Birth order effect found in Nobel Laureates in Physics
post by Bucky · 2018-09-04T12:17:53.269Z · LW · GW · 25 commentsContents
Methodology Results Discussion Autobiographies as source material Gender imbalance Conclusion None 25 comments
[Epistemic status: Three different data sets pointing to something similar is at least interesting, make your own mind up as to how interesting!]
Follow-up to: Fight Me, Psychologists, Birth Order Effects are Real and Very Strong, 2012 Survey Results [LW(p) · GW(p)], Historical mathematicians exhibit a birth order effect too [LW · GW]
In Eli Tyre’s analysis [LW · GW] of birth order in historical mathematicians, he mentioned analysing other STEM subjects for similar effects. In the comments I kinda–sorta [LW(p) · GW(p)] preregistered a study into this. Following his comments I dropped the age requirement I mentioned as it no longer seemed necessary.
I found that Nobel Laureates in Physics are more likely to be firstborn than would be expected by chance. This effect (10 percentage points) is smaller than the effect found in the rationalist community or historical mathematicians (22 and 16.7 percentage points respectively) but is significant (p=0.044).
More brothers were found in the study then sisters (125:92 (58%)). After correcting for the correct expected ratio (~52%) this was found to not be significant (p=0.11).
I was unable to find sufficient data on Fields medal, Abel prize and Turing award winners.
My data and analysis is documented here. With Eli's kind permission I used his spreadsheet as a template. I have kept Eli’s data on the same Table – rows 4-153 are his.
Methodology
My methods matched Eli’s closely except for the data sets I looked at, see his post for more information.
Initially I attempted to replicate Eli’s results in other mathematicians by analysing Fields medal and Abel prize winners. Unfortunately I was unable to gather sufficient additional data. This is partly due to crossover in names between these mathematicians and the list from which Eli was working.
It also seems to be the case that less biographical information is available for people born after ~1950. This might be partly due to these people and their siblings being more likely to be still alive so data protection rules prevent e.g. geni from listing their full details (siblings’ details are often set to “private”) but there could be other reasons. For Fields medals awarded before 1986 I found data on 12/30 recipients, after that only 3/30.
I had a brief look at Turing award winners, as this would have seemed a relevant field to compare to the results from the rationalist community that inspired the studies, but came across the same problem.
Finally, I looked at Nobel laureates in Physics. A massive help in data collection here was the fact that since the 1970s Nobel laureates have been asked to supply an autobiography, which is published on the Nobel website. Even before then there are biographies of each laureate although these seldom mention birth order.
Between the Nobel site, Wikipedia and geni I was able to find useful data on 100/207 Physics laureates. The other 107 either had no siblings or I couldn’t find sufficient data on them – either way they weren’t included in the analysis.
As a comment on data sources, I found geni to be somewhat unreliable. It contradicted the autobiographies or sometimes even contradicted itself. At other times, the list of siblings was incomplete or missing completely.
Results
Categorising by family size shows that for all family sizes with ≥10 data points there are more firstborns than would be expected by chance.
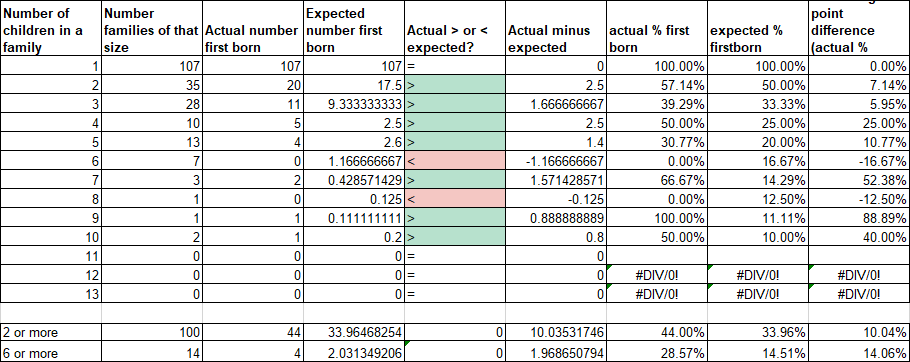
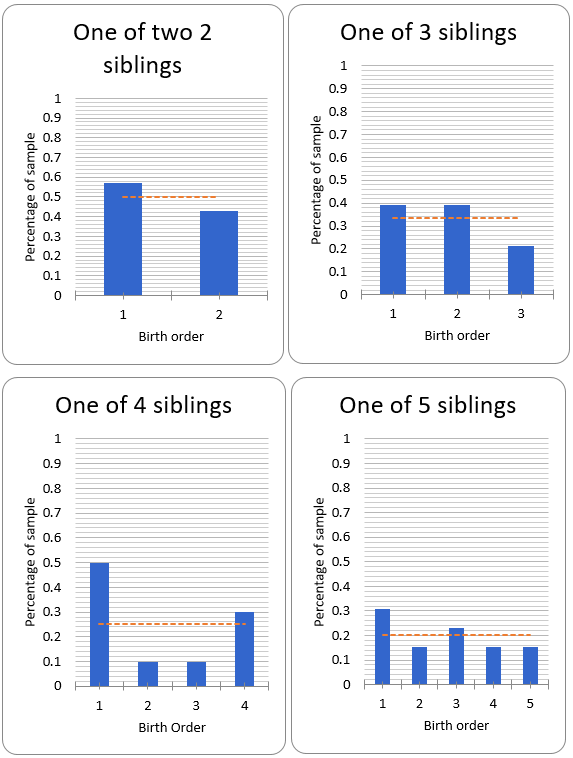
Due to small sample size I have grouped all families of 6+ siblings into a single bucket and even then n=14. Expected birth order then varies with higher birth order as there are fewer families in the sample with at least that many children.
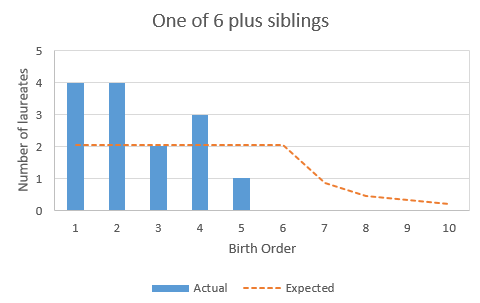
Analysing the data as a whole gives a 10 percentage point effect (0.2 to 19.8 percentage points, 95% confidence). This is less than both the SSC / Less Wrong surveys and Eli’s historical mathematicians analysis (22 and 17 percentage point respectively). I haven’t got a number for overall confidence level for the SSC data but due to the large data set and very low p quoted for the 2 sibling example, it is unlikely that the 95% confidence interval overlaps with this new data, suggesting that the effect is truly a different size and not due to chance.
Discussion
Autobiographies as source material
Using autobiographies as the source for a significant number of the data points should have helped with the reliability of the data. It is possible that when writing an autobiography one would be more likely to mention siblings and birth order if one was the eldest but this doesn't seem likely.
Gender imbalance
Eli discussed under reporting of females as a potential source of bias. However, he found that the brothers:sisters ratio in his data was not unreasonable.
Running the same analysis on the physics Nobel laureate data I get a ratio of 125:92 brothers:sisters. This makes the siblings 58% male, with p=0.03 (binomial distribution, two tailed). This effect is actually more significant than the birth order effect.
Looking at the SSC data and Eli’s data and found that there were 52% brothers in both. I did a little research and found that actually 51-52% is roughly the expected brother:sister ratio. I feel like this is something I should have already known but didn’t.
Another effect which might increase the proportion of Nobel laureates brothers is that men can have a disposition to have boys or a disposition to have girls. As almost all of the laureates are male it would be reasonable to think more of their Dads were predisposed to having boys. However as this isn’t seen in SSC or historical mathematicians data (both also male dominated) this doesn’t really get us much further.
Using 52% as the expected ratio (instead of 50%) means that the 58% result from Nobel laureates no longer rises to significance (p=0.11) and should instead be labelled as “hey, look at this interesting subgroup analysis” or possibly “slightly odd but not implausible”.
As I mentioned previously, most of the data since the 1970s Nobels is based on autobiographies. Looking at only data since then, the brother:sister ratio is 51:35 (59%). It seems unlikely that Nobel laureates forgot about some of their sisters, making it less likely that the gender imbalance is due to incorrect data.
One potential source of error in the gender balance may be in the siblings whose gender I was unable to determine. There were 50 of these. Most (41) of these came from families where I had no data except the number of siblings and the position of the laureate within the family (e.g. “I was the fourth of five children.”). It is possible that some of the missing sisters are in this category.
However, this would imply that if someone has more brothers they are more likely to list the genders of their siblings than if they have more sisters. Perhaps as most of the laureates were male they might have had more in common with brothers and spend more time with them, making them statistically more likely to mention their brothers’ gender. This seems plausible but unlikely to cause a big effect even if it were true.
For the moment, I am working with the assumption that the sample is accurate and that the gender imbalance is just an outlier. Any other thoughts on causes of bias are welcome. These would have to explain how this effect was seen both in data from both geni and the laureates’ autobiographies.
Conclusion
Nobel laureates in physics exhibit a birth order effect such that they are 10 percentage points more likely to be the eldest child than would be expected (p=0.044). This effect is less than data from both SSC readers and historical mathematicians (22 and 17 percentage points respectively).
There was a gender imbalance between brothers and sisters (58% brothers) but, taking into account the expected ratio of 52%, this was not significant (p=0.11). This effect is not seen in SSC readers or historical mathematicians (52% in both)
I would recommend that anyone who wishes to collate additional historical data consider Nobel laureates in other awards due to the availability of accurate data from the autobiographies. My analysis took perhaps 12 hours but a lot of that was spent on wild goose chases in looking for data on Fields medal and Abel prize recipients. I saved a lot of time by reusing Eli’s spreadsheet (thanks for the permission). I would estimate getting data on the entire history of another Nobel prize category and analysing it would take ~6-8 hours so it shouldn’t be too daunting for someone to take on.
25 comments
Comments sorted by top scores.
comment by Unnamed · 2018-09-04T22:41:38.976Z · LW(p) · GW(p)
Now that we have data on LWers/SSCers, mathematicians, and physicists, if anyone wants to put more work into this I'd like to see them look someplace different. We don't want to fall into the Wason 2-4-6 [LW · GW] trap of only looking for birth order effects among smart STEM folks. We want data that can distinguish Scott's intelligence / intellectual curiosity hypothesis from other possibilities like some non-big-5 personality difference or a general firstborns more likely phenomenon.
Replies from: Bucky↑ comment by Bucky · 2018-09-05T12:02:54.392Z · LW(p) · GW(p)
Very good point. That would mean examining Nobel laureates in chemistry, medicine and economics might not give much extra information.
Literature laureates would, I presume, have significant intellectual curiosity so might give an indication as to whether the effect is specific to STEM subjects or more generalised curiosity/something else.
I’m not sure about Peace laureates – a negative result wouldn’t tell us much but a positive result would be interesting.
Any other suggestions for data which might be publicly available and point us towards one hypothesis or another?
We’re only going to get a good picture of what’s going on by someone deciding to do a proper research project on this but I feel like any additional data which people could collect would be helpful to point the project in the right direction.
Replies from: Unnamed, mary-wang↑ comment by Unnamed · 2018-09-05T20:28:18.269Z · LW(p) · GW(p)
Seems interesting to get data on:
Some group that isn't heavily selected for intelligence / intellectual curiosity: skateboarders, protestors, professional hockey players...
Some non-STEM group that is selected for success based on mental skills: literature laureates, governors, ...
Not sure which groups it would be easy to get data on.
There is also the option of looking into existing research on birth order to see what groups other people have already looked at.
Replies from: elityre, Leafcraft, Pattern↑ comment by Eli Tyre (elityre) · 2018-09-08T21:08:34.281Z · LW(p) · GW(p)
I'm interested in teasing apart "high achievement" from "high achievement in a STEM field".
I'd be interested in analysis of fortune 500 CEOs, for instance.
↑ comment by Leafcraft · 2018-09-19T12:29:26.011Z · LW(p) · GW(p)
The suggestion about Fortune 500 CEO seems good; "self-made" millionaires are a category far enough from STEM, and, due to their status, they are more likely to have reliable biographical information. If you want to go in a completely different direction, how about something like the Darwin Awards?
↑ comment by Pattern · 2018-09-08T20:40:59.170Z · LW(p) · GW(p)
Staying 'out of the 2-4-6' does seem useful, but it'd also be nice to know if it is a 'STEM thing'.
Replies from: tenthkrige↑ comment by tenthkrige · 2018-09-12T14:17:55.497Z · LW(p) · GW(p)
Which you also can't know if you don't test other fields. I think there are at least 3 concentric levels to distinguish : ( famous ( intelligent ( STEM ) ) ).
Replies from: Bucky, Pattern↑ comment by Bucky · 2018-09-13T07:51:46.767Z · LW(p) · GW(p)
So potentially ( Sports players ( Literature laureates / governors ( Physicists / Mathematicians ) ) ) ?
Replies from: tenthkrige↑ comment by tenthkrige · 2018-09-13T16:23:27.378Z · LW(p) · GW(p)
Some sports players are pretty smart and probably some governors aren't. What about ( Reality TV celebrities ( heads of state of UNSC countries ( Physicists / Mathematicians / Engineers ) ) ).
(1 minute of thought did not provide another group of famous & not-even-a-little-bit-selected-for-intelligence people, unless there's a database of lottery winners, which I doubt. Curious for suggestions.)
(Famous engineers: of course Wikipedia does not disappoint.)
↑ comment by Mary Wang (mary-wang) · 2019-05-14T22:31:37.938Z · LW(p) · GW(p)
Olympic medalists? Not just intelligence but a certain kind of political savvy and perseverance.
comment by Bucky · 2019-12-12T21:38:06.523Z · LW(p) · GW(p)
This is a review of my own post.
The first thing to say is that for the 2018 Review Eli’s mathematicians post [LW · GW] should take precedence because it was him who took up the challenge in the first place and inspired my post. I hope to find time to write a review on his post.
If people were interested (and Eli was ok with it) I would be happy to write a short summary of my findings to add as a footnote to Eli’s post if it was chosen for the review.
***
This was my first post on LessWrong and looking back at it I think it still holds up fairly well.
There are a couple of things I would change if I were doing it again:
- Put less time into the sons vs daughters thing. I think this section could have two thirds of it chopped out without losing much.
- Unnamed’s comment [LW(p) · GW(p)]is really important in pointing out a mistake I was making in my final paragraph.
- I might have tried to analyse whether it is a firstborn thing vs an earlyborn thing. In the SSC data it is strongly a firstborn thing and if I combined Eli and my datasets I might be able to confirm whether this is also the case in our datasets. I’m not sure if this would provide a decisive answer as our sample size is much smaller even when combining the sets.
comment by Eli Tyre (elityre) · 2018-09-08T21:04:41.097Z · LW(p) · GW(p)
Thanks for doing this!
I feel more validated in having spent the time doing data-collection for the mathematician data set after seeing that it prompted someone else to investigate in this area. It's pretty encouraging to know that if I write up something of interest on LessWrong, other people might build on it.
comment by Ben Pace (Benito) · 2019-12-01T00:49:40.624Z · LW(p) · GW(p)
This feels like a pretty central example of 'things we found out on lesswrong in 2018'. Great work all round, so I'm nominating it. Next year, I'll also nominate the further work on this that came out in 2019.
comment by DanielFilan · 2019-12-01T01:25:14.694Z · LW(p) · GW(p)
This is now a hypothesis I look out for and see many places, thanks in part to this post.
comment by jmh · 2018-09-05T11:54:13.967Z · LW(p) · GW(p)
Just asking about the birth order here. What is the implication of the finding -- why is this seen? Any thoughts?
Replies from: Bucky, Pattern↑ comment by Bucky · 2018-09-19T11:01:43.595Z · LW(p) · GW(p)
One of the things I find most interesting is that the effect seems to be strongest for the rationality community.
I would suggest a sister theory to the intellectual curiosity angle that Scott mentioned. Eldest children spend their formative years without another child in the family to look up to. I would think that this would lead to, on average, a lower acceptance of information from authority.
This comes a bit my personal experience - I had an elder brother whose opinion I would take on as my own, even through my teens. I'd be interested to know if other younger siblings in the community have had a similar experience.
It would explain why the effect is so strong in the rationalist community. In Science and Maths it helps to challenge authoritative sources but this is actively encouraged, so the intrinsic effect needs to be less strong to get you to do it. The rationalist community is often challenging things which, culturally, aren't supposed to be challenged which would give a higher intrinsic bar to entry.
Replies from: TheMajor↑ comment by TheMajor · 2018-10-15T11:31:48.584Z · LW(p) · GW(p)
I would suggest Regression to the Mean instead - we are only interested in this hypothesis because of its unusual high number on the survey in the first place.
Replies from: Bucky↑ comment by Bucky · 2018-10-15T21:05:11.142Z · LW(p) · GW(p)
I wandered about regression to the mean but with the SSC data being so large there isn’t much room for a big effect - even moving 4SD on the SSC data won’t move the mean much. I’m afraid I don’t know how to do the maths beyond comparing confidence intervals as I did in the text.
Replies from: TheMajor↑ comment by Pattern · 2018-09-06T17:30:20.838Z · LW(p) · GW(p)
Just wild guesses.
I had a question about how adoption fits in to the picture, so two things come to mind:
A) It still exists for adopted kids.
Since it's not clear what the effect seems meaningless for single children, maybe it doesn't exist for them.
Maybe older siblings are trusted with more responsibility or specifically watching out for younger siblings, and that has way more effect than anyone expected. This would be a pain to test, but one might try to check by seeing if the gaps between the ages of kids matter. It's a pretty specific hypothesis though, so maybe it'd be something else about interacting a lot with younger kids while young (but older).
B) It doesn't.
That might mean it has something to do with birth, as opposed to differences in how later/earlier children are raised.
Replies from: jmh↑ comment by jmh · 2018-09-07T12:17:31.452Z · LW(p) · GW(p)
I did a search on the first born more intelligent query and go a hit to some article published in late 2016 or early 2017 -- news paper reported on the study in Feb 2017. What the hypothesis seemed to be was that parent interact with the first child differently than the later children and provide a more mentally stimulating environment for that child.
If so any bets on when the first law suit for compensation by the younger siblings will be filed for a great share of any inheritance? (semi-joking...)
Replies from: Pattern