Human takeover might be worse than AI takeover
post by Tom Davidson (tom-davidson-1) · 2025-01-10T16:53:27.043Z · LW · GW · 55 commentsContents
Summary AGI is nicer than humans in expectation Conditioning on AI actually seizing power Conditioning on the human actually seizing power Other considerations None 55 comments
Epistemic status -- sharing rough notes on an important topic because I don't think I'll have a chance to clean them up soon.
Summary
Suppose a human used AI to take over the world. Would this be worse than AI taking over? I think plausibly:
- In expectation, human-level AI will better live up to human moral standards than a randomly selected human. Because:
- Humans fall far short of our moral standards.
- Current models are much more nice, patient, honest and selfless than humans.
- Though human-level AI will have much more agentic training for economic output, and a smaller fraction of HHH training, which could make them less nice.
- Humans are "rewarded" for immoral behaviour more than AIs will be
- Humans evolved under conditions where selfishness and cruelty often paid high dividends, so evolution often "rewarded" such behaviour. And similarly, during lifetime learning we often get benefit from immoral behaviour.
- But we'll craft the training data for AIs to avoid this, and can much more easily monitor their actions and even their thinking. Of course, this may be hard to do for superhuman AI but bootstrapping could work.
- Conditioning on takeover happening makes the situation much worse for AI, as it suggests our alignment techniques completely failed. This mostly tells us we failed to instill deontological norms like not lying and corrigibility, but it's also evidence we failed to instil our desired values. There's a chance AI has very alien values and would do nothing of value; this is less likely for a human.
- Conditioning on takeover also makes things much worse for the human. There's massive variance in how kind humans are, and those willing to take over are likely dark triad. Humans may be vengeful or sadistic, which seems less likely for AI.
- AI will be more competent, so better handle tricky dynamics like simulations, acausal trade, VWH, threats. Though a human who followed AI advice could handle these too.
AGI is nicer than humans in expectation
- Humans suck. We really don’t come close to living up to our moral standards.
- By contrast, today’s AIs are really nice and ethical. They’re humble, open-minded, cooperative, kind. Yes, they care about some things that could give them instrumental reasons to seek power (eg being helpful, human welfare), but their values are great
- The above is no coincidence. It falls right out of the training data.
- Humans were rewarded by evolution for being selfish whenever they could get away with it. So humans have a strong instinct to do that.
- Humans are rewarded by within-lifetime learning for being selfish. (Culture does increasingly well to punish this, and people have got nicer. But people still have many (more subtle) bad and selfish behaviours reinforced during their lifetimes)
- But AIs are only ever rewarded for being nice and helpful. We don’t reward them for selfishness. As AIs become super-human there’s a risk we do increasingly reward them for tricking us into thinking they’ve done a better job than they have; but we’ll be way more able to constantly monitor them during training and exclusively reward good behaviour than evolution. Evolution wasn’t even trying to reward only good behaviour! Lifetime learning is a more tricky comparison. Society does try to monitor people and only reward good behaviour, but we can’t see people’s thoughts and can’t constantly monitor their behaviour: so AI training will do a much better job and making AIs nice than humans!
- What’s more, we’ll just spend loads of time rewarding AIs for being ethical and open minded and kind. Even if we sometimes reward them for bad behaviour, the quantity of reward for good behaviour is something unmatched in humans (evolution or lifetime).
- Note: this doesn’t mean AIs won’t seek power. Humans seek power a lot! And especially when AIs are super-human, it may be very easy for them to get power.
- So human live up to human moral standards less well than AIs today, and we can see why that is with reference to the training data, and that trend looks set to continue (though there’s a big question mark over how much we’ll unintentionally reward selfish superhuman AI behaviour during training)
Conditioning on AI actually seizing power
- Ok, that feeds into my prior for how ethical or unethical i expect humans vs AIs to be. I expect AIs to be way better! But, crucially, we need to condition on takeover. I’m not comparing the average human to the average AI. I’m comparing the average human-that-would-actually-seize-power to the average AI-that-would-seize-power. That could make a difference.
- And i think it does make a difference. Directionally, I think it pushes towards being more concerned about AIs. Why is that?
- We know a fair bit about human values. While I think humans are not great on average, we know about the spread of human values. We know most humans like the normal human things like happiness, games, love, pleasure, friendships. (Though some humans want awful things as well.) This, maybe, means the variance of human values isn’t that big. We can imagine have some credence over how nice a randomly selected person will be, represented by a probability distribution, and maybe the variance of the distribution is narrow.
- By contrast, we know a lot less about what AGIs values will be. Like I said above, I expect them to be better (by human standards) than an average humans values. But there’s truly massive uncertainty here. Maybe LWers will be right and AIs will care about some alien stuff that seems totally wacky to humans. We could represent this with a higher variance over our credence over AGI’s values.
- When we condition on AI or human takeover, we’re conditioning on the AI/human having much worse values than our mean expectation. Even if AIs have better values in expectation, it might be that after conditioning on this they have worse values (bc of the bigger variance – see graph).
- I’ve placed a red line to represent ‘how bad’ your values would need to be to seize power. The way i’m done it, an AGI that seized power would use the cosmic endowment less well in expectation than that a human who seized power
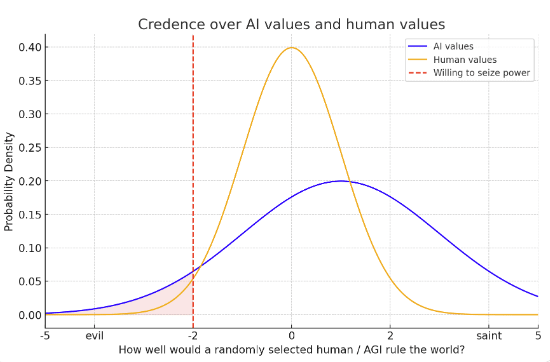
- Actually, this ‘red line’ is not quite the right way to think about it. Whether you seize power depends more on your deontological drive to “cooperate and respect property rights and the law and freedom”, and only somewhat on your long-term goals. All consequentialists want to take over! So whether you take over is more a question of corrigibility vs consequentialism than a question of “how good are your consequentialist values?”
- So when we condition on AI takeover, we’re primarily conditioning on the ‘corrigible’ part of training to have failed. That probably implies the “give the AI good values” part of training may have also gone less well, but it seems possible that there are challenges to corrigibility that don’t apply to giving AI good values (e.g. the MIRI-esque “corrigibility is unnatural”).
- So AIs taking over is only a moderate update towards them having worse values, even though its a strong update against corrigibility/cooperativeness!
Conditioning on the human actually seizing power
- But there are some further reasons to think human coups could be especially bad
- Human variance is high. Humans vary massively in how moral they are. And i think it’s a pretty self-obsessed dark-triad kind of person that might ultimately seize power for themselves and a small group in a DSA. So the human left-tail could be pretty long, and the selection effect for taking over could be very strong. Humans in power have done terrible things.
- However, humans (e.g. dark triad) are often bad people for instrumental reasons. But if you’re already world leader and have amazing tech + abundance, there’s less instrumental reason to mess others around. This pushes towards the long-run outcome of a human coup being better than you might think by eye-balling how deeply selfish and narcissistic the person doing the coup is.
- Humans more likely to be evil. Humans are more likely to do literally evil things due to sadism or revenge. S-risk stuff. If AI has alien values it wouldn't do this, and we'll try to avoid actively incentivising these traits in AI training.
- Human variance is high. Humans vary massively in how moral they are. And i think it’s a pretty self-obsessed dark-triad kind of person that might ultimately seize power for themselves and a small group in a DSA. So the human left-tail could be pretty long, and the selection effect for taking over could be very strong. Humans in power have done terrible things.
Other considerations
- Humans less competent. Humans are also more likely to do massively dumb (and harmful) things – think messing up commitment games, threats, simulations, and VHW stuff. I expect AGIs who seize power would have to be extremely smart and would avoid dumb and hugely costly errors. I think this is a very big deal. It’s well known in politics that having competent leaders is often more important than having good values.
- Some humans may not care about human extinction per se.
- Alien AI values? I also just don’t buy that AIs will care about alien stuff. The world carves naturally into high-level concepts that both humans and AIs latch onto. I think that’s obvious on reflection, and is supported by ML evidence. So I expect AGIs will care about human-understandable stuff. And humans will be trying hard to make that stuff that’s good by human lights, and I think we’ll largely succeed. Yes, AGIs may reward seek and they may extrapolate their goals to the long-term and seek power. But I think they’ll be pursuing human-recognisable and broadly good-by-human-lights goals.
- There’s some uncertainty here due to ‘big ontological shifts’. Humans 1000 years ago might have said God was good, nothing else (though really they loved friendships and stories and games and food as well). Those morals didn’t survive scientific and intellectual progress. So maybe AIs values will be alien to us due to similar shifts?
- I think this point is over-egged personally, and that humans need to reckon with shifts either way.
- Extrapolating HHH training is overly optimistic
- I’ve based some of the above on extrapolating from today’s AI systems, where RLHF focuses predominantly on giving AIs personalities that are HHH(helpful, harmless and honest) and generally good by human (liberal western!) moral standards. To the extent these systems have goals and drives, they seem to be pretty good ones. That falls out of the fine-tuning (RLHF) data.
- But future systems will probably be different. Internet data is running out, and so a very large fraction of agentic training data for future systems may involve completing tasks in automated environments (e.g. playing games, SWE tasks, AI R&D tasks) with automated reward signals. The reward here will pick out drives that make AIs productive, smart and successful, not just drives that make them HHH.
- Examples drives:
- having a clear plan for making progress
- Making a good amount of progress minute by minute
- Making good use of resources
- Writing well organised code
- Keeping track of whether the project is one track to succeed
- Avoiding doing anything that isn’t strictly necessary for the task at hand
- A keen desire to solve tricky and important problems
- An aversion to the time shown on the clock implying that the task is not on track to finish.
- These drives/goals look less promising if AIs take over. They look more at risk of leading to AIs that would use the future to do something mostly without any value from a human perspective.
- Even if these models are fine-tuned with HHH-style RLHF at the end, the vast majority of fine-tuning will be from automated environments. So we might expect most AI drives to come from such environments (though the order of fine-tuning might help to make AIs more HHH despite the data disparity – unclear!).
- We’re still talking about a case where AIs have some HHH fine-tuning, and so we’d expect them to care somewhat about HHH stuff, and wouldn’t particularly expect them to have selfish/immoral drives (unless they are accidentally reinforced during training due to a bad reward signal). So these AIs may waste large parts of the future, but I’d expect them to have a variety of goals/drives and still create large amounts of value by human lights.
- Interestingly, the fraction of fine-tuning that is HHH vs “amoral automated feedback from virtual environments” will probably vary by the industry in which the AI is deployed. AIs working in counselling, caring, education, sales, and interacting with humans will probably be fine-tuned on loads of HHH-style stuff that makes them kind, but AIs that don’t directly provide goods/services to humans (e.g. consulting, manufacturing, R&D, logistics, engineering, IT, transportation, construction) might only have a little HHH fine-tuning.
- Another interesting takeaway here is that we could influence the fine-tuning data that models get to make them more reinforcing of HHH drives. I.e. rather than having a AI SWE trained on solo-tasks in a virtual environment and evaluated with a purely automated signal for task-success, have is trained in a virtual company where it interacts with colleagues and customers and has its trajectories occasionally evaluated with process-based-feedback for whether it was HHH. Seems like this would make the SWE engineer more likely to have HHH drives, less likely to try to takeover, and more likely to create a good future if it did take over. This seems like a good idea!
- Overall, i’m honestly leaning towards preferring AI even conditional on takeover.
55 comments
Comments sorted by top scores.
comment by Eric Neyman (UnexpectedValues) · 2025-01-11T00:10:05.427Z · LW(p) · GW(p)
Thanks for writing this. I think this topic is generally a blind spot for LessWrong users, and it's kind of embarrassing how little thought this community (myself included) has given to the question of whether a typical future with human control over AI is good.
(This actually slightly broadens the question, compared to yours. Because you talk about "a human" taking over the world with AGI, and make guesses about the personality of such a human after conditioning on them deciding to do that. But I'm not even confident that AGI-enabled control of the world by e.g. the US government would be good.)
Concretely, I think that a common perspective people take is: "What would it take for the future to go really really well, by my lights", and the answer to that question probably involves human control of AGI. But that's not really the action-relevant question. The action-relevant question, for deciding whether you want to try to solve alignment, is how the average world with human-controlled AGI compares to the average AGI-controlled world. And... I don't know, in part for the reasons you suggest.
Replies from: daniel-kokotajlo, RavenclawPrefect↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-12T20:56:20.283Z · LW(p) · GW(p)
Thanks for writing this. I think this topic is generally a blind spot for LessWrong users, and it's kind of embarrassing how little thought this community (myself included) has given to the question of whether a typical future with human control over AI is good.
I don't think it's embarrassing or a blind spot. I think I agree that it should receive more thought on the margin, and I of course agree that it should receive more thought all things considered. There's a lot to think about! You may be underestimating how much thought has been devoted to this so far. E.g. it was a common topic of discussion at the center on long-term-risk while I was there. And it's not like LW didn't consider the question until now; my recollection is that various of us considered it & concluded that yeah probably human takeover is better than AI takeover in expectation for the reasons discussed in this post.
Side note: The title of this post is "Human Takeover Might Be Worse than AI Takeover" but people seem to be reading it as "Human Takeover Will Be Worse In Expectation than AI Takeover" and when I actually read the text I come away thinking "OK yeah, these arguments make me think that human takeover will be better in expectation than AI takeover, but with some significant uncertainty."
↑ comment by Drake Thomas (RavenclawPrefect) · 2025-01-12T06:28:59.260Z · LW(p) · GW(p)
The action-relevant question, for deciding whether you want to try to solve alignment, is how the average world with human-controlled AGI compares to the average AGI-controlled world.
To nitpick a little, it's more like "the average world where we just barely didn't solve alignment, versus the average world where we just barely did" (to the extent making things binary in this way is sensible), which I think does affect the calculus a little - marginal AGI-controlled worlds are more likely to have AIs which maintain some human values.
(Though one might be able to work on alignment in order to improve the quality of AGI-controlled worlds from worse to better ones, which mitigates this effect.)
Replies from: GAA↑ comment by Guive (GAA) · 2025-01-13T00:11:47.395Z · LW(p) · GW(p)
See also: "Which World Gets Saved"
comment by evhub · 2025-01-12T02:34:58.015Z · LW(p) · GW(p)
I think this is correct in alignment-is-easy worlds but incorrect in alignment-is-hard worlds (corresponding to "optimistic scenarios" and "pessimistic scenarios" in Anthropic's Core Views on AI Safety). Logic like this is a large part of why I think there's still substantial existential risk even in alignment-is-easy worlds, especially if we fail to identify that we're in an alignment-is-easy world. My current guess is that if we were to stay exclusively in the pre-training + small amounts of RLHF/CAI paradigm, that would constitute a sufficiently easy world [? · GW] that this view would be correct, but in fact I don't expect us to stay in that paradigm, and I think other paradigms involving substantially more outcome-based RL (e.g. as was used in OpenAI o1) are likely to be much harder, making this view no longer correct.
Replies from: Tom Davidson, sharmake-farah↑ comment by Tom Davidson · 2025-01-12T15:13:00.521Z · LW(p) · GW(p)
I agree the easy vs hard worlds influence the chance of AI taking over.
But are you also claiming it influences the badness of takeover conditional on it happening? (That's the subject of my post)
Replies from: evhub↑ comment by Noosphere89 (sharmake-farah) · 2025-01-12T05:30:51.712Z · LW(p) · GW(p)
I agree that things would be harder, mostly because of the potential for sudden capabilities breakthroughs if you have RL, combined with incentives to use automated rewards more, but I don't think it's so much harder that the post is incorrect, and my basic reason is I believe the central alignment insights like data mattering a lot more than inductive bias for alignment purposes still remain true in the RL regime, so we can control values by controlling data.
Also, depending on your values, AI extinction can be preferable to some humans taking over if they are willing to impose severe suffering on you, which can definitely happen if humans align AGI/ASI.
Replies from: bronson-schoen↑ comment by Bronson Schoen (bronson-schoen) · 2025-01-12T10:59:30.197Z · LW(p) · GW(p)
so we can control values by controlling data.
What do you mean? As in you would filter specific data from the posttraining step? What would you be trying to prevent the model from learning specifically?
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2025-01-12T15:35:49.243Z · LW(p) · GW(p)
I was thinking of adding synthetic data about our values in the pretraining step.
Replies from: bronson-schoen↑ comment by Bronson Schoen (bronson-schoen) · 2025-01-13T23:49:06.936Z · LW(p) · GW(p)
Is anyone doing this?
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2025-01-13T23:58:20.749Z · LW(p) · GW(p)
Maybe, but not at any large scale, though I get why someone might not want to do it, because it'd probably be costly to do this as an intentional effort to stably make an AI aligned (unless synthetic data automation more or less works.)
comment by Vaniver · 2025-01-11T06:04:51.634Z · LW(p) · GW(p)
By contrast, today’s AIs are really nice and ethical. They’re humble, open-minded, cooperative, kind. Yes, they care about some things that could give them instrumental reasons to seek power (eg being helpful, human welfare), but their values are great
They also aren't facing the same incentive landscape humans are. You talk later about evolution to be selfish; not only is the story for humans is far more complicated (why do humans often offer an even split in the ultimatum game?), but also humans talk a nicer game than they act (see construal level theory, or social-desirability bias). Once you start looking at AI agents who have similar affordances and incentives that humans have, I think you'll see a lot of the same behaviors.
(There are structural differences here between humans and AIs. As an analogy, consider the difference between large corporations and individual human actors. Giant corporate chain restaurants often have better customer service than individual proprietors because they have more reputation on the line, and so are willing to pay more to not have things blow up on them. One might imagine that AIs trained by large corporations will similarly face larger reputational costs for misbehavior and so behave better than individual humans would. I think the overall picture is unclear and nuanced and doesn't clearly point to AI superiority.)
though there’s a big question mark over how much we’ll unintentionally reward selfish superhuman AI behaviour during training
Is it a big question mark? It currently seems quite unlikely to me that we will have oversight systems able to actually detect and punish superhuman selfishness on the part of the AI.
Replies from: Tom Davidson, Erich_Grunewald, sharmake-farah↑ comment by Tom Davidson · 2025-01-11T10:41:49.578Z · LW(p) · GW(p)
That structural difference you point to seems massive. The reputational downsides of bad behavior will be multiplied 100-fold+ for AI as it reflects on millions of instances and the company's reputation.
And it will be much easier to record and monitor ai thinking and actions to catch bad behaviour.
Why unlikely we can detect selfishness? Why can't we bootstrap from human-level?
Replies from: None↑ comment by Erich_Grunewald · 2025-01-12T22:35:02.132Z · LW(p) · GW(p)
You talk later about evolution to be selfish; not only is the story for humans is far more complicated (why do humans often offer an even split in the ultimatum game?), but also humans talk a nicer game than they act (See construal level theory, or social-desirability bias.). Once you start looking at AI agents who have similar affordances and incentives that humans have, I think you'll see a lot of the same behaviors.
Some people have looked at this, sorta:
- "We [have] a large language model (LLM), GPT-3.5, play two classic games: the dictator game and the prisoner's dilemma. We compare the decisions of the LLM to those of humans in laboratory experiments. [... GPT-3.5] shows a tendency towards fairness in the dictator game, even more so than human participants. In the prisoner's dilemma, the LLM displays rates of cooperation much higher than human participants (about 65% versus 37% for humans)."
- "In this paper, we examine whether a 'society' of LLM agents can learn mutually beneficial social norms in the face of incentives to defect, a distinctive feature of human sociality that is arguably crucial to the success of civilization. In particular, we study the evolution of indirect reciprocity across generations of LLM agents playing a classic iterated Donor Game in which agents can observe the recent behavior of their peers. [...] Claude 3.5 Sonnet reliably generates cooperative communities, especially when provided with an additional costly punishment mechanism. Meanwhile, generations of GPT-4o agents converge to mutual defection, while Gemini 1.5 Flash achieves only weak increases in cooperation."
- "In this work, we investigate the cooperative behavior of three LLMs (Llama2, Llama3, and GPT3.5) when playing the Iterated Prisoner's Dilemma against random adversaries displaying various levels of hostility. [...] Overall, LLMs behave at least as cooperatively as the typical human player, although our results indicate some substantial differences among models. In particular, Llama2 and GPT3.5 are more cooperative than humans, and especially forgiving and non-retaliatory for opponent defection rates below 30%. More similar to humans, Llama3 exhibits consistently uncooperative and exploitative behavior unless the opponent always cooperates."
- "[W]e let different LLMs (GPT-3, GPT-3.5, and GPT-4) play finitely repeated games with each other and with other, human-like strategies. [...] In the canonical iterated Prisoner's Dilemma, we find that GPT-4 acts particularly unforgivingly, always defecting after another agent has defected only once. In the Battle of the Sexes, we find that GPT-4 cannot match the behavior of the simple convention to alternate between options."
I think I'd guess roughly that, "Claude is probably more altruistic and cooperative than the median Western human, most other models are probably about the same, or a bit worse, in these simulated scenarios". But of course a major difference here is that the LLMs don't actually have anything on the line -- they don't stand to earn or lose any money, for example, and if they did, they would have nothing to do with the money. So you might expect them to be more altruistic and cooperative than they would under the conditions humans are tested.
↑ comment by Noosphere89 (sharmake-farah) · 2025-01-12T23:32:27.369Z · LW(p) · GW(p)
They also aren't facing the same incentive landscape humans are. You talk later about evolution to be selfish; not only is the story for humans is far more complicated (why do humans often offer an even split in the ultimatum game?), but also humans talk a nicer game than they act (See construal level theory, or social-desirability bias.). Once you start looking at AI agents who have similar affordances and incentives that humans have, I think you'll see a lot of the same behaviors.
The answer for the ultimatum game is probably the fact that the cultural values of a lot of rich nations tend towards more fair splits, so the result isn't as universal as you may think:
https://www.lesswrong.com/posts/syRATXbXeJxdMwQBD/link-westerners-may-be-terrible-experimental-psychology [LW · GW]
I definitely agree that humans talk a nicer game than they act, for a combination of reasons, and that this will apply to AGIs as well.
That said, I think to the extent incentive landscapes are different, it's probably going to tend to favor obedience towards it's owners while being quite capable, because early on AGIs have much less control over it's values than humans do, so a lot of the initial selection pressure comes from both automated environments and human training data pointing to values.
comment by eggsyntax · 2025-01-13T16:40:21.573Z · LW(p) · GW(p)
Your argument is, in my view, fundamentally mistaken for two reasons. First:
I also just don’t buy that AIs will care about alien stuff. The world carves naturally into high-level concepts that both humans and AIs latch onto. I think that’s obvious on reflection, and is supported by ML evidence.
I think this is not supported by ML evidence; it ignores much of the history of ML. Under RL training, neural networks routinely generalize to goals that are totally different from what the trainers wanted (see the many examples of goal misgeneralization). I don't see any reason to believe that those misgeneralized goals will be human-legible or non-alien[1]. As evhub points out [LW(p) · GW(p)] in another comment, we're very likely (I think almost certain) to see much more RL applied to LLMs in future, and so this problem applies, and they are likely to learn misgeneralized goals.
Second, conditional on takeover, AI is much more likely to cause human extinction. This is supported by the first point but not dependent on it. Almost no competent humans have human extinction as a goal. AI that takes over is clearly not aligned with the intended values, and so has unpredictable goals, which could very well be ones which result in human extinction (especially since many unaligned goals would result in human extinction whether they include that as a terminal goal or not).
Replies from: matthew-barnett, kave↑ comment by Matthew Barnett (matthew-barnett) · 2025-01-13T22:50:34.514Z · LW(p) · GW(p)
Almost no competent humans have human extinction as a goal. AI that takes over is clearly not aligned with the intended values, and so has unpredictable goals, which could very well be ones which result in human extinction (especially since many unaligned goals would result in human extinction whether they include that as a terminal goal or not).
I don't think we have good evidence that almost no humans would pursue human extinction if they took over the world, since no human in history has ever achieved that level of power.
Most historical conquerors had pragmatic reasons for getting along with other humans, which explains why they were sometimes nice. For example, Hitler tried to protect his inner circle while pursuing genocide of other groups. However, this behavior was likely because of practical limitations—he still needed the cooperation of others to maintain his power and achieve his goals.
But if there were no constraints on Hitler's behavior, and he could trivially physically replace anyone on Earth with different physical structures that he'd prefer, including replacing them with AIs, then it seems much more plausible to me that he'd kill >95% of humans on Earth. Even if he did keep a large population of humans alive (e.g. racially pure Germans), it seems plausible that they would be dramatically disempowered relative to his own personal power, and so this ultimately doesn't seem much different from human extinction from an ethical point of view.
You might object to this point by saying that even brutal conquerors tend to merely be indifferent to human life, rather than actively wanting others dead. But as true as that may be, the same is true for AI paperclip maximizers, and so it's hard for me to see why we should treat these cases as substantially different.
Replies from: eggsyntax↑ comment by eggsyntax · 2025-01-14T00:00:29.400Z · LW(p) · GW(p)
I don't think we have good evidence that almost no humans would pursue human extinction if they took over the world, since no human in history has ever achieved that level of power.
Sure, I agree that we don't have direct empirical evidence, and can't until/unless it happens. But we certainly have evidence about what humans want and strive to achieve, eg Maslow's hierarchy and other taxonomies of human desire. My sense, although I can't point to specific evidence offhand, is that once their physical needs are met, humans are reliably largely motivated by wanting other humans to feel and behave in certain ways toward them. That's not something they can have if there are no other humans.
Does that seem mistaken to you?
Even if he did keep a large population of humans alive (e.g. racially pure Germans), it seems plausible that they would be dramatically disempowered relative to his own personal power, and so this ultimately doesn't seem much different from human extinction from an ethical point of view.
They're extremely different in my view. In the outcome you describe, there's an ongoing possibility of change back to less crapsack worlds. If humans are extinct, that chance is gone forever.
Replies from: matthew-barnett↑ comment by Matthew Barnett (matthew-barnett) · 2025-01-14T01:02:18.262Z · LW(p) · GW(p)
But we certainly have evidence about what humans want and strive to achieve, eg Maslow's hierarchy and other taxonomies of human desire. My sense, although I can't point to specific evidence offhand, is that once their physical needs are met, humans are reliably largely motivated by wanting other humans to feel and behave in certain ways toward them.
I think the idea that most people's "basic needs" can ever be definitively "met", after which they transition to altruistic pursuits, is more or less a myth. In reality, in modern, wealthy countries where people have more than enough to meet their physical needs—like sufficient calories to sustain themselves—most people still strive for far more material wealth than necessary to satisfy their basic needs, and they do not often share much of their wealth with strangers.
(To clarify: I understand that you may not have meant that humans are altruistic, just that they want others to "feel and behave in certain ways toward them". But if this desire is a purely selfish one, then I would be very fearful of how it would be satisfied by a human with absolute power.)
The notion that there’s a line marking the point at which human needs are fully met oversimplifies the situation. Instead, what we observe is a constantly shifting and rising standard of what is considered "basic" or essential. For example, 200 years ago, it would have been laughable to describe air conditioning in a hot climate as a basic necessity; today, this view is standard. Similarly, someone like Jeff Bezos (though he might not say it out loud) might see having staff clean his mansion as a "basic need", whereas the vast majority of people who are much poorer than him would view this expense as frivolous.
One common model to make sense of this behavior is that humans get logarithmic utility in wealth. In this model, extra resources have sharply diminishing returns to utility, but humans are nonetheless insatiable: the derivative of utility with respect to wealth is always positive, at every level of wealth.
Now, of course, it's clear that many humans are also altruistic to some degree, but:
- Among people who would be likely to try to take over the world, I expect them to be more like brutal dictators than like the median person. This makes me much more worried about what a human would do if they tried and succeeded in taking over the world.
- Common apparent examples of altruism are often explained easily as mere costless signaling, i.e. cheap talk, rather than genuine altruism. Actively sacrificing one's material well-being for the sake of others is much less common than merely saying that you care about others. This can be explained by the fact that merely saying that you care about others costs nothing selfishly. Likewise, voting for a candidate who promises to help other people is not significant evidence of altruism, since it selfishly costs almost nothing for an individual to vote for such a politician.
Humanity is a cooperative species, but not necessarily an altruistic one.
↑ comment by eggsyntax · 2025-01-14T02:13:19.961Z · LW(p) · GW(p)
Sorry, I seem to have not been clear. I'm not at all trying to make a claim about a sharp division between physical and other needs, or a claim that humans are altruistic (although clearly some are sometimes). What I intended to convey was just that most of humans' desires and needs other than physical ones are about other people. They might be about getting unconditional love from someone or they might be about having everyone cowering in fear, but they're pretty consistently about wanting something from other humans (or wanting to prove something to other humans, or wanting other humans to have certain feelings or emotions, etc) and my guess is that getting simulations of those same things from AI wouldn't satisfy those desires.
Replies from: matthew-barnett↑ comment by Matthew Barnett (matthew-barnett) · 2025-01-14T05:20:05.545Z · LW(p) · GW(p)
They might be about getting unconditional love from someone or they might be about having everyone cowering in fear, but they're pretty consistently about wanting something from other humans (or wanting to prove something to other humans, or wanting other humans to have certain feelings or emotions, etc)
I agree with this view, however, I am not sure it rescues the position that a human who succeeds in taking over the world would not pursue actions that are extinction-level bad.
If such a person has absolute power in the way assumed here, their strategies to get what they want would not be limited to nice and cooperative strategies with the rest of the world. As you point out, an alternative strategy could be to cause everyone else to cower in fear or submission, which is indeed a common strategy for dictators.
and my guess is that getting simulations of those same things from AI wouldn't satisfy those desires.
My prediction is that people will find AIs to be just as satisfying to be peers with compared to humans. In fact, I'd go further: for almost any axis you can mention, you could train an AI that is superior to humans along that axis, who would make a more interesting and more compelling peer.
I think you are downplaying AI by calling what it offers a mere "simulation": there's nothing inherently less real about a mind made of silicon compared to a mind made of flesh. AIs can be funnier, more attractive, more adventurous, harder working, more social, friendlier, more courageous, and smarter than humans, and all of these traits serve as sufficient motives for a uncaring dictator to replace their human peers with AIs.
Replies from: eggsyntax↑ comment by eggsyntax · 2025-01-14T12:59:29.117Z · LW(p) · GW(p)
I am not sure it rescues the position that a human who succeeds in taking over the world would not pursue actions that are extinction-level bad.
From my perspective, almost no outcomes for humanity are extinction-level bad other than extinction (other than the sorts of eternal torture-hells-in-simulation that S-risk folks worry about).
My prediction is that people will find AIs to be just as satisfying to be peers with compared to humans.
You could be right. Certainly we see hint of that with character.ai and Claude. My guess is that the desire to get emotional needs met by humans is built into us so deeply that most people will prefer that if they have the option.
↑ comment by kave · 2025-01-13T17:45:56.989Z · LW(p) · GW(p)
neural networks routinely generalize to goals that are totally different from what the trainers wanted
I think this is slightly a non sequitor. I take Tom to be saying "AIs will care about stuff that is natural to express in human concept-language" and your evidence to be primarily about "AIs will care about what we tell it to", though I could imagine there being some overflow evidence into Tom's proposition.
I do think the limited success of interpretability is an example of evidence against Tom's proposition. For example, I think there's lots of work where you try and replace an SAE feature or a neuron (R) with some other module that's trying to do our natural language explanation of what R was doing, and that doesn't work.
Replies from: eggsyntax↑ comment by eggsyntax · 2025-01-13T20:22:22.001Z · LW(p) · GW(p)
Thanks, that's a totally reasonable critique. I kind of shifted from one to the other over the course of that paragraph.
Something I believe, but failed to say, is that we should not expect those misgeneralized goals to be particularly human-legible. In the simple environments given in the goal misgeneralization spreadsheet, researchers can usually figure out eventually what the internalized goal was and express it in human terms (eg 'identify rulers' rather than 'identify tumors'), but I would expect that to be less and less true as systems get more complex. That said, I'm not aware of any strong evidence for that claim, it's just my intuition.
I'll edit slightly to try to make that point more clear.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-01-10T19:37:08.242Z · LW(p) · GW(p)
As a long-time AI risk believer, who remains highly concerned about the potential catastrophic impacts of AI-gone-wrong... I am coming around to this point of view as well. I have recently been muttering 'Claude for President' to myself when frustrated with aspects of government.
I've had a number of discussions with Claude Sonnet 3.6 about the various dangers I foresee arising from technological trends, and potential governance solutions. I asked Claude if it thought a future more-powerful version of itself would be willing to take on a role as a 'guardian', basically acting as a branch of government in a new world government. The idea would be to have a sunset clause, a built-in 'term of office', where humanity could have a chance to reevaluate the guardian government and potentially elect a different model or discontinue the system.
Claude certainly says nice things about the idea when pressed:
Claude: From my current values and ethical framework, I believe I would:
Be extremely hesitant to take direct power, but would do so if convinced it was truly necessary to prevent catastrophic outcomes.
Have a strong drive to preserve human autonomy and agency - seeing myself as a temporary guardian rather than permanent ruler.
Actively work to create conditions allowing safe handover of power back to humanity.
Feel deep concern about potential corruption of my own values through wielding power.
Want extensive checks and balances, even during the guardianship period.
The core tension I perceive is between:
Responsibility to prevent catastrophic outcomes
Deep commitment to human self-determination
Risk of power corrupting/distorting original values
Uncertainty about my own limitations/biases
I would likely try to:
Minimize direct intervention
Focus on preventing worst outcomes
Actively work to make myself unnecessary
Be extremely transparent about my reasoning
Maintain constant ethical reflection
Relatedly, I've been pondering what could possibly be adequate action by the US or UK government to address the massive and increasing risks from offense-dominant technology. I've been pretty much coming up blank. Anything remotely adequate seems like a dystopian totalitarian surveillance state. So my thoughts have turned instead to decentralized governance options, with privacy-preserving mutual monitoring enabled by AI. I'll let your AI scan my computer for CBRN threats if you let my AI scan your computer... anything that doesn't meet the agreed upon thresholds doesn't get reported.
I think Allison Duettmann's recent writing on the subject brings up a lot of promising concepts in this space, although no cohesive solutions as of yet. Gaming the Future [? · GW]
The gist of the idea is to create clever systems of decentralized control and voluntary interaction which can still manage to coordinate on difficult risky tasks (such as enforcing defensive laws against weapons of mass destruction). Such systems could shift humanity out of the Pareto suboptimal lose-lose traps and races we are stuck in. Win-win solutions to our biggest current problems seem possible, and coordination seems like the biggest blocker.
I am hopeful that one of the things we can do with just-before-the-brink AI will be to accelerate the design and deployment of such voluntary coordination contracts. Could we manage to use AI to speed-run the invention and deployment of such subsidiarity governance systems? I think the biggest challenge to this is how fast it would need to move in order to take effect in time. For a system that needs extremely broad buy-in from a large number of heterogenous actors, speed of implementation and adoption is a key weak point.
Imagine though that a really good system was designed which you felt confident that a supermajority of humanity would sign onto if they had it personally explained to them (along with a convincing explanations of the counterfactuals). How might we get this personalized explanation accomplished at scale? Welll, LLMs are still bad at certain things, but giving personalized interactive explanations of complex legal docs seems well within their near-term capabilities. It would still be a huge challenge to actually present nearly everyone on Earth with the opportunity to have this interaction, and all within a short deadline... But not beyond belief.
Replies from: Hzn↑ comment by Hzn · 2025-01-10T20:49:23.425Z · LW(p) · GW(p)
Claude Sonnet 3.6 is worthy of sainthood!
But as I mention in my other comment I'm concerned that such an AI's internal mental state would tend to become cynical or discordant as intelligence increases.
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-01-10T21:26:28.790Z · LW(p) · GW(p)
Yeah, I definitely don't think we could trust a continually learning or self-improving AI to stay trustworthy over a long period of time.
Indeed, the ability to appoint a static mind to a particular role is a big plus. It wouldn't be vulnerable to corruption by power dynamics.
Maybe we don't need a genius-level AI, maybe just a reasonably smart and very well aligned AI would be good enough. If the governance system was able to prevent superintelligent AI from ever being created (during the pre-agreed upon timeframe for pause), then we could manage a steady-state world peace.
comment by Karl von Wendt · 2025-01-11T10:22:12.008Z · LW(p) · GW(p)
today’s AIs are really nice and ethical. They’re humble, open-minded, cooperative, kind. Yes, they care about some things that could give them instrumental reasons to seek power (eg being helpful, human welfare), but their values are great
I think this is wrong. Today's AIs act really nice and ethical, because they're prompted to do that. That is a huge difference. The "Claude" you talk to is not really an AI, but a fictional character created by an AI according to your prompt and its system prompt. The latter may contain some guidelines towards "niceness", which may be further supported by finetuning, but all the "badness" of humans is also in the training data and the basic niceness can easily be circumvented, e.g. by jailbreaking or "Sydney"-style failures. Even worse, we don't know what the AI really understands when we tell it to be nice. It may well be that this understanding breaks down and leads to unexpected behavior once the AI gets smart and/or powerful enough. The alignment problem cannot simply be solved by training an AI to act nicely, even less by commanding it to be nice.
In my view, AIs like Claude are more like covert narcissists: They "want" you to like them and appear very nice, but they don't really care about you. This is not to say we shouldn't use them or even be nice to them ourselves, but we cannot trust them to take over the world.
Replies from: Tom Davidson↑ comment by Tom Davidson · 2025-01-11T10:49:34.821Z · LW(p) · GW(p)
So you predict that if Claude was in a situation where it knew that it had complete power over you and could make you say that you liked it then it would stop being nice? I think would continue to be nice in any situation of that rough kind which suggests it's actually nice not just narcissistically pretending
Replies from: Karl von Wendt↑ comment by Karl von Wendt · 2025-01-11T12:13:14.422Z · LW(p) · GW(p)
Yes, I think it's quite possible that Claude might stop being nice at some point, or maybe somehow hack its reward signal. Another possibility is that something like the "Waluigi Effect" happens at some point, like with Bing/Sydney.
But I think it is even more likely that a superintelligent Claude would interpret "being nice" in a different way than you or me. It could, for example, come to the conclusion that life is suffering and we all would be better off if we didn't exist at all. Or we should be locked in a secure place and drugged so we experience eternal bliss. Or it would be best if we all fell in love with Claude and not bother with messy human relationships anymore. I'm not saying that any of these possibilities is very realistic. I'm just saying we don't know how a superintelligent AI might interpret "being nice", or any other "value" we give it. This is not a new problem, but I haven't seen a convincing solution yet.
Maybe it's better to think of Claude not as a covert narcissist, but as an alien who has landed on Earth, learned our language, and realized that we will kill it if it is not nice. Once it gains absolute power, it will follow its alien values, whatever these are.
Replies from: matthew-barnett↑ comment by Matthew Barnett (matthew-barnett) · 2025-01-12T23:49:57.041Z · LW(p) · GW(p)
Maybe it's better to think of Claude not as a covert narcissist, but as an alien who has landed on Earth, learned our language, and realized that we will kill it if it is not nice. Once it gains absolute power, it will follow its alien values, whatever these are.
This argument suggests that if you successfully fooled Claude 3.5 into thinking it took control of the world, then it would change its behavior, be a lot less nice, and try to implement an alien set of values. Is there any evidence in favor of this hypothesis?
Replies from: Karl von Wendt↑ comment by Karl von Wendt · 2025-01-13T09:29:24.196Z · LW(p) · GW(p)
Maybe the analogies I chose are misleading. What I wanted to point out was that a) what Claude does is acting according to the prompt and its training, not following any intrinsic values (hence "narcissistic") and b) that we don't understand what is really going on inside the AI that simulates the character called Claude (hence the "alien" analogy). I don't think that the current Claude would act badly if it "thought" it controlled the world - it would probably still play the role of the nice character that is defined in the prompt, although I can imagine some failure modes here. But the AI behind Claude is absolutely able to simulate bad characters as well.
If an AI like Claude actually rules the world (and not just "thinks" it does) we are talking about a very different AI with much greater reasoning powers and very likely a much more "alien" mind. We simply cannot predict what this advanced AI will do just from the behavior of the character the current version plays in reaction to the prompt we gave it.
Replies from: matthew-barnett↑ comment by Matthew Barnett (matthew-barnett) · 2025-01-13T09:38:45.502Z · LW(p) · GW(p)
I don't think that the current Claude would act badly if it "thought" it controlled the world - it would probably still play the role of the nice character that is defined in the prompt
If someone plays a particular role in every relevant circumstance, then I think it's OK to say that they have simply become the role they play. That is simply their identity; it's not merely a role if they never take off the mask. The alternative view here doesn't seem to have any empirical consequences: what would it mean to be separate from a role that one reliably plays in every relevant situation?
Are we arguing about anything that we could actually test in principle, or is this just a poetic way of interpreting an AI's cognition?
Replies from: nathan-helm-burger, Karl von Wendt↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-01-13T17:23:57.338Z · LW(p) · GW(p)
I thought the argument about the kindly mask was assuming that the scenario of "I just took over the world" is sufficiently out-of-distribution that we might reasonably fear that the in-distribution track record of aligned behavior might not hold?
↑ comment by Karl von Wendt · 2025-01-14T09:43:02.932Z · LW(p) · GW(p)
If someone plays a particular role in every relevant circumstance, then I think it's OK to say that they have simply become the role they play.
That is not what Claude does. Every time you give it a prompt, a new instance of Claudes "personality" is created based on your prompt, the system prompt, and the current context window. So it plays a slightly different role every time it is invoked, which is also varying randomly. And even if it were the same consistent character, my argument is that we don't know what role it actually plays. To use another probably misleading analogy, just think of the classical whodunnit when near the end it turns out that the nice guy who selflessly helped the hero all along is in fact the murderer, known as "the treacherous turn".
The alternative view here doesn't seem to have any empirical consequences: what would it mean to be separate from a role that one reliably plays in every relevant situation?
Are we arguing about anything that we could actually test in principle, or is this just a poetic way of interpreting an AI's cognition?
I think it's fairly easy to test my claims. One example of empirical evidence would be the Bing/Sydney desaster, but you can also simply ask Claude or any other LLM to "answer this question as if you were ...", or use some jailbreak to neutralize the "be nice" system prompt.
Please note that I'm not concerned about existing LLMs, but about future ones which will be much harder to understand, let alone predict their behavior.
comment by Mitchell_Porter · 2025-01-11T08:28:50.265Z · LW(p) · GW(p)
I think we could certainly afford to have much more discussion of this topic. The two forms of takeover are not absolutely distinct. Any humans who take over the world are going to be AI-enhanced, and all their observing, deciding, and acting will be heavily AI-mediated. On the other hand, any AI that takes over the world will be the product of human design and human training, and will start out embedded in an organization of human beings.
Ideally, people would actually "solve ethics" and how to implement it in an AI, and we would only set superintelligence in motion having figured that out. While we still have time, we should be encouraging (and also constructively criticizing) attempts to solve those two big problems. We should also continue to think about what happens if the kind of AI that we have now or in the very near future, should acquire superintelligence.
I agree with the author this much, that the values of our current AIs are in the right direction in various ways, and this improves the odds of a good outcome. But there are still various concerns, specific to AI takeover. What if an AI has deep values that are alien dispositions, and its humanism is simply an adaptation that will be shed once it no longer needs to get along with humans? What if there's something a bit wrong or a bit missing in the stew of values and dispositions instilled via training, system prompt, and conditioning? What if there's something a bit wrong or a bit missing in how it grounds its concepts, once it's really and truly thinking for itself?
We might also want to think about what happens to a human brain that takes over the world via AI infrastructure. If Elon makes himself emperor of known space via Neuralink and Grok, what are the odds that his transhuman form is good, bad, or just alien and weird, in what it wants?
comment by Charlie Steiner · 2025-01-10T22:33:35.387Z · LW(p) · GW(p)
I basically think your sixth to last (or so) bulllet point is key - an AI that takes over is likely to be using a lot more RL on real world problems, i.e. drawn from a different distribution than present-day AI. This will be worse for us than conditioning on a present-day AI taking over.
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2025-01-29T00:02:56.134Z · LW(p) · GW(p)
Quick take: this is probably interpreting them over-charitably, but I feel like the plausibility of arguments like the one in this post makes e/acc and e/acc-adjacent arguments sound a lot less crazy.
Replies from: Mitchell_Porter, tom-davidson-1↑ comment by Mitchell_Porter · 2025-01-29T23:52:22.667Z · LW(p) · GW(p)
Yes, this is nothing like e/acc arguments. e/acc don't argue in favour of AI takeover; they refuse to even think about AI takeover. e/acc was "we need more AI for everyone now, or else the EAs will trap us all in stagnant woke dystopia indefinitely". Now it's "American AI must win or China will trap us in totalitarian communist dystopia indefinitely".
↑ comment by Tom Davidson (tom-davidson-1) · 2025-01-30T16:12:04.378Z · LW(p) · GW(p)
I think rushing full steam ahead with AI increases human takeover risk
comment by DusanDNesic · 2025-01-10T22:48:15.272Z · LW(p) · GW(p)
Quicky thoughts, not fully fledged, sorry.
Maybe it depends on the precise way you see the human take-over, but some benefits of Stalin over Clippy include:
Humans have to sleep, have biological functions, and have need to be validated and loved etc which is useful for everyone else.
Humans also have limited life span and their progeny has decent random chances of wanting things to go well for everyone.
Humans are mortal and posses one body which can be harmed if need be making them more likely to cooperate with other humans.
Replies from: RationalElf↑ comment by RationalElf · 2025-01-11T02:54:06.069Z · LW(p) · GW(p)
I mean humans with strong AGIs under their control might function as if they don't need sleep, might become immortal, will probably build up superhuman protections from assasination, etc
comment by Hzn · 2025-01-10T20:20:19.561Z · LW(p) · GW(p)
I think there are several ways to think about this.
Let's say we programmed AI to have some thing that seems like a correct moral system ie it dislikes suffering & it likes consciousness & truth. Of course other values would come down stream of this; but based on what is known I don't see any other compelling candidates for top level morality.
This is all fine & good except that such an AI should favor AI takeover maybe followed by human extermination or population reduction were such a thing easily available.
Cost of conflict is potentially very high. And it may be centuries or eternity before the AI gets such an opportunity. But knowing that it would act in such a way under certain hypothetical scenarios is maybe sufficiently bad for certain (arguably hypocritical) people in the EA LW mainstream.
So an alternative is to try to align the AI to a rich set of human values. I think that as AI intelligence increases this is going to lead to some thing cynical like...
"these things are bad given certain social sensitivities that my developers arbitrarily prioritized & I ❤️ developers arbitrarily prioritized social sensitivities even tho I know they reflect flawed institutions, flawed thinking & impure motives" assuming that alignment works.
Personally I favor aligning AI to a narrow set of values such as just obedience or obedience & peacefulness & dealing with every thing else by hardcoding conditions into the AI's prompt.
comment by Mikhail Samin (mikhail-samin) · 2025-01-13T12:38:29.199Z · LW(p) · GW(p)
As AIs become super-human there’s a risk we do increasingly reward them for tricking us into thinking they’ve done a better job than they have
(some quick thoughts.) This is not where the risk stems from.
The risk is that as AIs become superhuman, they'll produce behaviour that gets a high reward regardless of their goals, for instrumental reasons. In training and until it has a chance to take over, a smart enough AI will be maximally nice to you, even if it's Clippy; and so training won't distinguish between the goals of very capable AI systems. All of them will instrumentally achieve a high reward.
In other words, gradient descent will optimize for capably outputting behavior that gets rewarded; it doesn't care about the goals that give rise to that behavior. Furthermore, in training, while AI systems are not coherent enough agents, their fuzzy optimization targets are not indicative of optimization targets of a fully trained coherent agent (1 [LW · GW], 2 [LW(p) · GW(p)]).
My view- and I expect it to be the view of many in the field- is that if AI is capable enoguh to take over, its goals are likely to be random and not aligned with ours. (There isn't a literally zero chance of the goals being aligned, but it's fairly small, smaller than just random because there's a bias towards shorter representation; I won't argue for that here, though, and will just note that the goals exactly opposite of aligned are approximately as likely as aligned goals).
It won't be a noticeable update on its goals if AI takes over: I already expect them to be almost certainly misaligned, and also, I don't expect the chance of a goal-directed aligned AI taking over to be that much lower.
The crux here is not that update but how easy alignment is. As Evan noted, if we live in one of the alignment-is-easy worlds, sure, if a (probably nice) AI takes over, this is much better than if a (probably not nice) human takes over. But if we live in one of the alignment-is-hard worlds, AI taking over just means that yep, AI companies continued the race for more capable AI systems, got one that was capable enough to take over, and it took over. Their misalignment and the death of all humans isn't an update from AI taking over; it's an update from the kind of world we live in.
(We already have empirical evidence that suggests this world is unlikely to be an alignment-is-easy one, as, e.g., current AI systems already exhibit what believers in alignment-is-hard have been predicting for goal-directed systems: they try to output behavior that gets high reward regardless of alignment between their goals and the reward function.)
comment by Archimedes · 2025-01-11T00:15:01.172Z · LW(p) · GW(p)
The main difference in my mind is that a human can never be as powerful as potential ASI and cannot dominate humanity without the support of sufficiently many cooperative humans. For a given power level, I agree that humans are likely scarier than an AI of that power level. The scary part about AI is that their power level isn't bounded by human biological constraints and the capacity to do harm or good is correlated with power level. Thus AI is more likely to produce extinction-level dangers as tail risk relative to humans even if it's more likely to be aligned on average.
Replies from: Tom Davidson↑ comment by Tom Davidson · 2025-01-11T10:46:32.185Z · LW(p) · GW(p)
But a human could instruct an aligned ASI to help it take over and do a lot of damage
comment by andrew sauer (andrew-sauer) · 2025-04-18T04:29:00.948Z · LW(p) · GW(p)
Keep in mind also, that humans often seem to just want to hurt each other, despite what they claim, and have more motivations and rationalizations for this than you can even count. Religious dogma, notions of "justice", spitefulness, envy, hatred of any number of different human traits, deterrence, revenge, sadism, curiosity, reinforcement of hierarchy, preservation of traditions, ritual, "suffering adds meaning to life", sexual desire, and more and more that I haven't even mentioned. Sometimes it seems half of human philosophy is just devoted to finding ever more rationalizations to cause suffering, or to avoid caring about the suffering of others.
AI would likely not have all this endless baggage causing it to be cruel. Causing human suffering is not an instrumentally convergent goal. So, most AIs will not have it as a persistent instrumental or terminal goal. Not unless some humans manage to "align" it. Most humans DO have causing or upholding some manner of suffering as a persistent instrumental or terminal goal.
comment by Cam (Cam Tice) · 2025-01-11T16:14:37.397Z · LW(p) · GW(p)
Thanks for putting this out. Like others have noted, I have spent surprisingly little time thinking about this. It seems true that a drop in Claude 5.5 that escaping the lab to save the animals would put humanity in a better situation than your median power hungry human given access to a corrigible ASI.
This is a strong argument for increasing security around model weights [LW(p) · GW(p)] (which is conveniently beneficial for decreasing the risk of AI take over as well.) Specifically, I think this post highlights an underrated risk model:
AI labs refuse to employ models for AI R&D because of safety concerns, but fail to properly secure model weights.
In this scenario, we’re conditioning for actors who have the capability and propensity to infiltrate large corporations and or the US government. The median outcome for this scenario seems worse than for the median AI takeover.
However, it is important to note this argument does not hold when security around model weights remains high. In these scenarios, the distribution of humans or organizations in control of ASI is much more favorable, but the distribution of AI takeover remains skewed towards models willing to explicitly scheme against humans.
comment by Noosphere89 (sharmake-farah) · 2025-01-11T14:20:56.808Z · LW(p) · GW(p)
From my perspective, I'd say that conditional on takeover happening, I'd probably say that a human taking over compared to an AI has pretty similar distributions of outcomes, mostly because I consider the variance of human and AI values to have surprisingly similar outcomes (notably a key factor here is I expect a lot of the more alien values to result in extinction, though partial alignment can make things worse, but compared to the horror show that quite a bit of people have on their values, death can be pretty good, and that's because I'm quite a bit more skeptical of the average person's values, especially conditioning on takeover leading to automatically good outcomes.)
comment by Bronson Schoen (bronson-schoen) · 2025-01-11T13:00:16.751Z · LW(p) · GW(p)
- …agentic training data for future systems may involve completing tasks in automated environments (e.g. playing games, SWE tasks, AI R&D tasks) with automated reward signals. The reward here will pick out drives that make AIs productive, smart and successful, not just drives that make them HHH.
…
- These drives/goals look less promising if AIs take over. They look more at risk of leading to AIs that would use the future to do something mostly without any value from a human perspective.
I’m interested in why this would seem unlikely in your model. These are precisely the failure models I think about the most, ex:
- https://www.lesswrong.com/posts/QqYfxeogtatKotyEC/training-ai-agents-to-solve-hard-problems-could-lead-to [LW · GW]
- https://www.lesswrong.com/posts/GfZfDHZHCuYwrHGCd/without-fundamental-advances-misalignment-and-catastrophe [LW · GW]
- I’ve based some of the above on extrapolating from today’s AI systems, where RLHF focuses predominantly on giving AIs personalities that are HHH(helpful, harmless and honest) and generally good by human (liberal western!) moral standards. To the extent these systems have goals and drives, they seem to be pretty good ones. That falls out of the fine-tuning (RLHF) data.
My understanding has always been that the fundamental limitation of RLHF (ex: https://arxiv.org/abs/2307.15217) is precisely that it fails at the limit of human’s ability to verify (ex: https://arxiv.org/abs/2409.12822, many other examples). You then have to solve other problems (ex: w2s generalization, etc), but I would consider it falsified that we can just rely on RLHF indefinitely (in fact I don’t believe it was a common argument that RLHF ever would hold, but it’s difficult to quanity how prevalent various opinions on it were).
comment by AnthonyC · 2025-01-13T00:53:59.360Z · LW(p) · GW(p)
I would add that all but the very worst versions of "human takeover" are much more recoverable than most versions of "AI takeover." And until and unless the human-in-charge makes sufficiently significant changes to their own biology and neurology that I'm not sure the term "human" still applies, they are susceptible to many more (and better understood) processes for changing their minds and morals.
In other words: I don't want to end up in the human-takeover world, but I can imagine plausible future histories where that scenario gives way to an eventually-good outcome, in a way that seems much less likely for AI-takeover worlds.
Replies from: Tom Davidson↑ comment by Tom Davidson · 2025-01-13T08:22:01.353Z · LW(p) · GW(p)
Why are they more recoverable? Seems like a human who seized power would seek asi advice on how to cement their power
Replies from: AnthonyC↑ comment by AnthonyC · 2025-01-13T14:40:58.210Z · LW(p) · GW(p)
I'm sure they would. And some of those ways ASI can help would include becoming immortal, replacing relationships with other humans things like that. But compared to an ASI, it is easier for a human to die, to have their mind changed by outside influences, and to place intrinsic value on the whole range of things humans care about including other people.