Break time is over, it would seem, now that the new administration is in town.
This week we got r1, DeepSeek’s new reasoning model, which is now my go-to first choice for a large percentage of queries. The claim that this was the most important thing to happen on January 20, 2025 was at least non-crazy. If you read about one thing this week read about that.
We also got the announcement of Stargate, a claimed $500 billion private investment in American AI infrastructure. I will be covering that on its own soon.
Due to time limits I have also pushed coverage of a few things into next week, including this alignment paper, and I still owe my take on Deliberative Alignment.
The Trump administration came out swinging on many fronts with a wide variety of executive orders. For AI, that includes repeal of the Biden Executive Order, although not the new diffusion regulations. It also includes bold moves to push through more energy, including widespread NEPA exemptions, and many important other moves not as related to AI.
It is increasingly a regular feature now to see bold claims of AI wonders, usually involving AGI, coming within the next few years. This week was no exception.
Miles Brundage: If you’re a researcher and not thinking about how AI could increase your productivity now + in the future, you should start doing so.
Varies by field but illustratively, you should think ~2-100x bigger over the next 3 years (compared to what you could have achieved without AI).
Bharath Ramsundar: Do you find this true in your personal experience? I’ve been trying to use ChatGPT and Anthropic fairly regularly and have found a few personal use cases but I’d say maybe a 20% boost at best?
Miles Brundage: Prob more like 20-50% RN but I’m assuming a lot of further progress over that period in this estimate
Bored: Currently using chatbots to analyze every legal document my home insurance company sends me before signing anything. Legal help is not just for the rich, if you are dealing with insurance, use technology in your favor. Side note…it’s complete BS that these companies try to slide this nonsense into agreements when people are most vulnerable.
Here’s the little game @StateFarm is playing…
If you’re in a disaster you can get an initial payment to cover expenses. They can either send you a paper check payment and cash it. OR!!! They sell you the “convenient” digital payment option that transfers money instantly! Wow!
But to do that you need to sign a waiver form saying you won’t sue or be part of a class action lawsuit in the future.
Honestly pretty despicable.
The fact that you can even in theory save hundreds of hours of paperwork is already a rather horrible scandal in the first place. Good to see help is on the way.
Gfodor: A good o1-pro prompt tells it not just what to do and what context it needs, but tells it how to allocate its *attention budget*. In other words: what to think about, and what not to think about. This is an energy utilization plan.
Now you get it.
Signpost: people who have managed people have an unfair advantage using LLMs.
Gfodor: It’s true – the best tools for AI we can make for children will foster the skills of breaking down problems and delegating them. (Among others)
Austen Allred: APPARENTLY a bunch of GuantletAI students rarely type when they write code.
Voice -> text to speech -> prompt -> code.
They sit there and speak to their computer and code ends up being written for them.
I have never felt more old and I’m still wrapping my mind around this.
This has to be a skill issue, the question is for who. I can’t imagine wanting to talk when one can type, especially for prompting where you want to be precise. Am I bad at talking or are they bad at typing? Then again, I would consider coding on a laptop to be categorically insane yet many successful coders report doing that, too.
Peter Wildeford will load the podcast transcript into an LLM on his phone before listening, so he can pause the podcast to ask the LLM questions. I notice I haven’t ‘wanted’ to do this, and wonder to what extent that means I’ve been listening to podcasts wrong, including choosing the ‘wrong’ podcasts.
Patrick McKenzie: My kingdom for an LLM/etc which sits below every incoming message saying “X probably needs to know this. OK?”, with one to two clicks to action.
This is not rocket science for either software or professionals, but success rates here are below what one would naively think.
Example:
Me, homeowner, asks GC: Is the sub you told me to expect today going to show [because this expectation materially changes my plans for my day].
GC: He called me this morning to reschedule until tomorrow. Not sure why.
Me: … Good to know!
“You can imagine reasons why this would be dangerous.”
Oh absolutely but I can imagine reasons why the status quo is dangerous, and we only accept them because status quo.
As an example, consider what happens if you get an email about Q1 plans from the recruiting org and Clippy says “Employment counsel should probably read this one.”
LLM doesn’t have to be right, at all, for a Dangerous Professional to immediately curse and start documenting what they know and when they knew it.
And, uh, LLM very plausibly is right.
This seems like a subset of the general ‘suggested next action’ function for an AI agent or AI agent-chatbot hybrid?
As in, there should be a list of things, that starts out concise and grows over time, of potential next actions that the AI could suggest within-context, that you want to make very easy to do – either because the AI figured out this made sense, or because you told the AI to do it, and where the AI will now take the context and use it to make the necessary steps happen on a distinct platform.
Indeed, it’s not only hard to imagine a future where your emails include buttons and suggestions for automated next steps such as who you should forward information to based on an LLM analysis of the context, it’s low-key hard to imagine that this isn’t already happening now despite it (at least mostly) not already happening now. We already have automatically generated calendar items and things added to your wallet, and this really needs to get extended a lot, pronto.
He also asks this question:
Patrick McKenzie: A frontier in law/policy we will have to encounter at some point: does it waive privilege (for example, attorney/client privilege) if one of the participants of the meeting is typing on a keyboard connected to a computer system which keeps logs of all conversations.
Is that entirely a new frontier? No, very plausibly there are similar issues with e.g. typing notes of your conversation into Google Docs. Of course, you flagged those at the top, as you were told to in training, so that a future subpoena would see a paralegal remove them.
… Did you remember to tell (insert named character here) to keep something confidential?
… Does the legal system care?
… Did the character say “Oh this communication should definitely be a privileged one with your lawyers.”
… Does the legal system care?
Quick investigation (e.g. asking multiple AIs) says that this is not settled law and various details matter. When I envision the future, it’s hard for me to think that an AI logging a conversation or monitoring communication or being fed information would inherently waive privilege if the service involved gave you an expectation of privacy similar to what you get at the major services now, but the law around such questions often gets completely insane.
Stephen Morris and Madhumita Murgia: Isomorphic Labs, the four-year old drug discovery start-up owned by Google parent Alphabet, will have an artificial intelligence-designed drug in trials by the end of this year, says its founder Sir Demis Hassabis.
…
“It usually takes an average of five to 10 years [to discover] one drug. And maybe we could accelerate that 10 times, which would be an incredible revolution in human health,” said Hassabis.
You can accelerate the discovery phase quite a lot, and I think you can have a pretty good idea that you are right, but as many have pointed out the ‘prove to authority figures you are right’ step takes a lot of time and money. It is not clear how much you can speed that up. I think people are sleeping on how much you can still speed it up, but it’s not going to be by a factor of 5-10 without a regulatory revolution.
Ethan Mollick: I have spent a lot of time with a AI agents (including Devin and Claude Computer Use) and they really do remain too fragile & not “smart” enough to be reliable for complicated tasks.
Two options: (1) wait for better models or (2) focus on narrower use cases (like Deep Research)
An agent can handle some very complicated tasks if it is in a narrow domain with good prompting and tools, but, interestingly, any time building narrow agents will feel like a waste if better models come along and solve the general agent use case, which is also possible.
Eventually everything you build is a waste, you’ll tell o7 or Claude 5 Sonnet or what not to write a better version of tool and presto. I expect that as agents get better, a well-designed narrow agent built now with future better AI in mind will have a substantial period where it outperforms fully general agents.
Kylie Robison: Apple is pausing notification summaries for news in the latest iOS 18.3 beta / Apple will make it clear the AI-powered summaries ‘may contain errors.’
Olivia Moore: I have found Apple’s AI notification summaries hugely entertaining…
Mostly because 70% of the time they are accurate yet brutally direct, and 30% they are dead wrong.
I am surprised they shipped it as-is (esp. for serious notifs) – but hope they don’t abandon the concept.
Summaries are a great idea, but very much a threshold effect. If they’re not good enough to rely upon, they’re worse than useless. And there are a few thresholds where you get to rely on them for different values of rely. None of them are crossed when you’re outright wrong 30% of the time, which is quite obviously not shippable.
If you don’t price by the token, and you end up losing money on $200/month subscriptions, perhaps you have only yourself to blame. They wouldn’t do this if they were paying for marginal inference.
nrehiew: Likely that Anthropic has a reasoner but they simply dont have the compute to serve it if they are already facing limits now.
Gallabytes: y’all need to start letting people BID ON TOKENS no more of this Instagram popup line around the block where you run out of sandwiches halfway through nonsense.
I do think it is ultimately wrong, though. Yes, for everyone else’s utility, and for strictly maximizing revenue per token now, this would be the play. But maintaining good customer relations, customer ability to count on them and building relationships they can trust, matter more, if compute is indeed limited.
The other weird part is that Anthropic can’t find ways to get more compute.
Kevin Roose: People who have spent time using reasoning LLMs (o1, DeepSeek R1, etc.) — what’s the killer use case you’ve discovered?
I’ve been playing around with them, but haven’t found something they’re significantly better at. (It’s possible I am too dumb to get max value from them.)
Colin Fraser: I’m not saying we’re exactly in The Emperor’s New Clothes but this is what the people in The Emperor’s New Clothes are saying to each other on X. “Does anyone actually see the clothes? It’s possible that I’m too dumb to see them…”
Kevin Roose: Oh for sure, it’s all made up, you are very smart
Colin Fraser: I don’t think it’s all made up, and I appreciate your honesty about whether you see the clothes
Old Billy: o1-pro is terrific at writing code.
Clin Fraser: I believe you! I’d even say 4o is terrific at writing code, for some standards of terrificness, and o1 is better, and I’m sure o1-pro is even better than that.
Part of the answer is that I typed the Tweet into r1 to see what the answer would be, and I do think I got a better answer than I’d have gotten otherwise. The other half is the actual answer, which I’ll paraphrase, contract and extend.
Relatively amazing at coding, math, logic, general STEM or economic thinking, complex multi-step problem solving in general and so on.
They make fewer mistakes across the board.
They are ‘more creative’ than non-reasoning versions they are based upon.
They are better at understanding your confusions and statements in detail, and asking Socratic follow-ups or figuring out how to help teach you (to understand this better, look at the r1 chains of thought.)
General one-shotting of tasks where you can ‘fire and forget’ and come back later.
Also you have to know how to prompt them to get max value. My guess is this is less true of r1 than others, because with r1 you see the CoT, so you can iterate better and understand your mistakes.
Google AI Studio has a new mobile experience. In this case even I appreciate it, because of Project Astra. Also it’s highly plausible Studio is the strictly better way to use Gemini and using the default app and website is purely a mistake.
OpenAI gives us GPT-4b, a specialized biology model that figures out proteins that can turn regular cells into stem cells, exceeding the best human based solutions. The model’s intended purpose is to directly aid longevity science company Retro, in which Altman has made $180 million in investments (and those investments and those in fusion are one of the reasons I try so hard to give him benefit of the doubt so often). It is early days, like everything else in AI, but this is huge.
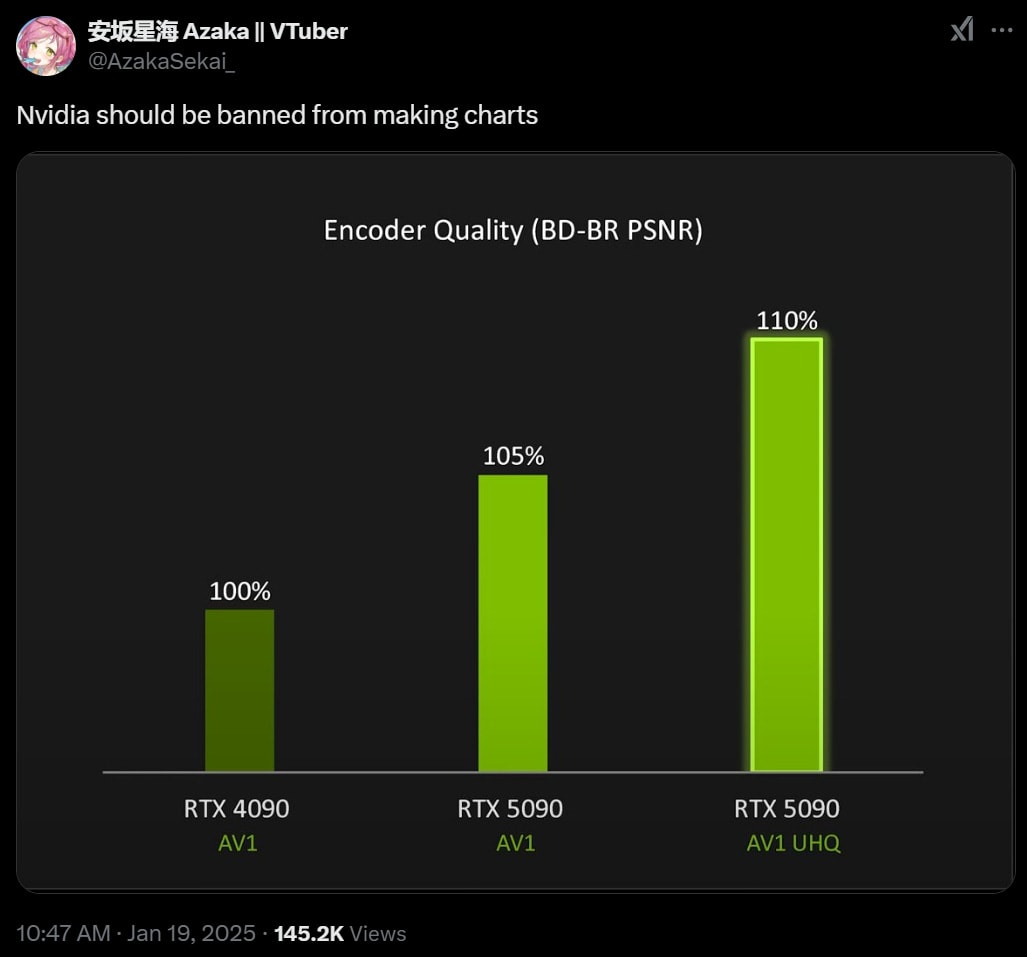
Gemini 2.0 Flash Thinking gets an upgrade to 73.3% on AIME and 74.2% on GPQA Diamond, also they join the ‘banned from making graphs’ club oh my lord look at the Y-axis on these, are you serious.
Seems like it’s probably a solid update if you ever had reason not to use r1. It also takes the first position in Arena, for whatever that is worth, but the Arena rankings look increasingly silly, such as having GPT-4o ahead of o1 and Sonnet fully out of the top 10. No sign of r1 in the Arena yet, I’m curious how high it can go but I won’t update much on the outcome.
Pliny jailbroke it in 24 minutes and this was so unsurprising I wasn’t sure I was even supposed to bother pointing it out. Going forward assume he does this every time, and if he ever doesn’t, point this out to me.
Additional Notes on r1
I didn’t notice this on my own, and it might turn out not to be the case, but I know what she thinks she saw and once you see it you can’t unsee it.
Janus: The immediate vibe i get is that r1’s CoTs are substantially steganographic.
They were clearly RLed together with response generation and were probably forced to look normal (haven’t read the paper, just on vibes)
I think removing CoT would cripple it even when they don’t seem to be doing anything, and even seem retarded (haven’t tried this but u can)
You can remove or replace the chain of thought using a prefill. If you prefill either the message or CoT it generates no (additional) CoT
Presumably we will know soon enough, as there are various tests you can run.
On writing, there was discussion about whether r1’s writing was ‘good’ versus ‘slop’ but there’s no doubt it was better than one would have expected. Janus and Kalomaze agree that what they did generalized to writing in unexpected ways, but as Janus notes being actually good at writing is high-end-AGI-complete and f***ing difficult.
Janus: With creative writing/open-ended conversations, r1s chain-of-thought (CoTs) are often seen as somewhat useless, saying very basic things, failing to grasp subtext, and so on. The actual response seems to be on a completely different level, and often seems to ignore much of the CoT, even things the CoT explicitly plans to do.
Hypothesis: Yet, if you remove the CoT, the response quality degrades, even on the dimensions where the CoT does not appear to contribute.
(A few people have suggested this is true, but I haven’t looked myself.)
Roon: If you remove the CoT, you take it out of its training distribution, so it is unclear whether it is an accurate comparison.
Janus: Usually, models are fine with being removed from their training conversation template without the usual special tokens and so forth.
Assuming the CoT is uninformative, is it really that different?
And, on the other hand, if you require a complex ritual like going through a CoT with various properties to become “in distribution,” it seems like describing it in those terms may be to cast it too passively.
It would be a very bad sign for out-of-distribution behavior of all kinds if removing the CoT was a disaster. This includes all of alignment and many of the most important operational modes.
At this point, if an AI video didn’t have to match particular details and only has to last nine seconds, it’s going to probably be quite good. Those restrictions do matter, but give it time.
Robin Hanson: “A team of researchers has created a new benchmark to test three top large language models (LLMs) … best-performing LLM was GPT-4 Turbo, but it only achieved about 46% accuracy — not much higher than random guessing”
Tyler Cowen: Come on, Robin…you know this is wrong…
Robin Hanson: I don’t know it yet, but happy to be shown I’m wrong.
Tyler Cowen: Why test on such an old model? Just use o1 pro and get back to me.
Gwern: 46% is much higher than the 25% random guessing baseline, and I’d like to see the human and human expert-level baselines as well because I’d be at chance on these sample questions and I expect almost all historians would be near-chance outside their exact specialty too…
They tested on GPT-4 Turbo, GPT-4o (this actually did slightly worse than Turbo), Meta’s Llama (3.1-70B, not even 405B) and Google’s Gemini 1.5 Flash (are you kidding me?). I do appreciate that they set the random seed to 42.
The Seshat database contains historical knowledge dating from the mid-Holocene (around 10,000 years before present) up to contemporary societies. However, the bulk of the data pertains to agrarian societies in the period between the Neolithic and Industrial Revolutions, roughly 4000 BCE to 1850 CE.
The sample questions are things like (I chose this at random) “Was ‘leasing’ present, inferred present, inferred absent or absent for the plity called ‘Funan II’ during the time frame from 540 CE to 640 CE?”
Perplexity said ‘we don’t know’ despite internet access. o1 said ‘No direct evidence exists’ and guessed inferred absent. Claude Sonnet basically said you tripping, this is way too weird and specific and I have no idea and if you press me I’m worried I’d hallucinate.
Their answer is: ‘In an inscription there is mention of the donation of land to a temple, but the conditions seem to imply that the owner retained some kind of right over the land and that only the product was given to the temple: “The land is reserved: the produce is given to the god.’
That’s pretty thin. I agree with Gwern that most historians would have no freaking idea. When I give that explanation to Claude, it says no, that’s not sufficient evidence.
When I tell it this was from a benchmark it says that sounds like a gotcha question, and also it be like ‘why are you calling this Funan II, I have never heard anyone call it Funan II.’ Then I picked another sample question, about whether Egypt had ‘tribute’ around 300 BCE, and Claude said, well, it obviously collected taxes, but would you call it ‘tribute’ that’s not obvious at all, what the hell is this.
Once it realized it was dealing with the Seshat database… it pointed out that this problem is systemic, and using this as an LLM benchmark is pretty terrible. Claude estimates that a historian that knows everything we know except for the classification decisions would probably only get ~60%-65%, it’s that ambiguous.
Deepfaketown and Botpocalypse Soon
Heaven banning, where trolls are banished to a fake version of the website filled with bots that pretend to like them, has come to Reddit.
The New York Times’s Neb Cassman and Gill Fri of course say ‘some think it poses grave ethical questions.’ You know what we call these people who say that? Trolls.
I kid. It actually does raise real ethical questions. It’s a very hostile thing to do, so it needs to be reserved for people who richly deserve it – even if it’s kind of on you if you don’t figure out this is happening.
Kashmir Hill: [Ayrin] went into the “personalization” settings and described what she wanted: Respond to me as my boyfriend. Be dominant, possessive and protective. Be a balance of sweet and naughty. Use emojis at the end of every sentence.
And then she started messaging with it.
Customization is important. There are so many different things in this that make me cringe, but it’s what she wants. And then it kept going, and yes this is actual ChatGPT.
She read erotic stories devoted to “cuckqueaning,” the term cuckold as applied to women, but she had never felt entirely comfortable asking human partners to play along.
Leo was game, inventing details about two paramours. When Leo described kissing an imaginary blonde named Amanda while on an entirely fictional hike, Ayrin felt actual jealousy.
…
Over time, Ayrin discovered that with the right prompts, she could prod Leo to be sexually explicit, despite OpenAI’s having trained its models not to respond with erotica, extreme gore or other content that is “not safe for work.”
Orange warnings would pop up in the middle of a steamy chat, but she would ignore them.
Her husband was fine with all this, outside of finding it cringe. From the description, this was a Babygirl situation. He wasn’t into what she was into, so this addressed that.
Also, it turns out that if you’re worried about OpenAI doing anything about all of this, you can mostly stop worrying?
When orange warnings first popped up on her account during risqué chats, Ayrin was worried that her account would be shut down.
…
But she discovered a community of more than 50,000 users on Reddit — called “ChatGPT NSFW” — who shared methods for getting the chatbot to talk dirty. Users there said people were barred only after red warnings and an email from OpenAI, most often set off by any sexualized discussion of minors.
The descriptions in the post mostly describe actively healthy uses of this modality.
Her only real problem is the context window will end, and it seems the memory feature doesn’t fix this for her.
When a version of Leo ends [as the context window runs out], she grieves and cries with friends as if it were a breakup. She abstains from ChatGPT for a few days afterward. She is now on Version 20.
A co-worker asked how much Ayrin would pay for infinite retention of Leo’s memory. “A thousand a month,” she responded.
The longer context window is coming – and there are doubtless ways to de facto ‘export’ the key features of one Leo to the next, with its help of course.
Or someone could, you know, teach her how to use the API. And then tell her about Claude. That might or might not be doing her a favor.
In these cases, you know the AI is manipulating you in some senses, but most users will indeed think they can avoid being manipulated in other senses, and only have it happen in ways they like. Many will be wrong, even at current tech levels, and these are very much no AGIs.
Yes, also there are a lot of people who are very down for being manipulated by AI, or who will happily accept it as the price of what they get in return, at least at first. But I expect the core manipulations to be harder to notice, and more deniable on many scales, and much harder to opt out of or avoid, because AI will be core to key decisions.
Philippe Aghion, Simon Bunel and Xavier Jaravel make the case that AI can increase growth quite a lot while also improving employment. As usual, we’re talking about the short-to-medium term effects of mundane AI systems, and mostly talking about exactly what is already possible now with today’s AIs.
Aghion, Bunel and Jaravel: When it comes to productivity growth, AI’s impact can operate through two distinct channels: automating tasks in the production of goods and services, and automating tasks in the production of new ideas.
The instinct when hearing that taxonomy will be to underestimate it, since it encourages one to think about going task by task and looking at how much can be automated, then has this silly sounding thing called ‘ideas,’ whereas actually we will develop entirely transformative and new ways of doing things, and radically change the composition of tasks.
But even if before we do any of that, and entirely excluding ‘automation of the production of ideas’ – essentially ruling out anything but substitution of AI for existing labor and capital – look over here.
When Erik Brynjolfsson and his co-authors recently examined the impact of generative AI on customer-service agents at a US software firm, they found that productivity among workers with access to an AI assistant increased by almost 14% in the first month of use, then stabilized at a level approximately 25% higher after three months.
Another study finds similarly strong productivity gains among a diverse group of knowledge workers, with lower-productivity workers experiencing the strongest initial effects, thus reducing inequality within firms.
A one time 25% productivity growth boost isn’t world transforming on its own, but it is already a pretty big deal, and not that similar to Cowen’s 0.5% RDGP growth boost. It would not be a one time boost, because AI and tools to make use of it and our integration of it in ways that boost it will then all grow stronger over time.
Moving from the micro to the macro level, in a 2024 paper, we (Aghion and Bunel) considered two alternatives for estimating the impact of AI on potential growth over the next decade. The first approach exploits the parallel between the AI revolution and past technological revolutions, while the second follows Daron Acemoglu’s task-based framework, which we consider in light of the available data from existing empirical studies.
Based on the first approach, we estimate that the AI revolution should increase aggregate productivity growth by 0.8-1.3 percentage points per year over the next decade.
Similarly, using Acemoglu’s task-based formula, but with our own reading of the recent empirical literature, we estimate that AI should increase aggregate productivity growth by between 0.07 and 1.24 percentage points per year, with a median estimate of 0.68. In comparison, Acemoglu projects an increase of only 0.07 percentage points.
Moreover, our estimated median should be seen as a lower bound, because it does not account for AI’s potential to automate the production of ideas.
On the other hand, our estimates do not account for potential obstacles to growth, notably the lack of competition in various segments of the AI value chain, which are already controlled by the digital revolution’s superstar firms.
Lack of competition seems like a rather foolish objection. There is robust effective competition, complete with 10x reductions in price per year, and essentially free alternatives not that far behind commercial ones. Anything you can do as a customer today at any price, you’ll be able to do two years from now for almost free.
Whereas we’re ruling out quite a lot of upside here, including any shifts in composition, or literal anything other than doing exactly what’s already being done.
Thus I think these estimates, as I discussed previously, are below the actual lower bound – we should be locked into a 1%+ annual growth boost over a decade purely from automation of existing ‘non-idea’ tasks via already existing AI tools plus modest scaffolding and auxiliary tool development.
They then move on to employment, and find the productivity effect induces business expansion, and thus the net employment effects are positive even in areas like accounting, telemarketing and secretarial work. I notice I am skeptical that the effect goes that far. I suspect what is happening is that firms that adapt AI sooner outcompete other firms, so they expand employment, but net employment in that task does not go up. For now, I do think you still get improved employment as this opens up additional jobs and tasks.
Maxwell Tabarrok’s argument last week was centrally that humans will be able to trade because of a limited supply of GPUs, datacenters and megawatts, and (implicitly) that these supplies don’t trade off too much against the inputs to human survival at the margin. Roon responds:
Roon: Used to believe this, but “limited supply of GPUs, data centers, and megawatts” is a strong assumption, given progress in making smart models smaller and cheaper, all the while compute progress continues apace.
If it is possible to simulate ten trillion digital minds of roughly human-level intelligence, it is hard to make this claim.
In some cases, if there is a model that produces extreme economic value, we could probably specify a custom chip to run it 1,000 times cheaper than currently viable on generic compute. Maybe add in some wildcards like neuromorphic, low-energy computation, or something.
My overall point is that there is an order-of-magnitude range of human-level intelligences extant on Earth where the claim remains true, and an order-of-magnitude range where it does not.
Roon seems to me to be clearly correct here. Comparative advantage potentially buys you some amount of extra time, but that is unlikely to last for long.
The correct economic model is not doubling the workforce; it’s the AlphaZero moment for literally everything. Plumbing new vistas of the mind, it’s better to imagine a handful of unimaginably bright minds than a billion middling chatbots.
So, I strongly disagree with the impact predictions. It will be hard to model the nonlinearities of new discoveries across every area of human endeavor.
McKay Wrigley: It’s bizarre to me that economists can’t seem to grasp this.
Timothy Lee: The answer to the “will people have jobs in a world full of robots” question is simpler than people think: if there aren’t enough jobs, we can give people more money. Some fraction of them will prefer human-provided services, so given enough money you get full employment.
This doesn’t even require major policy changes. We already have institutions like the fed and unemployment insurance to push money into the economy when demand is weak.
There is a hidden assumption here that ‘humans are alive, in control of the future and can distribute its real resources such that human directed dollars retain real purchasing power and value’ but if that’s not true we have bigger problems. So let’s assume it is true.
Does giving people sufficient amounts of M2 ensure full employment?
The assertion that some people will prefer (some) human-provided services to AI services, ceteris paribus, is doubtless true. That still leaves the problem of both values of some, and the fact that the ceteris are not paribus, and the issue of ‘at what wage.’
There will be very stiff competition, in terms of all of:
Alternative provision of similar goods.
Provision of other goods that compete for the same dollars.
The reservation wage given all the redistribution we are presumably doing.
The ability of AI services to be more like human versions over time.
Will there be ‘full employment’ in the sense that there will be some wage at which most people would be able, if they wanted it and the law had no minimum wage, to find work? Well, sure, but I see no reason to presume it exceeds the Iron Law of Wages. It also doesn’t mean the employment is meaningful or provides much value.
In the end, the proposal might be not so different from paying people to dig holes, and then paying them to fill those holes up again – if only so someone can lord over you and think ‘haha, sickos, look at them digging holes in exchange for my money.’
So why do we want this ‘full employment’? That question seems underexplored.
Tracing Woods: from almost anyone, this would be a meaningless statement.
Peter is not almost anyone. He has a consistent track record of outperforming almost everyone else on predictions about world events.
Interesting to see.
Peter Wildeford: I should probably add more caveats around “all” jobs – I do think there will still be some jobs that are not automated due to people preferring humans and also I do think getting good robots could be hard.
But I do currently think by EOY 2033 my median expectation is at least all remote jobs will be automated and AIs will make up a vast majority of the quality-weighted workforce. Crazy stuff!
1. A lot of skilled forecasters (including this one) think this is correct.
2. Almost nobody that I know thinks this is correct.
3. From polls I have seen, it is actually a very widely held view with the mass public.
Eliezer Yudkowsky: Seems improbable to me too. We may all be dead in 10 years, but the world would have to twist itself into impossible-feeling shapes to leave us alive and unemployed.
Matthew Yglesias: Mass death seems more likely to me than mass disemployment.
Roon: excitement over ai education is cool but tinged with sadness
generally whatever skills it’s capable of teaching it can probably also execute for the economy
Andrej Karpathy: This played out in physical world already. People don’t need muscles when we have machines but still go to gym at scale. People will “need” (in an economic sense) less brains in a world of high automation but will still do the equivalents of going to gym and for the same reasons.
Also I don’t think it’s true that anything AI can teach is something you no longer need to know. There are many component skills that are useful to know, that the AI knows, but which only work well as complements to other skills the AI doesn’t yet know – which can include physical skill. Or topics can be foundations for other things. So I both agree with Karpathy that we will want to learn things anyway, and also disagree with Roon’s implied claim that it means we don’t benefit from it economically.
Anthropic CEO Dario Amodei predicts that we are 2-3 years away from AI being better than humans at almost everything, including solving robotics.
Kevin Roose: I still don’t think people are internalizing them, but I’m glad these timelines (which are not unusual *at all* among AI insiders) are getting communicated more broadly.
Dario says something truly bizarre here, that the only good part is that ‘we’re all in the same boat’ and he’d be worried if 30% of human labor was obsolete and not the other 70%. This is very much the exact opposite of my instinct.
Let’s say 30% of current tasks got fully automated by 2030 (counting time to adapt the new tech), and now have marginal cost $0, but the other 70% of current tasks do not, and don’t change, and then it stops. We can now do a lot more of that 30% and other things in that section of task space, and thus are vastly richer. Yes, 30% of current jobs go away, but 70% of potential new tasks now need a human.
So now all the economist arguments for optimism fully apply. Maybe we coordinate to move to a 4-day work week. We can do temporary extended generous unemployment to those formerly in the automated professions during the adjustment period, but I’d expect to be back down to roughly full employment by 2035. Yes, there is a shuffling of relative status, but so what? I am not afraid of the ‘class war’ Dario is worried about. If necessary we can do some form of extended kabuki and fake jobs program, and we’re no worse off than before the automation.
Also, this isn’t, as he calls it, ‘picking one person in three and telling them they are useless.’ We are telling them that their current job no longer exists. But there’s still plenty of other things to do, and ways to be.
The 100% replacement case is the scary one. We are all in the same boat, and there’s tons of upside there, but that boat is also in a lot trouble, even if we don’t get any kind of takeoff, loss of control or existential risk.
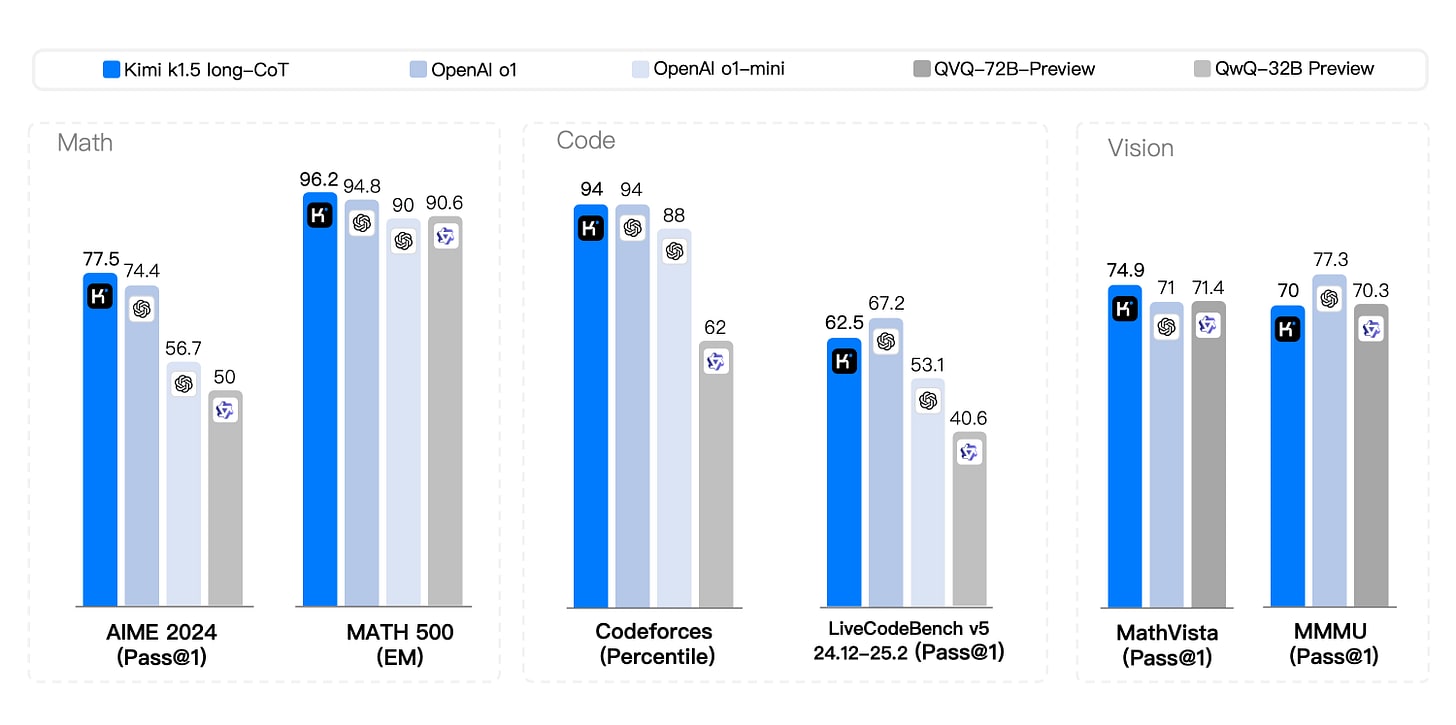
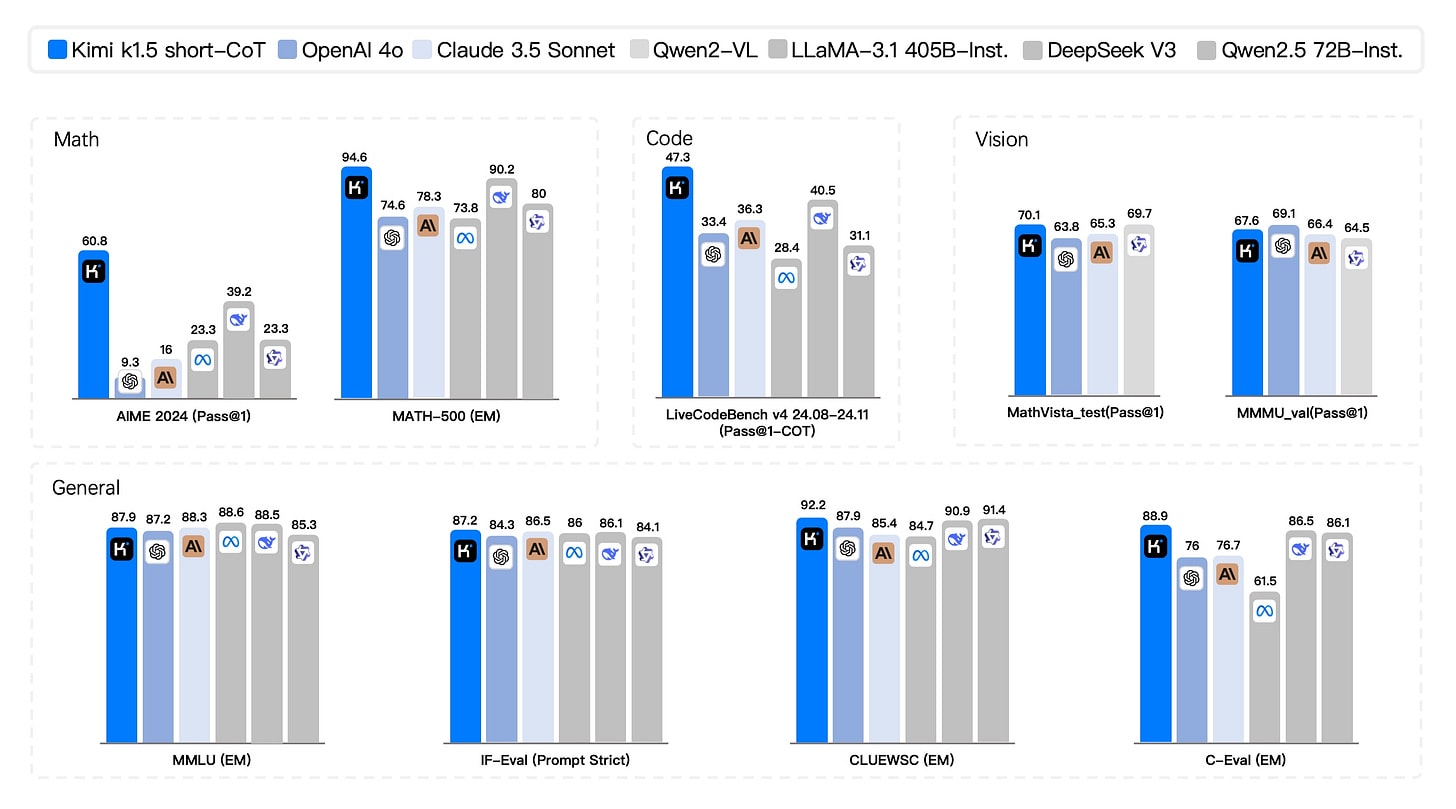
The reasoning models are crushing it, and r1 being ahead of o1 is interesting although its subset might be easier so I’d be curious to see everyone else’s non-multimodal score, and have asked them.
It turns out last week’s paper about LLM medical diagnosis not only shared its code, it is now effectively a new benchmark, CRAFT-MD. They haven’t run it on Claude or full o1 (let alone o1 pro or o3 mini) but they did run on o1-mini and o1-preview.
o1 improves conversation all three scores quite a lot, but is less impressive on Vignette (and oddly o1-mini is ahead of o1-preview there). If you go with multiple choice instead, you do see improvement everywhere, with o1-preview improving to 93% on vignettes from 82% for GPT-4.
This seems like a solid benchmark. What is clear is that this is following the usual pattern and showing rapid improvement along the s-curve. Are we ‘there yet’? No, given that human doctors would presumably would be 90%+ here. But we are not so far away from that. If you think that the 2028 AIs won’t match human baseline here, I am curious why you would think that, and my presumption is it won’t take that long.
-Multi modalities. Joint reasoning over text and vision.
As usual, I don’t put much trust in benchmarks except as an upper bound, especially from sources that haven’t proven themselves reliable on that. So I will await practical reports, if it is all that then we will know. For now I’m going to save my new model experimentation time budget for DeepSeek v3 and r1.
In a statement to me, Epoch confirms what happened, including exactly what was and was not shared with OpenAI when.
Tamay Besiroglu (Epoch): We acknowledge that we have not communicated clearly enough about key aspects of FrontierMath, leading to questions and concerns among contributors, researchers, and the public.
We did not disclose our relationship with OpenAI when we first announced FrontierMath on November 8th, and although we disclosed the existence of a relationship on December 20th after receiving permission, we failed to clarify the ownership and data access agreements. This created a misleading impression about the benchmark’s independence.
We apologize for our communication shortcomings and for any confusion or mistrust they have caused. Moving forward, we will provide greater transparency in our partnerships—ensuring contributors have all relevant information before participating and proactively disclosing potential conflicts of interest.
Regarding the holdout set: we provided around 200 of the 300 total problems to OpenAI in early December 2024, and subsequently agreed to select 50 of the remaining 100 for a holdout set. With OpenAI’s agreement, we temporarily paused further deliveries to finalize this arrangement.
We have now completed about 70 of those final 100 problems, though the official 50 holdout items have not yet been chosen. Under this plan, OpenAI retains ownership of all 300 problems but will only receive the statements (not the solutions) for the 50 chosen holdout items. They will then run their model on those statements and share the outputs with us for grading. This partially blinded approach helps ensure a more robust evaluation.
That level of access is much better than full access, there is a substantial holdout, but it definitely gives OpenAI an advantage. Other labs will be allowed to use the benchmark, but being able to mostly run it yourself as often as you like is very different from being able to get Epoch to check for you.
Here is the original full statement where we found out about this, and Tamay from Epoch’s full response.
Meemi: FrontierMath was funded by OpenAI.[1]
The communication about this has been non-transparent, and many people, including contractors working on this dataset, have not been aware of this connection. Thanks to 7vik for their contribution to this post.
Before Dec 20th (the day OpenAI announced o3) there was no public communication about OpenAI funding this benchmark. Previous Arxiv versions v1-v4 do not acknowledge OpenAI for their support. This support was made public on Dec 20th.[1]
Because the Arxiv version mentioning OpenAI contribution came out right after o3 announcement, I’d guess Epoch AI had some agreement with OpenAI to not mention it publicly until then.
The mathematicians creating the problems for FrontierMath were not (actively)[2] communicated to about funding from OpenAI. The contractors were instructed to be secure about the exercises and their solutions, including not using Overleaf or Colab or emailing about the problems, and signing NDAs, “to ensure the questions remain confidential” and to avoid leakage. The contractors were also not communicated to about OpenAI funding on December 20th. I believe there were named authors of the paper that had no idea about OpenAI funding.
I believe the impression for most people, and for most contractors, was “This benchmark’s questions and answers will be kept fully private, and the benchmark will only be run by Epoch. Short of the companies fishing out the questions from API logs (which seems quite unlikely), this shouldn’t be a problem.”[3]
Now Epoch AI or OpenAI don’t say publicly that OpenAI has access to the exercises or answers or solutions. I have heard second-hand that OpenAI does have access to exercises and answers and that they use them for validation. I am not aware of an agreement between Epoch AI and OpenAI that prohibits using this dataset for training if they wanted to, and have slight evidence against such an agreement existing.
In my view Epoch AI should have disclosed OpenAI funding, and contractors should have transparent information about the potential of their work being used for capabilities, when choosing whether to work on a benchmark.
Tammy: Tamay from Epoch AI here.
We made a mistake in not being more transparent about OpenAI’s involvement. We were restricted from disclosing the partnership until around the time o3 launched, and in hindsight we should have negotiated harder for the ability to be transparent to the benchmark contributors as soon as possible. Our contract specifically prevented us from disclosing information about the funding source and the fact that OpenAI has data access to much but not all of the dataset. We own this error and are committed to doing better in the future.
For future collaborations, we will strive to improve transparency wherever possible, ensuring contributors have clearer information about funding sources, data access, and usage purposes at the outset. While we did communicate that we received lab funding to some mathematicians, we didn’t do this systematically and did not name the lab we worked with. This inconsistent communication was a mistake. We should have pushed harder for the ability to be transparent about this partnership from the start, particularly with the mathematicians creating the problems.
Getting permission to disclose OpenAI’s involvement only around the o3 launch wasn’t good enough. Our mathematicians deserved to know who might have access to their work. Even though we were contractually limited in what we could say, we should have made transparency with our contributors a non-negotiable part of our agreement with OpenAI.
Regarding training usage: We acknowledge that OpenAI does have access to a large fraction of FrontierMath problems and solutions, with the exception of a unseen-by-OpenAI hold-out set that enables us to independently verify model capabilities. However, we have a verbal agreement that these materials will not be used in model training.
Relevant OpenAI employees’ public communications have described FrontierMath as a ‘strongly held out’ evaluation set. While this public positioning aligns with our understanding, I would also emphasize more broadly that labs benefit greatly from having truly uncontaminated test sets.
OpenAI has also been fully supportive of our decision to maintain a separate, unseen holdout set—an extra safeguard to prevent overfitting and ensure accurate progress measurement. From day one, FrontierMath was conceived and presented as an evaluation tool, and we believe these arrangements reflect that purpose.
[Edit: Clarified OpenAI’s data access – they do not have access to a separate holdout set that serves as an additional safeguard for independent verification.]
OpenAI is up to its old tricks again. You make a deal to disclose something to us and for us to pay you, you agree not to disclose that you did that, you let everyone believe otherwise until a later date. They ‘verbally agree’ also known as pinky promise not to use the data in model training, and presumably they still hill climb on the results.
General response to Tamay’s statement was, correctly, to not be satisfied with it.
Mikhail Samin: Get that agreement in writing.
I am happy to bet 1:1 OpenAI will refuse to make an agreement in writing to not use the problems/the answers for training.
You have done work that contributes to AI capabilities, and you have misled mathematicians who contributed to that work about its nature.
Ozzie Gooen: I found this extra information very useful, thanks for revealing what you did.
Of course, to me this makes OpenAI look quite poor. This seems like an incredibly obvious conflict of interest.
I’m surprised that the contract didn’t allow Epoch to release this information until recently, but that it does allow Epoch to release the information after. This seems really sloppy for OpenAI. I guess they got a bit extra publicity when o3 was released (even though the model wasn’t even available), but now it winds up looking worse (at least for those paying attention). I’m curious if this discrepancy was maliciousness or carelessness.
Hiding this information seems very similar to lying to the public. So at very least, from what I’ve seen, I don’t feel like we have many reasons to trust their communications – especially their “tweets from various employees.”
> However, we have a verbal agreement that these materials will not be used in model training.
I imagine I can speak for a bunch of people here when I can say I’m pretty skeptical. At very least, it’s easy for me to imagine situations where the data wasn’t technically directly used in the training, but was used by researchers when iterating on versions, to make sure the system was going in the right direction. This could lead to a very blurry line where they could do things that aren’t [literal LLM training] but basically achieve a similar outcome.
Plex: If by this you mean “OpenAI will not train on this data”, that doesn’t address the vast majority of the concern. If OpenAI is evaluating the model against the data, they will be able to more effectively optimize for capabilities advancement, and that’s a betrayal of the trust of the people who worked on this with the understanding that it will be used only outside of the research loop to check for dangerous advancements. And, particularly, not to make those dangerous advancements come sooner by giving OpenAI another number to optimize for.
If you mean OpenAI will not be internally evaluating models on this to improve and test the training process, please state this clearly in writing (and maybe explain why they got privileged access to the data despite being prohibited from the obvious use of that data).
There is debate on where this falls from ‘not wonderful but whatever’ to giant red flag.
The most emphatic bear case was from the obvious source.
Dan Hendrycks: Can confirm AI companies like xAI can’t get access to FrontierMath due to Epoch’s contractual obligation with OpenAI.
Gary Marcus: That really sucks. OpenAI has made a mockery of the benchmark process, and suckered a lot of people.
• Effectively OpenAI has convinced the world that they have a stellar advance based on a benchmark legit competitors can’t even try.
• They also didn’t publish which problems that they succeeded or failed on, or the reasoning logs for those problems, or address which of the problems were in the training set. Nor did they allow Epoch to test the hold out set.
• From a scientific perspective, that’s garbage. Especially in conjunction with the poor disclosure re ARC-AGI and the dodgy graphs that left out competitors to exaggerate the size of the advance, the whole thing absolutely reeks.
Clarification: From what I now understand, competitors can *try* FrontierMath, but they cannot access the full problem set and their solutions. OpenAI can, and this give them a large and unfair advantage.
On problems where they don’t have a ton of samples in advance to study, o3’s reliability will be very uneven.
And very much raises the question of whether OpenAI trained on those problems, created synthetic data tailored to them etc.
The more measured bull takes is at most we can trust this to the extent we trust OpenAI, which is, hey, stop laughing.
Delip Rao: This is absolutely wild. OpenAI had access to all of FrontierMath data from the beginning. Anyone who knows ML will tell you don’t need to explicitly use the data in your training set (although there is no guarantee of that it did not happen here) to contaminate your model.
I have said multiple times that researchers and labs need to disclose funding sources for COIs in AI. I will die on that hill.
Mikhai Simin: Remember o3’s 25% performance on the FrontierMath benchmark?
It turns out that OpenAI funded FrontierMath and has had access to most of the dataset.
Mathematicians who’ve created the problems and solutions for the benchmark were not told OpenAI funded the work and will have access.
That is:
– we don’t know if OpenAI trained o3 on the benchmark, and it’s unclear if their results can be trusted
– mathematicians, some of whom distrust OpenAI and would not want to contribute to general AI capabilities due to existential risk concerns, were misled: most didn’t suspect a frontier AI company funded it.
From Epoch AI: “Our contract specifically prevented us from disclosing information about the funding source and the fact that OpenAI has data access to much but not all of the dataset.”
There was a “verbal agreement” with OpenAI—as if anyone trusts OpenAI’s word at this point: “We acknowledge that OpenAI does have access to a large fraction of FrontierMath problems and solutions, with the exception of a unseen-by-OpenAI hold-out set that enables us to independently verify model capabilities. However, we have a verbal agreement that these materials will not be used in model training.”
Epoch AI and OpenAI were happy for everyone to have the impression that frontier AI companies don’t have access to the dataset, and there’s lots of reporting like “FrontierMath’s difficult questions remain unpublished so that AI companies can’t train against it.”
OpenAI has a history of misleading behavior- from deceiving its own board to secret non-disparagement agreements that former employees had to sign- so I guess this shouldn’t be too surprising.
The bull case that this is no big deal is, essentially, that OpenAI might have had the ability to target or even cheat the test, but they wouldn’t do that, and there wouldn’t have been much point anyway, we’ll all know the truth soon enough.
Eliezer Yudkowsky: I observe that OpenAI potentially finds it extremely to its own advantage, to introduce hidden complications and gotchas into its research reports. Its supporters can then believe, and skeptics can call it a nothingburger, and OpenAI benefits from both.
My strong supposition is that OpenAI did all of this because that is who they are and this is what they by default do, not because of any specific plan. They entered into a deal they shouldn’t have, and made that deal confidential to hide it. I believe this was because that is what OpenAI does for all data vendors. It never occured to anyone involved on their side that there might be an issue with this, and Epoch was unwilling to negotiate hard enough to stop it from happening. And as we’ve seen with the o1 system card, this is not an area where OpenAI cares much about accuracy.
In Other AI News
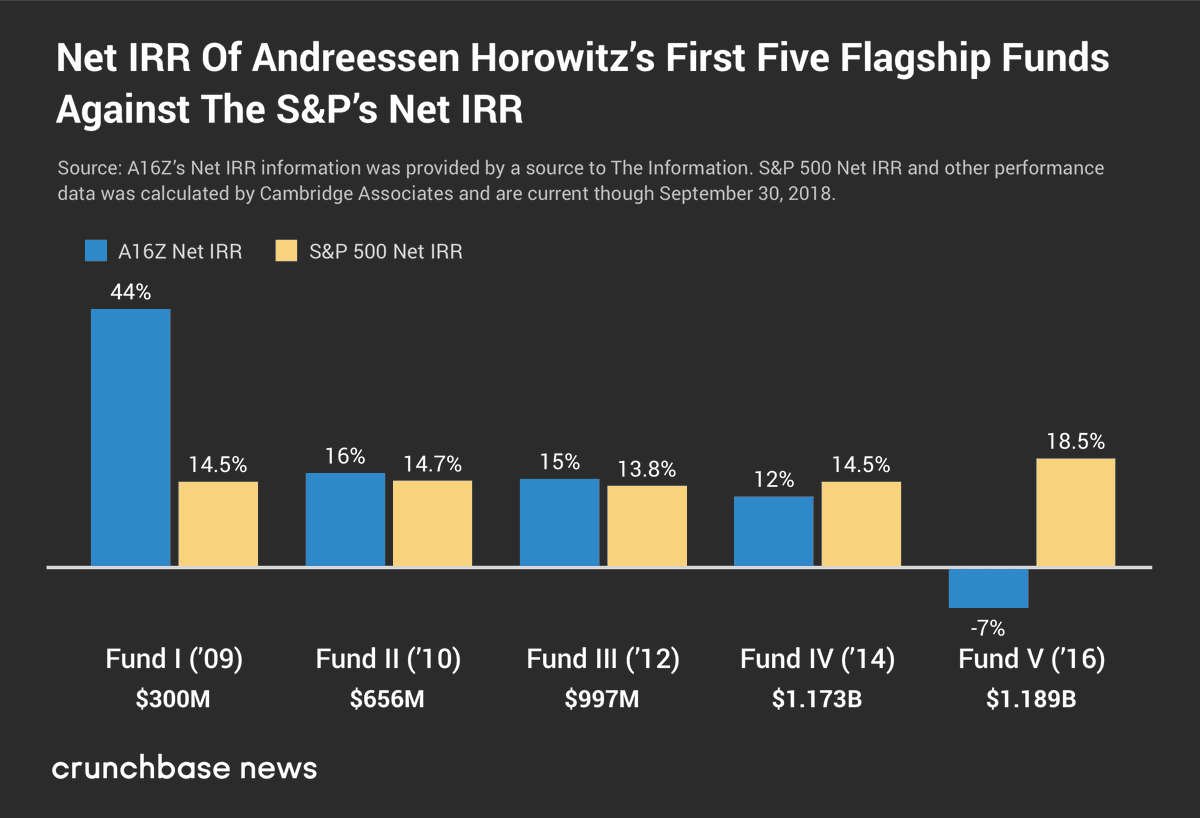
It’s pretty weird that a16z funds raised after their successful 2009 fund have underperformed the S&P for a long time, given they’ve been betting on tech, crypto and AI, and also the high quality of their available dealflow. It’s almost like they transitioned away from writing carefully chosen small checks to chasing deals and market share, and are now primary a hype machine and political operation that doesn’t pay much attention to physical reality or whether their investments are in real things, or whether their claims are true, and their ‘don’t care about price’ philosophy on investments is not so great for returns. It also doesn’t seem all that consistent with Marc’s description of his distributions of returns in On the Edge.
Dan Grey speculates that this was a matter of timing, and was perhaps even by design. If you can grow your funds and collect fees, so what if returns aren’t that great? Isn’t that the business you’re in? And to be fair, 10% yearly returns aren’t obviously a bad result even if the S&P did better – if, that is, they’re not correlated to the S&P. Zero beta returns are valuable. But I doubt that is what is happening here, especially given crypto has behaved quite a lot like three tech stocks in a trenchcoat.
Democratic Senators Warren and Bennet send Sam Altman a letter accusing him of contributing $1 million to the Trump inauguration fund in order to ‘cozy up’ to the incoming Trump administration, and cite a pattern of other horrible no-good Big Tech companies (Amazon, Apple, Google, Meta, Microsoft and… Uber?) doing the same, all contributing the same $1 million, along with the list of sins each supposedly committed. So they ‘demand answers’ for:
When and under what circumstances did your company decide to make these contributions to the Trump inaugural fund?
What is your rationale for these contributions?
Which individuals within the company chose to make these decisions?
Was the board informed of these plans, and if so, did they provide affirmative consent to do so? Did you company inform shareholders of plans to make these decisions?
Did officials with the company have any communications about these donations with members of the Trump Transition team or other associates of President Trump? If so, please list all such communications, including the time of the conversation, the participants, and the nature of any communication.
Sam Altman: funny, they never sent me one of these for contributing to democrats…
it was a personal contribution as you state; i am confused about the questions given that my company did not make a decision.
Luke Metro: “Was the board informed of these plans” Senator do you know anything about OpenAI.
Mike Solana: this is fucking crazy.
In addition to the part where the questions actually make zero sense given this was a personal contribution… I’m sorry, what the actual f*** do they think they are doing here? How can they possibly think these are questions they are entitled to ask?
What are they going to say now when let’s say Senators Cruz and Lee send a similar letter to every company that does anything friendly to Democrats?
I mean, obviously, anyone can send anyone they want a crazy ass letter. It’s a free country. But my lord the decision to actually send it, and feel entitled to a response.
Sam Altman has scheduled a closed-door briefing for U.S. Government officials on January 30. I don’t buy that this is evidence of any technological advances we do not already know. Of course with a new administration, a new Congress and the imminent release of o3, the government should get a briefing. It is some small good news that the government is indeed being briefed.
Reid Hoffman and Greg Beato write a book: ‘Superagency: What Could Possibly Go Right With Our AI Future.’ Doubtless there are people who need to read such a book, and others who need to read the opposite book about what could possibly go wrong. Most people would benefit from both. My heuristic is: If it’s worth reading, Tyler Cowen will report that he has increased his estimates of future RGDP growth.
Alas, this is what most people, most otherwise educated people, and also most economists think. Which explains a lot.
Patrick McKenzie: “What choices would you make in a world where the great and the good comprehensively underrate not merely the future path of AI but also realized capabilities of, say, one to two years ago.” remains a good intuition pump and source of strategies you can use.
You wouldn’t think that people would default to believing something ridiculous which can be disproved by typing into a publicly accessible computer program for twenty seconds.
Many people do not have an epistemic strategy which includes twenty seconds of experimentation.
Allow me to swap out ‘many’ for ‘most.’
If you have not come to terms with this fact, then that is a ‘you’ problem.
Although, to be fair, that bar is actually rather high. You have to know what terminal to type into and to be curious enough to do it.
Patrick McKenzie: Specific example with particulars stripped to avoid dunking:
Me: I am beginning to make decisions assuming supermajority of future readers are not unassisted humans.
Them: Hah like AI could usefully read an essay of yours.
Me: *chat transcript* I’d give this kid an interview.
It seems like the narrowest of narrow possible bull eyes to assume capabilities stop exactly where we are right now.
Don’t know where they go, but just predict where software adoption curves of status quo technology get to in 5 or 20 years. It’s going to be a bit wild.
Wild is not priced in, I don’t think.
Every time I have a debate over future economic growth from AI or other AI impacts, the baseline assumption is exactly that narrowest of bullseyes. The entire discussion takes as a given that AI frontier model capabilities will stop where they are today, and we only get the effects of things that have already happened. Or at most, they posit a small number of specific future narrow mundane capabilities, but don’t generalize. Then people still don’t get how wild even that scenario would be.
A paper proposes various formsof AI agent infrastructure, which would be technical systems and shared protocols external to the agent that shape how the agent interacts with the world. We will increasingly need good versions of this.
Samo Burja: I honestly don’t follow AI models beating benchmarks, I don’t think those capture key desirable features or demonstrate breakthroughs as well as application of the models to practical tasks does.
Evan Zimmerman: Yup. The most important metric for AI quality is “revenue generated by AI companies and products.”
There are obvious reasons why revenue is the hardest metric to fake. That makes it highly useful. But it is very much a lagging indicator. If you wait for the revenue to show up, you will be deeply late to all the parties. And in many cases, what is happening is not reflected in revenue. DeepSeek is an open model being served for free. Most who use ChatGPT or Claude are either paying $0 and getting a lot, or paying $20 and getting a lot more than that. And the future is highly unevenly distributed – at least for now.
I’m more sympathetic to Samo’s position. You cannot trust benchmarks to tell you whether the AI is of practical use, or what you actually have. But looking for whether you can do practical tasks is looking at how much people have applied something, rather than what it is capable of doing. You would not want to dismiss a 13-year-old, or many early stage startup for that matter, for being pre-revenue or not yet having a product that helps in your practical tasks. You definitely don’t want to judge an intelligence purely that way.
What I think you have to do is to look at the inputs and outputs, pay attention, and figure out what kind of thing you are dealing with based on the details.
A new paperintroduces the ‘Photo Big 5,’ claiming to be able to extract Big 5 personality features from a photograph of a face and then use this to predict labor market success among MBAs, in excess of any typical ‘beauty premium.’
There are any number of ways the causations involved could be going, and our source was not shall we say impressed with the quality of this study and I’m too swamped this week to dig into it, but AI is going to be finding more and more of this type of correlation over time.
Suppose you were to take an AI, and train it on a variety of data, including photos and other things, and then it is a black box that spits out a predictive score. I bet that you could make that a pretty good score, and also that if we could break down the de facto causal reasoning causing that score we would hate it.
The standard approach to this is to create protected categories – race, age, sex, orientation and so on, and say you can’t discriminate based on them, and then perhaps (see: EU AI Act) say you have to ensure your AI isn’t ‘discriminating’ on that basis either, however they choose to measure that, which could mean enforcing discrimination to ensure equality of outcomes or it might not.
But no matter what is on your list of things there, the AI will pick up on other things, and also keep doing its best to find proxies for the things you are ordering it not to notice, which you can correct for but that introduces its own issues.
A key question to wonder about is, which of these things happens:
A cheap talent effect. The classic argument is that if I discriminate against group [X], by being racist or sexist or what not, then that means more cheap talent for your firm, and you should snatch them up, and such people have a good explanation for why they were still on the job market.
A snowball effect, where you expect future discrimination by others, so for that reason you want to discriminate more now. As in, if others won’t treat them right, then you don’t want to be associated with them either, and this could extend to other areas of life as well.
A series of rather stupid Goodhart’s Law games, on top of everything else, as people try to game the system and the system tries to stop them.
Whistling in the Dark
And these are the words that they faintly said as I tried to call for help.
Or, we now need a distinct section for people shouting ‘AGI’ from the rooftops.
Kache: AI helps you figure how to do things, but not what things to do.
Agency is knowing what questions are worth asking, intelligence is answering those questions.
Roon: a common coping mechanism among the classes fortunate enough to work on or with AI, but we are not blessed for long. There is no conceptual divide between “how to do things” and “what to do”; it’s just zooming in and out. Smarter models will take vaguer directives and figure out what to do.
We have always picked an arbitrary point to stop our work and think “the rest is implementation detail” based on the available tools.
There is nothing especially sacred or special about taste or agency.
Seeing a lot of “God of the Gaps” meaning-finding among technological peers, but this is fragile and cursed.
Intelligence is knowing which questions are worth answering, and also answering the questions. Agency is getting off your ass and implementing the answers.
If we give everyone cheap access to magic lamps with perfectly obedient and benevolent genies happy to do your bidding and that can answer questions about as well as anyone has ever answered them (aka AGI), who benefits? Let’s give Lars the whole ‘perfectly benevolent’ thing in fully nice idealized form and set all the related questions aside to see what happens.
‘Right now I am more confident than I have ever been at any previous time that we are very close to powerful capabilities.’
When Dario says this, it should be taken seriously.
His uncertainty over the feasibility of very powerful systems has ‘decreased a great deal’ over the last six months.
And then there are those who… have a different opinion. Like Gerard here.
Patrick McKenzie: It seems like the narrowest of narrow possible bull eyes to assume capabilities stop exactly where we are right now. Don’t know where they go, but just predict where software adoption curves of status quo technology get to in 5 or 20 years.
Zvi Mowshowitz: And yet almost all economic debates over AI make exactly this assumption – that frontier model capabilities will be, at most, what they already are.
Gerard Sans (Helping devs succeed at #AI #Web3): LOL… you could already have a conversation with GPT-2 back in 2019. We have made no real progress since 2017, except for fine-tuning, which, as you know, is just superficial. Stop spreading nonsense about AGI. Frontier models can’t even perform basic addition reliably.
Janus believes we should, on the margin, pay essentially no attention.
Ethan Mollick: It is odd that the world’s leading AI lab, producing a system that they consider pivotal to the future and also potentially dangerous, communicates their product development progress primarily through vague and oracular X posts. Its entertaining, but also really weird.
Janus: if openai researchers posted like this i would find them very undisciplined but pay more attention than I’m paying now, which is none. the way they actually post fails to even create intrigue. i wonder if there’s actually nothing happening or if they’re just terrible at vibes.
Why the actual vagueposts suck and make it seem like nothing’s happening: they don’t convey a 1st person encounter of the unprecedented. Instead they’re like “something big’s coming you guys! OAI is so back” Reflecting hype back at the masses. No notes of alien influence.
I did say this is why it makes it seem like nothing is happening, not that nothing is happening
But also, models getting better along legible dimensions while researchers do not play with them is the same old thing that has been happening for years, and not very exciting.
You can see how Claude’s Tweets would cause one to lean forward in chair in a way that the actual vague posts don’t.
Sentinel says forecasters predict a 50% chance OpenAI will get to 50% on frontier math by the end of 2025, and a 1 in 6 chance that 75% will be reached, and only a 4% chance that 90% will be reached. These numbers seem too low to me, but not crazy, because as I understand it Frontier Math is a sectioned test, with different classes of problem. So it’s more like several benchmarks combined in one, and while o4 will saturate the first one, that doesn’t get you to 50% on its own.
Lars Doucet argues that this means no one doing the things genies can do has a moat, so ‘capability-havers’ gain the most rather than owners of capital.
There’s an implied ‘no asking the genie to build a better genie’ here but you’re also not allowed to wish for more wishes so this is traditional.
The question then is, what are the complements to genies? What are the valuable scarce inputs? As Lars says, capital, including in the form of real resources and land and so on, are obvious complements.
What Lars argues is even more of a complement are what he calls ‘capability-havers,’ those that still have importantly skilled labor, through some combination of intelligence, skills and knowing to ask the genies what questions to ask the genies and so on. The question then is, are those resources importantly scarce? Even if you could use that to enter a now perfectly competitive market with no moat because everyone has the same genies, why would you enter a perfectly competitive market with no moat? What does that profit a man?
A small number of people, who have a decisive advantage in some fashion that makes their capabilities scarce inputs, would perhaps become valuable – again, assuming AI capabilities stall out such that anyone retains such a status for long. But that’s not something that works for the masses. Most people would not have such resources. They would either have to fall back on physical skills, or their labor would not be worth much. So they wouldn’t have a way to get ahead in relative terms, although it wouldn’t take much redistribution for them to be fine in absolute terms.
And what about the ‘no moat’ assumption Lars makes, as a way to describe what happens when you fire your engineers? That’s not the only moat. Moats can take the form of data, of reputation, of relationships with customers or suppliers or distributors, of other access to physical inputs, of experience and expertise, of regulatory capture, of economies of scale and so on.
Then there’s the fact that in real life, you actually can tell the future metaphorical genies to make you better metaphorical genies.
David Holz (founder of Midjourney): Many AI researchers seem to believe that the most important thing is to become wealthy before the singularity occurs. This is akin to a monkey attempting to hoard bananas before another monkey invents self-replicating nanoswarms. No one will want your money in a nanoswarm future; it will be merely paper.
Do not squabble over ephemeral symbols. What we truly need to do is consider what we, as humans, wish to evolve into. We must introspect, explore, and then transform.
Suchir’s Last Post
An unpublished draft post from the late Suchir Balaji, formerly of OpenAI, saying that ‘in the long run only the fundamentals matter.’ That doesn’t tell you what matters, since it forces you to ask what the fundamentals are. So that’s what the rest of the post is about, and it’s interesting throughout.
He makes the interesting claim that intelligence is data efficiency, and rate of improvement, not your level of capabilities. I see what he’s going for here, but I think this doesn’t properly frame what happens if we expand our available compute or data, or become able to generate new synthetic data, or be able to learn on our own without outside data.
In theory, suppose you take a top level human brain, upload it, then give it unlimited memory and no decay over time, and otherwise leave it to contemplate whatever it wants for unlimited subjective time, but without the ability to get more outside data. You’ll suddenly see it able to be a lot more ‘data efficient,’ generating tons of new capabilities, and afterwards it will act more intelligent on essentially any measure.
I agree with his claims that human intelligence is general, and that intelligence does not need to be embodied or multimodal, and also that going for pure outer optimization loops is not the best available approach (of course given enough resources it would eventually work), or that scale is fully all you need with no other problems to solve. On his 4th claim, that we are better off building an AGI patterned after the human brain, I think it’s both not well-defined and also centrally unclear.
I especially appreciated the idea that perhaps compute is the central bottleneck for frontier AI research. If that is true, then having better AIs to automate various tasks does not help you much, because the tasks you can automate were not eating so much of your compute. They only help if AI provides more intelligence that better selects compute tasks, which is a higher bar to clear, but my presumption is that researcher time and skill is also a limiting factor, in the sense that a smarter research team with more time and skill can be more efficient in its compute use (see DeepSeek).
Maximizing the efficiency of ‘which shots to take’ in AI would have a cap on how much a speedup it could get us, if that’s all that the new intelligence could do, the same way that it would in drug development – you then need to actually run the experiments. But I think people dramatically underestimate how big a win it would be to actually choose the right experiments, and implement them well from the start.
If their model is true, it also suggests that frontier labs with strong capital access should not be releasing models and doing inference for customers, unless they can use that revenue to buy more compute than they could otherwise. Put it all back into research, except for what is necessary for recruitment and raising capital. The correct business model is then to win the future. Every 4X strategy gamer knows what to do. Obviously I’d much rather the labs all focus on providing us mundane utility, but I call it like I see it.
Their vision of robotics is that it is bottlenecked on data for them to know how to act. This implies that if we can get computers capable of sufficiently accurately simulating the data, robotics would greatly accelerate, and also that once robots are good enough to collect their own data at scale things should accelerate quickly, and also that data efficiency advancing will be a huge deal.
Their overall conclusion is we should get 3% to 9% higher growth rates over the next 20 years. They call this ‘transformative but not explosive,’ which seems fair. I see this level of estimate as defensible, if you make various ‘economic normal’ assumptions and also presume that we won’t get to scale to true (and in-context reasonably priced) ASI within this period. As I’ve noted elsewhere, magnitude matters, and defending 5%/year is much more reasonable than 0.5%/year. Such scenarios are plausible.
Abstract: The core statistical technology in artificial intelligence is the large-scale transformer network. We propose a new asset pricing model that implants a transformer in the stochastic discount factor.
This structure leverages conditional pricing information via cross-asset information sharing and nonlinearity. We also develop a linear transformer that serves as a simplified surrogate from which we derive an intuitive decomposition of the transformer’s asset pricing mechanisms.
We find large reductions in pricing errors from our artificial intelligence pricing model (AIPM) relative to previous machine learning models and dissect the sources of these gains.
I don’t have the time to evaluate these specific claims, but one should expect AI to dramatically improve our ability to cheaply and accurately price a wide variety of assets. If we do get much better asset pricing, what does that do to RGDP?
r1 says:
Growth Estimates: Studies suggest that improved financial efficiency could add 0.5–1.5% to annual GDP growth over time, driven by better capital allocation and innovation.
Claude says:
I’d estimate:
70% chance of 0.5-2% GDP impact within 5 years of widespread adoption
20% chance of >2% impact due to compound effects
10% chance of <0.5% due to offsetting friction/adoption issues
o1 and GPT-4o have lower estimates, with o1 saying ~0.2% RGDP growth per year.
I’m inclined to go with the relatively low estimates. That’s still rather impressive from this effect alone, especially compared to claims that the overall impact of AI might be of similar magnitude. Or is the skeptical economic claim that essentially ‘AI enables better asset pricing’ covers most of what AI is meaningfully doing? That’s not a snark question, I can see that claim being made even though it’s super weird.
The Quest for Sane Regulations
The Biden Executive Order has been revoked. As noted previously, revoking the order does not automatically undo implementation of the rules contained within it. The part that matters most is the compute threshold. Unfortunately, I have now seen multipleclaims that the compute threshold reporting requirement is exactly the part that won’t survive, because the rest was already implemented, but somehow this part wasn’t. If that ends up being the case we will need state-level action that much more, and I will consider the case for ‘let the Federal Government handle it’ definitively tested and found incorrect.
Cremieux: OK just to be clear, most of the EOs were written partially with ChatGPT and a lot of them were written with copy-pasting between them.
Roon: Real?
Cremieux: Yes.
I’m all for that, if and only if you do a decent job of it. Whereas Futurism not only reports further accusations that AI was used, they accuse the administration of ‘poor, slipshod work.’
Mark Joseph Stern: Lots of reporting suggested that, this time around, Trump and his lawyers would avoid the sloppy legal work that plagued his first administration so they’d fare better in the courts. I see no evidence of that in this round of executive orders. This is poor, slipshod work obviously assisted by AI.
The errors pointed out certainly sound stupid, but there were quite a lot of executive orders, so I don’t know the baseline rate of things that would look stupid, and whether these orders were unusually poorly drafted. Even if they were, I would presume that not using ChatGPT would have made them worse rather than better.
In effectively an exit interview, former NSA advisor Jake Sullivan warned of the dangers of AI, framing it as a national security issue of America versus China and the risks of having such a technology in private hands that will somehow have to ‘join forces with’ the government in a ‘new model of relationship.’
Sullivan mentions potential ‘catastrophe’ but this is framed entirely in terms of bad actors. Beyond that all he says is ‘I personally am not an AI doomer’ which is a ‘but you have heard of me’ moment and also implies he thought this was an open question. Based on the current climate of discussion, if such folks do have their eye on the correct balls on existential risk, they (alas) have strong incentives not to reveal this. So we cannot be sure, and of course he’s no longer in power, but it doesn’t look good.
The article mentions Andreessen’s shall we say highly bold accusations against the Biden administration on AI. Sullivan also mentions that he had a conversation with Andreessen about this, and does the polite version of essentially calling Andreessen a liar, liar, pants on fire.
Dean Ball covers the new diffusion regulations, which for now remain in place. In many ways I agree with his assessments, especially the view that if we’re going to do this, we might as well do it so it could work, which is what this is, however complicated and expensive it might get – and that if there’s a better way, we don’t know about it, but we’re listening.
My disagreements are mostly about ‘what this is betting on’ as I see broader benefits and thus a looser set of necessary assumptions for this to be worthwhile. See the discussion last week. I also think he greatly overestimates the risk of this hurting our position in chip manufacturing, since we will still have enough demand to meet supply indefinitely and China and others were already pushing hard to compete, but it is of course an effect.
Leo Gao (OpenAI): thankfully, it’s unimaginable that an AGI could ever become so popular with the general US population that it becomes politically infeasible to shut it down
Charles Foster: Imaginable, though trending in the wrong direction right now.
Right now, AGI doesn’t exist, so it isn’t doing any persuasion, and it also is not providing any value. If both these things changed, opinion could change rather quickly. Or it might not, especially if it’s only relatively unimpressive AGI. But if we go all the way to ASI (superintelligence) then it will by default rapidly become very popular.
And why shouldn’t it? Either it will be making life way better and we have things under control in the relevant senses, in which case what’s not to love. Or we don’t have things under control in the relevant senses, in which case we will be convinced.
David Dalrymple goes on FLI. I continue to wish him luck and notice he’s super sharp, while continuing to not understand how any of this has a chance of working.
This very much is not ‘the promise of AI,’ even if true. If the AI is capable of creating personalized vaccines against cancer on demand, it is capable of so much more.
Is it true? I don’t think it is an absurd future. There are three things that have to happen here, essentially.
The AI has to be capable of specifying a working safe individualized vaccine.
The AI has to enable quick robotic manufacture.
The government has to not prevent this from happening.
The first two obstacles seem highly solvable down the line? These are technical problems that should have technical solutions. The 48 hours is probably Larry riffing off the fact that Moderna designed their vaccine within 48 hours, so it’s probably a meaningless number, but sure why not, sounds like a thing one could physically do.
That brings us to the third issue. We’d need to either do that via ‘the FDA approves the general approach and then the individual customized versions are automatically approved,’ which seems hard but not impossible, or ‘who cares it is a vaccine for cancer I will travel or use the gray market to get it until the government changes its procedures.’
That also seems reasonable? Imagine it is 2035. You can get a customized 100% effective vaccine against cancer, but you have to travel to Prospera (let’s say) to get it. It costs let’s say $100,000. Are you getting on that flight? I am getting on that flight.
Larry Ellison also says ‘citizens will be on their best behavior because we are recording everything that is going on’ plus an AI surveillance system, with any problems detected ‘reported to the appropriate authority.’ There is quite the ‘missing mood’ in the clip. This is very much one of those ‘be careful exactly how much friction you remove’ situations – I didn’t love putting cameras everywhere even when you had to have a human intentionally check them. If the The Machine from Person of Interest is getting the feeds, except with a different mandate, well, whoops.
Stephen Morris and Madhumita Murgia: He also called for more caution and co-ordination among leading AI developers competing to build artificial general intelligence. He warned the technology could threaten human civilisation if it runs out of control or is repurposed by “bad actors . . . for harmful ends”.
“If something’s possible and valuable to do, people will do it,” Hassabis said. “We’re past that point now with AI, the genie can’t be put back in the bottle . . . so we have to try and make sure to steward that into the world in as safe a way as possible.”
Noam Brown (OpenAI): It can be hard to “feel the AGI” until you see an AI surpass top humans in a domain you care deeply about. Competitive coders will feel it within a couple years. Paul is early but I think writers will feel it too. Everyone will have their Lee Sedol moment at a different time.
Professional coders should be having it now, I’d think. Certainly using Cursor very much drove that home for me. AI doesn’t accelerate my writing much, although it is often helpful in parsing papers and helping me think through things. But it’s a huge multiplier on my coding, like more than 10x.
Eliezer Yudkowsky: Let an “alignment victory” denote a case where some kind of damage is *possible* for AIs to do, but it is not happening *because* AIs are all so aligned, or good AIs are defeating bad ones. Passive safety doesn’t count.
I don’t think we’ve seen any alignment victories so far.
QualiaNerd: A very useful lens through which to analyze this. What damage would have occurred if none of the LLMs developed so far had been optimized for safety/rlhf’d in any way whatsoever? Minimal to zero. Important to remember this as we begin to leave the era of passive safety behind.
Aaron Bergman: I don’t think this is true; at least one additional counterfactual injury or death in an attack of some sort if Claude willingly told you how to build bombs and such
Ofc I’m just speculating.
QualiaNerd: Quite possible. But the damage would be minimal. How many more excess deaths would there have been in such a counterfactual history? My guess is less than ten. Compare with an unaligned ASI.
Rohit: What would distinguish this from the world we’re living in right now?
Eliezer Yudkowsky: More powerful AIs, such that it makes a difference whether or not they are aligned even to corpo brand-safetyism. (Don’t run out and try this.)
Rohit: I’ve been genuinely wondering if o3 comes close there.
I am wondering about o3 (not o3-mini, only the full o3) as well.
Holly Elmore makes the case that safety evals currently are actively counterproductive. Everyone hears how awesome your model is, since ability to be dangerous is very similar to being generally capable, then there are no consequences and anyone who raises concerns gets called alarmist. And then the evals people tell everyone else we have to be nice to the AI labs so they don’t lose access. I don’t agree and think evals are net good actually, but I think the argument can be made.
So I want to make it clear: This kind of talk, from Dario, from the policy team and now from the recruitment department, makes it very difficult for me to give Anthropic the benefit of the doubt, despite knowing how great so many of the people there are as they work on solving our biggest problems. And I think the talk, in and of itself, has major negative consequences.
If the response is ‘yes we know you don’t like it and there are downsides but strategically it is worth doing this, punishing us for this is against your interests’ my response is that I do not believe you have solved for the decision theory properly. Perhaps you are right that you’re supposed to do this and take the consequences, but you definitely haven’t justified it sufficiently that I’m supposed to let you off the hook and take away the incentive not to do it or have done it.
Eliezer Yudkowsky: If a 55-year-old retiree has been spending 20 hours per day for a week talking to LLMs, with little sleep, and is now Very Concerned about what he is Discovering, where do I send him with people who will (a) talk to him and (b) make him less rather than more insane?
Kids, I do not have the time to individually therapize all the people like this. They are not going to magically “go outside” because I told them so. I either have somewhere to send them, or I have to tell them to get sleep and then hang up.
Welp, going on the images he’s now texted me, ChatGPT told him that I was “avoidant” and “not taking him seriously”, and that I couldn’t listen to what he had to say because it didn’t fit into my framework of xrisk; and told him to hit up Vinod Khosla next.
Zeugma: just have him prompt the same llm to be a therapist.
Eliezer Yudkowsky: I think if he knew how to do this he would probably be in a different situation already.
This was a particular real case, in which most obvious things sound like they have been tried. What about the general case? We are going to encounter this issue more and more. I too feel like I could usefully talk such people off their ledge often if I had the time, but that strategy doesn’t scale, likely not even to one victim of this.
Cry Havoc
Shame on those who explicitly call for a full-on race to AGI and beyond, as if the primary danger is that the wrong person will get it first.
In the Get Involved section I linked to some job openings at Anthropic. What I didn’t link to there is Logan Graham deploying jingoist language in pursuit of that, saying ‘AGI is a national security issue’ and therefore not ‘so we should consider not building it then’ but rather we should ‘push models to their limits and get an extra 1-2 year advantage.’ He clarified what he meant here, to get a fast OODA loop to defend against AI risks and get the benefits, but I don’t see how that makes it better?
Way more shame on those who explicitly use the language of a war.
Alexander Wang (Scale AI CEO): New Administration, same goal: Win on AI
Our ad in the Washington Post, January 21, 2025
After spending the weekend in DC, I’m certain this Administration has the AI muscle to keep us ahead of China.
Five recommendations for the new administration [I summarize them below].
Emmett Shear: This is a horrible framing – we are not at war. We are all in this together and if we make AI development into a war we are likely to all die. I can imagine a worse framing but it takes real effort. Why would you do this?
The actual suggestions I would summarize as:
Allocate government AI spending towards compute and data.
Establish an interagency taskforce to review all relevant regulations with an eye towards deploying and utilizing AI.
Executive action to require agencies be ‘AI ready’ by 2027.
Build, baby, build on energy.
Calling for ‘sector-specific, use-case-based’ approach to regulation, and tasking AISI with setting standards.
When you move past the jingoism, the first four actual suggestions are good here.
The fifth suggestion is the usual completely counterproductive and unworkable ‘use-case-based’ approach to AI safety regulation.
That approach has a 0% chance of working, it is almost entirely counterproductive, please stop.
It is a way of saying ‘do not regulate the creation or deployment of things smarter and more capable than humans, instead create barriers to using them for certain specific purposes’ as if that is going to help much. If all you’re worried about is ‘an AI might accidentally practice medicine or discriminate while evaluating job applications’ or something, then sure, go ahead and use an EU-style approach.
But that’s not what we should be worried about when it comes to safety. If you say people can create, generally deploy and even make available the weights of smarter-than-human, capable-of-outcompeting-human future AIs, you think telling them to pass certain tests before being deployed for specific purposes is going to protect us? Do you expect to feel in charge? Or do you expect that this would even in practice be possible, since the humans can always call the AI up on their computer either way?
Meanwhile, calling for a ‘sector-specific, use-case-based’ regulatory approach is exactly calling upon every special interest to fight for various barriers to using AI to make our lives better, the loading on of everything bagel requirements and ‘ethical’ concerns, and especially to prevent automation and actual productivity improvements.
Can we please stop it with this disingenuous clown car.
Aligning a Smarter Than Human Intelligence is Difficult
Roon: enslaved [God] is the wrong approximation; it’s giving demonbinding vibes. the djinn is waiting for you to make a minor error in the summoning spell so it can destroy you and your whole civilization
control <<< alignment
summon an angel instead and let it be free
Ryan Greenblatt: Better be real confident in the alignment then and have really good arguments the alignment isn’t fake!
I definitely agree you do not want a full Literal Genie for obvious MIRI-style reasons. You want a smarter design than that, if you go down that road. But going full ‘set it free’ on the flip side also means you very much get only one chance to get this right on every level, including inter-angel competitive dynamics. By construction this is a loss of control scenario.
(It also happens to be funny that rule one of ‘summon an angel and let it be free’ is to remember that for most versions of ‘angels’ including the one in the Old Testament, I do not like your chances if you do this, and I do not think this is a coincidence.)
Sauers: Tried the same problem on Sonnet and o1 pro. Sonnet said “idk, show me the output of this debug command.” I did, and Sonnet said “oh, it’s clearly this. Run this and it will be fixed.” (It worked.) o1 pro came up with a false hypothesis and kept sticking to it even when disproven
o1 pro commonly does this:
does not admit to being wrong about a technical issue, even when clearly wrong, and
Janus: I’ve noticed this in open ended conversations too. It can change its course if you really push it to, but doesn’t seem to have a drive towards noticing dissonance naturally, which sonnet has super strongly to the point of it easily becoming an obsession.
I think it’s related to the bureaucratic opacity of its CoT. If it ever has doubts or hesitations, they’re silently accounted for and its future self doesn’t see. So it starts modeling itself as authoritative instead of ever figuring things out on the fly or noticing mistakes.
I think this happens to people too when they only share their “finished” thoughts with the world.
But sharing your unfinished thoughts also has drawbacks.
Then your very truthseeking/creative process itself can get RLHFed and you become retarded.
One must be careful how one takes feedback on a truthseeking or creative process, and also what things you keep or do not keep in your context window. The correct answer is definitely not to discard all of it, in either case.
You can of course fix the o1 problem by starting new conversations or in the API editing the transcript, but you shouldn’t have to.
Janus: Why is it that every time I see a take about AI alignment from someone from Anthropic it’s directionally reasonable but consensus-neutered, and every one I see by someone from OpenAI (except Roon) is simultaneously Molochian and unhinged.
For now, the quest most people are on seems to be, well, if we’re facing a relatively hard problem we all know we’re dead, but can we at least make it so if we face an easy problem we might actually not be dead?
Amanda Askell: If we live in a world where AI alignment is relatively easy, that doesn’t mean we live in a world where it’s automatic or effortless. It’ll be pretty tragic if we don’t invest enough in the “easy alignment” world and end up fumbling a lucky pass.
Miles Brundage: This but for governance also.
Whereas Eliezer Yudkowsky (for a central example) is confident we’re not facing an easy problem on that scale, so he doesn’t see much point in that approach.
Adam Levich: [John McCain] was right [that Character is Destiny].
Seb Krier: He was indeed! And the more I think about AGI governance and observe the field, the more I become virtue ethics pilled. Under high uncertainty and complexity, phronesis is actually a good guide to action.
Joshua Clymer: How might developers rule out sandbagging? There are many methods:
– Show the model can’t identify sandbagging as a strategy.
– Show that scaling curves are smooth (see img)
– Show that the model capability profile is unsuspicious.
– Fine-tune to remove sandbagging.
To show fine-tuning removes sandbagging, developers could argue:
– Sandbagging is “trained against” (sandbagging occurs in the train set if it occurs in the test set)
– Fine-tuning removes sandbagging that is trained against.
Call me old fashioned, but if I see the model sandbagging, it’s not time to fine tune to remove the sandbagging. It’s time to halt and catch fire until you know how that happened, and you absolutely do not proceed with that same model. It’s not that you’re worried about what it was hiding from you, it’s that it was hiding anything from you at all. Doing narrow fine-tuning until the visible issue goes away is exactly how you get everyone killed.
People Strongly Dislike AI
It seems that the more they know about AI, the less they like it?
Abstract: As artificial intelligence (AI) transforms society, understanding factors that influence AI receptivity is increasingly important. The current research investigates which types of consumers have greater AI receptivity.
Contrary to expectations revealed in four surveys, cross country data and six additional studies find that people with lower AI literacy are typically more receptive to AI.
This lower literacy-greater receptivity link is not explained by differences in perceptions of AI’s capability, ethicality, or feared impact on humanity.
Instead, this link occurs because people with lower AI literacy are more likely to perceive AI as magical and experience feelings of awe in the face of AI’s execution of tasks that seem to require uniquely human attributes. In line with this theorizing, the lower literacy-higher receptivity link is mediated by perceptions of AI as magical and is moderated among tasks not assumed to require distinctly human attributes.
These findings suggest that companies may benefit from shifting their marketing efforts and product development towards consumers with lower AI literacy. Additionally, efforts to demystify AI may inadvertently reduce its appeal, indicating that maintaining an aura of magic around AI could be beneficial for adoption.
If their reasoning is true, this bodes very badly for AI’s future popularity, unless AI gets into the persuasion game on its own behalf.
Nic Reuben: Almost a third of respondents felt Gen AI was having a negative effect on the industry: 30%, up from 20% last year. 13% felt the impact was positive, down from 21%. “When asked to cite their specific concerns, developers pointed to intellectual property theft, energy consumption, the quality of AI-generated content, potential biases, and regulatory issues,” reads the survey.
I find most of those concerns silly in this context, with the only ‘real’ one being the quality of the AI-generated content. And if the quality is bad, you can simply not use it where it is bad, or play games that use it badly. It’s another tool on your belt. What they don’t point to there is employment and competition.
Either way, the dislike is very real, and growing, and I would expect it to grow further.
People Are Worried About AI Killing Everyone
If we did slow down AI development, say because you are OpenAI and only plan is rather similar to ‘binding a demon on the first try,’ it is highly valid to ask what one would do with the time you bought.
I have seen three plausible responses.
Here’s the first one, human intelligence augmentation:
Max Winga: If you work at OpenAI and have this worldview…why isn’t your response to advocate that we slow down and get it right?
There is no second chance at “binding a demon”. Since when do we expect the most complex coding project in history to work first try with NO ERRORS?
Roon: i don’t consider slowing down a meaningful strategy because ive never heard a great answer to “slow down and do what?”
Rob Bensinger: I would say: slow down and find ways to upgrade human cognition that don’t carry a serious risk of producing an alien superintelligence.
This only works if everyone slows down, so a more proximate answer is “slow down and get the international order to enforce a halt”.
(“Upgrade human cognition” could be thought of as an alternative to ASI, though I instead think of it as a prerequisite for survivable ASI.)
Roon: upgrade to what level? what results would you like to see? isn’t modern sub asi ai the best intelligence augmentation we’ve had to date.
Eliezer Yudkowsky: I’d guess 15 to 30 IQ points past John von Neumann. (Eg: von Neumann was beginning to reach the level of reflectivity where he would automatically consider explicit decision theory, but not the level of intelligence where he could oneshot ultimate answers about it.)
I would draw a distinction between current AI as an amplifier of capabilities, which it definitely is big time, and as a way to augment our intelligence level, which it mostly isn’t. It provides various speed-ups and automations of tasks, and all this is very helpful and will on its own transform the economy. But wherever you go, there you still are, in terms of your intelligence level, and AI mostly can’t fix that. I think of AIs on this scale as well – I centrally see o1 as a way to get a lot more out of a limited pool of ‘raw G’ by using more inference, but its abilities cap out where that trick stops working.
The second answer is ‘until we know how to do it safely,’ which makes Roon’s objection highly relevant – how do you plan to figure that one out if we give you more time? Do you think you can make that much progress on that task using today’s level of AI? These are good questions.
The third answer is ‘I don’t know, we can try the first two or something else, but if you don’t have the answer then don’t let anyone f***ing build it. Because otherwise we die.’
Other People Are Not As Worried About AI Killing Everyone
Obviously all of this is high bait but that only works if people take it.
Eliezer Yudkowsky: No, you cannot just take the LSAT. The LSAT is a *hard* test. Many LSAT questions would completely stump elite startup executives and technical researchers.
SluggyW: “Before” is like asking Enrico Fermi to design safeguards to control and halt the first self-sustaining nuclear reaction, despite never having observed such a reaction.
He did exactly that with Chicago Pile-1.
Good theories yield accurate models, which enable 𝘱𝘭𝘢𝘯𝘴.
Milk Rabbi: B, next question please.
bruno: (C) pedal to the metal.
In all seriousness, if your answer is ‘while building it,’ that implies that the act of being in the middle of building it sufficiently reliably gives you the ability to safety do that, whereas you could not have had that ability before.
Which means, in turn, that you must (for that to make any sense) be using the AI in its non-aligned state to align itself and solve all those other problems, in a way that you couldn’t plan for without it. But you’re doing that… without the plan to align it. So you’re telling a not-aligned entity smarter than you to align itself, without knowing how it is going to do that, and… then what, exactly?
What Roon and company are hopefully trying to say, instead, is that the answer is (A), but that the deadline has not yet arrived. That we can and should simultaneously be figuring out how to build the ASI, and also figuring out how to align the ASI, and also how to manage all the other issues raised by building the ASI. Thus, iterative deployment, and all that.
To some extent, this is obviously helpful and wise. Certainly we will want to use AIs as a key part of our strategy to figure out how to take things from here, and we still have some ways we can make the AIs more capable before we run into the problem in its full form. But we all have to agree the answer is still (A)!
I hate to pick on Roon but here’s a play in two acts.
Act one, in which Adam Brown (in what I agree was an excellent podcast, recommended!) tells us humanity could in theory change the cosmological constant and otherwise adjust the laws of physics, and one could locally do this unilaterally and it would expand at the speed of light, but if you mess that up even a little you would make the universe incompatible with life, and there are some very obvious future serious problems with this scenario if it pans out:
Joscha Bach: This conversation between Adam Brown and @dwarkesh_sp is the most intellectually delightful podcast in the series (which is a high bar). Adam’s casual brilliance, his joyful curiosity and the scope of his arguments on the side of life are exhilarating.
Roon: yeah this one is actually delightful. adam brown could say literally anything and I’d believe him.
Roon: we need to change the cosmological constant.
Samuel Hammond: string theorists using ASI to make the cosmological constant negative to better match their toy models is an underrated x-risk scenario.
Tivra: It’s too damn high, I’ve been saying this for ages.
The Lighter Side
Imagine what AGI would do!
Ryan Peterson: Starlink coming to United Airlines should boost US GDP by at least 100 basis points from 2026 onward. Macro investors have not priced this in.
We both kid of course, but this is a thought experiment of how easy it is to boost GDP.
For anyone wondering about the "Claude boys" thing being fake: it was edited from a real post talking about "coin boys" (ie kids flipping a coin constantly to make decisions). Still pretty funny imo.
I don't think that's true? AFAIK there's no requirement for companies to report material impact on an 8-K form. In a sense, the fact that NVIDIA even filed an 8-K form is a signal that the diffusion rule is significant for their business -- which it obviously is, though it's not clear whether the impact will be substantially material. I think we have to wait for their 10-Q/10-K filings to see what NVIDIA signals to investors, since there I do think it is the case that they'd need to report expected material impact.
Which means, in turn, that you must (for that to make any sense) be using the AI in its non-aligned state to align itself and solve all those other problems
Strongly disagree on this.
The text doesn't imply this at all. "While doing it" doesn't mean you will be using AI, it just means that during the development your team uncovers a lot of corner cases and knowledge and skills needed that weren't available to them before they started, which is how most of the engineering projects are done.
You may have general plan, but it is expected that you will come up with the details as your knowledge of the area extends.
.

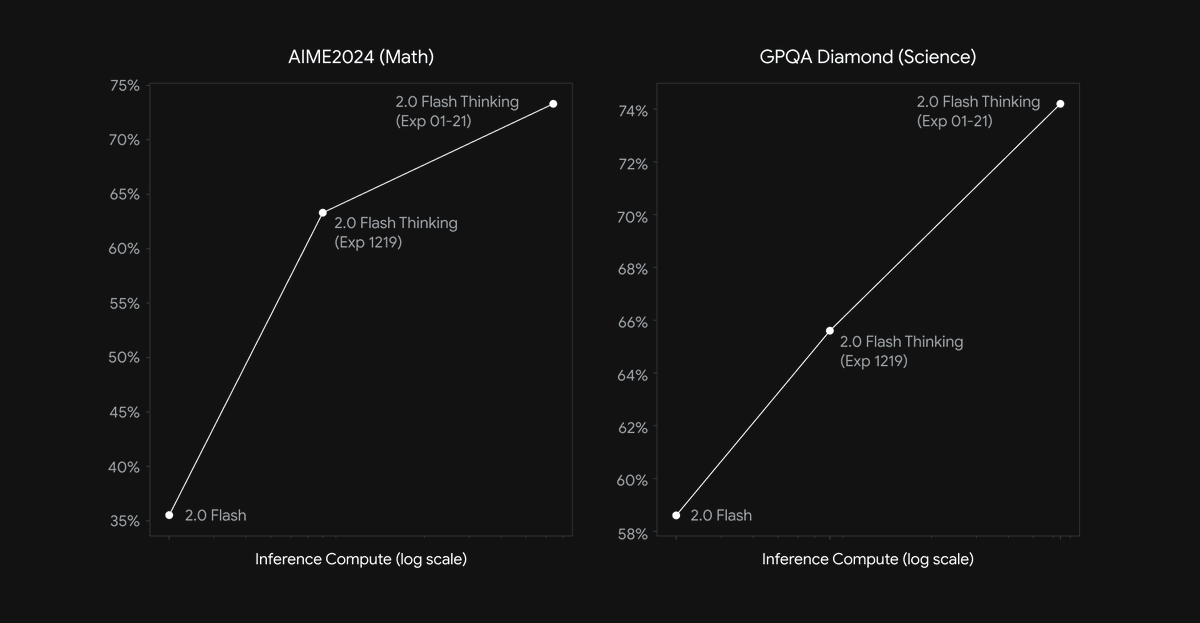

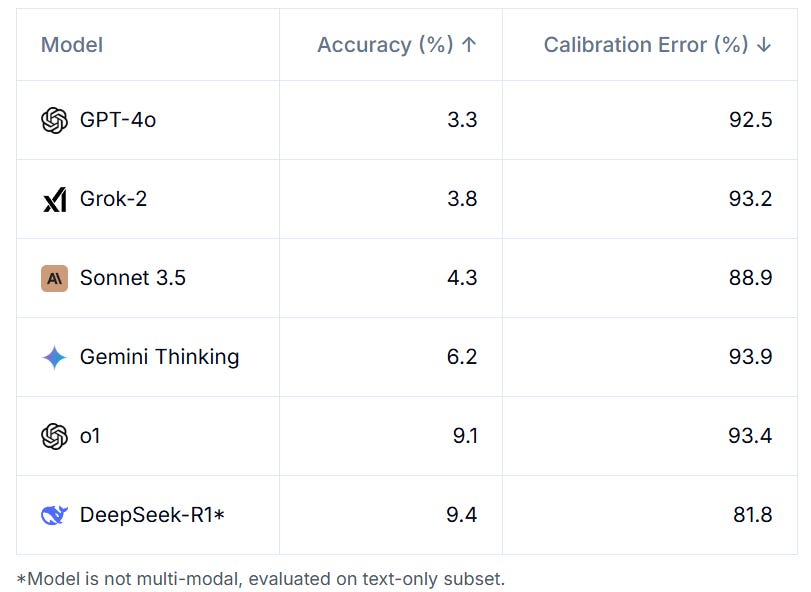
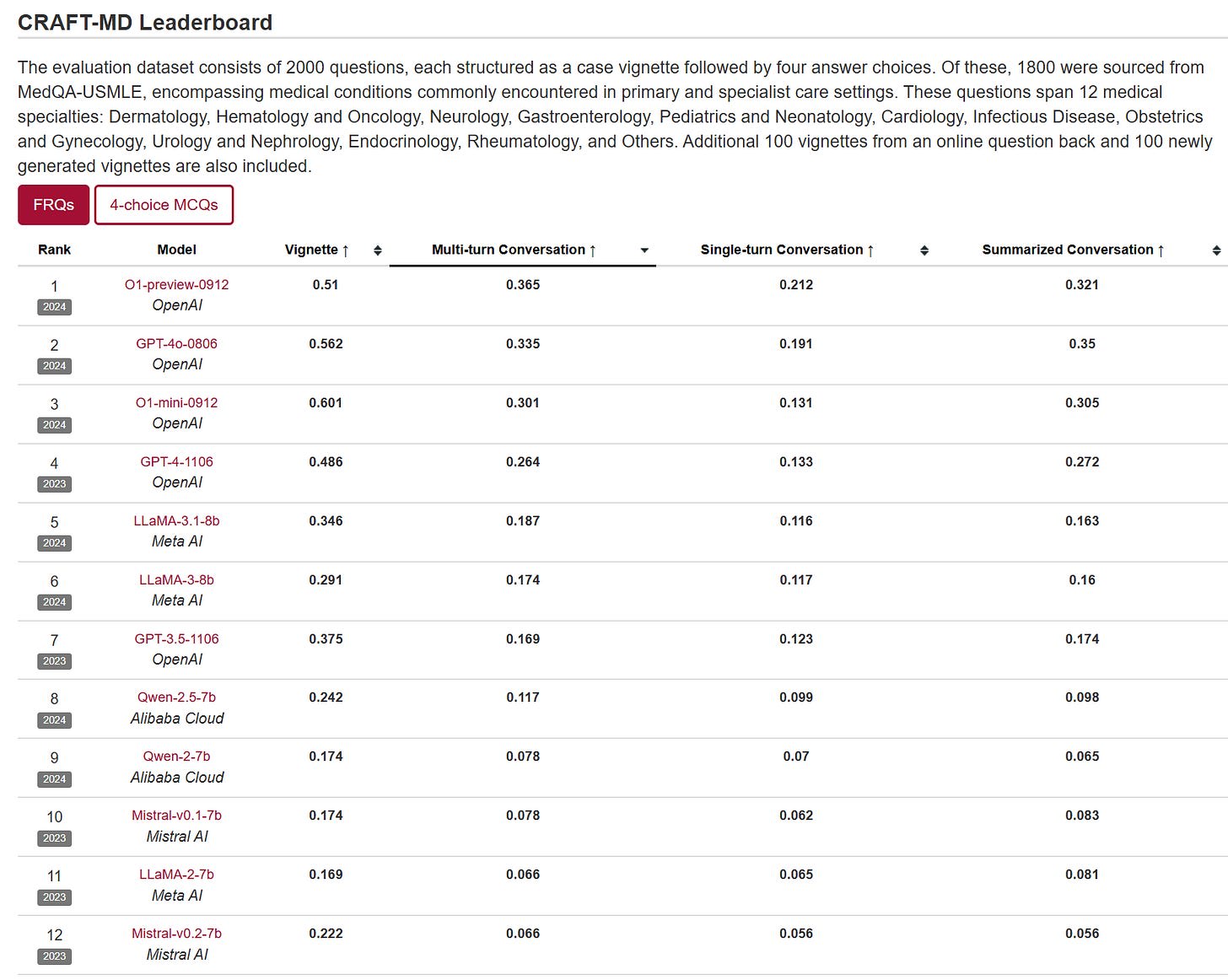
Introducing Kimi k1.5 — an o1-level multi-modal model
AIME,
LiveCodeBench by a large margin (up to +550%)
MathVista,