Concrete Methods for Heuristic Estimation on Neural Networks
post by Oliver Daniels (oliver-daniels-koch) · 2024-11-14T05:07:55.240Z · LW · GW · 0 commentsContents
Background Heuristic Estimation Surprise Accounting Mechanistic Anomaly Detection Example: Covariance Propagation on Arithmetic Circuits Setup Naive Estimator with Presumption of Independence Argument Space Surprise Accounting Surprise of the Estimate Description Length Information Gain Computational Cost Picking a Metric Estimation on Instances Recap: Ingredients of Heuristic Estimators Activation Modeling Heuristic Estimation with Layer-by-Layer Activation Modeling Setup Naive Estimator with Presumption of Independence Argument Space Surprise Accounting Estimation on Instances Empirical Activation Modeling: Beyond Analytic Propagation Joint Activation Modeling Empirical Activation Modeling Consistency Joint Empirical Activation Modeling Learning a Parameterized Basis Capacity Allocation Causal Scrubbing Background Heuristic Estimation with Path Patching Naive Estimator with Presumption of Independence Argument Space Surprise Accounting Description Length Information Gain Computational Cost Estimation on Instances Recap Heuristic Estimation with (Semantic) Causal Scrubbing Exhaustive Search Rejection Sampling Clustering, Retrieval, and Intelligence Future Directions Inter-Method Surprise Accounting Theories of Change Appendix Surprise Accounting on Boolean Circuits Description Length and Information Gain Hidden Information and Computation in Estimators Choosing a Graph Basis Negative Components and Cherry-Picking Arguments Negative Components and Mechanistic Anomaly Detection Negative Components and Completeness Searching For Negative Components Positive-Only Components Weight-Based Arguments None No comments
Thanks to Erik Jenner for helpful comments and discussion
(Epistemic Status: Tentative take on how to think about heuristic estimation and surprise accounting in the context of activation modeling and causal scrubbing. Should not be taken as authoritative/accurate representation of how ARC thinks about heuristic estimation)
I'm pretty excited about ARC's heuristic arguments agenda. The general idea that "formal(ish) arguments" about properties of a neural network could help improve safety has intuitive appeal.
ARC has done a good job recently communicating about high level intuitions, goals, and subproblems of the heuristic arguments agenda. Their most recent post "A birds eye of ARC's agenda" lays out their general vision of how heuristic arguments would help with alignment, contextualizes their research output to date, and enumerates open subproblems.
However, I still can find it difficult to synthesize their various lines of work. I find myself asking questions like: Is activation modeling actually just cumulant propagation? How would we do surprise accounting on activation models? Is causal scrubbing a heuristic estimation method? How could singular learning theory contribute? What is "capacity allocation" anyway?
This post aims to partially resolve (or at least clarify) these confusions. I
- define three notions of surprise (description length, information gain, and computational cost)
- map activation modeling and causal scrubbing to the heuristic estimation formalism, and define methods for surprise accounting on each
- compare (variants of) activation modeling and causal scrubbing according to computational cost
- describe three theories of impact for work on heuristic estimation
In the appendix, I motivate the three notions of surprise in the context of the boolean circuits, explore choosing a graph basis for causal scrubbing, connect "negative components" in mech-interp to cherry-picking in heuristic estimation, and gesture towards more "weight-based" notions of heuristic estimation
Background
Heuristic Estimation
Using the notation from here [AF · GW], a heuristic estimator is an algorithm that takes as input a mathematical expression and arguments , and outputs an estimate of given arguments : . The heuristic estimator makes some presumption(s) of independence, and arguments provide "correlational" information that update away from the naive estimate.
Surprise Accounting
ARC suggests surprise accounting [AF · GW] as a an objective for searching for heuristic arguments. Given an argument space , find an argument that minimizes:
the surprise of the argument + the surprise of the estimate (given the argument)
The surprise of the estimate should capture something like "the information required to encode the target, given the target estimate". Ideally, the estimator outputs a distribution over the target, and we can compute sample cross entropy or KL divergence. However, important details remain unclear (how to handle point estimates of outputs, metrics which do not track information, aggregating surprise over continuous vs discrete, finitely supported distributions to name a few)
The surprise of the argument is more complicated. ARC's post on surprise accounting and related works admit multiple plausible notions: description length, information gain, and computational cost.
Mechanistic Anomaly Detection
Mechanistic anomaly detection [LW · GW] is one of the central target applications of heuristic arguments, offering (part of) a possible solution to both eliciting latent knowledge and deceptive alignment. Again using previously introduced notation, let be a neural network trained on a dataset of inputs using the loss function/metric . Assume the network achieves low loss, i.e. is small. We determine whether a new input is an anomaly by
- Finding a set of arguments such that the heuristic estimation of the expected loss: is low.
- Using the same set of arguments, compute the heuristic estimate of the loss on the new input . If the heuristic estimate is high, flag the new input as an anomaly.
Note that mechanistic anomaly detection requires the heuristic estimator to operate both on the expected loss and the loss of individual instances, which as we'll see is a non-trivial property.
Example: Covariance Propagation on Arithmetic Circuits
(Note: We assume as background the first four sections of Appendix D in Formalizing the Presumption of Independence)
We start with the example of sparse-covariance propagation, a heuristic estimation algorithm for estimating the expected output of arithmetic circuits from ARC's first paper on heuristic arguments. We use sparse-covariance propagation to establish the four components of heuristic estimation for mechanistic anomaly detection:
- naive estimation with presumption(s) of independence
- an argument space
- surprise accounting
- estimation on individual instances
We introduce methods for surprise accounting on covariance propagation not explicitly described in prior work, and sketch out how "wick propagation" might work for extending covariance propagation to individual instances, though note that both these contributions are novel and could be confused.
Setup
Suppose we have an arithmetic circuit , with standard normal inputs , arithmetic nodes representing either addition and multiplication (with ), and wire values . We want to estimate the expected value of the output .
Naive Estimator with Presumption of Independence
In mean propagation, we assume all wires in the circuit are independent. For addition nodes, this makes no difference (). For multiplication nodes though, independence implies , since the covariance term is 0. We use this presumption of independence to propagate means to the output of the circuit:
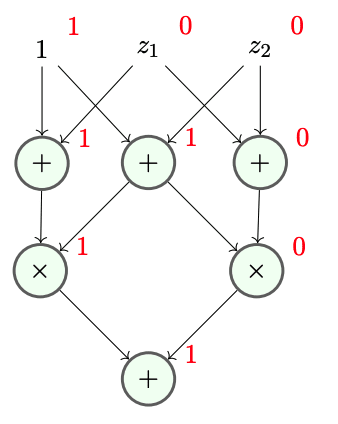
Mean propagation will act as our "naive" estimator: given no addition arguments, we assume all nodes are independent, and propagate means to compute the expected output of a circuit.
While estimating the mean of the output is sufficient for estimation purposes, for surprise accounting, we'll want to to produce distributions over each wire in the circuit. To do so, we propagate the variance (not covariance) of nodes with the following rules:
For :
For :
Performing variance propagation on the above example, we have
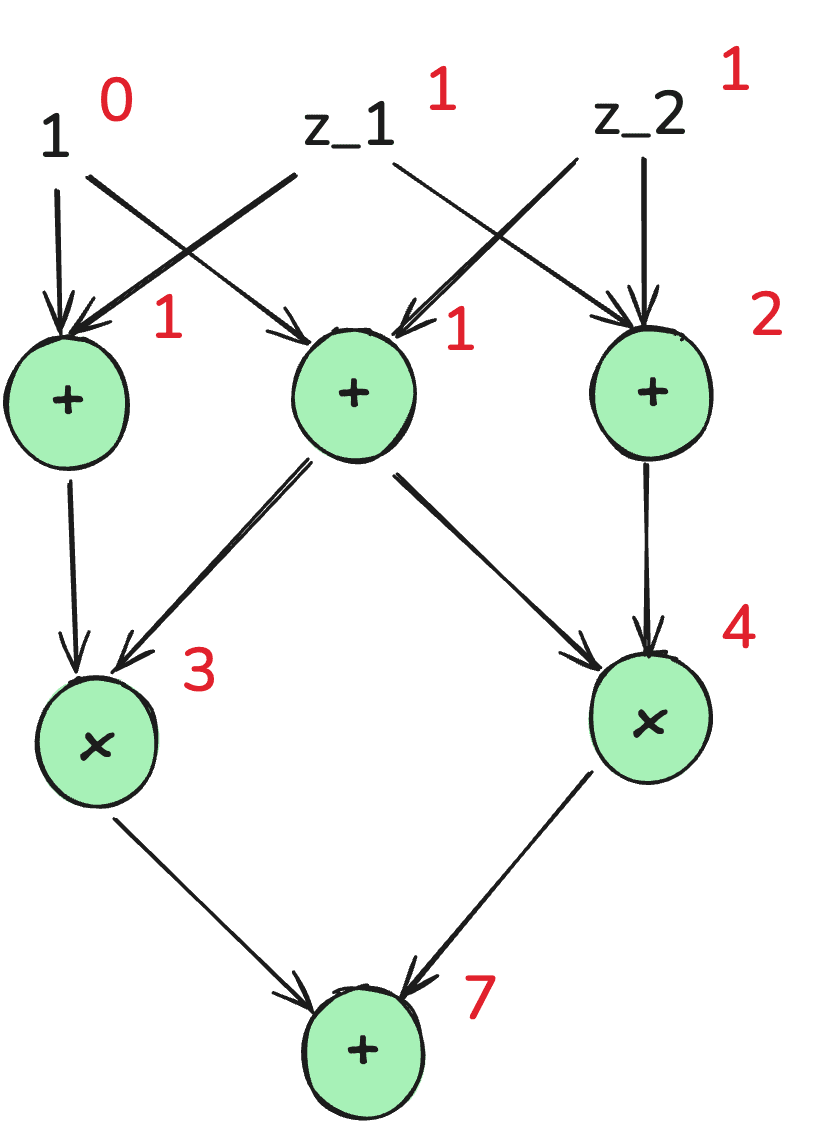
Assuming wires are distributed according to a joint gaussian, propagating the variance yields the joint distribution distribution over wires , with and the (vector valued) propagated mean and variance.
Argument Space
To improve our estimate of the expected output, we selectively violate the presumption of independence, tracking particular covariances between nodes and incorporating these covariances into our propagated mean and (co)variance computations. Concretely, let be the space of boolean matrices over each pair of wires in the circuit[1]. Then, for a given argument , we include the covariance if . Propagating means and covariances as before yields a distribution . Again note that is the only quantity that matters for estimating the output, but, as we'll see in the next section, we use the entire joint distribution to compute the surprise of .
Surprise Accounting
Recall that for surprise accounting, we want to compute
the surprise of the argument + the surprise of the estimate (given the argument)
In information theory, surprise is defined as the negative log probability of an event:
Applying the laws of probability, we can easily reconstruct the surprise objective as minimizing the joint surprise of the target and the arguments:
However, given we typically do not have access to a direct prior on the arguments, we instead appeal to broader notions of surprise and information. To reduce abiguity, we denote surprise with :
Surprise of the Estimate
Assuming we have a distribution over the output and can sample ground truth targets, in some sense the most natural measure of the surprise of the estimate is the empirical cross entropy loss:
However, this definition is unsatisfying for multiple reasons. First, it does not specific how many samples. Second, it is inconsistent with ARC's original surprise example, where surprise of the estimate is summed over the entire (finite) input distribution - it is unclear how to extend a similar procedure to the (continuous) (uncountably) infinite case. Third, it is unclear how to compute surprise of the a point estimate, rather than a distribution.
Description Length
To compute the surprise (information content) of the argument , we might appeal to description length. That is, computing the number of bits required to encode , relative to the empty explanation . For binary arguments (like in covariance propagation), this corresponds to (the number of tracked covariances) [2].
Information Gain
Note though, that our arguments "point out" information about latent variables (in the case of covariance propagation, wire values ), that in some sense was not available to the naive estimator. Thus we might measure the surprise of as the relative information gained about the latents from relative to . Formally, we estimate the surprise of the arguments as the expected information ratio of the argument distribution and the naive distribution, again estimating the surprise with samples of x:
Information gain has some intuitive appeal, and indeed a method along these lines is proposed at the end of this report. Further, in our appendix Surprise Accounting on Boolean Circuits [LW · GW], we show that information gain and description length are equivalent in the boolean circuit example from the original surprise accounting post. However, after many failed attempts to formalize the relationship between the information/description length of and expected information gain[3], I'm skeptical (and very confused) about whether information gain is a reasonable surprise metric. That caveat aside, much the remainder of this post builds off information gain as a surprise metric, so we will for now assume its validity.
Computational Cost
Thus far we have ignored the information content of itself, only measuring the surprise of the estimate and the arguments. But the estimator itself can contain information too, and beyond our presumptions of independence, there's not a principled way of separating the estimator and the arguments to the estimator.
For example, in sparse covariance propagation, our estimator starts with access to the full circuit and the distribution of the inputs, and assumes each node is independent. But the amount of surprise is relative to our definition of the estimator. We could instead parameterize the argument space as a single boolean: whether to run mean propagation or covariance propagation. The storage cost of the equivalent argument on the original estimator would be , compared to 1 for the new estimator. Similarly, we could presume the independence of all but one pair of nodes, such that the relative information gain only tracked the difference caused by tracking the covariance of this one pair.
However, we can potentially resolve these concerns by considering the computational cost of running the estimator with a given set of arguments. In sparse covariance propagation, every tracked covariance adds terms to summations, thus computational cost monotonically increases the number of tracked covariances. This metric is independent of the construction of the argument space, and also includes the "fixed" cost of the default estimator, making it useful for making comparisons across different estimators.
We also note that FLOPS are uses as a metric for argument length in Compact Proofs of Model Performance via Mechanistic Interpretability , and as a general budget in Estimating the Probabilities of Rare Outputs in Language Models, indicating that ARC and collaborators think computation cost is closely related to surprise of arguments.
Picking a Metric
In practice, we will typically fix the estimator , and search for arguments that minimize surprise. On this view, the description length and information gain definition of surprise will be used to optimize arguments, while the computational cost definition will be useful for comparing different estimation methods (we perform such a comparison in Inter-Method Surprise Accounting [LW · GW]). Ultimately, I think there's hope of unifying these three notions, pulling on the connections between algorithmic and statistical information theory.
Estimation on Instances
(Note - this section is inferred from a note on Wick Propagation at the end of the Max of k Heuristic Estimator report and Redwood's work on Generalized Wick Decomposition, and could be wrong/confused - I'm eager to get feedback)
Supposing we find that minimizes (some notion of) surprise, how would we produce an estimate on a single instance ?
When estimating the distribution, we applied update rules presuming variables were independent (taking covariance to be 0), unless are argument specified the covariance should be tracked. To apply the same arguments to instances, we need to define similar update rules, with corresponding terms tracking the analogue of covariance.
For example, consider a node . To compute the expectation , we decompose the expectation of a product as the sum of the product of expectations and the covariance. We apply our argument as a "weight" in this decomposition, yielding:
To produce an analogous decomposition for , we appeal to wick decomposition:
with defined according to our argument and the wick product. Note that is recursively defined, such that if , then . We call this procedure Wick Propagation (I think?).
I still don't have great intuitions about wick products and wick propagation, and as stated at the begging of this section, the details here could be off. The import point is that to perform mechanistic anomaly detection, our estimator must be able to operate on individual instances, which can require non-trivial extensions to the original definition of the estimator.
Recap: Ingredients of Heuristic Estimators
We have now defined all the elements for applying heuristic estimation to mechanistic anomaly detection. Given a quantity to estimate, we construct a naive estimator based on a presumption of independence. Next, we define an argument space that selectively "violates" the presumption of independence to improve our estimate. To select arguments, we define a surprise metric, capturing the surprise of the arguments and the surprise of the estimate given the arguments. Using the surprise metric (and Monte-Carlo samples from the ground truth distribution) we search for arguments that minimize the total surprise. To apply our arguments to mechanistic anomaly detection, we define a variant of our estimator that takes in the same arguments but estimates the target quantity on individual instances.
Equipped with the basic building blocks of heuristic estimation, we can now explore and compare various approaches to heuristic estimation on deep neural networks.
Activation Modeling
Activation modeling is an approach to heuristic estimation on neural networks that aims to produce a probability distribution on model activations while faithfully explaining some target expression (e.g. expected output). In what follows, we first briefly recap Layer-By-Layer activation modeling and connect it to heuristic estimation with a proposed method for surprise accounting. Next, we analyze problems with layer-by-layer activation modeling, making connections to mechanistic interpretability and various subproblems of heuristic arguments in general.
Heuristic Estimation with Layer-by-Layer Activation Modeling
(Note: We strongly recommend reading at least the A Possible Approach for Estimating Tail Risks [LW · GW] section of Estimating Tail Risks in Neural Networks).
Layer-by-Layer activation modeling [LW · GW] is essentially covariance propagation (when taking each distribution to be a multivariate gaussian) applied to neural networks. Roughly following the original notation, we have a neural network which can be expressed as a composition of functions (where denotes the domain of and we let denote the output domain). In general, to produce an output distribution , we successively fit distributions to the distribution produced by applying the next layer transformation to the prior distribution .
Note that the "strongest" form, activation modeling only requires a pre-specified distribution on the input, and fits each layer in roughly constant time. In later sections we'll relax both properties, leading to a distinction/spectrum between "analytic" and "empirical" activation modeling.
Below, we analyze the multivariate gaussian layer-by-layer activation modeling presented in the original post, defining a naive estimator, argument space, surprise metric, and estimator on instances.
Setup
Taking each distribution to be multivariate gaussian , we fit the next layer by taking to be the (sample), which, by the moment matching theorem, minimizes [4].
Naive Estimator with Presumption of Independence
We presume the independence between each pair of activations by setting all covariance terms to 0. We express the naive distribution at each layer as , with and estimated from the (masked) distribution of the previous layer.
Argument Space
Arguments are boolean masks over each covariance matrix: (with the naive argument initialized as the identity to allow for variance propagation). We denote the distribution at a given layer induced by an argument as
Surprise Accounting
As before, defining the surprise of the estimate given an argument is straightforward, but defining the surprise of the argument is still contingent on the chosen notion of surprise.
For computing the surprise of the estimate, we compute the cross entropy of the output distribution relative to Monte-Carlo samples of the true output distribution:
For computing the surprise of the argument, we can again appeal to description length or information gain:
Beyond both these definitions, we should also consider the computational cost of computing the estimate. In layer-by-layer activation modeling, cost scales roughly in roughly (with the number of layers), treating each propagation as constant. But as we explore more sampling-based approaches (or "empirical" activation modeling), we'll need to introduce the number of samples into our estimate.
Estimation on Instances
To run the activation model on a single instance , we could (I think) use Wick Propagation (but given my uncertainty on how to define wick propagation in general, I won't try to extend the definition here). Alternatively, instead of using the estimate of , we could leverage the distribution induced by our arguments, taking the log probability of the activations as an anomaly score[5]. Note that for an arbitrarily parameterized distribution this approach exactly recovers the (standard) anomaly detection method of fitting multivariate gaussians to activations. What makes the approach "heuristic arguments flavored" is the analytic propagation of selected parts of distributions.
In the following section, we explore a broader space of approaches which diverge from this a kind of heuristic argument platonic ideal, but in doing so address potential problems with layer-by-layer analytic activation modeling.
Empirical Activation Modeling: Beyond Analytic Propagation
A central concern with layer-by-layer activation modeling is that it forgets too much information [LW · GW]. Restating the example given in ARC's post, suppose we have the following boolean network:
with a pseudo-random function which can't be captured by the activation model model. The output of the function is always 1, but we will model is as . The basic problem here is we have no way to track that is being applied by multiple layers, causing the approximation errors to be highly correlated.
Joint Activation Modeling
ARC's suggested remedy is to abandon layer-by-layer modeling in favor of a "joint" activation model, which e.g. could capture as a common latent across both layers. But it's unclear to me how to produce such a model using "analytic" methods - the best I can do is point to analytic VAE's and cross-coders and say "combine those, somehow".
Empirical Activation Modeling
A more intuitive (albeit less interesting) approach to capturing lost information across layers is to just fit distributions to sample activations. We'll call this "empirical" activation modeling, though in its most basic form, this is identical to standard anomaly detention approaches. We fit distributions to maximize log likelihood of the observations, and use log likelihood on novel inputs as an anomaly score. How exactly to fit the distributions and compute surprise is another degree of freedom. We could follow the sparsity theme, only tracking specific empirical correlations between terms, and computing surprise with either the MDL or information gain. Alternatively, with the information gain principle we could make the parameters of the distribution arguments themselves, e.g. directly optimizing mean and covariance matrices to minimize the surprise of the estimate and divergence from the prior that treats each activation as independent.
Note though, that if we fit each layer independently, intermediate activations play no role in our model of the output. This feels like a distinct break from the original motivation of mechanistic anomaly detection - we want to capture anomalies in the models reasoning - how it translates inputs to outputs.
Consistency
To recover the relationship between input and output, we could impose a weaker form of layer-by-layer activation modeling, introducing a consistency term between adjacent layers. That is, in addition to the surprise of the estimate (log probability at each layer and low divergence from the prior), we could impose an additional term for "surprise of current layer distribution relative to the previous", i.e. , or the surprise of propagated last layer on the current layer samples [6].
Joint Empirical Activation Modeling
Exploring more parts of the design space, we could combine joint and empirical modeling, e.g. fitting a multivariate gaussian to all activations jointly. While this approach does allow for relationships between input, output, and intermediate layers, and we could apply the same activation modeling ingredients (sparse arguments, surprise accounting, etc), it feels like we've lost the causal structure of the model. Perhaps we could recover this again using some sort of causal/auto-regressive consistency loss, though I'll leave that as a gesture towards a method for now. Many of these variants mirror variants of cross-coders (global vs local, acausal vs causal), and future activation modeling work may pull a lot from them.
Learning a Parameterized Basis
But beyond cross-coders in particular, we should also discuss the general role learning a parameterized basis (e.g. sparse feature basis) can play in activation modeling. We can think of learning a parameterized basis as constructing a model where our presumptions of independence are more robust. For example, in neural networks we expect individual neurons to be highly correlated(by the superposition hypothesis, and more generally theories of distributed representation), such that we need to incur a lot of surprise relative to a prior that treats each neuron as independent. But (insofar as something like the superposition hypothesis holds) features in the sparse feature basis will be more independent, requiring less surprise for the same explanation quality. This is the general motivation behind using sparse features in ARC's Analytic Variational Inference, and also contextualized Quadratic Logit Decomposition (QLD). But when learning a parameterized basis, the parameters themselves should incur some surprise. Without a unified picture of surprise, its hard to make the direct comparisons, but in general we should think that learning a parameterized basis is "worth it" when the surprise savings from an improved presumption of independence out weigh the surprise cost of learning the basis.
Capacity Allocation
QLD also makes an interesting tradeoff in its allocation of samples, taking n samples to fit a distribution to the logits, and then generating "synthetic" samples from the fitted distribution. If we think of samples under the computation cost notion of surprise, there's a way in which QLD is allocating the surprise budget to the output distribution. In general, ARC calls this problem "capacity allocation" - how to allocate the representation capacity of the model to best achieve some downstream task. Capacity allocation implicitly runs through our earlier discussion of maintaining a relationship between the input and the output of the model - in some sense we only care about intermediate activations insofar as they effect the output. Intuitions along these lines inform work like attribution SAE's, and more ad-hoc mechanistic anomaly detection methods like fitting distributions to attribution scores. We might even think of fitting distributions to activations of concept probes as a kind of capacity allocation decision.
Stepping back, we see a few different axes of variation/design considerations for activation modeling:
- Analytic vs Empirical
- Layer-by-Layer vs Joint (or Causal vs Acausal)
- (Learned) Basis
- Capacity Allocation
While there's certainly more theory work to be done (especially in fleshing out the stricter analytic methods), combining these dimensions opens a rich set of (nearly) shovel ready approaches, we can start evaluating (approximately now) on downstream tasks like low probability estimation and mechanistic anomaly detection (with QLD as an early example for LPE).
Moving on from activation modeling, we now perform a similar heuristic arguments analysis for causal scrubbing.
Causal Scrubbing
The primary motivation behind causal scrubbing was to develop "a method for rigorously testing interpretability hypotheses". But the causal scrubbing authors take direct inspiration from ARC's work on heuristic arguments, using ideas like "defeasible reasoning" (formal arguments that are not proofs) and the presumption of independence to inform its design. Furthermore, there has been substantial speculation around applying causal scrubbing (or deeply related methods like path patching or automatic circuit discovery) to mechanistic anomaly detection, though to the best of my knowledge know published results.
In the following sections, we review causal scrubbing, map it to the heuristic arguments formalism, propose methods for surprise accounting on causal scrubbing hypotheses, and searching for hypotheses using the proposes surprise metric. I hope that this explication of the connection between causal scrubbing and heuristic arguments can motivate further empirical investigations into using causal scrubbing and related methods for mechanistic anomaly detection.
Background
First, we present causal scrubbing roughly following the original notation. We have a dataset with elements in domain , and a function mapping inputs to real values. Our goal is to estimate the expected value of on the dataset . For estimating the loss of a neural network on a labeled dataset, we have our dataset consist of input label tuples from the domain , define a neural network as a function from input space to output space, and a loss function from labels and outputs to real values, yielding . To form a hypothesis, we must define an extensionally equivalent computational graph (with nodes performing computations and edges carrying outputs). Below we depict an example graph decomposition:
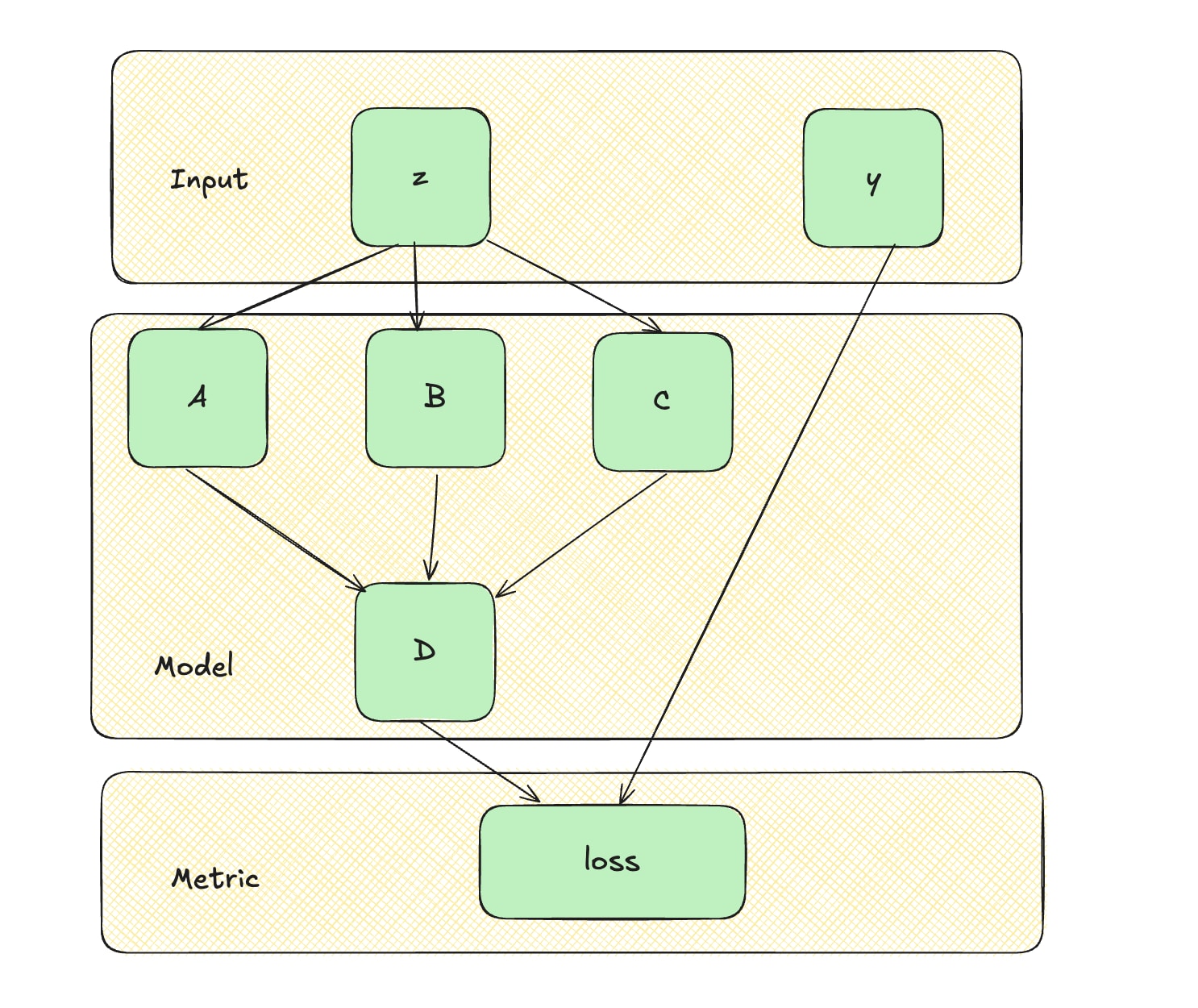
In the original formulation, a full hypothesis consists of a tuple , with an "interpretation" of the model in the form of a computational graph, and a correspondence function from nodes of to nodes of . Importantly, the semantic content of (along with its structure) dictate the allowable set of interventions on for a given input .
To perform interventions, causal scrubbing treeifies , recursively duplicating subtrees of parents such that each node has at most one child (see here [LW · GW], here, and especially here [LW · GW] for more thorough explanations). We let denote the treeified . See the example below:
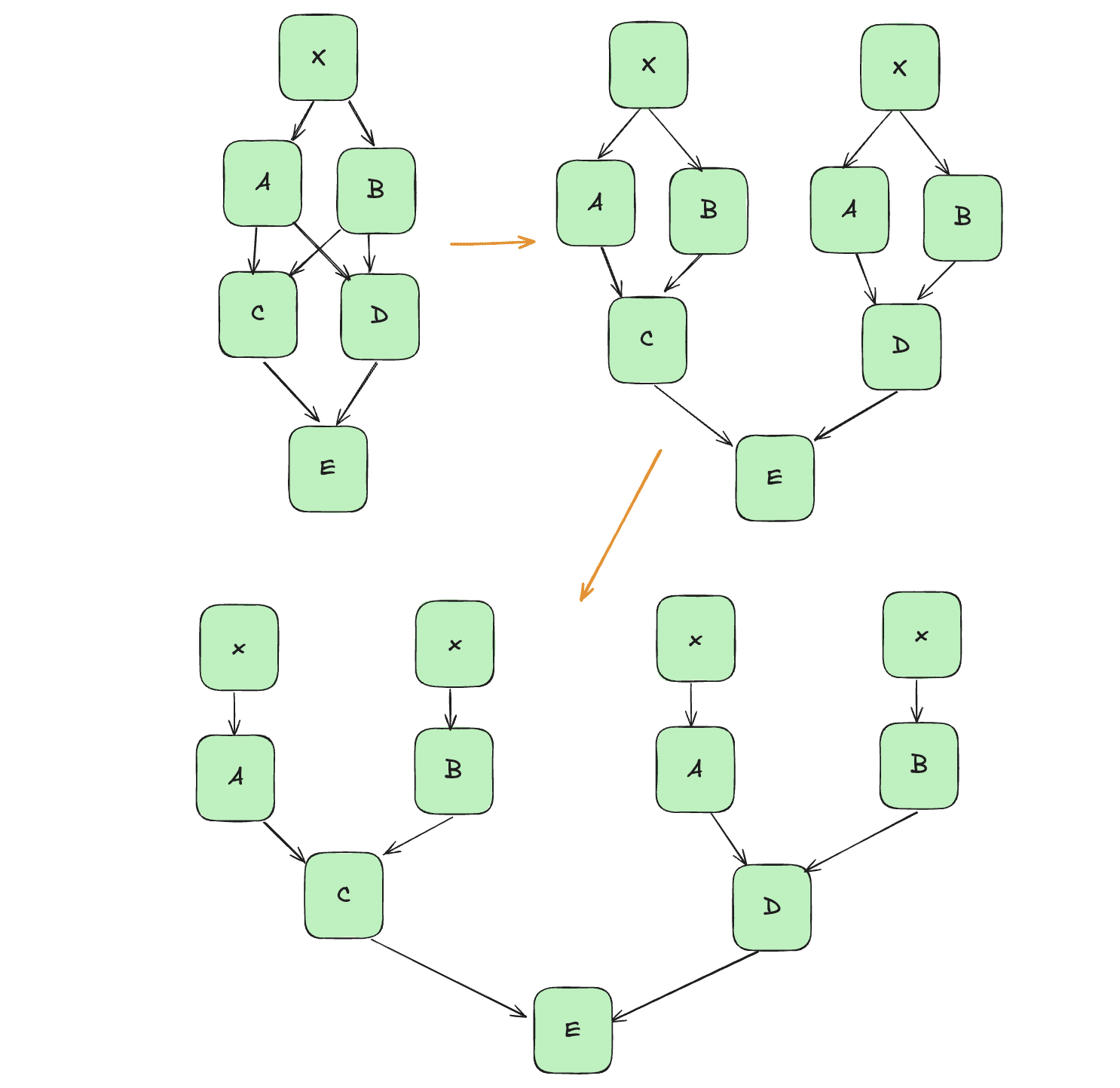
On a treeified graph, all interventions can be expressed as substituting the original input with alternate input on a specific path from input to output. To ablate node A in the graph above, we replace the input to A on both subgraphs, and to ablate the edge between B and D, we replace the input to B on the right subtree:
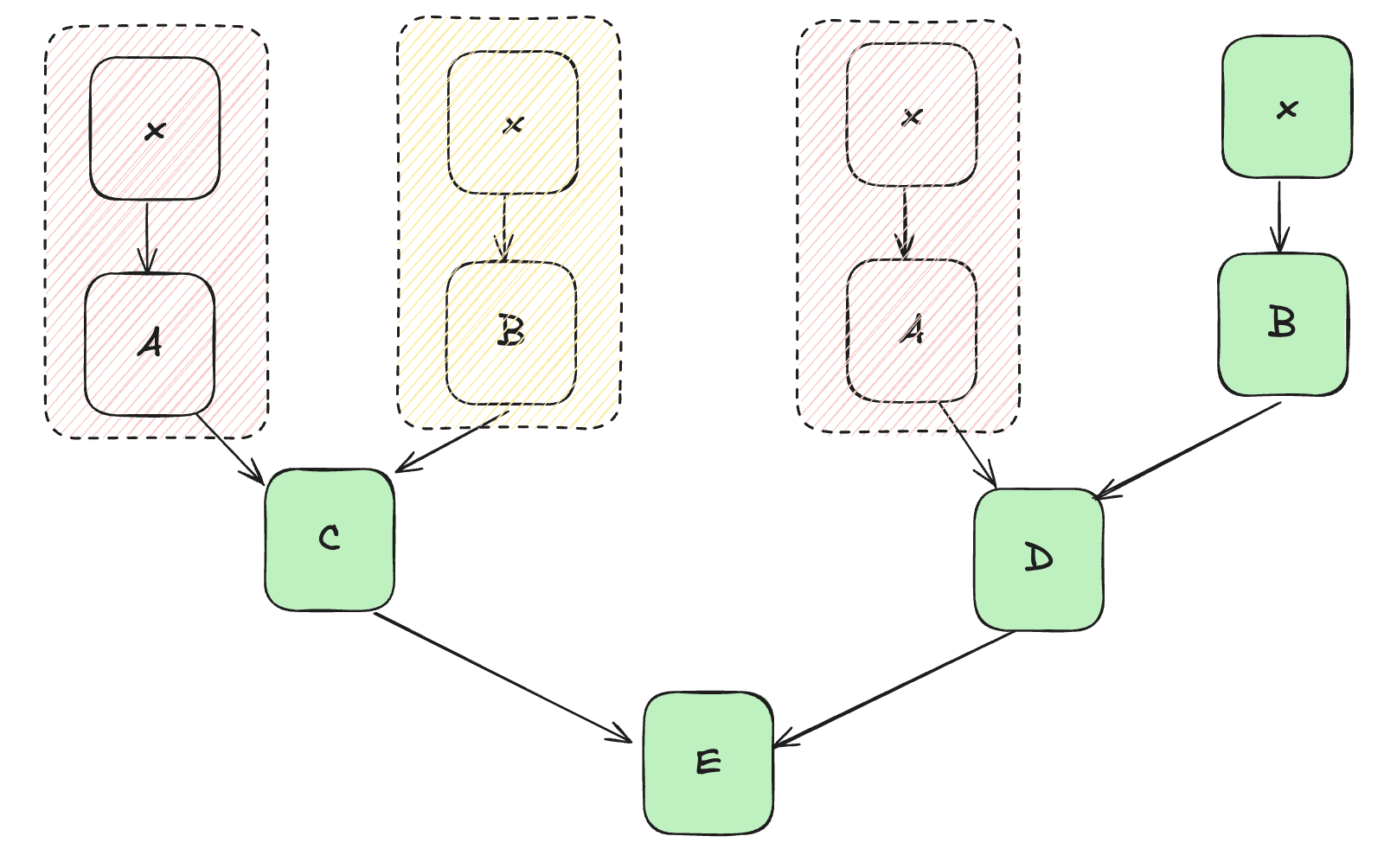
We call replacing inputs with alternate inputs resample ablations, as the input is resampled from a distribution specified by the interpretation . (Note that when dealing with labeled data, we only resample ablate the input , not the label ).
We can separate resample ablations into two types:
semantic ablations: ablations that preserve the meaning of - ablating paths with particular inputs as a function of the base input - see examples here [LW · GW]
structural ablations: ablations that remove unused components of - ablating paths with randomly sampled inputs, independent of the base input - see examples here [LW · GW]. Structural ablations are equivalent to path patches.
In what follows, we describe a heuristic estimator that makes use of structural ablations (i.e. path patching), introducing a novel surprise metric for causal scrubbing. Searching for admissible semantic ablations is significantly more challenging, as the search space expands to all combinations of inputs to to treeified paths. As an initial approach, we present an alternative view of hypotheses as specifying an admissibility function from inputs to sets of path inputs, and gesture at methods for learning such a function efficiently.
Heuristic Estimation with Path Patching
In path patching (which might also refer to as "structural" causal scrubbing), we try to find all the "unimportant" paths - i.e. paths that can be resample ablated. Arguments then, could be a boolean mask over whether each path input can be resampled. But unlike in the original causal scrubbing algorithm, by default we assume each input is resample ablated separately, using a different sample for each ablation. To capture important "correlations" between path inputs, where having the same input matters (even if the input is resampled), we can formulate our argument as partitions over paths (see Generalized Wick Decomposition), where paths in each partition are ablated with the same input, and one "ground truth" partition is not ablated at all.
In what follows, we formalize this version of causal scrubbing in the language of heuristic estimation, and introduce a novel surprise metric which will generalize beyond path patching to (semantic) causal scrubbing.
Naive Estimator with Presumption of Independence
Our naive estimator makes two presumptions of independence: between the input and output, and between each path input. To illustrate these presumption of independence we walk through our naive estimator: the terrified graph where every path input is resample ablated.
First, assume each ablated path is ablated with a common input (as in the original causal scrubbing formulation). That is, for each input , we replace with a resampled input . Note that under this setup, we are implicitly estimating the the expectation of the loss as the expectation over the labels of the expectation over the input of the loss given y:
i.e. presuming the independence of and (though note that we don’t actually compute the expectation this way because our arguments will introduce dependence between the input and output along certain paths). This presumption of independence also motivates the use the "randomized loss [LW · GW]" (loss from randomly shuffling model outputs and labels as a baseline in causal scrubbing.
Now consider the naive estimator that resamples each input independently. That is, for each path input we resample different inputs ’. We could then similarly chain expectations, with .
i.e. presuming the independence between each path input (again note that in practice we do not chain expectations in this way because we selectively violate the presumption of independence according to our arguments.
Argument Space
If we resample ablated each input with the same sample, our argument space could simply be a boolean vector in . However, we want to assume each input is resampled separately, and capture ablations with shared input in our arguments. To do so, we follow the wick decomposition formulation of path patching, treating our argument as a partition over the paths. This yields an argument space
with each a partition over , such that
is a set of disjoint, complete blocks of paths, with
(complete)
(disjoint)
We assume for each partition, there exists one block containing the paths which are not ablated, with all other paths resample ablated using the same inputs as the other paths in its block.
Surprise Accounting
As before, there there three distinct conceptions of surprise that will yield different "accounts".
Description Length
Applying description length would be trivial if we ablated all unimportant paths with the same samples - we could take the norm of the argument / number of important paths. But with the partition construction of the arguments, computing the MDL is non-trivial, and depends on our parameterization of the argument space - again see the appendix.
Information Gain
We can apply information gain independently of the parameterization of , but we need to specify a prior over some part of the network behavior induced by our naive estimator. In activation modeling, this prior was over the activations. But specifying an activation prior directly feels less natural in causal scrubbing, as our arguments modify the distribution of path inputs [LW · GW], and are in some sense agnostic to the activations in the treeified graph. We should define our prior then, over the distribution of admissible combinations of path inputs. Considering our naive estimator, note that for any input , our naive estimator samples a given combination of path inputs uniformly over all possible combinations of path inputs in the dataset. Noting the cardinality of this set is , for a give combination our prior assigns a probability 1 over the cardinality:
Equipped with this naive prior, we now we need to define a distribution parameterized by our argument. Considering only path patching now, note that all paths in the "important" block are fixed on every input, and paths in other blocks are fixed to whatever input is sampled for the block, effectively shrinking the number of paths that can be sampled to [7]. Again taking the uniform distribution, the probability of sampling a given input combination from the set of admissible input combinations is given by:
To compute information gain, we take the KL divergence between and :
Observe that the naive estimator, with the default argument of separating each path into a separate partition (and none in the important block) such that , yields 0 surprise. Conversely, including all arguments in the important block (such that ) produces maximum surprise of . In the next section, we show how this notion of information gain can be generalized to full causal scrubbing, using an "admissibility" function defining the set of combinations of inputs for each input in the dataset. For now, note that is definition exactly corresponds to maximizing the number of possible interventions [LW · GW], and selects arguments that least reduce the entropy of the treeified input distribution [LW · GW].
Computational Cost
We now move to the computational cost view of surprise. In some naive sense, with our current formulation, any argument (including the vacuous and full arguments) cost the same amount of compute: for each input, we sample from the distribution of admissible inputs, compute the output, and take the mean of the output metric over the dataset. Ideally we would have a notion that varies across argument size. One option is to try to treat all computations on resampled ablations as in some sense being "built in" or cached in the estimator, and only count the computations from important paths. Something like this might help us in comparing methods that use different base graphs (for example, it captures the intuition that edge circuits that are sparse in edges but use most or all of the graph nodes are not very explanatory). The computational cost view also suggests learning low-rank approximations/compressions of the weights of components, which we cover in more depth in the appendix Weight-Based Arguments [LW · GW].
To summarize, the information gain perspective feels most appropriate for applying causal scrubbing "as is", but the computation cost perspective suggests interesting new directions, and a principled way to compare different heuristic estimators. In particular, causal scrubbing scales in the cost of the forward pass ( for layers) and the size of dataset: , in contrast with analytic layer-by-layer propagation which is only linear in the number of layers (and is constant with respect to dataset size).
Estimation on Instances
Estimation on instances comes "for free" with causal scrubbing - on a new instance , we resample inputs according to our argument and run the treeified model. Optionally, we can take the mean over multiple samples, approximating the expectation:
Recap
Putting the pieces together, we have an heuristic estimator which estimates the expected value over a dataset of a metric on a model by constructing an extensionally equivalent graph , treeifying the graph to produce , and then resample ablating combinations of inputs to paths according to an admissible input distribution produced by our argument a partition over path inputs. We compute the surprise of as the the sum of the expected value of the metric on the treeified resample ablated graph and the KL divergence between the admissible distribution and naive uniform distribution over combinations of inputs to paths:
In the following sections, we cover extensions to and problems with the formulation presented above, making connections to other areas of mechanistic interpretability and general problems in heuristic estimation.
Heuristic Estimation with (Semantic) Causal Scrubbing
The original formulation of causal scrubbing allows for constructing arbitrary graphs extensionally equivalent to and interpretation graphs with semantic content specifying allowable interventions. But in what we've presented above, we choose a specific rewriting of G ahead of time, and search for unimportant paths within the treeified graph (with a partitioning of paths for shared resampled inputs). We can translate this partition into a corresponding isomorphic interpretation graph [LW · GW] , with no semantic content. In this way, patch patching is a kind of structural causal scrubbing - we only care about the structure of , rather than the semantic content. We now attempt to generalize our algorithm to include semantic causal scrubbing, taking into account the specific set of interventions allowed by the semantic content of the interpretation graph.
In structural causal scrubbing, our partition parameterized a condition distribution on combinations of path inputs. But because we take the uniform distribution over all admissible inputs, we can also think of as parameterizing an "admissibility function" that maps input instances to combinations of admissible inputs: . For structural causal scrubbing, the admissibility function was parameterized by the partitioning of path inputs:
But in semantic causal scrubbing, we allow arbitrary parameterizations of , and define the distribution of admissible inputs as uniform over the admissible set:
Most automatic circuit discovery work is a very narrow form of semantic causal scrubbing. We specify a computation graph (typically MLPs and Attention heads), and for each input , a contrastive pair which varies along a particular dimension of interest (e.g. replacing names in IOI). Then we find a mask over edges (typically in the edge, rather than treeified, basis), such that for a given :
with the number of edges. But in specifying contrastive pairs ahead of time, we basically reduce the semantic problem to a structural one. Furthermore, we severely restrict the size of relative to . If we want to be able to automatically learn low surprise semantic arguments that adequately capture model behavior on a real distribution, we need more expressive parameterizations of the admissibility function which are still efficient to compute.
Exhaustive Search
On an input distribution with finite support, we could exactly compute by exhaustive search, for each input checking all possible combinations of path inputs. In practice, even with finitely supported distributions exhaustive search is exponential in the number of path inputs .
Rejection Sampling
Instead of exhaustive search for , we could instead define a binary classifier on input and input combination pairs , and use rejection sampling from to estimate .
If we assume is a hard classifier with range , then, given a batch of path input combinations (with ), for each we input we only compute the surprise of the estimate on input combinations with , and estimate as , such that
For a probabilistic classier, we could perform a similar surprise estimate, weighting each combination of path input combinations according to their joint probability of being admitted. We can imagine a range of parameterization of , from a simple threshold on the difference between the treeified and full model, to a separate neural network classifier.
Ultimately though, the core worry with rejection sampling is sample efficiency - admission functions with very specific admissible inputs will require too many samples to accurately estimate.
Clustering, Retrieval, and Intelligence
To reduce variance/sampling cost, we would like to directly sample from . I don't have specific proposals for direct sampling, but tools like
- clustering (map to semantic clusters rather than specific instances)
- retrieval augmented generation (use embeddings to find specific instances or instances with certain properties, generate similar data)
- task quantization (break training data into discrete tasks, learn separate admission function for each task, in the spirit of section 5 of sparse feature circuits)
might be useful. However, given the current practice for generating semantic hypotheses in mechanistic interpretability is roughly "have humans / LLMs (see e.g. here, here look at max-activating examples and try to figure out what's going on", learning admission functions may require similar use of flexible intelligence. Using something like auto-interp[8] may be the path forward, leaning on evaluation being easier than generation, with "evaluation" performed algorithmically. However, causal scrubbing (and heuristic arguments in general) are vulnerable to adversarial arguments - which we explore in the appendix Negative Components and Cherry-Picking Arguments [LW · GW].
Future Directions
Overall, I'm pretty excited about evaluating different notions of surprise for causal scrubbing, and think there's interesting "shovel ready" empirical work to be done. I'll briefly sketch one such project idea.
Consider the max-of-k problem explored in Compact Proofs of Model Performance via Mechanistic Interpretability (and the corresponding report on heuristic estimation). Leaning on the analogy between backdoors and deceptive alignment, suppose we train the model to output min k sequences containing years from 2028-2100 (wink wink), but that such sequences are only of the training set. We then apply heuristic estimation with path patching, learning an argument (path ablations) that minimize total surprise. We then use the ablated model on a held-out test set with more frequent occurrences of the trigger and perform mechanistic anomaly detection using the ablated model loss.
While there are multiple points of failure in such a project (causal scrubbing is fundamentally flawed, the graph decomposition is wrong, our surprise metric is faulty, etc), exploring the source of potential failures could be valuable. In general, empirical work of this kind can help validate (or disprove) some of the high level intuitions around heuristic arguments, and provide a useful legible case study for e.g. other academics and AI safety researchers (see this comment [LW(p) · GW(p)] for related discussion)
Inter-Method Surprise Accounting
Without crisp notions of surprise and a common presumption of independence, we cannot directly compare different methods of heuristic estimation. However, using the computational cost notion of surprise, we can perform approximate comparisons that expose an important axis of variation across methods.
Assume we have a model with layers as described in Layer-by-Layer activation modeling, and (for some methods) a dataset . We approximate computational cost as the number of layer forward passes per argument update. Using this criteria, we evaluate analytic activation modeling, empirical activation modeling, and causal scrubbing (where analytic activation modeling uses no sampling):
- Analytic activation modeling uses layer forward passes, as the layer statistics propagate once through each layer.
- Empirical activation modeling uses forward passes, where is the number of samples.
- We can structure our samples depending on the structure of the model - for example, we might take samples from the input distribution and propagate each through the entire model, or alternatively take at each layer
- Causal scrubbing uses (something like) , where is the number of inputs to the treeified graph and N is the number of ablation resamples.
- is an overestimate of the cost of a treeified forward pass, but note that is already exponential in the number of layers.
This cursory analysis reveals that our methods descend a kind of hierarchy of computation cost, with analytic activation modeling the most efficient and causal scrubbing the least. Furthermore, causal scrubbing is in some sense a more empirical approach than empirical activation modeling, requiring estimation over the entire dataset, while also costing more per forward pass.
Theories of Change
Ok, but how is any of this actually going to improve safety? I see roughly three theories of change:
- Solve the alignment problem before human-level AI
- Give automated alignment researchers a head start
- Produce (incrementally) better methods for anomaly detection and adversarial training
Solve alignment before human-level AI seems really tough, especially under 2-10 year timelines. But on some more virtue-ethical/dignity/truth-seeking stance, it does feel like at least some researchers with promising approaches to the full problem should just be going for it.
But even if we don't get there in time, the effort won't be wasted, so the second theory goes. In a world where we have human-level AI with roughly sufficient incentive and control measures, the hope is we can leverage the human-level AI to "do our alignment homework", such that we can confidently deploy super-human models. In such a world, we want to have already done as much of the work as possible, allowing us to give the automated alignment researchers clearly scoped tasks which we can cheaply and reliably evaluate. If we really do our job well, the automated labor could look more like "AI assisted improvements on inspection of internal variables [LW · GW]", as we sketched in Clustering, Retrieval, and Intelligence [LW · GW].
Somewhat orthogonal to arbitrarily scalable approaches to alignment, research on heuristic arguments may also producing incremental improvements our toolbox for aligning/controlling human-level AI. In some sense this theory of change has too much of a "bank shot" feel (we might make more progress on anomaly detection by taking a more method agnostic approach), and my impression is the motivation of ARC's current empirical work is more to provide feedback on their general approach, more so than cashing out incremental safety wins. But if tools like the presumption of independence and surprise accounting are powerful, we should expect them to be useful prior to a "full solution" (in much the same way that SAE's might help with model debugging and steering even though we are far from "fully explaining the model loss").
On all three theories of change, I think's there a lot of low-hanging empirical fruit to pick, and I'm excited to try to pick it!
If you want to join me, feel free to reach out at odanielskoch@umass.edu
Appendix
Surprise Accounting on Boolean Circuits
In the made body, we showed that description length and information gain notions of surprise yield different surprise accounts. However, we should that description length and information gain produce the same account on the original boolean circuit example given in ARC's post on surprise accounting. We also motivate the "computational cost" notion of surprise in the boolean circuit case.
Description Length and Information Gain
In the original post, we start off with the following boolean circuit
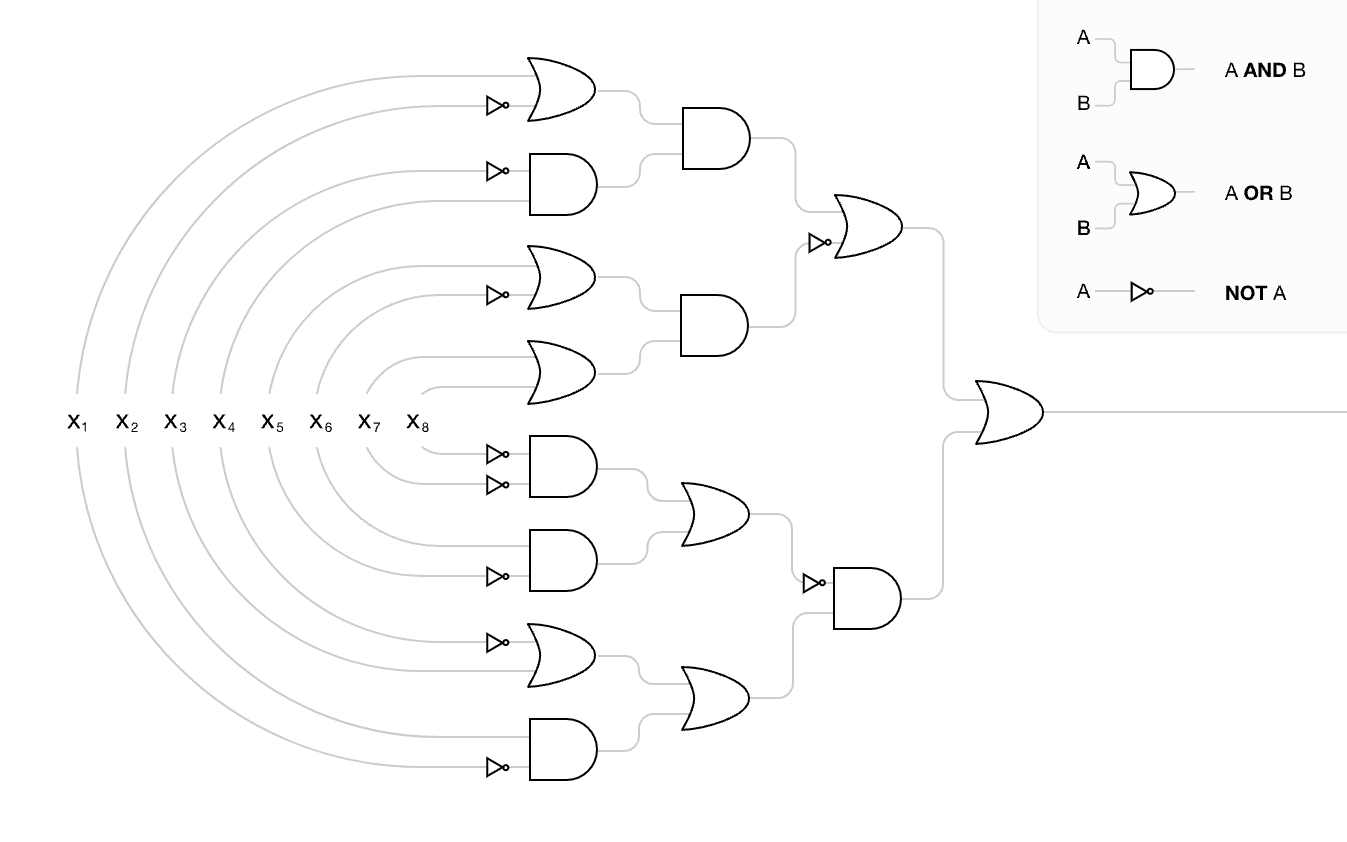
While the circuit appears basically random, the output is always True. The remainder of the post consists in making arguments about the circuit, and computing the total surprise (surprise of the estimate + surprise of the arguments).
The first observes that the final gate is an OR. This argument decreases the surprise of the estimate (now assigning 0.75 probability to True), and the argument incurs 1 bit of surprise. This seems intuitively right - selecting 1 of two options requires one bit. However, there are two distinct ways in which we could have arrived at one bit: description length and information gain.
According to description length, the argument costs 1 bit because we need exactly one bit to store the argument. If we think of the estimator as a program that takes variable numbers of booleans, we only need to pass one boolean to the program to execute the estimator.
According to the information gain, we specify a default distribution over relevant parameters of our estimator, and compute the surprise as the information gained relative to the default distribution. In the boolean circuit case, we can define an uninformative multivariate Bernoulli distribution over the values of each gate, with each gate independent and uniform over AND and OR. Noticing that the final gate is is OR produces an updated distribution (with , and we compute surprise as the relative information gain of P over Q:
Taken in expectation, this is the empirical KL divergence (with the expectation taken over the true distribution, not )
The equivalence of description length and information gain also holds for "correlations" between gates. Take the symmetry between the top half and the bottom half of the network, where every AND in the top half of the network corresponds to an OR in the bottom half, and vica versa
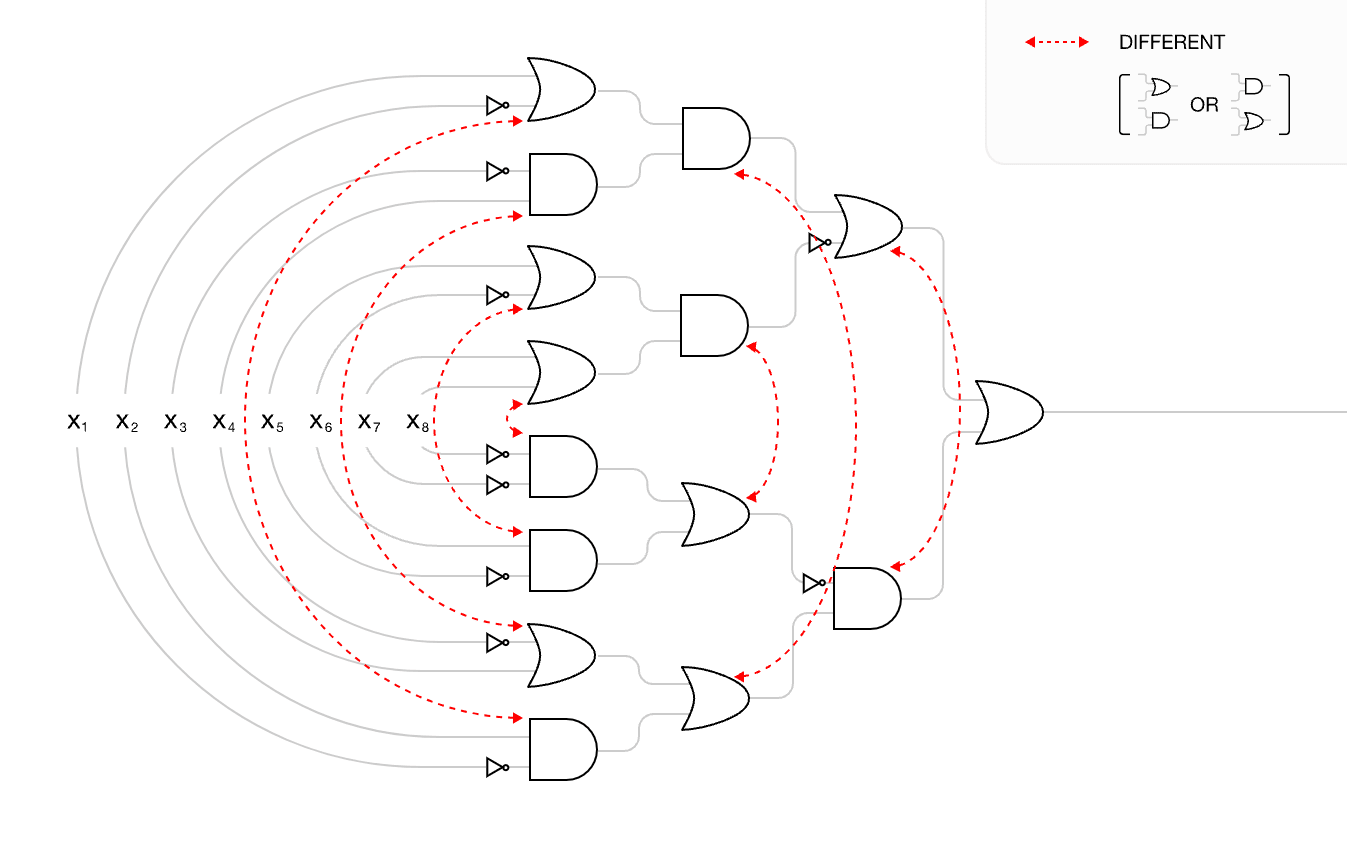
For description length, we simply count the number of red arrows as boolean parameters to pass to the explanation (7 arrows = 7 bits). For information gain, letting denote a pair of gates on the top and bottom half, we update our distribution such that
But by the presumption of independence, our naive distribution assumes any combination has equal probability:
Computing the information for a given pair we have
which gets multiplied by 7 for each pair.
Hidden Information and Computation in Estimators
Thus far we have only addressed the bits required to "encode" the explanation, keeping the estimator fixed. But, if we're not careful, the estimator can contain arbitrary amounts of information, potentially distorting our surprise computations. For example, for the boolean circuit we could define an argument space as a single binary variable whether to use the empirical estimate or naive (uniform) estimate. With this argument space, we could achieve a total surprise of 1 bit (0 surprise for the output, 1 bit for the explanation). In this case we "cheated" by smuggling the entire description of the network and distribution into the estimator.
But we may already have been cheating more subtly. Consider this set of arguments noticing connections between not gates:
For each input to a gate in the top half of a network, there is a corresponding input to a gate in the bottom half of the network. For the leftmost layer, the presence of a NOT gate is always different, and for every subsequent layer, the presence of a NOT gate is always the same:
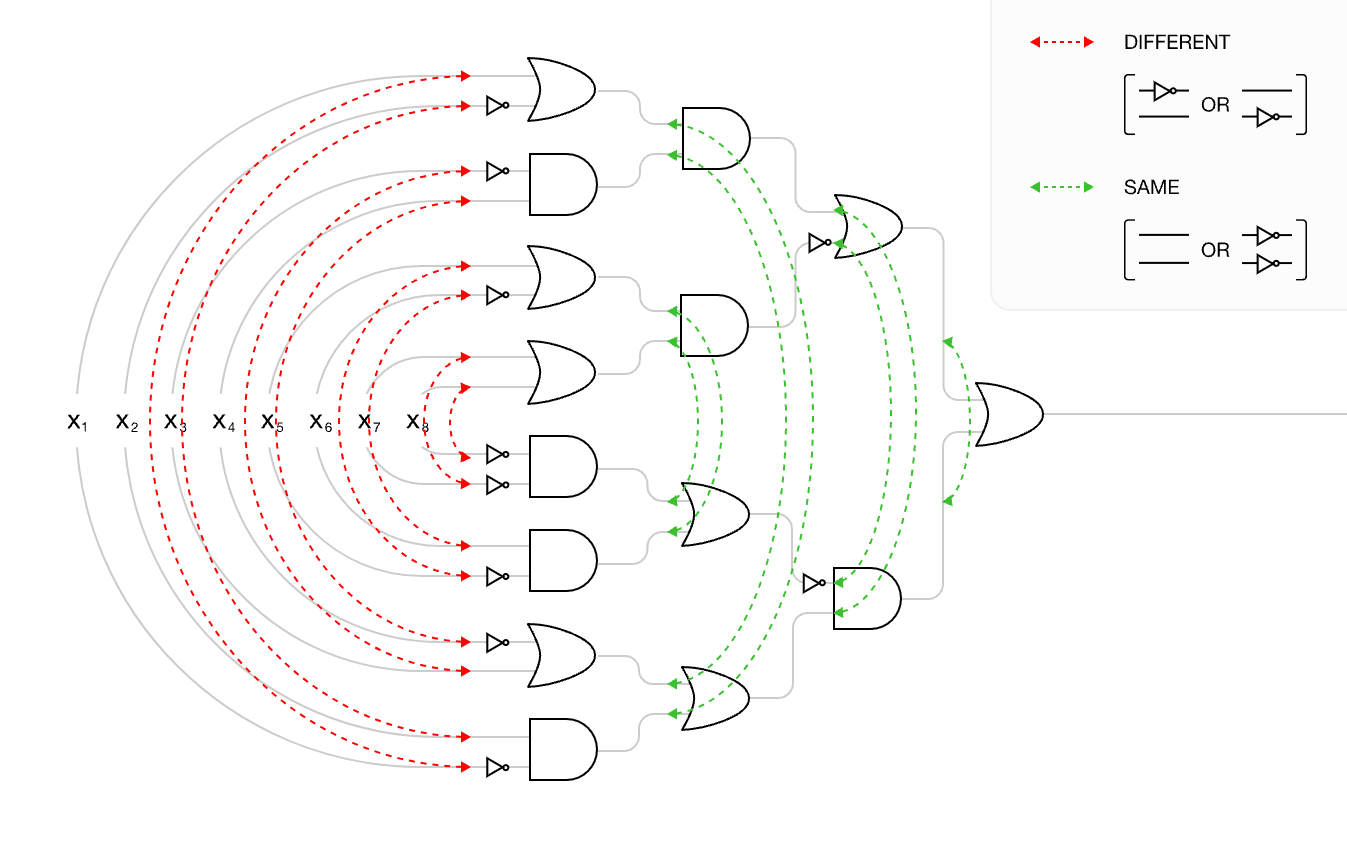
This means each gate input is anti-correlated with the corresponding input in the other half of the network: for the leftmost layer, the correlation is −1; for the next layer, the correlation is −0.5; for the layer after that, −0.25; and the two inputs to the final OR gate have a correlation of −0.125. Implicitly, these correlations assume that the AND and OR gates were chosen independently at random, since we have not yet noticed any particular structure to them.
The "substance" of the argument is the correlations between the not gates, and we count the surprise of the explanation by counting the number of connections (15). But after we make the argument, we have to "propagate" it through the network and perform the arithmetic in the second block quote. So even though our estimator is agnostic about the values of the gates, it still contains information about the structure of the network, and performs computation using that structure and the provided arguments. The larger our arguments get, the more computation we have to do (because we can no longer make certain presumptions of independence).
This point motives the notion of surprise as "computation used compute the estimate", and helps to contextualize the thee use of FLOPs as a metric of argument length in Compact Proofs of Model Performance via Mechanistic Interpretability, and a budget in Estimating the Probabilities of Rare Outputs in Language Models. The computational cost frame also helps with inter-model comparisons, as we saw in the main body.
Choosing a Graph Basis
To perform heuristic estimation with causal scrubbing, we have many degrees of freedom in how to construct the computation graph from our model . Interpretability on standard transformer language models often treats MLPs and attention heads as nodes, though more recent work uses sparse auto-encoders. Early work focuses only on node ablations, implicitly using computational graph where all the nodes at each layer only have one out-going edge to a common residual layer. Automatic circuit discovery instead leverages the residual stream decomposition to define separate edges between a component and all downstream components, allowing for more fine-grained intervention. See the example below, where ablating A1 corresponds to ablated two outgoing edges in the "edge" basis:
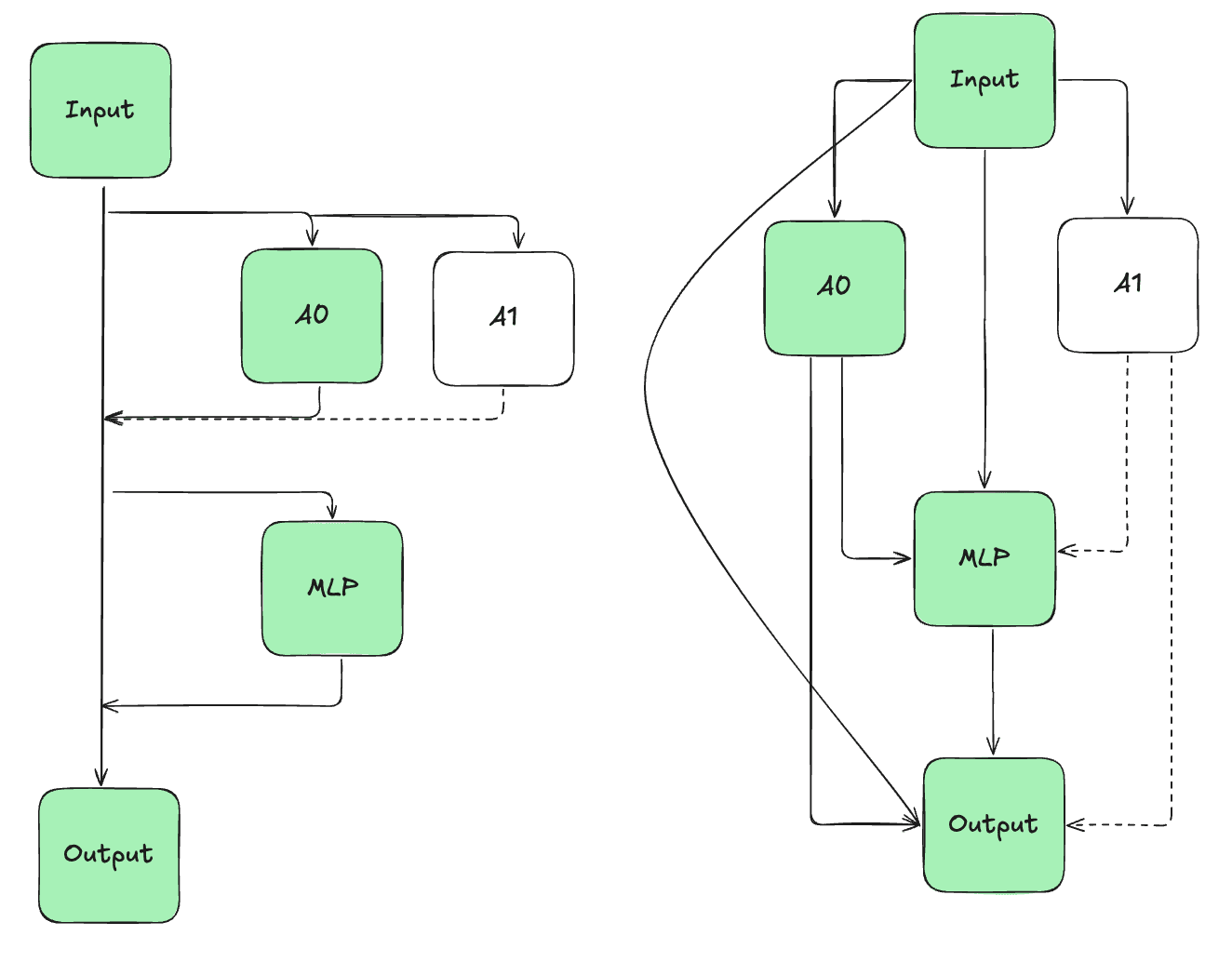
The treeification introduced by causal scrubbing allows for even more fine-grain intervention, with different inputs for each path. Se the example below, where ablating the edge from Input to A1 corresponds to ablations on two paths:
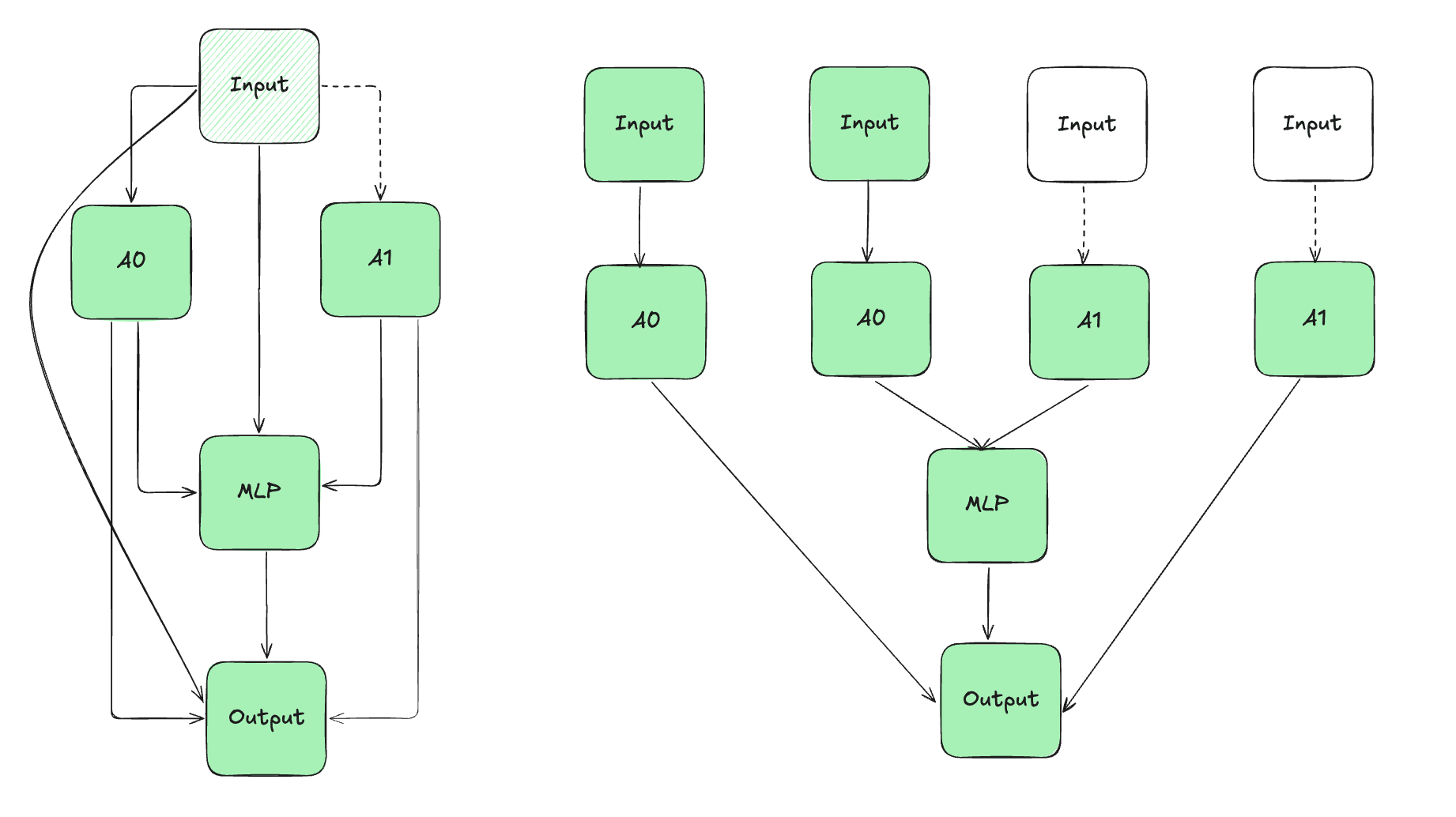
In each case, interventions on the coarse grain basis can correspond to multiple interventions on the fine-grained basis.
Considerations for picking a "graph basis" mostly mirror our discussion of learning a parameterized basis [LW · GW]. We want to find graphs that produce reasonable heuristic estimates when we treat edge values as independent, while minimizing extra learned parameters and computation cost. As a general heuristic, factoring the graph to allow for more fine-grained interventions seems good (we require less components to achieve the same behavior in the fine-grained basis), but without a unified notion of surprise, its hard to compare the expressivity gains of a fine-grained basis to the computation cost.
Negative Components and Cherry-Picking Arguments
(Largely a reformation of Appendix A8 of Causal Scrubbing [LW · GW], also see Attribution Across Reasons [LW · GW] for related discussion)
Multiple works in mechanistic interpretability has found that ablating certain components can improve model performance. Conversely, including these components degrades performance. We call these negative components, as they have in some sense negative attribution. While we don't have a clear understanding of why negative components exist (confidence mediation, self-repair, path dependencies in training, and polysemanticity [LW · GW] all plausibly contribute), they pose problems for checking that explanations capture a model's behavior. In particular, omitting negative components means positive components that "overcome" the negative components can also be omitted.
Negative components in causal scrubbing/automatic circuit discovery are a specific instance of the more general problem of cherry-picking arguments (see Appendix E for formalizing the presumption of independence). Because heuristic estimates do not monotonically improve with more arguments, arguments to be "cherry-picked" to arbitrarily distort the estimate.
In what follows, we elaborate on the problems negative components pose for mechanistic anomaly detection, detail the connection between negative arguments and notions of completeness in mechanistic interpretability, explain debate as an approach for handling cherry-picking arguments, and propose evaluating explains with respect to "maximally cherry-picked" explanations as an approximation to debate.
Negative Components and Mechanistic Anomaly Detection
Let denote an argument with n sub-arguments, with each sub-argument corresponding to the inclusion of a model component. Assume we have an argument including two positive components and one negative component , such that our estimator achieves low surprise with just the first positive component , high surprise with the first positive and negative component, but low surprise again when adding the second positive component .
If we were searching for the arguments with the lowest total surprise (assuming for now the description length notion), we would only include the first argument . But suppose we have a mechanistic anomaly such that including only the first positive component achieves low surprise but including all three arguments produces high surprise, because the mechanistic anomaly uses a different positive component . If we only include in our argument, we would fail to flag as a mechanistic anomaly, even though a component that was not required to achieve high performance on the trusted distribution.
Negative Components and Completeness
Problems arising from negative components are similar, though identical to, problems arising from "incomplete" circuits in mechanistic interpretability. A circuit is complete (as defined by Wang et al) if for every subset of the proposed components , our estimate using the complement of subset under the mechanisms should be equivalent to the estimate using the complement of the subset under the "full explanation" : (where the full explanation corresponds to no ablations).
In some cases, finding a complete circuit will require including negative components. For example, assume only has an effect when is present, and has an independent positive effect. Then we need to include all three mechanisms for our explanation to be complete (since ).
But in other cases, a complete circuit may not include all relevant negative (and positive) components. For example, if also offsets , then corresponds to a complete circuit (because ).
Completeness also may not be necessary for mechanistic anomaly detection. Let and be arguments that correspond to "primary" and "backup" sets of components (mechanisms), such that . Completeness says that we need to include both arguments, but it feels reasonable to flag a novel input as mechanistically anomalous if e.g. it can be sufficiently explained by but not (see here [LW · GW] for related discussion).
Searching For Negative Components
Most circuit discovery methods (ACDC, attribution patching) search for mechanisms that change (rather than exclusively improve) model performance. Such search procedures incorporate negative components by default. However, these methods are limited in that they only consider local effects of ablating/unablating a given component. Methods that can search for mechanisms jointly (with e.g. SGD) can account for more complex interactions between components and find smaller circuits that achieve comparable performance (see e.g. Bhaskar et. al. 2024). However, using SGD to find subcircuits that maximize performance disincentives the inclusion of negative components (see e.g. task specific metrics higher than model performance in (Bhaskar et. al. 2024), and generally finds less complete and "internally faithful" circuits than other methods (empirical results supporting this claim to be published in forthcoming work).
To address essentially this problem, the causal scrubbing authors propose adversarial argument selection [LW · GW] (i.e. debate) Two policies take turns proposing arguments that maximize/minimize performance, conditioned on the previous arguments. While ARC has found debate does not converge in general[9], in practice we might expect it to capture most of the important components / arguments.
Positive-Only Components
(See attribution across reasons for related discussion)
Recall that the core problem with negative components is that they cause the estimator to neglect important variations in positive components. In the mechanistic anomaly detection example, the estimator fails to flag that the mechanistic anomaly uses component instead of component , because (in the abscense of ) is sufficient to explain both the trusted distribution and anomaly.
One approach (discussed in the previous section) is to include all relevant negative components such that to produce an accurate estimate, the estimator must include all relevant positive components.
However, if including the negative components is just in service of including the positive arguments, another approach we instead try to ignore the negative components all together, and instead try to estimate the performance of a maximally cherry-picked estimator. Below we present a possible approach along these lines.
Let us take a simplified view of the effects of arguments as linearly separable, such that . Now, if we run our adversarial search process, we expect to find an argument which explains of the performance of the full argument :
Using linear separability, we can partition into positive and negative arguments such that:
Now, consider we run an adversarial search process with no penalty on the surprise of the explanation. Then we would expect to find an argument which contained all positive components, and no negative components. That is, if we partition the full argument by positive and negative components , then the argument should be equal to the positive components of the full argument . Substituting the partitioned full argument and rearranging terms, we have
Assuming is small and the negative partition of our argument captures most of the total negative arguments, we can can set the negative terms to 0 :, yielding .
Finally, if we run a separate search process, without an adversarial component, finding the smallest arguments that capture ) of the full positive argument performance, we (approximately) recover , without performing any adversarial training (note this is essentially equivalent to treating (a metric on) as the target quantity to estimate).
The above argument is highly dependent on the linear separability assumption, which clearly fails to hold in general. But while debate is cleaner theoretically, it still may fail to converge (due to the nature of the problem or practical difficulties similar to those encountered when training GANS. Searching for positive only arguments that explain is a more simple solution that may still overcome problems with negative arguments. In particular, I'm excited about applying the positive-only components approach for explaining task-specific behavior on pre-trained models, where there is a wide disparity between the full model and the full model with only positive components.
Weight-Based Arguments
In the boolean circuit surprise accounting example, our arguments were concerned with values of and connections between different logic gates. However both activation modeling and causal scrubbing made arguments with respect to activations (i.e. wires). In doing so, both methods assume full access to the weights (corresponding to gates) of the model. But assuming access to the trained weights may give us both too much and too little information about the model. Too much information in that the naive estimator may incorporate a lot of information about the weights (as is the case in both activation modeling and causal scrubbing), leaving less "explanatory space", and preventing the estimator from some kind of presuming independence between the training process and the model. Too little information in that the estimator does not access to the training process that produced the model, which may be critical for capturing important behaviors [AF · GW].
As an alternative to activation-based arguments, we could instead make arguments with respect to model weights. The exact nature of such arguments is unclear, but following the general principles of surprise accounting, they might take the form of low-rank, quantized representations of the weights that account for a large fraction of model performance. Notions of degeneracy from singular learning theory may be relevant here, especially when learning explanations in conjunction with model training. Proposals along these lines also feel promising for yielding a unified notion of surprise accounting, with more compressed representations of the weights requiring less computation, and information metrics (e.g. fisher information matrix) being central to learning faithful compressions.
While there are no shovel ready weight-based argument approaches, they feel closer to what the heuristic arguments agenda is ultimately shooting for, and I'm excited about more work in this vicinity.
- ^
Note that this space may contain covariances which are never used or are redundant - we define the space over every pair of nodes for simplicity.
- ^
ARC proposes exactly as an initial metric on the length of explanation (see section B.6, C.8 of Formalizing the Presumption of Independence) though they find various problems it
- ^
Here's one such attempt using minimum description length that maybe works. Let denote description length. Then for a finitely supported distribution and code , we have
where is the description length of distribution given the arguments. Now assume is the shortest description of . Then by the Kraft-McMillan Inequality, we have
That is, the average code length is bounded by the self-entropy of . Now assume (this is a load-bearing assumption) that is an "optimized code space", such that we can "trade-off" description length in with description length in the error , while fixing the total description length . Then for two arguments , we can compute the difference in their description length as the (negative) difference between the description length of their errors:
If we treat as the cross entropy of under (again unsure if this is valid) we recover the information gain:
In words: "if is an (optimized) code for , then its (average) length relative to is approximately the average extra information it provides about "
- ^
if f has a non-linearity, we can only approximate the mean and covariance using a low degree polynomial or numerical approximation - in general, we want to minimize the computation cost, in accordance with our third notion of surprise) of the there mean and covariance induced by
- ^
As suggested by ARC in footnote 37 (in section 7.3) of Towards a Law of Iterated Expectations for Heuristic Estimators
- ^
I think something in this vicinity is what ARC is getting at in their discussion of "consistency" and "explanation quality" in section 7.3 of Towards a Law of Iterated Expectations for Heuristic Estimators).
- ^
note that here denotes the cardinality of the partition (rather than the number of ablated inputs)
- ^
- ^
(see Appendix E.3 of Formalizing the Presumption of Independence)
0 comments
Comments sorted by top scores.