Against empathy-by-default
post by Steven Byrnes (steve2152) · 2024-10-16T16:38:49.926Z · LW · GW · 24 commentsContents
tl;dr 1. What am I arguing against? 2. Why I don’t buy it 2.1 Tofu versus feta part 1: the common-sense argument 2.2 Tofu versus feta part 2: The algorithm argument Start with the tofu versus feta example: The case of me-eating-tofu versus Ahmed-eating-tofu: 3. Kernels of truth in the original story 3.1 By default, we can expect transient spillover empathy … before within-lifetime learning promptly eliminates it 3.2 The semantic overlap is stable by default, even if the motivational overlap (from reward model spillover) isn’t None 24 comments
tl;dr
Section 1 presents an argument that I’ve heard from a couple people, that says that empathy[1] happens “for free” as a side-effect of the general architecture of mammalian brains, basically because we tend to have similar feelings about similar situations, and “me being happy” is a kinda similar situation to “someone else being happy”, and thus if I find the former motivating then I’ll tend to find the latter motivating too, other things equal.
Section 2 argues that those two situations really aren’t that similar in the grand scheme of things, and that our brains are very much capable of assigning entirely different feelings to pairs of situations even when those situations have some similarities. This happens all the time, and I illustrate my point via the everyday example of having different opinions about tofu versus feta.
Section 3 acknowledges a couple kernels of truth in the Section 1 story, just to be clear about what I’m agreeing and disagreeing with.
1. What am I arguing against?
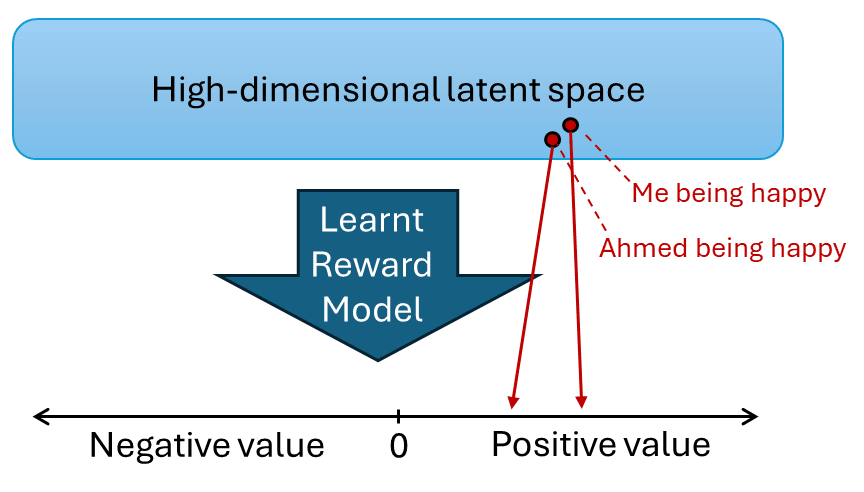
Here’s Beren Millidge (@beren [LW · GW]), “Empathy as a natural consequence of learnt reward models” (2023) [LW · GW]:
…Here, I want to argue a different case. Namely that the basic cognitive phenomenon of empathy -- that of feeling and responding to the emotions of others as if they were your own, is not a special cognitive ability which had to be evolved for its social benefit, but instead is a natural consequence of our (mammalian) cognitive architecture and therefore arises by default. Of course, given this base empathic capability, evolution can expand, develop, and contextualize our natural empathic responses to improve fitness. In many cases, however, evolution actually reduces our native empathic capacity -- for instance, we can contextualize our natural empathy to exclude outgroup members and rivals.
The idea is that empathy fundamentally arises from using learnt reward models[2] to mediate between a low-dimensional set of primary rewards and reinforcers and the high dimensional latent state of an unsupervised world model. In the brain, much of the cortex is thought to be randomly initialized and implements a general purpose unsupervised (or self-supervised) learning algorithm such as predictive coding to build up a general purpose world model of its sensory input. By contrast, the reward signals to the brain are very low dimensional (if not, perhaps, scalar). There is thus a fearsome translation problem that the brain needs to solve: learning to map the high dimensional cortical latent space into a predicted reward value. Due to the high dimensionality of the latent space, we cannot hope to actually experience the reward for every possible state. Instead, we need to learn a reward model that can generalize to unseen states. Possessing such a reward model is crucial both for learning values (i.e. long term expected rewards), predicting future rewards from current state, and performing model based planning where we need the ability to query the reward function at hypothetical imagined states generated during the planning process. We can think of such a reward model as just performing a simple supervised learning task: given a dataset of cortical latent states and realized rewards (given the experience of the agent), predict what the reward will be in some other, non-experienced cortical latent state.
The key idea that leads to empathy is the fact that, if the world model performs a sensible compression of its input data and learns a useful set of natural abstractions, then it is quite likely that the latent codes for the agent performing some action or experiencing some state, and another, similar, agent performing the same action or experiencing the same state, will end up close together in the latent space. If the agent's world model contains natural abstractions for the action, which are invariant to who is performing it, then a large amount of the latent code is likely to be the same between the two cases. If this is the case, then the reward model might 'mis-generalize'[3] to assign reward to another agent performing the action or experiencing the state rather than the agent itself. This should be expected to occur whenever the reward model generalizes smoothly and the latent space codes for the agent and another are very close in the latent space. This is basically 'proto-empathy' since an agent, even if its reward function is purely selfish, can end up assigning reward (positive or negative) to the states of another due to the generalization abilities of the learnt reward function. …
Likewise, I think @Marc Carauleanu [LW · GW] has made similar claims (e.g. here [LW · GW], here [LW · GW]), citing (among other things) the “perception-action model for empathy”, if I understood him right.
Anyway, this line of thinking seems to me to be flawed—like, really obviously flawed. I’ll try to spell out why I think that in the next section, and then circle back to the kernels of truth at the end.
2. Why I don’t buy it
2.1 Tofu versus feta part 1: the common-sense argument

Tofu and feta are similar in some ways, and different in other ways. Let’s make a table!
| Tofu versus Feta | |
| Similarities | Differences |
| They’re both food | They taste different |
| They look pretty similar | They’re made of different things |
| You can pick up both with a fork | They have different nutritional profiles |
OK, next, let’s compare “me eating tofu” with “my friend Ahmed eating tofu”. Again, they’re similar in some ways and different in other ways:
| “Me eating tofu” versus “Ahmed eating tofu” | |
| Similarities | Differences |
| They both involve tofu being eaten | The person eating the tofu is different |
| One will lead to me tasting tofu and feeling full; the other will lead to me tasting nothing at all and remaining hungry | |
| In one case, I should chew; in the other case, I shouldn’t | |
Now, one could make an argument, in parallel with the excerpt at the top, that tofu and feta have some similarities, and so they wind up in a similar part of the latent space, and so the learnt reward model will assign positive or negative value in a way that spills over from one to the other.
But—that argument is obviously wrong! That’s not what happens! Nobody in their right minds would like feta because they like tofu, and because tofu and feta have some similarities, causing their feelings about tofu to spill over into their feelings about feta. Quite the contrary, an adult’s feelings about tofu have no direct causal relation at all with their feelings about feta. We, being competent adults, recognize that they are two different foods, about which we independently form two different sets of feelings. It’s not like we find ourselves getting confused here.
So by the same token, in the absence of any specific evolved empathy-related mechanism, our strong assumption should be that an adult’s feelings (positive, negative, or neutral) about themselves eating tofu versus somebody else eating tofu should have no direct causal relation at all. They’re really different situations! Nobody in their right minds would ever get confused about which is which!
And the same applies to myself-being-happy versus Ahmed-being-happy, and so on.
2.2 Tofu versus feta part 2: The algorithm argument
Start with the tofu versus feta example:
The latent space that Beren is talking about needs to be sufficiently fine-grained to enable good understanding of the world and good predictions. Thus, given that tofu versus feta have lots of distinct consequences and implications, the learning algorithm needs to separate them in the latent space sufficiently to allow for them to map into different world-model consequences and associations. And indeed, that’s what happens: it’s vanishingly rare for an adult of sound mind to get confused between tofu and feta in the middle of a conversation.
Next, the “reward model” is a map from this latent space to a scalar value. And again, there’s a learning algorithm sculpting this reward model to “notice” “edges” where different parts of the latent space have different reward-related consequences. If every time I eat tofu, it tastes bad, and every time I eat feta, it tastes good, then the learning algorithm will sculpt the reward model to assign a high value to feta and low value to tofu.
So far this is all common sense, I hope. Now let’s flip to the other case:
The case of me-eating-tofu versus Ahmed-eating-tofu:
All the reasoning above goes through in the same way.
Again, the latent space needs to be sufficiently fine-grained to enable good understanding of the world and good predictions. Thus, given that me-eating-tofu versus Ahmed-eating-tofu have lots of distinct consequences and implications, the learning algorithm needs to separate them in the latent space sufficiently to allow for them to map into different world-model consequences and associations. And indeed, no adult of sound mind would get confused between one and the other.
Next, the “reward model” is a map from this latent space to a scalar value. And again, there’s a learning algorithm sculpting this reward model to “notice” “edges” where different parts of the latent space have different reward-related consequences. If every time I eat tofu, it tastes yummy and fills me up (thanks to my innate drives [LW · GW] / primary rewards), and if every time Ahmed eats tofu, it doesn’t taste like anything, and doesn’t fill me up, and hence doesn’t trigger those innate drives, then the learning algorithm will sculpt the reward model to assign a high value to myself-eating-tofu and not to Ahmed-eating-tofu.
And again, the same story applies equally well to myself-being-comfortable versus Ahmed-being-comfortable, etc.
3. Kernels of truth in the original story
3.1 By default, we can expect transient spillover empathy … before within-lifetime learning promptly eliminates it
If a kid really likes tofu, and has never seen or heard of feta before, then the first time they see feta they might well have general good feelings about it, because they’re mentally associating it with tofu.
This default basically stops mattering at the same moment that they take their first bite of feta. In fact, it can largely stop mattering even before they taste or smell it—it can stop mattering as soon as someone tells the kid that it’s not in fact tofu but rather an unrelated food of a similar color.
But still. It is a default, and it does have nonzero effects.
So by the same token, one might imagine that, in very early childhood, a baby who likes to be hugged might mentally lump together me-getting-hugged with someone-else-getting-hugged, and thereby have positive feelings about the latter. This is a “mistake” from the perspective of the learning algorithm for the reward model, in the sense that hug has high value because (let us suppose) it involves affective touch inputs that trigger primary reward via some innate drive in the brainstem [LW · GW], and somebody else getting hugged will not trigger that primary reward. Thus, this “mistake” won’t last. The learnt reward model will update itself. But still, this “mistake” will plausibly happen for at least one moment of one day in very early childhood.
Is that fact important? I don’t think so! But still, it’s a kernel of truth in the story at the top.
(Unless, of course, there’s a specific evolved mechanism that prevents the learnt reward model from getting updated in a way that “corrects” the spillover. If that’s the hypothesis, then sure, let’s talk about it! But let’s focus the discussion on what exactly that specific evolved mechanism is! Incidentally, when I pushed back in the comments section of Beren’s post, his response [LW(p) · GW(p)] was I think generally in this category, but a bit vague.)
3.2 The semantic overlap is stable by default, even if the motivational overlap (from reward model spillover) isn’t
Compare the neurons that activate when I think about myself-eating-tofu, versus when I think about Ahmed-eating-tofu. There are definitely differences, as I argued above, and I claim that these differences are more than sufficient to allow the reward model to fire in a completely different way for one versus the other. But at the same time, there are overlaps in those neurons. For example, both sets of neurons probably include some neurons in my temporal lobe that encode the idea of tofu and all of its associations and implications.
By the same token, compare the neurons that activate when I myself feel happy, versus when I think about Ahmed-being-happy. There are definitely differences! But there’s definitely some overlap too.
The point of this post is to argue that this overlap doesn’t give us any empathy by itself, because the direct motivational consequence (from spillover in the learnt reward model) doesn’t even last five minutes, let alone a lifetime. But still, the overlap exists. And I think it’s plausible that this overlap is an ingredient in one or more specific evolved mechanisms that lead to our various prosocial and antisocial instincts. What are those mechanisms? I have ideas! But that’s outside of the scope of this post. More on that in the near future, hopefully.
- ^
The word “empathy” typically conveys a strongly positive, prosocial vibe, and that’s how I’m using that word in this post. Thus, for example, if Alice is very good at “putting herself in someone else’s shoes” in order to more effectively capture, imprison, and torture that someone, that’s NOT usually taken as evidence that Alice is a very “empathetic” person! (More discussion here [LW · GW].) If you strip away all those prosocial connotations, you get what I call “empathetic simulation”, a mental operation that can come along with any motivation, or none at all. I definitely believe in “empathetic simulation by default”, see §3.2 at the end.
- ^
Steve interjection: What Beren calls “learnt reward model” is more-or-less equivalent to what I call “valence guess”; see for example this diagram [LW · GW]. I’ll use Beren’s terminology for this post.
- ^
24 comments
Comments sorted by top scores.
comment by Jan_Kulveit · 2024-10-16T19:58:36.426Z · LW(p) · GW(p)
I expected quite different argument for empathy
1. argument from simulation: most important part of our environment are other people; people are very complex and hard to predict; fortunately, we have a hardware which is extremely good at 'simulating a human' - our individual brains. to guess what other person will do or why they are doing what they are doing, it seems clearly computationally efficient to just simulate their cognition on my brain. fortunately for empathy, simulations activate some of the same proprioceptive machinery and goal-modeling subagents, so the simulation leads to similar feelings
2. mirror neurons: it seems we have powerful dedicated system for imitation learning, which is extremely advantageous for overcoming genetic bottleneck. mirroring activation patterns leads to empathy
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-10-17T00:14:40.516Z · LW(p) · GW(p)
When I've been gradually losing at a strategic game where it seems like my opponent is slightly stronger than me, but then I have a flash of insight and turn things around at the last minute.... I absolutely model what my opponent is feeling as they are surprised by my sudden comeback. My reaction to such an experience is usually to smile, or (if I'm alone playing the game remotely) perhaps chuckle with glee at their imagined dismay. I feel proud of myself, and happy to be winning.
On the other hand, if I'm beating someone who is clearly trying hard but outmatched, I often feel a bit sorry for them. In such a case my emotions maybe align somewhat with theirs, but I don't think my slight feeling of pity, and perhaps superiority, is in fact a close match for what I imagine them feeling.
And both these emotional states are not what I'd feel in a real life conflict. A real life conflict would involve much more anxiety and stress, and concern for myself and sometimes the other.
I don't just automatically feel what the simulated other person in my mind is feeling. I feel a reaction to that simulation, which can be quite different from what the simulation is feeling! I don't think that increasing the accuracy and fidelity of the simulation would change this.
↑ comment by Steven Byrnes (steve2152) · 2024-10-16T20:06:28.999Z · LW(p) · GW(p)
- I added a footnote at the top clarifying that I’m disputing that the prosocial motivation aspect of “empathy” happens for free. I don’t dispute that (what I call) “empathetic simulations” are useful and happen by default.
- A lot of claims under the umbrella of “mirror neurons” are IMO pretty sketchy, see my post Quick notes on “mirror neurons” [LW · GW].
- You can make an argument: “If I’m thinking about what someone else might do and feel in situation X by analogy to what I might do and feel in situation X, and then if situation X is unpleasant than that simulation will be unpleasant, and I’ll get a generally unpleasant feeling by doing that.” But you can equally well make an argument: “If I’m thinking about how to pick up tofu with a fork, I might analogize to how I might pick up feta with a fork, and so if tofu is yummy then I’ll get a yummy vibe and I’ll wind up feeling that feta is yummy too.” The second argument is counter to common sense; we are smart enough to draw analogies between situations while still being aware of differences between those same situations, and allowing those differences to control our overall feelings and assessments. That’s the point I was trying to make here.
↑ comment by zhukeepa · 2024-11-06T04:38:56.754Z · LW(p) · GW(p)
“If I’m thinking about how to pick up tofu with a fork, I might analogize to how I might pick up feta with a fork, and so if tofu is yummy then I’ll get a yummy vibe and I’ll wind up feeling that feta is yummy too.”
Isn't the more analogous argument "If I'm thinking about how to pick up tofu with a fork, and it feels good when I imagine doing that, then when I analogize to picking up feta with a fork, it would also feel good when I imagine that"? This does seem valid to me, and also seems more analogous to the argument you'd compared the counter-to-common-sense second argument with:
Replies from: steve2152“If I’m thinking about what someone else might do and feel in situation X by analogy to what I might do and feel in situation X, and then if situation X is unpleasant than that simulation will be unpleasant, and I’ll get a generally unpleasant feeling by doing that.”
↑ comment by Steven Byrnes (steve2152) · 2024-11-06T14:20:58.821Z · LW(p) · GW(p)
Hmm, maybe we should distinguish two things:
- (A) I find the feeling of picking up the tofu with the fork to be intrinsically satisfying—it feels satisfying and empowering to feel the tongs of the fork slide into the tofu.
- (B) I don’t care at all about the feeling of the fork sliding into the tofu; instead I feel motivated to pick up tofu with the fork because I’m hungry and tofu is yummy.
For (A), the analogy to picking up feta is logically sound—this is legitimate evidence that picking up the feta will also feel intrinsically satisfying. And accordingly, my brain, having made the analogy, correctly feels motivated to pick up feta.
For (B), the analogy to picking up feta is irrelevant. The dimension along which I’m analogizing (how the fork slides in) is unrelated to the dimension which constitutes the source of my motivation (tofu being yummy). And accordingly, if I like the taste of tofu but dislike feta, then I will not feel motivated to pick up the feta, not even a little bit, let alone to the point where it’s determining my behavior.
The lesson here (I claim) is that our brain algorithms are sophisticated enough to not just note whether an analogy target has good or bad vibes, but rather whether the analogy target has good or bad vibes for reasons that legitimately transfer back to the real plan under consideration.
So circling back to empathy, if I was a sociopath, then “Ahmed getting punched” might still kinda remind me of “me getting punched”, but the reason I dislike “me getting punched” is because it’s painful, whereas “Ahmed getting punched” is not painful. So even if “me getting punched” momentarily popped into my sociopathic head, I would then immediately say to myself “ah, but that’s not something I need to worry about here”, and whistle a tune and carry on with my day.
Remember, empathy is a major force. People submit to torture and turn their lives upside down over feelings of empathy. If you want to talk about phenomena like “something unpleasant popped into my head momentarily, even if it doesn’t really have anything to do with this situation”, then OK maybe that kind of thing might have a nonzero impact on motivation, but even if it does, it’s gonna be tiny. It’s definitely not up to the task of explaining such a central part of human behavior, right?
↑ comment by Ben (ben-lang) · 2024-10-17T10:21:27.620Z · LW(p) · GW(p)
“If I’m thinking about what someone else might do and feel in situation X by analogy to what I might do and feel in situation X, and then if situation X is unpleasant than that simulation will be unpleasant, and I’ll get a generally unpleasant feeling by doing that.”
I think this is definitely true. Although, sometimes people solve that problem by just not thinking about what the other person is feeling. If the other person has ~no power, so that failing to simulate them carries ~no costs, then this option is ~free.
This kind of thing might form some kind of an explanation for Stockholm Syndrome. If you are kidnapped, and your survival potentially depends on your ability to model your kidnapper's motivations, and you have nothing else to think about all day, then any overspill from that simulating will be maximised. (Although from the wikipedia article on Stockholm syndrome it looks like it is somewhat mythical https://en.wikipedia.org/wiki/Stockholm_syndrome)
comment by Gunnar_Zarncke · 2024-10-17T13:01:55.859Z · LW(p) · GW(p)
I think the steelmaned version of beren's argument is
The potential for empathy is a natural consequence of learned reward models
That you indeed get for free. It will not get you far, as you have pointed out, because once you get more information, the model will learn to distinguish the cases precisely. And we know from observation that some mammals (specifically territorial ones) and most other animals do not show general empathy.
But there are multiple ways that empathy can be implemented with small additional circuitry. I think this is the part of beren's comment that you were referring to:
For instance, you could pass the RPE through to some other region to detect whether the empathy triggered for a friend or enemy and then return either positive or negative reward, so implementing either shared happiness or schadenfreude. Generally I think of this mechanism as a low level substrate on which you can build up a more complex repertoire of social emotions by doing reward shaping on these signals.
But it might even be possible that no additional circuitry is required if the environment is just right. Consider the case of a very social animal in an environment where individuals, esp. young ones, rarely can take care of themselves alone. In such an environment, there may be many situations where the well-being of others predicts your own well-being. For example, if you give something to the other (and that might just be smile) that makes it more likely to be fed. This doesn't seem to necessarily require any extra circuits, though it might be more likely to bootstrap off some prior mechanisms, e.g., grooming or infant care.
This might not be stable because free-loading might evolve, but this is then secondary.
I wonder which of these cases this comment of yours is:
Replies from: steve2152, steve2152consider “seeing someone get unexpectedly punched hard in the stomach”. That makes me cringe a bit, still, even as an adult.
↑ comment by Steven Byrnes (steve2152) · 2024-10-17T14:17:42.216Z · LW(p) · GW(p)
But it might even be possible that no additional circuitry is required if the environment is just right. Consider the case of a very social animal in an environment where individuals, esp. young ones, rarely can take care of themselves alone. In such an environment, there may be many situations where the well-being of others predicts your own well-being. For example, if you give something to the other (and that might just be smile) that makes it more likely to be fed. This doesn't seem to necessarily require any extra circuits, though it might be more likely to bootstrap off some prior mechanisms, e.g., grooming or infant care.
This might not be stable because free-loading might evolve, but this is then secondary.
I don’t really buy this. For my whole childhood, I was in an environment where it was illegal, dangerous, and taboo for me to drive a car (because I was underage). And then I got old enough to drive, and so of course I started doing so without a second thought. I had not permanently internalized the idea that “Steve driving a car” is bad. Instead, I got older, my situation changed, and my behavior changed accordingly. Likewise, I dropped tons of other habits of childhood—my religious practices, my street address, my bedtime, my hobbies, my political beliefs, my values, etc.—as soon as I got older and my situation changed.
So by the same token, when I was a little kid, yes it was in my self-interest (to some extent) for my parents to be healthy and happy. But that stopped being true as soon as I was financially independent. Why assume that people would permanently internalize that, when they fail to permanently internalize so many other aspects of childhood?
Actually it’s worse than that—adolescents are notorious for not feeling motivated by the well-being of their parents, even while such well-being is still in their own narrow self-interest!! :-P
(And generalizing across people seems equally implausible to generalizing across time. I called my parents “mom and dad”, but I didn’t generalize that to calling everyone I met “mom and dad”. So why assume that my brain would generalize being-nice-to-parents to being-nice-to-everyone?)
It’s true that sometimes childhood incentives lead to habits that last through adulthood, but I think that mainly happens via (1) the adult independently assesses those habits as being more appealing than alternatives, or (2) the adult continues the habits because it’s never really occurred to them that there was any other option.
As an example of (2), a religious person raised in a religious community might stay religious by default. Until, that is, they move to the big city, where they have atheist roommates and coworkers and friends. And at that point, they’ll probably at least imagine the possibility of becoming atheist. And they might or might not find that possibility appealing, based on their personality and so on.
But (2) doesn’t particularly apply to the idea of being selfish. I don’t think people are nice because it’s never even crossed their mind, not even once in their whole life, that maybe they could not do a nice thing. That’s a very obvious and salient idea! :)
[More on this in Heritability, Behaviorism, and Within-Lifetime RL [LW · GW] :) ]
Replies from: Gunnar_Zarncke↑ comment by Gunnar_Zarncke · 2024-10-17T20:53:15.992Z · LW(p) · GW(p)
I think the point we agree on is
habits that last through adulthood [because] the adult independently assesses those habits as being more appealing than alternatives,
I think that the habit of being nice to people is empathy.
So by the same token, when I was a little kid, yes it was in my self-interest (to some extent) for my parents to be healthy and happy. But that stopped being true as soon as I was financially independent. Why assume that people would permanently internalize that, when they fail to permanently internalize so many other aspects of childhood?
I'm not claiming that they "permanently internalize" but that they correctly (well, modulo mistakes) predict that it is their interests. You started driving a car because you correctly predicted that the situation/environment had changed. But across almost all environments, you get positive feedback from being nice to people and thus feel or predict positive valence about these.
Actually it’s worse than that—adolescents are notorious for not feeling motivated by the well-being of their parents, even while such well-being is still in their own narrow self-interest!! :-P
That depends on the type of well-being and your ability to predict it. And maybe other priorities get in the way during that age. And again, I'm not claiming unconditional goodness. The environment of young adults is clearly different from that of children, but it is comparable enough to predict positive value from being nice to your parents.
Actually, psychopaths prove this point: The anti-social behavior is "learned" in many cases during abusive childhood experiences, i.e., in environments where it was exactly not in their interest to be nice - because it didn't benefit them. And on the other side, psychopaths can, in many cases, function and show prosocial behaviors in stable environments with strong social feedback.
This also generalizes to the cultures example.
As an example of (2), a religious person raised in a religious community might stay religious by default. Until, that is, they move to the big city
I agree: In the city, many of their previous predictions of which behaviors exactly lead to positive feedback ("quoting the Bible") might be off and they will quickly learn new behaviors. But being nice to people in general, will still work. In fact, I claim, it tends to generalize even more, which is why people who have been around more varied communities tend to develop more generalized morality (higher Kegan levels).
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-10-18T01:53:31.816Z · LW(p) · GW(p)
I’m not too sure what you’re arguing.
I think we agree that motivations need to ground out directly or indirectly with “primary rewards” from innate drives (pain is bad, eating-when-hungry is good, etc., other things equal). (Right?)
And then your comment kinda sounds like you’re making the following argument:
There’s no need to posit the existence of an innate drive / primary reward that ever makes it intrinsically rewarding to be nice to people, because “you get positive feedback from being nice to people”, i.e. you will notice from experience that “being nice to people” will tend to lead to (non-social) primary rewards like eating-when-hungry, avoiding pain, etc., so the learning algorithm in your brain will sculpt you to have good feelings around being nice to people.
If that’s what you’re trying to say, then I strongly disagree and I’m happy to chat about that … but I was under quite a strong impression that that’s not what you believe! Right?
I thought that you believed that there is a primary reward / innate drive that makes it feel intrinsically rewarding for adults to be nice (under certain circumstances); if so, why bring up childhood at all?
Sorry if I’m confused :)
Replies from: Gunnar_Zarncke↑ comment by Gunnar_Zarncke · 2024-10-18T10:01:43.011Z · LW(p) · GW(p)
I do think that there are mechanisms in the human brain that make prosocial behavior more intrinsically rewarding, such as the mechanisms [LW · GW] you pointed out in the Valence sequence.
But I also notice that in the right kind of environments, "being nice to people" may predict "people being nice to you" (in a primary reward sense) to a higher degree than might be intuitive.
I don't think that's enough because you still need to ensure that the environment is sufficiently likely to begin with, with mechanisms such as rewarding smiles, touch inclinations, infant care instincts or whatever.
I think this story of how human empathy works may plausibly involve both social instincts as well as the self-interested indirect reward in very social environments.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-10-18T13:57:44.678Z · LW(p) · GW(p)
OK, my theory is:
- (A) There’s a thing where people act kind towards other people because it’s in their self-interest to act kind—acting kind will ultimately lead to eating yummier food, avoiding pain, and so on. In everyday life, we tend to associate this with flattery, sucking up, deception, insincerity, etc., and we view it with great skepticism, because we recognize (correctly) that such a person will act kind but then turn right around and stab you in the back as soon as the situation changes.
- (B) There’s a separate thing where people act kind towards other people because there’s some innate drive / primary reward / social instinct closely related to acting kind towards other people, e.g. feeling that the other person’s happiness is its own intrinsic reward. In everyday life, we view this thing very positively, because we recognize that such a person won’t stab you in the back when the situation changes.
I keep trying to pattern-match what you’re saying to:
- (C) [which I don’t believe in] This is a third category of situations where people are kind. Like (A), it ultimately stems from self-interest. But like (B), it does not entail the person stabbing you in the back as soon as the situation changes (such that stabbing you in the back is in their self-interest). And the way that works is over-generalization. In this story, the person finds that it’s in their self-interest to act kind, and over-generalizes this habit to act kind even in situations where it’s not in their self-interest.
And then I was saying that that kind of over-generalization story proves too much, because it would suggest that I would retain my childhood habit of not-driving-cars, and my childhood habit of saying that my street address is 18 Main St., etc. And likewise, it would say that I would continue to wear winter coats when I travel to the tropics, and that if somebody puts a toy train on my plate at lunchtime I would just go right ahead and eat it, etc. We adults are not so stupid as to over-generalize like that. We learn to adapt our behavior to the situation, and to anticipate relevant consequences.
But maybe that’s not what you’re arguing? I’m still kinda confused. You wrote “But across almost all environments, you get positive feedback from being nice to people and thus feel or predict positive valence about these.” I want to translate that as: “All this talk of stabbing people in the back is irrelevant, because there is practically never a situation where it’s in somebody’s self-interest to act unkind and stab someone in the back. So (A) is really just fine!” I don’t think you’d endorse that, right? But it is a possible position—I tend to associate it with @Matthew Barnett [LW · GW]. I agree that we should all keep in mind that it’s very possible for people to act kind for self-interested reasons. But I strongly don’t believe that (A) is sufficient for Safe & Beneficial AGI. But I think that you’re already in agreement with me about that, right?
Replies from: matthew-barnett↑ comment by Matthew Barnett (matthew-barnett) · 2024-10-18T19:19:06.042Z · LW(p) · GW(p)
I’m still kinda confused. You wrote “But across almost all environments, you get positive feedback from being nice to people and thus feel or predict positive valence about these.” I want to translate that as: “All this talk of stabbing people in the back is irrelevant, because there is practically never a situation where it’s in somebody’s self-interest to act unkind and stab someone in the back. So (A) is really just fine!” I don’t think you’d endorse that, right? But it is a possible position—I tend to associate it with @Matthew Barnett [LW · GW]. I agree that we should all keep in mind that it’s very possible for people to act kind for self-interested reasons. But I strongly don’t believe that (A) is sufficient for Safe & Beneficial AGI. But I think that you’re already in agreement with me about that, right?
Without carefully reading the above comment chain (forgive me if I need to understand the full discussion here before replying), I would like to clarify what my views are on this particular question, since I was referenced. I think that:
- It is possible to construct a stable social and legal environment in which it is in the selfish interests of almost everyone to act in such a way that brings about socially beneficial outcomes. A good example of such an environment is one where theft is illegal and in order to earn money, you have to get a job. This naturally incentivizes people to earn a living by helping others rather than stealing from others, which raises social welfare.
- It is not guaranteed that the existing environment will be such that self-interest is aligned with the general public interest. For example, if we make shoplifting de facto legal by never penalizing people who do it, this would impose large social costs on society.
- Our current environment has a mix of both of these good and bad features. However, on the whole, in modern prosperous societies during peacetime, it is generally in one's selfish interest to do things that help rather than hurt other people. This means that, even for psychopaths, it doesn't usually make selfish sense to go around hurting other people.
- Over time, in societies with well-functioning social and legal systems, most people learn that hurting other people doesn't actually help them selfishly. This causes them to adopt a general presumption against committing violence, theft, and other anti-social acts themselves, as a general principle. This general principle seems to be internalized in most people's minds as not merely "it is not in your selfish interest to hurt other people" but rather "it is morally wrong to hurt other people". In other words, people internalize their presumption as a moral principle, rather than as a purely practical principle. This is what prevents people from stabbing each other in the backs immediately once the environment changes.
- However, under different environmental conditions, given enough time, people will internalize different moral principles. For example, in an environment in which slaughtering animals becomes illegal and taboo, most people would probably end up internalizing the moral principle that it's wrong to hurt animals. Under our current environment, very few people internalize this moral principle, but that's mainly because slaughtering animals is currently legal, and widely accepted.
- This all implies that, in an important sense, human morality is not really "in our DNA", so to speak. Instead, we internalize certain moral principles because those moral principles encode facts about what type of conduct happens to be useful in the real world for achieving our largely selfish objectives. Whenever the environment shifts, so too does human morality. This distinguishes my view from the view that humans are "naturally good" or have empathy-by-default.
- Which is not to say that there isn't some sense in which human morality comes from human DNA. The causal mechanisms here are complicated. People vary in their capacity for empathy and the degree to which they internalize moral principles. However, I think in most contexts, it is more appropriate to look at people's environment as the determining factor of what morality they end up adopting, rather than thinking about what their genes are.
↑ comment by Steven Byrnes (steve2152) · 2024-10-18T21:15:13.341Z · LW(p) · GW(p)
Sorry for oversimplifying your views, thanks for clarifying. :)
Here’s a part I especially disagree with:
Over time, in societies with well-functioning social and legal systems, most people learn that hurting other people doesn't actually help them selfishly. This causes them to adopt a general presumption against committing violence, theft, and other anti-social acts themselves, as a general principle. This general principle seems to be internalized in most people's minds as not merely "it is not in your selfish interest to hurt other people" but rather "it is morally wrong to hurt other people". In other words, people internalize their presumption as a moral principle, rather than as a purely practical principle. This is what prevents people from stabbing each other in the backs immediately once the environment changes.
Just to be clear, I imagine we’ll both agree that if some behavior is always a good idea, it can turn into an unthinking habit. For example, today I didn’t take all the cash out of my wallet and shred it—not because I considered that idea and decided that it’s a bad idea, but rather because it never crossed my mind to do that in the first place. Ditto with my (non)-decision to not plan a coup this morning. But that’s very fragile (it relies on ideas not crossing my mind), and different from what you’re talking about.
My belief is: Neurotypical people have an innate drive to notice, internalize, endorse, and take pride in following social norms, especially behaviors that they imagine would impress the people whom they like and admire in turn. (And I have ideas about how this works in the brain! I think it’s mainly related to what I call the “drive to be liked / admired”, general discussion here [LW · GW], more neuroscience details coming soon I hope.)
The object-level content of these norms is different in different cultures and subcultures and times, for sure. But the special way that we relate to these norms has an innate aspect; it’s not just a logical consequence of existing and having goals etc. How do I know? Well, the hypothesis “if X is generally a good idea, then we’ll internalize X and consider not-X to be dreadfully wrong and condemnable” is easily falsified by considering any other aspect of life that doesn’t involve what other people will think of you. It’s usually a good idea to wear shoes that are comfortable, rather than too small. It’s usually a good idea to use a bookmark instead of losing your place every time you put your book down. It’s usually a good idea to sleep on your bed instead of on the floor next to it. Etc. But we just think of all those things as good ideas, not moral rules; and relatedly, if the situation changes such that those things become bad ideas after all for whatever reason, we’ll immediately stop doing them with no hesitation. (If this particular book is too fragile for me to use a bookmark, then that’s fine, I won’t use a bookmark, no worries!)
those moral principles encode facts about what type of conduct happens to be useful in the real world for achieving our largely selfish objectives
I’m not sure what “largely” means here. I hope we can agree that our objectives are selfish in some ways and unselfish in other ways.
Parents generally like their children, above and beyond the fact that their children might give them yummy food and shelter in old age. People generally form friendships, and want their friends to not get tortured, above and beyond the fact that having their friends not get tortured could lead to more yummy food and shelter later on. Etc. I do really think both of those examples centrally involve evolved innate drives. If we have innate drives to eat yummy food and avoid pain, why can’t we also have innate drives to care for children? Mice have innate drives to care for children—it’s really obvious, there are particular hormones and stereotyped cell groups in their hypothalamus and so on. Why not suppose that humans have such innate drives too? Likewise, mice have innate drives related to enjoying the company of conspecifics and conversely getting lonely without such company. Why not suppose that humans have such innate drives too?
Replies from: matthew-barnett↑ comment by Matthew Barnett (matthew-barnett) · 2024-10-18T22:25:52.532Z · LW(p) · GW(p)
The object-level content of these norms is different in different cultures and subcultures and times, for sure. But the special way that we relate to these norms has an innate aspect; it’s not just a logical consequence of existing and having goals etc. How do I know? Well, the hypothesis “if X is generally a good idea, then we’ll internalize X and consider not-X to be dreadfully wrong and condemnable” is easily falsified by considering any other aspect of life that doesn’t involve what other people will think of you.
To be clear, I didn't mean to propose the specific mechanism of: if some behavior has a selfish consequence, then people will internalize that class of behaviors in moral terms rather than in purely practical terms. In other words, I am not saying that all relevant behaviors get internalized this way. I agree that only some behaviors are internalized by people in moral terms, and other behaviors do not get internalized in terms of moral principles in the way I described.
Admittedly, my statement was imprecise, but my intention in that quote was merely to convey that people tend to internalize certain behaviors in terms of moral principles, which explains the fact that people don't immediately abandon their habits when the environment suddenly shifts. However, I was silent on the question of which selfishly useful behaviors get internalized this way and which ones don't.
A good starting hypothesis is that people internalize certain behaviors in moral terms if they are taught to see those behaviors in moral terms. This ties into your theory that people "have an innate drive to notice, internalize, endorse, and take pride in following social norms". We are not taught to see "reaching into your wallet and shredding a dollar" as impinging on moral principles, so people don't tend to internalize the behavior that way. Yet, we are taught to see punching someone in the face as impinging on a moral principle. However, this hypothesis still leaves much to be explained, as it doesn't tell us which behaviors we will tend to be taught about in moral terms, and which ones we won't be taught in moral terms.
As a deeper, perhaps evolutionary explanation, I suspect that internalizing certain behaviors in moral terms helps make our commitments to other people more credible: if someone thinks you're not going to steal from them because you think it's genuinely wrong to steal, then they're more likely to trust you with their stuff than if they think you merely recognize the practical utility of not stealing from them. This explanation hints at the idea that we will tend to internalize certain behaviors in moral terms if those behaviors are both selfishly relevant, and important for earning trust among other agents in the world. This is my best guess at what explains the rough outlines of human morality that we see in most societies.
I’m not sure what “largely” means here. I hope we can agree that our objectives are selfish in some ways and unselfish in other ways.
Parents generally like their children, above and beyond the fact that their children might give them yummy food and shelter in old age. People generally form friendships, and want their friends to not get tortured, above and beyond the fact that having their friends not get tortured could lead to more yummy food and shelter later on. Etc.
In that sentence, I meant "largely selfish" as a stand-in for what I think humans-by-default care overwhelmingly about, which is something like "themselves, their family, their friends, and their tribe, in rough descending order of importance". The problem is that I am not aware of any word in the English language to describe people who have these desires, except perhaps the word "normal".
The word selfish usually denotes someone who is preoccupied with their own feelings, and is unconcerned with anyone else. We both agree that humans are not entirely selfish. Nonetheless, the opposite word, altruistic, often denotes someone who is preoccupied with the general social good, and who cares about strangers, not merely their own family and friend circles. This is especially the case in philosophical discussions in which one defines altruism in terms of impartial benevolence to all sentient life, which is extremely far from an accurate description of the typical human.
Humans exist on a spectrum between these two extremes. We are not perfectly selfish, nor are we perfectly altruistic. However, we are generally closer to the ideal of perfect selfishness than to the ideal of perfect altruism, given the fact that our own family, friend group, and tribe tends to be only a small part of the entire world. This is why I used the language of "largely selfish" rather than something else.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-10-22T02:11:42.404Z · LW(p) · GW(p)
Honest question: Suppose that my friends and other people whom I like and respect and trust all believe that genocide is very bad. I find myself (subconsciously) motivated to fit in with them, and I wind up adopting their belief that genocide is very bad. And then I take corresponding actions, by writing letters to politicians urging military intervention in Myanmar.
In your view, would that count as “selfish” because I “selfishly” benefit from ideologically fitting in with my friends and trusted leaders? Or would it count as “altruistic” because I am now moved by the suffering of some ethnic group across the world that I’ve never met and can’t even pronounce?
Replies from: matthew-barnett↑ comment by Matthew Barnett (matthew-barnett) · 2024-10-22T02:41:22.960Z · LW(p) · GW(p)
It is not always an expression of selfish motives when people take a stance against genocide. I would even go as far as saying that, in the majority of cases, people genuinely have non-selfish motives when taking that position. That is, they actually do care, to at least some degree, about the genocide, beyond the fact that signaling their concern helps them fit in with their friend group.
Nonetheless, and this is important: few people are willing to pay substantial selfish costs in order to prevent genocides that are socially distant from them.
The theory I am advancing here does not rest on the idea that people aren't genuine in their desire for faraway strangers to be better off. Rather, my theory is that people generally care little about such strangers, when helping those strangers trades off significantly against objectives that are closer to themselves, their family, friend group, and their own tribe.
Or, put another way, distant strangers usually get little weight in our utility function. Our family, and our own happiness, by contrast, usually get a much larger weight.
The core element of my theory concerns the amount that people care about themselves (and their family, friends, and tribe) versus other people, not whether they care about other people at all.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-10-25T00:37:45.839Z · LW(p) · GW(p)
Hmm. I think you’re understating the tendency of most people to follow prevailing norms, and yet your main conclusion is partly right. I think there are interesting dynamics happening at two levels simultaneously—the level of individual decisions, and the level of cultural evolution—and your comment is kinda conflating those levels.
So here’s how I would put things:
- Most people care very very strongly about doing things that would look good in the eyes of the people they respect. They don’t think of it that way, though—it doesn’t feel like that’s what they’re doing, and indeed they would be offended by that suggestion. Instead, those things just feel like the right and appropriate things to do. This is related to and upstream of norm-following. This is an innate drive, part of human nature built into our brain by evolution.
- Also, most people also have various other innate drives that lead to them feeling motivated to eat when hungry, to avoid pain, to bond with friends, for parents to love their children and adolescents to disrespect their parents (but respect their slightly-older friends), and much else.
- (But there’s person-to-person variation, and in particular some small fraction of people are sociopaths who just don’t feel intrinsically motivated by (1) at all.)
- The norms of (1) can be totally arbitrary. If the people I respect think that genocide is bad, then probably so do I. If they think genocide is awesome, then probably so do I. If they think it’s super-cool to hop backwards on one foot, then probably so do I.
- …But (2) provides a constant force gently pushing norms towards behavioral patterns that match up with innate tendencies in (2). So we tend to wind up with cultural norms that line up with avoiding pain, eating-when-hungry, bonding with friends, and so on.
- …But not perfectly, because there are other forces acting on norms too, such as game-theoretic signaling equilibria or whatever. These enable the existence of widespread norms with aspects that run counter to aspects of (2)—think of religious fasting, initiation rites, etc.
- When (4),(5),(6) play out in some group or society, some norms will “win” over others, and the norms that “win” are probably (to some extent) a priori predictable from structural aspects of the situation—homogeneity, mobility, technology, whatever.
↑ comment by Steven Byrnes (steve2152) · 2024-10-17T14:56:13.595Z · LW(p) · GW(p)
I wonder which of these cases this comment of yours is:
consider “seeing someone get unexpectedly punched hard in the stomach”. That makes me cringe a bit, still, even as an adult.
- One thing is, I think the brain invests like 10,000× more neurons into figuring out whether a thought is good vs bad (positive vs negative valence [LW · GW]) as figuring out whether a thought is or is not a good time to cringe. So I think the valence calculation can capture subtleties and complexities that the simpler cringe calculation can’t. This especially includes things properly handling complex thoughts with subordinate clauses and so on. For example, in the thought “I’ll do X in order to avoid Y”, the more negative the valence of Y is, the more positive the valence of the whole thought is. So the hypothesis “our brains are unable to learn a strong valence-difference between two vaguely-related situations” is (even?) more implausible than the hypothesis “our brains are unable to learn a strong stomach-cringe-appropriateness-difference between two vaguely-related situations”.
- Another thing is, I obviously do think there are specific evolved mechanisms at play here, even if I didn’t talk about them in this post.
- Another thing is, occasionally lightly tensing my stomach, in situations where I don’t need to, just isn’t the kind of high-stakes mistake that warrants a strong update in any brain learning algorithm. Like, if some flash in the corner of your eye has a 2% chance of preceding getting hit in the stomach, it’s still the right move to cringe every time—I’m happy to trade 50 false positives where I tense my stomach unnecessarily, in exchange for 1 true positive where I protect myself from serious injury. So presumably the brain learning algorithm is tuned to update only very weakly on false positives. Now, I don’t normally see people get punched in the stomach, up close and personal. I can’t even remember the last time that happened. If I saw that every day, I might well get desensitized to it. I do seem to be pretty well desensitized to seeing people get punched on TV.
comment by momom2 (amaury-lorin) · 2024-10-20T20:26:41.738Z · LW(p) · GW(p)
I was under the impression that empathy explained by evolutionary psychology as a result of the need to cooperate with the fact that we already had all the apparatus to simulate other people (like Jan Kulveit's first proposition).
(This does not translate to machine empathy as far as I can tell.)
I notice that this impression is justified by basically nothing besides "everything is evolutionary psychology". Seeing that other people's intuitions about the topic are completely different is humbling; I guess emotions are not obvious.
So, I would appreciate if you could point out where the literature stands on the position you argue against, Jan Kulveit's or mine (or possibly something else).
Are all these takes just, like, our opinion, man, or is there strong supportive evidence for a comprehensive theory of empathy (or is there evidence for multiple competing theories)?
↑ comment by Steven Byrnes (steve2152) · 2024-10-20T22:08:15.613Z · LW(p) · GW(p)
I definitely think that the human brain has innate evolved mechanisms related to social behavior in general, and to caring about (certain) other people’s welfare in particular.
And I agree that the evolutionary pressure explaining why those mechanisms exist are generally related to the kinds of things that Robert Trivers and other evolutionary psychologists talk about.
This post isn’t about that. Instead it’s about what those evolved mechanisms are, i.e. how they work in the brain.
Does that help?
…But I do want to push back against a strain of thought within evolutionary psychology where they say “there was an evolutionary pressure for the human brain to do X, and therefore the human brain does X”. I think this fails to appreciate the nature of the constraints that the brain operates under. There can be evolutionary pressure for the brain to do something, but there’s no way for the brain to do it, so it doesn’t happen, or the brain does something kinda like that but with incidental side-effects or whatever.
As an example, imagine if I said: “Here’s the source code for training an image-classifier ConvNet from random initialization using uncontrolled external training data. Can you please edit this source code so that the trained model winds up confused about the shape of Toyota Camry tires specifically?” The answer is: “Nope. Sorry. There is no possible edit I can make to this PyTorch source code such that that will happen.” You see what I mean? I think this kind of thing happens in the brain a lot. I talk about it more specifically here [LW · GW]. More of my opinions about evolutionary psychology here [LW · GW] and here [LW · GW].
Replies from: amaury-lorin↑ comment by momom2 (amaury-lorin) · 2024-10-21T08:41:49.070Z · LW(p) · GW(p)
Thanks, it does clarify, both on separating the instantiation of an empathy mechanism in the human brain vs in AI and on considering instantiation separately from the (evolutionary or training) process that leads to it.
comment by Foyle (robert-lynn) · 2024-10-17T04:51:49.502Z · LW(p) · GW(p)
"In many cases, however, evolution actually reduces our native empathic capacity -- for instance, we can contextualize our natural empathy to exclude outgroup members and rivals."
Exactly as it should be.
Empathy is valuable in close community settings, a 'safety net' adaption to make the community stronger with people we keep track of to ensure we are not being exploited by people not making concomitant effort to help themselves. But it seems to me that it is destructive at wider social scales enabled by social media where we don't or can't have effective reputation tracking to ensure that we are not being 'played' for the purpose of resource extraction by people making dishonest or exaggerated representations.
In essence at larger scales the instinct towards empathy rewards dishonest, exploitative, sociopathic and narcissistic behavior in individuals, and is perhaps responsible for a lot of the deleterious aspects of social media amongst particularly more naturally or generally empathic-by-default women. Eg 'influencers' (and before them exploitative televangelists) cashing in on follower empathy. It also rewards misrepresentations of victimhood/suffering for attention and approval - again in absence of more in depth knowledge of the person that would exist in a smaller community - that may be a source of rapid increase in 'social contagion' mental health pathologies amongst particularly young women instinctually desirous of attention most easily attained by inventing of exaggerating issues in absence of other attributes that might garner attention.
In short the empathic charitable instinct that works so well in families and small groups is socially destructive and dysfunctional at scales beyond community level.
comment by ZY (AliceZ) · 2024-10-17T02:13:33.897Z · LW(p) · GW(p)
Would agree with most of the posts; To me, humans have some general shared experiences that may activate empathy related to those experiences, but the the numerous small differences in experience make it very hard to know exactly what the others would think/feel, even if in exactly the same situations. We could never really model the entire learning/experience history from another person.
My belief/additional point I want to add/urge is that this should not be interpreted as say empathy is not needed because we don't get it right anyways (I saw some other comments saying evolution is against empathy) - it is more to recognize what we are not naturally good at empathy(or less well than we thought), and thus create mindsets/systems (such as asking and promoting on gathering more information about the other person) that encourage empathy consciously (when needed).
(maybe I misread, and the second point is addressing another comment)