Posts
Comments
Interesting.
If you're stating that generic intelligence was not likely simulated, but generic intelligence in our situation was likely simulated...
Doesn't that fall afoul of the mediocrity principle applied to generic intelligence overall?
(As an aside, this does somewhat conflate 'intelligence' and 'computation'; I am assuming that intelligence requires at least some non-zero amount of computation. It's good to make this assumption explicit I suppose.)
I should probably reread the paper.
That being said:
No, it doesn't, any more than "Godel's theorem" or "Turing's proof" proves simulations are impossible or "problems are NP-hard and so AGI is impossible".
I don't follow your logic here, which probably means I'm missing something. I agree that your latter cases are invalid logic. I don't see why that's relevant.
simulators can simply approximate
This does not evade this argument. If nested simulations successively approximate, total computation decreases exponentially (or the Margolus–Levitin theorem doesn't apply everywhere).
simulate smaller sections
This does not evade this argument. If nested simulations successively simulate smaller sections, total computation decreases exponentially (or the Margolus–Levitin theorem doesn't apply everywhere).
tamper with observers inside the simulation
This does not evade this argument. If nested simulations successively tamper with observers, this does not affect total computation - total computation still decreases exponentially (or the Margolus–Levitin theorem doesn't apply everywhere).
slow down the simulation
This does not evade this argument. If nested simulations successively slow down, total computation[1] decreases exponentially (or the Margolus–Levitin theorem doesn't apply everywhere).
cache results like HashLife
This does not evade this argument. Using HashLife, total computation still decreases exponentially (or the Margolus–Levitin theorem doesn't apply everywhere).
(How do we simulate anything already...?)
By accepting a multiplicative slowdown per level of simulation in the infinite limit[2], and not infinitely nesting.
- ^
See note 2 in the parent: "Note: I'm using 'amount of computation' as shorthand for 'operations / second / Joule'. This is a little bit different than normal, but meh."
- ^
You absolutely can, in certain cases, get no slowdown or even a speedup by doing a finite number of levels of simulation. However, this does not work in the limit.
Said argument applies if we cannot recursively self-simulate, regardless of reason (Margolus–Levitin theorem, parent turning the simulation off or resetting it before we could, etc).
In order for 'almost all' computation to be simulated, most simulations have to be recursively self-simulating. So either we can recursively self-simulate (which would be interesting), we're rare (which would also be interesting), or we have a non-zero chance we're in the 'real' universe.
Interesting.
I am also skeptical of the simulation argument, but for different reasons.
My main issue is: the normal simulation argument requires violating the Margolus–Levitin theorem[1], as it requires that you can do an arbitrary amount of computation[2] via recursively simulating[3].
This either means that the Margolus–Levitin theorem is false in our universe (which would be interesting), we're a 'leaf' simulation where the Margolus–Levitin theorem holds, but there's many universes where it does not (which would also be interesting), or we have a non-zero chance of not being in a simulation.
This is essentially a justification for 'almost exactly all such civilizations don't go on to build many simulations'.
- ^
A fundamental limit on computation:
- ^
Note: I'm using 'amount of computation' as shorthand for 'operations / second / Joule'. This is a little bit different than normal, but meh.
- ^
Call the scaling factor - of amount of computation necessary to simulate X amount of computation - . So e.g. means that to simulate 1 unit of computation you need 2 units of computation. If , then you can violate the Margolus–Levitin theorem simply by recursively sub-simulating far enough. If , then a universe that can do computation can simulate no more than total computation regardless of how deep the tree is, in which case there's at least a chance that we're in the 'real' universe.
Playing less wouldn’t decrease my score
Interesting. Is this typically the case with chess? Humans tend to do better with tasks when they are repeated more frequently, albeit with strongly diminishing returns.
being distracted is one of the effects of stress.
Absolutely, which makes it very difficult to tease apart 'being distracted as a result of stress caused by X causing a drop' and 'being distracted due to X causing a drop'.
solar+batteries are dropping exponentially in price
Pulling the data from this chart from your source:
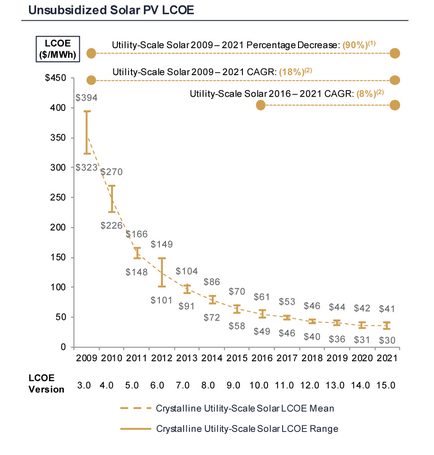
...and fitting[1] an exponential trend with offset[2], I get:
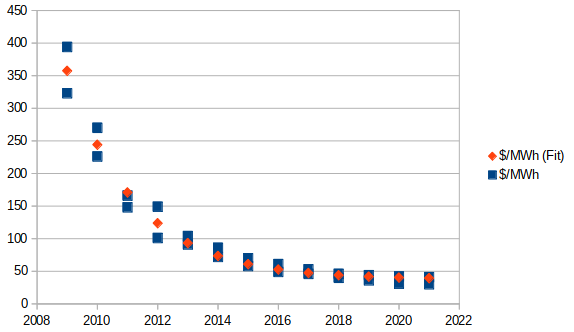
(Pardon the very rough chart.)
This appears to be a fairly good fit[3], and results in the following trend/formula:
This is an exponentially-decreasing trend... but towards a decidedly positive horizontal asymptote.
This essentially indicates that we will get minimal future scaling, if any. $37.71/MWh is already within the given range.
For reference, here's what the best fit looks like if you try to force a zero asymptote:
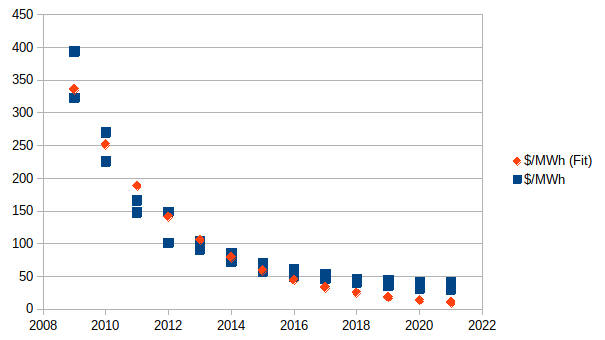
This is fairly obviously a significantly worse fit[5].
Why do you believe that solar has an asymptote towards zero cost?[6]
fossils usually don't need storage
Absolutely, which is one of the reasons why in the absence of wanting clean energy people tend to lean towards fossil fuels.
- ^
Nonlinear least squares.
- ^
I'm treating the high and low as two different data points for each year, which isn't quite right, but meh.
- ^
Admittedly, just from eyeballing it.
- ^
Yes, this could be simplified. That being said, I get numerical stability issues if I don't include the year offset; it's easier to just include said offset.
- ^
Admittedly, this is a 2-parameter fit not a 3-parameter fit; I don't know offhand of a good alternative third parameter to add to the fit to make it more of an apples-to-apples comparison.
- ^
As an aside, people fitting exponential trends without including an offset term and then naively extrapolating, when exponential trends with offset terms fit significantly better and don't result in absurd conclusions, is a bit of a pet peeve of mine.
Too bad. My suspects for confounders for that sort of thing would be 'you played less at the start/end of term' or 'you were more distracted at the start/end of term'.
First, nuclear power is expensive compared to the cheapest forms of renewable energy and is even outcompeted by other “conventional” generation sources [...] The consequence of the current price tag of nuclear power is that in competitive electricity markets it often just can’t compete with cheaper forms of generation.
[snip chart]
Source: Lazard
This estimate does not seem to include capacity factors or cost of required energy storage, assuming I read it correctly. Do you have an estimate that does?
Thirdly, nuclear power gives you energy independence. This became very clear during Russia’s invasion of Ukraine. France, for example, had much fewer problems cutting ties with Russia than e.g. Germany. While countries might still have to import Uranium, the global supplies are distributed more evenly than with fossil fuels, thereby decreasing geopolitical relevance. Uranium can be found nearly everywhere.
Also, you can extract uranium from seawater. This has its own problems, and is still more expensive than mines currently. However, this puts a cap on the cost of uranium for any (non-landlocked) country, which is a very good thing for contingency purposes.
(Also, there are silly amounts of uranium in seawater. 35 million tons of land-based reserves, and 4.6 billion in seawater. At very low concentrations, but still.)
How much did you play during the start / end of term compared to normal?
Here's an example game tree:
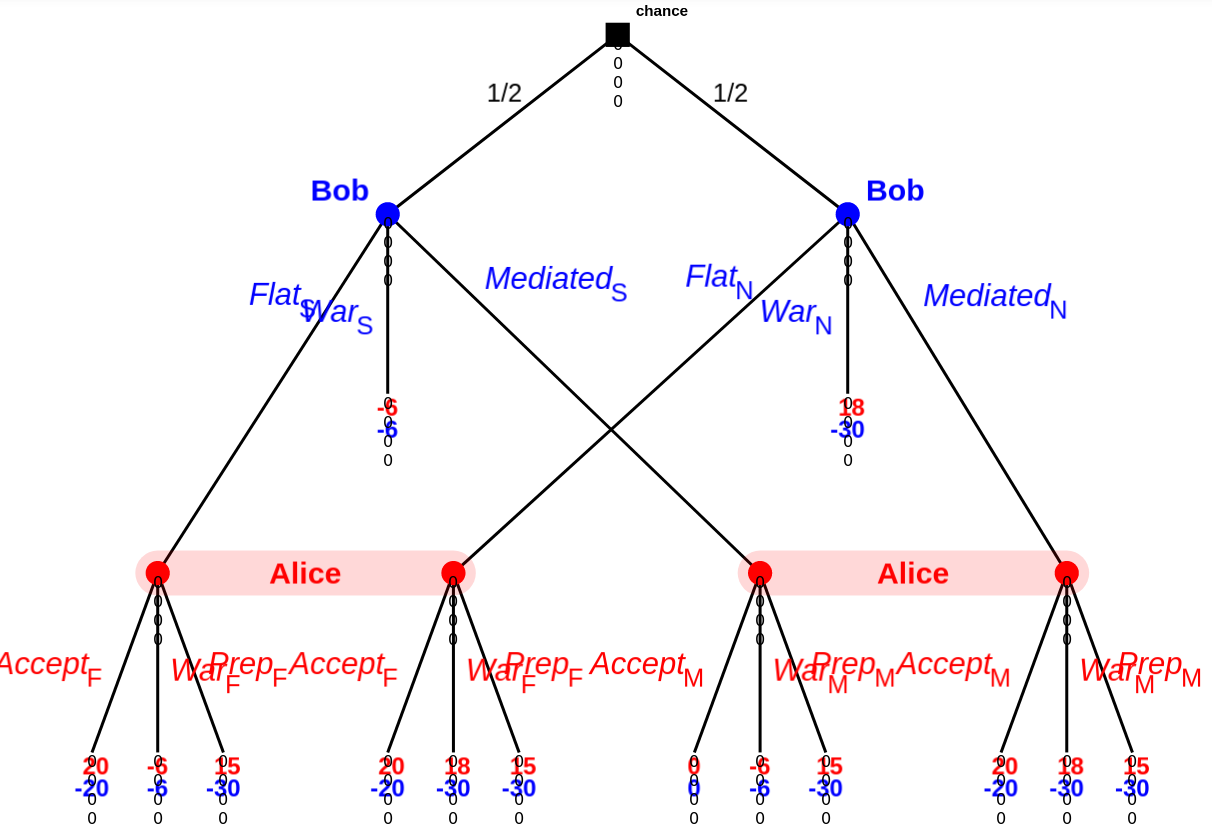
(Kindly ignore the zeros below each game node; I'm using the dev version of GTE, which has a few quirks.)
Roughly speaking:
- Bob either has something up his sleeve (an exploit of some sort), or does not.
- Bob either:
- Offers a flat agreement (well, really surrender) to Alice.
- Offers a (binding once both sides agree to it) arbitrated (mediated in the above; I am not going to bother redoing the screenshot above) agreement by a third party (Simon) to Alice.
- Goes directly to war with Alice.
- Assuming Bob didn't go directly to war, Alice either:
Wars cost the winner 2 and the loser 10, and also transfers 20 from the loser to the winner. (So normally war is normally +18 / -30 for the winner/loser.).
Alice doing an audit/preparing costs 3, on top of the usual, regardless of if there's actually an exploit.
Alice wins all the time unless Bob has something up his sleeve and Alice doesn't prepare. (+18/-30, or +15/-30 if Alice prepared.) Even in that case, Alice wins 50% of the time. (-6 / -6). Bob has something up his sleeve 50% of the time.
Flat offer here means 'do the transfer as though there was a war, but don't destroy anything'. A flat offer is then always +20 for Alice and -20 for Bob.
Arbitrated means 'do a transfer based on the third party's evaluation of the probability of Bob winning, but don't actually destroy anything'. So if Bob has something up his sleeve, Charlie comes back with a coin flip and the result is 0, otherwise it's +20/-20.
There are some 17 different Nash equilibria here, with an EP from +6 to +8 for Alice and -18 to -13 for Bob. As this is a lot, I'm not going to list them all. I'll summarize:
- There are 4 different equilibria with Bob always going to war immediately. Payoff in all of these cases is +6 / -18.
- There are 10 different equilibria with Bob always trying an arbitrated agreement if Bob has nothing up his sleeve, and going to war 2/3rds of the time if Bob has something up his sleeve (otherwise trying a mediated agreement in the other 1/3rd), with various mixed strategies in response. All of these cases are +8 / -14.
- There are 3 different equilibria with Bob always going to war if Bob has something up his sleeve, and always trying a flat agreement otherwise, with Alice always accepting a flat agreement and doing various strategies otherwise. All of these cases are +7 / -13.
Notably, Alice and Bob always offering/accepting an arbitrated agreement is not an equilibrium of this game[3]. None of these equilibria result in Alice and Bob always doing arbitration. (Also notably: all of these equilibria have the two sides going to war at least occasionally.)
There are likely other cases with different payoffs that have an equilibrium of arbitration/accepting arbitration; this example suffices to show that not all such games lead to said result as an equilibrium.
- ^
I use 'audit' in most of this; I used 'prep' for the game tree because otherwise two options started with A.
- ^
read: go 'uhoh' and spend a bunch of effort finding/fixing Bob's presumed exploit.
- ^
This is because, roughly, a Nash equilibrium requires that both sides choose a strategy that is best for them given the other party's response, but if Bob chooses MediatedS / MediatedN, then Alice is better off with PrepM over AcceptM. Average payout of 15 instead of 10. Hence, this is not an equilibrium.
As TLW's comment notes, the disclosure process itself might be really computationally expensive.
I was actually thinking of the cost of physical demonstrations, and/or the cost of convincing others that simulations are accurate[1], not so much direct simulation costs.
That being said, this is still a valid point, just not one that I should be credited for.
- ^
Imagine trying to convince someone of atomic weapons purely with simulations, without anyone ever having detonated one[2], for instance. It may be doable; it'd be nowhere near cheap.
Now imagine trying to do so without allowing the other side to figure out how to make atomic bombs in the process...
- ^
To be clear: as in alt-history-style 'Trinity / etc never happened'. Not just as in someone today convincing another that their particular atomic weapon works.
Ignore the suit of the cards. So you can draw a 1 (Ace) through 13 (King). Pulling two cards is a range of 2 to 26. Divide by 2 and add 1 means you get the same roll distribution as rolling two dice.
That's not the same roll distribution as rolling two dice[1]. For instance, rolling a 14 (pulling 2 kings) has a probability of , not [2].
(The actual distribution is weird. It's not even symmetrical, due to the division (and associated floor). Rounding to even/odd would help this, but would cause other issues.)
This also supposes you shuffle every draw. If you don't, things get worse (e.g. you can't 'roll' a 14 at all if at least 3 kings have already been drawn).
====
Fundamentally: you're pulling out 2 cards from the deck. There are 52 possible choices for the first card, and 51 for the second card. This means that you have 52*51 possibilities. Without rejection sampling this means that you're necessarily limited to probabilities that are a multiple of . Meanwhile, rolling N S-sided dice and getting exactly e.g. N occurs with a probability of . As N and S are both integers, and 52=2*2*13, and 51=3*17, the only combinations of dice you can handle without rejection sampling are:
- Nd1[3]
- 1d2, 1d3, 1d4, 1d13, 1d17, 1d26, ..., 1d(52*51)
- 2d2
...and even then many of these don't actually involve both cards. For instance, to get 2d2 with 2 pulled cards ignore the second card and just look at the suit of the first card.
Alice and Bob won't always cheat because they will get good rolls sometimes that will look like cheats but won't be.
Wait, do you mean:
- Decide to cheat or not cheat, then if not cheating do a random roll, or
- Do a random roll, and then decide to cheat or not?
I was assuming 1, but your argument is more suited for 2...
- ^
Aside from rolling a strange combination of a strangely-labelled d52 and a strangely-labelled d51, or somesuch.
- ^
import itertools import fractions import collections cards = list(range(1, 14))*4 dice_results = collections.Counter(a+b for a in range(1, 8) for b in range(1, 8)) dice_denom = sum(dice_results.values()) card_results = collections.Counter((a+b)//2+1 for a, b in itertools.permutations(cards, r=2)) card_denom = sum(card_results.values()) for val in range(2, 15): print(val, fractions.Fraction(card_results[val], card_denom), fractions.Fraction(dice_results[val], dice_denom), sep='\t')2 11/663 1/49 3 9/221 2/49 4 43/663 3/49 5 59/663 4/49 6 25/221 5/49 7 7/51 6/49 8 33/221 1/7 9 83/663 6/49 10 67/663 5/49 11 1/13 4/49 12 35/663 3/49 13 19/663 2/49 14 1/221 1/49 - ^
This is somewhat trivial, but I figured it was worth mentioning.
Interesting.
The other player gets to determine your next dice roll (again, either manually or randomly).
Could you elaborate here?
Alice cheats and say she got a 6. Bob calls her on it. Is it now Bob's turn, and hence effectively a result of 0? Or is it still Alice's turn? If the latter, what happens if Alice cheats again?
I'm not sure how you avoid the stalemate of both players 'always' cheating and both players 'always' calling out the other player.
Instead of dice, a shuffled deck of playing cards would work better. To determine your dice roll, just pull two cards from a shuffled deck of cards without revealing them to anyone but yourself, then for posterity you put those two cards face down on top of that deck.
How do you go from a d52 and a d51 to a single potentially-loaded d2? I don't see what to do with said cards.
Interesting!
How does said binding treaty come about? I don't see any reason for Alice to accept such a treaty in the first place.
Alice would instead propose (or counter-propose) a treaty that always takes the terms that would result from the simulation according to Alice's estimate.
Alice is always at least indifferent to this, and the only case where Bob is not at least indifferent to this is if Bob is stronger than Alice's estimate, in which case accepting said treaty would not be in Alice's best interest. (Alice should instead stall and hunt for exploits, give or take.)
Let's look at a relatively simple game along these lines:
Person A either cheats an outcome or rolls a d4. Then person B either accuses, or doesn't. If person B accuses, the game ends immediately, with person B winning (losing) if their accusation was correct (incorrect). Otherwise, repeat a second time. At the end, assuming person B accused neither time, person A wins if the total sum is at least 6. (Note that person A has a lower bound of a winrate of 3/8ths simply by never cheating.)
Let's look at the second round first.
First subcase: the first roll (legitimate or uncaught) was 1. Trivial win for person B.
Second subcase: the first roll was 2. Subgame tree is as follows: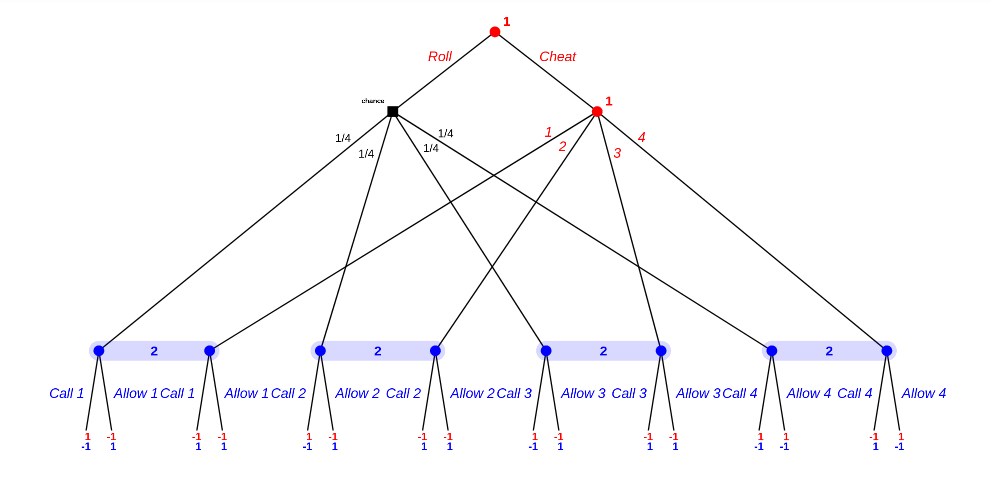
The resulting equlibria are:
- Person A always rolls.
- Person B allows 1-3, and either always calls 4, or calls 4 1/4 of the time.
Either way, expected value is -1/2 for Person A, which makes sense given person A plays randomly (1/4 die rolls win for person A).
Third subcase: the first roll was 3. Simplified subgame tree is as follows:
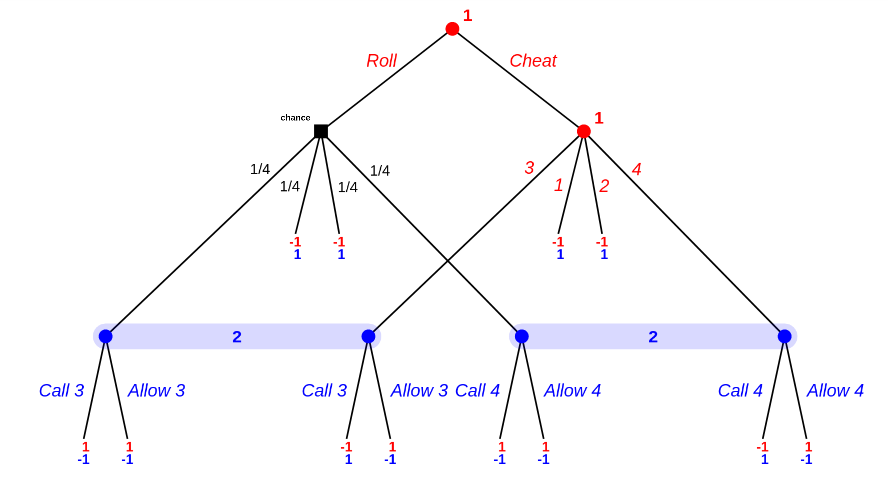
There are 5 (five) equlibria for this one:
- Person A always plays randomly.
- Person B always allows 1 and 2, and either always calls both 3 and 4, or always calls one of 3 or 4 and allows the other 50% of the time, or 50/50 allows 3/calls 4 or allows 4/calls 3, or 50/50 allows both / calls both.
Overall expected value is 0, which makes sense given person A plays randomly (2/4 die rolls win for person A).
Fourth subcase: the first roll was 4. I'm not going to enumerate the equlibria here, as there are 40 of them (!). Suffice to say, the result is, yet again, person A always playing randomly, with person B allowing 1 and calling 2-4 always or probabilistically in various combinations, with an expected value of +1/2.
And then the first round:
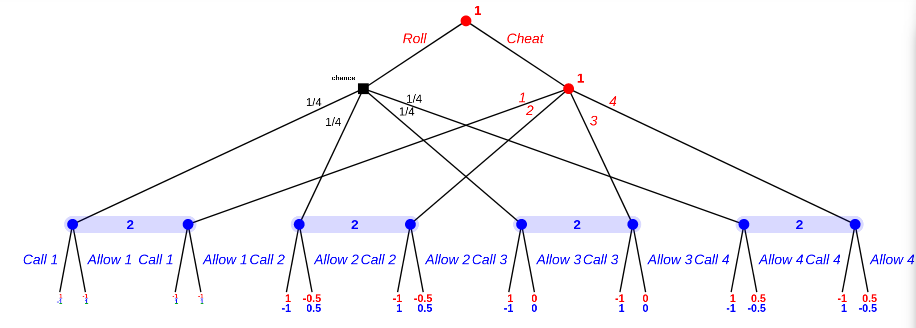
Overall equlibria are:
- Person A plays randomly 3/4 of the time, cheats 3 3/16th of the time, and cheats 4 1/16th of the time.
- Person B always allows 1 and 2, and does one of two mixes of calling/allowing 3 and 4. (0 | 5/32 | 7/16 | 13/32, or 5/32 | 0 | 9/32 | 9/16 of call/call | call/allow | allow/call | allow/allow).
Either way, expected value for person A is -5/32.
Tl;DR:
This (over)simplified game agrees with your intuition. There are mixed strategies on both sides, and cases where you 'may as well' always call, and cases where you want to cheat to a value below the max value.
(Most of this was done with http://app.test.logos.bg/ - it's quite a handy tool for small games, although note that it doesn't compute equilibria for single giant games. You need to break them down into smaller pieces, or fiddle with the browser debugger to remove the hard-coded 22 node limit.)
What's the drawback to always accusing here?
Though this does suggest a (unrealistically) high-coordination solution to at least this version of the problem: have both sides declare all their capabilities to a trusted third party who then figures out the likely costs and chances of winning for each side.
Is that enough?
Say Alice thinks her army is overwhelmingly stronger than Bob. (In fact Bob has a one-time exploit that allows Bob to have a decent chance to win.) The third party says that Bob has a 50% chance of winning. Alice can then update P(exploit), and go 'uhoh' and go back and scrub for exploits.
(So... the third-party scheme might still work, but only once I think.)
Conversely, if FDR wants a chicken in every pot, and then finds out that chickens don't exist, he would change his values to want a beef roast in every pot, or some such.
I do not believe his value function is "a chicken in every pot". It's likely closer to 'I don't want anyone to be unable to feed themselves', although even this is likely an over-approximation of the true utility function. 'A chicken in every pot' is one way of doing well on said utility function. If he found out that chickens didn't exist, the 'next best thing' might be a roast beef in every pot, or somesuch. This is not changing the value function itself, merely the optimum[1] solution.
If FDR's true value function was literally " a chicken in every pot", with no tiebreaker, then he has no incentive to change his values, and a weak incentive to not change his values (after all, it's possible that everyone was mistaken, or that he could invent chicken).
If FDR's true value function was e.g. "a chicken in every pot, or barring that some other similar food", then again he has no incentive to change his values. He may lean toward 'ok, it's very unlikely that chickens exist so it's better in expected value to work towards roast beef in every pot', but that again hasn't changed the underlying utility function.
- ^
This isn't likely to be the optimum, but at least is a 'good' point.
Demonstrating military strength is itself often a significant cost.
Say your opponent has a military of strength 1.1x, and is demonstrating it.
If you have the choice of keeping and demonstrating a military of strength x, or keeping a military of strength 1.2 and not demonstrating at all...
If you allow the assumption that your mental model of what was said matches what was said, then you don't necessarily need to read all the way through to authoritatively say that the work never mentions something, merely enough that you have confidence in your model.
If you don't allow the assumption that your mental model of what was said matches what was said, then reading all the way through is insufficient to authoritatively say that the work never mentions something.
(There is a third option here: that your mental model suddenly becomes much better when you finish reading the last word of an argument.)
I want to clarify that this is not a particularly useful type of utility function, and the post was a mostly-failed attempt to make it useful.
Fair! Here's another[1] issue I think, now that I've realized you were talking about utility functions over behaviours, at least if you allow 'true' randomness.
Consider a slight variant of matching pennies: if an agent doesn't make a choice, their choice is made randomly for them.
Now consider the following agents:
- Twitchbot.
- An agent that always plays (truly) randomly.
- An agent that always plays the best Nash equilibrium, tiebroken by the choice that results in them making the most decisions. (And then tiebroken arbitrarily from there, not that it matters in this case.)
These all end up with infinite random sequences of plays, ~50% heads and ~50% tails[2][3][4]. And any infinite random (50%) sequence of plays could be a plausible sequence of plays for either of these agents. And yet these agents 'should' have different decompositions into and .
- ^
Maybe. Or maybe I was misconstruing what you meant by 'if the randomness is true and the agent is actually maximizing, then the abstraction breaks down' and this is the same issue you recognized.
- ^
Twitchbot doesn't decide, so its decision is made randomly for it, so it's 50/50.
- ^
The random agent decides randomly, so it's 50/50.
- ^
'The' best Nash equilibrium is any combination of choosing 50/50 randomly, and/or not playing. The tiebreak means the best combination is playing 50/50.
Interesting!
Could you please explain why your arguments don't apply to compilers?
You would get a 1.01 multiplier in productivity, that would make the speed of development 1.01x faster, especially the development of a Copilot-(N+1),
...assuming that Copilot-(N+1) has <1.01x the development cost as Copilot-N. I'd be interested in arguments as to why this would be the case; most programming has diminishing returns where e.g. eking out additional performance from a program costs progressively more development time.
That's a very different definition of utility function than I am used to. Interesting.
What would the utility function over behaviors for an agent that chose randomly at every timestep look like?
(Disclaimer: not my forte.)
CLIP’s task is to invent a notation system that can express the essence of (1) any possible picture, and (2) any possible description of a picture, in only a brief list of maybe 512 or 1024 floating-point numbers.
How many bits is this? 2KiB / 16Kib? Other?
Has there been any work in using this or something similar as the basis of a high-compression compression scheme? Compression and decompression speed would be horrendous, but still.
Hm. I wonder what would happen if you trained a version on internet images and its own image errors. I suspect it might not converge, but it's still interesting to think about.
Assuming it did converge, take the final trained version and do the following:
- Encode the image.
- Take the difference between the image and output. Encode that.
- Take the difference between the image and output + delta output. Encode that.
- Repeat until you get to the desired bitrate or error rate.
Why is this style of pessimism repeatedly wrong?
Beware selection bias. If it wasn't repeatedly wrong, there's a good chance we wouldn't be here to ask the question!
The opposite view is that progress is a matter of luck.
Hm. I tend to not view the pessimistic side as luck so much as 'there's a finite number of useful techs, which we are rapidly burning through'.
I don't think I make this assumption.
You don't explicitly; it's implicit in the following:
It is well known that a utility function over behaviors/policies is sufficient to describe any policy.
The VNM axioms do not necessarily apply for bounded agents. A bounded agent can rationally have preferences of the form A ~[1] B and B ~ C but A ≻[2] C, for instance[3]. You cannot describe this with a straight utility function.
- ^
is indifferent to
- ^
is preferred over
- ^
See https://www.lesswrong.com/posts/AYSmTsRBchTdXFacS/on-expected-utility-part-3-vnm-separability-and-more?commentId=5DgQhNfzivzSdMf9o, which is similar but which does not cover this particular case. That being said, the same technique should 'work' here.
Kudos for not naively extrapolating past 100% of GDP invested into AI research.
Reduced Cost of Computation: Estimated to reduce by 50% every 2.5 years (about in-line with current trends), down to a minimum level of 1 / 106 (i.e., 0.0001%) in 50 years.
Increased Availability of Capital for AI: Estimated to reach a level of $1B in 2025, then double every 2 years after that, up to 1% of US GDP (currently would suggest $200B of available capital, and growing ~3% per year).
Our current trends in cost of computation are in combination with (seemingly) exponentially-increasing investment. If some or all of the reduced cost of computation is driven by increasing investment, using these numbers you'd expect a knee in the computation cost curve by about 2040[1] or so.
There are also other limits here. For instance: since 2010 DRAM bits/$ has been rising by ~18%[4] per year on average[2]. This is significant, but not the 32%[5]/year that 2x every 2.5 years would imply. For now, DRAM cost hasn't been the limiting factor... but with continued exponential scaling?
Estimated to reduce computation required by 50% every 2-3 years based on observed recent progress
I'd be careful extrapolating here. Compilers also made major progress in 'early' days, but have somewhere between a 2-5 decade output-efficiency doubling time at this point[3][6].
I also wonder how much of recent progress has been driven by increased investment. Do you have numbers on this?
- ^
. Actually slightly later, because GDP does grow somewhat over that time.
- ^
https://aiimpacts.org/trends-in-dram-price-per-gigabyte/ -> "Since 2010, the price has fallen much more slowly, at a rate that would yield an order of magnitude over roughly 14 years."
- ^
Proebsting's Law is an observation that compilers roughly double the performance of the output program, all else being equal, with an 18-year doubling time. The 2001 reproduction suggested more like 20 years under optimistic assumptions. A 2022 informal test showed a 10-15% improvement on average in the last 10 years, which is closer to a 50-year doubling time.
- ^
->
- ^
->
- ^
Personally, I think most seemingly-exponential curves are subexponential, but that's another matter.
See https://www.nytimes.com/2019/11/04/business/secret-consumer-score-access.html (taken from this comment.)
All of this is predicated on the agent having unlimited and free access to computation.
This is a standard assumption, but is worth highlighting.
endowed with the of probability calculation
I suspect dropped a word in that sentence.
Maybe "endowed with the power of probability calculation", or somesuch?
So, uh, how should we start preparing for the impact of this here in the West?
Push officials to redirect corn subsidies for ethanol toward food? Keeping American corn production alive in case it suddenly was required was one of the reasons for said subsidies[1], after all.
(Of course, this doesn't help the upstream portions of the food supply chain.)
- ^
...to the best of my knowledge, although I note that I can't find anything explicitly mentioning this at a quick look.
Alright, we are in agreement on this point.
I have a tendency to start on a tangential point, get agreement, then show the implications for the main argument. In practice a whole lot more people are open to changing their minds in this way than directly. This may be somewhat less important on this forum than elsewhere.
You stated:
In contrast, I think almost all proponents of libertarian free will would agree that their position predicts that an agent with such free will, such as a human, could always just choose to not do as they are told. If the distribution they are given looks like it's roughly uniform they can deterministically pick one action, and if it looks like it's very far from uniform they can just make a choice uniformly at random. The crux is that the function this defines can't be continuous, so I believe this forces advocates of libertarian free will to the position that agents with free will must represent discontinuous input-output relations.
(Emphasis added.)
One corollary of your conclusion is that it would imply that a continuous implies a lack of free will. - or in this case .
However, I've shown a case where a continuous nevertheless results in Omega having zero predictive power over the agent:
If the fixedpoint was 50/50 however, the fixedpoint is still satisfied by Omega putting in the money 50% of the time, but Omega is left with no predictive power over the outcome .
This then either means that:
- Your argument is flawed.
- My tangential point is flawed.
- This logic chain is flawed.
- You think that Omega having no predictive power over the outcome is still incompatible with the agent having free will.
- (If so, why?)
- (Note phrasing: this is not stating that the agent must have free will, only that it's not ruled out.)
It seems to me that you're (intentionally or not) trying to find mistakes in the post.
It is obvious we have a fundamental disagreement here, and unfortunately I doubt we'll make progress without resolving this.
Euclid's Parallel Postulate was subtly wrong. 'Assuming charity' and ignoring that would not actually help. Finding it, and refining the axioms into Euclidean and non-Euclidean geometry, on the other hand...
My point is that the fact that Omega can guess 50/50 in the scenario I set up in the post doesn't allow it to actually have good performance
That... is precisely my point? See my conclusion:
If the fixedpoint was 50/50 however, the fixedpoint is still satisfied by Omega putting in the money 50% of the time, but Omega is left with no predictive power over the outcome .
(Emphasis added.)
Paxlovid itself is free at point-of-sale (or at least the current supply is), so there's no monetary concern.
See "paxlovid is free".
Admittedly, I am not super familiar with the US hospital system, but I believe Paxlovid is only available by prescription - which itself is a nontrivial cost for many.
These patients have already been tested.
Not only did they get tested but they tested positive.
They already have covid, they aren't being asked to do something unusual and unpleasant to prevent an uncertain future harm.
They're literally being offered a prescription by a doctor and turning it down.
Note this quote:
Paxlovid was expected to be a major tool in the fight against COVID after it reduced hospitalizations or deaths in high-risk patients by around 90% in a clinical trial.
…
“We’re just not seeing as many people coming in for testing,”
(Emphasis added.)
Another case that violates the preconditions is if the information source is not considered to be perfectly reliable.
Imagine the following scenario:
Charlie repeatedly flips a coin, and tells person A and B the results.
Alice and Bon are choosing between the following hypotheses:
- The coin is fair.
- The coin always comes up heads.
- The coin is fair, but person C only reports when the coin comes up heads.
Alice has a prior of 40% / 40% / 20%. Bob has a prior of 40% / 20% / 40%.
Now, imagine that Charlie repeatedly reports 'heads'. What happens?
Answer: Alice asymptotes towards 0% / 66.7% / 33.3%; Bob asymptotes towards 0% / 33.3% / 66.7%. Their opinions remain distinct.
There was a good simulation of a more complicated scenario with many agents exhibiting much the same effect somewhere on this site, but I can't find it. Admittedly, I did not look particularly hard.
I can only conclude that most people do not much care about Covid.
...or people don't have the resources to be able to afford Paxlovid.
...or 'have you had a positive test in the past 14 days; if so you cannot work'-style questions, especially combined with nontrivial false-positive rates, have lead people to avoid getting tested in the first place.
...or people think that the cost to get tests outweighs the expected benefit.
...or people think that the cost to get Paxlovid outweighs the expected benefit.
...or people have started to discount 'do X to stop Covid; we really mean it this time' in general.
...or people simply haven't heard of Paxlovid.
64% (!)[1] of the US is living paycheque-to-paycheque. Missing a couple of shifts due to having to stay home can be the difference between making rent and becoming homeless.
If Omega predicts even odds on two choices and then you always pick one you've determined in advance
(I can't quite tell if this was intended to be an example of a different agent or if it was a misconstrual of the agent example I gave. I suspect the former but am not certain. If the former, ignore this.) To be clear: I meant an agent that flips a quantum coin to decide at the time of the choice. This is not determined, or determinable, in advance[1]. Omega can predict here fairly easily, but not .
There's a big difference between those two cases
Absolutely. It's the difference between 'average' predictive power over all agents and worst-case predictive power over a single agent, give or take, assuming I am understanding you correctly.
If Omega predicts even odds on two choices and then you always pick one you've determined in advance, it will be obvious that Omega is failing to predict your behavior correctly.
Ah. I think we are thinking of two different variants of the Newcomb problem. I would be interested in a more explicit definition of your Newcomb variant. The original Newcomb problem does not allow the box to contain odds, just a binary money/no money.
I agree that if Omega gives the agent the odds explicitly it's fairly simple for an agent to contradict Omega.
I was assuming that Omega would treat the fixed point instead as a mixed strategy (in the game theory sense) - that is if Omega predicted, say, 70/30 was a fixed point, Omega would roll a d10[2] and 70% of the time put the money in.
This "works", in the sense of satisfying the fixedpoint, and in this case results in Omega having... nowhere near perfect predictive power versus the agent, but some predictive power at least (58% correct, if I calculated it correctly; ).
If the fixedpoint was 50/50 however, the fixedpoint is still satisfied by Omega putting in the money 50% of the time, but Omega is left with no predictive power over the outcome .
I think this is a terminological dispute
Fair.
and is therefore uninteresting.
Terminology is uninteresting, but important.
There is a false proof technique of the form:
- A->B
- Example purportedly showing A'
- Therefore B
- [if no-one calls them out on it, declare victory. Otherwise wait a bit.]
- No wait, the example shows A (but actually shows A'')
- [if no-one calls them out on it, declare victory. Otherwise wait a bit.]
- No wait, the example shows A (but actually shows A''')
- [if no-one calls them out on it, declare victory. Otherwise wait a bit.]
- No wait, the example shows A (but actually shows A'''')
- etc.
Whereas your argument was:
- A->B
- Example purportedly showing A'
- Therefore B.
- [time passes]
- No wait, the example shows A.
These, at first glance, are the same.
By ignoring terminology as uninteresting and constructing arguments that initially are consistent with these false proof techniques, you're downgrading yourself in the eyes of anyone who uses Bayesian reasoning (consciously or unconsciously) and assigns a non-zero prior to you (deliberately or unwittingly) using a false proof technique.
In this case you've recovered by repairing the proof; this does not help for initial impressions (anyone encountering your reasoning for the first time, in particular before the proof has been repaired).
If you've already considered this and decided it wasn't worth it, fair I suppose. I don't think that's a good idea, but I can see how someone with different priors could plausibly come to a different conclusion. If you haven't considered this... hopefully this helps.
being continuous does not appear to actually help to resolve predictor problems, as a fixed point of 50%/50% left/right[1] is not excluded, and in this case Omega has no predictive power over the outcome [2].
If you try to use this to resolve the Newcomb problem, for instance, you'll find that an agent that simply flips a (quantum) coin to decide does not have a fixed point in , and does have a fixed point in , as expected, but said fixed point is 50%/50%... which means the Omega is wrong exactly half the time. You could replace the Omega with an inverted Omega or a fair coin. They all have the same predictive power over the outcome - i.e. none.
Is there e.g. an additional quantum circuit trick that can resolve this? Or am I missing something?
The result is that the function is continuous
Absolutely. I continue to agree with you on this.
The part I was noting was incorrect was "our understanding of physics seems to exclude effects that are truly discontinuous." (emphasis added).
is continuous. is not[1].
- ^
Or rather, may not be.
These are mostly combinations of a bunch of lower-confidence arguments, which makes them difficult to expand a little. Nevertheless, I shall try.
1. I remain unconvinced of prompt exponential takeoff of an AI.
...assuming we aren't in Algorithmica[1][2]. This is a load-bearing assumption, and most of my downstream probabilities are heavily governed by P(Algorithmica) as a result.
...because compilers have gotten slower over time at compiling themselves.
...because the optimum point for the fastest 'compiler compiling itself' is not to turn on all optimizations.
...because compiler output-program performance has somewhere between a 20[3]-50[4] year doubling time.
...because [growth rate of compiler output-program performance] / [growth rate of human time poured into compilers] is << 1[5].
...because I think much of the advances in computational substrates[6] have been driven by exponentially rising investment[7], which in turn stretches other estimates by a factor of [investment growth rate] / [gdp growth rate].
...because the cost of some atomic[8] components of fabs have been rising exponentially[9].
...because the amount of labour put into CPUs has also risen significantly[10].
...because R&D costs keep rising exponentially[11].
...because cost-per-transistor is asymptotic towards a non-zero value[12].
...because flash memory wafer-passes-per-layer is asymptotic towards a non-zero value[13].
...because DRAM cost-per-bit has largely plateaued[14].
...because hard drive areal density has largely plateaued[15].
...because cost-per-wafer-pass is increasing.
...because of my industry knowledge.
...because single-threaded cpu performance has done this, and Amdahl's Law is a thing[16]: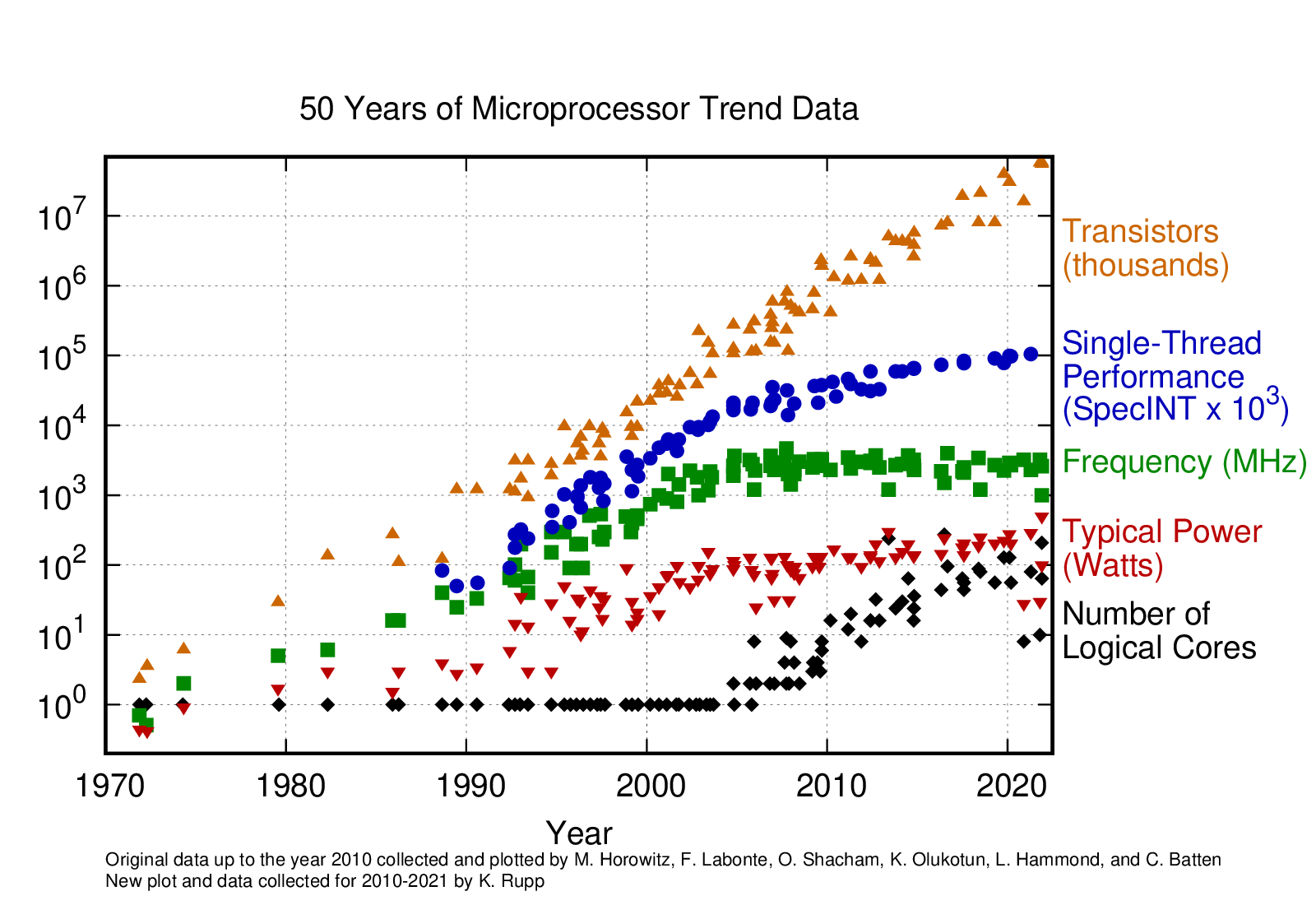 [17]
[17]
To drastically oversimplify: many of the exponential trends that people point to and go 'this continues towards infinity/zero; there's a knee here but that just changes the timeframe not the conclusion' I look at and go 'this appears to be consistent with a sub-exponential trend, such as an asymptote towards a finite value[18]'. Ditto, many of the exponential trends that people point to and go 'this shows that we are scaling' rely on associated exponential trends that cannot continue (e.g. fab costs 'should' hit GDP by ~2080), with (seemingly) no good argument why the exponential trend will continue but the associated trend, under the same assumptions, won't.
2. Most of the current discussion and arguments focus around agents that can do unbounded computation with zero cost.
...for instance, most formulations of Newcomb-like problems require either that the agent is bounded, or that the Omega does not exist, or that Omega violates the Church-Turing thesis[19].
...for instance, most formulations of e.g. FairBot[20] will hang upon encountering an agent that will cooperate with an agent if and only if FairBot will not cooperate with that agent, or sometimes variations thereof. (The details depend on the exact formulation of FairBot.)
...and the unbounded case has interesting questions like 'is while (true) {} a valid Bot'? (Or for (bigint i = 0; true ; i++){}; return (defect, cooperate)[i % 2];. Etc.)
...and in the 'real world' computation is never free.
...and heuristics are far more important in the bounded case.
...and many standard game-theory axioms do not hold in the bounded case.
...such as 'you can never lower expected value by adding another option'.
...or 'you can never lower expected value by raising the value of an option'.
...or 'A ≻ B if and only if ApC ≻ BpC'[21].
- ^
http://blog.computationalcomplexity.org/2004/06/impagliazzos-five-worlds.html - although note that there are also unstated assumptions that it's a constructive proof and the result isn't a galactic algorithm.
- ^
Heuristica or Pessiland may or may not also violate this assumption. "Problems we care about the answers of" are not random, and the question here is if they in practice end up hard or easy.
- ^
Proebsting's Law is an observation that compilers roughly double the performance of the output program, all else being equal, with an 18-year doubling time. The 2001 reproduction suggested more like 20 years under optimistic assumptions.
- ^
A 2022 informal test showed a 10-15% improvement on average in the last 10 years, which is closer to a 50-year doubling time.
- ^
Admittedly, I don't have a good source for this. I debated about doing comparisons of GCC output-program performance and GCC commit history over time, but bootstrapping old versions of GCC is, uh, interesting.
- ^
I don't actually know of a good term for 'the portions of computers that are involved with actual computation' (so CPU, DRAM, associated interconnects, compiler tech, etc, etc, but not e.g. human interface devices).
- ^
Fab costs are rising exponentially, for one. See also https://www.lesswrong.com/posts/qnjDGitKxYaesbsem/a-comment-on-ajeya-cotra-s-draft-report-on-ai-timelines?commentId=omsXCgbxPkNtRtKiC
- ^
In the sense of indivisible.
- ^
Lithography machines in particular.
- ^
Intel had 21.9k employees in 1990, and as of 2020 had 121k. Rise of ~5.5x.
- ^
- ^
A quick fit of on https://wccftech.com/apple-5nm-3nm-cost-transistors/ (billion transistors versus cost-per-transistor) gives . This essentially indicates that cost per transistor has plateaued.
- ^
String stacking is a tact admission that you can't really stack 3d nand indefinitely. So just stack multiple sets of layers... only that means you're still doing O(layers) wafer passes. Admittedly, once I dug into it I found that Samsung says they can go up to ~1k layers, which is far more than I expected.
- ^
https://aiimpacts.org/trends-in-dram-price-per-gigabyte/ -> "The price of a gigabyte of DRAM has fallen by about a factor of ten every 5 years from 1957 to 2020. Since 2010, the price has fallen much more slowly, at a rate that would yield an order of magnitude over roughly 14 years." Of course, another way to phrase 'exponential with longer timescale as time goes on' is 'not exponential'.
- ^
Note distinction here between lab-attained and productized. Productized aeral density hasn't really budged in the past 5 years ( https://www.storagenewsletter.com/2022/04/19/has-hdd-areal-density-stalled/ ) - with the potential exception of SMR which is a significant regression in other areas.
- ^
Admittedly, machine learning tends to be about the best-scaling workloads we have, as it tends to be mainly matrix operations and elementwise function application, but even so.
- ^
- ^
If you dig into the data behind [17] for instance, single-threaded performance is pretty much linear with time after ~2005. , with an . Linear increase in performance with exponential investment does not a FOOM make.
- ^
Roughly speaking: if the agent is Turing-complete, if you have an Omega I can submit an agent that runs said Omega on itself, and does whatever Omega says it won't do. Options are: a) no such Omega can exist, or b) the agent is weaker than the Omega, because the agent is not Turing-complete, or c) the agent is weaker than the Omega, because the agent is Turing-complete but the Omega is super-Turing.
- ^
FairBot has other issues too, e.g. https://www.lesswrong.com/posts/A5SgRACFyzjybwJYB/tlw-s-shortform?commentId=GrSr8aDtkLx8JHmnP
- ^
https://www.lesswrong.com/posts/AYSmTsRBchTdXFacS/on-expected-utility-part-3-vnm-separability-and-more?commentId=5DgQhNfzivzSdMf9o - when computation has a cost it may be better to flip a coin between two choices than to figure out which is better. This can then violate independence if the original choice is important enough to be worth calculating, but the probability is low enough that the probabilistic choice is not.
{kind=link}
For anyone else that can't read this quickly, this is what it looks like, un-reversed:
The rain in Spain stays mainly in the get could I Jages' rain in and or rain in the quages or, rain in the and or rain in the quages or rain in the and or rain in the quages or, rain in the and or rain in the quages or rain in the and or rain in the quages or rain in the and or rain in the quages or rain in the and or rain in the quages or rain in the and or rain in the quages or rain in the and or rain in the quages or rain in the and or rain in the quages or rain in the and or rain in the quages or rain in the and or rain in the quages or rain in the and or rain in the quages or rain in the and or rain in e
As an aside: what does GPT-3 complete it as when not reversed?
Ah, but perhaps your objection is that the difficulty of the AI alignment problem suggests that we do in fact need the analog of perfect zero correlation in order to succeed.
My objection is actually mostly to the example itself.
As you mention:
the idea is not to try ang contain a malign AGI which is already not on our side. The plan, to the extent that there is one, is to create systems that are on our side, and apply their optimization pressure to the task of keeping the plan on-course.
Compare with the example:
Suppose we’re designing some secure electronic equipment, and we’re concerned about the system leaking information to adversaries via a radio side-channel.
[...]
But what if we instead design the system so that the leaked radio signal has zero mutual information with whatever signals are passed around inside the system? Then it doesn’t matter how much optimization pressure an adversary applies, they’re not going to figure out anything about those internal signals via leaked radio.
This is analogous to the case of... trying to contain a malign AI which is already not on our side.
Sorry, are we talking about effects that are continuous, or effects that are discontinuous but which have probability distributions which are continuous?
I was rather assuming you meant the former considering you said 'effects that are truly discontinuous.'.
Both of your responses are the latter, not the former, assuming I am understanding correctly.
*****
You can't get around the continuity of unitary time evolution in QM with these kinds of arguments.
And now we're into the measurement problem, which far better minds than mine have spent astounding amounts of effort on and not yet resolved. Again, assuming I am understanding correctly.
I think this is interesting because our understanding of physics seems to exclude effects that are truly discontinuous.
This is not true. An electron and a positron will, or will not, annihilate. They will not half-react.
For example, real-world transistors have resistance that depends continuously on the gate voltage
This is incorrect. It depends on the # of electrons, which is a discrete value. It's just that most of the time transistors are large enough that it doesn't really matter. That being said, it's absolutely important for things like e.g. flash memory. Modern flash memory cell might have ~400 electrons per cell[1].
In any case, my world model says that an AGI should actually be able to recursively self-improve before reaching human-level intelligence. Just as you mentioned, I think the relevant intuition pump is "could I FOOM if I were an AI?" Considering the ability to tinker with my own source code and make lots of copies of myself to experiment on, I feel like the answer is "yes."
Counter-anecdote: compilers have gotten ~2x better in 20 years[1], at substantially worse compile time. This is nowhere near FOOM.
- ^
Proebsting's Law gives an 18-year doubling time. The 2001 reproduction suggested more like 20 years under optimistic assumptions, and a 2022 informal test showed a 10-15% improvement on average in the last 10 years (or a 50-year doubling time...)
It may be worthwhile to extend this to doctors who aren't perfect - that is are only correct most of the time - and see what happens.