BatchTopK: A Simple Improvement for TopK-SAEs
post by Bart Bussmann (Stuckwork), Patrick Leask (patrickleask), Neel Nanda (neel-nanda-1) · 2024-07-20T02:20:51.848Z · LW · GW · 0 commentsContents
Introduction BatchTopK Experimental Set-Up Results Inference with BatchTopK Limitations and Future Work None No comments
Work done in Neel Nanda’s stream of MATS 6.0.
Epistemic status: Tried this on a single sweep and seems to work well, but it might definitely be a fluke of something particular to our implementation or experimental set-up. As there are also some theoretical reasons to expect this technique to work (adaptive sparsity), it seems probable that for many TopK SAE set-ups it could be a good idea to also try BatchTopK. As we’re not planning to investigate this much further and it might be useful to others, we’re just sharing what we’ve found so far.
TL;DR: Instead of taking the TopK feature activations per token during training, taking the Top(K*batch_size) for every batch seems to improve SAE performance. During inference, this activation can be replaced with a single global threshold for all features.
Introduction
Sparse autoencoders (SAEs) have emerged as a promising tool for interpreting the internal representations of large language models. By learning to reconstruct activations using only a small number of features, SAEs can extract monosemantic concepts from the representations inside transformer models. Recently, OpenAI published a paper exploring the use of TopK activation functions in SAEs. This approach directly enforces sparsity by only keeping the K largest activations per sample.
While effective, TopK forces every token to use exactly k features, which is likely suboptimal. We came up with a simple modification that solves this and seems to improve its performance.
BatchTopK
Standard TopK SAEs apply the TopK operation independently to each sample in a batch. For a target sparsity of K, this means exactly K features are activated for every sample.
BatchTopK instead applies the TopK operation across the entire flattened batch:
- Flatten all feature activations across the batch
- Take the top (K * batch_size) activations
- Reshape back to the original batch shape
This allows more flexibility in how many features activate per sample, while still maintaining an average of K active features across the batch.
Experimental Set-Up
For both the TopK and the BatchTopK SAEs we train a sweep with the following hyperparameters:
- Model: gpt2-small
- Site: layer 8 resid_pre
- Batch size: 4096
- Optimizer: Adam (lr=3e-4, beta1 = 0.9, beta2=0.99)
- Number of tokens: 1e9
- Expansion factor: [4, 8, 16, 32]
- Target L0 (k): [16, 32, 64]
As in the OpenAI paper, the input gets normalized before feeding it into the SAE and calculating the reconstruction loss. We also use the same auxiliary loss function for dead features (features that didn’t activate for 5 batches) that calculates the loss on the residual using the top 512 dead features per sample and gets multiplied by a factor 1/32.
Results
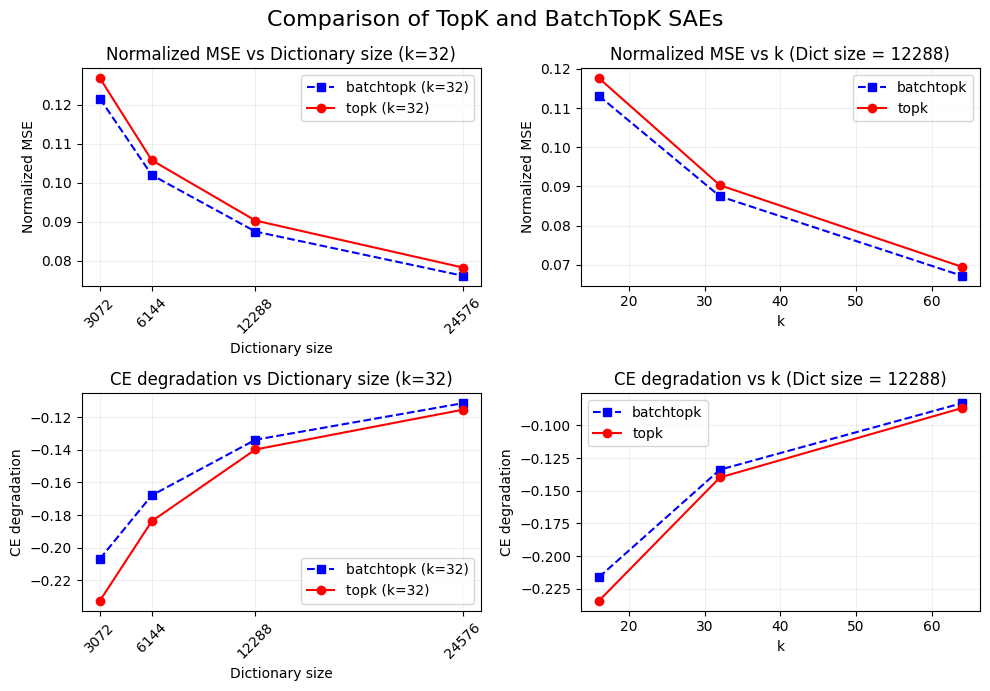
For a fixed number of active features (L0=32) the BatchTopK SAE has a lower normalized MSE than the TopK SAE and less downstream loss degradation across different dictionary sizes. Similarly, for fixed dictionary size (12288) BatchTopK outperforms TopK for different values of k.
Our main hypothesis for the improved performance is thanks to adaptive sparsity: some samples contain more highly activating features than others. Let’s have look at the distribution of number of active samples for the BatchTopK model.
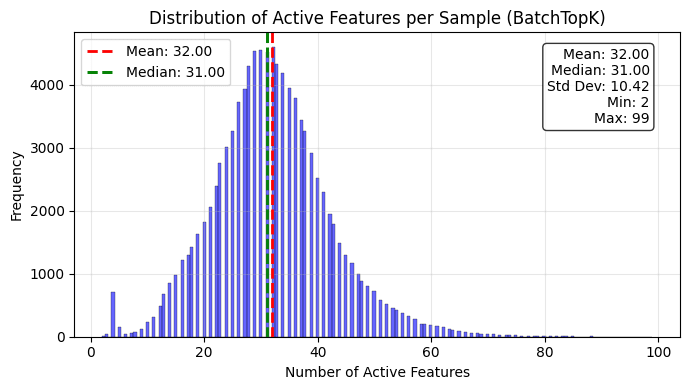
The BatchTopK model indeed makes use of its possibility to use different sparsities for different inputs. We suspect that the weird peak on the left side are the feature activations on BOS-tokens, given that its frequency is very close to 1 in 128, which is the sequence length. This serves as a great example of why BatchTopK might outperform TopK. At the BOS-token, a sequence has very little information yet, but the TopK SAE still activates 32 features. The BatchTopK model “saves” these activations such that it can use more features on tokens that are more information-dense.
Inference with BatchTopK
BatchTopK seems to work well as a training method, but might not be ideal to use during inference. Generally, it is a bit icky if during inference the activations of the features depend on whatever else there is present in your batch. Also, the SAE is trained on batches with mixed activations from many different sequences, whereas during inference the features in the batches (or individual sequences) will be correlated in all kinds of ways.
Instead, we can estimate a threshold T, which is the average minimum activation value above zero in a batch:
Where is the jth feature of the ith sample in a batch B. Now we can simply use this threshold during inference and just set all feature activations below this threshold to zero. Interestingly, the architecture is now equivalent to a ProLU [LW · GW] or JumpReLU (published today!), but with a global threshold for all features rather than an individual threshold and trained in a very different fashion.
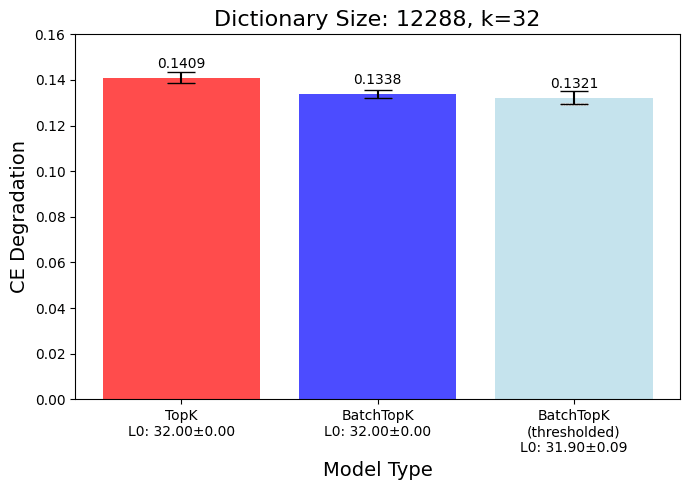
Using the threshold, the performance of the BatchTopK actually improves a bit further. This can be explained by the fact that without using the threshold, BatchTopK basically relies on using a noisier version of the same threshold.
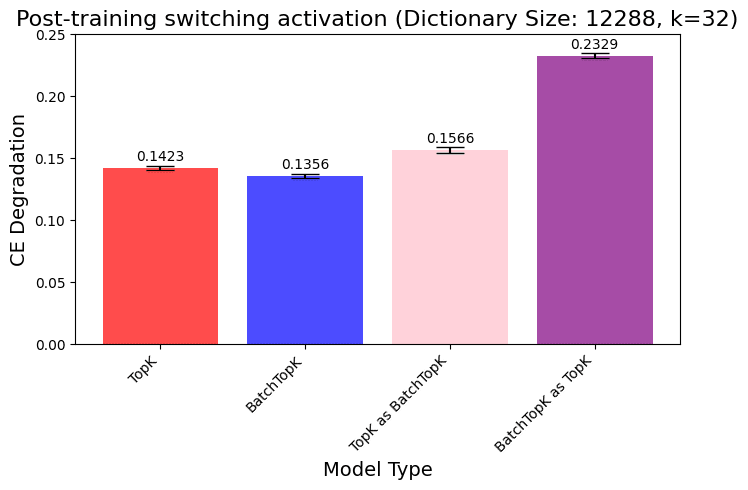
We also checked whether we can use the BatchTopK activation on a model trained with TopK into a model, and vice versa, but this doesn’t seem to work. This shows that the way that the activation function influences the training process for training these SAEs is actually an important factor, rather than that BatchTopK just selects higher activations in general.
Limitations and Future Work
As stated in the epistemic status, given the limited experiments we have run we are not very confident how much this result will generalize to other models, larger dictionary sizes, different hyperparameters, etc. We encourage others to experiment with this approach, validate the results, and explore further refinements. To this end, we are sharing the training code that we used to run these experiments.
Here are some ideas to further improve upon this work:
- Instead of selecting the TopK activations, we could track or estimate a target quantile (i.e. 1 - (target L0 / dictionary size)) activation during training and use this as a threshold for activations. BatchTopK is basically a method to do this where the quantile gets estimated per batch, but one can imagine that some kind of running average could improve results.
- Investigate the effect of batch size on BatchTopK.
- Compare the performance of BatchTopK to related architectures such as GatedSAEs and JumpReLU SAEs.
- Improve upon the auxiliary loss for BatchTopK SAEs. In order to make the comparison as easy and fair as possible we kept the TopK auxiliary loss from the OpenAI paper that uses a TopK of dead latents to estimate the residual. Possibly, when training BatchTopK SAEs, this auxiliary loss could be replaced by a loss that estimates the residual from the BatchTopK dead latents.
Thanks to Joseph Bloom for helpful comments on the experiments.
0 comments
Comments sorted by top scores.