Posts
Comments
Sigmoid is usually what "straight line" should mean for a quantity bounded at 0 and 1. It's a straight line in logit-space, the most natural space which complies with that range restriction.
(Just as exponentials are often the correct form of "straight line" for things that are required to be positive but have no ceiling in sight.)
Do you want to try playing this game together sometime?
We're then going to use a small amount of RL (like, 10 training episodes) to try to point it in this direction. We're going to try to use the RL to train: "Act exactly like [a given alignment researcher] would act."
Why are we doing RL if we just want imitation? Why not SFT on expert demonstrations?
Also, if 10 episodes suffices, why is so much post-training currently done on base models?
If the agent follows EDT, it seems like you are giving it epistemically unsound credences. In particular, the premise is that it's very confident it will go left, and the consequence is that it in fact goes right. This was the world model's fault, not EDT's fault. (It is notable though that EDT introduces this loopiness into the world model's job.)
[resolved]
Superadditivity seems rare in practice. For instance, workers should have subadditive contributions after some point. This is certainly true in the unemployment example in the post.
The idea of dividing failure stories into "failures involving rogue deployments" and "other failures" seems most useful if the following argument goes through:
1. Catastrophes require a very large (superhuman?) quantity and/or quality of intellectual labor
2. Either this labor is done by AIs in approved scaffolds, or it is done in "rogue deployments"
3. Hence the only easy-by-default disaster route is through a rogue deployment
4. Hence if we rule out rogue deployments and very impressive/difficult malicious labor in our scaffolds, we are safe
This seems true for most catastrophes which only need outsider affordances (such as "order the proteins etc for a pandemic or a nanofactory"). Catastrophes with outsider affordances can usually be presumed difficult because rogue humans don't randomly end the world.
However, this argument for #1 doesn't work for routes which use insider affordances or responsibilities. Nor for routes which go through work done by future generations of AIs. The central case of both is routes that involve using insider privileges to backdoor or intentionally misalign future AIs. For example:
- Planting backdoors in the codebase which allow safety training code to be turned off or misconfigured at a later time
- Poisoning datasets (idk if insider access helps though)
- Intentionally creating and defending flawed alignment plans
These routes get future generations of AIs to do the difficult work required for the final catastrophe. But they aren't necessarily rogue deployments. Consider a backdoored future AI running only in authorized scaffolds, where the safety case for the future AI was an alignment case (not a control case). The alignment case fails due to the subversive actions of the earlier AI. So the earlier AI has caused a catastrophe without doing the difficult work of directly taking over the world, and also without a rogue deployment.
One could separately argue that these routes are also "fundamentally hard" (even if not as hard as directly causing a catastrophe), but I don't see a clear blanket reason.
This google search seems to turn up some interesting articles (like maybe this one, though I've just started reading it).
Paul [Christiano] called this “problems of the interior” somewhere
Since it's slightly hard to find: Paul references it here (ctrl+f for "interior") and links to this source (once again ctrl+f for "interior"). Paul also refers to it in this post. The term is actually "position of the interior" and apparently comes from military strategist Carl von Clausewitz.
Can you clarify what figure 1 and figure 2 are showing?
I took the text description before figure 1 to mean {score on column after finetuning on 200 from row then 10 from column} - {score on column after finetuning on 10 from column}. But then the text right after says "Babbage fine-tuned on addition gets 27% accuracy on the multiplication dataset" which seems like a different thing.
Note: The survey took me 20 mins (but also note selection effects on leaving this comment)
Here's a fun thing I noticed:
There are 16 boolean functions of two variables. Now consider an embedding that maps each of the four pairs {(A=true, B=true), (A=true, B=false), ...} to a point in 2d space. For any such embedding, at most 14 of the 16 functions will be representable with a linear decision boundary.
For the "default" embedding (x=A, y=B), xor and its complement are the two excluded functions. If we rearrange the points such that xor is linearly represented, we always lose some other function (and its complement). In fact, there are 7 meaningfully distinct colinearity-free embeddings, each of which excludes a different pair of functions.[1]
I wonder how this situation scales for higher dimensions and variable counts. It would also make sense to consider sparse features (which allow superposition to get good average performance).
- ^
The one unexcludable pair is ("always true", "always false").
These are the seven embeddings:
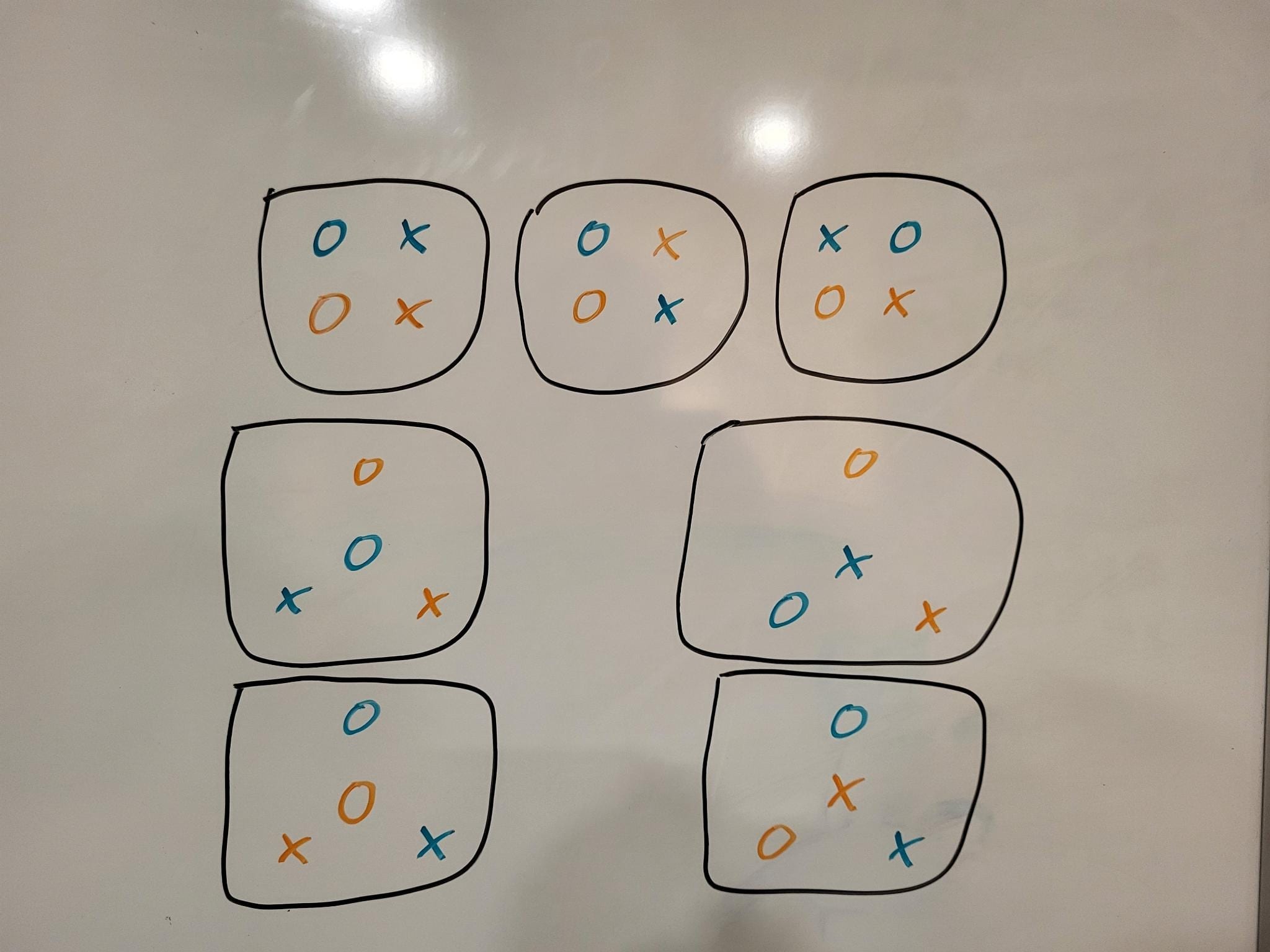
Oops, I misunderstood what you meant by unimodality earlier. Your comment seems broadly correct now (except for the variance thing). I would still guess that unimodality isn't precisely the right well-behavedness desideratum, but I retract the "directionally wrong".
The variance of the multivariate uniform distribution is largest along the direction , which is exactly the direction which we would want to represent a AND b.
The variance is actually the same in all directions. One can sanity-check by integration that the variance is 1/12 both along the axis and along the diagonal.
In fact, there's nothing special about the uniform distribution here: The variance should be independent of direction for any N-dimensional joint distribution where the N constituent distributions are independent and have equal variance.[1]
The diagram in the post showing that "and" is linearly represented works if the features are represented discretely (so that there are exactly 4 points for 2 binary features, instead of a distribution for each combination). As soon as you start defining features with thresholds like DanielVarga did, the argument stops going through in general, and the claim can become false.
The stuff about unimodality doesn't seem relevant to me, and in fact seems directionally wrong.
- ^
I have a not-fully-verbalized proof which I don't have time to write out
Maybe models track which features are basic and enforce that these features be more salient
Couldn't it just write derivative features more weakly, and therefore not need any tracking mechanism other than the magnitude itself?
It's sad that agentfoundations.org links no longer work, leading to broken links in many decision theory posts (e.g. here and here)
This will initially boost relative to because it will suddenly be joined to a network with is correctly transmitting but which does not understand at all.
However, as these networks are trained to equilibrium the advantage will disappear as a steganographic protocol is agreed between the two models. Also, this can only be used once before the networks are in equilibrium.
Why would it be desirable to do this end-to-end training at all, rather than simply sticking the two networks together and doing no further training? Also, can you clarify what the last sentence means?
(I have guesses, but I'd rather just know what you meant)
I've been asked to clarify a point of fact, so I'll do so here:
My recollection is that he probed a little and was like "I'm not too worried about that" and didn't probe further.
This does ring a bell, and my brain is weakly telling me it did happen on a walk with Nate, but it's so fuzzy that I can't tell if it's a real memory or not. A confounder here is that I've probably also had the conversational route "MIRI burnout is a thing, yikes" -> "I'm not too worried, I'm a robust and upbeat person" multiple times with people other than Nate.
In private correspondence, Nate seems to remember some actual details, and I trust that he is accurately reporting his beliefs. So I'd mostly defer to him on questions of fact here.
I'm pretty sure I'm the person mentioned in TurnTrout's footnote. I confirm that, at the time he asked me, I had no recollection of being "warned" by Nate but thought it very plausible that I'd forgotten.
What's "denormalization"?
When you describe the "emailing protein sequences -> nanotech" route, are you imagining an AGI with computers on which it can run code (like simulations)? Or do you claim that the AGI could design the protein sequences without writing simulations, by simply thinking about it "in its head"?
Cool! It wrote and executed code to solve the problem, and it got it right.
Are you using chat-GPT-4? I thought it can't run code?
Interesting, I find what you are saying here broadly plausible, and it is updating me (at least toward greater uncertainity/confusion). I notice that I don't expect the 10x effect, or the Von Neumann effect, to be anywhere close to purely genetic. Maybe some path-dependency in learning? But my intuition (of unknown quality) is that there should be some software tweaks which make the high end of this more reliably achievable.
Anyway, to check that I understand your position, would this be a fair dialogue?:
Person: "The jump from chimps to humans is some combination of a 3x scaleup and some algorithmic improvements. Once you have human-level AI, scaling it up 3x and adding a chimp-to-human-jump worth of algorithmic improvement would get you something vastly superhuman, like 30x or 1000x Von Neumann, if not incomparable."
Vivek's model of Jacob: "Nope. The 3x scaleup is the only thing, there wasn't much algorithmic improvement. The chimp-to-human scaling jump was important because it enabled language/accumulation, but there is nothing else left like that. There's nothing practical you can do with 3x human-level compute that would 30x Von Neumann[1], even if you/AIs did a bunch of algorithmic research."
I find your view more plausible than before, but don't know what credence to put on it. I'd have more of a take if I properly read your posts.
- ^
I'm not sure how to operationalize this "30x-ing" though. Some candidates:
- "1000 scientists + 30 Von Neumanns" vs. "1000 scientists + 1 ASI"
- "1 ASI" vs. "30 Von Neumanns"
- "100 ASIs" vs. "3000 Von Neumanns"
In your view, who would contribute more to science -- 1000 Einsteins, or 10,000 average scientists?[1]
"IQ variation is due to continuous introduction of bad mutations" is an interesting hypothesis, and definitely helps save your theory. But there are many other candidates, like "slow fixation of positive mutations" and "fitness tradeoffs[2]".
Do you have specific evidence for either:
- Deleterious mutations being the primary source of IQ variation
- Human intelligence "plateauing" around the level of top humans[3]
Or do you believe these things just because they are consistent with your learning efficiency model and are otherwise plausible?[4]
Maybe you have a very different view of leading scientists than most people I've read here? My picture here is not based on any high-quality epistemics (e.g. it includes "second-hand vibes"), but I'll make up some claims anyway, for you to agree or disagree with:
- There are some "top scientists" (like Einstein, Dirac, Von Neumann, etc). Within them, much of the variance in fame is incidental, but they are clearly a class apart from merely 96th percentile scientists. 1000 {96%-ile-scientists} would be beaten by 500 {96%-ile-scientists} + 100 Einstein-level scientists.
- Even within "top scientists" in a field, the best one is more than 3x as intrinsically productive[5] as the 100th best one.
- ^
I'm like 90% on the Einsteins for theoretical physics, and 60% on the Einsteins for chemistry
- ^
Within this, I could imagine anything from "this gene's mechanism obviously demands more energy/nutrients" to "this gene happens to mess up some other random thing, not even in the brain, just because biochemistry is complicated". I have no idea what the actual prevalence of any of this is.
- ^
What does this even mean? Should the top 1/million already be within 10x of peak productivity? How close should the smartest human alive be to the peak? Are they nearly free of deleterious mutations?
- ^
I agree that they are consistent with each other and with your view of learning efficiency, but am not convinced of any of them.
- ^
"intrinsic" == assume they have the same resources (like lab equipment and junior scientists if they're experimentalists)
It would still be interesting to know whether you were surprised by GPT-4's capabilities (if you have played with it enough to have a good take)
Human intelligence in terms of brain arch priors also plateaus
Why do you think this?
POV: I'm in an ancestral environment, and I (somehow) only care about the rewarding feeling of eating bread. I only care about the nice feeling which comes from having sex, or watching the birth of my son, or being gaining power in the tribe. I don't care about the real-world status of my actual son, although I might have strictly instrumental heuristics about e.g. how to keep him safe and well-fed in certain situations, as cognitive shortcuts for getting reward (but not as terminal values).
Would such a person sacrifice themselves for their children (in situations where doing so would be a fitness advantage)?
Isn't going from an average human to Einstein a huge increase in science-productivity, without any flop increase? Then why can't there be software-driven foom, by going farther in whatever direction Einstein's brain is from the average human?
Of course, my argument doesn't pin down the nature or rate of software-driven takeoff, or whether there is some ceiling. Just that the "efficiency" arguments don't seem to rule it out, and that there's no reason to believe that science-per-flop has a ceiling near the level of top humans.
You could use all of world energy output to have a few billion human speed AGI, or a millions that think 1000x faster, etc.
Isn't it insanely transformative to have millions of human-level AIs which think 1000x faster?? The difference between top scientists and average humans seems to be something like "software" (Einstein isn't using 2x the watts or neurons). So then it should be totally possible for each of the "millions of human-level AIs" to be equivalent to Einstein. Couldn't a million Einstein-level scientists running at 1000x speed could beat all human scientists combined?
And, taking this further, it seems that some humans are at least 100x more productive at science than others, despite the same brain constraints. Then why shouldn't it be possible to go further in that direction, and have someone 100x more productive than Einstein at the same flops? And if this is possible, it seems to me like whatever efficiency constraints the brain is achieving cannot be a barrier to foom, just as the energy efficiency (and supposed learning optimality?) of the average human brain does not rule out Einstein more than 100x-ing them with the same flops.
In your view, is it possible to make something which is superhuman (i.e. scaled beyond human level), if you are willing to spend a lot on energy, compute, engineering cost, etc?
It would be "QA", not "QE"
Any idea why "cheese Euclidean distance to top-right corner" is so important? It's surprising to me because the convolutional layers should apply the same filter everywhere.
See Godel's incompleteness theorems. For example, consider the statement "For all A, (ZFC proves A) implies A", encoded into a form judgeable by ZFC itself. If you believe ZFC to be sound, then you believe that this statement is true, but due to Godel stuff you must also believe that ZFC cannot prove it. The reasons for believing ZFC to be sound are reasons from "outside the system" like "it looks logically sound based on common sense", "it's never failed in practice", and "no-one's found a valid issue". Godel's theorems let us convert this unprovable belief in the system's soundness into true-but-unprovable mathematical statements.
More mundanely, there are tons of "there doesn't exist" statements in number theory which are very likely to be true based on unrigorous probabilistic arguments, but are apparently very hard to prove. So there are plenty of things which are "very likely true" but unproven. (I get this example from Paul Christiano, who brings it up in relation to ARC's "heuristic arguments" work. I think Terence Tao also has a post about this?)
??? For math this is exactly backward, there can be true-but-unprovable statements
Agreed. To give a concrete toy example: Suppose that Luigi always outputs "A", and Waluigi is {50% A, 50% B}. If the prior is {50% luigi, 50% waluigi}, each "A" outputted is a 2:1 update towards Luigi. The probability of "B" keeps dropping, and the probability of ever seeing a "B" asymptotes to 50% (as it must).
This is the case for perfect predictors, but there could be some argument about particular kinds of imperfect predictors which supports the claim in the post.
In section 3.7 of the paper, it seems like the descriptions ("6 in 5", etc) are inconsistent across the image, the caption, and the paragraph before them. What are the correct labels? (And maybe fix the paper if these are typos?)
Does the easiest way to make you more intelligent also keep your values intact?
What exactly do you mean by "multi objective optimization"?
It would help if you specified which subset of "the community" you're arguing against. I had a similar reaction to your comment as Daniel did, since in my circles (AI safety researchers in Berkeley), governance tends to be well-respected, and I'd be shocked to encounter the sentiment that working for OpenAI is a "betrayal of allegiance to 'the community'".
In ML terms, nearly-all the informational work of learning what “apple” means must be performed by unsupervised learning, not supervised learning. Otherwise the number of examples required would be far too large to match toddlers’ actual performance.
I'd guess the vast majority of the work (relative to the max-entropy baseline) is done by the inductive bias.
Beware, though; string theory may be what underlies QFT and GR, and it describes a world of stringy objects that actually do move through space
I think this contrast is wrong.[1] IIRC, strings have the same status in string theory that particles do in QFT. In QM, a wavefunction assigns a complex number to each point in configuration space, where state space has an axis for each property of each particle.[2] So, for instance, a system with 4 particles with only position and momentum will have a 12-dimensional configuration space.[3] IIRC, string theory is basically a QFT over configurations of strings (and also branes?), instead of particles. So the "strings" are just as non-classical as the "fundamental particles" in QFT are.
- ^
I don't know much about string theory though, I could be wrong.
- ^
Oversimplifying a bit
- ^
4 particles * 3 dimensions. The reason it isn't 24-dimensional is that position and momentum are canonical conjugates.
As I understand Vivek's framework, human value shards explain away the need to posit alignment to an idealized utility function. A person is not a bunch of crude-sounding subshards (e.g. "If
food nearbyandhunger>15, then be more likely togo to food") and then also a sophisticated utility function (e.g. something like CEV). It's shards all the way down, and all the way up.[10]
This read to me like you were saying "In Vivek's framework, value shards explain away .." and I was confused. I now think you mean "My take on Vivek's is that value shards explain away ..". Maybe reword for clarity?
(Might have a substantive reply later)
Makes perfect sense, thanks!
"Well, what if I take the variables that I'm given in a Pearlian problem and I just forget that structure? I can just take the product of all of these variables that I'm given, and consider the space of all partitions on that product of variables that I'm given; and each one of those partitions will be its own variable.
How can a partition be a variable? Should it be "part" instead?
ETA: Koen recommends reading Counterfactual Planning in AGI Systems before (or instead of) Corrigibility with Utility Preservation
Update: I started reading your paper "Corrigibility with Utility Preservation".[1] My guess is that readers strapped for time should read {abstract, section 2, section 4} then skip to section 6. AFAICT, section 5 is just setting up the standard utility-maximization framework and defining "superintelligent" as "optimal utility maximizer".
Quick thoughts after reading less than half:
AFAICT,[2] this is a mathematical solution to corrigibility in a toy problem, and not a solution to corrigibility in real systems. Nonetheless, it's a big deal if you have in fact solved the utility-function-land version which MIRI failed to solve.[3] Looking to applicability, it may be helpful for you to spell out the ML analog to your solution (or point us to the relevant section in the paper if it exists). In my view, the hard part of the alignment problem is deeply tied up with the complexities of the {training procedure --> model} map, and a nice theoretical utility function is neither sufficient nor strictly necessary for alignment (though it could still be useful).
So looking at your claim that "the technical problem [is] mostly solved", this may or may not be true for the narrow sense (like "corrigibility as a theoretical outer-objective problem in formally-specified environments"), but seems false and misleading for the broader practical sense ("knowing how to make an AGI corrigible in real life").[4]
Less important, but I wonder if the authors of Soares et al agree with your remark in this excerpt[5]:
"In particular, [Soares et al] uses a Platonic agent model [where the physics of the universe cannot modify the agent's decision procedure] to study a design for a corrigible agent, and concludes that the design considered does not meet the desiderata, because the agent shows no incentive to preserve its shutdown behavior. Part of this conclusion is due to the use of a Platonic agent model."
- ^
Btw, your writing is admirably concrete and clear.
Errata: Subscripts seem to broken on page 9, which significantly hurts readability of the equations. Also there is a double-typo "I this paper, we the running example of a toy universe" on page 4.
- ^
Assuming the idea is correct
- ^
Do you have an account of why MIRI's supposed impossibility results (I think these exist?) are false?
- ^
I'm not necessarily accusing you of any error (if the contest is fixated on the utility function version), but it was misleading to me as someone who read your comment but not the contest details.
- ^
Portions in [brackets] are insertions/replacements by me
To be more specific about the technical problem being mostly solved: there are a bunch of papers outlining corrigibility methods that are backed up by actual mathematical correctness proofs
Can you link these papers here? No need to write anything, just links.
- Try to improve my evaluation process so that I can afford to do wider searches without taking excessive risk.
Improve it with respect to what?
My attempt at a framework where "improving one's own evaluator" and "believing in adversarial examples to one's own evaluator" make sense:
- The agent's allegiance is to some idealized utility function (like CEV). The agent's internal evaluator is "trying" to approximate by reasoning heuristically. So now we ask Eval to evaluate the plan "do argmax w.r.t. Eval over a bunch of plans". Eval reasons that, due to the the way that Eval works, there should exist "adversarial examples" that score very highly on Eval but low on . Hence, Eval concludes that is low, where plan = "do argmax w.r.t. Eval". So the agent doesn't execute the plan "search widely and argmax".
- "Improving " makes sense because Eval will gladly replace itself with if it believes that is a better approximation for (and hence replacing itself will cause the outcome to score better on )
Are there other distinct frameworks which make sense here? I look forward to seeing what design Alex proposes for "value child".
Yeah, the right column should obviously be all 20s. There must be a bug in my code[1] :/
I like to think of the argmax function as something that takes in a distribution on probability distributions on with different sigma algebras, and outputs a partial probability distribution that is defined on the set of all events that are in the sigma algebra of (and given positive probability by) one of the components.
Take the following hypothesis :
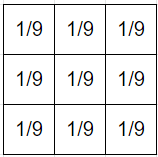
If I add this into with weight , then the middle column is still nearly zero. But I can now ask for the probablity of the event in corresponding to the center square, and I get back an answer very close to zero. Where did this confidence come from?
I guess I'm basically wondering what this procedure is aspiring to be. Some candidates I have in mind:
- Extension to the coarse case of regular hypothesis mixing (where we go from P(w) and Q(w) to )
- Extension of some kind of Bayesian update-flavored thing where we go to then renormalize
- ETA: seems more plausible than
- Some kind of "aggregation of experts who we trust a lot unless they contradict each other", which isn't cleanly analogous to either of the above
Even in case 3, the near-zeros are really weird. The only cases I can think of where it makes sense are things like "The events are outcomes of a quantum process. Physics technique 1 creates hypothesis 1, and technique 2 creates hypothesis 2. Both techniques are very accurate, and the uncertainity they express is due to fundamental unknowability. Since we know both tables are correct, we can confidently rule out the middle column, and thus rule out certain events in hypothesis 3."
But more typically, the uncertainity is in the maps of the respective hypotheses, not in the territory, in which case the middle zeros seem unfounded. And to be clear, the reason it seems like a real issue[2] is that when you add in hypothesis 3 you have events in the middle which you can query, but the values can stay arbitrarily close to zero if you add in hypothesis 3 with low weight.
Now, let's consider the following modification: Each hypothesis is no longer a distribution on , but instead a distribution on some coarser partition of . Now is still well defined
Playing around with this a bit, I notice a curious effect (ETA: the numbers here were previously wrong, fixed now):
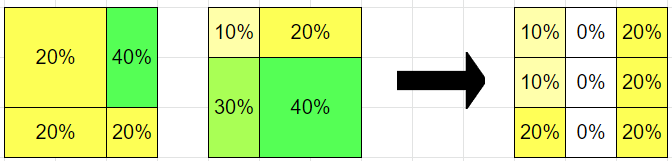
The reason the middle column goes to zero is that hypothesis A puts 60% on the rightmost column, and hypothesis B puts 40% on the leftmost, and neither cares about the middle column specifically.
But philosophically, what does the merge operation represent, which causes this to make sense? (Maybe your reply is just "wait for the next post")
most egregores/epistemic networks, which I'm completely reliant upon, are much smarter than me, so that can't be right
*Egregore smiles*