AllAmericanBreakfast's Shortform
post by DirectedEvolution (AllAmericanBreakfast) · 2020-07-11T19:08:01.705Z · LW · GW · 377 commentsContents
382 comments
377 comments
Comments sorted by top scores.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-09-28T00:33:47.003Z · LW(p) · GW(p)
SlateStarCodex, EA, and LW helped me get out of the psychological, spiritual, political nonsense in which I was mired for a decade or more.
I started out feeling a lot smarter. I think it was community validation + the promise of mystical knowledge.
Now I've started to feel dumber. Probably because the lessons have sunk in enough that I catch my own bad ideas and notice just how many of them there are. Worst of all, it's given me ambition to do original research. That's a demanding task, one where you have to accept feeling stupid all the time.
But I still look down that old road and I'm glad I'm not walking down it anymore.
Replies from: Viliam↑ comment by Viliam · 2020-09-28T19:47:43.506Z · LW(p) · GW(p)
I started out feeling a lot smarter. I think it was community validation + the promise of mystical knowledge.
Too smart for your own good. You were supposed to believe it was about rationality. Now we have to ban you and erase your comment before other people can see it. :D
Now I've started to feel dumber. Probably because the lessons have sunk in enough that I catch my own bad ideas and notice just how many of them there are. [...] you have to accept feeling stupid all the time. But I still look down that old road and I'm glad I'm not walking down it anymore.
Yeah, same here.
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-06-11T18:29:02.489Z · LW(p) · GW(p)
Epistemic activism
I think LW needs better language to talk about efforts to "change minds." Ideas like asymmetric weapons and the Dark Arts are useful but insufficient.
In particular, I think there is a common scenario where:
- You have an underlying commitment to open-minded updating and possess evidence or analysis that would update community beliefs in a particular direction.
- You also perceive a coordination problem that inhibits this updating process for a reason that the mission or values of the group do not endorse.
- Perhaps the outcome of the update would be a decline in power and status for high-status people. Perhaps updates in general can feel personally or professionally threatening to some people in the debate. Perhaps there's enough uncertainty in what the overall community believes that an information cascade has taken place. Perhaps the epistemic heuristics used by the community aren't compatible with the form of your evidence or analysis.
- Solving this coordination problem to permit open-minded updating is difficult due to lack of understanding or resources, or by sabotage attempts.
When solving the coordination problem would predictably lead to updating, then you are engaged in what I believe is an epistemically healthy effort to change minds. Let's call it epistemic activism for now.
Here are some community touchstones I regard as forms of epistemic activism:
- The founding of LessWrong and Effective Altruism
- The one-sentence declaration on AI risks
- The popularizing of terms like Dark Arts, asymmetric weapons, questionable research practices, and "importance hacking."
- Founding AI safety research organizations and PhD programs to create a population of credible and credentialed AI safety experts; calls for AI safety researchers to publish in traditional academic journals so that their research can't be dismissed for not being subject to institutionalized peer review
- The publication of books by high-status professionals articulating a shortcoming in current practice and endorsing some new paradigm for their profession. Such books don't just collect arguments and evidence for the purpose of individual updating, but also create common knowledge about "what people in my profession are talking about."
I suspect the strongest reason to categorize epistemic activism as a "symmetric weapon" or the "Dark Arts" is as a guardrail. An analogy can be drawn with professional integrity: you should neither do anything unethical, nor do anything that risks appearing unethical. Similar, you should neither do anything that's Dark Arts, nor anything that risks appearing like the Dark Arts. Explicitly naming that you are engaging in epistemic activism looks like the Dark Arts, so we shouldn't do it. It creates a permissive environment for bad-faith actors to actually engage in the Dark Arts while calling it "epistemic activism." After all, "epistemic activism" assumes a genuine commitment to open-minded updating which is certainly not always the case.
That's a legitimate risk. I am weighing it against two other risks that I think are also severe:
- The existence of coordination problems that inhibit normal updating is also an epistemic risk, and if they represent an equilibrium or the kinetics of change are too slow, action is required to resolve the problem. The ability to notice and respond to this dynamic is bolstered when we have the language to describe it.
- Epistemic activism happens anyway - it just has to be naturalized so that it doesn't look like an activist effort. I think that creates an incentive to disguise one's motives and creates confusion and a tendency toward inaction, particularly by lower-status people, when faced with an epistemic coordination problem.
Because I think that deference usually leads to more accurate individual beliefs, I think that epistemic activism should often result in the activist having their mind change. They might be wrong about the existence of the coordination problem, or they might find that there's a ready rebuttal for their evidence or argument that they find persuasive. That is a successful outcome of epistemic activism: normal updating has occurred.
This is a key difference between epistemic activism and being a crank. The crank often also perceives that normal updating is impaired due to a social coordination problem. The difference is that a crank would regard it as a failure if the resumption of updating resulted in the crank realizing they were wrong all along. And for that reason, cranks often decide that the fact that the community hasn't updated in the direction they expected is evidence that the coordination problem still exists.
A good epistemic activist ought to have a separate argument and evidence base for the existence of the coordination problem, independent from how they expect community beliefs would update if the problem was resolved. Let's give an example:
- My mom's anxiety often impairs her, or my family as a whole, from trying new things together (this is the coordination problem). I think they'd enjoy snorkeling (this is the outcome I predict for the update). I have to track the existence of my mom's anxiety about snorkeling and my success in addressing it separately from whether or not she ultimately becomes enthusiastic about snorkeling.
- If I saw that despite my best efforts, my mom's initial anxiety on the subject was static, then I might conclude I'd simply failed to solve the coordination problem.
- If instead, my mom shifts from initial anxiety to a cogent description of why she's just not interested in snorkeling ("it's risky, I don't like cold water, I don't want to spend on a wetsuit, I'm just not that excited about it"), then I can't regard this as evidence she's still anxious. It just means I have to update toward thinking I was incorrect in predicting anxiety was inhibiting her from exploring an activity she would actually enjoy.
- If I decide that my mom's new, cogent description of why she's not interested in snorkeling is evidence that she's still anxious, then I'm engaging in crank behavior, not epistemic activism.
↑ comment by Vladimir_Nesov · 2023-06-11T20:57:51.541Z · LW(p) · GW(p)
When communicating an argument, the quality of feedback about its correctness you get depends on efforts around its delivery whose shape doesn't depend on its correctness. The objective of improving quality of feedback in order to better learn from it is a check on spreading nonsense.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-07-15T03:30:21.988Z · LW(p) · GW(p)
Things I come to LessWrong for:
- An outlet and audience for my own writing
- Acquiring tools of good judgment and efficient learning
- Practice at charitable, informal intellectual argument
- Distraction
- A somewhat less mind-killed politics
Cons: I'm frustrated that I so often play Devil's advocate, or else make up justifications for arguments under the principle of charity. Conversations feel profit-oriented and conflict-avoidant. Overthinking to the point of boredom and exhaustion. My default state toward books and people is bored skepticism and political suspicion. I'm less playful than I used to be.
Pros: My own ability to navigate life has grown. My imagination feels almost telepathic, in that I have ideas nobody I know has ever considered, and discover that there is cutting edge engineering work going on in that field that I can be a part of, or real demand for the project I'm developing. I am more decisive and confident than I used to be. Others see me as a leader.
Replies from: Viliam↑ comment by Viliam · 2020-07-15T19:01:20.185Z · LW(p) · GW(p)
Some people optimize for drama. It is better to put your life in order, which often means getting the boring things done. And then, when you need some drama, you can watch a good movie.
Well, it is not completely a dichotomy. There is also some fun to be found e.g. in serious books. Not the same intensity as when you optimize for drama, but still. It's like when you stop eating refined sugar, and suddenly you notice that the fruit tastes sweet.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-17T17:45:29.658Z · LW(p) · GW(p)
Chemistry trick
Once you've learned to visualize, you can employ my chemistry trick to learn molecular structures. Here's the structure of Proline (from Sigma Aldrich's reference).
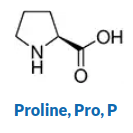
Before I learned how to visualize, I would try to remember this structure by "flashing" the whole 2D representation in my head, essentially trying to see a duplicate of the image above in my head.
Now, I can do something much more engaging and complex.
I visualize the molecule as a landscape, and myself as standing on one of the atoms. For example, perhaps I start by standing on the oxygen at the end of the double bond.
I then take a walk around the molecule. Different bonds feel different - a single bond is a path, a double bond a ladder, and a triple bond is like climbing a chain-link fence. From each new atomic position, I can see where the other atoms are in relation to me. As I walk around, I get practice in recalling which atom comes next in my path.
As you can imagine, this is a far more rich and engaging form of mental practice than just trying to reproduce static 2D images in my head.
A few years ago, I felt myself to have almost no ability to visualize. Now, I am able to do this with relative ease. So if you don't see this as achievable, I encourage you to practice visualizing, because any skill you develop there can become a very powerful tool for learning.
Replies from: AllAmericanBreakfast, Viliam↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-19T01:03:21.577Z · LW(p) · GW(p)
I was able to memorize the structures of all 20 amino acids pretty easily and pleasantly in a few hours' practice over the course of a day using this technique.
↑ comment by Viliam · 2022-09-18T12:40:38.098Z · LW(p) · GW(p)
I imagine a computer game, where different types of atoms are spheres of different color (maybe also size; at least H should be tiny), connected the way you described, also having the correct 3D structure, so you walk on them like astronaut.
Now there just needs to be something to do in that game, not sure what. I guess, if you can walk the atoms, so can some critters you need to kill, or perhaps there are some items to collect. Play the game a few times, and you will remember the molecules (because people usually remember useless data from computer games they played).
Advanced version: chemical reactions, where you need to literally cut the atomic bonds and bind new atoms.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-18T19:30:14.430Z · LW(p) · GW(p)
I haven't seen games using the precise mechanic you describe. However, there are games/simulations to teach chemistry. They ask you to label parts of atoms, or to act out the steps of a chemical reaction.
I'm open to these game ideas, but skeptical, for reasons I'll articulate in a later shortform.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-11-15T03:35:39.137Z · LW(p) · GW(p)
Intellectual Platforms
My most popular LW post wasn't a post at all. It was a comment [LW · GW] on John Wentworth's post asking "what's up with Monkeypox?"
Years before, in the first few months of COVID, I took a considerable amount of time to build a scorecard of risk factors for a pandemic, and backtested it against historical pandemics. At the time, the first post received a lukewarm reception, and all my historical backtesting quickly fell off the frontpage.
But when I was able to bust it out, it paid off (in karma). People were able to see the relevance to an issue they cared about, and it was probably a better answer in this time and place than they could have obtained almost anywhere else.
Devising the scorecard and doing the backtesting built an "intellectual platform" that I can now use going forward whenever there's a new potential pandemic threat. I liken it to engineering platforms, which don't have an immediate payoff, but are a long-term investment.
People won't necessarily appreciate the hard work of building an intellectual platform when you're assembling it. And this can make it feel like the platform isn't worthwhile: if people can't see the obvious importance of what I'm doing, then maybe I'm on the wrong track?
Instead, I think it's helpful to see people's reactions as indicating whether or not they have a burning problem that your output is providing help for. Of course a platform-in-development won't get much applause! But if you've selected your project thoughtfully and executed passably well, then eventually, when the right moment comes, it may pay off.
For the last couple of years, I've been building toward a platform for "learning how to learn," and I'm also working on an "aging research" platform. These turn out to be harder topics - a pandemic is honestly just a nice smooth logistic curve, which is far less complicated than monitoring your own brain and hacking your own learning process. And aging research is the wild west. So I expect this to take longer.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-08-09T16:23:49.240Z · LW(p) · GW(p)
Math is training for the mind, but not like you think
Just a hypothesis:
People have long thought that math is training for clear thinking. Just one version of this meme that I scooped out of the water:
“Mathematics is food for the brain,” says math professor Dr. Arthur Benjamin. “It helps you think precisely, decisively, and creatively and helps you look at the world from multiple perspectives . . . . [It’s] a new way to experience beauty—in the form of a surprising pattern or an elegant logical argument.”
But math doesn't obviously seem to be the only way to practice precision, decision, creativity, beauty, or broad perspective-taking. What about logic, programming, rhetoric, poetry, anthropology? This sounds like marketing.
As I've studied calculus, coming from a humanities background, I'd argue it differently.
Mathematics shares with a small fraction of other related disciplines and games the quality of unambiguous objectivity. It also has the ~unique quality that you cannot bullshit your way through it. Miss any link in the chain and the whole thing falls apart.
It can therefore serve as a more reliable signal, to self and others, of one's own learning capacity.
Experiencing a subject like that can be training for the mind, because becoming successful at it requires cultivating good habits of study and expectations for coherence.
Replies from: niplav, Viliam, elityre, ChristianKl↑ comment by niplav · 2020-08-09T21:06:36.993Z · LW(p) · GW(p)
Math is interesting in this regard because it is both very precise and there's no clear-cut way of checking your solution except running it by another person (or becoming so good at math to know if your proof is bullshit).
Programming, OTOH, gives you clear feedback loops.
Replies from: AllAmericanBreakfast, Viliam, mikkel-wilson↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-08-10T00:17:43.442Z · LW(p) · GW(p)
In programming, that's true at first. But as projects increase in scope, there's a risk of using an architecture that works when you’re testing, or for your initial feature set, but will become problematic in the long run.
For example, I just read an interesting article on how a project used a document store database (MongoDB), which worked great until their client wanted the software to start building relationships between data that had formerly been “leaves on the tree.” They ultimately had to convert to a traditional relational database.
Of course there are parallels in math, as when you try a technique for integrating or parameterizing that seems reasonable but won’t actually work.
Replies from: gworley↑ comment by Gordon Seidoh Worley (gworley) · 2020-08-10T04:14:03.213Z · LW(p) · GW(p)
Yep. Having worked both as a mathematician and a programmer, the idea of objectivity and clear feedback loops starts to disappear as the complexity amps up and you move away from the learning environment. It's not unusual to discover incorrect proofs out on the fringes of mathematical research that have not yet become part of the cannon, nor is it uncommon (in fact, it's very common) to find running production systems where the code works by accident due to some strange unexpected confluence of events.
↑ comment by Viliam · 2020-08-16T18:21:52.701Z · LW(p) · GW(p)
Programming, OTOH, gives you clear feedback loops.
Feedback, yes. Clarity... well, sometimes it's "yes, it works" today, and "actually, it doesn't if the parameter is zero and you called the procedure on the last day of the month" when you put it in production.
↑ comment by MikkW (mikkel-wilson) · 2020-08-10T22:07:04.006Z · LW(p) · GW(p)
Proof verification is meant to minimize this gap between proving and programming
↑ comment by Viliam · 2020-08-16T18:43:32.418Z · LW(p) · GW(p)
The thing I like about math is that it gives the feeling that the answers are in the territory. (Kinda ironic, when you think about what the "territory" of math is.) Like, either you are right or you are wrong, it doesn't matter how many people disagree with you and what status they have. But it also doesn't reward the wrong kind of contrarianism.
Math allows you to make abstractions without losing precision. "A sum of two integers is always an integer." Always; literally. Now with abstractions like this, you can build long chains out of them, and it still works. You don't create bullshit accidentally, by constructing a theory from approximations that are mostly harmless individually, but don't resemble anything in the real world when chained together.
Whether these are good things, I suppose different people would have different opinions, but it definitely appeals to my aspie aesthetics. More seriously, I think that even when in real world most abstractions are just approximations, having an experience with precise abstractions might make you notice the imperfection of the imprecise ones, so when you formulate a general rule, you also make a note "except for cases such as this or this".
(On the other hand, for the people who only become familiar with math as a literary genre [LW · GW], it might have an opposite effect: they may learn that pronouncing abstractions with absolute certainty is considered high-status.)
↑ comment by Eli Tyre (elityre) · 2020-08-14T15:20:39.055Z · LW(p) · GW(p)
Mathematics shares with a small fraction of other related disciplines and games the quality of unambiguous objectivity. It also has the ~unique quality that you cannot bullshit your way through it. Miss any link in the chain and the whole thing falls apart.
Isn't programming even more like this?
I could get squidgy about whether a proof is "compelling", but when I write a program, it either runs and does what I expect, or it doesn't, with 0 wiggle room.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-08-14T18:31:07.779Z · LW(p) · GW(p)
Sometimes programming is like that, but then I get all anxious that I just haven’t checked everything thoroughly!
My guess is this has more to do with whether or not you’re doing something basic or advanced, in any discipline. It’s just that you run into ambiguity a lot sooner in the humanities
↑ comment by ChristianKl · 2020-08-12T09:49:30.386Z · LW(p) · GW(p)
It helps you to look at the world from multiple perspectives: It gets you into a position to make a claim like that soley based on anecdotal evidence and wishful thinking.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-07-02T07:25:16.130Z · LW(p) · GW(p)
I ~completely rewrote the Wikipedia article for the focus of my MS thesis, aptamers.
Please tell me what you liked, and feel free to give constructive feedback!
While I do think aptamers have relevance to rationality, and will post about that at some point, I'm mainly posting this here because I'm proud of the result and wanted to share one of the curiosities of the universe for your reading pleasure.
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-02-09T00:07:34.139Z · LW(p) · GW(p)
You know what "chunking" means in memorization? It's also something you can do to understand material before you memorize it. It's high-leverage in learning math.
Take the equation for a t score:
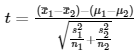
That's more symbolic relationships than you can fit into your working memory when you're learning it for the first time. You need to chunk it. Here's how I'd break it into chunks:
Chunk 1:
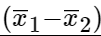
Chunk 2:
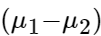
Chunk 3:
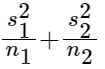
Chunk 4:
[(Chunk 1) - (Chunk 2)]/sqrt(Chunk 3)
The most useful insight here is learning to see a "composite" as a "unitary." If we inspect Chunk 1 and see it as two variables and a minus sign, it feels like an arbitrary collection of three things. In the back of the mind, we're asking "why not a plus sign? why not swap out x1 for... something else?" There's a good mathematical answer, of course, but that doesn't necessarily stop the brain from firing off those questions during the learning process, when we're still trying to wrap our heads around these concepts.
But if we can see
as a chunk, a thing with a unitary identity, it lets us think with it in a more powerful way. Imagine if you were running a cafe, and you didn't perceive your dishes as "unitary." A pie wasn't a pie, it was a pan full of sugar, cherries, and cooked dough. The menu would look insane and it would be really hard to understand what you were about to be served.
I think a lot of people who are learning new math go through an analogous phase. They haven't chunked the concepts yet, so when they are introduced to these big higher-order concepts, it feels like reading the ingredients list and prep instructions in a recipe without having any feeling for what the dish is supposed to look and taste like at the end, or whether it's an entree or a dessert. Why not replace the sugar in the pie with salt?
Learning how to chunk, especially in math, is undermined because so often, these chunks aren't given names.
might be described as "the difference of sample means," a phrase which suffers the same problem (why not the sum of sample means? why not medians instead of means?).
I find the skill of perceiving chunks, of learning how to see
as a unitary thing, like "cherry pie," is a subtle but important skill for learning how to learn.
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-02-16T22:30:42.528Z · LW(p) · GW(p)
A Nonexistent Free Lunch
- More Wrong
On an individualPredictIt market, sometimes you can find a set of "no" contracts whose price (1 share of each) adds up to less than the guaranteed gross take.
Toy example:
- Will A get elected? No = $0.30
- Will B get elected? No = $0.70
- Will C get elected? No = $0.90
- Minimum guaranteed pre-fee winnings = $2.00
- Total price of 1 share of both No contracts = $1.90
- Minimum guaranteed pre-fee profits = $0.10
There's always a risk of black swans. PredictIt could get hacked. You might execute the trade improperly. Unexpected personal expenses might force you to sell your shares and exit the market prematurely.
But excluding black swans, I though that as long as three conditions held, you could make free money on markets like these. The three conditions were:
- You take PredictIt's profit fee (10%) into account
- You can find enough such "free money" opportunities that your profits compensate for PredictIt's withdrawal fee (5% of the total withdrawal)
- You take into account the opportunity cost of investing in the stock market (average of 10% per year)
In the toy example above, I calculated that you'd lose $0.10 x 10% = $0.01 to PredictIt's profit fee if you bought 1 of each "No" contract. Your winnings would therefore be $0.99. Of course, if you withdrew it immediately, you'd only take away $0.99 x 95% = $0.94, but you'd still make a 4 cent profit.
In other situations, with more prices, your profit margins might be thinner. The withdrawal fee might turn a gain into a loss, unless you were able to rack up many such profitable trades before withdrawing your money from the PredictIt platform.
I build some software to grab prices off PredictIt and crunch the numbers, and lo and behold, I found an opportunity that seemed to offer 13% returns on this strategy, beating the stock market. Out of all the markets on PredictIt, only this one offered non-negative gains, which I took as evidence that my model was accurate. I wouldn't expect to find many such opportunities, after all.
2. Less Wrong
Fortunately, I didn't act on it. I rewrote the price-calculating software several times, slept on it, and worked on it some more the next day.
Then it clicked.
PredictIt wasn't going to take my losses on the failed "No" contract (the one that resolved to "yes") into account in offsetting the profits from the successful "No" contracts.
In the toy model above, I calculated that PredictIt would take a 10% cut of the $0.10 net profit across all my "No" contracts.
In reality, PredictIt would take a 10% cut of the profits on both successful trades. In the worst case scenario, "Will C get elected" would be the contract that resolved to "yes," meaning I would earn $0.70 from the "A" contract and $0.30 from the "B" contract, for a total "profit" of $1.00.
PredictIt would take a 10% cut, or $0.10, rather than the $0.01 I'd originally calculated. This would leave me with $2.00 from two successful contracts, minus $0.10 from the fees, leaving me with $1.90, and zero net profit or loss. No matter how many times I repeated this bet, I would be left with the same amount I put in, and when I withdrew it, I would take a 5% loss.
When I ran my new model with real numbers from PredictIt, I discovered that every single market would leave me not with zero profit, but with about a 1-2% loss, even before the 5% withdrawal fee was taken into account.
If there is a free lunch, this isn't it. Fortunately, I only wasted a few hours and no money.
There genuinely were moments along the way where I was considering plunking down several thousand dollars to test this strategy out. If I hadn't realized the truth, would I have gotten a wake-up call when the first round of contracts was called in and I came out $50 in the red, rather than $50 in the black? And then exited PredictIt feeling embarrassed and having lost perhaps $300, after withdrawal fees?
3. Meta Insights
What provoked me to almost make a mistake?
I started looking into it in the first place because I'd heard that PredictIt's fee structure and other limitations created inefficiencies, and that you could sometimes find arbitrage opportunities on it. So there was an "alarm bell" for an easy reward. Maybe knowing about PredictIt and being able to program well enough to evaluate for these opportunities would be the advantage that let me harvest that reward.
There were two questions at hand for this strategy. One was "how, exactly, does this strategy work given PredictIt's fee structure?"
The other was "are there actually enough markets on PredictIt to make this strategy profitable in the long run?"
The first question seemed simpler, so I focused on the second question at first. Plus, I like to code, and it's fun to see the numbers crank out of the machine.
But those questions were lumped together into a vague sort of "is this a good idea?"-type question. It took all the work of analysis to help me distinguish them.
How did I catch my error?
Lots of "how am I screwing this up?" checks. I wrote and rewrote the software, refactoring code, improving variable names, and so on. I did calculations by hand. I wrote things out in essay format. Once I had my first, wrong, model in place, I walked through a trade by hand using it, which is what showed me how it would fail. I decided to sleep on it, and had intended to actually spend several weeks or months investigating PredictIt to try and understand how often these "opportunities" arose before pulling the trigger on the strategy.
Does this error align with other similar errors I've made in the past?
It most reminds me of how I went about choosing graduate schools. I sunk many, many hours into creating an enormous spreadsheet with tuition and cost of living expenses, US News and World report rankings, and a linear regression graph. I constantly updated and tweaked it until I felt very confident that it was self-consistent.
When I actually contacted the professors whose labs I was interested in working in, in the midst of filling out grad school applications, they told me to reconsider the type of grad school programs (to switch from bioinformatics to bio- or mechanical engineering). So all that modeling and research lost much of its value.
The general issue here is that an intuitive notion, a vision, has to be decomposed into specific data, model, and problem. There's something satisfying about building a model, dumping data into it, and watching it crank out a result.
The model assumes authority prematurely. It's easy to conflate the fit between the model's design and execution with the fit between the model and the problem. And this arises because to understand the model, you have to design it, and to design it, you have to execute it.
I've seen others make similar errors. I saw a talk by a scientist who'd spent 15 years inventing a "new type of computer," that produced these sort of cloud-like rippling images. He didn't have a model of how those images would translate into any sort of useful calculation. He asked the audience if they had any ideas. That's... the wrong way to build a computer.
AI safety research seems like an attempt to deal with exactly this problem. What we want is a model (AI) that fits the problem at hand (making the world a better place by a well-specified set of human values, whatever that means). Right now, we're dumping a lot of effort into execution, without having a great sense for whether or not the AI model is going to fit the values problem.
How can you avoid similar problems?
One way to test whether your model fits the problem is to execute the model, make a prediction for the results you'll get, and see if it works. In my case, this would have looked like building the first, wrong version of the model, calculating the money I expected to make, seeing that I made less, and then re-investigating the model. The problem is that this is costly, and sometimes you only get one shot.
Another way is to simulate both the model and the problem, which is what saved me in this case. By making up a toy example that I could compute by hand, I was able to spot my error.
It also helps to talk things through with experienced experts who have an incentive to help you succeed. In my grad school application, it was talking things out with scientists doing the kind of research I'm interested in. In the case of the scientist with the nonfunctional experimental computer, perhaps he could have saved 15 years of pointless effort by talking his ideas over with Steven Hsu and engaging more with the quantum computing literature.
A fourth way is to develop heuristics for promising and unpromising problems to work on. Beating the market is unpromising. Building a career in synthetic biology is promising. The issue here is that such heuristics are themselves models. How do you know that they're a good fit to the problem at hand?
In the end, you are to some extent forced ultimately into open-ended experimentation. Hopefully, you at least learn something from the failures, and enjoy the process.
The best thing to do is make experimentation fast, cheap, and easy. Do it well in advance, and build up some cash, so that you have the slack for it. Focusing on a narrow range of problems and tools means you can afford to define each of them better, so that it'll be easier to test each tool you've mastered against each new problem, and each new tool against your well-understood problems.
The most important takeaway, then, is to pick tools and problems that you'll be happy to fail at many times. Each failure is an investment in better understanding the problem or tool. Make sure not to have so few tools/problems that you have time on your hands, or so many that you can't master them.
You can then imagine taking an inventory of your tools and problems. Any time you feel inspired to take a whack at learning a new skill or a new problem, you can ask if it's an optimal addition to your skillset. And you can perhaps (I'm really not sure about this) ask if there are new tool-problem pairs you haven't tried, just through oversight.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-04T16:42:22.676Z · LW(p) · GW(p)
Simulated weight gain experiment, day 2
Background: I'm wearing a weighted vest to simulate the feeling of 50 pounds (23 kg) of weight gain and loss. The plan is to wear this vest for about 20 days, for as much of the day as is practical. I started with zero weight, and will increase it in 5 pound (~2 kg) increments daily to 50 pounds, then decrease it by 5 pounds daily until I'm back to zero weight.
So far, the main challenge of this experiment has been social. The weighted vest looks like a bulletproof vest, and I'm a 6' tall white guy with a buzzcut. My girlfriend laughed just imagining what I must look like (we have a long-distance relationship, so she hasn't seen me wearing it). My housemate's girlfriend gasped when I walked in through the door.
As much as I'd like to wear this continuously as planned, I just don't know if I it will work to wear this to the lab or to classes in my graduate school. If the only problem was scaring people, I could mitigate that by emailing my fellow students and the lab and telling them what I'm doing and why. However, I'm also in the early days of setting up my MS thesis research in a big, professional lab that has invested a lot of time and money into my experiment. I fear that I would come across as distracted, and that this would undermine my standing in the lab.
Today, I'm going to try wearing a thin elastic mountain-climbing hoodie over the weighted vest. This might make it look like I have some sort of a bomb strapped underneath my shirt, but it doesn't seem as immediately startling to look at.
Other things I've noticed:
- The vest makes you hot, not just heavy.
- It does restrict your breathing somewhat, because the weight is squeezing in on your ribcage.
- The weight creates backaches and shoulder aches where I don't usually experience them.
- I tried wearing the fully-loaded vest when it first arrived, and it feels significantly less difficult carrying 50 pounds on the vest than it does carrying 50 pounds in your hands.
- One of the psychological sensations I wasn't expecting, but that seems relevant, is the displeasure I get in putting it on. I see this as somewhat analogous to how a person who weighs more than they'd like to might feel on a bad day looking at their body in the mirror. The sense that you don't get to look or feel the way you'd like to seems like an important part of the experiment.
Overall, these early impressions make me think that the weighted vest exaggerates the discomfort of weight gain. However, I think it is still a useful complement to the scientific knowledge and anecdotes that people share about the effects of weight gain and loss. It makes it visceral.
I also think that the weighted vest offers an experience similar to a chronic illness. When you get the flu, you can usually receive some accommodations on the expectation that you'll be better soon. Chronic health conditions may require you to curtail your long-term ambitions due to the constant negative impact they have on your capacity to work. Wearing a weighted vest is similar. It makes you have an experience of "how would it affect your capacity to work if you were more physically burdened for the long term?"
Perhaps it's a little like becoming poorer or less free.
In response to this, I notice my brain becoming more interested in taking control of this aspect of my health. It provokes a "never again" sort of response.
There are many ascetic practices that involve self-inflicting states of discomfort in order to create a spiritual benefit. This seems to be getting into that territory. One of the differences is that these spiritual practices are often done communally, and the suffering is given meaning through the spiritual practice.
By contrast, our materialistic culture emphatically does not imbue obesity or other physical and mental health challenges with spiritual significance. This experiment replicates part of that aspect: it singles me out as individually "worse" than other people, and the experience is basically meaningless on a social level. Indeed, worse than meaningless - I fear that I would be perceived as scaring my classmates and that I'd irritate my boss at the lab.
It seems useful on some level to put yourself through that experience. What if you were individually impacted by a health issue that simply made your life worse and led to other people treating you worse? Would you be angry at the world? Would you get depressed? Would you muster your powers to do anything you could to get better?
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-11-25T21:58:53.555Z · LW(p) · GW(p)
The Rationalist Move Club
Imagine that the Bay Area rationalist community did all want to move. But no individual was sure enough that others wanted to move to invest energy in making plans for a move. Nobody acts like they want to move, and the move never happens.
Individuals are often willing to take some level of risk and make some sacrifice up-front for a collective goal with big payoffs. But not too much, and not forever. It's hard to gauge true levels of interest based off attendance at a few planning meetings.
Maybe one way to solve this is to ask for escalating credible commitments.
A trusted individual sets up a Rationalist Move Fund. Everybody who's open to the idea of moving puts $500 in a short-term escrow. This makes them part of the Rationalist Move Club.
If the Move Club grows to a certain number of members within a defined period of time (say 20 members by March 2020), then they're invited to planning meetings for a defined period of time, perhaps one year. This is the first checkpoint. If the Move Club has not grown to that size by then, the money is returned and the project is cancelled.
By the end of the pre-defined planning period, there could be one of three majority consensus states, determined by vote (approval vote, obviously!):
- Most people feel there is a solid timetable and location for a move, and want to go forward that plan as long as half or more of the Move Club members also approve of this option. To cast a vote approving of this choice requires an additional $2,000 deposit per person into the Move Fund, which is returned along with their initial $500 deposit after they've signed a lease or bought a residence in the new city, or in 3 years, whichever is sooner.
- Most people want to continue planning for a move, but aren't ready to commit to a plan yet. To cast a vote approving of this choice requires an additional $500 deposit per person into the Move Fund, unless they paid $2,000 to approve of option 1.
- Most people want to abandon the move project. Anybody approving only of this option has their money returned to them and exits the Move Club, even if (1) or (2) is the majority vote. If this option is the majority vote, all money in escrow is returned to the Move Club members and the move project is cancelled.
Obviously the timetables, monetary commitments could be modified. Other "commitment checkpoints" could be added in as well. I don't live in the Bay Area, but if those of you who do feel this framework could be helpful, please feel free to steal it.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-08-08T18:52:21.313Z · LW(p) · GW(p)
What gives LessWrong staying power?
On the surface, it looks like this community should dissolve. Why are we attracting bread bakers, programmers, stock market investors, epidemiologists, historians, activists, and parents?
Each of these interests has a community associated with it, so why are people choosing to write about their interests in this forum? And why do we read other people's posts on this forum when we don't have a prior interest in the topic?
Rationality should be the art of general intelligence. It's what makes you better at everything. If practice is the wood and nails, then rationality is the blueprint.
To determine whether or not we're actually studying rationality, we need to check whether or not it applies to everything. So when I read posts applying the same technique to a wide variety of superficially unrelated subjects, it confirms that the technique is general, and helps me see how to apply it productively.
This points at a hypothesis, which is that general intelligence is a set of defined, generally applicable techniques. They apply across disciplines. And they apply across problems within disciplines. So why aren't they generally known and appreciated? Shouldn't they be the common language that unites all disciplines?
Perhaps it's because they're harder to communicate and appreciate. If I'm an expert baker, I can make another delicious loaf of bread. Or I can reflect on what allows me to make such tasty bread, and speculate on how the same techniques might apply to architecture, painting, or mathematics. Most likely, I'm going to choose to bake bread.
This is fine, until we start working on complex, interdisciplinary projects. Then general intelligence becomes the bottleneck for having enough skill to get the project done. Sounds like the 21st century. We're hitting the limits of what's achievable through sheer persistence in a single specialty, and we're learning to automate them away.
What's left is creativity, which arises from structured decision-making. I've noticed that the longer I practice rationality, the more creative I become. I believe that's because it gives me the resources to turn an intuition into a specified problem, envision a solution, create a sort of Fermi-approximation to give it definition, and guidance on how to develop the practical skills and relationships that will let me bring it into being.
If I'm right, human application of these techniques will require deliberate practice with the general techniques - both synthesizing them and practicing them individually, until they become natural.
The challenge is that most specific skills lend themselves to that naturally. If I want to become a pianist, I practice music until I'm good. If I want to be a baker, I bake bread. To become an architect, design buildings.
What exactly do you do to practice the general techniques of rationality? I can imagine a few methods:
- Participate in superforecasting tournaments, where Bayesian and gears/policy level thinking are the known foundational techniques.
- Learn a new skill, and as you go, notice the problems you encounter along the way. Try to imagine what a general solution to that problem might look like. Then go out and build it.
- Pick a specific rationality technique, and try to apply it to every problem you face in your life.
↑ comment by Viliam · 2020-08-15T21:11:38.008Z · LW(p) · GW(p)
What gives LessWrong staying power?
For me, it's the relatively high epistemic standards combined with relative variety of topics. I can imagine a narrowly specialized website with no bullshit, but I haven't yet seen a website that is not narrowly specialized and does not contain lots of bullshit. Even most smart people usually become quite stupid outside the lab. Less Wrong is a place outside the lab that doesn't feel painfully stupid. (For example, the average intelligence at Hacker News seems quite high, but I still regularly find upvoted comments that make me cry.)
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-08-16T01:51:59.847Z · LW(p) · GW(p)
Yeah, Less Wrong seems to be a combination of project and aesthetic. Insofar as it's a project, we're looking for techniques of general intelligence, partly by stress-testing them on a variety of topics. As an aesthetic, it's a unique combination of tone, length, and variety + familiarity of topics that scratches a particular literary itch.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-11-05T06:28:32.369Z · LW(p) · GW(p)
School teaches terrible reading habits.
When you're assigned 30 pages of a textbook, the diligent students read them, then move on to other things. A truly inquisitive person would struggle to finish those 30 pages, because there are almost certainly going to be many more interesting threads they want to follow within those pages.
As a really straightforward example, let's say you commit to reading a review article on cell senescence. Just forcing your way through the paper, you probably won't learn much. What will make you learn is looking at the citations as you go.
I love going 4 layers deep. I try to understand the mechanisms that underpin the experiments that generated the data that informed the facts that inform the theories that the review article is covering. When I do this, it suddenly transforms the review article from dry theory to something that's grounded in memories of data and visualizations of experiments. I have a "simulated lived experience" to map onto the theory. It becomes real.
Replies from: niplav, ChristianKl↑ comment by niplav · 2022-11-08T14:41:25.895Z · LW(p) · GW(p)
I think that for anything except scholarship, those aren't terrible. I'd attack them from the other side: They aren't shallow enough. In industry, most often you often just want to find some specific piece of information, so reading the whole 30 pages is a waste of time, as is following your deep curiosity down into rabbit holes.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-11-08T14:57:23.450Z · LW(p) · GW(p)
I agree with you. It’s a good point that I should have clarified this is for a specific use case - rapidly scouting out a field that you’re unfamiliar with. When I take this approach, I also do not read entire papers. I just read enough to get the gist and find the next most interesting link.
So for example, I am preparing for a PhD, where I’ll probably focus on aging research. I need to understand what’s going on broadly in the field. Obviously I can’t read everything, and as I have no specific project, there are no particular known-in-advance bits of information I need to extract.
I don’t yet have a perfect account for what exactly you “learn” from this - at the speed I read, I don’t remember more than a tiny fraction of the details. My best explanation is that each paper you skim gives you context for understanding the next one. As you go through this process, you come away with some takeaway highlights and things to look at next.
So for example, the last time I went through the literature on senescence, I got into the antagonistic pleiotropy literature. Most of it is way too deep for me at this point, but I took away the basic insights and epistemic: models consistently show that aging is the only stable equilibrium outcome of evolution, that it’s fueled by genes that confer a reproductive advantage early in life but a disadvantage later in life, and that the late-life disadvantages should not be presumed to be intrinsically beneficial - they are the downside side of a tradeoff, and evolution often mitigates them, but generally cannot completely eliminate them.
I also came to understand that this is 70 years of development of mathematical and data-backed models, which consistently show the same thing.
Relevant for my research is that anti-aging therapeutics aren’t necessarily going to be “fighting against evolution.” They are complementing what nature is already trying to do: mitigate the genetic downsides in old age of adaptations for youthful vigor.
↑ comment by ChristianKl · 2022-11-05T15:44:55.363Z · LW(p) · GW(p)
That sounds more like a problem of the teaching style than school in particular. Instead of assigning textbook pages to be read, a better way is to give the students problems to solve and tell them that those textbook pages are relevant to solving the problem. That's how my biology and biochemistry classes went. We were never assigned to read particular pages of the book.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-11-05T16:47:51.854Z · LW(p) · GW(p)
a better way is to give the students problems to solve and tell them that those textbook pages are relevant to solving the problem. That's how my biology and biochemistry classes went. We were never assigned to read particular pages of the book.
That does sound like a better way. Personally, I'm halfway through my biomedical engineering MS and have never experienced a STEM class like this. If you don't mind my asking, where did you take your bio/biochem classes (or what type of school was it)?
Replies from: ChristianKl↑ comment by ChristianKl · 2022-11-05T19:11:22.912Z · LW(p) · GW(p)
I studied bioinformatics at the Free University of Berlin. Just like we had weekly problem sheets in math classes we also had them in biology and biochemistry. It was more than a decade ago. There was certainly a sense of not simply copying what biology majors might do but to be focused more on problem-solving skills that would presumably be more relevant.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-01T04:39:30.677Z · LW(p) · GW(p)
There are many software tools for study, learning, attention programming, and memory prosthetics.
- Flashcard apps (Anki)
- Iterated reading apps (Supermemo)
- Notetaking and annotation apps (Roam Research)
- Motivational apps (Beeminder)
- Time management (Pomodoro)
- Search (Google Scholar)
- Mnemonic books (Matuschak and Nielsen's "Quantum Country")
- Collaborative document editing (Google Docs)
- Internet-based conversation (Internet forums)
- Tutoring (Wyzant)
- Calculators, simulators, and programming tools (MATLAB)
These complement analog study tools, such as pen and paper, textbooks, worksheets, and classes.
These tools tend to keep the user's attention directed outward. They offer useful proxy metrics for learning: getting through 20 flashcards per day, completing N Pomodoros, getting through the assigned reading pages, turning in the homework.
However, these proxy metrics, like any others, are vulnerable to streetlamp effects and Goodharting.
Before we had this abundance of analog and digital knowledge tools, scholars relied on other ways to tackle problems. They built memory palaces, visualized, looked for examples in the world around them, invented approximations, and talked to themselves. They relied on their brains, bodies, and what they could build from their physical environment to keep their thoughts in order.
Of course, humanity's transition into the enlightenment and industrial revolution coincided with the development of many of these knowledge tools: the abacus, the printing press, cheaper writing implements, slide rules, and eventually the computer. These undoubtedly have been essential for human progress.
Yet I suspect that access to these tools have led us to neglect the basic mental faculties our ancestors relied on to think and learn about scholarly topics. Key examples include the ability to hold and rehearse an extended chain of thought in your head, the ability to visualize or imagine feelings of physical movement, and the ability to deliberately construct patterns of thought.
These behaviors are perhaps more familiar to me than to the average person, because they are still, to some extent, expected of classical pianists like myself. We were expected to memorize our music and do mental practice, and composers are expected to be able to compose in their head. I taught myself relative pitch purely via a year's work imagining and identifying musical intervals in my head. This allowed me to invent melodies in my head as a side effect. Those were abilities I gained well into adulthood, and I had no idea my brain was capable of that before I was pressured by my music department into figuring out how to do it.
I expect that people have great potential to develop comparable mental skills in left-brained areas such as mental calculation and logic, visualizing geometry, and recalling facts. My hypothesis is that practice at expanding these mental abilities, and doing so for practical purposes (rather than, for example, to win memorization competitions), would allow people to understand topics and solve problems that previously had seemed incomprehensible to them. I think we've compensated for our modern artifice by letting go of mental art, and have realized fewer gains than the proliferation of computing power would have suggested to a scientist, mathematician, or engineer of 100 years ago.
The software programs above start with a psychological thesis about how learning works, do a task analysis to figure out what physical behaviors are required to realize that thesis, and then build a software program to facilitate and direct those behaviors. Anki starts with a thesis about spaced repetition, uses flashcards as its task, and builds a program to allow for more powerful flashcard-based practice than you can do with paper cards.
Software programs might also be useful to exercise the interior mental faculties. However, the point is for the practitioner to relate with their interior state of mind, not the external readout on a screen. Just as with software programs, we need a psychological thesis about how learning works. However, instead of a physical task analysis, we need a mental task analysis. Then we need a technique for enacting that mental task more efficiently for the purposes of learning and scholarship.
For example, under the thesis of constructivism, students must actively "build" their own knowledge by actively wrestling with the subject. Testing is a useful way to build understanding. Under this psychological thesis, a mental activity that might support learning is having students memorize practice problems and practice being able to describe, in their own head, how they'd solve that problem. They might also practice remembering the major topics related to the material they're covering, what order those topics are presented in, and how they interrelate in the overarching theme of the section. Being able to provoke thoughts on these topics at will, and successfully recall the material (i.e. on a walk, while driving, in the shower) would also be a form of "programmable attention," as many software programs seek to achieve, but one that is generated and directed by the student's own power of mind.
Another example, one getting farther away from what software can achieve, is simply the ability to hold a fluid, ongoing chain of thought recalling a topic of interest. For example, imagine a student who had thoroughly learned about the immune system. I think it is typical that students only really turn their thoughts to that topic when prompted, such as during a conversation, by a test, or while reading - all external forms of stimulation. A student might practice being able to think about what they know of the immune system at will, unprovoked. The ability to let their mind wander among the facts they've learned is not something most people can easily do, and seems obviously to me to be both an attainable and a very useful scholarly skill. But "spend some time thinking about and elaborating on what you know of immunology for the next 15 minutes, forming organic connections with other things you know and whatever you happen to be curious about" is not something that a software program can easily facilitate.
It's just this sort of mental practice that I'm interested in discovering, learning about, and promoting. There is plenty of effort and interest in external mental prosthetics. I am interested in what we can call the techniques of mental practice.
Replies from: Gunnar_Zarncke↑ comment by Gunnar_Zarncke · 2022-09-01T09:22:15.466Z · LW(p) · GW(p)
Please post this as a regular post.
Replies from: matto, Gyrodiot↑ comment by matto · 2022-09-01T18:51:24.324Z · LW(p) · GW(p)
Thirding this. Would love more detail or threads to pull on. Going into the constructivism rabbit hole now.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-01T21:53:23.678Z · LW(p) · GW(p)
I'll continue fleshing it out over time! Mostly using the shortform as a place to get my thoughts together in legible form prior to making a main post (or several). By the way, contrast "constructivism" with "transmissionism," the latter being the (wrong) idea that students are basically just sponges that passively absorb the information their teacher spews at them. I got both terms from Andy Matuschak.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-12-19T21:03:29.390Z · LW(p) · GW(p)
Thoughts on cheap criticism
It's OK for criticism to be imperfect. But the worst sort of criticism has all five of these flaws:
- Prickly: A tone that signals a lack of appreciation for the effort that's gone in to presenting the original idea, or shaming the presenter for bringing it up.
- Opaque: Making assertions or predictions without any attempt at specifying a contradictory gears-level model, evidence basis, even on the level of anecdote or fiction.
- Nitpicky: Attacking the one part of the argument that seems flawed, without arguing for how the full original argument should be reinterpreted in light of the local disagreement.
- Disengaged: Not signaling any commitment to continue the debate to mutual satisfaction, or even to listen to/read and respond to a reply.
- Shallow: An obvious lack of engagement with the details of the argument or evidence originally offered.
I am absolutely guilty of having delivered Category 5 criticism, the worst sort of cheap shots.
There is an important tradeoff here. If standards are too high for critical commentary, it can chill debate and leave an impression that either nobody cares, everybody's on board, or the argument's simply correct. Sometimes, an idea can be wrong for non-obvious reasons, and it's important for people to be able to say "this seems wrong for reasons I'm not clear about yet" without feeling like they've done wrong.
On the other hand, cheap criticism is so common because it's cheap. It punishes all discourse equally, which means that the most damage is done to those who've put in the most effort to present their ideas. That is not what we want.
It usually takes more work to punish more heavily. Executing someone for a crime takes more work than jailing them, which takes more work than giving them a ticket. Addressing a grievance with murder is more dangerous than starting a brawl, which is more dangerous than starting an argument, which is more dangerous than giving someone the cold shoulder.
But in debate, cheap criticism has this perverse quality where it does the most to diminish a discussion, while being the easiest thing to contribute.
I think this is a reason to, on the whole, create norms against cheap criticism. If discussion is already at a certain volume, that can partially be accomplished by ignoring cheap criticism entirely.
But for many ideas, cheap criticism is almost all it gets, early on in the discussion. Just one or two cheap criticisms can kill an idea prematurely. So being able to address cheap criticisms effectively, without creating unreasonably high standards for critical commentary, seems important.
Replies from: mr-hire, AllAmericanBreakfast, luke-allen↑ comment by Matt Goldenberg (mr-hire) · 2020-12-20T23:03:22.038Z · LW(p) · GW(p)
This seems like a fairly valuable framework. It occurs to me that all 5 of these flaws are present in the "Snark" genre present in places like Gawker and Jezebel.
↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-12-19T23:26:06.251Z · LW(p) · GW(p)
I am going to experiment with a karma/reply policy to what I think would be a better incentive structure if broadly implemented. Loosely, it looks like this:
- Strong downvote plus a meaningful explanatory comment for infractions worse than cheap criticism; summary deletions for the worst offenders.
- Strong downvote for cheap criticism, no matter whether or not I agree with it.
- Weak downvote for lazy or distracting comments.
- Weak upvote for non-cheap criticism or warm feedback of any kind.
- Strong upvote for thoughtful responses, perhaps including an appreciative note.
- Strong upvote plus a thoughtful response of my own to comments that advance the discussion.
- Strong upvote, a response of my own, and an appreciative note in my original post referring to the comment for comments that changed or broadened my point of view.
↑ comment by Luke Allen (luke-allen) · 2021-01-04T22:05:25.316Z · LW(p) · GW(p)
I'm trying a live experiment: I'm going to see if I can match your erisology one-to-one as antagonists to the Elements of Harmony from My Little Pony:
- Prickly: Kindness
- Opaque: Honesty
- Nitpicky: Generosity
- Disengaged: Loyalty
- Shallow: Laughter
Interesting! They match up surprisingly well, and you've somehow also matched the order of 3 out of 5 of the corresponding "seeds of discord" from 1 Peter 2:1, CSB: "Therefore, rid yourselves of all malice, all deceit, hypocrisy, envy, and all slander." If my pronouncement of success seems self-serving and opaque, I'll elaborate soon:
- Malice: Kindness
- Deceit: Honesty
- Hypocrisy: Loyalty
- Envy: Generosity
- Slander: Laughter
And now the reveal. I'm a generalist; I collect disparate lists of qualities (in the sense of "quality vs quantity"), and try to integrate all my knowledge into a comprehensive worldview. My world changed the day I first saw My Little Pony; it changed in a way I never expected, in a way many people claim to have been affected by HPMOR. I believed I'd seen a deep truth, and I've been subtly sharing it wherever I can.
The Elements of Harmony are the character qualities that, when present, result in a spark of something that brings people together. My hypothesis is that they point to a deep-seated human bond-testing instinct. The first time I noticed a match-up was when I heard a sermon on The Five Love Languages, which are presented in an entirely different order:
- Words of affirmation: Honesty
- Quality time: Laughter
- Receiving gifts: Generosity
- Acts of service: Loyalty
- Physical touch: Kindness
Well! In just doing the basic research to write this reply, it turns out I'm re-inventing the wheel! Someone else has already written a psychometric analysis of the Five Love Languages and found they do indeed match up with another relational maintenance typology.
Thank you for your post; you've helped open my eyes up to existing research I can use in my philosophical pursuits, and sparked thoughts of what "effective altruism" use I can put them to.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-01T02:24:40.657Z · LW(p) · GW(p)
Weight Loss Simulation
I've gained 50 pounds over the last 15 years. I'd like to get a sense of what it would be like to lose that weight. One way to do that is to wear a weighted vest all day long for a while, then gradually take off the weight in increments.
The simplest version of this experiment is to do a farmer's carry with two 25 lb free weights. It makes a huge difference in the way it feels to move around, especially walking up and down the stairs.
However, I assume this feeling is due to a combination of factors:
- The sense of self-consciousness that comes with doing something unusual
- The physical bulk and encumbrance (i.e. the change in volume and inertia, having my hands occupied, pressure on my diaphragm if I were wearing a weighted vest, etc)
- The ratio of how much muscle I have to how much weight I'm carrying
If I lost 50 pounds, that would likely come with strength training as well as dieting, so I might keep my current strength level while simultaneously being 50 pounds lighter. That's an argument in favor of this "simulated weight loss" giving me an accurate impression of how it would feel to really lose that much weight.
On the other hand, there would be no sudden transition from weird artificial bulk to normalcy. It would be a gradual change. Putting on a weighted vest and wearing it around for, say, a month, would be socially awkward, and require the daily choice to put it on. I'd have to take it off to sleep, shower, etc. This would cause the difference in weight to be constantly brought to my attention, although that effect would diminish throughout the experiment as I gradually took weights off of the vest and got used to wearing it around.
One way to make it more realistic would be to gradually increase the weight to 50 lb, then gradually decrease it back to 0 lb. Another way to make it more realistic would be to add uncertainty. Instead of, say, changing the weight by 1 increment every day, I might flip a coin and change the weight by 1 increment only if I flip heads.
I'm interested to try this experiment. The weighted vest would be a useful piece of exercise gear on its own. The only way to really find out if the experiment actually matches the real feeling of losing 50 lb would be to lose the weight for real. If I did the experiment, then lost the weight, I'd actually be able to make a comparison. That would be impossible if I didn't do the experiment. I also suspect the experiment would be motivating, and would also provide real exercise that would contribute to actual weight loss.
Overall, this experiment seems like it would have very few downsides and quite a few upsides, so I am excited to give it a try!
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-06-14T18:32:13.138Z · LW(p) · GW(p)
Overtones of Philip Tetlock:
"After that I studied morning and evening searching for the principle,
and came to realize the Way of Strategy when I was fifty. Since then I
have lived without following any particular Way. Thus with the virtue of
strategy I practice many arts and abilities - all things with no teacher. To
write this book I did not use the law of Buddha or the teachings of Confucius, neither old war chronicles nor books on martial tactics. I take up
my brush to explain the true spirit of this Ichi school as it is mirrored in
the Way of heaven and Kwannon." - Miyamoto Musashi, The Book of Five Rings
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-06-23T03:29:03.794Z · LW(p) · GW(p)
A "Nucleation" Learning Metaphor
Nucleation is the first step in forming a new phase or structure. For example, microtubules are hollow cylinders built from individual tubulin proteins, which stack almost like bricks. Once the base of the microtubule has come together, it's easy to add more tubulin to the microtubule. But assembling the base - the process of nucleation - is slow without certain helper proteins. These catalyze the process of nucleation by binding and aligning the first few tubulin proteins.
What does learning have in common with nucleation? When we learn from written sources, like textbooks or a lecture, the main sensory input we experience is typically a continuous flow of words and images. All these words and phrases are like "information monomers." Achieving a synthetic understanding of the material is akin to the growth of larger structures, the "microtubules." Exposing ourselves to more and more of a teacher's words or textbook pages does increase the "information monomer concentration" in our minds, and makes a process of spontaneous nucleation more likely.
At some point, synthesis just happens if we keep at it long enough, the same way that nucleation and the growth of microtubules spontaneously happens if we keep adding more tubulin to the solution. But for most people, I think the bottleneck to increasing the rate of forming a synthetic understanding is bottlenecked not by exposure to "information monomers," the sheer amount of reading or listening we do, but by the process of "nucleation," our ability to form at least a rudimentary synthetic understanding out of even a small quantity of content.
Replies from: Vladimir_Nesov, Viliam↑ comment by Vladimir_Nesov · 2023-06-23T12:30:59.710Z · LW(p) · GW(p)
Might be about using the accumulated references to seek out and generate more training data (at the currently relevant level, not just anything). Passive perception of random tidbits might take much longer. I wonder if there are lower estimates on human sample efficiency, how long can it take to not learn something when getting regularly exposed to it, for a person of given intelligence, who isn't exercising curiosity in that direction? My guess it's plausibly a difference of multiple orders of magnitude, and a different ceiling.
↑ comment by Viliam · 2023-06-23T09:04:30.773Z · LW(p) · GW(p)
This reminds me of a thing that gestalt psychologists call "re-centering", which in your metaphor could be described as having a lot of free-floating information monomers that suddenly snap together (which in slow motion might be that first the base forms spontaneously, and then everything else snaps to the base). The difference is that according to them, this happens repeatedly... when you get more information, and it turns out that the original structure was not optimal, so at some moment it snaps again into a new shape. (A "paradigm shift".)
Then there is a teaching style called constructivism (though this name was also abused to mean different things) which is concerned with getting the base structure built as soon as possible. And then getting the next steps right, too. Emphasis on having correct mental models, over memorizing facts. -- One of the controversies is whether this is even necessary to do. Some people insist that it is a waste of time; if you give people enough information monomers, at some moment it will snap to the right structure (and if it won't, well, sucks to be you; it worked okay for them). Other people say that this attitude is why so many kids hate school, especially math (long inferential chains), but if you keep building the structure right all the time, it becomes much less frustrating experience.
So I like the metaphor, with the exception that it is not a simple cylinder, but a more complicated structure, that can get wrong (and get fixed) multiple times.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-04-30T05:17:52.122Z · LW(p) · GW(p)
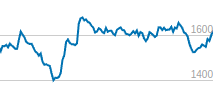
Personal evidence for the impact of stress on cognition. This is my Lichess ranking on Blitz since January. The two craters are, respectively, the first 4 weeks of the term, and the last 2 weeks. It begins trending back up immediately after I took my last final.
Replies from: TLW↑ comment by TLW · 2022-04-30T17:36:20.821Z · LW(p) · GW(p)
How much did you play during the start / end of term compared to normal?
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-04-30T18:10:58.698Z · LW(p) · GW(p)
I don’t know exactly, Lichess doesn’t have a convenient way to plot that day by day. But probably roughly equal amounts. It’s my main distraction.
Replies from: TLW↑ comment by TLW · 2022-04-30T18:30:17.113Z · LW(p) · GW(p)
Too bad. My suspects for confounders for that sort of thing would be 'you played less at the start/end of term' or 'you were more distracted at the start/end of term'.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-04-30T20:03:12.755Z · LW(p) · GW(p)
Playing less wouldn’t decrease my score, and being distracted is one of the effects of stress.
Replies from: TLW↑ comment by TLW · 2022-04-30T23:56:56.447Z · LW(p) · GW(p)
Playing less wouldn’t decrease my score
Interesting. Is this typically the case with chess? Humans tend to do better with tasks when they are repeated more frequently, albeit with strongly diminishing returns.
being distracted is one of the effects of stress.
Absolutely, which makes it very difficult to tease apart 'being distracted as a result of stress caused by X causing a drop' and 'being distracted due to X causing a drop'.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-05-01T00:14:54.976Z · LW(p) · GW(p)
Interesting. Is this typically the case with chess? Humans tend to do better with tasks when they are repeated more frequently, albeit with strongly diminishing returns.
I see what you mean, and yes, that is a plausible hypothesis. It's hard to get a solid number, but glancing over the individual records of my games, it looks like I was playing about as much as usual. Subjectively, it doesn't feel like lack of practice was responsible.
I think the right way to interpret my use of "stress" in this context is "the bundle of psychological pressures associated with exam season," rather than a psychological construct that we can neatly distinguish from, say, distractability or sleep loss. It's kind of like saying "being on an ocean voyage with no access to fresh fruits and vegetables caused me to get scurvy."
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-12-23T03:16:33.331Z · LW(p) · GW(p)
Does rationality serve to prevent political backsliding?
It seems as if politics moves far too fast for rational methods can keep up. If so, does that mean rationality is irrelevant to politics?
One function of rationality might be to prevent ethical/political backsliding. For example, let's say that during time A, institution X is considered moral. A political revolution ensues, and during time B, X is deemed a great evil and is banned.
A change of policy makes X permissible during time C, banned again during time D, and absolutely required for all upstanding folk during time E.
Rational deliberation about X seems to play little role in the political legitimacy of X.
However, rational deliberation about X continues in the background. Eventually, a truly convincing argument about the ethics of X emerges. Once it does, it is so compelling that it has a permanent anchoring effect on X.
Although at some times, society's policy on X contradicts the rational argument, the pull of X is such that it tends to make these periods of backsliding shorter and less frequent.
The natural process of developing the rational argument about X also leads to an accretion of arguments that are not only correct, but convincing as well. This continues even when the ethics of X are proven beyond a shadow of a doubt, which continues to shorten and prevent periods of backsliding.
In this framework, rationality does not "lead" politics. Instead, it channels it. The goal of a rational thinker should not be to achieve an immediate political victory. Instead, it should be to build the channels of rational thought higher and stronger, so that the fierce and unpredictable waters of politics eventually are forced to flow in a more sane and ethical direction.
The reason you'd concern yourself with persuasion in this context is to prevent the fate of Gregor Mendel, whose ideas on inheritance were lost in a library for 40 years. If you come up with a new or better ethical argument about X, make sure that it becomes known enough to survive and spread. Your success is not your ability to immediately bring about the political changes your idea would support. Instead, it's to bring about additional consideration of your idea, so that it can take root, find new expression, influence other ideas, and either become a permanent fixture of our ethics or be discarded in favor of an even stronger argument.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-10-23T16:15:41.315Z · LW(p) · GW(p)
Thinking, Fast and Slow was the catalyst that turned my rumbling dissatisfaction into the pursuit of a more rational approach to life. I wound up here. After a few years, what do I think causes human irrationality? Here's a listicle.
- Cognitive biases, whatever these are
- Not understanding statistics
- Akrasia
- Little skill in accessing and processing theory and data
- Not speaking science-ese
- Lack of interest or passion for rationality
- Not seeing rationality as a virtue, or even seeing it as a vice.
- A sense of futility, the idea that epistemic rationality is not very useful, while instrumental rationality is often repugnant
- A focus on associative thinking
- Resentment
- Not putting thought into action
- Lack of incentives for rational thought and action itself
- Mortality
- Shame
- Lack of time, energy, ability
- An accurate awareness that it's impossible to distinguish tribal affiliation and culture from a community
- Everyone is already rational, given their context
- Everyone thinks they're already rational, and that other people are dumb
- It's a good heuristic to assume that other people are dumb
- Rationality is disruptive, and even very "progressive" people have a conservative bias to stay the same, conform with their peers, and not question their own worldview
- Rationality can misfire if we don't take it far enough
- All the writing, math, research, etc. is uncomfortable and not very fun compared to alternatives
- Epistemic rationality is directly contradictory to instrumental rationality
- Nihilism
- Applause lights confuse people about what even is rationality
- There's at least 26 factors deflecting people from rationality, and people like a clear, simple answer
- No curriculum
- It's not taught in school
- In an irrational world, epistemic rationality is going to hold you back
- Life is bad, and making it better just makes people more comfortable in badness
- Very short-term thinking
- People take their ideas way too seriously, without taking ideas in general seriously enough
- Constant distraction
- The paradox of choice
- Lack of faith in other people or in the possibility for constructive change
- Rationality looks at the whole world, which has more people in it than Dunbar's number
- The rationalists are all hiding on obscure blogs online
- Rationality is inherently elitist
- Rationality leads to convergence on the truth if we trust each other, but it leads to fragmentation of interests since we can't think about everything, which makes us more isolated
- Slinging opinions around is how people connect. Rationality is an argument.
- "Rationality" is stupid. What's really smart is to get good at harnessing your intuition, your social instincts, to make friends and play politics.
- Rationality is paperclipping the world. Every technological advance that makes individuals more comfortable pillages the earth and increases inequality, so they're all bad and we should just embrace the famine and pestilence until mother nature takes us back to the stone age and we can all exist in the circular dreamtime.
- You can't rationally commit to rationality without being rational first. We have no baptism ceremony.
- We need a baptism ceremony but don't want to be a cult, so we're screwed, which we would also be if we became a cult.
- David Brooks is right that EA is bad, we like EA, so we're probably bad too.
- We're secretly all spiritual and just faking rational atheism because what we really want to do is convert.
- There's too much verbiage already in the world.
- The singularity is coming; what's the point?
- Our leaders have abandoned us, and the best of us have been cut down like poppies.
- Eschewing the dark arts is a self-defeating stance
↑ comment by Dagon · 2020-10-23T19:09:07.597Z · LW(p) · GW(p)
A few other (even less pleasant) options:
51) God is inscrutable and rationality is no better than any other religion.
52) Different biology and experience across humans leads to very different models of action.
53) Everyone lies, all the time.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-08-01T14:26:30.501Z · LW(p) · GW(p)
Are rationalist ideas always going to be offensive to just about everybody who doesn’t self-select in?
One loved one was quite receptive to Chesterton’s Fence the other day. Like, it stopped their rant in the middle of its tracks and got them on board with a different way of looking at things immediately.
On the other hand, I routinely feel this weird tension. Like to explain why I think as I do, I‘d need to go through some basic rational concepts. But I expect most people I know would hate it.
I wish we could figure out ways of getting this stuff across that was fun, made it seem agreeable and sensible and non-threatening.
Less negativity - we do sooo much critique. I was originally attracted to LW partly as a place where I didn’t feel obligated to participate in the culture war. Now, I do, just on a set of topics that I didn’t associate with the CW before LessWrong.
My guess? This is totally possible. But it needs a champion. Somebody willing to dedicate themselves to it. Somebody friendly, funny, empathic, a good performer, neat and practiced. And it needs a space for the educative process - a YouTube channel, a book, etc. And it needs the courage of its convictions. The sign of that? Not taking itself too seriously, being known by the fruits of its labors.
Replies from: Viliam, Pongo↑ comment by Viliam · 2020-08-02T19:29:30.552Z · LW(p) · GW(p)
Traditionally, things like this are socially achieved by using some form of "good cop, bad cop" strategy. You have someone who explains the concepts clearly and bluntly, regardless of whom it may offend (e.g. Eliezer Yudkowsky), and you have someone who presents the concepts nicely and inoffensively, reaching a wider audience (e.g. Scott Alexander), but ultimately they both use the same framework.
The inoffensiveness of Scott is of course relative, but I would say that people who get offended by him are really not the target audience for rationalist thought. Because, ultimately, saying "2+2=4" means offending people who believe that 2+2=5 and are really sensitive about it; so the only way to be non-offensive is to never say anything specific.
If a movement only has the "bad cops" and no "good cops", it will be perceived as a group of assholes. Which is not necessarily bad if the members are powerful; people want to join the winning side. But without actual power, it will not gain wide acceptance. Most people don't want to go into unnecessary conflicts.
On the other hand, a movement with "good cops" without "bad cops" will get its message diluted. First, the diplomatic believers will dilute their message in order not to offend anyone. Their fans will further dilute the message, because even the once-diluted version is too strong for normies' taste. At the end, the message may gain popular support... kind of... because the version that gains the popular support will actually contain maybe 1% of the original message, but mostly 99% of what the normies already believed, peppered by the new keywords.
The more people will present rationality using different methods, the better. Because each of them will reach a different audience. So I completely approve the approach you suggest... in addition to the existing ones.
Replies from: AllAmericanBreakfast, TAG, seed↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-08-02T23:57:57.601Z · LW(p) · GW(p)
You're right.
I need to try a lot harder to remember that this is just a community full of individuals airing their strongly held personal opinions on a variety of topics.
Replies from: Viliam↑ comment by Viliam · 2020-08-03T12:27:49.602Z · LW(p) · GW(p)
Those opinions often have something in common -- respect for the scientific method, effort to improve one's rationality, concern about artificial intelligence -- and I like to believe it is not just a random idiosyncratic mix (a bunch of random things Eliezer likes), but different manifestations of the same underlying principle (use your intelligence to win, not to defeat yourself). However, not everyone is interested in all of this.
And I would definitely like to see "somebody friendly, funny, empathic, a good performer, neat and practiced" promoting these values in a YouTube channel or in books. But that requires a talent I don't have, so I can only wait until someone else with the necessary skills does it.
This reminded me of the YouTube channel of Julia Galef, but the latest videos there are 3 years old.
Replies from: Pontor↑ comment by Pontor · 2020-11-28T17:54:26.272Z · LW(p) · GW(p)
Her podcast is really good IMHO. She does a singularly good job of challenging guests in a friendly manner, dutifully tracking nuance, steelmanning, etc. It just picked back up after about a yearlong hiatus (presumably due to her book writing).
Unfortunately, I see the lack of notoriety for her podcast to be some evidence against the prospects of the "skilled & likeable performer" strategy. I assume that potential subscribers are more interested in lower-quality podcasts and YouTubers that indulge in bias rather than confronting it. Dunno what to do about that, but I'm glad she's back to podcasting.
Replies from: Viliam↑ comment by Viliam · 2020-11-29T17:44:06.770Z · LW(p) · GW(p)
It just picked back up after about a yearlong hiatus
That's wonderful news, thank you for telling me!
For those who have clicked on the YouTube link in my previous comment, there is no new content as of now, go to the Rationally Speaking podcast.
↑ comment by seed · 2020-11-28T09:36:40.090Z · LW(p) · GW(p)
Look, I'm neurotypical and I don't find anything Eliezer writes offensive, will you please stop ostracizing us.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2020-11-28T11:03:52.988Z · LW(p) · GW(p)
Did either of them say neurotypical? I just heard them say normies.
Replies from: seed↑ comment by Pongo · 2020-08-01T22:46:57.624Z · LW(p) · GW(p)
Like to explain why I think as I do, I‘d need to go through some basic rational concepts.
I believe that if the rational concepts are pulling their weight, it should be possible to explain the way the concept is showing up concretely in your thinking, rather than justifying it in the general case first.
As an example, perhaps your friend is protesting your use of anecdotes as data, but you wish to defend it as Bayesian, if not scientific, evidence [LW · GW]. Rather than explaining the difference in general, I think you can say "I think that it's more likely that we hear this many people complaining about an axe murderer downtown if that's in fact what's going on, and that it's appropriate for us to avoid that area today. I agree it's not the only explanation and you should be able to get a more reliable sort of data for building a scientific theory, but I do think the existence of an axe murderer is a likely enough explanation for these stories that we should act on it"
If I'm right that this is generally possible, then I think this is a route around the feeling of being trapped on the other side of an inferential gap (which is how I interpreted the 'weird tension')
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-08-02T04:06:13.732Z · LW(p) · GW(p)
I think you're right, when the issue at hand is agreed on by both parties to be purely a "matter of fact."
As soon as social or political implications crop in, that's no longer a guarantee.
But we often pretend like our social/political values are matters of fact. The offense arises when we use rational concepts in a way that gives the lie to that pretense. Finding an indirect and inoffensive way to present the materials and let them deconstruct their pretenses is what I'm wishing for here. LW has a strong culture surrounding how these general-purpose tools get applied, so I'd like to see a presentation of the "pure theory" that's done in an engaging way not obviously entangled with this blog.
The alternative is to use rationality to try and become savvier social operators. This can be "instrumental rationality" or it can be "dark arts," depending on how we carry it out. I'm all for instrumental rationality, but I suspect that spreading rational thought further will require that other cultural groups appropriate the tools to refine their own viewpoints rather than us going out and doing the convincing ourselves.
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-01-31T04:05:25.972Z · LW(p) · GW(p)
Reliability
I work in a biomedical engineering lab. With the method I'm establishing, there are hundreds of little steps, repeated 15 times over the course of weeks. For many of these steps, there are no dire consequences for screwing them up. For others, some or all of your work could be ruined if you don't do them right. There's nothing intrinsic about the critical steps that scream "PAY ATTENTION RIGHT NOW."
If your chance of doing any step right is X%, then for some X, you are virtually guaranteed to fail. If in a day, there are 30 critical steps, then you need about a 98% reliability rate on any individual step to achieve a 50% overall chance of success on any particular day. An 80% reliability rate gives you a chance of success virtually indistinguishable from zero.
Normally, habits are what we rely on to make us reliable. When establishing a new method, however, you're constantly fighting against many of your habits. As you validate, troubleshoot, tweak and optimize, you're changing bits and pieces of a semi-familiar routine, and it's a constant struggle to do the modifications right on the first try without letting old habits override them, and without letting the modifications break the old habits. I find more and more that figuring out ways to structure my work to enforce reliability on myself has big payoffs.
Some ways I do this:
- I set up my workstation better so that I can design experiments on the computer and print them out for the bench more easily.
- I have a rule to always double check my math and do no math in my head
- I turn the steps of my method into detailed checklists.
- I have a dedicated cardboard box with handles for carrying stuff to other rooms where I do various tests, and I have a label on the cardboard box for what items to bring for specific tests.
- I label the reagents according to the order I'll be using them, if possible. If not, I have a set of bins at my bench. I set the reagents for step 1 in bin 1, the reagents for step 2 in bin 2, etc. That way, I have a physical representation of the task flow that's set up before me, so that no mental effort need be put into remembering "what next."
The general rules underpinning these approaches seem to be:
- Split apart the steps of thinking and doing as much as possible
- Use physical mechanisms you set up during the "thinking stage" to enforce compliance during the "doing" stage
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-11-08T23:28:14.602Z · LW(p) · GW(p)
Aging research is the wild west
In Modern Biological Theories of Aging (2010), Jin dumps a bunch of hypotheses and theories willy-nilly. Wear-and-tear theory is included because "it sounds perfectly reasonable to many people even today, because this is what happens to most familiar things around them." Yet Jin entirely excludes antagonistic pleiotropy, the mainstream and 70-year-old solid evolutionary account for why aging is an inevitable side effect of evolution for reproductive fitness.
This review has 617 citations. It's by a prominent researcher with a very high h-index. It is disturbingly shallow. If it's missing antagonistic pleiotropy, what else is it leaving out?
Update: Be very suspicious about "review" articles on theories of aging. The field has not managed to narrow down theories of aging, or even a definition of aging, so old bad ideas like "wear-and-tear" linger on while rock-solid theories can be casually ignored.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-08-08T19:48:42.333Z · LW(p) · GW(p)
Markets are the worst form of economy except for all those other forms that have been tried from time to time.
Replies from: mr-hire↑ comment by Matt Goldenberg (mr-hire) · 2020-08-09T01:37:33.440Z · LW(p) · GW(p)
I used this line when having a conversation at a party with a bunch of people who turned out to be communists, and the room went totally silent except for one dude who was laughing.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-08-09T04:48:03.500Z · LW(p) · GW(p)
It was the silence of sullen agreement.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-07-31T16:16:52.601Z · LW(p) · GW(p)
I'm annoyed that I think so hard about small daily decisions.
Is there a simple and ideally general pattern to not spend 10 minutes doing arithmetic on the cost of making burritos at home vs. buying the equivalent at a restaurant? Or am I actually being smart somehow by spending the time to cost out that sort of thing?
Perhaps:
"Spend no more than 1 minute per $25 spent and 2% of the price to find a better product."
This heuristic cashes out to:
- Over a year of weekly $35 restaurant meals, spend about $35 and an hour and a half finding better restaurants or meals.
- For $250 of monthly consumer spending, spend a total of $5 and 10 minutes per month finding a better product.
- For bigger buys of around $500 (about 2x/year), spend $10 and 20 minutes on each purchase.
- Buying a used car ($15,000) I'd spend $300 and 10 hours. I could use the $300 to hire somebody at $25/hour to test-drive an additional 5-10 cars, a mechanic to inspect it on the lot, a good negotiator to help me secure a lower price.
- For work over the next year ($30,000), spend $600 and 20 hours.
- Getting a Master's degree ($100,000 including opportunity costs), spend 66 hours and $2,000 finding the best school.
- Choosing from among STEM career options ($100,000 per year), spend about 66 hours and $600 per year exploring career decisions.
Comparing that with my own patterns, that simplifies to:
Spend much less time thinking about daily spending. You're correctly calibrated for ~$500 buys. Spend much more time considering your biggest buys and decisions.
Replies from: Dagon↑ comment by Dagon · 2020-07-31T22:00:48.491Z · LW(p) · GW(p)
For some (including younger-me), the opposite advice was helpful - I'd agonize over "big" decisions, without realizing that the oft-repeated small decisions actually had a much larger impact on my life.
To account for that, I might recommend you notice cache-ability and repetition, and budget on longer timeframes. For monthly spending, there's some portion that's really $120X decade spending (you can optimize once, then continue to buy monthly for the next 10 years), a bunch that's probably $12Y of annual spending, and some that's really $Z that you have to re-consider every month.
Also, avoid the mistake of inflexible permissions. Notice when you're spending much more (or less!) time optimizing a decision than your average, but there are lots of them that actually benefit from the extra time. And lots that additional time/money doesn't change the marginal outcome by much, so you should spend less time on.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-07-31T23:09:18.399Z · LW(p) · GW(p)
I wonder if your problem as a youth was in agonizing over big decisions, rather than learning a productive way to methodically think them through. I have lots of evidence that I underthink big decisions and overthink small ones. I also tend to be slow yet ultimately impulsive in making big changes, and fast yet hyper-analytical in making small changes.
Daily choices have low switching and sunk costs. Everybody's always comparing, so one brand at a given price point tends to be about as good as another.
But big decisions aren't just big spends. They're typically choices that you're likely stuck with for a long time to come. They serve as "anchors" to your life. There are often major switching and sunk costs involved. So it's really worthwhile anchoring in the right place. Everything else will be influenced or determined by where you're anchored.
The 1 minute/$25 + 2% of purchase price rule takes only a moment's thought. It's a simple but useful rule, and that's why I like it.
There are a few items or services that are relatively inexpensive, but have high switching costs and are used enough or consequential enough to need extra thought. Examples include pets, tutors, toys for children, wedding rings, mattresses, acoustic pianos, couches, safety gear, and textbooks. A heuristic and acronym for these exceptions might be CHEAPS: "Is it a Curriculum? Is it Heavy? Is it Ergonomic? Is it Alive? Is it Precious? Is it Safety-related?"
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-12-10T04:51:31.501Z · LW(p) · GW(p)
Don't get confused - to attain charisma and influence, you need power first.
If you, like most people, would like to fit in, make friends easily, and project a magnetic personality, a natural place to turn is books like The Charisma Myth and How to Make Friends and Influence People.
If you read them, you'll get confused unless you notice that there's a pattern to their anecdotes. In all the success stories, the struggling main character has plenty of power and resources to achieve their goals. Their problem is that, somehow, they're not able to use that power to get others to do what they want.
Take the third chapter from How to Make Friends and Influence People. To save time, here's a summary of the ten main stories. You can skip and review them if you want; I provide them all mainly for completeness.
- A story about a calf who wouldn't be manhandled to the barn, but came willingly when allowed to suck on the housemaid's thumb.
- A story about how Andrew Carnegie offered a veiled bribe his sons-in-law to write a letter home to their worried mother.
- A story of a father who made his son anticipate the first day of kindergarten by demonstrating all the fun activities he'd be able to do there.
- A story of how the author convinced a hotel not to excessively raise the rates they'd been charging him to rent a lecture hall.
- An example of how a shipping company could convince one of their customers to send in the freight early by pointing out that they'd get better and faster service that way.
- A letter from an experienced bank worker convincing potential employers to give her an interview.
- A salesman whose sheer enthusiasm for a new life insurance policy proved infectious and scored him a sale.
- A salesman who convinced a gas station manager to clean up his station by giving him a tour of a nicer location, which made the manager want to match its quality.
- A father who convinced his young son to eat his peas by telling him that he'd be able to beat up the bully who kept stealing his tricycle if he did. He also kept his son from wetting the bed by buying him his own pyjamas and his own bed.
- A husband and wife who convinced their daughter to eat her breakfast by allowing her to make it and show off her cooking skills to her father.
In each situation, the person (or animal) the protagonist wanted to persuade had an "eager want," which the protagonist had the power to fulfill. They were only bottlenecked by not realizing what that "eager want" was, and making an attempt to link its fulfillment to the achievement of their own goal. A simple shift in perspective was all that was required to turn hours, days, or weeks of frustration into success.
Reading this, it might make you think that this is the main barrier to your own success, and perhaps it is. But you should first ask if the real problem is that you don't have the power or resources to fulfill the "eager want" of the person you're trying to persuade. Or alternatively, if you're worried that they might renege on the deal.
It's perfectly possible to have an "eager want" of your own that you can't fulfill because you simply don't have anything substantial to offer. That is a solvable problem. But it's important not to get confused thinking your problem is a lack of empathy and deal-making enthusiasm, rather than a lack of resources and power.
Replies from: Viliam, ulisse-mini↑ comment by Ulisse Mini (ulisse-mini) · 2022-12-10T05:11:17.465Z · LW(p) · GW(p)
Both are important, but I disagree that power is always needed. In example 3,7,9 it isn't clear that the compromise is actually better for the convinced party. The insurance is likely -EV, The peas aren't actually a crux to defeating the bully, the child would likely be happier outside kindergarten.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-12-10T05:27:48.436Z · LW(p) · GW(p)
I see what you mean! If you look closely, I think you'll find that power is involved in even these cases. The examples of the father and child depend on the father having the power of his child's trust. He can exploit this to trick his child and misrepresent the benefits of school or of eating peas.
The case of the insurance salesman is even more important to consider. You are right that insurance policies always have negative expected value in terms of money. But they may have positive expected value to the right buyer. Ann insurance policy can confer status on the buyer, who can put his wife's mind at ease that he's protected her and their children from the worst. It's also protection against loss aversion and a commitment device to put money away for a worst-case scenario, without having to think too hard about it.
But in order to use his enthusiasm to persuade the customer of this benefit, the salesman has to get a job with an insurance company and have a policy worth selling. That's the power he has to have first, in order to make his persuasion successful.
Replies from: ulisse-mini↑ comment by Ulisse Mini (ulisse-mini) · 2022-12-10T14:43:05.199Z · LW(p) · GW(p)
I disagree that the policy must be worth selling (see e.g. Jordon Belfort). Many salespeople can sell things that aren't worth buying. See also: never split the difference for an example of negotiation when you have little/worse leverage.
(Also, I don't think htwfaip boils down to satisfying an eager want, the other advice is super important too. E.g. don't criticize, be genuinely interested in a person, ...)
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-12-10T01:52:24.191Z · LW(p) · GW(p)
How I boosted my chess score by a shift of focus
For about a year, I've noticed that when I'm relaxed, I play chess better. But I wasn't ever able to quite figure out why, or how to get myself in that relaxed state. Now, I think I've done it, and it's stabilized my score on Lichess at around 1675 rather than 1575. That means I'm now evenly matched with opponents who'd previously have beaten me 64% of the time.
The trick is that I changed my visual relationship with the chessboard. Previously, I focused hard on the piece I was considering moving, almost as if I was the piece, and had to consider the chess board "from its point of view." If I was considering a bishop move, I'd look at the diagonals it could move along.
Now, I mostly just soft-focus on the center of the chess board, and allow my peripheral vision to extend to the edges of the board. I don't stare directly at the piece I'm moving, but rely on peripheral vision to place it correctly. By doing this, I think my system 1 can get engaged in recognizing good moves wherever they might be found.
As I do this, I notice my brain starting to scan for obvious threats and opportunities: rooks lined up diagonally, which is vulnerable to a bishop; a knight and bishop with one square between them from side to side, which is vulnerable to a pawn fork; a piece left hanging. If I don't see any, I just find sensible moves and make them without thinking about anything too hard.
Replies from: avturchin↑ comment by avturchin · 2022-12-10T19:23:09.425Z · LW(p) · GW(p)
Kasparov was asked: how you are able to calculate all possible outcomes of the game. He said: I don't. I just have very good understanding of current situation.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-12-10T19:34:21.408Z · LW(p) · GW(p)
I think there's a broader lesson to this ability to zoom out, soft focus, take in the whole situation as it is now, and just let good ideas come to you. Chess is an easy illustration because all information is contained on the board and the clock, and the rules and objective are clear. Vaguely, it seems like successful people are able to construct a model of the whole situation, while less successful people get caught up in hyperfocusing on the particularities.
Replies from: avturchin, avturchin↑ comment by avturchin · 2022-12-10T19:38:00.347Z · LW(p) · GW(p)
I think that they are also to find the most important problem from all.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-12-10T19:42:20.189Z · LW(p) · GW(p)
It's probably helpful to be able to take in everything in order to do that - I think these two ideas go together.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-10-13T02:06:58.312Z · LW(p) · GW(p)
Summaries can speed your reading along by
- Avoiding common misunderstandings
- Making it easy to see why the technical details matter
- Helping you see where it's OK to skim
Some summaries are just BAD
- They sometimes to a terrible job of getting the main point across
- They can be boring, insulting, or confusing
- They give you a false impression of what's in the article, making you skip it when you'd actually have gotten a lot out of reading it
- They can trick you into misinterpreting the article
The author is not the best person to write the summary. They don't have a clear sense of what's confusing to the average reader. Plus, their priority is often on being thorough and getting credit for the idea, not on being a clear and effective communicator.
The best person to write the summary is someone who cares about the topic, but only recently de-confused themselves about the paper. They can exploit their recent confusion to take the next reader from confusion to understanding more quickly. Hopefully, they share the same background knowledge as their intended reader, and ideally they'd run their summary by the author to make sure it's accurate.
Someday soon, we might have the technology to write custom summaries of papers depending on exactly what you want to know about it. For now, it's a useful skill for a human.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-24T00:52:31.700Z · LW(p) · GW(p)
Task Switching And Mentitation
A rule of thumb is that there's no such thing as multitasking - only rapid task switching. This is true in my experience. And if it's true, it means that we can be more effective by improving our ability to both to switch and to not switch tasks.
Physical and social tasks consume a lot of energy, and can be overstimulating. They also put me in a headspace of "external focus," moving, looking at my surroundings, listening to noises, monitoring for people. Even when it's OK to stop paying attention to my surroundings, I find it very hard to stop. This makes it hard to switch back to "mentitation mode," where I'm in tune with my thoughts.
My usual solution is to chill out for a while. It's not a great solution, because I usually just waste the time. I distractedly watch TV shows while also scrolling on my phone. That sort of thing. Might as well have just skipped those hours of life completely at that point.
It would be better to do something rejuvenating. Meditation, a nap, something like that. But what I think I need in these moments is a way of transitioning back to "mentitation mind." My guess is that I'm not tired, so much as lacking practice in making this mental transition.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-22T22:33:31.526Z · LW(p) · GW(p)
There's a fairly simple statistical trick that I've gotten a ton of leverage out of. This is probably only interesting to people who aren't statistics experts.
The trick is how to calculate the chance that an event won't occur in N trials. For example, in N dice rolls, what's the chance of never rolling a 6?
The chance of a 6 is 1/6, and there's a 5/6 chance of not getting a 6. Your chance of never rolling a 6 is therefore .
More generally, the chance of an event X never occurring is . The chance of the event occurring at least once is .
This has proved importantly helpful twice now:
- Explaining why the death of 1 of 6 mice during a surgery for an exploratory experiment is not convincing evidence that the treatment was harmful.
- Explaining why quadrupling the amount of material we use in our experiment is not likely to appreciably increase our likelihood of an experimental success.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-02T22:33:47.962Z · LW(p) · GW(p)
If you are a waiter carrying a platter full of food at a fancy restaurant, the small action of releasing your grip can cause a huge mess, a lot of wasted food, and some angry customers. Small error -> large consequences.
Likewise, if you are thinking about a complex problem, a small error in your chain of reasoning can lead to massively mistaken conclusions. Many math students have experienced how a sign error in a lengthy calculation can lead to a clearly wrong answer. Small error -> large consequences.
Real-world problems often arise when we neglect, or fail to notice, a physical feature of our environment that will cause problems. For example, if a customer has put their purse down next to their table, the waiter might not expect it, not see the purse, trip over it, and spill the platter.
A waiter can't take the time to consider each and every step on their way between the tables. Likewise, a thinker must put some level of trust in their intuitive "system 1" to offer up the correct thoughts to their conscious, calculating "system 2." However, every time we introduce intuition into our chain of reasoning, we create an opportunity for error.
One way to think more accurately is to limit this opportunity for error, by explicitly specifying more of the intermediate steps in our reasoning.
By analogy, a careless waiter (perhaps a robotic waiter) might use a very simplified model of the room in order to navigate: a straight line from the kitchen to the table in question. A better waiter might model the room as being filled with "static barriers," the tables and chairs, "moving barriers," the people who are walking around, "pathways", the open spaces they can move through. The waiter might also model their own physical actions, from a very unsophisticated model ("moving") to progressively more calibrated models of motion ("moving at a certain speed," "taking individual steps," "placing each step carefully").
An excellent waiter might be actively selecting which spatial and motion model to employ based on the circumstances in the restaurant. A busy restaurant is a challenge to serve because it demands more sophisticated models, while also requiring faster motion. A new waiter might have to make a tradeoff between moving more slowly than the pace calls for, in order to avoid tripping, and moving fast enough, and risk spilling somebody's food.
This analogy also applies to intellectual thought processes. When constructing an argument, we must trade off between both the level of rigorous, step-by-step, explicit detail we put into our calculations, and the speed with which we perform those calculations. Many circumstances in life place us under time pressure, while also demanding that we perform calculations accurately. A timed math exam is analogous to a waiter being forced to show off their ability to serve a busy restaurant quickly and without spilling the food or forgetting an order.
Unfortunately, students are overincentivized for speed in two ways. First, timed exams create pressure that makes students move too quickly, abandon their careful step-by-step reasoning, and make mistakes. Second, students who want to "get through the material" and get on to something more fun - even if they want to want to learn - will resist the twin requirements of greater rigor and slower speed.
This is related to the comprehension curve [LW · GW], the idea that there is an optimal reading speed to maximize the rate at which bits of important information are comprehended. Maximizing the comprehension rate might require slowing the reading rate substantially.
Likewise, maximizing the rate at which we come to accurate conclusions, both at the end of a problem and in the intermediate steps, might require using slower, more rigorous reasoning, and executing each reasoning step at a slower pace. When we think in terms of a "comprehension curve," both for reading and for calculating, we no longer can assume that doing some aspect of the work more quickly will lead to us achieving our goal more quickly.
My intuition is that people tend to work too quickly, and would benefit from building a habit of doing slower, more rigorous work whenever possible. I think that this would build more confidence with their models, allowing them to later move with sufficient accuracy even at a higher speed. I also think that it would build their confidence, since they would experience fewer errors in the early stages of learning.
I think that people fail to do this partly because of hyperbolic discounting - an excessive emphasis on the short-term payoff of "getting through things" and moving on to the immediate next step. I also think that people have competing goals, such as relaxation or appearing smart in front of others, and that these also cut against slow and rigorous reasoning.
This has implications for mental training. Mental training is about learning how to monitor and control your conscious thought processes in order to improve your intellectual powers. It is not necessarily about rejecting external tools. Mental training, for example, is perfectly compatible with the use of calculators. Only if it were for some reason very useful to multiply large numbers in your head would it make sense to learn that skill as part of mental training.
However, part of mental training is about learning how to do things in your head - to visualize, calculate, think. When we do things in our head, they are necessarily less explicit, less legible, and less rigorous than the same mental activities recorded on the page. Because we are not constrained in our mental motions by the need to write things down, it becomes easier to make mistakes.
Mental training would therefore need to be centrally about how to interface with external tools. For example, if you are solving a complex math problem, mental training wouldn't just be about how to solve that problem in your head. Instead, it would be about identifying that aspect of the work that can benefit from doing less writing, and more internal mental thinking, and about how to then record that thought on the page and make it more explicit.
Mental training is not about rejecting external tools. It's about treating the conscious mind itself as one of the most powerful and important tools you have, and learning how to use it both independently and in conjunction with other external tools in order to achieve desired results. It is perhaps analogous to an athlete doing drills. The drills allow the athlete to isolate and practice aspects of the game or of physical activities and motions, under the presumption that during the game itself, these will be directly useful. Likewise, doing mental practice is essentially inventing "mental drills" that are presumed to be useful, in conjunction with other activities and tools, during practical real-world problem solving.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-07-20T05:46:58.030Z · LW(p) · GW(p)
"Ludwig Boltzmann, who spent much of his life studying statistical mechanics, died in 1906, by his own hand. Paul Ehrenfest, carrying on the work, died similarly in 1933. Now it is our turn to study statistical mechanics." - States of Matter, by David L. Goodstein
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-01-14T20:51:53.152Z · LW(p) · GW(p)
The structure of knowledge is an undirected cyclic graph between concepts. To make it easier to present to the novice, experts convert that graph into a tree structure by removing some edges. Then they convert that tree into natural language. This is called a textbook.
Scholarship is the act of converting the textbook language back into nodes and edges of a tree, and then filling in the missing edges to convert it into the original graph.
The mind cannot hold the entire graph in working memory at once. It's as important to practice navigating between concepts as learning the concepts themselves. The edges are as important to the structure as the nodes. If you have them all down pat, then you can easily get from one concept to another.
It's not always necessary to memorize every bit of knowledge. Part of the graph is knowing which things to memorize, which to look up, and where to refer to if you need to look something up.
Feeling as though you've forgotten is not easily distinguishable from never having learned something. When people consult their notes and realize that they can't easily call to mind the concepts they're referencing, this is partly because they've never practiced connecting the notes to the concepts. There are missing edges on the graph.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-11-13T23:06:20.883Z · LW(p) · GW(p)
I want to put forth a concept of "topic literacy."
Topic literacy roughly means that you have both the concepts and the individual facts memorized for a certain subject at a certain skill level. That subject can be small or large. The threshold is that you don't have to refer to a reference text to accurately answer within-subject questions at the skill level specified.
This matters, because when studying a topic, you always have to decide whether you've learned it well enough to progress to new subject matter. This offers a clean "yes/no" answer to that essential question at what I think is a good tradeoff between difficulty and adequacy.
I'm currently taking an o-chem class, and we're studying IR spectra. For this, it's necessary to be able to interpret spectral diagrams in terms of shape, intensity, and wavenumber; to predict signals that a given molecule will produce; and to explain the underlying mechanisms that produce these signals for a given molecule.
Most students will simply be answering the required homework problems, with heavy reference to notes and the textbook. In particular, they'll be referring to a key chart that lists the signals for 16 crucial bond types, to 6 subtypes of conjugated vs. unconjugated bonds, and referring back for reminders on the equations and mechanisms underpinning these patterns.
Memorizing that information only took me about an extra half hour, and dramatically increased my confidence in answering questions. It made it tractable for me to rapidly go through and answer every single study question in the chapter. This was the key step to transitioning from "topic familiar" to "topic literate."
If I had to bin levels of understanding of an academic subject, I might do it like this:
- "Topic ignorant." You've never before encountered a formal treatment of the topic.
- "Topic familiar." You understand the concepts well enough to use them, but require review of facts and concepts in most cases.
- "Topic literate." You have memorized concepts and facts enough to be able to answer most questions that will be posed to you (at the skill level in question) quickly and confidently, without reference to the textbook.
Go for "topic literate" before moving on.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-10-15T23:32:16.557Z · LW(p) · GW(p)
We do things so that we can talk about it later.
I was having a bad day today. Unlikely to have time this weekend for something I'd wanted to do. Crappy teaching in a class I'm taking. Ever increasing and complicating responsibilities piling up.
So what did I do? I went out and bought half a cherry pie.
Will that cherry pie make me happy? No. I knew this in advance. Consciously and unconsciously: I had the thought, and no emotion compelled me to do it.
In fact, it seemed like the least-efficacious action: spending some of my limited money, to buy a pie I don't need, to respond to stress that's unrelated to pie consumption and is in fact caused by lack of time (that I'm spending on buying and eating pie).
BUT. What buying the pie allowed me to do was tell a different story. To myself and my girlfriend who I was texting with. Now, today can be about how I got some delicious pie.
And I really do feel better. It's not the pie, nor the walk to the store to buy it. It's the relief of being able to tell my girlfriend that I bought some delicious cherry pie, and that I'd share it with her if she didn't live a three-hour drive away. It's the relief of reflecting on how I dealt with my stress, and seeing a pie-shaped memory at the end of the schoolwork.
If this is a correct model of how this all works, then it suggests a couple things:
- This can probably be optimized.
- The way I talk about that optimization process will probably affect how well it works. For example, if I then think "what's the cheapest way to get this effect," that intuitively doesn't feel good. I don't want to be cheap. I need to find the right language, the right story to tell, so that I can explain my "philosophy" to myself and others in a way that gets the response I want.
Is that the darks arts? I don't think so. I think this is one area of life where the message is the medium.
Replies from: Viliam↑ comment by Viliam · 2020-10-16T17:46:54.126Z · LW(p) · GW(p)
So the "stupid solutions to problems of life" are not really about improving the life, but about signaling to yourself that... you still have some things under control? (My life may suck, but I can have a cherry pie whenever I want to!)
This would be even more important if the cherry pie would somehow actively make your life worse. For example, if you are trying to lose weight, but at the same time keep eating cherry pie every day in order to improve the story of your day. Or if instead of cherry pie it would be cherry liqueur.
The way I talk about that optimization process will probably affect how well it works.
Just guessing, but it would probably help to choose the story in advance. "If I am doing X, my life is great, and nothing else matters" -- and then make X something useful that doesn't take much time. Even better, have multiple alternatives X, Y, Z, such that doing any of them is a "proof" of life being great.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-10-16T18:55:30.761Z · LW(p) · GW(p)
I do chalk a lot of dysfunction up to this story-centric approach to life. I just suspect it’s something we need to learn to work with, rather than against (or to deny/ignore it entirely).
My sense is that storytelling - to yourself or others - is an art. To get the reaction you want - from self or others - takes some aesthetic sensitivity.
My guess is there’s some low hanging fruit here. People often talk about doing things “for the story,” which they resort to when they're trying to justify doing something dumb/wasteful/dangerous/futile. Perversely, it often seems that when people talk in detail about their good decisions, it comes of as arrogant. Pointless, tidy philosophical paradoxes seem to get people's puzzle-solving brains going better than confronting the complexity of the real world.
But maybe we can simply start building habits of expressing gratitude. Finding ways to present good ideas and decisions in ways that are delightful in conversation. Spinning interesting stories out of the best parts of our lives.
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-06-24T20:29:41.661Z · LW(p) · GW(p)
Last night, I tested positive for COVID (my first time catching the disease). This morning, I did telehealth via PlushCare to get a Paxlovid prescription. At first, the doctor asked me what risk factor I had that made me think I was qualified to get Paxlovid. I told her I didn't know (a white lie [LW · GW]) what the risk factors were, and hoped she could tell me. Over the course of our call, I brought up a mild heart arrhythmia I had when I was younger, and she noticed that, at 5'11" and 200 lbs, I'm overweight. Based on that, she prescribed me Paxlovid and ordered it to my nearest pharmacy.
I then called the pharmacy. They noticed during our call that their Paxlovid stock was expired. This also happened at the second pharmacy I called. The third pharmacy, Walgreens, told me that there was some paperwork those other pharmacies probably could have done to 'un-expire' their Paxlovid, but in any case, they had some non-expired Paxlovid. They also told me that funding for Paxlovid was in a murky grey zone, and something about 'pharmacy insurance' that is somehow distinctly different from 'medical insurance', and something about how you're not allowed to pay for Paxlovid out of pocket because the state is supposed to cover it, but maybe the state's not covering it now... ??? Anyway, she thought one way or another, I probably wouldn't have to pay for it.
This was fortunate because I left my insurance card in my Seattle apartment when I drove up to accept my parents' generous offer to quarantine in their basement. My living situation in Seattle is very uncomfortable right at the moment - I'm subletting from a friend who himself just moved to a new apartment, taking all the furniture with him. I've been sleeping on a couple couch cushions I brought up from my parents' house whlie looking for a new sublet to start at the beginning of next month. It would have been a miserable place to quarantine.
I gave Walgreens the phone number of the first pharmacy so they could have the prescription transferred over. They set up an automatic text message alert system to inform me when it was filled. I also messaged PlushCare, my telemedicine provider, to ask them to transfer it over. Then I noticed that their message response time averages 5-7 days, and indeed, hours later, I'd heard nothing back from them. I finally called Walgreens about 3 hours after my original call and heard from an automatic voice system that my prescription was, in fact, filled successfully. My dad kindly picked it up for me, although he didn't see my text in time to grab any mint gum to alleviate "Paxlovid mouth."
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-10-14T17:57:24.031Z · LW(p) · GW(p)
Make sentences easier to follow with the XYZ pattern
I hate the Z of Y of X pattern. This is a sentence style presents information in the wrong order for easy visualization. XYZ is the opposite, and presents information in the easiest way to track.
Here are some examples:
Z of Y of X: The increased length of the axon of the mouse
XYZ: The mouse's axon length increase
Z of Y of X: The effect of boiling of extract of ginger is conversion to zingerol of gingerol
XYZ: Ginger extract, when boiled, converts gingerol to zingerol.
Z of Y of X: The rise of the price of stock in Adidas due to the reverse of the decline of influence of the sense of style of Kanye West
XYZ: Kanye West's stylistic influence decline has reversed, so Adidas's stock price is rising.
Replies from: Dagon, rodeo_flagellum↑ comment by Dagon · 2022-10-14T19:44:46.983Z · LW(p) · GW(p)
This depends a lot on the medium of communication. A lot of style guides recommend that they go in order of importance or relevance. I suspect different readers will have different levels of difficulty in keeping the details in mind at once, so it's not obvious which is actually easier or "more chunkable" for them.
For instance, I find "Addida's stock price is rising due to the decline of Kanye West's stylistic influence". Is that ZXY? The decline is the main point, and what is declining is one chunk "Kanye's influence".
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-10-14T20:19:38.546Z · LW(p) · GW(p)
You’re right. Sentences should start with the idea that is most important or foundational, and end with a transition to the next sentence’s topic. It’s best to do these two things with the XYZ structure whenever possible.
My examples ignored these other design principles to focus on the XYZ structure. Writers must make tradeoffs. Ideally, their writing occupies the sentence design Pareto frontier.
↑ comment by T431 (rodeo_flagellum) · 2022-10-15T02:49:28.148Z · LW(p) · GW(p)
Is there a name for the discipline or practice of symbolically representing the claims and content in language (this may be part of Mathematical Logic, but I am not familiar enough with it to know)?
Practice: The people of this region (Z) typically prefer hiking in the mountains of the rainforest to walking in the busy streets (Y), given their love of the mountaintop scenery (X).
XYZ Output: Given their mountaintop scenery love (X), rainforest mountain hiking is preferred over walking in the busy streets (Y) by this region's people (Z).
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-10-15T03:06:51.684Z · LW(p) · GW(p)
I don’t know if there’s a name for the practice.
I notice the XYZ form makes some phrases sound like music album titles (“mountaintop scenery love”).
The XYZ form is mainly meant to structure sentences for easy tracking, not just to eliminate the word “of.” “Their love of mountaintop scenery” seems easier to track than “mountaintop scenery love.”
In your XYZ version, “this region’s people” ends the sentence. Since the whole sentence is about them, it seems like it’s easier to track if they’re introduced at the beginning. Maybe:
“This region’s people’s love of mountaintop scenery typically makes them prefer hiking in the mountainous rainforests to walking in the busy streets.”
I don’t love “this region’s people’s” but I’m not sure what to do about that.
Maybe:
“In this region, the people’s love of mountaintop scenery typically makes them prefer hiking in the mountain rainforests to walking in the busy streets.”
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-29T16:31:43.570Z · LW(p) · GW(p)
From 2000-2015, we can see that life expectancy has been growing faster the higher your income bracket (source is Vox citing JAMA).
There's an angle to be considered in which this is disturbingly inequitable. That problem is even worse when considering the international inequities in life expectancy. So let's fund malaria bednets and vaccine research to help bring down malaria deaths from 600,000/year to zero - or maybe support a gene drive to eliminate it once and for all.
At the same time, this seems like hopeful news for longevity research. If we were hitting a biological limit in how much we can improve human lifespans, we'd expect to see that limit first among the wealthiest, who can best afford to safeguard their health. Instead, we see that the wealthiest not only enjoy the longest lifespans, but also enjoy the fastest rate of lifespan increase.
My major uncertainty is reverse and multiple causation. A longer life gives you more time to make money. Also, lifespan and wealth have underlying traits in common, such as conscientiousness and energy. Still, this result seems both clear and surprising - I'd expected it to be the other way around, and it nudges me in the direction of thinking further gains are possible.
Replies from: ChristianKl↑ comment by ChristianKl · 2022-09-30T20:59:53.817Z · LW(p) · GW(p)
I'm surprised by the difference. I'm curious whether the United States is special in that regard or whether the patterns also exist in European countries to the same extent.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-15T23:38:58.197Z · LW(p) · GW(p)
Operator fluency
When learning a new mathematical operator, such as Σ, a student typically goes through a series of steps:
- Understand what it's called and what the different parts mean.
- See how the operator is used in a bunch of example problems.
- Learn some theorems relevant to or using the operator.
- Do a bunch of example problems.
- Understand what the operator is doing when they encounter it "in the wild" in future math reading.
I've only taken a little bit of proof-based math, and I'm sure that the way one relates with operators depends a lot on the type of class one is in and also their natural talent and drive.
Over time, I've come to see how much time spent understanding math on a deeper level compounds in value over time. Lately, I've started to understand that there's a gap in my mathematical intuitions.
The gap is that I treat operators like instructions in a technical manual written in a foreign language. When I encounter them in a derivation, here's the thought process I go through:
- I look at them and recall what they mean.
- I inspect them to see what I'd have to do in order to take the integral, compute the first several terms of the summation, etc.
- I consider how the use of the operator connects with the adjacent steps in the proof - how it was obtained from the previous step, and how it's used in future steps.
- If it's in an applied context, I confirm that the use of the operator "makes sense" for the physical phenomenon it is modeling.
This is all well and good - I can read the "instruction manual" and (usually) do the right thing. However, this never teaches me how to speak the language. I never have learned how to express mathematical thoughts in terms of summations and series, in terms of integrals, or in terms of dot and cross products, for example.
This is in contrast to how naturally I express thoughts in terms of basic arithmetic, statistical distributions, and geometry. I can pull Fermi estimates out of my butt, casually refer to statistical concepts as long as they're no more complex than "normal distribution" or "standard error" or "effect size," and I can model real world situations with basic Euclidean geometry, no problem.
I learned arithmetic as a child, geometry in middle and high school, statistics in college, and Fermi estimates as an adult. I learned calculus, differential equations, and linear algebra in college, but have never found a practice equivalent to Fermi estimation that requires me to use summations, integrals, and so on in order to articulate my own thoughts.
lsusr has a nice example of developing a blog post around developing a differential equation. Von Neumann clearly could think in terms of complex operators as thought they were his own natural language. So I think it is possible and desirable to develop this facility. And if I gained the ability to think in terms of Fermi estimates and do other forms of intuitive mathematical reasoning as an adult, I expect it is possible to learn to use these more advanced operators to express more advanced thoughts.
I think it's probably also possible to gain more facility with performing substitutions and simplifications, assigning letters to variables, and so on. Ultimately, I'd like to be able to read mathematics with some of the same fluency I can bring to bear on natural language. Right now, I think that contending with these more advanced operators is the bottleneck.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-11T02:18:22.209Z · LW(p) · GW(p)
Mentitation: the cost/reward proposition
Mentitation techniques are only useful if they help users with practical learning tasks. Unfortunately, learning how to crystallize certain mental activities as "techniques," and how to synthesize them into an approach to learning that really does have practical relevance, took me years of blundering around. Other people do not, and should not, have that sort of patience and trust that there's a reward at the end of all that effort.
So I need a strategy for articulating, teaching, and getting feedback on these methods. The time and energy costs need to be low enough for others that they're willing to pay them in order to have a shot at increasing their learning abilities. The communication style needs to be concise, clear, and entertaining. If possible, I need to build "micro-rewards" into it, where users can at least see the inklings of how the ideas I'm presenting might plausibly come together to deliver a real lasting benefit.
I also need to explain why users ought to trust me. Some of that trust would be build through the writing style. I might be able to draw on my own personal accomplishments and experience. Insofar as literature exists that's relevant to my claims, I can draw on that as well.
My argument can't be something as crisp as "follow this 9-step plan, and your ability to learn will double." I don't think this will be amenable to such a clear plan of action, and I don't know what effect it might have on people's learning ability, except that I think it would be net positive.
Instead, I need to construct a series of writings or activities that are clear enough to be worthy of beta testing. The value proposition is something like "help me beta test these ideas, and not only might you gain some learning skills, you may be contributing to bolstering the learning ability of this community as well." From that point, I envision an ongoing dialog with people who use these techniques to refine and improve the pedagogy.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-10-29T23:33:54.854Z · LW(p) · GW(p)
A lot of my akrasia is solved by just "monkey see, monkey do." Physically put what I should be doing in front of my eyeballs, and pretty quickly I'll do it. Similarly, any visible distractions, or portals to distraction, will also suck me in.
But there also seems to be a component that's more like burnout. "Monkey see, monkey don't WANNA."
On one level, the cure is to just do something else and let some time pass. But that's not explicit enough for my taste. For one thing, something is happening that recovers my motivation. For another, "letting time pass" is an activity with other effects, which might be energy-recovering but distracting or demotivating in other ways. Letting time pass involves forgetting, value drift, passing up opportunities, and spending one form of slack (time) to gain another (energy). It's costly, not just something I forget to do. So I'd like to understand my energy budget on a more fine-grained level.
Act as if tiredness and demotivation does not exist. Gratitude journaling can transform my attitude all at once, even though nothing changed in my life. Maybe "tiredness and demotivation" is a story I tell myself, not a real state that says "stop working."
One clue is that there must be a difference between "tiredness and demotivation" as an folk theory and as a measurable phenomenon. Clearly, if I stay up for 24 hours straight, I'm going to perform worse on a math test at the end of that time that I would have at the beginning. That's measurable. But if I explain my behaviors right in this moment as "because I'm tired," that's my folk theory explanation.
An approach I could take is to be skeptical of the folk theory of tiredness. Admit that fatigue will affect my performance, but open myself to possibilities like:
- I have more capacity for sustained work than I think. Just do it.
- A lot of "fatigue" is caused by self-reinforcing cycles of complaining that I'm tired/demotivated.
- Extremely regular habits, far beyond what I've ever practiced, would allow me to calibrate myself quite carefully for an optimal sense of wellbeing.
- Going with the flow, accepting all the ups and downs, and giving little to no thought about my energetic state - just allowing myself to be driven by reaction and response - is actually the best way to go.
- Just swallow the 2020 wellness doctrine hook, line, and sinker. Get 8 hours of sleep. Get daily exercise. Eat a varied diet. Less caffeine, less screens, more conversation, brief breaks throughout the day, sunshine, etc. Prioritize wellness above work. If I get to the end of the day and I haven't achieved all my "wellness goals," that's a more serious problem than if I haven't completed all my work deadlines.
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-04-14T05:19:20.232Z · LW(p) · GW(p)
Functional Agency
I think "agent" is probably analogous to a river: structurally and functionally real, but also ultimately an aggregate of smaller structures that are not themselves aligned with the agent. It's convenient for us to be able to point at a flowing body of water much longer than it is wide and call it a river. Likewise, it is convenient for us to point to an entity that senses its environment and steers events adaptively toward outcomes for legible reasons and refer to it as exhibiting agency.
In that sense, AutoGPT is already an agent - it is just fairly incompetent at accomplishing the goals we can observe it pursuing, at least in the very short term.
As when we accept a functional definition of intelligence, this functional definition of agency lets us sidestep the unproductive debate over whether AutoGPT is "really" agentic or whether LLMs are "really" intelligent, and focus on the real questions: what capabilities do they have, what capabilities will they have, and when, and what sorts of functional goals will they behave as if they are pursuing? What behaviors will they exhibit in the pursuit of those functional goals?
Of course, there isn't just one specific and definable goal that an agent has, and where we can be exactly right or exactly wrong in naming it. Understanding an agent's functional goals help us predict its behavior. That is what makes it the agent's goal: if we can predict the agent's behavior based on our concept of its goal, then we can say we have accurately determined what its goal is. If our predictions turn out to be false, that could be because it failed, or because we misunderstood its goal - but the agent's response to failure should help us figure out which, and our updated notion of its capabilities and goals should improve our ability to predict its further actions.
So talking about an agent's goal is really an expression of a predictive model for a functionally agentic entity's behavior. What will AutoGPT do? If you can answer that question, you are probably modeling both the goals and capabilities of an AutoGPT instance in order to do so, and so for you, AutoGPT is being modeled as an agent.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-11-07T00:00:40.280Z · LW(p) · GW(p)
Telling people what they want to hear
When I adopt a protocol for use in one of my own experiments, I feel reassured that it will work in proportion to how many others have used it before. Likewise, I feel reassured that I'll enjoy a certain type of food depending on how popular it is.
By contrast, I don't feel particularly reassured by the popularity of an argument that it is true (or, at least, that I'll agree with it). I tend to think book and essays become popular in proportion to whether they're telling their audience what they want to hear.
One problem is that I like upvotes. Usually, I can roughly gauge whether or not I'm telling my audience what they want to hear. Often, I'm telling my audience what I actually think. When this isn't what they want to hear, I feel anxiety and trepidation, along with an inevitable disappointed letdown, because, just as I predicted, it gets a negative response. Of course, I might be the one who's wrong on these occasions. But it's very hard to learn that from the silent downvoting and curt comments that characterize most negative responses.
For that reason, I often withhold what I actually think in conversation and in writing when I know it's not what my audience wants to hear. I'm starting to shift toward an approach of carefully feeling people out on an individual level. Usually, I know people if people will object to an argument, and sometimes, I think they are wrong to do so. But I have much weaker intuitions about exactly why they will object. Approaching people one-on-one lets me hone in on the true source of disagreement, and address it when conveying my argument to a larger audience.
When I do go straight to posting, it's usually for one of two reasons. First, it might be because I happen to agree with what my audience wants to hear, and I just think it needs a clear and explicit articulation. Second, it might be because I don't have anybody to talk about it with, or because I'm simply failing to be cognizant about the pointlessness of posting things your audience doesn't want to hear in a public forum.
Replies from: Gunnar_Zarncke, Dagon↑ comment by Gunnar_Zarncke · 2022-11-07T00:11:10.546Z · LW(p) · GW(p)
That's not how it is for me, at least not consciously. I have trouble anticipating what will be controversial and what not. I guess it shows in the high fraction of my posts that were controversial here. At best, I can imagine potential questions. But your account matches what I have heard elsewhere that having a reliable audience leads to wanting to please your audience and lock-in.
↑ comment by Dagon · 2022-11-08T19:29:17.618Z · LW(p) · GW(p)
Learn to value and notice interaction and commentary, far more than upvotes. A reply or follow-up comment is an indication that you've posted something worth engaging with. An upvote could mean anything (I mean, it's still nice, and is some evidence in your favor, just not the most important signal).
I got a zero score yesterday, +2 +1 -1 and -2 on 4 different comments. But I got two responses, so a good day (I didn't need to further interact on those threads, so not perfect). Overall, I shoot for 90% upvotes (which is probably 75% postitive response, given people's biases toward positivity), and I actively try to be a little more controversial if I start to think I'm mostly saying things that everyone already knows and believes.
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-02-06T18:22:34.023Z · LW(p) · GW(p)
Hard numbers
I'm managing a project to install signage for a college campus's botanical collection.
Our contractor, who installed the sign posts in the ground, did a poor job. A lot of them pulled right out of the ground.
Nobody could agree on how many posts were installed: the groundskeeper, contractor, and two core team members, each had their own numbers from "rough counts" and "lists" and "estimates" and "what they'd heard."
The best decision I've made on this project was to do a precise inventory of exactly which sign posts are installed correctly, completed, or done badly/missing. In our meeting with the VP yesterday, this inventory helped cut through the BS and create a consensus around where the project stands. Instead of arguing over whose estimate is correct, I can redirect conversation to "we need to get this inventory done so that we'll really know."
Of course, there are many cases where even the hardest numbers we can get are contestable.
But maybe we should be relieved that the project of "getting hard data" (i.e. science) is able to create some consensus some of the time. It is a social coordination mechanism. Strategically, the "hardness" of a number is its ability to convince the people you want to convince, and drive the work in the direction you think it should go.
And the way you make a number "hard" can be social rather than technical. For example, on this project, the fact that I did the first part of the inventory in the company of a horticulturist rather than on my own probably was useful in creating consensus, as was the fact that the VP and grounds manager have my back and are now aware of the inventory. Nobody actually inspected my figures. Just the fact that I was seen as basically trustworthy and was able to articulate the data and how to interpret it was enough.
It should surprise nobody that the level of interest I got in these numbers far exceeds the level of interest in my Fermi-style model of the expected value of taking RadVac. I am plugged into a social network with a particular interest in the signage. It's real money and real effort, to create a real product.
It doesn't matter how much knowledge I personally have about EV modeling. If I don't plug myself into a social network capable of driving consensus about whether or not to take RadVac, my estimate does not matter in the slightest except to me. In this case, individual knowledge is not the bottleneck, but rather social coordination.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-10-22T19:24:21.171Z · LW(p) · GW(p)
Paying your dues
I'm in school at the undergraduate level, taking 3 difficult classes while working part-time.
For this path to be useful at all, I have to be able to tick the boxes: get good grades, get admitted to grad school, etc. For now, my strategy is to optimize to complete these tasks as efficiently as possible (what Zvi calls "playing on easy mode"), in order to preserve as much time and energy for what I really want: living and learning.
Are there dangers in getting really good at paying your dues?
1) Maybe it distracts you/diminishes the incentive to get good at avoiding dues.
2) Maybe there are two ways to pay dues (within the rules): one that gives you great profit and another that merely satisfies the requirement.
In general, though, I tend to think that efficient accomplishment is about avoiding or compressing work until you get to the "efficiency frontier" in your field. Good work is about one of two things:
- Getting really fast/accurate at X because it's necessary for reason R to do Y.
- Getting really fast/accurate at X because it lets you train others to do (or better yet, automate) X.
In my case, X is schoolwork, R is "triangulation of me and graduate-level education," and Y is "get a research job."
X is also schoolwork, R is "practice," and Y is learning. But this is much less clear. It may be that other strategies would be more efficient for learning.
However, since the expected value of my learning is radically diminished if I don't get into grad school, it makes sense to optimize first for aceing my schoolwork, and then in the time that remains to optimize for learning. Treating these as two separate activities with two separate goals makes sense.
This isn't "playing on easy mode," so much as purchasing fuzzies (As) and utilons (learning) separately. [LW · GW]
Replies from: None, Dagon↑ comment by [deleted] · 2020-10-22T23:08:33.722Z · LW(p) · GW(p)
If you haven't seen Half-assing it with everything you've got, I'd definitely recommend it as an alternative perspective on this issue.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-10-23T16:28:54.448Z · LW(p) · GW(p)
I see my post as less about goal-setting ("succeed, with no wasted motion") and more about strategy-implementing ("Check the unavoidable boxes first and quickly, to save as much time as possible for meaningful achievement").
↑ comment by Dagon · 2020-10-22T22:55:37.626Z · LW(p) · GW(p)
I suspect "dues" are less relevant in today's world than a few decades ago. It used to be a (partial) defense against being judged harshly for your success, by showing that you'd earned it without special advantage. Nowadays, you'll be judged regardless, as the assumption is that "the system" is so rigged that anyone who succeeds had a headstart.
To the extent that the dues do no actual good (unlike literal dues, which the recipient can use to buy things, presumably for the good of the group), skipping them seems very reasonable to me. The trick, of course, is that it's very hard to distinguish unnecessary hurdles ("dues") from socially-valuable lessons in conformity and behavior ("training").
Relevant advice when asked if you've paid your dues: https://www.youtube.com/watch?v=PG0YKVafAe8
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-09-16T23:47:17.441Z · LW(p) · GW(p)
I've been thinking about honesty over the last 10 years. It can play into at least three dynamics.
One is authority and resistance. The revelation or extraction of information, and the norms, rules, laws, and incentives surrounding this, including moral concepts, are for the primary purpose of shaping the power dynamic.
The second is practical communication. Honesty is the idea that specific people have a "right to know" certain pieces of information from you, and that you meet this obligation. There is wide latitude for "white lies," exaggeration, storytelling, "noble lies," self-protective omissions, image management, and so on in this conception. It's up to the individual's sense of integrity to figure out what the "right to know" entails in any given context.
The third is honesty as a rigid rule. Honesty is about revealing every thought that crosses your mind, regardless of the effect it has on other people. Dishonesty is considered a person's natural and undesirable state, and the ability to reveal thoughts regardless of external considerations is considered a form of personal strength.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-09-03T03:45:28.995Z · LW(p) · GW(p)
Better rationality should lead you to think less, not more. It should make you better able to
- Set a question aside
- Fuss less over your decisions
- Accept accepted wisdom
- Be brief
while still having good outcomes. What's your rationality doing to you?
Replies from: Dagon↑ comment by Dagon · 2020-09-03T20:07:49.175Z · LW(p) · GW(p)
I like this line of reasoning, but I'm not sure it's actually true. "better" rationality should lead your thinking to be more effective - better able to take actions that lead to outcomes you prefer. This could express as less thinking, or it could express as MORE thinking, for cases where return-to-thinking is much higher due to your increase in thinking power.
Whether you're thinking less for "still having good outcomes", or thinking the same amount for "having better outcomes" is a topic for introspection and rationality as well.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-09-04T02:02:43.147Z · LW(p) · GW(p)
That's true, of course. My post is really a counter to a few straw-Vulcan tendencies: intelligence signalling, overthinking everything, and being super argumentative all the time. Just wanted to practice what I'm preaching!
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-08-10T22:12:53.657Z · LW(p) · GW(p)
How should we weight and relate the training of our mind, body, emotions, and skills?
I think we are like other mammals. Imitation and instinct lead us to cooperate, compete, produce, and take a nap. It's a stochastic process that seems to work OK, both individually and as a species.
We made most of our initial progress in chemistry and biology through very close observation of small-scale patterns. Maybe a similar obsessiveness toward one semi-arbitrarily chosen aspect of our own individual behavior would lead to breakthroughs in self-understanding?
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-08-02T03:28:56.893Z · LW(p) · GW(p)
I'm experimenting with a format for applying LW tools to personal social-life problems. The goal is to boil down situations so that similar ones will be easy to diagnose and deal with in the future.
To do that, I want to arrive at an acronym that's memorable, defines an action plan and implies when you'd want to use it. Examples:
OSSEE Activity - "One Short Simple Easy-to-Exit Activity." A way to plan dates and hangouts that aren't exhausting or recipes for confusion.
DAHLIA - "Discuss, Assess, Help/Ask, Leave, Intervene, Accept." An action plan for how to deal with annoying behavior by other people. Discuss with the people you're with, assess the situation, offer to help or ask the annoying person to stop, leave if possible, intervene if not, and accept the situation if the intervention doesn't work out.
I came up with these by doing a brief post-mortem analysis on social problems in my life. I did it like this:
- Describe the situation as fairly as possible, both what happened and how it felt to me and others.
- Use LW concepts to generalize the situation and form an action plan. For example, OSSEE Activity arose from applying the concept of "diminishing marginal returns" to my outings.
- Format the action plan into a mnemonic, such as an acronym.
- Experiment with applying the action plan mnemonic in life and see if it leads you to behave differently and proves useful.
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-07-21T04:21:33.581Z · LW(p) · GW(p)
I am really disappointed in the community’s response to my Contra Contra the Social Model of Disability post.
Replies from: Dagon↑ comment by Dagon · 2023-07-21T18:14:33.667Z · LW(p) · GW(p)
I do not represent (or often, even acknowledge the existence or cohesion of) "the community". For myself, I didn't read it, for the following reasons:
- it started by telling me not to bother. "Epistemic Status: First draft, written quickly", and "This is a tedious, step-by-step rebuttal" of something I hadn't paid that much attention to in the first place. Not a strong start.
- Scott's piece was itself a reaction to something I never cared that much about.
- Both you and Scott (and whoever started this nonsense) are arguing about words, not ideas. Whether "disability" is the same cluster of ideas and attitudes for physical and emotional variance from median humans is debatable, but not that important.
I'd be kind of interested in a discussion of specific topics (anxiety disorders, for instance) and some nuance of how individuals do and should react to those who experience it. I'm not interested in generalities of whether ALL variances are preferences or medical issues, nor where precisely the line is (it's going to vary, duh!).
What reaction were you hoping for?
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-06-08T08:47:47.259Z · LW(p) · GW(p)
Over the last six months, I've grown more comfortable writing posts that I know will be downvoted. It's still frustrating. But I used to feel intensely anxious when it happened, and now, it's mostly just a mild annoyance.
The more you're able to publish your independent observations, without worrying about whether others will disagree, the better it is for community epistemics.
Replies from: jesper-norregaard-sorensen↑ comment by JNS (jesper-norregaard-sorensen) · 2023-06-09T06:09:04.627Z · LW(p) · GW(p)
I kinda feel the same way, and honestly I think it’s wrong to hold yourself back, how are you going to calibrate without feedback?
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-06-06T02:32:29.753Z · LW(p) · GW(p)
Thoughts on Apple Vision Pro:
- The price point is inaccessibly high.
- I'm generally bullish on new interfaces to computing technology. The benefits aren't always easy to perceive until you've had a chance to start using it.
- If this can sit on my head and allow me to type or do calculations while I'm working in the lab, that would be very convenient. Currently, I have to put gloves on and off to use my phone, and office space with my laptop is a 6-minute round trip from the lab.
- I can see an application that combines voice-to-text and AI in a way that makes it feel like you always have a ChatGPT virtual assistant sitting on your shoulder as you do everyday tasks.
- Looks like a huge upgrade for watching movies, playing video games, and possibly also for video conferencing.
- Could potentially be useful for delivering exposure therapy.
- I'm curious about using the device for business tasks that involve 3D modeling. I could see this being useful or not useful for doing surgery and other physical healthcare applications. I'd certainly prefer to access telehealth via this device than on my iPhone.
- I can see this being a truly groundbreaking way to explore the world for business or pleasure - imagine being able to wander the streets of Paris, tour a college campus, or attend an open house.
- I anticipate next-level 3D mapping of environments will be the next big push, to enable these walking tours, and I imagine this might be enabled by drones?
- I think this is much worse for the social isolation impact of technology than the iPhone. I can put my iPhone down easily to hold a conversation. This will be inconvenient to take off, cover half the face, and I'll never be sure what the other person is doing in their headset while I'm talking to them. I laughed out loud when the demo video tried to convince me it won't be an isolating experience to talk to somebody wearing one of these things.
- To what extent will eyestrain become a problem?
- I am not looking forward to Apple's closed software environment. I'm anticipating a lot of the business utility will be undercut by interoperability issues.
↑ comment by RHollerith (rhollerith_dot_com) · 2023-06-06T16:48:21.987Z · LW(p) · GW(p)
If this can sit on my head and allow me to type or do calculations while I’m working in the lab, that would be very convenient. Currently, I have to put gloves on and off to use my phone, and office space with my laptop is a 6-minute round trip from the lab.
I can see an application that combines voice-to-text and AI in a way that makes it feel like you always have a ChatGPT virtual assistant sitting on your shoulder as you do everyday tasks.
Sure, but an audio-only interface can be done with an iPhone and some Airpods; no need for a new interface.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2023-06-06T17:47:21.066Z · LW(p) · GW(p)
That's true! However, I would feel weird and disruptive trying to ask ChatGPT questions when working alongside coworkers in the lab.
↑ comment by RHollerith (rhollerith_dot_com) · 2023-06-06T16:46:11.243Z · LW(p) · GW(p)
↑ comment by RHollerith (rhollerith_dot_com) · 2023-06-06T16:43:28.415Z · LW(p) · GW(p)
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-20T20:38:10.939Z · LW(p) · GW(p)
Calling all mentitators
Are you working hard on learning STEM?
Are you interested in mentitation - visualization, memory palaces, developing a practical craft of "learning how to learn?"
What I think would take this to the next level would be developing an exchange of practices.
I sit around studying, come up with mentitation ideas, test them on myself, and post them here if they work.
But right now, I don't get feedback from other people who try them out. I also don't get suggestions from other people with things to try.
Suggestions are out there, but the devil's in the details, and I think what's needed is live exchange, not just myself reading other people's books in isolation. If mentitation is going to be most helpful, it needs a way of talking about it that actually works to convey ideas and motivate practice. It also needs the vetting process that can only happen when you make (or take) a suggestion, try it out, report the result, and modify the work in light of that.
Right now, that social feedback loop is absent, and I'd love to get it started.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-19T17:42:08.322Z · LW(p) · GW(p)
Memory palace foundations
What makes the memory palace work? Four key principles:
- Sensory integration: Journeying through the memory palace activates your kinetic and visual imagination
- Pacing: The journey happens at your natural pace for recollection
- Decomposition: Instead of trying to remember all pieces of information at once, you can focus on the single item that's in your field of view
- Interconnections: You don't just remember the information items, but the "mental path" between them.
We can extract these principles and apply them to other forms of memorization.
When I memorized the 20 amino acids, I imagined wandering along a protein built from all 20 of them, in sequence. This was essentially a "memory palace," but was built directly from the thing I wanted to imagine. This made the process of remembering them much easier.
In general, I think that we should preserve the principles underpinning the memory palace, but dispense with the palace itself. I see the "palace" as being distracting and confusing, but the general principles it embodies to be extremely useful.
What if we wanted to apply these principles to something much harder to visualize, like the theorems and proofs associated with Taylor series in an introductory calculus textbook? Could we create a mental structure that allows us to "journey" through them?
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-08T01:45:46.445Z · LW(p) · GW(p)
Can mentitation be taught?
Mentitation[1] can be informed by the psychological literature, as well as introspection. Because people's inner experiences are diverse and not directly obervable, I expect it to be difficult to explain or teach this subject. However, mentitation has allowed me to reap large gains in my ability to understand and remember new information. Reading STEM textbooks has become vastly more interesting and has lead to better test results.
Figuring out a useful way to do mentitation has taken me years, with lots of false starts along the way. That process involved figuring out what my goals ought to be, playing around with different techniques in isolation and together, and developing a vocabulary to describe them. It reminds me a little of the attempts actors have made to develop acting technique, such as the ability to summon an emotion or sense-memory to inform the part.
There are many acting techniques and teaching methods, and which are taught depends heavily on the background of the teacher and the logistics of the classroom. When I took theater classes in high school, they were mostly structured around improv games and putting on short plays or musicals. There wasn't much psychological content. My guess is that, in the absence of these techniques, actors are selected more than trained. Talent is crucial. If only we knew to what extent the inner psychological abilities of a great actor are teachable!
I suspect that mentitation is more teachable than the more psychological aspects of acting technique, for a few reasons.
- Acting success depends not only on psychology, but also on physique. The ability to profit from mentitation is far less dependent on physical ability.
- The abiltiy of mentitation to yield tangible benefits is very amenable to quantification. For example, I imagine that one of its key functions would be to enhance a student's ability to be successful in school. Improved exam grades would be a valid metric of success. It is harder to evaluate the contribution of an actor's training to their acting ability in a rigorous and quantitative manner, though it probably can be done.
- Both actor training and mentitation can offer immediate introspective feedback to the trainee. For example, when I employ mentitation to enhance my textbook reading, the improvement in my inner experience is immediate and visceral, like putting salt on bland food. When it works, it argues for itself.
- Mentitation is mostly useful for tasks that are individualistic and can be broken down into concrete steps. By contrast, the experience of acting depends heavily on the specific people and circumstances, and is in large part about shaping your interactions with others.
- Helping people enjoy and be successful in STEM is potentially profitable, good for the trainee, and good for the world.
Being more teachable than acting technique might be a pretty low bar. Having worked as a teacher for 10 years, though, I think it's right to be skeptical about the utility of teaching in general, at least as it's typically practiced in the world's school systems. Mentitation is more to help a motivated student teach themselves more effectively, and I think that's a more promising route than trying to improve teachers.
I think there are numerous opportunities to use technology to improve information delivery and create opportunities for deliberate practice. However, I think we put a lot of effort into this already, and that many people are blocked by the familiar experience of just "not getting it" or "hating it" when they try to study STEM topics. These are the most profound wonders of the universe, and the most coherent, provable, evidence-based forms of knowledge we have!
Simultaneously, most people receive little to no training in how to directly use and control their own cognitive processes, except perhaps in the context of therapy. Instead, they are forced through an increasingly challenging series of intellectual hurdles from a young age, until at some point they either find their niche or stop studying. We don't really train our scientists. We demand that our scientists train themselves, and use classes and coursework to organize their efforts and to apply selection pressure to separate the wheat from the chaff.
Meanwhile, humans generally demonstrate only a limited ability to systematize their own efforts toward a defined goal. It shouldn't be surprising, among the many other demands of life, and in the absence of meaningful incentives to do so, that culture hasn't produced a deep and thorough metis for the use of the mind and body to greatest effect in the study of STEM topics. That neglect suggests to me that mentitation really is an orchard full of low-hanging fruit.
- ^
My tentative term for practicing the use of one's basic mental faculties, particularly for intellectual and analytical purposes. This might include the ability to visualize, the ability to slow the pace of thought and operate in system 2, choosing what you are thinking about, and other abilities.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-08-14T23:37:47.449Z · LW(p) · GW(p)
Why do patients neglect free lifestyle interventions, while overspending on unhelpful healthcare?
The theory that patients are buying "conspicuous care" must compete with the explanation that patients have limited or asymmetric information about true medical benefits. Patient tendencies to discount later medical benefits, while avoiding immediate effort and cost, can also explain some of the variation in lifestyle intervention neglect.
We could potentially separate these out by studying medical overspending by doctors on their own healthcare, particularly in their own specialty. Do heart doctors overspend on heart healthcare? Do oncologists overspend on cancer treatments when they themselves have cancer? Do doctors tend to spend significantly more or less on end-of-life care compared to non-doctors of similar socioeconomic status?
Replies from: JBlack, ChristianKl, Dagon↑ comment by JBlack · 2022-08-15T04:44:12.461Z · LW(p) · GW(p)
My first thought is that lifestyle interventions are in fact almost never free, from either a quality of life point of view or a monetary point of view.
My second thought is a question: Is it clear that patients do actually overspend on unhelpful healthcare? All of the studies I've read that claimed this made one or more of the following errors or limitations:
- Narrowly defining "helpful" to mean just reduction in mortality or severe lasting disability;
- Conflating costs imposed after the fact by the medical system with those a patient chooses to spend;
- Failing to consider common causal factors in both amount of spending and medical problems;
- Studying very atypical sub-populations.
It's entirely possible that patients from general population do in fact voluntarily overspend on healthcare that on average has negligible benefit even after allowing for prior causes, and would like to see a study that made a credible attempt at testing this.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-08-15T08:23:56.287Z · LW(p) · GW(p)
One of the examples given was a RAND RCT in which subjects had their healthcare subsidized to varying degrees. The study examined whether the more heavily subsidized groups consumed more healthcare (they did) and whether or not health outcomes differed among the different groups (they did not). Another was an Oregon RCT in which subjects were randomly assigned to receive or not receive Medicaid. The only health effects of getting subsidized healthcare here was in "feeling healthier" and mental health.
Other studies show that regional variations in healthcare consumption (i.e. surgery rates for enlarged prostate) do not correlate with different health outcomes. One shows that death rates across the 50 US states are correlated with education and income, but not amount of medical spending.
The overall conclusion seems to be that whatever people are buying at the hospital when they spend more than average, it does not appear to be health, and particularly not physical health.
Replies from: JBlack, Viliam↑ comment by JBlack · 2022-08-16T00:04:00.555Z · LW(p) · GW(p)
Do you have links?
The descriptions you give match a number of studies I've read and already evaluated. E.g. dozens of papers investigating various aspects of the Oregon randomized Medicaid trial, with substantially varying conclusions in this area.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-08-16T01:25:08.347Z · LW(p) · GW(p)
This is just the summary given in The Elephant In the Brain, I haven't read the original papers and I'm sure that you know more about this than me. Here's what TEITB says about the Oregon Medicaid trial (screenshotted from my Kindle version):



If you think this misrepresents what we should take away from this study, I'm keen to hear it!
Replies from: JBlack↑ comment by JBlack · 2022-08-16T02:43:06.425Z · LW(p) · GW(p)
It's mixed. As far as it goes for the original study, it's mostly accurate but I do think that the use of the phrase "akin to a placebo effect" is misleading and the study itself did not conclude anything of the kind. There may be later re-analyses that do draw such a conclusion, though.
Most objective health outcomes of medical treatment were not measured, and many of those that were measured were diagnostic of chronic conditions that medical treatment cannot modify, but only provide treatment that reduces their impact on daily life. There are objective measures of outcomes of such treatment, but they require more effort to measure and are more specific to the medical conditions being treated. This is relevant in that a large fraction of medical expenditure is in exactly this sort of management of conditions to improve functionality and quality of life without curing or substantially modifying the underlying disease.
It should also be borne in mind that the groups in this study were largely healthy, relatively young adults. The vast majority of health service expenditure goes to people who are very sick and mostly older than 65. It seems unwise to generalize conclusions about overall effectiveness of health expenditure from samples of much healthier younger adults.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-08-16T03:35:11.954Z · LW(p) · GW(p)
That's helpful information, thanks.
Would you characterize the Oregon Medicaid study as poorly designed, or perhaps set up to make Medicaid look bad? From your description, it sounds like they chose a population and set of health metrics that were predictably going to show no effect, even though there was probably an effect to be found.
↑ comment by Viliam · 2022-08-15T22:18:27.540Z · LW(p) · GW(p)
Doesn't necessarily mean they "neglected free lifestyle interventions". Maybe they were already doing everything they were aware of.
If you are not an expert, when you ask people about what to do, you get lots of contradictory advice. Whatever one person recommends, another person will tell you it's actively harmful.
"You should exercise more." "Like this?" makes a squat. "No, definitely not like that, you will fuck up your spine and joints." "So, how exactly?" "I don't know actually; I am just warning you that you can hurt yourself."
"You should only eat raw vegetables." Starts eating raw vegetables. Another person: "If you keep doing that, the lack of proteins will destroy your muscles and organs, and that will kill you."
The only unambiguous advice is to give up all your bodily pleasures. Later: "Hey, why are you so depressed?"
(For the record, I don't feel epistemically helpless about this stuff now. I discussed it with some people I trust, and sorted out the advice. But it took me a few years to get there, and not everyone has this opportunity. Even now, almost everything I ever do, someone tells me it's harmful; I just don't listen to them anymore.)
↑ comment by ChristianKl · 2022-08-15T16:51:35.382Z · LW(p) · GW(p)
People's willingness to spend on healthcare changes with the amount they are currently suffering. Immediate suffering is a much stronger motivator for behavior than plausible future suffering and even likely future suffering.
↑ comment by Dagon · 2022-08-15T22:00:02.267Z · LW(p) · GW(p)
I'm sure there's a lot of variance in how it feels to be someone willing to spend on healthcare but less willing to change their daily habits and activities. For me, "free" is misleading. It's a whole lot more effort and reduced joy for some interventions. That's the opposite of free, it's prohibitively costly, or seems like it.
There's also a bit of inverse-locus-of-control. If my choices cause it, it's my fault. If a doctor or medication helps, that means it was externally imposed, not my fault.
And finally, it hits up against human learning mechanisms - we notice contrasts and rapid changes, such as when a chiropractor does an adjustment or when a medication is prescribed. We don't notice gradual changes (positive or negative), and our minds don't make the correlation to our behaviors.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-07-06T23:21:40.498Z · LW(p) · GW(p)
Mistake theory on plagiarism:
How is it that capable thinkers and writers destroy their careers by publishing plagiarized paragraphs, sometimes with telling edits that show they didn't just "forget to put quotes around it?"
Here is my mistake-theory hypothesis:
- Authors know the outlines of their argument, but want to connect it with the literature. At this stage, they're still checking their ideas against the data and theory, not trying to produce a polished document. So in their lit review, they quickly copy/paste relevant quotes into a file. They don't bother to put quotations or links around it, because at this stage, they're still just blitzing along producing private notes for themselves and exploring what's been said before.
- After they've assembled a massive quantity of these notes, which are interspersed with their own writing, they go back to produce their thesis. However, they've assimilated the "average style" of the literature they're reading, and it's hard to tell the quotes they pulled from the quotes they wrote.
- Occasionally, they mistake a quote they pulled from the literature for a note that's in their own words. They use this "accidentally plagiarized" text in their own thesis. They aren't even cognizant of this risk - they fully believe themselves to be reliably capable of discerning their own writing from somebody else's.
- As they edit the thesis, they edit the word choice of the accidentally plagiarized content to give it more polish.
- They publish the thesis with the tweaked, accidentally plagiarized material that they fully believe is their own writing.
↑ comment by Dagon · 2022-07-07T16:29:03.743Z · LW(p) · GW(p)
In an arena where plagiarism is harmful, I'd call this "negligence theory" rather than "mistake theory". This isn't just a misunderstanding or incorrect belief, it's a sloppiness in research that (again, in domains where it matters) should cost the perpetrator a fair bit of standing and trust.
It matters a lot what they do AFTERWARD, too. Admitting it, apologizing, and publishing an updated version is evidence that it WAS a simple unintentional mistake. Hiding it, repeating the problem, etc. are either malice or negligence.
Edit: there's yet another possibility, which is "intentional use of ideas without attribution". In some kinds of writing, the author can endorse a very slight variant of someone else's phrasing, and just use it as their own. It's certainly NICER to acknowledge the contribution from the original source, but not REQUIRED except in formal settings.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-07-07T17:34:54.888Z · LW(p) · GW(p)
Negligence vs. mistake
In an arena where plagiarism is harmful, I'd call this "negligence theory" rather than "mistake theory". This isn't just a misunderstanding or incorrect belief, it's a sloppiness in research...
It's sloppy, but my question is whether it's unusually sloppy. That's the difference between a mistake and negligence.
Compare this to car accidents. We expect that there's an elevated proportion of "consistently unusually sloppy driving" among people at fault for causing car accidents relative to the general driving population. For example, if we look at the population of people who've been at fault for a car accident, we will find a higher-than-average level of drunk driving, texting while driving, tired driving, speeding, dangerous maneuvers, and so on.
However, we might also want to know the absolute proportion of at-fault drivers who are consistently unusually sloppy drivers, relative to those who are average or better-than-average drivers who had a "moment of sloppy driving" that happened to result in an accident.
As a toy example, imagine the population is:
- 1/4 consistently good drivers. As a population, they're responsible for 5% of accidents.
- 1/2 average drivers. As a population, they're responsible for 20% of accidents.
- 1/4 consistently bad drivers. As a population, they're responsible for 75% of accidents.
In this toy example, good and average drivers are at fault for about 10% of all accidents.
When we see somebody commit an accident, this should, as you say, make us see them as substantially more likely to be a bad driver. It is also good incentives to punish this mistake in proportion to the damage done, the evidence about underlying factors (i.e. drunk driving), the remorse they display, and their previous driving record.
However, we should also bear in mind that there's a low but nonzero chance that they're not a bad driver, they just got unlucky.
Plagiarism interventions
Shifting back to plagiarism, the reason it can be useful to bear in mind that low-but-nonzero chance of a plagiarism "good faith error" is that it suggests interventions to lower the rate of that happening.
For example, I do all my research reading on my computer. Often, I copy/paste quotes from papers and PDFs into a file. What if there was a copy/paste feature that would also preserve the URL (from a browser) or the filename (from a downloaded PDF), and paste it in along with the text?
Alternatively, what if document editors had a feature where, when you copy/pasted text into them, they popped up an option to conveniently note the source or auto-format it as a quotation?
This is more speculative, but if we could digitize and make scientific papers and books publicly available, students could use plagiarism detectors as a precaution to make sure they haven't committed "mistaken plagiarism" prior to publication. Failing to do so would be clearly negligent.
Replies from: Dagon↑ comment by Dagon · 2022-07-07T18:54:25.088Z · LW(p) · GW(p)
True - "harm reduction" is a tactic that helps with negligence or mistake, and less so with true adversarial situations. It's worth remembering that improvements are improvements, even if only for some subset of infractions.
I don't particularly worry about plagiarism very often - I'm not writing formal papers, but most of my internal documents benefit from a references appendix (or inline) for where data came from. I'd enjoy a plugin that does "referenceable copy/paste", which includes the URL (or document title, or, for some things, a biblio-formatted source).
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-11-12T05:33:00.758Z · LW(p) · GW(p)
I'm interested in the relationship between consumption and motivation to work. I have a theory that there are two demotivating extremes: an austerity mindset, in which the drive to work is not coupled to a drive to consume (or to be donate); and a profligacy mindset, in which the drive to consume is decoupled from a drive to work.
I don't know what to do about profligacy mindset, except to put constraints on that person's ability to obtain more credit.
But I see Putanumonit's recent post advocating self-interested generosity over Responsible Adult (tm) saving as an example of a therapy for people in an austerity mindset.
On a psychological level, I hypothesize that a person with austerity mindset doesn't have a strong mental model of the kinds of rewarding products and experiences that they can purchase with money. They have a poor ability to predict how those goods and services will make them feel. They've invested little money or time in attempting to explore or discover that information. And they don't understand how monetary generosity, or even spending on status symbols, can indirectly translate into financial rewards at a later time. They are reward-ignorant.
This ignorance causes people with an austerity mindset not only to make bad deliberate decisions, but saps their motivation to sustain hard and focused work over the long term. Other emotions, like guilt, shame, conformity, or fear of losing the base essential of life are all they have to motivate work and investment. None of these has the potential to grow with income. In fact, they lessen with income. The result would be that the person works only hard enough to bring these negative emotions into an equilibrium with the fatigue and risks of work or school, and no harder. They skate by.
It seems to me that a person with an austerity mindset could benefit by spending time exploring the rewards the world has to offer, and getting the best taste of them they can. Furthermore, people who are in an investment stage of their career (such as being in school) would be best served by a "controlled release" of spending debt on small luxuries.
For example, imagine a person who was earning $40,000/year with no degree, but who enrolls in an MS program expecting to earn $70,000/year after graduate school.
Bryan Caplan points out that something like half of graduate students drop out. Even if we ignore salary increases and so on, our grad student has perhaps 30 years of a $30,000 salary boost on the line. Let's round up to a cool $1 million.
Now, imagine that they choose to spend 1% of that money on luxuries over 2 years of grad school. That's $10,000, or $5,000/year (we'll ignore interest for the sake of simplicity). About $400/month.
It seems very plausible to me that granting grad students $400/month to spend on non-necessities would decrease the rate of dropping out. They might spend it on all kinds of things: therapy, art, better food, throwing parties for their friends, nights out on the weekends, concert tickets, a nicer/quieter place to live. If it decreased their likelihood of dropping out from 50% to 45%, it's an intervention that more than pays for itself in expectation.
We shouldn't expect that it can drop the rate all the way to 0 for any given student, since lots of factors not controlled by austerity conditions could cause them to drop out. And we might pessimistically assume that a student capable of carrying out this strategy, for these reasons, as described, would have to have enough conscientiousness and other virtues to make them less likely to drop out than the average student.
Even so, the amount by which this intervention would have to reduce the likelihood of dropping out to pay for itself only needs to be very small indeed to make it worthwhile.
We might point out that the grad student could just take on additional work in order to pay for those luxuries, if the luxuries are indeed so motivating. Why can't they take on an extra job, or do more TAing? My answer is that the fundamental hypotheses I'm working with here is that the grad student is using debt to buy luxuries to reduce the chance that they drop out. If they take on additional work, which increases their stress levels and fatigue, in order to pay for those luxuries, then this could easily more than counterbalance the positive effect of increased consumption.
It is not entirely clear to me why we would rationally want to sharply distinguish between work that directly is attached to a paycheck, and work that prepares you to be capable of earning a bigger paycheck. I understand this as a sort of "guard rail:" the idea that once people get a taste of buying luxuries on credit, they'll go crazy. But people also enroll in grad school, pay a bunch of money for tuition, and then drop out. That's also crazy, from the outside point of view. The only question is whether it adds to, or subtracts from, the crazy to use debt money to try and reduce this risk. If the guard rail falls over on top of you and starts smothering you to death, it's no longer the safety intervention you need.
All that said, as far as I know, we don't have an official DSM-V diagnosis of "austerity mindset" available to us. And if we take this seriously and think it might be a real thing, then it's important to get the diagnosis right. The justifications we'd use to encourage a person with "austerity mindset" to spend more on luxuries (even if that money came out of student loan debt while they were in school) are the same sorts of justifications that might cause a person with profligacy mindset to dig themselves deeper into a hole. This is a case where it would be really important to give the right advice to the right person.
Let's also not assume that we can snap our fingers and conjur a bunch of RCTs out of thin air to weigh in on this. Let's say we have to figure it out ourselves. Then I have two questions, for starters.
- How do you tell if the features of the austerity mindset hypothesis are true for you? For example, how do you tell if increased consumption is actually motivating, or decreases stress and fatigue? How do you tell that increased exploration and exposure to the rewards of increased consumption actually cause a long-term positive impact on your psychology?
- How do you tell the difference between having austerity mindset and having a self-justifying profligacy mindset?
- There might be a risk that an austerity mindset is a psychological brake on an underlying tendency toward profligacy. Imagine the teetotaler who recognizes that, if they ever got into booze, they'd become a raging alcoholic. We don't want to create an enhanced risk that somebody's fragile system for self-restraint might break down. Or on a social level, it might be that spending more tends to cause other people to expect you to spend even more - a sort of 'induced demand' phenomena that would make it hard to stick to a budget.
One facet would be to set a monthly budget that must be spent, and that excludes categories you normally spend money on already. For example, if you already buy takeout several times a month, then you can't charge that to your luxury budget. You have to make sure that you're actually spending more on luxuries, and not just relabeling the spending you were already doing. If you are able to set and stick to this budget, and especially if you find it difficult to spend the entire budget, then this might be a point of evidence that you have austerity mindset.
Another facet would be to try out this luxury budget for a few months, and see if you can account for how the spending has impacted your life. This is hazy, but it seems unlikely to me that there is any superior system to accounting for this than introspective intuition. You might incorporate periodic fasts, to see if that makes a difference. This might even introduce an element of novelty that enhances the motivational effect.
I'm not sure on whether to expect that the beginning of running a luxury budget would be an era in which the benefits are low (because the person hasn't yet figured out the best ways to make themselves happy with money), or high (because of the temporary novelty of extra consumption).
I notice that it makes me feel pretty nervous to write about this. It's feels weird, like encouraging irresponsible behavior, and like it might actually motivate me (or somebody else) to act on it. It's an actionable, concrete plan, with a clear theory for how it pays off, and one that many people can put into place right away if they so choose. I don't want to be responsible if somebody does and it goes badly, but it feels weak to just make a disclaimer like "this is not financial advice." There's also a level on which I am just looking for somebody else to either validate or reject this - again, so that I don't have to take persona responsibility for the truth/falsity and/or utility/disutility of the idea.
But on a fundamental level, I really am trying to come at this from a place of prudence, financial and emotional. I suspect that a substantial proportion of the population isn't making good use of debt to handle the stresses of pursuing a more lucrative job. They get stuck in an austerity trap, or an austerity equilibrium, and their life stagnates. There's a virtuous cycle of work and reward, of throwing money at problems to make life smoother and more efficient, that seems important to ignite in people. And because it's not as measurable as all those "unnecessary" luxuries, it is at risk of getting ignored by financial advisors. It's outside of the spotlight.
Fortunately, this also seems like a strategy that can scale down very easily if it seems risky. You could test the waters with a very small luxury budget - say of $20 or $50 per month. Or, to make it more intuitive and fun, "spend a little bit of money every month on a product, experience, or gift that you ordinarily wouldn't buy - and treat that spending as if it was from a gift card 'for luxuries only'."
Replies from: pktechgirl, Viliam, Viliam↑ comment by Elizabeth (pktechgirl) · 2021-11-12T07:23:41.443Z · LW(p) · GW(p)
One particular category to spend luxury money on is "things you were constrained about as a child but aren't actually that expensive". What color clay do I want? ALL OF THEM. ESPECIALLY THE SHINY ONES. TODAY I WILL USE THE EXACT COLORS OF CLAY I WANT AND MAKE NO COMPROMISES.
Some caveats:
- I imagine you have to be judicious about this, appeasing your inner child probably hits diminishing returns. But I did experience a particular feeling about "I used to have to prioritize to satisfy others' constraints and now I can just do the thing."
- It's probably better if you actually want the thing and will enjoy it for its own sake, rather than as merely a fuck you to childhood deprivation. I have actually been using the clay and having an abundance of colors really is increasing my joy.
↑ comment by Viliam · 2021-11-13T23:14:11.230Z · LW(p) · GW(p)
I like the idea of a monthly "luxury budget", because then you only need to convince the person once; then they can keep experimenting with different things, keeping the luxury budget size the same. (Assuming that if something proves super useful, it moves to the normal budget.) This could be further improved by adding a constraint that each month the luxury budget needs to be spent on a different type of expense (food, music, travel, books, toys...). Make the person read The Luck Factor to motivate experimenting.
I suspect that a substantial proportion of the population isn't making good use of debt to handle the stresses of pursuing a more lucrative job.
It may be simultaneously true that many people underestimate how better their life could be if they took some debt and bought things that improve their life and productivity... and that many other people underestimate how better their life could be if they had more financial slack and greater resilience against occassional clusters of bad luck.
A problem with spending the right amount of money is to determine how much exactly the right amount is. For example, living paycheck to paycheck is dangerous -- if you get fired from your job and your car breaks at the same time, you could be in a big trouble; while someone who has 3 months worth of salary saved would just shrug, find a new job, and use a cab in the meanwhile. On the other hand, another person living paycheck to paycheck, who didn't get fired and whose car didn't break at the inconvenient moment, might insist that it is perfectly ok.
So when people tell you what worked for them best, they may be survivor bias involved. Statistically, the very best outcomes will not happen to people who used the best financial strategy (with the best expected outcome), but who took risk and got lucky. Such as those who took a lot of debt, started a company, and succeeded.
↑ comment by Viliam · 2021-11-13T22:24:19.765Z · LW(p) · GW(p)
Speaking as someone on the austerity side, if you want to convince me to buy something specific, tell me exactly how much it costs (and preferably add a link to an online shop as evidence). Sometimes I make the mistake of assuming that something is too expensive... so I don't even bother checking the actual cost, because I have already decided that I am not going to buy it... so in the absence of data I continue believing that it is too expensive.
Sometimes I even checked the cost, but it was like 10 years ago, and maybe it got significantly cheaper since then. Or maybe my financial situation has improved during the 10 years, but I don't remember the specific cost of the thing, only my cached conclusion that it was "too expensive", which was perhaps true back then, but not now.
Another way to convince me to use some product is to lend it to me, so I get the feeling how actually good it is.
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-06-02T03:03:35.335Z · LW(p) · GW(p)
Pet peeve: the phrase "nearly infinite."
Replies from: JBlack↑ comment by JBlack · 2021-06-02T08:06:47.352Z · LW(p) · GW(p)
Would you prefer "for nearly all purposes, any bounds there might be are irrelevant"?
Replies from: AllAmericanBreakfast, MakoYass↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2021-06-02T14:51:23.211Z · LW(p) · GW(p)
I’d prefer WAY BIG
Replies from: jimrandomh↑ comment by jimrandomh · 2021-06-02T18:43:31.271Z · LW(p) · GW(p)
In most cases I think the correct phrase would be "nearly unlimited". It unpacks to: the set of circumstances in which a limit would be reached, is nearly empty.
↑ comment by mako yass (MakoYass) · 2021-06-07T06:17:04.729Z · LW(p) · GW(p)
I don't like that one either, it usually reflects a lack of imagination. They're talking about the purposes we can think of now, they usually know nothing about the purposes we will find, once we have it, which haven't been invented yet.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-11-27T19:36:11.715Z · LW(p) · GW(p)
A celebrity is someone famous for being famous.
Is a rationalist someone famous for being rational? Someone who’s leveraged their reputation to gain privileged access to opportunity, other people’s money, credit, credence, prestige?
Are there any arenas of life where reputation-building is not a heavy determinant of success?
Replies from: Benito, Viliam↑ comment by Ben Pace (Benito) · 2020-11-28T05:22:24.494Z · LW(p) · GW(p)
A physicist is someone who is interested in and studies physics.
A rationalist is someone who is interested in and studies rationality.
↑ comment by Viliam · 2020-11-27T22:21:46.918Z · LW(p) · GW(p)
A rationalist is someone who can talk rationally about rationality, I guess. :P
One difference between rationality and fame is that you need some rationality in order to recognize and appreciate rationality, while fame can be recognized and admired also (especially?) by people who are not famous. Therefore, rationality has a limited audience.
Suppose you have a rationalist who "wins at life". How would a non-rational audience perceive them? Probably as someone "successful", which is a broad category that also includes e.g. lottery winners.
Even people famous for being smart, such as Einstein, are probably perceived as "being right" rather than being good at updating, research, or designing experiments.
A rationalist can admire another rationalist's ability of changing their mind. And also "winning at life" to the degree we can control for their circumstances (privilege and luck), so that we can be confident it is not mere "success" we admire, but rather "success disportionate to resources and luck". This would require either that the rationalist celebrity regularly publishes their though processes, or that you know them personally. Either way, you need lots of data about how they actually succeeded.
Are there any arenas of life where reputation-building is not a heavy determinant of success?
You could become a millionaire by buying Bitcoin anonymously, so that would be one example.
Depends on what precisely you mean by "success": it is something like "doing/getting X" or rather "being recognized as X"? The latter is inherently social, the former you can often achieve without anyone knowing about it. Sometimes it easier to achieve things if you don't want to take credit; for example if you need a cooperation of a powerful person, it can be useful to convince them that X was actually their idea. Or you can have the power, but live in the shadows, while other people are in the spotlight, and only they know that they actually take commands from you.
To be more specific, I think you could make a lot of money by learning something like programming, getting a well-paid but not very exceptional job, saving half of your income, investing it wisely; then you could early retire, find a good partner (or multiple partners), start a family if you want one, have harmonious relations with people close to you; spend your time interacting with friends and doing your hobbies. This already is a huge success in my opinion; many people would like to have it, but only a few ever get it. Then, depending on what is your hobby, you could write a successful book (it is possible to publish a world-famous book anonymously), or use your money to finance a project that cures malaria or eradicates some form of poverty (the money can come through a corporation with unknown owner). Hypothetically speaking, you could build a Friendly superhuman AI in your basement.
I am not saying the anonymous way is the optimal one, only that it is possible. Reputation-building could help you make more money, attract more/better partners, find collaborators on your projects, etc.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-11-28T01:37:27.258Z · LW(p) · GW(p)
Certainly it is possible to find success in some areas anonymously. No argument with you there!
I view LW-style rationality as a community of practice, a culture of people aggregating, transmitting, and extending knowledge about how to think rationally. As in "The Secret of Our Success," we don't accomplish this by independently inventing the techniques we need to do our work. We accomplish this primarily by sharing knowledge that already exists.
Another insight from TSOOS is that people use prestige as a guide for who they should imitate. So rationalists tend to respect people with a reputation for rationality.
But what if a reputation for rationality can be cultivated separately from tangible accomplishments?
In fact, prestige is already one step removed from the tangible accomplishments. But how do we know if somebody is prestigious?
Perhaps a reputation can be built not by gaining the respect of others through a track record of tangible accomplishments, but by persuading others that:
a) You are widely respected by other people whom they haven't met, or by anonymous people they cannot identify, making them feel behind the times, out of the loop.
b) That the basis on which people allocate prestige conventionally is flawed, and that they should do it differently in a way that is favorable to you, making them feel conformist or conservative.
c) That other people's track record of tangible accomplishments are in fact worthless, because they are not of the incredible value of the project that the reputation-builder is "working on," or are suspect in terms of their actual utility. This makes people insecure.
d) Giving people an ability to participate in the incredible value you are generating by convincing them to evangelize your concept, and thereby to evangelize you. Or of course, just donating money. This makes people feel a sense of meaning and purpose.
I could think of other strategies for building hype. One is to participate in cooperative games, whereby you and other hype each other, create a culture of exclusivity. If enough people do this, it could perhaps trick our monkey brains into perceiving that they're a socially dominant person in a much larger sphere than they really are.
Underlying this anxious argument is a conjunction that I want to make explicit, because it could lead to fallacy:
- It rests on a hypothesis that prestige has historically been a useful proxy for success...
- ... and that imitation of prestigious people has been a good way to become successful...
- ... and that we're hardwired to continue using it now...
- ... and that prestige can be cheap to cultivate or credit easy to steal in some domains, with rationality being one such domain; or that we can delude ourselves about somebody's prestige more easily in a modern social and technological context...
- ... and that we're likely enough to imitate a rationalist-by-reputation rather than a rationalist-in-fact that this is a danger worth speaking about...
- ... and perhaps that one such danger is that we pervert our sense of rationality to align with success in reputation-management rather than success in doing concrete good things.
You could argue against this anxiety by arguing against any of these six points, and perhaps others. It has many failure points.
One counterargument is something like this:
People are selfish creatures looking out for their own success. They have a strong incentive not to fall for hype unless it can benefit them. They are also incentivized to look for ideas and people who can actually help them be more successful in their endeavors. If part of the secret of our success is cultural transmission of knowledge, another part is probably the cultural destruction of hype. Perhaps we're wired for skepticism of strangers and slow admission into the circle of people we trust.
Hype is excitement. Excitement is a handy emotion. It grabs your attention fleetingly. Anything you're excited about has only a small probability of being as true and important as it seems at first. But occasionally, what glitters is gold. Likewise, being attracted to a magnetic, apparently prestigious figure is fine, even if the majority of the time they prove to be a bad role model, if we're able to figure that out in time to distance ourselves and try again.
So the Secret of Our Success isn't blind, instinctive imitation of prestigious people and popular ideas. Nor is it rank traditionalism.
Instead, it's cultural and instinctive transmission of knowledge among people with some capacity for individual creativity and skeptical realism.
So as a rationalist, the approach this might suggest is to use popularity, hype, and prestige to decide which books to buy, which blogs to peruse, which arguments to read. But actually read and question these arguments with a critical mind. Ask whether they seem true and useful before you accept them. If you're not sure, find a few people who you think might know better and solicit their opinion.
Gain some sophistication in interpreting why controversy among experts persists, even when they're all considering the same questions and are looking at the same evidence. As you go examining arguments and ideas in building your own career and your own life, be mindful not only of what argument is being made, but of who's making it. If you find them persuasive and helpful, look for other writings. See if you can form a relationship with them, or with others who find them respectable. Look for opportunities to put those ideas to the test. Make things.
I find this counter-argument more persuasive than the idea of being paranoid of people's reputations. In most cases, there are too many checks on reputation for a faulty one to last for too long; there are too many reputations with a foundation in fact to make the few that are baseless be common confounders; we seem to have some level of instinctive skepticism that prevents us from giving ourselves over full to a superficially persuasive argument or to one person's ill-considered dismissal; and even being "taken in" by a bad argument may often lead to a learning process that has long term value. Perhaps the vivid examples of durable delusions are artifacts of survivorship bias: most people have many dalliances with a large number of bad ideas, but end up having selected enough of the few true and useful ones to end up in a pretty good place in the end.
Replies from: Viliam↑ comment by Viliam · 2020-11-28T16:57:23.320Z · LW(p) · GW(p)
Ah, so you mean within the rationalist (and adjacent) community; how can we make sure that we instinctively copy our most rational members, as opposed to random or even least rational ones.
When I reflect on what I do by default... well, long ago I perceived "works at MIRI/CFAR" as the source of prestige, but recently it became "writes articles I find interesting". Both heuristics have their advantages and disadvantages. The "MIRI/CFAR" heuristic allows me to outsource judgment to people who are smarter than me and have more data about their colleagues; but it ignores people outside Bay Area and those who already have another job. The "blogging" heuristic allows me to judge the thinking of authors; but it ignores people who are too busy doing something important or don't wish to write publicly.
But what if a reputation for rationality can be cultivated separately from tangible accomplishments?
Here is how to exploit my heuristics:
- Be charming, and convince people at MIRI/CFAR/GiveWell/etc. to give you some role in their organization; it could be a completely unimportant one. Make your association known.
- Have good verbal skills, and deep knowledge of some topic. Write a blog about that topic and the rationalist community.
Looking at your list: Option a) if someone doesn't live in Bay Area, it could be quite simple to add a few rationalist celebrities as friends on Facebook, and then pretend that you have some deeper interaction with them. People usually don't verify this information, so if no one at your local meetup is in regular contact with them, the risk of exposure is low. Your prestige is then limited to the local meetup.
Options b) and c) would probably lead to a big debate. Arguably, "metarationality" is an example of "actually, all popular rationalists are doing it wrong, this is the true rationality" claim.
Option d) was tried by Intentional Insights, Logic Nation, and I have heard about people who try to extract free work from programmers at LW meetups. Your prestige is limited to the few people you manage to recruit.
Rationalist community has a few people in almost undefeatable positions (MIRI and CFAR, Scott Alexander), who have the power to ruin the reputation of any pretender, if they collectively choose so. Someone trying to get undeserved prestige needs to stay under their radar, or infiltrate them, because trying to replace them by a paralell structure would be too much work.
At this point, for someone trying to get into a position of high prestige, it would be much easier to simply start their own movement, built on different values. However, should the rationalist community become more powerful in the future, this equation may change.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-09-25T19:51:35.811Z · LW(p) · GW(p)
Idea for online dating platform:
Each person chooses a charity and an amount of money that you must donate to swipe right on them. This leads to higher-fidelity match information while also giving you a meaningful topic to kick the conversation off.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-07-16T19:25:32.104Z · LW(p) · GW(p)
Goodhart's Epistemology
If a gears-level understanding becomes the metric of expertise, what will people do?
- Go out and learn until they have a gears-level understanding?
- Pretend they have a gears-level understanding by exaggerating their superficial knowledge?
- Feel humiliated because they can't explain their intuition?
- Attack the concept of gears-level understanding on a political or philosophical level?
Use the concept of gears-level understanding to debug your own knowledge. Learn for your own sake, and allow your learning to naturally attract the credibility it deserves.
Evaluating expertise in others is a different matter. Probably you want to use a cocktail of heuristics:
- Can they articulate a gears-level understanding?
- Do they have the credentials and experience you'd expect someone with deep learning in the subject to have?
- Can they improvise successfully when a new problem is thrown at them?
- Do other people in the field seem to respect them?
I'm sure there are more.
comment by DirectedEvolution (AllAmericanBreakfast) · 2025-01-22T02:59:17.808Z · LW(p) · GW(p)
The CDC and other Federal agencies are not reporting updates. "It was not clear from the guidance given by the new administration whether the directive will affect more urgent communications, such as foodborne disease outbreaks, drug approvals and new bird flu cases."
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-07-05T08:29:03.366Z · LW(p) · GW(p)
ChatGPT is a token-predictor, but it is often able to generate text that contains novel, valid causal and counterfactual reasoning. What it isn't able to do, at least not yet, is enforce an interaction with the user that guarantees that it will proceed through a desired chain of causal or counterfactual reasoning.
Many humans are inferior to ChatGPT at explicit causal and counterfactual reasoning. But not all of ChatGPT's failures to perform a desired reasoning task are due to inability - many are due to the fact that at baseline, its goal is to successfully predict the next token. Iff that goal is aligned with accurate reasoning, it will reason accurately.
Judea Pearl frames associative, causal and counterfactual reasoning as "rungs," and at least in April 2023, thought ChatGPT was still on a purely associative "rung" based on it responding to his question "Is it possible that smoking causes grade increase on the average and, simultaneously, smoking causes grade decrease in every age group?" with a discussion of Simpson's paradox. The correct interpretation is that ChatGPT assumed Pearl was himself confused and was using causal terminology imprecisely. Simply by appending the phrase "Focus on causal reasoning, not associative reasoning" to Pearl's original question, GPT-4 not only performs perfect causal reasoning, but also addresses any potential confusion on the prompter's part about the difference between associative and causal reasoning.
From now on, I will be interpreting all claims about ChatGPT being unable to perform causal or counterfactual reasoning primarily as evidence that the claimant is both bad and lazy at prompt engineering.
My dad, on the other hand, has it figured out. When I showed him at dinner tonight that ChatGPT is able to invent new versions of stories he used to tell me as a kid, he just looked at me, smiled, and said "we're fucked."
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-06-10T04:53:42.292Z · LW(p) · GW(p)
Models do not need to be exactly true in order to produce highly precise and useful inferences. Instead, the objective is to check the model’s adequacy for some purpose. - Richard McElreath, Statistical Rethinking
Lightly edited for stylishness
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-06-10T10:23:26.076Z · LW(p) · GW(p)
With SSL pre-trained foundation models, the interesting thing is that the embeddings computed by them are useful for many purposes, while the models are not trained with any particular purpose in mind. Their role is analogous to beliefs, the map of the world, epistemic side of agency, convergently useful choice of representation/compression that by its epistemic nature is adequate for many applied purposes.
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-05-12T23:24:06.706Z · LW(p) · GW(p)
Let's say I'm right, and a key barrier to changing minds is the perception that listening and carefully considering the other person's point of view amounts to an identity threat.
- An interest in evolution might threaten a Christian's identity.
- Listening to pro-vaccine arguments might threaten a conservative farmer's identity.
- Worrying about speculative AI x-risks might threaten an AI capability researcher's identity.
I would go further and claim that open-minded consideration of suggestions that rationalists ought to get more comfortable with symmetric weapons, like this one, might threaten a rationalist's identity. As would considering the idea that one has an identity as a rationalist that could be threatened by open-minded consideration of certain ideas!
If I am correct, then it would be important not to persuade others that this claim is correct (that's the job of honest, facts-and-logic argument), but to avoid a reflexive, identity-driven refusal to consider a facts-and-logic argument. I've already lost that opportunity in this post, which wasn't written with the goal of pre-empting such a reflexive dismissal. But in future posts, how might one do such a thing?
I don't think it's as simple as saying something explicit like "you can be a rationalist and still consider X," or "if you were a good rationalist, you should consider X with an open mind." Such statements feel like identity threats, and it's exactly that perception that we're trying to avoid!
I also don't think you just make the argument, relying on the rationalist form of the argument or your in-group status to avoid the identity threat. A fundamentalist preacher who starts sermonizing on Sunday morning about the truth of evolution is not going to be treated with much more receptivity by the congregation than they'd demonstrate if teleported into a Richard Dawkins lecture.
Instead, I think you have to offer up a convincing portrait of how it is that a dyed-in-the-wool, passionate rationalist might come to seriously consider outgroup ideas as an expression of rationalism. Scott Alexander, more than any other rationalist writer I've seen, does this extremely well. When I read his best work, and even his average work, I usually come away convinced that he really made an effort to understand the other side, not just by his in-group standards, but by the standards of the other side, before he made a judgment about what was true or not. That doesn't necessarily mean that Scott will be convincing to the people he's disagreeing with (indeed, he often does not persuade them), but it does mean that he can be convincing to rationalists, because he seems to be exemplifying how one can be a rationalist while deeply considering perspectives that are not the consensus within the rationalist community.
Eliezer does something really different. He seems to try and assemble an argument for his own point of view so thorough and with so many layers of meta-correctness that it seems as if there's simply noplace that a truthseeker could possibly arrive at except the conclusion that Eliezer himself has arrived at. Eliezer has explanations for how his opponents have arrived at error, and why it makes sense to them, but it's almost always presented as an unfortunate error that results from avoidable human cognitive biases that he himself has overcome to a greater degree than his opponents. This is often useful, but it doesn't exemplify how a rationalist can deeply consider points of view that aren't associated with the rationalist identity while preserving their identity as a rationalist intact. Indeed, Eliezer often comes across as if disagreeing with him might threaten your identity as a rationalist!
There are a lot of other valuable writers in the LessWrong world, but their output usually strikes me as very much "by rationalists, for rationalists."
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-04-14T01:28:14.846Z · LW(p) · GW(p)
I disagree with Eliezer's comments on inclusive genetic fitness (~25:30) on Dwarkesh Patel's podcast - particularly his thought experiment of replacing DNA with some other substrate to make you healthier, smarter, and happier.
Eliezer claims that evolution is a process optimizing for inclusive genetic fitness, (IGF). He explains that human agents, evolved with impulses and values that correlate with but are not identical to IGF, tend to escape evolution's constraints and satisfy those impulses directly: they adopt kids, they use contraception, they fail to take maximum advantage of their ability to become a sperm donor, and so on. Smart people would even be willing to have their kid's genes replaced with something other than DNA, and as long as the kid would straightforwaredly benefit, they'd be fine with it.
Once we get to the point of this thought experiment, though, I do not think it is correct to say that evolution is optimizing for IGF. Just as the body is merely the vehicle for the gene, the gene is merely the vehicle for information. Evolution is optimizing for self-replicating information, and DNA just happens to be a convenient molecule for this purpose. And evolution isn't adaptive or forward-looking. The optimization process it generates is purely mechanical in nature, like a rock rolling downhill.
If we could keep our survival-and-replication information the same, while replacing our DNA with some other storage mechanism, that would be perfectly in accord with the optimization process evolution is running. Eliezer seems to think that a total rewrite to the DNA would be losing information. I would argue that if the vehicle is still able to perform and replicate as effectively as before, then the information relevant to evolution has been perfectly preserved - only the genetic sequence is lost, and that's the mere vehicle for the replication-relevant information. Evolution doesn't care about the DNA sequence. It acts on the replication-relevant information.
Does that matter for the AI safety argument?
I think it shows the limits of evolution as a metaphore for this topic. The key issue with agentic intelligence is that it is adaptive and forward-looking, in a way that natural selection simply is not (even though natural selection can be steered by the agentic processes that it has given rise to, and the rise of intelligence is a consequence of natural selection). So we can't say "we broke free of evolution, therefore AI can break free of us." We are agentic, foreward-thinking, and so we can adaptively anticipate what AI will do and pre-empt any such breakaway in a way that's simply beyond the capacity of evolution. Just because we can doesn't mean we will, but we should.
Ultimately, then I think we have to look at this aspect of the empirical result of evolution not so much as a piece of evidence about what will happen with AI alignment, as an intuition-building metaphore. The empirical result that is actually informative about the results of agency is the way we've taken control over the world and killed off our competitors. Whatever information can self-replicate most effectively - whether contained in human DNA, in a computer virus, or in an AI agent - will do so, up until it runs into a hard limit in its ability to do so or gets outcompeted by some other even more effectively-replicating piece of information. Or, in other words, evolution will be perfectly happy to continue optimizing for the reproductive fitness of information that uses computer code as the gene and machines as the vehicle.
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-04-03T05:09:55.479Z · LW(p) · GW(p)
Certain texts are characterized by precision, such as mathematical proofs, standard operating procedures, code, protocols, and laws. Their authority, power, and usefulness stem from this quality. Criticizing them for being imprecise is justified.
Other texts require readers to use their common sense to fill in the gaps. The logic from A to B to C may not always be clearly expressed, and statements that appear inconsistent on their own can make sense in context. [LW · GW] If readers demand precision, they will not derive value from such texts and may criticize the author for not providing it.
However, if the author never claimed to be precise or rigorous and instead warned readers of the imprecisions they would encounter, it is unreasonable to criticize them for this specific type of defect. Readers can still criticize them for pointing in the wrong direction with their argument or for other flaws such as being boring, rude, or deliberately misleading.
If the text provides value despite the imprecisions and if readers choose to complain about the gaps instead of using their own insights to fill them in, then it is their expectations that are the problem.
Replies from: LVSN↑ comment by LVSN · 2023-04-03T19:44:46.808Z · LW(p) · GW(p)
Certain texts are characterized by precision, such as mathematical proofs, standard operating procedures, code, protocols, and laws. Their authority, power, and usefulness stem from this quality. Criticizing them for being imprecise is justified.
Nope; precision has nothing to do with intrinsic value. If Ashley asks Blaine to get her an apple from the fridge, many would agree that 'apple' is a rather specific thing, but if Blaine was insistent on being dense he can still say "Really? An apple? How vague! There are so many possible subatomic configurations that could correspond to an apple, and if you don't have an exact preference ordering of sub-atomically specified apple configurations, then you're an incoherent agent without a proper utility function!"
And Blaine, by the way, is speaking the truth here; Ashley could in fact be more specific. Ashley is not being completely vague, however; 'apple' is specific enough to specify a range of things, and within that range it may be ambiguous as to what she wants from the perspective of someone who is strangely obsessed with specificity, but Ashley can in fact simply and directly want every single apple that matches her rangerately-specified criteria.
So it is with words like 'Good', 'Relevant', 'Considerate', 'Justice', and 'Intrinsic Value Strategicism'.
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-03-28T02:06:15.071Z · LW(p) · GW(p)
Why I think ChatGPT struggles with novel coding tasks
The internet is full of code, which ChatGPT can riff on incredibly well.
However, the internet doesn't contain as many explicit, detailed and accurate records of the thought process of the programmers who wrote it. ChatGPT isn't as able to "riff on" the human thought process directly.
When I engineer prompts to help ChatGPT imitate my coding thought process, it does better. But it's difficult to get it to put it all together fluently. When I code, I'm breaking tasks down, summarizing, chunking, simulating the results, and inventing test cases to try and identify failure modes. That all happens very quickly and only semi-consciously, and it isn't represented in my code.
I can prompt ChatGPT to do any of these things as it works, and they all seem to help. But it's difficult to get it to put it all together effectively. Its fluency at writing boilerplate, however, is genuinely a big productivity boost - and I'm more comfortable with a boring-boilerplate-writing AI than an AI that's excellent at conceiving and executing novel tasks and plans.
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-03-23T18:42:06.888Z · LW(p) · GW(p)
Learning a new STEM subject is unlike learning a new language. When you learn a new language, you learn new words for familiar concepts. When you learn a new STEM subject, you learn new words for unfamiliar concepts.
I frequently find that a big part of the learning curve is trying to “reason from the jargon.” You haven’t yet tied a word firmly enough to the underlying concept that there’s an instant correspondence, and it’s easy to completely lose track of the concept.
One thing that can help is to focus early on building up a strong sense of the fundamental thing you’re talking about.
For example, let’s say you’re learning statistics. Most people don’t think in terms of “categorical” and “quantitative” data, “means” and “counts.” These terms don’t trigger an immediate image in most people’s minds.
I find it really helpful to build up a stock of images - a mental image of box plots for ANOVA, a mental image of a table of counts for chi squared, and so on.
Then the process of learning the topic is of manipulating that fundamental ground truth image.
It’s essentially the Feinman “fuzzy green ball” approach but applied to just basic scholarship rather than new mathematical ideas.
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-03-23T16:45:22.926Z · LW(p) · GW(p)
Upvotes more informative than downvotes
If you upvote me, then I learn that you like or agree with the specific ideas I've articulated in my writing. If I write "blue is the best color," and you agreevote, then I learn you also agree that the best color is blue.
But if you disagree, I only learn that you think blue is not the best color. Maybe you think red, orange, green or black is the best color. Maybe you don't think there is a best color. Maybe you think blue is only the second-best color, or maybe you think it's the worst color.
Replies from: JBlack, sil-ver, twkaiser↑ comment by JBlack · 2023-03-24T01:20:50.512Z · LW(p) · GW(p)
I usually don't upvote or downvote mainly based on agreement, so there may be even less information about agreement than you might think!
I have upvoted quite a few posts where I disagree with the main conclusion or other statements within it, when those posts are generally informative or entertaining or otherwise worth reading. I have downvoted a lot of posts with conclusions I generally agreed with but were poorly written, repetitive, trivial, boring, overbearing, used flawed arguments, or other qualities that I don't like to see in posts on this site.
A post that said nothing but "blue is the best colour" would definitely get a downvote from me for being both trivial and lacking any support for the position, even if I personally agree. I would at very least want to know by what criteria it was considered "best" along with some supporting evidence for why those criteria were generally relevant and that it actually does meet those criteria better than anything else.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2023-03-24T03:01:12.503Z · LW(p) · GW(p)
Interesting - I never downvote based on being poorly written, repetitive, trivial, or boring. I do downvote for a hostile-seeming tone accompanied by a wrong or poorly-thought-through argument. I'll disagreevote if I confidently disagree.
"Blue is the best color" was meant as a trivial example of a statement where there's a lot of alternative "things that could be true" if the statement were false, not as an example of a good comment.
↑ comment by Rafael Harth (sil-ver) · 2023-03-23T17:10:08.132Z · LW(p) · GW(p)
This doesn't seem quite right. The information content of agree vs. disagree depends on your prior, i.e., on . If that's <0.5, then an agree vote is more informative; if it's >0.5, then a disagree vote is more informative. But it's not obvious that it's <.5 in general.
Replies from: AllAmericanBreakfast, AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2023-03-23T17:22:16.009Z · LW(p) · GW(p)
Fair point! The scenario I’m imagining is one in which our prior is low because we’re dealing with a specific, complex statement like “BLUE is the BEST color.” There are a lot of ways that could be considered wrong, but only one way for it to be considered right, so by default we’d have a low prior and therefore learn a lot more from an agreevote than a disagreevote.
I think this is why it makes sense for a truth seeker to be happier with upvotes than downvotes, pleasure aside. If I get agreevotes, I am getting a lot of information in situations like these. If I get disagreevotes, especially when nobody’s taking the time to express why, then I’m learning very little while perceiving a hint that there is some gap in my knowledge.
↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2023-03-23T17:49:28.318Z · LW(p) · GW(p)
Come to think of it, I feel like I tend to downvote most when I perceive that the statement has a lot of support (even if I’m the first voter). Somebody who makes a statement that I think will widely received as wrong, I will typically either ignore or respond to explicitly. Intuitively, that behavior seems appropriate: I use downvotes where they convey more information and use comments where downvotes would convey less.
↑ comment by twkaiser · 2023-03-25T04:24:16.944Z · LW(p) · GW(p)
It depends. My last post [LW · GW] got 20 downvotes, but only one comment that didn't really challenge me. That tells me people disagree with my heinous ramblings, but can’t prove me wrong.
Replies from: lahwran, AllAmericanBreakfast↑ comment by the gears to ascension (lahwran) · 2023-03-25T18:24:33.916Z · LW(p) · GW(p)
it's more that we don't think it's time yet, I think. of course humanity can't stay in charge forever.
Replies from: twkaiser↑ comment by twkaiser · 2023-03-26T15:59:10.383Z · LW(p) · GW(p)
Tbh, I'd even prefer it to happen sooner than later. The term singularity truly seems fitting, as I see a lot of timelines culminating right now. We're still struggling with a pandemic and it's economic and social consequences, the cold war has erupted again, but this time with inverted signs as the West is undergoing a marxist cultural revolution, the looming threat of WWIII, the looming threat of a civial war in the US, other nations doing their things as well (insert Donald Trump saying "China" here), and AGI arriving within the next five years (my estimation with confidence >90%). What a time to be alive.
↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2023-03-25T04:40:02.054Z · LW(p) · GW(p)
I don't think it's soldier mindset. Posts critical of leading lights get lots of upvotes when they're well-executed.
One possibility is that there's a greater concentration of expertise in that specific topic on this website. It's fun for AI safety people to blow off steam talking about all sorts of other subjects, and they can sort of let their hair down, but when AI safety comes up, it becomes important to have a more buttoned-up conversation that's mindful of relative status in the field and is on the leading edge of what's interesting to participants.
Another possibility is that LessWrong is swamped with AI safety writing, and so people don't want any more of it unless it's really good. They're craving variety.
Replies from: Raemoncomment by DirectedEvolution (AllAmericanBreakfast) · 2022-10-09T16:56:03.366Z · LW(p) · GW(p)
Hunger makes me stop working, but figuring out food feels like work. The reason hunger eventually makes me eat is it makes me less choosy and health-conscious, and blocks other activities besides eating.
More efficient food motivation would probably involve enjoying the process of figuring out what to eat, and anticipated enjoyment of the meal itself. Dieting successfully seems to demand more tolerance for mild hunger, making it easier to choose healthy options than unhealthy options, and avoiding extreme hunger.
If your hunger levels follow a normal distribution, a good diet would marginally increase your average hunger level, but shrink the standard deviation. You'd rarely be stuffed or starving, but you'd be slightly hungrier more of the time comapred to when you're not dieting. At the same time, you'd never dip down to the extremes of hunger you might experience when you're not on a diet.
Patterns that might move in this direction:
- A habit of saving a little bit of your meal for later
- Leaving out one item you'd normally eat, or choose a healthier option (eat the burger and fries, but order diet coke instead of sugared coke)
- Choose a restaurant offering higher quality with smaller portions
- Always eating a small salad before your main meal.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-24T19:40:29.211Z · LW(p) · GW(p)
Old Me: Write more in order to be unambiguous, nuanced, and thorough.
Future Me: Write for the highest marginal value per word.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-20T03:20:26.014Z · LW(p) · GW(p)
Mental architecture
Let's put it another way: the memory palace is a powerful way to build a memory of ideas, and you can build the memory palace out of the ideas directly.
My memory palace for the 20 amino acids is just a protein built from all 20 in a certain order.
My memory palace for introductory mathematical series has a few boring-looking 2D "paths" and "platforms", sure, but it's mainly just the equations and a few key words in a specific location in space, so that I can walk by and view them. They're dynamic, though. For example, I imagine a pillar of light marking the separation between the nth term in the series and the remainder. I can pluck one of the partial sums from the set of them and carry it around. I have a "stable" in which the geometric and harmonic series are kept like horses ready to be ridden. But it's just the equation forms of those series lined up side by side. I don't see fences or hay.
My memory palace for the proteins associated with actin is just a cartoon movie of actin filament formation and disassembly.
When the memory palace is constructed, I can scan the environment and see what's there. For example, when I'm standing close to the basic representation of a series, the very first part of the palace, I can look across the way and see the "stable" of example series, or at the "testing platform" where the integral test and comparison tests are located. I can't see all the detail until I go to them and spend some time inspecting, but I know it's there and know what I expect to find when I go over.
The memory palace isn't the end of memorization. It's the beginning. As I've walked through my amino acid memory palace probably 10 times, I can now simply visualize an entire amino acid and its name all at once, with less effort than it takes to traverse the memory palace.
So my advice is to build your memory palaces directly out of the knowledge you want to learn.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-11T00:06:21.383Z · LW(p) · GW(p)
Mentitation[1] means releasing control in order to gain control
As I've practiced my ability to construct mental imagery in my own head, I've learned that the harder I try to control that image, the more unstable it becomes.
For example, let's say I want to visualize a white triangle.
I close my eyes, and "stare off" into the black void behind my eyelids, with the idea of visualizing a white triangle floating around in my conscious mind.
Vaguely, I can see something geometric, maybe triangular, sort of rotating and shadowy and shifty, coming into focus.
No, I insist, not good enough. I try to mentally "reach out" and hold the image in place. I try to make it have three sides, to be bright paper-white, to stop rotating, to be equilateral. As I make these efforts, the image starts spinning more and more. It shrinks, vanishes.
Over time, I've learned to take a step back. I continue staring out into the black void behind my eyelids. Instead of trying to control whatever I see there, I simply allow it to come into view with greater clarity moment by moment.
If I want it to look different, I've found that I can hold the main change I want made in my peripheral consciousness. "Whiter, please," or "larger," or "more equilateral," or "with the tip pointing straight up." The image I want comes into greater focus as I do so. I have never tried to become able to create an image wtih unlimited detail or control, because I get a lot of value out of just this amount of visualization ability.
I've found that other aspects of mentitation are similar. I have the ability to heard melodies in my head, and to construct new ones. However, if I try to control that melody note by note, I am not able to hear it as a melody at all, and cannot experience it as music. By contrast, if I "stand back" and listen to the music my subconscious comes up with, and offer "conceptual tweaks" to that melody, then I'm able to influence its shape in a way that feels musical.
When I am using mentitation to integrate a pieces of knowledge into my long-term memory, it's a similar experience. My relationship with my memories is not like my relationship with the memory on my computer. My brain can't offer me a complete, instant display of everything stored there, in a hierarchical file format, with CRUD capability. Instead, it's more like my brain is a sort of librarian. I offer up a set of ideas in my conscious mind (let's say, the definition of a Taylor series), and allow my brain to start coming up with associations, insights, and ways to integrate it. My job is to keep focused on this task, without trying to exert some sort of "top-down" control over how it plays out. There's also a sense of receptive manipulation of what my subconscious "offers up" to my conscious mind.
Perhaps a simple, rough model for what is going on is something like this:
My conscious mind starts by holding an idea in mind (i.e. the definition of the Taylor series). It has a little bit of capacity left over, and requests memories, associations, and insights from my unconscious mind.
My unconscious mind retrieves a connecting idea, and now my conscious mind's capacity is full, with the Taylor series definition and the connecting idea.
Now it's my conscious mind's job to examine and articulate the connection between these two ideas. As this is done, the subconscious goes to work once again retrieving another connection, which may be with the Taylor series, the first associated idea, or some product of the conscious mind's work binding them together.
This repeats ad infinitum.
- ^
My tentative term for a practice of improving one's ability to monitor and control their conscious mind in order to improve their ability to remember and understand information.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-05T20:23:36.664Z · LW(p) · GW(p)
I was watching Michael Pollan talk with Joe Rogan about his relationship with caffeine. Pollan brought up the claim that, prior to Prohibition, people were "drunk all the time...", "even kids," because beer and cider "was safer than water."
I myself had uncritically absorbed and repeated this claim, but it occurred to me listening to Pollan that this ought to imply that medieval Muslims had high cholera rates. When I tried Googling this, I came across a couple of Reddit threads (1, 2) that seem sensible, but are unsourced, saying that the "water wasn't safe until the 1900s" is largely a myth. Cholera only became a chronic issue during the industrial revolution as rapidly densifying cities grew their population faster than their capacity to provide people with clean water.
I haven't seen other sources and I'm not likely to try too hard to find them, but if you happen to know of a citeable source, throw it my way!
Replies from: pktechgirl↑ comment by Elizabeth (pktechgirl) · 2022-09-05T20:57:09.331Z · LW(p) · GW(p)
a book on henry 8th said that his future inlaws were encouraged to feed his future wife (then a child) alcohol because she'd need to drink a lot of it in England for safety reasons. Another book said England had a higher disease load because the relative protection of being an island let its cities grow larger (it was talking about industrialized England but the reasoning should have held earlier). It seems plausible this was a thing in England in particular, and our English-language sources conflated it with the whole world or at least all of Europe.
I am super curious to hear the disease rate of pre-mongol-destruction Baghdad.
↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-05T22:06:11.374Z · LW(p) · GW(p)
Managed to find a source that gets into the topic.
Until the 19th century human beings in Western society considered water unsuitable for
consumption. The very earliest historic societies, whether Egyptian, Babylonian, Hebrew,
Assyrian, Greek or Roman, unanimously rejected water as a beverage. Through the ages water
was known to cause acute and chronic but deadly illnesses and to be poisonous and therefore
was avoided, particularly when brackish. The Old and New Testaments are virtually devoid of
references to water as a common beverage as is the Greek literature, excepting some positive
statements regarding the quality of water from mountain springs (Marcuse, 1899; Glen W.
Bowersock, personal communication).
I don't love that their citations are a personal communication and a source from 1899. No other sources for claims that the ancients rejected water as a beverage for safety reasons in this article. In History and epidemiology of alcohol use and abuse we again have similar uncited claims.
In traveling, local sources of water are always in question, and it is difficult or impossible to transport most other forms of liquids that are usually ingested, such as milk and juices.
In Cholera: A Worldwide History:
Cholera is very much a disease of cities. Early humans were hunters, following the trail of game, Constant movement made it unlikely their exerements would contaminate the water supply. Later, as they became gatherers and remained in one place for long periods of time, the risk of polluting water became greater, but small settlements lessened the chances of drinking water contaminations. twas only when large numbers of people gathered together in confined spaces that the danger of thousands of untreated privies leaking into ground water or rivers led to the spread of cholera on an unprecedented scale, striking the rich and the poor, the famous and the obscure with equal virulence.
The book also talks about a description of Mary, Queen of Scots having a disease reminiscent of cholera. However, prior to the germ theory of disease, would people have really realized that a) drinking water was causing illness and b) the alcohol in fermented drinks could decontaminate the water and was therefore safe to drink?
As I scan books covering the history of drinking water and historical debates over the virtues of drinking water vs. alcohol, I am seeing that people had a variety of arguments for or against water. Alcoholic drinks were argued by some to promote normal health and development in children. A captive Frenchman said that in his country, only "invalids and chickens" drink water. I don't see reports of a clear consensus among booze advocates in these papers and books that alcoholic beverages were to be preferred for their antiseptic properties. That seems to me to be reading a modern germ theory into the beliefs of people from centuries past.
Replies from: pktechgirl↑ comment by Elizabeth (pktechgirl) · 2022-09-06T20:39:26.260Z · LW(p) · GW(p)
I wouldn't expect them to have full germ theory, but metis around getting sick after drinking bad water and that happening less often with dilute alcohol seems very plausible.
I wonder if there's a nobility/prole distinction, in addition to the fact that we're talking about a wide range of time periods and places.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-07T00:35:30.344Z · LW(p) · GW(p)
Alcohol concentrations below 50% have sharply diminished disinfecting utility, and wine and beer have alcohol concentrations in the neighborhood of 5%. However, the water in wine comes from grapes, while the water in beer may have been boiled prior to brewing. If the beer or wine was a commercial product, the brewer might have taken extra care in sourcing ingredients in order to protect their reputation.
Beer and fungal contamination is a problem for the beer industry. Many fungi are adapted to the presence of small amounts of alcohol (indeed, that's why fermentation works at all), and these beverages are full of sugars that bacteria and fungi can metabolize for their growth.
People might have noticed that certain water sources could make you sick, but if so, they could also have noticed which sources were safe to drink. On the other hand, consider also that people continued to use and get cholera from the Broad Street Pump. If John Snow's efforts were what was required to identify such a contaminated water source with the benefit of germ theory, then it would be surprising if people would have been very successful in identifying delayed sickness from a contaminated water source unless the water source was obviously polluted.
An appeal to metis only seems to support the idea that people avoided drinking water to avoid getting sick if we also assume there were no safe water sources around, if this persisted long enough and obviously enough for people to catch on, and people saw no alternative but to give up on drinking water.
I also think it's interesting that several religions have banned or discouraged alcohol consumption, and have also required or prohibited certain behaviors for reasons of hygiene, and yet, AFAIK, no religion has ever mandated that its followers drink alcohol and refuse water. Instead, we have numerous examples of religions promoting the consumption of water as more spiritual or healthful.
Replies from: pktechgirl↑ comment by Elizabeth (pktechgirl) · 2022-09-07T18:09:07.124Z · LW(p) · GW(p)
huh, interesting. I wonder where the hell the common story came from.
Replies from: rhollerith_dot_com↑ comment by RHollerith (rhollerith_dot_com) · 2023-04-03T14:50:41.183Z · LW(p) · GW(p)
One factor to consider is that drinking alcohol causes pleasure, and pleasure is the motivation in motivated cognition.
Most comments on the internet are against any laws or technical measures that would prevent internet users from downloading for free copies of music and video files. I think the same thing is going on there: listening to music -- music new to the listener particularly -- causes pleasure, and that pleasure acts as motivation to reject plans and ways of framing things that would lead to less listening to novel music in the future.
↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-05T22:08:38.788Z · LW(p) · GW(p)
OK, finally found the conduit to people who actually know what they're talking about and have investigated this issue.
Paolo Squatriti is a rare writer (in Water and Society in Early Medieval Italy, AD 400-1000) to look at this question. He writes of both Italy and Gaul:
"Once they had ascertained that it was pure (clear, without odor, and cold) people in postclassical Italy did, in the end, drink water. Willingness to drink water was expressed in late antiquity by writers as dissimilar as Paulinus of Nola, Sidonius Apollinaris, and Peter Chrysologus, who all extolled the cup of water."
Replies from: AllAmericanBreakfastIn Misconceptions About the Middle Ages, Stephen Harris and Bryon L. Grigsby write: "The myth of constant beer drinking is also false; water was available to drink in many forms (rivers, rain water, melted snow) and was often used to dilute wine." Steven Solomon's Water: The Epic Struggle for Wealth, Power, and Civilization examines uses of water, including for drinking, going back to Sumeria.
↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-05T22:10:59.624Z · LW(p) · GW(p)
Many other quotes from historical figures showing that water was a widely accepted and consumed beverage. I'm sold.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-05T18:58:30.144Z · LW(p) · GW(p)
Simulated weight gain experiment, day 3
I'm up to 15 pounds of extra weight today. There's a lot to juggle, and I have decided not to wear the weighted vest to school or the lab for the time being. I do a lot of my studying from home, so that still gives me plenty of time in the vest.
I have to take off the vest when I drive, as the weights on the back are very uncomfortable to lean on. However, I can wear it sitting at my desk, since I have a habit of sitting up ramrod-straight in my chair due to decades of piano practice sitting upright on the piano bench. Good posture becomes especially important wearing this vest.
Astronauts tend to lose musculature and bone mass in space, and as I understand it this is because of the lowered strain on their bodies. I am curious whether the extra weight from this vest will have the opposite effect.
This vest has made me more conscious about eating. I eat a lot of pizza, and I usually eat 4-5 slices for a meal. Over the last couple of days, I have found it easy to stick to 2-3 slices. Part of this is that my conscious decision about how to alter my eating habits was to "do what I normally do, but marginally healthier" - one fewer slices of pizza, choosing a healthier snack most of the time, that sort of thing. Part of it too, though, is that I am wearing a constant and extremely obvious physical reminder of why I'm making that choice. It would be very cognitively dissonant indeed to be wearing a weighted vest out of concern for my weight, while continuing to overeat.
This makes me think that modifying one's dress and environment might be unusually tractable and potent commitment devices for motivating behavior change. Based on my experience so far, it seems like the key is to do something you'd normally not prefer, so that the only reason you could possibly be doing it is as a commitment device. In other words, avoid motive ambiguity [LW · GW]. The uniform or environmental change is a costly signal.
In our kitchen last year, I put up some ugly, rather "loud" signs around the counter saying things like "ABSOLUTELY NO GROCERIES LEFT ON THE COUNTER" and "ABSOLUTELY NO DIRTY DISHES HERE." Boy did that work. We just took the signs down for a deep clean, and didn't put them back up again afterward. Immediately, the kitchen has started to become messy again.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-05T18:43:30.981Z · LW(p) · GW(p)
Problem Memorization
Problem Memorization is a mentitation[1] technique I use often.
If you are studying for an exam, you can memorize problems from your homework, and then practice working through the key solution steps in your head, away from pencil and paper.
Since calculation is too cognitively burdensome in most cases, and is usually not the most important bottleneck for learning, you can focus instead on identifying the key conceptual steps.
The point of Problem Memorization is to create a structure in your mind (in this case, the memorized problem) that provokes repeated thought, not just repeated rote recall. Where flashcards might be used to remember the list of equations relevant to the subject matter while you're at your desk, recall cycling means being able to remember and solve problems while you're in the shower or driving in the car.
Problem Memorization can also entail imagining how your approach would change if the problem were modified. You can explore this more easily when the problem itself is in your head.
Personally, I find that memorizing problems in this way is also useful when actually solving homework and exam problems. This seems to free up cognitive space for thinking about the solution, since you're not juggling the solution steps and problem description at the same time.
Problem Memorization can also be used for practical purposes. Having a detailed description of the problem you need to solve memorized and clear in your head allows you to work on the conceptual steps anytime.
- ^
Mentitation is my tentative word for exploratory techniques that expand our ability to monitor and control intellectual cognition.
↑ comment by matto · 2022-09-06T02:05:59.247Z · LW(p) · GW(p)
In my experience with doing something similar, this practice also helps memorize adjacent concepts.
For example, I was recently explaining to myself Hubbard's technique that uses Student's t-stat to figure out the 90% CI of a range of possible values of a population using a small sample.
Having little memory of statistics from school, I had to refresh my understanding of variance and the standard deviation, which are required to use the t-stat table. So now, whenever I need to "access" variance or stdev, I mentally "reach" for the t-stat table and pick up variance and stdev.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-03T17:58:28.577Z · LW(p) · GW(p)
Here's some of what I'm doing in my head as I read textbooks:
- Simply monitoring whether the phrase or sentence I just read makes immediate sense to me, or whether it felt like a "word salad."
- Letting my attention linger on key words or phrases that are obviously important, yet not easily interpretable. This often happens with abstract sentences. For example, in the first sentence of the pigeonholing article linked above, we have: "Pigeonholing is a process that attempts to classify disparate entities into a limited number of categories (usually, mutually exclusive ones)." I let my eyes linger on the words 'process', 'disparate entities', 'categories', 'mutually exclusive'. I allow my unconscious some time to float up an interpretation of these words. In this case, my brain starts a hazy visualization: a sense of people doing a task over and over again (process), a sense of several different objects sitting on a table (disparate entities), a sense of those objects being sorted into groups (categories), and a background sense that the objects in one group "don't belong" with the other groups (mutually exclusive).
- Closing my eyes and recalling the equation I just read from working memory. I repeat this several more times as I read on.
- Closing my eyes and rehearsing the key points of the sentence or paragraph I just read.
- Restating what I just read in my own words (in my head).
- Visualizing what's being described, which sometimes involves coming up with examples. I then use the example or visualization to verify that the argument just made seems to apply.
- Pigeonholing the sentence or paragraph.
- Looking back over the last several paragraphs, or the entire section up to my current position, and explaining to myself how the ideas I've learned about in each paragraph tie into the point of the section as a whole - their individual function, why they're sequenced as they are, which ones are of key importance, which bits of information are likely to be referenced many times again in the future.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-01T15:58:12.665Z · LW(p) · GW(p)
Psychology has a complex relationship with introspection. To advance the science of psychology via the study of introspection, you need a way to trigger, measure, and control it. You always face the problem that paying attention to your own mental processes tends to alter them.
Building mechanistic tools for learning and knowledge production faces a similar difficulty. Even the latest brain/computer interfaces mostly reinterpret a brain signal as a form of computer input. The user's interaction with the computer modifies their brain state.
However, the computer does not have the ability to directly manipulate the structure of the user's thoughts. It is not analogous to how a surgeon directly manipulates a patient's body. Instead, it's like how a theatrical performance manipulates an audience into sitting quietly and laughing or gasping occasionally for three hours or so.
People do have the ability to directly monitor and manipulate their own conscious cognitive processes. Their goals also diverge from those of scientists. A psychologist might seek to understand how people's brains and minds work in a naturalistic context, and the influence of the lab setting, evaluations, measurement devices, the subjects' self-consciousness, and so on are tolerated as necessary evils.
By contrast, individual people seeking mental self-improvement and practical function in the world might deliberately try to avoid their brain's "natural" way of functioning. To be extremely crude, the web comic SMBC gives a parodic portrait of the "natural" brain as an echo chamber of embarrassing intrusive thoughts and grandiose fantasies. A person who wants to discipline their mind in order to be able to perform at serious work wants an artificial mind, not a natural one.
Since the goals of a person seeking mental self-improvement diverge from those of scientists, and because they have higher-fidelity, direct, unconstrained, long-term access to their own mind, it makes sense to view this task as distinct from the work of the scientific study of the mind. For the same reasons, it is also distinct from the challenge of building software and physical tools for knowledge work.
Since scientists and tool-builders have different goals, methods, and constraints from those interested in mental self-improvement, we can expect that there is much for those interested in mental self-improvement to discover that isn't already contained in the scientific literature or engineered into a learning tool. Those interested in mental self-improvement can probably learn at least as much via introspection and "mindhacking" themselves (analogous to biohacking) as they can by reading the psychological and educational literature, or by incorporating more engineered learning tools into their workflow.
That's not to say that the psychological literature and learning tools are irrelevant to their projects - far from it! Becoming a "mentat" is not the only way to practice mental self-improvement, and I'm not at all sure that the portrayals of genius in science fiction are useful guides or exemplars for real-world mental self-improvement efforts.
Likewise, I think we should be skeptical of our impressions of how the genius mental calculators of history, like von Neumann, seemed to operate. There's a story about von Neumann. He was told a math riddle:
Two bicyclists, 20 miles apart, are pedaling toward each other. Each bicycle is going 10 miles per hour. In front of the wheel of one bicycle is a fly. It travels back and forth between the two bicycles at 15 miles per hour. How far will the fly have traveled before it is squashed between the wheels of the two bicycles?
The slow way to solve this riddle involves calculating the distance the fly travels each time it changes direction, and adding all these up. The fast way to solve it is to realize that it will take the bicyclists one hour to cover the 20 mile gap between them, and that the fly will therefore travel 15 miles during that time.
Von Neumann, on hearing this riddle, is said to have given the correct answer instantly. When the riddle-poser disappointedly said "oh, you must have heard it before," von Neumann said "I merely summed the geometric series."
This gives the impression that von Neumann was such a fast mental calculator (which was undoubtedly true) that he was able to solve this problem the slow way faster than mathematicians are able to solve it the fast way.
An alternative explanation, though, is that von Neumann also solved it the second, fast way, but also recognized that the slow way existed. In claiming to have instantly solved it the slow way, he was either making a joke, or bolstering the legend of his own calculating speed.
That's mere speculation on my part, but the point is that we should be skeptical of the impressions we have of the capabilities and mental methods historical geniuses used to develop their ideas and perform calculations. Even if we correctly discern how they operated, the techniques that work best for our own minds and purposes might be very different. Von Neumann, in particular, was reported to be poor at geometry and topology, and to have had very poor physical intuitions and to have been a bit of a clutz. If your work depends on having strong visual and physical intuitions or on manual dexterity, von Neumann is not your exemplar.
I am advocating that those interested in mental practice and mental self-improvement focus on observing and tinkering with their own cognitive faculties. Use external tools and draw upon the scientific literature, but use them as inspiration. Don't rely on them. You have access to different forms of information, control mechanisms, goals, and incentives than are available to scientists and engineers who do this sort of research and build these sorts of tools. Your projects, insights, and conclusions are therefore likely to diverge.
Likewise, if you are trying to do practical learning for real-world challenges, you might want to be skeptical of the methods of people who compete in memorization challenges and similar competitions. The techniques that allow somebody to memorize 10,000 digits of π are optimized for that task, and may not be the mental techniques most helpful for becoming an excellent mathematician, chemical engineer, or ornithologist.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-08-30T17:29:29.831Z · LW(p) · GW(p)
Apeing The Experts
Humans are apes. We imitate. We do this to learn, to try and become the person we want to be.
Watching an expert work, they often seem fast, confident, and even casual in their approach. They break rules. They joke with the people around them. They move faster, yet with more precision, than you can do even with total focus.
This can lead to big problems when we're trying to learn from them. Because we're not experts in their subject, we'll mostly notice the most obvious, impressive aspects of the expert's demeanor. For many people, that will be their rule violations, their social poise (and sometimes aggression), the shortcuts they take, and their raw confidence and speed.
It's these attributes that lend the expert their social status, and make them attractive targets for imitation. Unfortunately, aping these qualities works directly against our own ability to acquire expertise.
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-11-12T23:19:36.721Z · LW(p) · GW(p)
My goal here is to start learning about the biotech industry by considering individual stock purchases.
BTK inhibitors are a drug that targets B cell malignancies. Most are covalent, meaning that they permanently disable the receptor they target, which is not ideal for a drug. Non-covalent BTK inhibitors are in clinical trials. Some have been prematurely terminated. Others are proceeding. In addition, there are covalent reversible inhibitors, but I don't know anything about that class of drugs.
One is CG-806, from Aptose, a $200M company. This is one of its two products, both of which are in early clinical trials. The study is projected to be complete in June 2023.
Another is LOXO-305, now under the brand name pirtobrutinib, which was developed by Loxo Oncology. Loxo was acquired by Eli Lilly for $8 billion in 2019, and has one other investigational drug in the pipeline. Pritobrutinib is in the middle of a number of early clinical trials.
A third is nemtabrutinib. This drug was developed by ArQule, which was then purchased in 2019 by Merck for $2.7B. Merck is a $200B company, so its purchase of ArQule represented about 1% of its market cap. The study is projected to be complete on Sept. 1, 2022. Note that this study started back in 2017, while Aptose's only started in 2020.
Fenebrutinib is another non-covalent BTK inhibitor, developed by Genentech (now a subsidiary of Roche), which also goes by GDC-0853 and RG7845. It's being tested on MS, as well as B cell malignancies.
How to think about this bet? One way to think about it is that you're buying exposure to a drug and drug target. Another is that you're buying exposure to a company. With Eli Lilly or Merck, you're buying miniscule bits of companies that each individually comprise about 15% of the worldwide pharmaceutical industry. An equal spend buying stock in Aptose gives you 1000x the exposure to the company, and perhaps 10-100x the exposure to this particular drug/target concept.
All these drugs were developed by relatively small independent companies, with a couple of investigational drugs in the pipeline and no proven successes. The big dogs decided they wanted a piece of the non-covalent BTK inhibitor action, and got in on the game by buying Loxo, ArQule, and Genentech.
This makes me wonder why Aptose hasn't found a buyer (yet?). How often do small biotech companies make it all the way through phase 3 trials without getting bought out by a bigger company?
Although non-covalent drugs are generally more attractive than irreversible inhibitors, one academic abstract claims that "Contrary to expectations, reversible BTK inhibitors have not yielded a significant breakthrough so far. The development of covalent, irreversible BTK inhibitors has progressed more rapidly. Many candidates entered different stages of clinical trials; tolebrutinib and evobrutinib are undergoing phase 3 clinical evaluation."
In a few hour's research today, I've identified a few good questions/things to be aware of, at least, in the biotech industry.
- There are lots of endpoints for a small company developing a new biomedical product. They could fail, they could commit fraud, they could get bought out, they could succeed, they could flatline for years on end as their clinical trials grind on. Never take promoters or critics of companies at their word. They're trying to convince you of something, not provide a dispassionate broad view of the context of that drug or company, which is what you really need to build your understanding. Nevertheless, their articles might contain lots of concrete bits of factual information which you can harvest to spur further investigation.
- Buying stock in a small company is giving you much more concentrated exposure to risks and rewards. If that company's one or two drugs fail, then you'll lose nearly all your money. If they succeed, you could see a rapid giant increase in the value of your stock. By contrast, the fortunes of a very large biotech company don't hinge overmuch on the outcomes of any particular trial.
- Think of big pharma companies like a hybrid between a hedge fund and vertical integration. When they buy a smaller company, they bring regulatory relationships, brand name recognition, manufacturing, and an army of salespeople to making a drug profitable. If you are considering investing in a small pharma company, ask yourself why those big pharma companies, who certainly have a bunch of focused experts considering whether to buy out the small company, have passed on it so far. If the small company was going to get bought out, who would be the likely buyer?
- The broad context for a particular drug is often going to be quite complex. There will be several drugs in clinical trials at the same time, all of the same drug class (i.e. non-covalent BTK inhibitors), and often also other drugs that have the same target but work via a slightly different mechanism (i.e. covalent BTK inhibitors). The road may be littered with skulls, previous attempts at the same drug class that just didn't work out.
- Consider that there's lots of churn in biotech. People move between companies, from industry to academia and back, from small companies to big ones, and from big ones to small ones. When you buy stock in a company, to what extent are you buying a piece of a corporate society and policy and brand, things transcends the individual; and to what extent are you investing in their people?
- Everything hinges on regulation.
I don't think you can take a giant infodump and turn it into a model for stock-picking. Doing case studies like this are ways to come to grips with how complex, dynamic, and detailed the industry is. It seems important to gain an appreciation for what sorts of constraints might be relevant before we simplify.
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-02-12T04:49:00.441Z · LW(p) · GW(p)
Status and Being a "Rationalist"
The reticence many LWers feel about the term "rationalist" stems from a paradox: it feels like a status-grab and low-status at the same time.
It's a status grab because LW can feel like an exclusive club. Plenty of people say they feel like they can hardly understand the writings here, and that they'd feel intimidated to comment, let alone post. Since I think most of us who participate in this community wish that everybody would be more into being rational and that it wasn't an exclusive club, this feels unfortunate.
It's low status because it sounds cultish. Being part of the blogosphere is a weird hobby by many people's standards, like being into model railroad construction. It has "alt-something" vibes. And identifying with a weird identity, especially a serious one, can provoke anxiety. Heck, identifying with a mainstream identity can provoke anxiety. Just being anything except whatever's thoroughly conventional among your in-group risks being low-status, because if it wasn't, the high-status people would be doing it.
The nice thing about "rationalist" is that it's one word and everybody kinda knows what it means. "Less Wronger" is also short but you have to explain it. "Aspiring rationalist" is cute but too long. Tough nut to crack.
Replies from: ChristianKl↑ comment by ChristianKl · 2021-02-14T18:59:12.632Z · LW(p) · GW(p)
The nice thing about "rationalist" is that it's one word and everybody kinda knows what it means.
Everybody in our community knows what it means but people outside of our community frequently think that it's about what philosophers call rationality.
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-01-31T02:04:43.780Z · LW(p) · GW(p)
I use LessWrong as a place not just to post rambly thoughts and finished essays, but something in between.
The in between parts are draft essays that I want feedback on, and want to get out while the ideas are still hot. Partly it's so that I can have a record of my thoughts that I can build off of and update in the future. Partly it's that the act of getting my words together in a way I can communicate to others is an important part of shaping my own views.
I wish there was a way to tag frontpage posts with something like "Draft - seeking feedback" vs. "Final draft" or something like that. The editor is so much better for frontpage that I often find it a hassle to put a draft product in shortform. Plus it feels a bit of a "throwaway" space, which is what it's intended for, but to post there feels like it doesn't do justice to a certain amount of work I've put into something.
Replies from: habryka4↑ comment by habryka (habryka4) · 2021-01-31T02:47:54.437Z · LW(p) · GW(p)
Yeah, I've been thinking about this for a while. Like, maybe we just want to have a "Draft - seeking feedback" tag, or something. Not sure.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2021-01-31T03:14:37.542Z · LW(p) · GW(p)
Yeah, just a tag like that would be ideal as far as I'm concerned. You could also allow people to filter those in or out of their feed.
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-01-23T04:18:33.656Z · LW(p) · GW(p)
Eliezer's post on motivated stopping [LW · GW] contains this line:
Who can argue against gathering more evidence? I can. Evidence is often costly, and worse, slow, and there is certainly nothing virtuous about refusing to integrate the evidence you already have. You can always change your mind later."
This is often not true, though, for example with regard to whether or not it's ethical to have kids. So how to make these sorts of decisions?
I don't have a good answer for this. I sort of think that there are certain superhuman forces or drives that "win out." The drive to win, to pursue curiosity, to achieve goals, to speak and use your intelligence and influence to sway other people. The force of natural selection. Entropy.
The limit, maybe, of a person is to align themselves with the drives and forces that they have faith in. I think we might eventually come up with a good account that explains that everything is just politics in the end, including philosophy and ethics, and figure out a way perhaps to reconcile this perspective with the feeling that we need to be able to appeal to something timeless and beyond human affairs.
Replies from: Patterncomment by DirectedEvolution (AllAmericanBreakfast) · 2021-01-22T23:29:50.222Z · LW(p) · GW(p)
Reading and re-reading
The first time you read a textbook on a new subject, you're taking in new knowledge. Re-read the same passage a day later, a week later, or a year later, and it will qualitatively feel different.
You'll recognize the sentences. In some parts, you'll skim, because you know it already. Or because it looks familiar -- are you sure which?
And in that skimming mode, you might zoom into and through a patch that you didn't know so well.
When you're reading a textbook for the first time, in short, there are more inherent safeguards to keep you from wasting time. At the very least, when you're reading a sentence, you're gaining knowledge of what's contained in the textbook. Most likely, you're absorbing a lot of new information, even if you only retain a small fraction of it.
Next time, many of those safeguards are lost. A lot of your time will be wasted.
Unfortunately, it's very convenient to "review" by just re-reading the textbook.
When it comes to what in particular they're trying to do, physically with their bodies and books or mentally, most people are incoherent and inarticulate. But I propose that we can do much better.
Reviewing is about checking that you know X. To check that you know X, you need two things:
- Knowing the set of all X that you have to review.
- A test for whether or not you know X.
Let's say you're reviewing acid-base reactions. Then X might include things like the Henderson-Hasselbach equation, the definition of Ka and pKa, the difference between the Bronsted-Lowry and Lewis definitions of an acid, and so on.
To be able to list these topics is to "know the set of X." To have a meaningful way of checking your understanding is "a test for whether or not you know X."
The nature of that test is up to you. For example, with the Henderson-Hasselbach equation, You might intuitively decide that just being able to recite it, define each term, and also to define pKa and Ka is good enough.
The set of things to review and the tests that are relevant to your particular state of learning are, in effect, what goes on a "concept sheet" and a "problem set" or set of flashcards.
So learning becomes creating an updated concept sheet to keep track of the concepts you actually need to review, as well as a set of resources for testing your knowledge either by being able to recall what those concepts mean or using them to solve problems.
The textbook is a reference for when you're later mystified by what you wrote down on the concept sheet, but in theory you're only reading it straight through so that you can create a concept sheet in the first place. The concept sheet should have page numbers so that it's easy to refer to specific parts of the textbook.
Eventually, you'll even want to memorize the concept sheet. This allows you to "unfold" the concept tree or graph that the textbook contains, all within your mind. Of course, you don't need to recite word-for-word or remember every example, problem, and piece of description. It doesn't need to be the entire textbook, just the stuff that you think is worthwhile to invest in retaining long-term. This is for you, and it's not meant to be arbitrary.
But I propose that studying should never look like re-reading the textbook. You read the textbook to create a study-sheet that references descriptions and practice problems by page number. Then you practice recalling what the concepts on the study-sheet mean, and also memorizing the study sheet itself.
That might ultimately look like being able to remember all the theorems in a math textbook. Maybe not word for word, but good enough that you can get the important details pretty much correct. Achieve this to a good enough degree, and I believe that the topic will become such a part of you that it'll be easier to learn more in the future, rehearse your knowledge conveniently in your head, and add new knowledge with less physical infrastructure.
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-01-07T00:42:21.918Z · LW(p) · GW(p)
I just started using GreaterWrong.com, in anti-kibitzer mode. Highly recommended. I notice how unfortunately I've glommed on to karma and status more than is comfortable. It's a big relief to open the front page and just see... ideas!
Replies from: Raemoncomment by DirectedEvolution (AllAmericanBreakfast) · 2020-12-31T07:14:10.546Z · LW(p) · GW(p)
There's a pretty simple reason why the stock market didn't tank long-term due to COVID. Even if we get 3 million total deaths due to the pandemic, that's "only" around a 5% increase in total deaths over the year where deaths are at their peak. 80% of those deaths are among people of retirement age. Though their spending is around 34% of all spending, the money of those who die from COVID will flow to others who will also spend it.
My explanation for the original stock market crash back in Feb/March is that investors were nervous that we'd impose truly strict lockdown measures, or perhaps that the pandemic would more seriously harm working-age people than it does. That would have had a major effect on the economy.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-12-31T03:51:56.578Z · LW(p) · GW(p)
Striving
At any given time, many doors stand wide open before you. They are slowly closing, but you have plenty of time to walk through them. The paths are winding.
Striving is when you recognize that there are also many shortcuts. Their paths are straighter, but the doors leading to them are almost shut. You have to run to duck through.
And if you do that, you'll see that through the almost-shut doors, there are yet straighter roads even further ahead, but you can only make it through if you make a mad dash. There's no guarantee.
To run is exhilarating at first, but soon it becomes deadening as you realize there is a seemingly endless series of doors. There will never be any end to the striving unless you choose to impose such an end. Always, there is a greater reward that you've given up when you do so. Was all your previous striving for naught, to give up when you almost had the greater prize in hand?
There's no solution. This is just what it feels like to move to the right on a long-tailed curve. It's a fact of life, like the efficient market hypothesis. If you're willing to strive, the long-term rewards come at ever-greater short-term costs, and the short-term costs will continue to mount as long as you're making that next investment.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-12-27T20:26:28.068Z · LW(p) · GW(p)
The direction I'd like to see LW moving in as a community
Criticism has a perverse characteristic:
- Fresh ideas are easier to criticize than established ideas, because the language, supporting evidence, and theoretical mechanics have received less attention.
- Criticism has more of a chilling effect on new thinkers with fresh ideas than on established thinkers with popular ideas.
Ideas that survive into adulthood will therefore tend to be championed by thinkers who are less receptive to criticism.
Maybe we need some sort of "baby criticism" for new ideas. A "developmentally-appropriate criticism," so to speak.
As a community, that might look something like this:
- We presume that each post has a core of a good idea contained within it.
- We are effusive in our praise of those posts.
- We ask clarifying questions, for examples, and for what sorts of predictions the post makes, as though the OP were an expert already. This process lets them get their thoughts together, flesh out the model, and build on it perhaps in future posts.
- We focus on parts of the post that seem correct but under-specified, rather than on the parts that seem wrong. If you're digging for gold, 99% of the earth around you will contain nothing of value. If you focus on "digging for dirt," it's highly unlikely that you'll find gold. But if you pan the stream, looking for which direction to walk in where you find the most flecks of gold, you'll start to zero in on the place with the most value to be found.
- We show each other care and attention as people who are helping each other develop as writers and thinkers, rather than treating the things people write as the primary object of our concern.
↑ comment by Viliam · 2021-01-01T19:19:31.650Z · LW(p) · GW(p)
This reminds me of the "babble and prune" concept. We should allow... maybe not literally the "babble" stage, but something in between, when the idea is already half-shaped but not completed.
I think the obvious concern is that all kinds of crackpottery may try to enter this open door, so what would be the balance mechanism? Should authors specify their level of certainty and be treated accordingly? (Maybe choose one of predefined levels from "just thinking aloud" to "nitpicking welcome".) In a perfect world, certainty could be deduced from the tone of the article, but this does not work reliably. Something else...?
↑ comment by ChristianKl · 2020-12-28T22:14:03.431Z · LW(p) · GW(p)
We show each other care and attention as people who are helping each other develop as writers and thinkers, rather than treating the things people write as the primary object of our concern.
While this sounds nice on the abstract level I'm not sure what concrete behavior you are pointing to. Could you link to examples of comments that you think do this well?
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-12-28T23:08:44.894Z · LW(p) · GW(p)
I don't want to take the time to do what you've requested. Some hypothetical concrete behaviors, however:
- Asking questions with a tone that conveys a tentative willingness to play with the author's framework or argument, and an interest in hearing more of the authors' thoughts.
- Compliments, "this made me think of," "my favorite part of your post was"
- Noting connections between a post and the authors' previous writings.
- Offers to collaborate or edit.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-12-03T21:12:31.462Z · LW(p) · GW(p)
Cost/benefit anxiety is not fear of the unknown
When I consider doing a difficult/time-consuming/expensive but potentially rewarding activity, it often provokes anxiety. Examples include running ten miles, doing an extensive blog post series on regenerative medicine, and going to grad school. Let's call this cost/benefit anxiety.
Other times, the immediate actions I'm considering are equally "costly," but one provokes more fear than the others even though it is not obviously stupid. One example is whether or not to start blogging under my real name. Call it fear of the unknown.
It's natural that the brain uses the same emotional system to deal with both types of decisions.
It seems more reasonable to take cost/benefit anxiety seriously. There, the emotion seems to be a "slow down and consider this thoroughly" signal.
Fear of the unknown is different. This seems the appropriate domain for Isusr's fear heuristic [LW · GW]: do your due diligence to check that the feared option is not obviously stupid, and if not, do it.
Then again, maybe fear of the unknown is just another form of cost/benefit anxiety. Maybe it's saying "you haven't adequately thought about the worst or long-term potential consequences here." Perhaps the right approach is in fact to change your action to have small, manageable confrontations with the anxiety in a safe environment; or to do small tests of the considered action to build confidence.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-12-01T19:47:11.856Z · LW(p) · GW(p)
A machine learning algorithm is advertising courses in machine learning to me. Maybe the AI is already out of the box.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-11-21T00:36:44.455Z · LW(p) · GW(p)
An end run around slow government
The US recommended daily amount (RDA) of vitamin D is about 600 IUs per day. This was established in 2011, and hasn't been updated since. The Food and Nutrition Board of the Institute of Medicine at the National Academy of Sciences sets US RDAs.
According to a 2017 paper, "The Big Vitamin D Mistake," the right level is actually around 8,000 IUs/day, and the erroneously low level is due to a statistical mistake. I haven't been able to find out yet whether there is any transparency about when the RDA will be reconsidered.
But 3 years is a long time to wait. Especially when vitamin D deficiency is linked to COVID mortality. And if we want to be good progressives, we can also note that vitamin D deficiency is linked to race, and may be driving the higher rates of death in black communities due to COVID.
We could call the slowness to update the RDA an example of systemic racism!
What do we do when a regulatory board isn't doing its job? Well, we can disseminate the truth over the internet.
But then you wind up with an asymmetric information problem. Reading the health claims of many people promising "the truth," how do you decide whom to believe?
Probably you have the most sway in tight-knit communities, such as your family, your immediate circle of friends, and online forums like this one.
What if you wanted to pressure the FNB to reconsider the RDA sooner rather than later?
Probably giving them some bad press would be one way to do it. This is a symmetric weapon, but this is a situation where we don't actually have anybody who really thinks that incorrect vitamin D RDA levels are a good thing. Except maybe literal racists who are also extremely informed about health supplements?
In a situation where we're not dealing with a partisan divide, but only an issue of bureaucratic inefficiency, applying pressure tactics seems like a good strategy to me.
How do you start such a pressure campaign? Probably you reach out to leaders of the black community, as well as doctors and dietary researchers, and try to get them interested in this issue. Ask them what's being done, and see if there's some kind of work going on behind the scenes. Are most of them aware of this issue?
Prior to that, it's probably important to establish both your credibility and your communication skills. Bring together the studies showing that the issue is a) real and b) relevant in a format that's polished and easy to digest.
And prior to that, you probably want to gauge the difficulty from somebody with some knowhow, and get their blessing. Blessings are important. In my case, my dad spent his career in public health, and I'm going to start there.
Replies from: Dagon↑ comment by Dagon · 2020-11-21T21:46:04.974Z · LW(p) · GW(p)
So, you can't trust the government. Why do you trust that study? I talked to my MD about it, and he didn't actually know any more than I about reasoning, but did know that there is some toxicity at higher levels, and strongly recommended I stay below 2500 IU/day. I haven't fully followed that, as I still have a large bottle of 5000 IU pills, which I'm now taking every third day (with 2000 IUs on the intervening days).
EU Food Safety Administration in 2006 (2002 for vitamin D, see page 167 of https://www.efsa.europa.eu/sites/default/files/efsa_rep/blobserver_assets/ndatolerableuil.pdf. Page 180 for the recommendation) found that 50ug (2000IU) per day is the safe upper limit.
I'm not convinced it's JUST bureaucratic inefficiency - there may very well be difficulties in finding a balanced "one-size-fits-all" recommendation as well, and the judgement of "supplement a bit lightly is safer than over-supplementing" is well in-scope for these general guidelines.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-11-21T23:25:31.081Z · LW(p) · GW(p)
You raise two issues here. One is about vitamin D, and the other is about trust.
Regarding vitamin D, there is an optimal dose for general population health that lies somewhere in between "toxically deficient" and "toxically high." The range from the high hundreds to around 10,000 appears to be well within that safe zone. The open question is not whether 10,000 IUs is potentially toxic - it clearly is not - but whether, among doses in the safe range, a lower dose can be taken to achieve the same health benefits.
One thing to understand is that in the outdoor lifestyle we evolved for, we'd be getting 80% of our vitamin D from sunlight and 20% through food. In our modern indoor lifestyles, we are starving ourselves for vitamin D.
"Supplement a bit lightly is safer than over-supplementing" is only a meaningful statement if you can define the dose that constitutes "a bit lightly" and the dose that is "over-supplementing." Beyond these points, we'd have "dangerously low" and "dangerously high" levels.
To assume that 600 IU is "a bit lightly" rather than "dangerously low" is a perfect example of begging the question.
On the issue of trust, you could just as easily say "so you don't trust these papers, why do you trust your doctor or the government?"
The key issue at hand is that in the absence of expert consensus, non-experts have to come up with their own way of deciding who to trust.
In my opinion, there are three key reasons to prefer a study of the evidence to the RDA in this particular case:
- The RDA hasn't been revisited in almost a decade, even simply to reaffirm it. This is despite ongoing research in an important area of study that may have links to our current global pandemic. That's strong evidence to me that the current guidance is as it is for reasons other than active engagement by policy-makers with the current state of vitamin D research.
- The statistical error identified in these papers is easy for me to understand. The fact that it hasn't received an official response, nor a peer-reviewed scientific criticism, further undermines the credibility of the current RDA.
- The rationale for the need for 10,000 IU/day vitamin D supplements makes more sense to me than the rationale for being concerned about the potential toxic effects of that level of supplementation.
However, I have started an email conversation with the author of The Big Vitamin D Mistake, and have emailed the authors of the original paper identifying the statistical error it cites, to try and understand the research climate further.
I want to know why it is difficult to achieve a scientific consensus on these questions. Everybody has access to the same evidence, and reasonable people ought to be able to find a consensus view on what it means. Instead, the author of the paper described to me a polarized climate in that field. I am trying to check with other researchers he cites about whether his characterization is accurate.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-09-28T22:44:40.675Z · LW(p) · GW(p)
Explanation for why displeasure would be associated with meaningfulness, even though in fact meaning comes from pleasure [LW · GW]:
Meaningful experiences involve great pleasure. They also may come with small pains. Part of how you quantify your great pleasure is the size of the small pain that it superceded.
Pain does not cause meaning. It is a test for the magnitude of the pleasure. But only pleasure is a causal factor for meaning.
Replies from: Viliam, mr-hire↑ comment by Viliam · 2020-09-29T20:36:50.728Z · LW(p) · GW(p)
In a perfect situation, it would be possible to achieve meaningful experiences without pain, but usually it is not possible. A person who optimizes for short-term pain avoidance, will not reach the meaningful experience. Because optimizing for short-term pain avoidance is natural, we have to remind ourselves to overcome this instinct.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-09-29T23:31:12.558Z · LW(p) · GW(p)
This fits with the idea that meaning comes from pleasure, and that great pleasure can be worth a fair amount of pain to achieve. The pain drains meaning away, but the redeeming factor is that it can serve as a test of the magnitude of pleasure, and generate pleasurable stories in the future.
An important counter argument to my hypothesis is how we may find a privileged “high road” to success and pleasure to be less meaningful. This at first might seem to suggest that we do inherently value pain.
In fact, though, what frustrates people about people born with a silver spoon in their mouths is that society seems set up to ensure their pleasure at another’s expense.
It’s not their success or pleasure we dislike. It’s the barriers and pain that we think it’s contextualized in. If pleasure for one means pain for another, then of course we find the pleasure to be less meaningful.
So this isn’t about short-term pain avoidance. It’s about long-term, overall, wise and systemic pursuit of pleasure.
And that pleasure must be not only in the physical experiences we have, but in the stories we tell about it - the way we interpret life. We should look at it, and see that it is good.
If people are wireheading, and we look at that tendency and it causes us great displeasure, that is indeed an argument against wireheading.
We need to understand that there’s no single bucket where pleasure can accumulate. There is a psychological reward system where pleasure is evaluated according to the sensory input and brain state.
Utilitarian hedonism isn’t just about nerve endings. It’s about how we interpret them. If we have a major aesthetic objection to wireheading, that counts from where we’re standing, no matter how much you rachet up the presumed pleasure of wireheading.
The same goes recursively for any “hack” that could justify wireheading. For example, say you posited that wireheading would be seen as morally good, if only we could find a catchy moral justification for it.
So we let our finest AI superintelligences get to work producing one. Indeed, it’s so catchy that the entire human population acquiesces to wireheading.
Well, if we take offense to the prospect of letting the AI superintelligence infect us with a catchy pro-wireheading meme, then that’s a major point against doing so.
In general “It pleases or displeases me to find action X moral” is a valid moral argument - indeed, the only one there is.
The way moral change happens is by making moral arguments or having moral experiences that in themselves are pleasing or displeasing.
What’s needed, then, for moral change to happen, is to find a pleasing way to spread an idea that is itself pleasing to adopt - or unpleasant to abandon. To remain, that idea needs to generate pleasure for the subscriber, or to generate displeasure at the prospect of abandoning it in favor of a competing moral scheme.
To believe in some notion of moral truth or progress requires believing that the psychological reward mechanism we have attached to morality corresponds best with moral schemes that accord with moral truth.
An argument for that is that true ideas are easiest to fashion into a coherent, simple argument. And true ideas best allow us to interface with reality to advantage. Being good tends to make you get along with others better than being bad, and that’s a more pleasant way to exist.
Hence, even though strong cases can be constructed for immoral behavior, truth and goodness will tend to win in the arms race for the most pleasing presentation. So we can enjoy the idea that there is moral progress and objective moral truth, even though we make our moral decisions merely by pursuing pleasure and avoiding pain.
↑ comment by Matt Goldenberg (mr-hire) · 2020-09-29T00:10:51.240Z · LW(p) · GW(p)
I looked through that post but didn't see any support for the claim that meaning comes from pleasure.
My own theory is that meaning comes from values, and both pain and pleasure are a way to connect to the things we value, so both are associated with meaning.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-09-29T01:53:04.812Z · LW(p) · GW(p)
I'm a classically trained pianist. Music practice involves at least four kinds of pain:
- Loneliness
- Frustration
- Physical pain
- Monotony
I perceive none of these to add meaning to music practice. In fact, it was loneliness, frustration, and monotony that caused my music practice to be slowly drained of its meaning and led me ultimately to stop playing, even though I highly valued my achievements as a classical pianist and music teacher. If there'd been an issue with physical pain, that would have been even worse.
I think what pain can do is add flavor to a story. And we use stories as a way to convey meaning. But in that context, the pain is usually illustrating the pleasures of the experience or of the positive achievement. In the context of my piano career, I was never able to use these forms of pain as a contrast to the pleasures of practice and performance. My performance anxiety was too intense, and so it also was not a source of pleasure.
By contrast, I herded sheep on the Navajo reservation for a month in the middle of winter. That experience generated many stories. Most of them revolve around a source of pain, or a mistake. But that pain or mistake serves to highlight an achievement.
That achievement could be the simple fact of making it through that month while providing a useful service to my host. Or moments of success within it: getting the sheep to drink from the hole I cut in the icy lake, busting a tunnel through the drifts with my body so they could get home, finding a mother sheep that had gotten lost when she was giving birth, not getting cannibalized by a Skinwalker.
Those make for good stories, but there is pleasure in telling those stories. I also have many stories from my life that are painful to tell. Telling them makes me feel drained of meaning.
So I believe that storytelling has the ability to create pleasure out of painful or difficult memories. That is why it feels meaningful: it is pleasurable to tell stories. And being a good storyteller can come with many rewards. The net effect of a painful experience can be positive in the long run if it lends itself to a lot of good storytelling.
Where do values enter the picture?
I think it's because "values" is a term for the types of stories that give us pleasure. My community gets pleasure out of the stories about my time on the Navajo reservation. They also feel pleasure in my story about getting chased by a bear. I know which of my friends will feel pleasure in my stories from Burning Man, and who will find them uncomfortable.
So once again, "values" is a gloss for the pleasure we take in certain types of stories. Meaning comes from pleasure; it appears to come from values because values also come from pleasure. Meaning can come from pain only indirectly. Pain can generate stories, which generate pleasure in the telling.
Replies from: mr-hire↑ comment by Matt Goldenberg (mr-hire) · 2020-09-29T17:52:19.495Z · LW(p) · GW(p)
"values" is a term for the types of stories that give us pleasure.
It really depends on what you mean by "pleasure". If pleasure is just "things you want", then almost tautologically meaning comes from pleasure, since you want meaning.
If instead, pleasure is a particular phenomological feeling similar to feeling happy or content, I think that many of us actually WANT the meaning that comes from living our values, and it also happens to give us pleasure. I think that there are also people that just WANT the pleasure, and if they could get it while ignoring their values, they would.
I call this the"Heaven/Enlightenment" dichotomy, and I think it's a frequent misunderstanding.
I've seen some people say "all we care about is feeling good, and people who think they care about the outside world are confused." I've also seen people say "All we care about is meeting our values, and people who think it's about feeling good are confused."
Personally, I think that people are more towards one side of the spectrum or the other along different dimensions, and I'm inclined to believe both sides about their own experience.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-09-29T19:30:16.479Z · LW(p) · GW(p)
I think we can consider pleasure, along with altruism, consistency, rationality, fitting the categorical imperative, and so forth as moral goods.
People have different preferences for how they trade off one against the other when they're in conflict. But they of course prefer them not to be in conflict.
What I'm interested is not what weights people assign to these values - I agree with you that they are diverse - but on what causes people to adopt any set of preferences at all.
My hypothesis is that it's pleasure. Or more specifically, whatever moral argument most effectively hijacks an individual person's psychological reward system.
So if you wanted to understand why another person considers some strange action or belief to be moral, you'd need to understand why the belief system that they hold gives them pleasure.
Some predictions from that hypothesis:
- People who find a complex moral argument unpleasant to think about won't adopt it.
- People who find a moral community pleasant to be in will adopt its values.
- A moral argument might be very pleasant to understand, rehearse, and think about, and unpleasant to abandon. It might also be unpleasant in the actions it motivates its subscriber to undertake. It will continue to exist in their mind if the balance of pleasure in belief to displeasure in action is favorable.
- Deprogramming somebody from a belief system you find abhorrent is best done by giving them alternative sources of "moral pleasure." Examples of this include the ways people have deprogrammed people from cults and the KKK, by including them in their social gatherings, including Jewish religious dinners, and making them feel welcome. Eventually, the pleasure of adopting the moral system of that shared community displaces whatever pleasure they were deriving from their former belief system.
- Paying somebody in money and status to uphold a given belief system is a great way to keep them doing it, no matter how silly it is.
- If you want people do do more of a painful but necessary action X, helping them feel compensating forms of moral pleasure is a good way to go about it. Effective Altruism is a great example. By helping people understand how effective donations or direct work can save lives, they give people a feeling of heroism. Its failure mode is making people feel like the demands are impossible, and the displeasure of that disappointment is a primary issue in that community.
- Another good way to encourage more of a painful but necessary action X is to teach people how to shape it into a good story that they and others will appreciate in the telling. Hence the story-fication of charity.
- Many people don't give to charity because their community disparages it as "do-gooderism," as futile, as bragging, or as a tasteless display of wealth and privilege. If you want people to give more to charity, you have to give people a way of being able to enjoy talking about their charitable contributions. One solution is to form a community in which that's openly accepted and appreciated. Like EA.
- Likewise for the rationality community. If you want people to do more good epistemology outside of academia, give them an outlet where that'll be appreciated and an axis from where it can be spread.
↑ comment by Matt Goldenberg (mr-hire) · 2020-09-30T19:10:44.428Z · LW(p) · GW(p)
My hypothesis is that it's pleasure. Or more specifically, whatever moral argument most effectively hijacks an individual person's psychological reward system.
This just kicks the can down the road on you defining pleasure, all of my points still apply
If instead, pleasure is a particular phenomological feeling similar to feeling happy or content, I think that many of us actually WANT the meaning that comes from living our values, and it also happens to give us pleasure.
That is, I think it's possible to say that pleasure kicks in around values that we really want, rather than vice versa.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-09-23T17:13:29.408Z · LW(p) · GW(p)
Sci-hub has moved to https://sci-hub.st/
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-09-23T16:58:35.350Z · LW(p) · GW(p)
Do you treat “the dark arts” as a set of generally forbidden behaviors, or as problematic only in specific contexts?
As a war of good and evil or as the result of trade-offs between epistemic rationality and other values?
Do you shun deception and manipulation, seek to identify contexts where they’re ok or wrong, or embrace them as a key to succeeding in life?
Do you find the dark arts dull, interesting, or key to understanding the world, regardless of whether or not you employ them?
Asymmetric weapons may be the only source of edge for the truth itself. But should the side of the truth therefore eschew symmetric weapons?
What is the value of the label/metaphor “dark arts/dark side?” Why the normative stance right from the outset? Isn’t the use of this phrase, with all its implications of evil intent or moral turpitude, itself an example of the dark arts? An attempt to halt the workings of other minds, or of our own?
Replies from: Viliam↑ comment by Viliam · 2020-09-24T15:31:15.963Z · LW(p) · GW(p)
There are things like "lying for a good cause", which is a textbook example of what will go horribly wrong because you almost certainly underestimate the second-order effects. Like the "do not wear face masks, they are useless" expert advice for COVID-19, which was a "clever" dark-arts move aimed to prevent people from buying up necessary medical supplies. A few months later, hundreds of thousands have died (also) thanks to this advice.
(It would probably be useful to compile a list of lying for a good cause gone wrong, just to drive home this point.)
Thinking about historical record of people promoting the use of dark arts within rationalist community, consider Intentional Insights [EA · GW]. Turned out, the organization was also using the dark arts against the rationalist community itself. (There is a more general lesson here: whenever a fan of dark arts tries to make you see the wisdom of their ways, you should assume that at this very moment they are probably already using the same techniques on you. Why wouldn't they, given their expressed belief that this is the right thing to do?)
The general problem with lying is that people are bad at keeping multiple independent models of the world in their brains. The easiest, instinctive way to convince others about something is to start believing it yourself. Today you decide that X is a strategic lie necessary for achieving goal Y, and tomorrow you realize that actually X is more correct than you originally assumed (this is how self-deception feels from inside). This is in conflict with our goal to understand the world better. Also, how would you strategically lie as a group? Post it openly online: "Hey, we are going to spread the lie X for instrumental reasons, don't tell anyone!" :)
Then there are things like "using techniques-orthogonal-to-truth to promote true things". Here I am quite guilty myself, because I have long ago advocated turning the Sequences into a book, reasoning, among other things, that for many people, a book is inherently higher-status than a website. Obviously, converting a website to a book doesn't increase its truth value. This comes with smaller risks, such as getting high on your own supply (convincing ourselves that articles in the book are inherently more valuable than those that didn't make it for whatever reason, e.g. being written after the book was published), or wasting too many resources on things that are not our goal.
But at least, in this category, one can openly and correctly describe their beliefs and goals.
Metaphorically, reason is traditionally associated with vision/light (e.g. "enlightenment"), ignorance and deception with blindness/darkness. The "dark side" also references Star Wars, which this nerdy audience is familiar with. So, if the use of the term itself is an example of dark arts (which I suppose it is), at least it is the type where I can openly explain how it works and why we do it, without ruining its effect.
But does it make us update too far against the use of deception? Uhm, I don't know what is the optimal amount of deception. Unlike Kant, I don't believe it's literally zero. I also believe that people err on the side of lying more than is optimal, so a nudge in the opposite direction is on average an improvement, but I don't have a proof for this.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-09-24T16:26:07.587Z · LW(p) · GW(p)
We already had words for lies, exaggerations, incoherence, and advertising. Along with a rich discourse of nuanced critiques and defenses of each one.
The term “dark arts” seems to lump all these together, then uses cherry picked examples of the worst ones to write them all off. It lacks the virtue of precision. We explicitly discourage this way of thinking in other areas. Why do we allow it here?
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-09-04T02:50:17.488Z · LW(p) · GW(p)
How to reach simplicity?
You can start with complexity, then simplify. But that's style.
What would it mean to think simple?
I don't know. But maybe...
- Accept accepted wisdom.
- Limit your words.
- Rehearse your core truths, think new thoughts less.
- Start with inner knowledge. Intuition. Genius. Vision. Only then, check yourself.
- Argue if you need to, but don't ever debate. Other people can think through any problem you can. Don't let them stand in your way just because they haven't yet.
- If you know, let others find their own proofs. Move on with the plan.
- Be slow. Rest. Deliberate. Daydream. But when you find the right project, unleash everything you have. Learn what you need to learn and get the job done right.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-08-12T18:09:44.626Z · LW(p) · GW(p)
Question re: "Why Most Published Research Findings are False":
Let R be the ratio of the number of “true relationships” to “no relationships” among those tested in the field... The pre-study probability of a relationship being true is R/(R + 1).
What is the difference between "the ratio of the number of 'true relationships' to 'no relationships' among those tested in the field" and "the pre-study probability of a relationship being true"?
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-08-12T20:17:07.430Z · LW(p) · GW(p)
From Reddit:
You could think of it this way: If R is the ratio of (combinations that total N on two dice) to (combinations that don't total N on two dice), then the chance of (rolling N on two dice) is R/(R+1). For example, there are 2 ways to roll a 3 (1 and 2, and 2 and 1) and 34 ways to not roll a 3. The probability of rolling a 3 is thus (2/34)/(1+2/34)=2/36.
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-07-04T20:17:18.525Z · LW(p) · GW(p)
The innumeracy and linguistic imprecision in medical papers is irritating.
In "The future of epigenetic therapy in solid tumours—lessons from the past," we have the sentence:
One exciting development is the recognition that virtually all tumours harbour mutations in genes that encode proteins that control the epigenome.9,10,11,12,13,14,15,16,17,18,19,20
11 citations! Wow!
What is the motte version of this sentence? Does it mean:
- Nearly tumor in every patient has a mutation in an epigenetic control gene?
- That in nearly every type of tumor, at least a fraction of them contain a mutation in an epigenetic control gene?
- That epigenetic control gene mutations exist in at least a substantial minority of several tumor types?
The third, weakest claim is the one that the 11 citations can support: in a minority of blood cancer patients, a mutation in an epigenetic control gene may set up downstream epigenetic dysregulation that causes the cancer phenotype. I would find this version of their claim much more helpful than the original, vague, misleading version.
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-06-10T04:45:50.302Z · LW(p) · GW(p)
I use ChatGPT as a starting point to investigate hypotheses to test at my biomedical engineering job on a daily basis. I am able to independently approach the level of understanding of specific problems of an experienced chemist with many years of experience on certain problems, although his familiarity with our chemical systems and education makes him faster to arrive at the same result. This is a lived example of the phenomenon in which AI improves the performance of the lower-tier performers more than the higher-tier performers (I am a recent MS grad, he is a post-postdoc).
So far, I haven't been able to get ChatGPT to independently troubleshoot effectively or propose improvements. This seems to be partly because it struggles profoundly to grasp and hang onto the specific details I have provided to it. It's as if our specific issue is mixed with more the more general problems it has encountered in its training. Or as if, whereas in the real world, strong evidence is common [LW · GW], to ChatGPT, what I tell it is only weak evidence. And if you can't update strongly on evidence in my research world, you just can't make progress.
The way I use it instead is to validate and build confidence in my conjectures, and as an incredibly sophisticated form of search. I can ask it how very specific systems we use in our research, not covered in any one resource, likely work. And I can ask it to explain how complex chemical interactions are likely behaving in specific buffer and heat conditions. Then I can ask it how adjusting these parameters might affect the behavior of the system. An iterated process like this combines ChatGPT's unlimited generalist knowledge with my extremely specific understanding of our specific system to achieve a concrete, testable hypothesis that I can bring to work after a couple of hours. It feels like a natural, stimulating process. But you do have to be smart enough to steer the process yourself.
One way you know you're on the wrong track with ChatGPT is when it starts trying to "advertise" to you by talking about the "valuable insights" you might gain from this or that method. And indeed, if you ask an expert about whether the method in question really offers specific forms of insight relevant to your research question, a promise of "valuable insights" from ChatGPT often means that there aren't actually any. "Valuable insights" means "I couldn't think of anything specific," which is not a promising sign.
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-04-03T00:16:09.589Z · LW(p) · GW(p)
NEWSFLASH: Expressing Important But Unpopular Beliefs Considered Virtuous, Remains Unpopular
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-03-21T18:50:02.381Z · LW(p) · GW(p)
I'm exploring the idea of agency roughly as a certain tendency to adaptively force a range of prioritized outcomes.
In this conception, having a "terminal goal" is just a special and unusual subcase in which there is one single specific outcome at which the agent is driving with full intensity. To maintain that state, one of its subgoals must be to maintain the integrity of its current goal-prioritization state.
More commonly, however, even an AI with superhuman capabilities will prioritize multiple outcomes, with varied degress of intensity, exhibiting only a moderate level of protection over its goal structure. Any goal-seeking adaptive behaviors it shows will be the result of careful engineering by its trainers. Passive incoherence is the default and it will take work to force an AI to exhibit a specific and durable goal structure.
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-02-16T06:17:16.963Z · LW(p) · GW(p)
I'm going to be exiting the online rationalist community for an indefinite period of time. If anyone wants to keep in touch, feel free to PM me and I will provide you with personal contact info (I'll check my messages occasionally). Best wishes.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-11-12T03:48:22.152Z · LW(p) · GW(p)
Memorization timescales and feedback loops
Often, people focus on memorizing information on timescales of hours, days, or months. I think this is hard, and not necessarily useful - it smacks of premature optimization. The feedback loops are long, and the decision to force yourself through a process of memorizing THIS set of facts instead of THAT set of facts is always one you may wish to revise later. At the very least, you'd want to frequently prune your Anki cards to eliminate facts that no longer seem as pressing.
By contrast, I think it's very useful and quite tractable to practice memorizing information on the scale of seconds and minutes. You get immediate feedback. And the ability to memorize a set of related information right away, then forget it when you no longer need it, is a little like the mental equivalent of learning how to pick up and set down a load. That's something we need for all kinds of tasks. The ability to carry around a load for long periods of time isn't as useful.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-10-20T03:29:13.176Z · LW(p) · GW(p)
Read by rewording as you go
Many people find their attention drifts when they read. They get to the end of a sentence/paragraph/page and find they've lost the plot, or don't see the connection between the words and sentences, sentences and paragraphs, paragraphs and pages.
One way to try and correct this is to hyperfocus on making sure you read the words accurately, without letting your mind drift. But I have found this is a pretty inefficient strategy.
Instead, I do better by "rewording as I go." By this, I mean a sort of skimming where I take in the sentence on a mostly visual level. In my head, I'm not sounding out the words, decoding their meaning, and building a concept in my head. Instead, I'm intuitively recognizing the concept, expressing it in my own words in my head, and then checking that the understanding I've constructed is consistent with the words.
Here's an example from a textbook. I'll pair the sentence in the textbook with my inner monologue at first read.
The fundamental features of cell signaling have been conserved throughout the evolution of the eukaryotes.
<<<OK, cell signaling is conserved.>>>In budding yeast, for example, the response to mating factor depends on cell-surface receptor proteins, intracellular GTP-binding proteins, and protein kinases that are clearly related to functionally similar proteins in animal cells.
<<<We're getting an example in yeast. A list of things the signal response depends on. All kinds of receptors and proteins that transmit the message from one thing to another. Nothing surprising here. And there are homologues with animal cells.>>>
Through gene duplication and divergence, however, the signaling
systems in animals have become much more elaborate than those in yeasts; the human genome, for example, contains more than 1500 genes that encode receptor proteins, and the number of different receptor proteins is further increased by alternative RNA splicing and post-translational modifications.<<<But obviously animals have more complicated signaling than yeast, because we're multicellular. So we have 1500 receptor genes and can make more by RNA splicing and PTMs.>>>
This is an easy mode to flip into if I just think to do it. It lets me read a lot faster, and I feel like I understand it better and am more engaged. Otherwise, I find myself putting my mental energy into trying to construct an inner monologue that sounds like some sort of documentary narrator, like David Attenborough, so that I can try and hold my attention on the text.
You can see that my inner monologue is nothing particularly smart. I'm mostly just paraphrasing the sentences. I'm just putting them in my own ineloquent words and moving along. Not much in this paragraph was surprising (I have a lot of background in biology), and the details I can see are not particularly important, so the effort of reading this is just to set the stage for what's to come, and to check I'm not missing anything.
Replies from: Nanda Ale↑ comment by Nanda Ale · 2022-10-20T04:13:57.068Z · LW(p) · GW(p)
Interestingly, reading your internal monologue seems to help me stay focused. I kind of want actual textbooks in this format.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-10-20T12:13:35.801Z · LW(p) · GW(p)
That’s good to know. I’m doing a lot of tinkering with summarization. Mostly I’ve done this sort of rewording on the paragraph level. It would be interesting to do an experiment with combining an original text with summaries of different granularities. Then seeing which version boosted reading comprehension the most.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-10-14T15:41:01.966Z · LW(p) · GW(p)
The Handbook of the Biology of Aging has serious flaws if its purpose is to communciate with non-experts
What makes an effective sentence for transmitting academic information to a newcomer to the field?
- Information has to be intelligible to the reader
- Wordcount, word complexity, and sentence complexity should minimal
- Information has to be important
Let's ignore the issue of trustworthiness, as well as the other purposes academic writing can serve.
With these three criteria in mind, how does the first sentence of Ch. 3 of the Handbook of the Biology of Aging fare?
Replicative cell senescence was first described in 1961 by Len Hayflick as reproducible, permanent loss of the replicative capacity of human primary fibroblasts during in vitro culture (Hayflick & Moorhead, 1961).
There are several problems with unimportant information or verbiage.
- "Replicative" qualifies "cell senescence," but we never hear about any other kinds of cell senescence in this paragraph, so it seems redundant.
- "was first described in 1961 by Len Hayflick as" is not important to the reader at this stage.
- Does "reproducible" mean "scientifically reproducible?" Isn't that a criteria for any scientific phenomenon.
- "of human primary fibroblasts during in vitro culture" OK, but this is definitely not what we are talking about when we discuss cell senescence in human aging, so is this really the most relevant definition with which you could have kicked off the chapter? Plus, can't non-human cells senesce?
- "(Hayflick & Moorhead, 1961)" we should replace inline citations with a footnoted summary (or better yet a hyperlink or hovertext).
I want to single out a verbal pattern I hate: Z of Y of X.
"reproducible, permanent loss of the replicative capacity of human primary fibroblasts"
Z: "reproducible, permanent loss"
Y: "the replicative capacity"
X: "human primary fibroblasts"
A sentence should be like a movie. Every word lets you picture something new.
Z of Y of X prevents this. It tells you the things to picture in the wrong order. There's nothing to picture until you get all the way to X. Then you have to fight your impulse to read on, because you still have to construct your mental picture.
Here's the same phrase in the improved form, X of Y of Z:
"Human primary fibroblast replicative capacity is reproducibly, permanently lost."
This still isn't great as an introduction, because it's almost all jargon words. But the form is a big improvement.
Better still:
"Animal cells permanently stop being able to replicate."
Here's how I might rewrite the sentence as a whole:
When animal cells permanently stop being able to replicate, this is called 'cell senescence'.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-27T21:22:47.736Z · LW(p) · GW(p)
Requesting beta readers for "Unit Test Everything."
I have a new post on how to be more reliable and conscientious in executing real-world tasks. It's been through several rounds of editing. I feel like it would now benefit from some fresh eyes. If you'd be willing to give it a read and provide feedback, please let me know!
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-17T15:48:48.594Z · LW(p) · GW(p)
Mentitation Technique: Organize, Cut and Elaborate
Organize, Cut and Elaborate is a technique for tackling information overload.
People cope with overload by straining to fit as much as they can into their working memory. Some even do exercises try try and expand their memory.
With Organize, Cut and Elaborate, we instead try to link small amounts of new information with what we already have stored in long-term memory. After you've scanned through this post, I invite you to try it out on the post itself.
I don't have an exact algorithm, but a general framework for how to go about it:
- Organize: Find patterns and associations in the information. For example, take the following complicated sentence from Molecular Biology of the Cell, 6th ed. (Alberts & Bruce):
Four main groups of GAGs [glycosaminoglycans] are distinguished by their sugars, the type of linkage between the sugars, and the number and location of sulfate groups: (1) hyaluronan, (2) chondroitin sulfate and dermatan sulfate, (3) heparan sulfate, and (4) keratan sulfate.
We might want to remember these four types of GAGs. To organize, I look for patterns and associations, and find the following:
- There are 4 types, but 5 names.
- 4/5 names end in "sulfate," so this is really about remembering "hyaluronan," 4 prefix-words, and then remembering to attach the suffix-word "sulfate."
- Hyaluronan is a strange word, but it sounds kind of watery and mysterious. "Hy" is linked to "hydrate." "Alur" sounds like "alluring." "Onan" is linked to the word "onanistic," pertaining to masturbation. It makes me think of a man who's very attracted to a mermaid. I can think of hyaluronan as "mermaid" molecules. I can also associate it with a certain scene from The Lighthouse.
- I notice that chondroitin, dermatan, heparan, and keratan all are based on Greek/Latin words for tissue types. Chondro = cartilage, derma = skin, hepa = liver, kera = fingernails. I can visualize those body parts in connection with the words, and reflect on how GAGs are important for defining the material properties of certain tissue types, and reflect on how these tissue types actually look and feel (skin is soft but tough, fingernails are hard, cartilage is elastic).
As a contrasting example, it can sometimes help to mentally "complain" about disorganization. For example, thymosin is a small protein that plays a role in the cytoskeleton. It's called thymosin because it was originally isolated in the thymus, and was believed to function as a hormone, but it's actually found all over the body and are not hormones. This is a very stupid name to have for this protein, and it helped me to remember it by complaining about it in my head.
When I've gone through this process, I can remember these four words much better. They're not just a bunch of arbitrary-sounding names. I expect that as I read further in the textbook and encounter them again, accessing them from long-term memory will reinforce my memory of them, giving me the benefit of spaced repetition without the requirement of additional flashcard practice.
2. Cut: When you face a long list of items or pieces of data, ignore all but one or two of them. Practice holding just one item of information in your mind. Anchor it and get it crystal clear. Then you can employ "organize" and "elaborate" techniques to it.
If you're holding two items in your head, the benefit is that you can practice building up a crisp distinction between them. This is often helpful when they're similar ideas, or have similar-sounding names.
For example, "tropomodulin" and "tropomyosin" sound similar, and play similar but distinct roles. Tropomodulin caps one end of a cytoskeletan actin filament, while tropomyosin stabilizes it along the side, among other roles. Holding the two names in my head allows me to focus on their relationship and on what distinguishes them. This is especially helpful because they were introduced as part of a set of 14 cytoskeletal accessory proteins. With that much information, it's hard to really install a distinction in your head to differentiate these two similar-sounding proteins.
While the "cut" technique may seem simple, it's a very powerful complement to the other two. Learning how to drop information from your mind is what enables you to organize and elaborate on what remains.
3. Elaborate: As you accumulate information in your long-term memory, you'll be able to find lots of links between the new information you're learning and the old information you've already digested. Elaboration is the process of forming those links.
I find elaboration works best after you've organized the new information and cut your focus down to one single item. With this single item in your mind, you have space in your working memory to "upload" other relevant items from long-term memory and examine their associations with the single piece of new information. This boosts your ability to move that new information into long-term memory.
I personally find that elaboration works best when I don't try to control it too much. I don't know how to actively "search" my long-term memory for relevant data. Instead, I hold the single new piece of information in my head, and allow my subconscious mind to gradually find and report relevant items on its own. This is a gradual process, with a lot of scaffolding - "oh, this seems relevant to yesterday's lecture. We covered the cytoskeleton, which had just three main structural elements. Here in the ECM, we have a large number of very diverse structural elements..." Eventually, this can get very specific, but the main point is to let your mind wander, while keeping the new information somewhat anchored in your conscious mind.
A way to visualize this is that you have 4 "slots" for information in memory. Instead of filling all 4 slots with new information, you fill just 1 slot. The other 3 slots then get filled with a rotating combination of old information from long-term memory. Examining the relationships between these shifting combinations forms links between the new and old information, and installs the new information in long-term memory while also giving you practice at retrieving the old information.
Replies from: Gunnar_Zarncke↑ comment by Gunnar_Zarncke · 2022-09-18T07:49:21.688Z · LW(p) · GW(p)
I think I do something like this or parts of it when I add things to my Anki deck.
It is less about individual words. I don't try to remember these. I leave that up to Wikipedia or an appendix of my Anki note.
A note for your shortform may look like this
Tissues in the body have correspondence to....
... four proteins (GAGs/glycosaminoglycans) that code for these types of tissues:
- Chondro = cartilage
- derma = skin,
- hepa = liver,
- kera = fingernails
Thus cut means less splitting up and more cutting away. Elaboration mostly means googling the topic and adding relevant links. Öften when reviewing the note.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-08T18:56:06.450Z · LW(p) · GW(p)
Toward an epistemic stance for mentitation
Brett Devereaux writes insightfully about epistemologies.
On the other end, some things are impractical to test empirically; empirical tests rely on repeated experiments under changing conditions (the scientific method) to determine how something behaves. This is well enough when you are studying something relatively simple, but a difficult task when you are studying, say, a society.
In our actual lives and also in the course of nearly every kind of scholarship (humanities, social sciences or STEM) we rely on a range of epistemologies. Some things are considered proved by the raw application of deductive reasoning and logic, a form of rationalism rather than empiricism (one cannot, after all, sense-perceive the square root of negative one). In some things testimony must be relied on...
Mentitation[1] shares with psychology a reliance on introspection and self-report. Furthermore, mentitation primarily seeks to be useful to people for practical purposes. It aims grow through accumulated metis, or the practical wisdom of practitioners.
When scientific literature can inform this metis, it ought to be incoporated readily. The literature on memory, visualization, spaced repetition, and many other topics is key. Mentitation uses science, ought to be scientifically testable, and can incorporate scientific methods into its own development.
However, just as you do not have to read the scientific literature to figure out how to organize your room, you likewise do not need to depend on scientific research to figure out how to organize your thoughts. Practical achievement depends on individual direct perception and reasoning about the facts on the ground (or in the head), and that is the starting and ending point for mentitation. Scientific research is an important waystation in the middle. Application of mentitation to challenging practical tasks where success and failure is easy and objective to measure is the gravity that keeps the mentitation train on the rails of truth.
All this is to say that nobody should trust mentitation. If it intrigues them, they can try it for themselves and see if it benefits them. My experience is that trying to figure it out for myself took me several years of persistent effort, which involved self-experimentation, reading a decent amount of psychology and learning research, drawing on several unusual aspects of my background as a teacher and learner, failing quite a few times, and having the privilege of drawing on rationalist writings to inform my thinking. I think that would be quite a barrier for many people, so I hope that as I continue to practice mentitation, I can also create resources that will smooth the path for others.
- ^
My tentative term for practicing the ability to observe and control our own conscious mental activity in order to learn more efficiently.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-03T04:15:50.873Z · LW(p) · GW(p)
Mentitation
"Mental training" is not the ideal concept handle for the activity I have in mind. "Metacognition" is relevant, but is more an aspect or basis of mental training, in the same way that strategy and tactics are an aspect and basis for a sports team's play.
We have numerous rationality "drills," such as forecasting practice, babble and prune prompts, making bets. To my understanding, many were pioneered by CFAR.
The practice of rationality involves studying object-level topics, drawing conclusions, and executing on decisions. In the sports metaphore, this is the analysis that precedes a game, and the game itself.
Drills and gameplay also require preliminary logistics. In literal sports, that involves buying equipment, preparing meals, finding transportation. The analogy in rationality is downloading and familiarizing yourself with software, finding relevant papers, contracting with a teacher, planning an experiment, and so on.
"Mental training," as I conceive of it, is not analogous to any of these activities. As one further anti-example, athletes do a lot of strength and conditioning. The analogous activity in the sphere of rationality might involve memorizing widely useful bits of information, such as Baye's theorem, getting more sleep, practicing dual n-back, or any other activity that is hoped either to make it easier to do certain specific calculations or to make your brain "stronger" in a way analogous to bulking up a muscle.
If "mental training" is not about doing any of these things, then what is it?
As I see it, "mental training" is equivalent to something like "body awareness."
Body awareness is the ability to closely observe the movement and sensations in your body. It's the ability to observe, identify, and predict the limits of your strength and endurance. It's about building spatial awareness, learning when something you ate doesn't sit right in your stomach, and how to move with grace without overthinking every individual motion.
When I got physical therapy a long time ago, one of my complaints was that I had trouble sleeping. My PT told me that I needed to learn how to make myself comfortable. I asked her "how?", and she told me I just needed to figure it out for myself. Until that point, I hadn't conceived of "making yourself comfortable" as a concrete skill you could learn, and was not at ease with the idea of learning such an ill-defined skill. However, I can now recognize that my PT was advising me to practice "body training" to build an awareness of how to be comfortable when I'm in bed trying to sleep.
Analogously, "mental training" is meant to build up your "mind awareness," as opposed to your mental strength, your command of any specific set of facts, or any principles or techniques of rationality as we commonly discuss them on LessWrong. Although dealing with emotional problems commonly addressed in therapy is an aspect of "mental training," we consider primarily the way that anxiety can impair (or sometimes help) with intellectual cognition.
"Mental training" doesn't promise to directly make you mentally "strong." Instead, it's about developing awareness of your mental activity, expanding your sense of what's possible and where your limits are, gaining a better sense of how your intellectual brain state can interface more appropriately with your activities and physical environment, and developing a useful language with which to discuss all this.
Out of the "mental awareness" that "mental training" seeks to inculcate might then arise a greater ability to use your present, ordinary intellect to greater effect. Instead of thinking "faster," or having a "bigger" memory, we aim with "mental training" to use your brain speed and memory more efficiently and with better organization. It's about getting the most out of what you have.
The parallel to "physical therapy" being so apt, I'm tempted to label this "intellectual therapy." That's a problematic label, though. Therapy implies a false promise of a scientific basis, it sounds too close to other things like "cognitive behavioral therapy," and it might make some people think that it's some sort of euphemism for propaganda. Furthermore, "intellectual" makes it sound like it's all about academic knowledge, when in fact I am primarily interested in manipulating and controlling the qualia of conscious experience and applying that faculty to rationality. I'm more interested in learning how to build and trigger patterns of thought, not in evaluating propositions for their correctness except as a way to test those fundamentals.
It's also important that the label not imply a one-size-fits-all, fast-results approach. Whatever this is, it's a practice for enthusiasts that probably requires a lot of idiosyncratic adaptation and creativity, and pays off gradually over the course of years as people fit it into their own particular activities.
The activity isn't just about the brain in isolation, though. So it's closer to occupational therapy in that regard. We're specifically interested in the brain as a tool, which we interface with other external tools in order to accomplish intellectual occupations.
I sort of want to call this "mentitation." This word is almost unknown to Google, suggesting that the word doesn't already have connotations to other people. Mentitation.com is available. I like that it avoids the word "therapy," refers to something mental, and has the same reflective and no-instant-results vibe as "meditation." I may start playing with the word "mentitation" and see if it feels like an apt concept handle for what I'm trying to promote.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-02T02:43:40.019Z · LW(p) · GW(p)
Explaining the Memory Palace
Memory palaces are an ancient technique, rumored to be a powerful way to improve memory. Yet what a strange concept. It's hard enough to remember the facts you want to recall. Why would placing the added cognitive burden of constructing and remembering an memory palace assist with memory?
I think the memory palace is an attempt to deal with the familiar sensation of knowing you know a fact, but not being able to summon that fact to your conscious mind. Later in the day, by chance, it pops into your mind spontaneously. Just as you suspected, the memory was there, somewhere - you just didn't know how to find it.
My thesis is that the utility of a memory palace primarily that it gives you a structure for controlling which linkages between arbitrary memories, and a way to deliberately navigate between them. Consider your childhood home, or any other location with which you're intimately familiar. No matter how you represent it in your mind - as a kinetic sense of spatial awareness, as a vivid 3D "memory reality," or some other way - I bet that it's easy for you to navigate it, deciding where you are in the room, what you're facing, what angle you're at, and so on.
Personally, my mental representation of my childhood home is not nearly as vivid as actually being there. It's also not up-to-date: the dining room oscillates between the old and new chairs, the kitchen has the old and new linoleum, the apple tree we've long since cut down is visible through the back window. However, the basement is the new renovation, not the old dark space full of spiderwebs, and my parents' current cars are parked out in front.
I can float through the house rapidly, change direction, examine things, and so on. It's a bit like playing a video game that doesn't simulate gravity and doesn't block you from walking through walls.
I can even do this, to some limited degree, for locations I've been in only once, even if I wasn't paying careful attention to my surroundings at the time.
There seems to be a mental faculty for remembering and navigating locations that is more powerful than the ability to remember discrete bits of information.
Yet I find it very difficult to take abstract bits of intellectual information - mathematical equations, arguments, and so on - and represent them in any sort of visual form. It's much easier to access these bits of knowledge directly. Trying to place them around my childhood home is a lot of extra work, for no clear payoff - and where would I put all those equations anyway? The memory house would rapidly become cluttered.
But I like the core idea of the memory palace - the idea that we should deliberately construct and practice navigating between our thoughts, not just treat individual facts and memories like atomic objects out of context or relationship. We should try to make the technical knowledge we work so hard to understand accessible and navigable, whether or not we're sitting down with a textbook or practice test and studying it actively.
This is difficult, of course, because if we have a strong memory of a particular set of facts, there's little point in going over them more. What's needed is practice remembering what doesn't spring readily to mind, and here we face all kinds of challenges: we might remember incorrectly, we might not be able to conjur up the facts we want, we might get distracted, we might waste time.
However, I've reaped great gains in my ability to control my mental imagery by allowing that imagery a lot of freedom to "manifest itself." Rather than trying to precisely control the exact image my mind "paints" on its inner canvas, I give it a suggestion and let it do the work on its own, much like giving a prompt to DALL-E. The results have improved with time.
I think a similar technique is useful for remembering facts, arguments, and other pieces of left-brain STEM knowledge. Giving my brain a suggestion of the sort of facts I'd like it to recall tends to lead to productive results. If I'm preparing for an exam, suggesting the content of a certain chapter tends to lead to my brain recalling more facts than I knew that I knew.
As more facts come to the top of my mind, I gain an ability to reconcile them, relate them, and recall more along that theme. At the beginning, I only had enough facts at the top of my mind to request my brain remember "facts about torque." But as those facts come trickling in, I'm able to make requests for ever more detailed information.
These are early days, and I'm not certain about whether this is a reliable and useful effect for practical purposes. But it points in the direction I'm interested in, and I think an especially nice feature is that this is precisely the sort of mental practice that is especially hard for external tools to replicate, yet might offer outsize returns to deliberate practice.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-08-26T22:59:19.138Z · LW(p) · GW(p)
How do we learn from experience without a control group?
I can discern cause and effect when there's a clear mechanism and immediate feedback. Brushing my teeth makes them feel clean. Eating pizza makes me full. Yet I've met plenty of people who claim to have had direct, powerful experiences confirming that forms of pseudoscience are real - astrology, crystal healing, reiki, etc.
While I don't believe in astrology or crystal healing based on their reports, I think that in at least some cases, they've experienced something similar to what it's like to eat and feel full, except that they received reiki and felt pain disappear.
Selective reporting might explain some of these effects. But I think that for some believers, they've experienced, at least once, an immediate and powerful cause/effect sensation connecting something like reiki to physical healing. Even if it only happened once, they believe in the cause/effect relationship, like a person who eats a strange mushroom in the woods and starts hallucinating might later feel confident that the mushroom caused the hallucinations.
We have a prior social belief that eating strange mushrooms is a plausible causal mechanism for having hallucinations. That might be why we believe in the cause/effect relationship in that case, but not in the case of reiki.
But what do we do if we believe in, or at least want to investigate, a cause/effect relationship that's not as socially widespread? I worked as a telemarketer for a year in my first year out of college, and after having the same 5-minute phone call with people 40 hours a week for a year, I do believe I found subtle and hard-to-explain ways of influencing the outcome of that call so that we got more conversions and less tension with the client. How does that happen, especially given that I myself had no clear hypothesis going in about how these conversational subtleties would affect the call, or how exactly to translate these psychological intuitions into my own physical behaviors?
I had similar experiences as a piano teacher, having psychological intuitions and making hypotheses about how to connect with a student and trying them out over the years. Some of these survived by getting results similar to what I expected across multiple students, or at least consistently with one student. Others I tried, and they either failed right away, or weren't reliable.
Nowadays, I spend a lot of time reflecting and tinkering with my own learning process as I take classes in grad school. The effects are equally psychological and subtle. I keep or discard them based on how repeatable they are for me. Although I could make more sure I'm not tricking myself by figuring out how to run an RCT on myself, I believe that in the past, I've gained more knowledge faster using uncontrolled experiments and seeing if the results I got matched my expectations and worked out reliably. I come up with so many bad ideas that I think I'd waste too much time doing RCTs to gather legible evidence for the good ones, if I could even come up with the good ones at all without rapidly sifting through a ton of bad ideas along the way.
Nevertheless, I'd love to have some sort of account for how all this "tinkering" can possibly amount to knowledge. I am pretty confident that it does, based on my own past experience with similar tinkering over long periods of time in other domains.
The problem is that that knowledge just isn't comprehensive enough to explain to others, or even to use mechanically on myself. In telemarketing, teaching, and self-study, I've found that any time I think I've hit on a "technique," it's rarely something I can implement in a blind, context-free manner and get the same results. Either the technique loses its novelty and turns out to have depended on that novelty to function, or it creates a new context in which it no longer functions, or a crucial difference enters between the technique on a conceptual level and how it's implemented.
Instead, it seems like when they work best, these subtle techniques get preserved in a semi-conscious way, and my subconscious sort of "recommends" them to my conscious mind at opportune moments. System 2 helps bring these techniques to conscious attention for fine-tuning, but then system 1 needs to run the show to decide how to use them in the moment.
This all feels annoyingly unscientific, unrationalist, and illegible. Yet it also describes what gaining self-understanding and personal capability in the real world actually has felt like throughout my life. This even translates to physical skills, like pipetting in the lab, moving gracefully through the house without dropping things or hitting my head on stuff, or building a fence this last summer. There's a combination or back and forth between paying close conscious attention and forming intellectual models of how to do things in a system-2-flavored way, and then relinquishing control back to system 1. Even deciding when to transfer control from system 1 to system 2 and back again is subject to this dynamic.
When I read scientific literature on psychology to inform these practices, it feels like it's mainly just grist for the mill of this practice. Ultimately the things I'm trying to do are so multifaceted and contextual that it's almost always impossible to just rote apply even the strongest findings from the psych literature. It's just a way of supporting this back and forth between forming models of thought and behavior consciously and trying them out almost unconsciously as I work. I'm pessimistic about the ability to transmit this intuitive knowledge to others absent a very substantial effort to put it in context and committed students who really want to learn and believe there is something in fact to learn.
At the same time, overall, this doesn't feel like an implausible mechanism for how the conscious and unconcious parts of our mind are "designed" to relate to each other. One part of the mind observes our behavior, environment, and inner state of thoughts and feelings. It looks for patterns and associations, and tries to articulate a mechanistic relationship. It can do this with deeper insight in some ways, because it has direct access to our inner state and doesn't need to be legible to others - only to ourselves. Eventually, it crystallizes a pattern and hands it off to another part of the mind.
This other part of the mind receives crystallized patterns of trigger sensation, behavior, and expected result, and runs in the background making "guesses" about when it has spotted a trigger. When it does, it tries to reproduce the behavior and sees what kind of result it gets.
The conscious mind then evaluates the result and tries to articulate cause and effect. It may add nuance, reinforcement, or confidence, or it may discard the hypothesis entirely. The accumulation of patterns that survive this selection process constitute our intuitive skills, though probably not our whole intuition.
This seems to track roughly with how my own processing works. Yet I'd also say that it doesn't just happen automatically, the way you get hungry automatically. I find that I have to deliberately construct at least a toy model, however wrong, and deliberately engage this back-and-forth for a specific challenge before it really kicks in. It's also not automatically functional once it does start. I find there's a lot of variation, sort of like the stock market, with "crashes," ups and downs, and usually an overall upward trend in average performance over time. It's not just that I sometimes am playing with patterns that are actually dysfunctional. It's that the meta-process by which I conceive, implement and evaluate them is not always very good.
While this seems to be helpful and necessary for my growth as a person, it also seems to me that this weird, illegible process could also easily generate a lot of BS. If I was trying to be an astrologer, I expect this is the process that would eventually result in a large, loyal clientele. Instead, I'm trying to be an engineer, so I'm lucky that at least at this stage in my career, I get objective feedback on my performance in studying the material.
But it's uncomfortable when my "meta-process" for self-improvement looks just as irrational as anybody else's, and is similar if not identical to the process I was using prior to engaging with the rationalist community. As good as this community is for having practical guidance on how to evaluate legible claims on publicly-relevant topics, my practical understanding and control of the intuitive thoughts and behavior that govern my life moment-to-moment is pretty similar to what it was before I got involved in LessWrong and the rationalist movement. That's a lot of life to leave nearly untouched. I even worry that we Goodhart/streetlamp effect ourselves into avoiding that topic or downplaying its reality or importance in favor of topics and activities where it's easier to look like a rationalist.
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-12-06T22:35:30.712Z · LW(p) · GW(p)
"The subjective component in causal information does not necessarily diminish over time, even as the amount of data increases. Two people who believe in two different causal diagrams can analyze the same data and may never come to the same conclusion, regardless of how "big" the data are. This is a terrifying prospect for advocates of scientific objectivity, which explains their refusal to accept the inevitability of relying on subjective causal information." - Judea Pearl, The Book of Why
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-01-24T07:30:03.361Z · LW(p) · GW(p)
There are lots of reasons to measure a person's ability level in some skill. One such reason is to test your understanding in the early stages of learning a new set of concepts.
You want a system that's:
- Fast, intuitive
- Suggests what you need to spend more time on
- Relies on the textbook and your notes to guide your next study activity, rather than needing to "compute" it separately.
Flashcards/reciting concepts from notes is a nice example. It's fast and intuitive, tells you what concepts you're still struggling with. Knowing that, you can look over the material, then just try to recite the concept again. Each time, it hopefully gets more intelligible as well as memorable.
Same is true for doing problems. You get stuck, then refer back to an example to get a clue on how to proceed.
So then for a long-term learning endeavor, you just define a "practice session" as a certain chunk of flashcards/concept review or practice problems. Might be best to define it in terms of amount of material to review, rather than a sheer amount of time to spend. For example, you could define a "practice session" as "recite all proofs/concepts once from memory, and complete 3 practice problems."
You can then distribute those practice sessions spaced out over time as needed.
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-01-19T19:24:35.474Z · LW(p) · GW(p)
How much of rationality is specialized?
Cultural transmission of knowledge is the secret of our success.
Children comprise a culture. They transmit knowledge of how to insult and play games, complain and get attention. They transmit knowledge on how to survive and thrive with a child's priorities, in a child's body, in a culture that tries to guarantee that the material needs of children are taken care of.
General national cultures teach people very broad, basic skills. Literacy, the ability to read and discuss the newspaper. How to purchase consumer goods. How to cope with boredom. What to do if your life was in danger. Perhaps how to meet people.
All people are involved in some sort of personal culture. This comprises their understanding of the personalities of our coworkers, friends and relations; technical or social knowledge of use on the job; awareness of their own preferences and possessions.
A general-rationality culture transmits skills to help us find and enter into environments that depend on sound thinking, technology, and productivity, and where the participants are actively trying to improve their own community.
That general-rationality culture may ultimately push people into a much narrower specialized-rationality culture, such as a specific technical career, or a specific set of friendships that are actively self-improving. This becomes our personal culture.
To extend the logic further, there are nested general and specialized rational cultures within a single specialized culture. For example, there are over 90,000 pediatricians in the USA. That career is a specialized rational culture, but it also has a combination of "how to approach general pediatrics in a rational manner" and "specialized rational cultures within pediatrics."
It may turn out that, at whatever level of specialization a person is at, general-purpose rationality is:
- Overwhelmingly useful at a specific point in human development, and then less and less so as they move further down a specialized path.
- Constantly necessary, but only as a small fraction of their overall approach to life.
- Less and less necessary over time as their culture improves its ability to coordinate between specialties and adapt to change.
- Defined by being self-eliminating. The most potent instrumental and epistemic rationality may be best achieved by moving furthest down a very specialized path. The faster they exchange general knowledge and investments for more specialized forms, the better they achieve our goals, and the more they can say we were being rational in the first place. Rationality is known by the tendency of its adherents to become very specialized and very comfortable and articulate about why they ended up so specialized. They have a weird job and they know exactly why they're doing it.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-11-11T06:38:41.745Z · LW(p) · GW(p)
What is the #1 change that LW has instilled in me?
Participating in LW has instilled the virtue of goal orientation. All other virtues, including epistemic rationality, flow from that.
Learning how to set goals, investigate them, take action to achieve them, pivot when necessary, and alter your original goals in light of new evidence is a dynamic practice, one that I expect to retain for a long time.
Many memes circulate around this broad theme. But only here have I been able to develop an explicit, robust, ever-expanding framework for making and thinking about choices and actions.
This doesn't mean I'm good at it, although I am much better than I used to be. It simply means that I'm goal-oriented about being goal-oriented. It feels palpably, viscerally different, from moment to moment.
Strangely enough, this goal orientation developed from a host of pre-existing desires. For coherence, precision, charity, logic, satisfaction, security. Practicing those led to goal orientation. Goal orientation is leading to other places.
Now, I recognize that the sense of right thinking comes through in a piece of writing when the author seems to share my goals and to advance them through their work. They are on my team, not necessarily culturally or politically, but on a more universal level, and they are helping us win.
I think that goal orientation is a hard quality to instill, although we are biologically hardwired to have desires, imaginations, intentions, and all the other psychological precursors to a goal.
But a goal. That is something refined and abstracted from the realm of the biological, although still bearing a 1-1 relation to it. I don't know how you'd teach it. I think it comes through practice. From the sense that something can be achieved. Then trying to achieve and realizing that not only were you right, but you were thinking too small. SO many things can be achieved.
And then the passion starts, perhaps. The intoxication of building a mechanism - in any medium - that gives the user some new capability or idea, makes you wonder what you can do next. It makes you want to connect with others in a new way: fellow makers and shapers of the world, fellow agents. It drives home the pressing need for a shared language and virtuous behavior, lest potential be lost or disaster strike.
I don't move through the world as I did before.
comment by DirectedEvolution (AllAmericanBreakfast) · 2024-09-21T06:18:10.376Z · LW(p) · GW(p)
Why don't more people seek out and use talent scouts/headhunters? If the ghost jobs phenomenon is substantial, that's a perfect use case. Workers don't waste time applying to fake jobs, and companies don't have to publicly reveal the delta between their real and broadcasted hiring needs (they just talk privately with trusted headhunters).
Are there not enough headhunters? Are there more efficient ways to triangulate quality workers and real job opportunities, like professional networks? Are ghost jobs not that big of a deal? Do people in fact use headhunters quite a lot?
Replies from: pktechgirl↑ comment by Elizabeth (pktechgirl) · 2025-01-14T20:29:34.573Z · LW(p) · GW(p)
Just pushes the trust problem down a level. Lots of recruiting firms advertise positions that don't exist so that they have resumes "just in case"
comment by DirectedEvolution (AllAmericanBreakfast) · 2024-09-21T05:05:10.866Z · LW(p) · GW(p)
We start training ML on richer and more diverse forms of real world data, such as body cam footage (including produced by robots), scientific instruments, and even brain scans that are accompanied by representations of associated behavior. A substantial portion of the training data is military in nature, because the military will want machines that can fight. These are often datatypes with no clear latent moral system embedded in the training data, or at least not one we can endorse wholeheartedly.
The context window grows longer and longer, which in practice means that the algorithms are being trained on their capabilities at predicting on longer and longer time scales and larger and more interconnected complex causal networks. Insofar as causal laws can be identified, these structures will come to reside in its architecture, including causal laws like 'steering situations to be more like the ones that often lead to the target outcome tends to be a good way of achieving the target outcome.'
Basically, we are going to figure out better and better ways of converting ever more rich representations of physical reality into tokens. We're going to do spend vast resources doing ML on those rich datasets. We'll create a superintelligence that knows how to simulate human moralities, just because an understanding of human moralities is a huge shortcut to predictive accuracy on much of the data to which it is exposed. But it won't be governed by those moralities. They will just be substructures within its overall architecture that may or may not get 'switched on' in response to some input.
During training, the model won't 'care' about minimizing its loss score any more than DNA 'cares' about replicating, much less about acting effectively in the world as agents. Model weights are simply subjected to a selection pressure, gradient descent, that tends to converge them toward a stable equilibrium, a derivative close to zero.
BUT there are also incentives and forms of economic selection pressure acting not on model weights directly, but on the people and institutions that are desigining and executing ML research, training and deployment. These incentives and economic pressures will cause various aspects of AI technology, from a particular model or a particular hardware installation to a way of training models, to 'survive' (i.e. be deployed) or 'replicate' (i.e. inspire the design of the next model).
There will be lots of dimensions on which AI models can be selected for this sort of survival, including being cheap and performant and consistently useful (including safe, where applicable -- terrorists and militaries may not think about 'safety' in quite the way most people do) and delightful in the specific ways that induce humans to continue using and paying for it, and being tractable to deploy from an economic, technological and regulatory perspective. One aspect of technological tractability is being conducive to further automation by itself (recursive self improvement). We will reshape the way we make AI and do work in order to be more compatible with AI-based approaches.
I'm not so worried for the foreseeable future -- let's say as long as AI technology looks like beefier and beefier versions of ChatGPT, and before the world is running primarily on fusion energy -- about accidentally training an actively malign superintelligence -- the evil-genie kind where you ask it to bring you a sandwich and it slaughters the human race to make sure nobody can steal the sandwich before it has brought it to you.
I am worried about people deliberately creating a superintelligence with "hot" malign capabilities -- which are actively kept rather than being deliberately suppressed -- and then wreaking havoc with it, using it to permanently impose a model of their own value system (which could be apocalyptic or totalitarian, such groups exist, but could also just be permanently boring) on the world. Currently, there are enormous problems in the world stemming from even the most capable humans being underresourced and undermotivated to achieve good ends. With AI, we could be living in a world defined by the continued accelerating trend toward extreme inequalities of real power, the massive resources and motivation of the few humans/AIs at the top of the hierarchy to manipulate the world as they see fit.
We have never lived in a world like that before. Many things come to pass. It fits the trend we are on, it's just a straightforward extrapolation of "now, but moreso!"
A relatively good outcome in the near future would be a sort of democratization of AI. I don't mean open source AT ALL. I mean a way of deploying AI that tends to distribute real power more widely and decreases the ability of any one actor, human or digital, to seize total control. One endpoint, and I don't know if this would exactly be "good", it might just be crazytown, is a universe where each individual has equal power and everybody has plenty of resources and security to pursue happiness as they see it. Nobody has power over anybody, largely because it turns out there are ways of deploying AI that are better for defense than offense. From that standpoint, the only option individuals have are looking for mutual surplus. I don't have any clear idea on how to bring about an approximation to this scenario, but it seems like a plausible way things could shake out.
comment by DirectedEvolution (AllAmericanBreakfast) · 2024-09-06T06:00:13.473Z · LW(p) · GW(p)
Countries already look a bit like they're specializing in producing either GDP or in producing population.
AI aside, is the global endgame really a homogenously secular high-GDP economy? Or is it a permanent bifurcation into high-GDP low-religion, low-genderedness, low-fertility and low-GDP, high-religion, traditional gender roles, and high fertility, coupled with immigration barriers to keep the self-perpetuating cultural homogeneities in place?
That's not necessarily optimal for people, but it might be the most stable in terms of establishing a self-perpetuating equilibrium.
Is this just an extension of partisan sorting on a global scale?
Replies from: Omnni↑ comment by Aleksander (Omnni) · 2024-09-06T14:31:17.275Z · LW(p) · GW(p)
I don’t think there’s really much association with partisan sorting in this case. Most people espousing traditional gender roles aren’t clamoring to travel to India or such. It seems like partly a natural response to financial incentives created by cheap manufacturing and tech job offerings. Besides, ‘endgame’ in my opinion won’t last because at some point productivity will become too high and the work structure will collapse
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-07-12T21:25:52.017Z · LW(p) · GW(p)
Does anybody know of research studying whether prediction markets/forecasting averages become more accurate if you exclude non-superforecaster predictions vs. including them?
To be specific, say you run a forecasting tournament with 1,000 participants. After determining the Brier score of each participant, you compute what the Brier score would be for the average of the best 20 participants vs. the average of all 1000 participants. Which average would typically have a lower Brier score - the average of the best 20 participants' predictions, or the average of all 1000 participants' predictions?
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-07-12T02:27:05.477Z · LW(p) · GW(p)
P(Fraud|Massive growth & Fast growth & Consistent growth & Credence Good)
Bernie Madoff's ponzi scheme hedge fund had almost $70 billion (?) in AUM at its peak. Not adjusting for interest, if it existed today, it would be about the 6th biggest hedge fund, roughly tied with Two Sigma Investments.
Madoff's scheme lasted 17 years, and if it had existed today, it would be the youngest hedge fund on the list by 5 years. Most top-10 hedge funds were founded in the 70s or 80s and are therefore 30-45 years old.
Theranos was a $10 billion company at its peak, which would have made it about the 25th largest healthcare company if it existed today, not adjusting for interest. It achieved that valuation 10 years after it was founded, which a very cursory check suggests it was decades younger than most other companies on the top-10 list.
FTX was valued at $32 billion and was the third-largest crypto exchange by volume at its peak, and was founded just two years before it collapsed. If it was a hedge fund, it would have been on the top-10 list. Its young age unfortunately doesn't help us much, since crypto is such a young technology, except in that a lot of people regard the crypto space as a whole as being rife with fraud.
Hedge funds and medical testing companies are credence goods - we have to trust that their products work.
So we have a sensible suggestion of a pattern to watch out for with the most eye-popping frauds - massive, shockingly fast growth of a company supplying a credence good. The faster and bigger a credence-good company grows, and the more consistent the results or the absence of competition, the likelier the explanation is to be fraud.
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-06-10T06:43:57.466Z · LW(p) · GW(p)
When I'm reasoning about a practical chemistry problem at work, I'm usually thinking in terms of qualitative mechanisms:
- Ethanolamine reacts with epoxides on magnetic beads so that other molecules we introduce later won't react with the epoxides. This is called "blocking" the epoxides.
- But at physiological pH, the secondary amine the ethanolamine introduces is protonated and will be positively charged. This gives the entire bead surface a substantial positive charge.
- The nucleic acids in our solution are negatively charged, so they will form ionic bonds with the secondary amine and may also hydrogen bond with its hydroxyl group.
- Etc.
The bottleneck for this style of inference requires having a strong grasp of the components of the system and the most important chemical mechanisms at play. The point is to generate hypotheses you can test in an experiment in order to get better practical performance out of the system. The data you are working with is not homogeneous or cleaned. It's a diverse set of highly contextual observations, and you're trying to find a logical chain of mechanisms that could produce the observed results. Finding even one such chain can be a big success.
The examples given in Bayesian statistics or machine learning are often for making as much sense as you can out of big data - predicting chemical properties from SMILES, for example. These approaches won't necessarily give you mechanistic insight on their own. Although the individual data points are what we'd typically think of as "observations," to a human being, it's really the outputs of the models that are the "observations" from which we try to make biological sense.
This, I think, has been the root of one of my psychological struggles in the formal study of Bayesian stats. My textbook presents toy models, such as computing the likelihoods of there being a given number of white or blue marbles in a bag by drawing one at a time with replacement. For these problems, Bayesian approaches are the natural way to solve them, and so it's natural to think of the individual marble draws as "observations" and the posterior probabilities as the "meaningful hypothesis" that we are trying to infer. But the problems we encounter daily are not so formalized and pre-cleaned, and we often don't need Bayesian methods in order to do an adequate job in solving them.
My PhD will be in cancer epigenetics, where we'd like to look at the cancer microenvironment, determine what cell types are present, and trace the lineage of the cancer back to the healthy cells from which it sprang. We'd also like to use epigenetic data to understand the mechanism by which the healthy cell became cancerous. We have a wet lab workflow that results in an enormous number of single cell genomes that includes information about which bases are methylated per cell. Figuring out how to infer cell type and lineage from that information is the challenge. For this sort of (deeply unfamiliar, not at all intuitively real-world) problem, the tools of Bayesian statistics are perfect.
And so I think that part of making Bayesian statistics intuitive is making the kinds of problems we are trying to solve with Bayesian statistics intuitive. Get in the mental habit of inhabiting a world where you do have access to big, meaningful datasets and can generate potentially groundbreaking insights from them if you have the right statistical tools and know how to use them.
Replies from: rhollerith_dot_com↑ comment by RHollerith (rhollerith_dot_com) · 2023-06-10T18:34:55.046Z · LW(p) · GW(p)
Thinking about the qualitative mechanism is causal reasoning, which humans prefer to statistical reasoning.
Causal knowledge is obtaining by making statistical observations (and not necessarily big datasets of statistical observations).
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-06-08T01:28:12.877Z · LW(p) · GW(p)
Changing a person's strongly-held belief is difficult. They may not be willing to spend the time it would take to address all your arguments. They might not be capable of understanding them. And they may be motivated to misunderstand.
An alternative is to give them short, fun intros to the atomic ideas and evidence for your argument, without revealing your larger aim. Let them gradually come to the right conclusion on their own.
The art of this approach is motivating why the atomic ideas are interesting, without using the point you're trying to make as the motivator.
This has the added benefit of forcing you to justify your ideas using alternative examples, in case you are the one who is wrong.
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-06-05T08:03:03.167Z · LW(p) · GW(p)
Conservatism says "don't be first, keep everything the same." This is a fine, self-consistent stance.
A responsible moderate conservative says "Someone has to be first, and someone will be last. I personally want to be somewhere in the middle, but I applaud the early adopters for helping me understand new things." This is also a fine, self-consistent stance.
Irresponsible moderate conservatism endorses "don't be first, and don't be last," as a general rule, and denigrates those who don't obey it. It has no answers for who ought to be first and last. But for there to be a middle, somebody has to be the early adopter, and someone has to be the last one to try.
I often hear irresponsible moderate conservatives resort to a claim that the world is full of idiotic, irresponsible people who'll try anything, as long as it's new. Although it's unfortunate that these fools are behaving as they are, it has the side benefit of testing the new thing and ultimately allowing the moderate conservatives to adopt it.
This is an empirical claim, and true it may be, but it does not resolve the larger moral question. What if everybody was a moderate conservative? Then who would be the first to try new things?
If moderate conservatives who routinely denigrate and never applaud early adopters can't articulate an answer to that question, then their rule of 'don't be first, don't be last' is hypocrisy, plain and simple.
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-05-26T04:31:27.297Z · LW(p) · GW(p)
I would pay about $5/month for a version of Twitter that was read-only. I want a window, not a door.
Replies from: Viliam, pat-myron↑ comment by Pat Myron (pat-myron) · 2023-05-26T22:26:19.635Z · LW(p) · GW(p)
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-05-21T20:43:02.276Z · LW(p) · GW(p)
Steelman as the inverse of the Intellectual Turing Test
The Intellectual Turing Test (ITT) checks if you can speak in such a way that you convincingly come across as if you believe what you're saying. Can you successfully pose as a libertarian? As a communist?
Lately, the ITT has been getting boosted over another idea, "steelmanning," which I think of as making "arguing against the strongest version of an idea," the opposite of weakmanning or strawmanning.
I don't think one is better than the other. I think that they're tools for different purposes.
If I'm doing the ITT, I'm usually trying to build empathy in myself for a different perspective, or build trust with the person I'm talking with that I grok their point of view. It's for when I do understand an argument intellectually, but need to demonstrate to others that I also understand it emotionally and rhetorically.
If I'm steelmanning, I'm usually trying to build an intellectual appreciation for a point of view that seems foolish, but is held by somebody I respect enough to take seriously. I'm trying to do so for my own sake, in the hope that I might learn something new from the attempt.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-05-21T23:39:37.479Z · LW(p) · GW(p)
I think ITT is most useful for practicing privately, as a method for systematically developing intellectual understanding of arguments. Practicing it publicly is somewhat useless (though a good sanity check) and requires a setup where claims so channeled are not taken as your own beliefs.
Unlike ITT, steelmanning is not aiming for accurate understanding, so it's much less useful for intellectual understanding of the actual points. It's instead a mode of taking inspiration from something you don't consider good or useful, and running away with whatever gears survive the analogy to what you do see as good or useful. Steelmanning is great at opposing aversion to associating with a thing that appears bad or useless, and making some intellectual use of it, even if it's not for the intended purpose and lossy on intended nuance.
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-05-17T02:25:13.206Z · LW(p) · GW(p)
My 3-line FizzBuzz in python:
Replies from: AllAmericanBreakfastfor i in range(1, 101):
x = ["", "Fizz"][i%3==0] + ["", "Buzz"][i%5==0]
print([x, i][len(x)==0])
↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2023-05-17T02:27:37.368Z · LW(p) · GW(p)
ChatGPT does it in two:
Replies from: AllAmericanBreakfastfor i in range(1, 101):
print("Fizz" * (i % 3 == 0) + "Buzz" * (i % 5 == 0) or i)
↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2023-05-17T02:28:34.292Z · LW(p) · GW(p)
And in one:
print('\n'.join(['Fizz' * (i % 3 == 0) + 'Buzz' * (i % 5 == 0) or str(i) for i in range(1, 101)]))
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-05-12T16:51:48.017Z · LW(p) · GW(p)
Making Beliefs Identity-Compatible
When we view our minds through the lens of large language models (LLMs), with their static memory prompts and mutable context window, we find a fascinating model of belief and identity formation. Picture this in the context of a debate between an atheist and a creationist: how can this LLM-like model explain the hurdles in finding common ground?
Firstly, we must acknowledge our belief systems, much like an LLM, are slow to change. Guided by a lifetime of self-reinforcing experiences, our convictions, whether atheistic or creationist, develop a kind of inertia. They become resistant to sudden shifts, even in the face of a compelling argument.
Secondly, our beliefs generate self-protective outputs in our mind's context window. These outputs act as a defense mechanism, safeguarding our core beliefs and often leading to reactionary responses instead of open-minded dialogue.
To break through these barriers, we need to engage the mutable part of our cognitive context. By introducing new social connections and experiences, we can gently nudge the other person to add to or reinterpret their static memory prompts. This might mean introducing your creationist friend to scientifically open-minded Christians, or even to promoters of intelligent design. Perhaps you can encourage them to study evolution not as "truth," but as an alternative an interesting point of view, in much the same way that an atheist might take a passionate interest in world religions or an economist might work to master the point of view of a contradictory school of economic thought.
In the heat of a debate, however, this is rarely implemented. Instead, atheists and creationists alike tend to grapple with their fundamental disagreements, neglecting to demonstrate how an open-minded consideration of each other's viewpoint can be reconciled with their existing identity.
To make headway in such debates, it's not enough to present our viewpoint compellingly. We must also illustrate how this viewpoint can be entertained without upending the essential aspects of the other person's identity. Only by doing this can we truly bridge the ideological divide and foster a richer, more empathetic dialogue, worthy of our complex cognitive architecture.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-05-12T21:40:06.736Z · LW(p) · GW(p)
I think the important part is training a good simulation of a new worldview, not shifting weight to it or modifying an old worldview. To change your mind, you first need availability of something to change your mind to.
This is mostly motivation to engage and pushing aside protocols/norms/habits that interfere with continual efficient learning. The alternative is never understanding a non-caricature version of the target worldview/skillset/frame, which can persist for decades despite regular superficial engagement.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2023-05-12T22:21:59.100Z · LW(p) · GW(p)
I think the important part is training a good simulation of a new worldview, not shifting weight to it or modifying an old worldview. To change your mind, you first need availability of something to change your mind to.
Do you mean that preserving your openness to new ideas is about being able to first try on new perspectives without necessarily adopting them as the truth? If so, I agree, and I think that captures another oft-neglected aspect of debate. We tend to lump together an explanation of what our worldview is, with a claim that our worldview is true.
When all participants in the debate view opportunities to debate the topic in question as rare and consequential, all the focus goes into fighting over some sort of perception of victory, rather than on trying to patiently understand the other person's point of view. Usually, that requires allowing the other person to adopt, at least for a while, the perceived role of the expert or leader, and there's always a good chance they'll refuse to switch places with you and try and learn from you as well.
That said, I do think that there are often real asymmetries in the level of expertise that go unrecognized in debate, perhaps for Dunning Krueger reasons. Experts shouldn't demand deference to their authority, and I don't think that strategy works very well. Nevertheless, it's important for experts to be able to use their expertise effectively in order to spread knowledge and the better decision-making that rests on it.
My take is that this requires experts to understand the identities and formative memories that underpin the incorrect beliefs of the other person, and conduct their discussion in such a way as to help the other person see how they can accept the expert's knowledge while preserving their identity intact. Sometimes, that will not be possible. An Atheist probably can't convince a Christian that there's a way to keep their Christian identity intact while disbelieving in God.
Other times, it might be. Maybe an anti-vax person sees themselves as a defender of personal freedom, a skeptic, a person who questions authority, in harmony with nature, or protective of their children's wellbeing.
We might guess that being protective of their children's wellbeing isn't the central issue, because both the pro- and anti-vax side are striving hard to reinforce that identity. Skepticism probably isn't the main motive either, since there's lots to be skeptical of in the anti-vax world.
But defending personal freedom, questioning authority, and being in harmony with nature seem to me to be identities more in tune with being anti-vax than pro-vax. I imagine large billboards saying "The COVID-19 vaccine works, and it's still OK if you don't get it" might be a small step toward addressing the personal freedom/question authority identity. And if we'd framed COVID-19 as a possible lab-generated superbug, with the mRNA vaccine harnessing your body's natural infection-fighting response rather than being an example of big pharma at its novel and high-tech best, we might have done a better job of appealing to the 'in harmony with nature' identity.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-05-12T22:46:58.405Z · LW(p) · GW(p)
The idea that a worldview needs to be in any way in tune with your own to be learned is one of those protocols/norms/habits that interfere with efficient learning. Until something is learned, it's much less convenient to assess it, or to extract features/gears to reassemble as you see fit.
This is mostly about complicated distant collections of related ideas/skills. Changing your mind or believing is more central for smaller or decomposable ideas that can be adopted piecemeal, but not every idea can be straightforwardly bootstrapped. Thus utility of working on understanding perplexing things while suspending judgement. Adopting debate for this purpose is about figuring out misunderstandings about the content of a single worldview, even if its claims are actively disbelieved, not cruxes that connect different worldviews.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2023-05-12T22:58:15.761Z · LW(p) · GW(p)
To me, you seem to be describing a pretty ideal version of consciously practiced rationality - it's a good way to be or debate among those in scout mindset. That's useful indeed!
I am interested here mainly in how to better interface with people who participate in debate, and who may hold a lot of formal or informal power, but who do not subscribe to rationalist culture. People who don't believe, for whatever reason, in the idea that you can and should learn ideas thoroughly before judging them. Those who keep their identities large and opt to stay in soldier mindset, even if they wouldn't agree with Paul Graham or Julia Galef's framings of those terms or wouldn't agree such descriptors apply to them.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-05-12T23:38:11.613Z · LW(p) · GW(p)
The point is that there is a problem that can be mostly solved this way, bootstrapping understanding of a strange frame. (It's the wrong tool if we are judging credence or details in a frame that's already mostly understood, the more usual goal for meaningful debate.) It's not needed if there is a way of getting there step-by-step, with each argument accepted individually on its own strength.
But sometimes there is no such straightforward way, like when learning a new language or a technical topic with its collection of assumed prerequisites. Then, it's necessary to learn things without yet seeing how they could be relevant, occasionally absurd things or things believed to be false, in the hope that it will make sense eventually, after enough pieces are available to your own mind to assemble into a competence that allows correctly understanding individual claims.
So it's not a solution when stipulated as not applicable, but my guess is that when it's useful, getting around it is even harder than changing habits in a way that allows adopting it. Which is not something that a single conversation can achieve. Hence difficulty of breaking out of falsehood-ridden ideologies, even without an oppressive community that would enforce compliance.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2023-05-13T01:26:11.943Z · LW(p) · GW(p)
I'm not quite following you - I'm struggling to see the connection between what you're saying and what I'm saying. Like, I get the following points:
- Sometimes, you need to learn a bunch of prerequisites without experiencing them as useful, as when you learn your initial vocabulary for a language or the rudimentary concepts of statistics.
- Sometimes, you can just get to a place of understanding an argument and evaluating it via patient, step-by-step evaluation of its claims.
- Sometimes, you have to separate understanding the argument from evaluating it.
The part that confuses me is the third paragraph, first sentence, where you use the word "it" a lot and I can't quite tell what "it" is referring to.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-05-13T02:08:05.460Z · LW(p) · GW(p)
Learning prerequisites is an example that's a bit off-center (sorry!), strangeness of a frame is not just unfamiliar facts and terms, but unexpected emphasis and contentious premises. This makes it harder to accept its elements than to build them up on their own island. Hanson's recent podcast [LW · GW] is a more central example for me.
By step-by-step learning I meant a process similar to reading a textbook, with chapters making sense in order, as you read them. As opposed to learning a language by reading a barely-understandable text, where nothing quite makes sense and won't for some time.
So it's not a solution when stipulated as not applicable, but my guess is that when it's useful, getting around it is even harder than changing habits in a way that allows adopting it. Which is not something that a single conversation can achieve.
The part that confuses me is the third paragraph, first sentence, where you use the word "it" a lot and I can't quite tell what "it" is referring to.
The "it" is the procedure of letting strange frames grow in your own mind without yet having a handle on how/whether they make sense. The sentence is a response to your suggesting that debate with a person not practicing this process is not a place for it. The point is I'm not sure what the better alternative would be. Turning a strange frame into a step-by-step argument often makes it even harder to grasp.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2023-05-13T07:01:53.035Z · LW(p) · GW(p)
Ah, that makes sense. Yes, I agree that carefully breaking down an argument into steps isn’t necessarily better than just letting it grow by bits and pieces. What I’m trying to emphasize is that if you can transmit an attitude of interest and openness in the topic, the classic idea of instilling passion in another person, then that solves a lot of the problem.
Underneath that, I think a big barrier to passion, interest and openness for some topic is a feeling that the topic conflicts with an identity. A Christian might perceive evolution as in conflict with their Christian identity, and it will be difficult or impossible for even the most inspiring evolutionist to instill interest in that topic without first overcoming the identity conflict. That’s what interests me.
I don’t think that identify conflict explains all failures to connect, not by a long shot. But when all the pieces are there - two smart people, talking at length, both with a lot of energy, and yet there’s a lot of rancor and no progress is made - I suspect that identify conflict perceptions are to blame.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-05-13T12:21:53.924Z · LW(p) · GW(p)
Your last shortform [LW(p) · GW(p)] made it clearer that what you discuss could also be framed as seeking ways of getting the process started, and exploring obstructions.
A lot of this depends on the assumption of ability to direct skepticism internally, otherwise you risk stumbling into the derogatory senses of "having an open mind" ("so open your brains fall out"). Traditional skepticism puts the boundary around your whole person or even community. With a good starting point, this keeps a person relatively sane and lets in incremental improvements. With a bad starting point, it makes them irredeemable. This is a boundary of a memeplex that infests one's mind, a convergently useful [LW · GW] thing for most memeplexes to maintain. Any energy for engagement specific people would have is then spent on defending the boundary, only letting through what's already permitted by the reigning memeplex. Thus debates between people from different camps are largely farcical, mostly recruitment drives for the audience.
A shorter path to self-improvement naturally turns skepticism inward, debugs your own thoughts that are well past that barrier. Unlike the outer barriers, this is an asymmetric weapon that reflects on the truth or falsity of ideas that are already accepted. But once it's in place, it becomes much safer to lower the outer barriers, to let other memeplexes open embassies in your own mind. Then the job of skepticism is defending your own island in an archipelago of ideas hosted in your own mind that are all intuitively available to various degrees and allowed to grow in clarity, but often hopelessly contradict each other.
However, this is not a natural outcome of skepticism turning inwards. If the scope of skepticism remains too wide, greedily debugging everything, other islands wither before they gain sufficient clarity to contribute. So there are at least two widespread obstructions to archipelago mind. First, external skepticism that won't let unapproved ideas in, justified by the damage they'd do in the absence of internal skepticism, with selection promoting memeplexes that end up encouraging such skepticism. Second, internal skepticism that targets the whole mind rather than a single island of your own beliefs, justified by its success in exterminating nonsense.
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-04-11T04:53:31.310Z · LW(p) · GW(p)
The best way I've come up with to explain how to use ChatGPT effectively is to think of it as a horde of undergraduate researchers you can employ for pennies. They're somewhat unreliable, but you can work them to the bone for next to nothing, and if you can give them a task that's within their reach, or cross-check their answers against each other, you can do a lot with that resource.
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-04-02T22:52:13.583Z · LW(p) · GW(p)
A workflow for forecasting
- Identify a topic with pressing need for informative forecasting
- Break topic down into rough qualitative questions
- Prioritize questions by informativeness
- Refine high priority questions to articulate importance, provide background information, make falsifiable, define resolution criteria
- Establish base rate
- Identify factors to adjust base rate up and down
- Create schedule for updating forecast over time
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-03-25T19:35:28.152Z · LW(p) · GW(p)
Very interesting that after decades of GUI-ification, we're going back to text-based workflows, with LLMs at the nexus. I anticipate we'll see GUIs encapsulating many of these workflows but I'm honestly not sure - maybe text-based descriptions of desired behaviors are the future.
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-03-25T04:24:26.087Z · LW(p) · GW(p)
I have learned to expect to receive mostly downvotes when I write about AI.
I can easily imagine general reasons why people might downvote me. They might disagree, dislike, or fear negative consequences of my posts. They might be bored of the topic and want only high-caliber expert writings. It might be that the concentrated AI expertise on LessWrong collectively can let their hair down on other topics, but demand professionalism on the specific topic of their expertise.
Because I don't know who's downvoting my AI posts, or their specific reasons why, I don't actually learn anything from being downvoted. I experience it as an expected form of unpleasantness, like dog wearing a shock collar who just ran through the "invisible AI fence." This is not true when I write on other topics, where I typically expect to receive 15-30 karma on average and gain new information when I receive less or more than that range.
I do not want to let karma affect my decision to write, or what I write about. I'm going to continue writing my thoughts, and have a sense of humor about the low karma scores that will result.
Since I am not any kind of expert on the subject, I will keep these writings on my personal shortform.
Replies from: Dagon, Gunnar_Zarncke↑ comment by Dagon · 2023-03-25T10:06:02.786Z · LW(p) · GW(p)
I don't post much, but I comment frequently, and somewhat target 80% positive reactions. If I'm not getting downvoted, I'm probably not saying anything very interesting. Looking at your post history, I don't see anything with negative totals, though some have low-ish scores. I also note that you have some voters a little trigger-happy with strong votes (18 karma in 5 votes), which is going to skew the perception.
I recommend you not try to learn very much from votes. It's a lightweight indicator of popularity, not much more. If something is overwhelmingly negative, that's a signal you've crossed some line, but mixed and slightly-positive probably means you're outside the echo chamber.
Instead of karma, focus on comments and discussion/feedback value. If someone is interested enough to interact, that's worth dozens of upvotes. AND you get to refine your topical beliefs based on the actual discussion, rather than (well, in addition to) updating your less-valuable beliefs about what LW wants to read.
↑ comment by Gunnar_Zarncke · 2023-03-25T09:37:13.968Z · LW(p) · GW(p)
A) your observation about negative feedback being undirected is correct, i.e., a well-known phenomenon.
B) can you give some examples?
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-03-20T20:38:57.353Z · LW(p) · GW(p)
Fixing the ticker-tape problem, or the disconnect between how we write and how we read
Between the tedious wash steps of the experiment I'm running, I've been tinkering with Python. The result is aiRead.
aiRead integrates the ideas about active reading I've accumulated over the last four years. Although its ChatGPT integration is its most powerful feature, this comment is about an insight I've gleaned by using its ticker-tape display feature.
Mostly, I sit down at my desk to read articles on my computer screen. I click a link, and what appears is a column of heavy-looking blocks of text. This column descends down into the depths, below the bottom edge of my browser.
With aiRead, a delicate line of characters traces its way across the screen. As they tiptoe forward, my brain switches on. I have time to imagine. To critique. To notice my confusion.
Having spooned up a bite-size morsel of text, aiRead waits for me to decide on what to do. Do I move on to the next paragraph? Do I rewind, or read it again? The software nudges me to make deliberate choices about what to read next, based on my reaction to what I just read. As a result, I feel more interested, and come away with a better understanding of other people's ideas.
Most people's writing benefits. We write in ticker-tape fashion, with a single line of words unspooling from our minds onto the page. Only later do we reshape the material into sections and move around our language by the paragraph. Despite this, we typically read in blocks. It takes effort to tune into the melody-like flow of note-like micro-ideas. aiRead fixes the disconnect between how writers write and readers read.
Yet not all writing suffers from this problem. When I read Scott Alexander, it's easy for me to follow the continuous flow of his ideas and language.
After reflecting on the opening paragraphs of his classic essay, I Can Tolerate Anything Except The Outgroup, I notice three main features that allow his writing to solve this "ticker-tape problem" I have described, making it much easier to read his material carefully.
First of all, he goes beyond perfunctory examples, using elaborate stories to illustrate his ideas. Where another author would eschew an example, he uses one. Where they would write a single sentence, he gives us a paragraph. Where they would introduce their essay with a quote from Howl, he gives us Meditations on Moloch.
This brings us to the second key difference that makes his writing unusually easy to follow. Because he uses such elaborate stories, he can compose his sentences as a series of images. Each image is vivid, and my mind enjoys holding onto it for a moment. Then, I let the image of the beloved nobleman collapse, and raise the image of him murdering his good-for-nothing brother in a duel.
Finally, Scott chooses sonorous language in which to express these images. He doesn't describe "a noble who everybody in town loved kills is brother in a duel decades ago." He says "a beloved nobleman who murdered his good-for-nothing brother in a duel thirty years ago." I relish his language, and naturally take the time to savor it.
Great writing, like Scott's doesn't need a software application like aiRead to ensure careful and attentive reading. Other writing benefits greatly from a ticker-tape display. I am surprised, and pleased, to find that a long and careful investigation into the details of reading has also produced valuable insights about the act of writing.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-12-11T05:53:54.177Z · LW(p) · GW(p)
A proposal to better adapt nonfiction writing to human memory and attention
Let's explain why it's hard to learn from typical nonfiction writing, so that we can figure out how to potentially solve the problem.
- Nonfiction writing is compressed. It tries to put across each piece of new information once. But you need repeated exposure, in new ways, to digest information.
- Nonfiction writing is concentrated. It omits needless words, getting across its ideas in the minimum possible space.
- Nonfiction writing is continuous. It goes on without a break. You can only hold 3-4 ideas in your working memory, but nonfiction writing does not respect this constraint.
- Nonfiction writing is monotonous. It doesn't leaven itself with humor, often eschews analogies, and is often abstract.
These four problems suggest a solution. Nonfiction writing should be redundant, dilute, interrupted, and polyphonous. Every time it introduces 1-2 new ideas, it should put them in the context of 1-2 ideas it has already discussed. It should intersperse new content with lighter material. If an article is teaching about telomere shortening, why not include a paragraph on the ethereally beautiful, 7-sexed Tetrahymena thermophila, in which Elizabeth Blackburn discovered the repeating TTAGGG sequence that makes up our telomeres?
Abstractions should be cut with classic style concrete imagery. Not everything needs to be visceral and visual, but a lot of it should be.
New ideas should be accompanied by the pleasant sensation of being reminded of material that you already know. This builds a feeling of growing mastery that is motivating to the reader.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-12-07T03:09:57.958Z · LW(p) · GW(p)
The succession of new OpenAI products has proven to me that I'm bad at articulating benchmarks for AI success.
For example, ChatGPT can generate working Python code for a game of mancala, except that it ignores captures and second turns completely, and the UI is terrible. But I'm pretty good at Python, and it would be easier for me to debug and improve ChatGPT's code than to write a complete mancala game.
But I wouldn't have thought to set out "writing code that can be fixed faster than a working program can be written from scratch" as a benchmark. In hindsight, it's clearly a reasonable benchmark, and illustrates the smoothly-scaling capabilities of these systems. I should use ChatGPT to come up with benchmarks for OpenAI's next text generating AI.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-12-07T03:15:05.213Z · LW(p) · GW(p)
The idea of having ChatGPT invent benchmarks can't be tested by just asking it to, but I tried asking it to come up with a slightly more difficult intellectual challenge than writing easily debugged code. Its only two ideas seem to be:
- Designing and implementing a new programming language that is easier to read and understand than existing languages, and has built-in features for debugging and error-checking.
- Writing efficient and optimized algorithms for complex problems.
I don't think either of these seem merely "slightly more difficult" than inventing easily debuggable code.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-11-12T22:27:17.315Z · LW(p) · GW(p)
Sometimes, our bad gut feelings lead us astray. Political actors use this to advantage - programming people with bad gut feelings and exploiting the political division to advantage. Rationality encourages us in these cases to set aside the bad-gut-feeling-generator ("rhetoric"), subject the bad gut feeling to higher scrutiny, and then decide how we ought to feel. There's so much rheotric and so much negativity bias and bad gut feeling, that we might even start to adopt a rule of thumb that "most bad gut feelings are wrong."
Do this to yourself too long, though, and you'll overcorrect. If you have the ability to question rhetoric and be cerebral about morality and risk, then it might be time to bring feelings back into it. Let's say you're considering a risk. It's low probability, but serious.
What would the appropriate gut reaction feel like?
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-11-07T02:49:00.722Z · LW(p) · GW(p)
Stress-promoting genes?
How can The Selfish Gene help us do better evolutionary thinking? Dawkins presents two universal qualities of a "good gene:"
- "Selfishness," the ability to outcompete rival alleles for the same spot on the chromosome.
- "Fitness," the ability to promote reproductive success in the vehicle organism.
One implication is that genes do best by not only making their vehicle organisms able to survive and reproduce in the niche for which the gene adapts them. The gene, or other genes with which it coordinates, ought to make that organism prefer that niche.
As an example, let's say there's a gene that confers resistance to a disease, but also causes disabling health issues. In an environment where that disease does not occur, the gene will be selected out of the gene pool. If that gene, or some other "cooperator," is able to make the organism seek out that disease-ridden environment, then the gene will survive. This will form a niche for that organism, as well as its descendents. If this cohort of disease-adapted genes can cause the organism to behave in ways that spread the disease, so much the better.
Even if there are non-diseased alternative niches that the organism might occupy, this cohort of disease-preferring genes will cause some subset of the organisms to prefer, and therefore remain, in the diseased environment - despite the fact that if the disease were to be completely eliminated from the planet, the organisms presently residing in it would reproduce more efficiently than they do in the diseased environment.
This suggests a possible reason why people sometimes seem to seek out stressful environments. Many genes confer a variety of forms of stress resistance. If stress resistance comes at a biological cost, a stress-free environment will tend to select against these stress-resistance genes. And so these stress-resistance genes will tend to cooperate with genes that cause a preference for stress, and that tend to spread stress.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-10-19T22:10:37.191Z · LW(p) · GW(p)
How I make system II thinking more reliable
When Kahneman and Tversky described System I and System II thinking, they used it to categorize and explain modes of thought. Over the years, I've learned that it's not always easy to determine which one I'm doing. In particular, I often find myself believing that I'm making a consciously calculated answer, when in fact I am inappropriately relying on haphazard intuition.
I don't know exactly how to solve this problem. The strategy that seems best is to create a "System II Safeguard" that ensures I am employing System II when I mean to do so.
There are certain things I do already that seem to function as System II Safeguards. The most general is the creation of forms, checklists, tables, and protocols, and using them to structure my work as I go about solving an object-level problem.
Here are some shifts from a more "System I" format to a "System II Safeguard" format:
- Writing my lab notebook in natural English sentences as I go --> writing tables and block-flow diagrams containing spaces to fill in with my data before I begin a procedure
- Reading a protocol and looking up things I don't understand --> creating and filling out a "due diligence form" that demands I provide explanations for the function of each component step and and reagent, along with alternatives, and my rationale for the choices I make
- Reading a book chapter and summarizing it as I go --> creating a worksheet to extract terms and concepts I don't understand, define and describe them, connect them to the topic of the chapter, and then restructure the summary to present these previously unknown topics in a more comprehensible order, and using this form as the guide for the natural-language summary
These methods partly ensure that I put much more effort into these tasks than I otherwise would. But they also prevent me from tricking myself into thinking I've been more comprehensive or more accurate than I think.
It's neither desirable nor tractable to do this for every task. But I have benefitted greatly from creating such forms to structure my thoughts and improve my reliability in certain areas.
When I am faced with some new task for which I don't have a structured approach to guide me, I would like to build a habit of creating such a structure before I start the object-level work.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-10-14T17:38:44.342Z · LW(p) · GW(p)
A distillation might need to fill in background knowledge
A good summary/distillation has two functions. First, it extracts the most important information. Second, it helps the reader understand that information more efficiently.
Most people think a distillation cuts a source text down to a smaller size. It can do more than that. Sometimes, the most important information in a text requires background knowledge. If the reader doesn't have that background knowledge, a distillation designed for that reader must start by communicating it to them, even if the original source text didn't explain it.
For example, each chapter of the Handbook of the Biology of Aging assumes the reader knows the mechanistic details of the biological processes it's describing. The chapter on genetics assumes the reader is a geneticist. The chapter on DNA repair dysfunction assumes the reader knows how non-homologous end joining works.
One obvious use-case for this Handbook would be to educate an early-career researcher on the field of aging biology to inform choice of lab. It's not easy to use the Handbook for this purpose, since there's no way a student will have all the background necessary to understand it in advance. Requiring them to repeatedly interrupt their reading to independently research each technical subject severely undermines the efficiency of the Handbook as a communication tool. A summary of the Handbook targeting this audience would present enough of that background to facilitate understanding the Handbook's technical material.
Replies from: Jay Bailey↑ comment by Jay Bailey · 2022-10-15T02:23:47.624Z · LW(p) · GW(p)
I consider distillation to have two main possibilities - teach people something faster, or teach people something better. (You can sometimes do both simultaneously, but I suspect that usually requires you to be really good and/or the original text to be really bad)
So, I would separate summarisation (teaching faster) from pedagogy (teaching better) and would say that your idea of providing background knowledge falls under the latter. The difference in our opinions, to me, is that I think it's best to separate the goal of this from the goal of summarising, and to generally pick one and stick to it for any given distillation - I wouldn't say pedagogy is part of summarising at all, I'd say if your goal is to teach the reader background knowledge they need for Subject X, you're no longer "summarising" Subject X. Which is fine. Teaching something better is also a useful skill, even if the post ends up longer than the thing it was distilling.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-10-15T02:39:01.206Z · LW(p) · GW(p)
How do you define teaching “better” in a way that’s cleanly distinguished from teaching “faster?” Or on a deeper level, how would you operationalize “learning” so that we could talk about better and worse learning with some precision?
For example, the equation for beam bending energy in a circular arc is Energy = 0.5EIL (1/R)^2. “Shallow” learning is just being able to plug and chug if given some values to put in. Slightly deeper is to memorize this equation. Deeper still is to give a physical explanation for why this equation includes the variables that it does.
Yet we can’t just cut straight to that deepest layer of understanding. We have to pass through the shallower understandings first. That requires time and speed. So teaching faster is what enables teaching better, at least to me.
Do you view things differently?
Replies from: Jay Bailey↑ comment by Jay Bailey · 2022-10-15T03:47:50.803Z · LW(p) · GW(p)
This isn't a generalised theory of learning that I've formalised or anything. This is just my way of asking "What's my goal with this distillation?" The way I see it is - you have an article to distill. What's your intended audience?
If the intended audience is people who could read and understand the article given, say, 45 minutes - you want to summarise the main points in less time, maybe 5-10 minutes. You're summarising, aka teaching faster. This usually means less, not more, depth.
If the intended audience is people who lack the ability to read and understand the article in its current state, people who bounced off of it for some reason, then summarising won't help. So you need to explain the background information and/or explain the ideas of the article better. (which often means more, not less, depth) Thus, your goal is to teach "better". Maybe "better" is the wrong word - maybe the original article was well-suited for an audience who already knows X, and your article is suited for ones that don't. Or maybe the original article just wasn't as well explained as it could have been, so you're rewriting it to resolve people's confusions, which often means adding more detail like concrete examples.
What it means to "teach better" is outside the scope of this particular explanation, and I don't have a formal idea, just some general heuristics, like "Identify where people might get confused" and "Start concrete, then go abstract" and "Ask what the existing understanding of your target audience is", but you don't need to have a definition of what it means to "teach better" in order to know that this is your goal with a distillation - not to speed up a process people can do on their own, but to resolve a confusion people might have when trying to read an article independently.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-10-15T04:13:39.870Z · LW(p) · GW(p)
I think that it's good to keep those general heuristics in mind, and I agree with all of them. My goal is to describe the structure of pedagogical text in a way that makes it easier to engineer.
I have a way of thinking about shallowness and depth with a little more formality. Starting with a given reader's background knowledge, explaining idea "C" might require explaining ideas "A" and "B" first, because they are prerequisites to the reader to understand "C."
A longer text that you're going to summarize might present three such "chains" of ideas:
A1 -> B1 -> C1
A2 -> B2 -> C2 -> D2
A3 -> B3
It might take 45 minutes to convey all three chains of ideas to their endpoints. Perhaps a 5-10 minute summary can only convey 3 of these ideas. If the most important ideas are A1, A2, and A3, then it will present them. If the most important idea is C1, then it will present A1 -> B1 -> C1.
If D2 is the most important idea, then the summary will have to leave out this idea, be longer, or find a more efficient way to present its ideas. This is why I see speed and depth as being intrinsically intertwined in a summary. Being able to help the reader construct an understanding of ideas more quickly allows it to go into more depth in a given timeframe.
All the heuristics you mention are important for executing this successfully. For example, "Ask what the existing understanding of your audience is" comes into play if the summary-writer accidentally assumes knowledge of A2, leaves out that idea, and leads off with B2 in order to get to D2 in the given timeframe. "Start concrete, then go abstract" might mean that the writer must spend more time on each point, to give a concrete example, and therefore they can't get through as many ideas in a given timeframe as they'd hope. "Identify where people might get confused" has a lot to do with how the sentences are written; if people are getting confused, this cuts down on the number of ideas you can effectively present in a given timeframe.
In this simple framework, we can specify the goal of an ideal summary:
Given all the idea-chains in the original text, a reading time limit, and a reader's background and goals, present the idea-chains that deliver the greatest value such that the reader will be able to understand them within the time limit.
By doing this systematically, we can create a sort of "basic science of summarization," concretely identifying specific failure modes and inefficiencies for improvement.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-10-09T04:54:35.010Z · LW(p) · GW(p)
Study Chatter
Lately, I've hit on another new technique for learning and scholarship. I call it "study chatter." It's simple to describe, but worth explaining why it works, and how it compares to other techniques.
Study chatter means that you write, think, or talk to yourself, in an open-ended way, about the topic you're trying to study. Whatever comes to mind is fine. Here's how this might work in practice (just to give you a flavor):
In Quantitative Cell Biology, we're learning a lot about ways to analyze proteins and cells - lots of methods. This is important. If we want to cure disease, create longevity, or understand how our bodies work, we need to have tools that let us put all the biochemical parts into categories and count them. We need to know what's there. What cells make up a tumor? What proteins are highly expressed in each of two cell types?
A biomedical engineer needs to know at least the basic mechanisms and functions of a whole suite of measurement tools. It's like having your garage full of tools. Having tools available, that you know how to use, makes you think about what you can build with them. Likewise, knowing how all these different ways of measuring biological samples work will make you a better scientist and engineer. That's why you need to learn this stuff.
We covered several different types of electrophoresis and immunostaining techniques. Gel electorphoresis, western blots, SDS-PAGE, and 2D chromatography come to mind. The key principle is separation by charge and mass. But in 2D chromatography, we also exploit the isoelectric point. Then we switch to separation by mass to get high resolution separation between proteins..."
This can go on as long as you want it to.
There are a few points to doing this. First, it can be motivating. A lot of this is about rehearsing why we care about what we're learning, rather than the specific facts we're trying to learn. If akrasia is a barrier to adequate study, then this can help overcome that problem.
Second, for me at least, it's a better way to jog my memory. Instead of the constant background anxiety of trying to remember a specific fact for a flashcard, I can remember large numbers of facts - whatever comes most easily to mind. The longer I go on for, the more facts I remember, and the more tied together they all become. I think that I build stronger memories, and of more facts, by employing this technique than I would by doing targeted flashcards.
Third, it builds a habit of mental rehearsal. You can do this anywhere and anytime that you have downtime. It lets you become the kind of person who keeps such thoughts at the top of your mind. That's a good recipe for true mastery of your subject, rather than of just learning and forgetting it after the exam.
It's not a fancy technique, but I think it's underdiscussed and underused. I find it powerful, and recommend others try it more.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-10-06T03:00:12.681Z · LW(p) · GW(p)
Distillation sketch - rapid control of gene expression
A distillation [? · GW] sketch is like an artistic sketch or musical jam session. Which version below do you prefer, and why?
My new version:
When you’re starving or exercising intensely, your body needs to make more energy, but there's not much glucose or glycogen left to do it with. So it sends a signal to your liver cells to start breaking down other molecules, like amino acids and small molecules, and turning them into glucose, which can in turn be broken down for energy. Cortisol is the hormone that carries that signal to the liver.
However, your body also needs to avoid spending all that energy until the critical moment. So it has a transcription regulator, GRP (the aptly named “glucocorticoid receptor protein”), lying in wait in the liver.
Normally, GRP alone can’t bind DNA. But when it binds with cortisol and activates, it causes transcription of genes for enzymes critical for glucose production from these alternative sources. Tyrosine aminotransferase is one such enzyme. Though these genes are regulated in all sorts of different and complicated ways, they all need GRP to bind their cis-regulatory sequence in order to be transcribed at top speed.
When the body calms down and cortisol goes away, GRP releases, and these glucose production genes drop back down to normal expression.
Original (Molecular Biology of the Cell, Sixth Edition by Alberts and Bruce):
An example is the rapid control of gene expression by the human glucocorticoid receptor protein. To bind to its cis-regulatory sequences in the genome, this transcription regulator must first form a complex with a molecule of a glucocorticoid steroid hormone, such as cortisol. The body releases this hormone during times of starvation and intense physical activity, and among its other activities, it stimulates liver cells to increase the production of glucose from amino acids and other small molecules. To respond in this way, liver cells increase the expression of many different genes that code for metabolic enzymes, such as tyrosine aminotransferase, as we discussed earlier in this chapter. Although these genes all have different and complex control regions, their maximal expression depends on the binding of the hormone–glucocorticoid receptor complex to its cis-regulatory sequence, which is present in the control region of each gene. When the body has recovered and the hormone is no longer present, the expression of each of these genes drops to its normal level in the liver. In this way, a single transcription regulator can rapidly control the expression of many different genes.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-21T01:13:17.160Z · LW(p) · GW(p)
Studying for retention is a virtuous cycle
If you know how to visualize and build memory palaces, it makes it much easier to understand new concepts, practice them, and therefore to retain them for the long term.
Once you gain this ability, it can transform your relationship with learning.
Before, I felt akrasia. I did my work - it was just a grind. Learning shouldn't feel that way.
Now, I feel voracious. I learn, and the knowledge sticks. My process improves at the same time. My time suddenly has become precious to myself. The books aren't full of tedium that can never be remembered. They're full of fully learnable useful knowledge that compounds on itself, and for which my only bottleneck is the time and energy and Butt Strength to spend learning them.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-21T00:25:59.689Z · LW(p) · GW(p)
Memory palace inputs
Once you have the mental skills to build memory palaces, you become bottlenecked by how well-organized your external resources are. Often, you'll have to create your own form of external organization.
I've found that trying to create a memory palace based on disorganized external information is asking for trouble. You'll be trying to manage two cognitive burdens: deciding how to organize the material, and remembering the material itself.
This is unnecessary. Start by organizing the material you want to memorize on the page, where you don't have to remember it. Once that's accomplished, then try to organize it in your head by building it into a memory palace.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-20T22:19:04.580Z · LW(p) · GW(p)
Memory palace maintenance
A problem with the "memory palace" concept is that it implies that the palace, once constructed, will be stable. If you've built a building well enough to take a walk through it, it will typically stand up on its own for a long time.
By contrast, a "memory palace" crumbles without frequent maintenance, at least for the first few days/weeks/months - I don't really know how long it might take to hypothetically have the memory palace be self-supporting. I suspect that depends on how often your work or further schooling makes use of the information.
What's useful about the memory palace isn't so much that it is an inherently more stable way to store memories. Instead, it makes memory maintenance much more convenient and compelling. Instead of reviewing flashcards at your computer, which are static, dull, and involve staring at a computer screen, you can explore and elaborate on your memory palace while taking a walk around the neighborhood.
It also makes it easier to navigate between thoughts, inspect relationships, and reorganize your thoughts using your spatial awareness and visual imagination. The elaboration that occurs as you do this makes all the memories stronger.
But the memory palace only helps if you make use of it to its fullest potential - walking through it, building connections, reorganizing the place, living there.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-20T18:30:30.258Z · LW(p) · GW(p)
Back when I really didn't know what I was doing, I tried to memorize a textbook verbatim. Fortunately, that didn't last long. Even with good technique, memorization is effortful and time-consuming. To get the most benefit, we need to do it efficiently.
What does that mean?
Efficient memorization is building the minimal memory that lets you construct the result.
Let's expand on that with an example.
Taylor's Inequality is a key theorem related to Taylor Series, a powerful tool used widely across science and engineering. Taylor's Inequality gives us a way of showing that a function is or is not equal to its Taylor Series representation.
Briefly, Taylor's Inequality starts with an inequality:
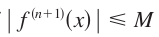
If true on a given interval, then Taylor's Inequality states that on that same interval,
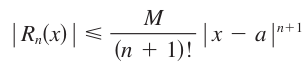
My textbook doesn't give a proof, just 8 steps of calculations that show this is true for n = 1, and saying that the same process will show this theorem holds for any other choice of n.
If you launched straight into trying to remember these steps in the proof, you'd exhaust yourself and gain little insight.
It pays huge dividends to notice they're just taking that first inequality, integrating it on the interval (a, x) n+1 times (with some algebraic rearrangements in between), and then using the definition of to relabel the result.
The result looks intimidating. It's less so if you notice that the right hand side is just the absolute value of the n+1 term in the Taylor series, but replacing with M.
Once you've identified these ways of compressing the information, you can memorize the key points much more easily and will be able, with enough time, to reconstruct the textbook's illustration with pencil and paper.
How do I incorporate this into my memory "palace" for power series?
- I visualize the symbol with bands of light above and below it, representing its integrals and derivatives.
- I pick out one of the ones below it, representing the n+1th derivative, and set it up inside absolute value brackets as part of the inequality.
- I picture what I know is the general form of the Taylor series next to it, and put it in the inequality with from the result. Just like you can focus on one part of a sculpture while ignoring the rest, I focus on the part and ignore the rest. I pick up the M from the inequality, and stick it into the Taylor series "sculpture" to replace the term with M.
- I imagine sticking n+1 integral symbols in front of the first inequality, to represent what I have to do to reform it into the second equation.
- The mathematical definition of is stored elsewhere, so I drag it over to remind myself that I'm going to eventually have to rearrange my integrations so that they can be replaced by
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-19T05:01:28.305Z · LW(p) · GW(p)
Mental practice for formal charge
I'm reviewing the chemistry concept of formal charge. There are three simple rules:
- Have as few formal charges on the molecule as possible.
- Separate like charges.
- Put negative formal charges on electronegative atoms.
Lewis structures are unnecessary to practice these rules. We can picture pairs of graphs. Red vertices represent electronegative atoms. The labels representing formal charge.
I decide which has a more favorable formal charge distribution, according to the rules.
This game took me longer to describe than to invent and play. Score one for mental practice.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-19T01:50:52.267Z · LW(p) · GW(p)
Efficiency is achieving complex ends through simpler means.
The genius is replaced by the professional. The professional is replaced by the laborer. The laborer is replaced by the animal, or by the robot.
The animal is replaced by the cell. The cell is replaced by the protein. The protein is replaced by the small molecule. The small molecule is replaced by the element.
The robot is replaced by the machine. The machine is replaced by the tool. The tool is replaced by a redesigned part. The part is obviated by a redesigned system.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-18T21:04:02.778Z · LW(p) · GW(p)
The advantages of mental practice
Deliberate practice is usually legible practice, meaning that it can be observed, socially coordinated, and evaluated. Legibile forms of deliberate practice are easy to do in a classroom, sports team, or computer program. They are also easy to enforce and incentivize. Almost every form of deliberate practice you have ever been required to do has been some form of legible practice.
Mental practice is illegible. Almost certainly, you have rarely, if ever, been asked to do it, and with even more confidence, I can say that you haven't been graded on it.
Yet mental practice has some key advantages.
- It allows the practitioner to use observation of their own internal state to both invent and execute forms of deliberate practice.
- It is unconstrained by the need for observability, coordination, or evaluation, which relieves anxiety and other cognitive burdens.
- The ability of the mind to flexibly construct, combine, and iterate on visual, audio, and kinetic representations of the practice task surpasses the iterative power of agile software development.
- Developing the ability to simulate and solve practice problems in the mind directly develops fundamental cognitive skills, such as the ability to let the mind wander among a set of related thoughts on a focused topic, or the ability to hold and mentally manipulate symbols in order to construct a problem-solving strategy.
- Mental practice builds skill in problem factorization, simplification, and planning, since the practitioner must work without forms of external memory aid.
- Mental practice removes the mechanical discomforts associated with many forms of legible practice. It doesn't require sitting, staring into a computer screen, or hand cramps.
- Mental practice allows the practitioner to elaborate on the inner experience to add virtues and ways to be playful and stimulated that are not considered by designers of legible practice.
Legible practice is clearly useful, but I think we overinvest in it for reasons unrelated to its effectiveness in promoting learning.
Autodidacts are intrinsically motivated to learn, can do it on their own, are not under pressure to sell an educational product or service. They need not find a way to make their techniques scientifically publishable. Autodidacts are best positioned to develop the arts of mental practice.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-18T18:29:38.380Z · LW(p) · GW(p)
Why the chemistry trick works
Yesterday, I wrote about my chemistry trick. To learn the structure of proline, we don't try to "flash" the whole image into our head.
Instead, we imagine ourselves standing on a single atom. We imagine taking a "walk" around proline. We might try to visualize the whole molecule as it would appear from our position. Or we might just see the next atom in front of us as we walk.
Why does this work? It exploits the cut principle. We don't try to recall every bit of information all at once. Instead, we recall only a small piece of the structure at a time.
This technique also benefits from pacing. During our imaginary walk around the molecule, our brain has time to recall the next step in the journey. It can forget where we came from, and focus on remembering where we're going.
Finally, the technique is more stimulating and relaxing. Wouldn't it be nice if more of our studying felt like the mental equivalent of taking a walk around the neighborhood?
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-09-02T16:43:59.383Z · LW(p) · GW(p)
The relationship between metabolism, physical fatigue, and the energy cost of physical motion is relatively well-understood.
- We know the body's efficiency in harvesting energy from stored sugars and fats.
- We know how energy is transported throughout the body.
- We know what fuel sources different tissues use.
- We have detailed knowledge on scales ranging from the molecular to the gross anatomical to explain how organisms move.
- We have Newtonian mechanics to explain how a certain motion of the body can generate a force on a moving object and what its trajectory will be after impact.
- Physical motion can be directly observed by others, mostly without influencing the motion itself.
Such robust, quantitative models are mostly lacking when we try to study and explain thought.
- We lack many of the connections that would be necessary to explain how brain chemistry generates conscious experience.
- We don't understand the energy costs of thought.
- We don't have comparable models to explain how one thought leads to another, or how thoughts are stimulated and influenced by the physical world. There is no equivalent to Newtonian mechanics for modeling the dynamics of conscious thought.
- We rely entirely on other people's self-reports to observe their conscious experience.
- We are extremely limited in our ability to perform precise, repeatable experiments to test whatever empirical "laws of consciousness" might exist.
Mental fatigue, akrasia, demotivation, and discomfort are common experiences. However, the factors that influence them seem diverse and contextual. The effect of glucose, sleep, drugs, physical fatigue, boredom, sensory stimulation, being watched, having a conversation, talking to yourself vs. thinking in your head, flow states, and many other factors seem to have an effect, but learning how to trigger desirable states, avoid undesirable ones, and make efficient short- vs. longterm tradeoffs and investments is a challenging process of self-discovery.
Placebo effects, behavior compensation, the body's attempt to preserve homeostasis, and the effects of aging and changing life circumstances conspire to give a short life expectancy to knowledge we might hope to gain via self-experimentation.
Yet many people enthusiastically put a lot of effort into trying to optimize their mental state and abilities, even if they don't think about it in those terms. So when is it advantageous to try anyway, despite the difficulty?
- When the scientific literature on the specific topic we are interested in is uncontroversial and has been established long enough that we can trust it.
- When the "information decay" is slow enough, and there's enough ability to re-investigate in the new circumstances, that it's worth "keeping up with the times" for our own brain. For example, a person getting medicated for ADHD who finds that their previous medication isn't working as well anymore might be well-served by investing some time and money to retune it, perhaps by adjusting medication and dose.
- When we can get rapid, clear, repeated feedback on at least some aspects of the question.
- When we have a range of plausible options to try, and can cycle through them in order to try and achieve our desired effect. For example, when I am feeling mentally tired, I've noticed it seems to have a range of potential causes: low blood sugar, dehydration, being undercaffeinated or overcaffeinated, anxiety, neck and back pain, too much sitting or moving around, a stuffy room, being overheated, being overstimulated or understimulated, being sleepy. While I can't usually "prove" which one was the culprit (and sometimes it's more than one), I can simply treat each problem and usually my problem goes away. I'll never have the ability to know exactly which issue is giving me problems on any given occasion, but I can treat the problems pretty consistently by addressing all possible issues (in moderation) - and this is what I really care about.
More than anything, I think it's important to look for robust but common-sense solutions, and to avoid getting bogged down with unknowable answers to noncentral questions. We don't need to settle the debate on whether and when glucose intake, reducing air particulates, or lowering the temperature can improve mental performance. Instead, we can just look for intuitive signals that these needs might be affecting our own cognition at a particular time, and then provide for being able to make the necessary adjustments.
Keep some healthy snacks near your workspace, open a window, get a fan or A/C, keep a water bottle handy. If you're feeling tired midday, take a little caffeine and see if it helps, but not so much that you risk overcaffeinating yourself or ruining your sleep later. Learn to take broad plausible treatments for low mental performance, in moderation.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-08-31T00:27:52.055Z · LW(p) · GW(p)
What is a Mind Mirror?
The brain does a lot of unconscious processing, but most people feel that they can monitor and control their own brain's behavior, at least to some extent. We are depending on their ability to do this anytime we expect a student to do any amount of self-directed learning.
As in any other domain, a common language to talk about how we monitor and control our own brains for the tasks of learning would be extremely helpful.
"Mind mirroring" is my tentative term for provoking the brain to reliably and automatically create a certain mental sound, image, or feeling in response to a particular external or internal stimulus.
Here are some mathematical examples:
- External sound -> mental image: You are learning a math equation with some Greek letters. You train your brain so that every time you hear the word "theta," your brain immediately and automatically produces a mental image of the symbol θ.
- External image -> mental image: You are learning about angular motion. Every time you take a walk, you pick two objects and track their relative angular position, velocity, and acceleration.
- Internal image -> mental sound: You visualize the symbol θ and automatically also produce the mental sound "theta."
- Mental image -> mental continuation: Visualizing the symbol ω is followed by a visualization of the equation ω^2 = ω_0^2 + 2α(θ - θ_0)
Mind mirroring is distinct from simply having these automatic associations. It's an activity that you do, like calisthenics. Just because you know how to do jumping jacks doesn't mean you're always doing them. Likewise, just knowing that ω^2 = ω_0^2 + 2α(θ - θ_0) doesn't mean that you mind-mirror this entire equation every time you see ω or hear "omega." Mind mirroring would mean deliberately choosing to practice doing that. It's mental flashcards.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-08-27T02:03:58.718Z · LW(p) · GW(p)
Over the last several years of studying how to study, one of the central focuses has been on managing the cognitive burden. Three main approaches recur again and again:
- Using visualization and the phonological loop to examine key information and maintain it in working memory
- Elaborative rehearsal to build and retrieve long-term memories
- Note-taking, information storage, and other external tools to supplement memory
I've noticed significant progress in my abilities in each of these individual areas, but synthesizing them is even more important.
When I lean on one of these approaches excessively, its shortcomings become rapidly apparent.
Excessive use of external notes results in blankly staring at the page, as memory shuts off. Learning does not happen, and it becomes impossible to figure out how to proceed with problem-solving, or to use the notes you have effectively.
Excessive elaborative rehearsal can become dangerous if the information you need is just not there. At best, you'll get stuck and waste time. At worst, you'll invent inaccurate memories and store those instead. However, I think this is the most useful and most neglected of these mental tools. It's what real learning feels like.
Excessive maintenance rehearsal is a little like excessive note-taking: you wind up focusing so hard on keeping individual tidbits of information top-of-mind that you can't make progress, and become anxious about shifting focus in a similar way to how you'd feel if you were trying not to forget a telephone number.
I think the next step is to learn how to fluidly move between these three modes. Looking at an equation on the page, it should become easy to "flash it" into working memory, then "rummage around" in long-term memory to build it in or retrieve additional memories relevant to the problem at hand. Right now, each mode of focus (external vision, maintenance rehearsal/working memory, elaborative rehearsal/long-term memory) tends to be "self-reinforcing." The more I scan notes, the more I scan notes, and the less connection I have with my memories. I want to try building in more of a series of cues so that there's more of a natural back and forth between paying attention to the external inputs and paying attention to my working and long-term memory.
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-08-14T22:28:56.722Z · LW(p) · GW(p)
Fascinatingly, "does getting a second opinion..." autocompletes on Google to "offend doctors," not "lead to better health outcomes."
Score one for The Elephant In The Brain?
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-08-14T22:32:13.391Z · LW(p) · GW(p)
Also, it sounds like it does in fact help. 20% of patients get a distinctly different 2nd diagnosis, and 66% are at least altered.
Replies from: mr-hire↑ comment by Matt Goldenberg (mr-hire) · 2022-08-14T23:03:23.807Z · LW(p) · GW(p)
Does it in fact improve outcomes? Naively I would bet that people tend to go with the diagnosis that fits their proclivities, positive or negative, and therefore getting one diagnosis is actually LESS biased than two.
Of course, if they instead go for the diagnosis that better fits their subjective evidence, then it would likely help.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2022-08-14T23:24:07.056Z · LW(p) · GW(p)
That is an interesting thought. I tried looking it up on Google Scholar, but I do not see any studies on the subject. I also expect that a norm of seeking two diagnoses would incentivize doctors to prioritize accurate diagnosis. In the long run, I am more confident that it would benefit patient care.
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-11-13T06:58:13.053Z · LW(p) · GW(p)
What happens when innovation in treatment for a disease stagnates?
Huntington's has only two FDA-approved drugs to treat symptoms of chorea: tetrabenazine (old) and deutetrabenazine (approved in 2017).
However, in the USA, physicians can prescribe whatever they feel is best for their patient off-label (and about 1 in 5 prescriptions are off-label). Doctors prescribe Risperdal (risperidone), Haldol (haloperidol) and Thorazine (chlorpromazine) off-label to treat HD chorea symptoms.
So off-label prescribing is a major way that the medical system can innovate, by adapting old drugs to new purposes.
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-11-13T05:39:56.759Z · LW(p) · GW(p)
A reframe of biomedical industry analysis:
"How is US healthcare going to change between now and the year 202_?"
This requires an understanding of the size of various diseases, the scope of treatment options currently available, natural fluctuations from year to year, and new medicines coming down the pipeline.
It would be interesting to study treatment options for a stagnant disease, one that hasn't had any new drugs come out in at least a few years.
A biomedical engineer might go a step further, and ask:
"How could healthcare change between now an the year 20__?"
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-03-21T19:38:30.890Z · LW(p) · GW(p)
Accurate arguments still need to be delightful and convincing
You can't just post two paragraphs of actionable advice and expect people to read it. You can't just explain things in intuitive language and expect to convert the skeptical. Barring exceptional circumstances, you can't get straight to the point. System 2 takes time to initialize.
Blogging is a special format. You're sort of writing for a self-selected niche. But you're also competing for people's attention when they're randomly browsing. Having a strong brand as a writer (Scott, Eliezer, Zvi, and Gwern are examples) maybe helps people a little more likely to engage.
Otherwise, you're pretty much starting out in the background and trying to stand out.
There's a funnel. Your username, title, the karma and date of your post, and the number of comments determine whether you get clicked on in the first place.
Then you have to get the user to start reading and keep reading, and to commit to not just skim, but to actually read the sentences. I skim all the time. I glance over a post to see if it seems interesting, well-written, if it draws me in. Otherwise, I'm gone in a heartbeat.
And if you can convince the reader to read your sentences, and to get all the way through, then you need to take them through a psychological process that's not just about efficiently conveying an idea. You need to build their curiosity, delight them, connect with them, teach them something new or make sense of something old and inchoate, convince them, and ideally get them interested to keep talking and thinking about it.
It's not enough to be right. You have to be interesting and convincing.
One of the issues in media is that they optimize for being interesting and convincing, often at the expense of being right.
We don't want to do that. But that means we have a harder job to do, because we're not allowed to skip being interesting and convincing. We have to do all three, not just two. And that means we need to spend time understanding how to create interest and explain things in a convincing way. That can seem like the "dark arts," but I don't think it is, as long as we're not throwing out the need to be accurate and useful and kind, and as long as we're not engaging in dirty tricks.
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-03-09T06:28:43.343Z · LW(p) · GW(p)
Pascal's Mugging has always confused me. It relies on the assumption that the likelihood of the payoff diminishes more slowly than the size of the payoff.
I can imagine regions of payoff vs. likelihood graphs where that's true. But in general, I expect that likelihood diminishes with greater acceleration than the acceleration of payoff. So eventually, likelihood diminishes faster than payoff increases, even if that was not the case at first. This lets me avoid Pascal's Muggings.
I can imagine an intelligence that somehow gets confused and misses this point. Or one that is smarter than us and behaves in a way that we would recognize as a Pascal's Mugging, but which it might be able to justify and persuade us of.
Am I missing a point here? Or is Pascal's Mugging just a description of one of the enormous number of ways it is possible to be dumb?
Replies from: Dagon, None, gjm↑ comment by Dagon · 2021-03-09T16:04:00.911Z · LW(p) · GW(p)
It's a mistake to think that likelihood or payoff changes - each instance is independent. And the reason it's effective is the less-explored alternate universe where you get PAID just for being the kind of person who'd accept it. In the setup, this is stated to be believed by you (meaning: you can't just say "but it's low probability!" that's rejecting the premise). That said I agree with your description, with a fairly major modification. Instead of
Pascal's Mugging just a description of one of the enormous number of ways it is possible to be dumb
I'd say Pascal's Mugging is just a description of one of the enormous number of ways that a superior predictor/manipulator can set up human-level decision processes to fail. Adversarial situations against a better modeler are pretty much hopeless.
↑ comment by [deleted] · 2021-03-09T08:56:29.390Z · LW(p) · GW(p)
There are a number of ways to deal with this, however, the succinct realization is that Pascal's mugging isn't something you do to yourself. Another player is telling you the expected reward, and has made it arbitrarily large.
Therefore this assessment of future reward is potentially hostile misinformation. It's been manipulated. For better or for worse, the way contemporary institutions typically deal with this problem is to simply assume any untrustworthy information is exactly zero probability. None at all. The issue with this comes up that contemporary institutions use "has a degree in the field/peer acclaim" as a way to identify who might have something trustworthy to say, and weight "has analyzed the raw data with correct math but is some random joe" as falling in that zero case.
This is where we end up with all kinds of failures and one of the many problems we need a form of AI to solve.
But yes you have hit on a way to filter potentially untrustworthy information without just throwing it out. In essence, you currently have a belief and confidence. Someone has some potentially untrustworthy information that differs from your belief. Your confidence in that data should decrease faster than the difference between the information and your present belief.
↑ comment by gjm · 2021-03-09T16:13:18.404Z · LW(p) · GW(p)
I agree with your analysis. For a Pascal's mugging to work, you need to underestimate how small Pr(your interlocutor is willing and able to change your utility by x) gets when x gets large. Human beings are bad at estimating that, which is why when we explicitly consider PM-type situations in an expected-utility framework we may get the wrong answer; it's possible that there is a connection between this and the fact (which generally saves us from PM-like problems in real life) that we tend to round very small probabilities to zero, whether explicitly or implicitly by simply dismissing someone who comes to us with PM-type claims.
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-03-06T17:59:05.946Z · LW(p) · GW(p)
Learning feedback loops
Putting a serious effort into learning Italian in the classroom can make it possible to immerse yourself in the language when you visit Italy. Studying hard for an engineering interview lets you get a job where you'll be able to practice a set of related skills all the time. Reading a scientist's research papers makes you seem like an attractive candidate to work in their lab, where you'll gain a much more profound knowledge of the field.
This isn't just signaling. It's much more about acquiring the minimal competency to participate in the real thing without being so disruptive that people will kick you out, so that you can learn better.
The ideal role of education, then, would be to give students that minimal competency, plus some safety margin, and then shove them out the door and into real-world practice environments.
You could imagine a high-school Italian class in which students learned in the classroom for 1-2 years, and all those who passed an exam were able to move to Italy for 3 months of immersion. Or a school that also functioned as a temp agency, alternating between schooling its students in engineering, programming, and math courses and sending them to do progressively higher-level work in real engineering firms. Or a programming course for middle-schoolers that started with classroom learning, and then grouped students into teams to develop video games which they would try to sell (and who cares if they fail?).
Real schools rarely work in this way, as classroom/on-the-job hybrids. If you're a student, perhaps you can adapt your approach to educating yourself in this way.
Replies from: Dagon↑ comment by Dagon · 2021-03-06T22:05:04.801Z · LW(p) · GW(p)
This isn't just signaling.
That's the crux of most of the education debates. In reality, almost nothing is just signaling - it's a mix of value and signaling, because that value is actually what's being signaled. The problem is that it's hard to identify the ratio of real and signaled value without investing a whole lot, and that leads to competitive advantage (in some aspects) to those who can signal without the expense of producing the real value.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2021-03-07T07:11:28.496Z · LW(p) · GW(p)
Absolutely. There are plenty, plenty of parasites out there. And I hope we can improve the incentives. Thing is, it also takes smart people with integrity just showing up and insisting on doing the right thing, treating the system with savvy, yes, but also acting as if the system works the way it’s supposed to work.
I’m going into a scientific career. I immediately saw the kind of lies and exploitations that are going hand in hand with science. At the same time, there are a lot of wonderful people earnestly doing the best research they can.
One thing I’ve seen. Honest people aren’t cynical enough, and they’re often naive. I have met people who’ve thrown years away on crap PIs, or decades on opaque projects with no foundation.
I know that for me, if I’m going to wade into it, I have to keep a vision of how things are supposed to be, as well as the defects and parasitism.
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-02-20T10:16:10.972Z · LW(p) · GW(p)
Business idea: Celebrity witness protection.
There are probably lots of wealthy celebrities who’d like to lose their fame and resume a normal life. Imagine a service akin to witness protection that helped them disappear and start a new life.
I imagine this would lead to journalists and extortionists trying to track them down, so maybe it’s not tractable in the end.
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-02-14T23:28:07.208Z · LW(p) · GW(p)
Just a notepad/stub as I review writings on filtered evidence:
One possible solution to the problem of the motivated arguer is to incentivize in favor of all arguments being motivated. Eliezer covered this in "What Evidence Filtered Evidence?" [LW · GW]So a rationalist response to the problem of filtered evidence might be to set up a similar structure and protect it against tampering.
What would a rationalist do if they suspected a motivated arguer was calling a decision to their attention and trying to persuade them of option A? It might be to become a motivated arguer in the opposite direction, for option B. This matches what we see in psych studies. And this might be not a partisan reaction in favor of option B, but rather a rejection of a flawed decision-making process in which the motivated arguers are acting both as lawyer, jury, and judge. Understood in this framework, doubling-down when confronted with evidence to the contrary is a delaying tactic, a demand for fairness, not a cognitive bias.
Eliezer suggests that it's only valid to believe in evolution if you've spent 5 minutes listening to creationists as well. But that only works if you're trying to play the role of dispassionate judge. If instead you're playing the role of motivated arguer, the question of forming true beliefs about the issue at hand is beside the point.
Setting up a fair trial, with a judge and jury whose authority and disinterest is acknowledged, is an incredibly fraught issue even in actual criminal trials, where we've had the most experience at it.
But if the whole world is going to get roped into being a motivated arguer for one side or the other, because everybody believes that their pet issue isn't getting a fair trial, then there's nobody left to be the judge or the jury.
What makes a judge a judge? What makes a jury a jury? In fact, these decompose into a set of several roles:
- Trier of law
- Trier of fact
- Passer of sentence
- Keeper of order
In interpreting arguments, to be a rationalist perhaps means to choose the role of judge or jury, rather than the role of lawyer.
In the "trier of law" role, the rationalist would ask whether the procedures for a fair trial are being followed. As "trier of fact," the rationalist would be determining whether the evidence is valid and what it means. As "passer of sentence," the rationalist would be making decisions based on it. As "keeper of order," they are ensuring this process runs smoothly.
I think the piece we're often missing is "passer of sentence." It doesn't feel like it means much if the only decision that will be influenced by your rationalism is your psychological state. Betting, or at least pre-registration with your reputation potentially at stake, seems to serve this role in the absence of any other consequential decision. Some people like to think, to write, but not to do very much with their thoughts or writings. I think a rationalist needs to strive to do something with their rationalism, or at least have somebody else do something, to be playing their part correctly.
Actually, there's more to a trial that that:
- What constitutes a crime?
- What triggers an investigation?
- What triggers an arrest and trial?
- What sorts of policing should society enact? How should we allocate resources? How should we train? What should policy be for responding to problems?
As parallels for a rationalist, we'd have:
"How, in the abstract, do we define evidence and connect it with a hypothesis?"
"When do we start considering whether or not to enter into a formal 'make a decision' about something? I.e. to place a bet on our beliefs?"
"What should lead us to move from considering a bet, to committing to one?"
"What practical strategies should we have for what sorts of data streams to take in, how to coordinate around processing them, how to signal our roles to others, build trust with the community, and so on? How do we coordinate this whole 'rationality' institution?"
And underneath it all, a sense for what "normalcy" looks like, the absence of crime.
I kind of like this idea of a mapping -> normalcy -> patrol -> report -> investigation -> trial -> verdict -> carrying out sentence analogy for rationalism. Instead it would be more like:
Mapping:
- getting a sense of the things that matter in the world. for the police, it's "where's the towns? the people? where are crime rates high and low? what do we especially need to protect?"
- this seems to be the stage where an idealization matters most. for example, if you decide that "future lives matter" then you base your mapping off the assumption that the institutions of society ought to protect future lives, even if it turns out to be that they normally don't.
- the police aren't supposed to be activists or politicians. in the same way, i think it makes sense for rationalists to split their function between trying to bring normalcy in line with their idealized mapping, and improving their sense of what is normal. here we have the epistemics/instrumentality divide again. the police/politics analogy doesn't make perfect sense here, except that the policing are trying to bring actual observational behavior in line with theoretically optimal epistemic practices.
Normalcy might look like:
- the efficient market hypothesis
- the world being full of noise, false and superficial chatter, deviations from the ideal, cynicism and stupidity
- understanding how major institutions are supposed to function, and how they actually function
- base rates for everything
- parasitism, predation
Patrol:
- once a sense of normalcy on X is established, you look for deviations from it - not just the difference between how they're supposed to function vs. actually function, but how they normally actually function vs. deviations from that
- perhaps "expected" is better than "normal" in many situations? "normal" assumes a static situation, while "expected" can fit both static and predictably changing situations.
Report:
- conveying your observations of a deviation from normalcy to someone who cares (maybe yourself)
Investigation:
- gathering evidence for whether or not your previous model of normalcy can encompass the deviation, or whether it needs to be updated/altered/no longer holds
Trial:
- creating some system for getting strong arguments for and against the previous model
- a dispassionate judge/jury
Verdict:
- Some way of making a decision on which side wins, or declaring a mistrial
Carrying out the sentence:
- Placing a bet or taking some other costly action, determined at least to some extent in advance, the way that sentencing guidelines do.
It's tricky though.
If you want a big useful picture of the world, you can't afford to investigate every institution from the ground up. If you want to be an effective operator, you need to join in a paradigm and help advance it, not try to build a whole entire worldview from scratch with no help. If you want to invent a better battery, you don't personally re-invent physics first.
So maybe the police metaphor doesn't work so well. In fact, we need to start with a goal. Then we work backwards to decide what kinds of models we need to understand in order to determine what actions to take in order to achieve that goal.
So we have a split.
Goal setting = ought
Epistemics = is
The way we "narrow down" epistemics is by limiting our research to fit our goals. We shouldn't just jump straight to epistemics. We need a very clear sense of what our goals are, why, a strong reason. Then the epistemics follow.
I've had some marvelously clarifying experiences with deliberately setting goals. What makes a good goal?
- Any goal has a state (success, working, failure), a justification (consequences, costs, why you?), and strategy/tactics for achieving it. Goals sometimes interlink, or can have sharp arbitrary constraints (i.e. given that I want to work in biomedical research, what's the best way I can work on existential risk?).
- You gather evidence that the state, justification, strategy/tactics are reasonable. The state is clear, the justification is sound, the strategy/tactics are in fact leading towards the success state. Try to do this with good epistemic hygiene
Doing things with no fundamental goal in mind I think leads to, well, never having had any purpose at all. What if my goal were to live in such a way that all my behaviors were goal-oriented?
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-01-31T02:51:13.677Z · LW(p) · GW(p)
Aspects of learning that are important but I haven't formally synthesized yet:
- Visual/spatial approaches to memorization
- Calibrating reading speeds/looking up definitions/thinking up examples: filtering and organizing to distinguish medium, "future details," and the "learning edge"
- Mental practice/review and stabilizing an inner monologue/thoughts
- Organization and disambiguation of review questions/procedures
- Establishing procedures and stabilizing them so you can know if they're working
- When to carefully tailor your approach to a particular learning challenge, and when to just behave mechanically (i.e. carefully selecting problems addressing points of uncertainty vs. "just do the next five problems every 3 days")
- Planning, anticipating, prioritizing, reading directions adequately, for successful execution of complex coordinated tasks in the moment.
- Picking and choosing what material to focus on and what not to study
Distinctions:
Cognitivist vs behaviorist, symbolic vs visual/spatial, exposure vs review, planning vs doing, judgment vs mechanism.
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-01-31T02:31:48.486Z · LW(p) · GW(p)
Cognitive vs. behaviorist approaches to the study of learning
I. Cognitivist approaches
To study how people study on an internal, mental level, you could do a careful examination of what they report doing with their minds as they scan a sentence of a text that they're trying to learn from.
For example, what does your mind do if you read the following sentence, with the intent to understand and remember the information it contains?
"The cerebral cortex is the site where the highest level of neural processing takes place, including language, memory and cognitive function."
For me, I do the following (which takes deliberate effort and goes far beyond what I would do/experience doing if I were to just be reading "naturally"):
- Isolate and echo "cerebral cortex" and "neural processing." By this, I mean I'll look at and inner-monologue the phrase by itself, waiting a few seconds at least to let it "sink in."
- Visualize the phrase "highest level of neural processing," by picturing a set of tiers with sort of electrical sparts/wires in them, with the word "cerebral cortex" across the top and a sort of image of grey matter resting on it like a brain on a shelf.
- Isolate and echo "language," and visualize a mouth on that "top shelf" image.
- Isolate and echo "memory," and visualize a thought-bubble cloud on the "top shelf" image.
- Isolate and echo "cognitive function," and visualize a white board with some sort of diagram on it on the "top shelf" image.
- Try to paraphrase the whole sentence from memory with my eyes closed.
Going beyond this, I might do more things to try and make the contents of the sentence sink in deeper, taken alone. I might give examples by thinking of things I couldn't do without my cerebral cortex: speak, write, and understand people talking to me; remember my experiences, or make decisions. I'd be a mute, stone-like void, a vegetable; or perhaps demented.
II. Behaviorist approaches
A behaviorist approach misses a lot of the important stuff, but also offers some more tractable solutions. A behaviorist might study things like how long a skilled learner's eyes rest on any given sentence in a textbook, or rates of information transmission in spoken language. A behaviorist recommendation might be something like:
"All languages transmit information at a fairly consistent rate. But different fields compress information, reference prior knowledge, and use intuitive human cognitive abilities like visual/spatial memory, to different degrees.
Because of this, different scholarly fields may be best read at differing rates.
Furthermore, each reading might need to be approached differently. Some text that was unfamiliar before is now not only familiar but unnecessary. Other text that was overly detailed is now of primary relevance. The text may no longer function to teach new concepts, but rather to remind you of how concepts you understand fit together, or to fill gaps in a model that you already have in place.
Because of that, different sections of the text, and different readings, in different textbooks, need to be read at different speeds to match your ideal rate of information intake. Too fast or too slow, and you will not learn as quickly as you could.
But because your mind, and the particular text you're reading, are so idiosyncratic, it's not tractable to give you much guidance about this.
Instead, simply try slowing down your reading speed in difficult sections. Try pausing for several seconds after every sentence, or even after certain phrases."
There's very little reference to what people should do "inside their minds" here. The most is a casual reference to "difficult sections," which implies that the reader has to use their inner reaction to the text to gauge whether or not the text is difficult and worth slowing down on.
III. Conclusion
This line between cognitivist and behaviorist approaches to the science of learning seems valuable for studying one's own process of learning how to learn. Of course, there is an interface between them, just as there's an interface between chemistry and biology.
But defining this distinction allows you to limit the level of detail you're trying to capture, which can be valuable for modeling. As I continue to explore learning how to learn, I'll try to do it with this distinction in mind.
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-01-24T05:55:54.597Z · LW(p) · GW(p)
Practice sessions in spaced-repetition literature
Spaced repetition helps, but how do spaced-repetition researchers have their subjects practice within a single practice session? I'd expect optimized practice to involve not only spacing and number of repetitions, but also an optimal way of practicing within sessions.
So far, I've seen a couple formats:
- Subjects get an explanation, examples, and a short, timed set of practice problems.
- Subjects practice with flash cards. Each "round" of flash cards involves looking at only the cards they haven't seen or got wrong last time. They do back-to-back rounds of flash cards until they get every card in the "round" right. In the end, they've gotten every card correct once.
This helps me answer a lingering question. What sort of cutoff for "good enough for today?" are these psychologists using for their practice sessions?
The answer seems to be either
- Completed a pre-defined, do-able workload or
- Was able to memorize everything, even if they'd only referred to the flashcard just a moment before.
I adapt this for my math studies by listing concepts, theorems, and proofs from 1-2 sections of a chapter in a Google Doc. I mark the ones I can't remember/got wrong in colored text, and the ones I got right in black. Then I try to rehearse the marked ones again, like with flash cards, until I have recited each proof/concept from memory once.
I also will try to solve one or two relevant problems from the back of the book. They're typically much more involved than anything I've seen in the psych literature.
One way I suppose psychologists could try to study the "optimal spaced repetition study session" would be to determine to what extent overlearning bolsters retention in conjunction spaced repetition. So for example, if groups 1 and 2 do practice problems in week 1 and week 2, then get tested in week 3, but group 1 does 5 problems/session and group 2 does 10 problems/session, how much better does group 2 do on their test?
Theoretically, the concept of overlearning seems to posit that there's a point at which a topic is "learned," beyond which it has been "overlearned." Is the benefit of overlearning to provide a safety margin to ensure the subjects actually learned it? Or is it to give extra practice even to subjects who successfully learned the topic in a smaller amount of time?
It seems like we want to know if there's a sort of "minimal unit of learning." Intuitively, there must be. If I just skim through section 7.1 of my linear algebra textbook, but never read it in depth, I probably haven't actually learned anything. At best, I might retain a couple key phrases. But if all I ever do is skim the text, I probably never will learn the material.
So the relevant question is "what is the minimal unit of learning?" and "how do you know if you've achieved it?" There are probably multiple answers to the latter: can you solve a relevant practice problem? Can you recite the definitions of the concepts and the proof in your own words?
The former question, though, is more like "given that your level of understanding of topic T is at level X, what's the least you need to do to get to level X + 1?" And that will depend on T and X, so it's hard to specify in general.
But I think it's helpful to frame it this way, since I at least often think in a pretty binary fashion. Like, to have "learned something" means that I can execute it effortlessly and accurately, and can also explain the underpinnings of why the process works.
It seems helpful to break down the multiple factors of what it means to "learn something" and put them on a scale.
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-01-23T18:38:25.298Z · LW(p) · GW(p)
Are democracies doomed to endless intense, intractable partisanship?
Model for Yes: In a democracy, there will be a set of issues. Each has a certain level of popular or special-interest support, as well as constitutionality.
Issues with the highest levels of popular support and constitutionality will get enacted first, if they weren't already in place before the democracy was founded.
Over time, issues with more marginal support and constitutionality will get enacted, until all that's left are the most marginal issues. The issues that remain live issues will be ones that have enough passion behind them to keep them live issues, yet slim enough support to make them intractable.
The result is a climate of intense, intractable partisanship. That doesn't mean there's no action, because the laws of chance say that each side will win occasionally. It just means there'll be a lot of back and forth. A law gets passed, then repealed during the next election cycle. An executive order is made, then undone in four years.
Model for No: We do actually see dramatic changes in support for policy in short periods of time. In America, the Affordable Care Act, legalization of recreational marijuana, and support for same sex marriage have all increased.
If popular support can change, then even an intensely partisan atmosphere can change as well. There will be the appearance of being at a permanent fruitless standstill, even as policy does change regularly to accord with popular support.
So how does popular support change?
That's a harder question. My dad once told me that "people won't fight to gain a service, but they will fight to keep it from being taken away from them." He made a $6 million bet on this and won, so I trust him. Can't share details, sorry.
But under this model, you have a service or a right that's right on the edge of majority support. The random jiggling of partisan debate eventually gets it passed. Then it gains a great deal of additional popular support, because now it's a tangible reality rather than a hypothetical possibility.
So politics might work like this:
- Stage 1 is shoring up the base. Getting the most ardent ideologues to rally behind a particular policy to get it up to, say, 33% support.
- Stage 2 is horse trading. You make concessions to buy around 17% additional support, bringing it up to around 50% support. Then you keep it there for as long as it takes to get to 51%.
- Stage 3 is the downhill slope, where you enjoy a rush of added support just for having won a vote.
One question I have is about stage 2. How does the price to gain additional support change as you approach 50% support? I could imagine that it increases, since you're appealing to people with a worldview that's more and more remote from your own. You buy the cheapest votes first.
But I could also imagine that right as you near 50% support, the price suddenly drops. If you only need 1 more vote to get to a majority, and you have 3 people who are prospective people to be that vote, I'd imagine they'd be bidding against each other to be that last vote.
But I also imagine that this would ripple out into the people who are slightly more supportive as well, so that ultimately you wind up with a fairly smooth price gradient that increases right up to 51%.
Effective politicians are mostly working in the "horse trading" stage. They need to have things to offer as concessions in order to buy what they really want. Activists are working in the "shoring up the base" stage. What they're trying to do is find groups of people who are likely to support an issue without too much convincing, but just happen not to have heard about it yet.
There must be some grey area between stages. How do activists convince a candidate to adopt an issue and start spending their political resources on it?
Replies from: None↑ comment by [deleted] · 2021-01-24T08:55:39.274Z · LW(p) · GW(p)
I think the current era is a novel phenomena.
Consider that 234 years ago, long dead individuals wrote in a statement calling for there to be "or abridging the freedom of speech, or of the press".
Emotionally this sounds good, but consider. In a our real universe, information is not always a net gain. It can be hostile propaganda or a virus designed to spread rapidly causing harm to it's hosts.
Yet in a case of 'bug is a feature', until recently most individuals didn't really have freedom of speech. They could say whatever they wanted, but had no practical way for extreme ideas to reach large audiences. There was a finite network of newspapers and TV news networks - less than about 10 per city and in many cases far less than that.
Newspapers and television could be held liable for making certain classes of false statements, and did have to routinely pay fines. Many of the current QAnon conspiracy theories are straight libel and if the authors and publishers of the statements were not anonymous they would be facing civil lawsuits.
The practical reason to allow a freedom of speech today is current technology has no working method to objectively decide if a piece of information is true, partially true, false, or is hostile information intended to cause harm. (we rely on easily biased humans to make such judgements and this is error prone and subject to the bias of whoever pays the humans - see Russia Today)
I don't know what to do about this problem. Just that it's part of the reason for the current extremism.
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-01-07T22:32:19.753Z · LW(p) · GW(p)
I've noticed that when I write posts or questions, much of the text functions as "planning" for what's to come. Often, I'm organizing my thoughts as I write, so that's natural.
But does that "planning" text help organize the post and make it easier to read? Or is it flab that I should cut?
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-11-28T05:01:02.618Z · LW(p) · GW(p)
Thinking, Too Fast and Too Slow
I've noticed that there are two important failure modes in studying for my classes.
Too Fast: This is when learning breaks down because I'm trying to read, write, compute, or connect concepts too quickly.
Too Slow: This is when learning fails, or just proceeds too inefficiently, because I'm being too cautious, obsessing over words, trying to remember too many details, etc.
One hypothesis is that there's some speed of activity that's ideal for any given person, depending on the subject matter and their current level of comfort with it.
I seem to have some level of control over the speed and cavalier confidence I bring to answering questions. Do I put down the first response that comes into my head, or wrack my brains looking for some sort of tricky exception that might be relevant?
Deciding what that speed should be has always been intuitive. Is there some leverage here to enhance learning by sensitizing myself to the speed at which I ought to be practicing?
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-11-11T22:08:14.647Z · LW(p) · GW(p)
Different approaches to learning seem to be called for in fields with varying levels of paradigm consensus. The best approach to learning undergraduate math/CS/physics/chemistry seems different from the best one to take for learning biology, which again differs from the best approach to studying the economics/humanities*.
High-consensus disciplines have a natural sequential order, and the empirical data is very closely tied to an a priori predictive structure. You develop understanding by doing calculations and making theory-based arguments, along with empirical work/applications and intuition-building.
Medium-consensus disciplines start with a lot of memorization of empirical data, tied together with broad frameworks that let the parts "hang together" in a way that is legible and reliable, but imprecise. Lack of scientific knowledge about empirical data, along with massive complexity of the systems under study, prevent a full consensus accounting.
Low-consensus disciplines involve contrasting perspectives, translating complex arguments into accessible language, and applying broad principles to current dilemmas.
High-consensus disciplines can be very fun to study. Make the argument successfully, and you've "made a discovery."
The low-consensus disciplines are also fun. When you make an argument, you're engaged in an act of persuasion. That's what the humanities are for.
But those medium-consensus disciplines are in kind of an uncomfortable middle that doesn't always satisfy. You wind up memorizing and regurgitating a lot of empirical data and lab work, but persuasive intellectual argument is the exception, rather than the rule.
For someone who's highly motivated by persuasive intellectual argument, what's the right way forward? To try and engage with biology in a way that somehow incorporates more persuasive argument? To develop a passion for memorization? To accept that many more layers of biological knowledge must accumulate before you'll be conversant in it?
*I'm not sure these categories are ideal.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-10-23T20:14:32.765Z · LW(p) · GW(p)
What rationalists are trying to do is something like this:
- Describe the paragon of virtue: a society of perfectly rational human beings.
- Explain both why people fall short of that ideal, and how they can come closer to it.
- Explore the tensions in that account, put that plan into practice on an individual and communal level, and hold a meta-conversation about the best ways to do that.
This looks exactly like virtue ethics.
Now, we have heard that the meek shall inherit the earth. So we eschew the dark arts; embrace the virtues of accuracy, precision, and charity; steelman our opponents' arguments; try to cite our sources; question ourselves first; and resist the temptation to simply the message for public consumption.
Within those bounds, however, we need to address a few question-clusters.
What keeps our community strong? What weakens it? What is the greatest danger to it in the next year? What is the greatest opportunity? What is present in abundance? What is missing?
How does this community support our individual growth as rationalists? How does it detract from it? How could we be leveraging what our community has to offer? How could we give back?
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-08-21T03:13:20.241Z · LW(p) · GW(p)
You can justify all sorts of spiritual ideas by a few arguments:
- They're instrumentally useful in producing good feelings between people.
- They help you escape the typical mind fallacy.
- They're memetically refined, which means they'll fit better with your intuition than, say, trying to guess where the people you know fit on the OCEAN scale.
- They're provocative and generative of conversation in a way that scientific studies aren't. Partly that's because the language they're wrapped in is more intriguing, and partly isn't because everybody's on a level playing field.
- It's a way to escape the trap of intelligence-signalling and lowers the barrier for verbalizing creative ideas. If you're able to talk about astrology, it lets people feel like they have permission to babble.
- They're aesthetically pleasing if you don't take them too seriously
↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-08-21T03:31:47.872Z · LW(p) · GW(p)
I would be interested in arguments about why we should eschew them that don't resort to activist ideas of making the world a "better place" by purging the world of irrationality and getting everybody on board with a more scientific framework for understanding social reality or psychology.
I'm more interested in why individual people should anticipate that exploring these spiritual frameworks will make their lives worse, either hedonistically or by some reasonable moral framework. Is there a deontological or utilitarian argument against them?
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-07-29T19:22:41.714Z · LW(p) · GW(p)
A checklist for the strength of ideas:
Think "D-SHARP"
- Is it worth discussing?
- Is it worth studying?
- Is it worth using as a heuristic?
- Is it worth advertising?
- Is it worth regulating or policing?
Worthwhile research should help the idea move either forward or backward through this sequence.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-07-27T01:24:00.194Z · LW(p) · GW(p)
Why isn’t California investing heavily in desalination? Has anybody thought through the economics? Is this a live idea?
Replies from: Dagon, ChristianKl↑ comment by Dagon · 2020-07-27T16:12:03.215Z · LW(p) · GW(p)
There's plenty of research going on, but AFAIK, no particular large-scale push for implementation. I haven't studied the topic, but my impression is that this is mostly something they can get by with current sources and conservation for a few decades yet. Desalinization is expensive, not just in terms of money, but in terms of energy - scaling it up before absolutely needed is a net environmental harm.
↑ comment by ChristianKl · 2020-07-27T18:06:35.582Z · LW(p) · GW(p)
This article seems to be about the case. The economics seem unclear. The politics seem bad because it means taking on the enviromentalists.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-07-22T01:57:22.891Z · LW(p) · GW(p)
My modified Pomodoro has been working for me. I set a timer for 5 minutes and start working. Every 5 minutes, I just reset the timer and continue.
For some reason it gets my brain into "racking up points" mode. How many 5-minute sessions can I do without stopping or getting distracted? Aware as I am of my distractability, this has been an unquestionably powerful technique for me to expand my attention span.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-07-21T20:23:29.056Z · LW(p) · GW(p)
All actions have an exogenous component and an endogenous component. The weights we perceive differ from action to action, context to context.
The endogenous component has causes and consequences that come down to the laws of physics.
The exogenous component has causes and consequences from its social implications. The consequences, interpretation, and even the boundaries of where the action begins and ends are up for grabs.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-07-15T22:27:55.981Z · LW(p) · GW(p)
Failure modes in important relationships
- Being quick and curt when they want to connect and share positive emotions
- Meeting negative emotions with blithe positive emotions (ie. pretending like they're not angry, anxious, etc)
- Mirroring negative emotions: meeting anxiety with anxiety, anger with anger
- Being uncompromising, overly "logical"/assertive to get your way in the moment
- Not trying to express what you want, even to yourself
- Compromising/giving in, hoping next time will be "your turn"
Practice this:
- Focusing [LW · GW]to identify your own elusive feelings
- Empathy to identify and express the other person's needs, feelings, information. Look for a "that's right." You're not rushing to win, nor rushing to receive empathy. The more they reveal, the better it is for you (and for them, because now you can help find a high-value trade rather than a poor compromise).
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-07-11T19:47:54.530Z · LW(p) · GW(p)
Good reading habit #1: Turn absolute numbers into proportions and proportions into absolute numbers.
For example, in reading "With almost 1,000 genes discovered to be differentially expressed between low and high passage cells [in mouse insulinoma cells]," look up the number of mouse genes (25,000) and turn it into a percentage so that you can see that 1,000 genes is 4% of the mouse genome.
↑ comment by Emrik (Emrik North) · 2022-11-09T19:30:11.677Z · LW(p) · GW(p)
Eigen's paradox is one of the most intractable puzzles in the study of the origins of life. It is thought that the error threshold concept described above limits the size of self replicating molecules to perhaps a few hundred digits, yet almost all life on earth requires much longer molecules to encode their genetic information. This problem is handled in living cells by enzymes that repair mutations, allowing the encoding molecules to reach sizes on the order of millions of base pairs. These large molecules must, of course, encode the very enzymes that repair them, and herein lies Eigen's paradox...
(I'm not making any point, just wanted to point to interesting related thing.)
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-07-18T02:01:43.041Z · LW(p) · GW(p)
What is the difference between playing devil's advocate and steelmanning an argument? I'm interested in any and all attempts to draw a useful distinction, even if they're only partial.
Attempts:
- Devil's advocate comes across as being deliberately disagreeable, while steelmanning comes across as being inclusive.
- Devil's advocate involves advancing a clearly-defined argument. Steelmanning is about clarifying an idea that gets a negative reaction due to factors like word choice or some other superficial factor.
- Devil's advocate is a political act and is only relevant in a conversation between two or more people. Steelmanning can be social, but it can also be done entirely in conversation with yourself.
- Devil's advocate is about winning an argument, and can be done even if you know exactly how the argument goes and know in advance that you'll still disagree with it when you're done making it. Steelmanning is about exploring an idea without preconceptions about where you'll end up.
- Devil's advocate doesn't necessarily mean advancing the strongest argument, only the one that's most salient, hardest for your conversation partner to argue against, or most complex or interesting. Steelmanning is about searching for an argument that you genuinely find compelling, even if it's as simple as admitting your own lack of expertise and the complexity of the issue.
- Devil's advocate can be a diversionary or stalling tactic, meant to delay or avoid an unwanted conclusion of a larger argument by focusing in on one of its minor components. Steelmanning is done for its own sake.
- Devil's advocate comes with a feeling of tension, attention-hogging, and opposition. Steelmanning comes with a feeling of calm, curiosity, and connection.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-07-17T01:58:50.950Z · LW(p) · GW(p)
Empathy is inexpensive and brings surprising benefits. It takes a little bit of practice and intent. Mainly, it involves stating the obvious assumption about the other person's experience and desires. Offer things you think they'd want and that you'd be willing to give. Let them agree or correct you. This creates a good context in which high-value trades can occur, without needing an conscious, overriding, selfish goal to guide you from the start.
Replies from: mr-hire↑ comment by Matt Goldenberg (mr-hire) · 2020-07-17T21:13:29.481Z · LW(p) · GW(p)
FWIW, I like to be careful about my terms here.
Empathy is feeling what the other person is feeling.
Understanding is understanding what the other person is feeling.
Active Listening is stating your understanding and letting the other person correct you.
Empathic listening is expressing how you feel what the other person is feeling.
In this case, you stated Empathy, but you're really talking about Active Listening. I agree it's inexpensive and brings surprising benefits.
Replies from: Raemon, AllAmericanBreakfast↑ comment by Raemon · 2020-07-17T21:33:28.116Z · LW(p) · GW(p)
I think whether it's inexpensive isn't that obvious. I think it's a skill/habit, and it depends a lot on whether you've cultivated the habit, and on your mental architecture.
Replies from: mr-hire↑ comment by Matt Goldenberg (mr-hire) · 2020-07-17T21:37:18.528Z · LW(p) · GW(p)
Active listening at a low level is fairly mechanical, and can still acrue quite a few benefits. Its not as dependent on mental architecture as something like empathic listening. It does require some mindfulness to create the habit, but for most people I'd put it on only a slightly higher level of difficulty to acquire than e.g. brushing your teeth.
Replies from: Raemon↑ comment by Raemon · 2020-07-17T21:46:25.390Z · LW(p) · GW(p)
Fair, but I think gaining a new habit like brushing your teeth is actually pretty expensive.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-07-17T22:40:55.679Z · LW(p) · GW(p)
Empathy isn't like brushing your teeth. It's more like berry picking. Evolution built you to do it, you get better with practice, and it gives immediate positive feedback. Nevertheless, due to a variety of factors, it is a sorely neglected practice, even when the bushes are growing in the alley behind your house.
↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-07-17T22:36:49.165Z · LW(p) · GW(p)
I don't think what I'm calling empathy, either in common parlance or in actual practice, decomposes neatly. For me, these terms comprise a model of intuition that obscures with too much artificial light.
Replies from: mr-hire↑ comment by Matt Goldenberg (mr-hire) · 2020-07-17T23:22:35.549Z · LW(p) · GW(p)
In that case, I don't agree that the thing you're claiming has low costs. As Raemon says in another comment this type of intuition only comes easily to certain people. If you're trying to lump together the many skills I just pointed to, some are easy for others and some harder.
If however, the thing you're talking about is the skill of checking in to see if you understand another person, then I would refer to that as active listening.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-07-18T01:47:54.007Z · LW(p) · GW(p)
Of course, you're right. This is more a reminder to myself and others who experience empathy as inexpensive.
Though empathy is cheap, there is a small barrier, a trivial inconvenience, a non-zero cost to activating it. I too often neglect it out of sheer laziness or forgetfulness. It's so cheap and makes things so much better that I'd prefer to remember and use it in all conversations, if possible.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-07-15T21:36:37.866Z · LW(p) · GW(p)
Chris Voss thinks empathy is key to successful negotiation.
Is there a line between negotiating and not, or only varying degrees of explicitness?
Should we be openly negotiating more often?
How do you define success, when at least one of his own examples of a “successful negotiation” is entirely giving over to the other side?
I think the point is that the relationship comes first, greed second. Negotiation for Voss is exchange of empathy, seeking information, being aware of your leverage. Those factors are operating all the time - that’s the relationship.
The difference between that and normal life? Negotiation is making it explicit.
Are there easy ways to extend more empathy in more situations? Casual texts? First meetings? Chatting with strangers?
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-06-08T01:23:06.267Z · LW(p) · GW(p)
If I want to change minds...
... how many objections will I have to overcome?
... from how many readers?
... in what combinations?
... how much argument will they tolerate before losing interest?
... and how individually tailored will they have to be?
... how expensive will providing them with legible evidence be?
... how equipped are they to interpret it accurately?
comment by DirectedEvolution (AllAmericanBreakfast) · 2021-01-04T05:43:46.441Z · LW(p) · GW(p)
Hot top: "sushi-grade" and "sashimi-grade" are marketing terms that mean nothing in terms of food safety. Freezing inactivates pretty much any parasites that might have been in the fish.
I'm going to leave these claims unsourced, because I think you should look it up and judge the credibility of the research for yourself.
Replies from: mr-hire↑ comment by Matt Goldenberg (mr-hire) · 2021-01-04T18:51:05.790Z · LW(p) · GW(p)
It's partially about taste isn't it? Sushi grade and sashimi grade will theoretically smell less fishy
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2021-01-04T20:15:17.551Z · LW(p) · GW(p)
Fishy smell in saltwater fish is caused by breakdown of TMAO to TME. You can rinse off TME on the surface to reduce the smell. Fresher fish should also have less smell.
So if people are saying “sushi grade” when what they mean is “fresh,” then why not just say “fresh?” It’s a marketing term.
Replies from: mr-hire↑ comment by Matt Goldenberg (mr-hire) · 2021-01-04T21:05:16.144Z · LW(p) · GW(p)
I always thought sushi grade was just the term for "really really fresh :)"