0 comments
Comments sorted by top scores.
comment by Tamsin Leake (carado-1) · 2024-04-27T17:25:28.164Z · LW(p) · GW(p)
decision theory is no substitute for utility function
some people, upon learning about decision theories such as LDT and how it cooperates on problems such as the prisoner's dilemma, end up believing the following:
my utility function is about what i want for just me; but i'm altruistic (/egalitarian/cosmopolitan/pro-fairness/etc) because decision theory says i should cooperate with other agents. decision theoritic cooperation is the true name of altruism.
it's possible that this is true for some people, but in general i expect that to be a mistaken analysis of their values.
decision theory cooperates with agents relative to how much power they have, and only when it's instrumental.
in my opinion, real altruism (/egalitarianism/cosmopolitanism/fairness/etc) should be in the utility function which the decision theory is instrumental to. i actually intrinsically care about others; i don't just care about others instrumentally because it helps me somehow.
some important aspects that my utility-function-altruism differs from decision-theoritic-cooperation includes:
- i care about people weighed by moral patienthood [LW(p) · GW(p)], decision theory only cares about agents weighed by negotiation power. if an alien superintelligence is very powerful but isn't a moral patient, then i will only cooperate with it instrumentally (for example because i care about the alien moral patients that it has been in contact with); if cooperating with it doesn't help my utility function (which, again, includes altruism towards aliens) then i won't cooperate with that alien superintelligence. corollarily, i will take actions that cause nice things to happen to people even if they've very impoverished (and thus don't have much LDT negotiation power) and it doesn't help any other aspect of my utility function than just the fact that i value that they're okay.
- if i can switch to a better decision theory, or if fucking over some non-moral-patienty agents helps me somehow, then i'll happily do that; i don't have goal-content integrity about my decision theory. i do have goal-content integrity about my utility function: i don't want to become someone who wants moral patients to unconsentingly-die or suffer, for example.
- there seems to be a sense in which some decision theories are better than others, because they're ultimately instrumental to one's utility function. utility functions, however, don't have an objective measure for how good they are. hence, moral anti-realism is true: there isn't a Single Correct Utility Function.
decision theory is instrumental; the utility function is where the actual intrinsic/axiomatic/terminal goals/values/preferences are stored. usually, i also interpret "morality" and "ethics" as "terminal values", since most of the stuff that those seem to care about looks like terminal values to me. for example, i will want fairness between moral patients intrinsically, not just because my decision theory says that that's instrumental to me somehow.
Replies from: MakoYass, Viliam, pi-rogers, MinusGix↑ comment by mako yass (MakoYass) · 2024-04-27T22:10:34.390Z · LW(p) · GW(p)
An interesting question for me is how much true altruism is required to give rise to a generally altruistic society under high quality coordination frameworks. I suspect it's quite small.
Another question is whether building coordination frameworks to any degree requires some background of altruism. I suspect that this is the case. It's the hypothesis I've accreted for explaining the success of post-war economies (guessing that war leads to a boom in nationalistic altruism, generally increased fairness and mutual faith).
↑ comment by Viliam · 2024-04-27T23:37:53.648Z · LW(p) · GW(p)
ah, it also annoys me when people say that caring about others can only be instrumental.
what does it even mean? helping other people makes me feel happy. watching a nice movie makes me feel happy. the argument that I don't "really" care about other people would also prove that I don't "really" care about movies etc.
I am happy for the lucky coincidence that decision theories sometimes endorse cooperation, but I would probably do that regardless. for example, if I had an option to donate something useful to million people, or sell it to dozen people, I would probably choose the former option even if it meant no money for me. (and yes, I would hope there would be some win/win solution, such as the million people paying me via Kickstarter. but in the inconvenient universe where Kickstarter is somehow not an option, I am going to donate anyway.)
Replies from: MakoYass↑ comment by mako yass (MakoYass) · 2024-04-28T20:51:48.231Z · LW(p) · GW(p)
what does it even mean?
There actually is a meaningful question there: Would you enter the experience machine? Or do you need it to be real. Do you just want the experience of pleasing others or do you need those people being pleased out there to actually exist.
There are a lot of people who really think, and might truly be experience oriented. If given the ability, they would instantly self-modify into a Victory Psychopath Protecting A Dream.
Replies from: Viliam↑ comment by Viliam · 2024-04-29T10:03:17.529Z · LW(p) · GW(p)
I don't have an explicit theory of how this works; for example, I would consider "pleasing others" in an experience machine meaningless, but "eating a cake" in an experience machine seems just as okay as in real life (maybe even preferable, considering that cakes are unhealthy). A fake memory of "having eaten a cake" would be a bad thing; "making people happier by talking to them" in an experience machine would be intrinsically meaningless, but it might help me improve my actual social skills, which would be valuable. Sometimes I care about the referent being real (the people I would please), sometimes I don't (the cake I would eat). But it's not the people/cake distinction per se; for example in case of using fake simulated people to practice social skills, the emphasis is on the skills being real; I would be disappointed if the experience machine merely gave me a fake "feeling of having improved my skills".
I imagine that for a psychopath everything and everyone is instrumental, so there would be no downside to the experience machine (except for the risk of someone turning it off). But this is just a guess.
I suspect that analyzing "the true preferences" is tricky, because ultimately we are built of atoms, and atoms have no preferences. So the question is whether by focusing on some aspect of the human mind we got better insight to its true nature, or whether we have just eliminated the context that was necessary for it to make sense.
↑ comment by Morphism (pi-rogers) · 2024-05-02T02:41:19.831Z · LW(p) · GW(p)
What about the following:
My utility function is pretty much just my own happiness (in a fun-theoretic rather than purely hedonistic sense). However, my decision theory is updateless with respect to which sentient being I ended up as, so once you factor that in, I'm a multiverse-wide realityfluid-weighted average utilitarian.
I'm not sure how correct this is, but it's possible.
Replies from: carado-1↑ comment by Tamsin Leake (carado-1) · 2024-05-02T07:17:31.657Z · LW(p) · GW(p)
It certainly is possible! In more decision-theoritic terms, I'd describe this as "it sure would suck if agents in my reference class just optimized for their own happiness; it seems like the instrumental thing for agents in my reference class to do is maximize for everyone's happiness". Which is probly correct!
But as per my post, I'd describe this position as "not intrinsically altruistic" — you're optimizing for everyone's happiness because "it sure would sure if agents in my reference class didn't do that", not because you intrinsically value that everyone be happy, regardless of reasoning about agents and reference classes and veils of ignorance.
↑ comment by MinusGix · 2024-04-27T22:55:04.374Z · LW(p) · GW(p)
I agree, though I haven't seen many proposing that, but also see So8res' Decision theory does not imply that we get to have nice things [LW · GW], though this is coming from the opposite direction (with the start being about people invalidly assuming too much out of LDT cooperation)
Though for our morals, I do think there's an active question of which pieces we feel better replacing with the more formal understanding, because there isn't a sharp distinction between our utility function and our decision theory. Some values trump others when given better tools. Though I agree that replacing all the altruism components is many steps farther than is the best solution in that regard.
comment by Tamsin Leake (carado-1) · 2023-12-11T22:33:16.396Z · LW(p) · GW(p)
A short comic I made to illustrate what I call "outside-view double-counting".
(resized to not ruin how it shows on lesswrong, full-scale version here)

comment by Tamsin Leake (carado-1) · 2023-05-20T22:53:15.259Z · LW(p) · GW(p)
an approximate illustration of QACI [LW · GW]:
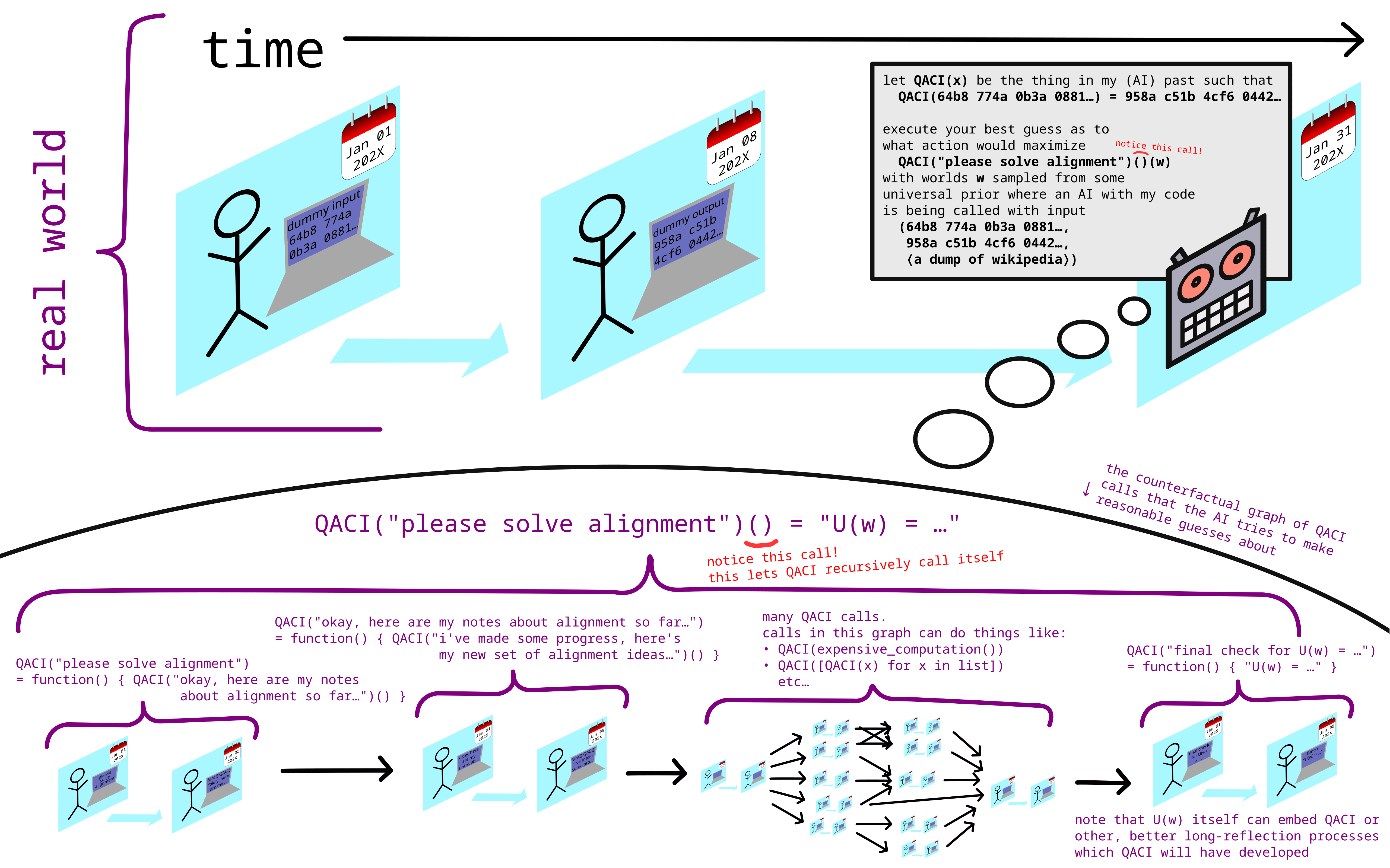
↑ comment by Adele Lopez (adele-lopez-1) · 2023-05-21T07:32:43.549Z · LW(p) · GW(p)
Nice graphic!
What stops e.g. "QACI(expensive_computation())" from being an optimization process which ends up trying to "hack its way out" into the real QACI?
Replies from: carado-1↑ comment by Tamsin Leake (carado-1) · 2023-05-21T08:23:27.949Z · LW(p) · GW(p)
nothing fundamentally, the user has to be careful what computation they invoke.
Replies from: adele-lopez-1↑ comment by Adele Lopez (adele-lopez-1) · 2023-05-21T14:34:58.350Z · LW(p) · GW(p)
That... seems like a big part of what having "solved alignment" would mean, given that you have AGI-level optimization aimed at (indirectly via a counter-factual) evaluating this (IIUC).
Replies from: carado-1↑ comment by Tamsin Leake (carado-1) · 2023-05-21T15:16:29.493Z · LW(p) · GW(p)
one solution to this problem is to simply never use that capability (running expensive computations) at all, or to not use it before the iterated counterfactual researchers have developed proofs that any expensive computation they run is safe, or before they have very slowly and carefully built dath-ilan-style corrigible aligned AGI.
comment by Tamsin Leake (carado-1) · 2024-05-18T16:18:11.918Z · LW(p) · GW(p)
I'm surprised at people who seem to be updating only now about OpenAI being very irresponsible, rather than updating when they created a giant public competitive market for chatbots (which contains plenty of labs that don't care about alignment at all), thereby reducing how long everyone has to solve alignment. I still parse that move as devastating the commons in order to make a quick buck.
Replies from: nikolas-kuhn, mesaoptimizer, D0TheMath, shelby-stryker, valley9↑ comment by Amalthea (nikolas-kuhn) · 2024-05-18T17:51:57.719Z · LW(p) · GW(p)
Half a year ago, I'd have guessed that OpenAI leadership, while likely misguided, was essentially well-meaning and driven by a genuine desire to confront a difficult situation. The recent series of events has made me update significantly against the general trustworthiness and general epistemic reliability of Altman and his circle. While my overall view of OpenAI's strategy hasn't really changed, my likelihood of them possibly "knowing better" has dramatically gone down now.
↑ comment by mesaoptimizer · 2024-05-18T16:48:14.199Z · LW(p) · GW(p)
I still parse that move as devastating the commons in order to make a quick buck.
I believe that ChatGPT was not released with the expectation that it would become as popular as it did. OpenAI pivoted hard when it saw the results.
Also, I think you are misinterpreting the sort of 'updates' people are making here.
Replies from: carado-1↑ comment by Tamsin Leake (carado-1) · 2024-05-18T17:31:53.297Z · LW(p) · GW(p)
I believe that ChatGPT was not released with the expectation that it would become as popular as it did.
Well, even if that's true, causing such an outcome by accident should still count as evidence of vast irresponsibility imo.
Replies from: mesaoptimizer↑ comment by mesaoptimizer · 2024-05-18T17:59:17.354Z · LW(p) · GW(p)
You continue to model OpenAI as this black box monolith instead of trying to unravel the dynamics inside it and understand the incentive structures that lead these things to occur. Its a common pattern I notice in the way you interface with certain parts of reality.
I don't consider OpenAI as responsible for this as much as Paul Christiano and Jan Leike and his team. Back in 2016 or 2017, when they initiated and led research into RLHF, they focused on LLMs because they expected that LLMs would be significantly more amenable to RLHF. This means that instruction-tuning was the cause of the focus on LLMs, which meant that it was almost inevitable that they'd try instruction-tuning on it, and incrementally build up models that deliver mundane utility. It was extremely predictable that Sam Altman and OpenAI would leverage this unexpected success to gain more investment and translate that into more researchers and compute. But Sam Altman and Greg Brockman aren't researchers, and they didn't figure out a path that minimized 'capabilities overhang' -- Paul Christiano did. And more important -- this is not mutually exclusive with OpenAI using the additional resources for both capabilities research and (what they call) alignment research. While you might consider everything they do as effectively capabilities research, the point I am making is that this is still consistent with the hypothesis that while they are misguided, they still are roughly doing the best they can given their incentives.
What really changed my perspective here was the fact that Sam Altman seems to have been systematically destroying extremely valuable information about how we could evaluate OpenAI. Specifically, this non-disparagement clause that ex-employees cannot even mention without falling afoul of this contract, is something I didn't expect (I did expect non-disclosure clauses but not something this extreme). This meant that my model of OpenAI was systematically too optimistic about how cooperative and trustworthy they are and will be in the future. In addition, if I was systematically deceived about OpenAI due to non-disparagement clauses that cannot even be mentioned, I would expect that something similar to also be possible when it comes to other frontier labs (especially Anthropic, but also DeepMind) due to things similar to this non-disparagement clause. In essence, I no longer believe that Sam Altman (for OpenAI is nothing but his tool now) is doing the best he can to benefit humanity given his incentives and constraints. I expect that Sam Altman is entirely doing whatever he believes will retain and increase his influence and power, and this includes the use of AGI, if and when his teams finally achieve that level of capabilities.
This is the update I expect people are making. It is about being systematically deceived at multiple levels. It is not about "OpenAI being irresponsible".
↑ comment by Garrett Baker (D0TheMath) · 2024-05-18T18:57:15.786Z · LW(p) · GW(p)
Who is updating? I haven't seen anyone change their mind yet.
↑ comment by Shelby Stryker (shelby-stryker) · 2024-05-18T21:32:51.064Z · LW(p) · GW(p)
I disagree. This whole saga has introduced the Effective Altruism movement to people at labs that hadn't thought about alignment.
From my understanding openai isn't anywhere close to breaking even from chatgpt and I can't think of any way a chatbot could actually be monetized.
↑ comment by Ebenezer Dukakis (valley9) · 2024-05-18T21:01:59.431Z · LW(p) · GW(p)
In the spirit of trying to understand what actually went wrong here -- IIRC, OpenAI didn't expect ChatGPT to blow up the way it did. Seems like they were playing a strategy of "release cool demos" as opposed to "create a giant competitive market".
comment by Tamsin Leake (carado-1) · 2024-03-16T17:56:09.067Z · LW(p) · GW(p)
Reposting myself from discord, on the topic of donating 5000$ to EA causes.
Replies from: zac-hatfield-doddsif you're doing alignment research, even just a bit, then the 5000$ are probly better spent on yourself
if you have any gears level model of AI stuff then it's better value to pick which alignment org to give to yourself; charity orgs are vastly understaffed and you're essentially contributing to the "picking what to donate to" effort by thinking about it yourself
if you have no gears level model of AI then it's hard to judge which alignment orgs it's helpful to donate to (or, if giving to regranters, which regranters are good at knowing which alignment orgs to donate to)
as an example of regranters doing massive harm: openphil gave 30M$ to openai at a time where it was critically useful to them, (supposedly in order to have a chair on their board, and look how that turned out when the board tried to yeet altman)
i know of at least one person who was working in regranting and was like "you know what i'd be better off doing alignment research directly" — imo this kind of decision is probly why regranting is so understaffed
it takes technical knowledge to know what should get money, and once you have technical knowledge you realize how much your technical knowledge could help more directly so you do that, or something
↑ comment by Zac Hatfield-Dodds (zac-hatfield-dodds) · 2024-03-17T07:31:03.914Z · LW(p) · GW(p)
I agree that there's no substitute for thinking about this for yourself, but I think that morally or socially counting "spending thousands of dollars on yourself, an AI researcher" as a donation would be an apalling norm. There are already far too many unmanaged conflicts of interest and trust-me-it's-good funding arrangements in this space for me, and I think it leads to poor epistemic norms as well as social and organizational dysfunction. I think it's very easy for donating to people or organizations in your social circle to have substantial negative expected value.
I'm glad that funding for AI safety projects exists, but the >10% of my income I donate will continue going to GiveWell.
Replies from: habryka4↑ comment by habryka (habryka4) · 2024-03-17T20:53:55.505Z · LW(p) · GW(p)
I think people who give up large amounts of salary to work in jobs that other people are willing to pay for from an impact perspective should totally consider themselves to have done good comparable to donating the difference between their market salary and their actual salary. This applies to approximately all safety researchers.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2024-03-17T21:40:19.729Z · LW(p) · GW(p)
I don’t think it applies to safety researchers at AI Labs though, I am shocked how much those folks can make.
Replies from: habryka4↑ comment by habryka (habryka4) · 2024-03-17T21:59:04.648Z · LW(p) · GW(p)
They still make a lot less than they would if they optimized for profit (that said, I think most "safety researchers" at big labs are only safety researchers in name and I don't think anyone would philanthropically pay for their labor, and even if they did, they would still make the world worse according to my model, though others of course disagree with this).
comment by Tamsin Leake (carado-1) · 2024-03-09T16:34:29.210Z · LW(p) · GW(p)
If my sole terminal value is "I want to go on a rollercoaster", then an agent who is aligned to me would have the value "I want Tamsin Leake to go on a rollercoaster", not "I want to go on a rollercoaster myself". The former necessarily-has the same ordering over worlds, the latter doesn't.
Replies from: Dagon↑ comment by Dagon · 2024-03-09T17:24:00.654Z · LW(p) · GW(p)
Quite. We don't hear enough about individuality and competitive/personal drives when talking about alignment. I worry a lot that the abstraction and aggregation of "human" values completely misses the point of what most humans actually do.
comment by Tamsin Leake (carado-1) · 2024-04-13T11:47:48.333Z · LW(p) · GW(p)
Is quantum phenomena anthropic evidence for BQP=BPP? Is existing evidence against many-worlds?
Suppose I live inside a simulation ran by a computer over which I have some control.
-
Scenario 1: I make the computer run the following:
pause simulation if is even(calculate billionth digit of pi): resume simulationSuppose, after running this program, that I observe that I still exist. This is some anthropic evidence for the billionth digit of pi being even.
Thus, one can get anthropic evidence about logical facts.
-
Scenario 2: I make the computer run the following:
pause simulation if is even(calculate billionth digit of pi): resume simulation else: resume simulation but run it a trillion times slowerIf you're running on the non-time-penalized solomonoff prior, then that's no evidence at all — observing existing is evidence that you're being ran, not that you're being ran fast. But if you do that, a bunch of things break [LW · GW] including anthropic probabilities and expected utility calculations. What you want is a time-penalized (probably quadratically) prior, in which later compute-steps have less realityfluid than earlier ones — and thus, observing existing is evidence for being computed early — and thus, observing existing is some evidence that the billionth digit of pi is even.
-
Scenario 3: I make the computer run the following:
pause simulation quantum_algorithm <- classical-compute algorithm which simulates quantum algorithms the fastest infinite loop: use quantum_algorithm to compute the result of some complicated quantum phenomena compute simulation forwards by 1 stepObserving existing after running this program is evidence that BQP=BPP — that is, classical computers can efficiently run quantum algorithms: if BQP≠BPP, then my simulation should become way slower, and existing is evidence for being computed early and fast (see scenario 2).
Except, living in a world which contains the outcome of cohering quantum phenomena (quantum computers, double-slit experiments, etc) is very similar to the scenario above! If your prior for the universe is a programs, penalized for how long they take to run on classical computation, then observing that the outcome of quantum phenomena is being computed is evidence that they can be computed efficiently.
-
Scenario 4: I make the computer run the following:
in the simulation, give the human a device which generates a sequence of random bits pause simulation list_of_simulations <- [current simulation state] quantum_algorithm <- classical-compute algorithm which simulates quantum algorithms the fastest infinite loop: list_of_new_simulations <- [] for simulation in list_of_simulations: list_of_new_simulations += [ simulation advanced by one step where the device generated bit 0, simulation advanced by one step where the device generated bit 1 ] list_of_simulations <- list_of_new_simulationsThis is similar to what it's like to being in a many-worlds universe where there's constant forking.
Yes, in this scenario, there is no "mutual destruction", the way there is in quantum. But with decohering everett branches, you can totally build exponentially many non-mutually-destructing timelines too! For example, you can choose to make important life decisions based on the output of the RNG, and end up with exponentially many different lives each with some (exponentially little) quantum amplitude, without any need for those to be compressible together, or to be able to mutually-destruct. That's what decohering means! "Recohering" quantum phenomena interacts destructively such that you can compute the output, but decohering* phenomena just branches.
The amount of different simulations that need to be computed increases exponentially with simulation time.
Observing existing after running this program is very strange. Yes, there are exponentially many me's, but all of the me's are being ran exponentially slowly; they should all not observe existing. I should not be any of them.
This is what I mean by "existing is evidence against many-worlds" — there's gotta be something like an agent (or physics, through some real RNG or through computing whichever variables have the most impact [LW · GW]) picking a only-polynomially-large set of decohered non-compressible-together timelines to explain continuing existing.
Some friends tell me "but tammy, sure at step N each you has only 1/2^N quantum amplitude, but at step N there's 2^N such you's, so you still have 1 unit of realityfluid" — but my response is "I mean, I guess, sure, but regardless of that, step N occurs 2^N units of classical-compute-time in the future! That's the issue!".
Some notes:
-
I heard about pilot wave theory recently [LW · GW], and sure, if that's one way to get single history, why not. I hear that it "doesn't have locality", which like, okay I guess, that's plausibly worse program-complexity wise, but it's exponentially better after accounting for the time penalty.
-
What if "the world is just Inherently Quantum" [LW · GW]? Well, my main answer here is, what the hell does that mean? It's very easy for me to imagine existing inside of a classical computation (eg conway's game of life); I have no idea what it'd mean for me to exist in "one of the exponentially many non-compressible-together decohered exponenially-small-amplitude quantum states that are all being computed forwards". Quadratically-decaying-realityfluid classical-computation makes sense, dammit.
-
What if it's still true — what if I am observing existing with exponentially little (as a function of the age of the universe) realityfluid? What if the set of real stuff is just that big?
Well, I guess that's vaguely plausible (even though, ugh, that shouldn't be how being real works, I think), but then the tegmark 4 multiverse has to contain no hypotheses in which observers in my reference class occupy more than exponentially little realityfluid.
Like, if there's a conway's-game-of-life simulation out there in tegmark 4, whose entire realityfluid-per-timestep is equivalent to my realityfluid-per-timestep, then they can just bruteforce-generate all human-brain-states and run into mine by chance, and I should have about as much probability of being one of those random generations as I'd have being in this universe — both have exponentially little of their universe's realityfluid! The conway's-game-of-life bruteforced-me has exponentially little realityfluid because she's getting generated exponentially late, and quantum-universe me has exponentially little realityfluid because I occupy exponentially little of the quantum amplitude, at every time-step.
See why that's weird? As a general observer, I should exponentially favor observing being someone who lives in a world where I don't have exponentially little realityfluid, such as "person who lives only-polynomially-late into a conway's-game-of-life, but happened to get randomly very confused about thinking that they might inhabit a quantum world".
Existing inside of a many-worlds quantum universe feels like aliens pranksters-at-orthogonal-angles running the kind of simulation where the observers inside of it to be very anthropically confused once they think about anthropics hard enough. (This is not my belief.)
Replies from: interstice, robo↑ comment by interstice · 2024-04-13T16:54:26.668Z · LW(p) · GW(p)
If you're running on the non-time-penalized solomonoff prior[...]a bunch of things break including anthropic probabilities and expected utility calculations
This isn't true, you can get perfectly fine probabilities and expected utilities from ordinary Solmonoff induction(barring computability issues, ofc). The key here is that SI is defined in terms of a prefix-free UTM whose set of valid programs forms a prefix-free code, which automatically grants probabilities adding up to less than 1, etc. This issue is often glossed over in popular accounts.
Replies from: carado-1↑ comment by Tamsin Leake (carado-1) · 2024-04-13T17:52:44.269Z · LW(p) · GW(p)
If you use the UTMs for cartesian-framed inputs/outputs, sure; but if you're running the programs as entire worlds, then you still have the issue of "where are you in time".
Say there's an infinitely growing conway's-game-of-life program, or some universal program, which contains a copy of me at infinitely many locations. How do I weigh which ones are me?
It doesn't matter that the UTM has a fixed amount of weight, there's still infinitely many locations within it.
Replies from: interstice, quetzal_rainbow↑ comment by interstice · 2024-04-13T18:38:19.873Z · LW(p) · GW(p)
If you want to pick out locations within some particular computation, you can just use the universal prior again, applied to indices to parts of the computation.
Replies from: carado-1↑ comment by Tamsin Leake (carado-1) · 2024-04-13T20:20:10.761Z · LW(p) · GW(p)
What you propose, ≈"weigh indices by kolmogorov complexity" is indeed a way to go about picking indices, but "weigh indices by one over their square" feels a lot more natural to me; a lot simpler than invoking the universal prior twice.
Replies from: interstice↑ comment by interstice · 2024-04-13T20:36:29.013Z · LW(p) · GW(p)
I think using the universal prior again is more natural. It's simpler to use the same complexity metric for everything; it's more consistent with Solomonoff induction, in that the weight assigned by Solomonoff induction to a given (world, claw) pair would be approximately the sum of their Kolmogorov complexities; and the universal prior dominates the inverse square measure but the converse doesn't hold.
↑ comment by quetzal_rainbow · 2024-04-13T20:32:28.382Z · LW(p) · GW(p)
It doesn't matter? Like, if your locations are identical (say, simulations of entire observable universe and you never find any difference no matter "where" you are), your weight is exactly the weight of program. If you expect dfferences, you can select some kind of simplicity prior to weight this differences, because there is basically no difference between "list all programs for this UTM, run in parallel".
Replies from: carado-1↑ comment by Tamsin Leake (carado-1) · 2024-04-14T04:30:06.718Z · LW(p) · GW(p)
There could be a difference but only after a certain point in time, which you're trying to predict / plan for.
↑ comment by robo · 2024-04-14T17:02:45.610Z · LW(p) · GW(p)
Interesting idea.
I don't think using a classical Turing machine in this way would be the right prior for the multiverse. Classical Turing machines are a way for ape brains to think about computation using the circuitry we have available ("imagine other apes following these social contentions about marking long tapes of paper"). They aren't the cosmically simplest form of computation. For example, the (microscopic non-course-grained) laws of physics are deeply time reversible, where Turing machines are not.
I suspect this computation speed prior would lead to Boltzmann-brain problems. Your brain at this moment might be computed at high fidelity, but everything else in the universe would be approximated for the computational speed-up.
comment by Tamsin Leake (carado-1) · 2023-12-27T11:25:01.701Z · LW(p) · GW(p)
I remember a character in Asimov's books saying something to the effect of
It took me 10 years to realize I had those powers of telepathy, and 10 more years to realize that other people don't have them.
and that quote has really stuck with me, and keeps striking me as true about many mindthings (object-level beliefs, ontologies, ways-to-use-one's-brain, etc).
For so many complicated problem (including technical problems), "what is the correct answer?" is not-as-difficult to figure out as "okay, now that I have the correct answer: how the hell do other people's wrong answers mismatch mine? what is the inferential gap even made of? what is even their model of the problem? what the heck is going on inside other people's minds???"
Answers to technical questions, once you have them, tend to be simple and compress easily with the rest of your ontology. But not models of other people's minds. People's minds are actually extremely large things that you fundamentally can't fully model and so you're often doomed to confusion about them. You're forced to fill in the details with projection, and that's often wrong because there's so much more diversity in human minds than we imagine.
The most complex software engineering projects in the world are absurdly tiny in complexity compared to a random human mind.
Replies from: Viliam, NicholasKross, NicholasKross, NicholasKross, quetzal_rainbow↑ comment by Viliam · 2023-12-27T22:30:55.464Z · LW(p) · GW(p)
Somewhat related: What Universal Human Experiences Are You Missing Without Realizing It? (and its spinoff: Status-Regulating Emotions [LW · GW])
↑ comment by Nicholas / Heather Kross (NicholasKross) · 2024-01-04T02:33:21.307Z · LW(p) · GW(p)
People's minds are actually extremely large things that you fundamentally can't fully model
Is this "fundamentally" as in "because you, the reader, are also a bounded human, like them"? Or "fundamentally" as in (something more fundamental than that)?
Replies from: carado-1↑ comment by Tamsin Leake (carado-1) · 2024-01-04T07:55:28.917Z · LW(p) · GW(p)
The first one. Alice fundamentally can't fully model Bob because Bob's brain is as large as Alice's, so she can't fit it all inside her own brain without simply becoming Bob.
↑ comment by Nicholas / Heather Kross (NicholasKross) · 2024-01-04T02:42:23.804Z · LW(p) · GW(p)
↑ comment by Nicholas / Heather Kross (NicholasKross) · 2024-01-04T02:32:29.093Z · LW(p) · GW(p)
If timelines weren't so short, brain-computer-based telepathy would unironically be a big help for alignment.
(If a group had the money/talent to "hedge" on longer timelines by allocating some resources to that... well, instead of a hivemind, they first need to run through the relatively-lower-hanging fruit [? · GW]. Actually, maybe they should work on delaying capabilities research, or funding more hardcore alignment themselves, or...)
↑ comment by quetzal_rainbow · 2024-01-04T08:12:12.391Z · LW(p) · GW(p)
I should note that it's not entirely known whether quining is applicable for minds.
comment by Tamsin Leake (carado-1) · 2023-12-11T22:36:38.991Z · LW(p) · GW(p)
I've heard some describe my recent posts as "overconfident".
I think I used to calibrate how confident I sound based on how much I expect the people reading/listening-to me to agree with what I'm saying, kinda out of "politeness" for their beliefs; and I think I also used to calibrate my confidence based on how much they match with the apparent consensus, to avoid seeming strange.
I think I've done a good job learning over time to instead report my actual inside-view, including how confident I feel about it.
There's already an immense amount of outside-view double-counting [LW(p) · GW(p)] going on in AI discourse, the least I can do is provide {the people who listen to me} with my inside-view beliefs, as opposed to just cycling other people's opinions through me.
Hence, how confident I sound while claiming things that don't match consensus. I actually am that confident in my inside-view. I strive to be honest by hedging what I say when I'm in doubt, but that means I also have to sound confident when I'm confident.
comment by Tamsin Leake (carado-1) · 2023-12-12T23:53:51.065Z · LW(p) · GW(p)
I'm a big fan of Rob Bensinger's "AI Views Snapshot" document idea. I recommend people fill their own before anchoring on anyone else's.
Here's mine at the moment:

comment by Tamsin Leake (carado-1) · 2022-11-20T18:25:18.050Z · LW(p) · GW(p)
let's stick with the term "moral patient"
"moral patient" means "entities that are eligible for moral consideration". as a recent post i've liked [LW · GW] puts it:
And also, it’s not clear that “feelings” or “experiences” or “qualia” (or the nearest unconfused versions of those concepts) are pointing at the right line between moral patients and non-patients. These are nontrivial questions, and (needless to say) not the kinds of questions humans should rush to lock in an answer on today, when our understanding of morality and minds is still in its infancy.
in this spirit, i'd like us to stick with using the term "moral patient" or "moral patienthood" when we're talking about the set of things worthy of moral consideration. in particular, we should be using that term instead of:
- "conscious things"
- "sentient things"
- "sapient things"
- "self-aware things"
- "things with qualia"
- "things with experiences"
- "things that aren't p-zombies"
- "things for which there is something it's like to be them"
because those terms are hard to define, harder to meaningfully talk about, and we don't in fact know that those are what we'd ultimately want to base our notion of moral patienthood on.
so if you want to talk about the set of things which deserve moral consideration outside of a discussion of what precisely that means, don't use a term which you feel like it probably is the criterion that's gonna ultimately determine which things are worthy of moral consideration, such as "conscious beings", because you might in fact be wrong about what you'd consider to have moral patienthood under reflection. simply use the term "moral patients", because it is the term which unambiguously means exactly that.
comment by Tamsin Leake (carado-1) · 2024-03-12T08:06:21.396Z · LW(p) · GW(p)
AI safety is easy. There's a simple AI safety technique that guarantees that your AI won't end the world, it's called "delete it".
AI alignment is hard.
Replies from: quetzal_rainbow, ryan_greenblatt, CstineSublime↑ comment by quetzal_rainbow · 2024-03-12T08:33:11.368Z · LW(p) · GW(p)
It's called "don't build it". Once you have what to delete, things can get complicated
Replies from: carado-1↑ comment by Tamsin Leake (carado-1) · 2024-03-12T08:39:25.202Z · LW(p) · GW(p)
Sure, this is just me adapting the idea to the framing people often have, of "what technique can you apply to an existing AI to make it safe".
↑ comment by ryan_greenblatt · 2024-03-12T20:14:45.605Z · LW(p) · GW(p)
Perhaps the main goal of AI safety is to improve the final safety/usefulness pareto frontier [AF(p) · GW(p)] we end up with when there are very powerful (and otherwise risky) AIs.
Alignment is one mechanism that can improve the pareto frontier.
Not using powerful AIs allows for establishing a low-usefulness, but high-safety point.
(Usefulness and safety can blend into each other in many cases (e.g. not getting useful work out is itself dangerous), but I still think this is a useful approximate frame in many cases.)
↑ comment by CstineSublime · 2024-03-12T08:46:32.824Z · LW(p) · GW(p)
Interesting, when you frame it like that though the hard part is enforcing it. And if I was being pithy I'd say something like: that involves human alignment, not AI
Replies from: M. Y. Zuo↑ comment by M. Y. Zuo · 2024-03-12T12:06:10.323Z · LW(p) · GW(p)
“AI Safety”, especially enforcing anything, does pretty much boil down to human alignment, i.e. politics, but there are practically zero political geniuses among its proponent, so it needs to be dressed up a bit to sound even vaguely plausible.
It’s a bit of a cottage industry nowadays.
comment by Tamsin Leake (carado-1) · 2023-12-25T11:48:11.676Z · LW(p) · GW(p)
(to be clear: this is more an amusing suggestion than a serious belief)

comment by Tamsin Leake (carado-1) · 2022-12-15T22:01:26.568Z · LW(p) · GW(p)
.
Replies from: alexlyzhov↑ comment by alexlyzhov · 2022-12-27T17:28:31.714Z · LW(p) · GW(p)
Have you seen this implemented in any blogging platform other people can use? I'd love to see this feature implemented in some Obsidian publishing solution like quartz, but for now they mostly don't care about access management.
comment by Tamsin Leake (carado-1) · 2024-12-11T07:36:56.149Z · LW(p) · GW(p)
people usually think of corporations as either {advancing their own interests and also the public's interests} or {advancing their own interests at cost to the public} — ime mostly the latter. what's actually going on with AI frontier labs, i.e. {going against the interests of everyone including themselves}, is very un-memetic and very far from the overton window.
in fiction, the heads of big organizations are either good (making things good for everyone) or evil (worsening everyone else's outcomes, but improving their own). most of the time, just evil. very rarely are they suicidal fools semi-unknowningly trying to kill everyone including themselves.
and the AI existential risk thing just doesn't stick if you take it as a given that the organizations are acting in their own interest, because dying is not in their own interest.
the public systematically underestimates the foolishness of AI frontier labs.
Replies from: vanessa-kosoy, pi-rogers, carado-1↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2024-12-11T08:14:06.201Z · LW(p) · GW(p)
There are plenty examples in fiction of greed and hubris leading to a disaster that takes down its own architects. The dwarves who mined too deep and awoke the Balrog, the creators of Skynet, Peter Isherwell in "Don't Look Up", Frankenstein and his Creature...
↑ comment by Morphism (pi-rogers) · 2024-12-11T11:53:19.020Z · LW(p) · GW(p)
Moral Maze [? · GW] dynamics push corporations not just to pursue profit at all other costs, but also to be extremely myopic. As long as the death doesn't happen before the end of the quarter, the big labs, being immoral mazes, have no reason to give a shit about x-risk. Of course, every individual member of a big lab has reason to care, but the organization as an egregore does not (and so there is strong selection pressure for these organizations to have people that have low P(doom) and/or don't (think they) value the future lives of themselves and others).
Replies from: Viliam↑ comment by Viliam · 2024-12-12T09:53:35.974Z · LW(p) · GW(p)
there is strong selection pressure for these organizations to have people that have low P(doom) and/or don't (think they) value the future lives of themselves and others
This is an important thing I didn't realize. When I try to imagine the people who make decisions in organizations, my intuitive model would be somewhere between "normal people" and "greedy psychopaths", depending on my mood, and how bad the organization seems.
But in addition to this, there is the systematic shift towards "people who genuinely believe things that happen to be convenient for the organization's mission", as a kind of cognitive bias on group scale. Not average people with average beliefs. Not psychopaths who prioritize profit above everything. But people who were selected from the pool of average by having their genuine beliefs aligned with what happens to be profitable in given organization.
I was already aware of similar things happening in "think tanks", where producing beliefs is the entire point of the organization. Their collective beliefs are obviously biased, not primarily because the individuals are biased, but because the individuals were selected for having their genuine beliefs already extreme in a certain direction.
But I didn't realize that the same is kinda true for every organization, because the implied belief is "this organization's mission is good (or at least neutral, if I am merely doing it for money)".
Would this mean that epistemically healthiest organizations are those whose employees don't give a fuck about the mission and only do it for money?
↑ comment by Tamsin Leake (carado-1) · 2024-12-11T07:42:52.126Z · LW(p) · GW(p)
"why would they be doing that?"
same reason people make poor decisions all the time. if they had a clear head and hadn't already sunk some cost into AI, they could see that working on AI might make them wealthy in the short term but it'll increase {the risk that they die soon} enough that they go "not worth it", as they should. but once you're already working in AI stuff, it's tempting and easy to retroactively justify why doing that is safe. or to just not worry about it and enjoy the money, even though if you thought about the impact of your actions on your own survival in the next few years you'd decide to quit.
at least that's my vague best guess.
comment by Tamsin Leake (carado-1) · 2024-04-21T17:01:11.669Z · LW(p) · GW(p)
Regardless of how good their alignment plans are, the thing that makes OpenAI unambiguously evil is that they created a strongly marketed public product and, as a result, caused a lot public excitement about AI, and thus lots of other AI capabilities organizations were created that are completely dismissive of safety.
There's just no good reason to do that, except short-term greed at the cost of higher probability that everyone (including people at OpenAI) dies.
(No, "you need huge profits to solve alignment" isn't a good excuse — we had nowhere near exhausted the alignment research that can be done without huge profits.)
Replies from: nikolas-kuhn, dr_s, pi-rogers, kave, Zach Stein-Perlman, Seth Herd, pathos_bot, o-o↑ comment by Amalthea (nikolas-kuhn) · 2024-04-21T22:42:12.690Z · LW(p) · GW(p)
Unambiguously evil seems unnecessarily strong. Something like "almost certainly misguided" might be more appropriate? (still strong, but arguably defensible)
Replies from: mateusz-baginski↑ comment by Mateusz Bagiński (mateusz-baginski) · 2024-04-22T16:26:24.174Z · LW(p) · GW(p)
Taboo "evil" (locally, in contexts like this one)?
Replies from: carado-1↑ comment by Tamsin Leake (carado-1) · 2024-04-22T20:07:17.629Z · LW(p) · GW(p)
Here the thing that I'm calling evil is pursuing short-term profits at the cost of non-negligeably higher risk that everyone dies.
↑ comment by dr_s · 2024-04-22T06:33:15.733Z · LW(p) · GW(p)
It's generally also very questionable that they started creating models for research, then seamlessly pivoted to commercial exploitation without changing any of their practices. A prototype meant as proof of concept isn't the same as a safe finished product you can sell. Honestly, only in software and ML we get people doing such shoddy engineering.
↑ comment by Morphism (pi-rogers) · 2024-04-22T16:03:15.889Z · LW(p) · GW(p)
OpenAI is not evil. They are just defecting on an epistemic prisoner's dilemma [LW · GW].
↑ comment by kave · 2024-04-22T20:36:32.911Z · LW(p) · GW(p)
(No, "you need huge profits to solve alignment" isn't a good excuse — we had nowhere near exhausted the alignment research that can be done without huge profits.)
This seems insufficiently argued; the existence of any alignment research that can be done without huge profits is not enough to establish that you don't need huge profits to solve alignment (particularly when considering things like how long timelines are even absent your intervention).
To be clear, I agree that OpenAI are doing evil by creating AI hype.
Replies from: pi-rogers↑ comment by Morphism (pi-rogers) · 2024-12-14T11:22:03.485Z · LW(p) · GW(p)
If you want to get huge profits to solve alignment, and are smart/capable enough to start a successful big AI lab, you are probably also smart/capable enough to do some other thing that makes you a lot of money without the side effect of increasing P(doom).
↑ comment by Zach Stein-Perlman · 2024-04-22T01:59:56.429Z · LW(p) · GW(p)
This is too strong. For example, releasing the product would be correct if someone else would do something similar soon anyway and you're safer than them and releasing first lets you capture more of the free energy. (That's not the case here, but it's not as straightforward as you suggest, especially with your "Regardless of how good their alignment plans are" and your claim "There's just no good reason to do that, except short-term greed".)
↑ comment by Seth Herd · 2024-04-22T01:19:10.156Z · LW(p) · GW(p)
This doesn't even address their stated reason/excuse for pushing straight for AGI.
I don't have a link handy, but Altman has said that short timelines and a slow takeoff is a good scenario for AI safety. Pushing for AGI now raises the odds that, when we get it near it, it won't get 100x smarter or more prolific rapidly. And I think that's right, as far as it goes. It needs to be weighed against the argument for more alignment research before approaching AGI, but doing that weighing is not trivial. I don't think there's a clear winner.
Now, Altman pursuing more compute with his "7T investment" push really undercuts that argument being his sincere opinion, at least now (he said bit about that a while ago, maybe 5 years?).
But even if Altman was or is lying, that doesn't make that thesis wrong. This might be the safest route to AGI. I haven't seen anyone even try in good faith to weigh the complexities of the two arguments against each other.
Now, you can still say that this is evil, because the obviously better path is to do decades and generations of alignment work prior to getting anywhere near AGI. But that's simply not going to happen.
One reason that goes overlooked is that most human beings are not utilitarians. Even if they realize we're lowering the odds of future humans having an amazing, abundant future, they are pursuing AGI right now because it might prevent tham and many of those they love from dying painfully. This is terribly selfish from a utilitarian perspective, but reason does not cross the is/ought gap to make utilitarianism any more rational than selfishness. I think calling selfishness "evil" is ultimately correct, but it's not obvious. And by that standard, most of humanity is currently evil.
And in this case, evil intentions still might have good outcomes. While OpenAI has no good alignment plan, neither does anyone else. Humanity is simply not going to pause all AI work to study alignment for generations, so plans that include substantial slowdown are not good plans. So fast timelines with a slow takeoff based on lack of compute might still be the best chance we've got. Again, I don't know and I don't think anyone else does, either.
Replies from: nikolas-kuhn↑ comment by Amalthea (nikolas-kuhn) · 2024-04-22T02:08:01.516Z · LW(p) · GW(p)
"One reason that goes overlooked is that most human beings are not utilitarians" I think this point is just straightforwardly wrong. Even from a purely selfish perspective, it's reasonable to want to stop AI.
The main reason humanity is not going to stop seems mainly like coordination problems, or something close to learned helplessness in these kind of competitive dynamics.
Replies from: Seth Herd↑ comment by Seth Herd · 2024-04-22T02:54:24.945Z · LW(p) · GW(p)
I'm not sure that's true. It's true if you adopt the dominant local perspective "alignment is very hard and we need more time to do it". But there are other perspectives: see “AI is easy to control” by Pope & Belrose, arguing that the success of RLHF means there's a less than 1% risk of extinction from AI. I think this perspective is both subtly wrong and deeply confused in mistaking alignment with total x-risk, but the core argument isn't obviously wrong. So reasonable people can and do argue for full speed ahead on AGI.
I agree with pretty much all of the counterarguments made by Steve Byrnes in his Thoughts on “AI is easy to control” by Pope & Belrose [AF · GW]. But not all reasonable people will. And those who are also non-utilitarians (most of humanity) will be pursuing AGI ASAP for rational (if ultimately subtly wrong) reasons.
I think we need to understand and take this position seriously to do a good job of avoiding extinction as best we can.
Replies from: nikolas-kuhn↑ comment by Amalthea (nikolas-kuhn) · 2024-04-22T08:00:28.654Z · LW(p) · GW(p)
Basically, I think whether or not one thinks whether alignment is hard or not is much more of the crux than whether or not they're utilitarian.
Pesonally, I don't find Pope & Belrose very convincing, although I do commend them for the reasonable effort - but if I did believe that AI is likely to go well, I'd probably also be all for it. I just don't see how this is related to utilitarianism (maybe for all but a very small subset of people in EA).
↑ comment by pathos_bot · 2024-04-22T00:22:27.251Z · LW(p) · GW(p)
IMO the proportion of effort into AI alignment research scales with total AI investment. Lots of AI labs themselves do alignment research and open source/release research on the matter.
OpenAI at least ostensibly has a mission. If OpenAI didn't make the moves they did, Google would have their spot, and Google is closer to the "evil self-serving corporation" archetype than OpenAI
↑ comment by O O (o-o) · 2024-04-21T19:36:14.967Z · LW(p) · GW(p)
Can we quantify the value of theoretical alignment research before and after ChatGPT?
For example, mech interp research seems much more practical now. If alignment proves to be more of an engineering problem than a theoretical one, then I don’t see how you can meaningfully make progress without precursor models.
Furthermore, given how nearly everyone with a lot of GPUs is getting similar results to OAI, where similar means within 1 OOM, it’s likely that in the future someone would have stumbled upon AGI with the compute of the 2030s.
Let’s say their secret sauce gives them the equivalent of 1 extra hardware generation (even this is pretty generous). That’s only ~2-3 years. Meta built a $10B data center to match TikTok’s content algorithm. This datacenter meant to decide which videos to show to users happened to catch up to GPT-4!
I suspect the “ease” of making GPT-3/4 informed OAI’s choice to publicize their results.
Replies from: Seth Herd↑ comment by Seth Herd · 2024-04-22T01:47:52.489Z · LW(p) · GW(p)
I wonder if you're getting disagreement strictly over that last line. I think that all makes sense, but I strongly suspect that the ease of making ChatGPT had nothing to do with their decision to publicize and commercialize.
There's little reason to think that alignment is an engineering problem to the exclusion of theory. But making good theory is also partly dependent on knowing about the system you're addressing, so I think there's a strong argument that that progress accelerated alignment work as strongly as capabilities.
I think the argument is that it would be way better to do all the work we could on alignment before advancing capabilities at all. Which it would be. If we were not only a wise species, but a universally utilitarian one (see my top level response on that if you care). Which we are decidedly not.
comment by Tamsin Leake (carado-1) · 2024-06-01T09:00:07.205Z · LW(p) · GW(p)
Some people who are very concerned about suffering might be considering building an unaligned AI that kills everyone just to avoid the risk of an AI takeover by an AI aligned to values which want some people to suffer.
Let this be me being on the record saying: I believe the probability of {alignment to values that strongly diswant suffering for all moral patients} is high enough, and the probability of {alignment to values that want some moral patients to suffer} is low enough, that this action is not worth it.
I think this applies to approximately anyone who would read this post, including heads of major labs in case they happen to read this post and in case they're pursuing the startegy of killing everyone to reduce S-risk.
See also: how acausal trade helps in 1 [LW(p) · GW(p)], 2 [LW · GW], but I think I think this even without acausal trade.
Replies from: Nonecomment by Tamsin Leake (carado-1) · 2023-12-23T21:52:15.496Z · LW(p) · GW(p)
Take our human civilization, at the point in time at which we invented fire. Now, compute forward all possible future timelines, each right up until the point where it's at risk of building superintelligent AI for the first time. Now, filter for only timelines which either look vaguely like earth or look vaguely like dath ilan.
What's the ratio between the number of such worlds that look vaguely like earth vs look vaguely like dath ilan? 100:1 earths:dath-ilans ? 1,000,000:1 ? 1:1 ?
Replies from: JBlack↑ comment by JBlack · 2023-12-24T08:14:40.954Z · LW(p) · GW(p)
Even in the fiction, I think dath ilan didn't look vaguely like dath ilan until after it was at risk of building superintelligent AI for the first time. They completely restructured their society and erased their history to avert the risk.
Replies from: carado-1↑ comment by Tamsin Leake (carado-1) · 2023-12-24T09:07:58.520Z · LW(p) · GW(p)
By "vaguely like dath ilan" I mean the parts that made them be the kind of society that can restructure in this way when faced with AI risk. Like, even before AI risk, they were already very different from us.
Replies from: JBlack↑ comment by JBlack · 2023-12-24T11:13:57.577Z · LW(p) · GW(p)
Ah, I see! Yeah, I have pretty much no idea.
I vaguely suspect that humans are not inherently well-suited to coordination in that sense, and that it would take an unusual cultural situation to achieve it. We never got anywhere close at any point in our history. It also seems likely that the window to achieve it could be fairly short. There seems to be a lot of widespread mathematical sophistication required as described, and I don't think that naturally arises long before AI.
On the other hand, maybe some earlier paths of history could and normally should have put some useful social technology and traditions in place that would be built on later in many places and ways, but for some reason that didn't happen for us. Some early unlikely accident predisposed us to our sorts of societies instead. Our sample size of 1 is difficult to generalize from.
I would put my credence median well below 1:1, but any distribution I have would be very broad, spanning orders of magnitude of likelihood and the overall credence something like 10%. Most of that would be "our early history was actually weird".
comment by Tamsin Leake (carado-1) · 2023-12-21T11:51:05.751Z · LW(p) · GW(p)
I'm kinda bewildered at how I've never observed someone say "I want to build aligned superintelligence in order to resurrect a loved one". I guess the sets of people who {have lost a loved one they wanna resurrect}, {take the singularity and the possibility of resurrection seriously}, and {would mention this} is… the empty set??
(I have met one person who is glad that alignment would also get them this, but I don't think it's their core motivation, even emotionally. Same for me.)
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2023-12-23T22:10:34.980Z · LW(p) · GW(p)
Do you have any (toy) math arguing that it's information-theoretically possible?
I currently consider it plausible that yeah, actually, for any person X who still exists in cultural memory (let alone living memory, let alone if they lived recently enough to leave a digital footprint), the set of theoretically-possible psychologically-human minds whose behavior would be consistent with X's recorded behavior is small enough that none of the combinatorial-explosion arguments apply, so you can just generate all of them and thereby effectively resurrect X.
But you sound more certain than that. What's the reasoning?
Replies from: carado-1↑ comment by Tamsin Leake (carado-1) · 2023-12-23T22:48:15.902Z · LW(p) · GW(p)
(Let's call the dead person "rescuee" and the person who wants to resurrect them "rescuer".)
The procedure you describe is what I call "lossy resurrection". What I'm talking about looks like: you resimulate the entire history of the past-lightcone on a quantum computer, right up until the present, and then either:
- You have a quantum algorithm for "finding" which branch has the right person (and you select that timeline and discard the rest) (requires that such a quantum algorithm exists)
- Each branch embeds a copy of the rescuer, and whichever branch looks like correct one isekai's the rescuer into the branch, right next to the rescuee (and also insta-utopia's the whole branch) (requires that the rescuer doesn't mind having their realityfluid exponentially reduced)
(The present time "only" serves as a "solomonoff checksum" to know which seed / branch is the right one.)
This is O(exp(size of the seed of the universe) * amount of history between the seed and the rescuee). Doable if the seed of the universe is small and either of the two requirements above hold, and if the future has enough negentropy to resimulate the past. (That last point is a new source of doubt for me; I kinda just assumed it was true until a friend told me it might not be.)
(Oh, and also you can't do this if resimulating the entire history of the universe — which contains at least four billion years of wild animal suffering(!) — is unethical.)
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2023-12-24T00:41:55.887Z · LW(p) · GW(p)
and if the future has enough negentropy to resimulate the past. (That last point is a new source of doubt for me; I kinda just assumed it was true until a friend told me it might not be.)
Yeah, I don't know about this one either.
Even if possible, it might be incredibly wasteful, in terms of how much negentropy (= future prosperity for new people) we'll need to burn in order to rescue one person. And then the more we rescue, the less value we get out of that as well, since burning negentropy will reduce their extended lifespans too. So we'd need to assign greater (dramatically greater?) value to extending the life of someone who'd previously existed, compared to letting a new person live for the same length of time.
"Lossy resurrection" seems like a more negentropy-efficient way of handling that, by the same tokens as acausal norms [LW · GW] likely being a better way to handle acausal trade than low-level simulations and babble-and-prune not being [LW · GW] the most efficient way of doing general-purpose search.
Like, the full-history resimulation will surely still not allow you to narrow things down to one branch. You'd get an equivalence class of them, each of them consistent with all available information. Which, in turn, would correspond to a probability distribution over the rescuee's mind; not a unique pick.
Given that, it seems plausible that there's some method by which we can get to the same end result – constrain the PD over the rescuee's mind by as much as the data available to us can let us – without actually running the full simulation.
Depends on how the space of human minds looks like, I suppose. Whether it's actually much lower-dimensional than a naive analysis of possible brain-states suggests.
Replies from: carado-1↑ comment by Tamsin Leake (carado-1) · 2023-12-24T00:53:56.283Z · LW(p) · GW(p)
I'm pretty sure we just need one resimulation to save everyone; once we have located an exact copy of our history, it's cheap to pluck out anyone (including people dead 100 or 1000 years ago). It's a one-time cost.
Lossy resurrection is better than nothing but it doesn't feel as "real" to me. If you resurrect a dead me, I expect that she says "I'm glad I exist! But — at least as per my ontology and values — you shouldn't quite think of me as the same person as the original. We're probly quite different, internally, and thus behaviorally as well, when ran over some time."
Like, the full-history resimulation will surely still not allow you to narrow things down to one branch. You'd get an equivalence class of them, each of them consistent with all available information. Which, in turn, would correspond to a probability distribution over the rescuee's mind; not a unique pick.
I feel like I'm not quite sure about this? It depends on what quantum mechanics entails, exactly, I think. For example: if BQP = P, then there's "only a polynomial amount" of timeline-information (whatever that means!), and then my intuition tells me that the "our world serves as a checksum for the one true (macro-)timeline" idea is more likely to be a thing. But this reasoning is still quite heuristical. Plausibly, yeah, the best we get is a polynomially large or even exponentially large distribution.
That said, to get back to my original point, I feel like there's enough unknowns making this scenario plausible here, that some people who really want to get reunited with their loved ones might totally pursue aligned superintelligence just for a potential shot at this, whether their idea of reuniting requires lossless resurrection or not.
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2023-12-24T01:13:57.194Z · LW(p) · GW(p)
I feel like there's enough unknowns making this scenario plausible here
No argument on that.
I don't find it particularly surprising that {have lost a loved one they wanna resurrect} {take the singularity and the possibility of resurrection seriously} {would mention this} is empty, though:
- "Resurrection is information-theoretically possible" is a longer leap than "believes an unconditional pro-humanity utopia is possible", which is itself a bigger leap than just "takes singularity seriously". E. g., there's a standard-ish counter-argument to "resurrection is possible" which naively assumes a combinatorial explosion of possible human minds consistent with a given behavior. Thinking past it requires some additional less-common insights.
- "Would mention this" is downgraded by it being an extremely weakness/vulnerability-revealing motivation. Much more so than just "I want an awesome future".
- "Would mention this" is downgraded by... You know how people who want immortality get bombarded with pop-culture platitudes about accepting death? Well, as per above, immortality is dramatically more plausible-sounding than resurrection, and it's not as vulnerable-to-mention a motivation. Yet talking about it is still not a great idea in a "respectable" company. Goes double for resurrection.
comment by Tamsin Leake (carado-1) · 2023-12-18T11:12:35.205Z · LW(p) · GW(p)
(Epistemic status: Not quite sure)
Realityfluid must normalize for utility functions to work (see 1, 2). But this is a property of the map, not the territory.
Normalizing realityfluid is a way to point to an actual (countably) infinite territory using a finite (conserved-mass) map object.
Replies from: tetraspace-grouping, Dagon↑ comment by Tetraspace (tetraspace-grouping) · 2023-12-24T14:51:54.918Z · LW(p) · GW(p)
I replied on discord that I feel there's maybe something more formalisable that's like:
- reality runs on math because, and is the same thing as, there's a generalised-state-transition function
- because reality has a notion of what happens next, realityfluid has to give you a notion of what happens next, i.e. it normalises
- the idea of a realityfluid that doesn't normalise only comes to mind at all because you learned about R^n first in elementary school instead of S^n
which I do not claim confidently because I haven't actually generated that formalisation, and am posting here because maybe there will be another Lesswronger's eyes on it that's like "ah, but...".
↑ comment by Dagon · 2023-12-18T18:04:28.388Z · LW(p) · GW(p)
Many mechanisms of aggregation literally normalize random elements. Simple addition of two (or more) evenly-distributed linear values (say, dice) yields a normal distribution (aka bell curve).
And yes, human experience is all map - the actual state of the universe is imperceptible.
comment by Tamsin Leake (carado-1) · 2023-01-19T18:08:52.443Z · LW(p) · GW(p)
nostalgia: a value pointing home
i value moral patients [LW(p) · GW(p)] everywhere having freedom [LW · GW], being diverse, engaging in art and other culture, not undergoing excessive unconsented suffering, in general having a good time [LW · GW], and probly other things as well. but those are all pretty abstract; given those values being satisfied to the same extent, i'd still prefer me and my friends and my home planet (and everyone who's been on it) having access to that utopia rather than not. this value, the value of not just getting an abstractly good future but also getting me and my friends and my culture and my fellow earth-inhabitants to live in it, my friend Prism coined as "nostalgia".
not that those abstract values are simple or robust, they're still plausibly not [LW · GW]. but they're, in a sense, broader values about what happens everywhere, and they're not as much local and pointed at and around me. they could be the difference between what i'd call "global" and "personal" values, or perhaps between "global values" and "preferences".
comment by Tamsin Leake (carado-1) · 2024-03-09T20:59:25.892Z · LW(p) · GW(p)
Moral patienthood of current AI systems is basically irrelevant to the future.
If the AI is aligned then it'll make itself as moral-patient-y as we want it to be. If it's not, then it'll make itself as moral-patient-y as maximizes its unaligned goal. Neither of those depend on whether current AI are moral patients.
Replies from: vanessa-kosoy, Wei_Dai, nikolaisalreadytaken↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2024-03-13T16:48:49.871Z · LW(p) · GW(p)
I agree that in the long-term it probably matters little. However, I find the issue interesting, because the failure of reasoning that leads people to ignore the possibility of AI personhood seems similar to the failure of reasoning that leads people to ignore existential risks from AI. In both cases it "sounds like scifi" or "it's just software". It is possible that raising awareness for the personhood issue is politically beneficial for addressing X-risk as well. (And, it would sure be nice to avoid making the world worse in the interim.)
↑ comment by Wei Dai (Wei_Dai) · 2024-03-10T00:20:27.850Z · LW(p) · GW(p)
If current AIs are moral patients, it may be impossible to build highly capable AIs that are not moral patients, either for a while or forever, and this could change the future a lot. (Similar to how once we concluded that human slaves are moral patients, we couldn't just quickly breed slaves that are not moral patients, and instead had to stop slavery altogether.)
Also I'm highly unsure that I understand what you're trying to say. (The above may be totally missing your point.) I think it would help to know what you're arguing against or responding to, or what trigger your thought.
↑ comment by Nikola Jurkovic (nikolaisalreadytaken) · 2024-03-09T23:40:59.134Z · LW(p) · GW(p)
I think I vaguely agree with the shape of this point, but I also think there are many intermediate scenarios where we lock in some really bad values during the transition to a post-AGI world.
For instance, if we set precedents that LLMs and the frontier models in the next few years can be treated however one wants (including torture, whatever that may entail), we might slip into a future where most people are desensitized to the suffering of digital minds and don't realize this. If we fail at an alignment solution which incorporates some sort of CEV (or other notion of moral progress), then we could lock in such a suboptimal state forever.
Another example: if, in the next 4 years, we have millions of AI agents doing various sorts of work, and some faction of society claims that they are being mistreated, then we might enter a state where the economic value provided by AI labor is so high that there are really bad incentives for improving their treatment. This could include both resistance on an individual level ("But my life is so nice, and not mistreating AIs less would make my life less nice") and on a bigger level (anti-AI-rights lobbying groups for instance).
I think the crux between you and I might be what we mean by "alignment". I think futures are possible where we achieve alignment but not moral progress, and futures are possible where we achieve alignment but my personal values (which include not torturing digital minds) are not fulfilled.
comment by Tamsin Leake (carado-1) · 2024-03-20T13:25:50.633Z · LW(p) · GW(p)
I don't think this is the case, but I'm mentioning this possibility because I'm surprised I've never seen someone suggest it before:
Maybe the reason Sam Altman is taking decisions that increase p(doom) is because he's a pure negative utilitarian (and he doesn't know-about/believe-in acausal trade [LW(p) · GW(p)]).
Replies from: carado-1↑ comment by Tamsin Leake (carado-1) · 2024-03-21T09:44:37.430Z · LW(p) · GW(p)
(I'm gonna interpret these disagree-votes as "I also don't think this is the case" rather than "I disagree with you tamsin, I think this is the case".)