Posts
Comments
Whoa, I hadn't realized you'd originated the term "anti-inductive"! Scott apparently didn't realize he was copying this from you, and neither I nor anyone else apparently realized this was your single-point-of-origin coinage, either.
Politics isn't quite a market for mindshare, as there are coercive equilibria at play. But I think it's another arena that can accurately be called anti-inductive. "This is an adversarial epistemic environment, therefore tune up your level of background assumption that apparent opportunity is not real" has [usefully IMO] become a central reflex of thought for me over the last few years. But to my surprise the phrase "politics is anti-inductive" turns up zero Google results except for this Tweet.
Subjectively assessed value. This judgment cannot be abdicated.
If you can't generate your parents' genomes and everything from memory, then yes, you are in a state of uncertainty about who they are, in the same qualitative way you are in a state of uncertainty about who your young children will grow up to be.
Ditto for the isomorphism between your epistemic state w.r.t. never-met grandparents vs your epistemic state w.r.t. not-yet-born children.
It may be helpful to distinguish the subjective future, which contains the outcomes of all not-yet-performed experiments [i.e. all evidence/info not yet known] from the physical future, which is simply a direction in physical time.
We can hardly establish the sense of anthropic reasoning if we can't establish the sense of counterfactual reasoning.
A root confusion may be whether different pasts could have caused the same present, and hence whether I can have multiple simultaneous possible parents, in an "indexical-uncertainty" sense, in the same way that I can have multiple simultaneous possible future children.
The same standard physics theories that say it's impossible to be certain about the future, also say it's impossible to be certain about the past.
Indexical uncertainty about the past may not be true, but you can't reject it without rejecting standard physics.
And if there is no indexical uncertainty and all counterfactuals are logical counterfactuals and/or in some sense illusory - well, we're still left uncomfortably aware of our subjective inability to say exactly what the future and past are and why exactly they must be that way.
thus we can update away from the doomsday argument, because we have way more evidence than the doomsday argument assumes.
I agree with this!
"Update away from" does not imply "discard".
alignment researchers are clearly not in charge of the path we take to AGI
If that's the case, we're doomed no matter what we try. So we had better back up and change it.
Don't springboard by RLing LLMs; you will get early performance gains and alignment will fail. We need to build something big we can understand. We probably need to build something small we can understand first.
I expect any tests to show unambiguously that it's "not being replaced at all and citations[/mentions] chaotically swirling". If I understand Evans correctly, these were all random eminent figures he picked, not selected to be falling out of fashion - and they do seem to be a pretty broad sample of the "old prestigious standard names" space.
The stand mixer is a clever analogy; I didn't previously have experience with the separation thing.
I presume you've seen Is Clickbait Destroying Our General Intelligence?, and probably Hanson's cultural evolution / cultural drift frame. I wonder if you're familiar with Callard's Distant Signals paradigm [ transcript available on episode page ], which I think is the most illuminating of the three.
Besides just the cost of ~instantaneous ~omnicast communication dropping to ~zero, I see a role for the fall of the gold standard in all this. See e.g. U.S. per capita energy usage since ~1970, international fertility since ~1970. My theory [ which I really need to make a more legible graphic for ] is that when people don't "own their money" and have to track the effects of distant inflation-adjusts from the Fed, inflation volatility [ the destructive macroeconomic thing this OP on /r/badeconomics is saying couldn't possibly be happening due to the fall of the gold standard ] goes way up. Incentives in the market for ideas are ultimately material [yes, virtual status goods influence material wealth, but it also goes the other way around], so the market for materials influences the market for ideas, and vice versa, in a vicious spiral of decline. Is the theory.
[ Look at those same authors with some other mention-counting tool, you mean? ]
Interesting question: why are people quickly becoming less interested in previous standards?
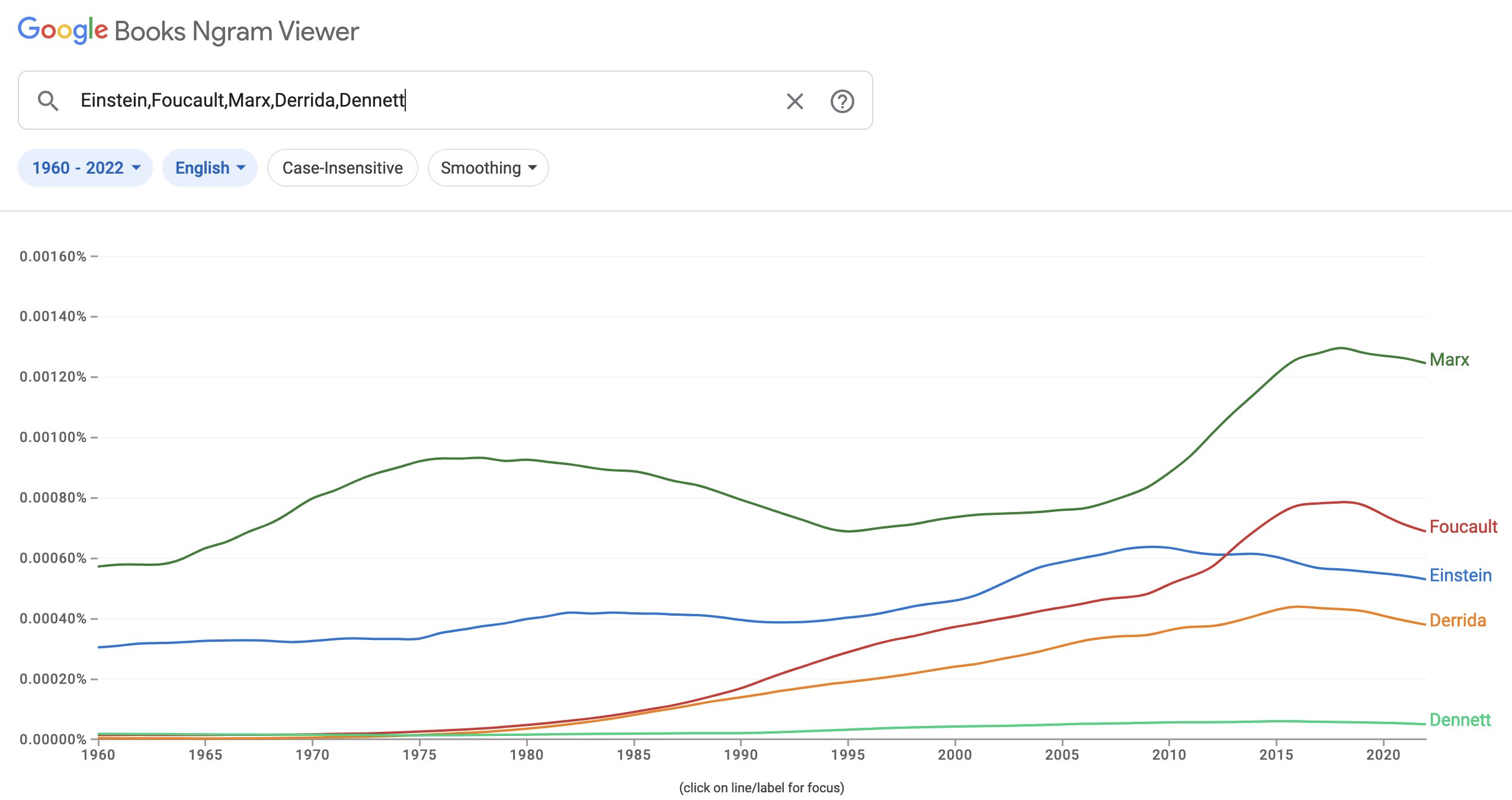
[ Source ]
Computer science fact of the day 2: JavaScript really was mostly-written in just a few weeks by Brendan Eich on contract-commission for Netscape [ to the extent that you consider it as having been "written [as a new programming language]", and not just specced out as a collective of "funny-looking macros" for Scheme. ] It took Eich several more months to finish the SpiderMonkey parser whose core I still use every time I browse the Internet today. However, e.g. the nonprofit R5RS did not ship a parser/interpreter [ likewise with similar committee projects ], yet it's not contested that the R5RS committee "wrote a programming language".
Computer science fact of the day 3: If you do consider JavaScript a Lisp, it's [as far as I know] the only living Lisp - not just the only popular living Lisp - to implement [ [1] first-class functions, [2] a full-featured base list fold/reduce that is available to the programmer, [3] a single, internally-consistent set of macros/idioms for operating on "typed" data ]. [1] and [2] are absolutely essential if you want to actually use most of the flexibility advantage of "writing in [a] Lisp"; [3] is essential for general usability. MIT Scheme has [1] and [2] [ and [3] to any extent, as far as I can tell ], and seems generally sensible; the major problem is that it is a dead Lisp. It has no living implementations. I have spent more than a year in a Lisp Discord server that seems full of generally competent programmers; MIT Scheme's death grip on Emacs as an interpretation/development environment seems to make it a no-go even for lots of people who aren't writing big projects and don't need, e.g., functional web crawling libraries. This has caused Scheme to fall so out of favor among working programmers that there is no Scheme option on Leetcode, Codewars, or the competitive programming site Codeforces [Codewars has a Common Lisp option, but none of the rest even have a Lisp]. For people who actually want to write production code in something that amounts to a "real Lisp", JavaScript is, today, far and away their best option. [ The vexing thing being: while functionally it is the best choice, in terms of flexible syntax, it does not offer a large % of the [very real] generally-advertised benefits of using a Lisp! ]
Computer science fact of the day: a true Lisp machine wouldn't need stack frames.
Boldface vs Quotation - i.e., the interrogating qualia skeptic, vs the defender of qualia as a gnostic absolute - is a common pattern. However, your Camp #1 and Camp #2 - Boldfaces who favor something like Global Workspace Theory, and Quotations who favor something like IIT - don't exist, in my experience.
Antonio Damasio is a Boldface who favors a body-mind explanation for consciousness which is quasi-neurological, but which is much closer to IIT than Global Workspace Theory in its level of description. Descartes was a Quotation who, unlike Chalmers, didn't feel like his qualia, once experienced, left anything to be explained. Most philosophers of consciousness who have ever written, in fact, have nothing to do with your proposed Camp #1 vs Camp #2 division, even though most can be placed somewhere along the Boldface-Quotation spectrum, because whether your intuition is more Boldface vs more Quotation is orthogonal to how confused you are about consciousness and how you go about investigating what confuses you. Your framing comes across as an attempt to decrement the credibility of people who advocate Quotation-type intuition by associating them with IIT, framing Boldfaces [your "Camp #1"] as the "sensible people" by comparison.
--
There's been discussion in these comments - more and less serious - about whether it's plausible Boldface and Quotation are talking past each other on account of neurological differences. I think this is quite plausible even before we get into the question of whether Boldfaces could truly lack the qualia Quotations are talking about, or not.
In the chapter of Consciousness Explained titled "Multiple Drafts Versus the Cartesian Theater", Dennett sets out to solve the puzzle of how the brain reconstructs conscious experiences of the same distant object to be simultaneous across sensory modes despite the fact that light travels faster [and is processed slower in the brain] than sound. He considers reconstruction of simultaneity across conscious modes part of what a quale is.
Yet, I have qualia if anyone does, and if someone bounces a basketball 30m away from me, I generally don't hear it bounce until a fraction of a second after I see it hit the ground. I've always been that way. As a grade-school kid, I would ask people about it; they'd say it wasn't that way for them, and I'd assume it was because they weren't paying close enough attention. Now I know people differ vastly in how they experience things and it's almost certainly an unusual neurological quirk.
Second example: it's commonly attributed to William James that he remarked on the slowness of qualia, relative to more atomic perception: "I see a bear, I run, I am afraid". This basic motto - the idea that emotion succeeds action - went a long way in James's philosophy of emotion, if I understand correctly.
I don't experience emotion [or other things that usually get called "qualia"] delayed relative to reflex action like that at all. Other people also don't usually report that experience, and I suspect James was pretty strange in that respect.
So even if everyone had qualia, yes, when we try to explain the contents of subjective awareness, we are quite frequently talking past each other because of the Typical Mind Fallacy.
--
Taking that as a given, it's still important whether some people [e.g., Dennett] actually don't have qualia. Is that possible?
Some people hear voices. Some people are gay. Some people are autistic. Some people are colorblind. There are still some reflexes left over in our culture from the days before reductionism, when philosophers would say of schizophrenics that they were touched by the divine or demonic, of gays that they were inspired by virtue or corruption [depending on the culture], and of autists that they were being deliberately contrarian, or else ill-affected by some bad air, or something. Of the colorblind people we don't have such leftover cultural narratives, probably because the differences that don't get noticed, don't get talked about. But if we did have one for colorblindness, it'd probably be that they were being performatively obtuse; and if the colorblind people had been able to express their private opinion [which would have been met with resistance], it probably would have been that everyone else was faking seeing the emperor's robe in impossible colors as a status signal or some such.
"Qualia" seem at least as easy to miss as color. So I find it quite plausible that there's a neurological difference underlying many of the arguments between Boldfaces and Quotations.
People in these replies have said that they are alienated from qualia, but aren't alienated from consciousness.
Qualia aren't particularly real; consciousness [in the sense of 'sentience', 'self-awareness', or 'subjective experience', not mere 'awakeness', like a fly might have] is real.
Vistas aren't particularly real; vision is real.
Set Chalmers aside, and define p-zombies as qualia-less people who act like qualia-less people. I think Dennett and other Boldfaces are such people.
Others in the comments have pointed out that it seems implausible that such "p-zombies" [as so defined] could report on the subjects of their own experience, because anything that is the subject of conscious [in the sense of "sentient" or "subjective"] experience, definitionally becomes a quale.
This, I think, is where the cruxy neurological difficulty lies in the mutually target-missing crosstalk between Boldfaces and Quotations. Quotations, when they get to talking about the philosophy of consciousness [/'awareness' / 'sentience' / 'subjective experience'] tend to talk about qualia as an inherently mystical or ineffable or non-reductionistic [ in the sense of violating reductionistic principles ] experience. E.g., the nature of Chalmers's confusion about qualia [unlike Dennett's, or Damasio's], isn't that they seem elusive or unreliable, but that they seem so obvious as to actively obstruct a properly reductionistic understanding of their internal composition - in a way that Chalmers presumably does not also feel about other classes of percept, like vision, sound, or visceral experience.
The Wikipedia article on qualia has an interesting note in the introduction:
qualia may be considered comparable and analogous to the concepts of jñāna found in Eastern philosophy and traditions.
"Jñāna" doesn't mean the same thing as the later Buddhist "jhana" - the later Buddhist "jhana" is a target mental state achieved through meditation, while the earlier "Vedic" "jñāna" simply refers to a thing-experienced the way "quale" does. Like "jhana", though, "jñāna" is a remote cognate with the English "know" and the Greek "gnosis". And like "quale", and "gnosis", "jñāna" - though not having been originally defined with prescriptive content - acquired mystical and spiritual connotations with use, implying that people tended to organically drift toward using that word in a mysterian way. It seems that across cultures, there is a whole class of people that insists on allowing mysticism to diffuse into our references to atomic conscious experience. This is very strange, if you think about it! Atomic conscious experience isn't mystical.
I think what happens is that people - especially people like me who can sometimes experience deep, but difficult-to-quickly-unpack, holistic percepts with a high subjective level of certitude - use "quale" [or "jñāna" or "gnosis"] to refer to hard-to-describe things we would not know except by directly experiencing them. Some mystics take advantage, and claim you should give money to their church for reasons they can't describe but are very certain of. So semantic drift associates the word with mysticism. [ Even while some people, like myself and Chalmers, continue using such words honestly, to refer to certain kinds of large high-certitude experiences whose internals frustrate our access. ]
Dennett and other Boldfaces seem [neurologically? I imagine] inclined to approach all situations, especially those involving reflective experiences, with a heavy emotional tone of doubt, which opens up questions and begs resolution.
[ E.g., Dennett writes:
Descartes claimed to doubt everything that could be doubted, but he never doubted that his conscious experiences had qualia, the properties by which he knew or apprehended them.
and this general approach holds in the rest of his writing, as far as I'm aware. ]
So given that people use the word "quale" [ which, again, like the word "vista" or "projection", refers to a category of thing that, if we're speaking precisely, isn't real ] so often to refer to their high-certitude opaque experiences, it makes sense that Dennett and Boldfaces would say that they don't have such experiences. Their experiences don't come with that gnostic certitude by which holistic thinkers [like me] sometimes fumblingly excuse our quick illegible conclusions.
--
You say "Camp #1" vs "Camp #2" has implications for research decisions, because
[T]he work you do to make progress on understanding a phenomenon is different if you expect the phenomenon to be low level vs. high level.
Demanding that consciousness must be explained as existing only on one level in the ontological hierarchy of description is a greater ask than we make of ordinary software documentation. Is the X window server "low level" or "high level"? It needs the assembly code to run, so it must be "low level", right? But we can only notice when it breaks by noticing whether our windows look good at a high level - whether they display with the right color and font, whether we can make several, whether their contents don't interfere with each other, etc. So our criteria are high-level - are we looking at a high-level phenomenon?
Like the X window system, operating systems, etc., consciousness inherently straddles layers of abstraction. It exists to facilitate supervenience. Neither Camp #1 nor Camp #2 is off on a very sensible research foot.
[A], just 'cause I anticipate the 'More and more' will turn people off [it sounds like it's trying to call the direction of the winds rather than just where things are at].
[ Thanks for doing this work, by the way. ]
No, what I'm talking about here has nothing to do with hidden-variable theories. And I still don't think you understand my position on the EPR argument.
I'm talking about a universe which is classical in the sense of having all parameters be simultaneously determinate without needing hidden variables, but not necessarily classical in the sense of space[/time] always being arbitrarily divisible.
Oh, sorry, I wasn't clear: I didn't mean a classical universe in the sense of conforming to Newton's assumptions about the continuity / indefinite divisibility of space [and time]. I meant a classical universe in the sense of all quasi-tangible parameters simultaneously having a determinate value. I think we could still use the concept of logical independence, under such conditions.
"building blocks of logical independence"? There can still be logical independence in the classical universe, can't there?
Is this your claim - that quantum indeterminacy "comes from" logical independence? I'm not confused about quantum indeterminacy, but I am confused about in what sense you mean that. Do you mean that there exists a formulation of a principle of logical independence which would hold under all possible physics, which implies quantum indeterminacy? Would this principle still imply quantum indeterminacy in an all-classical universe?
Imagine all humans ever, ordered by date of their birth.
All humans of the timeline I actually find myself a part of, or all humans that could have occurred, or almost occurred, within that timeline? Unless you refuse to grant the sense of counterfactual reasoning in general, there's no reason within a reductionist frame to dismiss counterfactual [but physically plausible and very nearly actual] values of "all humans ever".
Even if you consider the value of "in which 10B interval will I be born?" to be some kind of particularly fixed absolute about my existence, behind the veil of Rawls, before I am born, I don't actually know it. I can imagine the prior I would have about "in which 10B interval will I be born?" behind the veil of Rawls, and notice whether my observed experience seems strange in the face of that prior.
The Doomsday argument is not about some alternative history which we can imagine, where the past was different. It's about our history and its projection to the future. Facts of the history are given and not up to debate.
Consider an experiment where a coin is put Tails. Not tossed - simply always put Tails.
We say that the size sample space of such an experiment consists of one outcome: Tails. Even though we can imagine a different experiment with alternative rules where the coin is tossed or always put Heads.
It seems like maybe you think I think the Doomsday Argument is about drawing inferences about the past, or something? The Doomsday Argument isn't [necessarily] about drawing inferences about what happened in the past. It's about using factors that aren't particularly in the past, present, or future, to constrain our expectations of what will happen in the future, and our model of reality outside time.
Like Kolmogorov said,
It is [...] meaningless to ask about the quantity of information conveyed by the sequence
0 1 1 0about the sequence1 1 0 0.But if we take a perfectly specific table of random numbers of the sort commonly used in statistical practice, and for each of its digits we write the unit's digit of the units of its square according to the scheme
0 1 2 3 4 5 6 7 8 9
0 1 4 9 6 5 6 9 4 1
the new table will contain approximately
( log_2 10 - (8/10) ) * n
bits of information about the initial sequence (where n is the number of digits in the tables).†
I can see a single coin that was placed Tails, and I won't be able to infer anything beyond "that coin was placed Tails".
But if I see a hundred coins placed Tails, lined up in a row, I can validly start asking questions about "why?".
--
†Kolmogorov's illustration doesn't exactly map on to mine. I would note a couple things to clarify the exact analogy by which I'm using this illustration of Kolmogorov's to corroborate my point.
First, I think Kolmogorov would have agreed that, while it may be meaningless to talk about the quantity of information conveyed by the sequence 1 0 1 0 about the sequence 1 1 0 0 , it is not obviously meaningless to talk about the quantity of information conveyed by the sequence 1 1 1 0 1 0 1 0 1 0 1 0 1 about the sequence 0 1 1 1 0 1 1 1 0 1 1 1 0 1 1 1 0 1 1 1 0 1 1 1, since both obviously have internal structure, and there's a simple decompression algorithm that you can use to get from the former to the latter. Something similar seems true of a sequence of 100 coins facing Tails-up, and the simple decompression algorithm "for each of 100 coins, flip each to face Tails-up" - that is, they can communicate information about each other. Contrast with the single coin facing Tails-up, which is more like the sequence 1 1 0 0 in the [potential] presence of the sequence 1 0 1 0, in that it seems uninterestingly random.
Secondly, I think Kolmogorov's information theory is a strict improvement on Shannon's but weak in points. One of these weak points is that Kolmogorov doesn't provide any really practical mechanism for narrowing down the space of counterfactual minimal decompression algorithms ["programs"] which generated an observed sequence, even though he [I think rightly] uses the principle that the simplest algorithm can be discovered, as the basis for his measure of information. I think if you can say how much information a sequence communicates about another sequence after knowing the [clear-winner shortest] decompression scheme, you should be able to determine the decompression scheme and the seed data just from seeing the output sequence and assuming minimal information. This is what anthropics arguments [in part] aim to do, and this is what I'm trying to get at with the "100 coins all facing Tails-up" thought experiment.
I am not confused about the nature of quantum indeterminacy.
This is [...] Feynman's argument
.
I don't know why it's true, but it is in fact true
Oh, I hadn't been reading carefully. I'd thought it was your argument. Well, unfortunately, I haven't solved exorcism yet, sorry. BEGONE, EVIL SPIRIT. YOU IMPEDE SCIENCE. Did that do anything?
What we lack here is not so much a "textbook of all of science that everyone needs to read and understand deeply before even being allowed to participate in the debate". Rather, we lack good, commonly held models of how to reason about what is theory, and good terms to (try to) coordinate around and use in debates and decisions.
Yudkowsky's sequences [/Rationality: AI to Zombies] provide both these things. People did not read Yudkowsky's sequences and internalize the load-bearing conclusions enough to prevent the current poor state of AI theory discourse, though they could have. If you want your posts to have a net odds-of-humanity's-survival-improving impact on the public discourse on top of Yudkowsky's, I would advise that you condense your points and make the applications to concrete corporate actors, social contexts, and Python tools as clear as possible.
[ typo: 'Merman' -> 'Mermin' ]
The Aisafety[.]info group has collated some very helpful maps of "who is doing what" in AI safety, including this recent spreadsheet account of technical alignment actors and their problem domains / approaches as of 2024 [they also have an AI policy map, on the off chance you would be interested in that].
I expect "who is working on inner alignment?" to be a highly contested category boundary, so I would encourage you not to take my word for it, and to look through the spreadsheet and probably the collation post yourself [the post contains possibly-clueful-for-your-purposes short descriptions of what each group is working on], and make your own call as to who does and doesn't [likely] meet your criteria.
But for my own part, it looks to me like the major actors currently working on inner alignment are the Alignment Research Center [ARC] and Orthogonal.
You probably can't beat reading old MIRI papers and the Arbital AI alignment page. It's "outdated", but it hasn't actually been definitively improved on.
Yes, I think that's a validly equivalent and more general classification. Although I'd reflect that "survive but lack the power or will to run lots of ancestor-simulations" didn't seem like a plausible-enough future to promote it to consideration, back in the '00s.
But, ["I want my father to accept me"] is already a very high level goal and I have no idea how it could be encoded in my DNA. Thus maybe even this is somehow learned. [ . . . ] But, to learn something, there needs to be a capability to learn it - an even simpler pattern which recognizes "I want to please my parents" as a refined version of itself. What could that proto-rule, the seed which can be encoded in DNA, look like? [ . . . ] equip organisms with something like "fundamental uncertainty about the future, existence and food paired with an ability to recognize if probability of safety increases"
Humans [and animals in general] are adaptation-executers, not fitness-maximizers [ obligatory link, although my intention is not particularly to direct you to [re-]read ].
In the extreme limit, if natural [/sexual] selection could just compose us of the abstract principle "survive and reproduce", it would. But natural [/sexual] selection is a blind idiot god [obligatory link] without the capacity for such intelligent design; its entire career consists of resorting to crude hacks, precisely of the mold "directly wire in an instinctual compulsion for the child to please its father". I forcefully recommend Byrnes's writing on imprinting in animals and humans; it changed my mind about this some years ago.
"Why am I aligned with my own [stated] values [as opposed to my less-prosocial, subconscious urges]?"
and
"Why am I aligned with evolution's values [to the extent that I am]?"
are different questions.
[ Note: I strongly agree with some parts of jbash's answer, and strongly disagree with other parts. ]
As I understand it, Bostrom's original argument, the one that got traction for being an actually-clever and thought-provoking discursive fork, goes as follows:
Future humans in specific, will at least one of: [ die off early, run lots of high-fidelity simulations of our universe's history ["ancestor-simulations"], decide not to run such simulations ].
If future humans run lots of high-fidelity ancestor-simulations, then most people who subjectively experience themselves as humans living early in a veridical human history, will in fact be living in non-base-reality simulations of such realities, run by posthumans.
If one grants that our ancestors are likely to a] survive, and b] not elect to run vast numbers of ancestor-simulations [ both of which assumptions felt fairly reasonable back in the '00s, before AI doom and the breakdown of societal coordination became such nearly felt prospects ], then we are forced to conclude that we are more likely than not living in one such ancestor-simulation, run by future humans.
It's a valid and neat argument which breaks reality down into a few mutually-exclusive possibilities - all of which feel narratively strange - and forces you to pick your poison.
Since then, Bostrom and others have overextended, confused, and twisted this argument, in unwise attempts to turn it into some kind of all-encompassing anthropic theory. [ I Tweeted about this over the summer. ]
The valid, original version of the Simulation Hypothesis argument relies on the [plausible-seeming!] assumption that posthumans, in particular, will share our human interest in our species' history, in particular, and our penchant for mad science. As soon as your domain of discourse extends outside the class boundaries of "future humans", the Simulation Argument no longer says anything in particular about your anthropic situation. We have no corresponding idea what alien simulators would want, or why they would be interested in us.
Also, despite what Aynonymousprsn123 [and Bostrom!] have implied, the Simulation Hypothesis argument was never actually rooted in any assumptions about local physics. Changing our assumptions about such factors as [e.g.] the spatial infinity of our local universe, quantum decoherence, or a physical Landauer limit, doesn't have any implications for it. [ Unless you want to argue for a physical Landauer limit so restrictive it'd be infeasible for posthumans to run any ancestor-simulations at all. ]
So, while the Simulation Hypothesis argument can imply you're being simulated by posthumans, if and only if you strongly believe posthumans will both of [ a] not die, b] not elect against running lots of ancestor-simulations ], it can't prove you're being simulated in general. It's just not that powerful.
Then your neighbor wouldn't exist and the whole probability experiment wouldn't happen from their perspective.
From their perspective, no. But the answer to
In which ten billion interval your birth rank could've been
changes. If by your next-door neighbor marrying a different man, one member of the other (10B - 1) is thus swapped out, you were born in a different 10B interval.
Unless I'm misunderstanding what you mean by "In which ten billion interval"? What do you mean by "interval", as opposed to "set [of other humans]", or just "circumstances"?
If we're discussing the object-level story of "the breakfast question", I highly doubt that the results claimed here actually occurred as described, due [as the 4chan user claims] to deficits in prisoner intelligence, and that "it's possible [these people] lack the language skills to clearly communicate about [counterfactuals]".
Did you find an actual study, or other corroborating evidence of some kind, or just the greentext?
Is the quantum behavior itself, with the state of the system extant but stored in [what we perceive as] an unusual format, deterministic? If you grant that there's no in-the-territory uncertainty with mere quantum mechanics, I bet I can construct a workaround for fusing classical gravity with it that doesn't involve randomness, which you'll accept as just as plausible as the one that does.
To me the more interesting thing is not the mechanism you must invent to protect Heisenberg uncertainty from this hypothetical classical gravitational field, but the reason you must invent it. What, in Heisenberg uncertainty, are you protecting?
Does standard QED, by itself, contain something of the in-the-territory state-of-omitted-knowledge class you imagine precludes anthropic thinking? If not, what does it contain, that requires such in-the-territory obscurity to preserve its nature when it comes into contact with a force field that is deterministic?
[ Broadly agreed about the breakfast hypothetical. Thanks for clarifying. ]
In the domain of anthropics reasoning, the questions we're asking aren't of the form
A) I've thrown a six sided die, even though I could've thrown a 20 sided one, what is the probability to observe 6?
or
B) I've thrown a six sided die, what would be the probability to observe 6, if I've thrown a 20 sided die instead?
In artificial spherical-cow anthropics thought experiments [like Carlsmith's], the questions we're asking are closer to the form of
A six-sided die was thrown with 60% probability; with probability 40%, a 20-sided die was thrown. A six was observed. Now what are your posterior probabilities on which die was thrown?
In real-world, object-level anthropic reasoning [like the kind Hanson is doing], the questions we're asking are of the form
An unknown number of n-sided die were thrown, and landed according to unknown metaphysics to produce the reality observed, which locally works according to known deterministic physics, but contains reflective reasoners able to generate internally coherent counterfactuals which include apparently plausible violations of "what would happen according to physics alone". Attempt to draw any conclusions about metaphysics.
You say:
We know very well the size of set of possible outcomes for "In which ten billion interval your birth rank could've been". This size is 1. No amount of pregnancy complications could postpone or hurry your birth so that you managed to be in a different 10 billion group.
What if my next-door neighbor's mother had married and settled down with a different man?
I enjoyed reading this post; thank you for writing it. LessWrong has an allergy to basically every category Marx is a member of - "armchair" philosophers, socialist theorists, pop humanities idols - in my view, all entirely unjustified.
I had no idea Marx's forecast of utopia was explicitly based on extrapolating the gains from automation; I take your word for it somewhat, but from being passingly familiar with his work, I have a hunch you may be overselling his naivete.
Unfortunately, since the main psychological barrier to humans solving the technical alignment problem at present is not altruistic intentions, but raw cognitive intelligence, any meta-alignment scheme that proposes to succeed today has far more work cut out for it than just ensuring AGI-builders are accounting for risk to the best of their ability. It has to make the best of their ability good enough. That involves, at the very minimum, an intensive selection program for geniuses who are then placed in a carefully incentives-aligned research environment, and probably human intelligence enhancement.
Are you familiar with Yudkowsky's/Miles's/Christiano's AI Corrigibility concept?
So yes, I think this is a valid lesson that we can take from Principle (A) and apply to AGIs, in order to extract an important insight. This is an insight that not everyone gets, not even (actually, especially not) most professional economists, because most professional economists are trained to lump in AGIs with hammers, in the category of “capital”, which implicitly entails “things that the world needs only a certain amount of, with diminishing returns”.
This trilemma might be a good way to force people-stuck-in-a-frame-of-traditional-economics to actually think about strong AI. I wouldn't know; I honestly haven't spent a ton of time talking to such people.
Principle [A] doesn't just say AIs won't run out of productive things to do; it makes a prediction about how this will affect prices in a market. It's true that superintelligent AI won't run out of productive things to do, but it will also change the situation such that the prices in the existing economy won't be affected by this in the normal way prices are affected by "human participants in the market won't run out of productive things to do". Maybe there will be some kind of legible market internal to the AI's thinking, or [less likely, but conceivable] a multi-ASI equilibrium with mutually legible market prices. But what reason would a strongly superintelligent AI have to continue trading with humans very long, in a market that puts human-legible prices on things? Even in Hanson's Age of Em, humans who choose to remain in their meatsuits are entirely frozen out of the real [emulation] economy, very quickly in subjective time, and to me this is an obvious consequence of every agent in the market simply thinking and working way faster than you.
Wild ahead-of-of-time guess: the true theory of gravity explaining why galaxies appear to rotate too slowly for a square root force law will also uniquely explain the maximum observed size of celestial bodies, the flatness of orbits, and the shape of galaxies.
Epistemic status: I don't really have any idea how to do this, but here I am.
When I stated Principle (A) at the top of the post, I was stating it as a traditional principle of economics. I wrote: “Traditional economics thinking has two strong principles, each based on abundant historical data”,
I don't think you think Principle [A] must hold, but I do think you think it's in question. I'm saying that, rather than taking this very broad general principle of historical economic good sense, and giving very broad arguments for why it might or might not hold post-AGI, we can start reasoning about superintelligent manufacturing [including R&D] and the effects it will have, more granularly, out the gates.
Like, with respect to Principle [C] my perspective is just "well of course the historical precedent against extremely fast economic growth doesn't hold after the Singularity, that's more or less what the Singularity is".
Edit: Your rewrite of Principle [B] did make it clear to me that you're considering timelines that are at least somewhat bad for humans; thank you for the clarification. [Of course I happen to think we can also discard "AI will be like a manufactured good, in terms of its effects on future prices", out the gates, but it's way clearer to me now that the trilemma is doing work on idea-space.]
You seem to have misunderstood my text. I was stating that something is a consequence of Principle (A),
My position is that if you accept certain arguments made about really smart AIs in "The Sun is Big", Principle A, by itself, ceases to make sense in this context.
costs will go down. You can argue that prices will equilibriate to costs, but it does need an argument.
Assuming constant demand for a simple input, sure, you can predict the price of that input based on cost alone. The extent to which "the price of compute will go down", is rolled in to how much "the cost of compute will go down". But IIUC, you're more interested in predicting the price of less abstract assets. Innovation in chip technology is more than just making more and more of the same product at a lower cost. [ "There is no 'lump of chip'." ] A 2024 chip is not just [roughly] 2^10 2004 chips - it has logistical advantages, if nothing else. And those aren't accounted for if you insist on predicting chip price using only compute cost and value trendlines. Similar arguments hold for all other classes of material technological assets whose value increases in response to innovation.
"AI will [roughly] amount to X", for any X, including "high-skilled entrepreneurial human labor" is a positive claim, not a default background assumption of discourse, and in my reckoning, that particular one is unjustified.
Thank you for writing this and hopefully contributing some clarity to what has been a confused area of discussion.
So here’s a question: When we have AGI, what happens to the price of chips, electricity, and teleoperated robots?
(…Assuming free markets, and rule of law, and AGI not taking over and wiping out humanity, and so on. I think those are highly dubious assumptions, but let’s not get into that here!)
Principle (A) has an answer to this question. It says: prices equilibrate to marginal value, which will stay high, because AGI amounts to ambitious entrepreneurial skilled labor, and ambitious entrepreneurial skilled labor will always find more new high-value things to do. That, incidentally, implies that human labor will retain a well-paying niche—just as less-skilled labor today can still get jobs despite more-skilled labor also existing.
First off, I'm guessing you're familiar with the economic arguments in The Sun is Big.
Secondly -
If we're talking about prices for the same chips, [rate of] electricity, teleoperated robots, etc., of course they'll go down, as the AGI will have invented better versions.
AGI amounts to ambitious entrepreneurial skilled labor
This is really just a false thing to believe about AGI, from us humans' perspective. It amounts to a new world political order. Unless you specifically build it to prevent all other future creations of humanity from becoming politically interventionist superintelligences, while also not being politically interventionist itself.
I didn't say he wasn't overrated. I said he was capable of physics.
Did you read the linked post? Bohm, Aharonov, and Bell misunderstood EPR. Bohm's and Aharonov's formulation of the thought experiment is easier to "solve" but does not actually address EPR's concern, which is that mutual non-commutation of x-, y-, and z-spin implies hidden variables must not be superfluous. Again, EPR were fine with mutual non-commutation, and fine with entanglement. What they were pointing out was that the two postulates don't make sense in each other's presence.
Your linked post on The Obliqueness Thesis is curious. You conclude thus:
Obliqueness obviously leaves open the question of just how oblique. It's hard to even formulate a quantitative question here. I'd very intuitively and roughly guess that intelligence and values are 3 degrees off (that is, almost diagonal), but it's unclear what question I am even guessing the answer to. I'll leave formulating and answering the question as an open problem.
I agree, values and beliefs are oblique. The 3 spatial dimensions are also mutually oblique, as per General Relativity. A theory of obliqueness is meaningless if it cannot specify the angles [ I think in a correct general linear algebra, everything would be treated as [at least potentially] oblique to everything else, but that doesn't mean I refuse to ever treat the 3 spatial dimensions as mutually orthogonal ].
As with the 3 spatial dimensions in practical ballistics, with the value dimension and the belief dimension in practical AI alignment, there are domains of discussion where it is appropriate to account for the skew between the dimensions and domains where it is appropriate to simply treat them as orthogonal. Discussions of alignment theory such as the ones in which you seek to insert your Obliqueness thesis, are a domain in which the orthogonality assumption is appropriate. We cannot guess at the skew with any confidence in particular cases, and with respect to any particular pre-chosen utility/valence function term versus any particular belief-state [e.g. "what is the dollar value of a tulip?" • "is there a teapot circling Mars?"], the level of skew is almost certain to be negligible.
Planning for anthropically selected futures, on the other hand, is a domain where the skew between values and beliefs becomes relevant. There is less point reasoning in detail about pessimized futures or others that disagree with our values [such as the ones in which we are dead], no matter how likely or unlikely they might be "in a vacuum", if we're trying to hyperstition our way into futures we like. But this is an esoteric and controversial argument and not actually required to justify why I don't think it's useful to consider [sufficiently] strong AI as "what can eat the sun".
All that's required to justify why I don't think it's useful to consider [sufficiently] strong AI as "what can eat the sun", is that what you propose is a benchmark of capability, or intelligence. Benchmarks of intelligence [say, of bureaucrats or chimps] are not questions of fact. They are social fictions chosen for their usefulness. If, in the vast, vast supermajority of the worlds where the benchmark would otherwise be useful - in this case, the worlds where people deploy an AI that they do not know, ahead of time, if it will or will not be strong enough to eat the Sun - it will not be useful for contingent reasons - in this case, because we are all dead - then it is not, particularly, a benchmark we should be etching into the wood, from our present standpoint.
The characters don't live in a world where sharing or smoothing risk is already seen as a consensus-valuable pursuit; thus, they will have to be convinced by other means.
I gave their world weirdly advanced [from our historical perspective] game theory to make it easier for them to talk about the question.
Cowen, like Hanson, discounts large qualitative societal shifts from AI that lack corresponding contemporary measurables.
Einstein was not an experimentalist, yet was perfectly capable of physics; his successors have largely not touched his unfinished work, and not for lack of data.
Not to be too cheeky, the idea is that if we understand insurance, it should be easy to tell if the characters' arguments are sound-and-valid, or not.
The obtuse bit at the beginning was an accidental by-product of how I wrote it; I admittedly nerdsniped myself trying to find the right formula.
Dwarkesh asks, what would happen if the world population would double? Tyler says, depends what you’re measuring. Energy use would go up.
Yes, economics after von Neumann very much turned into a game of "don't believe in anything you can't already comparatively quantify". It is supremely frustrating.
On that note, I’d also point everyone to Dwarkesh Patel’s other recent podcast, which was with physicist Adam Brown. It repeatedly blew my mind in the best of ways, and I’d love to be in a different branch where I had the time to dig into some of the statements here. Physics is so bizarre.
You just inspired me to go listen myself. Maybe we should all take a node out of that branch. Unfortunately physics has suffered similar issues.
Last big piece: if one were to recruit a bunch of physicists to work on alignment, I think it would be useful for them to form a community mostly-separate from the current field. They need a memetic environment which will amplify progress on core hard problems, rather than... well, all the stuff that's currently amplified.
Yes, exactly. Unfortunately, actually doing this is impossible, so we all have to keep beating our heads against a wall just the same.
This does not matter for AI benchmarking because by the time the Sun has gone out, either somebody succeeded at intentionally engineering and deploying [what they knew was going to be] an aligned superintelligence, or we are all dead.
Are you familiar with CEV?
I'm willing to credit that increased velocity of money by itself made aristocracy untenable post-industrialization. Increased ease of measurement is therefore superfluous as an explanation.
Why believe we've ever had a meritocracy - that is, outside the high [real/underlying] money velocities of the late 19th and early 20th centuries [and the trivial feudal meritocracy of heredity]?
0 trips -> 1 trip is an addition to the number of games played, but it's also an addition to the percentage of income bet on that one game - right?
Dennis is also having trouble understanding his own point, FWIW. That's how the dialogue came out; both people in that part are thinking in loose/sketchy terms and missing important points.
The thing Dennis was trying to get at by bringing up the concrete example of an optimal Kelly fraction is that it doesn't make sense for willingness to make a risky bet to have no dependence on available capital; he perceives Jill as suggesting that this is the case.
Relevant to whether the hot/cold/wet/dry system is a good or a bad idea, from our perspective, is that doctors don't currently use people's star signs for diagnosis. Bogus ontologies can be identified by how they promise to usefully replace more detailed levels of description - i.e., provide a useful abstraction that carves reality at the joints - and yet don't actually do this, from the standpoint of the cultures they're being sold to.
To your first question:
I honestly think it would be imprudent of me to give more examples of [what I think are] ontology pyramid schemes; readers would either parse them as laughable foibles of the outgroup, and thus write off my meta-level point as trivial, or feel aggressed and compelled to marshal soldiers against my meta-level point to dispute a perceived object-level attack on their ingroup's beliefs.
I think [something like] this [implicit] reasoning is likely why the Sequences are around as sparse as this post is on examples, and I think it's wise that they were written that way.
To your second:
There's nothing logically against an ontology that's true being the subject of a pyramid scheme, any more than there's anything logically against the bogus widgets a physical pyramid scheme is selling, actually being inordinately useful. It just generally doesn't happen.