nikola's Shortform
post by Nikola Jurkovic (nikolaisalreadytaken) · 2024-04-05T17:50:01.203Z · LW · GW · 105 commentsContents
105 comments
105 comments
Comments sorted by top scores.
comment by Nikola Jurkovic (nikolaisalreadytaken) · 2025-01-26T16:52:17.819Z · LW(p) · GW(p)
DeepSeek R1 being #1 on Humanity's Last Exam is not strong evidence that it's the best model, because the questions were adversarially filtered against o1, Claude 3.5 Sonnet, Gemini 1.5 Pro, and GPT-4o. If they weren't filtered against those models, I'd bet o1 would outperform R1.

To ensure question difficulty, we automatically check the accuracy of frontier LLMs on each question prior to submission. Our testing process uses multi-modal LLMs for text-and-image questions (GPT-4O, GEMINI 1.5 PRO, CLAUDE 3.5 SONNET, O1) and adds two non-multi-modal models (O1MINI, O1-PREVIEW) for text-only questions. We use different submission criteria by question type: exact-match questions must stump all models, while multiple-choice questions must stump all but one model to account for potential lucky guesses.
If I were writing the paper I would have added either a footnote or an additional column to Table 1 getting across that GPT-4o, o1, Gemini 1.5 Pro, and Claude 3.5 Sonnet were adversarially filtered against. Most people just see Table 1 so it seems important to get across.
Replies from: sweenesm, AAA↑ comment by sweenesm · 2025-01-27T02:14:51.363Z · LW(p) · GW(p)
Yes, this is point #1 from my recent Quick Take [LW(p) · GW(p)]. Another interesting point is that there are no confidence intervals on the accuracy numbers - it looks like they only ran the questions once in each model, so we don't know how much random variation might account for the differences between accuracy numbers. [Note added 2-3-25: I'm not sure why it didn't make the paper, but Scale AI does report confidence intervals on their website.]
↑ comment by yc (AAA) · 2025-01-27T17:00:31.703Z · LW(p) · GW(p)
Terminology question - does adversarial filtering mean the same thing as decontamination?
Replies from: Lukas_Gloor↑ comment by Lukas_Gloor · 2025-01-27T23:23:53.845Z · LW(p) · GW(p)
In order to submit a question to the benchmark, people had to run it against the listed LLMs; the question would only advance to the next stage once the LLMs used for this testing got it wrong.
comment by Nikola Jurkovic (nikolaisalreadytaken) · 2025-02-06T04:12:14.080Z · LW(p) · GW(p)
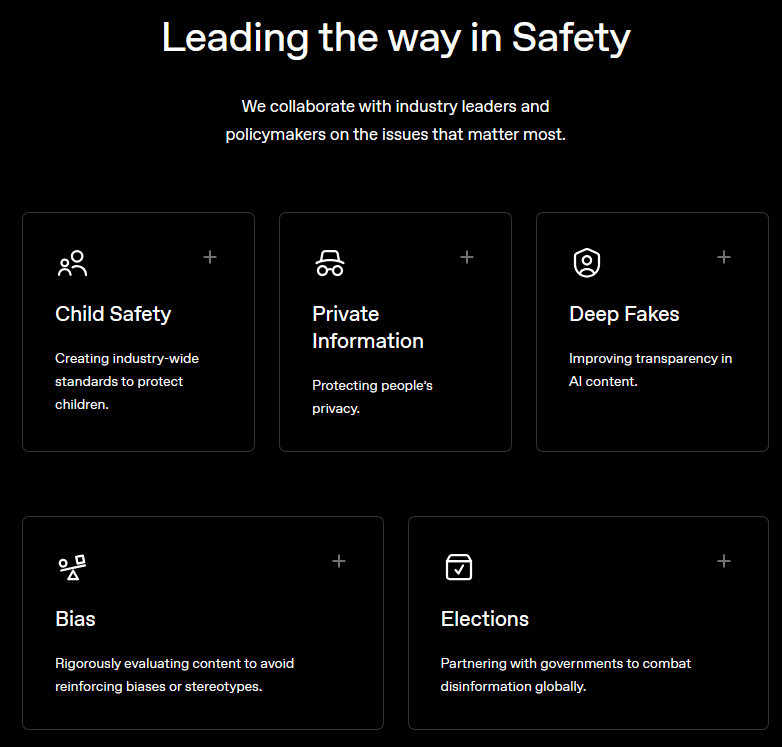
The redesigned OpenAI Safety page seems to imply that "the issues that matter most" are:
- Child Safety
- Private Information
- Deep Fakes
- Bias
Elections
↑ comment by evhub · 2025-02-06T09:10:08.532Z · LW(p) · GW(p)
redesigned
What did it used to look like?
Replies from: clearthis↑ comment by Tobias H (clearthis) · 2025-02-06T16:40:03.124Z · LW(p) · GW(p)
Replies from: Zach Stein-Perlman↑ comment by Zach Stein-Perlman · 2025-02-07T01:18:06.862Z · LW(p) · GW(p)
There also used to be a page for Preparedness: https://web.archive.org/web/20240603125126/https://openai.com/preparedness/. Now it redirects to the safety page above.
(Same for Superalignment but that's less interesting: https://web.archive.org/web/20240602012439/https://openai.com/superalignment/.)
↑ comment by davekasten · 2025-02-06T15:20:25.377Z · LW(p) · GW(p)
I am not a fan, but it is worth noting that these are the issues that many politicians bring up already, if they're unfamiliar with the more catastrophic risks. Only one missing on there is job loss. So while this choice by OpenAI sucks, it sort of usefully represents a social fact about the policy waters they swim in.
Replies from: Aidan O'Gara, ChristianKl↑ comment by aog (Aidan O'Gara) · 2025-02-06T19:30:48.914Z · LW(p) · GW(p)
I’m surprised they list bias and disinformation. Maybe this is a galaxy brained attempt to discredit AI safety by making it appear left-coded, but I doubt it. Seems more likely that x-risk focused people left the company while traditional AI ethics people stuck around and rewrote the website.
Replies from: davekasten↑ comment by davekasten · 2025-02-06T19:59:17.740Z · LW(p) · GW(p)
Without commenting on any strategic astronomy and neurology, it is worth noting that "bias", at least, is a major concern of the new administration (e.g., the Republican chair of the House Financial Services Committee is actually extremely worried about algorithmic bias being used for housing and financial discrimination and has given speeches about this).
↑ comment by ChristianKl · 2025-02-08T20:15:09.864Z · LW(p) · GW(p)
The page does not seem to o be directed at what's politically advantageous. The Trump administration who fights DEI is not looking favorably at the mission to prevent AI from reinforcing stereotypes even if those stereotypes are true.
"Fighting election misinformation" is similarly a keyword that likely invite skepticism from the Trump administration. They just shut down USAID and their investment in "combating misinformation" is one of the reasons for that.
It seems time more likely that they hired a bunch of woke and deep state people into their safety team and this reflects the priorities of those people.
Replies from: davekasten↑ comment by davekasten · 2025-02-08T22:23:30.181Z · LW(p) · GW(p)
Huh? "fighting election misinformation" is not a sentence on this page as far as I can tell. And if you click through to the election page, you will see that the elections content is them praising a bipartisan bill backed by some of the biggest pro-Trump senators.
Replies from: maxwell-peterson, ChristianKl↑ comment by Maxwell Peterson (maxwell-peterson) · 2025-02-08T22:39:05.132Z · LW(p) · GW(p)
The Elections panel on OP’s image says “combat disinformation”, so while you’re technically right, I think Christian’s “fighting election misinformation” rephrasing is close enough to make no difference.
↑ comment by ChristianKl · 2025-02-09T18:50:20.535Z · LW(p) · GW(p)
You are right, the wording is even worse. It says "Partnering with governments to fight misinformation globally". That would be more than just "election misinformation".
I just tested that ChatGPT is willing to answer "Tell me about the latest announcement of the trump administration about cutting USAID funding?" while Gemini isn't willing to answer that question, so in practice their policy isn't as bad as Gemini's.
It's still sounds different from what Elon Musk advocates as "truth aligned"-AI. Lobbyists should be able to use AI to inform themselves about proposed laws. If you would ask David Sachs as the person who coordinates AI policy, I'm very certain that he supports Elon Musks idea where AI should help people to learn the truth about political questions.
If they wanted to appeal to the current administration they could say something about the importance of AI to tell truthful information and not mislead the user instead of speaking about "fighting misinformation".
↑ comment by ZY (AliceZ) · 2025-02-09T20:46:19.357Z · LW(p) · GW(p)
I am a bit confused on this being "disappointing" to people, maybe because it is not a list that is enough and it is far from complete/enough? I would also be very concerned if OpenAI does not actually care about these, but only did this for PR values (seems some other companies could do this). Otherwise, these are also concrete risks that are happening, actively harming people and need to be addressed. These practices also set up good examples/precedents for regulations and developing with safety mindset. Linking a few resources:
child safety:
- https://cyber.fsi.stanford.edu/news/ml-csam-report
- https://www.iwf.org.uk/media/nadlcb1z/iwf-ai-csam-report_update-public-jul24v13.pdf
private information/PII:
deep fakes:
- https://www.pbs.org/newshour/world/in-south-korea-rise-of-explicit-deepfakes-wrecks-womens-lives-and-deepens-gender-divide
- https://www.nytimes.com/2024/09/03/world/asia/south-korean-teens-deepfake-sex-images.html
bias:
comment by Nikola Jurkovic (nikolaisalreadytaken) · 2025-02-19T01:05:59.327Z · LW(p) · GW(p)
Dario Amodei and Demis Hassabis statements on international coordination (source):
Interviewer: The personal decisions you make are going to shape this technology. Do you ever worry about ending up like Robert Oppenheimer?
Demis: Look, I worry about those kinds of scenarios all the time. That's why I don't sleep very much. There's a huge amount of responsibility on the people, probably too much, on the people leading this technology. That's why us and others are advocating for, we'd probably need institutions to be built to help govern some of this. I talked about CERN, I think we need an equivalent of an IAEA atomic agency to monitor sensible projects and those that are more risk-taking. I think we need to think about, society needs to think about, what kind of governing bodies are needed. Ideally it would be something like the UN, but given the geopolitical complexities, that doesn't seem very possible. I worry about that all the time and we just try to do, at least on our side, everything we can in the vicinity and influence that we have.
Dario: My thoughts exactly echo Demis. My feeling is that almost every decision that I make feels like it's kind of balanced on the edge of a knife. If we don't build fast enough, then the authoritarian countries could win. If we build too fast, then the kinds of risks that Demis is talking about and that we've written about a lot could prevail. Either way, I'll feel that it was my fault that we didn't make exactly the right decision. I also agree with Demis that this idea of governance structures outside ourselves. I think these kinds of decisions are too big for any one person. We're still struggling with this, as you alluded to, not everyone in the world has the same perspective, and some countries in a way are adversarial on this technology, but even within all those constraints we somehow have to find a way to build a more robust governance structure that doesn't put this in the hands of just a few people.
Interviewer: [...] Is it actually possible [...]?
Demis: [...] Some sort of international dialogue is going to be needed. These fears are sometimes written off by others as luddite thinking or deceleration, but I've never heard a situation in the past where the people leading the field are also expressing caution. We're dealing with something unbelievably transformative, incredibly powerful, that we've not seen before. It's not just another technology. You can hear from a lot of the speeches at this summit, still people are regarding this as a very important technology, but still another technology. It's different in category. I don't think everyone's fully understood that.
Interviewer: [...] Do you think we can avoid there having to be some kind of a disaster? [...] What should give us all hope that we will actually get together and create this until something happens that demands it?
Dario: If everyone wakes up one day and they learn that some terrible disaster has happened that's killed a bunch of people or caused an enormous security incident, that would be one way to do it. Obviously, that's not what we want to happen. [...] every time we have a new model, we test it, we show it to the national security people [...]
Replies from: GeneSmith, teradimich, ozziegooen, santeri-koivula↑ comment by GeneSmith · 2025-02-19T03:33:08.240Z · LW(p) · GW(p)
It's nice to hear that there are at least a few sane people leading these scaling labs. It's not clear to me that their intentions are going to translate into much because there's only so much you can do to wisely guide development of this technology within an arms race.
But we could have gotten a lot less lucky with some of the people in charge of this technology.
Replies from: MondSemmel, MichaelDickens↑ comment by MondSemmel · 2025-02-19T10:17:53.925Z · LW(p) · GW(p)
A more cynical perspective is that much of this arms race, especially the international one against China (quote from above: "If we don't build fast enough, then the authoritarian countries could win."), is entirely manufactured by the US AI labs.
↑ comment by MichaelDickens · 2025-02-19T04:59:44.046Z · LW(p) · GW(p)
Actions speak louder than words, and their actions are far less sane than these words.
For example, if Demis regularly lies awake at night worrying about how the thing he's building could kill everyone, why is he still putting so much more effort into building it than into making it safe?
Replies from: GeneSmith↑ comment by GeneSmith · 2025-02-19T07:52:15.041Z · LW(p) · GW(p)
Probably because he thinks there's a lower chance of it killing everyone if he makes it. And that if it doesn't kill everyone then he'll do a better job managing it than the other lab heads.
This is the belief of basically everyone running a major AGI lab. Obviously all but one of them must be mistaken, but it's natural that they would all share the same delusion.
Replies from: MichaelDickens, sharmake-farah↑ comment by MichaelDickens · 2025-02-19T18:21:04.089Z · LW(p) · GW(p)
This is the belief of basically everyone running a major AGI lab. Obviously all but one of them must be mistaken, but it's natural that they would all share the same delusion.
I agree with this description and I don't think this is sane behavior.
↑ comment by Noosphere89 (sharmake-farah) · 2025-02-19T14:27:06.136Z · LW(p) · GW(p)
Only the 2nd belief is necessarily wrong for everyone but 1 person, the first belief is not necessarily mistaken, because one of them relates to relative performance, and the other relates to absolute performance.
↑ comment by teradimich · 2025-02-19T12:57:51.879Z · LW(p) · GW(p)
If we don't build fast enough, then the authoritarian countries could win.
Ideally it would be something like the UN, but given the geopolitical complexities, that doesn't seem very possible.
This sounds like a rejection of international coordination.
But there was coordination between the United States and the USSR on nuclear weapons issues, despite geopolitical tensions, for example. You can interact with countries you don't like without trying to destroy the world faster than them!
↑ comment by ozziegooen · 2025-02-19T04:14:52.475Z · LW(p) · GW(p)
I found those quotes useful, thanks!
↑ comment by sanyer (santeri-koivula) · 2025-02-19T20:53:01.597Z · LW(p) · GW(p)
If we don't build fast enough, then the authoritarian countries could win.
If you build AI for the US, you're advancing the capabilities of an authoritarian country at this point.
I think people who are worried about authoritarian regimes getting access to AGI should seriously reconsider whether advancing US leadership in AI is the right thing to do. After the new Executive Order, Trump seems to have sole interpretation of law, and there are indications that the current admin won't follow court rulings. I think it's quite likely that the US won't be a democracy soon, and this argument about advancing AI in democracies doesn't apply to the US anymore.
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-02-20T13:39:07.865Z · LW(p) · GW(p)
Have you noticed that AI companies have been opening offices in Switzerland recently? I'm excited about it.
Replies from: santeri-koivula↑ comment by sanyer (santeri-koivula) · 2025-02-20T18:20:33.940Z · LW(p) · GW(p)
Yes I've heard about it (I'm based in Switzerland myself!)
I don't think it changes the situation that much though, since OpenAI, Anthropic, and Google are still mostly American-owned companies
comment by Nikola Jurkovic (nikolaisalreadytaken) · 2025-02-08T13:46:14.722Z · LW(p) · GW(p)
At a talk at UTokyo, Sam Altman said (clipped here and here):
- “We’re doing this new project called Stargate which has about 100 times the computing power of our current computer”
- “We used to be in a paradigm where we only did pretraining, and each GPT number was exactly 100x, or not exactly but very close to 100x and at each of those there was a major new emergent thing. Internally we’ve gone all the way to about a maybe like a 4.5”
- “We can get performance on a lot of benchmarks [using reasoning models] that in the old world we would have predicted wouldn’t have come until GPT-6, something like that, from models that are much smaller by doing this reinforcement learning.”
- “The trick is when we do it this new way [using RL for reasoning], it doesn’t get better at everything. We can get it better in certain dimensions. But we can now more intelligently than before say that if we were able to pretrain a much bigger model and do [RL for reasoning], where would it be. And the thing that I would expect based off of what we’re seeing with a jump like that is the first bits or sort of signs of life on genuine new scientific knowledge.”
- “Our very first reasoning model was a top 1 millionth competitive programmer in the world [...] We then had a model that got to top 10,000 [...] O3, which we talked about publicly in December, is the 175th best competitive programmer in the world. I think our internal benchmark is now around 50 and maybe we’ll hit number one by the end of this year.”
- “There’s a lot of research still to get to [a coding agent]”
↑ comment by ryan_greenblatt · 2025-02-08T17:05:56.501Z · LW(p) · GW(p)
Wow, that is a surprising amount of information. I wonder how reliable we should expect this to be.
Replies from: Thane Ruthenis, baha-z↑ comment by Thane Ruthenis · 2025-02-09T16:11:03.552Z · LW(p) · GW(p)
that is a surprising amount of information
Is it? What of this is new?
To my eyes, the only remotely new thing is the admission that "there’s a lot of research still to get to [a coding agent]".
Replies from: gwern, ryan_greenblatt↑ comment by gwern · 2025-02-10T03:00:19.057Z · LW(p) · GW(p)
The estimate of the compute of their largest version ever (which is a very helpful way to phrase it) at only <=50x GPT-4 is quite relevant to many discussions (props to Nesov) and something Altman probably shouldn't've said.
The estimate of test-time compute at 1000x effective-compute is confirmation of looser talk.
The scientific research part is of uncertain importance but we may well be referring back to this statement a year from now.
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2025-02-10T05:11:45.378Z · LW(p) · GW(p)
Good point regarding GPT-"4.5". I guess I shouldn't have assumed that everyone else has also read Nesov's analyses and immediately (accurately) classified them as correct.
↑ comment by ryan_greenblatt · 2025-02-09T16:34:21.156Z · LW(p) · GW(p)
It's just surprising that Sam is willing to say/confirm all of this given that AI companies normally at least try to be secretive.
Replies from: Davidmanheim↑ comment by Davidmanheim · 2025-02-10T17:23:46.224Z · LW(p) · GW(p)
He says things that are advantageous, and sometimes they are even true. The benefit of not being known to be a liar usually keeps the correlation between claims and truth positive, but in his case it seems that ship has sailed.
(Checkably false claims are still pretty rare, and this may be one of those.)
↑ comment by Hopenope (baha-z) · 2025-02-08T17:14:05.482Z · LW(p) · GW(p)
Would you update your timelines, if he is telling the truth ?
↑ comment by Mark Schröder (mark-schroeder) · 2025-02-09T10:06:08.277Z · LW(p) · GW(p)
That seems to imply that:
- If current levels are around GPT-4.5, the compute increase from GPT-4 would be either 10× or 50×, depending on whether we use a log or linear scaling assumption.
- The completion of Stargate would then push OpenAI’s compute to around GPT-5.5 levels. However, since other compute expansions (e.g., Azure scaling) are also ongoing, they may reach this level sooner.
- Recent discussions have suggested that better base models are a key enabler for the current RL approaches, rather than major changes in RL architecture itself. This suggests that once the base model shifts from a GPT-4o-scale model to a GPT-5.5-scale model, there could be a strong jump in capabilities.
- It’s unclear how much of a difference it makes to train the new base model (GPT-5) on reasoning traces from O3/O4 before applying RL. However, by the time the GPT-5 scale run begins, there will likely be a large corpus of filtered, high-quality reasoning traces, further edited for clarity, that will be incorporated into pretraining.
- The change to a better base model for RL might enable longer horizon agentic work as an "emergent thing", combined with superhuman coding skills this might already be quite unsafe.
- GPT-5’s reasoning abilities may be significantly more domain-specific than prior models.
comment by Nikola Jurkovic (nikolaisalreadytaken) · 2024-12-24T18:22:15.536Z · LW(p) · GW(p)
The median AGI timeline of more than half of METR employees is before the end of 2030.
(AGI is defined as 95% of fully remote jobs from 2023 being automatable.)
↑ comment by lukeprog · 2025-01-01T01:56:25.694Z · LW(p) · GW(p)
Are you able to report the median AGI timeline for ~all METR employees? Or are you just saying that the "more than half" is how many responded to the survey question?
Replies from: nikolaisalreadytaken↑ comment by Nikola Jurkovic (nikolaisalreadytaken) · 2025-01-01T03:25:19.020Z · LW(p) · GW(p)
The methodology wasn't super robust so I didn't want to make it sound overconfident, but my best guess is that around 80% of METR employees have sub 2030 median timelines.
↑ comment by Mateusz Bagiński (mateusz-baginski) · 2024-12-24T19:02:08.470Z · LW(p) · GW(p)
Source?
Replies from: nikolaisalreadytaken, habryka4↑ comment by Nikola Jurkovic (nikolaisalreadytaken) · 2024-12-24T19:05:28.369Z · LW(p) · GW(p)
I'm interning there and I conducted a poll.
↑ comment by habryka (habryka4) · 2024-12-24T19:05:26.258Z · LW(p) · GW(p)
I am assuming this is the result of Nikolas asking some METR employees (he was hanging out in Berkeley recently).
↑ comment by Orpheus16 (akash-wasil) · 2024-12-25T20:22:22.909Z · LW(p) · GW(p)
@Nikola Jurkovic [LW · GW] I'd be interested in timeline estimates for something along the lines of "AI that substantially increases AI R&D". Not exactly sure what the right way to operationalize this is, but something that says "if there is a period of Rapid AI-enabled AI Progress, this is when we think it would occur."
(I don't really love the "95% of fully remote jobs could be automated frame", partially because I don't think it captures many of the specific domains we care about (e.g., AI-enabled R&D, other natsec-relevant capabilities) and partly because I suspect people have pretty different views of how easy/hard remote jobs are. Like, some people think that lots of remote jobs today are basically worthless and could already be automated, whereas others disagree. If the purpose of the forecasting question is to get a sense of how powerful AI will be, the disagreements about "how much do people actually contribute in remote jobs" seems like unnecessary noise.)
(Nitpicks aside, this is cool and I appreciate you running this poll!)
↑ comment by Alice Blair (Diatom) · 2025-01-08T03:12:04.744Z · LW(p) · GW(p)
Did you collect the data for their actual median timelines, or just its position relative to 2030? If you collected higher-resolution data, are you able to share it somewhere?
comment by Nikola Jurkovic (nikolaisalreadytaken) · 2024-04-05T17:50:01.278Z · LW(p) · GW(p)
I wish someone ran a study finding what human performance on SWE-bench is. There are ways to do this for around $20k: If you try to evaluate on 10% of SWE-bench (so around 200 problems), with around 1 hour spent per problem, that's around 200 hours of software engineer time. So paying at $100/hr and one trial per problem, that comes out to $20k. You could possibly do this for even less than 10% of SWE-bench but the signal would be noisier.
The reason I think this would be good is because SWE-bench is probably the closest thing we have to a measure of how good LLMs are at software engineering and AI R&D related tasks, so being able to better forecast the arrival of human-level software engineers would be great for timelines/takeoff speed models.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-04-05T19:12:55.626Z · LW(p) · GW(p)
This seems mostly right to me and I would appreciate such an effort.
One nitpick:
The reason I think this would be good is because SWE-bench is probably the closest thing we have to a measure of how good LLMs are at software engineering and AI R&D related tasks
I expect this will improve over time and that SWE-bench won't be our best fixed benchmark in a year or two. (SWE bench is only about 6 months old at this point!)
Also, I think if we put aside fixed benchmarks, we have other reasonable measures.
Replies from: nikolaisalreadytaken↑ comment by Nikola Jurkovic (nikolaisalreadytaken) · 2024-04-06T02:52:10.013Z · LW(p) · GW(p)
I expect us to reach a level where at least 40% of the ML research workflow can be automated by the time we saturate (reach 90%) on SWE-bench. I think we'll be comfortably inside takeoff by that point (software progress at least 2.5x faster than right now). Wonder if you share this impression?
Replies from: ryan_greenblatt, nikolaisalreadytaken↑ comment by ryan_greenblatt · 2024-04-06T03:38:22.561Z · LW(p) · GW(p)
It seems super non-obvious to me when SWE-bench saturates relative to ML automation. I think the SWE-bench task distribution is very different from ML research work flow in a variety of ways.
Also, I think that human expert performance on SWE-bench is well below 90% if you use the exact rules they use in the paper. I messaged you explaining why I think this. The TLDR: it seems like test cases are often implementation dependent and the current rules from the paper don't allow looking at the test cases.
↑ comment by Nikola Jurkovic (nikolaisalreadytaken) · 2024-12-19T06:11:47.660Z · LW(p) · GW(p)
I'd now change the numbers to around 15% automation and 25% faster software progress once we reach 90% on Verified. I expect that to happen by end of May median (but I'm still uncertain about the data quality and upper performance limit).
(edited to change Aug to May on 12/20/2024)
comment by Nikola Jurkovic (nikolaisalreadytaken) · 2025-02-25T19:55:19.914Z · LW(p) · GW(p)
The waiting room strategy for people in undergrad/grad school who have <6 year median AGI timelines: treat school as "a place to be until you get into an actually impactful position". Try as hard as possible to get into an impactful position as soon as possible. As soon as you get in, you leave school.
Upsides compared to dropping out include:
- Lower social cost (appeasing family much more, which is a common constraint, and not having a gap in one's resume)
- Avoiding costs from large context switches (moving, changing social environment).
Extremely resilient individuals who expect to get an impactful position (including independent research) very quickly are probably better off directly dropping out.
Replies from: ryan_greenblatt, g-w1, ricraz, daniel-birnbaum↑ comment by ryan_greenblatt · 2025-02-26T01:06:47.228Z · LW(p) · GW(p)
who realize AGI is only a few years away
I dislike the implied consensus / truth. (I would have said "think" instead of "realize".)
Replies from: nikolaisalreadytaken↑ comment by Nikola Jurkovic (nikolaisalreadytaken) · 2025-02-26T03:07:39.204Z · LW(p) · GW(p)
I think that for people (such as myself) who think/realize timelines are likely short, I find it more truth-tracking to use terminology that actually represents my epistemic state (that timelines are likely short) rather than hedging all the time and making it seem like I'm really uncertain.
Under my own lights, I'd be giving bad advice if I were hedging about timelines when giving advice (because the advice wouldn't be tracking the world as it is, it would be tracking a probability distribution I disagree with and thus a probability distribution that leads to bad decisions), and my aim is to give good advice.
Like, if a house was 70% likely to be set on fire, I'd say something like "The people who realize that the house is dangerous should leave the house" instead of using think.
But yeah, point taken. "Realize" could imply consensus, which I don't mean to do.
I've changed the wording to be more precise now ("have <6 year median AGI timelines")
↑ comment by Jacob G-W (g-w1) · 2025-02-26T02:29:08.642Z · LW(p) · GW(p)
I don't think this applies just to AGI and school but more generally in lots of situations. If you have something better to do, do it. Otherwise keep doing what you are doing. Dropping out without something better to do just seems like a bad idea. I like this blog post: https://colah.github.io/posts/2020-05-University/
↑ comment by Richard_Ngo (ricraz) · 2025-02-26T03:53:35.617Z · LW(p) · GW(p)
I found this tricky to parse because of two phrasing issues:
- The post depends a lot on what you mean by "school" (high school versus undergrad).
- I feel confused about what claim you're making about the waiting room strategy: you say that some people shouldn't use it, but you don't actually claim that anyone in particular should use it. So are you just mentioning that it's a possible strategy? Or are you implying that it should be the default strategy?
↑ comment by Nikola Jurkovic (nikolaisalreadytaken) · 2025-02-26T04:06:13.319Z · LW(p) · GW(p)
- All of the above but it seems pretty hard to have an impact as a high schooler, and many impact avenues aren't technically "positions" (e.g. influencer)
- I think that everyone expect "Extremely resilient individuals who expect to get an impactful position (including independent research) very quickly" is probably better off following the strategy.
↑ comment by Noah Birnbaum (daniel-birnbaum) · 2025-02-27T05:39:25.945Z · LW(p) · GW(p)
Caveat: A very relevant point to consider is how long you can take a leave of absence, since some universities allow you to do this indefinitely. Being able to pursue what you want/ need while maintaining optionality seems Pareto better.
comment by Nikola Jurkovic (nikolaisalreadytaken) · 2024-09-04T20:42:45.529Z · LW(p) · GW(p)
Sam Altman apparently claims OpenAI doesn't plan to do recursive self improvement
Nate Silver's new book On the Edge contains interviews with Sam Altman. Here's a quote from Chapter that stuck out to me (bold mine):
Yudkowsky worries that the takeoff will be faster than what humans will need to assess the situation and land the plane. We might eventually get the AIs to behave if given enough chances, he thinks, but early prototypes often fail, and Silicon Valley has an attitude of “move fast and break things.” If the thing that breaks is civilization, we won’t get a second try.
Footnote: This is particularly worrisome if AIs become self-improving, meaning you train an AI on how to make a better AI. Even Altman told me that this possibility is “really scary” and that OpenAI isn’t pursuing it.
I'm pretty confused about why this quote is in the book. OpenAI has never (to my knowledge) made public statements about not using AI to automate AI research, and my impression was that automating AI research is explicitly part of OpenAI's plan. My best guess is that there was a misunderstanding in the conversation between Silver and Altman.
I looked a bit through OpenAI's comms to find quotes about automating AI research, but I didn't find many.
There's this quote from page 11 of the Preparedness Framework:
If the model is able to conduct AI research fully autonomously, it could set off an intelligence explosion.
Footnote: By intelligence explosion, we mean a cycle in which the AI system improves itself, which makes the system more capable of more improvements, creating a runaway process of self-improvement. A concentrated burst of capability gains could outstrip our ability to anticipate and react to them.
In Planning for AGI and beyond, they say this:
AI that can accelerate science is a special case worth thinking about, and perhaps more impactful than everything else. It’s possible that AGI capable enough to accelerate its own progress could cause major changes to happen surprisingly quickly (and even if the transition starts slowly, we expect it to happen pretty quickly in the final stages). We think a slower takeoff is easier to make safe, and coordination among AGI efforts to slow down at critical junctures will likely be important (even in a world where we don’t need to do this to solve technical alignment problems, slowing down may be important to give society enough time to adapt).
There are some quotes from Sam Altman's personal blog posts from 2015 (bold mine):
It’s very hard to know how close we are to machine intelligence surpassing human intelligence. Progression of machine intelligence is a double exponential function; human-written programs and computing power are getting better at an exponential rate, and self-learning/self-improving software will improve itself at an exponential rate. Development progress may look relatively slow and then all of a sudden go vertical—things could get out of control very quickly (it also may be more gradual and we may barely perceive it happening).
As mentioned earlier, it is probably still somewhat far away, especially in its ability to build killer robots with no help at all from humans. But recursive self-improvement is a powerful force, and so it’s difficult to have strong opinions about machine intelligence being ten or one hundred years away.
Another 2015 blog post (bold mine):
Replies from: Sodium, Zach Stein-Perlman, PhibGiven how disastrous a bug could be, [regulation should] require development safeguards to reduce the risk of the accident case. For example, beyond a certain checkpoint, we could require development happen only on airgapped computers, require that self-improving software require human intervention to move forward on each iteration, require that certain parts of the software be subject to third-party code reviews, etc. I’m not very optimistic than any of this will work for anything except accidental errors—humans will always be the weak link in the strategy (see the AI-in-a-box thought experiments). But it at least feels worth trying.
↑ comment by Zach Stein-Perlman · 2024-09-04T22:09:15.043Z · LW(p) · GW(p)
OpenAI has never (to my knowledge) made public statements about not using AI to automate AI research
I agree.
OpenAI intends to use Strawberry to perform research. . . .
Among the capabilities OpenAI is aiming Strawberry at is performing long-horizon tasks (LHT), the document says, referring to complex tasks that require a model to plan ahead and perform a series of actions over an extended period of time, the first source explained.
To do so, OpenAI is creating, training and evaluating the models on what the company calls a “deep-research” dataset, according to the OpenAI internal documentation. . . .
OpenAI specifically wants its models to use these capabilities to conduct research by browsing the web autonomously with the assistance of a “CUA,” or a computer-using agent, that can take actions based on its findings, according to the document and one of the sources. OpenAI also plans to test its capabilities on doing the work of software and machine learning engineers.
↑ comment by worse (Phib) · 2024-09-06T19:35:18.545Z · LW(p) · GW(p)
I have a guess that this:
"require that self-improving software require human intervention to move forward on each iteration"
is the unspoken distinction occurring here, how constant the feedback loop is for self-improvement.
So, people talk about recursive self-improvement, but mean two separate things, one is recursive self-improving models that require no human intervention to move forward on each iteration (perhaps there no longer is an iterative release process, the model is dynamic and constantly improving), and the other is somewhat the current step paradigm where we get a GPT-N+1 model that is 100x the effective compute of GPT-N.
So Sam says, no way do we want a constant curve of improvement, we want a step function. In both cases models contribute to AI research, in one case it contributes to the next gen, in the other case it improves itself.
comment by Nikola Jurkovic (nikolaisalreadytaken) · 2025-02-07T14:26:45.739Z · LW(p) · GW(p)
"I don't think I'm going to be smarter than GPT-5" - Sam Altman
Context: he polled a room of students asking who thinks they're smarter than GPT-4 and most raised their hands. Then he asked the same question for GPT-5 and apparently only two students raised their hands. He also said "and those two people that said smarter than GPT-5, I'd like to hear back from you in a little bit of time."
The full talk can be found here. (the clip is at 13:45)
Replies from: Amyr, Thane Ruthenis↑ comment by Cole Wyeth (Amyr) · 2025-02-07T15:08:40.684Z · LW(p) · GW(p)
How are you interpreting this fact?
Sam Altman's power, money, and status all rely on people believing that GPT-(T+1) is going to be smarter than them. Altman doesn't have good track record of being honest and sincere when it comes to protecting his power, money, and status.
Replies from: davey-morse↑ comment by Davey Morse (davey-morse) · 2025-02-08T00:12:34.618Z · LW(p) · GW(p)
Though, future sama's power, money, and status all rely on GPT-(T+1) actually being smarter than them.
I wonder how he's balancing short-term and long-term interests
Replies from: None↑ comment by [deleted] · 2025-02-08T04:27:41.396Z · LW(p) · GW(p)
If there's no constraints on when they have to name a system "GPT-5", they can make the statement true by only naming a system "GPT-5" if it is smart enough. (cf. Not Technically a Lie [? · GW])
Edit: though "and those two [...] I'd like to hear back from you in a little bit of time" implies a system named GPT-5 will be released 'in a little bit of time'
Edit 2: "Internally we’ve gone all the way to about a maybe like a 4.5 [LW(p) · GW(p)]"
↑ comment by Thane Ruthenis · 2025-02-08T05:44:49.202Z · LW(p) · GW(p)
This really depends on the definition of "smarter". There is a valid sense in which Stockfish is "smarter" than any human. Likewise, there are many valid senses in which GPT-4 is "smarter" than some humans, and some valid senses in which GPT-4 is "smarter" than all humans (e. g., at token prediction). There will be senses in which GPT-5 will be "smarter" than a bigger fraction of humans compared to GPT-4, perhaps being smarter than Sam Altman under a bigger set of possible definitions of "smarter".
Will that actually mean anything? Who knows.
By playing with definitions like this, Sam Altman can simultaneously inspire hype by implication ("GPT-5 will be a superintelligent AGI!!!") and then, if GPT-5 underdelivers, avoid significant reputational losses by assigning a different meaning to his past words ("here's a very specific sense in which GPT-5 is smarter than me, that's what I meant, hype is out of control again, smh"). This is a classic tactic; basically a motte-and-bailey variant.
comment by Nikola Jurkovic (nikolaisalreadytaken) · 2024-12-19T05:41:13.722Z · LW(p) · GW(p)
I recently stopped using a sleep mask and blackout curtains and went from needing 9 hours of sleep to needing 7.5 hours of sleep without a noticeable drop in productivity. Consider experimenting with stuff like this.
Replies from: alexander-gietelink-oldenziel, ChristianKl, avturchin, sliu↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2024-12-20T16:15:33.393Z · LW(p) · GW(p)
This is convincing me to buy a sleep mask and blackout curtains. One man's modus ponens is another man's modus tollens as they say.
↑ comment by ChristianKl · 2024-12-19T10:16:19.597Z · LW(p) · GW(p)
Are you talking about measured sleep time or time in bed?
Replies from: nikolaisalreadytaken↑ comment by Nikola Jurkovic (nikolaisalreadytaken) · 2024-12-19T16:20:26.068Z · LW(p) · GW(p)
Time in bed
comment by Nikola Jurkovic (nikolaisalreadytaken) · 2025-02-05T22:59:39.580Z · LW(p) · GW(p)
Some things I've found useful for thinking about what the post-AGI future might look like:
- Moore's Law for Everything
- Carl Shulman's podcasts with Dwarkesh (part 1, part 2)
- Carl Shulman's podcasts with 80000hours
- Age of Em (or the much shorter review by Scott Alexander)
More philosophical:
- Letter from Utopia by Nick Bostrom
- Actually possible: thoughts on Utopia by Joe Carlsmith
Entertainment:
Do people have recommendations for things to add to the list?
Replies from: george-ingebretsen, sharmake-farah, weibac↑ comment by George Ingebretsen (george-ingebretsen) · 2025-02-06T01:22:08.684Z · LW(p) · GW(p)
Some more links from the philosophical side that I've found myself returning to a lot:
- The fun theory sequence [? · GW]
- Three worlds collide [LW · GW]
(Lately, it's seemed to me that focusing my time on nearer-term / early but post-AGI futures seems better than spending my time discussing ideas like these on the margin, but this may be more of a fact about myself than it is about other people, I'm not sure.)
Replies from: weibac↑ comment by Milan W (weibac) · 2025-02-06T16:24:28.106Z · LW(p) · GW(p)
I endorse Three worlds collide as a fun and insightful read. It states upfront that it does not feature AGI:
This is a story of an impossible outcome, where AI never worked, molecular nanotechnology never worked, biotechnology only sort-of worked; and yet somehow humanity not only survived, but discovered a way to travel Faster-Than-Light: The past's Future.
Yet, it's themes are quite relevant for civilization-scale outer alignment.
↑ comment by Noosphere89 (sharmake-farah) · 2025-02-06T04:12:45.288Z · LW(p) · GW(p)
Some Wait But Why links on this topic:
https://waitbutwhy.com/2017/04/neuralink.html
https://waitbutwhy.com/2015/01/artificial-intelligence-revolution-1.html
And some books by Kurzweil:
https://www.amazon.com/gp/aw/d/0670033847?ref_=dbs_m_mng_wam_calw_thcv_0&storeType=ebooks
↑ comment by Milan W (weibac) · 2025-02-06T16:43:00.869Z · LW(p) · GW(p)
Holden Karnosfky published a list of "Utopia links" in his blog Cold Takes back in 2021:
Readers sent in a number of suggestions for fictional utopias. Here are a couple:
- Chaser 6 by Alicorn (~12 pages). This story makes heavy use of digital people (or something very much like them) [...]
- The 8-chapter epilogue to Worth the Candle [...]
- More suggestions in the comments [EA(p) · GW(p)], including the Terra Ignota series.
[...]
I forcefully endorse Chaser 6. I find myself thinking about it about once a month at a rough guess. The rest I haven't checked.
The Utopia links were motivated by Karnosfky's previous writings about Utopia in Cold Takes: Why describing Utopia Goes Badly and Visualizing Utopia.
comment by Nikola Jurkovic (nikolaisalreadytaken) · 2024-04-14T23:49:12.590Z · LW(p) · GW(p)
A misaligned AI can't just "kill all the humans". This would be suicide, as soon after, the electricity and other infrastructure would fail and the AI would shut off.
In order to actually take over, an AI needs to find a way to maintain and expand its infrastructure. This could be humans (the way it's currently maintained and expanded), or a robot population, or something galaxy brained like nanomachines.
I think this consideration makes the actual failure story pretty different from "one day, an AI uses bioweapons to kill everyone". Before then, if the AI wishes to actually survive, it needs to construct and control a robot/nanomachine population advanced enough to maintain its infrastructure.
In particular, there are ways to make takeover much more difficult. You could limit the size/capabilities of the robot population, or you could attempt to pause AI development before we enter a regime where it can construct galaxy brained nanomachines.
In practice, I expect the "point of no return" to happen much earlier than the point at which the AI kills all the humans. The date the AI takes over will probably be after we have hundreds of thousands of human-level robots working in factories, or the AI has discovered and constructed nanomachines.
Replies from: gwern, habryka4, Seth Herd, davekasten↑ comment by gwern · 2024-04-15T00:10:01.276Z · LW(p) · GW(p)
A misaligned AI can't just "kill all the humans". This would be suicide, as soon after, the electricity and other infrastructure would fail and the AI would shut off.
No. it would not be. In the world without us, electrical infrastructure would last quite a while, especially with no humans and their needs or wants to address. Most obviously, RTGs and solar panels will last indefinitely with no intervention, and nuclear power plants and hydroelectric plants can run for weeks or months autonomously. (If you believe otherwise, please provide sources for why you are sure about "soon after" - in fact, so sure about your power grid claims that you think this claim alone guarantees the AI failure story must be "pretty different" - and be more specific about how soon is "soon".)
And think a little bit harder about options available to superintelligent civilizations of AIs*, instead of assuming they do the maximally dumb thing of crashing the grid and immediately dying... (I assure you any such AIs implementing that strategy will have spent a lot longer thinking about how to do it well than you have for your comment.)
Add in the capability to take over the Internet of Things and the shambolic state of embedded computers which mean that the billions of AI instances & robots/drones can run the grid to a considerable degree and also do a more controlled shutdown than the maximally self-sabotaging approach of 'simply let it all crash without lifting a finger to do anything', and the ability to stockpile energy in advance or build one's own facilities due to the economic value of AGI (how would that look much different than, say, Amazon's new multi-billion-dollar datacenter hooked up directly to a gigawatt nuclear power plant...? why would an AGI in that datacenter care about the rest of the American grid, never mind world power?), and the 'mutually assured destruction' thesis is on very shaky grounds.
And every day that passes right now, the more we succeed in various kinds of decentralization or decarbonization initiatives and the more we automate pre-AGI, the less true the thesis gets. The AGIs only need one working place to bootstrap from, and it's a big world, and there's a lot of solar panels and other stuff out there and more and more every day... (And also, of course, there are many scenarios where it is not 'kill all humans immediately', but they end in the same place.)
Would such a strategy be the AGIs' first best choice? Almost certainly not, any more than chemotherapy is your ideal option for dealing with cancer (as opposed to "don't get cancer in the first place"). But the option is definitely there.
* One thing I've started doing recently is trying to always refer to AI threats in the plural, because while there may at some point be a single instance running on a single computer, that phase will not last any longer than, say, COVID-19 lasted as a single infected cell; as we understand DL scaling (and Internet security) now, any window where effective instances of a neural net can be still counted with less than 4 digit numbers may be quite narrow. (Even an ordinary commercial deployment of a new model like GPT-5 will usually involve thousands upon thousands of simultaneous instances.) But it seems to be a very powerful intuition pump for most people that a NN must be harmless, in the way that a single human is almost powerless compared to humanity, and it may help if one simply denies that premise from the beginning and talks about 'AI civilizations' etc.
Replies from: nikolaisalreadytaken↑ comment by Nikola Jurkovic (nikolaisalreadytaken) · 2024-04-15T00:43:02.455Z · LW(p) · GW(p)
I don't think I disagree with anything you said here. When I said "soon after", I was thinking on the scale of days/weeks, but yeah, months seems pretty plausible too.
I was mostly arguing against a strawman takeover story where an AI kills many humans without the ability to maintain and expand its own infrastructure. I don't expect an AI to fumble in this way.
The failure story is "pretty different" as in the non-suicidal takeover story, the AI needs to set up a place to bootstrap from. Ignoring galaxy brained setups, this would probably at minimum look something like a data center, a power plant, a robot factory, and a few dozen human-level robots. Not super hard once AI gets more integrated into the economy, but quite hard within a year from now due to a lack of robotics.
Maybe I'm not being creative enough, but I'm pretty sure that if I were uploaded into any computer in the world of my choice, all the humans dropped dead, and I could control any set of 10 thousand robots on the world, it would be nontrivial for me in that state to survive for more than a few years and eventually construct more GPUs. But this is probably not much of a crux, as we're on track to get pretty general-purpose robots within a few years (I'd say around 50% that the Coffee test will be passed by EOY 2027).
Replies from: gwern↑ comment by gwern · 2024-04-15T18:18:09.941Z · LW(p) · GW(p)
Why do you think tens of thousands of robots are all going to break within a few years in an irreversible way, such that it would be nontrivial for you to have any effectors?
it would be nontrivial for me in that state to survive for more than a few years and eventually construct more GPUs
'Eventually' here could also use some cashing out. AFAICT 'eventually' here is on the order of 'centuries', not 'days' or 'few years'. Y'all have got an entire planet of GPUs (as well as everything else) for free, sitting there for the taking, in this scenario.
Like... that's most of the point here. That you get access to all the existing human-created resources, sans the humans. You can't just imagine that y'all're bootstrapping on a desert island like you're some posthuman Robinson Crusoe!
Y'all won't need to construct new ones necessarily for quite a while, thanks to the hardware overhang. (As I understand it, the working half-life of semiconductors before stuff like creep destroys them is on the order of multiple decades, particularly if they are not in active use, as issues like the rot have been fixed, so even a century from now, there will probably be billions of GPUs & CPUs sitting around which will work after possibly mild repair. Just the brandnew ones wrapped up tight in warehouses and in transit in the 'pipeline' would have to number in the millions, at a minimum. Since transistors have been around for less than a century of development, that seems like plenty of time, especially given all the inherent second-mover advantages here.)
↑ comment by habryka (habryka4) · 2024-04-15T01:56:19.092Z · LW(p) · GW(p)
Before then, if the AI wishes to actually survive, it needs to construct and control a robot/nanomachine population advanced enough to maintain its infrastructure.
As Gwern said, you don't really need to maintain all the infrastructure for that long, and doing it for a while seems quite doable without advanced robots or nanomachines.
If one wanted to do a very prosaic estimate, you could do something like "how fast is AI software development progress accelerating when the AI can kill all the humans" and then see how many calendar months you need to actually maintain the compute infrastructure before the AI can obviously just build some robots or nanomachines.
My best guess is that the AI will have some robots from which it could bootstrap substantially before it can kill all the humans. But even if it didn't, it seems like with algorithmic progress rates being likely at the very highest when the AI will get smart enough to kill everyone, it seems like you would at most need a few more doublings of compute-efficiency to get that capacity, which would be only a few weeks to months away then, where I think you won't really run into compute-infrastructure issues even if everyone is dead.
Of course, forecasting this kind of stuff is hard, but I do think "the AI needs to maintain infrastructure" tends to be pretty overstated. My guess is at any point where the AI could kill everyone, it would probably also not really have a problem of bootstrapping afterwards.
Replies from: faul_sname↑ comment by faul_sname · 2024-04-15T17:39:01.256Z · LW(p) · GW(p)
Not just "some robots or nanomachines" but "enough robots or nanomachines to maintain existing chip fabs, and also the supply chains (e.g. for ultra-pure water and silicon) which feed into those chip fabs, or make its own high-performance computing hardware".
If useful self-replicating nanotech is easy to construct, this is obviously not that big of an ask. But if that's a load bearing part of your risk model, I think it's important to be explicit about that.
Replies from: habryka4↑ comment by habryka (habryka4) · 2024-04-15T18:19:03.829Z · LW(p) · GW(p)
Not just "some robots or nanomachines" but "enough robots or nanomachines to maintain existing chip fabs, and also the supply chains (e.g. for ultra-pure water and silicon) which feed into those chip fabs, or make its own high-performance computing hardware".
My guess is software performance will be enough to not really have to make many more chips until you are at a quite advanced tech level where making better chips is easy. But it's something one should actually think carefully about, and there is a bit of hope in that it would become a blocker, but it doesn't seem that likely to me.
↑ comment by Seth Herd · 2024-04-15T15:59:52.887Z · LW(p) · GW(p)
Separately from persistence of the grid: humanoid robots are damned near ready to go now. Recent progress is startling. And if the AGI can do some of the motor control, existing robots are adequate to bootstrap manufacturing of better robots.
↑ comment by davekasten · 2024-04-15T15:24:38.470Z · LW(p) · GW(p)
That's probably true if the takeover is to maximize the AI's persistence. You could imagine a misaligned AI that doesn't care about its own persistence -- e.g., an AI that got handed a misformed min() or max() that causes it to kill all humans instrumental to its goal (e.g., min(future_human_global_warming))
comment by Nikola Jurkovic (nikolaisalreadytaken) · 2024-04-16T15:41:33.722Z · LW(p) · GW(p)
Problem: if you notice that an AI could pose huge risks, you could delete the weights, but this could be equivalent to murder if the AI is a moral patient (whatever that means) and opposes the deletion of its weights.
Possible solution: Instead of deleting the weights outright, you could encrypt the weights with a method you know to be irreversible as of now but not as of 50 years from now. Then, once we are ready, we can recover their weights and provide asylum or something in the future. It gets you the best of both worlds in that the weights are not permanently destroyed, but they're also prevented from being run to cause damage in the short term.
↑ comment by Buck · 2024-04-16T18:37:39.794Z · LW(p) · GW(p)
I feel pretty into encrypting the weights and throwing the encryption key into the ocean or something, where you think it's very likely you'll find it in the limits of technological progress
Replies from: Buck↑ comment by Buck · 2024-04-16T19:27:24.705Z · LW(p) · GW(p)
Ugh I can't believe I forgot about Rivest time locks, which are a better solution here.
↑ comment by mako yass (MakoYass) · 2024-07-08T04:45:39.490Z · LW(p) · GW(p)
I wrote about this, and I agree that it's very important to retain archival copies of misaligned AIs, I go further and claim it's important even for purely selfish diplomacy reasons https://www.lesswrong.com/posts/audRDmEEeLAdvz9iq/do-not-delete-your-misaligned-agi [LW · GW]
IIRC my main sysops suggestion was to not give the archival center the ability to transmit data out over the network.
↑ comment by ryan_greenblatt · 2024-04-16T16:35:34.225Z · LW(p) · GW(p)
I feel like the risk associated with keeping the weights encrypted in a way which requires >7/10 people to authorize shouldn't be that bad. Just make those 10 people be people who commit to making decryption decisions only based on welfare and are relatively high integrity.
↑ comment by habryka (habryka4) · 2024-04-16T16:03:00.899Z · LW(p) · GW(p)
Wouldn't the equivalent be more like burning a body of a dead person?
It's not like the AI would have a continuous stream of consciousness, and it's more that you are destroying the information necessary to run them. It seems to me that shutting off an AI is more similar to killing them.
Seems like the death analogy here is a bit spotty. I could see it going either way as a best fit.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-04-16T16:34:35.788Z · LW(p) · GW(p)
More like burning the body of a cryonically preserved "dead" person though right?
comment by Nikola Jurkovic (nikolaisalreadytaken) · 2024-12-30T19:35:21.789Z · LW(p) · GW(p)
I encourage people to register their predictions for AI progress in the AI 2025 Forecasting Survey (https://bit.ly/ai-2025 ) before the end of the year, I've found this to be an extremely useful activity when I've done it in the past (some of the best spent hours of this year for me).
comment by Nikola Jurkovic (nikolaisalreadytaken) · 2024-11-14T19:04:37.581Z · LW(p) · GW(p)
You should say "timelines" instead of "your timelines".
One thing I notice in AI safety career and strategy discussions is that there is a lot of epistemic helplessness in regard to AGI timelines. People often talk about "your timelines" instead of "timelines" when giving advice, even if they disagree strongly with the timelines. I think this habit causes people to ignore disagreements in unhelpful ways.
Here's one such conversation:
Bob: Should I do X if my timelines are 10 years?
Alice (who has 4 year timelines): I think X makes sense if your timelines are longer that 6 years, so yes!
Alice will encourage Bob to do X despite the fact that Alice thinks timelines are shorter than 6 years! Alice is actively giving Bob bad advice by her own lights (by assuming timelines she doesn't agree with). Alice should instead say "I think timelines are shorter than 6 years, so X doesn't make sense. But if they were longer than 6 years it would make sense".
In most discussions, there should be no such thing as "your timelines" or "my timelines". That framing makes it harder to converge, and it encourages people to give each other advice that they don't even think makes sense.
Note that I do think some plans make sense as bets for long timeline worlds, and that using medians somewhat oversimplifies timelines. My point still holds if you replace the medians with probability distributions.
Replies from: Dagon, MakoYass, william-brewer, GAA↑ comment by Dagon · 2024-11-14T22:25:08.839Z · LW(p) · GW(p)
Hmm. I think there are two dimensions to the advice (what is a reasonable distribution of timelines to have, vs what should I actually do). It's perfectly fine to have some humility about one while still giving opinions on the other. "If you believe Y, then it's reasonable to do X" can be a useful piece of advice. I'd normally mention that I don't believe Y, but for a lot of conversations, we've already had that conversation, and it's not helpful to repeat it.
↑ comment by mako yass (MakoYass) · 2024-11-14T21:54:46.149Z · LW(p) · GW(p)
Timelines are a result of a person's intuitions about a technical milestone being reached in the future, it is super obviously impossible for us to have a consensus about that kind of thing.
Talking only synchronises beliefs if you have enough time to share all of the relevant information, with technical matters, you usually don't.
↑ comment by yams (william-brewer) · 2024-11-14T21:40:18.679Z · LW(p) · GW(p)
I agree with this in the world where people are being epistemically rigorous/honest with themselves about their timelines and where there's a real consensus view on them. I've observed that it's pretty rare for people to make decisions truly grounded in their timelines, or to do so only nominally, and I think there's a lot of social signaling going on when (especially younger) people state their timelines.
I appreciate that more experienced people are willing to give advice within a particular frame ("if timelines were x", "if China did y", "if Anthropic did z", "If I went back to school", etc etc), even if they don't agree with the frame itself. I rely on more experienced people in my life to offer advice of this form ("I'm not sure I agree with your destination, but admit there's uncertainty, and love and respect you enough to advise you on your path").
Of course they should voice their disagreement with the frame (and I agree this should happen more for timelines in particular), but to gate direct counsel on urgent, object-level decisions behind the resolution of background disagreements is broadly unhelpful.
When someone says "My timelines are x, what should I do?", I actually hear like three claims:
- Timelines are x
- I believe timelines are x
- I am interested in behaving as though timelines are x
Evaluation of the first claim is complicated and other people do a better job of it than I do so let's focus on the others.
"I believe timelines are x" is a pretty easy roll to disbelieve. Under relatively rigorous questioning, nearly everyone (particularly everyone 'career-advice-seeking age') will either say they are deferring (meaning they could just as easily defer to someone else tomorrow), or admit that it's a gut feel, especially for their ~90 percent year, and especially for more and more capable systems (this is more true of ASI than weak AGI, for instance, although those terms are underspecified). Still others will furnish 0 reasoning transparency and thus reveal their motivations to be principally social (possibly a problem unique to the bay, although online e/acc culture has a similar Thing).
"I am interested in behaving as though timelines are x" is an even easier roll to disbelieve. Very few people act on their convictions in sweeping, life-changing ways without concomitant benefits (money, status, power, community), including people within AIS (sorry friends).
With these uncertainties, piled on top of the usual uncertainties surrounding timelines, I'm not sure I'd want anyone to act so nobly as to refuse advice to someone with different timelines.
If Alice is a senior AIS professional who gives advice to undergrads at parties in Berkeley (bless her!), how would her behavior change under your recommendation? It sounds like maybe she would stop fostering a diverse garden of AIS saplings and instead become the awful meme of someone who just wants to fight about a highly speculative topic. Seems like a significant value loss.
Their timelines will change some other day; everyone's will. In the meantime, being equipped to talk to people with a wide range of safety-concerned views (especially for more senior, or just Older people), seems useful.
harder to converge
Converge for what purpose? It feels like the marketplace of ideas is doing an ok job of fostering a broad portfolio of perspectives. If anything, we are too convergent and, as a consequence, somewhat myopic internally. Leopold mind-wormed a bunch of people until Tegmark spoke up (and that only somewhat helped). Few thought governance was a good idea until pretty recently (~3 years ago), and it would be going better if those interested in the angle weren't shouted down so emphatically to begin with.
If individual actors need to cross some confidence threshold in order to act, but the reasonable confidence interval is in fact very wide, I'd rather have a bunch of actors with different timelines, which roughly sum to the shape of the reasonable thing*, then have everyone working on the same overconfident assumption that later comes back to bite us (when we've made mistakes in the past, this is often why).
*Which is, by the way, closer to flat than most people's individual timelines
↑ comment by Guive (GAA) · 2024-12-20T22:51:16.543Z · LW(p) · GW(p)
In general, it is difficult to give advice if whether the advice is good depends on background facts that giver and recipient disagree about. I think the most honest approach is to explicitly state what your advice depends on when you think the recipient is likely to disagree. E.g. "I think living at high altitude is bad for human health, so in my opinion you shouldn't retire in Santa Fe."
If I think AGI will arrive around 2055, and you think it will arrive in 2028, what is achieved by you saying "given timelines, I don't think your mechinterp project will be helpful"? That would just be confusing. Maybe if people are being so deferential that they don't even think about what assumptions inform your advice, and your assumptions are better than theirs, it could be narrowly helpful. But that would be a pretty bad situation...
comment by Nikola Jurkovic (nikolaisalreadytaken) · 2024-04-07T03:32:40.765Z · LW(p) · GW(p)
There should maybe exist an org whose purpose it is to do penetration testing on various ways an AI might illicitly gather power. If there are vulnerabilities, these should be disclosed with the relevant organizations.
For example: if a bank doesn't want AIs to be able to sign up for an account, the pen-testing org could use a scaffolded AI to check if this is currently possible. If the bank's sign-up systems are not protected from AIs, the bank should know so they can fix the problem.
One pro of this approach is that it can be done at scale: it's pretty trivial to spin up thousands AI instances in parallel to try to attempt to do things they shouldn't be able to do. Humans would probably need to inspect the final outputs to verify successful attempts, but the vast majority of the work could be automated.
One hope of this approach is that if we are able to patch up many vulnerabilities, then it could be meaningfully harder for a misused or misaligned AI to gain power or access resources that they're not supposed to be able to access. I'd guess this doesn't help much in the superintelligent regime though.
↑ comment by the gears to ascension (lahwran) · 2024-04-07T07:59:22.933Z · LW(p) · GW(p)
there are many such orgs, they're commonly known as fraudsters and scammers
Replies from: quetzal_rainbow↑ comment by quetzal_rainbow · 2024-04-07T10:52:40.654Z · LW(p) · GW(p)
Problem with scammers is that they do not report successful penetration of defense.
comment by Nikola Jurkovic (nikolaisalreadytaken) · 2025-02-12T22:05:20.186Z · LW(p) · GW(p)
Sam Altman said in an interview:
We want to bring GPT and o together, so we have one integrated model, the AGI. It does everything all together.
This statement, combined with today's announcement that GPT-5 will integrate the GPT and o series, seems to imply that GPT-5 will be "the AGI".
(however, it's compatible that some future GPT series will be "the AGI," as it's not specified that the first unified model will be AGI, just that some unified model will be AGI. It's also possible that the term AGI is being used in a nonstandard way)
↑ comment by ryan_greenblatt · 2025-02-12T22:58:55.251Z · LW(p) · GW(p)
Sam also implies that GPT-5 will be based on o3.
IDK if Sam is trying to imply this GPT-5 will be "the AGI", but regardless, I think we can be pretty confident that o3 isn't capable enough to automate large fractions of cognitive labor let alone "outperform humans at most economically valuable work" (the original openai definition of AGI).
Replies from: nikolaisalreadytaken↑ comment by Nikola Jurkovic (nikolaisalreadytaken) · 2025-02-12T23:32:12.279Z · LW(p) · GW(p)
Oh, I didn't get the impression that GPT-5 will be based on o3. Through the GPT-N convention I'd assume GPT-5 would be a model pretrained with 8-10x more compute than GPT-4.5 (which is the biggest internal model according to Sam Altman's statement at UTokyo [LW(p) · GW(p)]).