OpenAI releases deep research agent
post by Seth Herd · 2025-02-03T12:48:44.925Z · LW · GW · 21 commentsThis is a link post for https://openai.com/index/introducing-deep-research/
Contents
How it works None 21 comments
Experimental research project record here
Edit: the most important question raised in the comments was: How much of this capability actually comes from the end-to-end task-based RL on CoT, and how much just from a better prompting scheme of "ask the user for clarifications, do some research, then think about that research and decide what further research to do?"
This matters because end-to-end RL seems to carry greater risks of baking in instrumental goals. It appears that people have been trying to do such comparisons: Hugging Face researchers aim to build an ‘open’ version of OpenAI’s deep research tool, and the early answer seems to be that even o1 isn't quite as good as the Deep Research tool - but that could be because o3 is smarter, or the end-to-end RL on these specific tasks.
Back to the original post:
Today we’re launching deep research in ChatGPT, a new agentic capability that conducts multi-step research on the internet for complex tasks. It accomplishes in tens of minutes what would take a human many hours.
Deep research is OpenAI's next agent that can do work for you independently—you give it a prompt, and ChatGPT will find, analyze, and synthesize hundreds of online sources to create a comprehensive report at the level of a research analyst. Powered by a version of the upcoming OpenAI o3 model that’s optimized for web browsing and data analysis, it leverages reasoning to search, interpret, and analyze massive amounts of text, images, and PDFs on the internet, pivoting as needed in reaction to information it encounters.
The ability to synthesize knowledge is a prerequisite for creating new knowledge. For this reason, deep research marks a significant step toward our broader goal of developing AGI, which we have long envisioned as capable of producing novel scientific research.
...
How it works
Deep research was trained using end-to-end reinforcement learning on hard browsing and reasoning tasks across a range of domains. Through that training, it learned to plan and execute a multi-step trajectory to find the data it needs, backtracking and reacting to real-time information where necessary. ... As a result of this training, it reaches new highs on a number of public evaluations focused on real-world problems.
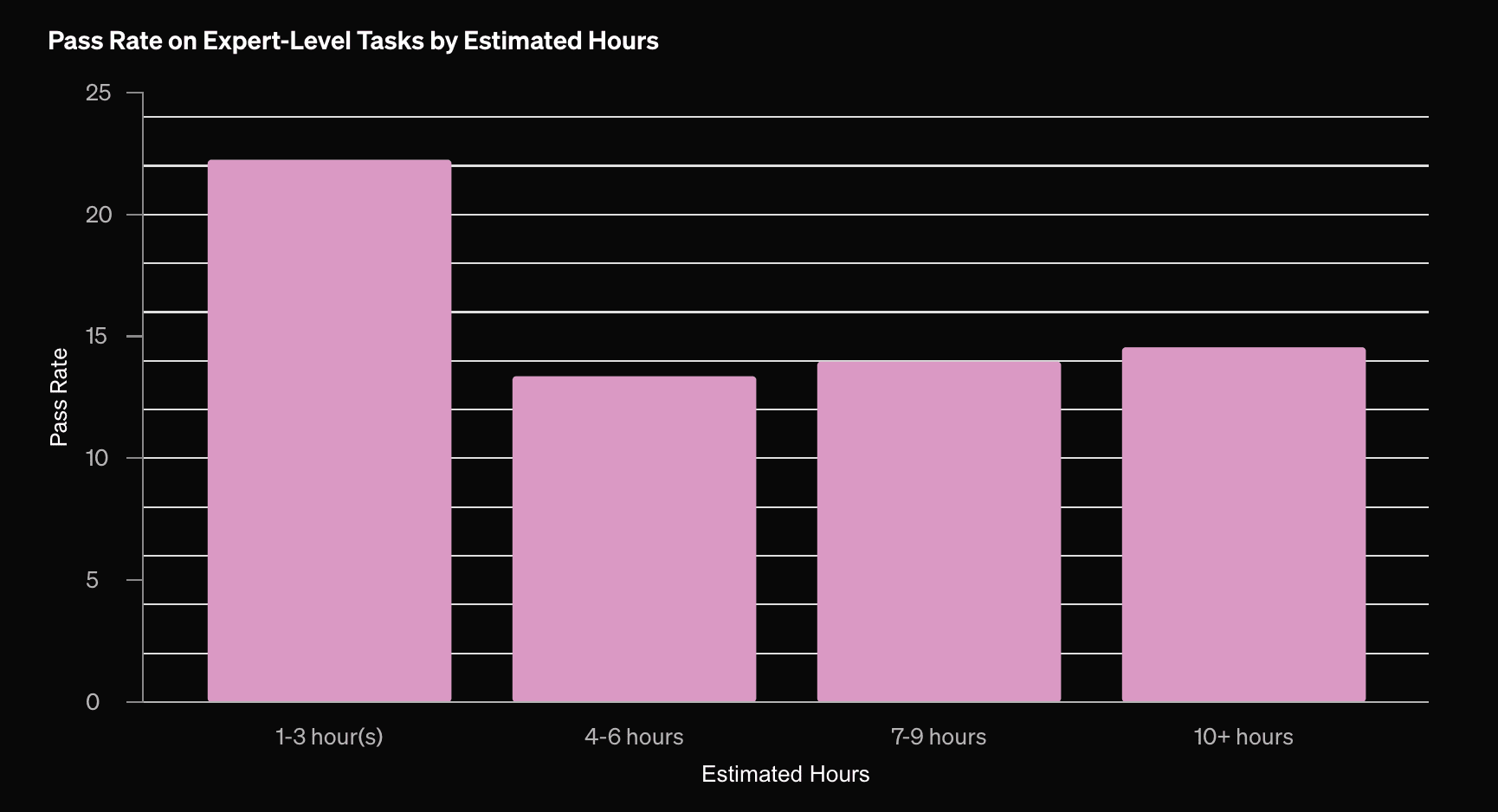
Note that the pass rates are around 15-25%, so it's not outright replacing any experts—and it remains to be seen whether the results are even useful to experts, given that they usually do not 'pass.' We do not get much information on what types of tasks these are, but they are judged by "domain experts"
It scores 26% on Humanity's Last Exam, compared to 03-mini-high's 13%. This is probably mostly driven by using a variant of full o3. This is much better than DeepSeek's ~10%.
It provides a detailed summary of its chain of thought while researching. Subjectively it looks a lot like how a smart human would summarize their research at different stages.
I've only asked for one research report, on a test topic I'm quite familiar with (faithful chain of thought in relation to AGI x-risk). Subjectively, its use as a research tool is limited - it found only 18 sources in a five-minute search, all of which I'd already seen (I think - it doesn't currently provide full links to sources it doesn't actively cite in the resulting report).
Subjectively, the resulting report is pretty impressive. The writing appears to synthesize and "understand" the relation among multiple papers and theoretical framings better than anything I've seen to date. But that's just one test. The report couldn't really be produced by a domain novice reading those papers, even if they were brilliant. They'd have to reread and think for a week. For rapidly researching new topics, this tool in itself will probably be noticeably faster than anything previously available. But that doesn't mean it's all that useful to domain experts.
Time will tell. Beyond any research usefulness, I am more interested in the progress on agentic AI. This seems like a real step toward medium-time-horizon task performance, and from there toward AI that can perform real research.
Their training method — end-to-end RL on tasks — is exactly what we don't want and have been dreading.
Looking further ahead, we envision agentic experiences coming together in ChatGPT for asynchronous, real-world research and execution. The combination of deep research, which can perform asynchronous online investigation, and Operator, which can take real-world action, will enable ChatGPT to carry out increasingly sophisticated tasks for you.
Thanks, I hate it.
21 comments
Comments sorted by top scores.
comment by Thomas Kwa (thomas-kwa) · 2025-02-03T18:46:41.043Z · LW(p) · GW(p)
I'm not happy about this but it seems basically priced in, so not much update on p(doom).
We will soon have Bayesian updates to make. If we observe that incentives created during end-to-end RL naturally produce goal guarding and other dangerous cognitive properties, it will be bad news. If we observe this doesn't happen, it will be good news (although not very good news because web research seems like it doesn't require the full range of agency).
Likewise, if we observe models' monitorability and interpretability start to tank as they think in neuralese, it will be bad news. If monitoring and interpretability are unaffected, good news.
Interesting times.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-02-03T20:15:25.999Z · LW(p) · GW(p)
How on earth could monitorability and interpretability NOT tank when they think in neuralese? Surely changing from English to some gibberish highdimensional vector language makes things harder, even if not impossible?
Replies from: thomas-kwa, Seth Herd↑ comment by Thomas Kwa (thomas-kwa) · 2025-02-03T23:49:14.431Z · LW(p) · GW(p)
- It's not clear whether agents will think in neuralese, maybe end-to-end RL in English is good enough for the next few years and CoT messages won't drift enough to allow steganography
- Once agents think in either token gibberish or plain vectors maybe self-monitoring will still work fine. After all agents can translate between other languages just fine. We can use model organisms or some other clever experiments to check whether the agent faithfully translates its CoT or unavoidably starts lying to us as it gets more capable.
- I care about the exact degree to which monitoring gets worse. Plausibly it gets somewhat worse but is still good enough to catch the model before it coups us.
↑ comment by Seth Herd · 2025-02-03T20:33:02.236Z · LW(p) · GW(p)
If we're using another instance of the same base model to do the monitoring and interpreting? It seems like that could partially preserve monitoring and interpreting. Another instance would "understand" the steganography it uses - but you might have to supply so much of the context that it would be almost the same instance - so likely to adopt the same goals and use the same deceptions, if any.
So that route does seem like dangerous territory. You'd rather not trust even a fresh instance of the same model to tell you what its agentic counterpart is "thinking" about.
I haven't gotten far in figuring out how well this might work, but it is a possibility. I'll say the little I have thought about in a soon-to-be-finished post.
I don't see how monitoring and interpretability could be unaffected.
(So I take this as modestly bad news — I wasn't totally sure orgs would use task-based end-to-end RL. I wasn't sure if agentic scaffolding might prove easier - see the other discussion thread here for questions about whether it might actually work just as well if someone bothered to implement it.)
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-02-03T21:30:24.458Z · LW(p) · GW(p)
https://x.com/Miles_Brundage/status/1886347097571774875
No system card, no preparedness evaluations? Even though it uses o3?
Replies from: Seth Herdcomment by Nikola Jurkovic (nikolaisalreadytaken) · 2025-02-03T13:14:09.897Z · LW(p) · GW(p)
Note that for HLE, most of the difference in performance might be explained by Deep Research having access to tools while other models are forced to reply instantly with no tool use.
Replies from: gwern, Seth Herd↑ comment by gwern · 2025-02-03T16:54:53.780Z · LW(p) · GW(p)
But does that necessarily matter? Many of those models can't use tools; and since much of the point of the end-to-end RL training of Deep Research is to teach tool use, showing DR results without tool use would be either irrelevant or misleading (eg. it might do worse than the original o3 model it is trained from, when deprived of the tools it is supposed to use).
Replies from: ozziegooen, nathan-helm-burger↑ comment by ozziegooen · 2025-02-03T19:13:17.562Z · LW(p) · GW(p)
I assume that what's going on here is something like,
"This was low-hanging fruit, it was just a matter of time until someone did the corresponding test."
This would imply that OpenAI's work here isn't impressive, and also, that previous LLMs might have essentially been underestimated. There's basically a cheap latent capabilities gap.
I imagine a lot of software engineers / entrepreneurs aren't too surprised now. Many companies are basically trying to find wins where LLMs + simple tools give a large gain.
So some people could look at this and say, "sure, this test is to be expected", and others would be impressed by what LLMs + simple tools are capable of.
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-02-03T20:04:11.117Z · LW(p) · GW(p)
I think the correct way to address this is by also testing the other models with agent scaffolds that supply web search and a python interpreter.
I think it's wrong to jump to the conclusion that non-agent-finetuned models can't benefit from tools.
See for example:
Frontier Math result
https://x.com/Justin_Halford_/status/1885547672108511281
o3-mini got 32% on Frontier Math (!) when given access to use a Python tool. In an AMA, @kevinweil / @snsf (OAI) both referenced tool use w reasoning models incl retrieval (!) as a future rollout.
METR RE-bench
Models are tested with agent scaffolds
AIDE and Modular refer to different agent scaffolds; Modular is a very simple baseline scaffolding that just lets the model repeatedly run code and see the results; AIDE is a more sophisticated scaffold that implements a tree search procedure.
↑ comment by Seth Herd · 2025-02-03T13:21:18.693Z · LW(p) · GW(p)
Yes, they do highlight this difference. I wonder how full o3 scores? It would be interesting to know how much imrovement is based on o3's improved reasoning and how much is the sequential research procedure.
Replies from: Vladimir_Nesov, sweenesm↑ comment by Vladimir_Nesov · 2025-02-03T15:57:49.721Z · LW(p) · GW(p)
And how much the improved reasoning is from using a different base model vs. different post-training. It's possible R1-like training didn't work for models below GPT-4 level, and then that same training started working at GPT-4 level (at which point you can iterate from a working prototype or simply distill to get it to work for weaker models). So it might work even better for the next level of scale of base models, without necessarily changing the RL part all that much.
↑ comment by sweenesm · 2025-02-03T13:40:57.443Z · LW(p) · GW(p)
How o3-mini scores: https://x.com/DanHendrycks/status/1886213523900109011
10.5-13% on text only part of HLE (text only are 90% of the questions)
[corrected the above to read "o3-mini", thanks.]
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2025-02-03T15:59:59.958Z · LW(p) · GW(p)
10.5-13% on text only part of HLE
This is for o3-mini, while the ~25% figure for o3 from the tweet you linked is simply restating deep research evals.
comment by Thane Ruthenis · 2025-02-03T19:00:36.830Z · LW(p) · GW(p)
I really wonder how much of the perceived performance improvement comes from agent-y training, as opposed to not sabotaging the format of the model's answer + letting it do multi-turn search.
Compared to most other LLMs, Deep Research is able to generate reports up to 10k words, which is very helpful for providing comprehensive-feeling summaries. And unlike Google's analogue, it's not been fine-tuned to follow some awful deliberately shallow report template[1].
In other words: I wonder how much of Deep Research's capability can be replicated by putting Claude 3.5.1 in some basic agency scaffold where it's able to do multi-turn web search, and is then structurally forced to generate a long-form response (say, by always prompting with something like "now generate a high-level report outline", then with "now write section 1", "now write section 2", and then just patching those responses together).
Have there been some open-source projects that already did so? If not, anyone willing to try? This would provide a "baseline" for estimating how well OpenAI's agency training actually works, how much improvement is from it.
Subjectively, its use as a research tool is limited - it found only 18 sources in a five-minute search
Another test to run: if you give those sources to Sonnet 3.5.1 (or a Gemini model, if Sonnet's context window is too small) and ask it to provide a summary, how far from Deep Research's does it feel in quality/insight?
- ^
Which is the vibe I got from Google's Deep Research when I'd been experimenting. I think its main issue isn't any lack of capability, but that the fine-tuning dataset for how the final reports are supposed to look had been bad: it's been taught to have an atrocious aesthetic taste.
↑ comment by Seth Herd · 2025-02-03T19:32:33.422Z · LW(p) · GW(p)
Good questions. I don't have much of a guess about whether this is discernably "smarter" than Claude or Gemini would be in how it understands and integrates sources.
If anyone is game for creating an agentic research scaffold like that Thane describes, I'd love to help design it and/or to know about the results.
I very much agree with that limitation on Google's deep research. It only accepts a short request for the report, and it doesn't seem like it can (at least easily) get much more in-depth than the default short gloss. But that doesn't mean the model isn't capable of it.
Along those lines, Notebook LM has similar limitations on its summary podcasts, and I did tinker with that enough to get some more satisfying results. Using keywords like "for an expert audience already familiar with all of the terms and concepts in these sources" and "technical details" did definitely bend it in a more useful direction. There I felt I ran into limitations on the core intelligence/expertise of the system; it wasn't going to get important but fine distinctions in alignment research. Hearing its summaries was sort of helpful in that new phrasings and strange ideas (when prompted to "think creatively") can be a useful new-thought-generation aid.
We shall see whether o3 has more raw reasoning ability that it can apply to really doing expert-level research.
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2025-02-03T20:57:27.291Z · LW(p) · GW(p)
If anyone is game for creating an agentic research scaffold like that Thane describes
Here's a more detailed the basic structure as envisioned after 5 minutes' thought:
- You feed a research prompt to the "Outer Loop" of a model, maybe have a back-and-forth fleshing out the details.
- The Outer Loop decomposes the research into several promising research directions/parallel subproblems.
- Each research direction/subproblem is handed off to a "Subagent" instance of the model.
- Each Subagent runs search queries on the web and analyses the results, up to the limits of its context window. After the analysis, it's prompted to evaluate (1) which of the results/sources are most relevant and which should be thrown out, (2) whether this research direction is promising and what follow-up questions are worth asking.
- If a Subagent is very eager to pursue a follow-up question, it can either run a subsequent search query (if there's enough space in the context window), or it's prompted to distill its current findings and replace itself with a next-iteration Subagent, in whose context it loads only the most important results + its analyses + the follow-up question.
- This is allowed up to some iteration count.
- Once all Subagents have completed their research, instantiate an Evaluator instance, into whose context window we dump the final results of each Subagent's efforts (distilling if necessary). The Evaluator integrates the information from all parallel research directions and determines whether the research prompt has been satisfactorily addressed, and if not, what follow-up questions are worth pursuing.
- The Evaluator's final conclusions are dumped into the Outer Loop's context (without the source documents, to not overload the context window).
- If the Evaluator did not choose to terminate, the next generation of Subagents is spawned, each prompted with whatever contexts are recommended by the Evaluator.
- Iterate, spawning further Evaluator instances and Subproblem instances as needed.
- Once the Evaluator chooses to terminate, or some compute upper-bound is reached, the Outer Loop instantiates a Summarizer, into which it dumps all of the Evaluator's analyses + all of the most important search results.
- The Summarizer is prompted to generate a high-level report outline, then write out each subsection, then the subsections are patched together into a final report.
Here's what this complicated setup is supposed to achieve:
- Do a pass over an actually large, diverse amount of sources. Most of such web-search tools (Google's, DeepSeek's, or this shallow replication) are basically only allowed to make one search query, and then they have to contend with whatever got dumped into their context window. If the first search query turns out poorly targeted, in a way that becomes obvious after looking through the results, the AI's out of luck.
- Avoid falling into "rabbit holes", i. e. some arcane-and-useless subproblems the model becomes obsessed with. Subagents would be allowed to fall into them, but presumably Evaluator steps, with a bird's-eye view of the picture, would recognize that for a failure mode and not recommend the Outer Loop to follow it.
- Attempt to patch together a "bird's eye view" on the entirety of the results given the limitations of the context window. Subagents and Evaluators would use their limited scope to figure out what results are most important, then provide summaries + recommendations based on what's visible from their limited vantage points. The Outer Loop and then the Summarizer instances, prompted with information-dense distillations of what's visible from each lower-level vantage point, should effectively be looking at (a decent approximation of) the full scope of the problem.
Has anything like this been implemented in the open-source community or one of the countless LLM-wrapper startups? I would expect so, since it seems like an obvious thing to try + the old AutoGPT scaffolds worked in a somewhat similar manner... But it's possible the market's totally failed to deliver.
It should be relatively easy to set up using Flowise plus e. g. Firecrawl. If nothing like this has been implemented, I'm putting a $500 $250 bounty on it.
Edit: Alright, this seems like something very close to it.
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-02-03T20:06:50.061Z · LW(p) · GW(p)
Worth taking model wrapper products into account.
For example:
- Perplexity
- You.com
↑ comment by Matt Goldenberg (mr-hire) · 2025-02-04T16:51:59.601Z · LW(p) · GW(p)
I would REALLY like to see some head to head comparisons with you.com from a subject matter expert, which I think would go a long way in answering this question.
Replies from: Seth Herd↑ comment by Seth Herd · 2025-02-05T18:27:54.224Z · LW(p) · GW(p)
Apparently people have been trying to do such comparisons:
Hugging Face researchers aim to build an ‘open’ version of OpenAI’s deep research tool
↑ comment by Davidmanheim · 2025-02-04T11:16:05.789Z · LW(p) · GW(p)
Clarifying question:
How, specifically? Do you mean Perplexity using the new model, or comparing the new model to Perplexity?