Posts
Comments
I'm not sure I buy that they will be more cautious in the context of an "arms race" with a foreign power. The Soviet Union took a lot of risks their bioweapons program during the cold war.
My impression is the CCP's number one objective is preserving their own power over China. If they think creating ASI will help them with that, I fully expect them to pursue it (and in fact to make it their number one objective)
So in theory I think we could probably validate IQ scores of up to 150-170 at most. I had a conversation with the guys from Riot IQ and they think that with larger sample sizes the tests can probably extrapolate out that far.
We do have at least one example of a guy with a height +7 standard deviations above the mean actually showing up as a really extreme outlier due to additive genetic effects.
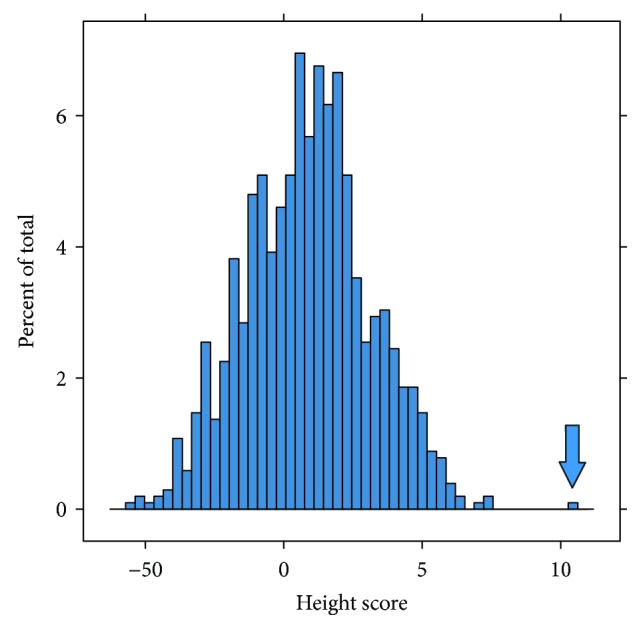
The outlier here is Shawn Bradley, a former NBA player. Study here
Granted, Shawn Bradley was chosen for this study because he is a very tall person who does not suffer from pituitary gland dysfunction that affects many of the tallest players. But that's actually more analogous to what we're trying to do with gene editing; increasing additive genetic variance to get outlier predispositions.
I agree this is not enough evidence. I think there are some clever ways we can check how far additivity continues to hold outside of the normal distribution, such as checking the accuracy of predictors at different PGSes, and maybe some clever stuff in livestock.
This is on our to-do list. We just haven't had quite enough time to do it yet.
The second point is the distinction between causal for the association observed in the data, and causal when intervening on the genome, I suspect more than half of the gene is only causal for the association. I also imagine there are a lot of genes that are indirectly causal for IQ such as making you an attentive parent thus lowering the probability your kid does not sleep in the room with a lot of mold, which would not make the super baby smarter, but it would make the subsequent generation smarter.
There are some, but not THAT many. Estimates from EA4, the largest study on educational attainment to date, estimated the indirect effects for IQ at (I believe) about 18%. We accounted for that in the second version of the model.
It's possible that's wrong. There is a frustratingly wide range of estimates for the indirect effect sizes for IQ in the literature. @kman can talk more about this, but I believe some of the studies showing larger indirect effects get such large numbers because they fail to account for the low test-retest reliability of the UK biobank fluid intelligence test.
I think 0.18 is a reasonable estimate for the proportion of intelligence caused by indirect effects. But I'm open to evidence that our estimate is wrong.
I'm being gaslit so hard right now
One data point that's highly relevant to this conversation is that, at least in Europe, intelligence has undergone quite significant selection in just the last 9000 years. As measured in a modern environment, average IQ went from ~70 to ~100 over that time period (the Y axis here is standard deviations on a polygenic score for IQ)
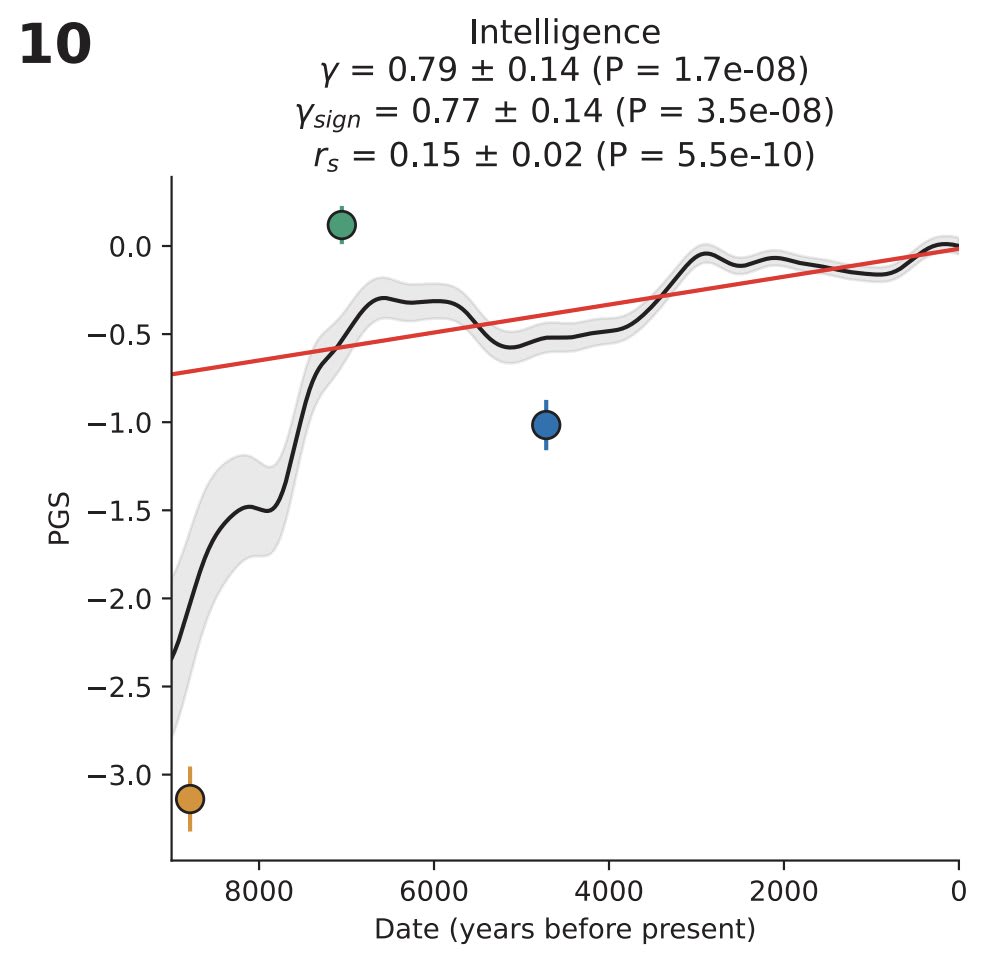
The above graph is from David Reich's paper
I don't have time to read the book "Innate", so please let me know if there are compelling arguments I am missing, but based on what I know the "IQ-increasing variants have been exhausted" hypothesis seems pretty unlikely to be true.
There's well over a thousand IQ points worth of variants in the human gene pool, which is not what you would expect to see if nature had exhaustively selected for all IQ increasing variants.
Unlike traits that haven't been heavily optimized (like resistance to modern diseases)
Wait, resistance to modern diseases is actually the single most heavily selected for thing in the last ten thousand years. There is very strong evidence of recent selection for immune system function in humans, particularly in the period following domestication of animals.
Like there has been so much selection for human immune function that you literally see higher read errors in genetic sequencing readouts in regions like the major histocompatibility complex (there's literally that much diversity!)
but suggests the challenge may be greater than statistical models indicate, and might require understanding developmental pathways at a deeper level than just identifying associated variants.
If I have one takeaway from the last ten years of deep learning, it's that you don't have to have a mechanistic understanding of how your model is solving a problem to be able to improve performance. This notion that you need a deep mechanical understanding of how genetic circuits operate or something is just not true.
What you actually need to do genetic engineering is a giant dataset and a means of editing.
Statistical methods like finemapping and adjusting for population level linkage disequilibrium help, but they're just making your gene editing more efficient by doing a better job of identifying causal variants. They don't take it from "not working" to "working".
Also if we look at things like horizontal gene transfer & shifting balance theory we can see these as general ways to discover hidden genetic variants in optimisation and this just feels highly non-trivial to me? Like competing against evolution for optimal information encoding just seems really difficult apriori? (Not a geneticist so I might be completely wrong here!)
Horizontal gene transfer doesn't happen in humans. That's mostly something bacteria do.
There IS weird stuff in humans like viral DNA getting incorporated into the genome, (I've seen estimates that about 10% of the human genome is composed of this stuff!) but this isn't particularly common and the viruses often accrue mutations over time that prevents them from activating or doing anything besides just acting like junk DNA.
Occasionally these viral genes become useful and get selected on (I think the most famous example of this is some ancient viral genes that play a role in placental development), but this is just a weird quirk of our history. It's not like we're prevented from figuring out the role of these genes in future outcomes just because they came from bacteria.
Sorry, I've been meaning to make an update on this for weeks now. We're going to open source all the code we used to generate these graphs and do a full write-up of our methodology.
Kman can comment on some of the more intricate details of our methodology (he's the one responsible for the graphs), but for now I'll just say that there are aspects of direct vs indirect effects that we still don't understand as well as we would like. In particular there are a few papers showing a negative correlation between direct and indirect effects in a way that is distinct for intellligence (i.e. you don't see the same kind of negative correlation for educational attainment or height or anything like that). It's not clear to us at this exact moment what's actually causing those effects and why different papers disagree on the size of their impact.
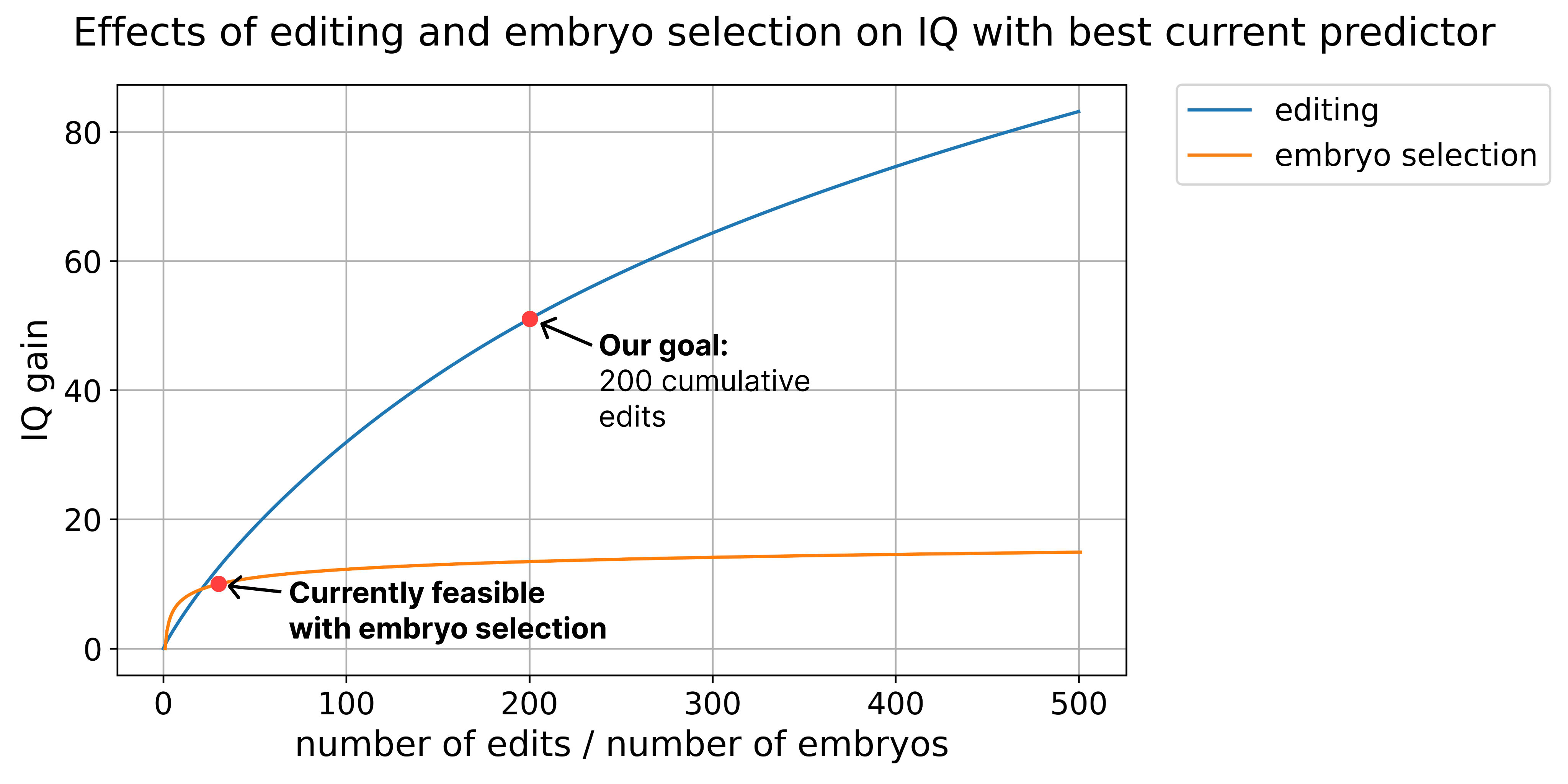
In the latest versions of the IQ gain graph we've made three updates:
- We fixed a bug where we squared a term that should not have been squared (this resulted in a slight reduction in the effect size estimate)
- We now assume only ~82% of the effect alleles are direct, further reducing benefit. Our original estimate was based on a finding that the direct effects of IQ account for ~100% of the variance using the LDSC method. Based on the result of the Lee et al Educational Attainment 4 study, I think this was too optimistic.
- We now assume our predictor can explain more of the variance. This update was made after talking with one of the embryo selection companies and finding their predictor is much better than the publicly available predictor we were using
The net result is actually a noticeable increase in efficacy of editing for IQ. I think the gain went from ~50 to ~85 assuming 500 edits.
It's a little frustrating to find that we made the two mistakes we did. But oh well; part of the reason to make stuff like this public is so others can point out mistakes in our modeling. I think in hindsight we should have done the traditional academic thing and ran the model by a few statistical geneticists before publishing. We only talked to one, and he didn't get into enough depth for us to discover the issues we later discovered.
I've been talking to people about this today. I've heard from two separate sources that it's not actually buyable right now, though I haven't yet gotten a straight answer as to why not.
Congrats on the new company! I think this is potentially quite an important effort, so I hope anyone browing this forum who has a way to get access to biobank data from various sources will reach out.
One of my greatest hopes for these new models is that they will provide a way for us to predict the effects of novel genetic variants on traits like intelligence or disease risk.
When I wrote my post on adult intelligence enhancement at the end of 2023, one of the biggest issues was just how many edits we would need to make to achieve significant change in intelligence.
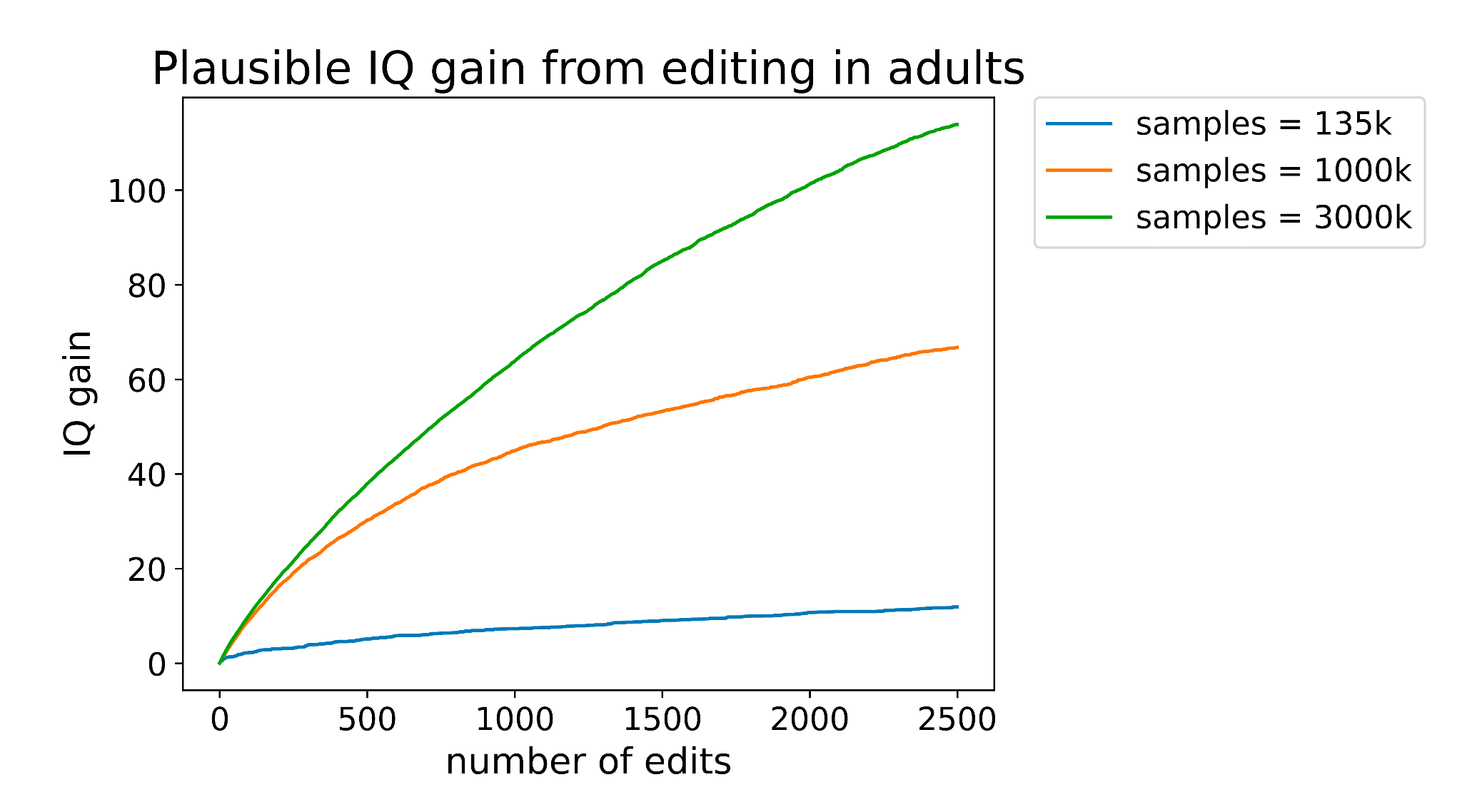
Neither delivery nor editing tech is good enough yet to make anywhere close to the number of edits needed for adult cognitive enhancement. But it's plausible that there exist a set of gene edits such that just 10 or 20 changes would have a significant impact.
One of my greatest hopes is that these foundation models will generalize well enough out-of-distribution that we can make reasonably accurate predictions about the effect of NEW genetic variants on traits like intelligence of health. If we can, (and ESPECIALLY if we can also predict tolerance to these edits), it could 10x the impact of gene editing.
This may end up being one of the most important technologies for adult cognitive enhancement. So I hope anyone who might be able to help with data access reaches out to you!
I’ve checked. Have heard from multiple people they “it’s not for sale in reality”
I don’t have any details yet. But obviously am interested.
I certainly hope we can do this one day. The biobanks that gather data used to make the predictors we used to identify variants for editing don't really focus on much besides disease. As a result, our predictors for personality and interpersonal behavior aren't yet very good.
I think as the popularity of embryo selection continues to increase, this kind of data will be gathered in exponentially increasing volumes, at which point we could start to think about editing or selecting for the kinds of traits you're describing.
There will be an additional question to what degree parents will decide to edit for those traits. We're going to have a limited budget for editing and for selection for quite some time, so parents will have to choose to make their child kinder and more benificent to others at the expense of some other traits. The polygenicity of those personality traits and the effect sizes of the common alleles could have a very strong effect on parental choices; if you're only giving up a tiny bit to make your child kinder then I think most parents will go for it. If it's a big sacrifice because it requires like 100 edits, I think far fewer will do so.
It may be that benificence towards others will make these kinds of children easier to raise as well, which I think many parents would be interested in.
In the last year it has really hit me at a personal level what graphs like these mean. I'm imagining driving down to Mountain View and a town once filled with people who had "made it" and seeing a ghost town. No more jobs, no more prestige, no more promise of a stable life. As the returns to capital grow exponentially and the returns to labor decline to zero, the gap between the haves and the have-nots will only grow.
If someone can actually get superintelligence to do what they want, then perhaps universal basic income can at the very least prevent actual starvation and maybe even provide a life of abundance.
But I can't help but feeling such a situation is fundamentally unstable. If the government's desires become disconnected from those of the people at any point, by what mechanism can balance be restored?
In the past the government was fundamentally reliant on its citizens for one simple reason; citizens produced taxable revenue.
That will no longer be the case. Every country will become a petro state on steroids.
I spoke with one of the inventors of bridge recombinases at a dinner a few months ago and (at least according to him), they work in human cells.
I haven't verified this independently in my lab, but it's at least one data point.
On a broader note, I find the whole field of gene therapy very confusing. In many cases it seems like there are exceptionally powerful tools that are being ignored in favor of sloppy, dangerous, imprecise alternatives.
Why are we still using lentiviral vectors to insert working copies of genes when we can usually just fix the broken gene using prime editors?
You look at gene therapies like Casgevy for sickle cell and they just make no fucking sense.
Sickle cell is predominantly cause by an adenine to thymine swap at the sixth codon in the HBB gene. Literally one letter change at a very well known spot in one protein.
You'd think this would be a perfect use case for gene editing, right? Just swap out that letter and call it a day!
But no. This is not how Casgevy works. Instead, Casgevy works by essentially flipping a switch to make the body stop producing adult hemoglobin and start producing fetal hemoglobin.
Fetal hemoglobin doesn't sickle, so this fixes sickle cell. But like... why? Why not just change the letter that's causing all the problems in the first place?
It's because they're using old school Cas9. And old school Cas9 editing is primarily used to break things by chopping them in half and relying on sloppy cellular repair processes like non-homologous end joining to stitch the DNA back together in a half-assed way that breaks whatever protein is being produced.
And that's exactly what Casgevy does; it uses Cas9 to induce a double stranded break in BCL11A, a zinc finger transcription factor that normally makes the cells produce adult hemoglobin instead of the fetal version. Once BCL11A is broken, the cells start producing fetal hemoglobin again.
But again...
Why?
Prime editors are very good at targeting the base pair swap needed to fix sickle cell. They've been around for SIX YEARS. They havery extremely low rates of off-target editing. Their editing efficiency is on-par with that of old-school Cas9. And they have lower rates of insertion and deletion errors near the edit site. So why don't we just FIX the broken base pair instead of this goofy work-around?
Yet the only thing I can find online about using them for sickle cell is a single line announcement from Beam Therapeutics that vaguely referecing a partnership with prime medicine that MIGHT use them for sickle cell.
This isn't an isolated incident either. You go to conferences on gene editing and literally 80% of academic research is still using sloppy double strand breaking Cas9 to do editing. It's like if all the electric car manufacturers decided to use lead acid batteries instead of lithium ion.
It's just too slow. Everything is too fucking slow. It takes almost a decade to get something from proof of concept to commercial product.
This, more than anything, is why I hope special economic zones like Prospera win. You can take a therapy from animal demonstration to commercial product in less than a year for $500k-$1 mil. If we had something like that in the US there would be literally 10-100x more therapeutics available.
I mean... I think adult gene therapy is great! It can cure diseases and provide treatments that are otherwise impossible. So I think it's more impactful than heated seats.
So I'm obviously talking my own book here but my personal view is that one of the more neglected ways to potentially reduce x-risk is to make humans more capable of handling both technical and governance challenges associated with new technology.
There are a huge number of people who implicitly believe this, but almost all effort goes into things like educational initiatives or the formation of new companies to tackle specific problems. Some of these work pretty well, but the power of such initiatives is pretty small compared to what you could feasibly achieve with tech to do genetic enhancement.
Nearly zero investment or effort being is being put into the latter, which I think is a mistake. We could potentially increase human IQ by 20-80 points, decrease mental health disorder risk, and improve overall health just using the knowledge we have today:
There ARE technical barriers to rolling this out; no one has pushed multiplex editing to the scale of hundreds of edits yet (something my company is currently working on demonstrating). And we don't yet have a way to convert an edited cell into an egg or an embryo (though there are a half dozen companies working on that technology right now).
I think in most worlds genetically enhanced humans don't have time to grow up before we make digital superintelligence. But in the ~10% of worlds where they do, this tech could have an absolutely massive positive impact. And given how little money it would take to get the ball rolling here (a few tens of millions to fund many of the most promising projects in the field), I think the counterfactual impact of funding here is pretty large.
If you'd like to chat more send me an email: genesmithlesswrong@gmail.com
You can also read more of the stuff I've written on this topic here
Cool! Are you working for an existing company or are you starting your own?
There is some overlap with adult enhancement. Specifically, if we could make a large number of changes to the genome with a single transfection, that would be quite helpful.
Population mean
I’ve seen this and will reply in the next couple of days. I want to give it the full proper response it deserves.
Also thanks for taking the time to write this. I don’t think I would get this level or quality of feedback anywhere else online outside of an academic journal.
I think superbabies would still have a massive positive impact on the world even if all we do is decrease disease risk and improve intelligence. But with this kind of thing I think the impact could be very robustly positive to an almost ridiculous degree.
My hope is as we scale operations and do more fundraising we can fund this kind of research.
It's possible I'm misunderstanding your comment, so please correct me if I am, but there's no reason you couldn't do superbabies at scale even if you care about alignment. In fact, the more capable people we have the better.
I'm having trouble understanding how concretely you think superbabies can lead to significantly improved chance of helping alignment.
Kman may have his own views, but my take is pretty simple; there are a lot of very technically challenging problems in the field of alignment and it seems likely smarter humans would have a much higher chance of solving them.
First of all, no one has really done large scale genetic engineering of animals before, so we wouldn't know.
Almost all mouse studies or genetic studies in other animals are very simple knockout experiments where they break a protein to try to assess its function.
We really haven't seen a lot of multiplex editing experiments in animals yet.
But even if someone were to do that it would be hard to evaluate the effects on intelligence in animals.
The genetic variants that control IQ in humans don't always have analogous sequences in animals. So you'd be working with a subset of possible edits at best.
The first proof of concept here will probably be something like "do tons of edits in cows to make them produce more milk and beef". In fact, that's one of the earliest commercial applications of this multiplex editing tech.
We're hoping to show a demonstration of this in the next couple of years as one of the first steps towards demonstrating plausible safety and efficacy in humans.
Well we have it in cows. Just not in mice.
I think many people in academia more or less share your viewpoint.
Obviously genetic engineering does add SOME additional risk of people coming to see human children like commodities, but in my view it's massively outweighed by the potential benefits.
you end up with a child whose purpose is to fulfill the parameters of their human designers
I think whether or not people (and especially parents) view their children this way depends much more on cultural values and much less on technology.
There are already some parents who have very specific goals in mind for their children and work obsessively to realize them. This doesn't always work that well, and I'm not sure it will work that well even with genetic engineering.
Sure we will EVENTUALLY be able to shape personality better with gene editing (though I would note we don't really have the ability to do so currently), but human beings are very complicated. Gene editing is a fairly crude tool for shaping human behavior. You can twist the knobs for dozens of human traits, but I think anyone trying to predetermine their child's future is going to be disappointed.
The tremendous effort involved in trying to fit the child to the design parameters betrays a lack of belief in the child's inherent value as themselves, and they will be able to tell.
The thing about this argument is you could easily apply it to other interventions like medicines or education. "The tremendous effort involved in trying to fit the child to the design parameters through tutoring and a specialized education program betrays a lack of belief in the child's inherent value as themselves, and they will be able to tell."
Does working hard to give your child the best shot of a healthy, happy and productive life show a lack of true affection for them? I think it shows the exact opposite; you loved them so much that you were willing to go to extra lengths to give them the best life you could. I think this is no different than parents moving to America to give their child a chance at economic opportunity, or parents working extra shifts to send their children to a better school.
But no "super" people can exist in an ethical system where people are of equal intrinsic worth.
The term "super" is not a description of the relative moral worth of these future children. It is a description of their capabilities and prospects for a healthy life.
Good genes enable human productivity and happiness. They don't determine moral worth. That exists independent of ability.
Confering a genetic immunity to HIV on a child might help them out, but it does not, for example, license them to win the trolly problem.
Agreed. I don't get the sense we have any disagreement about the moral worth of people being tied to their genetics.
It's written to explore the principle that there are no bad genes, only genes badly adapted to their environments, and our heroine is an aspiring apprentice baby designer with sickle cell. While it's a challenging position to take, I'm not sure it's a bad guiding principle for somebody made of genes.
I think we need to separate judgment of genes from judgment of the people who have them. You are not your genes. Sure they shape you and influence your experience of the world, but I think a lot of these kinds of books make the mistake of starting with the mistaken premise that our worth IS determined by our genes, and then ask how we can still be equal.
I think the premise is just wrong. It's like saying that you are your trauma, or you are your leg injury. People are much deeper than their experiences or their predispositions, even if all those things have a strong influence on their behavior.
I would love to try this in mice.
Unfortunately our genetic predictors for mice are terrible. The way mouse research works is not at all like how one would want it to work if we planned to actually use them as a testbed for the efficacy of genetic engineering.
Mice are mostly clones. So we don't have the kind of massive GWAS datasets on which genes are doing what and how large the effect sizes are.
Instead we have a few hundred studies mostly on the effects of gene knockouts to determine the function of particular proteins.
But we're mostly not interested in knockouts for genetic engineering. 2/3rds of the disease related alleles in humans are purely single letter base pair changes.
We have very little idea which specific single letter base pair changes affect things like disease risk in mice.
MAYBE some of the human predictors translate. We haven't actually explicitly tested this yet. And there's at least SOME hope here; we know that (amazingly), educational attainment predictors actually predict trainability in dogs with non-zero efficacy. So perhaps there's some chance some of our genetic predictors for human diseases would translate at least somewhat to mice.
We do need to do more thorough investigation of this but I'm not really that hopeful.
I think a far better test bed is in livestock, especially cows.
We have at least a few hundred thousand cow genomes sequenced and we have pretty well labelled phenotype data. It should be sufficient to get a pretty good idea of which alleles are causing changes in breed value, which is the main metric all the embryo selection programs are optimizing for.
Yes, I pretty much agree with this
I'm not saying his experiments show germline editing is safe in humans. In fact He Jiankui's technique likely WASN'T safe. Based on some talks I heard from Dieter Egli at Colombia, He was likely deleting chromosomes in a lot of embryos, which is why (if I recall correctly) only 3 out of about ~30 embryos that were transferred resulted in live birth. Normally the live birth rate per transfer rate would be between 30 and 70%.
It's also not entirely clear how effective the editing was because the technique He used likely created a fair degree of mosaicism since the editing continued after the first cell division. If the cells that ended up forming hematopoietic stem cells DIDN'T receive the edits then there would have been basically no benefit to the editing.
Anyways, I'm not really trying to defend He Jiankui. I don't think his technique was very good nor do I think he chose a particularly compelling reason to edit (HIV transmission can be avoided with sperm washing or anti-retroviral drugs to about the same degree of efficacy as CCR5 knockout). I just think the reaction was even more insane.
It doesn't make sense to ban germline editing just because one guy did it in a careless way. Yet in many places that's exactly what happened.
I'd be interested in hearing where specifically you think we are doing that.
Yes, the two other approaches not really talked about in this thread that could also lead to superbabies are iterated meiotic selection and genome synthesis.
Both have advantages over editing (you don't need to have such precise knowledge of causal alleles with iterated meiotic selection or with genome synthesis), but my impression is they're both further off than an editing approach.
I'd like to write more about both in the future.
It's just very hard for me to believe there aren't huge gains possible from genetic engineering. It goes against everything we've seen from a millenia of animal breeding. It goes against the estimates we have for the fraction of variance that's linear for all these highly polygenic traits. It goes against data we've seen from statisitcal outliers like Shawn Bradley, who shows up as a 4.6 standard deviation outlier in graphs of height:
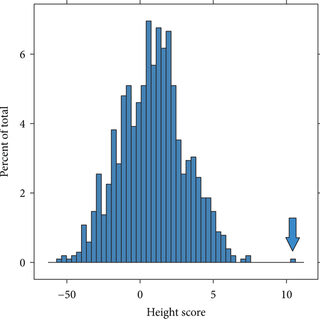
Do I buy that things will get noisier around the tails, and that we might not be able to push very far outside the +5 SD mark or so? Sure. That seems unlikely, but plausible.
But the idea that you're only going to be able to push traits by 2-3 standard deviations with gene editing before your predictor breaks down seems quite unlikely.
Maybe you've seen some evidence I haven't in which case I would like to know why I should be more skeptical. But I haven't seen such evidence so far.
There is one saving grace for us which is that the predictor we used is significantly less powerful than ones we know to exist.
I think when you account for both the squaring issue, the indirect effect things, and the more powerful predictors, they're going to roughly cancel out.
Granted, the more powerful predictor itself isn't published, so we can't rigorously evaluate it either which isn't ideal. I think the way to deal with this is to show a few lines: one for the "current publicly available GWAS", one showing a rough estimate of the gain using the privately developed predictor (which with enough work we could probably replicate), and then one or two more for different amounts of data.
All of this together WILL still reduce the "best case scenario" from editing relative to what we originally published (because with the better predictor we're closer to "perfect knowledge" than where we were with the previous predictor.
At some point we're going to re-run the calculations and publish an actual proper writeup on our methodology (likely with our code).
Also I just want to say thank you for taking the time to dive deep into this with us. One of the main reasons I post on LessWrong is because there is such high quality feedback relative to other sites.
Ha, sadly it is a pseudonym. My parents were neither that lucky nor that prescient when it came to naming me.
A brief summary of the current state of the "making eggs from stem cells" field:
- We've done it in mice
- We have done parts of it in humans, but not all of it
- The main demand for eggs is from women who want to have kids but can't produce them naturally (usually because they're too old but sometimes because they have a medical issue). Nobody is taking the warning to not "Build A Method For Simulating Ovary Tissue Outside The Body To Harvest Eggs And Grow Clone Workers On Demand In Jars" because no one is planning on doing that.
Even if you could make eggs from stem cells and you wanted to make "clone workers", it wouldn't work because every egg (even those from the same woman) has different DNA. They wouldn't even be clones.
Thanks for catching that! I hadn't heard. I will probably have to rewrite that section of the post.
What's your impression about the general finding about many autoimmune variants increasing protection against ancient plauges?
No, the problem really is technical right now.
There may be additional societal and political problems afterwards. But none of those problems actually matter unless the technology works.
Obviously we are going to do it in animals first. We have in fact DONE gene editing in animals many times (especially mice, but also some minor stuff in cows and other livestock). But you're correct that we need to test massive multiplex editing. My hope is we can have good data on this in cows in the next 1-3 years.
I don't understand your question
Agreed, though unfortunately it's going to take a while to make this tech available to everyone.
Also, if you want to prevent your children from getting hypertension, you can already do embryo selection right now! The reduction isn't always as large as what you can get for gene editing, but it's still noticeable. And it stacks generation after generation; your kids can use embryo selection to lower THEIR children's disease risk even more.
Kman and I probably differ somewhat here. I think it's >90% likely that if we continue along the current trajectory we'll get AGI before the superbabies grow up.
This technology only starts to become really important if there's some kind of big AI disaster or a war that takes down most of the world's chip fabs. I think that's more likely than people are giving it credit for and if it happens this will become the most important technology in the world.
Gene editing research is much less centralized than chip manufacturing. Basically all of the research can be done in normal labs of the type seen all over the world. And the supply chain for reagents and other inputs is much less centralized than the supply chain for chip fabrication.
You don't have a hundred billion dollar datacenter than can be bombed by hypersonic projectiles. The research can happen almost anywhere. So this stuff is just naturally a lot more robust than AI in the event of a big conflict.
Yes you're right. With current technology there's no way you could get anywhere close to 500 embryos. I know a couple trying to get 100 and even that seems crazy to me.
5-20 is more realistic for most people (and 5 is actually quite good if you have fertility issues).
But we wanted to show 500 edits to compare scaling of gene editing and embryo selection and there wasn't any easy way to do that without extending the graph for embryo selection.
Currently, we have smart people who are using their intelligence mainly to push capabilities. If we want to grow superbabies into humans that aren't just using their intelligence to push capabilities, it would be worth looking at which kind of personality traits might select for actually working on alignment in a productive fashion.
I think we need to think more broadly than this. There's some set of human traits, which is a combination of the following:
- Able to distinguish prosocial from antisocial things
- Willing and able to take abstract ideas seriously
- Long term planning ability
- Desire to do good for their fellow humans (and perhaps just life more broadly)
Like, I'm essentially trying to describe the components of "is reliably drawn towards doing things that improve the lives of others". I don't think there's much research on it in the literature. I haven't seen a single article discuss what I'm referring to.
It's not exactly altruism, at least not the naive kind. You want people that punish antisocial behavior to make society less vulnerable to exploitation.
Whatever this thing is, this is one of the main things that, at scale, would make the world a much, much better place.
I'm glad you liked the article!
Brain size is correlated with intelligence at maybe 0.3-0.4. If you were to just brain size max I think it would probably not yield the outcomes you actually want. It's better to optimize as directly as you can for the outcome you want.
I think almost everyone misunderstands the level of knowledge we have about what genetic variants will do.
Nature has literally run a randomized control trial for genes already. Every time two siblings are created, the set of genes they inherit from each parent are scrambled and (more or less) randomly assigned to each. That's INCREDIBLY powerful for assessing the effects of genes on life outcomes. Nature has run a literal multi-generational randomized control trial for the effect of genes on everything. We just need to collect the data.
This gives you a huge advantage over "shot-in-the-dark" type interventions where you're testing something without any knowledge about how it performs over the long run.
Also, nature is ALREADY running a giant parallelized experiment on us every time a new child is born. Again, the genes they get from their parents are randomized. If reshuffling genetic variants around were extremely dangerous we'd see a huge death rate in the newborn population. But that is not in fact what we see. You can in fact change around some common genetic variants without very much risk.
And if you have a better idea about what those genes do (which we increasingly do), then you can do even better.
There are still going to be risks, but the biggest ones I actually worry about are about getting the epigenetics right.
But there we can just copy what nature has done. We don't need to modify anything.
Agreed. I've actually had a post in draft for a couple of years that discusses some of the paralleles between alignment of AI agents and alignment of genetically engineered humans.
I think we have a huge advantage with humans simply because there isn't the same potential for runaway self-improvement. But in the long term (multiple generations), it would be a concern.
Do you have any estimate of how much more expensive testing in cynomolgus macaques or rhesus monkeys would be?
The issue is that it takes a long time for PGC-like cells to develop to eggs, if you're strictly following the natural developmental trajectory.
Thanks for the clarification. I'll amend the original post.
It's a fair concern. But the problem of predicting personality can be solved! We just need more data.
I also worry somewhat about brilliant psychopaths. But making your child a psychopath is not necessarily going to give them an advantage.
Also can you imagine how unpleasant raising a psychopath would be? I don't think many parents would willingly sign up for that.
Very little at the moment. Unlike intelligence and health, a lot of the variance in personality traits seems to be the result of combinations of genes rather than purely additive effects.
This is one of the few areas where AI could potentially make a big difference. You need more complex models to figure out the relationship between genes and personality.
But the actual limiting factor right now is not model complexity, but rather data. Even if you have more complex models, I don't think you're going to be able to actually train them until you have a lot more data. Probably a minimum of a few million samples.
We'd like to look into this problem at some point and make scaling law graphs like the ones we made for intelligence and disease risk but haven't had the time yet.
It's a good question. The remarkable thing about human genetics is that most of the variants ARE additive.
This sounds overly simplistic, like it couldn't possible work, but it's one of the most widely replicated results in the field.
There ARE some exceptions. Personality traits seem to be mostly the result of gene-gene interactions, which is one reason why SNP heritability (additive variance explained by common variants) is so low.
But for nearly all diseases and for many other traits like height and intelligence, ~80% of variance is additive. somewhere between 50 and 80% of the heritable variance is additive. And basically ALL of the variance we can identify with current genetic predictors is additive.
This might seem like a weird coincidence. After all, we know there is a lot of non-linearity in actual gene regulatory networks. So how could it be that all the common variants simply add together?
There's a pretty clear reason from an evolutionary point of view: evolution is able to operate on genes with additive effects much more easily than on those with non-additive effects.
The set of genetic variants inherited is scrambled every generation during the sperm and egg formation process. Those that need other common variants present to work their effects just have a much harder time spreading among the population because their benefits are inconsistent across generations.
So over time the genome ends up being enriched for additivity.
There IS lots of non-additivity happening in genes which are universal among the human population. If you were to modify two highly conserved regions, the effects of both edits could end up being much greater or much less than the sum of the effects of the two individual variants. But that's also not that surprising; evolution has had a lot of time to build dependencies on these regions, so we should expect modifying them to have effects that are hard to predict.
You also had a second question embedded within your first, which is about second order effects from editing, like increased IQ resulting in more mental instability or something.
You can just look at people who naturally have high IQ to see whether this is a concern. What we see is that, with the exception of aspbergers, higher IQ actually tends to be associated with LOWER rates of mental illness.
Also you can see from my chart looking at genetic correlations between diseases that, with a few exceptions, there just isn't that much correlation between diseases. The set of variants that affects two different diseases are mostly disjoint sets.
Yes, that's more or less the plan. I think it's pretty much inevitable that the United States will fully legalize germline gene editing at some point. It's going to be pretty embarassing if rich American parents are flying abroad to have healthier children.
You can already see the tide starting to turn on this. Last Month Nature actually published an article about germline gene editing. That would NEVER have happened even just a few years ago.
When you go to CRISPR conferences on gene editing, many of the scientists will tell you in private that germline gene editing makes sense. But if you ask them to go on the record as supporting it publicly, they will of course refuse.
At some point there's going to be a preference cascade. People are going to start wondering why the US government is blocking technology to its future citizens healthier, happier, and smarter.
This was a fun podcast. Thanks for having me on!
Probably because he thinks there's a lower chance of it killing everyone if he makes it. And that if it doesn't kill everyone then he'll do a better job managing it than the other lab heads.
This is the belief of basically everyone running a major AGI lab. Obviously all but one of them must be mistaken, but it's natural that they would all share the same delusion.