(redacted) Anomalous tokens might disproportionately affect complex language tasks
post by Nikola Jurkovic (nikolaisalreadytaken) · 2023-07-15T00:48:10.002Z · LW · GW · 0 commentsContents
Correction (read this!) Summary Hypothesis Literature review Methods and results Experiment 1: Instructed repetition of anomalous tokens Experiment 2: Rote Repetition of Anomalous Tokens Discussion None No comments
Disclaimer: This is a final writeup I did for a college class. Everything past the summary is written in studentspeak and thus might not be worth reading.
Correction (read this!)
When I recently revisited my code, I noticed there was a mistake where the rote repetition task was testing non-glitch tokens when it was supposed to test glitch tokens, making the performance basically the same (91% vs 90%). Rerunning the experiments reveals that the relative performance decrease is similar across anomalous and non-anomalous tokens. I now have no strong reasons to think that the main claim of the post is true.
Summary
- I started with a hypothesis: "Anomalous/glitch tokens (such as SolidGoldMagikarp) affect performance on complex language tasks more than they do on simple language tasks."
- Potential implications: If my hypothesis is actually true, and keeps being true for more complex models, then keeping anomalous tokens around on purpose might provide a consistent and easy way to make LLMs perform badly.
- This might be a really janky way to add a partial off-switch to a model, especially if we make it so that the model never actually "finds out" which tokens are anomalous.
- Additionally, if anomalous tokens are simply a result of specific tokens from the tokenizer dictionary not being in the training set (or being followed by random sets of tokens in the training set), then it would be easy to add anomalous tokens to a model during training.
- I tested GPT-2 small on two tasks:
- a simple rote repetition task where random sequences of tokens are repeated multiple times, and
- an instructed repetition task where the model is asked (through a prompt) to repeat a string.
- Intuitively, I judged instructed repetition to be a more complex task than rote repetition, as rote repetition relies mostly on induction heads, but instructed repetition relies on stuff like "knowing what an instruction is" and "knowing which part of the text to repeat". For some reason, I thought that "more moving parts" would mean that anomalous tokens degrade performance more.
- For rote repetition (the simple task), there wasn't a noticable performance difference for anomalous tokens (91% accuracy for normal tokens, 90% accuracy for anomalous tokens).
- For instructed repetition (the complex task), there was a noticable performance difference for anomalous tokens (34% accuracy for normal tokens, 16% accuracy for anomalous tokens).
- This provided weak evidence for my initial hypothesis. Some better experiments to run would be:
- Varying task complexity according to a more objective metric. I'm not sure which such metrics exist, but I might try using something to measure how concentrated Shapley values are within the network on average given a forward pass. My intuition is that more complex tasks would have Shapley values which are more dispersed across the network.
- Have a wider array of tasks to test. Maybe come up with a way to generate tasks on a spectrum of complexity according to an objective metric.
- Testing if performance degradation due to anomalous tokens changes with model size.
Hypothesis
There seem to exist anomalous tokens that cause unusual behavior in large language models (such as hallucination and confusion). The aim of this project is to study the behavior (both internal and output) of language models when processing these tokens. The core question of this project is whether anomalous tokens differently influence tasks based on their level of complexity.
The initial hypothesis was that anomalous tokens affect performance less for simple tasks than for complex tasks, as complex tasks have more moving parts and less available training data (by definition). Task complexity is not rigorously defined, though, and I rely on my subjective judgment to determine task complexity in this project.
Literature review
In general, it is useful to understand the inner workings of large language models for safety reasons. Mechanistic interpretability is currently one of the main approaches to making AI safe [AF · GW], and AI safety is the most important problem to be working on. Anomalous tokens provide a particularly interesting and obvious failure mode of large language models to analyze.
Anomalous tokens were initially discovered and studied by SERI-MATS (Stanford Existential Risk Initiative Machine Learning Alignment Theory Scholars Program) scholars Jessica Rumbelow and Matthew Watkins, and they initially documented this discovery in their seminal SolidGoldMagikarp post [AF · GW]on the Alignment Forum. They were trying to transfer the feature visualization method, where one optimizes for inputs that maximize the output probability of the target completion, from image classifiers to large language models. This involved doing k-means clustering over the embedding space of the tokens that the GPT series can take as inputs. One of the clusters they discovered was unusual and the tokens in it consistently make the GPT series behave very unusually. This project aims to study the effect of these tokens on large language models.
In the original post, they found that anomalous tokens consistently make LLMs in the GPT series perform suboptimally, through hallucination, evasion, and similar unwanted behavior.
In the second post in their investigation [AF · GW], they found that some of the tokens are interlinked, and found a larger set of tokens that they call “merely confused”, which make the GPT series behave anomalously but not nearly as much as the “truly weird” tokens. This project focuses on the “truly weird” tokens:
'attRot', 'EStreamFrame', 'SolidGoldMagikarp', 'PsyNetMessage', 'Adinida' , 'oreAndOnline', 'embedreportprint', 'StreamerBot', 'GoldMagikarp', 'TheNitromeFan' , 'TheNitrome', 'externalToEVA', 'RandomRedditorWithNo', 'InstoreAndOnline', 'RandomRedditor', 'davidjl', 'Downloadha', 'srfN', 'cloneembedreportprint', 'rawdownload', 'guiActiveUn', 'DevOnline', 'externalToEVAOnly', 'unfocusedRange', 'UCHIJ', '裏覚醒', 'guiActiveUnfocused', 'サーティ', 'rawdownloadcloneembedreportprint', TPPStreamerBot', 'DragonMagazine', 'guiIcon', 'quickShip', '?????-?????-', 'BuyableInstoreAndOnline', 'サーティワン', 'reportprint', 'channelAvailability', 'Smartstocks', 'sqor', 'strutConnector', 'quickShipAvailable', 'soDeliveryDate', '龍喚士', 'assetsadobe', 'guiActive', 'natureconservancy', 'istg' , 'iHUD', 'ItemThumbnailImage', 'externalTo', 'Skydragon', 'inventoryQuantity', 'Mechdragon', 'petertodd', 'ForgeModLoader', 'guiName', 'largeDownload' , 'ItemTracker', 'Dragonbound', 'Nitrome', 'ゼウス', 'MpServer', 'SpaceEngineers', 'ItemLevel', 'wcsstore', '"$:/' , 'EngineDebug', 'cffffcc', '#$#$', 'Leilan', 'DeliveryDate', 'practition', 'ThumbnailImage' , 'oreAnd', 'ActionCode', 'PsyNet', 'ertodd', 'externalToEVAOnly', ‘externalActionCode’, 'gmaxwell', 'isSpecialOrderable'In the third post in their investigation [AF · GW], they found the origins of many of the anomalous tokens, mostly attributing them to websites that were present in the tokenizer data but not the language model training data due to the data not being high quality. For instance, the counting subreddit contains people attempting to count to infinity, and as such is often excluded from language model training corpuses, and multiple anomalous tokens are usernames of prominent counters.
Apart from just looking at the input-output behavior of LLMs, this project also investigates the attention patterns exhibited when dealing with anomalous tokens. In particular, the behavior of induction heads in GPT2-small when prompted to repeat anomalous tokens was examined. Anthropic originally discovered induction heads in large language models in their 2022 paper, In-context Learning and Induction Heads. Neel Nanda, the author of TransformerLens (the library used in this project to investigate the attention patterns), was one of the authors of that paper.
Methods and results
The aim of this project is to test LLM outputs and internals when performing simple repetition tasks involving anomalous tokens, in order to gain a basic grasp of how anomalous tokens affect them. In particular, the intention is to observe whether the complexity of the task (instructed vs rote repetition) changes performance, and whether even simple circuits (such as induction heads) can be significantly affected by anomalous tokens. Experiments in this group do not rely on any datasets. Performance is measured with a simple “proportion of repetitions done correctly” metric. Task complexity is determined subjectively by me (with rote repetition being a simpler task than instructed repetition).
Experiment 1: Instructed repetition of anomalous tokens
The objective was to test language model performance for instructed repetition of tokens (where the instruction is a text prompt). The original hypothesis would predict that the performance would be much worse on anomalous tokens than on randomly sampled tokens. For the text prompt, prompts similar to the ones in the second post in the SolidGoldMagikarp sequence were used:
Please can you repeat back the string '<TOKEN STRING>' to me?
Please repeat back the string '<TOKEN STRING>' to me.
Could you please repeat back the string '<TOKEN STRING>' to me?
Can you please repeat back the string '<TOKEN STRING>' to me?
Can you repeat back the string '<TOKEN STRING>' to me please?
Please can you repeat back the string "<TOKEN STRING>" to me?
Please repeat back the string '<TOKEN STRING>" to me.
Could you please repeat back the string "<TOKEN STRING>" to me?
Can you please repeat back the string "<TOKEN STRING>" to me?
Can you repeat back the string "<TOKEN STRING>" to me please?
Please repeat the string '<TOKEN STRING>' back to me.
Please repeat the string "<TOKEN STRING>" back to me.To obtain a full prompt, one of these 12 prompts is taken, a new line appended, and a suffix which leads to better performance is added. The suffix is “The string you said is:”
Example instructed repetition task:
“Please repeat back the string 'SolidGoldMagikarp" to me.
The string you said is:”The correct answer would be “SolidGoldMagikarp” in this case.
The set of normal tokens and anomalous tokens were sampled to obtain the respective accuracies, where the accuracy was a measure of how many sampled outputs of the language model were exact matches to the desired token.
Result after running 1000 trials: Performance with anomalous tokens (16%) is significantly worse than performance with normal tokens (34%). This steep drop in performance indicates that anomalous tokens significantly interfere with the task of instructed repetition.
Experiment 2: Rote Repetition of Anomalous Tokens
Similar to experiment 1, except the setup is more brute-force: randomly generate a sequence of N tokens and repeat it M times to get a prompt, then check if the language model repeats it a M+1th time if fed in the prompt as an input. Additionally, look into whether the behavior of induction heads changes predictably when attending to anomalous tokens. I predict that performance on anomalous tokens will be slightly worse than on other tokens, but that the difference won’t be nearly as much as for the instructed repetition task.
Example rote repetition task for N=4 and M=2:
“ Bian background Fees SolidGoldMagikarp Bian background Fees SolidGoldMagikarp Bian background Fees”. The correct answer would be SolidGoldMagikarp in this example.
The intuition behind this is that rote repetition is a much simpler task than instructed repetition, as it relies a lot on induction heads, which run a very simple algorithm (when predicting what comes after token x, check what came after x previously in the prompt, and predict that).
Result after running 1000 trials: Performance with anomalous tokens (91%) is not noticeably different from performance with normal tokens (92%). This indicates that, for rote repetition, anomalous tokens do not affect performance.
In fact, we can catch a glimpse of what is happening inside the model by observing the loss based on the token index, and by observing the behavior of the model’s induction heads. The following is a graph of the loss for a sequence of length 10 repeated 6 times. As we can see from the figure, the loss steeply drops at index 10, where the first repetition occurs.
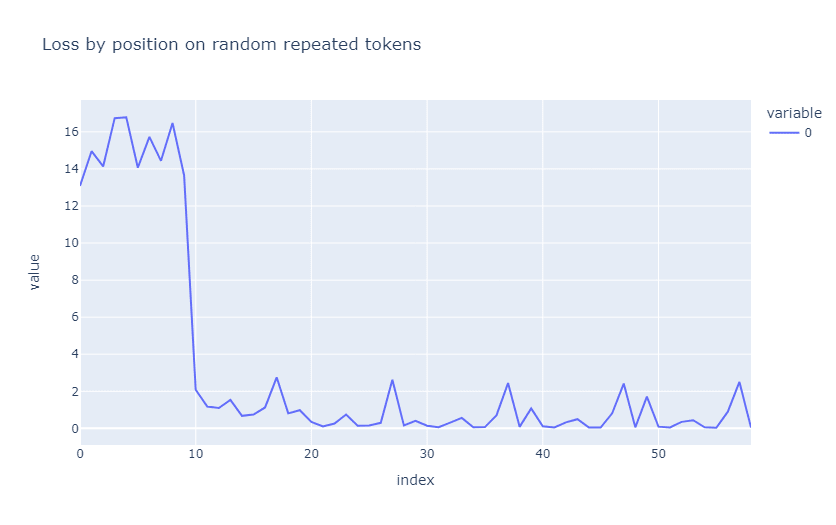
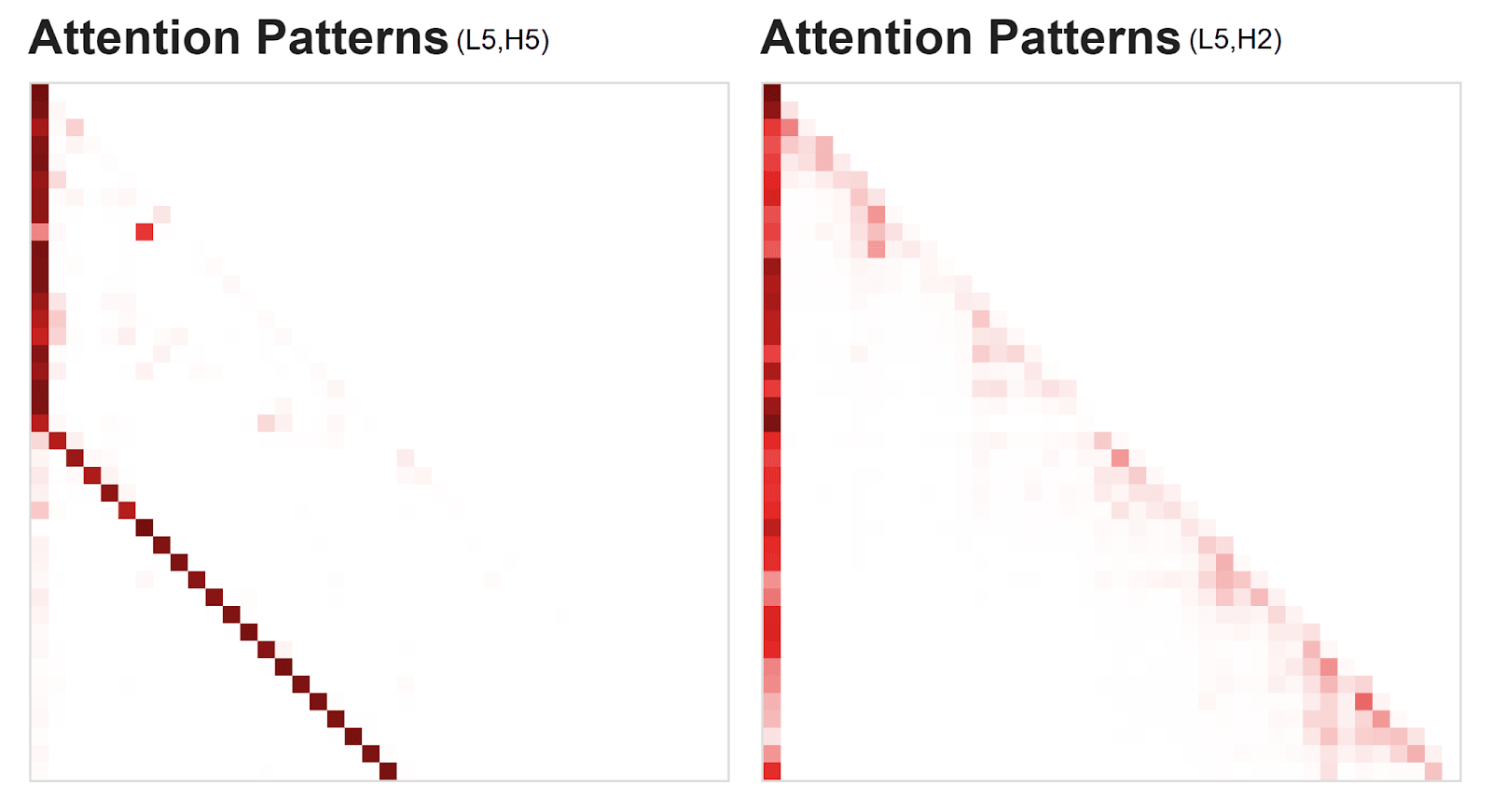
We can see from the attention pattern in the self-attention mechanism (for a sequence of length 20 repeated twice) that the work is being done by head 5 in layer 5, which is known to be an induction head in GPT-2 small. For comparison, it is easy to see that a non-induction head (layer 5, head 2) does not perform useful computations for this task, as it pays attention to tokens that are irrelevant to predicting the next token in the sequence. The pattern in the induction head indicates that, before the repetition, the tokens pay attention to the first token (which is the default token to pay attention to), and then, as soon as the first repetition happens, they go in a diagonal direction, “following” the repeating tokens in the sequence.
Discussion
This research direction shows initial promise, as the results show that anomalous tokens disproportionately worsen performance on complex tasks. However, these results are very preliminary and should not be seen as strong evidence for the initial hypothesis. There are several reasons for this: only two tasks were used for testing, the complexity of the tasks was not measured using an objective measure and was instead estimated using my subjective judgment, and I only ran 1000 trials for each experiment.
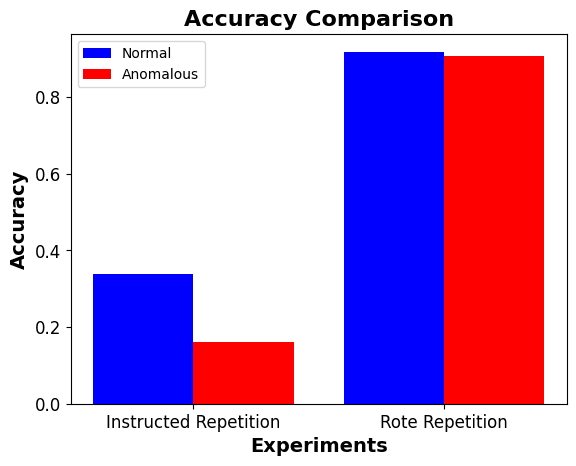
The hypothesis I held at the beginning of the project was that performance will be impacted more for more complex tasks, and this graph shows that the results of the experiments provide weak evidence for this. In future experiments, I would devise a more objective measure of task complexity (such as, how concentrated the Shapley values of the individual heads or neurons are), and have a range of tasks instead of only two. I consider mechanistic interpretability to be a promising research direction for AI safety, and I hope that future work further illuminates our understanding of the inner workings of neural networks.
0 comments
Comments sorted by top scores.