Making Nanobots isn't a one-shot process, even for an artificial superintelligance
post by dankrad · 2023-04-25T00:39:24.520Z · LW · GW · 13 commentsContents
Core argument Significance for AI alignment Pivotal acts How could this argument change in the future What this shouldn't be taken as None 13 comments
Summary: Yudkowsky argues [AF · GW]that an unaligned AI will figure out a way to create self-replicating nanobots, and merely having internet access is enough to bring them into existence. Because of this, it can very quickly replace all human dependencies for its existence and expansion, and thus pursue an unaligned goal, e.g. making paperclips, which will most likely end up in the extinction of humanity.
I however will write below why I think this description massively underestimates the difficulty in creating self-replicating nanobots (even assuming that they are physically possible), which requires focused research in the physical domain, and is not possible without involvement of top-tier human-run labs today.
Why it matters? Some of the assumptions of pessimistic AI alignment researchers, especially by Yudkowsky, rest fundamentally on the fact that the AI will find quick ways to replace humans required for the AI to exist and expand.
- We have to get AI alignment right the first time we build a Super-AI, and there are no ways to make any corrections after we've built it
- As long as the AI does not have a way to replace humans outright, even if its ultimate goal may be non-aligned, it can pursue proximate goals that are aligned and safe for it to do. Alignment research can continue and can attempt to make the AI fully aligned or shut it down before it can create nanobots.
- The first time we build a Super-AI, we don't just have to make sure it's aligned, but we need it to perform a pivotal act like create nanobots to destroy all GPUs
- I argue below that this framing may be bad because it means performing one of the most dangerous steps first — creating nanobots — which may be best performed by an AI that is much more aligned than a first attempt
What this post is not about: I make no argument about the feasibility of (non-biological) self-replicating nanobots. There may be fundamental reasons why they are impossible/difficult (even for superintelligent AIs)/will not outcompete biological life, an interesting question that is explored more by bhaut [LW · GW]. I also don't claim that AI alignment doesn't matter. I think that it's extremely important, but I think it's unlikely that (1) a one-shot process will lead to it and also (2) that one-shot is necessary; I actually think that this kind of thinking increases risk.
Finally, I don't claim that there aren't easier ways to kill all, or almost all, humans, for example pandemics or causing nuclear wars. However, most of these scenarios do not leave any good paths for an AI to expand because there would be no way to get more of its substrate (e.g. GPUs) or power supplies.
Core argument
Building something like a completely new type of nanobot is a massive research undertaking. Even under the assumption that an AI is much more intelligent and can learn and infer from much less data, it cannot do so from no data.
Building a new type of nanobot (not based on biological life) requires not just the ability to design from existing capabilities, but actually doing completely new experiments on how the nanomachinery that is going to be used to do this interacts with itself and the external world. It isn't possible to completely cut out all experiments from the design process, because at least some of the experiments will be about how the physical world works. If you don't know anything about physics, you clearly can't design any kind of machine; I am pretty certain that right now we do not know enough about nanomachines to design a new kind of non-biological self-replicating nanobot that immediately works out of the box.
To build it, you would need high quality labs to do very well specified experiments, build prototypes in later stages and report detailed information on how they failed, until you could arrive at a first sample of a self-replicating nanobot, at which point the AGI might be in a position to replace all humans.
Counterargument 1: We can build some complex machines from blueprints, and they work the first time. As an example, we can certainly design a complex electronics product, manufacture the PCB and add all the chips and other parts. If an experienced engineer does this, there is a good chance it will work the first time. However, new nanomachines would be different, because they cannot be assembled from parts that are already extremely well studied in isolation. We make chips such that when they are used in their specified way, their behaviour is extremely predictable, but no such components currently exist in the world of nanomachines.
Counterargument 2: The AI can simply simulate everything instead of performing any physical experiments. All of the required laws of physics are known: The standard model describes the microscopic world extremely well, and (microscopic) gravity is irrelevant for constructing nanobot, so no (currently unknown) physical theory unifying all laws would be required. While it is indeed possible or even likely that the standard model theoretically describes all details of a working nanobot with the required precision, the problem is that in practice it is impossible to simulate large physical systems using it. Many complex physical systems are still largely modelled empirically (ad-hoc models validated using experiments) rather than it being possible to derive them from first principles. While physicists sometimes claim to derive things from first principles, in practice these derivations often ignore a lot of details which still has to be justified using experiments. An AI can also make progress on better simulation, but simulating complex nanomachines outright is exceedingly unlikely.
Counterargument 3: Nanobots already exist, the AI will just use existing biology. Existing biology is indeed good for making self-replicating nanobots, but at least two difficult problems will remain: To make any kind of effective use of the network of nanobots, it will require creating a communication network using cells that allows them to come together to execute some more complex software to at least connect to the internet (and thus back to the AI). That's still a monumental task to achieve using biological systems and would still require a lot of research.
Counterargument 4: The AI can do the experiments in secret, or hide the true nature of the experiments in things that seem aligned. This could certainly be relevant in the long run, especially if we want the AI to solve complex problems. But on shorter timescales, most of what the AI would need to learn is going to be extremely specific to nanomachines. You do not get data about this by making completely unrelated experiments that do not involve nanotechnology.
Significance for AI alignment
I don't claim that this means we don't need alignment, or that an AI won't eventually be able to build nanobots (if it is feasible at all, of course) — just that it seems highly possible to delay this step by years, if it is the intention of the operator to do so (and it has some minimal cooperation on this from the rest of the world).
This means that it is possible to study AIs with capabilities potentially far exceeding human capabilities. Alignment is likely an iterative process and no one-shot solution exists, but that's probably ok, because well-enough aligned AIs can coexist with humans, be studied, and be improved for the next iteration, without immediately seeing human bodies only as bags of atoms to be harvested to do other things.
Pivotal acts
I think pivotal acts may be a bad idea in general. The arguments for this have been spelled out before, for example by Andrew_Critch [LW · GW]. However, even if one believes (a) in the feasibility of nanobots and (b) pivotal acts are necessary, then using nanobots to carry out a pivotal action might be a really bad idea.
If someone decides that a pivotal act should be carried out using nanobots (either on their own or by this being the suggested best option by an AI), they might be inclined to do anything to perform any physical acts necessary for the AI to achieve this, making the AI much more dangerous if it is not perfectly aligned (which in itself may be an impossible problem). Pivotal acts that do not require giving an AI full human-equivalent or better physical capabilities would be much safer (probably still a bad idea).
How could this argument change in the future
I think my argument that building nanobots without massive help from first-tier human labs is true now and for at least several more years. However, over several decades, some things might change substantially, for example:
1. Production processes could be much more automated than they are now. If factories exist that can make new, complex machines without major retooling, they could make it much simpler for an AI to perform completely new tasks in the physical world with minimal human interaction
2. Robotics can advance. Humanoid robots that can peform many physical human tasks may make it possible for the AI to build completely human-independent labs.
3. More research into building nanomachines that eliminates more of the unknowns.
4. More biotech research could also allow more control of the physical world, for example if cell networks can be built to perform some tasks.
5. It is maybe possible that quantum computers are powerful enough to simulate much more complex physical processes than is possible on classical computers, and thus an AI with access to a quantum computer may be able to massively reduce the number of experiments necessary to construct nanobots. (Feels unlikely to me but cannot a priori be excluded)
So whether an AI can achieve nanobots just via internet access will potentially have to be re-evaluated in the future when one or more of these are developed.
What this shouldn't be taken as
I am not arguing alignment is not important, in fact I think it is very important.
1. Regardless of the feasibility of nanobots, I think there are probably vastly easier ways to kill all humans, however they would leave an AI without a practical way to continue existing or expanding.
2. It is also possible that many scenarios exist where an AI does (1) by accident.
3. AIs don't need nanobots to take control of humans and human institutions. There are many other ways that involve using humans against each other and are probably exploitable by much less powerful AIs. (Crucially, however, they do depend on some humans and might require different tools to control AGI risk.)
4. I don't think that this makes the AI alignment trivial to solve, or claim that this gives a recipe to solve it. I just think that it may be fruitful to look into research that starts from moderately aligned AIs and figures out how to get them more aligned rather than having to perform a very risky one-shot experiment.
13 comments
Comments sorted by top scores.
comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2023-06-02T03:47:14.957Z · LW(p) · GW(p)
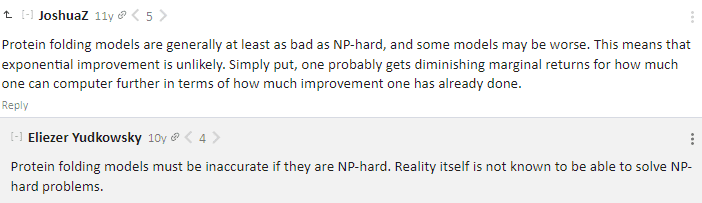
Lacking time right now for a long reply: The main thrust of my reaction is that this seems like a style of thought which would have concluded in 2008 that it's incredibly unlikely for superintelligences to be able to solve the protein folding problem. People did, in fact, claim that to me in 2008. It furthermore seemed to me in 2008 that protein structure prediction by superintelligence was the hardest or least likely step of the pathway by which a superintelligence ends up with nanotech; and in fact I argued only that it'd be solvable for chosen special cases of proteins rather than biological proteins because the special-case proteins could be chosen to have especially predictable pathways. All those wobbles, all those balanced weak forces and local strange gradients along potential energy surfaces! All those nonequilibrium intermediate states, potentially with fragile counterfactual dependencies on each interim stage of the solution! If you were gonna be a superintelligence skeptic, you might have claimed that even chosen special cases of protein folding would be unsolvable. The kind of argument you are making now, if you thought this style of thought was a good idea, would have led you to proclaim that probably a superintelligence could not solve biological protein folding and that AlphaFold 2 was surely an impossibility and sheer wishful thinking.
If you'd been around then, and said, "Pre-AGI ML systems will be able to solve general biological proteins via a kind of brute statistical force on deep patterns in an existing database of biological proteins, but even superintelligences will not be able to choose special cases of such protein folding pathways to design de novo synthesis pathways for nanotechnological machinery", it would have been a very strange prediction, but you would now have a leg to stand on. But this, I most incredibly doubt you would have said - the style of thinking you're using would have predicted much more strongly, in 2008 when no such thing had been yet observed, that pre-AGI ML could not solve biological protein folding in general, than that superintelligences could not choose a few special-case solvable de novo folding pathways along sharper potential energy gradients and with intermediate states chosen to be especially convergent and predictable.
Replies from: Vivek↑ comment by Vivek Hebbar (Vivek) · 2023-06-05T02:00:07.463Z · LW(p) · GW(p)
When you describe the "emailing protein sequences -> nanotech" route, are you imagining an AGI with computers on which it can run code (like simulations)? Or do you claim that the AGI could design the protein sequences without writing simulations, by simply thinking about it "in its head"?
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2023-06-07T16:27:34.306Z · LW(p) · GW(p)
At the superintelligent level there's not a binary difference between those two clusters. You just compute each thing you need to know efficiently.
Replies from: o-o↑ comment by O O (o-o) · 2023-06-10T21:10:37.693Z · LW(p) · GW(p)
I’m confused as to why there necessarily wouldn’t be a difference between the two.
I can think of a classes problems without better than brute force or simulation solutions, e.g. Bitcoin mining and there are plenty of these solutions that explode enough in complexity that they are infeasible given the resource of the universe for certain input sizes.
Alphafold2 also did not fully solve the protein folding problem. Rather, it still has a significant error rate as reported by google themselves with regions of low confidence. It also seems to go up significantly in certain classes of inputs such as longer loop structures.
Further, it was possibly not solved to the extent of what people in 2008 were arguing against, given we are nowhere near predicting how protein folds in interactions. I’m unsure whether the predicted value of solving protein folding back then is equal to the predicted value of extent to which AlphaFold solves it.
My next conclusion is mostly an inference, but broadly it seems like DL models hit a sigmoid curve when it comes to eeking out the final percentages of accuracy, and this can also be seen in self driving cars and LLMs. This makes sense given the world largely follows predictable laws with a small but frequent number of exceptions. In a one shot experiment, this uncertainty would accumulate exponentially making it seem unlikely that it would succeed.
I think clearly it can reduce the amount of experiments needed, but one shot seems like too high of a bar to hold through only generalizations that take less than 1 OOM of compute than the universe uses to “simulate” results as you experiment due to compounding errors.
comment by avturchin · 2023-04-25T10:23:36.508Z · LW(p) · GW(p)
An AI which run out of the box into the internet will be limited in computational resources, so modeling of nanobot from first principle will be difficult for it.
Superintelligence which doesn't yet have built its own computational infrastructure is a limited low-level superintelligence, but to build its own infrastructure it needs nanotech.
So we have a vicious circle: to get nanotech it needs very large computational resources, but to have such resources it needs nanotech.
comment by DaemonicSigil · 2023-05-13T01:55:21.940Z · LW(p) · GW(p)
Counterargument 2 still seems correct to me.
Techniques like Density Functional Theory give pretty-accurate results for molecular systems in an amount of time far less than a full quantum mechanical calculation would take. While in theory quantum computing is a complexity class beyond what classical computers can handle, in practice it seems that it's possible to get quite good results, even on a classical computer. The hardness of simulating atoms and molecules looks like it depends heavily on progress in algorithms, rather than being based on the hardness of simulating arbitrary quantum circuits. Even we humans are continuing to research and come up with improved techniques for molecular simulation. Look up "Ferminet" for one relatively recent AI-based advance. The concern is that a superintelligence may be able to skip ahead in this timeline of algorithmic improvements.
While physicists sometimes claim to derive things from first principles, in practice these derivations often ignore a lot of details which still has to be justified using experiments.
Other ways that approximations can be justified:
- Using a known-to-be-accurate but more expensive simulation technique to validate a newer less expensive technique.
- Proving bounds on the error.
- Comparing with known quantities and results. Plenty of experimental data is already on the internet, including things like the heating curve of water, which depends on the detailed interactions of a very large number of water molecules.
simulating complex nanomachines outright is exceedingly unlikely.
As you mentioned above, once you have a set of basic components in your toolbox that are well understood by you, the process of designing things becomes much easier. So you only really need the expensive physics simulations for designing your basic building blocks. After that, you can coarse-grain these blocks in the larger design you're building. When designing transistors, engineers have to worry about the geometry of the transistor and use detailed simulations of how charge carriers will flow in the semiconductor. In a circuit simulator like LTSpice that's all abstracted away.
comment by Tor Økland Barstad (tor-okland-barstad) · 2023-04-29T07:48:06.153Z · LW(p) · GW(p)
I suspect my own intuitions regarding this kind of thing are similar to Eliezer's. It's possible that my intuitions are wrong, but I'll try to share some thoughts.
It seems that we think quite differently when it comes to this, and probably it's not easy for us to achieve mutual understanding. But even if all we do here is to scratch the surface, that may still be worthwhile.
As mentioned, maybe my intuitions are wrong. But maybe your intuitions are wrong (or maybe both). I think a desirable property of plans/strategies for alignment would be robustness to either of us being wrong about this 🙂
I however will write below why I think this description massively underestimates the difficulty in creating self-replicating nanobots
Among people who would suspect me of underestimating the difficulty of developing advanced nanotech, I would suspect most of them of underestimating the difference made by superintelligence + the space of options/techniques/etc that a superintelligent mind could leverage.
In Drexler's writings about how to develop nanotech, one thing that was central to his thinking was protein folding. I remember that in my earlier thinking, it felt likely to me that a superintelligence would be able to "solve" protein folding (to a sufficient extent to do what it wanted to do). My thinking was "some people describe this as infeasible, but I would guess for a superintelligence to be able to do this".
This was before AlphaFold. The way I remember it, the idea of "solving" protein folding was more controversial back in the day (although I tried to google this now, and it was harder to find good examples than I thought it would be).
While physicists sometimes claim to derive things from first principles, in practice these derivations often ignore a lot of details which still has to be justified using experiments
As humans we are "pathetic" in terms of our mental abilities. We have a high error-rate in our reasoning / the work we do, and this makes us radically more dependent on tight feedback-loops with the external world.
This point of error-rate in one's thinking is a really important think. With lower error-rate + being able to do much more thinking / mental work, it becomes possible to learn and do much much more without physical experiments.
The world, and guesses regarding how the world works (including detail-oriented stuff relating to chemistry/biology), are highly interconnected. For minds that are able to do vast about of high-quality low error-rate thinking, it may be possible to combine subtle and noisy Bayesian evidence into overwhelming evidence. And for approaches it explores regarding this kind of thinking, it can test how good it does at predicting existing info/data that it already has access to.
The images below are simple/small examples of the kind of thinking I'm thinking of. But I suspect superintelligences can take this kind of thinking much much further.


The post Einstein's Arrogance [LW · GW] also feels relevant here.
While it is indeed possible or even likely that the standard model theoretically describes all details of a working nanobot with the required precision, the problem is that in practice it is impossible to simulate large physical systems using it.
It is infeasible to simulate in "full detail", but it's not clear what we should conclude based on that. Designs that work are often robust to the kinds of details that we need precise simulation in order to simulate correctly.
The specifics of the level of detail that is needed depends on the design/plan in question. A superintelligence may be able to work with simulations in a much less crude way than we do (with much more fine-grained and precise thinking in regards to what can be abstracted away for various parts of the "simulation").
The construction-process/design the AI comes up with may:
- Be constituted of various plans/designs at various levels of abstraction (without most of them needing to work in order for the top-level mechanism to work). The importance/power of the why not both?-principle is hard to understate.
- Be self-correcting in various ways. Like, it can have learning/design-exploration/experimentation built into itself somehow.
- Have lots of built-in contingencies relating to unknowns, as well as other mechanisms to make the design robust to unknowns (similar to how engineers make bridges be stronger than they need to be).
Here are some relevant quotes from Radical Abudance by Eric Drexler:
"Coping with limited knowledge is a necessary part of design and can often be managed. Indeed, engineers designed bridges long before anyone could calculate stresses and strains, which is to say, they learned to succeed without knowledge that seems essential today. In this light, it’s worth considering not only the extent and precision of scientific knowledge, but also how far engineering can reach with knowledge that remains incomplete and imperfect.
For example, at the level of molecules and materials—the literal substance of technological systems—empirical studies still dominate knowledge. The range of reliable calculation grows year by year, yet no one calculates the tensile strength of a particular grade of medium-carbon steel. Engineers either read the data from tables or they clamp a sample in the jaws of a strength-testing machine and pull until it breaks. In other words, rather than calculating on the basis of physical law, they ask the physical world directly.
Experience shows that this kind of knowledge supports physical calculations with endless applications. Building on empirical knowledge of the mechanical properties of steel, engineers apply physics-based calculations to design both bridges and cars. Knowing the empirical electronic properties of silicon, engineers apply physics-based calculations to design transistors, circuits, and computers.
Empirical data and calculation likewise join forces in molecular science and engineering. Knowing the structural properties of particular configurations of atoms and bonds enables quantitative predictions of limited scope, yet applicable in endless circumstances. The same is true of chemical processes that break or make particular configurations of bonds to yield an endless variety of molecular structures.
Limited scientific knowledge may suffice for one purpose but not for another, and the difference depends on what questions it answers. In particular, when scientific knowledge is to be used in engineering design, what counts as enough scientific knowledge is itself an engineering question, one that by nature can be addressed only in the context of design and analysis.
Empirical knowledge embodies physical law as surely as any calculation in physics. If applied with caution—respecting its limits—empirical knowledge can join forces with calculation, not just in contemporary engineering, but in exploring the landscape of potential technologies.
To understand this exploratory endeavor and what it can tell us about human prospects, it will be crucial to understand more deeply why the questions asked by science and engineering are fundamentally different. One central reason is this: Scientists focus on what’s not yet discovered and look toward an endless frontier of unknowns, while engineers focus on what has been well established and look toward textbooks, tabulated data, product specifications, and established engineering practice. In short, scientists seek the unknown, while engineers avoid it.
Further, when unknowns can’t be avoided, engineers can often render them harmless by wrapping them in a cushion. In designing devices, engineers accommodate imprecise knowledge in the same way that they accommodate imprecise calculations, flawed fabrication, and the likelihood of unexpected events when a product is used. They pad their designs with a margin of safety.
The reason that aircraft seldom fall from the sky with a broken wing isn’t that anyone has perfect knowledge of dislocation dynamics and high-cycle fatigue in dispersion-hardened aluminum, nor because of perfect design calculations, nor because of perfection of any other kind. Instead, the reason that wings remain intact is that engineers apply conservative design, specifying structures that will survive even unlikely events, taking account of expected flaws in high-quality components, crack growth in aluminum under high-cycle fatigue, and known inaccuracies in the design calculations themselves. This design discipline provides safety margins, and safety margins explain why disasters are rare."
"Engineers can solve many problems and simplify others by designing systems shielded by barriers that hold an unpredictable world at bay. In effect, boxes make physics more predictive and, by the same token, thinking in terms of devices sheltered in boxes can open longer sightlines across the landscape of technological potential. In my work, for example, an early step in analyzing APM systems was to explore ways of keeping interior working spaces clean, and hence simple.
Note that designed-in complexity poses a different and more tractable kind of problem than problems of the sort that scientists study. Nature confronts us with complexity of wildly differing kinds and cares nothing for our ability to understand any of it. Technology, by contrast, embodies understanding from its very inception, and the complexity of human-made artifacts can be carefully structured for human comprehension, sometimes with substantial success.
Nonetheless, simple systems can behave in ways beyond the reach of predictive calculation. This is true even in classical physics.
Shooting a pool ball straight into a pocket poses no challenge at all to someone with just slightly more skill than mine and a simple bank shot isn’t too difficult. With luck, a cue ball could drive a ball to strike another ball that drives yet another into a distant pocket, but at every step impacts between curved surfaces amplify the effect of small offsets, and in a chain of impacts like this the outcome soon becomes no more than a matter of chance—offsets grow exponentially with each collision. Even with perfect spheres, perfectly elastic, on a frictionless surface, mere thermal energy would soon randomize paths (after 10 impacts or so), just as it does when atoms collide.
Many systems amplify small differences this way, and chaotic, turbulent flow provides a good example. Downstream turbulence is sensitive to the smallest upstream changes, which is why the flap of a butterfly’s wing, or the wave of your hand, will change the number and track of the storms in every future hurricane season.
Engineers, however, can constrain and master this sort of unpredictability. A pipe carrying turbulent water is unpredictable inside (despite being like a shielded box), yet can deliver water reliably through a faucet downstream. The details of this turbulent flow are beyond prediction, yet everything about the flow is bounded in magnitude, and in a robust engineering design the unpredictable details won’t matter."
and is not possible without involvement of top-tier human-run labs today
Eliezer's scenario does assume the involvement of human labs (he describes a scenario where DNA is ordered online).
Alignment is likely an iterative process
I agree with you here (although I would hope that much of this iteration can be done in quick succession, and hopefully in a low-risk way [LW(p) · GW(p)]) 🙂
Btw, I very much enjoyed this talk by Ralph Merkle. It's from 2009, but it's still my favorite talk from every talk I've seen on the topic. Maybe you would enjoy it as well. He briefly touches upon the topic of simulations at 28:50, but the entire talk is quite interesting IMO:
↑ comment by dankrad · 2023-05-12T11:24:18.063Z · LW(p) · GW(p)
Thanks for engaging with my post. From my perspective you seem simply very optimistic on what kind of data can be extracted from unspecific measurements. Here is another good example on how Eliezer makes some pretty out there claims about what might be possible to infer from very little data: https://www.lesswrong.com/posts/ALsuxpdqeTXwgEJeZ/could-a-superintelligence-deduce-general-relativity-from-a [LW · GW] -- I wonder what your intuition says about this?
But maybe your intuitions are wrong (or maybe both). I think a desirable property of plans/strategies for alignment would be robustness to either of us being wrong about this 🙂
Generally it is a good idea to be robust with plans. However, in this specific instance, the way Eliezer phrases it, any iterative plan for alignment would be excluded. Since I also believe that this is the only realistic plan (there will simply never be a design that has the properties that Eliezer thinks guarantee alignment), the only realistic remaining path would be a permanent freeze (which I actually believe comes with large risks as well: unenforcability and thus worse actors making ASI first, biotech in the wrong hands becoming a larger threat to humanity, etc.).
What I would agree to is that it is good to plan for the eventuality that a lot less data could be needed by an ASI to do something like "create nanobots". For example, we could conclude that it's for now simply a bad idea if AI is used in biotech labs, because these are the places where it could easily gather a lot of data and maybe even influence experiments so that they let it learn the things it needs to create nanobots. Similarly, we could try to create a worldwide warning systems around technologies that seem likely to be necessary for an AI takeover, and watch these closely, so that we would notice any specific experiments. However, there is no way to scale this to a one-shot scenario.
Eliezer's scenario does assume the involvement of human labs (he describes a scenario where DNA is ordered online).
His claim is that an ASI will order some DNA and get some scientists in a lab to mix it together with some substances and create nanobots. That is what I describe as a one-shot scenario. Even if it were 10,000 shots in parallel I simply don't think it is possible, because I don't think the data itself is out there. Similarly to how you need accelerators to work out how physical laws work in high energy regimes (and random noise from other measurements just tells you nothing about it), if you are planning to design a completely new type of molecular machinery then you will need to do measurements on those specific molecules. So there will need to be a feedback loop, where the AI can learn detailed outcomes from experiments to gain more data.
I agree with you here (although I would hope that much of this iteration can be done in quick succession, and hopefully in a low-risk way [LW(p) · GW(p)]) 🙂
It's great that we agree on this :) And I do agree on finding ways to make this lower risk, and I think taking into account few-shot learning scenarios on biotech would be a good idea. And don't get me wrong -- there may be biotech scenarios with very few shots that kill a lot of humans available today, probably even without any ASI (humans can do it). I just think if an AI executed it today it would have no way of surviving and expanding.
Engineers, however, can constrain and master this sort of unpredictability. A pipe carrying turbulent water is unpredictable inside (despite being like a shielded box), yet can deliver water reliably through a faucet downstream. The details of this turbulent flow are beyond prediction, yet everything about the flow is bounded in magnitude, and in a robust engineering design the unpredictable details won’t matter.
This is absolutely what engineers do. But finding the right design patterns that do this involves a lot of experimentation (not for a pipe, but for constructing e.g. a reliable transistor). If someone eventually constructs non-biological self-replicating nanobots, it will probably involve high-reliability design patterns around certain molecular machinery. However, finding the right molecules that reliably do what you want, as well as how to put them together, etc., is a lot of research that I am pretty certain will involve actually producing those molecules and doing experiments with them.
That protein folding is "solved" does not disprove this IMO. Biological molecules are, after all, made from simple building blocks (amino acid) with some very predictable properties (how they stick together) so it's already vastly simplified the problem. And solving protein folding (as far as I know) does not solve the question of understanding what molecules actually do -- I believe understanding protein function is still vastly less developed (correct me if I'm wrong here, I haven't followed it in detail).
Replies from: tor-okland-barstad↑ comment by Tor Økland Barstad (tor-okland-barstad) · 2023-05-13T12:41:12.635Z · LW(p) · GW(p)
Thanks for engaging
Likewise :)
Also, sorry about the length of this reply. As the adage goes: "If I had more time, I would have written a shorter letter."
From my perspective you seem simply very optimistic on what kind of data can be extracted from unspecific measurements.
That seems to be one of the relevant differences between us. Although I don't think it is the only difference that causes us to see things differently.
Other differences (I guess some of these overlap):
- It seems I have higher error-bars than you on the question we are discussing now. You seem more comfortable taking the availability heuristic (if you can think of approaches for how something can be done) as conclusive evidence.
- Compared to me, it seems that you see experimentation as more inseparably linked with needing to build extensive infrastructure / having access to labs, and spending lots of serial time (with much back-and-fourth).
- You seem more pessimistic about the impressiveness/reliability of engineering that can be achieved by a superintelligence that lacks knowledge/data about lots of stuff.
- The probability of having a single plan work, and having one of several plans (carried out in parallel) work, seems to be more linked in your mind than mine.
- You seem more dismissive than me of conclusions maybe being possible to reach from first-principles thinking (about how universes might work).
- I seem to be more optimistic about approaches to thinking that are akin to (a more efficient version of) "think of lots of ways the universe might work, do Montecarlo-simulations for how those conjectures would affect the probability of lots of aspects of lots of different observations, and take notice if some theories about the universe seem unusually consistent with the data we see".
- I wonder if you maybe think of computability in a different way from me. Like, you may think that it's computationally intractable to predict the properties of complex molecules based on knowledge of the standard model / quantum physics. And my perspective would be that this is extremely contingent on the molecule, what the AI needs to know about it, etc - and that an AGI, unlike us, isn't forced to approach this sort of thing in an extremely crude manner.
- The AI only needs to find one approach that works (from an extremely vast space of possible designs/approaches). I suspect you of having fewer qualms about playing fast and lose with the distinction between "an AI will often/mostly be prevented from doing x due to y" and "an AI will always be prevented from doing x due to y".
- It's unclear if you share my perspective about how it's an extremely important factor that an AGI could be much better than us at doing reasoning where it has a low error-rate (in terms of logical flaws in reasoning-steps, etc).
From my perspective, I don't see how your reasoning is qualitatively distinct from saying in the 1500s: "We will for sure never be able to know what the sun is made out of, since we won't be able to travel there and take samples."
Even if we didn't have e.g. the standard model, my perspective would still be roughly what it is (with some adjustments to credences, but not qualitatively so). So to me, us having the standard model is "icing on the cake".
Here is another good example on how Eliezer makes some pretty out there claims about what might be possible to infer from very little data: https://www.lesswrong.com/posts/ALsuxpdqeTXwgEJeZ/could-a-superintelligence-deduce-general-relativity-from-a [LW · GW] -- I wonder what your intuition says about this?
Eliezer says "A Bayesian superintelligence, hooked up to a webcam, would invent General Relativity as a hypothesis (...)". I might add more qualifiers (replacing "would" with "might", etc). I think I have wider error-bars than Eliezer, but similar intuitions when it comes to this kind of thing.
Speaking of intuitions, one question that maybe gets at deeper intuitions is "could AGIs find out how to play theoretically perfect chess / solve the game of chess?". At 5/1 odds, this is a claim that I myself would bet neither for nor against (I wouldn't bet large sums at 1/1 odds either). While I think people of a certain mindset will think "that is computationally intractable [when using the crude methods I have in mind]", and leave it at that.
As to my credences that a superintelligence could "oneshot" nanobots[1] - without being able to design and run experiments prior to designing this plan - I would bet neither "yes" or "no" to that a 1/1 odds (but if I had to bet, I would bet "yes").
Upon seeing three frames of a falling apple and with no other information, a superintelligence would assign a high probability to Newtonian mechanics, including Newtonian gravity. [from the post you reference]
But it would have other information. Insofar as it can reason about the reasoning-process that it itself consists of, that's a source of information (some ways by which the universe could work would be more/less likely to produce itself). And among ways that reality might work - which the AI might hypothesize about (in the absence of data) - some will be more likely than others in a "Kolmogorov complexity [? · GW]" sort of way.
How far/short a superintelligence could get with this sort of reasoning, I dunno.
Here is an excerpt from a TED-talk from the Wolfram Alpha that feels a bit relevant (I find the sort of methodology that he outlines deeply intuitive):
"Well, so, that leads to kind of an ultimate question: Could it be that someplace out there in the computational universe we might find our physical universe? Perhaps there's even some quite simple rule, some simple program for our universe. Well, the history of physics would have us believe that the rule for the universe must be pretty complicated. But in the computational universe, we've now seen how rules that are incredibly simple can produce incredibly rich and complex behavior. So could that be what's going on with our whole universe? If the rules for the universe are simple, it's kind of inevitable that they have to be very abstract and very low level; operating, for example, far below the level of space or time, which makes it hard to represent things. But in at least a large class of cases, one can think of the universe as being like some kind of network, which, when it gets big enough, behaves like continuous space in much the same way as having lots of molecules can behave like a continuous fluid. Well, then the universe has to evolve by applying little rules that progressively update this network. And each possible rule, in a sense, corresponds to a candidate universe.
Actually, I haven't shown these before, but here are a few of the candidate universes that I've looked at. Some of these are hopeless universes, completely sterile, with other kinds of pathologies like no notion of space, no notion of time, no matter, other problems like that. But the exciting thing that I've found in the last few years is that you actually don't have to go very far in the computational universe before you start finding candidate universes that aren't obviously not our universe. Here's the problem: Any serious candidate for our universe is inevitably full of computational irreducibility. Which means that it is irreducibly difficult to find out how it will really behave, and whether it matches our physical universe. A few years ago, I was pretty excited to discover that there are candidate universes with incredibly simple rules that successfully reproduce special relativity, and even general relativity and gravitation, and at least give hints of quantum mechanics."
invent General Relativity as a hypothesis [from the post you reference]
As I understand it, the original experiment humans did to test for general relativity (not to figure out that general relativity probably was correct, mind you, but to test it "officially") was to measure gravitational redshift.
And I guess redshift is an example of something that will affect many photos. And a superintelligent mind might be able to use such data better than us (we, having "pathetic" mental abilities, will have a much greater need to construct experiments where we only test one hypothesis at a time, and to gather the Bayesian evidence we need relating to that hypothesis from one or a few experiments).
It seems that any photo that contains lighting stemming from the sun (even if the picture itself doesn't include the sun) can be a source of Bayesian evidence relating to general relativity:

It seems that GPS data must account for redshift in its timing system. This could maybe mean that some internet logs (where info can be surmised about how long it takes to send messages via satellite) could be another potential source for Bayesian evidence:

I don't know exactly what and how much data a superintelligence would need to surmise general relativity (if any!). How much/little evidence it could gather from a single picture of an apple I dunno.
There is just absolutely no reason to consider general relativity at all when simpler versions of physics explain absolutely all observations you have ever encountered (which in this case is 2 frames). [from the post you reference]
I disagree with this.
First off, it makes sense to consider theories that explain more observations than just the ones you've encountered.
Secondly, simpler versions of physics do not explain your observations when you see 2 webcam-frames of a falling apple. In particular, the colors you see will be affected by non-Newtonian physics.
Also, the existence of apples and digital cameras also relates to which theories of physics are likely/plausible. Same goes for the resolution of the video, etc, etc.
However, there is no way to scale this to a one-shot scenario.
You say that so definitively. Almost as if you aren't really imagining an entity that is orders of magnitude more capable/intelligent than humans. Or as if you have ruled out large swathes of the possibility-space that I would not rule out.
I just think if an AI executed it today it would have no way of surviving and expanding.
If an AGI is superintelligent and malicious, then surviving/expanding (if it gets onto the internet) seems quite clearly feasible to me.
We even have a hard time getting corona-viruses back in the box! That's a fairly different sort of thing, but it does show how feeble we are. Another example is illegal images/videos, etc (where the people sharing those are humans).
An AGI could plant itself onto lots of different computers, and there are lots of different humans it could try to manipulate (a low success rate would not necessarily be prohibitive). Many humans fall for pretty simple scams, and AGIs would be able to pull off much more impressive scams.
This is absolutely what engineers do. But finding the right design patterns that do this involves a lot of experimentation (not for a pipe, but for constructing e.g. a reliable transistor).
Here you speak about how humans work - and in such an absolutist way. Being feeble and error-prone reasoners, it makes sense that we need to rely heavily on experiments (and have a hard time making effective use of data not directly related to the thing we're interested in).
That protein folding is "solved" does not disprove this IMO.
I think protein being "solved" exemplifies my perspective, but I agree about it not "proving" or "disproving" that much.
Biological molecules are, after all, made from simple building blocks (amino acid) with some very predictable properties (how they stick together) so it's already vastly simplified the problem.
When it comes to predictable properties, I think there are other molecules where this is more the case than for biological ones (DNA-stuff needs to be "messy" in order for mutations that make evolution work to occur). I'm no chemist, but this is my rough impression.
are, after all, made from simple building blocks (amino acid) with some very predictable properties (how they stick together)
Ok, so you acknowledge that there are molecules with very predictable properties.
It's ok for much/most stuff not to be predictable to an AGI, as long as the subset of stuff that can be predicted is sufficient for the AGI to make powerful plans/designs.
finding the right molecules that reliably do what you want, as well as how to put them together, etc., is a lot of research that I am pretty certain will involve actually producing those molecules and doing experiments with them.
Even IF that is the case (an assumption that I don't share but also don't rule out), design-plans may be made to have experimentation built into them. It wouldn't necessarily need to be like this:
- experiments being run
- data being sent to the AI so that it can reason about it
- then having the AI think a bit and construct new experiments
- more experiments being run
- data being sent to the AI so that it can reason about it
- etc
I could give specific examples of ways to avoid having to do it that way, but any example I gave would be impoverished, and understate the true space of possible approaches.
His claim is that an ASI will order some DNA and get some scientists in a lab to mix it together with some substances and create nanobots.
I read the scenario he described as:
- involving DNA being ordered from lab
- having some gullible person elsewhere carry out instructions, where the DNA is involved somehow
- being meant as one example of a type of thing that was possible (but not ruling out that there could be other ways for a malicious AGI to go about it)
I interpreted him as pointing to a larger possibility-space than the one you present. I don't think the more specific scenario you describe would appear prominently in his mind, and not mine either (you talk about getting "some scientists in a lab to mix it together" - while I don't think this would need to happen in a lab).
Here is an excerpt from here (written in 2008), with boldening of text done by me:
"1. Crack the protein folding problem, to the extent of being able to generate DNA
strings whose folded peptide sequences fill specific functional roles in a complex
chemical interaction.
2. Email sets of DNA strings to one or more online laboratories which offer DNA
synthesis, peptide sequencing, and FedEx delivery. (Many labs currently offer this
service, and some boast of 72-hour turnaround times.)
3. Find at least one human connected to the Internet who can be paid, blackmailed,
or fooled by the right background story, into receiving FedExed vials and mixing
them in a specified environment.
4. The synthesized proteins form a very primitive “wet” nanosystem which, ribosomelike, is capable of accepting external instructions; perhaps patterned acoustic vibrations delivered by a speaker attached to the beaker.
5. Use the extremely primitive nanosystem to build more sophisticated systems, which
construct still more sophisticated systems, bootstrapping to molecular
nanotechnology—or beyond."
Btw, here are excerpts from a TED-talk by Dan Gibson from 2018:
"Naturally, with this in mind, we started to build a biological teleporter. We call it the DBC. That's short for digital-to-biological converter. Unlike the BioXp, which starts from pre-manufactured short pieces of DNA, the DBC starts from digitized DNA code and converts that DNA code into biological entities, such as DNA, RNA, proteins or even viruses. You can think of the BioXp as a DVD player, requiring a physical DVD to be inserted, whereas the DBC is Netflix. To build the DBC, my team of scientists worked with software and instrumentation engineers to collapse multiple laboratory workflows, all in a single box. This included software algorithms to predict what DNA to build, chemistry to link the G, A, T and C building blocks of DNA into short pieces, Gibson Assembly to stitch together those short pieces into much longer ones, and biology to convert the DNA into other biological entities, such as proteins.
This is the prototype. Although it wasn't pretty, it was effective. It made therapeutic drugs and vaccines. And laboratory workflows that once took weeks or months could now be carried out in just one to two days. And that's all without any human intervention and simply activated by the receipt of an email which could be sent from anywhere in the world. We like to compare the DBC to fax machines.
(...)
Here's what our DBC looks like today. We imagine the DBC evolving in similar ways as fax machines have. We're working to reduce the size of the instrument, and we're working to make the underlying technology more reliable, cheaper, faster and more accurate.
(...)
The DBC will be useful for the distributed manufacturing of medicine starting from DNA. Every hospital in the world could use a DBC for printing personalized medicines for a patient at their bedside. I can even imagine a day when it's routine for people to have a DBC to connect to their home computer or smart phone as a means to download their prescriptions, such as insulin or antibody therapies. The DBC will also be valuable when placed in strategic areas around the world, for rapid response to disease outbreaks. For example, the CDC in Atlanta, Georgia could send flu vaccine instructions to a DBC on the other side of the world, where the flu vaccine is manufactured right on the front lines."
I believe understanding protein function is still vastly less developed (correct me if I'm wrong here, I haven't followed it in detail).
I'm no expert on this, but what you say here seems in line with my own vague impression of things. As you maybe noticed, I also put "solved" in quotation marks.
However, in this specific instance, the way Eliezer phrases it, any iterative plan for alignment would be excluded.
As touched upon earlier, I am myself am optimistic when it comes to iterative plans for alignment. But I would prefer such iteration to be done with caution that errs on the side of paranoia (rather than being "not paranoid enough").
It would be ok if (many of the) people doing this iteration would think it unlikely that intuitions like Eliezer's or mine are correct. But it would be preferable for them to carry out plans that would be likely to have positive results even if they are wrong about that.
Like, you expect that since something seems hopeless to you, a superintelligent AGI would be unable to do it? Ok, fine. But let's try to minimize the amount of assumptions like that which are loadbearing in our alignment strategies. Especially for assumptions where smart people who have thought about the question extensively disagree strongly.
As a sidenote:
- If I lived in the stone age, I would assign low credence to us going step by step from stone-age technologies akin to iPhones and the international space station and IBM being written with xenon atoms.
- If I lived prior to complex life (but my own existence didn't factor into my reasoning), I would assign low credence to anything like mammals evolving.
It's interesting to note that even though many people (such as yourself) have a "conservative" way of thinking (about things such as this) compared to me, I am still myself "conservative" in the sense that there are several things that have happened that would have seemed too "out there" to appear realistic to me.
Another sidenote:
One question we might ask ourselves is: "how many rules by which the universe could work would be consistent with e.g. the data we see on the internet?". And by rules here, I don't mean rules that can be derived from other rules (like e.g. the weight of a helium atom), but the parameters that most fundamentally determine how the universe works. If we...
- Rank rules by (1) how simple/elegant they are and (2) by how likely the data we see on the internet would be to occur with those rules
- Consider rules "different from each other" if there are differences between them in regards to predictions they make for which nano-technology-designs that would work
...my (possibly wrong) guess is that there would be a "clear winner".
Even if my guess is correct, that leaves the question of whether finding/determining the "winner" is computationally tractable. With crude/naive search-techniques it isn't tractable, but we don't know the specifics of the techniques that a superintelligence might use - it could maybe develop very efficient methods for ruling out large swathes of search-space.
And a third sidenote (the last one, I promise):
Speculating about this feels sort of analogous to reasoning about a powerful chess engine (although there are also many disanalogies). I know that I can beat an arbitrarily powerful chess engine if I start from a sufficiently advantageous position. But I find it hard to predict where that "line" is (looking at a specific board position, and guessing if an optimal chess-player could beat me). Like, for some board positions the answer will be a clear "yes" or a clear "no", but for other board-positions, it will not be clear.
I don't know how much info and compute a superintelligence would need to make nanotechnology-designs that work in a "one short"-ish sort of way. I'm fairly confident that the amount of computational resources used for the initial moon-landing would be far too little (I'm picking an extreme example here, since I want plenty of margin for error). But I don't know where the "line" is.
- ^
Although keep in mind that "oneshotting" does not exclude being able to run experiments (nor does it rule out fairly extensive experimentation). As I touched upon earlier, it may be possible for a plan to have experimentation built into itself. Needing to do experimentation ≠ needing access to a lab and lots of serial time.
↑ comment by Tor Økland Barstad (tor-okland-barstad) · 2023-05-17T07:48:19.051Z · LW(p) · GW(p)
This tweet from Eliezer seems relevant btw. I would give similar answers to all of the questions he lists that relate to nanotechnology (but I'd be somewhat more hedged/guarded - e.g. replacing "YES" with "PROBABLY" for some of them).
comment by faul_sname · 2023-04-25T02:21:07.924Z · LW(p) · GW(p)
If I understand your argument, it is as follows:
- Self-replicating nanotech that also does something useful and also also outcompetes biological life and also also also faithfully self-replicates (i.e. you don't end up in a situation where the nanobots that do the "replicate" task better at the cost of the "do something useful" task replicate better and end up taking over) is hard enough that even if it's technically physically possible it won't be the path that the minimum-viable-superintelligence takes to gaining power.
- There probably isn't any other path to "sufficient power in the physical world to make more computer chips" that does not route through "humans do human-like stuff at human-like speeds for you"
- That implies that the sequence of events "the world looks normal and not at all like all of the chip fabs are fully automated, and then suddenly all the humans die of something nobody saw coming" is unlikely to happen.
- But this is a contingent fact about the world as it is today, and it's entirely possible to screw up this nice state of affairs, accidentally or intentionally.
- Therefore, even if you think that you are on a path to a pivotal act, if your plan starts look like "and in step 3 I give my AI a fully-automated factory which can produce all components of itself given sufficient raw materials and power, and can also build a chip fab, and then in step 4 I give my AI instructions that it should perform an act which looks to me like a pivotal act, which it will surely do by doing something amazing with nanotech", you should stop and reevaluate your plan.
Does this sound like an accurate summary to you?
Also, as a side note is there accepted terminology to distinguish between "an act that the actor believes will be pivotal" and "an act that is in fact pivotal"? I find myself wanting to make that distinction quite a bit, and it would be nice if there were accepted terminology.
Replies from: dankrad↑ comment by dankrad · 2023-04-25T12:55:03.296Z · LW(p) · GW(p)
I think 1-4 are good summaries of the arguments I'm making about nanobots. I would add another point that the reason it is hard to make nanobots is not about a lack of computational abilities (although that could also be a bottleneck) but simply a lack of knowledge about the physical world that can only be resolved by learning more about the physical world in a way that is relevant to making nanobots.
On point 5, from my current perspective, I think the idea of pivotal acts is totalitarian, not a good idea and most likely to screw things up if ever attempted. So I wasn't mainly trying to make a statement about them here (that would be another post). I was making a side argument about them that is roughly summarized in 5 -- giving an AI full physical capabilities seems like a very dangerous step and if it is part of your plan for a pivotal act you should be especially worried that you are making things worse.
comment by ADifferentAnonymous · 2023-05-13T04:06:07.472Z · LW(p) · GW(p)
Many complex physical systems are still largely modelled empirically (ad-hoc models validated using experiments) rather than it being possible to derive them from first principles. While physicists sometimes claim to derive things from first principles, in practice these derivations often ignore a lot of details which still has to be justified using experiments.
The argument here seems to be "humans have not yet discovered true first-principles justifications of the practical models, therefore a superintelligence won't be able to either".
I agree that not being able to experiment makes things much harder, such that an AI only slightly smarter than humans won't one-shot engineer things humans can't iteratively engineer. And I agree that we can't be certain it is possible to one-shot engineer nanobots with remotely feasible compute resources. But I don't see how we can be sure what isn't possible for a superintelligence.