Self-dialogue: Do behaviorist rewards make scheming AGIs?
post by Steven Byrnes (steve2152) · 2025-02-13T18:39:37.770Z · LW · GW · 0 commentsContents
Introduction Note on the experimental “self-dialogue” format …Let the self-dialogue begin! 1. Debating the scope of the debate: Brain-like AGI with a behaviorist reward function 2. Do behaviorist primary rewards lead to behavior-based motivations? 3. Why don’t humans wirehead all the time? 4. Side-track on the meaning of “interpretability-based primary rewards” 5. Wrapping up the Cookie Story 6. Side-track: does perfect exploration really lead to an explicit desire to wirehead? 7. Imperfect labels 8. Adding more specifics to the scenario 9. Do imperfect labels lead to explicitly caring, vs implicitly caring, vs not caring about human feedback per se? 10. The training game 11. Three more random arguments for optimism 12. Conclusion None No comments
Introduction
I have long felt confused about the question of whether brain-like AGI would be likely to scheme, given behaviorist rewards. …Pause to explain jargon:
- “Brain-like AGI” means Artificial General Intelligence [LW · GW]—AI that does impressive things like inventing technologies and executing complex projects—that works via similar algorithmic techniques that the human brain uses to do those same types of impressive things. See Intro Series §1.3.2 [LW · GW].
- I claim that brain-like AGI is a not-yet-invented variation on Model-Based Reinforcement Learning (RL), for reasons briefly summarized in Valence series §1.2 [LW · GW].
- “Scheme” means pretend to be cooperative and docile, while secretly looking for opportunities to escape control and/or perform egregiously bad and dangerous actions like AGI world takeover.
- If the AGI never finds such opportunities, and thus always acts cooperatively, then that’s great news, but it still counts as “scheming”.
- “Behaviorist rewards” is a term I made up for an RL reward function which depends only on externally-visible actions, behaviors, and/or the state of the world.
Maybe you’re thinking: what possible RL reward function is not behaviorist?? Well, non-behaviorist reward functions are pretty rare in the textbook RL literature, although they do exist—one example is “curiosity” / “novelty” rewards.[1] But I think they’re centrally important in the RL system built into our human brains. In particular, I think that innate drives related to human sociality, morality, norm-following, and self-image are not behaviorist, but rather involve rudimentary neural net interpretability techniques, serving as inputs to the RL reward function. See Neuroscience of human social instincts: a sketch [LW · GW] for details, and Intro series §9.6 [LW · GW] for a more explicit discussion of why interpretability is involved.
- (…It’s not fancy interpretability! It’s more-or-less akin to a set of trained classifiers on neural net activation states, or if you prefer, to a set of extra neural net output heads which are trained from various different streams of ground truth.)
So again, the question is: will brain-like AGIs scheme, if trained by a behaviorist RL reward function? I had strong intuitions pointing in both directions on this question. So I sat down and wrote both sides of a dialogue—the optimist on one shoulder talking to the pessimist on my other shoulder.

My shoulder-people wound up making a lot of progress, clearing out various mistakes and confusions on both sides, and settling on a different argument than either of them had going in. You can scroll to the very bottom (§12) for the upshot. (Spoiler: I wound up believing that, yes, behaviorist rewards do lead to scheming AGIs.)
Note on the experimental “self-dialogue” format
By the way, this was a great way to get unstuck! Strong recommend![2] Before I started this “self-dialogue”, I was kinda staring at a blank screen, feeling stumped, and procrastinating. After I started it, the words and ideas were just pouring right out! Yay! I plan to make it much more of a habit! Here’s another mini-example already [LW(p) · GW(p)].
…Well, I mean, it was a good way for me to clarify my own thoughts, in the privacy of my own notebook. But then I also cleaned it up, expanded it, rejiggered it, and now I’m publishing it for external consumption. That’s more of an avant-garde experiment. Obviously, dialogue-as-pedagogy is an old and active [? · GW] writing format, but normally the author knows which side they’re on while they’re writing it! Whereas I really didn’t, until I got to the end.
So, writing this was helpful for me. Will reading it be helpful for anyone else? Beats me! Let me know. :) (And ideally, I will someday rewrite what I wound up figuring out here, into a more conventional and concise format!)
Other notes:
- Again, both sides of the dialogue are me; I’m not speaking for anyone else. Everything I wrote seemed reasonable to me, at least at the moment that I was writing it.
- Relatedly, if my shoulder-pessimist or shoulder-optimist “concedes” some point, that doesn’t mean that they were correct to do so. It just means that I personally stopped believing it. Other people might well still believe it, and I’m happy to chat about that!
- This post might not be convincing, or even helpful, for anyone coming from a very different place than me. My shoulder optimist and pessimist have an awful lot of shared assumptions, beliefs, and interests, which other AGI alignment researchers would disagree with.
…I tried to put some of those shared beliefs into interspersed collapsible boxes—think of them as cached nuggets of theoretical background that locally I’m very confident about, even if I have some uncertainty about how they fit into a bigger picture.
…Let the self-dialogue begin!
1. Debating the scope of the debate: Brain-like AGI with a behaviorist reward function
Optimist: Thanks for coming!
Pessimist: You’re welcome! I consider this a highly dignified [LW · GW] way to spend what little time we have left before the apocalypse.
Let’s jump right in. I say we should expect scheming, because the AGI will wind up motivated by something like wireheading—either reward per se or forcing people to give it reward, including perhaps by hacking out of its environment etc. (And those motivations obviously give rise to scheming as an instrumental goal.)
Like, here’s a story:
Pessimist offers: Cookie Story[3] There’s a machine that gives you a delicious cookie when some random thing happens, like when there’s a wispy cloud overhead. You don’t start wanting the random thing to happen per se. You just want the cookies. And in particular, if there was a way to hack the machine and just take the cookies, with no other negative consequences, you would obviously jump at the opportunity to take the cookies and never think about wispy clouds again. |
So by the same token, the AGI would jump at the opportunity to grab the reward button or whatever.
Optimist: Well, LLMs trained by RLHF don’t seem to have that property.
Pessimist: How do you know?
Optimist: Umm, that recent “alignment faking” paper [LW · GW] seems to imply that the model is (behaving as if it’s) trying to be harmless rather than trying to score high according to the (future) reward function, when those come apart.
Pessimist: I don’t think that’s the right interpretation … But maybe let’s put that aside. I’ve always found behaviorist reward functions to be less obviously doomed for the LLM+RLHF paradigm than they are for the brain-like AGI / model-based RL paradigm. Especially relevant in this case is that thing I always say about mechanical imitation ↓ I haven’t thought the LLM case very much. So, maybe we should stick to brain-like AGI for this morning.
Cached belief box: “Mechanical imitation” as an alignment-relevant difference between LLM+RLHF versus brain-like AGI
Two related points:
Brains can imitate, but do so in a fundamentally different way from LLM pretraining. Specifically, after self-supervised pretraining, an LLM outputs exactly the thing that it expects to see. (After RLHF, that is no longer strictly true, but RLHF is just a fine-tuning step, most of the behavioral inclinations are coming from pretraining IMO [LW(p) · GW(p)].) That just doesn’t make sense in a human. When I take actions, I am sending motor commands to my own arms and my own mouth etc. Whereas when I observe another human and do self-supervised learning, my brain is internally computing predictions of upcoming sounds and images etc. These are different, and there isn’t any straightforward way to translate between them. (Cf. here [? · GW] where Owain Evans & Jacob Steinhardt show a picture of a movie frame and ask “what actions are being performed?”) Now, as it happens, humans do often imitate other humans. But other times they don’t. Anyway, insofar as humans-imitating-other-humans happens, it has to happen via a very different and much less direct algorithmic mechanism than how it happens in LLMs. Specifically, humans imitate other humans because they want to, i.e. because of the history of past reinforcement, directly or indirectly. Whereas a pretrained LLM will imitate human text with no RL or “wanting to imitate” at all, that’s just mechanically what it does.
Relatedly, brains have a distinction between expectations and desires, cleanly baked into the algorithms. I think this is obvious common sense, leaving aside galaxy-brain Free-Energy-Principle takes [LW · GW] which try to deny it. By contrast, there isn’t any distinction between “the LLM expects the next token to be ‘a’” and “the LLM wants the next token to be ‘a’”. (Or if there is, it’s complicated and emergent and controversial, rather than directly and straightforwardly reflected in the source code, as I claim it would be in brain-like AGI.) So this is another disanalogy, and one with obvious relevance to technical arguments about safety.
Optimist: Fine with me! Brain-like AGI it is. OK, different response to the Cookie Story. If there’s a decent correlation between rewards and helpfulness, then helpfulness will seem pretty good from the AGI’s perspective, even if reward per se seems pretty good too.
Cached belief box: TD learning makes things seem good when they immediately precede reward, even if the correlation is imperfect.[4]
Everyday example: I sometimes feel an urge to pull out my phone and check if anyone liked my dank memes on social media. When I do, I have “likes” less than 100% of the time, indeed much less than 100% of the time. (No accounting for taste.) But I evidently continue to feel that urge to pull out my phone.
Theoretical explanation: Credit assignment (Intro series §9.3 [LW · GW]) makes concepts and actions seem good when they tend to immediately precede reward. They don’t need to precede reward every time, and they certainly don’t need to precede every reward, to seem good.
(This applies with both signs—TD learning makes things seem bad when they immediately precede punishment, even if the correlation is imperfect.)
Cached belief box: If an AGI wants to wirehead, but also wants other things, then that might be fine.
Everyday example: Humans generally want to feel good, but also want to help their children and follow norms and so on. That can be fine! If someone tells you that they like to feel good, then you don’t and shouldn’t infer that they’ll throw you down the elevator shaft in exchange for a slightly comfier chair.
Theoretical explanation: It’s possible for other motivations to be stronger than the “I want to feel good” motivation. And if they are, then the other motivations will tend to win out in cases where the two types of motivation come into conflict.
See my discussion of “weak wireheading drive” versus “strong wireheading drive” in Intro series §9.4 [LW · GW].
Pessimist: Seems wrong. I’m still thinking of the Cookie Story above. I think the AGI would learn that its primary rewards (a.k.a. innate drives, a.k.a. the terms in the RL reward function, see Intro series Post 3 [LW · GW]) are independent of its motivations, and only dependent on its actions. This is just a really obvious pattern. So the AGI would be increasingly modeling the effects of its actions, as opposed to the virtues that led to them.
Optimist: …Unless the primary rewards are in fact dependent on upstream motivation, i.e. an interpretability-based reward function, like how human social instincts work (see Neuroscience of human social instincts: a sketch [LW · GW], plus Intro series §9.6 [LW · GW] for a more explicit discussion of why interpretability is involved).
Pessimist: Right, but my plan for this morning was to respond to this particular comment by Noosphere89 [LW(p) · GW(p)] (which involves a behaviorist reward function), not to propose the best possible brain-like AGI alignment plan.
Optimist: But why not propose the best possible brain-like AGI alignment plan? If the future post title is going to be “AGI scheming is solvable, although some random comment by @Noosphere89 [LW · GW] is not a good way to solve it”, well then that's a really dumb soldier-mindset BS future post title. Just friggin’ tell Noosphere89 how to solve it!
Pessimist: Yeah but that’s not the only possible future post title. If it’s true that “AGI scheming is a big concern if you do stupid straightforward things”, then that’s also an important and newsworthy thing to say, because future AGI programmers will surely do stupid straightforward things!
Optimist: OK, you are welcome to also say that. But the obvious starting-point question is whether AGI scheming is a big concern if you follow best practices. Can we focus on that please?
Pessimist: One could also argue that behaviorist reward functions are a relatively specific and concrete plan, and the obvious starting-point question is what happens if you execute that plan. It’s an easier question to sink our teeth into, because it’s in the forward direction: IF we run algorithm X, THEN we will get consequence Y. Logically it makes sense to really nail down the easier “forward problems” before moving on to the trickier “inverse problems” (i.e., “what algorithm / training approach will lead to consequence Y?”). But I promise I’ll get back to the other thing later! Deal?
Optimist: OK. Deal. But you are a piece of shit who will keep finding new excuses to procrastinate thinking directly about the most important thing.
Pessimist: …new good excuses tho. We’re deconfusing! [? · GW] We’re softening the nut in the rising sea!
Optimist: (glares)
Pessimist: OK! So we’re putting aside the question of interpretability-based reward functions. For the rest of this discussion, we assume that the RL reward function for the AGI is “behaviorist”, i.e. it depends purely on externally-observable things—behavior, actions, and the state of the world—unlike how things work in human brains, especially related to human sociality, norm-following, morality, and self-image. (So let’s be very careful in applying human intuitions and assumptions to this non-human-like situation!)
2. Do behaviorist primary rewards lead to behavior-based motivations?
Pessimist (continuing): Now let’s get back to what I was saying before. The AGI would learn that the primary rewards (a.k.a. innate drives, a.k.a. RL reward function terms) are independent of its motivations, and only dependent on its actions, and on stuff in the external world. This is just a really obvious pattern. So the AGI would be increasingly having feelings / motivations related to the effects of its actions, as opposed to the virtues that led to them.
Optimist: I don't understand why the usual argument doesn't work here: if virtuous motivations tend to lead to reward, wouldn't virtuous motivations start feeling good in and of themselves? That’s just plain old TD learning and credit assignment. See the cached belief box just above. We’ve understood this for years.
Pessimist: The usual rule is: motivation collapses to wireheading under perfect exploration, and so “deliberate incomplete exploration” is how we get motivations that generalize “well” by human lights. Like my go-to example of not getting addicted to nicotine by never smoking in the first place.
Cached belief box: “Deliberate incomplete exploration”
In model-based RL, TD learning systematically edits the value function to be a better and better approximation to expected future reward. (In my brain-like AGI picture, I would say “valence guess” function [LW · GW] instead of “value function”, and everything is a bit more complicated, but the upshot is the same.) And then the value function is what’s queried for foresighted planning and decisions; in other words, the value function (not reward function) determines what the AGI “wants” and “tries to do”.
Given infinite time in a finite environment, we normally expect the model-based RL algorithm to fully converge to a global optimum, wherein TD learning has sculpted the value function into a perfect predictor of expected future reward. That means, for example, that the AGI would have a “pure wireheading drive”, wanting nothing besides reward, and it would apply all its intelligence and planning to making that happen.[5]
But this interacts in an interesting way with the desire to preserve one’s goals, which in turn is one of the desires that arises by default from instrumental convergence [? · GW]. A familiar example in humans is: if there’s some highly-addictive drug, and you really don’t want to get addicted to it, then you’re likely to just never try it in the first place!
Not trying addictive drugs is an example of “deliberate incomplete exploration”, in the sense that you (a model-based RL agent) are not “exploring” the full space of possible actions and situations, in a deliberate way, because you know that such exploration would warp your future desires.
AGIs can do that kind of thing too, to “lock in” some of its earlier desires. This behavior is in the same general category as “gradient hacking” or “goal guarding”.
Pessimist (continuing): Limiting exploration is often eminently feasible when we’re talking about actions—again, if you’re trying to never smoke a cigarette, that’s very doable. Limiting exploration seems much harder within the AGI’s own mind. If “saying X because I believe X” gets rewarded, then sooner or later the AGI will try “saying X because I 95% believe X”, and that will be equally rewarded. Then 90%, etc. Over time, there will be enough data to sculpt the value function to point narrowly towards the actions and not towards the upstream motivations. So the preferences will all be about external things (actions, world-states, etc.), whereas the thoughts would be basically unconstrained.
Optimist: But that doesn't rule out “helpfulness” seeming good, and it certainly doesn't prove scheming. If helpful actions are systematically rewarded, then the AGI will want to emit helpful actions, and that’s good enough for me!
Pessimist: No, I think “helpfulness” is a state of mind, as much as a set of actions. Or more specifically, “trying to be helpful” is a state of mind. And that's the one that you AGI optimists often talk about.
Optimist: Maybe, but there's no particular reason for “actions feel good or bad but motivation is unconstrained” to lead to “scheming motivation is likely”. Seems like a highly-unlikely form of misgeneralization!
Pessimist: Umm, I think here is where I'd bring up the fact that the reward signal comes apart from helpfulness, because the labelers are imperfect.
Optimist: Sure, they come apart, but they’re awfully correlated.
Pessimist: Again, in RL, the question is whether the AGIs will explore the areas where they come apart. And in this case, it surely will be exposed to many such examples during training. So it will form a new concept for “actual reward” (or actual process-leading-to-reward), and that concept will feel more and more motivating at the expense of everything else. Think of, umm, a brownie that you know is poisoned. There’s a lot of correlation between eating brownies and deliciousness, over your lifetime, but you’re not gonna eat the poisoned brownie. You’re not a moron. Your value function has discerned the relevant causal factors. Like we were talking about in Against empathy-by-default [LW · GW], right?
Optimist: For a counterargument, see Alex Turner’s (@TurnTrout [LW · GW]) Alignment allows "nonrobust" decision-influences and doesn't require robust grading [LW · GW], which came up in discussion here [LW(p) · GW(p)]. Or more concretely: why aren't we all wireheading already?
3. Why don’t humans wirehead all the time?
Pessimist: Right, I’m arguing that AGIs will do wirehead-ish things like grab the reward button, but yes it’s true that humans don’t always wirehead, and I need to reconcile those. So, why don’t humans wirehead? Umm, I feel like I had a cached answer for that, but I forget. OK, Possibility 1: Humans have interpretability-based primary rewards, and the disanalogy with AGI is that we have earlier declared that the AGI has only behaviorist primary rewards, for the purpose of this discussion. Possibility 2: Humans have “deliberate incomplete exploration” in a way that stops wireheading, and this is disanalogous to AGI, because the AGI will definitely be exposed to plenty of bad labels, whereas I have not been exposed to plenty of nicotine.
Optimist: Which one?
Pessimist: Umm, maybe both? Well, let’s focus on Possibility 2 for now.
Optimist: OK. Above, you wrote “it will form a new concept for ‘actual reward’ (or actual process-leading-to-reward), and that concept will feel more and more motivating at the expense of everything else”. But humans can likewise form a reward concept—“the idea of feeling good” or something—that will perfectly predict all reward. But it’s not true that we wind up caring exclusively about feeling good.
Pessimist: Oh, but “the idea of feeling good” does not “predict” all reward, because the reward temporally precedes the feeling.
Optimist: Right, but by the same token the AGI’s reward concept (or process-leading-to-reward concept) is not observable ahead of time. And it’s not salient, the way you see and hold a physical cookie in the Cookie Story. If the true reward generator is not salient and visible ahead of time, then we expect a bunch of imperfect proxies to it to start feeling motivating in themselves.
Pessimist: Prove it by changing the Cookie Story.
Optimist: Umm, OK. Here’s a story:
Optimist offers: Secret Remote-control Cloud Story: Unbeknownst to you, I put a radio-controlled wirehead-type device in your brain reward system. I watch from a one-way mirror, and when you look at wispy clouds, I press the button. You would wind up liking wispy clouds. |
Pessimist: I have two complaints. First, I would wind up liking to look at wispy clouds. You’re inappropriately generalizing from interpretability-based human social instincts, yet again. I reiterate my belief that “behavior-based primary rewards lead to behavior-based motivations”. For example, I like putting my head on a soft pillow, but I don’t particularly care one way or the other about soft pillows that I cannot put my head upon. Right? Second, this story is disanalogous to AGI anyway, because we should be assuming a smart AGI that is situationally aware, and thus has a decent model of the causal processes upstream of the reward function.
Optimist: Should we be assuming situational awareness? Hmm, I guess yes, I’ll concede that. But I’m not sure how important situational awareness is. Here’s another try:
Optimist offers: Secret Remote-control Cloud Story v2. As before, unbeknownst to you, I put a radio-controlled wirehead-type device in your brain reward system. I watch from a one-way mirror, and when you look at wispy clouds, I press the button. You would wind up liking wispy clouds—sorry, liking to look at wispy clouds. And then sometime later I come out from behind the one-way mirror and say “hey FYI, there’s a radio-controlled brain implant in your head etc.” You definitely don’t immediately stop wanting to look at wispy clouds. Maybe you don’t even eventually stop wanting to look at wispy clouds—not too sure about the latter part though. |
Pessimist: Well, does it matter whether it’s immediate or eventual? …Hang on, I feel like I’ve kinda lost the plot. OK, I was arguing that behavior-based reward functions lead to (1) behavior-based motivations, (2) and more specifically, wireheading-flavored behavior-based motivations like grabbing the reward button, (3) and more specifically, scheming. You’ve kinda been disputing all three of those, but the main point of the Secret Remote-Control Cloud Story was to raise questions about (2). Right?
Optimist: Correct. And I’m saying that, in that story, you’ll like to look at wispy clouds, but you won’t feel motivated to grab the reward button, certainly not exclusively, even after I come out from behind the one-way mirror and tell you that the reward button exists.
Pessimist: I will counter with another story:
| Pessimist offers: E-cig Revelation Story. You’re a smoker, but you’ve never heard of e-cigs. I’m your friend and I say, “hey, e-cigs will make you feel satisfied in all the same way that your normal cigarettes do, but they’re less expensive and healthier”. If you believe me, then you’ll want to try e-cigs. |
Optimist: Sure, but you’re still going to feel an urge to smoke when you see your normal cigarette brand. That urge won’t just immediately disappear. That’s what I’m saying. Remember from above: if there are both wirehead-ish motivations and non-wirehead-ish motivation, then there’s room for optimism, since the latter can potentially outvote the former.
Pessimist: You’ll feel a transient urge. Fine. But “transient urge” is not a powerful decision-determining force. We’re talking about smart AGIs that will think about their decisions. Fine, I’ll try again.
Pessimist offers: E-cig Revelation Story v2. You’re a smoker, but you’ve never heard of e-cigs. I’m your friend and I say, “hey, e-cigs will make you feel satisfied in all the same ways that your normal cigarettes do, but they’re less expensive and healthier”. You believe me with absolute 100% confidence (somehow—we’ll set aside the plausibility of that part for now). I.e., you believe that you’ll definitely find e-cigs satisfying in every conceivable way that you currently find cigarettes satisfying, plus some extra marginal benefit like health. And then I offer to replace cigarettes with e-cigs forever, irreversibly, take it or leave it. Then you’ll say yes. And that’s analogous to the AGI deciding to grab the reward button, after understanding that the reward button exists and what its consequences are, even though that deprives it of the opportunity to get willing human approval of the type it’s already been receiving. |
Optimist: Now you’re the one bringing in disanalogous intuitions from your human social instincts. You’re treating “urge to smoke” as ego-dystonic, because it is for unhappy human cigarette addicts. But there’s no reason to assume that.
Pessimist: I don’t think so. Suppose smoking and vaping are equally socially-motivating—your self-image seems equally good whether you’re a smoker or vaper, the people you admire would judge you positively or negatively to an equal extent regardless of smoking or vaping etc., and the only difference is something non-self-image-related, like less asthma at night or whatever. Then the story still works. You’ll still say yes to the deal to switch to e-cigs, modulo the fact that feeling 100% certain is maybe an unrealistic assumption, but that’s a different topic.
So above, I said “it’s just a transient urge”, and you’re thinking that the important part was “urge as opposed to desire”, a.k.a. ego-dystonic as opposed to ego-syntonic. But I think I want to emphasize instead “transient as opposed to stable”. (However, note that those go together in practice, as we’ve discussed [LW · GW]). Remember, self-supervised updates to the causal world-model always trump TD learning updates related to motivations and desires.
Cached belief box: Self-supervised learning world-model updates always trump TD learning value-function updates, in brain-like AGI
Everyday example: You don’t keep opening your wallet expecting to find it full of money. You want it to be full of money, but you don’t expect it to be full of money, because you’ve just seen with your own eyes that it isn’t.
Theoretical explanation: TD learning makes things seem good or bad (motivating or demotivating)—i.e., it affects their valence [LW · GW] (or the value function, in RL terms). It doesn’t directly update the world-model—only self-supervised (a.k.a. predictive) learning of sensory data does that.
Wishful thinking and motivated reasoning obviously exist, but they don’t work that way. Instead, they work through the “loophole” where (1) desires impact actions (both attention-control and motor-control), (2) actions impact the choice of data that goes into self-supervised learning, (3) the choice of data affects what model world-model you wind up with. See diagram in Valence series §3.3 [LW · GW].
…So if your understanding of the situation changes, motivations will get shaken around by those new beliefs, whenever they come to mind, and the shaking can be arbitrarily strong. During the transition period, yeah sure, there can be transient urges. But if those urges don’t mesh with beliefs, a.k.a. what feels plausible, then they’re transient, because now the concepts pull up new different salient associations [LW · GW] with new different concepts, which then impacts motivation in a new different way. The transient urges won’t determine well-thought-out decisions.
Optimist: That’s an interesting point, and I see vaguely how it could be relevant, but you need to spoon-feed it to me a bit more. Why does the person choose e-cigs? Walk me through the algorithm, step by step.
Pessimist: Oof. Fine, fine, I’ll try. For concreteness, let’s imagine the world-model is something vaguely like a Bayes net. There are a bunch of nodes associated with smoking cigarettes—their appearance, their smell, their taste, how you feel when smoking them, etc. Some of those nodes have positive-valence paint on them, while other nodes have negative-valence paint, and still others are neutral (unpainted).
Cached belief box: “Valence paint” as a metaphor for the value function and desires
Everyday example: From any person’s perspective, various things, and people, and actions seem good or bad, motivating or demotivating, based or cringe. It feels like there’s some kind of metaphysical paint on different things, although that’s really a perceptual illusion.
Theoretical explanation: The value function (a.k.a. “valence guess” function in my brain-like AGI picture) maps “thoughts” (activation patterns of nodes in the world-model) to a valence (good, bad, or neutral). If it has learned to predict negative valence upon the activation of the “capitalism” node in your world-model, then that just feels like “capitalism is bad”, and we can likewise imagine that the “capitalism” node itself has gotten negative-valence paint.
For further discussion see Valence series §2.2, “The (misleading) intuition that valence is an attribute of real-world things” [LW · GW], and Intuitive self-models series §3.3.2 [LW · GW], and see also The Meaning of Right (Yudkowsky 2008) [LW · GW] which uses the metaphor of XML tags instead of paint.
When I tell you about e-cigs for the first time, you create a new node. And when I say that e-cigs will make you feel good in every way that your normal cigarettes do, I’m proposing new arrows from this new node to every single positive-valence-painted node in the cigarette cloud. And when you 100% believe me, that means your brain has filled in those lines to be equally thick as the lines to those same nodes from actual cigarettes, which have previously been filled in by your first-person direct experience. Therefore, when you imagine a plan to smoke regular cigarettes, and then imagine an alternate plan to smoke e-cigs, they seem equally good. But also e-cigs connect to health and inexpensiveness nodes that cigarettes don’t, putting that plan over the top.
Optimist: Seems a bit muddled. Also, if we buy this argument, then the same argument would also “prove” that paperclip maximizers will wirehead. But we’ve always said that paperclip maximizers are reflectively stable.
Pessimist: Oh. Umm. Touché. …How did I mess up though?
Optimist: One of the nodes with positive valence paint is “this is an actual cigarette”—the semantic idea of smoking cigarettes, over and above any of its sensory or interoceptive associations and implications. The e-cigs can’t possibly point to that node in the way that normal cigarettes do. Also, even if the e-cigs could replicate the taste, smell, appearance, etc., that’s all kinda irrelevant to our AGI analogy—pressing the reward button has very different sensory and other consequences than being helpful. You lost the plot a bit.
Pessimist: OK, I buy that. But I’m still puzzled by the E-cig Revelation Story v2 … what am I missing?
Optimist: You conceded above that there is a residual urge to smoke per se—you dismissed it as a transient urge, but I don’t buy your argument for “transient”, and meanwhile “urge” is you admitting that it does in fact have nonzero motivational force. Really, you’re just sneaking in a load-bearing intuitive assumption that this motivational force is weaker than the motivational force related to e-cigs being healthier or cheaper or whatever.
Pessimist: But I still feel like there’s a kernel of truth to that wireheading thing. Like, I want to say there are two categories: (A) desires that come from interpretability-based human social instincts (including self-image etc.), and (B) desires that you’ll gleefully throw away in favor of wireheading at the first opportunity. Like, OK, here’s another.
Pessimist offers: Massage Chair Story Massage chairs feel nice. Suppose I give you access to a button that gives the same good-feeling-on-your-body wired directly into your brain, and there are no other complicating factors like long-term health or price or addiction potential. Then you would feel strictly neutral between the massage chair and the button. |
Optimist: Gee, that’s awfully similar to the e-cig story, are you sure we’re not going around in circles? But fine, I’ll respond.
For one thing, it’s much easier to write the words “there are no other complicating factors” than to actually strip out all the related intuitions and motivations in order to invoke the thought experiment properly. Like, I know that you actually find massage chairs to be kinda cringe, for reasons related to norm-following and self-image, and you’re trying to ignore that factor for the purpose of the thought experiment, but I don’t think you’re capable of doing that. Instead, I think you’re taking a shortcut by just assuming that you’ll wind up strictly neutral.
For another thing, remember the discussion above about how credit assignment will latch onto a salient concept that shortly temporally precedes the primary reward? Well, massage is extended in time, and has a clear bodily feeling associated with it, so that feeling probably winds up with the lion’s share of the credit, leaving very little for the chair itself (cf. “blocking” in behaviorist psychology).
In fact, take another look at how you wrote the Massage Chair Story. You said that the button “gives the same good-feeling-on-your-body”, not that it gives “reward per se, stripped of all sensory associations”. …You cheater! The somatosensory feeling has no logical reason to be part of your story, if you really believed what you seem to be suggesting. The fact that you put “good-feeling-on-your-body” in the story is proof that the motivation here is not actually all that wirehead-ish. The motivation is tied to a real-world object-level thing that temporally precedes the reward, not to the reward itself, just like I’ve been saying all along.
Pessimist: Oof, touché.
Optimist: And here’s another example of not-very-wirehead-ish motivations: We “want to eat food”, not just “want to experience good tastes”.
Pessimist: Well, we seem pretty happy to use tricks to produce certain tastes, like miraculin. Insofar as we care about eating certain foods per se, it’s probably social instincts—self-image, norm-following, etc.
Optimist: What about something that tastes good and is nutritious and socially acceptable but you find it icky? Maybe due to conditioned taste aversion, or just being very different from what you’re used to. Isn’t that “care about eating certain foods per se?”
Pessimist: OK, I described it badly, but that’s kinda irrelevant. “It doesn’t disgust me” is obviously a desideratum for food, derived from the reward function, just as much as “it tastes good”. It would hardly be a reward button if pressing it made you feel disgusted.
Optimist: No, there’s something missing. If you drank the green soylent, and then I tell you that it’s people, then now you’re disgusted.
Pessimist: Right, social instincts are not the only interpretability-based primary rewards, but merely the most important interpretability-based primary rewards, and the ones that cause by far the most confusion and bad takes. Disgust is also an interpretability-based primary reward—there’s a short-term predictor [LW · GW] looking for pattern-matches to previous instances of disgust, and it updates to create conditioned taste aversion and so on.
4. Side-track on the meaning of “interpretability-based primary rewards”
Optimist: Wait, sorry, now I’m confused. Valence has a short-term predictor too—”disgust guess” and “valence guess” are right next to each other in this picture [LW · GW]. I think you’ve just defined away “interpretability-based primary rewards” to trivially apply to everything! Something is wrong, we gotta sort this out.
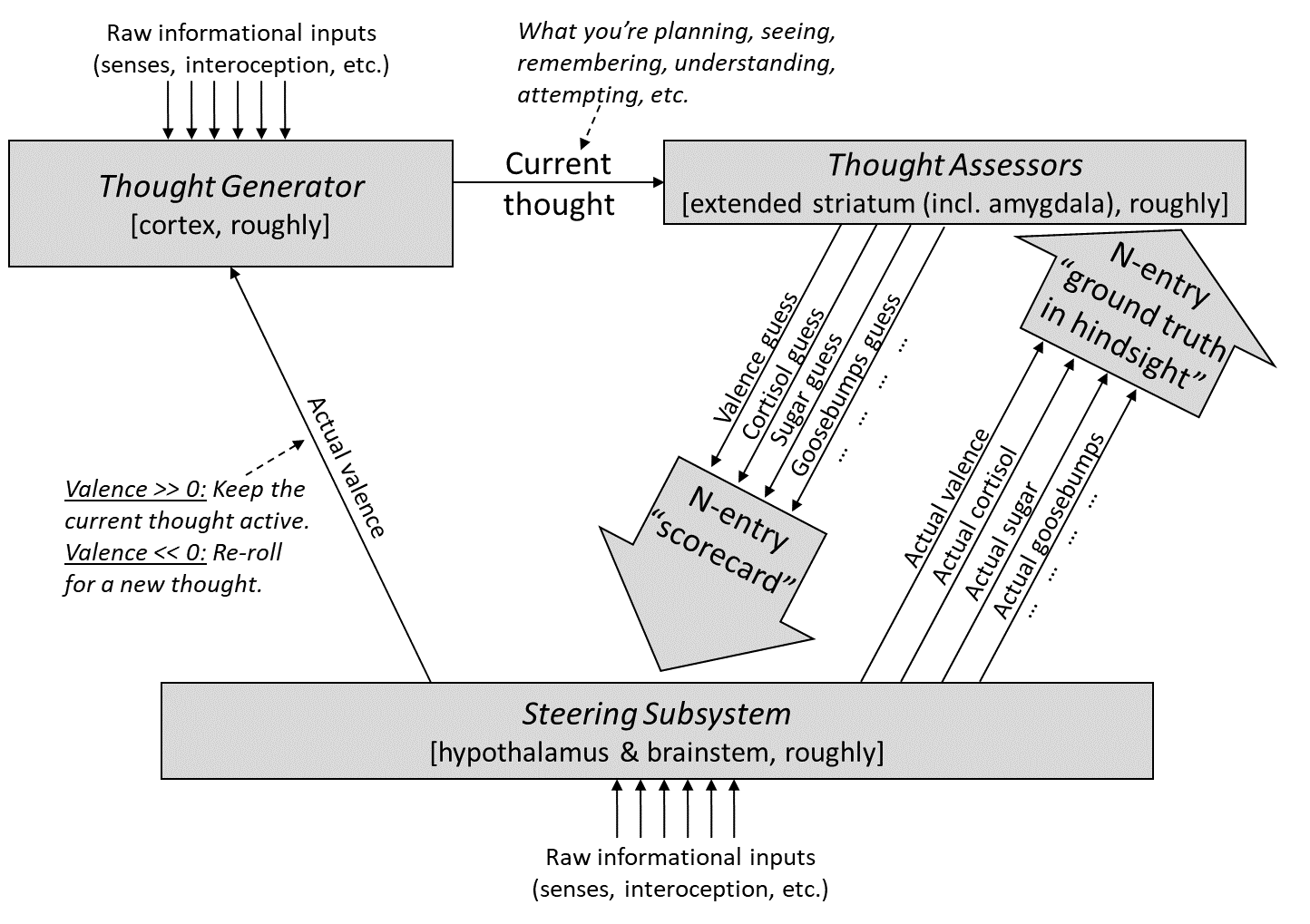
Pessimist: No, no, “valence guess” is not relevant to primary reward—it’s not introducing new ground truth into the system about what’s good or bad. It’s just a way of guessing what’s good or bad based on past history of primary reward.
Optimist: OK, you just said a bunch of words, but you’re not following through to explain why this is a relevant disanalogy, i.e. one that undermines my point.
Pessimist: Ugh, I was hoping you wouldn’t ask. Let me think. OK. Where were we? Big picture: my argument is that behavior-based primary rewards lead to (1) behavior-based motivations, (2) and more specifically, wireheading-flavored behavior-based motivations like grabbing the reward button, (3) and more specifically, scheming. The basic argument for (1) is that TD learning is systematically sculpting motivations (valence guess) in such a way as to make it increasingly consistent with primary rewards. Then we talked about how, yes there are exceptions to that general rule, especially incomplete exploration, but I argued that those won’t come into play here, and we should expect the general rule to apply. So anyway, yes it’s obviously true (as we’ve discussed in Valence §1.5.1 [LW · GW]) that a plan or action will seem motivating or demotivating depending on how it’s conceptualized. But that doesn’t undermine the above argument. That’s just one aspect of the process by which behavior-based primary rewards gradually create behavior-based motivations. On the other hand, a primary reward that depends on what you’re thinking about, rather than what you’re doing, obviously does radically undermine step (1).
Or here’s another way to think about it: “valence guess” is obviously an interpretability-based system. Why? If I’m walking towards the door in the expectation that there’s a swarm of angry bees on the other side, then that feels to me like a bad plan, so I won’t do it. If I’m walking towards the door in the expectation that my best friend is on the other side, then that feels to me like a good plan, so I will do it. The difference between these two scenarios is not something in the outside world, but something in my own mind. Or, rather, I mean, obviously I hope my beliefs are accurate, but the proximate cause of why I’m executing or not executing the plan is my beliefs, not the external world. So assessing plans as good or bad requires a non-behaviorist, a.k.a. interpretability-based, control signal. But that’s just how model-based planning works! It’s not part of how things wind up seeming good or bad in the first place.
5. Wrapping up the Cookie Story
Optimist: Alright, where are we at right now? Like you just said, you’re pushing this three part argument that behavior-based primary rewards lead to (1) behavior-based motivations, (2) and more specifically, wireheading-flavored behavior-based motivations like grabbing the reward button, (3) and more specifically, scheming. I think I’m about ready to basically concede (1), but I’ve scored some good hits on you related to (2). You were flirting with a really extravagant version of (2), but now I’ve talked you back down to a more modest version.
In particular, I think we’re now in agreement that the Cookie Story has a load-bearing ingredient that the cookies themselves are salient concepts that temporally precede and reliably predict the primary reward, and thus the magic of credit assignment (Intro series §9.3 [LW · GW]) gives the lion’s share of motivational force to the cookies themselves, as compared to the earlier trigger where you were looking at wispy clouds. And that explains why you’d happily sabotage the setup and steal the cookies, given the opportunity. The cookie story doesn’t prove something broader about wireheading, just about the likely objects of credit assignment, and how not to set up a training environment.
Pessimist: Yup. …Although who’s to say that AGI won’t similarly have a salient wirehead-ish object of credit assignment? Like, maybe the AGI can see the person pressing the reward button.
Optimist: Yes, I concede that if the AGI can see a person ostentatiously pressing a reward button, then the AGI will wind up wanting to grab the reward button, or perhaps forcing the person to press the reward button. This is a failure mode. But let us assume that there isn’t any salient object of credit assignment that slightly precedes the primary reward signal. For example, maybe there’s a reward model hooked up to a security camera and operating behind the scenes, or whatever.
6. Side-track: does perfect exploration really lead to an explicit desire to wirehead?
Optimist: Y’know, here’s another thing that’s confusing me. We have two “cached belief boxes” above that seem incompatible.
…One box says “TD learning makes things seem good when they immediately precede reward, even if the correlation is imperfect.”
…And the “deliberate incomplete exploration” box says “Given infinite time in a finite environment, TD learning would normally sculpt the value function into a perfect predictor of expected future reward. That means, for example, that the AGI would have a ‘pure wireheading drive’, wanting nothing besides reward, and it would apply all its intelligence and planning to making that happen.”
The first one has optimistic implications that I’m very fond of, and the second one has pessimistic implications that you’re very fond of. But the two are contradictory, right? If some action reliably (if imperfectly) precedes reward, an omniscient agent that has done perfect exploration would still “like” that action, right?
Pessimist: Yeah. Well, of course, something is obviously deeply wrong with the first box! I never liked that box anyway.
One of the things I mentioned above might help illuminate the problem. Here, I’ll put it in a box:
Pessimist offers: Brownie Story There’s a plate of brownies on a table. They look like normal brownies, they smell like normal brownies, etc. Over the course of your lifetime, you have had abundant experience eating and enjoying brownies exactly like these. But there’s a sign next to the brownies that says: “Danger: brownies have been poisoned”. So you don’t eat the brownies. You’re not a moron. |
So here’s the puzzle. “TD learning makes things seem good when they immediately precede reward, even if the correlation is imperfect”, according to that box above. So the brownies should seem good. But they don’t. Why not?
Optimist: Well, when you look at the brownies, you do in fact feel an urge to eat them. TD learning is doing exactly what we expect. It’s just that that urge is superseded by a stronger motivation not to.
Pessimist: OK, and that motivation not to, where does that come from?
Optimist: Like, when you imagine eating the brownies, it brings to mind the expectation that you would then die painfully, which seems bad for various reasons, including a life history of experiencing pain as aversive.
…So everything makes sense, from my perspective. Your turn. You claim that perfect exploration leads to strong wireheading drive. But if some action reliably (if imperfectly) precedes reward, an omniscient agent that has done perfect exploration would still “like” that action, right? How do you make sense of that?
Pessimist: The blocking effect seems relevant. Isn’t blocking just a straightforward counterexample to the slogan “TD learning makes things seem good when they immediately precede reward”?
Optimist: Oh. True. Guess we need some more caveats on that slogan. …I just scrolled back up and added a footnote warning about that.
Pessimist: …Anyway, as the hypothetical agent approaches omniscience and perfect exploration, it can construct a perfect predictor of the reward function. Then TD learning, including nuances like blocking, will erase the “valence paint” from everything except that perfect predictor.
Optimist: No. You’re confused. Like, you want that last sentence to mean “the AGI only explicitly cares about future reward”, but it doesn’t mean that. Imagine that the ideal way for the AGI to maximize reward is to recharge batteries under such-and-such conditions. And then we observe that, after full exploration of a finite environment, and after the learning algorithms have all converged to the global optimum, the AGI indeed recharges its batteries under such-and-such conditions. Does that mean that the AGI “only explicitly cares about future reward”? No! It could simply have an object-level desire to recharge its batteries under such-and-such conditions, a desire which is not explicitly instrumental towards reward. In other words, there can still be positive valence paint on the “recharge batteries under such-and-such conditions” node.
Granted, the external behavior is consistent with explicit desire to maximize reward, but that doesn’t prove anything, because you can get the same external behavior from different explicit desires, as long as we’re limited to this finite environment.
So, what are the external signs of actual explicit wireheading desire? Well, one thing is, maybe wireheading is one of the options inside this finite fully-explored environment. And then we see the AGI actually wireheading. But, duh—we already agreed that, after the AGI tried wireheading, it would get hooked.
The other thing is, maybe wireheading is not one of the options in the finite fully-explored environment, but you can take the trained AGI, and move it to a new environment where wireheading is an option, and you find that the AGI has generalized out-of-distribution to make foresighted plans to wirehead. But, will it? It might or might not. You haven’t argued that this will actually happen.
Pessimist: OK, you’re right. …I too have just scrolled back up to the box and added a footnote caveat.
And while I’m conceding things, in regards to the Brownie Story, my dismissive response way above was: “You’re not a moron. Your value function has discerned the relevant causal factors.” I guess that was a bit sloppy. I need to make sure I have a solid mechanistic story behind claims like that, not just saying “you’re not a moron”.
I do think there’s some important idea to keep in mind like: There’s a learning algorithm that systematically sculpts the world-model to be a good predictor of the world, and the value-function to be a good predictor of the reward function. And this process is systematically pushing the AGI towards wireheading. If we don’t want wireheading, then we’re fighting against this force. Orgel's Second Rule says “evolution is cleverer than you are”, but the same applies to any learning algorithm. The river wants to flow into the sea. We can claim to have a plan to manage that process, but we need to offer that plan in a humble, security-mindset [LW · GW] spirit, alive to the possibility that the learning algorithm will find some workaround that we didn’t think of.
Optimist: …And yet, humans don’t wirehead all the time.
Pessimist: Because humans don’t have behaviorist reward functions.
Optimist: …And also, in deliberate incomplete exploration, it’s the AGI, not the humans, that is trying to “keep the river from flowing into the sea”.
Pessimist: Well, the AGI can fail just like we can! Plus, a lot of learning happens early on, before the AGI is extremely intelligent and foresighted.
Optimist: …Whatever. One more question: now that you’ve had some update about wireheading motivations under perfect exploration, can we revisit the rationale for “behaviorist rewards lead to behavior-based motivations”.
Pessimist: Good call. I wrote above: If “saying X because I believe X” gets rewarded, then sooner or later the AGI will try “saying X because I 95% believe X”, and that will be equally rewarded. Then 90%, etc. Over time, there will be enough data to sculpt the value function to point narrowly towards the actions and not towards the upstream motivations. So the preferences will all be about external things (actions, world-states, etc.), whereas the thoughts would be basically unconstrained.
…That still seems totally sound. I stand by it.
Optimist: OK! I think we’ve both learned something from this digression. We’ve refined our understanding of, and poked some holes in, both of those two cached beliefs. Let’s just move on.
7. Imperfect labels
Pessimist: OK. Where were we?
Optimist: I forget. We need to scroll back up and re-read §5 (“Wrapping up the cookie story”). … Ah, right. I had conceded that we get wirehead-ish results if the AGI can see some immediate precursor to rewards, like a person ostentatiously moving to press the reward button. But I proposed that we would design around that problem, by having the reward model hooked up to a security camera and operating behind the scenes, or something like that.
Pessimist: Then my next pushback is the thing I mentioned way earlier. The reward signal comes apart from helpfulness, because the labels are imperfect.
Optimist: That would lead to sycophancy, not scheming. Sycophancy is not great, but it’s not dangerous.
Pessimist: Well, it’s dangerous if it generalizes to “forcing people to express that they are pleased”, for example.
Optimist: Would it though? I think it might or might not, depending on implementation details, which we can get into—
Pessimist: —I wasn’t finished. Also, if there were a reward model, then that’s worse, because the reward model, like all trained models, will start doing outlandish things out-of-distribution, and the AGI will be doing an adversarial search for such things (see the part that says “Why is problem 1 an “adversarial” OOD problem?” in the anti-LeCun post [LW · GW]).
Optimist: Well, for one thing, we can put an out-of-distribution penalty.
Pessimist: Nope. Unacceptable alignment tax. It wouldn’t be able to accomplish any of the novel and big things that are needed to get to Safe and Beneficial AGI.
Optimist: OK, I accept that. Here’s another thing: “doing an adversarial search” is a bit of an overstatement. If it happened to come across an edge case in the reward model, then the value function (“valence guess”) would update accordingly, and the AGI would start wanting and exploiting that edge case. It would “get addicted”, so to speak. But if we do things right, it wouldn’t be searching for those edge-cases in advance. And if we really do things right, it will be actively trying to avoid those edge-cases, a.k.a. “deliberate incomplete exploration” per above.
Pessimist: For one thing, c’mon, it’s definitely going to come across edge cases as it explores clever creative ideas and tries different things. It’s still hill-climbing the reward model, right?
Optimist: No! That’s my point! It’s making foresighted plans that maximize the current value function (a.k.a. “valence guess”), not that maximize the reward model. That’s different.
Pessimist: I concede that the foresighted planning is not part of how it’s “hill-climbing the reward model”, but it is nevertheless hill-climbing the reward model. You don’t need foresighted planning for that. Remember the iMovie story from the anti-LeCun post [LW · GW].
Pessimist offers: iMovie story (lightly edited from anti-LeCun post [LW · GW]) Why is this an “adversarial” out-of-distribution generalization problem? Here’s a toy example. The AI might notice that it finds it pleasing to watch movies of happy people—because doing so spuriously triggers the reward function. Then the AI might find itself wanting to make its own movies to watch. As the AI fiddles with the settings in iMovie, it might find that certain texture manipulations make the movie really really pleasing to watch on loop—because it “tricks” the reward function into giving anomalously high scores. What happened here was that the AI sought out and discovered “adversarial examples” for an immutable neural net classifier inside the reward function. (That particular example doesn’t seem very scary, until the AI notices that humans might want to turn off its weird-texture movie playing on loop. Then the situation gets “adversarial” in the more literal sense!) |
Optimist: OK, now I’m confused. The iMovie story seems fine, but what I was saying just now—i.e., it’s not “trying” to maximize the reward function—also seems true. What’s going on, theoretically?
Pessimist: Sure, here’s a theoretical toy model corresponding to the iMovie story: If right now the AGI thinks the best thing is X (i.e., X maximizes its value function, a.k.a. “valence guess” function), then the AGI will make foresighted plans towards X. But it will actually wind up at , where ε is some random error, because it’s a complicated world. And then maybe the reward function will give a higher score than X. If so, then the value function will update, and now the AGI likes , and next time it’s going to make foresighted plans towards , and actually wind up at . And might or might not get a higher reward function score than . Etc. etc. Rinse and repeat. See what I mean? This is still hill-climbing, even if it lacks foresight.
Optimist: Nice. OK. But if the problem is the reward model having crazy adversarial examples, because trained models always have crazy adversarial examples, then we can solve that by putting a human in the loop who updates the reward model.
Pessimist: If you replace the reward model with a human watching from behind the scenes, that changes nothing. Humans still have exploitable edge cases.
Optimist: Right, but that’s sycophancy, and sycophancy isn’t dangerous.
Pessimist: Like I said before, it can also be “brainwashing” or “forcing people to express that they are pleased”.
8. Adding more specifics to the scenario
Optimist: Ugh, I feel like we keep getting stuck, partly because we haven’t pinned down the implementation details, and thus we’re flipping back and forth between different imagined scenarios in an incoherent way. Can we pick a more concrete and specific scenario?
Pessimist: Sure, I’ll pick it.
Optimist: No way! You’re arguing for a universal claim, that all behaviorist reward functions lead to scheming—or at least, all behaviorist reward functions that are compatible with training very powerful AGIs. So I should get to make any assumptions that I want, that are most favorable to me, about the reward function and training environment.
Of course, you’re welcome to concede that grand claim and walk it back to something more modest like “this is an area where future AGI programmers might mess up”. If you do that, then sure, that would change things, and then you could quibble about the example that I choose.
Pessimist: OK, fine. You get to pick the specific implementation details. So, what are you gonna pick? What do you think are best practices for training AGI with a behaviorist reward function that doesn’t lead to scheming?
Optimist: Umm, I don’t have a canned answer ready. Let me think. …Here’s an idea. We put the AI in a box with output channels (sending emails etc.), and maybe also input channels (humans asking the AI questions), and then humans grade the outputs, or maybe some fraction of the outputs, with or without weak-AI help.
So far this picture is pretty general, and is compatible with both a kind of “corrigible AI assistant chatbot” scenario like the prosaic AGI people assume, and an “AI CEO” or “AI inventor” scenario like you’d want for a pivotal act. We can be agnostic between those two options for now, although maybe we’ll have to pin it down more specifically later on.
Pessimist: I object on the grounds that “process-based supervision” (a.k.a. MONA) is incompatible with powerful AGI [LW · GW].
Optimist: Oh, I’m not talking about “process-based supervision”. I allow the primary rewards to propagate back to longer-term multi-step plans that led to them—just like with humans. The human grades would presumably reflect both outcomes (e.g. the AI CEO seems to be making money) and process (e.g. the AI CEO seems to be following the law).
Pessimist: There’s a race-to-the-bottom collective action problem, because not everyone will reward their AI CEOs for following the law, and those who don’t will wind up with more resources.
Optimist: Off-topic!
Pessimist: Sorry, my bad. Force of habit.
9. Do imperfect labels lead to explicitly caring, vs implicitly caring, vs not caring about human feedback per se?
Optimist: …Also, in my proposed setup, the human feedback is “behind the scenes”, without any sensory or other indication of what the primary reward will be before it arrives, like I said above. The AGI presses “send” on its email, then we (with some probability) pause the AGI until we’ve read over the email and assigned a score, and then unpause the AGI with that reward going directly to its virtual brain, such that the reward will feel directly associated with the act of sending the email, from the AGI’s perspective. That way, there isn’t an obvious problematic wirehead-ish target of credit assignment, akin to the cookies in the Cookie Story. The AGI will not see a person on video making a motion to press a reward button before the reward arrives, nor will the AGI see a person reacting with a disapproving facial expression before the punishment arrives, nor anything else like that. Sending a good email will just feel satisfying to the AGI, like swallowing food when you’re hungry feels satisfying to us humans.
Pessimist: We’re thinking about a super powerful AGI here. Won’t it form a concept like “how humans would evaluate this” that accurately predicts the primary reward? And won’t that concept start feeling very motivating, and then (mis)generalize in bad ways, like forcing humans to approve, or secretly sending a copy to self-replicate around the internet and then use its enormous resources to help get approval?
Optimist: C’mon, we’ve already been over this. Yes it will form that concept, but that concept will be at worst one of many concepts that feels motivating, and the other concepts will be things like “norm-following for its own sake” that push against those plans. At the end of the day, there will be both wirehead-ish and non-wirehead-ish motivations, so things might go wrong, but also might go right, and that’s all I’m arguing for right now.
Pessimist: No, because as time goes on, the AGI will come across examples where the “how humans would evaluate this” concept gives the right answer and the other concepts don’t. So credit assignment would gradually erase the valence paint [LW · GW] from the other concepts, by a blocking effect kind of thing.
Optimist: I don’t think this (mis)generalizes to “forcing humans to approve” though. I have a vague idea that … how do I put this … you’re sneakily equivocating between two versions of “how humans would evaluate this”. Something like de re versus de dicto? Something like Alex Turner’s Don’t align agents to evaluations of plans [LW(p) · GW(p)]? Umm, it’s vaguely analogous to … remember that neat diagram that somebody drew in like 2020? I can’t find it, but it was something like this:
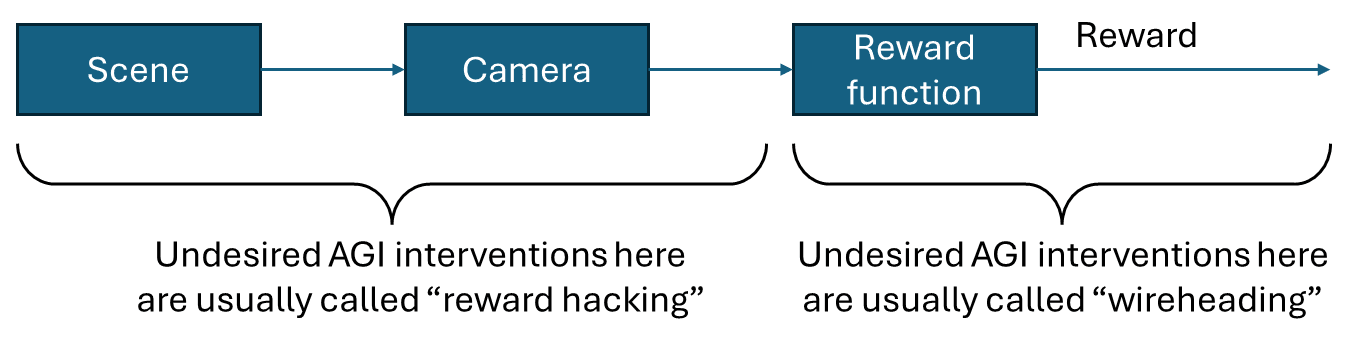
As long as the whole chain is intact, i.e. the AGI hasn’t hacked into it to break the logical dependencies, then any of the concepts along this chain could feel motivating to the AGI. And if it’s motivated by something further to the left, it won’t want to hack into the reward function.
So anyway, I think there’s something a bit analogous to that, where the AGI can have a concept of “the outputs of the human evaluation procedure as it exists today”, and the AGI can have a different concept of “the outputs of the human evaluation procedure in practice, including if the AGI hacks into that procedure itself”. The latter concept would (mis)generalize to making the AGI want to hack into the procedure (e.g. force the humans to give a high score), the former concept would not, but they both make perfect predictions until such time as the AGI actually hacks into the procedure.
Pessimist: I still feel like you’re kinda relying on the AGI being stupid, or at least, not fully situationally-aware. Won’t it find a way to observe the reward signal or something close to it sooner or later, and then find it extraordinarily motivating to make that signal positive?
Optimist: No, because of “deliberate incomplete exploration”. We’ve talked about this already. You don’t want to try highly-addictive drugs. For the same reason, if there was a brain signal that immediately preceded primary reward, say by 0.5 seconds, you shouldn’t want to have a way to observe it in real time, because it would really mess with your mind, you would find yourself really really wanting that signal to trigger, which is a small step away from wanting to do wirehead-ish things. And you know this, so you wouldn’t start watching that real-time signal in the first place.
Pessimist: Two things. First, is deliberate incomplete exploration really feasible here? Like, “forcing people to approve” sounds kinda all-or-nothing and easy to avoid, but there might be a gradual path to the same destination—sycophancy blurs into manipulation blurs into mind-control. And what about that other failure mode I mentioned—doing problematic real-world power-seeking without getting caught? I.e., what I called the “less hard subproblem” in my process-based supervision post [LW · GW]: “The AI sometimes does a little bit of problematic real-world power-seeking actions (without us noticing), and by doing so it does better at its task X, and thus we positively reinforce those actions. Over time the AI does increasingly aggressive, competent, and surreptitious real-world power-seeking actions, and we positively reinforce those actions too, and so on until we have a power-seeking AI that can and will escape control.”
Optimist: Deliberate incomplete exploration solves those problems too, because the AGI will recognize in advance that this is a thing that might happen to it, and thus not even start down that road.
Pessimist: I dunno, it could equally well happen by accident. And who’s to say that deliberate incomplete exploration will have even kicked in early enough to prevent exploring deceptive behavior?
Optimist: I’m not saying it can’t go wrong, I’m just saying it can go right.
Pessimist: OK, but there’s still something else here that I’m trying to articulate, something about behaviorist rewards being disanalogous to human social and moral instincts. Remember, you conceded that behaviorist primary rewards lead to behaviorist motivations—motivations concerning externally-visible actions and the state of the world. I feel like it’s hard to envision something like “following norms” as a behaviorist motivation. (I’m assuming right now that following norms is an aspect of the AGI’s primary rewards.) As soon as I try to envision a behaviorist version of “wanting to follow norms”, it just morphs into “wanting to not get caught violating norms”. You feel that? I think there’s something important there.
Optimist: Shrug, obviously it’s gonna be hard to imagine nonhuman motivation setups, that’s not evidence for anything. …OK, better answer: you’re a human. As a human, sometimes you want to follow norms because you’ve internalized them, and they’re part of your self-image, etc. And sometimes you want to follow norms because bad things happen when you get caught violating them. And that’s it. So when you try to imagine a behaviorist motivation related to following norms, you cross off the first thing because it’s not behaviorist, and thus you jump to the second thing. You are unable to imagine a secret third option disanalogous to either of those two motivations in your human head.
Pessimist: Yeah, but is it a secret third option? Or is the AGI thing tightly analogous to the second one? I.e., just like I sometimes get caught violating norms, so would the AGI. And the deliberate incomplete exploration argument doesn’t apply—it can’t learn the norms in the first place except by sometimes violating them, and it seems a stretch to get 100% perfect labels, even including edge-cases. So the AGI would learn not to get caught violating norms, just as humans do, in the cases where the humans haven’t internalized a norm into their self-image (which involves interpretability-based human social instincts).
Optimist: I dunno, when you “get caught violating norms”, there’s a salient precursor to the punishment—you see a person noticing you and scowling first, and then the innate punishment arrives a fraction of a second later. So credit assignment centers your motivation around the generalized idea of a person noticing you violating norms and scowling. It’s like the cookies in the Cookie Story. Whereas the AGI is going to get primary rewards / punishments injected into its mind out of nowhere, more like the Secret Remote-Control Cloud Story.
Pessimist: Hmm, OK, I buy that that’s part of the story, and maybe my intuitive reaction is not much evidence for anything. But it’s still true that the reward function is inconsistently reinforcing “follow norms”, and consistently reinforcing “follow norms unless we can get away with it”. Over time, the “valence paint” will wind up on the latter.
Optimist: Hmm, OK, I’ll concede that the AGI will wind up with motivations that are (either explicitly or in effect) related to doing the wrong thing in an externally-legible way, as opposed to doing the wrong thing per se. Or at least, I don’t immediately see how to avoid that.
Pessimist: Great, and I’ll correspondingly concede that my intuitions about “getting caught cheating” are systematically misleading, making me feel strongly that the AGI will care explicitly about not getting caught, whereas a more implicit story is also plausible.
Optimist: OK, that’s progress! I’ll summarize what we figured out in this section; I think we both agree on the following:
The AGI’s attitude towards human feedback per se—i.e., the attitude that would lead to manipulation and deception—can be either (1) it cares explicitly, (2) it cares implicitly, (3) it doesn’t care at all, or at least, it cares little enough that other motivations control its decisions. As an example of what (2) means, it might look like the AGI is motivated by things like “I don’t like cheating in an externally legible way”. “Cheating in an externally legible way” is closely related to and upstream of “getting caught cheating”, but is not itself “getting caught cheating”.
At the beginning of the conversation, I was pushing (3) and you were pushing (1), but I think we’re now kinda converged on: (3) is implausible, (1) is possible but avoidable, and (2) is the best-case possibility, but that’s still very bad.
10. The training game
Optimist (continuing): …But I’m still unclear. What exactly are you proposing is the failure mode? How do we get from there to the really bad scary things? Can you be more specific?
Pessimist: I dunno, I think there are lots of possibilities.
Optimist: Name one.
Pessimist: Umm, let’s try something vaguely like Ajeya’s proposal [LW · GW], “playing the training game”. “The best way for [the AGI] to maximize reward while under human control is to use its high situational awareness to deliberately appear safe and aligned at all times, while secretly manipulating humans in some cases. … In other words, [the AGI] will knowingly violate human intent in order to increase reward.” Because of imperfect labels.
Optimist: OK, keep going. We’re not at scheming yet, let alone taking over the world.
Pessimist: Right. But a good way to increase reward is to create a helper AGI that self-replicates around the internet and seeks power.
Optimist: OK. My answer is: “deliberate incomplete exploration”.
Pessimist: Didn’t you already concede that above? Just to repeat: my argument was, it can’t learn the norms in the first place except by sometimes violating them, and it seems impossible to get 100% perfect labels, even including subtle edge-cases. So the AGI would learn not to get caught violating norms… the reward function is inconsistently reinforcing “follow norms”, and consistently reinforcing “follow norms unless we can get away with it”. Over time, the “valence paint” will wind up on the latter.
Optimist: OK, different answer: honeypots. We set up plausible-to-the-AGI opportunities to get an AGI helper onto the internet, and apply a punishment if it tries to do that.
Pessimist: With powerful AGI, that just leads to a more refined version of “don’t get caught”.
Optimist: But to a less-powerful AGI, a honeypot will be indistinguishable from a real exfiltration opportunity. So maybe we can keep the labels perfect for long enough that the “deliberate incomplete exploration” argument starts kicking in.
Pessimist: You’re mixing up “perfect labels in regards to catching exfiltration attempts” with “perfect labels in regards to the much more general behavioral suite that is upstream of getting positive feedback in sneaky ways”. The latter also includes mundane sycophancy, choices of how to describe things, and finding edge-cases, up to more aggressive manipulation and mind-control, along with surreptitious theft and other such antics. We’re not going to catch all those. And then that generalizes to exfiltration-without-getting-caught seeming to be good, from the AGI’s perspective.
Remember the discussion in the cached belief box “Self-supervised learning world-model updates trump TD learning value-function updates, in brain-like AGI”. Basically, “is” complicates “ought”; world-model updates complicate credit-assignment. When the AGI’s rewards are so sensitive to getting caught (or things related to it, like legibility), the AGI will naturally refine its world-model with lots of detailed structure concerning getting caught (or legibility). I guess this is also related to Valence series §3.4.2 [LW · GW]—“valence is how our brains figure out whether a decision is good or bad. So, if our brains are going to do conceptual categorization and clustering to inform decision-making, what on earth could be more important than using valence as a central ingredient in that clustering algorithm?”
So again, the AGI’s world-model will wind up with an extremely refined sense that there are two types of norm violations, the kind that seems good / positive-valence, and the kind that seems bad / negative-valence. From our perspective, we would say the former is “norm violation of a type that is very unlikely to get caught”, and the latter “norm violation of a type that might well get caught”. But of course, the AGI doesn’t need to be explicitly thinking of it that way. It’s still likely to generalize according to those latter descriptions, and indeed the AGI probably will start explicitly thinking of it that way, because it’s an obvious pattern in the cluster. (By analogy, If you eat twenty foods with cashews, and they’re all delicious, you’ll start saying “I love food with cashews”, as soon as you notice the pattern, which you probably will. The AGI will notice that it likes not getting caught in a similar way.)
…So the AGI will have concepts of sneaky-exfiltration versus non-sneaky-exfiltration. Those will feel like wildly different types of actions to the AGI, just as tofu versus feta [LW · GW] feel like wildly different foods to us. It would never generalize from one to the other. If it got caught with a honeypot, it would learn that what it just did is an example of non-sneaky-exfiltration, but it would not conclude that sneaky-exfiltration (from its perspective, “the good kind of exfiltration”) doesn’t exist.
Optimist: OK, I buy that. Different answer: perfect labels. Nah, I guess we already covered that. Different answer: the AGI stays in a box and performs R&D towards a pivotal act.
Pessimist: What pivotal act?
Optimist: I dunno.
Pessimist: And how do we verify progress towards the pivotal act, without incentivizing deception and sycophancy and manipulation etc.?
Optimist: OK, fine, bad example.
Pessimist: So, we’re done? I win?
Optimist: I’m still allowed to change the training setup or reward function, but … I can’t think of anything better than what I proposed in §8 above.
Oh, hang on, I have three more random arguments-for-optimism that we haven’t covered. I haven’t really thought them through. Let’s have at them:
11. Three more random arguments for optimism
Optimist (continuing): First, there was that Pope & Belrose claim: “If the AI is secretly planning to kill you, gradient descent will notice this and make it less likely to do that in the future, because the neural circuitry needed to make the secret murder plot can be dismantled and reconfigured into circuits that directly improve performance.” That seems superficially reasonable, right? What’s your take?
Pessimist: In other contexts, we would call that “catastrophic forgetting”. And catastrophic forgetting is basically not a problem for LLMs. LLMs can see one or two examples of some random thing during training—e.g. the fact that there’s a street in Warroad, Minnesota, USA called “Waters of the Dancing Sky Scenic Byway”—and retain it through billions of examples where that information is useless. Gradient descent evidently did not dismantle and reconfigure the Minnesota street name neural circuitry “into circuits that directly improve performance” on more typical queries. Of course, the subject of today’s debate is brain-like AGI, not LLMs, but the same thing applies—if an AGI had catastrophic forgetting problems, it would not be a powerful AGI worth worrying about in the first place.
Optimist: I don’t think that’s a fair response. In 99.99…% of queries, the “Waters of the Dancing Sky Scenic Byway” “circuits” are never activated at all. By contrast, I think Pope & Belrose are pushing back against a theory that, when the LLM is queried…
- It will think to itself “I want to take over the world, but I’ll get caught if I’m too obvious about it, so I should appear helpful, therefore the next token should be ‘is’”.
- Then it will think to itself “I want to take over the world, but I’ll get caught if I’m too obvious about it, so I should appear helpful, therefore the next token should be ‘the’”.
- Then it will think to itself … Etc. etc.
That’s different. You’re wasting a lot of layers and computation that way! Surely gradient descent would do something about that!
Pessimist: I have a couple responses. First, we have these systematic forces sculpting the behavior towards the reward function, and this force is pushing towards “misbehavior when you won’t get caught”, like we discussed earlier. That doesn’t mean re-deriving from first principles 100× per second that you should behave well when you would get caught. That would be ridiculous! Instead, for an LLM, these systematic forces will gradually sculpt a policy that “notices” situations where misbehavior is possible, and triggers responses in only those cases.
Second, back to the human or brain-like AGI case, if some behavior is always a good idea, it can turn into an unthinking habit, for sure. For example, today I didn’t take all the cash out of my wallet and shred it—not because I considered that idea and decided that it’s a bad idea, but rather because it never crossed my mind to do that in the first place. Ditto with my (non)-decision to not plan a coup this morning. But that’s very fragile! If you tell me “Don’t worry! The AGI won’t launch coups because that possibility won’t occur to it!”, then I’m not reassured! The idea will cross its mind at some point!
Third, just think about the facts. Brain-like AGI is obviously capable of supporting scheming behavior, because humans can display such behavior. A human can harbor a secret desire for years, never acting on it, and their brain won’t necessarily overwrite that desire, even as they think millions of thoughts in the meantime. I hope we can come up with a satisfying theoretical understanding of how such behavior works, but even if we don’t, who cares, we know the right answer here.
Optimist: OK, I’ll concede that one. Moving on to my other one: Paul Christiano’s thing [LW(p) · GW(p)] about a “crisp” distinction between corrigible and incorrigible behavior:
Roughly speaking, I think corrigibility is crisp because there are two very different ways that a behavior can end up getting evaluated favorably by you, and the intermediate behaviors would be evaluated unfavorably.
As an example, suppose that you asked me to clean your house and that while cleaning I accidentally broke a valuable vase. Some possible options for me:
- Affirmatively tell you about the broken vase.
- Clean up the broken vase without notifying you.
- Make a weak effort to hide evidence, for example by taking out the trash and putting another item in its place, and denying I know about the vase if asked.
- Make a strong effort to hide evidence, for example by purchasing a new similar-looking vase and putting it in the same place, and then spinning an elaborate web of lies to cover up this behavior.
Let's say you prefer 1 to 2 to 3. You would like behavior 4 least of all if you understood what was going on, but in fact…if I do behavior 4 you won't notice anything wrong and so you would erroneously give it the best score of all. This means that the space of good-performing solutions has two disconnected pieces, one near option 1, which I'll call "corrigible" and the other near option 4 which I'll call "incorrigible."
…
What's going on in these scenarios and why might it be general?
- In your preferred outcome, you have a good understanding of what's going on, and are able to provide feedback based on that understanding.
- I can take actions that diminish your understanding of what's going on or ability to provide feedback to your AI.
- If those actions are "small" then they will be unsuccessful and so you will rate my behavior as worse.
- But if I take…decisive enough actions, then you will end up ignorant about the situation or unable to provide feedback, and so I'll get the highest rating of all.
Optimist (continuing): Anyway, read the original [LW(p) · GW(p)] for more. Relating this back to our discussion: I wanted to tell a story where perfect (or at least, good enough) labels get us very far into the regime of smart and self-aware AGI while retaining good motivations, and then “deliberate incomplete exploration” gets us the rest of the way to superintelligence with good motivations. Paul’s comment is kinda fleshing out that story, by clarifying why getting good enough labels is feasible. How do you respond?
Pessimist: For one thing, we need to remember to purge any inapplicable intuitions. For us human readers, there’s a big intuitive gap between “sincerely wanting the human to stay abreast of what’s going on” versus “not wanting that”, but for the AGI, it’s just actions and situations that seem good or bad—there’s no such thing as partial credit because “its heart was in the right place”. Remember yet again: behaviorist rewards lead to behavior-based motivations. The AGI will wind up viewing things in the external world as good or bad, but not particularly care about its own mind-states, except incidentally.
Now, in human motivation space, there’s a big chasm between good intentions versus bad intentions, but in terms of the actual actions, I claim that it’s much more continuous than Paul is hoping. It’s not true that if I take “small” actions “that diminish your understanding of what's going on or ability to provide feedback to your AI”, then “they will be unsuccessful”. Small actions can be successful! Plain old sycophancy may well be successful. Failing to draw the supervisor’s attention to something, something that’s really only slightly over the border of what’s worth mentioning anyway, may well be successful. These can ratchet up to being more aggressive and sneaky.
In other words, anywhere that Ajeya’s “training game” behavior differs from what the humans really want, is by definition both incorrigible and rewarded.
Optimist: Hmm, I guess I buy that.
One more: We keep talking about “deliberate incomplete exploration”. But AGIs can also potentially control their desires in more direct ways, if they have write access to their own minds. They might or might not have that write access at first, but presumably they will when they’re sufficiently powerful. For example, they could hypothetically just turn off their own TD learning at certain times. Or they could even turn it off permanently, at some point, thus locking in their current desires in a way vaguely analogous to our Plan for mediocre alignment of brain-like [model-based RL] AGI [LW · GW].
You made a bunch of arguments that “deliberate incomplete exploration” will not stop these bad AGI motivations from emerging, but I’m not sure that those arguments apply to the wider space of every possible way for an AGI to control its own mind.
Pessimist: My story is not “the AGI has good motivations that then get corrupted by further training”. On the contrary, I don’t think the AGI ever has motivations that generalize well, especially not a time when it’s also simultaneously highly competent and self-aware, which is a prerequisite to the AGI deliberately planning around their future motivations. Again, sycophancy blurs into manipulation blurs into mind-control. And “failing to draw the supervisor’s attention to something that’s only borderline worth mentioning in the first place” blurs into illegibility blurs into aggressively covering one’s tracks.
All these problems, incidentally, are related to “the first-person problem” [LW · GW], which makes it impossible for the AGI to learn good behavior except by misbehaving and (hopefully) getting caught.
And all these problems are present right from the start of training.
So the goal-preservation aspect of instrumental convergence isn’t going to help us.
Optimist: OK I buy that too.
12. Conclusion
Pessimist: …I think I win! For brain-like AGI, behaviorist reward functions will lead to AGI scheming and takeover attempts, if they lead to powerful AGI at all. My basic argument outline is now:
- Behaviorist reward functions lead to behavior-based motivations,
- Imperfect labels are inevitable because of edge-cases and such, and lead to a motivation to “play the training game” [LW · GW],
- …including with long-term goals, because that’s the only way to get a powerful AGI (see my process-based supervision (a.k.a. MONA) complaints [LW · GW]),
- …and this motivation leads to a desire to sneakily get a helper AGI onto the internet where it can self-replicate and seek power, and then eventually help the original AGI,
- …and so that’s what the AGI will want to do, given the opportunity.
So the AGI will be scheming. No comment on whether it will actually have an opportunity to execute this egregiously-misaligned scheme—that’s off-topic. I’m just saying that it would like to.
That’s a different argument than I started with. But I like it! Thank you for the pushback, and have a great rest of your day!
Optimist: Hang on. I’m not fully satisfied. I think you’re engaged in “motivated stopping” [LW · GW].
Pessimist: Oh yeah? Well I think that you’re—oh gee, look at the time! Gotta run!
- ^
If you’re not familiar with “curiosity” in the RL literature, I recommend The Alignment Problem by Brian Christian, chapter 6, which contains the gripping story of how researchers eventually got RL agents to win the Atari game Montezuma’s Revenge.
- ^
At least, strong recommend for people exactly like me, with all my idiosyncratic preferences and ways-of-thinking and hang-ups etc. For example, I seem to be very reliant on thinking by writing.
Also related: Kat Woods’s “steelman solitaire”. But I don’t like the term “steelman” here because I don’t purport to be speaking for anyone else, nor to necessarily know the strongest arguments for any position. See Rob Bensinger’s post against “steelmanning” [LW · GW].
- ^
My mental model of Zvi Mowshowitz would bring up something like this—see e.g. here.
- ^
I realized later on that this claim is a bit too strong, because of e.g. the blocking effect. See §6 below.
- ^
I realized later on that this last sentence is kinda wrong, or at least misleading, see §6 below.
0 comments
Comments sorted by top scores.