “monozygotic”) are more similar to each other than fraternal (“DZ”, dizygotic) twins are. Quantify that, and bam, you get an estimate of heritability, as follows.
The ACE model applied to a twin study looks like the following:
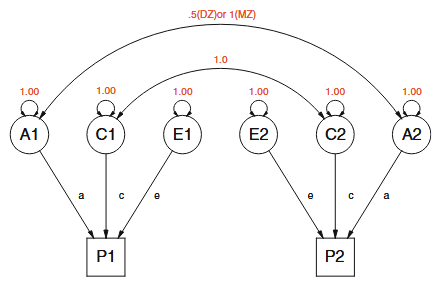
As you can check for yourself (assuming you know how Structural Equation Modeling works), the twin-study ACE formula winds up being surprisingly simple:
where and are the correlations in the outcome (labeled “P” in the figure) between DZ and MZ twins respectively, and A, C, and E are the fraction of overall population variance in the outcome that originates in each of those three categories.
1.2 What do these studies find?
By and large, if the study population is within the developed world (and excludes grinding poverty, as is usually the case), and if the outcome is measured in adulthood, then these kinds of studies find that about half the variance comes from additive genetic effects, and the other half from non-shared environment—in other words, , , . Obviously I’m grossly oversimplifying; it depends on the outcome being measured, the methodology used, and the study population. I’ll talk in §2.2 about some cases where C is large, and in §4 about how and why a different set of measurement techniques (GWAS’s) gives dramatically lower A’s in certain cases.
1.3 What does C (shared environment) ≈ 0% mean?
(For reasons I’ll get into later, you should be cautious in taking at face value the value of C from classic twin studies, because of non-additive genetic effects, a.k.a. epistasis. But adoption studies also often find for adult traits, and they don’t have that problem.)
Again, the theme of this section is: “you’re trying to guess someone’s likely adult traits based on their family history, and childhood environment”. So for example, I believe for pretty much any aspect of adult personality.[2] That means: if someone is adopted at birth, and you, a passively-observing third party, are interested in guessing whether that person will grow up to be neurotic, happy, anxious, etc., then it’s barely worth your time to ask questions about their childhood adoptive household. For example:
- Did their adoptive parents get divorced and move around all the time? Eh, don’t bother asking, it won’t much help you guess whether the kid will grow into an adult who is neurotic, happy, anxious, etc.
- Did their adoptive parents have anger management and drug issues? Eh, don’t bother asking, it won’t much help you guess whether the kid will grow into an adult who is neurotic, happy, anxious, etc.
- Did their adoptive parents give them organic food, or vaccines, or private schools, or cell phones? Eh, don’t bother asking, it won’t much help you guess whether the kid will grow into an adult who is neurotic, happy, anxious, etc.
After all, if any of those things were a major factor in adult personality, then we’d see in the data that growing up in the same household would make people more similar in their adult personality. And we don’t see that. (But see §2 for more nuances.)
1.4 What is E, really?
E (“non-shared environment”) is a catch-all; there’s a Scott Alexander post that lists some things that are part of E. Leaving aside all the elaboration and examples, he mentions the following list of some of the contributors to E:
Measurement noise for the outcome / trait. For example, people might put slightly different answers on a personality test depending on how they feel that day.
Luck of the draw, in life. For example, maybe both of a pair of MZ twins have friend groups with statistically-similar properties, but one of the friend groups happens to contain a friend who hooks the twin up with a wonderful job and spouse.
Biological sources of variation, such as biological random noise, randomness related to the immune system, and genes that differ between MZ twins (this study found ≈360 new mutations separating the average pair of identical twins). Epigenetic differences between MZ twins might or might not be in this category, depending on what’s upstream of those differences.
On the other hand, here’s something that seems not to meaningfully contribute to E:
[Apparently NOT a significant contribution to E]: Any aspect of “non-shared environment” that you can objectively measure, such as “differential parenting, differential peer relationships, differential sibling interaction, differential teacher relationships, family constellation (e.g., birth order, age, age spacing, gender differences)” (quote from Turkheimer & Waldron 2000). As it turns out, none of those things have an effect that can be statistically distinguished from zero. In his Three Laws of Behavior Genetics article mentioned above, Turkheimer calls this fact the “gloomy prospect”, since it’s bad news for those hoping to explain human differences. (However, see discussion of birth order in §2.2.3 below.)
1.5 Twin study assumptions
Calculating ACE from twin data is extremely simple if you make certain assumptions, and a horrifically complicated mess if you don’t. Examples of common assumptions (many of which, to be clear, can be quantified and controlled in more sophisticated analyses):
1.5.1 The simplest twin study analysis assumes that mitochondrial DNA isn’t important
Mitochondrial DNA has only a few dozen genes, but one might think that they’re inordinately important ones, being at the foundation of creating all the energy and building materials used by your body.[3] Whatever their effect is, it would erroneously wind up in the C category in twin studies, since they’re (approximately) shared between DZ twins. (In other words, mitochondrial DNA means that DZ twins are slightly more than 50% related on average.)
1.5.2 The simplest twin study analysis assumes that assortative mating isn’t important
Assortative mating entails parents being (in effect[4]) more genetically similar than two random people in the study population. This also erroneously puts genetic influence into the C category, for the same reason as above, i.e. making DZ twins more than 50% similar.
1.5.3 The simplest twin study analysis assumes no interaction between genes and shared environment
If genes have different influences in different family environments, then this effect would get erroneously lumped into A by the simplest twin-study methodology.
Here’s a made-up example, which is exaggerated for simplicity, but (on priors) seems like generally a kind of thing that could happen:

In this made-up example, there would in fact be in a twin study, because the left-column kids are going to college at a higher rate than the right-column kids. But this measured C would be “too small”, in a sense—it would not be reflecting the full extent of shared-environment effects. Suppose half the households are in each column. Then in a twin study, the genetic population variation related to being conformist / iconoclast would contribute entirely to A—it would look like a pure source of additive genetic variation. After all, insofar as conformism contributes to this outcome, the MZ twins will be more similar in the left-column households, and the MZ twins will also be more similar in the right-column households. But in fact, lumping this source of variation entirely into A is somewhat misleading, because the directional influence of those genes is wholly dependent on the shared environment.
OK, now that you hopefully understand what gene × environment interactions are, we can ask: are they important? I found an argument for “no” in this blog post by pseudonymous blogger “Cremieux”:
No one has been able to find evidence for this sort of thing at scale, and we have both methods and ample data to find out if it’s true … Another method to test for gene-environment interactions is to leverage adoption data. Halpern-Manners et al. did this in 2020 [for educational attainment, and found that] the biological and environmental effects of parents were additive, not interactive.
Hmm, I’m not an expert, but OK sure, that sounds reasonable.
1.5.4 The simplest twin study analysis involves the “Equal Environment Assumption” (EEA)
A popular complaint about classic twin studies is the claim that the environment of MZ twins is in fact more similar than the environment of DZ twins—in the lingo, that the EEA is false. If this complaint is valid, it would undermine the study design. After all, without EEA, MZ twins would have more similar genes than DZ twins, and MZ twins would have more similar environment than DZ twins. So then we take our measurements, and you guessed it, the MZ twins wind up more similar than the DZ twins. We wouldn’t learn anything useful from that!
Now, my statement of the EEA above was a bit imprecise, and this is actually a rather popular misunderstanding. In fact, the EEA can be valid even if parents treat MZ twins more similarly than DZ twins. The EEA is only violated if this difference is specifically because the twins are MZ twins, and the parents know it. This is a bit of a moot point in practice, for reasons below, but I think it’s conceptually helpful for understanding what heritability is and isn’t. So I put it in this box:
Box: The “Equal Environment Assumption” does not really require “equal environments”
Suppose that in general, throughout a population,
- (1) a kid’s genes can sometimes cause the kid being a strong-willed limit-tester,
- (2) if a kid is a strong-willed limit-tester, then that tends to cause his parents to be on average stricter and less affectionate towards him,
- (3) if parents are stricter and less affectionate towards a kid, then that tends to cause the kid to suffer from depression and anxiety many decades later. [I don’t endorse this step as plausible, I’m just trying to illustrate a narrow point.]
In this case, this (1-3) pathway contributes to measured heritability of the “adult depression and anxiety” outcome.
Does this (1-3) pathway lead to a violation of EEA? You might think so! After all, for DZ twins, it will more often be the case that parents are much stricter towards one twin than the other. By contrast, for MZ twins, it’s more likely that either both or neither of the pair will be a strong-willed limit-tester, so they’ll get a more similar parental treatment. You can just look—you’ll see that the environments are more similar for MZ twins. So EEA is violated, right?
Wrong! In fact, this (1-3) pathway should not count as an EEA violation. On the contrary, (1-3) is supposed to be part of heritability, and the twin study would be correct in counting it as A, and any other study design (e.g. adoption studies) would correctly capture this phenomenon as part of heritability as well.
If you think there’s a problem here, then you’re misunderstanding the definition of heritability! And conversely, if anyone treats “depression has ” as direct evidence against the possibility of (3), then they’re misunderstanding the definition of heritability too! (I think there’s a good argument against (3), but it requires more steps than just saying “ therefore (3) is false”.[5])
Genes in a population can affect outcomes through a great many causal pathways, and those pathways often involve the environment and other people, including their parents and teachers. See the redhead example at the top.
Well, anyway, when I flip through the literature, I get the impression that the above is a bit of a moot point anyway. Even when people (incorrectly) jump from the observation “parents spend more time with one sibling than another” to the conclusion “EEA is violated”, it doesn’t much matter, because those inequalities in parental treatment don’t measurably affect adult outcomes anyway! (See discussion of “the gloomy prospect” above.) For what it’s worth, Turkheimer discusses EEA briefly on p70 as follows:
The validity of the EEA is very difficult to evaluate empirically because there is no ready way to quantify the similarity of the rearing environment of two people. Some tests are possible, for example by examining twins whose parents had an incorrect impression of their zygosity, raising identical twins thinking they were fraternal, and vice versa. These tests generally support the idea that the EEA is at least reasonable, but I think a dose of skepticism is nevertheless warranted. The questionable validity of the EEA may not be a reason to suggest that the findings of twin studies are completely imaginary, but it is a reason not to obsess over the second decimals of heritability coefficients.
Good enough for me; I am perfectly happy to not obsess over the second decimals of heritability coefficients.
1.5.5 The simplest twin study analysis assumes there’s no non-additive genetic effects
I actually think these non-additive effects are very important for many (not all!) traits, including personality, mental health, and many aspects of behavior. Much more on this in §4.3.3 below.
When these effects are important, the ACE model is invalidated. If you mistakenly apply the ACE model anyway, in a classic twin study where there is in fact a lot of non-additive genetic effects:
- The calculated A winds up high, despite the fact that “additive genetic contribution to variance” is in fact low.
The calculated C winds up reflecting a balance:
(1) C gets pulled up by shared environment effects (obviously), along with a few other effects like assortative mating (§1.5.2)
(2) C gets pulled down by the non-additive genetics. Indeed, C can even wind up below zero!
The reason for (2) is simple: DZ twins share about half their genes, but only about a quarter of pairs of genes. So with gene × gene interactions, you can get as low as , and thus . (And likewise, if there’s gene × gene × gene interactions, then could be as low as , etc.)
So, reporting naive ACE results in the presence of non-additive genetic effects is misleading. And even more misleading is doing a naive ACE analysis in the presence of non-additive genetics, but sweeping the nonsensical result under the carpet, by treating as a constraint in the fitting. I’ve seen people do that too.
The correct approach, of course, is to not use an ACE model when there’s non-additive genetic effects, but rather to use an “ACDE” model instead. The D is the non-additive genetic contribution to variance.
If you don’t have an ACDE analysis on-hand from the literature, here’s my quick lazy qualitative recipe. First, you can guess the real shared-environment effect from adoption studies, which don’t have issues with non-additive genetic effects, and you’ll usually find for adult traits, with some exceptions in §2.2 below. Assuming that’s the case, second, check the classic twin studies for the inequality , which (in this case) is basically a tell-tale sign of non-additivity. The more that , the stronger the non-additivity, I think, although this clue can be hidden by shared environment and assortative mating, as mentioned above. Separately, another tell-tale sign of non-additive genetic effects is if the outcome / trait has an unusually large amount of “Missing Heritability”—I’ll explain what that is in §4 below.
Here’s a practical intuition to keep in mind for highly-non-additive genetic contributions to traits / outcomes: non-additive genetic effects leads to similarity that falls off extra-rapidly with relatedness. If you have an MZ twin, their traits are as predictive as ever, but as you move out to siblings and parents, then to half-siblings, then cousins, and so on, their relevance to your own likely outcomes falls off even faster than normal. So for example, I think personality traits and mental health outcomes generally have a lot of non-additive genetics (§4.4.2 below). So that means, as you look over your family tree to assess your likely adult personality, you can feel a little less concerned about turning out like your cranky reclusive Great Uncle Herbert.
So yeah, I think non-additive genetics is a great reason to question the interpretation of classic twin studies, particularly in the context of mental health, personality, and behavior. Again, more on this in §4.3.3 below. We can still rescue the “shared-environment effects are usually a small contributor to population variation of adult traits” rule-of-thumb via adoption studies—specifically, if pairs of siblings raised apart are generally about as similar as pairs of siblings raised together, then childhood home environment is probably not a huge contributor to population variation.
1.5.6 Summary: what do we make of these assumptions?
Here’s Turkheimer p73:
All these reasons to be skeptical of human heritability coefficients and the studies that generate them—the equal environments assumption, the assumptions of independence and additivity—are well known, more or less valid, and have been discussed to death. There are, in fact, many other similar assumptions about human behavior genetics that I have not bothered to mention. In adoption studies, for example, there is the fact that babies do not get put up for adoption at random, so there is selection of both biological and adoptive parents. To some extent, the babies from the best-off biological mothers get placed with the most affluent adoptive families, a phenomenon called selective placement. Babies are always exposed to the perinatal conditions provided by the biological mother, and since they are not always adopted right at birth, they are often exposed to the postnatal conditions as well. Does this mean that the results of adoption studies are meaningless, that the masses of evidence showing correlations between biological parents and their adopted away children might be illusory? No. There is too much evidence pointing in the same direction, arising from too wide a range of research designs, subject populations, and behavioral differences. What it does mean, however, is that obsessing over the values of heritability estimates from adoption studies is a waste of time.
That all sounds reasonable to me.
1.6 Side-note on comparing parents to children
Incidentally, if you're looking at parents and trying to guess what children will be like (i.e. parent-child correlation), and you want to know whether genes or environment is more important for this metric, then comparing A to C is misleading. You really want to be comparing A to , more or less, and that accentuates C because . The reason is: “vertical phenotypic transmission just has to pass once, from parent to child, whereas additive genetics has to pass twice, from parent genes to parent, and also from child genes to child.” (Source and details: “Tailcalled” on X.)
2. Maybe you care about heritability because: you’re trying to figure out whether some parenting or societal intervention will have a desired effect
Here’s a rule of thumb. Hopefully nobody is irresponsible enough to state this literally with no caveats, but it’s definitely a vibe you get in certain circles, like reading Judith Harris and Steven Pinker and Bryan Caplan [LW · GW]:
| The bio-determinist child-rearing rule of thumb [but see caveats below!]: Things you do as a parent will have generally small or zero effects on what the kid will be like as an adult—their personality, their intelligence and competence, their mental health, etc. Likewise if you’re a town official deciding the playground budget, and likewise if you’re a teacher offering advice or setting the curriculum, etc. |
Why should we believe that? Well, twin and adoption studies usually find small shared-environment effects, a.k.a. . In particular, biological siblings tend to turn out about as similar if they’re raised in the same household versus different households, and likewise adoptive siblings do not wind up that much more similar than any two random people in the population, once they reach adulthood—see handy table here [LW · GW]. But adoptive siblings tend to grow up with relatively similar (compared to population variation) amounts of screen time limitations, and of parents attending or not attending their football games, and of eating organic versus non-organic food, and of parents flying off the handle at them, and being in a better or worse school district, etc.
…But not so fast! That observation proves something important, but the rule-of-thumb box above is bulldozing over many important details. I’ll jump into four major caveats in §2.1–§2.4 next. Then in §2.5 I’ll circle back to the box itself, which (despite the caveats) still has a huge and important kernel of truth, and I’ll talk about its implications for how we think about children and childhood.
2.1 Caveat 1: The rule-of-thumb only applies within the distribution of reasonably common middle-class child-rearing practices
Adoption studies provide direct evidence for this rule-of-thumb, but only in cases where the thing you’re doing is pretty common, but not doing the thing would also be pretty common, in a way that’s not too stratified by class and country (since adoption studies tend to be within-class and within-country—otherwise the effects of adoption are larger). In other words, if some intervention happens to virtually everybody, or virtually nobody, in a population, then it’s possible for the intervention to be very impactful while nevertheless —remember, C is about explaining the population variation.
So here are some examples where the rule-of-thumb does not apply:
Grinding poverty, oppression, etc.: I added “middle class” in the section heading because shared-environment effects tend to be higher if the population includes grinding poverty. For example, there’s a common trope that adult IQ lacks shared-family effects, and this is generally true within the rich world, but international adoption of a child from an impoverished country to the rich world does increase their adult IQ (see e.g. Bryan Caplan—1, 2).
Extreme abuse and neglect: I find it pretty likely that extreme abuse and neglect could alter what the kid will be generally like as an adult. To take a clear-cut example: I think it’s well-established that there are very obvious lifelong effects from childhood malnourishment, or from being a feral child. So we should be at least open-minded to the possibility of lifelong systemic impacts from somewhat less extreme childhood conditions as well.[6]
New technologies, new cultural trends, etc.: Twin and adoption studies don’t directly offer any information about whether new unprecedented technologies, or new unprecedented cultural shifts, or new unprecedented parenting styles, etc., will change what the kid will be like as an adult, because those activities are not part of the study populations of any existing paper. (Granted, in some cases, the existing literature provides indirect evidence—is this thing really completely “unprecedented”?)
Skill issues, i.e. a scenario where it’s possible in principle for parents to wildly change some aspect of their children’s adult personalities, health, etc., by appropriate words and actions, but vanishingly few parents are able to actually do so. Or perhaps, vanishingly few are really even trying. Here’s an example, maybe. Famous Cognitive Behavioral Therapy pioneer David Burns claims he can pretty reliably cure people’s treatment-resistant depression in a single two-hour talk session, plus maybe another for relapse prevention training. And I believe him [LW · GW]! He even has a podcast where he does this on the air, and studies have found that reading David Burns books is about as effective as taking antidepressants. So here’s a hypothesis: “if you had grown up with David Burns as your adoptive father, you’d have a good chance of developing unusual skill in understanding and controlling your emotions, and this skill would remain useful even into adulthood, and it would manifest as a substantial reduction in your adult incidence of clinical depression and anxiety”. I find this hypothesis quite plausible! And importantly, twin and adoption studies offer approximately zero evidence either way about whether this hypothesis is true. The skills in question are too rare in the population. Even Burns himself struggles to convey those skills to his trainees [LW · GW].
2.2 Caveat 2: There are in fact some outcomes for which shared environment (C) explains a large part of the population variation.
2.2.1 “Setting defaults”
Hatemi and McDermott 2012 finds that “political party identification” has a strong shared-environment effect, but “overall ideology (liberal-conservative)” does not. Basically, people “pick a team” (Republican versus Democrat in the USA) based on childhood local culture, and often never change it. But both “teams” are big tents that offer an array of niches that people gravitate towards, in a way that depends more on their genes.
Similarly, Eaves et al. 1990 finds that “religious affiliation” has a strong shared-environment effect. That seems unsurprising: in my own experience at least, if someone I know was born Catholic, Muslim, or whatever, then they’re probably still Catholic, Muslim, or whatever, as an adult, at least nominally, if they claim any religion at all.
Regional accents are another famous example—they’re acquired in childhood and last a lifetime.
For regional accents and maybe also political party, I think the default comes more from “local culture”, especially friend groups, than from parents directly (see §2.5.1 below). But the parents do get to influence the local culture indirectly, by choosing where to live.
2.2.2 “Seeding ideas” and “creating possibilities”
For example, suppose I raise a child in the tiny obscure town of Churubusco, Indiana, USA. An average citizen of the USA has only a 1-in-100,000 chance of living in Churubusco as an adult. But my child would obviously have a much higher chance than that! So this is an adult trait that’s obviously strongly biased by child-rearing—i.e., it’s a shared environmental effect.
There are a lot more things like that. If I have an obscure hobby, or practice an obscure career path, or possess an unusual skill, my children (both biological and adopted!) are obviously much more likely to wind up sharing those traits, than the population average.[7]
The way to think about this is: if you raise a child in Churubusco, even if you move away later, you are seeding the idea that the child could live in Churubusco as an adult. They’ll know exactly what they’d be getting into, and it will be in their mind as a salient possibility. Moreover, they’ll have already climbed up various learning curves, such that it would be an easy thing to get back into. You’re not indoctrinating the child into wanting to live in Churubusco. It’s up to the child—they’ll decide what they want to do (see §2.5.1 below). But seeding the idea and clearing the pathway, by itself, is already a huge thumb on the scale, when we compare it to the far more typical situation of not even knowing that Churubusco exists!
If you’re familiar with the Reinforcement Learning literature, you can think of “seeding ideas” as related to the explore-exploit problem. A lot of possible behaviors in life are just really obvious—things like “Hey, what if I try being dishonest? Or antisocial? Or vain?”. By the time a person reaches adulthood, with 200,000 hours of life experience under their belt, they’ll have certainly tried those strategies, and either found them to be intrinsically appealing on balance (and thus kept doing them), or intrinsically unappealing on balance (and thus stopped). So “seeding ideas” is not relevant to these kinds of behaviors.
But for other things, like living in Churubusco or a needlework hobby, you can easily go your whole life without ever knowing what you’re missing. This is the “incomplete exploration” regime, in the reinforcement learning lingo. And that’s where “seeding ideas” and “creating possibilities” become more important. You’re creating a known possibility, and making its exploitation relatively cheap, easy, and salient.
2.2.3 Special case: birth order effects
This part is unnecessary for the rest of the article, but click the box for my explanation of why we see strong birth order effects in certain specialized contexts.
Box: Why birth order effects?
Here’s an example. My own niche online community has an extraordinarily lopsided share of eldest children—in one survey of thousands of readers, out of the respondents with exactly one sibling, 72% were the older sibling! And yet, studies generally show that birth order effects on intelligence and personality are quite small, if they exist at all. So why this giant effect? You can read that post and its comments for a bunch of possible explanations, but none of them seem to hang together, or be compatible with the big picture of twin and adoption studies etc. My proposed explanation instead focuses on the “seeding ideas” angle from §2.2.2 above.
Basically, I think getting into niche online communities requires a conjunction of two ingredients:
- You innately have a “niche online community type of personality”—i.e., your innate makeup is such that you would enjoy niche online communities, if only you spent enough time getting to know them to “see the appeal”.
- …And this actually happens! You do, in fact, at some point in your life, not only discover that niche online communities exist in the first place, but also spend enough time getting to know them that you get hooked.
My proposal is that the birth-order effect comes entirely from the second bullet point, not the first.
So, here’s a model.
Again, some small subset of the population has the “niche online community type of personality”. If a member of that select subpopulation has an older sibling (adopted or biological, doesn’t matter), then that older sibling probably doesn’t also have a “niche online community type of personality''. Rather, the older sibling is probably more “normal”, because of regression to the mean.
So the older sibling would be exposing their younger sibling to more “normal” interests. And those ideas would “crowd out” the time when the younger sibling might otherwise be discovering their natural (latent) affinity for niche online communities. And then that younger sibling might well go their whole life without discovering this potential interest. (Alas!)
By contrast, oldest siblings who have a “niche online community type of personality” would have much less of that crowding-out issue, especially if they’re kinda introverted (so don’t have much other exposure to mainstream interests and hobbies). I mean, I guess they could copy more mainstream interests and hobbies from parents or from younger siblings, but those options are both quite unappealing, from the perspective of a teen. Kids are strongly drawn to idolizing and imitating older kids. There’s an obvious evolutionary reason for that: if I’m a kid, then older kids tend to be doing things that I would benefit from immediately learning to do (more on this in §2.5.1).
I offer my own anecdotal experience as an example. I’m a nerdy, introverted younger sibling—very much “niche online community type of personality”—and it took me until age 24 until I found even a decent niche online community to call my own, and then it took me past age 30 before I found a niche online community that really suited me. And I kinda lucked into them; I can easily imagine missing them entirely. And meanwhile, a ton of my interests in my teenage years were things that I became aware of by copying my (much less nerdy) older sibling, who I thought was super cool. Those copied interests consisted of relatively mainstream music, movies, games, TV shows, etc. It took many more years before I gradually stopped excessively liking / admiring [LW · GW] my big sibling, and drifted back into the nerdy introverted mode of behavior that comes most naturally to me.
So to sum up, in this story, it’s not that the first-borns are constitutionally more smart or more iconoclastic or whatever than later-borns; it’s that nerdy introverted first-borns are much more adrift from the cultural mainstream than nerdy introverted later-borns, at least during their exploratory teenage years, and thus the first-borns are more likely to bounce around until they discover way-off-the-beaten-track activities and interests that feel intrinsically very appealing to them. And once they discover those activities, they’ll stick with them for a lifetime. Activities like … participating in niche online communities!
I think we can explain the overrepresentation of first-borns at the top echelons of physics [LW · GW] and math [LW · GW], and among Harvard students, in a similar way.
2.2.4 Stuff that happens during childhood
Any trait / outcome measured during childhood tends to have a substantially higher C than the same trait / outcome measured in adulthood, for obvious reasons. (See my post Heritability, Behaviorism, and Within-Lifetime RL [LW · GW] for further discussion.) As an example, Turkheimer (p74) brings up the Scarr-Rowe interaction for IQ: in one pioneering study he did, for the lowest socioeconomic levels, and , whereas in the highest socioeconomic levels, and . Turkheimer says that subsequent studies do not get such extreme results, but that the basic observation has held up. But all this, Turkheimer neglects to mention, is childhood IQ. As far as I can tell, once you get to adult IQ, it’s harder to find any C anywhere.
Another example: “Educational attainment” (EA) is a popular target of behavior genetics experiments, for reasons explained by Turkheimer as follows (p96):
GWAS [Genome-Wide Association Studies, more on which in §4 below] samples continued to grow, into the tens and then hundreds of thousands. Today some of them have more than a million participants. Such massive samples did, eventually, produce statistically significant associations between SNPs and behavioral differences. These were greeted with great enthusiasm, but they came with a cost. How do you give high-quality IQ tests to a million participants? The answer is, you can’t, so the field developed a workaround. When someone participates in a study of any kind, they fill out a demographics sheet before getting started. The sheet usually includes their age, gender, height and weight, self-reported race, and one other bit of information: their education level. Educational attainment has been an object of genetic studies since Galton. The reason is not so much that anyone had a literal interest in the genetics of educational differences. Instead, interest in education was based on three considerations: first, as a marker for the socioeconomic inequality Galtonians hoped to explain, or explain away, with genetics; second, as a proxy for IQ, without requiring a time-consuming in-person test; and finally, the simple fact of its easy availability in large samples.
Interestingly, EA seems to be one of those rare traits for which C is high. For example, “The role of the shared environment in college attainment: An adoption study” (Anderson et al., 2020) says educational attainment has , similar to A: “College attainment is one of the few phenotypes to have substantial variance accounted for by environmental factors shared by reared-together relatives.”
I think the explanation is obvious: most people decide whether or not to apply for college while still living with their parents. And their parents might even offer to help pay! So of course their parents will have a big impact on this decision. Just because you can measure the EA of an adult, doesn’t make EA an “adult trait”—at least, not entirely an adult trait.
2.3 Caveat 3: Adult decisions have lots of effect on kids, not all of which will show up in surveys of adult intelligence, personality, health, etc.
First and foremost, adult decisions affect kids in the here and now. Childhood is part of life. If you want someone to have a rich and happy life, part of that is having a rich and happy childhood. It’s not just a means-to-an-end towards growing up.
And even as an adult, you still have childhood memories, which can be a source of comfort or misery.
Also, things like college debt or a criminal record versus a trust fund might not show up on personality and intelligence tests, but can still make someone more or less able to accomplish life goals in adulthood.
Finally, some things can be learned the easy way or the hard way. There are a lot of important and non-obvious things to learn about yourself and your preferences—“life doesn’t come with an instruction manual”, as they say. Maybe, by the time your kid is 40, they’ll have almost certainly figured out everything there is to know about themselves and their preferences, regardless of their childhood. But man, it’s sure nice to learn those kinds of things earlier and more painlessly! For my part, I sure would have a lot of sage advice for my younger self—things that nobody ever told me, and that never even crossed my mind until I was in my 20s or even 30s.
I’ve never been one to blindly trust my parents’ advice, or follow their example. But, as above, they have certainly had the capability of seeding ideas in me. Just as parents can seed the non-obvious idea of living in the town of Churubusco, or of being a Soil Conservation Technician, they can likewise seed non-obvious ideas about how to live, behave, and know thyself. Granted, it’s ultimately up to the kid to keep or jettison those ideas (see §2.5.1 below). And granted, if some idea is not seeded in childhood, the kid may encounter it later in life regardless. But still, there’s a lot of value in seeding good ideas early!
2.4 Caveat 4: Good effects are good, and bad effects are bad, even if they amount to a small fraction of the population variation
There’s a critical difference between §1 and §2:
- Back in §1, we think of a possible source of variation in adult traits / outcomes as “big” or “small” as compared to the total variation across the population.
- Here in §2, we think of a possible source of variation in adult traits / outcomes as “worthwhile” or “not worthwhile” depending on how the costs of the intervention compare to its benefits.
For example, think back to the dumbest person in your high school. C’mon, be honest—you know exactly who they are. (Hi Bill! Nothing personal, I still think you’re a great guy!) The difference between extraordinarily skillful parenting and mediocre parenting are not going to turn Bill into the next Albert Einstein. But maybe it could shift things on the margin, meaningfully changing the probability that Bill would grow up able to hold down a job, take care of himself, and stay out of prison. And that’s still worth a lot![8]
Twin and adoption studies give us very little information on this topic. There’s so damn much population variation, that any hypothesis about “parents shifting things on the margin” gets drowned out by the noise. We just don’t know either way—at least, not from that kind of evidence.
Pseudonymous blogger “Cremieux”, who tends to be very strongly on the hereditarian side of things, nevertheless makes this same point in his post “The Status of the Shared Environment”:
‘Small’ proportions of the variance in a trait being explained by the shared environment, C, [does not] mean that C is unimportant and, consequently, can be dismissed.
(He then illustrates that point with a quantitative example.)
Again, benefits can be very small compared to “transforming the child from a psychopath to Gandhi”, and very small compared to “transforming the child from Bill-from-high-school into Albert Einstein”, but still large enough that we should fight for them. Especially if the costs are not too big, which is often the case. For example, the intervention of “try not to fly off the handle at your child” has no cost at all! It’s good for parents, and it’s good for children, in the here-and-now. Perhaps it also has some marginal benefit for what kind of adult the child grows into; if so, that’s a cherry on top. Likewise with other win-win interventions like not being a helicopter parent (also called “free-range parenting”) and not over-scheduling kids. At least, that’s my guess.
2.5 Implications
2.5.1 Children are active agents, not passive recipients of acculturation
I’m worried that people will read those caveats and say “OK wow that was a long list of caveats. Cool. Guess I can just discard the ‘bio-determinist child-rearing rule-of-thumb’ and just keep believing what I’ve always believed”. No!! The rule-of-thumb is very often applicable. If it seems unintuitive—i.e., counter to your intuitive understanding of child-rearing—then there’s something very wrong with your intuitive understanding of child-rearing!
So, what’s the mental model where the rule-of-thumb feels natural and intuitive? Here are a few perspectives:
Machine learning perspective: See my post Heritability, Behaviorism, and Within-Lifetime RL [LW · GW]. Also, see my comment here [LW(p) · GW(p)] elaborating (in ML terms) on the profound distinction between “parents train their kids” versus “parents are characters in their kids’ RL training environment”.
Evolutionary psychology perspective: Parents and children have different (albeit overlapping) evolutionary interests. This was pointed out by Robert Trivers in the 1970s—see parent-offspring conflict. So it’s evolutionary implausible that children would allow their parents to indoctrinate them.
This is especially obvious when we look at more traditional cultures. Examples (quoted from here [LW · GW]):
In rural Turkey the trait most valued by parents (60%) was obedience; least valued (18%) was independence.
And when a Javanese shellfish diver was asked whether she learned the trade from her mother, she replied:
My mother! she said loudly, She drove me away! I tried to follow her to the bottom to watch, but she shoved me back. When we were on the surface again, she practically screamed at me to move OFF and find my danged [shellfish] BY MYSELF.
In such an environment, if children weren’t fundamentally, actively, looking out for their own interests, resilient to any obstacles in their way—and if instead, children were passively trusting parents and authority figures to brainwash them with how to behave in the local culture—then those children would not survive and thrive.
Social learning perspective: I often talk about “liking / admiring” someone—a term that I use in a specific way, as defined and discussed in my post here [LW · GW]. At any given time in your life, there were people that you liked / admired, and others that you didn’t. Toddlers tend to like / admire their parents to some extent, and to like / admire somewhat-older kids to a similar or greater extent. As childhood goes on, kids’ liking / admiring of their parents typically gets weaker, and eventually negative in puberty, while their liking / admiring of their similar-age and slightly-older friends strengthens. As mentioned in §2.2.3 above, there’s an obvious evolutionary explanation for why kids like / admire older kids: older kids are demonstrating behaviors that are most useful to learn and imitate. Then after puberty, people might start liking / admiring their parents again, but also might not. Additionally, people of all ages tend to like / admire certain celebrities, public figures, and so on.
Anyway, liking / admiring comes with some special properties. As discussed in that same post [LW · GW], If I like / admire you, and you like X, then I’m gonna start liking X too, and I’m even liable to internalize the idea that X is objectively good and proper. This is how neurotypical children wind up internalizing cultural norms.
However, saying “we socialize kids”, or “we acculturate kids”, etc., is confused nonsense, because it puts the agency in the wrong place. It’s the kid’s brain that proactively determines, through its own complicated mechanisms, whom to like / admire. It’s the kid’s brain that makes the determination of what to copy and internalize, if anything. It’s the kid’s brain that makes the determination of whether to keep some previously-internalized idea, or drop it in favor of some hot new thing.
A nice illustration of this idea is cultural shifts. For example, our ancestors have been practicing breastfeeding back to the Cretaceous. But then, within a single generation in the mid 20th century, most USA women stopped doing it! (It got more common again later on.) Likewise with rapidly-changing attitudes towards gays, and Trumpism, etc. If you have a mental picture where “we socialize kids” or “we acculturate kids”, then these dramatic failures of socialization / acculturation should make you question that picture.
By contrast, in my model, it’s no surprise at all. People are not passively getting indoctrinated / socialized / acculturated. Rather, they’re deciding for themselves what they want to do (not necessarily in a conscious and self-aware way), which partly involves taking cues from people they respect. Those people are often peers, celebrities, and sometimes parents but not necessarily, as above. So new norms can blow in with the wind, and the old norms and behaviors are dropped.
Personal experience perspective: There’s a famous saying: “All parents are environmentalists until they have their second child”.
2.5.2 Anecdotes and studies about childhood that don’t control for genetics are garbage
There’s a giant mountain of studies that claim (or insinuate) that something happening in childhood affects adult outcomes, but that don’t control for genetics. These studies are all complete garbage. (Turkheimer agrees with this.)
And this kind of thinking is deep in the popular consciousness. Ask anyone on the street why they’re depressed, anxious, narcissistic, neurotic, smart, conservative, or whatever, and it’s a safe bet that they’ll talk about things that their parents did with them, or to them. It’s just so easy to see an outcome and make up a post hoc plausible-sounding story explaining it. Those stories feel true, but they are not to be trusted.
(There are also of course studies claiming that childhood events cause adult outcomes, that are also garbage, but for different reasons besides genetic confounding. Like the famous one about kindergarten teachers: their one positive result was almost certainly a random fluke. And here’s one that finds that adoptive parents are harsher towards their callous-unemotional kids; but rather than offer the obvious, sensible explanation—that parents react to their kids’ personalities—they propose instead that parents are sculpting the kids like a hunk of marble. I propose that the authors of that paper should be banned from further research until they have had two or more children.)
…And yes, all this applies to you too, dear reader.
You shouldn’t say “I’m liberal because I was raised in a liberal household”. You also shouldn’t say “I’m liberal because I was raised in a conservative household, and rebelled against that”.
(Even leaving aside the fact that , the fact that people say both those things is a good reason for skepticism, right?)
…Instead, you should just say those magic five words: “I don’t know the counterfactual”!
3. Maybe you care about heritability because: you’re trying to figure out whether you can change something about yourself through “free will”
For example, if you’re sad, maybe you can proactively figure out how to be happier. Read a book. Take a drug. I dunno.
Heritability studies are completely uninformative on whether something like this will work or not, because “deciding to apply your free will to try to change something about yourself” is itself an “outcome”, and thus heritable like everything else.
This observation cuts both ways:
- If you think everything is preordained, so you might as well not try hard to be your best self, then sorry, that’s not how it works.
- If you think that the heritability statistics don’t apply to you, because you are energetically applying your free will to be your best self every day, sorry that’s not how it works either! The fact that you’re energetically applying free will to be your best self is to some extent already “priced in” to the heritability statistics.
The takeaway is just the common-sense one: regardless of the heritability statistics, if you want to be your best self, you need to try. Do self-experiments. Search for anecdotes. Learn from the rare psych intervention study that isn’t p-hacked garbage. Do the best you can.
(There’s an old joke in the free will compatibilism philosophy literature: “I don’t know why Stockfish examined 100 million board positions of the game tree before making its move. It’s a deterministic algorithm! Its move was predetermined! Man, what a waste of electricity!”)
…But at the same time, if you’re really doing the best you can do, then don’t beat yourself up for not achieving more—just as you shouldn’t beat yourself up for lacking magical superpowers.
4. Maybe you care about heritability because: you want to create or use polygenic scores (PGSs)
The idea of a polygenic score is that, if some percent of variation in some outcome is attributable to genes, we can in theory just look at their genome and infer the genetic component of the variation. Insofar as this works, it has lots of applications.
For one thing, you can assess your own risk of eventually developing some mental or physical condition—say, alcoholism—and then perhaps take steps to prevent or mitigate it. We can already do that to some extent via family history, but a polygenic score (in theory!) could do it much better. For example, one sibling might be at more genetic risk for alcoholism than another, but siblings always have the exact same family history—i.e., the same number of n’th-degree relatives with alcoholism. Also, family history is not always available, or not always informative. For example, maybe you don’t know who your biological family is. Maybe there’s no alcoholism in your biological family, but only because your biological family consists entirely of Muslims living in Bangladesh, a country where alcohol is illegal and rare, but you live in the USA and converted to Baptism, so that family history doesn’t teach you anything.
There’s also embryo selection. For example, suppose you’re worried about your child being an alcoholic (e.g. because there’s family history), and you’re doing in vitro fertilization (IVF) anyway for some other reason. So you’re already in the position of implanting some embryos but not others, and you might already also have the genomic data of each. Then maybe you want to consult a polygenic score for alcoholism. There are debates about the ethics and wisdom of this activity, but here I’m just focusing on the scientific question: would that even work?
Turkheimer’s book has a lot of pedagogical discussion, which I will quote liberally in order to establish some background:
4.1 Single-Nucleotide Polymorphisms (SNPs)
Turkheimer p93:
Some background: our genome is made up of two very long strands of DNA. Each strand is a sequence of just four nucleotides: adenine (A), cytosine (C), guanine (G), and thymine (T). (Genes are sequences of these nucleotides.) At most positions on the genome, people don’t vary, but at some of them, people can take one of two values. These are called single nucleotide polymorphisms (SNPs, pronounced “snips”). In the early 2000s, technology was developed that allowed SNPs at many positions—tens of thousands initially, millions now—to be assessed quickly and cheaply. … For a few hundred dollars and some saliva in a tube, we can take a detailed snapshot of someone’s entire genome.
The technology he’s referring to is called a SNP array. A full genome sequence for each person would theoretically be better than a SNP genotype, but that’s expensive—remember, these studies may involve more than a million participants—and I think there are other technical issues too, like higher error rates. More on the limitations of SNP arrays in §4.3.2 below.
4.2 Genome-Wide Association Studies (GWASs), Polygenic scores (PGSs), and the Missing Heritability Problem
Turkheimer p105 introduces the basic idea:
One way to state the limitation of the heritability concept is that it is always a property of the population, not of individuals. If , the quantity of 40% refers to the population variance; it has no meaning in an individual person. It makes no sense to say that 40% of your educational attainment comes from your genes. GWAS [Genome-Wide Association Study], however, allows us to do something at the individual level that cannot be accomplished in twins. Let’s do height. Every SNP on a microarray has some very small correlation with height, and every person has a value for each SNP on the chip. We can take those values, weight them by the direction and size of their relationship with height, and add them together for each individual. This results in a numerical score for individual people that summarizes the total relationship of their genomic values with height, or indeed for any trait on which people differ. It has had a lot of names over the years. I will call it a polygenic score, or PGS.…
…It took a while, but polygenic scores to predict height are now remarkably effective, accounting for around 40% of the variance, enough to provide real information. Polygenic scores for medical conditions like diabetes and heart disease are at least close to the point where they might be useful clinically. The practical and bioethical questions surrounding when and if it might be a good idea to use PGS for any particular purpose are very complex, and we will mostly not get into them here, but it is important to know that for things like height, they work pretty damn well. Results for human behavior are much less compelling. For educational attainment, the EA4 study achieved about 15% of the variance, a correlation of around 0.4, which is certainly not trivial. I note, however, (a) we know essentially nothing about the causal basis of that relationship, and PGS are designed to ignore causal processes; (b) to the extent we do know anything, per the next development to be discussed, the effectiveness of the [Educational Attainment (EA)] PGS has been substantially reduced; (c) the effectiveness of all PGS is greatly reduced the farther one gets from the population in which it was originally estimated, for example a height PGS estimated in Europeans does not work very well in Africa; and (d) the EA PGS, studied intensively and easily measured, is much more effective than PGS for most other behavioral traits, many of which are barely different from zero. Let’s take these one at a time…
He discusses (a) and (c) a bit, then gets back to (d) on p107:
Finally, for most behavioral traits, PGS just don’t work very well. As I already mentioned, these days they do work well for height, and pretty well for some medical conditions or metabolic traits. The best PGS for EA accounts for 15% of the variance, which is superficially impressive, but see below. For most other behavioral traits for which we might hope to have good PGS, however, such as personality or depression, they barely work at all, consistently accounting for under 5% of the variance.…
Then finally, as a kicker, he circles back to (b) starting p109:
Suppose there was some bit of DNA that was correlated, in a red-haired kid sort of way, with being from an impoverished family. If being raised in an impoverished family has a negative effect on EA, the poverty-SNP will be correlated with EA and included in the PGS. However (and here is the crucial insight), that SNP will only contribute to prediction across people in different families that differ in their poverty levels, not to differences between siblings raised in the same family, who necessarily share their family’s socioeconomic status.
The first thing sibling comparisons do is control for population stratification. A SNP that is correlated with chopstick use in a [USA population consisting of half Asian immigrants and half European immigrants] will not predict chopstick use within pairs of Asian siblings, because they share the Asian culture which is the true cause of chopstick use. Sibling comparisons also control for other “family-level” effects like parental socioeconomic status. SNP correlations within sibling pairs are known as direct effects; correlations that only exist at the family level are called “indirect,” because the correlation is mediated by a characteristic of the family, outside the individual’s body. The designation of within-sibling effects as “direct” is sometimes taken to mean they are straightforwardly causal, especially because of the random genetic assortment that produces differences between siblings. One has to be cautious about this, however. Sibling comparisons don’t control for everything. In particular, they wouldn’t control for red-hair effects. Siblings differ in hair color, and in a ginger-hating society, the red-haired sibling would be expected to fare worse than the brunette. As always, ascribing causation without true experimentation is a dicey business.
Just to interject, I would describe this redhead example differently: yes the ginger genes are causal; they’re just not straightforwardly causal. Rather, the causal pathway routes through the environment. In and of itself, causal pathways that route through the environment are quite common, even for genes that we think of as straightforwardly causal! For example, consider a gene that “causes” obesity by making you feel hungry all the time so you eat a lot. This gene’s causal pathway also routes through the environment, in the sense that the gene only causes obesity if the environment does contain ample food, and doesn’t contain effective anti-obesity drugs.
Anyway, continuing with Turkheimer’s discussion:
The expectation is that to some extent, PGS correlations estimated in unrelated people across families, which include all of the indirect noncausal family-level confounds, will be higher than those for within-family sibling comparisons, for which those confounds have been controlled. That is indeed how things work out, especially for behavioral phenotypes. In EA3, for example, where the PGS accounted for 11% of the variance among unrelated people, it only accounted for 3–4% of the variance within sibling pairs. In a particularly interesting way, behavioral traits look quite different than physical traits in this regard. The height PGS, for example, works pretty much as well within sibling pairs as it does across families. This makes sense: presumably, the causal agents making you taller than me are the same as the causes of one sibling being taller than the other. In contrast, the reasons that a person from a rich family is better educated than a person from a poor family are probably different from the reasons one sibling is better educated than another.
After all this, it turns out there is an even more interesting way to demonstrate direct and indirect genetic associations. This method uses parents and their children. Think of how you obtained your PGS for EA. You inherited half of your mother’s SNPs and half of your father’s. Combined, weighted, and summed, these inherited SNPs form your PGS. But that process of inheritance also implies that you did not inherit the other half of your mother’s and your father’s SNPs. These non-inherited SNPs can also be weighted and combined to form a second PGS, one that remained with your parents, never making it into your body. It turns out that your non-inherited PGS also predicts your EA, even though the SNPs that compose it don’t reside in your body. …In EA4, the EA PGS accounted for 13% of the variance across unrelated people. When controlling for indirect effects from parental DNA, the direct effect was reduced to 3%. For the height PGS, in contrast, the total variance accounted for was 34%; controlling for parental DNA, the direct effect was 28%, a much smaller reduction.
As another interjection: Recall from §2.2.4 above that EA is one of the few measurements on adults for which twin and adoption studies show a strong shared-environment effect. So the indirect effects in EA are really what we should have expected all along, and isn’t representative of all outcomes. Indeed, when we get to my own bottom-line summary in §4.4.2 below, the shared-environment-sensitive outcomes like EA will get their own special category.
Moving on to p113, Turkheimer sums up the situation as follows:
Modern genomics of human behavior has had a very surprising result: it has decreased estimates of heritability from where they stood 50 years ago in the twin study era. The common assumption back then was that the heritability of pretty much everything was around 0.5, if not higher, and no matter how skeptical one becomes about the causal meaning of the second decimal place of heritability coefficients, more than half the variance is a lot to reckon with. But with SNP heritabilities, and then PGS as real-world instantiations of SNP heritabilities, and then SNP heritabilities and PGS that have been appropriately corrected for between-family effects, those numbers are a lot closer to 0.1 than they are to 0.5. For many traits (personality, most forms of psychopathology) they are closer to 0.01.
Those of us who consider ourselves anti-hereditarians should be reminded that there is no good reason to expect heritability coefficients to be cold stone zero. I have three children, all wonderful and all different. The reasons they are different are very complicated, and there is no specific scientific explanation of them, but if you were to tell me that 5% of the differences (reminding ourselves that the heritability metric does not apply to single families) were the result of (unknown) inborn genetic differences, would that be surprising, or a harbinger of either miraculous genetic explanations of human differences, or a hereditarian threat to human self-determination? I don’t think this conclusion would have surprised our great-grandparents; I don’t think it would have surprised Darwin’s great-grandparents. Apples, trees, and so forth.
This quote makes it clear that Turkheimer, in some sense, views the low within-family GWAS numbers as “correct”, and the high twin and adoption numbers as “incorrect”. Or at least, that’s the vibe he’s conveying. If so, is that a reasonable perspective? Following the theme of this post, it depends on the question you’re asking. If you’re asking the questions that motivated §1–§2 above, then I think those discussions above, with their high numbers, are as valid as ever. Whereas if you want to apply polygenic scores to embryo selection, you should clearly be using the much lower numbers that you get from SNP heritability corrected for between-family effects. And finally, if Turkheimer wants to understand why his three children are different from each other, as in the excerpt above, then I think I disagree with Turkheimer using “5%” in that context; I think the 50%-type numbers would have been more appropriate. After all, if they had been identical triplets, they would have been much more similar, not just slightly more similar.
(I think Turkheimer would agree that his kids would be much more similar if they had been identical triplets, but his perspective is that this doesn’t count as genetic causation because the causal pathways are complex, and route through the environment? I’m not sure though.)
Of course, the question looming over this discussion is: whence the giant discrepancy between the high numbers like 0.5, and the low numbers like 0.05? How do we reconcile those?
…And this is the “Missing Heritability Problem”!
4.3 Missing Heritability Problem: Three main categories of explanation
4.3.1 Possibility 1: Twin and adoption studies are methodologically flawed, indeed so wildly flawed that their results can be off by a factor of ≳10, or even entirely spurious
I talked about this in §1.5 above. I don’t buy it.
Turkheimer also doesn’t subscribe to this school of thought. Here’s p77 of his book:
I had been around too much twin data to believe it could all be the result of shoddy research methods and statistics. Identical twins really are more similar than any other pairs of people in the known universe. The correct rebuttal is not about the existence of identical twin similarity, but rather its meaning.
Or, again, on his blog:
Are you really ready to think that the only reason MZ twins are so similar is that their parents dressed them the same? (I agree, and have said many times, that the EEA is a very good reason not to obsess over whether the heritability of something is .4 or .6…)…
4.3.2 Possibility 2: GWAS technical limitations—rare variants, copy number variation, insufficient sample size, etc.
GWAS has historically only accounted for relatively-common SNPs, which leaves out some other sources of genetic variation. Hill et al. 2018 mentions “rare variants, copy number variants (CNVs) and structural variants”.
(Harris et al. 2024 says that there exist methods to extract CNVs from SNP data, but that they’re not widely used in practice today.)
Additionally, given finite sample size (plus genotype measurement noise), the polygenic score that we infer from our data is a noisy version of the ideal polygenic score, and this noise reduces its explanatory power.
There’s also phenotype (i.e., trait or outcome) measurement noise. Officially, that kind of noise should be off-topic—in ACE terms, it’s part of E, not A (see §1.4 above). But GWAS sample sizes tend to be much larger than twin and adoption study sample sizes, and thus GWAS researchers may (by necessity) rely on less-expensive, but noisier, phenotype measurement methods, at least in some cases. That could account for some lowering of percent-variance-explained in GWASs, compared to twin and adoption studies. I saw someone mentioning this factor in the context of IQ heritability measurements here.
(The claim in that last sentence traces back to Fawns-Ritchie & Deary 2020, which says that when people took the UK Biobank cognitive tests twice, four weeks apart, the test-retest correlation was Pearson r = 0.55. And when they also took “a range of well-validated cognitive tests (‘reference tests’)”, the correlation with the UK Biobank cognitive tests was “mean Pearson r = 0.53, range = 0.22 to 0.83”. I might well be screwing up the math here, but I thought that if some input explains X% of the variance of some outcome, then it explains of the variance of a noisy measurement of the outcome. So for , we’re lowering percent-variance-explained by a factor of >3, e.g. from 50% to 15%, I guess? Wow, that’s huge. That can’t be right, can it??)
Anyway, to the extent that the Missing Heritability is somewhere in this “GWAS technical limitations” category, then future better GWAS studies, with ever-larger sample sizes, and with ever-better measurements of genotypes and phenotypes, would find progressively less Missing Heritability.
4.3.3 Possibility 3: Non-additive genetics (a.k.a. “a nonlinear map from genomes to outcomes”) (a.k.a. “epistasis”)
As mentioned in §1.1 above, an additive genetic contribution would be something like: if you have gene variant 838723, then your expected height will be 34 μm higher than if you don’t; and if you have gene variant number 438061, then your expected height will be 12 μm lower than if you don’t; etc. Add up thousands more things like that, and that’s the genetic contribution to your height.
In linear algebra terms, “additive” means that the genetic contribution to height, viewed as a function from genome (viewed as a point in the high-dimensional abstract space of all possible human genomes) to height, is a linear function.
A non-additive map from genome to height (a.k.a. “epistasis”), by contrast, might for example involve gene × gene interactions: if you have both of a certain pair of gene variants, then that adds 17 μm to your height, etc. There could also be gene × gene × gene interactions, and so on.
If there are strong non-additive genetic effects, then there will be a lot of Missing Heritability: the polygenic scores (PGSs) will only explain a tiny fraction of population variation, because the effects cannot be traced to individual SNPs.
Now, the idea that non-additive genetics might explain the Missing Heritability Problem is well known. People usually cite Zuk et al. 2012 as an early exposition of this possibility. That paper uses the term “phantom heritability”, which I think conveys a vibe that the real heritability was low all along. But really, in the lingo, there’s “narrow-sense heritability” (just the additive contribution of genome to outcome) and “broad-sense heritability” (the total contribution of genome to outcome, whether additive or non-additive). The Zuk et al. paper is merely claiming that there may be “phantom” narrow-sense heritability. The broad-sense heritability is as “real” as ever.
Importantly, I think the nature of non-additive genetics is widely misunderstood. If you read the wikipedia article on epistasis, or Zuk et al. 2012, or any other discussion I’ve seen, you’ll get the idea that non-additive genetic effects happen for reasons that are very “organic”—things like genes for two different mutations of the same protein complex, or genes for two enzymes involved in the same metabolic pathway.
But here is a very different intuitive model, which I think is more important in practice for humans:[9]

As some examples:
- It’s conventional wisdom in Machine Learning that the “learning rate” has a sweet spot—if it’s either too high or too low, the learning algorithm doesn’t learn as well. If so, that would be a nonlinear (U-shaped) map from certain “traits” to certain “outcomes”. (The “outcomes” here might not include IQ, which is more about figuring things out quickly, but would include longer-term intellectual accomplishments.)
- You can dislike an activity because it’s understimulating, or you can dislike it because it’s overstimulating. Either way, you would engage in that activity less, and over time, wind up unusually bad at it from lack of practice. That would again be a nonlinear (U-shaped) dependence in the map from “traits” to certain “outcomes”. I presume it would show up in personality surveys, along with certain life outcomes.
- I think the antisocial personality disorder (ASPD) diagnosis gets applied in practice to two rather different clusters of people, one basically with an anger disorder, the other with low arousal [LW · GW]. So the map from the space of “traits” to the outcome of “ASPD” is a very nonlinear function, with two separate “bumps”, so to speak. The same idea applies to any outcome that can result from two or more rather different (and disjoint) root causes, which I suspect is quite common across mental health, personality, and behavior. People can wind up divorced because they were sleeping around, and people can wind up divorced because their clinical depression was dragging down their spouse. People can seek out company because they want to be widely loved, and people can seek out company because they want to be widely feared. Etc.
- I dunno, maybe “thrill-seeking personality” and “weak bones” interact multiplicatively towards the outcome of “serious sports injuries”. If so, that would be another nonlinear map from “traits” to certain “outcomes”.
All of these and many more would mathematically manifest as “gene × gene interactions” or “gene × gene × gene interactions”, or other types of non-additive genetic effects. For example, in the latter case, the interactions would look like (some gene variant related to thrill-seeking) × (some gene variant related to bone strength).
But that’s a very different mental image from things like multiple genes affecting the same protein complex, or the Zuk et al. 2012 “limiting pathway model”. In particular, given a gene × gene interaction, you can’t, even in principle, peer into a cell with a microscope, and tell whether the two genes are “interacting” or not. In that last example above, the thrill-seeking-related genes really don’t “interact” with the bone-strength-related genes—at least, not in the normal, intuitive sense of the word “interact”. Indeed, those two genes might never be expressed at the same time in the same cell. One gene might be expressed exclusively in the embryonic neural plate, while the other gene is expressed exclusively in ankle bones during puberty. Doesn’t matter. As long as their downstream effects get multiplied together en route to this specific outcome, namely sports injuries, it’s still a bona fide “gene × gene interaction”.
As far as I can tell, if you call this toy example “gene × gene interaction” or “epistasis”, then a typical genetics person will agree that that’s technically true, but they’ll only say that with hesitation, and while giving you funny looks. It’s just not the kind of thing that people normally have in mind when they talk about “epistasis”, or “non-additive genetic effects”, or “gene × gene interactions”, etc. And that’s my point: many people in the field have a tendency to think about those topics in an overly narrow way.
Incidentally, Turkheimer’s preferred solution to the Missing Heritability Problem for behavioral and mental health outcomes (IIUC) involves non-additive genetic effects, and has some slight overlap with my discussion in this section, but he describes it rather differently. He talks about it in a series of posts on his blog (part 1, part 2, part 3, I think another is forthcoming). For example, from part 2:
…individual differences in complex human characteristics do not, in general, have causes, neither genetic nor environmental. Complex human behaviour emerges out of a hyper-complex developmental network into which individual genes and individual environmental events are inputs. The systematic causal effects of any of those inputs are lost in the developmental complexity of the network. Causal explanations of complex differences among humans are therefore not going to be found in individual genes or environments any more than explanations of plate tectonics can be found in the chemical composition of individual rocks.
I agree with certain parts of this, but I think he’s throwing up his hands too soon. Turkheimer’s excerpt here does not seem compatible with the “mostly additive” nature of many traits (more on which shortly), nor with the obvious similarity of adult identical twins who were raised by different families in different cities. Those aren’t what I’d expect from a “hyper-complex developmental network”, nor from his mental image (in the posts) of a “quincunx”.
I prefer my little two-step diagram above. I think it’s more compatible with everything we know. And it implies a more hopeful picture where at least some components of that diagram may gradually crystallize into view.
4.4 Missing Heritability Problem: My take
4.4.1 Analysis plan
Given a trait / outcome, here’s how I propose to go about diagnosing its Missing Heritability:
Step 1: Check adoption studies to see if there’s a significant shared environment effect for this trait / outcome. Don’t take the exact numbers too literally, since there’s some non-randomness in which adoptive children are matched with which parents (see §1.5.6 above), but if biological siblings are about as similar when they’re raised together versus apart, and/or if adoptive siblings are about as different as randomly-selected members of the study population, then it’s a good guess that shared-environment effects are not a big part of the explanation of why people vary along this dimension, for the population in question.
OK, let’s assume that we find the common result (for adult traits, see §2.2) that shared-environment effects are not a big source of population variation. Next:
Step 2: Check whether the trait has substantial non-additive genetic effects. If you can’t find a proper analysis of this question in the literature, then in a pinch, you just pull up a classical twin study for the trait; the tell-tale sign of strong non-additive genetics is —because, as mentioned in §1.5.5 above, DZ twins share half their gene variants, but only a quarter of pairs of gene variants, eighth of triplets, etc.
(Again, checking for is a quick trick, not a rigorous rule. A better picture is that the ratio starts at ½, and then gets pulled down if there’s non-additive genetics (§1.5.5), but also gets pulled up if there are shared-environment effects (§1.3), or assortative mating (§1.5.2), among other things. We can only see the net effect of all those influences, when we look at classical twin study . That said, we can often rule out strong shared-environment effects via adoption studies (Step 1 just above). As for assortative mating, I think it tends to be nonzero but not huge, and for some traits you can find it quantified in the literature.)
Step 3: If there isn’t much shared-environment effect, and there isn’t much non-additive genetic effects, then whatever Missing Heritability there is, is probably (IMO) mostly in the category of GWAS technical limitations. Maybe you can write a letter to your congressperson asking for more funding for (even) bigger and better GWAS studies, or whatever.
4.4.2 Applying that analysis plan to different traits and outcomes
I didn’t go through this three-step plan very systematically, but here’s my impression so far:
1. Adult height, metabolism, blood cell count, etc. seem (at a glance!) to have in adoption studies, and also in classic twin studies, and I think something like half their heritability is missing in the latest studies. I think that this missing half of the heritability comes mostly[10] from GWAS technical limitations.
2. Adult IQ is I think also in that same “height etc.” category, more-or-less, although I didn’t look into it much. I refer interested readers to a recent back-and-forth debate, see “51” here. Also, as mentioned in §4.3.2 above, for this trait in particular, in addition to the half-or-so of heritability missing due to GWAS technical limitations, there’s probably a bunch of extra Missing Heritability from the fact that GWASs measure the phenotype in a more noisy way than the best twin studies do.
3. Adult personality, mental health, and behavioral outcomes seem (at a glance) to have in adoption studies, in classic twin studies, and a much larger amount of Missing Heritability than the half-or-so numbers suggested above. Taking those together, they strongly suggest that non-additive genetic effects are the main explanation for the extra Missing Heritability of these outcomes. I think this makes intuitive sense, in light of the discussion in §4.3.3 above. And here’s some evidence in the literature:
Box: Twin-study evidence of non-additive genetic effects on adult personality, mental health, and behavior
- Turkheimer’s book repeatedly brings up the twin study McGue & Lykken 1992, which found that divorce is heritable; the combined sample in that study has but , much less than half. (That paper doesn’t mention non-additive genetics; rather, it just ignores the negative C by saying “the proportion of variance associated with shared environmental factors was estimated at a boundary value of zero”!!)
- Maes et al. 2022 has a good discussion of the sign of C in twin studies, along with graphs showing for things like height but for things like ADHD.
- Van der Linden et al. 2017 finds that personality traits fit a “DE” model better than an “ACE” model. (D is non-additive a.k.a. broad-sense heritability.)
- An excerpt here says: “in a large twin family study of neuroticism, Finkel and McGue (29) reported biological sibling correlations of 0.07–0.14 and parent–offspring correlations of 0.12–0.19, less than half of the corresponding MZ correlations of 0.42–0.49…”.
OK, next, a bit more in the weeds. There’s a meta-analysis of twin studies—Polderman et al., 2015—which compiled vs for ≈18,000 traits across ≈3000 studies. They only find robust evidence for non-additive genetic effects () for hyperkinetic disorders (ADHD, more-or-less), out of a very long list of possibilities. But that particular claim involved mixing together studies on children and adults—and remember, children have more shared-environment effects, which push in the opposite direction as non-additivity in the data.
For adult-only results, I tried squinting at the tiny numbers in the third row of Fig. 3, looking through the pairs, and found a couple more apparent non-additive genetic effects (“function of brain” (.65, .19), “higher-level cognitive functions” (.68, .28)), along with a few apparent shared-environment effects () (“endocrine gland functions” (.53, .37), “mental and behavioral disorders due to use of tobacco” (.69, .41), “structure of mouth” (.89, .52)). I don’t know what “function of brain” or “higher-level cognitive functions” mean; as mentioned, my current weakly-held guess is that IQ is more linear, but adult intellectual accomplishment, which involves things like long-term learning and motivation, is probably more nonlinear. The idea that tobacco use has shared-environment effects seems very plausible, given that most smokers start the habit while still living with their parents. I have no idea what to make of “endocrine gland functions” and “structure of mouth”. (Childhood orthodontics??) Oh well. I didn’t check which of these are statistically significant anyway.
Interestingly, “depressive episode” shows little sign of non-additive genetics——which raises the question of why depression has so much Missing Heritability. Maybe the twin-study question wording included depressive episodes during childhood, such that there’s some shared-environment effect, and that cancels out the non-additive genetics in this data? Or maybe non-additive genetic effects can manifest rather weakly in MZ-DZ comparisons while still strongly impacting Missing Heritability? (I think there’s some analysis to that effect in the Zuk et al. 2012 supplementary information.) Shrug, I dunno. I’ll leave further analysis as an exercise to the reader.
4. Traits with strong shared-environment effects include Educational Attainment (EA), and almost anything measured during childhood, and a few other examples discussed in §2.2 above. Basically, EA is (in part) a roundabout way to measure the socioeconomic status / class of one’s childhood home. So we expect this to be a case where the predictivity of a polygenic score (PGS) is mostly “indirect”—i.e., the fraction of variance explained by the PGS may plummet when correcting for between-family effects. These kinds of traits are also places where I would intuitively be open-minded to gene × shared environment interactions, as in my exaggerated toy example of §1.5.3 above, but I guess the empirical data (cited in that section) shows that it’s not a major contributor, at least in the case of EA. Anyway, all of those things would contribute to Missing Heritability, on top of the usual GWAS technical limitations. (And in some cases, there might be non-additive genetic effects too.)
Incidentally, Hill et al. 2017 claims to have some fancy methodology that estimates the “GWAS technical limitations” category. They find that they can more-or-less resolve all the Missing Heritability for intelligence and Educational Attainment (EA), but not for neuroticism or extroversion. I didn’t try to follow that paper in detail, but if it’s true, then that’s beautifully consistent with my hypotheses above.
4.4.3 My rebuttal to some papers arguing against non-additive genetics being a big factor in human outcomes
The first thing to keep in mind is: for the kind of non-additive genetic effects I’m talking about (§4.3.3 above), there would be a massive number of “gene × gene interactions”, each with infinitesimal effects on the outcome.
If that’s not obvious, I’ll go through the toy example from above. Imagine a multiplicative interaction between thrill-seeking personality and fragile bone structure, which leads to the outcome of sports injuries. Let’s assume that there are 1000 gene variants, each with a tiny additive effect on thrill-seeking personality; and separately, let’s assume that there’s a different set of 1000 gene variants, each with a tiny additive effect on fragile bones. Then when you multiply everything together, you’d get 1000×1000=1,000,000 different gene × gene interactions involved in the “sports injury” outcome, each contributing a truly microscopic amount to the probability of injury.
In that model, if you go looking in your dataset for specific gene × gene interactions, you certainly won’t find them. They’re tiny—miles below the noise floor. So absence of (that kind of) evidence is not meaningful evidence of absence.
The second thing to keep in mind is: As above, I agree that there’s not much non-additive genetic effects for traits like height and blood pressure, and much more for things like neuroticism and divorce. And many papers on non-additive genetics are looking at things like height and blood pressure. So unsurprisingly, they don’t find much non-additive genetics.
OK, so here’s a quick review of some papers I’ve come across:
- The paper “Estimation of non-additive genetic variance in human complex traits from a large sample of unrelated individuals” (Hivert et al., 2021) has both the above problems. Their trait list is in Table S3, and they all feel intuitively much more like height than like divorce. And their signal-to-noise ratio is so low that they can’t really conclude much anyway. (“The lack of evidence for the additive-by-additive variance in our analyses is mostly due to the very large sampling variance…”)
- The paper “Detecting epistasis in human complex traits” (Wei et al., 2014) finds an absence of evidence for epistasis, but acknowledges that if there were a huge number of gene × gene interactions, each with a tiny effect, then we would have no chance of discovering that fact.
- The paper “Data and Theory Point to Mainly Additive Genetic Variance for Complex Traits” (Hill et al., 2008) doesn’t list most of the traits they look at, but the ones they do list are things like height and blood pressure, for which I wasn’t expecting much non-additivity. They have a handy histogram of for different traits in classical twin studies, and the average is zero, but there’s actually a substantial spread into both positive and negative territory! They seem to treat the positive values as noise, rather than meaningful evidence of non-additive genetic effects. Maybe that’s right, or maybe not; they don’t explain it or show error bars.
4.5 Implications for using polygenic scores (PGSs) to get certain outcomes
Some people in my professional circles talk about using PGSs to get certain outcomes, including “being very good at solving difficult problems” [LW · GW] and “robust mental health”. Setting aside lots of other potential issues, a technical issue related to the above discussion is that PGSs barely work at all if there’s a lot of non-additive genetics. To be clear, analyzing the genome to guess highly-non-additive traits is not impossible in principle. But it would require some profound methodological advance. It’s not just a matter of increasing the GWAS sample size etc.
Anyway, of those two items: “Robust mental health” almost definitely has a lot of non-additive genetics, as mentioned above. And “being very good at solving difficult problems”, I expect, will also have lots of non-additive genetics, even if IQ itself does not—because there’s much more to solving difficult problems than just IQ, which is mostly about fast pattern recognition and such. Solving difficult problems also involves motivation, personality, and figuring things out over the long term.
Indeed, if you look around, I think you’ll see many exceptionally bright people with massive blind spots propped up by motivated reasoning, self-aggrandizement, and ad hominem attacks.
And conversely, here’s a quote by a professional mathematician:
I've had the chance...to meet quite a number of people…who were much more brilliant, much more ‘gifted’ than I was. I admired the facility with which they picked up, as if at play, new ideas, juggling them as if familiar with them from the cradle - while for myself I felt clumsy, even oafish…faced with an amorphous mountain of things that I had to learn (so I was assured), things I felt incapable of understanding…
You know who wrote that? It was fucking Alexander Grothendieck, an absolute legend, widely regarded as the greatest mathematician of the 20th century. (See 1 [? · GW], 2 [? · GW], 3 [LW · GW].)
One more thing: I think the people interested in the “being very good at solving difficult problems” trait, want to push it to the extremes of the human distribution, or even beyond. And that adds another technical problem. Even if you find a target that seems not to have much non-additive genetics—well, just because a genome-outcome relationship is mostly linear in-distribution (i.e., within a naturally-existing human population), doesn’t mean that it will also be mostly linear (and with the same linear relationship) out-of-distribution. Indeed, it doesn’t even mean that it will be mostly linear (and with the same linear relationship) on the outer fringes of the existing natural distribution. (But it might be possible to check that latter part from existing data.)
Remember, as a general rule, lots of things are approximately linear when you don’t push them too far, but the linearity breaks down when you do—see Taylor series, linear approximation, etc.
5. Maybe you care about heritability because: you hope to learn something about how schizophrenia, extroversion, and other human traits work, from the genes that “cause” them
We learned a lot about eye color by finding the responsible genes. And we learned even more about Huntington’s disease. Well, if schizophrenia and introversion and everything else is heritable too, then maybe pinpointing the responsible genes will likewise help us understand those conditions?
Eric Turkheimer has a strong opinion, and his opinion is: Nope! Not gonna work. Not now, not ever.
To understand Turkheimer’s perspective, I think some historical context is helpful. Back in the day (I think 1990s and 2000s), people were hoping that there would be, for example, “genes for schizophrenia”, the way that there are genes for eye color and Huntington’s disease. People searched for, and found, so-called “candidate genes” for all sorts of things. Then GWASs came along, and it turned out that that whole literature was garbage. None of the “candidate genes” reproduced. Scott Alexander amusingly describes one example, “5-HTTLPR”, in a blog post here, or see Duncan et al. 2019 for a broader and more sober discussion of the whole fiasco.
It turns out that schizophrenia, intelligence, obesity, and so on, are just very different from eye color and Huntington’s disease. They’re impacted by thousands of gene variants, each with a tiny effect.
Anyway, I think people were historically hoping that gene studies would be a magic bullet for our nuts-and-bolts understanding of mental health, personality, and so on. If so, yeah that school of thought is wrong, and Turkheimer is justified in pushing back against it.
Still, I think Turkheimer is overstating his case. I think that one can reasonably expect gene studies to be slightly informative on the margin for these kinds of questions.
For one thing, Duncan et al. 2019 writes: “Based on available GWAS of psychiatric disorders, one important take home message is already clear: large effect variants – meaning variants that explain a substantial amount of phenotypic variance in the population – do not exist. In contrast, some very rare genetic variants have large per-allele effects on schizophrenia (e.g. odds ratio > 10) [31].”
…OK, so thanks to GWAS, we have found certain gene variants that make people >10× likelier to have schizophrenia (i.e., something like likely rather than likely). And we can go study what those particular gene variants do. I’m not an expert, but that seems like a pretty helpful lead to have in our back pocket, as we try to mechanistically understand schizophrenia, right? I don't know what if anything has come of this type of study to date, but it would surprise me if it were forever completely useless.
For another thing, Turkheimer acknowledges that you can statistically analyze the thousands of genes that correlate with some mental health condition or personality trait, and see if they have any common patterns. For example, p103:
It can be shown that more of the genes associated with both positive ([Educational Attainment]) and disadvantageous (schizophrenia) behavioral traits are more likely to be involved in brain processes than would be predicted by chance. This demonstrates that GWAS results are not random, but it is a long way from ‘specific genes that affect experience.’ It’s great to confirm that differences in educational attainment have something to do with the brain, but it is hardly stop-the-presses news.
I think his mocking conclusion in the last sentence is unwarranted. Turkheimer is being overly dismissive. Yes, “something to do with the brain” is unhelpful, but slightly more detailed (“something to do with myelination”, “something to do with dopamine”, etc.) would be a potentially useful and nontrivial hint as to what’s going on, and is still plausibly achievable.
Likewise, studies like Grotzinger et al. 2022 are (I think) based on the idea that, if there are a bunch of genes that increase or decrease the risk of multiple outcomes at once, in the same ratios, then there’s probably a “common pathway” through which those particular genes cause those outcomes. That seems like a plausibly useful type of thing to figure out!
I think this is related to the non-additive genetic effects discussion in §4.3.3 above. If there’s a linear(ish) map from genes to certain latent variables (let’s call them “traits”), and then there’s a highly-nonlinear map from those “traits” to outcomes like neuroticism, then that seems like the kind of thing that careful behavior genetics analysis ought to be able to tease out. If they do, what exactly is the list of “traits” that they would find? I myself am extremely interested in an answer to that question, and will probably read up on that literature at some point in the future.
…But still. If people have historically talked up gene studies as a magic bullet in the quest to understand mental health and personality, handing us mechanistic explanations on a silver platter—as opposed to “contributing some helpful hints”—then I think Turkheimer is right to pour cold water on that.
(If you want mechanistic explanations on a silver platter, you should instead … read my blog posts, of course!! I have grand theories about schizophrenia (1 [LW · GW],2 [LW · GW]), and autism and psychopathy [LW · GW], and NPD, depression, and mania [LW · GW], and DID [LW · GW], and more! You’re welcome!)
6. Other things
People talk about heritability for other reasons too, for better or worse—culture, inequality, society, and more. I have no professional interest or expertise in these areas, and the debates about them tend to turn into horrific toxic flaming dumpster fires that I don’t want to read, let alone participate in.
Turkheimer has very strong opinions on these matters (on the “anti-hereditarian” side), and you can read his book for lots of arguments. But interestingly, Turkheimer also says some nice things about the book The Genetic Lottery: Why DNA Matters for Social Equality, by his former student Kathryn Paige Harden. Unlike Turkheimer, Harden is much more willing to ascribe a straightforward causal role of genetics in intelligence and other traits. But Harden reaches essentially the same sociopolitical conclusions as Turkheimer (according to Turkheimer). I didn’t read Harden’s book, but I presume that those conclusions are things like “racism is bad”, “we should help the downtrodden”, “don’t be an asshole”, and so on—conclusions that I myself enthusiastically endorse as well. (See also: this Bryan Caplan post.) So, conveniently for us, it’s evidently possible for people on both sides of this scientific question to come together and agree on policy.
7. Conclusion
I don’t have any particular conclusion. That’s kinda the point. Heritability studies are a giant pile of data, from which we can learn a number of different things about a number of different topics. I feel much more comfortable reading and assessing that literature now than I did before, and hopefully you do too!
Again I recommend reading Turkheimer’s book, which covers many more topics than I included here, and has both valuable pedagogy and many opinions that differ from my own, in interesting ways.
I am extremely not an expert on heritability, but learning as I go, and very happy for feedback, discussion, and corrections!
Thanks “tailcalled” for patiently attempting to explain some of the finer technical points of heritability to me a while back. Thanks “tailcalled”, “GeneSmith”, and “Towards_Keeperhood” for critical comments on earlier drafts.
Changelog
In addition to miscellaneous minor wording tweaks etc.:
- 2025-01-18: After getting feedback from a couple people, I decided to change “epistasis” to “non-additive genetic effects” in a ton of places throughout the post. The word “epistasis” seems to have a lot of connotations that are contrary to what I’m trying to talk about, and that seems to have thrown people off. Hope it’s better now; let me know.
- 2025-01-18: I mentioned in a couple places that it might be possible to have non-additive genetic effects that are barely noticeable in -vs- comparisons, but still sufficient to cause substantial Missing Heritability. The Zuk et al. 2012 paper and its supplementary information have some calculations relevant to this, I think? I only skimmed it. I’m not really sure about this one. If we assume that there’s no assortative mating, no shared environment effects, etc., then is there some formula (or maybe inequality) relating -vs- to a numerical quantity of PGS Missing Heritability? I haven’t seen any such formula. This seems like a fun math problem—someone should figure it out or look it up, and tell me the answer!
- 2025-01-16: I added a paragraph to §4.3.2 where I tried to guess how much Missing Heritability comes from GWAS cognitive test measurement noise. It does seem to be a big part of the story, as I suspected, although I’m concerned that I messed up the math.
- ^
If anyone cares, here’s why I was reading this: I was interested in learning more about the heritability literature, since that seems useful for understanding the deep structure of personality variation (e.g. I want to have the background knowledge to assess papers like Grotzinger et al. 2022), which in turn seems useful for my quest to reverse-engineer human social instincts [LW · GW], which (as explained at that link) is part of my day job fighting for Safe and Beneficial Artificial General Intelligence. Well, that’s one reason I read the book. But also, it seemed interesting! Who could resist being nerd-sniped by something called the “missing heritability problem”?
- ^
See Bouchard et al. 1990. That study has a particularly simple and elegant design: they compared identical twins reared apart versus together, and found that the two types of twin pairs were almost exactly as similar in their personality variables.
- ^
At least, that’s the impression I got from reading Transformer by Nick Lane
- ^
Note that, when I say “more genetically similar than two random people in the population”, I mean something different than “more related than two random people in the population”. For example, if tall fathers tend to pair off with tall mothers and vice-versa, then fraternal twins will be extra similar along the tallness dimension, because they’re getting it from both sides. But there are hundreds or thousands of gene variants that contribute to height (see §4 below), and it’s possible that there’s no overlap whatsoever between the height-related gene variants on their mother’s and father’s sides. Their mother and father could have negligible relatedness—like, maybe they’re 20th cousins. Doesn’t matter. They don’t have to have overlapping genes, only genes with overlapping effects.
- ^
Specifically, the argument would be: if you look around middle-class families, some parents are obviously much less strict and more affectionate than others, not because of the child, but rather because of the parents’ personality. I think this is pretty obvious—notice, for example, that two parents of the very same child are sometimes substantially different along this axis. Anyway, given that, we can observe that (I think) siblings raised apart are about as similar as siblings raised together in their adult depression and anxiety, and likewise that adoptive siblings are not noticeably more similar in their adult depression and anxiety than any two random people, and it follows that (3) is unlikely to be a major factor in why adults in the population differ in their depression and anxiety, if indeed it’s a factor at all. Much more on this in §2 below.
- ^
Spanking was sufficiently widespread in recent memory, overlapping with twin and adoption study populations, that I think we can be pretty confident that spanking doesn’t have much impact on what the kid will be like as an adult. However, I hasten to add, spanking is still a terrible idea for lots of reasons! I strongly recommend the book No Bad Kids by Janet Lansbury, which includes lots of sensible, practical, and compassionate ways to respond to limit-testing behavior, especially for toddlers but also for teens.
- ^
I think we’ve all seen children following their parents into very specific career paths like Soil Conservation Technician, and I think it’s obvious common sense that this is a thing that happens way more often than chance, and has the obvious causal interpretation. …But if you want hard data, see Bouchard et al. 1990 Table 4, which shows strong shared-environment effects on a couple tests of vocational interests.
- ^
“Bill” turned out fine, don’t worry. Not only does he have a job, his income is probably 10× mine! And he’s more popular, and better-looking …
- ^
I didn’t draw environmental influences into this diagram, but here’s my opinion on them:
I think the center box of the diagram has mostly kinda “organic” environmental inputs, like availability of food, hormone treatments, etc.
I think the right box of the diagram has much more profound environmental inputs, including things like the society’s prevailing cultural norms. Basically, my picture [LW · GW] is that an adult will gradually find his way into the microenvironment and behavioral patterns that he finds most natural and suitable, given his innate makeup (“traits”). Those behavioral patterns will strongly depend on how he responds to his society, its people, and its ideas, and likewise on how his society responds to his behaviors.
- ^
Presumably there’s some nonzero amount of non-additive genetic effects too—that’s why I keep saying things like “mostly additive” instead of just “additive”. At a glance, I’m not sure exactly how to pin it down quantitatively. I’m sure it’s different for different traits anyway. As described in §4.4.1, keep in mind that if you see in a twin study, that’s not iron-clad proof that there’s negligible non-additive genetic effects. You can also get that result from a balance between mild non-additive genetics on the one hand, and mild shared-environment effects or assortative mating (§1.5.2) on the other hand. And I’m not sure how to translate between the vs comparison, and an actual quantity of Missing Heritability; I think it might be possible to get a lot of the latter with just a little of the former? (See Zuk et al. 2012.) Presumably this kind of thing could be figured out with more time than I want to spend right now, if it’s not already in the literature.
21 comments
Comments sorted by top scores.
comment by Kaj_Sotala · 2025-01-14T21:22:15.219Z · LW(p) · GW(p)
Fantastically detailed post, thank you for taking the time to write up all this!
I'd be curious to hear your thoughts about the following. There seems to be an obvious conflict between:
- Behavioral genetics, which has all these findings about the childhood environment only having a limited effect
- Therapy, where memory reconsolidation [LW · GW] can achieve significant chances in people's feelings and behavior by changing subconscious beliefs, and many of those beliefs seem to be related to childhood events and experiences
One hypothesis I've had for reconciling those is based on what evolutionary psychologists have learned about fear of snakes [LW · GW]. At one point, it was thought that humans might be hardwired with a fear of spiders and snakes in particular. But later work then suggested that this is wrong - instead, humans are evolutionarily biased towards paying extra attention to things like spiders and snakes.
Then because we pay more attention to things that look like that, it's more likely that we notice something scary about them. Or if we've been told that they're dangerous, then just repeatedly noticing them increases the chance that we develop a mild phobia around them (as it's increasing the prior of "this dangerous thing might be around and you should notice it"). And that seems to explain why things like spider and snake phobias are much more common than things like electricity phobias:
Seligman’s account suggested that specialised, central mechanisms of fear learning more readily connect aversive events, such as electric shock, with fear-relevant stimuli, such as snakes – which presented genuine threats to our evolutionary ancestors – than with ‘fear-irrelevant’ stimuli such as geometric shapes or flowers. This account predicts that fear of fear-relevant objects should be learned faster, and be extinguished more slowly when shock no longer occurs, as well as being resistant to topdown modification, for example, by instructions indicating that shocks will not occur.
The results of early experiments were consistent with some of these predictions (e.g., [50,51]), but none has withstood extended experimental investigation. Faster or better conditioning with fear-relevant stimuli has rarely been observed, and there is ample evidence that, like most associative learning (e.g., [52]), it can be modified by instruction (reviewed in [53,54]). Initially it seemed that responses to fear-relevant stimuli might extinguish more slowly. However, a recent systematic review [55] found that most positive findings came from a single laboratory, and a large majority of the full set of studies had failed to find differences between fear-relevant and fear-irrelevant stimuli in the rate of extinction.
These results suggest that fear of snakes and other fear-relevant stimuli is learned via the same central mechanisms as fear of arbitrary stimuli. Nevertheless, if that is correct, why do phobias so often relate to objects encountered by our ancestors, such as snakes and spiders, rather than to objects such as guns and electrical sockets that are dangerous now [10]? Because peripheral, attentional mechanisms are tuned to fear-relevant stimuli, all threat stimuli attract attention, but fear-relevant stimuli do so without learning (e.g., [56]). This answer is supported by evidence from conditioning experiments demonstrating enhanced attention to fear-relevant stimuli regardless of learning (Box 2), studies of visual search [57–59], and developmental psychology [60,61]. For example, infants aged 6–9 months show a greater drop in heart rate – indicative of heightened attention rather than fear – when they watch snakes than when they watch elephants [62].
Now suppose that some people carried genes that made them pay extra attention to snakes and/or spiders, and other people didn't. In that situation, you might observe both that:
- The probability of having a snake or spider phobia was strongly heritable - people with those genes were likely to develop that phobia, with parenting style having little effect
- Therapists employing memory reconsolidation-based methods for treating the phobia could often find some specific childhood experiences that had to do with spiders, that seemed to be at the root of the phobia (and doing reconsolidation on these experiences reliably helped with the phobia)
We could then suppose that a lot of other psychological traits are similar: if you have a certain set of genes, it will make you much more likely to have a particular kind of psychological reaction in response to external events. While a person with another set of genes would react differently. And while people in different kinds of environments will differ in exactly what kinds of events they are exposed, then assuming that they belong to a roughly similar social class within the same country, they will probably still have some experiences that are roughly similar.
For instance, when I was little, some older children in our neighborhood made up a story about a man going around the neighborhood and kidnapping children. I expect that a lot of kids who weren't particularly inclined toward high neuroticism soon forgot about the whole thing. Meanwhile I got really scared about it and asked my parents if we couldn't move somewhere else, and then much later as an adult found myself having minor anxiety that seemed to have its roots in this childhood experience.
Now if we hadn't lived in that particular middle-class neighborhood, I wouldn't have encountered that particular rumor and it wouldn't have left a mark on me. But given that I had high-neuroticism genes that made me seriously freaked out by some older children deciding to scare the younger ones a bit, probably something else would have happened in any other middle-class neighborhood that would have felt equally scary and made me somewhat more inclined to anxiety in the future.
That would again lead to the pattern where most major differences seem to come from genetic differences, and at the same time many people with psychological problems can consistently trace the source of their problems to childhood experiences.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2025-01-15T15:45:35.993Z · LW(p) · GW(p)
Thanks! Yeah, I think I would have said something pretty similar to that.
Actually, I might have gone a bit further and said:
Maybe, people have the experience
- (A) “First, I reprocessed the childhood scare experience. Second, I found some that my adult anxiety was generally relieved to some extent.”
…and they naturally conclude
- (B) “…Therefore, the childhood scare experience must have been (partly) causing the adult anxiety all along.”
…but I wonder if we could also entertain an alternate theory:
- (B’) “…Gee, I guess this reprocessing must have been a kind of ‘training / practice / exercise’ during which I could forge new better subconscious habits and associations related to ‘the feeling of anxiety’ in general. And these new subconscious habits and associations are now serving me well in a wide variety of adult contexts.”
After all, you can’t form new subconscious habits and associations related to “the feeling of anxiety” except by invoking “the feeling of anxiety” somehow in the process. It seems plausible to me that childhood memories would be very effective way to do that. After all, (1) I think emotions are generally very strong in childhood and teenage years, and (2) maybe there’s some sense in which long-ago memories are objectively “safer” since the situation is long over, and thus it’s easier to entertain the idea that the feeling is not serving any real purpose.
Also, AFAICT, people achieve great therapeutic success by methods that involve bringing up childhood memories, but other people [LW · GW] also achieve great therapeutic success by methods that don’t. :)
I’m not an expert like you are—indeed I have no personal experience whatsoever—so you can tell me if that doesn’t ring true. :)
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2025-01-15T18:19:18.293Z · LW(p) · GW(p)
Cool, thanks!
(B’) “…Gee, I guess this reprocessing must have been a kind of ‘training / practice / exercise’ during which I could forge new better subconscious habits and associations related to ‘the feeling of anxiety’ in general. And these new subconscious habits and associations are now serving me well in a wide variety of adult contexts.”
I think that there are definitely techniques that work on one's reaction to the feeling of anxiety in general, but the specific ones that I had in mind don't feel like they'd be doing that. Rather they seem much more localized, in that they eliminate some particular anxiety trigger or specific kind of anxiety from getting triggered in the first place. But then if something else happens to trigger the same or a similar anxiety, the person isn't necessarily any better at dealing with that.
So if someone feels the same kind of anxious around both spiders and snakes, then this kind of an intervention might eliminate the fear of spiders entirely, while leaving the reaction to snakes entirely unaffected (or vice versa).
Also, AFAICT, people achieve great therapeutic success by methods that involve bringing up childhood memories, but other people [LW · GW] also achieve great therapeutic success by methods that don’t. :)
Oh yeah definitely, didn't mean to imply that working with memories would be the only approach that worked.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2025-01-15T19:04:55.382Z · LW(p) · GW(p)
OK gotcha. But I can just rephrase slightly, let me try again:
- (B’’) “…Gee, I guess this reprocessing must have been a kind of ‘training / practice / exercise’ during which I could forge new better subconscious habits and associations related to ‘type-of-situation X’ (which used to invoke anxiety). And these new subconscious habits and associations are now serving me well when I encounter type-of-situation X (or anything that vaguely rings of it) an adult context too.”
After all, you can’t form new subconscious habits and associations related to “type-of-situation X” except by making “type-of-situation X” thoughts active somehow during that process. It seems plausible to me that invoking a childhood memory where type-of-situation X triggered unhealthy anxiety would be very effective way to do that.
~~
I think what I’m suggesting is not that different from what you’re suggesting. Maybe the difference is when you wrote “…some specific childhood experiences that had to do with spiders, that seemed to be at the root of the phobia…”.
My mental image is, like, there’s some neuron in the amygdala, and one day in childhood it forms Synapse S connecting some input related to the idea of spiders with some output related to fear reactions. Then the goal for the adult therapy session is to delete Synapse S (or form different connections that counteract its effects, or whatever). Basically, my proposal is:
One day in childhood → Synapse S forms
Adult sees spider → Synapse S → fear reactions
I’m contrasting that with:
[What I don’t believe, but it sounds like maybe you do?] Adult sees spider → childhood memory reactivates, at least a little bit → fear reactions
In other words, I want to say that the childhood experience is “at the root of the phobia” as a matter of the historical record of how Synapse S came to be there, but it’s not “at the root of the phobia” in the sense of the episodic memory itself playing a critical causal role in the real-time anxiety reaction.
…And I’m saying that my hypothesis would nevertheless be compatible with childhood-memory-based therapies being effective, because invoking the actual episodic childhood memory itself, in a therapeutic context, is one possible path to delete or inactivate Synapse S.
Well, hmm, on second thought, I guess both stories are possible, maybe they coexist.
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2025-01-16T10:05:57.548Z · LW(p) · GW(p)
So I think we have two separate questions here:
- Do psychological issues involve reactivation of an earlier memory such that the reactivation plays a causal role in the issue?
- Can you address an issue without explicitly working with an earlier memory?
For the first question, I'd say "it depends". On one end, we have something like PTSD flashbacks - here a reactivation of a memory is clearly in a causal role, since "a memory getting reactivated to such an extent that the person experiences themselves as literally reliving it" is what a flashback is.
Slightly less strong but still strongly suggestive of a causal role is something where a person imagines themselves doing something, but then - maybe just at the back of their mind - recalls a painful memory and flinches away from doing that. E.g. they consider speaking up, but then a flicker of a memory comes up about a time when they spoke up and somebody ridiculed them, and they quickly close their mouth. Here there seems to at least be a causal path from the memory to the issue, in that the memory is charged with negative affect and that the memory coming up causes the person to reorient to something that makes the memory recede in intensity.
Then we have cases where there's no obvious memory at first, but directing attention to the issue and asking questions about it brings up a memory, even though none of the questions ever ask about memories directly. For example, someone might feel like they have to act in a certain way in a particular social situation despite finding it unpleasant. Now a therapist might ask them something like "what would be bad about acting differently" and have them focus on what feels emotionally or intuitively bad about it (rather than what logical justifications their mind would offer). Then there might be a line of questioning that went something like:
- "I have difficulty getting a turn to speak because I tend to wait extra long to make sure others have finished speaking before I speak up. And then I wait so long that someone else always starts talking before I can."
- "Okay, so what would be bad about speaking up before you're certain that others have finished speaking?"
- "Then I might interrupt them before they're finished."
- "Okay, what would be bad about interrupting them before they're finished?"
- "That'd feel unfair toward them."
- "In what way does it feel unfair?"
- "Hmm, I'm getting a memory of a time when I was trying to speak up but my father interrupted me, and then I tried talking anyway and then he acted like I had interrupted him and that I should let him talk first. That felt really bad and unfair. I guess I want to make sure to act better than he did, and make sure that I never interrupt someone else when it's their turn to speak."
Is the memory in a causal role here? Probably depends on how exactly we define "causal". But at least it seems like there is some kind of a model about how the person wants to act or not act ("interrupting other people is unfair toward them, and should be avoided") that was formed due to an earlier experience. When one tries to elicit details about how exactly the model works, the model seems to structurally incorporate the original experience as a reference point for what exactly the core bad thing is. And working with the memory often seems to help with one's issues.
Given that this kind of a memory seems to have a similar character as the PTSD and the "I can hear the people mocking me" memories, just buried slightly deeper, to me the simplest and most plausible explanation would be that it has a causal role in the same way as the less-buried ones do.
Then on the other hand, it's not always the case that this kind of questioning leads to any clear-cut memory. Sometimes what comes up feels more like a general model that has been formed out of multiple different life experiences, with none of original instances having been stored. Or there might be an issue that seems to go back to an age young enough that the person doesn't have any explicit memories of it, and it has only left a general emotional imprint. In those cases the memory doesn't seem to have any causal role, because there doesn't seem to be any memory around to begin with.
Or at least not one that would be easily accessible. I've heard of claims from people who got into states of deep meditation or strong doses of psychedelics that they managed to access very early painful memories that wouldn't have been available in a normal therapeutic context, and then got independent confirmation for the truthfulness of those memories afterward. I've not looked into these in detail but I'm inclined to suspect they're true. In part due to my personal experiences of old memories spontaneously coming up in altered states of consciousness (and this sometimes shifting behaviors), in part because "all behaviors involve an original memory trace being stored somewhere and that trace then driving behavior, with some of those traces just being buried deep or in not normally forward-compatible storage formats" would again seem like the most parsimonious model.
As for the second question, I'd again say it depends. If someone is suffering from a PTSD flashback, it's going to be hard to do anything about that without working with the traumatic memory in some way! But for the ones where the problem isn't so directly driven by an explicit memory reactivation, there are definitely a lot of approaches that work by changing other parts of the model. E.g. if the model makes a particular prediction about the world in general ("people will always find it unfair if I speak up before being absolutely certain that they're finished"), then it's often possible to disprove that prediction without going into the details of the original memory. And while some therapies focus on the episodic memory component of the learned model, others work on different components.

↑ comment by Steven Byrnes (steve2152) · 2025-01-16T17:03:31.811Z · LW(p) · GW(p)
That’s very helpful, thanks!
comment by TsviBT · 2025-03-15T09:51:26.468Z · LW(p) · GW(p)
[Still have not read the post. Feel free to just point me at a section or something.]
Hold on, just to check, do you think there's actually much empirical evidence in favor of there being only very little linear genetic effects on various personality traits? (So I'm excluding the theories you present, not at all to say they are irrelevant, just to focus on the basics of what we know.)
The types of evidence positively showing the existence of "chaotic" heritability (by which I mean "not a nice function of a big weighted sum of genes") that I currently understand:
- The difference between MZ and DZ heritability.
- Actually seeing epistases, or more generally giving a nonlinear model that predicts better than "the nearest" linear model.
- The failure to find linear effects after having looked hard enough that you should have found them if they are there.
- Standard narrowsense heritability estimates saying "there's barely any". (ETA: maybe this is basically the same as 3.)
In this section you mention MZ/DZ: https://www.lesswrong.com/posts/xXtDCeYLBR88QWebJ/heritability-five-battles#4_4_2_Applying_that_analysis_plan_to_different_traits_and_outcomes [LW · GW]
But I'm unclear what you even think of the MZ/DZ heritability numbers you looked at, in terms of personality. Generally I'm unclear which pieces of evidence of the above form, or of other important forms, we actually have.
A suggestion from Steve Hsu: personality traits are harder to measure, so existing studies use noisy measurements; probably there's more heritability than we know, and more data would reveal plenty of linear effects.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2025-03-15T15:35:17.797Z · LW(p) · GW(p)
I don’t have any reason to believe that “chaotic” heritability exists at all, among traits that people have measured. Maybe it does, I dunno. I expect “nice function of a big weighted sum of genes” in most or all cases. That ASPD example in §4.3.3 is an especially good example, in my book.
The main observation I’m trying to explain is this Turkheimer quote:
Finally, for most behavioral traits, PGS just don’t work very well. As I already mentioned, these days they do work well for height, and pretty well for some medical conditions or metabolic traits. The best PGS for EA accounts for 15% of the variance, which is superficially impressive, but see below. For most other behavioral traits for which we might hope to have good PGS, however, such as personality or depression, they barely work at all, consistently accounting for under 5% of the variance…
Modern genomics of human behavior has had a very surprising result: it has decreased estimates of heritability from where they stood 50 years ago in the twin study era. The common assumption back then was that the heritability of pretty much everything was around 0.5, if not higher, and no matter how skeptical one becomes about the causal meaning of the second decimal place of heritability coefficients, more than half the variance is a lot to reckon with. But with SNP heritabilities, and then PGS as real-world instantiations of SNP heritabilities, and then SNP heritabilities and PGS that have been appropriately corrected for between-family effects, those numbers are a lot closer to 0.1 than they are to 0.5. For many traits (personality, most forms of psychopathology) they are closer to 0.01.
That’s my starting point, especially the last sentence. If Turkheimer is wrong (that SNP heritabilities of most personality and behavior measurements tend to account for well under 5% of the variance, and are often closer to 1%), then I’d be very interested to know that, and would probably want to revise parts of this post.
A suggestion from Steve Hsu: personality traits are harder to measure, so existing studies use noisy measurements; probably there's more heritability than we know, and more data would reveal plenty of linear effects.
The missing heritability problem is the idea that twin and adoption studies find that every adult trait is around 50% heritable, whereas SNP heritabilities are lower than that.
Measurement noise does not by default explain missing heritability, because the twin and adoption studies have measurement noise too. Measurement noise can only explain missing heritability if the GWAS studies have more measurement noise than the twin and adoption studies. …And that can happen! GWASs have far larger sample sizes, so the same kind of measurement instrument which would be cost-prohibitive in a GWAS may be fine in a twin study. And I think that’s part of what’s happening for IQ, i.e. it’s part of why there’s more missing heritability for IQ than (say) height, as I discuss in the OP (§4.3.2).
I’m open-minded to the possibility that this same thing (noisier measurements in GWASs than twin & adoption studies) is also true for personality and behavioral measurements. But I’m skeptical that that’s a big part of the explanation, if it’s even a factor at all. For one thing, there’s way more missing heritability for personality than IQ, as I understand it, but I don’t think it’s harder to get a low-noise measurement of personality than IQ. In fact, I’d guess it’s the opposite. Like, I would strongly guess that it takes many fewer minutes / survey questions to find out whether someone has a history of major depression, or to measure where they are on the introvert-vs-extrovert scale, than to measure their IQ, with equivalent noise levels. In fact, I wonder if the measurement instruments are even different at all between the GWASs and the twin & adoption studies, in the case of personality & mental health. This could be looked up, I suppose.
Replies from: TsviBTcomment by Seth Herd · 2025-01-15T22:43:48.953Z · LW(p) · GW(p)
Wow! That is a hell of a comprehensive writeup.
The bio-determinist child-rearing rule of thumb [but see caveats below!]: Things you do as a parent will have generally small or zero effects on what the kid will be like as an adult—their personality, their intelligence and competence, their mental health, etc.
I found it pretty interesting here and back when I was reading about it that this list does not include happiness. This is part of a larger societal disinterest in happiness. But I do wonder if it might be influenced by parents nontrivially by them seeding children with a life philosophy and a set of cognitive habits about how to think about life.
I also noticed that the data they tracked about how parents treat children included no efforts to determine how much parents actually loved their children, or how much they fought with their children. While most parents, particularly the middle-classers that take part in studies, love their children, how much and whether that prevents ongoing feuds with their children does seem to vary a good bit.
Of course that would be problematic, because how much parents love and feud with their children is also clearly influenced by how much said children are acting like little shits. :)
I doubt any of these would show large effects, I'm just noting their absence.
I used to care about genetics for reasons 2 (what effect do parents have) and 3 (do your adult decisions like attending therapy really matter), back when I planned to use my PhD in cognitive psychology and neuroscience to write about "free will" (really self-determination; do our decisions matter for our outcomes) in ourselves and our society. My thesis was that we have substantial self-determination but also substantial limitations in it; and that liberal American philosophies tend to emphasize the extent to which we don't, while conservative American philosophies emphasize the extent to which we do. Neither is entirely correct, causing strong adherents of either to make no sense and therefore be super irritating to talk to.
But those ambitions ended when I first read Yudkowsky, and decided free will was small potatoes in the face of an onrushing intelligence explosion and alignment crisis. Thus, my ideas related to genetics have never before been published, and probably won't be. Thanks for the excuse to rant.
Again, wow. I'll be referring anyone to this writeup if they express more than the vaguest interest in what we know about genetics.
comment by EmilOWK · 2025-01-18T21:15:53.990Z · LW(p) · GW(p)
Overall a sensible introduction. Turkheimer is very leftist by the field's standards, you may want to try out some others for opposite political slant or no slant. Not all authors color their work so heavily as he does.
You make a mistake in your terminology. Epistasis is not the same as nonlinearnity. Linearity stands in contrast to nonlinearity, which is called dominance. This is when a subject's phenotype does not change in a linear fashion from changing the alleles. So e.g., the change from TT to AT to AA does not have equal steps. This is common with severe genetic disorders, where having one copy usually does nothing. This is because a correct version of the protein (say) is still made half the time, and this is enough. Epistasis is gene-gene interactions between loci. In other words, there is no clean effect of changing from TT to AT because the effect depends on another locus where e.g. GG, or GC may be present.
There have been many papers looking for dominance and epistasis, but little has been found. EA4 tested across the genome for dominance and found nothing. Not due to low power. Epistasis generally causes MZ to be more than 2DZ, which is not commonly seen. Usually, the bias from assortative mating is stronger than any unmodelled epistasis or dominance.
↑ comment by tailcalled · 2025-01-18T22:02:05.188Z · LW(p) · GW(p)
Dominance is (a certain kind of) nonlinearity on a single locus, epistasis is nonlinearity across different loci.
↑ comment by Steven Byrnes (steve2152) · 2025-01-18T21:58:25.725Z · LW(p) · GW(p)
There have been many papers looking for dominance and epistasis, but little has been found. EA4 tested across the genome for dominance and found nothing.
See §4.4.3 for my response.
Epistasis generally causes MZ to be more than 2DZ, which is not commonly seen.
See the collapsible box labeled “Box: Twin-study evidence of epistasis in adult personality, mental health, and behavior” in §4.4.2 for many apparent examples of precisely this. Do you disagree with that? Is there more evidence I’m missing?
Remember, I’m claiming that non-additive genetics are important in adult personality, mental health, and behavioral things like divorce, but that they’re NOT very important in height or blood pressure or (I think) IQ or EA.
You make a mistake in your terminology.
This is very possible!! It wouldn’t be the first time. I can still make changes. I found the use of terminology in the literature confusing … and I find your comment confusing too. :(
My background is physics not genetics, and thus I’m using the word “nonlinearity” in the linear algebra sense. I.e., if we take a SNP array that measures N SNPs, we can put the set of all possible genomes (as measured by this array) into an N-dimensional abstract vector space, I think. Then there’s a map from this N-dimensional space to, let’s say, extroversion. Both what you call dominance, and what you call epistasis, would make this map “nonlinear” (in the linear algebra sense). See what I mean?
If it’s true that people in genetics use the term “nonlinearity” to refer specifically to nonlinearity-at-a-single-locus, then I would want to edit my post somehow! (Is it true? I don’t want to just take your word for it.) I don’t want people to be confused. However, nonlinearity-in-the-linear-algebra-sense is a very useful notion in this context. I will feel handicapped if I’m forbidden from referring to that concept. Maybe I’ll put in a footnote or something? Or switch from “nonlinearity” to “non-additivity”? (Does “non-additivity” subsume both dominance and epistasis?)
Update: I replaced the word “epistasis” with “non-additive genetic effects” in a bunch of places throughout the post. Hopefully that makes things clearer??
comment by Kaj_Sotala · 2025-01-19T14:58:23.280Z · LW(p) · GW(p)
But interestingly, Turkheimer also says some nice things about the book The Genetic Lottery: Why DNA Matters for Social Equality, by his former student Kathryn Paige Harden. Unlike Turkheimer, Harden is much more willing to ascribe a straightforward causal role of genetics in intelligence and other traits. But Harden reaches essentially the same sociopolitical conclusions as Turkheimer (according to Turkheimer). I didn’t read Harden’s book, but I presume that those conclusions are things like “racism is bad”, “we should help the downtrodden”, “don’t be an asshole”, and so on—conclusions that I myself enthusiastically endorse as well.
This New Yorker profile about Harden gets a bit into her philosophy. She wants society to use genetic data to design more effective social interventions for making people better off, and for an improved understanding of the effect of genetics to make people more receptive to programs designed to increase equality of outcome:
Replies from: Kaj_SotalaThe first thing that social-science genomics can do is help researchers control for confounding genetic variables that are almost universally overlooked. As Harden puts it in her book, “Genetic data gets one source of human differences out of the way, so that the environment is easier to see.” For example, beginning in 2002, the federal government spent almost a billion dollars on something called the Healthy Marriage Initiative, which sought to reduce marital conflict as a way of combatting poverty and juvenile crime. Harden was not surprised to hear that the policy had no discernible effect. Her own research showed that, when identical-twin sisters have marriages with different levels of conflict, their children have equal risk for delinquency. The point was not to estimate the effects of DNA per se, but to provide an additional counterfactual for analysis: would an observed result continue to hold up if the people involved had different genes? Harden can identify studies on a vast array of topics—Will coaching underresourced parents to speak more to their children reduce educational gaps? Does having dinner earlier improve familial relationships?—whose conclusions she considers dubious because the researchers controlled for everything except the fact that parents pass along to their children both a home environment and a genome.
She acknowledged that gwas techniques are too new, and the anxieties about behavior genetics too deeply entrenched, to have produced many immediately instrumental examples so far. But she pointed to a study from last year as proof of concept. A team of researchers led by Jasmin Wertz, at Duke, used GWAS results to examine four different “aspects of parenting that have previously been shown to predict children’s educational attainment: cognitive stimulation; warmth and sensitivity; household chaos (reverse-coded to indicate low household chaos); and the safety and tidiness of the family home.” They found that one of them—cognitive stimulation—was linked to children’s academic achievement and their mothers’ genes, even when the children did not inherit the relevant variants. Parental choices to read books, do puzzles, and visit museums might be conditioned by their own genes, but they nevertheless produced significant environmental effects.
Even the discovery that a particular outcome is largely genetic doesn’t mean that its effects will invariably persist. In 1972, the U.K. government raised the age at which students could leave school, from fifteen to sixteen. In 2018, a research group studied the effects of the extra year on the students as adults, and found that their health outcomes for measures like body-mass index, for whatever reason, improved slightly on average. But those with a high genetic propensity for obesity benefitted dramatically—a differential impact that might easily have gone unnoticed.
Some of Harden’s most recent research has looked at curricular tracking for mathematics, an intuitive instance of how gene-environment interactions can create feedback loops. Poor schools, Harden has found, tend to let down all their students: those with innate math ability are rarely encouraged to pursue advanced classes, and those who struggle are allowed to drop the subject entirely—a situation that often forecloses the possibility of college. The most well-off schools are able to initiate virtuous cycles in the most gifted math students, and break vicious cycles in the less gifted, raising the ceiling and the floor for achievement. [...]
Harden is not alone in her drive to fulfill Turkheimer’s dream of a “psychometric left.” Dalton Conley and Jason Fletcher’s book, “The Genome Factor,” from 2017, outlines similar arguments, as does the sociologist Jeremy Freese. Last year, Fredrik deBoer published “The Cult of Smart,” which argues that the education-reform movement has been trammelled by its willful ignorance of genetic variation. Views associated with the “hereditarian left” have also been articulated by the psychiatrist and essayist Scott Alexander and the philosopher Peter Singer. Singer told me, of Harden, “Her ethical arguments are ones that I have held for quite a long time. If you ignore these things that contribute to inequality, or pretend they don’t exist, you make it more difficult to achieve the kind of society that you value.” He added, “There’s a politically correct left that’s still not open to these things.” [...]
The ultimate claim of “The Genetic Lottery” is an extraordinarily ambitious act of moral entrepreneurialism. Harden argues that an appreciation of the role of simple genetic luck—alongside all the other arbitrary lotteries of birth—will make us, as a society, more inclined to ensure that everyone has the opportunity to enjoy lives of dignity and comfort. She writes, “I think we must dismantle the false distinction between ‘inequalities that society is responsible for addressing’ and ‘inequalities that are caused by differences in biology.’ ” She cites research showing that most people are much more willing to support redistributive policies if differences in opportunity are seen as arbitrarily unfair—and deeply pervasive.
As she put it to me in an e-mail, “Even if we eliminated all inequalities in educational outcomes between sexes, all inequalities by family socioeconomic status, all inequalities between different schools (which as you know are very confounded with inequalities by race), we’ve only eliminated a bit more than a quarter of the inequalities in educational outcomes.” She directed me to a comprehensive World Bank data set, released in 2020, which showed that seventy-two per cent of inequality at the primary-school level in the U.S. is within demographic groups rather than between them. “Common intuitions about the scale of inequality in our society, and our imaginations about how much progress we would make if we eliminated the visible inequalities by race and class, are profoundly wrong,” she wrote. “The science confronts us with a form of inequality that would otherwise be easy to ignore.”
The perspective of “gene blindness,” she believes, “perpetuates the myth that those of us who have ‘succeeded’ in twenty-first century capitalism have done so primarily because of our own hard work and effort, and not because we happened to be the beneficiaries of accidents of birth—both environmental and genetic.” She invokes the writing of the philosophers John Rawls and Elizabeth Anderson to argue that we need to reject “the idea that America is or could ever be the sort of ‘meritocracy’ where social goods are divided up according to what people deserve.” Her rhetoric is grand, though the practical implications, insofar as she discusses them, are not far removed from the mid-century social-democratic consensus—the priorities of, say, Hubert Humphrey. If genes play a significant role in educational attainment, then perhaps we ought to design our society such that you don’t need a college degree to secure health care.
↑ comment by Kaj_Sotala · 2025-01-19T15:16:11.686Z · LW(p) · GW(p)
And here's an excerpt from her book:
Replies from: ViliamIn this final chapter, then, I hope to start the conversation about what it means for science and policy to be actively anti-eugenicist, by offering five general principles:
1. Stop wasting time, money, talent, and tools that could be used to improve people’s lives.
2. Use genetic information to improve opportunity, not classify people.
3. Use genetic information for equity, not exclusion.
4. Don’t mistake being lucky for being good.
4. Consider what you would do if you didn’t know who you would be.For each of these principles, I will contrast three positions. First, the eugenic position positions genetic influence as a naturalizer of inequality. If social inequalities have genetic causes, then those inequalities are portrayed as the inevitable manifestations of a “natural” order. Genetic information about people can be used to slot them more effectively into that order. Second, the genome-blind position position sees genetic data as the enemy of social equality and so objects to any use of genetic information in social science and policy. Whenever possible, the genome-blind position seeks not to know: scientists ought not to study genetic differences or how they are linked to social inequalities, and other people in society ought not to use any scientific information that is generated for any practical purposes. These two positions can be contrasted with what I am proposing is an anti-eugenic position that does not discourage genetic knowledge but deliberately aims to use genetic science in ways that reduce inequalities in the distribution of freedoms, resources, and welfare. [...]
Stop Wasting Time, Money, Talent, and Tools
- EUGENIC: Point to the existence of genetic influence to deny the possibility of intervening to improve people’s lives.
- GENOME-BLIND: Ignore genetic differences even if it wastes resources and slows down science.
- ANTI-EUGENIC: Use genetic data to accelerate the search for effective interventions that improve people’s lives and reduce inequality of outcome. [...]
Use Genetic Information to Improve Opportunity, Not Classify People
- EUGENIC: Classify people into social roles or positions based on their genetics.
- GENOME-BLIND: Pretend that all people have an equal likelihood of achieving all social roles or positions after taking into account their environment.
- ANTI-EUGENIC: Use genetic data to maximize the real capabilities of people to achieve social roles and positions. [...]
Let’s go back to a specific example that I told you about in chapter 7, about the relationship between the educational attainment polygenic index and mathematics course-taking in high school. Students who had a higher polygenic index were more likely to be enrolled in geometry (versus algebra 1) in the ninth grade, which put them on track to complete calculus by the end of high school. Students who had a higher polygenic index were also less likely to drop out of math once it became optional. What can and should be done with that information?
The eugenic proposal would be to test students’ DNA and use it to assign them to mathematics tracks, such that students with low polygenic indices are excluded from opportunities to learn advanced mathematics. The gene-blind proposal would be to insist that the research connecting genetics and mathematics course taking shouldn’t have been done in the first place. The anti-eugenic proposal is to apply that genetic knowledge toward (a) understanding how teachers and schools can maximize the mathematics learning of their students, and (b) spotlighting how academic tracking entrenches inequalities between students.
Regarding the first goal, consider that one of the greatest challenges to understanding which teachers and schools are best serving the needs of students is that students with different learning needs are not randomly distributed across teachers and schools. A trenchant criticism of using standardized test scores as a metric for teacher and school “accountability”—that is, for identifying poorly performing teachers and schools—is that student test scores are highly correlated with student characteristics, such as family socioeconomic status, that precede the child’s entry to school and that are non-randomly clustered across schools. “Good” schools, defined as schools with high average test scores, are, in actuality, often better described as rich schools with high concentrations of affluent students. (A similar problem besieges identifying the best doctors and hospitals: the best doctor is not the one who avoids treating the sickest patients.)
Researchers have long recognized that estimating school effects on student academic outcomes is a tricky problem, and one can begin to make fair, “apples-to-apples” comparisons among schools only if one incorporates measures of student characteristics such as family background, previous levels of academic knowledge, etc. The appropriate question is not “How do students in school X fare differently than students in school Y?” because the students in school X could be already different from the students in school Y in ways other than the school they attend. The appropriate question is, “How would a particular student have fared differently if he had attended school X rather than school Y?” (Again, we see the importance of counterfactual reasoning for causal inference, as I explained in chapter 5).
In attempting to identify school effects, it is commonplace for researchers, educators, and policymakers to consider information about one accident of birth: a student’s socioeconomic status. But I and others have observed in our research that information from a student’s DNA, in the form of a polygenic index, also predicts academic outcomes, above and beyond information on family socioeconomic status. As I described above, this does not mean that we should use polygenic indices to classify students and restrict their opportunities to learn. It does mean, however, that we can evaluate how students who have equivalent polygenic indices fare differently in their outcomes when they attend different schools.
In one study of US high school students, we found that students with low education-related polygenic indices were, on average, less likely to continue in their mathematics education in high school. But their dropout rates differ substantially across school contexts. In schools that primarily serve students whose parents have high school diplomas, even students with low polygenic indices take a few years of math after the ninth grade. In fact, students with low polygenic indices in high-status schools fare about as well, in terms of their persistence in math, as students with average polygenic indices who attend low-status schools.
This finding is just barely scratching the surface. What, specifically, is happening in higher-status schools that keeps even students who are statistically likely to drop out of math from actually dropping out? How do you make the practices of such schools more widely available to all students? The path from basic research like this study to educational policy reform is long and tortuous.
But even though it is just a first step, this study is revealing a basic and important truth: given a certain fixed starting point in life—inheriting a certain combination of DNA variants—some people get much further in developing their capability to solve mathematical problems. These mathematical skills have lifelong benefits for an individual in terms of future education, participation in the labor force, and ease with navigating problems of everyday living. In fact, math literacy is so important for a student’s future that the opportunity to learn math has been called a civil right. Genetic data has thus revealed an inequality of environmental opportunity, one that calls out for redress.
Other environmental inequalities could be similarly diagnosed using genetic data. Which health interventions reach people who are currently most genetically at risk for poor outcomes? Which schools have the lowest rates of disciplinary problems among youth who are currently at most genetic risk for aggression, delinquency, or substance use problems? Which areas of the country are “opportunity zones,” where opportunity is defined not solely in terms of how children from low-income families fare, but also in terms of how children who are genetically at risk for school problems or mental health problems fare? If researchers embrace principle #1, and start embracing the possibilities of genetic data, we will have a wealth of new information to address these questions.
Use Genetic Information for Equity, Not Exclusion
- EUGENIC: Use genetic information to exclude people from health care systems, insurance markets, etc.
- GENOME-BLIND: Prohibit the use of genetic information per se but otherwise keep markets and systems the same.
- ANTI-EUGENIC: Create health care, educational, housing, lending, and insurance systems where everyone is included, regardless of the outcome of the genetic lottery. [...]
Don’t Mistake Being Lucky for Being Good
- EUGENIC: Point to genetic effects on intelligence as proof that some people naturally have more merit than others.
- GENOME-BLIND: Accept the logic of meritocracy while ignoring the role of genetic luck in developing skills and behaviors that are perceived as meritorious.
- ANTI-EUGENIC: Recognize genetics as a type of luck in life outcomes, undermining the meritocratic logic that people deserve their successes and failures on the basis of succeeding in school. [...]
Consider What You Would Do, If You Didn’t Know Who You Would Be
- EUGENIC: The biologically superior are entitled to greater freedoms and resources.
- GENOME-BLIND: Society should be structured as if everyone is exactly the same in their biology.
- ANTI-EUGENIC: Society should be structured to work to the advantage of people who were least advantaged in the genetic lottery.
↑ comment by Viliam · 2025-01-22T13:54:26.872Z · LW(p) · GW(p)
I get what the author wants to say, but...
Facts are value-neutral. If you say e.g. "IQ exists", will other people classify you as a good guy, or as a bad guy? If it's predictably the latter, we won't have enough "anti-eugenists", because anyone non-autistic who cares about other people will be discouraged from studying IQ seriously.
What if the "least advantaged" e.g. dumb people actively want things that will hurt everyone (including the least advantaged people themselves, in long term)? Maybe the dumber they are, the more kids they want to have. Or maybe the dumber they are, the more they want to make decisions about scientific research. Should the biologically privileged respect them as equals (and e.g. let themselves get outvoted democratically), or should they say no?
Shortly, you can make it sound easy by ignoring how this stuff works in real world.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2025-01-22T15:21:09.797Z · LW(p) · GW(p)
If you say e.g. "IQ exists", will other people classify you as a good guy, or as a bad guy?
That’s not a criticism of Harden’s book though, right? I think she’s trying (among other things) to make it more socially acceptable to say that IQ exists.
Maybe the dumber they are, the more kids they want to have.
Ah, good for them! Kids are wonderful! Let us celebrate life. Here’s a Bryan Caplan post for you.
What if the "least advantaged" e.g. dumb people actively want things that will hurt everyone (including the least advantaged people themselves, in long term)? …Or maybe the dumber they are, the more they want to make decisions about scientific research. Should the biologically privileged respect them as equals (and e.g. let themselves get outvoted democratically), or should they say no?
I think that people of all IQs vote against their interests. I’m not even sure that the sign of the correlation is what you think it is; for example, intellectuals were disproportionately supportive of communism back in the day, even while Stalin and Mao were killing tens of millions. I’m sure you can think of many more such examples, which I won’t list right here in order to avoid getting into politics fights.
The answer to questions like “what if [group] wants [stupid thing]” is that various groups have always been wanting stupid things. We should just keep fighting the good fight to try to push things in a good direction on the margin. For example, I think prediction market legalization and normalization would be excellent, as would widespread truth-seeking AI tools, and of course plain old-fashioned “advocating for causes you believe in”, etc. If some people in society are unusually wise, then let them apply their wisdom towards crafting very effective advocacy for good causes, or towards making money and funding good things, etc.
And this whole thing is moot anyway, because I would be very surprised if the genetic makeup of any country changes more than infinitesimally (via differential fertility) before we get superintelligent AGIs making all the important decisions in the world. The idea of humans making important government and business decisions in a post-ASI world is every bit as absurd as the idea of moody 7-year-olds making important government and business decisions in today’s world. Like, you’re talking about small putative population correlations between fertility and other things. If those correlations are real at all, and if they’re robust across time and future cultural and societal and technological shifts etc., (these are very big and dubious “ifs”!), then we’re still talking about dynamics that will play out over many generations. You really think nothing is going to happen in the next century or two that makes your extrapolations inapplicable? Not ASI? Not other technologies, e.g. related to medicine and neuroscience? Seems extremely unlikely to me. Think of how much has changed in the last 100 years, and the rate of change has only accelerated since then.
Replies from: Viliam↑ comment by Viliam · 2025-01-22T19:59:29.767Z · LW(p) · GW(p)
I agree that intellectuals were in favor of communism when communism was a new thing. (These days, in the post-communist countries, it is the other way round.) But I still think that on average, smarter people generate more positive externalities. Basically, most useful things we see around us were invented by someone smart.
Caplan's argument about outsourcing less challenging tasks to others has a few problem. First, smart people doing simple things is a waste of talent only because the smart people are rare (and if you let them do simple things, it means that the complicated things will not get done). In a society of Einsteins it wouldn't matter that some of them do the dishes, because there would still be enough of them left to invent the cool stuff. Second, anecdotal evidence suggests that the division of labor works worse than advertised; a few of my friends have complained to me about horrible job that was done by various manual workers e.g. when they hired someone to build or reconstruct their houses, so they ultimately had to find some tutorials on YouTube and fix the things themselves.
I agree about the prediction markets. (However, the main argument against them seems to be that the dumb people would immediately waste lost of money there, and then go and cause social unrest.)
comment by Gunnar_Zarncke · 2025-01-14T18:40:02.476Z · LW(p) · GW(p)
What would be your The Best Textbooks on Every Subject [LW · GW] on heritability?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2025-01-14T18:44:26.573Z · LW(p) · GW(p)
There’s no source that I especially like and endorse, that’s why I wrote this post :)
comment by dynomight · 2025-01-14T21:51:06.603Z · LW(p) · GW(p)
It ranges from 0% to 100%.
Small nitpick that doesn't have any significant consequences—this isn't technically true, it could be higher than 100%.