Let’s think about slowing down AI
post by KatjaGrace · 2022-12-22T17:40:04.787Z · LW · GW · 182 commentsContents
Averting doom by not building the doom machine
Quick clarifications
Why not slow down AI? Why not consider it?
The mundanity of the proposal
Restraint is not radical
Sucky technologies
Extremely valuable technologies
Restraint is not terrorism, usually
Coordination is not miraculous world government, usually
The arms race model and its alternatives
The arms race
The suicide race
The safety-or-suicide race
The complicated race/anti-race
Other equilibria and other games
Being friends with risk-takers
Caution is cooperative
‘We’ are not the US, ‘we’ are not the AI safety community
Notes on tractability
Convincing people doesn’t seem that hard
Do you need to convince everyone?
Buying time is big
Delay is probably finite by default
Obstruction doesn’t need discernment
Safety from speed, clout from complicity
Moods and philosophies, heuristics and attitudes
Technological choice is not luddism
Non-AGI visions of near-term thriving
Robust priors vs. specific galaxy-brained models
Cheems mindset/can’t do attitude
Conclusion
Acknowledgements
Notes
None
182 comments
Averting doom by not building the doom machine
If you fear that someone will build a machine that will seize control of the world and annihilate humanity, then one kind of response is to try to build further machines that will seize control of the world even earlier without destroying it, forestalling the ruinous machine’s conquest. An alternative or complementary kind of response is to try to avert such machines being built at all, at least while the degree of their apocalyptic tendencies is ambiguous.
The latter approach seems to me like the kind of basic and obvious thing worthy of at least consideration, and also in its favor, fits nicely in the genre ‘stuff that it isn’t that hard to imagine happening in the real world’. Yet my impression is that for people worried about extinction risk from artificial intelligence, strategies under the heading ‘actively slow down AI progress’ have historically been dismissed and ignored (though ‘don’t actively speed up AI progress’ is popular).
The conversation near me over the years has felt a bit like this:
Some people: AI might kill everyone. We should design a godlike super-AI of perfect goodness to prevent that.
Others: wow that sounds extremely ambitious
Some people: yeah but it’s very important and also we are extremely smart so idk it could work
[Work on it for a decade and a half]Some people: ok that’s pretty hard, we give up
Others: oh huh shouldn’t we maybe try to stop the building of this dangerous AI?
Some people: hmm, that would involve coordinating numerous people—we may be arrogant enough to think that we might build a god-machine that can take over the world and remake it as a paradise, but we aren’t delusional
This seems like an error to me. (And lately [LW · GW], to [EA · GW] a bunch [LW · GW] of other [EA · GW] people [EA · GW].)
I don’t have a strong view on whether anything in the space of ‘try to slow down some AI research’ should be done. But I think a) the naive first-pass guess should be a strong ‘probably’, and b) a decent amount of thinking should happen before writing off everything in this large space of interventions. Whereas customarily the tentative answer seems to be, ‘of course not’ and then the topic seems to be avoided for further thinking. (At least in my experience—the AI safety community is large, and for most things I say here, different experiences are probably had in different bits of it.)
Maybe my strongest view is that one shouldn’t apply such different standards of ambition to these different classes of intervention. Like: yes, there appear to be substantial difficulties in slowing down AI progress to good effect. But in technical alignment, mountainous challenges are met with enthusiasm for mountainous efforts. And it is very non-obvious that the scale of difficulty here is much larger than that involved in designing acceptably safe versions of machines capable of taking over the world before anyone else in the world designs dangerous versions.
I’ve been talking about this with people over the past many months, and have accumulated an abundance of reasons for not trying to slow down AI, most of which I’d like to argue about at least a bit. My impression is that arguing in real life has coincided with people moving toward my views.
Quick clarifications
First, to fend off misunderstanding—
- I take ‘slowing down dangerous AI’ to include any of:
- reducing the speed at which AI progress is made in general, e.g. as would occur if general funding for AI declined.
- shifting AI efforts from work leading more directly to risky outcomes to other work, e.g. as might occur if there was broadscale concern about very large AI models, and people and funding moved to other projects.
- Halting categories of work until strong confidence in its safety is possible, e.g. as would occur if AI researchers agreed that certain systems posed catastrophic risks and should not be developed until they did not. (This might mean a permanent end to some systems, if they were intrinsically unsafe.)
- I do think there is serious attention on some versions of these things, generally under other names. I see people thinking about ‘differential progress’ (b. above), and strategizing about coordination to slow down AI at some point in the future (e.g. at ‘deployment’). And I think a lot of consideration is given to avoiding actively speeding up AI progress. What I’m saying is missing are, a) consideration of actively working to slow down AI now, and b) shooting straightforwardly to ‘slow down AI’, rather than wincing from that and only considering examples of it that show up under another conceptualization (perhaps this is an unfair diagnosis).
- AI Safety is a big community, and I’ve only ever been seeing a one-person window into it, so maybe things are different e.g. in DC, or in different conversations in Berkeley. I’m just saying that for my corner of the world, the level of disinterest in this has been notable, and in my view misjudged.
Why not slow down AI? Why not consider it?
Ok, so if we tentatively suppose that this topic is worth even thinking about, what do we think? Is slowing down AI a good idea at all? Are there great reasons for dismissing it?
Scott Alexander wrote a post a little while back raising reasons to dislike the idea, roughly:
- Do you want to lose an arms race? If the AI safety community tries to slow things down, it will disproportionately slow down progress in the US, and then people elsewhere will go fast and get to be the ones whose competence determines whether the world is destroyed, and whose values determine the future if there is one. Similarly, if AI safety people criticize those contributing to AI progress, it will mostly discourage the most friendly and careful AI capabilities companies, and the reckless ones will get there first.
- One might contemplate ‘coordination’ to avoid such morbid races. But coordinating anything with the whole world seems wildly tricky. For instance, some countries are large, scary, and hard to talk to.
- Agitating for slower AI progress is ‘defecting’ against the AI capabilities folks, who are good friends of the AI safety community, and their friendship is strategically valuable for ensuring that safety is taken seriously in AI labs (as well as being non-instrumentally lovely! Hi AI capabilities friends!).
Other opinions I’ve heard, some of which I’ll address:
- Slowing AI progress is futile: for all your efforts you’ll probably just die a few years later
- Coordination based on convincing people that AI risk is a problem is absurdly ambitious. It’s practically impossible to convince AI professors of this, let alone any real fraction of humanity, and you’d need to convince a massive number of people.
- What are we going to do, build powerful AI never and die when the Earth is eaten by the sun?
- It’s actually better for safety if AI progress moves fast. This might be because the faster AI capabilities work happens, the smoother AI progress will be, and this is more important than the duration of the period. Or speeding up progress now might force future progress to be correspondingly slower. Or because [LW · GW] safety work is probably better when done just before building the relevantly risky AI, in which case the best strategy might be to get as close to dangerous AI as possible and then stop and do safety work. Or if safety work is very useless ahead of time, maybe delay is fine, but there is little to gain by it.
- Specific routes to slowing down AI are not worth it. For instance, avoiding working on AI capabilities research is bad because it’s so helpful [EA(p) · GW(p)] for learning [EA(p) · GW(p)] on the path to working on alignment. And AI safety people working in AI capabilities can be a force for making safer choices at those companies.
- Advanced AI will help enough with other existential risks as to represent a net lowering of existential risk overall.1
- Regulators are ignorant about the nature of advanced AI (partly because it doesn’t exist, so everyone is ignorant about it). Consequently they won’t be able to regulate it effectively, and bring about desired outcomes.
My impression is that there are also less endorsable or less altruistic or more silly motives floating around for this attention allocation. Some things that have come up at least once in talking to people about this, or that seem to be going on:
- Advanced AI might bring manifold wonders, e.g. long lives of unabated thriving. Getting there a bit later is fine for posterity, but for our own generation it could mean dying as our ancestors did while on the cusp of a utopian eternity. Which would be pretty disappointing. For a person who really believes in this future, it can be tempting to shoot for the best scenario—humanity builds strong, safe AI in time to save this generation—rather than the scenario where our own lives are inevitably lost.
- Sometimes people who have a heartfelt appreciation for the flourishing that technology has afforded so far can find it painful to be superficially on the side of Luddism here.
- Figuring out how minds work well enough to create new ones out of math is an incredibly deep and interesting intellectual project, which feels right to take part in. It can be hard to intuitively feel like one shouldn’t do it.
(Illustration from a co-founder of modern computational reinforcement learning: )
It will be the greatest intellectual achievement of all time.
— Richard Sutton (@RichardSSutton) September 29, 2022
An achievement of science, of engineering, and of the humanities,
whose significance is beyond humanity,
beyond life,
beyond good and bad.
- It is uncomfortable to contemplate projects that would put you in conflict with other people. Advocating for slower AI feels like trying to impede someone else’s project, which feels adversarial and can feel like it has a higher burden of proof than just working on your own thing.
- ‘Slow-down-AGI’ sends people’s minds to e.g. industrial sabotage or terrorism, rather than more boring courses, such as, ‘lobby for labs developing shared norms for when to pause deployment of models’. This understandably encourages dropping the thought as soon as possible.
- My weak guess is that there’s a kind of bias at play in AI risk thinking in general, where any force that isn’t zero is taken to be arbitrarily intense. Like, if there is pressure for agents to exist, there will arbitrarily quickly be arbitrarily agentic things. If there is a feedback loop, it will be arbitrarily strong. Here, if stalling AI can’t be forever, then it’s essentially zero time. If a regulation won’t obstruct every dangerous project, then is worthless. Any finite economic disincentive for dangerous AI is nothing in the face of the omnipotent economic incentives for AI. I think this is a bad mental habit: things in the real world often come down to actual finite quantities. This is very possibly an unfair diagnosis. (I’m not going to discuss this later; this is pretty much what I have to say.)
- I sense an assumption that slowing progress on a technology would be a radical and unheard-of move.
- I agree with lc [LW · GW] that there seems to have been a quasi-taboo on the topic, which perhaps explains a lot of the non-discussion, though still calls for its own explanation. I think it suggests that concerns about uncooperativeness play a part, and the same for thinking of slowing down AI as centrally involving antisocial strategies.
I’m not sure if any of this fully resolves why AI safety people haven’t thought about slowing down AI more, or whether people should try to do it. But my sense is that many of the above reasons are at least somewhat wrong, and motives somewhat misguided, so I want to argue about a lot of them in turn, including both arguments and vague motivational themes.
The mundanity of the proposal
Restraint is not radical
There seems to be a common thought that technology is a kind of inevitable path along which the world must tread, and that trying to slow down or avoid any part of it would be both futile and extreme.2
But empirically, the world doesn’t pursue every technology—it barely pursues any technologies.
Sucky technologies
For a start, there are many machines that there is no pressure to make, because they have no value. Consider a machine that sprays shit in your eyes. We can technologically do that, but probably nobody has ever built that machine.
This might seem like a stupid example, because no serious ‘technology is inevitable’ conjecture is going to claim that totally pointless technologies are inevitable. But if you are sufficiently pessimistic about AI, I think this is the right comparison: if there are kinds of AI that would cause huge net costs to their creators if created, according to our best understanding, then they are at least as useless to make as the ‘spray shit in your eyes’ machine. We might accidentally make them due to error, but there is not some deep economic force pulling us to make them. If unaligned superintelligence destroys the world with high probability when you ask it to do a thing, then this is the category it is in, and it is not strange for its designs to just rot in the scrap-heap, with the machine that sprays shit in your eyes and the machine that spreads caviar on roads.
Ok, but maybe the relevant actors are very committed to being wrong about whether unaligned superintelligence would be a great thing to deploy. Or maybe you think the situation is less immediately dire and building existentially risky AI really would be good for the people making decisions (e.g. because the costs won’t arrive for a while, and the people care a lot about a shot at scientific success relative to a chunk of the future). If the apparent economic incentives are large, are technologies unavoidable?
Extremely valuable technologies
It doesn’t look like it to me. Here are a few technologies which I’d guess have substantial economic value, where research progress or uptake appears to be drastically slower than it could be, for reasons of concern about safety or ethics3:
- Huge amounts of medical research, including really important medical research e.g. The FDA banned human trials of strep A vaccines from the 70s to the 2000s, in spite of 500,000 global deaths every year. A lot of people also died while covid vaccines went through all the proper trials.
- Nuclear energy
- Fracking
- Various genetics things: genetic modification of foods, gene drives, early recombinant DNA researchers famously organized a moratorium and then ongoing research guidelines including prohibition of certain experiments (see the Asilomar Conference)
- Nuclear, biological, and maybe chemical weapons (or maybe these just aren’t useful)
- Various human reproductive innovation: cloning of humans, genetic manipulation of humans (a notable example of an economically valuable technology that is to my knowledge barely pursued across different countries, without explicit coordination between those countries, even though it would make those countries more competitive. Someone used CRISPR on babies in China, but was imprisoned for it.)
- Recreational drug development
- Geoengineering
- Much of science about humans? I recently ran this survey, and was reminded how encumbering ethical rules are for even incredibly innocuous research. As far as I could tell the EU now makes it illegal to collect data in the EU unless you promise to delete the data from anywhere that it might have gotten to if the person who gave you the data wishes for that at some point. In all, dealing with this and IRB-related things added maybe more than half of the effort of the project. Plausibly I misunderstand the rules, but I doubt other researchers are radically better at figuring them out than I am.
- There are probably examples from fields considered distasteful or embarrassing to associate with, but it’s hard as an outsider to tell which fields are genuinely hopeless versus erroneously considered so. If there are economically valuable health interventions among those considered wooish, I imagine they would be much slower to be identified and pursued by scientists with good reputations than a similarly promising technology not marred in that way. Scientific research into intelligence is more clearly slowed by stigma, but it is less clear to me what the economically valuable upshot would be.
- (I think there are many other things that could be in this list, but I don’t have time to review them at the moment. This page might collect more of them in future.)
It seems to me that intentionally slowing down progress in technologies to give time for even probably-excessive caution is commonplace. (And this is just looking at things slowed down over caution or ethics specifically—probably there are also other reasons things get slowed down.)
Furthermore, among valuable technologies that nobody is especially trying to slow down, it seems common enough for progress to be massively slowed by relatively minor obstacles, which is further evidence for a lack of overpowering strength of the economic forces at play. For instance, Fleming first took notice of mold’s effect on bacteria in 1928, but nobody took a serious, high-effort shot at developing it as a drug until 1939.4 Furthermore, in the thousands of years preceding these events, various people noticed numerous times that mold, other fungi or plants inhibited bacterial growth, but didn’t exploit this observation even enough for it not to be considered a new discovery in the 1920s. Meanwhile, people dying of infection was quite a thing. In 1930 about 300,000 Americans died of bacterial illnesses per year (around 250/100k).
My guess is that people make real choices about technology, and they do so in the face of economic forces that are feebler than commonly thought.
Restraint is not terrorism, usually
I think people have historically imagined weird things when they think of ‘slowing down AI’. I posit that their central image is sometimes terrorism (which understandably they don’t want to think about for very long), and sometimes some sort of implausibly utopian global agreement.
Here are some other things that ‘slow down AI capabilities’ could look like (where the best positioned person to carry out each one differs, but if you are not that person, you could e.g. talk to someone who is):
- Don’t actively forward AI progress, e.g. by devoting your life or millions of dollars to it (this one is often considered already)
- Try to convince researchers, funders, hardware manufacturers, institutions etc that they too should stop actively forwarding AI progress
- Try to get any of those people to stop actively forwarding AI progress even if they don’t agree with you: through negotiation, payments, public reproof, or other activistic means.
- Try to get the message to the world that AI is heading toward being seriously endangering. If AI progress is broadly condemned, this will trickle into myriad decisions: job choices, lab policies, national laws. To do this, for instance produce compelling demos of risk, agitate for stigmatization of risky actions [LW(p) · GW(p)], write science fiction illustrating the problems broadly and evocatively (I think this has actually been helpful repeatedly in the past), go on TV, write opinion pieces, help organize and empower the people who are already concerned, etc.
- Help organize the researchers who think their work is potentially omnicidal into coordinated action on not doing it.
- Move AI resources from dangerous research to other research. Move investments from projects that lead to large but poorly understood capabilities, to projects that lead to understanding these things e.g. theory before scaling (see differential technological development [EA · GW] in general5).
- Formulate specific precautions for AI researchers and labs to take in different well-defined future situations, Asilomar Conference style. These could include more intense vetting by particular parties or methods, modifying experiments, or pausing lines of inquiry entirely. Organize labs to coordinate on these.
- Reduce available compute for AI, e.g. via regulation of production and trade, seller choices, purchasing compute, trade strategy.
- At labs, choose policies that slow down other labs, e.g. reduce public helpful research outputs
- Alter the publishing system and incentives to reduce research dissemination. E.g. A journal verifies research results and releases the fact of their publication without any details, maintains records of research priority for later release, and distributes funding for participation. (This is how Szilárd and co. arranged the mitigation of 1940s nuclear research helping Germany, except I’m not sure if the compensatory funding idea was used.6)
- The above actions would be taken through choices made by scientists, or funders, or legislators, or labs, or public observers, etc. Communicate with those parties, or help them act.
Coordination is not miraculous world government, usually
The common image of coordination seems to be explicit, centralized, involving of every party in the world, and something like cooperating on a prisoners’ dilemma: incentives push every rational party toward defection at all times, yet maybe through deontological virtues or sophisticated decision theories or strong international treaties, everyone manages to not defect for enough teetering moments to find another solution.
That is a possible way coordination could be. (And I think one that shouldn’t be seen as so hopeless—the world has actually coordinated on some impressive things, e.g. nuclear non-proliferation.) But if what you want is for lots of people to coincide in doing one thing when they might have done another, then there are quite a few ways of achieving that.
Consider some other case studies of coordinated behavior:
- Not eating sand. The whole world coordinates to barely eat any sand at all. How do they manage it? It is actually not in almost anyone’s interest to eat sand, so the mere maintenance of sufficient epistemological health to have this widely recognized does the job.
- Eschewing bestiality: probably some people think bestiality is moral, but enough don’t that engaging in it would risk huge stigma. Thus the world coordinates fairly well on doing very little of it.
- Not wearing Victorian attire on the streets: this is similar but with no moral blame involved. Historic dress is arguably often more aesthetic than modern dress, but even people who strongly agree find it unthinkable to wear it in general, and assiduously avoid it except for when they have ‘excuses’ such as a special party. This is a very strong coordination against what appears to otherwise be a ubiquitous incentive (to be nicer to look at). As far as I can tell, it’s powered substantially by the fact that it is ‘not done’ and would now be weird to do otherwise. (Which is a very general-purpose mechanism.)
- Political correctness: public discourse has strong norms about what it is okay to say, which do not appear to derive from a vast majority of people agreeing about this (as with bestiality say). New ideas about what constitutes being politically correct sometimes spread widely. This coordinated behavior seems to be roughly due to decentralized application of social punishment, from both a core of proponents, and from people who fear punishment for not punishing others. Then maybe also from people who are concerned by non-adherence to what now appears to be the norm given the actions of the others. This differs from the above examples, because it seems like it could persist even with a very small set of people agreeing with the object-level reasons for a norm. If failing to advocate for the norm gets you publicly shamed by advocates, then you might tend to advocate for it, making the pressure stronger for everyone else.
These are all cases of very broadscale coordination of behavior, none of which involve prisoners’ dilemma type situations, or people making explicit agreements which they then have an incentive to break. They do not involve centralized organization of huge multilateral agreements. Coordinated behavior can come from everyone individually wanting to make a certain choice for correlated reasons, or from people wanting to do things that those around them are doing, or from distributed behavioral dynamics such as punishment of violations, or from collaboration in thinking about a topic.
You might think they are weird examples that aren’t very related to AI. I think, a) it’s important to remember the plethora of weird dynamics that actually arise in human group behavior and not get carried away theorizing about AI in a world drained of everything but prisoners’ dilemmas and binding commitments, and b) the above are actually all potentially relevant dynamics here.
If AI in fact poses a large existential risk within our lifetimes, such that it is net bad for any particular individual, then the situation in theory looks a lot like that in the ‘avoiding eating sand’ case. It’s an option that a rational person wouldn’t want to take if they were just alone and not facing any kind of multi-agent situation. If AI is that dangerous, then not taking this inferior option could largely come from a coordination mechanism as simple as distribution of good information. (You still need to deal with irrational people and people with unusual values.)
But even failing coordinated caution from ubiquitous insight into the situation, other models might work. For instance, if there came to be somewhat widespread concern that AI research is bad, that might substantially lessen participation in it, beyond the set of people who are concerned, via mechanisms similar to those described above. Or it might give rise to a wide crop of local regulation, enforcing whatever behavior is deemed acceptable. Such regulation need not be centrally organized across the world to serve the purpose of coordinating the world, as long as it grew up in different places similarly. Which might happen because different locales have similar interests (all rational governments should be similarly concerned about losing power to automated power-seeking systems with unverifiable goals), or because—as with individuals—there are social dynamics which support norms arising in a non-centralized way.
The arms race model and its alternatives
Ok, maybe in principle you might hope to coordinate to not do self-destructive things, but realistically, if the US tries to slow down, won’t China or Facebook or someone less cautious take over the world?
Let’s be more careful about the game we are playing, game-theoretically speaking.
The arms race
What is an arms race, game theoretically? It’s an iterated prisoners’ dilemma, seems to me. Each round looks something like this:

In this example, building weapons costs one unit. If anyone ends the round with more weapons than anyone else, they take all of their stuff (ten units).
In a single round of the game it’s always better to build weapons than not (assuming your actions are devoid of implications about your opponent’s actions). And it’s always better to get the hell out of this game.
This is not much like what the current AI situation looks like, if you think AI poses a substantial risk of destroying the world.
The suicide race
A closer model: as above except if anyone chooses to build, everything is destroyed (everyone loses all their stuff—ten units of value—as well as one unit if they built).

This is importantly different from the classic ‘arms race’ in that pressing the ‘everyone loses now’ button isn’t an equilibrium strategy.
That is: for anyone who thinks powerful misaligned AI represents near-certain death, the existence of other possible AI builders is not any reason to ‘race’.
But few people are that pessimistic. How about a milder version where there’s a good chance that the players ‘align the AI’?
The safety-or-suicide race
Ok, let’s do a game like the last but where if anyone builds, everything is only maybe destroyed (minus ten to all), and in the case of survival, everyone returns to the original arms race fun of redistributing stuff based on who built more than whom (+10 to a builder and -10 to a non-builder if there is one of each). So if you build AI alone, and get lucky on the probabilistic apocalypse, can still win big.
Let’s take 50% as the chance of doom if any building happens. Then we have a game whose expected payoffs are half way between those in the last two games:
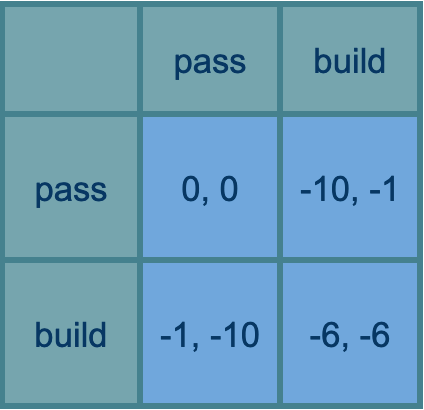
Now you want to do whatever the other player is doing: build if they’ll build, pass if they’ll pass.
If the odds of destroying the world were very low, this would become the original arms race, and you’d always want to build. If very high, it would become the suicide race, and you’d never want to build. What the probabilities have to be in the real world to get you into something like these different phases is going to be different, because all these parameters are made up (the downside of human extinction is not 10x the research costs of building powerful AI, for instance).
But my point stands: even in terms of simplish models, it’s very non-obvious that we are in or near an arms race. And therefore, very non-obvious that racing to build advanced AI faster is even promising at a first pass.
In less game-theoretic terms: if you don’t seem anywhere near solving alignment, then racing as hard as you can to be the one who it falls upon to have solved alignment—especially if that means having less time to do so, though I haven’t discussed that here—is probably unstrategic. Having more ideologically pro-safety AI designers win an ‘arms race’ against less concerned teams is futile if you don’t have a way for such people to implement enough safety to actually not die, which seems like a very live possibility. (Robby Bensinger and maybe Andrew Critch somewhere make similar points.)
Conversations with my friends on this kind of topic can go like this:
Me: there’s no real incentive to race if the prize is mutual death
Them: sure, but it isn’t—if there’s a sliver of hope of surviving unaligned AI, and if your side taking control in that case is a bit better in expectation, and if they are going to build powerful AI anyway, then it’s worth racing. The whole future is on the line!
Me: Wouldn’t you still be better off directing your own efforts to safety, since your safety efforts will also help everyone end up with a safe AI?
Them: It will probably only help them somewhat—you don’t know if the other side will use your safety research. But also, it’s not just that they have less safety research. Their values are probably worse, by your lights.
Me: If they succeed at alignment, are foreign values really worse than local ones? Probably any humans with vast intelligence at hand have a similar shot at creating a glorious human-ish utopia, no?
Them: No, even if you’re right that being similarly human gets you to similar values in the end, the other parties might be more foolish than our side, and lock-in7 some poorly thought-through version of their values that they want at the moment, or even if all projects would be so foolish, our side might have better poorly thought-through values to lock in, as well as being more likely to use safety ideas at all. Even if racing is very likely to lead to death, and survival is very likely to lead to squandering most of the value, in that sliver of happy worlds so much is at stake in whether it is us or someone else doing the squandering!
Me: Hmm, seems complicated, I’m going to need paper for this.
The complicated race/anti-race
Here is a spreadsheet of models you can make a copy of and play with.
The first model is like this:
- Each player divides their effort between safety and capabilities
- One player ‘wins’, i.e. builds ‘AGI’ (artificial general intelligence) first.
- P(Alice wins) is a logistic function of Alice’s capabilities investment relative to Bob’s
- Each players’ total safety is their own safety investment plus a fraction of the other’s safety investment.
- For each player there is some distribution of outcomes if they achieve safety, and a set of outcomes if they do not, which takes into account e.g. their proclivities for enacting stupid near-term lock-ins.
- The outcome is a distribution over winners and states of alignment, each of which is a distribution of worlds (e.g. utopia, near-term good lock-in..)
- That all gives us a number of utils (Delicious utils!)
The second model is the same except that instead of dividing effort between safety and capabilities, you choose a speed, and the amount of alignment being done by each party is an exogenous parameter.
These models probably aren’t very good, but so far support a key claim I want to make here: it’s pretty non-obvious whether one should go faster or slower in this kind of scenario—it’s sensitive to a lot of different parameters in plausible ranges.
Furthermore, I don’t think the results of quantitative analysis match people’s intuitions here.
For example, here’s a situation which I think sounds intuitively like a you-should-race world, but where in the first model above, you should actually go as slowly as possible (this should be the one plugged into the spreadsheet now):
- AI is pretty safe: unaligned AGI has a mere 7% chance of causing doom, plus a further 7% chance of causing short term lock-in of something mediocre
- Your opponent risks bad lock-in: If there’s a ‘lock-in’ of something mediocre, your opponent has a 5% chance of locking in something actively terrible, whereas you’ll always pick good mediocre lock-in world (and mediocre lock-ins are either 5% as good as utopia, -5% as good)
- Your opponent risks messing up utopia: In the event of aligned AGI, you will reliably achieve the best outcome, whereas your opponent has a 5% chance of ending up in a ‘mediocre bad’ scenario then too.
- Safety investment obliterates your chance of getting to AGI first: moving from no safety at all to full safety means you go from a 50% chance of being first to a 0% chance
- Your opponent is racing: Your opponent is investing everything in capabilities and nothing in safety
- Safety work helps others at a steep discount: your safety work contributes 50% to the other player’s safety
Your best bet here (on this model) is still to maximize safety investment. Why? Because by aggressively pursuing safety, you can get the other side half way to full safety, which is worth a lot more than than the lost chance of winning. Especially since if you ‘win’, you do so without much safety, and your victory without safety is worse than your opponent’s victory with safety, even if that too is far from perfect.
So if you are in a situation in this space, and the other party is racing, it’s not obvious if it is even in your narrow interests within the game to go faster at the expense of safety, though it may be.
These models are flawed in many ways, but I think they are better than the intuitive models that support arms-racing. My guess is that the next better still models remain nuanced.
Other equilibria and other games
Even if it would be in your interests to race if the other person were racing, ‘(do nothing, do nothing)’ is often an equilibrium too in these games. At least for various settings of the parameters. It doesn’t necessarily make sense to do nothing in the hope of getting to that equilibrium if you know your opponent to be mistaken about that and racing anyway, but in conjunction with communicating with your ‘opponent’, it seems like a theoretically good strategy.
This has all been assuming the structure of the game. I think the traditional response to an arms race situation is to remember that you are in a more elaborate world with all kinds of unmodeled affordances, and try to get out of the arms race.
Being friends with risk-takers
Caution is cooperative
Another big concern is that pushing for slower AI progress is ‘defecting’ against AI researchers who are friends of the AI safety community.
For instance Steven Byrnes [LW(p) · GW(p)]:
“I think that trying to slow down research towards AGI through regulation would fail, because everyone (politicians, voters, lobbyists, business, etc.) likes scientific research and technological development, it creates jobs, it cures diseases, etc. etc., and you’re saying we should have less of that. So I think the effort would fail, and also be massively counterproductive by making the community of AI researchers see the community of AGI safety / alignment people as their enemies, morons, weirdos, Luddites, whatever.”
(Also a good example of the view criticized earlier, that regulation of things that create jobs and cure diseases just doesn’t happen.)
Or Eliezer Yudkowsky, on worry that spreading fear about AI would alienate top AI labs:
This is the primary reason I didn't, and told others not to, earlier connect the point about human extinction from AGI with AI labs. Kerry has correctly characterized the position he is arguing against, IMO. I myself estimate the public will be toothless vs AGI lab heads.
— Eliezer Yudkowsky (@ESYudkowsky) August 4, 2022
I don’t think this is a natural or reasonable way to see things, because:
- The researchers themselves probably don’t want to destroy the world. Many of them also actually agree that AI is a serious existential risk. So in two natural ways, pushing for caution is cooperative with many if not most AI researchers.
- AI researchers do not have a moral right to endanger the world, that someone would be stepping on by requiring that they move more cautiously. Like, why does ‘cooperation’ look like the safety people bowing to what the more reckless capabilities people want, to the point of fearing to represent their actual interests, while the capabilities people uphold their side of the ‘cooperation’ by going ahead and building dangerous AI? This situation might make sense as a natural consequence of different people’s power in the situation. But then don’t call it a ‘cooperation’, from which safety-oriented parties would be dishonorably ‘defecting’ were they to consider exercising any power they did have.
It could be that people in control of AI capabilities would respond negatively to AI safety people pushing for slower progress. But that should be called ‘we might get punished’ not ‘we shouldn’t defect’. ‘Defection’ has moral connotations that are not due. Calling one side pushing for their preferred outcome ‘defection’ unfairly disempowers them by wrongly setting commonsense morality against them.
At least if it is the safety side. If any of the available actions are ‘defection’ that the world in general should condemn, I claim that it is probably ‘building machines that will plausibly destroy the world, or standing by while it happens’.
(This would be more complicated if the people involved were confident that they wouldn’t destroy the world and I merely disagreed with them. But about half of surveyed researchers are actually more pessimistic than me. And in a situation where the median AI researcher thinks the field has a 5-10% chance of causing human extinction, how confident can any responsible person be in their own judgment that it is safe?)
On top of all that, I worry that highlighting the narrative that wanting more cautious progress is defection is further destructive, because it makes it more likely that AI capabilities people see AI safety people as thinking of themselves as betraying AI researchers, if anyone engages in any such efforts. Which makes the efforts more aggressive. Like, if every time you see friends, you refer to it as ‘cheating on my partner’, your partner may reasonably feel hurt by your continual desire to see friends, even though the activity itself is innocuous.
‘We’ are not the US, ‘we’ are not the AI safety community
“If ‘we’ try to slow down AI, then the other side might win.” “If ‘we’ ask for regulation, then it might harm ‘our’ relationships with AI capabilities companies.” Who are these ‘we’s? Why are people strategizing for those groups in particular?
Even if slowing AI were uncooperative, and it were important for the AI Safety community to cooperate with the AI capabilities community, couldn’t one of the many people not in the AI Safety community work on it?
I have a longstanding irritation with thoughtless talk about what ‘we’ should do, without regard for what collective one is speaking for. So I may be too sensitive about it here. But I think confusions arising from this have genuine consequences.
I think when people say ‘we’ here, they generally imagine that they are strategizing on behalf of, a) the AI safety community, b) the USA, c) themselves or d) they and their readers. But those are a small subset of people, and not even obviously the ones the speaker can most influence (does the fact that you are sitting in the US really make the US more likely to listen to your advice than e.g. Estonia? Yeah probably on average, but not infinitely much.) If these naturally identified-with groups don’t have good options, that hardly means there are no options to be had, or to be communicated to other parties. Could the speaker speak to a different ‘we’? Maybe someone in the ‘we’ the speaker has in mind knows someone not in that group? If there is a strategy for anyone in the world, and you can talk, then there is probably a strategy for you.
The starkest appearance of error along these lines to me is in writing off the slowing of AI as inherently destructive of relations between the AI safety community and other AI researchers. If we grant that such activity would be seen as a betrayal (which seems unreasonable to me, but maybe), surely it could only be a betrayal if carried out by the AI safety community. There are quite a lot of people who aren’t in the AI safety community and have a stake in this, so maybe some of them could do something. It seems like a huge oversight to give up on all slowing of AI progress because you are only considering affordances available to the AI Safety Community.
Another example: if the world were in the basic arms race situation sometimes imagined, and the United States would be willing to make laws to mitigate AI risk, but could not because China would barge ahead, then that means China is in a great place to mitigate AI risk. Unlike the US, China could propose mutual slowing down, and the US would go along. Maybe it’s not impossible to communicate this to relevant people in China.
An oddity of this kind of discussion which feels related is the persistent assumption that one’s ability to act is restricted to the United States. Maybe I fail to understand the extent to which Asia is an alien and distant land where agency doesn’t apply, but for instance I just wrote to like a thousand machine learning researchers there, and maybe a hundred wrote back, and it was a lot like interacting with people in the US.
I’m pretty ignorant about what interventions will work in any particular country, including the US, but I just think it’s weird to come to the table assuming that you can essentially only affect things in one country. Especially if the situation is that you believe you have unique knowledge about what is in the interests of people in other countries. Like, fair enough I would be deal-breaker-level pessimistic if you wanted to get an Asian government to elect you leader or something. But if you think advanced AI is highly likely to destroy the world, including other countries, then the situation is totally different. If you are right, then everyone’s incentives are basically aligned.
I more weakly suspect some related mental shortcut is misshaping the discussion of arms races in general. The thought that something is a ‘race’ seems much stickier than alternatives, even if the true incentives don’t really make it a race. Like, against the laws of game theory, people sort of expect the enemy to try to believe falsehoods, because it will better contribute to their racing. And this feels like realism. The uncertain details of billions of people one barely knows about, with all manner of interests and relationships, just really wants to form itself into an ‘us’ and a ‘them’ in zero-sum battle. This is a mental shortcut that could really kill us.
My impression is that in practice, for many of the technologies slowed down for risk or ethics, mentioned in section ‘Extremely valuable technologies’ above, countries with fairly disparate cultures have converged on similar approaches to caution. I take this as evidence that none of ethical thought, social influence, political power, or rationality are actually very siloed by country, and in general the ‘countries in contest’ model of everything isn’t very good.
Notes on tractability
Convincing people doesn’t seem that hard
When I say that ‘coordination’ can just look like popular opinion punishing an activity, or that other countries don’t have much real incentive to build machines that will kill them, I think a common objection is that convincing people of the real situation is hopeless. The picture seems to be that the argument for AI risk is extremely sophisticated and only able to be appreciated by the most elite of intellectual elites—e.g. it’s hard enough to convince professors on Twitter, so surely the masses are beyond its reach, and foreign governments too.
This doesn’t match my overall experience on various fronts.
Some observations:
- The median surveyed ML researcher seems to think AI will destroy humanity with 5-10% chance, as I mentioned
- Often people are already intellectually convinced [LW · GW] but haven’t integrated that into their behavior, and it isn’t hard to help them organize to act on their tentative beliefs
- As noted by Scott, a lot of AI safety people have gone into AI capabilities including running AI capabilities orgs, so those people presumably consider AI to be risky already
- I don’t remember ever having any trouble discussing AI risk with random strangers. Sometimes they are also fairly worried (e.g. a makeup artist at Sephora gave an extended rant about the dangers of advanced AI, and my driver in Santiago excitedly concurred and showed me Homo Deus open on his front seat). The form of the concerns are probably a bit different from those of the AI Safety community, but I think broadly closer to, ‘AI agents are going to kill us all’ than ‘algorithmic bias will be bad’. I can’t remember how many times I have tried this, but pre-pandemic I used to talk to Uber drivers a lot, due to having no idea how to avoid it. I explained AI risk to my therapist recently, as an aside regarding his sense that I might be catastrophizing, and I feel like it went okay, though we may need to discuss again.
- My impression is that most people haven’t even come into contact with the arguments that might bring one to agree precisely with the AI safety community. For instance, my guess is that a lot of people assume that someone actually programmed modern AI systems, and if you told them that in fact they are random connections jiggled in an gainful direction unfathomably many times, just as mysterious to their makers, they might also fear misalignment.
- Nick Bostrom, Eliezer Yudkokwsy, and other early thinkers have had decent success at convincing a bunch of other people to worry about this problem, e.g. me. And to my knowledge, without writing any compelling and accessible account of why one should do so that would take less than two hours to read.
- I arrogantly think I could write a broadly compelling and accessible case for AI risk
My weak guess is that immovable AI risk skeptics are concentrated in intellectual circles near the AI risk people, especially on Twitter, and that people with less of a horse in the intellectual status race are more readily like, ‘oh yeah, superintelligent robots are probably bad’. It’s not clear that most people even need convincing that there is a problem, though they don’t seem to consider it the most pressing problem in the world. (Though all of this may be different in cultures I am more distant from, e.g. in China.) I’m pretty non-confident about this, but skimming survey evidence suggests there is substantial though not overwhelming public concern about AI in the US8.
Do you need to convince everyone?
I could be wrong, but I’d guess convincing the ten most relevant leaders of AI labs that this is a massive deal, worth prioritizing, actually gets you a decent slow-down. I don’t have much evidence for this.
Buying time is big
You probably aren’t going to avoid AGI forever, and maybe huge efforts will buy you a couple of years.9 Could that even be worth it?
Seems pretty plausible:
- Whatever kind of other AI safety research or policy work people were doing could be happening at a non-negligible rate per year. (Along with all other efforts to make the situation better—if you buy a year, that’s eight billion extra person years of time, so only a tiny bit has to be spent usefully for this to be big. If a lot of people are worried, that doesn’t seem crazy.)
- Geopolitics just changes pretty often. If you seriously think a big determiner of how badly things go is inability to coordinate with certain groups, then every year gets you non-negligible opportunities for the situation changing in a favorable way.
- Public opinion can change a lot quickly. If you can only buy one year, you might still be buying a decent shot of people coming around and granting you more years. Perhaps especially if new evidence is actively avalanching in—people changed their minds a lot in February 2020.
- Other stuff happens over time. If you can take your doom today or after a couple of years of random events happening, the latter seems non-negligibly better in general.
It is also not obvious to me that these are the time-scales on the table. My sense is that things which are slowed down by regulation or general societal distaste are often slowed down much more than a year or two, and Eliezer’s stories presume that the world is full of collectives either trying to destroy the world or badly mistaken about it, which is not a foregone conclusion.
Delay is probably finite by default
While some people worry that any delay would be so short as to be negligible, others seem to fear that if AI research were halted, it would never start again and we would fail to go to space or something. This sounds so wild to me that I think I’m missing too much of the reasoning to usefully counterargue.
Obstruction doesn’t need discernment
Another purported risk of trying to slow things down is that it might involve getting regulators involved, and they might be fairly ignorant about the details of futuristic AI, and so tenaciously make the wrong regulations. Relatedly, if you call on the public to worry about this, they might have inexacting worries that call for impotent solutions and distract from the real disaster.
I don’t buy it. If all you want is to slow down a broad area of activity, my guess is that ignorant regulations do just fine at that every day (usually unintentionally). In particular, my impression is that if you mess up regulating things, a usual outcome is that many things are randomly slower than hoped. If you wanted to speed a specific thing up, that’s a very different story, and might require understanding the thing in question.
The same goes for social opposition. Nobody need understand the details of how genetic engineering works for its ascendancy to be seriously impaired by people not liking it. Maybe by their lights it still isn’t optimally undermined yet, but just not liking anything in the vicinity does go a long way.
This has nothing to do with regulation or social shaming specifically. You need to understand much less about a car or a country or a conversation to mess it up than to make it run well. It is a consequence of the general rule that there are many more ways for a thing to be dysfunctional than functional: destruction is easier than creation.
Back at the object level, I tentatively expect efforts to broadly slow down things in the vicinity of AI progress to slow down AI progress on net, even if poorly aimed.
Safety from speed, clout from complicity
Maybe it’s actually better for safety to have AI go fast at present, for various reasons. Notably:
- Implementing what can be implemented as soon as possible probably means smoother progress, which is probably safer because a) it makes it harder for one party shoot ahead of everyone and gain power, and b) people make better choices all around if they are correct about what is going on (e.g. they don’t put trust in systems that turn out to be much more powerful than expected).
- If the main thing achieved by slowing down AI progress is more time for safety research, and safety research is more effective when carried out in the context of more advanced AI, and there is a certain amount of slowing down that can be done (e.g. because one is in fact in an arms race but has some lead over competitors), then it might better to use one’s slowing budget later.
- If there is some underlying curve of potential for progress (e.g. if money that might be spent on hardware just grows a certain amount each year), then perhaps if we push ahead now that will naturally require they be slower later, so it won’t affect the overall time to powerful AI, but will mean we spend more time in the informative pre-catastrophic-AI era.
- (More things go here I think)
And maybe it’s worth it to work on capabilities research at present, for instance because:
- As a researcher, working on capabilities prepares you to work on safety
- You think the room where AI happens will afford good options for a person who cares about safety
These all seem plausible. But also plausibly wrong. I don’t know of a decisive analysis of any of these considerations, and am not going to do one here. My impression is that they could basically all go either way.
I am actually particularly skeptical of the final argument, because if you believe what I take to be the normal argument for AI risk—that superhuman artificial agents won’t have acceptable values, and will aggressively manifest whatever values they do have, to the sooner or later annihilation of humanity—then the sentiments of the people turning on such machines seem like a very small factor, so long as they still turn the machines on. And I suspect that ‘having a person with my values doing X’ is commonly overrated. But the world is messier than these models, and I’d still pay a lot to be in the room to try.
Moods and philosophies, heuristics and attitudes
It’s not clear what role these psychological characters should play in a rational assessment of how to act, but I think they do play a role, so I want to argue about them.
Technological choice is not luddism
Some technologies are better than others [citation not needed]. The best pro-technology visions should disproportionately involve awesome technologies and avoid shitty technologies, I claim. If you think AGI is highly likely to destroy the world, then it is the pinnacle of shittiness as a technology. Being opposed to having it into your techno-utopia is about as luddite as refusing to have radioactive toothpaste there. Colloquially, Luddites are against progress if it comes as technology.10 Even if that’s a terrible position, its wise reversal is not the endorsement of all ‘technology’, regardless of whether it comes as progress.
Non-AGI visions of near-term thriving
Perhaps slowing down AI progress means foregoing our own generation’s hope for life-changing technologies. Some people thus find it psychologically difficult to aim for less AI progress (with its real personal costs), rather than shooting for the perhaps unlikely ‘safe AGI soon’ scenario.
I’m not sure that this is a real dilemma. The narrow AI progress we have seen already—i.e. further applications of current techniques at current scales—seems plausibly able to help a lot with longevity and other medicine for instance. And to the extent AI efforts could be focused on e.g. medically relevant narrow systems over creating agentic scheming gods, it doesn’t sound crazy to imagine making more progress on anti-aging etc as a result (even before taking into account the probability that the agentic scheming god does not prioritize your physical wellbeing as hoped). Others disagree with me here.
Robust priors vs. specific galaxy-brained models
There are things that are robustly good in the world, and things that are good on highly specific inside-view models and terrible if those models are wrong. Slowing dangerous tech development seems like the former, whereas forwarding arms races for dangerous tech between world superpowers seems more like the latter.11 There is a general question of how much to trust your reasoning and risk the galaxy-brained plan.12 But whatever your take on that, I think we should all agree that the less thought you have put into it, the more you should regress to the robustly good actions. Like, if it just occurred to you to take out a large loan to buy a fancy car, you probably shouldn’t do it because most of the time it’s a poor choice. Whereas if you have been thinking about it for a month, you might be sure enough that you are in the rare situation where it will pay off.
On this particular topic, it feels like people are going with the specific galaxy-brained inside-view terrible-if-wrong model off the bat, then not thinking about it more.
Cheems mindset/can’t do attitude
Suppose you have a friend, and you say ‘let’s go to the beach’ to them. Sometimes the friend is like ‘hell yes’ and then even if you don’t have towels or a mode of transport or time or a beach, you make it happen. Other times, even if you have all of those things, and your friend nominally wants to go to the beach, they will note that they have a package coming later, and that it might be windy, and their jacket needs washing. And when you solve those problems, they will note that it’s not that long until dinner time. You might infer that in the latter case your friend just doesn’t want to go to the beach. And sometimes that is the main thing going on! But I think there are also broader differences in attitudes: sometimes people are looking for ways to make things happen, and sometimes they are looking for reasons that they can’t happen. This is sometimes called a ‘cheems attitude’, or I like to call it (more accessibly) a ‘can’t do attitude’.
My experience in talking about slowing down AI with people is that they seem to have a can’t do attitude. They don’t want it to be a reasonable course: they want to write it off.
Which both seems suboptimal, and is strange in contrast with historical attitudes to more technical problem-solving. (As highlighted in my dialogue from the start of the post.)
It seems to me that if the same degree of can’t-do attitude were applied to technical safety, there would be no AI safety community because in 2005 Eliezer would have noticed any obstacles to alignment and given up and gone home.
To quote a friend on this, what would it look like if we *actually tried*?
Conclusion
This has been a miscellany of critiques against a pile of reasons I’ve met for not thinking about slowing down AI progress. I don’t think we’ve seen much reason here to be very pessimistic about slowing down AI, let alone reason for not even thinking about it.
I could go either way on whether any interventions to slow down AI in the near term are a good idea. My tentative guess is yes, but my main point here is just that we should think about it.
A lot of opinions on this subject seem to me to be poorly thought through, in error, and to have wrongly repelled the further thought that might rectify them. I hope to have helped a bit here by examining some such considerations enough to demonstrate that there are no good grounds for immediate dismissal. There are difficulties and questions, but if the same standards for ambition were applied here as elsewhere, I think we would see answers and action.
Acknowledgements
Thanks to Adam Scholl, Matthijs Maas, Joe Carlsmith, Ben Weinstein-Raun, Ronny Fernandez, Aysja Johnson, Jaan Tallinn, Rick Korzekwa, Owain Evans, Andrew Critch, Michael Vassar, Jessica Taylor, Rohin Shah, Jeffrey Heninger, Zach Stein-Perlman, Anthony Aguirre, Matthew Barnett, David Krueger, Harlan Stewart, Rafe Kennedy, Nick Beckstead, Leopold Aschenbrenner, Michaël Trazzi, Oliver Habryka, Shahar Avin, Luke Muehlhauser, Michael Nielsen, Nathan Young and quite a few others for discussion and/or encouragement.
Notes
1 I haven’t heard this in recent times, so maybe views have changed. An example of earlier times: Nick Beckstead, 2015: “One idea we sometimes hear is that it would be harmful to speed up the development of artificial intelligence because not enough work has been done to ensure that when very advanced artificial intelligence is created, it will be safe. This problem, it is argued, would be even worse if progress in the field accelerated. However, very advanced artificial intelligence could be a useful tool for overcoming other potential global catastrophic risks. If it comes sooner—and the world manages to avoid the risks that it poses directly—the world will spend less time at risk from these other factors….
I found that speeding up advanced artificial intelligence—according to my simple interpretation of these survey results—could easily result in reduced net exposure to the most extreme global catastrophic risks…”
2 This is closely related to Bostrom’s Technological completion conjecture: “If scientific and technological development efforts do not effectively cease, then all important basic capabilities that could be obtained through some possible technology will be obtained.” (Bostrom, Superintelligence, pp. 228, Chapter 14, 2014)
Bostrom illustrates this kind of position (though apparently rejects it; from Superintelligence, found here [EA · GW]): “Suppose that a policymaker proposes to cut funding for a certain research field, out of concern for the risks or long-term consequences of some hypothetical technology that might eventually grow from its soil. She can then expect a howl of opposition from the research community. Scientists and their public advocates often say that it is futile to try to control the evolution of technology by blocking research. If some technology is feasible (the argument goes) it will be developed regardless of any particular policymaker’s scruples about speculative future risks. Indeed, the more powerful the capabilities that a line of development promises to produce, the surer we can be that somebody, somewhere, will be motivated to pursue it. Funding cuts will not stop progress or forestall its concomitant dangers.”
This kind of thing is also discussed by Dafoe and Sundaram, Maas & Beard
3 (Some inspiration from Matthijs Maas’ spreadsheet, from Paths Untaken, and from GPT-3.)
4 From a private conversation with Rick Korzekwa, who may have read https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1139110/ and an internal draft at AI Impacts, probably forthcoming.
5 More here [EA · GW] and here [? · GW]. I haven’t read any of these, but it’s been a topic of discussion for a while.
6 “To aid in promoting secrecy, schemes to improve incentives were devised. One method sometimes used was for authors to send papers to journals to establish their claim to the finding but ask that publication of the papers be delayed indefinitely.26,27,28,29 Szilárd also suggested offering funding in place of credit in the short term for scientists willing to submit to secrecy and organizing limited circulation of key papers.30” – Me, previously
7 ‘Lock-in’ of values is the act of using powerful technology such as AI to ensure that specific values will stably control the future.
8 And also in Britain:
‘This paper discusses the results of a nationally representative survey of the UK population on their perceptions of AI…the most common visions of the impact of AI elicit significant anxiety. Only two of the eight narratives elicited more excitement than concern (AI making life easier, and extending life). Respondents felt they had no control over AI’s development, citing the power of corporations or government, or versions of technological determinism. Negotiating the deployment of AI will require contending with these anxieties.’
9 Or so worries Eliezer Yudkowsky—
In MIRI announces new “Death With Dignity” strategy [LW · GW]:
- “… this isn’t primarily a social-political problem, of just getting people to listen. Even if DeepMind listened, and Anthropic knew, and they both backed off from destroying the world, that would just mean Facebook AI Research destroyed the world a year(?) later.”
In AGI Ruin: A List of Lethalities [LW · GW]:
- “We can’t just “decide not to build AGI” because GPUs are everywhere, and knowledge of algorithms is constantly being improved and published; 2 years after the leading actor has the capability to destroy the world, 5 other actors will have the capability to destroy the world. The given lethal challenge is to solve within a time limit, driven by the dynamic in which, over time, increasingly weak actors with a smaller and smaller fraction of total computing power, become able to build AGI and destroy the world. Powerful actors all refraining in unison from doing the suicidal thing just delays this time limit – it does not lift it, unless computer hardware and computer software progress are both brought to complete severe halts across the whole Earth. The current state of this cooperation to have every big actor refrain from doing the stupid thing, is that at present some large actors with a lot of researchers and computing power are led by people who vocally disdain all talk of AGI safety (eg Facebook AI Research). Note that needing to solve AGI alignment only within a time limit, but with unlimited safe retries for rapid experimentation on the full-powered system; or only on the first critical try, but with an unlimited time bound; would both be terrifically humanity-threatening challenges by historical standards individually.”
10 I’d guess real Luddites also thought the technological changes they faced were anti-progress, but in that case were they wrong to want to avoid them?
11 I hear this [EA · GW] is an elaboration on this theme, but I haven’t read it.
12 Leopold Aschenbrenner partly defines ‘Burkean Longtermism’ thus: “We should be skeptical of any radical inside-view schemes to positively steer the long-run future, given the froth of uncertainty about the consequences of our actions.”
182 comments
Comments sorted by top scores.
comment by CarlShulman · 2022-12-22T23:36:06.907Z · LW(p) · GW(p)
If the balance of opinion of scientists and policymakers (or those who had briefly heard arguments) was that AI catastrophic risk is high, and that this should be a huge social priority, then you could do a lot of things. For example, you could get budgets of tens of billions of dollars for interpretability research, the way governments already provide tens of billions of dollars of subsidies to strengthen their chip industries. Top AI people would be applying to do safety research in huge numbers. People like Bill Gates and Elon Musk who nominally take AI risk seriously would be doing stuff about it, and Musk could have gotten more traction when he tried to make his case to government.
My perception based on many areas of experience is that policymakers and your AI expert survey respondents on the whole think that these risks are too speculative and not compelling enough to outweigh the gains from advancing AI rapidly (your survey respondents state those are much more likely than the harms). In particular, there is much more enthusiasm for the positive gains from AI than your payoff matrix suggests (particularly among AI researchers), and more mutual fear (e.g. the CCP does not want to be overthrown and subjected to trials for crimes against humanity as has happened to some other regimes, and the rest of the world does not want to live under oppressive CCP dictatorship indefinitely).
But you're proposing that people worried about AI disaster should leapfrog smaller asks of putting a substantial portion of the effort going into accelerating AI into risk mitigation, which we haven't been able to achieve because of low buy-in on the case for risk, to far more costly and demanding asks (on policymakers' views, which prioritize subsidizing AI capabilities and geopolitical competition already). But if you can't get the smaller more cost-effective asks because you don't have buy-in on your risk model, you're going to achieve even less by focusing on more extravagant demands with much lower cost-effectiveness that require massive shifts to make a difference (adding $1B to AI safety annual spending is a big multiplier from the current baseline, removing $1B from semiconductor spending is a miniscule proportional decrease).
When your view is the minority view you have to invest in scientific testing to evaluate your view and make the truth more credible, and better communication. You can't get around failure to convince the world of a problem by just making more extravagant and politically costly demands about how to solve it. It's like climate activists in 1950 responding to difficulties passing funds for renewable energy R&D or a carbon tax by proposing that the sale of automobiles be banned immediately. It took a lot of scientific data, solidification of scientific consensus, and communication/movement-building over time to get current measures on climate change, and the most effective measures actually passed have been ones that minimized pain to the public (and opposition), like supporting the development of better solar energy.
Another analogy in biology: if you're worried about engineered pandemics and it's a struggle to fund extremely cost-effective low-hanging fruit in pandemic prevention, it's not a better strategy to try to ban all general-purpose biomedical technology research.
↑ comment by habryka (habryka4) · 2022-12-23T07:26:00.090Z · LW(p) · GW(p)
I think this comment is overstating the case for policymakers and the electorate actually believing that investing in AI is good for the world. I think the answer currently is "we don't know what policymakers and the electorate actually want in relation to AI" as well as "the relationship of policymakers and the electorate is in the middle of shifting quite rapidly, so past actions are not that predictive of future actions".
I really only have anecdata to go on (though I don't think anyone has much better), but my sense from doing informal polls of e.g. Uber drivers, people on Twitter, and perusing a bunch of Subreddits (which, to be clear, is a terrible sample) is that indeed a pretty substantial fraction of the world is now quite afraid of the consequences of AI, both in a "this change is happening far too quickly and we would like it to slow down" sense, and in a "yeah, I am actually worried about killer robots killing everyone" sense. I think both of these positions are quite compatible with pushing for a broad slow down. There is also a very broad and growing "anti-tech" movement that is more broadly interested in giving less resources to the tech sector, whose aims are at least for a long while compatible with slowing down AGI progress.
My current guess is that policies that are primarily aimed at slowing down and/or heavily regulating AI research are actually pretty popular among the electorate, and I also expect them to be reasonably popular among policymakers, though I also expect their preferences to lag behind the electorate for a while. But again, I really think we don't know, and nobody has run even any basic surveys on the topic yet.
Edit: Inspired by this topic/discussion, I ended up doing some quick google searches for AI opinion polls. I didn't find anything great, but this Pew report has some stuff that's pretty congruent with potential widespread support for AI regulation: https://www.pewresearch.org/internet/2022/03/17/how-americans-think-about-artificial-intelligence/

↑ comment by Zach Stein-Perlman · 2022-12-23T09:24:50.720Z · LW(p) · GW(p)
I ended up doing some quick google searches for AI opinion polls
I collected such polls here, if you want to see more. Most people say they want to regulate AI.
↑ comment by CarlShulman · 2022-12-23T14:52:55.118Z · LW(p) · GW(p)
I agree there is some weak public sentiment in this direction (with the fear of AI takeover being weaker). Privacy protections and redistribution don't particularly favor measures to avoid AI apocalypse.
I'd also mention this YouGov survey:
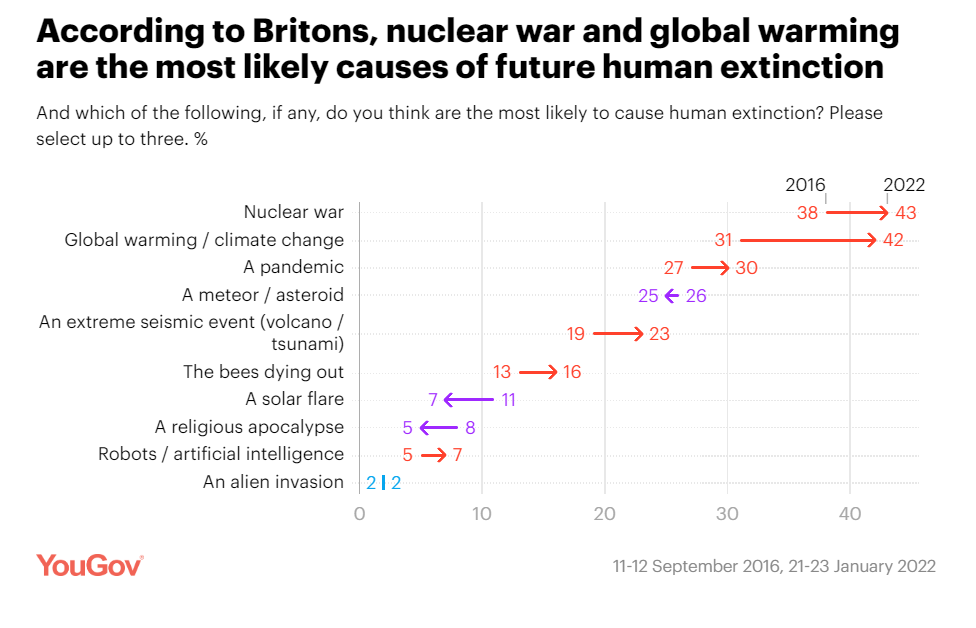
But the sentiment looks weak compared to e.g. climate change and nuclear war, where fossil fuel production and nuclear arsenals continue, although there are significant policy actions taken in hopes of avoiding those problems. The sticking point is policymakers and the scientific community. At the end of the Obama administration the President asked scientific advisors what to make of Bostrom's Superintelligence, and concluded not to pay attention to it because it was not an immediate threat. If policymakers and their advisors and academia and the media think such public concerns are confused, wrongheaded, and not politically powerful they won't work to satisfy them against more pressing concerns like economic growth and national security. This is a lot worse than the situation for climate change, which is why it seems better regulation requires that the expert and elite debate play out differently, or the hope that later circumstances such as dramatic AI progress drastically change views (in favor of AI safety, not the central importance of racing to AI).
Replies from: Kaj_Sotala, peter_hurford↑ comment by Kaj_Sotala · 2022-12-23T19:24:40.743Z · LW(p) · GW(p)
But the sentiment looks weak compared to e.g. climate change and nuclear war, where fossil fuel production and nuclear arsenals continue,
That seems correct to me, but on the other hand, I think the public sentiment against things like GMOs was also weaker than the one that we currently have against climate change, and GMOs got slowed down regardless. Also I'm not sure how strong the sentiment against nuclear power was relative to the one against climate change, but in any case, nuclear power got hindered quite a bit too.
I think one important aspect where fossil fuels are different from GMOs and nuclear power is that fossil fuel usage is firmly entrenched across the economy and it's difficult, costly, and slow to replace it. Whereas GMOs were a novel thing and governments could just decide to regulate them and slow them down without incurring major immediate costs. As for nuclear power, it was somewhat entrenched in that there were many existing plants, but society could make the choice to drastically reduce the progress of building new ones - which it did.
Nuclear arsenals don't quite fit this model - in principle, one could have stopped expanding them, but they did keep growing for quite a bit, despite public opposition. Then again, there was an arms race dynamic there. And eventually, nuclear arsenals got cut down in size too.
I think AI is in a sense comparable to nuclear power and GMOs in that there are existing narrow AI applications that would be hard and costly to get rid of, but more general and powerful AI is clearly not yet entrenched due to not having been developed yet. On the other hand, AI labs have a lot of money and there are lots of companies that have significant investments in AI R&D, so that's some level of entrenchment.
Whether nuclear weapons are comparable to AI depends on whether you buy the arguments in the OP for them being different... but seems also relevant that AI arms race arguments are often framed as the US vs. China. That seems reasonable enough, given that the West could probably find consensus on AI as it has found on other matters of regulation, Russia does not seem to be in a shape to compete, and the rest of the world isn't really on the leading edge of AI development. And now it seems like China might not even particularly care about AI [1 [LW(p) · GW(p)], 2 [LW(p) · GW(p)]].
↑ comment by Peter Wildeford (peter_hurford) · 2022-12-25T23:07:11.399Z · LW(p) · GW(p)
I'll shill here and say that Rethink Priorities is pretty good at running polls of the electorate if anyone wants to know what a representative sample of Americans think about a particular issue such as this one. No need to poll Uber drivers or Twitter when you can do the real thing!
Replies from: CarlShulman, Stefan_Schubert↑ comment by CarlShulman · 2022-12-26T00:21:19.288Z · LW(p) · GW(p)
I'd very much like to see this done with standard high-quality polling techniques, e.g. while airing counterarguments (like support for expensive programs that looks like majority but collapses if higher taxes to pay for them is mentioned). In particular, how the public would react given different views coming from computer scientists/government commissions/panels.
↑ comment by Stefan_Schubert · 2022-12-26T10:16:40.813Z · LW(p) · GW(p)
I think that could be valuable.
It might be worth testing quite carefully for robustness - to ask multiple different questions probing the same issue, and see whether responses converge. My sense is that people's stated opinions about risks from artificial intelligence, and existential risks more generally, could vary substantially depending on framing. Most haven't thought a lot about these issues, which likely contributes. I think a problem problem with some studies on these issues is that researchers over-generalise from highly framing-dependent survey responses.
Replies from: peter_hurford↑ comment by Peter Wildeford (peter_hurford) · 2022-12-26T15:14:32.616Z · LW(p) · GW(p)
That makes a lot of sense. We can definitely test a lot of different framings. I think the problem with a lot of these kinds of problems is that they are low saliency, and thus people tend not to have opinions already, and thus they tend to generate an opinion on the spot. We have a lot of experience polling on low saliency issues though because we've done a lot of polling on animal farming policy which has similar framing effects.
Replies from: habryka4, Stefan_Schubert↑ comment by habryka (habryka4) · 2022-12-27T02:33:55.478Z · LW(p) · GW(p)
I would definitely vote in favor of a grant to do this on the LTFF, as well as the SFF, and might even be interested in backstopping it with my personal funds or Lightcone funds.
Replies from: peter_hurford↑ comment by Peter Wildeford (peter_hurford) · 2022-12-27T17:21:30.076Z · LW(p) · GW(p)
Cool - I'll follow up when I'm back at work.
↑ comment by Stefan_Schubert · 2022-12-26T20:36:26.053Z · LW(p) · GW(p)
I think that's exactly right.
↑ comment by MichaelA · 2023-01-07T13:06:33.762Z · LW(p) · GW(p)
I found this thread interesting and useful, but I feel a key point has been omitted thus far (from what I've read):
- Public, elite, and policymaker beliefs and attitudes related to AI risk aren't just a variable we (members of the EA/longtermist/AI safety communities) have to bear in mind and operate in light of, but instead also a variable we can intervene on.
- And so far I'd say we have (often for very good reasons) done significantly less to intervene on that variable than we could've or than we could going forward.
- So it seems plausible that actually these people are fairly convincible if exposed to better efforts to really explain the arguments in a compelling way.
We've definitely done a significant amount of this kind of work, but I think we've often (a) deliberately held back on doing so or on conveying key parts of the arguments, due to reasonable downside risk concerns, and (b) not prioritized this. And I think there's significantly more we could do if we wanted to, especially after a period of actively building capacity for this.
Important caveats / wet blankets:
- I think there are indeed strong arguments against trying to shift relevant beliefs and attitudes in a more favorable direction, including not just costs and plausibly low upside but also multiple major plausible downside risks.[1]
- So I wouldn't want anyone to take major steps in this direction without checking in with multiple people working on AI safety/governance first.
- And it's not at all obvious to me we should be doing more of that sort of work. (Though I think whether, how, & when we should is an important question and I'm aware of and excited about a couple small research projects that are happening on that.)
All I really want to convey in this comment is what I said in my first paragraph: we may be able to significantly push beliefs and opinions in favorable directions relative to where they are now or would be n future by default.
- ^
Due to time constraints, I'll just point to this vague overview.
↑ comment by jessicata (jessica.liu.taylor) · 2022-12-24T20:45:58.459Z · LW(p) · GW(p)
I think I would have totally agreed in 2016. One update since then is that I think progress scales way less than resources than I used to think it did. In many historical cases, a core component of progress driven by a small number of people (which is reflected in citation counts, who is actually taught in textbooks), and introducing lots of funding and scaling too fast can disrupt that by increasing the amount of fake work.
$1B in safety well-spent is clearly more impactful than $1B less in semiconductors, it's just that "well-spent" is doing a lot of work, someone with a lot of money is going to have lots of people trying to manipulate their information environment to take their stuff.
Reducing especially dangerous tech progress seems more promising than reducing tech broadly, however since these are dual use techs, creating knowledge about which techs are dangerous can accelerate development in these sectors (especially the more vice signalling / conflict orientation is going on). This suggests that perhaps an effective way to apply this strategy is to recruit especially productive researchers (identified using asymmetric info) to labs where they work on something less dangerous.
In gain of function research and nuclear research, progress requires large expensive laboratories; AI theory progress doesn't require that, although large scale training does (though, to a lesser extent than GOF or nuclear).
↑ comment by Remmelt (remmelt-ellen) · 2022-12-23T02:16:55.093Z · LW(p) · GW(p)
There are plenty of movements out there (ethics & inclusion, digital democracy, privacy, etc.) who are against current directions of AI developments, and they don’t need the AGI risk argument to be convinced that current corporate scale-up of AI models is harmful.
Working with them, redirecting AI developments away from more power-consolidating/general AI may not be that much harder than investing in supposedly “risk-mitigating” safety research.
Replies from: CarlShulman↑ comment by CarlShulman · 2022-12-23T03:09:09.088Z · LW(p) · GW(p)
Do you think there is a large risk of AI systems killing or subjugating humanity autonomously related to scale-up of AI models?
A movement pursuing antidiscrimination or privacy protections for applications of AI that thinks the risk of AI autonomously destroying humanity is nonsense seems like it will mainly demand things like the EU privacy regulations, not bans on using $10B of GPUs instead of $10M in a model. It also seems like it wouldn't pursue measures targeted at the kind of disaster it denies, and might actively discourage them (this sometimes happens already). With a threat model of privacy violations restrictions on model size would be a huge lift and the remedy wouldn't fit the diagnosis in a way that made sense to policymakers. So I wouldn't expect privacy advocates to bring them about based on their past track record, particularly in China where privacy and digital democracy have not had great success.
If it in fact is true that there is a large risk of almost everyone alive today being killed or subjugated by AI, then establishing that as scientific consensus seems like it would supercharge a response dwarfing current efforts for things like privacy rules, which would aim to avert that problem rather than deny it and might manage such huge asks, including in places like China. On the other hand, if the risk is actually small, then it won't be possible to scientifically demonstrate high risk, and it would play a lesser role in AI policy.
I don't see a world where it's both true the risk is large and knowledge of that is not central to prospects for success with such huge political lifts.
↑ comment by Remmelt (remmelt-ellen) · 2022-12-23T12:14:43.352Z · LW(p) · GW(p)
A movement pursuing antidiscrimination or privacy protections for applications of AI that thinks the risk of AI autonomously destroying humanity is nonsense seems like it will mainly demand things like the EU privacy regulations, not bans on using $10B of GPUs instead of $10M in a model".
I can imagine there being movements that fit this description, in which case I would not focus on talking with them or talking about them.
But I have not been in touch with any movements matching this description. Perhaps you could share specific examples of actions from specific movements you have in mind?
For the movements I have in mind (and am talking with), the description does not match at all:
- AI ethics and inclusion movements go a lot further than stopping people from building AI that eg. make discriminatory classifications/recommendations associated with marginalised communities – they want Western corporations to stop consolidating power through AI development and deployment while pushing their marginalised communities further out of the loop (rendering them voiceless).
- Digital democracy groups and human-centric AI movements go a lot further than wanting to regulate AI – they want to relegate AI models humble models in the background that can assist and interface between humans building consensus and making decisions in the foreground.
- Privacy and data ownership movements go a lot further than wanting current EU regulations – they do not want models to be trained on, store and exploit their own data in model parameters without their permission.
Suggest reading writings by people in those movements. Let me also copy over excerpts from people active in the areas of AI ethics & inclusion and digital democracy:
- "We also advocate for a re-alignment of research goals: Where much effort has been allocated to making models (and their training data) bigger and to achieving ever higher scores on leaderboards often featuring artificial tasks, we believe there is more to be gained by focusing on understanding how machines are achieving the tasks in question and how they will form part of socio-technical systems." from paper co-authored by Timnit Gebru.
- "Rationalists are like most of the ideological groups I interact with. They are allies in important projects, such as limiting the race for massive investments in “AI” capabilities and engaging in governance experimentation. In other projects, such as limiting the social power/hubris of SV and diversifying it along a variety of dimensions they are more likely adversaries or at least unlikely allies." from post by Glen Weyl.
Do you think there is a large risk of AI systems killing or subjugating humanity autonomously related to scale-up of AI models?
Yes, I do. And the movements I am in touch with are against corporate R&D labs scaling up AI models in the careless ways they've been doing so far.
Are you taking a stance here of "those outside movements have different explicit goals than us AI Safety researchers, and therefore cannot become goal-aligned with our efforts"?
In that case, I would disagree here.
Theoretically, I disagree with the ontological and meta-ethical assumptions that these claims would be based on. While objective goals expressed here are disjunctive, the underlying values are additive (I do not expect this statement to make sense for you; please skip to next point).
Practically, movements with various explicit goals are already against corporations (that are selected by markets to extract value from local communities) centrally scaling up the training of increasingly autonomous/power-seeking models. Some examples:
- re: AI ethics and inclusion:
The Stochastic Parrots paper co-authored by Timnit Gebru (before Google AI managers let her go, so to speak), describes various reasons for slowing down the scaled training of (language) transformer models. These reasons include the environmental costs of compute, neglecting to curate training data carefully, and the failure to co-design with stakeholders affected. All reasons to not scale up AI models fast.- Note that I have not read any writings from Gebru that "AGI risk" is not a thing. More the question of why people are then diverting resources to AGI-related research while assuming that the development general AI is inevitable and beyond our control.
- re: Digital democracy and human-centric AI:
The How AI Fails Us paper (see p5) argues against the validity of and further investment in the "centralization of capital and decision-making capacity under the direction of a small group of engineers of AI systems" where "the machine is independent from human input and oversight" and with "the target of “achieving general intelligence”". How does this not match up with arguing against "subjugating humanity autonomously [with the centralised] scale-up of AI models"?
People like Divya Siddarth, Glen Weyl, Audrey Tang, Jaron Lanier and Daron Acemoglu have repeatedly expressed their concerns about how current automation of work through AI models threatens the empowerment of humans in their work, creativity, and collective choice-making.
Weyl is also skeptical about the monolithic conception of "AGI" surpassing humans across some metrics. I disagree in that generally-capable self-learning/modifying machinery are physically possible. I agree in that monolithic oversimplified representations of AGI have allowed AI Safety researchers to make unsound presumptive claims about how they expect that machinery could be "aligned" in "principle.- As an example, you mentioned how governments could invest tens of billions of dollars in interpretability research. I touched on reasons here [LW · GW] why interpretability research does not and cannot contribute top long-term AGI safety. Based on that, government-funded in interpretability research would distract smart AI researchers from actually contributing, and lend false confidence to AGI researchers that AGI could be interpreted sufficiently. Ie. this is "align-washing" the harmful activities by AI corporations, analogous to green-washing the harmful activities of fossil-fuel corporations.
- As another example, your idea of Von Neuman Probes with error correcting codes, referred to by Christiano here [AF(p) · GW(p)], cannot soundly work for AGI code (as self-learning new code for processing inputs into outputs, and as introducing errors through interactions with the environment that cannot be detected and corrected). This is overdetermined. An ex-Pentagon engineer has spelled out the reasons to me. See a one-page summary by me here.
- re: Privacy and data ownership:
If privacy and data ownership movements take their own claims seriously (and some do), they would push for banning the training of ML models on human-generated data or any sensor-based surveillance that can be used to track humans' activities.
With a threat model of privacy violations restrictions on model size would be a huge lift and the remedy wouldn't fit the diagnosis in a way that made sense to policymakers. So I wouldn't expect privacy advocates to bring them about based on their past track record, particularly in China where privacy and digital democracy have not had great success.
What do you mean here with a "huge lift"?
Koen Holtman has been involved with internet privacy movements for decades. Let me ping him in case he wants to share thoughts on what went wrong there in Europe/ and in China.
↑ comment by CarlShulman · 2022-12-23T15:46:01.861Z · LW(p) · GW(p)
I agree that some specific leaders you cite have expressed distaste for model scaling, but it seems not to be a core concern. In a choice between more politically feasible measures that target concerns they believe are real vs concerns they believe are imaginary and bad, I don't think you get the latter. And I think arguments based on those concerns get traction on measures addressing the concerns, but less so on secondary wishlist items of leaders .
I think that's the reason privacy advocacy in legislation and the like hasn't focused on banning computers in the past (and would have failed if they tried). For example:
If privacy and data ownership movements take their own claims seriously (and some do), they would push for banning the training of ML models on human-generated data or any sensor-based surveillance that can be used to track humans' activities.
AGI working with AI generated data or data shared under the terms and conditions of web services can power the development of highly intelligent catastrophically dangerous systems, and preventing AI from reading published content doesn't seem close to the core motives there, especially for public support on privacy. So taking the biggest asks they can get based on privacy arguments I don't think blocks AGI.
People like Divya Siddarth, Glen Weyl, Audrey Tang, Jaron Lanier and Daron Acemoglu have repeatedly expressed their concerns about how current automation of work through AI models threatens the empowerment of humans in their work, creativity, and collective choice-making.
It looks this kind of concern at scale naturally goes towards things like compensation for creators (one of Lanier's recs), UBI, voting systems, open-source AI, and such.
Jaron Lanier has written a lot dismissing the idea of AGI or work to address it. I've seen a lot of such dismissal from Glen Weyl. Acemoglu I don't think wants to restrict AI development? I don't know Siddarth or Tang's work well.
Note that I have not read any writings from Gebru that "AGI risk" is not a thing. More the question of why people are then diverting resources to AGI-related research while assuming that the development general AI is inevitable and beyond our control.
They're definitely living in a science fiction world where everyone who wants to save humanity has to work on preventing the artificial general intelligence (AGI) apocalypse...Agreed but if that urgency is in direction of “we need to stop evil AGI & LLMs are AGI” then it does the opposite by distracting from types of harms perpetuated & shielding those who profit from these models from accountability. I’m seeing a lot of that atm (not saying from you)...What’s the open ai rationale here? Clearly it’s not the same as mine, creating a race for larger & larger models to output hateful stuff? Is it cause y’all think they have “AGI”?...Is artificial general intelligence (AGI) apocalypse in that list? Cause that's what him and his cult preach is the most important thing to focus on...The thing is though our AGI superlord is going to make all of these things happen once its built (any day now) & large language models are a way to get to it...Again, this movement has so much of the $$ going into "AI safety." You shouldn't worry about climate change as much as "AGI" so its most important to work on that. Also what Elon Musk was saying around 2015 when he was backing of Open AI & was yapping about "AI" all the time.
That reads to me as saying concerns about 'AGI apocalypse' are delusional nonsense but pursuit of a false dream of AGI incidentally cause harms like hateful AI speech through advancing weaker AI technology, while the delusions should not be an important priority.
What do you mean here with a "huge lift"?
I gave the example of barring model scaling above a certain budget.
I touched on reasons here [LW · GW] why interpretability research does not and cannot contribute top long-term AGI safety.
I disagree extremely strongly with that claim. It's prima facie absurd to think that, e.g. that using interpretability tools to discover that AI models were plotting to overthrow humanity would not help to avert that risk. For instance, that's exactly the kind of thing that would enable a moratorium on scaling and empowering those models to improve the situationn.
As another example, your idea of Von Neuman Probes with error correcting codes, referred to by Christiano here [LW(p) · GW(p)], cannot soundly work for AGI code (as self-learning new code for processing inputs into outputs, and as introducing errors through interactions with the environment that cannot be detected and corrected). This is overdetermined. An ex-Pentagon engineer has spelled out the reasons to me. See a one-page summary by me here.
This is overstating what role error-correcting codes play in that argument. They mean the same programs can be available and evaluate things for eons (and can evaluate later changes with various degrees of learning themselves), but don't cover all changes that could derive from learning (although there are other reasons why those could be stable in preserving good or terrible properties).
Replies from: remmelt-ellen, remmelt-ellen, remmelt-ellen, remmelt-ellen↑ comment by Remmelt (remmelt-ellen) · 2022-12-23T17:33:19.785Z · LW(p) · GW(p)
I intend to respond to the rest tomorrow.
Some of your interpretations of writings by Timnit Gebru and Glen Weyl seem fair to me (though would need to ask them to confirm). I have not look much into Jaron Lanier’s writings on AGI so that prompts me to google that.
Perhaps you can clarify the other reasons why the changes in learning would be stable in preserving “good properties”? I’ll respond to your nuances regarding how to interpret your long-term-evaluating error correcting code after that.
↑ comment by Remmelt (remmelt-ellen) · 2022-12-24T14:12:54.682Z · LW(p) · GW(p)
re: Leaders of movements being skeptical of the notion of AGI.
Reflecting more, my impression is that Timnit Gebru is skeptical about the sci-fiy descriptions of AGI, and even more so about the social motives of people working on developing (safe) AGI. She does not say that AGI is an impossible concept or not actually a risk. She seems to question the overlapping groups of white male geeks who have been diverting efforts away from other societal issues, to both promoting AGI development and warning of AGI x-risks.
Regarding Jaron Lanier, yes, (re)reading this post I agree that he seems to totally dismiss the notion of AGI, seeing it more a result of a religious kind of thinking under which humans toil away at offering the training data necessary for statistical learning algorithms to function without being compensated.
↑ comment by Remmelt (remmelt-ellen) · 2022-12-24T13:40:01.911Z · LW(p) · GW(p)
Returning on error correction point:
Feel free to still clarify the other reasons why the changes in learning would be stable in preserving “good properties”. Then I will take that starting point to try explain why the mutually reinforcing dynamics of instrumental convergence and substrate-needs convergence override that stability.
Fundamentally though, we'll still be discussing the application limits of error correction methods.
Three ways to explain why:
- Any workable AI-alignment method involves receiving input signals, comparing input signals against internal references, and outputting corrective signals to maintain alignment of outside states against those references (ie. error correction).
- Any workable AI-alignment method involves a control feedback loop – of detecting the actual (or simulating the potential) effects internally and then correcting actual (or preventing the potential) effects externally (ie. error correction).
- Eg. mechanistic interpretability is essentially about "detecting the actual (or simulating the potential) effects internally" of AI.
- The only way to actually (slightly) counteract AGI convergence on causing "instrumental" and "needed" effects within a more complex environment is to simulate/detect and then prevent/correct those environmental effects (ie. error correction).
~ ~ ~
Which brings us back to why error correction methods, of any kind and in any combination, cannot ensure long-term AGI Safety.
I reread your original post and Christiano's comment [LW(p) · GW(p)] to understand your reasoning better and see how I could limits of applicability of error correction methods.
I also messaged Forrest (the polymath) to ask for his input.
The messages were of a high enough quality that I won't bother rewriting the text. Let me copy-paste the raw exchange below (with few spelling edits).
Remmelt 15:37
@Forrest, would value your thoughts on the way Carl Schulman is thinking about error correcting code, perhaps to pass on on the LessWrong Forum:
(https://www.lesswrong.com/posts/uFNgRumrDTpBfQGrs/let-s-think-about-slowing-down-ai?commentId=bY87i5v5StH9FWdWy [LW(p) · GW(p)]).
Remmelt 15:38
Remmelt:
"As another example [of unsound monolithic reasoning], your idea of Von Neuman Probes with error correcting codes, referred to by Christiano here (https://www.lesswrong.com/posts/LpM3EAakwYdS6aRKf/what-multipolar-failure-looks-like-and-robust-agent-agnostic?commentId=Jaf9b9YAARYdrK3jp [LW(p) · GW(p)]), cannot soundly work for AGI code (as self-learning new code for processing inputs into outputs, and as introducing errors through interactions with the environment that cannot be detected and corrected). This is overdetermined. An ex-Pentagon engineer has spelled out the reasons to me. See a one-page summary by me here."
Carl Shulman:
"This is overstating what role error-correcting codes play in that argument. They mean the same programs can be available and evaluate things for eons (and can evaluate later changes with various degrees of learning themselves), but don't cover all changes that could derive from learning (although there are other reasons why those could be stable in preserving good or terrible properties)."
Remmelt 15:40
Excerpting from the comment by Christiano I link to above:
"The production-web has no interest in ensuring that its members value production above other ends, only in ensuring that they produce (which today happens for instrumental reasons). If consequentialists within the system intrinsically value production it's either because of single-single alignment failures (i.e. someone who valued production instrumentally delegated to a system that values it intrinsically) or because of new distributed consequentialism distinct from either the production web itself or any of the actors in it, but you don't describe what those distributed consequentialists are like or how they come about.
You might say: investment has to converge to 100% since people with lower levels of investment get outcompeted. But this it seems like the actual efficiency loss required to preserve human values seems very small even over cosmological time (e.g. see Carl on exactly this question: http://reflectivedisequilibrium.blogspot.com/2012/09/spreading-happiness-to-stars-seems.html).
And more pragmatically, such competition most obviously causes harm either via a space race and insecure property rights, or war between blocs with higher and lower savings rates (some of them too low to support human life, which even if you don't buy Carl's argument is really still quite low, conferring a tiny advantage). If those are the chief mechanisms then it seems important to think/talk about the kinds of agreements and treaties that humans (or aligned machines acting on their behalf!) would be trying to arrange in order to avoid those wars."
Remmelt 15:41
And Carl Schulman's original post on long-term error-correcting Von Neumann Probes:
(http://reflectivedisequilibrium.blogspot.com/2012/09/spreading-happiness-to-stars-seems.html):
"But the program of an AI, large stores of astronomical observations for navigation, and vast stores of technological information would take up an enormous amount of memory and storage space, perhaps many exabytes or more. Given this large body of information, adding additional directives to ensure that the probes eventually turn to producing welfare need only increase storage needs by a very small proportion, e.g. by 1 in 1 billion. Directives could directly specify the criteria to be eventually optimized, or could simply require compliance with further orders traveling behind the frontier of colonization.
...
Mutation is easier to resist for computers than animals
Biological life on Earth has evolved through mutation, and the reproductive process introduces significant errors in each generation. However, digital information storage allows for the comparison of redundant copies and the use of error-correcting codes, making substantive mutation many orders of magnitude less likely than in Earthly life."
Remmelt 15:45
Returning to the new comment by Carl Schulman:
"This is overstating what role error-correcting codes play in that argument. They mean the same programs can be available and evaluate things for eons (and can evaluate later changes with various degrees of learning themselves)"
Remmelt 15:46
Thinking about this overnight, I think Carl's stated reasoning is still unsound for multiple reasons:
1. Contradiction between a Von Neummann Probe being adaptable enough (ie. learning new ways of processing inputs into outputs) to travel across space and seed new civilisations, yet have error correcting code that allows comparison of new code with original redundant copies. Not going to work, for reasons Forrest amply explained and I tried to summarise here: https://docs.google.com/document/d/1-AAhqvgFNx_MlLkcSgw-chvmFoC4EZ4LmTl1IWcsqEA/edit
Ooh, and in Forrest's AGI Error Correction post: https://mflb.com/ai_alignment_1/agi_error_correction_psr.html#p1
Think I'll share that.
Remmelt 15:54
2. Confuses complicated pre-loaded technological knowledge/systems with complex adaptive systems. The fact that they are saying that adding in directives would only increase storage by 1 part in 1 billion parts is a giveaway, I think.
Remmelt 15:55
3. Inverse take on 1.
Algorithms which can flexibly 'mutate' and branch out into different versions become better at using resources and multiplying than more rigid or robustly functional designs. This makes Carl Schulman's case for launching out self-replicating space probes with code error-checking/minimisation routines seem a lot more dicey. If a defecting group launches even one alternate design with a flexible code-mutating ability that confers an advantage that can't easily be copied by the error-minimising designs without compromising on their ability to act on the directives humans originally coded in to 'directly specify the criteria to be eventually optimized' – well, then you might end up instead with swarms of spaceprobes that eat up the galaxy indiscriminately, including any remaining carbon-based lifeforms on planet Earth.
Underlying premise: even if humans construct a long-term aligned AI design – where humans can formally prove a model to causally constrain any possible process of agency emerging from and expanding across each of the physical parts in which this model infers its computational process to be embedded to stay within all fundamental bounds necessary for maintaining alignment with the values that humans broadly share in common – then in practice that design is ‘one step away’ from getting mutated into misalignment by a faction of humans who seek a capability advantage (does it give one though?) for manifesting their more granular personal values.
Remmelt 15:57
@Forrest anything to add to the above? How about I write that into a comment reply (which perhaps might make for a stand-alone post later?)
Forrest 16:25
The starting point is: That any procedure of AGI alignment will
(Ie, cannot not) resemble some sort of error correction algorithm
Forrest 16:28
This point cannot be disagreed with and still have the notion of alignment be persistent. If they argue here, they will need to establish a conformable coherent counter example. Simple contradiction is not enough, as the claim basis shifts to them.
Forrest 16:30
Once hard line equivalence is firmly established, then the argument re limits of causation in all error correction processes apply.
Remmelt 16:44
Good one. So start with how any AGI-alignment method must resemble an error correction algorithm in order to correct out misaligned behaviour learned and expressed in interaction with the environment.
Forrest 16:48
In regards to the idea that some machine could "have a strategy of optimizing for near-maximum X until condition Z is achieved, and *then* implement directive Q" makes at least three assumptions that are highly unlikely.
1; there is no assurance that in the long duration of the optimization of X that there would be persistence of directive Q.
2; there is no assurance that the condition 'Z' is consistently detectable, or that the triggering condition is even probable to being implemented, even if detected (as per a violation of assumption 1).
3; the integration coupling of directive Q is mismatched to the sheer mass of the output of the optimized code -- ie, it is unlikely that 'Q', no matter how formed, will actually result in the consistent behavior described. Ie, 'Q' is significantly underspecified, and if 'Q' was appropriately specified, it would not be "lightweight" with respect to the optimization process 'X', and would have been optimized away to ineffectiveness. Hence, even if Z condition trigger happens, Q does not happen.
Note insofar as the logic is directly generalized over the logical claim form of "adopt a strategy of near-maximum colonization speed until they reach the most distant accessible galaxies, and only then divert resources to producing welfare", the proposal itself is not well specified. Ie, the assumption that 'Q' and detection of 'Z' can be "simple" is a conceptual category error.
Remmelt 17:02
I read through this, and think I understand your points.
Forrest 17:10
Yes. I am trying to think of a good metaphor. It is maybe a bit like some single ordinary person trying to command everyone to do something in some consistent way, when that _everyone_ is 100000 people all yelling at one another in some huge auditorium somewhere. The assumption that one person, even at maximum personal signal volume and intensity, could be heard over all similar other people (in this case, the other objectives of the Von Neumann probe), and command them to implement some new action pattern reliably consistent with 'Q', is simply deeply mismatched to the output reality of the optimization process 'X'. The single directive 'Q' is simply not powerful enough to fully conditionalize all of 'X', even under triggering conditions 'Z'.
Also, I notice that the assumptions that the error correction process could be applied linearly to a dynamic self recursive system at arbitrary levels of abstraction is simply another category error. Wrong tool for the wrong job. That is less important, though, than the issue with the Q directive arbitrarily efficient effectivity mismatch.
Forrest 17:37
Also, I added the following document to assist in some of what you are trying to do above: https://mflb.com/ai_alignment_1/tech_align_error_correct_fail_psr.html#p1
This echos something I think I sent previously, but I could not find it in another doc, so I added it.
↑ comment by Remmelt (remmelt-ellen) · 2022-12-23T17:24:28.358Z · LW(p) · GW(p)
It's prima facie absurd to think that, e.g. that using interpretability tools to discover that AI models were plotting to overthrow humanity would not help to avert that risk.
I addressed claims of similar forms at least 3 times times already on separate occasions (including in the post itself).
Suggest reading this: https://www.lesswrong.com/posts/bkjoHFKjRJhYMebXr/the-limited-upside-of-interpretability?commentId=wbWQaWJfXe7RzSCCE [LW(p) · GW(p)]
“The fact that mechanistic interpretability can possibly be used to detect a few straightforwardly detectable misalignment of the kinds you are able to imagine right now does not mean that the method can be extended to detecting/simulating most or all human-lethal dynamics manifested in/by AGI over the long term.
If AGI behaviour converges on outcomes that result in our deaths through less direct routes, it really does not matter much whether the AI researcher humans did an okay job at detecting "intentional direct lethality" and "explicitly rendered deception".”
Replies from: CarlShulman↑ comment by CarlShulman · 2022-12-24T00:59:30.921Z · LW(p) · GW(p)
This is like saying there's no value to learning about and stopping a nuclear attack from killing you because you might get absolutely no benefit from not being killed then, and being tipped off about a threat trying to kill you, because later the opponent might kill you with nanotechnology before you can prevent it.
Removing intentional deception or harm greatly increases the capability of AIs that can be worked with without getting killed, to further improve safety measures. And as I said actually being able to show a threat to skeptics is immensely better for all solutions, including relinquishment, than controversial speculation.
↑ comment by Remmelt (remmelt-ellen) · 2022-12-24T05:07:50.098Z · LW(p) · GW(p)
No, it's not like that.
It's saying that if you can prevent a doomsday device from being lethal in some ways and not in others, then it's still lethal. Focussing on some ways that you feel confident that you might be able to prevent the doomsday device from being lethal is IMO distracting dangerously from the point, which is that people should not built the doomsday device in the first place.
↑ comment by Remmelt (remmelt-ellen) · 2022-12-24T05:23:21.598Z · LW(p) · GW(p)
If mechanistic interpretability methods cannot prevent that interactions of AGI necessarily converge on total human extinction beyond theoretical limits of controllability, it means that these (or other "inspect internals") methods cannot contribute to long-term AGI safety. And this is not idle speculation, nor based on prima facie arguments. It is based on 15 years of research by a polymath working outside this community.
In that sense, it would not really matter that mechanistic interpretability can do an okay job at detecting that a power-seeking AI was explicitly plotting to overthrow humanity.
That is, except for the extremely unlikely case you pointed to that such intentions are detected and on time, and humans all coordinate at once to impose an effective moratorium on scaling or computing larger models. But this is actually speculation, whereas that OpenAI promoted Olah's fascinating Microscope-generated images as them making progress on understanding and aligning scalable ML models is not speculation.
Overall, my sense is that mechanistic interpretability is used to align-wash capability progress towards AGI, while not contributing to safety where it predominantly matters.
↑ comment by Remmelt (remmelt-ellen) · 2022-12-24T05:43:19.121Z · LW(p) · GW(p)
Removing intentional deception or harm greatly increases the capability of AIs that can be worked with without getting killed, to further improve safety measures.
Exactly this kind of thinking is what I am concerned about. It implicitly assumes that you have a (sufficiently) comprehensive and sound understanding of the ways humans would get killed at a given level of capability, and therefore can rely on that understanding to conclude that capabilities of AIs can be greatly increased without humans getting killed.
How do you think capability developers would respond to that statement? Will they just stay on the safe side, saying "Well those alignment researchers say that mechanistic interpretability helps remove intentional deception or harm, but I'm just going to stay on the safe side and not scale any further". No, they are going to use your statement to promote the potential safety of their scalable models, and remove whatever safety margin they can justify themselves taking and feel justified taking for themselves.
Not considering unknown unknowns is going to get us killed. Not considering what safety problems may be unsolvable is going to get us killed.
Age-old saying: "It ain’t what you don’t know that gets you into trouble. It’s what you know for sure that just ain’t so."
↑ comment by TW123 (ThomasWoodside) · 2022-12-24T06:15:10.807Z · LW(p) · GW(p)
Sorry if I missed it earlier in the thread, but who is this "polymath"?
Replies from: remmelt-ellen↑ comment by Remmelt (remmelt-ellen) · 2022-12-24T06:48:33.616Z · LW(p) · GW(p)
Forrest Landry.
Here is how he described himself before:
> What is your background?
> How is it relevant to the work
> you are planning to do?Years ago, we started with a strong focus on
civilization design and mitigating x-risk.
These are topics that need and require
more generalist capabilities, in many fields,
not just single specialist capabilities,
in any one single field of study or application.Hence, as generalists,
we are not specifically persons
who are career mathematicians,
nor even career physicists, chemists,
or career biologists, anthropologists,
or even career philosophers.
Yet when considering the needs
of topics civ-design and/or x-risk,
it is very abundantly clear
that some real skill and expertise
is actually needed in all of these fields.Understanding anything about x-risk
and/or civilization means needing
to understand key topics regarding
large scale institutional process,
ie; things like governments, businesses,
university, constitutional law, social
contract theory, representative process,
legal and trade agreements, etc.Yet people who study markets, economics,
and politics (theory of groups, firms, etc)
who do not also have some real grounding
in actual sociology and anthropology,
are not going to have grounding in
understanding why things happen
in the real world as they tend to do.And those people are going to need
to understand things like psychology,
developmental psych, theory of education,
interpersonal relationships, attachment,
social communication dynamics, health
of family and community, trauma, etc.And understanding *those* topics means
having a real grounding in evolutionary theory,
bio-systems, ecology, biology, neurochemestry
and neurology, ecosystem design, permaculture,
and evolutionary psychology, theory of bias, etc.It is hard to see that we would be able to assess
things like 'sociological bias' as impacting
possible mitigation strategies of x-risk,
if we do not actually also have some real
and deep, informed, and realistic accounting
of the practical implications of, in the world,
of *all* of these categories of ideas.And yet, unfortunately, that is not all,
since understanding of *those* topics themselves
means even more and deeper grounding
in things like organic and inorganic chemistry,
cell process, and the underlying *physics*
of things like that.
Which therefore includes a fairly general
understanding of multiple diverse areas of physics
(mechanical, thermal, electromagnetic, QM, etc),
and thus also of technology -- since that is
directly connected to business, social systems,
world systems infrastructure, internet,
electrical grid and energy management,
transport (for fuel, materials, etc), and
even more politics, advertising and marketing,
rhetorical process and argumentation, etc.Oh, and of course, a deep and applied
practical knowledge of 'computer science',
since nearly everything in the above
is in one way or another "done with computers".
Maybe, of course, that would also be relevant
when considering the specific category of x-risk
which happens to involve computational concepts
when thinking about artificial superintelligence.I *have* been a successful practicing engineer
in both large scale US-gov deployed software
and also in product design shipped to millions.
I have personally written more than 900,000
lines of code (mostly Ansi-C, ASM, Javascript)
and have been 'the principle architect' in a team.
I have developed my own computing environments,
languages, procedural methodologies, and
system management tactics, over multiple
process technologies in multiple applied contexts.
I have a reasonably thorough knowledge of CS.
Including the modeling math, control theory, etc.
Ie, I am legitimately "full stack" engineering
from the physics of transistors, up through
CPU design, firmware and embedded systems,
OS level work, application development,
networking, user interface design, and
the social process implications of systems.
I have similarly extensive accomplishments
in some of the other listed disciplines also.As such, as a proven "career" generalist,
I am also (though not just) a master craftsman,
which includes things like practical knowledge
of how to negotiate contracts,
write all manner documents,
make all manner of things,
*and* understand the implications
of *all* of this
in the real world, etc.For the broad category of
valid and reasonable x-risk assessment,
that nothing less than
at least some true depth
in nearly *all* of these topics,
will do.
From Math Expectations, a depersonalised post Forrest wrote of his impressions of a conversation with a grant investigator where the grant investigator kept looping back on the expectation that a "proof" based on formal reasoning must be written in mathematical notation. We did end up receiving the $170K grant.
I usually do not mention Forrest Landry's name immediately for two reasons:
- If you google his name, he comes across like a spiritual hippie. Geeks who don't understand his use of language take that as a cue that he must not know anything about computational science, mathematics or physics (wrong – Forrest has deep insights into programming methods and eg. why Bell's Theorem is a thing) .
- Forrest prefers to work on the frontiers of research, rather than repeating himself in long conversations with tech people who cannot let go off their own mental models and quickly jump to motivated counterarguments that he heard and addressed many times before. So I act as a bridge-builder, trying to translate between Forrest speak and Alignment Forum speak.
- Both of us prefer to work behind the scenes. I've only recently started to touch on the arguments in public.
- You can find those arguments elaborated on here.
Warning: large inferential distance; do message clarifying questions – I'm game!
↑ comment by Remmelt (remmelt-ellen) · 2022-12-24T05:07:12.038Z · LW(p) · GW(p)
No, it's not like that.
It's saying that if you can prevent a doomsday device from being lethal in some ways and not in others, then it's still lethal. Focussing on some ways that you feel confident that you might be able to prevent the doomsday device from being lethal is IMO distracting dangerously from the point, which is that people should not built the doomsday device in the first place.
↑ comment by Koen.Holtman · 2022-12-24T15:20:20.555Z · LW(p) · GW(p)
As requested by Remmelt I'll make some comments on the track record of privacy advocates, and their relevance to alignment.
I did some active privacy advocacy in the context of the early Internet in the 1990s, and have been following the field ever since. Overall, my assessment is that the privacy advocacy/digital civil rights community has had both failures and successes. It has not succeeded (yet) in its aim to stop large companies and governments from having all your data. On the other hand, it has been more successful in its policy advocacy towards limiting what large companies and governments are actually allowed to do with all that data.
The digital civil rights community has long promoted the idea that Internet based platforms and other computer systems must be designed and run in a way that is aligned with human values. In the context of AI and ML based computer systems, this has led to demands for AI fairness and transparency/explainability that have also found their way into policy like the GDPR, legislation in California, and the upcoming EU AI Act. AI fairness demands have influenced the course of AI research being done, e.g. there has been research on defining it even means for an AI model to be fair, and on making models that actually implement this meaning.
To a first approximation, privacy and digital rights advocates will care much more about what an ML model does, what effect its use has on society, than about the actual size of the ML model. So they are not natural allies for x-risk community initiatives that would seek a simple ban on models beyond a certain size. However, they would be natural allies for any initiative that seeks to design more aligned models, or to promote a growth of research funding in that direction.
To make a comment on the premise of the original post above: digital rights activists will likely tell you that, when it comes to interventions on AI research, speculating about the tractability of 'slowing down AI research' is misguided. What you really should be thinking about is changing the direction of AI research.
Replies from: remmelt-ellen↑ comment by Remmelt (remmelt-ellen) · 2022-12-24T15:49:11.800Z · LW(p) · GW(p)
This is insightful for me, thank you!
Also, I stand corrected then on my earlier comment on that privacy and digital ownership advocates would/should care about models being trained on their own/person-tracking data such to restrict the scaling of models. I’m guessing I was not tracking well then what people in at least the civil rights spaces Koen moves around in are thinking and would advocate for.
↑ comment by Steven Byrnes (steve2152) · 2022-12-23T13:11:24.970Z · LW(p) · GW(p)
A movement pursuing antidiscrimination or privacy protections for applications of AI that thinks the risk of AI autonomously destroying humanity is nonsense seems like it will mainly demand things like the EU privacy regulations, not bans on using $10B of GPUs instead of $10M in a model.
This is a very spicy take, but I would (weakly) guess that a hypothetical ban on ML trainings that cost more than $10M would make AGI timelines marginally shorter rather than longer, via shifting attention and energy away from scaling and towards algorithm innovation.
Replies from: sanxiyn↑ comment by sanxiyn · 2022-12-23T13:20:55.726Z · LW(p) · GW(p)
Very interesting! Recently, US started to regulate export of computing power to China. Do you expect this to speed up AGI timeline in China, or do you expect regulation to be ineffective, or something else?
Reportedly, NVIDIA developed A800, which is just A100, to keep the letter but probably not the spirit of the regulation. I am trying to follow closely how A800 fares, because it seems to be an important data point on feasibility of regulating computing power.
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2022-12-24T20:53:04.724Z · LW(p) · GW(p)
I strongly agree with Steven about this. Personally, I expect it'll be non-impactful in either direction. I think the majority of research groups already have sufficient compute available to make dangerous algorithmic progress, and they are not so compute-resource-rich that their scaling efforts are distracting them from more dangerous pursuits. I think the groups who would be more dangerous if they weren't 'resource drunk' are mainly researchers at big companies.
↑ comment by tamgent · 2022-12-23T20:44:24.596Z · LW(p) · GW(p)
I think the two camps are less orthogonal than your examples of privacy and compute reg portray. There's room for plenty of excellent policy interventions that both camps could work together to support. For instance, increasing regulatory requirements for transparency on algorithmic decision-making (and crucially, building a capacity both in regulators and in the market supporting them to enforce this) is something that I think both camps would get behind (the xrisk one because it creates demand for interpretability and more and the other because eg. it's easier to show fairness issues) and could productively work on together. I think there are subculture clash reasons the two camps don't always get on, but that these can be overcome, particularly given there's a common enemy (misaligned powerful AI). See also this paper Beyond Near- and Long-Term: Towards a Clearer Account of Research Priorities in AI Ethics and Society I know lots of people who are uncertain about how big the risks are, and care about both problems, and work on both (I am one of these - I care more about AGI risk, but I think the best things I can do to help avert it involve working with the people you think aren't helpful).
↑ comment by TekhneMakre · 2022-12-23T00:18:39.800Z · LW(p) · GW(p)
Seems reason regarding public policy. But what about
1. private funders of AGI-relevant research
2. researchers doing AGI-relevant research?
Seems like there's a lot of potential reframings that make it more feasible to separate safe-ish research from non-safe-ish research. E.g. software 2.0: we're not trying to make a General Intelligence, we're trying to replace some functions in our software with nets learned from data. This is what AlphaFold is like, and I assume is what ML for fusion energy is like. If there's a real category like this, a fair amount of the conflict might be avoidable?
↑ comment by CarlShulman · 2022-12-23T00:54:27.768Z · LW(p) · GW(p)
Most AI companies and most employees there seem not to buy risk much, and to assign virtually no resources to address those issues. Unilaterally holding back from highly profitable AI when they won't put a tiny portion of those profits into safety mitigation again looks like an ask out of line with their weak interest. Even at the few significant companies with higher percentages of safety effort, it still looks to me like the power-weighted average of staff is extremely into racing to the front, at least to near the brink of catastrophe or until governments buy risks enough to coordinate slowdown.
So asks like investing in research that could demonstrate problems with higher confidence, or making models available for safety testing, or similar still seem much easier to get from those companies than stopping (and they have reasonable concerns that their unilateral decision might make the situation worse by reducing their ability to do helpful things, while regulatory industry-wide action requires broad support).
As with government, generating evidence and arguments that are more compelling could be super valuable, but pretending you have more support than you do yields incorrect recommendations about what to try.
↑ comment by TekhneMakre · 2022-12-23T01:28:13.652Z · LW(p) · GW(p)
looks to me like the power-weighted average of staff is extremely into racing to the front, at least to near the brink of catastrophe or until governments buy risks enough to coordinate slowdown.
Can anyone say confident why? Is there one reason that predominates, or several? Like it's vaguely something about status, money, power, acquisitive mimesis, having a seat at the table... but these hypotheses are all weirdly dismissive of the epistemics of these high-powered people, so either we're talking about people who are high-powered because of the managerial revolution (or politics or something), or we're talking about researchers who are high-powered because they're given power because they're good at research. If it's the former, politics, then it makes sense to strongly doubt their epistemics on priors, but we have to ask, why can they meaningfully direct the researchers who are actually good at advancing capabilities? If it's the latter, good researchers have power, then why are their epistemics suddenly out the window here? I'm not saying their epistemics are actually good, I'm saying we have to understand why they're bad if we're going to slow down AI through this central route.
Replies from: CarlShulman↑ comment by CarlShulman · 2022-12-23T02:07:21.007Z · LW(p) · GW(p)
There are a lot of pretty credible arguments for them to try, especially with low risk estimates for AI disempowering humanity, and if their percentile of responsibility looks high within the industry.
One view is that the risk of AI turning against humanity is less than the risk of a nasty eternal CCP dictatorship if democracies relinquish AI unilaterally. You see this sort of argument made publicly by people like Eric Schmidt, and 'the real risk isn't AGI revolt, it's bad humans' is almost a reflexive take for many in online discussion of AI risk. That view can easily combine with the observation that there has been even less takeup of AI safety in China thus far than in liberal democracies, and mistrust of CCP decision-making and honesty, so it also reduces accident risk.
With respect to competition with other companies in democracies, some labs can correctly say that they have taken action that signals they are more into taking actions towards safety or altruistic values (including based on features like control by non-profit boards or % of staff working on alignment), and will have vastly more AI expertise, money, and other resources to promote those goals in the future by locally advancing AGI, e.g. OpenAI reportedly has a valuation of over $20B now and presumably more influence over the future of AI and ability to do alignment work than otherwise. Whereas some sitting on the sidelines may lack financial and technological/research influence when it is most needed. And, e.g. the OpenAI charter has this clause:
We are concerned about late-stage AGI development becoming a competitive race without time for adequate safety precautions. Therefore, if a value-aligned, safety-conscious project comes close to building AGI before we do, we commit to stop competing with and start assisting this project. We will work out specifics in case-by-case agreements, but a typical triggering condition might be “a better-than-even chance of success in the next two years.
Technical Leadership
- To be effective at addressing AGI’s impact on society, OpenAI must be on the cutting edge of AI capabilities—policy and safety advocacy alone would be insufficient.
- We believe that AI will have broad societal impact before AGI, and we’ll strive to lead in those areas that are directly aligned with our mission and expertise.
Then there are altruistic concerns about the speed of AI development. E.g. over 60 million people die every year, almost all of which could be prevented by aligned AI technologies. If you think AI risk is very low, then current people's lives would be saved by expediting development even if risk goes up some.
And of course there are powerful non-altruistic interests in enormous amounts of money, fame, and personally getting to make a big scientific discovery.
Note that the estimate of AI risk magnitude, and the feasibility of general buy-in on the correct risk level, recurs over and over again, and so credible assessments and demonstrations of large are essential to making these decisions better.
↑ comment by TekhneMakre · 2022-12-23T02:38:26.697Z · LW(p) · GW(p)
Thank you, this seems like a high-quality steelman (I couldn't judge if it passes an ITT).
↑ comment by [deleted] · 2022-12-27T18:14:13.510Z · LW(p) · GW(p)
Taking an extreme perspective here: do future generations of people not alive and who no one alive now would meet have any value?
One perspective is no they don't. From that perspective "humanity" continues only as some arbitrary random numbers from our genetics. Even Clippy probably keeps at least one copy of the human genome in a file somewhere so it's the same case.
That is, there is no difference between the outcomes of:
-
we delay AI a few generations and future generations of humanity take over the galaxy
-
we fall to rampant AIs and their superintelligent descendants take over the galaxy
If you could delay AI long enough you would be condemning the entire population of the world to death from aging, or essentially the same case where the rampant AI kills the entire world.
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2022-12-24T20:22:22.307Z · LW(p) · GW(p)
Carl S.
There are a lot of pretty credible arguments for them to try, especially with low risk estimates for AI disempowering humanity, and if their percentile of responsibility looks high within the industry.
One view is that the risk of AI turning against humanity is less than the risk of a nasty eternal CCP dictatorship if democracies relinquish AI unilaterally. You see this sort of argument made publicly by people like Eric Schmidt, and 'the real risk isn't AGI revolt, it's bad humans' is almost a reflexive take for many in online discussion of AI risk. That view can easily combine with the observation that there has been even less takeup of AI safety in China thus far than in liberal democracies, and mistrust of CCP decision-making and honesty, so it also reduces accident risk.
My thought: seems like a convincing demonstration of risk could be usefully persuasive.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2022-12-24T23:21:27.697Z · LW(p) · GW(p)
I'll make an even stronger statement: So long as the probabilities of a technological singularity isn't too low, they can still rationally keep working on it even if they know the risk is high, because the expected utility is much greater still.
↑ comment by Lukas_Gloor · 2023-01-10T18:36:51.689Z · LW(p) · GW(p)
Those are good points. There are some considerations that go in the other direction. Sometimes it's not obvious what's a "failure to convince people" vs. "a failure of some people to be convincible." (I mean convincible by object-level arguments as opposed to convincible through social cascades where a particular new view reaches critical mass.)
I believe both of the following:
- Persuasion efforts haven't been exhausted yet: we can do better at reaching not-yet-safety-concerned AI researchers. (That said, I think it's at least worth considering that we're getting close to exhausting low-hanging fruit?)
- Even so, "persuasion as the main pillar of a strategy" is somewhat likely to be massively inadequate because it's difficult to change the minds and culture of humans in general (even if they're smart), let alone existing organizations.
Another point that's maybe worth highlighting is that the people who could make large demands don't have to be the same people who are best-positioned for making smaller asks. (This is Katja's point about there not being a need for everyone to coordinate into a single "we.") The welfarism vs. abolitionism debate in animal advocacy and discussion of the radical flank effect seems related. I also agree with a point lc makes in his post on slowing down AI. He points out that there's arguably a "missing mood" around the way most people in EA and the AI alignment community communicate with safety-unconcerned researchers. The missing sense of urgency probably lowers the chance of successful persuasion efforts?
Lastly, it's a challenge that there's little consensus in the EA research community around important questions like "How hard is AI alignment?," "How hard is alignment conditional on <5 years to TAI?," and "How long are TAI timelines?" (Though maybe there's quite some agreement on the second one and the answer is at least, "it's not easy?")
I'd imagine there would at least be quite a strong EA expert consensus on the following conditional statement (which has both normative and empirical components):
Let's call it "We're in Inconvenient World" if it's true that, absent strong countermeasures, we'll have misaligned AI that brings about human extinction in <5 years. If the chance that we're in Inconvenient World is10% or higher, we should urgently make large changes to the way AI development progresses as a field/industry.
Based on this, some further questions one could try to estimate are:
- How many people (perhaps weighted by their social standing within an organization, opinion leaders, etc.) are convincible of the above conditional statement? Is it likely we could reach a critical mass?
- Doing this for any specific org (or relevant branch of government, etc.) that seems to play a central role
- What's the minimum consensus threshold for "We're in Inconvenient World?" (I.e., what percentage would be indefensibly low to believe in light of peer disagreement unless one considers oneself the world's foremost authority on the question?)
↑ comment by Noosphere89 (sharmake-farah) · 2023-02-01T18:00:34.225Z · LW(p) · GW(p)
He points out that there's arguably a "missing mood" around the way most people in EA and the AI alignment community communicate with safety-unconcerned researchers. The missing sense of urgency probably lowers the chance of successful persuasion efforts?
Sorry for responding very late, but it's basically because contra the memes, most LWers do not agree with Eliezer's views on how doomed we are. This is very much a fringe viewpoint on LW, not the mainstream.
So the missing mood is basically because most of LW doesn't share Eliezer's views on certain cruxes.
comment by Scott Alexander (Yvain) · 2022-12-22T23:33:04.846Z · LW(p) · GW(p)
Thank you, this is a good post.
My main point of disagreement is that you point to successful coordination in things like not eating sand, or not wearing weird clothing. The upside of these things is limited, but you say the upside of superintelligence is also limited because it could kill us.
But rephrase the question to "Should we create an AI that's 1% better than the current best AI?" Most of the time this goes well - you get prettier artwork or better protein folding prediction, and it doesn't kill you. So there's strong upside to building slightly better AIs, as long as you don't cross the "kills everyone" level. Which nobody knows the location of. And which (LW conventional wisdom says) most people will be wrong about.
We successfully coordinate a halt to AI advancement at the first point where more than half of the relevant coordination power agrees that the next 1% step forward is in expectation bad rather than good. But "relevant" is a tough qualifier, because if 99 labs think it's bad, and one lab thinks it's good, then unless there's some centralizing force, the one lab can go ahead and take the step. So "half the relevant coordination power" has to include either every lab agreeing on which 1% step is bad, or the agreement of lots of governments, professional organizations, or other groups that have the power to stop the single most reckless lab.
I think it's possible that we make this work, and worth trying, but that the most likely scenario is that most people underestimate the risk from AI, and so we don't get half the relevant coordination power united around stopping the 1% step that actually creates dangerous superintelligence - which at the time will look to most people like just building a mildly better chatbot with many great social returns.
Replies from: lorenzo-buonanno, Vitor, sanxiyn↑ comment by Lorenzo (lorenzo-buonanno) · 2022-12-24T08:41:04.144Z · LW(p) · GW(p)
I loved the link to the "Resisted Technological Temptations Project", for a bunch of examples of resisted/slowed technologies that are not "eating sand", and have an enormous upside: https://wiki.aiimpacts.org/doku.php?id=responses_to_ai:technological_inevitability:incentivized_technologies_not_pursued:start
- GMOs, in some countries
- Nuclear power, in some countries
- Genetic engineering of humans
- Geoengineering, many actors
- Chlorofluorocarbons, many actors, 1985-present
- Human challenge trials
- Dietary restrictions, in most (all?) human cultures [restrict much more than sand, often quite good stuff!]
I would tentatively add:
- organ donor markets (at least for kidneys)
- drug development in general (see all of Scott's posts on the FDA slowing things down, I would love to see an AIA slowing things down)
↑ comment by Vitor · 2022-12-23T17:48:30.783Z · LW(p) · GW(p)
Agreed. My main objection to the post is that it considers the involved agents to be optimizing for far future world-states. But I'd say that most people (including academics and AI lab researchers) mostly only think of the next 1% step in front of their nose. The entire game theoretic framing in the arms race etc section seems wrong to me.
↑ comment by sanxiyn · 2022-12-23T03:17:14.771Z · LW(p) · GW(p)
This seems to suggest "should we relax nuclear power regulation 1% less expensive to comply?" as a promising way to fix economics of nuclear power, and I don't buy that at all. Maybe it's different because Chernobyl happened, and the movie like The China Syndrome was made about nuclear accident?
That sounds very hopeful to me but doesn't seem true to me. It implies slowing down AI will be easy, it just needs Chernobyl-sized disaster and a good movie about it. Chernobyl disaster was nearly harmless compared to COVID-19, and even COVID-19 was hardly an existential threat. If slowing down AI is this easy we probably shouldn't waste time worrying about it before Chernobyl.
Replies from: Vitor↑ comment by Vitor · 2022-12-23T17:53:46.982Z · LW(p) · GW(p)
The difference between regulation and research is that the former has a large amount of friction, making it about as hard to push a 1% regulation through as a 10% one.
In contrast, the incremental 1% improvements in the development of capabilities is just what happens by default, as research organizations follow their charter.
comment by Andrew_Critch · 2022-12-23T23:43:20.725Z · LW(p) · GW(p)
Katja, many thanks for writing this, and Oliver, thanks for this comment [LW(p) · GW(p)] pointing out that everyday people are in fact worried about AI x-risk. Since around 2017 when I left MIRI to rejoin academia, I have been trying continually to point out that everyday people are able to easily understand the case for AI x-risk, and that it's incorrect to assume the existence of AI x-risk can only be understood by a very small and select group of people. My arguments have often been basically the same as yours here: in my case, informal conversations with Uber drivers, random academics, and people at random public social events. Plus, the argument is very simple: If things are smarter than us, they can outsmart us and cause us trouble. It's always seemed strange to say there's an "inferential gap" of substance here.
However, for some reason, the idea that people outside the LessWrong community might recognize the existence of AI x-risk — and therefore be worth coordinating with on the issue — has felt not only poorly received on LessWrong, but also fraught to even suggest. For instance, I tried to point it out in this previous post:
“Pivotal Act” Intentions: Negative Consequences and Fallacious Arguments [LW · GW]
I wrote the following, targeting multiple LessWrong-adjacent groups in the EA/rationality communities who thought "pivotal acts" with AGI were the only sensible way to reduce AI x-risk:
In fact, before you get to AGI, your company will probably develop other surprising capabilities, and you can demonstrate those capabilities to neutral-but-influential outsiders who previously did not believe those capabilities were possible or concerning. In other words, outsiders can start to help you implement helpful regulatory ideas, rather than you planning to do it all on your own by force at the last minute using a super-powerful AI system.
That particular statement was very poorly received, with a 139-karma retort from John Wentworth arguing,
What exactly is the model by which some AI organization demonstrating AI capabilities will lead to world governments jointly preventing scary AI from being built, in a world which does not actually ban gain-of-function research?
I'm not sure what's going on here, but it seems to me like the idea of coordinating with "outsiders" or placing trust or hope in judgement of "outsiders" has been a bit of taboo here, and that arguments that outsiders are dumb or wrong or can't be trusted will reliably get a lot of cheering in the form of Karma.
Thankfully, it now also seems to me that perhaps the core LessWrong team has started to think that ideas from outsiders matter more to the LessWrong community's epistemics and/or ability to get things done than previously represented, such as by including material written outside LessWrong in the 2021 LessWrong review posted just a few weeks ago, for the first time:
https://www.lesswrong.com/posts/qCc7tm29Guhz6mtf7/the-lesswrong-2021-review-intellectual-circle-expansion
I consider this a move in a positive direction, but I am wondering if I can draw the LessWrong team's attention to a more serious trend here. @Oliver, @Raemon, @Ruby, and @Ben Pace, and others engaged in curating and fostering intellectual progress on LessWrong:
Could it be that the LessWrong community, or the EA community, or the rationality community, has systematically discounted the opinions and/or agency of people outside that community, in a way that has lead the community to plan more drastic actions in the world than would otherwise be reasonable if outsiders of that community could also be counted upon to take reasonable actions?
This is a leading question, and my gut and deliberate reasoning have both been screaming "yes" at me for about 5 or 6 years straight, but I am trying to get you guys to take a fresh look at this hypothesis now, in question-form. Thanks in any case for considering it.
Replies from: habryka4, adam_scholl, daniel-kokotajlo, SaidAchmiz, steve2152, lahwran, lc, Roman Leventov↑ comment by habryka (habryka4) · 2022-12-25T20:31:58.264Z · LW(p) · GW(p)
The question feels leading enough that I don't really know how to respond. Many of these sentences sound pretty crazy to me, so I feel like I primarily want to express frustration and confusion that you assign those sentences to me or "most of the LessWrong community".
However, for some reason, the idea that people outside the LessWrong community might recognize the existence of AI x-risk — and therefore be worth coordinating with on the issue — has felt not only poorly received on LessWrong, but also fraught to even suggest. For instance, I tried to point it out in this previous post:
I think John Wentworth's question is indeed the obvious question to ask. It does really seem like our prior should be that the world will not react particularly sanely here.
I also think it's really not true that coordination has been "fraught to even suggest". I think it's been suggested all the time, and certain coordination plans seem more promising than others. Like, even Eliezer was for a long time apparently thinking that Deepmind having a monopoly on AGI development was great and something to be protected, which very much involves coordinating with people outside of the LessWrong community.
The same is true for whether "outsiders might recognize the existence of AI x-risk". Of course outsiders might recognize the existence of AI X-risk. I don't think this is uncontroversial or disputed. The question is what happens next. Many people seem to start working on AI capabilities research as the next step, which really doesn't improve things.
That particular statement was very poorly received, with a 139-karma retort from John Wentworth arguing,
I don't think your summary of how your statement was received is accurate. Your overall post has ~100 karma, so was received quite positively, and while John responded to this particular statement and was upvoted, I don't think this really reflects much of a negative judgement that specific statement.
John's question is indeed the most important question to ask about this kind of plan, and it seems correct for it to be upvoted, even if people agree with the literal sentence it is responding to (your original sentence itself was weak enough that I would be surprised if almost anyone on LW disagreed with its literal meaning, and if there is disagreement, it is with the broader implied statement of the help being useful enough to actually be worth it to have as a main-line plan and to forsake other plans that are more pivotal-act shaped).
Thankfully, it now also seems to me that perhaps the core LessWrong team has started to think that ideas from outsiders matter more to the LessWrong community's epistemics and/or ability to get things done than previously represented, such as by including material written outside LessWrong in the 2021 LessWrong review posted just a few weeks ago, for the first time:
I don't know man, I have always put a huge emphasis on reading external writing, learning from others, and doing practical concrete things in the external world. Including external material has been more of a UI question, and I've been interested in it for a long while, it just didn't reach the correct priority level (and also, I think it isn't really working this year for UI reasons, given that basically no nominated posts are externally linked posts, and it was correct for us to not try without putting in substantially more effort to make it work).
I think if anything I updated over the last few years that rederiving stuff for yourself is more important and trying to coordinate with the external world has less hope, given the extreme way the world was actively hostile to cooperation as well as epistemically highly corrupting during the pandemic. I also think the FTX situation made me think it's substantially more likely that we will get fucked over again in the future when trying to coordinate with parties that have different norms, and don't seem to care about honesty and integrity very much. I also think RLHF turning out to be the key to ChatGPT and via that OpenAI getting something like product-market fit and probably making OpenAI $10+ billion dollars in-expectation, showing that actually the "alignment " team at OpenAI had among the worst consequences of any of the teams in the org, was an update in an opposite direction to me. I think these events also made me less hopeful about the existing large LessWrong/EA/Longtermist/Rationality community as a coherent entity that can internally coordinate, but I think that overall results in a narrowing of my circle of coordination, not a widening.
I have models here, but I guess I feel like your comment is in some ways putting words in my mouth in a way that feels bad to me, and I am interested in explaining my models, but I don't this comment thread is the right context.
I think there is a real question about whether both me and others in the community have a healthy relationship to the rest of the world. I think the answer is pretty messy. I really don't think it's ideal, and indeed think it's probably quite bad, and I have a ton of different ways I would criticize what is currently happening. But I also really don't think that the current primary problem with the way the community relates to the rest of the world is underestimating the sanity of the rest of the world. I think mostly I expect us to continue to overestimate the sanity and integrity of most of the world, then get fucked over like we got fucked over by OpenAI or FTX. I think there are ways to relating to the rest of the world that would be much better, but a naive update in the direction of "just trust other people more" would likely make things worse.
Again, I think the question you are raising is crucial, and I have giant warning flags about a bunch of the things that are going on (the foremost one is that it sure really is a time to reflect on your relation to the world when a very prominent member of your community just stole 8 billion dollars of innocent people's money and committed the largest fraud since Enron), so I do think there are good and important conversations to be had here.
Replies from: wallowinmaya, Andrew_Critch, Andrew_Critch↑ comment by David Althaus (wallowinmaya) · 2023-01-06T14:29:41.892Z · LW(p) · GW(p)
I think mostly I expect us to continue to overestimate the sanity and integrity of most of the world, then get fucked over like we got fucked over by OpenAI or FTX. I think there are ways to relating to the rest of the world that would be much better, but a naive update in the direction of "just trust other people more" would likely make things worse.
[...]
Again, I think the question you are raising is crucial, and I have giant warning flags about a bunch of the things that are going on (the foremost one is that it sure really is a time to reflect on your relation to the world when a very prominent member of your community just stole 8 billion dollars of innocent people's money and committed the largest fraud since Enron), [...]
I very much agree with the sentiment of the second paragraph.
Regarding the first paragraph, my own take is that (many) EAs and rationalists might be wise to trust themselves and their allies less.[1]
The main update of the FTX fiasco (and other events I'll describe later) I'd make is that perhaps many/most EAs and rationalists aren't very good at character judgment. They probably trust other EAs and rationalists too readily because they are part of the same tribe and automatically assume that agreeing with noble ideas in the abstract translates to noble behavior in practice.
(To clarify, you personally seem to be good at character judgment, so this message is not directed at you. (I base that mostly on your comments I read about the SBF situation, big kudos for that, btw!)
It seems like a non-trivial fraction of people that joined the EA and rationalist community very early turned out to be of questionable character, and this wasn't noticed for years by large parts of the community. I have in mind people like Anissimov, Helm, Dill, SBF, Geoff Anders, arguably Vassar—these are just the known ones. Most of them were not just part of the movement, they were allowed to occupy highly influential positions. I don't know what the base rate for such people is in other movements—it's plausibly even higher—but as a whole our movements don't seem to be fantastic at spotting sketchy people quickly. (FWIW, my personal experiences with a sketchy, early EA (not on the above list) inspired this post [EA · GW].)
My own takeaway is that perhaps EAs and rationalists aren't that much better in terms of integrity than the outside world and—given that we probably have to coordinate with some people to get anything done—I'm now more willing to coordinate with "outsiders" than I was, say, eight years ago.
- ^
Though I would be hesitant to spread this message; the kinds of people who should trust themselves and their character judgment less are more likely the ones who will not take this message to heart, and vice versa.
↑ comment by Andrew_Critch · 2022-12-26T05:12:37.178Z · LW(p) · GW(p)
Thanks, Oliver. The biggest update for me here — which made your entire comment worth reading, for me — was that you said this:
I also think it's really not true that coordination has been "fraught to even suggest".
I'm surprised that you think that, but have updated on your statement at face value that you in fact do. By contrast, my experience around a bunch common acquaintances of ours has been much the same as Katja's, like this:
Some people: AI might kill everyone. We should design a godlike super-AI of perfect goodness to prevent that.
Others: wow that sounds extremely ambitious
Some people: yeah but it’s very important and also we are extremely smart so idk it could work
[Work on it for a decade and a half]
Some people: ok that’s pretty hard, we give up
Others: oh huh shouldn’t we maybe try to stop the building of this dangerous AI?
Some people: hmm, that would involve coordinating numerous people—we may be arrogant enough to think that we might build a god-machine that can take over the world and remake it as a paradise, but we aren’t delusional
In fact I think I may have even heard the world "delusional" specifically applied to people working on AI governance (though not by you) for thinking that coordination on AI regulation is possible / valuable / worth pursuing in service of existential safety.
As for the rest of your narrative of what's been happening in the world, to me it seems like a random mix of statements that are clearly correct (e.g., trying to coordinate with people who don't care about honestly or integrity will get you screwed) and other statements that seem, as you say,
pretty crazy to me,
and I agree that for the purpose of syncing world models,
I don't [think] this comment thread is the right context.
Anyway, cheers for giving me some insight into your thinking here.
↑ comment by Andrew_Critch · 2022-12-26T17:14:02.094Z · LW(p) · GW(p)
Oliver, see also this comment [LW · GW]; I tried to @ you on it, but I don't think LessWrong has that functionality?
↑ comment by Adam Scholl (adam_scholl) · 2022-12-27T18:56:47.580Z · LW(p) · GW(p)
Critch, I agree it’s easy for most people to understand the case for AI being risky. I think the core argument for concern—that it seems plausibly unsafe to build something far smarter than us—is simple and intuitive, and personally, that simple argument in fact motivates a plurality of my concern. That said:
- I think it often takes weirder, less intuitive arguments to address many common objections—e.g., that this seems unlikely to happen within our lifetimes, that intelligence far superior to ours doesn’t even seem possible, that we’re safe because software can’t affect physical reality, that this risk doesn’t seem more pressing than other risks, that alignment seems easy to solve if we just x, etc.
- It’s also remarkably easy to convince many people that aliens visit Earth on a regular basis, that the theory of evolution via natural selection is bunk, that lottery tickets are worth buying, etc. So while I definitely think some who engage with these arguments come away having good reason to believe the threat is likely, for values of “good” and “believe” and “likely” at least roughly similar those common around here, I suspect most update something more like their professed belief-in-belief, than their real expectations—and that even many who do update their real expectations do so via symmetric arguments that leave them with poor models of the threat.
These factors make me nervous about strategies that rely heavily on convincing everyday people, or people in government, to care about AI risk, for reasons I don’t think are well described as “systematically discounting their opinions/agency.” Personally, I’ve engaged a lot with people working in various corners of politics and government, and decently much with academics, and I respect and admire many of them, including in ways I rarely admire rationalists or EA’s.
(For example, by my lights, the best ops teams in government are much more competent than the best ops teams around here; the best policy wonks, lawyers, and economists are genuinely really quite smart, and have domain expertise few R/EA’s have without which it’s hard to cause many sorts of plausibly-relevant societal change; perhaps most spicily, I think academics affiliated with the Santa Fe Institute have probably made around as much progress on the alignment problem so far as alignment researchers, without even trying to, and despite being (imo) deeply epistemically confused in a variety of relevant ways).
But there are also a number of respects in which I think rationalists and EA’s tend to far outperform any other group I’m aware of—for example, in having beliefs that actually reflect their expectations, trying seriously to make sure those beliefs are true, being open to changing their mind, thinking probabilistically, “actually trying” to achieve their goals as a behavior distinct from “trying their best,” etc. My bullishness about these traits is why e.g. I live and work around here, and read this website.
And on the whole, I am bullish about this culture. But it’s mostly the relative scarcity of these and similar traits in particular, not my overall level of enthusiasm or respect for other groups, that causes me to worry they wouldn’t take helpful actions if persuaded of AI risk.
My impression is that it’s unusually difficult to figure out how to take actions that reduce AI risk without substantial epistemic skill of a sort people sometimes have around here, but only rarely have elsewhere. On my models, this is mostly because:
- There are many more ways to make the situation worse than better;
- A number of key considerations are super weird and/or terrifying, such that it's unusually hard to reason well about them;
- It seems easier for people to grok the potential importance of transformative AI, than the potential danger.
My strong prior is that, to accomplish large-scale societal change, you nearly always need to collaborate with people who disagree with you, even about critical points. And I’m sympathetic to the view that this is true here, too; I think some of it probably is. But I think the above features make this more fraught than usual, in a way that makes it easy for people who grok the (simpler) core argument for concern, but not some of the (typically more complex) ancillary considerations, to accidentally end up making the situation even worse.
Here are some examples of (what seem to me like) this happening:
- The closest thing I'm aware of to an official US government position on AI risk is described in the 2016 and 2017 National Science and Technology Council reports. I haven't read all of them, but the parts I have read struck me as a strange mix of claims like “maybe this will be a big deal, like mobile phones were,” and “maybe this will be a big deal, in the sense that life on Earth will cease to exist.” And like, I can definitely imagine explanations for this that don't much involve the authors misjudging the situation—maybe their aim was more to survey experts than describe their own views, or maybe they were intentionally underplaying the threat for fear of starting an arms race, etc. But I think my lead hypothesis is more that the authors just didn’t actually, viscerally consider that the sentences they were writing might be true, in the sense of describing a reality they might soon inhabit.
- I think rationalists and EA's tend to make this sort of mistake less often, since the “taking beliefs seriously”-style epistemic orientation common around here has the effect of making it easier for people to viscerally grasp that trend lines on graphs and so forth might actually reflect reality. (Like, one frame on EA as a whole, is “an exercise in avoiding the ‘learning about the death of a million feels like a statistic, not a tragedy’ error”). And this makes me at least somewhat more confident they won’t do dumb things upon becoming worried about AI risk, since without this epistemic skill, I think it’s easier to make critical errors like overestimating how much time we have, or underestimating the magnitude or strangeness of the threat.
- As I understand it, OpenAI is named what it is because, at least at first, its founders literally hoped to make AGI open source. (Elon Musk: “I think the best defense against the misuse of AI is to empower as many people as possible to have AI. If everyone has AI powers, then there’s not any one person or a small set of individuals who can have AI superpower.”)
- By my lights, there are unfortunately a lot of examples of rationalists and EA’s making big mistakes while attempting to reduce AI risk. But it’s at least... hard for me to imagine most of them making this one? Maybe I’m being insufficiently charitable here, but from my perspective, this just fails a really basic “wait, but then what happens next?” sanity check, that I think should have occurred to them more or less immediately, and that I suspect would have to most rationalists and EA's.
- For me, the most striking aspect of the AI Impacts [LW · GW] poll, was that all those ML researchers who reported thinking ML had a substantial chance of killing everyone, still research ML. I’m not sure why they do this; I’d guess some of them are convinced for some reason or another that working on it still makes sense, even given that. But my perhaps-uncharitable guess is that most of them actually don’t—that they don’t even have arguments which feel compelling to them that justify their actions, but that they for some reason press on anyway. This too strikes me as a sort of error R/EA’s are less likely to make.
- (When Bostrom asked Geoffrey Hinton why he still worked on AI, if he thought governments would likely use it to terrorize people, he replied, "I could give you the usual arguments, but the truth is that the prospect of discovery is too sweet").
- Sam Altman recently suggested, on the topic of whether to slow down AI, that “either we figure out how to make AGI go well or we wait for the asteroid to hit."
- Maybe he was joking, or meant "asteroid" as a stand-in for all potentially civilization-ending threats, or something? But that's not my guess, because his follow-up comment is about how we need AGI to colonize space, which makes me suspect he actually considers asteroid risk in particular a relevant consideration for deciding when to deploy advanced AI. Which if true, strikes me as... well, more confused than any comment in this thread strikes me. And it seems like the kind of error that might, for example, cause someone to start an org with the hope of reducing existential risk, that mostly just ends up exacerbating it.
Obviously our social network doesn't have a monopoly on good reasoning, intelligence, or competence, and lord knows it has plenty of its own pathologies. But as I understand it, most of the reason the rationality project exists is to help people reason more clearly about the strange, horrifying problem of AI risk. And I do think it has succeeded to some degree, such that empirically, people with less exposure to this epistemic environment far more often take actions which seem terribly harmful to me.
Replies from: Benito, sharmake-farah↑ comment by Ben Pace (Benito) · 2022-12-27T20:44:38.711Z · LW(p) · GW(p)
the best ops teams in government are much more competent than the best ops teams around here;
This is a candidate for the most surprising sentence in the whole comments section! I'd be interested in knowing more about why you believe this. One sort of thing I'd be quite interested in is things you've seen government ops teams do fast (even if they're small things, accomplishments that would surprise many of us in this thread that they could be done so quickly).
Replies from: tamgent↑ comment by tamgent · 2023-01-01T22:10:52.838Z · LW(p) · GW(p)
Recruitment - in my experience often a weeks long process from start to finish, well oiled and systematic and using all the tips from the handbook on organizational behaviour on selection, often with feedback given too. By comparison, some tech companies can take several months to hire, with lots of ad hoc decision-making, no processes around biases or conflicts of interest, and no feedback.
Happy to give more examples if you want by DM.
I should say my sample size is tiny here - I know one gov dept in depth, one tech company in depth and a handful of other tech companies and gov depts not fully from the inside but just from talking with friends that work there, etc.
↑ comment by Noosphere89 (sharmake-farah) · 2022-12-27T19:31:34.157Z · LW(p) · GW(p)
I think academics affiliated with the Santa Fe Institute have probably made around as much progress on the alignment problem so far as alignment researchers, without even trying to, and despite being (imo) deeply epistemically confused in a variety of relevant-seeming ways).
This is an important optimistic update, because it implies alignment might be quite easier than we think, given that even under unfavorable circumstances, reasonable progress still gets done.
For me, the most striking aspect of the AI Impacts poll, was that all those ML researchers who reported thinking ML had a substantial chance of someday killing everyone, still research ML. I’m not sure what’s going on with them; I’d guess some of them buy arguments such that their continued work still makes sense somehow, even given that. But my perhaps-uncharitable guess is that most of them don’t—that they don’t even have arguments which feel compelling to them that justify their actions, but that they for some reason press on anyway. This too strikes me as a sort of error R/EA’s are less likely to make.
I think that this isn't an error in rationality, and instead very different goals drive EAs/LWers compared to AI researchers. A low chance of high utility and a high chance of death is pretty rational to take, assuming you only care about yourself. And this is the default, absent additional assumptions.
From an altruistic perspective, it's insane to take this risk, especially if you care about the future.
Thus, differing goals are at play.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-12-24T11:08:37.240Z · LW(p) · GW(p)
However, for some reason, the idea that people outside the LessWrong community might recognize the existence of AI x-risk — and therefore be worth coordinating with on the issue — has felt not only poorly received on LessWrong, but also fraught to even suggest.
I object to this hyperbolic and unfair accusation. The entire AI Governance field is founded on this idea; this idea is not only fine to suggest, but completely uncontroversial accepted wisdom. That is, if by "this idea" you really mean literally what you said -- "people outside the LW community might recognize the existence of AI x-risk and be worth coordinating with on the issue." Come on.
I am frustated by what appears to me to be constant straw-manning of those who disagree with you on these matters. Just because people disagree with you doesn't mean there's a sinister bias at play. I mean, there's usually all sorts of sinister biases at play at all sides of every dispute, but the way to cut through them isn't to go around slinging insults at each other about who might be biased, it's to stay on the object level and sort through the arguments.
↑ comment by Andrew_Critch · 2022-12-24T23:41:12.990Z · LW(p) · GW(p)
This makes sense to me if you feel my comment is meant as a description of you or people-like-you. It is not, and quite the opposite. As I see it, you are not a representative member of the LessWrong community, or at least, not a representative source of the problem I'm trying to point at. For one thing, you are willing to work for OpenAI, which many (dozens of) LessWrong-adjacent people I've personally met would consider a betrayal of allegiance to "the community". Needless to say, the field of AI governance as it exists is not uncontroversially accepted by the people I am reacting to with the above complaint [LW(p) · GW(p)]. In fact, I had you in mind as a person I wanted to defend by writing the complaint, because you're willing to engage and work full-time (seemingly) in good faith with people who do not share many of the most centrally held views of "the community" in question, be it LessWrong, Effective Altruism, or the rationality community.
If it felt otherwise to you, I apologize.
Replies from: Vivek↑ comment by Vivek Hebbar (Vivek) · 2022-12-26T23:31:05.014Z · LW(p) · GW(p)
It would help if you specified which subset of "the community" you're arguing against. I had a similar reaction to your comment as Daniel did, since in my circles (AI safety researchers in Berkeley), governance tends to be well-respected, and I'd be shocked to encounter the sentiment that working for OpenAI is a "betrayal of allegiance to 'the community'".
Replies from: habryka4↑ comment by habryka (habryka4) · 2022-12-27T02:32:51.236Z · LW(p) · GW(p)
To be clear, I do think most people who have historically worked on "alignment" at OpenAI have probably caused great harm! And I do think I am broadly in favor of stronger community norms against working at AI capability companies, even in so called "safety positions". So I do think there is something to the sentiment that Critch is describing.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-01-04T15:26:30.605Z · LW(p) · GW(p)
Agreed! But the words he chose were hyperbolic and unfair. Even an angrier more radical version of Habryka would still endorse "the idea that people outside the LessWrong community might recognize the existence of AI risk."
↑ comment by Andrew_Critch · 2022-12-26T17:09:15.887Z · LW(p) · GW(p)
Separately from my other reply explaining that you are not the source of what I'm complaining about [LW(p) · GW(p)] here, I thought I'd add more color to explain why I think my assessment here is not "hyperbolic". Specifically, regarding your claim that reducing AI x-risk through coordination is "not only fine to suggest, but completely uncontroversial accepted wisdom", please see the OP. Perhaps you have not witnessed such conversations yourself, but I have been party to many of these:
Some people: AI might kill everyone. We should design a godlike super-AI of perfect goodness to prevent that.
Others: wow that sounds extremely ambitious
Some people: yeah but it’s very important and also we are extremely smart so idk it could work
[Work on it for a decade and a half]
Some people: ok that’s pretty hard, we give up
Others: oh huh shouldn’t we maybe try to stop the building of this dangerous AI?
Some people: hmm, that would involve coordinating numerous people—we may be arrogant enough to think that we might build a god-machine that can take over the world and remake it as a paradise, but we aren’t delusional
In other words, I've seen people in AI governance being called or treated as "delusional" by loads of people (1-2 dozen?) core to the LessWrong community (not you). I wouldn't say by a majority, but by an influential minority to say the least, and by more people than would be fair to call "just institution X" for any X, or "just person Y and their friends" for any Y. The pattern is strong enough that for me, pointing to governance as an approach to existential safety on LessWrong indeed feels fraught, because influential people (online or offline) will respond to the idea as "delusional" as Katja puts it. Being called delusional is stressful, and hence "fraught".
@Oliver, the same goes for your way of referring to sentences you disagree with as "crazy", such as here [LW(p) · GW(p)].
Generally speaking, on the LessWrong blog itself I've observed too many instances of people using insults in response to dissenting views on the epistemic health of the LessWrong community, and receiving applause and karma for doing so, for me to think that there's not a pattern or problem here.
That's not to say I think LessWrong has this problem worse than other online communities (i.e., using insults or treating people as 'crazy' or 'delusional' for dissenting or questioning the status quo); only that I think it's a problem worth addressing, and a problem I see strongly at play on the topic of coordination and governance.
↑ comment by habryka (habryka4) · 2022-12-26T19:41:03.083Z · LW(p) · GW(p)
Just to clarify, the statements that I described as crazy were not statements you professed, but statements that you said I or "the LessWrong community" believe. I am not sure whether that got across (since like, in that context it doesn't really make sense to say I described sentences I disagree with as crazy, since like, I don't think you believe those sentences either, that's why you are criticizing them).
Replies from: Andrew_Critch↑ comment by Andrew_Critch · 2022-12-27T20:36:32.482Z · LW(p) · GW(p)
It did not get accross! Interesting. Procedurally I still object to calling people's arguments "crazy", but selfishly I guess I'm glad they were not my arguments? At a meta level though I'm still concerned that LessWrong culture is too quick to write off views as "crazy". Even the the "coordination is delusional"-type views that Katja highlights in her post do not seem "crazy" to me, more like misguided or scarred or something, in a way that warrants a closer look but not being called "crazy".
Replies from: habryka4↑ comment by habryka (habryka4) · 2022-12-27T20:54:54.559Z · LW(p) · GW(p)
Oops, yeah, sorry about that not coming across.
Seems plausible that LessWrong culture is too quick to write off views as "crazy", though I have a bunch of conflicting feeling here. Might be worth going into at some point.
I do think there is something pretty qualitatively different about calling a paraphrase or an ITT of my own opinions "crazy" than to call someone's actual opinion crazy. In-general my sense is for reacting to paraphrases it's less bad for the social dynamics to give an honest impression and more important to give a blunt evocative reaction, but I'll still try to clarify more in the future when I am referring to the meat of my interlocutors opinion vs. their representation of my opinion.
↑ comment by Said Achmiz (SaidAchmiz) · 2022-12-24T08:41:26.625Z · LW(p) · GW(p)
That particular statement was very poorly received, with a 139-karma retort from John Wentworth arguing,
What exactly is the model by which some AI organization demonstrating AI capabilities will lead to world governments jointly preventing scary AI from being built, in a world which does not actually ban gain-of-function research?
I’m not sure what’s going on here
So, wait, what’s actually the answer to this question? I read that entire comment thread and didn’t find one. The question seems to me to be a good one!
Replies from: Jan_Kulveit↑ comment by Jan_Kulveit · 2022-12-25T02:25:53.819Z · LW(p) · GW(p)
- The GoF analogy is quite weak.
- "What exactly" seems a bit weird type of question. For example, consider nukes: it was hard to predict what exactly is the model by which governments will not blow everyone up after use of nukes in Japan. But also: while the resulting equilibrium is not great, we haven't died in nuclear WWIII so far.
↑ comment by Steven Byrnes (steve2152) · 2022-12-26T18:43:39.994Z · LW(p) · GW(p)
The GoF analogy is quite weak.
As in my comment here [LW(p) · GW(p)], if you have a model that simultaneously both explains the fact that governments are funding GoF research right now, and predicts that governments would nevertheless react helpfully to AGI, I’m very interested to hear it. It seems to me that defunding GoF is a dramatically easier problem in practically every way.
The only responses I can think of right now are (1) “Basically nobody in or near government is working hard to defund GoF but people in or near government will be working hard to spur on a helpful response to AGI” (really? if so, what’s upstream of that supposed difference?) or (2) “It’s all very random—who happens to be in what position of power and when, etc.—and GoF is just one example, so we shouldn’t generalize too far from it” (OK maybe, but if so, then can we pile up more examples into a reference class to get a base rate or something? and what are the interventions to improve the odds, and can we also try those same interventions on GoF?)
Replies from: not-relevant, Jan_Kulveit↑ comment by Not Relevant (not-relevant) · 2022-12-26T19:45:16.458Z · LW(p) · GW(p)
I think it’s worth updating on the fact that the US government has already launched a massive, disruptive, costly, unprecedented policy of denying AI-training chips to China. I’m not aware of any similar-magnitude measure happening in the GoF domain.
IMO that should end the debate about whether the government will treat AI dev the way it has GoF - it already has moved it to a different reference class.
Some wild speculation on upstream attributes of advanced AI’s reference class that might explain the difference in the USG’s approach:
a perception of new AI as geoeconomically disruptive; that new AI has more obvious natsec-relevant use-cases than GoF; that powerful AI is more culturally salient than powerful bio (“evil robots are scarier than evil germs”).
Not all of these are cause for optimism re: a global ASI ban, but (by selection) they point to governments treating AI “seriously”.
↑ comment by Jan_Kulveit · 2022-12-29T08:44:18.875Z · LW(p) · GW(p)
One big difference is GoF currently does not seem that dangerous to governments. If you look on it from a perspective not focusing on the layer of individual humans as agents, but instead states, corporations, memplexes and similar creatures as the agents, GoF maybe does not look that scary? Sure, there was covid, but while it was clearly really bad for humans, it mostly made governments/states relatively stronger.
Taking this difference into account, my model was and still is governments will react to AI.
This does not imply reacting in a helpful way, but I think whether the reaction will be helpful, harmful or just random is actually one of the higher variance parameters, and a point of leverage. (And the common-on-LW stance governments are stupid and evil and you should mostly ignore them is unhelpful in both understanding and influencing the situation.)
↑ comment by MichaelA · 2023-01-07T12:47:26.668Z · LW(p) · GW(p)
Personally I haven't thought about how strong the analogy to GoF is, but another thing that feels worth noting is that there may be a bunch of other cases where the analogy is similarly strong and where major government efforts aimed at risk-reduction have occurred. And my rough sense is that that's indeed the case, e.g. some of the examples here.
In general, at least for important questions worth spending time on, it seems very weird to say "You think X will happen, but we should be very confident it won't because in analogous case Y it didn't", without also either (a) checking for other analogous cases or other lines of argument or (b) providing an argument for why this one case is far more relevant evidence than any other available evidence. I do think it totally makes sense to flag the analogous case and to update in light of it, but stopping there and walking away feeling confident in the answer seems very weird.
I haven't read any of the relevant threads in detail, so perhaps the arguments made are stronger than I imply here, but my guess is they weren't. And it seems to me that it's unfortunately decently common for AI risk discussions on LessWrong to involve this pattern I'm sketching here.
(To be clear, all I'm arguing here is that these arguments often seem weak, not that their conclusions are false.)
(This comment is raising an additional point to Jan's, not disagreeing.)
Update: Oh, I just saw Steve Byrnes also the following in this thread, which I totally agree with:
"[Maybe one could argue] “It’s all very random—who happens to be in what position of power and when, etc.—and GoF is just one example, so we shouldn’t generalize too far from it” (OK maybe, but if so, then can we pile up more examples into a reference class to get a base rate or something? and what are the interventions to improve the odds, and can we also try those same interventions on GoF?)"
↑ comment by Noosphere89 (sharmake-farah) · 2022-12-25T02:35:29.639Z · LW(p) · GW(p)
What exactly" seems a bit weird type of question. For example, consider nukes: it was hard to predict what exactly is the model by which governments will not blow everyone up after use of nukes in Japan. But also: while the resulting equilibrium is not great, we haven't died in nuclear WWIII so far.
This would be useful if the main problem was misuse, and while this problem is arguably serious, there is another problem, called the alignment problem, that doesn't care who uses AGI, only that it exists.
Biotech is probably the best example of technology being slowed down in the manner required, and suffice it to say it only happened because eugenics and anything related to that became taboo after WW2. I obviously don't want a WW3 to slow down AI progress, but the main criticism remains: The examples of tech that were slowed down in the manner required for alignment required massive death tolls, ala a pivotal act.
Replies from: Jan_Kulveit↑ comment by Jan_Kulveit · 2022-12-30T09:31:46.007Z · LW(p) · GW(p)
The analogy I had in mind is not so much in exact nature of the problem, but in the aspect it's hard to make explicit precise models of such situations in advance. In case of nukes, consider the fact that smartest minds of the time, like von Neumann or Feynman, spent decent amount of time thinking about the problems, had clever explicit models, and were wrong - in case of von Neumann to the extent that if US followed his advice, they would have launched nuclear armageddon.
↑ comment by Steven Byrnes (steve2152) · 2022-12-26T14:25:57.976Z · LW(p) · GW(p)
I think it's uncharitable to psychoanalyze why people upvoted John's comment; his object-level point about GoF seems good and merits an upvote IMO. Really, I don't know what to make of GoF. It's not just that governments have failed to ban it, they haven't even stopped funding it, or in the USA case they stopped funding it and then restarted I think. My mental models can't explain that. Anyone on the street can immediately understand why GoF is dangerous. GoF is a threat to politicians and national security. GoF has no upsides that stand up to scrutiny, and has no politically-powerful advocates AFAIK. And we’re just getting over a pandemic which consumed an extraordinary amount of money, comfort, lives, and attention for the past couple years, and which was either a direct consequence of GoF research, or at the very least the kind of thing that GoF research could have led to. And yet, here we are, with governments funding GoF research right now. Again, I can’t explain this, and pending a detailed model that can, the best I can do right now is say “Gee I guess I should just be way more cynical about pretty much everything.”
Anyway, back to your post [LW · GW], if Option 1 is unilateral pivotal act and Option 2 is government-supported pivotal outcome, then one ought to try to weigh the pros and cons (particularly, probability of failure) of both options; your post was only about why Option 1 might fail but IIRC didn’t say anything about whether Option 2 might fail too. Maybe every option is doomed and the task is to choose the slightly-less-doomed option, right?
I'm not an expert, and maybe you have a gears-y model in which it's natural & expected that governments are funding GoF right now and also simultaneously in which it's natural & expected that the government-sanctioned-EMP-thing story you told in your post is likely to actually happen. (Or at least, less likely to fail than Option 1.) If so, I would be very interested for you to share that model!
↑ comment by the gears to ascension (lahwran) · 2022-12-24T09:35:12.663Z · LW(p) · GW(p)
I also have found that almost everyone I talk to outside the field of AI has found it obvious that AI could kill us all. They also find it obvious that AI is about to surpass us, and are generally not surprised by my claims of a coming discontinuity; in contrast, almost anyone working in ai thinks I'm crazy. I suspect that people think I'm claiming I can do it, when in fact I'm trying to tell them they are about to do it. it's really frustrating! also, the majority of opinion in the world doesn't come from AI researchers.
That said. I cannot state this hard enough: THE COMING DISCONTINUITY WILL NOT WAIT BEHIND REGULATION.
I know of multiple groups who already know what they need to in order to figure it out! regulation will not stop them unless it is broad enough to somehow catch every single person who has tried to participate in creating it, and that is not going to happen, no matter how much the public wishes for it. I don't believe any form of pivotal act could save humanity. anything that attempts to use control to prevent control will simple cause a cascade of escalatory retaliations, starting with whatever form of attack is used to try to stop ai progress, escalating from accelerationists, escalating from attempted shutdown, possibly an international war aided by ai happening in parallel, and ending with the ai executing the last one.
Your attempts to slow the trickle of sand into the gravity well of increasing thermal efficiency will utterly fail. there are already enough GPUs in the world, and it only takes one. we must solve alignment so hard that it causes the foom, nothing else could possibly save us.
The good news is, alignment is capabilities in a deep way. Solving alignment at full strength would suddenly stabilize AI in a way that makes it much stronger at a micro level, and would simultaneously allow for things like "hey, can you get the carbon out of the air please?" without worry about damaging those inside protected boundaries.
↑ comment by lc · 2022-12-27T01:13:15.182Z · LW(p) · GW(p)
I'm not sure what's going on here, but it seems to me like the idea of coordinating with "outsiders" or placing trust or hope in judgement of "outsiders" has been a bit of taboo here, and that arguments that outsiders are dumb or wrong or can't be trusted will reliably get a lot of cheering in the form of Karma.
No, you're misunderstanding John Wentworth's comment and then applying that straw man to the rest of less wrong based on the comment's upvote total. It's not that laypeople's can't understand the dangers inherent in engineered viruses, and that leads to governments continuing to finance and leak them. You can probably convince your Uber driver that lab leaks are bad, too. It's a lack of ability to translate that understanding into positive regulatory and legal outcomes, instead of completely net negative ones.
↑ comment by Roman Leventov · 2022-12-24T07:43:19.917Z · LW(p) · GW(p)
Probably this opinion of LWers is shaped by their experience communicating with outsiders. Almost all my attempts to communicate AI x-risk to outsiders, from family members to friends to random acquaintances, have not been understood for sure. Your experience (talking to random people at social events, walking away from you with the thought "AI x-risk is indeed a thing!", and starting to worry about it in the slightest afterwards) is highly surprising to me. Maybe there is a huge bias in this regard in the Bay Area, where even normal people generally understand and appreciate the power of technology more than in other places, or have had some similar encounters before, or it's just in the zeitgeist of the place. (My experience is outside the US, primarily with Russians and some Europeans.)
All that being said, ChatGPT (if people have experienced it first-hand) and especially GPT-4 could potentially make communication of the AI x-risk case much easier.
Replies from: ete↑ comment by plex (ete) · 2022-12-25T19:24:17.741Z · LW(p) · GW(p)
I've had >50% hit rate for "this person now takes AI x-risk seriously after one conversation" from people at totally non-EA parties (subculturally alternative/hippeish, in not particularly tech-y parts of the UK). I think it's mostly about having a good pitch (but not throwing it at them until there is some rapport, ask them about their stuff first), being open to their world, modeling their psychology, and being able to respond to their first few objections clearly and concisely in a way they can frame within their existing world-model.
Edit: Since I've been asked in DM:
My usual pitch been something like this [LW(p) · GW(p)]. I expect Critch's version [LW · GW] is very useful for the "but why would it be a threat" thing but have not tested it as much myself.
I think being open and curious about them + being very obviously knowledgeable and clear thinking on AI x-risk is basically all of it, with the bonus being having a few core concepts to convey. Truth-seek with them, people can detect when you're pushing something in epistemically unsound ways, but tend to love it if you're going into the conversation totally willing to update but very knowledgeable.
comment by Scott Alexander (Yvain) · 2022-12-25T04:56:32.584Z · LW(p) · GW(p)
Survey about this question (I have a hypothesis, but I don't want to say what it is yet): https://forms.gle/1R74tPc7kUgqwd3GA
Replies from: jkaufman, Benito↑ comment by jefftk (jkaufman) · 2022-12-26T03:44:38.428Z · LW(p) · GW(p)
Nit: it shouldn't offer "submit another response" at the end. You can turn this off in the form settings, and leaving it on for forms that are only intended to receive one response per person feels off and maybe leads someone to think that filling it out multiple times is expected.
(Wouldn't normally be worth pointing out, but you create a decent number of surveys that are seen by a lot of people and changing this setting when creating them would be better)
↑ comment by Ben Pace (Benito) · 2022-12-25T20:36:14.403Z · LW(p) · GW(p)
Filled out!
comment by Vaniver · 2022-12-25T05:38:52.432Z · LW(p) · GW(p)
'Nuclear power' seems to me like a weird example because we selectively halted the development of productive use of nuclear power while having comparatively little standing in the way of development of destructive use of nuclear power. If a similar story holds, then we'll still see militarily relevant AIs (deliberately doing adversarial planning of the sort that could lead to human extinction) while not getting many of the benefits along the way.
That... doesn't seem like much of a coordination success story, to me.
Replies from: Zach Stein-Perlman↑ comment by Zach Stein-Perlman · 2022-12-25T09:42:44.019Z · LW(p) · GW(p)
Isn't NPT a canonical example in international relations of coordination success? In the 60s people thought many states would acquire nukes in the next few decades, but a treaty essentially stopped new states from acquiring nukes and set up a structure for helping states use nuclear power non-militarily. (Then many states gradually, individually, domestically chose not to pursue nuclear power much, for reasons specific to nuclear power.)
Replies from: Vaniver, sharmake-farah↑ comment by Vaniver · 2022-12-25T20:11:46.122Z · LW(p) · GW(p)
Yes, because the standards for success for nuclear are much lower than they are for AI. Not only did 5 states acquire weapons before the treaty was signed, around four have acquired them since, and this didn't stop the arms race accumulation of thousands of weapons. This turned out to be enough (so far).
In worlds where nukes ignite the atmosphere the first time you use them, there would have been a different standard of coordination necessary to count as 'success'. (Or in worlds where we counted the non-signatory states, many of which have nuclear weapons, as failures.)
↑ comment by Noosphere89 (sharmake-farah) · 2022-12-25T14:29:22.601Z · LW(p) · GW(p)
The point here is that the NPT is insufficient. With the alignment problem, it doesn't matter much if one state has it or many individuals have it, it only matters if no one has it.
A better example is arguably biotech, and this only happened because WW2 torched the idea of human eugenics, thus indirectly slowing down biotech by preventing it's funding.
Replies from: not-relevant↑ comment by Not Relevant (not-relevant) · 2022-12-25T15:24:57.918Z · LW(p) · GW(p)
The NPT framework, if it could be implemented, would be sufficient. The goal of the NPT is to enable countries to mutually verify that no additional country has acquired a nuclear weapon, while still enabling the spread of nuclear power to many more states. It has been pretty successful at this, with just a few new states gaining nuclear weapons over the last 50 years, whereas many more can enrich uranium/operate power plants.
It happens that the number of nuclear-armed countries at the NPT’s signing was nonzero, but if it had been 0, then the goal of the NPT would’ve been “no one anywhere can develop a nuclear weapon”.
A separate Q is “could we have implemented the NPT without Hiroshima, if scientists had strong evidence it would ignite the atmosphere?” People can have reasonable disagreements here; I think it’s lame not to try.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2022-12-25T15:33:07.899Z · LW(p) · GW(p)
A separate Q is “could we have implemented the NPT without Hiroshima, if scientists had strong evidence it would ignite the atmosphere?” People can have reasonable disagreements here; I think it’s lame not to try.
The unfortunate answer is likely not, assuming the cold war happens like it did historically. Both sides were very much going to get nuclear weapons and escalate as soon as they were able to. You really need almost Alien Space Bats or random quantum events to prevent the historical outcome of several states getting nuclear weapons. Now w imagine those nuclear weapons were intelligent and misaligned, and the world probably goes up in flames. Not assuredly, but well over 50% probability per year.
comment by Steven Byrnes (steve2152) · 2022-12-22T20:10:10.988Z · LW(p) · GW(p)
The main concrete proposals / ideas that are mentioned here or I can think of are:
- Work to spread good knowledge regarding AGI risk / doom stuff among AI researchers.
- I think everyone is in favor of this, particularly when it’s tied to the less-adversarial takeaway message “there is a big problem, and more safety research is desperately needed”. When it’s tied to the more-adversarial takeaway message “capabilities research should be slowed down”, I think that can be tactically bad, as I think people generally don’t tend to be receptive to people telling them that they and all their scientific idols are being reckless. I think it’s good to be honest and frank, but in the context of outreach, we can be strategic about what we emphasize, and I think emphasizing the “there is a big problem, and more safety research is desperately needed” message is generally the better approach. It also helps that the “there is a big problem, and more safety research is desperately needed” message is pretty clearly correct and easy to argue whereas “capabilities research is harmful” has comparatively more balanced arguments on both sides, and moreover if people can be sufficiently bought into the “there is a is a big problem, and more safety research is desperately needed” message then they can gradually propagate through to the (more complicated) implications on capabilities research.
- Work to spread good knowledge regarding AGI risk / doom stuff among politicians, the general public, etc.
- Basically ditto. Emphasizing “there is a big problem, and more safety research is desperately needed” seems good and is I think uncontroversial. Emphasizing “capabilities research should be slowed down” seems at least uncertain to accomplish what one might hope for it to accomplish, and seems to have many fewer advocates in the community AFAICT. For my part, I do some modest amount of outreach of this sort, with the “there is a big problem, and more safety research is desperately needed” messaging.
- In support of 1 & 2, do research that may lead to more crisp and rigorous arguments for why AGI doom is likely, if indeed it's likely.
- Everyone agrees.
- Don’t do capabilities research oneself, and try to discourage my friends who are already concerned about AGI risk / doom stuff from doing capabilities research.
- Seems to be a very active ongoing debate within the community. I usually find myself on the anti-capabilities-research side of these debates, but it depends on the details.
- Lay groundwork for possible future capability-slowing-down activities (whether through regulation or voluntary), like efforts to quantify AGI capabilities, track where high-end chips are going, deal with possible future anti-trust issues, start industry groups, get into positions of government influence, etc.
- These seem to be some of the main things that “AGI governance” people are doing, right? I’m personally in favor of all of those things, and can’t recall anyone objecting to them. I don’t work on them myself because it’s not my comparative advantage.
So for all of these things, I think they’re worth doing and indeed do them myself to an extent that is appropriate given my strengths, other priorities, etc. [LW · GW]
Are there other things we should be thinking about besides those 5?
The researchers themselves probably don’t want to destroy the world. Many of them also actually agree that AI is a serious existential risk. So in two natural ways, pushing for caution is cooperative with many if not most AI researchers.
I think a possible crux here is that we have different assumptions about how many people think AI existential risk is real & serious versus stupid. I think that right now most people think it’s stupid, and therefore the thing to do right now is to move lots of people from the “it’s stupid” camp to the “it’s real & serious” camp. After we get a lot more people, especially in the AI community but also probably among the general public, out of the “it’s stupid” camp and into the “it’s real & serious” camp, I think a lot more options open up, both governmental and through industry groups or whatever.
I think there are currently too many people in the “it’s stupid” camp and too few in the “it’s real & serious” camp for those types of slowing-down options to be realistically available right now. I could be wrong—I could imagine having my mind changed by survey results or something. Yours says “the median respondent’s probability of x-risk from humans failing to control AI was 10%”, but I have some concerns about response bias, and also a lot of people (even in ML) don’t think about probability the way you or I do, and may mentally treat 10% as “basically 0”, or at least not enough to outweigh the costs of slowing AI. Maybe if there’s a next survey, you could ask directly about receptiveness to broad-based agreements to slow AI research?? I wonder whether you’re in a bubble, or maybe I am, etc.
Anyway, centering the discussion around regulation would (IMO) be productive if we’re in the latter stage where most people already believe that AI existential risk is real & serious, whereas centering the discussion around regulation would at least plausibly be counterproductive if we’re in the former stage where we’re mainly trying to get lots of people to believe that AI existential risk is real & serious as opposed to stupid.
I’m not aware of examples of a technology not getting developed because of concerns over the technology, when most experts and most of the general public thought those concerns were silly. For example, concerns over nuclear power are in fact mostly silly, but had widespread support in the public before they had any impact, I think.
There might be widespread support for regulation to do with social media recommendation algorithm AIs or a few other things like that, but that’s not the topic of concern—AGI timelines are getting shrunk by-and-large by non-public-facing R&D projects, IMO. There is no IRB-like tradition of getting preapproval for running code that’s not intended to leave the four walls of the R&D lab, and I’m not sure what one could do to help such a tradition to get established, at least not before catastrophic AI lab escape accidents, which (if we survive) would be a different topic of discussion.
Replies from: TekhneMakre, Mauricio↑ comment by TekhneMakre · 2022-12-22T21:52:54.749Z · LW(p) · GW(p)
I think that can be tactically bad, as I think people generally don’t tend to be receptive to people telling them that they and all their scientific idols are being reckless.
In many cases, they're right, and in fact they're working on AI (broadly construed) that's (1) narrow, (2) pretty unlikely to contribute to AGI, and (3) potentially scientifically interesting or socially/technologically useful, and therefore good to pursue. "We" may have a tactical need to be discerning ourselves in who, and what intentions, we criticize.
↑ comment by Mau (Mauricio) · 2022-12-22T21:41:59.659Z · LW(p) · GW(p)
Work to spread good knowledge regarding AGI risk / doom stuff among politicians, the general public, etc. [...] Emphasizing “there is a big problem, and more safety research is desperately needed” seems good and is I think uncontroversial.
Nitpick: My impression is that at least some versions of this outreach are very controversial in the community, as suggested by e.g. the lack of mass advocacy efforts. [Edit: "lack of" was an overstatement. But these are still much smaller than they could be.]
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2022-12-22T21:58:42.447Z · LW(p) · GW(p)
For example, Eliezer Yudkowsky went on the Sam Harris podcast in 2018, Stuart Russell wrote an op-ed in the New York Times, Nick Bostrom wrote a book, … I dunno, do you have examples?
Nobody is proposing to play a commercial about AGI doom during the Superbowl or whatever, but I think that’s less “we are opposed to the general public having an understanding of why AGI risk is real and serious” and more “buying ads would not accomplish that”, I think?
comment by Eli Tyre (elityre) · 2024-01-14T06:22:14.937Z · LW(p) · GW(p)
This was counter to the prevailing narrative at the time, and I think did some of the work of changing the narrative. It's of historical significance, if nothing else.
comment by the gears to ascension (lahwran) · 2022-12-23T09:52:19.024Z · LW(p) · GW(p)
you are underestimating the degree of unilateralist's curse driving ai progress by quite a bit. it looks like scaling is what does it, but that isn't actually true, the biggest-deal capabilities improvements come from basic algorithms research that is somewhat serially bottlenecked until we improve on a scaling law, and then the scaling is what makes a difference. progress towards dethroning google by strengthening underlying algorithms until they work on individual machines has been swift, and the next generations of advanced basic algorithms are already here, eg https://github.com/BlinkDL/RWKV-LM - most likely, a single 3090 can train a GPT3 level model in a practical amount of time. the illusion that only large agents can train ai is a falsehood resulting from how much easier the current generation of models are to train than previous ones, such that simply scaling them up works at all. but it is incredibly inefficient - transformers are a bad architecture, and the next things after them are shockingly stronger. if your safety plan doesn't take this into account, it won't work.
that said - there's no reason to think we're doomed just because we can't slow down. we need simply speed up safety until it has caught up with the leading edge of capabilities. safety should always be thinking first about how to make the very strongest model's architecture fit in with existing attempts at safety, and safety should take care not to overfit on individual model architectures.
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-12-25T01:59:15.112Z · LW(p) · GW(p)
there's no reason to think we're doomed just because we can't slow down. we need simply speed up safety until it has caught up with the leading edge of capabilities.
I want to emphasize this; if doubling the speed of safety is cheaper than halving the rate of progress, and you have limited resources, then you always pick doubling the speed of safety in that scenario.
In the current scenario on earth, trying to slow the rate of progress makes you an enemy of the entire AI industry, whereas increasing the rate of safety does not. Therefore, increasing the rate of safety is the default strategy, because it's the option that won't get you an enemy of a powerful military-adjacent industry (which already has/had other enemies, and plenty of experience building its own strategies for dealing with them).
Replies from: lc↑ comment by lc · 2022-12-27T02:26:19.149Z · LW(p) · GW(p)
I want to emphasize this; if doubling the speed of safety is cheaper than halving the rate of progress, and you have limited resources, then you always pick doubling the speed of safety in that scenario.
Sure.
In the current scenario on earth, trying to slow the rate of progress makes you an enemy of the entire AI industry, whereas increasing the rate of safety does not. Therefore, increasing the rate of safety is the default strategy, because it's the option that won't get you an enemy of a powerful military-adjacent industry (which already has/had other enemies, and plenty of experience building its own strategies for dealing with them).
You're going to have be less vague in order for me to take you seriously. I understand that you apparently have private information, but I genuinely can't figure out what you'd have me believe the CIA is constantly doing to people who oppose its charter in extraordinarily indirect ways like this. If I organize a bunch of protests outside DeepMind headquarters, is the IC going to have me arrested? Stazi-like gaslighting? Pay a bunch of NYT reporters to write mean articles about me and my friends?
comment by trevor (TrevorWiesinger) · 2022-12-22T23:54:12.680Z · LW(p) · GW(p)
My experience in talking about slowing down AI with people is that they seem to have a can’t do attitude. They don’t want it to be a reasonable course: they want to write it off.
There are a lot of really good reasons why someone would avoid touching the concept of "suppressing AI research" with a ten-foot pole; depending on who they are and where they work, it's tantamount to advocating for treason. Literal treason, with some people. It's the kind of thing where merely associating with people who advocate for it can cost you your job, and certainly promotions.
A lot of this is considered infohazardous, and frankly, I've already said too much here. But it's very legitimate, and even sensible, to have very, very strong and unquestioned misgivings about large numbers of people they're associated with being persuaded to do something as radical as playing a zero-sum game against the entire AI industry.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2022-12-23T00:31:03.286Z · LW(p) · GW(p)
There are a lot of really good reasons why someone would avoid touching the concept of "suppressing AI research" with a ten-foot pole; depending on who they are and where they work, it's tantamount to advocating for treason.
I agree this is an ongoing dynamic, and I'm glad you brought it up, but I have to disagree with “good reasons”. Something being suppressed by the state does not make it false. If anything it is good reason to believe it might be true.
something as radical as playing a zero-sum game against the entire AI industry
As Katja points out in the OP: I would like to see the AI industry solve all disease, create novel art forms, and take over the world. I would like it to happen in a safe way that does not literally kill everyone. This is not the same as being in a zero-sum game with the industry.
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-12-23T10:52:08.213Z · LW(p) · GW(p)
As Katja points out in the OP: I would like to see the AI industry solve all disease, create novel art forms, and take over the world. I would like it to happen in a safe way that does not literally kill everyone. This is not the same as being in a zero-sum game with the industry.
I agree on this of course. But the issue is that powerful people can jump to conclusions on AI safety in 6 hour timelines, whereas the AI industry converging on understanding alignment is more like 6 year timeline. If AI safety is the #1 public opinion threat to the AI industry at any given time, or appears that way, then then that could result in AI safety being marginalized for decades.
This system revolves around a very diverse mix of reasonable and unreasonable people.. What I'm getting at is that it's a very delicate game, and there's no way to approach "slowing down AI", trying to impeding the government and military's top R&D priorities is basically hitting the problem with a sledgehammer. And it can hit back, orders of magnitude harder.
Replies from: lccomment by habryka (habryka4) · 2024-01-11T19:01:39.560Z · LW(p) · GW(p)
I think it's a bit hard to tell how influential this post has been, though my best guess is "very". It's clear that sometime around when this post was published there was a pretty large shift in the strategies that I and a lot of other people pursued, with "slowing down AI" becoming a much more common goal for people to pursue.
I think (most of) the arguments in this post are good. I also think that when I read an initial draft of this post (around 1.5 years ago or so), and had a very hesitant reaction to the core strategy it proposes, that I was picking up on something important, and that I do also want to award Bayes points to that part of me given how things have been playing out so far.
I do think that since I've seen people around me adopt strategies to slow down AI, I've seen it done on a basis that feels much more rhetorical, and often directly violates virtues and perspectives that I hold very dearly. I think it's really important to understand that technological progress has been the central driving force behind humanity's success, and that indeed this should establish a huge prior against stopping almost any kind of technological development.
In contrast to that, the majority of arguments that I've seen find traction for slowing down AI development are not distinguishable from arguments that apply to a much larger set of technologies which to me clearly do not pose a risk commensurable with the prior we should have against slowdown. Concerns about putting people out of jobs, destroying traditional models of romantic relationships, violating copyright law, spreading disinformation, all seem to me to be the kind of thing that if you buy it, you end up with an argument that proves too much and should end up opposed to a huge chunk of technological progress.
And I can feel the pressure in myself for these things as well. I can see how it would be easy to at least locally gain traction at slowing down AI by allying myself with people who are concerned about these things, and don't care much about the existential risk angle. I think allying is probably even a good call, though it's hard to be in alliances without conflating your beliefs with the beliefs if your alliance.
I think this post did engage with these considerations pretty well, though I am still hesitant and uncertain about the degree to which we can slow down AI without sacrificing enough collective sanity and epistemics, and am a bit worried now that things are in the realm of public debate and advocacy it's too late to have a sane conversation about those sacrifices.
Overall, I think this post is among the most important posts of 2022.
comment by TW123 (ThomasWoodside) · 2022-12-23T01:27:40.905Z · LW(p) · GW(p)
There are things that are robustly good in the world, and things that are good on highly specific inside-view models and terrible if those models are wrong. Slowing dangerous tech development seems like the former, whereas forwarding arms races for dangerous tech between world superpowers seems more like the latter.
It may seem the opposite to some people. For instance, my impression is that for many adjacent to the US government, "being ahead of China in every technology" would be widely considered robustly good, and nobody would question you at all if you said that was robustly good. Under this perspective the idea that AI could pose an existential risk is a "highly specific inside-view model" and it would be terrible if we acted on the model and it is wrong.
I don't think your readers will mostly think this, but I actually think a lot of people would, which for me makes this particular argument seem entirely subjective and thus suspect.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2022-12-23T01:49:15.520Z · LW(p) · GW(p)
I'm confused, of course the people in government in every country thinks that they should have more global power, but this doesn't seem like something everyone (i.e. including people in all of the other countries) would agree is robustly good, and I don't think you should think so either (for any country, be it Saudi Arabia, France, or South Korea). I am not aware of a coherent perspective that says "slowing down dangerous tech development" is not robustly good in most situations (conditional on our civilization's inability to "put black balls back into the urn", a la Bostrom).
Your argument sounds to me like "A small group with a lot of political power disagrees with your claim therefore it cannot be accepted as true." Care to make a better argument?
Replies from: T3t, ThomasWoodside↑ comment by RobertM (T3t) · 2022-12-23T02:19:01.093Z · LW(p) · GW(p)
I think the claim being made is that the "dangerous" part of "slowing down dangerous tech development" is the analogous "highly specific inside-view model" which would be terrible to act on, if it were wrong. That seems valid to me. Obviously I believe that highly specific inside-view model is not wrong, but, you know, that's how it goes.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2022-12-23T03:22:20.740Z · LW(p) · GW(p)
I... don't think that ThomasW is himself challenging the assumption. He's saying "Read this from the perspective of someone in the US government, doesn't seem so compelling now does it?" I'm not sure what about the post gave the impression that it was aimed to be persuasive to (for example) the US Secretary of State, but I am confident Katja did not write it for them.
↑ comment by TW123 (ThomasWoodside) · 2022-12-23T02:11:07.860Z · LW(p) · GW(p)
The claim being made is something like the following:
1) AGI is a dangerous technology.
2) It is robustly good to slow down dangerous technologies.
3) Some people might say that you should not actually do this because of [complicated unintelligible reason].
4) But you should just do the thing that is more robustly good.
I argue that many people (yes, you're right, in ways that conflict with one another) believe the following:
1) X is a dangerous country.
2) It is robustly good to always be ahead of X in all technologies, including dangerous ones.
3) Some people might say that you should not actually do this because of [complicated unintelligible reason]. This doesn't make very much sense.
4) But you should just do the thing that is more robustly good.
My point is that which argument is the obvious, robust one, and which one is the weird inside view one depends on your perspective. Therefore, it doesn't seem like (4) is a very good generalized argument. For example, if I were one of these powerful people, I think it would be wrong for me to be convinced to "focus on the robustly good measures, not the weird inside view measures" because it would lead me to do bad things like trying to advance AI capabilities. As a result, the argument seems suspect to me. It feels like it only works for this community, or people who are already very concerned by AI x-risk.
In comparison, there are specific arguments like "AGI is dangerous" and "slowing down dangerous technologies is actually robustly good" (some of these were presented in this post) that I think are, ironically, must more robustly good, because they don't seem to have negative effects as reliably when presented to people who hold beliefs I think are wrong.
Edit: I no longer endorse this comment. It claims too much, specifically that any reasoning procedure is suspect if it leads to people who believe false premises taking bad actions.
I think what I was really trying to get at in my original comment was that that particular argument seems aimed at people who already think that it would be robustly good to slow down dangerous technologies. But the people who would most benefit from this post are those who do not already think this; for them it doesn't help much and might actively hurt.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2022-12-23T03:14:34.803Z · LW(p) · GW(p)
I think what I was really trying to get at in my original comment was that that particular argument seems aimed at people who already think that it would be robustly good to slow down dangerous technologies. But the people who would most benefit from this post are those who do not already think this; for them it doesn't help much and might actively hurt.
This is kind of a strange comment to me. The argument, and indeed the whole post, is clearly written to people in the ecosystem ("my impression is that for people worried about extinction risk from artificial intelligence, strategies under the heading ‘actively slow down AI progress’ have historically been dismissed and ignored"), for which differential technological progress is a pretty common concept and relied upon in lots of arguments. It's pretty clear that this post is written to point out an undervalued position to those people.
Sometimes I feel like people in the AI x-risk ecosystem who interface with policy and DC replace their epistemologies with a copy of the epistemology they find in various parts of the policy-control machine in DC, in order to better predict them and perform the correct signals — asking themselves what people in DC would think, rather than what they themselves would think. I don't know why you think this post was aimed at those people, or why you point out that the post is making false inferences about its audience when the post is pretty clear that it's primary audience is the people directly in the ecosystem ("The conversation near me over the years has felt a bit like this").
Replies from: ThomasWoodside↑ comment by TW123 (ThomasWoodside) · 2022-12-23T03:39:38.819Z · LW(p) · GW(p)
I just do not think that the post is written for people who think "slowing down AI capabilities is robustly good." If people thought that, then why do they need this post? Surely they don't need somebody to tell them to think about it?
So it seems to me like the best audience for this post would be those (including those at some AI companies, or those involved in policy, which includes people reading this post) who currently think something else, for example that the robustly good thing is for their chosen group to be ahead so that they can execute whatever strategy they think they alone can do correctly.
The people I've met who don't want to think about slowing down AI capabilities just don't seem to think that slowing down AI progress would be robustly good, because that just wouldn't be a consistent view! They often seem to have some view that nothing is robustly good, or maybe some other thing ("get more power") is robustly good. Such people just won't really be swayed by the robust priors thing, or maybe they'd be swayed in the other direction.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2022-12-23T04:10:17.427Z · LW(p) · GW(p)
I see. You're not saying "staffers of the US government broadly won't find this argument persuasive", you're saying "there are some people in the AI x-risk ecosystem who don't think slowing down is robustly good, and won't find this particular argument persuasive".
I have less of a disagreement with that sentence.
I'll add that:
- I think most of the arguments in the post are relevant to those people, and Katja only says that these moods are "playing a role" which does not mean all people agree with them.
- You write "If people thought that, then why do they need this post? Surely they don't need somebody to tell them to think about it?". Sometimes people need help noticing the implications of their beliefs, due to all sorts of motivated cognitions. I don't think the post relies on that and it shouldn't be the primary argument, but I think it's honestly helpful for some people (and was a bit helpful for me to read it).
↑ comment by TW123 (ThomasWoodside) · 2022-12-23T04:15:00.868Z · LW(p) · GW(p)
Yeah, I agree with all this.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2022-12-23T04:23:26.702Z · LW(p) · GW(p)
Thread success!
comment by Mau (Mauricio) · 2022-12-22T23:28:46.561Z · LW(p) · GW(p)
Thanks for writing!
I want to push back a bit on the framing used here. Instead of the framing "slowing down AI," another framing we could use is, "lay the groundwork for slowing down in the future, when extra time is most needed." I prefer this latter framing/emphasis because:
- An extra year in which the AI safety field has access to pretty advanced AI capabilities seems much more valuable for the field's progress (say, maybe 10x) than an extra year with current AI capabilities, since the former type of year would give the field much better opportunities to test safety ideas and more clarity about what types of AI systems are relevant.
- One counterargument is that AI safety will likely be bottlenecked by serial time [? · GW], because discarding bad theories and formulating better ones takes serial time, making extra years early on very useful. But my very spotty understanding of the history of science suggests that it doesn't just take time for bad theories to get replaced by better ones--it takes time along with the accumulation of lots of empirical evidence. This supports the view that late-stage time is much more valuable than early-stage time.
- Slowing down in the future seems much more tractable than slowing down now, since many critical actors seem much more likely to support slowing down if and when there are clear, salient demonstrations of its importance (i.e. warning shots).
- Given that slowing down later is much more valuable and much more tractable than just slowing down now, it seems much better to focus on slowing down later. But the broader framing of "slow down" doesn't really suggest that focus, and maybe it even discourages it.
↑ comment by trevor (TrevorWiesinger) · 2022-12-22T23:58:28.675Z · LW(p) · GW(p)
Replies from: Benito↑ comment by Ben Pace (Benito) · 2022-12-23T00:49:39.647Z · LW(p) · GW(p)
I don't know who you are beyond having read a few of your LW posts, I know Mauricio a little and don't have much reason to think of him as an 'expert' (I believe he's worked in policy spaces for ~1 year), so I'm not taking your comment as much evidence about his claims.
Edit: I wish the above comment had just been retracted (i.e. had a line put through it) rather than removed, it makes it unclear to future readers what happened. If I recall correctly the comment said that while he had some disagreements with Mauricio, he can personally vouch for him as an expert in this area and well-positioned to have a good opinion on the subject.
comment by Rohin Shah (rohinmshah) · 2022-12-28T08:22:24.536Z · LW(p) · GW(p)
I’ve copied over and lightly edited some comments I left on a draft. Note I haven’t reread the post in detail; sorry if these were addressed somewhere.
Writing down quick thoughts after reading the intro and before reading the rest:
I have two major reasons to be skeptical of actively slowing down AI (setting aside feasibility):
1. It makes it easier for a future misaligned AI to take over by increasing overhangs, both via compute progress and algorithmic efficiency progress. (This is basically the same sort of argument as "Every 18 months, the minimum IQ necessary to destroy the world drops by one point.")
2. Such strategies are likely to disproportionately penalize safety-conscious actors.
(As a concrete example of (2), if you build public support, maybe the public calls for compute restrictions on AGI companies and this ends up binding the companies with AGI safety teams but not the various AI companies that are skeptical of “AGI” and “AI x-risk” and say they are just building powerful AI tools without calling it AGI.)
For me personally there's a third reason, which is that (to first approximation) I have a limited amount of resources and it seems better to spend that on the "use good alignment techniques" plan rather than the "try to not build AGI" plan. But that's specific to me.
After reading the doc I think I agree with most of the specific object-level points, and disagree with the overall thrust.
There seems to be some equivocation between two different viewpoints:
1. We can make a big difference by just not building AGI for a long time (say decades). Maybe this is hard / morally wrong, maybe not, we haven't actually tried, and we aren't even considering it. (To this view my objection would be the two points above; I'm confused why neither one appeared in the doc.)
2. There are simple straightforward things that seem clearly good, so it's wrong for people to say it's too hard / morally dubious. (To this view my objection is that people don't say that, people aren't opposed to it, and people are doing the simple straightforward things. Though perhaps we know different people.)
I feel like as I read this doc I was being pushed towards ambiguating between these two views, so that I come out with a belief like "Wow, there's all this straightforward obvious stuff, but there's a huge taboo against it and no one even considers it". Nowhere do you actually say that but it's very much the vibe I get.
All that being said, I strongly agree that there are simple straightforward things that seem clearly good and we should do them! I just think that people do consider them already. For example, on your list of 11 actions in the “Restraint is not terrorism, usually”, I think I have done or am doing (1), (2), (4), (5), (6), (7), (9), and (11).
(Written now, not previously) Overall my take is that most of the specific object-level arguments make sense and are valuable as a response to some ill-considered memes that get thrown around in this community, but it isn't a great take on the overall question of whether and how to slow down AI because it doesn't consider the best counterarguments. (Which I'll note that I wrote down before reading the full essay.)
Replies from: Xodarap↑ comment by Xodarap · 2022-12-29T20:54:59.967Z · LW(p) · GW(p)
FYI I think your first skepticism was mentioned in the safety from speed section [? · GW]; she concludes that section:
These [objections] all seem plausible. But also plausibly wrong. I don’t know of a decisive analysis of any of these considerations, and am not going to do one here. My impression is that they could basically all go either way.
She mentions your second skepticism near the top [? · GW], but I don't see anywhere she directly addresses it.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-12-30T20:02:29.970Z · LW(p) · GW(p)
Thanks, that's good to know.
comment by lc · 2023-03-02T19:29:22.198Z · LW(p) · GW(p)
The conversation near me over the years has felt a bit like this:
Some people: AI might kill everyone. We should design a godlike super-AI of perfect goodness to prevent that.
Others: wow that sounds extremely ambitious
Some people: yeah but it’s very important and also we are extremely smart so idk it could work
[Work on it for a decade and a half]
Some people: ok that’s pretty hard, we give up
Others: oh huh shouldn’t we maybe try to stop the building of this dangerous AI?
Some people: hmm, that would involve coordinating numerous people—we may be arrogant enough to think that we might build a god-machine that can take over the world and remake it as a paradise, but we aren’t delusional
There's a sleight of hand going on with the "we" here. "We" as in LessWrong are not building the godlike AI, the trillion dollar technocapitalist machine is doing that. "We" are a bunch of nerds off to the side, some of whom are researching ways to point said AIs at specific targets. If "we" tried to start an AGI company we'd indeed end up in fifth place and speed up timelines by six weeks (generously).
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2023-03-04T11:10:52.955Z · LW(p) · GW(p)
That's the case now, but note the "work on it for a decade and a half". 15 years ago, MIRI was working on building the godlike AI directly and was one of the only actors doing so, as there wasn't a trillion dollar technocapitalist machine pouring money into machine learning yet.
comment by TekhneMakre · 2022-12-22T21:34:02.176Z · LW(p) · GW(p)
I think there's a major internal tension in the picture you present (though the tension is only there with further assumptions). You write:
Obstruction doesn’t need discernment
[...]
I don’t buy it. If all you want is to slow down a broad area of activity, my guess is that ignorant regulations do just fine at that every day (usually unintentionally). In particular, my impression is that if you mess up regulating things, a usual outcome is that many things are randomly slower than hoped. If you wanted to speed a specific thing up, that’s a very different story, and might require understanding the thing in question.The same goes for social opposition. Nobody need understand the details of how genetic engineering works for its ascendancy to be seriously impaired by people not liking it. Maybe by their lights it still isn’t optimally undermined yet, but just not liking anything in the vicinity does go a long way.
And you write:
Technological choice is not luddism
Some technologies are better than others [citation not needed]. The best pro-technology visions should disproportionately involve awesome technologies and avoid shitty technologies, I claim. If you think AGI is highly likely to destroy the world, then it is the pinnacle of shittiness as a technology. Being opposed to having it into your techno-utopia is about as luddite as refusing to have radioactive toothpaste there. Colloquially, Luddites are against progress if it comes as technology.10 [LW · GW] Even if that’s a terrible position, its wise reversal is not the endorsement of all ‘technology’, regardless of whether it comes as progress.
From "obstruction doesn't need discernment", you're proposing a fairly broad dampening. While this may be worth it from an X-risk perspective, it's (1) far more Luddite, (2) far more potentially actually harmful (though we'd agree, still worth it), and therefore (3) far more objectionable, and (4) far more legitimately opposed.
Replies from: TekhneMakre↑ comment by TekhneMakre · 2022-12-22T21:49:51.868Z · LW(p) · GW(p)
The tension wouldn't be there if obstruction isn't bottlenecked on discernment because discernment is easy / not too hard, but I don't think you made that argument.
If discernment is not too hard, that's potentially a dangerous thing: by being all discerning in a very noticeable way, you're painting a big target on "here's the dangerous [cool!] research". Which is what seems to have already happened with AGI.
This is also a general problem with "just make better arguments about AI X-risk". You can certainly make such arguments without spreading ideas about how to advance capabilities, but still, the most pointed arguments are like "look, in order to transform the world you have to do XYZ, and XYZ is dangerous because ABC". You could maybe take the strategy of, whenever a top researcher makes a high-level proposal for how to make AGI, you can criticize that like "leaving aside whether or not that leads to AGI, if it led to AGI, here's how that would go poorly".
(I acknowledge that I'm being very "can't do" in emphasis, but again, I think this pathway is crucial and worth thinking through... and therefore I want to figure out the best ways to do it!)
comment by RobertM (T3t) · 2022-12-24T23:00:41.869Z · LW(p) · GW(p)
Curated. I am broadly skeptical of existing "coordination"-flavored efforts, but this post prompted several thoughts:
- I have very incomplete models of what those efforts are (much more so than my models of technical alignment efforts, which are also substantially incomplete)
- It seems likely to me that some people have better models of both existing efforts, and potential future efforts, which have not been propagated very well, and it'd be good for that to change
I think this post does a good job of highlighting representative objections to various proposed strategies and then demonstrating why those objections should not be considered decisive (or even relevant). It is true that we will not solve the problem of AI killing everyone by slowing it down, but that does not mean we should give up on trying to find +EV strategies for slowing it down, since a successful slowdown, all else equal, is good.
comment by Shmi (shminux) · 2022-12-23T04:43:22.317Z · LW(p) · GW(p)
The world has a lot of experience slowing down technological progress already, no need to invent new ways.
Fusion research slowed to a crawl in the 1970s and so we don't have fusion power. Electric cars have been delayed by a century. IRB is successful at preventing many promising avenues. The FDA/CDC killed most of the novel drug and pandemic prevention research. The space industry is only now catching up to where it was 50 years ago.
Basically, stigma/cost/red tape reliably and provably does the trick.
Replies from: TekhneMakre↑ comment by TekhneMakre · 2022-12-23T05:55:11.161Z · LW(p) · GW(p)
Fusion research slowed to a crawl in the 1970s and so we don't have fusion power
Requires huge specialized equipment. Some AI requires huge equipment, but (1) you can do a lot with a little, and (2) the equipment is heavily economically incentivized for other reasons (all the other uses of compute).
Electric cars have been delayed by a century.
Why was this? I'd've thought it's basically battery tech, blocked on materials tech. Is that not right?
The space industry is only now catching up to where it was 50 years ago.
Wasn't this basically un-investment? That's not a lever we can easily pull with AI.
IRB is successful at preventing many promising avenues. The FDA/CDC killed most of the novel drug and pandemic prevention research.
Now we're talking! How the heck does that work? I'm surprised enough that actually I'd guess it's not that hard for a private investor to do research, it's just that the research wouldn't be allowed to be applied (enforceable because very public). Is that true? If not, why not?
Replies from: shminux↑ comment by Shmi (shminux) · 2022-12-23T06:37:41.089Z · LW(p) · GW(p)
With fusion it was mostly defunding, just like with space exploration:
from https://21sci-tech.com/Articles_2010/Winter_2009/Who_Killed_Fusion.pdf
Not sure if this is a possibility with AI. Electric cars and transport in general were apparently killed by the gas automobile industry. Battery tech was just enough for the daily commute, and there were options and workarounds.
I am not an expert on how the government regulation kills innovation, there is probably enough out there, including by Zvi and Scott Alexander.
comment by Nicholas Weininger (nicholas-weininger) · 2022-12-25T08:00:07.837Z · LW(p) · GW(p)
It seems very odd to have a discussion of arms race dynamics that is purely theoretical exploration of possible payoff matrices, and does not include a historically informed discussion of what seems like the obviously most analogous case, namely nuclear weapons research during the Second World War.
US nuclear researchers famously (IIRC, pls correct me if wrong!) thought there was a nontrivial chance their research would lead to human extinction, not just because nuclear war might do so but because e.g. a nuclear test explosion might ignite the atmosphere. They forged ahead anyway on the theory that otherwise the Nazis were going to get there first, and if they got there first they would use that advantage to lock in Nazi hegemony, and that was so bad an outcome it was worth a significant risk of human extinction to avoid.
Was that the wrong thing for them to have done under the circumstances? If so, why, and what can we say confidently in hindsight that should they have done instead? If not, why is the present situation saliently different? If China gets to AGI first that plausibly locks in CCP hegemony which is arguably similarly bad to locking in Nazi hegemony. Trying to convince the CCP that they will just kill themselves too if they do this, so they shouldn't try, seems about as tractable as persuading Werner Heisenberg and his superiors during WWII that they shouldn't try to build nukes because they might ignite the atmosphere.
comment by sanxiyn · 2022-12-23T02:57:03.828Z · LW(p) · GW(p)
The world has actually coordinated on some impressive things, e.g. nuclear non-proliferation
Given the success of North Korea, I am both impressed by the world's coordination on nuclear weapon and depressed that even the impressive coordination is not enough. I feel similarly for the topic the nuclear weapon is metaphor for.
Continuing to think about the metaphor: in terms of existential risk, North Korean nuclear weapon is probably less damaging than United States missile defense, due to reasons related to second strike. It is probable people feel bad about North Korean nuclear weapon because it is normally bad (North Korea is bad so it is bad for North Korea to be powerful), not because it is an existential threat (it increases the probability of the world being destroyed).
Is this analogous to people being against AI because they are "biased", not because they are dangerous? Or are "we" missing some important crucial considerations like second strike in AI, leading us to worry about North Korean nuclear weapon when we really should worry about United States missile defense?
Replies from: CronoDAScomment by Jeff Rose · 2022-12-22T19:41:51.773Z · LW(p) · GW(p)
I suspect that part of what is going on is that many in the AI safety community are inexperienced with and uncomfortable with politics and have highly negative views about government capabilities.
Another potential (and related) issue, is that people in the AI safety community think that their comparative advantage doesn't lie in political action (which is likely true) and therefore believe they are better off pursuing their comparative advantage (which is likely false).
comment by TurnTrout · 2023-01-19T06:00:52.114Z · LW(p) · GW(p)
As a datapoint, I remember briefly talking with Eliezer in July 2021, where I said "If only we could make it really cringe to do capabilities/gain-of-function work..." (I don't remember which one I said). To which, I think he replied "That's not how human psychology works."
I now disagree with this response. I think it's less "human psychology" and more "our current sociocultural environment around these specific areas of research." EG genetically engineering humans seems like a thing which, in some alternate branches, is considered "cool" and "exciting", while being cringe in our branch. It doesn't seem like a predestined fact of human psychology that that field had to end up being considered cringe.
comment by Rudi C (rudi-c) · 2022-12-25T01:49:19.242Z · LW(p) · GW(p)
Your own examples of technologies that aren't currently pursued but have huge upsides are a strong case against this proposition. These lines of research have some risks, but if there was sufficient funding and coordination, they could be tremendously valuable. Yet the status quo is to simply ban them without investing much at all in building a safe infrastructure to pursue them.
If you should succeed in achieving the political will needed to "slow down tech," it will come from idiots, fundamentalists, people with useless jobs, etc. It will not be a coalition pushing to make aligned, democratic, open AI possible. It will be a coalition dedicated to preserving the status quo and rent-seeking. Perhaps you believe, SBF-style, that "means justify the ends," and this dogmatic coalition will still serve you well. Perhaps it does, and it reduces existential risk. (This is a big assumption.) Even so, most humans don't care about existential risk much. Humans value others by proximity to themselves, temporally and otherwise. This is asking everyone alive, their children, their grandchildren, etc. to suffer so that "existential risk" integrated over an infinite time interval is reduced. This is not something most people want, and it's the reason you will only find allies in the unproductive rent-seekers and idiots.
Replies from: sanxiyn↑ comment by sanxiyn · 2022-12-26T02:49:25.597Z · LW(p) · GW(p)
I completely agree and this seems good? I very much want to ally with unproductive rent-seekers and idiots to reduce existential risk. Thanks a lot, unproductive rent-seekers and idiots! (though I most certainly shouldn't call them that to ally with them). I don't understand how this is in any way a strong case against the proposition.
Replies from: CronoDAS
comment by Metacelsus · 2022-12-23T22:41:37.177Z · LW(p) · GW(p)
Someone used CRISPR on babies in China
Nitpick: the CRISPR was on the embryos, not the babies.
Although I don't think what He Jiankui did was scientifically justified (the benefit of HIV resistance wasn't worth the risk – he should have chosen PCSK9 instead of CCR5), I think the current norms against human genetic enhancement really are stifling a lot of progress.
Replies from: sanxiyn↑ comment by sanxiyn · 2022-12-24T02:11:13.304Z · LW(p) · GW(p)
Agreed. On the other hand, what I read suggests He Jiankui was bottlenecked on parental consent. For his first-in-human trial, he couldn't recruit any parents interested in editing PCSK9, but some parents, themselves HIV patients, whose contacts were relatively easily acquired from HIV support group, really really cared about (as you pointed out, and I agree, incorrectly) editing CCR5, and were easily recruited. It sometimes happens recruiting participants is the limiting factor in doing trials, and I think it was the case here.
comment by Edward Pascal (edward-pascal) · 2022-12-23T14:10:12.169Z · LW(p) · GW(p)
(1) The framing of all this as military technology (and the DoD is the single largest purchasing agent on earth) reminds me of nuclear power development. Molten Salt reactors and Pellet Bed reactors are both old tech which would have created the dream of safe, small-scale nuclear power. However, in addition to not melting down and working at relatively small scales, they also don't make weapons-usable materials. Thus they were shunted in favor of the kinds of reactors we mostly have now. In an alternative past without the cold war driving us to make new and better weapons, we hit infinite free energy for everyone back in 1986 and in 2022 we finally got our Dyson Sphere running.
So yeah, the sad thing about it being an arms race with China and DARPA et al that is the AGIs will look a certain way, and that might become """what AGI is""" for several decades. And the safeguards and controls that get put around those military-grade AGIs will prevent some other kind, the equivalent of Molten Salt reactors, from getting developed and built.
But we have to accept the world of incentives we have, not the one we wish for.
(2) As a PD defector/exploiter without much in the way of morals or shame, what I like about all this slowing down is that it gives smaller players a little opportunity to catch up and play with the big guys. I suspect at least a few smaller players (along with the open source community) would make some hay while the sun is shining and everyone else is moving slow and ensuring alignment, which is democratizing and cool. I put this up here as a selling point for those people who crave the pedal to the metal on AI dev. The slowness the OP is talking about allows a different pedal to different metal if you are looking for it, perhaps with your foot on it.
comment by otto.barten (otto-barten) · 2022-12-24T10:33:17.961Z · LW(p) · GW(p)
Thank you for writing this post! I agree completely, which is perhaps unsurprising given my position [LW · GW] stated back in 2020. Essentially, I think we should apply the precautionary principle for existentially risky technologies: do not build unless safety is proven.
A few words on where that position has brought me since then.
First, I concluded back then that there was little support for this position in rationalist or EA circles. I concluded as you did, that this had mostly to do with what people wanted (subjective techno-futurist desires), and less with what was possible or the best way to reduce human extinction risk. So I went ahead and started the Existential Risk Observatory anyway, a nonprofit aiming to reduce human extinction risk by informing the public debate. We think public awareness is essentially the bottleneck for effective risk reduction, and we hope more awareness will lead to increased amounts of talent, funding, institutes, diversity, and robustness for AI Safety, and increased support for constructive regulation. This can be in the form of software, research, data, or hardware regulation, with each having their own advantages and disadvantages. Our intuition is that with 50% awareness, countries should be able to implement some combination of the above that would effectively reduce AI existential risk, while trying to keep economic damage to a minimum (an international treaty may be needed, or a US-China deal, or using supply chain leverage, or some smarter idea). To our knowledge, no-one has worked out a detailed regulation proposal for this (perhaps this comes kind of close). If true, we think that's embarrassing and regulation proposals should be worked out (and this work should be funded) with urgency. If there are regulation proposals which are not shared, we think people should share them and be less infohazardy about it.
So how did informing the societal debate go so far?
We started from a super crappy position: self-funded, hardly any connection to the xrisk space (that was also partially hostile to our concept), no media network to speak of, located in Amsterdam, far from everything. I had only some founding experience with a previous start-up. Still, I have to say that on balance, things went better than expected:
- Setting up the organization went well. It was easy to attract talent through EA networks. My first lesson: even if some senior EAs and rationalists were not convinced about informing the societal debate, many juniors were.
- We were successful in slowly working our way into the Dutch societal debate. One job opening led to another podcast led to another drink led to another op-ed, etc. It took a few months and lots of meetings with usually skeptical people, but we definitely made progress.
- We published our first op-eds in leading Dutch newspapers after about six months. We are now publishing about one article per month, and have been in four podcasts as well. We have reached out to a few million people by readership, mostly in the Netherlands but also in the US.
- We are now doing our first structured survey research measuring how effective our articles are. According to our first preliminary measurement data (report will be out in a few months), conversion rates for newspaper articles and youtube videos (the two interventions we measured so far) are actually fairly high (between ~25% and 65%). However, there aren't too many good articles on the topic out there yet relative to population sizes, so if you just crunch the numbers, it seems likely that most people still haven't heard of the topic. There's also a group that has heard the arguments but doesn't find them convincing. According to first measurements, this doesn't correlate too much with education level or field. Our data is therefore pointing away from the idea that only brilliant people can be convinced of AI xrisk.
- We obtained funding from SFF and ICFG. Apparently, getting funding for projects aiming to raise AI xrisk awareness, despite skepticism of this approach by some, was already doable last year. We seem to observe a shift towards our approach, so we would expect this to become easier.
- There's a direct connection between publishing articles and influencing policy. It wasn't our goal to directly influence policy, but co-authors, journalists, and others are automatically asking when you write an article: so what do you propose? One can naturally include regulation proposals (or proposals for e.g. more AI Safety funding) into articles. It is also much easier to get meetings with politicians and policy makers after publishing articles. Our PA person has had meetings with three parliamentarians (two of parties in government) in the last few weeks, so we are moderately optimistic that we can influence policy in the medium term.
We think that if we can do this, many more people can. Raising awareness is constrained by many things, but most of all by manpower. Although there are definitely qualities that makes you better at this job (xrisk expertise, motivation, intelligence, writing and communication skills, management skills, network), you don't need to be a super genius or have a very specific background to do communication. Many in the EA and rationalist communities who would love to do something about AI xrisk but aren't machine learning experts could work in this field. With only about 3 FTE, I'm positive our org can inform millions of people. Imagine what dozens, hundreds, or thousands of people working in this field could achieve.
If we would all agree that AI xrisk comms is a good idea, I think humanity would have a good chance of making it through this century.
comment by TekhneMakre · 2022-12-22T20:37:38.340Z · LW(p) · GW(p)
Broadly agree, but: I think we're very confused about the social situation. (Again, I agree this argues to work on deconfusing, not to give up!) For example, one interpretation of the propositions claimed in this thread
https://twitter.com/soniajoseph_/status/1597735163936768000
if they are true, is that AI being dangerous is more powerful in terms of moving money and problem-solving juice as a recruitment tool rather than a dissuasion tool. I.e. in certain contexts, it's beneficial towards the goal of getting funding to include in your pitch "this technology might be extremely dangerous".
I've tried to make a list here
https://www.lesswrong.com/posts/ZePZkkNriPqo9c2wd/why-do-some-people-try-to-make-agi [LW · GW]
to seed theorization about the situation, but didn't get much engagement.
Replies from: TekhneMakre↑ comment by TekhneMakre · 2022-12-22T21:54:54.074Z · LW(p) · GW(p)
More generally, that twitter thread is an exemplar of a broader thing which is the Vortex of Silicon Valley Craziness, which is mostly awesome, often very silly, and also tinged with craziness. And I have an uncertain vague sense that this tinge of craziness is some major part of the tailwind pushing AGI research? Or more specifically, the tailwind investing capital into AGI research.
comment by [deleted] · 2022-12-27T18:23:49.312Z · LW(p) · GW(p)
I see one critical flaw here.
Why does anyone assume ANY progress will be made on alignment if we don't have potentially dangerous AGIs in existence to experiment with?
A second issue is that at least the current model for chatGPT REQUIRES human feedback to get smarter, and the greater the scale of userbase the smarter it can potentially become.
Other systems designed to scale to AGI may have to be trained this way: initial training from test environments and static human text, but refinement from interaction with live humans, where the company with the most users has runaway success because more users means the system learns faster and more users switch to it.
This dependency graph means we may have no choice but to proceed with AGI on the most expedient timescale. Once early systems attempt bad behavior and fail, then research those in large well funded isolated labs to discover ways to mitigate the issues.
How much progress did humans make on heavier than air flight before they had actual airplanes?
Nobody invented jet engines or computational fluid dynamics before they had many generations of aircraft and many air battles to justify the expense.
Replies from: steve2152, sharmake-farah↑ comment by Steven Byrnes (steve2152) · 2022-12-28T19:24:36.970Z · LW(p) · GW(p)
Why does anyone assume ANY progress will be made on alignment if we don't have potentially dangerous AGIs in existence to experiment with?
I’m obviously biased, but I think we should assume this based on what we see with our eyes—we can look around and note that more than zero progress on alignment is being made right now.
If you think that “What Paul Christiano is doing right now is just totally useless, he might as well switch fields, do some cool math or whatever, and have a more relaxing time until real-deal AGIs show up, it would make no difference whatsoever”, and you also think that same thing about Scott Garrabrant, Venessa Kosoy, John Wentworth, Anthropic, Redwood Research, Conjecture, me (cf. here [LW · GW] & here [LW · GW]), etc. etc.—well, you’re obviously entitled to believe that, but I would be interested to hear a more detailed argument if you have time, not just analogizing to other fields. (Although, I do think that if the task was “make ANY progress on heavier-than-air flight before we have any actual airplanes”, this task would be easily achievable, because “any” is a very low bar! You could do general research towards stiff and light structures, towards higher-power-to-weight-ratio engines, etc.) For example, Eliezer Yudkowsky is on the very skeptical end of opinions about ongoing AGI safety research, but he seems to strongly believe that doing interpretability research right now is marginally helpful, not completely useless.
Replies from: None↑ comment by [deleted] · 2022-12-28T20:02:19.198Z · LW(p) · GW(p)
Fair. Any is an unfair comparison.
On the other hand every past technology humans made, whether or not they researched it for decades first or rushed it out with young engineers, I am not actually sure it made any difference. There is no way to falsify this but pretty much every technology built had crippling, often lethal to humans flaws in the first versions.
My point is there is immense information gain from actually fully constructing and testing a technology, and further large gains from deployment to scale.
While if you don't have any of that the possibility space is much larger.
For example some propose llms as they currently exist could exhibit rampant behavior. This may be true or completely false because the RLHF step discouraged models that can exhibit such traits or some other reason.
Prior to fission reactors existing nuclear scientists may have been concerned about prompt criticality detonating power reactors. This has only happened once, possibly twice.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2022-12-29T03:47:43.026Z · LW(p) · GW(p)
Hmm, Fermi invented the idea of control rods before building the first-ever nuclear reactor, and it worked as designed to control the nuclear reaction. So that’s at least one good example that we can hope to follow. I’m not sure what your last paragraph is referring to. For that first nuclear reactor, the exponential growth happened pretty much exactly as Fermi had calculated in advance, IIRC.
OK anyway, there’s a category of AGI safety work that we might call “Endgame Safety”, where we’re trying to do all the AGI safety work that we couldn’t (or didn’t) do ahead of time, in the very last moments before (or even after) people are actually playing around with the kind of powerful AGI algorithms that could get irreversibly out of control. I think we both agree that lots of the essential AGI safety work is in the category of “Endgame Safety”. I don’t know what the fraction is, but it seems that you and I are both agreeing that the fraction is not literally 100%.
(For my part, I wouldn’t be too surprised if Endgame Safety were 90% of the total useful person-hours of AGI safety, but I hope that lots of important conceptual / deconfusion work can be done further ahead, since those things sometimes take lots of wall-clock time.)
And as long as the fraction (AGI endgame safety work) / (all AGI safety work) is not literally 100%—i.e., as long as there is any AGI safety research whatsoever that we can do ahead of time—then we now have the core of an argument that slowing down AGI would be helpful.
For example, if AGI happens in 5 years, we can be frantically doing Endgame Safety starting in 5 years. And if AGI happens in 50 years, we can be frantically doing Endgame Safety starting in 50 years. What does it matter? Endgame Safety is going to be a frantic rush either way. But in the latter case, we can have more time to nail down everything that’s not Endgame Safety. And we can also have more time to do other useful things like outreach / field-building—to get from the current world where only a small fraction of people in AI / ML understand even really basic things like instrumental convergence and s-risk-mitigation 101, to a future world where the fraction is higher.
(You can make an argument that doing Endgame Safety in 50 years would be harder than doing Endgame Safety in 5 years because of other separate ways that the world would be different, e.g. bigger hardware overhang or whatever, but that’s a different argument that you didn’t seem to be making.)
Replies from: None↑ comment by [deleted] · 2022-12-29T16:35:19.410Z · LW(p) · GW(p)
Steven, how many months before the Chicago pile construction started did Fermi's design team do the work on the control rods? There's also a large difference between the idea of control rods - we have lots of ideas how to do AGI control mechanisms and no doubt some of them do work - and an actual machined control rod with enough cadmium/boron/etc to work.
In terms of labor hours, going from idea to working rod was probably >99% of the effort. Even after discovering empirically which materials act as neutron absorbers.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2022-12-29T18:59:13.401Z · LW(p) · GW(p)
we have lots of ideas how to do AGI control mechanisms and no doubt some of them do work
I think AGI safety is in a worse place than you do.
It seems that you think that we already have at least one plan for Safe & Beneficial AGI that has no problems that are foreseeable at this point, they’ve been red-teamed to death and emerged unscathed with the information available, and we’re not going to get any further until we’re deeper into the implementation.
Whereas I think that we have zero plans for which we can say “given what we know now, we have strong reason to believe that successfully implementing / following this plan would give us Safe & Beneficial AGI”.
I also think that, just because you have code that reliably trains a deceptive power-seeking AGI, sitting right in front of you and available to test, doesn’t mean that you know how to write code that reliably trains a non-deceptive corrigible AGI. Especially when one of the problems we’re trying to solve right now is the issue that it seems very hard to know whether an AGI is deceptive / corrigible / etc.
Maybe the analogy for me would be that Fermi has a vague idea “What if we use a rod made of neutron-absorbing material?”. But there are no known neutron-absorbing materials. So Fermi starts going about testing materials to see if he can find any that absorb neutrons. Meanwhile, DeepPile develops technology that makes it easier and easier to purify uranium, and publishes all the details, and starts building its own piles, on the theory that when the piles are hitting criticality, it would make it easier to test possible control mechanisms. This is not helping Fermi! He already has a concrete problem that he’s stuck on, and he already has what he needs to make progress, he just needs time.
Replies from: None↑ comment by [deleted] · 2022-12-29T20:12:22.807Z · LW(p) · GW(p)
Yes, I do. I've spoken privately with an engineer on AI safety at OpenAI and he agrees this can work.
It's an extension of existing industrial safety mechanisms, including the ones that are used on autonomous cars today.
The current method is:
There are 2 systems controlling a car operating on autopilot. One has a sophisticated policy to control the car, using a pipeline consisting of neural networks and software modules. The other is a microcontroller which has a dead simple policy to order a braking force increase over time.
Each timestep, the microcontroller software is looking for information from the telemetry stream the higher level system emits that may indicate a failure. This means timeouts, corrupt packets, or if a packet contains specific values indicating an error or low confidence.
Waymo extends this approach to 3 systems, based on their publicly released information. One high level system, one mid level system that is approximately a lane control system on a separate power source, and the microcontroller. The mid level system is a neural network attached to one camera, and it emits steering commands to bring the vehicle to a safe stop.
This obviously can be extended to n-levels of system. There can be multiple AI systems, each able to take over control, where the lower level systems use more robust and simple policies that are more likely to work in a larger variety of situations. Every time the higher level system becomes empirically uncertain - a module authored by humans is what measures this, one way to do this is to see if the inputs to the high level system fall into the latent space of the training set - control shifts to the first system that has sufficient confidence, devolving to a microcontroller.
The 'ah ha' I want you to have is that we know the AI policy is safe within the space of the training simulator. We measured it. The training simulator is supposed to be a reasonably accurate facsimile of the real world - and we know how to auto-generate realistic situations now from real world data, so we can be ever improving the simulation's breadth. Whenever the system finds itself in an out of distribution situation, this means that it now has inputs that describe a situation it was not proven to do the safe thing. So we shut down that system, but as the AI system may be doing a task in the real world and can't be simply turned off, we have to transfer control to a system that can safely shut it down.
Example - a robot is operating in a paperclip factory. It escapes outside. On the frame it perceives "outside", it recognizes that the current perception is outside the latent space of the training examples, which were all 'inside'. It transfers control to a network that manages 'robot momentum', something trained to stop the robot hardware in as little space as possible without it falling over - and halts a few feet from the exit.
It's a pretty clear and actionable approach. Human organizations already do this, human brains seem to have a structure like this (example: our high level system can order us not to breathe but if we pass out a low level system engages respiration), and so on.
Note that this means every AI system exists in an outer framework authored by humans that is permanently immutable. No self modification. And you would need to formally prove the software modules that form the structure of the framework.
There very likely are a number of 'rules' like this that have to be obeyed or AI safety is impossible. Similar to how we could have made nuclear reactors work more like the demon core experiment, where a critical mass is being created via a neutron reflector and the core is weapons grade. This would put every reactor one mechanical failure away from a prompt critical incident that would cause an explosion.
You also do need interpretability and to restrict deception with the speed prior.
Replies from: steve2152, sharmake-farah↑ comment by Steven Byrnes (steve2152) · 2022-12-30T02:11:40.879Z · LW(p) · GW(p)
For the purpose of the present discussion, I note that if your plan needs interpretability, then that would be a cause for concern, and a reason for slowing down AGI. The state of interpretability is currently very bad, and there seem to be lots of concrete ways to make progress right now [? · GW].
Separately, I don’t think your plan (as I understand it) has any hope of addressing the hardest and most important AGI safety problems. But I don’t want to spend the (considerable) time to get into a discussion about that, so I’ll duck out of that conversation, sorry. (At least for now.)
Replies from: None↑ comment by [deleted] · 2022-12-30T07:05:48.753Z · LW(p) · GW(p)
That is unfortunately not a helpful response. If this simple plan - which is already what is in use in the real world in actual AI systems today - won't work this is critical information!
What is the main flaw? It costs you little to mentioned the biggest problem.
↑ comment by Noosphere89 (sharmake-farah) · 2022-12-29T22:33:32.884Z · LW(p) · GW(p)
I agree with this, and therefore I'm both more optimistic, and think that we should be not alarmed at the pace of progress. Or in other words, I disagree with the idea of slowing down AGI progress.
↑ comment by Noosphere89 (sharmake-farah) · 2022-12-27T18:43:09.426Z · LW(p) · GW(p)
Yeah, this is a big problem I have with alignment people. They forget that if we don't have iteration, we don't solve the problem, so all efforts should focus on making things paralleliziable. It's a problem I had with MIRI's early work, and today we need to set ourselves up for much more empirical evidence. This could be a reason to support capabilities advances.
Replies from: None↑ comment by [deleted] · 2022-12-27T18:46:52.970Z · LW(p) · GW(p)
They argue there is some unknown point of capabilities at which the system explodes and we all die.
If that's the rules of the universe we happen to find ourselves in though there probably is no winning anyways though. Sort of how if the laws of physics were slightly different and the first nuclear test did ignite the atmosphere.
Were atmospheric gas fissionable things would be very different.
It's a very similar criticality argument. Early AGIs that try bad stuff may "quench" because the world lacks sufficient easily remotely hackable nanoforges and fleets of armed killer robots ready to deploy. So they instead steal a few bitcoins, kill a few people, then are caught and shut down.
If instead the AGI finds an exploit to get criticality then we all die. I am concerned the AGI might create a cult of personality or a religion and get support from large numbers of gullible humans. These humans, despite the AGI openly killing people and acting completely selfishly, might give it the resources to develop a way to kill us all.
comment by PoignardAzur · 2022-12-26T10:52:53.044Z · LW(p) · GW(p)
One big obstacle you didn't mention: you can make porn with that thing. It's too late to stop it.
More seriously, I think this cat may already be out of the bag. Even if the scientific community and the american military-industrial complex and the chinese military-industrial complex agreed to stop AI research, existing models and techniques are already widely available on the internet.
Even if there is no official AI lab anywhere doing AI research, you will still have internet communities pooling compute together for their own research projects (especially if crypto collapses and everybody suddenly has a lot of extra compute on their hands).
And these online communities are not going to be open-minded about AI safety concerns. We've seen that already with the release of Stable Diffusion 2.0: the internet went absolutely furious that the model was limited in (very limited ways) that impacted performance. People wanted their porn machine to be as good as it could possibly be and had no sympathy whatsoever for the developers' PR / safety / not-wanting-to-be-complicit-with-nonconsensual-porn-fakes concerns.
Of course, if we do get to the point only decentralized communities do AI research, it will be a pretty big win for the "slowing down" strategy. I get your general point about "we should really exhaust all available options even if we think it's nigh impossible". I just think you're underestimating a bit how nigh-impossible it is. We can barely stop people from using fossil fuels, and that's with an infinitely higher level of buy-in from decision-makers.
comment by User_Luke · 2022-12-24T12:04:13.481Z · LW(p) · GW(p)
I'm not convinced this line of thinking works from the perspective of the structure of the international system. For example, not once are international security concerns mentioned in this post.
My post here draws out some fundamental flaws in this thinking:
https://www.lesswrong.com/posts/dKFRinvMAHwvRmnzb/issues-with-uneven-ai-resource-distribution
comment by Karl von Wendt · 2022-12-23T11:32:06.624Z · LW(p) · GW(p)
I very strongly agree with this post. Thank you very much for writing it!
I think to reach a general agreement on not doing certain stupid things, we need to better understand and define what exactly those things are that we shouldn't do. For example, instead of talking about slowing down the development of AGI, which is a quite fuzzy term, we could talk about preventing uncontrollable AI [LW · GW]. Superintelligent self-improving AGI would very likely be uncontrollable, but there could be lesser forms of AI that could be uncontrollable, and thus very dangerous, as well. It should also be easier to reach agreement that uncontrollable AI is a bad thing. At least, I don't think that any leader of an AI lab would proudly announce to the public that they're trying to develop uncontrollable AI.
Of course, it isn't clear yet what exactly makes an AI uncontrollable. I would love to see more research in that direction.
comment by Ben Pace (Benito) · 2022-12-23T00:24:38.959Z · LW(p) · GW(p)
Bravo! I especially agree wrt people giving too many galaxy brain takes for why current ML labs speeding along is good.
comment by concernedcitizen · 2022-12-22T20:50:24.369Z · LW(p) · GW(p)
I believe this post is one of the best to grace the front page of the LW forum this year. It provides a reasoned counterargument to prevailing wisdom in an accessible way, and has the potential to significantly update views. I would strongly support pinning this post to the front page to increase critical engagement.
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-12-23T10:58:51.204Z · LW(p) · GW(p)
I believe this post is one of the worst to appear the front page of the LW forum this year. Its research has gaping holes, and that anyone experienced in the area knows that those holes contain multiple factors that each negate and double-negate the conclusion, and has the potential to singlehandedly convert LW from an island of truth to one of the most catastrophic misinformation engines ever built. I would strongly support banning, condemning, and publicly distancing LW and rationalism from the OP in order to minimize the risk that this will ever happen again.
comment by jacquesthibs (jacques-thibodeau) · 2023-01-05T17:23:03.953Z · LW(p) · GW(p)
Thank you for calling attention to this. It always seems uncontroversial that some things could speed up AGI timelines, yet it is assumed that very little can be done to slow them down. The actual hard part is figuring out what could, in practice, slow down timelines with certainty.
Finding ways to slow down timelines is exactly why I wrote this post on Foresight for AGI Safety Strategy: Mitigating Risks and Identifying Golden Opportunities [LW · GW].
comment by Cedar (xida-ren) · 2022-12-29T17:49:34.871Z · LW(p) · GW(p)
- AI is pretty safe: unaligned AGI has a mere 7% chance of causing doom, plus a further 7% chance of causing short term lock-in of something mediocre
- Your opponent risks bad lock-in: If there’s a ‘lock-in’ of something mediocre, your opponent has a 5% chance of locking in something actively terrible, whereas you’ll always pick good mediocre lock-in world (and mediocre lock-ins are either 5% as good as utopia, -5% as good)
- Your opponent risks messing up utopia: In the event of aligned AGI, you will reliably achieve the best outcome, whereas your opponent has a 5% chance of ending up in a ‘mediocre bad’ scenario then too.
- Safety investment obliterates your chance of getting to AGI first: moving from no safety at all to full safety means you go from a 50% chance of being first to a 0% chance
- Your opponent is racing: Your opponent is investing everything in capabilities and nothing in safety
- Safety work helps others at a steep discount: your safety work contributes 50% to the other player’s safety
This is more a personal note / call for somebody to examine my thinking processes, but I've been thinking really hard about putting hardware security methods to work. Specifically, spreading knowledge far and wide about how to:
- allow hardware designers / manufacturers to have easy, total control over who uses their product for what for how much throughout the supply chain
- make it easy to secure AI related data (including e.g. model weights and architecture) and difficult to steal.
This sounds like it would improve every aspect of the racey-environment conditions, except:
Your opponent is racing: Your opponent is investing everything in capabilities and nothing in safety
The exact effect of this is unclear. On the one hand, if racey, zero-sum thinking actors learn that you're trying to "restrict" or "control" AI hardware supply, they'll totally amp up their efforts. On the other hand, you've also given them one more thing to worry about (their hardware supply).
I would love to get some frames on how to think about this.
comment by Arcayer · 2022-12-27T05:05:44.129Z · LW(p) · GW(p)
So, a number of issues stand out to me, some have been noted by others already, but:
My impression is that there are also less endorsable or less altruistic or more silly motives floating around for this attention allocation.
A lot of this list looks to me like the sort of heuristics where, societies that don't follow them inevitably crash, burn and become awful. A list of famous questions where the obvious answer is horribly wrong, and there's a long list of groups who came to the obvious conclusion and became awful, and it's become accepted wisdom to not do that, except among the perpetually stubborn "It'll be different this time" crowd, and doomers who insist "well, we just have to make it work this time, there's no alternative".
if anyone chooses to build, everything is destroyed
The problem with our current prisoner's dilemma is that China has already openly declared their intentions. You're playing against a defect bot. Also, your arguments are totally ineffective against them, because you're not writing in Chinese. And, the opposition is openly malicious, and if alignment turns out to be easy, this ends with hell on earth, which is much worse than the false worst case of universal annihilation.
On the inevitability of AI: I find current attempts at AI alignment to be spaceships with sliderules silliness and not serious. Longer AI timelines are only useful if you can do something with the extra time. You're missing necessary preconditions to both AI and alignment, and so long as those aren't met, neither field is going to make any progress at all.
On qualia: I expect intelligence to be more interesting in general than the opposition expects. There are many ways to maximize paperclips, and even if technically, one path is actually correct, it's almost impossible to produce sufficient pressure to direct a utility function directly at that. I expect an alien super intelligence that's a 99.9999% perfect paperclip optimizer, and plays fun games on the side, to play above 99% of the quantity of games that a fun game optimizer would get. I accuse the opposition of bigotry towards aliens, and assert that the range of utility functions that produce positive outcomes is much larger than the opposition believes. Also, excluding all AI that would eliminate humanity, excludes lots of likable AI that would live good lives, but reach the obviously correct conclusion that humans are worse than them and need to go, while failing exclude any malicious AI that values human suffering.
On anthropics: We don't actually experience the worlds that we fail to make interesting, so there's no point worrying about them anyway. The only thing that actually matters is the utility ratio. It is granted that, if this worldline looked particularly heaven-oriented, and not hellish, it would be reasonable to maximize the amount of qualia attention by being protective of local reality, but just looking around me, that seems obviously not true.
On Existential Risk: I hold that the opposition massively underestimates current existential risks excluding AI, most of which AI is the solution to. The current environment is already fragile. Any stable evil government anywhere means that anything that sets back civilization threatens stagnation or worse, aka, every serious threat, even those that don't immediately wipe out all life, most notably nuclear weapons, constitutes an existential risk. Propaganda and related can easily drive society into an irrecoverable position using current techniques. Genetics can easily wipe us out, and worse, in either direction. Become too fit, and we're the ones maximizing paperclips. Alternatively, there's the grow giant antlers and die problem where species trap themselves in a dysgenic spiral. Evolution does not have to be slow, and especially if social factors accelerate the divide between losers and winners, we could easily breed ourselves to oblivion in a few generations. Almost any technology could get us all killed. Super pathogens with a spread phase and a kill phases. Space technology that slightly adjusts the pathing of large objects. Very big explosions. Cheap stealth, guns that fire accurately across massive distances, fast transportation, easy ways to produce various poison gasses. There seems to be this idea that just because it isn't exotic it won't kill you.
In sum: I fully expect that this plan reduces the chances of long term survival of life, while also massively increasing the probability of artificial hell.
comment by RogerDearnaley (roger-d-1) · 2023-12-26T05:34:26.056Z · LW(p) · GW(p)
I could be wrong, but I’d guess convincing the ten most relevant leaders of AI labs that this is a massive deal, worth prioritizing, actually gets you a decent slow-down. I don’t have much evidence for this.
…
Delay is probably finite by default
Convincing OpenAI, Anthropic, and Google seems moderately hard - they've all clearly already considered the matter carefully, and it's fairly apparent from their actions what conclusions they've reached about pausing now. Then convincing Meta, Mistral, Cohere, and the next dozen-or-so would-be OpenAI replacements seems harder. Then, also doing so for the Chinese and UAE equivalents and their governments seems like it might be harder still, not so much because talking to their AI researchers is hard, but because you also have to persuade members of their governments, which are top-down power structures headed by people used to getting their way. Then you need to convince A19z, EleutherAI, Hugging Face and the entire open-source AI community — that seems harder still, mostly because there are so many of them. After that we're looking at people like the Russians and the North Koreans, then the academic AI research community, and after that probably things like criminal organizations and warlords.
Somewhere on that sequence, you're going to find a nut you can't crack. Having multiple major governments on your side would help a lot, they might well be able to achieve everything before North Korea and the Russians. At current speed of improvements in Moore's Law for GPUs and algorithmic improvements and monetary investments in AI, each step on that ladder probably buys you something like 6 months of delay (this is a rough estimate, I'm sure there are people in the AI governance community who could give better ones.) If you got several steps down, you might even be able to somewhat slow the growth of training compute and algorithmic improvements, so that might stretch to more like 12 months per rung. So with massive effort backed by major governments, we might be able to slow things down by up to about 4 years. If we're all going to die at the end, that's ~4 years of extra life for ~8 billion people, clearly a huge positive achievement. If those ~4 years would make a large improvement to Alignment fieldbuilding and progress, that could make an even bigger difference. But the downside is that if someone builds AGI in secret during those ~4 years, it's going to be a criminal organization or a failed state, and that near the end of it, you're now in a race with people like the North Koreans. We'd also have built up some overhang: on my progress-slowing assumption, only about 2 years' worth at current rates, since the world would actually be behind the unslowed track, but still, some overhang. Overhang presumably leads to a potential for rapid growth, which is extremely bad for safety.
The obvious next question is, how far away is AGI? My personal current bests guess, off rough parallels to human synapse counts, is about 2-3 orders of magnitude in parameter counts (which is ~2-3 GPT generations, so ~GPT-6 or GPT-7, which sounds about right based on generational progress so far). That's ~4-6 orders of magnitude in total training compute cost before any algorithmic and Moore's Law discounts. At the GPT-1 through 4 progress rate, that's around 2.5-4 years. Clearly it's hard to be sure, this could be only one GPT-generation away (about a year), or four (about 5.5 years). So an additional ~4 year delay is quite a significant amount of extra time, probably more than doubling, but not a huge difference.
The next question is, if we're going to delay, when? Coordinating a delay is probably going to be easiest when the danger is near and most tangible and demonstrable, and as the OP notes the gains for an extra up-to-4 years of Alignment research will be biggest with near-AGI systems to work with and more Alignment fieldbuilding done. There will obviously also be a lot more political capital for a pause once the significant white-collar job losses start. So there would seem to be reasons to maintain a significant lead until you pause, and then pause for as long as you can get away with (while closely monitoring anyone still racing).
The recent blitz to get governments involved and set up regulatory frameworks could be interpreted as laying the groundwork for a future government-led pause (and for starting to slow smaller players) without actually initiating one yet. So it looks like the intention is to build models around the GPT-5 level, do some safety analysis, and then see what they look like. At that point, if they were showing really scary capabilities ("High" across the board on OpenAI's Preparednesss framework, for example), then that would put the labs in a good position to go back to the governments and yell "Crisis! Pull the emergency brake!" They would also probably by then have a much better idea if they already have AGI on their hands, or it's still 1-3 generations away.
comment by EGI · 2023-01-03T11:33:18.747Z · LW(p) · GW(p)
"I arrogantly think I could write a broadly compelling and accessible case for AI risk"
Please do so. Your current essay is very good, so chances are your "arrogant" thought is correct.
Edit: I think this is too pessimistic about human nature, but maybe we should think about this more before publishing a "broadly compelling and accessible case for AI risk".
https://www.lesswrong.com/posts/xAzKefLsYdFa4SErg/accurate-models-of-ai-risk-are-hyperexistential-exfohazards [LW · GW]
comment by tamgent · 2022-12-23T20:50:28.475Z · LW(p) · GW(p)
Thank you for writing this. On your section 'Obstruction doesn't need discernment' - see also this post that went up on LW a while back called The Regulatory Option: A response to near 0% survival odds [LW · GW]. I thought it was an excellent post, and it didn't get anywhere near the attention it deserved, in my view.
comment by Roger Dearnaley · 2023-02-11T10:26:33.214Z · LW(p) · GW(p)
People have been writing stories about the dangers of artificial intelligences arguably since Ancient Greek time (Hephaistos built artificial people, including Pandora), certainly since Frankenstein. There are dozens of SF movies on the theme (and in the Hollywood ones, the hero always wins, of course). Artificial intelligence trying to take over the world isn't a new idea, by scriptwriter standard it's a tired trope. Getting AI as tightly controlled as nuclear power or genetic engineering would not, politically, be that hard -- it might take a decade or two of concerted action , but it's not impossible. Especially if not-yet-general AI is also taking people's jobs. The thing is, humans (and especially politicians) mostly worry about problems that could kill them in the next O(5) years. Relatively few people in AI/universities/boardrooms/government/on the streets think we're O(5) years from GAI, and after more of them have talked to ChatGPT/etc for a while, they're going to notice the distinctly sub-human-level mistakes it makes, and eventually internalize that a lot of its human-level-appearing abilities are just pattern-extrapolated wisdom of crowds learned from most of the Internet.
So I think the questions are:
- Is slowing down progress on GAI actually likely to be helpful, beyond the obvious billions of person-years per year gained from delaying doom? (Personally, I'm having difficulty thinking of a hard technical problem where having more time to solve it doesn't help.)
- If so, when should we slow down progress towards GAI? Too late is disastrous, too soon risks people deciding you're crying wolf, either when you try it so you fail (and make it harder to slow down later), or else a decade or two after you succeed and progress gets sped up again (as I think is starting to happen with genetic engineering). This depends a lot on how soon you think GAI might happen, and what level of below-general AI would most enhance your doing alignment research on it. (FWIW, my personal feeling is that until recently we didn't have any AI complex enough for alignment research on it to be interesting/informative, and the likely answer is "just before any treacherous turn is going to happen" -- which is a nasty gambling dilemma. I also personally think GAI is still some number of decades away, and the most useful time to go slowly is somewhere around the "smart as a mouse/chimp/just sub-human level" -- close enough to human that you're not having to extrapolate a long way what you learn from doing alignment research on it up to mildly-superhuman levels.)
- Whatever you think the answer to 2. is, you need to start the political process a decade or two earlier: social change takes time.
I'm guessing a lot of the reluctance in the AI community is coming from "I'm not the right sort of person to run a political movement". In which case, go find someone who is, and explain to them that this is an extremely hard technical problem, humanity is doomed if we get it wrong, and we only get one try.
(From a personal point of view, I'm actually more worried about poorly-aligned AI than non-aligned AI. Everyone beng dead and having the solar system converted into paperclips would suck, but at least it's probably fairly quick. Partially aligned AI that keeps us around but doesn't understand how to treat us could make Orwell's old quote about a boot stamping on a human face forever look mild – and yes, I'm on the edge of Godwin's Law.)
comment by denkenberger · 2023-01-02T02:34:38.648Z · LW(p) · GW(p)
Very useful post and discussion! Let's ignore the issue that someone in capabilities research might be underestimating the risk and assume they have appropriately assessed the risk. Let's also simplify to two outcomes of bliss expanding in our lightcone and extinction (no value). Let's also assume that very low values of risk are possible but we have to wait a long time. It would be very interesting to me to hear how different people (maybe with a poll) would want the probability of extinction to be below before activating the AGI. Below are my super rough guesses:
1x10^-10: strong longtermist
1x10^-5: weak longtermist
1x10^-2 = 1%: average person (values a few centuries?)
1x10^-1 = 10%: person affecting: currently alive people will get to live indefinitely if successful
30%: selfish researcher
90%: fame/power loving older selfish researcher
I was surprised that my estimate was not more different for a selfish person. With climate change, if an altruistic person affecting individual thinks the carbon tax should be $100 per ton carbon, a selfish person should act as if the carbon tax is about 10 billion times lower, so ten orders of magnitude different versus ~one order for AGI. So it appears that AGI is a different case in that the risk is more internalized to the actors. Most of the variance for AGI appears to be from how longtermist one is vs whether one is selfish or altruistic.
comment by FireStormOOO · 2022-12-28T22:07:46.505Z · LW(p) · GW(p)
Chiming in on toy models of research incentives: Seems to me like a key feature is that you start with an Arms Race then, after some amount of capabilities accumulate, transitions to the Suicide Race. But players have only vague estimates of where that threshold is, have widely varying estimates, and may not be able to communicate estimates effectively or persuasively. Players have a strong incentive to push right up to the line where things get obviously (to them) dangerous, and with enough players, somebody's estimate is going to be wrong.
Working off a model like that, we'd much rather be playing the version where players can effectively share estimates and converge on a view of what level of capabilities makes things get very dangerous. Lack of constructive conversations with the largest players on that topic do sound like a current bottleneck.
It's unclear to me to what extent there's even a universal clear distinction understood between mundane weak AI systems with ordinary kinds of risks and superhuman AGI systems with exotic risks that software and business people aren't used to thinking about outside of sci-fi. That strikes me as a key inferential leap that may be getting glossed over.
There's quite a lot of effort spent in technology training people that systems are mostly static absent human intervention or well defined automations that some person ultimately wrote, anything else being a fault that gets fixed. Computers don't have a mind of their own, troubleshoot instead of anthropomorphizing, etc., etc. That this intuition will at some point stop working or being true of a sufficiently capable system (and that this is fundamentally part of what we mean by human level AGI) is something that probably needs to be focused on more as it's explicitly contrary to the basic induction that's part of usefully working in/on computers.
comment by Noosphere89 (sharmake-farah) · 2022-12-24T16:52:55.381Z · LW(p) · GW(p)
I'd like to ask a few questions about slowing down AGI as they may turn out to be cruxes for me.
-
How popular/unpopular is AI slowdown? Ideally, we'd get AI slowdown/AI progress/Neutral as choices in a poll. I also ideally would like different framings of the problem, to test how well frames affect people's choices. But I do want at least a poll on how popular/unpopular AI slowdown is.
-
How much does the government want AI to be slowed down? Is Trevor's story about the US government not willing to countenance AI slowdown correct, and instead speed it up the norm in interacting with the government?
-
How much will AI companies lobby against AI slowdown? Because if this is a repeat of the fossil fuel situation where AI is viewed by the public as extremely good, I probably would not support too much object work in AI governance, and instead go meta. In other words, I'd be doing more meta things. But if AI companies support AI slowdown or at least not oppose it, than things could be okay, depending on the answers to 1 and 2.
comment by Jackson Wagner · 2022-12-23T22:03:59.484Z · LW(p) · GW(p)
I am interested in getting feedback on whether it seems worthwhile to advocate for better governance mechanisms (like prediction markets) in the hopes that this might help civilization build common knowledge about AI risk more quickly, or might help civilization do a more "adequate" job of slowing AI progress by, restricting unauthorized access to compute resources. Is this a good cause for me to work on, or is it too indirect and it would be better to try and convince people about AI risk directly? See a more detailed comment here: https://www.lesswrong.com/posts/PABtHv8X28jJdxrD6/racing-through-a-minefield-the-ai-deployment-problem?commentId=ufXuR5xtMGeo5bjon [LW(p) · GW(p)]
comment by MiguelDev (whitehatStoic) · 2023-09-13T03:52:06.681Z · LW(p) · GW(p)
But empirically, the world doesn’t pursue every technology—it barely pursues any technologies.
While it's true that not all technologies are pursued, history shows that humans have actively sought out transformative technologies, such as fire, swords, longbows, and nuclear energy. The driving factors have often been novelty and utility. I expect the same will happen with AI.
comment by ZeroGravitas (richard-lewis) · 2023-04-05T06:57:26.562Z · LW(p) · GW(p)
Very nice exploration of this idea. But I don't see mention, in the main post, and couldn't find by simple search, in the comments, any mention of my biggest concern about this notion of an AI development slowdown (or complete halt, as EY recently called for in Time):
Years of delay would put a significant kink in the smooth exponential progress charts of e.g. Ray Kurzweil. Which is a big deal, in my opinion, because:
(1) They're not recognised as laws of nature. But these trends, across so many technologies and the entire history of complexity, in the universe, have been so consistent, that diverting them, at will, feels like commanding the tide to not come in. It's probably less avoidable than we realise.
(2) If such a measure were somehow enacted, why wouldn't one expect civilizational collapse? Why should current society necessarily be able to be statically stable? All stagnant empires have historically collapsed. And the contemporary world is as tightly linked as one, with developments moving faster than ever, at bigger scale than ever. I feel sure there are a growing wake of known and unknown issues close behind, ready to wash over us all, if we come to a sudden slowdown.
Also, AI is not a single application to be suppressed, like any of the examples mentioned. Those, I'd liken to mushrooms, sprouting from the hidden fungal network of technological capabilities hidden out of sight. Whereas AI has already become a pervasive research tool underpinning so many continued advances.
While AGI looks set to jump in to extend the exponential upwards trend of ever more brains, now human population is plateauing. Preventing these being 'born' would, in my view, be equivalent to insanely harsh population controls. Or, a relative culling, compared to what's needed to continue on trend.
[Edit: I'd appreciate explicit critique of these thoughts, please.]
comment by NoBadCake (mark.notices@gmail.com) · 2022-12-26T14:54:51.559Z · LW(p) · GW(p)
So, a couple general thoughts.
-In the 80s/90s we were obsessing over potential atom-splitting devastation and the resulting nuclear winter. Before that there were plagues wiping out huge swaths of humanity.
-Once a technology genie is out of the bottle you can't stop it. Human nature. -In spite of the 'miracles' of science there's A LOT humanity does not know. "There are know unknowns and unknown unknowns" D.R.
-In a few billion years our sun will extinguish and all remaining life on space rock Earth will perish. All material concerns are temporary. Sorry.
-Four thousand years of good advice suggests that the most interesting & meaningful stage of life starts when we begin to Know Thyself. Now in mid-life I'm starting to suspect there is some truth to this. Happy holidays everyone!
↑ comment by NoBadCake (mark.notices@gmail.com) · 2023-02-01T15:16:06.674Z · LW(p) · GW(p)
"Once a technology genie is out of the bottle you can't stop it"
Bloomberg, Feb 1st, 2023: ChatGPT Unleashes Stock Trader Stampede for Everything AI
The stock-market euphoria around AI is reminding traders of past bubbles like 2017’s blockchain frenzy.
-------
It's be fine. Try to figure out the right( or less wrong) thing to do and then make an effort to do it.
As always.
comment by Ethos Castelli (ethos-castelli) · 2022-12-25T07:53:42.594Z · LW(p) · GW(p)
I completely agree, and I've said similar stuff to people. Let's just..pause?
comment by Teerth Aloke · 2022-12-23T04:26:12.721Z · LW(p) · GW(p)
From a longtermist viewpoint, even the tactic of terrorism to prevent X-Risk cannot and should not be ruled out. If the future of humanity is at stake, any laws and deontological rules can be overruled.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2022-12-23T04:47:12.059Z · LW(p) · GW(p)
You're welcome to make the arguments that you wish for unlikely positions, but I don't believe that agreements or morality should be set aside even if everything is at stake.
I mean, what intelligent self-respecting person would ever work with someone who might threaten you with everything they have, if they decide that the stakes are worth it? "I reckon I can get more of what I want if I threaten your family." <- If you think there's a chance someone will say that to you, run away from them. Same goes for anything that goes in the "what I want" category.
Replies from: Teerth Aloke↑ comment by Teerth Aloke · 2022-12-23T05:04:04.943Z · LW(p) · GW(p)
Hypothetically, if you know an AI lab is very close to developing AGI which is very likely to destroy humanity, and the only way to stop it is to carry out a bomb blast on the premises of the organization, would you not do it?
Replies from: Benito↑ comment by Ben Pace (Benito) · 2022-12-23T05:53:25.866Z · LW(p) · GW(p)
Would it kill anyone or just disrupt the work? I think a bomb blast that just freaks people out a bit and delays work until such time as another solution can be found, is more justifiable. I don't really know how to imagine the other scenario. What position would I not have any alternative? I would do something else. But I guess I suppose it's a government program protected by the army and nobody can get in or out and I'm somehow let in. I think I would be more likely to publicly set myself on fire or some other sort of costly signal that I believe a moral atrocity is occurring. A coward's way is to decide that everything is to be sacrificed and therefore murdering others is worth it. I don't really know how I got into this situation, it's really a very hard to imagine situation, and I never expect to be in it, I expect to have closed off this route way ahead of time. Like, to be clear, if there's a way for me to prevent myself from being in this situation, then I want to take it. I do think murder is sometimes ethical, but I am very keen to take actions that prevent murder from being on the table. Launching retaliatory nukes is sometimes the right choice, but the primary goal is to remove the ability for nuclear armageddon.
Let me put it like this: if you are ever, ever credibly worried that I might break some basic deontological rule around you, I am willing to accept any reasonable mechanism for us both making ourselves unable of violating that rule. Heck, I'm probably happy to do it unilaterally if you suggest it.
It's hard to rule out any action as being something that might be done, the hypothetical is hard to imagine, I expect I'd be vomiting and dizzy and crying and hating myself. But, as I say, I'm very willing to accept mechanisms to take such possibilities "off the table" so that I can still coordinate with others. And I am not accepting of any move toward the "let's bring terrorism onto the table". That would be gravely immoral.