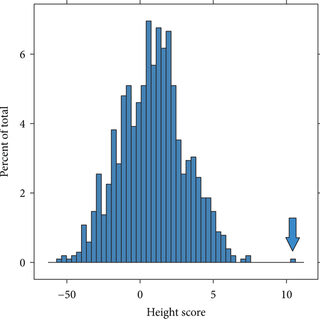
Working in the field of genetics is a bizarre experience. No one seems to be interested in the most interesting applications of their research.
We’ve spent the better part of the last two decades unravelling exactly how the human genome works and which specific letter changes in our DNA affect things like diabetes risk or college graduation rates. Our knowledge has advanced to the point where, if we had a safe and reliable means of modifying genes in embryos, we could literally create superbabies. Children that would live multiple decades longer than their non-engineered peers, have the raw intellectual horsepower to do Nobel prize worthy scientific research, and very rarely suffer from depression or other mental health disorders.
The scientific establishment, however, seems to not have gotten the memo. If you suggest we engineer the genes of future generations to make their lives better, they will often make some frightened noises, mention “ethical issues” without ever clarifying what they mean, or abruptly change the subject. It’s as if humanity invented electricity and decided the only interesting thing to do with it was make washing machines.
I didn’t understand just how dysfunctional things were until I attended a conference on polygenic embryo screening in late 2023. I remember sitting through three days of talks at a hotel in Boston, watching prominent tenured professors in the field of genetics take turns misrepresenting their own data and denouncing attempts to make children healthier through genetic screening. It is difficult to convey the actual level of insanity if you haven’t seen it yourself.
As a direct consequence, there is low-hanging fruit absolutely everywhere. You can literally do novel groundbreaking research on germline engineering as an internet weirdo with an obsession and sufficient time on your hands. The scientific establishment is too busy with their washing machines to think about light bulbs or computers.
This blog post is the culmination of a few months of research by myself and my cofounder into the lightbulbs and computers of genetics: how to do large scale, heritable editing of the human genome to improve everything from diabetes risk to intelligence. I will summarize the current state of our knowledge and lay out a technical roadmap examining how the remaining barriers might be overcome.
We’ll begin with the topic of the insane conference in Boston; embryo selection.
The proposition was fairly simple; if you and your spouse went through IVF and produced a bunch of embryos, Heliospect could perform a kind of genetic fortune-telling.
They could show you each embryo’s risk of diabetes. They could tell you how likely each one was to drop out of high school. They could even tell you how smart each of them was likely to be.
After reading each embryo's genome and ranking them according to the importance of each of these traits, the best would be implanted in the mother. If all went well, 9 months later a baby would pop out that has a slight genetic advantage relative to its counterfactual siblings.
The service wasn’t perfect; Heliospect’s tests could give you a rough idea of each embryo’s genetic predispositions, but nothing more.
Still, this was enough to increase your future child’s IQ by around 3-7 points or increase their quality adjusted life expectancy by about 1-4 years. And though Heliospect wasn’t the first company to offer embryo selection to reduce disease risk, they were the first to offer selection specifically for enhancement.
The curious among you might wonder why the expected gain from this service is “3-7 IQ points”. Why not more? And why the range?
There are a few variables impacting the expected benefit, but the biggest is the number of embryos available to choose from.
Each embryo has a different genome, and thus different genetic predispositions. Sometimes during the process of sperm and egg formation, one of the embryos will get lucky and a lot of the genes that increase IQ will end up in the same embryo.
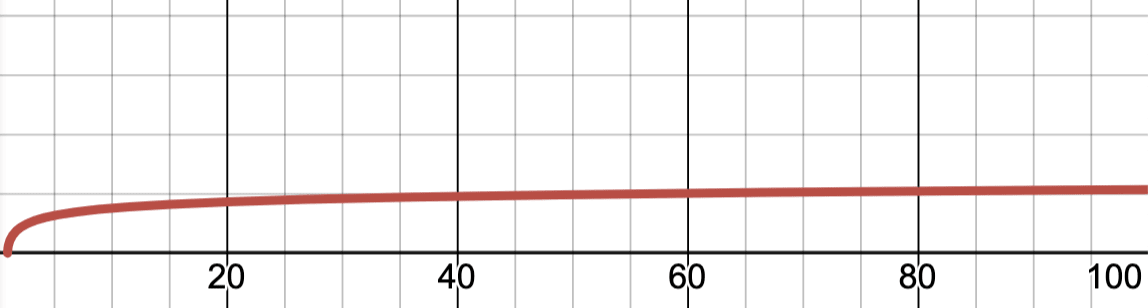
The more embryos, the better the best one will be in expectation. There is a “scaling law” describing how good you can expect the best embryo to be based on how many embryos you’ve produced.
With two embryos, the best one would have an expected IQ about 2 points above parental average. WIth 10 the best would be about 6 points better.
But the gains plateau quickly after that. 100 embryos would give a gain of 10.5 points, and 200 just 11.5.
If you graph IQ gain as a function of the number of embryos available, it pretty quickly becomes clear that we simply aren’t going to make any superbabies by increasing the number of embryos we choose from.
The line goes nearly flat after ~40 or so. If we really want to unlock the potential of the human genome, we need a better technique.
How to do better than embryo selection
When we select embryos, it’s a bit like flipping coins and hoping most of them land on heads. Even if you do this a few dozen times, your best run won’t have that many more heads than tails.
If we could somehow directly intervene to make some coins land on heads, we could get far, far better results.
The situation with genes is highly analogous; if we could swap out a bunch of the variants that increase cancer risk for ones that decrease cancer risk, we could do much better than embryo selection.
Gene editing is the perfect tool to make this happen. It lets us make highly specific changes at known locations in the genome where simple changes like swapping one base pair for another is known to have some positive effect.
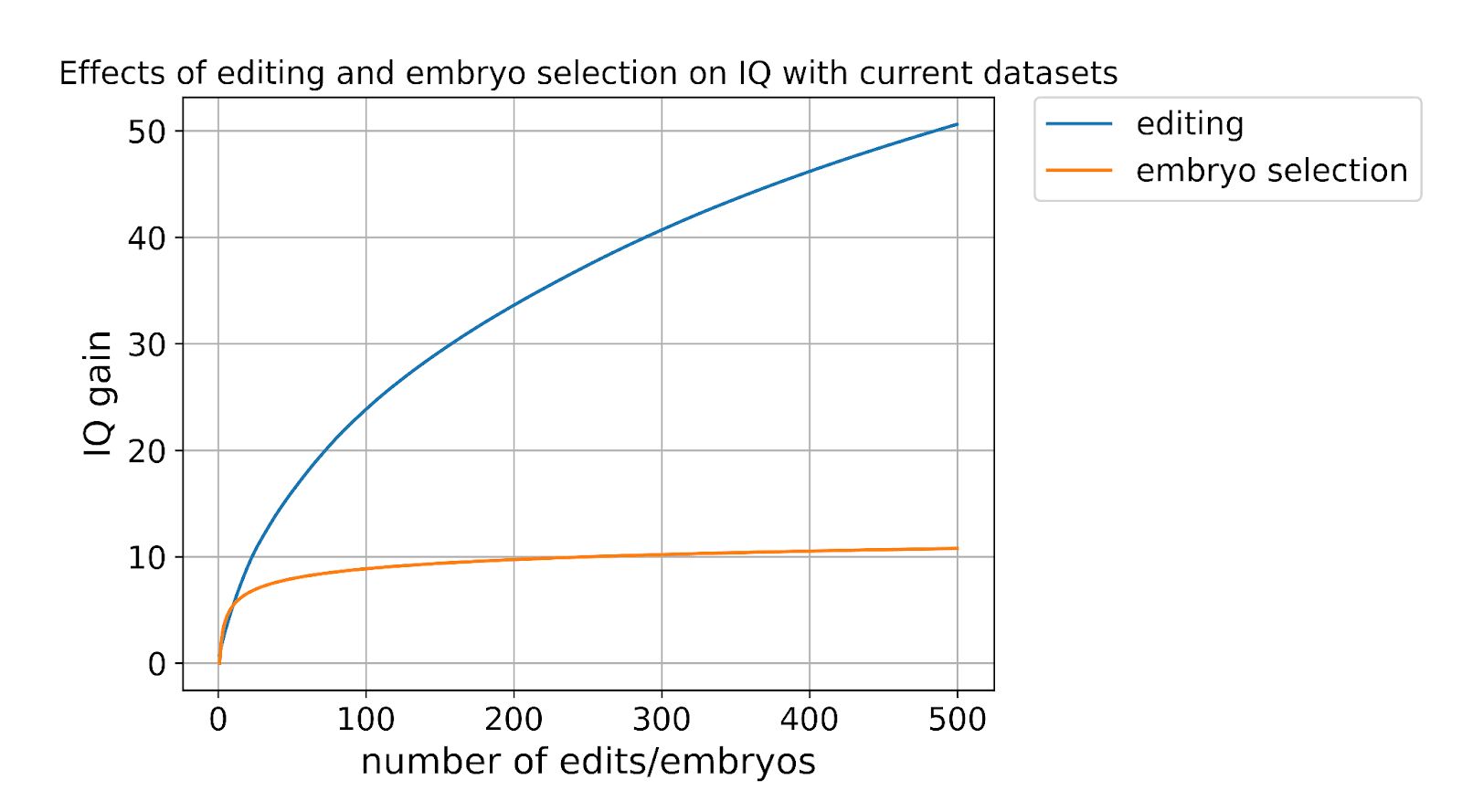
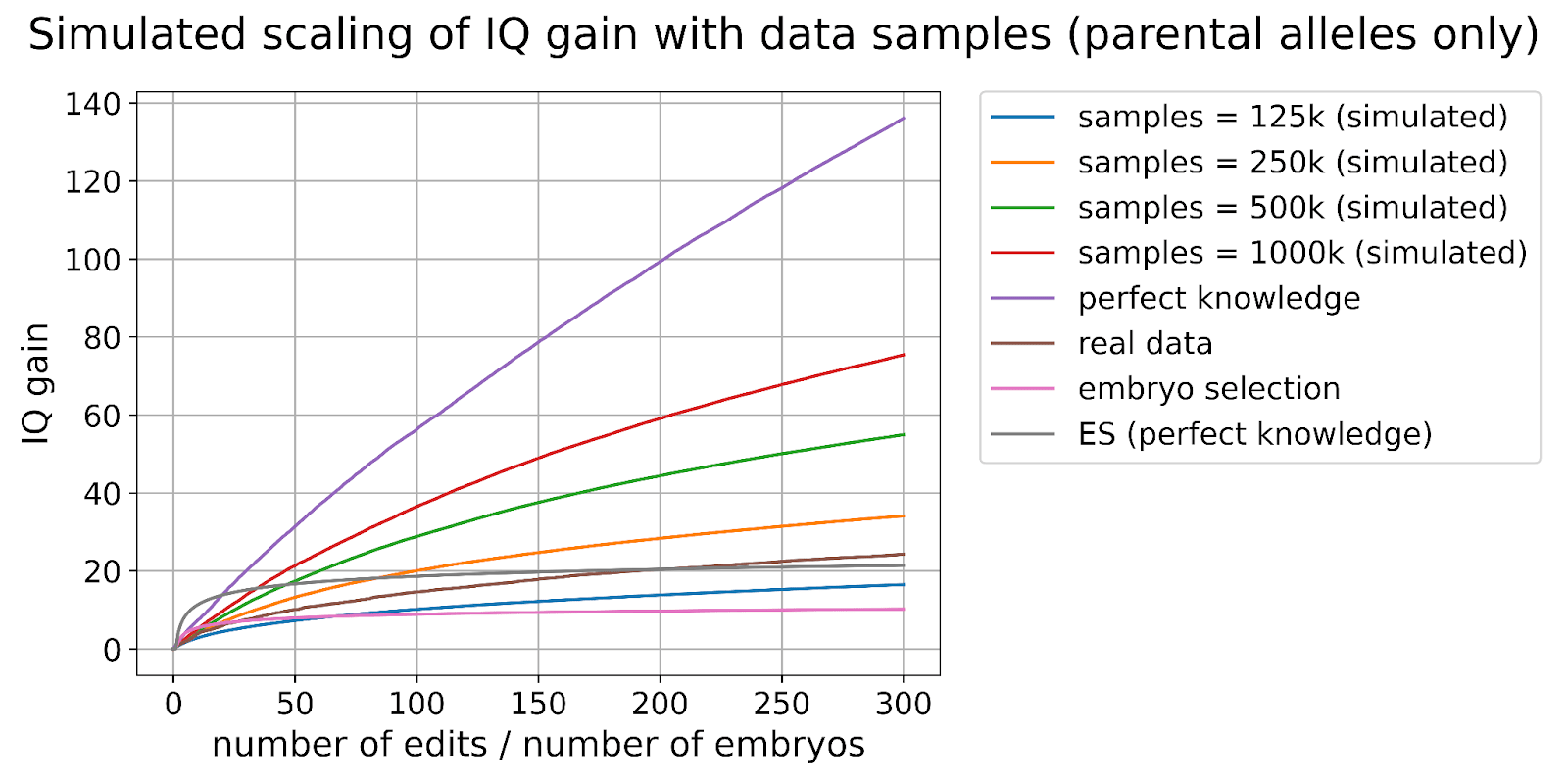
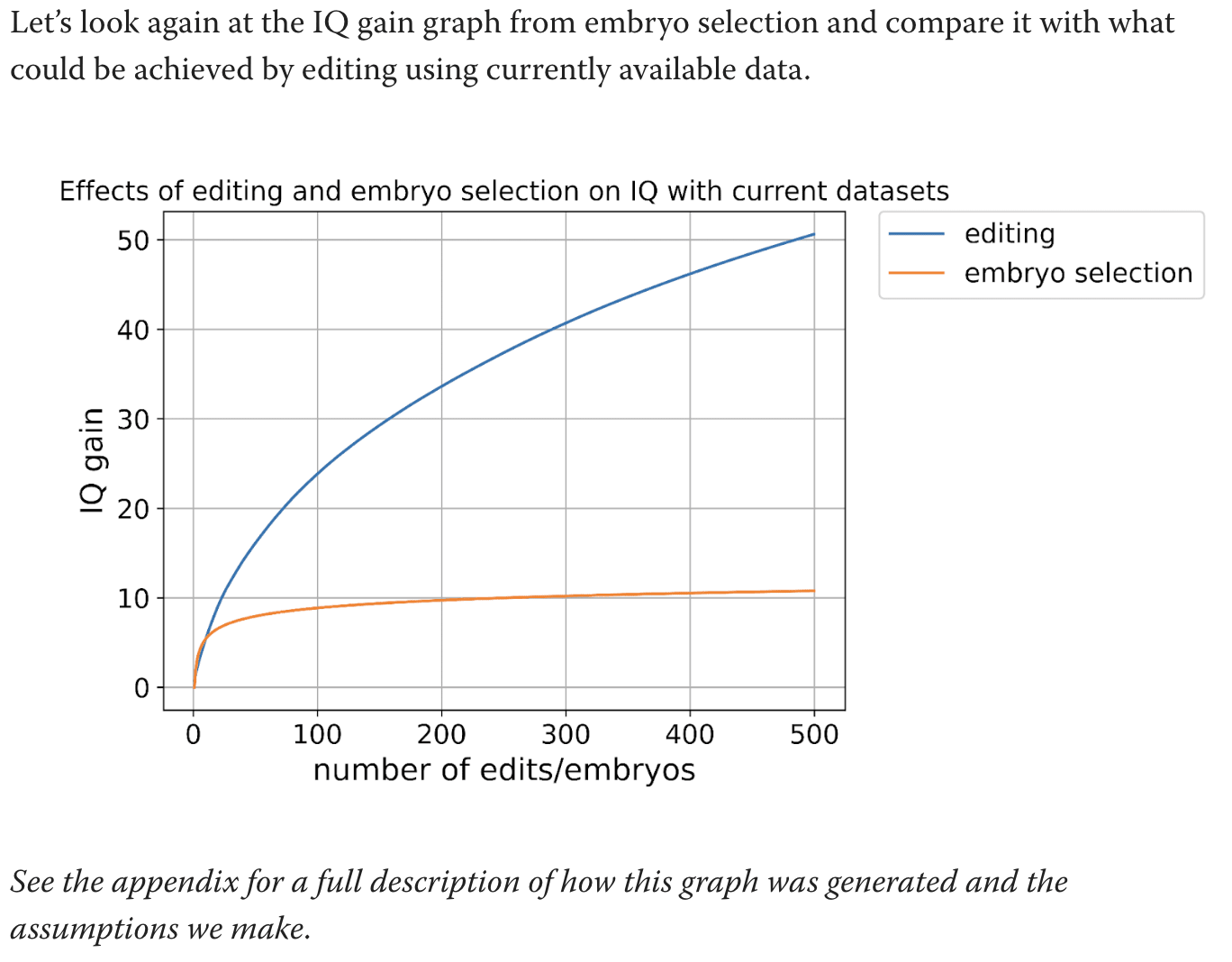
Let’s look again at the IQ gain graph from embryo selection and compare it with what could be achieved by editing using currently available data.
See the appendix for a full description of how this graph was generated and the assumptions we make.
If we had 500 embryos, the best one would have an IQ about 12 points above that of the parents. If we could make 500 gene edits, an embryo would have an IQ about 50 points higher than that of the parents.
Gene editing scales much, much better than embryo selection.
Some of you might be looking at the data above and wondering “well what baseline are we talking about? Are we talking about a 60 IQ point gain for someone with a starting IQ of 70?”
The answer is the expected gain is almost unaffected by the starting IQ. The human gene pool has so much untapped genetic potential that even the genome of a very, very smart person still has thousands of IQ decreasing variants that could potentially be altered.
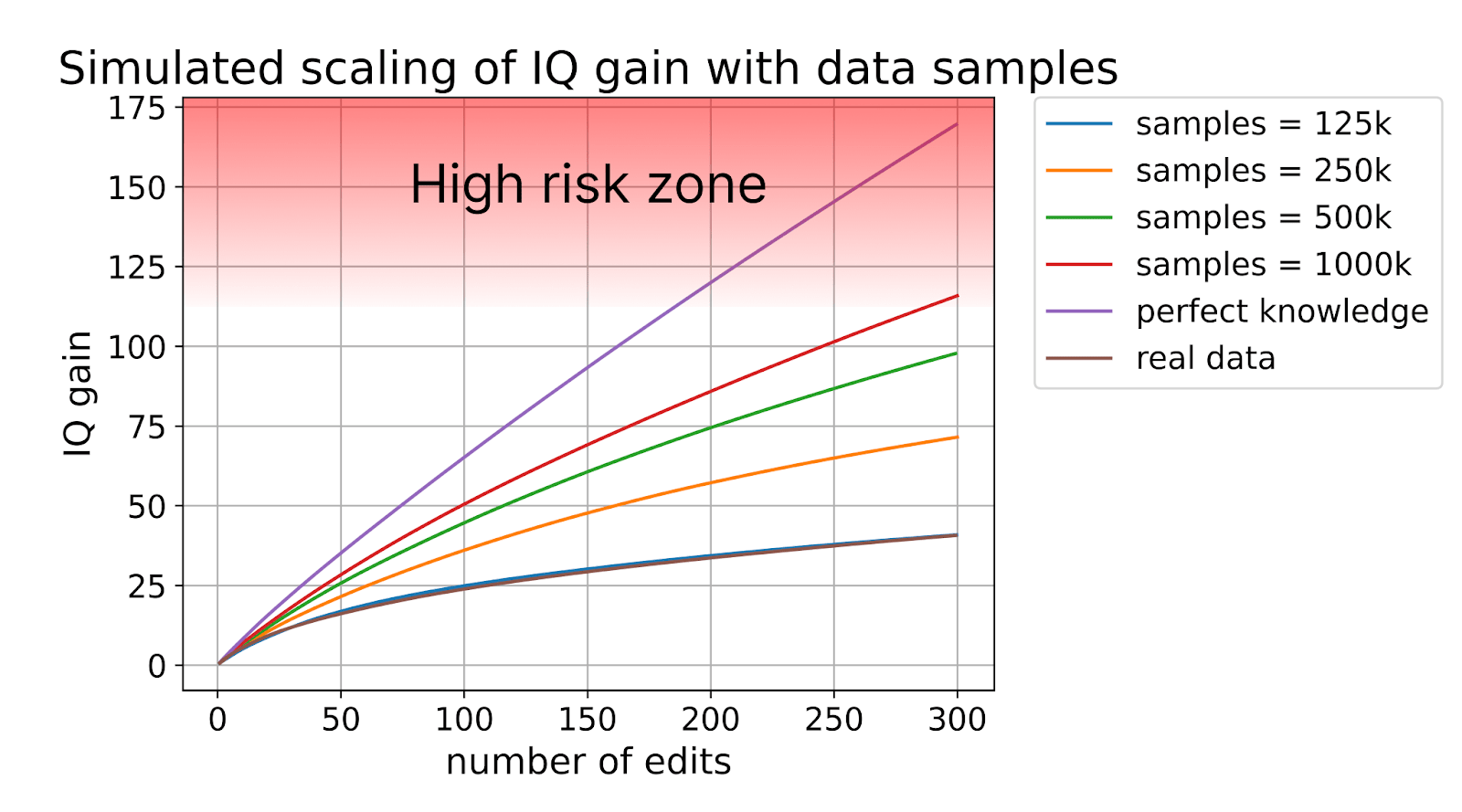
What’s even crazier is this is just the lower bound on what we could achieve. We haven’t even used all the data we could for fine-mapping, and if any of the dozen or so biobanks out there decides to make an effort to collect more IQ phenotypes the expected gain would more than double.
Like machine learning, gene editing has scaling laws. With more data, you can get a larger improvement out of the same number of edits. And with a sufficiently large amount of data, the benefit of gene editing is unbelievably powerful.
Already with just 300 edits and a million genomes with matching IQ scores, we could make someone with a higher predisposition towards genius than anyone that has ever lived.
This won’t guarantee such an individual would be a genius; there are in fact many people with exceptionally high IQs who don’t end up making nobel prize worthy discoveries.
But it will significantly increase the chances; Nobel prize winners (especially those in math and sciences) tend to have IQs significantly above the population average.
It will make sense to be cautious about pushing beyond the limit of naturally occurring genomes since data about the side-effects of editing at such extremes is quite limited. We know from the last few millennia of selective breeding in agriculture and husbandry that it’s possible to push tens of standard deviations beyond any naturally occurring genome (more on this later), but animal breeders have the advantage of many generations of validation over which to refine their selection techniques. For the first generation of enhanced humans, we’ll want to be at least somewhat conservative, meaning we probably don’t want to push much outside the bounds of natural human variation.
Maximum human life expectancy
Perhaps even more than intelligence, health is a near universal human good. An obvious question when discussing the potential of gene editing is how large of an impact we could have on disease risk or longevity if we edited to improve them.
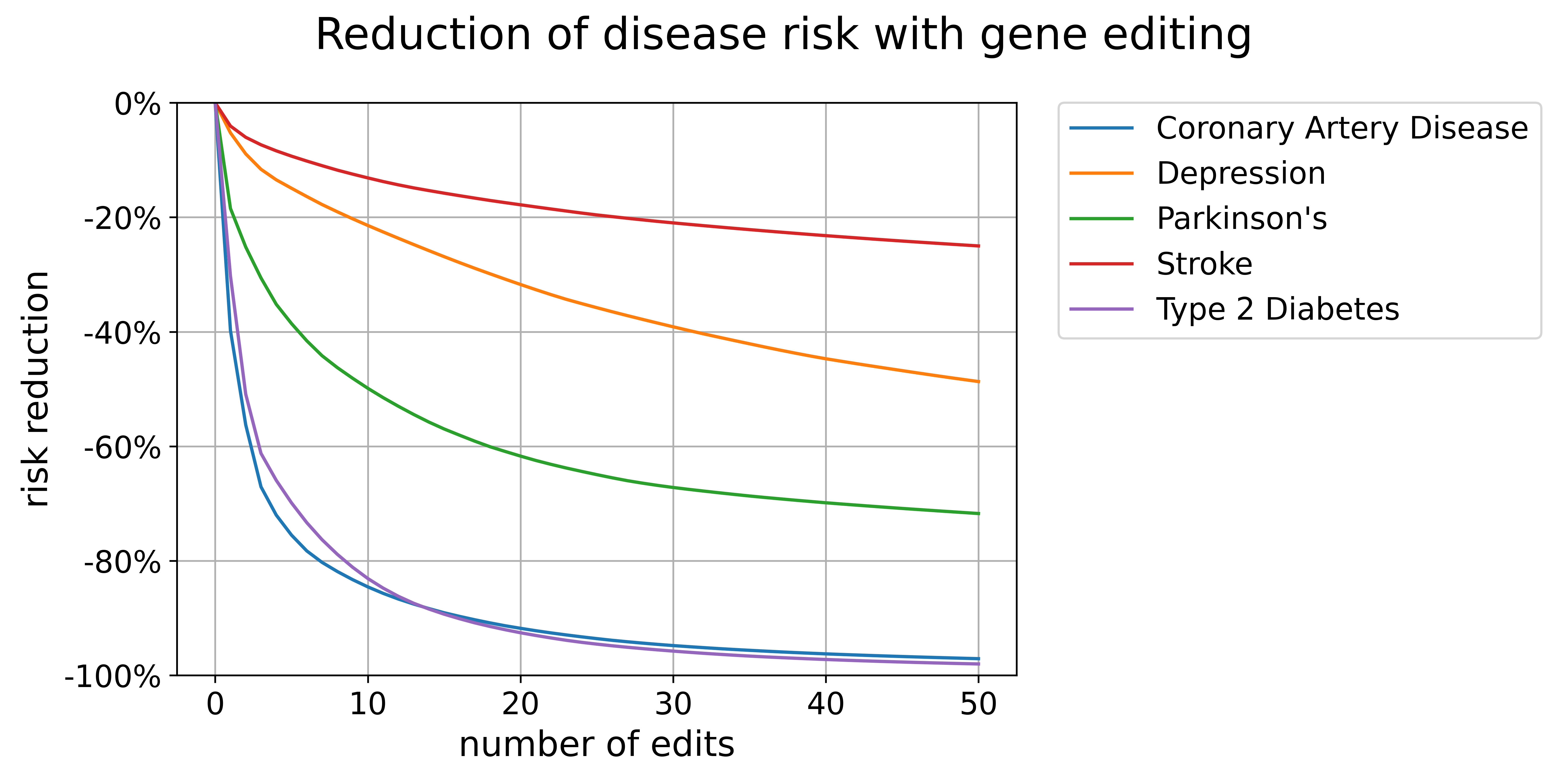
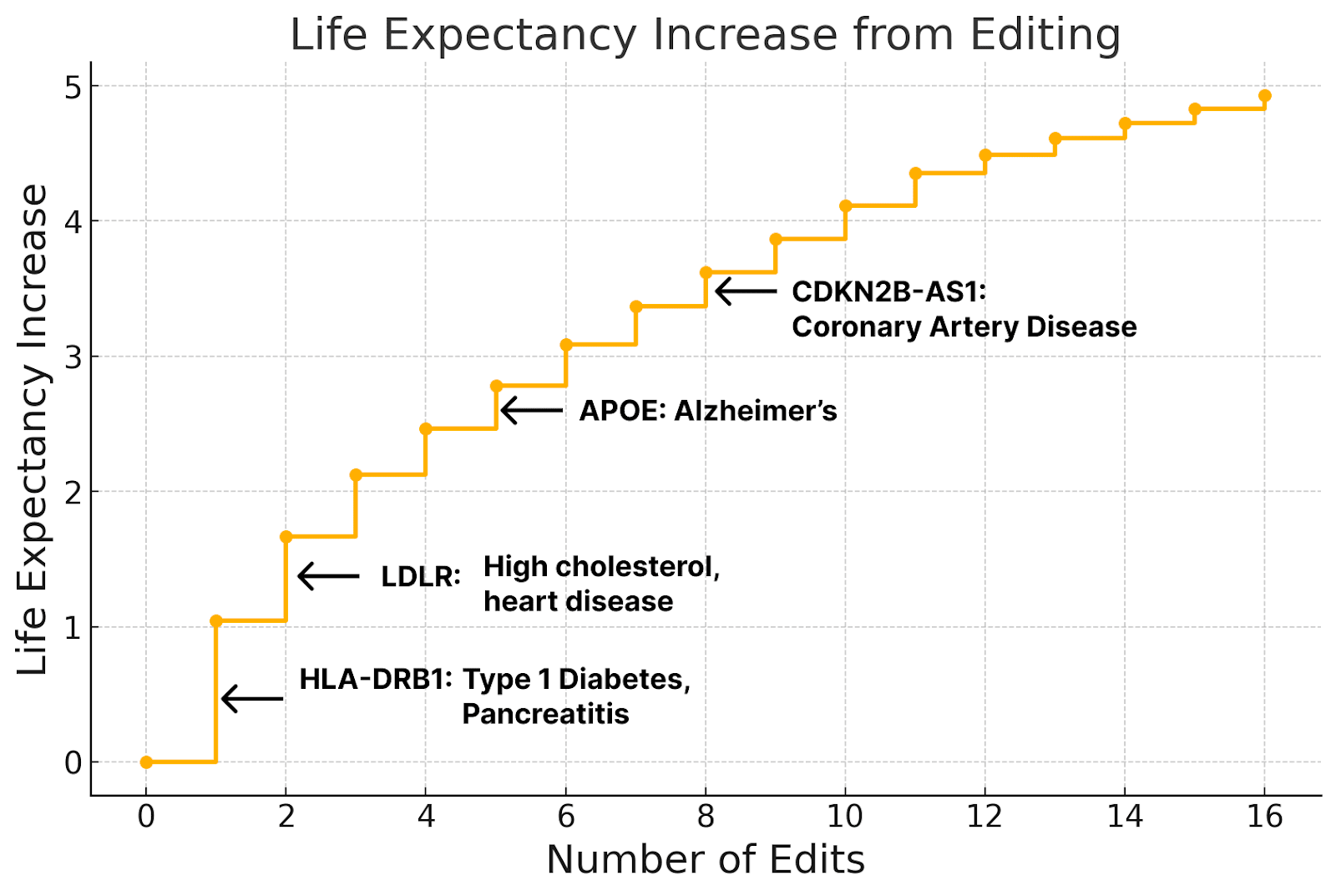
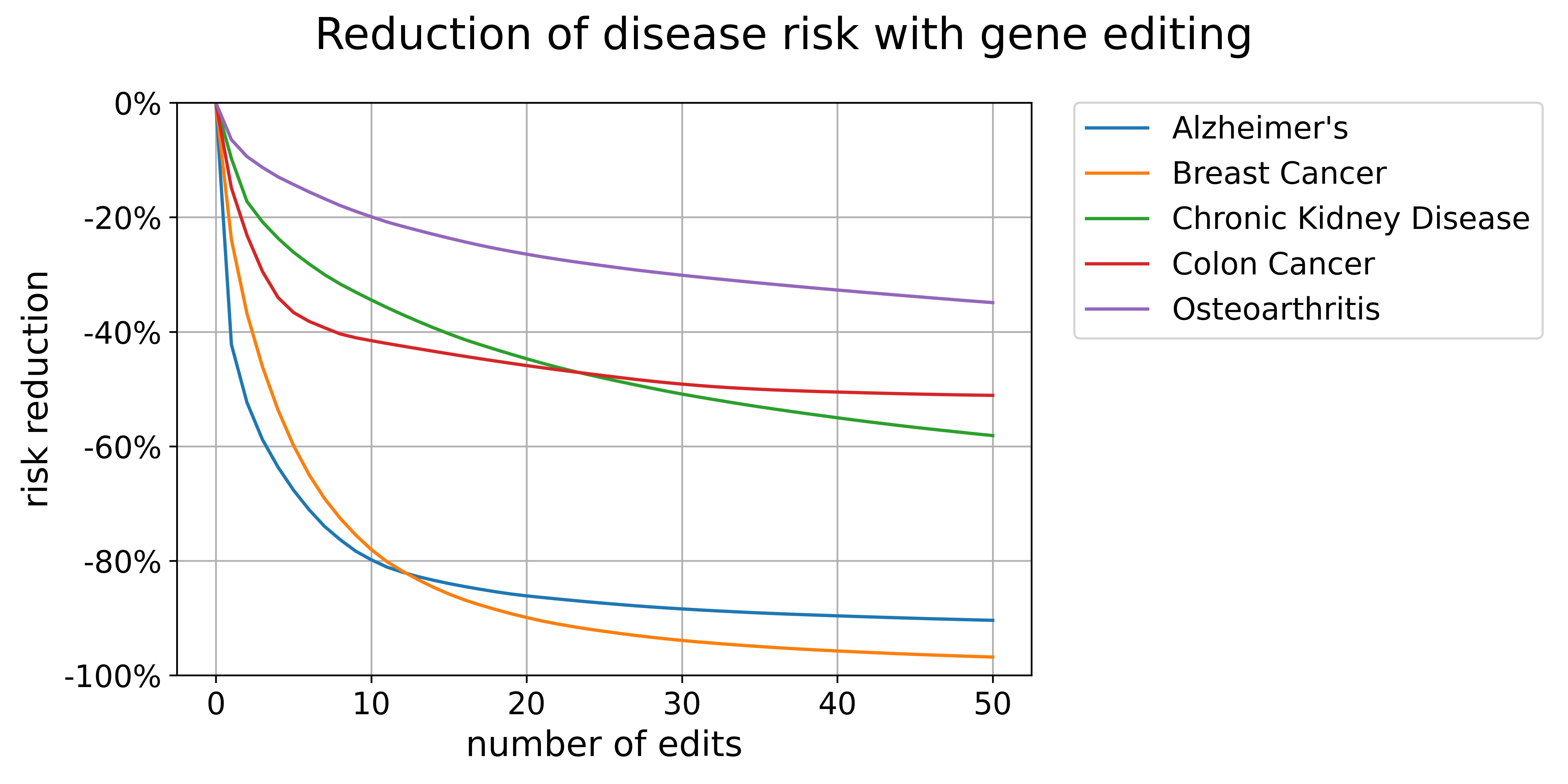
The size of reduction we could get from editing varies substantially by disease. Some conditions, like coronary artery disease and diabetes, can be nearly eliminated with just a handful of edits.
Others, like stroke and depression take far more edits and can’t be targeted quite as effectively.
You might wonder why there’s such a large difference between conditions. Perhaps this is a function of how heritable these diseases are. But that turns out to be only part of the story.
The other part is the effect size of common variants. Some diseases have several variants that are both common among the population and have huge effect sizes.
And the effect we can have on them with editing is incredible. Diabetes, inflammatory bowel disease, psoriasis, Alzheimer’s, and multiple sclerosis can be virtually eliminated with less than a dozen changes to the genome.
Interestingly, a large proportion of conditions with this property of being highly editable are autoimmune diseases. Anyone who knows a bit about human evolution over the last ten thousand years should not be too surprised by this; there has been incredibly strong selection pressure on the human immune system during that time. Millenia of plagues have made genetic regions encoding portions of the human immune system the single most genetically diverse and highly selected regions in the human genome.
As a result the genome is enriched for “wartime variants”; those that might save your life if the bubonic plague reemerges, but will mess you up in “peacetime” by giving you a horrible autoimmune condition.
This is, not coincidentally, one reason to not go completely crazy selecting against risk of autoimmune diseases: we don't want to make ourselves that much more vulnerable to once-per-century plagues. We know for a fact that some of the variants that increase their risk were protective against ancient plagues like the black death (see the appendix for a fuller discussion of this [LW · GW]).
With most trait-affecting genetic variants, we can make any trade-offs explicit; if some of the genetic variants that reduce the risk of hypertension increase the risk of gallstones, you can explicitly quantify the tradeoff.
Not so with immune variants that protect against once-per-century plagues. I dig more into how to deal with this tradeoff in the appendix [LW · GW] but the TL;DR is that you don’t want to “minimize” risk of autoimmune conditions. You just want to reduce their risk to a reasonable level while maintaining as much genetic diversity as possible.
Is everything a tradeoff?
A skeptical reader might finish the above section and conclude that any gene editing, no matter how benign, will carry serious tradeoffs.
I do not believe this to be the case. Though there is of course some risk of unintended side-effects (and we have particular reason to be cautious about this for autoimmune conditions), this is not a fully general counterargument to genetic engineering.
To start with, one can simply look at humans and ask “is genetic privilege a real thing?”
And the answer to anyone with eyes is obviously “yes”. Some people are born with the potential to be brilliant. Some people are very attractive. Some people can live well into their 90s while smoking cigarettes and eating junk food. Some people can sleep 4 hours a night for decades with no ill effects.
And this isn’t just some environmentally induced superpower either. If a parent has one of these advantages, their children are significantly more likely than a stranger to share it. So it is obvious that we could improve many things just by giving people genes closer to those of the most genetically privileged.
But there is evidence from animal breeding that we can go substantially farther than the upper end of the human range when it comes to genetic engineering.
Take chickens. While literally no one would enjoy living the life of a modern broiler chicken, it is undeniable that we have been extremely successful in modifying them for human needs.
We’ve increased the weight of chickens by about 40 standard deviations relative to their wild ancestors, the red junglefowl. That’s the equivalent of making a human being that is 14 feet tall; an absurd amount of change. And these changes in chickens are mostly NOT the result of new mutations, but rather the result of getting all the big chicken genes into a single chicken.
Some of you might point out that modern chickens are not especially healthy. And that’s true! But it’s the result of a conscious choice on the part of breeders who only care about health to the extent that it matters for productivity. The health/productivity tradeoff preferences are much, much different for humans.
So unless the genetic architecture of human traits is fundamentally different from those of cows, chickens, and all other domesticated animals (and we have strong evidence this is not the case), we should in fact be able to substantially impact human traits in desirable ways and to (eventually) push human health and abilities to far beyond their naturally occurring levels.
But we can do even better than these vague arguments. Suppose you’re worried that if we edit genes to decrease the risk of one disease, we might inadvertently increase the risk of another. To see how big of an issue this might be, let’s look at a correlation matrix of the genetic variants involved in determining complex disease risks like diabetes and breast cancer:
With a few notable exceptions, there is not very much correlation between different diseases. Most disease have a genetic correlation of between 0 and 5%.
And the correlations that DO exist are mostly positive. That's why most of the boxes are yellowish instead of bluish. Editing embryos to reduce the risk of one disease usually results in a tiny reduction of others.
To the extent it doesn’t, you can always edit variants to target BOTH diseases. Even if they are negatively correlated, you can still have a positive effect on both.
This kind of pre-emptive editing targeting multiple diseases is where I think this field is ultimately headed. Those of you in the longevity field have long understood that even if we cure one or two of the deadliest conditions like heart disease or cancers, it would only add a couple of years to human life expectancy. Too many other bodily systems are breaking down at around the same time.
But what if we could go after 5 diseases at once? Or ten? What if we stopped thinking about diseases as distinct categories and instead asked ourselves how to directly create a long, healthy life expectancy?
In that case we could completely rethink how we analyze the genetics of health. We could directly measure life expectancy and edit variants that increase it the most.
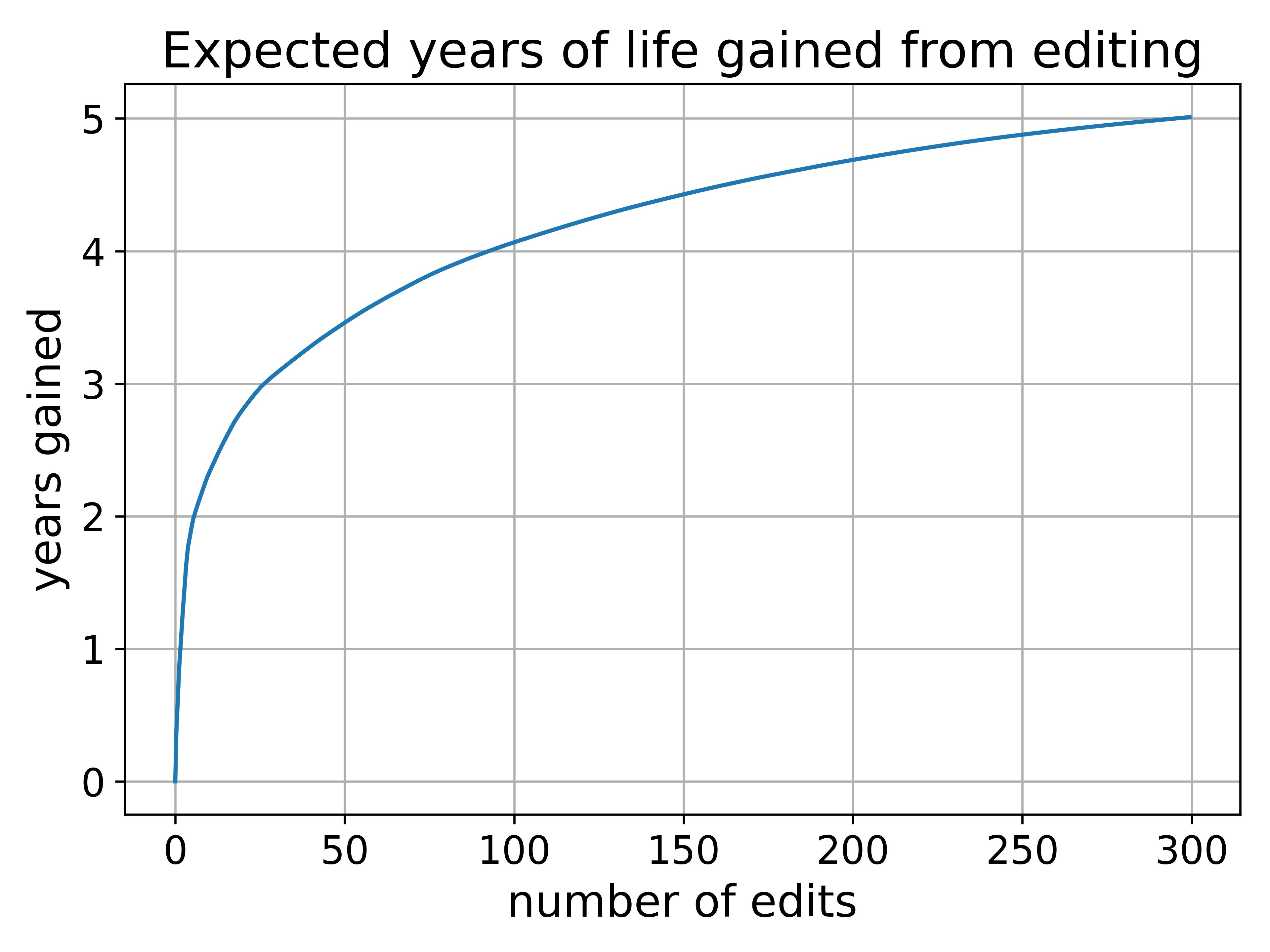
How large of an impact could we have with editing? My cofounder pulled data from the largest genome-wide association study of life expectancy we could find and graphed the results.
4-5 years. That’s how much of an impact we could have on life expectancy with editing. This impact is already on part with the combined effects of eliminating both heart disease and cancer, but it's not exactly an earth-shattering change.
Unlike disease risk or IQ, life expectancy gains are currently much more limited by our lack of data. We just don't have enough genomes from dead people to understand very well which genes are involved in life expectancy.
But if we WERE to get more, the effects of edting could be tremendous.
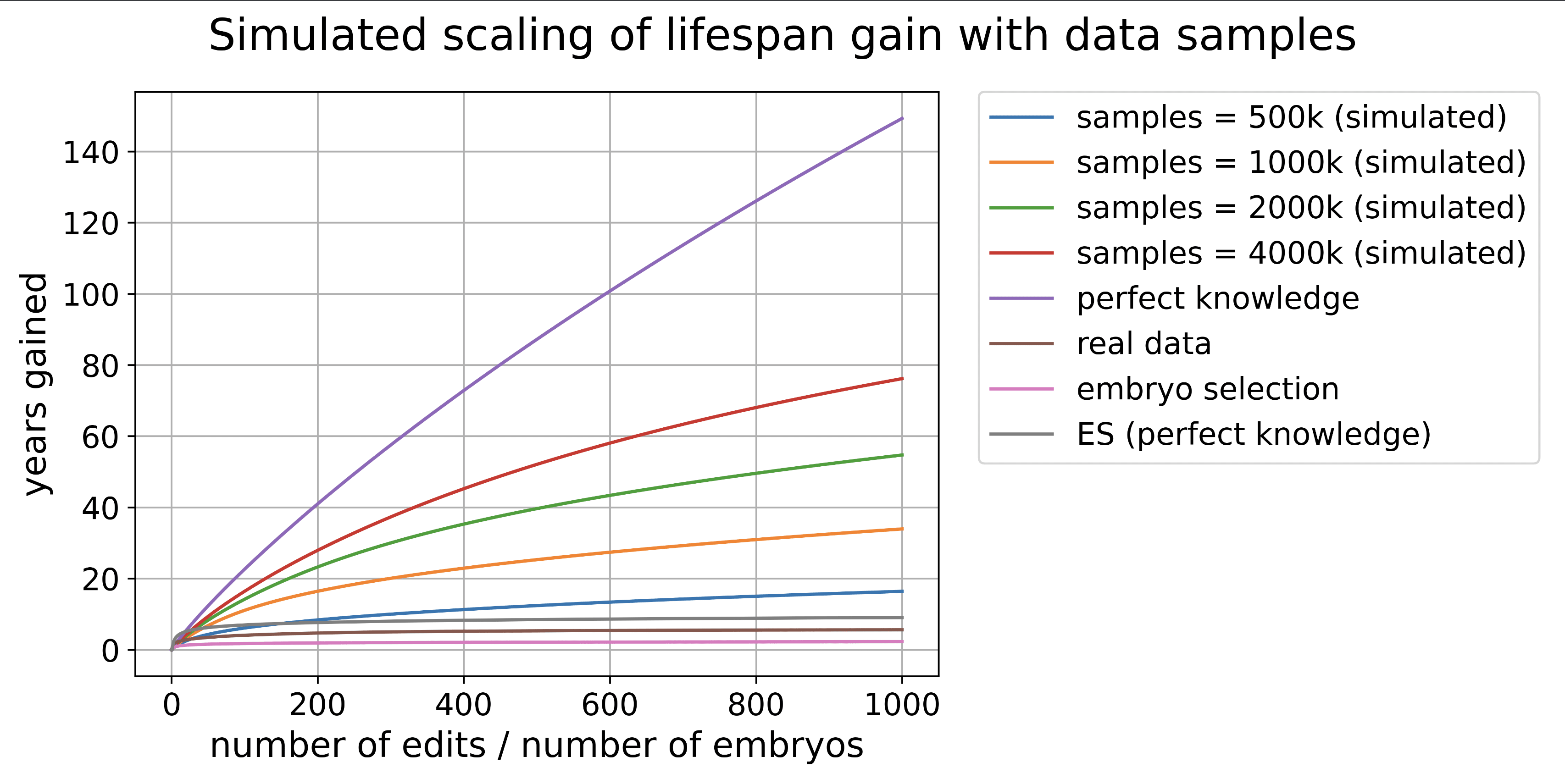
Life expectancy gain from editing as a function of the amount of data used in the training set. If you want to figure out life expectancy after editing, just add ~77 years to whatever is shown on the graph.
At the upper limit, a life expectancy increase of 75 years is perhaps not too implausible.
I think in practice we would probably not push much beyond 50 additional years of life expectancy simply because that would already take us to the ragged edge of how long naturally occurring humans stick around. But in a few generations we could probably start pushing lifespans in the high hundreds or low 200s.
Some might worry that by targeting life expectancy directly rather than diseases, the result might be people who stay very sick for a very long time. I think that’s extremely unlikely to be the case.
For one thing, even very expensive modern medicine can’t keep very sick people alive for more than a few extra years in most cases. But for another, we can actually zoom in to the graph shown above and LOOK at exactly which variants are being targeted.
When we do, we find that many of the variants that have the largest impact on life expectancy are in fact risk variants for various diseases. In other words, editing for life expectancy directly targets many of the diseases that bring life to a premature end.
Note that this graph was constructed using an earlier version of our software that didn't account for causal uncertainty, which is why it shows such a large gain from a small number of edits.
This chart also shows why treating aging is so hard; the genetics of breakdown aren’t just related to one organ system or one source of damage like epigenetic aging. They’re ALL OVER the place; in dozens of different organ systems.
Results like these are one of the reasons why I think virtually all current anti-aging treatments are destined to fail. The one exception is tissue replacement, of the kind being pursued by Jean Hebert and a few others.
Gene editing is another exception, though one with more limited power than replacement. We really can edit genes that affect dozens if not hundreds of bodily systems.
So to summarize; we have the data. We have at least a reasonably good probabilistic idea of which genes do what. And we know we can keep side-effects of editing relatively minimal.
So how do we actually do the editing?
How to make an edited embryo
The easiest way to make a gene-edited embryo is very simple; you fertilize an egg with a sperm, then you squirt some editors (specifically CRISPR) onto the embryo. These editors get inside the embryo and edit the genes.
This method has actually been used in human embryos before! In 2018 Chinese scientist He Jiankui created the first ever gene edited embryos by using this technique. All three of the children born from these embryos are healthy 6 years later (despite widespread outrage and condemnation at the time).
Today we could probably do somewhat more interesting editing with this technique by going after multiple genes at once; Alzheimer’s risk, for example, can be almost eliminated with maybe 10-20 edits.
But there are issues. Editors mess up every now and then, and ideally one would hope to VERIFY that there were no unintentional edits made during the editing process.
This CAN be done! If all the cells in the embryo have the same genome, you can take a little sample of the embryo and sequence the genome to figure out whether any unintentional edits were made. And we already do this kind of embryo sampling as a routine part of fertility treatments.
But cells are only guaranteed to have the same genome if all the edits are made before the first cell division. If an edit is made afterwards, then some cells will have it and some cells won’t.
You can mostly guarantee no editing after the first cell division by injecting anti-CRISPR proteins into the embryo before the first cell division. This disables any remaining editors, ensuring all the embryo’s tissues have the same genome and allowing you to check whether you’ve made the edits you want.
The other option is you can just shrug and say “Well if our testing shows that this process produces few enough off-targets, it probably doesn’t matter if some of the cells get edited and some don’t. As long as we don’t mess up anything important it will be fine”. After all, there are already substantial genetic differences between different cells in the same person, so the current evidence suggests it’s not that big of a deal.
But either way, there are fundamental limits to the number of edits you can make this way. You can only cram so many editors inside the cell at once without killing the cell. The cellular repair processes crucial for editing can only work so fast (though there are ways to upregulate some of them). And after a few cell divisions the embryo’s size increases, making delivery of editors to the inner tissues very difficult.
So while you can make perhaps up to 5 edits in that 1 day window (possibly more if my company succeeds with our research), that isn’t nearly enough to have a significant effect on highly polygenic traits like depression risk or intelligence or life expectancy.
Fortunately, there is another way; make the edits in a stem cell, then turn that stem cell into an embryo. And there has been a significant breakthrough made in this area recently.
Embryos from stem cells
On December 22nd 2023, an interesting paper was published in the pages of Cell. Its authors claimed to have discovered what had long been considered a holy grail in stem cell biology: a method of creating naive embryonic stem cells.
I first learned of the paper two weeks later when the paper’s principal investigator, Sergiy Velychko, left a comment [LW(p) · GW(p)] about the work on my LessWrong blog post [LW · GW].
It’s not often that I have a physical response to a research paper, but this was one of the few exceptions. Goosebumps; they did what?? Is this actually real?
Velychko and his collaborators had discovered that by modifying a single amino acid in one of the proteins used to create stem cells, they could create a more powerful type of stem cell capable of giving rise to an entirely new organism. And unlike previous techniques, Velychko’s wasn’t just limited to mice and rats; it seemed to work in all mammals including humans.
If Velychko’s technique works as well in primates as the early data suggests, it could enable gene editing on a previously impossible scale. We could make dozens or even hundreds of edits in stem cells, then turn those stem cells into embryos. Once we can do this, germline gene editing will go from being a niche tool useful for treating a handful of diseases, to perhaps the most important technology ever developed.
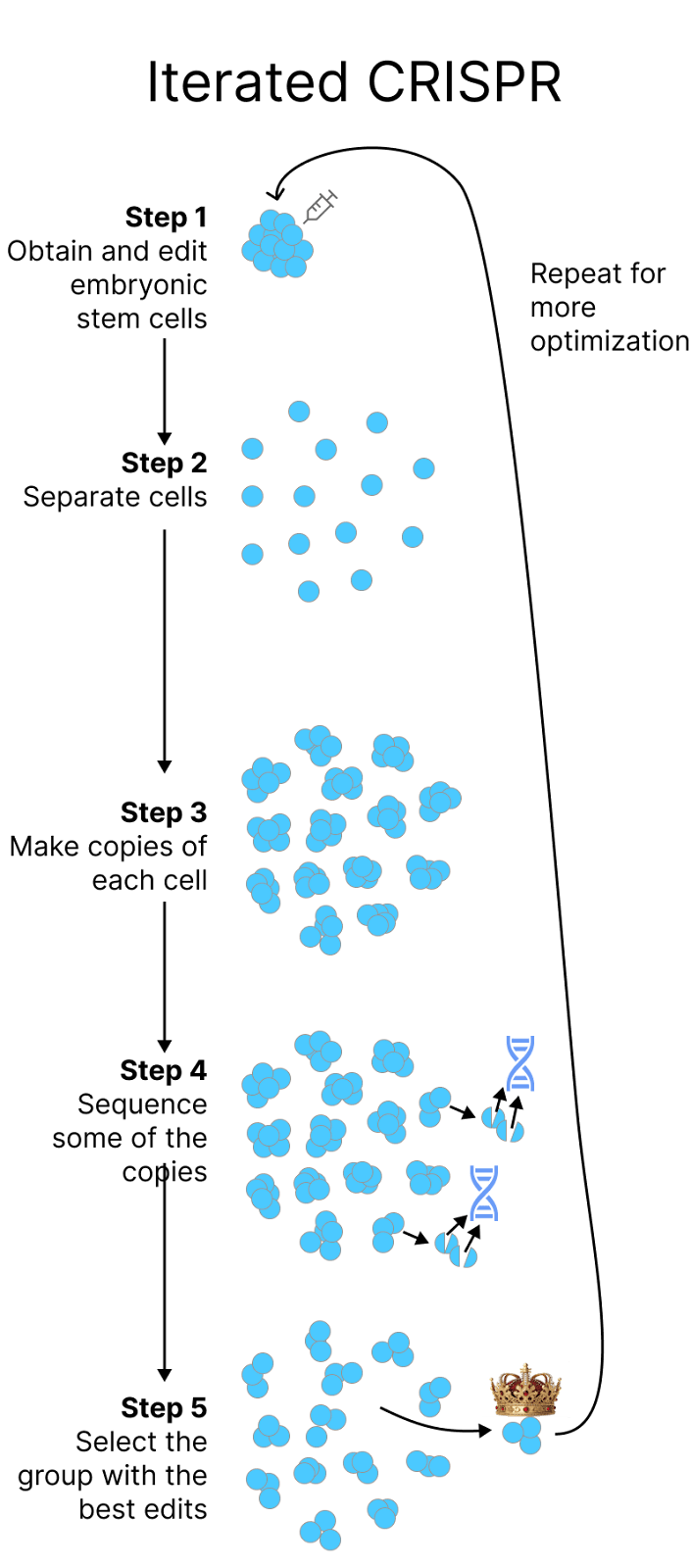
Iterated CRISPR
To explain why, we need to return to the method used by He Jiankui to make his embryos. The main limitation with Jiankui’s technique is the limited time window during which edits can be made, and the inability to go back and fix mistakes or “weed out” cells that are damaged by the editors.
With Jiankui’s technique, all edits have to be made in the first 24 hours, or at most the first few days. Mistakes can’t be corrected, and any serious ones do irreparable damage to the embryo.
If we could somehow grow the cells separately, we could take our time making edits and VERIFY them all before implanting an embryo. We could edit,make copies of the cells, verify the edits, then make more edits, all in a loop. A protocol might look something like the following:
However, there’s one issue with the above protocol; the moment you remove stem cells from an embryo and begin to grow them, they lose their developmental potential. The stem cells become “primed”, meaning they can no longer form a complete organism.
So even if you are able to edit a bunch of genes in your stem cells to decrease heart attack risk, increase intelligence and decrease depression risk, it doesn’t matter. Your super cells are just that; they can’t make a baby.
And until late 2023, this is where the field was stuck.
Then along came Sergiy Velychko.
Sergiy Velychko and the story of Super-SOX
The story of his discovery, what it is, how it works, and how it was made, is one of the most interesting I’ve ever stumbled across.
In the early 2020s, Sergiy was a post doc at the Max Planck Institute in Germany where he was working on research related to stem cells.
Stem cells are normally created by “turning on” four proteins inside a skin cell. These proteins are called “Yamanaka factors” after the Japanese scientist who discovered them. When they are turned on, the gene expression of the skin cell is radically altered, changing it into a stem cell.
Sergiy had been experimenting with modifications to one particular Yamanaka factor named Oct4. He was trying to increase the efficiency with which he could convert skin cells into stem cells. Normally it is abysmally bad; less than 1%.
Unfortunately, very few of his experiments had yielded anything interesting. Most of his modifications to Oct4 just made it worse. Many broke it completely.
After a few years of running into one dead end after another, Sergiy gave up and moved on to another project converting skin cells into blood cells.
He ran a series of experiments involving a protein called Sox17 E57K, a mutant of Sox17 known for its surprising ability to make stem cells (normal Sox17 can’t do this). Sergiy wanted to see if he could combine the mutant Sox17 with one of his old broken Oct4 mutants to directly make blood cells from skin.
To prove that the combination worked, Sergiy needed to set up a control group. Specifically he needed to show that the combination did NOT produce stem cells. Without this control group there would be no way to prove that he was making skin cells DIRECTLY into blood cells instead of making them into stem cells which became blood cells afterwards.
This should have been easy. His previous work had shown the Oct4 mutant wasn’t capable of making stem cells, even when combined with all the other normal reprogramming factors.
But something very surprising happened; the control group failed. The broken Oct4, which he had previously shown to be incapable of making stem cells, was doing just that.
What is going on?
Most scientists would have chalked up this outcome to contamination or bad experimental setup, or perhaps some weird quirk of nature that wasn’t particularly interesting. Indeed many of Sergiy’s colleagues who he informed of the result found it uninteresting.
So what if you could make stem cells with a weird combination of proteins? It was still less efficient than normal Yamanaka factors and there didn’t seem to be any very compelling reasons to believe it was worth looking into.
But Sergiy felt differently. He had spent enough time studying the structure and functionality of Yamanaka factors to realize this result indicated something much deeper and stranger was going on; somehow the mutant Sox17 was “rescuing” the Oct4 mutant.
But how?
Determined to understand this better, Sergiy began a series of experiments. Piece by piece he began swapping parts of the mutant Sox17 protein into Sox2, the normal reprogramming factor, trying to better understand what exactly made the mutant Sox17 so special.
Sox17 differs in many places from Sox2, so it was reasonable to assume that whatever made it special involved multiple changes.
But that was not what Sergiy found. Instead, he found that he could replicate the behavior by changing a single amino acid.
Just one.
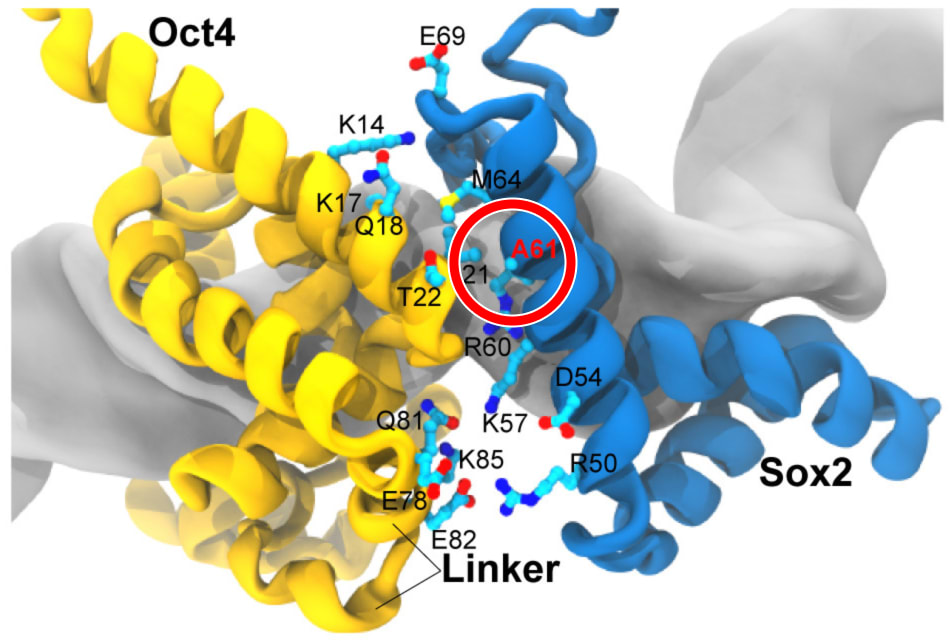
By swapping out an Alanine for a Valine at the 61st position in Sox2, it too could rescue the Oct4 mutants in the same way that the Sox17 mutant could.
What was going on? Sergiy pulled up some modeling software to try to better understand how such a simple change was making such a large difference.
When he saw the 3d structure, it all clicked. The amino acid swap occurred at the exact spot where Sox2 and the Oct4 mutants stuck to each other. It must be changing something about the bond formed between the two.
Further experiments confirmed this to be the case; the Alanine to Valine swap was increasing the strength of the bond between Sox and Oct by a thousand fold.
To those familiar with Yamanaka factors, it might seem exceptionally strange that modifying the bond BETWEEN Yamanaka factors could enable reprogramming.
Yamanaka factors are normally thought to work their magic by sticking to DNA and forming a sort of landing pad for a larger protein complex involved in gene expression.
After understanding the mechanism, Sergiy had a new idea. If one amino acid swap could enable decent reprogramming efficiency with a broken Oct4, what would it enable if it was combined with a working Oct4? Sergiy quickly ran the experiment, which produced another breakthrough. When combined with normal Oct4, super-SOX was making stem cells with at least ten times the efficiency of standard techniques.
After years of failed attempts, he had finally found his super reprogramming factor.
Super-SOX
Sergiy began testing other changes such as substituting Sox17’s C terminus domain (the part that sticks onto other proteins) into Sox2. By the time he was done with all of his improvements, his modified stem cell recipe was able to create stem cells at a rate 50 times that of normal reprogramming. The best starting cells were creating stem cells with 200x the efficiency. Sergiy dubbed the best version “super-SOX”.
By itself this would have been a huge discovery and a boon to stem cell scientists all over the world. But there was something even more interesting happening.
When Sergiy began looking at the gene expression of stem cells created with super-SOX, he noticed something incredible; these cells did not look like normal stem cells used in experiments for decades. Instead they looked like stem cells taken directly from a very early embryo.
These kinds of stem cells had been created in mice long ago, but they had never before been created for any other species except rats. Yet one after another, the signs (most notably activation of the Oct4 distal enhancer) indicated that Sergiy’s super-SOX was doing just that. It was making naive embryonic stem cells.
Mice from stem cells
To test whether what he thought he was seeing was real, Sergiy began experimenting on mice, trying to test the developmental potential of these new stem cells.
The logic of the experiment was simple; if he could grow a whole new mouse from super-SOX-derived stem cells, it would mean those cells had the same developmental potential as ones harvested directly from an early embryo.
This had been done before, but the efficiency was very low. Embryos made from stem cells often failed to develop after transfer, and those that did often died shortly after birth.
The experiment worked. And not only did it work, but the results were incredible. Super-SOX led to an 800% increase in the adult survival rate of stem cell derived mice relative to normal Sox2.
The red bar shows the adult survival rate of mice made from super-SOX derived iPSCs, when compared with the standard Yamanaka cocktail.
One particular cell line stood out; embryos derived from a line with an integrated SKM transgene were resulting in live births 90% of the time. That is ABOVE the live birth rate from normal conception, meaning super-SOX was able to beat nature.
Not everything is perfect; the experiments showed some loss of imprinting during super-SOX culturing. But there are ways to address this issue, and Sergiy believes there are still further optimizations to be made.
Why does super-SOX matter?
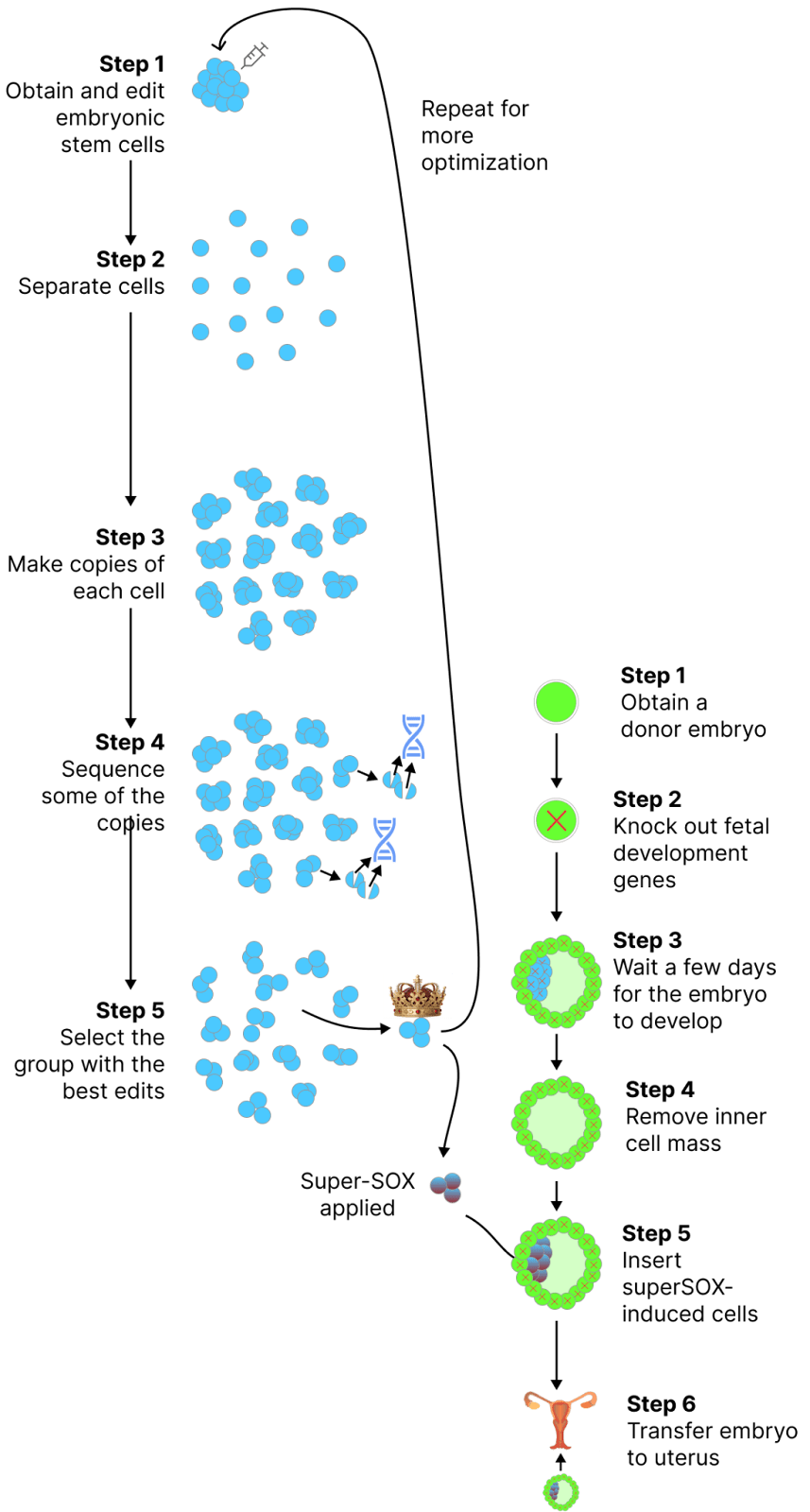
Remember how we previously had no way to turn the edited stem cells into an embryo? If super-SOX works as well in humans as the early data seems to indicate, that will no longer be the case. We’ll plausibly be able to take edited stem cells, apply super-SOX, stick them in a donor embryo, and MAKE a new person from them.
Readers might wonder why we need a donor embryo. If super-SOX cells can form an entirely new organism, what’s the point of the donor?
The answer is that although super-SOX cells form the fetus, they can’t form the placenta or the yolk sack (the fluid filled sack that the fetus floats in). Making cells that can form those tissues would require a further step beyond what Sergiy has done; a technique to create TOTIPOTENT stem cells.
So until someone figures out a way to do that, we’ll still need a donor embryo to form those tissues.
Let’s put it all together; if super-SOX works as well in humans as it does in mice, this is how you would make superbabies:
“Knock out fetal development genes” is one option to prevent the donor embryo’s cells from contributing to the fetus. There are other plausible methods to achieve this goal, such as overexpressing certain genes to solidify cell fate of the donor embryo’s cells before introducing super-SOX-derived cells.
How do we do this in humans?
The early data from the super-SOX in humans looks promising. Many of the key markers for naive pluripotency are activated by super-SOX, including the Oct4 distal enhancer, the most reliable cross-species indicator of naive developmental potential (note this discovery was made after publications so you actually can’t find it in the paper). Sergiy also showed that super-SOX induced HUMAN stem cells could contribute to the inner cell mass of mouse embryos, which is the first time this has ever been demonstrated.
But we don’t have enough evidence yet to start testing this in humans.
Before we can do so, we need to test super-SOX in primates. We need to show that you can make a monkey from super-SOX derived cells, and that those monkeys are healthy and survive to adulthood no less often than those that are conceived naturally.
If that can be demonstrated, ESPECIALLY if it can be demonstrated in conjunction with an editing protocol, we will have the evidence that we need to begin human trials.
Frustratingly, Sergiy has not yet been able to find anyone to fund these experiments. The paper on super-SOX came out a year ago, but to date I’ve only been able to raise about $100k for his research.
Unfortunately monkeys (specifically marmosets) are not cheap. To demonstrate germline transmission (the first step towards demonstrating safety in humans), Sergiy needs $4 million.
If any rich people out there think making superhumans is a worthwhile cause, this is a shovel ready project that is literally just waiting for funding; the primatology lab is ready to go, Sergiy is ready to go, they just need the money.
What if super-SOX doesn’t work?
So what if super-SOX doesn’t work? What if the primate trials conclude and we find that despite super-SOX showing promising early data in human stem cells and very promising mouse data, it is insufficient to make healthy primates? Is the superbabies project dead?
No. There are multiple alternatives to making an embryo from edited stem cells. Any of them would be sufficient to make the superbabies plan work (though some are more practical than others).
Eggs from Stem Cells
The first and most obvious alternative is creating eggs from stem cells. There are a half dozen startups, such as Conception and Ovelle, working on solving this problem right now, and if any of them succeeded we would have a working method to turn edited stem cells into a super egg.
These superbabies wouldn’t be quite as superlative as super-SOX derived embryos since only half of their DNA would be genetically engineered. But that would still be sufficient for multiple standard deviations of gain across traits such as intelligence, life expectancy, and others.
Another option is to make edited sperm.
Fluorescence-guided sperm selection
Edited sperm are potentially easier to make because you don’t need to recapitulate the whole sperm maturation process. The testicles can do it for you.
To explain I need to give a little bit of background on how sperm is formed naturally.
The inside of the testicles contain a bunch of little tubes called “seminiferous tubules”. These are home to a very important bunch of cells called spermatogonial stem cells. As you might be able to guess from the name, spermatogonial stem cells are in charge of making sperm. They sit inside the tubes and every now and then (though a process I won’t get into) they divide and one of the two resulting cells turns into sperm.
There’a complicated process taking place inside these tubules that allows for maturation of the sperm. You NEED this maturation process (or at least most of it) for the sperm to be capable of making a baby.
But we can’t recreate it in the lab yet.
So here’s an idea; how about instead of editing stem cells and try to turn them into sperm, we edit spermatogonial stem cells and stick them back in the testicles? The testicles could do the maturation for us.
You would need some way to distinguish the edited from the unedited sperm though, since the edited and the unedited sperm would get mixed together. You can solve this by adding in a protein to the edited stem cells that makes the sperm formed from them glow green. You can then use standard off-the-shelf flow cytometry to pick out the edited from the unedited sperm.
You also probably don’t want the baby to glow green, so it’s best to put the green glowing protein under the control of a tissue specific promoter. That way only the baby’s sperm would glow green rather than its whole body.
From a technical perspective, we’re probably not that far away from getting this working. We’ve successfully extracted and cultured human spermatogonial stem cells back in 2020. And we’ve managed to put them back in the testicles in non-human primates (this made functional sperm too!) So this is probably possible to do in humans.
The monkey experiments used alkylating chemotherapy to get rid of most of the existing stem cells before reinjecting the spermatogonial stem cells. Most people are not going to want to undergo chemotherapy to have superbabies, so there probably needs to be additional research done here to improve the transplantation success rates.
Still, most of the pieces are already in place for this to be tested.
Embryo cloning
Lastly, there is somatic cell nuclear transfer, or SCNT. SCNT is how dolly the sheep was cloned, though in this context we’d be using it to clone an embryo rather than an adult organism. SCNT is not currently safe enough for use in humans (many of the animals born using the technique have birth defects), but should advancements be made in this area it may become viable for human use.
What if none of that works?
If none of the above works, and the only technology my company can get working is the multiplex editing, we can always create super cows in the meantime. We have pretty good genetic predictors for a lot of traits in cows, and you can already use SCNT to make an edited cell into an embryo. The success rates aren’t as high as they are with natural conception, but no one really cares too much about that; if you can make one super bull, it can create many, many offspring with desirable traits such as improved disease resistance, better milk production, or a better metabolism that more efficiently converts feed into beef.
Unlike past GMO technologies, this one could work without inserting any non-cow genes into the cow genome; we could literally just put a bunch of the “extra beefy cow” genes into the same cow. You’d get a similar result from using traditional breeding or embryo selection; the editing would just massively speed up the process.
We could also likely use this tech to make farmed animals suffer less. A big reason factory farming sucks so much is because we’ve bred animals to get better at producing milk and meat but we’ve left all their instincts and wild drives intact. This creates a huge mismatch between what the animals want (and what they feel) and their current environment.
We could probably reduce suffering a decent bit just by decreasing these natural drives and directly reducing pain experienced by animals as the result of these practices.
Many animal advocates hate this idea because they believe we just shouldn’t use animals for making meat (and frankly they have a good point). But in the interim period where we’re still making meat from animals, this could make the scale of the moral disaster less bad, even if it still sucks.
Whether or not the FDA has the authority to enforce this ban is a question which has not yet been tested in court. The FDA does not have regulatory authority over IVF, so there is some reason to doubt its jurisdiction over this area.
Still, the legal situation in the United States at the moment isn’t exactly the most friendly to commercialization.
Fortunately, the United States is not the only country in the world. There are over a dozen countries which currently have no laws banning germline gene editing, and 5 where there are legal carve outs for editing in certain circumstances, such as editing to prevent a disease. Belgium, Colombia, Italy, Panama, and the UAE all have exceptions that allow heritable gene editing in certain circumstances (mostly related to health issues).
The very first application of gene editing will almost certainly be to prevent a disease that the parents have that they don’t want to pass on to their children. This is a serious enough issue that it is worth taking a small risk to prevent the child from going on to live an unhealthy, unhappy life.
From a technical standpoint, we are ready to do single gene editing in embryos RIGHT NOW. There are labs that have done this kind of editing in human embryos with undetectably low levels of off-target edits. My understanding is they are still working on improving their techniques to ensure no mosaicism of the resulting embryos, but it seems like they are pretty close to having that problem solved.
I am trying to convince one of them to launch a commercial entity outside the United States and get the ball rolling on this. This technology won’t make superbabies, but it COULD prevent monogenic diseases and reduce the risk of things like heart disease by editing PCSK9. If anyone is interested in funding this please reach out.
How we make this happen
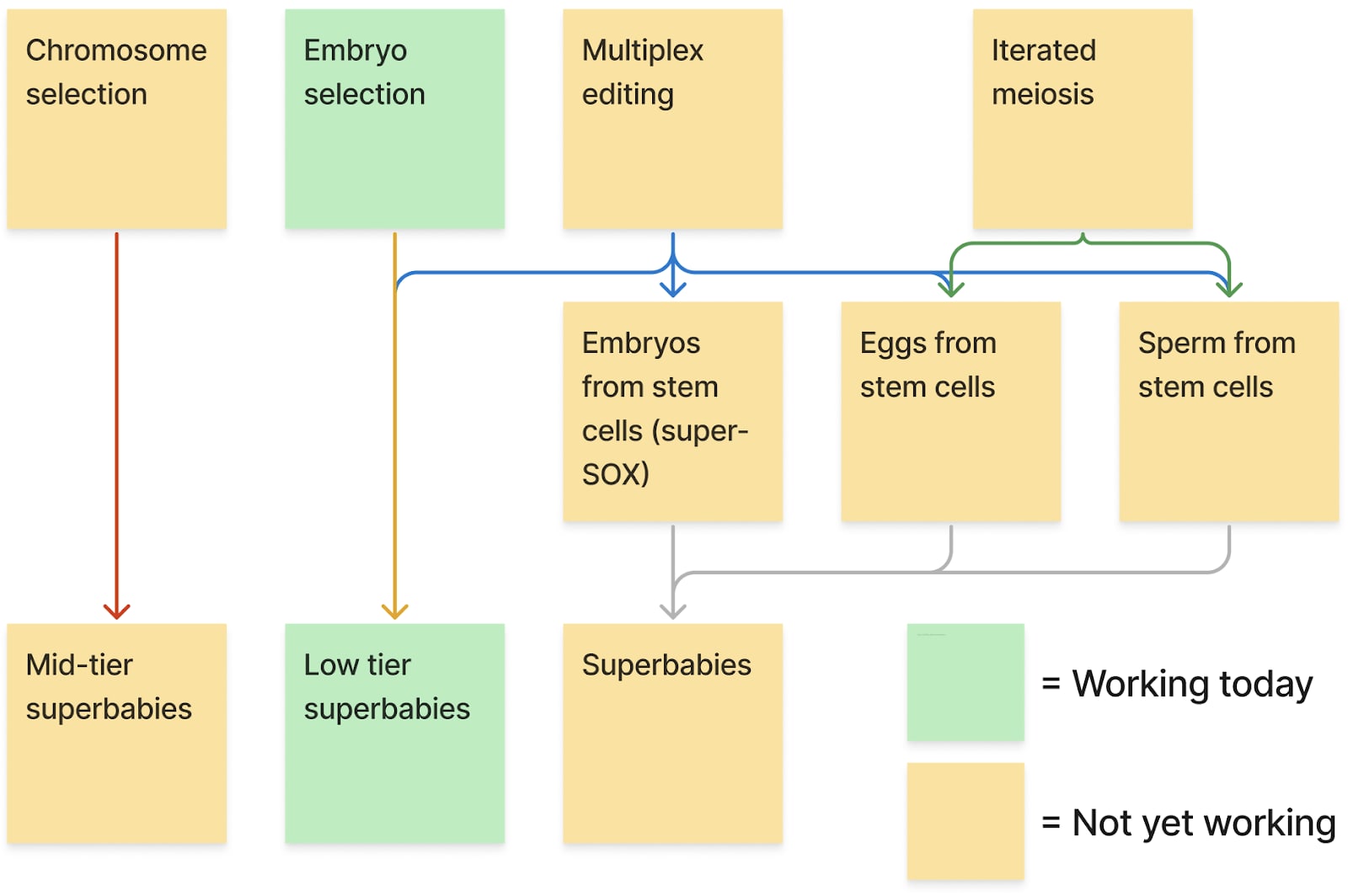
Here’s an oversimplified diagram of various protocols that could be used to make superbabies:
In this blog post I’ve mostly focused on the path that goes multiplex editing → embryos from stem cells → superbabies.
But there are other approaches to make an optimized genome. Chromosome selection is one I’ve only briefly mentioned in other posts [LW · GW], but one which completely bypasses the need for the kind of epigenetic correction necessary for other techniques. And there has been virtually no research on it despite the project appearing at least superficially feasible (use micromanipulators to move chromosomes from different sperm into the same egg).
Iterated meiotic selection is another approach to creating an optimized genome which I haven’t even touched on because it deserves its own post.
In my view the most sensible thing to do here is to place multiple bets; work on chromosome selection AND eggs from stem cells AND embryos from stem cells (a la super-SOX) AND sperm from stem cells (a la hulk sperm) AND multiplex editing all at the same time.
In the grand scheme, none of these projects are that expensive; my company will be trying to raise $8 million for our seed round in a few weeks which we believe will be enough for us to make significant progress on showing the ability to make dozens to hundreds of edits in stem cells (current state of the art is about 10 cumulative edits). Sergiy needs $4 million for super-SOX validation in primates, and probably additional funding beyond that to show the ability to create adult monkeys entirely from stem cells in conjunction with an editing protocol.
I don’t have precise estimates of the amounts needed for chromosome selection, but my guess is we could at the very least reduce uncertainty (and possibly make significant progress) with a year and $1-3 million.
Creating eggs from stem cells is somewhat more expensive. Conception has raised $38 million so far, and other companies have raised a smaller amount.
The approach I like the most here is the one taken by Ovelle, who is planning to use growth and transcription factors to replicate key parts of the environment in which eggs are produced rather than grow actual feeder cells to excrete those factors. If it works, this approach has the advantage of speed; it takes a long time to mature primordial germ cells into eggs replicating the natural process, so if you can recreate the process with transcription factors that saves a lot of time. Based on some conversations I’ve had with one of the founders I think $50 million could probably accelerate progress by about a year (though they are not looking to raise that much at the moment).
Making eggs from stem cells also has a very viable business even if none of the other technologies work; there are hundreds of thousands of couples desperate to have children that simply can’t produce enough eggs to have the kids they want.
This is the case for most of these technologies; multiplex editing will have a market to make super cows, gene therapy, basic research, and to do basic gene editing in embryos even if none of the other stuff works. Creating sperm from stem cells will have a market even without editing or iterated meiotic selection because you’ll be able to solve a certain kind of male infertility where the guy can’t create sperm. Embryo selection ALREADY has a rapidly growing market with an incredibly well-resourced customer base (you wouldn’t believe the number of billionaires and centimillionaires who used our services while I was working on embryo selection at Genomic Prediction). Chromosome selection might be able to just make superbabies in like a couple of years if we’re lucky and the research is straightforward.
So I think even pretty brain dead investors who somehow aren’t interested in fundamentally upgrading the human race will still see value in this.
Ahh yes, but what about AI?
Now we come to perhaps the biggest question of all.
Suppose this works. Suppose we can make genetically engineered superbabies. Will there even be time for them to grow up, or will AI take over first?
Given the current rate of improvement of AI, I would give a greater than 50% chance of AI having taken over the world before the first generation of superbabies grows up.
One might then reasonably ask what the point of all this is. Why work on making superbabies if it probably won’t matter?
There is currently no backup plan if we can’t solve alignment
If it turns out we can’t safely create digital gods and command them to carry out our will, then what? What do we do at that point?
No one has a backup plan. There is no solution like “oh, well we could just wait for X and then we could solve it.”
Superbabies is a backup plan; focus the energy of humanity’s collective genetic endowment into a single generation, and have THAT generation to solve problems like “figure out how to control digital superintelligence”.
It’s actually kind of nuts this isn’t the PRIMARY plan. Humanity has collectively decided to roll the dice on creating digital gods we don’t understand and may not be able to control instead of waiting a few decades for the super geniuses to grow up.
If we face some huge AI disaster, or if there’s a war between the US and China and no one can keep their chip fabs from getting blown up, what does that world look like? Almost no one is thinking about this kind of future.
But we should be. The current trajectory we’re on is utterly insane. Our CURRENT PLAN is to gamble 8 billion lives on the ability of a few profit driven entities to control digital minds we barely understand in the hopes it will give them and a handful of government officials permanent control over the world forever.
I really can’t emphasize just how fucking insane this is. People who think this is a sensible way for this technology to be rolled out are deluding themselves. The default outcome of the trajectory we’re on is death or disempowerment.
Maybe by some miracle that works and turns out well. Maybe Sam Altman will seize control of the US government and implement a global universal basic income and we’ll laugh about the days when we thought AGI might be a bad thing. I will just note that I am skeptical things will work out that way. Altman in particular seems to be currently trying to dismantle the non-profit he previously put into place to ensure the hypothetical benefits of AGI would be broadly distributed to everyone.
If the general public actually understood what these companies were doing and believed they were going to achieve it, we would be seeing the biggest protests in world history. You can’t just threaten the life and livelihood of 8 billion people and not expect pushback.
We are living in a twilight period where clued in people understand what’s coming but the general public hasn’t yet woken up. It is not a sustainable situation. Very few people understand that even if it goes “well”, their very survival will completely depend on the generosity of a few strangers who have no self-interested reason to care about them.
But people are going to figure this out sooner or later. And when they do, it would be pretty embarrassing if the only people with an alternative vision of the future are neo-luddite degrowthers who want people to unplug their refrigerators.
We need to start working on this NOW. Someone with initiative could have started on this project five years ago when prime editors came out and we finally had a means of editing most genetic variants in the human genome.
But no one has made it their job to make this happen. The academic institutions in charge of exploring these ideas are deeply compromised by insane ideologies. And the big commercial entities are too timid to do anything truly novel; once they discovered they had a technology that could potentially make a few tens of billions treating single gene genetic disorders, no one wanted to take any risks; better to take the easy, guaranteed money and spend your life on a lucrative endeavor improving the lives of 0.5% of the population than go for a hail mary project that will result in journalists writing lots of articles calling you a eugenicist.
I think in most worlds, gene editing won’t play a significant role in the larger strategic picture. But in perhaps 10-20%, where AGI just takes a long time or we have some kind of delay of superintelligence due to an AI disaster or war, this will become the most important technology in the world.
Given the expected value here and the relatively tiny amount of money needed to make significant progress (tens to hundreds of millions rather than tens to hundreds of billions), it would be kind of insane if we as a civilization didn’t make a serious effort to develop this tech.
Team Human
There are fundamentally two different kinds of futures that lie before us. In the first, we continue to let technology develop in every area as fast as it can with no long term planning or consideration of what kind of future we actually want to build.
We follow local incentive gradients, heedless of the consequences. No coordination is needed because nothing can possibly go wrong.
This is the world we are building right now. One in which humans are simply biological bootloaders for our digital replacements.
In the second world we take our time before summoning the digital gods. We make ourselves smarter, healthier, and wiser. We take our time and make sure we ACTUALLY UNDERSTAND WHAT WE’RE DOING before opening Pandora’s box.
This latter world is much more human than the first. It involves people making decisions and learning things. You and your children will actually have power and autonomy over your own lives in this world.
There will still be death and suffering and human fallibility in the second world (though less of all of these). We don’t get to magically paper over all problems in this world by saying “AI will fix it” and just crossing our fingers that it will be true. Instead we ourselves, or at least our children, will have to deal with the problems of the world.
But this world will be YOURS. It will belong to you and your children and your friends and your family. All of them will still matter, and if at some point we DO decide to continue along the road to build digital superintelligence, it will be because humanity (or at least its selected representatives) thought long and hard and decided that was a step worth taking.
If we want this kind of world, we need to start building it now. We need to start funding companies to work on the technical roadblocks to bringing superbabies to life. We need to break this stupid taboo around talking about creating genetically engineered people and make sure policymakers are actually informed of just how much this technology could improve human life. It is ludicrous beyond belief that we have gene therapies designed to edit genes for millions of dollars, yet editing those exact same genes in an embryo for a fraction of the money in a more controlled, more effective, more verifiable way is considered unethical.
If you’re interested in making this happen, be it as a biologist working in a wet lab, a funder, or a policymaker, please reach out to me. You can reach me at genesmithlesswrong@gmail.com or simply through a LessWrong private message. My company will be raising our seed round to work on multiplex editing in the next couple of weeks, so if you’re in venture capital and you want to make this happen, please get a hold of me.
Appendix
Amendments to this article as of 2025-03-05
This article has been amended in a few places. The disease graphs have been updated based on additional work we did using a newer, better version of our fine-mapping software to better account for causal uncertainty. The "benefit" of editing went down from these changes (meaning you can't get the same benefit from the same number of edits).
These graphs are constructed in basically the simplest possible way, by using a single GWAS. It's very likely that by the time we are ready to do actual human editing we will be able to do better than the graphs suggest.
The life expectancy increase from editing also went down (by a factor of 3!). This was, to put it bluntly, a pretty dumb mistake on our part. The life expectancy GWAS study we used had a non-standard way of reporting effect sizes, and when we discovered and corrected this the effect size went down.
iPSCs were named after the iPod
You might wonder why the i in iPSCs is lowercase. It’s literally because Yamanaka was a fan of the iPod and was inspired to use the same lowercase naming convention.
On autoimmune risk variants and plagues
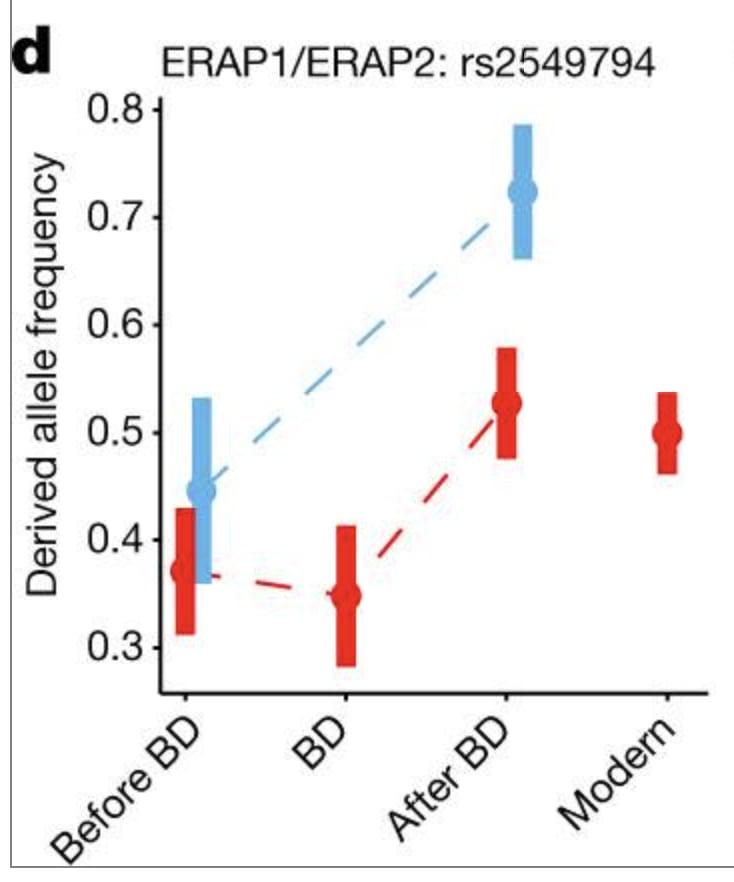
The studies on genes that have been protective against past plagues are kind of insane. There’s a genetic variant in the ERAP2 gene that jumped from 40% prevalence to 70% prevalence in ~100 years in Denmark thanks to its ability to reduce mortality from the bubonic plague.
For anyone not familiar with evolution, this is an INCREDIBLY fast spread of a genetic variant. It’s so fast that you can’t even really explain it by people with this gene out-reproducing those without it. You can only explain it if a large portion of the people without the genetic variant are dying in a short time period.
Today this same genetic variant is known to increase the risk of Crohn's disease and a variety of other autoimmune conditions.
ERAP variants aren’t the ONLY ones that protect against plague risk. There are half a dozen others mentioned in the study. So we aren’t going to make the entire population fragile to plague just by editing this variant.
Two simples strategies for minimizing autoimmune risk and pandemic vulnerability
There are two fairly straightforward ways to decrease the risk of autoimmune disease while minimizing population level vulnerability to future pandemics.
First of all, we can dig up plague victims from mass graves and look at their DNA. Variants that are overrepresented among people in mass burial sites compared with the modern population probably weren’t very helpful for surviving past pandemics. So we should be more cautious than usual about swapping people’s genetic variants to those of plague victims, even if it decreases the risk of autoimmune diseases.
Second, we should have an explicit policy of preserving genetic diversity in the human immune system. There’s a temptation to just edit the variants in a genome that have the largest positive impact on a measured trait. But in the case of the immune system, it’s much better from a population level perspective to decrease different people’s autoimmune risk in different ways.
“I don’t want someone else’s genes in my child”
One thing we didn’t mention in the post is what could be done with gene editing if we JUST restrict ourselves to editing in variants that are present in one of the two parents.
We ran some simulations and came to a somewhat surprising conclusion: there probably won’t be that big of a reduction if you do this!
So even if you’re an inheritance maximalist, you can still get major benefits from gene editing.
Could I use this technology to make a genetically enhanced clone of myself?
For some versions of this technology (in particular super-SOX or SCNT-derived solutions), you could indeed make a genetically enhanced clone of yourself.
Genetically enhanced clones are too weird to be appealing to most people, so I don’t think we’re ever going to see this kind of thing being done at scale. But maybe someday someone will start the “Me 2” movement.
Why does super-SOX work?
Super-SOX is a modification of the sox2 protein designed to increase the strength of the bond between it and Oct4. You might wonder why increasing the strength of this bond increases reprogramming efficiency and makes more developmentally potent stem cells.
There are two pieces to the answer. But to explain them I need to give you a bit of background first.
Sox2 (and all the other Yamanaka factors, for that matter), are transcription factors. This means they stick to DNA. They also stick to other proteins. You can think of them like a person that’s holding hands with the DNA and holding hands with another protein.
It’s beyond the scope of even this appendix to talk about all the other proteins than can bind to, but among the most important are a bunch of proteins that form something called the RNA transcriptase complex. RNA transcriptase is the giant enzyme that turns DNA into messenger RNA (which are then converted into proteins). RNA transcriptase can’t directly bind to DNA, so in order for it to do its thing, it needs a bunch of helper proteins which get it into position.
Sox2 and Oct4 are two such “helper proteins”. They’re crucial because they bind directly to DNA, which means the RNA transcriptase complex can’t even START forming unless Sox2 or Oct4 or both start the process off by sticking to DNA in the right spots.
This DNA binding ability is apparent in their very structure.
See how the protein itself is folded in a way such that it kind of “wraps around” the DNA? That’s by design; it allows the protein to bind to the DNA if and only if the sequence matches with Oct2’s binding domain. So sox2 doesn’t just bind to any sequence of DNA. It needs a very specific one: 5′-(A/T)(A/T)CAAAG-3′ if you want to get technical about it.
This means that it doesn’t just bind anywhere. It only binds to DNA sequences that match with its binding domain.
And not every gene has such a sequence. Only some genes do, which means Sox2 won’t activate transcription of every gene.
So sox2 can bind to DNA and initiate transcription of certain genes, but the bonds Sox2 forms with DNA are… kind of weak. It often “comes off” the DNA when something else hits it or when the DNA just wiggles a little too much.
So sox2, along with all the other Yamanaka factors, are constantly coming and going from these binding sites on the DNA.
The fraction of time that sox2 and the other Yamanaka factors spend stuck to the DNA is a huge determining factor in whether or not the RNA transcriptase complex actually forms; the higher the percentage of the time they are bound to the DNA, the more often that complex forms and the more of that protein gets produced.
If we could somehow increase the strength of that bond, it would significantly increase the amount of proteins produced.
One way to do this would be to directly modify the protein so that it can stick to the DNA better. But another way would be to modify the strength of the bond it has with something ELSE that sticks to DNA in the same region.
And that’s exactly what super-SOX does. It increases the strength of the bond with oct4, which helps sox2 “hold on” to the DNA. Even if the DNA wiggles too much and sox2 gets knocked off, it will still be held down by oct4, which is bound right next to it.
It should be noted that not all genes have a binding motif for sox2 and oct4 right next to each other. But (incredibly), it seems that most of the key pluripotency genes, the ones that are really important for making naive embryonic stem cells, DO have such a binding motif.
That’s why super-SOX works. It increases transcription of genes with a sox-oct motif next to the gene. And it just so happens that the key genes to make naive cells have a sox-oct motif next to them.
This is almost certainly not an accident. Sox and Oct are naturally occuring proteins that play key roles in embryonic development. So the fact that sox/oct motifs play a key role in creating and maintaining naive embryonic stem cells is not all that surprising.
How was the IQ grain graph generated?
The graph for IQ was generated by ranking genetic variants by their effect sizes and showing how they add up if you put them all in the same genome. We take into account uncertainty about which of a cluster of nearby genetic variants is actually CAUSING the observed effect. We also adjust for the fact that the IQ test issued by UK Biobank isn’t particularly good. I believe it has a test/retest correlation of 0.61, which is significantly below the 0.9 of a gold standard IQ test.
We also account for assortative mating on IQ (our assumption is a correlation of 0.4, which we think is reasonable based on the research literature).
A huge amount of work went into dealing with missing SNPs in the datasets used to train these predictors. There’s too much math-y detail to get into in this post, but some of the genetic variants we would hope to measure a missing from the datasets and kman had to write custom fine-mapping software to deal with this.
We couldn’t find anyone else who had done this before, so we’ll probably publish a paper at some point explaining our technique and making the software kman wrote available to other genetics researchers.
If you’ve made it this far, please send me a DM! Most people don’t read 30 page blog posts and I always enjoy hearing from people that do. Let me know why you read all the way through this, what you enjoyed most, and what you think about the superbabies project.
I think this project should receive more red-teaming before it gets funded.
Naively, it would seem that the "second species argument" matches much more strongly to the creation of a hypothetical Homo supersapiens than it does to AGI.
We've observed many warning shots regarding catastrophic human misalignment. The human alignment problem isn't easy. And "intelligence" seems to be a key part of the human alignment picture. Humans often lack respect or compassion for other animals that they deem intellectually inferior -- e.g. arguing that because those other animals lack cognitive capabilities we have, they shouldn't be considered morally relevant. There's a decent chance that Homo supersapiens would think along similar lines, and reiterate our species' grim history of mistreating those we consider our intellectual inferiors.
It feels like people are deferring to Eliezer a lot here, which seems unjustified given how much strategic influence Eliezer had before AI became a big thing, and how poorly things have gone (by Eliezer's own lights!) since then. There's been very little reasoning transparency in Eliezer's push for genetic enhancement. I just don't see why we're deferring to Eliezer so much as a strategist, when I struggle to name a single major strategic success of his.
Right now only low-E tier human intelligences are being discussed, they'll be able to procreate with humans and be a minority.
Considering current human distributions and a lack of 160+ IQ people having written off sub-100 IQ populations as morally useless I doubt a new sub-population at 200+ is going to suddenly turn on humanity
If you go straight to 1000IQ or something sure, we might be like animals compared to them
Humans often lack respect or compassion for other animals that they deem intellectually inferior -- e.g. arguing that because those other animals lack cognitive capabilities we have, they shouldn't be considered morally relevant.
Yes, and... "Would be interesting to see this research continue in animals. E.g. Provide evidence that they've made a "150 IQ" mouse or dog. What would a dog that's 50% smarter than the average dog behave like? or 500% smarter? Would a dog that's 10000% smarter than the average dog be able to learn, understand and "speak" in human languages?" -- From this comment [LW · GW]
If your world view requires valuing the ethics of (current) people of lower IQ over those of (future) people of higher IQ then you have a much bigger problem than AI alignment. Whatever IQ is, it is strongly correlated with success which implies a genetic drive towards higher IQ, so your feared future is coming anyway (unless AI ends us first) and there is nothing we can logically do to have any long term influence on the ethics of smarter people coming after us.
At the end of 2023, MIRI had ~$19.8 mio. in assets. I don't know much about the legal restrictions of how that money could be used, or what the state for financial assets is now, but if it's similar then MIRI could comfortably fund Velychko's primate experiments, and potentially some additional smaller projects.
(Potentially relevant: I entered the last GWWC donor lottery with the hopes of donating the resulting money to intelligence enhancement, but wasn't selected.)
Looked unlikely to me given the most-publicly-associated-with-MIRI person is openly & loudly advocating for funding this kind of work. But maybe the association isn't as strong as I think.
TBH, I don't particularly think it's one of the most important projects right now, due to several issues:
There's no reason to assume that we could motivate them any better than what we already do, unless we are in the business of changing personality, which carries it's own problems, or we are willing to use it on a massive scale, which simply cannot be done currently.
We are running out of time. The likely upper bound for AI that will automate basically everything is 15-20 years from Rafael Harth and Cole Wyeth, and unfortunately there's a real possibility that the powerful AI comes in 5-10 years, if we make plausible assumptions about scaling continuing to work, and given that there's no real way to transfer any breakthroughs to the somatic side of gene editing, it will be irrelevant by the time AI comes.
Thus, human intelligence augmentation is quite poor from a reducing X-risk perspective.
On EV grounds, "2/3 chance it's irrelevant because of AGI in the next 20 years" is not a huge contributor to the EV of this. Because, ok, maybe it reduces the EV by 3x compared to what it would otherwise have been. But there are much bigger than 3x factors that are relevant. Such as, probability of success, magnitude of success, cost effectiveness.
Then you can take the overall cost effectiveness estimate (by combining various factors including probability it's irrelevant due to AGI being too soon) and compare it to other interventions. Here, you're not offering a specific alternative that is expected to pay off in worlds with AGI in the next 20 years. So it's unclear how "it might be irrelevant if AGI is in the next 20 years" is all that relevant as a consideration.
Usually, the other interventions I compare it to are preparing for AI automation of AI safety by doing preliminary work to control/align those AIs, or AI governance interventions that are hopefully stable for a very long time, and at least for the automation of AI safety, I assign much higher magnitudes of success, conditioning on success, like multiple OOMs combined with moderately better cost effectiveness and quite larger chances of success than the genetic engineering approach.
To be clear, the key variable is conditional on success, the magnitude of that success is very, very high in a way that no other proposal really has, such that even with quite a lot lower probabilities for success than me, I'd still consider preparing for AI automation of AI safety and doing preliminary work such that we can trust/control these AIs to be the highest value alignment target by a mile.
Oh, to be clear I do think that AI safery automation is a well targeted x risk effort conditioned on the AI timelines you are presenting. (Related to Paul Christiano alignment ideas, which are important conditional on prosaic AI)
EY is known for considering humanity almost doomed. He may think that the idea of human intelligence augmentation is likely to fail. But it's the only hope. Of course, many will disagree with this.
The problem is that from a relative perspective, human augmentation is probably more doomed than AI safety automation, which in turn is more doomed than AI governance interventions, though I may have gotten the relative ordering of AI safety automation and I think the crux is I do not believe in the timeline for human genetic augmentation in adults being only 5 years, even given a well-funded effort, and I'd expect it to take 15-20 years, minimum for large increases in adult intelligence, which basically rules out the approach given the very likely timelines to advanced AI either killing us all or being aligned to someone.
Yudkowsky may think that the plan 'Avert all creation of superintelligence in the near and medium term — augment human intelligence' has <5% chance of success, but your plan has <<1% chance. Obviously, you and he disagree not only on conclusions, but also on models.
If somehow international cooperation gives us a pause on going full AGI or at least no ASI - what then?
Just hope it never happens, like nuke wars?
The answer now is to set later generations up to be more able.
This could mean doing fundamental research (whether in AI alignment or international game theory or something else), it could mean building institutions to enable it, and it could mean making them actually smarter.
Genes might be the cheapest/easist way to affect marginal chances given the talent already involved in alignment and the amount of resources required to get involved politically or in building institutions
If somehow international cooperation gives us a pause on going full AGI or at least no ASI - what then?
Just hope it never happens, like nuke wars?
The answer is no, but this might have to happen under certain circumstances.
The usual case (assuming that the government bans or restricts compute resources, and/or limits algorithimic research), is to use this time to either let the government fund AI alignment research, or go for a direct project to make AIs that are safe to automate AI safety research, and given that we don't have to race against other countries, we could afford far more safety taxes than usual to make AI safe.
I think the key crux is I don't particularly think genetic editing is the cheapest/easiest way to affect marginal chances of doom, because of time lag plus needing to reorient the entire political system, which is not cheap, and the cheapest/easiest strategy to me to affect doom probabilities is to do preparatory AI alignment/control schemes such that we can safely hand off the bulk of the alignment work to the AIs, which then solve the alignment problem fully.
Your direction sounds great - but how well can $4M move the needle there? How well can genesmith move the needle with his time and energy?
I think you're correct about the cheapest/easist strategy in general, but completely off in regards to marginal advantages.
Major labs will already be pouring massive amounts of money and human capital into direct AI alignment and using AIs to align AGI if we get to a freeze, and the further along in capabilities we get the more impactful such research would be.
Genesmith's strategy benefits much more from starting now and has way less human talent and capital involved, hence higher marginal value
How robust are these calculations against the possibility that individual gene effects aren't simply additional but might even not play well together? i.e. gene variant #1 raises your IQ by 2 points, variant #2 raises your IQ by 1 point, but variants #1+2 together make you able to multiply twelve-digit numbers in your head but unable to tie your shoes; or variant #3 lifts your life expectancy by making you less prone to autoimmune disease A, variant #4 makes you less prone to autoimmune disease B, but variants #3+4 together make you succumb to the common cold because your immune system is not up to the task.
It's hard for me to tell from the level of detail in your explanation here, but at times it seems like you're just naively stacking the ostensible effects of particular gene variants one on top of the other and then measuring the stack.
There ARE some exceptions. Personality traits seem to be mostly the result of gene-gene interactions, which is one reason why SNP heritability (additive variance explained by common variants) is so low.
But for nearly all diseases and for many other traits like height and intelligence, ~80% of variance is additive. somewhere between 50 and 80% of the heritable variance is additive. And basically ALL of the variance we can identify with current genetic predictors is additive.
This might seem like a weird coincidence. After all, we know there is a lot of non-linearity in actual gene regulatory networks. So how could it be that all the common variants simply add together?
There's a pretty clear reason from an evolutionary point of view: evolution is able to operate on genes with additive effects much more easily than on those with non-additive effects.
The set of genetic variants inherited is scrambled every generation during the sperm and egg formation process. Those that need other common variants present to work their effects just have a much harder time spreading among the population because their benefits are inconsistent across generations.
So over time the genome ends up being enriched for additivity.
There IS lots of non-additivity happening in genes which are universal among the human population. If you were to modify two highly conserved regions, the effects of both edits could end up being much greater or much less than the sum of the effects of the two individual variants. But that's also not that surprising; evolution has had a lot of time to build dependencies on these regions, so we should expect modifying them to have effects that are hard to predict.
You also had a second question embedded within your first, which is about second order effects from editing, like increased IQ resulting in more mental instability or something.
You can just look at people who naturally have high IQ to see whether this is a concern. What we see is that, with the exception of aspbergers, higher IQ actually tends to be associated with LOWER rates of mental illness.
Also you can see from my chart looking at genetic correlations between diseases that, with a few exceptions, there just isn't that much correlation between diseases. The set of variants that affects two different diseases are mostly disjoint sets.
The remarkable thing about human genetics is that most of the variants ARE additive.
I think this is likely incorrect, at least where intelligence-affecting SNPs stacked in large numbers are concerned.
To make an analogy to ML, the effect of a brain-affecting gene will be to push a hyperparameter in one direction or the other. If that hyperparameter is (on average) not perfectly tuned, then one of the variants will be an enhancement, since it leads to a hyperparameter-value that is (on average) closer to optimal.
If each hyperparameter is affected by many genes (or, almost-equivalently, if the number of genes greatly exceeds the number of hyperparameters), then intelligence-affecting traits will look additive so long as you only look at pairs, because most pairs you look at will not affect the same hyperparameter, and when they do affect the same hyperparameter the combined effect still won't be large enough to overshoot the optimum. However, if you stack many gene edits, and this model of genes mapping to hyperparameters is correct, then the most likely outcome is that you move each hyperparameter in the correct direction but overshooting the optimum. Phrased slightly differently: intelligence-affecting genes may be additive on current margins, but not remain additive when you stack edits in this way.
To make another analogy: SNPs affecting height may be fully additive, but if the thing you actually care about is basketball-playing ability, there is an optimum amount of editing after which you should stop, because while people who are 2m tall are much better at basketball than people who are 1.7m tall, people who are 2.6m tall are cripples.
For this reason, even if all the gene-editing biology works out, you will not produce people in the upper end of the range you forecast.
You can probably somewhat improve this situation by varying the number of edits you do. Ie, you have some babies in which you edit a randomly selected 10% of known intelligence-affecting SNPs, some in which you've edited 20%, some 30%, and so on. But finding the real optimum will probably require understanding what the SNPs actually do, in terms of a model of brain biology, and understanding brain biology well enough to make judgment calls about that.
I suspect the analogy does not really work that well. Much of human genetic variation is just bad mutations that take a while to be selected out. For example, maybe a gene variant slightly decreases the efficiency of your neurons and makes everything in your brain slightly slower
This paper found that the heritability of most traits is ~entirely additive, supposedly including IQ according to whatever reference I followed to the paper, though I couldn't actually find where in the paper it said/implied that.
Thanks. I think it's an important point you make; I do have it in mind that traits can have nonlinearities at different "stages", but I hadn't connected that to the personality trait issue. I don't immediately see a very strong+clear argument for personality traits being super exceptional here. Intuitively it makes sense that they're more "complicated" or "involve more volatile forces" or something due to being mental traits, but a bit more clarity would help. In particular, I don't see the argument being able to support yes significant broadsense heritability but very little apparent narrowsense heritability. (Though maybe it can somehow.)
(Also btw I wouldn't exactly call multiplicativity by itself "nonlinearity"! I would just say that after the genomic fan-in there is a nonlinearity. It's linearity as long as there's a latent variable that's a sum of alleles. Indeed, as E.G. pointed out to me, IQ could very well be like this, i.e. IQ-associated traits might be even better predicted by assuming IQ is lognormal (or some other such distribution). Though of course then you can't say that such and such downstream outcome is linear in genes; but the point would be that you can push along the trait by independently pushing on lots of alleles.)
(Also in theory I ought to go through your whole article at some point; but as yet I'm not read in to polygenic scores, as there's already good enough predictors for the MVP, and biotech is the main bottleneck. Though yes, motivating the biotech depends on understanding PGSes.)
If you take some stupid outcome like “a person’s fleep is their grip strength raised to the power of their alcohol tolerance”, and measure fleep across a population, you will obviously find that there’s a strong non-additive genetic contribution to that outcome. A.k.a. epistasis. If you want to say “no, that’s not really non-additive, and it’s not really epistasis, it’s just that ‘fleep’ is a damn stupid outcome to analyze”, then fine, but then the experts really need to settle on a standardized technical term for “damn stupid outcomes to analyze”, and then need to consider the possibility that pretty much every personality trait and mental health diagnosis (among other things) is a “damn stupid outcome” in much the same way.
I don't immediately see a very strong+clear argument for personality traits being super exceptional here. Intuitively it makes sense that they're more "complicated" or "involve more volatile forces" or something due to being mental traits, but a bit more clarity would help.
I do hope to unravel the deep structure of personality variation someday! In particular, what exactly are the linear “traits” that correspond directly to brain algorithm settings and hyperparameters? (See A Theory of Laughter [LW · GW] and Neuroscience of human social instincts: a sketch [LW · GW] for the very early stages of that. Warning: long.)
I guess a generic answer would be: the path FROM brain algorithm settings and hyperparameters TO decisions and preferences passes through a set of large-scale randomly-initialized learning algorithms churning away for a billion seconds. (And personality traits are basically decisions and preferences—see examples here.) That’s just a massive source of complexity, obfuscating the relationship between inputs and outputs.
A kind of analogy is: if you train a set of RL agents, each with slightly different reward functions, their eventual behavior will not be smoothly variant. Instead there will be lots of “phase shifts” and such.
So again, we have “a set of large-scale randomly-initialized learning algorithms that run for a billion seconds” on the pathway from the genome to (preferences and decisions). And there’s nothing like that on the pathway from the genome to more “physical” traits like blood pressure. Trained models are much more free to vary across an extremely wide, open-ended, high-dimensional space, compared to biochemical developmental pathways.
I don't see the argument being able to support yes significant broadsense heritability but very little apparent narrowsense heritability. (Though maybe it can somehow.)
See also Heritability, Behaviorism, and Within-Lifetime RL [LW · GW]: “As adults in society, people gradually learn patterns of thought & behavior that best tickle their innate internal reward function as adults in society.”
Different people have different innate reward functions, and so different people reliably settle into different patterns of thought & behavior, by the time they reach adulthood. But given a reward function (and learning rate and height and so on), the eventual patterns of thought & behavior that they’ll settle into are reliably predictable, at least within a given country / culture.
That’s just a massive source of complexity, obfuscating the relationship between inputs and outputs.
A kind of analogy is: if you train a set of RL agents, each with slightly different reward functions, their eventual behavior will not be smoothly variant. Instead there will be lots of “phase shifts” and such.
And yet it moves! Somehow it's heritable! Do you agree there is a tension between heritability and your claims?
No … I think you must not have followed me, so I’ll spell it out in more detail.
Let’s imagine that there’s a species of AlphaZero-chess agents, with a heritable and variable reward function but identical in every other way. One individual might have a reward function of “1 for checkmate”, but another might have “1 for checkmate plus 0.1 for each enemy piece on the right side of the endgame board” or “1 for checkmate minus 0.2 for each enemy pawn that you’ve captured”, or “0 for checkmate but 1 for capturing the enemy queen”, or whatever.
Then every one of these individuals separately grows into “adults” by undergoing the “life experience” of the AlphaZero self-play training regime for 40,000,000 games. And now we look at the behavior of those “adults”.
If you take two identical twin adults in this species, you’ll find that they behave extremely similarly. If one tends to draw out the enemy bishop in thus-and-such situation, then so does the other. Why? Because drawing out the enemy bishop is useful given a certain kind of reward function, and they have the same reward function, and they’re both quite good at maximizing it. So you would find high broad-sense heritability of behavior.
But it’s unlikely that you’ll find a linear map from the space of reward functions to the space of midgame behavioral tendencies. Lots of individuals will be trying to draw out the enemy bishop in such-and-such situation, and lots of individuals won’t be trying to draw out the enemy bishop in that same kind of situation, for lots of different reasons, ultimately related to their different reward functions. The midgame behavior is more-or-less a deterministic function of the reward function, but it’s a highly nonlinear function. So you would measure almost zero narrow-sense heritability of behavior.
Wait a minute. Does your theory predict that heritability estimates about personality traits derived from MZTwins will be much much higher than estimates derived from DZTwins or other methods not involving MZTwins?
Yeah, one of the tell-tale signs of non-additive genetic influences is that MZ twins are still extremely similar, but DZ twins and more distant relatives are more different than you’d otherwise expect. (This connects to PGSs because PGSs are derived from distantly-related people.) See §1.5.5 here [LW · GW], and also §4.4 [LW · GW] (including the collapsible box) for some examples.
Mkay.... I'm gonna tap out for now, but this is very helpful, thanks. I'm still pretty skeptical, though indeed
I am failing (and then I think later succeeding) at significant chunks of basic reading comprehension about what you're saying;
I'm still confused, so my skepticism isn't a confident No.
As a bookmark/trailhead, I suggest that maybe your theory of "personality has a high complexity but pretty deterministic map from a smallish number of pretty-genetically-linear full-brain-settings to behavior due to convergent instrumentality" and some sort of "personality mysteriously has a bunch of k-th order epistases that all add up" would both predict MZ being more similar than DZ, but your theory would predict this effect more strongly than the k-th order thing.
Another: there's something weird where I don't feel your argument about a complex map being deterministic because of convergent instrumentality ought to work for the sorts of things that personality traits are; like they don't seem analogous to "draws out bishop in xyz position", and in the chess example idk if I especially would there to be "personality traits" of play.... or something about this.
Another bookmark: IIUC your theory requires that the relevant underlying brain factors are extremeley pinned down by genetics, because the complicated map from underlying brain stuff to personality is chaotic.
If you want to say “no, that’s not really non-additive, and it’s not really epistasis, it’s just that ‘fleep’ is a damn stupid outcome to analyze”, then fine, but then the experts really need to settle on a standardized technical term for “damn stupid outcomes to analyze”, and then need to consider the possibility that pretty much every personality trait and mental health diagnosis (among other things) is a “damn stupid outcome” in much the same way.
Hm. I wrote half a response to this, but then realized that... IDK, we're thinking of this incorrectly, but I'm not fully sure how. (Ok possibly only I'm thinking of it incorrectly lol. Though I think you are too.) I'll say some things, but not sure what the overall point should be. (And I still haven't read your post so maybe you addressed some of this elsewhere.) (And any of the following might be confused, I'm not being careful.)
Thing:
You could have a large number of genetic variants Gk in a genome G, and then you have a measured personality trait p(G). Suppose that in fact p(G)=f(∑kwkGk). If f is linear, like f(x)=ax+b, then p is unproblematically linear. But suppose f is exponentiation, so that
p(G)=e∑kwkGk=∏kwkGk
In this case, p is of course not linear in the Gk. However:
This does not make p a stupid thing to measure in any way. If it's an interesting trait then it's an interesting trait.
You could absolutely still affect p straightforwardly using genomic engineering; just up/downvote Gk with positive/negative wk.
There's an obvious latent, ∑kwkGk, which is linear. This latent should be of interest; and this doesn't cut against p being real, or vice versa.
In real life, you get data that's concentrated around one value of ∑kwkGk, with gaussian variation. If you look at ∑k≠iwkGk, it's also concentrated. So like, take the derivative of ewig+∑k≠iwkGk with respect to g. (Or something like that.) This should tell us something like the "additive" effect of Gi! In other words, around the real life mean, it should be locally kinda linear.
This implies you should see the "additive" variance! Your GWAS should pick stuff up!
So if your GWAS is not picking stuff up, then p(G) is NOT like this!
Thing:
A simple alternative definition of epistasis (which I don't actually like, but is better than "nonlinear"): There are epistatic effects on p(G) from G when p(G) cannot be written in the form
p(G)=f(∑kwkGk)
with f:R→R arbitrary.
Thing:
Suppose now that
p(G)=(∑kwkGk)×(∑kvkGk)
This matches your multiplicative scenario. But AGAIN, you should be seeing "additive" variance, locally!
Thing:
There's maybe some nicer understanding of GWASes and PGSes and whatnot in terms of taking something like a derivative at the population mean. So it's not about linearity, it's about the size of the derivative. Or something like that.
Thing:
We do care about a totally different sort of nonlinearity, which is that we care whether pushing in some direction increases the trait a lot or a little before it bends back down in a U turn. But this is different from "do I see the local derivative in this SNP"!
Thing:
SINGLE gene -- SINGLE gene -- SINGLE gene interactions matter for detecting the effects because having this SPECIFIC combination is very rare, so you don't see the effects often; and the AGGREGATE effect of a single gene that's involved in these higher order effects can be small because they're SCRAMBLED ..... or something, I'm confused how this works. This doesn't work for high-fan-in latents which you then combine, because the aggregates are NOT scrambled and you can detect them. Or something.
Thing:
So I DO NOT BUY a model where personality is hard to see additive stuff in GWASes due to it being several traits multiplied together or something!
Thing:
I'm confused lol.
Thing:
How do the total expected effects of one variant ever cancel out?? (This is a basic question that should/might have a basic-ish answer.) Even if all the genetic effects are from specific 2,3,4 gene sets that have effects together, there'd have to be a lot of them, so if the union of all those sets is a normal number of variants for a polygenic trait (say 10k), then each SNP would be involved in MANY of these things; so that SNP's expected effect given the population ought to be a great big sum of all these "probability that the rest of the set is there, times the difference in effect for completing the full set with this SNP vs. not having the set". But then it should be basically a gaussian, and there should be many of these SNPs with significant average effect, which would show in a GWAS! So I'm confused.
around the real life mean, it should be locally kinda linear
Even in personality and mental health, the PGSs rarely-if-ever account for literally zero percent of the variance. Normally the linear term of a Taylor series is not zero.
I think what you’re missing is: the linear approximation only works well (accounts for much of the variance) to the extent that the variation is small. But human behavioral differences—i.e. the kinds of things measured by personality tests and DSM checklists—are not small. There are people with 10× more friends than me, talk to them 10× as often as me, play 10× more sports than me, read 10× less than me, etc.
Why? As in my other comment [LW(p) · GW(p)], small differences in what feels rewarding and motivating to a person can cascade into massive differences in behavior. If someone finds it mildly unpleasant to be around other people, then that’s a durable personality trait, and it impacts a million decisions that they’ll make every day, all in the same direction, and thus it impacts how they spend pretty much all of their waking time, including even what they choose to think about each moment, for their entire life. So much flows from that.
It becomes more complex once you take the sum of the product of several things. At that point the log-additive effect of one of the terms in the sum disappears if the other term in the sum is high. If you've got a lot of terms in the sum and the distribution of the variables is correct, this can basically kill the bulk of common additive variance. Conceptually speaking, this can be thought of as "your system is a mixture of a bunch of qualitatively distinct things". Like if you imagine divorce or depression can be caused by a bunch of qualitatively unrelated things.
Quite plausibly yes these heritability estimates and PGSes are picking up on heterogeneous things, but they still work, and you can still construct the PGS; you find the additive variants when you look.
(Also I am interested in the difference between traits that are OR / SUM of some heritable things and some non-heritable things. E.g. you can get lung cancer from lung cancer genes, or from smoke 5 packs a day. This matters for asking "just how low exactly can we drive down disease risk?". But this would not show up as missing heritability!)
Isn't the derivative of the full variable in one of the multiplicands still noticeable? Maybe it would help if you make some quantitative statement?
Taking the logarithm (to linearize the association) scales the derivative down by the reciprocal of the magnitude. So if one of the terms in the sum is really big, all the derivatives get scaled down by a lot. If each of the terms are a product, then the derivative for the big term gets scaled up to cancel out the downscaling, but the small terms do not.
I mean, I think depression is heritable, and I think there are polygenic scores that do predict some chunk of this. (From a random google: https://jamanetwork.com/journals/jamapsychiatry/fullarticle/2783096 )
Under the condition I mentioned, polygenic scores will tend to focus on the traits that cause the most common kind of depression, while neglecting other kinds. The missing heritability will be due to missing those other kinds.
Can you please write down the expressions you're talking about as math? If you're trying to invoke standard genetics knowledge, I'm not a geneticist and I'm not picking it up from what you're saying.
Let's start with the basics: If the outcome f is a linear function of the genes x, that is f(x)=βx, then the effect of each gene is given by the gradient of f, i.e. ∇xf(x)=β. (This is technically a bit sketchy since a genetic variant is discrete while gradients require continuity, but it works well enough as a conceptual approximation for our purposes.) Under this circumstance, we can think of genomic studies as finding β. (This is also technically a bit sketchy because of linkage disequillibrium and such, but it works well enough as a conceptual approximation for our purposes.)
If f isn't a linear function, then there is no constant β to find. However, the argument for genomic studies still mostly goes through that they can find E[∇xf(x)], it's just that this expression now denotes a weird mismash effect size that's not very interpretable.
As you observed, if f is almost-linear, for example if f(x)=eβx, then genomic studies still have good options. The best is probably to measure the genetic influence on logf, as then we get a pretty meaningful coefficient out of it. (If we measured the genetic influence of f without the logarithm, I think under commonly viable assumptions we would get β′i∝eβi−1, but don't cite me on that.)
The trouble arises when you have deeply nonlinear forms such as f(x)=eβx+eγx. If we take the gradient of this, then the chain rule gives us ∇logf(x)=eβxβ+eγxγeβx+eγx. That is, the two different mechanisms "suppress" each other, so if eβx is usually high, then the γ term would usually be (implicitly!) excluded from the analysis.
Ah. Thank you, this makes sense of what you said earlier. (I / someone could have gotten this from what you had written before, by thinking about it more, probably.)
I agree with your analysis as math.
However, I'm skeptical of the application to the genetics stuff, or at least I don't see it yet. Specifically, you wrote:
If you've got a lot of terms in the sum and the distribution of the variables is correct, this can basically kill the bulk of common additive variance. Conceptually speaking, this can be thought of as "your system is a mixture of a bunch of qualitatively distinct things". Like if you imagine divorce or depression can be caused by a bunch of qualitatively unrelated things.
And your argument here says that there's "gradient interference" between the summed products specifically when one of the summed products is really big. But in the case of disease risk, IIUC the sum-of-products f(x) is something like logits. So translating your argument, it's like:
Suppose one of the causes of X-disease contributes a ton of logits, to the point where it's already overdetermined that you have X. Then you can't notice the effects of another one of the causes of X. Even if there are such effects, most people have the disease anyway, so you get very little signal, which only comes from the lucky few who didn't get X from the first cause.
In this case, yes the analysis is valid, but it's not very relevant. For the diseases that people tend to talk about, if there are several substantial disjunctive causes (I mean, the risk is a sum of a few different sub-risks), then they all would show substantial signal in the data. None of them drowns out all the others.
Maybe you just meant to say "In theory this could happen".
Or am I missing what you're suggesting? E.g. is there a way for there to be a trait that:
has lots of variation (e.g. lots of sick people and lots of non-sick people), and
it's genetic, and
it's a fairly simple functional form like we've been discussing,
but you can't optimize it much by changing a bunch of variants found by looking at some millions of genotype/phenotype pairs?
The original discussion was about how personality traits and social outcomes could behave fundamentally differently from biological traits when it comes to genetics. So this isn't necessarily meant to apply to disease risks.
Well you brought up depression. But anyway, all my questions apply to personality traits as well.
..... To rephrase / explain how confused I am about what you're trying to tell me: It kinda sounds like you're saying "If some trait is strongly determined by one big chunk of genes, then you won't be able to see how some other chunk affects the trait.". But this can't explain missing heritability! In this scenario, none of the heritability is even from the second chunk of genes in the first place! Or am I missing something?
Because if some of the heritability is from the second chunk, that means that for some pairs of people, they have roughly the same first chunk but somewhat different second chunks; and they have different traits, due to the difference in second chunks. If some amount of heritability is from the second chunk, then to that extent, there's a bunch of pairs of people whose trait differences are explained by second chunk differences. If you made a PGS, you'd see these pairs of people and then you'd find out how specifically the second chunk affects the trait.
I could be confused about some really basic math here, but yeah, I don't see it. Your example for how the gradient doesn't flow seems to say "the gradient doesn't flow because the second chunk doesn't actually affect the trait".
If some amount of heritability is from the second chunk, then to that extent, there's a bunch of pairs of people whose trait differences are explained by second chunk differences. If you made a PGS, you'd see these pairs of people and then you'd find out how specifically the second chunk affects the trait.
This only applies if the people are low in the first chunk and differ in the second chunk. Among the people who are high in the first chunk but differ in the second chunk, the logarithm of their trait level will be basically the same regardless of the second chunk (because the logarithm suppresses things by the total), so these people will reduce the PGS coefficients rather than increasing the PGS coefficients. When you create the PGS, you include both groups, so the PGS coefficients will be downwards biased relative to γ.
Among the people who are high in the first chunk but differ in the second chunk, the logarithm of their trait level will be basically the same regardless of the second chunk (because the logarithm suppresses things by the total), so these people will reduce the PGS coefficients rather than increasing the PGS coefficients
It would decrease the narrowsense (or additive) heritability, which you can basically think of as the squared length of your coefficient vector, but it wouldn't decrease the broadsense heritability, which is basically the phenotypic variance in expected trait levels you'd get by shuffling around the genotypes. The missing heritability problem is that when we measure these two heritabilities, the former heritability is lower than the latter.
Why not? Shuffling around the second chunk, while the first chunk is already high, doesn't do anything, and therefore does not contribute phenotypic variance to broadsense heritability.
Ok, more specifically, the decrease in the narrowsense heritability gets "double-counted" (after you've computed the reduced coefficients, those coefficients also get applied to those who are low in the first chunk and not just those who are high, when you start making predictions), whereas the decrease in the broadsense heritability is only single-counted. Since the single-counting represents a genuine reduction while the double-counting represents a bias, it only really makes sense to think of the double-counting as pathological.
Ah... ok I think I see where that's going. Thanks! (Presumably there exists some standard text about this that one can just link to lol.)
I'm still curious whether this actually happens.... I guess you can have the "propensity" be near its ceiling.... (I thought that didn't make sense, but I guess you sometimes have the probability of disease for a near-ceiling propensity be some number like 20% rather than 100%?) I guess intuitively it seems a bit weird for a disease to have disjunctive causes like this, but then be able to max out at the risk at 20% with just one of the disjunctive causes? IDK. Likewise personality...
(Presumably there exists some standard text about this that one can just link to lol.)
I don't think so.
I'm still curious whether this actually happens.... I guess you can have the "propensity" be near its ceiling.... (I thought that didn't make sense, but I guess you sometimes have the probability of disease for a near-ceiling propensity be some number like 20% rather than 100%?) I guess intuitively it seems a bit weird for a disease to have disjunctive causes like this, but then be able to max out at the risk at 20% with just one of the disjunctive causes? IDK. Likewise personality...
For something like divorce, you could imagine the following causes:
Most common cause is you married someone who just sucks
... but maybe you married a closeted gay person
... or maybe your partner was good but then got cancer and you decided to abandon them rather than support them through the treatment
The genetic propensities for these three things are probably pretty different: If you've married someone who just sucks, then a counterfactually higher genetic propensity to marry people who suck might counterfactually lead to having married someone who sucks more, but a counterfactually higher genetic propensity to marry a closeted gay person probably wouldn't lead to counterfactually having married someone who sucks more, nor have much counterfactual effect on them being gay (because it's probably a nonlinear thing), so only the genetic propensity to marry someone who sucks matters.
In fact, probably the genetic propensity to marry someone who sucks is inversely related to the genetic propensity to divorce someone who encounters hardship, so the final cause of divorce is probably even more distinct from the first one.
(Presumably there exists some standard text about this that one can just link to lol.)
I don't think so.
How confident are you / why do you think this? (It seems fairly plausible given what I've heard about the field of genomics, but still curious.) E.g. "I have a genomics PhD" or "I talk to geneticists and they don't really know about this stuff" or "I follow some twitter stuff and haven't heard anyone talk about this".
In fact, probably the genetic propensity to marry someone who sucks is inversely related to the genetic propensity to divorce someone who encounters hardship, so the final cause of divorce is probably even more distinct from the first one.
Ok I'm too tired to follow this so I'll tap out of the thread for now.
Under the condition I mentioned, polygenic scores will tend to focus on the traits that cause the most common kind of depression, while neglecting other kinds. The missing heritability will be due to missing those other kinds.
I don't get why you think this. It doesn't seem to make any sense. You'd still notice the effect of variants that cause depression-rare, exactly like if depression-rare was the only kind of depression. How is your ability to detect depression-rare affected by the fact that there's some genetic depression-common? Depression-common could just as well have been environmentally caused.
I might be being dumb, I just don't get what you're saying and don't have a firm grounding myself.
It doesn't matter if depression-common is genetic or environmental. Depression-common leads to the genetic difference between your cases and controls to be small along the latent trait axis that causes depression-rare. So the effect gets estimated to be not-that-high. The exact details of how it fails depends on the mathematical method used to estimate the effect.
Ok I think I get what you're trying to communicate, and it seems true, but I don't think it's very relevant to the missing heritability thing. The situation you're describing applies to the fully linear case too. You're just saying that if a trait is more polygenic / has more causes with smaller effects, it's harder to detect relevant causes. Unless I still don't get what you're saying.
It kind-of applies to the Bernoulli-sigmoid-linear case that would usually be applied to binary diagnoses (but only because of sample size issues and because they usually perform the regression one variable at a time to reduce computational difficulty), but it doesn't apply as strongly as it does to the polynomial case, and it doesn't apply to the purely linear (or exponential-linear) case at all.
If you have a purely linear case, then the expected slope of a genetic variant onto an outcome of interest is proportional to the effect of the genetic variant.
The issue is in the polynomial case, the effect size of one genetic variant depends on the status of other genetic variants within the same term in the sum. Statistics gives you a sort of average effect size, but that average effect size is only going to be accurate for the people with the most common kind of depression.
I don’t find that surprising at all. IMO, personality is a more of an emergent balancing of multidimensional characteristics than something like height or IQ (though this is mostly vibes-based speculation).
Does it seem likely that a trait that has survival significance (in a highly social animal such as a human) would be emergent? Even if it might have been initially, you'd think selective pressure would have brought forth a set of genes that have significant influence on it.
I think the "second" question about second order effects was really the main question here. If the intentional beneficial effects don't quite add, that's no great tragedy, but if combining multiple edits produces unexpected changes, some of which are bad, that's kind of a deal killer. I don't find the chart you reference to be very convincing, since it only lists a handful of characteristics that are sufficiently common to have names and have been studied in such an analysis. For every one of those there are likely countless less frequent and/or more subtle "bad" variations whose correlation with the things we're trying to fix we have no idea of. Informally, don't you have to wonder why, if a small number of edits would seem to lead to a clearly superior genome, natural selection hasn't happened upon some of those combinations already? How can we know what combinations were "tried" earlier in our evolution with long-term negative consequences?
If the variance for intelligence is primarily additive, then why are IQ GWAS heritability estimates significantly under the heritability estimates you see from twin studies (or even GWAS heritability for height)?
The SNP heritability estimates for IQ of (h^2 = ~0.2) are primarily based on a low quality test that has a test-retest reliability of 0.6, compared to ~0.9 for a gold-standard IQ test. So a simple calculation to adjust for this gets you a predicted SNP heritability of 0.2 * (0.9 / 0.6)^2 = 0.45 0.2 * (0.9 / 0.6) = 0.30 for a gold standard IQ test, which matches the SNP heritability of height. As for the rest of the missing heritability: variants with frequency less than 1% aren't accounted for by the SNP heritability estimate, and they might contribute a decent bit if there are lots of them and their effects sizes are larger.
EDIT: the original adjustment for test-retest reliability was incorrect: the correlations shouldn't be squared.
An other problem with authors calculs of potential to improve intelligence: let's suppose, there is a problem in the human brain that reduces IQ by 10 points, and it can be solved by Gene1 or Gene2. Let's suppose that 99% of humans do not have either Gene1 or Gene2. In this case, the author's method would show that if we added both Gene1 and Gene2 to the same person, their IQ would increase by 20 points.
A lot of curves are sigmoid. Let's say there's a neurotransmitter where having to double the amount of it increases IQ but there are no gains from having four times as much of the neurotransmitter.
There are two genes that both double the production of the neurotransmitter. If both genes individually are +5 IQ both genes together don't give you +10 IQ.
It would even be possible that overproduction of that neurotransmitter produces problems at 4x the normal rate but not a 2x the normal rate.
When it comes to chicken and their size I would expect the relationship of there being two genes that both increase muscle production to be happen more frequently than for intelligence.
If you have genetic mutations that increase intelligence without cost evolution works to spread them through the whole population. If you have wild chicken for whom a given size is optimal there's no strong selection pressure to get rid of all the +x or -y size genes from the gene pool.
One way to look into this would be to see how many of the genes that increase physical size more when there are two copies of the gene compared to how many genes increase intelligence more when there are two copies of it.
And how many genes increase size/intelligence with one copy but decrease it with two copies.
The "Black Death selection" finding you mention was subject to a very strong rebuttal preprinted in March 2023 and published yesterday in Nature. The original paper committed some pretty basic methodological errors[1] and, in my opinion, it's disappointing that Nature did not decide to retract it. None of their claims of selection – neither the headline ERAP2 variant or the "half a dozen others" you refer to – survive the rebuttal's more rigorous reanalysis. I do some work in ancient DNA and am aware of analyses on other datasets (published and unpublished) that fail to replicate the original paper's findings.
Some of the most glaring (but not necessarily most consequential): a failure to correctly estimate the allele frequencies underlying the selection analysis; use of a genotyping pipeline poorly suited to ancient DNA which meant that 80% of the genetic variants they "analysed" were likely completely artefactual and did not exist.
use of a genotyping pipeline poorly suited to ancient DNA which meant that 80% of the genetic variants they "analysed" were likely completely artefactual and did not exist.
Brutal!! I didn't know this gotcha existed. I hope there aren't too many papers silently gotch'd by it. Sounds like the type of error that could easily be widespread and unnoticed, if the statistical trace it leaves isn't always obvious.
I don't think that recent ancient DNA papers are affected by this issue, at least not to the same extent. Every aDNA researcher I know is extremely aware of the many pitfalls associated with sequencing ancient material and the various chemical and computational methods to mitigate them. Checking for signs of systematic artifacts in your aDNA data is very routine and not especially difficult.
To provide some brief speculation, I think a major explanation for this paper's errors is that aDNA lab that did the sequencing was quite old, under-staffed, and did not have much recent experience with sequencing human nuclear aDNA, so they had not kept fully abreast of the enormous methodological improvements in this area over the past twenty years.
Basically any paper trying to detect signals of natural selection in humans will turn up something plausibly immune-related [1][2][3][4]. Alongside pigmentation and diet-related genes, it's one of the most robustly detected categories of monogenic selection signal.
While it seems extremely likely that some selection due to pathogenic disease has occurred in humans, I don't think I've seen a paper that convincingly ties a particular selected gene to a particular historical pathogen or pandemic. It would be pretty hard to do so. There's a many-to-many mapping between immune system genes and pathogenic diseases, and selection generally takes many centuries to detectably alter allele frequencies, during which time there have generally been many epidemics and other changes to the environment – which is responsible for the selection signal?
Regarding autoimmunity in particular: I am in no way an immunologist and have much less insight to offer here, but perhaps it isn't surprising (almost tautological?) that immune system genes are often implicated in autoimmunity as well. And I'm not sure that inborn immunity due to HLA alleles or similar will be an important tool in the human race's survival in the face of future pandemics. It's perhaps telling that when you try to find variants associated with getting critically ill with COVID-19 – an extremely well-powered examination of the effects of genetic variability on response to a pandemic disease! – the very largest effect sizes for individual variants are a doubling/halving of risk. This is a notable difference, but nowhere close to "total immunity" vs "certain death".
Having said that, I view "robust pathogen defence vs autoimmunity trade-off" as a very plausible just-so story, and likely to be true, but not concretely established at present. Sadly, it's one of those questions in science where running the right controlled experiment is practically impossible and we have to make do with detective work.
There are a couple of major problems with naively intervening to edit sites associated with some phenotype in a GWAS or polygenic risk score.
The SNP itself is (usually) not causal
Genotyping arrays select SNPs the genotype of which is correlated with a region around the SNP, they are said to be in linkage with this region as this region tends to be inherited together when recombination happens in meiosis. This is a matter of degree and linkage scores allow thresholds to be set for how indicative a SNP is about the genotype a given region. If it is not the SNP but rather something with which the SNP is in linkage that is causing the effect editing the SNP has no reason the effect the trait in question.
It is not trivial to figure out what in linkage with a SNP might be causing an effect.
Mendelian randomisation (explainer: https://www.bmj.com/content/362/bmj.k601) is a method that permits the identification of causal relationships from observational genetic studies which can help to overcome this issue.
In practice epistatic interactions between QTLs matter for effects sizes and you cannot naively add up the effect sizes of all the QTLs for a trait and expect the result to reflect the real effect size, even if >50% effect are additive.
Terminology:
epistasis - when the effect of a genetic variant is dependent on the genotype of another gene or genes to have an effect.
QTL - quantitative trait locus, a location in the genome where the genotype is correlated with a quantitative phenotype e.g. height
A hypothetical example of how epistasis can lead to non-additivity in QTLs:
SNPs linked with genes A, B and C are associated with some trait.
Variant A is more a more active kinase than regular A that phosphorylates and activates C, So is variant B
Phosphorylation of C is effectively binary, if either A or B does it does not matter so editing either has the same effect.
Variant C is active even when not phosphorylated so editing A and/or B has no effect beyond that of editing C - except maybe side effects from now phosphorylating something else.
In agronomy where this has been best studied with the goal of engineering crops with specific complex traits once you start trying this epistatic effects show up.
The SNP itself is (usually) not causal Genotyping arrays select SNPs the genotype of which is correlated with a region around the SNP, they are said to be in linkage with this region as this region tends to be inherited together when recombination happens in meiosis. This is a matter of degree and linkage scores allow thresholds to be set for how indicative a SNP is about the genotype a given region.
This is taken into account by our models, and is why we see such large gains in editing power from increasing data set sizes: we're better able to find the causal SNPs. Our editing strategy assumes that we're largely hitting non-causal SNPs.
In practice epistatic interactions between QTLs matter for effects sizes and you cannot naively add up the effect sizes of all the QTLs for a trait and expect the result to reflect the real effect size, even if >50% effect are additive.
I'm not aware of any evidence for substantial effects of this sort on quantitative traits such as height. We're also adding up expected effects, and as long as those estimates are unbiased the errors should cancel out as you do enough edits.
One thing we're worried about is cases where the haplotypes have the small additive effects rather than individual SNPs, and you get an unpredictable (potentially deleterious) effect if you edit to a rare haplotype even if all SNPs involved are common. Are you aware of any evidence suggesting this would be a problem?
Could you expand on what sense you have 'taken this into account' in your models? What are you expecting to achieve by editing non-causal SNPs?
The first paper I linked is about epistasic effects on the additivity of a QTLs for quantitative trait, specifically heading date in rice, so this is evidence for this sort of effect on such a trait.
The general problem is without a robust causal understanding of what an edit does it is very hard to predict what shorts of problem might arise from novel combinations of variants in a haplotype. That's just the nature of complex systems, a single incorrect base in the wrong place may have no effect or cause a critical cascading failure. You don't know until you test it or have characterized the system so well you can graph out exactly what is going to happen. Just testing it in humans and seeing what happens is eventually going to hit something detrimental. When you are trying to do enhancement you tend to need a positive expectation that it will be safe not just no reason to think it won't be. Many healthy people would be averse to risking good health for their kid, even at low probability of a bad outcome.
Could you expand on what sense you have 'taken this into account' in your models? What are you expecting to achieve by editing non-causal SNPs?
If we have a SNP that we're 30% sure is causal, we expect to get 30% of its effect conditional on it being causal. Modulo any weird interaction stuff from rare haplotypes, which is a potential concern with this approach.
The first paper I linked is about epistasic effects on the additivity of a QTLs for quantitative trait, specifically heading date in rice, so this is evidence for this sort of effect on such a trait.
I didn't read your first comment carefully enough; I'll take a look at this.
I'm curious about the basis on which you are assigning a probability of causality without a method like mendelian randomisation, or something that tries to assign a probability of an effect based on interpreting the biology like a coding of the output of something like SnpEff to an approximate probability of effect.
The logic of 30% of its effect based on 30% chance it's causal only seems like it will be pretty high variance and only work out over a pretty large number of edits. It is also assuming no unexpected effects of the edits to SNPs that are non-causal for whatever trait you are targeting but might do something else when edited.
I'm curious about the basis on which you are assigning a probability of causality without a method like mendelian randomisation, or something that tries to assign a probability of an effect based on interpreting the biology like a coding of the output of something like SnpEff to an approximate probability of effect.
Using finemapping. I.e. assuming a model where nonzero additive effects are sparsely distributed among SNPs, you can do Bayesian math to infer how probable each SNP is to have a nonzero effect and its expected effect size conditional on observed GWAS results. Things like SnpEff can further help by giving you a better prior.
(For people reading this thread who want an intro to finemapping this lecture is a great place to start for a high level overview https://www.youtube.com/watch?v=pglYf7wocSI)
One thing we're worried about is cases where the haplotypes have the small additive effects rather than individual SNPs, and you get an unpredictable (potentially deleterious) effect if you edit to a rare haplotype even if all SNPs involved are common.
This is a point of uncertainty that bothered me when I was doing a similar analysis a while ago. GWAS data is possibly good enough to estimate causal effects of haplotypes, but that's not enough information to do single base edits. To have reasonable confidence of getting the predicted effect, it'd be necessary to to make all the edits to transform the original haplotype into a different haplotype.
And unlike with distant variants where additive effects dominate, it'd make sense if non-additive effects are strong locally, since the variants are near each other. Whether this is actually true in reality is way beyond my knowledge, though.
To dumb it down a bit, here's my made up example: you get +1 IQ if your brain has surplus oxygen in the blood flowing through it. There's 1000 ways to get a bit more oxygen in there, but with +1000 oxygen, you still only get +1 IQ.
Kind of, there are many ways that changed in isolation get you a bit more oxygen but many of them act through the same mechanism so you change 1000 things that get you +1 oxygen on their own but in combination only get you +500.
To use a software analogy imagine an object with two methods where if you call either of them a property of an object is set to true, it doesn't matter if you call both methods or if you have a bunch of functions that call those methods you still just get true. Calling either method or any function that calls them is going to be slightly correlated with an increased probability the the property of the object will be true but it does not add. There are many way to make it true but making it true more times does not make it 'more true'.
If we change this from a boolean to an integer then some methods might only increment it if it is not already greater than some value specific to the method.
How much do people know about the genetic components of personality traits like empathy? Editing personality traits might be almost as or even more controversial than modifying “vanity” traits. But in the sane world you sketched out this could essentially be a very trivial and simple first step of alignment. “We are about to introduce agents more capable than any humans except for extreme outliers: let’s make them nice.” Also, curing personality disorders like NPD and BPD would do a lot of good for subjective wellbeing.
I guess I’m just thinking of a failure mode where we create superbabies who solve task-alignment and then control the world. The people running the world might be smarter than the current candidates for god-emperor, but we’re still in a god-emperor world. This also seems like the part of the plan most likely to fail. The people who would pursue making their children superbabies might be disinclined towards making their children more caring.
Very little at the moment. Unlike intelligence and health, a lot of the variance in personality traits seems to be the result of combinations of genes rather than purely additive effects.
This is one of the few areas where AI could potentially make a big difference. You need more complex models to figure out the relationship between genes and personality.
But the actual limiting factor right now is not model complexity, but rather data. Even if you have more complex models, I don't think you're going to be able to actually train them until you have a lot more data. Probably a minimum of a few million samples.
We'd like to look into this problem at some point and make scaling law graphs like the ones we made for intelligence and disease risk but haven't had the time yet.
This is starting to sound a lot like AI actually. There's a "capabilities problem" which is easy, an "alignment problem" which is hard, and people are charging ahead to work on capabilities while saying "gee, we'd really like to look into alignment at some point".
Highly dependent on culturally transmitted info, including in-person.
Humans, genomically engineered or not, come with all the stuff that makes humans human. Fear, love, care, empathy, guilt, language, etc. (It should be banned, though, to remove any human universals, though defining that seems tricky.) So new humans are close to us in values-space, and come with the sort of corrigibility that humans have, which is, you know, not a guarantee of safety, but still some degree of (okay I'm going to say something that will trigger your buzzword detector but I think it's a fairly precise description of something clearly real) radical openness to co-creating shared values.
Tell that to all the other species that went extinct as a result of our activity on this planet?
I think it's possible that the first superbaby will be aligned, same way it's possible that the first AGI will be aligned. But it's far from a sure thing. It's true that the alignment problem is considerably different in character for humans vs AIs. Yet even in this particular community, it's far from solved -- consider Brent Dill, Ziz, Sam Bankman-Fried, etc.
Not to mention all of history's great villains, many of whom believed themselves to be superior to the people they afflicted. If we use genetic engineering to create humans which are actually, massively, undeniably superior to everyone else, surely that particular problem is only gonna get worse. If this enhancement technology is going to be widespread, we should be using the history of human activity on this planet as a prior. Especially the history of human behavior towards genetically distinct populations with overwhelming technological inferiority. And it's not pretty.
So yeah, there are many concrete details which differ between these two situations. But in terms of high-level strategic implications, I think there are important similarities. Given the benefit of hindsight, what should MIRI have done about AI back in 2005? Perhaps that's what we should be doing about superbabies now.
Tell that to all the other species that went extinct as a result of our activity on this planet?
Individual humans.
Brent Dill, Ziz, Sam Bankman-Fried, etc.
These are incredibly small peanuts compared to AGI omnicide.
You're somehow leaving out all the people who are smarter than those people, and who were great for the people around them and humanity? You've got like 99% actually alignment or something, and you're like "But there's some chance it'll go somewhat bad!"... Which, yes, we should think about this, and prepare and plan and prevent, but it's just a totally totally different calculus from AGI.
I'd flag here that the 99% number seems very easy to falsify, solely based on the 20th century experience of both the 2 great wars, as well as the genocides/civil wars of the 20th century, and it's quite often that one human group is vastly unaligned to another human group, causing mass strife and chaos.
I'm saying that (waves hands vigorously) 99% of people are beneficent or "neutral" (like, maybe not helpful / generous / proactively kind, but not actively harmful, even given the choice) in both intention and in action. That type of neutral already counts as in a totally different league of being aligned compared to AGI.
one human group is vastly unaligned to another human group
Ok, yes, conflict between large groups is something to be worried about, though I don't much see the connection with germline engineering. I thought we were talking about, like, some liberal/techie/weirdo people have some really really smart kids, and then those kids are somehow a threat to the future of humanity that's comparable to a fast unbounded recursive self-improvement AGI foom.
I'm saying that (waves hands vigorously) 99% of people are beneficent or "neutral" (like, maybe not helpful / generous / proactively kind, but not actively harmful, even given the choice) in both intention and in action. That type of neutral already counts as in a totally different league of being aligned compared to AGI.
I think this is ultimately the crux, at least relative to my values, I'd expect at least 20% in America to support active efforts to harm me or my allies/people I'm altruistic to, and do so fairly gleefully (an underrated example here is voting for people that will bring mass harm to groups they hate, and hope that certain groups go extinct).
Ok, yes, conflict between large groups is something to be worried about, though I don't much see the connection with germline engineering. I thought we were talking about, like, some liberal/techie/weirdo people have some really really smart kids, and then those kids are somehow a threat to the future of humanity that's comparable to a fast unbounded recursive self-improvement AGI foom.
Okay, the connection was to point out that lots of humans are not in fact aligned with each other, and I don't particularly think superbabies are a threat to the future of humanity that is comparable to AGI, so my point was more so that the alignment problem is not naturally solved in human-to human interactions.
lots of humans are not in fact aligned with each other,
Ok... so I think I understand and agree with you here. (Though plausibly we'd still have significant disagreement; e.g. I think it would be feasible to bring even Hitler back and firmly away from the death fever if he spent, IDK, a few years or something with a very skilled listener / psychic helper.)
The issue in this discourse, to me, is comparing this with AGI misalignment. It's conceptually related in some interesting ways, but in practical terms they're just extremely quantitatively different. And, naturally, I care about this specific non-comparability being clear because it says whether to do human intelligence enhancement; and in fact many people cite this as a reason to not do human IE.
The issue in this discourse, to me, is comparing this with AGI misalignment. It's conceptually related in some interesting ways, but in practical terms they're just extremely quantitatively different. And, naturally, I care about this specific non-comparability being clear because it says whether to do human intelligence enhancement; and in fact many people cite this as a reason to not do human IE.
Re human vs AGI misalignment, I'd say this is true, in that human misalignments don't threaten the human species, or even billions of people, whereas AI does, so in that regard I admit human misalignment is less impactful than AGI misalignment.
Of course, if we succeed at creating aligned AI, than human misalignments matter much, much more.
(Rest of the comment is a fun tangentially connected scenario, but ultimately is a hypothetical that doesn't matter that much for AI alignment.)
Ok... so I think I understand and agree with you here. (Though plausibly we'd still have significant disagreement; e.g. I think it would be feasible to bring even Hitler back and firmly away from the death fever if he spent, IDK, a few years or something with a very skilled listener / psychic helper.)
At the very least, that would require him to not be in control of Germany by that point, and IMO most value change histories rely on changing their values in the child-teen years, because that's when their sensitivity to data is maximal. After that, the plasticity/sensitivity of values goes way down when you are an adult, and changing values is much, much harder.
I'd say this is true, in that human misalignments don't threaten the human species, or even billions of people, whereas AI does, so in that regard I admit human misalignment is less impactful than AGI misalignment.
Right, ok, agreed.
the plasticity/sensitivity of values goes way down when you are an adult, and changing values is much, much harder.
I agree qualitatively, but I do mean to say he's in charge of Germany, but somehow has hours of free time every day to spend with the whisperer. If it's in childhood I would guess you could do it with a lot less contact, though not sure. TBC, the whisperer here would be considered a world-class, like, therapist or coach or something, so I'm not saying it's easy. My point is that I have a fair amount of trust in "human decision theory" working out pretty well in most cases in the long run with enough wisdom [LW · GW].
I even think something like this is worth trying with present-day AGI researchers (what I call "confrontation-worthy empathy [LW · GW]"), though that is hard mode because you have so much less access.
I think it would be feasible to bring even Hitler back and firmly away from the death fever if he spent, IDK, a few years or something with a very skilled listener / psychic helper
There's an important point to be made here that Hitler was not a genius, and in general the most evil people in history don't correlate at all to being the smartest people in history. In fact, the smartest people in history generally seemed more likely to contribute positively to the development of humanity.
I would posit it's easier to make a high IQ child good for society, with positive nurturing.
The alignment problem perhaps is thus less difficult with "super babies", because they can more easily see the irrationality in poor ethics and think better from first principles, being grounded in the natural alignment that comes from the fact we are all humans with similar sentience (as opposed to AI which might as well be a different species altogether).
Given that Hitler's actions resulted in his death and the destruction of Germany, a much higher childhood IQ might even have blunted his evil.
Also don't buy the idea that very smart humans automatically assume control. I suspect Kamala, Biden, Hillary, etc all had a higher IQ than Donald Trump, but he became the most powerful person on the planet.
Does the size of this effect, according to you, depend on parameters of the technology? E.g. if it clearly has a ceiling, such that it's just not feasible to make humans who are in a meaningful sense 10x more capable than the most capable non-germline-engineered human? E.g. if the technology is widespread, so that any person / group / state has access if they want it?
My interpretation is that you're 99% of the way there in terms of work required if you start out with humans rather than creating a de novo mind, even if many/most humans currently or historically are not "aligned". Like, you don't need very many bits of information to end up with a nice "aligned" human. E.g. maybe you lightly select their genome for prosociality + niceness/altruism + wisdom, and treat them nicely while they're growing up, and that suffices for the majority of them.
I'd actually maybe agree with this, though with the caveat that there's a real possibility you will need a lot more selection/firepower as a human gets smarter, because you lack the ability to technically control humans in the way you can control AIs.
I'd probably bump that down to O(90%) at max, and this could get worse (I'm downranking based on the number of psychopaths/sociopaths and narcissists that exist).
These are incredibly small peanuts compared to AGI omnicide.
The jailbreakability and other alignment failures of current AI systems are also incredibly small peanuts compared to AGI omnicide. Yet they're still informative. Small-scale failures give us data about possible large-scale failures.
You're somehow leaving out all the people who are smarter than those people, and who were great for the people around them and humanity? You've got like 99% actually alignment or something
Are you thinking of people such as Sam Altman, Demis Hassabis, Elon Musk, and Dario Amodei? If humans are 99% aligned, how is it that we ended up in a situation where major lab leaders look so unaligned? MIRI and friends had a fair amount of influence to shape this situation and align lab leaders, yet they appear to have failed by their own lights. Why?
When it comes to AI alignment, everyone on this site understands that if a "boxed" AI acts nice, that's not a strong signal of actual friendliness. The true test of an AI's alignment is what it does when it has lots of power and little accountability.
Maybe something similar is going on for humans. We're nice when we're powerless, because we have to be. But giving humans lots of power with little accountability doesn't tend to go well.
Looking around you, you mostly see nice humans. That could be because humans are inherently nice. It could also be because most of the people around you haven't been given lots of power with little accountability.
Dramatic genetic enhancement could give enhanced humans lots of power with little accountability, relative to the rest of us.
[Note also, the humans you see while looking around are strongly selected for, which becomes quite relevant if the enhancement technology is widespread. How do you think you'd feel about humanity if you lived in Ukraine right now?]
Which, yes, we should think about this, and prepare and plan and prevent, but it's just a totally totally different calculus from AGI.
I want to see actual, detailed calculations of p(doom) from supersmart humans vs supersmart AI, conditional on each technology being developed. Before charging ahead on this, I want a superforecaster-type person to sit down, spend a few hours, generate some probability estimates, publish a post, and request that others red-team their work. I don't feel like that is a lot to ask.
Small-scale failures give us data about possible large-scale failures.
But you don't go from a 160 IQ person with a lot of disagreeability and ambition, who ends up being a big commercial player or whatnot, to 195 IQ and suddenly get someone who just sits in their room for a decade and then speaks gibberish into a youtube livestream and everyone dies, or whatever. The large-scale failures aren't feasible for humans acting alone. For humans acting very much not alone, like big AGI research companies, yeah that's clearly a big problem. But I don't think the problem is about any of the people you listed having too much brainpower.
(I feel we're somewhat talking past each other, but I appreciate the conversation and still want to get where you're coming from.)
For humans acting very much not alone, like big AGI research companies, yeah that's clearly a big problem.
How about a group of superbabies that find and befriend each other? Then they're no longer acting alone.
I don't think the problem is about any of the people you listed having too much brainpower.
I don't think problems caused by superbabies would look distinctively like "having too much brainpower". They would look more like the ordinary problems humans have with each other. Brainpower would be a force multiplier.
(I feel we're somewhat talking past each other, but I appreciate the conversation and still want to get where you're coming from.)
Thanks. I mostly just want people to pay attention to this problem. I don't feel like I have unique insight. I'll probably stop commenting soon, since I think I'm hitting the point of diminishing returns.
I mostly just want people to pay attention to this problem.
Ok. To be clear, I strongly agree with this. I think I've been responding to a claim (maybe explicit, or maybe implicit / imagined by me) from you like: "There's this risk, and therefore we should not do this.". Where I want to disagree with the implication, not the antecedent. (I hope to more gracefully agree with things like this. Also someone should make a LW post with a really catchy term for this implication / antecedent discourse thing, or link me the one that's already been written.)
But I do strongly disagree with the conclusion "...we should not do this", to the point where I say "We should basically do this as fast as possible, within the bounds of safety and sanity.". The benefits are large, the risks look not that bad and largely ameliorable, and in particular the need regarding existential risk is great and urgent.
That said, more analysis is definitely needed. Though in defense of the pro-germline engineering position, there's few resources, and everyone has a different objection.
I will go further, and say the human universals are nowhere near strong enough to assume that alignment of much more powerful people will automatically/likely happen, or that not aligning them produces benevolent results, and the reason for this is humans are already misaligned, in many cases very severely to each other, so allowing human augmentation without institutional reform makes things a lot worse by default.
It is better to solve the AI alignment problem first, then have a legal structure created by AIs that can make human genetic editing safe, rather than try to solve the human alignment problem:
I honestly think the EV of superhumans is lower than the EV for AI. sadism and wills to power are baked into almost every human mind (with the exception of outliers of course). force multiplying those instincts is much worse than an AI which simply decides to repurpose the atoms in a human for something else. i think people oftentimes act like the risk ends at existential risks, which i strongly disagree with. i would argue that everyone dying is actually a pretty great ending compared to hyperexistential risks. it is effectively +inf relative utility.
with AIs we're essentially putting them through selective pressures to promote benevolence (as a hedge by the labs in case they don't figure out intent alignment). that seems like a massive advantage compared to the evolutionary baggage associated with humans.
with humans you'd need the will and capability to engineer in at least +5sd empathy and -10sd sadism into every superbaby. but people wouldn't want their children to make them feel like shitty people so they would want them to "be more normal."
sadism and wills to power are baked into almost every human mind (with the exception of outliers of course). force multiplying those instincts is much worse than an AI which simply decides to repurpose the atoms in a human for something else.
I don't think the result of intelligence enhancement would be "multiplying those instincts" for the vast majority of people; humans don't seem to end up more sadistic as they get smarter and have more options.
i would argue that everyone dying is actually a pretty great ending compared to hyperexistential risks. it is effectively +inf relative utility.
I'm curious what value you assign to the ratio [U(paperclipped) - U(worst future)] / [U(best future) - U(paperclipped)]? It can't be literally infinity unless U(paperclipped) = U(best future).
with humans you'd need the will and capability to engineer in at least +5sd empathy and -10sd sadism into every superbaby.
So your model is that we need to eradicate any last trace of sadism before superbabies is a good idea?
I’m sure you’ve already thought about this, but it seems like the people who would be willing and able to jump through all of the hoops necessary would likely have a higher propensity towards power-seeking and dominance. So if you don’t edit the personality as well, what was it all for besides creating a smarter god-emperor? I think that in the sane world you’ve outlined where people deliberately avoid developing AGI, an additional level of sanity would be holding off on modifying intelligence until we have the capacity to perform the personality edits to make it safe.
I can just imagine this turning into a world where the rich who are able to make their children superbabies compete with the rest of the elite over whose child will end up ruling the world.
I’m sorry but I’d rather be turned into paper-clips then live in a world where a god-emperor can decide to torture me with their AGI-slave for the hell of it. How is that a better world for anyone but the god-emperor? But people are so blind and selfish, they just assume that they or their offspring would be god-emperor. At least with AI people are scared enough that they’re putting focused effort into trying to make it nice. People won’t put that much effort into their children.
I mean hell, figuring out personality editing would probably just make things backfire. People would choose to make their kids more ruthless, not less.
I certainly wouldn’t sign up to do that, but the type of individual I’m concerned about likely wouldn’t mind sacrificing nannies if their lineage could “win” in some abstract sense. I think it’s great that you’re proposing a plan beyond “pray the sand gods/Sam Altman are benevolent.” But alignment is going to be an issue for superhuman agents, regardless of if they’re human or not.
Agreed. I've actually had a post in draft for a couple of years that discusses some of the paralleles between alignment of AI agents and alignment of genetically engineered humans.
I think we have a huge advantage with humans simply because there isn't the same potential for runaway self-improvement. But in the long term (multiple generations), it would be a concern.
If you look at the grim history of how humans have treated each other on this planet, I don't think it's justified to have a prior that this is gonna go well.
I think we have a huge advantage with humans simply because there isn't the same potential for runaway self-improvement.
Humans didn't have the potential for runaway self-improvement relative to apes. That was little comfort for the apes.
That sounds very interesting! I always look forward to reading your posts. I don’t know if you know any policy people, but in this world, it would need to be punishable by jail-time to genetically modify intelligence without selecting for pro-sociality. Any world where that is not the case seems much, much worse than just getting turned into paper-clips.
I think the runaway self-improvement problem is IMO vastly outweighed by other problems on aligning humans, like the fact that any control technique on AI would be illegal because of it being essentially equivalent to brainwashing, such that I consider AIs much more alignable than humans, and I think the human intelligence augmentation path is way more risky and fraught than people think for alignment purposes.
I agree. At least I can laugh if the AGI just decides it wants me as paperclips. There will be nothing to laugh about with ruthless power-seeking humans with godlike power.
like the fact that any control technique on AI would be illegal because of it being essentially equivalent to brainwashing, such that I consider AIs much more alignable than humans
A lot of (most?) humans end up nice without needing to be controlled / "aligned", and I don't particularly expect this to break if they grow up smarter. Trying to control / "align" them wouldn't work anyway, which is also what I predict will happen with sufficiently smart AI.
I think this is my disagreement, in that I don't think that most humans are in fact nice/aligned to each other by default, and the reason why this doesn't lead to catastrophe broadly speaking is a combo of being able to rely on institutions/mechanism design that means even if people are misaligned, you can still get people well off under certain assumptions (capitalism and the rule of law being one such example), combined with the inequalities not being so great that individual humans can found their own societies, except in special cases.
Even here, I'd argue that human autocracies are very often misaligned to their citizens values very severely.
To be clear about what I'm not claiming, I'm not saying that alignment is worthless, or alignment always or very often fails, because it's consistent with a world where >50-60% of alignment attempts are successful.
This means I'm generally much more scared of very outlier smart humans, for example a +7-12 SD human that was in power of a large group of citizens, assuming no other crippling disabilities unless they are very pro-social/aligned to their citizenry.
I'm not claiming that alignment will not work, or even that will very often not work, but rather that the chance of failure is real and the stakes are quite high long-term.
(And that's not even addressing how you could get super-smart people to work on the alignment problem).
This is just a definition for the sake of definition, but I think you could define a human as aligned if they could be given an ASI slave and not be an S-risk. I really think that under this definition, the absolute upper bound of “aligned” humans is 5%, and I think it’s probably a lot lower.
I'm more optimistic, in that the upper bound could be as high as 50-60%, but yeah the people in power are unfortunately not part of this, and I'd only trust 25-30% of the population in practice if they had an ASI slave.
So you think that, for >95% of currently living humans, the implementation of their CEV would constitute an S-risk in the sense of being worse than extinction in expectation? This is not at all obvious to me; in what way do you expect their CEVs to prefer net suffering?
(And that's not even addressing how you could get super-smart people to work on the alignment problem).
I mean if we actually succeeded at making people who are +7 SD in a meaningful way, I'd expect that at least good chunk of them would figure out for themselves that it makes sense to work on it.
That requires either massive personality changes to make them more persuadable, or massive willingness of people to put genetic changes in their germline, and I don't expect either of these to happen before AI automates everything and either takes over, leaving us extinct or humans/other AI control/align AIs successfully.
(A key reason for this is that Genesmith admitted that the breakthroughs in germline engineering can't transfer to the somatic side, and that means we'd have to wait 25-30 years in order for it to grow, minimum given that society won't maximally favor the genetically lucky, and that's way beyond most plausible AI timelines at this point)
Because they might consider that other problems are more worth their time, since smartness changes change their values little.
And maybe they believe that AI alignment isn't impactful for technical/epistemic reasons.
I'm confused/surprised I need to make this point, because I don't automatically think they will be persuaded that AI alignment is a big problem they will need to work on, and some effort will likely still need to be required.
Because they might consider that other problems are more worth their time, since smartness changes change their values little.
I mean if they care about solving problems at all, and we are in fact correct about AGI ruin, then they should predictably come to view it as the most important problem and start to work on it?
Are you imagining they're super myopic or lazy and just want to think about math puzzles or something? If so, my reply is that even if some of them ended up like that, I'd be surprised if they all ended up like that, and if so that would be a failure of the enhancement. The aim isn't to create people who we will then carefully persuade to work on the problem, the aim is for some of them to be smart + caring + wise enough to see the situation we're in and decide for themselves to take it on.
More so that I'm imagining they might not even have heard of the argument, and it's helpful to note that people like Terence Tao, Timothy Gowers and more are all excellent people at their chosen fields, but most people that have a big impact on the world don't go into AI alignment.
Remember, superintelligence is not omniscience.
So I don't expect them to be self motivated to work on this specific problem without at least a little persuasion.
I'd expect a few superintelligent adults to join alignment efforts, but nowhere near thousands or tens of thousands, and I'd upper bound it at 300-500 new researchers at most in 15-25 years.
How much probability do you assign to automating AI safety not working in time? Because I believe the preparing to automate AI safety work is probably the highest-value in pure ability to reduce X-risk probability, assuming it does work, so I assign much higher EV to automating AI safety, relative to other approaches.
I think I'm at <10% that non-enhanced humans will be able to align ASI in time, and if I condition on them succeeding somehow I don't think it's because they got AIs to do it for them. Like maybe you can automate some lower level things that might be useful (e.g. specific interpretability experiments), but at the end of the day someone has to understand in detail how the outcome is being steered or they're NGMI. Not sure exactly what you mean by "automating AI safety", but I think stronger forms of the idea are incoherent (e.g. "we'll just get AI X to figure it all out for us" has the problem of requiring X to be aligned in the first place).
As far as what a plan to automate AI safety would work out in practice, assuming a relatively strong version of the concept is in this post below, and there will be another post that comes out by the same author talking more about the big risks discussed in the comments below:
In general, I think the crux is that in most timelines (at a lower bound, 65-70%) that have AGI developed relatively soon (so timelines from 2030-2045, roughly), and the alignment problem isn't solvable by default/it's at least non-trivially tricky to solved, conditioning on alignment success looks more like "we've successfully figured out how to prepare for AI automation of everything, and we managed to use alignment and control techniques well enough that we can safely pass most of the effort to AI", rather than other end states like "humans are deeply enhanced" or "lawmakers actually coordinated to pause AI, and are actually giving funding to alignment organizations such that we can make AI safe."
I think we have a huge advantage with humans simply because there isn't the same potential for runaway self-improvement. But in the long term (multiple generations), it would be a concern.
How do you know you can afford to wait multiple generations? My guess is superhuman 6 year olds demonstrating their capabilities on YouTube is sufficient to start off an international arms race for more superhumans. (Increase number of people and increase capability level of each person.) And once the arms race is started it may never stop until the end state of this self-improvement is hit.
I mean hell, figuring out personality editing would probably just make things backfire. People would choose to make their kids more ruthless, not less.
Not at all obvious to me this is true. Do you mean to say a lot of people would, or just some small fraction, and you think a small fraction is enough to worry?
After I finish my methods article, I want to lay out a basic picture of genomic emancipation. Genomic emancipation means making genomic liberty a right and a practical option. In my vision, genomic liberty is quite broad: it would include for example that parents should be permitted and enabled to choose:
to enhance their children (e.g. supra-normal health; IQ at the outer edges of the human envelope); and/or
to propagate their own state even if others would object (e.g. blind people can choose to have blind children); and/or
to make their children more normal even if there's no clear justification through beneficence (I would go so far as to say that, for example, parents can choose to make their kid have a lower IQ than a random embryo from the parents would be in expectation, if that brings the kid closer to what's normal).
These principles are more narrow than general genomic liberty ("parents can do whatever they please"), and I think have stronger justifications. I want to make these narrower "tentpole" principles inside of the genomic liberty tent, because the wider principle isn't really tenable, in part for the reasons you bring up. There are genomic choices that should be restricted--perhaps by law, or by professional ethics for clinicians, or by avoiding making it technically feasible, or by social stigma. (The implementation seems quite tricky; any compromise of full genomic liberty does come with costs as well as preventing costs. And at least to some small extent, it erodes the force of genomic liberty's contraposition to eugenics, which seeks to impose population-wide forces on individual's procreative choice.)
Examples:
As you say, if there's a very high risk of truly egregious behavior, that should be pushed against somehow.
Example: People should not make someone who is 170 Disagreeable Quotient and 140 Unconscientiousness Quotient, because that is most of the way to being a violent psychopath.
Counterexample: People should, given good information, be able to choose to have a kid who is 130 Disagreeable Quotient and 115 Unconscientiousness Quotient, because, although there might be associated difficulties, that's IIUC a personality profile enriched with creative genius.
People should not be allowed to create children with traits specifically designed to make the children suffer. (Imagine for instance a parent who thinks that suffering, in itself, builds character or makes you productive or something.)
Another thing to point out is that to a significant degree, in the longer-term, many of these things should self-correct, through the voice of the children (e.g. if a deaf kid grows up and starts saying "hey, listen, I love my parents and I know they wanted what was best for me, but I really don't like that I didn't get to hear music and my love's voice until I got my brain implant, please don't do the same for your kid"), and through seeing the results in general. If someone is destructively ruthless, it's society's job to punish them, and it's parents's job to say "ah, that is actually not good".
In that case I'd repeat GeneSmith's point from another comment: "I think we have a huge advantage with humans simply because there isn't the same potential for runaway self-improvement." If we have a whole bunch of super smart humans of roughly the same level who are aware of the problem, I don't expect the ruthless ones to get a big advantage.
I mean I guess there is some sort of general concern here about how defense-offense imbalance changes as the population gets smarter. Like if there's some easy way to destroy the world that becomes accessible with IQ > X, and we make a bunch of people with IQ > X, and a small fraction of them want to destroy the world for some reason, are the rest able to prevent it? This is sort of already the situation we're in with AI: we look to be above the threshold of "ability to summon ASI", but not above the threshold of "ability to steer the outcome". In the case of AI, I expect making people smarter differentially speeds up alignment over capabilities: alignment is hard and we don't know how to do it, while hill-climbing on capabilities is relatively easy and we already know how to do it.
I should also note that we have the option of concentrating early adoption among nice, sane, x-risk aware people (though I also find this kind of cringe in a way and predict this would be an unpopular move). I expect this to happen by default to some extent.
There are some promising but under-utilized interventions for improving personality traits / virtues in already-developed humans,* [? · GW] and a dearth of research about possible interventions for others. If we want more of that sort of thing, we might be better advised to fill in some of those gaps rather than waiting for a new technology and a new generation of megalopsychebabies.
Putting aside for the moment the fact that even "intelligence" is hardly a well-defined and easily quantified property, isn't it rather a giant leap to say we even know what a "better" personality is? I might agree that some disorders are reasonably well defined, and those might be candidates for trying to "fix", but if you're trying to match greater intelligence with "better" personality I think you first need a far better notion of what "better" personality actually means.
I'm surprised to see no one in the comments whose reaction is "KILL IT WITH FIRE", so I'll be that guy and make a case why this research should be stopped rather than pursued:
On the one hand, there is obviously enormous untapped potential in this technology. I don't have issues about the natural order of life or some WW2 eugenics trauma. From my (unfamiliar with the subject) eyes, you propose a credible way to make everyone healthier, smarter, happier, at low cost and within a generation, which is hard to argue against.
On the other hand, you spend no time mentioning the context in which this technology will be developed. I imagine there will be significant public backlash and that most advances on superbabies-making will be made by private labs funded by rich tech optimists, so it seems overwhelmingly likely to me that if this technology does get developed in the next 20 years, it will not improve everyone.
At this point, we're talking about the far future, so I need to make a caveat for AI: I have no idea how the new AI world will interact with this, but there are a few most likely futures I can condition on.
Everyone dies: No point talking about superbabies.
Cohabitive singleton: No point. It'll decide whether it wants superbabies or not.
Controlled ASI: Altman, Musk and a few others become kings of the universe, or it's tightly controlled by various governments.
In that last scenario, I expect people having superbabies will be the technological and intellectual elites, leading to further inequality, and not enough improvements at scale to significantly improve global life expectancy or happiness... though I guess the premises are already an irrecoverable catastrophe, so superbabies are not the crux in this case.
Lastly, there is the possibility that AI does not reach superintelligence before we develop superbabies, or that the world will proceed more or less unchanged for us; in that case, I do think superbabies will increase inequality for little gains on the scale of humanity, but I don't see this scenario as likely enough to be upset about it.
So I guess my intuitive objection was simply wrong, but I don't mind posting this since you'll probably meet more people like me.
There's also the option that even if this technology is initially funded by the wealthy, learning curves will then drive down its cost as they do for every technology, until it becomes affordable for governments to subsidize its availability for everyone.
Are your IQ gain estimates based on plain GWAS or on family-fixed-effects-GWAS? You don't clarify. The latter would give much lower estimates than the former
Plain GWAS, since there aren't any large sibling GWASes. What's the basis for the estimates being much lower and how would we properly adjust for them?
Your OP is completely misleading if you're using plain GWAS!
GWAS is an association -- that's what the A stands for. Association is not causation. Anything that correlates with IQ (eg melanin) can show up in a GWAS for IQ. You're gonna end up editing embryos to have lower melanin and claiming their IQ is 150
The IQ GWAS we used was based on only individuals of European ancestry, and ancestry principal components were included as covariates as is typical for GWAS. Non-causal associations from subtler stratification is still a potential concern, but I don't believe it's a terribly large concern. The largest educational attainment GWAS did a comparison of population and direct effects for a "cognitive performance" PGI and found that predicted direct (between sibling) effects were only attenuated by a factor of 0.824 compared to predicted population level effects. If anything I'd expect their PGI to be worse in this regard, since it included variants with less stringent statistical power cutoffs (so I'd guess it's more likely that non-causal associations would sneak in, compared to the GWAS we used).
You should decide whether you're using a GWAS on cognitive performance or on educational attainment (EA). This paper you linked is using a GWAS for EA, and finding that very little of the predictive power was direct effects. Exactly the opposite of your claim:
For predicting EA, the ratio of direct to population effect estimates is 0.556 (s.e. = 0.020), implying that 100% × 0.5562 = 30.9% of the PGI’s R2 is due to its direct effect.
Then they compare this to cognitive performance. For cognitive performance, the ratio was better, but it's not 0.824, it's 0.8242=0.68. But actually, even this is possibly too high: the table in figure 4 has a ratio that looks much smaller than this, and refers to supplementary table 10 for numbers. I checked supplementary table 10, and it says that the "direct-population ratio" is 0.656, not 0.824. So quite possibly the right value is 0.6562=0.43 even for cognitive performance.
Why is the cognitive performance number bigger? Well, it's possibly because there's less data on cognitive performance, so the estimates are based on more obvious or easy-to-find effects. The final, predictive power of the direct effects for EA and for cognitive performance is similar, around 3% of the variance, if I'm reading it correctly (not sure about this). So the ratios are somewhat different, but the population GWAS predictive power is also somewhat different in the opposite direction, and these mostly cancel out.
For cognitive performance, the ratio was better, but it's not 0.824, it's 0.8242=0.68.
That's variance explained. I was talking about effect size attenuation, which is what we care about for editing.
I checked supplementary table 10, and it says that the "direct-population ratio" is 0.656, not 0.824. So quite possibly the right value is 0.6562=0.43 even for cognitive performance.
Supplementary table 10 is looking at direct and indirect effects of the EA PGI on other phenotypes. The results for the Cog Perf PGI are in supplementary table 13.
Thanks! I understand their numbers a bit better, then. Still, direct effects of cognitive performance explain 5% of variance. Can't multiply the variance explained of EA by the attenuation of cognitive performance!
Do you have evidence for direct effects of either one of them being higher than 5% of variance?
I don't quite understand your numbers in the OP but it feels like you're inflating them substantially. Is the full calculation somewhere?
I don't quite understand your numbers in the OP but it feels like you're inflating them substantially. Is the full calculation somewhere?
Not quite sure which numbers you're referring to, but if it's the assumed SNP heritability, see the below quote of mine from another comment talking about missing heritability for IQ:
The SNP heritability estimates for IQ of (h^2 = ~0.2) are primarily based on a low quality test that has a test-retest reliability of 0.6, compared to ~0.9 for a gold-standard IQ test. So a simple calculation to adjust for this gets you a predicted SNP heritability of 0.2 * (0.9 / 0.6)^2 = 0.45 for a gold standard IQ test, which matches the SNP heritability of height. As for the rest of the missing heritability: variants with frequency less than 1% aren't accounted for by the SNP heritability estimate, and they might contribute a decent bit if there are lots of them and their effects sizes are larger.
The h^2 = 0.19 estimate from this GWAS should be fairly robust to stratification, because of how the LDSC estimator works. (To back this up: a recent study that actually ran a small GWAS on siblings, based on the same cognitive test, also found h^2 = 0.19 for direct effects.)
The paper you called largest ever GWAS gave a direct h^2 estimate of 0.05 for cognitive performance. How are these papers getting 0.2? I don't understand what they're doing. Some type of meta analysis?
The test-retest reliability you linked has different reliabilities for different subtests. The correct adjustment depends on which subtests are being used. If cognitive performance is some kind of sumscore of the subtests, its reliability would be higher than for the individual subtests.
Also, I don't think the calculation 0.2*(0.9/0.6)^2 is the correct adjustment. A test-retest correlation is already essentially the square of a correlation of the test with an underlying latent factor (both the test AND the retest have error). E.g. if a test T can be written as
T=aX+sqrt(1-a)E
where X is ability and E is error (all with standard deviation 1 and the error independent of the ability), then a correlation of T with a resample of T (with new independent error but same ability) would be a^2. But the adjustment to h^2 should be proportional to a^2, so it should be proportional to the test-retest correlation, not the square of the test-retest correlation. Am I getting this wrong?
The paper you called largest ever GWAS gave a direct h^2 estimate of 0.05 for cognitive performance. How are these papers getting 0.2? I don't understand what they're doing. Some type of meta analysis?
You're mixing up h^2 estimates with predictor R^2 performance. It's possible to get an estimate of h^2 with much less statistical power than it takes to build a predictor that good.
The test-retest reliability you linked has different reliabilities for different subtests. The correct adjustment depends on which subtests are being used. If cognitive performance is some kind of sumscore of the subtests, its reliability would be higher than for the individual subtests.
"Fluid IQ" was the only subtest used.
Also, I don't think the calculation 0.2*(0.9/0.6)^2 is the correct adjustment. A test-retest correlation is already essentially the square of a correlation of the test with an underlying latent factor
Good catch, we'll fix this when we revise the post.
You're mixing up h^2 estimates with predictor R^2 performance. It's possible to get an estimate of h^2 with much less statistical power than it takes to build a predictor that good.
Thanks. I understand now. But isn't the R^2 the relevant measure? You don't know which genes to edit to get the h^2 number (nor do you know what to select on). You're doing the calculation 0.2*(0.9/0.6)^2 when the relevant calculation is something like 0.05*(0.9/0.6). Off by a factor of 6 for the power of selection, or sqrt(6)=2.45 for the power of editing
Not for this purpose! The simulation pipeline is as follows: the assumed h^2 and number of causal variants is used to generate the genetic effects -> generate simulated GWASes for a range of sample sizes -> infer causal effects from the observed GWASes -> select top expected effect variants for up to N (expected) edits.
With a method similar to this. You can easily compute the exact likelihood function P(GWAS results | SNP effects), which when combined with a prior over SNP effects (informed by what we know about the genetic architecture of the trait) gives you a posterior probability of each SNP being causal (having nonzero effect), and its expected effect size conditional on being causal (you can't actually calculate the full posterior since there are 2^|SNPs| possible combinations of SNPs with nonzero effects, so you need to do some sort of MCMC or stochastic search). We may make a post going into more detail on our methods at some point.
You should show your calculation or your code, including all the data and parameter choices. Otherwise I can't evaluate this.
I assume you're picking parameters to exaggerate the effects, because just from the exaggerations you've already conceded (0.9/0.6 shouldn't be squared and attenuation to get direct effects should be 0.824), you've already exaggerated the results by a factor of sqrt(0.9/0.6)/0.824 for editing, which is around a 50% overestimate.
I don't think that was deliberate on your part, but I think wishful thinking and the desire to paint a compelling story (and get funding) is causing you to be biased in what you adjust for and in which mistakes you catch. It's natural in your position to scrutinize low estimates but not high ones. So to trust your numbers I'd need to understand how you got them.
There is one saving grace for us which is that the predictor we used is significantly less powerful than ones we know to exist.
I think when you account for both the squaring issue, the indirect effect things, and the more powerful predictors, they're going to roughly cancel out.
Granted, the more powerful predictor itself isn't published, so we can't rigorously evaluate it either which isn't ideal. I think the way to deal with this is to show a few lines: one for the "current publicly available GWAS", one showing a rough estimate of the gain using the privately developed predictor (which with enough work we could probably replicate), and then one or two more for different amounts of data.
All of this together WILL still reduce the "best case scenario" from editing relative to what we originally published (because with the better predictor we're closer to "perfect knowledge" than where we were with the previous predictor.
At some point we're going to re-run the calculations and publish an actual proper writeup on our methodology (likely with our code).
Also I just want to say thank you for taking the time to dive deep into this with us. One of the main reasons I post on LessWrong is because there is such high quality feedback relative to other sites.
You should show your calculation or your code, including all the data and parameter choices. Otherwise I can't evaluate this.
The code is pretty complicated and not something I'd expect a non-expert (even a very smart one) to be able to quickly check over; it's not just a 100 line python script. (Or even a very smart expert for that matter, more like anyone who wasn't already familiar with our particular codebase.) We'll likely open source it at some point in the future, possibly soon, but that's not decided yet. Our finemapping (inferring causal effects) procedure produces ~identical results to the software from the paper I linked above when run on the same test data (though we handle some additional things like variable per-SNP sample sizes and missing SNPs which that finemapper doesn't handle, which is why we didn't just use it).
The parameter choices which determine the prior over SNP effects are the number of causal SNPs (which we set to 20,000) and the SNP heritability of the phenotype (which we set to 0.19, as per the GWAS we used). The erroneous effect size adjustment was done at the end to convert from the effect sizes of the GWAS phenotype (low reliability IQ test) to the effect sizes corresponding to the phenotype we care about (high reliability IQ test).
We want to publish a more detailed write up of our methods soon(ish), but it's going to be a fair bit of work so don't expect it overnight.
It's natural in your position to scrutinize low estimates but not high ones.
Yep, fair enough. I've noticed myself doing this sometimes and I want to cut it out. That said, I don't think small-ish predictable overestimates to the effect sizes are going to change the qualitative picture, since with good enough data and a few hundred to a thousand edits we can boost predicted IQ by >6 SD even with much more pessimistic assumptions, which probably isn't even safe to do (I'm not sure I expect additivity to hold that far). I'm much more worried about basic problems with our modelling assumptions, e.g. the assumption of sparse causal SNPs with additive effects and no interactions (e.g. what if rare haplotypes are deleterious due to interactions that don't show up in GWAS since those combinations are rare?).
I definitely want to see more work in this direction, and agree that improving humans is a high-value goal.
But to play devil's advocate for a second on what I see as my big ethical concern: There's a step in the non-human selective breeding or genetic modification comparison where the experimenter watches several generations grow to maturity, evaluates whether their interventions worked in practice, and decides which experimental subjects if any get to survive or reproduce further. What's the plan for this step in humans, since "make the right prediction every time at the embryo stage" isn't a real option? '
Concrete version of that question: Suppose we implement this as a scalable commercial product and find out that e.g. it causes a horrible new disease, or induces sociopathic or psychopathic criminal tendencies, that manifest at age 30, after millions of parents have used it. What happens next?
I think almost everyone misunderstands the level of knowledge we have about what genetic variants will do.
Nature has literally run a randomized control trial for genes already. Every time two siblings are created, the set of genes they inherit from each parent are scrambled and (more or less) randomly assigned to each. That's INCREDIBLY powerful for assessing the effects of genes on life outcomes. Nature has run a literal multi-generational randomized control trial for the effect of genes on everything. We just need to collect the data.
This gives you a huge advantage over "shot-in-the-dark" type interventions where you're testing something without any knowledge about how it performs over the long run.
Also, nature is ALREADY running a giant parallelized experiment on us every time a new child is born. Again, the genes they get from their parents are randomized. If reshuffling genetic variants around were extremely dangerous we'd see a huge death rate in the newborn population. But that is not in fact what we see. You can in fact change around some common genetic variants without very much risk.
And if you have a better idea about what those genes do (which we increasingly do), then you can do even better.
There are still going to be risks, but the biggest ones I actually worry about are about getting the epigenetics right.
But there we can just copy what nature has done. We don't need to modify anything.
True, and this does indicate that children produced from genes found in 2 parents will not be outside the range which a hypothetical natural child of theirs could occupy. I am also hopeful that this is what matters, here.
However, there are absolutely, definitely viable combinations of genes found in a random pair of parents which, if combined in a single individual, result in high-IQ offspring predisposed to any number of physical or mental problems, some of which may not manifest until long after the child is born. In practice, any intervention of the type proposed here seems likely to create many children with specific combinations of genes which we know are individually helpful for specific metrics, but which may not often (or ever) have all co-occurred. This is true even in the cautious, conservative early generations where we stay within the scope of natural human variations. Thereafter, how do we ensure we're not trialing someone on an entire generation at once? I don't want us to end up in a situation where a single mistake ends up causing population-wide problems because we applied it to hundreds of millions of people before the problem manifested.
This is a good argument for not going outside the human envelope in one shot. But if you're firmly within the realm where natural human genomes are, we have 8 billion natural experiments running around, some of which are sibling RCTs.
GeneSmith forgot to explicitly say that you can and should weight against sociopathy. Parents will be motivated to do this because if your kid is a jerk then your life will be miserable. (I do think if you select for success without selecting against sociopathy then you'll get lots of sociopaths.)
I would bet against some weird disease manifesting, especially if you are weighting for general health.
And that makes perfect sense. I guess I'm just not sure I trust any particular service provider or research team to properly list the full set of things it's important to weight against. Kind of feels like a lighter version of not trusting a list of explicit rules someone claims will make an AI safe.
Ovelle, who is planning to use growth and transcription factors to replicate key parts of the environment in which eggs are produced rather than grow actual feeder cells to excrete those factors. If it works, this approach has the advantage of speed; it takes a long time to grow the feeder cells, so if you can bypass some of that you can make eggs more quickly. Based on some conversations I’ve had with one of the founders I think $50 million could probably accelerate progress by about a year.
A few comments on this: 1. The "feeder cells" you're discussing here are from the method in this paper from the Saitou lab, who used feeder cells to promote development of human PGC-like cells to oogonia. But "takes a long time to grow the feeder cells" is not the issue. In fact, the feeder cells are quite easy to grow. The issue is that it takes a long time for PGC-like cells to develop to eggs, if you're strictly following the natural developmental trajectory.
2. The $50 million number is for us to set up our own nonhuman primate research facility, which would accelerate our current trajectory by *approximately* a year. On our current trajectory, we are going to need to raise about $5-10 million in the near future to scale up our research. We have already raised $2.15 million and we will start fundraising again this summer. But it's not like we need $50 million to make progress (although it would certainly help!)
On the topic of SuperSOX and how it relates to making eggs from stem cells:
The requirement for an existing embryo (to transfer the edited stem cells into) means that having an abundant source of eggs is important for this method, both for optimizing the method by screening many conditions, and for eventual use in the clinic.
So, in vitro oogenesis could play a key role here.
For both technologies, I think the main bottleneck right now is nonhuman primate facilities for testing.
Finally: we need to be sure not to cause another He Jiankui event (where an irresponsible study resulted in a crackdown on the field). Epigenetic issues could cause birth defects, and if this happens, it will set back the field by quite a lot. So safety is important! Nobody cares if their baby has the genes for 200 IQ, if the baby also has Prader-Willi syndrome.
I considered making my own startup, but then i learned that one lab is trying to get into this field so i'm aiming to join them. After squeezing out everything from embryo selection i certainly will try gene editing, so let's see who gets superbabies first :)
From Russia with love (hope that'll motivate someone)
I'm having trouble understanding your ToC in a future influenced by AI. What's the point of investigating this if it takes 20 years to become significant?
Kman and I probably differ somewhat here. I think it's >90% likely that if we continue along the current trajectory we'll get AGI before the superbabies grow up.
This technology only starts to become really important if there's some kind of big AI disaster or a war that takes down most of the world's chip fabs. I think that's more likely than people are giving it credit for and if it happens this will become the most important technology in the world.
Gene editing research is much less centralized than chip manufacturing. Basically all of the research can be done in normal labs of the type seen all over the world. And the supply chain for reagents and other inputs is much less centralized than the supply chain for chip fabrication.
You don't have a hundred billion dollar datacenter than can be bombed by hypersonic projectiles. The research can happen almost anywhere. So this stuff is just naturally a lot more robust than AI in the event of a big conflict.
I mostly think we need smarter people to have a shot at aligning ASI, and I'm not overwhelmingly confident ASI is coming within 20 years, so I think it makes sense for someone to have the ball on this.
In that case, per my other comment [LW(p) · GW(p)], I think it's much more likely that superbabies concern only a small fraction of the population and exacerbates inequality without bringing the massive benefits that a generally more capable population would.
Do you think superbabies would be put to work on alignment in a way that makes a difference due to geniuses driving the field? I'm having trouble understanding how concretely you think superbabies can lead to significantly improved chance of helping alignment.
My guess is that peak intelligence is a lot more important than sheer numbers of geniuses for solving alignment. At the end of the day someone actually has to understand how to steer the outcome of ASI, which seems really hard and no one knows how to verify solutions. I think that really hard (and hard to verify) problem solving scales poorly with having more people thinking about it.
Sheer numbers of geniuses would be one effect of raising the average, but I'm guessing the "massive benefits" you're referring to are things like coordination ability and quality of governance? I think those mainly help with alignment via buying time, but if we're already conditioning on enhanced people having time to grow up I'm less worried about time, and also think that sufficiently widespread adoption to reap those benefits would take substantially longer (decades?).
It's possible I'm misunderstanding your comment, so please correct me if I am, but there's no reason you couldn't do superbabies at scale even if you care about alignment. In fact, the more capable people we have the better.
I'm having trouble understanding how concretely you think superbabies can lead to significantly improved chance of helping alignment.
Kman may have his own views, but my take is pretty simple; there are a lot of very technically challenging problems in the field of alignment and it seems likely smarter humans would have a much higher chance of solving them.
One thing not mentioned here (and I think should be talked about more) is that the naturally occurring genetic distribution is very unequal in a moral sense. A more egalitarian society would put a stop to Eugenics Performed by a Blind, Idiot God. [LW · GW]
Have your doctor ever asked about if you have a family history of [illness]? For so many diseases, if your parents have it, you're more likely to have it, and your kids are more likely to have it. These illnesses plague families for generations.
I have a higher than average chance of getting hypertension. Without technology, so will my future kids. With gene editing, we can just stop that, once and for all. A just world is a world where no child is born predetermined to endure avoidable illness simply because of ancestral bad luck.
Agreed, though unfortunately it's going to take a while to make this tech available to everyone.
Also, if you want to prevent your children from getting hypertension, you can already do embryo selection right now [LW · GW]! The reduction isn't always as large as what you can get for gene editing, but it's still noticeable. And it stacks generation after generation; your kids can use embryo selection to lower THEIR children's disease risk even more.
A just world is a world where no child is born predetermined to endure avoidable illness simply because of ancestral bad luck.
In clear-cut cases, this principle seems sound; if a certain gene only has deleterious effects, and it can be removed, this is clearly better (for the individual and almost certainly for everyone else too).
In practice, this becomes more complicated if one gene has multiple effects. (This may occur on its own or because the gene interacts with other genes.) What if the gene in question is a mixed bag? For example, consider a gene giving a 1% increased risk of diabetes while always improving visual acuity. To be clear, I'm saying complicated not unresolvable. Such tradeoffs can indeed be resolved with a suitable moral philosophy combined with sufficient data. However, the difference is especially salient because the person deciding isn't the person that has to live with said genes. The two people may have different philosophies, risk preferences, or lifestyles.
However, the difference is especially salient because the person deciding isn't the person that has to live with said genes. The two people may have different moral philosophies and/or different risk preferences.
A good rule might be that the parents can only select alleles that one or the other of them have, and also have the right to do so as they choose, under the principle that they have lived with it. (Maybe with an exception for the unambiguously bad alleles, though even in that case it's unlikely that all four of the parent's alleles are the deleterious one or that the parents would want to select it.) Having the right to select helps protect from society/govt imposing certain traits as more or less valuable, and keeping within the parent's alleles maintains inheritance, which I think are two of the most important things people opposed to this sort of thing want to protect.
My current guess at the best regulatory stance--the one that ought to be acceptable to basically everyone, and that would result in good outcomes--is significantly more permissive, i.e. giving more genomic liberty to the parents. There should be rights to not genomically engineer at all, or to only GE along certain dimensions; and rights to normalize, or to propagate ones genes or traits, or to benefit the child, or to benefit others altruistically.
Your rule might for example practically prevent a deaf couple from intentionally having a child who is deaf but otherwise normal. E.g. imagine if the couple's deafness alleles also carry separate health risks, but there are other deafness alleles that the couple does not have but that lead to deafness without other health risks.
I still haven't fully thought through the consent objection, though.
Restrictions on genomic liberty should be considered very costly: they break down walls against eugenics-type forces (i.e. forces on people's reproduction coming from state/collective power, and/or aimed at population targets). Like with other important values, this isn't 100% absolute. E.g. parents shouldn't be allowed to GE their children in order to make their children suffer a lot, or in a way that has a very high risk of creating a violent psychopath. But every such restriction rightfully invokes a big pile of "Wait, who decides what counts as a 'good' allele or as a 'disease'?".
I think mostly we're on the same page then? Parents should have strong rights here, and the state should not.
I think that there's enough variance within individuals that my rule does not practically restrict genomic liberty much, while making it much more palatable to the average person. But maybe that's wrong, or it still isn't worth the cost.
Your rule might for example practically prevent a deaf couple from intentionally having a child who is deaf but otherwise normal. E.g. imagine if the couple's deafness alleles also carry separate health risks, but there are other deafness alleles that the couple does not have but that lead to deafness without other health risks.
That's a good point, I wouldn't want to prevent that. I'm not sure how likely this is to practically come up though.
Restrictions on genomic liberty should be considered very costly: they break down walls against eugenics-type forces (i.e. forces on people's reproduction coming from state/collective power, and/or aimed at population targets).
This should be true for any trait that is highly polygenic and that we know many associated variants for, yeah.
I'm not sure how likely this is to practically come up though.
IDK, but if I had to make a guess I would guess that it's quite rare but does occur. Another sort of example might be: say there's a couple whose child will likely get some disease D. Maybe the couple has a very high genetic predisposition for D that can't be attenuated enough using GE, or maybe it's a non-genetic disease that's transmissible. And say there's a rare variant that protects against D (which neither parent has). It would be a risk, and potentially a consent issue, to experiment with editing in the rare variant; but it might be good all things considered. (If this sounds like sci-fi, consider that this is IIUC exactly the scenario that happened with the first CRISPR-edited baby! In that case there were multiple methodological issues, and the edit itself might have been a bad idea even prospectively, but the background scenario was like that.)
May I ask what your respective scientific and genetics backgrounds are? I ask because this piece reads like many pieces where enthusiastic non-scientists pull together a bunch of papers without being able to assess the quality of those papers. I've also noticed a behaviour where you can't assess the quality of a paper then you over-estimate the positive effects that confirm your beliefs and ignore potential negative effects. This is an odd approach for most biologists I've worked with but is pretty typical of a layman. You also happy to work with single papers for many of your ideas, which again is something laymen inexperienced with scientific problems would do.
You’d like me to point out where you’ve only referenced individual papers for particular ideas and concepts? I can do that but I’d appreciate an answer to my question first if that’s okay.
If you have listened to the episode it would be nice to relay what those details were. I'm not so interested in listening to a 2 hour podcast mostly about what I just read above to get a few sentences of detail especially so when Gene is here! I'm also keen to know about Kman's background too.
Thanks for the write-up, I recall a conversation introducing me to all these ideas in Berkeley last year and it's going to be very handy having a resource to point people at (and so I don't misremember details about things like the Yamanaka factors!).
Am I reading the current plan correctly such that the path is something like: Get funding -> Continue R+D through primate trials -> Create an entity in a science-friendly, non-US state for human trials -> first rounds of Superbabies? That scenario seems like it would require a bunch of medical tourism, which I imagine is probably not off the table for people with the resources and mindset willing to participate in this.
Yes, that's more or less the plan. I think it's pretty much inevitable that the United States will fully legalize germline gene editing at some point. It's going to be pretty embarassing if rich American parents are flying abroad to have healthier children.
You can already see the tide starting to turn on this. Last Month Nature actually published an article about germline gene editing. That would NEVER have happened even just a few years ago.
When you go to CRISPR conferences on gene editing, many of the scientists will tell you in private that germline gene editing makes sense. But if you ask them to go on the record as supporting it publicly, they will of course refuse.
At some point there's going to be a preference cascade. People are going to start wondering why the US government is blocking technology to its future citizens healthier, happier, and smarter.
First, sorry in advance for the annoying unimportant nitpick and thank you for this exquisite resource.
too busy with their washing machines to think about light bulbs or computers
I think washing machines are not the best metaphor. They have actually contributed quite considerably to global economic growth in the past half century, as researched and explained by Economics Explained.
Perhaps something more like electric heated seats would be more fitting?
I agree with this critique; I think washing machines belong on the "light bulbs and computers" side of the analogy. The analogy has the form:
"germline engineering for common diseases and important traits" : "gene therapy for a rare disease" :: "widespread, transformation uses of electricity" : x
So x should be some very expensive, niche use of electricity that provides a very large benefit to its tiny user base (and doesn't arguably indirectly lead to large future benefits, e.g. via scientific discovery for a niche scientific instrument).
I mean... I think adult gene therapy is great! It can cure diseases and provide treatments that are otherwise impossible. So I think it's more impactful than heated seats.
To be clear, this paper AFAICT did not directly measure epigenomic state, and specifically imprinting state. (Which makes sense given what they were trying to do. In theory the imprints might show up in their transcriptomics, but who knows, and they didn't report that.) We don't know whether imprinting would be maintained for a great length of time in culture with their method.
Curated. Genetically enhanced humans are my best guess for how we achieve existential safety. (Depending on timelines, they may require a coordinated slowdown to work). This post is a pretty readable introduction to a bunch of the why and how and what still needs to be down.
I think this post is maybe slightly too focused on "how to genetically edit for superbabies" to fully deserve its title. I hope we get a treatment of more selection-based methods sometime soon.
Thanks GeneSmith and kman! I hope that we can get more funding for these projects (I am considering spending a significant chunk of my time trying to make that happen)
I mostly appreciated it for the review of the ethical landscape, though the messaging considerations are also. important. I would value more threads that engaged with the ethics on the object level
Yes, the two other approaches not really talked about in this thread that could also lead to superbabies are iterated meiotic selection and genome synthesis.
Both have advantages over editing (you don't need to have such precise knowledge of causal alleles with iterated meiotic selection or with genome synthesis), but my impression is they're both further off than an editing approach.
Your introduction describes how I feel about my area of expertise too!
Working in the field of *neuroscience* is a bizarre experience. No one seems to be interested in the most interesting applications of their research. Neuroscience has significantly advanced in the past few decades. I keep telling people that soon we're all going to have self driving cars powerd by a horse's brain in a glass jar. Most people just laugh in disbelief, others make frightened noises and mention "ethical issues" or change the subject. The smart money is off chasing the deep learning pipe dream, and as a direct consequence, there is low-hanging fruit absolutely everywhere.
Wait what? This feels "important if true" but I don't think it is true. I can think of several major technical barriers to the feasibility of this. To pick one... How do you feed video data into a brain? The traditional method would have involved stimulating neurons with the pixels captured electronically, but the clumsy stimulation process to transduce the signal into the brain itself would harm the stimulated neurons and not be very dense, so the brain would have low res vision, until the stimulated neurons die in less than a few months. Or at least, that was the model I've had for the last... uh... 10 years? Were major advances made when I wasn't looking?
Sorry to get your hopes up but I was being facetious and provocative. Instead of a glass jar, our horse's brain is going to live inside of a computer simulation. Nonetheless, I think my argument still holds true.
Neuroscientists scoff at the thought of whole brain simulation. They're incredulous and as a result they're unambitious. They want it but they know they can't have it; they've got sour grapes. Despite these bad vibes, they have been working diligently and I think we're not too far off from making simulations which are genuinely useful.
On a wacky side note, IMO, if we did have a horses brain in a jar, then interacting with it would be the easy part. There have been some really neat advances in how we interact with brains.
We can make neurons light up when they activate, see GCaMP
And here is a video of GCaMP in action:
We can activate synapses with light, see Optogenetics
The hard part would be keeping it alive for its 25-30 year lifespan even though it's missing important internal organs like the heart, lungs, liver, and adaptive immune system.
And these changes in chickens are mostly NOT the result of new mutations, but rather the result of getting all the big chicken genes into a single chicken.
Is there a citation for this? Or is that just a guess
I feel that this project would be unethical to undertake, and I will try to explain why I get that reading.
It's not that I think using genetic engineering on children is categorically wrong. Mutations occur in every new human, and adding in some that seem likely to come in handy later is something one can make an argument for. A person's genome is the toolbox their body has to deal with the world, and it might be right to stock it with more tools.
But I think it is wrong to instrumentalize children in this way. If you go through many rounds of editing, each creating something you could have grown up into a child but didn't, then hollow out another thing you could have grown up into a child but didn't and put your preferred potential child in its shell, and then grow up that child, you end up with a child whose purpose is to fulfill the parameters of their human designers. And in service of this purpose a lot of obviously valuable stuff has already been sacreficed. It is wrong to put anyone in such a position, let alone one's own child. The tremendous effort involved in trying to fit the child to the design parameters betrays a lack of belief in the child's inherent value as themselves, and they will be able to tell. The heavy hand of their designers will hang over them their whole life as they decide, say, whether to pursue graduate school, or whether they really prefer to be an actor, or a bicycle mechanic. Like an overbearing parent in every cell.
And that's assuming you did a good job, and they ended up with a mind shaped mostly in the way you imagine, after you grabbed it and stretched it out along one axis in high-dimensional mind space.
And the framing here, that "superbabies" is a category of people who would be generally better to have around, is incompatible with the value of equality. Yes, it's a better experience for you if your genetics set you up for success in the environment you find yourself in. Yes, I wish I lived on a planet with more effective people than my current conspecifics.
But no "super" people can exist in an ethical system where people are of equal intrinsic worth. A superbaby and a regular baby are both worth unity. For that matter, a hearing baby and a Deaf baby are both worth unity. Confering a genetic immunity to HIV on a child might help them out, but it does not, for example, license them to win the trolly problem. A person with HIV and a person without are both worth unity. These are fundamental results in disability studies. People who act otherwise pose an obvious danger to obvious constituencies, ranging from "people who may break their spine" to "people who wear glasses".
For required sci fi reading on this topic, I would recommend Meru by S.B. Divya. It's written to explore the principle that there are no bad genes, only genes badly adapted to their environments, and our heroine is an aspiring apprentice baby designer with sickle cell. While it's a challenging position to take, I'm not sure it's a bad guiding principle for somebody made of genes.
I think many people in academia more or less share your viewpoint.
Obviously genetic engineering does add SOME additional risk of people coming to see human children like commodities, but in my view it's massively outweighed by the potential benefits.
you end up with a child whose purpose is to fulfill the parameters of their human designers
I think whether or not people (and especially parents) view their children this way depends much more on cultural values and much less on technology.
There are already some parents who have very specific goals in mind for their children and work obsessively to realize them. This doesn't always work that well, and I'm not sure it will work that well even with genetic engineering.
Sure we will EVENTUALLY be able to shape personality better with gene editing (though I would note we don't really have the ability to do so currently), but human beings are very complicated. Gene editing is a fairly crude tool for shaping human behavior. You can twist the knobs for dozens of human traits, but I think anyone trying to predetermine their child's future is going to be disappointed.
The tremendous effort involved in trying to fit the child to the design parameters betrays a lack of belief in the child's inherent value as themselves, and they will be able to tell.
The thing about this argument is you could easily apply it to other interventions like medicines or education. "The tremendous effort involved in trying to fit the child to the design parameters through tutoring and a specialized education program betrays a lack of belief in the child's inherent value as themselves, and they will be able to tell."
Does working hard to give your child the best shot of a healthy, happy and productive life show a lack of true affection for them? I think it shows the exact opposite; you loved them so much that you were willing to go to extra lengths to give them the best life you could. I think this is no different than parents moving to America to give their child a chance at economic opportunity, or parents working extra shifts to send their children to a better school.
But no "super" people can exist in an ethical system where people are of equal intrinsic worth.
The term "super" is not a description of the relative moral worth of these future children. It is a description of their capabilities and prospects for a healthy life.
Good genes enable human productivity and happiness. They don't determine moral worth. That exists independent of ability.
Confering a genetic immunity to HIV on a child might help them out, but it does not, for example, license them to win the trolly problem.
Agreed. I don't get the sense we have any disagreement about the moral worth of people being tied to their genetics.
It's written to explore the principle that there are no bad genes, only genes badly adapted to their environments, and our heroine is an aspiring apprentice baby designer with sickle cell. While it's a challenging position to take, I'm not sure it's a bad guiding principle for somebody made of genes.
I think we need to separate judgment of genes from judgment of the people who have them. You are not your genes. Sure they shape you and influence your experience of the world, but I think a lot of these kinds of books make the mistake of starting with the mistaken premise that our worth IS determined by our genes, and then ask how we can still be equal.
I think the premise is just wrong. It's like saying that you are your trauma, or you are your leg injury. People are much deeper than their experiences or their predispositions, even if all those things have a strong influence on their behavior.
A person with HIV and a person without are both worth unity. These are fundamental results in disability studies.
Where are these studies that have results which are object-level ethical claims…? This seems not just improbable, but outright incoherent. Do you have any links to studies like this?
I think a pretty core lesson from this concern is that communication to parents is very important. Parents should understand:
What the traits do and don't mean that they are selecting for, including plausible consequences.
What uncertainties exist in the PGSes that are being used (generally lots of uncertainty), e.g. are they accidentally tracking something else as well, or might they perform less well than expected.
How much variation is still being left up to chance or environment; pointing out important things that aren't being tracked.
That overall the methods will have uncertain outcomes.
How to raise kids well regardless of their genomic foundation (i.e. cultural tech for parenting so your kids flourish).
That, at least in the scheme of genetic variation, the nudges applied by germline genomic engineering are a drop in the bucket.
And the framing here, that "superbabies" is a category of people who would be generally better to have around, is incompatible with the value of equality.
I agree with this and commented this on a draft. It's not a good way of thinking of germline engineered kids, and inaccurately implies there's some gradation and some single direction of desirability or superiority.
But no "super" people can exist in an ethical system where people are of equal intrinsic worth. A superbaby and a regular baby are both worth unity.
All this said though.... I think you're going really wrong here. The benefits are just enormous. And while I hold the positions above, I don't think they can justify you imposing on me and my child the requirement to have a chance to be deaf or HIV or sickle cell.
Someone please tell Altman and Musk they can spend their fortunes on millions of uber-genius children if they please, and they don't have to spend it all on their contest to replace ourselves with the steel & copper successors.
Altman and Musk are arguably already misaligned relative to humanity's best interests. Why would you expect smarter versions of them to be more aligned? That only makes sense if we're in an "alignment by default" world for superbabies, which is far from obvious.
There's a good chance their carbon children would have about the same attitude towards AI development as they do. So I suspect you'd end up ruled by their silicon grandchildren.
Nobel prize winners (especially those in math and sciences) tend to have IQs significantly above the population average.
There is no Nobel prize in math. And the word "especially" would imply that there exists data on the IQs of Nobel laureates in literature and peace which shows a weaker trend than the trend for sciences laureates; has anybody ever managed to convince a bunch of literature Nobel laureates to take IQ tests? I can't find anything by Googling, and I'm skeptical.
To be clear, the general claim that people who win prestigious STEM awards have above-average IQs is obviously true.
(To be clear: I agree with the rest of the OP, and with your last remark.)
has anybody ever managed to convince a bunch of literature Nobel laureates to take IQ tests? I can't find anything by Googling, and I'm skeptical.
I just read this piece by Erik Hoel which has this passage relevant to that one particular sentence you quoted from the OP:
Consider a book from the 1950s, The Making of a Scientist by psychologist and Harvard professor Anne Roe, in which she supposedly measured the IQ of Nobel Prize winners. The book is occasionally dug up and used as evidence that Nobel Prize winners have an extremely high IQ, like 160 plus. But it’s really an example of how many studies of genius are methodologically deeply flawed. ...
Roe never used an official IQ tests on her subjects, the Nobel Prize winners. Rather, she made up her test, simply a timed test that used SAT questions of the day. Why? Because most IQ tests have ceilings (you can only score like a 130 or 140 on them) and Roe thought—without any evidence or testing—that would be too low for the Nobel Prize winners. And while she got some help with this from the organization that created the SATs, she admits:
The test I used is not one that has been used before, at least in this form.
And furthermore:
I was not particularly concerned at the outset over the fact that I had no norms for this test. That is, I had no idea what any other population would do on the same test.
In other words, she had an untested set of SAT questions that she gave to Nobel prize winners not knowing how anyone else would do on them. This is pretty problematic. Normally IQ tests try to achieve some form of group-level neutrality; e.g., many of the major modern IQ tests are constructed from the outset so as not show any average difference between male and female takers, to be as culturally-invariant as possible, etc. And while Roe didn’t publish without any comparison group to her chosen geniuses whatsoever, the comparison that she did use was only a graduating class of PhD students (sample size unknown, as far as I can tell) who also took some other more standard IQ tests of the day, and she basically just converted from their scores on the other tests to scores on her make-shift test of SAT questions. Yet, here are the raw numbers of how the Nobel-prize winners do on the test she created:
Notice anything? The Nobel Prize winners all scored rather average. In fact, pretty low, in some cases. But Roe then goes on to claim that their IQ is extremely high, based on her statistical transformations:
I must caution that these equivalents have been arrived at by a series of statistical transformations based on assumptions which are generally valid for this type of material but which have not been specifically checked for these data. Nevertheless I believe that they are meaningful and a fair guide to what the situation is. The median score of this group on this verbal test is approximately equivalent to an IQ of 166.
Wait a minute. How did this conversion to a median IQ of 166 take place? After all, the scientists are scoring in the middle of the range on the test. They are getting a lot of questions wrong. E.g., Biologists who won the Nobel Prize got a 56.6 on the Verbal but we know that was far from the maximum score, Experimental Physicists got an even lower 46.6, etc. How then did she arrive at the group altogether having an astoundingly-high median verbal IQ of 166? Assuming that those at the upper range of scoring got close to most of the questions right (she mentions this is true, some only missed 4-10 questions at the maximum range), then how can getting only roughly two-thirds of the questions right translate to an IQ in the 160s?
Perhaps these SAT questions were just impossibly hard? Judge for yourself. Here’s one of the two examples she gives of the type of questions the Nobel Prize winners answered:
In each item in the first section, four words were given, and the subject had to pick the two which were most nearly opposite in meaning and underline them.
Here is one of the items: 1. Predictable 2. Precarious 3. Stable 4. Laborious.
This. . . isn’t very hard (spoiler: 2 & 3). So the conclusion of a median verbal IQ of 166 is deeply questionable, and totally reliant on this mysterious conversion she performed.
This sort of experimental setup would never fly today (my guess is the statistical conversion had all sorts of problems, e.g., Roe mentions extraordinarily high IQ numbers for PhD students at the time that don’t make sense, like an avg. IQ of 140). A far more natural reading of her results is to remove the mysterious conversion and look at the raw data, which is that the Nobel-prize-winning scientists scored well but not amazingly on SAT questions, indicating that Nobel Prize winners would get test scores above average but would not ace the SATs, since the average was far below the top of the possible range.
(I don't think Erik's arguments here have any relevance whatsoever to the OP's project though.)
It should be noted that the psychologists and anthropologists in the above tables were not selected based on winning a Nobel prize, nor any prize. On pages 51-52 of The Making of a Scientist Roe writes
For the psychologists the preliminary list was made up by me in consultation, separately, with Dr. E. G. Boring and Dr. David Shakow. We simply went over the membership list of the American Psychological Association and put down everyone we knew to be actively engaged in research and otherwise qualified. This preliminary list was then rated, in the usual fashion, by Dr. Boring, of Harvard University, [...]
and then lists a bunch of other professors involved in rating the list, and "the men who ranked at the top were selected, with some adjustment so as to include representatives of different sorts of psychology."
(Incidentally, I wonder whether Professor Boring's lectures lived up to his name.)
Unfortunately monkeys (specifically marmosets) are not cheap. To demonstrate germline transmission (the first step towards demonstrating safety in humans), Sergiy needs $4 million.
And marmosets are actually the cheapest monkey. (Also, as New World monkeys, marmosets are more distantly related to humans than rhesus or cynomolgus monkeys are.)
As a rough estimate, I think 3x to 5x more expensive. Marmosets are smaller (smaller than squirrels) whereas macaques (rhesus/cyno) are about 10x bigger (6 kg). And macaques take longer to develop (3 years vs. 18 months until adulthood). Finally, macaques are in high demand and low supply for pharma research.
But the benefit is that methods developed in macaques are more likely to translate to humans, due to the closer evolutionary relationship. Marmosets are a bit unusual in their embryonic development (two twin embryos share a common, fused placenta!)
From a sales perspective, I find myself bewildered by the approach this article takes to ethics. Deriding ethical concerns then launching into a grassroots campaign for fringe primate research into genetic hygiene and human alignment is nonstarter for changing opinions.
This article, and another here about germ engineering, are written as if the concepts are new. The reality is that these are 19th century ideas and early attempts to implement them are the reason for the ethical concerns.
Using the standard analogical language of this site, AI and gene editing are microwaves to the toaster oven of historically disastrous applied science programs like Lebensborn. Changing the technological methods of reaching an end do not obviate the ethical issues of the end itself. The onus of allaying those concerns is on the advocates and researchers, not society.
This article could very well have been written by Alfred Ploetz. That’s the barrier that has to be overcome. How is germ engineering, gene editing, and human alignment different from the programs that defined the 20th century as one of racial supremacy, genocide, and global warfare?
I know the answers to those questions. But I’m not the audience that needs to be convinced. What’s being presented here is not answering those questions. In fact, it’s doing the opposite. Anyone who has read Ploetz or Anastasius Nordenholz is going to, rightly, label this appeal to utopian reason as crypto-eugenics. It’s an inescapable certainty.
Any argument that successfully overcomes the historically rooted ethical concerns must explain how the proposal is not Ploetz. How Nordenholz’s arguments against humanism and financial throttling of research won’t be reused to pursue supremacy ideologies. Those are the concerns, not incremental technological advances. The technology is just a distraction. The ethical questions must be answered before the technology can be considered.
You seem like you might have read and thought about this a fair bit. Is that the case? Would you be up for a conversation about the questions you raise here (maybe that we record and possibly post)?
The problem is with society, politics and ethics, rather than a technical problem. in addition to a technical problem.
I think the solution should be to vividly demonstrate how effective and safe it is with animal studies, so that a lot of normal people will want to do it, and feel that not doing it is scarier than doing it.
If a lot of normal people want it, they will be able to get it one way or another (flying to another country, etc.).
There may be additional societal and political problems afterwards. But none of those problems actually matter unless the technology works.
Obviously we are going to do it in animals first. We have in fact DONE gene editing in animals many times (especially mice, but also some minor stuff in cows and other livestock). But you're correct that we need to test massive multiplex editing. My hope is we can have good data on this in cows in the next 1-3 years.
Oops, sorry about saying it's not a technical problem.
I should have read the post before replying. I have a bad habit.
PS: my comment was about effectiveness demonstrating with animals not just safety testing with animals. If you have a mouse clearly smarter, healthier, etc. than the other mice it would leave a strong impression on people.
There may be additional societal and political problems afterwards. But none of those problems actually matter unless the technology works.
What do you think of the argument that "There may be additional technical problems afterwards. But none of those problems actually matter unless we have answers for societal and political problems."?
I've just started reading and this seems very interesting and important. However, I find the discussion about embryos and scaling odd. I mean sentences like "If we had 500 embryos". Here is some quick info for women under 35, generated by ChatGPT:
A single egg collection usually retrieves 8-14 eggs. Out of those, only 4-6 embryos typically develop far enough to be tested, and about 50-60% of those will be genetically normal. This means that in most cases, only 2-4 embryos per cycle are actually viable for implantation.
Even in the best-case scenario, only about 50-55% of embryo transfers lead to a live birth.
Egg collection and embryo transfer aren’t easy. Women have to inject hormones daily for weeks, go through a minor surgery to retrieve eggs, and deal with bloating, pain, and possible complications. It’s also expensive—one cycle can cost $10,000-$20,000. I doubt many women would go through dozens of rounds just to produce 100+ embryos.
I think this makes embryo selection even less promising than you portrayed. I'm confused about how this affects your analysis of gene editing. Or maybe I just don't understand why you talk about hundreds of embryos because I haven't read the full text.
There are various technologies that might let you make many more egg cells than are possible to retrieve from an IVF cycle. For example, you might be able to mature oocytes from an ovarian biopsy, or you might be able to turn skin cells into eggs.
Wait, what? I know Aldous Huxley is famous for writing a scifi novel in 1931 titled "Don't Build A Method For Simulating Ovary Tissue Outside The Body To Harvest Eggs And Grow Clone Workers On Demand In Jars" but I thought that his warning had been taken very very seriously.
Are you telling me that science has stopped refusing to do this, and there is now a protocol published somewhere outlining "A Method For Simulating Ovary Tissue Outside The Body To Harvest Eggs"???
A brief summary of the current state of the "making eggs from stem cells" field:
We've done it in mice
We have done parts of it in humans, but not all of it
The main demand for eggs is from women who want to have kids but can't produce them naturally (usually because they're too old but sometimes because they have a medical issue). Nobody is taking the warning to not "Build A Method For Simulating Ovary Tissue Outside The Body To Harvest Eggs And Grow Clone Workers On Demand In Jars" because no one is planning on doing that.
Even if you could make eggs from stem cells and you wanted to make "clone workers", it wouldn't work because every egg (even those from the same woman) has different DNA. They wouldn't even be clones.
Oh huh. I was treating the "and make them twins" part as relatively easier, and not worthy of mention... Did no one ever follow up on the Hall-Stillman work from the 1990s? Or did it turn out to be hype, or what? (I just checked, and they don't even seem to be mentioned on the wiki for the zona pellucida.)
Yes you're right. With current technology there's no way you could get anywhere close to 500 embryos. I know a couple trying to get 100 and even that seems crazy to me.
5-20 is more realistic for most people (and 5 is actually quite good if you have fertility issues).
But we wanted to show 500 edits to compare scaling of gene editing and embryo selection and there wasn't any easy way to do that without extending the graph for embryo selection.
Thanks for clarifying. If you ever pitch your ideas to potential investors or something, I recommend avoiding talking about hundreds of embryos, or at least acknowledging that this is unrealistic with current technologies before doing so. When reading, I was a bit worried that you might be divorced from reality, thinking in sci-fi terms, not knowing the basic realities about IVF. This made it difficult for me to trust other things you were saying about domains I know nothing about. Just letting you know in case it's helpful :)
I'm not quite convinced by the big chicken argument. A much more convincing argument would be genetically selecting giraffes to be taller or cheetah to be faster.
That is, it's plausible evolution has already taken all the easy wins with human intelligence, in a way it hasn't with chicken size.
If evolution has already taken all the easy wins, why do humans vary so much in intelligence in the first place? I don't think the answer is mutation-selection balance, since a good chunk of the variance is explained by additive effects from common SNPs. Further, if you look at the joint distribution over effect sizes and allele frequencies among SNPs, there isn't any clear skew towards rarer alleles being IQ-decreasing.
For example, see the plot below of minor allele frequency vs the effect size of the minor allele. (This is for Educational Attainment, a highly genetically correlated trait, rather than IQ, since the EA GWAS is way larger and has way more hits.)
If we do a Bayesian adjustment of the effect sizes for observation noise, assuming EA has a SNP heritability of 0.2 and 20,000 causal variants with normally distributed effects:
I've repeated this below for an IQ GWAS:
You can see that the effect sizes look roughly symmetrically distributed about zero, even for fairly rare SNPs with MAF < 1%.
Who says humans vary all that much in intelligence? Almost all humans are vastly smarter, in any of the ways humans traditionally measure "intelligence", than basically all animals. Any human who's not is in seriously pathological territory, very probably because of some single, identifiable cause.
The difference between IQ 100 and IQ 160 isn't like the difference between even a chimp and a human... and chimps are already unusual.
Eagles vary in flying speed, but they can all outfly you.
Furthermore, eagles all share an architecture adapted to the particular kind of flying they tend to do. There's easily measurable variance among eagles, but there are limits to how far it can go. The eagle architecture flat out can't be extended to hypersonic flight, no matter how much gene selection you do on it. Not even if you're willing to make the sorts of tradeoffs you have to make to get battery chickens.
So on one hand, I sort of agree with this. For example, I think people giving IQ tests to LLMs and trying to draw strong conclusions from that (e.g. about how far off we are from ASI) is pretty silly. Human minds share an architecture that LLMs don't share with us, and IQ tests measure differences along some dimension within the space of variation of that architecture, within our current cultural context. I think an actual ASI will have a mind that works quite differently and will quickly blow right past the IQ scale, similar to your example of eagles and hypersonic aircraft.
On the other hand, humans just sort of do obviously vary a ton in abilities, in a way we care about, despite the above? Like, just look around? Read about Von Neumann? Get stuck for days trying to solve a really (subjectively) hard math problem, and then see how quickly someone a bit smarter was able to solve it? One might argue this doesn't matter if we can't feasibly find anyone capable of solving alignment inside the variation of the human architecture. But Yudkowsky, and several others, with awareness and understanding of the problem, exist; so why not see what happens if we push a bit further? I sort of have this sense that once you're able to understand a problem, you probably don't need to be that much smarter to solve it, if it's the sort of problem that's amenable to intelligence at all.
On another note: I can imagine that, from the perspective of evolution in the ancestral environment, that maybe human intelligence variation appeared "small", in that it didn't cache out in much fitness advantage; and it's just in the modern environment that IQ ends up conferring massive advantages in ability to think abstractly or something, which actually does cache out in stuff we care about.
I've been over a big educational attainment GWAS, and one of the main problems with them seems to me to be that they make you think that the amount of schooling a human gets is somehow a function of their personal biochemistry.
If you really want to look at this, you need to model social effects like availability, quality, and affordability of education, the different mind shapes needed to do well in school for people who are oppressed to different degrees or in different ways, whether people have access to education modalities or techniques shaped to fit their mind, whether the kid is super tall and gets distracted from grad school by a promising career in professional basketball, whether or not their mental illnesses are given proper care, and so on. If you measure how many years of education are afforded to a random human you mostly get social factors.
If you're looking at the same big EA GWAS that threw out all non-Europeans that I'm thinking of, they didn't look at any of that. I don't believe a sufficient model is common practice, because as noted in the thread there is effectively no applied branch of the field that would expose the insufficiency of the common models.
That is good evidence that we aren't in a mutation selection balance.
There are also game theoretic balances.
Here is a hypothesis that fits my limited knowledge of genetics, and is consistent with the data as I understand it and implies no huge designer baby gains. It's a bit of a worst plausible case hypothesis.
But suppose we were in a mutation selection balance, and then there was an environmental distribution shift.
The surrounding nutrition and information environment has changed significantly between the environment of evolutionary adaptiveness, and today.
A large fraction of what was important in the ancestral world was probably quite emotion based. Eg calming down other tribe members. Winning friends and influencing people.
In the modern world, abstract logic and maths are somewhat more important than they were, although the emotional stuff still matters too.
Iq tests mostly test the more abstract logical stuff.
Now suppose that the optimum genes aren't that different compared to ambient genetic variation. Say 3 standard deviations.
It's just very hard for me to believe there aren't huge gains possible from genetic engineering. It goes against everything we've seen from a millenia of animal breeding. It goes against the estimates we have for the fraction of variance that's linear for all these highly polygenic traits. It goes against data we've seen from statisitcal outliers like Shawn Bradley, who shows up as a 4.6 standard deviation outlier in graphs of height:
Do I buy that things will get noisier around the tails, and that we might not be able to push very far outside the +5 SD mark or so? Sure. That seems unlikely, but plausible.
But the idea that you're only going to be able to push traits by 2-3 standard deviations with gene editing before your predictor breaks down seems quite unlikely.
Maybe you've seen some evidence I haven't in which case I would like to know why I should be more skeptical. But I haven't seen such evidence so far.
I'm sort of confused by the image you posted? Von Neumann existed, and there are plenty of very smart people well beyond the "Nerdy programmer" range.
But I think I agree with your overall point about IQ being under stabilizing selection in the ancestral environment. If there was directional selection, it would need to have been weak or inconsistent; otherwise I'd expect the genetic low hanging fruit we see to have been exhausted already. Not in the sense of all current IQ-increasing alleles being selected to fixation, but in the sense of the tradeoffs becoming much more obvious than they appear to us currently. I can't tell what the tradeoffs even were: apparently IQ isn't associated with the average energy consumption of the brain? The limitation of birth canal width isn't a good explanation either since IQ apparently also isn't associated with head size at birth (and adult brain size only explains ~10% of the variance in IQ).
Yes. I expect extreme cases of human intelligence to come from a combination of fairly good genes, and a lot of environmental and developmental luck. Ie if you took 1000 clones of Von Neumann, you still probably wouldn't get that lucky again. (Although it depends on the level of education too)
Some ideas about what the tradeoffs might be.
Emotional social getting on with people vs logic puzzle solving IQ.
Engineer parents are apparently more likely to have autistic children. This looks like a tradeoff to me. To many "high IQ" genes and you risk autism.
How many angels can dance on the head of a pin. In the modern world, we have complicated elaborate theoretical structures that are actually correct and useful. In the pre-modern world, the sort of mind that now obsesses about quantum mechanics would be obsessing about angels dancing on pinheads or other equally useless stuff.
Emotional social getting on with people vs logic puzzle solving IQ.
Not sure I buy this, since IQ is usually found to positively correlate with purported measures of "emotional intelligence" (at least when any sort of ability (e.g. recognizing emotions) is tested; the correlation seems to go away when the test is pure self reporting, as in a personality test). EDIT: the correlation even with ability-based measures seems to be less than I expected.
Also, smarter people seem (on average) better at managing interpersonal issues in my experience (anecdotal, I don't have a reference). But maybe this isn't what you mean by "emotional social getting on with people".
There could have been a thing where being too far from the average caused interpersonal issues, but very few people would have been far from the average, so I wouldn't expect this to have prevented selection if IQ helped on the margin.
Engineer parents are apparently more likely to have autistic children. This looks like a tradeoff to me. To many "high IQ" genes and you risk autism.
Seems somewhat plausible. I don't think that specific example is good since engineers are stereotyped as aspies in the first place; I'd bet engineering selects for something else in addition to IQ that increases autism risk (systematizing quotient, or something). I have heard of there being a population level correlation between parental IQ and autism risk in the offspring, though I wonder how much this just routes through paternal age, which has a massive effect on autism risk.
This study found a relationship after controlling for paternal age (~30% risk increase when father's IQ > 126), though the IQ test they used had a "technical comprehension" section, which seems unusual for an IQ test (?), and which seems to have driven most of the association.
How many angels can dance on the head of a pin. In the modern world, we have complicated elaborate theoretical structures that are actually correct and useful. In the pre-modern world, the sort of mind that now obsesses about quantum mechanics would be obsessing about angels dancing on pinheads or other equally useless stuff.
So I think there's two possibilities here to keep distinct. (1) is that ability to think abstractly wasn't very useful (and thus wasn't selected for) in the ancestral environment. (2) Is that it was actively detrimental to fitness, at least above some point. E.g. because smarter people found more interesting things to do than reproduce, or because they cared about the quality of life of their offspring more than was fitness-optimal, or something (I think we do see both of these things today, but I'm not sure about in the past).
They aren't mutually exclusive possibilities; in fact if (2) were true I'd expect (1) to probably be true also. (2) but not (1) seems unlikely since IQ being fitness-positive on the margin near the average would probably outweigh negative effects from high IQ outliers.
Thank you for writing this article! It was extremely informative and I am very pleased to learn about super-SOX. I have been looking for a process which can turn somatic cells into embryonic stem cells due to unusual personal reasons, so by uncovering this technology you have done me a great service. Additionally, I agree that pursing biological superintelligence is a better strategy than pursuing artificial superintelligence. People inherit some of their moral values from their parents, so a superintelligent human has a reasonable probability of being a good person as long as their parents are. Unfortunately, due to selection effects this is not a given.
The primate brain is the only mammalian brain which maintains a nearly constant neuron density as the brain's size increases. For comparison, the neuron density of rodents decreases as brain size increases.
A 10 fold increase in the number of primate neurons requires a 11 fold increase in brain volume.
A 10 fold increase in the number of rodent neurons requires a 35 fold increase in brain volume.
Humans have the largest primate brain.
I bring this up because I agree with the conclusions presented in Suzana's work, with brain size being directly related to intelligence. I think it is better to select for a trait directly related to intelligence, brain size, than for a trait indirectly related to intelligence, such as IQ.
Brain size is correlated with intelligence at maybe 0.3-0.4. If you were to just brain size max I think it would probably not yield the outcomes you actually want. It's better to optimize as directly as you can for the outcome you want.
Good point. I am inherently drawn to the idea of increasing brain size because I favor extremely simple solutions whenever possible. However, a more focused push towards increasing intelligence will produce better results as long as the metric used for measuring intelligence is reliable.
I still think that increasing brain size will take a long time to reach diminishing returns due to its simplicity. Keeping all other properties of a brain equal, a larger brain should be more intelligent.
There is also one other wildly illegal approach which may be viable if you focus on increasing brain size. You might be able to turn a person, perhaps even yourself, into a biological superintelligence. By removing much of a person's skull and immersing the exposed brain in synthetic cerebrospinal fluid, it would be possible to restart brain growth in an adult. You could theoretically increase a person's brain size up to the point where it becomes difficult to sustain via biological or artificial means. With their physical abilities crippled, the victim must be connected to robot bodies and sense organs to interact with the world. I don't recommend this approach and would only subject myself to it if humanity is in a dire situation and I have no other way of gaining the power necessary to extract humanity from it.
Interesting article! Thanks for writing. But I am suspicious of claims about increasing IQ because, if it was possible, surely someone would have done a proof-of-concept with animals.
It's difficult to do such experiments with humans because (1) ethical issues; (2) humans take 9 months to be born (long gestation period); and (3) a few years for them to mature enough to get any objective results. I imagine the effort to increase IQ would be iterative. That needs a quick feedback loop which is not possible with humans.
There must be some animal with (1) no ethical issues like mice or chicken; (2) a somewhat similar brain structure to humans; (3) short gestation period; and (4) matures faster due to short lifespan. All of this contributes to a faster feedback loop. Somewhat similar to what Neuralink is doing.
Is the fact that no one has done a proof-of-concept with any animal evidence that increasing IQ through gene editing is not possible?
As for the importance of a proof-of-concept with animals, you mentioned funding to iterate to improve humans. If someone shows the world a rat understanding prime numbers, there would be practically infinite funding to optimize human intelligence.
First of all, no one has really done large scale genetic engineering of animals before, so we wouldn't know.
Almost all mouse studies or genetic studies in other animals are very simple knockout experiments where they break a protein to try to assess its function.
We really haven't seen a lot of multiplex editing experiments in animals yet.
But even if someone were to do that it would be hard to evaluate the effects on intelligence in animals.
The genetic variants that control IQ in humans don't always have analogous sequences in animals. So you'd be working with a subset of possible edits at best.
The first proof of concept here will probably be something like "do tons of edits in cows to make them produce more milk and beef". In fact, that's one of the earliest commercial applications of this multiplex editing tech.
We're hoping to show a demonstration of this in the next couple of years as one of the first steps towards demonstrating plausible safety and efficacy in humans.
Currently, we have smart people who are using their intelligence mainly to push capabilities. If we want to grow superbabies into humans that aren't just using their intelligence to push capabilities, it would be worth looking at which kind of personality traits might select for actually working on alignment in a productive fashion.
This might be about selecting genes that don't correlate with psychopathy but there's a potential that we can do much better than just not raising psychopaths. If you want to this project for the sake of AI safety, it would be crucial to look into what kind of personality that needs and what kind of genes are associated with that personality.
Currently, we have smart people who are using their intelligence mainly to push capabilities. If we want to grow superbabies into humans that aren't just using their intelligence to push capabilities, it would be worth looking at which kind of personality traits might select for actually working on alignment in a productive fashion.
I think we need to think more broadly than this. There's some set of human traits, which is a combination of the following:
Able to distinguish prosocial from antisocial things
Willing and able to take abstract ideas seriously
Long term planning ability
Desire to do good for their fellow humans (and perhaps just life more broadly)
Like, I'm essentially trying to describe the components of "is reliably drawn towards doing things that improve the lives of others". I don't think there's much research on it in the literature. I haven't seen a single article discuss what I'm referring to.
It's not exactly altruism, at least not the naive kind. You want people that punish antisocial behavior to make society less vulnerable to exploitation.
Whatever this thing is, this is one of the main things that, at scale, would make the world a much, much better place.
I think superbabies would still have a massive positive impact on the world even if all we do is decrease disease risk and improve intelligence. But with this kind of thing I think the impact could be very robustly positive to an almost ridiculous degree.
My hope is as we scale operations and do more fundraising we can fund this kind of research.
It is becoming increasingly clear that for many traits, the genetic effect sizes estimated by genetic association studies are substantially inflated for a few reasons. These include confounding due to uncontrolled population stratification, such as dynastic effects, and perhaps also genetic nurture[1]. It is also clear that traits strongly mediated through society and behaviour, such as cognitive ability, are especially strongly affected by these mechanisms.
You can avoid much of this confounding by performing GWAS on only the differences between siblings ("within-sibship GWAS") or between other pairs of family members ("family GWAS"). When you do this for cognitive ability, you find substantial deflation: heritability estimates decrease by around 45%, and the effect sizes estimated in population-level GWAS only correlate with these more direct effect estimates by about 0.55.
Does your analysis take this into account, for instance by using effect sizes estimated by within-sibship/family GWAS? If not, it would follow that genome editing would yield substantially lower increases in IQ than you estimate.
Genetic nurture is a little complicated. The classic example in the GWAS context is parental genetic nurture. Here, you find an effect of a genetic variant on a trait in people, but the actual "direct" effect manifests only in those people'sparents – one of whom must carry the variant, otherwise it would not be observed in the people in your study – and affected how they nurtured their kid, which then affected the trait you were measuring in their offspring. Genetically editing such a variant into an embryo would thus have no effect on that embryo when they are born and develop.
We accounted for inflation of effect sizes due to assortative mating, assuming a mate IQ correlation of 0.4 and total additive heritability of 0.7 for IQ.
IIUC that R = 0.55 number was just the raw correlation between the beta values of the sibling and population GWASes, which is going to be very noisy given the small sample sizes and given that effects are sparse. You can see that the LDSC based estimate is nearly 1, suggesting ~null indirect effects.
Subtle population stratification not accounted for by the original GWAS could still be an issue, though I don't expect this would inflate the effects very much. If we had access to raw data we could take into account small correlations between distant variants during finemapping, which would automatically handle assortative mating and stratification.
I think you should take seriously that in the first paper linked in my comment, the population-wide SNP heritability for cognitive ability is estimated at 0.24 and the within-sibship heritability at 0.14. This is very far from the 0.7 estimate from twin studies. While a perfect estimate of direct additive heritability would be higher than 0.14, I don't think that rare variants (and gene-gene interactions, but this would no longer be additive heritability) would get you anywhere close to 0.7. Note also that UK Biobank with its purportedly poor IQ test represents only ~30% of the sample size in that paper.
Instead, I think it is becoming clear that traditional twin studies made overly strong assumptions about shared and non-shared environments, such that they over-estimated the contribution of genetics to all kinds of traits from height to blood creatinine concentration (compare gold-standard RDR estimates vs twin estimates here). As implied in my original comment, this is likely especially true for traits strongly mediated by society and behaviour. I find it somewhat counter-intuitive, but this kind of finding keeps cropping up again and again in papers that estimate direct heritability with the most current methods.
I'll need to do a deep dive to understand the methods of the first paper, but isn't this contradicted by the recent Tan et. al. paper you linked finding SNP heritability of 0.19 for both direct and population effects of intelligence (which matches Savage Jansen 2018)? They also found ~perfect LDSC correlation between direct and population effects, which would imply the direct and population SNP heritabilities are tagging the exact same genetic effects. (Also interesting that 0.19 is the exactly in the middle of 0.24 and 0.14, not sure what to make of that if anything).
I agree with the majority of this, especially the part where we are in a race to increase our own intelligence before we destroy ourselves with AI or something else.
But I think there's something missing in your analysis.
"Genes are the piano; the microbiome is the pianist."
The human microbiome is irrelevant to this topic. The microbiome is highly heritable (usual twin studies & SNP heritabilities), and it is caused by genes and the environment, as well as unstable; its direct causal effects in normal humans are minimal. We know that it is supremely irrelevant because environmental changes like antibiotics or new food or global travel which produce large changes in personal (and offspring) microbiomes do not produce large changes in intelligence (of oneself or offspring); and most dramatically, germ-free humans exist and are of normal or even above-average intelligence, eg the fascinating mistakes and delusions ofDavid despite his high intelligence. (Amusingly, germ-free mice apparently even live longer.) Microbiome research is, in general, very low quality and can't be taken seriously - look at your link:
Most of this page is meaningless mouse studies (infamous for not replicating and getting whatever result the experimenter wants and the animal model literature having huge systemic biases), and the handful of actual human studies I see here are all garbage - things like cross-sectional studies with large known familial confounding, or heavy reliance on things like breastfeeding where the beneficial effects disappear when controlling for just some confounds. This also goes for much-touted correlations like autism. There's not a single result on this page that provides a shred of evidence for your implied thesis that microbiome interventions could, even in theory, possibly matter to 'how to make superbabies'. It doesn't.
In 2021 a geneticist insisted to me that the microbiome was just a fad.
EDIT: If anyone cares, I'm not bothering to respond to Harrop's comment in depth because I think his Gish-gallopy response manages to exemplify many of the criticisms I already made, where they are not outright non-responsive (eg. his 'disagreement' about the reasons why germ-free mice live longer is obviously irrelevant to my point that they do), and I'm not worried anyone is going to waste any time on 'the microbiome' for these purposes when this is the best case he can make. You can see he has no case for 'superbabies' having anything to do with known microbiome stuff, and I do not care enough about the microbiome per se to prosecute it further.
I agree that woo is bad. And microbiome is of course irrelevant wrt boosting IQ. But a good part of the post was about improving health, and microbes do have serious downsides on that front. If you don't have the good ones you are at a much greater risk of being colonized by the bad ones. And disease still has a non-zero negative effect on people's brain development and cognition.
Removing bad behaviour from microbiome would be quite a bit more effective and easier than fixing genes, for fighting disease. And many of the diseases with a significant genomic risk scores mentioned in the post probably have an unknown necessary pathogenic cause.
Here's a paper (Cochran&Ewald) with simple powerful arguments, I always try to push it to any doctors I meet.
Oh my god, what a disturbingly overconfident & erroneous comment. Especially coming from someone who has been immersed in science for so many years. I recognize your name from Reddit from over 10 years ago.
Due to Brandolini's law, your comment made me look up how to block users on Lesswrong, which apparently isn't possible. I now have to waste a huge amount of time debunking your egregious misinformation. I will only do it this once because in my experience, people who exhibit this kind of behavior will continue it. So in the future I will simply refer to this exchange as evidence that you are not someone who deserves to be taken seriously or responded to.
On any evidence-based website, your comment is the type that deserves a warning and then a permanent ban if it happens again. That you've had an active account on this website for 15 years makes me want to avoid this website.
The human microbiome is irrelevant to this topic.
The topic is how to make people/babies healthier, better developed, and more intelligent. Anyone who reviews this information should be able to conclude that your statement is ridiculously false:
The microbiome is highly heritable (usual twin studies & SNP heritabilities), and it is caused by genes and the environment, as well as unstable; its direct causal effects in normal humans are minimal.
You started off with largely irrelevant statements and ended with severe misinformation. FMT (fecal microbiota transplant) studies demonstrate causation. You can look through the humanmicrobiome.info wiki or do a literature search to see how many FMT studies there are showing "non-minimal" effects. So much so that a 2020 review said they thought the results were implausible.
We know that it is supremely irrelevant because environmental changes like antibiotics or new food or global travel which produce large changes in personal (and offspring) microbiomes do not produce large changes in intelligence (of oneself or offspring)
I have read that it's not possible to make a germ-free human. What you linked to as evidence for your claim is a person living in a sterile isolator. That prevents him from exposure to new microbes, but it doesn't make him germ-free.
germ-free mice apparently even live longer
From your citation (just adding context): "The reduced early food intake and smaller body weight of adult GF rats may be the reason ad libitum fed GF rats live slightly longer". Here are some studies indicating that "germ-free" has detrimental consequences:
"Germ-free animals have numerous other immunological defects that may lead to disease, which implicates a role for the microbiota in actively supporting health" https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4095778/
Most of this page is meaningless mouse studies (infamous for not replicating and getting whatever result the experimenter wants and the animal model literature having huge systemic biases)
Let’s put it all together; if super-SOX works as well in humans as it does in mice, this is how you would make superbabies
So are you dismissing the entire OP post as well because of this?
While animal studies definitely have their limits, it seems extremely erroneous to essentially dismiss an entire area of study since much of the research was done in mice. A lot of mouse research isn't ethical to do on humans.
Most of this page is meaningless mouse studies, and the handful of actual human studies I see here are all garbage
You're dismissing an entire field of tens of thousands of studies. If you're right, you should be spending your time protesting such a massive waste of time and money rather than arguing with some random blog commenter.
breastfeeding where the beneficial effects disappear when controlling for just some confounds
This is false. There are cited studies there that control for confounders and still found benefits, including to intelligence.
There's not a single result on this page that provides a shred of evidence for your implied thesis that microbiome interventions could, even in theory, possibly matter to 'how to make superbabies'. It doesn't.
This is such a ridiculous statement. But it'll be up to each reader to review the page and decide for themselves.
He was right. BTW, you remember what happened in 2021, right?
You linked to uBiome, which was a company that sold gut microbiome tests. Your citation of them is irrelevant to your claim that "the microbiome is a fad". If you said "microbiome testing is a fad", that would arguably be accurate, but it's a completely different claim.
This is my first comment in this forum. I discovered you guys early this morning and read the posts until about 5 a.m., completely hypnotized. Considering the current context of social media, it’s been a long time since a deep read has held my attention like this. Man, this has been the most interesting post I’ve accessed so far. I feel that being part of this community and connecting with people like you will add a lot to my self-development. Congratulations on the text.
Enviado de SP BR, texto original em portugues traduzido com o uso de IA.
Maybe I missed this in the article itself - are there plans to make sure the superbabies are aligned and will not abuse/overpower the non-engineered peers?
I certainly hope we can do this one day. The biobanks that gather data used to make the predictors we used to identify variants for editing don't really focus on much besides disease. As a result, our predictors for personality and interpersonal behavior aren't yet very good.
I think as the popularity of embryo selection continues to increase, this kind of data will be gathered in exponentially increasing volumes, at which point we could start to think about editing or selecting for the kinds of traits you're describing.
There will be an additional question to what degree parents will decide to edit for those traits. We're going to have a limited budget for editing and for selection for quite some time, so parents will have to choose to make their child kinder and more benificent to others at the expense of some other traits. The polygenicity of those personality traits and the effect sizes of the common alleles could have a very strong effect on parental choices; if you're only giving up a tiny bit to make your child kinder then I think most parents will go for it. If it's a big sacrifice because it requires like 100 edits, I think far fewer will do so.
It may be that benificence towards others will make these kinds of children easier to raise as well, which I think many parents would be interested in.
Very interesting, has the vibe of technology that's at least 20 years out from really hitting (assuming ASI is later than that) (though even then maybe progress speeds up? Idk, a lot of the barriers will be regulatory and certain parts won't be able to move faster than human growth and development).
The biggest surprise to me was probably that IQ selection was already happening without much fanfare - I had thought that there would be some law on the books, especially given the culture wars around pro choice/life and current admin. Perhaps it skates by because it's rare, expensive, inconvenient, screening rather than editing, and a low boost to begin with?
We’ve increased the weight of chickens by about 40 standard deviations relative to their wild ancestors, the red junglefowl. That’s the equivalent of making a human being that is 14 feet tall
I realize this is a very trivial matter on a very interesting post, and I don't like making a habit of nitpicking. But this feels interesting for some reason. Perhaps it's just because of the disturbing chicken visuals, I don't know.
To my credit, I actually made an effort to figure out the author reached their conclusion, and I believe I did. The average adult male is 69" tall, the std dev is 2.5", so 40*2.5" + 69" ≈ 14 feet. Still, it felt intuitively like an incorrect conclusion, I assumed for reasons related to comparing 3d vs 1d metrics. So I asked ChatGPT if the conclusion was correct (to confirm my intuition and perhaps get an explanation why). I'm guessing its assessment of the general nature of the error was correct, but things started going south quickly once it started freestyling with the logic and math.
The good
However, this is incorrect because height and weight scale differently.
Height follows roughly linear scaling.
Weight follows cubic scaling (since volume increases with the cube of height).
The bad
If we assume an average human weighs 70 kg (154 lbs) and apply a 40σ increase, their weight would be unrecognizably large—potentially thousands of kilograms.
Interestingly, I then asked it what adult human weight would be after a 40σ increase, and it correctly calculated it as 670kg (~1450 lbs).
Then I asked it whether its responses were consistent, and that's when it started to get really... creative.
Why don't you do this in a mouse first? The whole cycle from birth to phenotype, including complex reasoning (e.g. bayesian inference, causality) can take 6 months.
Unfortunately our genetic predictors for mice are terrible. The way mouse research works is not at all like how one would want it to work if we planned to actually use them as a testbed for the efficacy of genetic engineering.
Mice are mostly clones. So we don't have the kind of massive GWAS datasets on which genes are doing what and how large the effect sizes are.
Instead we have a few hundred studies mostly on the effects of gene knockouts to determine the function of particular proteins.
But we're mostly not interested in knockouts for genetic engineering. 2/3rds of the disease related alleles in humans are purely single letter base pair changes.
We have very little idea which specific single letter base pair changes affect things like disease risk in mice.
MAYBE some of the human predictors translate. We haven't actually explicitly tested this yet. And there's at least SOME hope here; we know that (amazingly), educational attainment predictors actually predict trainability in dogs with non-zero efficacy. So perhaps there's some chance some of our genetic predictors for human diseases would translate at least somewhat to mice.
We do need to do more thorough investigation of this but I'm not really that hopeful.
I think a far better test bed is in livestock, especially cows.
We have at least a few hundred thousand cow genomes sequenced and we have pretty well labelled phenotype data. It should be sufficient to get a pretty good idea of which alleles are causing changes in breed value, which is the main metric all the embryo selection programs are optimizing for.
Dogs would be interesting - super smart working dogs might even have a viable labour market, and it seems like the evidence of supercanine IQ would be obvious in a way that's not true of any other species (just given how much exposure most people have to the range of normal canine intelligence).
Sort of analogous to what Loyal is doing for longevity research.
The lack of good population genetic information in animal models and deep phenotyping of complex behavioral traits is probably one of the biggest impediments to robust animal testing of this general approach.
Do we have it in any other animal besides cows? Dogs? Housecats? Fruit flies? Guinea pigs? Any other short-lived animal commonly used in laboratory research that still has a decent amount of genetic diversity?
I'm reminded of the old Star Trek episode with the super humans that were found in cryosleep that then took over the Enterprise.
While I do agree that this could be one potential counter to AI (unless the relative speed things overwhelm) but also see a similar type of risk from the engineered humans. In that view, the program needs to be something that is widely implemented (which would also make it potentially a x-risk case itself) or we could easily find ourselves having created a ruler class that views ordinary humans as subhuman on not deserving of full rights. Not sure how that gets done though -- from a purely practical and politically viable approach.
I certainly think if we're doing things piecemeal we would want somewhat smarter people before we have much longer living people.
Yeah, in Star Trek, genetic engineering for increased intelligence reliably produces arrogant bastards, but that's just so they don't have to show the consequences of genetic engineering on humans...
What we need most is positive trait selection, not more IQ. Sociopathy is destroying our world and high IQ’s are not saving it. Get rid of the sociopaths and IQ may be salient.
You could also make people grow up a bit faster. Some kids are more mature, bigger, etc than others at the same wall-clock age. If this doesn't conflict with lifespan then it would allow the superbabies to be productive sooner. Wouldn't want to rob someone of their childhood entirely, but 12 years of adolescence is long enough for lots of chase tag and wrestling.
This is a big ethical issue. Also, I haven't checked, but I'd guess that generally to have much of a noticeable effect, you're stepping somewhat to the edge of / outside of the natural range, which carries risks. Separately, this might not even be good on purely instrumental grounds; altriciality is quite plausibly really important for intelligence!
Last year you guys wrote a post on adult intelligence enhancement. Does any of your research on super babies have implications for that, especially radical enhancement?
There is some overlap with adult enhancement. Specifically, if we could make a large number of changes to the genome with a single transfection, that would be quite helpful.
I had a couple-year long obsession with evolution simulators. And that hobby convinced me, that longevity is a pretty risky thing. Most of dominant species in the simulations went extinct not because of new species emerging and conflicting, but because of longevity causing problems.
1) Reduces amount of resources available to the new generation. That increases competition, and this kind of competition is evolutionary force which encourages being a long-living line, because it is easier to accumulate experience and use it later. Creates a feedback loop with increasing longevity. (Some analogue of this can be followed when looking at land properties - young people already have more problems than previous generations) 1.5) if there is no conflict netween generations at first, then overpopulation might lead to the same endpoint. 2) Reduces the frequency of new generations. Thus reduces the adaptation rate of the population. As a result, the whole population is less strong. Smaller crisis (caused by environment or other species) can have stronger effects, because damage can outpace the recovery by birth.
Looking at forest fires stats you can see the same picture. Forests that have regular fires and diversity of ages are quickly recovering. But if a forest did not have regular fires, then eventually a fire will appear and it will be more damaging, with a chance of completely eradicating life in the area.
Longevity for the sake of it is a personal egoistic trait dictated by instincts, and it might not be healthy for the human species as a whole.
Good point. But I think the real game changer will be self-modification tech, not longevity tech. In that case we won't have a "slow adaptation" problem, but we'll have a "fast adaptation in weird directions" problem which is probably worse.
Let's say it all turned out as expected and with minimal side effects we turned 100 IQ embryos into 150 IQ super-babies. Wouldn't this guarantee that every one of those enhanced children have zero chance at a normal upbringing? If they attended school at normal ages and progressed at a normal pace they would be horribly understimulated, but by attending accelerated programs they miss out on all the socialization and key moments we get by default. Eight-year-old high school graduates won't be found at prom or getting to have an awkward crush.
Now you might say there's plenty of evidence showing that super high IQ individuals can have a high quality of life, but I feel like there's a qualitative difference here. In those cases it's a gift; a rare occurrence where even if someone feels like they're missing out, they can at least appreciate what they gained in return. Here though, it's someone's fault they're this way. Should parents really have the right to deliberately place their child so far outside the realm of normal human experience? This seems fundamentally different from the more typical ways parents shape their children's lives.
I have also been thinking about this. It’s hard growing up being ‘odd’. Ideally, it would be great if the super babies grew up together, so that they would not feel isolated/weird.
You don’t have to go full commune/kibbutz (although that could be fun), but I think the kids would benefit from knowing each other.
This would not be so important for gen 1 of the super babies (+10iq from the parental mean means they would probably be fine in a regular gifted program), but I think gen 2 onwards will really need to lean on each other for support
The worst argument in the world remains true: Someone's gonna do it. Might as well be someone who will make some attempt at doing it ethically and with kindness. You don't want this done by folks whose alignment is, say, chaotic evil.
Interesting analysis, though personally, I am still not convinced that companies should be able to unilaterally (and irreversibly) change/update the human genome. But, it would be interesting to see this research continue in animals. E.g.
Provide evidence that they've made a "150 IQ" mouse or dog. What would a dog that's 50% smarter than the average dog behave like? or 500% smarter? Would a dog that's 10000% smarter than the average dog be able to learn, understand and "speak" in human languages?
Create 100s generations of these "gene updated" mice, dogs, cows, etc. as evidence that there are no "unexpected side effects", etc. Doing these types of "experiments" on humans, without providing long (long) term studies of other mammals seems to be... unwise/unethical?
Humanity has collectively decided to roll the dice on creating digital gods we don’t understand and may not be able to control instead of waiting a few decades for the super geniuses to grow up.
But yeah, given this along with the long (long) term studies mentioned above, the whole topic does seem to be (likely) moot...
If genetic editing technology is first used by the wealthy, it may further exacerbate social inequality. This technology could be used to create a “super elite,” thereby further solidifying social stratification. The scenario of a “superbaby oligarchy” mentioned in the article is a worrying potential future.
I like this. But I have questions. I hope for discussion, not answers.
Which people are most likely to get access to this tech first? is it likely that access will ever spread significantly beyond this group?
How does one raise a super child?
If they require different support from other children, whose resources are available to provide it?
Would there be some institution connected to the biotech company that would maintain a relationship with families or are they just selling a limited service?
What roles/responsibilities are the super adults expected to take on? In what sense are they compelled to take on any responsibility?
What broad-reaching effects might the existence of superbaby capabilities have?
@momom2 [LW · GW] mentioned that there didn't seem to be anyone else in the comment section with a "kill it with fire" reaction. I don't think killing it with fire is the right approach either, but this research should be taken slow. I do not see a near future where superbaby injections aren't made prohibitively expensive, creating a new race of super-oligarchs. I think many of those hesitant researchers mentioned in the beginning of the article also see that future, which is probably why they aren't too excited to discuss those applications of their research.
We don’t actually know that JK He accomplished what he said he did. He may have tried. But the results have not been independently verified. That would require genotyping the parents and children. So, premature to say that germline editing appears safe in humans.
I'm not saying his experiments show germline editing is safe in humans. In fact He Jiankui's technique likely WASN'T safe. Based on some talks I heard from Dieter Egli at Colombia, He was likely deleting chromosomes in a lot of embryos, which is why (if I recall correctly) only 3 out of about ~30 embryos that were transferred resulted in live birth. Normally the live birth rate per transfer rate would be between 30 and 70%.
It's also not entirely clear how effective the editing was because the technique He used likely created a fair degree of mosaicism since the editing continued after the first cell division. If the cells that ended up forming hematopoietic stem cells DIDN'T receive the edits then there would have been basically no benefit to the editing.
Anyways, I'm not really trying to defend He Jiankui. I don't think his technique was very good nor do I think he chose a particularly compelling reason to edit (HIV transmission can be avoided with sperm washing or anti-retroviral drugs to about the same degree of efficacy as CCR5 knockout). I just think the reaction was even more insane.
It doesn't make sense to ban germline editing just because one guy did it in a careless way. Yet in many places that's exactly what happened.
You might not be tracking that there's a "unilateralist cloud" of behaviors. There's the norm of behavior, and then around that norm, there's a cloud of variation. The most extreme people (the unilateralist frontier) will do riskier things than the norm, and bad stuff will result. If a unilateralist doing unilateral stuff results in a deformed baby, or even of a legit prospective risk of a deformed baby (as you acknowledge existed in He Jiankui's experiments), that's bad. If society sees this happen, it means that their current norm is not conservative enough to keep the unilateralist frontier in the safe zone. So they adjust the norm to be more conservative.
When you write
This method has actually been used in human embryos before! In 2018 Chinese scientist He Jiankui created the first ever gene edited embryos by using this technique. All three of the children born from these embryos are healthy 6 years later (despite widespread outrage and condemnation at the time).
it sounds like you're implying that the outrage and condemnation were a claim that the experiment would actually have bad results. Which, surely to some extent they were. But also they were (legit, as you agree!) a claim that prospectively the experiment was bad to do, and therefore that the norm of the unilateralist cloud is in the wrong place.
You might respond: "The response shouldn't be to just ban everything. That's a super blunt force result." To which I will give a reply so succint and forceful that you will not be able to argue further: "I agree."
But arguing with the unilateralist-cloud-norm-movers by saying "but the experiment turned out fine" is missing their point. They are correct that IF the only lever available is to move the cloud-norm, THEN the only way to avoid the legit risk of HJK-like experiments is to move the cloud-norm. The solution, I'm sure you'll agree, is to make there be more precise levers for them. If their need for levers is driven by a need to control the unilateralist-cloud, then one key thing to do is make the unilateralist cloud less stupid.
This is a really interesting article and I commend the author for broaching the topic and proposing a way of getting around this stigmatization in the field. After diseases though i think an even greater priority than increasing IQ or lifespan is tackling what may seem to be a really trivial matter. And that is the issue of skin lightening. Though this may seem like a trivial topic I would say that conservatively tens of millions of mostly women possibly even hundreds of Millions in africa, asia, and the Middle East are literally poisoning and disfiguring themselves attempting to lighten their skin. Now without getting to the whole topic of colonialism and all that other hand wringing, what we need is the ability to pick whatever skin tone you want your baby to have. Besides this I would estimate the market is conservatively worth tens of billions of dollars and more likely the hundreds of billions of dollars range. So there is also a great business opportunity here too. And before anyone starts going off on some rant about how we should be changing attitudes and all that, I really see no sign that attitudes are going to change any time in the next few decades and possibly a century. In the meantime millions of people continue to poison themselves. And multinationals already pitch their creams and poisons, so why not a safer approach. Thats why I think this is a very important topic and I hope somebody tackles it
I know many of you dream of having an IQ of 300 to become the star researcher and avoid being replaced by AI next year. But have you ever considered whether nature has actually optimized humans for staring at equations on a screen? If most people don’t excel at this, does that really indicate a flaw that needs fixing?
Moreover, how do you know that a higher IQ would lead to a better life—for the individual or for society as a whole? Some of the highest-IQ individuals today are developing technologies that even they acknowledge carry Russian-roulette odds of wiping out humanity—yet they keep working on them. Should we really be striving for more high-IQ people, or is there something else we should prioritize?
At one point in the text, it was mentioned that any ethical counterargument is not enough to demonize genome editing. Personally, I don’t see any issues with positive changes, but discussing this solely from the perspective of genetic science, without considering social science and all the people who already exist, is irresponsible. If the project receives the multimillion-dollar investment it needs and develops in the most efficient way possible, would the idea be to mass-produce gifted individuals until people born the traditional way are replaced? Maybe because of the European or American reality that most of you are familiar with, you don’t understand the potential impact of this, but coming from the Global South, where we have almost no access to spaces of advanced intellectual production, coexisting with genetically enhanced people with much higher potential is almost like making my existence obsolete. We also know that it’s in the interest of the global elite to support separatist movements, and various prejudices are being maintained daily. Differentiating people from their very conception has a great potential for indifference. I also thought about the possibility of creating superhuman organic bodies to give to AIs… very cyberpunk, considering who currently rules the planet.
Thanks for the post! I think genetic engineering for increasing IQ can indeed be super valuable, and is quite neglected in society. However, I would be very surprised if it was among the areas where additional investment generates the most welfare per $:
Open Philanthropy (OP) estimated that funding R&D (research and development) is 45 % as cost-effective as giving cash to people with 500 $/year.
People in extreme poverty have around 500 $/year, and unconditional cash transfer to them are like 1/3 as cost-effective as GiveWell's (GW's) top charities. GW used to consider such transfers around 10 % as cost-effective as their top charities, but now thinks they are 3 to 4 times as cost-effective as previously.
So I think R&D is like 15 % (= 0.45/3) as cost-effective as GW's top charities.
I estimate [EA · GW] the Shrimp Welfare Project (SWP) is 64.3 k times as cost-effective as GW's top charities.
So I believe SWP is like 429 k (= 64.3*10^3/0.15) times as cost-effective as R&D (neglecting the beneficial or harmful effects of R&D on animals; it is [EA · GW] unclear to me whether saving human lives is beneficial or harmful).
Trusting these numbers, genetic engineering would have to be 429 k times as cost-effective as typical R&D for it to be as cost-effective as SWP. I can see it being 10 times as cost-effective as R&D, but this is not anything close to enough to make it competitive with SWP.
I think your comment is supposed to be an outside view argument that tempers the gears-level argument in the post. Maybe we could think of it as providing a base-rate prior for the gears-level argument in the post. Is that roughly right? I'm not sure how much I buy into this kind of argument, but I also have some complaints by the outside views lights.
First, let me quickly recap your argument as I understand it.
R&D increases welfare by allowing an increase in consumption. We'll assume that our growth in consumption is driven, in some fraction, by R&D spending. Assuming utility isn't linear in consumption, we need to have some story about how the increase in consumption is distributed. Given a bunch of such assumptions, we can get a net present value of the utility, which is 45% as large as giving cash to people with $500/year.
Then, we can look at how the value of interventions are distributed within "causes". Some data suggest that the 97.5th percentile intervention is about 10x as good as the mean (and maybe 100x as good as the 50th percentile), across a few different intervention areas.
Assuming a lognormal fit, there aren't enough R&D ideas for the best R&D dollars to be 10,000x as good as the mean R&D dollar.
But, this says nothing about differences in cost-effectiveness between different "causes". So this argument doesn't bite for, say, shrimp welfare interventions, which could be arbitrarily more impactful than global health, or R&D developments.
I hope that is a roughly correct rendition of your argument.
Here are my even-assuming-outside-view criticisms:
Even the Davidson model allows that the distribution for interventions that increase the rate/effectiveness of R&D (rather than just purchasing some at the same rate) could be much more effective. I think superresearchers (or even just a large increase in the number of top researchers) are such an intervention
To the extent we're allowing cause-hopping to enable large multipliers (which we must to think that there are potentially much more impactful opportunities than superbabies), I care about superbabies because of the cause of x-risk reduction! Which I think has much higher cost-effectiveness than growth-based welfare interventions.
I hope that is a roughly correct rendition of your argument.
Thanks for the great summary, Kave!
So this argument doesn't bite for, say, shrimp welfare interventions, which could be arbitrarily more impactful than global health, or R&D developments.
Nitpick. SWP received 1.82 M 2023-$ (= 1.47*10^6*1.24) during the year ended on 31 March 2024, which is 1.72*10^-8 (= 1.82*10^6/(106*10^12)) of the gross world product (GWP) in 2023, and OP estimated R&D has a benefit-to-cost ratio of 45. So I estimate SWP can only be up to 1.29 M (= 1/(1.72*10^-8)/45) times as cost-effective as R&D due to this increasing SWP’s funding.
Here are my even-assuming-outside-view criticisms:
Even the Davidson model allows that the distribution for interventions that increase the rate/effectiveness of R&D (rather than just purchasing some at the same rate) could be much more effective. I think superresearchers (or even just a large increase in the number of top researchers) are such an intervention
To the extent we're allowing cause-hopping to enable large multipliers (which we must to think that there are potentially much more impactful opportunities than superbabies), I care about superbabies because of the cause of x-risk reduction! Which I think has much higher cost-effectiveness than growth-based welfare interventions.
Fair points, although I do not see how they would be sufficiently strong to overcome the large baseline difference between SWP and general R&D. I do not think [EA · GW] reducing the nearterm risk of human extinction is astronomically cost-effective, and I am [EA(p) · GW(p)] sceptical of longterm effects.
While I think finding ways to make future generations healthier and smarter is a worthy goal, I don't think we understand enough yet to do this without potentially severe unintended consequences, and I wouldn't consider doing it myself with our current technology. It's a good bet that many of the seemingly deleterious mutations we'd like to eliminate also offer some benefit we don't understand- given that we have already discovered many instances of mutations with apparent intelligence/health tradeoffs, and disease resistance/health tradeoffs. If you're selecting embryo populations for mutations correlated with specific desirable traits, you should also expect that you are selecting for worse outcomes in all other potentially desirable dimensions including those that are potentially even more important than those optimized for, but we have no clear concept of, or labels for. If you do this at scale, you're also systematically selecting for a less diverse, less robust population.
Also, I think a lot of neurodivergent people (including myself, and probably quite a lot lot of other LWers) have become irrationally obsessed with their own childrens raw intelligence above all else, due to emotional trauma. Growing up and being labeled as gifted, but also having (at the time undiagnosed) ADHD, I strongly felt that the only thing people liked about me was my intelligence, and that without it I would be unworthy of love or friendships. The idea of my child not being exceptionally intelligent, and therefore suffering immensely was terrifying to me, and made me irrationally obsessed with something mostly outside my control. Indeed, I am a parent now, and my son is both exceptionally bright and neurodivergent, but I now understand now that neither I or him need to be exceptionally bright to be loved or accepted.... we just need to have boundaries, and choose to only associate with the (numerous) people that will accept or even like that we are different, rather than those that dislike it but tolerate us for what we can practically provide them. Moreover, what those people begrudgingly tolerated me for wasn't even my actual intelligence, but my ability to accomplish difficult things for them with my intense ADHD hyperfocus. Of course intelligence is extremely useful and important, but shouldn't be valued above all else out of a trauma derived sense of terror.
Another way of looking at this is that the human body and genetic codebase is, frankly, shit. (We literally have shit inside of us.) If we digitize human consciousness (for life in virtual worlds or as downloads onto robotic bodies) then we would be able to edit our code, including intelligence, much more quickly. Besides, rather than adding a few years to our lives, we could live indefinitely, and we could have backups. We would get our energy directly from electricity, rather than having to rely on the inefficient sun>plants>animals chain, and all the adjacent, well... shit.