Posts
Comments
LW feature request/idea: something like Quick Takes, but for questions (Quick Questions?). I often want to ask a quick question or for suggestions/recommendations on something, and it feels more likely I'd get a response if it showed up in a Quick Takes like feed rather than as an ordinary post like Questions currently do.
It doesn't feel very right to me to post such questions as Quick Takes, since they aren't "takes". (I also tried this once, and it got downvoted and no responses.)
I'm looking for recommendations for frameworks/tools/setups that could facilitate machine checked math manipulations.
More details:
- My current use case is to show that an optimized reshuffling of a big matrix computation is equivalent to the original unoptimized expression
- Need to be able to index submatrices of an arbitrary sized matrices
- I tried doing the manipulations with some CASes (SymPy and Mathematica), which didn't work at all
- IIUC the main reason they didn't work is that they couldn't handle the indexing thing
- I have very little experience with proof assistants, and am not willing/able to put the effort into becoming fluent with them
- The equivalence proof doesn't need to be a readable by me if e.g. an AI can cook up a complicated equivalence proof
- So long as I can trust that it didn't cheat e.g. by sneaking in extra assumptions
I agree with this critique; I think washing machines belong on the "light bulbs and computers" side of the analogy. The analogy has the form:
"germline engineering for common diseases and important traits" : "gene therapy for a rare disease" :: "widespread, transformation uses of electricity" : x
So x should be some very expensive, niche use of electricity that provides a very large benefit to its tiny user base (and doesn't arguably indirectly lead to large future benefits, e.g. via scientific discovery for a niche scientific instrument).
I think you're mixing up max with argmax?
Something I didn't realize until now: P = NP would imply that finding the argmax of arbitrary polynomial time (P-time) functions could be done in P-time.
Proof sketch
Suppose you have some polynomial time function f: N -> Q. Since f is P-time, if we feed it an n-bit input x it will output a y with at most max_output_bits(n) bits as output, where max_output_bits(n) is at most polynomial in n. Denote y_max and y_min as the largest and smallest rational numbers encodable in max_output_bits(n) bits.
Now define check(x, y) := f(x) >= y, and argsat(y) := x such that check(x, y) else None. argsat(y) is in FNP, and thus runs in P-time if P = NP. Now we can find argmax(f(x)) by running a binary search over all values y in [y_min, y_max] on the function argsat(y). The binary search will call argsat(y) at most max_output_bits(n) times, and P x P = P.
I'd previously thought of argmax as necessarily exponential time, since something being an optimum is a global property of all evaluations of the function, rather than a local property of one evaluation.
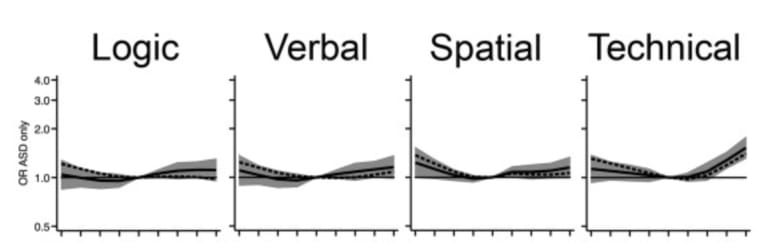
- The biggest discontinuity is applied at the threshold between spike and slab. Imagine we have mutations that before shrinkage have the values +4 IQ, +2 IQ, +1.9 IQ, and 1.95 is our spike vs. slab cutoff. Furthermore, let's assume that the slab shrinks 25% of the effect. Then we get 4→3, 2→1.5, 1.9→0, meaning we penalize our +2 IQ mutation much less than our +1.9 mutation, despite their similar sizes, and we penalize our +4 IQ effect size more than the +2 IQ effect size, despite it having the biggest effect, this creates an arbitrary cliff where similar-sized effects are treated completely differently based on which side of the cutoff they fall on, and where the one that barely makes it, is the one we are the least skeptical off"
There isn't any hard effect size cutoff like this in the model. The model just finds whatever configurations of spikes have high posteriors given the assumption of sparse normally distributed nonzero effects. I.e., it will keep adding spikes until further spikes can no longer offset their prior improbability via higher likelihood (note this isn't a hard cutoff, since we're trying to approximate the true posterior over all spike configurations; some lower probability configurations with extra spikes will be sampled by the search algorithm).
My guess is that peak intelligence is a lot more important than sheer numbers of geniuses for solving alignment. At the end of the day someone actually has to understand how to steer the outcome of ASI, which seems really hard and no one knows how to verify solutions. I think that really hard (and hard to verify) problem solving scales poorly with having more people thinking about it.
Sheer numbers of geniuses would be one effect of raising the average, but I'm guessing the "massive benefits" you're referring to are things like coordination ability and quality of governance? I think those mainly help with alignment via buying time, but if we're already conditioning on enhanced people having time to grow up I'm less worried about time, and also think that sufficiently widespread adoption to reap those benefits would take substantially longer (decades?).
Emotional social getting on with people vs logic puzzle solving IQ.
Not sure I buy this, since IQ is usually found to positively correlate with purported measures of "emotional intelligence" (at least when any sort of ability (e.g. recognizing emotions) is tested; the correlation seems to go away when the test is pure self reporting, as in a personality test). EDIT: the correlation even with ability-based measures seems to be less than I expected.
Also, smarter people seem (on average) better at managing interpersonal issues in my experience (anecdotal, I don't have a reference). But maybe this isn't what you mean by "emotional social getting on with people".
There could have been a thing where being too far from the average caused interpersonal issues, but very few people would have been far from the average, so I wouldn't expect this to have prevented selection if IQ helped on the margin.
Engineer parents are apparently more likely to have autistic children. This looks like a tradeoff to me. To many "high IQ" genes and you risk autism.
Seems somewhat plausible. I don't think that specific example is good since engineers are stereotyped as aspies in the first place; I'd bet engineering selects for something else in addition to IQ that increases autism risk (systematizing quotient, or something). I have heard of there being a population level correlation between parental IQ and autism risk in the offspring, though I wonder how much this just routes through paternal age, which has a massive effect on autism risk.
This study found a relationship after controlling for paternal age (~30% risk increase when father's IQ > 126), though the IQ test they used had a "technical comprehension" section, which seems unusual for an IQ test (?), and which seems to have driven most of the association.
How many angels can dance on the head of a pin. In the modern world, we have complicated elaborate theoretical structures that are actually correct and useful. In the pre-modern world, the sort of mind that now obsesses about quantum mechanics would be obsessing about angels dancing on pinheads or other equally useless stuff.
So I think there's two possibilities here to keep distinct. (1) is that ability to think abstractly wasn't very useful (and thus wasn't selected for) in the ancestral environment. (2) Is that it was actively detrimental to fitness, at least above some point. E.g. because smarter people found more interesting things to do than reproduce, or because they cared about the quality of life of their offspring more than was fitness-optimal, or something (I think we do see both of these things today, but I'm not sure about in the past).
They aren't mutually exclusive possibilities; in fact if (2) were true I'd expect (1) to probably be true also. (2) but not (1) seems unlikely since IQ being fitness-positive on the margin near the average would probably outweigh negative effects from high IQ outliers.
So on one hand, I sort of agree with this. For example, I think people giving IQ tests to LLMs and trying to draw strong conclusions from that (e.g. about how far off we are from ASI) is pretty silly. Human minds share an architecture that LLMs don't share with us, and IQ tests measure differences along some dimension within the space of variation of that architecture, within our current cultural context. I think an actual ASI will have a mind that works quite differently and will quickly blow right past the IQ scale, similar to your example of eagles and hypersonic aircraft.
On the other hand, humans just sort of do obviously vary a ton in abilities, in a way we care about, despite the above? Like, just look around? Read about Von Neumann? Get stuck for days trying to solve a really (subjectively) hard math problem, and then see how quickly someone a bit smarter was able to solve it? One might argue this doesn't matter if we can't feasibly find anyone capable of solving alignment inside the variation of the human architecture. But Yudkowsky, and several others, with awareness and understanding of the problem, exist; so why not see what happens if we push a bit further? I sort of have this sense that once you're able to understand a problem, you probably don't need to be that much smarter to solve it, if it's the sort of problem that's amenable to intelligence at all.
On another note: I can imagine that, from the perspective of evolution in the ancestral environment, that maybe human intelligence variation appeared "small", in that it didn't cache out in much fitness advantage; and it's just in the modern environment that IQ ends up conferring massive advantages in ability to think abstractly or something, which actually does cache out in stuff we care about.
I'm sort of confused by the image you posted? Von Neumann existed, and there are plenty of very smart people well beyond the "Nerdy programmer" range.
But I think I agree with your overall point about IQ being under stabilizing selection in the ancestral environment. If there was directional selection, it would need to have been weak or inconsistent; otherwise I'd expect the genetic low hanging fruit we see to have been exhausted already. Not in the sense of all current IQ-increasing alleles being selected to fixation, but in the sense of the tradeoffs becoming much more obvious than they appear to us currently. I can't tell what the tradeoffs even were: apparently IQ isn't associated with the average energy consumption of the brain? The limitation of birth canal width isn't a good explanation either since IQ apparently also isn't associated with head size at birth (and adult brain size only explains ~10% of the variance in IQ).
Don't have much to say on it right now, I really need to do a deep dive into this at some point.
You should show your calculation or your code, including all the data and parameter choices. Otherwise I can't evaluate this.
The code is pretty complicated and not something I'd expect a non-expert (even a very smart one) to be able to quickly check over; it's not just a 100 line python script. (Or even a very smart expert for that matter, more like anyone who wasn't already familiar with our particular codebase.) We'll likely open source it at some point in the future, possibly soon, but that's not decided yet. Our finemapping (inferring causal effects) procedure produces ~identical results to the software from the paper I linked above when run on the same test data (though we handle some additional things like variable per-SNP sample sizes and missing SNPs which that finemapper doesn't handle, which is why we didn't just use it).
The parameter choices which determine the prior over SNP effects are the number of causal SNPs (which we set to 20,000) and the SNP heritability of the phenotype (which we set to 0.19, as per the GWAS we used). The erroneous effect size adjustment was done at the end to convert from the effect sizes of the GWAS phenotype (low reliability IQ test) to the effect sizes corresponding to the phenotype we care about (high reliability IQ test).
We want to publish a more detailed write up of our methods soon(ish), but it's going to be a fair bit of work so don't expect it overnight.
It's natural in your position to scrutinize low estimates but not high ones.
Yep, fair enough. I've noticed myself doing this sometimes and I want to cut it out. That said, I don't think small-ish predictable overestimates to the effect sizes are going to change the qualitative picture, since with good enough data and a few hundred to a thousand edits we can boost predicted IQ by >6 SD even with much more pessimistic assumptions, which probably isn't even safe to do (I'm not sure I expect additivity to hold that far). I'm much more worried about basic problems with our modelling assumptions, e.g. the assumption of sparse causal SNPs with additive effects and no interactions (e.g. what if rare haplotypes are deleterious due to interactions that don't show up in GWAS since those combinations are rare?).
I know the answers to those questions. But I’m not the audience that needs to be convinced.
The audience that needs to be convinced isn't the target audience of this post. But overall your point is taken.
I'll need to do a deep dive to understand the methods of the first paper, but isn't this contradicted by the recent Tan et. al. paper you linked finding SNP heritability of 0.19 for both direct and population effects of intelligence (which matches Savage Jansen 2018)? They also found ~perfect LDSC correlation between direct and population effects, which would imply the direct and population SNP heritabilities are tagging the exact same genetic effects. (Also interesting that 0.19 is the exactly in the middle of 0.24 and 0.14, not sure what to make of that if anything).
With a method similar to this. You can easily compute the exact likelihood function P(GWAS results | SNP effects), which when combined with a prior over SNP effects (informed by what we know about the genetic architecture of the trait) gives you a posterior probability of each SNP being causal (having nonzero effect), and its expected effect size conditional on being causal (you can't actually calculate the full posterior since there are 2^|SNPs| possible combinations of SNPs with nonzero effects, so you need to do some sort of MCMC or stochastic search). We may make a post going into more detail on our methods at some point.
This is based on inferring causal effects conditional on this GWAS. The assumed heritability affects the prior over SNP effect sizes.
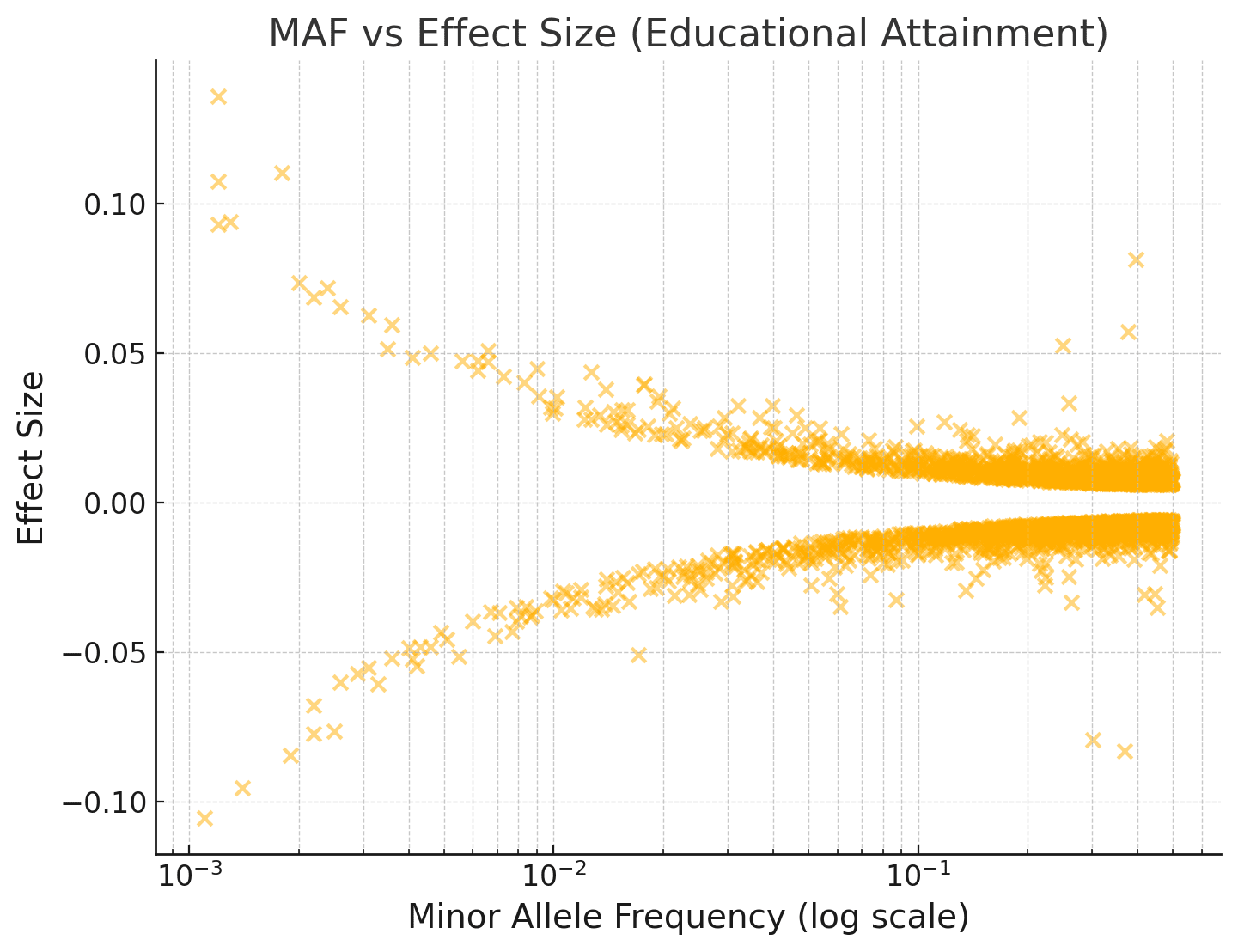
If evolution has already taken all the easy wins, why do humans vary so much in intelligence in the first place? I don't think the answer is mutation-selection balance, since a good chunk of the variance is explained by additive effects from common SNPs. Further, if you look at the joint distribution over effect sizes and allele frequencies among SNPs, there isn't any clear skew towards rarer alleles being IQ-decreasing.
For example, see the plot below of minor allele frequency vs the effect size of the minor allele. (This is for Educational Attainment, a highly genetically correlated trait, rather than IQ, since the EA GWAS is way larger and has way more hits.)
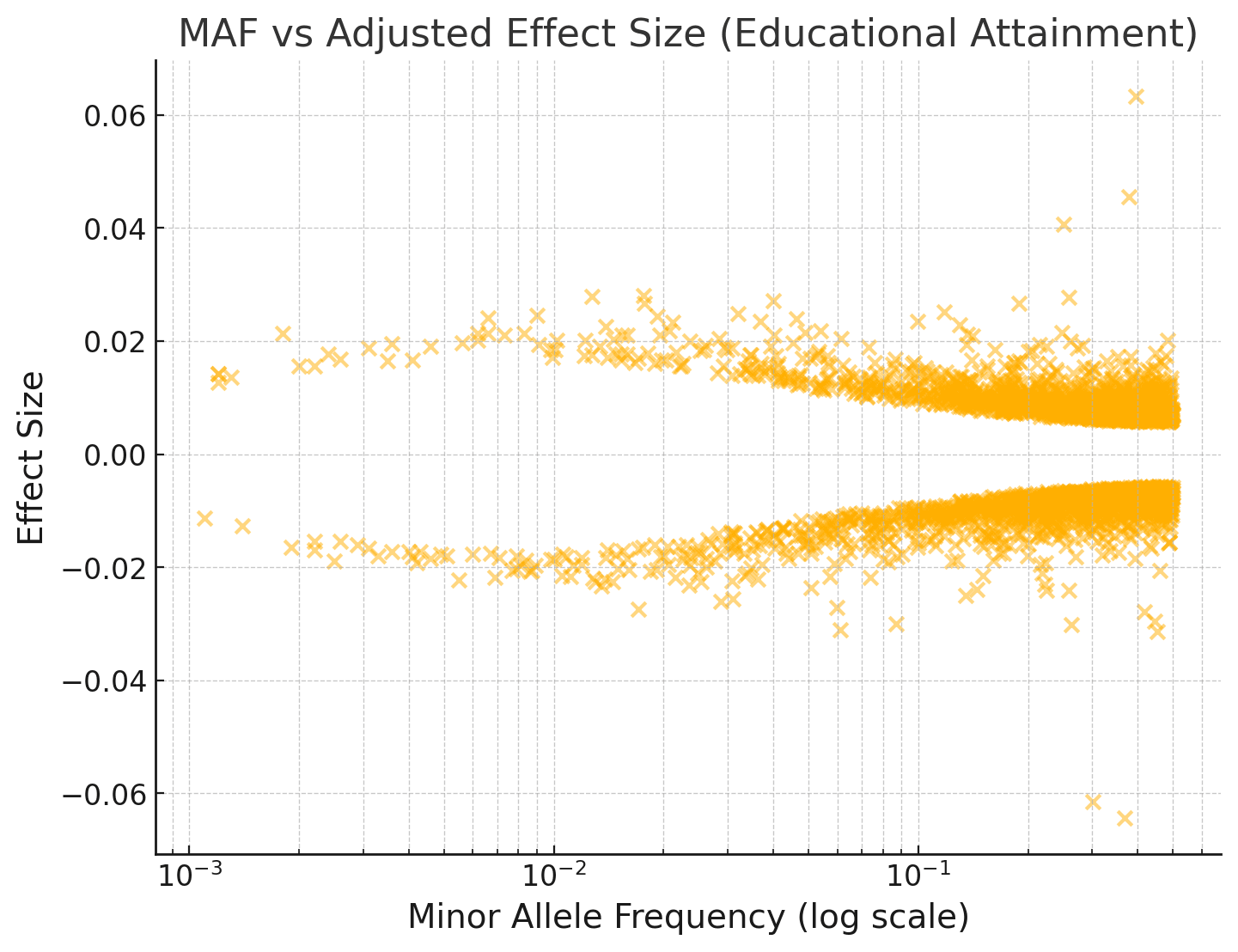
If we do a Bayesian adjustment of the effect sizes for observation noise, assuming EA has a SNP heritability of 0.2 and 20,000 causal variants with normally distributed effects:
I've repeated this below for an IQ GWAS:
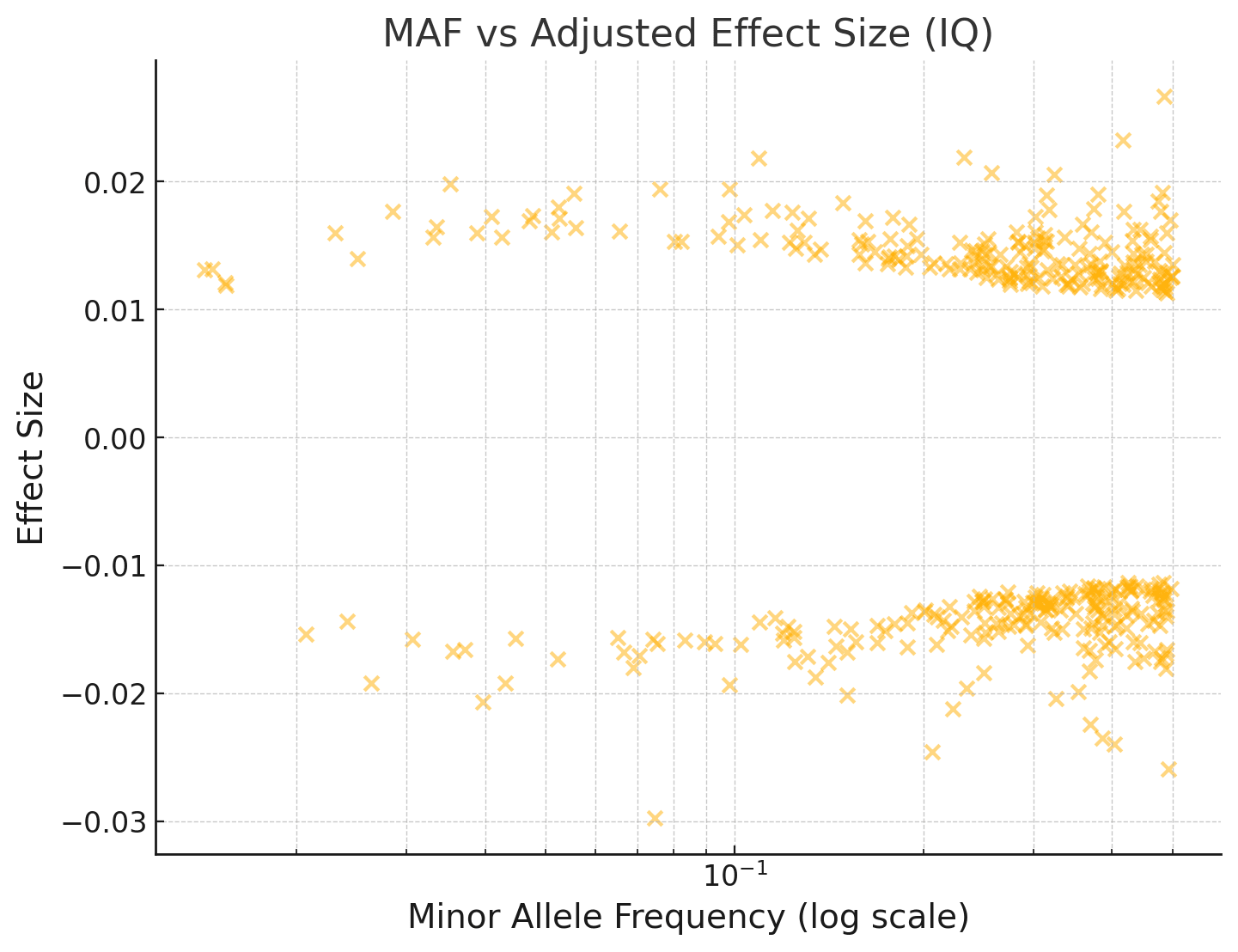
You can see that the effect sizes look roughly symmetrically distributed about zero, even for fairly rare SNPs with MAF < 1%.
But isn't the R^2 the relevant measure?
Not for this purpose! The simulation pipeline is as follows: the assumed h^2 and number of causal variants is used to generate the genetic effects -> generate simulated GWASes for a range of sample sizes -> infer causal effects from the observed GWASes -> select top expected effect variants for up to N (expected) edits.
The paper you called largest ever GWAS gave a direct h^2 estimate of 0.05 for cognitive performance. How are these papers getting 0.2? I don't understand what they're doing. Some type of meta analysis?
You're mixing up h^2 estimates with predictor R^2 performance. It's possible to get an estimate of h^2 with much less statistical power than it takes to build a predictor that good.
The test-retest reliability you linked has different reliabilities for different subtests. The correct adjustment depends on which subtests are being used. If cognitive performance is some kind of sumscore of the subtests, its reliability would be higher than for the individual subtests.
"Fluid IQ" was the only subtest used.
Also, I don't think the calculation 0.2*(0.9/0.6)^2 is the correct adjustment. A test-retest correlation is already essentially the square of a correlation of the test with an underlying latent factor
Good catch, we'll fix this when we revise the post.
I don't quite understand your numbers in the OP but it feels like you're inflating them substantially. Is the full calculation somewhere?
Not quite sure which numbers you're referring to, but if it's the assumed SNP heritability, see the below quote of mine from another comment talking about missing heritability for IQ:
The SNP heritability estimates for IQ of (h^2 = ~0.2) are primarily based on a low quality test that has a test-retest reliability of 0.6, compared to ~0.9 for a gold-standard IQ test. So a simple calculation to adjust for this gets you a predicted SNP heritability of 0.2 * (0.9 / 0.6)^2 = 0.45 for a gold standard IQ test, which matches the SNP heritability of height. As for the rest of the missing heritability: variants with frequency less than 1% aren't accounted for by the SNP heritability estimate, and they might contribute a decent bit if there are lots of them and their effects sizes are larger.
The h^2 = 0.19 estimate from this GWAS should be fairly robust to stratification, because of how the LDSC estimator works. (To back this up: a recent study that actually ran a small GWAS on siblings, based on the same cognitive test, also found h^2 = 0.19 for direct effects.)
For cognitive performance, the ratio was better, but it's not 0.824, it's .
That's variance explained. I was talking about effect size attenuation, which is what we care about for editing.
I checked supplementary table 10, and it says that the "direct-population ratio" is 0.656, not 0.824. So quite possibly the right value is even for cognitive performance.
Supplementary table 10 is looking at direct and indirect effects of the EA PGI on other phenotypes. The results for the Cog Perf PGI are in supplementary table 13.
sadism and wills to power are baked into almost every human mind (with the exception of outliers of course). force multiplying those instincts is much worse than an AI which simply decides to repurpose the atoms in a human for something else.
I don't think the result of intelligence enhancement would be "multiplying those instincts" for the vast majority of people; humans don't seem to end up more sadistic as they get smarter and have more options.
i would argue that everyone dying is actually a pretty great ending compared to hyperexistential risks. it is effectively +inf relative utility.
I'm curious what value you assign to the ratio [U(paperclipped) - U(worst future)] / [U(best future) - U(paperclipped)]? It can't be literally infinity unless U(paperclipped) = U(best future).
with humans you'd need the will and capability to engineer in at least +5sd empathy and -10sd sadism into every superbaby.
So your model is that we need to eradicate any last trace of sadism before superbabies is a good idea?
The IQ GWAS we used was based on only individuals of European ancestry, and ancestry principal components were included as covariates as is typical for GWAS. Non-causal associations from subtler stratification is still a potential concern, but I don't believe it's a terribly large concern. The largest educational attainment GWAS did a comparison of population and direct effects for a "cognitive performance" PGI and found that predicted direct (between sibling) effects were only attenuated by a factor of 0.824 compared to predicted population level effects. If anything I'd expect their PGI to be worse in this regard, since it included variants with less stringent statistical power cutoffs (so I'd guess it's more likely that non-causal associations would sneak in, compared to the GWAS we used).
Plain GWAS, since there aren't any large sibling GWASes. What's the basis for the estimates being much lower and how would we properly adjust for them?
I mostly think we need smarter people to have a shot at aligning ASI, and I'm not overwhelmingly confident ASI is coming within 20 years, so I think it makes sense for someone to have the ball on this.
I'm curious about the basis on which you are assigning a probability of causality without a method like mendelian randomisation, or something that tries to assign a probability of an effect based on interpreting the biology like a coding of the output of something like SnpEff to an approximate probability of effect.
Using finemapping. I.e. assuming a model where nonzero additive effects are sparsely distributed among SNPs, you can do Bayesian math to infer how probable each SNP is to have a nonzero effect and its expected effect size conditional on observed GWAS results. Things like SnpEff can further help by giving you a better prior.
The SNP heritability estimates for IQ of (h^2 = ~0.2) are primarily based on a low quality test that has a test-retest reliability of 0.6, compared to ~0.9 for a gold-standard IQ test. So a simple calculation to adjust for this gets you a predicted SNP heritability of 0.2 * (0.9 / 0.6)^2 = 0.45 0.2 * (0.9 / 0.6) = 0.30 for a gold standard IQ test, which matches the SNP heritability of height. As for the rest of the missing heritability: variants with frequency less than 1% aren't accounted for by the SNP heritability estimate, and they might contribute a decent bit if there are lots of them and their effects sizes are larger.
EDIT: the original adjustment for test-retest reliability was incorrect: the correlations shouldn't be squared.
Could you expand on what sense you have 'taken this into account' in your models? What are you expecting to achieve by editing non-causal SNPs?
If we have a SNP that we're 30% sure is causal, we expect to get 30% of its effect conditional on it being causal. Modulo any weird interaction stuff from rare haplotypes, which is a potential concern with this approach.
The first paper I linked is about epistasic effects on the additivity of a QTLs for quantitative trait, specifically heading date in rice, so this is evidence for this sort of effect on such a trait.
I didn't read your first comment carefully enough; I'll take a look at this.
I definitely don't expect additivity holds out to like +20 SDs. We'd be aiming for more like +7 SDs.
I think I'm at <10% that non-enhanced humans will be able to align ASI in time, and if I condition on them succeeding somehow I don't think it's because they got AIs to do it for them. Like maybe you can automate some lower level things that might be useful (e.g. specific interpretability experiments), but at the end of the day someone has to understand in detail how the outcome is being steered or they're NGMI. Not sure exactly what you mean by "automating AI safety", but I think stronger forms of the idea are incoherent (e.g. "we'll just get AI X to figure it all out for us" has the problem of requiring X to be aligned in the first place).
Much less impactful than automating AI safety.
I don't think this will work.
So you think that, for >95% of currently living humans, the implementation of their CEV would constitute an S-risk in the sense of being worse than extinction in expectation? This is not at all obvious to me; in what way do you expect their CEVs to prefer net suffering?
Because they might consider that other problems are more worth their time, since smartness changes change their values little.
I mean if they care about solving problems at all, and we are in fact correct about AGI ruin, then they should predictably come to view it as the most important problem and start to work on it?
Are you imagining they're super myopic or lazy and just want to think about math puzzles or something? If so, my reply is that even if some of them ended up like that, I'd be surprised if they all ended up like that, and if so that would be a failure of the enhancement. The aim isn't to create people who we will then carefully persuade to work on the problem, the aim is for some of them to be smart + caring + wise enough to see the situation we're in and decide for themselves to take it on.
My interpretation is that you're 99% of the way there in terms of work required if you start out with humans rather than creating a de novo mind, even if many/most humans currently or historically are not "aligned". Like, you don't need very many bits of information to end up with a nice "aligned" human. E.g. maybe you lightly select their genome for prosociality + niceness/altruism + wisdom, and treat them nicely while they're growing up, and that suffices for the majority of them.
Sure, sounds hard though.
The SNP itself is (usually) not causal Genotyping arrays select SNPs the genotype of which is correlated with a region around the SNP, they are said to be in linkage with this region as this region tends to be inherited together when recombination happens in meiosis. This is a matter of degree and linkage scores allow thresholds to be set for how indicative a SNP is about the genotype a given region.
This is taken into account by our models, and is why we see such large gains in editing power from increasing data set sizes: we're better able to find the causal SNPs. Our editing strategy assumes that we're largely hitting non-causal SNPs.
In practice epistatic interactions between QTLs matter for effects sizes and you cannot naively add up the effect sizes of all the QTLs for a trait and expect the result to reflect the real effect size, even if >50% effect are additive.
I'm not aware of any evidence for substantial effects of this sort on quantitative traits such as height. We're also adding up expected effects, and as long as those estimates are unbiased the errors should cancel out as you do enough edits.
One thing we're worried about is cases where the haplotypes have the small additive effects rather than individual SNPs, and you get an unpredictable (potentially deleterious) effect if you edit to a rare haplotype even if all SNPs involved are common. Are you aware of any evidence suggesting this would be a problem?
This paper found that the heritability of most traits is ~entirely additive, supposedly including IQ according to whatever reference I followed to the paper, though I couldn't actually find where in the paper it said/implied that.
IIUC that R = 0.55 number was just the raw correlation between the beta values of the sibling and population GWASes
Actually I don't think this is correct, it accounted for sampling error somehow. I'll need to look into this deeper.
Subtle population stratification not accounted for by the original GWAS could still be an issue, though I don't expect this would inflate the effects very much. If we had access to raw data we could take into account small correlations between distant variants during finemapping, which would automatically handle assortative mating and stratification.
We accounted for inflation of effect sizes due to assortative mating, assuming a mate IQ correlation of 0.4 and total additive heritability of 0.7 for IQ.
IIUC that R = 0.55 number was just the raw correlation between the beta values of the sibling and population GWASes, which is going to be very noisy given the small sample sizes and given that effects are sparse. You can see that the LDSC based estimate is nearly 1, suggesting ~null indirect effects.
If they're that smart, why will they need to be persuaded?
What would it mean for them to have an "ASI slave"? Like having an AI that implements their personal CEV?
(And that's not even addressing how you could get super-smart people to work on the alignment problem).
I mean if we actually succeeded at making people who are +7 SD in a meaningful way, I'd expect that at least good chunk of them would figure out for themselves that it makes sense to work on it.
In that case I'd repeat GeneSmith's point from another comment: "I think we have a huge advantage with humans simply because there isn't the same potential for runaway self-improvement." If we have a whole bunch of super smart humans of roughly the same level who are aware of the problem, I don't expect the ruthless ones to get a big advantage.
I mean I guess there is some sort of general concern here about how defense-offense imbalance changes as the population gets smarter. Like if there's some easy way to destroy the world that becomes accessible with IQ > X, and we make a bunch of people with IQ > X, and a small fraction of them want to destroy the world for some reason, are the rest able to prevent it? This is sort of already the situation we're in with AI: we look to be above the threshold of "ability to summon ASI", but not above the threshold of "ability to steer the outcome". In the case of AI, I expect making people smarter differentially speeds up alignment over capabilities: alignment is hard and we don't know how to do it, while hill-climbing on capabilities is relatively easy and we already know how to do it.
I should also note that we have the option of concentrating early adoption among nice, sane, x-risk aware people (though I also find this kind of cringe in a way and predict this would be an unpopular move). I expect this to happen by default to some extent.
like the fact that any control technique on AI would be illegal because of it being essentially equivalent to brainwashing, such that I consider AIs much more alignable than humans
A lot of (most?) humans end up nice without needing to be controlled / "aligned", and I don't particularly expect this to break if they grow up smarter. Trying to control / "align" them wouldn't work anyway, which is also what I predict will happen with sufficiently smart AI.
I mean hell, figuring out personality editing would probably just make things backfire. People would choose to make their kids more ruthless, not less.
Not at all obvious to me this is true. Do you mean to say a lot of people would, or just some small fraction, and you think a small fraction is enough to worry?
I think I mostly agree with the critique of "pause and do what, exactly?", and appreciate that he acknowledged Yudkowsky as having a concrete plan here. I have many gripes, though.
Whatever name they go by, the AI Doomers believe the day computers take over is not far off, perhaps as soon as three to five years from now, and probably not longer than a few decades. When it happens, the superintelligence will achieve whatever goals have been programmed into it. If those goals are aligned exactly to human values, then it can build a flourishing world beyond our most optimistic hopes. But such goal alignment does not happen by default, and will be extremely difficult to achieve, if its creators even bother to try. If the computer’s goals are unaligned, as is far more likely, then it will eliminate humanity in the course of remaking the world as its programming demands. This is a rough sketch, and the argument is described more fully in works like Eliezer Yudkowsky’s essays and Nick Bostrom’s Superintelligence.
This argument relies on several premises: that superintelligent artificial general intelligence is philosophically possible, and practical to build; that a superintelligence would be more or less all-powerful from a mere human perspective; that superintelligence would be “unfriendly” to humanity by default; that superintelligence can be “aligned” to human values by a very difficult engineering program; that superintelligence can be built by current research and development methods; and that recent chatbot-style AI technologies are a major step forward on the path to superintelligence. Whether those premises are true has been debated extensively, and I don’t have anything useful to add to that discussion which I haven’t said before. My own opinion is that these various premises range from “pretty likely but not proven” to “very unlikely but not disproven.”
I'm thoroughly unimpressed with these paragraphs. It's not completely clear what the "argument" is from the first paragraph, but I'm interpreting it as "superintelligence might be created soon and cause human extinction if not aligned, therefore we should stop".
Firstly, there's an obvious conjunction fallacymultiple stage fallacy thing going on where he broke the premises down into a bunch of highly correlated things and listed them separately to make them sound more far fetched in aggregate. E.g. the 3 claims:
- [that superintelligence is] practical to build
- that superintelligence can be built by current research and development methods
- that recent chatbot-style AI technologies are a major step forward on the path to superintelligence
are highly correlated. If you believe (1) there's a good chance you believe (2), and if you believe (2) then you probably believe (3).
There's also the fact that (3) implies (2) and (2) implies (1), meaning (3) is logically equivalent to (1) AND (2) AND (3). So why not just say (3)?
I'm also not sure why (3) is even a necessary premise; (2) should be cause enough for worry.
I have more gripes with these paragraphs:
that superintelligent artificial general intelligence is philosophically possible
What is this even doing here? I'd offer AIXI as a very concrete existence proof of philosophical possibility. Or to be less concrete but more correct: "something epistemically and instrumentally efficient relative to all of humanity" is a simple coherent concept. He's only at "pretty likely but not proven" on this?? What would it even mean for it to be "philosophically impossible"?
That superintelligence can be “aligned” to human values by a very difficult engineering program
Huh? Why would alignment not being achievable by "a very difficult engineering program" mean we shouldn't worry?
that a superintelligence would be more or less all-powerful from a mere human perspective
It just needs to be powerful enough to replace and then kill us. For example we can very confidently predict that it won't be able to send probes faster than light, and somewhat less confidently predict that it won't be able to reverse a secure 4096 bit hash.
Here's a less multiple-stagey breakdown of the points that are generally contentious among the informed:
- humans might soon build an intelligence powerful enough to cause human extinction
- that superintelligence would be “unfriendly” to humanity by default
Some other comments:
Of course, there is no indication that massive intelligence augmentation will be developed any time soon, only very weak reasons to suspect that it’s obtainable at all without multiple revolutionary breakthroughs in our understanding both of genetics and of the mind
Human intelligence variation is looking to be pretty simple on a genetic level: lots of variants with small additive effects. (See e.g. this talk by Steve Hsu)
and no reason at all to imagine that augmenting human intelligence would by itself instill the psychological changes towards humility and caution that Yudkowsky desires.
No reason at all? If Yudkowsky is in fact correct, wouldn't we expect people to predictably come to agree with him as we made them smarter (assuming we actually succeeded at making them smarter in a broad sense)? If we're talking about adult enhancement, you can also just start out with sane, cautious people and make them smarter.
The plan is a bad one, but it does have one very important virtue. The argument for the plan is at least locally valid, if you grant all of its absurd premises.
I hope I've convinced the skeptical reader that the premises aren't all that absurd?
EDIT: I'd incorrectly referred to the multiple stage fallacy as the "conjunction fallacy" (since it involves a big conjunction of claims, I guess). The conjunction fallacy is when someone assesses P(A & B) > P(A).
You acknowledge this but I feel you downplay the risk of cancer - an accidental point mutation in a tumour suppressor gene or regulatory region in a single founder cell could cause a tumour.
For each target the likely off-targets can be predicted, allowing one to avoid particularly risky edits. There may still be issues with sequence-independent off-targets, though I believe these are a much larger problem with base editors than with prime editors (which have lower off-target rates in general). Agree that this might still end up being an issue.
Unless you are using the term “off-target” to refer to any incorrect edit of the target site, and wider unwanted edits - in my community this term referred specifically to ectopic edits elsewhere in the genome away from the target site.
This is exactly it -- the term "off-target" was used imprecisely in the post to keep things simple. The thing we're most worried about here is misedits (mostly indels) at noncoding target sites. We know a target site does something (if the variant there is in fact causal), so we might worry that an indel will cause a big issue (e.g. disabling a promoter binding site). Then again, the causal variant we're targeting has a very small effect, so maybe the sequence isn't very sensitive and an indel won't be a big deal? But it also seems perfectly possible that the sequence could be sensitive to most mutations while permitting a specific variant with a small effect. The effect of an indel will at least probably be less bad than in a coding sequence, where it has a high chance of causing a frameshift mutation and knocking out the coded-for protein.
The important figure of merit for editors with regards to this issue is the ratio of correct edits to misedits at the target site. In the case of prime editors, IIUC, all misedits at the target site are reported as "indels" in the literature (base editors have other possible outcomes such as bystander edits or conversion to the wrong base). Some optimized prime editors have edit:indel ratios of >100:1 (best I've seen so far is 500:1, though IIUC this was just at two target sites, and the rates seem to vary a lot by target site). Is this good enough? I don't know, though I suspect not for the purposes of making a thousand edits. It depends on how large the negative effects of indels are at noncoding target sites: is there a significant risk the neuron gets borked as a result? It might be possible to predict this on a site-by-site basis with a better understanding of the functional genomics of the sequences housing the causal variants which affect polygenic traits (which would also be useful for finding the causal variants in the first place without needing as much data).
This seems unduly pessimistic to me. The whole interesting thing about g is that it's easy to measure and correlates with tons of stuff. I'm not convinced there's any magic about FSIQ compared to shoddier tests. There might be important stuff that FSIQ doesn't measure very well that we'd ideally like to select/edit for, but using FSIQ is much better than nothing. Likewise, using a poor man's IQ proxy seems much better than nothing.
This may have missed your point, you seem more concerned about selecting for unwanted covariates than 'missing things', which is reasonable. I might remake the same argument by suspecting that FSIQ probably has some weird covariates too -- but that seems weaker. E.g. if a proxy measure correlates with FSIQ at .7, then the 'other stuff' (insofar as it is heritable variation and not just noise) will also correlate with the proxy at .7, and so by selecting on this measure you'd be selecting quite strongly for the 'other stuff', which, yeah, isn't great. FSIQ, insofar as it had any weird unwanted covariates, would probably much less correlated with them than .7
Non-coding means any sequence that doesn't directly code for proteins. So regulatory stuff would count as non-coding. There tend to be errors (e.g. indels) at the edit site with some low frequency, so the reason we're more optimistic about editing non-coding stuff than coding stuff is that we don't need to worry about frameshift mutations or nonsense mutations which knock-out the gene where they occur. The hope is that an error at the edit site would have a much smaller effect, since the variant we're editing had a very small effect in the first place (and even if the variant is embedded in e.g. a sensitive binding site sequence, maybe the gene's functionality can survive losing a binding site, so at least it isn't catastrophic for the cell). I'm feeling more pessimistic about this than I was previously.