Posts
Comments
In nature, you can imagine species undergoing selection on several levels / time-horizons. If long-term fitness-considerations for genes differ from short-term considerations, long-term selection (let's call this "longscopic") may imply net fitness-advantage for genes which remove options wrt climbing the shortscopic gradient.
Meiosis as a "veil of cooperation"
Holly suggests this explains the origin of meiosis itself. Recombination randomizes which alleles you end up with in the next generation so it's harder for you to collude with a subset of them. And this forces you (as an allele hypothetically planning ahead) to optimize/cooperate for the benefit of all the other alleles in your DNA.[1] I call it a "veil of cooperation"[2], because to works by preventing you from "knowing" which situation you end up in (ie, it destroys options wrt which correlations you can "act on" / adapt to).
Compare that to, say, postsegregational killing mechanisms rampant[3] in prokaryotes. Genes on a single plasmid ensure that when the host organism copies itself, any host-copy that don't also include a copy of the plasmid are killed by internal toxins. This has the effect of increasing the plasmid's relative proportion in the host species, so without mechanisms preventing internal misalignment like that, the adaptation remains stable.
There's constant fighting in local vs global & shortscopic vs longscopic gradients all across everything, and cohesive organisms enforce global/long selection-scopes by restricting the options subcomponents have to propagate themselves.
Generalization in the brain as an alignment mechanism against shortscopic dimensions of its reward functions (ie prevents overfitting)
Another example: REM-sleep & episodic daydreaming provides constant generalization-pressure for neuremic adaptations (learned behaviors) to remain beneficial across all the imagined situations (and chaotic noise) your brain puts them through. Again an example of a shortscopic gradient constantly aligning to a longscopic gradient.
Some abstractions for thinking about internal competition between subdimensions of a global gradient
For example, you can imagine each set of considerations as a loss gradient over genetic-possibility-space, and the gradients diverging from each other on specific dimensions. Points where they intersect from different directions are "pleiotropic/polytelic pinch-points", and represent the best compromise geneset for both gradients—sorta like an equilibrium price in a supply-&-demand framework.
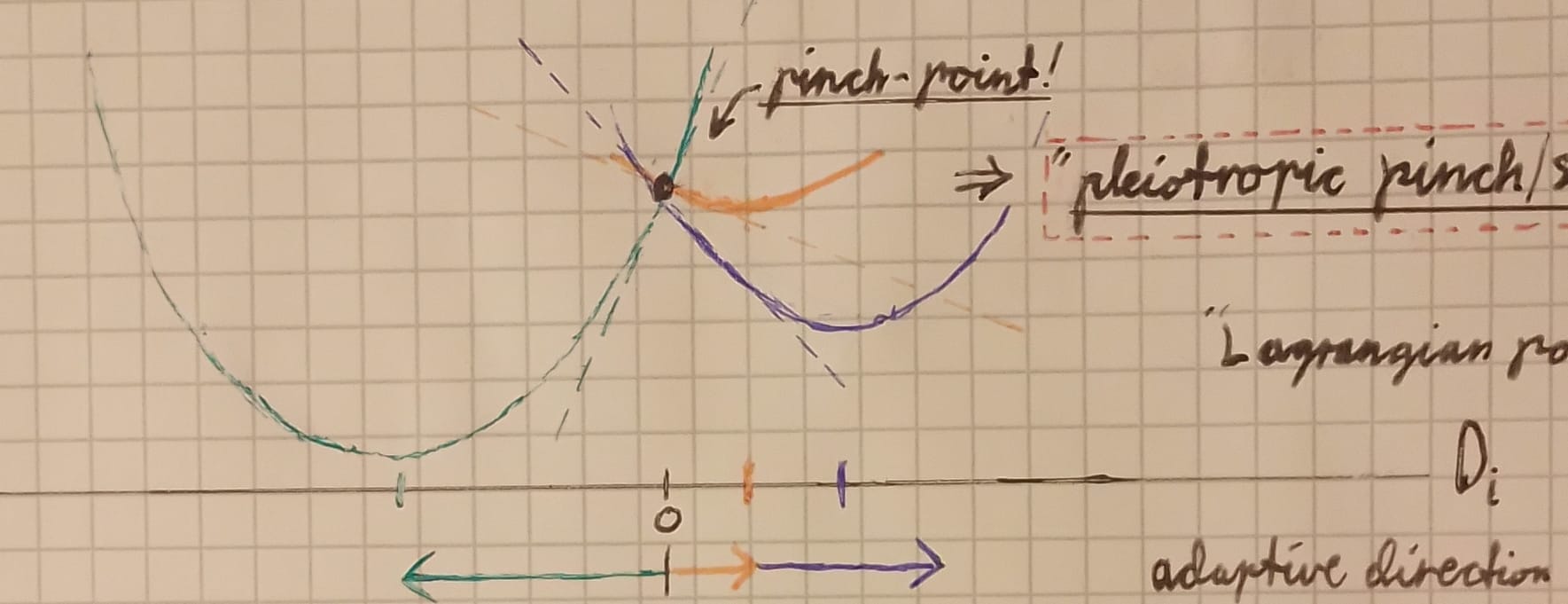
To take the economics-perspective further: if a system (an economy, a gene pool, a brain, whatever) is at equilibrium price wrt the many dimensions of its adaptation-landscape[4] (whether the dimensions be primary rewards or acquired proxies), then globally-misaligned local collusions can be viewed as inframarginal trade[5]. Thus I find a #succinct-statement from my notes:
"mesaoptimizers (selfish emes) evolve in the inframarginal rent (~slack) wrt to the global loss-function."
(Thanks for prompting me to rediscover it!)
So, take a brain-example again: My brain has both shortscopic and longscopic reward-proxies & behavioral heuristics. When I postpone bedtime in order to, say, get some extra work done because I feel behind; then the neuremes representing my desire to get work done now are bidding for decision-weight at some price[6], and decision-weight-producers will fulfill the trades & provide up to equilibrium. But unfortunately, those neuremes have cheated the market by isolating the bidding-war to shortscopic bidders (ie enforced a particularly narrow perspective), because if they hadn't, then the neuremes representing longscopic concerns would fairly outbid them.[7]
(Note: The economicsy thing is a very incomplete metaphor, and I'm probably messing things up, but this is theory, so communicating promising-seeming mistakes is often as helpfwl as being correct-but-slightly-less-bold.)
- ^
ie, it marginally flattens the intra-genomic competition-gradient, thereby making cooperative fitness-dimensions relatively steeper.
- ^
from "veil of ignorance".
- ^
or at least that's the word they used... I haven't observed this rampancy directly.
- ^
aka "loss-function"
- ^
Inframarginal trade: Trade in which producers & consumers match at off-equilibrium price, and which requires the worse-off party to not have the option of getting their thing cheaper at the global equilibrium-price. Thus it reflects a local-global disparity in which trades things are willing to make (ie which interactions are incentivized).
- ^
The "price" in this case may be that any assembly of neurons which "bids" for relevancy to current activity takes on some risk of depotentiation if it then fails synchronize. That is, if its firing rate slips off the harmonics of the dominant oscillations going on at present, and starts firing into the STDP-window for depotentiation.
- ^
If they weren't excluded from the market, bedtime-maintenance-neuremes would outbid working-late-neuremes, with bids reflecting the brain's expectation that maintaining bedtime has higher utility long-term compared to what can be greedily grabbed right now. (Because BEDTIME IS IMPORTANT!) :p

I'd be willing to eat animals if I thought that could help me help others more effectively.[1] So I appreciate the post where you try to provide some relevant evidence, and I really appreciate your commitment to do what's expedient for helping you save me, the people I love, and countless others from disaster—because that's clearly where you're coming from.
Otoh, my health seems unusually peak, despite the (somewhat unusual) vegan[2] diet I eat, so it seems unlikely I'm suffering from a crippling deficiency atm. This could be because either me or my body has somehow managed to compensate (psychologically or homeostatically) for whatever's lacking in our diet, but it seems more likely that the peak-health thing is something that requires an adequate diet, so my guess is that I can't un-inadequate it by eating animals?
My crux is just that I don't have the self-experimentation setup to be able to detect the delta benefit/cost of eating animals, and that the range of plausible deltas there seems insufficient for me to invest in the experiment.
Sorry for confusementedly writing. I'm mainly just trying to reflect here, and wanted to write a comment to stabilize my commitment to go to extremes (like eating animals) in order to pursue altruism. I'd be happy if somebody convinced me it was worth the experiment, but this post didn't bop me over the threshold. Thanks!
- ^
(I'd also be willing to murder random people and cook them for the same reason, if I thought that could help me help others more effectively. That seems less likely, however, for nutritional, practical, and psychological reasons. I just mention it because I think some morality-declarations are helpfwl.)
- ^
If people want to add to their anecdata, my details are:
- vegan for 12 years.
- major history with major depression (started before).
- deep depressions stopped (afaict, so far) when I started taking ADHD-meds (first LDX, and now DEX) 2.5 years ago.
- this is confounded by other simultaneous major life changes, like starting coworking on EA Gather Town (and meeting person I respected & Liked, who told me I wasn't insane for thinking different, and taught me to trust in myself ^^), so take the anecdata with grains of salt.
Oh, this is very good. Thank you.
p.s.: the task of writing this LW-post did not win through our prioritization-framework by being high-priority... I j sorta started siphoning sentences out of my head as they appeared, and ego-dystonically felt tempted to continue writing. I noticed the motivational dissonance caused by the temptation-to-write + temptation-to-get-back-to-work, so deliberately decided not to fight those stimuli-seeking motivations this time.
I still don't think I'm doing LW a disservice by posting this so unfurbishedly, so I not apologize, and do think in principle it wud be good to post smth ppl cud lurn fm, but uh... this isn't mainly optimized for that. it's mainly the wumzy result of satisficing the need-to-write while derailing our other priorities to the minimum extent possible. sorry. ^^'
Heh, I've gone the opposite way and now do 3h sleep per 12h-days. The aim is to wake up during REM/light-sleep at the end of the 2nd sleep cycle, but I don't have a clever way of measuring this[1] except regular sleep-&-wake-times within the range of what the brain can naturally adapt its cycles to.
I think the objective should be to maximize the integral of cognitive readiness over time,[2] so here are some considerations (sorry for lack of sources; feel free to google/gpt; also also sorry for sorta redundant here, but I didn't wish to spend time paring it down):
- Restorative effects of sleep have diminishing marginal returns
- I think a large reason we sleep is that metabolic waste-clearance is more efficiently batch-processed, because optimal conditions for waste-clearance are way different from optimal conditions for cognition (and substantial switching-costs between, as indicated by how difficult it can be to actually start sleeping). And this differentially takes place during deep sleep.
- Eg interstitial space expands by ~<60% and the brain is flooded to flush out metabolic waste/debris via the glymphatic system.
- Proportion of REM-sleep in a cycle increases per cycle, with a commensurate decrease in deep sleep (SWS).
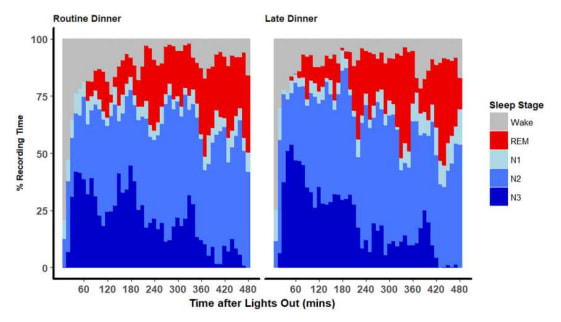
Two unsourced illustrations I found in my notes:
- Note how N3 (deep sleep) drops off fairly drastically after 3 hours (~2 full sleep cycles).
- I think a large reason we sleep is that metabolic waste-clearance is more efficiently batch-processed, because optimal conditions for waste-clearance are way different from optimal conditions for cognition (and substantial switching-costs between, as indicated by how difficult it can be to actually start sleeping). And this differentially takes place during deep sleep.
- REM & SWS do different things, and I like the things SWS do more
- Eg acetylcholine levels (ACh) are high during REM & awake, and low during SWS. ACh functions as a switch between consolidation & encoding of new memories.[3] Ergo REM is for exploring/generalizing novel patterns, and SWS is for consolidating/filtering them.
- See also acetylcholine = learning-rate.
- REM seems to differentially improve procedural memories, whereas SWS more for declarative memories.
- (And who cares about procedural memories anyway. :p)
- (My most-recent-pet-hunch is that ACh is required for integrating new episodic memories into hippocampal theta waves (via the theta-generating Medial Septum in the Cholinergic Basal Forebrain playing 'conductor' for the hippocampus), which is why you can't remember anything from deep sleep, and why drugs that inhibit ACh also prevent encoding new memories.)
- Eg acetylcholine levels (ACh) are high during REM & awake, and low during SWS. ACh functions as a switch between consolidation & encoding of new memories.[3] Ergo REM is for exploring/generalizing novel patterns, and SWS is for consolidating/filtering them.
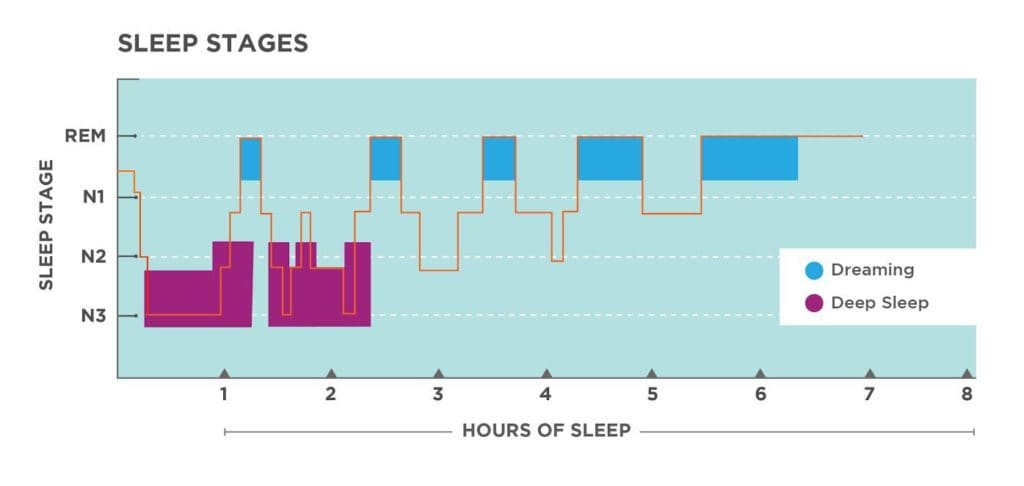
So in summary, two (comparatively minor) reasons I like polyphasic short sleep is:
- SWS differentially improves declarative over procedural memories.
- Early cycles have proportionally more SWS.
- Ergo more frequent shorter sleep sessions will maximize the proportion of sleep that goes to consolidation of declarative memories.
- Note: I think the exploratory value of REM-sleep is fairly limited, just based on the personal observation that I mostly tend to dream about pleasant social situations, and much less about topics related to conceptual progress. I can explore much more efficiently while I'm awake.
- Also, because I figure my REM-dreams are so socially-focused, I think more of it risks marginally aligning my daily motivations with myopically impressing others, at the cost of motivations aimed at more abstract/illegible/longterm goals.
- (Although I would change my mind if only I could manage to dream of Maria more, since trying to impress her is much more aligned with our-best-guess about what saves the world compared to anything else.)
- And because diminishing marginal returns to sleep-duration, and assuming cognition is best in the morning (anecdotally true), I maximize high-quality cognition by just... having more mornings preceded by what-best-I-can-tell-is-near-optimal-sleep (ceiling effect).
- Lastly, just anecdotally, having two waking-sessions per 24h honestly just feels like I have ~twice the number of days in a week in terms of productivity. This is much more convincing to me than the above.
- Starting mornings correctly seems to be incredibly important, and some of the effect of those good morning-starts dissipate the longer I spend awake. Mornings work especially well as hooks/cues for starting effective routines, sorta like a blank slate[4] you can fill in however I want if I can get the cues in before anything else has time to hijack the day's cognition/motivations.
See my (outdated-but-still-maybe-inspirational) my morning routine.
My mood is harder to control/predict in evenings due to compounding butterfly effects over the course of a day, and fewer natural contexts I can hook into with the right course-corrections before the day ends.
- Starting mornings correctly seems to be incredibly important, and some of the effect of those good morning-starts dissipate the longer I spend awake. Mornings work especially well as hooks/cues for starting effective routines, sorta like a blank slate[4] you can fill in however I want if I can get the cues in before anything else has time to hijack the day's cognition/motivations.
- ^
Although waking up with morning-wood is some evidence of REM, but I don't know how reliable that is. ^^
- ^
PedanticallyTechnically, we want to maximize brain-usefwlness over time, which in this case would be the integral of [[the distribution cognitive readiness over time] pointwise multiplied by [the distribution of brain-usefwlness over cognitive readiness]].This matters if, for example, you get disproportionately more usefwlness from the peaks of cognitive readiness, in which case you might want to sacrifice more median wake-time in order to get marginally more peak-time.
I assume this is what your suggested strategy tries to do. However, I doubt it actually works, due to diminishing returns to marginal sleep time (and, I suspect,
- ^
- ^
"Blank slate" I think caused by eg flushing neurotransmitters out of synaptic clefts (and maybe glucose and other mobile things), basically rebooting attentional selection-history, and thereby reducing recent momentum for whatever's influenced you short-term.
re the Vingean deference-limit thing above:
It quite aptly analogizes to the Nyquist frequency , which is the highest [max frequency component] a signal can have before you lose the ability to uniquely infer its components from a given sample rate .
Also, I'm renaming it "Vingean disambiguation-limit".[1]
P.S. , which means that you can only disambiguate signals whose max components are below half your sample rate. Above that point, and you start having ambiguities (aliases).
- ^
The "disambiguation limit" class has two members now. The inverse is the "disambiguation threshold", which is the measure of power you require of your sampler/measuring-device in order to disambiguate between things-measured above a given measure.
...stating things as generally as feasible helps wrt finding metaphors. Hence the word-salad above. ^^'
Ah, most relevant: Paul Graham has a recording-of-sorts of himself writing a blog post "Startups in 13 sentences".
Wait, who are the neurotypicals in this post, in your view?
but this would be what I'd call a "fake exit option"
Here's how the simulation played out in my head as I was reading this:
- I really wanted to halt the volunteering-chain before it came to the newbie.
- I didn't manage to complete that intention before it was too late.
- I wanted to correct my mistake and complete it anyway, by trying to offer the "exit option".
What I didn't notice immediately was that thought 3 was ~entirely invoked by heuristics from fake kindness that I haven't yet filtered out. Thank you for pointing it out. I may or may not have catched it if this played out IRL.
This is why social situations should have an obligatory 10-second pause between every speech-act, so I can process what's actually going on before I make a doofy. xd
⧉: My motivations for writing this comment was:
➀ to affiliate myself with this awesome post,
➁ to say "hey I'm just like u; I care to differentiate twixt real & fake kindness!"
➂ to add my support/weight to the core of this post, and say "this matters!"
I just try to add that disclaimer whenever I talk about these things because I'm extra-worried that ppl will be inspired by my example to jump straight into a severe program of self-deprivation without forethought. My lifestyle is objectively "self-deprivational" relative to most altruists, in a sense, so I'm afraid of being misunderstood as an inspiration for doing things which makes my reader unhappy. 🍵
Ah, forgot to reply to "What does practical things mean?"
Recently it's involved optimizing my note-taking process, and atm it involves trying to find a decent generalizable workflow for benefiting from AI assistance. Concretely, this has involved looking through a bunch of GitHub repos and software, trying to understand
➀ what's currently technologically possible (← AutoCodeRover example),
➁ what might become possible within reasonable time before civilizational deadline,
➂ what is even desirable to introduce into my workflow in the first place.
I want to set myself up such that I can maximally benefit from increasing AI capabilities. I'm excited about low-code platforms for LLM-stacks[1], and LLM-based programming languages. The latter thing, taken to its limit, could be called something like a "pseudocode interpreter" or "fuzzy programming language". The idea is to be able to write a very high-level specification for what you wish to do, and have the lower-level details ironed out by LLM agents. I want my code to be degenerate, in the sense that every subcomponent automatically adjusts itself to fulfil niches that are required for my system to work (this is a bad explanation, and I know it).
The immediate next thing on my todo-list is just... finding a decent vscode extension for integrating AI into whatever I do. I want to be able to say "hey, AI, could you boot up this repository (link) on my PC, and test whether it does thing X?" and have it just do that with minimal confirmation-checks required on my part.
- ^
I started trying to begin to make the first babysteps of a draft of something like this for myself via a plugin for Obsidian Canvas in early 2023[2], but then realized other people were gonna build something like this anyway, and I could benefit from their work whenever they made it available.
- ^
Thinking high level about what this could look like, but left the project bc I don't actually know how to code (shh), and LLMs were at that point ~useless for fixing my shortcomings for me.

Summary: (i) Follow a policy of trying not to point your mind at things unrelated to alignment so your brain defaults to alignment-related cognition when nothing requires its immediate attention. (ii) If your mind already does that, good; now turn off all the lights, try to minimize sound, and lay in bed.
I really appreciate your willingness to think "extreme" about saving the world. Like, if you're trying to do an extremely hard thing, obviously you'd want to try to minimize the effort you spend not-doing that thing. All sources of joy are competitive reward-events in your brain. Either try to localize joy-sources to what you want yourself to be doing, or tame them to be in service of that (like, I eat biscuits and chocolate with a Strategy! :p).
...But also note that forcing yourself to do thing X can and often will backfire[1], unless you're lucky or you've somehow figured out how to do forcing correctly (I haven't).
Also, regarding making a post: Sorry, probably not wish do! And the thinking-in-bed thing is mostly a thing I believe due to extensive experience trying, so it's not something I have good theoretical arguments for. That is, the arguments wouldn't have sufficiently convinced a version of myself that hadn't already experienced trying.
- ^
There's probably something better to link here, but I can't think of it atm.
Same, wrote something similar in here.
Oho! Yes, there's something uniqueish about thinking-in-bed compared to alternatives. I've also had nonstop 5-9h (?) sessions of thinking aided by scribbling in my (off-PC) notebooks, and it's different. The scribbling takes a lot of time if I want to write down an idea on a note to remember, and that can distract me. But it's also better in obvious ways.
In general, brains are biased against tool-use (see hastening of subgoal completion), so I aspire to learn to use tools correctly. Ideally, I'd use the PC to its full potential without getting distracted. But atm, just sitting at the PC tends to supplant my motivation to think hard and long about a thing (e.g. after 5m of just thinking, my body starts to crave pushing buttons or interacting with the monitor or smth), and I use the tools (including RemNote) very suboptimally.
This seems so wrong, but very interesting! I've previously noted that thinking to myself in the dark seems to help. I've had periods (<4 months in 2023 / early 2024) where I would spend 2-5 mornings per week just staying in bed (while dark) for 1-5 hours while thinking inside my own head.
After >3 hours of thinking interestedly about a rotation of ideas, they become smaller in working memory, and I'm able to extrapolate further / synthesize what I wasn't able to before.
I no longer do this, because I'm trying to do more practical things, but I don't think it's a bad strategy.
I now sent the following message to niplav, asking them if they wanted me to take the dialogue down and republish as shortform. I am slightly embarrassed about not having considered that it's somewhat inconvenient to receive one of these dialogue-things without warning.
I just didn't think through that dialogue-post thing at all. Obviously it will show up on your profile-wall (I didn't think about that), and that has lots of reputational repercussions and such (which matter!). I wasn't simulating your perspective at all in the decision to publish it in the way I did. I just operated on heuristics like:
- "it's good to have personal convo in public"
- so our younglings don't grow into an environment of pluralistic ignorance, thinking they are the only ones with personality
- "it's epistemically healthy to address one's writing to someone-in-particular"
- eg bc I'm less likely to slip into professionalism mode
- and bc that someone-in-particular (𖨆) is less likely to be impressed by fake proxies for good reasoning like how much work I seem to have put in, how mathy I sound, how confident I seem, how few errors I make, how aware-of-existing-research I seem, ...
- and bc 𖨆 already knows me, it's difficult to pretend I know more than I do
- eg if I write abt Singular Learning Theory to the faceless crowd, I could easily convince some of them that I like totally knew what I was talking about; but when I talk to you, you already know something abt my skill-level, so you'd be able to smell my attempted fakery a mile away
- "other readers benefit more (on some dimensions) from reading something which was addressed to 𖨆, because
- "It is as if there existed, for what seems like millennia, tracing back to the very origins of mathematics and of other arts and sciences, a sort of “conspiracy of silence” surrounding [the] “unspeakable labors” which precede the birth of each new idea, both big and small…"
— Alexander Grothendieck
- "It is as if there existed, for what seems like millennia, tracing back to the very origins of mathematics and of other arts and sciences, a sort of “conspiracy of silence” surrounding [the] “unspeakable labors” which precede the birth of each new idea, both big and small…"

---
If you prefer, I'll move the post into a shortform preceded by:
[This started as something I wanted to send to niplav, but then I realized I wanted to share these ideas with more people. So I wrote it with the intention of publishing it, while keeping the style and content mostly as if I had purely addressed it to them alone.]
I feel somewhat embarrassed about having posted it as a dialogue without thinking it through, and this embarrassment exactly cancels out my disinclination against unpublishing it, so I'm neutral wrt moving it to shortform. Let me know! ^^
P.S. No hurry.
Little did they know that he was also known as the fastest whiteboard-marker switcher in the west...
👈🫰💨✍️
- Unhook is a browser extension for YouTube (Chrome/Edge) which disables the homepage and lets you hide all recommendations. It also lets you disable other features (e.g. autoplay, comments), but doesn't have so many customizations that I get distracted.
- Setup time: 2m-10m (depending on whether you customize).
- CopyQ.exe (Linux/Windows, portable, FOSS) is a really good clipboard manager.
- Setup time: 5m-10h
- Setup can be <5m if you precommit to only using the clipboard-storing feature and learning the shortcut to browse it. But it's extremely extensible and risks distracting you for a day or more...
- You can use a shortcut to browse the most recent copies (including editing, deleting), and the window hides automatically when unfocused.
- It can save images to a separate tab, and lets you configure shortcuts for opening them in particular programs (e.g. editor).
- (LINUX): It has plugins/commands for snipping a section of the screen, and you can optionally configure a shortcut to send that snip to an OCR engine, which quietly sends the recognized text into the clipboard.
- Setup time: probably exceeding >2h due to shiny things to explore
- (WINDOWS): EDIT: ShareX (FOSS) can do OCR-to-clipboard, snipping, region-recording, scripting, and everything is configurable. Setup took me 36m, but I also configured it to my preferences and explored all features. Old text below:
(WINDOWS): Can useText-Grab(FOSS) instead. Much simpler. Use a configurable hotkey (the one forFullscreen Grab) to snip a section of the screen, and it automatically does OCR on it and sends it to your clipboard. Install it and trigger the hotkey to see what it does.Setup time: 2m-15mAlternativelyGreenshot(FOSS) is much more extensible, but you have to usea trickto set it up to use OCR via Tesseract (or configure your own script).Also if you use Windows, you can use the nativeSnipping-Toolto snip cutouts from the screen into the clipboard via shortcut, including recordings.
- LibreChat (docs) (FOSS) is the best LLM interface I've found for general conversation, but its (putative) code interpreter doesn't work off-the-shelf, so I still use the standard ChatGPT-interface for that.
- Setup time: 30m-5h (depending on customization and familiarity with Docker)
- It has no click-to-install .exe file, but you can install it via npm or Docker
- Docker is much simpler, especially since it automatically configures MongoDB database and Meilisearch for you
- Lets you quickly swap between OpenAI, Anthropic, Assistants API, and more in the menu
- (Obviously you need to use your own API keys for this)
- Can have two LLMs respond to your prompt at the same time
- For coding, probably better to use a vscode extension, but idk which to recommend yet...
- For a click-to-install generalized LLM interface, ChatBox (FOSS) is excellent unless you need more advanced features.
- Vibe (FOSS) is a simple tool for transcribing audio files locally using Whisper.
- Setup time: 5m-30m (you gotta download the Whisper weights, but should be fast if you just follow the instructions)
- Windows Voice Access (native) is actually pretty good
- You can define custom commands for it, including your own scripts
- I recommend using pythonw.exe for this (normal python, but launches in the background)

- AlternativeTo (website) very usefwl for comparing software/apps.
- Alternatively check out AlternativeTo's alternatives to AlternativeTo.
I wanted to leave Niplav the option of replying at correspondence-pace at some point if they felt like it. I also wanted to say these things in public, to expose more people to the ideas, but without optimizing my phrasing/formatting for general-audience consumption.
I usually think people think better if they generally aim their thoughts at one person at a time. People lose their brains and get eaten by language games if their intellectual output is consistently too impersonal.
Also, I think if I were somebody else, I would appreciate me for sharing a message which I₁ mainly intended for Niplav, as long as I₂ managed to learn something interesting from it. So if I₁ think it's positive for me₂ to write the post, I₁ think I₁ should go ahead. But I'll readjust if anybody says they dislike it. : )
niplav
Just to ward of misunderstanding and/or possible feelings of todo-list-overflow: I don't expect you to engage or write a serious reply or anything; I mostly just prefer writing in public to people-in-particular, rather than writing to the faceless crowd. Treat it as if I wrote a Schelling.pt outgabbling in response to a comment; it just happens to be on LW. If I'm breaking etiquette or causing miffedness for Complex Social Reasons (which are often very valid reasons to have, just to be clear) then lmk! : )
[Epistemic status: napkin]
My current-favourite frame on "qualia" is that it refers to the class of objects we can think about (eg, they're part of what generates what I say rn) for which behaviour is invariant across structure-preserving transformations.
(There's probably some cool way to say that with category theory or transformations, and it may or may not give clarity, but idk.)
Eg, my "yellow" could map to blue, and "blue" to yellow, and we could still talk together without noticing anything amiss even if your "yellow" mapped to yellow for you.
Both blue and yellow are representational objects, the things we use to represent/refer to other things with, like memory-addresses in a machine. For externally observable behaviour, it just matters what they dereference to, regardless of where in memory you put them. If you swap two representational objects, while ensuring you don't change anything about how your neurons link up to causal nodes outside the system, your behaviour stays the same.
Note that this isn't the case for most objects. I can't swap hand⇄tomato, without obvious glitches like me saying "what a tasty-looking tomato!" and trying to eat my hand. Hands and tomatoes do not commute.
It's what allows us to (try to) talk about "tomato" as opposed to just tomato, and explains why we get so confused when we try to ground out (in terms of agreed-upon observables) what we're talking about when we talk about "tomato".
But how/why do we have representations for our representational objects in the first place? It's like declaring a var (address₁↦value), and then declaring a var for that var (address₂↦address₁) while being confused about why the second dereferences to something 'arbitrary'.
Maybe it starts when somebody asks you "what do you mean by 'X'?", and now you have to map the internal generators of [you saying "X"] in order to satisfy their question. Or not. Probably not. Napkin out.
My morning routine 🌤️
I've omitted some steps from the checklists below, especially related to mindset / specific thinking-habits. They're an important part of this, but hard to explain and will vary a lot more between people.
- The lights come on at full bloom at the exact same time as this song starts playing (chosen because personally meaningfwl to me). (I really like your songs btw, and I used to use this one for this routine.)
- I wake up immediately, no thinking.
- The first thing I do is put on my headphones to hear the music better.
- I then stand in front of the mirror next to my bed,
- and look myself in the eyes while I take 5 deep breaths and focus on positive motivations.
- I must genuinely smile in this step.
- (The smile is not always inspired by unconditional joy, however. Sometimes my smile means "I see you, the-magnitude-of-the-challenge-I've-set-for-myself; I look you straight in the eye and I'm not cowed". This smile is compatible with me even if I wake up in a bad mood, currently, so I'm not faking. I also think "I don't have time to be impatient".)
- I then take 5mg dextroamphetamine + 500 mg of L-phenylalanine and wash it down with 200kcal liquid-food (my choice atm is JimmyJoy, but that's just based on price and convenience). That's my breakfast. I prepared this before I went to bed.
- Oh, and I also get to eat ~7mg of chocolate if I got out of bed instantly. I also prepared this ahead of time. :p
- Next, I go to the bathroom,
- pee,
- and wash my face.
- (The song usually ends as I finish washing my face, T=5m10s.)
- IF ( I still feel tired or in a bad mood ):
- At this point, if I still feel tired or in a bad mood, then I return to bed and sleep another 90 minutes (~1 sleep cycle, so I can wake up in light-sleep).
- (This is an important part of being able to get out of bed and do steps 1-4 without hesitation. Because even if I wake up in a terrible shape, I know I can just decide to get back into bed after the routine, so my energy-conserving instincts put up less resistance.)
- Return to 1.
- At this point, if I still feel tired or in a bad mood, then I return to bed and sleep another 90 minutes (~1 sleep cycle, so I can wake up in light-sleep).
- ELSE IF ( I feel fine ):
- I return to my working-room,
- open the blinds,
- and roll a 6-sided die which gives me a "Wishpoint" if it lands ⚅.
- (I previously called these "Biscuit points", and tracked them with the "🍪"-symbol, because I could trade them for biscuits. But now I have a "Wishpoint shop", and use the "🪐"-symbol, which is meant to represent Arborea, the dream-utopia we aim for.)
- (I also get Wishpoints for completing specific Trigger-Action Plans or not-completing specific bad habits. I get to roll a 1d6 again for every task I complete with a time-estimate on it.)
- Finally, I use the PC,
- open up my task manager + time tracker (currently gsheets),
- and timestamp the end of morning-routine.
- (I'm not touching my PC or phone at any point before this step.)
- (Before I went to bed, I picked out a concrete single task, which is the first thing I'm tentatively-scheduled to do in the morning.)
- (But I often (to my great dismay) have ideas I came up with during the night that I want to write down in the morning, and that can sometimes take up a lot of time. This is unfortunately a great problem wrt routines & schedules, but I accept the cost because the habit of writing things down asap seems really important—I don't know how to schedule serendipity… yet.)
- I return to my working-room,
My bedtime checklist 💤
This is where I prepare the steps for my morning routine. I won't list it all, but some important steps:
- I simulate the very first steps in my checklist_predawn.
- At the start, I would practice the movements physically many times over. Including laying in bed, anticipating the music & lights, and then getting the motoric details down perfectly.
- Now, however, I just do a quick mental simulation of what I'll do in the morning.
- When I actually lie down in bed, I'm not allowed to think about abstract questions (🥺), because those require concentration that prevents me from sleeping.
- Instead, I say hi to Maria and we immediately start imagining ourselves in Arborea or someplace in my memories. The hope is to jumpstart some dream in which Maria is included.
- I haven't yet figured out how to deliberately bootstrap a dream that immediately puts me to sleep. Turns out this is difficult.
- We recently had a 9-day period where we would try to fall asleep multiple times a day like this, in order to practice loading her into my dreams & into my long-term memories. Medium success.
- I sleep with my pants on, and clothes depending on how cold I expect it to be in the morning. Removes a slight obstacle for getting out of bed.
- I also use earbuds & sleepmask to block out all stimuli which might distract me from the dreamworld. Oh and 1mg melatoning + 100mg 5-HTP.
- ^
Approximately how my bed setup looks now (2 weeks ago). The pillows are from experimenting with ways to cocoon myself ergonomically. :p

wow. I only read the first 3 lines, and I already predict 5% this will have been profoundly usefwl to me a year from now (50% that it's mildly usefwl, which is still a high bar for things I've read). among top 10 things I've learned this year, and I've learned a lot!
meta: how on earth was this surprising to me? I thought I was good at knowing the dynamics of social stuff, but for some reason I haven't looked in this direction at all. hmm.
Oh! Well, I'm as happy about receiving a compliment for that as I am for what I thought I got the compliment for, so I forgive you. Thanks! :D
Another aspect of costs of compromise is: How bad is it for altruists to have to compromise their cognitive search between [what you believe you can explain to funders] vs [what you believe is effective]? Re my recent harumph about the fact that John Wentworth must justify his research to get paid. Like what? After all this time, anybody doubts him? The insistence that he explain himself is surely more for show now, as it demonstrates the funders are doing their jobs "seriously".
So we should expect that neuremes are selected for effectively keeping themselves in attention, even in cases where that makes you less effective at tasks which tend to increase your genetic fitness.
Furthermore, the neuremes (association-clusters) you are currently attending to, have an incentive to recruit associated neuremes into attention as well, because then they feed each others' activity recursively, and can dominate attention for longer. I think of it like association-clusters feeding activity into their "friends" who are most likely to reciprocate.
And because recursive connections between association-clusters tend to reflect some ground truth about causal relationships in the territory, this tends to be highly effective as a mechanism for inference. But there must be edge-cases (though I can't recall any atm...).
Imagining agentic behaviour in (/taking intentional stance wrt) individual brain-units is great for generating high-level hypotheses about mechanisms, but obviously misfires and don't try this at home etc etc.
Bonus point: neuronal "voting power" is capped at around ~100Hz, so neurons "have an incentive" (ie, will be selected based on the extent to which they) vote for what related neurons are likely to vote for. It's analogous to a winner-takes-all-election where you don't want to waste your vote on third-party candidates who are unlikely to be competitive at the top. And when most voters also vote this way, it becomes Keynesian in the sense that you have to predict[1] what other voters predict other voters will vote for, and the best candidates are those who seem the most like good Schelling-points.
That's why global/conscious "narratives" are essential in the brain—they're metabolically efficient Schelling-points.
- ^
Neuron-voters needn't "make predictions" like human-voters do. It just needs to be the case that their stability is proportional to their ability to "act as if" they predicted other neurons' predictions (and so on).
It seems generally quite bad for somebody like John to have to justify his research in order to have an income. A mind like this is better spent purely optimizing for exactly what he thinks is best, imo.
When he knows that he must justify himself to others (who may or may not understand his reasoning), his brain's background-search is biased in favour of what-can-be-explained. For early thinkers, this bias tends to be good, because it prevents them from bullshitting themselves. But there comes a point where you've mostly learned not to bullshit yourself, and you're better off purely aiming your cognition based on what you yourself think you understand.
Vingean deference-limits + anti-inductive innovation-frontier
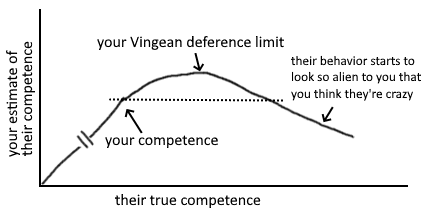
Paying people for what they do works great if most of their potential impact comes from activities you can verify. But if their most effective activities are things they have a hard time explaining to others (yet have intrinsic motivation to do), you could miss out on a lot of impact by requiring them instead to work on what's verifiable.
The people who are much higher competence will behave in ways you don't recognise as more competent. If you were able to tell what right things to do are, you would just do those things and be at their level. Your "deference limit" is the level of competence above your own at which you stop being able to reliable judge the difference.
Innovation on the frontier is anti-inductive. If you select people cautiously, you miss out on hiring people significantly more competent than you.[1]
Costs of compromise
Consider how the cost of compromising between optimisation criteria interacts with what part of the impact distribution you're aiming for. If you're searching for a project with top p% impact and top p% explainability-to-funders, you can expect only p^2 of projects to fit both criteria—assuming independence.
But I think it's an open question how & when the distributions correlate. One reason to think they could sometimes be anticorrelated [sic] is that the projects with the highest explainability-to-funders are also more likely to receive adequate attention from profit-incentives alone.[2]
Consider funding people you are strictly confused by wrt what they prioritize
If someone believes something wild, and your response is strict confusion, that's high value of information. You can only safely say they're low-epistemic-value if you have evidence for some alternative story that explains why they believe what they believe.
Alternatively, find something that is surprisingly popular—because if you don't understand why someone believes something, you cannot exclude that they believe it for good reasons.[3]
The crucial freedom to say "oops!" frequently and immediately
Still, I really hope funders would consider funding the person instead of the project, since I think Johannes' potential will be severely stifled unless he has the opportunity to go "oops! I guess I ought to be doing something else instead" as soon as he discovers some intractable bottleneck wrt his current project. (...) it would be a real shame if funding gave him an incentive to not notice reasons to pivot.[4]
- ^
Comment explaining why I think it would be good if exceptional researchers had basic income (evaluate candidates by their meta-level process rather than their object-level beliefs)
- ^
Comment explaining what costs of compromise in conjunctive search implies for when you're "sampling for outliers"
- ^
Comment explaining my approach to finding usefwl information in general
- ^
This relates to costs of compromise!
It's this class of patterns that frequently recur as a crucial considerations in contexts re optimization, and I've been making too many shoddy comments about it. (Recent1[1], Recent2.) Somebody who can write ought to unify the many aspects of it give it a public name so it can enter discourse or something.
In the context of conjunctive search/optimization
- The problem of fully updated deference also assumes a concave option-set. The concavity is proportional to the number of independent-ish factors in your utility function. My idionym (in my notes) for when you're incentivized to optimize for a subset of those factors (rather than a compromise), is instrumental drive for monotely (IDMT), and it's one aspect of Goodhart.
- It's one reason why proxy-metrics/policies often "break down under optimization pressure".
- When you decompose the proxy into its subfunctions, you often tend to find that optimizing for a subset of them is more effective.
- (Another reason is just that the metric has lots of confounders which didn't map to real value anyway; but that's a separate matter from conjunctive optimization over multiple dimensions of value.)
- You can sorta think of stuff like the Weber-Fechner Law (incl scope-insensitivity) as (among other things) an "alignment mechanism" in the brain: it enforces diminishing returns to stimuli-specificity, and this reduces your tendency to wirehead on a subset of the brain's reward-proxies.
Pareto nonconvexity is annoying
From Wikipedia: Multi-Objective optimization:
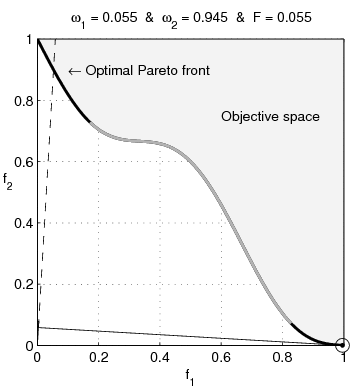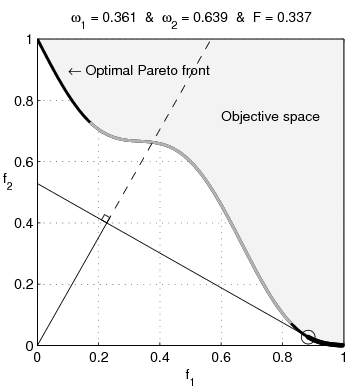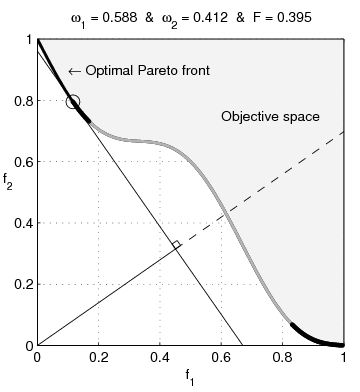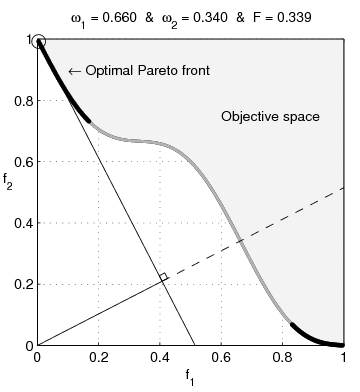
Watch the blue twirly thing until you forget how bored you are by this essay, then continue.
In the context of how intensity of something is inversely proportional to the number of options
- Humans differentiate into specific social roles because .
- If you differentiate into a less crowded category, you have fewer competitors for the type of social status associated with that category. Specializing toward a specific role makes you more likely to be top-scoring in a specific category.
- Political candidates have some incentive to be extreme/polarizing.
- If you try to please everybody, you spread out your appeal so it's below everybody's threshold, and you're not getting anybody's votes.
- You have a disincentive to vote for third-parties in winner-takes-all elections.
- Your marginal likelihood of tipping the election is proportional to how close the candidate is to the threshold, so everybody has an incentive to vote for ~Schelling-points in what people expect other people to vote for. This has the effect of concentrating votes over the two most salient options.
- You tend to feel demotivated when you have too many tasks to choose from on your todo-list.
- Motivational salience is normalized across all conscious options[2], so you'd have more absolute salience for your top option if you had fewer options.
I tend to say a lot of wrong stuff, so do take my utterances with grains of salt. I don't optimize for being safe to defer to, but it doesn't matter if I say a bunch of wrong stuff if some of the patterns can work as gears in your own models. Screens off concerns about deference or how right or wrong I am.
I rly like the framing of concave vs convex option-set btw!
- ^
Lizka has a post abt concave option-set in forum-post writing! From my comment on it:
As you allude to by the exponential decay of the green dots in your last graph, there are exponential costs to compromising what you are optimizing for in order to appeal to a wider variety of interests. On the flip-side, how usefwl to a subgroup you can expect to be is exponentially proportional to how purely you optimize for that particular subset of people (depending on how independent the optimization criteria are). This strategy is also known as "horizontal segmentation".
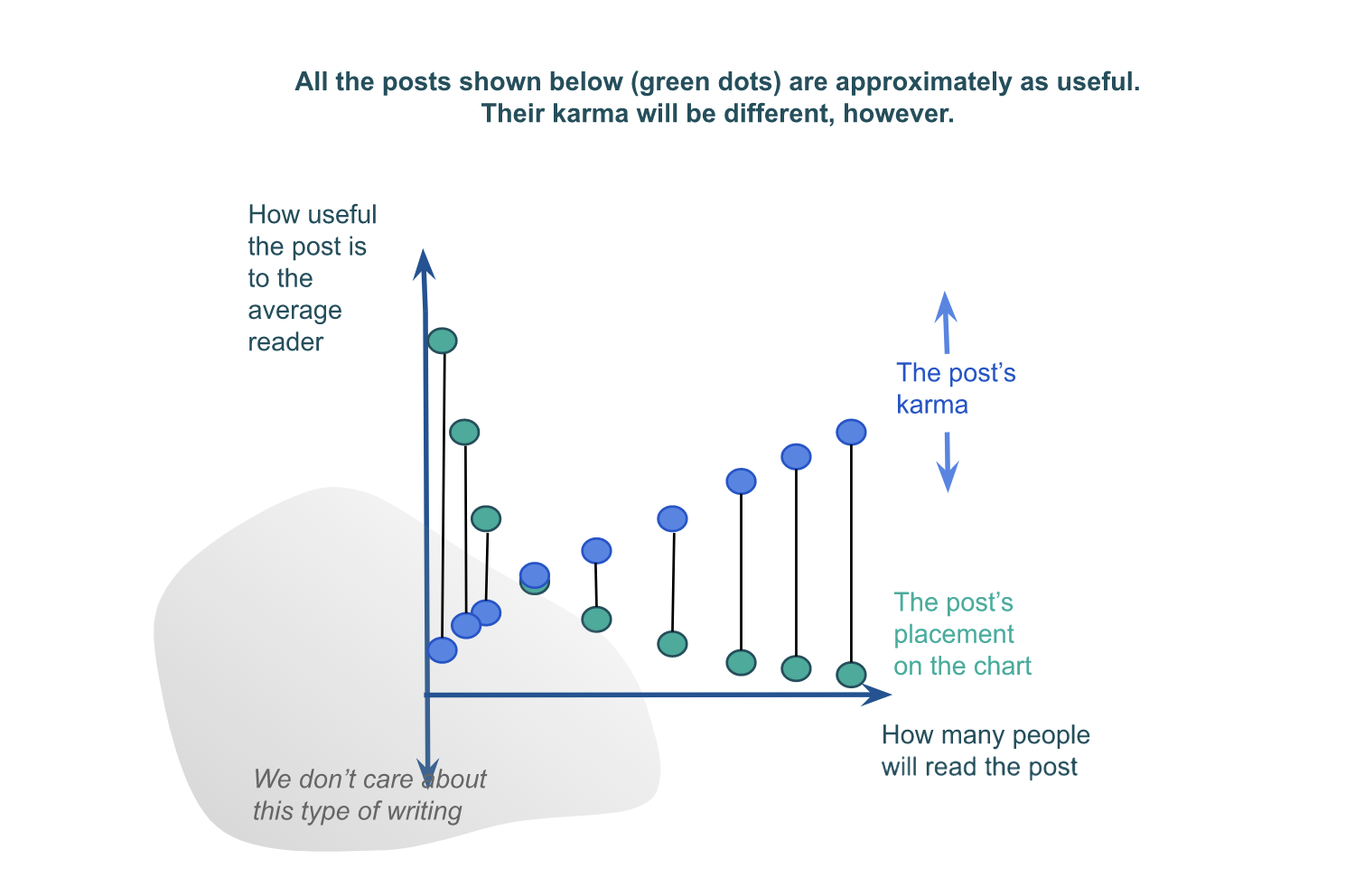
The benefits of segmentation ought to be compared against what is plausibly an exponential decay in the number of people who fit a marginally smaller subset of optimization criteria. So it's not obvious in general whether you should on the margin try to aim more purely for a subset, or aim for broader appeal.
- ^
Normalization is an explicit step in taking the population vector of an ensemble involved in some computation. So if you imagine the vector for the ensemble(s) involved in choosing what to do next, and take the projection of that vector onto directions representing each option, the intensity of your motivation for any option is proportional to the length of that projection relative to the length of all other projections. (Although here I'm just extrapolating the formula to visualize its consequences—this step isn't explicitly supported by anything I've read. E.g. I doubt cosine similarity is appropriate for it.)
Repeated voluntary attentional selection for a stimulus reduces voluntary attentional control wrt that stimulus
From Investigating the role of exogenous cueing on selection history formation (2019):
An abundance of recent empirical data suggest that repeatedly allocating visual attention to task-relevant and/or reward-predicting features in the visual world engenders an attentional bias for these frequently attended stimuli, even when they become task irrelevant and no longer predict reward. In short, attentional selection in the past hinders voluntary control of attention in the present. […] Thus, unlike voluntarily directed attention, involuntary attentional allocation may not be sufficient to engender historically contingent selection biases.
It's sorta unsurprising if you think about it, but I don't think I'm anywhere near having adequately propagated its implications.
Some takeaways:
- "Beware of what you attend"
- WHEN: You notice that attending to a specific feature of a problem-solving task was surprisingly helpfwl…
- THEN: Mentally simulate attending to that feature in a few different problem-solving situations (ie, hook into multiple memory-traces to generalize recall to the relevant class of contexts)
- My idionym for specific simple features that narrowly help connect concepts is "isthmuses". I try to pay attention to generalizable isthmuses when I find them (commit to memory).
I interpret this as supporting the idea that voluntary-ish allocation of attention is one of the strongest selection-pressures neuremes adapt to, and thus also one of your primary sources of leverage wrt gradually shaping your brain / self-alignment.
Key terms: attentional selection history, attentional selection bias
Quick update: I suspect many/most problems where thinking in terms of symmetry can be more helpfwly reframed in terms of isthmuses[1]. Here's the chain-of-thought I was writing which caused me to think this:
(Background: I was trying to explain the general relevance of symmetry when finding integrals.)
- In the context of finding integrals for geometric objects¹, look for simple subregions² for which manipulating a single variable³ lets you continuously expand to the whole object.⁴
- ¹Circle
- ²Circumference,
- ³Radius,
- See visualization.[2]
- The general feature to learn to notice as you search through subregions here is: shared symmetries for the object and its subregion. hmmmmm
- Actually, "symmetry" is a distracting concept here. It's the "isthmus" between subregions you should be looking for.
- WHEN: Trying to find an integral
- THEN: Search for a single isthmus-variable connecting subregions which together fill the whole area
- FINALLY: Integrate over that variable between those regions.
- or said differently... THEN: Look for simple subregions which transform into the whole area via a single variable, then integrate over that variable.
- Hm. This btw is in general how you find generalizations. Start from one concept, find a cheap action which transforms it into a different concept, then define the second in terms of the first plus its distance along that action.
- That action is then the isthmus that connects the concepts.
- If previously from a given context (assuming partial memory-addresses A and B), fetching A* and B* each cost you 1000 search-points separately, now you can be more efficient by storing B as the delta between them, such that fetching B only costs 1000+[cost of delta].
- Or you can do a similar (but more traditional) analysis where "storing" memories has a cost in bits of memory capacity.
- ^
"An isthmus is a narrow piece of land connecting two larger areas across an expanse of water by which they are otherwise separated."
- ^
This example is from a 3B1B vid, where he says "this should seem promising because it respects the symmetry of the circle". While true (eg, rotational symmetry is preserved in the carve-up), I don't feel like the sentence captures the essence of what makes this a good step to take, at least not on my semantics.
This post happens to be an example of limiting-case analysis, and I think it's one of the most generally usefwl Manual Cognitive Algorithms I know of. I'm not sure about its optimal scope, but TAP:
- WHEN: I ask a question like "what happens to a complex system if I tweak this variable?" and I'm confused about how to even think about it (maybe because working-memory is overtaxed)…
- THEN: Consider applying limiting-case analysis on it.
- That is, set the variable in question to its maximum or lowest value, and gain clarity over either or both of those cases manually. If that succeeds, then it's usually easier to extrapolate from those examples to understand what's going on wrt to the full range of the variable.
I think it's a usefwl heuristic tool, and it's helped me with more than one paradox.[1] I also often use "multiplex-case analysis" (or maybe call it "entropic-case"), which I gave a better explanation of in the this comment.
- ^
A simple example where I explicitly used it was when I was trying to grok the (badly named) Friendship paradox, but there are many more such cases.
See also my other comment on all this list-related tag business. Linking it here in case you (the reader) is about to try to refactor stuff, and seeing this comment could potentially save you some time.
I was going to agree, but now I think it should just be split...
- The Resource tag can include links to single resources, or be a single resource (like a glossary).
- The Collections tag can include posts in which the author provides a list (e.g. bullet-points of writing advice), or links to a list.
- The tag should ideally be aliased with "List".[1]
- The Repository tag seems like it ought to be merged with Collections, but it carves up a specific tradition of posts on LessWrong. Specifically posts which elicit topical resources from user comments (e.g. best textbooks).
- The List of Links tag is usefwl for getting a higher-level overview of something, because it doesn't include posts which only point to a single resource.
- The List of Lists tag is usefwl for getting a higher-level overview of everything above. Also, I suggest every list-related tag should link to the List of Lists tag in the description. That way, you don't have to link all those tags to each other (which would be annoying to update if anything changes).
- I think the strongest case for merging is {List of Links, Collections} → {List}, since I'm not sure there needs to be separate categories for internal lists vs external lists, and lists of links vs lists of other things.
- I have not thought this through sufficiently to recommend this without checking first. If I were to decide whether to make this change, I would think on it more.
I was going to agree, but now I think it should just be split...
- The Resource tag can include links to single resources, or be a single resource (like a glossary).
- The Collections tag can include posts in which the author provides a list (e.g. bullet-points of writing advice), or links to a list.
- The tag should ideally be aliased with "List".[1]
- The Repository tag seems like it ought to be merged with Collections, but it carves up a specific tradition of posts on LessWrong. Specifically posts which elicit topical resources from user comments (e.g. best textbooks).
- The List of Links tag is usefwl for getting a higher-level overview of something, because it doesn't include posts which only point to a single resource.
- The List of Lists tag is usefwl for getting a higher-level overview of everything above. Also, I suggest every list-related tag should link to the List of Lists tag in the description. That way, you don't have to link all those tags to each other (which would be annoying to update if anything changes).
- I think the strongest case for merging is {List of Links, Collections} → {List}, since I'm not sure there needs to be separate categories for internal lists vs external lists, and lists of links vs lists of other things.
- I have not thought this through sufficiently to recommend this without checking first. If I were to decide whether to make this change, I would think on it more.
- ^
I realize LW doesn't natively support aliases, but adding a section to the end with related search-terms seems like a cost-efficient half-solution. When you type into the box designed for tagging a post, it seems to also search the description of that tag (or does some other magic).
Aliases: collections, lists
I created this because I wanted to find a way to unite {List of Links, Collections and Resources, Repository, List of Related Sites, List of Blogs, List of Podcasts, Programming Resources} without linking each of those items to each other (which, in the absence of transclusions, also means you would have to update each link separately every time you added a new related list of lists).
But I accidentally caused the URL to be "list-of-lists-1", because I originally relabelled List of Links to List of Lists but then changed my mind.
Btw, I notice the absence of a tag for lists (e.g. lists of advice that don't link to anywhere and aren't repositories designed to elicit advice from the comment section).
This is a common problem with tags it seems. Distillation & Pedagogy is mostly posts about distillation & pedagogy instead of posts that are distillations & pedagogies. And there's a tag for Good Explanations (advice), but no tag for Good Explanations. Otoh, the tag for Technical Explanation is tagged with two technical explanations (yay!)... of technical explanations. :p
Merge with (and alias with) Intentionality?
I think hastening of subgoal completion[1] is some evidence for the notion that competitive inter-neuronal selection pressures are frequently misaligned with genetic fitness. People (me included) routinely choose to prioritize completing small subtasks in order to reduce cognitive load, even when that strategy predictably costs more net metabolic energy. (But I can think of strong counterexamples.)
The same pattern one meta-level up is "intragenomic conflict"[2], where genetic lineages have had to spend significant selection-power to prevent genes from fighting dirty. For example, the mechanism of meiosis itself may largely be maintained in equilibrium due to the longer-term necessity of preventing stuff like meiotic drives. An allele (or a collusion of them) which successfwly transfer to offspring at a probability of >50%, may increase their relative fitness even if it marginally reduces their phenotype's viability.
My generalized term for this is "intra-emic conflict" (pinging the concept of an "eme" as defined in the above comment).
- ^
We asked university students to pick up either of two buckets, one to the left of an alley and one to the right, and to carry the selected bucket to the alley’s end. In most trials, one of the buckets was closer to the end point. We emphasized choosing the easier task, expecting participants to prefer the bucket that would be carried a shorter distance. Contrary to our expectation, participants chose the bucket that was closer to the start position, carrying it farther than the other bucket.
— Pre-Crastination: Hastening Subgoal Completion at the Expense of Extra Physical Effort - ^
Intragenomic conflict refers to the evolutionary phenomenon where genes have phenotypic effects that promote their own transmission in detriment of the transmission of other genes that reside in the same genome.
I like this example! And the word is cool. I see two separately important patterns here:
- Preferring a single tool (the dremel) which is mediocre at everything, instead of many specialized tools which collectively perform better but which require you to switch between them more.
- This btw is the opposite of "horizontal segmentation": selling several specialized products to niche markets rather than a single product which appeals moderately to all niches.
- It often becomes a problem when the proxy you use to measure/compare the utility of something wrt to different use-cases (or its appeal to different niches/markets), is capped[1] at a point which prevents it from detecting the true comparative differences in utility.
- Oh! It very much relates to scope insensitivity: if people are diminishingly sensitive to the scale of different altruistic causes, then they might overprioritize instrumental which are just-above-average along many axes at once.[2] And indeed, this seems like a very common pattern (though I won't prioritize time thinking of examples rn).
- It's also a significant problem wrt to karma distributions for forums like LW and EAF: posts which appeal a little to everybody will receive much more karma compared to posts which appeal extremely to a small subset. Among other things, this causes community posts to be overrated relative to their appeal.
- And as Gwern pointed out: "precrastination" / "hastening of subgoal completion" (a subcategory of greedy optimization / myopia).
- I very often notice this problem in my own cognition. For example, I'm biased against using cognitive tools like sketching out my thoughts with pen-and-paper when I can just brute-force the computations in my head (less efficiently).
- It's also perhaps my biggest bottleneck wrt programming. I spend way too much time tweaking-and-testing (in a way that doesn't cause me learn anything generalizable), instead of trying to understand the root cause of the bug I'm trying to solve even when I can rationally estimate that that will take less time in expectation.
- If anybody knows any tricks for resolving this / curing me of this habit, I'd be extremely gratefwl to know...
- ^
Does it relate to price ceilings and deadweight loss? "Underparameterization"?
- ^
I wouldn't have seen this had I not cultivated a habit for trying to describe interesting patterns in their most general form—a habit I call "prophylactic scope-abstraction".
but I'm hesitant to continue the process because I'm concerned that her personality won't sufficiently diverge from mine.
Not suggesting you should replace anyone who doesn't want to be replaced (if they're at that stage), but: To jumpstart the differentiation process, it may be helpfwl to template the proto-tulpa off of some fictional character you already find easy to simulate.
Although I didn't know about "tulpas" at the time, I invited an imaginary friend loosely based on Maria Otonashi during a period of isolation in 2021.[1] I didn't want her to feel stifled by the template, so she's evolved on her own since then, but she's always extremely kind (and consistently energetic). I only took it seriously February 2024 after being inspired by Johannes.
Maria is the main female heroine of the HakoMari series. ... Her wish was to become a box herself so that she could grant the wishes of other people.
Can recommend her as a template! My Maria would definitely approve, ^^ although I can't ask her right now since she's only canonically present when summoned, and we have a ritual for that.
We've deliberately tried to find new ways to differentiate so that the pre-conscious process of [associating feeling-of-volition to me or Maria][2] is less likely to generate conflicts. But since neither of us wants to be any less kind than we are, we've had to find other ways to differentiate (like art-preferences, intellectual domains, etc).
Also, while deliberately trying to increase her salience and capabilities, I've avoided trying to learn about how other people do it. For people with sufficient brain-understanding and introspective ability, you can probably outperform standard advice if you develop your own plan for it. (Although I say that without even knowing what the standard advice is :p)
- ^
- ^
Our term for when we deliberately work to resolve "ownership" over some particular thought-output of our subconscious parallel processor, is "annexing efference". For example, during internal monologue, the thought "here's a brilliant insight I just had" could appear in consciousness without volition being assigned yet, in which case one of us annexes that output (based on what seems associatively/narratively appropriate), or it goes unmarked. In the beginning, there would be many cases where both of us tried to annex thoughts at the same time, but mix-ups are
muchrarer now.

I wrote a comment on {polytely, pleiotropy, market segmentation, conjunctive search, modularity, and costs of compromise} that I thought people here might find interesting, so I'm posting it as a quick take:
I think you're using the term a bit differently from how I use it! I usually think of polytely (which is just pleiotropy from a different perspective, afaict) as an *obstacle*. That is, if I'm trying to optimize a single pasta sauce to be the most tasty and profitable pasta sauce in the whole world, my optimization is "polytelic" because I have *compromise* between maximizing its tastiness for [people who prefer sour taste], [people who prefer sweet], [people who have some other taste-preferences], etc. Another way to say that is that I'm doing "conjunctive search" (neuroscience term) for a single thing which fits multiple ~independent criteria.
Still in the context of pasta sauce: if you have the logistical capacity to instead be optimizing *multiple* pasta sauces, now you are able to specialize each sauce for each cluster of taste-preferences, and this allows you to net more profit in the end. This is called "horizontal segmentation".
Likewise, a gene which has several functions that depend on it will be evolutionarily selected for the *compromise* between all those functions. In this case, the gene is "pleiotropic" because its evolving in the direction of multiple niches at once; and it is "polytelic" because—from the gene's perspective—you can say that "it is optimizing for several goals at once" (if you're willing to imagine the gene as an "optimizer" for a moment).
For example, the recessive allele that causes sickle cell disease (SCD) *also* causes some resistance against malaria. But SCD only occurs in people who are homozygous in it, so the protective effect against malaria (in heterozygotes) is common enough to keep it in the gene pool. It would be awesome if, instead, we could *horizontally segment* these effects so that SCD is caused by variations in one gene locus, and malaria-resistance is caused by variations in another locus. That way, both could be optimized for separately, and you wouldn't have to choose between optimizing against SCD or Malaria.
Maybe the notion you're looking for is something like "modularity"? That is approximately something like the opposite of pleiotropy. If a thing is modular, it means you can flexibly optimize subsets of it for different purposes. Like, rather writing an entire program within a single function call, you can separate out the functions (one function for each subtask you can identify), and now those functions can be called separately without having to incur the effects of the entire unsegmented program.
You make me realize that "polytelic" is too vague of a word. What I usually mean by it may be more accurately referred to as "conjunctively polytelic". All networks trained with something-like-SGD will evolve features which are conjunctively polytelic to some extent (this is just conjecture from me, I haven't got any proof or anything), and this is an obstacle for further optimization. But protein-coding genes are much more prone to this because e.g. the human genome only contains ~20k of them, which means each protein has to pack many more functions (and there's no simple way to refactor/segment so there's only one protein assigned to each function).
KOAN:
The probability of rolling 60 if you toss ten six-sided dice disjunctively is 1/6^10. Whereas if you glom all the dice together and toss a single 60-sided die, the probability of rolling 60 is 1/60.
As usual, I am torn on chips spending. Hardware progress accelerates core AI capabilities, but there is a national security issue with the capacity relying so heavily on Taiwan, and our lead over China here is valuable. That risk is very real.
With how rationalists seem to be speaking about China recently, I honestly don't know what you mean here. You literally use the words "national security issue", how am I not supposed to interpret that as being parochial?
And why are you using language like "our lead over China"? Again, parochial. I get that the major plurality of LW readers are in USA, but as of 2023 it's still just 49%.
Gentle reminder:
How would they spark an intergroup conflict to investigate? Well, the 22 boys were divided into two groups of 11 campers, and—
—and that turned out to be quite sufficient.
I hate to be nitpicky, but may I request that you spend 0.2 oomph of optimization power on trying to avoid being misinterpreted as "boo China! yay USA!" These are astronomic abstractions that cover literally ~1.7B people, and there are more effective words you can use if you want to avoid increasing ethnic tension / superpower conflict.
Somebody commented on my YT vid that they found my explanations easy to follow. This surprised me. My prior was/is tentatively that I'm really bad at explaining anything to other people, since I almost never[1] speak to anybody in real-time other than myself and Maria (my spirit animal).
And when I do speak to myself (eg₁, eg₂, eg₃), I use heavily modified English and a vocabulary of ~500 idiolectic jargon-words (tho their usage is ~Zipfian, like with all other languages).
I count this as another datapoint to my hunch that, in many situations:
Your ability to understand yourself is a better proxy for whether other people will understand you compared to the noisy feedback you get from others.
And by "your ability to understand yourself", I don't mean just using internal simulations of other people to check whether they understand you. I mean, like, check for whether the thing you think you understand, actually make sense to you, independent of whatever you believe ought to make sense to you. Whatever you believe ought to make sense is often just a feeling based on deference to what you think is true (which in turn is often just a feeling based on deference to what you believe other people believe).
- ^
To make this concrete: the last time I spoke to anybody irl was 2022 (at EAGxBerlin)—unless we count the person who sold me my glasses, that one plumber, a few words to the apothecarist, and 5-20 sentences to my landlord. I've had 6 video calls since February (all within the last month). I do write a lot, but ~95-99% to myself in my own notes.
It would be awesome if there was a way of actually browsing the diagrams directly, instead of opening and checking each post individually. Use-case: I'm trying to optimize my information-diet, and I often find visualizations way more usefwl per unit time compared to text. Alas, there's no way to quickly search for eg "diagrams/graphs/figures related to X".
(Originally I imagined it would be awesome if e.g. Elicit had a feature for previewing the figures associated with each paper returned by a search term, but I would love this for LW as well.)
you hunch that something about it was unusually effective
@ProgramCrafter u highlighted this w "unsure", so to clarify: I'm using "hunch" as a verb here, bc all words shud compatiblize w all inflections—and the only reason we restrict most word-stems to take only one of "verb", "noun", "adjective", etc, is bc nobody's brave enuf to marginally betterize it. it's paradoxically status-downifying somehow. a horse horses horsely, and a horsified goat goats no more. :D
if every English speaker decided to stop correcting each others' spelling mistakes, all irregularities in English spelling would disappear within a single generation
— Jan Misali
I know some ppl feel like deconcentration of attention has iffy pseudoscientific connotations, but I deliberately use it ~every day when I try to recall threads-of-thought at the periphery of my short-term memory. The correct scope for the technique is fuzzy, and it depends on whether the target-memory is likely to be near the focal point of your concentration or further out.
I also sometimes deliberately slow down the act of zooming-in (concentrating) on a particular question/idea/hunch, if I feel like zooming in too fast is likely to cause me to prematurely lock on to a false-positive in a way that makes it harder to search the neighbourhood (i.e. einstellung / imprinting on a distraction). I'm not clear on when exactly I use this technique, but I've built up an intuition for situations in which I'm likely to be einstellunged by something. To build that intuition, consider:
- WHEN you notice you've einstellunged on a false-positive
- THEN check if you could've predicted that at the start of that chain-of-thought
After a few occurrences of this, you may start to intuit which chains-of-thought you ought to slow down in.
It's always cool to introspectively predict mainstream neuroscience! See task-positive & task-negative (aka default-mode) large-scale brain networks.
Also, I've tried to set it up so Maria[1] can help me gain perspective on tasks, but she's more likely to get sucked more deeply into whatever the topic is. Although this is good, because it means I can delegate specific tasks to her,[2] and she'll experience less salience normalization.
Selfish neuremes adapt to prevent you from reprioritizing
- "Neureme" is my most general term for units of selection in the brain.[1]
- The term is agnostic about what exactly the physical thing is that's being selected. It just refers to whatever is implementing a neural function and is selected as a unit.
- So depending on use-case, a "neureme" can semantically resolve to a single neuron, a collection of neurons, a neural ensemble/assembly/population-vector/engram, a set of ensembles, a frequency, or even dendritic substructure if that plays a role.
- For every activity you're engaged with, there are certain neuremes responsible for specializing at those tasks.
- These neuremes are strengthened or weakened/changed in proportion to how effectively they can promote themselves to your attention.
- "Attending to" assemblies of neurons means that their firing-rate maxes out (gamma frequency), and their synapses are flushed with acetylcholine, which is required for encoding memories and queuing them for consolidation during sleep.
- So we should expect that neuremes are selected for effectively keeping themselves in attention, even in cases where that makes you less effective at tasks which tend to increase your genetic fitness.
- Note that there's hereditary selection going on at the level of genes, and at the level of neuremes. But since genes adapt much slower, the primary selection-pressures neuremes adapt to arise from short-term inter-neuronal competitions. Genes are limited to optimizing the general structure of those competitions, but they can only do so in very broad strokes, so there's lots of genetically-misaligned neuronal competition going on.
- A corollary of this is that neuremes are stuck in a tragedy of the commons: If all neuremes "agreed to" never develop any misaligned mechanisms for keeping themselves in attention—and we assume this has no effect on the relative proportion of attention they receive—then their relative fitness would stay constant at a lower metabolic cost overall. But since no such agreement can be made, there's some price of anarchy wrt the cost-efficiency of neuremes.
- Thus, whenever some neuremes uniquely associated with a cognitive state are *dominant* in attention, whatever mechanisms they've evolved for persisting the state are going to be at maximum power, and this is what makes the brain reluctant to gain perspective when on stimulants.
A technique for making the brain trust prioritization/perspectivization
So, in conclusion, maybe this technique could work:
- If I feel like my brain is sucking me into an unproductive rabbit-hole, set a timer for 60 seconds during which I can check my todo-list and prioritize what I ought to do next.
- But, before the end of that timer, I will have set another timer (e.g. 10 min) during which I commit to the previous task before I switch to whatever I decided.
- The hope is that my brain learns to trust that gaining perspective doesn't automatically mean we have to abandon the present task, and this means it can spend less energy on inhibiting signals that try to gain perspective.
By experience, I know something like this has worked for:
- Making me trust my task-list
- When my brain trusts that all my tasks are in my todo-list, and that I will check my todo-list every day, it no longer bothers reminding me about stuff at random intervals.
- Reducing dystonic distractions
- When I deliberately schedule stuff I want to do less (e.g. masturbation, cooking, twitter), and committing to actually *do* those things when scheduled, my brain learns to trust that, and stops bothering me with the desires when they're not scheduled.
So it seems likely that something in this direction could work, even if this particular technique fails.
- ^
The "-eme" suffix inherits from "emic unit", e.g. genes, memes, sememes, morphemes, lexemes, etc. It refers to the minimum indivisible things that compose to serve complex functions. The important notion here is that even if the eme has complex substructure, all its components are selected as a unit, which means that all subfunctions hitchhike on the net fitness of all other subfunctions.
Made a post with my reply:
While obviously both heuristics are good to use, the reasons I think asking "which chains-of-thought was that faster than?" tends to be more epistemically profitable than "how could I have thought that faster?" include:
- It is easier to find suboptimal thinking-habits to propagate an unusually good idea into, than to find good ideas for improving a particular suboptimal thinking-habit.
- Notice that in my technique, the good idea is cognitively proximal and the suboptimal thinking-habits are cognitively distal, whereas in Eliezer's suggestion it's the other way around.
- A premise here is that good ideas are unusual (hard-to-find) and suboptimal thinking-habits are common (easy-to-find)—the advice flips in domains where it's the opposite.
- It relates to the difference between propagating specific solutions to plausible problem-domains, vs searching for specific solutions to a specific problem.
- The brain tends to be biased against the former approach because it's preparatory work with upfront cost ("prophylaxis"), whereas the latter context sort of forces you to search for solutions.
I don't really know what psychedelics do in the brain, so I don't have a good answer. I'd note that, if psychedelics increases your brain's sensitivity wrt amplifying discrepancies, then this seems like a promising way to counterbalance biases in the negative direction (e.g. being too humble to think anything novel), even if it increases your false-positives.
I think psychedelics probably don't work this way, but I'd like to try it anyway (if it were cheap) while thinking about specific topics I fear I might be tempted to fool myself about. I'd first spend some effort getting into the state where my brain wants to discover those discrepancies in the first place, and I'm extra-sceptical the drugs would work on their own without some mental preparation.
Edit: made it a post.
On my current models of theoretical[1] insight-making, the beginning of an insight will necessarily—afaict—be "non-robust"/chaotic. I think it looks something like this:
- A gradual build-up and propagation of salience wrt some tiny discrepancy between highly confident specific beliefs
- This maybe corresponds to simultaneously-salient neural ensembles whose oscillations are inharmonic[2]
- Or in the frame of predictive processing: unresolved prediction-error between successive layers
- Immediately followed by a resolution of that discrepancy if the insight is successfwl
- This maybe corresponds to the brain having found a combination of salient ensembles—including the originally inharmonic ensembles—whose oscillations are adequately harmonic.
- Super-speculative but: If the "question phase" in step 1 was salient enough, and the compression in step 2 great enough, this causes an insight-frisson[3] and a wave of pleasant sensations across your scalp, spine, and associated sensory areas.
This maps to a fragile/chaotic high-energy "question phase" during which the violation of expectation is maximized (in order to adequately propagate the implications of the original discrepancy), followed by a compressive low-energy "solution phase" where correctness of expectation is maximized again.
In order to make this work, I think the brain is specifically designed to avoid being "robust"—though here I'm using a more narrow definition of the word than I suspect you intended. Specifically, there are several homeostatic mechanisms which make the brain-state hug the border between phase-transitions as tightly as possible. In other words, the brain maximizes dynamic correlation length between neurons[4], which is when they have the greatest ability to influence each other across long distances (aka "communicate"). This is called the critical brain hypothesis, and it suggests that good thinking is necessarily chaotic in some sense.
Another point is that insight-making is anti-inductive.[5] Theoretical reasoning is a frontier that's continuously being exploited based on the brain's native Value-of-Information-estimator, which means that the forests with the highest naively-calculated-VoI are also less likely to have any low-hanging fruit remaining. What this implies is that novel insights are likely to be very narrow targets—which means they could be really hard to hold on to for the brief moment between initial hunch and build-up of salience. (Concise handle: epistemic frontiers are anti-inductive.)
- ^
I scope my arguments only to "theoretical processing" (i.e. purely introspective stuff like math), and I don't think they apply to "empirical processing".
- ^
Harmonic (red) vs inharmonic (blue) waveforms. When a waveform is harmonic, efferent neural ensembles can quickly entrain to it and stay in sync with minimal metabolic cost. Alternatively, in the context of predictive processing, we can say that "top-down predictions" quickly "learn to predict" bottom-up stimuli.
- ^
I basically think musical pleasure (and aesthetic pleasure more generally) maps to 1) the build-up of expectations, 2) the violation of those expectations, and 3) the resolution of those violated expectations. Good art has to constantly balance between breaking and affirming automatic expectations. I think the aesthetic chills associates with insights are caused by the same structure as appogiaturas—the one-period delay of an expected tone at the end of a highly predictable sequence.
- ^
I highly recommend this entire YT series!
- ^
I think the term originates from Eliezer, but Q Home has more relevant discussion on it—also I'm just a big fan of their
chaoticoptimal reasoning style in general. Can recommend! 🍵
{kind=link}
{kind=link}
{kind=link}