[Intro to brain-like-AGI safety] 7. From hardcoded drives to foresighted plans: A worked example
post by Steven Byrnes (steve2152) · 2022-03-09T14:28:19.729Z · LW · GW · 0 commentsContents
7.1 Post summary / Table of contents 7.2 Reminder from the previous post: big picture of motivation and decision-making 7.3 Building a probabilistic generative world-model in the cortex 7.4 Credit assignment when I first bite into the cake 7.5 Planning towards goals via reward-shaping 7.5.1 The other Thought Assessors. Or: The heroic feat of ordering a cake for next week, when you’re feeling nauseous right now Changelog None No comments
(Last revised: July 2024. See changelog at the bottom.)
7.1 Post summary / Table of contents
Part of the “Intro to brain-like-AGI safety” post series [? · GW].
(Much of this post had been originally published here [AF · GW].)
The previous post [AF · GW] presented a big picture of how I think motivation works in the human brain, but it was a bit abstract. In this post, I will walk through an example. To summarize, the steps will be:
- (Section 7.3) Our brains gradually develop a probabilistic generative model of the world and ourselves;
- (Section 7.4) There’s a “credit assignment” process, where something in the world-model gets flagged as “good”;
- (Section 7.5) There’s a “valence” signal [LW · GW] roughly tracking the expected probability of the “good” thing, along with processes that systematically lead to higher-valence thoughts over lower-valence ones. This signal drives us to “try” to make the “good” thing happen, including via foresighted planning.
All human goals and motivations come ultimately from relatively simple, genetically-hardcoded circuits in the Steering Subsystem [AF · GW] (hypothalamus and brainstem), but the details can be convoluted in some cases. For example, sometimes I’m motivated to do a silly dance in front of a full-length mirror. Exactly what genetically-hardcoded hypothalamus or brainstem circuits are upstream of that motivation? I don’t know! Indeed, I claim that the answer is currently Not Known To Science. I think it would be well worth figuring out! Umm, well, OK, maybe that specific example is not worth figuring out. But the broader project of reverse-engineering certain aspects of the human Steering Subsystem (see my discussion of “Category B” in Post #3 [AF · GW])—especially those upstream of social instincts like altruism and status-drive—is a project that I consider desperately important for AGI safety, and utterly neglected. More on that in Posts #12 [AF · GW]–#13 [AF · GW].
In the meantime, I’ll pick an example of a goal that to a first approximation comes from an especially straightforward and legible set of Steering Subsystem circuitry. Here goes.
Let’s say (purely hypothetically… 👀) that I ate a slice of prinsesstårta cake two years ago, and it was really yummy, and ever since then I’ve wanted to eat one again. So my running example of an explicit goal in this post will be “I want a slice of prinsesstårta”.

Eating a slice of prinsesstårta is not my only goal in life, or even a particularly important one—so it has to trade off against my other goals and desires—but it is nevertheless a goal of mine (at least when I’m thinking about it), and I would indeed make complicated plans to try bring about that goal. Like, for example, dropping subtle hints to my family. In blog posts. When my birthday is coming up. Purely hypothetically!!
7.2 Reminder from the previous post: big picture of motivation and decision-making
From the previous post [AF · GW], here’s my diagram of motivation in the brain:
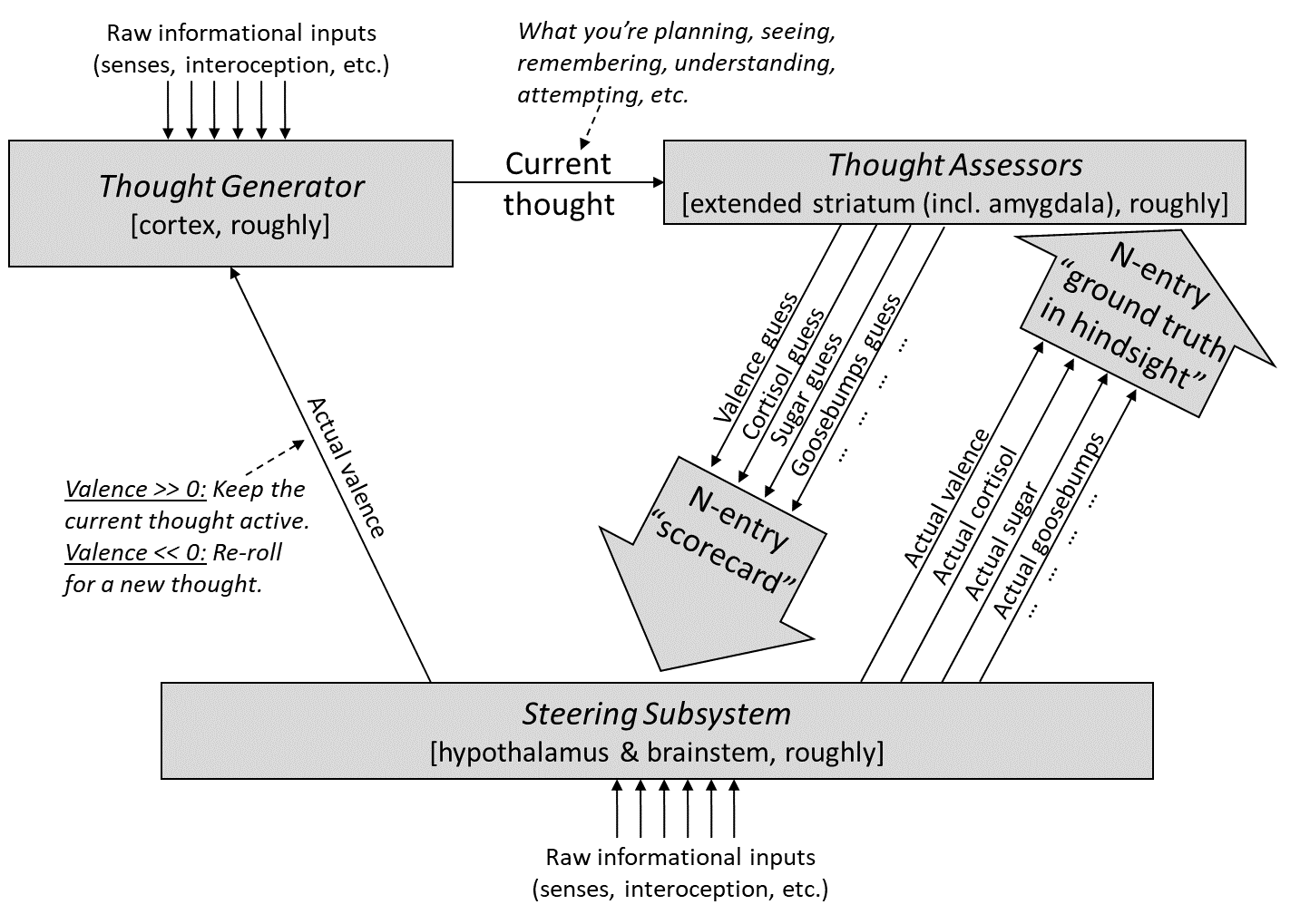
As also discussed in the previous post [AF · GW], we can split this up by which parts are “hardcoded” by the genome, versus learned within a lifetime—i.e., Steering Subsystem versus Learning Subsystem [AF · GW]:
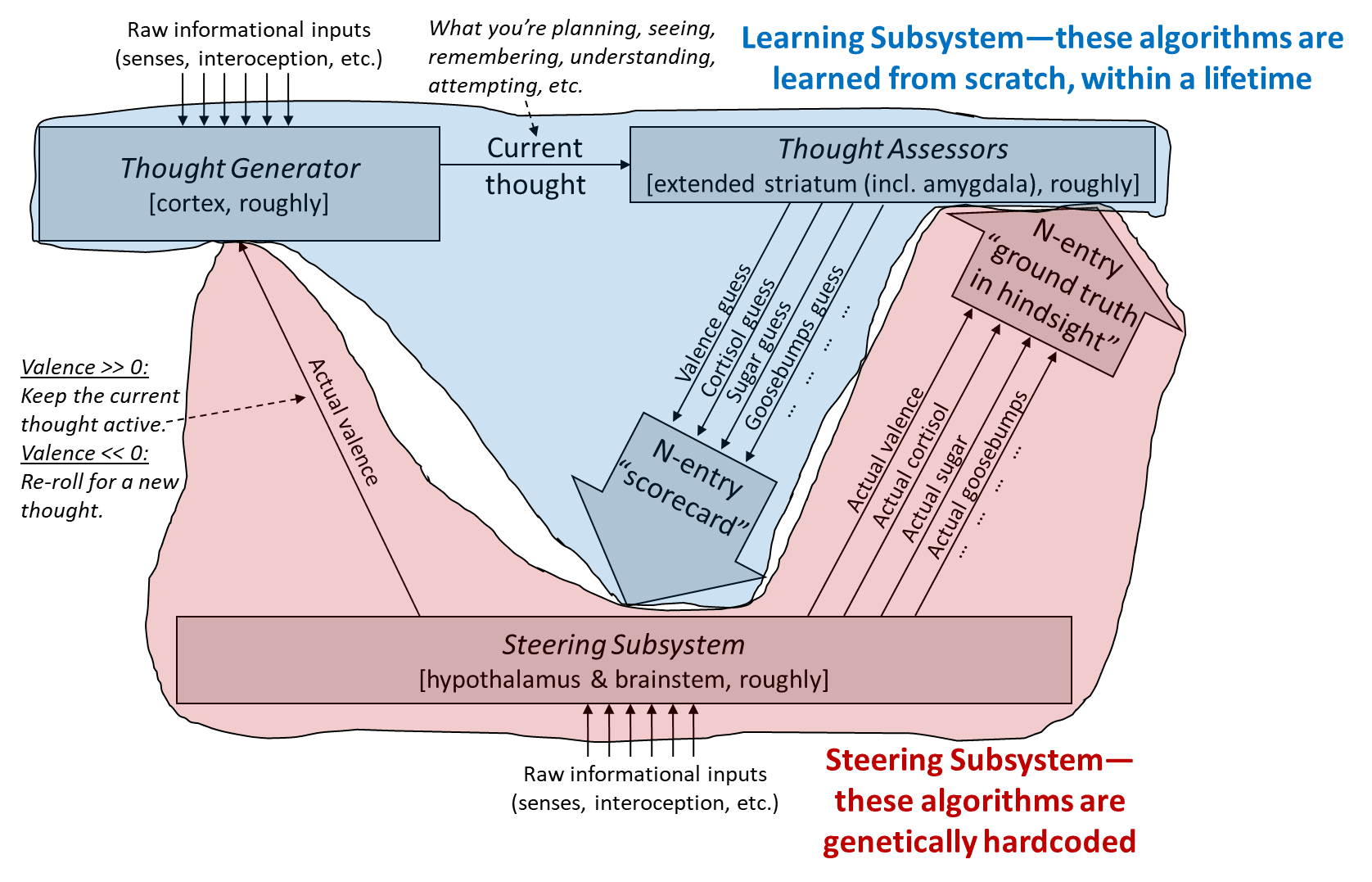
7.3 Building a probabilistic generative world-model in the cortex
The first step in our story is that, over my lifetime, my cortex (specifically, the Thought Generator in the top-left of the diagram above) has been building up a probabilistic generative model, mostly by predictive learning of sensory inputs (Post #4, Section 4.7 [AF · GW]) (a.k.a. “self-supervised learning”).
Basically, we learn patterns in our sensory input, and patterns in the patterns, etc., until we have a nice predictive model of the world (and of ourselves)—a giant web of interconnected entries like “grass” and “standing up” and “slices of prinsesstårta”.
Predictive learning of sensory inputs is not fundamentally dependent on supervisory signals from the Steering Subsystem. Instead, “the world” provides the ground truth about whether a prediction was correct. Contrast this with, for example, navigating the tradeoff between searching-for-food versus searching-for-a-mate: there is no “ground truth” in the environment for whether the animal is trading off optimally, except after generations of hindsight. In that case, we do need supervisory signals from the Steering Subsystem, which estimate the “correct” tradeoff using heuristics hardcoded by evolution. You can kinda think of the is/ought divide, with the Steering Subsystem providing the “ought” (“to maximize genetic fitness, what ought the organism to do?”) and predictive learning of sensory inputs providing the “is” (“what is likely to happen next, under such-and-such circumstances?”) That said, the Steering Subsystem is indirectly involved even in predictive learning of sensory inputs—for example, I can be motivated to go learn about a topic.
Anyway, every thought I can possibly think, and every plan I can possibly plan, can be represented as some configuration of this generative world-model data structure. The data structure is also continually getting edited, as I learn and experience new things.
When you think of this world-model data structure, imagine many gigabytes of inscrutable entries—imagine things like, for example,
“PATTERN 847836 is defined as the following sequence: {PATTERN 278561, then PATTERN 657862, then PATTERN 128669}.”
Some entries have references to sensory inputs and/or motor outputs. And that giant inscrutable mess comprises my entire understanding of the world and myself.
7.4 Credit assignment when I first bite into the cake
As I mentioned at the top, on a fateful day two years ago, I ate a slice of prinsesstårta, and it was really good.
Step back to a couple seconds earlier, as I was bringing the cake towards my mouth to take my first-ever bite. At that moment, I didn’t yet have any particularly strong expectation of what it would taste like, or how it would make me feel. But once it was in my mouth, mmmmmmm, oh wow, that’s good cake.
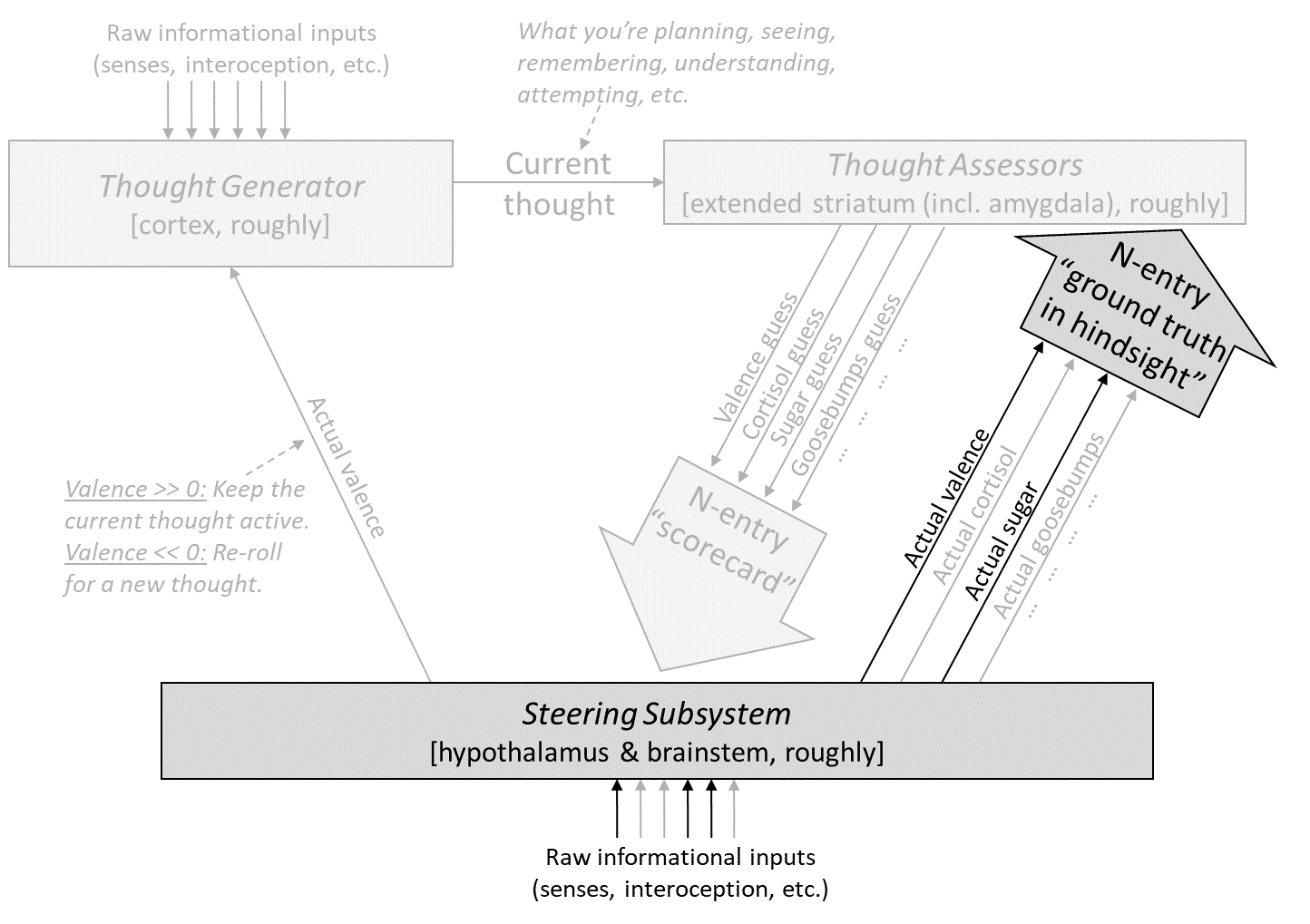
So, as I took that bite, my body had a suite of autonomic reactions—releasing certain hormones, salivating, changing my heart rate and blood pressure, etc. Why? The key is that, as described in Post #3, Section 3.2.1 [AF · GW], all sensory inputs split:
- One copy of any given sensory signal goes to the Learning Subsystem, to be integrated into the predictive world-model. (See “Informational inputs” at the top left of the diagram.)
- A second copy of the same signal goes to the Steering Subsystem, where it serves as an input to genetically-hardwired circuitry. (See “Informational inputs” at the bottom-center of the diagram.)
Taste bud inputs are no exception: the former signal winds up at the gustatory cortex within the insula (part of the neocortex, in the Learning Subsystem), the latter at the gustatory nucleus of the medulla (part of the brainstem, in the Steering Subsystem). After its arrival at the medulla, the taste inputs feed into various genetically-hardcoded brainstem circuits, which, when also prompted with the taste and mouth-feel of the cake, and also accounting for my current physiological state and so on, execute all those autonomic reactions I mentioned.
As I mentioned, before I first bit into the cake, I didn’t expect it to be that good. Well, maybe intellectually I expected it—if you had asked me, I would have said and believed that the cake would be really good. But I didn’t viscerally expect it.
What do I mean by “viscerally”? What’s the difference? The things I viscerally expect are over on the “Thought Assessor” side. People don’t have voluntary control over their Thought Assessors—the latter are trained exclusively by the “ground truth in hindsight” signals from the brainstem. You do have some ability to manipulate them by controlling what you’re thinking about, as discussed in the previous post (Section 6.3.3) [AF · GW], but to a first approximation they’re doing their own thing, independent of what you want them to be doing. From an evolutionary perspective, this design makes good sense as a defense against wireheading—see my post Reward Is Not Enough [LW · GW].
So when I bit into the cake, my Thought Assessors were wrong! They expected the cake to cause mild “yummy”-related autonomic reactions, but in fact the cake caused intense “yummy”-related autonomic reactions. And the Steering Subsystem knew that the Thought Assessors had been wrong. So it sent correction signals up to the Thought Assessor algorithms, as shown in the diagram above. Those algorithms then edited themselves, so that going forward, every time I bring a fork-full of prinsesstårta towards my mouth, the Thought Assessors will be more liable to predict intense hormones, goosebumps, valence, and all the other reactions that I did in fact get.
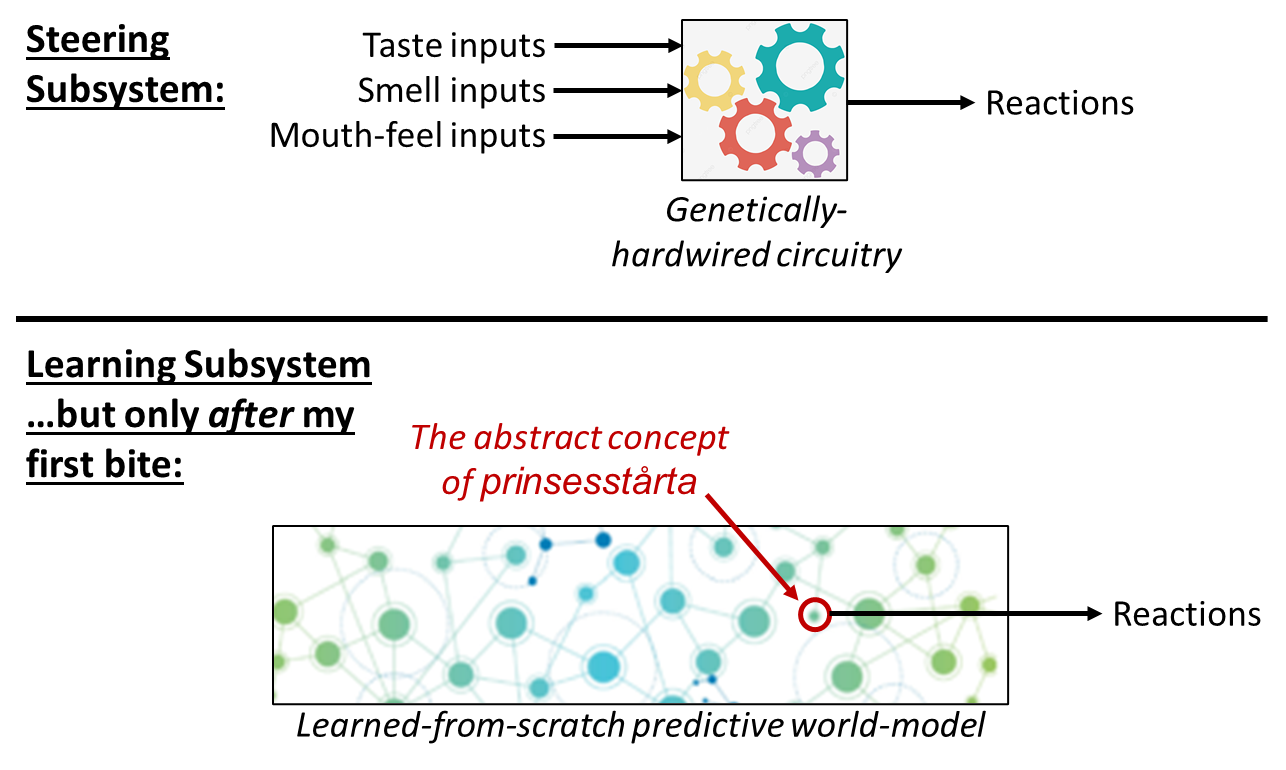
A cool thing just happened here. We started with a simple-ish hardwired algorithm: Steering Subsystem circuits turning certain types of taste inputs into certain hormones and autonomic reactions. But then we transferred that information into functions on the learned world-model—recall that giant inscrutable database I was talking about in the previous section.
(Let me pause to spell this out a bit: The “ground truth in hindsight” signal tweaks some of the Thought Assessors. The Thought Assessors, you’ll recall from Post #5 [AF · GW], are a set of maybe hundreds of models, each trained by supervised learning. The inputs to those trained models, or what I call “context” signals (see Post #4 [AF · GW]), include neurons from inside the predictive world-model that encode “what thought is being thunk right now”. So we wind up with a function (trained model) whose input includes things like “whether my current thought activates the abstract concept of prinsesstårta”, and whose output is a signal that tells the Steering Subsystem to consider salivating etc.)
I call this step—where we edit the Thought Assessors—“credit assignment”. Much more about that process in upcoming posts, including how it can go awry.
So now the Thought Assessors have learned that whenever the “myself eating prinsesstårta” concept “lights up” in the world-model, they should issue predictions of the corresponding hormones, other reactions, and positive valence. However, I think most of these are only active in the seconds before I bite into a prinsesstårta, and only valence is able to drive long-term planning (see my discussion at Incentive Learning vs Dead Sea Salt Experiment [LW · GW]).
7.5 Planning towards goals via reward-shaping
I don’t have a particularly rigorous model for this step, but I think I can lean on intuitions a bit, in order to fill in the rest of the story:
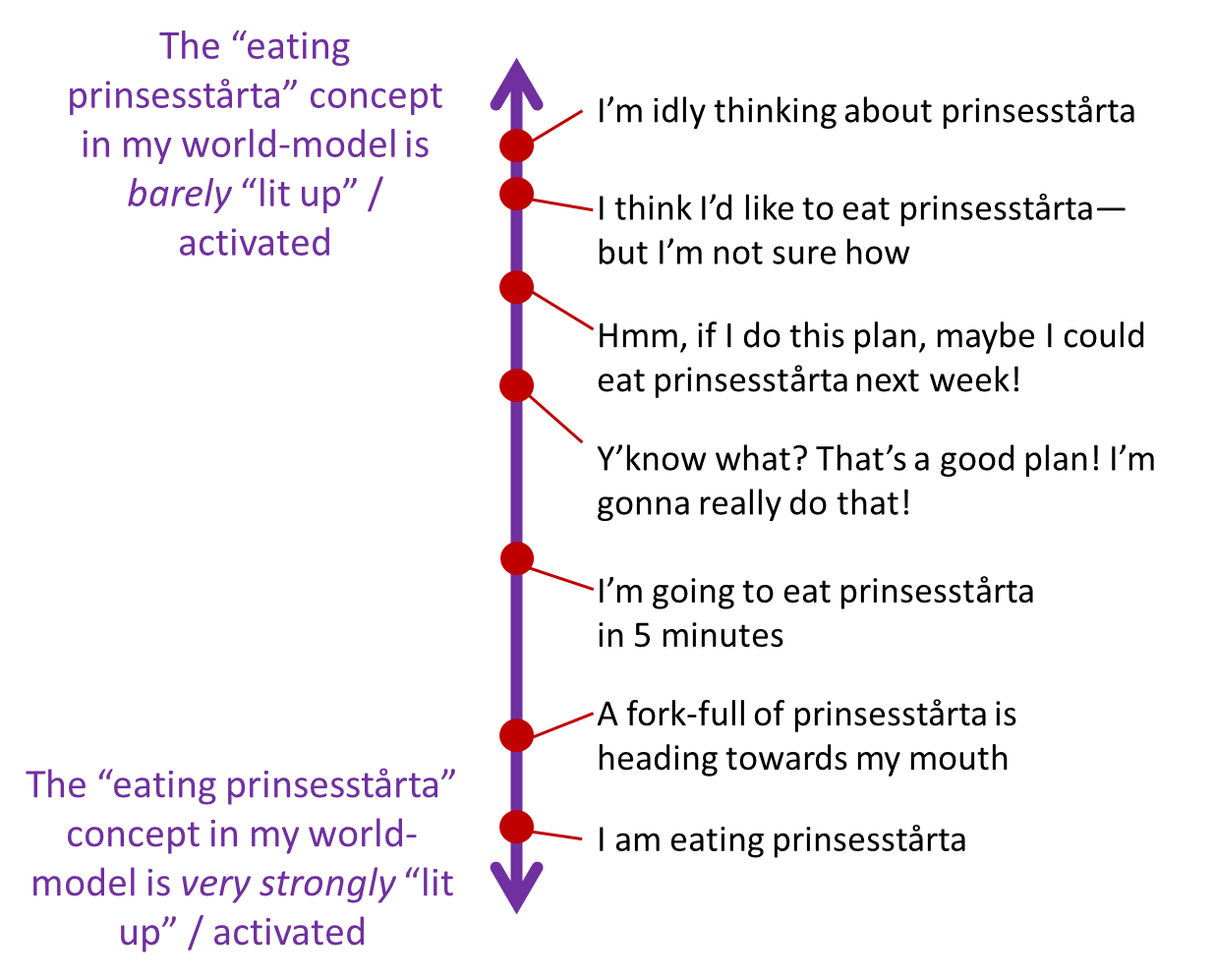
Remember, ever since my first bite of prinsesstårta two years ago, the Thought Assessors in my brain have been inspecting each thought I think, checking whether the “myself eating prinsesstårta” concept in my world-model is “lit up” / “activated”, and to the extent that it is, issuing a suggestion to prepare for valence, salivation, goosebumps, and so on.
The diagram above suggests a series of thoughts that I think would “light up” the world-model concept more and more, as we go from top to bottom.
To get the intuition here, maybe try replacing “prinsesstårta” with “super-salty cracker”. Then go down the list, and try to feel how each thought would make you salivate more and more. Or better yet, replace “eating prinsesstårta” with “asking my crush out on a date”, go down the list, and try to feel how each thought makes your heart rate jump up higher and higher.
Here's another way to think about it: If you imagine the world-model being vaguely like a Bayes net, you can imagine that the “degree of pattern-matching” corresponds roughly to the probability assigned to the “eating prinsesstårta” node. For example, if you’re confident in X, and X weakly implies Y, and Y weakly implies Z, and Z weakly implies “eating prinsesstårta”, then “eating prinsesstårta” gets a very low but nonzero probability, a.k.a. weak activation, and this is akin to having a far-fetched but not completely impossible plan to eat prinsesstårta. (Don’t take this paragraph too literally, I’m just trying to summon intuitions here.)
I’m really hoping this kind of thing is intuitive. After all, I’ve seen it reinvented numerous times! For example, David Hume: “The first circumstance, that strikes my eye, is the great resemblance betwixt our impressions and ideas in every other particular, except their degree of force and vivacity.” And here’s William James: “It is hardly possible to confound the liveliest image of fancy with the weakest real sensation.” In both these cases, I think the authors are gesturing at the idea that imagination activates some of the same mental constructs (latent variables in the world-model) as perception does, but that imagination activates them more weakly than perception.
OK, if you’re still with me, let’s go back to my decision-making model, now with different parts highlighted:
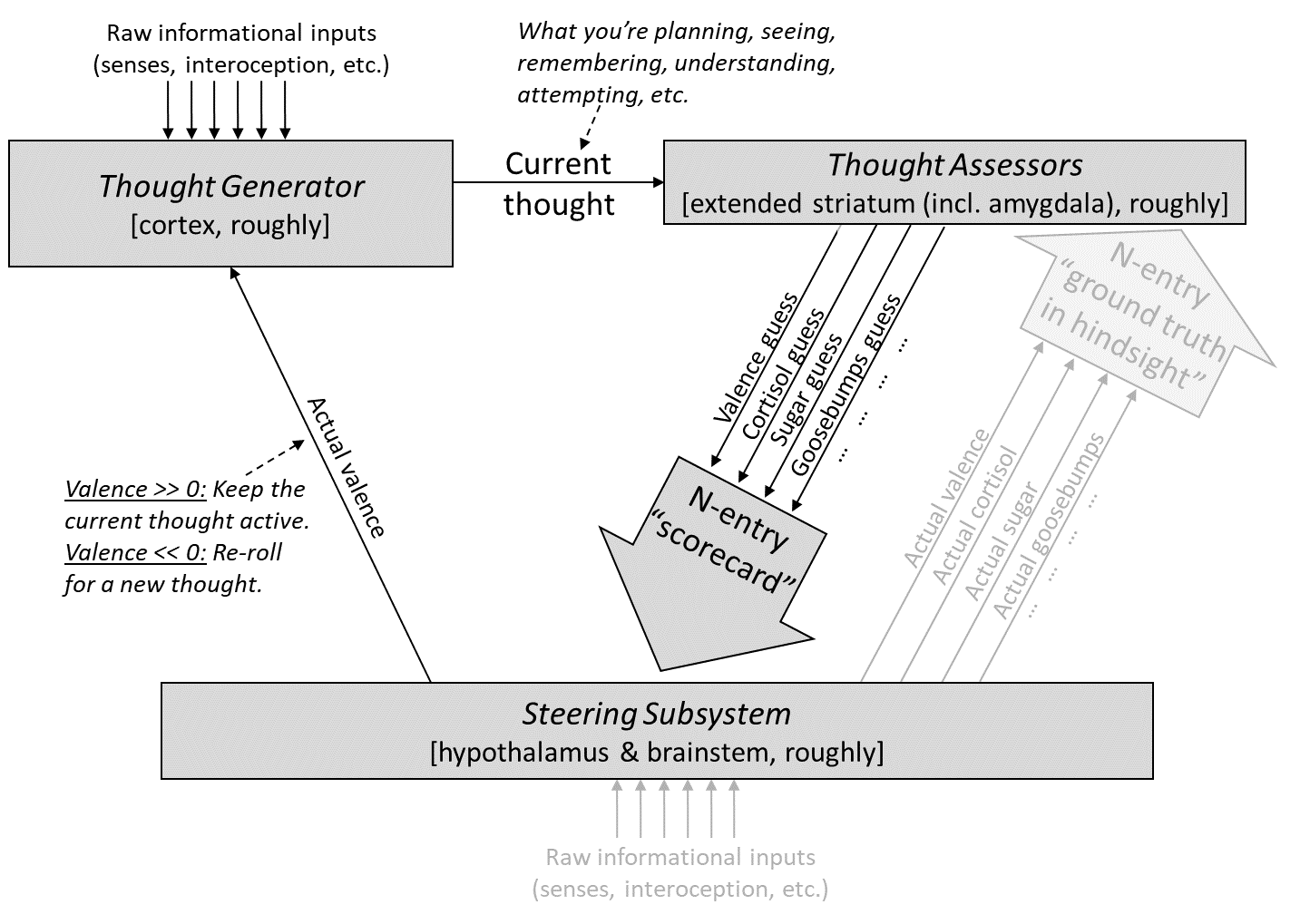
Again, every time I think a thought, the Steering Subsystem looks at the corresponding “scorecard”, and issues a corresponding valence. Recall also that the active thought / plan gets thrown out when its valence is negative, and it gets kept and strengthened when its valence is positive.
I’ll oversimplify for a second, and ignore everything except the valence. (This is not much of an oversimplification—as I argue here [LW · GW], valence is generally the main factor at play in long-term planning, more on which below.) And I’ll also assume the Steering Subsystem is in defer-to-predictor mode for the valence signal, rather than override mode (see Post #6, Section 6.4.2 [AF · GW]). In this case, each time our thoughts move down a notch on the purple arrow diagram above—from idle musing about prinsesstårta, to a hypothetical plan to get prinsesstårta, to a decision to get prinsesstårta, etc.—there’s an immediate increase in valence, such that the new thought tends to persist at the expense of the old one. And conversely, each time we move back up the list—from decision to hypothetical plan to to idle musing—there’s an immediate decrease in valence. Leaving aside mechanistic details, the algorithms are designed so as to generate thoughts with as high valence as possible. So the system tends to move its way down the list, making and executing a good plan to eat cake.
So there you have it! From this kind of setup, I think we're well on the way to explaining the full suite of behaviors associated with humans doing foresighted planning towards explicit goals—including knowing that you have the goal, making a plan, pursuing instrumental strategies as part of the plan, replacing good plans with even better plans, updating plans as the situation changes, pining in vain for unattainable goals, and so on.
7.5.1 The other Thought Assessors. Or: The heroic feat of ordering a cake for next week, when you’re feeling nauseous right now
By the way, what of the other Thought Assessors? Prinsesstårta, after all, is not just associated with “valence guess”, but also “sweet taste guess”, “salivation guess”, etc. Do those play any role?
Sure! For one thing, as I bring the fork towards my mouth, on the verge of consummating my cake-eating plan, I’ll start salivating and releasing cortisol in preparation.
But what about the process of foresighted planning (calling the bakery etc.)? I argued here [LW · GW] that rodents seem to relying exclusively on valence for decisions whose consequences are more than a few seconds out. But I wouldn’t make such a strong statement for humans. For humans (and I think other primates), I think the other, non-valence-function, Thought Assessors are at least somewhat involved even in long-term planning.
For example, imagine you’re feeling terribly nauseous. Of course your Steering Subsystem knows that you’re feeling terribly nauseous. And then suppose it sees you thinking a thought that seems to be leading towards eating. In that case, the Steering Subsystem may say: “That’s a terrible thought! Negative valence!”
OK, so you’re feeling nauseous, and you pick up the phone to place your order at the bakery. This thought gets weakly but noticeably flagged by the Thought Assessors as “likely to lead to eating”. Your Steering Subsystem sees that and says “Boo, given my current nausea, that seems like a bad thought.” It will feel a bit aversive. “Yuck, I’m really ordering this huge cake??” you say to yourself.
Logically, you know that come next week, when you actually receive the cake, you won’t feel nauseous anymore, and you’ll be delighted to have the cake. But still, right now, you feel kinda gross and unmotivated to order it.
Do you order the cake anyway? Sure! Maybe the valence Thought Assessor is strong enough to overrule the effects of the “will lead to eating” Thought Assessor. Or maybe you call up a different motivation: you imagine yourself as the kind of person who has good foresight and makes good sensible decisions, and who isn’t stuck in the moment. That’s a different thought in your head, which consequently activates a different set of Thought Assessors, and maybe that gets high valence from the Steering Subsystem. Either way, you do in fact call the bakery to place the cake order for next week, despite feeling nauseous right now. What a heroic act!
Changelog
July 2024: Since the initial version, I’ve updated the diagrams (see changelog of previous two posts), and used the term “valence” much more (e.g. instead of “reward” or “value”) now that I have my valence series to link to.
I also added text in various places suggesting that long-term planning is mainly reliant on the “valence guess” Thought Assessor, and that the “visceral” Thought Assessors are comparatively unimportant if we’re talking about more than a few seconds in advance (see here [LW · GW]). I didn’t appreciate that fact when I first wrote this.
I also made various smaller wording changes, including in my (vague) discussion of how the brain moves down the purple arrow towards higher-valence thoughts.
0 comments
Comments sorted by top scores.