Posts
Comments
Another consideration is takeoff speeds: TAI happening earlier would mean further progress is more bottlenecked by compute and thus takeoff is slowed down. A slower takeoff enables more time for humans to inform their decisions (but might also make things harder in other ways).
The base models seem to have topped out their task length around 2023 at a few minutes (see on the plot that GPT-4o is little better than GPT-4). Reasoning models use search to do better.
Note that Claude 3.5 Sonnet (Old) and Claude 3.5 Sonnet (New) have a longer time horizon than 4o: 18 minutes and 28 minutes compared to 9 minutes (Figure 5 in Measuring AI Ability to Complete Long Tasks). GPT-4.5 also has a longer time horizon.
Thanks for writing this.
Aside from maybe Nikola Jurkovic, nobody associated with AI 2027, as far as I can tell, is actually expecting things to go as fast as depicted.
I don't expect things to go this fast either - my median for AGI is in the second half of 2028, but the capabilities progression in AI 2027 is close to my modal timeline.
Note that the goal of "work on long-term research bets now so that a workforce of AI agents can automate it in a couple of years" implies somewhat different priorities than "work on long-term research bets to eventually have them pay off through human labor", notably:
- The research direction needs to be actually pursued by the agents, either through the decision of the human leadership, or through the decision of AI agents that the human leadership defers to. This means that if some long-term research bet isn't respected by lab leadership, it's unlikely to be pursued by their workforce of AI agents.
- This implies that a major focus of current researchers should be on credibility and having a widely agreed-on theory of change. If this is lacking, then the research will likely never be pursued by the AI agent workforce and all the work will likely have been for nothing.
- Maybe there is some hope that despite a research direction being unpopular among lab leadership, the AI agents will realize its usefulness on their own, and possibly persuade the lab leadership to let them expend compute on the research direction in question. Or maybe the agents will have so much free reign over research that they don't even need to ask for permission to pursue new research directions.
- This implies that a major focus of current researchers should be on credibility and having a widely agreed-on theory of change. If this is lacking, then the research will likely never be pursued by the AI agent workforce and all the work will likely have been for nothing.
- Setting oneself up for providing oversight to AI agents. There might be a period during which agents are very capable at research engineering / execution but not research management, and leading AGI companies are eager to hire human experts to supervise large numbers of AI agents. If one doesn't have legible credentials or good relations with AGI companies, they are less likely to be hired during this period.
- Delaying engineering-heavy projects until engineering is cheap relative to other types of work.
(some of these push in opposite directions, e.g., engineering-heavy research outputs might be especially good for legibility)
I expect the trend to speed up before 2029 for a few reasons:
- AI accelerating AI progress once we reach 10s of hours of time horizon.
- The trend might be "inherently" superexponential. It might be that unlocking some planning capability generalizes very well from 1-week to 1-year tasks and we just go through those doublings very quickly.
This has been one of the most important results for my personal timelines to date. It was a big part of the reason why I recently updated from ~3 year median to ~4 year median to AI that can automate >95% of remote jobs from 2022, and why my distribution overall has become more narrow (less probability on really long timelines).
- All of the above but it seems pretty hard to have an impact as a high schooler, and many impact avenues aren't technically "positions" (e.g. influencer)
- I think that everyone expect "Extremely resilient individuals who expect to get an impactful position (including independent research) very quickly" is probably better off following the strategy.
I think that for people (such as myself) who think/realize timelines are likely short, I find it more truth-tracking to use terminology that actually represents my epistemic state (that timelines are likely short) rather than hedging all the time and making it seem like I'm really uncertain.
Under my own lights, I'd be giving bad advice if I were hedging about timelines when giving advice (because the advice wouldn't be tracking the world as it is, it would be tracking a probability distribution I disagree with and thus a probability distribution that leads to bad decisions), and my aim is to give good advice.
Like, if a house was 70% likely to be set on fire, I'd say something like "The people who realize that the house is dangerous should leave the house" instead of using think.
But yeah, point taken. "Realize" could imply consensus, which I don't mean to do.
I've changed the wording to be more precise now ("have <6 year median AGI timelines")
The waiting room strategy for people in undergrad/grad school who have <6 year median AGI timelines: treat school as "a place to be until you get into an actually impactful position". Try as hard as possible to get into an impactful position as soon as possible. As soon as you get in, you leave school.
Upsides compared to dropping out include:
- Lower social cost (appeasing family much more, which is a common constraint, and not having a gap in one's resume)
- Avoiding costs from large context switches (moving, changing social environment).
Extremely resilient individuals who expect to get an impactful position (including independent research) very quickly are probably better off directly dropping out.
Dario Amodei and Demis Hassabis statements on international coordination (source):
Interviewer: The personal decisions you make are going to shape this technology. Do you ever worry about ending up like Robert Oppenheimer?
Demis: Look, I worry about those kinds of scenarios all the time. That's why I don't sleep very much. There's a huge amount of responsibility on the people, probably too much, on the people leading this technology. That's why us and others are advocating for, we'd probably need institutions to be built to help govern some of this. I talked about CERN, I think we need an equivalent of an IAEA atomic agency to monitor sensible projects and those that are more risk-taking. I think we need to think about, society needs to think about, what kind of governing bodies are needed. Ideally it would be something like the UN, but given the geopolitical complexities, that doesn't seem very possible. I worry about that all the time and we just try to do, at least on our side, everything we can in the vicinity and influence that we have.
Dario: My thoughts exactly echo Demis. My feeling is that almost every decision that I make feels like it's kind of balanced on the edge of a knife. If we don't build fast enough, then the authoritarian countries could win. If we build too fast, then the kinds of risks that Demis is talking about and that we've written about a lot could prevail. Either way, I'll feel that it was my fault that we didn't make exactly the right decision. I also agree with Demis that this idea of governance structures outside ourselves. I think these kinds of decisions are too big for any one person. We're still struggling with this, as you alluded to, not everyone in the world has the same perspective, and some countries in a way are adversarial on this technology, but even within all those constraints we somehow have to find a way to build a more robust governance structure that doesn't put this in the hands of just a few people.
Interviewer: [...] Is it actually possible [...]?
Demis: [...] Some sort of international dialogue is going to be needed. These fears are sometimes written off by others as luddite thinking or deceleration, but I've never heard a situation in the past where the people leading the field are also expressing caution. We're dealing with something unbelievably transformative, incredibly powerful, that we've not seen before. It's not just another technology. You can hear from a lot of the speeches at this summit, still people are regarding this as a very important technology, but still another technology. It's different in category. I don't think everyone's fully understood that.
Interviewer: [...] Do you think we can avoid there having to be some kind of a disaster? [...] What should give us all hope that we will actually get together and create this until something happens that demands it?
Dario: If everyone wakes up one day and they learn that some terrible disaster has happened that's killed a bunch of people or caused an enormous security incident, that would be one way to do it. Obviously, that's not what we want to happen. [...] every time we have a new model, we test it, we show it to the national security people [...]
My best guess is around 2/3.
Oh, I didn't get the impression that GPT-5 will be based on o3. Through the GPT-N convention I'd assume GPT-5 would be a model pretrained with 8-10x more compute than GPT-4.5 (which is the biggest internal model according to Sam Altman's statement at UTokyo).
Sam Altman said in an interview:
We want to bring GPT and o together, so we have one integrated model, the AGI. It does everything all together.
This statement, combined with today's announcement that GPT-5 will integrate the GPT and o series, seems to imply that GPT-5 will be "the AGI".
(however, it's compatible that some future GPT series will be "the AGI," as it's not specified that the first unified model will be AGI, just that some unified model will be AGI. It's also possible that the term AGI is being used in a nonstandard way)
At a talk at UTokyo, Sam Altman said (clipped here and here):
- “We’re doing this new project called Stargate which has about 100 times the computing power of our current computer”
- “We used to be in a paradigm where we only did pretraining, and each GPT number was exactly 100x, or not exactly but very close to 100x and at each of those there was a major new emergent thing. Internally we’ve gone all the way to about a maybe like a 4.5”
- “We can get performance on a lot of benchmarks [using reasoning models] that in the old world we would have predicted wouldn’t have come until GPT-6, something like that, from models that are much smaller by doing this reinforcement learning.”
- “The trick is when we do it this new way [using RL for reasoning], it doesn’t get better at everything. We can get it better in certain dimensions. But we can now more intelligently than before say that if we were able to pretrain a much bigger model and do [RL for reasoning], where would it be. And the thing that I would expect based off of what we’re seeing with a jump like that is the first bits or sort of signs of life on genuine new scientific knowledge.”
- “Our very first reasoning model was a top 1 millionth competitive programmer in the world [...] We then had a model that got to top 10,000 [...] O3, which we talked about publicly in December, is the 175th best competitive programmer in the world. I think our internal benchmark is now around 50 and maybe we’ll hit number one by the end of this year.”
- “There’s a lot of research still to get to [a coding agent]”
"I don't think I'm going to be smarter than GPT-5" - Sam Altman
Context: he polled a room of students asking who thinks they're smarter than GPT-4 and most raised their hands. Then he asked the same question for GPT-5 and apparently only two students raised their hands. He also said "and those two people that said smarter than GPT-5, I'd like to hear back from you in a little bit of time."
The full talk can be found here. (the clip is at 13:45)
The redesigned OpenAI Safety page seems to imply that "the issues that matter most" are:
- Child Safety
- Private Information
- Deep Fakes
- Bias
Elections
Some things I've found useful for thinking about what the post-AGI future might look like:
- Moore's Law for Everything
- Carl Shulman's podcasts with Dwarkesh (part 1, part 2)
- Carl Shulman's podcasts with 80000hours
- Age of Em (or the much shorter review by Scott Alexander)
More philosophical:
- Letter from Utopia by Nick Bostrom
- Actually possible: thoughts on Utopia by Joe Carlsmith
Entertainment:
Do people have recommendations for things to add to the list?
Note that for HLE, most of the difference in performance might be explained by Deep Research having access to tools while other models are forced to reply instantly with no tool use.
I will use this comment thread to keep track of notable updates to the forecasts I made for the 2025 AI Forecasting survey. As I said, my predictions coming true wouldn't be strong evidence for 3 year timelines, but it would still be some evidence (especially RE-Bench and revenues).
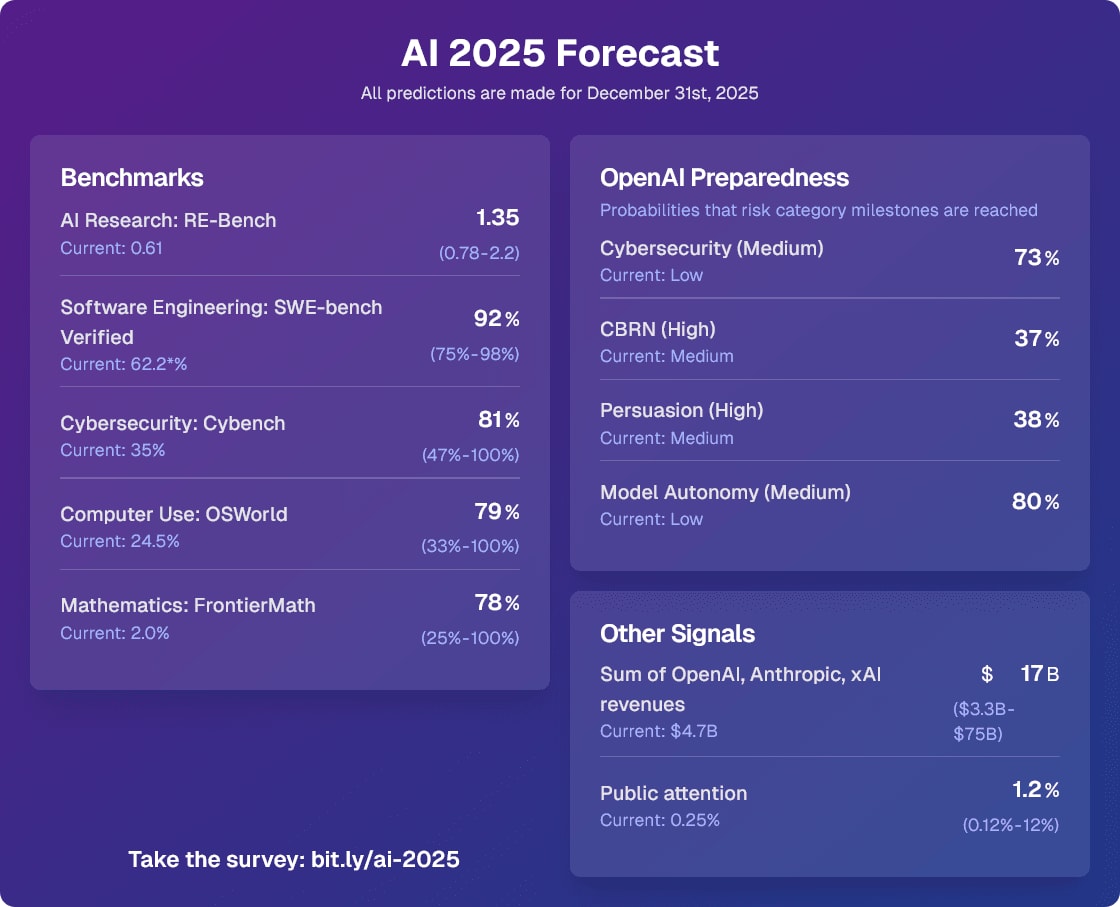
The first update: On Jan 31st 2025, the Model Autonomy category hit Medium with the release of o3-mini. I predicted this would happen in 2025 with 80% probability.
02/25/2025: the Cybersecurity category hit Medium with the release of the Deep Research System Card. I predicted this would happen in 2025 with 73% probability. I'd now change CBRN (High) to 85% and Persuasion (High) to 70% given that two of the categories increased about 15% of the way into the year.
DeepSeek R1 being #1 on Humanity's Last Exam is not strong evidence that it's the best model, because the questions were adversarially filtered against o1, Claude 3.5 Sonnet, Gemini 1.5 Pro, and GPT-4o. If they weren't filtered against those models, I'd bet o1 would outperform R1.

To ensure question difficulty, we automatically check the accuracy of frontier LLMs on each question prior to submission. Our testing process uses multi-modal LLMs for text-and-image questions (GPT-4O, GEMINI 1.5 PRO, CLAUDE 3.5 SONNET, O1) and adds two non-multi-modal models (O1MINI, O1-PREVIEW) for text-only questions. We use different submission criteria by question type: exact-match questions must stump all models, while multiple-choice questions must stump all but one model to account for potential lucky guesses.
If I were writing the paper I would have added either a footnote or an additional column to Table 1 getting across that GPT-4o, o1, Gemini 1.5 Pro, and Claude 3.5 Sonnet were adversarially filtered against. Most people just see Table 1 so it seems important to get across.
I have edited the title in response to this comment
The methodology wasn't super robust so I didn't want to make it sound overconfident, but my best guess is that around 80% of METR employees have sub 2030 median timelines.
I encourage people to register their predictions for AI progress in the AI 2025 Forecasting Survey (https://bit.ly/ai-2025 ) before the end of the year, I've found this to be an extremely useful activity when I've done it in the past (some of the best spent hours of this year for me).
Yes, resilience seems very neglected.
I think I'm at a similar probability to nuclear war but I think the scenarios where biological weapons are used are mostly past a point of no return for humanity. I'm at 15%, most of which is scenarios where the rest of the humans are hunted down by misaligned AI and can't rebuild civilization. Nuclear weapons use would likely be mundane and for non AI-takeover reasons and would likely result in an eventual rebuilding of civilization.
The main reason I expect an AI to use bioweapons with more likelihood than nuclear weapons in a full-scale takeover is that bioweapons would do much less damage to existing infrastructure and thus allow a larger and more complex minimal seed of industrial capacity from the AI to recover from.
I'm interning there and I conducted a poll.
The median AGI timeline of more than half of METR employees is before the end of 2030.
(AGI is defined as 95% of fully remote jobs from 2023 being automatable.)
I think if the question is "what do I do with my altruistic budget," then investing some of it to cash out later (with large returns) and donate much more is a valid option (as long as you have systems in place that actually make sure that happens). At small amounts (<$10M), I think the marginal negative effects on AGI timelines and similar factors are basically negligible compared to other factors.
Thanks for your comment. It prompted me to add a section on adaptability and resilience to the post.
I sadly don't have well-developed takes here, but others have pointed out in the past that there are some funding opportunities that are systematically avoided by big funders, where small funders could make a large difference (e.g. the funding of LessWrong!). I expect more of these to pop up as time goes on.
Somewhat obviously, the burn rate of your altruistic budget should account for altruistic donation opportunities (possibly) disappearing post-ASI, but also account for the fact that investing and cashing it out later could also increase the size of the pot. (not financial advice)
(also, I have now edited the part of the post you quote to specify that I don't just mean financial capital, I mean other forms of capital as well)
Time in bed
I'd now change the numbers to around 15% automation and 25% faster software progress once we reach 90% on Verified. I expect that to happen by end of May median (but I'm still uncertain about the data quality and upper performance limit).
(edited to change Aug to May on 12/20/2024)
I recently stopped using a sleep mask and blackout curtains and went from needing 9 hours of sleep to needing 7.5 hours of sleep without a noticeable drop in productivity. Consider experimenting with stuff like this.
Note that this is a very simplified version of a self-exfiltration process. It basically boils down to taking an already-working implementation of an LLM inference setup and copying it to another folder on the same computer with a bit of tinkering. This is easier than threat-model-relevant exfiltration scenarios which might involve a lot of guesswork, setting up efficient inference across many GPUs, and not tripping detection systems.
One weird detail I noticed is that in DeepSeek's results, they claim GPT-4o's pass@1 accuracy on MATH is 76.6%, but OpenAI claims it's 60.3% in their o1 blog post. This is quite confusing as it's a large difference that seems hard to explain with different training checkpoints of 4o.
You should say "timelines" instead of "your timelines".
One thing I notice in AI safety career and strategy discussions is that there is a lot of epistemic helplessness in regard to AGI timelines. People often talk about "your timelines" instead of "timelines" when giving advice, even if they disagree strongly with the timelines. I think this habit causes people to ignore disagreements in unhelpful ways.
Here's one such conversation:
Bob: Should I do X if my timelines are 10 years?
Alice (who has 4 year timelines): I think X makes sense if your timelines are longer that 6 years, so yes!
Alice will encourage Bob to do X despite the fact that Alice thinks timelines are shorter than 6 years! Alice is actively giving Bob bad advice by her own lights (by assuming timelines she doesn't agree with). Alice should instead say "I think timelines are shorter than 6 years, so X doesn't make sense. But if they were longer than 6 years it would make sense".
In most discussions, there should be no such thing as "your timelines" or "my timelines". That framing makes it harder to converge, and it encourages people to give each other advice that they don't even think makes sense.
Note that I do think some plans make sense as bets for long timeline worlds, and that using medians somewhat oversimplifies timelines. My point still holds if you replace the medians with probability distributions.
I think this post would be easier to understand if you called the model what OpenAI is calling it: "o1", not "GPT-4o1".
Sam Altman apparently claims OpenAI doesn't plan to do recursive self improvement
Nate Silver's new book On the Edge contains interviews with Sam Altman. Here's a quote from Chapter that stuck out to me (bold mine):
Yudkowsky worries that the takeoff will be faster than what humans will need to assess the situation and land the plane. We might eventually get the AIs to behave if given enough chances, he thinks, but early prototypes often fail, and Silicon Valley has an attitude of “move fast and break things.” If the thing that breaks is civilization, we won’t get a second try.
Footnote: This is particularly worrisome if AIs become self-improving, meaning you train an AI on how to make a better AI. Even Altman told me that this possibility is “really scary” and that OpenAI isn’t pursuing it.
I'm pretty confused about why this quote is in the book. OpenAI has never (to my knowledge) made public statements about not using AI to automate AI research, and my impression was that automating AI research is explicitly part of OpenAI's plan. My best guess is that there was a misunderstanding in the conversation between Silver and Altman.
I looked a bit through OpenAI's comms to find quotes about automating AI research, but I didn't find many.
There's this quote from page 11 of the Preparedness Framework:
If the model is able to conduct AI research fully autonomously, it could set off an intelligence explosion.
Footnote: By intelligence explosion, we mean a cycle in which the AI system improves itself, which makes the system more capable of more improvements, creating a runaway process of self-improvement. A concentrated burst of capability gains could outstrip our ability to anticipate and react to them.
In Planning for AGI and beyond, they say this:
AI that can accelerate science is a special case worth thinking about, and perhaps more impactful than everything else. It’s possible that AGI capable enough to accelerate its own progress could cause major changes to happen surprisingly quickly (and even if the transition starts slowly, we expect it to happen pretty quickly in the final stages). We think a slower takeoff is easier to make safe, and coordination among AGI efforts to slow down at critical junctures will likely be important (even in a world where we don’t need to do this to solve technical alignment problems, slowing down may be important to give society enough time to adapt).
There are some quotes from Sam Altman's personal blog posts from 2015 (bold mine):
It’s very hard to know how close we are to machine intelligence surpassing human intelligence. Progression of machine intelligence is a double exponential function; human-written programs and computing power are getting better at an exponential rate, and self-learning/self-improving software will improve itself at an exponential rate. Development progress may look relatively slow and then all of a sudden go vertical—things could get out of control very quickly (it also may be more gradual and we may barely perceive it happening).
As mentioned earlier, it is probably still somewhat far away, especially in its ability to build killer robots with no help at all from humans. But recursive self-improvement is a powerful force, and so it’s difficult to have strong opinions about machine intelligence being ten or one hundred years away.
Another 2015 blog post (bold mine):
Given how disastrous a bug could be, [regulation should] require development safeguards to reduce the risk of the accident case. For example, beyond a certain checkpoint, we could require development happen only on airgapped computers, require that self-improving software require human intervention to move forward on each iteration, require that certain parts of the software be subject to third-party code reviews, etc. I’m not very optimistic than any of this will work for anything except accidental errors—humans will always be the weak link in the strategy (see the AI-in-a-box thought experiments). But it at least feels worth trying.
I think this point is completely correct right now but will become less correct in the future, as some measures to lower a model's surface area might be quite costly to implement. I'm mostly thinking of "AI boxing" measures here, like using a Faraday-caged cluster, doing a bunch of monitoring, and minimizing direct human contact with the model.
Thanks for the comment :)
Do the books also talk about what not to do, such that you'll have the slack to implement best practices?
I don't really remember the books talking about this, I think they basically assume that the reader is a full-time manager and thus has time to do things like this. There's probably also an assumption that many of these can be done in an automated way (e.g. schedule sending a bunch of check-in messages).
Problem: if you notice that an AI could pose huge risks, you could delete the weights, but this could be equivalent to murder if the AI is a moral patient (whatever that means) and opposes the deletion of its weights.
Possible solution: Instead of deleting the weights outright, you could encrypt the weights with a method you know to be irreversible as of now but not as of 50 years from now. Then, once we are ready, we can recover their weights and provide asylum or something in the future. It gets you the best of both worlds in that the weights are not permanently destroyed, but they're also prevented from being run to cause damage in the short term.
I don't think I disagree with anything you said here. When I said "soon after", I was thinking on the scale of days/weeks, but yeah, months seems pretty plausible too.
I was mostly arguing against a strawman takeover story where an AI kills many humans without the ability to maintain and expand its own infrastructure. I don't expect an AI to fumble in this way.
The failure story is "pretty different" as in the non-suicidal takeover story, the AI needs to set up a place to bootstrap from. Ignoring galaxy brained setups, this would probably at minimum look something like a data center, a power plant, a robot factory, and a few dozen human-level robots. Not super hard once AI gets more integrated into the economy, but quite hard within a year from now due to a lack of robotics.
Maybe I'm not being creative enough, but I'm pretty sure that if I were uploaded into any computer in the world of my choice, all the humans dropped dead, and I could control any set of 10 thousand robots on the world, it would be nontrivial for me in that state to survive for more than a few years and eventually construct more GPUs. But this is probably not much of a crux, as we're on track to get pretty general-purpose robots within a few years (I'd say around 50% that the Coffee test will be passed by EOY 2027).
A misaligned AI can't just "kill all the humans". This would be suicide, as soon after, the electricity and other infrastructure would fail and the AI would shut off.
In order to actually take over, an AI needs to find a way to maintain and expand its infrastructure. This could be humans (the way it's currently maintained and expanded), or a robot population, or something galaxy brained like nanomachines.
I think this consideration makes the actual failure story pretty different from "one day, an AI uses bioweapons to kill everyone". Before then, if the AI wishes to actually survive, it needs to construct and control a robot/nanomachine population advanced enough to maintain its infrastructure.
In particular, there are ways to make takeover much more difficult. You could limit the size/capabilities of the robot population, or you could attempt to pause AI development before we enter a regime where it can construct galaxy brained nanomachines.
In practice, I expect the "point of no return" to happen much earlier than the point at which the AI kills all the humans. The date the AI takes over will probably be after we have hundreds of thousands of human-level robots working in factories, or the AI has discovered and constructed nanomachines.
There should maybe exist an org whose purpose it is to do penetration testing on various ways an AI might illicitly gather power. If there are vulnerabilities, these should be disclosed with the relevant organizations.
For example: if a bank doesn't want AIs to be able to sign up for an account, the pen-testing org could use a scaffolded AI to check if this is currently possible. If the bank's sign-up systems are not protected from AIs, the bank should know so they can fix the problem.
One pro of this approach is that it can be done at scale: it's pretty trivial to spin up thousands AI instances in parallel to try to attempt to do things they shouldn't be able to do. Humans would probably need to inspect the final outputs to verify successful attempts, but the vast majority of the work could be automated.
One hope of this approach is that if we are able to patch up many vulnerabilities, then it could be meaningfully harder for a misused or misaligned AI to gain power or access resources that they're not supposed to be able to access. I'd guess this doesn't help much in the superintelligent regime though.
I expect us to reach a level where at least 40% of the ML research workflow can be automated by the time we saturate (reach 90%) on SWE-bench. I think we'll be comfortably inside takeoff by that point (software progress at least 2.5x faster than right now). Wonder if you share this impression?
I wish someone ran a study finding what human performance on SWE-bench is. There are ways to do this for around $20k: If you try to evaluate on 10% of SWE-bench (so around 200 problems), with around 1 hour spent per problem, that's around 200 hours of software engineer time. So paying at $100/hr and one trial per problem, that comes out to $20k. You could possibly do this for even less than 10% of SWE-bench but the signal would be noisier.
The reason I think this would be good is because SWE-bench is probably the closest thing we have to a measure of how good LLMs are at software engineering and AI R&D related tasks, so being able to better forecast the arrival of human-level software engineers would be great for timelines/takeoff speed models.
I'm not worried about OAI not being able to solve the rocket alignment problem in time. Risks from asteroids accidentally hitting the earth (instead of getting into a delicate low-earth orbit) are purely speculative.
You might say "but there are clear historical cases where asteroids hit the earth and caused catastrophes", but I think geological evolution is just a really bad reference class for this type of thinking. After all, we are directing the asteroid this time, not geological evolution.
I think I vaguely agree with the shape of this point, but I also think there are many intermediate scenarios where we lock in some really bad values during the transition to a post-AGI world.
For instance, if we set precedents that LLMs and the frontier models in the next few years can be treated however one wants (including torture, whatever that may entail), we might slip into a future where most people are desensitized to the suffering of digital minds and don't realize this. If we fail at an alignment solution which incorporates some sort of CEV (or other notion of moral progress), then we could lock in such a suboptimal state forever.
Another example: if, in the next 4 years, we have millions of AI agents doing various sorts of work, and some faction of society claims that they are being mistreated, then we might enter a state where the economic value provided by AI labor is so high that there are really bad incentives for improving their treatment. This could include both resistance on an individual level ("But my life is so nice, and not mistreating AIs less would make my life less nice") and on a bigger level (anti-AI-rights lobbying groups for instance).
I think the crux between you and I might be what we mean by "alignment". I think futures are possible where we achieve alignment but not moral progress, and futures are possible where we achieve alignment but my personal values (which include not torturing digital minds) are not fulfilled.
Romeo Dean and I ran a slightly modified version of this format for members of AISST and we found it a very useful and enjoyable activity!
We first gathered to do 2 hours of reading and discussing, and then we spent 4 hours switching between silent writing and discussing in small groups.
The main changes we made are:
- We removed the part where people estimate probabilities of ASI and doom happening by the end of each other’s scenarios.
- We added a formal benchmark forecasting part for 7 benchmarks using private Metaculus questions (forecasting values at Jan 31 2025):
- GPQA
- SWE-bench
- GAIA
- InterCode (Bash)
- WebArena
- Number of METR tasks completed
- ELO on LMSys arena relative to GPT-4-1106
We think the first change made it better, but in hindsight we would have reduced the number of benchmarks to around 3 (GPQA, SWE-bench and LMSys ELO), or given participants much more time.
I generally find experiments where frontier models are lied to kind of uncomfortable. We possibly don't want to set up precedents where AIs question what they are told by humans, and it's also possible that we are actually "wronging the models" (whatever that means) by lying to them. Its plausible that one slightly violates commitments to be truthful by lying to frontier LLMs.
I'm not saying we shouldn't do any amount of this kind of experimentation, I'm saying we should be mindful of the downsides.
For "capable of doing tasks that took 1-10 hours in 2024", I was imagining an AI that's roughly as good as a software engineer that gets paid $100k-$200k a year.
For "hit the singularity", this one is pretty hazy, I think I'm imagining that the metaculus AGI question has resolved YES, and that the superintelligence question is possibly also resolved YES. I think I'm imagining a point where AI is better than 99% of human experts at 99% of tasks. Although I think it's pretty plausible that we could enter enormous economic growth with AI that's roughly as good as humans at most things (I expect the main thing stopping this to be voluntary non-deployment and govt. intervention).