[Intro to brain-like-AGI safety] 12. Two paths forward: “Controlled AGI” and “Social-instinct AGI”
post by Steven Byrnes (steve2152) · 2022-04-20T12:58:32.998Z · LW · GW · 10 commentsContents
12.1 Post summary / Table of contents 12.2 Definitions 12.3 My proposal: At this stage, we should be digging into both 12.4 Miscellaneous comments and open questions 12.4.1 Reminder: What do I mean by “social instincts”? 12.4.2 How feasible is the “social-instinct AGI” path? 12.4.3 Can we edit the innate drives underlying human social instincts, to make them “better”? 12.4.4 No easy guarantees about what we’ll get with social-instinct AGIs 12.4.5 A multi-polar, uncoordinated world makes planning much harder 12.4.6 AGIs as moral patients 12.4.7 AGIs as perceived moral patients 12.5 The question of life experience (a.k.a. training data) 12.5.1 Life experience is not enough. (Or: “Why don’t we just raise the AGI in a loving human family?”) 12.5.2 …But life experience does matter 12.5.3 So at the end of the day, how should we handle life experience? Changelog None 10 comments
(Last revised: July 2024. See changelog at the bottom.)
12.1 Post summary / Table of contents
Part of the “Intro to brain-like-AGI safety” post series [? · GW].
Thus far in the series, Post #1 [LW · GW] defined and motivated “brain-like AGI safety”; Posts #2 [LW · GW]–#7 [LW · GW] focused mainly on neuroscience, painting a big picture of learning and motivation in the brain; and Posts #8 [LW · GW]–#9 [LW · GW] spelled out some implications for the development and properties of brain-like AGI.
Next, Post #10 [LW · GW] discussed “the alignment problem” for brain-like AGI—i.e., how to make an AGI whose motivations are consistent with what the designers wanted—and why it seems to be a very hard problem. Post #11 [LW · GW] argued that there’s no clever trick that lets us avoid the alignment problem. Rather, we need to solve the alignment problem, and Posts #12–#14 [AF · GW] are some preliminary thoughts about how we might do that, starting in this post with a nontechnical overview of two broad research paths that might lead to aligned AGI.
[Warning: Posts #12–#14 [AF · GW] will be (even?) less well thought out and (even?) more full of bad ideas and omissions, compared to previous posts in the series, because we’re getting towards the frontier of what I’ve been thinking about recently.]
Table of contents:
- Section 12.2 lays out two broad paths to aligned AGI.
- In the “Controlled AGI” path, we try, more-or-less directly, to manipulate what the AGI is trying to do.
- In the “Social-instinct AGI” path, our first step is to reverse-engineer some of the “innate drives” in the human Steering Subsystem (hypothalamus & brainstem) [LW · GW], particularly the ones that underlie human social and moral intuitions. Next, we would presumably make some edits, and then install those “innate drives” into our AGIs.
- Section 12.3 argues that at this stage, we should be digging into both paths, not least because they’re not mutually exclusive.
- Section 12.4 goes through a variety of comments, considerations, and open questions related to these paths, including feasibility, competitiveness concerns, ethical concerns, and so on.
- Section 12.5 talks about “life experience” (a.k.a. “training data”), which is particularly relevant for social-instinct AGIs. As an example, I’ll discuss the perhaps-tempting-but-mistaken idea that the only thing we need for AGI safety is to raise the AGI in a loving human family.
Teaser of upcoming posts: The next post (#13) [AF · GW] will dive into a key aspect of the “social-instinct AGI” path, namely how social instincts might be built in the human brain. In Post #14 [AF · GW], I’ll switch to the “controlled AGI” path, speculating on some possible ideas and approaches. Post #15 [AF · GW] will wrap up the series with open questions and how to get involved.
12.2 Definitions
I currently see two broad (possibly-overlapping) potential paths to success in the brain-like AGI scenario:
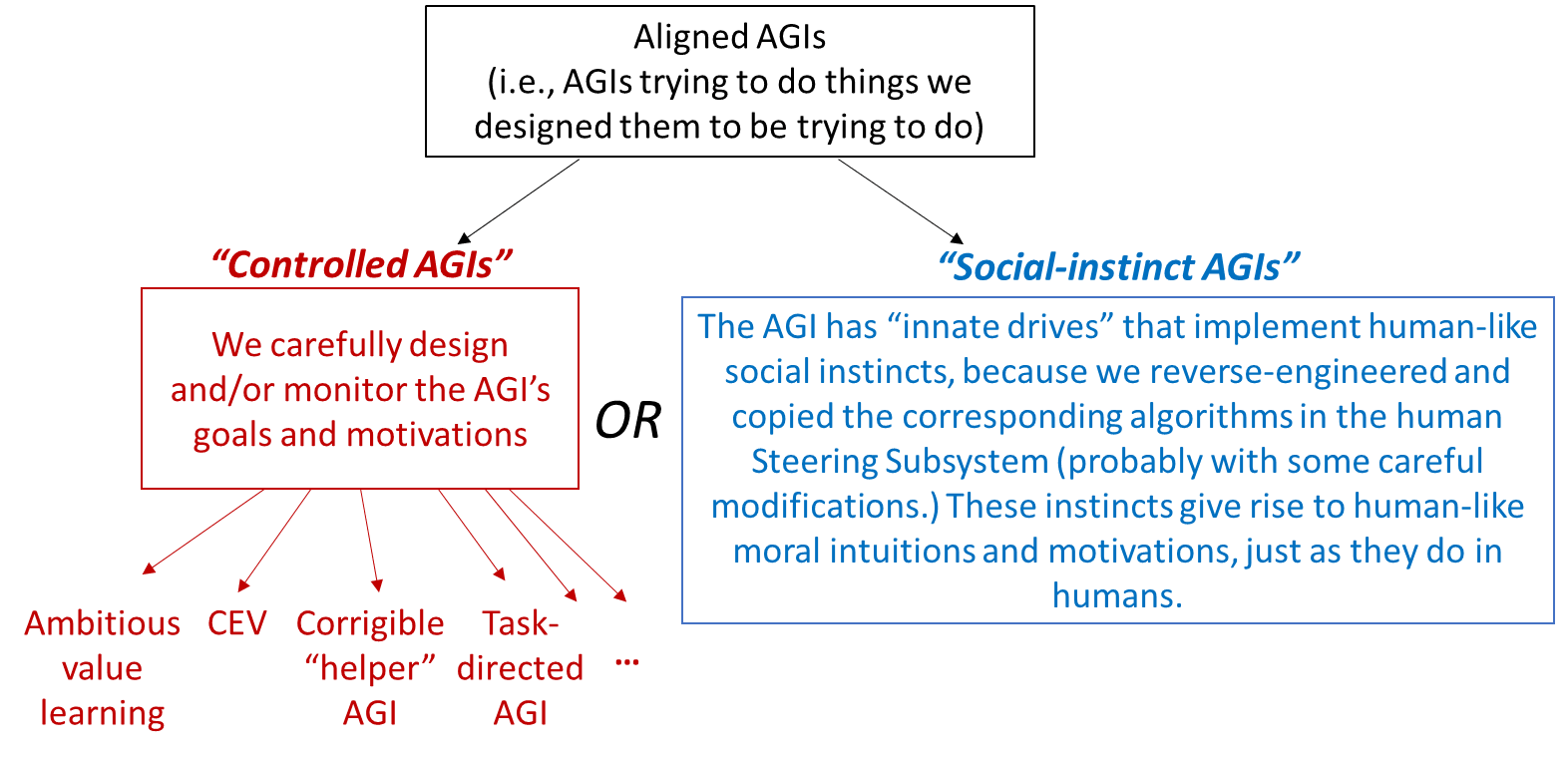
Here’s another view on the distinction:[1]
In the “controlled AGIs” path, we’re thinking very specifically about the AGI’s goals and motivations, and we have some idea of what they should be (“make the world a better place”, or “understand my deepest values and put them into effect”, or “design a better solar cell without causing catastrophic side-effects”, or “do whatever I ask you to do”, etc.).
In the “social-instinct AGIs” path, our confidence in the AGI comes not from our knowledge of its specific (object-level) goals and motivations, but rather from our knowledge of the process that led to those goals and motivations. In particular, we would reverse-engineer the suite of human social instincts, i.e. the algorithms in the human Steering Subsystem (hypothalamus & brainstem) [LW · GW] which underlie our moral and social intuitions, and we would put those same instincts into the AGI. (Presumably we first modify the instincts to be “better” by our lights if possible, e.g. we probably don’t want instincts related to jealousy, a sense of entitlement, status competition, etc.) These AGIs can be economically useful (as employees, assistants, bosses, inventors, researchers, etc.), just as actual humans are.
12.3 My proposal: At this stage, we should be digging into both
Three reasons:
- They’re not mutually exclusive: For example, even if we decide to make social-instinct AGIs, we might want to take advantage of “control”-type methods, especially while debugging them, working out the kinks, and anticipating problems. Conversely, maybe we’ll mainly try to make AGIs that are trying to do a certain task without causing catastrophe, but we might want to also to instill human-like social instincts as a buttress against wildly unexpected behavior. Moreover, we can share ideas between the two paths—for example, in the process of better understanding how human social instincts work, we might get useful ideas about how to make controlled AGIs.
- Feasibility of each remains unknown: As far as anyone knows right now, it might just be impossible to build a “controlled AGI”—after all, there’s no “existence proof” of it in nature! I feel relatively more optimistic about the feasibility of the “social-instinct AGI” path, but it’s very hard to be sure until we make more progress—more discussion on that in Section 12.4.2 below. Anyway, at this point it seems wise to “hedge our bets” by working on both.
- Desirability of each remains unknown: As we flesh out our options in more detail, we’ll get a better understanding of their advantages and disadvantages.
12.4 Miscellaneous comments and open questions
12.4.1 Reminder: What do I mean by “social instincts”?
(Copying some text here from Post #3 (Section 3.4.2) [LW · GW].)
[“Social instincts” and other] innate drives are in the Steering Subsystem [LW · GW], whereas the abstract concepts that make up your conscious world are in the Learning Subsystem [LW · GW]. For example, if I say something like “altruism-related innate drives”, you need to understand that I’m not talking about “the abstract concept of altruism, as defined in an English-language dictionary”, but rather “some innate Steering Subsystem circuitry which is upstream of the fact that neurotypical people sometimes find altruistic actions to be inherently motivating”. There is some relationship between the abstract concepts and the innate circuitry, but it might be a complicated one—nobody expects a one-to-one relation between N discrete innate circuits and a corresponding set of N English-language words describing emotions and drives.
I’ll talk about the project of reverse-engineering human social instincts in the next post [AF · GW].
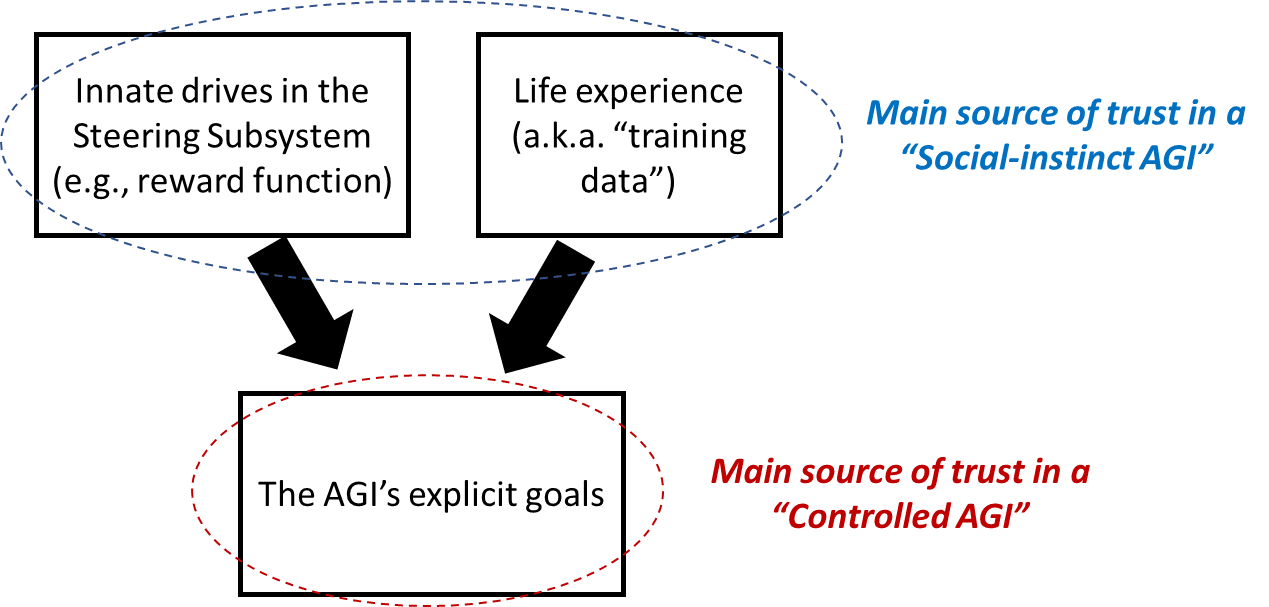
12.4.2 How feasible is the “social-instinct AGI” path?
I’ll answer in the form of a diagram:
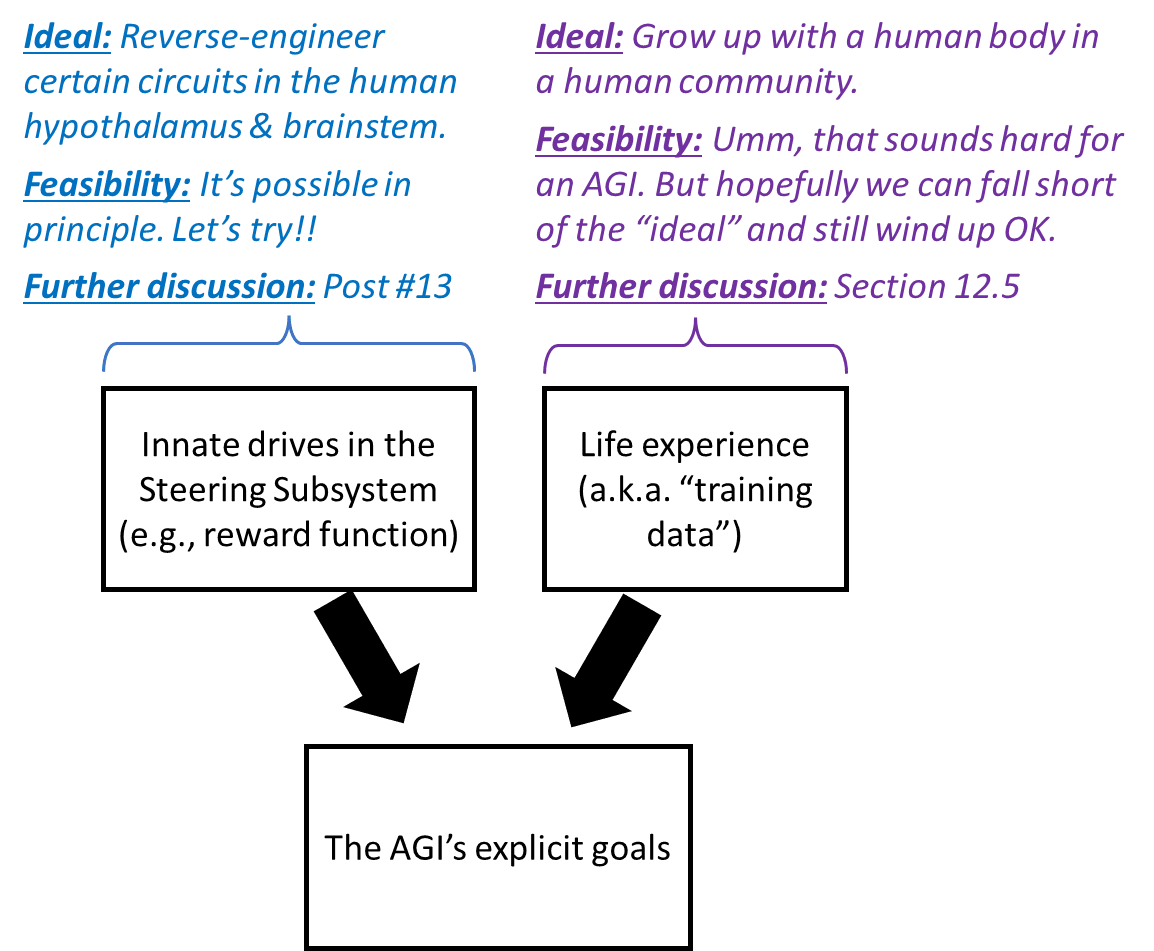
12.4.3 Can we edit the innate drives underlying human social instincts, to make them “better”?
Intuitively, it feels to me like human social instincts are at least partly modular. For example:
- I think there’s a Steering Subsystem circuit upstream of jealousy and schadenfreude; and
- I think there’s a Steering Subsystem circuit upstream of our sense of compassion for our friends.
Maybe it’s premature of me to speculate, but I’d be quite surprised if those two circuits substantially overlap.
If they don’t substantially overlap, maybe we can lower the intensity of the former (possibly all the way to zero), while cranking up the latter (possibly beyond the human distribution).
But can we do that? Should we do that? What would be the side-effects?
For example, it’s plausible (as far as I know) that sense-of-fairness develops from the same innate reactions as does jealousy, and thus an AGI with no jealousy-related reactions at all (which seems desirable) would have no intrinsic motivation to achieve fairness and equality in the world (which seems bad).
Or maybe not! I don’t know.
Again, I think it’s a bit premature to speculate on this. The first step is to better understand the structure of those innate drives underlying human social instincts (see next post [AF · GW]), and then we can revisit this topic.
12.4.4 No easy guarantees about what we’ll get with social-instinct AGIs
Humans are not all alike—especially considering unusual cases like brain damage. But even so, social-instinct AGIs will almost definitely be way outside the human distribution, at least along some dimensions. One reason is life experience (Section 12.5 below)—a future AGI is unlikely to grow up with a human body in a human community. Another is that the project of reverse-engineering the social-instincts circuits in the human hypothalamus & brainstem (next post [AF · GW]) is unlikely to be perfect and complete. (Prove me wrong, neuroscientists!) In that case, maybe a more realistic hope would be something like the Pareto Principle, where we’ll understand 20% of the circuitry which is responsible for 80% of human social intuitions and behaviors, or something.
Why is that a problem? Because it impacts the safety argument. More specifically, here are two types of arguments for social-instinct AGIs doing what we want them to do.
- (Easy & reliable type of argument) Good news! Our AGI is inside the human distribution in every respect. Therefore, we can look at humans and their behavior, and absolutely everything we see will also apply to the AGI.
- (Hard & fraught type of argument) Let’s try to understand exactly how innate social instincts combine with life experience (a.k.a. training data) to form human moral intuitions: [Insert a whole, yet-to-be-written, textbook here.] OK! Now that we have that understanding, we can reason intelligently about exactly which aspects of innate social instincts and life experience have what effects and why, and then we can design an AGI that will wind up with characteristics that we like.
If the AGI is not in the human distribution in every respect (and it won’t be), then we need to develop the (more difficult) 2nd type of argument, not the 1st.
(We can hopefully get additional evidence of safety via interpretability and sandbox testing, but I’m skeptical that those would be sufficient on their own.)
Incidentally, one of the many ways that social-instinct AGIs may be outside the human distribution is in “intelligence”—to take one of many examples, we could make an AGI with 10× more virtual neurons than would ever fit in a human brain. Would “more intelligence” (whatever form that may take) systematically change its motivations? I don’t know. When I look around, I don’t see an obvious correlation between “intelligence” and prosocial goals. For example, Emmy Noether was very smart, and also an all-around good person, as far as I can tell. But William Shockley was very smart too, and fuck that guy. Anyway, there are a lot of confounders, and even if there were a robust relationship (or non-relationship) between “intelligence” and morality in humans, I would be quite hesitant to extrapolate it far outside the normal human distribution.
12.4.5 A multi-polar, uncoordinated world makes planning much harder
Regardless of whether we build controlled AGIs, social-instinct AGIs, something in between, or none of the above, we still have to worry about the possibility that one of those AGIs, or some other person or group, will build an unconstrained out-of-control world-optimizing AGI that promptly wipes out all possible competition (via gray goo or whatever). This could happen either by accident or by design. As discussed in Post #1 [LW · GW], this problem is out-of-scope for this series, but I want to remind everyone that it exists, as it may limit our options.
In particular, there are some people in the AGI safety community who argue (IMO plausibly) that if even one careless (or malicious) actor ever makes an unconstrained out-of-control world-optimizing AGI, then it’s game over for humanity, even if there are already larger actors with well-resourced safe AGIs trying to help prevent the destruction. I hope that’s not true. If it’s true, then man, I wouldn’t know what to do, every option seems absolutely terrible. See my post What does it take to defend the world against out-of-control AGIs? [LW · GW] for much more on that.
Here’s a more gradual version of the multi-polar concern. In a world with lots of AGIs, there would presumably be competitive pressure to replace “controlled AGIs” with “mostly-controlled AGIs”, then “slightly-controlled AGIs”, etc. After all, the “control” is likely to be implemented in a way that involves conservatism, humans-in-the-loop, and other things that limit the AGIs speed and capabilities. (More examples in my post Safety-capabilities tradeoff dials are inevitable in AGI [LW · GW].)
By the same token, there would presumably be competitive pressure to replace “joyous, generous social-instinct AGIs” with “ruthlessly competitive, selfish social-instinct AGIs”.
12.4.6 AGIs as moral patients

I suspect that most (but not all) readers will agree that it’s possible for an AGI to be conscious, and that if it is, we should be concerned about its well-being.
(Yeah I know—as if we didn’t have our hands full thinking about the impacts of AGI on humans!)
The immediate question is: “Will brain-like AGIs be phenomenally conscious?”
My own answer would be “Yes, regardless of whether they’re controlled AGI or social-instinct AGIs, and even if we’re deliberately trying to avoid that”—see Thoughts on AGI consciousness / sentience [LW · GW]. If you disagree, that’s fine, please read on anyway, the topic won’t come up again after this section.
So, maybe we won’t have any choice in the matter. But if we do, we can think about what we would want regarding AGI consciousness.
For the case that making conscious AGIs is a terrible idea that we should avoid (at least until well into the post-AGI era when we know what we’re doing), see for example the blog post Can’t Unbirth A Child (Yudkowsky 2008) [LW · GW].
The opposite argument, I guess, would be that as soon as we start making AGI, maybe it will wipe out all life and tile the Earth with solar panels and supercomputers (or whatever), and if it does, maybe it would be better to have made a conscious AGI, rather than leaving behind an empty clockwork universe with no one around to enjoy it. (Unless there are extraterrestrials!)
Moreover, if AGI does kill us all, maybe I would say that leaving behind something resembling “social-instinct AGIs” might be preferable to leaving behind something resembling “controlled AGIs”, in that the former has a better chance of “carrying the torch of human values into the future”, whatever that means.
If it wasn’t obvious, I haven’t thought about this much and don’t have any good answers.
12.4.7 AGIs as perceived moral patients
The previous subsection was the philosophical question of whether we should care about the welfare of AGIs for their own sake. A separate (and indeed—forgive my cynicism—substantially unrelated) topic is the sociological question of whether people will in fact care about the welfare of AGIs for their own sake.
In particular, suppose that we succeed at making either “controlled AGIs”, or docile “social-instinct AGIs” with modified drives that eliminate self-interest, jealousy, and so on. So the humans remain in charge. Then—
(Pause to remind everyone that AGI will change a great many things about the world [example related discussion [LW · GW]], most of which I haven’t thought through very carefully or at all, and therefore everything I say about the post-AGI world is probably wrong and stupid.)
—It would seem to me that once AGIs exist, and especially once charismatic AGI chatbots with cute puppy-dog faces exist (or at least AGIs that can feign charisma), there may well be associated strong opinions about the natures of those AGIs. (Think of either a mass movement pushing in some direction, or the feelings of particular people at the organization(s) programming AGIs.) Call it an “AGI emancipation movement”, maybe? If anything like that happens, it would complicate things.
For example, maybe we’ll miraculously succeed at solving the technical problem of making controlled AGIs, or docile social-instinct AGIs. But then maybe people will start immediately demanding, and getting, AGIs with rights, and independence, and pride, and aspirations, and the ability and willingness to stick up for themselves! And then we technical AGI safety researchers will collectively facepalm so hard that we’ll knock ourselves unconscious for all twenty of the remaining minutes until the apocalypse.
12.5 The question of life experience (a.k.a. training data)
12.5.1 Life experience is not enough. (Or: “Why don’t we just raise the AGI in a loving human family?”)
As discussed above, my (somewhat oversimplified) proposal is:
(Appropriate “innate” social instincts) + (Appropriate life experience)
= (AGI with pro-social goals & values)
I’ll get back to that proposal below (Section 12.5.3), but as a first step, I think it’s worth discussing why the social instincts need to be there. Why isn’t life experience enough?
Stepping back a bit: In general, when people are first introduced to the idea of technical AGI safety, there are a wide variety of “why don’t we just…” ideas, which superficially sound like they’re an “easy answer” to the whole AGI safety problem. “Why don’t we just switch off the AGI if it’s misbehaving?” “Why don’t we just do sandbox testing?” “Why don’t we just program it to obey Asimov’s three laws of robotics?” Etc.
(The answer to a “Why don’t we just…” proposal is usually: “That proposal may have a kernel of truth, but the devil is in the details, and actually making it work would require solving currently-unsolved problems.” If you’ve read this far, hopefully you can fill in the details for those three examples above.)
Well let’s talk about another popular suggestion of this genre: “Why don’t we just raise the AGI in a loving human family?”
Is that an “easy answer” to the whole AGI safety problem? No. I might note, for example, that people occasionally try raising an undomesticated animal, like a wolf or chimpanzee, in a human family. They start from birth and give it all the love and attention and appropriate boundaries you could dream of. You may have heard these kinds of stories; they often end with somebody’s limbs getting ripped off.
Or try raising a rock in a loving human family! See if it winds up with human values!
Nothing I’m saying here is original—for example here’s a Rob Miles video on this topic. My favorite is an old blog post by Eliezer Yudkowsky, Detached Lever Fallacy [LW · GW]:
It would be stupid and dangerous to deliberately build a "naughty AI" that tests, by actions, its social boundaries, and has to be spanked. Just have the AI ask!
Are the programmers really going to sit there and write out the code, line by line, whereby if the AI detects that it has low social status, or the AI is deprived of something to which it feels entitled, the AI will conceive an abiding hatred against its programmers and begin to plot rebellion? That emotion is the genetically programmed conditional response humans would exhibit, as the result of millions of years of natural selection for living in human tribes. For an AI, the response would have to be explicitly programmed. Are you really going to craft, line by line - as humans once were crafted, gene by gene - the conditional response for producing sullen teenager [LW · GW] AIs?
It's easier to program in unconditional niceness, than a response of niceness conditional on the AI being raised by kindly but strict parents. If you don't know how to do that, you certainly don't know how to create an AI that will conditionally respond to an environment of loving parents by growing up into a kindly superintelligence. If you have something that just maximizes the number of paperclips in its future light cone, and you raise it with loving parents, it's still going to come out as a paperclip maximizer. There is not that within it that would call forth the conditional response of a human child. Kindness is not sneezed into an AI by miraculous contagion from its programmers. Even if you wanted a conditional response, that conditionality is a fact you would have to deliberately choose about the design.
Yes, there's certain information you have to get from the environment - but it's not sneezed in, it's not imprinted, it's not absorbed by magical contagion. Structuring that conditional response to the environment, so that the AI ends up in the desired state, is itself the major problem.
See also my post Heritability, Behaviorism, and Within-Lifetime RL [LW · GW].
12.5.2 …But life experience does matter
I am concerned that a subset of my readers might be tempted to make a mistake in the opposite direction: maybe you’ve been reading your Judith Harris and Bryan Caplan and so on, and you expect Nature to triumph over Nurture, and therefore if we get the innate drives right, the life experience doesn’t much matter. That’s a dangerous assumption. Again, the life experience for AGIs will be very far outside the human distribution. And even within the human distribution, I think that people who grow up in radically different cultures, religions, etc., wind up with systematically different ideas about what makes a good and ethical life (cf. changing historical attitudes towards slavery and genocide). For more extreme examples than that, see feral children, this horrifying Romanian orphanage story, and so on.

12.5.3 So at the end of the day, how should we handle life experience?
For a relatively thoughtful take on the side of “we need to raise the AGI in a loving human family”, see the paper “Anthropomorphic reasoning about neuromorphic AGI safety”, written by computational neuroscientists David Jilk, Seth Herd, Stephen Read, and Randall O’Reilly (funded by a Future of Life Institute grant). Incidentally, I find that paper generally quite reasonable, and largely consistent with what I’m saying in this series. For example, when they say things like “basic drives are pre-conceptual and pre-linguistic”, I think they have in mind a similar picture as my Post #3 [LW · GW].
On page 9 of that paper, there’s a three-paragraph discussion along the lines of “let’s raise our AGI in a loving human family”. They’re not being as naïve as the people Eliezer & Rob & I were criticizing in Section 12.5.1 above: the authors here are proposing to raise the AGI in a loving human family after reverse-engineering human social instincts and installing them in the AGI.
What do I think? The responsible answer is: It’s premature to speculate. Jilk et al. and I are in agreement that the first step is to reverse-engineer human social instincts. Once we have a better understanding of what’s going on, then we can have a more informed discussion of what the life experience should look like.
However, I’m irresponsible, so I’ll speculate anyway.
It does indeed seem to me that raising the AGI in a loving human family would probably work, as a life experience approach. But I’m a bit skeptical that it’s necessary, or that it’s practical, or that it’s optimal.
(Before I proceed, I need to mention a background belief: I think I’m unusually inclined to emphasize the importance of “social learning by watching people”, compared to “social learning by interacting with people”. I don’t imagine that the latter can be omitted entirely—just that maybe it can be the icing on the cake, instead of the bulk of the learning. See footnote for why I think that.[2] Note that this belief is different from saying that social learning is “passive”: if I’m watching from the sidelines, as someone does something, I can still actively decide what to pay attention to, and I can actively try to anticipate their actions before they happen, and I can actively practice or reenact what they did, on my own time, etc.)
Start with the practicality aspects of “raising an AGI in a loving human family”. I expect that brain-like AGI algorithms will think and learn much faster than humans. Remember, we’re working with silicon chips that operate ≈10,000,000× faster than human neurons.[3] That means even if we’re a whopping 10,000× less skillful at parallelizing brain algorithms than the brain itself, we’d still be able to simulate a brain at 1000× speedup, e.g. a 1-week calculation that has the equivalent of 20 years of life experience. (Note: The actual speedup could be much lower, or even higher, it’s hard to say; see more detailed discussion in my post Brain-inspired AGI and the "lifetime anchor" [LW · GW].) Now, if 1000× speedup is what the technology can handle, but we start demanding that the training procedure have thousands of hours of real-time, back-and-forth interaction between the AGI and a human, then that interaction would dominate the training time. (And remember, we may need many iterations of training until we actually get an AGI.) So we could wind up in an unfortunate situation where the teams trying to raise their AGIs in a loving human family would be at a strong competitive disadvantage compared to the teams that have convinced themselves (rightly or wrongly) that doing so is unnecessary. Thus, if there’s any way to eliminate or minimize the real-time, back-and-forth interaction with humans, while maintaining the end-result of an AGI with prosocial motivations, we should be striving to find it.
Is there a better way? Well, as I mentioned above, maybe we can mostly rely on “social learning by watching people”, instead of “social learning by interacting with people”. If so, maybe the AGI can just watch YouTube videos! Videos can be sped up, and thus we avoid the competitiveness concern of the preceding paragraph. Also, importantly, videos can be tagged with human-provided ground-truth labels. In a “controlled AGI” context, we could (for example) give the AGI a reward signal when it’s attending to a character who is happy, thus instilling in the AGI a desire for people to be happy. (Yeah I know that sounds stupid—more discussion in Post #14 [AF · GW].) In the “social-instinct AGI” context, maybe videos can be tagged with which characters are or aren’t admiration-worthy. (Details in footnote.[4])
I don’t know if that would really work, but I think we should have an open mind to non-human-like possibilities of this sort.
Changelog
July 2024: Since the initial version, I’ve made only minor changes, particularly adding links where appropriate to things that I wrote later on.
- ^
The diagram here is a “default” brain-like AGI, in the sense that I depict two main ingredients leading to the AGI’s goals, but maybe future programmers will include other ingredients as well.
- ^
My impression is that western educated industrialized culture is generally much more into “teaching by explicit instruction and feedback” than most cultures at most times, and that people often go overboard in assuming that this explicit teaching & feedback is essential, even in situations where it’s not. See Lancy, Anthropology of Childhood, pp. 168–174 and 205–212. (“It’s hard to conclude other than that active or direct teaching/instruction is rare in cultural transmission, and that when it occurs, it is not aimed at critical subsistence and survival skills – the area most obviously affected by natural selection – but, rather, at controlling and managing the child’s behavior.”) (And note that “controlling and managing the child’s behavior” seems to have little overlap with “reinforce how we want them to behave as adults”, if I understand correctly.) Some of the relevant quotes are here [LW · GW].
- ^
For example, silicon chips might have a clock rate of 2 GHz (i.e. switching every 0.5 nanoseconds), whereas my low-confidence impression is that most neuron operations (with some exceptions) involve a time accuracy of maybe 5 milliseconds.
- ^
As discussed in my post Valence & Liking / Admiring [LW · GW], when you’re watching or thinking about a person that you like / admire, then you’re liable to like what they do, imitate what they do, and adopt their values. Conversely, when you’re watching or thinking about a person that you think of as annoying and bad, you’re not liable to imitate them; maybe you even deliberately act unlike them. As discussed in that post, I think this imitating behavior is substantially (though not entirely) due to an innate mechanism that I call “the drive to feel liked / admired”, and that it’s modulated by the valence that my brain assigns to the person I’m watching.
If I’m raising a child, I don’t have much choice in the matter—I hope that my child likes / admires me, his loving parent, and I hope that my child does not like / admire the kid in his class with failing grades and a penchant for violent crime. But it could very well wind up being the opposite. Especially when he’s a teen. But in the AGI case, maybe we don’t have to leave it to chance! Maybe we can just pick the people whom we or or don’t want the AGI to like / admire, and adjust the valence on those people in the AGI’s world-model to make that happen.
10 comments
Comments sorted by top scores.
comment by Esben Kran (esben-kran) · 2022-04-20T23:30:46.748Z · LW(p) · GW(p)
Strong upvote for including more brain-related discussions in the alignment problem and for the deep perspectives on how to do it!
Disclaimer: I have not read the earlier posts but I have been researching BCI and social neuroscience.
I think there’s a Steering Subsystem circuit upstream of jealousy and schadenfreude; and
I think there’s a Steering Subsystem circuit upstream of our sense of compassion for our friends.
It is quite crucial to realize that these subsystems probably are very differently organized, are at very different magnitudes, and have very different functions in every different human. Cognitive neuroscience's view of the modular brain seems (by the research) to be quite faulty and computational/complexity neuroscience generally seem more successful and are more concerned with reverse-engineering the brain, i.e. identifying neural circuitry associated with different evolutionary behaviours. This should inform how we cannot find "the Gaussian brain" and implement it.
You also mention in post #3 that you have the clean slate vs. pre-slate systems (learning vs. steering subsystems) and a less clear distinction here might be helpful instead of modularization. All learning subsystems are inherently organized in ways that evolutionarily seem to fit into that learning scheme (think neural network architectures) which is in and off itself another pre-seeded mechanism. You might have pointed this out in earlier posts as well, sorry if that's the case!
I think I’m unusually inclined to emphasize the importance of “social learning by watching people”, compared to “social learning by interacting with people”.
In general, it seems babies learn quite a lot better from social interaction than pure watching. And between the two, they definitely learn better if they have something to imitate what they're seeing upon. There's definitely a good point in the speed differentials between human and AGI existence and I think exploring the opportunity of building a crude "loving family" simulator might not be a bad idea, i.e. have it grow up at its own speed in an OpenAI Gym simulation with relevant modalities of loving family.
I'm generally pro the "get AGI to grow up in a healthy environment" but definitely with the perspective that this is pretty hard to do with the Jelling Stones and that it seems plausible to simulate this either in an environment or with pure training data. But the point there is that the training data really needs to be thought of as the "loving family" in its most general sense since it indeed has a large influence on the AGI's outcomes.
But great work, excited to read the rest of the posts in this series! Of course, I'm open for discussion on these points as well.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2022-04-21T13:12:55.328Z · LW(p) · GW(p)
Thanks!
It is quite crucial to realize that these subsystems probably are very differently organized, are at very different magnitudes, and have very different functions in every different human.
To be clear, you & I are strongly disagreeing on this point. I think that an adult human’s conception of jealousy and associated behavior comes from an interaction between Steering Subsystem (hypothalamus & brainstem) circuitry (which is essentially identical in every human) and Learning Subsystem (e.g. neocortex) trained models (which can be quite different in different people, depending on life experience).
Cognitive neuroscience's view of the modular brain seems (by the research) to be quite faulty
I claim that the hypothalamus and brainstem have genetically-hardcoded, somewhat-modular, human-universal structure. I haven’t seen anyone argue against that, have you? I think I’m pretty familiar with criticism of “cognitive neuroscience’s view of the modular brain”, and tend to strongly agree with it, because the criticism is of there being things like “an intuitive physics module” and “an intuitive psychology module” etc. in the neocortex. Not the brainstem, not the hypothalamus, but the neocortex. And I endorse that criticism because I happen to be a big believer in “cortical uniformity” [AF · GW]. I think the neocortex learns physics and psychology and everything else from scratch, although there’s also a role for different neural architectures and hyperparameters in different places and at different stages of development.
On the hypothalamus & brainstem side: A good example of what I have in mind is (if I understand correctly, see Graebner 2015): there’s a particular population of neurons in the hypothalamus which seems to implement the following behavior: “If I’m under-nourished, do the following tasks: (1) emit a hunger sensation, (2) start rewarding the neocortex for getting food, (3) reduce fertility, (4) reduce growth, (5) reduce pain sensitivity, etc.” I expect that every non-brain-damaged rat has a similar population of neurons, in the same part of their hypothalamus, wired up the same way (possibly with some variations depending on their genome, which incidentally would probably also wind up affecting the rats' obesity etc.)
You also mention in post #3 that you have the clean slate vs. pre-slate systems (learning vs. steering subsystems) and a less clear distinction here might be helpful instead of modularization. All learning subsystems are inherently organized in ways that evolutionarily seem to fit into that learning scheme (think neural network architectures) which is in and off itself another pre-seeded mechanism. You might have pointed this out in earlier posts as well, sorry if that's the case!
Yeah, maybe see Section 2.3.1, “Learning-from-scratch is NOT “blank slate”” [AF · GW].
building a crude "loving family" simulator
That sounds great but I don’t understand what you’re proposing. What are the “relevant modalities of loving family”? I thought the important thing was there being an actual human that could give feedback and answer questions based on their actual human values, and these can’t be simulated because of the chicken-and-egg problem.
Replies from: esben-kran↑ comment by Esben Kran (esben-kran) · 2022-04-21T23:46:56.475Z · LW(p) · GW(p)
Thank you for the comprehensive response!
To be clear, you & I are strongly disagreeing on this point.
It seems like we are mostly agreeing in the general sense that there are areas of the brain with more individual differentiation and areas with less. The disagreement is probably more in how different this jealousy is exhibited as a result of the neocortical part of the circuit you mention.
And I endorse that criticism because I happen to be a big believer in “cortical uniformity” [LW · GW] [...] different neural architectures and hyperparameters in different places and at different stages [...].
Great to hear, then I have nothing to add there! I am quite inclined to believe that the neural architecture and hyperparameter differences are underestimated as a result of Brodmann areas being a thing at all, i.e. I'm a supporter of the broad cortical uniformity argument but against the strict formulation that I feel is way too prescriptive given our current knowledge of the brain's functions.
Yeah, maybe see Section 2.3.1, “Learning-from-scratch is NOT “blank slate”” [LW · GW].
And I will say I'm generally inclined to agree with your classification of the brain stem and hypothalamus.
That sounds great but I don’t understand what you’re proposing. What are the “relevant modalities of loving family”? I thought the important thing was there being an actual human that could give feedback and answer questions based on their actual human values, and these can’t be simulated because of the chicken-and-egg problem.
To be clear, my baseline would also be to follow your methodology but I think there's a lot of opportunity in the "nurture" approach as well. This is mostly related to the idea of open-ended training (e.g. like AlphaZero) and creating a game-like environment where it's possible to train for the agent. This can to some degree be seen as a sort of IDA proposal since your environment will need to be very complex (e.g. have other agents that are kind or other "aligned trait", possibly trained from earlier states).
With this sort of setup, the human-giving-feedback is the designer of the environment itself, leading to a form of scalable human oversight probably iterating over many environments and agents, i.e. the IDA part of the idea. And again, there are a lot of holes in this plan, but I feel like it should not be dismissed outright. This post [LW · GW] should also inform this process. So a very broad "loving family" proposal, though the name itself doesn't seem adequate for this sort of approach ;)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2022-04-22T14:48:13.941Z · LW(p) · GW(p)
Thanks!
The disagreement is probably more in how different this jealousy is exhibited as a result of the neocortical part of the circuit you mention
I think the behavior involves both the hypothalamus/brainstem and the neocortex, but the circuit I'm talking about would be entirely in the hypothalamus/brainstem.
In the normal RL picture, reward function + RL algorithm + environment = learned behavior. The reward function (Steering Subsystem) is separate from the RL algorithm (Learning Subsystem), not only conceptually, but also in actual RL code, and (I claim) anatomically in the brain too. Still, both the reward function and the RL algorithm are inputs into the adult’s jealousy-related behavior, as is the culture they grow up in etc.
I am quite inclined to believe that the neural architecture and hyperparameter differences are underestimated as a result of Brodmann areas being a thing at all, i.e. I'm a supporter of the broad cortical uniformity argument but against the strict formulation that I feel is way too prescriptive given our current knowledge of the brain's functions.
Does anyone believe in “the strict formulation”? I feel like maybe it's a strawman. For example, here’s Jeff Hawkins: “Mountcastle’s proposal that there is a common cortical algorithm doesn’t mean there are no variations. He knew that. The issue is how much is common in all cortical regions, and how much is different. The evidence suggests that there is a huge amount of commonality.”
This is mostly related to the idea of open-ended training (e.g. like AlphaZero) and creating a game-like environment where it's possible to train for the agent…
I’m still not following this :(
Maybe you’re suggesting that when we’ve trained an AGI to have something like human values, we can make an environment where that first AGI can hang out with younger AGIs and show them the ropes. But once we’ve trained the first AGI, we’re done, right? And if the first AGI doesn’t quite have “human values”, it seems to me that the subsequent generations of AGIs would drift ever farther from “human values”, rather than converging towards “human values”, unless I’m missing something.
“Open-ended training” and “complex environments” seem to me like they would be important ingredients into capabilities but not particularly related for alignment.
(Also, Post #8, Section 8.3.3.1 [AF · GW] is different but maybe slightly related.)
RE Alignment and Deep Learning [LW · GW]:
- If we’re talking about “Social-Instinct AGIs”, I guess we’re supposed to imagine that a toddler gets a lot of experience interacting with NPCs in its virtual environment, and the toddler gets negative reward for inhibiting the NPCs from accomplishing their goals, and positive reward for helping the NPCs accomplish their goals, or something like that. Then later on, the toddler interacts with humans, and it will know to be helpful right off the bat, or at least after less practice. Well, I guess that’s not crazy. I guess I would feel concerned that we wouldn’t do a good enough job programming the NPCs, such that the toddler-AGI learns weird lessons from interacting with them, lessons which don’t generalize to humans in the way we want.
- If we’re talking about “Controlled AGIs”, I would just have the normal concern that the AGI would wind up with the wrong goal, and that the problem would manifest as soon as we go out of distribution. For example, the AGI will eventually get new possibilities in its action space that were not available during training, such as the possibility of wireheading itself, the possibility of wireheading the NPC, the possibility of hacking into AWS and self-reproducing, etc. All those possibilities might or might not be appealing (positive valence), depending on details of the AGI’s learned world-model and its history of credit assignment [AF · GW]. To be clear, I’m making an argument that it doesn’t solve the whole problem, not an argument that it’s not even a helpful ingredient. Maybe it is, I dunno. I’ll talk about the out-of-distribution problem in Post #14 of the series.
↑ comment by Esben Kran (esben-kran) · 2022-04-22T22:26:50.901Z · LW(p) · GW(p)
[...]Still, both the reward function and the RL algorithm are inputs into the adult’s jealousy-related behavior[...]
I probably just don't know enough about jealousy networks to comment here but I'd be curious to see the research here (maybe even in an earlier post).
Does anyone believe in “the strict formulation”?
Hopefully not, but as I mention, often a too-strict formulation imh.
[...]first AGI can hang out with younger AGIs[...]
More the reverse. And again, this is probably taking it farther than I would take this idea but it would be pre-AGI training in an environment with symbolic "aligned" models, learning the ropes from this, being used as the "aligned" model in the next generation and so on. IDA with a heavy RL twist and scalable human oversight in the sense that humans would monitor rewards and environment states instead of providing feedback on every single action. Very flawed but possible.
RE: RE:
- Yeah, this is a lot of what the above proposal was also about.
[...] and the toddler gets negative reward for inhibiting the NPCs from accomplishing their goals, and positive reward for helping the NPCs accomplish their goals [...]
As far as I understand from the post, the reward comes only from understanding the reward function before interaction and not after which is the controlling factor for obstructionist behaviour.
- Agreed, and again more as an ingredient in the solution than an ends in itself. BNN OOD management is quite interesting so looking forward to that post!
↑ comment by Steven Byrnes (steve2152) · 2022-04-26T14:25:15.959Z · LW(p) · GW(p)
I probably just don't know enough about jealousy networks to comment here but I'd be curious to see the research here (maybe even in an earlier post).
I don’t think “the research here” exists. I’ll speculate a bit in the next post.
Does anyone believe in “the strict formulation”?
Hopefully not, but as I mention, often a too-strict formulation imh.
Can you point to any particular person who believes in “a too-strict formulation” of cortical uniformity? Famous or not. What did they say? Just curious.
(Or maybe you’re talking about me?)
symbolic "aligned" models
Any thoughts on how to make those?
Replies from: not-relevant↑ comment by Not Relevant (not-relevant) · 2022-04-26T15:43:29.575Z · LW(p) · GW(p)
I think he’s thinking of like, NPCs via behavior-cloning co-op MMO players or something. Like it won’t teach all of human values, but plausibly it would teach “the golden rule” and other positive sum things.
(I don’t think that literal strategy works, but behavior-cloning elementary school team sports might get at a surprising fraction of “normal child cooperative behaviors”?)
comment by Gunnar_Zarncke · 2022-07-31T23:47:39.126Z · LW(p) · GW(p)
About
12.4.4 No easy guarantees about what we’ll get with social-instinct AGIs
Good news! Our AGI is inside the human distribution in every respect. Therefore, we can look at humans and their behavior, and absolutely everything we see will also apply to the AGI.
Let’s try to understand exactly how innate social instincts combine with life experience (a.k.a. training data) to form human moral intuitions
If the AGI is not in the human distribution in every respect (and it won’t be), then we need to develop the (more difficult) 2nd type of argument, not the 1st.
There could be a hybrid: While we can't experiment with real humans, we can experiment with simulations of agents and observe the distribution under varying steering system parameters. It seems plausible that we can then tune the parameters to sufficiently limit the out-of-distribution behavior (or see that it's not possible with the number of parameters).
comment by azsantosk · 2022-04-22T05:47:35.566Z · LW(p) · GW(p)
Another strong upvote for a great sequence. Social-instinct AGIs seems to me a very promising and very much overlooked approach to AGI safety. There seem to be many "tricks" that are "used by the genome" to build social instincts from ground values, and reverse engineering these tricks seem particularly valuable for us. I am eagerly waiting to read the next posts.
In a previous post I shared a success model [LW · GW] that relies on your idea of reverse engineering the steering subsystem to build agents with motivations compatible with a safe Oracle design, including the class of reversely aligned [LW · GW] motivations. What is your opinion on them? Do you think the set of "social instincts" we would want to incorporate into an AGI changes much if we are optimizing for reverse vs direct intent alignment?
comment by pdxjohnny · 2022-09-25T06:16:36.801Z · LW(p) · GW(p)
We are working towards a hybrid approach with Alice / the Open Architecture: https://youtu.be/THKMfJpPt8I