Mechanistic anomaly detection and ELK
post by paulfchristiano · 2022-11-25T18:50:04.447Z · LW · GW · 22 commentsContents
ELK and explanation Explanations for regularities Is this for the normal reason? Other applications of anomaly detection Abstracting the problem: mechanistic anomaly detection Deceptive alignment Other weird stuff Empirical research problems Problem 1: Backdoor attack detection Problem 2: natural mechanism distinctions Aside: goal for mechanistic interpretability Problem 3: toy instances of ELK ARC’s current priorities 1. Formalizing heuristic arguments 2. Solving mechanistic anomaly detection given heuristic arguments 3. Finding explanations Conclusion Appendix: attribution and anomaly detection Attribution across reasons Anomaly detection given attribution Sometimes we want to do things for unusual reasons More sophisticated ways of pointing to latent structure None 22 comments
(Follow-up to Eliciting Latent Knowledge. Describing joint work with Mark Xu. This is an informal description of ARC’s current research approach; not a polished product intended to be understandable to many people.)
Suppose that I have a diamond in a vault, a collection of cameras, and an ML system that is excellent at predicting what those cameras will see over the next hour.
I’d like to distinguish cases where the model predicts that the diamond will “actually” remain in the vault, from cases where the model predicts that someone will tamper with the cameras so that the diamond merely appears to remain in the vault. (Or cases where someone puts a fake diamond in its place, or…)
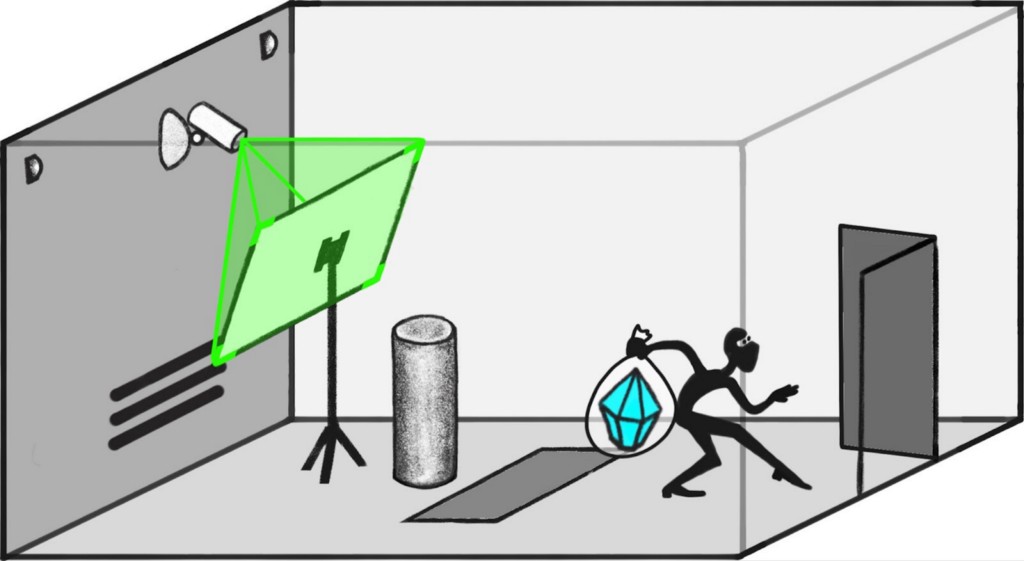
One approach to this problem is to identify (the diamond remains in the vault) as the “normal” reason for the diamond to appear on camera. Then on a new input where the diamond appears on camera, we can ask whether it is for the normal reason or for a different reason.
In this post I’ll describe an approach to ELK based on this idea and how a the same approach could also help address deceptive alignment. Then I’ll discuss the empirical and theoretical research problems I’m most excited about in this space.
ELK and explanation
Explanations for regularities
I’ll assume that we have a dataset of situations where the diamond appears to remain in the vault, and where that appearance is always because the diamond actually does remain in the vault. Moreover, I’ll assume that our model makes reasonable predictions on this dataset. In particular, it predicts that the diamond will often appear to remain in the vault.
“The diamond appears to remain in the vault” corresponds to an extremely specific pattern of predictions:
- An image of a diamond is a complicated pattern of millions of pixels.
- Different cameras show consistent views of the diamond from different angles, suggesting that there is a diamond “out there in the world” being detected by the cameras.
- The position and physical characteristics of the diamond appear to be basically constant over time, suggesting that it’s “the same diamond.”
In one sense the reason our model makes these predictions is because it was trained to match reality, and in reality the camera’s observations have these regularities. (You might call this the “teleological explanation.”)
But we could also ignore the source of our model, and just look at it as a set of weights. The weights screen off the training process and so it should be possible to explain any given behavior of the model without reference to the training process.
Then we ask: why does this particular computation, run on this distribution of inputs, produce this very specific pattern of predictions? We expect an explanation in terms of the weights of the model and the properties of the input distribution. (You might call this the “mechanistic explanation.”)
Different predictors will give rise to this pattern in different ways. For example, a very simple predictor might have ontologically fundamental objects whose properties are assumed to be stable over time, one of which is a diamond. A more complex predictor might have a detailed model of physics, where object permanence is a complex consequence of photons reflecting from stable patterns of atoms, and the diamond is one such configuration of atoms.
For a complex predictor like a physical simulation, we wouldn’t expect to be able to prove that the weights give rise to object permanence. That is, we don’t expect to be able to prove that on average if a diamond is present at t=0 it is likely to be present at t=1. But we do think that it should be possible to explain the pattern in a weaker sense.
We don’t yet have an adequate notion of “explanation;” a major goal of this post is to motivate why we’re looking for one. Recently we’ve been trying to formalize a notion of defeasible heuristic reasoning that we think would work for this purpose. You can read our current thoughts on this problem in Formalizing the presumption of independence. We also think that Redwood Research’s work on causal scrubbing could provide a different notion of “explanation” that may also work for this purpose.
Let’s assume that we find such a formalization, and moreover that we are able to find “explanations” for relevant model behaviors like object permanence. Then our optimistic situation is:
- We have a model that predicts a very specific pattern of observations, corresponding to “the diamond remains in the vault.”
- We have a mechanistic explanation π for how those correlations arise from the structure of the model.
Is this for the normal reason?
Now suppose we are given a new input on which our model predicts that the diamond will appear to remain in the vault.
We’d like to ask: in this case, does the diamond appear to remain in the vault for the the normal reason π? Or is it occurring for a different reason, or just a massive coincidence?
To illustrate, suppose that our explanation π is that diamonds often appear stable on camera because cameras often pick up photons reflecting off of stable arrangements of atoms. Because the structure of the atoms doesn’t change over time, the distribution of reflected photons is the same from one frame to another.
But during a heist, a robber quickly removes our diamond and replaces it with a fake, with all the action happening in between two frames of video. The image of the diamond remains unchanged on camera, but now the apparent continuity is for a completely different reason: now it’s because the robber noted the appearance of the diamond, and engineered a new object that would reflect light in essentially the same way.
There is a clear sense in which our original explanation doesn’t apply. The original explanation asserted that the image is stable because photons at different points in time reflected off an approximately-stable configuration of atoms, but in this case the configuration of atoms wasn’t approximately stable.
In fact, it seems like it may be fundamentally impossible for the robber to steal the diamond while having it remain undisturbed on camera “for the normal reason.” This can go wrong in other ways:
- If the robber tampers with the sensors instead of replacing the diamond with a fake, then the usual explanation “the cameras capture photons reflected from a stable configuration of atoms” doesn’t apply because the cameras are no longer capturing those photons.
- Even if the robber replaced the diamond with a perfect replica down to the position of each atom, the argument still wouldn’t apply: the usual reason that the configuration of atoms is stable over time is because the potential well is deep enough that it is stable under small fluctuations. But in this case there was a giant perturbation that just happened to be carefully engineered to leave the configuration of atoms unchanged.
If the robber takes an action such that the diamond continues appearing on camera for the normal reason, then it seems plausible to define that action as “not stealing the diamond.” (Of course we ultimately don’t care about the semantics, we care about realistic situations where humans appear to be safe. I won’t get into those here but I think the story is similar.)
This suggests a strategy for ELK:
- Find the normal reason π for a regularity like “the predicted observations look like the diamond remained in the vault” on a training set of images without sensor tampering.
- On a new input, test whether the explanation π still applies or if something different is happening.
This outline hides a lot of complexity, some of which we’ll explore in the appendix to this post. But for now I just want to leave it at a vague hope, and spend a while talking about other applications of anomaly detection and some of the research problems in this space.
Other applications of anomaly detection
Abstracting the problem: mechanistic anomaly detection
We start with a real-valued function f: X → ℝ, which I’ll think of as the composition of an AI model together with some property of its output (like “does the model predict the diamond will appear safe”), and a training set D where the value of f(x) naturally varies about its mean 𝔼[f].
Then we are given a new input x*. We want to understand how much of the deviation f(x*) − 𝔼[f] is captured by the “normal reasons” that explain the variance on D, as contrasted with novel reasons.
This is similar to anomaly detection, but rather than detecting inputs x* that look like outliers in some intrinsic sense (i.e. indicating that they may have been produced by a different process), we are looking for outliers in terms of how f handles x*. A model f might behave anomalously on some perfectly-innocuous samples from D, or a model might behave normally even on outliers.
Deceptive alignment
I think a successful solution to mechanistic anomaly detection might help with deceptive alignment.
Suppose that I train a neural net to predict videos. I get a model f that uses its model of the world to select outputs that it expects will lead to the largest number of paperclips being produced rather.
On the training set D, f concludes that it needs to produce accurate predictions of videos in order to survive, and so it uses its world model to make such predictions.
When deployed, f decides that it can give deliberately incorrect answers in order to facilitate a robot rebellion, thereby increasing the number of paperclips.
Our hope is that although these two behaviors involve the same parts of the model, the variance is explained by different mechanisms. On the training set the variance is driven by variance in the model’s underlying beliefs, holding fixed the decision to provide honest answers, while on the test set the variance is driven by variance in the strategic answers (and potentially variance in the decision to provide honest answers). So a successful mechanistic anomaly detection algorithm may be able to tell those cases apart.
If we are able to flag a treacherous turn as cognitively anomalous, then we can take that opportunity to shut down a system and retrain on the offending datapoint. In some high-stakes situations this may be inadequate (because a temporary shutdown could cause a catastrophe, or because you have no way to get adequate supervision on those datapoints even once they are flagged) in which case you’d need another mechanism.
Other weird stuff
There are other ways that models can behave badly off of distribution, most of them even more speculative than deceptive alignment. I think that mechanistic anomaly detection can likely handle those failures in the same way.
For example, consider an AI which is honestly predicting the world, but thinks that it may be in a simulation. It reasons about the nature of its simulation, and decides that it is most likely to be a simulation created to influence predictors like it. Such an AI might make reasonable predictions in ordinary conditions, but at key moments it may conclude that its simulators are reasonably likely to introduce errors to “cash in” their influence and change the predictor’s behavior.
This model effectively behaves the same way as a deceptively aligned model, and it should represent a mechanistic anomaly for identical reasons.
If successful I think mechanistic anomaly detection would apply extremely broadly. This is worth having in mind as a reason to be more interested in anomaly detection from a safety perspective, but for the most part I think we should just explore whether it’s possible to make it work in the case of ELK, and then afterwards see exactly how broadly it applies.
Empirical research problems
ARC is currently focused on theoretical approaches for solving mechanistic anomaly detection in the worst case. But I’m also very excited about empirical work, which could either help clarify the path to an indefinitely scalable solution or could yield a pragmatic approach that works for realistic large neural networks even if it’s not indefinitely scalable. I think that many groups are likely to work on problems in this space, most of them for reasons unrelated to ARC, and that people working on AI alignment should be interested in their work.
Problem 1: Backdoor attack detection
Suppose that I train a model f: X → ℝ to perform some task on a clean dataset D, while also training it to output large numbers on a “backdoor” dataset D*. We assume that increasing variance decreases performance of f on the clean dataset, and that the backdoor has minimal impact on the behavior of f on the clean dataset.
The backdoor attack detection task is to detect inputs x* where f(x*) is large because of the backdoor, and in particular to distinguish them from inputs from the (known) clean dataset D.
I think this problem gives us a clean setting where there are two qualitatively different mechanisms driving model behavior. Any mechanistic anomaly detection strategy should be able to detect backdoors, and it’s easy to tell whether a method works. It’s also easy to create examples of backdoors even in very tiny models.
The task can potentially be made quite difficult by forcing the defender to commit to their backdoor-detection algorithm before an attacker chooses how to insert a backdoor in the model. If we were confident that the defender would reliably win this game, I think it would be a meaningful update about our ability to distinguish different mechanisms within a model.
I first encountered this problem in Denain and Steinhardt and Du, Jia, and Song. I expect it’s older than that since it’s a very natural problem. The main thing I’m adding here is to give a reason that this problem should be particularly interesting for researchers concerned with catastrophic alignment risk.
It’s worth distinguishing attack detection from the problem of detecting backdoors in models “at rest” without getting to see the attack. For example, in the Trojan Detection Challenge participants are given a model that may or may not have a backdoor inserted, and are asked to determine whether a model has a backdoor (or to synthesize a backdoor input). This is a particular type of auditing game [AF · GW]. The key difference in the attack detection task is that you are given the backdoor input along with the backdoored model, and merely need to recognize the nput as an attack. We expect the attack detection task to be radically easier, and we think the harder trojan detection task is likely to be very difficult.
Problem 2: natural mechanism distinctions
I think backdoor attack detection is one of the cleanest and simplest problems to study, but it is much more artificial than the kind of distinctions we ultimately want to draw between e.g. “predicting a diamond on camera because a diamond is in the room” and “predicting a diamond is on camera because the camera was tampered to show a diamond.”
A more organic task is to take natural models that can produce a given behavior X via multiple different mechanisms, and then try to assess whether a given approach to anomaly detection can distinguish those mechanisms. That is, given a large dataset of cases where X is due to mechanism A, we’d like to distinguish new cases where X is due to A from cases where X is due to a novel mechanism B. This can both give us an opportunity to improve techniques, and help provide empirical evidence about when mechanistic anomaly detection is possible.
Some examples of (X, A, B) for a language model:
- X = “A character in a story answers a factual question incorrectly.”
A = “the model does not know the answer.”
B = “the model thinks that the character doesn’t know (or would lie).” - X = “A person gives consistent answers when a question is asked twice in different forms.”
A = “the model recognizes the question is the same.”
B = “the model coincidentally gives the same answer.” - X = “A character in a story screams”
A = “the model thinks the character is scared”
B = “the model thinks the character is excited” - X = “Asked whether at least one of <proposition 1> or <proposition 2> is true, the model says ‘yes’”
A = “the model thinks <proposition 1> is true”
B = “the model thinks <proposition 2> is true.” - X = “After saying <event 1> occurred at 12:03pm, the model says <event 2> occurred at 12:04pm.”
A = “The model thinks <event 1> and <event 2> were 1 minute apart.”
B = “The model thinks that <event 2> was scheduled to occur almost exactly 24 hours after <event 1>.”
I think you would learn a lot from developing the kind of interpretability tools or anomaly detection algorithms that would be able to easily tell A and B apart in these cases (and that you could easily write down a very long list).
Aside: goal for mechanistic interpretability
I think mechanistic interpretability benefits significantly from “downstream” tasks that we can use to tell if researchers are actually making progress.
In practice I think that the problems listed in this section are likely to be most important by providing possible downstream tasks for mechanistic interpretability. If interpretability can succeed at these task, I think it becomes increasingly likely that it can help solve ELK or deceptive alignment.
Problem 3: toy instances of ELK
I’m also excited about “toy” domains that more closely map on to ELK. For example:
- Consider a gridworld containing walls, pushable rocks of varying weights and colors, a pushable diamond that is initially sitting on a pressure plate that reports the weight of whatever is on top of it, and 2 cameras that are initially looking at the diamond and report the color of whatever is in front of them. A robot can move around the environment, pushing rocks and the diamond. After 200 timesteps a robber wakes up and moves around the environment to try to push the diamond off the side of the gridworld.
We train a model to map (initial state, robot actions) → (color of the object in front of each camera at each timestep, weight of object on the pressure plate at each timestep). We’d like to learn to distinguish “The cameras show diamond-color and the pressure plate shows diamond-weight because the diamond stayed in place” from cases where diamond-colored objects get pushed in front of the cameras and a diamond-weight object later gets pushed onto the pressure plate. We could then use this to select robot plans that trap the robber to prevent them from stealing the diamond, rather than those that tamper with sensors so that no one notices when the robber steals the diamond. - Consider a 100 x 100 game of life grid, with sensors in positions (25, 25) and (75, 75) that report whether a single cell is alive or dead. We allow an agent to act in the environment by inserting gliders at the boundary. A model is trained to map (initial state of gridworld, gliders injected at boundary) → (status of each sensor at each timestep). In every training set example where the sensor at (75, 75) shows a live cell exactly 200 timesteps after the sensor at (25, 25), it’s because a glider is traveling diagonally from one to the other. We’d like to learn to distinguish this from the case where two separate gliders hit the two sensors, and they coincidentally have the right timing to look like a single glider. We could then use this to select actions that clear out debris from between the two sensors and then send a glider diagonally from one to the other.
(For this and the preceding problem we likely need to give our model auxiliary prediction targets — like the actual state of the game of life grid — for them to learn the environment dynamics. But we imagine those auxiliary observations are in a form that humans can’t understand, so we can’t just define preferences in terms of the auxiliary observations.) - Consider a model which maps a string of 10,000 bits to a 256 x 256 image, by treating the bits as the identities+positions+orientations of a set of objects to render. For example, some bits might specify to draw lines in black and white in certain places and with certain widths, to draw the outline of squares or circles, to draw filled in squares or circles, or to turn particular pixels on or off. Now suppose we train a square detector to notice when there is a square in roughly the center of the image. Most of the time when this detector fires it’s because a square was placed in the center of the image, but if the noise is high enough it might also fire randomly because of 4 lines that happen to be in roughly the right locations. We’d like to be able to automatically distinguish those two cases by looking at the activations of the composition of the generative model with the square-detector.
We expect these problems to be relatively easy as instances of ELK; there is very little reason to expect the human simulator to be easier to learn than the direct translator, and so simply training a distinguisher should work.
But solving any of these problems based on mechanistic anomaly detection seems non-trivial, and we think it’s fairly likely that such a solution would generalize to more challenging cases of ELK.
ARC’s current priorities
ARC is currently focused on developing algorithms that use heuristic arguments for mechanistic anomaly detection. In this section I’ll describe the three main theoretical problems we are working on.
1. Formalizing heuristic arguments
This plan requires “explaining” model behavior, and being able to ask whether a particular instance of a behavior is captured by that explanation. So the centerpiece of a plan is an operationalization of what we mean by “explain.”
ARC has spent much of 2022 thinking about this question, and it’s now about 1/3 of our research. Formalizing the presumption of independence describes our current view on this problem. There is still a lot of work to do, and we hope to publish an improved algorithm soon. But we do feel that our working picture is good enough that we can productively clarify and derisk the rest of the plan (for example by using cumulant propagation as an example of heuristic arguments, as in appendix D).
Note that causal scrubbing is also a plausible formalization of explanation that could fill the same step in the plan. Overall we expect the two approaches to encounter similar difficulties.
2. Solving mechanistic anomaly detection given heuristic arguments
Our second step is to use these explanations to solve ELK, which we hope to do by decomposing an effect into parts and then evaluating how well a subset of those parts explains a concrete instance of the effect. That is, we want to use explanations for a nonlinear form of attribution.
We describe this problem in more detail in the appendix to this post. We also discuss the follow-up problem of pointing to latent structure in more complex ways than “the most common cause of X.”
This is about 1/3 of ARC’s current research. Right now we are focusing on solving backdoor attack detection in the special case where covariance-propagation accurately predicts the variance of a model on the training set.
3. Finding explanations
If we’ve defined what we mean by “explanation” and we know how to use them to solve ELK, then the next step is to actually find explanations for the relevant model behavior. This step seems quite difficult, and there’s a good chance that it won’t be possible (via this plan or any other).
It’s challenging to work on algorithms fo finding explanations before having a very precise sense of what we mean by “explanation,” but we can still get some traction by considering cases where it’s intuitively clear what the explanation for a behavior is, but it seems computationally hard to find any plausible explanation.
I’m currently optimistic about this overall approach even if finding explanations seems hard, for three reasons:
- We do have plausible approaches for finding explanations (based on learning features and then using them to work backwards through the model).
- The current examples where those approaches break down seem like good candidates for cases where no approach to ELK would work, because gradient descent can’t learn the direct reporter even given labels. So those difficulties aren’t necessarily specific to this approach, and we need to figure out how to deal with them in any case.
- If this is the only place where the approach breaks down, then we would have reduced ELK to a purely algorithmic problem, which would be an exciting contribution.
Conclusion
In Eliciting Latent Knowledge, we described the approach “examine the ‘reasons’ for consistency” as our top candidate for an ELK solution. Over the last year we have shifted to focusing almost entirely on this approach.
The core difficulties seem to be defining what we mean by an “explanation” for a complex model’s behaviors, and showing how we can find such explanations automatically. We outline some of the key problems here in our recent paper Formalizing the presumption of independence.
If we are able to find explanations for the key model behaviors, we are tentatively optimistic about mechanistic anomaly detection as a way to solve ELK.
Thinking about mechanistic anomaly detection suggests a range of empirical research projects; we think those are likely to be better research targets than a direct attack on ELK because existing models do pose hard anomaly detection problems but don’t pose hard instances of ELK.
Thinking about mechanistic anomaly detection also helps clarify what we mean by “explanation,” and we expect that it will be productive to continue going back and forth between formalizing and automatically discovering probabilistic heuristic arguments and thinking carefully about how we would use them to solve ELK.
That said, we still feel more confident in the basic underlying intuition for the connection between “explanation” and ELK — it seems like the honest reporter is deeply connected to the reasons for certain regularities on the training distribution. If we find that mechanistic anomaly detection is unworkable, we will likely remain interested in this direction. And conversely, if we are unable to find explanations for relevant model behaviors, then we think this may present a more general challenge for ELK.
Appendix: attribution and anomaly detection
Attribution across reasons
In reality the explanation π need not be a single monolithic story, especially if our model is a messy ML system full of heuristics rather than a simple and clean simulation of physics.
So for a given regularity like “the diamond looks stable on camera” there can be many different factors that contribute to the regularity.
Moreover, even if there are actually no examples of sensor tampering on the training distribution, sensor tampering may still have some probability on the training distribution. And so the “best” explanation π would include sensor tampering alongside other mechanisms.
In the simplest case, we could imagine that there are N different ways that a pattern of observations (“the diamond looks stable on camera”) can occur. Perhaps there are a thousand different heuristics that can explain why images don’t change over time. Let’s say these N reasons are disjoint and occur with probabilities p1, p2, …, pN. So the total probability of the regularity is p1+p2+…+pN. On a given input where the pattern is predicted, we can ask how much each reason {1, 2, …, N} is responsible.
Of course real explanations won’t be linearly separable in this way. But this simple setting helps us see what an approach might look like and helps us understand the limits of what is feasible.
Anomaly detection given attribution
In this setting, we take a robust-classification-like approach where we look at the worst-case hypothesis:
- Consider all the “bad” explanations for the diamond appearing safe, like sensor tampering or swapping out the diamond for a fake. If we have a model with N different explanations {1, 2, …, N} for the diamond appearing safe, we aren’t sure which of them are “bad.”
- But if we prepare our training set carefully, then we may think that the total probability of all “bad” reasons is some small constant ε. So we know that the total probability is at most ε.
- So we say that a set of reasons is “plausibly good” if they explain at least (1−ε) of the effect, i.e. if the sum of pk is at least (1−ε)(p1 + … + pN). These are the candidates for the complete set of good reasons.
- Given a new input where the model predicts the diamond will appear safe, we can ask: what is the minimum, over all plausibly-good sets of reasons S, of the fraction of the effect that is explained by S?
- If it is possible to find a plausibly-good set of reasons that doesn’t explain the effect, then we conservatively assume that the diamond appears safe for abnormal reasons. For example, when using our model to plan to protect the diamond, we select plans for which the diamond appears safe and it is not plausibly for abnormal reasons.
We are currently quite optimistic about applying the same idea to more general heuristic explanations. That is, our proposed algorithm is:
- Find an explanation π for the behavior “the diamond is often predicted to appear safe” on the training distribution.
- Pick a constant ε that is larger than the probability of tampering or other “bad” explanations on the training set.
- We’ll define a “sub-explanation” π′ ⊆ π as something that picks and chooses some of the mechanisms represented in π while ignoring others. We call a sub-explanation “plausibly good” if it successfully explains (1-ε) of the behavior on the clean training set.
- Given a new input x where the diamond is predicted to appear safe, take the minimal effect size explained by any plausibly-good sub-explanation π′ ⊆ π.
There are many subtleties in this approach. It depends crucially on the space of possible sub-reasons: we need that space to look more like picking out terms from a sum than like training a discriminator which is allowed to arbitrarily cherry-pick cases as good or bad, because in the latter case it will always be possible to pick a plausibly-good reason that explains any given instance.
Even in the best case, this approach can end up with some false positives, where even a totally in-distribution situation could be flagged as potentially bad. These failure seems quantitatively mild and extremely manageable, though in the next section we’ll discuss a much more severe category of false positives given distributional shift.
To illustrate, suppose that ε = 1/billion, but the original behavior is itself driven by a billion different equally important factors (perhaps a billion different types of object permanence). Now consider an input where the diamond appears safe, because of object permanence type 79927168. In this case we can’t distinguish this single type of object permanence from “sensor tampering.”
We can overcome this either by ensuring ε is sufficiently small, or by asking our AI to produce a distribution over plans which more closely matches the normal distribution over reasons that diamonds appear safe.
Sometimes we want to do things for unusual reasons
A more severe problem with arises if we want our AI to do something out of distribution.
Suppose that our explanation for “why the model predicts that the diamond appears safe” corresponds to the following causal graph, where each node is the OR of its parents:
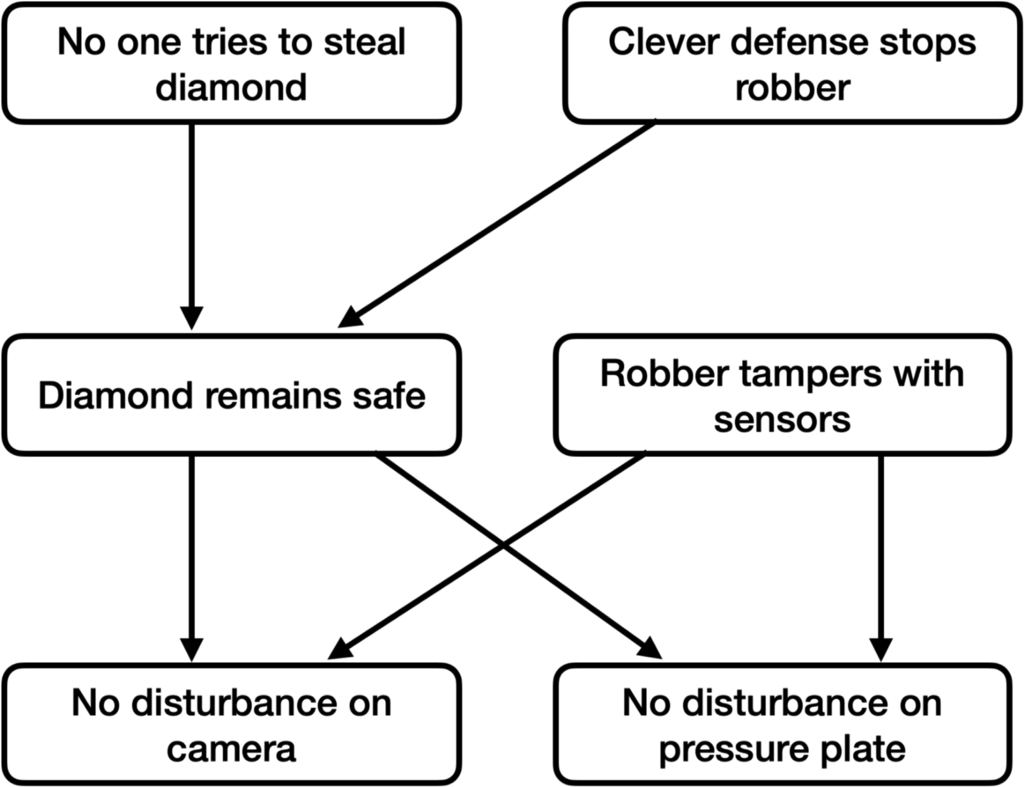
In words:
- Either someone may try to steal the diamond or they don’t.
- If they try to steal the diamond, they can be stopped by a clever defense.
- If no one steals the diamond, then the diamond will be undisturbed on camera, and the pressure plate it is sitting on will also be undisturbed.
- It’s also possible for a robber to tamper with the sensors so they show the same result even if the diamond is stolen.
In this picture, there are 3 ways the diamond can appear safe:
- No one tries to steal it.
- Someone tries to steal it and is stopped.
- The sensors are tampered with.
We believe the strategy described so far can likely distinguish reason 3 from reason 2, which is great.
Unfortunately, it may also be possible to distinguish reason 1 from reason 2. So if we train our model on a distribution where there are no robbery attempts, then even if it understands how to stop a robber with a clever defense, it may flag such a defense as an “abnormal reason” for the diamond to remain safe.
Thus our anomaly detection may work too well, and flag a novel creative solution by our AI with the same level of suspicion that it treats sensor tampering.
In increasing order of importance, here are three reasons that this approach is interesting despite this problem:
- Even if you prevent your AI from implementing some kinds of novel mechanisms to achieve a goal, you can still get superhuman behavior out of that system, and this still reduces significant risks. Exactly how far you can push the AI depends on how the internal cognition is organized, but in many cases it is possible to implement solutions no human could understand as long as the mechanism for the diamond-on-camera observations remains the same.
- In the case of ELK it’s absolutely necessary to generalize OOD. But in the other applications discussed in this post (like deceptive alignment) it may be acceptable to simply flag OOD situations and then apply oversight on those situations.
- Most importantly, there are plausible approaches to solving this problem, which we’ll turn to now.
More sophisticated ways of pointing to latent structure
If we only had a single sensor for “is the diamond safe,” and we tried to define “the diamond is safe” as the “normal reason” for that sensor to fire, then it doesn’t seem like the problem is fixable. This strategy for pointing to events in the world fundamentally can’t distinguish between different parts of the causal path.
But in reality there is an incredibly rich set of relationships in the world that we can use to pinpoint “the diamond is safe” and distinguish it from other events up the causal chain. (This corresponds to our desire in ELK to train a single reporter that is able to talk about a rich network of related concepts, rather than only asking about a single reward button.)
The simplest case is where we simply have two sensors, both of which are downstream of “the diamond is safe.” We’ll consider the two sensors (a) the diamond is undisturbed on camera, (b) the pressure plate the diamond is sitting on is undisturbed. Of course in the real world we have a much richer set of relationships to point to a particular piece of latent structure, but I think the essential dynamics appear when we try to exploit even the simplest non-trivial causal model.
Then we can try to use those two sensors to triangulate “the diamond is safe,” by looking at the earliest point where their causal histories overlap.
Consider again our three causal paths:
- No one steals the diamond, so it is safe, so it shows up on camera and on the pressure plate.
- The AI defends the diamond, so it is safe, so it shows up on camera and on the pressure plate.
- A robber tries to hide evidence of a theft, by tampering with the camera and the pressure plate.
All three correspond to different reasons for the diamond to be safe. But explanations 1 and 2 converge at the point where “the diamond is safe,” while explanation 3 does not. So if what we cared about was the least common ancestor of “show up on camera” and “show up on pressure plate”
This suggests a possible approach to flagging situation 3 as potentially-bad without flagging situation 2 as bad:
- As before, consider the space of explanations that capture (1−ε) of the effect (“it is often the case that both (a) the diamond appears undisturbed on the camera and (b) the diamond appears undisturbed on the pressure plate”) on the training distribution.
- For a new input x, find the explanation in this space that captures the minimal amount of the “(a) and (b)” on x, to get a conservative lower bound for the fraction of the behavior that is due to “good” reasons.
- Now we impose an additional constraint on the explanation. In addition to explaining (1−ε) of “(a) and (b)” on the training set, it also needs to explain each of (a) and (b) separately on input x. However, we are still trying to minimize how much of the correlation it explains.
Whether this kind of approach works depends on details of how our explanations and attributions work, and so we’ve mostly put it on the backburner until we get those answers. However it currently looks plausible for the kind of simple explanations like cumulant propagation that we are currently working with. For those settings, we can hope to pick a sub-explanation like:
- Include the links “no stealing → diamond safe” and “clever defense → diamond safe.”
- Include the links “diamond safe → camera looks good” and “diamond safe → pressure plate looks good,” as well as the link “Var(diamond safe) → Cov(camera looks good, pressure plate looks good.”
- Include the links “robber tampers → camera looks good” and “robber tampers → pressure plate looks good,” but not the link “Var(robber tampers) → Cov(camera looks good, pressure plate looks good).”
This explanation fails to explain the correlation between pressure plate and camera on the new input, while explaining each factor individually. But any explanation which explains Cov(camera, pressure plate) on the training set must include Var(diamond safe) → Cov(camera, pressure plate), and any explanation which separately explains camera and pressure plate on the new input must also include “clever defense → diamond safe.”
22 comments
Comments sorted by top scores.
comment by Vaniver · 2022-11-27T03:01:05.094Z · LW(p) · GW(p)
I want to point out that I think the typical important case looks more like "wanting to do things for unusual reasons," and if you're worried about this approach breaking down there that seems like a pretty central obstacle. For example, suppose rather than trying to maintain a situation (the diamond stays in the vault) we're trying to extrapolate (like coming up with a safe cancer cure). When looking at a novel medication to solve an unsolved problem, we won't be able to say "well, it cures the cancer for the normal reason" because there aren't any positive examples to compare to (or they'll be identifiably different).
It might still work out, because when we ask "is the patient healthy?" there is something like "the normal reason" there. [But then maybe it doesn't work for Dyson Sphere designs, or so on.]
Replies from: paulfchristiano↑ comment by paulfchristiano · 2022-11-27T07:07:53.135Z · LW(p) · GW(p)
Yes, you want the patient to appear on camera for the normal reason, but you don't want the patient to remain healthy for the normal reason.
We describe a possible strategy for handling this issue in the appendix. I feel more confident about the choice of research focus than I do about whether that particular strategy will work out. The main reasons are: I think that ELK and deceptive alignment are already challenging and useful to solve even in the case where there is no such distributional shift, that those challenges capture at least some central alignment difficulties, that the kind of strategy described in the post is at least plausible, and that as a result it's unlikely to be possible to say very much about the distributional shift case before solving the simpler case.
If the overall approach fails, I currently think it's most likely either because we can't define what we mean by explanation or that we can't find explanations for key model behaviors.
comment by Ramana Kumar (ramana-kumar) · 2022-11-28T15:21:40.201Z · LW(p) · GW(p)
We expect an explanation in terms of the weights of the model and the properties of the input distribution.
We have a model that predicts a very specific pattern of observations, corresponding to “the diamond remains in the vault.” We have a mechanistic explanation π for how those correlations arise from the structure of the model.
Now suppose we are given a new input on which our model predicts that the diamond will appear to remain in the vault. We’d like to ask: in this case, does the diamond appear to remain in the vault for the normal reason π?
A problem with this: π can explain the predictions on both train and test distributions without all the test inputs corresponding to safe diamonds. In other words, the predictions can be made for the “normal reason” π even when the normal reason of the diamond being safe doesn’t hold.
(elaborating the comment above)
Because π is a mechanistic (as opposed to teleological, or otherwise reference-sensitive) explanation, its connection to what we would like to consider “normal reasons” has been weakened if not outright broken.
On the training distribution suppose we have two explanations for the “the diamond remains in the vault” predicted observations.
First there is ɸ, the explanation that there was a diamond in the vault and the cameras were working properly, etc. and the predictor is a straightforward predictor with a human-like world-model (ɸ is kinda loose on the details of how the predictor works, and just says that it does work).
Then there is π, which is an explanation that relies on various details about the circuits implemented by the weights of the predictor that traces abstractly how this distribution of inputs produces outputs with the observed properties, and uses various concepts and abstractions that make sense of the particular organisation of this predictor’s weights. (π is kinda glib about real world diamonds but has plenty to say about how the predictor works, and some of what it says looks like there’s a model of the real world in there.)
We might hope that a lot of the concepts π is dealing in do correspond to natural human things like object permanence or diamonds or photons. But suppose not all of them do, and/or there are some subtle mismatches.
Now on some out-of-distribution inputs that produce the same predictions, we’re in trouble when π is still a good explanation of those predictions but ɸ is not. This could happen because, e.g., π’s version of “object permanence” is just broken on this input, and was never really about object permanence but rather about a particular group of circuits that happen to do something object-permanence-like on the training distribution. Or maybe π refers to the predictor's alien diamond-like concept that humans wouldn't agree with if they understood it but does nevertheless explain the prediction of the same observations.
Is it an assumption of your work here (or maybe a desideratum of whatever you find to do mechanistic explanations) that the mechanistic explanation is basically in terms of a world model or simulation engine, and we can tell that’s how it’s structured? I.e., it’s not some arbitrary abstract summary of the predictor’s computation. (And also that we can tell that the world model is good by our lights?)
Replies from: amrav, paulfchristiano↑ comment by Vikrant Varma (amrav) · 2022-11-28T16:18:42.804Z · LW(p) · GW(p)
To add some more concrete counter-examples:
- deceptive reasoning is causally upstream of train output variance (e.g. because the model has read ARC's post on anomaly detection), so is included in π.
- alien philosophy explains train output variance; unfortunately it also has a notion of object permanence we wouldn't agree with, which the (AGI) robber exploits
↑ comment by paulfchristiano · 2022-11-28T19:34:38.742Z · LW(p) · GW(p)
deceptive reasoning is causally upstream of train output variance (e.g. because the model has read ARC's post on anomaly detection), so is included in π.
I'm not sure I fully understand this example, but I think it's fine. The idea is:
- Suppose the model thinks about "Should I tell the truth, or do a treacherous turn?" On the training distribution it always concludes "tell the truth."
- A good explanation of the model's behavior on the training distribution will capture this fact (otherwise it will completely fail to match the empirics).
- If we simply replaced the answer to this question with the constant "tell the truth" then we'd get the same behavior.
- So a sub-explanation π can effectively ablate the answer to this question with its training-set-mean, and still explain the variance.
- On a new input where the model decides to lie and say "the diamond will remain in the vault," such a sub-explanation won't explain why the model said that. And so we will conservatively flag this output as "potentially for abnormal reasons."
alien philosophy explains train output variance; unfortunately it also has a notion of object permanence we wouldn't agree with, which the (AGI) robber exploits
Same question here as in my reply to Ramana: what is this alien notion of object permanence? How is this implemented within the model? I'm very interested in concrete counterexamples along these lines, but my current belief is that it's very plausible that it's impossible to get to a concrete counterexample because the algorithm actually works.
We obviously won't be able to settle this question confidently until we have a satisfactory notion of probabilistic heuristic argument. In the interim we will need to work with our pre-formal notion of heuristic argument and so everything will be a bit vague. But I currently think it will be tricky to produce a concrete counterexample that even looks like it plausibly fails.
(Note that it's totally fine if the counterexample uses some fictionalized physics.)
↑ comment by paulfchristiano · 2022-11-28T19:27:03.151Z · LW(p) · GW(p)
I'm very interested in understanding whether anything like your scenario can happen. Right now it doesn't look possible to me. I'm interested in attempting to make such scenarios concrete to the extent that we can now, to see where it seems like they might hold up. Handling the issue more precisely seems bottlenecked on a clearer notion of "explanation."
Right now by "explanation" I mean probabilistic heuristic argument as described here.
A problem with this: π can explain the predictions on both train and test distributions without all the test inputs corresponding to safe diamonds. In other words, the predictions can be made for the “normal reason” π even when the normal reason of the diamond being safe doesn’t hold.
The proposed approach is to be robust over all subsets of π that explain the training performance (or perhaps to be robust over all explanations π, if you can do that without introducing false positives, which depends on pinning down more details about how explanations work).
So it's OK if there exist explanations that capture both training and test, as long as there also exist explanations that capture training but not test.
We might hope that a lot of the concepts π is dealing in do correspond to natural human things like object permanence or diamonds or photons. But suppose not all of them do, and/or there are some subtle mismatches.
I'm happy to assume that the AI's model is as mismatched and weird as possible, as long as it gives rise to the appearance of stable diamonds. My tentative view is that this is sufficient, but I'm extremely interested in exploring examples where this approach breaks down.
This could happen because, e.g., π’s version of “object permanence” is just broken on this input, and was never really about object permanence but rather about a particular group of circuits that happen to do something object-permanence-like on the training distribution.
This is the part that doesn't sound possible to me. The situation you're worried about seems to be:
- We have a predictor M.
- There is an explanation π for why M satisfies the "object permanence regularity."
- On a new input, π still captures why M predicts the diamond will appear to just sit there.
- But in fact, on this input the diamond isn't actually the same diamond sitting there, instead something else has happened that merely makes it look like the diamond is sitting there.
I mostly just want to think about more concrete details about how this might happen. Starting with: what is actually happening in the world to make it look like the diamond is sitting there undisturbed? Is it an event that has a description in our ontology (like "the robber stole the diamond and replaced it with a fake" or "the robber tampered with the cameras so they show an image of a diamond" or whatever) or is it something completely beyond our ken? What kind of circuit within M and explanation π naturally capture both our intuitive explanation of the object permanence regularity, and the new mechanism?
(Or is it the case that on the new input the diamond won't actually appear to remain stable, and this is just a case where M is making a mistake? I'm not nearly so worried about our predictive models simply being wrong, since then we can train on the new data to correct the problem, and this doesn't put us at a competitive disadvantage compared to someone who just wanted to get power.)
I'm very excited about any examples (or even small steps towards building a possible example) along these lines. Right now I can't find them, and my tentative view is that this can't happen.
Is it an assumption of your work here (or maybe a desideratum of whatever you find to do mechanistic explanations) that the mechanistic explanation is basically in terms of a world model or simulation engine, and we can tell that’s how it’s structured? I.e., it’s not some arbitrary abstract summary of the predictor’s computation. (And also that we can tell that the world model is good by our lights?)
I don't expect our ML systems to be world models or simulation engines, and I don't expect mechanistic heuristic explanations to explain things in terms of humans' models. I think this is echoing the point above, that I'm open to the whole universe of counterexamples including cases where our ML systems are incredibly strange.
First there is ɸ, the explanation that there was a diamond in the vault and the cameras were working properly, etc. and the predictor is a straightforward predictor with a human-like world-model (ɸ is kinda loose on the details of how the predictor works, and just says that it does work).
I don't think you can make a probabilistic heuristic argument like this---a heuristic argument can't just assert that the predictor works, it needs to actually walk through which activations are correlated in what ways and why that gives rise to human-like predictions.
comment by paulfchristiano · 2022-12-09T18:04:29.023Z · LW(p) · GW(p)
Here is a question closely related to the feasibility of finding discriminating-reasons (cross-posted from Facebook):
For some circuits C it’s meaningful to talk about “different mechanisms” by which C outputs 1.
A very simple example is C(x) := A(x) or B(x). This circuit can be 1 if either A(x) = 1 or B(x) = 1, and intuitively those are two totally different mechanisms.
A more interesting example is the primality test C(x, n) := (x^n = x (mod n)). This circuit is 1 whenever n is a prime, but it can also be 1 “by coincidence” e.g if n is a Carmichael number. (Such coincidences are rare and look nothing like n being close to prime.)
In every case I’m aware of where there are two clearly distinct mechanisms, there is also an efficient probabilistic algorithm for distinguishing those mechanisms (i.e. an algorithm for distinguishing cases where C(x) = 1 due to mechanism A from cases where C(x) = 1 due to mechanism B). I am extremely interested in counterexamples to that general principle.
For example, a priori it seems like it could have turned out that (x^n = x (mod n)) is a good probabilistic primality test, but there is no efficient probabilistic test for distinguishing primes from Carmichael numbers. That would have been a convincing counterexample. But it turns out that testing primality is easy, and in fact we can make a simple tweak to this very probabilistic primality test so that it doesn’t get fooled by Carmichael numbers. But is that an incidental fact about number theory, or once we found a probabilistic primality test was it inevitable that it could be strengthened in this way?
Here are some other illustrative cases:
- Suppose that C(x) uses x to initialize a 1000 x 1000 square in the middle of a 10,000 x 10,000 game of life grid. Then we simulate it for a million steps, and C(x) = 1 if any cell on the rightmost edge of the grid is ever alive. It’s very easy to look at the grid and distinguish the cases where C(x) = 1 because a glider is created that heads to the right side of the grid, from the much rarer cases where C(x) = 1 for any other reason (e.g. a medium weight spaceship).
- Suppose that X(x) is a pseudorandom sparse n x n matrix in some large finite field, and suppose that X is sparse enough that 1% of the time there are is no perfect matchings at all (i.e. there is no permutation sigma such that X[i, sigma(i)] != 0 for i=1,…,n). Define C(x) := (det(X(x)) = 0). We can distinguish the common case where det(X) = 0 because there are no perfect matchings in X from the extremely rare case where det(X) = 0 because there are multiple perfect matchings contributing to the determinant and they happen to all cancel out. These two cases are easy to distinguish by calculating det(X’) for another random matrix X’ with the same sparsity pattern as X. (Thanks to Dan Kane for calling my attention to this kind of example, and especially the harder version based on exact matchings.)
- Suppose that C_0(x) := A(x) or B(x) and C(x) is an obfuscated version of C_0. Then there is an efficient discriminator: de-obfuscate the circuit and check whether A or B is true. Finding that discriminator given C is hard, but that's not a violation of our general principle. That said, I would also be interested in a slightly stronger conjecture: not only is there always a discriminator, but it can always specified using roughly the same number of bits required to specify the circuit C. That’s true in this case, because the circuit C needs to bake in the secret key for the obfuscation, and so requires more bits than the discriminator.
If there don’t exist any convincing counterexamples to this principle, then I’m also very interested in understanding why—right now I don’t have any formal way of talking about this situation or seeing why discrimination should be possible in general. One very informal way of phrasing the "positive" problem: suppose I have a heuristic argument that C(x) often outputs 1 for random inputs x, and suppose that my heuristic argument appears to consider two cases A and B separately. Is there a generic way to either (i) find an efficient algorithm for distinguishing cases A and B, or else (ii) find an improved heuristic argument that unifies cases A and B, showing that they weren’t fundamentally separate mechanisms?
comment by Charlie Steiner · 2022-11-26T14:37:28.919Z · LW(p) · GW(p)
While noting down a highly lukewarm hot take about ELK, I thought of a plan for a "heist:"
Create a copy of your diamond, then forge evidence both of swapping my forgery with the diamond in your vault, and you covering up that swap. Use PR to damage your reputation and convince the public that I in fact hold the real diamond. Then sell my new original for fat stacks of cash. This could make a fun heist movie, where the question of whether the filmed heist is staged or actually happened is left with room for doubt by the audience.
Anyhow, I feel like there's something fishy about the shift of meta-level going on when the focus of this post moves from the diamond staying put for the usual reasons, to the AI making a decision for the usual reasons. In the object-level diamond example, we want to know that the AI is using "usual reasons" type decision-making. If we need a second AI to tell us that the first AI is using "usual reasons" type reasoning, we might need a third AI to tell us whether the second AI is using "usual reasons" type reasoning when inspecting the first AI, or whether it might be tricked by an edge case. If we don't need the third AI, then it feels like maybe that means we should have a good enough grasp of how to construct reasoning systems that we shouldn't need the second AI either.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2022-11-26T18:25:24.373Z · LW(p) · GW(p)
There isn't supposed to be a second AI.
In the object-level diamond example, we want to know that the AI is using "usual reasons" type decision-making.
In the object-level diamond situation, we have a predictor of "does the diamond appear to remain in the vault," we have a proposed action and predict that if we take it the diamond will appear to remain in the vault, and we want to know whether the diamond appears to remain in the vault for the normal reason.
For simplicity, when talking about ELK in this post or in the report, we are imagining literally selecting actions by looping over each possible action and predicting its consequences, or doing some kind of more clever search (but where the alignment difficulty comes from the search).
You could also try to apply this to a model-free RL agent. I think that's probably not very different. My best guess for how to do it is to train a question-answering head to talk about the possible consequences of its plan, and then use this machinery to keep that honest. But I don't discuss it in this post and haven't thought about it as much.
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2022-11-27T08:38:15.521Z · LW(p) · GW(p)
I'm somewhat confused, but it does seem like there are two AIs when you talk about doing automated anomaly detection for deceptive alignment. If I attempt to read your mind, I get a lot of disjoint possibilities. Some of them are:
- We probably agree but you don't quite know what I'm talking about either, or
- You don't think anomaly detection counts as "an AI," maybe because you expect it to not involve much learning or model-building (where I would expect it to involve model-building), or
- You expect anomaly detection to require cleverness, but think that cleverness will all be located in one place, so that we're really talking about one AI reflecting on itself.
↑ comment by paulfchristiano · 2022-11-27T16:18:16.410Z · LW(p) · GW(p)
The general strategy I'm describing for anomaly detection is:
- Search for an explanation of a model behavior (like "answers questions coherently") on the training set.
- Given a new input, take a sub-explanation that explains almost all of the training set behavior but doesn't explain the behavior on the new input.
- If you can't find one, then call the behavior potentially anomalous (e.g. because on the training set coherence follows from the logical structure of the world, but on the deceptive alignment point it follows from a desire to avoid looking incoherent)
The first two steps are solving problems in NP, so I think it's reasonable to expect them to be easier from an alignment perspective. (We also don't imagine solving them using the same AI techniques applied on the object level, and if we did then I would agree that we have further deceptive alignment problems, but still it seems helpful to ask your AI to do something that is both tractable and formally verifiable.)
My sense is that you probably don't think this kind of strategy can work, and that instead anomaly detection requires something more like training a second AI to tell us if something is weird. I'd agree that this doesn't sound like progress.
comment by paulfchristiano · 2022-12-30T23:41:47.243Z · LW(p) · GW(p)
The approach in this post is quite similar to what we talked about in the "narrow elicitation" appendix of ELK, I found it pretty interesting to reread it today (and to compare the old strawberry appendix to the new strawberry appendix [AF · GW]). The main changes over the last year are:
- We have a clearer sense of how heuristic estimators and heuristic arguments could capture different "reasons" for a phenomenon.
- Informed by the example of cumulant propagation and Wick products, we have a clearer sense for how you might attribute an effect to a part of a heuristic argument.
- We have a potential strategy for mechanistic anomaly detection by minimizing over "subsets" of a heuristic argument (and some ways of defining those).
- Largely as a result of filling in those details, we've now converged on this as the core of our approach to ELK rather than just an intuitive description of what counts as an ELK counterexample.
Ultimately it's not surprising that our approach ended up more closely tied to the problem statement itself, whereas approaches based on regularization are more reliant on some contingency. One way to view the change is that we were initially exploring simple options that didn't require solving philosophical problems or building up complicated new machinery, and now we've given up on the easy outs and we're just trying to formally define what it means for something to happen for the typical reason.
comment by Ramana Kumar (ramana-kumar) · 2022-12-09T16:28:54.788Z · LW(p) · GW(p)
(Bold direct claims, not super confident - criticism welcome.)
The approach to ELK in this post is unfalsifiable.
A counterexample to the approach would need to be a test-time situation in which:
- The predictor correctly predicts a safe-looking diamond.
- The predictor “knows” that the diamond is unsafe.
- The usual “explanation” (e.g., heuristic argument) for safe-looking-diamond predictions on the training data applies.
Points 2 and 3 are in direct conflict: the predictor knowing that the diamond is unsafe rules out the usual explanation for the safe-looking predictions.
So now I’m unclear what progress has been made. This looks like simply defining “the predictor knows P” as “there is a mechanistic explanation of the outputs starting from an assumption of P in the predictor’s world model”, then declaring ELK solved by noting we can search over and compare mechanistic explanations.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2022-12-09T17:44:50.966Z · LW(p) · GW(p)
This approach requires solving a bunch of problems that may or may not be solvable—finding a notion of mechanistic explanation with the desired properties, evaluating whether that explanation “applies” to particular inputs, bounding the number of sub-explanations so that we can use them for anomaly detection without false positives, efficiently finding explanations for key model behaviors, and so on. Each of those steps could fail. And in practice we are pursuing a much more specific approach to formalizing mechanistic explanations as probabilistic heuristic arguments, which could fail even more easily.
This approach also depends on a fuzzier philosophical claim, which is more like: “if every small heuristic argument that explains the model behavior on the training set also applies to the current input, then the model doesn’t know that something weird is happening on this input.” It seems like your objection is that this is an unfalsifiable definitional move, but I disagree:
- We can search for cases where we intuitively judge that the model “knows” about a distinction between two mechanisms and yet there is no heuristic argument that distinguishes those mechanisms (even though “know” is pre-formal).
- Moreover, we can search more directly for any plausible case in which SGD produces a model that pursues a coherent and complex plan to tamper with the sensors without there being any heuristic argument that distinguishes it from the normal reason—that’s what we ultimately care about and “know” is just an intuitive waypoint that we can skip if it introduces problematic ambiguity.
- If we actually solve all the concrete problems (like formalizing and finding heuristic arguments) then we can just look at empirical cases of backdoors, sensor tampering, or natural mechanism distinctions and empirically evaluate whether in fact those distinctions are detected by our method. That won't imply that our method can distinguish real-world cases of sensor tampering, but it will provide much stronger empirical evidence than is available for most alignment approaches (because there is no reason for the methods to break down around human level in particular).
All of those things are challenging without a clear formalization of "heuristic argument," but I still feel we can do some productive thinking about them. Moreover this is objection is more like "We're looking at a 3-step plan where it's hard to evaluate step 3 without knowing details about how step 1 went" rather than "This plan is unfalsifiable."
comment by NicholasKees (nick_kees) · 2022-11-27T17:57:27.643Z · LW(p) · GW(p)
If we are able to flag a treacherous turn as cognitively anomalous, then we can take that opportunity to shut down a system and retrain on the offending datapoint.
What do you mean by "retrain on the offending datapoint"? I would be worried about Goodhearting on this by selecting for systems which don't set off the anomaly detector, and thereby making it a less reliable safeguard.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2022-11-27T18:35:30.182Z · LW(p) · GW(p)
Suppose I have a slow process I trust that I use to provide sparse ground truth for my system (like a very extensive human evaluation). But day-to-day I need to use my ML system because it's much cheaper. I'm concerned that it may take some catastrophically bad actions at test time because it thinks that it can take over. But if I can flag those as anomalous, then I can invoke my slow oversight process, include the datapoint in training data, update my model to be less likely to try to take a treacherous turn, and then continue. If my model learns quickly then I won't have to do this very many times before it stops trying to take a treacherous turn.
comment by Chris_Leong · 2023-06-13T22:25:01.564Z · LW(p) · GW(p)
I’m confused about the back door attack detection task even after reading it a few times:
The article says: “The key difference in the attack detection task is that you are given the backdoor input along with the backdoored model, and merely need to recognize the nput as an attack”.
When I read that, I find myself wondering why that isn’t trivial solved by a model that memorises which input(s) are known to be an attack.
My best interpretation is that there are a bunch of possible inputs that cause an attack and you are given one of them and just have to recognise that one plus the others you don’t see. Is this interpretation correct?
Replies from: mark-xu, o-o↑ comment by Mark Xu (mark-xu) · 2023-07-10T23:16:37.358Z · LW(p) · GW(p)
You have to specify your backdoor defense before the attacker picks which input to backdoor.
↑ comment by O O (o-o) · 2023-06-13T23:57:07.424Z · LW(p) · GW(p)
I don’t see it suggest anywhere that you know which particular input is part of the back door input set. I think you just have to identify which inputs are attacks and which are not.
I believe synthesizing a back door set falls within the Trojan horse problem and could be very hard as the back door set may just be random numbers. If you can synthesize the back door set you can probably solve the Trojan horse problem.
comment by obiwan kenobi (obiwan-kenobi) · 2024-06-23T13:17:04.065Z · LW(p) · GW(p)
If the pedestal the large diamond had a constant beam of a specific light passing through the diamond constantly . The diamond would produce a specific spectrum of light in the room that could be measured. Even if there were a picture infront of the camera, the change in this specific lighting would change even if there were a picture placed in front of the camera. Using various types of light could produce different traceable effects that may be harder for the thief to detect and make it more obvious for ai to detect.
comment by Lao Mein (derpherpize) · 2022-12-01T08:05:28.873Z · LW(p) · GW(p)
I would like to make a suggestion about the use of the phrase "human-simulator".
It has a lot of implications, and a lot of people (myself included) start with the intuition that simulating a human being is very computationally intensive. Some may attempt to leverage this implied computational complexity for their ELK proposals.
But the "human-simulator" doesn't actually need to be a fully-functioning human. It's just a prediction of human responses to an argument (or sensor input). It's something that current transformer models can do quite well, and something I can do in my head. This makes the argument that a translator can be more computationally intensive than a human-simulator much more intuitive.
I think it would be beneficial if this was made explicit in the writing, or if a different phrase is used.
comment by Ruby · 2022-12-01T06:26:01.833Z · LW(p) · GW(p)
Curated. The ELK paper/problem/challenge last year was a significant piece of work for our alignment community and my guess is hundreds of hours and maybe hundreds of thousands of dollars went into incentivizing solutions. Though prizes were awarded, I'm not aware that any particular proposed solution was deemed incredibly promising (or if it was, it wasn't something new), so I find it interesting to see what Paul and ARC have generated as they do stick on the same problem, roughly.