[Intro to brain-like-AGI safety] 4. The “short-term predictor”
post by Steven Byrnes (steve2152) · 2022-02-16T13:12:14.331Z · LW · GW · 11 commentsContents
4.1 Post summary / Table of contents Table of contents: 4.2 Motivating example: flinching before getting hit in the face 4.3 Terminology: Context, Output, Supervisor 4.4 Extremely simplified toy example of how this could work in biological neurons 4.5 Comparison to other algorithmic approaches 4.5.1 “Short-term predictor” versus a hardwired circuit 4.5.2 “Short-term predictor” vs an RL agent: Faster learning thanks to error gradients 4.6 “Short-term predictor” example #1: The cerebellum 4.6.1 My theory of the cerebellum 4.6.2 How my cerebellum theory relates to others in the literature 4.7 “Short-term predictor” example #2: Predictive learning of sensory inputs in the cortex 4.8 Other example applications of “short-term predictors” Changelog None 11 comments
(Last revised: July 2024. See changelog at the bottom.)
4.1 Post summary / Table of contents
Part of the “Intro to brain-like-AGI safety” post series [? · GW].
The previous two posts (#2 [AF · GW], #3 [AF · GW]) presented a big picture of the brain, consisting of a Steering Subsystem (brainstem and hypothalamus) and Learning Subsystem (everything else), with the latter “learning from scratch” in a particular sense defined in Post #2 [AF · GW].
I suggested that our explicit goals (e.g. “I want to be an astronaut!”) emerge from an interaction between these two subsystems, and that understanding that interaction is critical if we want to assess how to sculpt the motivations of a brain-like AGI, so that it winds up trying to do things that we want it to be trying to do, and thus avoid the kinds of catastrophic accidents I discussed in Post #1 [AF · GW].
These next three posts (#4–#6 [AF · GW]) are working our way up to that story. This post provides an ingredient that we’ll need: “the short-term predictor”.
Short-term prediction is one of the things the Learning Subsystem does—I’ll talk about others in future posts. A short-term predictor has a supervisory signal (a.k.a. “ground truth”) from somewhere, and then uses a learning algorithm to build a predictive model that anticipates that signal a short time (e.g. a fraction of a second) in the future.
This post will be a general discussion of how short-term predictors work and why they’re important. They will turn out to be a key building block of motivation and reinforcement learning, as we’ll see in the subsequent two posts.
Teaser for the next couple posts: The next post (#5) [AF · GW] will discuss how a certain kind of closed-loop circuit wrapped around a short-term predictor turns it into a “long-term predictor”, which has connections to the temporal difference (TD) learning algorithm. I will argue that the brain has a large number of these long-term predictors, built out of loops between the two subsystems, and that a subset of these predictors amount to the “critic” part of actor-critic reinforcement learning. The “actor” part is the subject of Post #6 [LW · GW].
Table of contents:
- Section 4.2 gives a motivating example, of flinching just before getting hit in the face. This can be formulated as a supervised learning problem, in the sense that there is a ground-truth signal to learn from. (If you just got hit in the face, then you should have flinched!) The resulting circuit is what I call a “short-term predictor”.
- Section 4.3 defines terminology: “context signals”, “output signals”, and “supervisory signals”. (In ML terminology, these correspond respectively to “trained model inputs”, “trained model outputs”, and “labels”.)
- Section 4.4 offers a sketch of an extremely simple short-term predictor that could be built out of biological neurons, just so you can have something concrete in mind.
- Section 4.5 discusses the benefits of short-term predictors compared to alternative approaches including (in the flinching example) a hardwired circuit for deciding when to flinch, or a reinforcement learning (RL) agent that is rewarded for appropriate flinching. For the latter, a short-term predictor can learn faster than an RL agent because it gets an error gradient “for free” each query—or in simpler terms, when it screws up, it gets some indication of what it did wrong, e.g. whether the error is an overshoot vs. undershoot.
- Sections 4.6-4.8 cover various examples of short-term predictors in the human brain. None of these are especially important for AGI safety—the really important one is the topic of the next post [AF · GW]—but they come up sufficiently often that they warrant a brief discussion:
- Section 4.6 covers the cerebellum, with my theory that it's a collection of ≈300,000 short-term predictors, used to (in effect) reduce the latency on ≈300,000 signals traveling around the brain and body.
- Section 4.7 covers predictive learning of sensory inputs in the cortex—i.e., you’re constantly predicting what you’re about to see, hear, feel, etc., and the corresponding prediction errors are used to update your internal models.
- Section 4.8 briefly covers a few other neat random things that short-term predictor circuits can do for an animal.
4.2 Motivating example: flinching before getting hit in the face
Suppose you have a job or hobby in which there’s a particular, recognizable sensory cue (e.g. someone yelling “FORE!!!” in golf), and then half a second after that cue you very often get whacked in the face. Your brain is going to learn to (involuntarily) flinch in response to the cue. There’s a learning algorithm inside your brain, commanding these flinches; it presumably evolved to protect your face. That learning algorithm is what I want to talk about in this post.
I’m calling it a “short-term predictor”. It’s a “predictor” because the goal of the algorithm is to predict something in advance (i.e., an upcoming whack in the face). It’s “short-term” because we only need to predict what will happen a fraction of a second into the future. It’s more specifically a type of supervised learning algorithm, because there is a “ground truth” signal indicating what the prediction output should have been in hindsight.
4.3 Terminology: Context, Output, Supervisor
Our “short-term predictor” has three ingredients in its “API” (“application programming interface”—i.e., the channels through which other parts of the brain interact with the “short-term predictor” module):
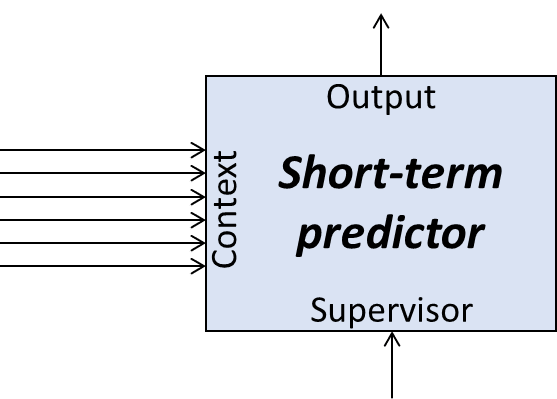
- An output signal is the algorithm’s prediction.
- In our example above, this would be a signal that triggers a flinch reaction.
- A supervisory signal provides “ground truth” (in hindsight) about what the algorithm’s output should have been.
- In our example above, this would be a signal that indicates that I just got whacked in the face (and therefore, implicitly, I should have flinched).
- In ML terminology, “supervisory signals” are often called “labels”.
- In the actual implementation, the supervisor-type input to the short-term predictor does not have to be the ground truth. It could also be an error signal, or a negative error signal, etc. From my perspective, this is an unimportant low-level implementation detail.
- Context signals carry information about what’s going on.
- In our example above, this might be a random assortment of signals (corresponding to latent variables) coming from the visual cortex and auditory cortex. With luck, some of those signals might carry predictively-useful information: maybe one signal conveys the fact that I am on a golf course, and another signal conveys the fact that someone near me just yelled “FORE!”.
- In ML terminology, “context signals” would instead be called “inputs to the trained model”.
The context signals don’t all have to be relevant to the prediction task. We can just throw a whole bunch of crap in there, and the learning algorithm will automatically go searching for the context data that are useful for the prediction task, and ignore everything else.
4.4 Extremely simplified toy example of how this could work in biological neurons
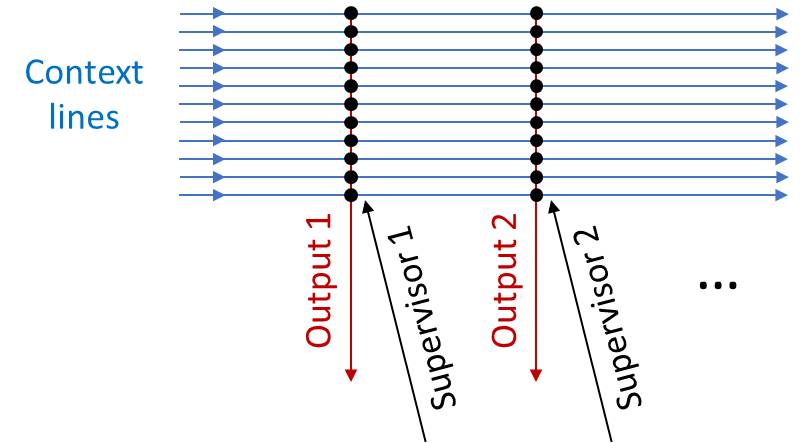
How might a short-term predictor work at a low level?
Well, suppose we want an output signal that precedes the supervisor signal by 0.3 seconds—as above, for example, maybe we want to learn to flinch before getting hit. We grab a bunch of context data that might be relevant—for example, neurons carrying partially-processed visual information. We track which of those context lines is disproportionately likely to fire 0.3 seconds before the supervisor does. Then we wire up those context lines to the output.
And we’re done! Easy peasy.
In biology, this would look something like synaptic plasticity with a “three-factor learning rule”—i.e., the synapse gets stronger or weaker as a function of the activity of three different neurons (context, supervisor, output), and their relative timings.
To be clear, a short-term predictor can be much, much more complicated than this. Making it more complicated can give better performance. To pick a fun example that I just learned about the other day, apparently the short-term predictors in the cerebellum (Section 4.6 below) have neurons that can somehow store an adjustable time-delay parameter within the neuron itself (!!) (ref—it came up on this podcast). Other possible bells and whistles include pattern separation (Post #2, Section 2.5.4 [AF · GW]), and training multiple outputs with the same supervisor and pooling them (ref), or better yet training multiple outputs with the same supervisor but with different hyperparameters, in order to get a probability distribution,[1] and so on.
So this subsection is an oversimplification. But I won’t apologize. I think these kinds of grossly-oversimplified toy models are important to talk about and keep in mind. From a conceptual perspective, we get to feel like there’s probably no deep mystery hidden behind the curtain. From an evolutionary perspective, we get to feel like there’s a plausible story of how early animals can start with a very simple (but still useful) circuit, and the circuit can get gradually more complicated over many generations. So get used to it—many more grossly-oversimplified toy models are coming up in future posts!
4.5 Comparison to other algorithmic approaches
4.5.1 “Short-term predictor” versus a hardwired circuit
Let’s go back to the example above: flinching before getting whacked in the face. I suggested that a good way to decide when to flinch is with a “short-term predictor” learning algorithm. Here’s an alternative: we can hardwire a circuit that decides when to flinch. For example, if there’s a blob in the field-of-view whose size is rapidly increasing, then it’s probably a good time to flinch. A detector like that could plausibly be hardwired into the brain.
How do those two solutions compare? Which is better? Answer: no need to decide! They’re complementary. We can have both. But still, it’s pedagogically helpful to spell out their comparative advantages and disadvantages.
The main (only?) advantage of the hardwired flinching system is that it works from birth. Ideally, you wouldn’t get whacked in the face even once. By contrast, the short-term predictor is a learning algorithm, and thus generally needs to “learn things the hard way”.
In the other direction, the short-term predictor has two powerful advantages over the hardwired solution—one obvious, one not-so-obvious.
The obvious advantage is that a short-term predictor is powered by within-lifetime learning, not evolution, and therefore can learn cues for flinching that were rarely or never present in previous generations. If I tend to bonk my head whenever I walk into a certain cave, I’ll learn to flinch. There’s no chance that my ancestors evolved a reflex to flinch at this particular part of this particular cave. My ancestors might have never been to this cave. The cave might not have existed until last week!
The less obvious, but very important, advantage is that a short-term predictor can learn to trigger on learned-from-scratch patterns (a.k.a. latent variables) (Post #2 [AF · GW]), whereas a hardwired flinching system can’t. The argument here is the same as Section 3.2.1 of the previous post [AF · GW]: the genome cannot know exactly which neurons (if any) will store any particular learned-from-scratch pattern, and therefore cannot hardwire a connection to them.
The ability to leverage learned-from-scratch patterns is a big benefit. For example, there may well be good cues for flinching that depend on learned-from-scratch semantic patterns (e.g. the knowledge “I am playing golf right now”), learned-from-scratch visual patterns (e.g. the visual appearance of a person swinging a golf club) or learned-from-scratch location tags (e.g. “this particular room, which has a low ceiling”), and so on.
4.5.2 “Short-term predictor” vs an RL agent: Faster learning thanks to error gradients
The short-term prediction circuit is a special case of supervised learning.
Supervised learning is when you have a learning algorithm receiving a ground-truth signal like this:
“Hey learning algorithm: you messed up—you should have done thus-and-such instead.”
Compare that to reinforcement learning (RL), where the learning algorithm gets a much less helpful ground-truth signal:
“Hey learning algorithm: you messed up."
(a.k.a negative reward). Obviously, you can learn much faster with supervised learning than with reinforcement learning. The supervisory signals, at least in principle, tell you exactly what parameter settings to change and how, if you want to do better next time you’re in a similar situation. Reinforcement learning doesn’t; instead you need trial-and-error.
In technical ML terms, supervised learning provides a full error gradient “for free” on each query, whereas reinforcement learning does not.
Evolution can’t always use supervised learning. For example, if you’re a professional mathematician trying to prove a theorem, and your latest proof attempt didn’t work, there is no “ground truth” signal that says what to do differently next time—not in your brain, not out there in the world. Sorry! You’re in a very-high-dimensional space of possible things to do, with no real guideposts. At some level, trial-and-error is your only option. Tough luck.
But evolution can sometimes use supervised learning, as in the examples in this post. And my point is: if it can, it probably will.
4.6 “Short-term predictor” example #1: The cerebellum
I’ll jump right into what I think the cerebellum is for, and then I’ll talk about how my theory relates to other proposals in the literature.
4.6.1 My theory of the cerebellum
My claim is that the cerebellum is housing lots short-term prediction circuits.
How many short-term predictors? My best guess is: around 300,000 of them.[2]
What on earth?? Why does your brain need 300,000 short-term predictors?
I have an opinion! I think the cerebellum sits there, watching lots of signals in the brain, and it learns to preemptively send those same signals itself.
That’s it. That’s my whole theory of the cerebellum.
In other words, the cerebellum might discover the rule “Given the current context information, I predict that cortical output neuron #187238 is going to fire in 0.3 seconds”. Then the cerebellum goes ahead and sends a signal right now, to the same place. Or in the opposite direction, the cerebellum might discover the rule “Given the current context information, I predict that proprioceptive nerve #218502 is going to fire in 0.3 seconds”. Again, the cerebellum goes ahead and sends a signal right now, to the same place.
Some vaguely-analogous concepts:
- When the cerebellum is predicting-and-preempting the cortex and striatum, we can think of it as vaguely akin to “memoization” in software engineering, or “knowledge distillation” in machine learning, or this recent paper proposing (so-called) “neural surrogates”.
- When the cerebellum is predicting-and-preempting peripheral nerves, we can think of it as building a bunch of predictive models of the body, each narrowly-tailored to predict a different peripheral nerve signal. Then when the cortex and striatum are doing motor control, and they need peripheral feedback signals, they can use those predictive models as feedback, instead of the real thing. This trick is called “Smith Predictors” in control theory.
Basically, I think the brain has these issues where the throughput (a.k.a. bandwidth) of a subsystem is adequate, but its latency is too high. In the peripheral nerve case, the latency is high because the signals need to travel a great distance. In the cortex case, the latency is high because the signals need to travel a shorter-but-still-substantial distance, and moreover need to pass through multiple sequential processing steps. In any case, the cerebellum can magically reduce the latency, at the cost of occasional errors. The cerebellum sits in the middle of the action, always saying to itself “what signal is about to appear here?”, and then it preemptively sends it. And then a fraction of a second later, it sees whether its prediction was correct, and updates its models if it wasn’t. It’s like a little magical time-travel box—a delay line whose delay is negative.

And now we have our answer: why do we need ≈300,000 short-term predictors? Because there are lots of peripheral nerves, and there are lots of cortex output lines, and maybe other things too. And a great many of those signals can benefit from being predicted-and-preempted! Heck, if I understand correctly, the cerebellum can even predict-and-preempt a signal that goes from the cortex to a different part of the cortex!
That’s my theory. I haven’t run simulations or anything; it’s just an idea. See here [LW · GW] and here [LW · GW] for two examples in which I’ve used this model to try to understand observations in neuroscience and psychology. Everything else I know about the cerebellum—neuroanatomy, how it’s connected to other parts of the brain, lesion and imaging studies, etc.—all seem to fit this theory really well, as far as I can tell. But really, this little section is almost the sum total of what I know about this topic.
4.6.2 How my cerebellum theory relates to others in the literature
(I’m not an expert here and am open to correction.)
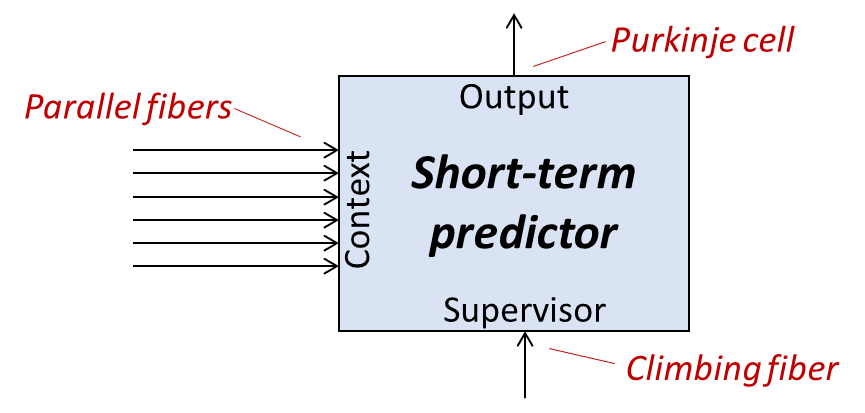
I think it’s widely agreed that the cerebellum is involved in supervised learning. I believe that idea is called the Marr-Albus-Ito model, cf. Marr 1969 or Albus 1971, or the fun Brains Explained YouTube channel.
Recall from above that a short-term predictor is an example of a supervised learning algorithm, but supervised learning is a broader category. So the supervised learning part is not a distinguishing feature of my proposal above, and in particular that diagram above (with cerebellum neuroanatomy in red) is compatible with the usual Marr-Albus-Ito story. Instead, the distinguishing aspect of my theory concerns what the ground truth signals are (or what the error signals are—which amounts to the same thing).
I mentioned in Post #2 [AF · GW] that when I see a within-lifetime learning algorithm, my immediate question is: “What’s the ground truth that it’s learning from?” I also mentioned that usually, when I go looking for an answer in the literature, I wind up feeling confused and unsatisfied. The cerebellum literature is a perfect example.
For example, I often hear something to the effect of “cerebellar synapses are updated when there’s a motor error”. But who’s to say what constitutes a motor error?
- If you’re trying to walk to school, then slipping on a banana peel is a motor error.
- If you’re trying to slip on a banana peel, then slipping on a banana peel is bang-on!
How is the cerebellum supposed to know? I don’t get it.
I’ve read a number of computational theories of the cerebellum. They tend to be way more complicated than mine. And they still leave me feeling like I don’t understand where the ground truth is coming from. The only exceptions are papers proposing theories that are very similar to my own, of which I eventually found two examples, namely: “Is the Cerebellum a Smith Predictor?” by Miall, Weir, Wolpert & Stein (1993) and Learning Anticipatory Behaviour Using a Simple Cerebellar Model” by Harri Valpola (2006). The first has accumulated 1200 citations over the past 30 years, leaving me confused about the fact that my theory above is still not universally accepted, or even commonly mentioned as a serious contender. Isn’t it just obviously right? What am I missing??[3]
Well, whatever. It doesn’t really impact this series. As I mentioned earlier, you can be a functioning adult able to live independently, hold down a job, etc., without a cerebellum at all. So if I’m totally wrong about the cerebellum, it shouldn’t really impact the big picture.
4.7 “Short-term predictor” example #2: Predictive learning of sensory inputs in the cortex
Your cortex has a rich generative model of the world, including yourself. Every fraction of a second, your brain uses that model to predict incoming sensory inputs (sight, sound, touch, proprioception, interoception, etc.), and when its predictions are wrong, the model is updated on the error. Thus, for example, you can open your closet door, and know immediately that somebody oiled the hinge. You were predicting that it would sound and feel a certain way, and the prediction was falsified.
In my view, predictive learning of sensory inputs is the jumbo jet engine bringing information from the world into our cortical world-model. I endorse the Yann LeCun quote: “If intelligence is a cake, the bulk of the cake is [predictive learning of sensory inputs], the icing on the cake is [other types of] supervised learning, and the cherry on the cake is reinforcement learning.” The sheer number of bits of data we get from predictive learning of sensory inputs swamps everything else.
Predictive learning of sensory inputs—in the specific sense I’m using it here—is not a grand unified theory of cognition. The big problem occurs when it collides with “decisions” (what muscles to move, what to pay attention to, etc.). Consider the following: I can predict that I’ll sing, and then I sing, and my prediction was correct. Or I can predict that I’ll dance, and then I dance, and then that prediction was correct. Thus, predictive learning is at a loss; it can’t help me do the right thing here. That’s why we also need the Steering Subsystem (Post #3) [AF · GW] to send supervisory signals and RL reward signals. Those signals can promote good decisions in a way that predictive learning of sensory inputs cannot. (Related: Why I’m not into the free energy principle [LW · GW].)
Nevertheless, predictive learning of sensory inputs is a very big deal for the brain, and there’s a lot to be said about it. However, I’ve come to see it as one of many topics that seems very directly important for building a brain-like AGI, but only slightly relevant for brain-like-AGI safety. So I’ll mention it from time to time, but if you’re looking for gory details, you’re on your own.
4.8 Other example applications of “short-term predictors”
These also won’t be important for this series, so I won’t say much about them, but just for fun, here are three more random things that I think Evolution can do with a short-term predictor circuit.
- Filtering—for example, my brain can make a short-term predictor of my audio input stream, with the constraint that its context inputs only carry information about my own jaw motion and my own vocal cord activity. The predictor should wind up with a model of purely the self-generated contribution to my audio input stream. That’s very useful because my brain can subtract it off, leaving only externally-generated sounds.
- Input data compression—this is kinda a more extreme version of filtering. Instead of merely filtering out information that’s predictable from self-generated activity, we filter out information that’s predictable from any information whatsoever that we already know. By the way, this is how I’m tentatively thinking about the dorsal cochlear nucleus, a little structure in the auditory input processing chain that looks suspiciously like the cerebellum. See here [LW · GW]. Warning: It’s possible that this idea makes no sense; I go back and forth.
- Novelty detection—see discussion here [LW · GW].
Changelog
July 2024: Since the initial version, I added a two references to discussions of the cerebellum similar to mine, along with the “Smith Predictor” terminology that I got from those papers, and a footnote with a sample of literature discussion about this model, where someone disagrees with that model for reasons that I regard as stupid and confused. All other changes were minor wording, adding links, etc.
- ^
Short-term predictors have hyperparameters in their learning algorithms, two of which are “how strongly to update upon a false-positive (overshoot) error”, and “how strongly to update upon a false-negative (undershoot) error”. As the ratio of these two hyperparameters varies from 0 to ∞, the resulting predictor behavior varies from “fire the output if there’s even the faintest chance that the supervisor will fire” to “never fire the output unless it’s all but certain that the supervisor will fire”.
Therefore, if we have many predictors, each with a different ratio of those hyperparameters, then we can (at least approximately) output a probability distribution for the prediction, rather than a point estimate. This is called “distributional learning”.
A recent set of experiments from DeepMind and collaborators found evidence (based on measurements of dopamine neurons) that the brain does in fact use this trick, at least for a certain type of short-term predictor in the striatum associated with valence / reward prediction. I wouldn’t be surprised if this trick were almost universal among short-term predictors in the brain; it seems pretty easy to implement, and useful.
- ^
There are 15 million Purkinje cells (ref), but this paper says that one predictor consists of “a handful of” Purkinje cells with a single supervisor and a single (pooled) output. What does “handful” mean? The paper says “around 50”. Well, 50 in mice. I can’t immediately find the corresponding number for humans. I’m assuming it’s still 50, but that’s just a guess. Anyway, that’s how I wound up guessing that there are 300,000 predictors
- ^
I did a quick search for papers explaining why they don’t like the Miall et al. 1993 Smith Predictor model, and found this one. The authors (1) complain that there’s no “natural” supervisory signal for the Smith predictor, then (2) acknowledge in the next sentence that there is an fact a supervisory signal if you allow eligibility traces (i.e., allowing for a time-delay before the ground truth arrives, just like I’ve been arguing for in this post), then (3) cite some sources saying that the eligibility traces are “only” up to 200 milliseconds, and then (4) proceed to ignore the whole eligibility trace possibility for the rest of the discussion. Huh?? For one thing, 200 milliseconds is huge—that’s plenty of time for signals to arrive all the way from your toes. For another thing, later experimental work seems to imply that 200 milliseconds was never a hard ceiling anyway. I also think the model of Smith predictors in that paper is unnecessarily complicated. If the cerebellum makes a short-term predictor for some peripheral signal, the cerebellum doesn’t need to care whether the predictor is effectively modeling the “motor plant”, or effectively modeling the signal propagation delay, or effectively modeling some inextricable combination of both. It’s the exact same “short-term predictor” learning algorithm regardless! Maybe Miall et al. 1993 were throwing everyone off by making things too complicated? If so, I hope my simple story in this post will help.
11 comments
Comments sorted by top scores.
comment by TLW · 2022-02-19T04:12:12.408Z · LW(p) · GW(p)
The cerebellum sits in the middle of the action, always saying to itself “what signal is about to appear here?”, and then it preemptively sends it. And then a fraction of a second later, it sees whether its prediction was correct, and updates its models if it wasn’t.
How does this cope with feedback loops?
Or is the implicit assumption here that the prediction lookahead is always less than the minimum feedback time delay? (If so, how does it know that?)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2022-02-19T13:12:40.239Z · LW(p) · GW(p)
I've been assuming the latter... Seems to me that there's enough latency in the whole system that it can be usefully reduced somewhat without any risk of reducing it below zero and thus causing instability etc.
I can imagine different signals being hardwired to different time-intervals (possibly as a function of age).
I can also imagine the interval starts low, and creeps up, millisecond by millisecond over the weeks, as long as the predictions keep being accurate, and conversely creeps down when the predictions are inaccurate. (I think that would work in principle, right?)
That's all just idle speculation. I can't immediately think of cerebellum-specific information that would shed light on this. It's a good question :)
comment by TLW · 2022-02-19T04:00:43.014Z · LW(p) · GW(p)
The argument here is the same as Section 3.2.1 of the previous post [LW · GW]: the genome cannot know exactly which neurons (if any) will store any particular learned-from-scratch pattern, and therefore cannot hardwire a connection to them.
This may be more suited as a comment on the previous post. However, it ties into this, so I'll put it here.
I understand the argument that if the upstream circuit learns entirely from scratch, you can't really have hardwired downstream predictors, for lack of anything stable to hardwire them to.
I don't see a clear argument for the premise. Approaching this as a programming problem (...when all you have is a hammer...), consider the following hilariously oversimplified sketch of how to have hardwired predictors in an otherwise mainly-learning-from-scratch circuit:
- Genome encodes that most neurons are initially set to parameters that are tuned such that:
- They, by and large, act as (maybe-noisy[1]) passthroughs for "special" signals.
- They, by and large[1], don't create "special" signals from anything other than a "special" input signal.
- Both of these constraints are fairly 'cheap' to encode in the genome.
- These constraints do have the potential to hurt learning rate. They aren't free.
- Genome encodes that a few neurons are initially set to hardwired parameters:
- Said parameters are set to work with 'special' signals, and (mostly[1]) ignore non-'special' signals.
- Said neurons are spaced such that, statistically speaking, there is a path between them.
- These constraints are likely fairly expensive to encode in the genome.
- These constraints put a fairly low upper bound on how dense the hardwiring can be.
- All neurons learn over time.
- 'Special' signals become less special over time, as a result.
- 'hardwired' neurons become less and less differentiated over time, as a result.
(Note: I'm saying 'special'. I don't actually know enough to say special how. Specific timing? Specific amplitude? Other?)
Hence, I can see a path to having simple initial training wheels while the main learning network gets up to speed.
And I can see why having initial hardcoded behaviors at t=0 could be useful.
(I don't know if the benefits outweigh the costs.)
The main (only?) advantage of the hardwired flinching system is that it works from birth. Ideally, you wouldn’t get whacked in the face even once. By contrast, the short-term predictor is a learning algorithm, and thus generally needs to “learn things the hard way”.
Alternatively: you take a short-term predictor. You hardcode some of its initial parameters to embed a hardwired flinching system, as above.
This works to an extent at t=0, while still getting better and adapting over time.
- ^
Noise is important here, or else the neuron may never learn.
↑ comment by Steven Byrnes (steve2152) · 2022-02-22T02:57:33.830Z · LW(p) · GW(p)
Thanks for the great comment!
if the upstream circuit learns entirely from scratch, you can't really have hardwired downstream predictors, for lack of anything stable to hardwire them to. I don't see a clear argument for the premise.
That would be Post #2 [AF · GW] :-)
consider the following hilariously oversimplified sketch of how to have hardwired predictors in an otherwise mainly-learning-from-scratch circuit…
I don't have strong a priori opposition to this (if I understand it correctly), although I happen to think that it's not how any part of the brain works.
If it were true, it would mean that “learning from scratch” is wrong, but not in a really significant way that impacts the big-picture lessons I draw from it. There still needs to be a learning algorithm. There still needs to be supervisory signals. It's still the case that the eventual meaning of any particular neuron in this learning system is unreliable from the genome's perspective. There still needs to be a separate non-learning sensory processing system [AF · GW] if we want specific instinctual reactions with specific sensory triggers that are stable throughout life. It's still the case that 99.99…% of the bits of information in the adult network coming from the learning algorithm rather than the genome. Etc. Basically everything of significance that I'll be talking about in the series would still be OK, I think. (And, again, assuming that I'm understanding you correctly.)
Alternatively: you take a short-term predictor. You hardcode some of its initial parameters to embed a hardwired flinching system, as above.
This works to an extent at t=0, while still getting better and adapting over time.
Thinking about this, I recall a possible example in the fruit fly, where Li et al. 2020 found that there were so-called “atypical” MBONs (= predictor output neurons) that received input not only from dopamine supervisors, and inputs from randomly-pattern-separated [AF · GW] Kenyon Cell context signals, but also inputs from various other signals in the brain—signals which (I think) do not pass through any randomizing pattern-separator.
If so, and if those connections are playing a “context” role (as opposed to being supervisory signals or real-time hyperparameter settings—I'm not sure which it is), then they could in principle allow the MBONs to do a bit better than chance from birth.
My comments above also apply here—in the event that this is true (which I'd still bet against, at least in the human case), it wouldn't impact anything of significance for the series, I think.
Replies from: TLW↑ comment by TLW · 2022-02-22T06:27:12.787Z · LW(p) · GW(p)
Fair! There are many plausible models that the human brain isn't.
My comments above also apply here—in the event that this is true (which I'd still bet against, at least in the human case), it wouldn't impact anything of significance for the series, I think.
I haven't seen much of anything (beyond the obvious) that said sketch explicitly contradicts, I agree.
I realize now that I probably should have explained the why (as opposed to the what) of my sketch a little better[1].
Your model makes a fair bit of intuitive sense to me; your model has an immediately-obvious[2] potential flaw/gap of "if only the hypothalamus and brainstem are hardwired and the rest learns from scratch, how does that explain <insert innately-present behavior here>[3]", that you do acknowledge but largely gloss over.
My sketch (which is really more of a minor augmentation - as you say it coexists with the rest of this fairly well) can explain that sort of thing[4], with a bunch of implications that seem intuitively plausible[5].
- ^
Read: at all.
- ^
I mean, it was to me? Then again I find myself questioning my calibration of obviousness more and more...
- ^
I find myself skeptical of treating e.g. the behavior of Virginia opossum newborns[6] as either solely driven by the hypothalamus and brainstem[7] ("newborn opossums climb up into the female opossum's pouch and latch onto one of her 13 teats.", especially when combined with "the average litter size is 8–9 infants") or learnt from scratch (among other things, gestation lasts 11–13 days).
- ^
And, in general, can explain behaviors 'on the spectrum' from fully-innate to fully-learnt. Which, to be fair, is in some ways a strike against it.
- ^
E.g. if everyone starts with the same basic rudimentary audio and video processing and learns from there I would expect people to have closer audio and video processing 'algorithms' than might be expected if everything was learnt from scratch - and indeed see e.g. Bouba/Kiki[8].
- ^
Admittedly, found after a quick search on Wikipedia for short gestation periods.
- ^
This is a testable hypothesis I suppose. Although likely not one that will ever be tested for various reasons.
- ^
Which shows up even in 4-month-olds. (Though note n=12 with 13 excluded from the study...)
↑ comment by Steven Byrnes (steve2152) · 2022-02-24T19:01:59.027Z · LW(p) · GW(p)
I find myself skeptical of treating e.g. the behavior of Virginia opossum newborns as either solely driven by the hypothalamus and brainstem ("newborn opossums climb up into the female opossum's pouch and latch onto one of her 13 teats.", especially when combined with "the average litter size is 8–9 infants") or learnt from scratch (among other things, gestation lasts 11–13 days).
Hmm. Why don't you think that behavior might be solely driven by the hypothalamus & brainstem?
For what it's worth, decorticate infant rats (rats whose cortex was surgically removed [yikes]) “appear to suckle normally” according to Carter, Witt, Kolb, Whishaw 1982. That’s not definitive evidence (decortication is only a subset of the hypothetical de-Learning-Subsystem-ification) but I find it suggestive, at least in conjunction with other things I know about the brainstem.
Which shows up even in 4-month-olds. (Though note n=12 with 13 excluded from the study...)
As I noted in Post #2 [AF · GW], “even a 3-month-old infant has had 4 million waking seconds of “training data” to learn from”. That makes it hard to rule out learning, or at least it's hard in the absence of additional arguments, I think.
Replies from: TLW↑ comment by TLW · 2022-02-25T01:11:26.652Z · LW(p) · GW(p)
Why don't you think that behavior might be solely driven by the hypothalamus & brainstem?
I tend to treat hypothalamus & brainstem reactions as limited to a single rote set of (possibly-repetitive) motions driven by a single clear stimulus. The sort of thing that I could write a bit of Python-esque pseudocode for.
Withdrawal reflexes match that. Hormonal systems match that[1]. Blink reflex matches that. Suckling matches that. Pathfinding from point A to any of points B-Z in the presence of dynamic obstacles, properly orienting, then suckling? Not so much...
(That being said, this is not my area of expertise.)
As I noted in Post #2 [LW · GW], “even a 3-month-old infant has had 4 million waking seconds of “training data” to learn from”. That makes it hard to rule out learning, or at least it's hard in the absence of additional arguments, I think.
On the one hand, fair.
On the other hand, one of the main interesting points about the Bouba/Kiki effect is that it appears to be a human universal[2]. I'd consider it unlikely[3] that there's enough shared training data across a bunch of 3-month-olds to bias them towards said effect[4][5][6].
- ^
From what I've seen, anyway. I haven't spent too too much time digging into details here.
- ^
Or as close as anything psychological ever gets to a human universal, at least.
- ^
Though not impossible. See also the mouth-shape hypothesis for the Bouba/Kiki effect.
- ^
Obvious caveat is obvious: said study did not test 3-month-olds across a range of cultures.
- ^
There's commonalities in e.g. the laws of Physics, of course.
- ^
Arguably, this is "additional arguments".
↑ comment by Steven Byrnes (steve2152) · 2022-02-25T01:47:46.330Z · LW(p) · GW(p)
I'm not 100% sure and didn't chase down the reference, but in context, I believe the claim “the [infant decorticate rats] appear to suckle normally and develop into healthy adult rats” should be read as “they find their way to their mother's nipple and suckle”, not just “they suckle when their mouth is already in position”.
Pathfinding to a nipple doesn't need to be “pathfinding” per se, it could potentially be as simple as moving up an odor gradient, and randomly reorienting when hitting an obstacle. I dunno, I tried watching a couple videos of neonatal mice suckling their mothers (1,2) and asking myself “could I write python-esque pseudocode that performed as well as that?” and my answer was “yeah probably, ¯\_(ツ)_/¯”. (Granted, this is not a very scientific approach.)
“Shared training data” includes not only the laws of physics but also the possession of a human brain and body. For example, I might speculate that both sharp objects and “sharp” noises are causes of unpleasantness thanks to our innate brainstem circuits, and all humans have those circuits, therefore all humans might have a shared tendency to give similar answers to the bouba/kiki thing. Or even if that specific story is wrong, I can imagine that something vaguely like that might be responsible.
Replies from: TLWcomment by Tapatakt · 2022-03-19T14:10:53.586Z · LW(p) · GW(p)
>Heck, if I understand correctly, the cerebellum can even predict-and-preempt a signal that goes from the telencephalon to itself!
Help me please, I can't understand how to correctly translate this part: "to itself" == "to telencephalon" or "to itself" == "to cerebellum"?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2022-03-19T14:21:24.803Z · LW(p) · GW(p)
The former. I'll edit the wording, thank you.