What a compute-centric framework says about AI takeoff speeds
post by Tom Davidson (tom-davidson-1) · 2023-01-23T04:02:07.672Z · LW · GW · 30 commentsContents
The framework Takeaways about capabilities takeoff speed Even without any discontinuities, takeoff could last < 1 year We should assign some probability to takeoff lasting >5 years Takeoff won’t last >10 years unless 100%-AI is very hard to develop Time from AGI to superintelligence is probably less than 1 year Takeaways about impact takeoff speed If we align AGI, I weakly expect impact takeoff to be slower than capabilities takeoff If we don’t align AGI, I expect impact takeoff to be faster than capabilities takeoff Some chance of <$3tr/year economic impact from AI before we have AI that could disempower humanity Takeaways about AI timelines Multiple reasons to have shorter timelines compared to what I thought a few years ago Harder than I thought to avoid AGI by 2060 Takeaways about the relationship between takeoff speed and AI timelines The easier AGI is to develop, the faster takeoff will be Holding AGI difficulty fixed, slower takeoff → earlier AGI timelines How does the report relate to previous thinking about takeoff speeds? Eliezer Yudkowsky’s Intelligence Explosion Microeconomics Paul Christiano Notes None 30 comments
As part of my work for Open Philanthropy I’ve written a draft report on AI takeoff speeds, the question of how quickly AI capabilities might improve as we approach and surpass human-level AI. Will human-level AI be a bolt from the blue, or will we have AI that is nearly as capable many years earlier?
Most of the analysis is from the perspective of a compute-centric framework, inspired by that used in the Bio Anchors report [LW · GW], in which AI capabilities increase continuously with more training compute and work to develop better AI algorithms.
This post doesn’t summarise the report. Instead I want to explain some of the high-level takeaways from the research which I think apply even if you don’t buy the compute-centric framework.
The framework
h/t Dan Kokotajlo for writing most of this section
This report accompanies and explains https://takeoffspeeds.com (h/t Epoch for building this!), a user-friendly quantitative model of AGI timelines and takeoff, which you can go play around with right now. (By AGI I mean “AI that can readily[1] perform 100% of cognitive tasks” as well as a human professional; AGI could be many AI systems working together, or one unified system.)
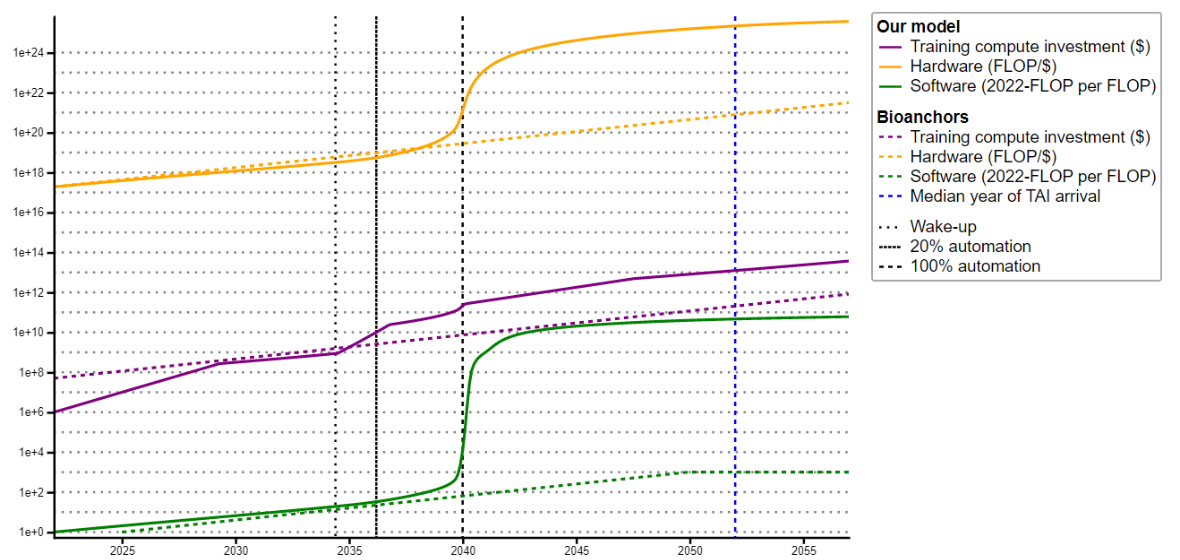 Takeoff simulation with Tom’s best-guess value for each parameter.
Takeoff simulation with Tom’s best-guess value for each parameter.
The framework was inspired by and builds upon the previous “Bio Anchors” report. The “core” of the Bio Anchors report was a three-factor model for forecasting AGI timelines:
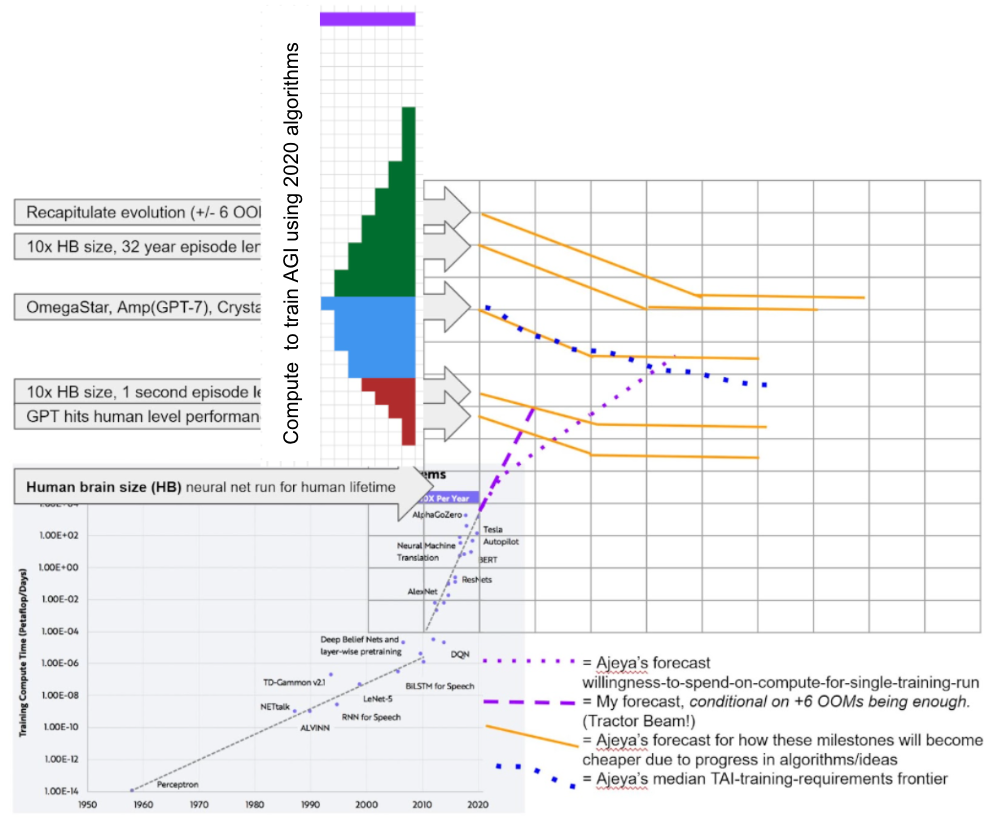
Dan’s visual representation of Bio Anchors report
- Compute to train AGI using 2020 algorithms. The first and most subjective factor is a probability distribution over training requirements (measured in FLOP) given today’s ideas. It allows for some probability to be placed in the “no amount would be enough” bucket.
- The probability distribution is shown by the coloured blocks on the y-axis in the above figure.
- Algorithmic progress. The second factor is the rate at which new ideas come along, lowering AGI training requirements. Bio Anchors models this as a steady exponential decline.
- It’s shown by the falling yellow lines.
- Bigger training runs. The third factor is the rate at which FLOP used on training runs increases, as a result of better hardware and more $ spending. Bio Anchors assumes that hardware improves at a steady exponential rate.
- The FLOP used on the biggest training run is shown by the rising purple lines.
Once there’s been enough algorithmic progress, and training runs are big enough, we can train AGI. (How much is enough? That depends on the first factor!)
This draft report builds a more detailed model inspired by the above. It contains many minor changes and two major ones.
The first major change is that algorithmic and hardware progress are no longer assumed to have steady exponential growth. Instead, I use standard semi-endogenous growth models from the economics literature to forecast how the two factors will grow in response to hardware and software R&D spending, and forecast that spending will grow over time. The upshot is that spending accelerates as AGI draws near, driving faster algorithmic (“software”) and hardware progress.
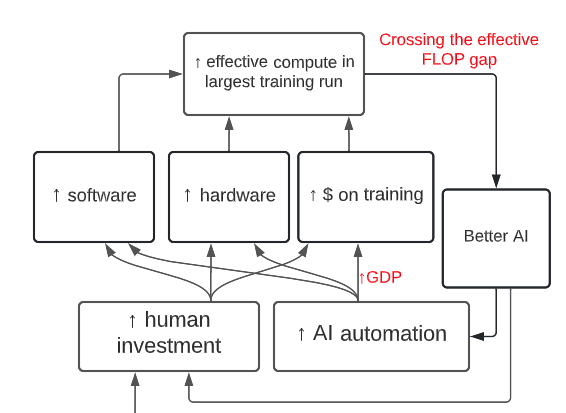
The key dynamics represented in the model. “Software” refers to the quality of algorithms for training AI.
The second major change is that I model the effects of AI systems automating economic tasks – and, crucially, tasks in hardware and software R&D – prior to AGI. I do this via the “effective FLOP gap:” the gap between AGI training requirements and training requirements for AI that can readily perform 20% of cognitive tasks (weighted by economic-value-in-2022). My best guess, defended in the report, is that you need 10,000X more effective compute to train AGI. To estimate the training requirements for AI that can readily perform x% of cognitive tasks (for 20 < x < 100), I interpolate between the training requirements for AGI and the training requirements for AI that can readily perform 20% of cognitive tasks.
Modeling the cognitive labor done by pre-AGI systems makes timelines shorter. It also gives us a richer language for discussing and estimating takeoff speeds. The main metric I focus on is “time from AI that could readily[2] automate 20% of cognitive tasks to AI that could readily automate 100% of cognitive tasks”. I.e. time from 20%-AI to 100%-AI.[3] (This time period is what I’m referring to when I talk about the duration of takeoff, unless I say otherwise.)
My personal probabilities[4] are still very much in flux and are not robust.[5] My current probabilities, conditional on AGI happening by 2100, are:
- ~10% to a <3 month takeoff [this is especially non-robust]
- ~25% to a <1 year takeoff
- ~50% to a <3 year takeoff
- ~80% to a <10 year takeoff
Those numbers are time from 20%-AI to 100%-AI, for cognitive tasks in the global economy. One factor driving fast takeoff here is that I expect AI automation of AI R&D to happen before AI automation of the global economy.[6] So by the time that 20% of tasks in the global economy could be readily automated, I expect that more than 20% of AI R&D will be automated, which will drive faster AI progress.
If I instead start counting from the time at which 20% of AI R&D can be automated, and stop counting when 100% of AI R&D can be automated, this factor goes away and my takeoff speeds are slower:
- ~10% to a <1 year takeoff
- ~30% to a <3 year takeoff
- ~70% to a <10 year takeoff
(Unless I say otherwise, when I talk about the duration of takeoff I’m referring to the time 20%-AI to 100%-AI for cognitive tasks in the global economy, not AI R&D.)
It’s important to note that my median AGI training requirements are pretty large - 1e36 FLOP using 2020 algorithms. Using lower requirements makes takeoff significantly faster. If my median AGI training requirements were instead ~1e31 FLOP with 2020 algorithms, my takeoff speeds would be:
- ~40% to a <1 year takeoff
- ~70% to a <3 year takeoff
- ~90% to a <10 year takeoff
The report also discusses the “time from AGI to superintelligence”. My best guess is that this takes less than a year absent humanity choosing to go slower (which we definitely should!).
Takeaways about capabilities takeoff speed
I find it useful to distinguish capabilities takeoff – how quickly AI capabilities improve around AGI – from impact takeoff – how quickly AI’s impact on a particular domain grows around AGI. For example, the latter is much more affected by deployment decisions and various bottlenecks.
The metric “time from 20%-AI to 100%-AI” is about capabilities, not impact, because 20%-AI is defined as AI that could readily automate 20% of economic tasks, not as AI that actually does automate them.
Even without any discontinuities, takeoff could last < 1 year
Even if AI progress is continuous, without any sudden kinks, the slope of improvement could be steep enough that takeoff is very fast.
Even in a continuous scenario, I put ~15% on takeoff lasting <1 year, and ~60% on takeoff lasting <5 years.[7] Why? On a high level, because:
- It might not be that much harder to develop 100%-AI than 20%-AI.
- AI will probably be improving very quickly once we have 20%-AI.
Going into more detail:
- It might not be that much harder to develop 100%-AI than 20%-AI.
- Perhaps chimps couldn’t perform 20% of tasks, even if they’d been optimized to do so. Humans have ~3X bigger brains than chimps by synapse count. That could mean that you only need to increase model size by 3X to go from 20%-AI to 100%-AI which, with Chinchilla scaling, would take 10X more training FLOP.
- You might need to increase model size by less than 3X.
-
With Chinchilla scaling, a 3X bigger model gets 3X more data during training. But human lifetime learning only lasts 1-2X longer than chimp lifetime learning.[8]
-
So intelligence might improve more from a 3X increase in model size with Chinchilla scaling than from chimps to humans.
-
- You might need to increase model size by less than 3X.
- Brain size - IQ correlations suggest a similar conclusion. A 10% bigger brain is associated with ~5 extra IQ points. This isn't much, but extrapolating the relationship implies that a 3X bigger brain would be ~60 IQ points smarter; and ML models may gain more from scale than humans as bigger models will be trained on more data (unlike bigger-brained humans).
- It is pretty hard to partially automate a job, e.g. for AI to automate 20% of the tasks. All of the tasks are interconnected in a messy way! Everything is set up for one human, with full context, to do the work.
- Normally, we restructure business processes to allow for partial automation. But this takes a lot of effort and time - typically decades! If the transition from 20%-AI to 100%-AI happens in just a few years (as implied by the other arguments in this section) there won’t be time for this kind of restructuring to happen.
- In this case, I still expect partial automation to happen earlier than full automation because it will still be somewhat easier to develop AI that can partially automate a job (with only small efforts restructuring processes) than AI that can fully automate the job (with similarly small efforts restructuring processes). But it might only be slightly easier.
- In other words, the lack of time for restructuring processes narrows the difficulty gap between developing 20%-AI and 100%-AI, but doesn’t eliminate it entirely.
- (This point is closely related to the “sonic boom” argument for fast takeoff.)
- Perhaps chimps couldn’t perform 20% of tasks, even if they’d been optimized to do so. Humans have ~3X bigger brains than chimps by synapse count. That could mean that you only need to increase model size by 3X to go from 20%-AI to 100%-AI which, with Chinchilla scaling, would take 10X more training FLOP.
- AI will probably be improving very quickly once we have 20%-AI.
-
Algorithmic progress is already very fast. OpenAI estimates a 16 month doubling time for algorithmic efficiency on ImageNet; an recent Epoch analysis estimates just 10 months for the same quantity. My sense is that progress is if anything faster for LMs.
-
Hardware progress is already very fast. Epoch estimates [LW · GW] that FLOP/$ has been doubling every 2.5 years.
-
Spending on AI development – AI training runs, AI software R&D, and hardware R&D – might rise rapidly after we have 20%-AI, and the strategic and economic benefits of AI are apparent.
-
20%-AI could readily add ~$10tr/year to global GDP.[9] Compared to this figure, investments in hardware R&D (~$100b/year) and AI software R&D (~$20b/year) are low.
-
For <1 year takeoffs, fast scale-up of spending on AI training runs, simply by using a larger fraction of the world’s chips, plays a central role.
-
-
Once we have 20%-AI (AI that can readily[10] automate 20% of cognitive tasks in the general economy), AI itself will accelerate AI progress. The easier AI R&D is to automate compared to the general economy, the bigger this effect.
- How big might this effect be? This is a massive uncertainty for me but here are my current guesses. By the time we have 20%-AI I expect:
- Conservatively, AI will have automated 20% of cognitive tasks in AI R&D, speeding up AI R&D progress by a factor of ~1.3. I think it’s unlikely (~15%) the effect is smaller than this.
- Somewhat aggressively, AI will have automated 40% of cognitive tasks in AI R&D, speeding up AI R&D progress by a factor of ~1.8. I think there’s a decent chance (~30%) of getting bigger effects than this.
- The speed up increases over time as AI automates more of AI R&D. When we simulate this dynamic we find AI automation reduces “time from 20%-AI to 100%-AI” by ~2.5X.
- How big might this effect be? This is a massive uncertainty for me but here are my current guesses. By the time we have 20%-AI I expect:
-
Combining the above, I think the “effective compute” on training runs (which incorporates better algorithms) will probably rise by >5X each year between 20%-AI and 100%-AI, and could rise by 100X each year.
-
We should assign some probability to takeoff lasting >5 years
I have ~40% on takeoff lasting >5 years. On a high-level my reasons are:
- It might be a lot harder to develop 100%-AI than 20%-AI.
- AI progress might be slower once we reach 20%-AI than it is today.
Going into more detail:
- It might be a lot harder to develop 100%-AI than 20%-AI.
-
The key reason is that AI may have a strong comparative advantage at some tasks over other tasks, compared with humans. Its comparative advantages might allow it to automate 20% of tasks long before it can automate the full 100%. The bullets below expand on this basic point.
-
AI, and computers more generally, already achieve superhuman performance in many domains by exploiting massive AI-specific advantages (lots of experience/data, fast thinking, reliability, memorisation). It might be far harder for AI to automate tasks where these advantages aren’t as relevant.
-
We can visualise this using (an adjusted version of) the graph Dan Kokotajlo drew in his review of Joe Carlsmith’s report on power-seeking AI.
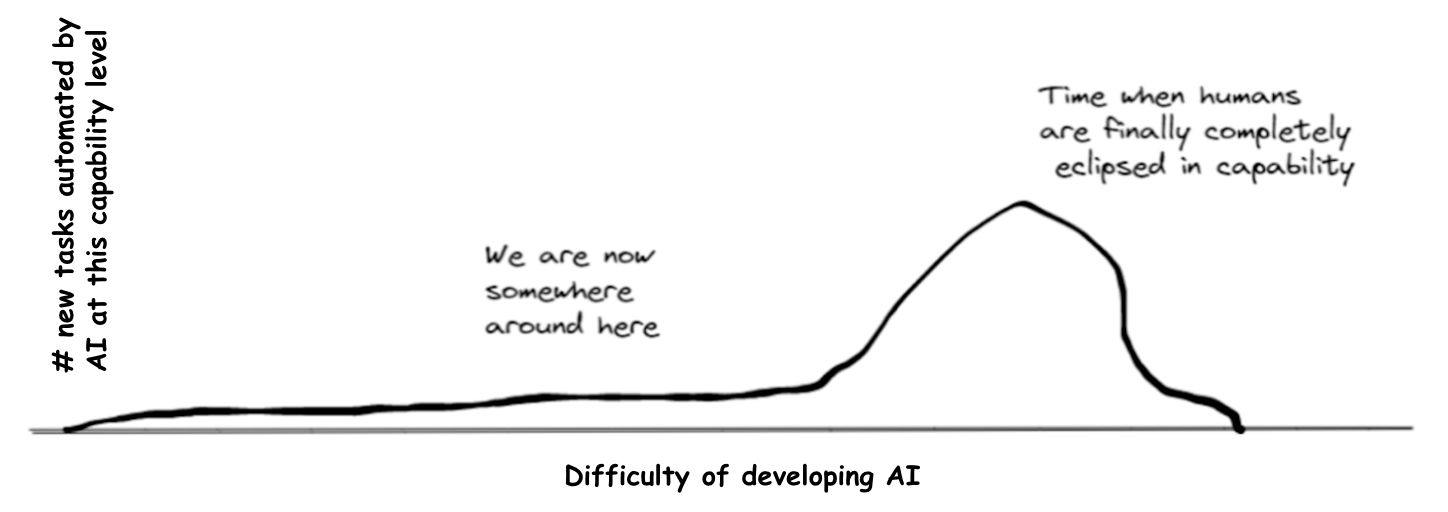 We’re currently in the left tail, where AI’s massive comparative advantages allow it to automate certain tasks despite being much less capable than humans overall. If AI automates 20% of tasks before the big hump, or the hump is wide, it will be much easier to develop 20%-AI than 100%-AI.
We’re currently in the left tail, where AI’s massive comparative advantages allow it to automate certain tasks despite being much less capable than humans overall. If AI automates 20% of tasks before the big hump, or the hump is wide, it will be much easier to develop 20%-AI than 100%-AI. -
Outside of AI, there’s generally a large precedent for humans finding simple, dumb ways to automate significant fractions of labour.
- We may have automated >80% of the cognitive tasks that humans performed as of 1700 (most people worked in agriculture), but using methods that don’t get us close to automating 100% of them.
- By analogy, AI may automate 20% of 2020 cognitive tasks using methods that don’t get AI close to automating 100% of them. If this happens gradually over many decades, it might feel like “progress as normal” rather than “AI is on the cusp of having a transformative economic impact”.
-
Within AI, there are many mechanisms that could give AI comparative advantages at some tasks but not others. AI is better placed to perform tasks with the following features:
-
AI can learn to perform the task with “short horizon training”, without requiring “long horizon training”.[11]
-
The task is similar to what AI is doing during pre-training (e.g. similar to “next word prediction”, in the case of large language models).
-
It’s easier to get large amounts of training data for the task, e.g. from human demonstrations.
-
Memorising lots of information improves task performance.
-
It’s important to “always be on” (no sleep), or to consistently maintain focus (no getting bored or slacking).
-
It’s easier to verify that an answer is correct than to generate the correct answer. (This helps to generate training data and allows us to trust AI outputs.)
-
The task doesn’t require strong sim2real transfer.
-
The downside of poor performance is limited. (We might not trust AI in scenarios where a mistake is catastrophic, e.g. driving.)
-
-
Human brains were “trained” by evolution and then lifetime learning in a pretty different way to how AIs are trained, and humans seem to have pretty different brain architectures to AIs in many ways. So humans might have big comparative advantages over AIs in certain domains. This could make it very difficult to develop 100%-AI.
-
GPT-N [LW · GW] looks like it will solve some LM benchmarks with ~4 OOMs less training FLOP. In other words, it has strong “comparative advantages” at some benchmarks over others. I expect cognitive tasks throughout the entire economy to have more variation along many dimensions than these LM benchmarks, suggesting this example underestimates the difficulty gap between developing 20%-AI and 100%-AI.
-
It’s notable that most of the evidence discussed above for a small difficulty gap between 20%-AI and 100%-AI (in particular “chimps vs humans” and “brain size - IQ correlations”) completely ignore this point about “large comparative advantage at certain tasks” by assuming intelligence is on a one-dimensional spectrum.[12]
-
I find it most plausible that there’s a big difficulty gap between 20%-AI and 100%-AI if 100%-AI is very difficult to develop.
-
- AI progress might be slower once we reach 20%-AI than it is today (though my best guess is that it will be faster).
- A lot of recent AI progress has come from increasing the fraction of computer chips used to train AI. This can only go on for so long!
- Hardware progress might be much more difficult by this time, as we approach the ultimate limits of the current hardware paradigm.
- Both of these reasons are more likely to apply if 20%-AI is hard to develop, i.e. if timelines are long.
- Above I discussed reasons why AI progress will probably be faster once we have 20%-AI: larger total $ investments in AI and AI automation. But these reasons may not apply strongly:
- It might be hard to quickly convert “more $” into faster AI progress.
- It may take years for new talent to be able to contribute to the cutting edge (especially with hardware R&D). So growing the total quality-adjusted talent in AI R&D might be slow.
- Even if you could quickly double the amount of quality-adjusted R&D talent, that less-than-doubles the rate of progress due to duplication of effort and difficulties parallelising work (“nine mothers can’t make a baby in one month”).
- Hard to scale up global production of AI chips, due to the immense complexity of the supply chain.
- Limited effects of AI automation on AI R&D progress.
- There will be some lags before AI is deployed in AI R&D.
- Progress will be bottlenecked by the tasks AI can still not perform.
- It might be hard to quickly convert “more $” into faster AI progress.
- After we reach 20%-AI, we may become more concerned about various AI risks and deliberately slow down.
Takeoff won’t last >10 years unless 100%-AI is very hard to develop
As discussed above, AI progress is already very fast and will probably become faster once we have 20%-AI. If you think that even 10 years of this fast rate of progress won’t be enough to reach 100%-AI, that implies that 100%-AI is way harder to develop than 20%-AI.
In addition, I think that today’s AI is quite far from 20%-AI: its economic impact is pretty limited (<$100b/year), suggesting it can’t readily[13] automate even 1% of tasks. So I personally expect 20%-AI to be pretty difficult to develop compared to today’s AI.
This means that, if takeoff lasts >10 years, 100%-AI is a lot harder to develop than 20%-AI, which is itself a lot harder to develop than today’s AI. This all only works out if you think that 100%-AI is very difficult to develop. Playing around with the compute-centric model, I find it hard to get >10 year takeoff without assuming that 100%-AI would have taken >=1e38 FLOP to train with 2020 algorithms (which was the conservative “long horizon” anchor in Bio Anchors).
Time from AGI to superintelligence is probably less than 1 year
Recall that by AGI I mean AI that can readily perform ~100% of cognitive tasks as well as a human professional. By superintelligence I mean AI that very significantly surpasses humans at ~100% of cognitive tasks. My best guess is that the time between these milestones is less than 1 year, the primary reason being the massive amounts of AI labour available to do AI R&D, once we have AGI. More.
Takeaways about impact takeoff speed
Here I mostly focus on economic impact.
If we align AGI, I weakly expect impact takeoff to be slower than capabilities takeoff
I think there will probably just be a few years (~3 years) from 20%-AI to 100%-AI (in a capabilities sense). But, if AI is aligned, I think time from actually deploying AI in 20% to >95% of economic tasks will take many years (~10 years):
- Standard deployment lags. It typically takes decades for new technologies to noticeably affect GDP growth, e.g. computers and the internet.
- Political economy. Workers and organizations on course to be replaced by AI will attempt to block its deployment.
- Caution. We should be, and likely will be, very cautious about handing over ~all decision making to advanced AI, even if we have strong evidence that it’s safe and aligned. (E.g. imagine the resistance to letting AI run the government.) This would probably mean that humans remain a “bottleneck” on AI’s economic impact for some time.
- Even if we have compelling reasons to hand over all decisions to AI, I still expect there to be a lot of (perhaps unreasonable) caution – AIs making decisions will feel creepy and weird to many people.
I’m not confident about this. Here are some countervailing considerations:
- Less incentive to deploy AI before superintelligence.
- If a lab faces a choice between deploying their current SOTA AIs in the economy vs investing in improving SOTA, they may choose the latter if they think they could automate AI R&D and thereby accelerate their lab’s AI progress.
- Eventually though, after the “better AI → faster AI R&D progress” feedback loop has fizzled out (perhaps after they’ve developed superhuman AI), labs’ incentive will simply be to deploy. There could be an extremely fast impact takeoff when labs suddenly start trying to deploy their superhuman AIs.
- Superhuman AIs quickly circumvent barriers to deployment. Perhaps pre-AGI systems mostly aren’t deployed due to barriers like regulations. But superhuman aligned AI might be able to quickly navigate these barriers, e.g. good-faith convincing human regulators to deploy it more widely so it can cure diseases.
Many of the above points, on both sides, apply more weakly to the impact of AI on AI R&D than on the general economy. For example, I expect regulation to apply less strongly in AI R&D, and also for lab incentives to favour deployment of AIs in AI R&D (especially software R&D). So I expect impact takeoff within AI R&D to match capabilities takeoff fairly closely.
If we don’t align AGI, I expect impact takeoff to be faster than capabilities takeoff
If AGI isn’t aligned, then AI’s impact could increase very suddenly at the point when misaligned AIs first collectively realise that they can disempower humanity and try to do so. Before this point, human deployment decisions (influenced by regulation, general caution, slow decision making, etc) limit AI’s impact; afterwards AIs forcibly circumvent these decisions.[14]
Some chance of <$3tr/year economic impact from AI before we have AI that could disempower humanity
I’m at ~15% for this. (For reference, annual revenues due to AI today are often estimated at ~$10-100b,[15] though this may be smaller than AI’s impact on GDP.)
Here are some reasons this could happen:
- Fast capabilities takeoff. There might be only a few years from “AI that could readily add $3tr/year to world GDP” to AI that could disempower humanity. See above arguments.
- Significant lags to deploying AI systems in the broader economy. See above points.
- As above, I expect there will be fewer lags to deployment in AI R&D. I’m not counting work done by AI within AI R&D as counting towards the “$3tr”.
- Labs may prioritise improving SOTA AI over deploying it. Discussed above; this could continue until labs develop AI that could disempower humanity.
- On the other hand, even if leading labs strongly prioritise deploying AIs internally, they’ll probably expend some effort plucking the low-hanging fruit for deploying it in the broader economy to make money and generate more investment. And even if leading labs don’t do this, other labs may specialise in training AI to be deployed in the broader economy.
Why am I not higher on this?
-
$3tr/year only corresponds to automating ~6% of cognitive tasks;[16] I expect AI will be able to perform >60%, and probably >85% of cognitive tasks before it can disempower humanity. That’s a pretty big gap in AI capabilities!
-
People will be actively trying to create economic value from AI and also actively trying to prevent AI from being able to disempower humanity.
- We’ll train AI specifically to be good at economically valuable tasks and not train AI to be good at “taking over the world” tasks (modulo the possibility of using AI in the military).
- We’ll make adjustments to workflows etc. to facilitate AI having economic impact, and (hopefully!) make adjustments to protect against AI takeover.
-
I have a fairly high estimate of the difficulty of developing AGI. I think we’re unlikely to develop AGI by 2030, by which time AI may already be adding >$3tr/year to world GDP.
My “15%” probability here feels especially non-robust, compared to the others in this post.
Takeaways about AI timelines
Multiple reasons to have shorter timelines compared to what I thought a few years ago
Here’s a list (including some repetition from above):
- Growing $ investment in training runs, software R&D and hardware R&D, once AI can readily automate non-trivial fractions of cognitive labour (e.g >3%).
- AI automation of AI R&D accelerating AI progress. Firstly, it may be easier to fully automate AI R&D than to fully automate cognitive labour in general. Secondly, even partial R&D automation can significantly speed up AI progress.
- “Swimming in runtime compute”.
-
If AGI can’t be trained by ~2035 (as I think is likely), then we’ll have a lot of runtime compute lying around, e.g. enough to run 100s of millions of SOTA AIs.[17]
-
It may be possible to leverage this runtime compute to “boost” the capabilities of pre-AGI systems. This would involve using existing techniques for this like “chain of thought”, “best of N sampling” and MCTS, as well as finding novel techniques. As a result, we might fully automate AI R&D much sooner than we otherwise would.
-
I think this factor alone could easily shorten timelines by ~5 years if AGI training requirements are my best guess (1e36 FLOP with 2020 algorithms). It shortens timelines more(/less) if training requirements are bigger(/smaller).
-
- Faster software progress. I put more probability on algorithmic progress for training AGI being very fast than previously. This is from fast software progress for LMs (e.g. Chinchilla scaling) and recent analysis from Epoch.
Harder than I thought to avoid AGI by 2060
To avoid AGI by 2060, we cannot before 2040 develop “AI that is so good that AGI follows within a couple of decades due to [rising investment and/or AI itself accelerating AI R&D progress]”. As discussed above, this latter target might be much easier to hit. So my probability of AGI by 2060 has risen.
Relatedly, I used to update more on growth economist-y concerns like “ah but if AI can automate 90% of tasks but not the final 10%, that will bottleneck its impact”. Now I think “well if AI automates 90% of cognitive tasks that will significantly accelerate AI R&D progress and attract more investment in AI, so it won’t be too long before AI can perform 100%”.
Takeaways about the relationship between takeoff speed and AI timelines
The easier AGI is to develop, the faster takeoff will be
Probably the biggest determinant of takeoff speeds is the difficulty gap between 100%-AI and 20%-AI. If you think that 100%-AI isn’t very difficult to develop, this upper-bounds how large this gap can be and makes takeoff faster.
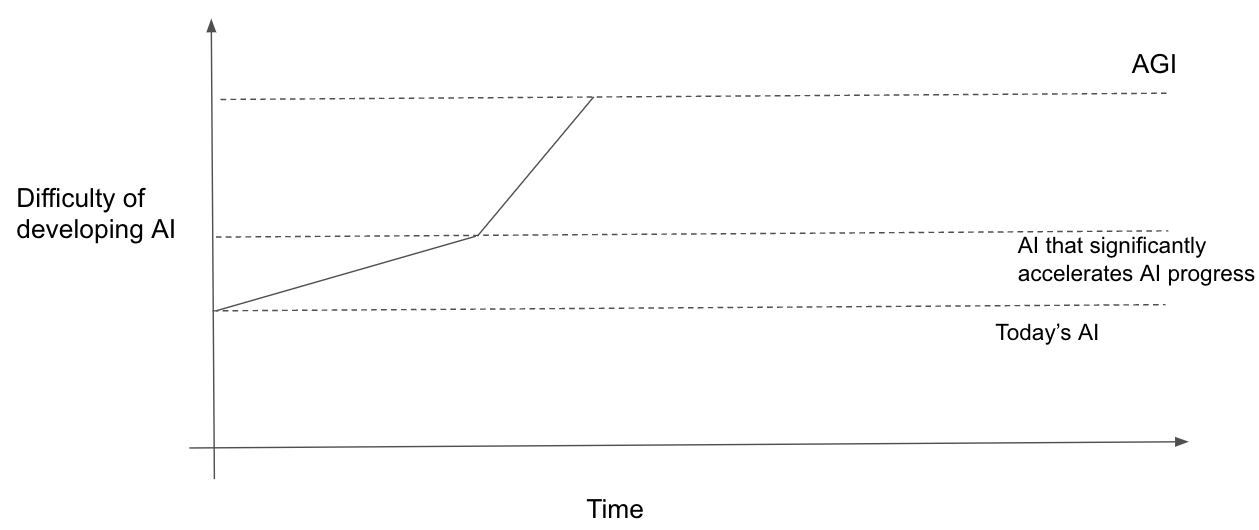
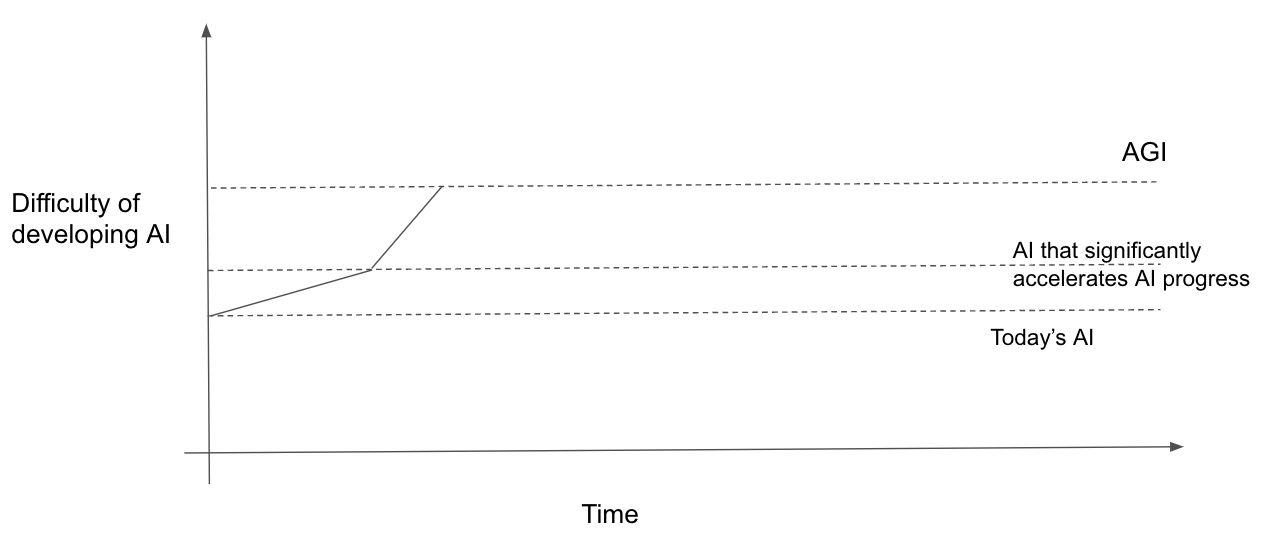
In the lower scenario AGI is easier to develop and, as a result, takeoff is faster.
Holding AGI difficulty fixed, slower takeoff → earlier AGI timelines
If takeoff is slower, there is a bigger difficulty gap between AGI and “AI that significantly accelerates AI progress”. Holding fixed AGI difficulty, that means “AI that significantly accelerates AI progress” happens earlier. And so AGI happens earlier. (This point has been made before [LW · GW].)
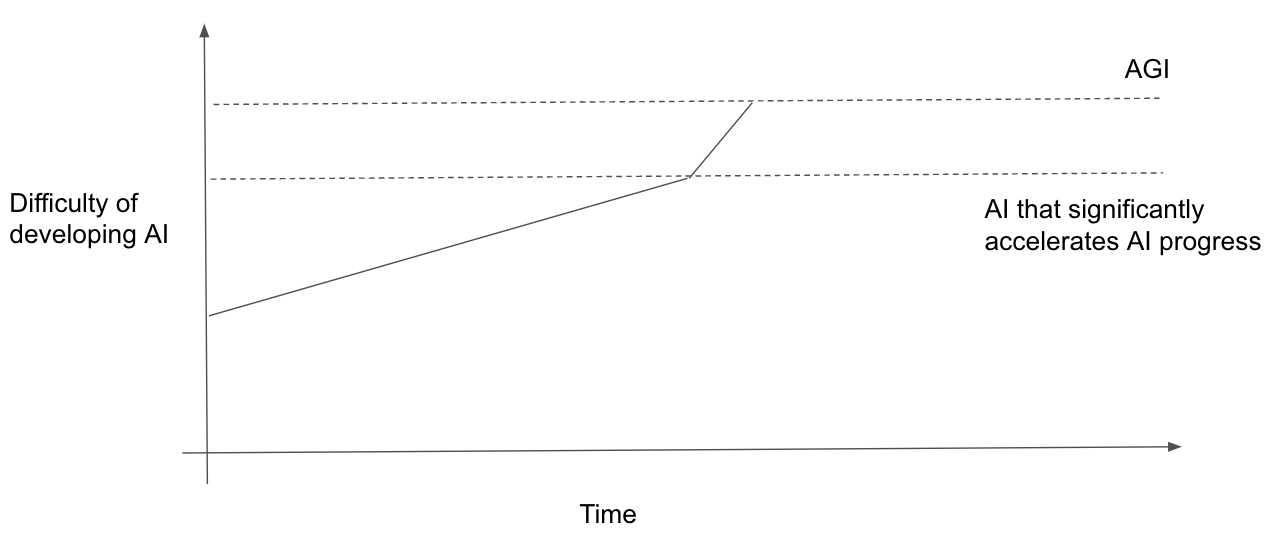
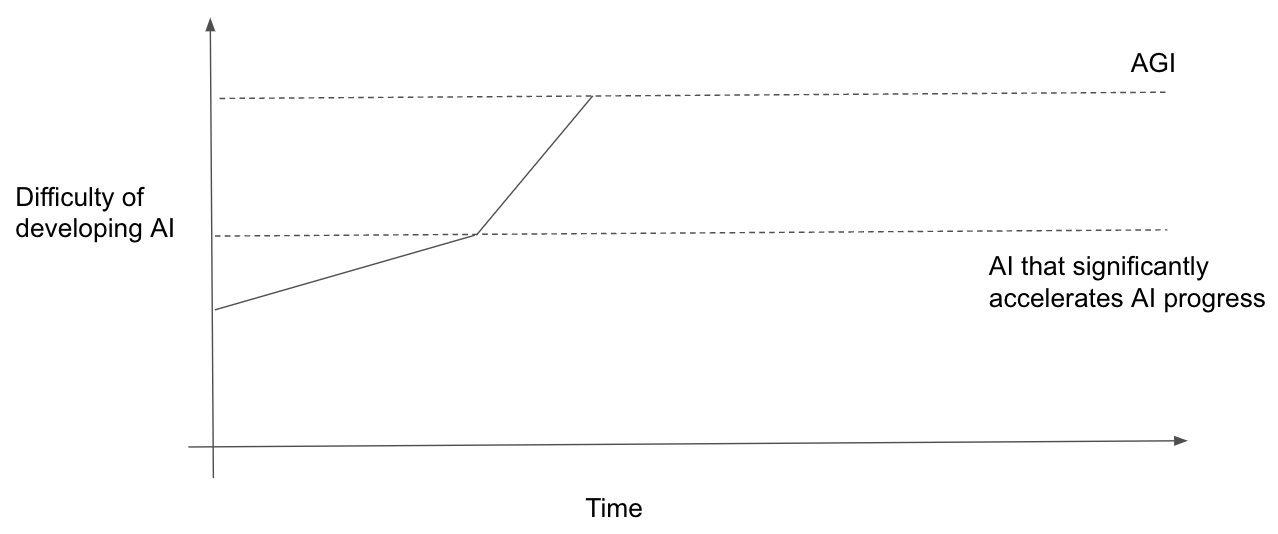
Two scenarios with the same AGI difficulty. In the lower scenario takeoff is slower and, as a result, AGI happens sooner.
The model in the report quantifies this tradeoff. When I play around with it I find that, holding the difficulty of AGI constant, decreasing the time from 20%-AI to 100%-AI by two years delays 100%-AI by three years.[19] I.e. make takeoff two years shorter → delay 100%-AI by three years.
How does the report relate to previous thinking about takeoff speeds?
Eliezer Yudkowsky’s Intelligence Explosion Microeconomics
- Intelligence explosion microeconomics (IEM) doesn’t argue for takeoff happening in weeks rather than in years, so doesn’t speak to whether takeoff is faster or slower than I conclude. More.
- I think of my report as providing one possible quantitative framework for Intelligence Explosion Microeconomics. It makes IEM’s qualitative claims quantitative by drawing on empirical evidence about the returns to hardware + software R&D, how intelligence scales with additional compute and better algorithms, and how cognitive output scales with intelligence. More.
- I think Eliezer’s thinking about takeoff speeds is influenced by his interpretation of the chimp-human transition. I chatted to Nate Soares about this transition and its implications for AI takeoff speeds; I describe my understanding of Nate’s view here.
- I currently and tentatively put ~6% on a substantial discontinuity[20] in AI progress around the human range; but this was not the main focus of my research. More.
Paul Christiano
I think Paul Christiano’s 2018 blog post does a good job of arguing that takeoff is likely to be continuous. It also claims that takeoff will probably be slow. My report highlights the possibility that takeoff could be continuous but still be pretty fast, and the Monte Carlo analysis spits out the probability that takeoff is “fast” according to the definitions in the 2018 blog post.

More.
Notes
By “AI can readily perform a task” I mean “performing the task with AI could be done with <1 year of work spent engineering and rearranging workflows, and this would be profitable”. ↩︎
Recall that “readily” means “automating the task with AI would be profitable and could be done within 1 year”. ↩︎
100%-AI is different from AGI only in that 100%-AI requires that we have enough runtime compute to actually automate all instances of cognitive tasks that humans perform, whereas AGI just requires that AI could perform any (but not all) cognitive tasks. ↩︎
To arrive at these probabilities I took the results of the model’s Monte Carlo analysis and adjusted them based on the model’s limitations – specifically the model excluding certain kinds of discontinuities in AI progress and ignoring certain frictions to developing and deploying AI systems. ↩︎
Not robust means that further arguments and evidence could easily change my probabilities significantly, and that it’s likely that in hindsight I’ll think these numbers were unreasonable given the current knowledge available to me. ↩︎
Why? Firstly, I think the cognitive tasks in AI R&D will be particularly naturally suited for AI automation, e.g. because there is lots of data for writing code, AI R&D mostly doesn’t require manipulating things in the real world, and indeed AI is already helping with AI R&D [LW · GW]. Secondly, I expect AI researchers to prioritise automating AI R&D over other areas because they’re more familiar with AI R&D tasks, there are fewer barriers to deploying AI in their own workflows (e.g. regulation, marketing to others), and because AI R&D will be a very valuable part of the economy when we’re close to AGI. ↩︎
These probabilities are higher than the ones above because here I’m ignoring types of discontinuities that aren’t captured by having a small “effective FLOP gap” between 20%-AI and 100%-AI. ↩︎
Chimps reach sexual maturity around 7 and can live until 60, suggesting humans have 1-2X more time for learning rather than 3X. ↩︎
World GDP is ~$100tr, about half of which is paid to human labour. If AI automates 20% of that work, that’s worth ~$10tr/year. ↩︎
Reminder: “AI can readily automate X” means “automating X with AI would be profitable and could be done within 1 year”. ↩︎
The “horizon length” concept is from Bio Anchors. Short horizons means that each data point requires the model to “think” for only a few seconds; long horizons means that each data point requires the model to “think” for months, and so training requires much more compute. ↩︎
Indeed, my one-dimensional model of takeoff speeds predicts faster takeoff. ↩︎
Reminder: “AI can readily automate X” means “automating X with AI would be profitable and could be done within 1 year”. ↩︎
This falls under “Superhuman AIs quickly circumvent barriers to deployment”, from above. ↩︎
E.g. here, here, here, here. I don’t know how reliable these estimates are, or even their methodologies. ↩︎
World GDP is ~$100tr, about half of which is paid to human labour. If AI automates 6% of that work, that’s worth ~$3tr/year. ↩︎
Here's a rough BOTEC (h/t Lukas Finnveden). ↩︎
Reminder: x%-AI is AI that could readily automate x% of cognitive tasks, weighted by their economic value in 2020. ↩︎
By “ substantial discontinuous jump” I mean “>10 years of progress at previous rates occurred on one occasion”. (h/t AI impacts for that definition) ↩︎
30 comments
Comments sorted by top scores.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-01-23T04:09:23.285Z · LW(p) · GW(p)
I'm so excited to see this go live! I've learned a lot from it & consider it to do for takeoff speeds what Ajeya's report did for timelines, i.e. it's an actual fucking serious-ass gears-level model, the best that exists in the world for now. Future work will critique it and build off it rather than start from scratch, I say. Thanks Tom and Epoch and everyone else who contributed!
I strongly encourage everyone reading this to spend 10min playing around with the model, trying out different settings, etc. For example: Try to get it to match what you intuitively felt like timelines and takeoff would look like, and see how hard it is to get it to do so. Or: Go through the top 5-10 variables one by one and change them to what you think they should be (leaving unchanged the ones about which you have no opinion) and then see what effect each change has.
Almost two years ago I wrote this story [LW · GW] of what the next five years would look like on my median timeline. At the time I had the bio anchors framework in mind with a median training requirements of 3e29. So, you can use this takeoff model as a nice complement to that story:
- Go to takeoffspeeds.com and load the preset: best guess scenario.
- Set AGI training requirements to 3e29 instead of 1e36
- (Optional) Set software returns to 2.5 instead of 1.25 (I endorse this change in general, because it's more consistent with the empirical evidence. See Tom's report for details & decide whether his justification for cutting it in half, to 1.25, is convincing.)
- (Optional) Set FLOP gap to 1e2 instead of 1e4 (In general, as Tom discusses in the report, if training requirements are smaller then probably the FLOP gap is smaller too. So if we are starting with Tom's best guess scenario and lowering the training requirements we should also lower the FLOP gap.)
- The result:
In 2024, 4% of AI R&D tasks are automated; then 32% in 2026, and then singularity happens around when I expected [LW(p) · GW(p)], in mid 2028. This is close enough to what I had expected when I wrote the story that I'm tentatively making it canon.
Replies from: daniel-kokotajlo, None, None↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-01-23T04:12:18.258Z · LW(p) · GW(p)
Oh, also, a citation about my contribution to this post (Tom was going to make this a footnote but ran into technical difficulties): The extremely janky graph/diagram was made by me in may 2021, to help explain Ajeya's Bio Anchors model. The graph that forms the bottom left corner came from some ARK Invest webpage which I can't find now.
Replies from: Zach Stein-Perlman↑ comment by Zach Stein-Perlman · 2023-01-23T08:49:29.252Z · LW(p) · GW(p)
(ARK Invest source is here, and they basically got it from the addendum to AI and Compute.)
↑ comment by [deleted] · 2023-01-23T23:37:27.319Z · LW(p) · GW(p)
Have you considered the quantity of inference silicon required?
You buy out a large fraction of all of TSMC's annual production and get the training compute. You now have one AGI. Replacing the cognitive work of one human requires a certain amount of silicon per human replaced, and the AGI model itself is large, it likely requires multiple nodes - possibly 100s - fully populated with 16 x <Nvidia's latest accelerator> x $25,000 each.
So if say we need 250 nodes, times 16, times 25k, that's 100 million USD. Say it is cognitively as effective as 10 humans in the top .1% of intelligence. That's still not really changing anything unless it's malicious. At this cost - 10 million an equivalent person - it's just slightly more cost effective than training humans.
At this point there would be a 'warning' period as very large sums of money would have to be spent to scale production of the silicon to bring these costs down and to supply enough copies of the hardware that it's equivalent to enough people cognitively to make a difference.
It is a positive feedback loop - each set of inference silicon is paying for itself in value in 10-20 years. Moreover once you have enough sets you could make a knockoff design for the chip and stop paying Nvidia, only paying for the silicon itself which is probably $2000 instead of $25,000. So an OOM more effective and it just gets faster from here.
Replies from: dsj↑ comment by dsj · 2023-01-25T15:48:13.890Z · LW(p) · GW(p)
The model does take into account the cost of runtime compute and how that affects demand, but mostly costs are dominated by training compute, not runtime compute. In the default settings for the model, it costs about 13 orders of magnitude more to train an AGI than to run one for 8 hours a day on 250 days (a typical human work year).
You can see and adjust those settings here: https://takeoffspeeds.com/
Note that mostly the model is modeling the takeoff to AGI and how pre-human level AI might affect things, especially the speed of that takeoff, rather than the effects of AGI itself.
↑ comment by [deleted] · 2023-01-23T23:35:02.489Z · LW(p) · GW(p)
Training the AGI may not be the expensive part. If we think current model architectures are flawed - they don't use robust enough neural network architectures, they do not have the right topology needed to solve "AGI" grade cognitive tasks - then we need to search the spaces of:
1. Network subcomponents. Activation functions, larger blocks like transformers
2. Network architectures. Aka "n x m dimension of <architecture type X>, feeding into n x m dimension of <architecture type Y>".
3. Cognitive architectures. Aka "system 1 output from a network of architecture type C feeds into a task meta controller that based on confidence either feeds the output to the robotics estimate module or...". These are collections of modules, some of which will not even use neural networks, that form the cognitive architecture of the machine.
Technically an AGI is the combination of architectures that achieves "AGI level performance" (whatever heuristic we use) on a large and diverse benchmark of "AGI level tasks". (tasks hard enough that 50% of humans will fail to pass them, or 99.9% depending on your AGI definition)
A superintelligence would be a machine that both passes a large AGI benchmark but scores better than all living humans (in the statistical sense, they are enough std devs away from the mean for humans that less than 1 in 8 billion humans are expected to be that good) on most tasks.
So if you think about it, searching this space - by making many failed AGI candidates to gain information about the possibility space - could eat up many OOMs more compute. If we have to make 1e6 full AGI models for example, each one failing the benchmark but some doing better than others.
It may not be this difficult though, and it's possible that ANY architecture that has something for the minimum essential parts and sufficient compute to train it will pass the bench.
comment by Jacob Pfau (jacob-pfau) · 2023-01-24T18:42:00.173Z · LW(p) · GW(p)
My deeply concerning impression is that OpenPhil (and the average funder) has timelines 2-3x longer than the median safety researcher. Daniel has his AGI training requirements set to 3e29, and I believe the 15th-85th percentiles among safety researchers would span 1e31 +/- 2 OOMs. On that view, Tom's default values are off in the tails.
My suspicion is that funders write-off this discrepancy, if noticed, as inside-view bias i.e. thinking safety researchers self-select for scaling optimism. My, admittedly very crude, mental model of an OpenPhil funder makes two further mistakes in this vein: (1) Mistakenly taking the Cotra report's biological anchors weighting as a justified default setting of parameters rather than an arbitrary choice which should be updated given recent evidence. (2) Far overweighting the semi-informative priors report despite semi-informative priors abjectly failing to have predicted Turing-test level AI progress. Semi-informative priors apply to large-scale engineering efforts which for the AI domain has meant AGI and the Turing test. Insofar as funders admit that the engineering challenges involved in passing the Turing test have been solved, they should discard semi-informative priors as failing to be predictive of AI progress.
To be clear, I see my empirical claim about disagreement between the funding and safety communities as most important -- independently of my diagnosis of this disagreement. If this empirical claim is true, OpenPhil should investigate cruxes separating them from safety researchers, and at least allocate some [? · GW] of their budget on the hypothesis that the safety community is correct.
↑ comment by dsj · 2023-01-25T15:52:56.541Z · LW(p) · GW(p)
What concrete cruxes would you most like to see investigated?
Replies from: daniel-kokotajlo, jacob-pfau↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-01-26T19:55:45.298Z · LW(p) · GW(p)
To elaborate on what Jacob said:
A long time ago I spent a few months reading and thinking about Ajeya's bio anchors report. I played around with the spreadsheet version of it, trying out all sorts of different settings, and in particular changing the various settings to values that I thought were more plausible.
As a result I figured out what the biggest cruxes were between me and Ajeya -- the differences in variable-settings that led to the largest differences in our timelines.
The biggest one was (unsurprisingly, in retrospect) the difference in where we put our probability mass for the training requirements distribution. That in turn broke down into several sub-cruxes.
I wrote Fun with +12 OOMs [? · GW] to draw everyone's attention to that big uber-crux. In addition to just pointing out that uber-crux, my post also operationalized it and explained it so that people didn't have to be super familiar with Ajeya's report to understand what the debate was about. Also, I gave five examples of things you could do with +12 OOMs, very concrete examples, which people could then argue about, in the service of answering the uber-crux.
So, what I would like to see now is the same thing I wanted to see after writing the post, i.e. what I hoped to inspire with the post: A vigorous debate over questions like "What are the reasons to think OmegaStar [LW · GW] would constitute AGI/TAI/etc.? What are the reasons to think it wouldn't?" and "What about Crystal Nights [LW · GW]?" and "What about a smaller version of OmegaStar, that was only +6 OOMs instead of +12? Is that significantly less likely to work, or is the list of reasons why it might or might not work basically the same?" All in the service of answering the Big Crux, i.e. probability that +12 OOMs would be enough / more generally, what the probability distribution over OOMs should be.
↑ comment by Jacob Pfau (jacob-pfau) · 2023-01-25T18:20:11.912Z · LW(p) · GW(p)
This is an empirical question, so I may be missing some key points. Anyway here are a few:
- My above points on Ajeya anchors and semi-informative priors
- Can deception precede economically TAI?
- Possibly offer a prize on formalizing and/or distilling the argument for deception (Also its constituents i.e. gradient hacking, situational awareness, non-myopia)
- How should we model software progress? In particular, what is the right function for modeling short-term return on investment to algorithmic progress?
- My guess is that most researchers with short timelines think, as I do, that there’s lots of low-hanging fruit here. Funders may underestimate the prevalence of this opinion, since most safety researchers do not talk about details here to avoid capabilities acceleration.
↑ comment by Noosphere89 (sharmake-farah) · 2023-01-24T18:53:09.162Z · LW(p) · GW(p)
Basically, a rational reason to have longer timelines is the fact that there's a non-trivial chance that safety researchers are wrong due to selection effects, community epistemic problems, and overestimating the impact of AGI.
Link below:
https://forum.effectivealtruism.org/posts/L6ZmggEJw8ri4KB8X/my-highly-personal-skepticism-braindump-on-existential-risk#comments [EA · GW]
Replies from: daniel-kokotajlo, jacob-pfau↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-01-25T15:47:07.229Z · LW(p) · GW(p)
There's definitely a bias/selection effect pushing this community towards having shorter timelines. However, there's also definitely a bias/selection effect pushing the world in general towards having longer timelines -- the anti-weirdness heuristic, wanting-to-not-sound-like-a-crackpot heuristic, wanting-to-sound-like-a-sober-skeptic bias, and probably lots of others that I'm not thinking of. Oh yeah, and just general ignorance of history and the topic of tech progress in particular. I suspect that on the whole, the biases pushing people towards longer timelines are stronger than the biases pushing people towards shorter timelines. (Obviously it differs case by case; in some people the biases are stronger one way, in other people the biases are stronger in the other way. And in a few rare individuals the biases mostly cancel out or are not strong in the first place.)
I generally prefer to make up my mind about important questions by reasoning them through on the object level, rather than by trying to guess which biases are strongest and then guess how much I should adjust to correct for them. And I especially recommend doing that in this case.
↑ comment by Jacob Pfau (jacob-pfau) · 2023-01-24T19:19:10.106Z · LW(p) · GW(p)
That post seems to mainly address high P(doom) arguments and reject them. I agree with some of those arguments and the rejection of high P(doom). I don't see as direct of a relevance to my previous comment. As for the broader point of self-selection, I think this is important, but cuts both ways: funders are selected to be competent generalists (and are biased towards economic arguments) as such they are pre-disposed to under-update on inside views. As an extreme case of this consider e.g. Bryan Caplan.
Here are comments on two of Nuno's arguments which do apply to AGI timelines:
(A) "Difference between in-argument reasoning and all-things-considered reasoning" this seems closest to my point (1) which is often an argument for shorter timelines.
(B) "there is a small but intelligent community of people who have spent significant time producing some convincing arguments about AGI, but no community which has spent the same amount of effort". This strikes me as important, but likely not true without heavy caveats. Academia celebrates works pointing out clear limitations of existing work e.g. Will Merill's work [1,2] and Inverse Scaling Laws. It's true that there's no community organized around this work, but the important variables are incentives/scale/number-of-researcher-hours -- not community.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-01-24T19:49:53.470Z · LW(p) · GW(p)
Yeah, I agree that the disagreement is probably more important to resolve, and I haven't much addressed that.
comment by [deleted] · 2023-01-23T22:58:51.200Z · LW(p) · GW(p)
Are you using the information from chatGPT's results?
- chatGPT uses ~3000 times less data to run than a human brain. (source from another post here, I would be interested in tighter estimates). This seems to be fairly compelling evidence that your model may be off by several OOMs.
- It seems to be able to match, even exceed human performance in some areas
- There are very obvious low hanging fruit that might radically improve it's performance: a. Give it a calculator and RL problems to exercise this capability. This isn't even an AI advance, it's just missing it! b. Integrate it with perception and visualization models like DALL-E so it can extract information about the contents of an image and produce visualizations to illustrate when needed c. RL training on programming tasks d. RL training on all available english language multiple choice tests at high school/college level e. Give it a way to obtain information from the internet
f. add a second neural network and have the machine always presented with a 'salient context', or the most valuable tokens from the set of all prior tokens in this session with a user.
Will this hit 20% of cognitive tasks without further improvement? It might, and we will likely see an llm with all 6 improvements either in 2023 or 2024. (I would say I am certain we will see at least one before the end of 2023 and probably 3 or 4 by the end of 2024. I would estimate a greater than 50 percent chance all these improvements will be made and several more by EOY 2024.
Replies from: AnthonyRepetto, None↑ comment by AnthonyRepetto · 2023-01-24T06:15:49.709Z · LW(p) · GW(p)
Thank you for making the point about existing network efficiencies! :)
The assumption, years ago, was that AGI would need 200x as many artificial weights and biases when compared to a human's 80 to 100 Trillion synapses. Yet - we see the models beating our MBA exams, now, using only a fraction of the number of neurons! The article above pointed to the difference between "capable of 20%" and "impacting 20%" - I would guess that we're already at the "20% capability" mark, in terms of the algorithms themselves. Every time a major company wants to, they can presently reach human-level results with narrow AI that uses 0.05% as many synapses.
Replies from: None↑ comment by [deleted] · 2023-01-24T07:26:50.331Z · LW(p) · GW(p)
Yes. And regarding the narrow AI : one idea I had a few years ago was that sota results from a major company are a process. A replicable, automatable process. So a major company could create a framework where you define your problem, provide large amounts of examples (usually via simulation), and the framework attempts a library of know neural network architectures in parallel and selects the best performing ones.
This would let small companies get sota solutions for their problems.
The current general models suggest that may not be even necessary.
↑ comment by [deleted] · 2023-12-21T18:04:32.666Z · LW(p) · GW(p)
Holy shit I seen to have been correct about every single prediction.
A. Calculator. Yep, python interpreter and Wolfram B. Perception, yep, gpt-4v. Visualization, yep. Both gemini and gpt4 can do this decently. C. RL on programming. Yep, alpha code 2. D. RL on college. Yep, open sources models have been refined this way. E. Internet browsing, yep old news F. Salient context: announced as a feature for gpt-4, not actually available at scale I don't think. Update: I was wrong about this. Tons of different GPT-4 wrapper bots use a vector embeddings database that effective gives the model salient context. So this was satisfied before EOY 2023.
Can this do 20 percent of cognitive tasks? Eh maybe? Issue is that since it can't do the other 80 percent and it can be fooled many ways gpt-4 can't actually do something like sell cars or other complete tasks. A human has to be there to help the model and check it's work etc.
If you broke every task that humans do at all into a list, especially if you scaled by frequency, gpt-4 probably can in fact do 20 percent. (Frequency scaling means that easy tasks like "find all the goods in the store on the shopping list" happen millions of times per day while improving the bleeding edge of math is something few humans are doing)
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-12-16T20:06:33.420Z · LW(p) · GW(p)
The takeoffspeeds.com model Davidson et al worked on is still (unfortunately) the world's best model of AGI takeoff. I highly encourage people to play around with it, perhaps even to read the research behind it, and I'm glad LessWrong is a place that collects and rewards work like this.
comment by Not Relevant (not-relevant) · 2023-01-23T14:44:54.510Z · LW(p) · GW(p)
Something that confuses me about this type of model: for humans to be willing to delegate ~100% of AI research to pre-AGIs, that implies a very high degree of trust in their systems. Especially given that over time, a larger and larger share of the “things AI still can’t do” are “produce an output that a human trusts enough not to need to review”.
But if we’ve solved the “trust” bottleneck for pre-AGI systems, is that not equivalent to having basically enabled automated alignment research? In what ways is AGI alignment different from just-barely-pre-AGI alignment, which is itself a necessary precondition for ~100% of AI-research being automated?
Unless in your model AI research is entirely about “making the gradients flow more”, and not at all about things like finding new failure modes (eg honesty, difficulty-to-verify-explanations), characterizing them, and then proposing principled solutions. Which seems wrong to me - I expect those to be the primary bottlenecks to genuine automation.
Replies from: CarlShulman, tom-davidson-1, None↑ comment by CarlShulman · 2023-01-23T17:30:18.173Z · LW(p) · GW(p)
This is the terrifying tradeoff, that delaying for months after reaching near-human-level AI (if there is safety research that requires studying AI around there or beyond) is plausibly enough time for a capabilities explosion (yielding arbitrary economic and military advantage, or AI takeover) by a more reckless actor willing to accept a larger level of risk, or making an erroneous/biased risk estimate. AI models selected to yield results while under control that catastrophically take over when they are collectively capable would look like automating everything was largely going fine (absent vigorous probes) until it doesn't, and mistrust could seem like paranoia.
↑ comment by Tom Davidson (tom-davidson-1) · 2023-01-23T16:35:29.068Z · LW(p) · GW(p)
I agree that the final tasks that humans do may look like "check that you understand and trust the work the AIs have done", and that a lack of trust is a plausible bottleneck to full automation of AI research.
I don't think the only way for humans at AI labs to get that trust is to automate alignment research, though that is one way. Human-conducted alignment research might lead them to trust AIs, or they might have a large amount of trust in the AIs' work without believing they are aligned. E.g. they separate the workflow into lots of narrow tasks that can be done by a variety of non-agentic AIs that they don't think pose a risk; or they set up a system of checks and balances (where different AIs check each other's work and look for signs of deception) that they trust despite thinking certain AIs may be unaligned, they do such extensive adversarial training that they're confident that the AIs would never actual try to do anything deceptive in practice (perhaps because they're paranoid that a seeming opportunity to trick humans is just a human-designed test of their alignment). TBC, I think "being confident that the AIs are aligned" is better and more likely than these alternative routes to trusting the work.
Also, when I'm forecasting AI capabilities i'm forecasting AI that could readily automate 100% of AI R&D, not AI that actually does automate it. If trust was the only factor preventing full automation, that could count as AI that could readily automate 100%.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-01-23T17:13:52.812Z · LW(p) · GW(p)
Also, they might let the AIs proceed with the research anyway even though they don't trust that they are aligned, or they might erroneously trust that they are aligned due to deception. If this sounds irresponsible to you, well, welcome to Earth.
↑ comment by [deleted] · 2023-01-23T23:53:53.767Z · LW(p) · GW(p)
Why would AGI research be anything other than recursion.
We make a large benchmark of automatically gradeable cognitive tasks. Things like "solve all these multiple choice tests" from some enormous set of every test given in every program at an institution willing to share.
"Control this simulated robot and diagnose and repair these simulated machines"
"Control this simulated robot and beat Minecraft"
"Control this simulated robot and wash all the dishes"
And so on and so forth.
Anyways, some tasks would be "complete all the auto gradeable coursework for this program of study in AI" and "using this table of information about prior attempts, design a better AGI to pass this test".
We want the machine to have generality - use information it learned from one task on others - and to perform well on all the tasks, and to make efficient use of compute.
So the scoring heuristic would reflect that.
The "efficient use of compute" would select for models that don't have time to deceive, so it might in fact be safe.
comment by Review Bot · 2024-03-22T13:11:37.350Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by RogerDearnaley (roger-d-1) · 2023-12-24T03:08:52.392Z · LW(p) · GW(p)
Time from AGI to superintelligence is probably less than 1 year
I think you're omitting an effect. Current LLMs can train on vast amounts (petabytes to exabytes) of content created by humans. This is valuable training data for systems up to about human-level, and can perhaps even be extrapolated some distance beyond human level. But to take the process further, we will have to extend the training set to a larger training set of more sophisticated content, containing superhumas art/science/culture/engineering, one larger than the entire product of human civilization so far. This is not impossible, but it is a very large amount of intellectual work, some of which requires not just computation but also rate-limited real-world interactions to do things like constructing scientific apparatus and performing scientific experiments. This problem recurs each time you scale capabilities enough that extrapolation isn't practicable. See my post LLMs May Find it Hard to FOOM [LW · GW] for more details. You need to estimate this and account for it in your estimate of time from AGI to superintelligence.
comment by Maxime Riché (maxime-riche) · 2023-08-28T13:39:20.901Z · LW(p) · GW(p)
1) In the web interface, the parameter "Hardware adoption delay" is:
Meaning: Years between a chip design and its commercial release.
Best guess value: 1
Justification for best guess value: Discussed here. The conservative value of 2.5 years corresponds to an estimate of the time needed to make a new fab. The aggressive value (no delay) corresponds to fabless improvements in chip design that can be printed with existing production lines with ~no delay.
Is there another parameter for the delay (after the commercial release) to produce the hundreds of thousands of chips and build a supercomputer using them?
(With maybe an aggressive value for just "refurnishing" an existing supercomputer or finishing a supercomputer just waiting for the chips)
2) Do you think that in a scenario with quick large gains in hardware efficiency, the delay for building a new chip fab could be significantly larger than the current estimate because of the need to also build new factories for the machines that will be used in the new chip fab? (e.g. ASMI could also need to build factories, not just TSMC)
3) Do you think that these parameters/adjustments would significantly change the relative impact on the takeoff of the "hardware overhang" when compared to the "software overhang"? (e.g. maybe making hardware overhang even less important for the speed of the takeoff)
Replies from: tom-davidson-1↑ comment by Tom Davidson (tom-davidson-1) · 2023-10-19T18:58:10.758Z · LW(p) · GW(p)
Good questions!
Is there another parameter for the delay (after the commercial release) to produce the hundreds of thousands of chips and build a supercomputer using them?
There's no additional parameter, but once the delay is over it still takes months or years before enough copies of the new chip is manufactured for the new chip to be a significant fraction of total global FLOP/s.
2) Do you think that in a scenario with quick large gains in hardware efficiency, the delay for building a new chip fab could be significantly larger than the current estimate because of the need to also build new factories for the machines that will be used in the new chip fab? (e.g. ASMI could also need to build factories, not just TSMC)
I agree with that. The 1 year delay was averaging across improvements that do and don't require new fabs to be built.
3) Do you think that these parameters/adjustments would significantly change the relative impact on the takeoff of the "hardware overhang" when compared to the "software overhang"? (e.g. maybe making hardware overhang even less important for the speed of the takeoff)
Yep, additional delays would raise the relative importance of software compared to hardware.
comment by Aleksi Liimatainen (aleksi-liimatainen) · 2023-01-25T08:11:30.013Z · LW(p) · GW(p)
If the neocortex is a general-purpose learning architecture as suggested by Numenta's Thousand Brains Theory of Intelligence, it becomes likely that cultural evolution has accumulated significant optimizations. My suspicion is that learning on cultural corpus progresses rapidly until somewhat above human level and then plateaus to some extent. Further progress may require compute and learning opportunities more comparable to humanity-as-a-whole than individuals.