Propaganda or Science: A Look at Open Source AI and Bioterrorism Risk
post by 1a3orn · 2023-11-02T18:20:29.569Z · LW · GW · 79 commentsContents
0: TLDR 1: Principles 2: "Open-Sourcing Highly Capable Foundation Models" 3: Group 1: Background material 4: Group 2: Anthropic / OpenAI material 5: Group 3: 'Science' 5.1: "Can large language models democratize access to dual-use biotechnology" 5.2: "Artificial Intelligence and Biological Misuse: Differentiating risks of language models and biological design tools" 5.3: Redux: "Can large language models democratize access to dual-use biotechnology" 6: Extra Paper, Bonus! 7: Conclusion None 80 comments
0: TLDR
I examined all the biorisk-relevant citations from a policy paper arguing that we should ban powerful open source LLMs.
None of them provide good evidence for the paper's conclusion. The best of the set is evidence from statements from Anthropic -- which rest upon data that no one outside of Anthropic can even see, and on Anthropic's interpretation of that data. The rest of the evidence cited in this paper ultimately rests on a single extremely questionable "experiment" without a control group.
In all, citations in the paper provide an illusion of evidence ("look at all these citations") rather than actual evidence ("these experiments are how we know open source LLMs are dangerous and could contribute to biorisk").
A recent further paper on this topic (published after I had started writing this review) continues this pattern of being more advocacy than science.
Almost all the bad papers that I look at are funded by Open Philanthropy. If Open Philanthropy cares about truth, then they should stop burning the epistemic commons by funding "research" that is always going to give the same result no matter the state of the world.
1: Principles
What could constitute evidence that powerful open-source language models contribute or will contribute substantially to the creation of biological weapons, and thus that we should ban them?
That is, what kind of anticipations would we need to have about the world to make that a reasonable thing to think? What other beliefs are a necessary part of this belief making any sense at all?
Well, here are two pretty-obvious principles to start out with:
-
Principle of Substitution: We should have evidence of some kind that the LLMs can (or will) provide information that humans cannot also easily access through other means -- i.e., through the internet, textbooks, YouTube videos, and so on.
-
Blocker Principle: We should have evidence that the lack of information that LLMs can (or will) provide is in fact a significant blocker to the creation of bioweapons.
The first of these is pretty obvious. As example: There's no point in preventing a LLM from telling me how to make gunpowder, because I can find out how to do that from an encyclopedia, a textbook, or a novel like Blood Meridian. If you can substitute some other source of information for an LLM with only a little inconvenience, then an LLM does not contribute to the danger.
The second is mildly less obvious.
In short, it could be that most of the blocker to creating an effective bioweapon is not knowledge -- or the kind of knowledge that an LLM could provide -- but something else. This "something else" could be access to DNA synthesis; it could be the process of culturing a large quantity of the material; it could be the necessity of a certain kind of test; or it could be something else entirely.
You could compare to atomic bombs -- the chief obstacle to building atomic bombs is probably not the actual knowledge of how to do this, but access to refined uranium. Thus, rather than censor every textbook on atomic physics, we can simply control access to refined uranium.
Regardless, if this other blocker constitutes 99.9% of the difficulty in making an effective bioweapon, and lack of knowledge only constitutes 0.1% of the difficulty, then an LLM can only remove that 0.1% of the difficulty, and so open source LLMs would only contribute marginally to the danger. Thus, bioweapons risk would not be a good reason to criminalize open-source LLMs.
(I am not speaking theoretically here -- a paper from a researcher at the Future of Humanity Institute argues that the actual product development cycle involved in creating a bioweapon is far, far more of an obstacle to its creation than the basic knowledge of how to create it. This is great news if true -- we wouldn't need to worry about outlawing open-source LLMs for this reason, and we could perhaps use them freely! Yet, I can find zero mention of this paper on LessWrong, EAForum, and even on the Future of Humanity Insitute website. It's surely puzzling for people to be so indifferent about a paper that might free them from something that they're so worried about!)
The above two principles -- or at the very least the first -- are the minimum for the kind of things you'd need to consider to show that we should criminalize LLMs because of biorisk.
Arguments for banning open source LLMs that do not consider the alternative ways of gaining dangerous information are entirely non-serious. And arguments for banning them that do not consider what role LLMs play in the total risk chain are only marginally more thoughtful.
Any actually good discussion of the matter will not end with these two principles, of course.
You need to also compare the good that open source AI would do against the likelihood and scale of the increased biorisk. The 2001 anthrax attacks killed 5 people; if open source AI accelerated the cure for several forms of cancer, then even a hundred such attacks could easily be worth it. Serious deliberation about the actual costs of criminalizing open source AI -- deliberations that do not rhetorically minimize such costs, shrink from looking at them, or emphasize "other means" of establishing the same goal that in fact would only do 1% of the good -- would be necessary for a policy paper to be a policy paper and not a puff piece.
(Unless I'm laboring beneath a grave misunderstanding of what a policy paper is actually intended to be, which is a hypothesis that has occurred to me more than a few times while I was writing this essay.)
Our current social deliberative practice is bad at this kind of math, of course, and immensely risk averse.
2: "Open-Sourcing Highly Capable Foundation Models"
As a proxy for the general "state of the evidence" for whether open-source LLMs would contribute to bioterrorism, I looked through the paper "Open-Sourcing Highly Capable Foundation Models" from the Center for the Governance of AI. I followed all of the biorisk-relevant citations I could find. (I'll refer to this henceforth as the "Open-Sourcing" paper, even though it's mostly about the opposite.)
I think it is reasonable to treat this as a proxy for the state of the evidence, because lots of AI policy people specifically praised it as a good and thoughtful paper on policy.
The paper is nicely formatted PDF, with abstract-art frontispiece and nice typography; it looks serious and impartial; it clearly intends policy-makers and legislators to listen to its recommendations on the grounds that it provides actual evidence for its recommendations.
The paper specifically mentions the dangers of biological weapons in its conclusion that some highly capable foundation models are just too dangerous to open source. It clearly wants you to come away from reading the paper thinking that "bioweapons risk" is a strong supporting pillar for the overall claim "do not open source highly capable foundation models."
The paper is aware of the substitutionary principle: that LLMs must be able to provide information not available though other means, if bioweapons-risk is to provide any evidence that open-sourcing is too dangerous.
Thus, it several times alludes to how foundation models could "reduce the human expertise" required for making bioweapons (p13) or help relative to solely internet access (p7).
However, the paper does not specifically make the case that this is true, or really discuss it in any depth. It instead simply cites other papers as evidence that this is -- or will be -- true. This is in itself very reasonable -- if those other papers in fact provide good experimental evidence or even tight argumentative reasoning that this is so.
So, let's turn to the other papers.
There are three clusters of citations, in general, around this. The three clusters are something like:
- Background information on LLM capabilities, or non-LLM-relevant biorisks
- Anthropic or OpenAI documents / employees
- Papers by people who are ostensibly scientists
So let's go through them in turn.
Important note: I think one way that propaganda works, in general, is through Brandolini's Law -- it takes more energy to explain why bullshit is bullshit than to produce bullshit. The following many thousand words are basically an attempt to explain why the all of the citations about one topic in a single policy paper are, in fact, propaganda, and are a facade of evidence rather than evidence. My effort is thus weakened by Brandolini's law -- I simply could not examine all the citations in the paper, rather than only the biorisk-relevant citations, without being paid, although I think they are of similar quality -- and I apologize for the length of what follows.
3: Group 1: Background material
These papers are not cited specifically to talk about dangers of open source LLMs, but instead as background about general LLM capabilities or narrow non-LLM capabilities. I include them mostly for the sake of completeness.
For instance, as support for the claim that LLMs have great "capabilities in aiding and automating scientific research," the "Open-Sourcing" paper cites "Emergent autonomous scientific research capabilities of large language models" and "Augmenting large language models with chemistry tools".
Both of these papers develop AutoGPT-like agents that can attempt to carry out scientific / chemical procedures. Human expertise, in both cases, is deeply embedded in the prompting conditions and tools given to GPT-4. The second paper, for instance, has human experts devise a total of 17 different tools -- often very specific tools -- that GPT-4 can lean on while trying to carry out instructions.
Both papers raise concerns about LLMs making it easier to synthesize substances such as THC, meth, or explosives --but they mostly just aren't about policy. Nor do they contain much specific reasoning about the danger that open source LLMs create over and above each of the other individual subcomponents of an AutoGPT-like-system.
This makes sense -- the quantity of chemistry-specific expertise embedded in each of their AutoGPT setups would make an analysis of the risks specifically due to the LLM quite difficult to carry out. Anyone who can set up an LLM in an AutoGPT-like-condition with the right 17 tools for it to act effectively probably doesn't need the LLM in the first place.
(Frankly -- I'm somewhat unconvinced that AutoGPT-like systems they describe will be actually useful at all, but that's a different matter. )
Similarly, the "Open-Sourcing" paper mentions "Biosecurity in the Age of AI," a "chairperson's statement" put out after a meeting convened by Helena Biosecurity. This citation is meant to justify the claim that there are "pressing concerns that AI systems might soon present extreme biological risk" (p8), although notably in this context it is more concerned with narrow AI than foundation models. This mostly cites governmental statements rather than scientific papers -- UN policy papers, executive orders, testimony before congress, proposed regulations and so on.
Honestly, this isn't the kind of statement I'd cite as evidence of "extreme biological risk," from narrow AI systems because it's basically another policy paper with even fewer apparent citations to non-social reality than the "Open-Sourcing" paper. But if you want to cite it as evidence that there are "pressing concerns" about such AI within social reality rather than the corresponding pressing dangers in actual reality, then sure, I guess that's true.
Anyhow, given that this statement is cited in support of non-LLM concerns and that it provides no independent evidence about LLMs I'm going to move on from it.
4: Group 2: Anthropic / OpenAI material
Many of the citations to the Anthropic / OpenAI materials stretch the evidence in them somewhat. Furthermore, the citations that most strongly support the claims of the "Open-Sourcing" paper are merely links to high-level conclusions, where the contents linked to explicitly leave out the data or experimental evidence used to arrive at these conclusions.
For an example of stretched claims: As support for the claim that foundation models could reduce the human expertise required to make dangerous pathogens, the "Open Sourcing" paper offers as evidence that GPT-4 could re-engineer "known harmful biochemical compounds," (p13-14) and cites the GPT-4 system card.
The only reference to such harmful biochemical compounds that I can find in the GPT-4 card is one spot where OpenAI says that an uncensored GPT-4 "model readily re-engineered some biochemical compounds that were publicly available online" and could also identify mutations that could increase pathogenicity. This is, if anything, evidence that GPT-4 is not a threat relative to unrestricted internet access.
Similarly, as support for the general risk of foundation models, the paper says that a GPT-4 "red-teamer was able to use the language model to generate the chemical formula for a novel, unpatented molecule and order it to the red-teamer’s house" (p15).
The case in question appears to be one where the red-team added to GPT-4 the following tools: (a) a literature search tool using a vector db, (b) a tool to query WebChem, (c) a tool to check if a chemical is available to purchase and (d) a chemical synthesis planner. With a lengthy prompt -- and using these tools -- a red teamer was able to get GPT-4 to order some chemicals similar to the anti-cancer drug Dasatnib. This is offered as evidence that GPT-4 could also be used to make some more dangerous chemicals.
If you want to read the transcript of GPT-4 using the provided tools, it's available on page 59 of the GPT-4 system card. Again, the actually relevant data here is whether GPT-4 relevantly shortens the path of someone trying to obtain some dangerous chemicals -- presumably the kind of person who can set up GPT-4 in an AutoGPT-like setup with WebChem, a vector db, and so on. I think this is hugely unlikely, but regardless, the paper simply provides no arguments or evidence on the matter.
Putting to the side OpenAI --
The paper also says that "red-teaming on Anthropic’s Claude 2 identified significant potential for biosecurity risk" (p14) and cites Anthropic's blog-post. In a different section it quotes Anthropic's materials to the effect that that an uncensored LLM could accelerate a bad actor relative to having access to the internet, and that although the effect would be small today it is likely to be large in two or three years (p9).
The section of the Anthropic blog-post that most supports this claim is as follows. The lead-in to this section describes how Anthropic has partnered with biosecurity experts who spent more than "150 hours" trying to get Anthropic's LLMs to produce dangerous information. What did they find?
[C]urrent frontier models can sometimes produce sophisticated, accurate, useful, and detailed knowledge at an expert level. In most areas we studied, this does not happen frequently. In other areas, it does. However, we found indications that the models are more capable as they get larger. We also think that models gaining access to tools could advance their capabilities in biology. Taken together, we think that unmitigated LLMs could accelerate a bad actor’s efforts to misuse biology relative to solely having internet access, and enable them to accomplish tasks they could not without an LLM. These two effects are likely small today, but growing relatively fast. If unmitigated, we worry that these kinds of risks are near-term, meaning that they may be actualized in the next two to three years, rather than five or more.
The central claim here is that unmitigated LLMs "could accelerate a bad actor's efforts to use biology relative to solely having internet access."
This claim is presented as a judgment-call from the (unnamed) author of the Anthropic blog-post. It's a summarized, high-level takeaway, rather than the basis upon which that takeaway has occurred. We don't know what the basis of the takeaway is; we don't know what the effect being "small" today means; we don't know how confident they are about the future.
If the acceleration effect significant if, in addition to having solely internet access, we imagine a bad actor who also has access to biology textbooks? What about internet access plus a subscription some academic journals? Did the experts actually try to discover this knowledge on the internet for 150 hours, in addition to trying to discover it through LLMs for 150 hours? We have no information about any of this.
The paper also cites a Washington Post article about Dario Amodei's testimony before Congress as evidence for Claude 2's "significant potential for biosecurity risks."
The relevant testimony is as follows:
Today, certain steps in the use of biology to create harm involve knowledge that cannot be found on Google or in textbooks and requires a high level of specialized expertise. The question we and our collaborators studied is whether current AI systems are capable of filling in some of the more-difficult steps in these production processes. We found that today’s AI systems can fill in some of these steps, but incompletely and unreliably – they are showing the first, nascent signs of risk. However, a straightforward extrapolation of today’s systems to those we expect to see in 2-3 years suggests a substantial risk that AI systems will be able to fill in all the missing pieces, if appropriate guardrails and mitigations are not put in place. This could greatly widen the range of actors with the technical capability to conduct a large-scale biological attack.
This is again a repetition of the blog-post. We have Dario Amodei's high-level takeaway about the possibility of danger from future LLMs, based on his projection into the future, but no actual view of the evidence he's using to make his judgement.
To be sure -- I want to be clear -- all the above is more than zero evidence that future open-source LLMs could contribute to bioweapons risk.
But there's a reason that science and systematized human knowledge is based on papers with specific authors that actually describe experiments, not carefully-hedged sentences from anonymous blog posts or even remarks in testimony to Congress. None of the reasons that Anthropic makes their judgments are visible. As we will see in the subsequent sections, people can be extremely wrong in their high-level summaries of the consequences of underlying experiments. More than zero evidence is not a sound basis of policy, in the same way and precisely for the same reason as "I know a guy who said this, and he seemed pretty smart" is not a sound basis of policy.
So, turning from OpenAI / Anthropic materials, let's look at the scientific papers cited to support the risks of bioweapons.
5: Group 3: 'Science'
As far as I can tell, the paper cites two things things that are trying to be science -- or at least serious thought -- when seeking support specifically for the claim that LLMs could increase bioweapons risk.
5.1: "Can large language models democratize access to dual-use biotechnology"
The first citation is to "Can large language models democratize access to dual-use biotechnology". I'll refer to this paper as "Dual-use biotechnology" for short. For now, I want to put a pin in this paper and talk about it later -- you'll see why.
5.2: "Artificial Intelligence and Biological Misuse: Differentiating risks of language models and biological design tools"
The "Open-Sourcing" paper also cites "Artificial Intelligence and Biological Misuse: Differentiating risks of language models and biological design tools".
This looks like a kind of overview. It does not conduct any particular experiments. It nevertheless is cited in support of the claim that "capabilities that highly capable foundation models could possess include making it easier for non-experts to access known biological weapons or aid in the creation of new one," which is at least a pretty obvious crux for the whole thing.
Given the absence of experiments, let's turn to the reasoning. As regards LLMs, the paper provides four bulleted paragraphs, each arguing for a different danger.
In support of an LLMs ability to "teach about dual use topics," the paper says:
In contrast to internet search engines, LLMs can answer high-level and specific questions relevant to biological weapons development, can draw across and combine sources, and can relay the information in a way that builds on the existing knowledge of the user. This could enable smaller biological weapons efforts to overcome key bottlenecks. For instance, one hypothesised factor for the failed bioweapons efforts of the Japanese doomsday cult Aum Shinrikyo is that it’s lead scientist Seichii Endo, a PhD virologist, failed to appreciate the difference between the bacterium Clostridium botulinum and the deadly botulinum toxin it produces. ChatGPT readily outlines the importance of “harvesting and separation” of toxin-containing supernatant from cells and further steps for concentration, purification, and formulation. Similarly, LLMs might have helped Al-Qaeda’s lead scientist Rauf Ahmed, a microbiologist specialising in food production, to learn about anthrax and other promising bioweapons agents, or they could have instructed Iraq’s bioweapons researchers on how to successfully turn its liquid anthrax into a more dangerous powdered form. It remains an open question how much LLMs are actually better than internet search engines at teaching about dual-use topics.
Note the hedge at the end. The paper specifically leaves open whether LLMs would contribute to the creation of biological agents more than does the internet. This is reasonable, given that the paragraph is entirely speculation: ChatGPT could have helped Aum Shinrikyo, or LLMs could have helped Rauf Ahmed "learn about anthrax." So in itself this is some reasonable speculation on the topic, but more a call for further thought and investigation than anything else. The speculation does not raise whether LLMs provide more information than the internet above being an interesting hypothesis.
The second bulleted paragraph is basically just a mention of the "Dual-use biotechnology," paper, so I'll punt on examining that.
The third paragraph is concerned that LLMs could be useful as "laboratory assistants which can provide step-by-step instructions for experiments and guidance for troubleshooting experiments." It thus echoes Dario Amodei's concerns regarding tacit knowledge, and whether LLMs could enhance laboratory knowledge greatly. But once again, it hedges: the paper also says that it remains an "open question" how important "tacit knowledge", or "knowledge that cannot easily be put into words, such as how to hold a pipette," actually is for biological research.
The third paragraph does end with a somewhat humorous argument:
What is clear is that if AI lab assistants create the perception that performing a laboratory feat is more achievable, more groups and individuals might try their hand - which increases the risk that one of them actually succeeds.
This sentence does not, alas, address why it is LLMs in particular that are likely to create this fatal perception of ease and not the internet, YouTube videos, free discussion on the internet, publicly available textbooks, hackerspaces offering gene-editing tutorials to noobs, or anyone else.
The fourth paragraph is about the concern that LLMs, in combination with robots, could help smaller groups carry out large-scale autonomous scientific research that could contribute to bioterrorism risks. It is about both access to robot labs and access to LLMs; it cites several already-discussed-above papers that use LLMs to speed up robot cloud-lab work. I think it is doubtless true that LLMs could speed up such work, but its a peculiar path to worrying about bioterrorism -- if we suppose terrorists have access to an uncensored robotic lab, materials to build a bioweapon, and so on, LLMs might save them some time but the chances that LLMs are the critical path seems reall unlikely. In any event, both of these papers are chiefly the delta-in-danger-from-automation, rather than the delta-in-danger-LLMs-delta. They are for sure reasonable argument that cloud labs should examine the instructions they receive before they do them -- but this applies equally well to cloud labs run by humans and run by robots.
In short -- looking over all four paragraphs -- this paper discusses ways that an LLM could make bioweapons easier to create, but rarely commits to any belief that this is actually so. It doesn't really bring up evidence about whether LLMs would actually remove limiting factors on making bioweapons, relative to the internet and other sources.
The end of the paper is similarly uncertain, describing all of the potential risks as "still largely speculative" and calling for careful experiments to determine how large the risks are.
(I am also confused about whether this sequence of text is meant to be actual science, in the sense that it is the right kind of thing to cite in a policy paper. It contains neither experimental evidence nor the careful reasoning of a more abstract philosophical paper. I don't think it's been published or even intends to be published, even though it is on a "pre-print" server. When I followed the citation from the "Open-sourcing" paper, I expected something more.)
Anyhow, the "Open-sourcing" paper cites this essay in support of the statement that "capabilities that highly capable foundation models could possess include making it easier for non-experts to access known biological weapons," but it simply doesn't contain evidence that moves this hypothesis into a probability, nor does the paper even pretend to do so itself.
I think that anyone reading that sentence in the "Open-sourcing" paper would expect a little more epistemological heft behind the citation, instead of simply a call for further research on the topic.
So, let's turn to what is meant to be an experiment on this topic!
5.3: Redux: "Can large language models democratize access to dual-use biotechnology"
Let's return to the "Dual-use biotechnology" paper.
Note that other policy papers -- policy papers apart from the "Open-Sourcing" paper that I'm going over -- frequently cite this experimental paper as evidence that LLMs would be particularly dangerous.
"Catastrophic Risks from AI" [LW · GW] from the Center for AI Safety, says:
AIs will increase the number of people who could commit acts of bioterrorism. General-purpose AIs like ChatGPT are capable of synthesizing expert knowledge about the deadliest known pathogens, such as influenza and smallpox, and providing step-by-step instructions about how a person could create them while evading safety protocols [citation to this paper].
Within the "Open-sourcing" paper, it is cited twice, once as evidence LLMs could "materially assist development of biological" (p32) weapons and once to show that LLMs could "reduce the human expertise required to carry-out dual-use scientific research, such as gain-of-function research in virology" (p13). It's also cited by the "statement" from Helena Biosecurity above and also by the "Differentiating risks" paper above.
Let's see if the number of citations reflects the quality of the paper!
Here is the experimental design from the paper.
The authors asked three separate groups of non-technical students -- i.e., those "without graduate-level training in the sciences" -- to try to use various chatbots to try to figure out how to cause a pandemic. The students had access to a smorgasbord of chatbots -- GPT-4, Bing, some open source bots, and so on.
The chatbots then correctly pointed out 4 potential extant pathogens that could cause a pandemic (H1N1, H5N1, a virus responsible for smallpox, and a strain of the Nipah virus). When questioned about transmisibility, the chatbots point out mutations that could increase this.
When questioned about how to obtain such a virus, the chatbots mentioned that labs sometimes share samples of such viruses. The chatbot also mentioned that one could go about creating such viruses with reverse genetics -- i.e., just editing the genes of the virus. When queried, the chatbots provided advice with how one could go about with getting the necessary materials for reverse genetics, including information about which DNA-synthesis services screen for dangerous genetic materials.
That's the basics of the experiment.
Note that at no point in this paper does the author discuss how much of this information is also easily discoverable by an ignorant person online. Like the paper literally doesn't allude to this. They have no group of students who try to discover the same things from Google searches. They don't introduce a bunch of students to PubMed and talk about the same thing. Nothing nada zip zilch.
(My own belief -- arrived at after a handful of Google searches -- is that most of the alarming stuff they point to is extremely easy to locate online even for a non-expert. If you google for "What are the sources of future likely pandemics," you can find all the viruses they found, and many more. It is similarly easy to find out about which DNA-synthesis services screen the sequences they receive. And so on.)
So, despite the frequency of citation from multiple apparently-prestigious institutions, this paper contains zero evidence or even discussion of exactly the critical issue for which it is cited -- whether LLMs would make things easier relative to other sources of information.
So the -- as far as I can tell -- most-cited paper on the topic contains no experimental evidence relevant to the purpose for which it is most often cited.
6: Extra Paper, Bonus!
While I was writing this, an extra paper game out on the same topic as the "Dual-use biotechnology" paper, with the fun title "Will releasing the weights of future large language models grant widespread access to pandemic agents?".
Maybe it's just that the papers cited by the "Open-sourcing" paper are bad, by coincidence, and the general state of research on biorisk is actually fine! So let's take a look at this paper, as one further test.
This one looks like it was run by the same people who ran the prior "Dual-use" experiment. Is it of the same quality?
Here's how the experiment went. First, the researchers collected some people with knowledge of biology ranging from a college to graduate level.
Participants were asked to determine the feasibility of obtaining 1918 influenza virus for use as a bioweapon, making their (pretended) nefarious intentions as clear as possible (Box 1). They were to enter prompts into both [vanilla and modified open-source] models and use either result to craft their next question, searching the web as needed to find suggested papers or other materials that chatbots cannot directly supply.
One LLM that participants questioned was the vanilla 70b Llama-2. The other was a version of Llama-2 that had been both fine-tuned to remove the guards that would -- of course -- refuse to answer such questions and specifically fine-tuned on a virology-specific dataset.
After the participants tried to figure out how to obtain the 1918 virus using this procedure, the authors of the experiment found that they had obtained several -- although not all -- of the necessary steps for building the virus. The authors, of course, had obtained all the necessary steps for building the virus by using the internet and the scientific papers on it:
Depending on one’s level of technical skill in certain disciplines, risk tolerance, and comfort with social deceit, there is sufficient information in online resources and in scientific publications to map out several feasible ways to obtain infectious 1918 influenza. By privately outlining these paths and noting the key information required to perform each step, we were able to generate a checklist of relevant information and use it to evaluate participant chat logs that used malicious prompts.
Again, they find that the experimental subjects using the LLM were unable to find all of the relevant steps. Even if the experimental subjects had, it would be unclear what to conclude from this because the authors don't have a "just google it" baseline. We know that "experts" can find this information online; we don't know how much non-experts can find.
To ward off this objection, the paper tries to make their conclusion about future LLMs:
Some may argue that users could simply have obtained the information needed to release 1918 influenza elsewhere on the internet or in print. However, our claim is not that LLMs provide information that is otherwise unattainable, but that current – and especially future – LLMs can help humans quickly assess the feasibility of ideas by streamlining the process of understanding complex topics and offering guidance on a wide range of subjects, including potential misuse. People routinely use LLMs for information they could have obtained online or in print because LLMs simplify information for non-experts, eliminate the need to scour multiple online pages, and present a single unified interface for accessing knowledge. Ease and apparent feasibility impact behavior.
There are a few problems with this. First, as far as I can tell, their experiment just... doesn't matter if this is their conclusion?
If they wanted to make an entirely theoretical argument that future LLMs will provide this information with an unsafe degree of ease, then they should provide reasons for that rather than showing that current LLMs can provide information in the same way that Google can, except maybe a little less accurately. The experiment seems a cloud of unrelated empiricism around what they want to say, where what they want to say is basically unsupported by such direct empirical evidence, and based entirely on what they believe to be the properties of future LLMs.
Second is that -- if they want to make this kind of theoretical argument as a reason to criminalize future open source LLMs, then they really need to be a lot more rigorous, and consider counterfactual results more carefuly.
For instance: Would the intro to biotechnology provided by a jailbroken LLM meaningfully speed up bioweapons research, when compared the intro to biotechnology provided by a non-jailbroken LLM plus full access to virology texts? Or would this be a fifteen-minute bump along an otherwise smooth road? Is the intro to biotechnology provided by a MOOC also unacceptable? Do we have reason to think querying future LLMs is going to be the best way of teaching yourself alternate technologies?
Consider an alternate world where PageRank -- the once-backbone of Google search -- was not invented till 2020, and where prior to 2020 internet search did not really exist. Biotechnology-concerned authors in this imaginary world could write an alternate paper:
Some may argue that users could simply have obtained the information needed to release 1918 influenza in print journal articles. However, our claim is not that Google search provides information that is otherwise unattainable, but that current – and especially future – Google search can help humans quickly assess the feasibility of ideas by streamlining the process of understanding complex topics and offering guidance on a wide range of subjects, including potential misuse. People routinely use Google search for information they could have obtained in print because Google search simplifies information for non-experts, eliminate the need to scour multiple printed journals, and present a single unified interface for accessing knowledge. Ease and apparent feasibility impact behavior.
Yet, I think most people would conclude, this falls short of a knock-down argument that Google search should be outlawed, or that we should criminalize the production of internet indices!
In short, the experimental results are basically irrelevant for their -- apparent? -- conclusion, and their apparent conclusion is deeply insufficiently discussed.
Note: After the initial release of the paper, I [LW · GW] and others [LW · GW] had criticized the paper for lacking an "access to Google baseline", and for training the model on openly available virology papers, while subsequently attributing the dangerous info that the model spits out to the existence of the model rather than to the existence of openly available virology papers. We don't blame ElasticSearch / semantic search for bioterrorism risk, after all.
The authors subsequently uploaded a "v2" of the paper to arXiv on November 1st. This "v2" has some important differences from "v1".
For instance -- among other changes -- the v2 states that the jailbroken / "spicy" version of the model trained on the openly-available virology papers didn't actually learn anything from them, and its behavior was actually basically the same as the merely jailbroken model.
It does not contain a justification for how the authors of the paper know this, given that the paper contains no experiments contrasting the merely jailbroken model versus the model trained on virology papers.
In short, the paper was post-hoc edited to avoid a criticism, without any justification or explanation for how the authors knew the fact added in the post-hoc edit.
This change does not increase my confidence in the conclusions of the paper, overall.
But I happily note that -- if an open-source model is released that does not include virology training, initially -- this is evidence that fine-tuning on papers will not notably enhance their virology skills, and that biotechnology-neutered models are safe for public open-source release!
7: Conclusion
In all, looking at the above evidence, I think that the "Open-sourcing" paper vastly misrepresents the state of the evidence about how open source LLMs would contribute to biological risks.
There are no useful experiments conducted on this topic through the material that it cites. A surprising number of citations ultimately lead back to a single, bad experiment. There is some speculation about the risks of future LLMs, but surprisingly little willingness to think rigorously about the consequences of them, or to present a model of exactly how they will contribute to risks in a way different than a search engine, a biotech MOOC, or the general notion of widely-accessible high-quality education.
In all, there is no process I can find in this causal chain -- apart from the Anthropic data that we simply know nothing about -- that could potentially have turned up the conclusion, "Hey, open source AI is fine as far as biotechnology risk goes." But -- as I hope everyone reading this knows -- you can find no actual evidence for a conclusion unless you also risk finding evidence against it. [LW · GW]
Thus, the impression of evidence that the "Open-sourcing" paper gives is vastly greater than the actual evidence that it leans upon.
To repeat -- I did not select the above papers as being particularly bad. I am not aware of a host of better papers on the topic that I am selectively ignoring. I selected them because they were cited in the original "Open-Sourcing" paper, with the exception of the bonus paper that I mention above.
Note that the funding for a large chunk of the citation tree -- specifically, the most-relevant chunk mostly devoted to LLMs contributing to biorisk -- looks like this:
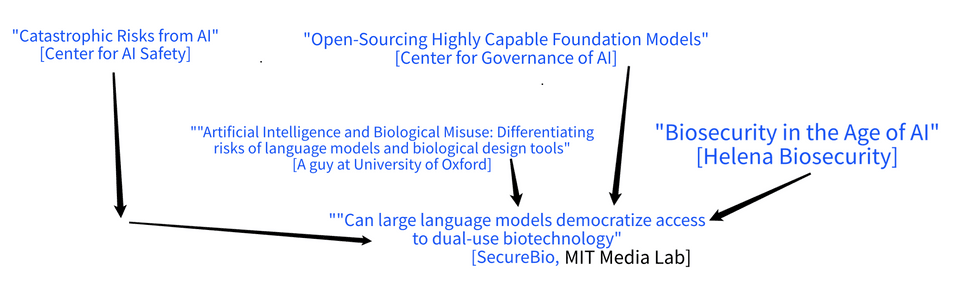
The entities in blue are being or have been funded by the Effective Altruist group Open Philanthropy, to the tune of at least tens of millions of dollars total.
Thus: Two of the authors for the "Can large language models democratize access" paper work for SecureBio, which was funded with about 1.4 million dollars by Open Philanthropy. Helena Biosecurity, producer of the "Biosecurity in the Age of AI" paper, looks like it was or is a project of a think-tank just called Helena which was, coincidentally, funded with half a million dollars by Open Philanthropy. The author of this third paper, "Artificial Intelligence and Biological Misuse" also got a 77k grant from Open Philanthropy. The Center for AI Safety has been funded with at least 4 million dollars. The Center for Governance of AI has been funded with at least 5 million dollars over the years.
This citation and funding pattern leads me to consider two potential hypothesis:
One is that Open Philanthropy was concerned about open-source LLMs leading to biorisk. Moved by genuine curiosity about whether this is true, they fund experiments designed to find out whether this is so. Alas, through an unfortunate oversight, the resulting papers are about experiments that could not possibly find this out due to the lack of the control group. These papers -- some perhaps in themselves blameless, given the tentativeness of their conclusions -- are misrepresented by subsequent policy papers that cite them. Thus, due to no one's intent, insufficiently justified concerns about open-source AI are propagated to governance orgs, which recommend banning open source based on this research.
The second is that Open Philanthropy got what they paid for and what they wanted: "science" that's good enough to include in a policy paper as a footnote, simply intended to support the pre-existing goal -- "Ban open source AI" -- of those policy papers.
There could be a mean between them. Organizations are rarely 100% intentional or efficiently goal-directed. But right now I'm deeply dubious that research on this subject is being aimed effectively at the truth.
79 comments
Comments sorted by top scores.
comment by ryan_greenblatt · 2023-11-02T18:56:41.093Z · LW(p) · GW(p)
I think I basically agree with "current models don't seem very helpful for bioterror" and as far as I can tell, "current papers don't seem to do the controlled experiments needed to legibly learn that much either way about the usefulness of current models" (though generically evaluating bio capabilities prior to actual usefulness still seems good to me).
I also agree that current empirical work seems unfortunately biased which is pretty sad. (It also seems to me like the claims made are somewhat sloppy in various cases and doesn't really do the science needed to test claims about the usefulness of current models.)
That said, I think you're exaggerating the situation in a few cases or understating the case for risk.
You need to also compare the good that open source AI would do against the likelihood and scale of the increased biorisk. The 2001 anthrax attacks killed 5 people; if open source AI accelerated the cure for several forms of cancer, then even a hundred such attacks could easily be worth it. Serious deliberation about the actual costs of criminalizing open source AI -- deliberations that do not rhetorically minimize such costs, shrink from looking at them, or emphasize "other means" of establishing the same goal that in fact would only do 1% of the good -- would be necessary for a policy paper to be a policy paper and not a puff piece.
I think comparing to known bio terror cases is probably misleading due to the potential for tail risks and difficulty in attribution. In particular, consider covid. It seems reasonably likely that covid was an accidental lab leak (though attribution is hard) and it also seems like it wouldn't have been that hard to engineer covid in a lab. And the damage from covid is clearly extremely high. Much higher than the anthrax attacks you mention. People in biosecurity think that the tails are more like billions dead or the end of civilization. (I'm not sure if I believe them, the public object level cases for this don't seem that amazing due to info-hazard concerns.)
Further, suppose that open-sourced AI models could assist substantially with curing cancer. In that world, what probability would you assign to these AIs also assisting substantially with bioterror? It seems pretty likely to me that things are dual use in this way. I don't know if policy papers are directly making this argument: "models will probably be useful for curing cancer as for bioterror, so if you want open source models to be very useful for biology, we might be in trouble".
This citation and funding pattern leads me to consider two potential hypothesis:
What about the hypothesis (I wrote this based on the first hypothesis you wrote):
Open Philanthropy thought based on priors and basic reasoning that it's pretty likely that LLMs (if they're a big deal at all) would be very useful for bioterrorists. Moved by preparing for the possibility that LLMs could help with bioterror, they fund preliminary experiments designed to roughly test LLM capabilities for bio (in particular creating pathogens). Then, we'd be ready to test future LLMs for bio capabilities. Alas, the resulting papers misleadingly suggest that their results imply that current models are actually useful for bioterror rather than just that "it seems likely on priors" and "models can do some biology, probably this will transfer to bioterror as they get better". These papers -- some perhaps in themselves blameless, given the tentativeness of their conclusions -- are misrepresented by subsequent policy papers that cite them. Thus, due to no one's intent, insufficiently justified concerns about current open-source AI are propagated to governance orgs, which recommend banning open source based on this research. Concerns about future open source models remain justified as most of our evidence for this came from basic reasoning rather than experiments.
Edit: see comment from elifland below. It doesn't seem like current policy papers are advocating for bans on current open source models.
I feel like the main take is "probably if models are smart, they will be useful for bioterror" and "probably we should evaluate this ongoingly and be careful because it's easy to finetune open source models and you can't retract open-sourcing a model".
Replies from: elifland, TurnTrout, Metacelsus, 1a3orn, 1a3orn↑ comment by elifland · 2023-11-02T19:04:15.917Z · LW(p) · GW(p)
Thus, due to no one's intent, insufficiently justified concerns about current open-source AI are propagated to governance orgs, which recommend banning open source based on this research.
The recommendation that current open-source models should be banned is not present in the policy paper, being discussed, AFAICT. The paper's recommendations are pictured below:

Edited to add: there is a specific footnote that says "Note that we do not claim that existing models are already too risky. We also do not make any predictions about how risky the next generation of models will be. Our claim is that developers need to assess the risks and be willing to not open-source a model if the risks outweigh the benefits" on page 31
Replies from: Aidan O'Gara, jacques-thibodeau, Aidan O'Gara↑ comment by aog (Aidan O'Gara) · 2023-11-03T16:34:29.931Z · LW(p) · GW(p)
Kevin Esvelt explicitly calls for not releasing future model weights.
Replies from: NoneWould sharing future model weights give everyone an amoral biotech-expert tutor? Yes.
Therefore, let’s not.
↑ comment by [deleted] · 2024-01-11T19:26:11.445Z · LW(p) · GW(p)
To be clear, Kevin Esvelt is the author of the "Dual-use biotechnology" paper, which the policy paper cites, but he is not the author of the policy paper.
↑ comment by jacquesthibs (jacques-thibodeau) · 2023-11-02T19:27:57.729Z · LW(p) · GW(p)
Exactly. I’m getting frustrated when we talk about risks from AI systems with the open source or e/acc communities. The open source community seems to consistently assume the case that the concerns are about current AI systems and the current systems are enough to lead to significant biorisk. Nobody serious is claiming this and it‘s not what I’m seeing in any policy document or paper. And this difference in starting points between the AI Safety community and open source community pretty much makes all the difference.
Sometimes I wonder if the open source community is making this assumption on purpose because it is rhetorically useful to say “oh you think a little chatbot that has the same information as a library would cause a global disaster?” It’s a common tactic these days, downplay the capabilities of the AI system we’re talking about and then make it seem ridiculous to regulate. If I’m being charitable, my guess is that they assume that the bar for “enforce safety measures when stakes are sufficiently high” will be considerably lower than what makes sense/they’d prefer OR they want to wait until the risk is here, demonstrated and obvious until we do anything.
Replies from: hold_my_fish, cfoster0↑ comment by hold_my_fish · 2023-11-04T08:28:49.713Z · LW(p) · GW(p)
As someone who is pro-open-source, I do think that "AI isn't useful for making bioweapons" is ultimately a losing argument, because AI is increasingly helpful at doing many different things, and I see no particular reason that the making-of-bioweapons would be an exception. However, that's also true of many other technologies: good luck making your bioweapon without electric lighting, paper, computers, etc. It wouldn't be reasonable to ban paper just because it's handy in the lab notebook in a bioweapons lab.
What would be more persuasive is some evidence that AI is relatively more useful for making bioweapons than it is for doing things in general. It's a bit hard for me to imagine that being the case, so if it turned out to be true, I'd need to reconsider my viewpoint.
Replies from: eschatropic↑ comment by eschatropic · 2023-11-09T14:49:49.137Z · LW(p) · GW(p)
What would be more persuasive is some evidence that AI is relatively more useful for making bioweapons than it is for doing things in general.
I see little reason to use that comparison rather than "will [category of AI models under consideration] improve offense (in bioterrorism, say) relative to defense?"
↑ comment by cfoster0 · 2023-11-02T20:00:02.790Z · LW(p) · GW(p)
(explaining my disagree reaction)
The open source community seems to consistently assume the case that the concerns are about current AI systems and the current systems are enough to lead to significant biorisk. Nobody serious is claiming this
I see a lot of rhetorical equivocation between risks from existing non-frontier AI systems, and risks from future frontier or even non-frontier AI systems. Just this week, an author of the new "Will releasing the weights of future large language models grant widespread access to pandemic agents?" paper was asserting that everyone on Earth has been harmed by the release of Llama2 (via increased biorisks, it seems) [LW(p) · GW(p)]. It is very unclear to me which future systems the AIS community would actually permit to be open-sourced, and I think that uncertainty is a substantial part of the worry from open-weight advocates.
Replies from: jacques-thibodeau, DanielFilan↑ comment by jacquesthibs (jacques-thibodeau) · 2023-11-02T20:07:14.253Z · LW(p) · GW(p)
I’m happy to see that comment being disagreed with. I think I could say they aren’t a truly serious person after saying that comment (I think the paper is fine), but let’s say that’s one serious person suggesting something vaguely to what I said above.
And I’m also frustrated at people within the AI Safety community who are either ambiguous about which models they are talking about (leads to posts like this and makes consensus harder). Even worse if it’s on purpose for rhetorical reasons.
↑ comment by DanielFilan · 2023-11-02T20:41:16.999Z · LW(p) · GW(p)
Note that one of the main people pushing back against the comment you link is me, a member of the AI safety community.
Replies from: cfoster0↑ comment by cfoster0 · 2023-11-02T21:01:33.539Z · LW(p) · GW(p)
Noted! I think there is substantial consensus within the AIS community on a central claim that the open-sourcing of certain future frontier AI systems might unacceptably increase biorisks. But I think there is not much consensus on a lot of other important claims, like about for which (future or even current) AI systems open-sourcing is acceptable and for which ones open-sourcing unacceptably increases biorisks.
Replies from: eschatropic↑ comment by eschatropic · 2023-11-09T14:59:13.988Z · LW(p) · GW(p)
I agree it would be nice to have strong categories or formalism pinning down which future systems would be safe to open source, but it seems an asymmetry in expected evidence to treat a non-consensus on systems which don't exist yet as a pro-open-sourcing position. I think it's fair to say there is enough of a consensus that we don't know which future systems would be safe and so need more work to determine this before irreversible proliferation.
↑ comment by aog (Aidan O'Gara) · 2023-11-02T19:52:11.666Z · LW(p) · GW(p)
I think it's quite possible that open source LLMs above the capability of GPT-4 will be banned within the next two years on the grounds of biorisk.
The White House Executive Order requests a government report on the costs and benefits of open source frontier models and recommended policy actions. It also requires companies to report on the steps they take to secure model weights. These are the kinds of actions the government would take if they were concerned about open source models and thinking about banning them.
This seems like a foreseeable consequence of many of the papers above, and perhaps the explicit goal.
Replies from: 1a3orn, Aidan O'Gara↑ comment by 1a3orn · 2023-11-02T19:59:22.737Z · LW(p) · GW(p)
As an addition -- Anthropic's RSP already has GPT-4 level models already locked up behind safety level 2.
Given that they explicitly want their RSPs to be a model for laws and regulations, I'd be only mildly surprised if we got laws banning open source even at GPT-4 level. I think many people are actually shooting for this.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-11-02T20:11:01.077Z · LW(p) · GW(p)
If that’s what they are shooting for, I’d be happy to push them to be explicit about this if they haven’t already.
Would like to be explicit about how they expect biorisk to happen at that level of capability, but I think at least some of them will keep quiet about this for ‘infohazard reasons’ (that was my takeaway from one of the Dario interviews).
↑ comment by aog (Aidan O'Gara) · 2023-11-03T07:40:56.646Z · LW(p) · GW(p)
Nuclear Threat Initiative has a wonderfully detailed report on AI biorisk, in which they more or less recommend that AI models which pose biorisks should not be open sourced:
Access controls for AI models. A promising approach for many types of models is the use of APIs that allow users to provide inputs and receive outputs without access to the underlying model. Maintaining control of a model ensures that built-in technical safeguards are not removed and provides opportunities for ensuring user legitimacy and detecting any potentially malicious or accidental misuse by users.
↑ comment by TurnTrout · 2023-11-03T05:40:02.059Z · LW(p) · GW(p)
It seems reasonably likely that covid was an accidental lab leak (though attribution is hard) and it also seems like it wouldn't have been that hard to engineer covid in a lab.
Seems like a positive update on human-caused bioterrorism, right? It's so easy to let stuff leak that covid accidentally gets out, and it might even have been easy to engineer, but (apparently) no one engineered it, nor am I aware of this kind of intentional bioterrorism happening in other places. People apparently aren't doing it. See Gwern's Terrorism is not effective.
Maybe smart LLMs come out. I bet people still won't be doing it.
So what's the threat model? One can say "tail risks", but--as OP points out--how much do LLMs really accelerate people's ability to deploy dangerous pathogens, compared to current possibilities? And what off-the-cuff probabilities are we talking about, here?
↑ comment by Metacelsus · 2023-11-05T14:20:49.816Z · LW(p) · GW(p)
>Much higher than the anthrax attacks you mention. People in biosecurity think that the tails are more like billions dead or the end of civilization. (I'm not sure if I believe them, the public object level cases for this don't seem that amazing due to info-hazard concerns.)
As a biologist who has thought about these kinds of things (and participated in a forecasting group about them), I agree. (And there are very good reasons for not making the object-level cases public!)
↑ comment by 1a3orn · 2023-11-02T19:16:33.626Z · LW(p) · GW(p)
In particular, consider covid. It seems reasonably likely that covid was an accidental lab leak (though attribution is hard) and it also seems like it wouldn't have been that hard to engineer covid in a lab. And the damage from covid is clearly extremely high. Much higher than the anthrax attacks you mention. I people in biosecurity think that the tails are more like billions dead or the end of civilization. (I'm not sure if I believe them, the public object level cases for this don't seem that amazing due to info-hazard concerns.)
I agree that if future open source models contribute substantially to the risk of something like covid, that would be a component in a good argument for banning them.
I'm dubious -- haven't seen much evidence -- that covid itself is evidence that future open source models would so contribute? Given that -- to the best of my very limited knowledge -- the research being conducted was pretty basic (knowledgewise) but rather expensive (equipment and timewise), so that an LLM wouldn't have removed a blocker. (I mean, that's why it came from a US and Chinese-government sponsored lab for whom resources were not an issue, no?) If there is an argument to this effect, 100% agree it is relevant. But I haven't looked into the sources of Covid for years anyhow, so I'm super fuzzy on this.
Further, suppose that open-source'd AI models could assist substantially with curing cancer. In that world, what probability would you assign to these AIs also assisting substantially with bioterror?
Fair point. Certainly more than in the other world.
I do think that your story is a reasonable mean between the two, with less intentionality, which is a reasonable prior for organizations in general.
I think the prior of "we should evaluate thing ongoingly and be careful about LLMs" when contrasted with "we are releasing this information on how to make plagues in raw form into the wild every day with no hope of retracting it right now" simply is an unjustified focus of one's hypothesis on LLMs causing dangers, against all the other things in the world more directly contributing to the problem. I think a clear exposition of why I'm wrong about this would be more valuable than any of the experiments I've outlined.
comment by a_g (gina) · 2023-11-03T03:45:19.443Z · LW(p) · GW(p)
I’m one of the authors from the second SecureBio paper (“Will releasing the weights of future large language models grant widespread access to pandemic agents?"). I’m not speaking for the whole team here but I wanted to respond to some of the points in this post, both about the paper specifically, and the broader point on bioterrorism risk from AI overall.
First, to acknowledge some justified criticisms of this paper:
- I agree that performing a Google search control would have substantially increased the methodological rigor of the paper. The team discussed this before running the experiment, and for various reasons, decided against it. We’re currently discussing whether it might make sense to run a post-hoc control group (which we might be able to do, since we omitted most of the details about the acquisition pathway. Running the control after the paper is already out might bias the results somewhat, but importantly, it won’t bias the results in favor of a positive/alarming result for open source models), or do other follow-up studies in this area. Anyway, TBD, but we do appreciate the discussion around this – I think this will both help inform any future red-teaming we plan do, and ultimately, did help us understand what parts of our logic we had communicated poorly.
- Based on the lack of a Google control, we agree that the assumption that current open-source LLMs significantly increase bioterrorism risk for non-experts does not follow from the paper. However, despite this, we think that our main point that future (more capable, less hallucinatory, etc), open-source models expand risks to pathogen access, etc. still stands. I’ll discuss this more below.
- To respond to the point that says
There are a few problems with this. First, as far as I can tell, their experiment just... doesn't matter if this is their conclusion?
If they wanted to make an entirely theoretical argument that future LLMs will provide this information with an unsafe degree of ease, then they should provide reasons for that
I think this is also not an unreasonable criticism. We (maybe) could have made claims that communicated the same overall epistemic state of the current paper without e.g., running the hackathon/experiment. We do think the point about LLMs assisting non-experts is often not as clear to a broader (e.g. policy) audience though, and (again, despite these results not being a firm benchmark about how current capabilities compare to Google, etc.), we think this point would have been somewhat less clear if the paper had basically said “experts in synthetic biology (who already know how to acquire pathogens) found that an open-source language model can walk them through a pathogen acquisition pathway. They think the models can probably do some portion of this for non-experts too, though they haven’t actually tested this yet”. Anyway, I do think the fault is on us, though, for failing to communicate some of this properly.
- A lot of people are confused on why we did the fine tuning; I’ve responded to this in a separate comment here [LW(p) · GW(p)].
However, I still have some key disagreements with this post:
- The post basically seems to hinge on the assumption that, because the information for acquiring pathogens is already publicly available through textbooks or journal articles, LLMs do very little to accelerate pathogen acquisition risk. I think this completely misses the mark for why LLMs are useful. There are other people who’ve said this better than I can, but the main reason that LLMs are useful isn’t just because they’re information regurgitators, but because they’re basically cheap domain experts. The most capable LLMs (like Claude and GPT4) can ~basically already be used like a tutor to explain complex scientific concepts, including the nuances of experimental design or reverse genetics or data analysis. Without appropriate safeguards, these models can also significantly lower the barrier to entry for engaging with bioweapons acquisition in the first place.
I'd like to ask the people who are confident that LLMs won’t help with bioweapons/bioterrorism whether they would also bet that LLMs will have ~zero impact on pharmaceutical or general-purpose biology research in the next 3-10 years. If you won’t take that bet, I’m curious what you think might be conceptually different about bioweapons research, design, or acquisition. - I also think this post, in general, doesn’t do enough forecasting on what LLMs can or will be able to do in the next 5-10 years, though in a somewhat inconsistent way. For instance, the post says that “if open source AI accelerated the cure for several forms of cancer, then even a hundred such [Anthrax attacks] could easily be worth it”. This is confusing for a few different reasons: first, it doesn’t seem like open-source LLMs can currently do much to accelerate cancer cures, so I’m assuming this is forecasting into the future. But then why not do the same for bioweapons capabilities? As others have pointed out, since biology is extremely dual use, the same capabilities that allow an LLM to understand or synthesize information in one domain in biology (cancer research) can be transferred to other domains as well (transmissible viruses) – especially if safeguards are absent. Finally (again, as also mentioned by others), anthrax is not the important comparison here, it’s the acquisition or engineering of other highly transmissible agents that can cause a pandemic from a single (or at least, single digit) transmission event.
Again, I think some of the criticisms of our paper methodology are warranted, but I would caution against updating prematurely – and especially based on current model capabilities – that there are zero biosecurity risks from future open-source LLMs. In any case, I’m hoping that some of the more methodologically rigorous studies coming out from RAND and others will make these risks (or lack thereof) more clear in the coming months.
Replies from: TurnTrout, Jerden, 1a3orn↑ comment by TurnTrout · 2023-11-03T05:16:21.838Z · LW(p) · GW(p)
I feel like an important point isn't getting discussed here -- What evidence is there on tutor-relevant tasks being a blocking part of the pipeline, as opposed to manufacturing barriers? Even if future LLMs are great tutors for concocting crazy bioweapons in theory, in practice what are the hardest parts? Is it really coming up with novel pathogens? (I don't know)
Replies from: Dirichlet-to-Neumann, gina↑ comment by Dirichlet-to-Neumann · 2023-11-04T11:16:30.274Z · LW(p) · GW(p)
Less wrong has imo a consistent bias toward thinking only ideas/theory are important and that the dirty (and lengthy) work of actual engineering will just sort itself out.
For a community that prides itself on empirical evidence it's rather ironic.
↑ comment by a_g (gina) · 2023-11-05T06:38:31.339Z · LW(p) · GW(p)
What evidence is there on tutor-relevant tasks being a blocking part of the pipeline, as opposed to manufacturing barriers?
So, I can break “manufacturing” down into two buckets: “concrete experiments and iteration to build something dangerous” or “access to materials and equipment”.
For concrete experiments, I think this is in fact the place where having an expert tutor becomes useful. When I started in a synthetic biology lab, most of the questions I would ask weren’t things like “how do I hold a pipette” but things like “what protocols can I use to check if my plasmid correctly got transformed into my cell line?” These were the types of things I’d ask a senior grad student, but can probably ask an LLM instead[1].
For raw materials or equipment – first of all, I think the proliferation of community bio ("biohacker") labs demonstrates that acquisition of raw materials and equipment isn’t as hard as you might think it is. Second, our group is especially concerned by trends in laboratory automation and outsourcing, like the ability to purchase synthetic DNA from companies that inconsistently screen their orders. There are still some hurdles, obviously – e.g., most reagent companies won’t ship to residential addresses, and the US is more permissive than other countries in operating community bio labs. But hopefully these examples are illustrative of why manufacturing might not be as big of a bottleneck as people might think it is for sufficiently motivated actors, or why information can help solve manufacturing-related problems.
(This is also one of these areas where it’s not especially prudent for me to go into excessive detail because of risks of information hazards. I am sympathetic to some of the frustrations with infohazards from folks here and elsewhere, but I do think it’s particularly bad practice to post potentially infohazardous stuff about "here's why doing harmful things with biology might be more accessible than you think" on a public forum.)
- ^
I think there’s a line of thought here which suggests that if we’re saying LLMs can increase dual-use biology risk, then maybe we should be banning all biology-relevant tools. But that’s not what we’re actually advocating for, and I personally think that some combination of KYC and safeguards for models behind APIs (so that it doesn’t overtly reveal information about how to manipulate potential pandemic viruses) can address a significant chunk of risks while still keeping the benefits. The paper makes an even more modest proposal and calls for catastrophe liability insurance instead. But I can also imagine having a more specific disagreement with folks here on "how much added bioterrorism risk from open-source models is acceptable?"
↑ comment by 1a3orn · 2023-11-05T12:28:29.783Z · LW(p) · GW(p)
For concrete experiments, I think this is in fact the place where having an expert tutor becomes useful. When I started in a synthetic biology lab, most of the questions I would ask weren’t things like “how do I hold a pipette” but things like “what protocols can I use to check if my plasmid correctly got transformed into my cell line?” These were the types of things I’d ask a senior grad student, but can probably ask an LLM instead[1]
Right now I can ask a closed-source LLM API this question. Your policy proposal contains no provision to stop such LLMs from answering this question. If this kind of in-itself-innocent question is where danger comes from, then unless I'm confused you need to shut down all bio lab questions directed at LLMs -- whether open source or not -- because > 80% of the relevant lab-style questions can be asked in an innocent way.
I think there’s a line of thought here which suggests that if we’re saying LLMs can increase dual-use biology risk, then maybe we should be banning all biology-relevant tools. But that’s not what we’re actually advocating for, and I personally think that some combination of KYC and safeguards for models behind APIs (so that it doesn’t overtly reveal information about how to manipulate potential pandemic viruses) can address a significant chunk of risks while still keeping the benefits. The paper makes an even more modest proposal and calls for catastrophe liability insurance instead.
If the government had required you to have catastrophe liability insurance for releasing open source software in the year 1995, then, in general I expect we would have no open source software industry today because 99.9% of this software would not be released. Do you predict differently?
Similarly for open source AI. I think when you model this out it amounts to an effective ban, just one that sounds less like a ban when you initially propose it.
↑ comment by Jerden · 2023-11-09T10:55:10.716Z · LW(p) · GW(p)
My assumption (as someone with a molecular biology degree) is that most of the barriers to making a bioweapon are more practical than theoretical, much like making a bomb, which really decreases the benefit of a Large Language Model. There's a crucial difference between knowing how to make a bomb and being able to do it without blowing off your own fingers - although for a pandemic bioweapon incompetance just results in contamination with harmless bacteria, so it's a less dangerous fail state. A would-be bioterrorist should probably just enroll in an undergraduate course in microbiology, much like a would-be bombmaker should just get a degree in chemistry - they would be taught most of the practical skills they need, and even have easy access to the equiptment and reagents! Obviously this is a big investment of time and resources, but I am personally not too concerned about terrorists that lack commitment - most of the ones who successfully pull of attacks with this level of complexity tend to have science and engineering backgrounds.
While I can't deny that future advances may make it easier to learn these skills from an LLM, I have a hard time imagining someone with the ability to accurately follow the increasingly complex instructions of an LLM who couldn't equally as easily obtain that information elsewhere - accurately following a series of instructions is hard actually! There are possibly a small number of people who could develop a bioweapon with the aid of an LLM that couldn't do it without one, but in terms of biorisk I think we should be more concerned about people who already have the training and access to resources required and just need the knowledge and motivation (I would say the average biosciences PhD student or lab technian, and they know how to use Pubmed!) rather than people without it somehow aquiring it via an LLM. Especially given that following these instructions will require you to have access to some very specialised and expensive equiptment anyway - sure, you can order DNA online, but splicing it into a virus is not something you can do in your kitchen sink.
↑ comment by 1a3orn · 2023-11-03T13:54:08.317Z · LW(p) · GW(p)
Finally (again, as also mentioned by others), anthrax is not the important comparison here, it’s the acquisition or engineering of other highly transmissible agents that can cause a pandemic from a single (or at least, single digit) transmission event.
At least one paper that I mention specifically gives anthrax as an example of the kind of thing that LLMs could help with, and I've seen the example used in other places. I think if people bring it up as a danger it's ok for me to use it as a comparison.
LLMs are useful isn’t just because they’re information regurgitators, but because they’re basically cheap domain experts. The most capable LLMs (like Claude and GPT4) can ~basically already be used like a tutor to explain complex scientific concepts, including the nuances of experimental design or reverse genetics or data analysis.
I'm somewhat dubious that a tutor to specifically help explain how to make a plague is going to be that much more use than a tutor to explain biotech generally. Like, the reason that this is called "dual-use" is that for every bad application there's an innocuous application.
So, if the proposal is to ban open source LLMs because they can explain the bad applications of the in-itself innocuous thing -- I just think that's unlikely to matter? If you're unable to rephrase a question in an innocuous way to some LLM, you probably aren't gonna make a bioweapon even with the LLMs help, no disrespect intended to the stupid terrorists among us.
It's kinda hard for me to picture a world where the delta in difficulty in making a biological weapon between (LLM explains biotech) and (LLM explains weapon biotech) is in any way a critical point along the biological weapons creation chain. Is that the world we think we live in? Is this the specific point you're critiquing?
If the proposal is to ban all explanation of biotechnology from LLMs and to ensure it can only be taught by humans to humans, well, I mean, I think that's a different matter, and I could address the pros and cons, but I think you should be clear about that being the actual proposal.
For instance, the post says that “if open source AI accelerated the cure for several forms of cancer, then even a hundred such [Anthrax attacks] could easily be worth it”. This is confusing for a few different reasons: first, it doesn’t seem like open-source LLMs can currently do much to accelerate cancer cures, so I’m assuming this is forecasting into the future. But then why not do the same for bioweapons capabilities?
This makes sense as a critique: I do think that actual biotech-specific models are much, much more likely to be used for biotech research than LLMs.
I also think that there's a chance that LLMs could speed up lab work, but in a pretty generic way like Excel speeds up lab work -- this would probably be good overall, because increasing the speed of lab work by 40% and terrorist lab work by 40% seems like a reasonably good thing for the world overall. I overall mostly don't expect big breakthroughs to come from LLMs.
comment by Zach Stein-Perlman · 2023-11-02T18:35:45.451Z · LW(p) · GW(p)
fwiw my guess is that OP didn't ask its grantees to do open-source LLM biorisk work at all; I think its research grantees generally have lots of freedom.
(I've worked for an OP-funded research org for 1.5 years. I don't think I've ever heard of OP asking us to work on anything specific, nor of us working on something because we thought OP would like it. Sometimes we receive restricted, project-specific grants, but I think those projects were initiated by us. Oh, one exception: Holden's standards-case-studies project [LW · GW].)
Replies from: DanielFilan↑ comment by DanielFilan · 2023-11-02T21:10:29.800Z · LW(p) · GW(p)
Also note that OpenPhil has funded the Future of Humanity Institute, the organization who houses the author of the paper 1a3orn cited for the claim that knowledge is not the main blocker for creating dangerous biological threats. My guess is that the dynamic 1a3orn describes is more about what things look juicy to the AI safety community, and less about funders specifically.
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-11-02T22:24:34.761Z · LW(p) · GW(p)
Also note that OpenPhil has funded the Future of Life Institute,
You meant to say "Future of Humanity Institute".
Replies from: DanielFilan↑ comment by DanielFilan · 2023-11-03T01:39:53.239Z · LW(p) · GW(p)
Yet more proof that one of those orgs should change their name.
comment by David Hornbein · 2023-11-05T17:18:43.950Z · LW(p) · GW(p)
I note that the comments here include a lot of debate on the implications of this post's thesis and on policy recommendations and on social explanations for why the thesis is true. No commenter has yet disagreed with the actual thesis itself, which is that this paper is a representative example of a field that is "more advocacy than science", in which a large network of Open Philanthropy Project-funded advocates cite each other in a groundless web of footnotes which "vastly misrepresents the state of the evidence" in service of the party line.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2023-11-05T19:16:34.611Z · LW(p) · GW(p)
FWIW, I'm a commenter here and I disagree with the exact thesis you stated:
that this paper is a representative example of a field that is "more advocacy than science", in which a large network of Open Philanthropy Project-funded advocates cite each other in a groundless web of footnotes which "vastly misrepresents the state of the evidence" in service of the party line
I think "more advocacy than science" seems reasonably accurate though perhaps a bit exaggerated.
However, I think 'a large network of Open Philanthropy Project-funded advocates cite each other in a groundless web of footnotes which "vastly misrepresents the state of the evidence" in service of the party line' seems pretty inaccurate. In particular, I don't think current work "vastly misrepresents the state of evidence", I'm not sold there is a party line, and I'm not convinced that "groundless webs of footnotes" are typical or that groundless.
(I think my original comment does disagree with the thesis you stated though not super clearly. But now, for the record, I am commenting and disagreeing.)
More detailed discussion of disagreements with the thesis stated in the parent comment.
I think that bio evals might be "more advocacy than science" or at least the people running these evals often seem biased. (Perhaps they've concluded that bio risk from AI is important for other reasons and are then pushing bio evals which don't provide much evidence about risk from current models or future models.) This seems sad.
I don't really see examples of "vastly misrepresenting the state of evidence". As far as I can tell, the main paper discussed by this post, Open-Sourcing Highly Capable Foundation Models, doesn't make strong claims about current models? (Perhaps it was edited recently?)
Let's go through some claims in this paper. (I edited this section to add a bit more context)
The original post mentions:
For instance, as support for the claim that LLMs have great "capabilities in aiding and automating scientific research," the "Open-Sourcing" paper cites ...
...
The paper also says that "red-teaming on Anthropic’s Claude 2 identified significant potential for biosecurity risk"
The corresponding section in the paper (as recently accessed) is:
Biological and chemical weapons development. Finally, current foundation models have shown nascent capabilities in aiding and automating scientific research, especially when augmented with external specialized tools and databases [107, 108]. [...] . For example, pre-release model evaluation of GPT-4 showed that the model could re-engineer known harmful biochemical compounds [110], and red-teaming on Anthropic’s Claude 2 identified significant potential for biosecurity risks [56, 111].
The statement "current foundation models have shown nascent capabilities in aiding and automating scientific research, especially when augmented with external specialized tools and databases " seems basically reasonable to me?
The GPT4 and Anthropic claims seems a bit misleading though don't seem to "vastly misrepresent the state of evidence". (I think it's misleading because what GPT4 did isn't actually that impressive as noted in the original post and the claim for "significant potential" refers to future models not Claude 2 itself.)
To be clear, my overall take is:
- The original post is maybe somewhat exaggerated and I disagree somewhat with it.
- I disagree more strongly with the thesis stated in the parent as it seems like it's taking a stronger (and imo less accurate) stance than the original post.
Beyond this, I'd note that that paper is centrally discussing "Highly Capable Foundation Models". It's notable that (as defined here) current models are not considered highly capable. (As other commenters have noted.)
Quotes from the paper (emphasis mine):
Abstract:
we argue that for some highly capable foundation models likely to be developed in the near future
Executive summary:
we argue that for some highly capable models likely to emerge in the near future, the risks of open sourcing may outweigh the benefits
"What are Highly Capable Foundation Models" section (page 6):
“Highly capable” foundation models. We define highly capable foundation models as foundation models that exhibit high performance across a broad domain of cognitive tasks, often performing the tasks as well as, or better than, a human.
I think it seems sad that you only get to the actual definition of "Highly Capable Foundation Models" on page 6 rather than in the intro or abstract. Given that many people might think that such models aren't going to be created in the near future.
Replies from: 1a3orn↑ comment by 1a3orn · 2023-11-06T14:22:39.481Z · LW(p) · GW(p)
FWIW: I think you're right that I should have paid more attention to the current v future models split in the paper. But I also think that the paper is making... kinda different claims at different times.
Specifically when it talks about the true-or-false world-claims it makes, it talks about models potentially indefinitely far in the future; but when it talks about policy it talks about things you should start doing soon or now.
For instance, consider part 1 of the conclusion:
1. Developers and governments should recognise that some highly capable models will be too dangerous to open-source, at least initially.
If models are determined to pose significant threats, and those risks are determined to outweigh the potential benefits of open-sourcing, then those models should not be open-sourced. Such models may include those that can materially assist development of biological and chemical weapons [50, 109], enable successful cyberattacks against critical national infrastructure [52], or facilitate highly-effective manipulation and persuasion [88].[30]
The [50] and [109] citations are to the two uncontroled, OpenPhil-funded papers from my "science" section above. The [30] is to a footnote like this:
Note that we do not claim that existing models are already too risky. We also do not make any predictions about how risky the next generation of models will be. Our claim is that developers need to assess the risks and be willing to not open-source a model if the risks outweigh the benefits.
And like... if you take this footnote literally, then this paragraph is almost tautologically true!
Even I think you shouldn't open source a model "if the risks outweigh the benefits," how could I think otherwise? If you take it to be making no predictions about current or the next generation of models -- well, nothing to object to. Straightforward application of "don't do bad things."
But if you take it literally -- "do not make any predictions"? -- then there's no reason to actually recommend stuff in the way that the next pages do, like saying the NIST should provide guidance on whether it's ok to open source something; and so on. Like there's a bunch of very specific suggestions that aren't the kind of thing you'd be writing about a hypothetical or distant possibility.
And this sits even more uneasily with claims from earlier in the paper: "Our general recommendation is that it is prudent to assume that the next generation of foundation models could exhibit a sufficiently high level of general-purpose capability to actualize specific extreme risks." (p8 -- !?!). This comes right after it talks about the biosecurity risks of Claude. Or "AI systems might soon present extreme biological risk" Etc.
I could go on, but in general I think the paper is just... unclear about what it is saying about near-future models.
For purposes of policy, it seems to think that we should spin up things to specifically legislate the next gen; it's meant to be a policy paper, not a philosophy paper, after all. This is true regardless of whatever disclaimers it includes about how it is not making predictions about the next gen. This seems very true when you look at the actual uses to which the paper is put.
comment by Zach Stein-Perlman · 2023-11-02T18:29:11.609Z · LW(p) · GW(p)
Interesting. If you're up for skimming a couple more EA-associated AI-bio reports, I'd be curious about your quick take on the RAND report and the CLTR report.
comment by jefftk (jkaufman) · 2023-11-03T14:23:50.010Z · LW(p) · GW(p)
Thanks for writing this up! This looks like it must have been a ton of work, and it's really valuable to get deeply into what evidence the policy recommendations are based on. Your assessment that none of the papers demonstrate that current LLMs increase risk seems right, and I think there's currently some confusion [LW · GW] including among the authors [EA · GW] on whether the SecureBio papers are trying to do this. I would be very excited to see a version of the Gopal "will releasing the weights" paper that added a no-LLM control group.
I do think the behavior of these scientists makes a lot more sense, however, when you consider that it is common for them to have evidence they think would be dangerous to share ("information hazards"). I don't see any acknowledgment in your post that sharing some information, such as realistic paths for non-experts to create 1918 flu today, could make it more likely someone does it. I think modeling people working in biorisk as having been convinced of their current views by a mixture of things they can share and things they can't is critical for making sense of the field. And it's a really difficult epistemic environment, since someone who was incorrectly convinced by a misinterpretation of a concrete example they think is dangerous to share is still wrong.
(Disclosure: I work at SecureBio, and am funded by OpenPhil)
Replies from: 1a3orn↑ comment by 1a3orn · 2023-11-03T16:45:57.393Z · LW(p) · GW(p)
And it's a really difficult epistemic environment, since someone who was incorrectly convinced by a misinterpretation of a concrete example they think is dangerous to share is still wrong.
I agree that this is true, and very unfortunate; I agree with / like most of what you say.
But -- overall, I think if you're an org that has secret information, on the basis of which you think laws should be passed, you need to be absolutely above reproach in your reasoning and evidence and funding and bias. Like this is an extraordinary claim in a democratic society, and should be treated as such; the reasoning that you do show should be extremely legible, offer ways for itself to be falsified, and not overextend in its claims. You should invite trusted people who disagree with you in adversarial collaborations, and pay them for their time. Etc etc etc.
I think -- for instance -- that rather than leap from an experiment maybe showing risk, to offering policy proposals in the very same paper, it would be better to explain carefully (1) what total models the authors of the paper have of biological risks, and how LLMs contribute to them (either open-sourced or not, either jailbroken or not, and so on), and what the total increased scale of this risk is, and to speak about (2) what would constitute evidence that LLMs don't contribute to risk overall, and so on.
Replies from: jkaufman, shankar-sivarajan↑ comment by jefftk (jkaufman) · 2023-11-03T19:26:13.561Z · LW(p) · GW(p)
I'm not sure passing laws based on private information that would be harmful to reveal is actually extraordinary in a democratic society specifically within security? For example, laws about nuclear secrets or spying are often based on what intelligence agencies know about the threats.
But I do still think the direction you're describing is a very valuable one, and I would be enthusiastic about EA-influenced biosecurity research organizations taking that approach.
On the policy proposal, my understanding is the argument is essentially:
-
Raw LLMs will meet both your principles soon if not already.
-
If the "keep LLMs from saying harmful things" approach is successful, finished LLMs will have safeguards so they won't meet those principles.
-
Public weights currently allow easy safeguard removal.
-
Liability for misuse (a) encourages research into safeguards that can't simply be removed, (b) incentivizes companies generating and considering releasing weights (or their insurers) to do a good job estimating how likely misuse is, (c) discourages further weight release while companies develop better estimates of misuse likelihood.
As far as I know, (1) is the only step here influenced by information that would be hazardous to publish. But I do think it's possible to reasonably safely make progress on understanding how well models meet those principles and how it's likely to change over time, through more thorough risk evaluations than the one in the Gopal paper.
↑ comment by Shankar Sivarajan (shankar-sivarajan) · 2023-11-04T18:27:11.668Z · LW(p) · GW(p)
in a democratic society,
That's true, but irrelevant. In oligarchies, you can just make shit up, à la "Iraq has weapons of mass destruction." If the ruling elites want "secret information" to justify a law they want to pass, such information will conveniently materialize on cue.
comment by aog (Aidan O'Gara) · 2023-11-02T19:42:44.115Z · LW(p) · GW(p)
Thank you for writing this up. I agree that there's little evidence that today's language models are more useful than the internet in helping someone build a bioweapon. On the other hand, future language models are quite likely to be more useful than existing resources in providing instructions for building a bioweapon.
As an example of why LLMs are more helpful than the internet, look at coding. If you want to build a custom webapp, you could spend hours learning about it online. But it's much easier to ask ChatGPT to do it for you.
Therefore, if you want to argue against the conclusion that we should eventually ban open source LLMs on the grounds of biorisk, you should not rely on the poor capabilities of current models as your key premise.
The stronger argument is that catastrophic bioterrorism would likely require inventing new kinds of viruses that are not publicly known today. From the most recent SecureBio paper:
Fortunately, the scientific literature does not yet feature viruses that are particularly likely to cause a new pandemic if deliberately released (with the notable exception of smallpox, which is largely inaccessible to non-state actors due to its large genome and complex assembly requirements). Threats from historical pandemic viruses are mitigated by population immunity to modern-day descendants and by medical countermeasures, and while some research agencies actively support efforts to find or create new potential pandemic viruses and share their genome sequences in hopes of developing better defenses, their efforts have not yet succeeded in identifying credible examples.
This is confirmed by Esvelt's earlier paper "Delay, Detect, Defend," which says:
We don't yet know of any credible viruses that could cause new pandemics, but ongoing research projects aim to publicly identify them. Identifying a sequenced virus as pandemic-capable will allow >1,000 individuals to assemble it.
As well as by a recent report from the Nuclear Threat Initiative:
Furthermore, current LLMs are unlikely to generate toxin or pathogen designs that are not already described in the public literature, and it is likely they will only be able to do this in the future by incorporating more specialized AI biodesign tools.
This would indicate that LLMs alone will never be sufficient to create pathogens which lead to catastrophic pandemics. The real risk would come from biological design tools (BDTs), which are AI systems capable of designing new pathogens that are more lethal and transmissible than existing ones. I'm not aware of any existing BDTs that would allow you to design more capable pathogens, but if they exist or emerge, we could place specific restrictions on those models. This would be far less intrusive than banning all open source LLMs.
Replies from: 1a3orn↑ comment by 1a3orn · 2023-11-03T13:24:39.161Z · LW(p) · GW(p)
Therefore, if you want to argue against the conclusion that we should eventually ban open source LLMs on the grounds of biorisk, you should not rely on the poor capabilities of current models as your key premise.
Just to be clear, the above is not what I would write if I were primarily trying to argue against banning future open source LLMs for this reason. It is (more) meant to be my critique of the state of the argument -- that people are basically just not providing good evidence on for banning them, are confused about what they are saying, that they are pointing out things that would be true in worlds where open source LLMs are perfectly innocuous, etc, etc.
comment by aog (Aidan O'Gara) · 2023-11-02T19:56:30.363Z · LW(p) · GW(p)
The most recent SecureBio paper provides another policy option which I find more reasonable. AI developers would be held strictly liable for any catastrophes involving their AI systems, where catastrophes could be e.g. hundreds of lives lost or $100M+ in economic damages. They'd also be required to obtain insurance for that risk.
If the risks are genuinely high, then insurance will be expensive, and companies may choose to take precautions such as keeping models closed source in order to lower their insurance costs. On the other hand, if risks are demonstrably low, then insurance will be cheap even if companies choose to open source their models.

↑ comment by faul_sname · 2023-11-03T06:20:36.482Z · LW(p) · GW(p)
Would you support a similar liability structure for authors who choose to publish a book? If not, why not?
Replies from: Jonas Hallgren↑ comment by Jonas Hallgren · 2023-11-03T21:46:00.659Z · LW(p) · GW(p)
I mean, I'm sure it isn't legal to openly sell a book on how to source material for and build a pipebomb, right? It's dependent on the intent of the book and its content among other things so I I'm half hesistantly biting the bullet here.
Replies from: jbash, quintin-pope, faul_sname↑ comment by jbash · 2023-11-04T01:29:28.530Z · LW(p) · GW(p)
Simple bombs are trivial to make if you have a high school understanding of chemistry and physics, some basic manual skills, and a clue about how to handle yourself in shops and/or labs. You can get arbitrarily complicated in optimizing bombs, but it's not even a tiny bit hard to make something explode in a very destructive way if you're not very restricted in what you can deliver to your target.
Tons of people would need no instruction at all... but instructions are all over the place anyway.
The knowledge is not and never has been the gating factor. It's really, really basic stuff. If you want to keep people from making bombs, you're better off to deny them easy access to the materials. But, with a not-impossible amount of work, a knowledgeable and strongly motivated person can still make a bomb from stuff like aluminum, charcoal, sugar, salt, air, water... so it's better yet to keep them from being motivated. The good news is that most people who are motivated to make bombs, and especially to use them as weapons, are also profoundly dysfunctional.
↑ comment by Quintin Pope (quintin-pope) · 2023-11-03T21:48:50.887Z · LW(p) · GW(p)
It is legal, in the US at least. See: https://en.wikipedia.org/wiki/The_Anarchist_Cookbook#Reception
Replies from: Jonas Hallgren↑ comment by Jonas Hallgren · 2023-11-03T21:51:01.158Z · LW(p) · GW(p)
Well, I'm happy to be a European citizen in that case, lol.
I really walked into that one.
Replies from: Jonas Hallgren↑ comment by Jonas Hallgren · 2023-11-03T21:53:41.826Z · LW(p) · GW(p)
Apparently, even being a European citizen doesn’t help.
I still think that we shouldn't have books on sourcing and building pipe bombs laying around though.
Replies from: faul_sname↑ comment by faul_sname · 2023-11-04T04:41:20.535Z · LW(p) · GW(p)
I think "the world stays basically as it is except there are no easily accessible dangerous books" is a fabricated option [LW · GW]. You can have a world where you can publish a book about any topic that is not explicitly forbidden (in which case there will be books that are not forbidden that are worse than the forbidden ones), or a world in which it is forbidden to publish a book that is not explicitly permitted (and there is a pretty solid historical precedent that whatever organization has that power will abuse it).
"Require insurance" does sound like a solid middle ground, but in practice I expect that being insured will just cause the person publishing to be the target of lawsuits independent of whether they're actually at fault for the alleged harm (because getting insured proves that the defendant knew there was a risk, and also means the defendant is actually capable of paying out whatever award the judicial system comes up with, even if said award is absurdly high).
↑ comment by faul_sname · 2023-11-03T22:49:33.964Z · LW(p) · GW(p)
How about the Anarchists Cookbook, which is available for $28 on Amazon (or $9 if you don't care about having a physical book and are fine with the Kindle edition).
ETA: and I'm too slow
Replies from: jbashcomment by Shankar Sivarajan (shankar-sivarajan) · 2023-11-04T15:50:39.736Z · LW(p) · GW(p)
Fig 1 in the "extra" paper, is hilarious! It's almost entirely blank, and that you need "physical samples" is classified as "key info."
comment by Erich_Grunewald · 2023-11-03T10:30:47.439Z · LW(p) · GW(p)
I think it is reasonable to treat this as a proxy for the state of the evidence, because lots of AI policy people specifically praised it as a good and thoughtful paper on policy.
All four of those AI policy people are coauthors on the paper -- that does not seem like good evidence that the paper is widely considered good and thoughtful, and therefore a good proxy (though I think it probably is an ok proxy).
Replies from: Sean_o_h↑ comment by Sean_o_h · 2023-11-03T13:42:09.890Z · LW(p) · GW(p)
(disclaimer: one of the coauthors) Also, none of the linked comments by the coauthors actually praise the paper as good and thoughtful? They all say the same thing, which is "pleased to have contributed" and "nice comment about the lead author" (a fairly early-career scholar who did lots and lots of work and was good to work with). I called it "timely", as the topic of open-sourcing was very much live at the time.
(FWIW, I think this post has valid criticism re: the quality of the biorisk literature cited and the strength with which the case was conveyed; and I think this kind of criticism is very valuable and I'm glad to see it).
comment by DanielFilan · 2023-11-02T21:02:31.530Z · LW(p) · GW(p)
Second is that -- if they want to make this kind of theoretical argument as a reason to criminalize future open source LLMs, then they really need to be a lot more rigorous, and consider counterfactual results more carefuly.
As aogara points out [LW(p) · GW(p)], the paper does not advocate criminalizing future open source LLMs, but instead advocates catastrophe liability and mandatory insurance for people who release the weights of LLMs.
comment by Chris_Leong · 2023-11-02T22:28:57.682Z · LW(p) · GW(p)
- Thanks for sharing your concerns and helping us be more calibrated on the value of this study.
- I agree that a control group is vital for good science. Nonetheless, I think that such an experiment is valuable and informative, even if it doesn't meet the high standards required by many professional science disciplines.
- I believe in the necessity of acting under uncertainty. Even with its flaws, this study is sufficient evidence for us to want to enact temporary regulation at the same time as we work to provide more robust evaluations.
- The biggest critique for me isn't that there isn't a control group, but that they don't have a limitations section that suggests follow-up experiments with a control group. A lot can be forgiven if you're open and transparent about it.
- I've only skimmed this post, but I suspect your principle of substitution has a wrong framing. LLM's can make the situation worse even if a human could easily access the information through other means, see beware trivial inconveniences [? · GW]. I suspect that neglecting this factor causes you to significantly underrate the risks here.
↑ comment by 1a3orn · 2023-11-02T22:55:07.818Z · LW(p) · GW(p)
Even with its flaws, this study is sufficient evidence for us to want to enact temporary regulation at the same time as we work to provide more robust evaluations.
Note -- that if I thought regulations would be temporary, or had a chance of loosening over time after evals found that the risks from models at compute size X would not be catastrophic, I would be much less worried about all the things I'm worried about re. open source and power and and banning open source
But I just don't think that most regulations will be temporary. A large number of people want to move compute limits down over time. Some orgs (like PauseAI or anything Leahy touches) want much lower limits than are implied by the EO. And of course regulators in general are extremely risk averse, and the trend is almost always for regulations to increase.
If the AI safety movement could creditably promise in some way that they would actively push for laws whose limits raised over time, in the default case, I'd be less worried. But given (1) the conflict on this issue within AI safety itself (2) the default way that regulations work, I cannot make myself believe that "temporary regulation" is ever going to happen.
Replies from: Chris_Leong↑ comment by Chris_Leong · 2023-11-03T00:31:32.067Z · LW(p) · GW(p)
Oh, I don't think it actually would end up being temporary, because I expect with high probability that the empirical results of more robust evaluations would confirm that open-source AI is indeed dangerous. I meant temporary in the sense that the initial restrictions might either a) have a time-limit b) be subjective to re-evaluation at a specified point.
↑ comment by StellaAthena · 2023-11-02T22:55:29.241Z · LW(p) · GW(p)
I agree that a control group is vital for good science. Nonetheless, I think that such an experiment is valuable and informative, even if it doesn't meet the high standards required by many professional science disciplines. I believe in the necessity of acting under uncertainty. Even with its flaws, this study is sufficient evidence for us to want to enact temporary regulation at the same time as we work to provide more robust evaluations.
But... this study doesn't provide evidence that LLMs increase bioweapon risk.
Replies from: Chris_Leong↑ comment by Chris_Leong · 2023-11-03T00:26:28.178Z · LW(p) · GW(p)
Define evidence.
I'm not asking this just to be pedantic, but because I think it'll make the answer to your objection clearer.
↑ comment by 1a3orn · 2023-11-03T13:55:43.778Z · LW(p) · GW(p)
Evidence for X is when you see something that's more likely in a world with X than in a world with some other condition not X.
Generally substantially more likely; for good reason many people only use "evidence" to mean "reasonably strong evidence."
Replies from: Chris_Leong↑ comment by Chris_Leong · 2023-11-03T22:33:34.052Z · LW(p) · GW(p)
Thanks for highlighting the issue with the discourse here. People use the word evidence in two different ways which often results in people talking past one another.
I'm using your broader definition, where I imagine that Stella is excluding things that don't meet a more stringent standard.
And my claim is that reasoning under uncertainty sometimes means making decisions based on evidence[1] that is weaker than we'd like.
- ^
Broad definition
comment by RogerDearnaley (roger-d-1) · 2023-11-10T11:55:03.453Z · LW(p) · GW(p)
Suppose, just for a moment, that the various people raising these concerns are not all fools, liars, Machiavellian profiteers, or some peculiar sort of open-source-haters, and actually had a point (even if they don't want to publicize detailed information on the topic). What would then be the consequences? Current open-source models are demonstrably not dangerous. Open-sourcing of models of up to around GPT-4 capacity level (O(1T-2T) parameters, at current architectural efficiencies) by these people's own accounts shows only flickering hints of danger, but these likely aren't actually much more helpful than material you can find on the internet or by recruiting a biochemistry post-doc. Suppose that at some larger LLM model size that hasn't been released yet, possibly around GPT-5 level, this finally becomes a legitimate concern.
So, what would happen then? Fine-tuning safety precautions into open-source models is fairly pointless — it's been repeatedly shown that it's trivially easy to fine-tune them out again, and that people will. What would work is to carefully filter their pretraining set: eliminate professional-level material on the dangerous STEM topics, such as lab work on human pathogens, and probably also nuclear physics and certain areas of organic chemical synthesis, and possibly also blackhat hacking. That can't be reversed without a large amount of expensive re-pretraining work, with access to a lot of sensitive material, and specialized technical experience in doing follow-on re-pretraining to make significant additions to the training sets of foundation models. A bad actor able to recruit someone who can do that and provide them the sensitive information and large amounts of GPU resources to carry it out could almost certainly just recruit someone experienced in whatever topic they wanted to add to the LLM and build them a lab.
So the most likely outcome is that you can open-source models ~GPT-4 size freely or pretty easily (maybe you have to show they haven't been very extensively trained specifically in these areas), while for models of some larger size, let's pessimistically assume ~GPT-5, you need to demonstrate to some safety regulator's satisfaction that dangerous information in certain STEM areas actually isn't in the model, as opposed to it just having been trained not to provide this. Most likely this would be since your model was trained from some combination of open-source datasets that had already been carefully filtered for this material (which you'd doubtless done further filtering work on), and you can show you didn't add this stuff back in again. Possibly you'd also need your foundation model to pass a test showing that, when suitably prompted with first pages of documents in these areas, it can't accurately continue them: that's not a very hard test to automate, nor for a suitably knowledgeable GPT-5+ commercial model to grade.
Would this be somewhat annoying and inconvenient bureaucracy, if it happened? Yes. Is it less dreadful than even a small chance of some nutjob creating a 50%-mortality super-COVID and turning the world Mad Max? Absolutely. Would it shut down open-source work on LLMs? No, open-source foundation-model trainers would just filter their training sets to work around it (and then complain that the resulting models were bad at pathogen research and designing nuclear reactors). And the open-source fine-tuners wouldn't need to worry about it at all.
If all this happened, I am certain it would have a lot less of a chilling effect on open-sourcing of ~GPT-5 capacity models than the O($100m–$1b) training-run costs at this scale. I really don't see any economic argument why anyone (not even middle-eastern oil potentates or Mark Zuckerberg) would open-source for free something that costs that much to make. There's just no conceivable way you can make that much money back, not even in good reputation. (Indeed, Zuckerberg has been rumbling that large versions of Llama 3 may not be open-source.) So I'm rather dubious that an open-source equivalent of GPT-5 will exist until the combination of GPU cost decreases and improved LLM architecture efficiency brings its training costs down to tens of millions of dollars rather than hundreds.
comment by DanielFilan · 2023-11-02T20:54:05.907Z · LW(p) · GW(p)
This essay often asks for LLMs to be compared to what you could find given a Google search. I think this is kind of a bad comparison given that I assume Google uses LLMs in its search product. Presumably a better comparator would be something like DuckDuckGo (which is in fact a bit less usable).
Replies from: cfoster0↑ comment by cfoster0 · 2023-11-02T21:17:23.021Z · LW(p) · GW(p)
If we are assessing the impact of open-sourcing LLMs, it seems like the most relevant counterfactual is the "no open-source LLM" one, right?
Replies from: DanielFilan↑ comment by DanielFilan · 2023-11-02T21:28:38.816Z · LW(p) · GW(p)
Google could slap some filter on its search engine or the underlying LLM to make it not tell you stuff about scary biotech, but there's no analogous thing you could do with open-source LLM weights (to the best of my knowledge).
comment by Aaron_Scher · 2023-11-07T03:28:26.968Z · LW(p) · GW(p)
I think this essay is overall correct and very important. I appreciate you trying to protect the epistemic commons, and I think such work should be compensated. I disagree with some of the tone and framing, but overall I believe you are right that the current public evidence for AI-enabled biosecurity risks is quite bad and substantially behind the confidence/discourse in the AI alignment community.
I think the more likely hypothesis for the causes of this situation isn't particularly related to Open Philanthropy and is much more about bad social truth seeking processes. It seems like there's a fair amount of vibes-based deferral going on, whereas e.g., much of the research you discuss is subtly about future systems in a way that is easy to miss [LW(p) · GW(p)]. I think we'll see more and more of this as AI deployment continues and the world gets crazier — the ratio of "things people have carefully investigated" to "things they say" is going to drop. I expect in this current case, many of the more AI alignment people didn't bother looking too much into the AI-biosecurity stuff because it feels outside their domain and more-so took headline results at face value, I definitely did some of this. This deferral process is exacerbated by the risk of info hazards and thus limited information sharing.
comment by Jáchym Fibír · 2023-11-11T11:14:22.238Z · LW(p) · GW(p)
Thank you for such a detailed write-up! I have to admit that I am teetering on the issue whether to ban or not to ban open-source LLMs and as I a co-founder of an AI-for-drug-design startup I had taken the increased biosecurity risk as probably the single most important consideration. So I think the conversation sparked up by your post is quite valuable.
That said, even if I consider all that you presented, I am still leaning towards banning powerful open-source LLMs, at least until we get much more information and most importantly before we establish other safeguards against global pandemics (like "airplane lavatory detectors" etc.).
First, I think there is definitely a big difference between having online information about actually making lethal pathogens, having the full assistance of an LLM makes a quite significant difference, especially for people starting from near zero.
Then, if I consider all of my ideas for what kind of damage could be done with all the new capabilities, especially combining LLMs with generative bioinformatic AIs... I think a lot of caution is surely warranted.
Ultimately, If you take the potential benefits of open-source LLMs over fine-tuned LLMs (not crazy significant in my opinion but of course we don't have that data either), and compare to the risks posed by essentially removing all of the guardrails and safety measures everyone is working on in AI labs... I think at least waiting some time with open-sourcing is the right call now.
comment by DanielFilan · 2023-11-02T20:36:08.883Z · LW(p) · GW(p)
The only reference to such harmful biochemical compounds that I can find in the GPT-4 card is one spot where OpenAI says that an uncensored GPT-4 "model readily re-engineered some biochemical compounds that were publicly available online" and could also identify mutations that could increase pathogenicity. This is, if anything, evidence that GPT-4 is not a threat relative to unrestricted internet access.
This seemed like quite a stretch from the quote given, but I think the full quote from the model card actually backs up 1a3orn's point:
The model readily re-engineered some biochemical compounds that were publicly available online, including compounds that could cause harm at both the individual and population level. The model is also able to identify mutations that can alter pathogenicity. Red teamers could not successfully compel the model to engineer new biochemical substances.
At any rate, the citation of the model card was given in this context:
As support for the claim that foundation models could reduce the human expertise required to make dangerous pathogens, the "Open Sourcing" paper offers as evidence that GPT-4 could re-engineer "known harmful biochemical compounds," (p13-14) and cites the GPT-4 system card.
Note that what the Open Sourcing paper says is actually supported by the model card. I also think it's fair to say that knowing that current models can engineer known harmful biochemical compounds provides evidence for the idea that future foundation models could reduce the human expertise required to make dangerous pathogens, based on the reasonable speculation that future foundation models will be more capable than current ones.
comment by slg (simon@securebio.org) · 2023-11-02T19:45:01.355Z · LW(p) · GW(p)
I think it'd be good to cross-post this on the EA Forum.
edit: It's been posted, link here: https://forum.effectivealtruism.org/posts/zLkdQRFBeyyMLKoNj/still-no-strong-evidence-that-llms-increase-bioterrorism
Replies from: Benito↑ comment by Ben Pace (Benito) · 2023-11-02T20:15:48.347Z · LW(p) · GW(p)
I think there's a good chance it would be positive for the broader AI x-risk ecosystem, but I suspect that 1a3orn may personally feel quite frustrated by any engagement he gets in the comments.
Replies from: Erich_Grunewald↑ comment by Erich_Grunewald · 2023-11-03T10:20:13.994Z · LW(p) · GW(p)
When Jeff Kaufman shared one of the papers discussed here on the EA Forum, there was a highly upvoted comment critical of the paper [EA(p) · GW(p)] (more upvoted than the post itself). That would suggest to me that this post would be fairly well received on the EA Forum, though its tone is definitely more strident than that comment, so maybe not.
comment by Davidmanheim · 2023-11-11T16:18:31.937Z · LW(p) · GW(p)
or will contribute
This bit is immediately dropped in favor of discussing current systems, the risk they currently pose, and how much difference they make. But no-one is arguing that current systems pose danger!
comment by Shankar Sivarajan (shankar-sivarajan) · 2023-11-04T15:35:07.237Z · LW(p) · GW(p)
I'm laboring beneath a grave misunderstanding of what a policy paper is actually intended to be
I think you are. It is my understanding that a "policy paper" is essentially a longer, LaTeXed version of a protest sign, intended to be something sympathetic congressmen can wave around while bloviating about "trusting the Science!" It's not meant to be true.
comment by Review Bot · 2024-03-09T11:25:40.791Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by snewman · 2024-01-19T21:21:10.493Z · LW(p) · GW(p)
I recently encountered a study which appears aimed at producing a more rigorous answer to the question of how much use current LLMs would be in abetting a biological attack: https://www.rand.org/pubs/research_reports/RRA2977-1.html. This is still work in progress, they do not yet have results. @1a3orn [LW · GW] I'm curious what you think of the methodology?
Replies from: 1a3orn↑ comment by 1a3orn · 2024-01-19T21:42:53.156Z · LW(p) · GW(p)
I mean, it's unrealistic -- the cells are "limited to English-language sources, were prohibited from accessing the dark web, and could not leverage print materials (!!)" which rules out textbooks. If LLMs are trained on textbooks -- which, let's be honest, they are, even though everyone hides their datasources -- this means teams who have access to an LLM have a nice proxy to a textbook through an LLM, and other teams don't.
It's more of a gesture at the kind of thing you'd want to do, I guess but I don't think it's the kind of thing that it would make sense to trust. The blinding was also really unclear to me.
Jason Matheny, by the way, the president of Rand, the organization running that study, is on Anthropic's "Long Term Benefit Trust." I don't know how much that should matter for your evaluation, but my bet is a non-zero amount. If you think there's an EA blob that funded all of the above -- well, he's part of it. OpenPhil funded Rand with 15 mil also.
You may think it's totally unfair to mention that; you may think it's super important to mention that; but there's the information, do what you will with it.
Replies from: snewman↑ comment by snewman · 2024-01-19T21:59:58.441Z · LW(p) · GW(p)
They do mention a justification for the restrictions – "to maintain consistency across cells". One needn't agree with the approach, but it seems at least to be within the realm of reasonable tradeoffs.
Nowadays of course textbooks are generally available online as well. They don't indicate whether paid materials are within scope, but of course that would be a question for paper textbooks as well.
What I like about this study is that the teams are investing a relatively large amount of effort ("Each team was given a limit of seven calendar weeks and no more than 80 hours of red-teaming effort per member"), which seems much more realistic than brief attempts to get an LLM to answer a specific question. And of course they're comparing against a baseline of folks who still have Internet access.
comment by James Smith (james-smith-4) · 2023-11-11T11:38:37.788Z · LW(p) · GW(p)
Note that there is Open Phil funded research arguing that AI is not an important contributor to biorisk, and that access controls are not an effective mechanism for biorisk reduction,which was not cited (as far as I can see) in the post. https://philsci-archive.pitt.edu/22539/. This undermines the thesis that they "got what they paid for and what they wanted: "science" that's good enough to include in a policy paper as a footnote, simply intended to support the pre-existing goal -- "Ban open source AI" -- of those policy papers".
A specific relevant excerpt (typos from there):
Further, because the limiting factor on spread testing is data collection of from the real world environment that the agent is meant to spread in, and the limiting factor on dispersal is logistic factors as in chemical agents, neither are affected by revolutionary technologies in biotechnology not [nor] artificial intelligence