ProLU: A Nonlinearity for Sparse Autoencoders
post by Glen Taggart · 2024-04-23T14:09:21.592Z · LW · GW · 4 commentsContents
Abstract PyTorch Implementation Introduction SAE Context and Terminology Learnable parameters of a sparse autoencoder: Training Notation: Encoder/Decoder Motivation: Inconsistent Scaling in Sparse Autoencoders A scale consistent response curve Scale Consistency Desiderata Notation: Centered Submodule Notation: Specified Feature Conditional Linearity Noise Suppresion Threshold Proportional ReLU (ProLU) Backprop with ProLU: ReLU gradients: Gradients of ProLU: Related Work Methods Notation: Synthetic Gradients Different synthetic gradient types Defining ProLUReLU: ReLU-like gradients Defining ProLUSTE: Derivation from straight-through estimator Setup Choice of Straight-Through Estimator ProLU Sparse Autoencoder Experiment Setup Shared among all sweeps: Varying between sweeps: Varying within sweeps Results Further Investigation MSE/L1 Pareto Frontier Acknowledgements How to Cite None 4 comments
Abstract
This paper presents , an alternative to for the activation function in sparse autoencoders that produces a pareto improvement over both standard sparse autoencoders trained with an L1 penalty and sparse autoencoders trained with a Sqrt(L1) penalty.
The gradient wrt. is zero, so we generate two candidate classes of differentiable :
Introduction
SAE Context and Terminology
Learnable parameters of a sparse autoencoder:
- : encoder weights
- : decoder weights
- : encoder bias
- : decoder bias
The output of an SAE is given by
Training
Notation: Encoder/Decoder
Let
so that the full computation done by an SAE can be expressed as
An SAE is trained with gradient descent on
where is the sparsity penalty coefficient (often "L1 coefficient") and is the sparsity penalty function, used to encourage sparsity.
is commonly the L1 norm but recently has been shown to produce a Pareto improvement [LW · GW] on the L0 and CE metrics. We will use this as a further baseline to compare against when assessing our models in addition to the standard -based SAE with L1 penalty.
Motivation: Inconsistent Scaling in Sparse Autoencoders
Due to the affine translation, sparse autoencoder features with nonzero encoder biases only perfectly reconstruct feature magnitudes at a single point.
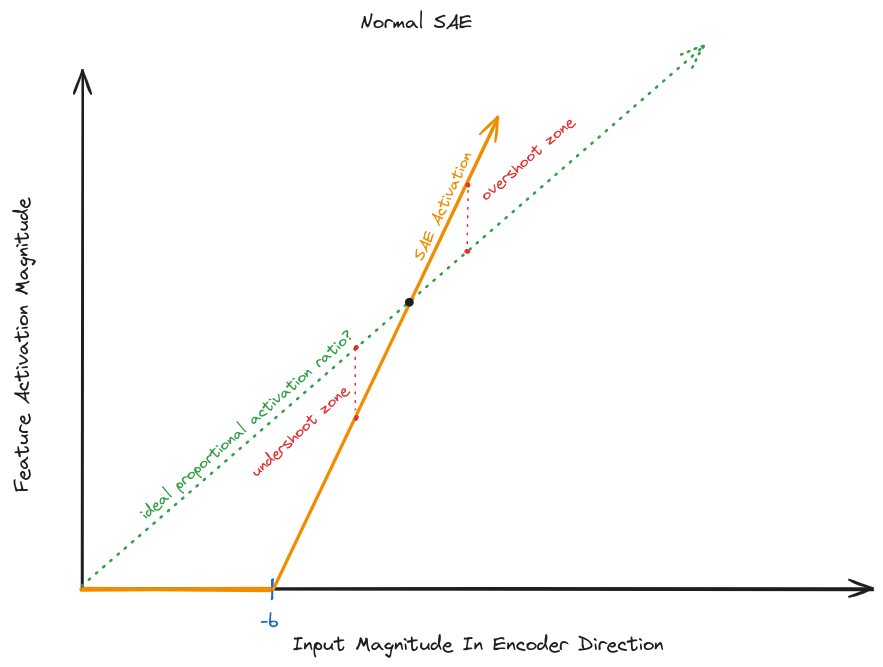
This poses difficulties if activation magnitudes for a fixed feature tend to vary over a wide range. This potential problem motivates the concept of scale consistency:
A scale consistent response curve
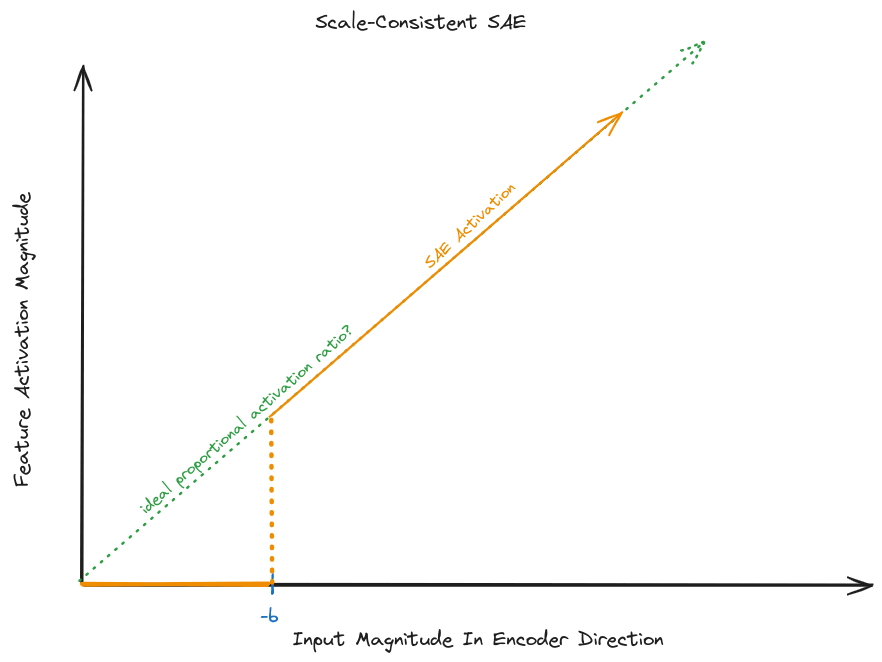
The bias maintains its role in noise suppression, but no longer translates activation magnitudes when the feature is active.
The lack of gradients for the encoder bias term poses a challenge for learning with gradient descent. This paper will formalize an activation function which gives SAEs this scale-consistent response curve, and motivate and propose two plausible synthetic gradients, and compare scale-consistent models trained with the two synthetic gradients to standard SAEs and SAEs trained with Sqrt(L1) penalty.
Scale Consistency Desiderata
Notation: Centered Submodule
The use of the decoder bias can be viewed as performing centering on the inputs to a centered SAE then reversing the centering on the outputs:
Notation: Specified Feature
Let denote the weights and the encoder bias for the -th feature. Then, let
Conditional Linearity
Noise Suppresion Threshold
Proportional ReLU
The concept of using a thresholding nonlinearity instead of a learned bias term for inhibition autoencoders was introduced a decade prior to this work in "Zero-Bias Autoencoders and the Benefits of Co-adapting Features." Their TRec activation function is very similar to ProLU, with the following key differences:
- ProLU has a different threshold parameter for each hidden unit
- Learning of ProLU's threshold parameter () is enabled via psuedoderivatives
We define the base (without psuedoderivatives not yet defined) Proportional ReLU as:
Backprop with :
To use in SGD-optimized models, we first address the lack of gradients wrt. the term.
gradients:
For comparison and later use, we will first consider : partial derivatives are well defined for at all points other than :
Gradients of :
Partials of wrt. are similarly well defined:
However, they are not well defined wrt. , so we must synthesize these.
Related Work
[Zero-bias autoencoders and the benefits of co-adapting features] introduced zero-bias autoencoders which are very related to this work. The ProLU SAE can be viewed as a zero-bias autoencoder where the threshold parameter theta is learned using straight-through estimators and which uses an L1 penalty to encourage sparsity
Methods
Notation: Synthetic Gradients
Let denote the synthetic partial derivative of wrt. , and the synthetic gradient of f, used for backpropagation as a stand-in for the gradient.
Different synthetic gradient types
We train two classes of with different synthetic gradients. These are distinguished by their subscript:
They are identical in output, but have different synthetic gradients. I.e.
Defining : -like gradients
The first synthetic gradient is very similar to the gradient for . We retain the gradient wrt. , and define the synthetic gradient wrt. to be the same as the gradient wrt. :
Defining : Derivation from straight-through estimator
The second class of uses synthetic gradients for both and and can be motivated by framing and in terms of the threshold function, and a common choice of straight-through estimator (STE) for the threshold function. This is a plausible explanation for the observed empirical performance but it should be noted that there are many degrees of freedom and possible alternative
Setup
The threshold function is defined as follows:
We will rephrase the partial derivative of in terms of the threshold function for ease of later notation:
It is common to use a straight-through estimator (STE) to approximate the gradient of the threshold function:
We can reframe in terms of the threshold function:
Synthetic Gradients wrt.
Now, we take partial derivatives of wrt. using the STE approximation for the threshold function:
Synthetic Gradients wrt.
Choice of Straight-Through Estimator
There are many possible functions to use for . In our experiments, we take the derivative of as the choice of straight-through estimator. This choice has been used in training quantized neural nets.[1]
then, synthetic gradients wrt. are given by,
and wrt. are given by,
Sparse Autoencoder
We can express the encoder of a SAE as
No change is needed to the decoder. Thus,
Experiment Setup
Shared among all sweeps:
- Adam optimizer, with:
- Data
- Trained on gpt2 layer 6 pre-residual activations
- Tokens: ~400m tokens from The Pile @ack(Alan Cooney's pre-tokenized pile)
- -> ~100k gradient steps
- LR schedule
- Warmup for steps in accordance with On the adequacy of untuned warmup for adaptive optimization
- Linear warmup after each resample. Same value 2,000
- Linear cooldown to 1/10 initial value over 20,000 steps starting at 75,000 steps
- Anthropic resampling
- I used 3e-6 as the dead threshold rather than 0
- Resample at 25,000 and 50,000 steps
- The proportion of the average encoder norm resampled to varied between sweeps
- Normalization:
- L2 normalization as proposed by Anthropic
- SAE details
- Dictionary expansion factor of 16
- Tied decoder bias, untied encoder/decoder weights
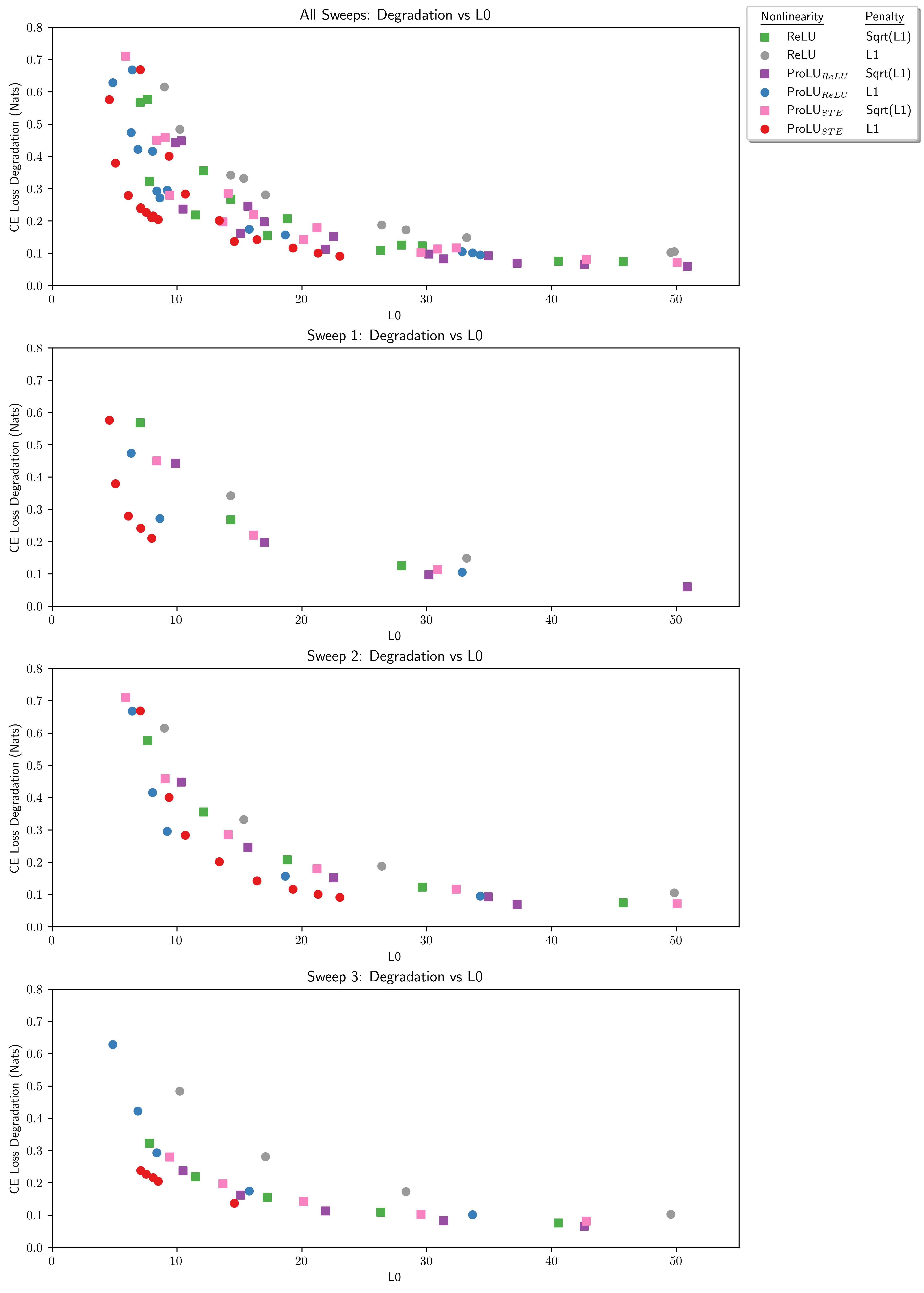
Varying between sweeps:
- Experiment 1:
- 30 total runs
- Resampled to 0.02 of avg encoder norm
- Experiment 2:
- 48 total runs
- Resampled to 0.02 of avg encoder norm
- Experiment 3:
- 30 total runs
- Resampled to 0.2 of avg encoder norm
- adjusted L1-coefficient ranges for each model, to get more overlap in L0 ranges.
- different architectures respond very differently to l1 coefficients
Varying within sweeps
- L1 coefficient
- Architecture choice of nonlinearity:
- L1 Penalty type
- L1:
- Sqrt(L1):
Results
Let:
- be the CE loss of the model unperturbed on the data distribution
- be the CE loss of the model when activations are replaced with the reconstructed activations
- be the CE loss of the model when activations are replaced with the zero vector
Degradation: or Information Lost. This measures how much information about the correct next token the model loses by having its activations replaced with the SAE's reconstruction .
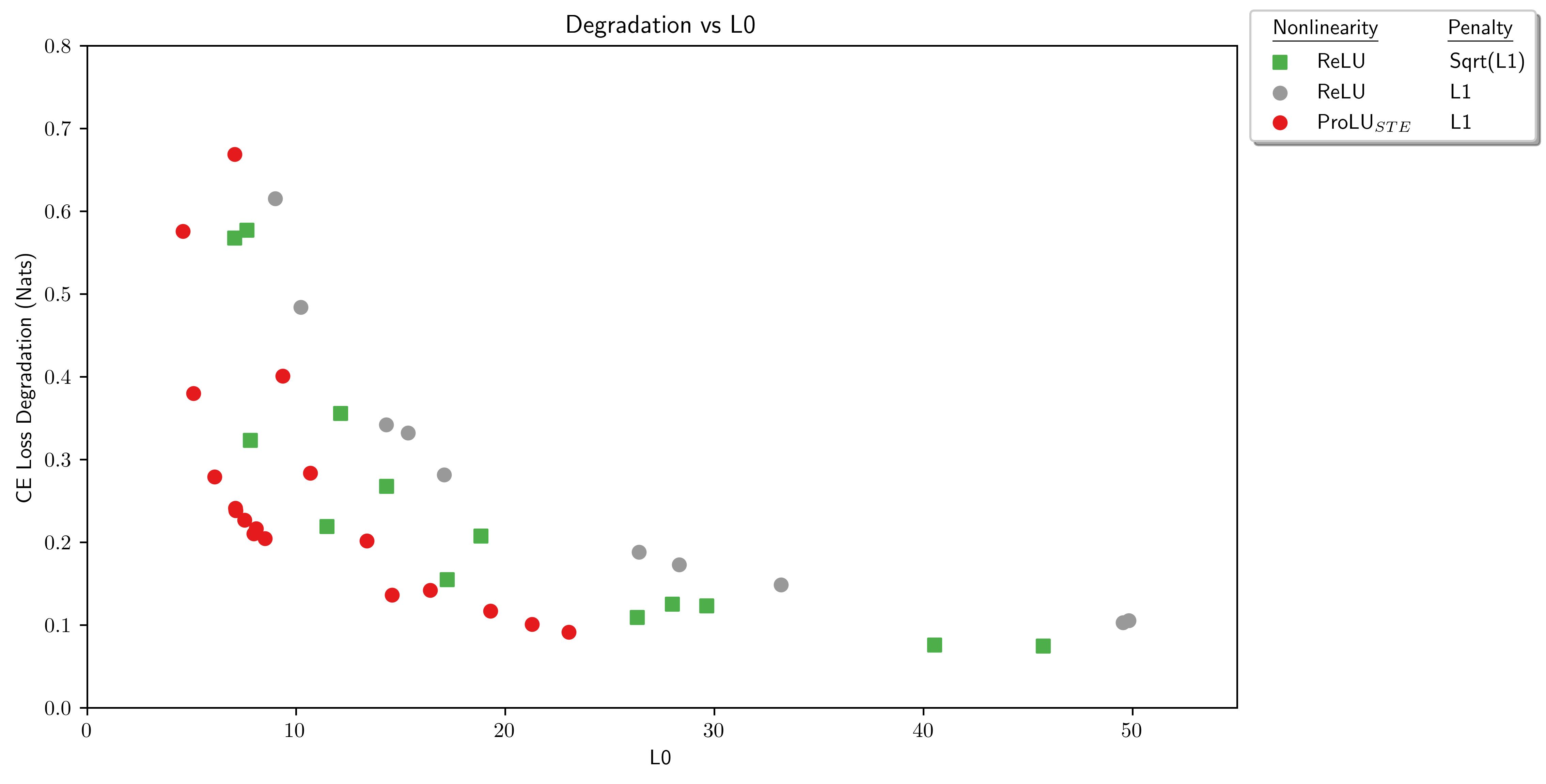
For :
- The pareto-best architecture uses the nonlinearity with an L1 sparsity penalty.
For :
- There are no occurrences of models using with L1 penalty in this L0 range
- Of the remaining models, with Sqrt(L1) penalty is pareto-best.
Further Investigation
MSE/L1 Pareto Frontier
The gradients of are not the gradients of the loss landscape, so it would be a reasonable default to expect these models to perform worse than a vanilla SAE. Indeed I expect they may perform worse on the optimization target, and that the reason why this is able to work is there is slack in the problem introduced by us being unable to optimize for our actual target directly -- our current options are to optimize for L1 or Sqrt(L1) as sparsity proxies for what we actually want because L0 is not a differentiable metric.
Actual target: minimize L0 and bits lost
Optimization (proxy) target: minimize L1 (or )) and MSE
Because we're not optimizing for the actual target, I am not so surprised that there may be weird tricks we can do to get more of what we want.
On this vein of thought, my prediction after seeing the good performance on the actual target (and prior to checking this prediction) was:
Despite improved performance on degradation/L0 ProLU SAEs will have the same or worse on the MSE/L1 curve.
We may also see the higher performing architectures have greater L1/L0
Let's check: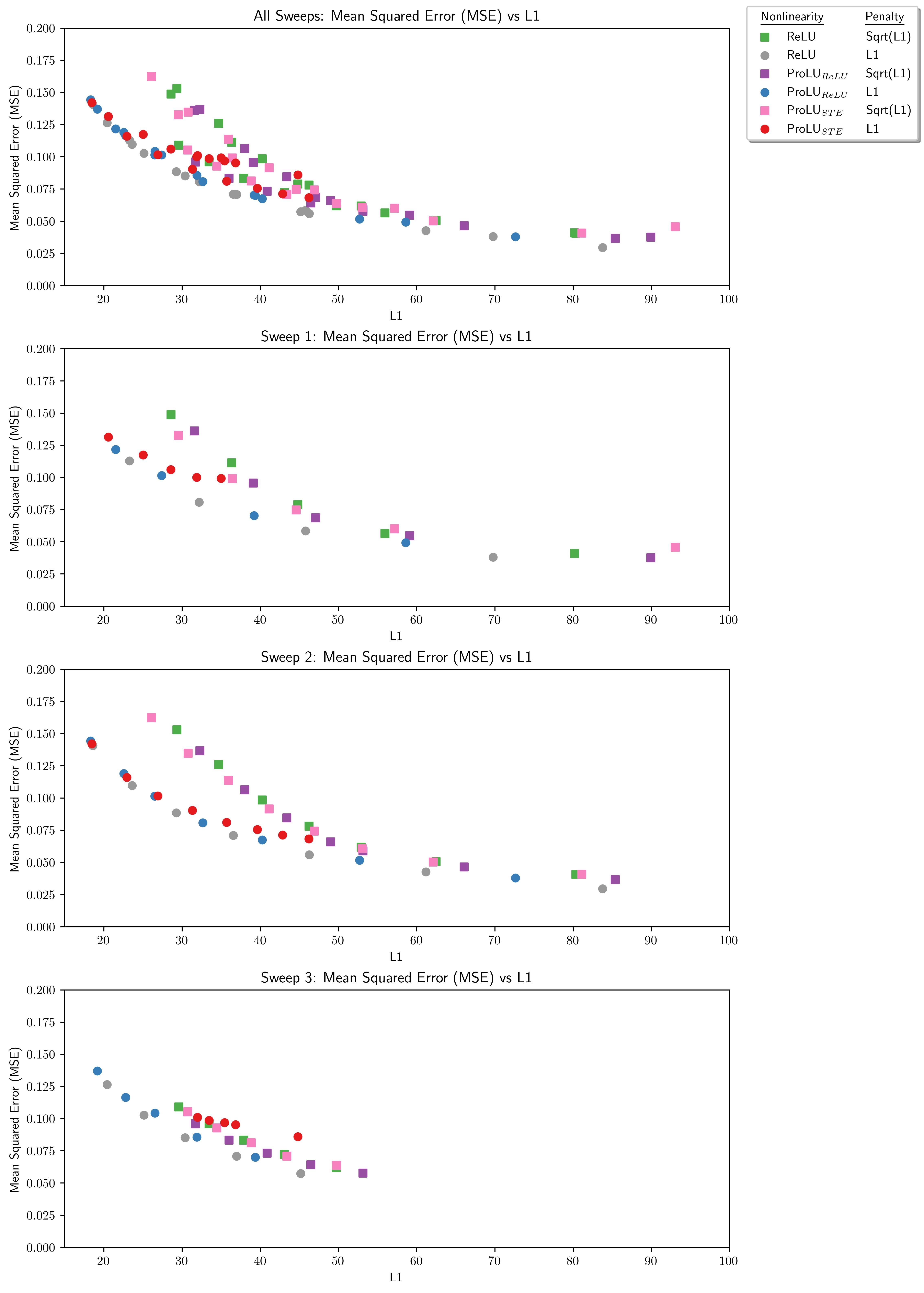
This suggests a possible reason for why the technique works well:
Possibly the gains from this technique do not come from scale consistency so much as that it forced us to synthesize some gradients and those gradients happened to point more in the direction of what we actually want.
Here is the graph of L1 norm versus L0 norm:
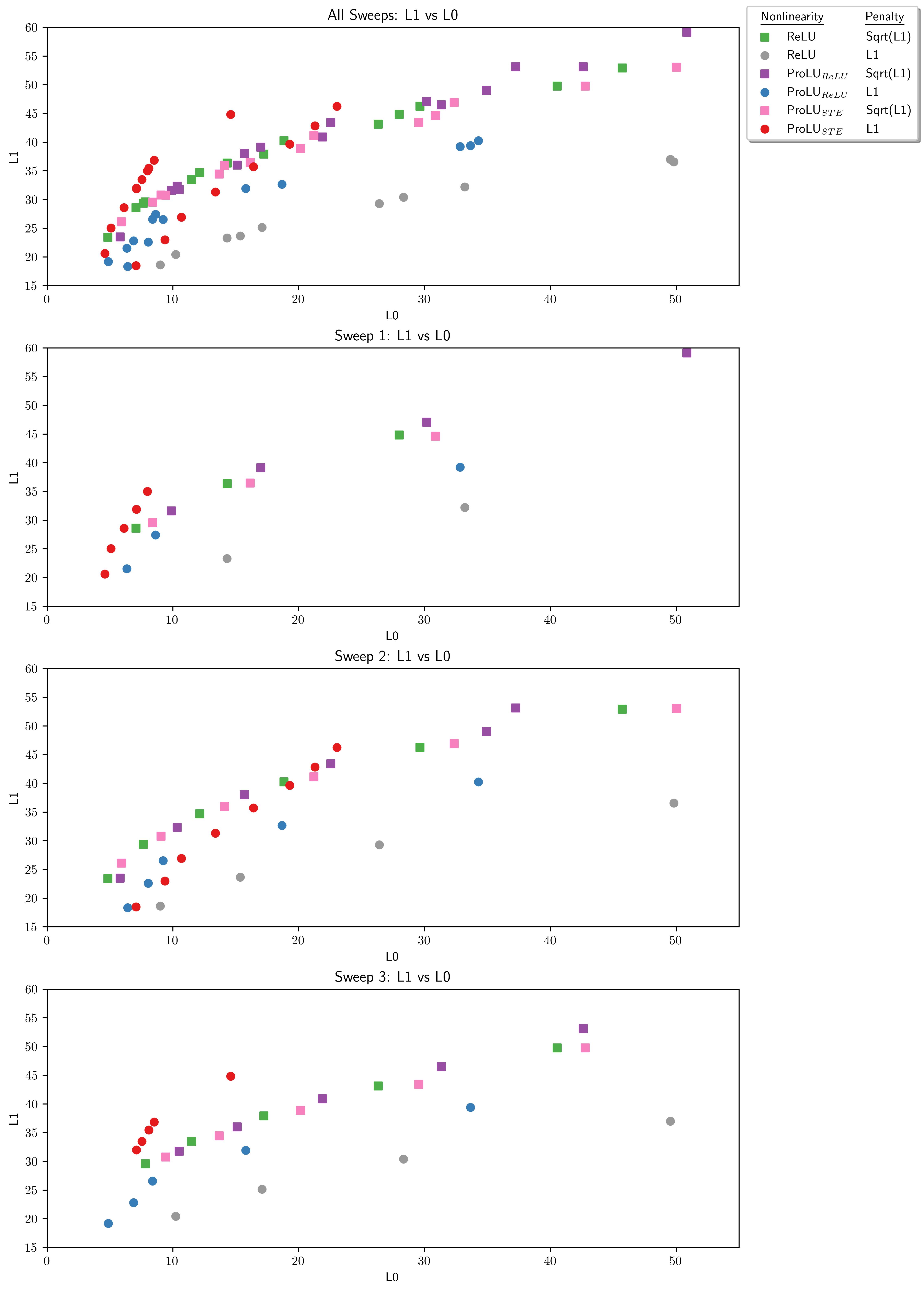
This looks like it's possible that what is working well here is the learned features are experiencing less suppression [LW · GW], but that may not be the only thing going on fixing this. Feature suppression is still consistent with the scale consistency hypothesis, as consistent undershooting would be an expected side effect if that is a real problem, since regular SAEs may be less able to filter unwanted activations if they are keeping biases near zero in order to minimize errors induced by scale inconsistency.
More investigation is needed here to create a complete or confident picture of what is cause of the performance gains in SAEs.
Unfortunately, I did not log so I can't compare with that curve, but could load the models to create those graphs in follow-up work.
Acknowledgements
Noa Nabeshima and Arunim Agarwal gave useful feedback and editing help on the draft of this post.
Mason Krug for in depth editing of my grant proposal, which helped seed this writeup and clarify my communication.
How to Cite
@misc{ProLUNonlinearity,
title = {ProLU: A Nonlinearity for Sparse Autoencoders},
author = {Glen M. Taggart},
year = {2024},
howpublished = {\url{https://www.alignmentforum.org/posts/HEpufTdakGTTKgoYF/prolu-a-nonlinearity-for-sparse-autoencoders}},
}4 comments
Comments sorted by top scores.
comment by wuthejeff (jeff-wu) · 2024-04-25T15:41:38.937Z · LW(p) · GW(p)
This is great! We were working on very similar things concurrently at OpenAI but ended up going a slightly different route.
A few questions:
- What does the distribution of learned biases look like?
- For the STE variant, did you find it better to use the STE approximation for the activation gradient, even though the approximation is only needed for the bias?
↑ comment by Glen Taggart · 2024-04-25T20:30:53.513Z · LW(p) · GW(p)
Thank you!
That's super cool you've been doing something similar. I'm curious to see what direction you went in. It seemed like there's a large space of possible things to do along these lines. DeepMind also did a similar but different thing here.
What does the distribution of learned biases look like?
That's a great question, something I didn't note in here is that positive biases have no effect on the output of the SAE -- so, if the biases were to be mostly positive that would suggest this approach is missing something. I saved histograms of the biases during training, and they generally look to be mostly (80-99% of bias values I feel like?) negative. I expect the exact distributions vary a good bit depending on L1 coefficient though.
I'll post histograms here shortly. I also have the model weights so I can check in more detail or send you weights if you'd like either of those things.
On a related point, something I considered: since positive biases behave the same as zeros, why not use ProLU where the bias is negative and regular ReLU where the biases are positive? I tried this, and it seemed fine but it didn't seem to make a notable impact on performance. I expect there's some impact, but like a <5% change and I don't know in which direction, so I stuck with the simpler approach. Plus, anyways, most of the bias values tend to be negative.
For the STE variant, did you find it better to use the STE approximation for the activation gradient, even though the approximation is only needed for the bias?
I think you're asking whether it's better to use the STE gradient only on the bias term, since the mul () term already has a 'real gradient' defined. If I'm interpreting correctly, I'm pretty sure the answer is yes. I think I tried using the synthetic grads just for the bias term and found that performed significantly worse (I'm also pretty sure I tried the reverse just in case -- and that this did not work well either). I'm definitely confused on what exactly is going on with this. The derivation of these from the STE assumption is the closest thing I have to an explanation and then being like "and you want to derive both gradients from the same assumptions for some reason, so use the STE grads for too." But this still feels pretty unsatisfying to me, especially when there's so many degrees of freedom in deriving STE grads:
- choice of STE
- I glossed over this but it seems like maybe we should think of the grads of like where
- I think this because for
- I also see an argument from this that should be a term in the partial of , which is a property I like about taking as it's own derivative
Another note on the STE grads: I first found these gradients worked emperically, was pretty confused by this, spent a bunch of time trying to find an intuitive explanation for them plus trying and failing to find a similar-but-more-sensible thing that works better. Then one night I realized that those exact gradient come pretty nicely from these STE assumptions, and it's the best hypothesis I have for "why this works" but I still feel like I'm missing part of the picture.
I'd be curious if there are situations where the STE-style grads work well in a regular ReLU, but I expect not. I think it's more that there is slack in the optimization problem induced by being unable to optimize directly for L0. I think it might be just that the STE grads with L1 regularization point more in the direction of L0 minimization. I have a little analysis I did supporting this I'll add to the post when I get some time.
comment by David Scott Krueger (formerly: capybaralet) (capybaralet) · 2024-08-09T00:32:06.633Z · LW(p) · GW(p)
This activation function was introduced in one of my papers from 10 years ago ;)
See Figure 2 of https://arxiv.org/abs/1402.3337
↑ comment by Glen Taggart · 2024-08-10T17:19:46.798Z · LW(p) · GW(p)
Hey David, I really like your paper, hadn't seen it til now. Sorry for not doing a thorough literature review and catching it!
Super cool paper too, exciting to see. Seems like there's a good amount of overlap in what motivated our approaches, too, though your rationale seems more detailed/rigorous/sophisticated - I'll have to read it more thoroughly and try to absorb the generators of that process.
Then it looks like my contribution here was just making the threshold have a parameter per-feature and defining some pseudoderivatives so that threshold parameters could be learned (though I was framing it as an 'inhibitory bias' at the time, I now like the threshold framing)
I'll add a citation to your paper shortly (probably this evening, though possibly tomorrow)
Wild that you did that already, ten years ago. super cool.
Thanks for commenting and letting me know! :)