A Correspondence Theorem
post by johnswentworth · 2020-10-26T23:28:06.305Z · LW · GW · 6 commentsContents
The Claim
Key Ideas From The Math
Applicability
Conclusion
Appendix: Proofs
Correspondence Only If Independent Variation Subject to Deterministic Constraint
Correspondence If Independent Variation Subject to Deterministic Constraint
None
6 comments
I’ve been thinking lately [LW · GW] about formalizations of the Correspondence Principle - the idea that new theories should reproduce old theories, at least in the places where the old theories work. Special relativity reduces to Galilean relativity at low speed/energy, general relativity reduces to Newtonian gravity when the fields are weak, quantum mechanics should reproduce classical mechanics at large scale, etc. More conceptually, it’s the idea that flowers are “real”: any model which does a sufficiently-good job of predicting the world around me should have some kind of structure in it corresponding to my notion of a flower (though it may not be ontologically basic).
I want theorems telling me when my models are of the right kind, and sufficiently-well-nailed-down, that I can expect some kind of correspondence along these lines to apply for any future theory (assuming the future theory has sufficiently strong predictive power). Ideally, this would allow us to take a model and extract the “generalizable” information from it, construct some universal representation of certain components of the model which lets us find the “corresponding” components in any other model with sufficiently-good predictive performance on the same data. (This problem [LW · GW] is one example of a potential application.)
This post introduces one such theorem. We’ll show that a (particular type of) correspondence theorem applies in exactly those cases where our model is able to make deterministic predictions about the relationship between some observable variables.
I've tried to keep the hairiest of the math in the appendices and the "key ideas from the math" section. If you want the key ideas with minimal math, then skip those sections.
The Claim
Here’s the setup. We have two random variables, and , and we have enough data that we can perfectly figure out their joint distribution . We don’t necessarily know what physical process generates these variables - i.e. we don’t know the true underlying generative model. You can imagine some scientific experiment where we can collect lots of independent samples of , then brute-force count how often each pair occurs in order to estimate , but we don’t have any way to experimentally probe the “internals” of the experimental setup. In other words, it's the traditional setup from frequentist probability.
We’ll assume that the class of “theories” we’re interested in are generative models - i.e. programs which take in some independent uniform variables and spit out . For our purposes, we’ll assume these programs are represented as systems of circuits/causal DAGs/Bayes nets - see here [? · GW] for what that sort of representation looks like. (Note that this representation is Turing complete, so we’re not imposing any significant restriction.)
As long as and are not independent, any generative model which reproduces the distribution must have some variable(s) upstream of both and - some common upstream cause(s) which account for the relationship between the variables. The claim I’d like to make is: any upstream variable(s) capable of accounting for the relationship between and must contain some “minimal” information. Formally: we can construct some variable (defined by the distributions ) such that and are independent given :
… and, for any other which induces conditional independence of and , is a (possibly stochastic) function of : for all such that
... we have
.
Conceptually: is the “minimal” information about the relationship between and . It must be “included in” any variable capable of accounting for the relationship between those two variables.
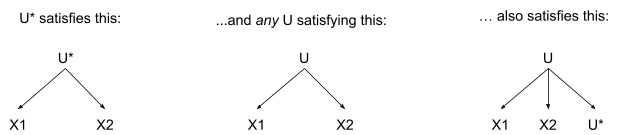
That’s the claim I’d like to make. However, that claim is too strong - not all distributions have such a . Indeed, in some sense “most” do not, though we can work around that to a large extent. The next section will explain exactly when we can construct such a , and the appendix gives the proof. Specifically, we can construct in exactly those cases where the relationship between and is independent variation subject to a deterministic constraint. Formally: we can construct exactly when can be represented as
… for some deterministic functions (here is the indicator function). In that case, we can choose .
Key Ideas From The Math
We have to be able to calculate our “universal” upstream from any which induces independence of . In particular, and are independent given either or itself - so we can choose either of those to be . Combine that with the original requirements, and we have:
- independent of given
- independent of given
- independent of given
This three-way conditional independence requirement is the main constraint which determines which distributions have a .
One easy way to satisfy this three-way conditional independence is when , , and are all just completely independent. Another is when all three are deterministically equal - i.e. implies , implies , etc. And of course we can rename variable values while maintaining three-way conditional independence - e.g. we could rename values from to . So all three variables isomorphic - rather than equal - also works: , with and invertible.
We could also combine these two possibilities: , , and could each have two components, where one component is independent and the other component is fully determined by either of the other variables. For instance, we could have , , , with , , and all completely independent, but , , and all deterministically isomorphic. Again, we can also rename variable values, so our variables don’t need to literally be written with two components.
… and that turns out to be the most general possibility.
Visually: if we lay out the distribution in a matrix (with rows corresponding to values and columns corresponding to values), then we can arrange that matrix to look like this:
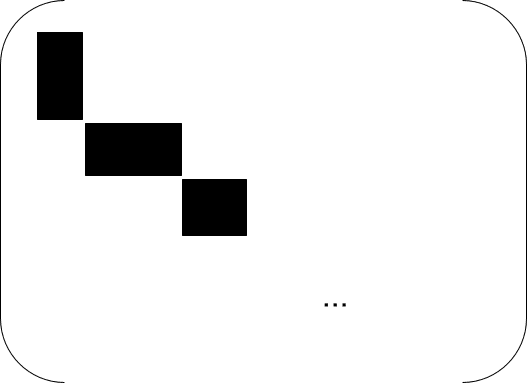
Here the dark blocks are nonzero values; everything else is zero. Within the dark blocks, we have - i.e. the dark blocks are each rank-1 submatrices. Intuitively, our distribution consists of a deterministic relationship (the choice of which block we’re in) plus independent variation (choice of values within the block). This generalizes in the obvious way to the full distribution : the full distribution consists of non-overlapping 3D blocks of nonzeros, with the three variables independent within each block.
For the full proof that these are the only distributions for which we can construct , see the appendix.
Note that we do still have a degree of freedom in choosing - we can add or remove independent components. The obvious choice is to remove all the independent components from , and just keep the deterministic component. Visually, we take to “choose a block” in the graphic above. (In fact, we could have just specified upfront that is a deterministic function of any possible , rather than the more general stochastic function, but I usually prefer to use the more general version just in case the problem has some implicit embedded game with mixed equilibria - the stochastic function allows to “randomize its strategy”. In this case, it turns out that the generality doesn’t buy us anything, and that is itself useful to know; it means there’s probably no diagonalization shenanigans going on.)
The appendix proves that this choice of indeed satisfies all of our original conditions.
To wrap up this section, let’s write out the shape of mathematically. Each value of has nonzero probability in only one “block”, so we can create a function which picks out the block for each value. Likewise for . can be nonzero only if and are in the same block: . The chance of landing in a particular block is (which is equal to , since and must always be equal). Within the block (i.e. conditional on ), and are independent. Put all that together, and we get
Since picks out the block, and is the block choice, .
Applicability
At first glance, it looks like the conditions required to use this theorem are pretty restrictive. But there’s an easy trick to generalize it somewhat.
Suppose we have a distribution which does not fully satisfy the requirements, but it does have a deterministic constraint: with probability 1. Then we can’t apply our correspondence theorem to and , but we can apply it to and . We can construct satisfying this:
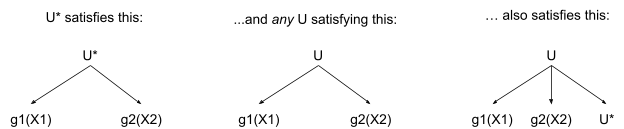
In particular, we can choose .
So: whenever we can identify a deterministic constraint in the world, we can apply this correspondence theorem. In other words, deterministic constraints in one model should have corresponding structures in other models, to the extent that all models match the environment.
Note that “deterministic constraints” is exactly the content of most models in the hard sciences. For instance, equations in physics are almost always deterministic constraints on the trajectory of world-states. To the extent that these equations match the real world, we should see corresponding constraints in future theories/models which also match the real world.
We can push this further.
We haven’t talked about approximations here, but let’s assume that the theorem generalizes to approximations in the obvious way - i.e. approximately deterministic constraints give approximate correspondence, with independencies replaced by approximate independencies. Once we have approximations, we can construct deterministic constraints via statistical identification.
Here’s what that means. Consider something like the ideal gas law, . Observing a few specific particles will not tell us the pressure or temperature of the gas. Individual particles have only partial information about the high-level variables, so we don’t have a correspondence theorem. However, if we bucket together a whole bunch of particles, then we can get a very precise estimate of temperature and pressure - in stats terminology, and can be “identified” from our many independent particles. We can then have deterministic relationships between the identified variables, like . Then we can apply the correspondence theorem.
Similarly, we could identify variables using multiple “bunches of particles” - or, more generally, multiple meaurements/multiple lines of evidence. For instance, maybe we can use a whole bunch of measurements to determine the gravitational constant. If we do this again with another set of measurements, we expect to get the same number. That’s a deterministic constraint: gravitational constant calculated from one set of measurements should equal gravitational constant calculated from another. To the extent that this constraint matches the real world, our correspondence theorem says the gravitational constant should correspond to something in any future theory.
Conclusion
In some ways, this theorem leaves a lot to be desired. In particular, it assumes access to the “true distribution”, which I’d really like to get rid of. I expect there are other correspondence theorems to be found, with very different formulations, some of which would be better in that regard. For instance, for maximum entropy models, there’s an easy correspondence theorem which says “given an old model and a new model, either the constraints of the old model are satisfied by the new model, or we can construct a third model which strictly outperforms the new model”. (That theorem is unimpressive in other ways, however - it doesn’t really say anything about the “internal structure” of the models.)
Aside from direct use as a correspondence theorem, “independent variation subject to deterministic constraints” is an interesting thing to see pop out. It’s a common pattern in the sciences - it describes far-apart low-level variables in any abstraction [? · GW] where the high-level model is deterministic. I also think it’s equivalent to zero distributed information, which I previously predicted [? · GW] ought to show up quite often when looking at information relevant far away in a system. On top of that, humans often have a (mistaken) intuition that information works like sets - information comes in discrete chunks, and a variable either contains a chunk or it doesn’t. This leads to some common mistakes when studying information theory. For systems in which variation is independent subject to deterministic constraints, the “information is like sets” intuition is correct, and I suspect that it’s the only case where that picture works in general (for some formulation of “in general”).
It seems like there’s something fundamental about this pattern, and this correspondence theorem is another hint.
Appendix: Proofs
Even having guessed the answer, I found these proofs surprisingly difficult. There’s probably some way to set things up so it’s more obvious what to do, but I’m not sure what it is, other than that someone will tell me it has something to do with category theory.
The problem: we want for which
and for all such that , we have
.
We’ll show that:
- This is only possible when for some
- When has that form, the choice works.
Correspondence Only If Independent Variation Subject to Deterministic Constraint
We'll start off the same as earlier: we want (in English: independent of given ) for any satisfying . Well, there’s two choices for which definitely satisfy : namely, and themselves. So:
… and by assumption, . So, any two of the variables , , and are independent given the third.
Let’s write out in two different ways, using two of our conditional independencies:
Note that , so we can cancel those terms out and find
… if . Note that, since our three-way independence condition is symmetric in the variables, we can also switch around the variables to get:
- when
- when
These are quite strong. Pick any two values, and , for which any value has both and . (Terminology: we’ll say that these two values “overlap” on , i.e. either value occurs with nonzero probability when . We'll also say that values of two different variables overlap when they have nonzero joint probability, e.g. overlaps iff ). Then
Furthermore, since for all , any with will also have . In other words, if two values overlap on any value, then they also overlap on all values which overlap either value. That, in turn, means
… for any value on which overlap. Finally, this also means that two values which overlap on any value overlap on all values which overlap either value: ( and ) for any implies that on all with , and vice versa.
That last condition is especially useful, since it means that overlap is transitive: if and overlap, and and overlap, then and overlap, and all three overlap on the same values.
That finally lets us construct our functions and . Since we have transitivity of overlap, we can use overlap as an equivalence relation, and let choose the equivalence class into which falls. chooses the equivalence class of values with which overlaps (note that there can only be one, since this class contains all the values which overlap with this value). This is the “choice of block” from our earlier visual.
The rest follows (relatively) easily. From the definition of overlap, whenever . Our independence conditions from earlier give (since all values in an overlap equivalence class give the same conditional distributions), so we have conditional independence given :
Then, we just expand:
Since , we have
… which gives us our final expression:
(And note that we can freely switch with here.)
One side note: I’ve defined and here as selecting equivalence classes, which is kind of annoying - it doesn’t give us a clean explicit representation. If we want an explicit representation, we can choose , and likewise for . This leads to “fun” expressions like . See the Minimal Map [LW · GW] post for how to interpret expressions like that.
Correspondence If Independent Variation Subject to Deterministic Constraint
Now we assume that has the right form, declare that and are independent given some , and show that (or equivalently, ) is a function of , implying that it’s independent of and given .
Suppose that is not a function of - i.e. there is some value of for which could have two different values each with nonzero probability. Then, since and are independent given :
Since with probability 1, we must have . Substituting:
Now, by assumption:
- and are different
- and are both nonzero
… thus .
… but that’s a contradiction, because that means there’s a nonzero probability that .
Thus, is always a function of , and is therefore independent of and (and anything else) given .
6 comments
Comments sorted by top scores.
comment by johnswentworth · 2022-01-17T20:29:34.754Z · LW(p) · GW(p)
Note to self: use infinitely many observable variables instead of just two, and the condition for should probably be that no infinite subset of the 's are mutually dependent (or something along those lines). Intuitively: for any "piece of latent information", either we have infinite data on that piece and can precisely estimate it, or it only significantly impacts finitely many variables.
comment by abramdemski · 2024-05-23T20:03:51.729Z · LW(p) · GW(p)
Noting that images currently look broken to me, in this post.
Replies from: johnswentworth↑ comment by johnswentworth · 2024-05-28T21:02:54.145Z · LW(p) · GW(p)
Should be fixed now, thanks for the heads-up. The same problem also broke images on a bunch of my other old posts; please do leave comments if you find more which I haven't fixed yet.
comment by Roger Dearnaley · 2023-04-25T01:45:07.824Z · LW(p) · GW(p)
flowers are “real”
I really wish you'd said 'birds' here :-)
comment by drocta · 2020-10-27T01:44:11.757Z · LW(p) · GW(p)
There are a few places where I believe you mean to write a but instead have instead. For example, in the line above the "Applicability" heading.
I like this.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-10-27T02:07:11.203Z · LW(p) · GW(p)
Ah, thanks. I think I got them all now.