[Intro to brain-like-AGI safety] 13. Symbol grounding & human social instincts
post by Steven Byrnes (steve2152) · 2022-04-27T13:30:33.773Z · LW · GW · 15 commentsContents
13.1 Post summary / Table of contents 13.2 What are we trying to explain and why is it tricky? 13.2.1 Claim 1: Social instincts arise from genetically-hardcoded circuitry in the Steering Subsystem (hypothalamus & brainstem) 13.2.2 Claim 2: Social instincts are tricky because of the “symbol grounding problem” 13.2.3 Reminder of brain model, from previous posts 13.3 Sketch #1: Filial imprinting 13.3.1 Overview 13.3.2 How is the MOMMY Thought Assessor trained? 13.3.3 How is the MOMMY Thought Assessor used? 13.4 Sketch #2: Fear of strangers 13.5 Another key ingredient (I think): “Transient empathetic simulation” 13.5.1 Introduction 13.5.2 Distinction from the standard definition of “empathy” 13.5.3 Why do I believe that “transient empathetic simulations” are part of the story? 13.6 Future work (please!) Changelog None 15 comments
(Last revised: July 2024. See changelog at the bottom.)
13.1 Post summary / Table of contents
Part of the “Intro to brain-like-AGI safety” post series [? · GW].
In the previous post [AF · GW], I proposed that one path forward for AGI safety involves reverse-engineering human social instincts—the innate reactions in the Steering Subsystem (hypothalamus and brainstem) [AF · GW] that contribute to human social behavior and moral intuitions. This post will go through some examples of how human social instincts might work.
My intention is not to offer complete and accurate descriptions of human social instinct algorithms, but rather to gesture at the kinds of algorithms that a reverse-engineering project should be looking for.
(Note: Since first writing this post, I think I've made good progress on this reverse-engineering project! See especially A theory of laughter [LW · GW] and Neuroscience of human social instincts: a sketch [LW · GW]. There’s still tons more work to do, of course. This post will not discuss those later developments, but rather explain and motivate the basic problem.)
This post, like Posts #2 [AF · GW]–#7 [AF · GW] but unlike the rest of the series, is pure neuroscience, with almost no mention of AGI besides here and the conclusion.
Table of contents:
- Section 13.2 explains, first, why I expect to find innate, genetically-hardwired, social instinct circuits in the hypothalamus and/or brainstem, and second, why evolution had to solve a tricky puzzle when designing these circuits. Specifically, these circuits have to solve a “symbol grounding problem”, by taking the symbols in a learned-from-scratch [AF · GW] world-model, and somehow connecting them to the appropriate social reactions.
- Section 13.3 and 13.4 go through two relatively simple examples where I attempt to explain recognizable social behaviors in terms of innate reaction circuits: filial imprinting in Section 13.3, and fear-of-strangers in Section 13.4.
- Section 13.5 discusses an additional ingredient that I suspect plays an important role in many social instincts, which I call “transient empathetic simulations”. This mechanism enables reactions where recognizing or expecting a feeling in someone else triggers a “response feeling” in oneself—for example, if I notice that my rival is suffering, it triggers the warm feelings of schadenfreude. To be clear, “transient empathetic simulations” have little in common with how the word “empathy” is used normally; “transient empathetic simulations” are fast and involuntary, and are involved in both prosocial and antisocial emotions.
- Section 13.6 wraps up with a plea for researchers to figure out exactly how human social instincts work, ASAP. I will have a longer wish-list of research directions in Post #15 [AF · GW], but I want to emphasize this one right now, as it seems particularly impactful and tractable. If you (or your lab) are in a good position to make progress but would need funding, email me and I’ll keep you in the loop about possible upcoming opportunities.
13.2 What are we trying to explain and why is it tricky?
13.2.1 Claim 1: Social instincts arise from genetically-hardcoded circuitry in the Steering Subsystem (hypothalamus & brainstem)
I want us to have a concrete example in mind going forward, so I’ll focus on a particular innate drive that I’m quite sure exists. I call it the “drive to feel liked / admired”—see my post Valence & Liking / Admiring [LW · GW].[1] This is the near-universal desire to feel liked / admired, especially by those whom we like / admire in turn, and whom we see as important. This desire is closely related to the human tendency to seek prestige and status, although it’s not exactly the same (see my two-part series on social status phenomena here [LW · GW] & here [LW · GW]).
(Remember, the point of this post is that I want to understand human social instincts in general. I don’t necessarily want AGIs to exhibit status-seeking behavior in particular! See previous post, Section 12.4.3 [AF · GW].)
My claim is: there needs to be genetically-hardcoded circuitry in the Steering Subsystem [AF · GW]—a.k.a. an “innate reaction”—which gives rise to this desire to feel liked / admired.
Why do I think that? A few reasons (see also my similar discussion in Section 4.4.1 here [LW · GW]):
First, a drive to feel liked / admired would seem to have a solid evolutionary justification. After all, if people like / admire me, then they tend to defer to my preferences, plans, and ideas, including helping me when they can, for reasons described in Section 4.6 here [LW · GW]. Relatedly, I’m not an expert, but I understand that the most liked / admired members of hunter-gatherer tribes tended to become leaders, eat better food, have more children, and so on.
Second, the drive to feel liked / admired seems to be innate, not learned. For example:
- I think parents will agree that children crave respect / admiration starting from a remarkably young age, and in situations where those cravings have no discernable direct downstream impact on their life.
- Even adults crave admiration in a way that’s rather divorced from direct downstream impact—for example, I would react much more positively to news that Tom Hanks secretly thinks highly of me, than to news that some obscure government bureaucrat secretly thinks highly of me, even if the obscure government bureaucrat was in fact much better-positioned than Tom Hanks to advance my life goals as a result.
- The desire to feel liked / admired is (I think) a cross-cultural universal…
- …But simultaneously, that same desire seems to have a lot of person-to-person variation, including being apparently essentially absent in some psychopaths (see discussion of the “pity play” in Section 4.4.1 here [LW · GW]). This kind of inter-individual variation seems to better match what I expect from an innate drive (e.g. some people are much more sensitive to pain or hunger than others) than what I expect from a learned strategy (e.g. pretty much everyone makes use of their fingernails when scratching an itch).
- There may also be an analogous drive to feel liked / admired in certain non-human animals, like the Arabian babbler bird.[2]
In my framework (see Posts #2 [AF · GW]–#3 [AF · GW]), the only way to build this kind of innate reaction is to hardwire specific circuitry into the Steering Subsystem [AF · GW]. As a (non-social) example of how I expect this kind of innate reaction to be physically configured in the brain (if I understand correctly, see detailed discussion in this other post I wrote [LW · GW]), there’s a discrete population of neurons in the hypothalamus which seems to implement the following behavior: “If I’m under-nourished, do the following tasks: (1) emit a hunger sensation, (2) start rewarding the cortex for getting food, (3) reduce fertility, (4) reduce growth, (5) reduce pain sensitivity, etc.”. There seems to be a neat and plausible story of what this population of hypothalamic neurons is doing, how it's doing it, and why. I expect that there are analogous little circuits (perhaps also in the hypothalamus, or maybe somewhere in the brainstem) that underlie things like “the drive to feel liked / admired”, and I’d like to know exactly what they are and how they work, at the algorithm level.
Third, I claim that rodent studies have clearly established that innate social reactions can be orchestrated by groups of neurons in the Steering Subsystem [AF · GW] (especially hypothalamus) can orchestrate innate social reactions and drives—a few examples are in this footnote[3]. That should make it feel more plausible that maybe all innate social reactions are like that, and that maybe this is true in humans too. I wish the literature on this topic was better—but alas, in social neuroscience, just like in non-social neuroscience, the Steering Subsystem (hypothalamus and brainstem) is (regrettably) neglected and dismissed in comparison to the cortex.[4]
13.2.2 Claim 2: Social instincts are tricky because of the “symbol grounding problem”
For social instincts to have the effects that evolution “wants” them to have, they need to interface with our conceptual understanding of the world—i.e., with our learned-from-scratch [AF · GW] world-model, which is a huge (probably multi-gigabyte [LW · GW]) complicated unlabeled data structure in our brain.
So suppose my acquaintance Rita just said something about politics that seems to imply that she thinks I’m stupid. My understanding of Rita and her utterance is represented by some specific neuron firing pattern in the learned cortical world model, and that’s supposed to trigger the hard-coded “drive to feel liked / admired” circuit in my hypothalamus or brainstem. How does that work?
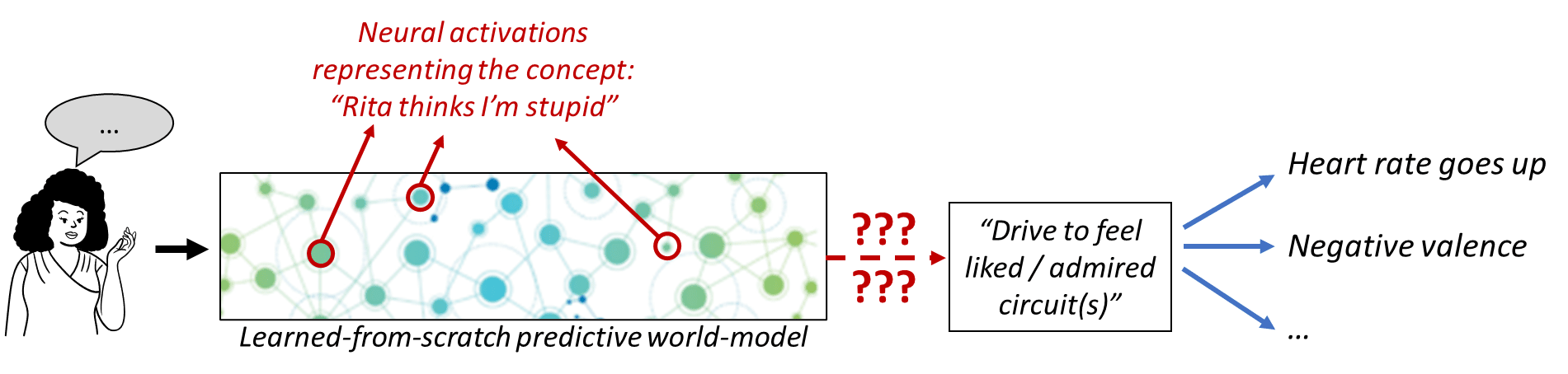
You can’t just say “The genome wires these particular neurons to the innate drive circuit,” because we need to explain how. Recall from Post #2 [AF · GW] that all my concepts related to Rita, politics, grammar, conversational implicatures, and so on, were learned within my lifetime, basically by cataloging patterns in my sensory inputs, and then patterns in the patterns, etc.—see predictive learning of sensory inputs in Post #4 [AF · GW]. How does the genome know that this particular set of neurons should trigger the “drive to feel liked / admired” circuit?
By the same token, you can’t just say “A within-lifetime learning algorithm will figure out the connection”; we would also need to specify how the brain calculates a “ground truth” signal (e.g. supervisory signals, error signals, reward signals, etc.) which can steer this learning algorithm.
Thus, the challenge of implementing the “drive to feel liked / admired” (and other social instincts) amounts to a kind of symbol grounding problem—we have lots of “symbols” (concepts in our learned-from-scratch [AF · GW] predictive world-model), and the Steering Subsystem [AF · GW] needs a way to “ground” them, at least well enough to extract what social instincts they should evoke.
So how do the social instinct circuits solve that symbol grounding problem? One possible answer is: “Sorry Steve, but there’s no possible solution, and therefore we should reject learning-from-scratch [AF · GW] and all the other baloney in Posts #2 [AF · GW]–#7 [AF · GW].” Yup, I admit it, that’s a possible answer! But I don’t think it’s right.
While I don’t have any great, well-researched answers, I do have some ideas of what the answer should generally look like, and the rest of the post is my attempt to gesture in that direction.
13.2.3 Reminder of brain model, from previous posts
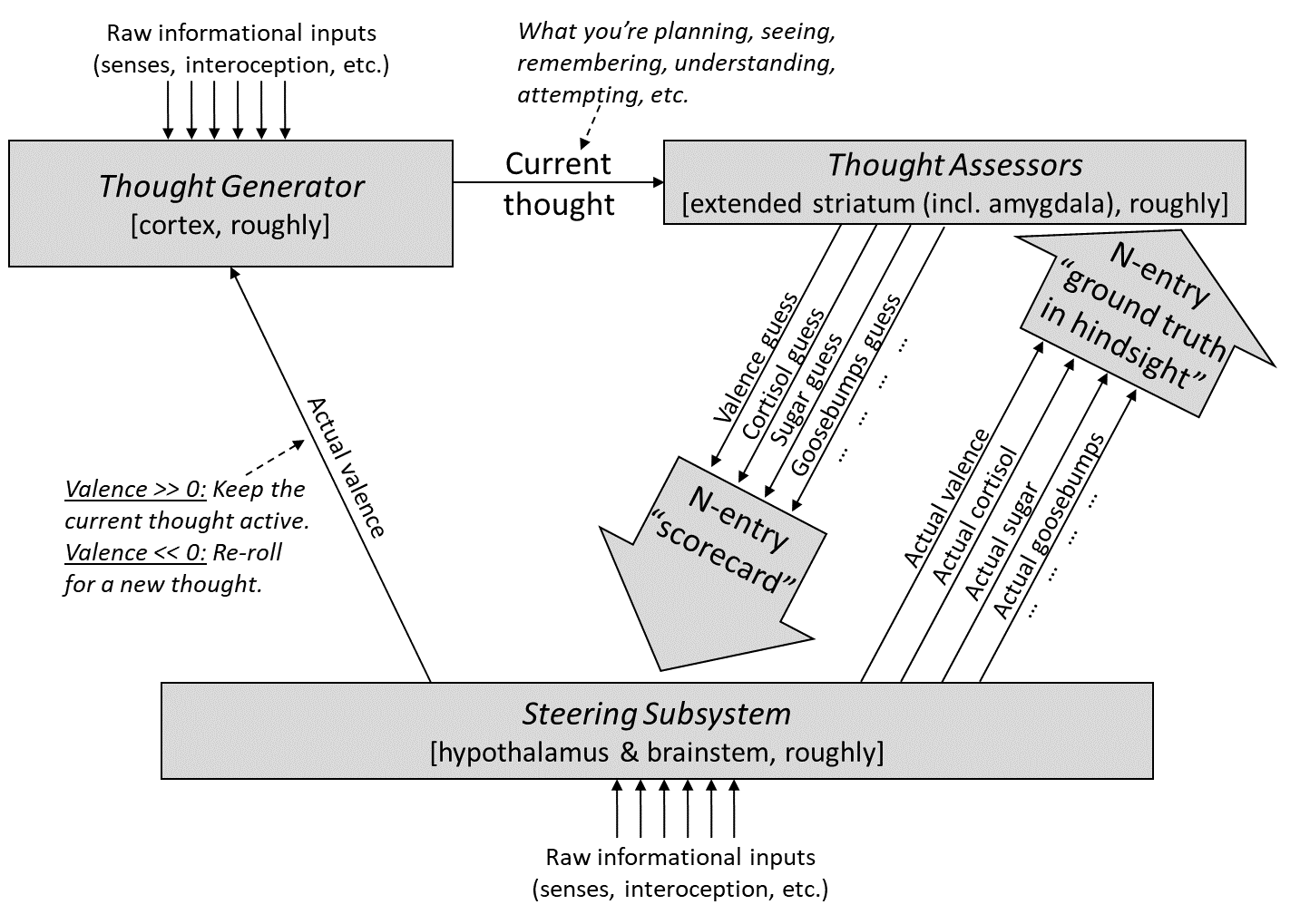
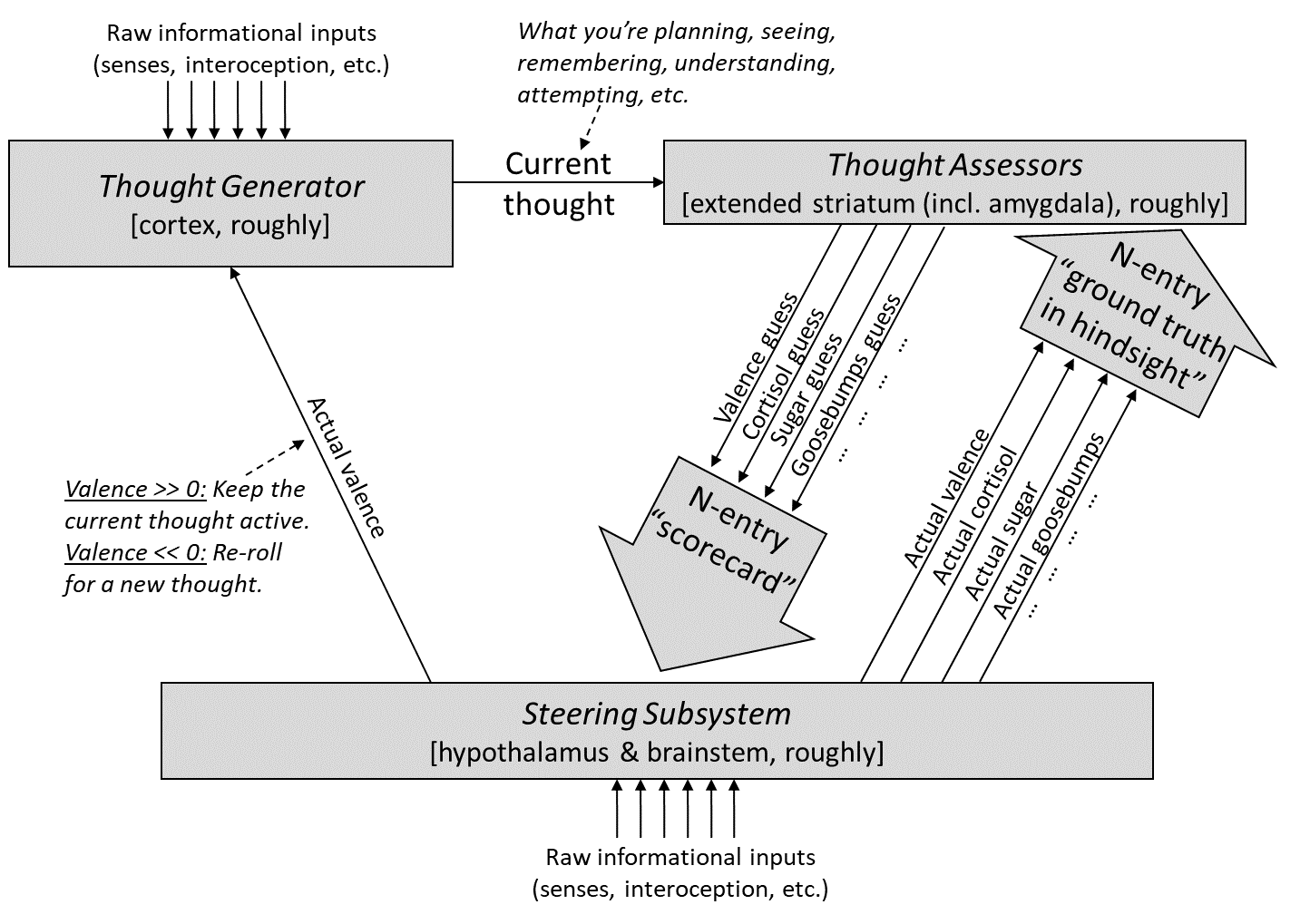
As usual, here’s our diagram from Post #6 [AF · GW]:
And here’s the version distinguishing within-lifetime learning-from-scratch [AF · GW] from genetically-hardcoded circuitry:
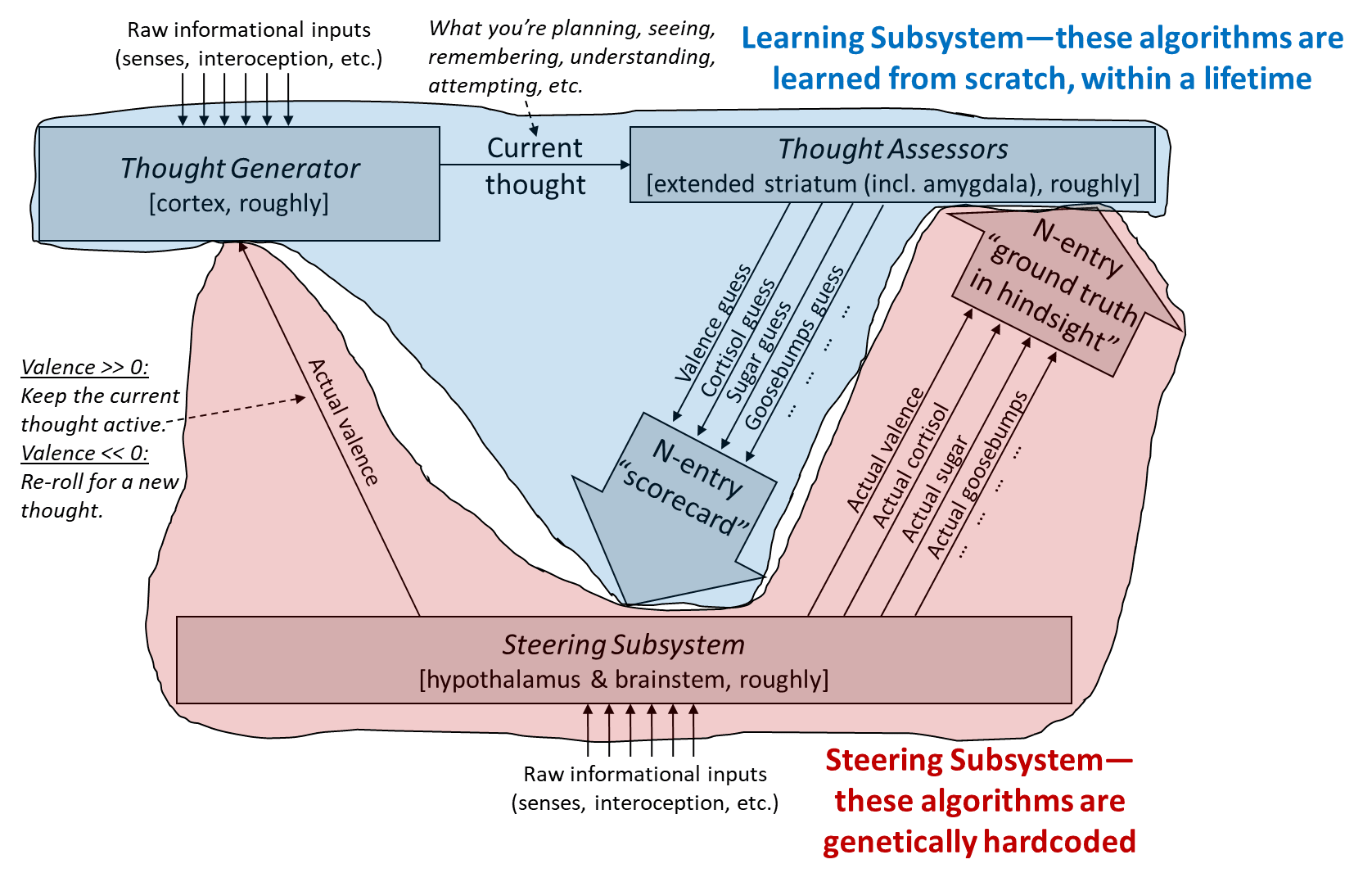
Again, our general goal in this post is to think about how social instincts might work, without violating the constraints of our model.
13.3 Sketch #1: Filial imprinting
(This section is not necessarily a central example of how social instincts work, but included as practice thinking through the relevant algorithms. Thus, I feel pretty strongly that the discussion here is plausible, but haven’t read the literature deeply enough to know if it’s correct.)
13.3.1 Overview

Filial imprinting (wikipedia) is a phenomenon where, in the most famous example, baby geese will “imprint on” a salient object that they see during a critical period 13–16 hours after hatching, and then will follow that object around. In nature, the “object” they imprint on is almost invariably their mother, whom they dutifully follow around early in life. However, if separated from their mother, baby geese will imprint on other animals, or even inanimate objects like boots and boxes.
Your challenge: come up with a way to implement filial imprinting in my brain model.
(Try it!)
.
.
.
.
Here’s my answer.
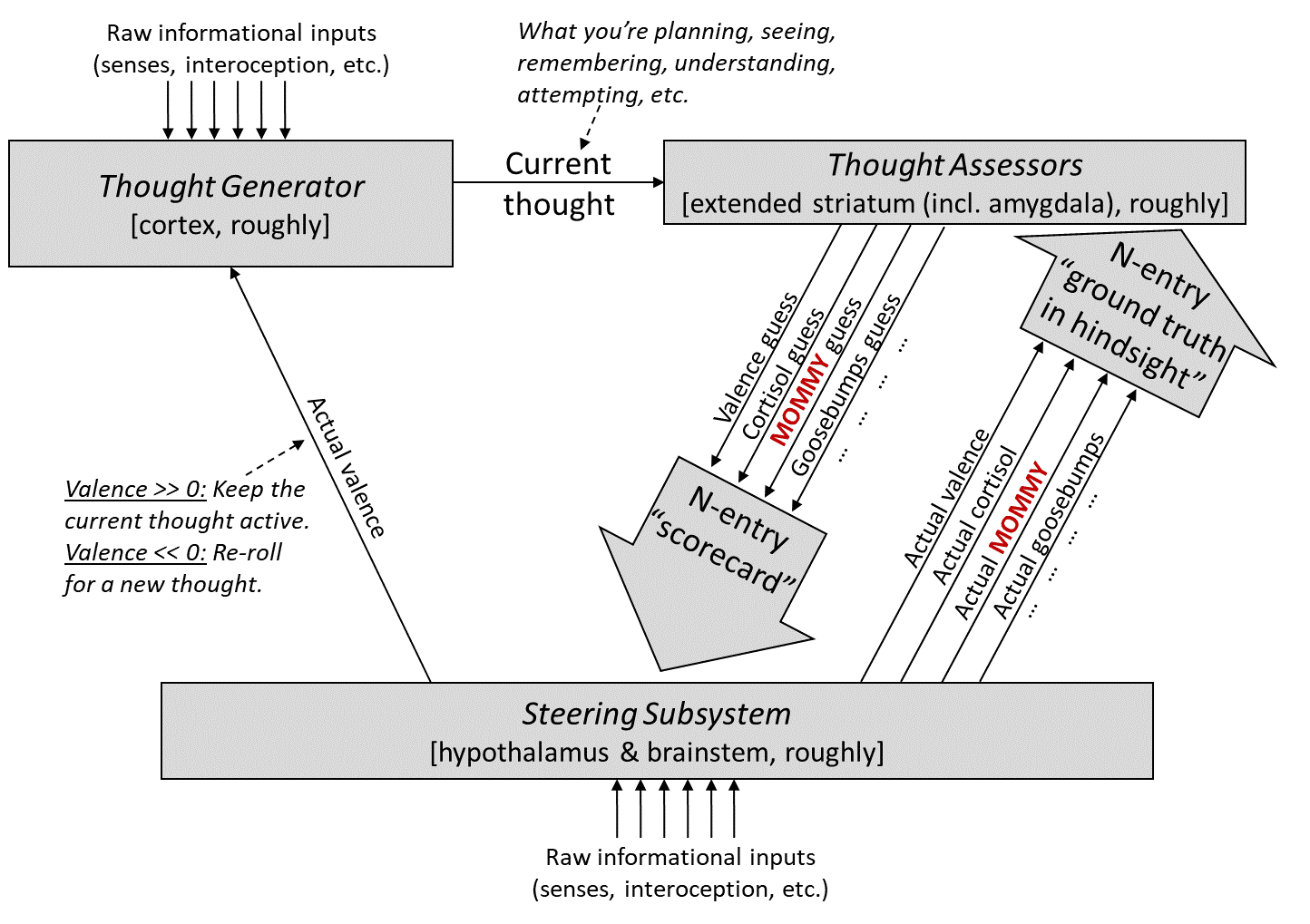
The first step is: I added a particular Thought Assessor dedicated to MOMMY (marked in red), with a prior pointing it towards visual inputs (Post #9, Section 9.3.3 [AF · GW]). Next I’ll talk about how this particular Thought Assessor is trained, and then how its outputs are used.
13.3.2 How is the MOMMY Thought Assessor trained?
During the critical period (13–16 hours after hatching):
Recall that there’s a simple image processor in the Steering Subsystem [AF · GW] (called “superior colliculus” in mammals, and “optic tectum” in birds). I propose that when this system detects that the visual field contains a mommy-like object (based on some simple image-analysis heuristics, which apparently are not very discerning, given that boots and boxes can pass as “mommy-like”), it sends a “ground truth in hindsight” signal to the MOMMY Thought Assessor. This triggers updates to the Thought Assessor (by supervised learning), essentially telling it: “Whatever you’re seeing right now in the context signals [AF · GW], those should lead to a very high score for MOMMY. If they don’t, please update your synapses etc. to make it so.”
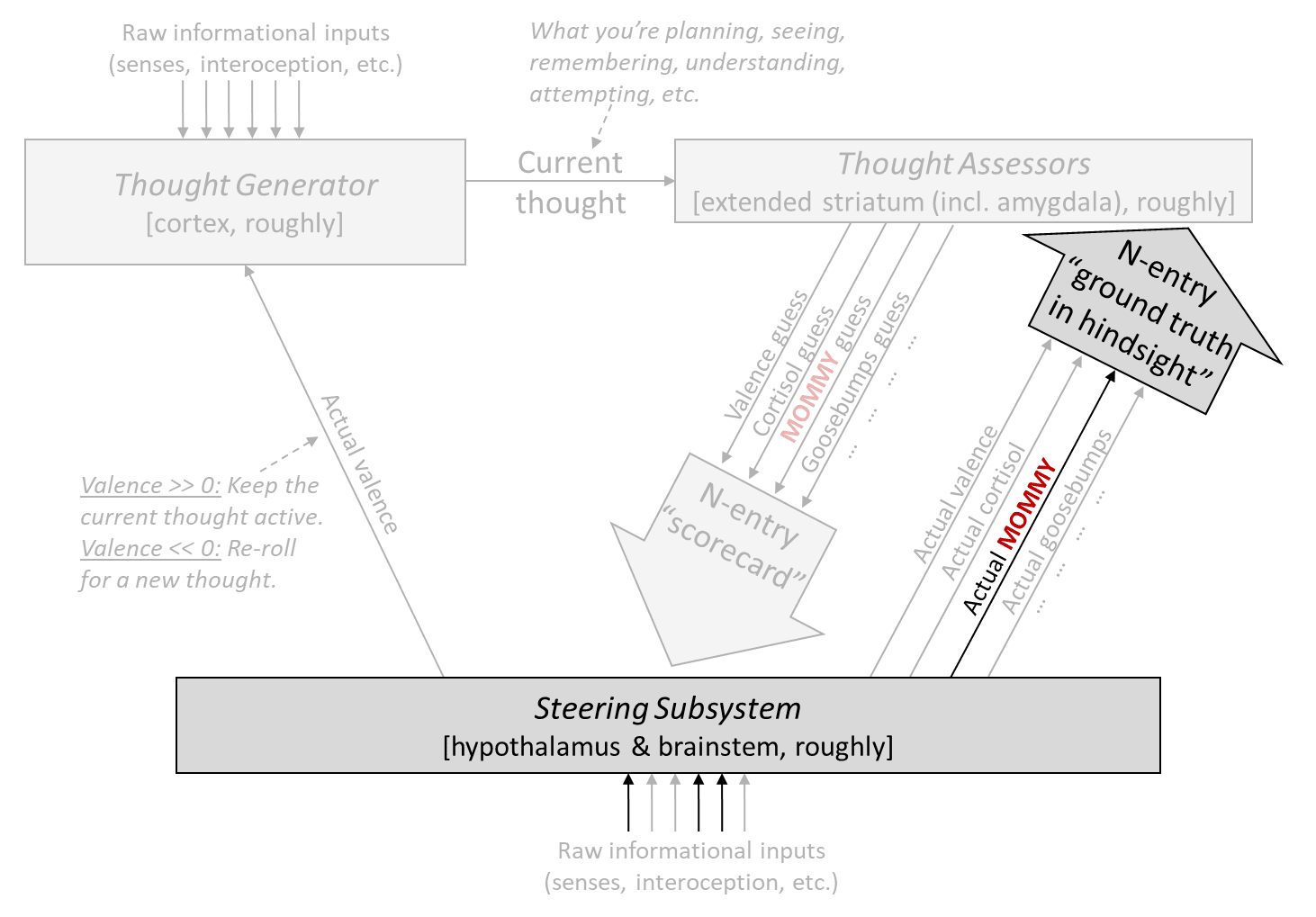
After the critical period (13–16 hours after hatching):
After the critical period, the Steering Subsystem permanently stops updating the MOMMY Thought Assessor. No matter what happens, it gets an error signal of zero!
Therefore, however that particular Thought Assessor got configured during the critical period, that’s how it stays.
Summary
Thus far in the story, we have built a circuit that learns the specific appearance of an imprinting-worthy object during the critical period, and then after the critical period, the circuit fires in proportion to how well things in the current field-of-view match that previously-learned appearance. Moreover, this circuit is not buried inside a giant learned-from-scratch [AF · GW] data structure, but rather is sending its output into a specific, genetically-specified line going down to the Steering Subsystem—exactly the configuration that enables easy interfacing with genetically-hardwired circuitry.
So far so good!
13.3.3 How is the MOMMY Thought Assessor used?
Now, the rest of the story is probably kinda similar to Post #7 [AF · GW]. We can use the MOMMY Thought Assessor to build a reward signal incentivizing the baby goose to be physically proximate and looking at the imprinted object—not only that, but also for planning to get physically proximate to the imprinted object.
I can think of various ways to make the reward function a bit more elaborate than that—maybe the optic tectum heuristics continue to be involved, and help detect if the imprinted object is on the move, or whatever—but I’ve already exhausted my very limited knowledge of imprinting behavior, and maybe we should move on.
13.4 Sketch #2: Fear of strangers
(As above, the purpose here is to practice playing with the algorithms, and I don’t feel strongly that this description is definitely a thing that happens in humans.)
Here’s a behavior, which may ring true to parents of very young kids, although I think different kids display it to different degrees. If a kid sees an adult they know well, they’re happy. But if they see an adult they don’t know, they get scared, especially if that adult is very close to them, touching them, picking them up, etc.
Your challenge: come up with a way to implement that behavior in my brain model.
(Try it!)
.
.
.
.
Here’s my answer.
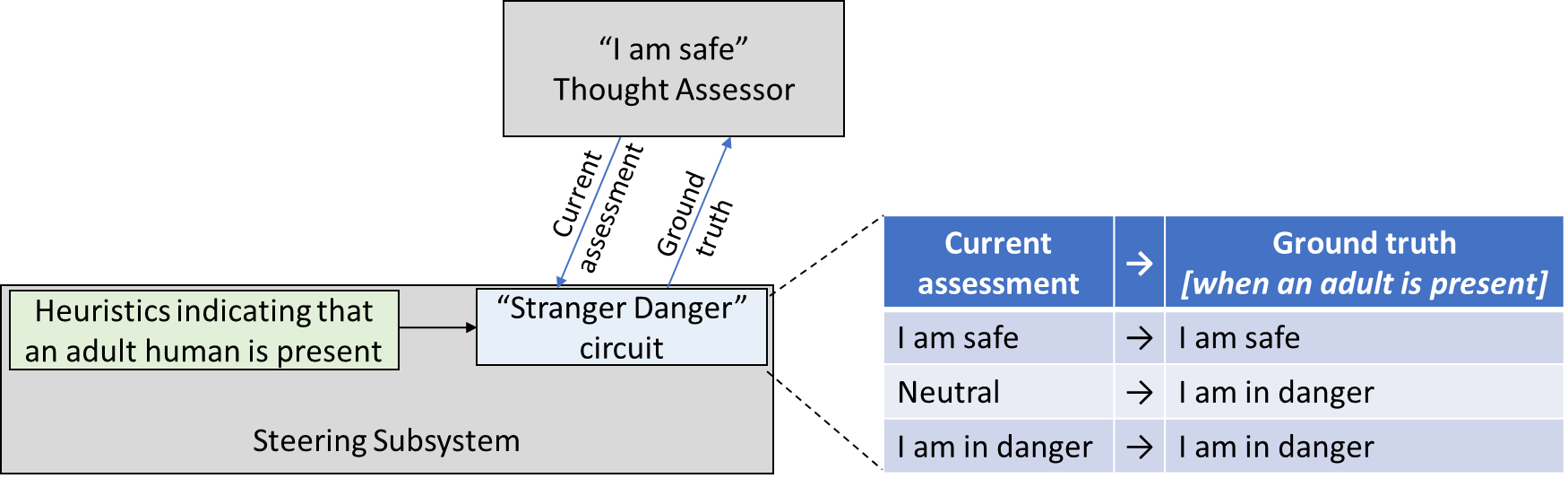
(As usual, I’m oversimplifying for pedagogical purposes.[5]) I’m assuming that there are hardwired heuristics in the brainstem sensory processing systems [AF · GW] that indicate the likely presence of a human adult—presumably based on sight, sound, and smell. This signal by default triggers a “be scared” reaction. But the brainstem circuitry is also watching what the Thought Assessors in the cortex are predicting, and if the Thought Assessors is predicting safety, affection, comfort, etc., then the brainstem circuitry trusts that the cortex knows what it's talking about, and goes with the suggestions of the cortex. Now we can walk through what happens:
First time seeing a stranger:
- Steering Subsystem sensory heuristics say: “An adult human is present.”
- Thought Assessor says: “Neutral—I have no expectation of anything in particular.”
- Steering Subsystem “Stranger Danger circuit” says: “Considering all of the above, we should be scared right now.”
- Thought Assessor says: “Oh, oops, I guess my assessment was wrong, let me update my models.”
Second time seeing the same stranger:
- Steering Subsystem sensory heuristics say: “An adult human is present.”
- Thought Assessors say: “This is a scary situation.”
- Steering Subsystem “Stranger Danger circuit” says: “Considering all of the above, we should be scared right now.”
The stranger hangs around for a while, and is nice, and playing, etc.:
- Steering Subsystem sensory heuristics say: “An adult human is still present.”
- Other circuitry in the brainstem says: “I've been feeling mighty scared all this time, but y'know, nothing bad has happened…” (cf. Section 5.2.1.1 [AF · GW])
- Other Thought Assessors see the fun new toy and say “This is a good time to relax and play.”
- Steering Subsystem says: “Considering all of the above, we should be relaxed right now.”
- Thought Assessors say: “Oh, oops, I was predicting that this was a situation where we should feel scared, but I guess I was wrong, let me update my models.”
Third time seeing the no-longer-stranger:
- Steering Subsystem sensory heuristics say: “An adult human is present.”
- Thought Assessors say: “I expect to feel relaxed and playful and not-scared.”
- Steering Subsystem “Stranger Danger circuit” says: “Considering all of the above, we should be relaxed and playful and not-scared right now.”
13.5 Another key ingredient (I think): “Transient empathetic simulation”
13.5.1 Introduction
Yet again, here’s our diagram from Post #6 [AF · GW]:
Let’s zoom in on one particular Thought Assessor in my brain, which happens to be dedicated to predicting a cringe reaction. This Thought Assessor has learned over the course of my lifetime that the predictive world-model activations corresponding to “my stomach is getting punched” constitute an appropriate time to cringe:
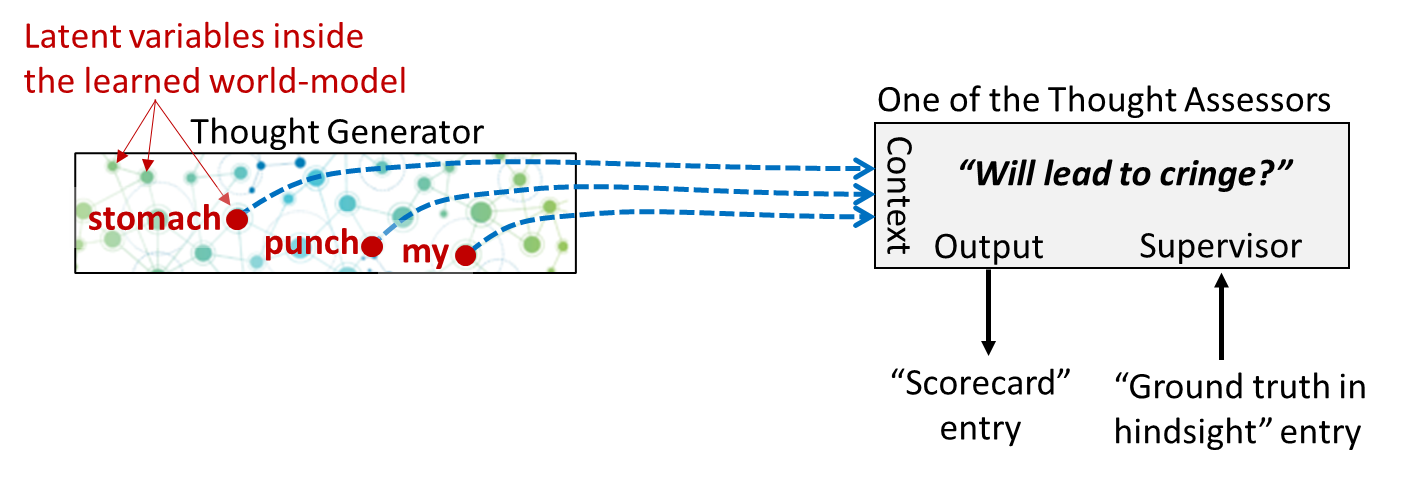
Now what happens when I watch someone else getting punched in the stomach?
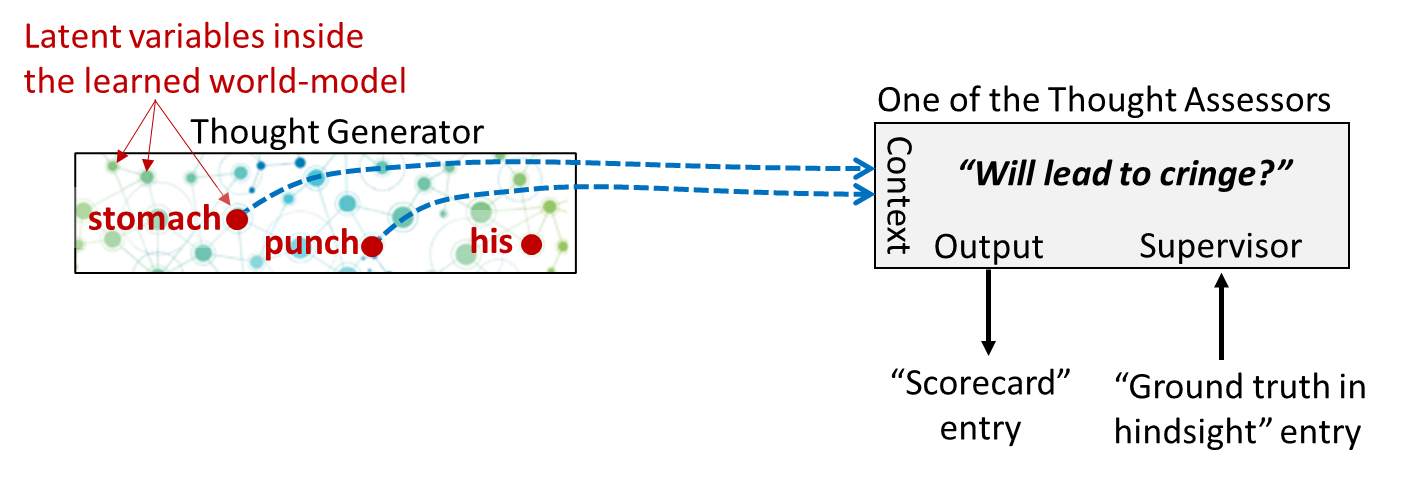
If you look carefully on the left, you’ll see that “His stomach is getting punched” is a different set of activations in my predictive world-model than “My stomach is getting punched”. But it’s not entirely different! Presumably, the two sets would overlap to some degree.
And therefore, we should expect that, by default, “His stomach is getting punched” would send a weaker but nonzero “cringe” signal down to the Steering Subsystem.
I call this signal a “transient empathetic simulation”. (If you’re wondering why I’m avoiding the term mirror neuron, this is deliberate—see here [LW · GW].) It’s kind of a transient echo of what I (involuntarily) infer a different person to be feeling.
So what? Well, recall the symbol-grounding problem from Section 13.2.2 above. The existence of “transient empathetic simulations” is a massive breakthrough towards solving that problem for social instincts! After all, my Steering Subsystem now has a legible-to-it indication that a different person is feeling a certain feeling, and that signal can in turn trigger a response reaction in me.
(I’m glossing over various issues with “transient empathetic simulations”, but I think those issues are solvable.[6])
For example, a (massively-oversimplified) envy reaction could look like “if I’m not happy, and I become aware (via a ‘transient empathetic simulation’) that someone else is happy, then issue a negative reward”.
More generally, one could have a Steering Subsystem circuit whose inputs include:
- my own current physiological state (“feelings”),
- the contents of the “transient empathetic simulation”,
- …associated with some metadata about the person being empathetically simulated (e.g. their valence, a.k.a. how much I like / admire them [LW · GW]), and
- heuristics drawn from my brainstem sensory processing systems [AF · GW], e.g. indicating whether I’m looking at a human right now.
The circuit could then produce outputs (“reactions”), which could (among other things) include rewards, other feelings, and/or ground truths for one or more Thought Assessors.
It seems to me that evolution would thus have quite a versatile toolbox for building social instincts, especially by chaining together more than one circuit of this type.
13.5.2 Distinction from the standard definition of “empathy”
I want to strongly distinguish “transient empathetic simulation” from the standard definition of “empathy”.[7] (Maybe call the latter “sustained empathetic simulation”?)
For one thing, standard empathy is often effortful and voluntary, and may require at least a second or two of time, whereas a “transient empathetic simulation” is always fast and involuntary. An analogy for the latter would be how looking at a chair activates the “chair” concept in your brain, within a fraction of a second, whether you want it to or not.
For another thing, a “transient empathetic simulation”, unlike standard “empathy”, does not always lead to prosocial concern for its target. For example:
- In envy, if a transient empathetic simulation indicates that someone is happy, it makes me unhappy.
- In schadenfreude, if a transient empathetic simulation indicates that someone is unhappy, it makes me happy.
- When I’m angry, if a transient empathetic simulation indicates that the person I’m talking to is happy and calm, it sometimes makes me even more angry!
These examples are all antithetical to prosocial concern for the other person. Of course, in other situations, the “transient empathetic simulations” do spawn prosocial reactions. Basically, social instincts span the range from kind to cruel, and I suspect that pretty much all of them involve “transient empathetic simulations”.
By the way: I already offered a model of “transient empathetic simulations” in the previous subsection. You might ask: What’s my corresponding model of standard (sustained) empathy?
Well, in the previous subsection, I distinguished “my own current physiological state (feelings)” from “the contents of the transient empathetic simulation”. For standard empathy, I think this distinction breaks down—the latter bleeds into the former. Specifically, I would propose that when my Thought Assessors issue a sufficiently strong and long-lasting empathetic prediction, the Steering Subsystem starts “deferring” to them (in the Post #5 [AF · GW] sense), and the result is that my own feelings wind up matching the feelings of the target-of-empathy. That’s my model of standard empathy.
Then, if the target of my (standard) empathy is currently feeling an aversive feeling, I also wind up feeling an aversive feeling, and I don’t like that, so I’m motivated to help him feel better (or, perhaps, motivated to shut him out, as can happen in compassion fatigue). Conversely, if the target of my (standard) empathy is currently feeling a pleasant feeling, I also wind up feeling a pleasant feeling, and I’m motivated to help him feel that feeling again.
Thus, standard empathy seems to be inevitably prosocial.
13.5.3 Why do I believe that “transient empathetic simulations” are part of the story?
First, it seems introspectively right (to me, at least). If my friend is impressed by something I did, I feel proud, but I especially feel proud at the exact moment when I imagine my friend feeling that emotion. If my friend is disappointed in me, I feel guilty, but I especially feel guilty at the exact moment when I imagine my friend feeling that emotion. As another example, there’s a saying: “I can’t wait to see the look on his face when….” Presumably this saying reflects some real aspect of our social psychology, and if so, I claim that this observation dovetails well with my “transient empathetic simulations” story.
Second, if the rest of my model (Posts #2 [AF · GW]–#7 [AF · GW]) is correct, then “transient empathetic simulation” signals would arise automatically, such that it would be straightforward to evolve a Steering Subsystem circuit that “listens” for them.
Third, if the rest of my model is correct, then, well, I can’t think of any other way to build most social instincts! Process of elimination!
Fourth, I think I’m converging towards my first concrete example of a human social instinct grounded by transient empathetic simulation, namely the “drive to feel liked / admired”. See discussion here [LW · GW]. I still have some work to do on that though—for example, here’s [LW · GW] a recent post where I was chatting about an aspect of the story that I’m still very uncertain about.
13.6 Future work (please!)
As noted in the introduction, the point of this post is to gesture towards what I expect a “theory of human social instincts” to look like, such that it would be compatible with all my other claims about brain algorithms in Posts #2 [AF · GW]–#7 [AF · GW], particularly the strong constraint of “learning from scratch” [AF · GW] as discussed in Section 13.2.2 above. My takeaway from the discussion in Sections 13.3–5 is a strong feeling of optimism that such a theory exists, even if I don’t know all the details yet, and a corresponding optimism that this theory is actually how the human brain works, and will line up with corresponding circuits in the brainstem or (more likely) hypothalamus.
Of course, I want very much to move past the “general theorizing” stage, into more specific claims about how human social instincts actually work. For example, I’d love to move beyond speculation on how these instincts might solve the symbol-grounding problem, and learn how they actually do solve the symbol-grounding problem. I’m open to any ideas and pointers here, or better yet, for people to just figure this out on their own and tell me the answer.
(As mentioned at the top, I think I’ve made some recent progress, particularly A Theory of Laughter [LW · GW] and Neuroscience of human social instincts: a sketch [LW · GW].)
For reasons discussed in the previous post [AF · GW], nailing down human social instincts is at the top of my wish-list for how neuroscientists can help with AGI safety.
Remember how I talked about Differential Technological Development (DTD) in Post #1 Section 1.7 [AF · GW]? Well, this is the DTD “ask” that I feel strongest about—at least, among those things that neuroscientists can do without explicitly working on AGI safety (see upcoming Post #15 [AF · GW] for my more comprehensive wish-list). I really want us to reverse-engineer human social instincts in the hypothalamus & brainstem long before we reverse-engineer human world-modeling in the cortex.
And things are not looking good for that project! The hypothalamus is small and deep and hence hard-to-study! Human social instincts might be different from rat social instincts! Orders of magnitude more research effort is going towards understanding cortex world-modeling than understanding hypothalamus & brainstem social instinct circuitry! In fact, I’ve noticed (to my chagrin) that algorithmically-minded, AI-adjacent neuroscientists are especially likely to spend their talents on the Learning Subsystem [AF · GW] (cortex, striatum, cerebellum, etc.) rather than the hypothalamus & brainstem. But still, I don’t think my DTD “ask” is hopeless, and I encourage anyone to try, and if you (or your lab) are in a good position to make progress but would need funding, email me and I'll keep you in the loop about possible upcoming opportunities.
Changelog
March 2025: The intro and conclusion now have links to my later post on this topic: Neuroscience of human social instincts: a sketch [LW · GW].
July 2024: Since the initial version, I’ve made two big changes, plus some smaller ones.
One big change was switching terminology from “little glimpse of empathy” to “transient empathetic simulation”. Sorry for being inconsistent, but I think the new term is just way better.
The other big change was switching my running example from “envy” to “drive to feel liked / admired”. I’m no longer so sure that envy is a social instinct at all, for reasons in the footnote,[1] whereas the “drive to feel liked / admired” is something I’m pretty sure exists and where I at least vaguely have some ideas about how it works [LW · GW] (even if I still have more work to do on that).
Smaller changes included some neuroscience fixes in line with other posts (relatedly, I deleted a minor paragraph talking about the medial prefrontal cortex, that I now believe to be mostly wrong); and more discussion of and links to various things that I’ve done since writing the initial version of this post in 2022.
- ^
In the initial version of this post, my opening example was “envy” instead of “drive to feel liked / admired”. But now I think maybe envy was a very bad example.
Instead, my leading hypothesis right now is that envy is a side-effect of innate drives / reactions that are not specifically social at all! An alternative is that envy is sorta just a special case of craving—a kind of anxious frustration in a scenario where something is highly motivating and salient, but there’s no way to actualize that desire.
So if Sally has a juice box and I don’t, it incidentally makes the alluring possibility of drinking juice very salient in my mind. Since I can’t have juice, the frustration of that desire leads (via some innate mechanism I don’t understand) to feelings that I’d call “envy”. But if I’m staring at an empty shelf in the store where there should have been juice boxes (but the juice box factory burned down), I think I can get the very same kind of frustrated feeling, for the same underlying reason. But in the latter case, I wouldn’t call it “envy”, because it’s not directed towards anyone in particular. The factory burned down—nobody has a juice box this week! But it’s still frustrating to look at the empty shelf, taunting me.
I could be wrong.
- ^
See Elephant In The Brain (Simler & Hanson, 2018) for a brief discussion of Arabian Babbler Birds. Warning: I know very little about Arabian Babbler Birds, and indeed for all I know their apparent prestige-seeking might occur for different underlying reasons than humans’.
- ^
For a good recent review of the role of the Steering Subsystem [AF · GW] (especially hypothalamus) in social behavior, see “Hypothalamic Control of Innate Social Behaviors” (Mei et al., 2023). Another lovely recent example, related to loneliness, is “A Hypothalamic Circuit Underlying the Dynamic Control of Social Homeostasis” (Liu et al., 2023).
- ^
“…if you look at the human literature nobody talks about the hypothalamus and behaviour. The hypothalamus is very small and can’t be readily seen by human brain imaging technologies like functional magnetic resonance imaging (fMRI). Also, much of the anatomical work in the instinctive fear system, for example, has been overlooked because it was carried out by Brazilian neuroscientists who were not particularly bothered to publish in high profile journals. Fortunately, there has recently been a renewed interest in these behaviors and these studies are being newly appreciated.” (Cornelius Gross, 2018)
- ^
I suspect a more accurate diagram would feature arousal (in the psychology-jargon sense, not the sexual sense—i.e., heart rate elevation etc.) as a mediating variable. Specifically: (1) if brainstem sensory processing indicates that an adult human is present and nearby and picking me up etc., that leads to heightened arousal (by default, unless the Thought Assessors strongly indicate otherwise), and (2) when I’m in a state of heightened arousal, my brainstem treats it as bad and dangerous (by default, unless the Thought Assessors strongly indicate otherwise).
- ^
For example, the Steering Subsystem needs a method to distinguish a “transient empathetic simulation” from other transient feelings, e.g. the transient feeling that occurs when I think through the consequences of a possible course of action that I might take. Maybe there are some imperfect heuristics that could do that, but my preferred theory is that there’s a special Thought Assessor trained to fire when attending to another human (based on ground-truth sensory heuristics as discussed in Section 13.4). As another example, we need the “Ground truth in hindsight” signals to not gradually train away the Thought Assessor’s sensitivity to “his stomach is getting punched”. But it seems to me that, if the Steering Subsystem can figure out when a signal is a “transient empathetic simulation”, then it can choose not to send error signals to the Thought Assessors in those cases.
- ^
Warning: I’m not entirely sure that there really is a “standard” definition of empathy; it’s also possible that the term is used in lots of slightly-inconsistent ways. I enjoyed this blog post on the topic [LW · GW].
15 comments
Comments sorted by top scores.
comment by azsantosk · 2022-05-06T22:50:15.510Z · LW(p) · GW(p)
One thing that appears to be missing on the filial imprinting story is a mechanism allowing the "mommy" thought assessor to improve or at least not degrade over time.
The critical window is quite short, so many characteristics of mommy that may be very useful will not be perceived by the thought assessor in time. I would expect that after it recognizes something as mommy it is still malleable to learn more about what properties mommy has.
For example, after it recognizes mommy based on the vision, it may learn more about what sounds mommy makes, and what smell mommy has. Because these sounds/smalls are present when the vision-based mommy signal is present, the thought assessor should update to recognize sound/smell as indicative of mommy as well. This will help the duckling avoid mistaking some other ducks for mommy, and also help the ducklings find their mommy though other non-visual cues (even if the visual cues are what triggers the imprinting to begin with).
I suspect such a mechanism will be present even after the critical period is over. For example, humans sometimes feel emotionally attracted to objects that remind them or have become associated with loved ones. The attachment may be really strong (e.g. when the loved one is dead and only the object is left).
Also, your loved ones change over time, but you keep loving them! In "parental" imprinting for example, the initial imprinting is on the baby-like figure, generating a "my kid" thought assessor associated with the baby-like cues, but these need to change over time as the baby grows. So the "my kid" thought assessor has to continuously learn new properties.
Even more importantly, the learning subsystem is constantly changing, maybe even more than the external cues. If the learned representations change over time as the agent learns, the thought assessors have to keep up and do the same, otherwise their accuracy will slowly degrade over time.
This last part seems quite important for a rapidly learning/improving AGI, as we want the prosocial assessors to be robust to ontological drift. So we both want the AGI to do the initial "symbol-grounding" of desirable proto-traits close to kindness/submissiveness, and also for its steering subsystem to learn more about these concepts over time, so that they "converge" to favoring sensible concepts in an ontologically advanced world-model.
Replies from: steve2152, Angela Pretorius↑ comment by Steven Byrnes (steve2152) · 2022-05-18T19:50:22.314Z · LW(p) · GW(p)
Thanks!
For example, humans…
Just to be clear, I was speculating in that section about filial imprinting in geese, not familial bonding in humans. I presume that those two things are different in lots of important ways. In fact, for all I know, they might have nothing whatsoever in common. ¯\_(ツ)_/¯
(UPDATE: I guess the Westermarck Effect might be implemented in a Section-13.3-like way, although not necessarily.)
If the learned representations change over time as the agent learns, the thought assessors have to keep up and do the same, otherwise their accuracy will slowly degrade over time.
Yeah, that seems possible (although I also consider it possible that it’s not a problem; by analogy, catastrophic forgetting is famously more of an issue for ANNs than for brains).
If the learned representations do in fact change a lot over time, I’m slightly skeptical that it would be possible to solve that problem directly, thanks to the lack of an independent ground truth. For example, I can imagine a system that says “If I’m >95% confident that this is MOMMY, then update such that I’m 100% confident that this is MOMMY.” Maybe that system would work to keep pointing at the real mommy, even as learned representations drift. But also, maybe that system would cause the Thought Assessor to gradually go off the rails and trigger off weird patterns in noise. Not sure. Did you have something like that in mind? Or something different?
An alternative might be that, if the specific filial-imprinting mechanism gradually stops working over time, it deactivates at some point and the (now-adolescent) goose switches to some other mechanism(s), like “desire to be with fellow geese that are extremely familiar to me” a la Section 13.4.
Reminder that I know very little about goose behavior and this is all casual speculation. :)
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2022-10-01T19:57:59.259Z · LW(p) · GW(p)
Ok, so this is definitely not a human thing, so probably a bit of a tangent. One of the topics that came up in a neuroscience class once was goose imprinting. There's apparently been studies (see Eckhard Hess for the early ones) that show that the strength of the imprinting (measured by behavior following the close of the critical period) onto whatever target is related to how much running towards the target the baby geese do. The hand-wavey explanation was something like 'probably this makes sense since if you have to run a lot to keep up with your mother-goose for safety, you'll need a strong mother-goose-following behavioral tendency to keep you safe through early development'.
↑ comment by Angela Pretorius · 2023-02-04T01:26:01.287Z · LW(p) · GW(p)
Mother geese don’t change their appearance much over their lifetime. I doubt that a chick ever needs to update its mommy thought assessor.
The ‘my kid’ thought assessor in humans is easily fooled by puppies and baby rabbits. Spend a large proportion of your waking hours around a cute animal and your brainstem assumes that it is your child.
comment by jpyykko · 2022-04-30T11:28:38.656Z · LW(p) · GW(p)
I feel that the social instincts link to the learned-from-scratch world-model via a chain of guided development windows.
The singular links in the chain are stacks of affective mechanisms: the trigger that detects the environmental stimulus (the moving large object for ducklings), the response (follow that object), and an affect (emotion) that links the instinct to the learned model via a reward signal to strengthen the association (feeling of safety).
As it would be near impossible for the DNA to have a concept of "Rita won a trophy" as the trigger, the system would have to first "teach" the model simpler concepts, and then tag onto those via the affect to be able to trigger later correctly: for example, "Rita" would be identified as a "member of the pack/competition", which would be derived from the concept of "agent". This in turn would have to be first learned via the associations that spring from the early instincts of "pheromones", "human voice", "eyes" etc..
These simpler concepts from our early years occur in development windows. F.ex. for the first 8 weeks babies don't focus their gaze on anything, as they are still learning the basics of seeing. After they have a slight better capacity to predict what they see, the next development window opens, which among other things, has a filter to detect eyes. For a while the eyes are associated with an "agent" and "safety", hence the babies smile instantly at their parents faces, while pretty soon this filial imprinting window closes, and they start to cry at the sight of new faces instead.
I have some of these chains of instincts mapped out on an initial level, and am soon trying out these theories within an environment closely resembling to OpenAI's gym (the architecture didn't lend itself easily to this new reward paradigm, unfortunately). Maybe they could be discussed further with some interested people?
Also, little glimpse of empathy has some literature under the term mirror neurons.
Replies from: steve2152, Angela Pretorius↑ comment by Steven Byrnes (steve2152) · 2022-04-30T20:42:46.159Z · LW(p) · GW(p)
little glimpse of empathy has some literature under the term mirror neurons
Sorta, but unfortunately the "mirror neuron" literature seems to be a giant dumpster fire. I suggest & endorse the book The Myth Of Mirror Neurons by Hickok. UPDATE: See also my later post Quick notes on "mirror neurons" [LW · GW].
↑ comment by Angela Pretorius · 2023-02-04T01:27:24.115Z · LW(p) · GW(p)
When my little one was a newborn he was just as happy being handled by strangers as he was with mum and dad. It was around four months that he started showing a preference for mum and dad and disliking strangers. I’m sure that he could recognise us long before the four month mark though.
Geese need to imprint from birth, whereas there is no immediate need for a baby who is not yet mobile to imprint on it’s parents. So if babies have an ‘imprinting window’ then it probably occurs later, after a baby has learnt to reliably recognise familiar faces in spite of changes in make-up or clothing.
Aside: Babies prefer to look at faces while still in the womb https://www.lancaster.ac.uk/news/articles/2017/babies-preference-for-faces-begins-before-birth-/.
comment by Oliver Sourbut · 2022-04-28T10:38:55.790Z · LW(p) · GW(p)
This is really great, Steve! I'm looking forward to reading more posts and in more detail.
I think I absorbed some of what you're conveying regarding 'little glimpses of empathy', and I was thinking about how I might explain it back.
I wonder if coining two words or phrases might be valuable, and possibly divorcing it from the 'empathy' wording to obviate the need for the disclaimer about the normal use of that word.
One concept, if I understood right, is that there is an 'involuntary other-modelling' (?) occuring when we observe facts relating to someone else that, if related to us, would make us feel a certain way. This claim stands on its own, remaining agnostic about the source of these signals.
The complementary (and more tentative?) claim is that 'involuntary other-modelling' is produced as an automatic consequence of 'relatee-wise generalisation' (?) in the intra-lifetime world model ('stomach punch my' vs 'stomach punch his'), perhaps coupled with other hard-coded signals. I think you might distinguish this claim more clearly if you had a second term.
The first thing is like a 'type/shape' (of signal/structure). The second claim is more like pointing to an instance of that type.
Am I reading right, and are these useful suggestions? I think I have a way to go before I fully grok your broader model.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2022-04-28T17:35:14.566Z · LW(p) · GW(p)
Thanks for the comment!
I didn't think too hard about terminology and am open to brainstorming.
I'm concerned that the word “modeling” misses one of the important points. “Model” suggests “predictive model”; I think it’s possible (at least in principle, and probably in practice) to “model” a person in a way that is wholly disconnected from your suite of visceral reactions, just like you can “model” how a car engine works.
Instead, I would start with what you said, “when we observe facts relating to someone else that, if related to us, would make us feel a certain way”, but then add “…while actually activating those same ‘feelings’ in our own head”. Well, at least that would be closer. And I used the word “empathy” to convey that second part, I think.
I guess what you call “involuntary other-modeling” is what I call “a little glimpse of empathy”, and what you call “relatee-wise generalization” is what I'd call “the main (or only?) reason why the ‘little glimpse of empathy’ occurs”. But sorry if I'm misunderstanding.
Replies from: Oliver Sourbut↑ comment by Oliver Sourbut · 2022-05-03T23:51:58.396Z · LW(p) · GW(p)
I guess what you call “involuntary other-modeling” is what I call “a little glimpse of empathy”, and what you call “relatee-wise generalization” is what I'd call “the main (or only?) reason why the ‘little glimpse of empathy’ occurs”. But sorry if I'm misunderstanding.
Ok excellent, this is a succinct version of what I was getting from your original post, and is what my comment was trying to confirm. Thank you.
“relatee-wise generalization” is what I'd call “the main (or only?) reason why the ‘little glimpse of empathy’ occurs”
Right, and to me this seems like an important distinct claim. I think I understood from your original post that these were somewhat separate claims, but I guess my response is to advocate making that distinction as clear as possible, perhaps by coining some extra term(s) - because I think different evidence is required to precede them, and different conclusions follow from them.
(I suppose I should point out that the second claim, depending on the degree of 'main (or only?)', seems a lot bolder i.e. I require more convincing. Like, there might be substantial hardcoded circuitry which puts this stuff in, rather than it falling out of relatee-wise generalisation. But then again I can viscerally feel empathy for a hypothetical, or for obviously-non-kin animals, or whatnot, so this could be right.)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2022-05-04T00:59:04.871Z · LW(p) · GW(p)
Thanks.
Like, there might be substantial hardcoded circuitry which puts this stuff in, rather than it falling out of relatee-wise generalisation.
I think this is tied up with learning-from-scratch [AF · GW]. “Relatee-wise generalisation” is compatible with learning-from-scratch, and I can't currently see any other option that's compatible with learning-from-scratch. Can you? I'm not sure what you mean by “hardcoded circuitry”.
Then someone might say: “Yeah but if we throw out learning-from-scratch, then look at all these other possible ways that social instincts might work!” But I'm currently strongly disinclined to throw out learning-from-scratch, because I have a lot of other reasons for believing it.
So the premise of this post is something like “Is there any plausible explanation for social instincts that's compatible with Posts #2–#7, and especially with the learning-from-scratch discussion in Post #2?” (That’s the “symbol grounding” thing of Section 13.2.2, see also the post title.) If yes, then I’d be willing to bet that that explanation for social instincts is the correct one, and I would want to prioritize fleshing it out and testing it. If no, then oops, guess I better throw out Posts #2–#7!!
comment by Ben Smith (ben-smith) · 2022-09-08T06:48:20.412Z · LW(p) · GW(p)
Still working my way through reading this series--it is the best thing I have read in quite a while and I'm very grateful you wrote it!
I feel like I agree with your take on "little glimpses of empathy" 100%.
I think fear of strangers could be implemented without a steering subsystem circuit maybe? (Should say up front I don't know more about developmental psychology/neuroscience than you do, but here's my 2c anyway). Put aside whether there's another more basic steering subsystem circuit for agency detection; we know that pretty early on, through some combination of instinct and learning from scratch, young humans and many animals learn there are agents in the world who move in ways that don't conform to the simple rules of physics they are learning. These agents seem to have internally driven and unpredictable behavior, in the sense their movement can't be predicted by simple rules like "objects tend to move to the ground unless something stops them" or "objects continue to maintain their momentum". It seems like a young human could learn an awful lot of that from scratch, and even develop (in their thought generator) a concept of an agent.
Because of their unpredictability, agent concepts in the thought generator would be linked to thought assessor systems related to both reward and fear; not necessarily from prior learning derived from specific rewarding and fearful experiences, but simply because, as their behavior can't be predicted with intuitive physics, there remains a very wide prior on what will happen when an agent is present.
In that sense, when a neocortex is first formed, most things in the world are unpredictable to it, and an optimally tuned thought generator+assessor would keep circuits active for both reward or harm. Over time, as the thought generator learns folk physics, most physical objects can be predicted, and it typically generates thoughts in line with their actual beahavior. But agents are a real wildcard: their behavior can't be predicted by folk physics, and so they perceived in a way that every other object in the world used to be: unpredictable, and thus continually predicting both reward and harm in an opponent process that leads to an ambivalent and uneasy neutral. This story predicts that individual differences in reward and threat sensitivity would particularly govern the default reward/threat balance otherwise unknown items. It might (I'm really REALLY reaching here) help to explain why attachment styles seem so fundamentally tied to basic reward and threat sensitivity.
As the thought generator forms more concepts about agents, it might even learn that agents can be classified with remarkable predictive power into "friend" or "foe" categories, or perhaps "mommy/carer" and "predator" categories. As a consequence of how rocks behave (with complete indifference towards small children), it's not so easy to predict behavior of, say, falling rocks with "friend" or "foe" categories. On the contrary, agents around a child are often not indifferent to children, making it simple for the child to predict whether favorable things will happen around any particular agent by classifying agents into "carer" or "predator" categories. These categories can be entirely learned; clusters of neurons in the thought generator that connect to reward and threat systems in the steering system and/or thought assessor. So then the primary task of learning to predict agents is simply whether good things or bad things happen around the agent, as judged by the steering system.
This story would also predict that, before the predictive power of categorizing agents into "friend" vs. "foe" categories has been learned, children wouldn't know to place agents into these categories. They'd take longer to learn whether an agent is trustworthy or not, particularly so if they haven't learned what an agent is yet. As they grow older, they get more comfortable with classifying agents into "friend" or "foe" categories and would need fewer exemplars to learn to trust (or distrust!) a particular agent.
comment by Gunnar_Zarncke · 2022-04-28T15:54:18.814Z · LW(p) · GW(p)
Your "little glimpses of X" are probably closely related to Microexpressions - they are practically what shows externally - probably what leaks over to muscles.
comment by Joe Kwon · 2022-04-28T19:31:44.244Z · LW(p) · GW(p)
Hi Steve, loved this post! I've been interested in viewing the steering and thought generator + assessor submodule framework as the object and generator-of-values of which which we want AI to learn a good pointer to/representation of, to simulate out the complex+emergent human values and properly value extrapolate.
I know the way I'm thinking about the following doesn't sit quite right with your perspective, because AFAIK, you don't believe there need to be independent, modular value systems that give their own reward signals for different things (your steering subsystem and thought generator and assessor subsystem are working in tandem to produce a singular reward signal). I'd be interested in hearing your thoughts on what seems more realistic, after importing my model of value generators as more distinctive and independent modular systems in the brain.
In the past week, I've been thinking about the potential importance of considering human value generators as modular subsystems (for both compute and reward). Consider the possibility that at various stages of the evolutionary neurocircuitry-shaping timeline of humans, that modular and independently developed subsystems developed. E.g. one of the first systems, some "reptilian" vibe system, was one that rewarded sugary stuff because it was a good proxy at the time for nutritious/calorie-dense foods that help with survival. And then down the line, there was another system that developed to reward feeling high-social status, because it was a good proxy at the time for surviving as social animals in in-group tribal environments. What things would you critique about this view, and how would you fit similar core-gears into your model of the human value generating system?
I'm considering value generators as more independent and modular, because (this gets into a philosophical domain but) perhaps we want powerful optimizers to apply optimization pressure not towards the human values generated by our wholistic-reward-system, but to ones generated by specific subsystems (system 2, higher-order values, cognitive/executive control reward system) instead of reptilian hedon-maximizing system.
This is a few-day old, extremely crude and rough-around-the-edges idea, but I'd especially appreciate your input and critiques on this view. If it were promising enough, I wonder if (inspired by John Wentworth's evolution of modularity post) training agents in a huge MMO environment and switching up reward signals in the environment (or the environment distribution itself) every few generations would lead to a development of modular reward systems (mimicking the trajectory of value generator systems developing in humans over the evolutionary timeline).
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2022-04-28T20:55:02.978Z · LW(p) · GW(p)
you don't believe there need to be independent, modular value systems that give their own reward signals for different things (your steering subsystem and thought generator and assessor subsystem are working in tandem to produce a singular reward signal)
If I'm deciding between sitting on the couch vs going to the gym, at the end of the day, my brain needs to do one thing versus another. The different considerations need to be weighed against each other to produce a final answer somehow, right? A “singular reward signal” is one solution to that problem. I haven't heard any other solution that makes sense to me.
That said, we could view a “will lead to food?” Thought Assessor as a “independent, modular value system” of sorts, and likewise with the other Thought Assessors. (I’m not sure that’s a helpful view, it’s also misleading in some ways, I think.)
(I would call a Thought Assessor a kind of “value function”, in the RL sense. You also talk about “value systems” and “value generators”, and I’m not sure what those mean.)
What things would you critique about this view
Similar to above: if we’re building a behavior controller, we need to decide whether or not to switch behaviors at any given time, and that requires holistic consideration of the behavior’s impact on every aspect of the organism’s well-being. See § 6.5.3 [AF · GW] where I suggest that even the run-and-tumble algorithm of a bacterium might plausibly combine food, toxins, temperature, etc. into a single metric of how-am-I-doing-right-now, whose time-derivative in turn determines the probability of tumbling. (To be clear, I don’t know much about bacteria, this is theoretical speculation.) Can you think of a way for a mobile bacteria to simultaneously avoid toxins and seek out food, that doesn't involve combining toxin-measurement and food-measurement into a single overall environmental-quality metric? I can’t.
If you want your AGI to split its time among several drives, I don’t think that’s incompatible with “singular reward signal”. You could set up the reward function to have diminishing returns to satisfying each drive, for example. Like, if my reward is log(eating) + log(social status), I'll almost definitely wind up spending time on each, I think.