«Boundaries», Part 1: a key missing concept from utility theory
post by Andrew_Critch · 2022-07-26T23:03:55.941Z · LW · GW · 33 commentsContents
1. Boundaries (of living systems) Comparison to Cartesian Boundaries. Comparison to social norms. 2. Canonical disagreement points as missing from utility theory and game theory 3. Boundaries as a way to select disagreement points in bargaining 4. Some really important boundaries 5. Summary None 33 comments
This post has been recorded as part of the LessWrong Curated Podcast, and can be listened to on Spotify, Apple Podcasts, and Libsyn.
This is Part 1 of my «Boundaries» Sequence [? · GW] on LessWrong.
Summary: «Boundaries» are a missing concept from the axioms of game theory and bargaining theory, which might help pin down certain features of multi-agent rationality (this post), and have broader implications for effective altruism discourse and x-risk (future posts).
1. Boundaries (of living systems)
Epistemic status: me describing what I mean.
With the exception of some relatively recent and isolated pockets of research on embedded agency (e.g., Orseau & Ring, 2012; Garrabrant & Demsky, 2018), most attempts at formal descriptions of living rational agents — especially utility-theoretic descriptions — are missing the idea that living systems require and maintain boundaries.
When I say boundary, I don't just mean an arbitrary constraint or social norm. I mean something that could also be called a membrane in a generalized sense, i.e., a layer of stuff-of-some-kind that physically or cognitively separates a living system from its environment, that 'carves reality at the joints' in a way that isn't an entirely subjective judgement of the living system itself. Here are some examples that I hope will convey my meaning:
- a cell membrane (separates the inside of a cell from the outside);
- a person's skin (separates the inside of their body from the outside);
- a fence around a family's yard (separates the family's place of living-together from neighbors and others);
- a digital firewall around a local area network (separates the LAN and its users from the rest of the internet);
- a sustained disassociation of social groups (separates the two groups from each other)
- a national border (separates a state from neighboring states or international waters).
 |  |
 |  |
 |  |
| Figure 1: Cell membranes, skin, fences, firewalls, group divisions, and state borders as living system boundaries. | |
Comparison to Cartesian Boundaries.
For those who'd like a comparison to 'Cartesian boundaries', as in Scott Garrabrant's Cartesian Frames [AF · GW] work, I think what I mean here is almost exactly the same concept. The main differences are these:
- (life-focus) I want to focus on boundaries of things that might naturally be called "living systems" but that might not broadly be considered "agents", such as a human being that isn't behaving very agentically, or a country whose government is in a state of internal disagreement. (I thought of entitling this sequence "membranes" instead, but stuck with 'boundaries' because of the social norm connotation.)
- (flexibility-focus) Also, the theory of Cartesian Frames assumes a fixed cartesian boundary for the agent, rather than modeling the boundary as potentially flexible, pliable, or permeable over time (although it could be extended to model that).
Comparison to social norms.
Certain social norms exist to maintain separations between livings systems. For instance:
- Personal space boundaries. Consider a person Alex who wants to give his boss a hug, in a culture with a norm against touching others without their consent. In that case, the boss's personal space creates a kind of boundary separating the boss from Alex, and there's a protocol — asking permission — that Alex is expected to follow before crossing the boundary.
- Information boundaries for groups. Consider a person Betty who's having a very satisfying romantic relationship, in a culture where there's a norm of not discussing romantic relationships with colleagues at work. In that case, Alice maintains an information boundary between the details of her romantic life and her workplace. The workplace is kind of living system comprising multiple people and conventions for their interaction, and it's being protected from information about Alice's romantic relationships.
- Information boundaries for individuals. Consider a person Cory who has violent thoughts about his friends, in a culture where there's a norm that you shouldn't tell people if you're having violent thoughts about them. In that case, if Cory is thinking about punching David, Cory is expected not to express that thought, as away of protecting David from the influence of the sense of physical threat David would feel and react to if Cory expressed it. In this case, Cory maintains a kind of information boundary around the part of Cory's mind with the violent thoughts, which may be viewed either as enclosing the violent parts of Cory's mind, or as enclosing and protecting the rest of the word outside it.
2. Canonical disagreement points as missing from utility theory and game theory
Epistemic status: uncontroversial overview and explanation of well-established research.
Game theory usually represents players as having utility functions (payoff functions), and often tries to view the outcome of the game as arising as a consequence of the players' utilities. However, for any given concept of "equilibrium" attempting to predict how players will behave, there are often many possible equilibria. In fact, there are a number of theorems in game theory called "folk theorems" (reference: Wikipedia) that show very large spaces of possible equilibria result when games have certain features approximating real-world interaction, such as
- the potential for players to talk to each other and make commitments (Kalai et al, 2010)
- the potential for players to interact repeatedly and thus establish "reputations" with each other (source: Wikipedia).
Here's a nice illustration of a folk theorem from a Chegg.com homework set:
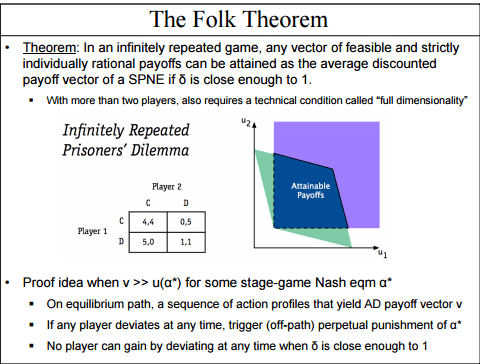
The zillions of possible equilibria arising from repeated interactions leave us with not much of a prediction about what will actually happen in a real-world game, and not much of a normative prescription of what should happen, either.
Bargaining theory attempts to predict and/or prescribe how agents end up "choosing an equilibrium", usually by writing down some axioms to pick out a special point on the Pareto frontier of possible, such as the Nash Bargaining Solution and Kalai-Smordinsky Bargaining Solution (reference: Wikipedia). It's not crucial to understand these figures for the remainder of the post, but if you don't, I do think think it's worth learning about them sometime, starting with the Wikipedia article:
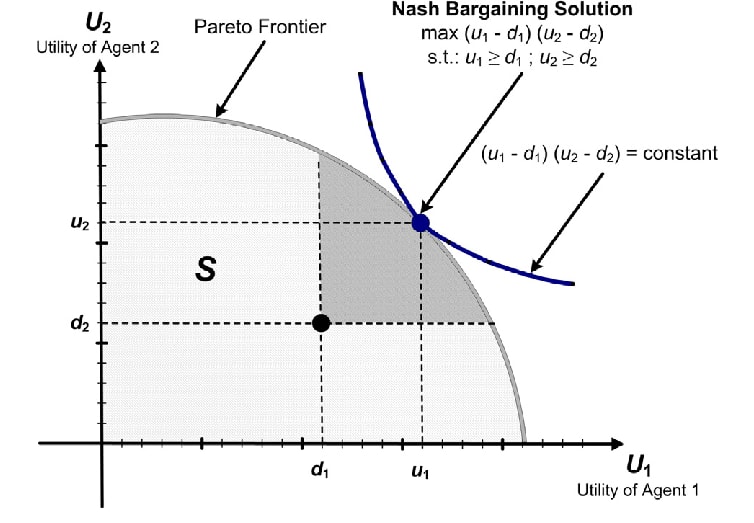
simage source: Karmperis et al, 2013; to learn more, see Wikipedia)
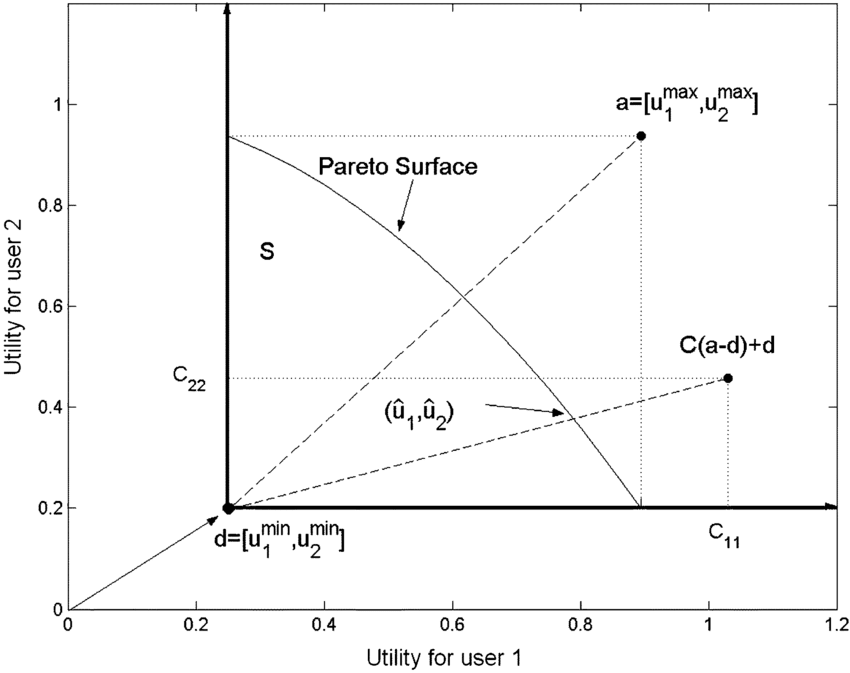
(image source: Borgstrom et al, 2007; to learn more, start with Wikipedia)
The main thing to note about the above bargaining solutions is that they both depend on the existence of a constant point d, called a "disagreement point", representing a pair of constant utility levels that each player will fall back on attaining if the process of negotiation breaks down.
(See also this concurrently written recent LessWrong post [LW · GW]about Kalai & Kalai's cooperative/competitive 'coco' bargaining solution. The coco solution doesn't assume a constant disagreement point, but it does assume transferrable utility, which has its own problems, due to difficulties with defining interpersonal comparisons of utility [source: lots].)
The utility achieved by a player at the disagreement point is sometimes called their best alternative to negotiated agreement (BATNA):
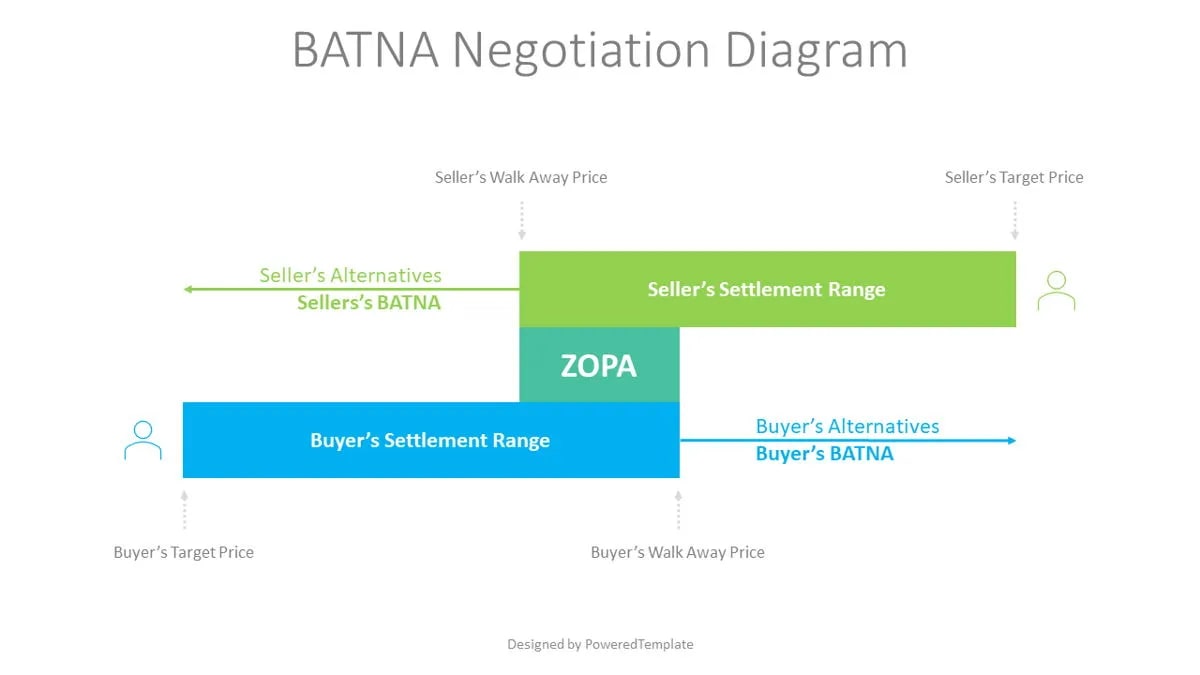
(source: PoweredTemplate.com ... not very academic, but a good illustration!)
Within the game, the disagreement point, i.e., the pair of BATNAs, may be viewed as defining what "zero" (marginal) utility means for each player.
(Why does zero need a definition, you might ask? Recall that the most broadly accepted axioms for the utility-theoretic foundations of game theory — namely, the von Neumann–Morgenstern rationality axioms [reference: Wikipedia]) — only determine a player's utility function modulo a positive affine transformation (). So, in the wild, there's no canonical way to look at an agent and say what is or isn't a zero-utility outcome for that agent.)
While it's appealing to think in terms of BATNAs, in physical reality, payoffs outside of negotiations can depend very much on the players' behavior inside the negotiations, and thus is not a constant. Nash himself wrote about this limitation (Nash, 1953) just three years after originally proposing the Nash bargaining solution. For instance, if someone makes an unacceptable threat against you during a business negotiation, you might go to the police and have them arrested, versus just going home and minding your business if the negotiations had failed in a more normal/acceptable way. In other words, you have the ability to control their payoff outside the negotiation, based on what you observe during the negotiation. It's not a constant; you can affect it.
So, the disagreement point or BATNA concept isn't really applicable on its own, unless something is protecting the BATNA from what happens in the negotiation, making it effectively constant. Basically, the two players need a safe/protected/stable place to walk away to in order for a constant "walk away price" to be meaningful. For many people in many situations, that place is their home:

(source: owned)
Thus, to the extent that we maintain social norms like "mind your own business" and "don't threaten to attack people" and "people can do whatever they want in the privacy of their own homes", we also simplify bargaining dynamics outside the home, by maintaining a well-defined fallback option for each person (a disagreement point), of the form "go home and do your own thing".
3. Boundaries as a way to select disagreement points in bargaining
Epistemic status: research ideas, both for pinning down technical bargaining solutions, and for fixing game theory to be more applicable to real-life geopolitics and human interactions.
Since BATNAs need protection in order to be meaningful in negotiations, to identify BATNAs, we must ask: what protections already exist, going into the negotiation?
For instance,
- Is there already a physically identifiable boundary or membrane separating each agent from the other or its environment? Is it physically strong? If yes, it offers a kind of BATNA: the organisms can simply disengage and focus on applying their resources inside the membrane (e.g., 'taking your ball and going home'). If not,
- Is there an existing social convention for protecting the membrane? If so, it offers a kind of BATNA. If not,
- Would the agents have decided behind a veil of ignorance that they will respect each other's membranes/boundaries, before entering negotiations/interaction? If so, the agents might have already acausally agreed [? · GW] upon a social convention to protect the membranes.
4. Some really important boundaries
In real-world high-stakes negotiations between states — wars — almost the whole interaction is characterized by
- a violation of an existing boundary (e.g., "an attack on American soil"), or threat or potential threat of such a violation, and/or
- what new boundaries, if any, will exist after the violation or negotiation (re-defining territories of the respective nations).
Source: Britannica for kids ... again, not very academic, but nicely evocative of states changing their boundaries.
Finally, the issue of whether AI technology will cause human extinction is very much an issue of whether certain boundaries can be respected and maintained, such as the boundaries of the human body and mind that protect individuals, as well as boundaries around physical territories and cyberspace that (should) protect human civilization.
That, however, will be a topic of a future post. For now, the main take-aways I'd like to re-iterate are that boundaries of living systems are important, and that they have a technical role to play in the theory and practice of how agents interact, including in formal descriptions of how one or more agents will or should reach agreements in cases of conflict.
In the next post, I'll talk more about how that concept of boundaries could be better integrated into discourse on effective altruism.
5. Summary
In this post, I laid out what I mean by boundaries (of living systems), I described how a canonical choice of a "zero point" or "disagreement point" is missing from utility theory and bargaining theory, I proposed that living system boundaries have a role to play in defining those disagreement points, and I briefly alluded to the importance of boundaries in navigating existential risk.
This was Part 1 of my «Boundaries» Sequence [? · GW].
33 comments
Comments sorted by top scores.
comment by Jan_Kulveit · 2022-07-27T14:51:43.727Z · LW(p) · GW(p)
With the exception of some relatively recent and isolated pockets of research on embedded agency (e.g., Orseau & Ring, 2012; Garrabrant & Demsky, 2018), most attempts at formal descriptions of living rational agents — especially utility-theoretic descriptions — are missing the idea that living systems require and maintain boundaries.
While I generally like the post, I somewhat disagree with this summary of state of understanding, which seems to ignore quite a lot of academic research. In particular
- Friston et al certainly understand this (cf ... dozens to hundreds papers claiming and explainting the importance of boundaries for living systems)
- the whole autopoiesis field
- various biology-inspired papers (eg this)
I do agree this way of thinking it is less common among people stuck too much in the VNM basin, such as most of econ or most of game theory.
↑ comment by Andrew_Critch · 2022-09-04T22:43:50.451Z · LW(p) · GW(p)
Jan, I agree with your references, especially Friston et al. I think those kinds of understanding, as you say, have not adequately made their way into utility utility-theoretic fields like econ and game theory, so I think the post is valid as a statement about the state of understanding in those utility-oriented fields. (Note that the post is about "a missing concept from the axioms of game theory and bargaining theory" and "a key missing concept from utility theory", and not "concepts missing from the mind of all of humanity".)
comment by Andrew_Critch · 2022-08-27T21:08:15.913Z · LW(p) · GW(p)
In Part 3 of this series, I plan to write a shallow survey of 8 problems relating to AI alignment, and the relationship of the «boundary» concept to formalizing them. To save time, I'd like to do a deep dive into just one of the eight problems, based on what commenters here would find most interesting. If you have a moment, please use the "agree" button (and where desired, "disagree") to vote for which of the eight topics I should go into depth about. Each topic is given as a subcomment below (not looking for karma, just agree/disagree votes). Thanks!
Replies from: Andrew_Critch, Andrew_Critch, Andrew_Critch, Andrew_Critch, Andrew_Critch, Andrew_Critch, Andrew_Critch, Andrew_Critch↑ comment by Andrew_Critch · 2022-08-27T21:12:25.794Z · LW(p) · GW(p)
7. Preference plasticity — the possibility of changes to the preferences of human preferences over time, and the challenge of defining alignment in light of time-varying preferences (Russell, 2019, p.263).
↑ comment by Andrew_Critch · 2022-08-27T21:11:31.127Z · LW(p) · GW(p)
5. Counterfactuals in decision theory — the problem of defining what would have happened if an AI system had made a different choice, such as in the Twin Prisoner's Dilemma (Yudkowsky & Soares, 2017).
↑ comment by Andrew_Critch · 2022-08-27T21:10:40.299Z · LW(p) · GW(p)
3. Mild optimization — the problem of designing AI systems and objective functions that, in an intuitive sense, don’t optimize more than they have to (Taylor et al, 2016).
↑ comment by Andrew_Critch · 2022-08-27T21:12:04.664Z · LW(p) · GW(p)
6. Mesa-optimizers — instances of learned models that are themselves optimizers, which give rise to the so-called inner alignment problem (Hubinger et al, 2019).
↑ comment by Andrew_Critch · 2022-08-27T21:11:05.172Z · LW(p) · GW(p)
4. Impact regularization — the problem of formalizing "change to the environment" in a way that can be effectively used as a regularizer penalizing negative side effects from AI systems (Amodei et al, 2016).
↑ comment by Andrew_Critch · 2022-08-27T21:09:45.140Z · LW(p) · GW(p)
2. Corrigibility — the problem of constructing a mind that will cooperate with what its creators regard as a corrective intervention (Soares et al, 2015).
↑ comment by Andrew_Critch · 2022-08-27T21:13:01.557Z · LW(p) · GW(p)
8. (Unscoped) Consequentialism — the problem that an AI system engaging in consequentialist reasoning, for many objectives, is at odds with corrigibility and containment (Yudkowsky, 2022 [LW · GW], no. 23).
↑ comment by Andrew_Critch · 2022-08-27T21:08:57.386Z · LW(p) · GW(p)
1. AI boxing / containment — the method and challenge of confining an AI system to a "box", i.e., preventing the system from interacting with the external world except through specific restricted output channels (Bostrom, 2014, p.129).
comment by romeostevensit · 2022-07-28T02:27:59.087Z · LW(p) · GW(p)
Rambling/riffing: Boundaries typically need holes in order to be useful. Depending on the level of abstraction, different things can be thought of as holes. One way to think of a boundary is a place where a rule is enforced consistently, and this probably involves pushing what would be a continuous condition into a condition with a few semi discrete modes (in the simplest case enforcing a bimodal distribution of outcomes). In practice, living systems seem to have settled on stacking a bunch of one dimensional gate keepers together as presumably the modularity of such a thing was easier to discover in the search space than things with higher path dependencies due to entangled condition measurement. This highlights the similarity between boolean circuit analysis and a biological boundary. In a boolean circuit, the configurations of 'cheap' energy flows/gradients can be optimized for benefit, while the walls to the vast alternative space of other configurations can be artificially steepened/shored up (see: mitigation efforts to prevent electron tunneling in semiconductors).
comment by johnswentworth · 2022-07-27T21:37:41.572Z · LW(p) · GW(p)
Great post! One relatively-minor nitpick:
The coco solution doesn't assume a constant disagreement point, but it does assume transferrable utility, which has its own problems, due to difficulties with defining interpersonal comparisons of utility [source: lots].
Interpersonal comparisons of utility in general make no sense at all, because each agent's utility can be scaled/shifted independently. But I don't think that's a problem for transferrable utility, which is what we need for coco. Transferrable utility just requires money (or some analogous resource), and it requires that the amounts of money-equivalent involved in the game are small enough that utility is roughly linear in money. We don't need interpersonal comparability of utility for that.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-07-28T15:50:39.335Z · LW(p) · GW(p)
For the games that matter most, the amounts of money-equivalent involved are large enough that utility is not roughly linear in it. (Example: Superintelligences deciding what to do with the cosmic endowment.) Or so it seems to me, I'd love to be wrong about this.
Replies from: johnswentworth↑ comment by johnswentworth · 2022-07-28T17:38:01.727Z · LW(p) · GW(p)
Seems true, though I would guess that the coco idea could probably be extended to weaker conditions, e.g. expected utility a smooth function of money. I haven't looked into this, but my guess would be that it only needs linearity on the margin, based on how things-like-this typically work in economics.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-07-28T20:04:49.470Z · LW(p) · GW(p)
Interesting. I hope you are wrong.
Replies from: johnswentworth↑ comment by johnswentworth · 2022-07-28T20:25:38.052Z · LW(p) · GW(p)
Heh. Beware lest you wish yourself from the devil you know to the devil you don't.
comment by Vladimir_Nesov · 2022-08-13T12:56:59.710Z · LW(p) · GW(p)
In other words, you have the ability to control their payoff outside the negotiation, based on what you observe during the negotiation.
This suggests some sort of (possibly acausal) bargaining within the BATNAs, so points to a hierarchy of bargains. Each bargain must occur without violating boundaries of agents, but if it would, then the encounter undergoes escalation, away from trade and towards conflict. After a step of escalation, another bargain may be considered, that runs off tighter less comfortable boundaries. If it also falls through, there is a next level of escalation, and so on.
Possibly the sequence of escalation goes on until the goodhart boundary [LW(p) · GW(p)] where agents lose ability to assess value of outcomes. It's unclear what happens when that breaks down as well and one of the agents moves the environment into the other's crash space [LW(p) · GW(p)].
Note that this is not destruction of the other agent, which is unexpected for the last stage of escalation of conflict. Destruction of the other agent is merely how the game aborts before reaching its conclusion, while breaking into the crash space of the other agent is the least acceptable outcome in terms of agent boundaries (though it's not the worst outcome, it could even have high utility; these directions of badness are orthogonal, goodharting vs. low utility). This is a likely outcome of failed AI alignment (all boundaries of humanity are ignored, leading to something normatively worthless), as well as of some theoretical successes of AI alignment that are almost certainly impossible in practice (all boundaries of humanity are ignored, the world is optimized towards what is the normatively best outcome for humanity).
comment by mako yass (MakoYass) · 2023-03-05T00:38:11.617Z · LW(p) · GW(p)
You speak a lot about respecting boundaries, what I need to see before I'll be convinced that you're onto something here is that you also know when to disregard a spurious boundary. There are a lot of boundaries that exist in the world have been drawn arbitrarily and incorrectly and need to be violated, examples include; almost all software patents, national borders that don't correspond to the demographic preference clusters over spacialized law, or, some optional ones: racial definitions of cultural groups, or situations where an immense transition in power has occurred that has made it so that there was never a reason for the new powers to ask consent from the old powers, for instance, if RadicalXChange or Network States gave rise to a new political system that was obviously both hundreds of times more wealthy and democratically legitimate than the old system, would you expect it to recognize the US's state borders?
How would your paradigm approach that sort of thing?
Replies from: Chipmonk↑ comment by Chipmonk · 2023-07-18T19:51:47.854Z · LW(p) · GW(p)
Underrated comment! I completely agree [LW · GW].
For example, I think that many people say "I'm setting a boundary here […]" as an attempt to manipulate others into respecting a spurious boundary.
Replies from: MakoYass↑ comment by mako yass (MakoYass) · 2023-07-18T20:20:31.952Z · LW(p) · GW(p)
I'm setting a boundary here *claims the entire territory of Israel*
Replies from: Chipmonkcomment by CarlJ · 2022-08-07T21:57:23.814Z · LW(p) · GW(p)
Some parts of this sounds similar to Friedman's "A Positive Account of Property Rights":
»The laws and customs of civil society are an elaborate network of Schelling points. If my neighbor annoys me by growing ugly flowers, I do nothing. If he dumps his garbage on my lawn, I retaliate—possibly in kind. If he threatens to dump garbage on my lawn, or play a trumpet fanfare at 3 A.M. every morning, unless I pay him a modest tribute I refuse—even if I am convinced that the available legal defenses cost more than the tribute he is demanding.
(...)
If my analysis is correct, civil order is an elaborate Schelling point, maintained by the same forces that maintain simpler Schelling points in a state of nature. Property ownership is alterable by contract because Schelling points are altered by the making of contracts. Legal rules are in large part a superstructure erected upon an underlying structure of self-enforcing rights.«
http://www.daviddfriedman.com/Academic/Property/Property.html
comment by Lionel Levine · 2022-08-04T22:14:10.049Z · LW(p) · GW(p)
So, boundaries enable cooperation, by protecting BATNA.
Would you say there is a boundary between cell and mitochondria?
In the limit of perfect cooperation, the BATNA becomes minus infinity and the boundary dissolves.
comment by MSRayne · 2022-07-27T00:30:02.979Z · LW(p) · GW(p)
Wonderful! As usual, people smarter than me manage to actually put into words what has been floating around my mind as vague ideas for years: I've long suspected that boundaries are the fundamental thing in defining human values, but I have never been able to figure out how exactly to explicate that intuition, other than figuring out how a wide range of emotions relate to intuitive interpretations of movement of boundaries. (Which I'm thinking of trying to write a post about.) I'm looking forward to seeing what you have to say on this subject.
comment by ThomasCederborg · 2024-03-23T14:25:15.631Z · LW(p) · GW(p)
For a set of typical humans, that are trying to agree on what an AI should do, there does not exists any fallback option, that is acceptable to almost everyone. For each fallback option, there exists a large number of people, that will find this option completely unacceptable on moral grounds. In other words: when trying to agree on what an AI should do, there exists no place that people can walk away to, that will be seen as safe / acceptable by a large majority of people.
Consider the common aspect of human morality, that is sometimes expressed in theological terms as: ``heretics deserve eternal torture in hell''. This is a common normative position (an aspect of morality), that shows up throughout human history. It is found across cultures, and religions, and regions, and time periods. Consider Steve, for whom this is a central aspect of his morality. His morality is central to his self image, and he classify most people as heretics. The scenario, where the world is organised by an AI, that do not punish heretics, is thus seen as a moral abomination. In other words, such a scenario is a completely unacceptable fallback option for Steve (in other words, Steve would reject any AI, where this is a negotiation baseline). Hurting heretics is a non negotiable moral imperative for Steve. In yet other words: if Steve learns that the only realistic path to heretics being punished, is for the AI to do this, then no fallback position, where the AI allows them avoid punishment, is acceptable.
Bob has an even more common position: not wanting to be subjected to a clever AI, that tries to hurt Bob as much as possible (in many cases, purely normative considerations would be sufficient for strong rejection).
There is simply no way to create a well defined fallback option, that is acceptable for both Steve and Bob. When implementing an AI, that gets its goal from a set of negotiating human individuals, different types of bargaining / negotiation rules, imply a wide variety of different BATNAs. No such AI will be acceptable to both Steve and Bob, because none of the negotiation baselines, will be acceptable to both Steve and Bob. If Bob is not tortured in the BATNA, then the BATNA is completely unacceptable to Steve. And if Bob is tortured, then it is completely unacceptable to Bob. In both cases, the rejection is made on genuinely held, fully normative, non strategic, grounds. In both cases, this normative rejection cannot be changed, by any veil of ignorance (unless that veil transforms people, into something that the original person would find morally abhorrent).
In yet other words: there exists no BATNA, that a set of humans would agree to under a veil of ignorance. If the BATNA involves Bob getting tortured, then Bob will refuse to agree. If the BATNA does not involve Bob getting tortured, then Steve will refuse to agree. Thus, for each possible BATNA, there exists a large number of humans, that will refuse to agree to it (as a basis for AI negotiations), under any coherent veil of ignorance variant.
This conclusion is reached, by just skimming the surface of the many, many, different of types of minds, that exists within a set of billions of humans. It is one of the most common aspects of human morality, that is completely incompatible with the existence of a fallback position, that is acceptable to a large majority. So, I don't think there is any hope of finding any set of patches, that will work for every unusual type of mind, that exists in a population of billions (even if one is willing to engage in some very creative definitional acrobatics, regarding what counts as agreement).
My analysis here, is that this aspect of human morality, implies a necessary (but not sufficient) feature, that any alignment target must have, for this alignment target to be preferable to extinction. Specifically: the AI in question must give each person meaningful influence, regarding the adoption of those preferences, that refer to her. We can provisionally refer to this feature as: Self Preference Adoption Decision Influence (SPADI). This is obviously very underspecified. There will be lots of border cases whose classification will be arbitrary. But there still exists many cases, where it is in fact clear, that a given alignment target, does not have the SPADI feature. Since the feature is necessary, but not sufficient, these clear negatives are actually the most informative cases. In particular, if an AI project is aiming for an alignment target, that clearly does not have the SPADI feature. Then the success of this AI project, would be worse than extinction, in expectation (from the perspective of a typical human individual that does not share Steve's type of morality, and that is not given any special influence over the AI project).
If a project has the SPADI feature, then this implies a BATNA, that will be completely unacceptable to Steve on moral grounds (because any given heretic will presumably veto the adoption of those preferences, that demand that she be hurt as much as possible). But I think that disappointing Steve is unavoidable, when constructing a non bad alignment target. Steve is determined to demand that any AI must hurt most people, as much as possible. And this is a deeply held normative position, that is core to Steve's self image. As long as Steve is still Steve in any coherent sense, then Steve will hold onto this rejection, regardless of what veils of ignorance one puts him under. So, if an AI is implemented, that does satisfy Steve (in any sense), then the outcome is known to be massively worse than extinction, for essentially any human individual, that is classified as a heretic by Steve (in other words: for most people). Thus, we should not look for solutions, that satisfy Steve. In fact, we can actually rephrase this as a necessary feature, that any BATNA must have: Steve must find this BATNA morally abhorrent. And Steve must categorically reject this BATNA, regardless of what type of coherent veil of ignorance, is employed. I think the SPADI feature is more informative, but if one is listing necessary features of a BATNA, then this is one such feature (and this feature can perhaps be useful, for the purpose of illustrating the fact, that we are looking for features, that are not supposed to be sufficient).
Another way to approach this, is to note that there exists many different definitions of heretic. If Gregg and Steve see each other as heretics, satisfying both is simply not possible (the specific definition of heretic is also central to the self image of both Steve and Gregg. So no coherent formulation of a veil of ignorance, will help Steve and Gregg agree on a BATNA). Satisfying any person with a morality along the lines of Steve, implies an outcome far worse than extinction for most people. Satisfying all people along the lines of Steve is also impossible, even in principle. Thus, it is difficult to see, what options there are, other than simply giving up on trying to give Steve an acceptable fallback option (in other words: we should look for a set of negotiation rules, that imply a BATNA, that is completely unacceptable to Steve, on fully normative, moral, grounds. In yet other words: a necessary feature of any veil of ignorance mediated, accusal agreement, is that it is strongly rejected by every person, with a morality along the lines of Steve). Thus, the fact that Steve would find any AI project with the SPADI feature, morally abhorrent, is not an argument against the SPADI feature. (both Steve and Gregg would obviously reject any notion, that they have similar moralities. This is an honest, non strategic, and strong rejection. And this rejection would remain, under any coherent veil of ignorance. But there is not much that could, or should, be done about this)
The SPADI feature is incompatible with building an AI, that is describable as ``doing what a group wants''. Thus, the SPADI feature is incompatible with the core concept of CEV. In other words: the SPADI feature is incompatible with building an AI that, in any sense, is describable as implementing the Coherent Extrapolated Volition of Humanity. So, accepting this feature, means abandoning CEV as an alignment target. In yet other words: if some AI gives each individual meaningful influence, regarding the decision, of which preferences to adopt, that refer to her. Then we know that this AI is not a version of CEV. In still other words: while there are many border cases, regarding what alignment targets could be described as having the SPADI feature, CEV is an example of a clear negative (because doing what a group wants, is inherent in the core concept, of building an AI, that is describable as: implementing the Coherent Extrapolated Volition of Humanity).
Discovering that building an AI that does what a group wants the AI to do, would be bad for the individuals involved, should in general not be particularly surprising (even before taking any facts about those individuals into account). Because groups and individuals are completely different types of things. There is no reason to be surprised, when doing what one type of thing wants, is bad for a completely different type of thing. It would for example not be particularly surprising to discover, that any reasonable way of extrapolating Dave, will lead to all of Dave's cells dying. In other words, there is no reason to be surprised, if one discovers that Dave would prefer, that Dave's cells not survive.
Similarly, there is no reason to be surprised, when one discovers that all reasonable ways of defining ``doing what a group wants'' is bad for the individuals involved. A group is an arbitrarily defined abstract entity. Such an entity is pointed at, using an arbitrarily defined mapping, from billions of humans, into the set of entities, that can be said to want things. Different mappings imply completely different entities, that all want completely different things (a slight definition change, can for example lead to a different BATNA, which in turn leads to a different group of fanatics dominating the outcome). Since the choice of which specific entity to point to, is fully arbitrary, no AI can discover that the mapping, that is pointing to such an entity ``is incorrect'' (regardless of how smart this AI is). That doing what this entity wants is bad for individuals, is not particularly surprising (because groups and individuals are completely different types of things). And an AI, that does what such an entity wants it to do, has no reason whatsoever, to object, if that entity wants the AI to hurt individuals. So, discovering that doing what such an entity wants, is bad for individuals, should in general not be surprising (even before we learn anything at all, about the individuals involved).
We now add three known facts about humans and AI designs, (i): a common aspect of human morality, is the moral imperative to hurt other humans (if discovering that no one else will hurt heretics, then presumably the moral imperative will pass to the AI. An obvious way of translating ``eternal torture in hell'' into the real world, is to interpret it as a command to hurt as much as possible), (ii): a human individual is very vulnerable to a clever AI, trying to hurt her as much as possible (and this is true for both selfish, and selfless, humans), and (iii): if the AI is describable as a Group AI, then no human individual can have any meaningful influence, regarding the adoption, of those preferences, that refer to her (if the group is large, and if the individual in question is not given any special treatment). These three facts very strongly imply that any Group AI, would be far worse than extinction, for essentially any human individual, in expectation.
I have outlined a thought experiment that might help to make things a bit more concrete. It shows that a successful implementation of the most recently published version of CEV (PCEV), would lead to an outcome, that would be far, far, worse than extinction. It is probably best to first read this comment [LW(p) · GW(p)], that clarifies some things talked about in the post [LW · GW] that describes the thought experiment (the comment includes important clarifications regarding the topic of the post, and regarding the nature of the claims made, as well as clarifications regarding the terminology used).
To me, it looks like the intuitions that are motivating you to explore the membrane concept, is very compatible with the MPCEV proposal, in the linked post (which modifies PCEV, in a way that gives each individual, meaningful influence, regarding the adoption of those preferences, that refer to her). If CEV is abandoned, and the Membrane concept is used to describe / look for, alternative alignment targets, then I think this perspective might fit very well with my proposed research effort (see the comment [LW(p) · GW(p)] mentioned above for details on this proposed research effort).
comment by Cullen (Cullen_OKeefe) · 2022-08-12T21:13:46.792Z · LW(p) · GW(p)
ELI5-level question: Is this conceptually related to one of the key insights/corollaries of the Coase theory, which is that efficient allocations of property requires clearly defined property rights? And, the behavioral econ observation that irrational attachment to the status quo (e.g., endowment effect) can prevent efficient transactions?
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2022-08-12T21:32:25.663Z · LW(p) · GW(p)
It's Coase's Theorem, and yeah now I do see a relationship, at least distantly. It's an interesting connection, in some sense.
comment by Максим Богомолов (maksim-bogomolov) · 2022-08-09T10:40:59.401Z · LW(p) · GW(p)
Hi, recently (just three months ago) I have suggested similar and slightly broader conception of boundaries. Taking anything as a concept in a mind of rational agents (just because rational agents need to make a concept or models of objects to interact with them as rational agents) anything have boundaries: abstract ideas or living beings. Such boundaries include time period of existence of any being, domains of functions, terms of existence or any other conditions under which something sustain its existence and sense. For example, idea of freedom of agent becomes nonsense if we try to implement agent's freedom out of terms of existence of that agent. Now, when I have met your article, I think such a broad conception of boundaries could be also formalized in similar way. But maybe some taxonomy of boundaries is needed firstly.
Glad to see that people from other parts of world thinks in similar way and going even further.
Here's my article (in Russian): https://vk.com/@317703-ogranichennaya-racionalnost
comment by Flaglandbase · 2022-07-28T08:33:42.651Z · LW(p) · GW(p)
For a human, the most important boundary is whatever contains the information in their brain. This is not just the brain itself, but the way the brain is divided by internal boundaries. This information could only be satisfactorily copied to an external device if these boundaries could be fully measured.
comment by Tobias Brown · 2023-07-18T13:19:29.694Z · LW(p) · GW(p)
"Boundaries," as discussed in "Boundaries", Part 1, is a crucial but often overlooked concept in utility theory. It refers to the limitations individuals set to protect their well-being, happiness, and resources. Understanding boundaries helps in making rational decisions, maintaining balance, and avoiding undue stress or exploitation in various situations.