Historical mathematicians exhibit a birth order effect too
post by Eli Tyre (elityre) · 2018-08-21T01:52:33.807Z · LW · GW · 20 commentsContents
Methodology Results A discussion of bias in this data Higher reporting rate for first born children Underreporting of females Conclusion None 20 comments
[Epistemic status: pilot study. I'm hoping that others will help to verify or falsify my conclusion here. I've never done an analysis of this sort before, and would appreciate correction of any errors.
A previous version of this post has some minor errors in the analysis, which have since been corrected. Most notably, deviation from expected rate of first borns was originally noted as 14.98 percentage points. It is actually 16.65 percentage points.]
A big thank you to Dan Keys for working through the statistics with me.
Follow-up to: Fight Me, Psychologists, Birth Order Effects are Real and Very Strong, 2012 Survey Results [LW(p) · GW(p)]
Since the late 1800's, pop psychology has postulated that a person's birth order (whether one is the first, last, middle, etc. of one's siblings) has an impact on his/her lifetime personality traits. However, rigorous large-scale analyses have reliably found no significant effect on stable personality, with some evidence for a small effect on intelligence. (The Wikipedia page lists some relevant papers on birth order effects on personality (1, 2, 3) and on intelligence (1, 2, 3).)
So, we were all pretty surprised when, around 2012, survey data suggested a very strong birth order effect amongst those in the broader rationality community.
The Less Wrong community is demographically dominated by first-borns: a startlingly large percentage of us have only younger siblings. On average, it looks like there's about a twenty-two percentage point difference between the actual rate of first borns and the expected rate, from the 2018 Slate Star Codex Survey data Scott cites in the linked post above. (More specifically, the expected rate of first-borns is 39% and the actual occurrence in the survey data is 62%.) The 2012 Less Wrong survey [LW(p) · GW(p)] also found a 22 percentage point difference. This effect is highly significant, including after taking into account other demographic factors.
A few weeks ago, Scott Garrabrant (one of the researchers at MIRI) off-handedly wondered aloud if great mathematicians (who plausibly share some important features with LessWrongers), also exhibit this same trend towards being first born.
The short answer: Yes, they do, as near as I can tell, but not as strongly as LessWrongers.
My data and analysis is documented here.
Methodology
Following Sarah Constantin's fact post [LW · GW] methodology, I started by taking a list of the 150 greatest mathematicians from here. This is perhaps not the most accurate or scientific ranking of historical math talent, but in practice, there's enough broad agreement about who the big names are, that quibbles over who should be included are mostly irrelevant to our purpose. If a person could plausibly be included on a list of the greatest 150 mathematicians in history, he/she was probably a pretty good mathematician.
I then went through the list, and tried to find out how many older and younger siblings each mathematician had. For the most part this amounted to googling "[mathematician's name] siblings" and then trawling through the results to find one that gave me the information I wanted. Where possible, I noted not just the birth order and number of siblings, but also the sex of the siblings and whether they died during infancy. (For the ones for whom I couldn't get data, I marked the row as "Couldn't find" or "Unknown")
Most biographical sources don't list the number of siblings of the family of origin. The sources that I ended up relying on the most were:
- Geni.com: a platform for people to build out their family trees, and store historical or biographical information (family photos, dates of life events, etc.)
- TheFamousPeople.com
- The individual biographies on the MacTutor History of Mathematics Archive
This was a very quick cursory search, so my data is probably not super reliable. At least twice, I found two sources that disagreed, and I don't know how much I would have encountered conflicting information if I had dug deeper into each person's biography, instead of moving on to the next mathematician as soon as I found a sentence that answered my query.
If you happen to personally know biographical details of elite mathematicians and you can correct any errors in these data, I'd be pleased to make those corrections.
Results
The simplest analysis is to categorize the data by family size (all the mathematicians that had no siblings, one sibling, 2 siblings, etc.), count how many first borns there were in each bucket, and compare that to the number we would expect by chance.
For nearly every bucket, the frequency of first born children exceeded random chance. Across all categories, the difference in percentage points between the actual and expected frequencies was about 16.5%.
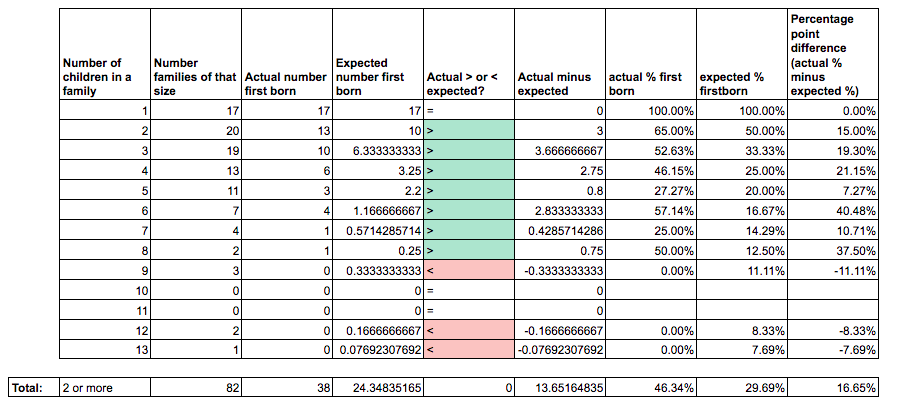
After removing the individuals that I couldn't find data for, we had a sample size of 82. A paired t-test, comparing the number of first-borns with the expected number of first-borns (one data point for each of the 82 mathematicians) was statistically significant, t(81)=3.14, p = 0.00239.
I can show you some bar graphs, like Scott uses in his post, but because this data is of a much smaller sample and the effect isn't as large, they don't look as neat. (Also, I don't know how to include those nice dotted lines marking the expected frequency.)
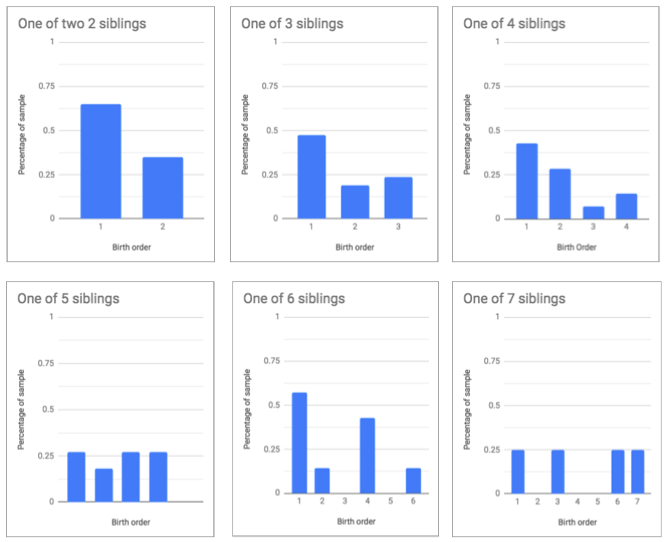
Nevertheless, you can see a systematic trend: being the first of n siblings is overrepresented among the mathematicians in the sample I used.
The effect in these data (17 percentage points) is smaller than the effect in either the Less Wrong or Slate Star Codex surveys (22 percentage points). The 95% confidence interval for the mathematician data is a range of 6 percentage points to 27 percentage points. Given this range, we can't rule out that the difference in effect sizes is due to noise, but it seems most plausible that there is a real difference in the size of the underlying effect between the populations.
A discussion of bias in this data
As I say, my data is not very reliable, it seems plausible that some of my sources were faulty, and I was going quickly, so I may have made some errors in doing data collection. Furthermore, I was only able to find data for 82 of the 150 mathematicians.
But in expectation, those errors will cancel out, unless there's some systematic bias in the sources I was using. I can think of at least two causes of bias, but neither one seems like it could be the cause of the observed trend.
Higher reporting rate for first born children
First, maybe first borns are recorded more readily? If the first born child was the heir to a family's property, then they may have been more likely to be mentioned in legal and other documents, so there may be much better historical records of first-born children.
But our subjects are all famous mathematicians, independent from their inheritance-status. So, if there was a historical reporting bias that favored the first born, this would actually push against our observed effect. First born members of our sample would either be listed as only children, or noted as having an unknown number of siblings. Younger-sibling mathematicians, on the other hand, would be noted as younger siblings, because their older brother is added to the historical record on the basis of their heirship.
Underreporting of females
Another way in which the available record of sibling data may be biased, which does not directly affect the validity of this analysis, is that women might have gone unrecorded more often than men. The size of this effect tells us something about the extent to which the available record of sibling data is biased.
It was relatively easy to do a quick check for a reporting bias in favor of male siblings: I just summed all the brothers that I found, and all the sisters.
All together, I recorded 110.5 brothers and half brothers and 100.5 sisters and half sisters. (The point five comes from Jean-Baptiste Joseph Fourier's entry. I found that he had 3 half siblings by his father's first marriage, but I didn't know of what sex. So I split the difference by saying he had 1.5 half brothers and 1.5 half sisters, in expectation. I was comfortable doing this because I mostly care about whether siblings are younger or older, and only secondarily about if they are male or female.)
So there are slightly more males listed, at least in the sources I could find. But a difference of 10 out of 211 siblings with recorded sex, isn't very large. I'm sure there are some statistics I could do to show it, but I don't think that slight bias is sufficient to account for our observed birth order effect.
I'm hoping that others can think of reasons why we might see a trend in these data even if the birth order effect wasn't real.
Conclusion
This is a pretty intriguing result, and I'm surprised no one (that I know of) has noticed it before now.
I think this post should be thought of as a pilot study. I put in about 20 hours to investigate the hypothesis, but only in a quick and cursory way. I would be excited for others, who are better informed and better-equipped than I am, to do a more in-depth analysis into these topics.
Do mathematicians of lesser renown display this birth order effect? What about prominent (or average) individuals from other STEM fields? Non-STEM fields? I'd be interested to see an analysis of the most successful business executives, for instance.
Furthermore, more investigation could uncover detail about how having older siblings gives rise to this effect.
Some explanations for this phenomenon rest on social interaction with older siblings in one's first few years. Others depend on biological consequences of spending one's fetal period in a womb that was previously occupied by older siblings. In principle we should be able to tease out which of these mechanisms generates the effect by looking at much more data that tracks older siblings that died in infancy, and older half siblings. (Siblings that died in infancy can't mediate the social effect, while half siblings can mediate a biological effect depending on which parent is shared, and can mediate a social effect depending on whether they were living in the household at the time of birth.) If someone found a larger dataset that tracked these factors, we might be able to falsify one or the other of these stories.
And again, please inform me of any errors.
20 comments
Comments sorted by top scores.
comment by Ben Pace (Benito) · 2018-08-29T18:18:54.266Z · LW(p) · GW(p)
I curated this post for these reasons (starting with the most important):
- This post is a central example of the sort of intellectual labour that many people can do, is actually useful, and that I’d love to see people doing more on LessWrong. Taking on a nearby operationalisation of the question (great mathematicians), spending 20 hours gathering + analysing data, and open-sourcing it all, really helps shine a light on an empirical question like this.
- The post is surprisingly clearly written. It uses an academic structure (intro, methodology, results, discussion, conclusion) yet doesn’t add needless complexity, and is short. I enjoyed reading it.
- It adds to prior work done by a member of the broader rationality community. I might have thought there’d just been some weird mistake with LW/SSC community data, but having it for this independent group is starting to become a much stronger argument.
Thoughts on further work:
- As the OP says, seeing some more replication attempts on other populations (e.g. less famous mathematicians, but also vastly different parts of society) would be interesting.
- Some people developing first-principles models that predict this effect (e.g. models of biology/chemistry in the womb, models of socialising effects of siblings), that make other testable predictions we can explore, would also be great to see (as the OP points to in the conclusion).
- If people think of strong reasons why this dataset (or the earlier LW/SSC ones) are biased, that would also be a big help.
Overall, this is a great replication work. Please do more of this!
comment by Bucky · 2018-08-21T09:48:49.397Z · LW(p) · GW(p)
Would it be fair to say that any historical data on successful scientists/mathematicians will be over represented by firstborns due to primogeniture inheritance laws and customs? Historically those involved in the sciences mainly had to be independently wealthy and being a first born would tend to help with that with those born after more likely to have to work for a living. Maybe famous historical lawyers would tend to be under represented by firstborns?
I'd expect this to be a fairly large selection effect similar in size to the Less Wrong survey but presumably caused by a different mechanism.
Possibly a data set which would have more bearing on the question of birth order effects in modern times would be Fields medal, Abel prize, Turing award, Nobel prizes in Physics, Chemistry, Medicine and Economics in the last 30 years or so - I don't have a great feel for how long ago the primogeniture inheritance thingy stopped being relevant but given an average Nobel laureate age of 59 this would mean people born since ~1930. These might be easier to find data on than Thales of Miletus too!!
Replies from: elityre↑ comment by Eli Tyre (elityre) · 2018-08-22T05:10:27.807Z · LW(p) · GW(p)
Historically those involved in the sciences mainly had to be independently wealthy
There have been professorships of mathematics in Europe since at least the 1500's, and most of the mathematicians on this list were employed by universities. Funding doesn't seem to have been a constraint, at least for mathematicians of this caliber.
Education, however does seem relevant. Going through the data, I frequently noticed the biographical pattern "X-person's exceptional mathematical talent was noticed in [early schooling], and he was sent to [some university]." I don't know how common it was for children to attend the equivalent of elementary school before the 1900s.
From my very cursory look at the biographical details of these mathematicians I can say that...
- At least a few came from very poor families, but nevertheless received early schooling of some kind. (I don't know how rare this was, maybe only one out of 50 poor families send their kids to school.)
- Siblings were often mentioned to have also received an education at the same institution. This leads me to guess that schooling was not a privilege awarded to only some of the (male, at least) children of a family.
Again, if anyone knows more about these things than I do, feel free to chip in.
Possibly a data set which would have more bearing on the question of birth order effects in modern times would be Fields medal, Abel prize, Turing award, Nobel prizes in Physics, Chemistry, Medicine and Economics in the last 30 years or so
Yep. I think that would be useful.
Replies from: Bucky
↑ comment by Bucky · 2018-08-22T10:04:45.609Z · LW(p) · GW(p)
Thanks, that seems to rule inheritance laws out as a significant factor. I'm quite tempted to create that data set myself. Any objection if I use your analysis spreadsheet as a template?
Replies from: elityre↑ comment by Eli Tyre (elityre) · 2018-08-22T19:31:20.691Z · LW(p) · GW(p)
Feel free!
comment by Bucky · 2019-12-16T11:26:49.911Z · LW(p) · GW(p)
I was going to write a longer review but I realised that Ben’s curation notice [LW(p) · GW(p)] actually explains the strengths of this post very well so you should read that!
In terms of including this in the 2018 review I think this depends on what the review is for.
If the review is primarily for the purpose of building common knowledge within the community then including this post maybe isn’t worth it as it is already fairly well known, having been linked from SSC.
On the other hand if the review process is at least partly for, as Raemon put it [LW · GW]:
“I want LessWrong to encourage extremely high quality intellectual labor.”
Then this post feels like an extremely strong candidate.
(Personal footnote: This post was essentially what converted me from a LessWrong lurker to a regular commentor/contributor - I think it was mainly just being impressed with how thorough it was and thinking that's the kind of community I'd like to get involved with.)
Replies from: elityre↑ comment by Eli Tyre (elityre) · 2019-12-18T17:47:02.795Z · LW(p) · GW(p)
(Personal footnote: This post was essentially what converted me from a LessWrong lurker to a regular commentor/contributor - I think it was mainly just being impressed with how thorough it was and thinking that's the kind of community I'd like to get involved with.)
: )
comment by Eli Tyre (elityre) · 2018-11-28T03:57:16.366Z · LW(p) · GW(p)
A (completely unvetted) idea that was just suggested to me by someone:
There's some folk wisdom that first born children are born later, and spend more time in the womb on average. If this is true, perhaps it mediates the intelligence boosting effect? (I have no strong reason to suspect that it does, but it seems good to note possible hypotheses here.)
Does anyone know if the folk wisdom is true? Does being first born correlate with a longer natal incubation time?
comment by gwern · 2018-08-21T04:07:39.559Z · LW(p) · GW(p)
After removing the individuals that I couldn’t find data for, we had a sample size of 86. A paired t-test, comparing the number of first-borns with the expected number of first-borns (one data point for each of the 86 mathematicians) was statistically significant, t(85)=2.86, p = 0.00529.
Wouldn't this be a chi-squared/proportion test? Or a binomial regression? (What would you be comparing means of, taking birth category as an integer and averaging them?)
Replies from: Unnamed↑ comment by Unnamed · 2018-08-21T07:14:29.942Z · LW(p) · GW(p)
For each mathematician, actual firstbornness was coded as 0 or 1, and expected firstbornness as 1/n (where n is the number of children that their parents had). Then we just did a paired t-test, which is equivalent to subtracting actual minus expected for each data point and then doing a one sample t-test against a mean of 0. You can see this all in Eli's spreadsheet here; the data are also all there for you to try other statistical tests if you want to.
Replies from: Thrasymachus↑ comment by Thrasymachus · 2018-08-21T11:22:49.112Z · LW(p) · GW(p)
I not sure t-tests are the best approach to take compared to something non-parametric, given smallish sample, considerable skew, etc. (this paper's statistical methods section is pretty handy). Nonetheless I'm confident the considerable effect size (in relative terms, almost a doubling) is not an artefact of statistical technique: when I plugged the numbers into a chi-squared calculator I got P < 0.001, and I'm confident a permutation technique or similar would find much the same.
comment by Ben Pace (Benito) · 2019-12-01T00:49:01.135Z · LW(p) · GW(p)
This feels like a pretty central example of 'things we found out on lesswrong in 2018'. Great work all round, so I'm nominating it. Next year, I'll also nominate the further work on this that came out in 2019.
comment by Thomas Kwa (thomas-kwa) · 2020-06-03T21:54:35.055Z · LW(p) · GW(p)
> So there are slightly more males listed, at least in the sources I could find. But a difference of 10 out of 211 siblings with recorded sex, isn't very large. I'm sure there are some statistics I could do to show it, but I don't think that slight bias is sufficient to account for our observed birth order effect.
Almost all of these mathematicians were male and the sex of successive siblings is [correlated](https://www.biorxiv.org/content/biorxiv/early/2015/11/12/031344.full.pdf). Combined with random variation, I don't think we can conclude bias in this sample.
comment by orthonormal · 2019-12-07T22:11:44.848Z · LW(p) · GW(p)
I would not include this in the Best-of-2018 Review.
While it's good and well-researched, it's more or less a footnote to the Slate Star Codex post linked above. (I think there's an argument for back-porting old SSC posts to LW with Scott's consent, and if that were done I'd have nominated several of those.)
comment by DanielFilan · 2019-12-01T01:24:18.793Z · LW(p) · GW(p)
This is now a hypothesis I look out for and see many places, thanks in part to this post.
comment by BronecianFlyreme · 2018-09-03T16:39:54.269Z · LW(p) · GW(p)
Is the premise that while the effect of birth order on mean intelligence is small, we can see it magnified among our community members and in great mathematicians because each group is likely far more intelligent than average?
I recall reading this https://putanumonit.com/2015/11/10/003-soccer1/, which demonstrates that small mean differences will have outsized effects on groups comprised by the distributions' tails.
Replies from: elityre↑ comment by Eli Tyre (elityre) · 2018-09-05T18:06:06.929Z · LW(p) · GW(p)
Not a premise, but a plausible hypothesis, I think.
If you select very strongly for intelligence, you're going to tend to select for first borns, since those correlate.
But my guess is that isn't all that's happening, because the effect size is smaller for the Mathematicians than for LessWrongers. Rationalists are pretty smart, but these are some of the most brilliant people who have ever lived.
It seems like there might be an additional trend, amongst rationalists, towards being first born, even after accounting for high intelligence.
[edit: or maybe the first born effect isn't mediated by intelligence at all.]
comment by Pattern · 2018-08-22T20:25:11.913Z · LW(p) · GW(p)
Others depend on biological consequences of spending one's fetal period in a womb that was previously occupied by older siblings.
The effect has been referenced with regards to 'First born/s'. Could it be oldest child instead? (Adoption might distinguish between them, but I don't know if it's common enough to tell. We also probably wouldn't have the data on whether an adopted child is a 'first born' or not.)
comment by whestler · 2025-02-25T11:32:40.543Z · LW(p) · GW(p)
I'm surprised to see so little discussion of educational attainment and it's relation to birth order here. It seems that a lot of the discussion is around biological differences. Did I miss something?
Families may only have enough money to send one child to school or university, and this is commonly the first born. As a result, I'd expect to see a trend of more first-borns in academic fields like mathematics, as well as on LessWrong.
As a quick example to back up this hunch, this paper seems to reach the same conclusion:
https://www.sciencedirect.com/science/article/abs/pii/S0272775709001368
"birth order turns out to have a significant negative effect on educational attainment. This decline in years of schooling with birth order turns out to be approximately linear."
I'd be interested if the effect still exists if we control for educational attendance/ resources somehow.
comment by Lev Protter (lev-protter) · 2024-04-13T19:30:01.888Z · LW(p) · GW(p)
There's a pretty good reason old Hunter Gatherer types obsess about maternal diet before pregnancy. I also expect to find a much higher number of postpartum issues after non first born births. Basically blame nutritional deficiencies for this effect.