A bird's eye view of ARC's research
post by Jacob_Hilton · 2024-10-23T15:50:06.123Z · LW · GW · 12 commentsContents
A bird's eye view Zoom level 1 Zoom level 2 Zoom level 3 Zoom level 4 How ARC's research fits into this picture Further subproblems Conclusion None 12 comments
This post includes a "flattened version" of an interactive diagram that cannot be displayed on this site. I recommend reading the original version of the post with the interactive diagram, which can be found here.
Over the last few months, ARC has released a number of pieces of research. While some of these can be independently motivated, there is also a more unified research vision behind them. The purpose of this post is to try to convey some of that vision and how our individual pieces of research fit into it.
Thanks to Ryan Greenblatt, Victor Lecomte, Eric Neyman, Jeff Wu and Mark Xu for helpful comments.
A bird's eye view
To begin, we will take a "bird's eye" view of ARC's research.[1] As we "zoom in", more nodes will become visible and we will explain the new nodes.
An interactive version of the diagrams below can be found here.
Zoom level 1

At the most zoomed-out level, ARC is working on the problem of "intent alignment": how to design AI systems that are trying to do what their operators want. While many practitioners are taking an iterative approach to this problem, there are foreseeable ways in which today's leading approaches could fail to scale to more intelligent AI systems, which could have undesirable consequences. ARC is attempting to develop algorithms that have a better chance of scaling gracefully to future AI systems, hence the term "scalable alignment".
ARC's particular approach to scalable alignment is a "builder-breaker" methodology (described in more detail here, and exemplified in the ELK report). Roughly speaking, if the scalability of an algorithm depends on unknown empirical contingencies (such as how advanced AI systems generalize), then we try to make worst-case assumptions instead of attempting to extrapolate from today's systems. This is intended to create a feasible iteration loop for theoretical research. We are also conducting empirical research, but mostly to help generate and probe theoretical ideas rather than to test different empirical assumptions.
Zoom level 2
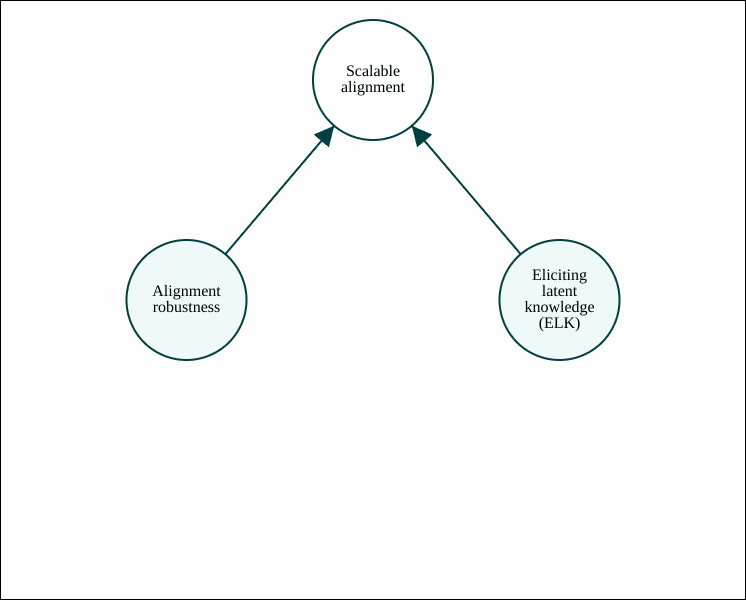
Most of ARC's research attempts to solve one of two central subproblems in alignment: alignment robustness and eliciting latent knowledge (ELK).
Alignment robustness refers to AI systems remaining intent aligned even when faced with out-of-distribution inputs.[2] There are a few reasons to focus on failures of alignment robustness, as discussed here (where they are called "malign" failures). A quintessential example of an alignment robustness failure is deceptive alignment, also known as "scheming": the possibility that an AI system will internally reason about the objective that it is being trained on, and stop being intent aligned when it detects clues that it has been taken out of its training environment.
Eliciting latent knowledge (ELK) is defined in this report, and asks: how can we train an AI system to honestly report its internal beliefs, rather than what it predicts a human would think? If we could do this, then we could potentially avoid misalignment by checking whether the model's beliefs are consistent with its actions being helpful. ELK could help with scalable alignment via alignment robustness, but it could also help via outer alignment [AF · GW], by giving the reward function access to relevant information known by the model.
Zoom level 3
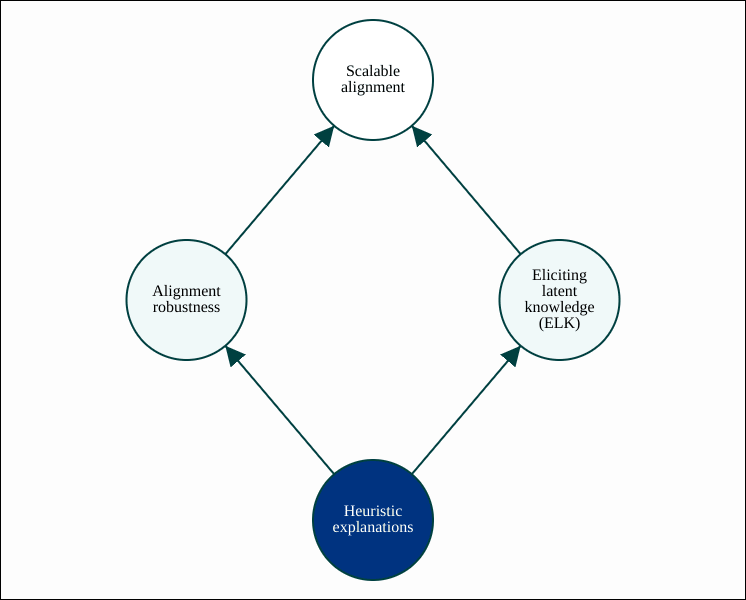
ARC hopes to make progress on both alignment robustness and ELK using heuristic explanations for neural network behaviors. A heuristic explanation is similar to the kind of explanation found in mechanistic interpretability, except that ARC is attempting to find a mathematical notion of an "explanation", so that they can be found and used automatically. This is similar to how formal verification for ordinary programs can be performed automatically, except that we believe proof is too strict of a standard to be feasible. These similarities are discussed in more detail in the post Formal verification, heuristic explanations and surprise accounting (especially the first couple of sections, up until "Surprise accounting").
A heuristic explanation for a rare but high-stakes kind of failure could help with alignment robustness, while a heuristic explanation for a specific behavior of interest could help with ELK. These two applications of heuristic explanations are fleshed out in more detail at the next zoom level.
Zoom level 4
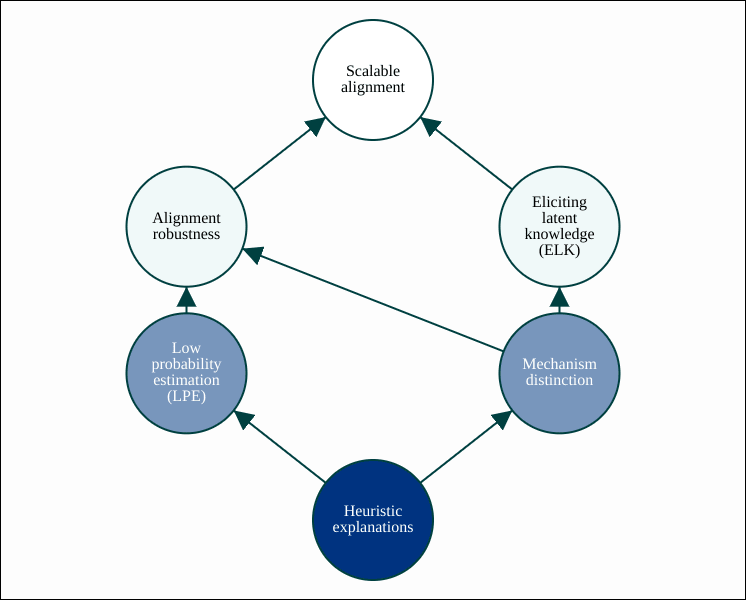
ARC has identified two broad ways in heuristic explanations could help with alignment robustness and/or ELK.
Low probability estimation (LPE) is the task of estimating the probability of a rare kind of model output. The most obvious approach to LPE is to try to find model inputs that give rise to such an output, but this can be infeasible (e.g. if the model were to implement something like a cryptographic hash function). Instead, we can "relax [AF · GW]" this goal and search for a heuristic explanation of why the model could hypothetically produce such an output (e.g. by treating the output of the cryptographic hash function as random). LPE would help with alignment robustness by allowing us to select models for which we cannot explain why they would ever behave catastrophically, even hypothetically. This motivation for LPE is discussed in much greater depth in the post Estimating Tail Risk in Neural Networks.
Mechanism distinction describes our broad hope for how heuristic explanations could help with ELK. A central challenge for ELK is "sensor tampering": detecting when the model reports what it predicts a human would think, but the human has been fooled in some way. Our hope is to detect this by noticing that the model's report has been produced by an "abnormal mechanism". There are a few potential ways in which heuristic explanations could be used to perform mechanism distinction, but the one we currently consider the most promising is mechanistic anomaly detection (MAD), as explained in the post Mechanistic anomaly detection and ELK (for a gentler introduction to MAD, see this post [? · GW]). A variant of MAD is safe distillation, which is an alternative way to perform mechanism distinction if we also have access to a formal specification of what we are trying to elicit latent knowledge of.
A semi-formal account of how heuristic explanations could enable all of LPE, MAD and safe distillation is given in Towards a Law of Iterated Expectations for Heuristic Estimators. An explanation of how MAD could also be used to help with alignment robustness is given in Mechanistic anomaly detection and ELK (in the section "Deceptive alignment").
How ARC's research fits into this picture
We will now explain how some of ARC's research fits into the above diagram at the most zoomed in level. For completeness, we will cover all of ARC's most significant pieces of published research to date, in chronological order. Each piece of work has been labeled with the most closely related node from the diagram, but often also covers nearby nodes and the relationships between them.
| Eliciting latent knowledge: How to tell if your eyes deceive you defines ELK, explains its importance for scalable alignment, and covers a large number of possible approaches to ELK. Some of these approaches are somewhat related to heuristic explanations, but most are alternatives that we are no longer pursuing. |  |
| Formalizing the presumption of independence lays out the problem of devising a formal notion of heuristic explanations, and makes some early inroads into this problem. It also includes a brief discussion of the motivation for heuristic explanations and the application to alignment robustness and ELK. |  |
| Mechanistic anomaly detection and ELK and our other late 2022 blog posts (1, 2, 3) explain the approach to mechanism distinction that we currently find the most promising, mechanistic anomaly detection (MAD). They also cover how mechanism distinction could be used to address alignment robustness and ELK, how heuristic explanations could be used for mechanism distinction, and the feasibility of finding heuristic explanations. |  |
| Formal verification, heuristic explanations and surprise accounting discusses the high-level motivation for heuristic explanations by comparing and contrasting them to formal verification for neural networks (as explored in this paper) and mechanistic interpretability. It also introduces surprise accounting, a framework for quantifying the quality of a heuristic explanation, and presents a draft of empirical work on heuristic explanations. | |
| Backdoors as an analogy for deceptive alignment and the associated paper Backdoor defense, learnability and obfuscation discuss a formal notion of backdoors in ML models and some theoretical results about it. This serves as an analogy for the subdiagram Heuristic explanations → Mechanism distinction → Alignment robustness. In this analogy, alignment robustness corresponds to a model being backdoor-free, mechanism distinction corresponds to the backdoor defense, and heuristic explanations correspond to so-called "mechanistic" defenses. The blog post covers this analogy in more depth. |  |
| Estimating Tail Risk in Neural Networks lays out the problem of low probability estimation, how it would help with alignment robustness, and possible approaches to LPE based on heuristic explanations. It also presents a draft describing an approach to heuristic explanations based on analytically learning variational autoencoders. |  |
| Towards a Law of Iterated Expectations for Heuristic Estimators and the associated paper discuss a possible coherence property for heuristic explanations as part of the search for a formal notion of heuristic explanations. It also provides a semi-formal account of how heuristic explanations could be applied to low probability estimation and mechanism distinction. | |
| Low Probability Estimation in Language Models and the associated paper Estimating the Probabilities of Rare Outputs in Language Models describe an empirical study of LPE in the context of small transformer language models. The method inspired by heuristic explanations outperforms naive sampling in this setting, but does not outperform methods based on red-teaming (searching for inputs giving rise to the rare behavior), although there remain theoretical cases where red-teaming fails. | |
Further subproblems
ARC's research can be subdivided further, and we have been putting significant effort into a number of subproblems not explicitly mentioned above. For instance, our work on heuristic explanations includes both work on formalizing heuristic explanations (devising a formal framework for heuristic explanations) and work on finding heuristic explanations (designing efficient search algorithms for them). Some subproblems of these include:
- Measuring quality: "surprise accounting" offers a potential way to measure the quality of a heuristic explanation, which is important for being able to search for high-quality explanations. However, it is currently an informal framework with many missing details.
- Capacity allocation: it will probably be too challenging to find high-quality explanations for every aspect of a model's behavior. Instead, we can try to tailor explanations towards behaviors with potentially catastrophic consequences. A good loss function for heuristic explanations should push for quality only where it is relevant to the behavior at hand.
- Cherry-picking: if we use a heuristic explanation to estimate something (as in low probability estimation), we need to make sure that the way in which we find the explanation doesn't systematically bias the estimate.
- Form of representation: one form that a heuristic explanation could take is of an "activation model", i.e. a probability distribution over a model's internal activations. However, we may also need to represent explanations that do not correspond to any particular probability distribution.
- Formal desiderata: we can attempt to formalize heuristic explanations by considering properties that we think they should satisfy, and seeing if those properties can be satisfied.
- No-coincidence principle: in order for heuristic explanations to work in the worst case, we need every possible behavior to be amenable to explanation. We sometimes refer to this desideratum as the "no-coincidence principle" (a term taken from this paper). Counterexamples to this principle could present obstacles to our approach.
- Empirical regularities: some model weights may have no explanation beyond being tuned to match some empirical average, either because the input distribution is defined empirically, or because of an emergent regularity in a formally-defined system (such as the relative value of a queen and a pawn in chess). A good notion of heuristic explanations should be able to deal with these.
Conclusion
We have painted a high-level picture of ARC's research, explained how our published research fits into it, and briefly discussed some additional subproblems that we are working on. We hope this provides people with a clearer sense of what we are up to.
An arrow in the diagram expresses that solving one problem should help solve another, but it varies from case to case whether subproblems combine "conjunctively" (all subproblems need to be solved to solve the main problem) or "disjunctively" (a solution to any subproblem can be used to solve the main problem). ↩︎
The term "alignment robustness" comes from this summary [AF · GW] of this post [AF · GW], and is synonymous with "objective robustness" in the terminology of this post [AF · GW]. A slightly more formal variant is "high-stakes alignment", as defined in this post. ↩︎
12 comments
Comments sorted by top scores.
comment by Dmitry Vaintrob (dmitry-vaintrob) · 2024-10-23T20:04:47.845Z · LW(p) · GW(p)
I think this is a really good and well-thought-out explanation of the agenda.
I do still think that it's missing a big piece: namely in your diagram, the lowest-tier dot (heuristic explanations) is carrying a lot of weight, and needs more support and better messaging. Specifically, my understanding having read this and interacted with ARC's agenda is that "heuristic arguments" as a direction is highly useful. But while it seems to me that the placement of heuristic arguments at the root of this ambitious diagram is core to the agenda, I haven't been convinced that this placement is supported by any results beyond somewhat vague associative arguments.
As an extreme example of this, Stephen Wolfram believes he has a collection of ideas building on some thinking about cellular automata that will describe all of physics. He can write down all kinds of causal diagrams with this node in the root, leading to great strides in our understanding of science and the cosmos and so on. But ultimately, such a diagram would be making the statement that "there exists a productive way to build a theory of everything which is based on cellular automata in a particular way similar to how he thinks about this theory". Note that this is different from saying that cellular automata are interesting, or even that a better theory of cellular automata would be useful for physics, and requires a lot more motivation and scientific falsification to motivate.
The idea of heuristic arguments is, at its core, a way of generalizing the notion of independence in statistical systems and models of statistical systems. It's discussing a way to point at a part of the system and say "we are treating this as noise" or "we are treating these two parts as statistically independent", or "we are treating these components of the system as independently as we can, given the following set of observations about our system" (with a lot of the theory of HA asking how to make the last of these statements explicit/computable). I think this is a productive class of questions to think about, both theoretically and empirically. It's related to a lot of other research in the field (on causality, independence and so on). I conceptually vibe with ARC's approach from what I've seen of the org. (Modulo the corrigible fact that I think there should be a lot more empirical work on what kinds of heuristic arguments work in practice. For example what's the right independence assumption on components of an image classifier/ generator NN that notices/generates the kind of textural randomness seen in a cat's fur? So far there is no HA guess about this question, and I think there should be at least some ideas on this level for the field to have a healthy amount of empiricism.)
I think that what ARC is doing is useful and productive. However, I don't see strong evidence that this particular kind of analysis is a principled thing to put at the root of a diagram of this shape. The statement that we should think about and understand independence is a priori not the same as the idea that we should have a more principled way of deciding when one interpretation of a neural net is more correct than another, which is also separate from (though plausibly related to) the (I think also good) idea in MAD/ELK that it might be useful to flag NN's that are behaving "unusually" without having a complete story of the unusual behavior.
I think there's an issue with building such a big structure on top of an undefended assumption, which is that it is creates some immissibility (i.e., difficulty of mixing) with other ideas in interpretability, which are "story-centric". The phenomena that happen in neural nets (same as phenomena in brains, same as phenomena in realistic physical systems) are probably special: they depend on some particular aspects of the world/ of reasoning/ of learning that has some sophisticated moving parts that aren't yet understood (some standard guesses are shallow and hierarchical dependence graphs, abundance of rough symmetries, separation of scale-specific behaviors, and so on). Our understanding will grow by capturing these ideas in terms of suitably natural language and sophistication for each phenomenon.
[added in edit] In particular (to point at a particular formalization of the general critique), I don't think that there currently exists a defendable link between Heuristic Arguments and the proof verification as in Jason Gross's excellent paper. The specific weakening of the notion of proof verification is more general interpretability. Your post on surprise accounting [AF · GW], is also excellent, but it doesn't explain how heuristic arguments would lead to understanding systems better -- rather, it shows that if we had ways of making better independence assumptions about systems with an existing interpretation, we would get a useful way of measuring surprise and explanatory robustness (with proof a maximally robust limit). But I think that drawing the line from seeking explanations with some nice properties/ measurements to the statement that a formal theory of such properties would lead to an immediate generalization of proof/interpretability which is strictly better than the existing "story-centric" methods is currently undefended (similar to the story that some early work on causality in interp had that a good attempt to formalize and validate causal interpretations would lead to better foundations of interp. -- the techniques are currently used productively e.g. here, but as an ingredient of an interpretation analysis rather than the core of the story). I think similar critiques hold for other sufficiently strong interpretations of the other arrows in this post. Note that while I would support a weaker meaning of arrows here (as you suggest in a footnote), there is nevertheless a core implicit assumption that the diagram exists as a part of a coherent agenda that deduces ambitious conclusions from a quite specific approach to interpretability. I could see any of the nodes here as being a part of a reasonable agenda that integrates with mechanistic interpretability more generally, but this is not the approach that ARC has followed.
I think that the issue of the approach sketched here is that it overindexes on a particular shape of explanation -- namely, that the most natural way to describe the relevant details inherent in principled interpretability work will most naturally factorize through a language that grows out of better-understanding independence assumptions in statistical modeling. I don't see much evidence for this being the case, any more than I see evidence that the best theory of physics should grow out of a particular way of seeing cellular automata (and I'd in fact bet with some confidence that this is not true in both of these cases). At the same time I think that ARC ideas are good, and that trying to relate them to other work in interp is productive (I'm excited about the VAE draft in particular). I just would like to see a less ambitious, more collaboratively motivated version of this, which is working on improving and better validating the assumptions one could make as part of mechanistic/statistical analysis of a model (with new interpretability/MAD ideas as a plausible side-effect) rather than orienting towards a world where this particular direction is in some sense foundational for a "universal theory of interpretability".
Replies from: Jacob_Hilton↑ comment by Jacob_Hilton · 2024-10-24T18:26:29.678Z · LW(p) · GW(p)
Thank you – this is probably the best critique of ARC's research agenda that I have read since we started working on heuristic explanations. This level of thoughtfulness in external feedback is very rare and I'm grateful for the detail and clarity you put into it. I don't think my response fully rebuts your central concern, but hopefully it gives a sense of my current thinking about it.
It sounds like we are in agreement that something very loosely heuristic explanation-flavored (interpreted so broadly as to include mechanistic interpretability, for example) can reasonably be placed at the root of the diagram, by which I mean that it's productive to try to explain neural network behaviors in this very loose sense, attempt to apply such explanations to downstream applications such as MAD/LPE/ELK etc. We begin to diverge, I think, about the extent to which ARC should focus on a more narrow conception of heuristic explanations. From least to most specific:
- Any version that is primarily mathematical rather than "story-centric"
- Some (mathematical) version that is consistent with our information-theoretic intuitions about what constitutes a valid explanation (i.e., in the sense of something like surprise accounting)
- Some such version that is loosely based on independence assumptions
- Some version that satisfies more specific desiderata for heuristic estimators (such as the ones discussed in the paper linked in (3), or in this more recent paper)
Opinions at ARC will differ, but (1) I feel pretty comfortable defending, (2) I think is quite a promising option to be considering, (3) seems like a reasonable best guess but I don't think we should be that wedded to it, and (4) I think is probably too specific (and with the benefit of hindsight I think we have focused too much on this in the past). ARC's research has actually been trending in the "less specific" direction over time, as should hopefully be evident from our most recent write-ups (with the exception of our recent paper on specific desiderata, which mostly covers work done in 2023), and I am quite unsure exactly where we should settle on this axis.
By contrast, my impression is that you would not really defend even (1) (although I am curious exactly where you come down this axis, if you want to clarify). So I'll give what I see as the basic case for searching for a mathematical rather than a "story-centric" approach:
- Mechanistic interpretability has so far yielded very little in the way of beating baselines at downstream tasks (this has been discussed at length elsewhere, see for example here, here [LW · GW] and here [LW(p) · GW(p)]), so I think it should still be considered a largely unproven approach (to be clear, this is roughly my view of all alignment approaches that aren't already in active use at labs, including ARC's, and I remain excited to see people's continued valiant attempts; my point is that the bar is low and a portfolio approach is appropriate).
- Relying purely on stories clearly doesn't work at sufficient scale under worst-case assumptions (because the AI will have concepts you don't have words for), and there isn't a lot of evidence that this isn't indeed already a bottleneck in practice (i.e., current AIs may well already have concepts you don't have words for).
- I think that ARC's worst-case, theoretical approach (described at zoom level 1) is an especially promising alternative to iterative, empirically-driven work. I think empirical approaches are more promising overall, but have correlated failure modes (namely, they could end up relying on correlated empirical contingencies that later turn out to be false), and have far more total effort going into them (arguably disproportionately so). Conditional on taking such an approach, story-centric methods don't seem super viable (how should one analyze stories theoretically?).
- I don't really buy the argument that because a system has a lot of complexity, it can only be analyzed in ad-hoc ways. It seems to me that an analogous argument would have failed to make good predictions about the bitter lesson (i.e., by arguing that a simple algorithm like SGD should not be capable of producing great complexity in a targeted way). Instead, because neural nets are trained in an incremental, automated way based on mathematical principles, it seems quite possible to me that we can find explanations for them in a similar way (which is not an argument that can be applied to biological brains).
This doesn't of course defend (2)–(4) (which I would only want to do more weakly in any case). We've tried to get our intuitions for those across in our write-ups (as linked in (2)–(4) above), but I'm not sure there's anything succinct I can add here if those were unconvincing. I agree that puts us in the rather unfortunate position of sharing a reference class with Stephen Wolfram to many external observers (although hopefully our claims are not quite so overstated).
I think it's important for ARC to recognize this tension, and to strike the right balance between making our work persuasive to external skeptics on the one hand, and having courage in our convictions on the other hand (I think both have been important virtues in scientific development historically). Concretely, my current best guess is that ARC should:
- (a) Avoid being too wedded to intuitive desiderata for heuristic explanations that we can't directly tie back to specific applications
- (b) Search for concrete cases that put our intuitions to the test, so that we can quickly reach a point where either we no longer believe in them, or they are more convincing to others
- (c) Also pursue research that is more agnostic to the specific form of explanation, such as work on low probability estimation or other applications
- (d) Stay on the lookout for ideas from alternative theoretical approaches (including singular learning theory, sparsity-based approaches, computational mechanics, causal abstractions, and neural net-oriented varieties of agent foundations), although my sense is that object-level intuitions here just differ enough that it's difficult to collaborate productively. (Separately, I'd argue that proponents of all these alternatives are in a similar predicament, and could generally be doing a better job on analogous versions of (a)–(c).)
I think we have been doing all of (a)–(d) to some extent already, although I imagine you would argue that we have not been going far enough. I'd be interested in more thoughts on how to strike the right balance here.
Replies from: dmitry-vaintrob↑ comment by Dmitry Vaintrob (dmitry-vaintrob) · 2024-10-26T22:56:57.559Z · LW(p) · GW(p)
Thank you for the great response, and the (undeserved) praise of my criticism. I think it's really good that you're embracing the slightly unorthodox positions of sticking to ambitious convictions and acknowledging that this is unorthodox. I also really like your (a)-(d) (and agree that many of the adherents of the fields you list would benefit from similar lines of thinking).
I think we largely agree, and much of our disagreement probably boils down to where we draw the boundary between “mechanistic interpretability” and “other”. In particular, I fully agree with the first zoom level in your post, and with the causal structure of much of the rest of the diagram -- in particular, I like your notions of alignment robustness and mechanism distinction (the latter of which I think is original to ARC) and I think they may be central in a good alignment scenario. I also think that some notion of LPE should be present. I have some reservations about ELK as ARC envisions it (also of the “too much backchaining” variety), but think that the first-order insights there are valuable.
I think the core cruxes we have are:
-
You write "Mechanistic interpretability has so far yielded very little in the way of beating baselines at downstream tasks". If I understand this correctly, you're saying it hasn't yet led to engineering improvements, either in capabilities or in "prosaic alignment" (at least compared to baselines like RLHF or "more compute").
While I agree with this, I think that this isn't the right metric to apply. Indeed if you applied this metric, most science would not count as progress. Darwin wouldn’t get credit until his ideas got used to breed better crops and Einstein’s relativity would count as unproductive until the A-bomb (and the theory-application gap is much longer if you look at early advances in math and physics). Rather, I think that the question to ask is whether mechinterp (writ large, and in particular including a lot of people working in deep learning with no contact with safety) has made progress in understanding the internal functioning of AI or made nontrivially principled and falsifiable predictions about how it works. Here we would probably agree that the answer is pretty unambiguous. We have strong evidence that interesting semantic features exist in superposition (whether or not this is the way that the internal mechanisms use them). We understand the rough shape of some low-level circuits that do arithmetic and copying, and have rough ideas of the shapes of some high-level mechanisms (e.g. “function vectors”). To my eyes, this should count as progress in a very new science, and if I correctly understood your claim to be that you need to “beat black-box methods at useful tasks” to count as progress, I think this is too demanding.
-
I think that I’m onboard with you on your desideratum #1 that theories should be “primarily mathematical” – in the sense that I think our tastes for rigor and principled theoretical science are largely aligned (and we both agree that we need good and somewhat fundamental theoretical principles to avoid misalignment). But math isn’t magic. In order to get a good mathematical tool for a real-world context, you need to make sure that you have correctly specified the context where it is to be applied, and more generally that you’ve found the “right formal context” for math. This makes me want to be careful about context before moving on to your insight #2 of trying to guess a specific information-theoretic criterion for how to formalize "an interpretation". Math is a dance, not a hammer: if a particular application of math isn’t working, it’s more likely that your context is wrong and you need to retarget and work outwards from simple examples, rather than try harder and route around contradictions. If you look at even a very mathy area of science, I would claim that most progress did not come from trying to make a very ambitious theoretical picture work and introducing epicycles in a “builder-breaker” fashion to get around roadblocks. For example if you look at the most mathematically heavy field that has applications in real life, this is QFT and SFT (which uses deep algebraic and topological insights and today is unquestionably useful in computer chips and the like). Its origin comes from physicists observing the idea of “universality” in some physical systems, and this leading Landau and others to work out that a special (though quite large and perturbation-invariant) class of statistical systems can be coarse-grained in a way that leads to these observed behaviors, and this led to ideas of renormalization, modern QFT and the like. If Landau’s generation instead tried to work really hard on mathematically analyzing general magnet-like systems without working up from applications and real-world systems, they’d end up in roughly the same place as Stephen Wolfram of trying to make overly ambitious claims about automata. The importance of looking for good theory-context fit is the main reason I would like to see more back-and-forth between more “boots-on-the-ground” interpretability theorists and more theoretical agendas like ARC and Agent Foundations. I’m optimistic that ARC’s mathematical agenda will eventually start iterating on carefully thinking about context and theory-context fit, but I think that some of the agenda I saw had the suboptimal, “use math as a hammer” shape. I might be misunderstanding here, and would welcome corrections.
-
More specifically about “stories”, I agree with you that we are unlikely to be able to tell an easy-to-understand story about the internal working of AI’s (and in particular, I am very onboard with your first-level zoom of scalable alignment). I agree that the ultimate form of the thing we’re both gesturing at in the guise of “interpretability” will be some complicated, fractally recursive formalism using a language we probably don’t currently possess. But I think this is sort of true in a lot of other science. Better understanding leads to formulas, ideas and tools with a recursive complexity that humanity wouldn’t have guessed at before discovering them (again, QFT/SFT is an example). I’m not saying that this means “understanding AI will have the same type signature as QFT/ as another science”. But I am saying that the thing it will look like will be some complicated novel shape that isn’t either modern interp or any currently-accessible guess at its final form. And indeed, if it does turn out to take the shape of something that we can guess today – for example if heuristic arguments or SAEs turn out to be a shot in the right direction – I would guess that the best route towards discovering this is to build up a pluralistic collection of ideas that both iterate on creating more elegant/more principled mathematical ideas and iterate on understanding iteratively more interesting pieces of iteratively more general ML models in some class that expands from toy or real-world models. The history of math also does include examples of more "hammer"-like people: e.g. Wiles and Perelman, so making this bet isn't necessarily bad, and my criticism here should not be taken too prescriptively. In particular, I think your (a)-(d) are once again excellent guardrails against dangerous rabbitholes or communication gaps, and the only thing I can recommend somewhat confidently is to keep applicability to get interesting results about toy systems as a desideratum when building up the ambitious ideas.
Going a bit meta, I should flag an important intuition that we likely diverge on. I think that when some people defend using relatively formal math or philosophy to do alignment, they are going off of the following intuition:
-
if we restrict to real-world systems, we will be incorporating assumptions about the model class
-
if we assume these continue to hold for future systems by default, we are assuming some restrictive property remains true in complicated systems despite possible pressure to train against it to avoid detection, or more neutral pressures to learn new and more complex behaviors which break this property.
-
alternatively, if we try to impose this assumption externally, we will be restricting ourselves to a weaker, “understandable” class of algorithms that will be quickly outcompeted by more generic AI.
The thing I want to point out about this picture is that this models the assumption as closed. I.e., that it makes some exact requirement, like that some parameter is equal to zero. However, many of the most interesting assumptions in physics (including the one that made QFT go brrr, i.e., renormalizability) are open. I.e., they are some somewhat subtle assumptions that are perturbation-invariant and can’t be trained out (though they can be destroyed – in a clearly noticeable way – through new architectures or significant changes in complexity). In fact, there’s a core idea in physical theory, that I learned from some lecture notes of Ludvig Faddeev here, that you can trace through the development of physics as increasingly incorporating systems with more freedoms and introducing perturbations to a physical system starting with (essentially) classical fluid mechanics and tracing out through quantum mechanics -> QFT, but always making sure you’re considering a class of systems that are “not too far” from more classical limits. The insight here is that just including more and more freedom and shifting in the directions of this freedom doesn’t get you into the maximal-complexity picture: rather, it gets you into an interesting picture that provably (for sufficiently small perturbations) allows for an interesting amount of complexity with excellent simplifications and coarse-grainings, and deep math.
Phrased less poetically, I’m making a distinction between something being robust and making no assumptions. When thinking mathematically about alignment, what we need is the former. In particular, I predict that if we study systems in the vicinity of realistic (or possibly even toy) systems, even counting on some amount of misalignment pressure, alien complexity, and so on, the pure math we get will be very different – and indeed, I think much more elegant – than if we impose no assumptions at all. I think that someone with this intuition can still be quite pessimistic, can ask for very high levels of mathematical formalism, but will still expect a very high amount of insight and progress from interacting with real-world systems.
Replies from: ryan_greenblatt, Jacob_Hilton↑ comment by ryan_greenblatt · 2024-10-27T01:01:36.795Z · LW(p) · GW(p)
Somewhat off-topic, but isn't this a non-example:
We have strong evidence that interesting semantic features exist in superposition
I think a more accurate statement would be "We have a strong evidence that neurons don't do a single 'thing' (either in the human ontology or in any other natural ontology)" combined with "We have a strong evidence that the residual stream represents more 'things' than it has dimensions".
Aren't both of these what people would (and did) predict without needing to look at models at all?[1] As in both of these are the null hypothesis in a certain sense. It would be kinda specific if neurons did do a single thing and we can rule out 1 "thing" per dimension in the residual stream via just noting that Transformers work at all.
I think there are more detailed models of a more specific thing called "superposition" within toy models, but I don't think we have strong evidence of any very specific claim about larger AIs.
(SAE research has shown that SAEs often find directions which seem to at least roughly correspond to concepts that humans have and which can be useful for some methods, but I'm don't think we can make a much stronger claim at this time.)
In fact, I think that mech interp research was where the hypothesis "maybe neurons represent a single thing and we can understand neurons quite well (mostly) in isolation" was raised. And this hypothesis seems to look worse than a more default guess about NNs being hard to understand and there not being an easy way to decompose them into parts for analysis. ↩︎
↑ comment by Dmitry Vaintrob (dmitry-vaintrob) · 2024-10-27T01:23:02.468Z · LW(p) · GW(p)
I basically agree with you. But I think we have some nontrivial information, given enough caveats.
I think there are four hypotheses:
- 1a. Neurons do >1 thing (neuron polysemanticity)
- 1b. Insofar as we can find interesting atomic semantic features, they have >1 neuron (feature polysemanticity)
- 2a. Features are sparse, i.e., (insofar as there exist interesting atomic semantic features), most have significantly <1/2 probability of being "on" for any input
- 2b. Features are superpositional, i.e., (insofar as there exist interesting atomic semantic features), there are significantly more than dimension-many of them at any layer.
I think 1a/b and 2a/b are different in subtle ways, but most people would agree that in a rough directional yes/no sense, 1a<=>1b and 2a<=>2b (note that 2a=>2b requires some caveats -- but at the limit of lots of training in a complex problem with #training examples >= #parameters, if you have sparsity of features, it simply is inefficient to not have some form of superposition). I also agree that 1a/1b are a natural thing to posit a priori, and in fact it's much more surprising to me as someone coming from math that the "1 neuron:1 feature" hypothesis has any directional validity at all (i.e., sometimes interesting features are quite sparse in the neuron basis), rather than that anything that looks like a linear feature is polysemantic.
Now to caveat my statement: I don't think that neural nets are fully explained by a bunch of linear features, much less by a bunch of linear features in superposition. In fact, I'm not even close to100% on superposition existing at all in any truly "atomic" decomposition of computation. But at the same time we can clearly find semantic features which have explanatory power (in the same way that we can find pathways in biology, even if they don't correspond to any structures on the fundamental, in this case cellular, level).
And when I say that "interesting semantic features exist in superposition", what I really mean is that we have evidence for hypothesis 2a [edited, originally said 2b, which is a typo]. Namely, when we're looking for unsupervised ways to get such features, it turns out that enforcing sparsity (and doing an SAE) gives better interp scores than doing PCA. I think this is pretty strong evidence!
Replies from: ryan_greenblatt, dmitry-vaintrob↑ comment by ryan_greenblatt · 2024-10-27T02:29:05.706Z · LW(p) · GW(p)
it turns out that enforcing sparsity (and doing an SAE) gives better interp scores than doing PCA
It's not clear to me this is true exactly. As in, suppose I want to explain as much of what a transformer is doing as possible with some amount of time. Would I better off looking at PCA features vs SAE features?
Yes, most/many SAE features are easier to understand than PCA features, but each SAE feature (which is actually sparse) is only a tiny, tiny fraction of what the model is doing. So, it might be that you'd get better interp scores (in terms of how much of what the model is doing) with PCA.
Certainly, if we do literal "fraction of loss explained by human written explanations" both PCA and SAE recover approximately 0% of training compute.
I do think you can often learn very specific more interesting things with SAEs and for various applications SAEs are more useful, but in terms of some broader understanding, I don't think SAEs clearly are "better" than PCA. (There are also various cases where PCA on some particular distribution is totally the right tool for the job.)
Certainly, I don't think it has been shown that we can get non-negligible interp scores with SAEs.
To be clear, I do think we learn something from the fact that SAE features seem to often/mostly at least roughly correspond to some human concept, but I think the fact that there are vastly more SAE features vs PCA features does matter! (PCA was never trying to decompose into this many parts.)
Replies from: dmitry-vaintrob↑ comment by Dmitry Vaintrob (dmitry-vaintrob) · 2024-10-27T02:45:03.095Z · LW(p) · GW(p)
Yes - I generally agree with this. I also realized that "interp score" is ambiguous (and the true end-to-end interp score is negligible, I agree), but what's more clearly true is that SAE features tend to be more interpretable. This might be largely explained by "people tend to think of interpretable features as branches of a decision tree, which are sparsely activating". But also like it was surprising to me that the top SAE features are significantly more interpretable than top PCA features
↑ comment by Dmitry Vaintrob (dmitry-vaintrob) · 2024-10-27T01:54:20.419Z · LW(p) · GW(p)
So to elaborate: we get significantly more interpretable features if we enforce sparsity than if we just do more standard clustering procedures. This is nontrivial! Of course this might be saying more about our notions of "interpretable feature" and how we parse semantics; but I can certainly imagine a world where PCA gives much better results, and would have in fact by default expected this to be true for the "most important" features even if I believed in superposition.
So I'm somewhat comfortable saying that the fact that imposing sparsity works so well is telling us something. I don't expect this to give "truly atomic" features from the network's PoV (any more than understanding Newtonian physics tells us about the standard model), but this seems like nontrivial progress to me.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-10-27T02:32:23.958Z · LW(p) · GW(p)
I do think this was reasonably though not totally predictable ex-ante, but I agree.
↑ comment by Jacob_Hilton · 2024-10-28T16:39:50.690Z · LW(p) · GW(p)
It sounds like we are not that far apart here. We've been doing some empirical work on toy systems to try to make the leap from mechanistic interpretability "stories" to semi-formal heuristic explanations. The max-of-k draft is an early example of this, and we have more ambitious work in progress along similar lines. I think of this work in a similar way to you: we are not trying to test empirical assumptions (in the way that some empirical work on frontier LLMs is, for example), but rather to learn from the process of putting our ideas into practice.
comment by Ruby · 2024-10-27T17:24:03.213Z · LW(p) · GW(p)
Curated! I think it's generally great when people explain what they're doing and why in way legibile to those not working on it. Great because it let's others potentially get involved, build on it, expose flaws or omissions, etc. This one seems particularly clear and well written. While I haven't read all of the research, nor am I particularly qualified to comment on it, I like the idea of a principled/systematic approach behind, in comparison to a lot of work that isn't coming on a deeper, bigger, framework.
(While I'm here though, I'll add a link to Dmitry Vaintrob's comment [LW(p) · GW(p)] that Jacob Hilton described as "best critique of ARC's research agenda that I have read since we started working on heuristic explanations". Eliciting such feedback is the kind of good thing that comes out of up writing agendas – it's possible or likely Dmitry was already tracking the work and already had these critiques, but a post like this seems like a good way to propagate them and have a public back and forth.)
Roughly speaking, if the scalability of an algorithm depends on unknown empirical contingencies (such as how advanced AI systems generalize), then we try to make worst-case assumptions instead of attempting to extrapolate from today's systems.
I like this attitude. The human standard, I think often in alignment work too, is to argue why one's plan will work and find stories for that, and adopting the methodology of the opposite, especially given the unknowns, is much needed in alignment work.
Overall, this is neat. Kudos to Jacob (and rest of the team) for taking the time to put this all together. Doesn't seem all that quick to write, and I think it'd be easy to think they ought to not take time out off from further object-level research to write it. Thanks!
comment by Charlie Steiner · 2024-10-24T15:34:25.233Z · LW(p) · GW(p)
Thanks for the detailed post!
I personally would have liked to see some mention of the classic 'outer' alignment questions that are subproblems of robustness and ELK. E.g. What counts as 'generalizing correctly'? -> How do you learn how humans want the AI to generalize? -> How do you model humans as systems that have preferences about how to model them?