Introduction to Cartesian Frames
post by Scott Garrabrant · 2020-10-22T13:00:00.000Z · LW · GW · 32 commentsContents
1. Definition 2. Normal-Form Games 2.1. Coarse World Models 2.2. Symmetry 2.3. Relation to Extensive-Form Games 3. Controllables 3.1. Closure Properties 3.2. Examples of Controllables 4. Observables 4.1. Closure Properties 4.2. Examples of Observables 5. Controllables and Observables Are Disjoint 5.1. Properties That Are Both Observable and Ensurable Are Inevitable 5.2. Controllables and Observables in Degenerate Frames 5.3. A Suggestion of Time 6. Why Cartesian Frames? 6.1. Cybernetic Agent Model 6.2. Deriving Functional Structure 6.3. Contents Footnotes None 32 comments
This is the first post in a sequence on Cartesian frames, a new way of modeling agency that has recently shaped my thinking a lot.
Traditional models of agency have some problems, like:
- They treat the "agent" and "environment" as primitives with a simple, stable input-output relation. (See "Embedded Agency [? · GW].")
- They assume a particular way of carving up the world into variables, and don't allow for switching between different carvings or different levels of description.
Cartesian frames are a way to add a first-person perspective (with choices, uncertainty, etc.) on top of a third-person "here is the set of all possible worlds," in such a way that many of these problems either disappear or become easier to address.
The idea of Cartesian frames is that we take as our basic building block a binary function which combines a choice from the agent with a choice from the environment to produce a world history.
We don't think of the agent as having inputs and outputs, and we don't assume that the agent is an object persisting over time. Instead, we only think about a set of possible choices of the agent, a set of possible environments, and a function that encodes what happens when we combine these two.
This basic object is called a Cartesian frame. As with dualistic agents [? · GW], we are given a way to separate out an “agent” from an “environment." But rather than being a basic feature of the world, this is a “frame” — a particular way of conceptually carving up the world.
We will use the combinatorial properties of a given Cartesian frame to derive versions of inputs, outputs and time. One goal here is that by making these notions derived rather than basic, we can make them more amenable to approximation and thus less dependent on exactly how one draws the Cartesian boundary. Cartesian frames also make it much more natural to think about the world at multiple levels of description, and to model agents as having subagents.
Mathematically, Cartesian frames are exactly Chu spaces. I give them a new name because of my specific interpretation about agency, which also highlights different mathematical questions.
Using Chu spaces, we can express many different relationships between Cartesian frames. For example, given two agents, we could talk about their sum (), which can choose from any of the choices available to either agent, or we could talk about their tensor (), which can accomplish anything that the two agents could accomplish together as a team.
Cartesian frames also have duals () which you can get by swapping the agent with the environment, and and have De Morgan duals ( and respectively), which represent taking a sum or tensor of the environments. The category also has an internal hom, , where can be thought of as " with a -shaped hole in it." These operations are very directly analogous to those used in linear logic.
1. Definition
Let be a set of possible worlds. A Cartesian frame over is a triple , where represents a set of possible ways the agent can be, represents a set of possible ways the environment can be, and is an evaluation function that returns a possible world given an element of and an element of .
We will refer to as the agent, the elements of as possible agents, as the environment, the elements of as possible environments, as the world, and elements of as possible worlds.
Definition: A Cartesian frame over a set is a triple , where and are sets and . If is a Cartesian frame over , we say , , , and .
A finite Cartesian frame is easily visualized as a matrix, where the rows of the matrix represent possible agents, the columns of the matrix represent possible environments, and the entries of the matrix are possible worlds:
.
E.g., this matrix tells us that if the agent selects and the environment selects , then we will end up in the possible world .
Because we're discussing an agent that has the freedom to choose between multiple possibilities, the language in the definition above is a bit overloaded. You can think of as representing the agent before it chooses, while a particular represents the agent's state after making a choice.
Note that I'm specifically not referring to the elements of as "actions" or "outputs"; rather, the elements of are possible ways the agent can choose to be.
Since we're interpreting Cartesian frames as first-person perspectives tacked onto sets of possible worlds, we'll also often phrase things in ways that identify a Cartesian frame with its agent. E.g., we will say " is a subagent of " as a shorthand for "'s agent is a subagent of 's agent."
We can think of the environment as representing the agent's uncertainty about the set of counterfactuals, or about the game that it's playing, or about "what the world is as a function of my behavior."
A Cartesian frame is effectively a way of factoring the space of possible world histories into an agent and an environment. Many different Cartesian frames can be put on the same set of possible worlds, representing different ways of doing this factoring. Sometimes, a Cartesian frame will look like a subagent of another Cartesian frame. Other times, the Cartesian frames may look more like independent agents playing a game with each other, or like agents in more complicated relationships.
2. Normal-Form Games
When viewed as a matrix, a Cartesian frame looks much like the normal form of a game, but with possible worlds rather than pairs of utilities as entries.
In fact, given a Cartesian frame over , and a function from to a set , we can construct a Cartesian frame over by composing them in the obvious way. Thus, if we had a Cartesian frame and a pair of utility functions and , we could construct a Cartesian frame over , given by , where . This Cartesian frame will look exactly like the normal form of a game. (Although it is a bit weird to think of the environment set as having a utility function.)
We can use this connection with normal-form games to illustrate three features of the ways in which we will use Cartesian frames.
2.1. Coarse World Models
First, note that we can talk about a Cartesian frame over , even though one would not normally think of as a set of possible worlds.
In general, we will often want to talk about Cartesian frames over "coarse" models of the world, models that leave out some details. We might have a world model that fully specifies the universe at the subatomic level, while also wanting to talk about Cartesian frames over a set of high-level descriptions of the world.
We will construct Cartesian frames over by composing Cartesian frames over with the function from to that sends more refined, detailed descriptions of the universe to coarser descriptions of the same universe.
In this way, we can think of an element of as the coarse, high-level possible world given by "Those possible worlds for which and ."
Definition: Given a Cartesian frame over , and a function , let denote the Cartesian frame over , , where .
2.2. Symmetry
Second, normal-form games highlight the symmetry between the players.
We do not normally think about this symmetry in agent-environment interactions, but this symmetry will be a key aspect of Cartesian frames. Every Cartesian frame has a dual which swaps and and transposes the matrix.
2.3. Relation to Extensive-Form Games
Third, much of what we'll be doing with Cartesian frames in this sequence can be summarized as "trying to infer extensive-form games from normal-form games" (ignoring the "games" interpretation and just looking at what this would entail formally).
Consider the ultimatum game. We can represent this game in extensive form:
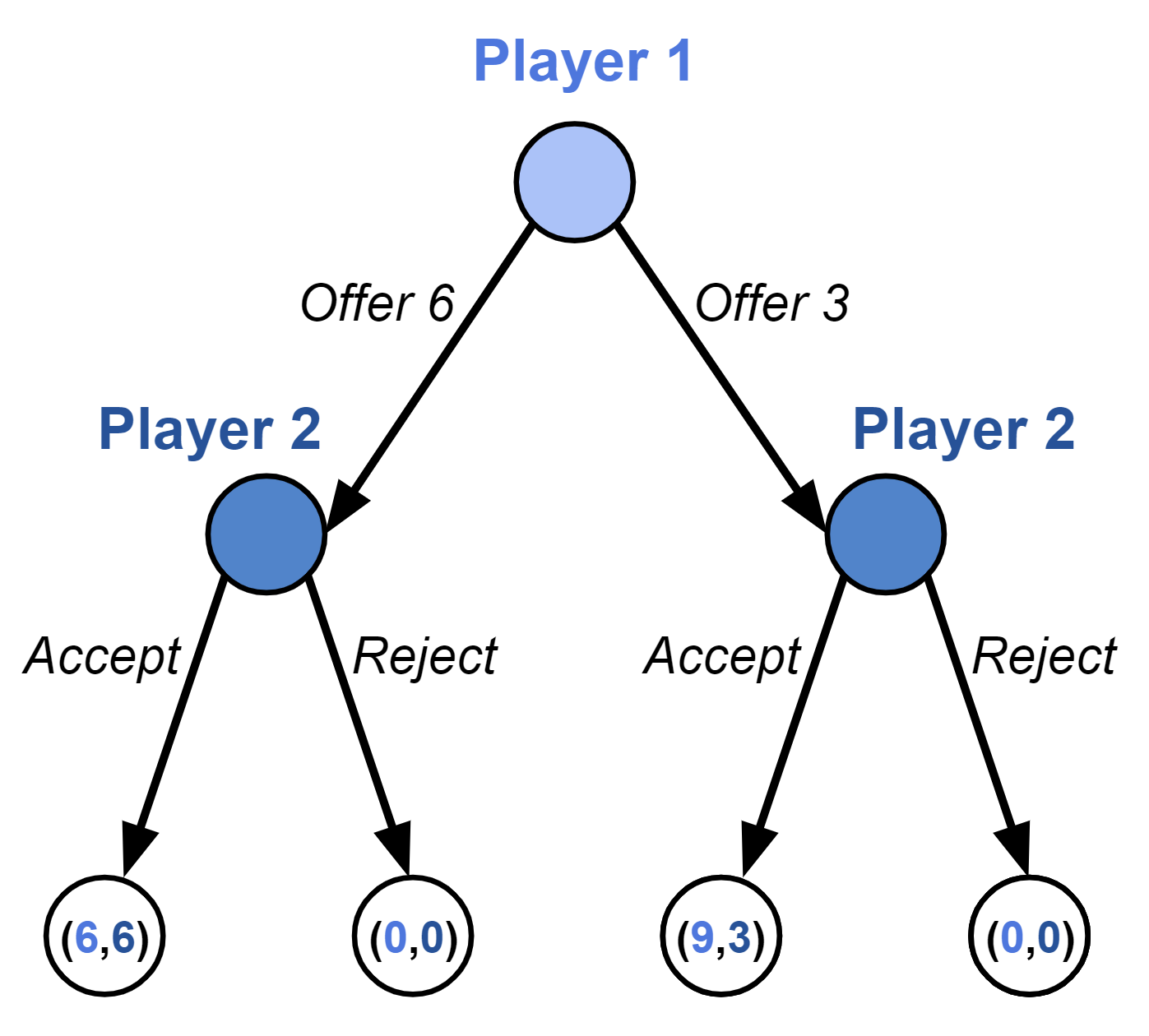
Given any game in extensive form, we can then convert it to a game in normal form. In this case:
The strategies in the normal-form game are the policies in the extensive-form game.
If we then delete the labels [LW · GW], so now we just have a bunch of combinatorial structure about which things send you to the same place, I want to know when we can infer properties of the original extensive-form game, like time and information states.
Although we've used games to note some features of Cartesian frames, we should be clear that Cartesian frames aren't about utilities or game-theoretic rationality. We are not trying to talk about what the agent does, or what the agent should do. In fact, we are effectively taking as our most fundamental building block that an agent can freely choose from a set of available actions.
The theory of Cartesian frames is trying to understand what agents' options are. Utility functions and facts about what the agent actually does can possibly later be placed on top of the Cartesian frame framework, but for now we will be focusing on building up a calculus of what the agent could do.
3. Controllables
We would like to use Cartesian frames to reconstruct ideas like "an agent persisting over time," inputs (or "what the agent can learn"), and outputs (or "what the agent can do"), by taking as basic:
- an agent's ability to "freely choose" between options;
- a collection of possible ways those options can correspond to world histories; and
- a notion of when world histories are considered the same in some coarse world model.
In this way, we hope to find new ways of thinking about partial and approximate versions of these concepts.
Instead of thinking of the agent as an object with outputs, I expect a more embedded view to think of all the facts about the world that the agent can force to be true or false.
This includes facts of the form "I output foo," but it also includes facts that are downstream from immediate outputs. Since we're working with "what can I make happen?" rather than "what is my output?", the theory becomes less dependent on precisely answering questions like "Is my output the way I move my mouth, or is it the words that I say?"
We will call the analogue of outputs in Cartesian frames controllables. The types of our versions of "outputs" and "inputs" are going to be subsets of , which we can think of as properties of the world. E.g., might be the set of worlds in which woolly mammoths exist; we could then think of "controlling " as "controlling whether or not mammoths exist."
We'll define what an agent can control as follows. First, given a Cartesian frame over , and a subset of , we say that is ensurable in if there exists an such that for all , we have . Equivalently, we say that is ensurable in if at least one of the rows in the matrix only contains elements of .
Definition: .
If an agent can ensure , then regardless of what the environment does — and even if the agent doesn't know what the environment does, or its behavior isn't a function of what the environment does — the agent has some strategy which makes sure that the world ends up in . (In the degenerate case where the agent is empty, the set of ensurables is empty.)
Similarly, we say that is preventable in if at least one of the rows in the matrix contains no elements of .
Definition: .
If is both ensurable and preventable in , we say that is controllable in .
Definition: .
3.1. Closure Properties
Ensurability and preventability, and therefore also controllability, are closed under adding possible agents to and removing possible environments from .
Claim: If and , and if for all and we have , then .
Proof: Trivial.
Ensurables are also trivially closed under supersets. If I can ensure some set of worlds, then I can ensure some larger set of worlds representing a weaker property (like "mammoths exist or cave bears exist").
Claim: If , and , then .
Proof: Trivial.
is similarly closed under subsets. need not be closed under subsets or supersets.
Since and will often be large, we will sometimes write them using a minimal set of generators.
Definition: Let denote the the closure of under supersets. Let denote the closure of under subsets.
3.2. Examples of Controllables
Let us look at some simple examples. Consider the case where there are two possible environments, for rain, and for sun. The agent independently chooses between two options, for umbrella, and for no umbrella. and . There are four possible worlds, . We interpret as the world where the agent has an umbrella and it is raining, and similarly for the other worlds. The Cartesian frame, , looks like this:
.
, or
and , or
Therefore .
The elements of are not actions, but subsets of : rather than assuming a distinction between "actions" and other events, we just say that the agent can guarantee that the actual world is drawn from the set of possible worlds in which it has an umbrella (), and it can guarantee that the actual world is drawn from the set of possible worlds in which it doesn't have an umbrella ().
Next, let's modify the example to let the agent see whether or not it is raining before choosing whether or not to carry an umbrella. The Cartesian frame will now look like this:
.
The agent is now larger, as there are two new possibilities: it can carry the umbrella if and only if it rains, or it can carry the umbrella if and only if it is sunny. will also be larger than . .
Under one interpretation, the new options and feel different from the old ones and . It feels like the agent's basic options are to either carry an umbrella or not, and the new options are just incorporating and into more complicated policies.
However, we could instead view the agent's "basic options" as a choice between "I want my umbrella-carrying to match when it rains" and "I want my umbrella-carrying to match when it's sunny." This makes and feel like the conditional policies, while and feel like the more basic outputs. Part of the point of the Cartesian frame framework is that we are not privileging either interpretation.
Consider now a third example, where there is a third possible environment, , for meteor. In this case, a meteor hits the earth before the agent is even born, and there isn't a question about whether the agent has an umbrella. There is a new possible world, which we will also call , in which the meteor strikes. The Cartesian frame will look like this:
.
, and . As a consequence, .
This example illustrates that nontrivial agents may be unable to control the world's state. Because the agent can't prevent the meteor, the agent in this case has no controllables.
This example also illustrates that agents may be able to ensure or prevent some things, even if there are possible worlds in which the agent was never born. While the agent of cannot ensure that it exists, the agent can ensure that if there is no meteor, then it carries an umbrella ().
If we wanted to, we could instead consider the agent's ensurables (or its ensurables and preventables) its "outputs." This lets us avoid the counter-intuitive result that agents have no outputs in worlds where their existence is contingent.
I put the emphasis on controllables because they have other nice features; and as we'll see later, there is an operation called "assume" which we can use to say: "The agent, under the assumption that there's no meteor, has controllables."
4. Observables
The analogue of inputs in the Cartesian frame model is observables. Observables can be thought of as a closure property on the agent. If an agent is able to observe , then the agent can take policies that have different effects depending on .
Formally, let be a subset of . We say that the agent of a Cartesian frame is able to observe whether if for every pair , there exists a single element which implements the conditional policy that copies in possible worlds in (i.e., for every , if , then ) and copies in possible worlds outside of .
When implements the conditional policy "if then do , and if not then do " in this way, we will say that is in the set .
Definition: Given , a Cartesian frame over , a subset of , and , let denote the set of all such that for all , and.
Agents in this setting observe events, which are true or false, not variables in full generality. We will say that 's observables, , are the set of all such that 's agent can observe whether .
Definition: .
Another option for talking about what the agent can observe would be to talk about when 's agent can distinguish between two disjoint subsets and . Here, we would say that the agent of can distinguish between and if for all , there exists an such that for all , either or , and whenever , , and whenever , . This more general definition would treat our observables as the special case . Perhaps at some point we will want to use this more general notion, but in this sequence, we will stick with the simpler version.
4.1. Closure Properties
Claim: Observability is closed under Boolean combinations, so if then , , and are also in .
Proof: Assume . We can see easily that by swapping and . It suffices to show that , since an intersection can be constructed with complements and union.
Given and , since , there exists an such that for all , we have . Then, since , there exists an such that for all , we have . Unpacking and combining these, we get for all , . Since we could construct such an from an arbitrary , we know that .
This highlights a key difference between our version of "inputs" and the standard version. Agent models typically draw a strong distinction between the agent's immediate sensory data, and other things the agent might know. Observables, on the other hand, include all of the information that logically follows from the agent's observations.
Similarly, agent models typically draw a strong distinction between the agent's immediate motor outputs, and everything else the agent can control. In contrast, if an agent can ensure an event , it can also ensure everything that logically follows from .
Since will often be large, we will sometimes write it using a minimal set of generators under union. Since is closed under Boolean combinations, such a minimal set of generators will be a partition of (assuming is finite).
Definition: Let denote the the closure of under union (including , the empty union).
Just like what's controllable, what's observable is closed under removing possible environments.
Claim: If , and if for all and we have , then .
Proof: Trivial.
It is interesting to note, however, that what's observable is not closed under adding possible agents to .
4.2. Examples of Observables
Let's look back at our three examples from earlier. The first example, , looked like this:
.
. This is the smallest set of observables possible. The agent can act, but it can't change its behavior based on knowledge about the world.
The second example looked like:
.
Here, . The agent can observe whether or not it's raining. One can verify that for any pair of rows, there is a third row (possibly equal to one or both of the first two) that equals the first if it is or , and equals the second otherwise.
The third example looked like:
.
Here, , which is
This example has an odd feature: the agent is said to be able to "observe" whether the meteor strikes, even though the agent is never instantiated in worlds in which it strikes. Since the agent has no control when the meteor strikes, the agent can vacuously implement conditional policies.
Let's look at two more examples. First, let's modify to represent the point of view of a powerless bystander:
.
Here, the agent has no decisions, and everything is in the hands of the environment.
Alternatively, we can modify to represent the point of view of the agent from and environment from together. The resulting frame looks like this:
.
and , so . Meanwhile, .
On the other hand, , and are the closure of under supersets and subsets respectively, and .
In the first case, the agent's ability to observe the world is maximal and its ability to control the world is minimal; while in the second case, observability is minimal and controllability is maximal. An agent with full control over what happens will not be able to observe anything, while an agent that can observe everything can change nothing.
This is perhaps counter-intuitive. If meant "I can go look at something to check whether we're in an world," then one might look at and say: "This agent is all-powerful. It can do anything. Shouldn't we then think of it as all-seeing and all-knowing, rather than saying it 'can't observe anything'?" Similarly, one might look at and say: "This agent's choices can't change the world at all. But then it seems bizarre to say that everything is 'observable' to the agent. Shouldn't we rather say that this agent is powerless and blind?"
The short answer is that, when working with Cartesian frames, we are in a very "What choices can you make?" paradigm, and in that kind of paradigm, the thing closest to an "input" is "What can I condition my choices on?" (Which is a closure property on the agent, rather than a discrete action like "turning on the Weather Channel.")
In that context, an agent with only one option automatically has maximal "inputs" or "knowledge," since it can vacuously implement every conditional policy. At the same time, an agent with too many options can't have any "inputs," since it could then use its high level of control to diagonalize against the observables it is conditioning on and make them false.
5. Controllables and Observables Are Disjoint
A maximally observable frame has minimal controllables, and vice versa. This turns out to be a special case of our first interesting result about Cartesian frames: an agent can't observe what it controls, and can't control what it observes.
To see this, first consider the following frame:
.
Here, if , then would not be able to be either or . If it were , then it would have to copy , and . But if it were , then it would have to copy , and . So is empty in this case.
Notice that in this example, isn't empty merely because our lacks the right to implement the conditional policy. Rather, the conditional policy is impossible to implement even in principle.
Fortunately, before checking whether 's agent can observe , we can perform a simpler check to rule out these problematic cases. It turns out that if , then every column in consists either entirely of elements of or entirely of elements outside of . (This is a necessary condition for being observable, not a sufficient one.)
Definition: Given a Cartesian frame over , and a subset of , let denote the subset .
Lemma: If , then for all , it is either the case that or .
Proof: Take , and assume for contradiction that there exists an in neither nor . Thus, there exists an such that and an such that . Since , there must exist an such that . Consider whether or not . If , then . However, if , then . Either way, this is a contradiction.
This lemma immediately gives us the following theorem showing that in nontrivial Cartesian frames, observables and controllables are disjoint.
Theorem: Let be a Cartesian frame over , with nonempty. Then,.
Proof: Let , and suppose for contradiction that . Since , there exists an such that . Since , there exists an such that . This contradicts our lemma above.
5.1. Properties That Are Both Observable and Ensurable Are Inevitable
We also have a one-sided result showing that if is both observable and ensurable in , then must be inevitable — i.e., the entire matrix must be contained in .
We'll first define a Cartesian frame's image, which is the subset of containing every possible world that is actually hit by the evaluation function — the set of worlds that show up in the matrix.
Definition: .
can be thought of as a degenerate form of either or , where in the first case, the agent must make it the case that , and in the second case the agent can do conditional policies because the condition is never realized.1 [LW(p) · GW(p)] Conversely, if an agent can both observe and ensure , then the observability and the ensurability must both be degenerate.
Theorem: if and only if and is nonempty.
Proof: Let be a Cartesian frame over . First, if , then , since for all . If is also nonempty, then , there exists an , and for all , .
Conversely, if is empty, is empty, so . If , then there exist and such that . Then , since if , there exists an such that in particular , so is in neither nor , which implies .
Corollary: If is nonempty, .
Proof: Trivial.
5.2. Controllables and Observables in Degenerate Frames
All of the results so far have shown that an agent's observables and controllables cannot simultaneously be too large. We also have some results that in some extreme cases, and cannot be too small. In particular, if there are few possible agents, observables must be large, and if there are few possible environments, controllables must be large.
Claim: If , .
Proof: If is empty, for all vacuously. If is a singleton, then for all , because .
Claim: If is nonempty and is empty, then . If is nonempty and is a singleton, and .
Proof: If is nonempty and is empty, for all vacuously.
If is nonempty and is a singleton, every that intersects nontrivially is in , since if , there must be some such that , this satisfies for all . Conversely, if and are disjoint, no can satisfy this property. The result for then follows trivially from the result for .
5.3. A Suggestion of Time
Cartesian frames as we've been discussing them are agnostic about time. Possible agents, environments, and worlds could represent snapshots of a particular moment in time, or they could represent lengthy processes.
The fact that an agent's controllables and observables are disjoint, however, suggests a sort of arrow of time, where facts an agent can observe must be “before” the facts that agent has control over. This hints that we may be able to use Cartesian frames to formally represent temporal relationships.
One reason it would be nice to represent time is that we could model agents that repeatedly learn things, expanding their set of observables. Suppose that in some frame includes choices the agent makes over an entire calendar year. 's observables would only include the facts the agent can condition on at the start of the year, when it's first able to act; we haven't defined a way to formally represent the agent learning new facts over the course of the year.
It turns out that this additional temporal structure can be elegantly expressed using Cartesian frames. We will return to this topic in the very last post in this sequence. For now, however, we only have this hint that particular Cartesian frames have something like a "before" and "after."
6. Why Cartesian Frames?
The goal of this sequence will be to set up the language for talking about problems using Cartesian frames.
Concretely, I'm writing this sequence because:
- I've recently found that I have a new perspective to bring to a lot of other MIRI researchers' work. This perspective seems to me to be captured in the mathematical structure of Cartesian frames, but it's the new perspective rather than the mathematical structure per se that seems important to me. I want to try sharing this mathematical object and the accompanying philosophical interpretation, to see if it successfully communicates the perspective.
- I want collaborators to work with on Cartesian frames. If you're a math person who finds the things in this sequence exciting, I'd be interested in talking about it more. You can comment, PM, or email me.
- I want help with paradigm-building, but I also want there to be an ecosystem where people do normal science within this paradigm. I would consider it a good outcome if there existed a decent-sized group of people on the AI Alignment Forum and LessWrong for whom it makes just as much sense to pull out the Cartesian frames paradigm as it makes to pull out the cybernetic agent paradigm.
Below, I will say more about the cybernetic agent model and other ideas that helped motivate Cartesian frames, and I will provide an overview of upcoming posts in the sequence.
6.1. Cybernetic Agent Model
The cybernetic agent model describes an agent and an environment interacting over time:

In "Embedded Agency [? · GW]," Abram Demski and I noted that cybernetic agents like Marcus Hutter's AIXI are dualistic, whereas real-world agents will be embedded in their environment. Like a Cartesian soul, AIXI is crisply separated from its environment.
The dualistic model is often useful, but it's clearly a simplification that works better in some contexts than in others. One thing it would be nice to have is a way to capture the useful things about this simplification, while treating it as a high-level approximation with known limitations — rather than treating it as ground truth.
Cartesian frames carve up the world into a separate "agent" and "environment," and thereby adopt the basic conceit of dualistic Hutter-style agents. However, they treat this as a "frame" imposed on a more embedded, naturalistic world.2 [LW(p) · GW(p)]
Cartesian frames serve the same sort of intellectual function as the cybernetic agent model, and are intended to supersede this model. Our hope is that a less discrete version of ideas like "agent," "action," and "observation" will be better able to tolerate edge cases. E.g., we want to be able to model weirder, loopier versions of “inputs” that operate across multiple levels of description.
We will also devote special attention in this sequence to subagents, which are very difficult to represent in traditional dualistic models. In game theory, for example, we carve the world into different "agent" and "non-agent" parts, but we can't represent nontrivial agents that intersect other agents. A large part of the theory in this sequence will be giving us a language for talking about subagents.
6.2. Deriving Functional Structure
Another way of summarizing this sequence is that we'll be applying reasoning like Pearl's to objects like game theory's, with a motivation like Hutter's.
In Judea Pearl's causal models [LW · GW], you are given a bunch of variables, and an enormous joint distribution over the variables. The joint distribution is a large object that has a relational structure as opposed to a functional structure.
You then deduce something that looks like time and causality out of the combinatorial properties of the joint distribution. This takes the form of causal diagrams, which give you functions and counterfactuals.
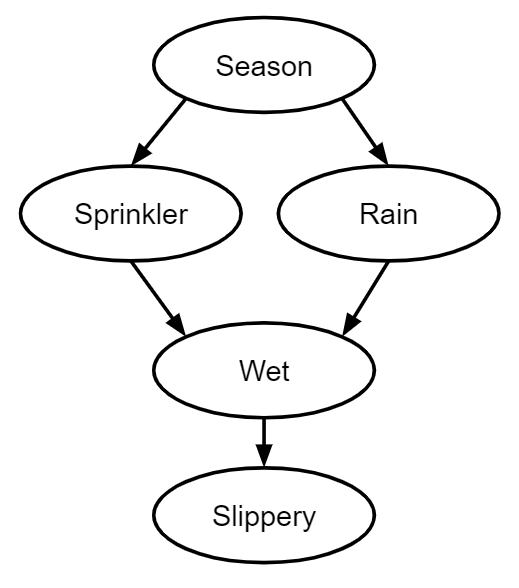
This has some similarities to how we'll be using Cartesian frames, even though the formal objects we'll be working with are very different from Pearl's. We want a model that can replace the cybernetic agent model with something more naturalistic, and our plan for doing this will involve deriving things like time from the combinatorial properties of possible worlds.
We can imagine the real world as an enormous static object, and we can imagine zooming in on different levels of the physical world and sometimes seeing things that look like local functions. ("Ah, no matter what the rest of the world looks like, I can compute the state of from the state of , relative to my uncertainty.") Switching which part of the world we're looking at, or switching which things we're lumping together versus splitting, can then change which things look like functions.
Agency itself, as we normally think about it, is functional in this way: there are multiple "possible" inputs, and whichever "option" we pick yields a deterministic result.
We want an approach to agency that treats this functional behavior less like a unique or fundamental feature of the world, and more like a special case of the world's structure in general — and one that may depend on what we're splitting or lumping together.
"We want to apply Pearl-like methods to Cartesian frames" is also another way of saying "we want to do the formal equivalent of inferring extensive-form games from normal-form games," our summary from before. The analogy is:
| base information | derived information | |
| causality | joint probability distribution | causal diagram |
| games | normal-form game | extensive-form game |
| agency | Cartesian frame | control, observation, subagents, time, etc. |
The game theory analogy is more relevant formally, while the Pearl analogy better explains why we're interested in this derivation.
Just as notions of time and information state are basic in causal diagrams and extensive-form games, so are they basic in the cybernetic agent model; and we want to make these aspects of the cybernetic agent model derived rather than basic, where it's possible to derive them. We also want to be able to represent things like subagents that are entirely missing from the cybernetic agent model.
Because we aren't treating high-level categories like "action" or "observation" as primitives, we can hope to end up with an agent model that will let us model more edge cases and odd states of the system. A more derived and decomposable notion of time, for example, might let us better handle settings where two agents are both trying to reach a decision based on their model of the other agent's future behavior.
We can also hope to distinguish features of agency that are more description-invariant from features that depend strongly on how we carve up the world.
One philosophical difference between our approach and Pearl's is that we will avoid the assumption that the space of possible worlds factors nicely into variables that are given to the agent. We want to instead just work with a space of possible worlds, and derive the variables for ourselves; or we may want to work in an ontology that lets us reason with multiple incompatible factorizations into variables.3 [LW(p) · GW(p)]
6.3. Contents
The rest of the sequence will cover these topics:
2. Additive Operations on Cartesian Frames [LW · GW] - We talk about the category of Chu spaces, and introduce two additive operations one can do on Cartesian frames: sum , and product . We talk about how to interpret these operations philosophically, in the context of agents making choices to affect the world. We also introduce the small Cartesian frame , and its dual .
3. Biextensional Equivalence [LW · GW] - We define homotopy equivalence for Cartesian frames, and introduce the small Cartesian frames , , and .
4. Controllables and Observables, Revisited [LW · GW] - We use our new language to redefine controllables and observables.
5. Functors and Coarse Worlds [LW · GW] - We show how to compare frames over a detailed world model and frames over a coarse version of that world model . We demonstrate that observability is a function not only of the observer and the observed, but of the level of description of the world.
6. Subagents of Cartesian Frames - We introduce the notion of a frame whose agent is the subagent of a frame , written . A subagent is an agent playing a game whose stakes are another agent's possible choices. This notion turns out to yield elegant descriptions of a variety of properties of agents.
7. Multiplicative Operations on Cartesian Frames - We introduce three new binary operations on Cartesian frames: tensor , par , and lollipop .
8. Sub-Sums and Sub-Tensors - We discuss spurious environments, and introduce variants of sum, , and tensor, , that can remove some (but not too many) spurious environments.
9. Additive and Multiplicative Subagents - We discuss the difference between additive subagents, which are like future versions of the agent after making some commitment; and multiplicative subagents, which are like agents acting within a larger agent.
10. Committing, Assuming, Externalizing, and Internalizing - We discuss the additive notion of producing subagents and sub-environments by committing or assuming, and the multiplicative notion of externalizing (moving part of the agent into the environment) and internalizing (moving part of the environment into the agent).
11. Eight Definitions of Observability - We use our new tools to provide additional definitions and interpretations of observables. We talk philosophically about the difference between defining what's observable using product and defining what's observable using tensor, which corresponds to the difference between updateful and updateless observations.
12. Time in Cartesian Frames - We show how to formalize temporal relations with Cartesian frames.
I'll be releasing new posts most non-weekend days between now and November 11.
As Ben noted in his announcement post [LW · GW], I'll be giving talks and holding office hours this Sunday at 12-2pm PT and the following three Sundays at 2-4pm PT, to answer questions and discuss Cartesian frames. Everyone is welcome.
The online talks, covering much of the content of this sequence, will take place this Sunday at 12pm PT (Zoom link added: recording of the talk [LW · GW]) and next Sunday at 2pm PT.
This sequence is communicating ideas I have been developing slowly over the last year. Thus, I have gotten a lot of help from conversation with many people. Thanks to Alex Appel, Rob Bensinger, Tsvi Benson-Tilsen, Andrew Critch, Abram Demski, Sam Eisenstat, David Girardo, Evan Hubinger, Edward Kmett, Alexander Gietelink Oldenziel, Steve Rayhawk, Nate Soares, and many others.
Footnotes
1. This assumes a non-empty . Otherwise, could be empty and therefore a subset of , even though is not ensurable (because you need an element of in order to ensure anything). ↩ [LW · GW]
2. This is one reason for the name "Cartesian frames." Another reason for the name is to note the connection to Cartesian products. In linear algebra, a frame of an inner product space is a generalization of a basis of a vector space to sets that may be linearly dependent. With Cartesian frames, then, we have a Cartesian product that projects onto the world, not necessarily injectively. (Cartesian frames aren't actually "frames" in the linear-algebra sense, so this is only an analogy.) ↩ [LW · GW]
3. This, for example, might let us talk about a high-level description of a computation being "earlier" in some sort of logical time than the exact details of that same computation.
Problems like agent simulates predictor [LW · GW] make me think that we shouldn't treat the world as factorizing into a single "true" set of variables at all, though I won't attempt to justify that claim here. ↩ [LW · GW]
32 comments
Comments sorted by top scores.
comment by Rohin Shah (rohinmshah) · 2020-11-29T23:32:56.692Z · LW(p) · GW(p)
Planned summary (of the full sequence) for the Alignment Newsletter:
The <@embedded agency sequence@>(@Embedded Agents@) hammered in the fact that there is no clean, sharp dividing line between an agent and its environment. This sequence proposes an alternate formalism: Cartesian frames. Note this is a paradigm that helps us _think about agency_: you should not be expecting some novel result that, say, tells us how to look at a neural net and find agents within it.
The core idea is that rather than _assuming_ the existence of a Cartesian dividing line, we consider how such a dividing line could be _constructed_. For example, when we think of a sports team as an agent, the environment consists of the playing field and the other team; but we could also consider a specific player as an agent, in which case the environment consists of the rest of the players (on both teams) and the playing field. Each of these are valid ways of carving up what actually happens into an “agent” and an “environment”, they are _frames_ by which we can more easily understand what’s going on, hence the name “Cartesian frames”.
A Cartesian frame takes **choice** as fundamental: the agent is modeled as a set of options that it can freely choose between. This means that the formulation cannot be directly applied to deterministic physical laws. It instead models what agency looks like [“from the inside”](https://www.lesswrong.com/posts/yA4gF5KrboK2m2Xu7/how-an-algorithm-feels-from-inside [LW · GW]). _If_ you are modeling a part of the world as capable of making choices, _then_ a Cartesian frame is appropriate to use to understand the perspective of that choice-making entity.
Formally, a Cartesian frame consists of a set of agent options A, a set of environment options E, a set of possible worlds W, and an interaction function that, given an agent option and an environment option, specifies which world results. Intuitively, the agent can “choose” an agent option, the environment can “choose” an environment option, and together these produce some world. You might notice that we’re treating the agent and environment symmetrically; this is intentional, and means that we can define analogs of all of our agent notions for environments as well (though they may not have nice philosophical interpretations).
The full sequence uses a lot of category theory to define operations on these sorts of objects and show various properties of the objects and their operations. I will not be summarizing this here; instead, I will talk about their philosophical interpretations.
First, let’s look at an example of using a Cartesian frame on something that isn’t typically thought of as an agent: the atmosphere, within the broader climate system. The atmosphere can “choose” whether to trap sunlight or not. Meanwhile, in the environment, either the ice sheets could melt or they could not. If sunlight is trapped and the ice sheets melt, then the world is Hot. If exactly one of these is true, then the world is Neutral. Otherwise, the world is Cool.
(Yes, this seems very unnatural. That’s good! The atmosphere shouldn’t be modeled as an agent! I’m choosing this example because its unintuitive nature makes it more likely that you think about the underlying rule, rather than just the superficial example. I will return to more intuitive examples later.)
**Controllables**
A _property_ of the world is something like “it is neutral or warmer”. An agent can _ensure_ a property if it has some option such that no matter what environment option is chosen, the property is true of the resulting world. The atmosphere could ensure the warmth property above by “choosing” to trap sunlight. Similarly the agent can _prevent_ a property if it can guarantee that the property will not hold, regardless of the environment option. For example, the atmosphere can prevent the property “it is hot”, by “choosing” not to trap sunlight. The agent can _control_ a property if it can both ensure and prevent it. In our example, there is no property that the atmosphere can control.
**Coarsening or refining worlds**
We often want to describe reality at different levels of abstraction. Sometimes we would like to talk about the behavior of various companies; at other times we might want to look at an individual employee. We can do this by having a function that maps low-level (refined) worlds to high-level (coarsened) worlds. In our example above, consider the possible worlds {YY, YN, NY, NN}, where the first letter of a world corresponds to whether sunlight was trapped (Yes or No), and the second corresponds to whether the ice sheets melted. The worlds {Hot, Neutral, Cool} that we had originally are a coarsened version of this, where we map YY to Hot, YN and NY to Neutral, and NN to Cool.
**Interfaces**
A major upside of Cartesian frames is that given the set of possible worlds that can occur, we can choose how to divide it up into an “agent” and an “environment”. Most of the interesting aspects of Cartesian frames are in the relationships between different ways of doing this division, for the same set of possible worlds.
First, we have interfaces. Given two different Cartesian frames <A, E, W> and <B, F, W> with the same set of worlds, an interface allows us to interpret the agent A as being used in place of the agent B. Specifically, if A would choose an option a, the interface maps this one of B’s options b. This is then combined with the environment option f (from F) to produce a world w.
A valid interface also needs to be able to map the environment option f to e, and then combine it with the agent option a to get the world. This alternate way of computing the world must always give the same answer.
Since A can be used in place of B, all of A’s options must have equivalents in B. However, B could have options that A doesn’t. So the existence of this interface implies that A is “weaker” in a sense than B. (There are a bunch of caveats here.)
(Relevant terms in the sequence: _morphism_)
**Decomposing agents into teams of subagents**
The first kind of subagent we will consider is a subagent that can control “part of” the agent’s options. Consider for example a coordination game, where there are N players who each individually can choose whether or not to press a Big Red Button. There are only two possible worlds: either the button is pressed, or it is not pressed. For now, let’s assume there are two players, Alice and Bob.
One possible Cartesian frame is the frame for the entire team. In this case, the team has perfect control over the state of the button -- the agent options are either to press the button or not to press the button, and the environment does not have any options (or more accurately, it has a single “do nothing” option).
However, we can also decompose this into separate Alice and Bob _subagents_. What does a Cartesian frame for Alice look like? Well, Alice also has two options -- press the button, or don’t. However, Alice does not have perfect control over the result: from her perspective, Bob is part of the environment. As a result, for Alice, the environment also has two options -- press the button, or don’t. The button is pressed if Alice presses it _or_ if the environment presses it. (The Cartesian frame for Bob is identical, since he is in the same position that Alice is in.)
Note however that this decomposition isn’t perfect: given the Cartesian frames for Alice and Bob, you cannot uniquely recover the original Cartesian frame for the team. This is because both Alice and Bob’s frames say that the environment has some ability to press the button -- _we_ know that this is just from Alice and Bob themselves, but given just the frames we can’t be sure that there isn’t a third person Charlie who also might press the button. So, when we combine Alice and Bob back into the frame for a two-person team, we don’t know whether or not the environment should have the ability to press the button or not. This makes the mathematical definition of this kind of subagent a bit trickier though it still works out.
Another important note is that this is relative to how coarsely you model the world. We used a fairly coarse model in this example: only whether or not the button was pressed. If we instead used a finer model that tracked which subset of people pressed the button, then we _would_ be able to uniquely recover the team’s Cartesian frame from Alice and Bob’s individual frames.
(Relevant terms in the sequence: _multiplicative subagents, sub-tensors, tensors_)
**Externalizing and internalizing**
This decomposition isn’t just for teams of people: even a single “mind” can often be thought of as the interaction of various parts. For example, hierarchical decision-making can be thought of as the interaction between multiple agents at different levels of the hierarchy.
This decomposition can be done using _externalization_. Externalization allows you to take an existing Cartesian frame and some specific property of the world, and then construct a new Cartesian frame where that property of the world is controlled by the environment.
Concretely, let’s imagine a Cartesian frame for Alice, that represents her decision on whether to cook a meal or eat out. If she chooses to cook a meal, then she must also decide which recipe to follow. If she chooses to eat out, she must decide which restaurant to eat out at.
We can externalize the high-level choice of whether Alice cooks a meal or eats out. This results in a Cartesian frame where the environment chooses whether Alice is cooking or eating out, and the agent must then choose a restaurant or recipe as appropriate. This is the Cartesian frame corresponding to the low-level policy that must pursue whatever subgoal is chosen by the high-level planning module (which is now part of the environment). The agent of this frame is a subagent of Alice.
The reverse operation is called internalization, where some property of the world is brought under the control of the agent. In the above example, if we take the Cartesian frame for the low-level policy, and then internalize the cooking / eating out choice, we get back the Cartesian frame for Alice as a unified whole.
Note that in general externalization and internalization are _not_ inverses of each other. As a simple example, if you externalize something that is already “in the environment” (e.g. whether it is raining, in a frame for Alice), that does nothing, but when you then internalize it, that thing is now assumed to be under the agent’s control (e.g. now the “agent” in the frame can control whether or not it is raining). We will return to this point when we talk about observability.
**Decomposing agents into disjunctions of subagents**
Our subagents so far have been “team-based”: the original agent could be thought of as a supervisor that got to control all of the subagents together. (The team agent in the button-pressing game could be thought of as controlling both Alice and Bob’s actions; in the cooking / eating out example Alice could be thought of as controlling both the high-level subgoal selection as well as the low-level policy that executes on the subgoals.)
The sequence also introduces another decomposition into subagents, where the superagent can be thought of as a supervisor that gets to choose _which_ of the subagents gets to control the overall behavior. Thus, the superagent can do anything that either of the subagents could do.
Let’s return to our cooking / eating out example. We previously saw that we could decompose Alice into a high-level subgoal-choosing subagent that chooses whether to cook or eat out, and a low-level subgoal-execution subagent that then chooses which recipe to make or which restaurant to go to. We can also decompose Alice as being the choice of two subagents: one that chooses which restaurant to go to, and one that chooses which recipe to make. The union of these subagents is an agent that first chooses whether to go to a restaurant or to make a recipe, and then uses the appropriate subagent to choose the restaurant or recipe: this is exactly a description of Alice.
(Relevant terms in the sequence: _additive subagents, sub-sums, sums_)
**Committing and assuming**
One way to think about the subagents of the previous example is that they are the result of Alice _committing_ to a particular subset of choices. If Alice commits to eating out (but doesn’t specify at what restaurant), then the resulting frame is equivalent to the restaurant-choosing subagent.
Similarly to committing, we can also talk about _assuming_. Just as commitments restrict the set of options available to the agent, assumptions restrict the set of options available to the environment.
Just as we can union two agents together to get an agent that gets to choose between two subagents, we can also union two environments together to get an environment that gets to choose between two subenvironments. (In this case the agent is more constrained: it must be able to handle the environment regardless of which way the environment chooses.)
(Relevant terms in the sequence: _product_)
**Observables**
The most interesting (to me) part of this sequence was the various equivalent definitions of what it means for something to be observable. The overall story is similar to the one in [Knowledge is Freedom](https://www.alignmentforum.org/posts/b3Bt9Cz4hEtR26ANX/knowledge-is-freedom [AF · GW]): an agent is said to “observe” a property P if it is capable of making different decisions based on whether P holds or not.
Thus we get our first definition of observability: **a property P of the world is _observable_ if, for any two agent options a and b, the agent also has an option that is equivalent to “if P then a else b”.**
Intuitively, this is meant to be similar to the notion of “inputs” to an agent. Intuitively, a neural net should be able to express arbitrary computations over its inputs, and so if we view the neural net as “choosing” what computation to do (by “choosing” what its parameters are), then the neural net can have its outputs (agent options) depend in arbitrary ways on the inputs. Thus, we say that the neural net “observes” its inputs, because what the neural net does can depend freely on the inputs.
Note that this is a very black-or-white criterion: we must be able to express _every_ conditional policy on the property for it to be observable; if even one such policy is not expressible then the property is not observable.
One way to think about this is that an observable property needs to be completely under the control of the environment, that is, the environment option should completely determine whether the resulting world satisfies the property or not -- nothing the agent does can matter (for this property). To see this, suppose that there was some environment option e that didn’t fully determine a property P, so that there are agent options a and b such that the world corresponding to (a, e) satisfies P but the one corresponding to (b, e) does not. Then our agent cannot implement the conditional policy “if P then b else a”, because it would lead to a self-referential contradiction (akin to “this sentence is false”) when the environment chooses e. Thus, P cannot be observable.
This is not equivalent to observability: it is possible for the environment to fully control P, while the agent is still unable to always condition on P. So we do need something extra. Nevertheless, this intuition suggests a few other ways of thinking about observability. The key idea is to identify a decomposition of the agent based on P that should only work if the environment has all the control, and then to identify a union step that puts the agent back together, that automatically adds in all of the policies that are conditional on P. I’ll describe these definitions here; the sequence proves that they are in fact equivalent to the original definition above.
First, recall that externalization and internalization are methods that allow us to “transfer” control of some property from the agent to the environment and vice versa. Thus, if all the control of P is in the environment, one would hope that internalization followed by externalization just transfers the control back and forth. In addition, when we externalize P, the externalization process will enforce that the agent can condition on P arbitrarily (this is how it is defined). This suggests the definition: **P is observable if and only if internalizing P followed by externalizing P gives us back the original frame.**
Second, if the environment has all of the control over P, then we should be able to decompose the agent into two parts: one that decides what to do when P is true, and one that decides what to do when P is false. We can achieve this using _assumptions_, that is, the first agent is the original agent under the assumption that P is true, and the second is under the assumption that P is false. Note that if the environment didn’t have perfect control over P, this would not work, as the environment options where P is not guaranteed to be true or false would simply be deleted, and could not be reconstructed from the two new agents.
We now need to specify how to put the agents back together, in a way that includes all the conditional policies on P. There are actually two variants in how we can do this:
In the first case, we combine the agents by unioning the environments, which lets the environment choose whether P is true or not. Given how this union is defined, the new agent is able to specify both what to do given the environment’s choice, _as well as_ what it would have done in the counterfactual case where the environment had decided P differently. This allows it to implement all conditional policies on P. So, **P is observable if and only if decomposing the frame using assumptions on P, and then unioning the environments of the resulting frames gives back the original frame.**
The second case, after getting agents via assumption on P, you extend each agent so that in the case where its assumption is false, it is as though it takes a noop action. Intuitively, the resulting agent is an agent that is hobbled so that it has no power in worlds where P comes out differently than was assumed. These agents are then combined into a team. Intuitively, the team selects an option of the form “the first agent tries to do X (which only succeeds when P is true) and the second agent tries to do Y (which only succeeds when P is false)”. Like the previous decomposition, this specifies both what to do in whatever actual environment results, as well as what would have been done in the counterfactual world where the value of P was reversed. Thus, this way of combining the agents once again adds in all conditional policies on P. So, **P is observable if and only if decomposing the frame using assumptions on P, then hobbling the resulting frames in cases where their assumptions are false, and then putting the agents back in a team, is equivalent to the original frame.**
**Time**
Cartesian frames do not have an intrinsic notion of time. However, we can still use them to model sequential processes, by having the agent options be _policies_ rather than actions, and having the worlds be histories or trajectories rather than states.
To say useful things about time, we need to broaden our notion of observables. So far I’ve been talking about whether you can observe binary properties P that are either true or false. In fact, all of the definitions can be easily generalized to n-ary properties P that can take on one of N values. We’ll be using this notion of observability here.
Consider a game of chess where Alice plays as white and Bob as black. Intuitively, when Alice is choosing her second move, she can observe Bob’s first move. However, the property “Bob’s first move” would not be observable in Alice’s Cartesian frame, because Alice’s _first_ move cannot depend on Bob’s first move (since Bob hasn’t made it yet), and so when deciding the first move we can’t implement policies that condition on what Bob’s first move is.
Really, we want some way to say “after Alice has made her first move, from the perspective of the rest of her decisions, Bob’s first move is observable”. But we know how to remove some control from the agent in order to get the perspective of “everything else” -- that’s externalization! In particular, in Alice’s frame, if we externalize the property “Alice’s first move”, then the property “Bob’s first move” _is_ observable in the new frame.
This suggests a way to define a sequence of frames that represent the passage of time: we define the Tth frame as “the original frame, but with the first T moves externalized”, or equivalently as “the T-1th frame, but with the Tth move externalized”. Each of these frames are subagents of the original frame, since we can think of the full agent (Alice) as the team of “the agent that plays the first T moves” and “the agent that plays the T+1th move and onwards”. As you might expect, as “time” progresses, the agent loses controllables and gains observables. For example, by move 3 Alice can no longer control her first two moves, but she can now observe Bob’s first two moves, relative to Alice at the beginning of the game.
Planned opinion:
Replies from: Scott Garrabrant, riceissaI like this way of thinking about agency: we’ve been talking about “where to draw the line around the agent” for quite a while in AI safety, but there hasn’t been a nice formalization of this until now. In particular, it’s very nice that we can compare different ways of drawing the line around the agent, and make precise various concepts around this, such as “subagent”.
I’ve also previously liked the notion that “to observe P is to be able to change your decisions based on the value of P”, but I hadn’t really seen much discussion about it until now. This sequence makes some real progress on conceptual understanding of this perspective: in particular, the notion that observability requires “all the control to be in the environment” is not one I had until now. (Though I should note that this particular phrasing is mine, and I’m not sure the author would agree with the phrasing.)
One of my checks for the utility of foundational theory for a particular application is to see whether the key results can be explained without having to delve into esoteric mathematical notation. I think this sequence does very well on this metric -- for the most part I didn’t even read the proofs, yet I was able to reconstruct conceptual arguments for many of the theorems that are convincing to me. (They aren’t and shouldn’t be as convincing as the proofs themselves.) However, not all of the concepts score so well on this -- for example, the generic subagent definition was sufficiently unintuitive to me that I did not include it in this summary.
↑ comment by Scott Garrabrant · 2020-11-30T01:02:47.510Z · LW(p) · GW(p)
Looks like a pretty good summary to me.
↑ comment by riceissa · 2020-12-01T21:24:21.245Z · LW(p) · GW(p)
So the existence of this interface implies that A is “weaker” in a sense than A’.
Should that say B instead of A', or have I misunderstood? (I haven't read most of the sequence.)
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2020-12-02T17:14:30.503Z · LW(p) · GW(p)
It should, good catch, thanks!
comment by Ramana Kumar (ramana-kumar) · 2021-05-17T08:25:51.241Z · LW(p) · GW(p)
A formalisation of the ideas in this sequence in higher-order logic, including machine verified proofs of all the theorems, is available here.
comment by Sven Nilsen (bvssvni) · 2020-10-24T07:54:08.800Z · LW(p) · GW(p)
The use of Chu spaces is very interesting. This is also a great introduction to Chu spaces.
I was able to formalize the example in the research automated theorem prover Avalog: https://github.com/advancedresearch/avalog/blob/master/source/chu_space.txt
It is still very basic, but shows potential. Perhaps Avalog might be used to check some proofs about Cartesian frames.
comment by Mark Xu (mark-xu) · 2020-10-22T16:43:31.163Z · LW(p) · GW(p)
This is very exciting. Looking forward to the rest of the sequence.
As I was reading, I found myself reframing a lot of things in terms of the rows and columns of the matrix. Here's my loose attempt to rederive most of the properties under this view.
- The world is a set of states. One way to think about these states is by putting them in a matrix, which we call "cartesian frame." In this frame, the rows of the matrix are possible "agents" and the columns are possible "environments".
- Note that you don't have to put all the states in the matrix.
- Ensurables are the part of the world that the agent can always ensure we end up in. Ensurables are the rows of the matrix, closed under supersets
- Preventables are the part of the world that the agent can always ensure we don't end up in. Preventables are the complements of the rows, closed under subsets
- Controllables are parts of the world that are both ensurable and preventable. Controlables are rows (or sets of rows) for which there exists rows that are disjoint. [edit: previous definition of "contains elements not found in other rows" was wrong, see comment by crabman]
- Observeables are parts of the environment that the agent can observe and act conditionally according to. Observables are columns such that for every pair of rows there is a third row that equals the 1st row if the environment is in that column and the 2nd row otherwise. This means that for every two rows, there's a third row that's made by taking the first row and swapping elements with the 2nd row where it intersects with the column.
- Observables have to be sets of columns because if they weren't, you can find a column that is partially observable and partially not. This means you can build an action that says something like "if I am observable, then I am not observable. If I am not observable, I am observable" because the swapping doesn't work properly.
- Observables are closed under boolean combination (note it's sufficient to show closure under complement and unions):
- Since swapping index 1 of a row is the same as swapping all non-1 indexes, observables are closed under complements.
- Since you can swap indexes 1 and 2 by first swapping index 1, then swapping index 2, observables are closed under union.
- This is equivalent to saying "If A or B, then a0, else a2" is logically equivalent to "if A, then a0, else (if B, then a0, else a2)"
- Since controllables are rows with specific properties and observables are columns with specific properties, then nothing can be both controllable and observable. (The only possibility is the entire matrix, which is trivially not controllable because it's not preventable)
- This assumes that the matrix has at least one column
- The image of a cartesian frame is the actual matrix part.
- Since an ensurable is a row (or superset) and an observable is a column (or set of columns), then if something is ensurable and observable, then it must contain every column, so it must be the whole matrix (image).
- If the matrix has 1 or 0 rows, then the observable constraint is trivially satisfied, so the observables are all possible sets of (possible) environment states (since 0/1 length columns are the same as states).
- "0 rows" doesn't quite make sense, but just pretend that you can have a 0 row matrix which is just a set of world states.
- If the matrix has 0 columns, then the ensurable/preventable contraint is trivially satisfied, so the ensurables are the same as the preventables are the same as the controllables, which are all possible sets of (possible) environment states (since "length 0" rows are the same as states).
- "0 columns doesn't make that much sense either but pretend that you can have a 0 column matrix which is just a set of world state.
- If the matrix has exactly 1 column, then the ensurable/preventable constraint is trivially satisfied for states in the image (matrix), so the ensurables are all non-empty sets of states in the matrix (since length 1 columns are the same as states), closed under union with states outside the matrix. It should be easy to see that controllables are all possible sets of states that intersect the matrix non-trivially, closed under union with states outside the matrix.
↑ comment by Tetraspace (tetraspace-grouping) · 2020-10-26T20:22:53.033Z · LW(p) · GW(p)
This means you can build an action that says something like "if I am observable, then I am not observable. If I am not observable, I am observable" because the swapping doesn't work properly.
Constructing this more explicitly: Suppose that and . Then must be empty. This is because for any action in the set , if was in then it would have to equal which is not in , and if was not in it would have to equal which is in .
Since is empty, is not observable.
↑ comment by philip_b (crabman) · 2020-10-25T17:36:46.771Z · LW(p) · GW(p)
According to your interpretation of controllables, in , isn't controllable, because it contains , which can be found in another row. By the original definition, it's controllable.
Replies from: mark-xu↑ comment by Mark Xu (mark-xu) · 2020-10-25T17:41:40.340Z · LW(p) · GW(p)
Good point - I think the correct definition is something like "rows (or sets of rows) for which there exists a row which is disjoint"
↑ comment by magfrump · 2020-12-27T08:31:50.748Z · LW(p) · GW(p)
I feel like this analogy should make it possible to compress the definition of some agents; for example the agent that consists of the intersection of two agents, I would expect to be able to be represented as some combination of the two rows representing those two agents. It's not clear to me how to do that, in particular because the elements of the matrix are "outcomes" which don't have any arithmetic structure.
comment by Diffractor · 2020-10-22T19:16:06.355Z · LW(p) · GW(p)
I will be hosting a readthrough of this sequence on MIRIxDiscord again, PM for a link.
comment by Ben Pace (Benito) · 2021-12-27T18:35:27.528Z · LW(p) · GW(p)
Introduction to Cartesian Frames [LW · GW] is a piece that also gave me a new philosophical perspective on my life.
I don't know how to simply describe it. I don't know what even to say here.
One thing I can say is that the post formalized the idea of having "more agency" or "less agency", in terms of "what facts about the world can I force to be true?". The more I approach the world by stating things that are going to happen, that I can't change, the more I'm boxing-in my agency over the world. The more I treat constraints as things I could fight to change, the more I have power and agency over the world. If I can't imagine a fact being false, I don't have agency over it. (This applies to mathematical and logical claims too, which ties into logical induction and decision theory.)
Writing the last sentence I realize the idea is one with the post I wrote "Taking your environment as object" vs "Being subject to your environment" [LW · GW] which is another chunk of this element of growth I've experienced in the last year.
Anyway, that was a big deal — the first few times I read the math of cartesian frames I didn't get the idea at all, then after seeing some examples and reflecting on it, it clicked and helped me understand this whole thing better.
(Also that Scott has formalized it is very valuable and impressive, and even more so is this notion of factorizations of a set and the apparently new sequence he discovered which is insane and can't be true. Factorization of a set seems like the third thing you'd invent about sets once you thought of the idea, and if Scott discovered it in 2020 I'll be like wtaf.)
(But this is not the primary reason I'm endorsing it in the review. The primary reason is that it captures something that seems philosophically important to me.)
In retrospect I'm bumping this up to a +9 for the review. I didn't think about it properly in the early vote, and it's a lot of technical stuff and I forgot about the core concepts I got from it.
(This review is taken from my post Ben Pace's Controversial Picks for the 2020 Review [LW · GW].)
comment by Ramana Kumar (ramana-kumar) · 2020-12-05T08:34:02.460Z · LW(p) · GW(p)
Do we lose much by restricting attention to finite Cartesian frames (i.e., with finite agent and environment)? I ask because I'm formalising [LW(p) · GW(p)] these results in higher-order logic (HOL), and the category is too big to represent if it really must contain frames with infinite agents and also for any pair of frames the frame whose agents are the morphisms between them. The root problem is probably that I require any category's class of objects to be a set, but it's hard to avoid this requirement in HOL in a nice way. Everything should work out for finite frames though. (I haven't come across any compelling examples of infinite frames, but I haven't tried hard to think of them.)
Replies from: Scott Garrabrant, ramana-kumar↑ comment by Scott Garrabrant · 2020-12-18T00:48:26.486Z · LW(p) · GW(p)
I don't think you lose much by focusing on finite Cartesian frames. I have mostly only been imagining finite cases.
I think there is some potential for later extending the theory to encompass game theory and probabilistic strategies, and then we might want to think of the infinite space of mixed strategies as the agent, but it wouldn't surprise me if in doing this, we also put continuity into the system and want to assume compactness.
↑ comment by Ramana Kumar (ramana-kumar) · 2020-12-17T15:26:39.953Z · LW(p) · GW(p)
To see that some restriction is required here (not imposed by HOL), consider that if may contain arbitrary Cartesian frames over then we would have an injection that, for example, encodes a set as the Cartesian frame with (the environment and evaluation function are unimportant), which runs afoul of Cantor's theorem regarding the cardinality of .
I wouldn't be surprised if a similar encoding/injection could be made using just the operations used to construct Cartesian frames that appear in this sequence - though I have not found one explicitly myself yet.
comment by Charlie Steiner · 2020-10-22T17:47:45.967Z · LW(p) · GW(p)
If every pair led to a different world-state, this would be the boring case of complete factorizability, right? As in, you couldn't distinguish this from the world having no dynamics at all, just a recording of the choices of and . Therefore it seems important that your dynamics send some pairs of choices to identical states.
But that's not necessarily how the micro-scale laws of physics work. You can't squish state space irreversibly like that. And so can't be the actual microphysical world, it has to be some macro-level abstract model of it, or else it's boring.
So I'm a little confused about what you have in mind when you talk about putting different bases and onto the same . What's so great about keeping the same , if it's an abstraction of the microphysical world, tailor-made to help us model exactly this agent? I suspect that the answer is that you're using this to model an agent that also has subagents, so I'm excited for that post :)
Replies from: Scott Garrabrant↑ comment by Scott Garrabrant · 2020-10-22T18:08:21.220Z · LW(p) · GW(p)
Your suspected answer right.
comment by Ben Pace (Benito) · 2020-10-24T00:12:36.722Z · LW(p) · GW(p)
Curated.
I'm exceedingly excited about this sequence. The Embedded Agency sequence laid out a core set of confusions, and it seems like this is a formal system that deals with those issues far better than the current alternatives e.g. the cybernetics model. This post lays out the basics of Cartesian Frames clearly and communicates key parts of the overall approach ("reasoning like Pearl's to objects like game theory's, with a motivation like Hutter's"). I've also never seen math explained with as much helpful philosophical justification (e.g. "Part of the point of the Cartesian frame framework is that we are not privileging either interpretation"), and I appreciate all of that quite a bit.
It seems likely that by the end of this sequence it will be on a list of my all-time favorite things posted to LessWrong 2.0. I'm looking forward to getting to grips with Cartesian Frames, understanding how they work, and to start applying those intuitions to my other discussions of agency.
I'm also curating it a little quickly to let people know that Scott is giving a talk on this sequence this Sunday at 12:00PM PT [LW · GW]. Furthermore, Scott is holding weekly office hours (see the same link for more info) for people to ask questions, and Diffractor is running a reading group in the MIRIx Discord, which I recommend people PM him [LW · GW] to get an invite to (I just did so myself, it's a nice Discord server).
comment by Mark Xu (mark-xu) · 2020-10-22T14:54:56.597Z · LW(p) · GW(p)
In 4.1:
Given a0 and a1, since S∈Obs(C), there exists an a2∈A such that for all e∈E, we have a2∈if(S,a0,a1). Then, since T∈Obs(C), there exists an a3∈A such that for all e∈E, we have a3∈if(S,a0,a2). Unpacking and combining these, we get for all e∈E, a3∈if(S∪T,a0,a1). Since we could construct such an a3 from an arbitrary a0,a1∈A, we know that S∪T∈Obs(C). □
I think there's a typo here. Should be , not .
(also not sure how to copy latex properly).
Replies from: Scott Garrabrant↑ comment by Scott Garrabrant · 2020-10-22T16:46:19.538Z · LW(p) · GW(p)
Yep. Fixed. Thanks.
comment by Stuart_Armstrong · 2021-02-16T16:24:59.921Z · LW(p) · GW(p)
Did posts on generalised models as a category [LW · GW] and how one can see Cartesian frames as generalised models [LW · GW].
comment by lemonhope (lcmgcd) · 2021-02-06T16:13:53.964Z · LW(p) · GW(p)
Printable PDF of whole sequence with comments
https://drive.google.com/file/d/1gW6btBWvk1mMCPItLt9wPYApc8caiUCa/view?usp=drivesdk
comment by jsalvatier · 2022-09-15T21:56:33.034Z · LW(p) · GW(p)
I struggle to satisfyingly interpret ⋅, the 'evaluation function'. Or maybe struggling to interpret W, the world timelines (presumably full world evolutions). Any advice on how to think about them?
In particular, how should I understand a ⋅ e = a_0 ⋅ e = w? the agent is different, but the worlds are the same. So then what's the difference between e and w?
I guess ⋅ is something like "the world partitioned into things that are relevantly different for me"? Would appreciate anyone's clarifying thoughts.
comment by Stuart_Armstrong · 2021-02-04T12:18:33.194Z · LW(p) · GW(p)
I like it. I'll think about how it fits with my ways of thinking (eg model splintering).
comment by Edouard Harris · 2020-10-23T02:53:48.076Z · LW(p) · GW(p)
Great framework - feels like this is touching on something fundamental.
I'm curious: is the controllable / observable terminology intentionally borrowed from control theory? Or is that a coincidence?
Replies from: Scott Garrabrant↑ comment by Scott Garrabrant · 2020-10-23T03:00:02.740Z · LW(p) · GW(p)
coincidence
comment by JessRiedel · 2024-01-29T05:34:02.940Z · LW(p) · GW(p)
Note that I'm specifically not referring to the elements of as "actions" or "outputs"; rather, the elements of are possible ways the agent can choose to be.
I don't know what distinction is being drawn here. You probably need an example to illustrate.
comment by martinkunev · 2023-12-06T01:35:51.769Z · LW(p) · GW(p)
There seems to be a mistake in section 4.2.
Prevent(C5) is said to be the closure of {{ur}, {nr}, {us}, {ns}} under subsets.
It should be {{nr, us, ns}, {ur, us, ns}, {ur, nr, ns}, {ur, nr, us}}.
comment by Jack O'Brien (jack-o-brien) · 2023-06-09T02:32:56.034Z · LW(p) · GW(p)
Definition: .
A useful alternate definition of this is:
Where refers to . Proof:
comment by a bottle cap · 2020-10-24T03:12:24.832Z · LW(p) · GW(p)
"Because we're discussing an agent that has the freedom to choose between multiple possibilities"
Where is this freedom, exactly? Freedom meaning a lack of being utterly and totally constrained by prior causes.
↑ comment by justinpombrio · 2020-10-24T20:57:32.281Z · LW(p) · GW(p)
First: https://www.lesswrong.com/posts/Mc6QcrsbH5NRXbCRX/dissolving-the-question [LW · GW] and then: http://lesswrong.com/lw/r0/thou_art_physics/