Causal scrubbing: Appendix
post by LawrenceC (LawChan), Adrià Garriga-alonso (rhaps0dy), Nicholas Goldowsky-Dill (nicholas-goldowsky-dill), ryan_greenblatt, jenny, Ansh Radhakrishnan (anshuman-radhakrishnan-1), Buck, Nate Thomas (nate-thomas) · 2022-12-03T00:58:45.850Z · LW · GW · 4 commentsContents
1 More on Hypotheses 1.1 Example behaviors 1.2 Extensional equality, and common rewrites of G and I 1.3 Interpretations at multiple levels of specificity 2 What metric should causal scrubbing use? 2.1 “Percentage of loss recovered” as a measure of hypothesis quality 2.2 Why not compare the full distribution, rather than expectations? 3 Further discussion of zero and mean ablation 1) Zero and mean ablations take your model off distribution in an unprincipled manner. 2) Zero and mean ablations can have unpredictable effects on measured performance. 3) Zero and mean ablations remove variation that your model might depend on for performance. 4 Unimportant inputs and isomorphic hypotheses 4.1 Should unimportant inputs be taken from the same or different datapoints? 4.2 Including unimportant inputs in the hypothesis 5 An alternative formalism: constructing a distribution on treeified inputs 6 How causal scrubbing handles polysemanticity 6.1 Underestimating interference by neglecting correlations in model errors 7 An additional example of approving a false hypothesis 8 Adversarial validation might be able to elicit true hypotheses None 4 comments
* Authors sorted alphabetically.
An appendix to this post [LW · GW].
1 More on Hypotheses
1.1 Example behaviors
As mentioned above, our method allows us to explain quantitatively measured model behavior operationalized as the expectation of a function on a distribution .
Note that no part of our method distinguishes between the part of the input or computational graph that belongs to the “model” vs the “metric.”[1]
It turns out that you can phrase a lot of mechanistic interpretability in this way. For example, here are some results obtained from attempting to explain how a model has low loss:
- Nanda and Lieberum’s analysis of the structure of a model that does modular addition [AF · GW] explains the observation that their model gets low loss on the validation dataset.
- The indirect object identification circuit explains the observation that the model gets low loss on the indirect object identification task, as measured on a synthetic distribution.
- Induction circuits (as described in Elhage et al. 2021) explain the observation that the model gets low loss when predicting tokens that follow the heuristic: “if AB has occurred before, then A is likely to be followed by B”.
That being said, you can set up experiments using other metrics besides loss as well:
- Cammarata et al identify curve detectors in the Inception vision model by using the response of various filters on synthetic datasets to explain the correlation between: 1) the activation strength of some neuron, and 2) whether the orientation of an input curve is close to a reference angle.
1.2 Extensional equality, and common rewrites of and
If you’re trying to explain the expectation of , we always consider it a valid move to suggest an alternative function if on every input (“extensional equality”), and then explain instead. In particular, we’ll often start with our model’s computational graph and a simple interpretation, and then perform “algebraic rewrites” on both graphs to naturally specify the correspondence.
Common rewrites include:
- When the output of a single component of the model is used in different ways by different paths, we’ll duplicate that node in , such that each copy can correspond to a different part of .
- When multiple components of the model compute a single feature we can either:
- duplicate the node in , to sample the components separately; or
- combine the nodes of into a single node, to sample the components together.
- Sometimes, we want to test claims of the form “this subspace of the activation contains the feature of interest”. We can express this by rewriting the output as a sum of the activation projected into subspace and the orthogonal component. We can then propose that only the projected subspace encodes the feature.
- An even more complicated example is when we want to test a theorized function that maps from an input to a predicted activation of a component. We can then rewrite the output as the sum of two terms: and the residual (the error of the estimate), and then claim only the phi term contains important information. If your estimate is bad, the error term will be large in important ways. This is especially useful to test hypotheses about scalar quantities (instead of categorical ones).[2]
Note that there are many trivial or unenlightening algebraic rewrites. For example, you could always replace f’ with a lookup table of f, and in cases where the model performs perfectly, you can also replace f with the constant zero function. Causal scrubbing is not intended to generate mechanistic interpretations or ensure that only mechanistic interpretations are allowed, but instead to check that a given interpretation is faithful. We discuss this more in the limitations [LW · GW] section of the main post.
1.3 Interpretations at multiple levels of specificity
We allow hypotheses at a wide variety of levels of specificity. For example, here are two potential interpretations of the same :
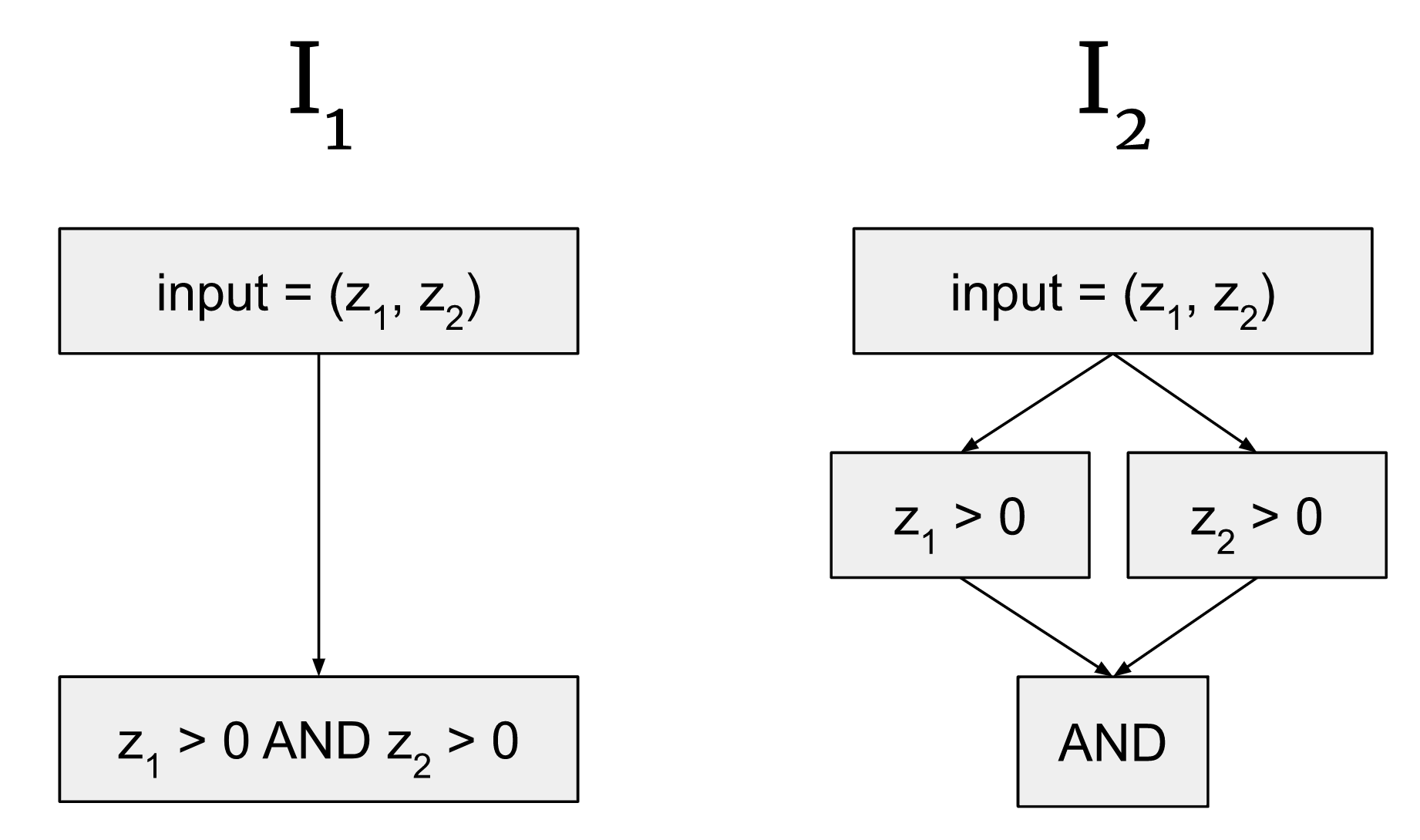
These interpretations correspond to the same input-output mappings, but the hypothesis on the right is more specific, because it's saying that there are three separate nodes in the graph expressing this computation instead of one. So when we construct to correspond to we would need three different activations that we claim are important in different ways, instead of just one for mapping to . In interpretability, we all-else-equal prefer more specific explanations, but defining that is out of scope here–we’re just trying to provide a way of looking at the predictions made by hypotheses, rather than expressing any a priori preference over them.
2 What metric should causal scrubbing use?
2.1 “Percentage of loss recovered” as a measure of hypothesis quality
In both of these results posts, in order to measure the similarity between the scrubbed and unscrubbed models, we use % loss recovered.
As a baseline we use , the ‘randomized loss’, defined as the loss when we shuffle the connection between the correct labels and the model’s output. Note this randomized loss will be higher than the loss for a calibrated guess with no information. We use randomized loss as the baseline since we are interested in explaining why the model makes the guesses it makes. If we had no idea, we could propose the trivial correspondence that the model’s inputs and outputs are unrelated, for which .
Thus we define:
This percentage can exceed 100% or be negative. It is not very meaningful as a fraction, and is rather an arithmetic aid for comparing the magnitude of expected losses under various distributions. However, it is the case that hypotheses with a “% loss recovered” closer to 100% result in predictions that are more consistent with the model.
2.2 Why not compare the full distribution, rather than expectations?
Above, we rate our hypotheses using the distance between the expectation under the dataset and the scrubbed distribution, .[3]
You could instead rate hypotheses by comparing the full distribution of input-output behavior. That is, the difference between the distribution of the random variable under the data set , and under .
In this work, we prefer the expected loss. Suppose that one of the drivers of the model’s behavior is noise: trying to capture the full distribution would require us to explain what causes the noise. For example, you’d have to explain the behavior of a randomly initialized model despite the model doing ‘nothing interesting’.
3 Further discussion of zero and mean ablation
Earlier, we noted our preference for “resampling ablation” of a component of a model (patch an activation of that component from a randomly selected input in the dataset) over zero or mean ablation of that component (set that component’s activation to 0 or its mean over the entire dataset, respectively) in order to test the claim “this component doesn’t matter for our explanation of the model”. We also mentioned three specific problems we see with using zero or mean ablation to test this claim. Here, we’ll discuss these problems in greater detail.
1) Zero and mean ablations take your model off distribution in an unprincipled manner.
The first problem we see with these ablations is that they destroy various properties of the distribution of activations in a way that seems unprincipled and could lead to the ablated model performing either worse or better than it should.
As an informal argument, imagine we have a module whose activations are in a two dimensional space. In the picture below we’ve drawn some of its activations as gray crosses, the mean as a green cross, and the zero as a red cross:

It seems to us that zero ablating takes your model out of distribution in an unprincipled way. (If the model was trained with dropout, it’s slightly more reasonable, but it’s rarely clear how a model actually handles dropout internally.) Mean ablating also takes the model out of distribution because the mean is not necessarily on the manifold of plausible activations.
2) Zero and mean ablations can have unpredictable effects on measured performance.
Another problem is that these ablations can have unpredictable effects on measured performance. For example, suppose that you’re looking at a regression model that happens to output larger answers when the activation from this module is at its mean activation (which, let’s suppose, is off-distribution and therefore unconstrained by SGD). Also, suppose you’re looking at it on a data distribution where this module is in fact unimportant. If you’re analyzing model performance on a data subdistribution where the model generally guesses too high, then mean ablation will make it look like ablating this module harms performance. If the model generally guesses too low on the subdistribution, mean ablation will improve performance. Both of these failure modes are avoided by using random patches, as resampling ablation does, instead of mean ablation.
3) Zero and mean ablations remove variation that your model might depend on for performance.
The final problem we see with these ablations is that they neglect the variation in the outputs of the module. Removing this variation doesn’t seem reasonable when claiming that the module doesn't matter.
For an illustrative toy example, suppose we’re trying to explain the performance of a model with three modules M1, M2, and M3. This model has been trained with dropout and usually only depends on components M1 and M2 to compute its output, but if dropout is active and knocks out M2, the model uses M3 instead and can perform almost as well as if it were able to use M1 and M2.
If we zero/mean ablate M2 (assume mean 0), it will look like M2 wasn't doing anything at all and our hypothesis that it wasn't relevant will be seemingly vindicated. If instead we resample ablate M2, the model will perform significantly worse (exactly how much worse is dependent on exactly how the output of M2 is relevant to the final output).
This example, while somewhat unrealistic, hopefully conveys our concern here: sometimes the variation in the outputs of a component is important to your model and performing mean or zero ablation forces this component to only act as a fixed bias term, which is unlikely to be representative of its true contribution to the model’s outputs.
We think these examples provide sufficient reasons to be skeptical about the validity of zero or mean ablation and demonstrate our rationale for preferring resampling ablation.
4 Unimportant inputs and isomorphic hypotheses
4.1 Should unimportant inputs be taken from the same or different datapoints?
Suppose we have the following hypothesis where I maps to the nodes of G in blue:
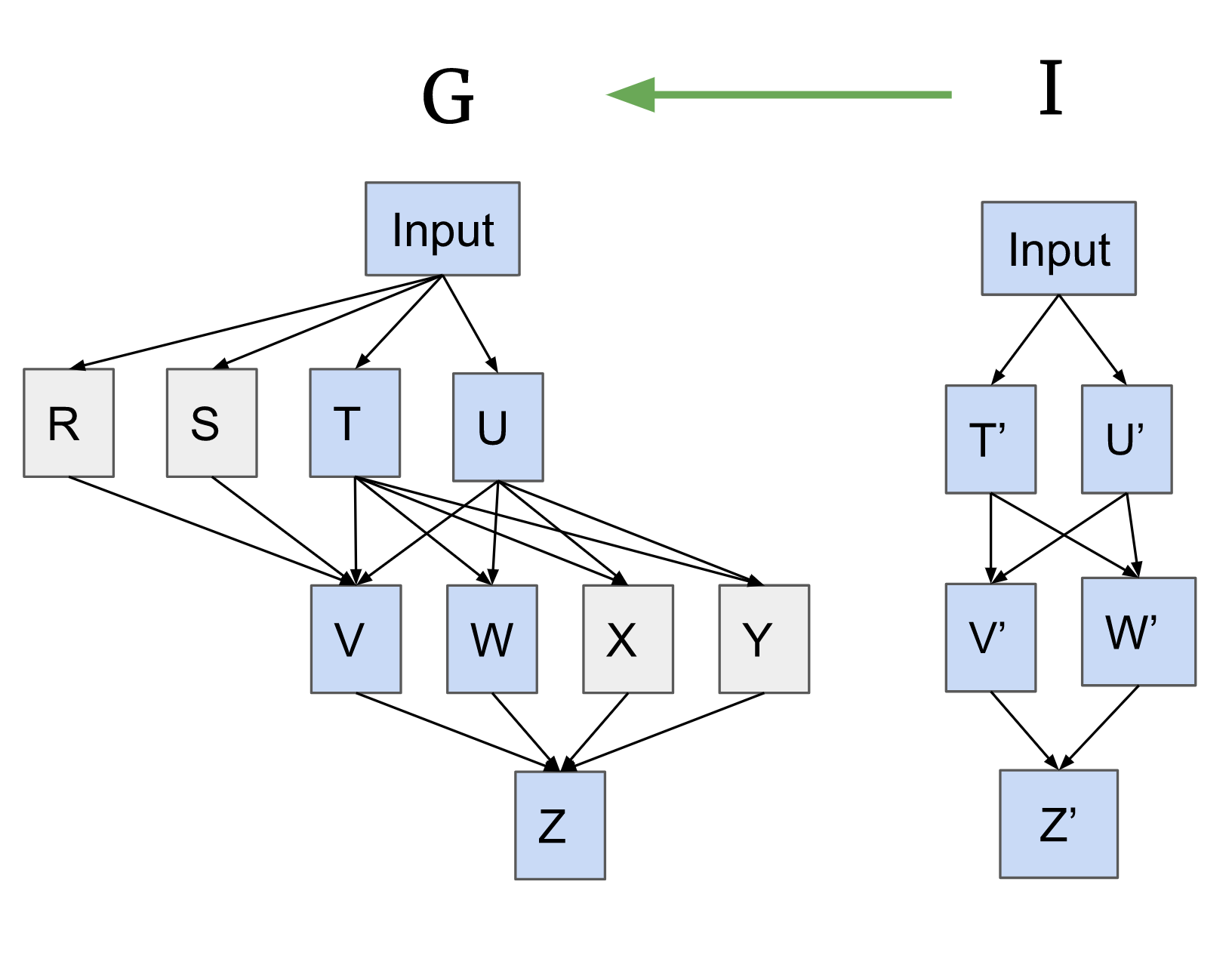
There are four activations in that we claim are unimportant.
Causal scrubbing requires performing a resampling ablation on these activations. When doing so, should we pick one data point to get all four activations on? Two different data points, one for R and S (which both feed into V) and a different one for X and Y? Or four different data points?
In our opinion, all are reasonable experiments that correspond to subtly different hypotheses. This may not be something you considered when proposing your informal hypothesis, but following the causal scrubbing algorithm forces you to resolve this ambiguity. In particular, the more we sample unimportant activations independently, the more specific the hypothesis becomes, because it allows you to make strictly more swaps. It also sometimes makes it easier for the experimenter to reason about the correlations between different inputs. For a concrete example where this matters, see the paren balance checker experiment.
And so, in the pseudocode above we sample the pairs (R, S) and (X, Y) separately, although we allow hypotheses that require all unimportant inputs throughout the model to be sampled together.[4]
Why not go more extreme, and sample every single unimportant node separately? One reason is that it is not well-defined: we can always rewrite our model to an equivalent one consisting of a different set of nodes, and this would lead to completely different sampling! Another is that we don’t actually intend this: we do believe it’s important that the inputs to our treeified model be “somewhat reasonable”, i.e. have some of the correlations that they usually do in the training distribution, though we’re not sure exactly which ones matter. So if we started from saying that all nodes are sampled separately, we’d immediately want to hypothesize something about them needing to be sampled together in order for our scrubbed model to not get very high loss. Thus this default makes it simpler to specify hypotheses.
4.2 Including unimportant inputs in the hypothesis
In general we don’t require hypotheses to be surjective, meaning not all nodes of need to be mapped onto by , nor do we require that contains all edges of . This is convenient for expressing claims that some nodes (or edges) of are unimportant for the behavior. It leaves a degree of freedom, however, in how to treat these unimportant nodes, as discussed in the preceding section.
It is possible to remove this ambiguity by requiring that the correspondence be an isomorphism between and . In this section we’ll demonstrate how to do this in a way that is consistent with the pseudocode presented, by combining all the unimportant parents of each important node.
In the example below, both R and S are unimportant inputs to the node V, and both X and Y are unimportant inputs to the node Z. We make the following rewrites in the example below:
- If a single important node has multiple unimportant inputs, we combine them. This forms the new node (X, Y) in G2. We also combine all upstream nodes, such that there is a single path from the input to this new combined node, forming (T, U) which (X, Y) depends on. This ensures we’ll only sample one input for all of them in the treeified model.
- We do the same for (R, S) into node V.
- Then we extend with new nodes to match the entirety of rewritten . For all of these new nodes that correspond to unimportant nodes (or nodes upstream of unimportant nodes), our interpretation says that all inputs map to a single value (the unit type). This ensures that we can sample any input.
- While we also draw the edges to match the structure of the rewritten , we will not have other nodes in be sensitive to the values of these unit nodes.

If you want to take a different approach to sampling the unimportant inputs, you can rewrite the graphs in a different way (for instance, keeping X and Y as separate nodes).
One general lesson from this is that rewriting the computational graphs and is extremely expressive. In practice, we have found that with some care it allows us to run the experiments we intuitively wanted to.
5 An alternative formalism: constructing a distribution on treeified inputs
Suppose we have a function to which we want to apply the causal scrubbing algorithm. Consider an isomorphic (see above [LW · GW]) treeified hypothesis for . In this appendix we will show that causal scrubbing preserves the joint distribution of inputs to each node of (Lemma 1). Then we show that the distribution of inputs induced by causal scrubbing is the maximum entropy distribution satisfying this constraint (Theorem 2).
Let be the domain of and be the input distribution for (a distribution on ). Let be the distribution given by the causal scrubbing algorithm (so the domain of is , where is the number of times that the input is repeated in ).
We find it useful to define two sets of random variables: one set for the values of wires (i.e. edges) in when is run on a consistent input drawn from (i.e. on for some ); and one set for the values of wires in induced by the causal scrubbing algorithm:
Definition (-consistent random variables): For all the edges of , we call the “-consistent random variable” the result of evaluating the interpretation on , for a random input . For each node , we will speak of the joint distribution of its input wires, and call the resulting random variable the “-consistent inputs (to )”. We also refer to the value of the wire going out of as the “-consistent output (to )”.
Definition (scrubbed random variables): Suppose that we run on . In the same way, this defines a set of random variables, which we call the scrubbed random variables (and use the terms "scrubbed inputs" and "scrubbed output" accordingly).
Lemma 1: For every node , the joint distribution of scrubbed inputs to is equal to the product distribution of -consistent inputs to .
Proof: Recall that the causal scrubbing algorithm assigns a datum in to every node of , starting from the root and moving up. The key observation is that for every node of , the distribution of the datum of is exactly . We can see this by induction. Clearly this is true for the root. Now, consider an arbitrary non-root node and assume that this claim is true for the parent of . Consider the equivalence classes on defined as follows: and are equivalent if has the same value at as when is run on each input. Then the datum of is chosen by sampling from subject to being in the same equivalence class as the datum of . Since (by assumption) the datum of is distributed according to , so is the datum of .
Now, by the definition of the causal scrubbing algorithm, for every node , the scrubbed inputs to are equal to the inputs to when is run on the datum of . Since the datum of is distributed according to , it follows that the joint distribution of scrubbed inputs to is equal to the joint distribution of -consistent inputs to .
Theorem 2: The joint distribution of (top-level) scrubbed inputs is the maximum-entropy distribution on , subject to the constraints imposed by Lemma 1.
Proof: We proceed by induction on a stronger statement: consider any way to "cut" through in a way that separates all of the inputs to from the root (and does so minimally, i.e. if any edge is un-cut then there is a path from some leaf to the root). (See below for an example.) Then the joint scrubbed distribution of the cut wires has maximal entropy subject to the constraints imposed by Lemma 1 on the joint distribution of scrubbed inputs to all nodes lying on the root's side of the cut.

Our base case is the cut through the input wires to the root (in which case Theorem 2 is vacuously true). Our inductive step will take any cut and move it up through some node , so that if previously the cut passed through the output of , it will now pass through the inputs of . We will show that if the original cut satisfies our claim, then so will the new one.
Consider any cut and let be the node through which we will move the cut up. Let denote the vector of inputs to , be the output of (so ), and denote the values along all cut wires besides . Note that and are independent conditional on ; this follows by conditional independence rules on Bayesian networks ( and are -separated by ).
Next, we show that this distribution is the maximum-entropy distribution. The following equality holds for *any* random variables such that is a function of :
Where is mutual information. The first step follows from the fact that is a function of . The second step follows from the identity . The third step follows from the identity that . The last step follows from the fact that , again because is a function of .
Now, consider all possible distributions of subject to the constraints imposed by Lemma 1 on the joint distribution of scrubbed inputs to all nodes lying on the root's side of the updated cut. The lemma specifies the distribution of and (therefore) . Thus, subject to these constraints, is equal to plus , which is a constant. By the inductive hypothesis, is as large as possible subject to the lemma's constraints. Mutual information is non-negative, so it follows that if , then is as large as possible subject to the aforementioned constraints. Since and are independent conditional on , this is indeed the case.
This concludes the induction. So far we have only proven that the joint distribution of scrubbed inputs is *some* maximum-entropy distribution subject to the lemma's constraints. Is this distribution unique? Assuming that the space of possible inputs is finite (which it is if we're doing things on computers), the answer is yes: entropy is a strictly concave function and the constraints imposed by the lemma on the distribution of scrubbed inputs are convex (linear, in particular). A strictly concave function has a unique maximum on a convex set. This concludes the proof.
Fun Fact 3: The entropy of the joint distribution of scrubbed inputs is equal to the entropy of the output of , plus the sum over all nodes of the information lost by (i.e. the entropy of the joint input to minus the entropy of the output). (By Lemma 1, this number does not depend on whether we imagine being fed -consistent inputs or scrubbed inputs.) By direct consequence of the proof of Theorem 2, we have (with as in the proof of Theorem 2). Proceeding by the same induction as in Theorem 2 yields this fact.
6 How causal scrubbing handles polysemanticity
In our polysemanticity toy model paper [AF · GW], we introduced an analytically tractable setting where the optimal model represents features in superposition. In this section, we’ll analyze this model using causal scrubbing, as an example of what it looks like to handle polysemantic activations.
The simplest form of this model is the two-variable, one-neuron case, where we have independent variables x1 and x2 which both have zero expectation and unit variance, and we are choosing the parameters c and d to minimize loss in the following setting:
Where is our model, and are the parameters we’re optimizing, and and are part of the task definition. As discussed in our toy model paper, in some cases (when you have some combination of a and b having similar values and and having high kurtosis (e.g. because they are usually equal to zero)), c and d will both be set to nonzero values, and so can be thought of as a superposed representation of both and .
To explain the performance of this model with causal scrubbing, we take advantage of function extensionality and expand y_tilde:
And then we explain it with the following hypothesis:
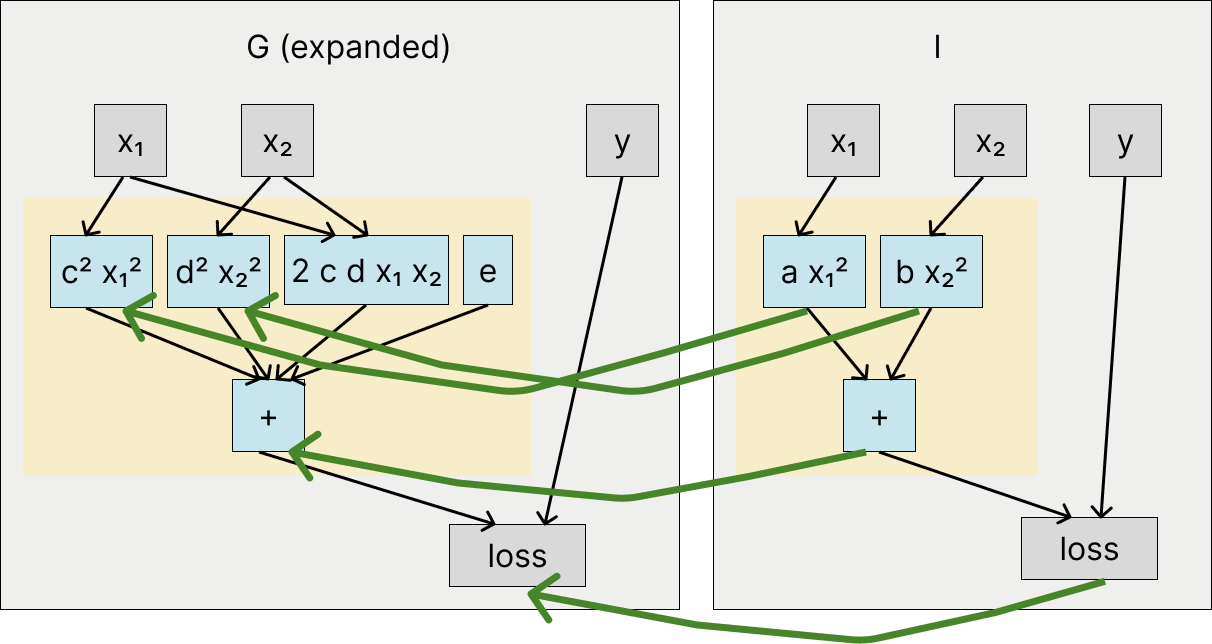
When we sample outputs using our algorithm here, we’re going to sample the interference term from random other examples. And so the scrubbed model will have roughly the same estimated loss as the original model–the errors due to interference will no longer appear on the examples that actually suffer from interference, but the average effect of interference will be approximately reproduced.
In general, this is our strategy for explaining polysemantic models: we do an algebraic rewrite on the model so that the model now has monosemantic components and an error term, and then we say that the monosemantic components explain why the model is able to do the computation that it does, and we say that we don’t have any explanation for the error term.
This works as long as the error is actually unstructured–if the model was actively compensating for the interference errors (as in, doing something in a way that correlates with the interference errors to reduce their cost), we’d need to describe that in the explanation in order to capture the true loss.
This strategy also works if you have more neurons and more variables–we’ll again write our model as a sum of many monosemantic components and a residual. And it’s also what we’d do with real models–we take our MLP or other nonlinear components and make many copies of the set of neurons that are required for computing a particular feature.
This strategy means that we generally have to consider an explanation that’s as large as the model would be if we expanded it to be monosemantic. But it’s hard to see how we could have possibly avoided this.
Note that this isn’t a solution to finding a monosemantic basis - we’re just claiming that if you had a hypothesized monosemantic reformulation of the model you could test it with causal scrubbing.
This might feel vacuous–what did we achieve by rewriting our model as if it was monosemantic and then adding an error term? We claim that this is actually what we wanted. The hypothesis explained the loss because the model actually was representing the two input variables in a superposed fashion and resigning itself to the random error due to interference. The success of this hypothesis reassures us that the model isn’t doing anything more complicated than that. For example, if the model was taking advantage of some relationship between these features that we don’t understand, then this hypothesis would not replicate the loss of the model.
6.1 Underestimating interference by neglecting correlations in model errors
Now, suppose we rewrite the model from the form we used above:
To the following form:
Where we’ve split the noise term into two pieces. If we sample these two parts of the noise term independently, we will have effectively reduced the magnitude of the noise, for the usual reason that averages of two samples from a random variable have lower variance than single samples. And so if we ignore this correlation, we’ll estimate the cost of the noise to be lower than it is for the real model. This is another mechanism by which ignoring a correlation can cause the model to seem to perform better than the real model does; as before, this error gives us the opportunity to neglect some positive contribution to performance elsewhere in the model.
7 An additional example of approving a false hypothesis
We can construct cases where the explanation can make the model look better by sneaking in information. For example, consider the following setting:
The model’s input is a tuple of a natural number and the current game setting, which is either EASY or HARD (with equal frequency). The model outputs the answer either “0”, “1”, or “I don’t know”. The task is to guess the last bit of the hash of the number.
Here’s the reward function for this task:
| Game mode | Score if model is correct | Score if model is incorrect | Score if model says “I don’t know” |
| EASY | 2 | -1 | 0 |
| HARD | 10 | -20 | 0 |
If the model has no idea how to hash numbers, its optimal strategy is to guess when in EASY mode and say “I don’t know” in HARD mode.
Now, suppose we propose the hypothesis that claims that the model outputs:
- on an EASY mode input, what the model would guess; and
- on a HARD mode input, the correct answer.
To apply causal scrubbing, we consider the computational graph of both the model and the hypothesis to consist of the input nodes and a single output node. In this limited setting, the projected model runs the following algorithm:
- Replace the input with a random input that would give the same answer according to the hypothesis; and
- Output what the model outputs on that random input.
Now consider running the projected model on a HARD case. According to the hypothesis, we output the correct answer, so we replace the input
- half the time with another HARD mode input (with the same answer), on which the model outputs “I don’t know”; and
- half the time with an EASY mode input chosen such the model will guess the correct answer.
So, when you do causal scrubbing on HARD cases, the projected model will now guess correctly half the time, because half its “I don’t know” answers will be transformed into the correct answer. The projected model’s performance will be worse on the EASY cases, but the HARD cases mattered much more, so the projected model’s performance will be much better than the original model’s performance, even though the explanation is wrong!
In examples like this one, hypotheses can cheat and get great scores while being very false.
8 Adversarial validation might be able to elicit true hypotheses
(Credit for the ideas in this section is largely due to ARC.)
We might have hoped that we’d be able to use causal scrubbing as a check on our hypotheses analogous to using a proof checker like Lean or Coq to check our mathematical proofs, but this doesn’t work. Our guess is that it’s probably impossible to have an efficient algorithm for checking interpretability explanations which always rejects false explanations. This is mostly because we suspect that interpretability explanations should be regarded as an example of defeasible reasoning. Checking interpretations in a way that rejects all false explanations is probably NP-hard, and so we want to choose a notion of checking which is weaker.
We aren’t going to be able to check hypotheses by treating as uncorrelated everything that the hypotheses claimed wasn’t relevantly correlated. This would have worked if ignoring correlations could only harm the model. But as shown above, we have several cases where ignoring correlations helps the model.
So we can’t produce true explanations by finding hypotheses subject to the constraint that they predict the observed metrics. As an alternative proposal, we can check if hypotheses are comprehensive by seeing if any adversarial additions to the hypothesis would cause the predicted metric to change considerably. In all of the counterexamples above, the problem is that the metric was being overestimated because there were important correlations that were being neglected and which would reduce the estimated metric if they were included. If we explicitly check for additional details to add to our hypotheses which cause the estimated metric to change, all the counterexamples listed above are solved.
To set up this adversarial validation scheme, we need some mechanism for hypotheses to be constructed adversarially. That is, we need to handle cases where the adversary wants to rewrite f to an extensionally-equal function. One way of thinking about this is that we want a function `join` which is a binary operation on hypotheses, taking the two hypotheses to the hypothesis which preserves all structure in the model that either of the two hypotheses preserved.
Here are two ways of defining this operation:
- Swap-centric. You can think of a hypothesis as a predicate on activation swaps (of the same activation on two different inputs). From this perspective, you can define join(h1, h2) to be the hypothesis which permits a swap iff h1 and h2 both permit it.
- Computation graph centric. You can equivalently construct the joined hypothesis by the following process. First, ensure that each of the correspondences are bijections, and that both and have the same shape, adding extra no-op nodes as necessary. Now we can define of the joined hypothesis to be the graph where every node contains the tuple of the values from the two earlier interpretations.
The main failure of the algorithm listed above is that we don’t know how to handle cases where the adversary wants to rewrite f to an extensionally-equal function in a way which is mutually incompatible with the original hypothesis (for example, because their computational graphs have different shapes and there’s no way to splice the two computational graphs together). This is a pretty bad problem because the function extensionality move seems very important in practice. ARC has worked on basically this problem for a while and hasn’t yet solved it, regrettably.
Some other questions that we haven’t answered:
- How do we incentivize specific explanations? We don’t know (but haven’t thought about it that much). Our current proposals look something like having a budget for how much hypotheses can reduce entropy.
- The explanations produced by this process will probably by default be impossible for humans to understand; is there some way to fix this? We also don’t have good ideas here. (Note that this isn’t a failure that’s specific to causal scrubbing; it seems fundamentally challenging to generate human-understandable interpretations for complicated superhuman models.) That being said, a lot of our optimism about interpretability comes from applications where the interpretability tools are used by AIs or by human-coded algorithms, rather than by humans, so plausibly we’re fine even if humans can’t understand the interpretability results.
Overall, it seems plausible that these problems can be overcome, but they are definitely not currently solved. We hold out hope for an interpretability process which has validity properties which allow us to use powerful optimization inside it and still trust the conclusions, and hope to see future work in this direction.
- ^
This is also true when you’re training models with an autodiff library–you construct a computational graph that computes loss, and run backprop on the whole thing, which quickly recurses into the model but doesn’t inherently treat it differently.
- ^
This allows for testing out human interpretable approximations to neural network components: ‘Artificial Artificial Neural networks’. We think it’s more informative to see how the model performs with the residual of this approximation resampling ablated as opposed to zero ablated.
- ^
In general, you could have the output be non-scalar with any distance metric to evaluate the deviation of the scrubbed expectation, but we’ll keep things simple here.
- ^
Another way of thinking about this is: when we consider the adversarial game setting [LW · GW], we would like each side to be able to request that terms are sampled together. By default therefore we would like terms (even random ones!) to be sampled separately.
4 comments
Comments sorted by top scores.
comment by eca · 2022-12-24T07:09:34.578Z · LW(p) · GW(p)
Great stuff! Excited to see this extended and applied. I hope to dive deeper into this series and your followup work.
Came to the appendix for 2.2 on metrics, still feel curious about the metric choice.
I’m trying to figure out why this is wrong: “loss is not a good basis for a primary metric even though its worth looking at and intuitive, because it hides potentially large+important changes to the X-> Y mapping learned by the network that have equivalent loss. Instead, we should just measure how yscrubbed_i has changed from yhat_i (original model) at each xi we care about.” I think I might have heard people call this a “function space” view (been a while since I read that stuff) but that is confusing wording with your notation of f.
Dumb regression example. Suppose my training dataset is scalar (x,y) pairs that almost all fall along y=sin(x). I fit a humungo network N and when i plot N(x) for all my xs I see a great approximation of sin(x). I pick a weird subset of my data where instead of y=sin(x), this data is all y=0 (as far as I can tell this is allowed? I don’t recall restrictions on training distribution having to match) and use it to compute my mse loss during scrubbing. I find a hypothesis that recovers 100% of performance! But I plot and it looks like cos(x), which unless I’m tired has the same MSE from the origin in expectation.
I probably want to know if I my subnetwork is actually computing a very different y for the same exact x, right? Even if it happens to have a low or even equal or better loss?
(I see several other benefits of comparing model output against scrubbed model output directly, for instance allowing application to data which is drawn from your target distribution but not labelled)
Even if this is correct, I doubt this matters much right now compared to the other immediate priorities for this work, but I’d hope someone was thinking about it and/ or I can become less confused about why the loss is justified
Replies from: LawChan↑ comment by LawrenceC (LawChan) · 2022-12-24T07:55:08.621Z · LW(p) · GW(p)
I think this is a great question.
First, we do mention this a bit in 2.2:
In this work, we prefer the expected loss. Suppose that one of the drivers of the model’s behavior is noise: trying to capture the full distribution would require us to explain what causes the noise. For example, you’d have to explain the behavior of a randomly initialized model despite the model doing ‘nothing interesting’.
We also discuss this a bit in the Limitations section of the main post [LW · GW], specifically, the part starting:
Another limitation is that causal scrubbing does not guarantee that it will reject a hypothesis that is importantly false or incomplete.
That being said, it's worth noting that your performance metric gives you an important degree of freeodm. In your case, if the goal is to explain "why the predictor explains y = sin(x)", it makes more sense to use the performance metric f(x) = |sin(x) - model(x)|. If you use the metric (model(x) - y|)^2 you're trying to explain, why does the predictor sin(x) do as well (as poorly) as it does. In which case, yes, cos(x) does as poorly as sin(x) on the data.
Replies from: eca↑ comment by eca · 2022-12-24T19:13:19.871Z · LW(p) · GW(p)
Really appreciate the response :)
Totally acknowledge the limitations you outlined.
I was aiming to construct an example which would illustrate how the loss metric would break in a black box setting (where X and Y are too gnarly to vis). In that case you have no clue that your model implements sin(x), and so I dont see how that could be the goal. In the black box setting you do get access to distance between scrubbed y and y_true (loss) and distance between scrubbed_y and original_y (my proposal, lets call it output distance). When you look at loss, it is possible for causal scrubbing to yield an explanation of the model’s performance which, from my perspective, is an obviously bad one in that it it causes the function implemented by the model to be radically different.
If that is one of classes of “importantly false or i complete hypotheses” then why not check the predicted ys against each other and favor hypotheses that have both close outputs and low loss?
(I think these converge to the same thing as the original model’s loss go to zero, but prior to that driving output distance to zero is the only way to get an equivalent function to the original network, I claim)
Replies from: LawChan↑ comment by LawrenceC (LawChan) · 2022-12-25T04:36:50.693Z · LW(p) · GW(p)
If that is one of classes of “importantly false or i complete hypotheses” then why not check the predicted ys against each other and favor hypotheses that have both close outputs and low loss?
It doesn't actually fix the problem! Suppose that your model behavior worked as follows:
That is, there are three components, two of which exhibit the behavior and one of which is inhibitory. (For example, we see something similar in the IOI paper with name movers and backup name movers.) Then if you find a single circuit of the form sin(x), you would still be missing important parts of the network. That is, close model outputs doesn't guarantee that you've correctly captured all the considerations, since you can still miss considerations that "cancel out". (Though they will have fewer false positives.)
However, swapping from low loss to close outputs requires sacrificing other nice properties you want. For example, while loss is an inherently meaningful metric, KL distance or L2 distance to the original outputs is rarely the thing you care about. And the biggest issue is that you have to explain a bunch of noise, which we might not care about.
Of course, I still encourage people to think about what their metrics are actually measuring, and what they could be failing to capture. And if your circuit is good according to one metric but bad according to all of the others, there's a good chance that you've overfit to that metric!