The "Minimal Latents" Approach to Natural Abstractions
post by johnswentworth · 2022-12-20T01:22:25.101Z · LW · GW · 24 commentsContents
Background: The Language-Learning Argument What We’ll Do In This Post Background: Latent Variables “Minimal” Latents The Connection to Redundancy The Connection to Information At A Distance Weakening the Conditional Independence Requirement Takeaways None 24 comments
Background: The Language-Learning Argument
How many functions are there from a 1 megabyte image to a yes/no answer to the question “does this image contain an apple?”.
Well, there are 8M bits in the image, so possible images. The function can assign “yes” or “no” independently to each of those images, so possible functions. Specifying one such function by brute force (i.e. not leveraging any strong prior information) would therefore require bits of information - one bit specifying the output on each of the possible images. Even if we allow for some wiggle room in ambiguous images, those ambiguous images will still be a very tiny proportion of image-space, so the number of bits required would still be exponentially huge.
Empirically, human toddlers are able to recognize apples by sight after seeing maybe one to three examples. (Source: people with kids.)
Point is: nearly-all the informational work done in a toddler’s mind of figuring out which pattern is referred to by the word “apple” must be performed by priors and general observations of the world, not by examples of apples specifically. Before the toddler ever hears the word, they must already have some internal data structure which represents the-things-we-call-apples as a natural category (though possibly implicitly rather than explicitly), just waiting to have a word attached to it. In ML terms, nearly-all the informational work of learning what “apple” means must be performed by unsupervised learning, not supervised learning. Otherwise the number of examples required would be far too large to match toddlers’ actual performance.
Furthermore, humans are empirically able to communicate; one human can say words, the other can guess what those words refer to, and then the two humans will both agree on what physical thing was referred to by the words. Admittedly this outcome is less robust than we might like (i.e. miscommunication still happens a lot), but it happens ridiculously more often than chance, to the point where exceptions are more notable than non-exceptions.
So, not only must unsupervised learning perform nearly-all the informational work of learning what words mean, but that unsupervised learning method must also somehow coordinate on (at least roughly) the same potential-word-meanings across different humans.
We can even go a step further: other kinds of minds, like dogs or neural nets, are also able to coordinate on (at least roughly) the same potential-word-meanings as humans. For now they usually require a lot more examples than human children, but nowhere near the exponentially huge number required to learn meanings by full brute force. Most of the informational work must still be done by some unsupervised process.
What We’ll Do In This Post
The language-learning argument adds up to a weak version of the Natural Abstraction Hypothesis [? · GW]: a wide variety of minds converge to using the same “natural abstractions”, i.e. the potential-word-meanings. Those abstractions are “natural” in the sense that they’re a fairly general property of minds (i.e. priors) plus the environment; a wide variety of minds are able to learn them in an unsupervised way just from the environment plus whatever priors are common to all these different kinds of minds.
My other writing on natural abstraction usually starts from thinking of natural abstractions as summaries of information relevant at a distance [? · GW], or of information which is highly redundant [LW · GW] - both properties which are mostly informational features of the environment, and mostly avoid explicitly talking about minds. They’re “bottom-up” notions of natural abstraction: they start from a low-level environment model, and build up to natural high-level features. The hope would be that we can later prove such features are convergently useful for minds via e.g. selection theorems [LW · GW].
But we can also come from a “top-down” direction: start from the idea of natural abstractions as features used convergently by a wide variety of minds. For instance, taking a theoretical angle, we can use a standard theoretical model of minds (i.e. Bayesianism), combine it with some natural criterion which might make a feature convergently useful, and ask what “natural abstractions” are implied.
That’s the idea behind this post.
More specifically, we’ll start from the usual idea of a Bayesian mind which can learn the environment-distribution arbitrarily well via observation, but has some freedom around which latent variables to use in order to represent that distribution efficiently. Those latent variables are the features/concepts/potential-word-meanings. Then, we’ll ask if there’s some “minimal” or “most general” latent variables, some latents such that any other latents must contain at least as much information - the idea being that such “minimal” latents might be naturally convergent, and natural coordination points for agents to coordinate on potential-word-meanings.
Then, the main technical result: these “minimal” latents are the same natural abstractions we get from the “information which is highly redundant” or “information relevant at a distance” views.
Background: Latent Variables
Here’s a standard conceptual model for how an agent figures out the concept of e.g. trees. First, the agent receives a bunch of observations from the world (images, for instance), many of which show what you or I would call trees. The agent then clusters together data based on similarity. More precisely, the agent looks for patterns which are well-modeled (i.e. compressed) by assuming that they were generated in the same way. For instance, all those subimages which show what you or I would call trees can be compressed a lot by assuming that there’s a common pattern-generator (i.e. the general concept of “trees”), which is mostly not generating the patterns in other subimages. That common pattern-generator, or whatever set of variables parameterize the pattern-generator, is the “latent” variable.
Mathematically, we usually assume that the latent variable summarizes all the information which any subset of the trees tells us about the rest - i.e. by observing particular trees, we learn general facts about trees (including general facts about particular tree-species), which in turn tell us about the rest of the trees. That means the individual tree-instances are all conditionally independent, given the latent variable. That’s the most common form used for Bayesian clustering models: we try to simultaneously cluster and fit latents such that instances in the same cluster are independent given that cluster’s latent.
The standard formula: we have a bunch of instances all in the same cluster. Then, conditional on the latent variable , the instances should be independent:
Or, graphically:
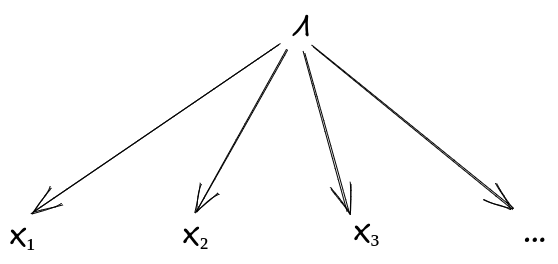
(There is some room to complain here - for instance, maybe it intuitively seems like the concept of trees should only include general facts about trees, not about specific species of tree, so instances from the same species should not be independent even conditional on the general concept of trees. We’ll come back to that near the end of the post, once we’ve connected this all back to other approaches to natural abstraction.)
Under this frame, the latents themselves take center stage, and the clusters become less central. Given the latent concept of trees, it’s pretty easy to recognize a tree; the interesting question is what models/parameterizations/etc to use for the general model of trees. More generally, given the latents, it’s relatively easy to compute the probability that any particular instance was generated by a particular latent (i.e. figure out what cluster the instance is in). The main question is what latent models/parameterizations/etc to use for each cluster.
And that’s where the notion of “minimal” or “most general” latents enters.
“Minimal” Latents
The key condition for a valid latent is that each instance be independent given the latent. All trees must be independent given the general concept of/facts about trees. But that still leaves a lot of options. For instance, we could declare that the tree-concept consists of all facts about all trees ever. Mathematically, . That is obviously a terrible choice; we gain nothing by using that latent. But it does technically satisfy the conditional independence requirement.
What we’d really like is a latent on the other end of the spectrum - one which includes as little information about the instances as possible, while still satisfying the conditional independence condition. Conceptually, I’ll operationalize that as follows: first, I want some latent which satisfies the conditional independence condition. Second, if anyone else comes along with another latent which satisfies the conditional factorization condition, then I should find that their latent contains at least all the information about the instances which is present in my latent. Or, to put it differently: all information in about must also be present in any other which satisfies the conditional independence condition. Third, for cleanliness, we’ll assume that doesn’t contain any extra “irrelevant” information, e.g. random bits which have nothing at all to do with . (The third condition just eliminates some obviously-silly possibilities; we’ll mostly ignore it.)
Mathematically: call my special minimal latent . First, must itself satisfy the conditional independence condition:
Second, given any other which satisfies the conditional independence condition, must contain at least all the information in about . Graphically,
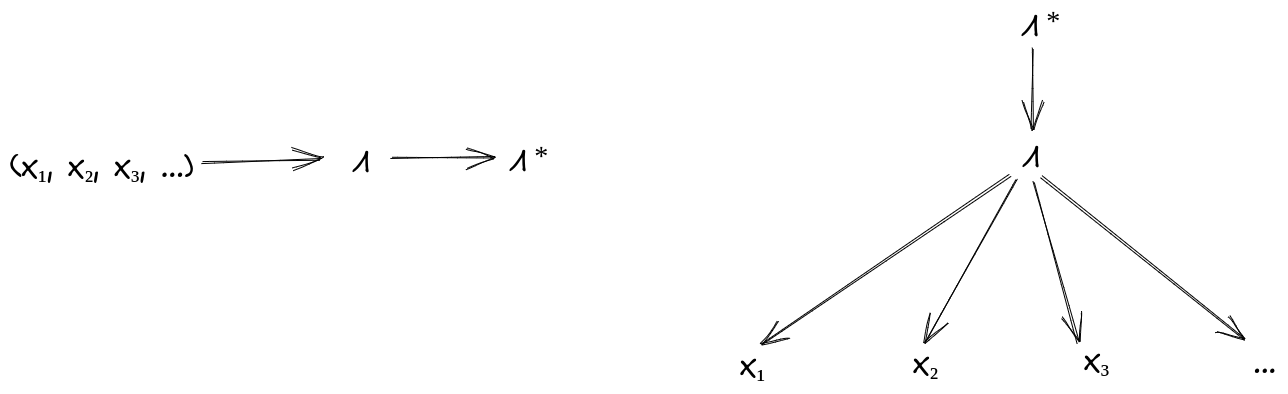
That second diagram, in equation form:
Caution: the notation and wording have hidden some potentially-confusing conceptual pieces here. When I say e.g. “I have a latent ” or “I want some latent ”, what I really have/want is not the value of random variable , but rather the factorization of the distribution using , i.e.
In other words, I have/want a way to model the distribution of using as a latent, and is in some sense “defined by” the distributions I use. The relevant mathematical object is not itself, but rather the distributions and , which must reproduce the observed distribution over . Similarly, the condition on and asserts that there exists some joint distribution such that the factorization holds, and the marginals match the given distributions , , , . Another way to say this: if I later learn that some other person is using a different latent-factorization to model the same tree-cluster as me, with the same observable distribution over the same physically-observable trees , then I should be able to model their latent, and my latent and the observables all in one distribution , while still being consistent with all the marginals and the conditions.
Anyway, the big question now is: when can I find some which satisfies all conditions - i.e. which satisfies the conditional independence condition and contains at least as little info as any other which satisfies the conditional independence condition?
The Connection to Redundancy
Now for the main trick. To illustrate, we’ll start with a simplified case, in which we have only two instances and (e.g. only two trees).
Our “minimality” condition says that all information about which is in must also be in , for any other latent allowed by conditional independence. So, we’re allowed to pick any latent such that and are independent given . Well, is always independent of everything (including ) given itself. Likewise, is always independent of everything (including ) given itself. So, we could pick either or to be .
Our “minimal” must therefore satisfy:
- All information about which is in must also be in
- All information about which is in must also be in
In other words: all information about which is in must be redundantly present in both and . We must have both:
- independent of given , and
- independent of given
Generalizing beyond the two-instance case, we can’t just use as a latent any more; two tree are not necessarily independent given a third tree. But we can use all but one tree as a latent - i.e. . Any subset of the ’s are independent given all but one . Our “minimal” latent must therefore satisfy: all information about which is in must also be in for any . Any choice of all-but-one instance must still include the information in . In that sense, depends on only the “perfectly redundant” information in .
This connects us directly to natural abstractions as redundant information [LW · GW]. Indeed, we can carry over the same idea from that formulation: since contains all the information relevant to , we can resample any individually without changing our information about . Therefore, can only depend on via quantities conserved under repeatedly resampling each individually.
Now to answer our big question from the previous section: I can find some satisfying the conditions exactly when all of the ’s are independent given the “perfectly redundant” information. In that case, I just set to be exactly the quantities conserved under the resampling process, i.e. the perfectly redundant information itself. Conversely, if the ’s are not independent given the perfectly redundant information, then I can’t find any satisfying the conditions.
(A somewhat more complete proof is in A Correspondence Theorem [LW · GW], though it doesn’t make explicit the connection to resampling because the resampling framework for natural abstraction didn’t yet exist when it was written. The results here are essentially a repackaging of that correspondence theorem, but with context, hindsight and a lot more understanding of natural abstraction from other angles.)
The Connection to Information At A Distance
Via redundancy, we can also connect to natural abstraction as information relevant at a distance. By the Telephone Theorem [LW · GW], in order for information to propagate over a long distance, it needs to be near-perfectly conserved through many intermediate layers; therefore the information is arbitrarily-perfectly redundantly represented in the variables constituting each of those layers. Conversely, in a local model (i.e. a model where most things only interact directly with a few “nearby” things), information needs to propagate over a long distance in order to reach very many variables, and therefore needs to propagate over a long distance in order to be redundantly represented in very many variables. Thus the equivalence between information relevant at a distance and highly redundant information, at least in local models. (Abstractions as Redundant Information [LW · GW] contains more formal and fleshed-out versions of these arguments, though still not fully rigorous.)
That said, our conditions for so far aren’t quite equivalent to information relevant at a distance. Information relevant at a distance requires massive redundancy, information redundantly represented in many different “places” (i.e. many different or disjoint subsets thereof). In other words, we have to be able to throw away a whole bunch of ’s and still be able to reconstruct . Our conditions so far only require enough redundancy to throw away one at a time, and still reconstruct . If exactly two trees have some perfectly redundant information between them, and that information is entirely absent from all other trees, that would be included in under our current conditions, but might be omitted from information relevant at a distance (modulo some degrees of freedom around what to consider the low-level variables and what corresponding notion of “distance” to use, e.g. if we have separate variables for the state of each tree at each time then even a single tree may be very redundant and contain info relevant to that same tree at a far-distant time). So: includes all information relevant at a distance (at least when exists at all), but may include some other stuff too.
That said, since we’ve found that doesn’t always exist, our conditions probably aren’t quite right anyway. Let’s fix that.
Weakening the Conditional Independence Requirement
We have a minor problem: if the ’s are not conditionally independent given whatever perfectly redundant information they contain, then there isn’t any “minimal” latent satisfying the conditional independence condition.
One simple response: weaken the conditional independence condition. We already mentioned earlier that e.g. it intuitively seems like the concept of trees should only include general facts about trees, not about specific species of tree, so instances from the same species should not be independent even conditional on the general concept of trees. Maybe we can still require most trees to be independent given the general latent concept of trees, but allow for some exceptions?
Coming from another direction: when formulating natural abstractions as information relevant at a distance, the key condition is not that all the variables be conditionally independent, but that variables “far apart” be conditionally independent. Since locality in a large model implies that most variables are “far apart” from most other variables, weakening the conditional independence condition to conditional independence amongst most variables again makes sense.
So, here’s a new conditional independence condition for “large” systems, i.e. systems with an infinite number of ’s: given , any finite subset of the ’s must be approximately independent (i.e. mutual information below some small ) of all but a finite number of the other ’s. Now must satisfy this new condition, and be “minimal” (in the same sense as earlier) among latents which satisfy the new condition.
Returning to our argument about redundancy and resampling: in the step where we chose to be , we can now instead take for any finite subset . Otherwise, the argument remains the same. As before, we take to be whatever quantities are conserved by the resampling process, i.e. the highly redundant information. But now, perfect redundancy between two variables is no longer enough for conservation in the resampling process; will only include highly redundant information, information present in enough variables that we can drop any finite subset and still exactly recompute the information. Is that highly redundant information enough to satisfy our new independence condition?
At least in systems where each variable directly interacts with only a finite number of neighbors (e.g. a Bayes net or Markov random field of bounded degree), the answer is “yes”. Similar to the arguments in the “Connection to Information At A Distance” section earlier, information would have to propagate over a long distance in order to end up relevant to infinitely many variables, and therefore by the Telephone Theorem such information must be highly redundant, so that information is fully encoded in . Conditional on , then, only finitely many variables can have mutual information above a given cutoff . The relevant mathematical argument here is that information at a distance approaches zero conditional on the quantities conserved by resampling, which is in Abstractions as Redundant Information [LW · GW].
I also currently expect that we can extend beyond systems in which each variable directly interacts with only a finite number of neighbors. Intuitively, it seems like should exist for large systems in full generality, under our weakened conditional independence condition. It also seems like approximate versions of the arguments should go through. But I don’t have proofs or even proof sketches for those claims yet.
Takeaways
There are currently three main framings of natural abstraction which I think about: information at a distance, highly redundant information, and minimal latents. We can view the concept of trees as:
- A summary of information about a bunch of trees which is relevant to far-away trees
- Information which is highly redundant across many trees
- The minimal latent variables which induces approximate conditional independence between most trees
(In all cases, the abstract-summarization-method is coupled with clustering to figure out which chunks of reality to consider trees in the first place.)
For infinite systems with locality (i.e. variables only directly interact with a bounded number of neighbors), these three framings yield equivalent abstract summaries. Though I don’t have full proofs yet, I expect that the redundancy and minimal latent framings are equivalent even without locality (in which case the “information relevant far away” frame doesn’t apply, since it inherently requires locality). I'd love if someone else proved this claim, by the way!
The convergence between these three approaches to natural abstraction, which look so different at first glance, is currently one of my main pieces of mathematical evidence that they’re on the right track.

{kind=link}
24 comments
Comments sorted by top scores.
comment by Vivek Hebbar (Vivek) · 2022-12-21T22:57:13.933Z · LW(p) · GW(p)
In ML terms, nearly-all the informational work of learning what “apple” means must be performed by unsupervised learning, not supervised learning. Otherwise the number of examples required would be far too large to match toddlers’ actual performance.
I'd guess the vast majority of the work (relative to the max-entropy baseline) is done by the inductive bias.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-12-22T07:52:38.437Z · LW(p) · GW(p)
You don't need to guess; it's clearly true. Even a 1 trillion parameter network where each parameter is represented with 64 bits can still only represent at most different functions, which is a tiny tiny fraction of the full space of possible functions. You're already getting at least of the bits just by choosing the network architecture.
(This does assume things like "the neural network can learn the correct function rather than a nearly-correct function" but similarly the argument in the OP assumes "the toddler does learn the correct function rather than a nearly-correct function".)
Replies from: LawChan↑ comment by LawrenceC (LawChan) · 2022-12-22T08:06:39.540Z · LW(p) · GW(p)
See also Superexponential Concept Space, and Simple Words [LW · GW], from the Sequences:
By the time you're talking about data with forty binary attributes, the number of possible examples is past a trillion—but the number of possible concepts is past two-to-the-trillionth-power. To narrow down that superexponential concept space, you'd have to see over a trillion examples before you could say what was In, and what was Out. You'd have to see every possible example, in fact.
[...]
From this perspective, learning doesn't just rely on inductive bias [? · GW], it is nearly all inductive bias—when you compare the number of concepts ruled out a priori, to those ruled out by mere evidence.
comment by davidad · 2022-12-20T01:35:46.432Z · LW(p) · GW(p)
As a category theorist, I am confused by the diagram that you say you included to mess with me; I’m not even sure what I was supposed to think it means (where is the cone for ? why does the direction of the arrow between and seem inconsistent?).
I think a “minimal latent,” as you have defined it equationally, is a categorical product (of the ) in the coslice category where is the category of Markov kernels and is the implicit sample space with respect to which all the random variables are defined.
Replies from: tailcalled↑ comment by tailcalled · 2022-12-30T16:52:22.690Z · LW(p) · GW(p)
Are you sure? Wouldn't the categorical product need to make the independent not just from each other but also from ?
comment by Lucius Bushnaq (Lblack) · 2022-12-20T19:20:51.072Z · LW(p) · GW(p)
Epistemic status: sleep deprived musings
If I understand this right, this is starting to sound very testable.
Feed a neural network inputs consisting of variables . Configurations in a 2D Ising model, cat pictures, or anything else we humans think we know the latent variables for.
Train neural networks to output a set of variables over the inputs. The loss function scores based on how much the output induces conditional independence of inputs over the training data set.
E.g., take the divergence between and . Then, penalise with a higher information content through a regularisation term. E.g. the divergence between and .[1]
Then, you can check if the solutions found match the ones other networks, or humans and human science, would give for that system. Either by comparing , or by looking at directly.
You can also train a second network to reconstruct from the latents and see what comes out.
You might also be able to take a network stitched together from the latent generation and a latent read-out network, and see how well it does on various tasks over the dataset. Image labelling, calculating the topological charge of field configurations, etc. Then compare that to a generic network trained to solve these tasks.
If the hypothesis holds strongly, generic networks of sufficient generality go through the same process when they propose solutions. Just with less transparency. So you’d expect the stitched and conventional networks to score similarly.
My personal prediction would be that you'd usually need to require solving a few different tasks on the data for that to occur, otherwise the network doesn't need to understand all the abstractions in the system to get the answer, and can get away with learning less latents.
I think we kind of informally do a lot of this already when we train an image classifier and then Anthropic opens up the network to see e.g. the dog-head-detection function/variable in it. But this seems like a much cleaner, more secure and well defined cooking formula for finding latents to me, which may be rote implementable for any system or problem.
Unless this is already a thing in Interpretability code bases and I don’t know about it?
- ^
I haven't checked the runtime on this yet, you'd need to cycle through the whole dataset once per loss function call to get the distributions. But it's probably at least doable for smaller problems, and for bigger datasets a stochastic sampling ought to be enough.
comment by Shmi (shminux) · 2022-12-20T10:13:11.932Z · LW(p) · GW(p)
nearly-all the informational work done in a toddler’s mind of figuring out which pattern is referred to by the word “apple” must be performed by priors and general observations of the world, not by examples of apples specifically.
Mildly related: Most image/sound/etc. lossy compression algorithms (and that is what an abstraction is, a form of lossy data compression) are based on the Discrete Cosine Transform. Do you think that the brain does something like the DCT when relating visible apples to the concept of apple?
Replies from: Jon Garcia↑ comment by Jon Garcia · 2022-12-21T08:21:40.157Z · LW(p) · GW(p)
The cortex uses traveling waves of activity that help it organize concepts in space and time. In other words, the locally traveling waves provide an inductive bias for treating features that occur close together in space and time as part of the same object or concept. As a result, cortical space ends up mapping out conceptual space, in addition to retinotopic, somatic, or auditory space.
This is kind of like DCT in the sense that oscillations are used as a scaffold for storing or reconstructing information. I think that Neural Radiance Fields (NeRF) use a similar concept, using positional encoding (3D coordinates plus viewing angle, rather than 2D pixel position) to generate images, especially when the positional encoding uses Fourier features. Of course, Transformers also use such sinusoidal positional encodings to help with natural language understanding.
All that is to say that I agree with you. Something similar to DCT will probably be very useful for discovering natural abstractions. For one thing, I imagine that these sorts of approaches could help overcome texture bias in DNNs by incorporating more large-scale shape information.
Replies from: shminux↑ comment by Shmi (shminux) · 2023-01-14T08:58:35.840Z · LW(p) · GW(p)
Thanks! Your links led me down some interesting avenues.
comment by Thane Ruthenis · 2022-12-20T07:44:56.402Z · LW(p) · GW(p)
This touches on some issues I'd wanted to discuss: abstraction hierarchies, and incompatible abstraction layers.
So, here’s a new conditional independence condition for “large” systems, i.e. systems with an infinite number of ’s: given , any finite subset of the ’s must be approximately independent (i.e. mutual information below some small ) of all but a finite number of the other ’s
Suppose we have a number of tree-instances . Given a sufficiently large , we can compute a valid "general tree abstraction". But what if we've picked a lower , and are really committed to keeping it low, for some reason?
Here's a trick:
We separate tree-instances into sets such that we can compute the corresponding "first-order" abstractions over each set, and they would be valid, in the sense that any two would have mutual information below when conditioned on [1]. Plausibly, that would recover a set of abstractions corresponding to "tree species".
Then we repeat the trick: split the first-order abstractions into sets, and generate second-order abstractions . That may recover, say, genuses.
We do this iteratively until getting a single nth-order abstraction , standing-in for "all trees".
I think it would all have sensible behavior. Conditioning any given tree-instance on would only explain general facts about the trees, as we wanted. Conditioning on the appropriate lower-level abstractions would explain progressively more information about . Conditioning a on , in turn, would turn up some information that's in excess, or make some wrong predictions, but get the general facts right. (And you can also condition first-order abstractions on higher-order abstractions, etc.)
The question is: how do we pick ? One potential answer is that, given some set of instances , we always try for the lowest possible[1]. Perhaps that's the mathematical description of taxonomy, even? "Given a set of instances, generate the abstraction hierarchy that minimizes at each abstraction-level."
There's a different way to go about it, though. Suppose that, instead of picking and then deciding on groupings, we first split instances into sets, according to some rule? We have to be able to do that: we've somehow decided to abstract over these specific to begin with, so we already have some way to generate groupings. (We've somehow arrived at a set of tree-instances to abstract over, instead of a mixture of cars, trees, towels, random objects...)
So, we pick some "rule", which is likely a natural abstraction in itself, or defined over one. Like "trees that are N years old" with separate set for every N, or "this tree has leaves" y/n, or "trees in %person%'s backyard" for every %person%. Then we split the instances into sets according to that rule, and try to summarize every set.
Important: that way, we may get meaningfully different s for every set! For example, suppose we cluster trees by whose backyard they're in.
- Person A has trees of several different species growing in their yard. For them, we compute , the corresponding abstraction/summary [2], and some that makes be a valid abstraction.
- Person B only plants trees of a single species. Again, we compute , , .
- Obviously, .
What does this approach yield us?
- It's a tool of analysis. We can try different rules on for size, and see if that reveals any interesting data. (Do most people grow only trees of a single species in their yard?)
- It's potentially useful for general-purpose search via constraints [LW · GW]. Consider two different first-order abstractions, "trees of species z" and trees-in-my-backyard . Computing the second-order abstraction from them would be rather arbitrary, but it's something we may want to do during a specific planning process!
- (Though note that combining any two nth-order abstractions would result in a (n+1)th-order abstraction that has at least as much information as . I. e., any given valid abstraction hierarchy over a given set of instances terminates in the same max-level abstraction. I'm not sure if that's useful.)
- It allows abstraction layers, as outlined below.
Consider humans, geopolitical entities, and ideological movements. They don't have a clear hierarchy: while humans are what constitutes the latter two "layers", ideological movements are not split across geopolitical lines (same ideologies can be present in different countries), and geopolitical entities are not split along ideological lines (a given government can have multiple competing ideologies). By implication, once you're viewing the world in terms of ideologies, you can't recover governments from this data; nor vice versa.
Similarly: As we've established, we can split trees by species and by "whose backyard they're in" . But: we would not be able to recover genuses from the backyard-data ! Once we've committed to the backyard-classification, we've closed-off species-classification!
I propose calling such incompatible abstraction hierarchies abstraction layers. Behind every abstraction layer, there's some rule by which we're splitting instances into sets, and such rules are/are-defined-over natural abstractions, in turn.
Does all that make sense, on your model?
- ^
And, I guess, such that there's at least one set with more than one instance, to forbid the uninteresting trivial case where there's a one-member set for every initial instance. More generally, we'd want the number of sets to be "small" compared to the number of instances, in some sense of "small".
- ^
Reason for the change in notation from will be apparent later.
- ^
Or maybe it's still useful, for general-purpose search via constraints [LW · GW]?
comment by DanielFilan · 2023-01-14T09:10:11.254Z · LW(p) · GW(p)
Empirically, human toddlers are able to recognize apples by sight after seeing maybe one to three examples. (Source: people with kids.)
Wait but they see a ton of images that they aren't told contain apples, right? Surely that should count. (Probably not 2^big_number bits tho)
Replies from: johnswentworth↑ comment by johnswentworth · 2023-01-14T18:32:32.161Z · LW(p) · GW(p)
Yes! There's two ways that can be relevant. First, a ton of bits presumably come from unsupervised learning of the general structure of the world. That part also carries over to natural abstractions/minimal latents: the big pile of random variables from which we're extracting a minimal latent is meant to represent things like all those images the toddler sees over the course of their early life.
Second, sparsity: most of the images/subimages which hit my eyes do not contain apples. Indeed, most images/subimages which hit my eyes do not contain instances of most abstract object types. That fact could either be hard-coded in the toddler's prior, or learned insofar as it's already learning all these natural latents in an unsupervised way and can notice the sparsity. So, when a parent says "apple" while there's an apple in front of the toddler, sparsity dramatically narrows down the space of things they might be referring to.
comment by Thane Ruthenis · 2023-01-04T17:56:26.896Z · LW(p) · GW(p)
What are your current thoughts on the exact type signature of abstractions? In the Telephone Theorem post [LW · GW], they're described as distributions over the local deterministic constraints. The current post also mentions that the "core" part of an abstraction is the distribution , and its ability to explain variance in individual instances of .
Applying the deterministic-constraint framework to trees, I assume it says something like "given certain ground-truth conditions (e. g., the environment of a savannah + the genetic code of a given tree), the growth of tree branches of that tree species is constrained like so, the rate of mutation is constrained like so, the spread of saplings like so, and therefore we should expect to see such-and-such distribution of trees over the landscape, and they'll have such-and-such forms".
Is that roughly correct? Have you arrived at any different framework for thinking about type signatures?
Replies from: johnswentworth↑ comment by johnswentworth · 2023-01-04T23:42:19.892Z · LW(p) · GW(p)
Roughly, yeah. I currently view the types of and as the "low-level" type signature of abstraction, in some sense to be determined. I expect there are higher-level organizing principles to be found, and those will involve refinement of the types and/or different representations.
comment by DragonGod · 2022-12-21T12:52:28.135Z · LW(p) · GW(p)
A hypothesis based on this post:
Consider the subset of "human values" that we'd be "happy" (where we fully informed) for powerful systems to optimise for.
[Weaker version: "the subset of human values that it is existentially safe for powerful systems to optimise for".]
Let's call this subset "ideal values".
I'd guess that the "most natural" abstraction of values isn't "ideal values" themselves but something like "the minimal latents [LW · GW] of ideal values".
Examples of what I mean by a concept being a "more natural" abstraction:
- The concept is highly privileged by the inductive biases of most learning algorithms that can efficiently learn our universe
- More privileged → more natural
- Most efficient representations of our universe contain simple embeddings of the concept
- Simpler embeddings → more natural
comment by romeostevensit · 2022-12-20T19:27:39.962Z · LW(p) · GW(p)
Related background on the philosophical problem: gavagai
comment by tailcalled · 2022-12-20T12:00:55.449Z · LW(p) · GW(p)
One thing I've also been thinking about is how concepts spread in large-scale social networks. If you've got a social network A - B - C - D, i.e. where person A knows person B and person B knows person C, but person A does not know person C, and so on, then it's possible that basically none of the concrete things that person A's ideas are about will be things that person D knows of. However, many abstract/general things might still apply; so memes that are about general information can spread much further.
I suspect we're underrating the extent to which this affects our concept-language.
Replies from: unicode-70↑ comment by Ben Amitay (unicode-70) · 2022-12-21T10:33:51.789Z · LW(p) · GW(p)
I also find the question very interesting, but have different intuition about what travel father. I think that in general, concrete things are actually quite similar wherever there are humans, at least in the distances that where relevant for most of our history. If I am a Judean I know what a cow looks like, and every other Hebrew speaker know too, and almost every speaker of any language similar to Hebrew knows too - though maybe they have a little different variant of cow. From the other hand, if I'm a Hindu starting a new religion that is about how to get enlightenment - chances are that in the next greenstone there would be 4 competing schools with mutually exclusive understanding of the word "enlightenment". The reason is that we generally synchronize our language around shared experience of the concrete, and have much less degrees of freedom when conceptualising it.
Replies from: tailcalled↑ comment by tailcalled · 2022-12-21T10:48:07.775Z · LW(p) · GW(p)
"A cow" is abstract and general, Betty the cow who you have years of experience with is concrete.
Replies from: unicode-70↑ comment by Ben Amitay (unicode-70) · 2022-12-21T12:41:38.593Z · LW(p) · GW(p)
Abstract and general are spectra. I agree that the maximally-specific is not good at spreading - but neither is the maximally-general
Replies from: tailcalled↑ comment by tailcalled · 2022-12-21T14:28:38.179Z · LW(p) · GW(p)
General might be more relevant than abstract.
General means something that applies in lots of different places/situations. I'm not sure memes about religious enlightenment applies in lots of places/situations; they seem to be dependent on weird states of mind and for weird purposes.
The aspect of abstract that is most relevant is probably avoiding excessive detail. Detail is expensive to transmit, so ideas with very brief accurate descriptions are better at spreading than ideas that require a lot of context. But this is not the only aspect of abstractness, as abstractness also tends to be about something only being a thought and not having concrete physical existence.
comment by Leon Lang (leon-lang) · 2023-02-16T01:15:16.411Z · LW(p) · GW(p)
Now to answer our big question from the previous section: I can find some satisfying the conditions exactly when all of the ’s are independent given the “perfectly redundant” information. In that case, I just set to be exactly the quantities conserved under the resampling process, i.e. the perfectly redundant information itself.
In the original post on redundant information, I didn't find a definition for the "quantities conserved under the resampling process". You name this F(X) in that post.
Just to be sure: is your claim that if F(X) exists that contains exactly the conserved quantities and nothing else, then you can define like this? Or is the claim even stronger and you think such can always be constructed?
Edit: Flagging that I now think this comment is confused. One can simply define as the conditional, which is a composition of the random variable and the function
comment by bhishma (NomadicSecondOrderLogic) · 2023-01-07T18:33:12.301Z · LW(p) · GW(p)
. Before the toddler ever hears the word,
It goes even back for certain visual stimuli
We examined fetal head turns to visually presented upright and inverted face-like stimuli. Here we show that the fetus in the third trimester of pregnancy is more likely to engage with upright configural stimuli when contrasted to inverted visual stimuli, in a manner similar to results with newborn participants. The current study suggests that postnatal experience is not required for this preference.
https://www.cell.com/current-biology/fulltext/S0960-9822(17)30580-8#secsectitle0015
comment by Ben Amitay (unicode-70) · 2022-12-21T10:45:49.924Z · LW(p) · GW(p)
I have similar but more geometric way of thinking about it. I think of the distribution of properties as a topography of many mountains and valleys. Then we get hierarchical clustering as mountains with multiple tops, and for each cluster we get the structure of a lower dimensional manifold by looking only at the directions for which the mountain is relatively wide and flat.
Of course, the underlying geometry and as a result the distribution density are themselves subjective and dependant on what we care about - pixel-by-pixel or atom-by-atom comparison would not yield similarity between trees even of the same species