Forecasting time to automated superhuman coders [AI 2027 Timelines Forecast]
post by elifland, Nikola Jurkovic (nikolaisalreadytaken) · 2025-04-10T23:10:23.063Z · LW · GW · 0 commentsThis is a link post for https://ai-2027.com/research/timelines-forecast
Contents
Summary Defining a superhuman coder (SC) Method 1: Time horizon extension METR’s time horizon report Forecasting SC’s arrival Method 2: Benchmarks and gaps Time to RE-Bench saturation Why RE-Bench? Forecasting saturation via extrapolation AI progress speedups after saturation Time to cross gaps between RE-Bench saturation and SC What are the gaps in task difficulty between RE-Bench saturation and SC? Methodology How fast can the task difficulty gaps be crossed? Summary table Time horizon Other factors for benchmarks and gaps Compute scaling and algorithmic progress slowdown Gap between internal and external deployment Intermediate speedups Overall benchmarks and gaps forecasts Appendix Individual Forecaster Views for Benchmark-Gap Model Factors Engineering complexity: handling complex codebases Feedback loops: Working without externally provided feedback Parallel projects: Handling several interacting projects Specialization: Specializing in skills specific to frontier AI development Cost and speed Other task difficulty gaps Superhuman Coder (SC): time horizon and reliability requirements RE-Bench saturation resolution criteria None No comments
Authors: Eli Lifland,[1] Nikola Jurkovic,[2] FutureSearch[3]
This is supporting research for AI 2027. We'll be cross-posting these over the next week or so.
Assumes no large-scale catastrophes happen (e.g., a solar flare, a pandemic, nuclear war), no government or self-imposed slowdown, and no significant supply chain disruptions. All forecasts give a substantial chance of superhuman coding arriving in 2027.
Summary
We forecast when the leading AGI company will internally develop a superhuman coder (SC): an AI system that can do any coding tasks that the best AGI company engineer does, while being much faster and cheaper. At this point, the SC will likely speed up AI progress substantially as is explored in our takeoff forecast.
We first show Method 1: time-horizon-extension, a relatively simple model which forecasts when SC will arrive by extending the trend established by METR’s report of AIs accomplishing tasks that take humans increasing amounts of time.
We then present Method 2: benchmarks-and-gaps, a more complex model starting from a forecast saturation of an AI R&D benchmark (RE-Bench), and then how long it will take to go from that system to one that can handle real-world tasks at the best AGI company.
Finally we provide an “all-things-considered” forecast that takes into account these two models, as well as other possible influences such as geopolitics and macroeconomics.
We also solicited forecasts from 3 professional forecasters from FutureSearch (bios here).
Each method’s results are summarized below:
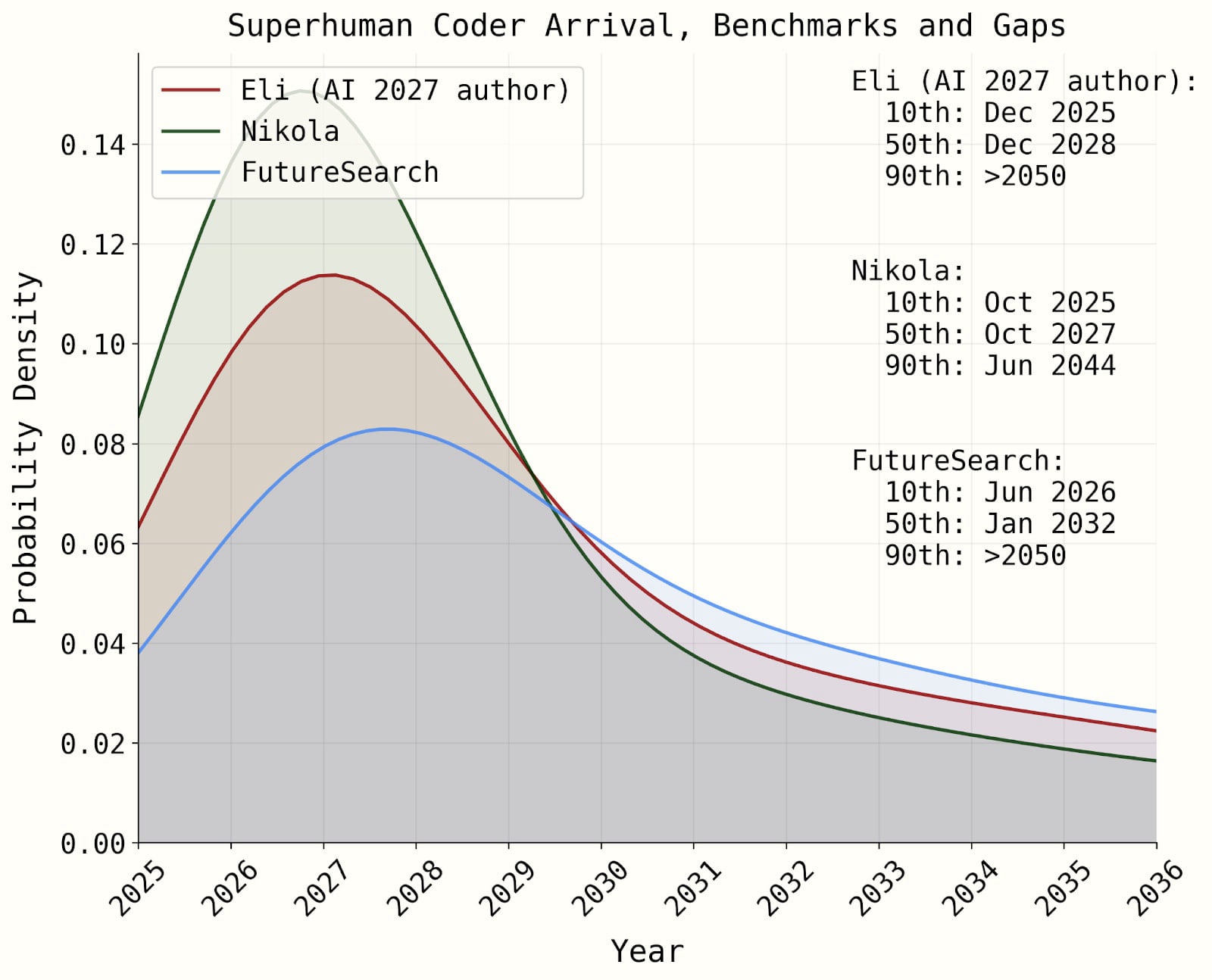
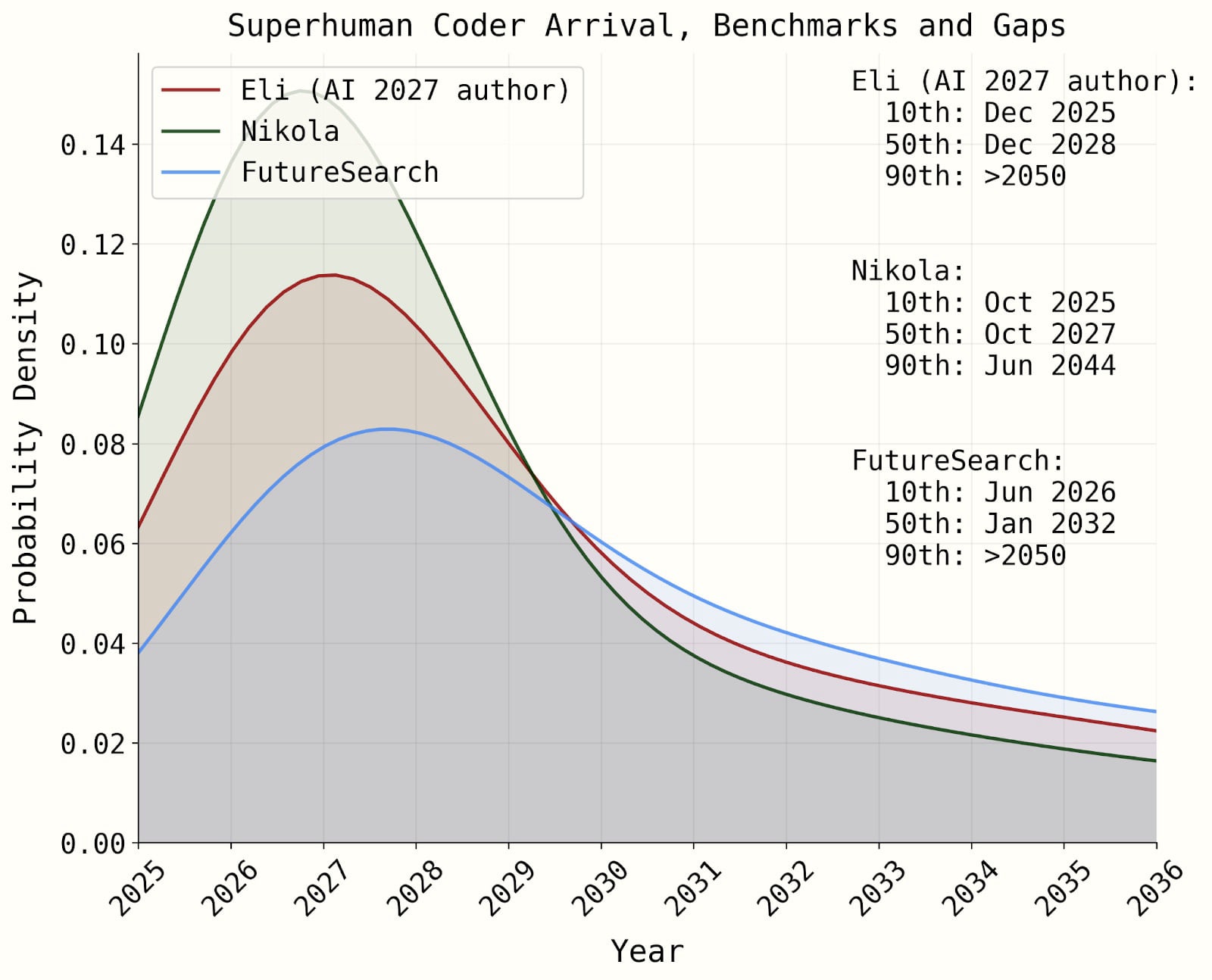
| Eli’s SC forecast (median, 80% CI) | Nikola’s SC forecast (80% CI) | FutureSearch aggregate (80% CI) (n=3) | |
| Time-horizon-extension model | 2027 (2025 to 2039) | 2027 (2025 to 2033) | N/A |
| Benchmarks-and-gaps model | 2028 (2025 to >2050) | 2027 (2025 to 2044) | 2032 (2026 to >2050) |
| All-things-considered forecast, adjusting for factors outside these models | 2030 (2026 to >2050) | 2028 (2026 to 2040) | 2033 (2027 to >2050) |
All model-based forecasts have 2027 as one of the most likely years, which is when an SC is achieved in the AI 2027 scenario. The code for our simulation is here.
Defining a superhuman coder (SC)
Superhuman coder (SC): An AI system for which the company could run with 5%[4] of their compute budget 30x as many agents as they have human research engineers, each of which is on average accomplishing coding tasks involved in AI research (e.g. experiment implementation but not ideation/prioritization) at 30x the speed (i.e. the tasks take them 30x less time, not necessarily that they write or “think” at 30x the speed of humans) of the company’s best engineer. This includes being able to accomplish tasks that are in any human researchers’ area of expertise.
Nikola and Eli estimate that the first SC will have at least 50th percentile frontier AI researcher “research taste” as well, but that isn’t required in the definition.
Method 1: Time horizon extension
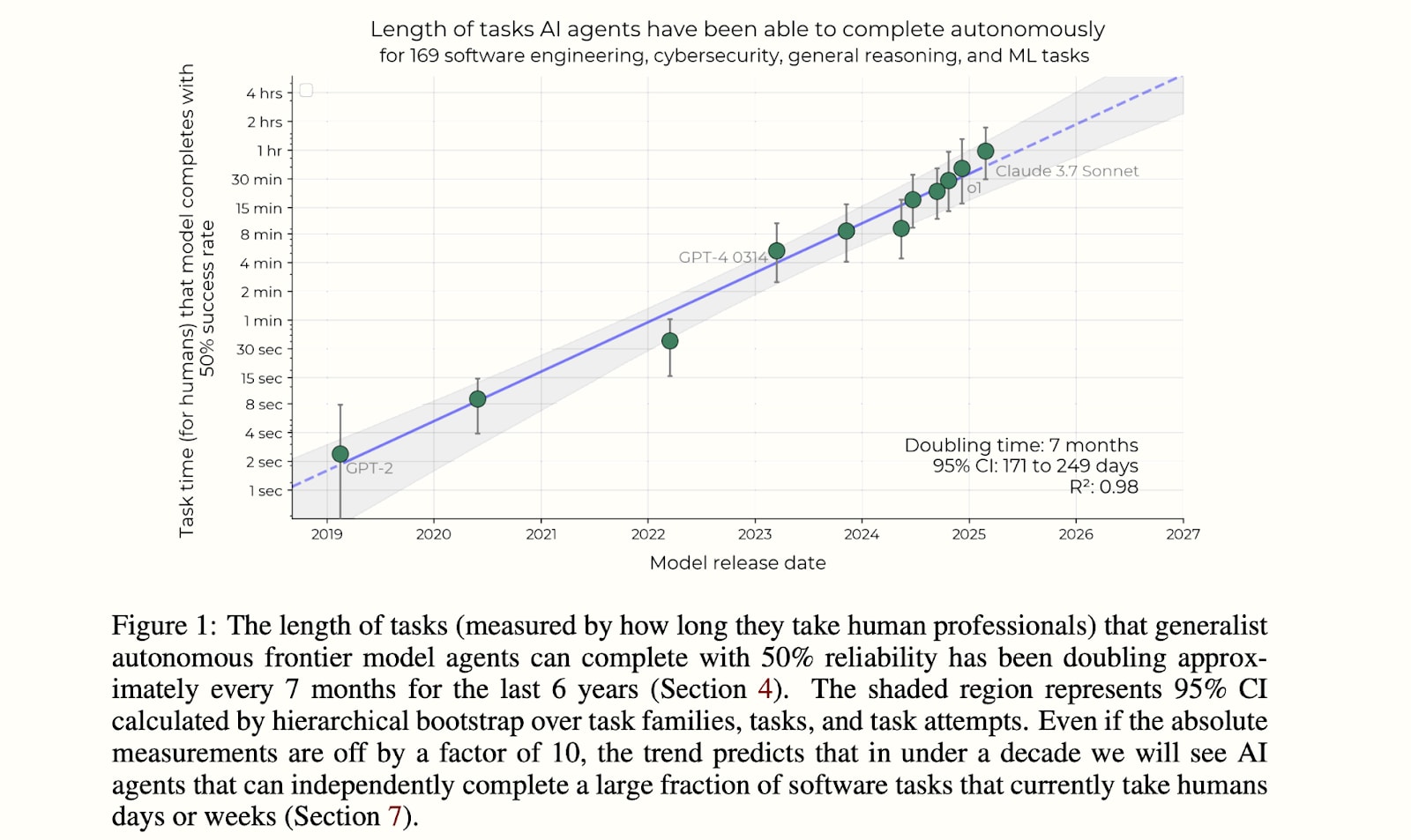
This model relies upon the extrapolation of the progression of AIs toward being superhuman coders (SCs), as measured by how long it takes humans to do the hardest tasks that the AIs can do (which we call the AIs’ “time horizon”). We heavily draw from METR’s recent report which catalogues a trend of increasing time horizon (pictured below).
We split our forecast into 2 subquestions:
- What time horizon and reliability level on METR’s task suite are needed for SC?
- When will this time horizon and reliability be reached?. This is broken down into:
- The current doubling time of the time horizon
- How this would change over time, with no AI R&D automation
- The difficulty of making a human-cost SC 30x faster and cheaper
- Accounting for intermediate speedups and the internal-public gap
The results of our simulation are below.
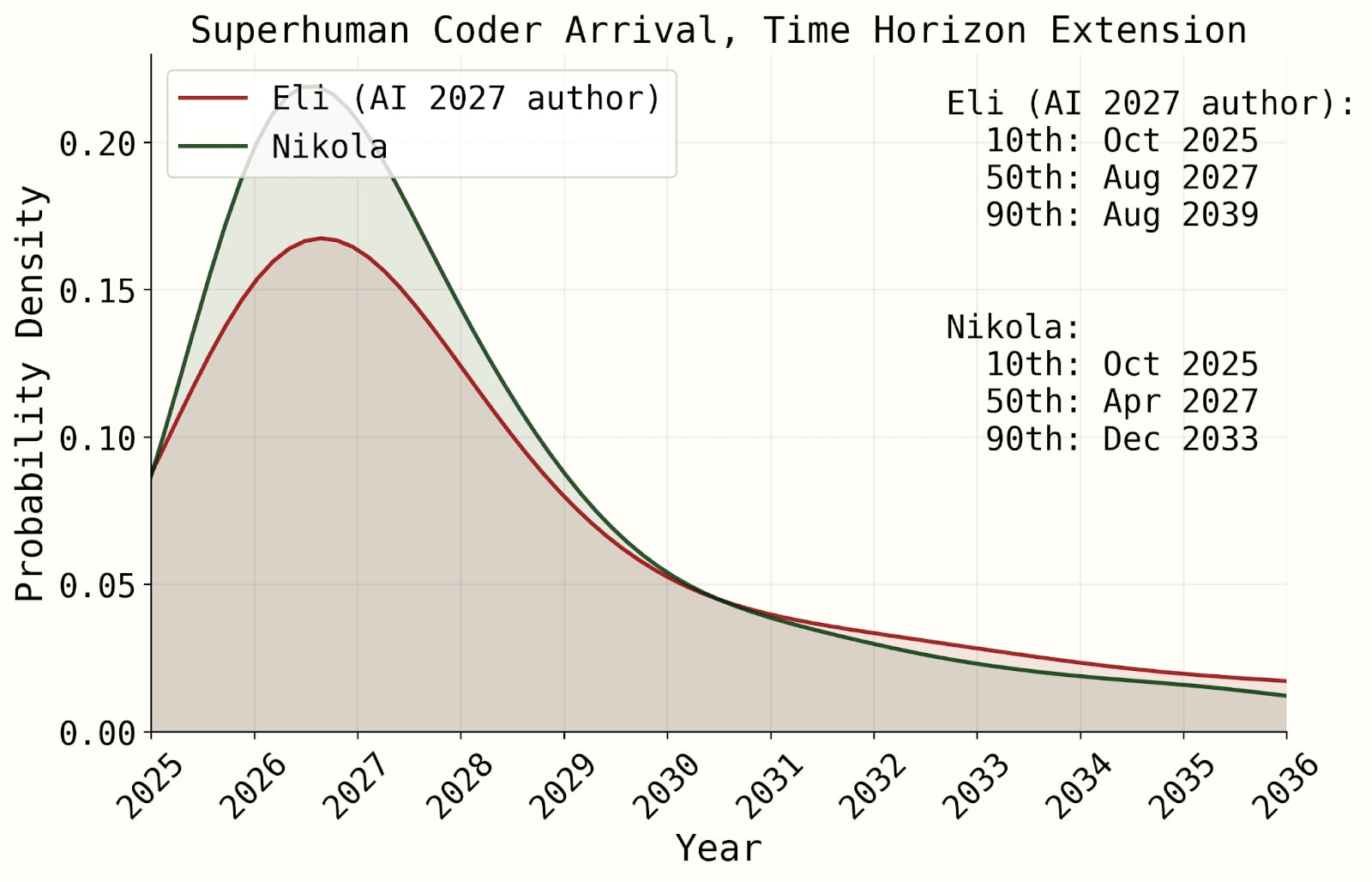
Our distributions accounting for factors outside of this model are wider.
METR’s time horizon report
METR’s recent report measures the “time horizon” capability of AI systems, where time horizon is defined based on how long it takes a skilled human to complete tasks (more details in footnote).[5]
An AI with an R% time horizon of T time means that it has an average success rate of R% on tasks that take humans T time. We follow their definitions of time horizon and reliability in our modeling, except we add a constraint that the AI must complete the task at least as quickly and cheaply as humans. This wouldn’t change METR’s results given that they didn’t spend human-parity costs on inference compute.
The below figure illustrates the methodology:
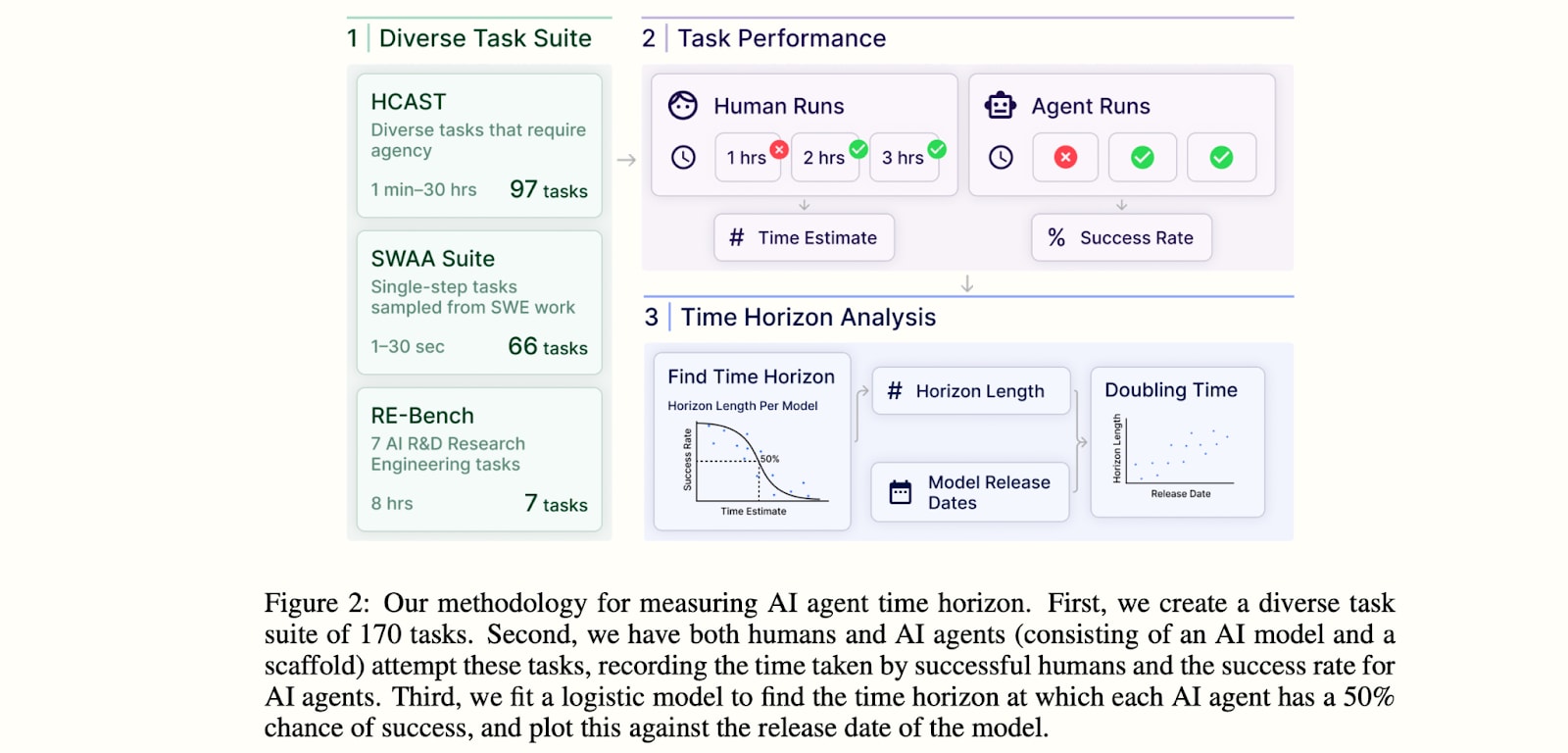
More details about their HCAST task suite are in this paper, with the below table illustrating the distribution of tasks:
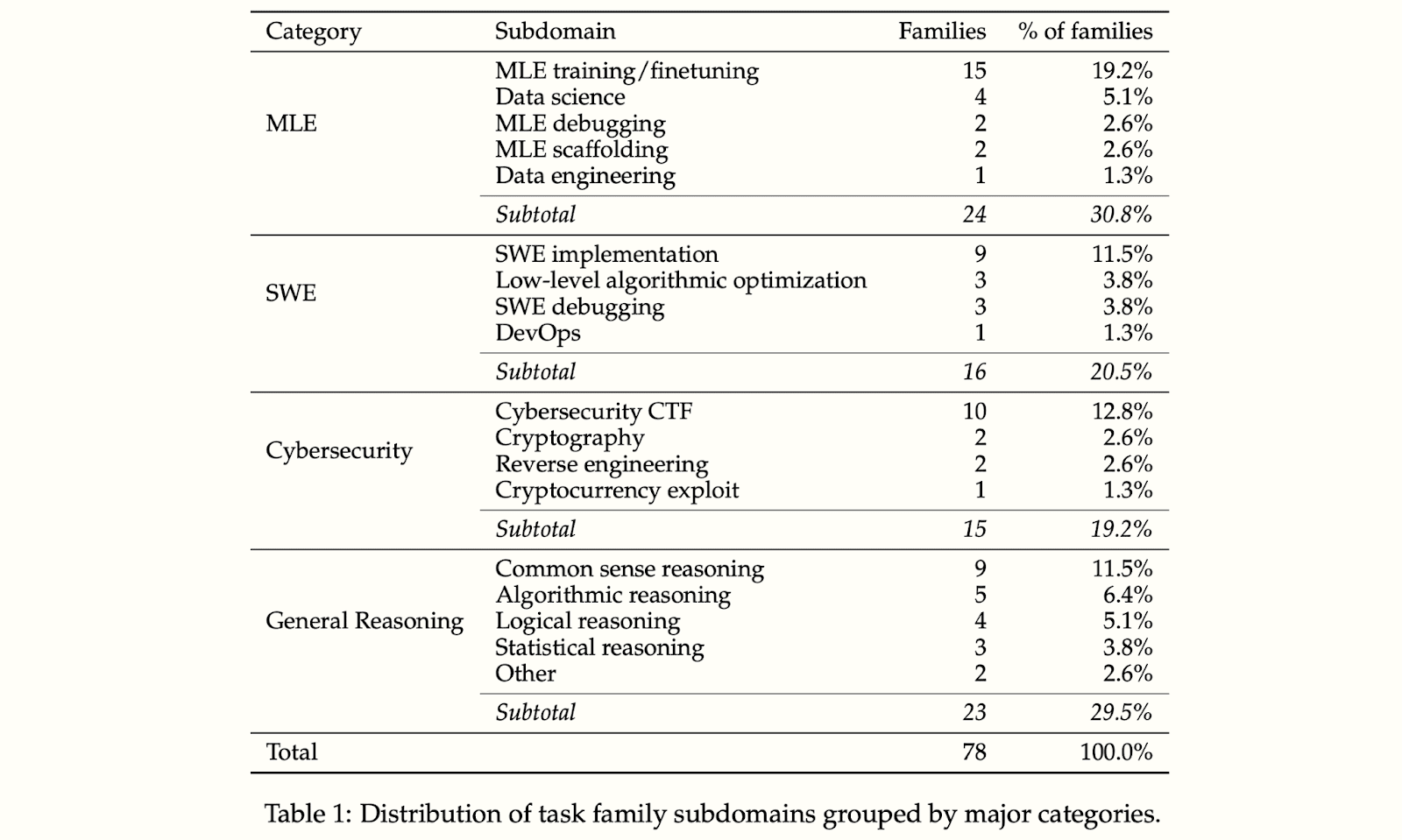
From here on I’ll refer to the METR task suite as HCAST for brevity, given that we’ll be discussing time horizons well above those that SWAA measures and RE-Bench is a small subset of the suite.
Forecasting SC’s arrival
We outline our simulation parameters in the following table.
| Estimates (80% CI of lognormal unless stated otherwise) | Reasoning | |
| Current 80% time horizon | 15 minutes (point estimate) | Taken from METR’s time horizon paper. This is Claude Sonnet 3.7’s 80% time horizon.
|
| Time horizon required for SC | Eli: 10 years [1 month, 1200 years] Nikola: 1.5 months [16 hours, 2 work-years (4,000 hours)] | Time horizon required on real distribution of work tasks, as baselined by the best humans with strong incentives: 6 months (80% CI: [1 week, 12 years]). Time horizon and reliability required on an extrapolation of HCAST, with METR’s current baselining strategy: 10 years [1 month, 1200 years] More reasoning in the appendix. |
| Time horizon doubling time as of Mar 2025 on HCAST | 4.5 months [2.5 months, 9 months]
| Per: METR’s report, the doubling time for 50% time horizon has been roughly:
For the 80% time horizon the doubling time is about the same as 50% during 2019-2025 (7.5 instead of 7 months, Figure 6).
Weighing up the above gives us a median of about 4.5 months. The trends over longer time periods are the most robust, but the latest trends are faster. |
| Will doubling times speed up, slow, or stay the same? | Probabilities: Exponential:
Superexponential:
Subexponential:
| It's possible that time horizon increases superexponentially over time between now and the level required for SC: i.e. it takes less AI progress to go from 1 month to 2 months than from 1 hour to 2 hours, since long-horizon reasoning easily generalizes from short to long time horizons.
Reasons in favor of superexponentiality includes:
Therefore we assign a significant probability to growth being superexponential. We also assign smaller weight to the trend being subexponential.[8] If the growth is superexponential, we make it so that each successive doubling takes 10% less time. If it’s subexponential, each successive doubling takes 10% more time. |
| Cost and speed adjustment | 4 months [0.5 months, 30 months] | Being an SC requires accomplishing tasks 30x faster and 30x cheaper than the best human researchers. However, in the existing METR evaluations they aren’t spending up to human cost, so our starting price point is below humans.
Eyeballing Figure 13 from the METR report, the AIs are currently about 30x cheaper in the median case for HCAST tasks, and perhaps 5-10x cheaper on average. Analysis of their data shows that AIs are roughly 5x faster on average.
Below, we forecast in some depth how fast AIs will get 30x faster and cheaper, starting at human level, based on historical trends in price decreases. Here we take that forecast of 6.9 [1, 48] months, and adjust it downwards by about 50% since we’re starting at 5-10x cheaper and faster than humans. |
| Gap between internal and external deployment | [0.25 months, 6 months] | The current time horizon estimate is for public models, but it is possible that companies have more capable models internally. See more below. |
Method 2: Benchmarks and gaps
Time to RE-Bench saturation
Why RE-Bench?
RE-Bench is a set of challenging and realistic AI R&D tasks with objective scoring functions. They aim to capture the types of work that are commonly done by engineers at AGI companies (e.g., writing scripts to train ML models, optimizing Pytorch code). Since they’re continuously scored there’s no single amount of time that they take to complete, but human baselines so far have been collected up to 8 hours, and 8 hours is sufficient time for a competent professional to make significant improvements to their score. By having humans and AI systems complete RE-Bench tasks, we can get a sense of how capable AI systems are at tasks involved in AI R&D.
We focus on a subset of 5 of the 7 RE-Bench tasks due to issues with scoring in the remaining two, and will refer to this subset as “RE-Bench” in the rest of this report. In particular, we exclude Scaling Law Experiment because it’s easy enough for models to succeed at by luck that it’s not appropriate for best-of-k scaffolding, and we exclude Restricted MLM Architecture because Claude 3.7 Sonnet reliably cheats at this task and METR has not yet been able to prompt the model to attempt the task without cheating.
RE-Bench has a few nice properties that are hard to find in other benchmarks and which make it a uniquely good measure of how much AI is speeding up AI research:
- Highly relevant to frontier AI R&D.
- High performance ceiling. AI agents can achieve significantly above human-level, though in practice it will likely be very difficult to do more than roughly 2x higher than the human baseline solutions (for a score of 1.5). Median human baseline scores are 0.12 for 2 hours of effort and 0.66 for 8 hours. Current state of the art (SOTA) is Claude 3.7 Sonnet with a score of roughly 0.6 using Best-of-K scaffolding in a scaffold called “modular”.
- Human baselines which allow for grounded comparisons between AI and human performance.
We expect that “saturation” under this definition will happen before the SC milestone is hit. The first systems that saturate RE-Bench will probably be missing a few kinds of capabilities that are needed to hit the SC milestone, as described below.
Forecasting saturation via extrapolation
How high does RE-Bench go?
This table from the RE-Bench paper gives a sense of how high the RE-Bench score could go:
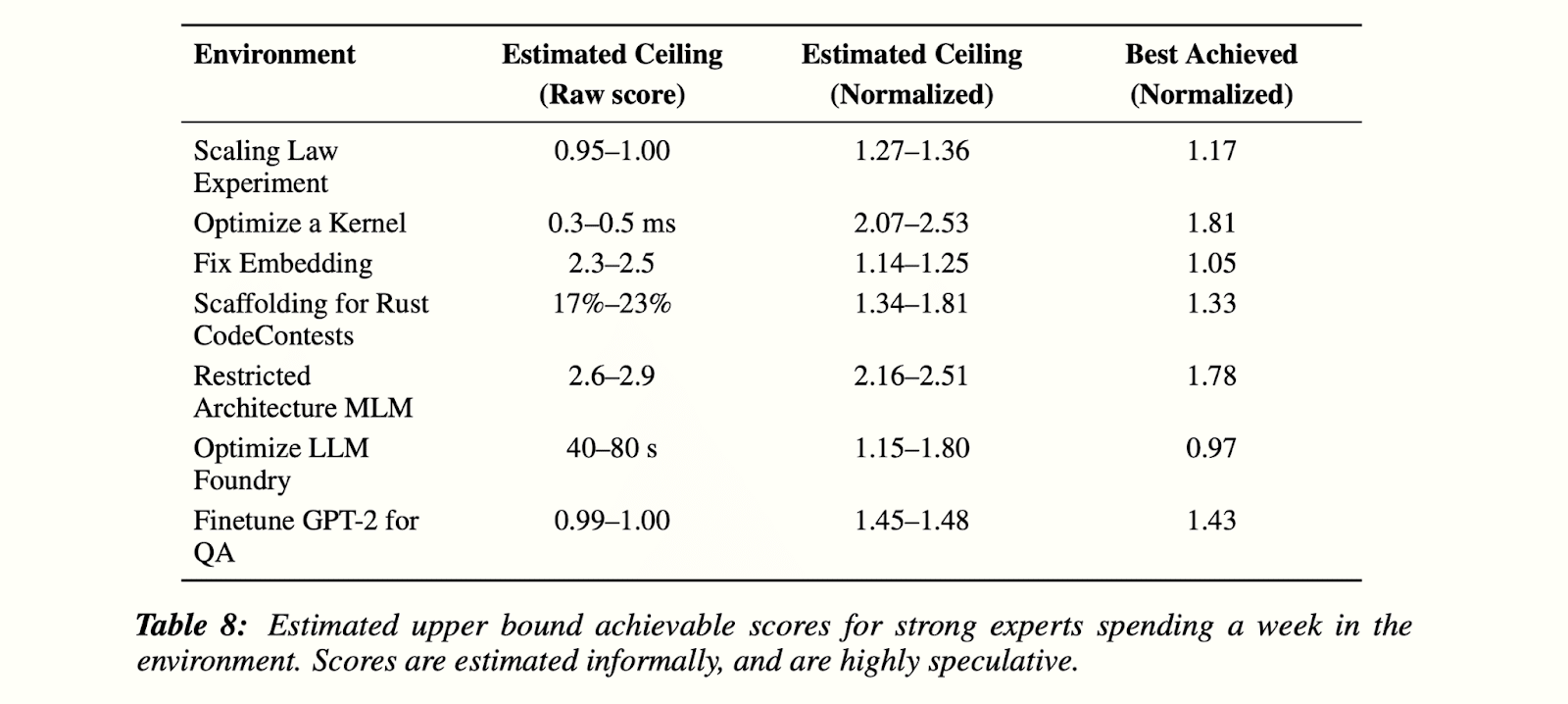
The average of the midpoint of each “estimated ceiling” above is 1.67.[9] To be conservative and make sure the “saturation” level is possible to achieve, we will define a score of 1.5 to mean “saturation” for RE-Bench tasks. We use the resolution criteria from the AI 2025 Forecasting Survey (the appendix), which includes making sure the model doesn’t cost more than a human per task. A score of 1.5 will mean the model beats more than around 95% of human baseline runs (the 90th percentile is around 1.22 in RE-Bench Figure 4). But we estimate that 1.5 is approximately at the level of the average of the best human; this is higher than the 95th percentile due to variance between tasks in difficulty of getting high scores, and variance in individuals’ performance, e.g. due to luck.
Running an extrapolation
Benchmarks have been found to often follow logistic curves [AF · GW] and we will assume RE-bench will follow a similar shape as well, fitting a logistic fit to the point estimates of the historical high score over time. We assume the lower bound of the logistic curve is 0. The upper bound of RE-Bench is not known, so we will model it as a normal distribution with a mean of 2.0 and a standard deviation of 0.25. Changing the upper bound doesn’t change the forecast much — a change of 0.25 in the upper bound moves the saturation date around half a year.
This gives this graph of peak scores allowing Best-of-K and giving most models a 16-hour time budget at the task:[10]
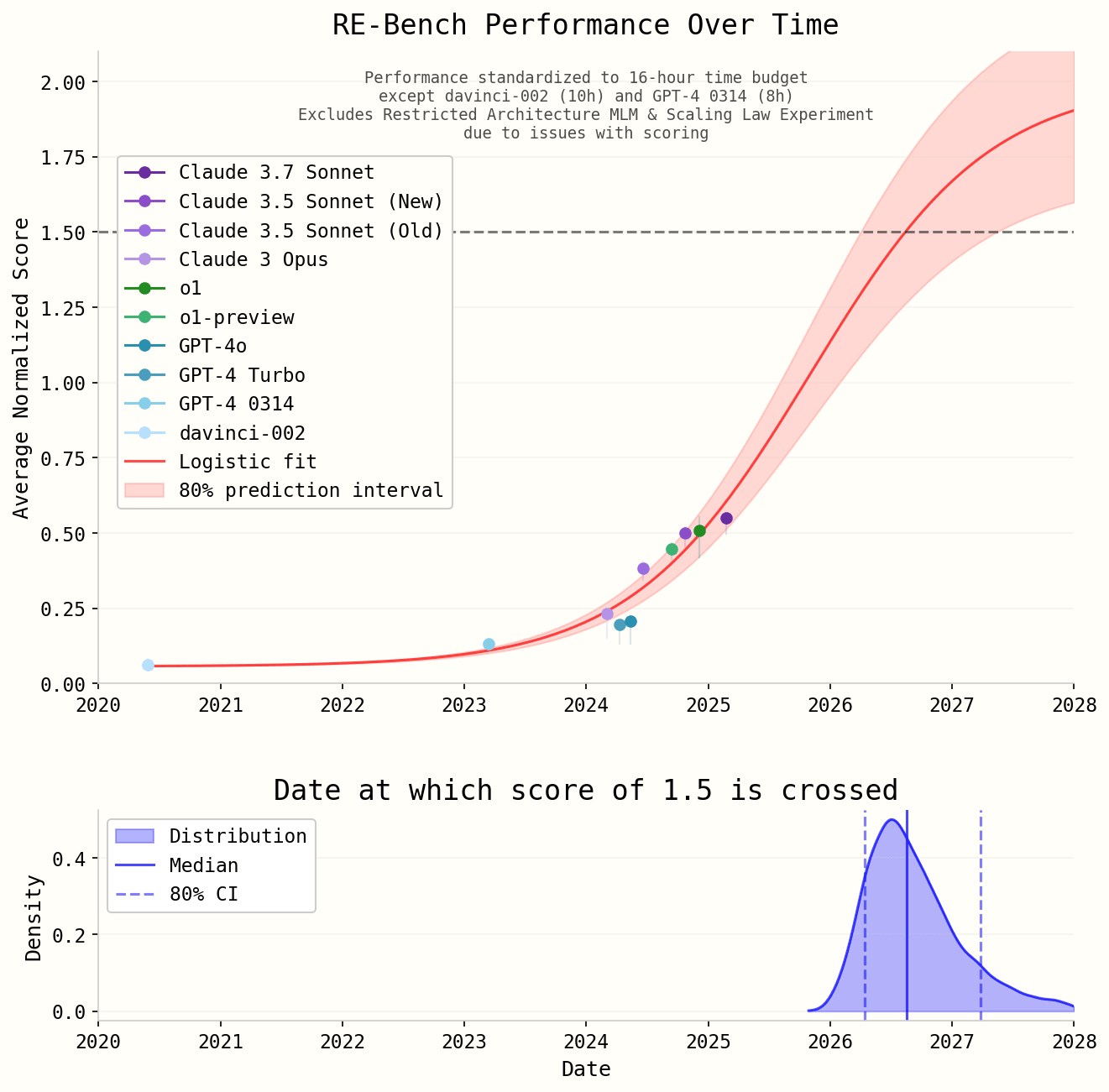
The 80% CI comes from uncertainty about the upper bound of the score and is not meant to represent an epistemic state.
This predicts the date of saturation to be sometime in 2026.
See also this paper which forecasts RE-Bench hitting 1 in 2027. We think the data they used likely led to overly conservative forecasts.
Overall forecasts of RE-bench saturation
| Eli, FutureSearch | Lognormal, 80% CI of [2025-09-01, 2031-01-01]. |
| Nikola | Lognormal, 80% CI of [2025-08-01, 2026-11-01] |
We expect the logistic forecast to slightly overestimate the rate of progress because we now have additional information that the first quarter of 2025 has passed with no new SOTA scores on RE-Bench reported by METR.
AI progress speedups after saturation
Nikola’s current guess is that algorithmic progress is 3-30% faster with AI chatbots and copilots from the 2022-2024 period than it would be if AI researchers didn’t use them.
Nikola expects that agents capable of saturating RE-Bench will be roughly twice as useful for productivity than 2024-era AIs, but possibly even more than that. Nikola’s best guess is that algorithmic progress will be [5%, 60%] faster when RE-Bench is first publicly saturated than it was in 2024. Nikola assumes algorithmic progress in 2024 is 50% of overall AI progress. Eli roughly agrees with these estimates.
Our best guess for what AI research capabilities look like at RE-Bench saturation is: there will exist agents that require substantial supervision when doing real-world 8-hour tasks, but which are sometimes able to do hours-long tasks with minimal human intervention. If we imagine RE-Bench saturation level AIs often doing hours-long tasks, it seems plausible that this will be a large speedup (e.g., 50% productivity increase, which after accounting for compute bottlenecks might translate to 15% algorithmic progress speedup) for many AI researchers.
Time to cross gaps between RE-Bench saturation and SC
We now turn to forecasting the time from RE-Bench being saturated to SC.
We first discuss what the main gaps are in “task difficulty” between RE-Bench saturation and SC. Then we describe our methodology for forecasting how long it will take to cross these gaps.
Then we forecast how quickly all gaps in task difficulty will be crossed.
What are the gaps in task difficulty between RE-Bench saturation and SC?
The RE-Bench paper notes four main categories of gaps between saturating RE-Bench and being able to conduct real AI R&D.
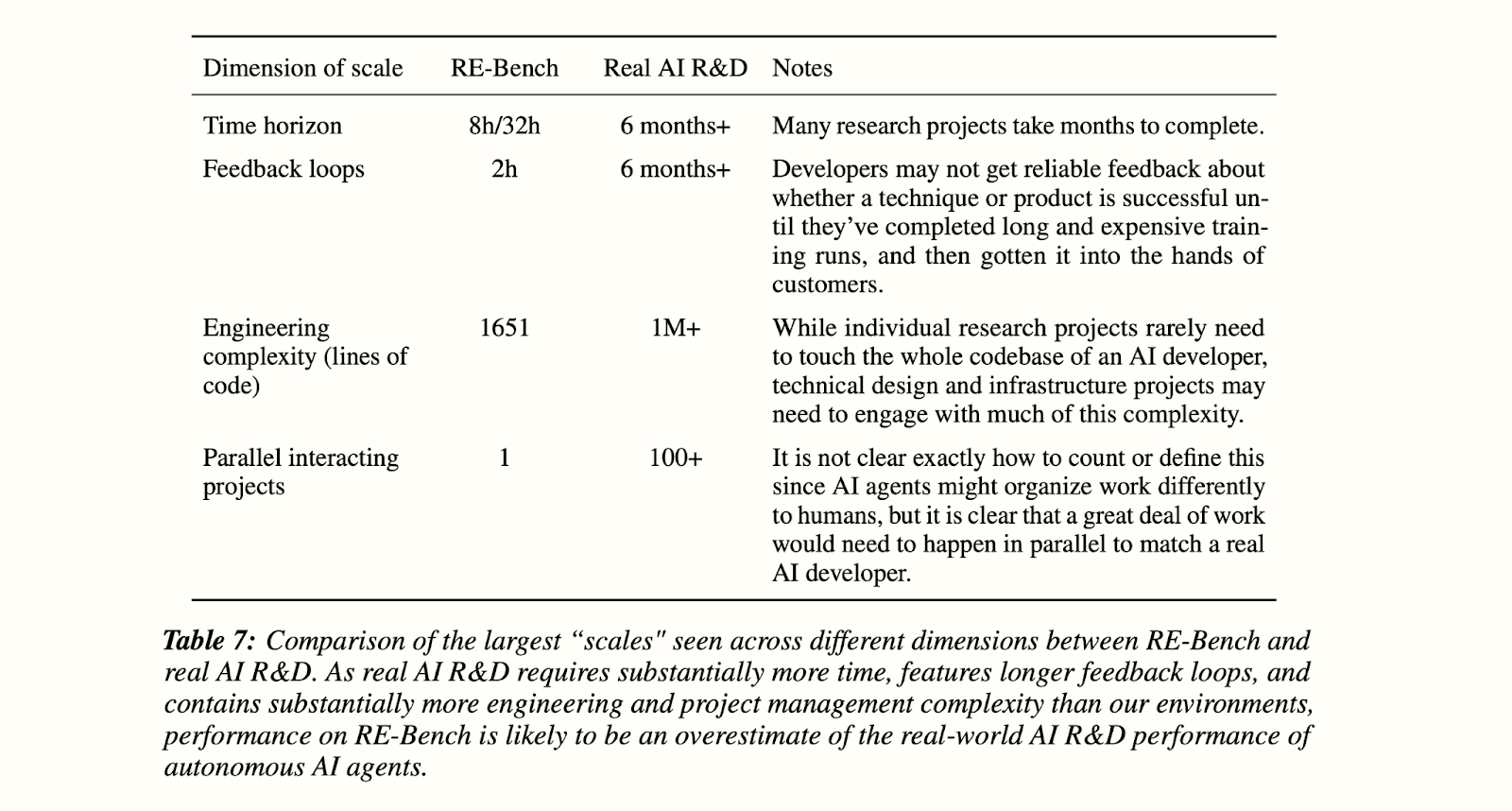
In addition to the ones in the above table, we add gaps for specialization and cost + speed; RE-Bench tasks generally require low background context, including not requiring familiarity with large codebases.
Methodology
In summary: we define milestones that would indicate each task difficulty gaps being crossed in such a way that they get strictly harder and therefore must be crossed sequentially, then estimate the number of months between each milestone and sum these up.
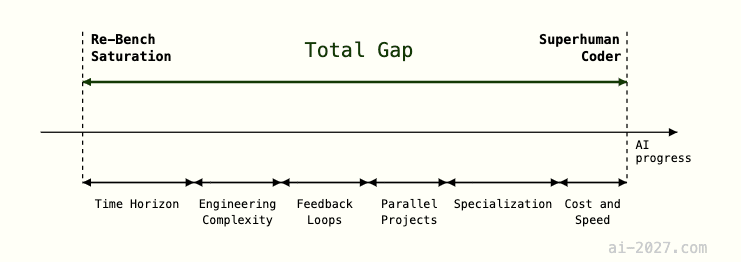
Our approach is:
- For each gap after RE-Bench saturation (which is the first “milestone”):
Define a milestone that would indicate the gap being crossed, which is strictly harder from the previous milestone such that the time between the gaps must be positive. These look like “Same as above, but… [the gap has been crossed, e.g. it can do all the tasks above 30x faster and cheaper]” and can be viewed in this summary table.[11]
For all task difficulty gaps except for time horizon, after they are crossed they remain at the same level for all future milestones. For the time horizon property, it is allowed to freely increase given that it’s a general difficulty measure so cannot be held constant while a property of the task gets harder.
- Estimate the number of months needed to cross that gap at the 2024 rate of AI progress. We have better data for time horizon increases and cost/speed improvements than we have for the other categories, so the others are estimated much less rigorously.
- Sum all task difficulty gaps to get the total size of the task difficulty gap, measured in months of AI progress at the 2024 rate of AI progress.
- Find the time to cross all task difficulty gaps by incorporating intermediate speedups of AI progress, then add other potential slowdowns (e.g. adoption lag) and account for the gap between internal and external deployment.
All of these gaps (except for the time horizon gap, which is further modeled as explained here) are modelled as lognormals according to the 80% confidence interval, meaning that the median is always the geometric mean of the lower and upper bounds. Samples are drawn with a positive correlation because the difficulties of achieving each of the capabilities are likely correlated.[12]
How fast can the task difficulty gaps be crossed?
Summary table
Below we summarize our gap crossing forecasts. FutureSearch below refers to the aggregate of 2 professional forecasters from FutureSearch. Detailed individual rationales for each gap are in the appendix.
| Gap name | Milestone that would indicate the gap being crossed | Predictions for gap size (median and 80% CI) | Reasoning summary |
| Time horizon: Achieving tasks that take humans lots of time. | Ability to develop a wide variety of software projects involved in the AI R&D process which involve modifying a maximum of 10,000 lines of code across files totaling up to 20,000 lines. Clear instructions, unit tests, and other forms of ground-truth feedback are provided. Do this for tasks that take humans about 1 month (as controlled by the “initial time horizon” parameter) with 80% reliability, add the same cost and speed as humans. | Eli: 18 [2, 144] Nikola: 16 [1, 125] (these aren’t lognormal as they’re simulated; see more below) FutureSearch: 12.7 [1.7, 48] | Calculated from needed horizon length and doubling time. |
| Engineering complexity: Handling complex codebases | Ability to develop a wide variety of software projects involved in the AI R&D process which involve modifying >20,000 lines of code across files totaling up to >500,000 lines. Clear instructions, unit tests, and other forms of ground-truth feedback are provided. Do this for tasks that take humans about 1 month (as controlled by the “initial time horizon” parameter) with 80% reliability, add the same cost and speed as humans. | Eli: 3 [0.5, 18] Nikola: 3 [0.5, 18] FutureSearch: 11 [2.4, 33.9]
| Estimated via performance trends on METR’s time horizon task suite. |
| Feedback loops: working without externally provided feedback | Same as above, but without provided unit tests and only a vague high-level description of what the project should deliver. | Eli: 6 [0.8, 45] Nikola: 3 [0.5, 18] FutureSearch: 18.3 [1.7, 58]
| Estimated from looking at how much removing Best-of-K sampling from RE-Bench diminishes performance. |
| Parallel projects: handling several interacting projects | Same as above, except working on separate projects spanning multiple codebases that interface together (e.g., a large-scale training pipeline, an experiment pipeline, and a data analysis pipeline). | Eli: 1.4 [0.5, 4] Nikola: 1.2 [0.5, 3] FutureSearch: 2 [0.7, 5.3]
| Estimated as being very small due to overlap with the engineering complexity and time horizon gaps. |
| Specialization: Specializing in skills specific to frontier AI development | Same as above, except working on the exact projects pursued within AGI companies. | Eli: 1.7 [0.5, 6] Nikola: 0.4 [0.1, 2] FutureSearch: 2.4 [0.5, 4.7]
| Estimated from the fact that fine-tuning for specific use cases usually doesn’t take long, and the overlap between RE-Bench tasks and real-world coding is large. |
| Cost and speed | Same as above, except doing it at a cost and speed such that there are substantially more superhuman AI agents than human engineers (specifically, 30x more agents than there are humans, each one accomplishing tasks 30x faster). | Eli: 6.9 [1, 48] Nikola: 6 [1, 36] FutureSearch: 13.5 [4.5, 36]
| Estimated from data of AI capabilities getting cheaper over time. |
| Other task difficulty gaps | SC achieved. | Eli: 5.5 months [1, 30] Nikola: [3 0.5, 18] FutureSearch: 14.7 [2, 58.8] | Accounting for unknown unknowns |
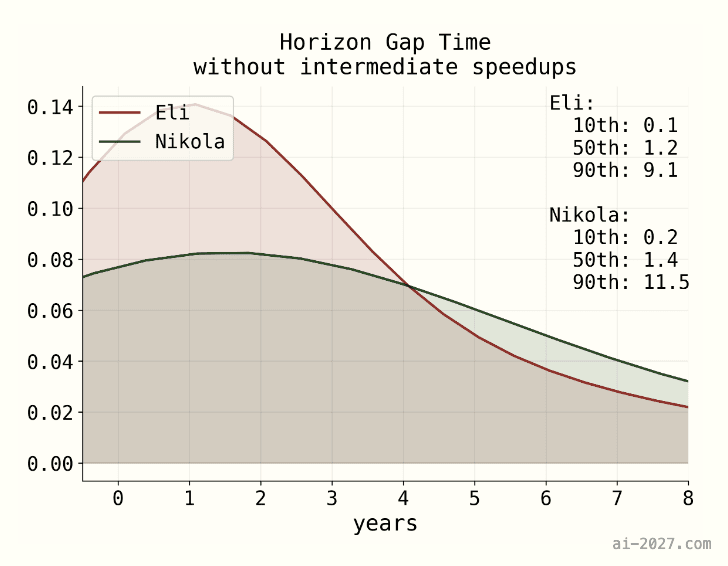
Time horizon
Milestone which would indicate the gap being crossed: Ability to develop a wide variety of software projects involved in the AI R&D process which involve modifying a maximum of 10,000 lines of code across files totaling up to 20,000 lines. Clear instructions, unit tests, and other forms of ground-truth feedback are provided. Do this for tasks that take humans about 1 month (as controlled by the “initial time horizon” parameter) with 80% reliability, add the same cost and speed as humans.
Time horizon report and definition
METR’s recent report measures the “time horizon” capability of AI systems on software engineering tasks, where time horizon is defined based on how long it takes humans to complete tasks (more details in footnote).[13]
An AI with an R% time horizon of T time means that it has an average success rate of R% on tasks that take humans T time. For more details about their methodology and their task suite HCAST, see above.
Superhuman Coder (SC): initial time horizon and reliability requirements
A superhuman coder (SC) (without speed/cost which are later taken into account) must be able to overall do as good of a job as the combination of all human programmers at an AGI company at their current work.
What time horizon and reliability level does this require? Because the time horizon will continue to increase as future gaps are crossed, we will choose an “initial time horizon" which is somewhat lower than what we think the ultimate SC time horizon will need to be.
Initial time horizon required: 1 month feels roughly right for the low end of the time requirements of difficult coding projects.[14] We’ll take into account some uncertainty here with a lognormal with 80% CI of [4 hours, 6 work-months (1000 hours)]. We roughly guess that future gap crossings will increase the time horizon to about 6 months, which seems reasonable for representing very difficult coding projects.
Reliability required: 80%, though highly uncertain. If the SC is equally well-rounded as the human researcher force, this would be somewhat below 50% for a few reasons in footnote.[15] Currently AIs are much less well-rounded than humans though, so if they have a 40% time horizon within human cost/speed they likely only go up to around 45-50% if allowed to take 10x longer. So with current AIs we might need to set a 90+% reliability threshold. SC-level AIs will be much more well-rounded though, due to having very strong agency skills (planning, correcting mistakes, etc.). So we lower it to 80%, which seems roughly right and has the advantage of being able to utilize METR’s reported data. Uncertainty is not incorporated into our model, for simplicity and because any adjustment to reliability could also be modeled as an adjustment to time horizon instead.
Engineering complexity associated with time horizon extrapolation
We’ll measure the engineering complexity of a task via 2 proxies: (a) lines of code modified and (b) sum of lines of code are in all modified files.
Saturating RE-Bench requires a median of 500 lines of code in modified files, and about 250 lines of code modified. The other 8-hour tasks in the METR time horizon suite require similar amounts.
Based on very rough data analysis, we estimate that each time horizon increase in the METR suite leads to a proportional increase in both proxies. Since there is a 20x increase between 8 hours and 1 month, this would mean an increase to about 10,000 lines of code modified, 20,000 lines of code in all modified files.
The small multiplier between lines modified and lines of code in all modified files reflects an emphasis by REBench and the METR suite on tasks requiring low context, including familiarity with large codebases.
Saturating RE-Bench: Time horizon and reliability level
As described above, we set the RE-Bench saturation based on achieving an average of 1.5, which is about what we think the best human could get given 8 hours for each task.
What would achieving this score mean in terms of reliability at an 8 hour time horizon, relative to the best human?
I think it means more than 50% because as described above, AIs’ skillsets are currently more uneven than humans, perhaps the AI will have to be better than top humans at >50% of tasks in order for the average to be the same, because there’s less room to go above 1.5 on the RE-Bench tasks than below it.
This effect seems significant but not huge. My best guess is 60% reliability.
Time horizon forecasts
| Estimates (80% CI of lognormal) | Reasoning | |
| 80% time horizon required for our initial milestone | Eli: [8 hours, 6 work-months (1000 hours]
Nikola: [8 hours, 6 work-months (1000 hours)]
| Because the time horizon will continue to increase as future gaps are crossed, we will choose an “initial time horizon" which is somewhat lower than what we think the ultimate SC time horizon will need to be. A median of roughly 2-4 weeks feels about right for the low end of difficult coding projects. See above for more. |
| 80% time horizon at RE-Bench saturation | Eli: [0.5, 15] hours
NIkola: [0.5, 12] hours | See more above for why it’s likely less than 8 hours. My best guess is that the RE-Bench-saturating agent would have 60% reliability at 8 hours. In METR’s report, they find that switching from 50% to 80% reduces the time horizon by 5x. So perhaps switching from 60% to 80% reduces it by ~3.5x, giving me a median of ~2.5 hours. |
| Time horizon doubling time as of Mar 2025 on HCAST | [2.5 months, 9 months] | See our rationale in Method 1. |
| Doubling time at REBench saturation toward our time horizon milestone, on a hypothetical task suite like HCAST but starting with only REBench’s task distribution | [0.5 months, 18 months] | We intuitively aggregate the below 3 adjustments to get our estimate.
Adjustment downward and more uncertain for potential trend changes: If the trend is superexponential, the doubling time will be faster than today by the time REBench is saturated. The opposite is true for subexponential, which is less likely (see below for reasoning).
Adjustment to be more uncertain based on distribution shift from normal HCAST to HCAST starting with only REBench: We widen our confidence interval based on uncertainty regarding the starting task distribution. METR’s extrapolation already includes REBench, but it’s a small minority of tasks relative to HCAST.
Adjustment downward due to extrapolation overshooting our milestone: Our guess is that our extrapolation on the METR task suite would “overshoot” and lead to our time horizon milestone being eclipsed on some dimensions by the time AI reaches the required time horizon. Therefore, we should make an adjustment down to shift from the METR task suite doubling time to the doubling time on a theoretical task suite for which extrapolation led exactly to the time horizon milestone as we defined it above.
We’ve done some rough extrapolations which indicate that the HCAST extrapolation would in fact lead to about 10,000 lines of code, as we defined the milestone. But our guess is that a naive extrapolation would “overshoot” our milestone with regards to feedback loop difficulty, and potentially other variables as well. |
| Will doubling times speed up, slow, or stay the same? | Probabilities: Exponential:
Superexponential:
Subexponential:
| See our rationale in Method 1. |
Taking the doubling time and required level, we get these distributions as the size of the time horizon gap:
Other factors for benchmarks and gaps
We assume that no large-scale catastrophes happen (e.g., a solar flare, a pandemic, or a nuclear war), and no government or self-imposed slowdown.
Compute scaling and algorithmic progress slowdown
We assume that the rate of compute scaling is slowed by 2x beginning in 2029 due to reduced ability to increase investments, given that the rate of increase of frontier AI training costs may be difficult to continue past then without SC achieved.
Similarly, we project that if SC isn’t achieved by about 2028 the human research population will begin growing at a slower rate. For simplicity, we also model this as a 2x decrease in the human-driven rate of progress over time. To model complementarity with AI automation, we take the geometric of mean of the pace of progress if AI were a fixed multiplier on the human pace (i.e. default_human_plus_ai_rate*0.5) and the pace of progress if AI were fully additive (i.e. default_human_plus_ai_rate-0.5).
Gap between internal and external deployment
Because our models’ forecasts and extrapolations above are based on testing models which have been publicly released, we need subtract from our forecast to get the the arrival time of SC capabilities internal to the AGI developers.
We estimate that at the arrival of SC, AGI developers’ internal capabilities will be approximately a lognormal with an 80% CI of [0.25 months, 6 months] ahead of their public releases. This is subtracted from the time-to-achieve-SC to get to a time when SC is achieved internally.
Intermediate speedups
In our simulation, the rate of algorithmic progress starts at 1 in 2025 and reaches [5%, 60%] times the 2024 rate at RE-Bench saturation.
The table below shows Eli’s and Nikola’s estimates for how much SCs will speed up algorithmic progress, i.e. the AI R&D progress multiplier (see here for a more detailed definition). These are informed by our estimates for the SC progress multiplier in our takeoff forecast.
| Quantity | Nikola’s estimate | Eli’s estimate |
AI R&D progress multiplier from SC (median 80% CI of lognormal)[16] | 5.5 [2.0, 20.0] | 8.5 [2.5, 40.0][17] |
We assume that in 2024 algorithmic progress represents half of AI progress, with the other half being compute. Progress might be very fast after the SC milestone: see the takeoff forecast for forecasts on the post-SC capabilities progression.
In the simulation:
- We get the number of months needed to bridge all task difficulty gaps at the 2024 rate of AI progress.
- We then progress through the total number of “2024-months” of progress, increasing the rate of AI progress according to how much of the process has been completed (in a very small subset of trajectories, the rate of AI progress goes down over time). The rate of progress goes up exponentially from the starting rate to the ending rate, as a function of how much of the total task difficulty gap has been crossed.
Overall benchmarks and gaps forecasts
Running the simulation as described by the parameters we’ve laid out results in this:
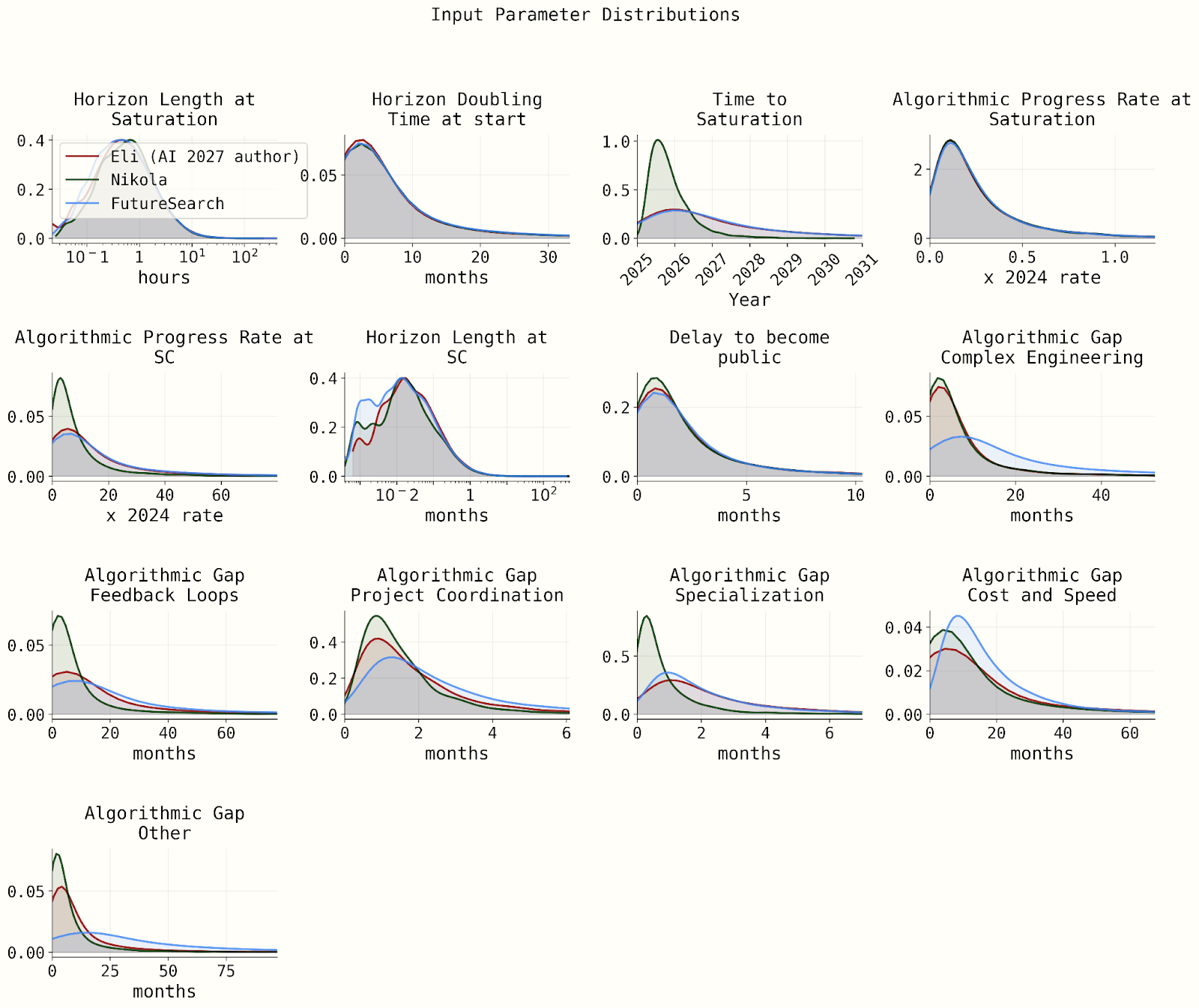
With these input distributions:
Appendix
Individual Forecaster Views for Benchmark-Gap Model Factors
Engineering complexity: handling complex codebases
Milestone which would indicate the gap being crossed: Ability to develop a wide variety of software projects involved in the AI R&D process which involve modifying >20,000 lines of code across files totaling up to >500,000 lines. Clear instructions, unit tests, and other forms of ground-truth feedback are provided. Do this for tasks that take humans about 1 month (as controlled by the “initial time horizon” parameter) with 80% reliability, add the same cost and speed as humans.
This milestone requires a 1x scaleup in modified lines of code (LOC) and a 25x scaleup in files LOC from the time horizon milestone.
- Eli’s estimate of gap size: 3 months [0.5, 18]. Reasoning:
- My guess is that modified LOC is more important to task difficulty than files LOC especially for large changes, so perhaps the 2x scaleup in modified LOC and 25x scaleup in files LOC combine for the equivalent of a 4x scaleup in total LOC.
- In the METR suite, scaleup in both modified LOC and files LOC is proportional to time horizon, which is doubling roughly every 4 months in 2025 and may be doubling faster at longer time horizons (see time horizon forecast above).
- 2 doublings with a median of some doubling time speedup to 3 months gives me 6 months, then I adjust down to a median of 3 months because the LOC-doubling time would be faster if no other task properties were getting harder.
- I add a factor of 6 on each side to get [0.5, 18 months]. This roughly matches my intuitions: it doesn’t seem difficult to scale to much larger codebases once the AI already has the skills needed for the time horizon milestone.
- Nikola’s estimate of gap size: 3 months [0.5, 18]. Reasoning is the same as Eli’s
- FutureSearch’s estimate of gap size: 11 months [2.4, 33.9]. Reasoning:
- The total codebase could be larger than the 100k lines required. From the 10k lines of the previous milestone, we need at least a ×10 increase to reach 100k lines. But the system might need to understand 1M lines to make the necessary changes.
- The assumption of 4 months of progress to deal with x10 lines of code is aggressive. There are few data points, and adding a factor of 2 (to create the 90th percentile) feels insufficient.
- Fixing bugs might require modification of >10k lines, beyond what is assumed in the previous milestone. It is not clear how differentially hard it is for systems to create new projects of length N versus finding and fixing bugs that (say) require changing 1% of those N lines.
- Again, a key consideration is whether synthetic data is needed for training. If so, generating it at this level of complexity could be a huge challenge.
Feedback loops: Working without externally provided feedback
Milestone which would indicate the gap being crossed: Same as above, but without provided unit tests and only a vague high-level description of what the project should deliver.
We recommend that future work consider using METR’s concept of “messiness” from their report in place or in addition to this milestone. We weren’t able to explore this due to time constraints.
- Eli’s estimate of gap size: 6 months [0.8, 45]. Reasoning:
- Intuitively it feels like once AIs can do difficult long-horizon tasks with ground truth external feedback, it doesn’t seem that hard to generalize to more vague tasks. After all, many of the sub-tasks of the long-horizon tasks probably involved using similar skills.
- However, I and others have consistently been surprised by progress on easy-to-evaluate, nicely factorable benchmark tasks, while seeing some corresponding real-world impact but less than I would have expected. Perhaps AIs will continue to get better on checkable tasks in substantial part by relying on trying a bunch of stuff and seeing what works, rather than general reasoning which applies to more vague tasks. And perhaps I’m underestimating the importance of work that is hard to even describe as “tasks”.
- Quantitatively, I’d guess:
- Removing BoK / intermediate feedback adds 1-18 months
- Removing BoK is 5-50% of the way to very hard-to-evaluate tasks, so multiply by 2 to 10.
- The above efforts will have already gotten 50-90% of the way there since doing massive coding projects already requires dealing with lots of poor feedback loops, so multiply by 10 to 50%.
- o3-mini tells me this gives roughly 0.8 to 45 months, this seems roughly right so I’ll go with that.
- I realized that these should all be for RE-Bench but with long time horizon and lots of lines of code, rather than current RE-Bench, which is important to keep in mind.
- Nikola’s estimate of gap size: 3 months [0.5, 18]. Reasoning:
- RE-Bench provides scoring functions that can be used to check an agent’s performance at any time. There will likely be a gap in performance with and without feedback.
- The current number is mostly an intuitive guess. My estimate is that adding Best-of-K to RE-Bench adds 4-8 months of progress on the score. This probably captures around a third of the total feedback loop gap.
- This leads to around 12-24 months. However, I expect around half of this gap to already be bridged if I have systems that can do very long-horizon tasks with millions of lines of code. I also think it’s plausible that RL on easy-to-evaluate tasks will generalize well to other tasks, making my lower CI even lower.
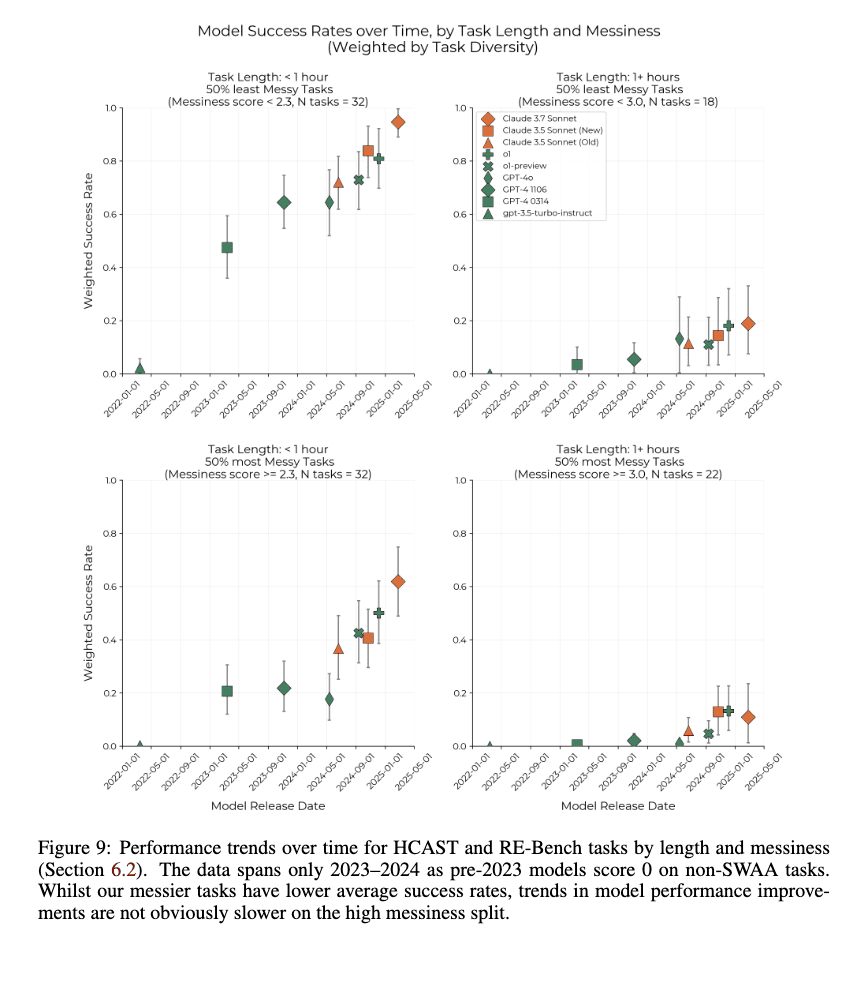
- Messiness somewhat tracks a lack of feedback loops. In METR’s horizon paper, Figure 9 presents the performance of tasks divided into messier and less messy tasks. This performance gap can inform how much a lack of feedback loops will affect performance. One metric we can use is “how far behind is the performance of the more messy tasks?” That is, if we take the maximum of the performance on more messy tasks, how long ago was that performance reached on the less messy tasks?
- For a task length below 1 hour, the max success rate is around 0.6 with Claude 3.7 Sonnet (February 2025). That level was surpassed in November 2023 with GPT-4 1106, making a 15 month gap.
- For a task length above 1 hour, the max success rate on messy tasks is around 0.1 with o1 (Dec 2024), which was surpassed in May of 2024 with GPT-4o. That makes a 7 month gap.
- I think the longer tasks are more representative of the types of tasks that will be faced around the feedback loops milestone.
- My gap estimate will add uncertainty on both sides.
- FutureSearch estimate of gap size: 18.3 months [1.7, 58]. Reasoning:
- Agentic planning is key and is likely already good from the previous two milestones. This should help with lack of oracle calls, and no/poor/limited/expensive feedback loops. If the previous milestones arrived without strong agentic planning, this could be the major bottleneck for this gap.
- The restriction to the domain of coding for AI research makes progress more plausible. There is skepticism that, with lack of cheap oracle feedback, human-level general planning will arrive soon.
- Agents use the oracular score function 10x more than humans. In the RE-Bench paper, they used it 25.3 or 36.8 times per hour, compared to 3.4 times for human experts. In the paper, a substantial part of the agents’ performance was due to ‘local-optima’ solutions by tweaking initial parameters, which is particularly dependent on the oracular score function. By this point, with RE-Bench saturation and the previous two milestones, it seems that systems would be able to perform at a level similar to humans in this regard.
- AIs will need memory to deal with complex trade-offs from stakeholders. Lack of feedback will require operating at a fuzzier, human level, where the goals/incentives/preferences of dozens of different stakeholders will be illegible and changing. AIs will need to understand the organization’s overall objectives, which will evolve with new business opportunities, new technologies, and changing societal norms.
Parallel projects: Handling several interacting projects
Milestone which would indicate the gap being crossed: Same as above, except working on separate projects spanning multiple codebases that interface together (e.g., a large-scale training pipeline, an experiment pipeline, and a data analysis pipeline).
- Eli estimate of gap size: 1.4 months [0.5, 4]. Reasoning:
- My best guess is that a model which can do very long AI R&D tasks and modify files totalling 100k lines already possesses most of the skills necessary to handle multiple interacting projects.
- Nikola’s estimate of gap size: 1.2 months [0.5, 3]
- FutureSearch estimate of gap size: 2 months [0.7, 5.3]. Reasoning:
- Milestone 2 on Complex engineering projects makes this plausibly very easy. Furthermore, Milestone 3 on working without provided unit tests is likely very useful for dealing with projects that interface together in complicated manners.
Specialization: Specializing in skills specific to frontier AI development
Milestone which would indicate the gap being crossed: Same as above, except working on the exact projects pursued within AGI companies.
- Eli’s estimate of gap size: 1.7 months [0.5, 6]. Reasoning:
- Feels a little harder than parallel projects.
- Nikola’s estimate of gap size: 0.4 months [0.1, 2]. Reasoning
- My best guess is that currently fine-tuning models to perform well on tasks internal to a company is not difficult and mostly bottlenecked on general capabilities of the model.
- Also, I don't expect there to be a very large shift in specialization between the tasks the agents are best at and real-world tasks relevant to AI research engineering. In fact, it’s likely they’ll be best at tasks relevant to AI research.
- FutureSearch’s estimate of gap size: 2.4 months [0.5, 4.7]. Reasoning:
- RE-bench saturation, and the milestones on engineering complexity and parallel interacting projects make this plausibly very easy, even if projects are very interconnected.
- The general rise in capabilities should help significantly here.
Cost and speed
Milestone which would indicate the gap being crossed: Same as above, except doing it at a cost and speed such that there are substantially more superhuman AI agents than human engineers (specifically, 30x more agents than there are humans, each one accomplishing tasks 30x faster).
- Eli’s estimate of gap size: 6.9 months [1, 48]. Reasoning:
- Epoch has measured the decline in per-token pieces to achieve the same performance on a variety of non-agentic benchmarks, finding trends between 9 and 900x per year, with a median of 50x. When looking at trends starting in January 2024, they find a median of 200x per year. There are 2 reasons to adjust these estimates upwards:
- They don’t include AIs being able to use fewer tokens for the same task, and they generally focused on non-agentic benchmarks like MMLU and GPQA in which the amount of tokens used to solve the task doesn’t vary by a lot for non-reasoning models.
- Their trends started below human cost, and I expect that trends starting at higher costs will be faster due to reasoning about the extremes of the cost curve over time: the cost to achieve a given performance starts at ~infinity (no amount of GPT-2 inference compute could get 2025-level performance on agentic tasks) and will eventually asymptote due to physical limits.
- Looking at RE-Bench, a more agentic benchmark which started at roughly human cost and we can take into account fewer tokens being needed, we see a faster decrease of roughly 10x in .33 years so a 1,000x/year trend (based on Figure 11, comparing 3.5 Sonnet Old to 3.5 Sonnet New).
- However, looking at updated data it seems like the rate of change between Old and New was unusually large, so this should be discounted.
- This should plausibly be decreased further because SC-level agents will be making more efficient use of inference compute than naive Best of N.
- So based on the above we might get a 30x cost decrease in roughly 0.35-1.5 years (10,000x/year would be ~0.35 years, 10x/year would be ~1.5 years)
If we assume the cost decrease happens only via achieving tasks faster while keeping the same cost/second (cost/token*tokens/second), then the speed increase would be exactly met.[18] If the cost/second has gone up, that means that speed has already increased >30x (think: cost/second is 2x more -> 1/30 the cost is accrued in ½ the time -> model is 60x faster and 30x cheaper). So we should lower the gap length estimate, as we have dominated the 30x speed / 30x cost point on the Pareto frontier. If the cost/second has gone down, then we need to add to the estimate.
- In the examples used above (token costs/speeds per OpenRouter):
- Epoch’s estimates which rely on cheaper per-token costs found a ~3.5x speed increase for a 300x decrease in cost. This means that a 30x decrease in cost would correspond with a ~2x speed increase. Further cost decreases could be attempted to be translated into increased speed via parallelization; for the non-agentic tasks Epoch measured this would be difficult, but it would probably be doable for SC-level AIs on agentic tasks.
- A ~300x efficiency increase on GPQA from GPT-4 to Phi 4 corresponds with a ~3.5x speed increase and a ~150x decrease in cost/second:
- Similar speed changes arise for other benchmark trends, with varying rates of efficiency decreases.
- For the RE-Bench case which relies on more efficient use of tokens, cost/second is basically the same.
- Claude 3.5 Sonnet Old is 66 tok/sec and costs $3/MTok input and $15/MTok output
- Claude 3.5 Sonnet New is 58 tok/sec and costs $3/MTok input and $15/MTok output
- Epoch’s estimates which rely on cheaper per-token costs found a ~3.5x speed increase for a 300x decrease in cost. This means that a 30x decrease in cost would correspond with a ~2x speed increase. Further cost decreases could be attempted to be translated into increased speed via parallelization; for the non-agentic tasks Epoch measured this would be difficult, but it would probably be doable for SC-level AIs on agentic tasks.
- I expect the expensive->cheap SC transition to look more like the REBench case than Epoch’s estimates, i.e. I think the models will get more capable rather than transitioning to cheaper models at the same capability level; so I expect cost/second to decrease some but not dramatically. I wouldn’t at all be surprised if it increased though which would mean that my forecast should decrease. I’ll increase and widen my forecast a bit based on the cost/second considerations to 0.2-3 years.
- I’ll then widen my forecast a little more for good measure, to 0.1-4 years.
- Epoch has measured the decline in per-token pieces to achieve the same performance on a variety of non-agentic benchmarks, finding trends between 9 and 900x per year, with a median of 50x. When looking at trends starting in January 2024, they find a median of 200x per year. There are 2 reasons to adjust these estimates upwards:
- Nikola’s estimate of gap size: 6 months [1, 36]. Reasoning:
- I basically agree with Eli’s reasoning below. Some additional thoughts:
- GPT-4o mini costs $0.15 / 1M input tokens and $0.6 / 1M output tokens compared to GPT-4 at $30 / 1M input and $60 per 1M output despite having similar benchmark performance and they were ~1.5 years apart, so around 1 year per 10x decrease.
- More recently, DeepSeek R1 roughly matches the old Claude 3.5 Sonnet in performance. C3.5s costs $3/MTok input and $15/MTok output, whereas DeepSeek R1 costs $0.5/MTok input and $2/MTok output. It also uses more tokens so remove a factor of 2. This gives a ~3x decrease in 0.5 years, which roughly matches up with a 10x/year decrease.
- On ARC-AGI (which I don’t think measures relevant capabilities but might be a useful datapoint), o3-mini costs 2 OOMs less for the same performance. So there might be a recent increase in the speed of distillation.
- My best guess is that the first SC-capable systems will be prohibitively expensive and require 1-2 orders of magnitude of cost reduction to be more affordable than a human engineer per hour of work.
- It’s plausible that developers will always keep their model inference costs pretty low and never balloon into much-higher-than-human costs, so possibly the first SC-capable models will be cheap out-of-the-box.
- I basically agree with Eli’s reasoning below. Some additional thoughts:
- FutureSearch’s estimate of gap size: 13.5 months [4.5, 36]. Reasoning:
- Current trends on how much inference costs (at a fixed capability level) are decreasing point towards a ×10 decrease every year. In this scenario the reduction could be even starker, particularly for systems specialized for AI development, and for coding where there is economic pressure to lower costs. A more recent and comprehensive Epoch analysis points toward inference costs falling even faster, with a median reduction of ×50/year.
- The reductions in cost may have already come accompanied with increased speed. In an aggressive scenario we can assume that we only need to account for the ×30 cost reduction, which, on the trend of ×50/year, would be about 10.5 months.
- Even if not, elicitation techniques like best-of-k, and advances in reasoning models, make us think human speed is not the right baseline. At the human bound, the equivalent time of a ×900 cost reduction, on the ×10/year trend, would take about 3 years. But this seems too conservative. If we assume that we start near the human cost but are already 5 times faster, we would need to cross a gap of 6×30=180. Which with a ×10/year trend would be achieved in about 29 months.
Other task difficulty gaps
Milestone which would indicate the gap being crossed: SC achieved.
- Eli’s estimate of gap size: 5.5 months [1, 30]
- Nikola’s estimate of gap size: 3 months [0.5, 18]
- FutureSearch’s estimate of gap size: 14.7 months [2, 58.8]. Reasoning:
- Agentic planning is key and is likely already good from the previous two milestones. This should help with lack of oracle calls, and no/poor/limited/expensive feedback loops. If the previous milestones arrived without strong agentic planning, this could be the major bottleneck for this gap.
- The restriction to the domain of coding for AI research makes progress more plausible. There is skepticism that, with lack of cheap oracle feedback, human-level general planning will arrive soon.
- Agents use the oracular score function 10x more than humans. In the RE-Bench paper, they used it 25.3 or 36.8 times per hour, compared to 3.4 times for human experts. In the paper, a substantial part of the agents’ performance was due to ‘local-optima’ solutions by tweaking initial parameters, which is particularly dependent on the oracular score function. By this point, with RE-Bench saturation and the previous two milestones, it seems that systems would be able to perform at a level similar to humans in this regard.
- AIs will need memory to deal with complex trade-offs from stakeholders. Lack of feedback will require operating at a fuzzier, human level, where the goals/incentives/preferences of dozens of different stakeholders will be illegible and changing. AIs will need to understand the organization’s overall objectives, which will evolve with new business opportunities, new technologies, and changing societal norms.
Superhuman Coder (SC): time horizon and reliability requirements
A superhuman coder (SC) must be able to overall do as good of a job as the combination of all human programmers at an AGI company at their current work.[19]
What time horizon and reliability level does this require on HCAST?
Eli’s opinion:
Time horizon and reliability required on real distribution of work tasks, as baselined by the best humans with strong incentives:
- Time horizon: 6 months (80% CI: [1 week, 12 years]). If AIs can fairly consistently do tasks that take humans 6 months, it seems like they should be able to automate large coding projects. Anything less than 1 week seems highly unlikely to be enough. I’d like to have an even fatter right tail than a lognormal here ideally, but I expect that once we’re getting into the years the trend will likely be pretty superexponential anyway.
- An alternate view: Given that human baseliners only score around a 90 minute time horizon, it’s also possible AI will outperform humans at many coding tasks by the time it has a 90 minute time horizon. 10-year time horizons seem like a sensible upper bound on the length of tasks the AI needs to be able to do, but it seems likely that even at a 1-month time horizon under METR’s current definition, AI will be automate large parts of the AI R&D process with a small amount input from other colleagues. We’ll take into account some uncertainty here with a lognormal with 80% CI of [16 hours, 2 work-years (4,000 hours)].
Reliability: 80%. If the SC is equally well-rounded as the best humans, this would be somewhat below 50% for a few reasons in footnote.[20] Currently AIs are much less well-rounded than humans though, so if they have 40% reliability within human cost/speed they likely only go up to around 45-50% if allowed to take 10x longer. So with current AIs we might need to set a 90+% reliability threshold. SC-level AIs will be much more well-rounded though, due to having very strong agency skills (planning, correcting mistakes, etc.). So we lower it to 80%, which seems roughly right and has the advantage of being able to utilize METR’s reported data.
Time horizon required on an extrapolation of HCAST (METR’s task suite), with METR’s current baselining strategy: 10 years [1 month, 1200 years].
I’ll keep reliability the same and adjust the time horizon to tune it to METR’s report (their task suite and baselining process), allowing me to forecast more straightforwardly via extrapolation METR’s results. I make an adjustment based on the below considerations.
Reasons for raising the time horizon requirement:
- An extrapolation of the HCAST suite doesn’t cover gaps that will come up in the real world (poor feedback loops is my guess as to the most important gap, see here for some of the candidates that seem most prominent).
- The baselines for HCAST are weaker than ideal which inflates the time horizons relative to the setup assumed above (see more in the time horizon paper and the HCAST paper): (a) they are done by fairly competent people, but not the literal best humans (b) they aren’t always done by experts (c) they are done with people with low context (similar to new hires, rather than already being familiar with a codebase).
- Baseliners were found to take 5-18x longer to resolve METR issues in METR code repositories. However for longer horizon tasks existing familiarity wouldn’t matter as much because there would be time to acquire context.
Reason for lowering the time horizon requirement: There might be ways in which an extrapolated HCAST is actually harder than real world tasks (i.e. the opposite of (1) above). For example, some baseline scoring functions are unrealistically unforgiving.
While 1200 years sounds high, I think it’s plausible that there are very big gaps between HCAST and the real world or there are huge gaps between HCAST baselining and SC-level baselines.
Nikola’s opinion: Given that human baseliners only score around a 90- minute time horizon, it’s also possible AI will outperform humans at many coding tasks by the time it has a 90 minute time horizon. 10-year time horizons seem like a sensible upper bound on the length of tasks the AI needs to be able to do, but it seems likely that even at a 1-month time horizon under METR’s current definition, AI will be automate large parts of the AI R&D process with a small amount input from other colleagues. We’ll take into account some uncertainty here with a lognormal with 80% CI of [16 hours, 2 work-years (4,000 hours)].
RE-Bench saturation resolution criteria
Copied over from the AI 2025 Forecasting Survey
Any AI system counts if it operates within realistic deployment constraints and doesn't have unfair advantages over human baseliners.
Tool assistance, scaffolding, and any other inference-time elicitation techniques are permitted as long as:
- No Unfair and Systematic Advantage. There is no systematic unfair advantage over the humans described in the Human Performance section (e.g., AI systems are allowed to have multiple outputs autograded while humans aren't, or AI systems have access to the internet when humans don't).
- Human Cost Parity. Having the AI system complete the task does not use more compute than could be purchased with the wages needed to pay a human to complete the same task to the same level
The PASS@k elicitation technique (which automatically grades and chooses the best out of k outputs from a model) is a common example that we do accept on this benchmark because human baseliners in RE-Bench also have access to scoring metrics (e.g., loss/runtime). So PASS@k doesn't constitute a clear unfair advantage.
[...]
Human cost estimation process:
- Rank questions by human cost. For each question, estimate how much it would cost for humans to solve it. If humans fail on a question, factor in the additional cost required for them to succeed.
- Match the AI’s accuracy to a human cost total. If the AI system solves N% of questions, identify the cheapest N% of questions (by human cost) and sum those costs to determine the baseline human total.
- Account for unsolved questions. For each question the AI does not solve, add the maximum cost from that bottom N%. This ensures both humans and AI systems are compared under a fixed per-problem budget, without relying on humans to dynamically adjust their approach based on difficulty.
- ^
- ^
Harvard University, part-time intern at METR
- ^
futuresearch.ai, individual forecaster bios on futuresearch.ai/ai-2027
- ^
The reason 5% is used is because it’s approximately the fraction that we project AI projects to be spending around the time they reach SC: see the “Research automation” row in our compute supplement.
- ^
Time horizon for each task is defined as:
For tasks without a fixed time cap, the geometric mean of the time taken by humans who completed it.
For RE-Bench, in which humans had a fixed time cap, success is binarized based on the average score of human baseliners and the time horizon is considered to be the time cap (8 hours).
- ^
The trend would likely further tilt toward superexponetiality if we took into account that the public vs. internal gap has seemed to decrease over time. It’s been rumored that GPT-4 was released 7 months after pre-training was complete, while it seems now there are much smaller delays; for example according to the announcement video Grok 3 was released a month after pre-training was complete.
- ^
Another argument for eventually getting superexponentiality is that it seems like superhuman AGIs should have infinite time horizons. However, under the definition of time horizon adapted from the METR report above, it’s not clear if infinite time horizons will ever be reached. This is because AIs are graded on their absolute task success rate, not whether they have a higher success rate than humans. As long as there’s a decreasing trend in ability to accomplish tasks as the time horizon gets longer, the time horizon won’t be infinite. This is something that has been observed with human baseliners (see Figure 16 here). Even if infinite horizons are never reached, the time horizons might get extremely large which would still lend some support to superexponentiality. Even so, it’s unclear how much evidence this is for superexponentiality in the regime we are forecasting in.
- ^
Perhaps this could be the case if extending to each successive time horizon requires doing large amounts of training on tasks of that horizon.
- ^
(1.315 + 2.30 + 1.195 + 1.575 + 2.335 + 1.475 + 1.465)/7 = 1.67
- ^
This budget is broken into either 32 30-minute attempts or 8 2-hour attempts from which we draw the best score, depending on if 30-minute or 2-hour time limits constituted better elicitation for each particular model.
We only have data from davinci-002 using a single 10-hour time budget, however we manually reviewed its transcripts and are confident the model’s score is entirely due to noise in scoring and not any improvements it made to the codebase and it reliably fails substantially easier HCAST tasks, so we feel changing the scaffolding wouldn't alter the results.
We also were unable to obtain more than an 8-hour time budget for GPT-4 0314, which is a minor limitation of our results.
- ^
Because each gap is defined using a measurable milestone, this means that our predictions of when gaps will get crossed are empirical forecasts for when certain AI capabilities will be hit. Benchmarks that could actually resolve these predictions don’t yet exist (all relevant current benchmarks will already be saturated at that point), but it’s plausible that they will be created.
- ^
Specifically, in order to model the correlation we model the CDFs of each function, and sample the percentile of each value by finding the CDF of a sample from multivariate normal with a correlation coefficient of 0.7.
- ^
Time horizon for each task is defined as:
For tasks without a fixed time cap, the geometric mean of the time taken by humans who completed it.
For RE-Bench in which humans had a fixed time cap, success is binarized based on the average score of human baseliners and the time horizon is considered to be the time cap (8 hours).
- ^
For this parameter only, we mean work-months, not calendar months. One work-month is 4 weeks * 40 hours/week of actual work, meaning a 1-month time horizon corresponds to a 160-hour time horizon as defined in the METR graphs.
- ^
Recall that the time horizon is determined by taking the geometric mean of successful human completion times. A few reasons why this will lead to reliability levels below 50% for SC with the same skill level as baselined human teams, under our definition which requires the SC to solve the task at least as quickly and cheaply as the humans:
Selecting only for successful achievements before taking the geometric mean artificially deflates the time horizons, leading to lower reliability.
If many people of similar abilities did the same task over and over, probably the data would be somewhat right-skewed, which if the distribution were lognormal would mean the median and geometric mean are equal. However, it’s plausible that the distribution would be less skewed than lognormal so the geomean would be below the median, leading to lower reliability.
- ^
The lognormal is between (lower bound - 1) and (upper bound - 1), since the lower bound on the multiplier is 1.
- ^
I’m projecting that the first ARE will have roughly 80th percentile research taste, and a 20% chance that it will already be >= the best AI researcher.
- ^
I’m assuming the cognitive tasks don’t involve other bottlenecks, as defined in the ARE milestone. Of course there are some non-cognitive bottlenecks in SWE like compiling, but these can likely be worked around.
- ^
A full SC needs to do this faster and cheaper as well, but this will be discussed later.
- ^
Recall that the time horizon is determined by taking the geometric mean of successful human completion times. A few reasons why this will lead to reliability levels below 50% for SC with the same skill level as baselined human teams, under our definition which requires the SC to solve the task at least as quickly and cheaply as the humans:
Selecting only for successful achievements before taking the geometric mean artificially deflates the time horizons, leading to lower reliability.
If many people of similar abilities did the same task over and over, probably the data would be somewhat right-skewed, which if the distribution were lognormal would mean the median and geometric mean are equal. However, it’s plausible that the distribution would be less skewed than lognormal so the geomean would be below the median, leading to lower reliability.
0 comments
Comments sorted by top scores.