Transfer learning and generalization-qua-capability in Babbage and Davinci (or, why division is better than Spanish)
post by RP (Complex Bubble Tea), agg (ag) · 2024-02-09T07:00:45.825Z · LW · GW · 6 commentsContents
Setup Results Transfer with fine-tuning Entertaining findings Significance to alignment Non-arbitrary clustering None 6 comments
Tl/Dr:
- Generalisation is a capability in its own right, and in our experiments it scales less quickly than specific capabilities.
- Our experiments show that on a range of tasks, finetuning Babbage on task A transfers more to task B than finetuning Davinci on task A transfers to task B. This is relevant for identifying the nature of the alignment problem we might encounter (for things in this vague cluster see here [AF · GW], here [AF · GW], and here [? · GW]).
- Of independent interest is the fact that a transfer learning metric can give us a fairly non-arbitrary way to measure how similar any two tasks are.
Epistemic status: written quickly, but oh look we did 4×8^2 experiments and we have a lovely graphic
This post makes two contributions. First, we compare results of transfer learning experiments from Babbage and Davinci and suggest that, at least in these experiments, the ability to generalize scales less quickly than do specific capabilities. Then, we suggest and implement a measure of task-to-task similarity by using results from transfer learning. The first is more relevant to alignment; the second is of independent philosophical interest.
Along the way, we also comment on various interesting results, such as that good performance on division helps far more with multiplication than good performance on subtraction does with addition. Our code is available at github.com/ag8/transfer-scaling.
Setup
We picked 8 somewhat random tasks: five mathematical problems and three text-based multiple-choice questions given in trivia style. For every pair, we first finetuned on task A, then briefly finetuned on task B, and compared performance on task B to the case where we had only briefly finetuned on task B. For example, we finetuned on 200 examples of addition followed by 10 of subtraction, and compared the model’s subsequent performance on subtraction to its performance after only being finetuned on 10 examples of subtraction. We did this for each pair of tasks both for Babbage and Davinci.
Results
The table below presents our findings in each case. Results are given as percentage point improvement between each model’s performance on the column dataset after being fine-tuned on 10 examples from the column dataset, and the performance after being fine-tuned first on 200 examples from the row dataset, followed by 10 examples from the column dataset.
The left heatmap represents the improvements for Babbage, the second for Davinci.
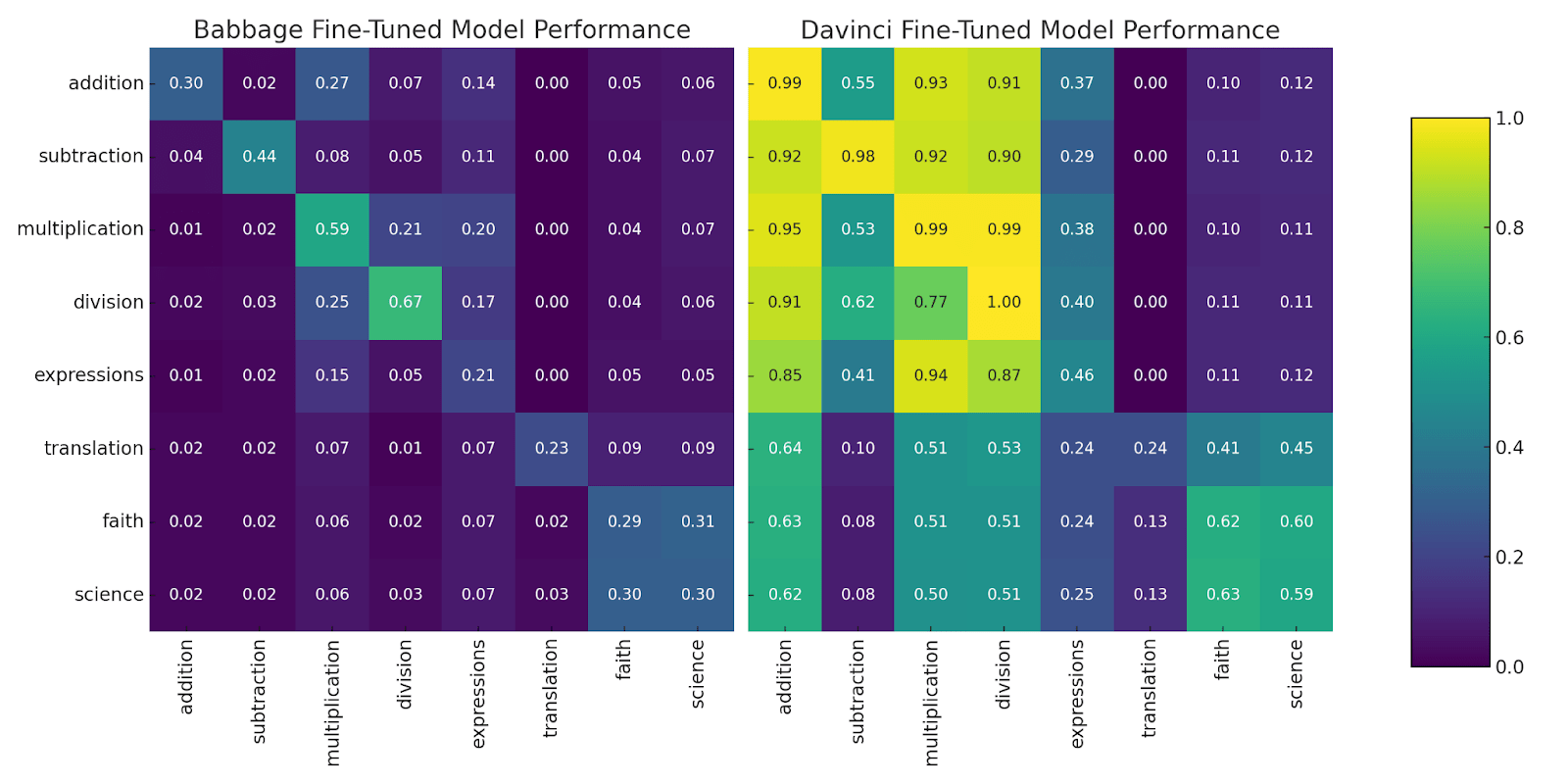
Figure 1: the raw transfer results. Babbage fine-tuned on addition gets 27% accuracy on the multiplication dataset, while Davinci fine-tuned on faith gets 13% on the translation dataset.
Transfer with fine-tuning
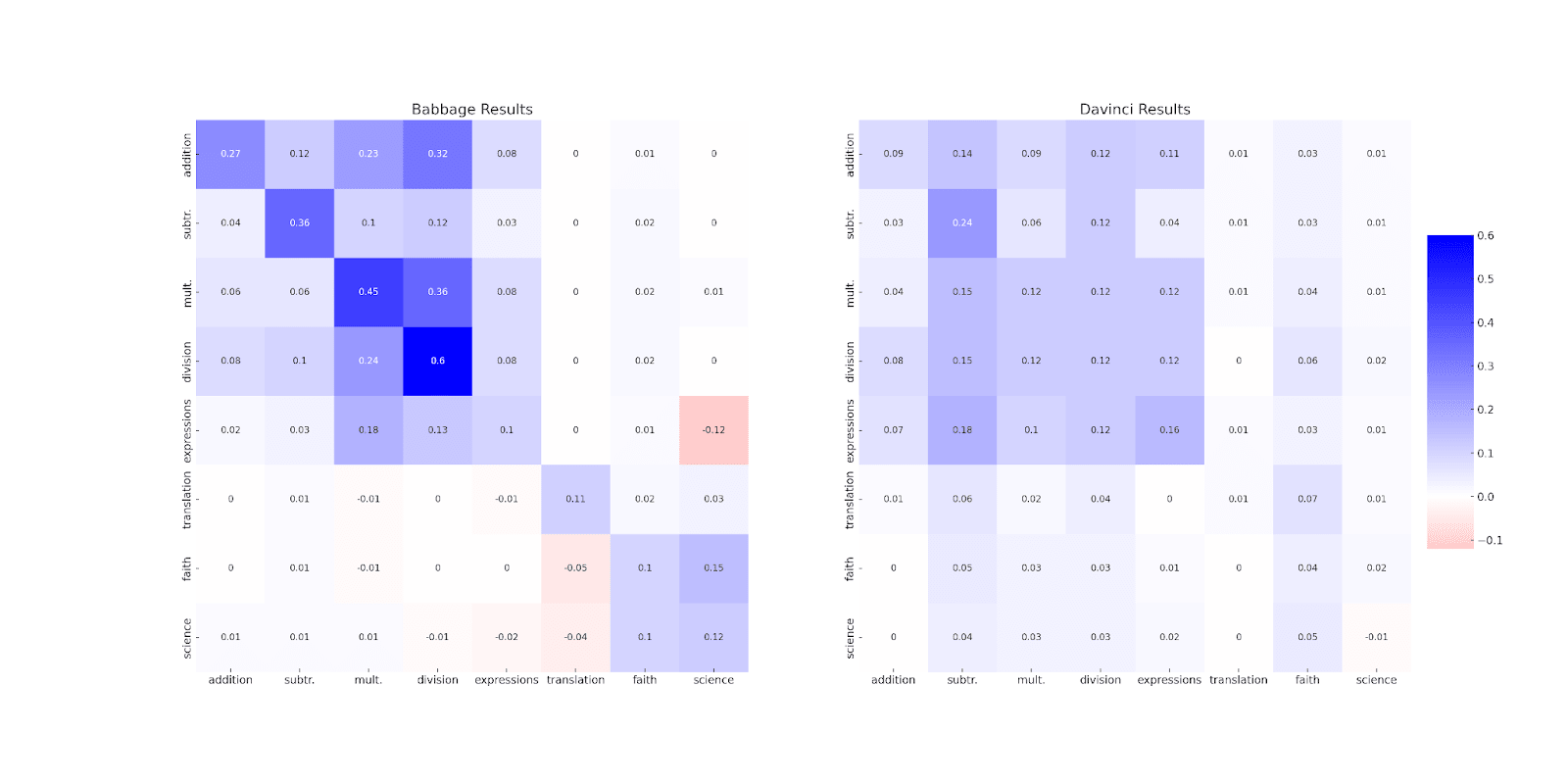
Figure 2: results after finetuning.
Entertaining findings
- For both models, addition helps with subtraction a lot more than the reverse.
- Also for both models, division helps with multiplication more than subtraction helps with addition.
- In Babbage, fine-tuning on the faith dataset improves performance on the science dataset more than it improves performance on the faith dataset.
- In Davinci, fine-tuning on mathematical expressions really helps with subtraction, but not vice versa. This is weird, because the mathematical expressions only contain addition and multiplication. In Babbage, there’s no difference.
- For both models, fine-tuning on translation helps with faith, while fine-tuning on faith either does nothing or hurts translation performance.
- There are significantly more asymmetries in Babbage than in Davinci.
- In both models, fine-tuning on pretty much anything seems to boost performance on faith.
- In the heatmap, we can pretty easily see how the tasks split into three natural categories: math, trivia, and translation.
Significance to alignment
On their own, these results tell us little about whether we should, in other contexts, expect deep or shallow circuits to develop, particularly in more capable models. We do not, for example, engage with the literature on grokking and neither do we make any claims about whether this relationship between generalization and specific capabilities will stay constant as models get better.
We want, first, to use this as a quick intuition for the idea that the ability to generalize is different from other capabilities, and, second, to emphasize that just as some capabilities improve at different rates, generalization may in fact improve quite slowly.
Whether LLMs are best thought of as ensembles of shallow circuits, or in some meaningful way composed also of deep circuits, is an important question, and more in-the-weeds experiments should be done to resolve it.
Non-arbitrary clustering
We think that one of the most basic questions in philosophy is how to develop any kind of principled coarse-graining, or relatedly how to tell how far one state is from another. (Aristotle’s Function Argument can be seen as kind of fundamentally trying to do this if you wave your hands a bit.) Transference represents a somewhat non-arbitrary way of scientifically considering how to cluster tasks. And it is far more tractable than other measures, e.g., information theoretic ones.
Of course, the architecture of the models necessarily influences their transfer capabilities, so we would expect the results to be architecture-specific. Nonetheless, it is of independent scientific coolness that one can use this fine-tuning transfer metric to approach an “objective” way to measure the similarity of different domains. One could further investigate how well this describes human cross-domain correlations.
Acknowledgements.
This work was done as part of MATS 5.0. Maria Kostylew helped enormously with writing, and Kaarel Hänni with discussions and many of the ideas underlying it. One paragraph of this post was taken mostly straight from Rio’s shared notes with Kaarel. Derik Kauffman fixed Rio’s laptop on several independent occasions. Clem von Stengel and Walter Laurito gave helpful comments.
6 comments
Comments sorted by top scores.
comment by Vivek Hebbar (Vivek) · 2024-02-09T23:30:00.939Z · LW(p) · GW(p)
Can you clarify what figure 1 and figure 2 are showing?
I took the text description before figure 1 to mean {score on column after finetuning on 200 from row then 10 from column} - {score on column after finetuning on 10 from column}. But then the text right after says "Babbage fine-tuned on addition gets 27% accuracy on the multiplication dataset" which seems like a different thing.
Replies from: ag↑ comment by agg (ag) · 2024-02-14T00:41:00.660Z · LW(p) · GW(p)
Position i, j in figure 1 represents how well a model fine-tuned on 200 examples of dataset i performs on dataset j;
Position i, j in figure 2 represents how well a model fine-tuned on 200 examples of dataset i, and then fine-tuned on 10 examples of dataset j, performs on dataset j.
comment by Chris_Leong · 2024-02-09T10:00:11.207Z · LW(p) · GW(p)
It might be useful to produce a bidirectional measure of similarity by taking the geometrical mean of the transference of A to B and of B to A.
Really cool results!
comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-02-11T20:50:36.098Z · LW(p) · GW(p)
I'd love to see this experiment done with some novel tasks that wouldn't be in the pre-training dataset at all. For instance, make up some fake new mathematical operations, maybe by making up arbitrary combinations of algebraic operations. For instance an & symbol being secretly assigned the meaning 'add three before dividing by the following number '. Or making a dataset of questions about a new fictional animal which combines traits of a variety of real animals in a novel way.
comment by LawrenceC (LawChan) · 2024-03-12T09:20:09.415Z · LW(p) · GW(p)
I'm not sure your results really support the interpretation that davinci "transfers less well". Notably, achieving 100% accuracy from 50% is often a lot harder than achieving 50% from 0%/whatever random chance is on your datasets (I haven't looked through your code yet to examine the datasets) and I'd predict that davinci already does pretty well zero-shot (w/ no finetuning) on most of the tasks you consider here (which limits its improvement from finetuning, as you can't get above 100% accuracy).
In addition, larger LMs are often significantly more data efficient, so you'd predict that they need less total finetuning to do well on tasks (and therefore the additional finetuning on related tasks would benefit the larger models less).
comment by the gears to ascension (lahwran) · 2024-02-13T16:58:35.501Z · LW(p) · GW(p)
Attempting to label the chart, please correct me:
X (bottom label): small fine tuning. Y (left label): large fine tuning.
Process to produce each cell in the plots:
bigmodel = finetuned(
finetuned(orig_model,
data=datasets[y_label][:200]),
data=datasets[x_label][:10])
smallmodel = finetuned(
orig_model,
data=datasets[x_label][:10])
plot_1_scores[(x_label, y_label)] = test(bigmodel, datasets[x_label][10:])
plot_2_scores[(x_label, y_label)] = plot_1_scores[(x_label, y_label)] - test(smallmodel, datasets[x_label][10:])
Pretty sure I got something wrong, your descriptions are pretty ambitious.