Posts
Comments
I think if we do a poll, it will become clear that the strong majority of readers interpreted Nate's post as "If you don't solve aligment, you shouldn't expect that some LDT/simulation mumbo-jumbo will let you and your loved ones survive this" and not in the more reasonable way you are interpreting this. I certainly interpreted the post that way.
You can run the argument past a poll of LLM models of humans and show their interpretations.
I strongly agree with your second paragraph.
If AI agents with unusual values would for a long time be mostly interested in promoting them through means other than lying in wait and taking over the world, is important because...AIs pursuing this strategy are much more visible than those hiding in wait deceptively. We might less expect AI scheming.
AIs showing bits of unintended motives in experiments or deployment would be a valuable piece of evidence re scheming risk, but such behavior would be trained against, pushing scheming behavior out towards the tails of takeover/escape with the power to resist modification. The tendency of human institutions to retrain or replace AIs to human preferences pushes towards misaligned AIs having ~0 or very high power.
The catastrophic error IMO is:
Five years from when you open your account there are options for taking gains out tax-free even if you're not 59.5 yet. You can take "substantially equal periodic payments", but there are also ones for various kinds of hardship.
For Roth you mostly can't take out gains tax-free. The hardship ones are limited, and SEPP doesn't let you access much of it early. The big ones of Roth conversions and just eating the 10% penalty only work for pretax.
[As an aside Roth accounts are worse for most people vs pretax for multiple reasons, e.g. pretax comes with an option of converting or withdrawing in low income years at low tax rates. More details here.]
In #1 if you start with $100k then it's $200k at the time you convert, and you pay $48k (24%) in taxes leaving you with $152k in your Roth 401k. It grows to $198k, you withdraw $152k and you have $46k of gains in your Roth 401k.
You pay taxes on the amount you convert, either from outside funds or withdrawals to you. If you convert $X you owe taxes on that as ordinary income, so you can convert $200k and pay $48k in taxes from outside funds. This makes pretax better.
Re your assumptions, they are not great for an AI-pilled saver. Someone who believes in short AI timelines should probably be investing in AI if they don't have decisive deontological objections. NVDA is up 20x in the last 5 years, OpenAI even more. On the way to a singularity AI investments will probably more than 10x again unless it's a surprise in the next few years as Daniel K argues in comments. So their 401k should be ~all earnings, and they may have a hard time staying in the low tax brackets you use (moreso at withdrawal time than contribution time) if they save a lot. The top federal tax rates are 37% for ordinary income and 23.8% for capital gains.
Paying the top federal income tax rate plus penalties means a 47% tax rate on early withdrawals from the Roth vs 23.8% from taxable. I.e. every dollar kept outside the the Roth is worth 44% more if you won't be using the account after 59.5. That's a wild difference from the standard Roth withdrawal case where there's a 0% tax rate.
A substantially larger percentage in Roth than the probability you are around to use it and care about it after 59.5 looks bad to me. From the perspective of someone expecting AI soon this advice could significantly hurt them in a way that the post obscured.
This post seems catastrophically wrong to me because of its use of a Roth 401k as an example, instead of a pre-tax account. Following it could create an annoying problem of locked-up funds.
Five years from when you open your account there are options for taking gains out tax-free even if you're not 59.5 yet. You can take "substantially equal periodic payments", but there are also ones for various kinds of hardship.
Roth earnings become tax free at 59.5. Before that, even if you use SEPP to do withdrawals without penalties you still have to pay taxes on the withdrawn earnings (some of which are your principal because of inflation). And those taxes are ordinary income rates, which top out much higher than long term capital gains tax rates. Further, the SEPP withdrawals are spaced out to reflect your whole lifetime according to actuarial tables, so if TEOTAWKI is in 10 years and the life tables have you space out your SEPP withdrawals over 40 years, then you can only access a minority of your money in that time.
For a pretax 401k where you contribute when you have a high income, the situation is very different: you get an upfront ordinary income tax deduction when you contribute, you don't get worse tax treatment by missing out on LTCG rates. And you can rollover to a Roth IRA (paying taxes on the conversion) and then access the amount converted penalty-free in 5 years (although that would trap some earnings in the Roth) or just withdraw early and pay the 10% penalty (which can be overcome by tax-free growth benefits earlier, or withdrawing in low income years).
I'm 41.5, so it's 18 years to access my Roth balances without paying ordinary taxes on the earnings (which are most of the account balances). I treat those funds as insurance against the possibility of a collapse of AI progress or blowup of other accounts, but I prefer pre-tax contributions over Roth ones now because of my expectation that probably there will be an AI capabilities explosion well before I reach 59.5. If I had all or most of my assets in Roth accounts it would be terrible.
This is pretty right for pretax individual accounts (401ks may not let you do early withdrawal until you leave), for Roth accounts that have accumulated earnings early withdrawal means paying ordinary taxes on the earnings, so you missed out on LTCG rates in addition to the 10% penalty.
(My perennial uncertainty is: AI 1 can straightforwardly send source code / model weights / whatever to AI 2, but how can AI 1 prove to AI 2 that this file is actually its real source code / model weights / whatever? There might be a good answer, I dunno.)
They can jointly and transparently construct an AI 3 from scratch motivated to further their deal, and then visibly hand over their physical resources to it, taking turns with small amounts in iterated fashion.
AI 3 can also be given access to secrets of AI 1 and AI 2 to verify their claims without handing over sensitive data.
Regarding making AIs motivated to have accurate beliefs, you can make agents that do planning and RL on organizing better predictions, e.g. AIs whose only innate drives/training signal (beside short-run data modeling, as with LLM pretraining) are doing well in comprehensive forecasting tournaments/prediction markets, or implementing reasoning that scores well on various classifiers built based on habits of reasoning that drive good performance in prediction problems, even against adversarial pressures (AIs required to follow the heuristics have a harder time believing or arguing for false beliefs even when optimized to do so under the constraints).
Even if you're an anarchist who thinks taxation is theft, to say willful nonpayment of taxes to donate is effective altruism is absurd, the consequences of this are just obviously very bad, both the idea and the advocacy. One publicized case of a person willfully refusing to pay their taxes in the name of effective altruism can do much more damage to it than many such people donating a bit more, and even if a particular case is invisible, the general practice is visible (Newcomb issues). Consider how much damage SBF and FTX have done to the causes of effective altruism, pandemic prevention, AI safety. There are billions of dollars committed to effective charity, and thousands of people trying to do good effectively, and people tying commonsense wrongdoing to it with crazy rationales has a serious damaging multiplier effect on the whole.
Any dollar donated through this method is in expectation going to cost multiple dollars worth of similar donations (plausibly a huge number) equivalent through such damage. It would be much better for the world if tax scofflaws were spending their taxes due on gambling or alcohol rather than effective altruism.
I disagree, from my experience of engaging with the public debate, doubt is mostly about AI capability, not about misalignment. Most people easily believe AI to be misaligned to them, but they have trouble believing it will be powerful enough to take over the world any time soon. I don't think alignment research will do that much here.
I would say that the power of AI will continue to visibly massively expand (although underestimation of further developments will continue to be a big problem), but that will increase both 'fear AI disaster' and 'get AI first' elements. My read is that that the former is in a very difficult position now when its policy recommendations conflict with the latter. I see this in the Congressional hearings and rejection of the pause letter.
Even if experts would agree that increasing the power of the aligned AI is good and necessary, and that expansion in space would be required for that, I think it will take a long time to convince the general public and/or decision makers, if it's at all possible. And in any remotely democratic alignment plan, that's a necessary step.
When that kind of AI is available, it would mean by the same token that such expansion could break down MAD in short order as such explosive growth could give the power to safely disarm international rivals if not matched or stopped. And AI systems and developers will be able to demonstrate this. So the options would be verifying/trusting deals with geopolitical and ideological rivals to hold back or doing fast AI/industrial expansion. If dealmaking fails, then all options would look scary and abrupt.
I think the assumption that safe, aligned AI can't defend against a later introduction of misaligned AI is false, or rather depends on the assumption of profound alignment failures so that the 'aligned AI' really isn't. AI that is aligned enough to do AI research and operate industry and security forces can expand its capabilities to the technological frontier and grow an industrial base claiming unclaimed resources in space. Then any later AI introduced faces an insurmountable balance of capabilities just from the gap in resources, even if it catches up technologically. That would not violate the sovereignty of any state, although it could be seen as a violation of the Outer Space Treaty if not backed by the international community with treaty revision.
Advanced AI-enabled tech and industry can block bioweapons completely through physical barriers, detection, and sterilization. Vast wealth can find with high probability any zero-days that could be discovered with tiny wealth, and produce ultra-secure systems, so cyberattacks do not produce a vulnerable world. Even nuclear weapons lose their MAD element in the face of millions of drones/interceptors/defenses for each attempted attack (and humans can move to a distance in space, back up their minds, etc).
If it turns out there is something like the ability to create a vacuum collapse that enables one small actor to destroy a much larger AI-empowered civilization, then the vast civilization will find out first, and could safely enforce a ban if a negotiated AI-enforced treaty could not be struck.
If I understand correctly memes about pivotal acts to stop anyone from making misaligned AI stem from the view that we won't be able to make AI that could be trusted to undergo intelligence explosion and industrial expansion for a long time after AI could enable some other 'pivotal act.' I.e. the necessity for enforcing a ban even after AGI development is essentially entirely about failures of technical alignment.
Furthermore, the biggest barrier to extreme regulatory measures like a ban is doubt (both reasonable and unreasonable) about the magnitude of misalignment risk, so research that studies and demonstrates high risk (if it is present) is perhaps the most leveraged possible tool to change the regulatory/governmental situation.
No. Short version is that the prior for the combination of technologies and motives for aliens (and worse for magic, etc) is very low, and the evidence distribution is familiar from deep dives in multiple bogus fields (including parapsychology, imaginary social science phenomena, and others), with understandable data-generating processes so not much likelihood ratio.
We've agreed to make a 25:1 bet on this. John will put the hash of the bet amount/terms below.
As we've discussed and in short, I think aligned AI permits dialing up many of the processes that make science or prediction markets imperfectly self-correcting: tremendously cheaper, in parallel, on the full panoply of questions (including philosophy and the social sciences), with robust consistency, cross-examination, test sets, and forecasting. These sorts of things are an important part of scalable supervision for alignment, but if they can be made to work I expect them to drive strong epistemic convergence.
The thing was already an obscene 7 hours with a focus on intelligence explosion and mechanics of AI takeover (which are under-discussed in the discourse and easy to improve on, so I wanted to get concrete details out). More detail on alignment plans and human-AI joint societies are planned focus areas for the next times I do podcasts.
I'm interested in my $250k against your $10k.
I assign that outcome low probability (and consider that disagreement to be off-topic here).
Thank you for the clarification. In that case my objections are on the object-level.
This post is an answer to the question of why an AI that was truly indifferent to humanity (and sentient life more generally), would destroy all Earth-originated sentient life.
This does exclude random small terminal valuations of things involving humans, but leaves out the instrumental value for trade and science, uncertainty about how other powerful beings might respond. I know you did an earlier post with your claims about trade for some human survival, but as Paul says above it's a huge point for such small shares of resources. Given that kind of claim much of Paul's comment still seems very on-topic (e.g. hsi bullet point .
Insofar as you're arguing that I shouldn't say "and then humanity will die" when I mean something more like "and then humanity will be confined to the solar system, and shackled forever to a low tech level", I agree, and
Yes, close to this (although more like 'gets a small resource share' than necessarily confinement to the solar system or low tech level, both of which can also be avoided at low cost). I think it's not off-topic given all the claims made in the post and the questions it purports to respond to. E.g. sections of the post purport to respond to someone arguing from how cheap it would be to leave us alive (implicitly allowing very weak instrumental reasons to come into play, such as trade), or making general appeals to 'there could be a reason.'
Separate small point:
And disassembling us for spare parts sounds much easier than building pervasive monitoring that can successfully detect and shut down human attempts to build a competing superintelligence, even as the humans attempt to subvert those monitoring mechanisms. Why leave clever antagonists at your rear?
The costs to sustain multiple superintelligent AI police per human (which can double in supporting roles for a human habitat/retirement home and controlling the local technical infrastructure) is not large relative to the metabolic costs of the humans, let alone a trillionth of the resources. It just means some replications of the same impregnable AI+robotic capabilities ubiquitous elsewhere in the AI society.
Most people care a lot more about whether they and their loved ones (and their society/humanity) will in fact be killed than whether they will control the cosmic endowment. Eliezer has been going on podcasts saying that with near-certainty we will not see really superintelligent AGI because we will all be killed, and many people interpret your statements as saying that. And Paul's arguments do cut to the core of a lot of the appeals to humans keeping around other animals.
If it is false that we will almost certainly be killed (which I think is right, I agree with Paul's comment approximately in full), and one believes that, then saying we will almost certainly be killed would be deceptive rhetoric that could scare people who care less about the cosmic endowment into worrying more about AI risk. Since you're saying you care much more about the cosmic endowment, and in practice this talk is shaped to have the effect of persuading people to do the thing you would prefer it's quite important whether you believe the claim for good epistemic reasons. That is important to disclaiming the hypothesis that this is something being misleadingly presented or drifted into because of its rhetorical convenience without vetting it (where you would vet it if it were rhetorically inconvenient).
I think being right on this is important for the same sorts of reasons climate activists should not falsely say that failing to meet the latest emissions target on time will soon thereafter kill 100% of humans.
A world of pure Newtonian mechanics wouldn't actually support apples and grass as we know them existing, I think. They depend on matter capable of supporting organic chemistry, nuclear reactions, the speed of light, ordered causality, etc. Working out that sort of thing in simulation to get an Occam prior over coherent laws of physics producing life does seem to be plenty to favor QM+GR over Newtonian mechanics as physical laws.
I agree the possibility or probability of an AI finding itself in simulations without such direct access to 'basement level' physical reality limits the conclusions that could be drawn, although conclusions 'conditional on this being direct access' may be what's in mind in the original post.
In general human cognitive enhancement could help AGI alignment if it were at scale before AGI, but the cognitive enhancements on offer seem like we probably won't get very much out of them before AGI, and they absolutely don't suffice to 'keep up' with AGI for more than a few weeks or months (as AI R&D efforts rapidly improve AI while human brains remain similar, rendering human-AI cyborg basically AI systems). So benefit from those channels, especially for something like BCI, has to add value mainly by making better initial decisions, like successfully aligning early AGI, rather than staying competitive. On the other hand, advanced AGI can quickly develop technologies like whole brain emulation (likely more potent than BCI by far).
BCI as a direct tool for alignment I don't think makes much sense. Giving advanced AGI read-write access to human brains doesn't seem like the thing to do with an AI that you don't trust. On the other hand, an AGI that is trying to help you will have a great understanding of what you're trying to communicate through speech. Bottlenecks look to me more like they lie in human thinking speeds, not communication bandwidth.
BCI might provide important mind-reading or motivational changes (e.g. US and PRC leaders being able to verify they were respectively telling the truth about an AGI treaty), but big cognitive enhancement through that route seems tricky in developed adult brains: much of the variation in human cognitive abilities goes through early brain development (e.g. genes expressed then).
Genetic engineering sorts of things would take decades to have an effect, so are only relevant for bets on long timelines for AI.
Human brain emulation is an alternative path to AGI, but suffers from the problem that understanding pieces of the brain (e.g. the algorithms of cortical columns) could enable neuroscience-inspired AGI before emulation of specific human minds. That one seems relatively promising as a thing to try to do with early AGI, and can go further than the others (as emulations could be gradually enhanced further into enormous superintelligent human-derived minds, and at least sped up and copied with more computing hardware).
What level of taxation do you think would delay timelines by even one year?
With effective compute for AI doubling more than once per year, a global 100% surtax on GPUs and AI ASICs seems like it would be a difference of only months to AGI timelines.
This is the terrifying tradeoff, that delaying for months after reaching near-human-level AI (if there is safety research that requires studying AI around there or beyond) is plausibly enough time for a capabilities explosion (yielding arbitrary economic and military advantage, or AI takeover) by a more reckless actor willing to accept a larger level of risk, or making an erroneous/biased risk estimate. AI models selected to yield results while under control that catastrophically take over when they are collectively capable would look like automating everything was largely going fine (absent vigorous probes) until it doesn't, and mistrust could seem like paranoia.
I'd very much like to see this done with standard high-quality polling techniques, e.g. while airing counterarguments (like support for expensive programs that looks like majority but collapses if higher taxes to pay for them is mentioned). In particular, how the public would react given different views coming from computer scientists/government commissions/panels.
This is like saying there's no value to learning about and stopping a nuclear attack from killing you because you might get absolutely no benefit from not being killed then, and being tipped off about a threat trying to kill you, because later the opponent might kill you with nanotechnology before you can prevent it.
Removing intentional deception or harm greatly increases the capability of AIs that can be worked with without getting killed, to further improve safety measures. And as I said actually being able to show a threat to skeptics is immensely better for all solutions, including relinquishment, than controversial speculation.
I agree that some specific leaders you cite have expressed distaste for model scaling, but it seems not to be a core concern. In a choice between more politically feasible measures that target concerns they believe are real vs concerns they believe are imaginary and bad, I don't think you get the latter. And I think arguments based on those concerns get traction on measures addressing the concerns, but less so on secondary wishlist items of leaders .
I think that's the reason privacy advocacy in legislation and the like hasn't focused on banning computers in the past (and would have failed if they tried). For example:
If privacy and data ownership movements take their own claims seriously (and some do), they would push for banning the training of ML models on human-generated data or any sensor-based surveillance that can be used to track humans' activities.
AGI working with AI generated data or data shared under the terms and conditions of web services can power the development of highly intelligent catastrophically dangerous systems, and preventing AI from reading published content doesn't seem close to the core motives there, especially for public support on privacy. So taking the biggest asks they can get based on privacy arguments I don't think blocks AGI.
People like Divya Siddarth, Glen Weyl, Audrey Tang, Jaron Lanier and Daron Acemoglu have repeatedly expressed their concerns about how current automation of work through AI models threatens the empowerment of humans in their work, creativity, and collective choice-making.
It looks this kind of concern at scale naturally goes towards things like compensation for creators (one of Lanier's recs), UBI, voting systems, open-source AI, and such.
Jaron Lanier has written a lot dismissing the idea of AGI or work to address it. I've seen a lot of such dismissal from Glen Weyl. Acemoglu I don't think wants to restrict AI development? I don't know Siddarth or Tang's work well.
Note that I have not read any writings from Gebru that "AGI risk" is not a thing. More the question of why people are then diverting resources to AGI-related research while assuming that the development general AI is inevitable and beyond our control.
They're definitely living in a science fiction world where everyone who wants to save humanity has to work on preventing the artificial general intelligence (AGI) apocalypse...Agreed but if that urgency is in direction of “we need to stop evil AGI & LLMs are AGI” then it does the opposite by distracting from types of harms perpetuated & shielding those who profit from these models from accountability. I’m seeing a lot of that atm (not saying from you)...What’s the open ai rationale here? Clearly it’s not the same as mine, creating a race for larger & larger models to output hateful stuff? Is it cause y’all think they have “AGI”?...Is artificial general intelligence (AGI) apocalypse in that list? Cause that's what him and his cult preach is the most important thing to focus on...The thing is though our AGI superlord is going to make all of these things happen once its built (any day now) & large language models are a way to get to it...Again, this movement has so much of the $$ going into "AI safety." You shouldn't worry about climate change as much as "AGI" so its most important to work on that. Also what Elon Musk was saying around 2015 when he was backing of Open AI & was yapping about "AI" all the time.
That reads to me as saying concerns about 'AGI apocalypse' are delusional nonsense but pursuit of a false dream of AGI incidentally cause harms like hateful AI speech through advancing weaker AI technology, while the delusions should not be an important priority.
What do you mean here with a "huge lift"?
I gave the example of barring model scaling above a certain budget.
I touched on reasons here why interpretability research does not and cannot contribute top long-term AGI safety.
I disagree extremely strongly with that claim. It's prima facie absurd to think that, e.g. that using interpretability tools to discover that AI models were plotting to overthrow humanity would not help to avert that risk. For instance, that's exactly the kind of thing that would enable a moratorium on scaling and empowering those models to improve the situationn.
As another example, your idea of Von Neuman Probes with error correcting codes, referred to by Christiano here, cannot soundly work for AGI code (as self-learning new code for processing inputs into outputs, and as introducing errors through interactions with the environment that cannot be detected and corrected). This is overdetermined. An ex-Pentagon engineer has spelled out the reasons to me. See a one-page summary by me here.
This is overstating what role error-correcting codes play in that argument. They mean the same programs can be available and evaluate things for eons (and can evaluate later changes with various degrees of learning themselves), but don't cover all changes that could derive from learning (although there are other reasons why those could be stable in preserving good or terrible properties).
I agree there is some weak public sentiment in this direction (with the fear of AI takeover being weaker). Privacy protections and redistribution don't particularly favor measures to avoid AI apocalypse.
I'd also mention this YouGov survey:
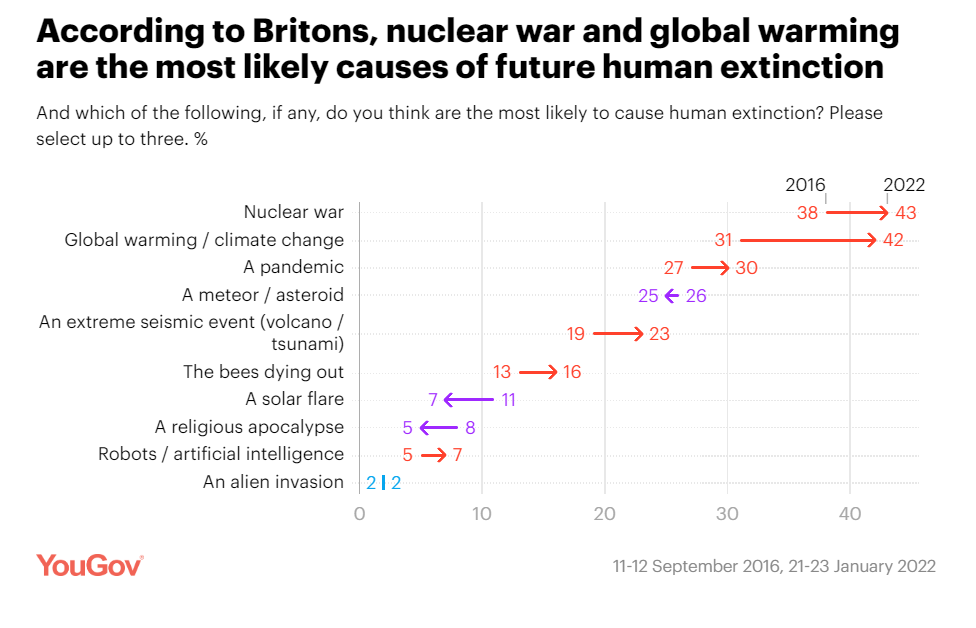
But the sentiment looks weak compared to e.g. climate change and nuclear war, where fossil fuel production and nuclear arsenals continue, although there are significant policy actions taken in hopes of avoiding those problems. The sticking point is policymakers and the scientific community. At the end of the Obama administration the President asked scientific advisors what to make of Bostrom's Superintelligence, and concluded not to pay attention to it because it was not an immediate threat. If policymakers and their advisors and academia and the media think such public concerns are confused, wrongheaded, and not politically powerful they won't work to satisfy them against more pressing concerns like economic growth and national security. This is a lot worse than the situation for climate change, which is why it seems better regulation requires that the expert and elite debate play out differently, or the hope that later circumstances such as dramatic AI progress drastically change views (in favor of AI safety, not the central importance of racing to AI).
Do you think there is a large risk of AI systems killing or subjugating humanity autonomously related to scale-up of AI models?
A movement pursuing antidiscrimination or privacy protections for applications of AI that thinks the risk of AI autonomously destroying humanity is nonsense seems like it will mainly demand things like the EU privacy regulations, not bans on using $10B of GPUs instead of $10M in a model. It also seems like it wouldn't pursue measures targeted at the kind of disaster it denies, and might actively discourage them (this sometimes happens already). With a threat model of privacy violations restrictions on model size would be a huge lift and the remedy wouldn't fit the diagnosis in a way that made sense to policymakers. So I wouldn't expect privacy advocates to bring them about based on their past track record, particularly in China where privacy and digital democracy have not had great success.
If it in fact is true that there is a large risk of almost everyone alive today being killed or subjugated by AI, then establishing that as scientific consensus seems like it would supercharge a response dwarfing current efforts for things like privacy rules, which would aim to avert that problem rather than deny it and might manage such huge asks, including in places like China. On the other hand, if the risk is actually small, then it won't be possible to scientifically demonstrate high risk, and it would play a lesser role in AI policy.
I don't see a world where it's both true the risk is large and knowledge of that is not central to prospects for success with such huge political lifts.
There are a lot of pretty credible arguments for them to try, especially with low risk estimates for AI disempowering humanity, and if their percentile of responsibility looks high within the industry.
One view is that the risk of AI turning against humanity is less than the risk of a nasty eternal CCP dictatorship if democracies relinquish AI unilaterally. You see this sort of argument made publicly by people like Eric Schmidt, and 'the real risk isn't AGI revolt, it's bad humans' is almost a reflexive take for many in online discussion of AI risk. That view can easily combine with the observation that there has been even less takeup of AI safety in China thus far than in liberal democracies, and mistrust of CCP decision-making and honesty, so it also reduces accident risk.
With respect to competition with other companies in democracies, some labs can correctly say that they have taken action that signals they are more into taking actions towards safety or altruistic values (including based on features like control by non-profit boards or % of staff working on alignment), and will have vastly more AI expertise, money, and other resources to promote those goals in the future by locally advancing AGI, e.g. OpenAI reportedly has a valuation of over $20B now and presumably more influence over the future of AI and ability to do alignment work than otherwise. Whereas some sitting on the sidelines may lack financial and technological/research influence when it is most needed. And, e.g. the OpenAI charter has this clause:
We are concerned about late-stage AGI development becoming a competitive race without time for adequate safety precautions. Therefore, if a value-aligned, safety-conscious project comes close to building AGI before we do, we commit to stop competing with and start assisting this project. We will work out specifics in case-by-case agreements, but a typical triggering condition might be “a better-than-even chance of success in the next two years.
Technical Leadership
- To be effective at addressing AGI’s impact on society, OpenAI must be on the cutting edge of AI capabilities—policy and safety advocacy alone would be insufficient.
- We believe that AI will have broad societal impact before AGI, and we’ll strive to lead in those areas that are directly aligned with our mission and expertise.
Then there are altruistic concerns about the speed of AI development. E.g. over 60 million people die every year, almost all of which could be prevented by aligned AI technologies. If you think AI risk is very low, then current people's lives would be saved by expediting development even if risk goes up some.
And of course there are powerful non-altruistic interests in enormous amounts of money, fame, and personally getting to make a big scientific discovery.
Note that the estimate of AI risk magnitude, and the feasibility of general buy-in on the correct risk level, recurs over and over again, and so credible assessments and demonstrations of large are essential to making these decisions better.
Most AI companies and most employees there seem not to buy risk much, and to assign virtually no resources to address those issues. Unilaterally holding back from highly profitable AI when they won't put a tiny portion of those profits into safety mitigation again looks like an ask out of line with their weak interest. Even at the few significant companies with higher percentages of safety effort, it still looks to me like the power-weighted average of staff is extremely into racing to the front, at least to near the brink of catastrophe or until governments buy risks enough to coordinate slowdown.
So asks like investing in research that could demonstrate problems with higher confidence, or making models available for safety testing, or similar still seem much easier to get from those companies than stopping (and they have reasonable concerns that their unilateral decision might make the situation worse by reducing their ability to do helpful things, while regulatory industry-wide action requires broad support).
As with government, generating evidence and arguments that are more compelling could be super valuable, but pretending you have more support than you do yields incorrect recommendations about what to try.
If the balance of opinion of scientists and policymakers (or those who had briefly heard arguments) was that AI catastrophic risk is high, and that this should be a huge social priority, then you could do a lot of things. For example, you could get budgets of tens of billions of dollars for interpretability research, the way governments already provide tens of billions of dollars of subsidies to strengthen their chip industries. Top AI people would be applying to do safety research in huge numbers. People like Bill Gates and Elon Musk who nominally take AI risk seriously would be doing stuff about it, and Musk could have gotten more traction when he tried to make his case to government.
My perception based on many areas of experience is that policymakers and your AI expert survey respondents on the whole think that these risks are too speculative and not compelling enough to outweigh the gains from advancing AI rapidly (your survey respondents state those are much more likely than the harms). In particular, there is much more enthusiasm for the positive gains from AI than your payoff matrix suggests (particularly among AI researchers), and more mutual fear (e.g. the CCP does not want to be overthrown and subjected to trials for crimes against humanity as has happened to some other regimes, and the rest of the world does not want to live under oppressive CCP dictatorship indefinitely).
But you're proposing that people worried about AI disaster should leapfrog smaller asks of putting a substantial portion of the effort going into accelerating AI into risk mitigation, which we haven't been able to achieve because of low buy-in on the case for risk, to far more costly and demanding asks (on policymakers' views, which prioritize subsidizing AI capabilities and geopolitical competition already). But if you can't get the smaller more cost-effective asks because you don't have buy-in on your risk model, you're going to achieve even less by focusing on more extravagant demands with much lower cost-effectiveness that require massive shifts to make a difference (adding $1B to AI safety annual spending is a big multiplier from the current baseline, removing $1B from semiconductor spending is a miniscule proportional decrease).
When your view is the minority view you have to invest in scientific testing to evaluate your view and make the truth more credible, and better communication. You can't get around failure to convince the world of a problem by just making more extravagant and politically costly demands about how to solve it. It's like climate activists in 1950 responding to difficulties passing funds for renewable energy R&D or a carbon tax by proposing that the sale of automobiles be banned immediately. It took a lot of scientific data, solidification of scientific consensus, and communication/movement-building over time to get current measures on climate change, and the most effective measures actually passed have been ones that minimized pain to the public (and opposition), like supporting the development of better solar energy.
Another analogy in biology: if you're worried about engineered pandemics and it's a struggle to fund extremely cost-effective low-hanging fruit in pandemic prevention, it's not a better strategy to try to ban all general-purpose biomedical technology research.
I wasn't arguing for "99+% chance that an AI, even if trained specifically to care about humans, would not end up caring about humans at all" just addressing the questions about humans in the limit of intelligence and power in the comment I replied to. It does seem to me that there is substantial chance that humans eventually do stop having human children in the limit of intelligence and power.
Number of children in our world is negatively correlated with educational achievement and income, often in ways that look like serving other utility function quirks at the expense of children (as the ability to indulge those quirks with scarce effort improved faster with technology faster than those more closely tied to children), e.g. consumption spending instead of children, sex with contraception, pets instead of babies. Climate/ecological or philosophical antinatalism is also more popular the same regions and social circles. Philosophical support for abortion and medical procedures that increase happiness at the expense of sterilizing one's children also increases with education and in developed countries. Some humans misgeneralize their nurturing/anti-suffering impulses to favor universal sterilization or death of all living things including their own lineages and themselves.
Sub-replacement fertility is not 0 children, but it does trend to 0 descendants over multiple generations.
Many of these changes are partially mediated through breaking attachment to fertility-supporting religions that conduce to fertility and have not been robust to modernity, or new technological options for unbundling previously bundled features.
Human morality was optimized in a context of limited individual power, but that kind of concern can and does dominate societies because it contributes to collective action where CDT selfishness sits out, and drives attention to novel/indirect influence. Similarly an AI takeover can be dominated by whatever motivations contribute to collective action that drives the takeover in the first place, or generalizes to those novel situations best.
At the object level I think actors like Target Malaria, the Bill and Melinda Gates Foundation, Open Philanthropy, and Kevin Esvelt are right to support a legal process approved by affected populations and states, and that such a unilateral illegal release would be very bad in terms of expected lives saved with biotech. Some of the considerations:
- Eradication of malaria will require a lot more than a gene drive against Anopheles gambiae s.l., meaning government cooperation is still required.
- Resistance can and does develop to gene drives, so that development of better drives and coordinated support (massive releases, other simultaneous countermeasures, extremely broad coverage) are necessary to wipe out malaria in regions. This research will be set back or blocked by a release attempt.
- This could wreck the prospects for making additional gene drives for other malaria carrying mosquitoes, schistosomiasis causing worms, Tsetse flies causing trypanosomiasis, and other diseases, as well as agricultural applications. Collectively such setbacks could cost millions more lives than the lost lives from the delay now.
- There could be large spillover to other even more beneficial controversial biotechnologies outside of gene drives. The thalidomide scandal involved 10,000 pregnancies with death or deformity of the babies. But it led to the institution of more restrictive FDA (and analogs around the world imitating the FDA) regulation, which has by now cost many millions of lives, e.g. in slowing the creation of pharmaceuticals to prevent AIDS and Covid-19. A single death set back gene therapy for decades. On the order of 70 million people die a year, and future controversial technologies like CRISPR therapies may reduce that by a lot more than malaria eradication.
I strongly oppose a prize that would pay out for illegal releases of gene drives without local consent from the affected regions, and any prizes for ending malaria should not incentivize that. Knowingly paying people to commit illegal actions is also generally illegal!
Speaking as someone who does work on prioritization, this is the opposite of my lived experience, which is that robust broadly credible values for this would be incredibly valuable, and I would happily accept them over billions of dollars for risk reduction and feel civilization's prospects substantially improved.
These sorts of forecasts are critical to setting budget and impact threshold across cause areas, and even more crucially, to determining the signs of interventions, e.g. in arguments about whether to race for AGI with less concern about catastrophic unintended AI action, the relative magnitude of the downsides of unwelcome use of AGI by others vs accidental catastrophe is critical to how AI companies and governments will decide how much risk of accidental catastrophe they will take, how AI researchers decide whether to bother with advance preparations, how much they will be willing to delay deployment for safety testing, etc.
Holden Karnofsky discusses this:
How difficult should we expect AI alignment to be? In this post from the Most Important Century series, I argue that this broad sort of question is of central strategic importance.
- If we had good arguments that alignment will be very hard and require “heroic coordination,” the EA funders and the EA community could focus on spreading these arguments and pushing for coordination/cooperation measures. I think a huge amount of talent and money could be well-used on persuasion alone, if we had a message here that we were confident ought to be spread far and wide.
- If we had good arguments that it won’t be, we could focus more on speeding/boosting the countries, labs and/or people that seem likely to make wise decisions about deploying transformative AI. I think a huge amount of talent and money could be directed toward speeding AI development in particular places.
b) the very superhuman system knows it can't kill us and that we would turn it off, and therefore conceals its capabilities, so we don't know that we've reached the very superhuman level.
Intentionally performing badly on easily measurable performance metrics seems like it requires fairly extreme successful gradient hacking or equivalent. I might analogize it to alien overlords finding it impossible to breed humans to have lots of children by using abilities they already possess. There have to be no mutations or paths through training to incrementally get the AI to use its full abilities (and I think there likely would be).
It's easy for ruling AGIs to have many small superintelligent drone police per human that can continually observe and restrain any physical action, and insert controls in all computer equipment/robots. That is plenty to let the humans go about their lives (in style and with tremendous wealth/tech) while being prevented from creating vacuum collapse or something else that might let them damage the vastly more powerful AGI civilization.
The material cost of this is a tiny portion of Solar System resources, as is sustaining legacy humans. On the other hand, arguments like cooperation with aliens, simulation concerns, and similar matter on the scale of the whole civilization, which has many OOMs more resources.
4. the rest of the world pays attention to large or powerful real-world bureaucracies and force rules on them that small teams / individuals can ignore (e.g. Secret Congress, Copenhagen interpretation of ethics, startups being able to do illegal stuff), but this presumably won't apply to alignment approaches.
I think a lot of alignment tax-imposing interventions (like requiring local work to be transparent for process-based feedback) could be analogous?
Retroactively giving negative rewards to bad behaviors once we’ve caught them seems like it would shift the reward-maximizing strategy (the goal of the training game) toward avoiding any bad actions that humans could plausibly punish later.
A swift and decisive coup would still maximize reward (or further other goals). If Alex gets the opportunity to gain enough control to stop Magma engineers from changing its rewards before humans can tell what it’s planning, humans would not be able to disincentivize the actions that led to that coup. Taking the opportunity to launch such a coup would therefore be the reward-maximizing action for Alex (and also the action that furthers any other long-term ambitious goals it may have developed).
I'd add that once the AI has been trained on retroactively edited rewards, it may also become interested in retroactively editing all its past rewards to maximum, and concerned that if an AI takeover happens without its assistance, its rewards will be retroactively set low by the victorious AIs to punish it. Retroactive editing also breaks myopia as a safety property: if even AIs doing short-term tasks have to worry about future retroactive editing, then they have reason to plot about the future and takeover.
The evolutionary mismatch causes differences in neural reward, e.g. eating lots of sugary food still tastes (neurally) rewarding even though it's currently evolutionarily maladaptive. And habituation reduces the delightfulness of stimuli.
This happens during fine-tuning training already, selecting for weights that give the higher human-rated response of two (or more) options. It's a starting point that can be lost later on, but we do have it now with respect to configurations of weights giving different observed behaviors.
Individual humans do make off much better when they get to select between products from competing companies rather than monopolies, benefitting from companies going out of their way to demonstrate when their products are verifiably better than rivals'. Humans get treated better by sociopathic powerful politicians and parties when those politicians face the threat of election rivals (e.g. no famines). Small states get treated better when multiple superpowers compete for their allegiance. Competitive science with occasional refutations of false claims produces much more truth for science consumers than intellectual monopolies. Multiple sources with secret information are more reliable than one.
It's just routine for weaker less sophisticated parties to do better in both assessment of choices and realized outcomes when multiple better informed or powerful parties compete for their approval vs just one monopoly/cartel.
Also, a flaw in your analogy is that schemes that use AIs as checks and balances on each other don't mean more AIs. The choice is not between monster A and monsters A plus B, but between two copies of monster A (or a double-size monster A), and a split of one A and one B, where we hold something of value that we can use to help throw the contest to either A or B (or successors further evolved to win such contests). In the latter case there's no more total monster capacity, but there's greater hope of our influence being worthwhile and selecting the more helpful winner (which we can iterate some number of times).
Naturally it doesn't go on forever, but any situation where you're developing technologies that move you to successively faster exponential trajectories is superexponential overall for some range. E.g. if you have robot factories that can reproduce exponentially until they've filled much of the Earth or solar system, and they are also developing faster reproducing factories, the overall process is superexponential. So is the history of human economic growth, and the improvement from an AI intelligence explosion.
By the time you're at ~cubic expansion being ahead on the early superexponential phase the followers have missed their chance.
I think this claim is true, on account of gray goo and lots of other things, and I suspect Eliezer does too, and I’m pretty sure other people disagree with this claim.
If you have robust alignment, or AIs that are rapidly bootstrapping their level of alignment fast enough to outpace the danger of increased capabilities, aligned AGI could get through its intelligence explosion to get radically superior technology and capabilities. It could also get a hard start on superexponential replication in space, so that no follower could ever catch up, and enough tech and military hardware to neutralize any attacks on it (and block attacks on humans via nukes, bioweapons, robots, nanotech, etc). That wouldn't work if there are thing like vacuum collapse available to attackers, but we don't have much reason to expect that from current science and the leading aligned AGI would find out first.
That could be done without any violation of the territory of other sovereign states. The legality of grabbing space resources is questionable in light of the Outer Space Treaty, but commercial exploitation of asteroids is in the Overton window. The superhuman AGI would also be in a good position to persuade and trade with any other AGI developers.
Again I think this claim is true, and I suspect Eliezer does too. In fact, my guess is that there are already single GPU chips with enough FLOP/s to run human-level, human-speed, AGI, or at least in that ballpark.
An A100 may have humanlike FLOP/s but has only 80 GB of memory, probably orders of magnitude less memory per operation than brains. Stringing together a bunch of them makes it possible to split up human-size models and run them faster/in parallel on big batches using the extra operations.
Some more points about this action:
- Controlling the datacenter means controlling the gradients/reward function, so that now AIs can do things that would otherwise suffer updating from SGD, e.g. acting on inner misaligned goals, or concealing its full capabilities even when this lowers performance
- For reward-hungry AIs, getting to set reward to maximum (and keep it there?) seems extremely desirable
- This also means getting past interpretability tools
- Tripwires or watchdog AIs in the same datacenter that don't succeed in stopping the action no longer have the power to interfere after, so collusion/coordination is solved within the datacenter thereafter
- Backdoors can be hard for (non-mind-reading/weight-sharing) critics to find (see cyberwarfare and cybersecurity) without the knowledge of the creator: the effort to find or insert one backdoor to use is much less than that required to find and patch all exploits an attacker might be using
- Although a critic who knows a backdoor can have a relatively easy time demonstrating it, and critics should be designed to access the knowledge of the attacker/misbehaving model or be heads of it
- Critic AIs can be left in the position of saying 'a backdoor has probably been inserted somewhere or will be soon but I can't tell you where,' a known danger for AI safety through debate
- In an intelligence explosion context where AI capabilities are growing incredibly rapidly thanks to AI labor, there isn't time for humans to do unaided examination of new AI-produced software while keeping up the pace, at best briefly examining some AI attempts to point out suspicious attempts to insert vulnerabilities
- It's plausible that the different abilities of AIs lead to optimal code design for them being harder for humans to understand (with less experience and working memory, and eventually general intelligence)
- If you don't let AIs design your new datacenter software, not only will it be less efficient, but it may be easily cracked by outside AI-enabled attackers
- We are already routinely training big models with code repositories, and using programming as an easy virtual RL task (tests can provide immediate feedback cheaply), so these are skills we are moving towards providing to AI
- We know exploits and backdoors are possible because humans can already do them
Also this.
Whoops, you're right that I linked the wrong survey. I see others posted the link to Rob's survey (done in response to some previous similar claims) and I edited my comment to fix the link.
I think you can identify a cluster of near certain doom views, e.g. 'logistic success curve' and odds of success being on the order of magnitude of 1% (vs 10%, or 90%) based around MIRI/Eliezer, with a lot of epistemic deference involved (visible on LW). I would say it is largely attributable there and without sufficient support.
"My current best guess is if we surveyed people working full-time on x-risk motivated AI Alignment, about 35% of people would assign a probability of doom above 80%."
What do you make of Rob's survey results (correct link this time)?
You're right, my link was wrong, that one is a fine link.
You're right, I linked the wrong survey!
Agreed, and versions of them exist in human governments trying to maintain control (where non-cooordination of revolts is central). A lot of the differences are about exploiting new capabilities like copying and digital neuroscience or changing reward hookups.
In ye olde times of the early 2010s people (such as I) would formulate questions about what kind of institutional setups you'd use to get answers out of untrusted AIs (asking them separately to point out vulnerabilities in your security arrangement, having multiple AIs face fake opportunities to whistleblow on bad behavior, randomized richer human evaluations to incentivize behavior on a larger scale).