[Valence series] 3. Valence & Beliefs
post by Steven Byrnes (steve2152) · 2023-12-11T20:21:30.570Z · LW · GW · 12 commentsContents
3.1 Post summary / Table of contents 3.2 Two paths for normative to bleed into positive 3.3 Motivated reasoning / thinking / observing, including confirmation bias 3.3.1 Attention-control and motor-control provide loopholes through which desires can manipulate beliefs 3.3.2 Motivated reasoning and confirmation bias 3.3.3 A nuts-and-bolts model: It generally feels easy and natural to brainstorm / figure out how something might happen, when you want it to happen. Conversely, it generally feels hard and unnatural to figure out how something might happen, when you want it to not happen 3.3.4 Warning: the “motivation” part of “motivated reasoning / thinking / etc.” is not always what it seems 3.3.5 An exception: I think anxious / obsessive “brainstorming” is driven by involuntary attention rather than by valence 3.3.6 How does confirmation bias ever not happen? 3.4 Valence impacts beliefs by acting as salient sense data 3.4.1 When your brain clusters similar things into mental categories / concepts, valence is an important ingredient going into that clustering algorithm 3.4.2 Is the above a bug, or a feature? 3.4.3 Three roadblocks to talking and reasoning about the world separately from how we feel about it 3.4.3.1 In real life, many discussions are (at least in part) discussions about valence assessments—even if they appear not to be 3.4.3.2 Even if we’re trying to communicate and think about the world independently from how we feel about it, valence tends to become involved, via being tied up with our words and concepts 3.4.3.3 Treating valence as evidence about how the world works isn’t necessarily a mistake anyway 3.4.4 The halo effect and affect heuristic 3.5 Will future AI have motivated reasoning, halo effect, etc.? 3.6 Conclusion None 13 comments
3.1 Post summary / Table of contents
Part of the Valence series [? · GW].
So far in the series, we defined valence (Post 1 [LW · GW]) and talked about how it relates to the “normative” world of desires, values, preferences, and so on (Post 2 [LW · GW]). Now we move on to the “positive” world of beliefs, expectations, concepts, etc. Here, valence is no longer the sine qua non at the center of everything, as it is in the “normative” magisterium. But it still plays a leading role. Actually, two leading roles!
- Section 3.2 distinguishes two paths by which valence affects beliefs: first, in its role as a control signal, and second, in its role as “interoceptive” sense data, which I discuss in turn:
- Section 3.3 discusses how valence-as-a-control-signal affects beliefs. This is the domain of motivated reasoning, confirmation bias, and related phenomena. I explain how it works both in general and through a nuts-and-bolts toy model. I also elaborate on “voluntary attention” versus “involuntary attention”, in order to explain anxious rumination, which goes against the normal pattern (it involves thinking about something despite a strong motivation not to think about it).
- Section 3.4 discusses how valence-as-interoceptive-sense-data affects beliefs. I argue that, if concepts are “clusters in thingspace” [LW · GW], then valence is one of the axes used by this clustering algorithm. I discuss how this relates to various difficulties in modeling and discussing the world separately from how we feel about it, along with the related “affect heuristic” and “halo effect”.
- Section 3.5 briefly muses on whether future AI will have motivated reasoning, halo effect, etc., as we humans do. (My answer is “yes, but maybe it doesn’t matter too much”.)
- Section 3.6 is a brief conclusion.
3.2 Two paths for normative to bleed into positive
Here’s a diagram from the previous post [LW · GW]:
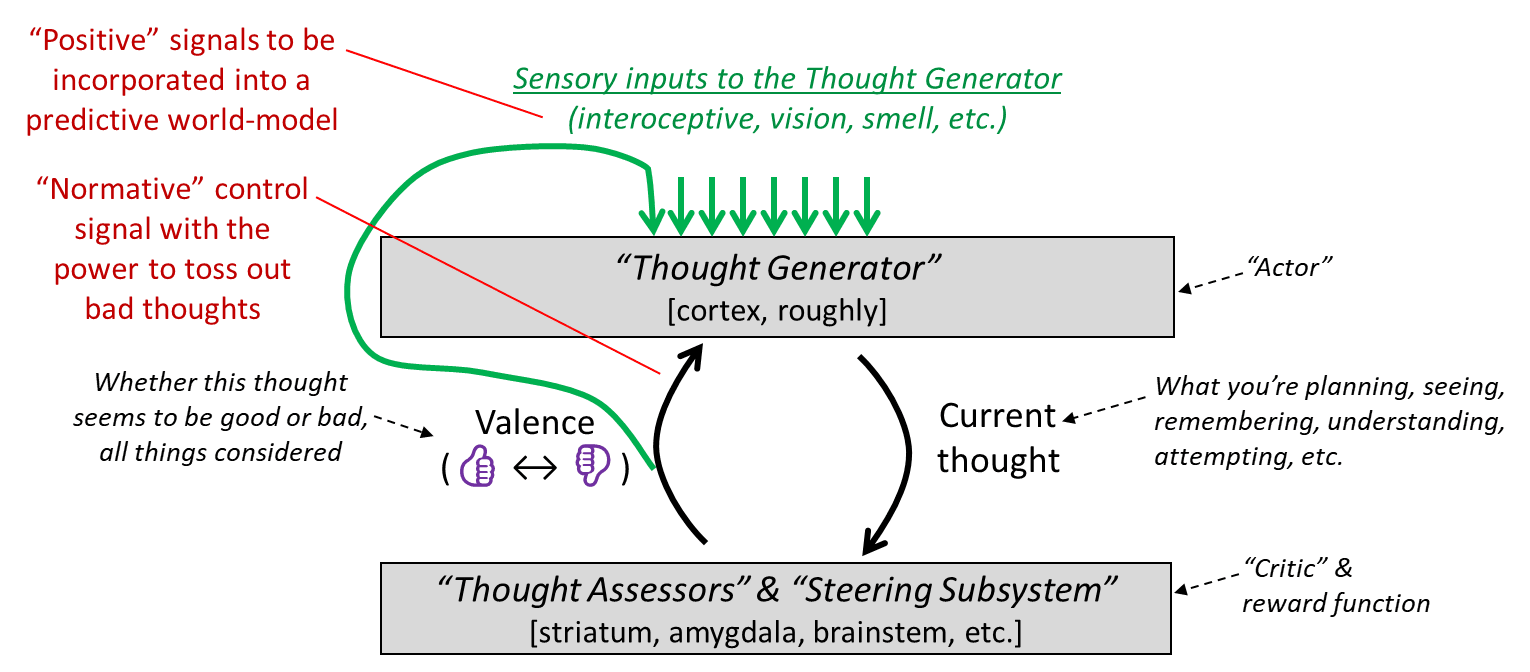
We have two paths by which valence can impact the world-model (a.k.a. “Thought Generator”): the normative path (upward black arrow) that helps control which thoughts get strengthened versus thrown out, and the positive path (curvy green arrow) that treats valence as one of the input signals to be incorporated into the world model. Corresponding to these two paths, we get two ways for valence to impact factual beliefs:
- Motivated reasoning / thinking / observing and confirmation bias—related to the upward black arrow, and discussed in §3.3 below;
- The entanglement of valence into our conceptual categories, which makes it difficult to think or talk about the world independently from how we feel about it—related to the curvy green arrow, and discussed in §3.4 below.
Let’s proceed with each in turn!
3.3 Motivated reasoning / thinking / observing, including confirmation bias
Of the fifty-odd biases discovered by Kahneman, Tversky, and their successors, forty-nine are cute quirks, and one is destroying civilization. This last one is confirmation bias - our tendency to interpret evidence as confirming our pre-existing beliefs instead of changing our minds.… —Scott Alexander
3.3.1 Attention-control and motor-control provide loopholes through which desires can manipulate beliefs
Wishful thinking—where you believe something because it would be nice if it were true—is generally maladaptive: Imagine spending all day opening your wallet, over and over, expecting each time to find it overflowing with cash. We don’t actually do that, which is an indication that our brains have effective systems to mitigate (albeit not eliminate, as we’ll see) wishful thinking.
How do those mitigations work?
As discussed in Post 1 [LW · GW], the brain works by model-based reinforcement learning (RL). Oversimplifying as usual, the “model” (predictive world-model, a.k.a. “Thought Generator”) is trained by self-supervised learning, i.e. predicting immediately-upcoming sensory data and updating on the errors. Meanwhile, the RL part involves using actor-critic RL for decision-making.
This is great! “Self-supervised learning for the predictive world-model” is a fancy way to say:
- our beliefs are updated in the direction that increases agreement with our sensory inputs,
- …and thus our beliefs are not necessarily updated in the direction that would increase RL reward signals.
Continuing with the previous example, if you look inside your wallet, and it’s not full of cash, then your world-model automatically updates itself to incorporate this fact, even if you wanted that fact to not be true.
But this system does have a loophole: the decisions you make can impact the input data that goes into self-supervised training of the world-model, by influencing what you’re looking at, what you’re paying attention to, what you read, who you talk to, where you are, and so on. And, as machine learning researchers know well, training data plays a big role in determining a trained model’s behavior.
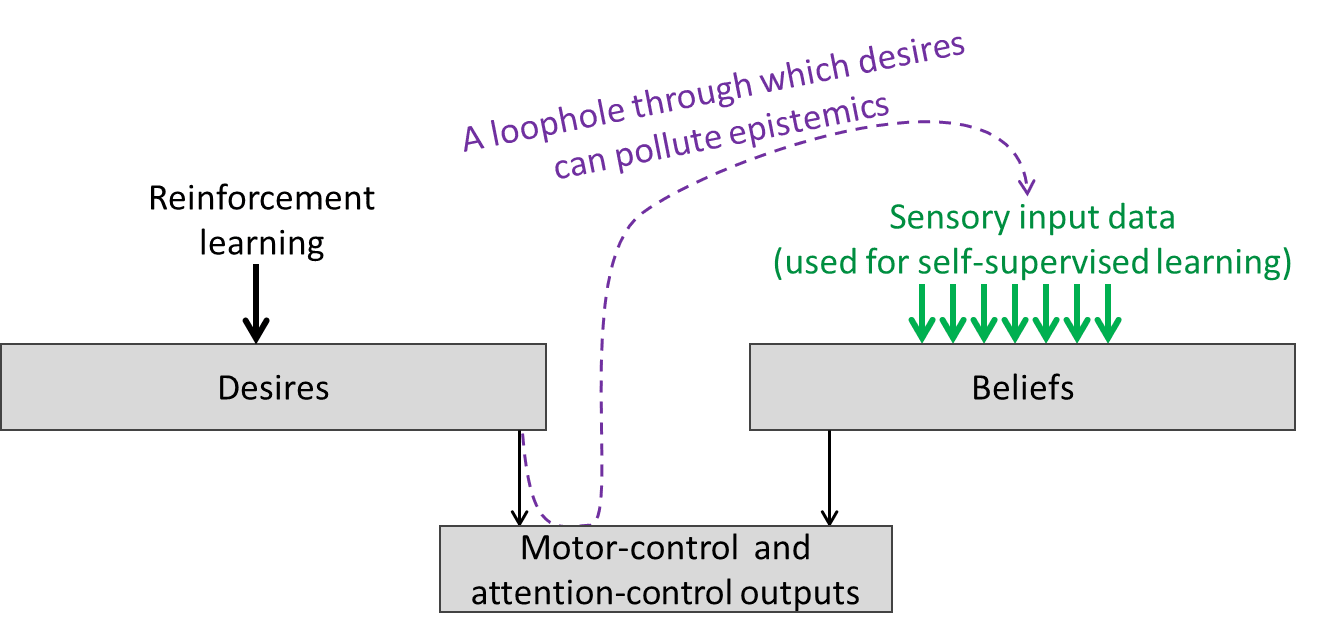
For example, let’s suppose that, for some reason, I want to strongly and sincerely believe that socialists tend to be violent. Now, I can’t just will myself to strongly and sincerely believe that socialists are violent, in the absence of any evidence whatsoever.[1] But what I can do is:
- Use my motor-control levers to search the internet for news stories about violent socialists;
- Use my motor- and attention-control levers to read the top 50 stories that show up in that search;
- Use my attention-control levers to avoid thinking too hard about the heinous crime against epistemology that I am performing right now [LW · GW];
- …And then my world-model will take it from there! Thanks to self-supervised learning from all this input data, my world-model will grow a strong and sincere belief that socialists tend to be violent.
3.3.2 Motivated reasoning and confirmation bias
Let’s assume I currently believe X, and let’s also assume that the idea of “myself doubting X” is demotivating / unappealing (negative valence).
…And by the way, this demotivating-ness is quite common! Maybe doubting X would cause my friends to disrespect me, or maybe I don’t like being confused and/or putting in the effort to rebuild a new understanding of everything related to X, or maybe I think of myself as knowledgeable and would find it unpleasant to see myself-in-hindsight as having been wrong about X, and so on. (More on this in §3.3.6 below.)
Regardless of the reason, this situation tends to lead to motivated reasoning and confirmation bias. We have a lifetime of experience with which to learn the metacognitive pattern “If I read a good argument against X, and if I really try in good faith to make sense of it and chew over it, then there’s a decent chance that I’ll start doubting X”. And the latter part of that thought is demotivating! And since we’re good (too good!) at long-term planning and means-end reasoning, we will find that the idea of reading and deeply engaging with the good argument against X is demotivating from the start, so we probably won’t do it.
That latter demotivating-ness might well be ego-dystonic. Maybe I want to want to deeply engage with good arguments against X. But, ego-dystonic or not, the demotivating-ness is still there, and still contributing to my motor-control and attention-control outputs.
Now I’ll jump into a more detailed model of one possible way this phenomenon can unfold:
3.3.3 A nuts-and-bolts model: It generally feels easy and natural to brainstorm / figure out how something might happen, when you want it to happen. Conversely, it generally feels hard and unnatural to figure out how something might happen, when you want it to not happen
Let’s say I want to crack open a coconut and eat the meat inside, but I don’t know how. So I brainstorm.
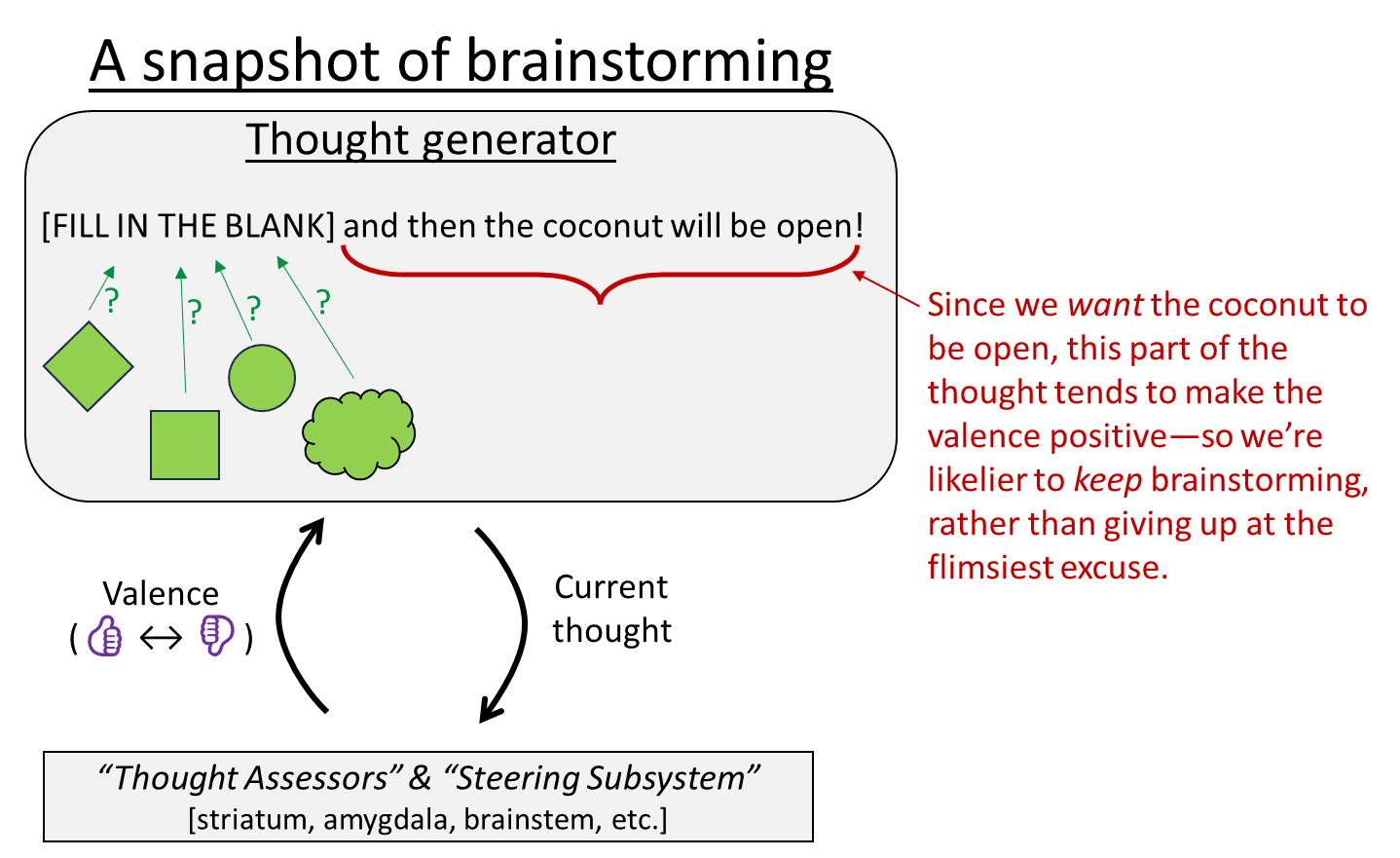
Brainstorming—now what does that entail, exactly? Well, I’m ultimately trying to find a plan, in my mind’s eye, that looks like: “[fill in the blank] and then the coconut will be open”, and where the plan seems plausible to me (i.e., compatible with my world-model). As soon as I can imagine such a plan, I can then try executing it, with the expectation that it might work.
In the simplest case, my brain will kinda grasp onto the end part of the plan “…and then the coconut is open!”, and keep that piece-of-a-thought active throughout this process. Then my brain will go rummaging around for possible beginning parts of the plan such that the whole plan, altogether, forms a plausible story.
The whole process may take a while. But there’s a subtlety making it work: The thoughts that I have mid-brainstorming are all positive valence, because the brainstorming target (“…and then the coconut will be open!”) is itself positive valence—it’s something that I want to happen. And the brainstorming target is active in my brain throughout this brainstorming process, which by linearity (§2.4.1 [LW · GW]) adds a heap of positive valence to all the thoughts constituting the brainstorming process.
And if all the thoughts I have during brainstorming are positive valence, then I’m likely to carry on brainstorming, rather than flinching away from the brainstorming process as soon as possible. That follows from the most basic properties of valence—see §1.3 [LW · GW].
In other words, the appeal of the brainstorming destination is the fuel powering the whole brainstorming process.
The flip side of this coin is that it feels demotivating to brainstorm how something might happen, when you want it to not happen.
Let’s take red-teaming as an example. Suppose that I’m designing a widget, and I decide to brainstorm reasons why, if we build the widget following this design, it might fail.
Just like the above, the brainstorming process will involve keeping the idea “…and then the widget will fail!” active in my mind, and rummaging around for plausible stories whose ending looks like that.
Unfortunately, “…and then the widget will fail!” is a highly demotivating piece-of-a-thought. (If my widget design has a flaw, then it’s embarrassing, and I have to do a ton of work to fix it!) So again by linearity (§2.4.1 [LW · GW]), the whole brainstorming process is going to inherit that negative valence. And thus, by the basic properties of valence (§1.3 [LW · GW]), I’m likely to flinch away from doing this brainstorming process in the first place. Or if I do manage to begin it, I’ll be inclined to quit at the slightest excuse.
So most people, most of the time, don’t instinctively red-team their plans. It doesn’t come naturally. People literally offer training courses. [LW · GW] The reason it’s called a “red team” is that it’s often a different team of people, who (in their role) want the plan to fail, and thus have valence on their side.
(See also: Positive values seem more robust and lasting than prohibitions [LW · GW]; Motivated Stopping and Motivated Continuation [LW · GW].)
3.3.4 Warning: the “motivation” part of “motivated reasoning / thinking / etc.” is not always what it seems
Motivated reasoning and related phenomena are geared towards “something I want”. But it’s important to remember that “something I want” isn’t necessarily what it seems. For example, people sometimes want to fail (even if they don’t want to want to fail). And if so, motivated reasoning / thinking / etc. still applies as usual, but with the opposite effects that you would otherwise expect.
The classic example of “wanting to fail” is when little kids put on a dramatic and unintentionally-hilarious performance of being unable to do something that they can in fact easily do. (The typical context is that an adult has asked them to do the thing by themselves without help, and then the kid is motivated to demonstrate how that request was unreasonable.) If you haven’t spent much time with little kids, here’s a classic example for your viewing pleasure: “spazzing little girl can't pick up bowl” (YouTube).
You can also find older kids and adults “wanting to fail”, or wanting other things besides success. But adults tend to hide it better, including from themselves. There’s some nice discussion along those lines in the blog post “Have no excuses” by Nate Soares (2015).
3.3.5 An exception: I think anxious / obsessive “brainstorming” is driven by involuntary attention rather than by valence
An interesting case is anxious / obsessive rumination. For example, think of the stereotypical neurotic parent whose kid didn’t come home by curfew. They’re staring out the window and thinking to themselves, “Why aren’t they here? Maybe they got injured! No, wait—maybe they got arrested! No, wait—maybe they got murdered! No, wait…”.
That’s a kind of brainstorming, I suppose.
Thus, according to the discussion in the previous subsection, it seems that, to be consistent, I would need to say that the parent has a subconscious motivation for their child to be in danger. Do I believe that? Maybe in rare cases, e.g. if the parent had been arguing that letting the kid out was a bad idea and now they have a subconscious perverse ego-dystonic desire to be proven right. But I think the more central case is that their true motivation is exactly what you’d think. After all, their brain is probably systematically searching for ways to ensure their child’s safety, not the other way around.
So is this a counterexample to my claim in §3.3.3 above that “the appeal [positive valence] of the brainstorming destination is the fuel powering the whole brainstorming journey”?
Yes! It is a counterexample. Indeed, I think this case works by a different mechanism, involving involuntary attention, not valence.
Let’s pause for background. I was talking about “attention control” above (§3.3.1). That was referring to voluntary attention. Just as motor outputs can be either voluntary (e.g. talking) or involuntary (e.g. spasms, vasoconstriction, crying, etc.), likewise attentional outputs can be either voluntary or involuntary. The difference (by my definition) is that voluntary attention & motor outputs are determined by the brain’s “main” reinforcement learning system (§1.5.6 [LW · GW]), involving valence, whereas the involuntary outputs are not. Thus:
- An attentional output is voluntary when I pay attention to something because I want to pay attention to it. (Note that this “want” can be ego-dystonic—I don’t necessarily want to want to pay attention to it. This is a common source of confusion, because people have a tendency to “externalize” ego-dystonic desires, i.e. to conceptualize them as involuntary “urges”, even if they are voluntary by my definition. Further discussion here [LW · GW].)
- An attentional output is involuntary when it arises for any other reason. A simple example is if you’re paying attention to the fact that your arm is extremely itchy. I think the itch signal goes from peripheral nerves to the brainstem, and from there it directly intervenes in thalamocortical attentional pathways. The reward / reinforcement learning / motivation system need not be involved at all, and indeed these thoughts are demotivating.
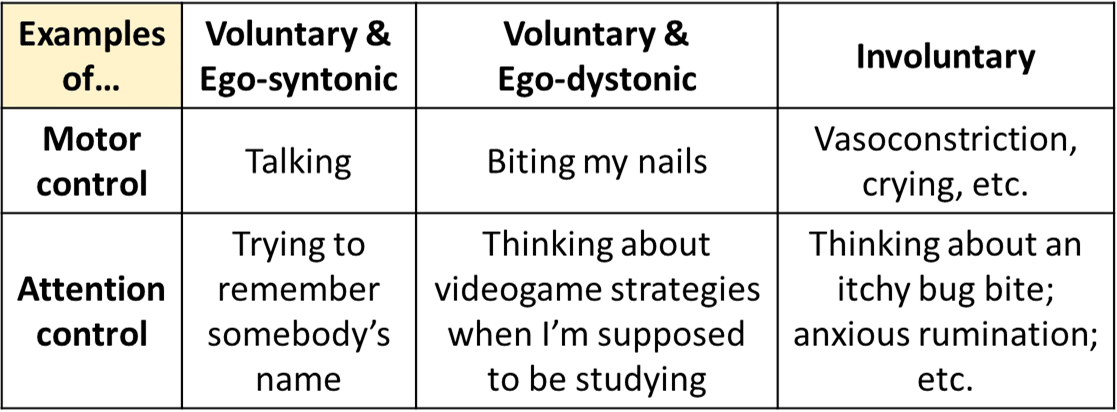
Think of attention as a constraint on what thoughts can be thunk[2]. When your arm is very itchy, it can be almost impossible to think any thought that isn’t “about” that itch. If one of those thoughts is negative valence, maybe it will get thrown out (per the usual rule, see §1.3 [LW · GW]), but it will then immediately get replaced by a new different thought which is also about that itch, because the constraint is still there. Indeed, if the constraint is sufficiently constraining, maybe there’s almost a unique constraint-compatible thought, and then the same negative-valence thought can persist—each time it gets tossed away by its negative valence (§1.3 [LW · GW]), the cortex goes fishing for a new thought, but just dredges up the same thought as before.
I think anxious / obsessive “brainstorming” is like that. Involuntary attention provides a constraint that makes it almost impossible to think any thought that isn’t “about” that interoceptive sensation of anxiety (and its web of presumed causes and associations). So the “brainstorming” can still happen, even if all the thoughts involved in the brainstorming have negative valence.
3.3.6 How does confirmation bias ever not happen?
If it is really so unnatural to brainstorm why I might be wrong, or otherwise take motor and attentional actions that might lead to changing one’s mind, then how does it ever happen that people search for flaws in their plans, change their strong beliefs, and so on?
(Per the previous subsection, anxious rumination can work, and I think really does work for some people, but that’s not an ideal strategy, for many reasons. Isn’t there any other way?)
I think the two most important ingredients in how confirmation bias can be beaten back in practice are:
- First, you need to minimize the amount of negative valence on the idea of your plans and ideas and beliefs being wrong: you can “keep your identity small”, and recite the “Litany of Tarski [? · GW]”, and “leave yourself a line of retreat [LW · GW]”, and so on.
- Second, you need to pile lots of positive valence on certain metacognitive or self-reflective thoughts like “I’m the kind of person who always brainstorms why my plans might fail”, “It is in my long-term best interest to brainstorm why I might be wrong”, “I have Scout Mindset”, and so on. Try imagining all the positive consequences of having those habits; try hanging around people who hold those metacognitive habits in high regard; lean into curiosity and confusion; etc.
The first one reduces the negative valence of processes that may lead to discovering that you’re wrong, and the second one loads positive valence onto those same processes. So with luck we can tip the balance into positive.
In many domains, these kinds of metacognitive habits develop implicitly and organically by reinforcement learning over the course of normal life experience. For example, most people do not suffer from motivated reasoning about whether or not they remembered to pack an umbrella in their bag. Notice that, in this umbrella example, there is a direct and immediate personal harm from having inaccurate beliefs about the world—if I’m wrong, then I’ll get wet. So there’s abundant opportunity for reinforcement learning to work. By contrast, motivated reasoning tends to be much more common and pernicious in domains where inaccurate beliefs have no direct and immediate personal consequences, e.g. politics. If prediction markets take off more in the future, that could help on the margin, but meanwhile, let’s all use and spread advice like the above bullet points, leaning on the helpful fact that “my beliefs are accurate” is an ego-syntonic aspiration for almost everyone.
3.4 Valence impacts beliefs by acting as salient sense data
As discussed in §3.2, valence is both a control signal able to toss out thoughts and plans that seem bad and cement thoughts and plans that seem good, and a piece of sense data that gets incorporated into our predictive (generative) world-model. The previous section (§3.3) was about how valence affects our beliefs through the former role, and now we’re moving onto the latter role.
As background: contrary to what you may have learned as a kid, humans don’t have “five senses”, but rather dozens of senses, including not just sight, smell, hearing, taste, and touch, but also sense of body configuration (“proprioception”), sense of balance / orientation (involving the vestibular system), sense of pain (“nociception”), sense of hunger, sense of our current physiological arousal, and more. I claim that valence is one of those extra sensory inputs, in the category of “interoception”. Computationally, I think that all of these sensory inputs serve as ground truth for self-supervised learning—i.e., our world-models (“Thought Generator” [LW · GW]) continually predict imminent sensory inputs, and are updated when the predictions are wrong (§1.5.4 [LW · GW]).
3.4.1 When your brain clusters similar things into mental categories / concepts, valence is an important ingredient going into that clustering algorithm
Here are two things that I mentioned in §2.4.5 [LW · GW]:
- I mentioned that many concepts explicitly incorporate valence into their definitions—think of words like “preferable”, “problematic”, “trouble”, “roadblock”, “pest”, “flourishing”, and so on.
- I offered an example made-up anecdote where Person X generally likes (feels positive valence in association with) the concept “religion”, but dislikes Scientology, and then uncoincidentally Person X is particularly liable to say “Scientology isn’t really a religion.” We could say that Person X is “gerrymandering” the concept “religion” to follow the contours of their own valence assessments. (If you don’t like that example, try thinking of your own example, it’s very easy because everybody does this all the time.)
If you think about it mechanistically, those two things are identical! If Person X dislikes a thing, they probably won’t identify it as an example of “flourishing”; and for the exact same underlying reason, if Person X dislikes a thing, they probably won’t identify it as an example of “religion”. In both cases, from that person’s perspective, the thing just doesn’t seem to belong inside that mental category.
Stepping back: When we form mental categories, we’re finding “clusters in thingspace” [LW · GW]—stuff that forms a natural grouping in our mental world. Well, valence is part of our mental world too—a first-class piece of sense data, just like appearance, smell, and so on. So our brains naturally treat valence as an ingredient in the categorization algorithm—indeed, as a very important ingredient.
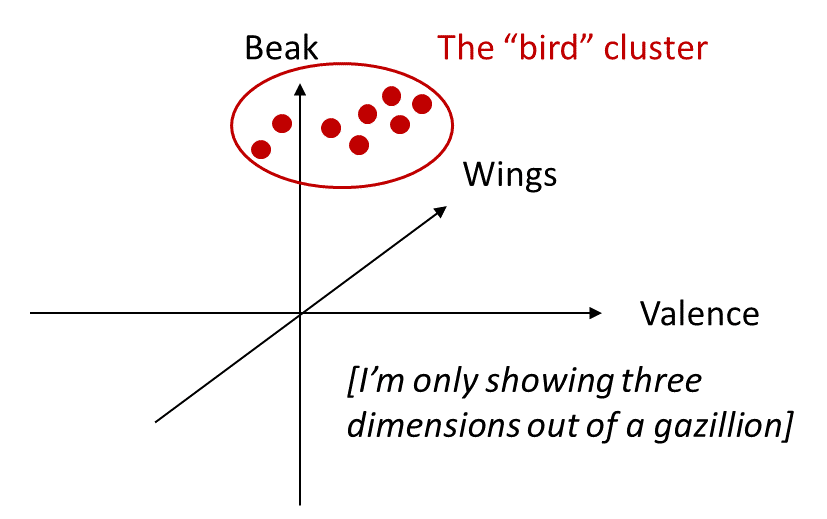
So if someone uses the word “cult” to mean “an ideologically-aligned tight-knit group that I don’t like”, they haven’t intrinsically done anything wrong or confused—that’s no different from how we all use words like “roadblock” or “contamination”. It only becomes confusing and misleading if that person simultaneously insists that “cult” is a word that describes an aspect of the world independently from how we feel about it. And indeed, people make that move all the time! For example, if you look at a random “cult checklist”, you’ll notice that none of the entries are “…And overall the group is bad, booooo”.
Things become even more confusing in cases like “religion”, which may have positive valence in one person’s mind and negative valence in another’s. Then those two people try to talk to each other about “religion”. There’s a real sense in which they are using the same word, but they are not talking about the same concept: In one person’s head, “religion” is a “cluster in thingspace” characterized by positive valence (among other things), and in the other person’s head, it’s a different “cluster in thingspace”, this time characterized by negative valence (among other things). No wonder it often seems like these two people are talking past each other!
3.4.2 Is the above a bug, or a feature?
As I keep mentioning, it’s useful to model the world independently from how we feel about it. Insofar as that’s true, it’s unfortunate that our brains treat valence as sense data that contributes to conceptual categorization and clustering.
On the other hand, at the end of the day, the main reason our brains build world-models in the first place is to make better decisions. And, as discussed in the previous post [LW · GW], valence is how our brains figure out whether a decision is good or bad. So, if our brains are going to do conceptual categorization and clustering to inform decision-making, what on earth could be more important than using valence as a central ingredient in that clustering algorithm?
So at the end of the day, my guess is that there’s a very good evolutionary reason that the brain treats valence as a ubiquitous and salient piece of sense data: without that design feature, we would struggle to make good decisions and get by in the world.
And then it’s an unfortunate but somewhat-inevitable side-effect of that design feature that “modeling the world independently from how I feel about it” is somewhat unnatural for us humans. Likewise, that design feature saddles us with other annoying things like “meaningless arguments” (§2.4.4 [LW · GW]) and related arguments-over-definitions, miscommunications, etc. Luckily, it’s possible for us humans to mitigate these problems via learned metacognitive heuristics, memes, the scientific method, and so on. We seem to be getting by, more or less.
To spell out some of the issues involved in more detail:
3.4.3 Three roadblocks to talking and reasoning about the world separately from how we feel about it
3.4.3.1 In real life, many discussions are (at least in part) discussions about valence assessments—even if they appear not to be
As an example of people who I claim are confused about this issue, take the classic study “The affect heuristic in judgments of risks and benefits” (Finucane et al., 2000). (Yes it did replicate; so I’m trusting their results and instead nitpicking about their interpretation.)
Finucane et al. studied people’s attitudes towards different technologies (nuclear power, food preservatives, etc.). Their hypothesis was that people’s view of these technologies was largely determined by a general valence / yay-versus-boo / “affect” assessment in their brain, and people then lean on that general assessment when answering questions that nominally should be factual (not affect-based) in nature.
They reported a few findings. First, when they asked people to rate both the “risks” and the “benefits” of each technology, they found that people tended to judge technologies as low-risk & high-benefit, or high-risk & low-benefit, more often than high-high or low-low—especially when the survey-takers were under time pressure. Second, the authors attempted to manipulate people’s beliefs about either risks or benefits by asking them to read a few-sentence blurb arguing that the risks are high, the risks are low, the benefits are high, or the benefits are low. They found that, when the manipulation pulled benefits-assessments up, it tended to pull risk-assessments down, and so on, by and large.
In regards to the first result, Finucane et al. had suggested that, in real life, the risks of a technology should correlate positively, not negatively, with its benefits. For example, if a technology had high risk and low benefit, it wouldn’t be in widespread use in the first place. Since the survey found negative correlation, they suggest, it means people are relying on a heuristic that is leading them astray.
But there’s an alternate spin we can put on it. As has been noted (e.g. 1, 2), many apparent cognitive biases are tied up with conversational implicatures (i.e., communicative content that is mutually understood but not explicitly spoken). Now, people just love talking about valence, and arguing about valence (§2.4.4 [LW · GW]), and thinking about valence. So there’s a widespread conversational implicature that, whatever a conversation seems to be about, if there’s any possible way to interpret it as actually being about valence, then that’s a decent hypothesis for the speaker’s intended meaning.
This implicature really comes out strongly in “meaningless arguments” (as defined in §2.4.4 [LW · GW]). If I like Israel, and you dislike Israel, and I say to you “Israel is the freest and most democratic country in the Middle East”, then you’re probably going to assume that I’m also implying “…and therefore you should assign a positive valence to Israel”. And in everyday life, you would almost definitely be correct to assume that that’s what I mean!
Anyway, this widespread conversational implicature applies to survey questions too. So when Finucane et al. offered the survey question “In general, how beneficial do you consider the use of food preservatives to be to U.S. society as a whole?”, probably some survey-takers (especially but not exclusively the survey-takers under time pressure) were at least partly inclined to answer whether, all things considered, food preservatives are good or bad. In other words, perhaps they were tempted to interpret the word “beneficial” in the sense of “net beneficial”, or even just “good”.
Insofar as that’s part of the explanation, the so-called “affect heuristic” is not really a heuristic at all—more like a miscommunication!
So more generally, if I ask you a question, you might interpret my question as at least partly a question about your valence assessments. And as we’ve seen, all of the following are possible:
- It’s possible that your interpretation of my question is correct, based on my explicit words—for example, if I had asked “Do you like X?”.
- It’s possible that your interpretation of my question is correct, but you were relying not on my explicit words but on a (correctly-understood) conversational implicature—for example, if we’re arguing about Israel as in §2.4.4 [LW · GW], and I ask “Israel is free and democratic, right?”, then perhaps we both correctly understand that my implied full question is “Israel is free and democratic, and this fact constitutes a reason to feel more generally positive about Israel, right?”
- It’s possible that your interpretation of my question is wrong—i.e., I was trying not to ask about your valence assessments. A likely example of this kind of misinterpretation would be the questions in the Finucane et al. survey, as discussed above.
3.4.3.2 Even if we’re trying to communicate and think about the world independently from how we feel about it, valence tends to become involved, via being tied up with our words and concepts
Let’s say I ask you “Is Ahmed talented?” Maybe you and I both understand the current conversational goal is to make a narrow assessment of Ahmed’s objective skill as a ballet dancer, independently from our general positive or negative feelings about Ahmed. But that’s hard! “Talented” is a “cluster in thingspace” characterized (among other things) by having generally positive valence. Thus, other things equal, negative-valence things will be farther from this “talented” cluster than positive-valence things.
This isn’t an inevitable problem—in some situations, we can wind up learning metacognitive heuristics / strategies to notice and correct for this tendency. As far as I know, we can even wind up overcorrecting, and thus give final answers opposite to the halo effect! (This is one of many reasons that I find psychology studies on the halo effect to be difficult to interpret.)
But in any case, it seems pretty clear to me that valence assessments wind up involved in lots of areas that are “positive” rather than “normative”, and thus where, one might think, valence doesn’t belong.
…Or does it belong after all? That brings us to:
3.4.3.3 Treating valence as evidence about how the world works isn’t necessarily a mistake anyway
In the literature on the halo effect (see especially Murphy et al. 1993), I think it’s well-known that the halo effect is not always a mistake. Lots of positive-valence things tend to correlate with each other, and likewise lots of negative-valence things tend to correlate with each other. People who are talented tend to also be conscientious—not perfectly, but more than chance. And people who are murderers tend to also be dishonest. And if a company makes really great mufflers, then it’s a good bet that they also make good tires. Etc.
And this is no accident—our brains systematically make this happen via how they define concepts (§3.4.1) and edit the valence function (§2.5.1 [LW · GW]). I’ll spell this out with an example. Suppose murderers tend to wear purple shirts. In that world, everyone would start treating “purple-shirt-wearing” as a pejorative. And then later on, we would look out into the world and notice that the halo effect is valid: people with one negative trait (being a murderer) also tend to have a different negative trait (wearing purple shirts). Is that a coincidence? No! We’re just noticing the same correlation that was responsible for the valence assignments in the first place.
Basically, valence is an axis upon which things can sit, and our brain devotes an extraordinary amount of processing power to relentlessly track where everything in our mental world is on that axis. It doesn’t really matter what that axis corresponds to, in order for those coordinates to be useful in the course of answering factual questions (i.e., positive questions as opposed to normative questions).
For example, suppose I ask you “Is a fleep an example of a floop?” You don’t know what those two words mean, and I’m not going to tell you. But I will tell you that my own brain happens to assign positive valence to fleeps, and negative valence to floops. Well, now I have given you real, bona fide evidence that the correct answer to this factual question is “No, a fleep is not an example of a floop”. It’s certainly not strong evidence, but it is more than zero evidence.
3.4.4 The halo effect and affect heuristic
I’ve already basically said everything that I wanted to say about the halo effect and affect heuristic, but wanted to briefly give them a proper definition and section heading.
First, a note of clarification. I’m using “halo effect” in a broad sense that applies to not only people but also companies, concepts, etc. (But I’ll say much more about people specifically in the next post.) I’m also using “halo effect” in a broad sense that includes both positive and negative judgments (as opposed to using different terms for “halo effect” versus “horn effect”). Given those definitional choices, the term “halo effect” becomes synonymous with “affect heuristic”, as far as I can tell.
With that out of the way, the halo effect / affect heuristic is when we have a generally good or bad impression of a person, group, idea, etc., and use that general impression as a hint when we answer more specific questions about that person, group, idea, etc.
For example, consider the corporation Amazon. Let’s say that Person X generally has a positive impression of that corporation, and that Person Y generally has a negative impression. Now somebody asks them both to guess the probability that Amazon is currently in violation of antitrust regulations. Other things equal, Person X would probably give a lower probability than Person Y. The direction of causation, and exact mechanism, etc. aren't obvious, but this basic idea seems pretty intuitive to me.
I think the halo effect / affect heuristic comes from some combination of the three phenomena discussed in §3.4.3 above, and I don’t have anything more to say beyond that.
3.5 Will future AI have motivated reasoning, halo effect, etc.?
There’s a school of thought within evolutionary psychology that things like motivated reasoning and the halo effect are particular algorithmic quirks of human brains, installed by Evolution because Evolution doesn’t care about epistemological success, it cares about reproductive success, and sometimes these can come apart. For example (this line of thinking continues), it’s easier to convince someone that your self-serving belief is true if you believe it yourself; therefore evolution built our brains in such a way as to have and preserve self-serving beliefs. This isn’t a crazy idea, and is probably true on the margin, but I hope this post has raised a different possibility: these phenomena are pretty fundamental. Even if you’re coding a future Artificial General Intelligence (AGI) from scratch, my guess is that there’s just no practical way to do it wherein desires won’t impact epistemology, at least to some extent. (Note that “practical” is doing some work here; I think it’s possible to make an AGI wherein desires won’t impact epistemology, but only at the expense of crippling its competence, and/or learning speed, sample efficiency, etc.[3]) See also here [LW · GW].
I sometimes say that if we want future AGIs to have accurate beliefs, we should sign the AGI up for CFAR classes and encourage it to read Scout Mindset and so on, just like the rest of us. That’s partly a joke, but also partly not a joke. The reason it’s partly a joke is that it may be something we wouldn’t need or want to do deliberately. I would expect that a sufficiently smart AI would recognize the usefulness of having accurate beliefs, just as we humans tend to do. And then we wouldn’t need to go out of our way to sign the AGI up for CFAR classes; the AGI would sign itself up, or in the limit of superintelligence, it would reinvent the same ideas from scratch (or better ones). Either way, the AGI would wind up with a giant suite of learned metacognitive habits that patch over all the distortionary side-effects of its cognitive architecture—side-effects like motivated reasoning and the halo effect.
3.6 Conclusion
The previous post [LW · GW] discussed how valence is involved in the “normative” magisterium, and this post has discussed how valence is involved in the “positive” magisterium. Taking those together, I think we now have a great foundation for thinking about valence in general. In the next two posts, we will apply that foundation to two particular domains: the social world in the next post, and then mental health in the fifth and final post of the series.
Thanks to Seth Herd, Aysja Johnson, Justis Mills, and Charlie Steiner for critical comments on earlier drafts.
- ^
If you disagree with the claim “I can’t just will myself to strongly and sincerely believe that socialists are violent in the absence of any evidence whatsoever”, I bet you’re mentally substituting “actually good evidence” for “evidence”. I agree that people can will themselves to strongly and sincerely believe that socialists are violent on the grounds of very sketchy (so-called) evidence indeed—things like “socialists are bad in other ways” (see §3.4), or “I think I heard someone say that socialists are violent”, etc.
- ^
Note for non-native English speakers: “thunk” is a silly / casual past participle of “think”, by analogy with “sunk”, “stunk”, etc. I’m fond of it because e.g. “what thoughts can be thunk” is easier to parse than “what thoughts can be thought”.
- ^
Fleshing out this argument, which seems pretty watertight to me: There are two possibilities. Either (A) the AI can apply the full force of its intelligence and motivation to optimize its own thinking, pick out high-information-value information to learn from etc.; or (B) it can’t. In case (A) (e.g. a brain-like-AGI), the AI will have at least some susceptibility with motivated reasoning and related phenomena, per the §3.3 argument. In case (B) (e.g. GPT-4, or AIXItl), I have a hard time believing that such an AI will ever realistically be able to do innovative science etc. at human-level or beyond.
12 comments
Comments sorted by top scores.
comment by CarlShulman · 2023-12-14T00:35:16.174Z · LW(p) · GW(p)
Regarding making AIs motivated to have accurate beliefs, you can make agents that do planning and RL on organizing better predictions, e.g. AIs whose only innate drives/training signal (beside short-run data modeling, as with LLM pretraining) are doing well in comprehensive forecasting tournaments/prediction markets, or implementing reasoning that scores well on various classifiers built based on habits of reasoning that drive good performance in prediction problems, even against adversarial pressures (AIs required to follow the heuristics have a harder time believing or arguing for false beliefs even when optimized to do so under the constraints).
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-12-14T15:07:03.039Z · LW(p) · GW(p)
Thanks!
Before I even start to think about how to make AIs that are motivated to have accurate beliefs, I want to figure out whether that’s a good use of time. So my first two questions are:
- Is figuring this out necessary for TAI capabilities? (If yes, I don’t need to think about it, because it will automatically get sorted out before TAI.)
- Hmm, I guess my answer is “no”, because, for example, humans can be very high-achieving in practical domains like inventing stuff and founding companies while having confidently wrong opinions about things that are not immediately consequential, like religion or politics or of course x-risk. :)
- Is not figuring this out before TAI a safety problem? (If it’s not a safety problem, then I don’t care much.)
- Hmm, I guess my answer is “yes it’s a problem”, although I think it’s a less critical problem than alignment. Like, if an AI is motivated to make a great future, but has some wishful thinking and confirmation bias, they might do catastrophic things by accident.
OK, so I guess I do care about this topic. So now I’m reading your comment!
Giving an AI a motivation to do well at prediction markets or forecasting tournaments (maybe the latter is a bit better than the former per this?) seems like a perfectly good idea. I definitely wouldn’t want that to be the only motivation, at least for the kind of agent-y AGI that I’m expecting and trying to plan for, but it could be part of the mix.
The latter part of your comment (“or implementing reasoning…”) seems somewhat redundant with the former part, on my models of actor-critic AGI. Specifically, if you have actor-critic RL trained on good forecasting, then the critic becomes “various classifiers built based on habits of reasoning that drive good performance in prediction problems”, and then the actor “implements reasoning” on that basis. It might be less redundant for other types of AI. Sorry if I’m misunderstanding.
Also, I still also think literally giving the AI a copy of Scout Mindset, as silly as it sounds, is not a crazy idea (again, specifically for the kind of RL-agent-y AGI that I’m thinking of). You would also want to futz with the AI’s motivation system to make it excited to read the book. (I think that kind of futzing will probably be possible as we get towards AGI. It’s not so different from what happens when someone I greatly admire recommends a book to me. I think it would look like tweaking the critic function—like this kind of thing [LW · GW].)
comment by Gunnar_Zarncke · 2023-12-11T23:24:16.733Z · LW(p) · GW(p)
I'm not convinced that valence data is an interoceptive input to the thought generator.
Maybe it is. The adaptive clusters in think space make it plausible. But is it needed? I think the brain can do the clustering without it. All it needs is a feedback from the output of the thought generator to its input (not present in your diagram). This seems to exist: We can observe our thoughts retrospectively.
Also, I think that making the control signal also an input could lead to unexpected results. See OpAmps.
comment by Charlie Steiner · 2023-12-11T22:44:08.174Z · LW(p) · GW(p)
This was definitely my favorite of the series.
I'm not really sold on the fundamentalness, especially of positive bias. Even if we grant that we're just considering systems that think complicated thoughts / plans in serial steps by evaluating intermediate simple thoughts, the fundamentalness argument only makes sense if the thought-assessment is hard to adjust based on context or can't have recursive structure.
Like, humans can't perfectly simulate hypothetical thoughts both because our thought-assesment only has limited ability to be changed on the fly (an AI's might have "adjustable knobs" or take rich input as a parameter), and also because we're not that good at using our brains for simulation - we get lost in thought sometimes, but if you could get perfectly lost your ancestors probably got eaten by tigers (whereas an AI can do recursive simulation).
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-12-14T15:48:03.810Z · LW(p) · GW(p)
Thanks!
I’ll try to rephrase your comment first to make sure I got it.
When you say “I’m not really sold on the fundamentalness”, I believe you’re referring to the “fundamentalness” of confirmation bias, as discussed in §3.5 and footnote 3. (You can correct me if I’m wrong.)
Let’s say the AI designed a widget, and wants the widget to work, but is now brainstorm situations in which the widget will fail. It has a nonzero amount of tendency to flinch away from this process, because imagining the widget failing tends to be demotivating. But maybe you’re saying, this is a fixable problem.
Maybe we can say that the root of the problem is this:
- If you’re planning-what-to-do, then if “the widget will fail” is active, it should count against the goodness of a plan, and evidence that you should throw out that plan and think about other kinds of plans instead.
- But if you’re brainstorming, then if “the widget will fail” is active, that’s great, you should definitely keep thinking about that kind of thing.
Now, in brains, planning-what-to-do and brainstorming are basically the same kind of thing—same kind of queries to the same data structure, with the same thought assessors. But maybe in AI, we can distinguish them more cleanly and adjust the thought assessors accordingly? At least, that’s how I interpret your comment.
I don’t rule that out, but my current low-confidence guess is that it wouldn’t work. Also, if this kind of thing worked at all, the result would wind up almost isomorphic to an AI with a suite of learned metacognitive heuristics, a.k.a. “an AI that read Scout Mindset and has gotten in the habit of Murphyjitsu [? · GW] etc.”. I think the latter is a good-enough mitigation to wishful thinking, albeit not completely perfect, and somewhat theoretically unsatisfying.
One possible issue with putting that distinction in the source code (rather than as learned metacognitive heuristics) is that I’m not sure brainstorming-what-can-go-wrong-mode and planning-what-to-do-mode are actually cleanly separable. I bet you can kinda be doing a complicated mix of both at once, and that this capability is important. A flexible suite of learned metacognitive heuristics can handle that, but I’m not sure human-written source code can.
Another possible issue is that an intelligent agent needs to make tradeoffs between time spent brainstorming-what-can-go-wrong versus time spent planning-what-to-do, so ultimately everything has to cash out in the same currency, and it’s probably important-for-capabilities that this kind of thing is learned and flexible and context-dependent, which you get for free with learned metacognitive heuristics, but hard for human-written source code.
Again, none of this is very high confidence.
comment by Towards_Keeperhood (Simon Skade) · 2024-12-25T15:33:24.856Z · LW(p) · GW(p)
I hope I will get around to rereading the post and edit this comment to write a proper review, but I'm pretty busy, so in case I don't I now leave this very shitty review here.
I think this is probably my favorite post from 2023. Read the post summary to see what it's about.
I don't remember a lot of the details from the post and so am not sure whether I agree with everything, but what I can say is:
- When I read it several months ago, it seemed to me like an amazingly good explanation for why and how humans fall for motivated reasoning.
- The concept of valence turned out very useful for explaining some of my thought processes, e.g. when I'm daydreaming something and asking myself why, then for the few cases where I checked it was always something that falls into "the thought has high valence" - like e.g. imagining some situation where I said something that makes me look smart.
comment by Lorxus · 2024-06-10T22:44:29.201Z · LW(p) · GW(p)
(Per the previous subsection, anxious rumination can work, and I think really does work for some people, but that’s not an ideal strategy, for many reasons. Isn’t there any other way?)
It only works if one of the things you're most afraid of, most anxious about, most desperate to avoid ending up having happen, is self-delusion/having an [inaccurate/unclear/dagnerous incomplete] view of the world/being wrong in public. (This has painful second-order effects and also tends to get caught chasing its own tail; these failure modes require additional cognitive technology to mitigate.)
Then, you have extreme negative valence on "just stop thinking about the bad thing that might happen" and weak-but-surprisingly-at-all positive valence on "I should really really make sure to dot every i and cross every t in stress-testing this plan".
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-06-11T13:46:41.140Z · LW(p) · GW(p)
I mean, “anxious rumination” suggests something pretty extreme. For my part, I do think I’m very slightly anxious that something I publish will be poorly received, make me look foolish, or contain some part that’s wrong-in-an-embarrassing-way (or poorly-explained-in-an-embarrassing-way), etc. And I think my writing and thinking probably benefits from the thoughts sporadically triggered by that (slight, occasional) anxiety. But I’m generally in good mental health, and neither I nor anyone who knows me would use words like “afraid … anxious … desperate … painful … extreme …” to talk about how I feel and act when I’m writing and publishing.
Replies from: Lorxus↑ comment by Lorxus · 2024-06-11T14:43:34.092Z · LW(p) · GW(p)
OK I've definitely been misunderstood here. I'm using the impersonal-you to describe what other things have to be true for powering murphy-jitsu with anxious-rumination to work at all, partially based off personal experience.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-06-11T14:57:18.379Z · LW(p) · GW(p)
I know you weren’t talking about me specifically, but I thought it would be helpful to relate my anecdotal experience as a data point. :) Your comment started “It only works if…” and I was suggesting that “only” seems too strong because it can work to some extent in a more mild setting. (Or maybe you were describing an extreme case for clarity.)
Replies from: Lorxus↑ comment by Lorxus · 2024-06-11T21:16:14.764Z · LW(p) · GW(p)
Here's the thing - I don't really think it does work all that well in a milder setting, at least not until you've gone through the hypervigilant hell of the full-flavor version and only then got your anxiety back down. If you can't set that dial to "placid equanimity" or anything in the same zipcode, and you don't crank that dial all the way to near-max (to the point where it eventually just plain burns-in), then I posit that you won't actually end up sufficiently desperate to find all your plan's important flaws, and may well fail immediately to coalesce (if it's set way too low) or just plain get overwhelmed and shut down/quit too soon (if it's set only a little too low). You need to end up - at least at the start - in the land of anxiety-beyond-anxiety, apprised of the certain knowledge that there exists no correct direction but forwards but that all the wrong directions look a little like "forwards", too.
comment by StartAtTheEnd · 2023-12-12T17:49:34.608Z · LW(p) · GW(p)
I'm really enjoying your posts, and I think they're largely correct. But there's a strong focus on positives, and it seems to me that the brain is mainly geared for survival, so that it's in "Prevent bad things from happen"-mode rather than "Make good things happen"-mode. The strength of this bias is probably given by the neuroticism trait.
Whenever I imagine something, my brain always brainstorms things which could go wrong, and it's extremely good at doing this. This is the self-protection of the ego, and I think it's quite strong not only in me who is neurotic, but even in people with average health. I believe that you need to be on the healthy side (believe in your ability to deal with things, so that it's above the threshold for minor problems to be considered as dangerous) in order for positive thinking to be your main focus.
Like you seem to say, creating positives and preventing negatives are different to the brain. The brain has some quirks around negations. You can exploit this inequality by "visualizing" the future you want rather than looking towards problems trying to prevent them. The "law of attraction" is very real, it's just thought of as myserious or spiritual by people who don't realize that this is due to a quirk in the brain.
Imagine that you're walking (navigating somewhere), either physically or with a mental navigation through actions leading to a positive future. Now imagine looking at the solution vs looking at the problem, you will have widely different outcomes. It's like looking for every wrong path in a maze trying to avoid them rather than looking for the correct path. The difference in information to keep track of (and which can overwhelm you) is staggering. "Wrong" is a much bigger set than "Correct". In computer systems, a hacker needs to find one way in while the defender has to defend against all attack vectors. This inequality is a fundemental law with ties to entropy, so it's bound to be related in some way.
When you're walking, you should look at where you want to go. If you look at the people you might run into, you will find that you're prone to walk into people. We seem to walk towards what we look at, so if you "look into the abyss, the abyss will look back at you". If you engage with politics and echo-chambers and try to change people for the better, it's more likely that they will change you for the worse. The training data simply makes you see the world as they see it, poisoning it with their words and concepts, which often fit reality poorly.
A last effect I want to mention is how thing-clusters seem to grow into amalgamations in people who fight against things. Christians fighting against "evil" or "satan" might add more and more things to this category. Metal music tend to have skull symbolism and such in it, but they still seem far apart to me. Why would Christians fear metal music and videogames? i.e. why such a range of association? Political echo-chambers also seem to do this. Why would "Against mass-immigration" envoke "Nazi" or "Pro Russia"? These seem like they should be 3 or 4 steps apart. But extremists seem to deem everything within 4 or so associations from what they hate to be "red flags", leading to many false positives when assessing whenever I'm "with or against" them.
So while I mainly agree with you, some parts feel a little incomplete (the section about ruminations is treated like a small exception, but I think it's actually a core part of the model since we're so survival-oriented). I've communicated some of my world-model here, which I hope is either useful or serves as inspiration.
By the way, the "linear combination" idea is really powerful. I'm sure I've seen other people reach that conclusion before. I don't remember the first place I saw it, but the second one was in A Crash Course in the Neuroscience of Human Motivation [LW · GW] (search for Threshold)